

Introduction
The science of SETI has always suffered from a lack of quantitative substance (purely resulting from its reliance on one-sample statistics) relative to its sister astronomical sciences. In 1961, Frank Drake took the first steps to quantifying the field by developing the now-famous Drake Equation, a simple algebraic expression which provides an estimate for the number of communicating civilizations in the Milky Way. Unfortunately, its simplistic nature leaves it open to frequent re-expression, hence there are in fact many variants of the equation, and no clear canonical form. For the purpose of this paper, the following form will be used (Walters et al. Reference Walters, Hoover and Kotra1980):
with the symbols having the following meanings:
- N=
the number of Galactic civilizations who can communicate with Earth;
- R *=
the mean star formation rate of the Milky Way;
- f g=
the fraction of stars that could support habitable planets;
- f p=
the fraction of stars that host planetary systems;
- n e=
the number of planets in each system that are potentially habitable;
- f l=
the fraction of habitable planets where life originates and becomes complex;
- f i=
the fraction of life-bearing planets that bear intelligence;
- f c=
the fraction of intelligence bearing planets where technology can develop;
- L=
the mean lifetime of a technological civilization within the detection window.
The equation itself does suffer from some key weaknesses: it relies strongly on mean estimations of variables such as the star formation rate; it is unable to incorporate the effects of the physico-chemical history of the galaxy, or the time-dependence of its terms (Cirkovic & Cathcart 2004b). Indeed, it is criticized for its polarizing effect on ‘contact optimists’ and ‘contact pessimists’, who ascribe very different values to the parameters, and return values of N between 10−5 and 106 (!).
A decade before, Enrico Fermi attempted to analyse the problem from a different angle, using order of magnitude estimates for the timescales required for an Earth-like civilization to arise and colonize the galaxy to arrive at the conclusion that the Milky Way should be teeming with intelligence, and that they should be seen all over the sky. This lead him to pose the Fermi Paradox, by asking, ‘Where are they?’. The power of this question, along with the enormous chain of events required for intelligent observers to exist on Earth to pose it, has lead many to the conclusion that the conditions for life to flourish are rare, possibly even unique to Earth (Ward & Brownlee Reference Ward and Brownlee2000). The inference by Lineweaver (Reference Lineweaver2001) that the median age of terrestrial planets in the Milky Way is 1.8±0.9 Gyr older than Earth would suggest that a significant number of Earth-like civilizations have had enough time to evolve, and hence be detectable: the absence of such detection lends weight to the so-called ‘Rare Earth’ hypothesis. However, there have been many posited solutions to the Fermi Paradox that allow ETI to be prevalent, such as:
• they are already here, in hiding;
• contact with Earth is forbidden for ethical reasons;
• they were here, but they are now extinct;
• they will be here, if Mankind can survive long enough.
Some of these answers are inherently sociological, and are difficult to model. Others are dependent on the evolution of the galaxy and its stars, and are much more straightforward to verify. As a whole, astrobiologists are at a tremendous advantage in comparison with Drake and Fermi: the development of astronomy over the last fifty years – in particular the discovery of the first extra solar planet (Mayor et al. Reference Mayor, Queloz, Marcy, Butler, Korzennik, Krochenberger, Nisenson, Brown, Kennelly and Rowland1995) and some hundreds thereafter, as well as the concepts of habitable zones, both stellar (Hart Reference Hart1979) and galactic (Lineweaver et al. Reference Lineweaver, Fenner and Gibson2004) – have allowed a more in-depth analysis of the problem. However, the key issue still affecting SETI (and astrobiology as a whole) is that there is no consensus as to how to assign values to the key biological parameters involved in the Drake Equation and Fermi Paradox. Furthermore, there are no means of assigning confidence limits or errors to these parameters, and therefore no way of comparing hypotheses for life (e.g. panspermia (for a review, see Dose (Reference Dose1986) ) or the ‘Rare Earth’ hypothesis (Ward & Brownlee Reference Ward and Brownlee2000)). This paper outlines a means for applying Monte Carlo Realization techniques to investigate the parameter space of intelligent civilizations more rigorously, and to help assign errors to the resulting distributions of life and intelligence.
The paper is organized as follows: in the following section the techniques are described; in the Inputs section the input data is discussed; in the Results section the results from several tests are shown, and in the Conclusions the method is reviewed.
Method
The overall procedure can be neatly summarized as:
1. generate a galaxy of N * stars, with parameters that share the same distribution as observations;
2. generate planetary systems for these stars;
3. assign life to some of the planets depending on their parameters (e.g. distance from the habitable zone);
4. for each life-bearing planet, follow life's evolution into intelligence using stochastic equations.
This will produce one Monte Carlo Realization (MCR) of the Milky Way in its entirety. The concept of using MCR techniques in astrobiology is itself not new: recent work by Vukotic & Cirkovic (Reference Vukotic and Cirkovic2007, Reference Vukotic and Cirkovic2008) uses similar procedures to investigate timescale forcing by global regulation mechanisms such as those suggested by Annis (Reference Annis1999). In order to provide error estimates, this procedure must be repeated many times, so as to produce many MCRs, and to hence produce results with a well-defined sample mean and sample standard deviation. The procedure relies on generating parameters in three categories: stellar, planetary and biological.
Stellar properties
The study of stars in the Milky Way has been extensive, and their properties are well-constrained. Assuming the stars concerned are all main sequence objects allows much of their characteristics to be determined by their mass. Stellar masses are randomly sampled to reproduce the observed initial mass function (IMF) of the Milky Way, which is taken from Scalo & Miller (Reference Scalo and Miller1979) (see Fig. 1).

Fig. 1. The stellar IMF used in this work (Scalo & Miller Reference Scalo and Miller1979). This is an example produced as part of a single MCR.
Stellar radii can then be calculated using (Prialnik Reference Prialnik2000):
where n=4 if the primary fusion mechanism is the p–p chain (M *⩽1.1M ⊙), and n=16 if the primary fusion mechanism is the CNO cycle (M *>1.1M ⊙). (Please note that in this paper, the subscript ⊙ denotes the Sun, e.g. M ⊙ indicates the value of one solar mass.) The luminosity is calculated using a simple mass-luminosity relation:
The main sequence lifetime therefore is
The stars' effective temperature can be calculated, assuming a black body:
![T_{ \displaystyle\ast } \equals \mathop {\left[ {{{L_{ \displaystyle\ast } } \over {4\pi R_{ \displaystyle\ast }^{\setnum{2}} \rmsigma _{SB} }}} \right]}\nolimits^{\setnum{1}\sol \setnum{4}}.](https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20151007150828562-0879:S1473550408004321_eqn5.gif?pub-status=live)
The star's age is sampled to reproduce the star formation history of the Milky Way (Twarog Reference Twarog1980), see Fig. 2.

Fig. 2. The star formation history used in this work (Twarog Reference Twarog1980).
The metallicity of the star is dependent on the metallicity gradient in the galaxy, and hence its galactocentric radius, r gal. This is sampled so that the surface mass density of the galaxy is equivalent to that of the Milky Way (assuming a simple two-dimensional disc structure):
where r h is the galactic scale length (taken to be 3.5 kpc). Therefore, given its galactocentric radius, the metallicity of the star, in terms of ![]() , is calculated using the simple parametrization of the abundance gradient:
, is calculated using the simple parametrization of the abundance gradient:
where z grad is taken to be 0.07 (Hou et al. Reference Hou, Prantzos and Boissier2000). The star is then placed at its galactocentric radius into one of four logarithmic spiral arms (mimicking the four main logarithmic spiral arms of the Milky Way, see Fig. 3).

Fig. 3. An example star map, taken from one MCR. Brighter areas indicate greater stellar mass.

Fig. 4. The planetary mass function, constructed from the Exoplanet Encyclopedia data (http://exoplanet.eu).

Fig. 5. The distribution of planetary orbital radii, constructed from the Exoplanet Encyclopedia data (http://exoplanet.eu).
Finally, stars are assigned planets based on their metallicity (sampling the current relations for extrasolar planets, see Figs 4, 5 and 6). Some stars will have no planets, some will have only one, and some may have multiple systems (based on the multiplicity of current extrasolar planetary systems). (Although not considered here, it should be noted that too high a metallicity may be as negative a factor as low metallicity, as high metallicity systems will tend to produce ocean worlds (Leger et al. Reference Leger, Selsis, Sotin, Guillot, Despois, Mawet, Ollivier, Labèque, Valette and Brachet2004), which may prove hostile to the formation of intelligent life.)

Fig. 6. The distribution of host star metallicity, constructed from the Exoplanet Encyclopedia data (http://exoplanet.eu).
Planetary properties
Since the discovery of 51 Peg B (Mayor et al. Reference Mayor, Queloz, Marcy, Butler, Korzennik, Krochenberger, Nisenson, Brown, Kennelly and Rowland1995), the data garnered on exoplanets has grown at an increasing rate. At the time of writing, there are over 300 known exoplanets, discovered with a variety of observational techniques (radial velocity, transits, microlensing, etc). This data provides distributions of planetary parameters that can be sampled from the planetary mass function (PMF), the distribution of planetary orbital radii, and the host star metallicity distribution.
Therefore, as with the stellar parameters, a population of planets can be created around the parent stars, with statistical properties matching what can be observed. However, this statistical data is still subject to strong observational bias, and the catalogues are still strongly incomplete. There is insufficient data to reproduce a distribution of terrestrial planets: therefore it is assumed that life evolves around the satellites of the planets simulated here. In essence, this constitutes a lower limit on the number of inhabited planets: the work of Ida and Lin (Reference Ida and Lin2004) shows that, as a function of metallicity, habitable terrestrial planets are comparable in frequency (or higher) than currently detectable giant planets. This data is hence still useful for illustrating the efficacy of the Monte Carlo method (at least, until observations of terrestrial exoplanets become statistically viable). All this should be borne in mind when the results of this work are considered (Figs 4 and 5).
Two further parameters to be sampled, for which observational data is difficult to obtain, are P life, the probability that life can originate on a given planet, and N resets, the number of biologically damaging events that a planet will experience during the evolution of its indigenous life (such as local supernovae, gamma ray bursts (Annis Reference Annis1999), cometary impacts, etc). At this point, the model goes beyond relatively well-constrained parameters, and becomes hypothesis. N resets is defined as a function of galactocentric radius – more resetting events (most notably SNe) occur as distance to the Galactic Centre decreases:
where μresets,0 is set to 5, reflecting the so-called ‘Big Five’ mass extinction events in the Earth's fossil record (Raup & Sepkoski Reference Raup and Sepkoski1982). It should be noted that this is a simple parameterization: the real distribution of resetting events is more complex, in particular for short GRBs and Type I SNe, which have less well-defined spatial relationships. This simple expression is provided to prevent a blurring of the issue: future work will include a more rigorous expression. All planetary data was collected from the Exoplanets Encyclopaedia website (http://exoplanet.eu): in total, 242 planets were used to construct the data, as these had entries in all required data fields.
Biological parameters
Life parameters
The model now enters the realm of essentially pure conjecture: all the available data for these parameters is derived from observations of a single biosphere, and hence there is little that can be done to constrain these parameters (at least without making wide-ranging assumptions about the mechanisms of life as a whole). The model implicitly assumes the ‘hard step’ scenario of evolution (e.g. Carter Reference Carter2008), i.e., life must achieve essential evolutionary goals in order to become intelligent organisms with the ability to construct sufficiently complex technological artifacts. The key biological parameters are listed as follows:
• N stages: the number of stages life must evolve through to become intelligent;
• τi: the time required for each of these stages to be reached;
• τint: the time required for an intelligent technological civilization to form from life's creation;
• P annihilate: the probability that a reset event will cause complete annihilation.
The intelligence timescale τint is calculated by the following stochastic process: if life does evolve on a planet, N stages is randomly sampled. The resetting events N resets are placed uniformly throughout each of the stages. If N resets>N stages, then any given stage may suffer several reset events. Then the following procedure occurs for each stage i:
1. τi is sampled;
2. if a reset occurs, test if that reset results in annihilation: if annihilation occurs, life is exterminated, and the process ends; otherwise, i decreases by 1;
3. τint is increased by some fraction of τi (or simply by τi if no resets occur);
4. increase i by 1, and return to 1.
This procedure continues until either (a) life has reached the final stage (an intelligent technologically capable civilization has evolved), or (b) the intelligence timescale becomes greater than the main sequence lifetime of the parent star: τint>τMS. Once a civilization has formed, it is assumed that detectable signals or signal leakage begins to be emitted. This emission will continue until either (a) the civilization destroys itself or (b) the parent star moves off the main sequence (see next section). This in itself is a conservative estimate of the length of time a civilization may be detected, as civilizations may in fact migrate between the stars, or use stellar engineering to prolong their parent's stars life.
The P annihilate parameter is defined as
Along with the metallicity gradient and the N resets parameter specified in the previous sections, this defines a Galactic Habitable Zone which mimics that defined by Lineweaver et al. (Reference Lineweaver, Fenner and Gibson2004) : an annular region of the galaxy where the metallicity is sufficiently high for planets (and life) to form, and the number of biologically destructive events is sufficiently small (and their destructive capability sufficiently low) to allow life to evolve at all.
Civilization parameters
Once a technologically capable civilization has formed, it must move through a ‘fledgling phase’: it is susceptible to some catastrophic event caused partially or fully by its own actions (e.g. war, plague, catastrophic climate change, botched macro-engineering projects (Cirkovic & Cathcart 2004a)). This is described by the parameter P destroy: the probability that a fledgling civilization will destroy itself. If a civilization can survive this phase, it becomes sufficiently advanced to prevent such self-destruction events, and becomes stable, on a timescale τadv. If a civilization is destroyed, then it will survive some fraction of τadv before destruction.
What advanced civilizations can then do is at the behest of the user: civilizations may colonize all planets within their solar system, resulting in signals appearing on all planets in that system. Probes may be sent into the galaxy at large, which could define an explorable volume of the galaxy for a given advanced civilization. Civilizations may even attempt to generate new biospheres on neighbouring planets – the ‘directed panspermia’ model (Crick & Orgel Reference Crick and Orgel1973). The results in this paper assume colonization of all uninhabited planets in the system will occur once a civilization becomes advanced (colonization being an umbrella term for placing both manned and unmanned installations on the surface or in orbit of said planets). It is reasonable to assume that a pre-existing biosphere, perhaps with intelligent life would be a more suitable candidate for colonization rather than a lifeless planet; however, to prevent statistical confusion (and to avoid dealing with the possibilities of interplanetary conflict between intelligent species) colonization occurs only on uninhabited planets.
The key civilization parameters are:
• τadv: the timescale for a civilization to move from ‘fledgling’ to ‘advanced’;
• P destroy: the probability that a fledgling civilization will destroy itself;
• L signal: the lifetime of any signal or leakage from a civilization.
The signal lifetime of a self-destroying civilization is
where x is a uniformly sampled number between 0 and 1. If the civilization becomes advanced, this becomes
(i.e., civilizations exist until their parent star leaves the Main Sequence). For a planet colonized by an advanced civilization, this is
At the end of any MCR run, each planet will have been assigned a habitation index based on its biological history:

If the planet has habitation index 1 or 2, the biological process has been ended by the destruction of the parent star. Planets with an index of −1 or 1 may contain biomarkers in their atmosphere (e.g. ozone or water spectral features), which could be detected. Planets with an index of 2 or higher will emit signals or signal leakage. Planets with an index of 4 or 5 may display evidence of a postbiological civilization or of large-scale ‘macro-engineering’ projects, e.g. Dyson spheres (Dyson Reference Dyson1960). Signals from these systems may even be consistent with those expected from Kardashev Type II civilizations (those which can harness all the energy of their parent star), and hence could produce characteristic stellar spectral signatures that Earth astronomers could detect.
Inputs
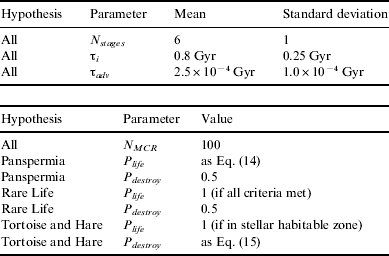
When comparing hypotheses, it is important to keep the number of free parameters to a minimum. To achieve this, a biological version of the Copernican Principle is invoked: the Terran biosphere is not special or unique. Therefore, life on other planets will share similar values of characteristic parameters. This implies that many parameters can be held constant throughout all hypotheses: in particular, those that deal with the approach to intelligence. These are sampled from Gaussian distribution functions (assuming that each variable is the result of many subfactors, and implicitly applying the Central Limit Theorem). The mean value for N stages is taken to be 6, reflecting the major stages life went through on Earth – biogenesis, the advent of bacteria, the advent of eukaryotes, combigenesis, the advent of metazoans and the birth of technological civilization (Carter Reference Carter2008). 100 MCRs were produced for each hypothesis: the parameters used for all testing can be found in Table 1. The three hypotheses tested are described below.
Table 1. Parameters used for all hypotheses
The Panspermia hypothesis
This well-documented theory suggests life may spread from one originating planet to many others, causing life to form concurrently in multiple systems. In this model, if life forms on any planet in a star system, then other planets may be seeded, according to the following prescription:

Life can move between planets if the distance between the destination planet and the original inhabited planet (ΔR) is sufficiently small, and the stellar luminosity is sufficiently low that ionizing radiation will not destroy biological organisms in transit. It is assumed that life emerges on the original planet while a significant amount of planetary bombardment is in progress, and the seeding of other planets (from rocky fragments expelled from the inhabited planet's surface by asteroid impacts) is therefore effectively instantaneous. P destroy is specified a priori to be 0.5, reflecting current ignorance about the development of extraterrestrial civilization.
This hypothesis restricts panspermia to planets in the same star system only: unfortunately, the model is currently incapable of modelling the interesting possibility of interstellar panspermia (Napier Reference Napier2004; Wallis & Wickramasinghe Reference Wallis and Wickramasinghe2004). This in itself is strong motivation to improve the model further, and is left as an avenue for future work.
The Rare Life hypothesis
Due to the current dearth of data on Earth-like exoplanets, the famous ‘Rare Earth hypothesis’ (Ward & Brownlee Reference Ward and Brownlee2000) cannot be tested fully. A different hypothesis is possible (assuming Jovian planets in the habitable zone may have stable Earth-like moons on which life could arise) with this code. The hypothesis is as follows. Once life arises, it is assumed to be tenacious, and can easily evolve into intelligence. However, the initial appearance of life is itself hard: the planetary niche must satisfy certain criteria before life can evolve. The criteria are:
1. the planet is in the stellar habitable zone;
2. the parent star mass is less than 2M ⊙;
3. the system has at least one extra planet (protection from bombardment);
4. the star's metallicity must be at least solar or higher (Z * ⩾Z ⊙).
If all criteria are met, then life can evolve. P destroy is set to 0.5 for the same reason as previously. It should be noted again that this is significantly different from the Rare Earth hypothesis, and should not be considered as a comparison. A more accurate comparison would have the last few stages of life (the development of metazoans and intelligent life) be rare: this would be better suited for future work after the model has been refined.
The Tortoise and Hare hypothesis
As a final example, this hypothesis demonstrates the ability of the code to model more sociological hypotheses. Life evolves easily on many planets, but the evolution towards intelligence and advanced civilization is more complex. Essentially, civilizations that arise too quickly are more susceptible to self-destruction, whereas those that take longer to emerge are more likely to survive the fledgling phase. This is parameterized as
where τ0=N stagesτmin is a normalization constant that describes the minimum evolution timescale (if N resets=0, and each stage takes the minimum amount of time τmin) (Note: if this calculation is applied to Mankind, our own destruction probability is around 0.8 (!)) If a planet is in the habitable zone, then P life=1, in the same vein as the other hypotheses. It should be noted that this is an oversimplification: the potential existence of liquid water on Enceladus and Europa (both outside the solar habitable zone) suggests that P life should be a distribution in orbital radius with tails that extend outside the zone; however, for the purposes of this paper, a simple step function will be sufficient.
Results
The Panspermia hypothesis
The single number statistics for this hypothesis can be seen in Table 2. As expected, around half of all emerging civilizations destroy themselves (as P destroy=0.5). Around 0.1% of all planets are inhabited by either primitive or intelligent life during the Galaxy's lifetime, and roughly 10% of all inhabited planets host intelligent lifeforms. Compared to the Tortoise and Hare hypothesis (see below), the inhabited fraction has not greatly increased with the possibility of seeding amongst neighbours: this is mostly due to the low multiplicity of current exoplanets (around 11%).
Table 2. Statistics for the Panspermia hypothesis
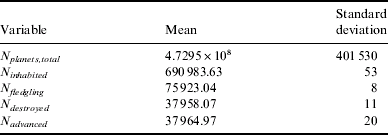
Figure 7 shows the Galactic Habitable Zone for this hypothesis: at low galactocentric radii, the annihilation rate increases to the point where civilizations cannot develop (although life itself can emerge there, it is quickly eradicated by destructive astrophysical events). The right panel of Fig. 7 shows the breakdown of inhabited planets by type over the life of the Galaxy. The large number of planets with index -1 (annihilated biospheres) indicates the solar systems with low galactocentric radii that are metal rich, and form planets (and hence life) more easily, but suffer rapid biological catastrophe. The colonization fraction (planets with habitation index 5) is quite low: this is most likely due to panspermia seeding reducing the number of neighbouring empty planets available for colonization.

Fig. 7. The distribution of galactocentric radius (left) and habitation index (right) under the Panspermia hypothesis.
The distribution of stellar properties for civilized planets (Fig. 8) indicates a predilection for low-mass stars. This comes from the selection bias of the so-called ‘Hot Jupiters’: these objects are of such low orbital radii that if they are to exist in the habitable zone, it must also be of low radius, and hence belong to a low-mass star. The metallicity reflects the Galactic Habitable Zone: civilizations have a minimum galactocentric radius, and hence a maximum metallicity. Considering the signal lifetime distribution, it is heavily influenced by the main sequence lifetime of the parent stars, which is a function of mass. Studying the mass relation, it is clear that the two are correlated. If the signals are plotted as a function of time (Fig. 9, right panel), it can be seen that the signal history undergoes a transition from low to high N around t t H, where t H is the Hubble time (i.e., the age of the universe). This is symptomatic of the Copernican Principle invoked to constrain the majority of the biological parameters: on average, any given civilization will have an intelligence timescale similar to ours.

Fig. 8. The distribution of host star mass (left) and metallicity (right) under the Panspermia hypothesis.

Fig. 9. The distribution of signal lifetimes (left) and the signal history of the Galaxy (right) under the Panspermia hypothesis.
The Rare Life hypothesis
The stringent nature of this hypothesis can be seen in its decreased population of life-bearing planets in comparison to the other hypotheses (with an inhabited fraction of only 0.01%). However, despite this stringency, there is a significant number of civilizations forming over the Galaxy's lifetime: around 1% of all life-bearing planets produce intelligent species. Again, as expected, around half of all civilizations destroy themselves (Table 3).
Table 3. Statistics for the Rare Life hypothesis
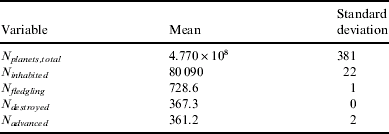
The distribution of galactocentric radii (Fig. 10, left panel) is quite sharply peaked: this is because life requires Z *⩾Z ⊙ (which is clearly seen in Fig. 11, right panel) under this hypothesis, and fixes a maximum r gal, beyond which life cannot begin. Considering the habitation index (Fig. 10, right panel), it can be seen that there is a great deal of colonization occurring. This is due to the criterion that life can only develop in multiple planetary systems, and hence any intelligence that becomes advanced must take part in colonization. The distribution of star mass, although greatly reduced, is qualitatively the same as for the Panspermia hypothesis, and hence the signal lifetime has a similar distribution also (Fig. 12).

Fig. 10. The distribution of galactocentric radius (left) and habitation index (right) under the Rare Life hypothesis.

Fig. 11. The distribution of host star mass (left) and metallicity (right) under the Rare Life hypothesis.

Fig. 12. The distribution of signal lifetimes (left) and the signal history of the Galaxy (right) under the Rare Life hypothesis.
The Tortoise and Hare hypothesis
The biological data for this hypothesis is not markedly different from the Panspermia hypothesis, again with an inhabited fraction of around 0.1%. However, the true difference is in the civilization data: instead of there being an approximate 1:1 ratio between self-destruction and advancement, it can be seen that this hypothesis weakly favours self-destruction for a given fledgling civilization, with a ratio of approximately 1.38:1. Despite this, around 4% of inhabited planets develop intelligent life that survives the fledgling phase (Table 4).
Table 4. Statistics for the Tortoise and Hare hypothesis
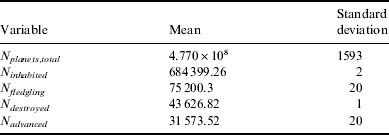
The Galactic Habitable Zone is similar to that for the Panspermia hypothesis: the weak favouring of self-destruction can be seen in the right panel of Fig. 13. Comparing the data between this hypothesis and the Panspermia hypothesis, both the qualitative and the quantitative behaviour is similar. This reflects the similarity of the two hypotheses in terms of biological parameters, and that the key difference is in the sociological parameter P destroy (Figs 14 and 15).

Fig. 13. The distribution of galactocentric radius (left) and habitation index (right) under the Tortoise and Hare hypothesis.

Fig. 14. The distribution of host star mass (left) and metallicity (right) under the Tortoise and Hare hypothesis.

Fig. 15. The distribution of signal lifetimes (left) and the signal history of the Galaxy (right) under the Tortoise and Hare hypothesis.
Conclusions
The results for all three hypotheses show clear trends throughout. In all cases, the inhabited planets orbit low-mass stars (a symptom of the Hot Jupiter bias present in the current data); and the signal lifetimes are correspondingly dependent on these masses (as expected, given its functional form). The signal history of all three hypotheses shows a period of transition between low-signal number and high-signal number at around t t H, again symptomatic of the Biological Copernican Principle used to constrain τi, N stages, etc.
This paper has outlined a means by which key SETI variables can be estimated, taking into account the diverse planetary niches that are known to exist in the Milky Way and the stochastic evolutionary nature of life, as well as providing estimates of errors on these variables. However, two notes of caution must be offered.
1. The reader may be suspicious of the high precision of the statistics quoted. It is worth noting that the standard deviations of these results are indeed low, and the data is precise, but its accuracy is not as certain. The output data will only be as useful as the input data will allow (the perennial ‘garbage in, garbage out’ problem). Current data on exoplanets, while improving daily, is still insufficient to explore the parameter space in mass and orbital radii, and as such all results here are very much incomplete. Conversely, as observations improve and catalogues attain higher completeness, the efficacy of the MCR method also improves. Future studies will also consider planetary parameters that are sampled as to match current planet formation theory, rather than current observations.
2. The method currently does not produce a realistic age metallicity relation (AMR). Age, metallicity and galactocentric radius are intrinsically linked in this setup: to obtain realistic data for all three self-consistently requires an improved three-dimensional galaxy model that takes into account its various components (the bulge, the bar, etc), as well as the time evolution of the Galaxy. Future work will attempt to incorporate a more holistic model that allows all three parameters to be sampled correctly. In particular, future efforts will be able to take advantage of better numerical models for the star formation history (e.g. Rocha-Pinto et al. Reference Rocha-Pinto, Scalo, Maciel and Flynn2000), and the spatial distribution of stars (e.g. Dehnen & Binney Reference Dehnen and Binney1998).
Although this paper applies the ‘hard step scenario’ to the biological processes modelled, the method itself is flexible enough to allow other means of evolving life and intelligence. The minutiae of how exactly the biological parameters are calculated do not affect the overall concept: this work has shown that it is possible to simulate a realistic backdrop (in terms of stars and planets) for the evolution of ETI, whether it is modelled by the ‘hard step’ scenario or by some other stochastic method. Incorporating new empirical input from the next generation of terrestrial planet finders, e.g. Kepler (Borucki et al. Reference Borucki, Koch, Basri, Batalha, Brown, Caldwell, Christensen-Dalsgaard, Cochran, Dunham and Gautier2008), as well as other astrobiological research into the model, alongside new theoretical input by adding more realistic physics and biology will strengthen the efficacy of this Monte Carlo technique, providing a new avenue of SETI research, and a means to bring many disparate areas of astronomical research together.
Acknowledgements
The author would like to thank the referee for valuable comments and suggestions that greatly improved this paper. The simulations described in this paper were carried out using high-performance computing funded by the Scottish Universities Physics Alliance (SUPA).



















