

INTRODUCTION
Free and fair elections, the cornerstone of modern democratic government, require officials to count and aggregate ballots accurately (Enikolopov et al. Reference Enikolopov, Korovkin, Petrova, Sonin and Zakharov2013; Klimek et al. Reference Klimek, Yegorov, Hanel and Thurner2012; Lehoucq Reference Lehoucq2003). The international community spends hundreds of millions of dollars every year trying to ensure fair elections in developing countries with widespread electoral malpractice (Bjornlund Reference Bjornlund2004). One common donor policy deploys election observers to improve electoral integrity (Bjornlund et al. Reference Bjornlund, Bratton and Gibson1992; Hyde Reference Hyde2007, Reference Hyde2010, Reference Hyde2011; Kelley Reference Kelley2012). Such missions, however, have not typically followed scientific designs to detect, nor have they had any consistent effects on, electoral malfeasance (Kelley Reference Kelley2012; Simpser and Donno Reference Simpser and Donno2012). This means that the widely publicized observer verdicts of whether an election is “free or fair” are based largely on anecdotal and unsystematic data.
While some research demonstrates positive effects from monitoring in certain settings (Enikolopov et al. Reference Enikolopov, Korovkin, Petrova, Sonin and Zakharov2013; Hyde Reference Hyde2007, Reference Hyde2010, Reference Hyde2011), other studies using cross-national data show that international efforts are actually more likely to be associated with null or negative impacts on electoral processes (Kelley Reference Kelley2012; Simpser and Donno Reference Simpser and Donno2012). This divergence may result from the protocols of standard observation missions, which typically do not measure their effect on electoral irregularities. First, observers are either sent to a non-random set of centers or deviate from randomized assignment protocols (by mistake or because they go to centers they believe more likely to experience fraud) (Enikolopov et al. Reference Enikolopov, Korovkin, Petrova, Sonin and Zakharov2013; Hyde Reference Hyde2007, Reference Hyde2010).Footnote 1 Election officials may predict observer deployments ex ante and strategically choose locations to commit fraud elsewhere. Second, observers pursue a variety of tasks during their missions, making it difficult to identify or measure any precise intervention. These diverse activities may include interacting with polling staff, voters, other observers, and party agents; inspecting voting materials; and watching voting and counting processes. Moreover, observers spend varying amounts of time on these activities. Third, observer missions typically do not employ precise outcome measures.Footnote 2 Since electoral irregularities, including fraud, come in a variety of forms, verdicts of “free and fair” implicitly refer to all of them while not necessarily measuring any of them systematically. Fourth, observation efforts rarely compare visited with non-visited polling centers, preventing an assessment of a monitoring treatment against an unmonitored control.Footnote 3 Finally, international observers seldom harness innovations in ICT. ICT allows users to increase government accountability and transparency by quickly and cheaply aggregating diffuse information that is useful for auditing, such as polling station results, with the ability to scale coverage significantly beyond where international observers typically visit. Recent research also demonstrates how ICT can catalyze democratic mobilization through effective organization building and crowd-sourcing (Bond et al. Reference Bond, Fariss, Jones, Kramer, Marlow and Settle2012; Nisbet et al. Reference Nisbet, Stoycheff and Pearce2012; Pickard et al. Reference Pickard, Rahwan, Pan, Cebrian, Crane, Madan and Pentland2011; Valenzuela Reference Valenzuela2013). The shortcomings of standard election monitoring procedures thus hinder researchers and policymakers from accurately measuring the effect of observation on electoral integrity in a consistent, reliable, comparable, or scalable manner.
To address these challenges, we present results from a nation-wide randomized controlled trial (RCT) using a precise intervention and ICT designed to reduce irregularities and fraud associated with vote tallies at the polling center level conducted during Uganda's 2011 national election. Many fragile democracies like Uganda suffer from institutional weaknesses that foster bureaucratic corruption (Cohen Reference Cohen2008). Given the high return on rents from gaining office, unscrupulous political agents frequently threaten the integrity of electoral processes. They may do so locally by influencing the actions of polling center managers, or more centrally by using their control over the government's electoral machinery (Callen and Long Reference Callen and Long2015). Yet detecting and deterring such malfeasance is difficult since the illicit actions intended to manufacture electoral victories are often hidden.
Our intervention compares smartphone photographs of Declaration of Results forms—which are posted publicly at polling stations and list vote totals for each candidate—against the corresponding records published by the Election Commission at the conclusion of the election. In theory, this approach should allow us to perfectly observe any votes that are altered during the aggregation process. Our experiment involves delivering a randomized announcement of election monitoring, indicating the use of this smartphone technology. We measure the impacts of communicating information related to both monitoring and to punishments for malfeasance on election fraud. Specifically, we argue that in line with standard corruption models, the delivery of a letter announcing the monitoring of vote tallies by domestic researchers to polling center officials should increase the likelihood that ballots are correctly aggregated. We call this the “Monitoring” letter. This intervention derives from insights from the political economy of corruption that officials will change their expectation about the probability that potentially illegal behavior will be detected once monitoring is announced (Becker Reference Becker1968; Becker and Stigler Reference Becker and Stigler1974; Björkman and Svensson Reference Björkman and Svensson2009; Olken Reference Olken2007; Olken and Pande Reference Olken and Pande2013). Additionally, we investigate another treatment that reminds polling officials about the penalties for tally malfeasance, which we call the “Punishment” letter (Shleifer and Vishny Reference Shleifer and Vishny1993). Assuming some non-zero baseline probability that fraud is detected, announcing penalties could make them salient to election officials and therefore reduce the likelihood of irregularities. Including these two treatment arms allows us to compare the “Punishment” treatment to the “Monitoring” treatment. Moreover, since both messages in one letter may have an overall stronger effect, we also estimate the interaction of “Monitoring” and “Punishment.”
From our approach, we hypothesize
-
1. The incidence of electoral irregularities decreases in stations that received a “Monitoring” letter compared to control stations with no announcement (no letter delivery).
-
2. The incidence of election irregularities decreases in stations that received a “Punishment” letter compared to control stations with no announcement (no letter delivery).
-
3. The combination of “Monitoring” and “Punishment” messages decreases electoral irregularities to a greater degree than either message on its own.
Given that the incumbent president in a race has more institutional control over the electoral process than his or her rivals, we examine a fourth hypothesis:
-
4. The votes for the incumbent president decrease in stations that received any letter when compared to control stations.
SAMPLE
Our sample included 1,095 total polling streams clustered within 1,001 total polling centers drawn from Uganda's official national list of polling centers, by registered voters. Occasionally, polling centers will have more than one stream (for example, a school may be a polling center, with multiple voting locations, or streams, like individual classrooms). We consider any stream within a center to be “treated” since a polling center manager is responsible for all streams within a center. We sampled polling centers for this project using two separate protocols. In the Central, West, and East regions, we sampled polling centers using a multi-stage cluster design. In the first stage, we selected 25 counties, stratified by presidential margin of victory in the previous 2006 election. The two main competitors for office in 2011, incumbent president Yoweri Museveni and opposition leader Kizza Besigye, had both competed in 2006.Footnote 4 Specifically, we split counties into quintiles based on Museveni's margin of victory and selected two counties in the most competitive quintile, three counties in the second quintile, five counties in the third quintile, seven counties in the fourth quintile, and eight counties in the least competitive quintile. We define “competitive” as the proportion of the vote that went to Museveni as reported by the Electoral Commission (EC). We predicted that fraud would more likely occur in areas that were less competitive given the ability of the incumbent Museveni to exercise greater political control over electoral institutions and polling center officials in his areas of strong support.Footnote 5 Therefore, our approach oversampled less competitive counties. In the second stage, we drew 95 subcounties in total from within the 25 sampled counties. The number of subcounties per county ranges from 2 to 15, proportionate to the number of registered voters. In the third and final stage, we drew 601 total polling centers with about 5.8 polling centers in each subcounty. Our sample for the Western, Central, and Eastern regions therefore consisted of 25 counties, 95 subcounties, and 601 polling centers.
In the North, we sampled only polling centers in subcounties that experienced violence during the war between the Ugandan Government and the Lord's Resistance Army (LRA) over the period 1987–2008 based on data from Armed Conflict Location and Event Dataset (ACLED). We sampled the North differently than the rest of the country because our funder required that we focus our study only in subcounties affected by conflict, so non-conflict Northern subcounties had zero probability of selection.Footnote 6 This requirement was later removed. We therefore also present results from the North separately from the Central, West, and East regions to analyze our data across the entire national sample, while maintaining the representativeness of the sample that excludes the Northern region. 30 counties, 56 subcounties, and 400 polling centers comprise our Northern sample. Footnote 7
TREATMENT
Our interventions consisted of letters delivered by researchers to polling center officials during voting on election day. Three versions of the letter's message constituted the treatment arms of the experiment: (1) The “Monitoring” letter informed officials that researchers would return to take a photograph of the Declaration of Results form—the tally—that electoral law requires managers to post publicly at the polling center after ballot counting, and that these results would be compared with the center's final count as certified by the Ugandan EC. (2) The “Punishment” letter reminded polling center managers of the 2.4 million Ugandan shilling fine (approximately 1,000 USD, not purchasing power parity adjusted) and/or five years imprisonment for inaccurately reporting voting returns. (3) The third letter included the text of both the monitoring and punishment treatments. Control centers received no letter. We include the text of the “Monitoring” message, the “Punishment” message, and “Both” messages versions of the letters in Appendix A, Figures A1–A3. We randomized the ordering of the “Monitoring” and “Punishment” messages in the “Both” messages version to test for possible order effects. We divided the total sample to include 227 centers in each treatment arm, and 320 centers in the control, based on power calculations of anticipated treatment effects. We sent researchers to photograph tallies of all centers in the sample the day after the election.
To assign treatment status, we conducted a baseline survey in late January 2011, approximately one month before the election. The survey used the polling centers in the experimental sample as primary sampling units (PSUs), so that the survey sampling followed the experimental sampling described above. Enumerators instituted random walk patterns from the polling center location, selecting every fourth house on the left. Within households, enumerators randomly selected voting eligible (18 years or older) respondents via Kish grid. The survey has a 56–44 percent male to female ratio. Enumerators interviewed five respondents per polling center catchment area, yielding a total national sample of 5,007 respondents. The survey probed questions on political attitudes and perceptions, as well as demographic covariates, as shown in Table A1 in the Appendix. Table A1 also checks the balance of these measures across treatment arms.
We stratified our treatment assignment on (i) county, (ii) the share of survey respondents on our baseline survey who indicated that they had read a newspaper in the last seven days, and (iii) on the share who indicated that Museveni's performance as president had been “good” or “excellent.” After randomly assigning treatment status, we assessed covariate balance between treatment and control polling centers. In instances where differences in covariate means were statistically significant below a threshold of p = 0.25, we instituted a procedure of re-randomization with 691 iterations. This so-called “big stick” approach follows the re-randomization procedures described by Bruhn and McKenzie (Bruhn and McKenzie, Reference Bruhn and McKenzie2009).Footnote 8
We provided letters, smartphones, and training to 370 Ugandan researchers and field managers. After being credentialed by the EC as an election observer group as the University of California, each member of the group applied for—and received—accreditation as official observers, certifying them to carry out the research although the EC did not know the substance of the study or the sample of polling centers. We furnished each researcher with an HTC Android-compatible smartphone, equipped with a custom application designed by Qualcomm, Inc. that allowed the photo capture of tallies and the completion of a short survey. Appendix Figure A4 displays the application. Researchers delivered the treatment letters to polling center managers on February 18 (election day) and returned to photograph tallies on February 19 when they were legally required to be posted publicly. We note near universal compliance with letter delivery save for one polling center that fell out of sample on election day, with 95 percent of polling center managers acknowledging receipt by agreeing to sign a copy of the delivered letter. Each tally photo had a unique polling center identification number, as well as a time and date stamp embedded in the data packet to ensure compliance. Figure A5 shows an example of an actual tally photo. After entry on the smartphone, data were immediately sent via Uganda's cellular networks to a server located at the University of California, San Diego. If the smartphones did not carry a signal due to poor network coverage, the application sent the data packet once within network range.
RESULTS
We measure the effect of the intervention by comparing vote totals from treated and control polling centers on two sets of data: the official count at the polling center level produced by the EC and differences in votes in our set of photographed tallies compared to EC results. Given that potentially corrupt polling managers will try to hide illicit behavior, we employ three measures to determine irregular electoral activities that we can observe, which can range from unknowingly committed illegal administrative acts to intentional fraud.Footnote 9 First, we use instances of the absence of provisional tallies, which we label as “Missing.” The handbook that the EC used to train presiding officers clearly states that Ugandan law requires the posting of tallies, and that failure to do so is an abdication of duty and can result in official censure.Footnote 10 The election law requires tallies to be posted publicly to prevent efforts to rig the election through an obviously manipulated local ballot count or in the process of changing the count in the aggregation process.Footnote 11 Data for “Missing” come from our researchers’ visits to polling centers to document the presence or absence of tallies. 77.5 percent of our sample had missing tallies, demonstrating widespread violations of Uganda's election law, which left most Ugandans unable to know or verify the count at their own polling center. Second, we record whether the last two digits in the winning candidate's vote total are adjacent, which we label “Adjacent.” The analysis of adjacent digits—a commonly used measure of electoral fraud—comes from studies in behavioral psychology that document the tendency of humans to disproportionately use adjacent digits when manufacturing numbers (Beber and Scacco Reference Beber and Scacco2012). If election officials are inventing numbers when writing down vote totals rather than recording the actual ballot count, they will likely use numbers with adjacent digits more frequently than at random. The data for the “Adjacent” tests come from the EC's official election results. We note that adjacent digits produced at random should occur 18 percent of the time, but in our sampled polling centers, occurred much more frequently (see Table 1). Third, following other studies that examine the effects of monitoring on votes for powerful candidates (Callen and Long Reference Callen and Long2015; Hyde Reference Hyde2007, Reference Hyde2010), we use the log of the total votes for the incumbent president Yoweri Museveni (“Museveni Votes”), the candidate most likely to benefit from rigging given his executive control over electoral administration. Descriptive statistics for these outcome variables can be found in Appendix Table A4. We estimate the treatment effects on our three dependent variables using six separate linear regressions, with standard errors clustered by polling center and stratum fixed effects. Intercepts represent the mean outcome in the control sample, with coefficients showing the percentage point change in the likelihood of the outcome resulting from treatment.
Table 1 OLS Estimates of the Effects of the Treatment Letters on Missing Tallies, Adjacent Digits, and Votes for Museveni
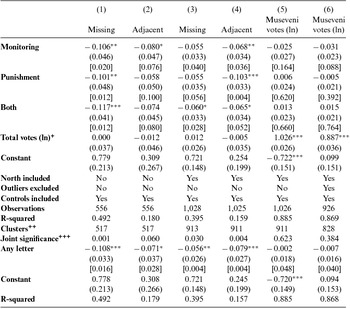
Notes: Estimation is conducted with stratum fixed effects. Coefficients in the top panel are the point estimates for effect of each type of letter intervention. +Log of total votes at each station accounts for station size. ++Standard errors are clustered at the polling center level to account for the intra-class correlation of errors within polling centers (where multiple polling stations vote at a single location, typically a school or church). Fisher Exact Test P-values corresponding to the Sharp Null of no treatment effect for any unit are reported in brackets. Fisher Exact Tests are calculated based on 250 hypothetical treatment assignments following the same assignment protocol as the actual assignment. “Missing” is a dummy variable equal to one if the Declaration of Results form (the tally) was missing at the polling center when our interviewers visited to take a photograph. “Adjacent” is a dummy variable equal to one if the last two digits in the vote total for the top vote recipient at a given polling center are adjacent (e.g. 34 or 21) in the EC's official report of votes. P-values corresponding to a standard difference in means test are denoted by superscript stars: ***p < 0.01, **p < 0.05, *p < 0.1. For example, in column 1, the “Monitoring” letter reduced the number of missing tallies by 10.6 percentage points at the p < 0.05 level. +++Test of joint significance: probability that the null hypothesis can be rejected. Sample sizes differ by polling center and stream due to data availability of tallies and EC certified results. The lower panel reports estimate for “Any letter” being delivered. Note that the specification of the model otherwise is identical, as are the number of clusters and observations.
Our tests indicate that the letter interventions reduced irregular electoral activities. The results found in column 1 of Table 1 (corresponding to Appendix Figure A6, panel A), shows that the “Monitoring” letter decreased missing tallies by 10.6 percentage points in the non-North sample. Table 1 column 2, which uses adjacent digits as the fraud indicator on the same sample, shows that point estimates are always negative although less significant: “Monitoring” decreased adjacent digits by 8 percentage points, “Punishment” by 5.8 percentage points, and “Both” by 7.4 percentage points (corresponding to Appendix Figure A6 panel B). Column 3 in Table 1 uses the entire sample and shows a significant reduction of 6 percentage points of missing tallies for the “Both” letter, and insignificant but negative point estimates for “Monitoring” (5.5 percent) and “Punishment” (5.5 percent) (corresponding to Appendix Figure A6 panel C). Table 1 column 4 displays the effect of the letters over the entire sample on the presence of adjacent digits. All three letters reduced adjacency at a significant level: “Monitoring” by 6.8 percentage points, “Punishment” by 10.3 percentage points, and “Both” by 6.5 percentage points (corresponding to Appendix Figure A6 panel D). There are no consistent patterns between the effects of the three letters. Thus, while all three treatment letters had an effect, the results do not indicate that one treatment is unambiguously stronger than another’s, or that they interact. We therefore pool our treatments, testing the impact of “Any Letter” in the lower panel of Table 1. Delivering any letter reduces missing tallies by 10.8 percentage points in the non-North and 5.6 percentage points in the entire sample (specifications 1 and 3 in the lower panel of Table 1). Similarly, adjacent digits are reduced by 7.1 percentage points in the non-North and 7.9 percentage points in the entire sample (specifications 2 and 4 in the lower panel of Table 1).
We report the effects of the treatment on the log of Museveni votes in columns 5 and 6 in Table 1. Column 5 shows no effect from the three treatments at standard levels of significance. This null finding for hypothesis 4 may arise from the ineffectiveness of monitoring in polling centers under the control of the incumbent Museveni or of one of his competitors. When we exclude the polling centers in the bottom and top five percentiles of the log of Museveni votes from the sample, the “Monitoring” letter decreased Museveni's vote share by more than 3 percentage points (column 6), and we reject the Sharp Null of no effect with a p-value of 0.088, providing some weak support for hypothesis 4. We note that the small effect of the “Monitoring” treatment on Museveni's votes may arise from the lack of a credible threat posed by reminders of penalties to polling officials who may alter votes on his behalf.
Beneath the estimated coefficients corresponding to the treatment effect of “Monitoring”, “Punishment,” and “Both” in Table 1 we also report p-values corresponding to the Fisher Exact Test of the Null of no treatment effect for any unit. The randomization inference approach we use, therefore, tests a hypothesis that is distinct from the standard null of no average effect corresponding to a difference in means test. The Fisher p-value is calculated by comparing the treatment effect estimated based on the actual assignment with treatment effects given by hypothetical assignments using the same randomization protocol. Figure 1 demonstrates this approach by plotting the position of our estimated treatment effect of −0.047 log points as a vertical line in the cumulative distribution of simulated treatment effect estimates. Of 250 simulated treatment assignments, two produce estimates of a more negative treatment effect, yielding a Fisher p-value of 0.016. We take this approach as it addresses two challenges for inference in our setting. First, because the p-value is calculated based on a comparison of hypothetical assignments obtained using the same randomization protocol, we can be confident that our result is not an artifact of our specific assignment protocol. Second, because the approach is non-parametric and the p-value simply reflects where the actual estimate sits in the distribution of potential estimates, we can perform inference without making assumptions on the appropriate form of the standard errors, including the level of clustering. We reject the Sharp Null in every case where we reject the null from a difference in means test. We also reject the Sharp Null for six additional estimates in the top panel of Table 1 where we do not reject the null of no average treatment effect at the 10 percent level.
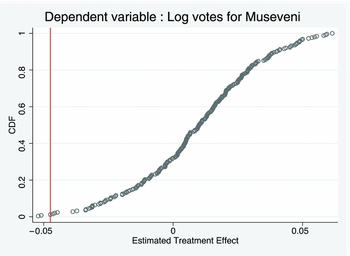
Figure 1
Figure A7 shows the effects of the letters on Museveni's vote total, using only the sample for which we have photographs comparing those results to the EC data. Recall that a majority of tallies were not posted in our treatment sample, generating the smaller and non-random sample we use in Figure A7. Given treatment-related attrition in this sample, we cannot estimate treatment effects across the entire sample using the results from the tests found in Table A3 in Appendix A.Footnote 12 These bounds include zero, but only under the extreme assumption that treatment induced presiding officers to post tallies in polling centers where Museveni received the largest number of votes in the observed treatment sample. There is considerable fraud in this sample. In Figure A7, the lighter bars show the difference between the treatment and the control groups on photographed tallies in this non-representative sample; the darker bars represent the difference on the official results published by the EC. The point estimates are consistent with treatment reducing the number of votes Museveni received as photographed in the tallies. In the sample excluding the North, the “Monitoring” letter reduced Museveni votes by about 30 from an average of 307 votes per polling center; the “Punishment” letter by 26 votes, and “Both” by almost 49 votes—a decrease of 16 percent.
The darker bars in Figure A7 show that the reduction in Museveni's vote due to the treatment letters is still detectable after the EC received and amended the tallies to produce their official, certified results. Under all three treatments, however, the decrease in votes for the incumbent is less than the effect found in photographed tallies. This result could reflect attempts by officials in higher echelons of the electoral administration to offset reductions caused by the treatment letters to Museveni's vote totals after receiving the polling station counts, although we have no additional evidence to support this possibility.Footnote 13
DISCUSSION
We believe our findings provide insights for theory and policy, with application to elections in other emerging democracies. We contribute to studies regarding efforts to reduce corruption (Becker Reference Becker1968; Becker and Stigler Reference Becker and Stigler1974; Björkman and Svensson Reference Björkman and Svensson2009; Ferraz and Finan Reference Ferraz and Finan2008; Olken Reference Olken2007; Olken and Pande Reference Olken and Pande2013; Shleifer and Vishny Reference Shleifer and Vishny1993), and improve electoral integrity. We provide evidence that the intervention letters: (1) decreased the illegal practice of not publicly posting tallies; (2) reduced the number of adjacent digits found on tally sheets; and (3) reduced the vote share for the incumbent President Museveni under certain specifications. The data also show the letter that included both monitoring and punishment messages did not consistently strengthen the treatment effect, and that the decreases in polling center votes for Museveni caused by the letters is systematically related to the inclusion of additional votes at the level of the EC.
Our study also provides important lessons for future election observation efforts. Despite their considerable cost, standard international election missions lack consistent scientific evidence to claim that they improve electoral integrity. While such missions may provide other benefits, such as offering international support for a democratic process, election observation per se does not typically employ research designs that precisely measure their impact on irregular or illicit electoral activities in a representative sample of polling locations. Our study presents a novel, cost-effective, and scalable technique to do so. It contributes to existing approaches by combining experimental design and ICT to enhance the efforts of groups seeking to detect and reduce illicit behavior.
We conclude with some general observations on the potential cost-effectiveness of this approach relative to standard missions. While those missions have a broader set of capacity building objectives beyond reducing election fraud, we believe these comparisons remain salutary. The European Union (EU) provides the total number of polling stations and expenditure data for only two of its 142 mission reports (Guinea-Bissau, 2009 and Nigeria, 2009), with each costing over $20,000 per polling station, although these high costs could include other types of electoral support (European Union 2013). The EU reports that it spends approximately $4 million on an average observation mission (European Union 2006). While the EU declined to publicize their budget for their mission to the 2011 election in Uganda, they report visits to 643 polling centers and tally centers (European Union 2011). Using their average budget, we calculate a $6,220 cost per polling center, with no scientific evidence of impact documented in their report. With a project budget of $40,000 and 1,001 sampled polling centers, our price per polling center was about $40. We note that our design can be adopted easily across a range of countries, and while it would likely be most suitable for domestic groups that can scale their efforts beyond the generally smaller international observation teams, it also points to design features that these groups could use to generate systematic information upon which to base their judgments about election quality. We note that we designed our intervention to target certain behaviors, and any increase in scaling could temporarily off-set gains made at observed polling stations by displacing fraud to unobserved polling stations or to other rigging strategies. For these reasons, we believe scaling with ICT via citizen-based viral adoption may prove the most fruitful avenue to obtain near-universal monitoring coverage of polling centers in a country to report on a variety of illicit activities.
SUPPLEMENTARY MATERIAL
For supplementary material for this article, please visit Cambridge Journals Online: http://dx.doi.org/10.1017/XPS.2015.14.



