



1. Introduction
1.1. Bulk models and uncertainty
Bulk, integral, lumped or coarse-grained models in fluid mechanics involve integrating equations that govern the local (pointwise in space) evolution of a system over a control volume. Such models are useful for providing a macroscopic picture at scales that are directly relevant to a given application. A prevalent example comes from the concept of entrainment across the boundary of a control volume, which is typically defined to demarcate the turbulent parts of a flow from a non-turbulent surrounding environment (Ellison & Turner Reference Ellison and Turner1959; van Reeuwijk, Vassilicos & Craske Reference van Reeuwijk, Vassilicos and Craske2021). However, over a century of intensive research into fluid turbulence has shown that nature does not always yield to coarse representations, demanding, in return, case-dependent closures and probabilistic approaches.
Probabilistic approaches are particularly appropriate for bulk models because the contents of control volumes is typically heterogeneous. A relevant example comes from the field of building ventilation, where it is often assumed that the air in each room or ‘zone’ of a building is well mixed and, therefore, of uniform temperature. However, it is now acknowledged, not least due to concerns raised during the COVID-19 pandemic, that the secondary flows and temperature structures within rooms play an important role in determining the fate of contaminants, energy demands and thermal comfort (see, for example, Vouriot et al. Reference Vouriot, Higton, Linden, Hughes, van Reeuwijk and Burridge2023; Bhagat et al. Reference Bhagat, Dalziel, Davies Wykes and Linden2024). An additional complication, which renders the underlying challenge probabilistic, is that boundary and internal forcing conditions are almost never known precisely and typically fluctuate stochastically in time (see, for example, Andrian & Craske Reference Andrian and Craske2023). Rare events arising from the mentioned considerations can have a significant effect in a wide range of natural and artificial environments (Villermaux Reference Villermaux2019). On this basis, the present work forsakes detailed local deterministic information in physical space for a limited amount of probabilistic information about a control volume; we focus on what is inside a control volume at the expense of knowing precisely where it is occurring.
Although probabilistic approaches to turbulence are common (see, for example, Monin & Yaglom Reference Monin and Yaglom2013), the complete statistical (sometimes referred to as ‘functional’, due to the fact that the sought-after probability distributions are characterised by functionals of infinite dimensional spaces) formulation (Hopf Reference Hopf1952; Lewis & Kraichnan Reference Lewis and Kraichnan1962) is less common. The functional formulation has been explored, in a variety of guises, by mathematicians, physicists and engineers in parallel and somewhat independently. It is therefore appropriate to summarise the similarities and limitations of the various perspectives before highlighting their connection with the concept of available potential energy and stating the specific aims of the present work.
1.2. Background
In the full functional formulation of the Navier–Stokes equations (Hopf Reference Hopf1952; Lewis & Kraichnan Reference Lewis and Kraichnan1962; Lundgren Reference Lundgren1967; McComb Reference McComb1990; Monin & Yaglom Reference Monin and Yaglom2013), one seeks to understand the evolution of a flow’s probability distribution in phase space, which, consisting of infinite dimensions, produces a problem that is typically intractable. However, a happy consequence of ‘lifting’ the problem to an infinite-dimensional space is that the functional formulation renders the problem linear. The resulting Frobenius–Perron and Liouville operators, depending on whether time is regarded as discrete or continuous, respectively, underpin statistical mechanics (Gaspard Reference Gaspard1998; Lasota & Mackey Reference Lasota and Mackey1998; Ruelle Reference Ruelle2004).
An alternative perspective is afforded by observables of a flow, whose expected evolution is determined by Koopman and Lie operators for discrete and continuous time, respectively (Koopman Reference Koopman1931; Mezić Reference Mezić2005,Reference Mezić2013). Although the two (Frobenius–Perron and Koopman) approaches are dual in certain settings, they typically rely on different approximations (Brunton et al. Reference Brunton, Budišić, Kaiser and Kutz2022). Approximations of the Frobenius–Perron operator commonly involve the evolution of a large number of initial conditions for a relatively short time using Ulam’s method (Li Reference Li1976), whereas approximations of the Koopman operator involve evolution from a relatively small number of initial conditions over a long time (Klus, Koltai & Schütte Reference Klus, Koltai and Schütte2016).
Frobenius–Perron and Koopman operators naturally accommodate stochastic differential equations, the latter by considering expectations of observables (Lasota & Mackey Reference Lasota and Mackey1998; Črnjarić-Žic et al. Reference Črnjarić-Žic, Maćešić and Mezić2020). In this regard, the two perspectives described in the previous paragraphs correspond to forward and backward Kolmogorov equations for continuous Markov processes, respectively (Pavliotis Reference Pavliotis2014).
Independently, and particularly in an engineering context, probability density function (p.d.f.) methods were developed towards the latter half of the twentieth century, primarily in the fields of combustion (Pope Reference Pope1981, Reference Pope1985; Kollmann Reference Kollmann1990; Pope Reference Pope1994, Reference Pope2000; Fox Reference Fox2003) and those involving turbulent dispersion (Fischer et al. Reference Fischer, List, Koh, Imberger and Brooks1979; Hunt Reference Hunt1985). The equations used in p.d.f. methods typically focus on conditional probability distributions from single points in space and can therefore be regarded as a subset or projection of the full functional formulations described previously. Therefore, in a prognostic capacity, they contain expectations of gradients that require closure (see, for example, Minier & Pozorski Reference Minier and Pozorski1997; Pope Reference Pope2000; Fox Reference Fox2003). Diagnostically, however, they have been used recently to study vorticity dynamics (Li, Qian & Zhou Reference Li, Qian and Zhou2022) and to analyse Rayleigh–Bénard convection (Lülff et al. Reference Lülff, Wilczek and Friedrich2011, Reference Lülff, Wilczek, Stevens, Friedrich and Lohse2015). Although well suited to the task, p.d.f. models have not been used extensively to describe systems with external stochastic forcing. In this regard, their link with the more formal derivations of forward and backward Kolmogorov equations in stochastic processes, or with Frobenius–Perron/Koopman formalisms, is not well established.
Although an attractive feature of p.d.f. methods is that advection and state-dependent forcing terms, such as buoyancy, appear in closed form (Pope Reference Pope2000), their potential as either a diagnostic or prognostic tool for buoyancy-driven flows and stratified turbulence has not been explored. This is surprising, because, as highlighted by Tseng & Ferziger (Reference Tseng and Ferziger2001), the bulk quantities that are routinely used to diagnose the energetics behind mixing in such fields are expressed naturally as functionals of p.d.f.s. In particular, the reference state that is used to define global available potential energy (Margules Reference Margules1903; Lorenz Reference Lorenz1955; Winters et al. Reference Winters, Lombard, Riley and D’Asaro1995; Tailleux Reference Tailleux2013), which quantifies the maximum amount of potential energy that can be released during a volume-preserving and adiabatic rearrangement of fluid parcels, is a functional of the joint p.d.f. of buoyancy and geopotential height. While such constructions are difficult to wrestle with in physical space, due to the global nature of the rearrangement, their expression in terms of joint p.d.f.s is natural and therefore convenient. There is consequently an opportunity for advances made in p.d.f. methods to be applied to a broader class of problems and, conversely, for the knowledge about the available energetics behind transport and mixing to inform closures. Establishing a connection in this regard might provide a means of generating operational stochastic models or, at least, an alternative means of interpreting existing low-dimensional stochastic models of stratified turbulence (Kerstein Reference Kerstein1999; Wunsch & Kerstein Reference Wunsch and Kerstein2005).
The aim of the present work is to develop a general and extensible framework for deriving evolution equations for the joint probability distribution of a set of spatially heterogeneous and stochastic flow observables over arbitrary control volumes. To this end, we generalise and shed new light on classical p.d.f. methods in the following ways.
-
(i) The present perspective is macroscopic (top down) in dealing with joint probability distributions for the heterogeneous contents of distributed regions in space (such as those discussed by Villermaux (Reference Villermaux2019)), rather than point observations. The concept is simple to implement, yet general in encompassing both Eulerian and Lagrangian control volumes as particular cases. In this context, a prevalent role is played by boundary fluxes of probability density into and out of zones, which, rather than possessing a sharp boundary, can overlap to form a so-called mixture distribution (Lindsay Reference Lindsay1995) of a parent domain.
-
(ii) We make use of the classical derivation of the (weaker) forward Kolmogorov equation from the (stronger) backward Kolmogorov equation from stochastic processes and the Feynman–Kac formula (Pavliotis Reference Pavliotis2014). An advantage in proceeding from this dual perspective is that one more readily obtains a versatile and complete framework, in which the forward and backward equations both have distinct physical significance. The dual perspective provides an alternative to using a ‘fine-grained’ microscopic p.d.f., corresponding to a delta distribution (Pope Reference Pope1985), to derive the forward Kolmogorov equation. In doing so, we establish a closer connection with the field of stochastic processes, in the hope that its methods can be applied to the development of bulk stochastic models that faithfully account for the underlying fluid mechanics.
The core part of the framework described previously is presented in § 3, and is followed by a discussion of drift and diffusion coefficients in §§ 4 and 5, respectively. The decomposition of a parent domain into non-uniform overlapping conditional components (see point (i)) is explained in § 6. Example applications are discussed in § 7, before approaches to closure are summarised in § 8. First, we illustrate the basic ideas behind viewing the contents of a control volume probabilistically, with relatively simple introductory examples for one- and two-dimensional domains.
2. Introductory examples
This work addresses the following question: what is the probability that a given vector of field variables
 $\boldsymbol{Y}$
, evaluated at a randomly selected point
$\boldsymbol{Y}$
, evaluated at a randomly selected point
 $\omega$
from a control volume
$\omega$
from a control volume
 $\varOmega$
, parameterised by coordinates
$\varOmega$
, parameterised by coordinates
 $\boldsymbol{X}$
, will have values lying in a given range?
$\boldsymbol{X}$
, will have values lying in a given range?
Here, the term ‘randomly’ refers to a prescribed probability distribution
 $f_{\boldsymbol{X}}$
for space, which determines the probability of selecting or sampling a given region from the control volume. An Eulerian point
$f_{\boldsymbol{X}}$
for space, which determines the probability of selecting or sampling a given region from the control volume. An Eulerian point
 $\omega$
becomes an element of a sample space
$\omega$
becomes an element of a sample space
 $\varOmega \ni \omega$
parametrised by coordinate functions
$\varOmega \ni \omega$
parametrised by coordinate functions
 $\boldsymbol{X}$
. The field variables
$\boldsymbol{X}$
. The field variables
 $\boldsymbol{Y}=\varphi (\boldsymbol{X})$
are quantities such as velocity, temperature or scalar concentration. We are therefore interested in the distribution of
$\boldsymbol{Y}=\varphi (\boldsymbol{X})$
are quantities such as velocity, temperature or scalar concentration. We are therefore interested in the distribution of
 $\boldsymbol{Y}$
with respect to the given sampling distribution in space.
$\boldsymbol{Y}$
with respect to the given sampling distribution in space.
The answer to the question is given by the probability density
 $f_{\boldsymbol{Y}}$
(or, more generally, distribution) associated with
$f_{\boldsymbol{Y}}$
(or, more generally, distribution) associated with
 $\boldsymbol{Y}$
, which does not contain information about the precise relationship between
$\boldsymbol{Y}$
, which does not contain information about the precise relationship between
 $\boldsymbol{Y}$
and
$\boldsymbol{Y}$
and
 $\boldsymbol{X}$
. Indeed, the probability density corresponds to an infinite number of possible functions
$\boldsymbol{X}$
. Indeed, the probability density corresponds to an infinite number of possible functions
 $\varphi$
of
$\varphi$
of
 $\boldsymbol{X}$
that produce the same distribution of
$\boldsymbol{X}$
that produce the same distribution of
 $\boldsymbol{Y}$
. Informally, the construction involves tipping the fields
$\boldsymbol{Y}$
. Informally, the construction involves tipping the fields
 $\boldsymbol{Y}$
into a sack that does not store values of
$\boldsymbol{Y}$
into a sack that does not store values of
 $\boldsymbol{X}$
; the probability density ‘weighs’ the various values of
$\boldsymbol{X}$
; the probability density ‘weighs’ the various values of
 $\boldsymbol{Y}$
, without caring about from where they came.
$\boldsymbol{Y}$
, without caring about from where they came.

Figure 1. (b) Probability distribution
 $f_{Y}$
of (a) the value of a function
$f_{Y}$
of (a) the value of a function
 $Y=\varphi (X)$
parametrised by the coordinate
$Y=\varphi (X)$
parametrised by the coordinate
 $X$
, which has an associated density
$X$
, which has an associated density
 $f_{X}$
. Stationary points of the function
$f_{X}$
. Stationary points of the function
 $Y$
(highlighted by horizontal lines) correspond to singularities in the distribution
$Y$
(highlighted by horizontal lines) correspond to singularities in the distribution
 $f_{Y}$
. To account for parts of
$f_{Y}$
. To account for parts of
 $Y$
that are constant (dashed), the distribution contains a Dirac measure
$Y$
that are constant (dashed), the distribution contains a Dirac measure
 $\delta$
, weighted by the probability
$\delta$
, weighted by the probability
 $\mathbb{P}(\mathcal{X})$
associated with the selection of a point in the domain over which
$\mathbb{P}(\mathcal{X})$
associated with the selection of a point in the domain over which
 $Y$
is equal to the given constant.
$Y$
is equal to the given constant.
Figure 1 illustrates an example in one dimension for which the vector ‘
 $\boldsymbol{Y}$
’ can therefore be replaced with the scalar ‘
$\boldsymbol{Y}$
’ can therefore be replaced with the scalar ‘
 $Y$
’. As explained more precisely in Appendix A, the construction of
$Y$
’. As explained more precisely in Appendix A, the construction of
 $f_{Y}$
involves determining the proportion of
$f_{Y}$
involves determining the proportion of
 $\varOmega$
taken up by a given value of
$\varOmega$
taken up by a given value of
 $Y$
. Analytically, this involves considering intervals of
$Y$
. Analytically, this involves considering intervals of
 $\varOmega$
over which
$\varOmega$
over which
 $Y=\varphi (X)$
is strictly monotone with respect to
$Y=\varphi (X)$
is strictly monotone with respect to
 $X$
and, therefore, invertible. Such intervals lie between the stationary points of
$X$
and, therefore, invertible. Such intervals lie between the stationary points of
 $\varphi$
. Each point within the interval contributes a density that is inversely proportional to the gradient of
$\varphi$
. Each point within the interval contributes a density that is inversely proportional to the gradient of
 $\varphi$
with respect to
$\varphi$
with respect to
 $X$
at that point, because relatively large gradients in
$X$
at that point, because relatively large gradients in
 $\varphi$
account for a relatively small proportion of
$\varphi$
account for a relatively small proportion of
 $\varOmega$
.
$\varOmega$
.
Intervals
 $\mathcal{X}\ni X$
over which
$\mathcal{X}\ni X$
over which
 $\varphi$
is invertible contribute to the density
$\varphi$
is invertible contribute to the density
 $f_{Y}$
in proportion to their probability
$f_{Y}$
in proportion to their probability
 $\mathbb{P}(\mathcal{X}):=\int _{\mathcal{X}}f_{X}(x)\,\textrm{d} x$
, which gives the density the appearance of consisting of folds and caustics (see also figure 2
b). The overall contribution that a given value of
$\mathbb{P}(\mathcal{X}):=\int _{\mathcal{X}}f_{X}(x)\,\textrm{d} x$
, which gives the density the appearance of consisting of folds and caustics (see also figure 2
b). The overall contribution that a given value of
 $Y$
makes to the probability density therefore depends on the number of occurrences of that value in
$Y$
makes to the probability density therefore depends on the number of occurrences of that value in
 $\varOmega$
as well as its gradients. For example, the probability density of
$\varOmega$
as well as its gradients. For example, the probability density of
 $Y=\varphi (X)=\textrm{cos}(\pi nX)$
for
$Y=\varphi (X)=\textrm{cos}(\pi nX)$
for
 $n\in \mathbb{N}^{+}$
and uniformly distributed
$n\in \mathbb{N}^{+}$
and uniformly distributed
 $X\in [0,1)$
is
$X\in [0,1)$
is
 $f_Y(y)=\pi ^{-1}(1-y^{2})^{-1/2}$
for
$f_Y(y)=\pi ^{-1}(1-y^{2})^{-1/2}$
for
 $y\in (-1,1)$
, and is therefore independent of
$y\in (-1,1)$
, and is therefore independent of
 $n$
.
$n$
.

Figure 2.
 $(a)$
Relative buoyancy (blue to red) and vertical velocity isolines (white and dashed for negative velocity) at time
$(a)$
Relative buoyancy (blue to red) and vertical velocity isolines (white and dashed for negative velocity) at time
 $t$
of the two-dimensional fields corresponding to a point on the Lorenz attractor described in Appendix B (
$t$
of the two-dimensional fields corresponding to a point on the Lorenz attractor described in Appendix B (
 $r=28$
,
$r=28$
,
 $s=10$
,
$s=10$
,
 $b:=4\pi ^{2}(k^{2}+\pi ^{2})^{-1}=8/3$
for horizontal wave number
$b:=4\pi ^{2}(k^{2}+\pi ^{2})^{-1}=8/3$
for horizontal wave number
 $k$
). The shaded/unshaded rectangles correspond to regions over which the Jacobian
$k$
). The shaded/unshaded rectangles correspond to regions over which the Jacobian
 $\partial \varphi _{\!t}/\partial \boldsymbol{X}$
is non-singular.
$\partial \varphi _{\!t}/\partial \boldsymbol{X}$
is non-singular.
 $(b)$
Joint probability density (shaded colour) of vertical velocity (
$(b)$
Joint probability density (shaded colour) of vertical velocity (
 $y^{1}$
) and relative buoyancy (
$y^{1}$
) and relative buoyancy (
 $y^{2}$
) corresponding to the field shown in panel
$y^{2}$
) corresponding to the field shown in panel
 $(a)$
. The solid black line marks singularities in the density and the dashed black line corresponds to the position of the singularities at
$(a)$
. The solid black line marks singularities in the density and the dashed black line corresponds to the position of the singularities at
 $t+0.04$
. The light grey arrows are tangential to the probability flux induced by the Lorenz equations (B3) that is responsible for the time evolution of the density. https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig02/fig02.ipynb.
$t+0.04$
. The light grey arrows are tangential to the probability flux induced by the Lorenz equations (B3) that is responsible for the time evolution of the density. https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig02/fig02.ipynb.
Points at which
 $Y$
is stationary produce singularities in the distribution
$Y$
is stationary produce singularities in the distribution
 $f_{Y}$
shown on the right of figure 1. In exceptional cases, intervals of finite size over which
$f_{Y}$
shown on the right of figure 1. In exceptional cases, intervals of finite size over which
 $Y=y$
is constant are not described by a density function but rather a Dirac measure or distribution, weighted by the proportion of the domain over which
$Y=y$
is constant are not described by a density function but rather a Dirac measure or distribution, weighted by the proportion of the domain over which
 $Y$
is constant, as indicated by the horizontal dashed part of
$Y$
is constant, as indicated by the horizontal dashed part of
 $\varphi (X)$
and corresponding
$\varphi (X)$
and corresponding
 $\delta$
in figure 1 (see also chapter 1 of Chung (Reference Chung2001)).
$\delta$
in figure 1 (see also chapter 1 of Chung (Reference Chung2001)).
We now consider a two-dimensional example using velocity and buoyancy fields from Lorenz’s 1963 model for convection (Lorenz Reference Lorenz1963) shown in figure 2(a) (details of the model and calculations required to construct the corresponding distribution
 $f_{\boldsymbol{Y}}$
can be found in Appendix B). In this example,
$f_{\boldsymbol{Y}}$
can be found in Appendix B). In this example,
 $\boldsymbol{X}:=(X^{1},X^{2})^{\top }\in [0,2\pi /k)\times [0,1]$
are the horizontal and vertical coordinates,
$\boldsymbol{X}:=(X^{1},X^{2})^{\top }\in [0,2\pi /k)\times [0,1]$
are the horizontal and vertical coordinates,
 $k$
is a horizontal wavenumber,
$k$
is a horizontal wavenumber,
 $f_{\boldsymbol{X}}\equiv k/(2\pi )$
is a uniform distribution, and
$f_{\boldsymbol{X}}\equiv k/(2\pi )$
is a uniform distribution, and
 $\boldsymbol{Y}_{\!t}:=(Y_{\!t}^{1},Y_{\!t}^{2})^{\top }=\varphi _{\!t}(\boldsymbol{X})\in \mathbb{R}^{2}$
denotes the vertical velocity and buoyancy, relative to the static state of linear conduction, at time
$\boldsymbol{Y}_{\!t}:=(Y_{\!t}^{1},Y_{\!t}^{2})^{\top }=\varphi _{\!t}(\boldsymbol{X})\in \mathbb{R}^{2}$
denotes the vertical velocity and buoyancy, relative to the static state of linear conduction, at time
 $t$
, respectively. Figure 2(b) depicts the joint probability density
$t$
, respectively. Figure 2(b) depicts the joint probability density
 $f_{\boldsymbol{Y}}(-,t):\mathbb{R}^{2}\rightarrow \mathbb{R}^{+}$
corresponding to the fields shown in figure 2(a), such that the probability of finding a value of
$f_{\boldsymbol{Y}}(-,t):\mathbb{R}^{2}\rightarrow \mathbb{R}^{+}$
corresponding to the fields shown in figure 2(a), such that the probability of finding a value of
 $\boldsymbol{Y}_{\!t}$
in any subset
$\boldsymbol{Y}_{\!t}$
in any subset
 $\mathcal{Y}\subset \mathbb{R}^{2}$
of the function’s codomain is
$\mathcal{Y}\subset \mathbb{R}^{2}$
of the function’s codomain is
 \begin{equation} \mathbb{P}\{\boldsymbol{Y}_{\!t}\in \mathcal{Y}\} = \int \limits _{\mathcal{Y}}f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}, \end{equation}
\begin{equation} \mathbb{P}\{\boldsymbol{Y}_{\!t}\in \mathcal{Y}\} = \int \limits _{\mathcal{Y}}f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}, \end{equation}
where
 $\boldsymbol{y}:=(y^{1},y^{2})^{\top }$
denotes the argument to the probability density corresponding to the capitalised random variable
$\boldsymbol{y}:=(y^{1},y^{2})^{\top }$
denotes the argument to the probability density corresponding to the capitalised random variable
 $\boldsymbol{Y}_{\!t}$
. The density
$\boldsymbol{Y}_{\!t}$
. The density
 $f_{\boldsymbol{Y}}$
determines the expectation of any observable
$f_{\boldsymbol{Y}}$
determines the expectation of any observable
 $g$
, which can also be computed as an integral over physical coordinates:
$g$
, which can also be computed as an integral over physical coordinates:
 \begin{equation} \mathbb{E}[g(\boldsymbol{Y}_{\!t})] = \int \limits _{\mathbb{R}^{2}}g(\boldsymbol{y})f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y} = \int \limits _{\mathbb{R}^{2}}g(\varphi _{\!t}(\boldsymbol{x}))f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}, \end{equation}
\begin{equation} \mathbb{E}[g(\boldsymbol{Y}_{\!t})] = \int \limits _{\mathbb{R}^{2}}g(\boldsymbol{y})f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y} = \int \limits _{\mathbb{R}^{2}}g(\varphi _{\!t}(\boldsymbol{x}))f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}, \end{equation}
where, in general, the sample distribution
 $f_{\boldsymbol{X}}$
accounts for the physical extent and distributed weight assigned to the control volume, but is uniform for the example illustrated in figure 2. Note that
$f_{\boldsymbol{X}}$
accounts for the physical extent and distributed weight assigned to the control volume, but is uniform for the example illustrated in figure 2. Note that
 $f_{\boldsymbol{Y}}$
does not provide information about how
$f_{\boldsymbol{Y}}$
does not provide information about how
 $\boldsymbol{Y}_{\!t}$
is correlated with
$\boldsymbol{Y}_{\!t}$
is correlated with
 $\boldsymbol{X}$
. In particular,
$\boldsymbol{X}$
. In particular,
 $f_{\boldsymbol{Y}}$
does not provide information about multipoint statistics or spatial gradients, unless they are included in
$f_{\boldsymbol{Y}}$
does not provide information about multipoint statistics or spatial gradients, unless they are included in
 $\boldsymbol{Y}_{\!t}$
.
$\boldsymbol{Y}_{\!t}$
.
To understand the p.d.f. shown in figure 2(b), it is helpful to consider the regions over which
 $\varphi _{\!t}$
is invertible. Such regions are highlighted as shaded/unshaded rectangles in figure 2(a), in which the Jacobian
$\varphi _{\!t}$
is invertible. Such regions are highlighted as shaded/unshaded rectangles in figure 2(a), in which the Jacobian
 $\partial \varphi _{\!t}/\partial {\boldsymbol{X}}$
is non-singular. The solid black lines, separating the regions, denote points for which
$\partial \varphi _{\!t}/\partial {\boldsymbol{X}}$
is non-singular. The solid black lines, separating the regions, denote points for which
 $|\partial \varphi _{\!t}/\partial {\boldsymbol{X}}|=0$
, which account for the singularities in figure 2(b). In particular,
$|\partial \varphi _{\!t}/\partial {\boldsymbol{X}}|=0$
, which account for the singularities in figure 2(b). In particular,
 $|\partial \varphi _{\!t}/\partial {\boldsymbol{X}}|=0$
over the sets
$|\partial \varphi _{\!t}/\partial {\boldsymbol{X}}|=0$
over the sets
 $S_{1}:=\{X^{1}=\pi /k, X^{2}\in [0,1]\}$
and
$S_{1}:=\{X^{1}=\pi /k, X^{2}\in [0,1]\}$
and
 $S_{2}:=\{X^{1}=[0,2\pi /k), X^{2}=1/2\pm 1/4\}$
. The set
$S_{2}:=\{X^{1}=[0,2\pi /k), X^{2}=1/2\pm 1/4\}$
. The set
 $S_{1}$
corresponds to the solid black line that looks like ‘
$S_{1}$
corresponds to the solid black line that looks like ‘
 $\infty$
’ in figure 2(b), while
$\infty$
’ in figure 2(b), while
 $S_{2}$
corresponds to the nearly horizontal lines that define its convex hull. As explained for the previous one-dimensional example, the folded appearance of
$S_{2}$
corresponds to the nearly horizontal lines that define its convex hull. As explained for the previous one-dimensional example, the folded appearance of
 $f_{\boldsymbol{Y}}$
shown in figure 2(b) is due to the fact that a given value of
$f_{\boldsymbol{Y}}$
shown in figure 2(b) is due to the fact that a given value of
 $\boldsymbol{Y}_{\!t}$
contributes to
$\boldsymbol{Y}_{\!t}$
contributes to
 $f_{\boldsymbol{Y}}$
from more than one region in the domain.
$f_{\boldsymbol{Y}}$
from more than one region in the domain.
As the fields shown in figure 2(a) evolve in time, the density is transported over the phase space shown in figure 2(b). Since the density integrates to unity, it is useful to regard probability, like mass, as a conserved quantity. From this perspective, the governing equations for
 $\boldsymbol{Y}_{\!t}$
over the entire control volume correspond to a two-dimensional velocity field that produces a flux of density in phase space. The direction of the density flux for this example is shown in figure 2(b) by grey lines. The density flux determines the subsequent evolution of
$\boldsymbol{Y}_{\!t}$
over the entire control volume correspond to a two-dimensional velocity field that produces a flux of density in phase space. The direction of the density flux for this example is shown in figure 2(b) by grey lines. The density flux determines the subsequent evolution of
 $f_{\boldsymbol{Y}}$
, whose singularities a short time after
$f_{\boldsymbol{Y}}$
, whose singularities a short time after
 $t$
are depicted with dashed lines in figure 2(b). Understanding how the evolution of
$t$
are depicted with dashed lines in figure 2(b). Understanding how the evolution of
 $f_{\boldsymbol{Y}}$
depends on the evolution of the field variables
$f_{\boldsymbol{Y}}$
depends on the evolution of the field variables
 $\boldsymbol{Y}_{\!t}$
is the central topic of this article.
$\boldsymbol{Y}_{\!t}$
is the central topic of this article.
3. Governing equations
In this section, an evolution equation is derived for the joint probability density
 $f_{\boldsymbol{Y}}$
of a multicomponent random variable
$f_{\boldsymbol{Y}}$
of a multicomponent random variable
 $\boldsymbol{Y}_{\!t}$
drawn from a domain according to the spatial distribution
$\boldsymbol{Y}_{\!t}$
drawn from a domain according to the spatial distribution
 $f_{\boldsymbol{X}}$
. First, § 3.1 defines an infinitesimal generator, which gives the expected time rate of change of an observable evaluated along the trajectories of a stochastic differential equation. Here, the stochastic differential equation, defined in (3.1), is a generic transport equation that can represent the Navier–Stokes or advection–diffusion equations as special cases. Next, in § 3.2, the generator is decomposed to distinguish transport across a bounding region defined by
$f_{\boldsymbol{X}}$
. First, § 3.1 defines an infinitesimal generator, which gives the expected time rate of change of an observable evaluated along the trajectories of a stochastic differential equation. Here, the stochastic differential equation, defined in (3.1), is a generic transport equation that can represent the Navier–Stokes or advection–diffusion equations as special cases. Next, in § 3.2, the generator is decomposed to distinguish transport across a bounding region defined by
 $|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
and internal mixing over
$|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
and internal mixing over
 $f_{\boldsymbol{X}}$
. Then, § 3.3 uses the resulting operator to define a backward Kolmogorov equation, whose solution backwards in time gives the expected value of an observable, conditioned on an earlier state. Finally, the dual (forward Kolmogorov) equation describing the evolution of probability density is obtained in § 3.4.
$f_{\boldsymbol{X}}$
. Then, § 3.3 uses the resulting operator to define a backward Kolmogorov equation, whose solution backwards in time gives the expected value of an observable, conditioned on an earlier state. Finally, the dual (forward Kolmogorov) equation describing the evolution of probability density is obtained in § 3.4.
3.1. Local governing equations
For the purposes of emphasising a probabilistic perspective that focuses on control volumes, we regard the spatial domain
 $\varOmega$
as a sample space,
$\varOmega$
as a sample space,
 $\boldsymbol{X}:\varOmega \rightarrow \mathbb{R}^{d}$
as coordinate functions and
$\boldsymbol{X}:\varOmega \rightarrow \mathbb{R}^{d}$
as coordinate functions and
 $\boldsymbol{Y}_{\!t}:\varOmega \rightarrow \mathbb{R}^{n}$
as random variables, as illustrated in figure 3. Let the Eulerian evolution of
$\boldsymbol{Y}_{\!t}:\varOmega \rightarrow \mathbb{R}^{n}$
as random variables, as illustrated in figure 3. Let the Eulerian evolution of
 $\boldsymbol{Y}_{\!t}$
at a given point in the domain be determined by the stochastic differential equation
$\boldsymbol{Y}_{\!t}$
at a given point in the domain be determined by the stochastic differential equation
 \begin{equation} \,\textrm{d} \boldsymbol{Y}_{\!t}=(\boldsymbol{I}_{\!t}-\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J}_{\!t})\,\textrm{d} t+\boldsymbol{\sigma }\,\textrm{d} \boldsymbol{W}_{\!t}, \end{equation}
\begin{equation} \,\textrm{d} \boldsymbol{Y}_{\!t}=(\boldsymbol{I}_{\!t}-\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J}_{\!t})\,\textrm{d} t+\boldsymbol{\sigma }\,\textrm{d} \boldsymbol{W}_{\!t}, \end{equation}
where
 $\boldsymbol{I}_{\!t}\in \mathbb{R}^{n}$
represents internal sources/sinks,
$\boldsymbol{I}_{\!t}\in \mathbb{R}^{n}$
represents internal sources/sinks,
 $\boldsymbol{J}_{\!t}\in \mathbb{R}^{d\times n}$
is a matrix of fluxes,
$\boldsymbol{J}_{\!t}\in \mathbb{R}^{d\times n}$
is a matrix of fluxes,
 $\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J}_{\!t}\in \mathbb{R}^{n}$
is the divergence of the flux of each component of
$\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J}_{\!t}\in \mathbb{R}^{n}$
is the divergence of the flux of each component of
 $\boldsymbol{Y}_{\!t}$
and
$\boldsymbol{Y}_{\!t}$
and
 $\boldsymbol{W}_{\!t}\in \mathbb{R}^{m}$
is a vector of independent Wiener processes. In general, the matrix coefficient
$\boldsymbol{W}_{\!t}\in \mathbb{R}^{m}$
is a vector of independent Wiener processes. In general, the matrix coefficient
 $\boldsymbol{\sigma }$
could depend on both
$\boldsymbol{\sigma }$
could depend on both
 $\boldsymbol{X}$
and
$\boldsymbol{X}$
and
 $\boldsymbol{Y}_{\!t}$
, such that
$\boldsymbol{Y}_{\!t}$
, such that
 $\boldsymbol{\sigma }(\boldsymbol{X},\boldsymbol{Y}_{\!t})\in \mathbb{R}^{n\times m}$
determines
$\boldsymbol{\sigma }(\boldsymbol{X},\boldsymbol{Y}_{\!t})\in \mathbb{R}^{n\times m}$
determines
 $m$
modes of forcing from
$m$
modes of forcing from
 $\boldsymbol{W}_{\!t}$
for each of the
$\boldsymbol{W}_{\!t}$
for each of the
 $n$
components of
$n$
components of
 $\boldsymbol{Y}_{\!t}$
.
$\boldsymbol{Y}_{\!t}$
.

Figure 3. Sample space
 $\varOmega$
as the domain of random variables corresponding to coordinates
$\varOmega$
as the domain of random variables corresponding to coordinates
 $\boldsymbol{X}$
and field variables
$\boldsymbol{X}$
and field variables
 $\boldsymbol{Y}_{\!t}=\varphi _{\!t}(\boldsymbol{X})$
. (a) Two fields
$\boldsymbol{Y}_{\!t}=\varphi _{\!t}(\boldsymbol{X})$
. (a) Two fields
 $Y_{\!t}^{1}$
(dark blue isolines) and
$Y_{\!t}^{1}$
(dark blue isolines) and
 $Y_{\!t}^{2}$
(red/pink filled isoregions) over the region in space defined by the density
$Y_{\!t}^{2}$
(red/pink filled isoregions) over the region in space defined by the density
 $f_{\boldsymbol{X}}$
. In panel (a), the arrows labelled ‘in’ and ‘out’ denote fluxes of
$f_{\boldsymbol{X}}$
. In panel (a), the arrows labelled ‘in’ and ‘out’ denote fluxes of
 $\boldsymbol{Y}_{\!t}$
at a fixed value of
$\boldsymbol{Y}_{\!t}$
at a fixed value of
 $Y_{\!t}^{1}=c_{1}$
over a boundary region defined by
$Y_{\!t}^{1}=c_{1}$
over a boundary region defined by
 $\boldsymbol{\nabla }f_{\boldsymbol{X}}$
(see § 3.2). (b) Section through the current and future probability density
$\boldsymbol{\nabla }f_{\boldsymbol{X}}$
(see § 3.2). (b) Section through the current and future probability density
 $f_{\boldsymbol{Y}}$
with thick and dashed blue lines, respectively. As demonstrated in § 3 and illustrated by the ‘in‘ and ‘out‘ arrows in panel (b), the boundary fluxes lead to drift in the equation governing the joint distribution
$f_{\boldsymbol{Y}}$
with thick and dashed blue lines, respectively. As demonstrated in § 3 and illustrated by the ‘in‘ and ‘out‘ arrows in panel (b), the boundary fluxes lead to drift in the equation governing the joint distribution
 $f_{\boldsymbol{Y}}$
(for
$f_{\boldsymbol{Y}}$
(for
 $y^{1}=c_{1}$
, the drift is in the positive
$y^{1}=c_{1}$
, the drift is in the positive
 $y^{2}$
direction for those values of
$y^{2}$
direction for those values of
 $Y^{2}$
for which
$Y^{2}$
for which
 $\boldsymbol{J}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}\gt 0$
and in the negative
$\boldsymbol{J}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}\gt 0$
and in the negative
 $y^{2}$
direction for those values of
$y^{2}$
direction for those values of
 $Y^{2}$
for which
$Y^{2}$
for which
 $\boldsymbol{J}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}\lt 0$
). At the same time,
$\boldsymbol{J}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}\lt 0$
). At the same time,
 $f_{\boldsymbol{Y}}$
is made narrower due to irreversible mixing, which homogenises the fields.
$f_{\boldsymbol{Y}}$
is made narrower due to irreversible mixing, which homogenises the fields.
In what follows, it should be remembered that with
 $\varOmega$
regarded as a sample space, the precise relationship
$\varOmega$
regarded as a sample space, the precise relationship
 $\boldsymbol{Y}_{\!t}=\varphi _{\!t}(\boldsymbol{X})$
is not assumed to be known. In this context, the gradient
$\boldsymbol{Y}_{\!t}=\varphi _{\!t}(\boldsymbol{X})$
is not assumed to be known. In this context, the gradient
 $\boldsymbol{\nabla }\boldsymbol{Y}_{\!t}$
should be regarded as an unknown random variable, rather than a known gradient of
$\boldsymbol{\nabla }\boldsymbol{Y}_{\!t}$
should be regarded as an unknown random variable, rather than a known gradient of
 $\varphi _{\!t}(\boldsymbol{X})$
. It is unknown in the sense that (3.1) does not provide
$\varphi _{\!t}(\boldsymbol{X})$
. It is unknown in the sense that (3.1) does not provide
 $\boldsymbol{\nabla }\boldsymbol{Y}_{\!t}$
with its own governing equation. Noting that
$\boldsymbol{\nabla }\boldsymbol{Y}_{\!t}$
with its own governing equation. Noting that
 $\boldsymbol{J}_{\!t}$
typically depends on
$\boldsymbol{J}_{\!t}$
typically depends on
 $\boldsymbol{\nabla }\boldsymbol{Y}_{\!t}$
, the system (3.1) is therefore unclosed because it consists of more unknowns than equations. If spatial derivatives were included in
$\boldsymbol{\nabla }\boldsymbol{Y}_{\!t}$
, the system (3.1) is therefore unclosed because it consists of more unknowns than equations. If spatial derivatives were included in
 $\boldsymbol{Y}_{\!t}$
, their evolution equations would include higher derivatives and one would be faced with the infinite hierarchy of equations that constitutes the closure problem of turbulence (see McComb Reference McComb1990, and § 8 for a discussion of closures in the context of the present work).
$\boldsymbol{Y}_{\!t}$
, their evolution equations would include higher derivatives and one would be faced with the infinite hierarchy of equations that constitutes the closure problem of turbulence (see McComb Reference McComb1990, and § 8 for a discussion of closures in the context of the present work).
To determine the evolution of the probability distribution of
 $\boldsymbol{Y}_{\!t}$
, consider the infinitesimal generator
$\boldsymbol{Y}_{\!t}$
, consider the infinitesimal generator
 $\mathscr{L}$
(Pavliotis Reference Pavliotis2014, § 2.3) acting on an observable
$\mathscr{L}$
(Pavliotis Reference Pavliotis2014, § 2.3) acting on an observable
 $g:\mathbb{R}^{n}\rightarrow \mathbb{R}$
:
$g:\mathbb{R}^{n}\rightarrow \mathbb{R}$
:
 \begin{equation} \mathscr{L}g(\boldsymbol{y},s):=\lim \limits _{t\rightarrow s}\frac {\mathbb{E}[g(\boldsymbol{Y}_{\!t})|\boldsymbol{Y}_{\!s}=\boldsymbol{y}]-g(\boldsymbol{y})}{t-s}, \end{equation}
\begin{equation} \mathscr{L}g(\boldsymbol{y},s):=\lim \limits _{t\rightarrow s}\frac {\mathbb{E}[g(\boldsymbol{Y}_{\!t})|\boldsymbol{Y}_{\!s}=\boldsymbol{y}]-g(\boldsymbol{y})}{t-s}, \end{equation}
where the conditional expectation accounts for the behaviour of all points within the domain where
 $\boldsymbol{Y}_{\!s}=\boldsymbol{y}$
. In a deterministic context, without the expectation around
$\boldsymbol{Y}_{\!s}=\boldsymbol{y}$
. In a deterministic context, without the expectation around
 $g(\boldsymbol{Y}_{\!t})$
, (3.2) corresponds to the infinitesimal generator of the Koopman operator (Brunton et al. Reference Brunton, Budišić, Kaiser and Kutz2022).
$g(\boldsymbol{Y}_{\!t})$
, (3.2) corresponds to the infinitesimal generator of the Koopman operator (Brunton et al. Reference Brunton, Budišić, Kaiser and Kutz2022).
Using Itô’s formula to determine the time rate of change of the observable
 $g$
, the limit in (3.2) can, noting that the time integral of the resulting Wiener process has an expected value of zero, be expressed as (see § 3.4 and Lemma 3.2, Pavliotis Reference Pavliotis2014):
$g$
, the limit in (3.2) can, noting that the time integral of the resulting Wiener process has an expected value of zero, be expressed as (see § 3.4 and Lemma 3.2, Pavliotis Reference Pavliotis2014):
 \begin{equation} \mathscr{L}g(\boldsymbol{y},s)=\mathbb{E}\left [\left(I_{s}^{i}-\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J}_{s}^{i}\right)\dfrac {\partial g(\boldsymbol{Y}_{\!s})}{\partial Y_{s}^{i}}\bigg |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ]+\frac {1}{2}\varSigma ^{\textit{ij}}_{s}\frac {\partial ^{2}g(\boldsymbol{y})}{\partial y^{i}\partial y^{j}}, \end{equation}
\begin{equation} \mathscr{L}g(\boldsymbol{y},s)=\mathbb{E}\left [\left(I_{s}^{i}-\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J}_{s}^{i}\right)\dfrac {\partial g(\boldsymbol{Y}_{\!s})}{\partial Y_{s}^{i}}\bigg |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ]+\frac {1}{2}\varSigma ^{\textit{ij}}_{s}\frac {\partial ^{2}g(\boldsymbol{y})}{\partial y^{i}\partial y^{j}}, \end{equation}
where
 \begin{equation} \boldsymbol{\varSigma }_{s}:=\mathbb{E}\big[\boldsymbol{\sigma }\boldsymbol{\sigma }^{\top }|\boldsymbol{Y}_{\!s}=\boldsymbol{y}\big], \end{equation}
\begin{equation} \boldsymbol{\varSigma }_{s}:=\mathbb{E}\big[\boldsymbol{\sigma }\boldsymbol{\sigma }^{\top }|\boldsymbol{Y}_{\!s}=\boldsymbol{y}\big], \end{equation}
and Einstein summation notation has been used over components of
 $\boldsymbol{Y}_{\!s}$
.
$\boldsymbol{Y}_{\!s}$
.
We will follow standard arguments to construct backward and forward Kolmogorov equations in terms of the generator
 $\mathscr{L}$
(see, e.g. Gardiner Reference Gardiner1990; Pavliotis Reference Pavliotis2014). Along the way, integration by parts will be applied to produce boundary and irreversible interior mixing terms that will appear in the associated Kolmogorov equations as forcing and anti-diffusion terms, respectively.
$\mathscr{L}$
(see, e.g. Gardiner Reference Gardiner1990; Pavliotis Reference Pavliotis2014). Along the way, integration by parts will be applied to produce boundary and irreversible interior mixing terms that will appear in the associated Kolmogorov equations as forcing and anti-diffusion terms, respectively.
3.2. Transport and mixing
To understand the physics behind the evolution of the probability density of
 $\boldsymbol{Y}_{\!t}$
with respect to a prescribed spatial sample distribution
$\boldsymbol{Y}_{\!t}$
with respect to a prescribed spatial sample distribution
 $f_{\boldsymbol{X}}$
, it is useful to decompose the transport terms in (3.3) into those associated with internal irreversible mixing and transport across the sample distribution’s ‘boundary’, which will now be defined.
$f_{\boldsymbol{X}}$
, it is useful to decompose the transport terms in (3.3) into those associated with internal irreversible mixing and transport across the sample distribution’s ‘boundary’, which will now be defined.
If the sample distribution
 $f_{\boldsymbol{X}}$
is uniform over a subset of
$f_{\boldsymbol{X}}$
is uniform over a subset of
 $\varOmega$
, the boundary associated with
$\varOmega$
, the boundary associated with
 $f_{\boldsymbol{X}}$
is simply the boundary of the associated subset. However, more generally,
$f_{\boldsymbol{X}}$
is simply the boundary of the associated subset. However, more generally,
 $f_{\boldsymbol{X}}$
could be non-uniform and would therefore not correspond to a classical set with a sharp bounding surface. As explained later and illustrated in figure 4, a natural definition of the bounding region in this regard proves to be the unnormalised density
$f_{\boldsymbol{X}}$
could be non-uniform and would therefore not correspond to a classical set with a sharp bounding surface. As explained later and illustrated in figure 4, a natural definition of the bounding region in this regard proves to be the unnormalised density
 $|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
, which defines a sharp surface as
$|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
, which defines a sharp surface as
 $f_{\boldsymbol{X}}$
becomes proportional to an indicator function. The approach therefore generalises the traditional notion of a bounding surface in a way that can be expressed in terms of probability distributions. The manipulations described later are relatively simple because of (rather than in spite of) the generality of this approach.
$f_{\boldsymbol{X}}$
becomes proportional to an indicator function. The approach therefore generalises the traditional notion of a bounding surface in a way that can be expressed in terms of probability distributions. The manipulations described later are relatively simple because of (rather than in spite of) the generality of this approach.
To establish a connection between expectations obtained via conditioning on
 $\boldsymbol{X}$
compared with conditioning on
$\boldsymbol{X}$
compared with conditioning on
 $\boldsymbol{Y}$
, recall the elementary property
$\boldsymbol{Y}$
, recall the elementary property
 \begin{equation} \mathbb{E}[\square ]=\mathbb{E}[\mathbb{E}[\square |\boldsymbol{Y}]] =\mathbb{E}[\mathbb{E}[\square |\boldsymbol{X}]]=\int \limits _{\mathbb{R}^{d}}\mathbb{E}[\square |\boldsymbol{X}=\boldsymbol{x}]f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}, \end{equation}
\begin{equation} \mathbb{E}[\square ]=\mathbb{E}[\mathbb{E}[\square |\boldsymbol{Y}]] =\mathbb{E}[\mathbb{E}[\square |\boldsymbol{X}]]=\int \limits _{\mathbb{R}^{d}}\mathbb{E}[\square |\boldsymbol{X}=\boldsymbol{x}]f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}, \end{equation}
which means that expectations can be computed from those conditioned on
 $\boldsymbol{Y}$
or those conditioned on
$\boldsymbol{Y}$
or those conditioned on
 $\boldsymbol{X}$
. The latter are useful because they correspond to variables in physical space to which it is possible to apply integration by parts to distinguish boundary fluxes from interior mixing. In this regard, note that use of the product and chain rule implies
$\boldsymbol{X}$
. The latter are useful because they correspond to variables in physical space to which it is possible to apply integration by parts to distinguish boundary fluxes from interior mixing. In this regard, note that use of the product and chain rule implies
 \begin{equation} -(\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J})^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}} = -\boldsymbol{\nabla }\boldsymbol{\cdot }\left (\boldsymbol{J}^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\right ) +\boldsymbol{J}^{i}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{j}\frac {\partial ^{2}g(\boldsymbol{Y})}{\partial Y^{i}\partial Y^{j}}. \end{equation}
\begin{equation} -(\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J})^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}} = -\boldsymbol{\nabla }\boldsymbol{\cdot }\left (\boldsymbol{J}^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\right ) +\boldsymbol{J}^{i}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{j}\frac {\partial ^{2}g(\boldsymbol{Y})}{\partial Y^{i}\partial Y^{j}}. \end{equation}

Figure 4. (a) the spatial sample distribution
 $f_{\boldsymbol{X}}(\boldsymbol{x}):=N_{k}/(1+\exp (k p(\boldsymbol{x})))$
, where
$f_{\boldsymbol{X}}(\boldsymbol{x}):=N_{k}/(1+\exp (k p(\boldsymbol{x})))$
, where
 $p(\boldsymbol{x}):=x_{1}^{4}+x_{2}^{4}+x_{1}x_{2}-1$
and
$p(\boldsymbol{x}):=x_{1}^{4}+x_{2}^{4}+x_{1}x_{2}-1$
and
 $N_{k}$
is a normalisation constant. (b) the bounding region of
$N_{k}$
is a normalisation constant. (b) the bounding region of
 $f_{\boldsymbol{X}}$
defined by the unnormalised density
$f_{\boldsymbol{X}}$
defined by the unnormalised density
 $|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
(red) and vector field
$|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
(red) and vector field
 $\boldsymbol{\nabla }f_{\boldsymbol{X}}$
(blue). As
$\boldsymbol{\nabla }f_{\boldsymbol{X}}$
(blue). As
 $k\rightarrow \infty$
, the distribution describes well-defined subsets of
$k\rightarrow \infty$
, the distribution describes well-defined subsets of
 $\mathbb{R}^{2}$
with a sharp boundary.
$\mathbb{R}^{2}$
with a sharp boundary.
It will be assumed that
 $f_{\boldsymbol{X}}(\boldsymbol{x})$
either has compact support on
$f_{\boldsymbol{X}}(\boldsymbol{x})$
either has compact support on
 $\mathbb{R}^{d}$
or tends to zero sufficiently fast as
$\mathbb{R}^{d}$
or tends to zero sufficiently fast as
 $|\boldsymbol{x}|\rightarrow \infty$
. Then, making use of (3.5), (3.6) and applying integration by parts to the first term on the right-hand side of (3.6) yields
$|\boldsymbol{x}|\rightarrow \infty$
. Then, making use of (3.5), (3.6) and applying integration by parts to the first term on the right-hand side of (3.6) yields
 \begin{align} -\mathbb{E}\left [(\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J})^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\right ] &= \int \limits _{\mathbb{R}^{d}}\mathbb{E}\left [\boldsymbol{J}^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\bigg |\boldsymbol{X}=\boldsymbol{x}\right ]\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}\nonumber\\ &\quad +\int \limits _{\mathbb{R}^{d}}\mathbb{E}\left [\boldsymbol{J}^{i}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{j}\frac {\partial ^{2}g(\boldsymbol{Y})}{\partial Y^{i}\partial Y^{j}}\bigg |\boldsymbol{X}=\boldsymbol{x}\right ] f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}, \end{align}
\begin{align} -\mathbb{E}\left [(\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J})^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\right ] &= \int \limits _{\mathbb{R}^{d}}\mathbb{E}\left [\boldsymbol{J}^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\bigg |\boldsymbol{X}=\boldsymbol{x}\right ]\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}\nonumber\\ &\quad +\int \limits _{\mathbb{R}^{d}}\mathbb{E}\left [\boldsymbol{J}^{i}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{j}\frac {\partial ^{2}g(\boldsymbol{Y})}{\partial Y^{i}\partial Y^{j}}\bigg |\boldsymbol{X}=\boldsymbol{x}\right ] f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}, \end{align}
where the first and second term on the right-hand side correspond to boundary transport and internal mixing, respectively. The first can be expressed in terms of the original density by including the weight
 $\boldsymbol{\nabla }f_{\boldsymbol{X}}/f_{\boldsymbol{X}}=\boldsymbol{\nabla }\log f_{\boldsymbol{X}}$
inside the expectation:
$\boldsymbol{\nabla }f_{\boldsymbol{X}}/f_{\boldsymbol{X}}=\boldsymbol{\nabla }\log f_{\boldsymbol{X}}$
inside the expectation:
 \begin{equation} \int \limits _{\mathbb{R}^{d}}\mathbb{E}[\square |\boldsymbol{X}=\boldsymbol{x}]\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x} = \int \limits _{\mathbb{R}^{d}}\mathbb{E}\left [\square \boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{X}=\boldsymbol{x}\right ]f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}; \end{equation}
\begin{equation} \int \limits _{\mathbb{R}^{d}}\mathbb{E}[\square |\boldsymbol{X}=\boldsymbol{x}]\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x} = \int \limits _{\mathbb{R}^{d}}\mathbb{E}\left [\square \boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{X}=\boldsymbol{x}\right ]f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d} \boldsymbol{x}; \end{equation}
hence, using (3.5),
 \begin{equation} -\mathbb{E}\left [(\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J})^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\bigg |\boldsymbol{Y}\right ] = \underbrace {\mathbb{E}\left [\boldsymbol{J}^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{Y}\right ]}_{\textrm{boundary transport}}+ \underbrace {\mathbb{E}\left [\boldsymbol{J}^{i}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{j}\frac {\partial ^{2}g(\boldsymbol{Y})}{\partial Y^{i}\partial Y^{j}}\bigg |\boldsymbol{Y}\right ]}_{\textrm{internal mixing}}. \end{equation}
\begin{equation} -\mathbb{E}\left [(\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{J})^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\bigg |\boldsymbol{Y}\right ] = \underbrace {\mathbb{E}\left [\boldsymbol{J}^{i}\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{Y}\right ]}_{\textrm{boundary transport}}+ \underbrace {\mathbb{E}\left [\boldsymbol{J}^{i}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{j}\frac {\partial ^{2}g(\boldsymbol{Y})}{\partial Y^{i}\partial Y^{j}}\bigg |\boldsymbol{Y}\right ]}_{\textrm{internal mixing}}. \end{equation}
Physically, the factor
 $\boldsymbol{\nabla }\log f_{\boldsymbol{X}}$
conditions the flux against the normal direction of the boundary region. To see why, note that
$\boldsymbol{\nabla }\log f_{\boldsymbol{X}}$
conditions the flux against the normal direction of the boundary region. To see why, note that
 $-\boldsymbol{\nabla }f_{\boldsymbol{X}}/|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
defines an outward unit vector that is perpendicular to isosurfaces of
$-\boldsymbol{\nabla }f_{\boldsymbol{X}}/|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
defines an outward unit vector that is perpendicular to isosurfaces of
 $f_{\boldsymbol{X}}$
and that
$f_{\boldsymbol{X}}$
and that
 $|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
is the (unnormalised) density associated with the bounding region. Therefore, introducing the normalisation factor
$|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
is the (unnormalised) density associated with the bounding region. Therefore, introducing the normalisation factor
 $N$
and using
$N$
and using
 $\tilde {\mathbb{E}}$
to denote the expectation of a random variable
$\tilde {\mathbb{E}}$
to denote the expectation of a random variable
 $\square$
over the boundary region:
$\square$
over the boundary region:
 \begin{equation} \tilde {\mathbb{E}}[\square ]:=\frac {1}{N}\int \limits _{\mathbb{R}^{d}}\square |\boldsymbol{\nabla }f_{X}|\,\textrm{d} \boldsymbol{x}, \end{equation}
\begin{equation} \tilde {\mathbb{E}}[\square ]:=\frac {1}{N}\int \limits _{\mathbb{R}^{d}}\square |\boldsymbol{\nabla }f_{X}|\,\textrm{d} \boldsymbol{x}, \end{equation}
the formula for conditional expectations under a change in measure, removing a factor of
 $N^{-1}$
from both sides, yields (see, for example Shreve Reference Shreve2004, § 5.2.1)
$N^{-1}$
from both sides, yields (see, for example Shreve Reference Shreve2004, § 5.2.1)
 \begin{equation} \mathbb{E}\left [\square \boldsymbol{\cdot }\boldsymbol{\nabla }\textrm{log}f_{\boldsymbol{X}}|\boldsymbol{Y}\right ]= \tilde {\mathbb{E}}\left [\square \boldsymbol{\cdot }\frac {\boldsymbol{\nabla }f_{\boldsymbol{X}}}{|\boldsymbol{\nabla }f_{\boldsymbol{X}}|}\big |\boldsymbol{Y}\right ] \mathbb{E}\left [\frac {|\boldsymbol{\nabla }f_{\boldsymbol{X}}|}{f_{\boldsymbol{X}}}\big |\boldsymbol{Y}\right ]. \end{equation}
\begin{equation} \mathbb{E}\left [\square \boldsymbol{\cdot }\boldsymbol{\nabla }\textrm{log}f_{\boldsymbol{X}}|\boldsymbol{Y}\right ]= \tilde {\mathbb{E}}\left [\square \boldsymbol{\cdot }\frac {\boldsymbol{\nabla }f_{\boldsymbol{X}}}{|\boldsymbol{\nabla }f_{\boldsymbol{X}}|}\big |\boldsymbol{Y}\right ] \mathbb{E}\left [\frac {|\boldsymbol{\nabla }f_{\boldsymbol{X}}|}{f_{\boldsymbol{X}}}\big |\boldsymbol{Y}\right ]. \end{equation}
The first term on the right-hand side of (3.11) is the expected flux
 $\square$
into the region defined by
$\square$
into the region defined by
 $f_{\boldsymbol{X}}$
. The second term is the expected value of the normalised density ratio
$f_{\boldsymbol{X}}$
. The second term is the expected value of the normalised density ratio
 $N^{-1}|\boldsymbol{\nabla }f_{\boldsymbol{X}}|/f_{\boldsymbol{X}}$
multiplied by
$N^{-1}|\boldsymbol{\nabla }f_{\boldsymbol{X}}|/f_{\boldsymbol{X}}$
multiplied by
 $N$
and conditioned on
$N$
and conditioned on
 $\boldsymbol{Y}$
. Now consider the probability that
$\boldsymbol{Y}$
. Now consider the probability that
 $\boldsymbol{Y}\in \mathcal{Y}$
(where
$\boldsymbol{Y}\in \mathcal{Y}$
(where
 $\mathcal{Y}\subseteq \mathbb{R}^{n}$
is an arbitrary subset) over the boundary region using the indicator function
$\mathcal{Y}\subseteq \mathbb{R}^{n}$
is an arbitrary subset) over the boundary region using the indicator function
 $\mathbb{I}_{\mathcal{Y}}$
:
$\mathbb{I}_{\mathcal{Y}}$
:
 \begin{equation} \tilde {\mathbb{P}}\{\boldsymbol{Y}\in \mathcal{Y}\}:=\tilde {\mathbb{E}}[\mathbb{I}_{\mathcal{Y}}]=\mathbb{E}\left [\mathbb{I}_{\mathcal{Y}}\frac {|\boldsymbol{\nabla }f_{\boldsymbol{X}}|}{Nf_{\boldsymbol{X}}}\right ]=\int \limits _{\mathcal{Y}}\underbrace {\mathbb{E}\left [\frac {|\boldsymbol{\nabla }f_{\boldsymbol{X}}|}{f_{\boldsymbol{X}}}\big |\boldsymbol{Y}=\boldsymbol{y}\right ]\frac {f_{\boldsymbol{Y}}(\boldsymbol{y})}{N}}_{=:\tilde {f}_{\boldsymbol{Y}}(\boldsymbol{y})}\,\textrm{d}\boldsymbol{y}, \end{equation}
\begin{equation} \tilde {\mathbb{P}}\{\boldsymbol{Y}\in \mathcal{Y}\}:=\tilde {\mathbb{E}}[\mathbb{I}_{\mathcal{Y}}]=\mathbb{E}\left [\mathbb{I}_{\mathcal{Y}}\frac {|\boldsymbol{\nabla }f_{\boldsymbol{X}}|}{Nf_{\boldsymbol{X}}}\right ]=\int \limits _{\mathcal{Y}}\underbrace {\mathbb{E}\left [\frac {|\boldsymbol{\nabla }f_{\boldsymbol{X}}|}{f_{\boldsymbol{X}}}\big |\boldsymbol{Y}=\boldsymbol{y}\right ]\frac {f_{\boldsymbol{Y}}(\boldsymbol{y})}{N}}_{=:\tilde {f}_{\boldsymbol{Y}}(\boldsymbol{y})}\,\textrm{d}\boldsymbol{y}, \end{equation}
which defines the probability density
 $\tilde {f}_{\boldsymbol{Y}}$
of
$\tilde {f}_{\boldsymbol{Y}}$
of
 $\boldsymbol{Y}$
when
$\boldsymbol{Y}$
when
 $\boldsymbol{X}$
is sampled from the boundary region and enables the final term in (3.11) to be expressed as
$\boldsymbol{X}$
is sampled from the boundary region and enables the final term in (3.11) to be expressed as
 $N\tilde {f}_{\boldsymbol{Y}}/f_{\boldsymbol{Y}}$
. The normalisation constant
$N\tilde {f}_{\boldsymbol{Y}}/f_{\boldsymbol{Y}}$
. The normalisation constant
 $N$
can be interpreted as the relative size of the boundary region. In particular, as
$N$
can be interpreted as the relative size of the boundary region. In particular, as
 $f_{\boldsymbol{X}}$
tends to the indicator function
$f_{\boldsymbol{X}}$
tends to the indicator function
 $\mathbb{I}_{\mathcal{X}}$
, selecting a subset
$\mathbb{I}_{\mathcal{X}}$
, selecting a subset
 $\mathcal{X}\subseteq \mathbb{R}^{d}$
,
$\mathcal{X}\subseteq \mathbb{R}^{d}$
,
 $N$
tends to the ratio of the surface area of
$N$
tends to the ratio of the surface area of
 $\mathcal{X}$
to its volume. If, for example,
$\mathcal{X}$
to its volume. If, for example,
 $\mathcal{X}$
is a unit interval of
$\mathcal{X}$
is a unit interval of
 $\mathbb{R}$
, the unnormalised distribution
$\mathbb{R}$
, the unnormalised distribution
 $|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
would tend to a delta measure at either end of the interval and the required normalisation constant
$|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
would tend to a delta measure at either end of the interval and the required normalisation constant
 $N$
would, therefore, tend to
$N$
would, therefore, tend to
 $2$
.
$2$
.
3.3. Backward Kolmogorov equation
For random variables
 $\square$
and
$\square$
and
 $\boldsymbol{Y}$
, and a function
$\boldsymbol{Y}$
, and a function
 $g:\mathbb{R}^{n}\rightarrow \mathbb{R}$
, the expected value of
$g:\mathbb{R}^{n}\rightarrow \mathbb{R}$
, the expected value of
 $g(\boldsymbol{Y})$
, conditional on
$g(\boldsymbol{Y})$
, conditional on
 $\boldsymbol{Y}=\boldsymbol{y}$
, is
$\boldsymbol{Y}=\boldsymbol{y}$
, is
 $g(\boldsymbol{y})$
. Therefore,
$g(\boldsymbol{y})$
. Therefore,
 $\mathbb{E}[\square g(\boldsymbol{Y})|\boldsymbol{Y}=\boldsymbol{y}]=\mathbb{E}[\square |\boldsymbol{Y}=\boldsymbol{y}]g(\boldsymbol{y})$
and (3.3) becomes
$\mathbb{E}[\square g(\boldsymbol{Y})|\boldsymbol{Y}=\boldsymbol{y}]=\mathbb{E}[\square |\boldsymbol{Y}=\boldsymbol{y}]g(\boldsymbol{y})$
and (3.3) becomes
 \begin{equation} \mathscr{L}g(\boldsymbol{y})=\unicode{x1D63F}_{1}^{\,i}\dfrac {\partial g}{\partial y^{i}}+\unicode{x1D63F}_{2}^{\textit{,ij}}\frac {\partial ^{2}g}{\partial y^{i}\partial y^{j}}. \end{equation}
\begin{equation} \mathscr{L}g(\boldsymbol{y})=\unicode{x1D63F}_{1}^{\,i}\dfrac {\partial g}{\partial y^{i}}+\unicode{x1D63F}_{2}^{\textit{,ij}}\frac {\partial ^{2}g}{\partial y^{i}\partial y^{j}}. \end{equation}
Using the results from § 3.2, the so-called drift velocity is
 \begin{equation} \unicode{x1D63F}_{1}:=\mathbb{E}\left [\boldsymbol{I}_{s}+\boldsymbol{J}_{s}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ] \end{equation}
\begin{equation} \unicode{x1D63F}_{1}:=\mathbb{E}\left [\boldsymbol{I}_{s}+\boldsymbol{J}_{s}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ] \end{equation}
and the symmetric diffusion coefficient is
 \begin{equation} \unicode{x1D63F}_{2}:=\frac {1}{2}\mathbb{E}\left [\boldsymbol{J}^{\top }_{s}\boldsymbol{\nabla }\boldsymbol{Y}_{\!s}+\boldsymbol{\nabla }\boldsymbol{Y}_{\!s}^{\top }\boldsymbol{J}_{s}|\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ]+\frac {1}{2}\boldsymbol{\varSigma }. \end{equation}
\begin{equation} \unicode{x1D63F}_{2}:=\frac {1}{2}\mathbb{E}\left [\boldsymbol{J}^{\top }_{s}\boldsymbol{\nabla }\boldsymbol{Y}_{\!s}+\boldsymbol{\nabla }\boldsymbol{Y}_{\!s}^{\top }\boldsymbol{J}_{s}|\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ]+\frac {1}{2}\boldsymbol{\varSigma }. \end{equation}
If
 $u(\boldsymbol{y},s):=\mathbb{E}[g(\boldsymbol{Y}_{\!t})|\boldsymbol{Y}_{\!s}=\boldsymbol{y}]$
, then
$u(\boldsymbol{y},s):=\mathbb{E}[g(\boldsymbol{Y}_{\!t})|\boldsymbol{Y}_{\!s}=\boldsymbol{y}]$
, then
 \begin{equation} -\partial _{s}u(\boldsymbol{y},s)=\mathscr{L}u(\boldsymbol{y},s) \end{equation}
\begin{equation} -\partial _{s}u(\boldsymbol{y},s)=\mathscr{L}u(\boldsymbol{y},s) \end{equation}
is solved backwards in time from the end condition
 $u(\boldsymbol{y},t)=g(\boldsymbol{y})$
, so that
$u(\boldsymbol{y},t)=g(\boldsymbol{y})$
, so that
 $u(\boldsymbol{y},s)$
is the expected value of
$u(\boldsymbol{y},s)$
is the expected value of
 $g(\boldsymbol{Y}_{\!t})$
given
$g(\boldsymbol{Y}_{\!t})$
given
 $\boldsymbol{Y}_{\!s}=\boldsymbol{y}$
for
$\boldsymbol{Y}_{\!s}=\boldsymbol{y}$
for
 $s\leqslant t$
. The generator
$s\leqslant t$
. The generator
 $\mathscr{L}$
therefore ‘pulls back’ the observation
$\mathscr{L}$
therefore ‘pulls back’ the observation
 $g$
along the dynamics specified by (3.1).
$g$
along the dynamics specified by (3.1).
A local (in space) diffusivity with what looks like the same form as (3.15) is found in classical p.d.f. methods (Pope Reference Pope1981). Here, however, the spatial conditioning is distributed over an arbitrary control volume, as defined by the sample distribution
 $f_{\boldsymbol{X}}$
(see item (i) at the end of § 1), which leads to the boundary fluxes in (3.14) and has been derived from the dual perspective of observables
$f_{\boldsymbol{X}}$
(see item (i) at the end of § 1), which leads to the boundary fluxes in (3.14) and has been derived from the dual perspective of observables
 $g$
(see item (ii) at the end of § 1). Consequently, (3.15) readily accounts for distributed stochastic forcing through
$g$
(see item (ii) at the end of § 1). Consequently, (3.15) readily accounts for distributed stochastic forcing through
 $\boldsymbol{\varSigma }$
. The following section explains how
$\boldsymbol{\varSigma }$
. The following section explains how
 $\unicode{x1D63F}_{1}$
and
$\unicode{x1D63F}_{1}$
and
 $\unicode{x1D63F}_{2}$
determine the evolution of probability density using duality.
$\unicode{x1D63F}_{2}$
determine the evolution of probability density using duality.
3.4. Forward Kolmogorov equation
The ‘forward’ equation corresponding to (3.16) is derived by expressing the time rate of change of the conditional expectation
 $\mathbb{E}[g(\boldsymbol{Y}_{\!t})|\boldsymbol{Y}_{\!s}=\boldsymbol{y}]$
in terms of a conditional probability density
$\mathbb{E}[g(\boldsymbol{Y}_{\!t})|\boldsymbol{Y}_{\!s}=\boldsymbol{y}]$
in terms of a conditional probability density
 $f_{\boldsymbol{Y}_{\!t}|\boldsymbol{Y}_{\!s}}$
, as described by Pavliotis (Reference Pavliotis2014, pp. 45–50). Here, we present an abridged version to highlight the main idea without introducing new notation.
$f_{\boldsymbol{Y}_{\!t}|\boldsymbol{Y}_{\!s}}$
, as described by Pavliotis (Reference Pavliotis2014, pp. 45–50). Here, we present an abridged version to highlight the main idea without introducing new notation.
If the density
 $f_{\boldsymbol{Y}}(\boldsymbol{y},t)$
is understood as being conditional on a specified density
$f_{\boldsymbol{Y}}(\boldsymbol{y},t)$
is understood as being conditional on a specified density
 $f_{\boldsymbol{Y}}(\boldsymbol{y},0)$
at
$f_{\boldsymbol{Y}}(\boldsymbol{y},0)$
at
 $t=0$
, the expected value of
$t=0$
, the expected value of
 $g$
resulting from the initial density
$g$
resulting from the initial density
 $f_{\boldsymbol{Y}}(\boldsymbol{y},0)$
satisfies
$f_{\boldsymbol{Y}}(\boldsymbol{y},0)$
satisfies
 \begin{equation} \partial _{t}\mathbb{E}[g(\boldsymbol{Y}_{\!t})]=\partial _{t}\int \limits _{\mathbb{R}^{n}}g(\boldsymbol{y})f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d}\boldsymbol{y}=\int \limits _{\mathbb{R}^{n}}g(\boldsymbol{y})\partial _{t}f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d}\boldsymbol{y}. \end{equation}
\begin{equation} \partial _{t}\mathbb{E}[g(\boldsymbol{Y}_{\!t})]=\partial _{t}\int \limits _{\mathbb{R}^{n}}g(\boldsymbol{y})f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d}\boldsymbol{y}=\int \limits _{\mathbb{R}^{n}}g(\boldsymbol{y})\partial _{t}f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d}\boldsymbol{y}. \end{equation}
Alternatively, using
 $\mathscr{L}$
, integrating by parts and assuming that either
$\mathscr{L}$
, integrating by parts and assuming that either
 $f_{\boldsymbol{Y}}$
or
$f_{\boldsymbol{Y}}$
or
 $g$
decay sufficiently fast as
$g$
decay sufficiently fast as
 $|\boldsymbol{y}|\rightarrow \infty$
,
$|\boldsymbol{y}|\rightarrow \infty$
,
 \begin{equation} \partial _{t}\mathbb{E}[g(\boldsymbol{Y}_{\!t})]=\int \limits _{\mathbb{R}^{n}}\mathscr{L}g(\boldsymbol{y})f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}=\int \limits _{\mathbb{R}^{n}}g(\boldsymbol{y})\mathscr{L}^{\dagger }f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}. \end{equation}
\begin{equation} \partial _{t}\mathbb{E}[g(\boldsymbol{Y}_{\!t})]=\int \limits _{\mathbb{R}^{n}}\mathscr{L}g(\boldsymbol{y})f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}=\int \limits _{\mathbb{R}^{n}}g(\boldsymbol{y})\mathscr{L}^{\dagger }f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}. \end{equation}
Therefore, equating (3.17) and (3.18), and noting that they are valid for all suitable observables
 $g$
,
$g$
,
 \begin{equation} \partial _{t}f_{\boldsymbol{Y}}(\boldsymbol{y},t)=\mathscr{L}^{\dagger }f_{\boldsymbol{Y}}(\boldsymbol{y},t), \end{equation}
\begin{equation} \partial _{t}f_{\boldsymbol{Y}}(\boldsymbol{y},t)=\mathscr{L}^{\dagger }f_{\boldsymbol{Y}}(\boldsymbol{y},t), \end{equation}
where
 \begin{equation} \mathscr{L}^{\dagger }f_{\boldsymbol{Y}}(\boldsymbol{y},t):=-\dfrac {\partial }{\partial y^{i}}(\unicode{x1D63F}_{1}^{\,i}f_{\boldsymbol{Y}}(\boldsymbol{y},t))+\frac {\partial ^{2}}{\partial y^{i}\partial y^{j}}(\unicode{x1D63F}^{\,\textit{ij}}_{2}f_{\boldsymbol{Y}}(\boldsymbol{y},t)). \end{equation}
\begin{equation} \mathscr{L}^{\dagger }f_{\boldsymbol{Y}}(\boldsymbol{y},t):=-\dfrac {\partial }{\partial y^{i}}(\unicode{x1D63F}_{1}^{\,i}f_{\boldsymbol{Y}}(\boldsymbol{y},t))+\frac {\partial ^{2}}{\partial y^{i}\partial y^{j}}(\unicode{x1D63F}^{\,\textit{ij}}_{2}f_{\boldsymbol{Y}}(\boldsymbol{y},t)). \end{equation}
The forward equation evolves
 $f_{\boldsymbol{Y}}$
forwards in time from the initial density
$f_{\boldsymbol{Y}}$
forwards in time from the initial density
 $f_{\boldsymbol{Y}}(\boldsymbol{y},0)$
.
$f_{\boldsymbol{Y}}(\boldsymbol{y},0)$
.
3.5. Physical interpretation
Sources
 $\boldsymbol{I}$
and boundary fluxes
$\boldsymbol{I}$
and boundary fluxes
 $\boldsymbol{J}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}/|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
into/out of the control volume contribute to positive/negative drift
$\boldsymbol{J}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}/|\boldsymbol{\nabla }f_{\boldsymbol{X}}|$
into/out of the control volume contribute to positive/negative drift
 $\unicode{x1D63F}_{1}$
in the evolution of the density
$\unicode{x1D63F}_{1}$
in the evolution of the density
 $f_{\boldsymbol{Y}}$
. As discussed in § 3.2 beneath (3.12), the boundary fluxes are scaled to account for the relative size of the boundary. Both processes contribute to drift because they determine a rate of gradual change in
$f_{\boldsymbol{Y}}$
. As discussed in § 3.2 beneath (3.12), the boundary fluxes are scaled to account for the relative size of the boundary. Both processes contribute to drift because they determine a rate of gradual change in
 $\boldsymbol{Y}$
, rather than an immediate addition or removal of fluid with a given value of
$\boldsymbol{Y}$
, rather than an immediate addition or removal of fluid with a given value of
 $\boldsymbol{Y}$
. An exception to this interpretation occurs when advection due to a velocity field is included in
$\boldsymbol{Y}$
. An exception to this interpretation occurs when advection due to a velocity field is included in
 $\boldsymbol{J}$
, which will be discussed in § 4.
$\boldsymbol{J}$
, which will be discussed in § 4.
Expectations of the cross-gradient mixing terms
 $\boldsymbol{J}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}$
determine the diffusion coefficient
$\boldsymbol{J}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}$
determine the diffusion coefficient
 $\unicode{x1D63F}_{2}$
in (3.15). The sign of
$\unicode{x1D63F}_{2}$
in (3.15). The sign of
 $\unicode{x1D63F}_{2}$
will be discussed in detail in § 5. In many practical applications, and according to Fick’s law, each column of
$\unicode{x1D63F}_{2}$
will be discussed in detail in § 5. In many practical applications, and according to Fick’s law, each column of
 $\boldsymbol{J}$
points in the direction of each column of
$\boldsymbol{J}$
points in the direction of each column of
 $-\boldsymbol{\nabla }\boldsymbol{Y}$
, making it reasonable to expect
$-\boldsymbol{\nabla }\boldsymbol{Y}$
, making it reasonable to expect
 $\unicode{x1D63F}_{2}$
to be negative semidefinite. This property corresponds to the fact that down-gradient molecular transport homogenises
$\unicode{x1D63F}_{2}$
to be negative semidefinite. This property corresponds to the fact that down-gradient molecular transport homogenises
 $\boldsymbol{Y}$
, which leads to greater certainty in the value of
$\boldsymbol{Y}$
, which leads to greater certainty in the value of
 $\boldsymbol{Y}_{\!t}$
and lower entropy of the distribution
$\boldsymbol{Y}_{\!t}$
and lower entropy of the distribution
 $f_{\boldsymbol{Y}}$
.
$f_{\boldsymbol{Y}}$
.
The following sections (§§ 4 and 5) consider fluxes that comprise advection and diffusion:
 \begin{equation} \boldsymbol{J}=\boldsymbol{U}\otimes \boldsymbol{Y}-\boldsymbol{\nabla }\boldsymbol{Y}\boldsymbol{\alpha }, \end{equation}
\begin{equation} \boldsymbol{J}=\boldsymbol{U}\otimes \boldsymbol{Y}-\boldsymbol{\nabla }\boldsymbol{Y}\boldsymbol{\alpha }, \end{equation}
where
 $\boldsymbol{U}$
is a solenoidal velocity field (i.e.
$\boldsymbol{U}$
is a solenoidal velocity field (i.e.
 $\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{U}\equiv 0$
) and
$\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{U}\equiv 0$
) and
 $\boldsymbol{\alpha }\in \mathbb{R}^{n\times n}$
is a (typically diagonal) multicomponent diffusion matrix. More generally,
$\boldsymbol{\alpha }\in \mathbb{R}^{n\times n}$
is a (typically diagonal) multicomponent diffusion matrix. More generally,
 $\boldsymbol{\alpha }$
could also account for anisotropic diffusion, which would make it a four-dimensional tensor.
$\boldsymbol{\alpha }$
could also account for anisotropic diffusion, which would make it a four-dimensional tensor.
4. Stirring due to advection
To understand the role that the advective component of the flux
 $\boldsymbol{J}$
in (3.21) plays it is useful to revisit the identity (3.6) in § 3.2, recognising that if
$\boldsymbol{J}$
in (3.21) plays it is useful to revisit the identity (3.6) in § 3.2, recognising that if
 $\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{U}\equiv 0$
, the chain rule implies
$\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{U}\equiv 0$
, the chain rule implies
 \begin{equation} -\boldsymbol{\nabla }\boldsymbol{\cdot }(\boldsymbol{U} Y^{i})\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}} = -\boldsymbol{\nabla }\boldsymbol{\cdot }(\boldsymbol{U}g). \end{equation}
\begin{equation} -\boldsymbol{\nabla }\boldsymbol{\cdot }(\boldsymbol{U} Y^{i})\dfrac {\partial g(\boldsymbol{Y})}{\partial Y^{i}} = -\boldsymbol{\nabla }\boldsymbol{\cdot }(\boldsymbol{U}g). \end{equation}
Consequently, by applying the steps described in § 3.2 to (4.1), the contributions that the flux
 $\boldsymbol{U}\otimes \boldsymbol{Y}$
makes to the right-hand side of (3.20) through
$\boldsymbol{U}\otimes \boldsymbol{Y}$
makes to the right-hand side of (3.20) through
 $\unicode{x1D63F}_{1}$
and
$\unicode{x1D63F}_{1}$
and
 $\unicode{x1D63F}_{2}$
can be replaced with a single sink term
$\unicode{x1D63F}_{2}$
can be replaced with a single sink term
 $-Vf_{\boldsymbol{Y}}$
:
$-Vf_{\boldsymbol{Y}}$
:
 \begin{equation} \partial _{t}f_{\boldsymbol{Y}}=(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}}, \end{equation}
\begin{equation} \partial _{t}f_{\boldsymbol{Y}}=(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}}, \end{equation}
where
 \begin{equation} V(\boldsymbol{y},t):=-\mathbb{E}\left [\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{Y}_{\!t}=\boldsymbol{y}\right ]. \end{equation}
\begin{equation} V(\boldsymbol{y},t):=-\mathbb{E}\left [\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{Y}_{\!t}=\boldsymbol{y}\right ]. \end{equation}
Unlike the drift and diffusion terms in (3.20),
 $V$
modifies
$V$
modifies
 $f_{\boldsymbol{Y}}$
by accounting for the addition or removal of fluid, with a scalar field value of
$f_{\boldsymbol{Y}}$
by accounting for the addition or removal of fluid, with a scalar field value of
 $\boldsymbol{y}$
, over the sample distribution’s boundary. The inclusion of
$\boldsymbol{y}$
, over the sample distribution’s boundary. The inclusion of
 $V$
is the subject of the Feynman–Kac formula, which is discussed in Appendix C and provides an interpretation of
$V$
is the subject of the Feynman–Kac formula, which is discussed in Appendix C and provides an interpretation of
 $V$
as modifying the expectation with respect to which
$V$
as modifying the expectation with respect to which
 $u(\boldsymbol{y},s)$
in (3.16) is defined. As expected, if
$u(\boldsymbol{y},s)$
in (3.16) is defined. As expected, if
 $\boldsymbol{U}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}\equiv 0$
, then the boundary fluxes are zero and the velocity field serves to stir the various scalar fields internally without affecting
$\boldsymbol{U}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}\equiv 0$
, then the boundary fluxes are zero and the velocity field serves to stir the various scalar fields internally without affecting
 $f_{\boldsymbol{Y}}$
. The incorporation of time-dependent sample distributions
$f_{\boldsymbol{Y}}$
. The incorporation of time-dependent sample distributions
 $f_{\boldsymbol{X}}$
, which produce further contributions to
$f_{\boldsymbol{X}}$
, which produce further contributions to
 $V$
, are discussed in Appendix C.1. In particular, Appendix C.1 demonstrates that if
$V$
, are discussed in Appendix C.1. In particular, Appendix C.1 demonstrates that if
 $f_{\boldsymbol{X}}$
is defined as a Lagrangian control distribution, advected by the fluid, then
$f_{\boldsymbol{X}}$
is defined as a Lagrangian control distribution, advected by the fluid, then
 $V\equiv 0$
.
$V\equiv 0$
.
For
 $f_{\boldsymbol{Y}}$
to evolve as a probability density, the integral of
$f_{\boldsymbol{Y}}$
to evolve as a probability density, the integral of
 $Vf_{\boldsymbol{Y}}$
over
$Vf_{\boldsymbol{Y}}$
over
 $\mathbb{R}^{n}$
must vanish. Although it looks as though the sink term on the right-hand side of (4.2) might violate this requirement, it should be recalled, using (3.5), that
$\mathbb{R}^{n}$
must vanish. Although it looks as though the sink term on the right-hand side of (4.2) might violate this requirement, it should be recalled, using (3.5), that
 \begin{equation} \int \limits _{\mathbb{R}^{n}}Vf_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d}\boldsymbol{y}= \mathbb{E}\left [\mathbb{E}\left [\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{Y}_{\!t}=\boldsymbol{y}\right ]\right ] = \mathbb{E}\left [\mathbb{E}\left [\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{X}=\boldsymbol{x}\right ]\right ], \end{equation}
\begin{equation} \int \limits _{\mathbb{R}^{n}}Vf_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d}\boldsymbol{y}= \mathbb{E}\left [\mathbb{E}\left [\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{Y}_{\!t}=\boldsymbol{y}\right ]\right ] = \mathbb{E}\left [\mathbb{E}\left [\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}\big |\boldsymbol{X}=\boldsymbol{x}\right ]\right ], \end{equation}
where, using integration by parts, the final expectation can be expressed as
 \begin{equation} \int \limits _{\mathbb{R}^{d}}\mathbb{E}[\boldsymbol{U}_{\!t}|\boldsymbol{X}=\boldsymbol{x}]\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}\,\textrm{d}\boldsymbol{x}= -\mathbb{E}[\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{U}_{\!t}]=0, \end{equation}
\begin{equation} \int \limits _{\mathbb{R}^{d}}\mathbb{E}[\boldsymbol{U}_{\!t}|\boldsymbol{X}=\boldsymbol{x}]\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}\,\textrm{d}\boldsymbol{x}= -\mathbb{E}[\boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{U}_{\!t}]=0, \end{equation}
which demonstrates that the integral of
 $f_{\boldsymbol{Y}}$
is invariant to the sources and sinks arising from advection over the boundary region. A similar expression to (4.5) can be found from Pope (Reference Pope2000, § 12.6.2, (12.217)) when
$f_{\boldsymbol{Y}}$
is invariant to the sources and sinks arising from advection over the boundary region. A similar expression to (4.5) can be found from Pope (Reference Pope2000, § 12.6.2, (12.217)) when
 $f_{\boldsymbol{X}}$
is regarded as a particle position density.
$f_{\boldsymbol{X}}$
is regarded as a particle position density.
5. Mixing due to diffusion
In this section, the focus will be on the effect that mixing has in the forward equation for probability density (3.19). It is therefore convenient to start by neglecting
 $\boldsymbol{\varSigma }$
, which, being positive semidefinite by construction, typically acts in (3.15) to oppose the effects of mixing.
$\boldsymbol{\varSigma }$
, which, being positive semidefinite by construction, typically acts in (3.15) to oppose the effects of mixing.
Neglecting
 $\boldsymbol{\varSigma }$
, using (3.21) and applying the result from § 4, the diffusion coefficient (3.15) becomes
$\boldsymbol{\varSigma }$
, using (3.21) and applying the result from § 4, the diffusion coefficient (3.15) becomes
 \begin{equation} \unicode{x1D63F}_{2}:=-\frac {1}{2}\mathbb{E}\left [\boldsymbol{\alpha }^{\top }\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}+\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}\boldsymbol{\alpha }|\boldsymbol{Y}=\boldsymbol{y}\right ]. \end{equation}
\begin{equation} \unicode{x1D63F}_{2}:=-\frac {1}{2}\mathbb{E}\left [\boldsymbol{\alpha }^{\top }\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}+\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}\boldsymbol{\alpha }|\boldsymbol{Y}=\boldsymbol{y}\right ]. \end{equation}
If, in particular, a sampling distribution
 $f_{\boldsymbol{X}}$
completely encompasses a scalar field, such that the boundary fluxes in
$f_{\boldsymbol{X}}$
completely encompasses a scalar field, such that the boundary fluxes in
 $\unicode{x1D63F}_{1}$
are zero, then the forward equation for probability density (4.2) for a single scalar
$\unicode{x1D63F}_{1}$
are zero, then the forward equation for probability density (4.2) for a single scalar
 $Y$
with diffusivity
$Y$
with diffusivity
 $\alpha \gt 0$
can by multiplied by
$\alpha \gt 0$
can by multiplied by
 $y^{2}$
and integrated to give the well-known evolution of variance (Zeldovich Reference Zeldovich1937):
$y^{2}$
and integrated to give the well-known evolution of variance (Zeldovich Reference Zeldovich1937):
 \begin{equation} \frac {1}{2}\dfrac {\textrm{d}}{\textrm{d} {t}}\mathbb{E}\big[Y_{\!t}^{2}\big] = -\alpha \mathbb{E}\big[|\boldsymbol{\nabla }Y_{\!t}|^{2}\big], \end{equation}
\begin{equation} \frac {1}{2}\dfrac {\textrm{d}}{\textrm{d} {t}}\mathbb{E}\big[Y_{\!t}^{2}\big] = -\alpha \mathbb{E}\big[|\boldsymbol{\nabla }Y_{\!t}|^{2}\big], \end{equation}
which illustrates that the diffusivity
 $\alpha$
reduces the variance of
$\alpha$
reduces the variance of
 $Y_{\!t}$
due to the fact that
$Y_{\!t}$
due to the fact that
 $\unicode{x1D63F}_{2}\lt 0$
.
$\unicode{x1D63F}_{2}\lt 0$
.
Indeed, for many practical applications, it is reasonable to expect
 $\unicode{x1D63F}_{2}$
to be negative semidefinite, corresponding to the fact that down-gradient molecular transport homogenises
$\unicode{x1D63F}_{2}$
to be negative semidefinite, corresponding to the fact that down-gradient molecular transport homogenises
 $\boldsymbol{Y}$
, which leads to greater certainty in the value of
$\boldsymbol{Y}$
, which leads to greater certainty in the value of
 $\boldsymbol{Y}$
. For example, in physical space, the eventual steady state of a scalar subjected to diffusion in an insulated domain will be uniform, which corresponds to a Dirac measure in the probability distribution.
$\boldsymbol{Y}$
. For example, in physical space, the eventual steady state of a scalar subjected to diffusion in an insulated domain will be uniform, which corresponds to a Dirac measure in the probability distribution.
More generally, however, the properties of (5.1) are intriguing because they depend on both the relative diffusivities
 $\boldsymbol{\alpha }$
of the observed quantities
$\boldsymbol{\alpha }$
of the observed quantities
 $\boldsymbol{Y}$
and the a priori unknown correlation between gradients
$\boldsymbol{Y}$
and the a priori unknown correlation between gradients
 $\boldsymbol{\nabla }\boldsymbol{Y}$
. It is therefore useful to understand when to expect negative semidefinite
$\boldsymbol{\nabla }\boldsymbol{Y}$
. It is therefore useful to understand when to expect negative semidefinite
 $\unicode{x1D63F}_{2}$
(which will be denoted
$\unicode{x1D63F}_{2}$
(which will be denoted
 $\unicode{x1D63F}_{2}\preceq 0$
or, equivalently,
$\unicode{x1D63F}_{2}\preceq 0$
or, equivalently,
 $-\unicode{x1D63F}_{2}\succeq 0$
when it is convenient to refer to positive semidefinite matrices).
$-\unicode{x1D63F}_{2}\succeq 0$
when it is convenient to refer to positive semidefinite matrices).
Begin by noting that outer products
 $\boldsymbol{r}\otimes \boldsymbol{r}$
for
$\boldsymbol{r}\otimes \boldsymbol{r}$
for
 $\boldsymbol{r}\in \mathbb{R}^{n}$
are extreme rays and, therefore, generators of the convex cone of positive semidefinite
$\boldsymbol{r}\in \mathbb{R}^{n}$
are extreme rays and, therefore, generators of the convex cone of positive semidefinite
 $n\times n$
matrices (Blekherman, Parrilo & Thomas Reference Blekherman, Parrilo and Thomas2012). In particular, the matrix product
$n\times n$
matrices (Blekherman, Parrilo & Thomas Reference Blekherman, Parrilo and Thomas2012). In particular, the matrix product
 $\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}\succeq 0$
, because, noting that
$\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}\succeq 0$
, because, noting that
 $\boldsymbol{\nabla }\boldsymbol{Y}\in \mathbb{R}^{d\times n}$
, it can be represented as the sum of
$\boldsymbol{\nabla }\boldsymbol{Y}\in \mathbb{R}^{d\times n}$
, it can be represented as the sum of
 $d$
outer products (one for gradients with respect to each spatial dimension
$d$
outer products (one for gradients with respect to each spatial dimension
 $X^{1},X^{2},\ldots ,X^{d}$
). Indeed, the expectation of such products also produces positive semidefinite matrices, because
$X^{1},X^{2},\ldots ,X^{d}$
). Indeed, the expectation of such products also produces positive semidefinite matrices, because
 $\boldsymbol{\partial }^{\top }\mathbb{E}[\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}|\boldsymbol{Y}=\boldsymbol{y}]\boldsymbol{\partial }=\mathbb{E}[(\boldsymbol{\partial }^{\top }\boldsymbol{\nabla }\boldsymbol{Y}^{\top })(\boldsymbol{\nabla }\boldsymbol{Y}\boldsymbol{\partial })|\boldsymbol{Y}=\boldsymbol{y}]\geqslant 0$
for all non-zero vectors
$\boldsymbol{\partial }^{\top }\mathbb{E}[\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}|\boldsymbol{Y}=\boldsymbol{y}]\boldsymbol{\partial }=\mathbb{E}[(\boldsymbol{\partial }^{\top }\boldsymbol{\nabla }\boldsymbol{Y}^{\top })(\boldsymbol{\nabla }\boldsymbol{Y}\boldsymbol{\partial })|\boldsymbol{Y}=\boldsymbol{y}]\geqslant 0$
for all non-zero vectors
 $\boldsymbol{\partial }\in \mathbb{R}^{n}$
is a sum of squares, which implies that
$\boldsymbol{\partial }\in \mathbb{R}^{n}$
is a sum of squares, which implies that
 \begin{equation} \mathbb{E}[\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}|\boldsymbol{Y}=\boldsymbol{y}]\succeq 0. \end{equation}
\begin{equation} \mathbb{E}[\boldsymbol{\nabla }\boldsymbol{Y}^{\top }\boldsymbol{\nabla }\boldsymbol{Y}|\boldsymbol{Y}=\boldsymbol{y}]\succeq 0. \end{equation}
The (negative) diffusion coefficient
 $-\unicode{x1D63F}_{2}$
in (3.15), however, is effectively generated by the outer product of the vectors
$-\unicode{x1D63F}_{2}$
in (3.15), however, is effectively generated by the outer product of the vectors
 $\boldsymbol{\alpha }^{\top }\boldsymbol{r}$
and
$\boldsymbol{\alpha }^{\top }\boldsymbol{r}$
and
 $\boldsymbol{r}$
. If the diffusivities of each observable quantity
$\boldsymbol{r}$
. If the diffusivities of each observable quantity
 $\boldsymbol{Y}$
are equal and non-negative, such that
$\boldsymbol{Y}$
are equal and non-negative, such that
 $\boldsymbol{\alpha }$
can be replaced with a single scalar
$\boldsymbol{\alpha }$
can be replaced with a single scalar
 $\alpha \in \mathbb{R}_{\geqslant 0}$
, then
$\alpha \in \mathbb{R}_{\geqslant 0}$
, then
 $\boldsymbol{\alpha }^{\top }\boldsymbol{r}$
and
$\boldsymbol{\alpha }^{\top }\boldsymbol{r}$
and
 $\boldsymbol{r}$
point in the same direction and, following the above-mentioned arguments,
$\boldsymbol{r}$
point in the same direction and, following the above-mentioned arguments,
 $\unicode{x1D63F}_{2}$
is negative semidefinite (
$\unicode{x1D63F}_{2}$
is negative semidefinite (
 $-\unicode{x1D63F}_{2}\succeq 0$
). More generally, however, when
$-\unicode{x1D63F}_{2}\succeq 0$
). More generally, however, when
 $\boldsymbol{\alpha }$
cannot be replaced with a scalar, the outer product
$\boldsymbol{\alpha }$
cannot be replaced with a scalar, the outer product
 $\boldsymbol{\alpha }^{\top }\boldsymbol{r}\otimes \boldsymbol{r}$
creates the possibility of
$\boldsymbol{\alpha }^{\top }\boldsymbol{r}\otimes \boldsymbol{r}$
creates the possibility of
 $\unicode{x1D63F}_{2}$
being sign indefinite, as illustrated by the shaded region of figure 5(a). The determining factor in such cases is the correlation between the gradients of the various components of
$\unicode{x1D63F}_{2}$
being sign indefinite, as illustrated by the shaded region of figure 5(a). The determining factor in such cases is the correlation between the gradients of the various components of
 $\boldsymbol{Y}$
, since it is possible for the sum of sign indefinite matrices to be positive semidefinite. Weaker correlation between the gradients provides stronger mitigation of the effects of unequal diffusivities in
$\boldsymbol{Y}$
, since it is possible for the sum of sign indefinite matrices to be positive semidefinite. Weaker correlation between the gradients provides stronger mitigation of the effects of unequal diffusivities in
 $\boldsymbol{\alpha }$
. For example, if
$\boldsymbol{\alpha }$
. For example, if
 $\boldsymbol{\alpha }$
is any non-negative diagonal matrix and the
$\boldsymbol{\alpha }$
is any non-negative diagonal matrix and the
 $n$
columns of
$n$
columns of
 $\boldsymbol{\nabla }\boldsymbol{Y}$
are uncorrelated, such that
$\boldsymbol{\nabla }\boldsymbol{Y}$
are uncorrelated, such that
 $\mathbb{E}_{Y}[\boldsymbol{\nabla }Y^{i}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{j}]=0$
for
$\mathbb{E}_{Y}[\boldsymbol{\nabla }Y^{i}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{j}]=0$
for
 $i\neq j$
, then
$i\neq j$
, then
 $\unicode{x1D63F}_{2}\preceq 0$
is a negative semidefinite diagonal matrix. More generally, it is also worth noting that the scalar diffusion coefficients associated with the marginal distributions of
$\unicode{x1D63F}_{2}\preceq 0$
is a negative semidefinite diagonal matrix. More generally, it is also worth noting that the scalar diffusion coefficients associated with the marginal distributions of
 $Y^{1}, Y^{2},\ldots ,Y^{n}$
correspond to the diagonal elements of
$Y^{1}, Y^{2},\ldots ,Y^{n}$
correspond to the diagonal elements of
 $\boldsymbol{\alpha }$
.
$\boldsymbol{\alpha }$
.

Figure 5. (a) Violation of positive semidefiniteness in the generator
 $\boldsymbol{\alpha }^{\top }\boldsymbol{r}\otimes \boldsymbol{r}$
of
$\boldsymbol{\alpha }^{\top }\boldsymbol{r}\otimes \boldsymbol{r}$
of
 $-\unicode{x1D63F}_{2}$
when the quantities
$-\unicode{x1D63F}_{2}$
when the quantities
 $\boldsymbol{Y}$
have different diffusivities
$\boldsymbol{Y}$
have different diffusivities
 $\boldsymbol{\alpha }$
. (b) Relationship between the ratio of diffusivities
$\boldsymbol{\alpha }$
. (b) Relationship between the ratio of diffusivities
 $\alpha$
and the correlation coefficient
$\alpha$
and the correlation coefficient
 $\theta$
that ensures that
$\theta$
that ensures that
 $\unicode{x1D63F}_{2}$
in (5.4) is negative semidefinite (white region).
$\unicode{x1D63F}_{2}$
in (5.4) is negative semidefinite (white region).
A simple two-dimensional example illustrates the combined effects of correlation in the gradients
 $\boldsymbol{\nabla }\boldsymbol{Y}$
and unequal diffusivities in
$\boldsymbol{\nabla }\boldsymbol{Y}$
and unequal diffusivities in
 $\boldsymbol{\alpha }$
. Let
$\boldsymbol{\alpha }$
. Let
 $\alpha _{11}=1$
,
$\alpha _{11}=1$
,
 $\alpha _{22}=\alpha$
and
$\alpha _{22}=\alpha$
and
 $\alpha _{12}=\alpha _{21}=0$
, and assume, without loss of generality, that
$\alpha _{12}=\alpha _{21}=0$
, and assume, without loss of generality, that
 $\mathbb{E}[\boldsymbol{\nabla }Y^{1}|\boldsymbol{Y}=\boldsymbol{y}]=\mathbb{E}[\boldsymbol{\nabla }Y^{2}|\boldsymbol{Y}=\boldsymbol{y}]=1$
to normalise the problem. Define the correlation coefficient
$\mathbb{E}[\boldsymbol{\nabla }Y^{1}|\boldsymbol{Y}=\boldsymbol{y}]=\mathbb{E}[\boldsymbol{\nabla }Y^{2}|\boldsymbol{Y}=\boldsymbol{y}]=1$
to normalise the problem. Define the correlation coefficient
 $\theta :=\mathbb{E}[\boldsymbol{\nabla }Y^{1}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{2}|\boldsymbol{Y}=\boldsymbol{y}]$
, such that
$\theta :=\mathbb{E}[\boldsymbol{\nabla }Y^{1}\boldsymbol{\cdot }\boldsymbol{\nabla }Y^{2}|\boldsymbol{Y}=\boldsymbol{y}]$
, such that
 \begin{equation} -\unicode{x1D63F}_{2}= \begin{bmatrix} 1 &\quad \theta (1+\alpha )/2 \\ \theta (1+\alpha )/2 &\quad \alpha \end{bmatrix} \end{equation}
\begin{equation} -\unicode{x1D63F}_{2}= \begin{bmatrix} 1 &\quad \theta (1+\alpha )/2 \\ \theta (1+\alpha )/2 &\quad \alpha \end{bmatrix} \end{equation}
from (3.15). The (negative) symmetric diffusion coefficient
 $-\unicode{x1D63F}_{2}$
in (5.4) is positive semidefinite if its minimum eigenvalue
$-\unicode{x1D63F}_{2}$
in (5.4) is positive semidefinite if its minimum eigenvalue
 \begin{equation} \lambda = \frac { (1+\alpha ) -\sqrt {(1+\alpha )^{2}+\theta ^{2}(1+\alpha )^{2}-4\alpha } }{2} \end{equation}
\begin{equation} \lambda = \frac { (1+\alpha ) -\sqrt {(1+\alpha )^{2}+\theta ^{2}(1+\alpha )^{2}-4\alpha } }{2} \end{equation}
is non-negative, which means that
 \begin{equation} |\theta |\leqslant \frac {2\sqrt {\alpha }}{1+\alpha } \end{equation}
\begin{equation} |\theta |\leqslant \frac {2\sqrt {\alpha }}{1+\alpha } \end{equation}
is the required relation between correlation and diffusivity that guarantees
 $-\unicode{x1D63F}_{2}\succeq 0$
and is illustrated in figure 5(b). If
$-\unicode{x1D63F}_{2}\succeq 0$
and is illustrated in figure 5(b). If
 $\theta \in \{-1,1\}$
, any difference in
$\theta \in \{-1,1\}$
, any difference in
 $\alpha$
from unity will lead to a sign indefinite diffusion coefficient
$\alpha$
from unity will lead to a sign indefinite diffusion coefficient
 $\unicode{x1D63F}_{2}$
, as motivated in the text following (5.3) and figure 5(a). However, for weaker correlations
$\unicode{x1D63F}_{2}$
, as motivated in the text following (5.3) and figure 5(a). However, for weaker correlations
 $|\theta |\lt 1$
, the ratio of the diffusivities
$|\theta |\lt 1$
, the ratio of the diffusivities
 $\alpha$
has to be either large or small to produce a sign indefinite diffusion coefficient
$\alpha$
has to be either large or small to produce a sign indefinite diffusion coefficient
 $\unicode{x1D63F}_{2}$
, as illustrated by the grey regions in figure 5(b). For reference, the ratio of thermal diffusivity to salt diffusivity in the oceans is approximately
$\unicode{x1D63F}_{2}$
, as illustrated by the grey regions in figure 5(b). For reference, the ratio of thermal diffusivity to salt diffusivity in the oceans is approximately
 $100$
and can be regarded as corresponding to
$100$
and can be regarded as corresponding to
 $\alpha$
in the previous example. Therefore, according to (5.6), in that case,
$\alpha$
in the previous example. Therefore, according to (5.6), in that case,
 $|\theta |$
would need to be less than approximately
$|\theta |$
would need to be less than approximately
 $0.2$
for
$0.2$
for
 $\unicode{x1D63F}_{2}$
to be negative semidefinite.
$\unicode{x1D63F}_{2}$
to be negative semidefinite.

Figure 6. Spectrahedra corresponding to the condition that
 $-\unicode{x1D63F}_{2}\succeq 0$
for correlation coefficients
$-\unicode{x1D63F}_{2}\succeq 0$
for correlation coefficients
 $\theta _{1}$
,
$\theta _{1}$
,
 $\theta _{2}$
and
$\theta _{2}$
and
 $\theta _{3}$
, and different relative diffusivities
$\theta _{3}$
, and different relative diffusivities
 $\alpha _{2}$
and
$\alpha _{2}$
and
 $\alpha _{3}$
in (5.7). (a)
$\alpha _{3}$
in (5.7). (a)
 $\alpha _{2}=1$
and
$\alpha _{2}=1$
and
 $\alpha _{3}=10$
, and (b)
$\alpha _{3}=10$
, and (b)
 $\alpha _{2}=0.1$
and
$\alpha _{2}=0.1$
and
 $\alpha _{3}=10$
. The red regions correspond to
$\alpha _{3}=10$
. The red regions correspond to
 $\unicode{x1D63F}_{2}\preceq 0$
, whilst the larger grey region corresponds to the feasibility requirement (5.3) for the correlations. The range of all axes is
$\unicode{x1D63F}_{2}\preceq 0$
, whilst the larger grey region corresponds to the feasibility requirement (5.3) for the correlations. The range of all axes is
 $[-1,1]$
.
$[-1,1]$
.
When
 $\boldsymbol{\alpha }$
is prescribed, it is useful to know the correlation coefficients
$\boldsymbol{\alpha }$
is prescribed, it is useful to know the correlation coefficients
 $\boldsymbol{\theta }\in \mathbb{R}^{n(n-1)/2}$
that produce negative semidefinite diffusion coefficients
$\boldsymbol{\theta }\in \mathbb{R}^{n(n-1)/2}$
that produce negative semidefinite diffusion coefficients
 $\unicode{x1D63F}_{2}$
. In such cases, the condition that
$\unicode{x1D63F}_{2}$
. In such cases, the condition that
 $-\unicode{x1D63F}_{2}\succeq 0$
can be represented by spectrahedra, which are formally defined as the intersection of the convex cone of positive semidefinite matrices (5.3) in
$-\unicode{x1D63F}_{2}\succeq 0$
can be represented by spectrahedra, which are formally defined as the intersection of the convex cone of positive semidefinite matrices (5.3) in
 $\mathbb{R}^{n\times n}$
with an affine subspace (Blekherman et al. Reference Blekherman, Parrilo and Thomas2012). In three dimensions, setting
$\mathbb{R}^{n\times n}$
with an affine subspace (Blekherman et al. Reference Blekherman, Parrilo and Thomas2012). In three dimensions, setting
 $\alpha _{11}=1$
,
$\alpha _{11}=1$
,
 $\alpha _{22}=\alpha _{2}$
and
$\alpha _{22}=\alpha _{2}$
and
 $\alpha _{33}=\alpha _{3}$
,
$\alpha _{33}=\alpha _{3}$
,
 \begin{equation} -\unicode{x1D63F}_{2}= \begin{bmatrix} 1 &\quad \theta _{3}(1+\alpha _{2})/2 &\quad \theta _{2}(1+\alpha _{3})/2 \\ \theta _{3}(1+\alpha _{2})/2 &\quad \alpha _{2} &\quad \theta _{1}(\alpha _{2}+\alpha _{3})/2 \\ \theta _{2}(1+\alpha _{3})/2 &\quad \theta _{1}(\alpha _{2}+\alpha _{3})/2 &\quad \alpha _{3} \end{bmatrix}, \end{equation}
\begin{equation} -\unicode{x1D63F}_{2}= \begin{bmatrix} 1 &\quad \theta _{3}(1+\alpha _{2})/2 &\quad \theta _{2}(1+\alpha _{3})/2 \\ \theta _{3}(1+\alpha _{2})/2 &\quad \alpha _{2} &\quad \theta _{1}(\alpha _{2}+\alpha _{3})/2 \\ \theta _{2}(1+\alpha _{3})/2 &\quad \theta _{1}(\alpha _{2}+\alpha _{3})/2 &\quad \alpha _{3} \end{bmatrix}, \end{equation}
where
 $\theta _{1}$
,
$\theta _{1}$
,
 $\theta _{2}$
and
$\theta _{2}$
and
 $\theta _{3}$
are correlation coefficients. Spectrahedra corresponding to
$\theta _{3}$
are correlation coefficients. Spectrahedra corresponding to
 $-\unicode{x1D63F}_{2}\succeq 0$
are shown in red in figure 6. The larger spectrahedron shown in grey corresponds to (5.3), which constrains the possible values of
$-\unicode{x1D63F}_{2}\succeq 0$
are shown in red in figure 6. The larger spectrahedron shown in grey corresponds to (5.3), which constrains the possible values of
 $\boldsymbol{\theta }$
. Values of
$\boldsymbol{\theta }$
. Values of
 $\boldsymbol{\theta }$
that lie between the red and the grey regions therefore correspond to permissible but sign indefinite diffusion coefficients
$\boldsymbol{\theta }$
that lie between the red and the grey regions therefore correspond to permissible but sign indefinite diffusion coefficients
 $\unicode{x1D63F}_{2}$
. In figure 6(a),
$\unicode{x1D63F}_{2}$
. In figure 6(a),
 $\alpha _{2}=1$
and
$\alpha _{2}=1$
and
 $\alpha _{3}=10$
, which leads to a narrower range of
$\alpha _{3}=10$
, which leads to a narrower range of
 $\theta _{1}$
and
$\theta _{1}$
and
 $\theta _{2}$
values for which
$\theta _{2}$
values for which
 $-\unicode{x1D63F}_{2}\succeq 0$
. In figure 6(b),
$-\unicode{x1D63F}_{2}\succeq 0$
. In figure 6(b),
 $\alpha _{2}=0.1$
and
$\alpha _{2}=0.1$
and
 $\alpha _{3}=10$
, which narrows the range further and increases the possibility that
$\alpha _{3}=10$
, which narrows the range further and increases the possibility that
 $\unicode{x1D63F}_{2}$
is sign indefinite.
$\unicode{x1D63F}_{2}$
is sign indefinite.
For situations involving stochastic forcing, diagnosing the sign of
 $\unicode{x1D63F}_{2}$
is complicated by the presence of
$\unicode{x1D63F}_{2}$
is complicated by the presence of
 $\boldsymbol{\varSigma }\succeq 0$
in (3.15), which, in contrast to mixing, leads to greater uncertainty in the state of the system.
$\boldsymbol{\varSigma }\succeq 0$
in (3.15), which, in contrast to mixing, leads to greater uncertainty in the state of the system.
6. Partitions and mixture distributions
The construction in § 3 gives an evolution equation for
 $f_{\boldsymbol{Y}}$
that is conditional on the specification of the spatial probability density
$f_{\boldsymbol{Y}}$
that is conditional on the specification of the spatial probability density
 $f_{\boldsymbol{X}}$
. It therefore generalises immediately to collections of densities describing the distribution of random variables within different zones of a domain. In statistics, such a decomposition is called a mixture distribution. To paraphrase Lindsay (Reference Lindsay1995) giving a simple example, they would arise naturally when sampling from a population consisting of several homogeneous subpopulations, highlighting the potential of mixture distributions to decompose a heterogeneous flow into (approximately) homogeneous sub flows.
$f_{\boldsymbol{X}}$
. It therefore generalises immediately to collections of densities describing the distribution of random variables within different zones of a domain. In statistics, such a decomposition is called a mixture distribution. To paraphrase Lindsay (Reference Lindsay1995) giving a simple example, they would arise naturally when sampling from a population consisting of several homogeneous subpopulations, highlighting the potential of mixture distributions to decompose a heterogeneous flow into (approximately) homogeneous sub flows.
Using the ‘latent’ random variable
 $Z\in \mathbb{Z}$
to denote a given zone, defined by the conditional density
$Z\in \mathbb{Z}$
to denote a given zone, defined by the conditional density
 $f_{\boldsymbol{X}|Z}$
, the original density can be recovered from Bayes’ theorem:
$f_{\boldsymbol{X}|Z}$
, the original density can be recovered from Bayes’ theorem:
 \begin{equation} f_{\boldsymbol{X}}(\boldsymbol{x})=\sum _{z\in \mathbb{Z}}f_{\boldsymbol{X}|Z}(\boldsymbol{x}|z)\mathbb{P}\{Z=z\}, \end{equation}
\begin{equation} f_{\boldsymbol{X}}(\boldsymbol{x})=\sum _{z\in \mathbb{Z}}f_{\boldsymbol{X}|Z}(\boldsymbol{x}|z)\mathbb{P}\{Z=z\}, \end{equation}
where
 $\mathbb{P}\{Z=z\}$
is the proportion of the original control volume attributed to zone
$\mathbb{P}\{Z=z\}$
is the proportion of the original control volume attributed to zone
 $z$
. An illustration of (6.1) is shown in figure 7, consisting of a decomposition of the uniform distribution over the interval
$z$
. An illustration of (6.1) is shown in figure 7, consisting of a decomposition of the uniform distribution over the interval
 $X\in [0,1]$
.
$X\in [0,1]$
.

Figure 7. A uniform mixture distribution
 $f_{X}\equiv 1$
over the unit interval (blue line) obtained from the sum of
$f_{X}\equiv 1$
over the unit interval (blue line) obtained from the sum of
 $f_{X|Z}(x|z)\mathbb{P}\{Z=z\}$
according to (6.1) for
$f_{X|Z}(x|z)\mathbb{P}\{Z=z\}$
according to (6.1) for
 $Z\in \{1,2,3,4,5\}$
. In the regions where the distributions overlap, the probability that
$Z\in \{1,2,3,4,5\}$
. In the regions where the distributions overlap, the probability that
 $X$
is associated with a given component (i.e.
$X$
is associated with a given component (i.e.
 $f_{Z|X}$
) is
$f_{Z|X}$
) is
 $f_{X|Z}(x|z)\mathbb{P}\{Z=z\}$
.
$f_{X|Z}(x|z)\mathbb{P}\{Z=z\}$
.
The distribution
 $f_{\boldsymbol{Y}}$
, or any distribution of
$f_{\boldsymbol{Y}}$
, or any distribution of
 $\boldsymbol{Y}$
conditional on
$\boldsymbol{Y}$
conditional on
 $Z$
belonging to a subset of
$Z$
belonging to a subset of
 $\mathbb{Z}$
, can be decomposed in a similar way:
$\mathbb{Z}$
, can be decomposed in a similar way:
 \begin{equation} f_{\boldsymbol{Y}}(\boldsymbol{y})=\sum _{z\in \mathbb{Z}}f_{\boldsymbol{Y}|Z}(\boldsymbol{y}|z)\mathbb{P}\{Z=z\}, \end{equation}
\begin{equation} f_{\boldsymbol{Y}}(\boldsymbol{y})=\sum _{z\in \mathbb{Z}}f_{\boldsymbol{Y}|Z}(\boldsymbol{y}|z)\mathbb{P}\{Z=z\}, \end{equation}
where the distribution
 $f_{\boldsymbol{Y}|Z}$
associated with each zone satisfies the forward Kolmogorov equation (3.19), provided that
$f_{\boldsymbol{Y}|Z}$
associated with each zone satisfies the forward Kolmogorov equation (3.19), provided that
 $f_{\boldsymbol{X}}$
is replaced with
$f_{\boldsymbol{X}}$
is replaced with
 $f_{\boldsymbol{X}|Z}$
.
$f_{\boldsymbol{X}|Z}$
.
For periodic domains with a uniformly distributed mixture distribution
 $f_{\boldsymbol{X}}$
(cf. figure 7), boundary fluxes arising from
$f_{\boldsymbol{X}}$
(cf. figure 7), boundary fluxes arising from
 $\boldsymbol{J}$
in
$\boldsymbol{J}$
in
 $\unicode{x1D63F}_{1}$
vanish because
$\unicode{x1D63F}_{1}$
vanish because
 $\boldsymbol{\nabla }f_{\boldsymbol{X}}\equiv \boldsymbol{0}$
. Consequently, the sum of boundary fluxes for each component
$\boldsymbol{\nabla }f_{\boldsymbol{X}}\equiv \boldsymbol{0}$
. Consequently, the sum of boundary fluxes for each component
 $f_{\boldsymbol{X}|Z}$
, representing exchange between the components, also vanishes:
$f_{\boldsymbol{X}|Z}$
, representing exchange between the components, also vanishes:
 \begin{equation} \sum _{z\in \mathbb{Z}}\mathbb{E}\left [ \boldsymbol{J}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}|Z}|\boldsymbol{Y}=\boldsymbol{y},Z=z\right ]f_{\boldsymbol{Y}|Z}\mathbb{P}\{Z=z\}=0. \end{equation}
\begin{equation} \sum _{z\in \mathbb{Z}}\mathbb{E}\left [ \boldsymbol{J}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}|Z}|\boldsymbol{Y}=\boldsymbol{y},Z=z\right ]f_{\boldsymbol{Y}|Z}\mathbb{P}\{Z=z\}=0. \end{equation}
In this way, the decomposition of a mixture distribution generalises the classical partition of a domain into non-overlapping control volumes with sharp boundaries to components of
 $f_{\boldsymbol{X}}$
that can overlap, which will be used in § 7.4 to analyse Rayleigh–Bénard convection.
$f_{\boldsymbol{X}}$
that can overlap, which will be used in § 7.4 to analyse Rayleigh–Bénard convection.
7. Example applications
The following subsections each illustrate particular aspects of the results derived in § 3 by providing simple example applications.
7.1. Advection and diffusion by the ABC flow
An Arnold–Beltrami–Childress (ABC) flow with coefficients equal to unity is the three-dimensional divergence-free velocity field
 \begin{equation} \boldsymbol{U} := (\sin (X^3) + \cos (X^2),\ \sin (X^1) + \cos (X^3),\ \sin (X^2) + \cos (X^1))^{\top }. \end{equation}
\begin{equation} \boldsymbol{U} := (\sin (X^3) + \cos (X^2),\ \sin (X^1) + \cos (X^3),\ \sin (X^2) + \cos (X^1))^{\top }. \end{equation}
It is an exact solution of the Euler equations in a periodic domain and is known to exhibit chaotic streamlines (Dombre et al. Reference Dombre, Frisch, Greene, Hénon, Mehr and Soward1986), which makes it an ideal candidate to study mixing. Couched in the format of (3.1), the evolution of a passive scalar concentration
 $Y_t$
due to the combined effects of advection by
$Y_t$
due to the combined effects of advection by
 $\boldsymbol{U}$
and diffusion is
$\boldsymbol{U}$
and diffusion is
 \begin{equation} \dfrac {\textrm{d}{Y_t}}{\textrm{d}{t}} = -\boldsymbol{U} \boldsymbol{\cdot }\boldsymbol{\nabla }Y_t + \alpha \Delta Y_t, \end{equation}
\begin{equation} \dfrac {\textrm{d}{Y_t}}{\textrm{d}{t}} = -\boldsymbol{U} \boldsymbol{\cdot }\boldsymbol{\nabla }Y_t + \alpha \Delta Y_t, \end{equation}
where
 $\alpha$
denotes the constant scalar diffusivity. The corresponding forward Kolmogorov equation governing the evolution of
$\alpha$
denotes the constant scalar diffusivity. The corresponding forward Kolmogorov equation governing the evolution of
 $f_{Y}(y,t)$
is given by (3.19):
$f_{Y}(y,t)$
is given by (3.19):
 \begin{equation} \frac {\partial f_Y}{ \partial t} = -\frac {\partial ^2 }{ \partial y^2} \big ( \underbrace {\alpha \mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_t=y]}_{=:-\unicode{x1D63F}_{2}} f_{Y} \big ). \end{equation}
\begin{equation} \frac {\partial f_Y}{ \partial t} = -\frac {\partial ^2 }{ \partial y^2} \big ( \underbrace {\alpha \mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_t=y]}_{=:-\unicode{x1D63F}_{2}} f_{Y} \big ). \end{equation}
The coefficients
 $V$
and
$V$
and
 $\unicode{x1D63F}_{1}$
from § 3.3 are both zero because the periodic domain does not have boundaries. Although (7.3) cannot be solved, as
$\unicode{x1D63F}_{1}$
from § 3.3 are both zero because the periodic domain does not have boundaries. Although (7.3) cannot be solved, as
 $\unicode{x1D63F}_{2}$
is unknown, we can examine estimates of
$\unicode{x1D63F}_{2}$
is unknown, we can examine estimates of
 $\unicode{x1D63F}_{2}$
by solving (7.2) numerically. Space is treated using a Fourier pseudo-spectral method and time using a Crank–Nicolson discretisation with a resolution of
$\unicode{x1D63F}_{2}$
by solving (7.2) numerically. Space is treated using a Fourier pseudo-spectral method and time using a Crank–Nicolson discretisation with a resolution of
 $64^3$
modes and time step of
$64^3$
modes and time step of
 $\Delta t = 5 \times 10^{-3}$
, respectively. Choosing an initial condition consisting of a front separating two regions of different concentration
$\Delta t = 5 \times 10^{-3}$
, respectively. Choosing an initial condition consisting of a front separating two regions of different concentration
 $Y_{0} = \tanh (10\boldsymbol{X}^{\top }\boldsymbol{1})$
and setting
$Y_{0} = \tanh (10\boldsymbol{X}^{\top }\boldsymbol{1})$
and setting
 $\alpha =1/10$
, we numerically integrate with respect to
$\alpha =1/10$
, we numerically integrate with respect to
 $t\in [0,4]$
. Then, by approximating the density
$t\in [0,4]$
. Then, by approximating the density
 $f_{Y}(y,t)$
and
$f_{Y}(y,t)$
and
 $\mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_t=y]$
with a histogram, constructed from a single snapshot of field data, we estimate the terms in (7.3).
$\mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_t=y]$
with a histogram, constructed from a single snapshot of field data, we estimate the terms in (7.3).

Figure 8. (a) Time evolution of a cross-section of the concentration field
 $Y_{\!t}$
and (b) its corresponding probability density
$Y_{\!t}$
and (b) its corresponding probability density
 $f_{Y}(y,t)$
(shaded) and (negative) diffusion coefficient
$f_{Y}(y,t)$
(shaded) and (negative) diffusion coefficient
 $\alpha \mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_{\!t}=y]$
. https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig08/fig08.ipynb.
$\alpha \mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_{\!t}=y]$
. https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig08/fig08.ipynb.
A time evolution of a cross-section of the scalar field
 $Y_{t}$
alongside its corresponding density
$Y_{t}$
alongside its corresponding density
 $f_{Y}(y,t)$
and the conditional expectation
$f_{Y}(y,t)$
and the conditional expectation
 $\mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_t=y]$
are shown in figure 8. At
$\mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_t=y]$
are shown in figure 8. At
 $t=0.5$
, the scalar field, consisting of two regions of approximately uniform concentration separated by a relatively sharp interface, is represented in probability space by spikes at
$t=0.5$
, the scalar field, consisting of two regions of approximately uniform concentration separated by a relatively sharp interface, is represented in probability space by spikes at
 $y = \pm 1$
. As the concentration field is mixed irreversibly, the amplitude of these spikes reduces and the density associated with values of
$y = \pm 1$
. As the concentration field is mixed irreversibly, the amplitude of these spikes reduces and the density associated with values of
 $y$
in the vicinity of zero increases. Mixing subsequently homogenises the scalar field to the extent that no evidence of the initial distribution remains by
$y$
in the vicinity of zero increases. Mixing subsequently homogenises the scalar field to the extent that no evidence of the initial distribution remains by
 $t=2$
. As there is no injection of concentration to balance the homogenising effects of diffusion,
$t=2$
. As there is no injection of concentration to balance the homogenising effects of diffusion,
 $Y_t$
will ultimately tend to a constant uniformly over the domain and the density
$Y_t$
will ultimately tend to a constant uniformly over the domain and the density
 $f_{Y}(y,t)$
in the limit
$f_{Y}(y,t)$
in the limit
 $t\rightarrow \infty$
would tend to a Dirac distribution.
$t\rightarrow \infty$
would tend to a Dirac distribution.
The expectation
 $\mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_{\!t}=y]$
, which quantifies the rate of mixing and, therefore, negative diffusion in (7.3) is maximised by
$\mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_{\!t}=y]$
, which quantifies the rate of mixing and, therefore, negative diffusion in (7.3) is maximised by
 $y=0$
. For
$y=0$
. For
 $t=0.5$
and
$t=0.5$
and
 $t=1.0$
, scalar concentrations that are less probable are associated with the most mixing. This observation is not surprising because, as discussed in the examples in § 2 and illustrated in figure 1, large gradients are associated with small probability densities, unless they occur over sufficiently many branches of the function’s inverse. In this regard, it should also be noted that
$t=1.0$
, scalar concentrations that are less probable are associated with the most mixing. This observation is not surprising because, as discussed in the examples in § 2 and illustrated in figure 1, large gradients are associated with small probability densities, unless they occur over sufficiently many branches of the function’s inverse. In this regard, it should also be noted that
 $\mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_t=y]$
is zero for the minimum (
$\mathbb{E}[|\boldsymbol{\nabla }Y_t|^2|Y_t=y]$
is zero for the minimum (
 $y=-1$
) and maximum (
$y=-1$
) and maximum (
 $y=1$
) values of
$y=1$
) values of
 $Y_{\!t}$
, at which
$Y_{\!t}$
, at which
 $\boldsymbol{\nabla }Y_t=\boldsymbol{0}$
. In the absence of diffusion at these values of
$\boldsymbol{\nabla }Y_t=\boldsymbol{0}$
. In the absence of diffusion at these values of
 $y$
, the density
$y$
, the density
 $f_{Y}$
consequently maintains compact support (i.e. mixing interpolates and cannot produce values that lie outside the range of values that were there in the first place).
$f_{Y}$
consequently maintains compact support (i.e. mixing interpolates and cannot produce values that lie outside the range of values that were there in the first place).
7.2. Stochastic boundary conditions
To sustain a finite variance of a diffusive scalar field, it is necessary to apply a forcing. Given that a wide variety of physical systems are sustained by a boundary forcing, often characterised by substantial fluctuations and uncertainty, it is natural to consider how these forces manifest in the evolution equation governing the system’s probability density. A simple example of such a problem that is sufficient to highlight several of the terms discussed in § 3 is the diffusion of heat through a one-dimensional rod of unit length forced by Ornstein–Uhlenbeck processes (i.e. normally distributed thermal fluctuations) at the boundary. When cast in the form of (3.1), for unit thermal diffusivity (
 $\alpha =1$
), the temperature
$\alpha =1$
), the temperature
 $Y_{\!t}$
evolves according to
$Y_{\!t}$
evolves according to
 \begin{equation} {\dfrac {\textrm{d}{Y_t}}{\textrm{d}{t}}} = \partial ^{2}_{X}Y_t\quad \textrm{for}\quad X\in [0,1], \end{equation}
\begin{equation} {\dfrac {\textrm{d}{Y_t}}{\textrm{d}{t}}} = \partial ^{2}_{X}Y_t\quad \textrm{for}\quad X\in [0,1], \end{equation}
where values of
 $Y_{\!t}$
for points on the boundary
$Y_{\!t}$
for points on the boundary
 $\partial \varOmega$
(corresponding to
$\partial \varOmega$
(corresponding to
 $X\in \{0,1\}$
) evolve according to
$X\in \{0,1\}$
) evolve according to
 \begin{equation} \,\textrm{d} Y_t(\omega ) = -aY_t(\omega )\,\textrm{d} t + \sigma \,\textrm{d} W_t(\omega )\quad \textrm{for}\quad \omega \in \partial \varOmega , \end{equation}
\begin{equation} \,\textrm{d} Y_t(\omega ) = -aY_t(\omega )\,\textrm{d} t + \sigma \,\textrm{d} W_t(\omega )\quad \textrm{for}\quad \omega \in \partial \varOmega , \end{equation}
where
 $a,\sigma$
are real constants and
$a,\sigma$
are real constants and
 $W_t(\omega )$
is a Wiener process. In the context of (3.1),
$W_t(\omega )$
is a Wiener process. In the context of (3.1),
 $J_{\!t}=-\partial _{X}Y_{\!t}$
is the (diffusive) scalar flux. Since we are interested in the entire domain, the sampling distribution is
$J_{\!t}=-\partial _{X}Y_{\!t}$
is the (diffusive) scalar flux. Since we are interested in the entire domain, the sampling distribution is
 $f_{X}\equiv 1$
and
$f_{X}\equiv 1$
and
 $\partial _{X} \log f_{X}$
in the calculation of
$\partial _{X} \log f_{X}$
in the calculation of
 $\unicode{x1D63F}_{1}$
should be regarded as changing the distribution under which the expectation is calculated from
$\unicode{x1D63F}_{1}$
should be regarded as changing the distribution under which the expectation is calculated from
 $f_{X}$
to point evaluation at the (two) boundaries (see discussion following (3.9) in § 3.2):
$f_{X}$
to point evaluation at the (two) boundaries (see discussion following (3.9) in § 3.2):
 \begin{equation} \mathbb{E}[J_{\!t}\partial _{X}\log f_{X}|Y_{\!t}]f_{Y}=2\mathbb{E}[\partial _{n}Y_{\!t}|Y_{\!t}]\tilde {f}_{Y}, \end{equation}
\begin{equation} \mathbb{E}[J_{\!t}\partial _{X}\log f_{X}|Y_{\!t}]f_{Y}=2\mathbb{E}[\partial _{n}Y_{\!t}|Y_{\!t}]\tilde {f}_{Y}, \end{equation}
where
 $\partial _{n}Y_{\!t}$
is the boundary normal derivative of
$\partial _{n}Y_{\!t}$
is the boundary normal derivative of
 $Y_{\!t}$
,
$Y_{\!t}$
,
 $\tilde {f}_{Y}$
is the probability density of
$\tilde {f}_{Y}$
is the probability density of
 $Y_{\!t}$
, conditional on evaluation at a boundary, and the factor
$Y_{\!t}$
, conditional on evaluation at a boundary, and the factor
 $2$
accounts for there being two boundaries separated by a distance of one unit.
$2$
accounts for there being two boundaries separated by a distance of one unit.

Figure 9. (a) Space–time plot of
 $Y_t$
for the one-dimensional diffusion (7.4) forced by an Ornstein–Ulhenbeck process (7.5) with
$Y_t$
for the one-dimensional diffusion (7.4) forced by an Ornstein–Ulhenbeck process (7.5) with
 $a=5,\sigma =1$
, and (b) joint density
$a=5,\sigma =1$
, and (b) joint density
 $\tilde {f}_{Y, \partial _{n}Y}$
conditioned on the boundaries. The positive covariance of this plot reflects the tendency of heat to flow down gradients at the boundaries. https://www.
cambridge.org/S0022112025106319/JFM-Notebooks/files/fig09-10/fig09-10.ipynb.
$\tilde {f}_{Y, \partial _{n}Y}$
conditioned on the boundaries. The positive covariance of this plot reflects the tendency of heat to flow down gradients at the boundaries. https://www.
cambridge.org/S0022112025106319/JFM-Notebooks/files/fig09-10/fig09-10.ipynb.
Figure 9(a) shows a space–time plot of the system, for which the temperature at the boundaries fluctuates on the integral time scale (
 $1/a$
) of the Ornstein–Uhlenbeck processes (7.5). The solution is obtained numerically using second-order finite differences in space with
$1/a$
) of the Ornstein–Uhlenbeck processes (7.5). The solution is obtained numerically using second-order finite differences in space with
 $32$
grid points and an Euler–Maruyama discretisation in time with a time step of
$32$
grid points and an Euler–Maruyama discretisation in time with a time step of
 $2.5 \times 10^{-3}$
. Towards the centre of the domain, the effects of diffusion reduce the amplitude of the fluctuations.
$2.5 \times 10^{-3}$
. Towards the centre of the domain, the effects of diffusion reduce the amplitude of the fluctuations.
Using (7.6), the forward Kolmogorov equation, which describes how the probability density
 $f_{Y}(y,t)$
evolves in time, is given by (3.20):
$f_{Y}(y,t)$
evolves in time, is given by (3.20):
 \begin{equation} \frac {\partial f_Y}{ \partial t} = -\frac {\partial }{ \partial y} \Big ( \underbrace {2\mathbb{E}[ \partial _{n}Y_t|Y_{\!t}=y] \frac {\tilde {f}_{Y}}{f_{Y}}}_{=:\unicode{x1D63F}_{1}} f_{Y} \Big ) - \frac {\partial ^2 }{ \partial y^2} \big ( \underbrace {\mathbb{E}[|\partial _{X} Y_t|^2|Y_{\!t}=y]}_{=:-\unicode{x1D63F}_{2}} f_{Y} \big ), \end{equation}
\begin{equation} \frac {\partial f_Y}{ \partial t} = -\frac {\partial }{ \partial y} \Big ( \underbrace {2\mathbb{E}[ \partial _{n}Y_t|Y_{\!t}=y] \frac {\tilde {f}_{Y}}{f_{Y}}}_{=:\unicode{x1D63F}_{1}} f_{Y} \Big ) - \frac {\partial ^2 }{ \partial y^2} \big ( \underbrace {\mathbb{E}[|\partial _{X} Y_t|^2|Y_{\!t}=y]}_{=:-\unicode{x1D63F}_{2}} f_{Y} \big ), \end{equation}
According to (7.5),
 $Y_{\!t}$
sampled at the boundary is an Ornstein–Uhlenbeck process and therefore has a stationary density given by
$Y_{\!t}$
sampled at the boundary is an Ornstein–Uhlenbeck process and therefore has a stationary density given by
 $\tilde {f}_{Y}(y)=\sqrt {a/(\pi \sigma ^{2})}\,\textrm{exp}(-ay^{2}/\sigma ^{2})$
(Gardiner Reference Gardiner1990), which, using the approach described following (3.12), is used to express
$\tilde {f}_{Y}(y)=\sqrt {a/(\pi \sigma ^{2})}\,\textrm{exp}(-ay^{2}/\sigma ^{2})$
(Gardiner Reference Gardiner1990), which, using the approach described following (3.12), is used to express
 $\unicode{x1D63F}_{1}$
.
$\unicode{x1D63F}_{1}$
.
As there is no advection in (7.4), the coefficient
 $V$
from § 4 is zero. However, due to conduction and, in turn, boundary fluxes of heat, (7.7) has non-zero drift and diffusion terms. Although (7.7) cannot be solved prognostically without a model for the unknown coefficients, the coefficients can be approximated numerically by constructing an ensemble satisfying (7.4) and (7.5).
$V$
from § 4 is zero. However, due to conduction and, in turn, boundary fluxes of heat, (7.7) has non-zero drift and diffusion terms. Although (7.7) cannot be solved prognostically without a model for the unknown coefficients, the coefficients can be approximated numerically by constructing an ensemble satisfying (7.4) and (7.5).
Figure 10 shows the drift
 $\unicode{x1D63F}_{1}$
and diffusion
$\unicode{x1D63F}_{1}$
and diffusion
 $\unicode{x1D63F}_{2}$
coefficients, as well as the stationary density
$\unicode{x1D63F}_{2}$
coefficients, as well as the stationary density
 $f_{Y}(y)$
using time and ensemble averaging. An ensemble of 500 paths each containing 1950 snapshots in time was constructed numerically by simulating (7.4), (7.5) for
$f_{Y}(y)$
using time and ensemble averaging. An ensemble of 500 paths each containing 1950 snapshots in time was constructed numerically by simulating (7.4), (7.5) for
 $t\in [0,5]$
and discarding the initial 50 snapshots. In § 7.1, molecular diffusion acted to homogenise the scalar field
$t\in [0,5]$
and discarding the initial 50 snapshots. In § 7.1, molecular diffusion acted to homogenise the scalar field
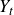 $Y_t$
in the ABC flow and drive its corresponding density towards a Dirac measure. Were the value of
$Y_t$
in the ABC flow and drive its corresponding density towards a Dirac measure. Were the value of
 $Y_t$
at the boundaries in this example to be fixed at zero, the distribution would, due to the negative diffusion
$Y_t$
at the boundaries in this example to be fixed at zero, the distribution would, due to the negative diffusion
 $\unicode{x1D63F}_{2}$
(figure 10
d), also tend towards a Dirac measure at zero, irrespective of the precise initial conditions. Instead, random forcing at the system’s boundary creates variance that balances the destruction of variance described by
$\unicode{x1D63F}_{2}$
(figure 10
d), also tend towards a Dirac measure at zero, irrespective of the precise initial conditions. Instead, random forcing at the system’s boundary creates variance that balances the destruction of variance described by
 $\unicode{x1D63F}_{2}$
. To illustrate how, figure 9(b) shows the conditional joint density
$\unicode{x1D63F}_{2}$
. To illustrate how, figure 9(b) shows the conditional joint density
 $\tilde {f}_{Y, \partial _{n} Y_{\!t}}$
of
$\tilde {f}_{Y, \partial _{n} Y_{\!t}}$
of
 $Y_t$
and its boundary-normal gradient
$Y_t$
and its boundary-normal gradient
 $\partial _{n}Y_{\!t}$
. The conditional density reveals the expected positive correlation between
$\partial _{n}Y_{\!t}$
. The conditional density reveals the expected positive correlation between
 $Y_t$
and
$Y_t$
and
 $\partial _{n}Y_t$
, which means that heat flux into/out of the domain is typically accompanied by positive/negative temperatures at the boundary. Therefore,
$\partial _{n}Y_t$
, which means that heat flux into/out of the domain is typically accompanied by positive/negative temperatures at the boundary. Therefore,
 $\unicode{x1D63F}_{1}\lessgtr 0$
for
$\unicode{x1D63F}_{1}\lessgtr 0$
for
 $y\lessgtr 0$
, as shown in figure 10(a), which implies that
$y\lessgtr 0$
, as shown in figure 10(a), which implies that
 $\unicode{x1D63F}_{1}$
corresponds to divergent transport of probability density away from the origin.
$\unicode{x1D63F}_{1}$
corresponds to divergent transport of probability density away from the origin.

Figure 10. (a,b,d) Drift coefficient
 $\unicode{x1D63F}_{1}$
, diffusion coefficient
$\unicode{x1D63F}_{1}$
, diffusion coefficient
 $\unicode{x1D63F}_{2}$
and probability density
$\unicode{x1D63F}_{2}$
and probability density
 $f_Y(y)$
, respectively, of the forward Kolmogorov equation corresponding to a stationary state of the system (7.4) with
$f_Y(y)$
, respectively, of the forward Kolmogorov equation corresponding to a stationary state of the system (7.4) with
 $a=5,\sigma =1$
. (c) A numerical verification of the balance between boundary forcing and mixing. https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig09-10/fig09-10.ipynb.
$a=5,\sigma =1$
. (c) A numerical verification of the balance between boundary forcing and mixing. https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig09-10/fig09-10.ipynb.
Computing the balance of the terms in the right-hand side of (7.7), as shown in figure 10(c), verifies (7.7). It is worth noting that while incorporating uncertainty into (7.4) required a Monte Carlo approach to be employed in order to estimate
 $f_Y(y)$
, such boundary conditions pose no particular additional difficulty in (7.7), which accommodates stochastic forcing naturally.
$f_Y(y)$
, such boundary conditions pose no particular additional difficulty in (7.7), which accommodates stochastic forcing naturally.
7.3. Boussinesq equations
The following example demonstrates that coordinates, regarded here as functions
 $\boldsymbol{X}$
over the sample space
$\boldsymbol{X}$
over the sample space
 $\varOmega$
, can be included in the state vector
$\varOmega$
, can be included in the state vector
 $\boldsymbol{Y}_{\!t}$
. For instance, if one wishes to understand probability distributions over horizontal slices of a domain, the vertical coordinate can be included in
$\boldsymbol{Y}_{\!t}$
. For instance, if one wishes to understand probability distributions over horizontal slices of a domain, the vertical coordinate can be included in
 $\boldsymbol{Y}_{\!t}$
. More generally, other functions, such as geopotential height, could be incorporated into
$\boldsymbol{Y}_{\!t}$
. More generally, other functions, such as geopotential height, could be incorporated into
 $\boldsymbol{Y}_{\!t}$
. The equations developed in § 3 are therefore very general in being able to generate equations that are specific to a particular problem and circumvent the need for case-specific derivations.
$\boldsymbol{Y}_{\!t}$
. The equations developed in § 3 are therefore very general in being able to generate equations that are specific to a particular problem and circumvent the need for case-specific derivations.
In a Boussinesq context, the pointwise deterministic equations governing the behaviour of the velocity field
 $\boldsymbol{U}_{\!t}$
and the buoyancy
$\boldsymbol{U}_{\!t}$
and the buoyancy
 $B_{t}$
are
$B_{t}$
are
 \begin{align} {\dfrac {\textrm{d}{\boldsymbol{U}_{\!t}}}{\textrm{d}{t}}}&=B_{t}\boldsymbol{e}_{3}-\boldsymbol{\nabla }P_{\!t} -\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\boldsymbol{U}_{\!t}+\alpha _{1}\Delta \boldsymbol{U}_{\!t},\nonumber\\ \boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{U}_{\!t}&=0,\nonumber \\ {\dfrac {\textrm{d}{B_{t}}}{\textrm{d}{t}}}&=-\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }{B}_{\!t} +\alpha _{2}\Delta B_{t}, \end{align}
\begin{align} {\dfrac {\textrm{d}{\boldsymbol{U}_{\!t}}}{\textrm{d}{t}}}&=B_{t}\boldsymbol{e}_{3}-\boldsymbol{\nabla }P_{\!t} -\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\boldsymbol{U}_{\!t}+\alpha _{1}\Delta \boldsymbol{U}_{\!t},\nonumber\\ \boldsymbol{\nabla }\boldsymbol{\cdot }\boldsymbol{U}_{\!t}&=0,\nonumber \\ {\dfrac {\textrm{d}{B_{t}}}{\textrm{d}{t}}}&=-\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }{B}_{\!t} +\alpha _{2}\Delta B_{t}, \end{align}
where
 $\boldsymbol{e}_{3}$
is the unit vector in the vertical direction. Since the vertical direction plays a distinguished role in corresponding to the direction of gravity, let
$\boldsymbol{e}_{3}$
is the unit vector in the vertical direction. Since the vertical direction plays a distinguished role in corresponding to the direction of gravity, let
 $\boldsymbol{Y}_{\!t}:=(W_{\!t},B_{t},Z)^{\top }$
, where
$\boldsymbol{Y}_{\!t}:=(W_{\!t},B_{t},Z)^{\top }$
, where
 $W_{\!t}:=\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{e}_{3}$
is the vertical velocity (not to be confused with the vector of Wiener processes
$W_{\!t}:=\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{e}_{3}$
is the vertical velocity (not to be confused with the vector of Wiener processes
 $\boldsymbol{W}_{\!t}$
used in § 3) and
$\boldsymbol{W}_{\!t}$
used in § 3) and
 $Z=X^{3}$
is the (time independent) vertical coordinate. Writing
$Z=X^{3}$
is the (time independent) vertical coordinate. Writing
 $\,\textrm{d} Z/\,\textrm{d} t=W_{\!t}-\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }Z=0$
, and noting that
$\,\textrm{d} Z/\,\textrm{d} t=W_{\!t}-\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }Z=0$
, and noting that
 $\alpha _{11}=\alpha _{1}$
,
$\alpha _{11}=\alpha _{1}$
,
 $\alpha _{22}=\alpha _{2}$
,
$\alpha _{22}=\alpha _{2}$
,
 $\alpha _{33}=0$
and
$\alpha _{33}=0$
and
 $\alpha _{\textit{ij}}=0$
for
$\alpha _{\textit{ij}}=0$
for
 $i\neq j$
implies that
$i\neq j$
implies that
 $V$
is given by (4.3),
$V$
is given by (4.3),
 \begin{equation} \unicode{x1D63F}_{1}= \begin{pmatrix} b\\ 0\\ w \end{pmatrix} - \mathbb{E} \left [\begin{array}{@{}c|c@{}} \partial _{Z} P_{\!t}+\alpha _{1}\boldsymbol{\nabla }W_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}} & \\ \alpha _{2}\boldsymbol{\nabla }B_{t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}} & \boldsymbol{Y}_{\!t}=\boldsymbol{y} \\ 0 & \end{array}\right ], \end{equation}
\begin{equation} \unicode{x1D63F}_{1}= \begin{pmatrix} b\\ 0\\ w \end{pmatrix} - \mathbb{E} \left [\begin{array}{@{}c|c@{}} \partial _{Z} P_{\!t}+\alpha _{1}\boldsymbol{\nabla }W_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}} & \\ \alpha _{2}\boldsymbol{\nabla }B_{t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}} & \boldsymbol{Y}_{\!t}=\boldsymbol{y} \\ 0 & \end{array}\right ], \end{equation}
and
 \begin{equation} \unicode{x1D63F}_{2}=-\frac {1}{2} \mathbb{E} \left [\begin{array}{@{}ccc|c@{}} 2\alpha _{1} |\boldsymbol{\nabla }W_{\!t}|^{2} & (\alpha _{1}+\alpha _{2})\boldsymbol{\nabla }W_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }B_{t} & \alpha _{1} \partial _{Z}W_{\!t} & \\ (\alpha _{1}+\alpha _{2})\boldsymbol{\nabla }W_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }B_{t} & 2\alpha _{2}|\boldsymbol{\nabla }B_{t}|^{2} & \alpha _{2} \partial _{Z}B_{t} & \boldsymbol{Y}_{\!t}=\boldsymbol{y}\\ \alpha _{1} \partial _{Z}W_{\!t} & \alpha _{2} \partial _{Z}B_{t} & 0 & \end{array}\right ], \end{equation}
\begin{equation} \unicode{x1D63F}_{2}=-\frac {1}{2} \mathbb{E} \left [\begin{array}{@{}ccc|c@{}} 2\alpha _{1} |\boldsymbol{\nabla }W_{\!t}|^{2} & (\alpha _{1}+\alpha _{2})\boldsymbol{\nabla }W_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }B_{t} & \alpha _{1} \partial _{Z}W_{\!t} & \\ (\alpha _{1}+\alpha _{2})\boldsymbol{\nabla }W_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }B_{t} & 2\alpha _{2}|\boldsymbol{\nabla }B_{t}|^{2} & \alpha _{2} \partial _{Z}B_{t} & \boldsymbol{Y}_{\!t}=\boldsymbol{y}\\ \alpha _{1} \partial _{Z}W_{\!t} & \alpha _{2} \partial _{Z}B_{t} & 0 & \end{array}\right ], \end{equation}
where
 $\boldsymbol{y}:=(w, b, z)^{\top }$
. In
$\boldsymbol{y}:=(w, b, z)^{\top }$
. In
 $\unicode{x1D63F}_{1}$
,
$\unicode{x1D63F}_{1}$
,
 $b$
is responsible for drift in the
$b$
is responsible for drift in the
 $w$
direction, because buoyancy increases
$w$
direction, because buoyancy increases
 $W_{\!t}$
and, in turn,
$W_{\!t}$
and, in turn,
 $w$
is responsible for drift in the
$w$
is responsible for drift in the
 $z$
direction, because vertical velocity increases
$z$
direction, because vertical velocity increases
 $Z$
. When interpreting the latter, it should be borne in mind that for the closed domain in this example
$Z$
. When interpreting the latter, it should be borne in mind that for the closed domain in this example
 $\mathbb{E}[W_{\!t}|Z]=0$
, which, therefore, does not affect the marginal distribution of
$\mathbb{E}[W_{\!t}|Z]=0$
, which, therefore, does not affect the marginal distribution of
 $Z$
(i.e. the domain does not change its shape over time). The unknown conditionally averaged vertical pressure gradient also affects the evolution of the joint density through
$Z$
(i.e. the domain does not change its shape over time). The unknown conditionally averaged vertical pressure gradient also affects the evolution of the joint density through
 $\unicode{x1D63F}_{1}$
, whose remaining terms account for boundary fluxes of
$\unicode{x1D63F}_{1}$
, whose remaining terms account for boundary fluxes of
 $W_{\!t}$
and
$W_{\!t}$
and
 $B_{t}$
, scaled by the relative size of the boundary.
$B_{t}$
, scaled by the relative size of the boundary.
While the drift
 $\unicode{x1D63F}_{1}$
is responsible for moving and stretching the joint density, the diffusion coefficient
$\unicode{x1D63F}_{1}$
is responsible for moving and stretching the joint density, the diffusion coefficient
 $\unicode{x1D63F}_{2}$
accounts for the effects of irreversible mixing. As discussed in § 5,
$\unicode{x1D63F}_{2}$
accounts for the effects of irreversible mixing. As discussed in § 5,
 $\unicode{x1D63F}_{2}$
is expected to be negative semidefinite (
$\unicode{x1D63F}_{2}$
is expected to be negative semidefinite (
 $\unicode{x1D63F}_{2}\preceq 0$
) in most applications, which means that it typically represents anti-diffusion. In particular, if
$\unicode{x1D63F}_{2}\preceq 0$
) in most applications, which means that it typically represents anti-diffusion. In particular, if
 $\alpha _{1}=\alpha _{2}=1$
, then
$\alpha _{1}=\alpha _{2}=1$
, then
 $\unicode{x1D63F}_{2}\preceq 0$
can be guaranteed. For other combinations of
$\unicode{x1D63F}_{2}\preceq 0$
can be guaranteed. For other combinations of
 $\alpha _{1}$
and
$\alpha _{1}$
and
 $\alpha _{2}$
,
$\alpha _{2}$
,
 $\unicode{x1D63F}_{2}\preceq 0$
depends on the correlations among
$\unicode{x1D63F}_{2}\preceq 0$
depends on the correlations among
 $\boldsymbol{\nabla }W_{\!t}$
,
$\boldsymbol{\nabla }W_{\!t}$
,
 $\boldsymbol{\nabla }B_{t}$
and
$\boldsymbol{\nabla }B_{t}$
and
 $\boldsymbol{\nabla }Z$
, as discussed in § 5. The gradients,
$\boldsymbol{\nabla }Z$
, as discussed in § 5. The gradients,
 $\boldsymbol{\nabla }W_{\!t}$
and
$\boldsymbol{\nabla }W_{\!t}$
and
 $\boldsymbol{\nabla }B_{t}$
are a priori unknown and therefore require closure (see § 8), which would involve postulating their dependence on the joint density
$\boldsymbol{\nabla }B_{t}$
are a priori unknown and therefore require closure (see § 8), which would involve postulating their dependence on the joint density
 $f_{\boldsymbol{Y}}$
and/or the independent variables
$f_{\boldsymbol{Y}}$
and/or the independent variables
 $\boldsymbol{y}:=(w, b, z)^{\top }$
.
$\boldsymbol{y}:=(w, b, z)^{\top }$
.
7.4. Rayleigh–Bénard convection with a stochastic boundary condition
This section describes an example of the domain partition discussed in § 6 applied to Rayleigh–Bénard convection. Here, the zonal sample distributions are defined using the diffusive vertical buoyancy flux and therefore separate the bulk central part of the flow from the top and bottom boundary layers (see figure 11, which displays instantaneous fields alongside weighted sample distributions
 $f_{\boldsymbol{X}|Z}$
for each zone). To illustrate how the partition yields useful information, we focus on the contributions to the equations governing
$f_{\boldsymbol{X}|Z}$
for each zone). To illustrate how the partition yields useful information, we focus on the contributions to the equations governing
 $f_{\boldsymbol{Y}|Z}$
from
$f_{\boldsymbol{Y}|Z}$
from
 $V$
and
$V$
and
 $\unicode{x1D63F}_{1}$
arising from transport between the zones.
$\unicode{x1D63F}_{1}$
arising from transport between the zones.

Figure 11. (a) Snapshot of the vertical velocity
 $Y^{1}_{\!t}=W_{\!t}$
(dashed/solid white contours for negative/positive vertical velocity, respectively) and buoyancy field
$Y^{1}_{\!t}=W_{\!t}$
(dashed/solid white contours for negative/positive vertical velocity, respectively) and buoyancy field
 $Y^{2}_{\!t}=B_{t}$
(red is positive; blue is negative) following a negative fluctuation in the buoyancy at the bottom boundary. (b) Partition of the vertical domain into three zones
$Y^{2}_{\!t}=B_{t}$
(red is positive; blue is negative) following a negative fluctuation in the buoyancy at the bottom boundary. (b) Partition of the vertical domain into three zones
 $Z\in \{z_{1},z_{2},z_{3}\}$
defined by
$Z\in \{z_{1},z_{2},z_{3}\}$
defined by
 $f_{\boldsymbol{X}|Z}$
, where
$f_{\boldsymbol{X}|Z}$
, where
 $f_{\boldsymbol{X}|Z}(\boldsymbol{x}|z_{2})$
(the central zone) is proportional to the horizontally and time-averaged vertical buoyancy flux
$f_{\boldsymbol{X}|Z}(\boldsymbol{x}|z_{2})$
(the central zone) is proportional to the horizontally and time-averaged vertical buoyancy flux
 $W_{\!t}B_{t}$
. In the boundary-layer zones above and below the bottom and top boundary,
$W_{\!t}B_{t}$
. In the boundary-layer zones above and below the bottom and top boundary,
 $f_{\boldsymbol{X}|Z}$
is proportional to the horizontally and time-averaged diffusive buoyancy flux
$f_{\boldsymbol{X}|Z}$
is proportional to the horizontally and time-averaged diffusive buoyancy flux
 $-\alpha _{2}\partial _{X^{3}}B_{t}$
. The constant of proportionality
$-\alpha _{2}\partial _{X^{3}}B_{t}$
. The constant of proportionality
 $\mathbb{P}\{Z=z\}$
for each zone is chosen to ensure that the sum of
$\mathbb{P}\{Z=z\}$
for each zone is chosen to ensure that the sum of
 $f_{\boldsymbol{X}|Z}\mathbb{P}$
over the zones is the uniform distribution (black line) (cf. (6.1) in § 6). https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig11-12/fig11-12.ipynb.
$f_{\boldsymbol{X}|Z}\mathbb{P}$
over the zones is the uniform distribution (black line) (cf. (6.1) in § 6). https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig11-12/fig11-12.ipynb.
The data for this example were obtained from direct numerical simulation of the Boussinesq equations (7.8) on a two-dimensional and horizontally periodic domain of unit height, as shown in figure 11(a). A spatially uniform buoyancy equal to
 $-1/2$
is imposed on the top boundary. On the bottom boundary, the imposed buoyancy is spatially uniform but follows an Ornstein–Uhlenbeck process in time, as described in § 7.2. The Ornstein–Uhlenbeck process has a mean of
$-1/2$
is imposed on the top boundary. On the bottom boundary, the imposed buoyancy is spatially uniform but follows an Ornstein–Uhlenbeck process in time, as described in § 7.2. The Ornstein–Uhlenbeck process has a mean of
 $1/2$
, unit variance and a time scale (corresponding to
$1/2$
, unit variance and a time scale (corresponding to
 $1/a$
in § 7.2) of
$1/a$
in § 7.2) of
 $2$
units. The governing equations can therefore be regarded as non-dimensionalised on the domain height and mean buoyancy difference between the horizontal boundaries. In terms of these scales, the Rayleigh number is
$2$
units. The governing equations can therefore be regarded as non-dimensionalised on the domain height and mean buoyancy difference between the horizontal boundaries. In terms of these scales, the Rayleigh number is
 $10^{7}$
, which corresponds to a (non-dimensionalised) viscosity and diffusivity of
$10^{7}$
, which corresponds to a (non-dimensionalised) viscosity and diffusivity of
 $\alpha _{1}=\sqrt {10^{7}}$
and
$\alpha _{1}=\sqrt {10^{7}}$
and
 $\alpha _{2}=\sqrt {10^{7}}$
, respectively, for a Prandtl number of unity.
$\alpha _{2}=\sqrt {10^{7}}$
, respectively, for a Prandtl number of unity.
The governing equations are approximated numerically using the pseudo-spectral method provided by Dedalus (Burns et al. Reference Burns, Vasil, Oishi, Lecoanet and Brown2020). Fourier and Chebyshev bases are used for the horizontal (
 $X^{1}$
) and vertical (
$X^{1}$
) and vertical (
 $X^{3}$
) directions, with
$X^{3}$
) directions, with
 $512$
and
$512$
and
 $128$
grid points, respectively. The grid points are spaced uniformly in the horizontal direction and non-uniformly in the vertical direction, where they correspond to Gauss–Chebyshev quadrature nodes. A single simulation is run for
$128$
grid points, respectively. The grid points are spaced uniformly in the horizontal direction and non-uniformly in the vertical direction, where they correspond to Gauss–Chebyshev quadrature nodes. A single simulation is run for
 $4000$
time units, where one time unit corresponds to a typical turnover time. The probability densities discussed later and presented in figure 12 were constructed from field data sampled at regular time intervals of
$4000$
time units, where one time unit corresponds to a typical turnover time. The probability densities discussed later and presented in figure 12 were constructed from field data sampled at regular time intervals of
 $2$
units following a discarded transitory period of
$2$
units following a discarded transitory period of
 $100$
time units.
$100$
time units.
Following §§ 3.4 and 6, the joint probability density for each zone evolves according to
 $\partial _{t}f_{\boldsymbol{Y}|Z}=(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}|Z}$
, where
$\partial _{t}f_{\boldsymbol{Y}|Z}=(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}|Z}$
, where
 $\mathscr{L}$
and
$\mathscr{L}$
and
 $V$
are specific to each zone. For example, the source/sink term is
$V$
are specific to each zone. For example, the source/sink term is
 \begin{equation} V(\boldsymbol{Y}_{\!t}|Z,t):=-\mathbb{E}[\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}|Z}|\boldsymbol{Y}_{\!t},Z] \end{equation}
\begin{equation} V(\boldsymbol{Y}_{\!t}|Z,t):=-\mathbb{E}[\boldsymbol{U}_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}|Z}|\boldsymbol{Y}_{\!t},Z] \end{equation}
and the drift coefficient is
 \begin{equation} \unicode{x1D63F}_{1}(\boldsymbol{Y}_{\!t}|Z,t):= \begin{pmatrix} b\\ 0 \end{pmatrix} - \mathbb{E} \left [\begin{array}{@{}c|c@{}} \partial _{X^{3}} P_{\!t} & \\ 0 & {\boldsymbol{Y}_{\!t},Z} \end{array}\right ] - \underbrace {\mathbb{E} \left [\begin{array}{@{}c|c@{}} \alpha _{1}\boldsymbol{\nabla }W_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}|Z} & \\ \alpha _{2}\boldsymbol{\nabla }B_{t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}|Z} & {\boldsymbol{Y}_{\!t},Z} \end{array}\right ]}_{\unicode{x1D63F}_{1}^{\textit{wall}}+\unicode{x1D63F}_{1}^{\textit{zone}}}, \end{equation}
\begin{equation} \unicode{x1D63F}_{1}(\boldsymbol{Y}_{\!t}|Z,t):= \begin{pmatrix} b\\ 0 \end{pmatrix} - \mathbb{E} \left [\begin{array}{@{}c|c@{}} \partial _{X^{3}} P_{\!t} & \\ 0 & {\boldsymbol{Y}_{\!t},Z} \end{array}\right ] - \underbrace {\mathbb{E} \left [\begin{array}{@{}c|c@{}} \alpha _{1}\boldsymbol{\nabla }W_{\!t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}|Z} & \\ \alpha _{2}\boldsymbol{\nabla }B_{t}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}|Z} & {\boldsymbol{Y}_{\!t},Z} \end{array}\right ]}_{\unicode{x1D63F}_{1}^{\textit{wall}}+\unicode{x1D63F}_{1}^{\textit{zone}}}, \end{equation}
where
 $\unicode{x1D63F}_{1}^{\textit{wall}}$
and
$\unicode{x1D63F}_{1}^{\textit{wall}}$
and
 $\unicode{x1D63F}_{1}^{\textit{zone}}$
distinguish between transport across the bottom and top boundaries (
$\unicode{x1D63F}_{1}^{\textit{zone}}$
distinguish between transport across the bottom and top boundaries (
 $X^{3}\in \{0,1\}$
), which was discussed in the example in § 7.2, from transport between zones, labelled
$X^{3}\in \{0,1\}$
), which was discussed in the example in § 7.2, from transport between zones, labelled
 $\unicode{x1D63F}_{1}^{\textit{zone}}$
. In each of these expressions, it is important to appreciate that the expectation is conditioned, and therefore particular, to a zone
$\unicode{x1D63F}_{1}^{\textit{zone}}$
. In each of these expressions, it is important to appreciate that the expectation is conditioned, and therefore particular, to a zone
 $Z$
. Integration with respect to
$Z$
. Integration with respect to
 $w$
of the governing equation for
$w$
of the governing equation for
 $f_{\boldsymbol{Y}|Z}$
recovers an equation for
$f_{\boldsymbol{Y}|Z}$
recovers an equation for
 $f_{B|Z}$
, the marginal probability density for the buoyancy in each zone:
$f_{B|Z}$
, the marginal probability density for the buoyancy in each zone:
 \begin{align} \partial _{t}f_{B|Z}&=\int _{\mathbb{R}}(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}|Z} \,\textrm{d} w=(\overline {\mathscr{L}}^{\dagger }-\overline {V})f_{B|Z}\nonumber\\ &=-\overline {V}f_{B|Z}-\partial _{b}((\overline {\unicode{x1D63F}}^{\textit{wall}}_{1}+\overline {\unicode{x1D63F}}^{\textit{zone}}_{1})f_{B|Z})+\partial _{b}^{2}(\overline {\unicode{x1D63F}}_{2}f_{B|Z}) \end{align}
\begin{align} \partial _{t}f_{B|Z}&=\int _{\mathbb{R}}(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}|Z} \,\textrm{d} w=(\overline {\mathscr{L}}^{\dagger }-\overline {V})f_{B|Z}\nonumber\\ &=-\overline {V}f_{B|Z}-\partial _{b}((\overline {\unicode{x1D63F}}^{\textit{wall}}_{1}+\overline {\unicode{x1D63F}}^{\textit{zone}}_{1})f_{B|Z})+\partial _{b}^{2}(\overline {\unicode{x1D63F}}_{2}f_{B|Z}) \end{align}
for which
 $\overline {\square }$
denotes the projection of the operator
$\overline {\square }$
denotes the projection of the operator
 $\square$
defined by the integral in (7.13).
$\square$
defined by the integral in (7.13).
Figure 11(a) displays a snapshot of the vertical velocity
 $Y^{1}_{\!t}:=W_{\!t}$
and the buoyancy
$Y^{1}_{\!t}:=W_{\!t}$
and the buoyancy
 $Y^{2}_{\!t}:=B_{t}$
, which correspond to the fields displayed in the example derived from the Lorenz equations presented in § 2, a short time after a negative fluctuation in the buoyancy of the bottom boundary. Figure 11(b) displays the three sample distributions used to define the control volume zones
$Y^{2}_{\!t}:=B_{t}$
, which correspond to the fields displayed in the example derived from the Lorenz equations presented in § 2, a short time after a negative fluctuation in the buoyancy of the bottom boundary. Figure 11(b) displays the three sample distributions used to define the control volume zones
 $z_{1}$
(bottom boundary layer),
$z_{1}$
(bottom boundary layer),
 $z_{2}$
(bulk central region) and
$z_{2}$
(bulk central region) and
 $z_{3}$
(top boundary layer). For
$z_{3}$
(top boundary layer). For
 $z_{1}$
,
$z_{1}$
,
 $f_{\boldsymbol{X}|Z}$
is proportional to the horizontally and time-averaged diffusive buoyancy flux
$f_{\boldsymbol{X}|Z}$
is proportional to the horizontally and time-averaged diffusive buoyancy flux
 $-\alpha _{2}\partial _{X^{3}}\mathbb{E}[B_{t}|X^{3}]$
in the lower half of the domain and zero above. Conversely, for
$-\alpha _{2}\partial _{X^{3}}\mathbb{E}[B_{t}|X^{3}]$
in the lower half of the domain and zero above. Conversely, for
 $z_{3}$
,
$z_{3}$
,
 $f_{\boldsymbol{X}|Z}$
is proportional to
$f_{\boldsymbol{X}|Z}$
is proportional to
 $-\alpha _{2}\partial _{X^{3}}\mathbb{E}[B_{t}|X^{3}]$
in the upper half of the domain and zero below. In the central region (
$-\alpha _{2}\partial _{X^{3}}\mathbb{E}[B_{t}|X^{3}]$
in the upper half of the domain and zero below. In the central region (
 $Z=z_{2}$
),
$Z=z_{2}$
),
 $f_{\boldsymbol{X}|Z}$
is proportional to the mean convective buoyancy flux
$f_{\boldsymbol{X}|Z}$
is proportional to the mean convective buoyancy flux
 $\mathbb{E}[WB|X^{3}]$
. For a given zone
$\mathbb{E}[WB|X^{3}]$
. For a given zone
 $z$
, the constant of proportionality for each
$z$
, the constant of proportionality for each
 $f_{\boldsymbol{X}|Z}$
can be expressed as the total (diffusive plus convective) volume-integrated vertical buoyancy flux divided by
$f_{\boldsymbol{X}|Z}$
can be expressed as the total (diffusive plus convective) volume-integrated vertical buoyancy flux divided by
 $\mathbb{P}\{Z=z\}$
, which implies that
$\mathbb{P}\{Z=z\}$
, which implies that
 $\mathbb{P}\{Z=z\}$
corresponds to the fraction of the volume-integrated vertical buoyancy flux over a given zone, leading to the partition of unity by
$\mathbb{P}\{Z=z\}$
corresponds to the fraction of the volume-integrated vertical buoyancy flux over a given zone, leading to the partition of unity by
 $f_{\boldsymbol{X}|Z}\mathbb{P}\{Z=z\}$
illustrated in figure 11(b).
$f_{\boldsymbol{X}|Z}\mathbb{P}\{Z=z\}$
illustrated in figure 11(b).

Figure 12. (a), (b) and (c) Information relating to the joint density
 $f_{\boldsymbol{Y}|Z}$
conditioned on zone
$f_{\boldsymbol{Y}|Z}$
conditioned on zone
 $z_{1}$
(bottom boundary layer),
$z_{1}$
(bottom boundary layer),
 $z_{2}$
(bulk central zone) and
$z_{2}$
(bulk central zone) and
 $z_{3}$
(top boundary layer), respectively. Panel (b) displays the joint density
$z_{3}$
(top boundary layer), respectively. Panel (b) displays the joint density
 $f_{\boldsymbol{Y}|Z}$
(red contours) along with the flux
$f_{\boldsymbol{Y}|Z}$
(red contours) along with the flux
 $\unicode{x1D63F}^{\,\textit{zone}}_{1}f_{\boldsymbol{Y}|Z}$
(blue arrows) and isoregions of
$\unicode{x1D63F}^{\,\textit{zone}}_{1}f_{\boldsymbol{Y}|Z}$
(blue arrows) and isoregions of
 $-Vf_{\boldsymbol{Y}|Z}$
corresponding to
$-Vf_{\boldsymbol{Y}|Z}$
corresponding to
 $(-\infty ,-0.1]$
(light grey and labelled
$(-\infty ,-0.1]$
(light grey and labelled
 $\underline {\downarrow }, \overline {\uparrow }$
) and
$\underline {\downarrow }, \overline {\uparrow }$
) and
 $[0.1,\infty )$
(dark grey and labelled
$[0.1,\infty )$
(dark grey and labelled
 $\underline {\uparrow }, \overline {\downarrow }$
). Panels (a) and (c) display the marginal distribution for buoyancy
$\underline {\uparrow }, \overline {\downarrow }$
). Panels (a) and (c) display the marginal distribution for buoyancy
 $f_{B|Z}$
(red bars) along with the source/sink term
$f_{B|Z}$
(red bars) along with the source/sink term
 $-\overline {V}f_{B|Z}$
(light grey) and zonal flux term
$-\overline {V}f_{B|Z}$
(light grey) and zonal flux term
 $-\partial _{b}(\overline {\unicode{x1D63F}}_{1}^{\textit{zone}}f_{B|Z})$
(blue line) in (7.13). The horizontal lines in panels (a) and (c) demarcate the range of the vertical axis in panel (b). https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig11-12/fig11-12.ipynb.
$-\partial _{b}(\overline {\unicode{x1D63F}}_{1}^{\textit{zone}}f_{B|Z})$
(blue line) in (7.13). The horizontal lines in panels (a) and (c) demarcate the range of the vertical axis in panel (b). https://www.cambridge.org/S0022112025106319/JFM-Notebooks/files/fig11-12/fig11-12.ipynb.
Figure 12 displays stationary joint and marginal distributions of
 $\boldsymbol{Y}_{t}$
, along with contributions to
$\boldsymbol{Y}_{t}$
, along with contributions to
 $-Vf_{\boldsymbol{Y}|Z}$
and
$-Vf_{\boldsymbol{Y}|Z}$
and
 $-\partial _{\boldsymbol{y}}\unicode{x1D63F}_{1}^{\textit{zone}}f_{\boldsymbol{Y}|Z}$
arising from transport between the control volumes. The range of buoyancy in zone
$-\partial _{\boldsymbol{y}}\unicode{x1D63F}_{1}^{\textit{zone}}f_{\boldsymbol{Y}|Z}$
arising from transport between the control volumes. The range of buoyancy in zone
 $z_{1}$
(figure 12
a) is larger than it is in zone
$z_{1}$
(figure 12
a) is larger than it is in zone
 $z_{3}$
due to the stochastic boundary condition. Indeed, the marginal distribution
$z_{3}$
due to the stochastic boundary condition. Indeed, the marginal distribution
 $f_{B|Z}$
in zone
$f_{B|Z}$
in zone
 $z_{3}$
is noticeably skewed; buoyancy in the top zone does not appear to fall below the fixed value of
$z_{3}$
is noticeably skewed; buoyancy in the top zone does not appear to fall below the fixed value of
 $-1/2$
imposed on the top boundary, but reaches values up to
$-1/2$
imposed on the top boundary, but reaches values up to
 $1/2$
due to exchange with the bulk zone below. The projected convective transport
$1/2$
due to exchange with the bulk zone below. The projected convective transport
 $-\overline {V}f_{B|Z}$
and the diffusive transport
$-\overline {V}f_{B|Z}$
and the diffusive transport
 $-\partial _{b}(\overline {\unicode{x1D63F}}^{\textit{zone}}_{1}f_{B|Z})$
for both boundary layer zones are the same order of magnitude and exhibit similar behaviour. In zone
$-\partial _{b}(\overline {\unicode{x1D63F}}^{\textit{zone}}_{1}f_{B|Z})$
for both boundary layer zones are the same order of magnitude and exhibit similar behaviour. In zone
 $z_{1}$
, fluid with relatively large (
$z_{1}$
, fluid with relatively large (
 $b\approx 0.5$
) buoyancy is transported out of the zone, whereas fluid with buoyancy that is close to the volume average (
$b\approx 0.5$
) buoyancy is transported out of the zone, whereas fluid with buoyancy that is close to the volume average (
 $b\approx 0$
) is transported into the zone. In this regard, it is interesting that fluid with a buoyancy (
$b\approx 0$
) is transported into the zone. In this regard, it is interesting that fluid with a buoyancy (
 $b\lt -0.5$
), which must have been created in the vicinity of a large negative fluctuation in the buoyancy imposed on the bottom boundary (see figure 11
a), is transported out of the zone. Similar remarks apply to zone
$b\lt -0.5$
), which must have been created in the vicinity of a large negative fluctuation in the buoyancy imposed on the bottom boundary (see figure 11
a), is transported out of the zone. Similar remarks apply to zone
 $z_{3}$
, except that
$z_{3}$
, except that
 $-Vf_{B|Z}$
, which accounts for convective transport, tends to zero as
$-Vf_{B|Z}$
, which accounts for convective transport, tends to zero as
 $b$
tends to the value
$b$
tends to the value
 $-0.5$
of buoyancy imposed on the top boundary. In contrast, transport from zone
$-0.5$
of buoyancy imposed on the top boundary. In contrast, transport from zone
 $z_{3}$
into zone
$z_{3}$
into zone
 $z_{2}$
(the central region) is negative and large in magnitude in the vicinity of the buoyancy
$z_{2}$
(the central region) is negative and large in magnitude in the vicinity of the buoyancy
 $b=-0.5$
of the top boundary.
$b=-0.5$
of the top boundary.
Zones
 $z_{1}$
and
$z_{1}$
and
 $z_{3}$
interact with the central bulk zone
$z_{3}$
interact with the central bulk zone
 $z_{2}$
, whose joint probability density for vertical velocity
$z_{2}$
, whose joint probability density for vertical velocity
 $W_{t}$
and buoyancy
$W_{t}$
and buoyancy
 $B_{t}$
is displayed in figure 12(b). The vector field depicted with blue arrows represents the flux of probability density
$B_{t}$
is displayed in figure 12(b). The vector field depicted with blue arrows represents the flux of probability density
 $\unicode{x1D63F}^{\textit{zone}}_{1}f_{\boldsymbol{Y}|Z}$
due to diffusion to the boundary layers, whose divergence corresponds to a sink in the budget for
$\unicode{x1D63F}^{\textit{zone}}_{1}f_{\boldsymbol{Y}|Z}$
due to diffusion to the boundary layers, whose divergence corresponds to a sink in the budget for
 $f_{\boldsymbol{Y}|Z}$
. For this particular problem, the vector field resembles a saddle node, converging with respect to vertical velocity (
$f_{\boldsymbol{Y}|Z}$
. For this particular problem, the vector field resembles a saddle node, converging with respect to vertical velocity (
 $w$
) and diverging with respect to buoyancy (
$w$
) and diverging with respect to buoyancy (
 $b$
). This structure is due to the fact that the boundary layers are sinks of velocity/momentum and sources of buoyancy.
$b$
). This structure is due to the fact that the boundary layers are sinks of velocity/momentum and sources of buoyancy.
The light and dark shaded regions in figure 12(b) correspond to negative (velocity directed out of the control volume) and positive (velocity directed into the control volume) contributions to
 $\partial _{t} f_{\boldsymbol{Y}|Z}$
from
$\partial _{t} f_{\boldsymbol{Y}|Z}$
from
 $-Vf_{\boldsymbol{Y}|Z}$
, respectively. Positively buoyant fluid tends to be transported by positive vertical velocity from the bottom boundary layer (
$-Vf_{\boldsymbol{Y}|Z}$
, respectively. Positively buoyant fluid tends to be transported by positive vertical velocity from the bottom boundary layer (
 $\underline {\uparrow }$
), while negatively buoyant fluid tends to be transported by negative vertical velocity from the top boundary layer (
$\underline {\uparrow }$
), while negatively buoyant fluid tends to be transported by negative vertical velocity from the top boundary layer (
 $\overline {\downarrow }$
). Both of these processes correspond to positive forcing of
$\overline {\downarrow }$
). Both of these processes correspond to positive forcing of
 $f_{\boldsymbol{Y}|Z}$
(i.e.
$f_{\boldsymbol{Y}|Z}$
(i.e.
 $-V f_{\boldsymbol{Y}|Z}\gt 0$
). The remaining negative regions identified in figure 12(b) typically correspond to mixed fluid, with buoyancy close to zero, transported from the bulk into the bottom or top boundary layer (denoted
$-V f_{\boldsymbol{Y}|Z}\gt 0$
). The remaining negative regions identified in figure 12(b) typically correspond to mixed fluid, with buoyancy close to zero, transported from the bulk into the bottom or top boundary layer (denoted
 $\underline {\downarrow }$
and
$\underline {\downarrow }$
and
 $\overline {\uparrow }$
, respectively).
$\overline {\uparrow }$
, respectively).
7.5. Available potential energy
Available potential energy is the part of potential energy of a body of fluid that is theoretically ‘available’ for conversion into kinetic energy. The other part, known as background potential energy, cannot be converted into kinetic energy and is associated with a stable equilibrium (Lorenz Reference Lorenz1955). For example, kinetic energy cannot typically be extracted from a stably stratified environment (in which a fluid’s density decreases with height) and therefore possesses zero available potential energy.
When divided by the volume of the domain, the potential energy of the fluid modelled in § 7.3 corresponds to the expectation of the product
 $-B_{t}Z$
(see, for example Winters et al. Reference Winters, Lombard, Riley and D’Asaro1995):
$-B_{t}Z$
(see, for example Winters et al. Reference Winters, Lombard, Riley and D’Asaro1995):
 \begin{equation} -\mathbb{E}\left [B_{t}Z\right ]=-\int \limits _{\mathbb{R}^{n}}bz f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}, \end{equation}
\begin{equation} -\mathbb{E}\left [B_{t}Z\right ]=-\int \limits _{\mathbb{R}^{n}}bz f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}, \end{equation}
where
 $f_{\boldsymbol{Y}}(\boldsymbol{y},t)$
is the joint density for the variables
$f_{\boldsymbol{Y}}(\boldsymbol{y},t)$
is the joint density for the variables
 $\boldsymbol{Y}_{\!t}:=(W_{\!t},B_{t},Z)^{\top }$
from the example in § 7.3 evaluated at
$\boldsymbol{Y}_{\!t}:=(W_{\!t},B_{t},Z)^{\top }$
from the example in § 7.3 evaluated at
 $\boldsymbol{y}:=(w,b,z)^{\top }$
and the minus sign accounts for relatively warm parcels of fluid having greater potential energy when they are moved downwards. The so-called ‘reference’ buoyancy profile
$\boldsymbol{y}:=(w,b,z)^{\top }$
and the minus sign accounts for relatively warm parcels of fluid having greater potential energy when they are moved downwards. The so-called ‘reference’ buoyancy profile
 $b^{*}:\mathbb{R}\rightarrow \mathbb{R}$
in available potential energy theory is a volume-preserving function of height that minimises potential energy (see e.g. Winters et al. Reference Winters, Lombard, Riley and D’Asaro1995). ‘Volume-preserving’ in this context means that the mapping
$b^{*}:\mathbb{R}\rightarrow \mathbb{R}$
in available potential energy theory is a volume-preserving function of height that minimises potential energy (see e.g. Winters et al. Reference Winters, Lombard, Riley and D’Asaro1995). ‘Volume-preserving’ in this context means that the mapping
 $b^{*}$
does not change the marginal distribution of buoyancy, which, in the present context, means that
$b^{*}$
does not change the marginal distribution of buoyancy, which, in the present context, means that
 $\mathbb{E}[g\circ b^{*}(Z)]=\mathbb{E}[g(B_{t})]$
for any observable
$\mathbb{E}[g\circ b^{*}(Z)]=\mathbb{E}[g(B_{t})]$
for any observable
 $g$
.
$g$
.
The potential energy (7.14) is minimised by placing positively buoyant parcels at the top of the domain and negatively buoyant parcels at the bottom of the domain. The required mapping
 $b^{*}$
is monotonic and corresponds to
$b^{*}$
is monotonic and corresponds to
 \begin{equation} b^{*}:=F_{B}^{-1}\circ F_{Z}, \end{equation}
\begin{equation} b^{*}:=F_{B}^{-1}\circ F_{Z}, \end{equation}
where
 $F_{B}$
and
$F_{B}$
and
 $F_{Z}$
are the marginal cumulative distribution functions for
$F_{Z}$
are the marginal cumulative distribution functions for
 $B_{t}$
and
$B_{t}$
and
 $Z$
, respectively. In the field of optimal transport,
$Z$
, respectively. In the field of optimal transport,
 $b^{*}$
minimises the expected squared distance between two variables and has been known for a long time (Knott & Smith Reference Knott and Smith1984; McCann Reference McCann1995). The reference state allows the available potential energy to be computed as the difference between the actual potential energy and the (minimum) potential energy associated with the reference state:
$b^{*}$
minimises the expected squared distance between two variables and has been known for a long time (Knott & Smith Reference Knott and Smith1984; McCann Reference McCann1995). The reference state allows the available potential energy to be computed as the difference between the actual potential energy and the (minimum) potential energy associated with the reference state:
 \begin{equation} \mathbb{E}\left [b^{*}(Z)Z\right ]-\mathbb{E}\left [B_{t}Z\right ]=\int \limits _{\mathbb{R}^{n}}(b^{*}(z)-b)zf_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}\geqslant 0. \end{equation}
\begin{equation} \mathbb{E}\left [b^{*}(Z)Z\right ]-\mathbb{E}\left [B_{t}Z\right ]=\int \limits _{\mathbb{R}^{n}}(b^{*}(z)-b)zf_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d} \boldsymbol{y}\geqslant 0. \end{equation}
As described by Craske (Reference Craske2021), available potential energy can be decomposed into contributions from subvolumes of a domain. Each contribution consists of ‘inner’ and ‘outer’ parts, corresponding to the potential energy that can be released within a subvolume and by combining the subvolume with its parent domain, respectively. The approach generalises to subvolumes that are specified by the conditional sample distributions
 $f_{\boldsymbol{X}|Z}$
described in § 6. The resulting constructions formally resemble Bayes’ theorem due to their connection with probability theory.
$f_{\boldsymbol{X}|Z}$
described in § 6. The resulting constructions formally resemble Bayes’ theorem due to their connection with probability theory.
A key related quantity in stratified turbulence is the horizontally averaged vertical buoyancy flux
 $\mathbb{E}[W_{\!t}B_{t}|Z=z]$
, which is responsible for the reversible conversion of available potential energy to and from kinetic energy (see, for example, Caulfield Reference Caulfield2020). In the averaged Boussinesq equations, the horizontally averaged vertical buoyancy flux requires closure, but from the perspective of the joint density for
$\mathbb{E}[W_{\!t}B_{t}|Z=z]$
, which is responsible for the reversible conversion of available potential energy to and from kinetic energy (see, for example, Caulfield Reference Caulfield2020). In the averaged Boussinesq equations, the horizontally averaged vertical buoyancy flux requires closure, but from the perspective of the joint density for
 $W_{\!t}$
and
$W_{\!t}$
and
 $B_{t}$
, conditional on
$B_{t}$
, conditional on
 $Z$
, it is known exactly in terms of independent and dependent variables:
$Z$
, it is known exactly in terms of independent and dependent variables:
 \begin{equation} \mathbb{E}[W_{\!t}B_{t}|Z=z]=\iint \limits _{\mathbb{R}^{2}}wbf_{BW|Z}(b,w|z,t)\,\textrm{d} w\,\textrm{d} b,\quad \quad \forall z: f_{Z}(z)\neq 0, \end{equation}
\begin{equation} \mathbb{E}[W_{\!t}B_{t}|Z=z]=\iint \limits _{\mathbb{R}^{2}}wbf_{BW|Z}(b,w|z,t)\,\textrm{d} w\,\textrm{d} b,\quad \quad \forall z: f_{Z}(z)\neq 0, \end{equation}
which suggests that the evolution equations for
 $f_{\boldsymbol{Y}}$
might be a useful perspective to adopt for modelling stratified turbulence and making use of available energetics in a prognostic capacity.
$f_{\boldsymbol{Y}}$
might be a useful perspective to adopt for modelling stratified turbulence and making use of available energetics in a prognostic capacity.
8. Closure
As described in § 1, the primary aim of this work was to develop a framework for analysing heterogeneous and stochastic flow observables over arbitrary control volumes using joint probability distributions. Although the forward equation (4.2) can be used diagnostically to analyse data,
 $V$
,
$V$
,
 $\unicode{x1D63F}_{1}$
and
$\unicode{x1D63F}_{1}$
and
 $\unicode{x1D63F}_{2}$
involve unclosed terms that would need to be modelled for (3.19) to be used prognostically. Modelling in this regard must account for the effects of averaging over states that are not measurable in the variable
$\unicode{x1D63F}_{2}$
involve unclosed terms that would need to be modelled for (3.19) to be used prognostically. Modelling in this regard must account for the effects of averaging over states that are not measurable in the variable
 $\boldsymbol{Y}_{\!t}$
. As with any coarse-grained representation, one’s aim is to forecast a marginal distribution
$\boldsymbol{Y}_{\!t}$
. As with any coarse-grained representation, one’s aim is to forecast a marginal distribution
 $f_{\boldsymbol{Y}}$
that is a good approximation to the corresponding projection of the full (infinite dimensional) state of the system.
$f_{\boldsymbol{Y}}$
that is a good approximation to the corresponding projection of the full (infinite dimensional) state of the system.
In the context of local p.d.f. methods (describing a single Eulerian or Lagrangian point), a variety of models to address the closure problem are reviewed by Pope (Reference Pope2000) and Fox (Reference Fox2003). Unlike their moment-based counterparts, for which closures are typically sought for fluxes or correlations such as
 $\mathbb{E}[WB|\boldsymbol{X}=\boldsymbol{x}]$
from § 7.3, the modelling of irreversible mixing by molecular diffusion (i.e.
$\mathbb{E}[WB|\boldsymbol{X}=\boldsymbol{x}]$
from § 7.3, the modelling of irreversible mixing by molecular diffusion (i.e.
 $\unicode{x1D63F}_{2}$
) becomes the central issue in local probability density methods (Pope Reference Pope2000).
$\unicode{x1D63F}_{2}$
) becomes the central issue in local probability density methods (Pope Reference Pope2000).
If
 $-\unicode{x1D63F}_{2}\succeq 0$
(as discussed in § 5), ‘diffusion’ in (3.20) is negative and results in greater certainty as time increases regarding the observable
$-\unicode{x1D63F}_{2}\succeq 0$
(as discussed in § 5), ‘diffusion’ in (3.20) is negative and results in greater certainty as time increases regarding the observable
 $\boldsymbol{Y}_{\!t}$
. A simple approach to modelling this term is to replace it with a mean-restoring drift, for which the contribution to
$\boldsymbol{Y}_{\!t}$
. A simple approach to modelling this term is to replace it with a mean-restoring drift, for which the contribution to
 $\unicode{x1D63F}_{1}$
would be proportional to
$\unicode{x1D63F}_{1}$
would be proportional to
 $\boldsymbol{y}-\mathbb{E}[\boldsymbol{Y}]$
, known as ‘interaction by exchange with the mean’ (Villermaux & Devillon Reference Villermaux and Devillon1972; Dopazo & O’Brien Reference Dopazo and O’Brien1974). The closure is exact for a statistically homogeneous Gaussian field (Pope Reference Pope2000). Unfortunately, it has the undesirable effect in one dimension of preserving the shape of other distributions too, which contradicts the expected relaxation towards a Gaussian distribution. This particular issue is overcome by ‘mapping closures’ (Chen, Chen & Kraichnan Reference Chen, Chen and Kraichnan1989; Pope Reference Pope1991; Gao & O’Brien Reference Gao and O’Brien1991), which evolve a map from statistically homogeneous Gaussian fields to surrogate fields that have the same p.d.f. as
$\boldsymbol{y}-\mathbb{E}[\boldsymbol{Y}]$
, known as ‘interaction by exchange with the mean’ (Villermaux & Devillon Reference Villermaux and Devillon1972; Dopazo & O’Brien Reference Dopazo and O’Brien1974). The closure is exact for a statistically homogeneous Gaussian field (Pope Reference Pope2000). Unfortunately, it has the undesirable effect in one dimension of preserving the shape of other distributions too, which contradicts the expected relaxation towards a Gaussian distribution. This particular issue is overcome by ‘mapping closures’ (Chen, Chen & Kraichnan Reference Chen, Chen and Kraichnan1989; Pope Reference Pope1991; Gao & O’Brien Reference Gao and O’Brien1991), which evolve a map from statistically homogeneous Gaussian fields to surrogate fields that have the same p.d.f. as
 $\boldsymbol{Y}_{\!t}$
. Their assumption is that conditional expectations of the derivatives of the surrogate fields are the same as those of
$\boldsymbol{Y}_{\!t}$
. Their assumption is that conditional expectations of the derivatives of the surrogate fields are the same as those of
 $\boldsymbol{Y}_{\!t}$
. Chen et al. (Reference Chen, Chen and Kraichnan1989) suggest that the mapping closure would benefit from the inclusion of spatial derivatives in
$\boldsymbol{Y}_{\!t}$
. Chen et al. (Reference Chen, Chen and Kraichnan1989) suggest that the mapping closure would benefit from the inclusion of spatial derivatives in
 $\boldsymbol{Y}_{\!t}$
, which would come at the expense of complicating the structure of the various mapping dependencies between the fields (Pope Reference Pope1991). Both closures discussed in this paragraph result in a nonlinear forward equation for probability density (see, e.g. Frank Reference Frank2005), in view of their assumed dependence of
$\boldsymbol{Y}_{\!t}$
, which would come at the expense of complicating the structure of the various mapping dependencies between the fields (Pope Reference Pope1991). Both closures discussed in this paragraph result in a nonlinear forward equation for probability density (see, e.g. Frank Reference Frank2005), in view of their assumed dependence of
 $\unicode{x1D63F}_{1}$
and
$\unicode{x1D63F}_{1}$
and
 $\unicode{x1D63F}_{2}$
on
$\unicode{x1D63F}_{2}$
on
 $f_{\boldsymbol{Y}}$
.
$f_{\boldsymbol{Y}}$
.
Regarding the random variables
 $\boldsymbol{Y}_{\!t}$
as particles in phase space, evolving according to a stochastic equation to produce the distribution predicted by (4.2), provides an efficient means of dealing with a large number of observables and affords a different perspective for closure. In this vein, the closure described by Curl (Reference Curl1963) randomly selects and merges pairs of particles (at a rate specified as the mixing time scale). In the context of models for stratified turbulence, Kerstein (Reference Kerstein1999) and, recently, Petropoulos, de Bruyn Kops & Caulfield (Reference Petropoulos, de Bruyn Kops and Caulfield2025) also adopt a particle perspective, the latter accounting for competing effects of turbulent fluctuations and buoyancy with a resetting process.
$\boldsymbol{Y}_{\!t}$
as particles in phase space, evolving according to a stochastic equation to produce the distribution predicted by (4.2), provides an efficient means of dealing with a large number of observables and affords a different perspective for closure. In this vein, the closure described by Curl (Reference Curl1963) randomly selects and merges pairs of particles (at a rate specified as the mixing time scale). In the context of models for stratified turbulence, Kerstein (Reference Kerstein1999) and, recently, Petropoulos, de Bruyn Kops & Caulfield (Reference Petropoulos, de Bruyn Kops and Caulfield2025) also adopt a particle perspective, the latter accounting for competing effects of turbulent fluctuations and buoyancy with a resetting process.
Heterogeneous flows are more challenging for closures and involve joint p.d.f.s over a larger number of dimensions. In this regard, the flexibility of the framework described in the present work should prove useful. It can accommodate arbitrary coordinates as observables and allows one to decompose a domain into overlapping control volumes that are themselves defined as probability densities. As illustrated in § 6, a coarse grained approach to a heterogeneous flow might decompose a domain into constituent parts that are approximately homogeneous and, therefore, more amenable to the closures discussed. An outstanding challenge would then be modelling of the boundary fluxes between the control volumes in
 $\unicode{x1D63F}_{1}$
and/or
$\unicode{x1D63F}_{1}$
and/or
 $V$
(see § 4 and the example in § 7.4), for which the concepts relating to available potential energy discussed in § 7.5 might be instructive.
$V$
(see § 4 and the example in § 7.4), for which the concepts relating to available potential energy discussed in § 7.5 might be instructive.
Like the formulation presented here, the p.d.f.s of Villermaux (Reference Villermaux2019) describe the heterogeneous distribution of concentration over a control volume. Therefore, the simplified p.d.f. models characterising the evolution of lamellae discussed by Villermaux (Reference Villermaux2019) effectively provide a closure to the forward equation. Conversely, such models could be examined in the light of the forward equation (4.2) to establish a better understanding of the diffusivity
 $\unicode{x1D63F}_{2}$
.
$\unicode{x1D63F}_{2}$
.
9. Conclusions
We have derived and explained an equation that governs the evolution of the joint probability distribution
 $f_{\boldsymbol{Y}}$
of a set of stochastically forced multicomponent observables
$f_{\boldsymbol{Y}}$
of a set of stochastically forced multicomponent observables
 $\boldsymbol{Y}$
drawn randomly from points in space that are distributed according to
$\boldsymbol{Y}$
drawn randomly from points in space that are distributed according to
 $f_{\boldsymbol{X}}$
. Our use of the distribution
$f_{\boldsymbol{X}}$
. Our use of the distribution
 $f_{\boldsymbol{X}}$
to describe space generalises the classical definition of a control volume by relaxing the notion of set membership in accounting for the possibility of gradual transitions between regions (cf. § 6 and figure 7). The generality of the approach clarifies the role of boundary fluxes and accommodates a wide range of applications, including those for which properties of a flow are used to define control volumes.
$f_{\boldsymbol{X}}$
to describe space generalises the classical definition of a control volume by relaxing the notion of set membership in accounting for the possibility of gradual transitions between regions (cf. § 6 and figure 7). The generality of the approach clarifies the role of boundary fluxes and accommodates a wide range of applications, including those for which properties of a flow are used to define control volumes.
Fluxes of multicomponent scalars over the bounding region of the sample distribution
 $f_{\boldsymbol{X}}$
contribute to drift in probability space. The factor
$f_{\boldsymbol{X}}$
contribute to drift in probability space. The factor
 $\boldsymbol{\nabla }\log f_{\boldsymbol{X}}$
that multiplies such fluxes defines the normal direction of the bounding region, as well as its relative size, in transforming the measure with respect to which conditional expectations are taken. In contrast, irreversible mixing leads to diffusion in probability space. Although the sign of the resulting diffusion coefficient is typically negative semidefinite, representing the homogenising effect of irreversible mixing, circumstances for which the coefficient could be sign indefinite were explored in § 5.
$\boldsymbol{\nabla }\log f_{\boldsymbol{X}}$
that multiplies such fluxes defines the normal direction of the bounding region, as well as its relative size, in transforming the measure with respect to which conditional expectations are taken. In contrast, irreversible mixing leads to diffusion in probability space. Although the sign of the resulting diffusion coefficient is typically negative semidefinite, representing the homogenising effect of irreversible mixing, circumstances for which the coefficient could be sign indefinite were explored in § 5.
The approach can be applied to control volumes defined by any sample distribution, shape, size and dimension, and readily accommodates an arbitrary number of flow observables. As demonstrated in § 7.3, coordinates can be regarded as observables, which means that the equations derived in § 3 can be applied without modification to slices of a domain parametrised by a coordinate, or, for example, geopotential height. In this regard, the work illustrates that the equations governing global constructions of available and background potential energy (Winters et al. Reference Winters, Lombard, Riley and D’Asaro1995) are specific examples of the more general principles that determine the evolution of probability distributions.
In addition to unifying a wide range of possible applications, an advantage in formulating the problem in terms of the density
 $f_{\boldsymbol{X}}$
, rather than traditional sets, is that
$f_{\boldsymbol{X}}$
, rather than traditional sets, is that
 $\boldsymbol{\nabla }\log f_{\boldsymbol{X}}$
implicitly accounts for the size and orientation of the bounding region without requiring further factors or notation. The use of
$\boldsymbol{\nabla }\log f_{\boldsymbol{X}}$
implicitly accounts for the size and orientation of the bounding region without requiring further factors or notation. The use of
 $f_{\boldsymbol{X}}$
also proves useful in producing relatively smooth boundary information from limited data from simulations, from which evaluation of fluxes across an arbitrary surface is challenging and subject to large uncertainty.
$f_{\boldsymbol{X}}$
also proves useful in producing relatively smooth boundary information from limited data from simulations, from which evaluation of fluxes across an arbitrary surface is challenging and subject to large uncertainty.
As explained in § 6, the sample distribution
 $f_{\boldsymbol{X}}$
can be treated as a mixture distribution that decomposes into a sum of conditional distributions
$f_{\boldsymbol{X}}$
can be treated as a mixture distribution that decomposes into a sum of conditional distributions
 $f_{\boldsymbol{X}|Z}$
. Using the conditional distributions to describe (sub)regions of a flow that are approximately homogeneous might provide a viable means of generating bulk stochastic models for heterogeneous flows using the closures discussed in § 8. A particularly attractive possibility in this regard would be the use of time-dependent distributions defined by a flow observable (an example would be the use of enstropy to discriminate between turbulent/non-turbulent regions of van Reeuwijk et al. (Reference van Reeuwijk, Vassilicos and Craske2021)). For such cases, the effect that the time-dependence of
$f_{\boldsymbol{X}|Z}$
. Using the conditional distributions to describe (sub)regions of a flow that are approximately homogeneous might provide a viable means of generating bulk stochastic models for heterogeneous flows using the closures discussed in § 8. A particularly attractive possibility in this regard would be the use of time-dependent distributions defined by a flow observable (an example would be the use of enstropy to discriminate between turbulent/non-turbulent regions of van Reeuwijk et al. (Reference van Reeuwijk, Vassilicos and Craske2021)). For such cases, the effect that the time-dependence of
 $f_{\boldsymbol{X}}$
would have on the evolution of
$f_{\boldsymbol{X}}$
would have on the evolution of
 $f_{\boldsymbol{Y}}$
can be readily interpreted using the Feynman–Kac formula, as shown in Appendix C.1.
$f_{\boldsymbol{Y}}$
can be readily interpreted using the Feynman–Kac formula, as shown in Appendix C.1.
The present work is aimed at engineers and physicists who wish to diagnose or model bulk transport and mixing processes from a probabilistic perspective. The resulting equations are nevertheless of mathematical interest and perhaps worthy of study in their own right. If the terms
 $V$
,
$V$
,
 $\unicode{x1D63F}_{1}$
and
$\unicode{x1D63F}_{1}$
and
 $\unicode{x1D63F}_{2}$
requiring closure are, in general, regarded as a function of the joint density
$\unicode{x1D63F}_{2}$
requiring closure are, in general, regarded as a function of the joint density
 $f_{\boldsymbol{Y}}$
, the resulting partial differential equation is a nonlinear Fokker–Planck equation, reminiscent of mean field theory (Frank Reference Frank2005; Barbu & Röckner Reference Barbu and Röckner2024) and the associated McKean–Vlasov stochastic differential equation (McKean Reference McKean1966).
$f_{\boldsymbol{Y}}$
, the resulting partial differential equation is a nonlinear Fokker–Planck equation, reminiscent of mean field theory (Frank Reference Frank2005; Barbu & Röckner Reference Barbu and Röckner2024) and the associated McKean–Vlasov stochastic differential equation (McKean Reference McKean1966).
Supplementary material
Computational Notebook files are available as supplementary material at https://doi.org/10.1017/jfm.2025.10631 and online at https://www.cambridge.org/S0022112025106319/JFM-Notebooks
Funding
This work was supported by the Engineering and Physical Sciences Research Council [grant number EP/V033883/1] as part of the [D
 $^{*}$
]stratify project.
$^{*}$
]stratify project.
Declaration of interests
The authors report no conflict of interest.
Data availability statement
The data that support the findings of this study are openly available in the JFM notebooks at https://www.cambridge.org/S0022112025106319/JFM-Notebooks.
Appendix A. The transformation of probability density
A function
 $\varphi :\mathbb{R}^{d}\rightarrow \mathbb{R}^{n}$
that assigns to coordinates
$\varphi :\mathbb{R}^{d}\rightarrow \mathbb{R}^{n}$
that assigns to coordinates
 $\boldsymbol{X}\in \mathbb{R}^{d}$
the value of the dependent variables
$\boldsymbol{X}\in \mathbb{R}^{d}$
the value of the dependent variables
 $\boldsymbol{Y}\in \mathbb{R}^{n}$
, transforms a distribution over
$\boldsymbol{Y}\in \mathbb{R}^{n}$
, transforms a distribution over
 $\mathbb{R}^{d}$
into a distribution over
$\mathbb{R}^{d}$
into a distribution over
 $\mathbb{R}^{n}$
. We will start by assuming that
$\mathbb{R}^{n}$
. We will start by assuming that
 $n=d$
and discuss what happens when
$n=d$
and discuss what happens when
 $n\neq d$
at the end of this section.
$n\neq d$
at the end of this section.
The joint probability density
 $f_{\boldsymbol{Y}}:\mathbb{R}^{n}\rightarrow \mathbb{R}$
(if it exists) must provide a consistent means of computing the expectation of an observable
$f_{\boldsymbol{Y}}:\mathbb{R}^{n}\rightarrow \mathbb{R}$
(if it exists) must provide a consistent means of computing the expectation of an observable
 $g:\mathbb{R}^{n}\rightarrow \mathbb{R}$
:
$g:\mathbb{R}^{n}\rightarrow \mathbb{R}$
:
 \begin{equation} \mathbb{E}[g]=\int \limits _{\mathbb{R}^{n}}g(\boldsymbol{y})f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d}\boldsymbol{y}=\int \limits _{\mathbb{R}^{d}}g\circ \varphi (\boldsymbol{x})f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d}\boldsymbol{x}. \end{equation}
\begin{equation} \mathbb{E}[g]=\int \limits _{\mathbb{R}^{n}}g(\boldsymbol{y})f_{\boldsymbol{Y}}(\boldsymbol{y},t)\,\textrm{d}\boldsymbol{y}=\int \limits _{\mathbb{R}^{d}}g\circ \varphi (\boldsymbol{x})f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d}\boldsymbol{x}. \end{equation}
Notice that if
 $\varphi (\boldsymbol{x})$
is constant over subsets of
$\varphi (\boldsymbol{x})$
is constant over subsets of
 $\mathbb{R}^{d}$
for which
$\mathbb{R}^{d}$
for which
 $f_{\boldsymbol{X}}(\boldsymbol{x})\neq 0$
, then such a density
$f_{\boldsymbol{X}}(\boldsymbol{x})\neq 0$
, then such a density
 $f_{\boldsymbol{Y}}$
does not exist. In that case,
$f_{\boldsymbol{Y}}$
does not exist. In that case,
 $f_{\boldsymbol{Y}}\,\textrm{d} \boldsymbol{y}$
would need to be replaced with the pushforward measure
$f_{\boldsymbol{Y}}\,\textrm{d} \boldsymbol{y}$
would need to be replaced with the pushforward measure
 $\nu (\,\textrm{d}\boldsymbol{y})$
(Chung Reference Chung2001; Bogachev Reference Bogachev2007) to account for individual values
$\nu (\,\textrm{d}\boldsymbol{y})$
(Chung Reference Chung2001; Bogachev Reference Bogachev2007) to account for individual values
 $\boldsymbol{y}$
that occur over subsets of
$\boldsymbol{y}$
that occur over subsets of
 $\mathbb{R}^{d}$
of finite size (referred to as ‘atoms’ of
$\mathbb{R}^{d}$
of finite size (referred to as ‘atoms’ of
 $\nu$
(Chung Reference Chung2001)). If, in the cases where the density
$\nu$
(Chung Reference Chung2001)). If, in the cases where the density
 $f_{\boldsymbol{Y}}$
does exist, we pick
$f_{\boldsymbol{Y}}$
does exist, we pick
 $g$
as the indicator function for the sub-codomain
$g$
as the indicator function for the sub-codomain
 $\mathcal{Y}(\boldsymbol{y}):\{\boldsymbol{y}'\in \mathbb{R}^{n}:y'^{i}\leqslant y^{i}\}$
, then
$\mathcal{Y}(\boldsymbol{y}):\{\boldsymbol{y}'\in \mathbb{R}^{n}:y'^{i}\leqslant y^{i}\}$
, then
 \begin{equation} f_{\boldsymbol{Y}}(\boldsymbol{y})=\frac {\partial ^{n}}{\partial y^{1}\ldots \partial y^{n}}\int \limits _{\varphi ^{-1}(\mathcal{Y}(\boldsymbol{y}))}f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d}\boldsymbol{x}, \end{equation}
\begin{equation} f_{\boldsymbol{Y}}(\boldsymbol{y})=\frac {\partial ^{n}}{\partial y^{1}\ldots \partial y^{n}}\int \limits _{\varphi ^{-1}(\mathcal{Y}(\boldsymbol{y}))}f_{\boldsymbol{X}}(\boldsymbol{x})\,\textrm{d}\boldsymbol{x}, \end{equation}
where
 $\varphi ^{-1}(\mathcal{Y}(\boldsymbol{y})):=\{\boldsymbol{X}\in \mathbb{R}^{d}:\varphi (\boldsymbol{X})\in \mathcal{Y}(\boldsymbol{y})\}$
is the preimage of
$\varphi ^{-1}(\mathcal{Y}(\boldsymbol{y})):=\{\boldsymbol{X}\in \mathbb{R}^{d}:\varphi (\boldsymbol{X})\in \mathcal{Y}(\boldsymbol{y})\}$
is the preimage of
 $\mathcal{Y}$
, which accounts for the possibility that several distinct values
$\mathcal{Y}$
, which accounts for the possibility that several distinct values
 $\boldsymbol{X}$
might map onto the same value
$\boldsymbol{X}$
might map onto the same value
 $\boldsymbol{Y}$
. If, however,
$\boldsymbol{Y}$
. If, however,
 $\varphi |_{\mathcal{X}}$
is the restriction of
$\varphi |_{\mathcal{X}}$
is the restriction of
 $\varphi$
to a subdomain
$\varphi$
to a subdomain
 $\mathcal{X}\subset \mathbb{R}^{d}$
over which
$\mathcal{X}\subset \mathbb{R}^{d}$
over which
 $\varphi$
is invertible, then
$\varphi$
is invertible, then
 \begin{equation} f_{\boldsymbol{Y}|\mathcal{X}}(\boldsymbol{y})=f_{\boldsymbol{X}}(\varphi |_{\mathcal{X}}^{-1}(\boldsymbol{y}))\bigg |\dfrac {\partial \varphi |_{\mathcal{X}}^{-1}}{\partial \boldsymbol{y}}\bigg |, \end{equation}
\begin{equation} f_{\boldsymbol{Y}|\mathcal{X}}(\boldsymbol{y})=f_{\boldsymbol{X}}(\varphi |_{\mathcal{X}}^{-1}(\boldsymbol{y}))\bigg |\dfrac {\partial \varphi |_{\mathcal{X}}^{-1}}{\partial \boldsymbol{y}}\bigg |, \end{equation}
where
 $f_{\boldsymbol{Y}|\mathcal{X}}$
is the probability density conditional on
$f_{\boldsymbol{Y}|\mathcal{X}}$
is the probability density conditional on
 $\boldsymbol{X}\in \mathcal{X}$
. The density
$\boldsymbol{X}\in \mathcal{X}$
. The density
 $f_{\boldsymbol{Y}}$
can be calculated from (A3) using Bayes’ theorem to account for a set
$f_{\boldsymbol{Y}}$
can be calculated from (A3) using Bayes’ theorem to account for a set
 $\mathscr{P}\ni \mathcal{X}$
of disjoint subdomains:
$\mathscr{P}\ni \mathcal{X}$
of disjoint subdomains:
 \begin{equation} f_{\boldsymbol{Y}}(\boldsymbol{y})=\sum _{\mathcal{X}\in \mathscr{P}}f_{\boldsymbol{Y}|\mathcal{X}}(\boldsymbol{y},t)\mathbb{P}(\mathcal{X}). \end{equation}
\begin{equation} f_{\boldsymbol{Y}}(\boldsymbol{y})=\sum _{\mathcal{X}\in \mathscr{P}}f_{\boldsymbol{Y}|\mathcal{X}}(\boldsymbol{y},t)\mathbb{P}(\mathcal{X}). \end{equation}
When
 $n\lt d$
, the sample space is large in comparison with
$n\lt d$
, the sample space is large in comparison with
 $n$
and
$n$
and
 $(d-n)$
auxiliary variables, such as
$(d-n)$
auxiliary variables, such as
 $X_{n+1},X_{n+2},\ldots ,X_{d}$
need to be appended to
$X_{n+1},X_{n+2},\ldots ,X_{d}$
need to be appended to
 $\boldsymbol{Y}$
to construct the Jacobian in (A3). The joint distribution (A4) can then be integrated with respect to the auxiliary variables to produce the (marginal) distribution that was originally sought. If
$\boldsymbol{Y}$
to construct the Jacobian in (A3). The joint distribution (A4) can then be integrated with respect to the auxiliary variables to produce the (marginal) distribution that was originally sought. If
 $d\lt n$
, however, the sample space is relatively small. Auxiliary dimensions
$d\lt n$
, however, the sample space is relatively small. Auxiliary dimensions
 $X_{d+1},X_{d+2},\ldots ,X_{n}$
, with regards to which
$X_{d+1},X_{d+2},\ldots ,X_{n}$
, with regards to which
 $\boldsymbol{Y}$
is assumed constant, can be appended to
$\boldsymbol{Y}$
is assumed constant, can be appended to
 $\boldsymbol{X}$
, which will produce Dirac measures in the resulting distribution, as discussed in § 7. In general,
$\boldsymbol{X}$
, which will produce Dirac measures in the resulting distribution, as discussed in § 7. In general,
 $f_{\boldsymbol{Y}}$
in this case will be ‘sparse’ in the sense that the (possibly fractal) dimension associated with the singular/non-zero parts of the distribution will be less than
$f_{\boldsymbol{Y}}$
in this case will be ‘sparse’ in the sense that the (possibly fractal) dimension associated with the singular/non-zero parts of the distribution will be less than
 $n$
. This idea can be made precise by considering the information dimension of
$n$
. This idea can be made precise by considering the information dimension of
 $\boldsymbol{Y}$
(Rényi Reference Rényi1959).
$\boldsymbol{Y}$
(Rényi Reference Rényi1959).
Appendix B. Lorenz (Reference Lorenz1963) model
Lorenz’s model for convection (Lorenz Reference Lorenz1963) is a truncated solution of the Boussinesq equations for which the vertical velocity
 $Y^{1}_{\!t}$
and buoyancy field
$Y^{1}_{\!t}$
and buoyancy field
 $Y^{2}_{\!t}$
, relative to linear conduction, on a horizontally periodic domain
$Y^{2}_{\!t}$
, relative to linear conduction, on a horizontally periodic domain
 $\mathcal{X}:=[0,2\pi /k)\times [0,1]\ni \boldsymbol{X}:=(X^{1},X^{2})$
, are
$\mathcal{X}:=[0,2\pi /k)\times [0,1]\ni \boldsymbol{X}:=(X^{1},X^{2})$
, are
 \begin{align} Y_{\!t}^{1}&=\varphi _{\!t}^{1}(X^{1},X^{2}):=\frac {\sqrt {2}}{\pi }\left (k^{2}+\pi ^{2}\right )a_{1}(t)\textrm{cos}(kX^{1})\textrm{sin}(\pi X^{2}), \end{align}
\begin{align} Y_{\!t}^{1}&=\varphi _{\!t}^{1}(X^{1},X^{2}):=\frac {\sqrt {2}}{\pi }\left (k^{2}+\pi ^{2}\right )a_{1}(t)\textrm{cos}(kX^{1})\textrm{sin}(\pi X^{2}), \end{align}
 \begin{align} Y_{\!t}^{2}&=\varphi _{\!t}^{2}(X^{1},X^{2}):=\frac {\sqrt {2}}{\pi r}a_{2}(t)\textrm{cos}(kX^{1})\textrm{sin}(\pi X^{2})-\frac {1}{\pi r}a_{3}(t)\textrm{sin}(2\pi X^{2}), \end{align}
\begin{align} Y_{\!t}^{2}&=\varphi _{\!t}^{2}(X^{1},X^{2}):=\frac {\sqrt {2}}{\pi r}a_{2}(t)\textrm{cos}(kX^{1})\textrm{sin}(\pi X^{2})-\frac {1}{\pi r}a_{3}(t)\textrm{sin}(2\pi X^{2}), \end{align}
where
 $r$
is a renormalised Rayleigh number. The amplitudes
$r$
is a renormalised Rayleigh number. The amplitudes
 $\boldsymbol{a}:=(a_{1},a_{2},a_{3})^{\top }$
evolve in time according to
$\boldsymbol{a}:=(a_{1},a_{2},a_{3})^{\top }$
evolve in time according to
 \begin{equation} {\dfrac {\textrm{d}{a_{1}}}{\textrm{d}{t}}}=s(a_{2}-a_{1}),\quad {\dfrac {\textrm{d}{a_{2}}}{\textrm{d}{t}}}=ra_{1}-a_{2}-a_{1}a_{3},\quad {\dfrac {\textrm{d}{a_{3}}}{\textrm{d}{t}}}=a_{1}a_{2}-ba_{3}, \end{equation}
\begin{equation} {\dfrac {\textrm{d}{a_{1}}}{\textrm{d}{t}}}=s(a_{2}-a_{1}),\quad {\dfrac {\textrm{d}{a_{2}}}{\textrm{d}{t}}}=ra_{1}-a_{2}-a_{1}a_{3},\quad {\dfrac {\textrm{d}{a_{3}}}{\textrm{d}{t}}}=a_{1}a_{2}-ba_{3}, \end{equation}
where
 $b:=4\pi ^{2}(k^{2}+\pi ^{2})^{-1}$
characterises the aspect ratio of the domain and
$b:=4\pi ^{2}(k^{2}+\pi ^{2})^{-1}$
characterises the aspect ratio of the domain and
 $s$
is the Prandtl number. Following Appendix A, to construct the density
$s$
is the Prandtl number. Following Appendix A, to construct the density
 $f_{\boldsymbol{Y}}(-,t):\mathbb{R}^{n}\rightarrow \mathbb{R}$
, it is sufficient to consider half the horizontal domain (i.e.
$f_{\boldsymbol{Y}}(-,t):\mathbb{R}^{n}\rightarrow \mathbb{R}$
, it is sufficient to consider half the horizontal domain (i.e.
 $X^{1}\in [0,\pi /k)$
) and the subdomains
$X^{1}\in [0,\pi /k)$
) and the subdomains
 $\mathcal{X}_{1}:=[0,\pi /k)\times ((0,1/4)\cup (3/4,1))$
and
$\mathcal{X}_{1}:=[0,\pi /k)\times ((0,1/4)\cup (3/4,1))$
and
 $\mathcal{X}_{2}:=[0,\pi /k)\times (1/4,3/4)$
. Over
$\mathcal{X}_{2}:=[0,\pi /k)\times (1/4,3/4)$
. Over
 $\mathcal{X}_{1}$
and
$\mathcal{X}_{1}$
and
 $\mathcal{X}_{2}$
, the Jacobian
$\mathcal{X}_{2}$
, the Jacobian
 $\partial \varphi _{\!t}/\partial \boldsymbol{X}$
is non-singular, which means that
$\partial \varphi _{\!t}/\partial \boldsymbol{X}$
is non-singular, which means that
 $\varphi _{\!t}$
has a single-valued inverse when its domain is restricted to
$\varphi _{\!t}$
has a single-valued inverse when its domain is restricted to
 $\mathcal{X}_{1}$
and
$\mathcal{X}_{1}$
and
 $\mathcal{X}_{2}$
, and can be found by manipulation of (B1)–(B2).
$\mathcal{X}_{2}$
, and can be found by manipulation of (B1)–(B2).
Appendix C. Feynman–Kac formula
As discussed in § 3, solutions of the backward Kolmogorov equation give the expected value of
 $g(\boldsymbol{Y}_{\!t})$
given that
$g(\boldsymbol{Y}_{\!t})$
given that
 $\boldsymbol{Y}_{\!s}=\boldsymbol{y}$
, where
$\boldsymbol{Y}_{\!s}=\boldsymbol{y}$
, where
 $s\leqslant t$
. A more general relationship comes from considering the expectation of functionals that include integrals with respect to time, which is the subject of the Feynman–Kac formula (Kac Reference Kac1949).
$s\leqslant t$
. A more general relationship comes from considering the expectation of functionals that include integrals with respect to time, which is the subject of the Feynman–Kac formula (Kac Reference Kac1949).
In particular, the conditional expectation
 \begin{equation} u(\boldsymbol{y},s)=\mathbb{E}\left [\exp \left (-\int _{s}^{t}V(\boldsymbol{Y}_{\tau },\tau )\,\textrm{d}\tau \right )g(\boldsymbol{Y}_{\!t})\big |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ] \end{equation}
\begin{equation} u(\boldsymbol{y},s)=\mathbb{E}\left [\exp \left (-\int _{s}^{t}V(\boldsymbol{Y}_{\tau },\tau )\,\textrm{d}\tau \right )g(\boldsymbol{Y}_{\!t})\big |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ] \end{equation}
satisfies (see, for example, Shreve Reference Shreve2004,Theorem 6.4.3)
 \begin{equation} -\partial _{s}u(\boldsymbol{y},s)=(\mathscr{L}-V)u(\boldsymbol{y},s), \end{equation}
\begin{equation} -\partial _{s}u(\boldsymbol{y},s)=(\mathscr{L}-V)u(\boldsymbol{y},s), \end{equation}
which, in comparison with (3.16), contains the additional decay rate
 $V(\boldsymbol{y},s)$
. Following the same steps as those leading to (3.19), the forward equation corresponding to (C2) is
$V(\boldsymbol{y},s)$
. Following the same steps as those leading to (3.19), the forward equation corresponding to (C2) is
 $\partial _{t}f_{\boldsymbol{Y}}=(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}}$
, where it is seen that
$\partial _{t}f_{\boldsymbol{Y}}=(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}}$
, where it is seen that
 $V(\boldsymbol{y},t)$
affects neither the drift nor diffusion associated with
$V(\boldsymbol{y},t)$
affects neither the drift nor diffusion associated with
 $\boldsymbol{Y}_{\!t}$
, but rather the relative weight or importance ascribed to different trajectories in the calculation of
$\boldsymbol{Y}_{\!t}$
, but rather the relative weight or importance ascribed to different trajectories in the calculation of
 $\mathbb{E}[g(\boldsymbol{Y}_{\!t})|\boldsymbol{Y}_{\!s}=\boldsymbol{y}]$
. As noted in § 4, if
$\mathbb{E}[g(\boldsymbol{Y}_{\!t})|\boldsymbol{Y}_{\!s}=\boldsymbol{y}]$
. As noted in § 4, if
 $\mathbb{E}[V(\boldsymbol{Y}_{\!t},t)]=0$
, then
$\mathbb{E}[V(\boldsymbol{Y}_{\!t},t)]=0$
, then
 $f_{\boldsymbol{Y}}$
remains a legitimate probability density in spite of the forcing term
$f_{\boldsymbol{Y}}$
remains a legitimate probability density in spite of the forcing term
 $-Vf_{\boldsymbol{Y}}$
.
$-Vf_{\boldsymbol{Y}}$
.
C.1. Time dependent sample distributions
In § 3, the spatial sampling distribution
 $f_{\boldsymbol{X}}$
was treated as being independent of time. However, in some circumstances,
$f_{\boldsymbol{X}}$
was treated as being independent of time. However, in some circumstances,
 $f_{\boldsymbol{X}}$
might depend on time, which would be the case if it were defined in terms of the state observables
$f_{\boldsymbol{X}}$
might depend on time, which would be the case if it were defined in terms of the state observables
 $\boldsymbol{Y}$
, for example, such that
$\boldsymbol{Y}$
, for example, such that
 $f_{\boldsymbol{X}}:\mathbb{R}^{d}\times \mathbb{R}^{n}\times \mathbb{R}\rightarrow \mathbb{R}$
. To account for a possible time-dependence of
$f_{\boldsymbol{X}}:\mathbb{R}^{d}\times \mathbb{R}^{n}\times \mathbb{R}\rightarrow \mathbb{R}$
. To account for a possible time-dependence of
 $f_{\boldsymbol{X}}$
, let
$f_{\boldsymbol{X}}$
, let
 \begin{equation} V(\boldsymbol{Y}_{\tau },\tau ):=-\mathbb{E}\left [{\dfrac {\textrm{d}}{\textrm{d}{\tau }}}\log f_{\boldsymbol{X}}(\boldsymbol{X},\boldsymbol{Y}_{\tau }, \tau )|\boldsymbol{Y}_{\tau }\right ]+\ldots . \end{equation}
\begin{equation} V(\boldsymbol{Y}_{\tau },\tau ):=-\mathbb{E}\left [{\dfrac {\textrm{d}}{\textrm{d}{\tau }}}\log f_{\boldsymbol{X}}(\boldsymbol{X},\boldsymbol{Y}_{\tau }, \tau )|\boldsymbol{Y}_{\tau }\right ]+\ldots . \end{equation}
where ‘
 $\ldots$
’ is the contribution to
$\ldots$
’ is the contribution to
 $V$
in (4.2) from advective transport across the boundary. To understand the meaning of the first term on the right-hand side, we evaluate (C1):
$V$
in (4.2) from advective transport across the boundary. To understand the meaning of the first term on the right-hand side, we evaluate (C1):
 \begin{equation} u(\boldsymbol{y},s)=\mathbb{E}\left [\frac {f_{\boldsymbol{X}}(\boldsymbol{X},\boldsymbol{Y}_{\!t},t)}{f_{\boldsymbol{X}}(\boldsymbol{X},\boldsymbol{Y}_{\!s},s)}g(\boldsymbol{Y}_{\!t})\big |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ]=\tilde {\mathbb{E}}\left [g(\boldsymbol{Y}_{\!t})\big |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ], \end{equation}
\begin{equation} u(\boldsymbol{y},s)=\mathbb{E}\left [\frac {f_{\boldsymbol{X}}(\boldsymbol{X},\boldsymbol{Y}_{\!t},t)}{f_{\boldsymbol{X}}(\boldsymbol{X},\boldsymbol{Y}_{\!s},s)}g(\boldsymbol{Y}_{\!t})\big |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ]=\tilde {\mathbb{E}}\left [g(\boldsymbol{Y}_{\!t})\big |\boldsymbol{Y}_{\!s}=\boldsymbol{y}\right ], \end{equation}
where
 $\tilde {\mathbb{E}}$
denotes the expectation with respect to the sample distribution at time
$\tilde {\mathbb{E}}$
denotes the expectation with respect to the sample distribution at time
 $t$
. Equation (C4) therefore states the relationship between the expectation
$t$
. Equation (C4) therefore states the relationship between the expectation
 $\mathbb{E}$
under
$\mathbb{E}$
under
 $f_{\boldsymbol{Y}}(\boldsymbol{y},s)$
and the expectation
$f_{\boldsymbol{Y}}(\boldsymbol{y},s)$
and the expectation
 $\tilde {\mathbb{E}}$
under
$\tilde {\mathbb{E}}$
under
 $f_{\boldsymbol{Y}}(\boldsymbol{y},t)$
, which corresponds to the rule for transforming conditional expectations under a change of measure (see, for example, Shreve Reference Shreve2004, Lemma 5.2.2). Note, in particular, that if
$f_{\boldsymbol{Y}}(\boldsymbol{y},t)$
, which corresponds to the rule for transforming conditional expectations under a change of measure (see, for example, Shreve Reference Shreve2004, Lemma 5.2.2). Note, in particular, that if
 $f_{\boldsymbol{X}}$
is a probability density, then (C3) implies that
$f_{\boldsymbol{X}}$
is a probability density, then (C3) implies that
 $\mathbb{E}[V(\boldsymbol{Y}_{\!t},t)]=0$
and, therefore, that the
$\mathbb{E}[V(\boldsymbol{Y}_{\!t},t)]=0$
and, therefore, that the
 $f_{\boldsymbol{Y}}(\boldsymbol{y},t)$
obtained from
$f_{\boldsymbol{Y}}(\boldsymbol{y},t)$
obtained from
 $\partial _{t}f_{\boldsymbol{Y}}=(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}}$
and used to define the expectation
$\partial _{t}f_{\boldsymbol{Y}}=(\mathscr{L}^{\dagger }-V)f_{\boldsymbol{Y}}$
and used to define the expectation
 $\tilde {\mathbb{E}}$
in (C4) would also be a probability density.
$\tilde {\mathbb{E}}$
in (C4) would also be a probability density.
If the sample distribution is advected with the flow, then its material derivative is zero, such that
 $\partial _{t}f_{\boldsymbol{X}}=-\boldsymbol{U}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}$
and
$\partial _{t}f_{\boldsymbol{X}}=-\boldsymbol{U}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}$
and
 \begin{equation} V(\boldsymbol{Y}_{\tau },\tau ):=\mathbb{E}\left [\boldsymbol{U}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}|\boldsymbol{Y}_{\tau }\right ]+\ldots , \end{equation}
\begin{equation} V(\boldsymbol{Y}_{\tau },\tau ):=\mathbb{E}\left [\boldsymbol{U}\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}|\boldsymbol{Y}_{\tau }\right ]+\ldots , \end{equation}
which exactly balances the contribution to
 $V$
labelled ‘
$V$
labelled ‘
 $\ldots$
’ from (4.2) due to advection over the sample distribution’s boundary, resulting in
$\ldots$
’ from (4.2) due to advection over the sample distribution’s boundary, resulting in
 $V\equiv 0$
. More generally, if a sample distribution is defined to evolve according to
$V\equiv 0$
. More generally, if a sample distribution is defined to evolve according to
 $\partial _{t}f_{\boldsymbol{X}}=-\boldsymbol{U}_{\boldsymbol{X}}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}$
, where
$\partial _{t}f_{\boldsymbol{X}}=-\boldsymbol{U}_{\boldsymbol{X}}\boldsymbol{\cdot }\boldsymbol{\nabla }f_{\boldsymbol{X}}$
, where
 $\boldsymbol{U}_{\boldsymbol{X}}$
is not necessarily the same as the flow velocity, the resulting expression for
$\boldsymbol{U}_{\boldsymbol{X}}$
is not necessarily the same as the flow velocity, the resulting expression for
 $V$
would be
$V$
would be
 \begin{equation} V(\boldsymbol{Y}_{\tau },\tau ):=\mathbb{E}\left [(\boldsymbol{U}_{\boldsymbol{X}}-\boldsymbol{U})\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}|\boldsymbol{Y}_{\tau }\right ]. \end{equation}
\begin{equation} V(\boldsymbol{Y}_{\tau },\tau ):=\mathbb{E}\left [(\boldsymbol{U}_{\boldsymbol{X}}-\boldsymbol{U})\boldsymbol{\cdot }\boldsymbol{\nabla }\log f_{\boldsymbol{X}}|\boldsymbol{Y}_{\tau }\right ]. \end{equation}
Equation (C6) highlights the generality of the framework in accommodating Eulerian control volumes (
 $\boldsymbol{U}_{\boldsymbol{X}}=0$
) and Lagrangian control volumes (
$\boldsymbol{U}_{\boldsymbol{X}}=0$
) and Lagrangian control volumes (
 $\boldsymbol{U}_{\boldsymbol{X}}=\boldsymbol{U}$
) as particular cases.
$\boldsymbol{U}_{\boldsymbol{X}}=\boldsymbol{U}$
) as particular cases.



























































































































 Open access
Open access