


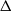
Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Gagnon, Philippe
and
Maire, Florian
2024.
An asymptotic Peskun ordering and its application to lifted samplers.
Bernoulli,
Vol. 30,
Issue. 3,
Choi, Michael C.H.
and
Wolfer, Geoffrey
2025.
Markov chain entropy games and the geometry of their Nash equilibria
.
Latin American Journal of Probability and Mathematical Statistics,
Vol. 22,
Issue. 2,
p.
925.
Gagnon, Philippe
and
Maire, Florian
2026.
Theoretical guarantees for lifted samplers.
Stochastic Processes and their Applications,
Vol. 199,
Issue. ,
p.
104937.