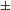1 Introduction
The question of naturalness has long been a central topic in both diachronic and synchronic phonology (Bach & Harms Reference Bach, Harms, Stockwell and Macaulay1972; Stampe Reference Stampe1973; Catford Reference Catford1974; Dressler Reference Dressler1974; Hyman & Schuh Reference Hyman and Schuh1974; Hyman Reference Hyman1975; Hellberg Reference Hellberg1978; Donegan & Stampe Reference Donegan, Stampe and Dinnsen1979; Anderson Reference Anderson1981; Westbury & Keating Reference Westbury and Keating1986; Archangeli & Pulleyblank Reference Archangeli and Pulleyblank1994; Lass Reference Lass1997; Hayes Reference Hayes, Darnell and Moravscik1999; Buckley Reference Buckley2000; Hyman Reference Hyman, Hume and Johnson2001; Blevins Reference Blevins2004, Reference Blevins and Good2008a, Reference Blevins, Willems and De Cuypereb; Yu Reference Yu2004; Blust Reference Blust2005; Wilson Reference Wilson2006; Hayes, Siptár, Zuraw & Londe Reference Hayes, Siptár, Zuraw and Londe2009; Carpenter Reference Carpenter2010; Becker, Ketrez & Nevins Reference Becker, Ketrez and Nevins2011; Hayes & White Reference Hayes and White2013; White Reference White2013; Honeybone Reference Honeybone2016, i.a). The term naturalness itself has received several interpretations in the literature with seemingly no consensus on what constitutes (un)natural processes. Most commonly, processes with some articulatory or perceptual motivation are considered natural and processes without it unnatural. The question of the existence of unnatural processes remains challenged both in synchronic and diachronic literature. While some unnatural processes have been argued to exist as productive synchronic alternations (e.g. post-nasal devoicing in Tswana by Coetzee & Pretorius Reference Coetzee and Pretorius2010), others, like final voicing, have been argued to be impossible in synchronic grammar (Kiparsky Reference Kiparsky2006, Reference Kiparsky and Good2008). Such typological gaps have been used to deduce properties of universal phonological grammar (especially within the OT-family of approaches via factorial typology; Prince & Smolensky Reference Prince and Smolensky1993/2004), which is why the existence of unnatural processes has direct synchronic implications. The question of naturalness is relevant to the theory of sound change as well (Catford Reference Catford1974; Chen Reference Chen1974; Dressler Reference Dressler1974; Blust Reference Blust2005, Reference Blust2017; Garrett & Johnson Reference Garrett and Johnson2013; Garrett Reference Garrett, Bowern and Evans2015). It has long been believed that sound changes are always phonetically motivated, and therefore natural. This position goes back to the Neogrammarian school of thought and posits that ‘typologies of sound change and possible phonetic precursors correspond perfectly’ (Garrett Reference Garrett, Bowern and Evans2015: 232). Recently, however, Blust (Reference Blust2005, Reference Blust2017) has most notably challenged this long-held assumption by presenting a number of sound changes that lack phonetic motivation.
Several strategies have been used to motivate unnatural sound changes. The case of post-nasal devoicing (PND), for instance, has been analyzed variously as a phonetically motivated process (Solé Reference Solé, Solé and Recasens2012), a result of Ohala’s (Reference Ohala, Masek, Hendrick and Miller1981) hypercorrection, and a case of perceptual enhancement (Stanton Reference Stanton2016b). Some proposals have also argued that PND is the result of a number of sound changes (Dickens Reference Dickens1984, Hyman Reference Hyman, Hume and Johnson2001).
Several questions regarding the status of unnatural alternations and sound changes thus remain open. This paper addresses two crucial questions in this discussion: whether unnatural sound changes exist and how unnatural synchronic alternations arise. My proposal features four crucial components. First, I argue for a new subdivision of naturalness (Section 2), whereby processes traditionally labeled as unnatural should be subdivided into unmotivated and unnatural processes. Second, based on a particular reported unnatural synchronic alternation and sound change, post-nasal devoicing, I contend that sound change is always phonetically motivated and cannot operate in a phonetically unnatural direction. In other words, one of the rare reported cases of an unnatural sound change can be explained through a combination of natural sound changes (Section 3), not only in Tswana and Shekgalagari (as proposed in Dickens Reference Dickens1984, Hyman Reference Hyman, Hume and Johnson2001), but in all other cases collected in this paper. I present new evidence from Sogdian, Yaghnobi, and other languages that crucially contributes to this conclusion. This allows us to maintain the long-held position that sound change can only operate in a phonetically natural direction. Third, based on the discussion of PND, the paper establishes a diachronic model for deriving and explaining unnatural alternations called the Blurring Process. The Blurring Process describes the exact mechanism for how unnatural alternations arise and can be employed to explain unnatural processes beyond PND. I argue that the Blurring Process explains the data better than hypercorrection, perceptual enhancement, or phonetic motivation (Section 3.2). Fourth, I argue with a formal proof that a minimum of three sound changes are required for an unnatural segmental alternation to arise and a minimum of two for an unmotivated alternation (Minimal Sound Change Requirement (MSCR)) (Section 4).
By establishing the mechanisms of how unnatural alternations arise and by proving that minimally three sound changes are required for an unnatural alternation to arise, this paper also partially answers the question of why some unmotivated and unnatural processes are rare or non-existent. In the final part of this paper (Section 5), I discuss implications of the two concepts proposed in this paper (the Blurring Process and the MSCR) for the derivation of typology within the Channel Bias approach and point to future directions this line of research should take.
2 Naturalness and sound change
2.1 Subdivision of naturalness
Natural and unnatural processes have traditionally been distinguished by specifying that the former are phonetically motivated and typologically common while the latter are unmotivated and typologically rare. However, this division is insufficient, as it fails to capture crucial distinctions within the unnatural group. In the new division I propose, natural processes are phonetically motivated (as in previous proposals): they operate in the direction of universal phonetic tendencies (for the term, see Hyman Reference Hyman1972). I define a universal phonetic tendency (UPT) as one which exhibits three crucial properties: (i) passive operation, (ii) cross-linguistic operation, and (iii) the ability to result in common sound patterns.

Passive operation of a phonetic tendency means that the tendency targeting some phonetic feature operates automatically (at least in initial stages without active control by the speakers, Kingston & Diehl Reference Kingston and Diehl1994), even in languages with full phonological contrast of the equivalent feature in a given position. For example, the observation that voiceless stops have universally more phonetic voicing into closure in post-nasal position compared to the elsewhere position (Hayes & Stivers Reference Hayes and Stivers2000), even for languages with full contrast of voice post-nasally, fulfills the criterion that post-nasal voicing (PNV) operates passively in the world’s languages.
I argue that within the traditionally labeled ‘unnatural’ group, we find two types of processes. I label unmotivated those processes that lack phonetic motivation, but do not operate against any UPT. In other words, while unmotivated processes do not correspond to a particular universal articulatory/perceptual force, they are also not operating specifically against such a force. Unnatural processes,Footnote [3] on the other hand, are those that operate precisely against some UPT and are not a UPT themselves.

An example of an unmotivated process would be Eastern Ojibwe ‘palatalization’ of /n/ to [ʃ] before front vowels (e.g. ![]() ‘you fetch him’ vs.
‘you fetch him’ vs. ![]() ‘you fetch us’; Barnes Reference Barnes2002). This process lacks phonetic motivation, but its reverse process
‘you fetch us’; Barnes Reference Barnes2002). This process lacks phonetic motivation, but its reverse process ![]() is not a UPT. Examples of unnatural processes include final voicing, intervocalic devoicing, and PND.Footnote
[4]
All of these processes operate directly against clear and well-motivated articulatory phonetic tendencies (see Section 3).
is not a UPT. Examples of unnatural processes include final voicing, intervocalic devoicing, and PND.Footnote
[4]
All of these processes operate directly against clear and well-motivated articulatory phonetic tendencies (see Section 3).
It has to be noted that phonetic motivation of a process must always be evaluated with respect to the context. For example, devoicing of voiced stops is a natural process word-finally, but unnatural post-nasally (Sections 3 and 3.2). Some processes might be motivated in both directions by different mechanisms; the voicing and devoicing of stops, or the fricativization of stops and the occlusion of fricatives are two examples of diametrically opposed processes. However, naturalness always needs to be evaluated in a given context; evaluated globally, in all positions, devoicing of stops and occlusion of fricatives are natural, i.e. phonetically motivated (the first due to Aerodynamic Voicing Constraint, the latter due to a greater level of articulatory precision of fricatives compared to stops; see Section 3.4, Ohala Reference Ohala and MacNeilage1983, Reference Ohala2011; Ladefoged & Maddieson Reference Ladefoged and Maddieson1996; Beguš Reference Beguš2018). In a leniting environment, such as intervocalic or post-nasal position, on the other hand, voicing or fricativization of stops is the natural direction (see Section 3, Kaplan Reference Kaplan2010, Beguš Reference Beguš2018). Different contexts that determine the naturalness of a process can sometimes superficially overlap, e.g. in a language that lacks target segments in those contexts that distinguish the natural from the unnatural direction (as we will see, this is precisely what happens in the case of PND). While it is possible that two diametrically opposed processes could both be phonetically motivated in the exactly same context, no detailed research is, to my knowledge, available on such sound changes (cf. Honeybone Reference Honeybone2016). Vocalic sound change, for example, is usually less unidirectional, but even there, clear principles can be established in which only one direction is the natural one (Labov Reference Labov1994). Further research on this topic is a desideratum.
Most of the treatments of unnatural phenomena in phonology in fact discuss unmotivated processes, according to the definition in (2) (Buckley Reference Buckley2000; Blevins Reference Blevins2004; Blevins Reference Blevins and Good2008a, Reference Blevins, Willems and De Cuypereb; Blust Reference Blust2005; Blust Reference Blust2017), and considerably fewer works treat unnatural processes (as defined in (2)). This paper focuses on an unnatural process, PND, and its implications for both theoretical and historical phonology.
While naturalness and how to represent it in the grammar design has been primarily the focus of synchronic studies (Stampe Reference Stampe1973, Hellberg Reference Hellberg1978, Anderson Reference Anderson1981, Archangeli & Pulleyblank Reference Archangeli and Pulleyblank1994, Hayes Reference Hayes, Darnell and Moravscik1999, Hyman Reference Hyman, Hume and Johnson2001, Coetzee & Pretorius Reference Coetzee and Pretorius2010), it has been the subject of debate within the theory of sound change as well. The well-accepted Neogrammarian position that sound change is always natural and that some sound changes are impossible (for an overview of the literature on this position, see Blust Reference Blust2005: 219–223, Honeybone Reference Honeybone2016) has recently been challenged. Blust (Reference Blust2005, Reference Blust2017) identifies several unnatural sound changes and argues they had to operate as unitary sound changes. The survey of consonantal sound changes in Kümmel (Reference Kümmel2007) also lists a number of unnatural sound changes, although they are not labeled as such. A subset of Blust’s unnatural sound changes have been explained as a result of a sequence of multiple natural sound changes (Blevins Reference Blevins2007, Goddard Reference Goddard and Nussbaum2007, Garrett Reference Garrett, Bowern and Evans2015). However, the most robust cases of unnatural sound change reported in Blust (Reference Blust2005), including PND, have yet to receive a sufficient explanation.
In this paper, I collect all known cases of PND. The collection derives from several sources: a survey of sound changes in Kümmel (Reference Kümmel2007) that examines approximately 294 languages; a UniDia database of 10,349 sound changes from 302 languages (Hamed & Flavier Reference Hamed, Flavier, Dufresne, Dupuis and Vocaj2009); a survey of unnatural sound changes in Blust (Reference Blust2005), Goddard (Reference Goddard and Nussbaum2007), and Blevins (Reference Blevins, Willems and De Cuypere2008b); a survey of the *NT constraint in Hyman (Reference Hyman, Hume and Johnson2001); and a recent description of post-nasal devoicing in Brown (Reference Brown2017).Footnote [5] Isolated cases have been reported in Merrill (Reference Merrill2014, Reference Merrill2016a, Reference Merrillb).
So far, all cases of PND have been treated in isolation, which has led to several opposing explanations of the phenomenon. Explanations of PND rely variously on appeals to hypercorrection (Xromov Reference Xromov1972, Blust Reference Blust2005), combinations of sound changes (Dickens Reference Dickens1984, Hyman Reference Hyman, Hume and Johnson2001), claims that unnatural sound changes do exist (Blust Reference Blust2005), or claims that PND is articulatorily or perceptually motivated (Gouskova, Zsiga & Boyer Reference Gouskova, Zsiga and Boyer2011, Solé Reference Solé, Solé and Recasens2012, Stanton Reference Stanton2016b). I shine light on this murky discussion by showing that, in all thirteen casesFootnote [6] of PND I have compiled, there exists either direct or strong indirect evidence that PND emerges as the combined result of three separate instances of single, natural sound changes (as has been argued for Tswana in Dickens Reference Dickens1984 and Hyman Reference Hyman, Hume and Johnson2001). I focus primarily on evidence from Yaghnobi and Sogdian, showing that the two languages present direct historical evidence that PND results from a combination of sound changes. Examining all cases of PND together also allows me to generalize common properties and develop a diachronic model for explaining unnatural phenomena. Furthermore, showing that one of the rare reported unnatural sound changes is in fact a product of a combination of natural sound changes lends support to the position that sound change has to be natural and cannot operate against UPTs (pace Blust Reference Blust2005).
That combinations of sound changes produce unmotivated results is a long-standing and well-known claim. ‘Telescoping’, for example, describes a phenomenon in which a sound change A
 ${>}$
B in the environment X is followed by B
${>}$
B in the environment X is followed by B
 ${>}$
C, resulting in a sound change A
${>}$
C, resulting in a sound change A
 ${>}$
C that may not be phonetically motivated in environment X (Wang Reference Wang1968; Kenstowicz & Kisseberth Reference Kenstowicz and Kisseberth1977: 64; Anderson Reference Anderson1981; Stausland Johnsen Reference Stausland Johnsen2012). This paper, however, takes the concept of telescoping one step further, by focusing on alternations that are not only unmotivated, but that operate in exactly the opposite direction of UPTs. I show that for unnatural processes to arise we need a special type of combination of sound changes which I term the Blurring Process.
${>}$
C that may not be phonetically motivated in environment X (Wang Reference Wang1968; Kenstowicz & Kisseberth Reference Kenstowicz and Kisseberth1977: 64; Anderson Reference Anderson1981; Stausland Johnsen Reference Stausland Johnsen2012). This paper, however, takes the concept of telescoping one step further, by focusing on alternations that are not only unmotivated, but that operate in exactly the opposite direction of UPTs. I show that for unnatural processes to arise we need a special type of combination of sound changes which I term the Blurring Process.
2.2 Sound change
Before we turn to a more detailed discussion of unnatural alternations and sound changes, a clarification of the term sound change is necessary (Blevins Reference Blevins2004, Garrett Reference Garrett, Bowern and Evans2015). Despite more than a century of scientific research on sound change, Garrett (Reference Garrett, Bowern and Evans2015) in his recent overview of the field acknowledges that sound change has ‘no generally accepted definition’. Many definitions involve the concept of ‘phonologization’ (Hyman Reference Hyman and Juilland1976, Reference Hyman2013; Barnes Reference Barnes2002) ‘whereby an automatic phonetic property evolves into a language-specific phonological one’ (Garrett Reference Garrett, Bowern and Evans2015: 227, see also Kiparsky Reference Kiparsky, Hsiao and Wee2015) and this process constitutes a sound change. The question remains, however, at what level of abstraction should we define sound change: at a ‘language-specific’ phonetic or phonological ‘structured’ level (Hyman Reference Hyman1972: 170; Lass Reference Lass1997; Hyman Reference Hyman2013: 3,7; Fruehwald Reference Fruehwald2016)? Even more relevant for our discussion is the question of what distinguishes a single sound change from a combination of sound changes.
Every model, be it phonological or diachronic, has to operate with some level of abstraction. We could assume that sound change is a change of any articulatory target/gesture (cf. Browman & Goldstein Reference Browman and Goldstein1992) or, in exemplar-theoretic terms, any change in a label of a category (Bybee Reference Bybee2001, Pierrehumbert Reference Pierrehumbert, Bybee and Hopper2001), regardless of how small the difference between the two diachronic stages would be (see also Lass Reference Lass1997). For example, a minimally higher degree of coarticulation (fronting of [k] in [ki]-sequences) or a minimal change in the F1 target in low vowels would constitute a sound change according to this definition. In such a model, for example, a gradual sound change [a]
 ${>}$
[æ] would involve an infinite or at least a very large number of individual sound changes. To be sure, each of these minimal sound changes would have no phonological implications: languages cannot contrast /a/
and
${>}$
[æ] would involve an infinite or at least a very large number of individual sound changes. To be sure, each of these minimal sound changes would have no phonological implications: languages cannot contrast /a/
and ![]() with a minor difference in the F1 target or other similarly minimal phonetic differences. While such a radical and phonetically oriented model, in which sound change represents a change in any phonetic specification that is not automatic, might be valid, it would fail to provide results that would be meaningful to phonological theory. For a discussion on the ‘notoriously fuzzy boundary’ (Hyman Reference Hyman2013: 7) between phonetics and phonology, see Kingston & Diehl (Reference Kingston and Diehl1994), Cohn (Reference Cohn, Fanselow, Féry and Schlesewsky2006), Keyser & Stevens (Reference Keyser and Stevens2006).
with a minor difference in the F1 target or other similarly minimal phonetic differences. While such a radical and phonetically oriented model, in which sound change represents a change in any phonetic specification that is not automatic, might be valid, it would fail to provide results that would be meaningful to phonological theory. For a discussion on the ‘notoriously fuzzy boundary’ (Hyman Reference Hyman2013: 7) between phonetics and phonology, see Kingston & Diehl (Reference Kingston and Diehl1994), Cohn (Reference Cohn, Fanselow, Féry and Schlesewsky2006), Keyser & Stevens (Reference Keyser and Stevens2006).
The focus of this paper is on phonological alternations (allophonic or neutralizing) that result, via phonologization, from non-analogical regular sound changes (regardless of the mechanisms of their origin; for an overview, see Garrett & Johnson Reference Garrett and Johnson2013, Garrett Reference Garrett, Bowern and Evans2015).Footnote [7] For this reason, I adopt the concept of features from phonology, together with the level of abstraction of the phonological feature system (Chomsky & Halle Reference Chomsky and Halle1968, Keyser & Stevens Reference Keyser and Stevens2006, Hall Reference Hall and de Lacy2007, Hyman Reference Hyman2013) and define sound change as a change in one feature that is phonologized (i.e. results in a synchronic alternation) and non-automatic (Hyman Reference Hyman2013, Keyser & Stevens Reference Keyser and Stevens2006) and that operates throughout the lexicon in a given environment. Synchronic alternations are alternations of at least one feature in a given environment, but can also involve alternations of multiple features simultaneously. I posit that a single instance of sound change can only involve change of a single feature in a given environment. That a single sound change involves a change in a single ‘phonetic property’ has in fact been previously claimed by Donegan & Stampe (Reference Donegan, Stampe and Dinnsen1979) and Picard (Reference Picard1994: 18) (see also Lass Reference Lass1997). Picard (Reference Picard1994: 18) calls this assumption the ‘minimality’ principle: ‘sound changes are always minimal, and so can involve no more than one basic phonetic property’. The minimality principle arises from the assumption that ‘the substituted sound’ should be ‘as perceptually similar to the original target as possible’ (Donegan & Stampe Reference Donegan, Stampe and Dinnsen1979: 137). There is also an articulatory argument for the minimality principle: variation in coarticulation which is the initial mechanism of sound change (cf. Ohala Reference Ohala and MacNeilage1983, Lindblom Reference Lindblom, Hardcastle and Marchai1990, Lindblom et al. Reference Lindblom, Guion, Hura, Moon and Willerman1995, Beddor Reference Beddor2009) is often continuous and gradual (cf. Pierrehumbert Reference Pierrehumbert, Bybee and Hopper2001, Garrett Reference Garrett, Bowern and Evans2015), which means that phonologically relevant change proceeds through minimal phonetic changes, and minimal phonetic changes are usually not substantial enough to change two phonological features. I adopt this assumption of minimality (Donegan & Stampe Reference Donegan, Stampe and Dinnsen1979, Picard Reference Picard1994) and posit that a single sound change is a change in one feature in a given environment. A combination of sound changes is a set of such individual sound changes operating in a given language.

To my knowledge, no detailed studies exist on the question of whether a single sound change can involve a change of more than one feature simultaneously. Direct evidence of such a sound change is hard to obtain because we have only limited access to sound changes in progress and even apparent sound changes in process might not always yield conclusive results: it is, for example, possible that what seems to be a sound change in progress that targets two features simultaneously might in fact be variation between two end points that result from operation of two individual sound changes. Typological surveys of sound change support the minimality hypothesis, at least as a strong tendency: the substantial majority of sound changes surveyed in Kümmel (Reference Kümmel2007) do involve a change of only a single feature. Likewise, in a phylogenetic modeling of sound changes in Turkic in Hay, Pierrehumbert, Walker & LaShell (Reference Hay, Pierrehumbert, Walker and LaShell2015), 79% of consonantal and 70% of vocalic sound changes involved a change in a single feature. It is reasonable to assume that at least a subset of the two-feature changes involve an additional sound change that is not observed on the surface, although this assumption cannot be proven (see discussion below).
To be sure, universally redundant (hence referred to as ‘automatic’) features (cf. Keyser & Stevens Reference Keyser and Stevens2006, Hyman Reference Hyman2013) do not contribute to sound change minimality: if stops nasalize (D
 ${>}$
N), [
${>}$
N), [
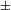 $\pm$
sonorant] is changed along with [
$\pm$
sonorant] is changed along with [
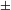 $\pm$
nasal], but [
$\pm$
nasal], but [
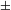 $\pm$
sonorant] is not contrastive in either nasals or voiced stops and this change does not count as an instance of an additional sound change. More problematic for the minimality assumption are (i) cases of perceptually driven sound changes that involve change of place of articulation, (ii) cases of total assimilation, and (iii) cases of epenthesis, metathesis, or deletion. Some of the recurrent sound changes that appear to target more than a single feature simultaneously are changes that primarily arise due to perceptual similarity, e.g. changes between [ɣ] and [w],
$\pm$
sonorant] is not contrastive in either nasals or voiced stops and this change does not count as an instance of an additional sound change. More problematic for the minimality assumption are (i) cases of perceptually driven sound changes that involve change of place of articulation, (ii) cases of total assimilation, and (iii) cases of epenthesis, metathesis, or deletion. Some of the recurrent sound changes that appear to target more than a single feature simultaneously are changes that primarily arise due to perceptual similarity, e.g. changes between [ɣ] and [w], ![]() and [p], or
and [p], or ![]() and [t] (Ohala Reference Ohala, Breivik and Jahr1989). It is nevertheless reasonable to assume that a subset of such changes proceed through intermediate stages, e.g. [ɣ]
and [t] (Ohala Reference Ohala, Breivik and Jahr1989). It is nevertheless reasonable to assume that a subset of such changes proceed through intermediate stages, e.g. [ɣ]
 ${>}$
[β]
${>}$
[β]
 ${>}$
[w]. While Ohala (Reference Ohala, Breivik and Jahr1989) argues strongly against such proposals, there is independent evidence that makes such intermediate stages plausible. Ohala (Reference Ohala, Breivik and Jahr1989), for example, specifically argues against Whatmough (Reference Whatmough1937) (via Ohala Reference Ohala, Breivik and Jahr1989) who claims that Proto-Indo-European
${>}$
[w]. While Ohala (Reference Ohala, Breivik and Jahr1989) argues strongly against such proposals, there is independent evidence that makes such intermediate stages plausible. Ohala (Reference Ohala, Breivik and Jahr1989), for example, specifically argues against Whatmough (Reference Whatmough1937) (via Ohala Reference Ohala, Breivik and Jahr1989) who claims that Proto-Indo-European ![]() develops to Greek [pp] through an interstage with
develops to Greek [pp] through an interstage with ![]() Northwest Caucasian languages, however, confirm that labialized alveolar stops
Northwest Caucasian languages, however, confirm that labialized alveolar stops ![]() or
or ![]() can and do develop to doubly articulated bilabio-alveolar stops
can and do develop to doubly articulated bilabio-alveolar stops ![]() or
or ![]() (for example in Ubykh), even though these are typologically much rarer than bilabio-velar stops (Catford Reference Catford, Rigault and Charbonneau1972, Ladefoged & Maddieson Reference Ladefoged and Maddieson1996, Garrett & Johnson Reference Garrett and Johnson2013, Beguš Reference Begušto appear). Some dialects of Ubykh then merge these with plain labial stops [p] and [b] (Fenwick Reference Fenwick2011), which means we have the full chain of developments
(for example in Ubykh), even though these are typologically much rarer than bilabio-velar stops (Catford Reference Catford, Rigault and Charbonneau1972, Ladefoged & Maddieson Reference Ladefoged and Maddieson1996, Garrett & Johnson Reference Garrett and Johnson2013, Beguš Reference Begušto appear). Some dialects of Ubykh then merge these with plain labial stops [p] and [b] (Fenwick Reference Fenwick2011), which means we have the full chain of developments ![]()
 ${>}$
${>}$
![]()
 ${>}$
[p] attested. Intermediate stages can thus be motivated at least for a subset of cases that are traditionally used as examples of non-gradual changes involving more than a single feature. In other words, not all changes targeting two features that appear to result from perceptual confusion necessarily lack intermediate stages.
${>}$
[p] attested. Intermediate stages can thus be motivated at least for a subset of cases that are traditionally used as examples of non-gradual changes involving more than a single feature. In other words, not all changes targeting two features that appear to result from perceptual confusion necessarily lack intermediate stages.
While it has been stipulated that assimilation in more than one feature often (or always) arises through interstages or that a segment often (or always) deletes with an intermediate stage with [ʔ], [h], or a glide [j] (Hock Reference Hock1991 or McCarthy Reference McCarthy2008 for a synchronic perspective), one of the most well-studied sound changes in progress, final t/d-deletion in English, points to the contrary as no intermediate stages are observed.Footnote
[8]
Moreover, while epenthesis can be a gradual process (Morley Reference Morley2012), it would be difficult to represent it with a change of a single feature value. Complete deletion or epenthesis of a segment/feature matrix thus has to count as a single sound change under my approach. Metathesis is another non-canonical sound change: it does not involve a change in a feature’s value, but rather a change in the ordering of features/feature matrices. While usually a sporadic sound change, metathesis can be regular and it can also be gradual (Lass Reference Lass1997, Blevins & Garrett Reference Blevins and Garrett1998), involving several intermediate stages. Slavic metathesis (/VRC/
 ${>}$
/RVC/), for example, most likely involves an interstage with vowel epenthesis (/V
${>}$
/RVC/), for example, most likely involves an interstage with vowel epenthesis (/V
 $_{1}$
RC/
$_{1}$
RC/
 ${>}$
/V
${>}$
/V
 $_{1}$
RV
$_{1}$
RV
 $_{2}$
C/) and vowel deletion (/V
$_{2}$
C/) and vowel deletion (/V
 $_{1}$
RV
$_{1}$
RV
 $_{2}$
C/
$_{2}$
C/
 ${>}$
/RV
${>}$
/RV
 $_{2}$
C/) (Blevins & Garrett Reference Blevins and Garrett1998).Footnote
[9]
$_{2}$
C/) (Blevins & Garrett Reference Blevins and Garrett1998).Footnote
[9]
In sum, I adopt phonological features to represent sound changes that via phonologization result in synchronic alternations. By the word change in (3) I mean either a change of one non-automatic feature value in a given environment, a complete deletion/insertion of a feature matrix, or a change of ordering of features/feature matrices in two diachronic stages. In all cases, my assumption is that a single sound change is minimal: it involves a change of a single feature or deletion/epenthesis/reordering of a single feature matrix. Further research on sound changes in progress is needed to confirm the minimality assumption – currently, I can claim that the minimality assumption is a strong tendency: it holds for at least the majority of sound changes documented and it is articulatorily and perceptually well grounded. It is possible that a relatively small subset of sound changes can indeed target more than a single feature simultaneously. Such sound changes are likely rare and the concepts proposed in the rest of the paper (MSCR) hold as strong tendencies even if the minimality principle is not exceptionless.
3 Post-nasal devoicing
The claim that PND is an unnatural process according to the definition in (2) is supported by strong articulatory phonetic evidence. Post-nasal voicing ![]() the exact inverse process to PND, is a UPT: it is phonetically well motivated, operates passively in world languages, and is typologically common.
the exact inverse process to PND, is a UPT: it is phonetically well motivated, operates passively in world languages, and is typologically common.
The phonetics of PNV are thoroughly investigated in Hayes & Stivers (Reference Hayes and Stivers2000) (cf. Hayes Reference Hayes, Darnell and Moravscik1999, Pater Reference Pater, Kager and van1999). Supported by previous work including Rothenberg (Reference Rothenberg1968), Kent & Moll (Reference Kent and Moll1969), Ohala (Reference Ohala and MacNeilage1983), Ohala & Ohala (Reference Ohala, Ohala, Huffman and Krakow1993), and others, the authors identify two phonetic factors that render stops in post-nasal position prone to voicing: (i) nasal airflow leak and (ii) expansion of oral cavity volume during velic rising. Both of these factors promote voicing, i.e. counter the anti-voicing effects of closure (Hayes & Stivers Reference Hayes and Stivers2000). It has long been known that coarticulation occurs in the transition from nasal to oral stops: the velum must rise from a low position to a high position, at which point it closes the nasal cavity. During this process, airflow can leak through the nasal cavity, which means that the airflow necessary to maintain voicing that would otherwise stop during the closure can be maintained longer (Hayes & Stivers Reference Hayes and Stivers2000). Moreover, when the velum rises from a high position to complete closure, the volume of the oral cavity increases, which again allows a longer period of sufficient airflow that would otherwise stop due to closure (Hayes & Stivers Reference Hayes and Stivers2000).
Not only is post-nasal voicing phonetically motivated, it is also universally present as a passive phonetic tendency: that is to say, phonetic voicing is found even in languages without phonological PNV, such as English. Hayes & Stivers (Reference Hayes and Stivers2000) show that speakers produce more passive phonetic voicing on voiceless stops in post-nasal position than elsewhere. Speakers produce ‘significantly more closure voicing’ in words like [tampa] than in words like [tarpa] (Hayes & Stivers Reference Hayes and Stivers2000: 29). The data in Davidson (Reference Davidson2016, Reference Davidson2017) show that English voiceless and voiced stops have the highest percentage of voicing into closure precisely in post-nasal position. PNV thus meets all the criteria for being a UPT.
PNV is commonly attested not only as a phonological and phonetic process, but also as a sound change. Locke (1983) identifies 15 languages, out of a sample of 197, that exhibit PNV as a synchronic process (reported in Hayes & Stivers Reference Hayes and Stivers2000). Kümmel (Reference Kümmel2007: 53–54) lists approximately 32 languages in a survey of approximately 294 in which PNV operates as a sound change. By comparison, PND in the same survey is reported only twice: in one instance it targets stops and in the other affricates.
While PNV is a well-motivated and natural process – the opposite process, devoicing of voiced stops in post-nasal position, is unnatural: it operates against a UPT. For reasons discussed above (nasal leakage and increased volume of oral cavity; see Hayes & Stivers Reference Hayes and Stivers2000, Coetzee & Pretorius Reference Coetzee and Pretorius2010), the post-nasal environment is in all aspects antagonistic to devoicing (compared to other positions, e.g. word-initial and word-final), in the sense that it counters the anti-voicing effects of the closure in stops. In other words, in the transition from nasal to oral stop, the velum does not close instantaneously; as a result, air leakage occurs into a portion of the following stop closure, prohibiting the ‘air pressure buildup’ necessary to articulate a voiceless stop (Coetzee & Pretorius Reference Coetzee and Pretorius2010: 405). Expansion of the oral cavity due to velic rising also has an effect of promoting voicing during the closure: greater volume allows longer period of time before the air pressure buildup (for a discussion on phonetics, see Hayes & Stivers Reference Hayes and Stivers2000, Coetzee & Pretorius Reference Coetzee and Pretorius2010, and literature therein). Moreover, to my knowledge, PND has not been reported as a passive tendency in any language. For a discussion on the unnaturalness of PND, see also Sections 3.2 and 3.4.
3.1 The data
According to my survey, the existence of PND as a sound change has been reported in thirteen languages and dialects from eight language families.
3.1.1 Yaghnobi
PND was first proposed for Yaghnobi by Xromov (Reference Xromov1972). Yaghnobi is an Iranian language, spoken by approximately 13,500 speakers in five different areas of Tajikistan (Paul et al. Reference Paul, Abbess, Müller, Tiessen and Tiessen2010: 4). It is the only living descendant of Sogdian, an Eastern Iranian language that was spoken around the fourth century CE. Xromov (Reference Xromov1972) observes that NT sequences in Yaghnobi correspond to ND sequences in ancestral Sogdian; on the basis of this observation, he posits a sound change ![]() in the development from Sogdian to Yaghnobi. Table 1 lists cognates from Yaghnobi and Sogdian that confirm this correspondence.Footnote
[10]
in the development from Sogdian to Yaghnobi. Table 1 lists cognates from Yaghnobi and Sogdian that confirm this correspondence.Footnote
[10]
Table 1 PND in Yaghnobi (from Xromov Reference Xromov1972: 128).

Outside of post-nasal position, original voiced stops surface as voiced fricatives [β, ð, ɣ] in Sogdian: this is the result of a sound change that turns voiced stops into voiced fricatives except post-nasally. In Yaghnobi, velar and labial fricatives in the elsewhere condition are preserved as fricatives [w/β] and [ɣ]. The Sogdian dental fricative [ð], on the other hand, surfaces as a stop: [dah] ‘ten’ for Sogdian [ðəsa] (data from Novák Reference Novák2010: 31; Novák Reference Novák2014). Voiceless stops remain unchanged in Sogdian, except post-nasally, where they become voiced (Yoshida Reference Yoshida2016) before being devoiced in Yaghnobi.
Regarding the Yaghnobi synchronic system, Novák (Reference Novák2010) reports voiceless stops to be aspirated except pre-consonantally and voiced stops to be phonetically voiced, although no instrumental studies are offered. Synchronic Yaghnobi phonology contrasts voiced and voiceless stops in all positions: initially, finally, intervocalically, in clusters, and post-nasally. The fact that [
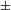 $\pm$
voice] contrasts fully in NT and ND sequences in synchronic Yaghnobi means that PND is not an active alternation anymore. The post-nasal contrast in the feature [
$\pm$
voice] contrasts fully in NT and ND sequences in synchronic Yaghnobi means that PND is not an active alternation anymore. The post-nasal contrast in the feature [
 $\pm$
voice] is, however, likely secondary, introduced late in the language’s development through borrowings from Tajik (cf. Xromov Reference Xromov1972). Some examples of borrowed ND sequences from Tajik are given in Xromov (Reference Xromov1972: 128): [angiʃt] ‘coal’, [ʧanɡ] ‘dust’, [baland] ‘high’, [lunda] ‘round’. It is even possible to find pairs of native and borrowed words with and without devoicing. For example, the inherited Yaghnobi [vant] ‘tie’ – with an unvoiced stop after a nasal – stands in contrast to the borrowed [band] ‘tie’ with a voiced variant.
$\pm$
voice] is, however, likely secondary, introduced late in the language’s development through borrowings from Tajik (cf. Xromov Reference Xromov1972). Some examples of borrowed ND sequences from Tajik are given in Xromov (Reference Xromov1972: 128): [angiʃt] ‘coal’, [ʧanɡ] ‘dust’, [baland] ‘high’, [lunda] ‘round’. It is even possible to find pairs of native and borrowed words with and without devoicing. For example, the inherited Yaghnobi [vant] ‘tie’ – with an unvoiced stop after a nasal – stands in contrast to the borrowed [band] ‘tie’ with a voiced variant.
3.1.2 Tswana, Shekgalagari, and Makhuwa
PND has been reported as a synchronic phonological process in the languages/dialects of the Sotho-Tswana group of Southern Bantu languages, especially in Tswana and Shekgalagari (Hyman Reference Hyman, Hume and Johnson2001, Solé, Hyman & Monaka Reference Solé, Hyman and Monaka2010), but also in Sotho (Janson Reference Janson1991/1992). The three languages are closely related and mutually intelligible (Makalela Reference Makalela2009). Because PND is least well described in Sotho, I will focus on Tswana and Shekgalagari. Tswana is spoken by approximately 4–5 million people in Botswana, Namibia, Zimbabwe, and South Africa (Coetzee & Pretorius Reference Coetzee and Pretorius2010), and Shekgalagari by approximately 272,000 people in Botswana (Solé et al. Reference Solé, Hyman and Monaka2010).
In Makhuwa, PND is reported as a sound change followed by nasal deletion (Janson Reference Janson1991/1992). Makhuwa is closely related to Sotho-Tswana too and is spoken by approximately 3.5 million speakers in Mozambique (Simons & Fennig Reference Simons and Fennig2018).
Table 2 shows that synchronic voiced stops (that surface as voiced stops in the elsewhere condition) in Shekgalagari become voiceless when preceded by a nasal. Voiceless stops remain unchanged both post-nasally and elsewhere.
Table 2 PND in Shekgalagari (table from Solé et al. Reference Solé, Hyman and Monaka2010). The N-prefix functions as the first person singular prefix, e.g. χʊ-pak-a ‘to praise’ vs. χʊ-m-pak-a ‘to praise me’ (Solé et al. Reference Solé, Hyman and Monaka2010).

Both Tswana and Shekgalagari have unaspirated voiced (D) and voiceless (T) and aspirated voiceless stops ![]() in their inventories (for phonetic studies, see Coetzee & Pretorius Reference Coetzee and Pretorius2010 and Solé et al. Reference Solé, Hyman and Monaka2010): they surface initially, intervocalically, and post-nasally. The only permitted syllable structures are ‘V, CV, CGV, N’ (where G
in their inventories (for phonetic studies, see Coetzee & Pretorius Reference Coetzee and Pretorius2010 and Solé et al. Reference Solé, Hyman and Monaka2010): they surface initially, intervocalically, and post-nasally. The only permitted syllable structures are ‘V, CV, CGV, N’ (where G
 $=$
glide and N
$=$
glide and N
 $=$
syllabic nasal; Coetzee & Pretorius Reference Coetzee and Pretorius2010: 406). Detailed instrumental acoustic studies of the Tswana and Shekgalagari stop system in Coetzee & Pretorius (Reference Coetzee and Pretorius2010) and in Solé et al. (Reference Solé, Hyman and Monaka2010) confirm that post-nasal devoicing is indeed realized as change in the feature [
$=$
syllabic nasal; Coetzee & Pretorius Reference Coetzee and Pretorius2010: 406). Detailed instrumental acoustic studies of the Tswana and Shekgalagari stop system in Coetzee & Pretorius (Reference Coetzee and Pretorius2010) and in Solé et al. (Reference Solé, Hyman and Monaka2010) confirm that post-nasal devoicing is indeed realized as change in the feature [
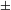 $\pm$
voice], and not as a change in [
$\pm$
voice], and not as a change in [
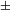 $\pm$
spread glottis].
$\pm$
spread glottis].
Several peculiarities need to be noted with respect to Tswana. First, /ɡ/ never surfaces as a voiced stop: while it is devoiced to [k] post-nasally, it gets deleted elsewhere, e.g. [χʊ-at-a] for /χʊ-ɡat-a/ (cf. [χʊ-ŋ-kat-a], Solé et al. Reference Solé, Hyman and Monaka2010). Second, voiced alveolar stop [d] surfaces as an allophone of /l/ before the high vowels /i/ and /u/ (Coetzee & Pretorius Reference Coetzee and Pretorius2010). Third, voiced stops in nasal clusters of secondary origin (from NVD after vowel deletion) do not undergo devoicing, but undergo assimilation in Tswana (see Table 3). Finally, the nasal in NT sequences Tswana (and Shekgalagari) is retained when stressed and in the 1st person object prefix, but gets deleted elsewhere (see Dickens Reference Dickens1984). Hyman (Reference Hyman, Hume and Johnson2001) gives an example of preservation of N-: in the case of class 9 and 10 prefix, when roots are monosyllabic.
In Shekgalagari, secondary ND clusters (from NVD after vowel deletion) remain voiced (Table 3). /d/ can surface in the elsewhere condition (not only before /i/ and /u/), but it does not alternate with devoiced [nt]
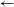 $\leftarrow$
/nd/ (because /d/ corresponds to Tswana /tl/). Shekgalagari (unlike Tswana) also features the palatal series of stops that enters PND (Solé et al. Reference Solé, Hyman and Monaka2010). For a detailed discussion of differences between Tswana and Shekgalagari, see Dickens (Reference Dickens1984) and Solé et al. (Reference Solé, Hyman and Monaka2010).
$\leftarrow$
/nd/ (because /d/ corresponds to Tswana /tl/). Shekgalagari (unlike Tswana) also features the palatal series of stops that enters PND (Solé et al. Reference Solé, Hyman and Monaka2010). For a detailed discussion of differences between Tswana and Shekgalagari, see Dickens (Reference Dickens1984) and Solé et al. (Reference Solé, Hyman and Monaka2010).
Table 3 PND in Tswana and Shekgalagari (table from Solé et al. Reference Solé, Hyman and Monaka2010).

Makhuwa is also reported to undergo PND as a sound change. Sequences of a nasal and a voiced stop (ND) develop to voiceless unaspirated stops (T) (Janson Reference Janson1991/1992), but the process did not develop into a synchronic alternation in Makhuwa. To my knowledge, no elaborate accounts of the phonetic realization of voiced and voiceless stops in the elsewhere condition exist for Makhuwa.
Because the languages are closely related and there are other instances of common innovation between Sotho-Tswana and Makhuwa, Janson (Reference Janson1991/1992) and Hyman (Reference Hyman, Hume and Johnson2001) imply that PND in the three languages is likely a common innovation. For the same reason, I will treat these three languages together in this study. Since the description of PND in Makhuwa (and Sotho) is sparse and lacking in detailed phonetic descriptions, I will focus my discussion on Tswana and Shekgalagari; however in principle, the arguments for these two languages apply to Makhuwa as well.
3.1.3 Bube and Mpongwe
Unlike Makhuwa, Bube is not closely related to Tswana and Shekgalagari. Janssens (Reference Janssens1993) reports that Bube also features PND. As will be shown below, several aspects of Bube PND are highly reminiscent of the process reported for Tswana, Shekgalagari, and Makhuwa despite the languages not being closely related. Bube is a Northwest A Bantu language, spoken by approximately 51,000 speakers on Bioko island (Simons & Fennig Reference Simons and Fennig2018). Sequences of a nasal and a voiced stop in Pre-Bube develop to voiceless stops in Bube. Table 4 illustrates the development.
Table 4 PND in Bube (table from Janssens Reference Janssens1993).
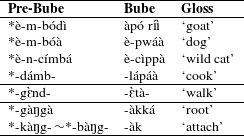
Table 4 illustrates that Pre-Bube sequences of a nasal and voiced stop (ND) yield a single voiceless stop (T) with the nasal being lost. In the elsewhere condition, the labial voiced stop surfaces as such, the dental develops to [r/l], and the voiced velar stop gets lost (similar to the situation in Tswana and Shekgalagari) (Janssens Reference Janssens1993). Voiceless stops can either delete, develop to [h] (in the labial series), or continue to surface as voiceless stops. NT sequences develop to a plain voiceless stop (T; Janssens Reference Janssens1993). The Bube synchronic system has no alternation between voiceless and voiced stops in the post-nasal vs. elsewhere condition, but the development is intriguing from a diachronic perspective: it appears as if PND operated in Pre-Bube.
In the Mpongwe dialect of Myene (Bantu B language, spoken in Gabon, Simons & Fennig Reference Simons and Fennig2018), PND is reported marginally for root initial [ɡ] after some prefixes that historically ended in a nasal, e.g. *gàmb-
 ${>}$
[i-kamba] (Mouguiama-Daouda Reference Mouguiama-Daouda1990). However, because PND is marginal in Mpongwe – it is morphologically limited and does not apply categorically – I will for the most part leave it out of the ensuing discussion.Footnote
[11]
${>}$
[i-kamba] (Mouguiama-Daouda Reference Mouguiama-Daouda1990). However, because PND is marginal in Mpongwe – it is morphologically limited and does not apply categorically – I will for the most part leave it out of the ensuing discussion.Footnote
[11]
3.1.4 Konyagi
Recently, PND as a sound change has been discovered in Konyagi (also known as Wamey, among others; Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb). Konyagi, a member of the Atlantic subfamily of the Niger-Congo group, is spoken by approximately 21,000 speakers in Senegal (Simons & Fennig Reference Simons and Fennig2018). Note that Konyagi is not part of the Bantu family, which means that it is only very distantly related to the Bantu languages above with PND. Merrill (Reference Merrill2014, Reference Merrill2016a, Reference Merrillb, p.c.) reconstructs a detailed picture of Konyagi’s pre-history. Notable in this reconstruction is a series of voiceless stops in post-nasal position that correspond to voiced stops in the neighboring languages Bedik and Basari of the Tenda group (data in Table 5 is from Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb, based on Ferry Reference Ferry1991 and Santos Reference Santos1996). It thus appears as if Konyagi underwent PND. Voiceless NT sequences develop to a plain voiceless stop (T) in Konyagi. Both voiceless and voiced stops fricativize in the elsewhere condition. Table 5 illustrates PND in Konyagi.
Table 5 PND in Konyagi (from Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb).

Synchronically, Konyagi features voiceless and voiced stops as well as voiceless and voiced fricatives. Non-nasal clusters are not permitted. Post-nasally, only voiceless stops are allowed. Elsewhere, voiceless and voiced stops can contrast with voiceless and voiced fricatives, except initially where only fricatives are allowed (Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb). PND is part of a synchronic mutation process in Konyagi: devoiced stops after prefixes that historically ended in a nasal alternate with voiced fricatives after prefixes that historically ended in a vowel and voiced stops after prefixes that ended in another consonant (see Table 27 and Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb). No instrumental phonetic data is available for Konyagi.
3.1.5 South Italian dialects
Sicilian and Calabrian are dialects of Italian spoken in the corresponding regions of Italy by approximately 4.7 million speakers (Simons & Fennig Reference Simons and Fennig2018). PND has been reported for these dialects in Rohlfs (Reference Rohlfs1949: 424–425). The peculiarity of South Italian PND is that the sound change targets only the voiced affricate *ʤ, which is devoiced to [ʧ] after the nasal ![]() Elsewhere, *ʤ develops to [j] in these dialects (Rohlfs Reference Rohlfs1949: 265, 358–359; Kümmel Reference Kümmel2007: 376). Voiced stops are not reported to be devoiced in the post-nasal position: the feature [
Elsewhere, *ʤ develops to [j] in these dialects (Rohlfs Reference Rohlfs1949: 265, 358–359; Kümmel Reference Kümmel2007: 376). Voiced stops are not reported to be devoiced in the post-nasal position: the feature [
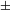 $\pm$
voice] is contrastive for stops. The voiceless affricate either remains unchanged or develops to [ʃ] (Rohlfs Reference Rohlfs1949). Table 6 illustrates PND in Sicilian and Calabrian.
$\pm$
voice] is contrastive for stops. The voiceless affricate either remains unchanged or develops to [ʃ] (Rohlfs Reference Rohlfs1949). Table 6 illustrates PND in Sicilian and Calabrian.
Table 6 PND in South Italian (from Rohlfs Reference Rohlfs1949: 424–425).

3.1.6 Buginese and Murik
PND has been reported in three Austronesian languages: Buginese, Murik, and the Bengoh dialect of Land Dayak (Blust Reference Blust2005, Reference Blust2013). PND in the latter is simply mentioned without accompanying data (Rensch et al. Reference Rensch, Rensch, Noeb and Ridu2006: 69; Blust Reference Blust2013); I therefore leave Land Dayak out of the discussion that follows. Buginese is spoken by approximately 5 million people in Sulawesi (Indonesia); Murik is spoken in Sarawak (Malaysia and Brunei) by approximately 1,000 speakers (Simons & Fennig Reference Simons and Fennig2018). These three Austronesian languages are not closely related, so we cannot attribute PND to developments in a common ancestor; it is likely that PND developed independently in all three branches (Blust Reference Blust2005, Reference Blust2013).
Apparent PND in Buginese is represented in Table 7, showing the development of Proto-Malayo-Polynesian (PMP) voiced stops (data from Blust Reference Blust2013). Velar stops are devoiced post-nasally. Labial stops appear devoiced after nasals, but surface as [w] initially and word-internally (with a sporadic reflex [b] in initial position). The dental stop *d is not implicated in PND; Pre-Buginese *d develops to /r/ in all positions, which does not undergo devoicing, e.g. *dindiŋ
 ${>}$
[renriŋ]. Word-initially, however, *d is sporadically preserved as a voiced stop [d] or develops to [l]. The voiced fricative *z is occluded to a voiced palatal stop initially, and develops to a sonorant [r] intervocalically. Post-nasally, *z is devoiced to [c]. Word-finally, all stops develop to [ʔ]. Voiceless NT sequences develop to a geminate voiceless stop (TT) in Buginese (Mills Reference Mills1975, Blust Reference Blust2005). Voiceless stops remain unchanged in the elsewhere position (Mills Reference Mills1975).
${>}$
[renriŋ]. Word-initially, however, *d is sporadically preserved as a voiced stop [d] or develops to [l]. The voiced fricative *z is occluded to a voiced palatal stop initially, and develops to a sonorant [r] intervocalically. Post-nasally, *z is devoiced to [c]. Word-finally, all stops develop to [ʔ]. Voiceless NT sequences develop to a geminate voiceless stop (TT) in Buginese (Mills Reference Mills1975, Blust Reference Blust2005). Voiceless stops remain unchanged in the elsewhere position (Mills Reference Mills1975).
Table 7 Summary of PND in Buginese.
The data cited as evidence of PND as a sound change in Buginese are given in Table 8.
Table 8 PND in Buginese with cognates from reconstructed Proto-South-Sulawesi (Proto-SS; from Blust Reference Blust2005, Reference Blust2013).

In Murik, labials, alveolars, and velars undergo devoicing in post-nasal position. In the elsewhere condition, the developments vary according to the place of articulation. Bilabial voiced stops surface as such in the elsewhere condition. Voiced alveolars appear as [l] word-initially and [r] word-internally. Velars are devoiced not only post-nasally, but sporadically also in the elsewhere condition. PMP *z develops to the voiced palatal affricate [ɟʝ] initially, to [s] word-internally, and to the voiceless palatal affricate [cc¸] post-nasally. Table 9 illustrates the development of voiced stops from Proto-Kayan-Murik. Voiceless NT sequences develop to a plain voiceless stop (T) in Murik, while plain voiceless stops remain unchanged (Blust Reference Blust1974, Reference Blust2005).
Table 9 Summary of PND in Murik (as reconstructed in Blust Reference Blust2005).

PND is confirmed for Murik by the examples in Table 10.
Table 10 PND in Murik (from Blust Reference Blust2005: 259–262; Blust Reference Blust2013: 668).

Synchronically, PND in Buginese is reported to be an active phonological alternation (Sirk Reference Sirk1983) as well as an active sandhi process (Noorduyn Reference Noorduyn and Macknight2012/1955; see Section 3.5 and Table 26). Buginese contrasts voiceless and voiced stops (Noorduyn Reference Noorduyn and Macknight2012/1955), but voiced labial, palatal, and velar stops /b, d, ɡ/ and a glide /w/ are reported to devoice (and change to a stop in the case of /w/) post-nasally in synchronic Buginese (see also Table 26 below). In Murik, PND is reported as a synchronic alternation only for the palatal stop series which alternates between [ɟ] in the elsewhere condition and [c] post-nasally. For other places of articulation, Blust (Reference Blust2005: 260) reports PND to be synchronically inactive due to ‘phonemic restructuring’.
3.1.7 Nasioi
The most recent report of PND is that in Brown (Reference Brown2017) for the South Bougainville language Nasioi, spoken in Papua New Guinea by approximately 20,000 speakers (Simons & Fennig Reference Simons and Fennig2018). Brown (Reference Brown2017), based on Hurd & Hurd (Reference Hurd and Hurd1970), claims that PND in Nasioi is a synchronic alternation and supports this claim by showing that while bilabial and alveolar voiced stops /b/ and /d/ contrast in voicing with unaspirated voiceless /p/ and /t/ word-initially and after a glottal stop, only voiceless variants appear in post-nasal position. Elsewhere, stops fully contrast in the feature [
 $\pm$
voice], but are not permitted other than word-initially and after a glottal stop: intervocalically, labial and alveolar stops surface as a voiced fricative [β] and a flap [ɾ], respectively. The velar voiced stop /ɡ/ does not occur in the system. This distribution points to a clear case of PND. PND in Nasioi is not only a phonotactic restriction, but also seems to be an active synchronic alternation, which is illustrated by the example in (4) from Brown (Reference Brown2017). The voiceless version of the personal pronoun -p/b- surfaces post-nasally; the voiced one surfaces elsewhere.
$\pm$
voice], but are not permitted other than word-initially and after a glottal stop: intervocalically, labial and alveolar stops surface as a voiced fricative [β] and a flap [ɾ], respectively. The velar voiced stop /ɡ/ does not occur in the system. This distribution points to a clear case of PND. PND in Nasioi is not only a phonotactic restriction, but also seems to be an active synchronic alternation, which is illustrated by the example in (4) from Brown (Reference Brown2017). The voiceless version of the personal pronoun -p/b- surfaces post-nasally; the voiced one surfaces elsewhere.

Brown (Reference Brown2017) specifically argues that PND is an innovation in Nasioi and that the fact that a related language, Nagovisi, shows traces of post-nasal voicing (with a speculation that this might be indicative of the proto-language) suggests that Nasioi PND operated as a single sound change. In other words, this suggests that PND is not ‘derived from the confluence of multiple independent changes’ (according to Brown Reference Brown2017: 275).
The data presented in this subsection seem to suggest, at first glance, that PND operated as a single sound change in the development of all thirteen of these languages. However, I will demonstrate below that a thorough investigation reveals a common pattern of complementary distribution in all thirteen cases along with other pieces of evidence, strongly suggesting that a combination of natural sound changes operated in place of a single PND sound change.
3.2 Explanations of PND
Several accounts in the literature understand PND as a single sound change; explanations for this process run the gamut from appeals to hypercorrection (Xromov Reference Xromov1972, Blust Reference Blust2005), to perceptual enhancement (Kirchner Reference Kirchner2000, Stanton Reference Stanton2016b, Lapierre Reference Lapierre2018), to arguments that PND is actually a phonetically plausible or even natural process (Solé et al. Reference Solé, Hyman and Monaka2010, Solé Reference Solé, Solé and Recasens2012). Three problems arise with such accounts. First, they struggle to explain why devoicing would operate in post-nasal position, where nasal leakage and volume expansion (Hayes & Stivers Reference Hayes and Stivers2000, Coetzee & Pretorius Reference Coetzee and Pretorius2010) militate against the anti-voicing pressure of closure (Ohala & Riordan Reference Ohala, Riordan, Wolf and Klatt1979), whereas in other contexts, where speakers have to accommodate for voicing considerably more than post-nasally, voicing is preserved (see also the discussion in Section 3.4). Second, they each examine and account for only a single instance of PND, examined in isolation without the relevant cross-linguistic data. Finally, most of the existing proposals fail to explain recurrent patterns that are observed in all thirteen languages (e.g. fricativization of voiced stops elsewhere or devoicing of other voiced stops/voiced stops in related dialects; see Section 3.3). In Section 3.3, I argue that all cases of reported PND (that have until now been studied in isolation) in fact result from a combination of sound changes. This explanation was proposed for Tswana already in Dickens (Reference Dickens1984) and Hyman (Reference Hyman, Hume and Johnson2001).
3.2.1 Hypercorrection
Xromov (Reference Xromov1972) appears to invoke hypercorrection to explain PND in Yaghnobi. He postulates that in Sogdian and Yaghnobi, all stops voice post-nasally, but that this sound change is in progress, which results in variation between [NT]
 ${\sim}$
[ND] for the underlying /NT/. He further claims that the underlying /ND/ joined this pattern (probably through hypercorrection), which means that at some stage variation between [NT]
${\sim}$
[ND] for the underlying /NT/. He further claims that the underlying /ND/ joined this pattern (probably through hypercorrection), which means that at some stage variation between [NT]
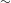 ${\sim}$
[ND] existed for /ND/ as well. Once the voicing process was finished, the voiceless variant became more frequent for both inputs. No motivation is given for why the voiceless variant becomes prevalent, except for an assumption that devoicing might have been influenced by morphological analogy in dentals and then spread to other places of articulation. Xromov’s explanation might be more convincing if we assumed hypercorrection arose from an interaction between two hypothetical dialects, where one voices all stops, and the other preserves the contrast; speakers of the neutralizing dialect could then hypercorrect their voiced stops to voiceless ones in post-nasal position. Not only do we lack evidence for the stage with the two dialects, but this assumption also fails to explain the connection between PND and the development of voiced stops to voiced fricatives in the elsewhere condition.
${\sim}$
[ND] existed for /ND/ as well. Once the voicing process was finished, the voiceless variant became more frequent for both inputs. No motivation is given for why the voiceless variant becomes prevalent, except for an assumption that devoicing might have been influenced by morphological analogy in dentals and then spread to other places of articulation. Xromov’s explanation might be more convincing if we assumed hypercorrection arose from an interaction between two hypothetical dialects, where one voices all stops, and the other preserves the contrast; speakers of the neutralizing dialect could then hypercorrect their voiced stops to voiceless ones in post-nasal position. Not only do we lack evidence for the stage with the two dialects, but this assumption also fails to explain the connection between PND and the development of voiced stops to voiced fricatives in the elsewhere condition.
Blust (Reference Blust2005, Reference Blust2013) offers three possible explanations for the emergence of PND in Buginese, Murik, and Land Dayak. First, he notes that, much as PNV can be understood as an assimilation of stops to a voiced environment, PND can be explained as dissimilation. This assumption, however, lacks explanatory power: it simply restates that PND is the opposite process from PNV and does not specify whether such dissimilation would be driven by perceptual or other factors. Blust (Reference Blust2013: 668) himself notes that ‘this does little to explain why a change of this type would occur’.
Blust’s second explanation for Austronesian PND postulates that the three languages in question first underwent PNV: voiceless stops became voiced in post-nasal position, thus eliminating NT sequences. According to Blust (Reference Blust2013: 669), after PNV, ‘voice was free to vary’ post-nasally, and the ‘voiceless variant of post-nasal obstruents prevailed over time’. In other words, Blust (Reference Blust2005) seems to suggest that the lack of contrast in [
 $\pm$
voice] enables devoicing in this position. There are three major issues with this approach. First, it is not parsimonious to assume the independent occurrence of PNV three times without any comparative evidence. Second, it is difficult to explain why a voiceless variant would prevail in an environment in which voicing is preferred compared to other environments (e.g. word-initially), but would fully contrast in those other environments, where voicing is dispreferred. While it is true that the functional load/frequency of phonemes can influence the probability of a merger (Wedel Reference Wedel2012, Wedel, Kaplan & Jackson Reference Wedel, Kaplan and Jackson2013, Hay et al. Reference Hay, Pierrehumbert, Walker and LaShell2015), it is unclear why a merger would first happen to voiced stops and then to voiceless stops.Footnote
[12]
Finally, this line of reasoning, like many others proposed thus far, fails to explain some common patterns, such as fricativization in the elsewhere condition or the presence of unconditioned devoicing in related languages/dialects (e.g. in Tswana, Section 3.1).
$\pm$
voice] enables devoicing in this position. There are three major issues with this approach. First, it is not parsimonious to assume the independent occurrence of PNV three times without any comparative evidence. Second, it is difficult to explain why a voiceless variant would prevail in an environment in which voicing is preferred compared to other environments (e.g. word-initially), but would fully contrast in those other environments, where voicing is dispreferred. While it is true that the functional load/frequency of phonemes can influence the probability of a merger (Wedel Reference Wedel2012, Wedel, Kaplan & Jackson Reference Wedel, Kaplan and Jackson2013, Hay et al. Reference Hay, Pierrehumbert, Walker and LaShell2015), it is unclear why a merger would first happen to voiced stops and then to voiceless stops.Footnote
[12]
Finally, this line of reasoning, like many others proposed thus far, fails to explain some common patterns, such as fricativization in the elsewhere condition or the presence of unconditioned devoicing in related languages/dialects (e.g. in Tswana, Section 3.1).
Somewhat related to Blust’s (Reference Blust2005) second proposal is the idea that the loss of contrasts could influence the operation of sound change (cf. Keyser & Stevens Reference Keyser, Stevens and Kenstowicz2001, Hyman Reference Hyman2013). PND is, however, attested both in languages in which [
 $\pm$
voice] likely does not contrast post-nasally (e.g. in Yaghnobi) as well as in languages in which [
$\pm$
voice] likely does not contrast post-nasally (e.g. in Yaghnobi) as well as in languages in which [
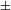 $\pm$
voice] fully contrasts post-nasally at the time of devoicing (e.g. in Konyagi or Tswana; see Table 2 and Section 3.3.2). Similarly, an analysis of devoicing as a loss of contrast in [
$\pm$
voice] fully contrasts post-nasally at the time of devoicing (e.g. in Konyagi or Tswana; see Table 2 and Section 3.3.2). Similarly, an analysis of devoicing as a loss of contrast in [
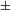 $\pm$
voice] in the elsewhere condition is not appealing. Devoicing is attested in languages in which voiced stops fricativize elsewhere (which means that the contrast is that of T
$\pm$
voice] in the elsewhere condition is not appealing. Devoicing is attested in languages in which voiced stops fricativize elsewhere (which means that the contrast is that of T
 ${\sim}$
Z, e.g. in the Austronesian languages) and there are no voiceless fricatives (S) in the systems, meaning [
${\sim}$
Z, e.g. in the Austronesian languages) and there are no voiceless fricatives (S) in the systems, meaning [
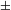 $\pm$
voice] could be redundant (and [
$\pm$
voice] could be redundant (and [
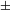 $\pm$
continuant] contrastive), as well as in languages in which the contrast in the elsewhere position is between voiceless and voiced fricatives (S
$\pm$
continuant] contrastive), as well as in languages in which the contrast in the elsewhere position is between voiceless and voiced fricatives (S
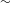 ${\sim}$
Z, e.g. in Konyagi or Tswana) and stops surface only post-nasally (and contrast in voice), meaning [
${\sim}$
Z, e.g. in Konyagi or Tswana) and stops surface only post-nasally (and contrast in voice), meaning [
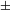 $\pm$
voice] cannot be redundant. Finally, the fact that complete devoicing occurs in some subdialects of Tswana without any contrast being lost beforehand and that in Yaghnobi devoicing targets all stops, not only post-nasal ones, speaks against this line of reasoning (see also Sections 3.3.1 and 3.3.2 for further discussion).
$\pm$
voice] cannot be redundant. Finally, the fact that complete devoicing occurs in some subdialects of Tswana without any contrast being lost beforehand and that in Yaghnobi devoicing targets all stops, not only post-nasal ones, speaks against this line of reasoning (see also Sections 3.3.1 and 3.3.2 for further discussion).
A third explanation offered in Blust (Reference Blust2005) invokes dissimilation by hypercorrection. Blust notes that NT sequences in Buginese and Murik develop either to T or TT. This means that, at a certain point, NT sequences were absent from the language and only voiced stops surfaced after nasals (ND). At this point, according to Blust (Reference Blust2005: 261), speakers ‘may have assumed that pre-nasalized obstruents had acquired voicing by assimilation’ and then ‘undid’ that assumed voicing. This account faces three major difficulties. As already pointed out by Blust (Reference Blust2005: 261), it is unclear what would ‘prompt speakers to assume that voicing assimilation had taken place in earlier clusters’ of ND. Second, even if they had made this assumption, the speakers would still have to apply dissimilation, i.e. devoicing in a context that strongly promotes voicing compared to other positions. Finally, this particular approach with hypercorrection lacks broader explanatory power, since it cannot be extended to cases of apparent PND in other languages, where the sound change NT
 ${>}$
TT, T is not attested (e.g. in Tswana).
${>}$
TT, T is not attested (e.g. in Tswana).
3.2.2 Phonetic motivation
Some analyses have attempted to account for PND by motivating the process phonetically. Solé et al. (Reference Solé, Hyman and Monaka2010: 612) specifically identify PND as a ‘historical process’, suggesting that they assume PND operated as a single instance of sound change. Moreover, these authors claim that PND is not necessarily an unnatural process and may in fact have a phonetic explanation. The main evidence for this claim comes from Shekgalagari, which is assumed to feature ‘early velic rising’ (Solé et al. Reference Solé, Hyman and Monaka2010: 612) in NT sequences. This process is supposed to follow from the fact that (i) speakers do not show any passive voicing in the NT sequences in Shekgalagari, and (ii) underlying nasal-fricative sequences /nz/ yield a nasal affricate [nts]. This process of early velic rising, which is argued to account for both of these observations, would also have caused a ‘long stop closure’ in ND sequences. Because voicing is difficult to maintain, especially during longer closure, the result would be devoicing of the stop (Solé et al. Reference Solé, Hyman and Monaka2010: 612).
This explanation has three major drawbacks. First, secondary ND sequences surface as NN in Tswana and ND in Shekgalagari. The two examples in Table 11 (repeated from Table 3) illustrate this distribution.
Table 11 Secondary ND sequences in Tswana and Shekgalagari (table from Solé et al. Reference Solé, Hyman and Monaka2010).

If early velic rising in Shekgalagari were indeed a phonetic process, we should expect to see devoicing in secondary ND sequences as well. The fact that the stops in secondary ND sequences surface as voiced speaks against the proposal in Solé et al. (Reference Solé, Hyman and Monaka2010) and Solé (Reference Solé, Solé and Recasens2012). Of course, one could assume that early velic rising operated prior to the period during which secondary ND sequences arose. However, there is a flaw in this assumption: Solé et al. (Reference Solé, Hyman and Monaka2010) provide evidence for early velic rising from synchronic phonetic data. If we postulate that early velic rising is responsible for PND as a synchronic phonetic process, we should expect secondary sequences to undergo devoicing as well. Conversely, if we posit that early velic rising should have been completed by the time secondary ND sequences were introduced, we should not expect to find continuing evidence for this process in the current phonetic data. The only reasoning that could explain why secondary ND sequences do not undergo devoicing under the early velic rising approach would be to assume that devoicing is blocked in order to prevent the merger of two grammatical morphemes, /m-/ and /mʊ-/. Even if this is indeed the case, it still means that early velic rising is not completely automatic in synchronic Shekgalagari, but can be overridden for functional reasons. Also, Solé et al. (Reference Solé, Hyman and Monaka2010) note that Shekgalagari has ND sequences in approximately ten items that do not arise from the /mʊ-/ morpheme. While ‘most’ of the ten items are assumed to be borrowings, it is unclear if all items indeed are borrowings (at least one of them is a grammatical marker [ǹde-]). This reinforces the view that early velic rising is not a completely automatic phonetic tendency in Shekgalagari, but can be blocked by at least functional and loanword factors. Second, realization of /nz/ as [nts] is typologically common and proceeds from general phonetic tendencies cross-linguistically (cf. Ali, Daniloff & Hammarberg Reference Ali, Daniloff and Hammarberg1979, Steriade Reference Steriade, Huffman and Krakow1993, Ohala Reference Ohala1997, Busà Reference Busà, Solé and Speeter2007, Kümmel Reference Kümmel2007; see also Section 3.4). The fact that Shekgalagari /nz/ surfaces as [nts] hardly tells us anything about early velic rising. Third, an explanation along these lines fails to account for other cross-linguistic cases of apparent PND where no traces of early velic rising can be found. If PND were indeed motivated by early velic rising, we should expect to find evidence that early velic rising is similarly responsible for reported cases of PND outside Tswana and Shekgalagari (to my knowledge, there exist no studies of this phenomenon). Finally, the explanation proffered in Solé et al. (Reference Solé, Hyman and Monaka2010) fails to explain the connection between PND and the recurrent pattern of fricativization in the elsewhere condition or the pattern of unconditioned devoicing of voiced stop found in subdialects of Tswana (see Section 3.3.2 and Table 16).
3.2.3 Perceptual enhancement
This paper also speaks to a long-standing discussion on the role of production vs. perception in sound change and phonology in general. One of the approaches that understands PND as a natural process is the perceptual account outlined in Kirchner (Reference Kirchner2000) and Stanton (Reference Stanton2016b). Post-nasal devoicing can be analyzed as a contrast enhancement with the following reasoning: sequences of a nasal and a voiced stop (ND) are perceptually very close to plain nasal stops (N). In order to enhance the perceptual contrast between N and ND, speakers can devoice stops in the latter sequence to NT. There is no doubt that perceptual (or auditory in Garrett and Johnson’s Reference Garrett and Johnson2013 terms) enhancement plays a role in sound change and phonology (for an overview, see Garrett & Johnson Reference Garrett and Johnson2013, Garrett Reference Garrett, Bowern and Evans2015, Fruehwald Reference Fruehwald2016). For example, lip protrusion in [ʃ] has no articulatory grounding, but a clear perceptual one: lip protrusion results in lowering of the frequency peak, which in turn results in perceptual enhancement of the contrast [ʃ]
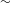 ${\sim}$
[s]. The majority of cases of perceptual enhancement discussed in Garrett & Johnson (Reference Garrett and Johnson2013) or Garrett (Reference Garrett, Bowern and Evans2015), however, involve phonetic properties of phonemes in all positions. Additionally, I am not aware of cases of perceptual enhancement that would operate in the unnatural direction, as would be the case for PND. Perceptual factors usually play a role in enhancing a contrast that already has some underlying articulatory motivation and consequently underlying phonetic motivation (e.g. vowel lengthening before voiced stops in English; de Jong Reference de Jong1991, Reference de Jong2004; Solé Reference Solé, Solé and Beddor2007; Beguš Reference Beguš2017).Footnote
[13]
Below, I argue that the unnatural PND does not result from perceptual enhancement, but from a combination of three natural sound changes. To be sure, this does not suggest that perceptual enhancement is not a possible mechanism for sound change, but only that perceptual enhancement is likely not the underlying cause of PND.
${\sim}$
[s]. The majority of cases of perceptual enhancement discussed in Garrett & Johnson (Reference Garrett and Johnson2013) or Garrett (Reference Garrett, Bowern and Evans2015), however, involve phonetic properties of phonemes in all positions. Additionally, I am not aware of cases of perceptual enhancement that would operate in the unnatural direction, as would be the case for PND. Perceptual factors usually play a role in enhancing a contrast that already has some underlying articulatory motivation and consequently underlying phonetic motivation (e.g. vowel lengthening before voiced stops in English; de Jong Reference de Jong1991, Reference de Jong2004; Solé Reference Solé, Solé and Beddor2007; Beguš Reference Beguš2017).Footnote
[13]
Below, I argue that the unnatural PND does not result from perceptual enhancement, but from a combination of three natural sound changes. To be sure, this does not suggest that perceptual enhancement is not a possible mechanism for sound change, but only that perceptual enhancement is likely not the underlying cause of PND.
Two studies of apparent PND have recently argued that the process is perceptually motivated. Stanton (Reference Stanton2016b: 1106) identifies a number of languages that devoice sequences of ND to NT word-finally, but not word-medially: Neverver, Kobon, Naman, Avava, Páez, and Tape. This distribution can be analyzed as contrast enhancement word-finally, where the contrast is additionally reduced. Lapierre (Reference Lapierre2018) similarly argues that devoicing of ND to NT in Panará can be motivated as perceptual enhancement of the contrast between the following nasal and oral vowels.
These proposals, however, face problems. First, it needs to be stressed that all languages with alleged PND in Stanton (Reference Stanton2016b) and Lapierre (Reference Lapierre2018) lack plain voiced stops in their inventories altogether: all voiced stops are pre-nasalized (ND) and there is no series of plain voiced stops (D). The reported PND is thus better analyzed as unconditioned (or word-final) devoicing of voiced stops and as such does not qualify as a true case of PND: it is not the case that voiced stops devoice post-nasally and not elsewhere. For example, the languages with reported PND in word-final position in Stanton (Reference Stanton2016b: 1106) (Neverver, Kobon, Naman, Avava, Páez, and Tape) lack plain voiced stops completely. Final ![]() can thus simply be analyzed as devoicing of voiced stops in word-final position, which is a phonetically well-motivated development and does not lend support to the perceptual enhancement explanation.
can thus simply be analyzed as devoicing of voiced stops in word-final position, which is a phonetically well-motivated development and does not lend support to the perceptual enhancement explanation.
The Panará example is even more relevant to our discussion (Lapierre Reference Lapierre2018). Panará and Timbira lack phonemic voiced stops altogether: the inventory only features voiceless stops and nasals. Nasals (N) and pre-nasalized stops (ND) are in complementary distribution in Proto-Jê: before an oral vowel, the nasal stop /N/ is realized as [ND]. Proto-Jê ND surfaces as devoiced NT in Panará and Timbira (Lapierre Reference Lapierre2018). The Panará example rules out devoicing as an enhancement between N and ND: in Pre-Panará, N and ND do not contrast, but are in allophonic distribution (one before nasal vowels and the other before oral vowels), which means there is no contrast between N and ND to be enhanced. It is true that devoicing can still be analyzed as enhancement of the contrast between the following nasal and oral vowel (as proposed in Lapierre Reference Lapierre2018). Herbert (Reference Herbert1986) (via Stanton Reference Stanton2018b), Stanton (Reference Stanton2018b), and others propose that shielding (e.g. NV
 $\rightarrow$
NDV) is contrast enhancement – but oral closure in ND is sufficient that the nasalization would not spread into the following vowel. The perceptual analysis should show that devoicing (or longer oral release along the lines of Stanton’s Reference Stanton2018a explanation) increases the contrast between the following V and Ṽ. The mechanisms for this enhancement are not immediately obvious and experimental evidence is, to my knowledge, lacking. The alternative proposal where devoicing of ND in Panará and Timbira is analyzed as unconditioned devoicing of voiced stops is strongly supported by comparative evidence. All voiced stops (both plain and pre-nasalized) in other closely related languages devoice unconditionally (either simultaneously or D devoices before ND) (Nikulin Reference Nikulin2017). In other words, unconditioned devoicing of voiced stops operated as a sound change in the pre-history of Panará and Timbira. Devoicing of the pre-nasalized voiced series (ND) is thus just an extension of such a sound change. In Section 3.3, I will propose that such unconditioned devoicing of stops is precisely what underlies all thirteen cases of PND in which voiced stops seemingly devoice only post-nasally and are preserved elsewhere.
$\rightarrow$
NDV) is contrast enhancement – but oral closure in ND is sufficient that the nasalization would not spread into the following vowel. The perceptual analysis should show that devoicing (or longer oral release along the lines of Stanton’s Reference Stanton2018a explanation) increases the contrast between the following V and Ṽ. The mechanisms for this enhancement are not immediately obvious and experimental evidence is, to my knowledge, lacking. The alternative proposal where devoicing of ND in Panará and Timbira is analyzed as unconditioned devoicing of voiced stops is strongly supported by comparative evidence. All voiced stops (both plain and pre-nasalized) in other closely related languages devoice unconditionally (either simultaneously or D devoices before ND) (Nikulin Reference Nikulin2017). In other words, unconditioned devoicing of voiced stops operated as a sound change in the pre-history of Panará and Timbira. Devoicing of the pre-nasalized voiced series (ND) is thus just an extension of such a sound change. In Section 3.3, I will propose that such unconditioned devoicing of stops is precisely what underlies all thirteen cases of PND in which voiced stops seemingly devoice only post-nasally and are preserved elsewhere.
The fact that in some varieties of Setswana, PND involves not only devoicing but also ejection likewise fails to support the enhancement explanation. Gouskova et al. (Reference Gouskova, Zsiga and Boyer2011) observe that PND in Setswana occasionally results in ejective stops. This distribution would be in line with the perceptual enhancement approach: to maximize the contrast, the speaker can use ejection as an additional cue for the original N
 ${\sim}$
ND contrast. While it is true that some stops in Setswana are realized with ‘weak’ ejection, this does not necessarily point to perceptual enhancement either. Setswana has three series of stops: voiced (D), voiceless aspirated
${\sim}$
ND contrast. While it is true that some stops in Setswana are realized with ‘weak’ ejection, this does not necessarily point to perceptual enhancement either. Setswana has three series of stops: voiced (D), voiceless aspirated ![]() and voiceless unaspirated that are in variation with ejective articulation (T/T’). While at first glance, the alternation between voiced stops elsewhere and voiceless unaspirated/ejective (T/T’) in post-nasal position appears to be fortition, it can also be analyzed simply as devoicing and is actually expected under the historical approach presented below. From the data described in Gouskova et al. (Reference Gouskova, Zsiga and Boyer2011), it appears that the ratio of voiceless unaspirated vs. ejective articulation in the T/T’-series of stops is not much higher in post-nasal position than in the elsewhere condition. For example, Gouskova et al. (Reference Gouskova, Zsiga and Boyer2011) count the number of recorded tokens that have ambiguous acoustics (can be interpreted as either ejective or voiceless aspirated) and the number of unambiguous ejectives. In post-nasal position, the ratio is 41 (ambiguous) to 60 (ejective), and in intervocalic position 43 (ambiguous) to 54 (ejective). This means that ejection in post-nasal position can be analyzed as part of the common trend in Setswana to realize unaspirated voiceless stops (and in our case, devoiced stops) with ejection. In fact, I will argue below that PND in Tswana results from a combination of sound changes (following Dickens Reference Dickens1984, Hyman Reference Hyman, Hume and Johnson2001), one of which is the devoicing of all voiced stops. Because voiced stops have significantly less aspiration than voiceless aspirated stops, we expect a devoiced variant of an unaspirated voiced stop to be phonetically closest to the voiceless unaspirated series (T). This series of stops can then get realized as ejective (either when devoicing occurs or after), which would explain the Setswana distribution without resorting to post-nasal fortition or contrast enhancement.
and voiceless unaspirated that are in variation with ejective articulation (T/T’). While at first glance, the alternation between voiced stops elsewhere and voiceless unaspirated/ejective (T/T’) in post-nasal position appears to be fortition, it can also be analyzed simply as devoicing and is actually expected under the historical approach presented below. From the data described in Gouskova et al. (Reference Gouskova, Zsiga and Boyer2011), it appears that the ratio of voiceless unaspirated vs. ejective articulation in the T/T’-series of stops is not much higher in post-nasal position than in the elsewhere condition. For example, Gouskova et al. (Reference Gouskova, Zsiga and Boyer2011) count the number of recorded tokens that have ambiguous acoustics (can be interpreted as either ejective or voiceless aspirated) and the number of unambiguous ejectives. In post-nasal position, the ratio is 41 (ambiguous) to 60 (ejective), and in intervocalic position 43 (ambiguous) to 54 (ejective). This means that ejection in post-nasal position can be analyzed as part of the common trend in Setswana to realize unaspirated voiceless stops (and in our case, devoiced stops) with ejection. In fact, I will argue below that PND in Tswana results from a combination of sound changes (following Dickens Reference Dickens1984, Hyman Reference Hyman, Hume and Johnson2001), one of which is the devoicing of all voiced stops. Because voiced stops have significantly less aspiration than voiceless aspirated stops, we expect a devoiced variant of an unaspirated voiced stop to be phonetically closest to the voiceless unaspirated series (T). This series of stops can then get realized as ejective (either when devoicing occurs or after), which would explain the Setswana distribution without resorting to post-nasal fortition or contrast enhancement.
There exists some additional evidence against the perceptual enhancement explanation of PND. First, there are currently no experimental studies supporting the claim that NT is perceptually more salient than N or ND in intervocalic position. Kaplan (Reference Kaplan2008) is the only study known to me that tests this contrast perceptually and does not limit it to final position (Katzir Cozier Reference Katzir Cozier2008). While NT is more salient than N and ND word-finally,Footnote
[14]
no such significant effect has been found word-medially: all three stimuli, N, NT, and ND, were perceived with equal rates (Kaplan Reference Kaplan2008). While this result could also be due to a ceiling effect, it nevertheless shows that the contrast between ND/N and NT is substantially more salient in intervocalic position than word-finally. This means that, according to the perceptual enhancement approach, we would expect many more cases of word-final PND than of unrestricted PND. As already mentioned, all cases in Stanton (Reference Stanton2016b) are better analyzed as word-final stop devoicing and, to my knowledge, no cases of true word-final PND are attested (where voiced stops remain voiced word-finally except if preceded by a nasal). Second, PND is not attested as a repair strategy even in cases where we should expect it. For example, many languages disallow NC
 $_{1}$
VNC
$_{1}$
VNC
 $_{2}$
sequences. A recent study in Stanton (Reference Stanton, Hammerly and Prickett2016a, Reference Stanton2018a) suggests that avoidance of these sequences constitutes a strategy to avoid a difficult contrast with NVNC
$_{2}$
sequences. A recent study in Stanton (Reference Stanton, Hammerly and Prickett2016a, Reference Stanton2018a) suggests that avoidance of these sequences constitutes a strategy to avoid a difficult contrast with NVNC
 $_{2}$
. The vowel in NC
$_{2}$
. The vowel in NC
 $_{1}$
VNC
$_{1}$
VNC
 $_{2}$
is universally phonetically nasalized, a process which reduces cues for the contrast between NC
$_{2}$
is universally phonetically nasalized, a process which reduces cues for the contrast between NC
 $_{1}$
and N. One way to repair this contrast would be to devoice the first consonant C
$_{1}$
and N. One way to repair this contrast would be to devoice the first consonant C
 $_{1}$
. However, the survey in Stanton (p.c.) shows that NDVNC
$_{1}$
. However, the survey in Stanton (p.c.) shows that NDVNC
 ${>}$
NTVNC is not attested. It is unclear to me how this gap is explained within the perceptual enhancement approach. Finally, while perceptual enhancement might explain PND, it cannot, to my knowledge, explain other unnatural processes discussed elsewhere (especially intervocalic devoicing; Beguš Reference Beguš2018).
${>}$
NTVNC is not attested. It is unclear to me how this gap is explained within the perceptual enhancement approach. Finally, while perceptual enhancement might explain PND, it cannot, to my knowledge, explain other unnatural processes discussed elsewhere (especially intervocalic devoicing; Beguš Reference Beguš2018).
As already mentioned, this paper does not argue against the existence of perceptual enhancement as a sound change in general. A number of arguments presented here, however, favor the three-sound-changes approach over the perceptual enhancement approach when dealing with PND. It seems suspect to suggest that a contrast will only be enhanced when a set of three sound changes happen to operate in the pre-history of a system. Future research involving processes other than PND should show whether other unnatural processes are better explained by perceptual enhancement or the three-sound-change approach called the Blurring Process proposed here.
While I am claiming that PND did not arise as contrast enhancement, I do, however, acknowledge the possibility that perceptual factors play a role in the phonologization of PND and the preservation of the alternation once it arises. It is thus possible that perceptual enhancement helps PND survive as a productive process longer than would be expected otherwise.
3.2.4 Multiple sound changes
Finally, Dickens (Reference Dickens1984) and Hyman (Reference Hyman, Hume and Johnson2001) propose an explanation for PND in Tswana that assumes a set of three non-PND sound changes that conspire to produce apparent PND: fricativization, devoicing of stops, and occlusion of fricatives. I will argue in the remainder of this paper that this is in fact the correct explanation not only for Tswana and Shekgalagari, but that an essentially similar historical scenario played out in all thirteen cases of reported PND described above. Unfortunately, at the time of Dickens’ and Hyman’s work, no historical parallels existed in the literature that would support their explanation, which led other authors to propose alternative accounts of the data (see the three types of explanations in Sections 3.2.1, 3.2.2, and 3.2.3 above). Admittedly, in the absence of typological parallels, one might judge an explanation that operates with a single sound change (motivated by perceptual enhancement, articulatory factors, or hypercorrection) more parsimonious and justified than an explanation that requires three separate sound changes. By bringing numerous cases of PND from disparate language families together and arguing that diachronic developments very similar to that proposed for Tswana in Dickens (Reference Dickens1984) and Hyman (Reference Hyman, Hume and Johnson2001) operated in all thirteen languages, the next section dispels this concern and validates the three-sound-change analysis on typological grounds. In addition, I provide crucial new evidence in favor of the three-sound-change approach and argue that the three sound changes are directly historically attested in Avestan, Sogdian, and Yaghnobi, three languages in an ancestral relationship.
3.3 A combination of sound changes
A closer look into the collected data from Section 3.1 reveals an important generalization: for all cases of PND, either direct evidence or clear indirect evidence can be found that, at some stage of development, voiced stops surfaced as voiced fricatives except in post-nasal position. In other words, in the first stage of the development of PND, a natural sound change operates that fricativizes voiced stops except post-nasally ![]() This sound change results in a complementary distribution: voiced stops surface post-nasally, voiced fricatives elsewhere. I argue that in all thirteen cases PND is a result of this complementary distribution plus the unconditioned devoicing of voiced stops: because voiced stops surface only post-nasally, the unconditioned devoicing results in apparent PND. While this explanation has been proposed for Tswana in Dickens (Reference Dickens1984) and Hyman (Reference Hyman, Hume and Johnson2001), this section argues that the same diachronic scenario plays out in all thirteen cases by pointing to thus far unobserved pieces of evidence in favor of the three-sound-change approach. I also present data from Yaghnobi which offers the most direct evidence in favor of the three-sound-change approach, since all three diachronic stages are historically attested in written sources. Yaghnobi also provides crucial evidence in favor of the assumption that the second sound change, devoicing of voiced stops, is unconditioned.
This sound change results in a complementary distribution: voiced stops surface post-nasally, voiced fricatives elsewhere. I argue that in all thirteen cases PND is a result of this complementary distribution plus the unconditioned devoicing of voiced stops: because voiced stops surface only post-nasally, the unconditioned devoicing results in apparent PND. While this explanation has been proposed for Tswana in Dickens (Reference Dickens1984) and Hyman (Reference Hyman, Hume and Johnson2001), this section argues that the same diachronic scenario plays out in all thirteen cases by pointing to thus far unobserved pieces of evidence in favor of the three-sound-change approach. I also present data from Yaghnobi which offers the most direct evidence in favor of the three-sound-change approach, since all three diachronic stages are historically attested in written sources. Yaghnobi also provides crucial evidence in favor of the assumption that the second sound change, devoicing of voiced stops, is unconditioned.
3.3.1 Yaghnobi
Yaghnobi is a descendant of Sogdian, a Middle Iranian language spoken in the first millennium CE and preserved in documents from that period.Footnote
[15]
In Sogdian, all voiced stops surface as voiced fricatives except post-nasally. This complementary distribution is directly attested in Sogdian and confirmed by the writing system (cf. Sims-Williams Reference Sims-Williams and Schmitt1987: 178). It is equally clear that the Sogdian pattern developed through a sound change ![]() in an earlier stage of the language. In Avestan, which is closely related to Sogdian (but more archaic) and can be used to represent the parent language of Sogdian, voiced stops correspond to Sogdian voiced fricatives except post-nasally, e.g. Avestan [dasa] vs. Sogdian [ðasa] ‘ten’, Avestan [gari-] vs. Sogdian [ɣarí] ‘mountain’ (Kümmel Reference Kümmel2006), Avestan [asənga-] vs. Sogdian [sang] ‘stone’ (Bartholomae Reference Bartholomae1961: 210).Footnote
[16]
in an earlier stage of the language. In Avestan, which is closely related to Sogdian (but more archaic) and can be used to represent the parent language of Sogdian, voiced stops correspond to Sogdian voiced fricatives except post-nasally, e.g. Avestan [dasa] vs. Sogdian [ðasa] ‘ten’, Avestan [gari-] vs. Sogdian [ɣarí] ‘mountain’ (Kümmel Reference Kümmel2006), Avestan [asənga-] vs. Sogdian [sang] ‘stone’ (Bartholomae Reference Bartholomae1961: 210).Footnote
[16]
Given the complementary distribution attested in Sogdian, I propose that, on the way to Yaghnobi, an additional sound change operated: unconditioned devoicing of voiced stops (D
 ${>}$
T; for phonetic motivation and attestations of this change, see Section 3.4). Evidence for this sound change in Yaghnobi is attested as directly as a sound change can be attested diachronically: Stage 2 (Sogdian) which is attested in written sources features voiced stops which surface as voiceless at Stage 3 (Yaghnobi). Because voiced stops surface after nasals, this combination of sound changes results in apparent PND. The development is summarized in Table 12.
${>}$
T; for phonetic motivation and attestations of this change, see Section 3.4). Evidence for this sound change in Yaghnobi is attested as directly as a sound change can be attested diachronically: Stage 2 (Sogdian) which is attested in written sources features voiced stops which surface as voiceless at Stage 3 (Yaghnobi). Because voiced stops surface after nasals, this combination of sound changes results in apparent PND. The development is summarized in Table 12.
Table 12 Development of PND from Avestan to Yaghnobi.

Sogdian thus provides direct historical evidence showing that the apparent case of PND in Yaghnobi is a side effect of two natural and well-attested sound changes: (i) fricativization of voiced stops except in post-nasal position ![]() and (ii) unconditioned devoicing of voiced stops (D
and (ii) unconditioned devoicing of voiced stops (D
 ${>}$
T).
${>}$
T).
To get PND, we need a third sound change: occlusion of voiced fricatives to stops (Z
 ${>}$
D). Yaghnobi provides additional evidence for this process too: the original voiced labial and velar stops (Avestan [b] and [g] that develop to Sogdian [β] and [ɣ] in the elsewhere position) still surface as voiced fricatives [v] and [ɣ] in the elsewhere position in modern Yaghnobi (e.g. Yagh. [vant] ‘tie’ from Sogd. [βand]; Yagh. [ɣar] ‘mountain’ from Sogd. [ɣarí]). Nevertheless, the voiced dental fricative (Sogdian [ð]) in the elsewhere position gets occluded in Yaghnobi and surfaces as a voiced stop [d] (Xromov Reference Xromov1972: 123), thus blurring the original complementary distribution. Apparent PND in Yaghnobi thus fully holds only for the dental series of stops, because only this series of stops underwent a sound change that turned the original voiced fricatives ‘back’ to stops (Z
${>}$
D). Yaghnobi provides additional evidence for this process too: the original voiced labial and velar stops (Avestan [b] and [g] that develop to Sogdian [β] and [ɣ] in the elsewhere position) still surface as voiced fricatives [v] and [ɣ] in the elsewhere position in modern Yaghnobi (e.g. Yagh. [vant] ‘tie’ from Sogd. [βand]; Yagh. [ɣar] ‘mountain’ from Sogd. [ɣarí]). Nevertheless, the voiced dental fricative (Sogdian [ð]) in the elsewhere position gets occluded in Yaghnobi and surfaces as a voiced stop [d] (Xromov Reference Xromov1972: 123), thus blurring the original complementary distribution. Apparent PND in Yaghnobi thus fully holds only for the dental series of stops, because only this series of stops underwent a sound change that turned the original voiced fricatives ‘back’ to stops (Z
 ${>}$
D). Table 13 illustrates the three sound changes that operated on the dental series of stops to produce PND.
${>}$
D). Table 13 illustrates the three sound changes that operated on the dental series of stops to produce PND.
Table 13 Development of coronals from Avestan to Yaghnobi.

Yaghnobi and Sogdian contain yet more crucial evidence in favor of the three-sound-change approach outlined above. One of the most serious objections to the three-sound-change approach in Yaghnobi and elsewhere is that devoicing should not be analyzed as unconditioned, but as post-nasal – precisely because it operates only in post-nasal position. This being the case, devoicing should indeed be considered unnatural according to the definition in (2). However, Sogdian and Yaghnobi provide strong and unique evidence to suggest that devoicing of voiced stops is in fact unconditioned. I show below that devoicing targets all surface voiced stops in Yaghnobi, not just those in post-nasal position.
It is true that voiced stops surface primarily in post-nasal position in Sogdian, but they also surface in one additional, more marginal context: after voiced fricatives. The origin of such a distribution is straightforward: original voiced stops did not fricativize (i) after nasals (as already mentioned above) and (ii) after another fricative in order to avoid clusters of two fricatives. This property of Sogdian and Yaghnobi, which has up to now been a less discussed fact (Novák Reference Novák2013), essentially means that voiced stops surface as fricatives in Sogdian in all positions except post-nasally (ND) and occasionally after a voiced fricative (ZD). We already saw that ND sequences devoice to NT in Yaghnobi. Crucially, Sogdian sequences of a voiced fricative and a voiced stop (ZD), too, devoice in the development from Sogdian to Yaghnobi – to ST (in central and western dialects),Footnote
[17]
e.g. Sogd. [pəzda], Yagh. [past] or [pajst] ‘smoke’; potentially also Sogd. ![]() Yagh. [duxtar]; Sogd. [suɣd-], Yagh. [suxta]; Sogd. [əχʃɨβdi], Yagh. [xiʃift]Footnote
[18]
(from Novák Reference Novák2013, Reference Novák2014 and Xromov Reference Xromov1987). This devoicing is automatically explained by my proposal that voiced stops devoice unconditionally in Yaghnobi. ZD is thus predicted to first develop to ZT and then to ST when the voiced fricative assimilates in voicing to the following voiceless stop. That this scenario indeed took place is suggested by evidence from Western Yaghnobi, in which forms like [avd] and [avt] for Sogd. [əβd´a] are attested (data from Novák Reference Novák2014). While the first form [avd] dialectally lacks devoicing, the second form [avt] shows that only voiced stops devoice: the fricative is not yet assimilated to the following voiceless stop (compare the assimilated form from Eastern Yaghnobi [aft]).
Yagh. [duxtar]; Sogd. [suɣd-], Yagh. [suxta]; Sogd. [əχʃɨβdi], Yagh. [xiʃift]Footnote
[18]
(from Novák Reference Novák2013, Reference Novák2014 and Xromov Reference Xromov1987). This devoicing is automatically explained by my proposal that voiced stops devoice unconditionally in Yaghnobi. ZD is thus predicted to first develop to ZT and then to ST when the voiced fricative assimilates in voicing to the following voiceless stop. That this scenario indeed took place is suggested by evidence from Western Yaghnobi, in which forms like [avd] and [avt] for Sogd. [əβd´a] are attested (data from Novák Reference Novák2014). While the first form [avd] dialectally lacks devoicing, the second form [avt] shows that only voiced stops devoice: the fricative is not yet assimilated to the following voiceless stop (compare the assimilated form from Eastern Yaghnobi [aft]).
Conversely, my model proposes voiced fricatives and consequently clusters of voiced fricatives do not devoice. This proposal is borne out by the data: Sogdian clusters of two voiced fricatives (that arise from a cluster of a voiced fricative and an approximant [dw]), [ðβ], do not devoice in Yaghnobi:Footnote
[19]
Sogd. [ðβəri] ‘door’ and [əzβa:k] ‘tongue, language’ yield Yagh. ![]() and
and ![]() (Novák Reference Novák2013). Table 14 illustrates the development of voiced fricative–stop and fricative–fricative sequences.
(Novák Reference Novák2013). Table 14 illustrates the development of voiced fricative–stop and fricative–fricative sequences.
Table 14 Correspondences of ZD and ZZ sequences.

Sequences of a voiced fricative and a voiced stop ZD that devoice in Yaghnobi to ST strongly support the claim that voiced stops undergo unconditioned (not only post-nasal) devoicing in Yaghnobi: all voiced stops that surface in the Sogdian and pre-Yaghnobi system get devoiced in the development of Yaghnobi. The development of ZD clusters in Yaghnobi is summarized in Table 15.
Table 15 Development of ZD sequences from Sogdian to Yaghnobi.

In the other twelve languages with PND, non-nasal clusters are generally not allowed (or they became simplified before the emergence of PND), so we do not see devoicing anywhere other than in post-nasal position. Devoicing in clusters in Yaghnobi thus offers a crucial piece of evidence in favor of the proposal that the devoicing of voiced stops that occurs in the development of PND is unconditioned; if it were not, we would not be able to unify our account of the devoicing of ND and ZD.
3.3.2 Tswana, Shekgalagari, and Makhuwa
If Yaghnobi provides crucial evidence for the three-sound-change approach on historical grounds, Tswana offers crucial dialectal evidence for this hypothesis. There are at least three different systems of stops in the microdialects of Tswana. Among one set of speakers, voiced stops get devoiced in all environments: no voiced stops are allowed in the system. Speakers of this system have been labeled ‘devoicers’ (Coetzee, Lin & Pretorius Reference Coetzee, Lin, Pretorius, Trouvain and Barry2007: 861). Another set of speakers changes voiced stops into fricatives in all positions but post-nasally (these speakers are called ‘leniters’; Coetzee et al. Reference Coetzee, Lin, Pretorius, Trouvain and Barry2007: 861). A third set of speakers use the so-called PND system: for these speakers, voiced stops surface as voiceless only post-nasally (Zsiga, Gouskova & Tlale Reference Zsiga, Gouskova, Tlale, Davis and Rose2006, Coetzee et al. Reference Coetzee, Lin, Pretorius, Trouvain and Barry2007, Coetzee & Pretorius Reference Coetzee and Pretorius2010). The three systems of Tswana are represented in Table 16.
Table 16 Microdialects of Tswana (from Zsiga et al. Reference Zsiga, Gouskova, Tlale, Davis and Rose2006, Coetzee et al. Reference Coetzee, Lin, Pretorius, Trouvain and Barry2007).

As Hyman (Reference Hyman, Hume and Johnson2001) argues, the PND system arises precisely through the combination of two other (devoicing and leniting) systems: leniters take on fricativization except after nasals ![]() while devoicers undergo unconditioned devoicing (D
while devoicers undergo unconditioned devoicing (D
 ${>}$
T). Following Dickens (Reference Dickens1984), Hyman (Reference Hyman, Hume and Johnson2001) argues that post-nasal devoicers undergo both sound changes. In other words, Dickens (Reference Dickens1984) and Hyman (Reference Hyman, Hume and Johnson2001) argue that PND in Tswana results from a combination of three sound changes, the first of which is fricativization of voiced stops except post-nasally (the sound change that operates in the leniters’ system). Unconditioned devoicing happens next (the sound change that operates in the devoicers’ system), and because voiced stops surface only after nasals, the result is apparent PND. This interstage is confirmed by Kutswe, a variety of Sotho in which the alternation is between [p] post-nasally and [β] elsewhere (as mentioned in Dickens Reference Dickens1984). This pattern is obscured in Tswana and Shekgalagari, however, by an additional change in the dialect with PND: unconditioned occlusion of fricatives (Z
${>}$
T). Following Dickens (Reference Dickens1984), Hyman (Reference Hyman, Hume and Johnson2001) argues that post-nasal devoicers undergo both sound changes. In other words, Dickens (Reference Dickens1984) and Hyman (Reference Hyman, Hume and Johnson2001) argue that PND in Tswana results from a combination of three sound changes, the first of which is fricativization of voiced stops except post-nasally (the sound change that operates in the leniters’ system). Unconditioned devoicing happens next (the sound change that operates in the devoicers’ system), and because voiced stops surface only after nasals, the result is apparent PND. This interstage is confirmed by Kutswe, a variety of Sotho in which the alternation is between [p] post-nasally and [β] elsewhere (as mentioned in Dickens Reference Dickens1984). This pattern is obscured in Tswana and Shekgalagari, however, by an additional change in the dialect with PND: unconditioned occlusion of fricatives (Z
 ${>}$
D). After this change, voiced stops surface as voiceless after nasals and, crucially, the feature [
${>}$
D). After this change, voiced stops surface as voiceless after nasals and, crucially, the feature [
 $\pm$
voice] is fully contrastive in the elsewhere condition (Hyman Reference Hyman, Hume and Johnson2001). Recall that this final sound change also occurred in Yaghnobi, but only for the dental series of stops.
$\pm$
voice] is fully contrastive in the elsewhere condition (Hyman Reference Hyman, Hume and Johnson2001). Recall that this final sound change also occurred in Yaghnobi, but only for the dental series of stops.
The attestation of the subdialect of Tswana that has unconditioned devoicing of voiced stops also speaks against analyses that assume PND results from the reduced functional load of the contrast in the feature [
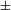 $\pm$
voice] in post-nasal stops, when voiced stops develop to voiced fricatives elsewhere (see Section 3.2). In the ‘devoicer’ subdialect (Coetzee et al. Reference Coetzee, Lin, Pretorius, Trouvain and Barry2007: 861), unconditioned devoicing occurs without the development of voiced stops to fricatives (i.e. when the feature [
$\pm$
voice] in post-nasal stops, when voiced stops develop to voiced fricatives elsewhere (see Section 3.2). In the ‘devoicer’ subdialect (Coetzee et al. Reference Coetzee, Lin, Pretorius, Trouvain and Barry2007: 861), unconditioned devoicing occurs without the development of voiced stops to fricatives (i.e. when the feature [
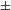 $\pm$
voice] is fully contrastive).
$\pm$
voice] is fully contrastive).
The pattern of development of Tswana voiceless stops provides a structural parallel that speaks in favor of the proposed explanation. As Hyman (Reference Hyman, Hume and Johnson2001) points out, voiceless stops underwent fricativization (except post-nasally) along with voiced stops. Table 17 shows this development.
Table 17 Development of voiceless stops in Tswana with examples (table from Hyman Reference Hyman, Hume and Johnson2001).

The data in Table 17 provide yet another piece of evidence that complementary distribution occurred first in the development of PND in Tswana and related dialects, in both the voiced and voiceless series of stops (Hyman Reference Hyman, Hume and Johnson2001). The voiceless and voiced series underwent lenition except in post-nasal position (as in the leniters dialect), and then voiced stops underwent further changes (unconditioned devoicing, as in the devoicers dialect) to produce PND, whereas voiceless stops retained the complementary distribution (Table 17).Footnote [20]
3.3.3 Bube and Mpongwe
Despite the fact that Bube and Mpongwe are not closely related to Tswana, Shekgalagari, and Makhuwa, we find striking similarities between these languages that uniformly point to the conclusion that complementary distribution (with lenition of voiced stops except post-nasally) operated in the pre-history of Bube and Mpongwe, too. The data for the two languages, however, is sparse and detailed phonetic descriptions are lacking.
Several indicators in Bube data clearly point to a pre-stage with complementary distribution. Janssens (Reference Janssens1993: 37) reports that in the labial series, the voiced stop and voiced fricative [b] and [β] are in free variation in medial position. Also, exactly parallel to Tswana, the voiced velar stop is lost in Bube, pointing indirectly to an interstage with [ɣ] (also reconstructed independently in Janssens Reference Janssens1993: 27). Finally, the dental series of stops undergoes lenition as expected: in the elsewhere condition, [d] develops to [l] or [r] (likely through an interstage *[ð]), depending on the vowel quality, e.g. ![]() (Janssens Reference Janssens1993: 23). In fact, Janssens independently reconstructs a proto-stage of Bube with exactly the complementary distribution we observe in other languages with PND: voiced stops surface as fricatives except post-nasally.
(Janssens Reference Janssens1993: 23). In fact, Janssens independently reconstructs a proto-stage of Bube with exactly the complementary distribution we observe in other languages with PND: voiced stops surface as fricatives except post-nasally.
In Mpongwe, PND that targets only the velar series also arises through a combination of three sound changes. Mouguiama-Daouda (Reference Mouguiama-Daouda1990) independently reconstructs a stage in which [g] surfaced as a voiced velar fricative [ɣ] except post-nasally, citing as evidence the fact that the voiced velar stop is still realized as [ɣ] by some older speakers (Mouguiama-Daouda Reference Mouguiama-Daouda1990). PND in Bube and Mpongwe thus follows the usual trajectory: complementary distribution and unconditioned devoicing of stops that surface only post-nasally.
3.3.4 Konyagi
Konyagi and related languages, too, provide strong evidence in favor of a stage with complementary distribution, just like in Yaghnobi or Tswana. Proto-Tenda, an ancestor of Konyagi, is reconstructed on the basis of Konyagi and its neighboring languages Basari and Bedik (Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb). The first stage of Proto-Tenda features a phonemic inventory with voiced and voiceless stops and fricatives. In Stage II, all stops fricativized everywhere but in post-nasal position. This fricativization in Proto-Tenda was quite radical, targeting both voiced and voiceless stops, as well as nasal stops (Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb) and, as I reconstruct, geminates/clusters.Footnote [21] The fricativization is directly confirmed by the Basari dialect, which preserves the Proto-Tenda II stage with minor deviations. Table 18 shows the development of consonants in non-post-nasal position from Proto-Tenda I and II to Basari and Konyagi. Just like in Basari, original voiced stops surface as fricatives in Konyagi (further developing to sonorants in some places of articulation), except after nasals.
Table 18 Development of non-post-nasal consonants from Proto-Tenda to Konyagi (table from Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb; Santos Reference Santos1996).

As already mentioned, Proto-Tenda voiced stops remain stops in post-nasal position. Table 19 summarizes the development of consonants in post-nasal position in the descendants of Proto-Tenda (from Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb, p.c.).Footnote [22] Post-nasally, no fricatives occur in either Konyagi or Basari.
Table 19 Development of post-nasal consonants from Proto-Tenda to Konyagi (table from Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb; Santos Reference Santos1996).

While in Bedik and Basari, original post-nasal voiced stops remain voiced, they devoice in Konyagi. Here too, however – like in all other cases of PND – the voiced stops that devoice post-nasally were in fact the only voiced stops in the language (the stage confirmed in today’s Basari). Thus, again, the sound change operating in Konyagi is in fact unconditioned devoicing of voiced stops. The apparent PND is once more the result of a combination of sound changes.
The third sound change, occlusion back to stops, is lacking in Konyagi. As a result, it is not voiceless and voiced stops that alternate at some stage of development in Konyagi, but rather voiced fricatives and voiceless stops. Konyagi, however, does not lack voiced stops completely: original fricative geminates were later occluded to stops and simplified, resulting in voiced stops being reintroduced into the synchronic inventory.Footnote [23] All these changes result in a synchronic mutation system that involves voiced and voiceless stops and voiced fricatives or approximants (see Section 3.5).
So far, I have argued that all cases of apparent PND can be accounted for through a combination of two or three well-motivated sound changes. I now turn to a case of PND from the South Italian dialects to illustrate that such sound change combinations involving complementary distribution are not limited to stops, but can apply to other segments as well.
3.3.5 South Italian
On the surface, the data in South Italian suggest that *ʤ devoices to [ʧ] only in post-nasal position (Section 3.1.5). However, if we look at the development of *ʤ elsewhere, we observe that it gets de-occluded and further develops to [j] except after nasals (e.g. *faʤina
 ${>}$
Calabrian [fajina], *leʤere
${>}$
Calabrian [fajina], *leʤere
 ${>}$
Calabrian [lejere], Sicilian [lejiri]; Rohlfs Reference Rohlfs1949: 358). Given the cases of PND discussed so far, de-occlusion of the affricate and the development to the glide provides evidence for a stage with complementary distribution. At the point when *ʤ appears post-nasally and [j] (or probably *ʒ) elsewhere, an unconditioned devoicing of voiced affricates occurs. This, too, is a well-attested and motivated sound change: voiced affricates are highly dispreferred, which is why devoicing is a natural tendency in these segments. Voice is difficult to maintain, especially in affricates, which combine two articulations that are highly antagonistic to voicing: closure and frication (Ohala Reference Ohala and MacNeilage1983, Reference Ohala and Brown2006). Table 20 illustrates the reconstructed development: Stage 2 shows a period of complementary distribution, and Stage 3 represents the development after the unconditioned devoicing of voiced affricates.
${>}$
Calabrian [lejere], Sicilian [lejiri]; Rohlfs Reference Rohlfs1949: 358). Given the cases of PND discussed so far, de-occlusion of the affricate and the development to the glide provides evidence for a stage with complementary distribution. At the point when *ʤ appears post-nasally and [j] (or probably *ʒ) elsewhere, an unconditioned devoicing of voiced affricates occurs. This, too, is a well-attested and motivated sound change: voiced affricates are highly dispreferred, which is why devoicing is a natural tendency in these segments. Voice is difficult to maintain, especially in affricates, which combine two articulations that are highly antagonistic to voicing: closure and frication (Ohala Reference Ohala and MacNeilage1983, Reference Ohala and Brown2006). Table 20 illustrates the reconstructed development: Stage 2 shows a period of complementary distribution, and Stage 3 represents the development after the unconditioned devoicing of voiced affricates.
Table 20 Devoicing of post-nasal affricates in South Italian.

Note that this set of sound changes is in principle the same as in the previous cases, but here complementary distribution targets affricates instead of stops. Also, Stage 4 is absent from South Italian: the change that would occlude [j] to [ʤ] is absent.
3.3.6 Buginese and Murik
The emergent pattern that we have seen in all the apparent cases of PND so far can be generalized as follows: (1) a set of segments enters complementary distribution; (2) a sound change occurs that operates on the unchanged subset of those segments; (3) optionally, another sound change occurs that blurs the original complementary distribution.
Let us now turn to the three Austronesian languages. On the surface, the data from Buginese and Murik seem to point to PND operating as a single sound change. Moreover, there is no direct historical or dialectal evidence to suggest otherwise, as is the case for Yaghnobi, Tswana, and Konyagi. If the only attested instances of PND were those found in Austronesian languages, we would likely be forced to assume the operation of a single sound change – PND. However, these languages do, at least, show clear traces of a stage with complementary distribution. Below, I argue that the three-sound-change explanation again better captures the data, despite the lack of direct historical or dialectal evidence.
The main evidence against PND as a single sound change in Austronesian comes from the voiced labial stop in Buginese. Already in Proto-South-Sulawesi (PSS; from which Buginese developed), *b had developed to [w] except word-initially and post-nasally (Mills Reference Mills1975: 547). Later, the change *b
 ${>}$
[w] also targeted the word-initial position, as is clear from initial stop in cases like *bumbun
${>}$
[w] also targeted the word-initial position, as is clear from initial stop in cases like *bumbun
 ${>}$
[wumpun]. Thus, at one stage in the language’s development, voiced labial stops surfaced only post-nasally: again, we have clear evidence for complementary distribution. From there, the development followed the trajectory described above: unconditioned devoicing of voiced stops occurred, but produced apparent PND because voiced stops surfaced only post-nasally. The development is illustrated in Table 21.
${>}$
[wumpun]. Thus, at one stage in the language’s development, voiced labial stops surfaced only post-nasally: again, we have clear evidence for complementary distribution. From there, the development followed the trajectory described above: unconditioned devoicing of voiced stops occurred, but produced apparent PND because voiced stops surfaced only post-nasally. The development is illustrated in Table 21.
Table 21 Development of PND in bilabials in Buginese.

In Buginese, /w/ continues to surface as a non-plosive (since only two changes operated in the labial series). Based on the development of the labial series, we can reconstruct that the velar series likewise undergoes complementary distribution and unconditioned devoicing. Unlike the labial series, however, the voiced velar fricative *ɣ undergoes occlusion to [ɡ] (all three sound changes operated in the velar series), thus obscuring evidence for an interstage with complementary distribution. Note that this is precisely the same scenario attested in Yaghnobi, with the only difference being that, in Yaghnobi, it was the dental series of fricatives that underwent occlusion, whereas in Buginese, it was the velar series. The development leading to apparent PND in velars (with all three sound changes operating) is illustrated in Table 22.
Table 22 Development of PND in velars in Buginese.

The dental series of stops in Buginese escapes PND because *d developed to [r] in all positions (*dindiŋ
 ${>}$
[renriŋ]) and, as such, became ineligible for the devoicing of voiced stops. The development of *z also conforms to the proposal above: intervocalically, it undergoes rhotacism to [r] (possibly through an interstage with *ʝ); post-nasally, I reconstruct it occludes to *ɟ and devoices to [c] (according to the unconditioned devoicing of voiced stops which predictably targets the palatals); initially, it remains a fricative *ʝ and later occludes together with *ɣ to [ɟ] (in other words, there was likely a stage of complementary distribution: *ɟ post-nasally, *ʝ/r elsewhere).
${>}$
[renriŋ]) and, as such, became ineligible for the devoicing of voiced stops. The development of *z also conforms to the proposal above: intervocalically, it undergoes rhotacism to [r] (possibly through an interstage with *ʝ); post-nasally, I reconstruct it occludes to *ɟ and devoices to [c] (according to the unconditioned devoicing of voiced stops which predictably targets the palatals); initially, it remains a fricative *ʝ and later occludes together with *ɣ to [ɟ] (in other words, there was likely a stage of complementary distribution: *ɟ post-nasally, *ʝ/r elsewhere).
The initial stage with complementary distribution in Buginese stops is additionally confirmed by a recent description of Buginese by Valls (Reference Valls2014) which reports that voiced stops [b, d, g] have voiced fricatives [β, ð/ɾ, ɣ] as allophones in apparent free variation in non-post-nasal position. This suggests that the last sound change that turns voiced fricatives to voiced stops is likely in progress in Buginese.
Just like in Buginese, evidence exists that complementary distribution underlies PND in Murik as well. The main evidence comes from the development of voiced alveolar stops. On the surface, Proto-Kayan-Murik *d surfaces as [l] initially, [r] intervocalically, and [t] post-nasally (see Table 23). These data point to a stage with complementary distribution (PKM in Table 23). I propose a historical development with the following trajectory: Proto-Kayan-Murik *d lenited to [l] or [r] (probably through an interstage with *ð) initially and intervocalically. After a nasal, however, *d remained a stop.
Table 23 Reconstructed development of alveolars in Murik.

Next, I argue that unconditioned devoicing of voiced stops occurred. Because devoicing operated during a period when voiced stops surfaced only after nasals, apparent PND is the result. Based on the development of the alveolar series, I reconstruct that fricativization targeted labials and velars too: original voiced stops fricativized to *β and *ɣ (except after a nasal), at which point voiced stops (surfacing only post-nasally) got devoiced (e.g. *b
 ${>}$
[p], *g
${>}$
[p], *g
 ${>}$
[k]). Unlike the alveolars, *β and *ɣ then underwent occlusion ‘back’ to stops, resulting in apparent PND. Table 24 traces the proposed trajectory from (Pre-)Proto-Kayan-Murik to Murik for the labial series of stops.
${>}$
[k]). Unlike the alveolars, *β and *ɣ then underwent occlusion ‘back’ to stops, resulting in apparent PND. Table 24 traces the proposed trajectory from (Pre-)Proto-Kayan-Murik to Murik for the labial series of stops.
Table 24 Reconstructed development of labials in Murik.

A peculiarity of the development in Murik is that it combines the PND of stops that we saw, for example, in Tswana, with the PND of affricates that we saw in Sicilian and Calabrian – i.e., whereas the previously discussed languages devoice either stops or affricates, Murik devoices both. The development of stops in this language is straightforward – it follows the usual trajectory of PND: complementary distribution, unconditioned devoicing, and then optional occlusion to stops (as we saw above). The development of affricates is more complicated, but nevertheless revealing. PMP *z develops to *s intervocalically already in Proto-Kayan-Murik (Blust Reference Blust2005); this development cannot be considered part of PND, because it happens at an earlier stage. Elsewhere, *z is preserved as voiced and palatalizes to *ʝ. Post-nasally, occlusion to an affricate *ɟʝ takes place.Footnote [24] The affricate then gets devoiced, exactly as in Sicilian and Calabrian, together with devoicing of other voiced stops. Because they surface only post-nasally at the time of unconditioned devoicing, the result is apparent PND. I further reconstruct that the initial fricative *ʝ then gets occluded to a voiced stop, together with other voiced fricatives in Murik.Footnote [25]
In sum, even though Buginese and Murik offer neither dialectal nor historical evidence for complementary distribution, there is enough language-internal evidence to posit that, at one stage, voiced stops (and affricates) surfaced only after nasals: the original voiced labial stops surface as fricatives even today in Buginese, whereas in Murik voiced alveolar stops surface as lenited [r] or [l], in accordance with the reconstructed complementary distribution.
3.3.7 Nasioi
That PND in Nasioi results from a combination of three natural sound changes is strongly suggested by Nasioi internal evidence and by diachronic development of its related languages. Evidence for a stage with complementary distribution comes from Nasioi itself: voiced stops /b/ and /d/ surface as a fricative [β] and a flap [ɾ] intervocalically. Lenition of voiced stops in related languages strongly suggests that a complementary distribution consisting of voiced stops developing to voiced fricatives except post-nasally, operated already in pre-Nasioi. In Buin and Nagovisi, for example, [ɾ] and [d] are in complementary distribution whereby [d] surfaces post-nasally and [ɾ] elsewhere (Brown Reference Brown2017). In Motuna, the complementary distribution is not limited to alveolars, but targets labials as well. The stops [b] and [d] are in complementary distribution with [w] and [r] such that the stops surface only post-nasally and the approximants surface elsewhere, including in word-initial position (Onishi 2012). Table 25 summarizes the development of Motuna voiced labial and alveolar stops.
Table 25 Summary of the development of Motuna labial and velar stops (Onishi Reference Onishi2011).

It is reasonable to assume that Motuna represents the proto-stage of Nasioi. In the development of Nasioi, voiced stops devoice, but because they surface only post-nasally, the change looks like post-nasal devoicing. Finally, Nasioi undergoes occlusion of fricatives to stops (like Tswana and Shekgalagari, Yaghnobi, and Buginese and Murik), but this occlusion is contextually limited to the initial and post-obstruent positions (see Section 3.1.7). Intervocalically, voiced fricatives still surface as fricatives. Occlusion of fricatives that is limited to initial position or to clusters is a well-motivated and common sound change (see Kümmel Reference Kümmel2007 and the discussion in Section 3.4 below).
3.4 Naturalness of the three sound changes
All sound changes assumed by the proposals above are natural, that is, both phonetically well motivated and typologically well attested, with clear phonetic precursors. A survey of sound changes in Kümmel (Reference Kümmel2007) lists approximately 56 cases in which voiced stops undergo fricativization in either post-vocalic or intervocalic position (in four cases the non-nasal environment is specifically mentioned), plus an additional two cases in which voiced fricatives occlude to stops post-nasally. Moreover, only two of the 17 surveyed languages with NC sequences permit sequences of nasal
 $+$
continuant phonotactically (Maddieson Reference Maddieson1984, reported in Steriade Reference Steriade, Huffman and Krakow1993). The articulatory reasons for the occlusion of post-nasal fricatives are clear: if in the transition from nasal stop to oral fricative the velum rises early, it causes ‘denasalization of the final portion of the nasal consonant’ (Busà Reference Busà, Solé and Speeter2007: 157) and results ultimately in a period of oral (denasalized) occlusion (see also Ohala Reference Ohala and Jones1993, Reference Ohala1997; Ali et al. Reference Ali, Daniloff and Hammarberg1979). Moll & Daniloff (Reference Moll and Daniloff1971) show that in 83% of English NC(CC) and NCN sequences, the gesture toward velar closure onsets during the nasal consonant: ‘movement toward velar closure is initiated long before the articulatory contact for the non-nasal consonant, usually during the preceding nasal’ (Moll & Daniloff Reference Moll and Daniloff1971: 681). Because the majority of velar closure movements onset simultaneously with the ‘moment of nasal consonant contact’, Moll & Daniloff (Reference Moll and Daniloff1971) speculate that precisely the nasal contact articulation might trigger the early velar movement (also supported by Kent, Carney & Severeid Reference Kent, Carney and Severeid1974).Footnote
[26]
While the mechanisms of epenthetic occlusion in NS clusters are well described, there are relatively few phonetic studies of the process available. The few existing studies observe that epenthetic closure (in NS) is shorter than underlying closure (in NTS), although in some studies this difference fails to reach statistical significance (Fourakis & Port Reference Fourakis and Port1986, Yoo & Blankenship Reference Yoo and Blankenship2003, Recasens Reference Recasens2012, and a discussion in Warner & Weber Reference Warner and Weber2001). A number of properties of epenthesis in NS clusters suggest that the processes is a passive phonetic tendency: epenthesis is often not a categorical process, it operates gradiently, and phonetic properties of epenthetic oral closure differ from the closure of underlying stops.Footnote
[27]
Further phonetic studies on languages other than English are desired (to my knowledge, the only proper phonetic account of this phenomena outside of English is Recasens’s (Reference Recasens2012) study of Valencian Catalan). Despite the lack of phonetic studies, it is safe to assume dispreference of frication post-nasally is a UPT that is typologically common and well motivated.
$+$
continuant phonotactically (Maddieson Reference Maddieson1984, reported in Steriade Reference Steriade, Huffman and Krakow1993). The articulatory reasons for the occlusion of post-nasal fricatives are clear: if in the transition from nasal stop to oral fricative the velum rises early, it causes ‘denasalization of the final portion of the nasal consonant’ (Busà Reference Busà, Solé and Speeter2007: 157) and results ultimately in a period of oral (denasalized) occlusion (see also Ohala Reference Ohala and Jones1993, Reference Ohala1997; Ali et al. Reference Ali, Daniloff and Hammarberg1979). Moll & Daniloff (Reference Moll and Daniloff1971) show that in 83% of English NC(CC) and NCN sequences, the gesture toward velar closure onsets during the nasal consonant: ‘movement toward velar closure is initiated long before the articulatory contact for the non-nasal consonant, usually during the preceding nasal’ (Moll & Daniloff Reference Moll and Daniloff1971: 681). Because the majority of velar closure movements onset simultaneously with the ‘moment of nasal consonant contact’, Moll & Daniloff (Reference Moll and Daniloff1971) speculate that precisely the nasal contact articulation might trigger the early velar movement (also supported by Kent, Carney & Severeid Reference Kent, Carney and Severeid1974).Footnote
[26]
While the mechanisms of epenthetic occlusion in NS clusters are well described, there are relatively few phonetic studies of the process available. The few existing studies observe that epenthetic closure (in NS) is shorter than underlying closure (in NTS), although in some studies this difference fails to reach statistical significance (Fourakis & Port Reference Fourakis and Port1986, Yoo & Blankenship Reference Yoo and Blankenship2003, Recasens Reference Recasens2012, and a discussion in Warner & Weber Reference Warner and Weber2001). A number of properties of epenthesis in NS clusters suggest that the processes is a passive phonetic tendency: epenthesis is often not a categorical process, it operates gradiently, and phonetic properties of epenthetic oral closure differ from the closure of underlying stops.Footnote
[27]
Further phonetic studies on languages other than English are desired (to my knowledge, the only proper phonetic account of this phenomena outside of English is Recasens’s (Reference Recasens2012) study of Valencian Catalan). Despite the lack of phonetic studies, it is safe to assume dispreference of frication post-nasally is a UPT that is typologically common and well motivated.
Unconditioned devoicing of voiced stops is a well-motivated process too. Closure is in all respects antagonistic to voicing for clear aerodynamic reasons: the closure causes air pressure buildup in the oral cavity, which results in an equalization of subglottal and oral pressure. When this happens, the vocal folds are unable to vibrate due to the lack of airflow and voicing ceases. This mechanism has long been known as the Aerodynamic Voicing Constraint (Ohala Reference Ohala and MacNeilage1983, Onishi Reference Onishi2011). The antagonism of closure to voicing is also confirmed by typology: of 706 languages surveyed, 166 have only voiceless stops (Ruhlen Reference Ruhlen1975, reported in Ohala Reference Ohala and MacNeilage1983), among others ‘Cantonese, Hawaiian, Zuñi, Ainu, and Quechua’ (Onishi Reference Onishi2011: 64). In contrast, only four languages are reported to have only voiced stops (Ohala Reference Ohala and MacNeilage1983), and even in those languages, it appears that stops are voiceless initially.Footnote [28] Unconditioned devoicing is also attested as a sound change. In Tocharian and in some subdialects of Tswana (Gouskova et al. Reference Gouskova, Zsiga and Boyer2011), in addition to other examples listed in Kümmel (Reference Kümmel2007), all voiced stops devoice in all positions, including the post-nasal position.
One might question the naturalness of unconditioned devoicing when voiced stops surface exclusively in post-nasal position: what mechanisms motivate devoicing if it operates only in the post-nasal position which itself favors voicing? As defined in (2), naturalness must always be evaluated with respect to a given context. Post-nasally, voicing of voiceless stops is indeed a UPT: voicing passively continues into closure in post-nasal position because nasal leakage and volume expansion counter the anti-voicing effect of closure (compared to stops in other positions). The increased amount of passive voicing, which is a phonetic precursor based on coarticulation, can result in a sound change of PNV. However, voiced stops absent a specific context are nevertheless articulatorily dispreferred when compared to voiceless stops: closure is always antagonistic to voicing for clear aerodynamic reasons. Closure causes airflow to cease because of pressure buildup (Ohala & Riordan Reference Ohala, Riordan, Wolf and Klatt1979). To counter this effect, speakers must passively or actively accommodate for voicing by expanding the volume of the oral cavity; otherwise vocal folds cease to vibrate after 5–15 ms (without any accommodation) or after approximately 70 ms (with only passive accommodation) from the onset of closure (Ohala & Riordan Reference Ohala, Riordan, Wolf and Klatt1979). Because of nasal leakage and volume expansion due to velum rising, speakers need to accommodate for voicing the least in post-nasal condition; much less than, for example, word-initially or word-finally (Westbury & Keating Reference Westbury and Keating1986, Steriade Reference Steriade1997, Iverson & Salmons Reference Iverson, Salmons, van Oostendorp, Ewen, Hume and Rice2011). This means that devoicing that only targets the post-nasal position in a language that has voiced stops in other positions would indeed be unnatural. Despite nasal leakage and volume expansion, however, speakers still need to accommodate for voicing (all else being equal), in order to counter the anti-voicing effect of closure – even in post-nasal position. Failure to accommodate for voicing will result in devoicing, which means that devoicing is motivated post-nasally when it targets other positions as well. If voiced stops happen not to surface other than post-nasally due to an earlier sound change, devoicing is still phonetically motivated precisely because closure is antagonistic to voicing and speakers have to accommodate for voicing in all positions (despite the fact that some environments counter the antagonistic effect of closure on voicing).
That voicing of stops is a phonetic tendency post-nasally, while devoicing is a tendency evaluated on a global, unconditioned level (even for post-nasal position) is strongly suggested by data in Davidson (Reference Davidson2016). Davidson (Reference Davidson2016) acoustically analyzes the percentage of phonation into closure in English voiced obstruents. To my knowledge, the study is one of the largest of its kind and includes 37 speakers and 10,610 tokens. Davidson (Reference Davidson2016) measures voicing into closure of English voiced stops [b], [d], and [ɡ] and divides the stops into three categories: stops are devoiced if phonation ceases within the first 10% of the closure; stops are fully voiced if phonation continues for 90% of the closure; and stops that fall between these two categories are considered partially voiced. The data show that stops have the highest proportion of fully voiced closure precisely in post-nasal position. In other words, evaluating contextually, post-nasal position favors voicing more strongly than any other position, because post-nasal position counters the anti-voicing effects of closure more than other positions (see above for articulatory argumentation). Despite this distribution, devoicing of stops is still a phonetic tendency when evaluated globally, precisely due to the anti-voicing effect of closure (Aerodynamic Voicing Constraint). English voiced stops [b], [d], and [ɡ], despite being phonemically voiced, are devoiced or partially voiced in 22% of cases in word-internal post-nasal prevocalic position ![]() In other words, in 22% of recorded underlying voiced stops in word-medial post-nasal prevocalic position (N
In other words, in 22% of recorded underlying voiced stops in word-medial post-nasal prevocalic position (N
 $=$
272),Footnote
[29]
voicing ceases less than 90% of the way through the closure. This tendency reflects the anti-voicing effect of closure that operates in all environments, including the post-nasal environment, although it is more suppressed post-nasally compared to other positions for clear articulatory reasons.
$=$
272),Footnote
[29]
voicing ceases less than 90% of the way through the closure. This tendency reflects the anti-voicing effect of closure that operates in all environments, including the post-nasal environment, although it is more suppressed post-nasally compared to other positions for clear articulatory reasons.
Two pieces of evidence from the data independently support the position that unconditioned devoicing operates in the development of PND. None of the languages with reported PND, with the exception of Yaghnobi, have non-nasal clusters or permit voiced stops to surface in any other position than post-nasally (at some stage of development). This means that the effect of unconditioned devoicing can only be observed post-nasally. Yaghnobi, however, shows that devoicing of voiced stops operated in its pre-history, not only post-nasally ![]() but also in the other position where voiced stops surfaced: after voiced fricatives
but also in the other position where voiced stops surfaced: after voiced fricatives ![]() In other words, devoicing in Yaghnobi had to be unconditioned rather than limited to post-nasal position, which is clear from the fact that devoicing targeted all positions where voiced stops surfaced: both ND and the more marginal ZD clusters.
In other words, devoicing in Yaghnobi had to be unconditioned rather than limited to post-nasal position, which is clear from the fact that devoicing targeted all positions where voiced stops surfaced: both ND and the more marginal ZD clusters.
The second piece of evidence in support of the articulatory motivation of unconditional devoicing comes from Tswana. As already mentioned, there are at least three microdialects within Tswana: a devoicing dialect, a leniting dialect, and a PND dialect (Table 16).Footnote [30] Phonetic studies of the dialect that devoices all stops in all positions show that devoicing is complete and unconditioned: devoiced stops that trace back to voiced stops are voiceless in all positions, including the post-nasal position (for instance, the devoiced post-nasal labial and alveolar stop have only 11% of closure voiced, compared to 7% and 12% intervocalically;Footnote [31] Gouskova et al. Reference Gouskova, Zsiga and Boyer2011). These instrumental results support the claim that unconditioned devoicing is an attested sound change, motivated by the anti-voicing effect of closure, even if it appears to operate only post-nasally. The devoicing microdialect of Tswana confirms that where unconditioned devoicing happens, it targets stops in all positions, including the post-nasal position, precisely because closure is always antagonistic to voicing. Furthermore, the fact that unconditioned devoicing, confirmed by instrumental phonetic studies, operates precisely in the subdialect of the language that features PND, additionally strengthens the assumption that the second sound change in the three-sound-change combination leading to PND was unconditioned devoicing.
Finally, unconditioned occlusion of non-sibilant fricatives to stops is also well attested and motivated.Footnote [32] Non-sibilant fricatives are typologically and articulatorily dispreferred (Maddieson Reference Maddieson1984). There are many languages without fricatives in their inventories, but none without stops (21 or 6.6% of the languages surveyed in Maddieson Reference Maddieson1984 lack any fricative, even a strident fricative). Moreover, fricatives require a greater level of articulatory precision than other manners of articulation: compared to stops, the articulatory targets and shape of the vocal tract require greater precision (Ladefoged & Maddieson Reference Ladefoged and Maddieson1996: 137). Deviation from precise articulatory targets can thus lead to the occlusion of fricatives to stops. Kümmel (Reference Kümmel2007) identifies at least six languages in which a sound change turned voiced fricatives into voiced stops for all places of articulation, as well as several more in which occlusion is limited to a single place of articulation. Kümmel (Reference Kümmel2007) also identifies cases of occlusion of fricatives that is limited to the initial position or to clusters (as is reconstructed for Pre-Nasioi).
3.5 PND as a synchronic alternation
Buginese, Konyagi, Nasioi, and especially Tswana and Shekgalagari, confirm that a combination of sound changes can and do result in productive unnatural synchronic processes. Note that, according to Kiparsky (Reference Kiparsky and Good2008), the third sound change in the series of the three sound changes that result in PND is expected to be blocked by UG, since the combination would result in an unnatural process and the surface pattern does not allow for phonological reanalysis.Footnote [33] However, this blocking clearly does not happen: sound change that blurs the original complementary distribution and thus produces a synchronically unnatural process is attested in Buginese, Konyagi, Nasioi, and Tswana and Shekgalagari in particular.
As mentioned above, the combination of three sound changes is reported to yield a synchronic alternation in Buginese derivational morphology. Sirk (Reference Sirk1983: 35–37) shows that sequences of N
 $+$
D yield NT (except for dentals), while the sequence N
$+$
D yield NT (except for dentals), while the sequence N
 $+$
[w] yields [mp]. He also argues that the only permissible non-geminate clusters in Buginese are NT (to the exclusion of ND) (Sirk Reference Sirk1983: 35–37).
$+$
[w] yields [mp]. He also argues that the only permissible non-geminate clusters in Buginese are NT (to the exclusion of ND) (Sirk Reference Sirk1983: 35–37).
Table 26 Buginese PND (from Sirk Reference Sirk1983: 35–37).

Noorduyn (Reference Noorduyn and Macknight2012/1955) describes PND in Buginese as part of a sandhi phenomenon. A word-final nasal before a word-initial labial approximant [w] in sandhi results in the sequence [mp], e.g. /rilaleŋ wanua/ becomes [rilalempanua]. Noorduyn (Reference Noorduyn and Macknight2012/1955) also reports that PND in sandhi occasionally targets voiced labial stops as well, e.g. /telluŋ bocco/
 $\rightarrow$
[tellumpoco], but the process is no longer productive. Data on this phenomenon are sparse, however, and detailed phonetic descriptions are lacking.
$\rightarrow$
[tellumpoco], but the process is no longer productive. Data on this phenomenon are sparse, however, and detailed phonetic descriptions are lacking.
PND is also reported in Konyagi as part of a synchronic consonant mutation process in adjectives, depending on the prefix and its grade of mutation (Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb). Adjectives surface with a sonorant in initial position after vowel-final prefixes that go back to vowel-final prefixes (-V
 $_{V}$
), while voiced stops surface in the initial position of these adjectives after vowel-final prefixes that go back to consonant-final prefixes (-V
$_{V}$
), while voiced stops surface in the initial position of these adjectives after vowel-final prefixes that go back to consonant-final prefixes (-V
 $_{C}$
). Finally, adjectives surface with voiceless stops in initial position after a nasal-final prefix (-N) (Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb).
$_{C}$
). Finally, adjectives surface with voiceless stops in initial position after a nasal-final prefix (-N) (Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb).
Table 27 Konyagi PND ‘mutation’ depending on the historical sources of prefixes (table from Merrill Reference Merrill2014, Reference Merrill2016a, Reference Merrillb; Santos Reference Santos1996).
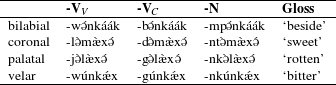
PND is reported as a synchronic alternation in Nasioi as well. Voiceless and voiced labial and alveolar stops contrast initially and after a glottal stop. Intervocalically, voiced stops are lenited to a voiced fricative and a flap, but post-nasally they devoice and merge with voiceless stops. The alternation (PND) that might be morphologically limited is reported for two morphemes: the second person object suffix /-d/ and the third person object suffix /-b/ (e.g. [oo-d-a-
 $\varnothing$
-maan] ‘I see you’ vs. [manton-t-a-
$\varnothing$
-maan] ‘I see you’ vs. [manton-t-a-
 $\varnothing$
-maan] ‘I feel you’; Brown Reference Brown2017).Footnote
[34]
Further research is required to establish the synchronic status of PND in Nasioi.
$\varnothing$
-maan] ‘I feel you’; Brown Reference Brown2017).Footnote
[34]
Further research is required to establish the synchronic status of PND in Nasioi.
Buginese, Konyagi, and Nasioi have a synchronic process of PND, although the scope of PND in these languages is limited in that either it involves an alternation Z
 ${\sim}$
NT instead of D
${\sim}$
NT instead of D
 ${\sim}$
NT, or it is morphologically limited, or it targets only a subset of voiced stops. Detailed phonetic descriptions of PND in these languages are lacking. In Tswana and Shekgalagari, on the other hand, PND is not only reported as a productive synchronic alternation, but we also have detailed acoustic and experimental studies of it.
${\sim}$
NT, or it is morphologically limited, or it targets only a subset of voiced stops. Detailed phonetic descriptions of PND in these languages are lacking. In Tswana and Shekgalagari, on the other hand, PND is not only reported as a productive synchronic alternation, but we also have detailed acoustic and experimental studies of it.
Two major contributions addressing the synchronic status and productivity of PND are Coetzee & Pretorius (Reference Coetzee and Pretorius2010) and Solé et al. (Reference Solé, Hyman and Monaka2010). These papers first show that the process in question in Tswana and Shekgalagari is in fact a phonetic devoicing of stops in post-nasal position. For seven speakers of Tswana (out of twelve total), voiced stops devoice and completely merge with the voiceless series post-nasally (Coetzee & Pretorius Reference Coetzee and Pretorius2010); for example, /m-bV/ completely merges with /m-pV/, and the stops in post-nasal position (both the underlyingly voiceless and the devoiced) ‘agree nearly completely’ (Coetzee & Pretorius Reference Coetzee and Pretorius2010: 413) in all relevant parameters with /re-pV/ and significantly differ from the underlying /re-bV/. The same conclusion is drawn for Shekgalagari based on acoustic and laryngographic data in Solé et al. (Reference Solé, Hyman and Monaka2010).Footnote [35]
Second, Coetzee & Pretorius (Reference Coetzee and Pretorius2010: 411) show that PND is fully productive, extending to nonce words at the same rate as it applies to the native vocabulary in Tswana. The results from nonce-word experiments suggest that PND is not lexicalized, but rather a productive phonological process in the synchronic grammar of Tswana speakers. This means that unnatural alternations (according to the definition in (2)) produced by combinations of sound changes can become part of productive synchronic grammars.
Finally, Coetzee & Pretorius (Reference Coetzee and Pretorius2010) show that the natural process of PNV operates passively even in cases in which PND is a phonological process. The system containing the unnatural synchronic phonological process PND is attested for seven of the thirteen speakers. For the other five speakers, however, Coetzee & Pretorius (Reference Coetzee and Pretorius2010: 417) observe that they often realize the whole closure ‘with voicing’ in post-nasal position. This suggests that the five speakers have introduced a new rule into their system, which is the natural, phonetically motivated, and exact inverse process to PND: PNV.Footnote [36]
4 The Blurring Process
4.1 The Blurring Cycle and Blurring Chain
In Section 3 above, I argued that one of the rare reported cases of unnatural sound changes, PND, did not operate as a single unnatural sound change, but as a combination of natural sound changes in all thirteen languages in which PND is reported either as a synchronic alternation or as a sound change. This typological study provides a basis for establishing a new diachronic model for explaining unnatural phenomena, the Blurring Process, which I present in this section. Using the Blurring Process, I also provide a proof that at least three sound changes are required for an unnatural process to arise: the MSCR.
We saw above that all cases of PND proceed along a common trajectory of development. For all cases, I reconstruct a stage with fricativization, devoicing of voiced stops, and occlusion of fricatives. More schematically, PND arises from a complementary distribution, which is followed by an unconditioned sound change. To get a synchronic unnatural alternation, another sound change has to operate that blurs the original complementary distribution. I label these diachronic conditions that result in an unnatural synchronic process a Blurring Process.

Based on (5), I can identify several trajectories that result in unnatural processes: subtypes of the Blurring Process. Let us assume that A
 $\rightarrow$
B
$\rightarrow$
B
 $/$
X is a natural alternation and a UPT, whereby A and B represent feature matrices that select one or more segments in a given language and X specifies the environment of the alternation. Because A
$/$
X is a natural alternation and a UPT, whereby A and B represent feature matrices that select one or more segments in a given language and X specifies the environment of the alternation. Because A
 $\rightarrow$
B
$\rightarrow$
B
 $/$
X is a UPT, A and B differ in exactly one feature,
$/$
X is a UPT, A and B differ in exactly one feature,
 $\unicode[STIX]{x1D719}_{1}$
, such that the value of
$\unicode[STIX]{x1D719}_{1}$
, such that the value of
 $\unicode[STIX]{x1D719}_{1}$
in B is universally preferred in the environment X. This means that its inverse process, B
$\unicode[STIX]{x1D719}_{1}$
in B is universally preferred in the environment X. This means that its inverse process, B
 $\rightarrow$
A
$\rightarrow$
A
 $/$
X, is an unnatural process: the value of
$/$
X, is an unnatural process: the value of
 $\unicode[STIX]{x1D719}_{1}$
in A is universally dispreferred in X. How does B
$\unicode[STIX]{x1D719}_{1}$
in A is universally dispreferred in X. How does B
 $\rightarrow$
A
$\rightarrow$
A
 $/$
X arise? There are a number of possible trajectories, but I will focus on two main trajectories, i.e. combinations of sound changes, that are attested as historical developments. I will refer to the first development in (6) as the Blurring Cycle and the second development in (6) as the Blurring Chain. The crucial difference between the two is that in the Blurring Cycle, the sound change B
$/$
X arise? There are a number of possible trajectories, but I will focus on two main trajectories, i.e. combinations of sound changes, that are attested as historical developments. I will refer to the first development in (6) as the Blurring Cycle and the second development in (6) as the Blurring Chain. The crucial difference between the two is that in the Blurring Cycle, the sound change B
 ${>}$
A does operate, but because it is unconditioned, i.e. not limited to the unnatural environment X, it can be phonetically motivated. In the Blurring Chain, on the other hand, B
${>}$
A does operate, but because it is unconditioned, i.e. not limited to the unnatural environment X, it can be phonetically motivated. In the Blurring Chain, on the other hand, B
 ${>}$
A never operates. Instead a ‘chain’ of developments occurs: B
${>}$
A never operates. Instead a ‘chain’ of developments occurs: B
 ${>}$
C (/X)
${>}$
C (/X)
 ${>}$
D
${>}$
D
 ${>}$
A. The motivation for the term ‘cycle’ is clear: the last sound change in the Blurring Cycle reverses the first sound change (although the two differ in their contexts). In other words, the last sound change targets the outcome and results in the target of the first sound change. The term ‘chain’ is likewise motivated: the outcomes of a sound change in Blurring Chain become targets for following sound changes. Both developments ‘blur’ the original complementary distribution, resulting in an alternation that operates against UPT (B
${>}$
A. The motivation for the term ‘cycle’ is clear: the last sound change in the Blurring Cycle reverses the first sound change (although the two differ in their contexts). In other words, the last sound change targets the outcome and results in the target of the first sound change. The term ‘chain’ is likewise motivated: the outcomes of a sound change in Blurring Chain become targets for following sound changes. Both developments ‘blur’ the original complementary distribution, resulting in an alternation that operates against UPT (B
 ${>}$
A
${>}$
A
 $/$
X).Footnote
[37]
The Blurring Cycle and Blurring Chain are schematized in (6) with the unnatural alternation (B
$/$
X).Footnote
[37]
The Blurring Cycle and Blurring Chain are schematized in (6) with the unnatural alternation (B
 $\rightarrow$
A
$\rightarrow$
A
 $/$
X) that results from a combination of the three sound changes appearing under the line.
$/$
X) that results from a combination of the three sound changes appearing under the line.

PND in all thirteen cases is a result of the Blurring Cycle.

The Blurring Process approach explains further unnatural data beyond PND. I argue that the Blurring Chain explains the unnatural voicing of voiceless stops in Tarma Quechua (Adelaar Reference Adelaar1977, Puente Baldoceda Reference Puente Baldoceda1977, Nazarov Reference Nazarov2008) and unnatural intervocalic devoicing in Berawan dialects (Blust Reference Blust2005, Reference Blust2013; Burkhardt Reference Burkhardt2014). The Blurring Chain in these languages, however, requires a separate treatment which goes beyond the scope of the present paper (Beguš & Nazarov Reference Beguš and Nazarov2017, Reference Beguš and Nazarovto appear, Beguš Reference Beguš2018).
As already mentioned, rule telescoping (Wang Reference Wang1968; Kenstowicz & Kisseberth Reference Kenstowicz and Kisseberth1977: 64; Anderson Reference Anderson1981; Stausland Johnsen Reference Stausland Johnsen2012) has long been known to produce unmotivated results. However, to derive unnatural alternations (as defined in (2)), we need a special combination of sound changes defined here: the Blurring Process. Establishing the Blurring Process has another advantage: to my knowledge, this paper presents the first proof establishing the minimal number of sound changes required for different degrees of naturalness (see Section 4.2).
The Blurring Process thus serves as a diachronic model for explaining seemingly unnatural sound changes and synchronic processes and should be considered as an alternative to other strategies. The most common strategies for explaining unnatural sound changes or alternations thus far are the hypercorrection approach (Ohala Reference Ohala, Masek, Hendrick and Miller1981) and the perceptual enhancement approach (Stanton Reference Stanton2016b). Most studies that have tried to explain PND in isolation have invoked hypercorrection: speakers analyze sequences of ND as voiced from NT and mentally ‘undo’ this voicing. However, in the absence of any restriction, hypercorrection as an explanation for unnatural phenomena leads to overgeneration. Unrestricted hypercorrection leads to the conclusion that every unnatural sound change should be possible (but perhaps very rare) – since, by definition, unnatural sound changes operate against UPTs. Speakers can analyze the surface data as having undergone a UPT and ‘undo’ the UPT, which would yield the unnatural process with a single sound change. This is the reason why Ohala (Reference Ohala, Masek, Hendrick and Miller1981: 193) himself restricts the operation of hypercorrection to ‘those consonantal features
 $[\ldots ]$
which have important perceptual cues spreading onto adjacent segments’. He specifically notes that the voice feature is unlikely to undergo dissimilation based on hypercorrection (see also Blust Reference Blust2005). I have argued here that the Blurring Process approach is superior to hypercorrection in the case of PND; elsewhere (Beguš & Nazarov Reference Beguš and Nazarov2017, Reference Beguš and Nazarovto appear; Beguš Reference Beguš2018), I argue that the Blurring Process better explains other unnatural processes, such as intervocalic devoicing. In Section 3, I also present evidence against the perceptual enhancement explanation of PND and point to the advantages of the Blurring Process approach over the perceptual enhancement approach. While this paper does not argue against the existence of hypercorrection or perceptual enhancement, I do claim that the Blurring Process approach explains the data better than alternative proposals at least in case of the unnatural PND. Further research should reveal whether other unnatural processes are better explained by one or the other strategy.
$[\ldots ]$
which have important perceptual cues spreading onto adjacent segments’. He specifically notes that the voice feature is unlikely to undergo dissimilation based on hypercorrection (see also Blust Reference Blust2005). I have argued here that the Blurring Process approach is superior to hypercorrection in the case of PND; elsewhere (Beguš & Nazarov Reference Beguš and Nazarov2017, Reference Beguš and Nazarovto appear; Beguš Reference Beguš2018), I argue that the Blurring Process better explains other unnatural processes, such as intervocalic devoicing. In Section 3, I also present evidence against the perceptual enhancement explanation of PND and point to the advantages of the Blurring Process approach over the perceptual enhancement approach. While this paper does not argue against the existence of hypercorrection or perceptual enhancement, I do claim that the Blurring Process approach explains the data better than alternative proposals at least in case of the unnatural PND. Further research should reveal whether other unnatural processes are better explained by one or the other strategy.
4.2 Minimal Sound Change Requirement
As already mentioned, the Blurring Process provides the groundwork for establishing the minimal number of sound changes required for natural, unmotivated, and unnatural processes to arise. Specifically, I argue that we can prove formally what we observe typologically: that the emergence of an unnatural process requires at least three sound changes to operate in combination.
Let us assume that A
 ${>}$
B
${>}$
B
 $/$
X is a natural sound change, whereas B
$/$
X is a natural sound change, whereas B
 ${>}$
A
${>}$
A
 $/$
X is unnatural. As per the definition in (3), we assume that a single instance of sound change means a change of one feature in a given environment (Section 2.2). This means that for a natural sound change (A
$/$
X is unnatural. As per the definition in (3), we assume that a single instance of sound change means a change of one feature in a given environment (Section 2.2). This means that for a natural sound change (A
 ${>}$
B
${>}$
B
 $/$
X), A and B differ in exactly one feature
$/$
X), A and B differ in exactly one feature
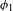 $\unicode[STIX]{x1D719}_{1}$
(for example [
$\unicode[STIX]{x1D719}_{1}$
(for example [
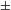 $\pm$
voice] in the case of PNV or final voicing), so that a given value of
$\pm$
voice] in the case of PNV or final voicing), so that a given value of
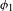 $\unicode[STIX]{x1D719}_{1}$
in B is universally preferred in environment X and its opposite value
$\unicode[STIX]{x1D719}_{1}$
in B is universally preferred in environment X and its opposite value
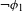 $\neg \unicode[STIX]{x1D719}_{1}$
in A is dispreferred in the same environment X. How do we get the unnatural B
$\neg \unicode[STIX]{x1D719}_{1}$
in A is dispreferred in the same environment X. How do we get the unnatural B
 ${>}$
A
${>}$
A
 $/$
X? With one single natural sound change, it is impossible, because B
$/$
X? With one single natural sound change, it is impossible, because B
 ${>}$
A
${>}$
A
 $/$
X is by definition unnatural and therefore impossible under the assumption that sound change has to be natural (see Section 2). Moreover, a combination of two natural sound changes also cannot yield B
$/$
X is by definition unnatural and therefore impossible under the assumption that sound change has to be natural (see Section 2). Moreover, a combination of two natural sound changes also cannot yield B
 ${>}$
A
${>}$
A
 $/$
X. Why? A and B differ in one feature only (
$/$
X. Why? A and B differ in one feature only (
 $\unicode[STIX]{x1D719}_{1}$
). For a B
$\unicode[STIX]{x1D719}_{1}$
). For a B
 ${>}$
A
${>}$
A
 $/$
X sound change to arise, therefore, we first need B to change into something other than A (it cannot change to A directly because such a sound change is unnatural). So, let B change to C, where B and C differ in one feature,
$/$
X sound change to arise, therefore, we first need B to change into something other than A (it cannot change to A directly because such a sound change is unnatural). So, let B change to C, where B and C differ in one feature,
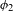 $\unicode[STIX]{x1D719}_{2}$
, but, to be sure, a different feature from the one that separates A and B (
$\unicode[STIX]{x1D719}_{2}$
, but, to be sure, a different feature from the one that separates A and B (
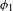 $\unicode[STIX]{x1D719}_{1}$
). From this point, it is impossible for an unnatural sound change to arise without a third sound change. Indeed, C cannot develop directly to A, since the two segments differ in two features: feature
$\unicode[STIX]{x1D719}_{1}$
). From this point, it is impossible for an unnatural sound change to arise without a third sound change. Indeed, C cannot develop directly to A, since the two segments differ in two features: feature
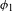 $\unicode[STIX]{x1D719}_{1}$
, which distinguishes A and B, and feature
$\unicode[STIX]{x1D719}_{1}$
, which distinguishes A and B, and feature
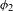 $\unicode[STIX]{x1D719}_{2}$
, which distinguishes B and C, with
$\unicode[STIX]{x1D719}_{2}$
, which distinguishes B and C, with
 $\unicode[STIX]{x1D719}_{1}\neq \unicode[STIX]{x1D719}_{2}$
. Since, by definition, two sound changes are required in order to change two features (see the discussion in Section 2.2), it follows that at least three sound changes must take place in order for an unnatural process to arise. This proof can be formalized as the Minimal Sound Change Requirement:
$\unicode[STIX]{x1D719}_{1}\neq \unicode[STIX]{x1D719}_{2}$
. Since, by definition, two sound changes are required in order to change two features (see the discussion in Section 2.2), it follows that at least three sound changes must take place in order for an unnatural process to arise. This proof can be formalized as the Minimal Sound Change Requirement:

The MSCR is derived even more clearly if we use feature notation to represent the Blurring Process. Let
 $\unicode[STIX]{x1D719}_{1}$
and
$\unicode[STIX]{x1D719}_{1}$
and
 $\unicode[STIX]{x1D719}_{1+n}$
be two features in a feature matrix. Let us assume that a change in the direction
$\unicode[STIX]{x1D719}_{1+n}$
be two features in a feature matrix. Let us assume that a change in the direction
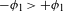 $-\unicode[STIX]{x1D719}_{1}>+\unicode[STIX]{x1D719}_{1}$
is a UPT, given value
$-\unicode[STIX]{x1D719}_{1}>+\unicode[STIX]{x1D719}_{1}$
is a UPT, given value
 $\unicode[STIX]{x1D6FC}$
of one or more other features
$\unicode[STIX]{x1D6FC}$
of one or more other features
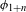 $\unicode[STIX]{x1D719}_{1+n}$
in the feature matrix (and other participating features) and given an environment X. How does the unnatural change in the direction
$\unicode[STIX]{x1D719}_{1+n}$
in the feature matrix (and other participating features) and given an environment X. How does the unnatural change in the direction
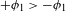 $+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
arise? According to the definition in (3) and the requirement that sound change be natural, sound change cannot produce
$+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
arise? According to the definition in (3) and the requirement that sound change be natural, sound change cannot produce
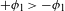 $+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
in a single step, given the constant value
$+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
in a single step, given the constant value
 $\unicode[STIX]{x1D6FC}$
of
$\unicode[STIX]{x1D6FC}$
of
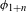 $\unicode[STIX]{x1D719}_{1+n}$
. The change from
$\unicode[STIX]{x1D719}_{1+n}$
. The change from
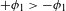 $+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
, however, can be phonetically motivated with different values of
$+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
, however, can be phonetically motivated with different values of
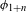 $\unicode[STIX]{x1D719}_{1+n}$
(e.g. in a Blurring Chain) or when [
$\unicode[STIX]{x1D719}_{1+n}$
(e.g. in a Blurring Chain) or when [
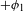 $+\unicode[STIX]{x1D719}_{1}$
,
$+\unicode[STIX]{x1D719}_{1}$
,
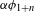 $\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
] only appears in a given environment, which means the context becomes irrelevant (
$\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
] only appears in a given environment, which means the context becomes irrelevant (
 $\varnothing$
) for evaluating naturalness (as is the case in the Blurring Cycle). In other words, we cannot change [
$\varnothing$
) for evaluating naturalness (as is the case in the Blurring Cycle). In other words, we cannot change [
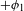 $+\unicode[STIX]{x1D719}_{1}$
,
$+\unicode[STIX]{x1D719}_{1}$
,
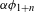 $\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
] to [
$\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
] to [
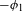 $-\unicode[STIX]{x1D719}_{1}$
,
$-\unicode[STIX]{x1D719}_{1}$
,
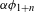 $\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
], but it is possible that
$\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
], but it is possible that
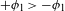 $+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
is motivated under the
$+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
is motivated under the
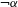 $\neg \unicode[STIX]{x1D6FC}$
value of
$\neg \unicode[STIX]{x1D6FC}$
value of
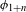 $\unicode[STIX]{x1D719}_{1+n}$
or
$\unicode[STIX]{x1D719}_{1+n}$
or
 $\varnothing$
(motivated under a different context). This means that first, a sound change that targets
$\varnothing$
(motivated under a different context). This means that first, a sound change that targets
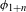 $\unicode[STIX]{x1D719}_{1+n}$
has to operate and change its value, either in a given environment X (Blurring Chain) or in the elsewhere condition
$\unicode[STIX]{x1D719}_{1+n}$
has to operate and change its value, either in a given environment X (Blurring Chain) or in the elsewhere condition
 $\neg$
X (Blurring Cycle). Under the changed
$\neg$
X (Blurring Cycle). Under the changed
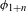 $\unicode[STIX]{x1D719}_{1+n}$
, the change
$\unicode[STIX]{x1D719}_{1+n}$
, the change
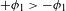 $+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
can be motivated (which is the second sound change in the Blurring Process). Finally, in order for the change
$+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
can be motivated (which is the second sound change in the Blurring Process). Finally, in order for the change
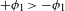 $+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
to appear unnatural, the value of
$+\unicode[STIX]{x1D719}_{1}>-\unicode[STIX]{x1D719}_{1}$
to appear unnatural, the value of
 $\unicode[STIX]{x1D719}_{1+n}$
has to change to the initial stage (the third sound change). Feature values of each stage in the Blurring Process that produce the unnatural [
$\unicode[STIX]{x1D719}_{1+n}$
has to change to the initial stage (the third sound change). Feature values of each stage in the Blurring Process that produce the unnatural [
 $+\unicode[STIX]{x1D719}_{1}$
,
$+\unicode[STIX]{x1D719}_{1}$
,
 $\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
]
$\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
]
 ${>}$
[
${>}$
[
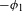 $-\unicode[STIX]{x1D719}_{1}$
,
$-\unicode[STIX]{x1D719}_{1}$
,
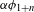 $\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
] are illustrated in Table 28. At least three changes are needed to get from Stage 1 to Stage 4 (MSCR).
$\unicode[STIX]{x1D6FC}\unicode[STIX]{x1D719}_{1+n}$
] are illustrated in Table 28. At least three changes are needed to get from Stage 1 to Stage 4 (MSCR).
Table 28 Changes in feature values in a Blurring Process.
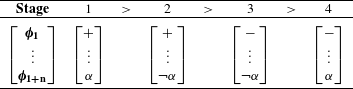
The MSCR gives a lower bound on the number of sound changes required for a process to arise, but not an upper bound. More than one sound change can in some cases result in what would usually be analyzed as a natural alternation. This is primarily true for processes that allow multiple intermediate stages in their development. For example, the natural process ![]() can arise through a combination of individual sound changes as defined in Section 2.2 (with intermediate stages such as [c]
can arise through a combination of individual sound changes as defined in Section 2.2 (with intermediate stages such as [c]
 ${>}$
[cɕ]). The resulting process,
${>}$
[cɕ]). The resulting process, ![]() is nevertheless natural because it operates in the direction of a UPT of fronting velars before front vowels (Guion Reference Guion1996).
is nevertheless natural because it operates in the direction of a UPT of fronting velars before front vowels (Guion Reference Guion1996).
4.2.1 Potential exceptions
There are two potential exceptions to the MSCR. First, unnatural alternations might arise from less than three sound changes when the change from
 $+\unicode[STIX]{x1D719}_{1}$
to
$+\unicode[STIX]{x1D719}_{1}$
to
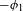 $-\unicode[STIX]{x1D719}_{1}$
(Stage 2 to 3 in Table 28) automatically entails the change from
$-\unicode[STIX]{x1D719}_{1}$
(Stage 2 to 3 in Table 28) automatically entails the change from
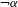 $\neg \unicode[STIX]{x1D6FC}$
to
$\neg \unicode[STIX]{x1D6FC}$
to
 $\unicode[STIX]{x1D6FC}$
in
$\unicode[STIX]{x1D6FC}$
in
 $\unicode[STIX]{x1D719}_{1+n}$
(Stage 3 to 4 in Table 28). In other words, if a change in one feature (such as a change from [
$\unicode[STIX]{x1D719}_{1+n}$
(Stage 3 to 4 in Table 28). In other words, if a change in one feature (such as a change from [
 $-$
nas] to [
$-$
nas] to [
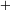 $+$
nas]) entails the change of another, automatic (redundant) feature (e.g. [
$+$
nas]) entails the change of another, automatic (redundant) feature (e.g. [
 $-$
son] to [
$-$
son] to [
 $+$
son]), or if one of the changes in the Blurring Process is a perceptual change that can target two features simultaneously and precisely those two features play a role in the Blurring Process, then the unnatural alternation might arise from two changes, as we know that the minimality principle holds only for non-automatic non-redundant features and might be violated in some cases (see Section 2.2). We expect such cases, if they exist at all, to be extremely rare because of the restriction that the change of two features in the Blurring Process be automatic/redundant or simultaneous.
$+$
son]), or if one of the changes in the Blurring Process is a perceptual change that can target two features simultaneously and precisely those two features play a role in the Blurring Process, then the unnatural alternation might arise from two changes, as we know that the minimality principle holds only for non-automatic non-redundant features and might be violated in some cases (see Section 2.2). We expect such cases, if they exist at all, to be extremely rare because of the restriction that the change of two features in the Blurring Process be automatic/redundant or simultaneous.
Second, the MSCR might not hold in rare cases in which a phonetic change allows a reinterpretation of the phonological status of certain segments. Such cases are, however, expected to be rare and, more importantly, probably always allow alternative analyses. Let us imagine a language in which voiceless stops shorten in word-final position or in coda position more generally. Post-vocalically, voiceless stops universally have some degree of voicing into closure as it is difficult to cease voicing immediately after the vowel (Westbury & Keating Reference Westbury and Keating1986, Davidson Reference Davidson2016). If the closure duration of such voiceless stops shortens significantly in the coda position, the percentage of voicing into closure will increase. Such shortened voiceless stops can be analyzed either as shortened voiceless stops or as voiced stops, because of the higher percentage of voicing into closure due to their shorter duration.Footnote [38] In such cases that do not undergo the Blurring Process, however, the conditioning factor for a change is still present in the synchronic system. In the presence of this conditioning factor, alternative analyses are possible. Finally, even if unnatural patterns can arise outside of the Blurring Process, they are comparatively rare, as this paper argues. All unnatural processes known to me for which no alternative explanations exist result from the Blurring Process (Beguš & Nazarov Reference Beguš and Nazarov2017, Reference Beguš and Nazarovto appear; Beguš Reference Beguš2018). Under this less strong position, then, the MSCR is at least a strong tendency and the rest of the argumentation that follow from the MSCR still holds.
The MSCR is also limited in scope to segmental phenomena. Prosodic/ suprasegmental processes cannot be represented by feature matrices as in Table 28 and require an independent tier under most approaches to prosodic phonology (Goldsmith Reference Goldsmith1976, Hayes Reference Hayes1995). Because the changes on a prosodic tier can be independent from changes in the segmental tier, unnatural prosodic processes can arise from less than three sound changes. Unnatural prosodic phenomena are beyond the scope of this paper. A more detailed investigation of what constitutes an unnatural change and whether the lack of the MSCR restriction in the prosodic domain translates into a higher rate of unnatural processes would be desired.
4.2.2 Phonotactic restrictions
It is important to note that fewer than three sound changes are required to produce unnatural static phonotactic restrictions. For instance, Kiparsky (Reference Kiparsky2006) provides several trajectories of two or more sound changes leading to the unnatural process of final voicing. Most of his scenarios, however, would result in a phonotactic restriction against voiceless stops word-finally and not in FV as an alternation. Even a single sound change might produce an unnatural phonotactic restriction: if a sound change targets voiceless stops to the exclusion of voiced stops, the resulting phonological system would allow only voiced stops in word-final position. Similarly, post-vocalic voicing of stops would result in a system that would restrict word-final voiceless stops and allow voiced stops in word-final position. While such a system would better be analyzed as a natural restriction against post-vocalic voiceless stops, another sound change reintroducing prevocalic voiceless stops into the system would create an unnatural phonotactic restriction where voicing of stops would be contrastive initially and word-medially, but not word-finally – where only voiced stops would surface.
For the purposes of modeling the diachronic development of unnatural processes, this paper distinguishes between static phonotactic restrictions and alternations. The difference is that the latter require a segment to alternate in a given phonetic environment within the same morphological unit. In other words, the MSCR holds for alternations in which a segment B surfaces as a segment A in an environment X within the same morpheme.
One of the advantages of constraint-based approaches to phonology is that static phonotactics and alternations are modeled simultaneously with the same theoretical devices (Prince & Smolensky Reference Prince and Smolensky1993/2004; Hayes Reference Hayes, Kager, Pater and Zonneveld2004; Pater & Tessier Reference Pater, Tessier, Slabakova, Montrul and Prévost2006). It is likely that productive phonotactic restrictions and productive alternations have the same underlying grammatical mechanisms and should therefore not be distinguished in synchronic grammars (Pater & Tessier Reference Pater, Tessier, Slabakova, Montrul and Prévost2006). There are three main reasons for why such a distinction is justified when modeling unnatural processes diachronically. Alternations provide considerably more and more reliable evidence for learners. In the case of alternations, learners are faced with surface forms within the same morpheme that contain both A and B. If a combination of sound changes does not result in an alternation, learners are faced with either categorical or gradient distributions. There is no doubt that phonotactic restrictions can be active phonological processes, but the likelihood of learners not acquiring a distribution of segments as an active process is much higher if evidence for the distribution does not surface in the same morpheme (e.g. Becker et al. Reference Becker, Ketrez and Nevins2011). Because of this increased likelihood that a combination of sound changes that provides only distributional evidence will not result in a productive process, combined with the fact that the typology of unnatural phonotactics is more challenging to establish (see below), I make a distinction between alternations and static phonotactics when modeling the diachronic development of unnatural processes. In fact, the two unnatural phonotactic restrictions which I argue elsewhere show signs of productivity, Berawan and Tarma Quechua (Beguš & Nazarov Reference Beguš and Nazarov2017, Reference Beguš and Nazarovto appear; Beguš Reference Beguš2018), did indeed arise from a combination of sound changes that would also give evidence for an alternation if all changes operated categorically. The fact that evidence for the unnatural phonotactic restriction was morphological (which resulted from the Blurring Process) likely contributed to the productivity of the unnatural phonotactic restrictions.
Second, phonotactic restrictions that do not arise from a Blurring Process might allow alternative analyses. In the scenario outlined above in which post-vocalic voicing of stops is followed by a sound change that reintroduces voiceless stops in post-vocalic (but not final) position, a potential analysis could treat the newly introduced stops as a distinct series, especially if some phonetic properties of the segments the new series develops from are preserved. While such an analysis is undesirable, it is available in the case of phonotactic restrictions and impossible in the case of alternations: one cannot assume a different phoneme within the same morphological unit.
Finally, I distinguish phonotactic restrictions from alternations for practical purposes. It appears that many unnatural phonotactic restrictions go unnoticed in the literature or are not analyzed as unnatural, probably precisely due to the reasons described above. Identifying unnatural distributions/phonotactic restrictions is a harder task not only for the learner, but also for linguists describing languages. For this reason, it is considerably more difficult to create typological studies of unnatural phonotactic restrictions. For example, I have found two languages which potentially allow only voiced but not voiceless stops in word-final position and which have not been discussed in the literature on unnatural processes. Ho and some dialects of Spanish might have a restriction against final voiceless stops while allowing word-final voiced stops for at least a subset of places of articulation. In Ho, for example, voiceless stops do not appear word-finally (except in some loanwords), but voiced labial and retroflex stops do surface word-finally (Pucilowski Reference Pucilowski2013). Word-final voiceless stops and labial and velar voiced stops in Spanish are restricted to loanwords. Word-final /d/, however, surfaces in native vocabulary. In a variety of Madrid Spanish, word-final /d/ is most frequently deleted or surfaces as a voiceless fricative, but in citation form, /d/ is recorded as surfacing as a voiced stop [d] in 30% of cases (Burkard & Dziallas Reference Burkard, Dziallas, Belz, Mooshammer, Fuchs, Jannedy, Rasskazova and Żygis2018).Footnote [39] It needs to be acknowledged that these cases are preliminary descriptions and detailed phonetic data is needed to confirm these restrictions. If the stops in word-final position are indeed phonetically real, these cases would suggest that a phonotactic restriction that allows word-final voiced stops while banning voiceless stops might be more common than previously thought. This would align well with the distinction between unnatural alternations that follow the MSCR and unnatural phonotactics that do not.
In sum, the MSCR states that unnatural segmental alternations always arise from at least three sound changes. Unnatural phonotactic restrictions or prosodic alternations can arise from fewer sound changes. This paper distinguishes between alternations and phonotactic restrictions because the first are more likely to result in productive processes, lack alternative analyses, and are easier to detect. While the MSCR does not apply to unnatural phonotactic restrictions, two cases I describe elsewhere (Berawan and Tarma Quechua; Beguš & Nazarov Reference Beguš and Nazarov2017, Reference Beguš and Nazarovto appear; Beguš Reference Beguš2018) that did result in productive unnatural phonotactic restrictions actually did arise from the three sound changes in the Blurring Process. A further study of unnatural phonotactics and their diachronic developments would reveal how readily restrictions arising from fewer than three sound changes result in productive processes.
We saw that, while a single sound change is constrained to follow phonetic naturalness, a combination of sound changes appears unconstrained: a number of single instances of sound change can operate on each other (limited of course by the timeframe of active operation), and even if such a combination results in unnatural alternation, the synchronic grammar can still incorporate it (Section 3.5); the final sound change will not be blocked (pace Kiparsky Reference Kiparsky2006, Reference Kiparsky and Good2008). However, if we assume that the combination of sound changes is unconstrained, we still need to explain why unnatural processes (B
 ${>}$
A
${>}$
A
 $/$
X) are rare – as in the case of PND – or even unattested – as in the case of final voicing. Section 5 discusses implications of the Blurring Process and the MSCR for deriving typology within the Channel Bias approach.
$/$
X) are rare – as in the case of PND – or even unattested – as in the case of final voicing. Section 5 discusses implications of the Blurring Process and the MSCR for deriving typology within the Channel Bias approach.
5 Implications for the Channel Bias model of typology
Immediately related to the question of naturalness is the question of derivation of phonological typology. Two major lines of thought have emerged in the discussion on phonological typology: the Analytic Bias (AB) and Channel Bias (CB) approaches (Moreton Reference Moreton2008). The AB approach assumes that typological patterns emerge because of cognitive biases against certain phonological processes. In other words, some processes (especially unnatural ones) are assumed to be more difficult to learn and these learnability biases result in surface typology (Hayes Reference Hayes, Darnell and Moravscik1999; Tesar & Smolensky Reference Tesar and Smolensky2000; Kiparsky Reference Kiparsky and Goldsmith1995, Reference Kiparsky2006, Reference Kiparsky and Good2008; Wilson Reference Wilson2006; Hayes et al. Reference Hayes, Siptár, Zuraw and Londe2009; Becker et al. Reference Becker, Ketrez and Nevins2011; de Lacy & Kingston Reference de Lacy and Kingston2013; Hayes & White Reference Hayes and White2013; White Reference White2017; for an overview of the experimental AB literature, see Moreton & Pater Reference Moreton and Pater2012a, Reference Moreton and Paterb). The CB approach, on the other hand, assumes that systematic phonetic tendencies or phonetic precursors in the transmission from speaker to hearer result in surface typology. In other words, constraints on sound change are responsible for typological patterns: a predictable pattern of phonetic processes and phonologizations ultimately determines surface typology (cf. Greenberg Reference Greenberg and Greenberg1978; Ohala Reference Ohala, Masek, Hendrick and Miller1981, Reference Ohala and MacNeilage1983, Reference Ohala and Jones1993; Lindblom Reference Lindblom, Ohala and Jaeger1986; Barnes Reference Barnes2002; Blevins Reference Blevins2004, Reference Blevins2007, Reference Blevins and Good2008a, Reference Blevins, Willems and De Cuypereb; Morley Reference Morley2012; see also Hansson Reference Hansson2008 and Garrett & Johnson Reference Garrett and Johnson2013 for an overview of the literature).
A major objection against the CB approach is that it fails to explain why some processes, especially unnatural ones, are never attested (Kiparsky Reference Kiparsky2006, Reference Kiparsky and Good2008; de Lacy & Kingston Reference de Lacy and Kingston2013). In other words, combinations of sound changes (or a single sound change, if we allow it to be unnatural, as proposed in Blust Reference Blust2005, Reference Blust2017) could in principle produce a number of unnatural alternations – yet, it seems that some hypothetically available processes are never attested. In fact, Kiparsky (Reference Kiparsky2006, Reference Kiparsky and Good2008) goes a step further and assumes some processes are impossible in synchronic grammar. This position is also encoded in the classical Optimality Theory (OT; Prince & Smolensky Reference Prince and Smolensky1993/2004) and its factorial typology, where unnatural constraints are excluded from the universal constraint inventory (Con). On this approach, some output candidates are harmonically bounded and consequently some processes are impossible in synchronic grammars. For example, Kiparsky (Reference Kiparsky2006, Reference Kiparsky and Good2008) identifies several combinations of sound changes that would lead to final voicing, but the process is never attested (or at least is morphologically limited; see Blevins Reference Blevins2004, Yu Reference Yu2004, de Lacy Reference de Lacy2002). CB faces difficulties explaining this mismatch and AB is invoked to explain it (Kiparsky Reference Kiparsky2006, Reference Kiparsky and Good2008; de Lacy & Kingston Reference de Lacy and Kingston2013).
The standard explanation offered for typology within CB is that ‘common sound patterns often reflect common instances of sound change’ (Blevins Reference Blevins, Honeybone and Salmons2013: 485, also Greenberg Reference Greenberg and Greenberg1978: 75–76). In other words, the more common a sound change is, the more common the synchronic alternation it will produce. However, by assuming only this factor, we face the crucial problem: if sound change has to be natural, why do we nevertheless see unnatural alternations? Of course, we can assume that unnatural alternations arise through combinations of sound changes (as is argued for in this paper). Under this hypothesis, however, we are faced with the problem that was raised by Kiparsky (Reference Kiparsky2006, Reference Kiparsky and Good2008) and de Lacy & Kingston (Reference de Lacy and Kingston2013): if any combination of sound changes is possible, why are some patterns very common, others less common, and even more importantly, some non-existent?
The Blurring Process model allows us to maintain the long-held position that a single sound change is always phonetically motivated (natural) and that a single sound change cannot operate against a UPT. The Blurring Process, however, also allows derivation of unnatural alternations through a combination of natural sound changes. In other words, natural alternations are phonologized instances of at least one sound change. Unmotivated alternations are phonologized combinations of at least two sound changes. Unnatural alternations are phonologized combinations of minimally three sound changes. Crucially, the number of sound changes required for a process to arise determines that process’s relative frequency: all else being equal, the probability of a single sound change occurring will be greater than the probability of two or three particular sound changes occurring in sequence, which translates into a scale of probability in which natural alternations are the most likely to occur, followed by unmotivated changes, and then unnatural alternations. Even if we do not assume that a sound change is strictly minimal, but can in some instances involve changes of more than one feature simultaneously which would mean the MSCR is a strong tendency rather than a categorical rule (Sections 2.2 and 4.2), the typology in (9) still holds: even if we admit simultaneous sound changes of multiple features in the set of possible sound changes, they are still considerably less frequent than sound changes that target only one feature (see Sections 2.2 and 4.2). The overall probability of an unnatural alternation will thus nevertheless be smaller than the probability of an unmotivated alternation, all else being equal.
The idea that unusual rules are rare because they require complex history is not new. The low probability of combinations of changes has previously been relied on to account for the rarity of certain phonological processes (Bell Reference Bell1970, Reference Bell1971; Greenberg Reference Greenberg and Greenberg1978: 75–76; Cathcart Reference Cathcart, Bui and Özyıldz2015; Morley Reference Morley2015). Bell (Reference Bell1970, Reference Bell1971), Greenberg (Reference Greenberg and Greenberg1978: 75–76), and Cathcart (Reference Cathcart, Bui and Özyıldz2015) attempt to quantify the rarity of phonological processes based on the number of states in their pre-history and their transition probabilities (Markov Model; Greenberg Reference Greenberg and Greenberg1978) or based on the number of permutations that result in unnatural processes (compared to all possible permutations of sound changes; Cathcart Reference Cathcart, Bui and Özyıldz2015). The models in Greenberg (Reference Greenberg and Greenberg1978) and Cathcart (Reference Cathcart, Bui and Özyıldz2015), however, do not take into consideration the crucial distinctions made in this paper: the subdivision of unusual rules into unnatural versus unmotivated rules, paired with the proof that the latter require at least three sound changes to arise (MSCR). In other words, to my knowledge, none of the proposals so far actually explain the mechanism for why the least frequent processes are also phonetically unnatural and less frequent phonetically unmotivated, a generalization that follows automatically from the MSCR. In addition, the models in Greenberg (Reference Greenberg and Greenberg1978) and Cathcart (Reference Cathcart, Bui and Özyıldz2015) face implementation challenges (Beguš Reference Beguš2018). The surveys of changes that Greenberg’s (Reference Greenberg and Greenberg1978) model of transition probabilities is based on are not representative enough for the result to be reliable. Cathcart’s (Reference Cathcart, Bui and Özyıldz2015) model, on the other hand, requires surveys of sound changes to be representative for all possible sound changes, which is a considerable obstacle. In Beguš (Reference Beguš2018), I show that the Blurring Process and the MSCR facilitate a quantitative model of typology within CB. With the Blurring Process and MSCR, we can identify sound changes required for a process to arise, which means surveys (samples) need to be representative only for sound changes involved in the estimated alternation.
While the Blurring Process and the MSCR do not solve the problem of why some unnatural processes (such as final voicing) are not attested, while others (such as PND) are, they provide the first step in this direction. Unnatural processes are predicted to be less frequent than natural and unmotivated processes (see (9)). Our estimation of the probability that an alternation arises based on diachronic factors, however, does not need to end here. Estimation of individual probabilities of sound changes in a Blurring Process that leads to an unnatural alternation has the potential to explain individual differences in probabilities within the unnatural group of alternations. It is possible that some unnatural processes are unattested because the probabilities of individual sound changes and consequently the joint probability of the three sound changes in the Blurring Process are sufficiently low that the combination would never arise diachronically. The estimation of individual probabilities of sound changes is beyond the scope of this paper, but this line of reasoning has the potential to explain why some unnatural processes are never attested (while others are) without invoking the AB explanation (Beguš Reference Beguš2018).
The lower probability of a combination of sound changes in the Blurring Process is not the only reason why unnatural processes are rare. Crucially, as soon as an unnatural process operating against UPT does arise and become fully and productively incorporated into the synchronic phonological grammar (B
 $\rightarrow$
A
$\rightarrow$
A
 $/$
X), the inverse UPT (A
$/$
X), the inverse UPT (A
 ${>}$
B
${>}$
B
 $/$
X) will begin operating against it. As a result, the probability that an unnatural alternation will survive is even further reduced by the fact that a common sound change (and universal passive phonetic tendency) operates progressively against its existence. This erosion is precisely what we see happening in Tswana: in a system with unnatural alternation (PND), a single instance of natural and opposite sound change (PNV) is in the process of operating against the unnatural alternation (see Section 3.5).
$/$
X) will begin operating against it. As a result, the probability that an unnatural alternation will survive is even further reduced by the fact that a common sound change (and universal passive phonetic tendency) operates progressively against its existence. This erosion is precisely what we see happening in Tswana: in a system with unnatural alternation (PND), a single instance of natural and opposite sound change (PNV) is in the process of operating against the unnatural alternation (see Section 3.5).
One could argue that, even though combinations of sound changes are less frequent than any single instance of sound change, over the course of an almost unlimited timespan, sound changes ought to ‘stack up,’ yielding multiple unnatural alternations in any given language. In other words, given that every language has a several-thousand-year history during which sound changes have occurred continuously, we should perhaps expect many more unnatural alternations than are actually attested. Consider, however, that any given sound change has a time of operation. In other words, a sound change becomes active at one point in time and ceases to operate at another point in time (Chen Reference Chen1974). This is primarily evident from the fact that, at some point in any language, certain sound changes cease to apply to novel vocabulary, loanwords, and morphological alternations. For an unnatural phonological alternation to arise, all the sound changes that play a part in the Blurring Process must be active as ordered: a sound change in the Blurring Process must be active and exceptionless, but can cease to operate by the time of the following sound change, provided that substantial novel/loan vocabulary or morphological contexts are not introduced that would fail to undergo the change.Footnote [40] Thus, the timespan available to produce such unnatural alternations is not unlimited, but rather limited by the time in which single sound changes that combine to yield the alternation in question are active/affect all lexical items and morphological alternations in a given language. In probabilistic terms, we would say that language history is not a pure-birth process, but rather a birth–death process.
As Moreton (Reference Moreton2008: 84) points out, the AB and CB approaches have in the past often been treated as mutually exclusive, either explicitly or implicitly. A mounting body of research, however, argues that both AB and CB shape typology (Hyman Reference Hyman, Hume and Johnson2001; Myers Reference Myers2002; Moreton Reference Moreton2008; Moreton & Pater Reference Moreton and Pater2012a, Reference Moreton and Paterb; de Lacy & Kingston Reference de Lacy and Kingston2013). The goal of phonological theory should be to disambiguate the two influences: what aspects and what proportions of phonological typology are caused by learnability/learning biases (AB) and how much of phonological typology is due to the directionality of sound change (CB)? To disambiguate the two influences, we first need a good understanding of how exactly each of them results in typology. The Blurring Process and MSCR provide the first step toward the goal of quantifying the CB influences of phonology. Based on the Blurring Process, we can maintain that the directionality of sound change is restricted to phonetically motivated processes. This restriction can be employed in probabilistic estimation of the CB influences on phonological typology. The MSCR quantifies the number of sound changes required for natural, unmotivated, and unnatural processes. This quantification already predicts the relative frequencies of natural, unmotivated, and unnatural processes (see (9)). The derivation of CB does not need to stop here: the next step is to quantify the probability of each individual sound change in the Blurring Process. By combining the Blurring Process and the MSCR with probabilistic estimation of sound change, we can quantify the CB influence on typology with a relatively high accuracy (Beguš Reference Beguš2018). The estimation of each individual sound change is, however, not a trivial task and is beyond the scope of this paper (Beguš Reference Beguš2018).
6 Conclusion
This paper addressed two outstanding questions in synchronic and diachronic phonology: whether unnatural sound changes exist, and how unnatural alternations arise. By collecting all known cases of PND, one of the rare reported unnatural sound changes, I showed that common patterns emerge, yielding the conclusion that PND is the result of three natural sound changes, not only in Tswana and Shekgalagari (Dickens Reference Dickens1984, Hyman Reference Hyman, Hume and Johnson2001), but in all thirteen cases. This conclusion allows us to maintain the long-held position that sound change cannot operate against a UPT. I provided new crucial evidence from Sogdian and Yaghnobi that historically confirms the reconstructed development. On this basis, I then presented a new diachronic model, the Blurring Process, which describes the exact diachronic trajectory required for an unnatural alternation to arise and can serve as a strategy for explaining unnatural phenomena beyond PND. I argued that, at least for PND, the Blurring Process approach explains the data better than the hypercorrection and perceptual enhancement approaches. Application of the Blurring Process to further unnatural processes should reveal whether other cases of unnatural processes more commonly arise by hypercorrection, perceptual enhancement, or by the Blurring Process. The result of such an investigation should have implications for our understanding of the relationship between production, perception, sound change, and synchronic alternations. The Blurring Process also provided grounds to define an MSCR. The paper presented a proof that at least three sound changes are required for an unnatural segmental alternation to arise and at least two for an unmotivated one (MSCR). The two concepts combined present the first step in the ultimate goal of quantifying the Channel Bias approaches to typology. The MSCR quantifies the relative rarity of unnatural processes compared to natural or unmotivated processes based on the number of sound changes they require. It also provides a groundwork for performing more detailed estimates: in addition to quantifying the probability of combinations of sound changes, we can estimate the probability of each individual sound change required for an alternation to arise. A model combining the two concepts should provide a more accurate estimation of the Channel Bias influences on typology.