

1. Motivation
What exactly can dialect maps tell us about the language variation in a specific region? How reliable are they when it comes to considering individual data at particular locations? As shown in Rumpf, Pickl, Elspaß, König and Schmidt (Reference Rumpf, Pickl, Elspaß, König and Schmidt2009, Reference Rumpf, Pickl, Elspaß, König and Schmidt2010) and Pickl and Rumpf (Reference Pickl and Rumpf2011, Reference Pickl and Rumpf2012), the data contained in dialect atlases and similar geolinguistic data collections tend to have the disadvantage of limited reliability when viewed in detail. For instance, a single record at a single site that was uttered by an informant in a specific interview situation may or may not reflect common usage in the local dialect. A range of influencing factors can reduce the accuracy of an informant's answers, such as poor memory, observer effects, or personal background. Not all of these factors can be controlled entirely, especially as they are subject to a certain degree of randomness. The responses of an individual informant to a specific question may even differ from day to day. Methodological restrictions (such as observer effects) aside, this is also a manifestation of the fundamental probabilistic nature of language variation (cf. Cedergren & Sankoff, Reference Cedergren and Sankoff1974; Pickl, Reference Pickl2013:13, 41–42, 205–207). Individual records of variants are thus little more than statistical samples. Even though the overall picture that a dialect map of a specific variable gives is in all likelihood a good representation of the actual geographical distribution of that variable, the individual details of such maps can be inaccurate. A further problem is that in many cases dialect atlases only show one or two records per site, but no information about their relative frequencies is given.
All analyses and examples in this paper are based on data from the Sprachatlas von Bayerisch-Schwaben (SBS), a dialect atlas covering an area of approximately 11,000 km2 in Southern Germany, which is based on explorations carried out in the 1980s and 1990s. Featuring data from 272 record locations, the atlas's 14 volumes comprise approximately 2,700 individual maps. Map 1, an original point-symbol map taken from the SBS, features responses for the concept ‘woodlouse.’ Each symbol stands for one specific variant; the small triangle symbol that is prevalent in the north-west, for instance, stands for the lexical variant Maueresel (or similar). The number of recorded variants per location ranges from zero (symbol “+”) to three. Although at most of the locations only one variant is recorded, it seems likely that a different sample of informants at one of the sites—or even the same informants at another time—may have come up with different variants, e.g. with divergent variants that were recorded at neighbouring locations.

Map 1 Map 63 from vol. 8 of the SBS, showing the distribution of the variants for ‘woodlouse’. (a) Point-symbol map; (b) Legend.
One way to deal with this uncertainty is to “aggregate the differences in many linguistic variables in order to strengthen their signals” (Nerbonne, Reference Nerbonne2010:3822). This is the approach of traditional, aggregative dialectometry, which is useful for making global, overall structures in large corpora of dialect maps visible. The pivotal instrument of aggregative dialectometry is a distance (or similarity) matrix that is derived from the maps of a large number of variables. The matrix contains the overall (i.e., aggregated) relations among every possible pair of locations in the data collection, and can be used, for instance, to produce similarity maps that show degrees of similarity in relation to one location in question. By aggregating the differences between locations across linguistic variables, however, the distinctiveness of these variables and their variants’ distributions is made void—the variation among these distributions collapses. For some research interests, however, it is essential to maintain and analyse exactly these differences, e.g., when one wishes to investigate which variants’ distributions behave similarly or which are affected by certain extra-linguistic factors. Standard aggregative dialectometry is not suitable for this kind of study. Only recently, a number of works have appeared that try to overcome the problem of losing sight of individual variants when viewing the larger picture, using different methodological approaches (cf. e.g. Shackleton, Reference Shackleton2005, Reference Shackleton2007; Nerbonne, Reference Nerbonne2006; Grieve, Reference Grieve2009; Grieve, Speelman & Geeraerts, Reference Grieve, Speelman and Geeraerts2011; Wieling & Nerbonne, Reference Wieling and Nerbonne2011; Pickl, Reference Pickl2013; Reference Pröll, Pickl and SpettlPröll, Pickl & Spettl, forthcoming).
One such approach, which is also aimed at ‘strengthening the signals’ of individual variables, is so-called intensity estimation (cf. Rumpf, Pickl, Elspaß, König & Schmidt, Reference Rumpf, Pickl, Elspaß, König and Schmidt2009, Reference Rumpf, Pickl, Elspaß, König and Schmidt2010; Pickl & Rumpf, Reference Pickl and Rumpf2011, Reference Pickl and Rumpf2012). In intensity estimation, it is not the information from other variables that is employed to stabilize the overall signal; instead, the information from nearby locations is used to stabilize the information for individual locations. The simple assumption that justifies such a course of action has been formulated by Nerbonne and Kleiweg (Reference Nerbonne and Kleiweg2007:154) as the Fundamental Dialectological Postulate: “Geographically proximate varieties tend to be more similar than distant ones”, or, put more generally by Tobler: “Everything is related to everything else, but near things are more related than distant things” (Tobler's so-called “First Law of Geography”; Tobler, Reference Tobler1970:236). Based on this principle, it is to a certain extent legitimate to infer the variants used at a site from the variants recorded at surrounding sites. In intensity estimation as introduced in Rumpf etal. (Reference Rumpf, Pickl, Elspaß, König and Schmidt2009, Reference Rumpf, Pickl, Elspaß, König and Schmidt2010) and Pickl and Rumpf (Reference Pickl and Rumpf2011, Reference Pickl and Rumpf2012), the geographical proximity of two sites is used as a measure of how well these two sites can ‘speak for one another’. If, for example, site a has a record for variant x and neighbouring site b features variant y, then there is some probability that x is also used at b by some speakers with a certain frequency, especially if all other sites surrounding b also have x. Thus, all locations in an area under investigation are mutually dependent, near ones more so than distant ones, and hence each location can be assigned a specific ‘intensity’ for each variant, based on how densely the actual records for this variant are distributed in the location's vicinity.Footnote 1 In a probabilistic interpretation, a variant's intensity can also be seen as representing the variant's estimated relative frequency of occurrence, or its probability.
2. Intensity Estimation
The equation for the calculation of the intensity
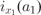 $$--><$>{{i}_{{{x}_1}}}({{a}_1}) $$$
of variant x
1 at location a
1 based on geographical proximity is the following (for its derivation and explanation cf. Rumpf etal., Reference Rumpf, Pickl, Elspaß, König and Schmidt2009, or Reference Pickl and RumpfPickl & Rumpf, 2011):Footnote
2
$$--><$>{{i}_{{{x}_1}}}({{a}_1}) $$$
of variant x
1 at location a
1 based on geographical proximity is the following (for its derivation and explanation cf. Rumpf etal., Reference Rumpf, Pickl, Elspaß, König and Schmidt2009, or Reference Pickl and RumpfPickl & Rumpf, 2011):Footnote
2
 $${{{i}_{{{x}_1}}}({{a}_1}) = \frac{1}{{{{\sum }_{x \in X}}{{\sum }_{a \in A}}K(d({{a}_1},a),h) \cdot {{w}_x}(a)}} \cr &#x0026;\cdot {{\sum }_{a \in A}}K(d({{a}_1},a),h) \cdot {{w}_{{{x}_1}}}(a)\eqno\rm$$
$${{{i}_{{{x}_1}}}({{a}_1}) = \frac{1}{{{{\sum }_{x \in X}}{{\sum }_{a \in A}}K(d({{a}_1},a),h) \cdot {{w}_x}(a)}} \cr &#x0026;\cdot {{\sum }_{a \in A}}K(d({{a}_1},a),h) \cdot {{w}_{{{x}_1}}}(a)\eqno\rm$$
X: The set of variants of the respective variable
A: The set of record locations in the area under investigation
wx (a): The ‘weight’ of variant x at site a, meaning the proportion of records for x in all records for the respective variable at a
d(a 1, a 2): The geographical distance between the sites a 1 and a 2
h: The so-called ‘bandwidth’ of the intensity estimation, a parameter that defines how quickly the influence between two sites decreases with increasing distance
(There are several algorithms that optimize the bandwidth automatically.Footnote 3 )
K(d,h): The so-called kernel, another parameter that defines how the actual influence between sites at a certain distance is calculated
(Often, the two-dimensional normal distribution is used for K. In this study, the so-called K 3-kernel, a very similar kernel that has some advantages over the normal distribution (cf. Silverman, 1986:76–77, 88–89) is also used.)
After applying this equation to every variant and every site, the results can be visualized as a set of maps, each with the intensity field of one variant (see Rumpf etal., Reference Rumpf, Pickl, Elspaß, König and Schmidt2009, Reference Rumpf, Pickl, Elspaß, König and Schmidt2010; Pickl & Rumpf, Reference Pickl and Rumpf2011 or Reference Pickl and Rumpf2012 for examples), or alternatively as one map that integrates the intensities of all variants. In order to do the latter, each location is assigned to the variant that has the highest intensity locally, which is the ‘dominant’ local variant. The result is a graded area-class map, which features fuzzy variant areas that are delimited by the relative dominance of the respective variants, but graded in their shades to display the dominant variants’ intensities and to illustrate the fact that these variants overlap in space to a certain extent.
Map 2 is an example of such a graded area-class map. The different colours stand for different variants; their local intensity or dominance is represented by different colour shades. The orange lines delimit areas of dominance, which implies that they do not represent clear-cut isoglosses but centres of transition zones: In the lighter-shaded zones, less frequent non-dominant variants are also present.

Map 2 Map 63 from vol. 8 of the SBS, intensity estimation, geographical distance, Level 2, K 3, h=22 km (CL).Footnote 4
Area-class maps of this kind are not only abstracted visualizations of point-symbol data, they are also the basis for further analyses. Rumpf etal. (Reference Rumpf, Pickl, Elspaß, König and Schmidt2010) performed analyses to investigate whether variables with similar intensity distributions are also related on an extra-linguistic level, and found, for instance, that lexical variables from the semantic field ‘crop’ tend to have similar geolinguistic configurations. This points to similar patterns of spatial diffusion that led to these distributions. Certain characteristic measures that are derived from the intensity information can further be used in statistical testing (cf. Pickl, Reference Pickl2013:125–140; Pröll, Reference Pröll2013:149–153). Moreover, the resulting (fuzzy) isoglosses can be used to validate presumed dialect borders (cf. Pickl, Reference Pickl2013:141–157). For further applications of intensity maps cf. Meschenmoser and Pröll (Reference Meschenmoser and Pröll2012a, Reference Meschenmoser and Pröllb).
3. Problem
In some of the applications of intensity estimation as depicted in the preceding section, the way in which the data is abstracted towards an overall distribution pattern can be problematic. As intensity estimation is basically a form of geographically conditioned smoothing, some basic characteristics of individual maps can be levelled out. If, for example, one or more of the locations in the area under investigation are language islands, this fact will have no consequences for area-class maps produced with intensity estimation. The reason is that even locations that consistently have variants diverging from their neighbours will be treated as outliers and ‘smoothed over.’ The same problem holds for dialect borders. Any structure that entails significant dialect differences will not have any relevance for individual area-class maps, as the majority of features are not taken into account. Therefore, it frequently happens that differences in individual variables that coincide with structural dialect borders are straightened, shifted, or otherwise blurred. All kinds of geographical structures that are systematic in the sense that they show up on a lot of individual maps will not be recognized or rendered as such by geographically-informed intensity estimation.
In Map 2, this problem becomes visible (or rather not visible) in the cases of several larger cities and towns whose records differ from the variants recorded in the surrounding countryside, e.g., Augsburg (122), Günzburg (96), or Memmingen (205) (cf. Map 1). While it is not surprising that densely populated places of urban character behave linguistically differently from rural areas, this difference is not reproduced in the area-class map: All these locations are smoothed out; they become indistinguishable parts of larger areas. The same is true for the river Lech (cf. Map 1, Map 3), which is a well-known and well accounted for strong dialect border in this region; also, in the case of ‘woodlouse,’ the Lech shows a clear separating effect on the level of linguistic variants (cf. Map 1), dividing the line-shaped symbol in the east from the triangle and rectangle symbols in the west. However, the corresponding isogloss in Map 2 has become fuzzy like all the other isoglosses; what is more, the isogloss itself is shifted significantly to the east (especially in the south). In these instances, intensity estimation does not do justice to the data. Relying entirely on geographical distances, intensity estimation is, so to speak, less informed than we are, because we have knowledge about linguistically relevant geographical structures that go beyond pure geometry.

Map 3 Shape of the river Lech in the area under investigation in Voronoi rendering.
A possible solution to this problem lies in a combination of traditional, i.e., aggregative, dialectometry and intensity estimation. While the latter allows us to process individual maps quantitatively, the former has the advantage of taking all the available data into account to draw a much more general picture. A straightforward integration of the two concepts is to use linguistic distances instead of geographical distances in intensity estimation. The idea behind this approach is that geographical space is not the only determinant of geolinguistic processes–other conditions, like accessibility, traffic routes, terrain structure, attractiveness of places etc. also shape the way in which people from different areas interact and the way in which dialects come into contact. Several studies have investigated to what extent dialect similarity is related to variables like travel distance, population density, migration and others (cf. e.g. Trudgill, Reference Trudgill1974; Gooskens, Reference Gooskens2004; Inoue, Reference Inoue2004, Reference Inoue2006; Szmrecsanyi, Reference Szmrecsanyi2012). All of them find that using more sophisticated distance measures based on such extra-linguistic variables in addition to geographical distances leads to a better representation of dialect similarity. The exact impact of these variables on dialect similarities or distances is, however, of minor importance for our study. Their influence is already condensed in the form of dialect distances (probably including a certain amount of random effects). If we use measurable dialect distances instead of geographical distances, all these effects are therefore virtually automatically included, and isolated language islands as well as dialect borders are represented in the model by higher linguistic distances (either in relation to geographically surrounding locations or to locations ‘across the border,’ respectively). Linguistic distances render exactly those effects that actually did influence variant distributions in the past. Hence they provide what could be seen as a model of linguistic space (as opposed to Euclidean space; cf. Pickl, Reference Pickl2013:62–63). Linguistic space can be understood as the network of mutual relations between local dialects that is constituted by pairwise contact probabilities, and which establishes a framework in which dialectal accommodations and diffusion of features take place. This network is shaped also, but not exclusively, by Euclidean distances. As the effect of geographical distances on this linguistic network is rendered indirectly through the extent to which dialect similarities are influenced by them, geographical distances as such can be disregarded on the whole throughout the intensity estimation introduced in this article.
4. Linguistic Distance Measures in Dialectometry
There are various implementations of linguistic distance; one of the most popular is Goebl's Relative Distance Value RDV jk (cf. e.g. Goebl, Reference Goebl2010), which is suitable especially for nominal-scale data such as lexical variants. Simply put, RDV jk is the percentage of variables for which two locations j and k have different variants. The exact value is calculated using the following formula:
 $${\rm{RD}}{{{\rm{V}}}_{jk}} = 100 \cdot \frac{{\sum _{{i = 1}}^{p} {{{({\rm{CO}}{{{\rm{D}}}_{jk}})}}_i}}}{{\sum _{{i = 1}}^{p} {{{({\rm{CO}}{{{\rm{I}}}_{jk}})}}_i} + \sum _{{i = 1}}^{p} {{{({\rm{CO}}{{{\rm{D}}}_{jk}})}}_i}}}\eqno\rm$$
$${\rm{RD}}{{{\rm{V}}}_{jk}} = 100 \cdot \frac{{\sum _{{i = 1}}^{p} {{{({\rm{CO}}{{{\rm{D}}}_{jk}})}}_i}}}{{\sum _{{i = 1}}^{p} {{{({\rm{CO}}{{{\rm{I}}}_{jk}})}}_i} + \sum _{{i = 1}}^{p} {{{({\rm{CO}}{{{\rm{D}}}_{jk}})}}_i}}}\eqno\rm$$
In this notation, (COD jk ) i is a so-called co-difference function that returns 0 if the locations j and k have the same variant for variable i and 1 if they have different variants for variable i. The co-identity function (COI jk ) i does the opposite, returning 1 for identical values and 0 for different values. Thus RDV jk is the fraction of different answers at the location j and k within p variables. By using the sum of CODs and COIs instead of the total p, it is ensured that variables with missing values for the locations in question are disregarded.
One fundamental restriction of RDV is that it is only defined for unequivocal answers, i.e., for the case that for each variable and each location there is only one variant in the data.Footnote 5 As modern dialectological atlases and other geolinguistic data sources often feature a range of different answers at a location, RDV is applicable to this kind of data format only if a substantial portion of the data is discarded previous to analysis.Footnote 6 For this kind of data, an adaption of the RDV (or a completely different approach) is necessary. Speelman, Grondelaers and Geeraerts (Reference Speelman, Grondelaers and Geeraerts2003:320–321) (cf. also Speelman & Geeraerts Reference Speelman and Geeraerts2008) present what they call “city block distance” (Speelman etal., Reference Speelman, Grondelaers and Geeraerts2003:320) or “profile-based dissimilarity” (Speelman & Geeraerts, Reference Speelman and Geeraerts2008:227–228), a distance measure between linguistic profiles, i.e., percentages of answers that add up to 100%. This distance is defined for each pair of locations and for each variable as the average of the differences between variants’ percentages. For instance, if the variable is ‘jeans,’ and at one location 70% of the answers belong to the variant jeans and 30% to the variant spijkerbroek, while at the other location 97% belong to jeans and 3% belong to spijkerbroek, then the difference is 27% for jeans and also 27% for spijkerbroek. The sum is 54%, but we have counted the same difference twice, so we divide by 2 and receive a distance of 27% or 0.27. Subsequently, the individual distances for variables can be aggregated to overall distances by arithmetic averaging. Again, this measure is especially suitable for nominal-scale and therefore particularly for lexical data. Even for phonetic data, a nominal-scale approach can be appropriate (Pröll, Reference Pröll2013:48–51).
Phonetic information, however, can also be treated as interval-scale data. The so-called Levenshtein distance is a very popular phonetic distance measure. It is a string edit distance between two strings of phonetic (typically IPA) transcriptions. The Levenshtein distance measure counts insertions, deletions and (mis)matches of characters between two transcription strings. For this purpose the two strings have to be aligned previously by following certain rules. In contrast to RDV, it is suitable for the calculation of graded distances even between individual word pronunciations. Still, they are usually aggregated in order to obtain more solid overall distances. For a detailed account of the Levenshtein distance measure cf. Heeringa (Reference Heeringa2004:121–143).
5. Implementation and Application
Regardless of which distance measure is chosen, its implementation in intensity estimation is rather straightforward. Firstly, the linguistic distances between all location pairs have to be calculated, based on the specified measure and the corpus of maps to be investigated. Then equation (1) has to be adapted in that the geographical distance d has to be replaced by a linguistic distance d ling; apart from that the equation remains unchanged.
In this section, this procedure is applied to data from the SBS, more specifically to a lexical sub-corpus of maps comprising 736 variables. The linguistic distance used is based on this subcorpus and calculated following the Speelman etal. (Reference Speelman, Grondelaers and Geeraerts2003) approach. It is therefore a purely lexical distance. For an individual variable X with variants x 1; …; xn ∈X, the lexical distance between locations ai and aj is defined as follows:
 $${{d}_X}({{a}_i},{{a}_j}) = \frac{1}{2}{{\sum }_{x \in X}}|{{w}_x}({{a}_i}){\rm{ - }}{{w}_x}({{a}_j})|\eqno\rm$$
$${{d}_X}({{a}_i},{{a}_j}) = \frac{1}{2}{{\sum }_{x \in X}}|{{w}_x}({{a}_i}){\rm{ - }}{{w}_x}({{a}_j})|\eqno\rm$$
For a corpus of maps
![]() with variables X
1;…; Xn
∈
with variables X
1;…; Xn
∈
![]() , the overall lexical distance between locations ai
and aj
is:
, the overall lexical distance between locations ai
and aj
is:
 $${{d}_{\Bbb M}}({{a}_i},{{a}_j}) = \frac{1}{{{{\sum }_{X \in {\Bbb M}}}{{n}_X}({{a}_i},{{a}_j})}}{{\sum }_{X \in {\Bbb M}}}{{d}_X}({{a}_i},{{a}_j}) \cdot {{n}_X}({{a}_i},{{a}_j})\eqno\rm$$
$${{d}_{\Bbb M}}({{a}_i},{{a}_j}) = \frac{1}{{{{\sum }_{X \in {\Bbb M}}}{{n}_X}({{a}_i},{{a}_j})}}{{\sum }_{X \in {\Bbb M}}}{{d}_X}({{a}_i},{{a}_j}) \cdot {{n}_X}({{a}_i},{{a}_j})\eqno\rm$$
In this equation, nX (ai , aj ) is 1 if both locations ai and aj have a record for X and 0 if at least one of them has no record for X. Thus if two locations cannot be compared reasonably with respect to a specific variable, this variable is excluded.
The
 $$--><$>{{d}_{\Bbb M}}({{a}_i},{{a}_j})$$$
value is now calculated for all possible pairs of locations. With a total of 272 locations, this yields a matrix with 36,856 individual values. It is to be expected that these values are correlated to a high degree with the respective geographical distances. At the same time, it is desirable that the correlation is not too high, so that there actually is an improvement in the representation of linguistically relevant relations between locations. In the current study, the Pearson correlation coefficient is 0.80, which corresponds to an explained variance of 64% using a linear regression model. As the corresponding scatter plot (Figure 1) reveals, however, the relation seems to be logarithmic rather than linear.
$$--><$>{{d}_{\Bbb M}}({{a}_i},{{a}_j})$$$
value is now calculated for all possible pairs of locations. With a total of 272 locations, this yields a matrix with 36,856 individual values. It is to be expected that these values are correlated to a high degree with the respective geographical distances. At the same time, it is desirable that the correlation is not too high, so that there actually is an improvement in the representation of linguistically relevant relations between locations. In the current study, the Pearson correlation coefficient is 0.80, which corresponds to an explained variance of 64% using a linear regression model. As the corresponding scatter plot (Figure 1) reveals, however, the relation seems to be logarithmic rather than linear.

Figure 1 Scatter plot of geographical vs. lexical distances and logarithmic regression curve. In the visualization on the right, the location pairs that are separated by the river Lech are highlighted.
This is in line with the findings of a number of other studies investigating the relation between linguistic and geographical distances, e.g. Heeringa and Nerbonne (Reference Heeringa and Nerbonne2001), Nerbonne and Heeringa (Reference Nerbonne and Heeringa2007:288–289), Nerbonne (Reference Nerbonne2010), Szmrecsanyi (Reference Szmrecsanyi2012). A logarithmic regression analysis returns 69.3% of explained variance. The circumstance that the difference first rises rather steeply and then gradually goes towards a ceiling is a pattern that is commonly found in linguistic distances and is easily explained:Footnote 7 If the spatial lexical replacement rate, i.e., the proportion of variants that change on average if a certain distance is crossed, is relatively homogeneous, then a certain number of variants is usually different at a location that is at a certain distance. If the distance is doubled, the percentage of different variants is not doubled, because some of the already different variables may change again, not affecting the overall difference. Thus, the farther away a location lies, the smaller the role is that distance plays, even if this may sound paradoxical. The reason is that dialects that are separated by a large distance are already relatively different, so there is not much leeway for them to differ much more.
Still, this interpretation only explains the logarithmic shape of the scatter plot; it does not tell us anything about an improvement brought about by linguistic distances. About 30% of the values of linguistic distance in relation to geographical distance cannot be accounted for by logarithmic relation. These 30% can be due to random fluctuations or additional effects. While naturally a certain amount of randomness is to be expected, the scatter plot reveals certain hints about what else makes linguistic distances different from geographical ones. One such hint is the fact that the distribution of dots in Figure 1 has more than one concentration area. While the majority scatters around the regression line, there is a second, rather hard to distinguish concentration area forming a long stretch above the major concentration. These dots, which have been highlighted in the visualization on the right in Figure 1, represent those location pairs that are separated by the river Lech (cf. Map 3), a recognized dialect barrier, and therefore have an increased linguistic distance in relation to their geographical distance. On the whole, these pairs contribute to the logarithmic shape of the distribution, but they add a significant effect that cannot be accounted for by geographical distance. This effect is even stronger if other parts of the map corpus—not the lexical subcorpus—are used for the calculation of the linguistic distance. Figure 2 shows the respective scatter plots of distances built on phonetic and morphological sub-corpora, as well as on the whole corpus. Again, the location pairs separated by the river Lech have been highlighted in the right-hand visualization.

Figure 2 Scatter plots of geographical vs. linguistic (from top to bottom: Morphological, phonetic, all) distances and logarithmic regression curves. In the visualizations on the right, the location pairs that are separated by the river Lech are highlighted.
In these figures, up to three agglomeration areas can be discerned. These concentrations are best visible for morphological distances. One of them is apparently caused by the separating effect of the river Lech. What the exact meaning of other agglomerations is remains as yet unclear, but it is very likely that they represent some kind of geolinguistic barriers. Other such peculiarities are the pairs that appear as outliers in the scatter plot; these pairs can be outliers for various reasons, for instance if they include dialect islands. These additional features that go beyond pure geographical information promise to make linguistic distance a more suitable distance measure for intensity estimation.
As mentioned above, the procedure for implementing linguistic distances in intensity estimation is simply to substitute the geographical distance d in equation (1) with the linguistic distance. The result for the data underlying Map 1 and 2 (Map 63 from vol. 8 of the SBS) is shown in Map 4.

Map 4 Map 63 for vol. 8 of the SBS, intensity estimation, lexical distance, Level 2, K 3, h=0.55 (CL).
Compared to Map 2, the differences are immediately clear. The shapes of the isoglosses are more jagged, and the colour shades representing intensity values are distributed less equally across the area. Also the fringe of lighter colours that accompanies each isogloss in Map 2 is less regular here. What is also noteworthy is that the isogloss running from north to south now follows the river Lech almost exactly (the only exception is location 199, Landsberg am Lech, a district capital). Also, structures that do not appear in Map 2 do show up here, for instance individual locations that have variants that diverge from the variants that are prevalent in their surroundings, such as the towns Memmingen (205) or Neu-Ulm (109). Most of the locations that ‘behave’ differently from their surroundings are larger towns or cities, which is also true for Günzburg (96), Schongau (269), Königsbrunn (156), Augsburg (122), and Augsburg's borough Lechhausen (123). Königsbrunn is a peculiar case—being a relatively young colony, founded only in the 19th century, its settlers came mostly from the northwest of Bavarian Swabia. This explains why Königsbrunn features the same variant as the northwest of the area under investigation—coloured in blue—like on many other maps (cf. Pickl, Reference Pickl2013:172). This specialty is lost on practically all area-class maps based on geographical distance but is rendered clearly on linguistic-distance-based area-class maps like Map 4. Generally speaking, while linguistic-distance-based maps do an equally good job at abstracting away from the original data, more details are preserved.
Despite the clear improvement in these points, some problems that arise from the use of linguistic distance also have to be addressed.
One of these problems is that deficits in the data layer at individual locations (e.g., due to a large number of missing records at a site or a generally unreliable informant) will lead to flaws in the resulting maps. With our test corpus of maps, this effect only rarely led to visible problems.
Another, more fundamental and theoretical problem is that the reliance on linguistic distances equals an exclusive reliance on the data that are the basis for these distances. In other words, if the linguistic distances are calculated from lexical data only, it is plausible that they are suitable for drawing lexical maps, but probably not for drawing phonetic maps. This leads to the general question of how the dataset that is used to calculate the distances should be chosen. Would it, for instance, be ‘better’ to use maps from all linguistic levels for the distances, or to establish an individual distance matrix for each of the levels? And, which criteria should we use to define what is ‘better’?
Finally, we use linguistic distances to construct a network of locations which is then used for the estimation of linguistic distributions. At first glance, this may appear to involve a circularity problem, because linguistic distances obtained from a geolinguistic dataset are used for the estimation of underlying distributions in individual maps of the same dataset. Yet, there is no circular reference, because the linguistic distances are computed using the original weights of variants. As the proportion of the information referring to one variable is relatively small in relation to the whole dataset, only a very small fraction of the data is used twice in each estimation. This is not a problem in practice, and there is no theoretical reason why the data of the considered map should be excluded from linguistic distance computations.
In the following section, the second of these problems, being quantifiable, will be discussed. The central question will be, however, whether linguistic distances have a measurable advantage over geographical distances in the generation of area-class maps.
6. Validation
The question of whether the linguistically based implementation of intensity estimation is ‘better’ than the geographically based intensity estimation cannot be answered conclusively, but certain quality criteria can be defined and then compared.
In our case, we have chosen to analyse the accuracy that is achieved using the two distance measures in ‘predicting’ individual records. By accuracy of prediction we mean the frequency with which intensity estimation yields intensities at a location that favour the variant(s) actually recorded there, if the estimation is performed without taking this location's records into account. Concretely, we perform intensity estimation for each map as often as there are locations on the map (in our case 272), each time with one of the locations omitted. This technique is known as leave-one-out cross-validation. It tells us how well the intensity estimation ‘predicts’ the actual record. For each location and each variable, we assign a score that expresses the distance between actual records and intensities inferred. A well-performing implementation of intensity estimation will yield low scores in this kind of leave-one-out cross-validation, all the while providing a reasonable degree of smoothing.
For our study, we have defined a score that compares the dominant variant estimated for a location with the record(s) found in the raw data. This means that we establish how well the visible division into variant areas reflects the raw data. Specifically, we assign a score to individual locations for each variable that quantifies the difference between the estimated dominant variant and the actual records at the location. It is defined as 1 minus the local weight of the dominant variant (cf. Section 2), which can take on only the values 0, 1/3, 1/2, 2/3, or 1 with our data. The score is therefore 0 if the dominant variant equals the only variant at that location for that variable in the raw data, between 0 and 1 if the dominant variant equals one of two or more variants at that location for that variable in the raw data, and 1 if the dominant variant is a variant that is not attested at that location for that variable in the raw data. The lower the score, the better the areal division of the intensity map reflects the raw linguistic data.
We calculated average scores for intensity maps based on geographical and linguistic distances, using two different kernels (K Gauß, K 3) and two different bandwidth algorithms (LCV, CL). In direct comparison, linguistic distances yield better results in most cases (cf. Figure 3). The best overall result is attained with a combination of K Gauß, LCV and linguistic distance. Note that likelihood-cross-validation (LCV, cf. Reference SilvermanSilverman, 1986:52–53) chooses the bandwidth such that the predicted densities match the weights of the variants (cf. Section 2) best. Leave-one-out cross-validation is a special case of LCV and its idea is therefore the same, with the only difference that (in our case) dominant variants are compared, not the estimated density values themselves. Nonetheless, it is to be expected that LCV yields almost optimal (i.e., low) average scores. CL as a cost-curve approach that tries to balance map complexity vs. map fidelity cannot compete with LCV in this validation approach, but it often produces graded area-class maps that are visually more appealing (more smoothing for high-complexity maps, less smoothing for very homogeneous maps). Especially in combination with K Gauß, CL clearly does not provide the best results for both geographical and linguistic distances.

Figure 3 Average scores for lexical and geographical distances in an application of intensity estimation to 736 lexical maps across all locations and all variables (lower is better).
A more detailed perspective can be provided by calculating average scores for each location separately. This is done using once linguistic and once geographic distances. The resulting values can then be mapped in combined maps such that each location is assigned a colour value depending on which of the two scores is lowest, i.e. which of the two methods of estimation gets closer to the recorded data (cf. Map 5). In these maps, the blue locations are the ones where better results are obtained using the linguistic distance; the red locations are the ones where geographical distance is better. Generally, linguistic distances yield better results for sensitive areas, as exemplified by the regions around Augsburg and along the river Lech, even in the map for K Gauß and CL (Map 5b), where geographical distances do better globally.

Map 5 Average scores for linguistic (blue) and geographical (red) distances in an application of intensity estimation to 736 lexical maps across all locations. The respective lower value (linguistic or geographical) was colour-coded at the individual locations, the colour intensity being higher for scores with a larger advantage over the respective other one. (a) K Gauß, LCV; (b) K Gauß, CL; (c) K 3, LCV; (d) K 3, CL.
While these findings suggest that the use of linguistic distances does lead to improvements in the generation of area-class maps with intensity estimation in most scenarios, the question remains of how the map corpus used for the calculation of distances should be chosen in the first place.
Generally, two possibilities seem plausible: 1) The use of the subcorpus of maps that represents the linguistic level in which the individual maps are situated (in our case the lexical subcorpus), or 2) the use of the entire map corpus comprising maps for variables from all linguistic levels. The latter could be helpful if the subcorpus to be analysed is very small, or if it is assumed that subcorpora representing other linguistic levels have certain relevance for the distributions in the subcorpus in question. What is not suggested, however, is to exclude the maps to be analysed using intensity estimation from the calculation of distances and to use maps from subcorpora representing other levels only. It is simply not plausible that, for instance, a morphological dataset should make a better statement about relations that are relevant for lexical items than a dataset containing other lexical information.
To get an initial empirical idea of how well the individual subcorpora are suited for intensity estimation based on linguistic distances, we calculated the average scores for the three subcorpora (lexical, morphological and phonetic data) and the entire map corpus comprising all these levels based on distances calculated from exactly the same maps that are contained in these test corpora (cf. Figure 4). We used K Gauß and LCV as parameters as these yielded the best results with the lexical subcorpus, as discussed above.

Figure 4 Average scores for linguistic distances (d lex etc.) in an application of intensity estimation to the respective test corpus (lex etc.) across all locations and all variables (lower is better).
Somewhat surprisingly, the morphological and phonological subcorpora achieve much better results than the lexical subcorpus (and hence also than the entire corpus). This is probably due to the fact that there is a tendency in morphological and phonological maps toward larger and more solid variant areas, which makes them less susceptible to intensity estimation induced smoothing (cf. Pröll, Reference Pröll2013:151).
In the next step, we calculated the average scores for the lexical subcorpus, each time with a different distance measure based on the lexical subcorpus, on the morphological subcorpus, on the phonological subcorpus, and on the entire map corpus (cf. Figure 5).

Figure 5 Average scores for linguistic distances (d lex etc.) in an application of intensity estimation to the lexical subcorpus (lex) across all locations and all variables (lower is better).
As is to be expected, the best results are achieved with distances calculated from the lexical corpus and the complete corpus, but the use of the morphological or the phonological maps for the calculation of distances leads only to a minimal deterioration. This suggests that the choice of corpus for distance extraction is not crucial, especially as the magnitude of its effect lies well within the range of effects caused by smoothing parameter selection (cf. Figure 3). This finding is corroborated by a look at the average scores for all combinations of test corpora and corpora used for distance extraction (cf. Figure 6); again, the quality of the estimation depends on the test corpus more than on the distance corpus. It should be emphasized, however, that the base corpus for the extraction of distances should not be too small, as this would reduce the accuracy of intensity estimation because there would not be enough information about the relations between sites.

Figure 6 Average scores for linguistic distances (d lex etc.) in an application of intensity estimation to the all test corpora (lex etc.) across all locations and all variables (lower is better).
7. Summary
The use of intensity estimation for the drawing of graded area-class maps is a means to deal with uncertainty in geolinguistic data, to provide a quantitative account of the geographical configuration of an individual variable's map, and to provide visual abstractions from pointwise data for better and quicker inspection. This article presents a method to improve the accuracy of the results of intensity estimation by utilizing linguistic instead of geographical distances. Visual inspection of the results obtained with this new approach shows that significant geographical structures like dialect barriers (such as, in this case, a river) or dialect islands (in this case towns or a colony) are rendered much more faithfully when using linguistic rather than geographical distances. These findings are corroborated by leave-one-out cross-validation, which shows that with most parameter settings and especially in ‘critical’ regions of the area (i.e., regions where geographical structures influence the distribution of dialectal variants), linguistic distances lead to better results. The best overall results for linguistic distances are attained in combination with LCV bandwidth optimization and the two-dimensional normal distribution kernel. In some, especially less ‘interesting’ regions, different parameter settings can lead to a better prediction of left-out records. As this study is restricted to a certain dialect area in the south of Germany and to a specific data set (the SBS), it is clear that in a different region and with other data, the results could be in favour of other parameter settings or even of geographical distances. We hope to have shown, however, that the use of linguistic distances can be an improvement of intensity estimation, thus honing the results of the estimation, which are useful for subsequent statistical analyses, as well as the resulting maps, which provide unsupervised visualisations of geolinguistic data.
Acknowledgements
The authors’ work is supported by the Deutsche Forschungsgemeinschaft through the research project Neue Dialektometrie mit Methoden der stochastischen Bildanalyse (‘New Dialectometry Using Methods from Stochastic Image Analysis’).











