Refine listing
Actions for selected content:
1745 results in 60Jxx
Remarks on Kolmogorov’s constant for simple branching processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 28 April 2026, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Recent investigations have argued that there is a simple explicit representation for the Kolmogorov constant c associated with the subcritical Galton–Watson branching process. We exhibit examples showing that although this representation can be valid, it more often is not. Our work is presented in terms of the limiting conditional mean population size
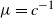 $\mu=c^{-1}$. The analogous quantity for the Markov branching process is denoted by
$\mu=c^{-1}$. The analogous quantity for the Markov branching process is denoted by 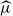 $\widehat\mu$. We show that the simple representation put forward for
$\widehat\mu$. We show that the simple representation put forward for 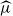 $\widehat\mu$ in fact is an upper bound that is attained only if the offspring-number probability-generating function is quadratic. The conditional mean
$\widehat\mu$ in fact is an upper bound that is attained only if the offspring-number probability-generating function is quadratic. The conditional mean 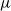 $\mu$ is the limit of a computable increasing sequence
$\mu$ is the limit of a computable increasing sequence 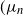 $(\mu_n$). Estimates of n are determined ensuring that, for any small positive number
$(\mu_n$). Estimates of n are determined ensuring that, for any small positive number  $\varepsilon$,
$\varepsilon$, 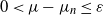 $0\lt\mu-\mu_n\le \varepsilon$.
$0\lt\mu-\mu_n\le \varepsilon$.
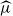
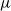
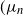

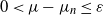
Does Hamiltonian Monte Carlo mix faster than a random walk on multimodal densities?
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 23 April 2026, pp. 1-48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Hamiltonian Monte Carlo (HMC) is a very popular collection of Markov chain Monte Carlo (MCMC) algorithms. One explanation for the popularity of HMC algorithms is their excellent performance as the dimension d of the target becomes large: theoretical analyses show that popular versions of HMC can have a running time that scales as well as
 $d^{0.25}$ in good conditions, while even an optimally tuned random-walk metropolis (RWM) algorithm will not do better than d. In this paper, we investigate a different scaling question: does HMC beat RWM for targets with well-separated modes? We find that the answer is often no. Our main tool for answering this question is a novel and simple formula for the conductance of HMC based on Liouville’s theorem, and we also show how this new formula can be used to give very short proofs of results that seem tedious to show with the usual formula. We also use this result to compute the spectral gap of HMC algorithms, for both the classical HMC with isotropic momentum and the recent Riemannian HMC, for multimodal targets. While we focus on the concrete comparison of RWM and HMC, we expect qualitatively similar conclusions to hold for other gradient-based algorithms.
$d^{0.25}$ in good conditions, while even an optimally tuned random-walk metropolis (RWM) algorithm will not do better than d. In this paper, we investigate a different scaling question: does HMC beat RWM for targets with well-separated modes? We find that the answer is often no. Our main tool for answering this question is a novel and simple formula for the conductance of HMC based on Liouville’s theorem, and we also show how this new formula can be used to give very short proofs of results that seem tedious to show with the usual formula. We also use this result to compute the spectral gap of HMC algorithms, for both the classical HMC with isotropic momentum and the recent Riemannian HMC, for multimodal targets. While we focus on the concrete comparison of RWM and HMC, we expect qualitatively similar conclusions to hold for other gradient-based algorithms.

Quasistatic approximation to time-inhomogeneous stochastic differential equations
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 22 April 2026, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This work studies time averages of an observable
 $h(t,X_t)$, where
$h(t,X_t)$, where  $X_t$ is the solution to a time-inhomogeneous stochastic differential equation (SDE) driven by drift, b(t, x), and diffusion,
$X_t$ is the solution to a time-inhomogeneous stochastic differential equation (SDE) driven by drift, b(t, x), and diffusion,  $\sigma(t{,}{\kern.5pt}x)$, that change sufficiently slowly in time. In this quasistatic regime we derive an approximation to the time average that is computable from properties of the time-homogeneous SDEs driven by
$\sigma(t{,}{\kern.5pt}x)$, that change sufficiently slowly in time. In this quasistatic regime we derive an approximation to the time average that is computable from properties of the time-homogeneous SDEs driven by  $b(t,\cdot)$ and
$b(t,\cdot)$ and  $\sigma(t,\cdot)$ with fixed t; specifically, we utilize
$\sigma(t,\cdot)$ with fixed t; specifically, we utilize  $\log$-Sobolev inequalities for the instantaneous invariant distribution and generator for each t. We obtain explicit non-asymptotic error bounds on this quasistatic approximation, both in the form of concentration inequalities and bounds on the expected value. The error bounds demonstrate a competition between the speed of convergence to the instantaneous invariant distributions and their rate of change, matching the intuition that underlies the quasistatic approximation.
$\log$-Sobolev inequalities for the instantaneous invariant distribution and generator for each t. We obtain explicit non-asymptotic error bounds on this quasistatic approximation, both in the form of concentration inequalities and bounds on the expected value. The error bounds demonstrate a competition between the speed of convergence to the instantaneous invariant distributions and their rate of change, matching the intuition that underlies the quasistatic approximation.






A star is born: Explosive Crump–Mode–Jagers branching processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 13 April 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Persistence of AR(
 $1$) sequences with Rademacher innovations and linear mod
$1$) sequences with Rademacher innovations and linear mod 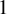 $1$ transforms
$1$ transforms
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems , First View
- Published online by Cambridge University Press:
- 07 April 2026, pp. 1-52
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the probability that an AR(1) Markov chain
 $X_{n+1}=aX_n+\xi _{n+1}$, where
$X_{n+1}=aX_n+\xi _{n+1}$, where  $a\in (0,1)$ is a constant, stays non-negative for a long time. We find the exact asymptotics of this probability and the weak limit of
$a\in (0,1)$ is a constant, stays non-negative for a long time. We find the exact asymptotics of this probability and the weak limit of  $X_n$ conditioned to stay non-negative, assuming that the independent and identically distributed innovations
$X_n$ conditioned to stay non-negative, assuming that the independent and identically distributed innovations  $\xi _n$ take only two values
$\xi _n$ take only two values 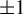 $\pm 1$ and
$\pm 1$ and 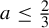 $a \le \tfrac 23$. This limiting distribution is quasi-stationary. It has no atoms and is singular with respect to the Lebesgue measure when
$a \le \tfrac 23$. This limiting distribution is quasi-stationary. It has no atoms and is singular with respect to the Lebesgue measure when 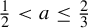 $\tfrac 12< a \le \tfrac 23$, except for the case when
$\tfrac 12< a \le \tfrac 23$, except for the case when  $a=\tfrac 23$ and
$a=\tfrac 23$ and  $\mathbb P(\xi _n=1)=\tfrac 12$, where this distribution is uniform on the interval
$\mathbb P(\xi _n=1)=\tfrac 12$, where this distribution is uniform on the interval 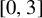 $[0,3]$. This is similar to the properties of Bernoulli convolutions. For
$[0,3]$. This is similar to the properties of Bernoulli convolutions. For  $0 < a \le \tfrac 12$, the situation is much simpler and the limiting distribution is a
$0 < a \le \tfrac 12$, the situation is much simpler and the limiting distribution is a 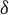 $\delta $-measure. To prove these results, we uncover a close connection between
$\delta $-measure. To prove these results, we uncover a close connection between  $X_n$ killed at exiting
$X_n$ killed at exiting  $[0, \infty )$ and the classical dynamical system defined by the piecewise linear mapping
$[0, \infty )$ and the classical dynamical system defined by the piecewise linear mapping 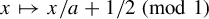 $x \mapsto x/a + 1/2\ \pmod 1$. Namely, the trajectory of this system started at
$x \mapsto x/a + 1/2\ \pmod 1$. Namely, the trajectory of this system started at 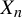 $X_n$ deterministically recovers the values of the killed chain in reversed time. We use this fact to construct a suitable Banach space, where the transition operator of the killed chain has the compactness properties that allow us to apply a conventional argument of the Perron–Frobenius type.
$X_n$ deterministically recovers the values of the killed chain in reversed time. We use this fact to construct a suitable Banach space, where the transition operator of the killed chain has the compactness properties that allow us to apply a conventional argument of the Perron–Frobenius type.

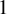




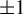
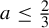
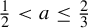


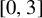

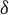


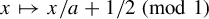
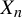
A forward algorithm for a class of Markov zero-sum stopping games
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 31 March 2026, pp. 1-28
-
- Article
- Export citation
Efficient simulation of fractional Brownian motion
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 26 March 2026, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Fractional Brownian motion, with its long-time correlated increments, has been applied in many fields in recent years. Since volatility was shown to be rough by Gatheral, Jaisson, and Rosenbaum, fractional Brownian motion has gained popularity as a financial model. In this work, we revisit the definitions and properties of the univariate and multivariate fractional Brownian motions, and consider four simulation methods. We demonstrate the issues associated with applying the standard Euler scheme for simulating stochastic processes driven by fractional Brownian motion with
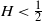 $H < \frac{1}{2}$ (which we call the rough models). We then introduce a novel approximate method for simulating such rough models based on the fast algorithm by Ma and Wu, which accounts for a factor of 10 speedup. Finally, we consider applications of these methods to option pricing.
$H < \frac{1}{2}$ (which we call the rough models). We then introduce a novel approximate method for simulating such rough models based on the fast algorithm by Ma and Wu, which accounts for a factor of 10 speedup. Finally, we consider applications of these methods to option pricing.
Large deviations for Cox–ingersoll–ross processes with state-dependent fast switching
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 26 March 2026, pp. 1-34
-
- Article
- Export citation
-
We study large deviations for Cox–Ingersoll–Ross processes with small noise and state-dependent fast switching via associated Hamilton–Jacobi–Bellman equations. As time scales separate, when the noise goes to 0 and the rate of switching goes to
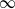 $\infty$, we get a limit equation characterized by the averaging principle. Moreover, we prove the large deviation principle with an action-integral form rate function to describe the asymptotic behavior of such systems. The new ingredient is establishing the comparison principle in the singular context. The proof is carried out using the nonlinear semigroup method from Feng and Kurtz’s book [14].
$\infty$, we get a limit equation characterized by the averaging principle. Moreover, we prove the large deviation principle with an action-integral form rate function to describe the asymptotic behavior of such systems. The new ingredient is establishing the comparison principle in the singular context. The proof is carried out using the nonlinear semigroup method from Feng and Kurtz’s book [14].
An EM algorithm for estimating phase-type distributions with left-truncated and right-censored data
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 24 March 2026, pp. 1-20
-
- Article
- Export citation
Strong survival and extinction for branching random walks via new order for generating functions
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-19
-
- Article
- Export citation
-
We consider general discrete-time multitype branching processes on a countable set X. According to these processes, a particle of type
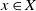 $x\in X$ generates a random number of children and chooses their type in X, not necessarily independently nor with the same law for different parent types. We introduce a new type of stochastic ordering of multitype branching processes, generalising the germ order introduced by Hutchcroft, which relies on the generating function of the process. We prove that given two multitype branching processes with laws
$x\in X$ generates a random number of children and chooses their type in X, not necessarily independently nor with the same law for different parent types. We introduce a new type of stochastic ordering of multitype branching processes, generalising the germ order introduced by Hutchcroft, which relies on the generating function of the process. We prove that given two multitype branching processes with laws 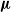 ${\boldsymbol{\mu}}$ and
${\boldsymbol{\mu}}$ and  ${\boldsymbol{\nu}}$ respectively, with
${\boldsymbol{\nu}}$ respectively, with 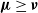 ${\boldsymbol{\mu}}\ge{\boldsymbol{\nu}}$, then in every set where there is survival according to
${\boldsymbol{\mu}}\ge{\boldsymbol{\nu}}$, then in every set where there is survival according to  ${\boldsymbol{\nu}}$, there is also survival according to
${\boldsymbol{\nu}}$, there is also survival according to 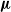 ${\boldsymbol{\mu}}$. Moreover, in every set where there is strong survival according to
${\boldsymbol{\mu}}$. Moreover, in every set where there is strong survival according to  ${\boldsymbol{\nu}}$, there is also strong survival according to
${\boldsymbol{\nu}}$, there is also strong survival according to 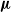 ${\boldsymbol{\mu}}$, provided that the supremum of the global extinction probabilities for the
${\boldsymbol{\mu}}$, provided that the supremum of the global extinction probabilities for the  ${\boldsymbol{\nu}}$ process, taken over all starting points x, is strictly smaller than 1. New conditions for survival and strong survival for inhomogeneous multitype branching processes are provided. We also extend a result of Moyal which claims that, under some conditions, the global extinction probability for a multitype branching process is the only fixed point of its generating function, whose supremum over all starting coordinates may be smaller than 1.
${\boldsymbol{\nu}}$ process, taken over all starting points x, is strictly smaller than 1. New conditions for survival and strong survival for inhomogeneous multitype branching processes are provided. We also extend a result of Moyal which claims that, under some conditions, the global extinction probability for a multitype branching process is the only fixed point of its generating function, whose supremum over all starting coordinates may be smaller than 1.
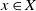
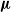

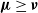

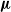

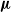

The largest subcritical component in inhomogeneous random graphs of preferential attachment type
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 04 March 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
De Finetti’s control for refracted skew Brownian motion
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 03 March 2026, pp. 1-42
-
- Article
- Export citation
On asymptotic behavior of time of extinction of critical bisexual branching process in random environment
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 02 March 2026, pp. 1-13
-
- Article
- Export citation
-
We consider a critical bisexual branching process in a random environment generated by independent and identically distributed random variables. Assuming that the process starts with a large number of pairs N, we prove that its extinction time is of order
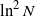 $\ln^2 N$. Interestingly, this result is valid for a general class of mating functions. Among these are the functions describing the monogamous and polygamous behavior of couples, as well as the function reducing the bisexual branching process to the simple one.
$\ln^2 N$. Interestingly, this result is valid for a general class of mating functions. Among these are the functions describing the monogamous and polygamous behavior of couples, as well as the function reducing the bisexual branching process to the simple one.
Analysing heavy-tail properties of stochastic gradient descent by means of stochastic recurrence equations
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 10 February 2026, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In recent works on the theory of machine learning, it has been observed that heavy tail properties of stochastic gradient descent (SGD) can be studied in the probabilistic framework of stochastic recursions. In particular, Gürbüzbalaban et al. (2021) considered a setup corresponding to linear regression for which iterations of SGD can be modelled by a multivariate affine stochastic recursion
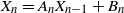 $X_n=A_nX_{n-1}+B_n$ for independent and identically distributed pairs
$X_n=A_nX_{n-1}+B_n$ for independent and identically distributed pairs 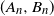 $(A_n,B_n)$, where
$(A_n,B_n)$, where 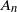 $A_n$ is a random symmetric matrix and
$A_n$ is a random symmetric matrix and 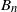 $B_n$ is a random vector. However, their approach is not completely correct and, in the present paper, the problem is put into the right framework by applying the theory of irreducible-proximal matrices.
$B_n$ is a random vector. However, their approach is not completely correct and, in the present paper, the problem is put into the right framework by applying the theory of irreducible-proximal matrices.
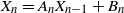
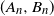
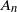
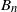
Euler–Maruyama approximation for stable stochastic differential equations with Markovian switching and related asymptotics
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 05 February 2026, pp. 1-29
-
- Article
- Export citation
-
We investigate the EM approximation for
 $\mathbb{R}^d$-valued ergodic stochastic differential equations (SDEs) driven by rotationally invariant
$\mathbb{R}^d$-valued ergodic stochastic differential equations (SDEs) driven by rotationally invariant  $\alpha$-stable processes (
$\alpha$-stable processes ( $\alpha\in(1,2)$) with Markovian switching. The coefficient g violates the dissipative condition for certain states of the switching process. Using the Lindeberg principle, we establish quantitative error bounds between the original process
$\alpha\in(1,2)$) with Markovian switching. The coefficient g violates the dissipative condition for certain states of the switching process. Using the Lindeberg principle, we establish quantitative error bounds between the original process  $(X_t,R_t)_{t\geqslant 0}$ and its Euler–Maruyama (EM) scheme under a specially designed metric. Furthermore, we derive both a central limit theorem and a moderate derivation principle for the empirical measures of both the SDE and its EM scheme. The theoretical results are subsequently validated through a concrete example.
$(X_t,R_t)_{t\geqslant 0}$ and its Euler–Maruyama (EM) scheme under a specially designed metric. Furthermore, we derive both a central limit theorem and a moderate derivation principle for the empirical measures of both the SDE and its EM scheme. The theoretical results are subsequently validated through a concrete example.




Quantitative convergence rates for stochastically monotone Markov chains
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 21 January 2026, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Comparing the Efficiency of General State Space Reversible MCMC Algorithms
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 15 January 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove new results about comparing the efficiency of general state space Markov chain Monte Carlo algorithms that randomly select a possibly different reversible method at each step (previously known only for finite state spaces). We also provide new, simpler, more accessible proofs of key results, and analyse numerous examples. We provide a full proof of the formula for the asymptotic variance for real-valued functionals on
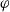 $\varphi$-irreducible reversible Markov chains, first introduced by Kipnis and Varadhan (1986, Commun. Math. Phys. 104, 1–19). Given two Markov kernels P and Q with stationary measure
$\varphi$-irreducible reversible Markov chains, first introduced by Kipnis and Varadhan (1986, Commun. Math. Phys. 104, 1–19). Given two Markov kernels P and Q with stationary measure 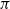 $\pi$, we say that the Markov kernel P efficiency-dominates the Markov kernel Q if the asymptotic variance with respect to P is at most the asymptotic variance with respect to Q for every real-valued functional
$\pi$, we say that the Markov kernel P efficiency-dominates the Markov kernel Q if the asymptotic variance with respect to P is at most the asymptotic variance with respect to Q for every real-valued functional 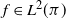 $f\in L^2(\pi)$. Assuming only a basic background in functional analysis, we prove that for two reversible Markov kernels P and Q, P efficiency-dominates Q if and only if the operator
$f\in L^2(\pi)$. Assuming only a basic background in functional analysis, we prove that for two reversible Markov kernels P and Q, P efficiency-dominates Q if and only if the operator 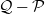 $\mathcal{Q}-\mathcal{P}$, where
$\mathcal{Q}-\mathcal{P}$, where 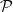 $\mathcal{P}$ is the operator on
$\mathcal{P}$ is the operator on 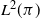 $L^2(\pi)$ that maps
$L^2(\pi)$ that maps 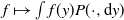 $f\mapsto\int f(y)P(\cdot,\mathrm{d}y)$ and similarly for
$f\mapsto\int f(y)P(\cdot,\mathrm{d}y)$ and similarly for 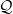 $\mathcal{Q}$, is positive on
$\mathcal{Q}$, is positive on 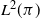 $L^2(\pi)$, i.e.
$L^2(\pi)$, i.e.  $\langle f,\left(\mathcal{Q}-\mathcal{P}\right)f\rangle\geq0$ for every
$\langle f,\left(\mathcal{Q}-\mathcal{P}\right)f\rangle\geq0$ for every 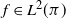 $f\in L^2(\pi)$ (previous proofs for general state spaces use technical results from monotone operator function theory). We use this result to show that under mild conditions, sandwich variants of data augmentation algorithms efficiency-dominate the original algorithm. We also provide other easy-to-check sufficient conditions for efficiency dominance, some of which are generalized from the finite state space case. We also provide a proof based on that of Tierney (1998, Ann. Appl. Prob. 8, 1–9) that Peskun dominance is a sufficient condition for efficiency dominance for reversible kernels. Using these results, we show that Markov kernels formed by random selection of other ‘component’ Markov kernels will always efficiency-dominate another Markov kernel formed in this way, as long as the component kernels of the former efficiency-dominate those of the latter. These results on the efficiency dominance of combining component kernels generalizes the results on the efficiency dominance of combined chains introduced by Neal and Rosenthal (2024, J. Appl. Prob. 62, 188–208) from finite state spaces to general state spaces.
$f\in L^2(\pi)$ (previous proofs for general state spaces use technical results from monotone operator function theory). We use this result to show that under mild conditions, sandwich variants of data augmentation algorithms efficiency-dominate the original algorithm. We also provide other easy-to-check sufficient conditions for efficiency dominance, some of which are generalized from the finite state space case. We also provide a proof based on that of Tierney (1998, Ann. Appl. Prob. 8, 1–9) that Peskun dominance is a sufficient condition for efficiency dominance for reversible kernels. Using these results, we show that Markov kernels formed by random selection of other ‘component’ Markov kernels will always efficiency-dominate another Markov kernel formed in this way, as long as the component kernels of the former efficiency-dominate those of the latter. These results on the efficiency dominance of combining component kernels generalizes the results on the efficiency dominance of combined chains introduced by Neal and Rosenthal (2024, J. Appl. Prob. 62, 188–208) from finite state spaces to general state spaces.
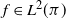
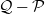
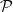
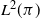
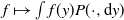
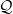
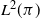

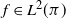
Degree-penalized contact processes
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 14 / 2026
- Published online by Cambridge University Press:
- 15 January 2026, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper we study degree-penalized contact processes on Galton-Watson (GW) trees and the configuration model. The model we consider is a modification of the usual contact process on a graph. In particular, each vertex can be either infected or healthy. When infected, each vertex heals at rate one. Also, when infected, a vertex u with degree
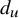 $d_u$ infects its neighboring vertex v with degree
$d_u$ infects its neighboring vertex v with degree 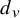 $d_v$ with rate
$d_v$ with rate 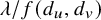 $\lambda / f(d_u, d_v)$ for some positive function f. In the case
$\lambda / f(d_u, d_v)$ for some positive function f. In the case 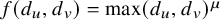 $f(d_u, d_v)=\max (d_u, d_v)^\mu $ for some
$f(d_u, d_v)=\max (d_u, d_v)^\mu $ for some 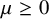 $\mu \ge 0$, the infection is slowed down to and from high-degree vertices. This is in line with arguments used in social network science: people with many contacts do not have the time to infect their neighbors at the same rate as people with fewer contacts.
$\mu \ge 0$, the infection is slowed down to and from high-degree vertices. This is in line with arguments used in social network science: people with many contacts do not have the time to infect their neighbors at the same rate as people with fewer contacts.We show that new phase transitions occur in terms of the parameter
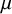 $\mu $ (at
$\mu $ (at 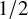 $1/2$) and the degree distribution D of the GW tree.
$1/2$) and the degree distribution D of the GW tree. • When
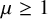 $\mu \ge 1$, the process goes extinct for all distributions D for all sufficiently small
$\mu \ge 1$, the process goes extinct for all distributions D for all sufficiently small 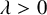 $\lambda>0$;
$\lambda>0$;• When
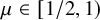 $\mu \in [1/2, 1)$, and the tail of D weakly follows a power law with tail-exponent less than
$\mu \in [1/2, 1)$, and the tail of D weakly follows a power law with tail-exponent less than 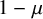 $1-\mu $, the process survives globally but not locally for all
$1-\mu $, the process survives globally but not locally for all 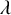 $\lambda $ small enough;
$\lambda $ small enough;• When
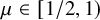 $\mu \in [1/2, 1)$, and
$\mu \in [1/2, 1)$, and 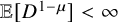 $\mathbb {E}[D^{1-\mu }]<\infty $, the process goes extinct almost surely, for all
$\mathbb {E}[D^{1-\mu }]<\infty $, the process goes extinct almost surely, for all 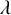 $\lambda $ small enough;
$\lambda $ small enough;• When
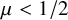 $\mu <1/2$, and D is heavier than stretched exponential with stretch-exponent
$\mu <1/2$, and D is heavier than stretched exponential with stretch-exponent 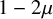 $1-2\mu $, the process survives (locally) with positive probability for all
$1-2\mu $, the process survives (locally) with positive probability for all 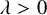 $\lambda>0$.
$\lambda>0$.
We also study the product case, where
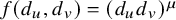 $f(d_u,d_v)=(d_u d_v)^\mu $. In that case, the situation for
$f(d_u,d_v)=(d_u d_v)^\mu $. In that case, the situation for 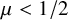 $\mu < 1/2$ is the same as the one described above, but
$\mu < 1/2$ is the same as the one described above, but 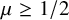 $\mu \ge 1/2$ always leads to a subcritical contact process for small enough
$\mu \ge 1/2$ always leads to a subcritical contact process for small enough 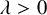 $\lambda>0$ on all graphs. Furthermore, for finite random graphs with prescribed degree sequences, we establish the corresponding phase transitions in terms of the length of survival.
$\lambda>0$ on all graphs. Furthermore, for finite random graphs with prescribed degree sequences, we establish the corresponding phase transitions in terms of the length of survival.
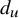
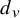
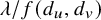
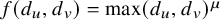
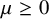
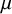
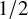
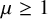
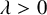
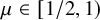
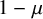
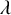
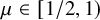
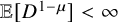
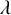
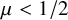
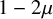
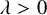
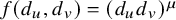
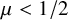
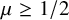
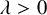
Competition of small targets in planar domains: from Dirichlet to Robin and Steklov boundary condition
- Part of
-
- Journal:
- European Journal of Applied Mathematics , First View
- Published online by Cambridge University Press:
- 12 January 2026, pp. 1-48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multitype branching processes with immigration generated by point processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 12 January 2026, pp. 1-21
-
- Article
- Export citation
