


1 Introduction
1.1 The perceptual assessment of voice quality
Voice quality (hereafter VQ) is broadly defined as the combination of long-term, quasi-permanent laryngeal and supralaryngeal parameters or settings and their associated perceptual effects. Many authors have adopted this broad sense of voice quality, which draws on the view that each of the organs of the vocal apparatus has a bearing on a speaker's VQ (e.g. Laver Reference Laver1980, Klatt & Klatt Reference Klatt and Klatt1990, Beck Reference Beck2005). This interpretation differs from narrower definitions which restrict VQ to effects derived from vocal fold activity alone. In this study we have adopted the broad definition of VQ.
Two main ideas underlie the broad concept of VQ. First, VQ is defined as quasipermanent: Abercrombie (Reference Abercombie1967: 91) points out that VQ refers to ‘those characteristics that are present more or less all the time that a person is talking’. Thus many authors also refer to VQ as ‘timbre’ or the characteristic ‘colouring’ of a voice (Laver Reference Laver1975, Trask Reference Trask1996). Secondly, its definition lies at the intersection between physiologically-grounded qualities and psychoacoustic phenomena. This is so because, even though VQ dimensions derive from vocal production (i.e. states of the larynx and the vocal tract), the resulting qualities are necessarily evaluated and classified through perceptual processes in an intertwined process that remains to be fully understood. Thus, Kreiman & Sidtis (Reference Kreiman and Diana Sidtis2011: 9) summarize VQ as ‘an interaction between a listener and a signal’.
Our aim in conducting the present investigation is twofold:
1. To assess the reliability of Vocal Profile Analysis (VPA) ratings across three analysts by testing different measures of inter-rater agreement.
2. To evaluate the extent to which VPA settings are independent, i.e. to explore the degree of correlation between them.
More generally, our objective is to provide a model for how to make the VPA protocol a workable tool for use by those involved in a range of domains including speech therapy, dialectology, and forensic phonetics. While the study was undertaken as part of a larger, forensically-oriented research project, we do not claim that the end product of the study – a version of the VPA to which various modifications have been made – is one best suited for use by forensic phoneticians. As we explain below, the data set on which it was developed lacks the diversity found in typical forensic recordings. However, the methodology set out here may serve as an example for those wishing to make adaptations of the VPA for forensic applications.
In the next sections we briefly discuss different methods for the perceptual assessment of VQ (Section 1.2), and the main applications, issues and challenges of the VPA scheme – the most commonly used protocol in forensic speech science (Section 1.3). Although these sections serve as a necessary background for the rest of the investigation, readers familiar with VQ analysis may wish to move directly to Section 2 for a description of the materials and methods, leading to the results presented in Section 3. We specifically tackle aims 1 and 2 in Sections 3.2 and 3.3, respectively.
1.2 Systems for VQ analysis
In terms of methodology, VQ can be approached from different perspectives: articulatory, acoustic, and perceptual. Hybrid approaches, however, are also widespread. Articulatory studies typically involve laryngoscopy (Abberton & Fourcin Reference Abberton, Fourcin, Ball and Code1978), electroglottography (Kitzing Reference Kitzing1982) or measurements of nasal and oral airflow (Hirano, Koike & Von Leden Reference Hirano, Koike and Leden1968). Acoustic investigations include analyses of different dimensions of the speech signal, such as the Long Term Average Spectrum (Löfqvist Reference Löfqvist1986, Harmegnies & Landercy Reference Harmegnies and Landercy1988). Most investigations, however, are concerned with the search for acoustic correlates of perceptual categories (Eskenazi, Childers & Hicks Reference Eskenazi, Childers and Hicks1990, Hanson Reference Hanson1997, Keller Reference Keller2004; see further Maryn et al. Reference Maryn, Roy, De Bodt, Van Cauwenberge and Corthals2009, Gil & San Segundo Reference Gil, Segundo, Garayzábal and Reigosa2013). Correlations between some acoustic measures and a certain – perceptually rated – VQ setting are usually considered an important aid for clinicians as well as a possible solution to the subjectivity implied in purely auditory evaluations of VQ.
Although a range of instrumental and objective measures exists to evaluate VQ, perceptual approaches continue to be the ‘gold standard’ to which other analyses are compared (Ma & Yu Reference Ma and Yu2005). This is because there are few, if any, single, independent acoustic correlates of individual VQ settings. Hence the importance of understanding what the perceptual assessment of VQ exactly is, and how and why it is used by different voice professionals and researchers.
A wide range of protocols has been proposed for perceptual assessment of VQ. These formal evaluation schemes require the listener to document diverse aspects of a speaker's VQ in some systematic way (Carding et al. Reference Carding, Carlson, Epstein, Mathieson and Shewell2001). The number of specific VQ features – as well as the rating system used to assess their degree – varies across protocols, and sometimes in accordance with the purpose of the evaluation. Most of them, however, originated in a clinical context with the aim of characterizing different forms of dysphonia and quantifying their severity. Kreiman et al. (Reference Kreiman, Gerratt, Kempster, Erman and Berke1993) identified around 60 different perceptual voice protocols in the USA, the Buffalo III Voice Profile being the most widely used (Wilson Reference Wilson1987). Three main schemes are in use in the UK: the Vocal Profile Analysis scheme (Laver et al. Reference Laver, Wirz, Beck and Hiller1981, Laver Reference Laver1991), the GRBAS Scale (Hirano Reference Hirano1981), and the Buffalo III Voice Profile (Wilson Reference Wilson1987). Two further protocols have been designed more recently and are also widely used: The Stockholm Voice Evaluation Approach (SVEA) (Hammarberg Reference Hammarberg2000), and the Consensus Auditory Perceptual Evaluation (CAPE-V) (Kempster et al. Reference Kempster, Gerratt, Abbott, Barkmeier-Kraemer and Hillman2009).
The main reasons why these protocols were created are: (i) to obtain a comprehensive overview of the characteristics of a voice; (ii) to compare the information provided by the perceptual VQ evaluation with other voice assessment methods; (iii) as a basis for planning and monitoring therapy; and (iv) as a way of facilitating communication with other professionals (see Carding et al. Reference Carding, Carlson, Epstein, Mathieson and Shewell2001, Beck Reference Beck2005). While these represent the most typical uses of perceptual VQ assessment by a clinician, in the next section we comment on some of the specific uses of these auditory tools – particularly the VPA – which have recently appeared in a wider range of linguistic fields, including forensic phonetics.
1.3 The Vocal Profile Analysis: Applications, issues and challenges
In this section we briefly introduce the main characteristics of the Vocal Profile Analysis (VPA), the protocol used for our study (see also Section 2.2.1). We then outline the main research areas that have shown an interest in using the VPA beyond clinical applications, and finally we highlight some of the problems that its use typically entails.
The main characteristics of the VPA can be summarized as follows (see Laver Reference Laver, Kent and Ball2000, Beck Reference Beck2005; see also Wirz & Mackenzie Beck Reference Wirz, Beck and Wirz1995 for fuller descriptions):
(a) The VPA is a componential (i.e. featural) approach to VQ, involving various components or settings. There is some debate over the degree of independence of these settings. Carding et al. (Reference Carding, Carlson, Epstein, Mathieson and Shewell2001) claim that they are ‘independent’, while other commentators acknowledge that this is not always the case. Beck (Reference Beck2005) describes the VPA settings as ‘more or less independent’, while Kreiman & Sidtis (Reference Kreiman and Diana Sidtis2011) use the term ‘quasi-independent’.
(b) Settings have an articulatory basis that gives rise to the perceptual effect that is captured in the VPA analysis. Drawing on the concept introduced by Honikman (Reference Honikman, Abercrombie, Fry, MacCarthy, Scott and Trimm1964) in the context of teaching the pronunciation of a foreign language, a ‘setting’ is defined as ‘the common articulatory tendency underlying (or arising from) the momentary actions of segmental performance . . . with its auditory consequences’ (Laver Reference Laver, Kent and Ball2000: 39).
(c) A variable number of settings make up the VPA, depending on the version of the protocol, as it has undergone slight modifications since its inception in the 1980s. Typically between 30 and 40 settings are included. Whether the protocol includes prosodic and other global features (e.g. speaking rate or loudness), as in Beck (Reference Beck2007), or it is limited to supralaryngeal and laryngeal features, its most distinctive feature is its comprehensiveness and exhaustiveness in the physiological domain. Recent versions of the protocol include muscular tension settings besides supralaryngeal and laryngeal settings (Beck Reference Beck2007), although these settings of overall degrees of muscular tension exercising their effect throughout the vocal system were introduced by Laver (Reference Laver1980).
(d) Individual settings are defined in relation to a ‘neutral setting’. This serves as a reference and baseline for raters to judge whether a voice is non-neutral and, if so, to what extent. Laver & Hanson (Reference Laver, Hanson and Darby1981), Laver (Reference Laver, Kent and Ball2000) and Beck (Reference Beck2007) provide detailed articulatory and acoustic characterizations of the neutral setting, which is considered purely a ‘convenient theoretical construct’ (Laver Reference Laver, Kent and Ball2000: 40).
(e) A six-point rating scale is used to mark potential deviations from the neutral setting. Scalar degrees 1–3 are considered typical of non-pathological populations, where 4–6 are considered extreme degrees, typically found in speakers with some voice or speech disorder. According to Beck (Reference Beck2007), the rating of voices follows a two-stage process. In a ‘first pass’, raters note if the voices are neutral or non-neutral for each setting; in the ‘second pass’, raters specify the exact nature of the deviation from ‘neutral’.
Besides its clinical applications (e.g. Scott & Caird Reference Scott and Caird1983, Mackenzie et al. Reference Mackenzie, Deary, Sellars and Wilson1998, Webb et al. Reference Webb, Carding, Deary, Mackenzie, Steen N and Wilson2004), the VPA has been used in a number of dialectological, sociolinguistic and forensic investigations. Esling (Reference Esling1978) and Stuart-Smith (Reference Stuart-Smith, Foulkes and Docherty1999) describe the VQ of English speakers from Edinburgh and Glasgow, respectively, taking into account a wide range of variables (e.g. age, sex/gender and social background). More recently, Coadou & Rougab (Reference Coadou and Rougab2007) and Wormald (Reference Wormald2016) complement their VPA-based assessments of English varieties with either acoustic (Long Term Average Spectrum, LTAS) or articulatory analyses (ultrasound techniques).
VQ is also regularly analysed in forensic phonetics, particularly in forensic speaker comparison (FSC) tasks (Nolan Reference Nolan2005). Note, however, that Nolan (Reference Nolan2005) specifies that it is VQ in a holistic sense –not necessarily following a protocol such as the VPA– that is commented on in most forensic reports. All in all, in FSC tasks the voice recording of an offender is compared with that of the suspect using a range of methods (e.g. auditory and acoustic phonetic analyses, automatic speaker recognition systems, or a combination of these; see Foulkes & French Reference Foulkes, French, Solan and Tiersma2012 and French & Stevens Reference French, Stevens, Jones and Knight2013). It seems logical that VQ plays an important role in speaker identification since classical descriptions of VQ suggest its speaker-specific nature. For example, Laver (Reference Laver1980: 2) states that ‘voice quality is one of the primary means by which speakers project their identity – their physical, psychological, and social characteristics to the world’. Other studies highlight the fact that listeners often use voice quality cues to judge personality factors (Scherer Reference Scherer, Scherer and Giles1979, as cited in Kreiman & Sidtis Reference Kreiman and Diana Sidtis2011).
Some recent studies have explored the speaker discriminatory potential of VQ. Here we focus only on those investigations applying the VPA protocol. For instance, Stevens & French (Reference Stevens and French2012) explored how telephone transmission affects VPA settings, indicating whether perceived VQ (e.g. nasality, creakiness) increased, decreased or remained the same when comparing high quality recordings and telephone-degraded recordings. We have investigated possible correlations between different long-term vocal tract output measures – including supralaryngeal settings – with the aim of finding how VQ analysis can complement long-term formant distributions (LTFDs) and Mel frequency cepstral coefficients calculated across entire speech samples (MFCCs; French et al. Reference French, Foulkes, Harrison, Hughes, Segundo and Stevens2015, Hughes et al. Reference Hughes, Harrison, Foulkes, French, Kavanagh and Segundo2017).
San Segundo, Tsanas & Gómez-Vilda (Reference San Segundo, Tsanas and Gómez-Vilda2017) propose a preliminary simplification of the VPA which enables the quantification of speaker similarity using Euclidean distances. San Segundo & Mompeán (Reference San Segundo and Mompeán2017) elaborate on the idea of extracting a VQ similarity index to compare speaker pairs, and also show that it is possible to obtain high intra- and inter-rater agreement using a simplified VPA version.
In addition, earwitness evidence can greatly benefit from research on VPA. As a case in point, San Segundo, Foulkes & Hughes (Reference San Segundo, Foulkes, French, Harrison and Hughes2016) used VPA ratings by experts to select the most similar-sounding voices in a perceptual experiment aimed at testing perceived speaker similarity by naïve listeners.
All in all, the range of possibilities that the VPA offers is wide. Nonetheless, it has some clear limitations. Nolan (Reference Nolan2005) highlights the main obstacles to a more widespread use of the VPA in forensic phonetics: (i) lack of training in the use of the protocol, (ii) practical considerations of time in casework due to the magnitude of the assessment task (although depending on the number of speakers or the length of the samples this may not be the case), (iii) high variability of VQ settings within a sample (e.g. VQ can be manipulated for pragmatic effects on a temporary basis) and largely unexplored intra-speaker variability between non-contemporaneous recordings and (iv) VQ can be compromised by the distorting effects of telephone transmission, background noise, and emotional speech that often characterize forensic recordings.
Here we are concerned with the issues – and challenges – that emerge from the methodological process involved in the perceptual evaluation by independent raters:
(a) Isolation of settings. The assumption that listeners are able to separate a perceptual dimension, or setting, from several co-occurring dimensions has been often questioned (Kent Reference Kent1996, Kreiman, Gerratt & Ito Reference Kreiman, Gerratt and Ito2007). This problem is shared with other componential analyses of VQ. The added difficulty of the VPA is that the settings are based on the speaker and his / her articulatory possibilities, and not on the perceptual processing of such settings by the listener. As Kreiman & Sidtis (Reference Kreiman and Diana Sidtis2011: 19) point out, there is no indication of ‘whether (or when, or why) some features might be more important than others, or how dimensions interact perceptually’.
(b) Scope and number of settings. Beck (Reference Beck2005: 293) comments on the trade-off between the scope and number of parameters included in the VPA scheme, and its ease of use. The more settings added to the protocol, the more sensitive this is. Unfortunately, that runs parallel with an increased complexity and a potentially decreased inter-rater agreement.
(c) Setting interdependence. Kent (Reference Kent1996) suggests that the high degree of interdependence between perceptual dimensions justifies attempts to simplify complex and multidimensional protocols. He argues that ‘multiple dimensions not only require more time from the clinician, but they may also yield diminishing returns if the various dimensions are highly correlated’ (Kent Reference Kent1996: 17), a point that also applies to FSC since forensic analyses should rely on non-correlated features in order to avoid overweighting evidence (Gold & Hughes 2015, Rose Reference Rose2006).
In order to reduce dimensionality, some studies have used factor analyses to investigate how perceptual dimensions overlap and group (e.g. Bele Reference Bele2007), although those approaches are not without limitations. For instance, the results of factor analyses are strongly dependent on the type of stimuli and rating scales (see Kreiman & Sidtis Reference Kreiman and Diana Sidtis2011).
(d) Verbal descriptors and terminological issues. Kent (Reference Kent1996: 16) claims that ‘it cannot be taken for granted that any given term used in perceptual assessment will have the same meaning for any two judges, or that two judges will share a verbal description of a clinical speech sample’. Even though the VPA verbal descriptors are mostly based on physiological terms – that is, they are not impressionistic, aesthetic terms (e.g. bright or thin) – the need for standard and well defined terms across different raters is still key in the use of this protocol.
(e) Reaching agreement. The question of how to best measure intra- and inter-rater reliability is a longstanding issue in VQ research. It is not uncommon to find low inter-rater agreement reported (see Kreiman & Gerratt Reference Kreiman and Gerratt1998), so several methodological proposals have been implemented to solve what Kreiman & Gerratt (Reference Kreiman and Gerratt2010) call the ‘unreliable rater problem’: from using fewer scale values to increasing the training sessions of raters.
The few studies which have tested inter-rater agreement using the VPA protocol have failed to generate a consensus over how to best measure it. The kappa statistic is the most widely used measure when ratings are treated as nominal (Webb et al. Reference Webb, Carding, Deary, Mackenzie, Steen N and Wilson2004). However, Beck (Reference Beck2005) provides only raw percentage agreement results, which is a less robust and cruder measure of reliability, as it does not correct for the degree of agreement that could be expected by chance (Stemler Reference Stemler2004, Multon Reference Multon and Salking2010). For instance, when rating a population of 25 non-pathological adult speakers, the two raters in the study mentioned in Beck (Reference Beck2005) reached maximum agreement (100%) in two settings: protruded jaw and labiodentalization. Due to the rare occurrence of those settings in a normophonic population, agreement could be unintentionally inflated: it is easier for raters to agree when a setting is rare.
(f) Key segments. One of the advantages of the VPA – and potentially also one of its disadvantages – is that it relies strongly on the existence of certain ‘key segments’ that would be affected by each setting. They are defined as the ‘most susceptible [segments] to the performance effects of a given setting or those on which the auditory perceptual effects are most perceptually salient’ (Beck Reference Beck2005: 297). Beck (Reference Beck2007) provides a detailed account of the main key segments per setting. For instance, lip spreading has a significant effect on segments which are normally rounded (e.g. /u/), whereas /i/ is expected to be marked by lip spreading in any case and hence not susceptible to lip spreading. The use of key segments is intended to serve as an economical listening strategy.
However, it can often be difficult to disentangle what is a long-term setting and what is better described as segmental (Abercrombie Reference Abercombie1967). While they can be different outcomes of the same articulatory configuration, segments are short-lived while true settings are long term (Laver Reference Laver, Kent and Ball2000).
In summary, then, the use of the VPA presents a number of difficulties. Acknowledging them is a first step towards trying to propose some methodological solutions, which is what concerns us in this investigation.
2 Materials and methods
2.1 Materials
Data for analysis were drawn from the DyViS corpus (Dynamic Variability in Speech; Nolan et al. Reference Nolan, McDougall, De Jong and Hudson2009). This corpus was constructed specifically as a publicly-available tool for experimental work in forensic speech science. It contains recordings of 100 male speakers of Standard Southern British English (SSBE), aged 18–25 years. The corpus is divided into various sections or speaking tasks, including samples of spontaneous speech, read text, and speech transmitted via telephone. For the purposes of the research reported here, recordings from Task 2 were used. Task 2 is a telephone conversation, with the target speaker recorded at the near end of the telephone line (i.e. the acoustic signal was not transmitted through the telephone line). These are high-quality recordings (44.1 kHz sample rate, 16-bit resolution) with around seven minutes net speech, after the audio files were manually edited to remove overlapping speech, background noise, and long portions of silence. According to Beck (Reference Beck2005), VPA analyses should be based on recordings of at least 40 seconds of connected speech, and spontaneous speech provides the most realistic representation of a speaker's habitual VQ.
None of the speakers reported having any speech pathology or hearing difficulty. A few were bilingual in English and another language, but they were all native SSBE speakers. They form a largely homogeneous group of speakers, with the majority of them being or having been students of the University of Cambridge. Therefore, the DyViS population is much more homogeneous than the populations encountered in, for example, forensic or clinical casework. The inter-rater results presented here need to be considered in light of this (discussed below).
Our analyses were based on 99 speakers. One speaker (#080) was excluded because of technical problems with his recording. (The recordings are publicly available, and we therefore refer throughout to speaker numbers as shown in the original DyViS corpus.)
2.2 Methods
2.2.1 Adapted VPA scheme
It was mentioned in the introduction that there are several versions of the VPA scheme. The one adopted here is based on Beck (Reference Beck2007) and comprises 32 features: 21 supralaryngeal, seven laryngeal and four referring to muscular tension (see Figure A1 in the appendix). This version was developed in part at JP French Associates, a forensic speech and acoustics laboratory in the UK, and modified for this investigation in light of a calibration exercise (see Section 2.2.2).
In terms of setting repertoire, the main difference between the VPA protocol used in this study and the one described in Beck (Reference Beck2007) lies in the reduction of settings. For example, both protruded jaw and audible nasal escape were removed, as they are considered rare or associated with some speech disorder (e.g. audible nasal escape only admits the extreme scalar degrees in Beck Reference Beck2007). Several separate settings in Beck (Reference Beck2007) were merged: fronted tongue body and raised tongue body; backed tongue body and lowered tongue body; creak and creaky; whisper and whispery. The justification for these mergers lies in the very slight differences in the articulatory strategy necessary to achieve the settings (e.g. ‘general laryngeal characterization of creak and creaky voice’, as described by Laver (Reference Laver1980: 126); see also Ladefoged Reference Ladefoged1971: 15). By contrast, murmur was included because we considered that this was necessary to complete the range of phonatory possibilities (see Esling & Harris Reference Esling and Harris2005), and this setting is included in the modified version used by JP French Associates.
Besides the division between (i) vocal tract features, (ii) overall muscular tension features, and (iii) phonation features, another common distinction is sometimes made between configurational settings – the majority of settings in the VPA scheme, describing the long-term configuration of the vocal tract – and articulatory range settings, a smaller class of settings which relate to the habitual range of articulatory movement. There are three settings of this sort in Beck (Reference Beck2007): range of lip, jaw, and tongue movement. In all cases, the two possible deviations from neutral are minimized and extensive (lip/jaw/tongue) range.
Beck (Reference Beck2007) includes three further setting groups in a supplementary page of the VPA: (iv) prosodic features, including pitch and loudness; (v) temporal organization features, including continuity and range; and (vi) other features, comprising respiratory support or diplophonia. These were not included in the adapted VPA we used since they generally either refer to acoustically measurable features (f0, loudness), or are relevant for pathological speech (diplophonia).
Apart from the differences in the setting repertoire, an important characteristic of the VPA that we used for this investigation lies in the reduction of scalar degrees. As points 4–6 in the VPA are defined as pathological settings, these were removed from our adapted version. Deviation from neutral was thus marked on a three-point scale, where 1, 2 and 3 are defined as slight, marked and extreme, respectively.
An important decision taken for this adapted VPA scheme was not to mark intermittent features. This is a scoring convention useful to characterize speakers who adopt a setting only sporadically. Sometimes a percentage of frequency of occurrence can be written alongside the scalar degree (Beck Reference Beck2007). However, Ball, Esling & Dickson (Reference Ball, Esling and Dickson1995: 72) note that ‘any particular setting will only have an intermittent effect throughout an utterance’. When raters indicate a certain setting in the protocol, it does not mean that all segments, or even all examples of key segments (Section 3.1), are uttered with that setting configuration. As exemplified by Ball et al. (Reference Ball, Esling and Dickson1995: 72), ‘a nasalized voice does not mean that all sounds are uttered with a lowered velum; rather the term suggests a perceptually greater use than normal of nasal and nasalized articulations’. Although some raters opted for marking intermittent features in their notes, during the calibrations sessions a firm decision on whether the setting was absent or present, and to which degree, was taken to enable cross-rater agreed profiles and inter-rater agreement measurements. For our final agreed VPAs we retained settings that were impressionistically in evidence throughout the majority of a recording, but eliminated any that had been initially marked as intermittent if they occurred only occasionally.
A section for ‘notes’ was added to the protocol in order to admit a first impressionistic and holistic assessment of voices, to be completed while the raters were listening to voices individually. Any perceptual label could be used in this first stage, like ‘bright’ or ‘lively’. In a second step, the raters attempted to establish which VPA setting(s) best suited that first perceptual impression. This part was also useful during the calibration sessions, as raters often found that they were referring to the same perceptual impression, but had then conceptualized it differently within the set of VPA pre-established labels (see also Section 3.1 below). Note that we did not follow the strict two-stage process described by Beck (Reference Beck2007). That is, if raters decided the voice was non-neutral for a particular setting, they generally at the same time decided on the extent to which the voice deviated from neutral.
2.2.2 Perceptual assessment
Three analysts conducted the perceptual evaluation of voices: authors San Segundo (ES), Foulkes (PF) and French (JPF). All were trained in the use of the VPA protocol and had used this protocol for forensic purposes before, in casework, forensically-oriented research, or both. PF and JPF had gathered most of their experience in rating British English speakers, while ES was trained in the perceptual assessment of Spanish speakers. The length of experience was variable, with only JPF having used it extensively in forensic casework. Beck (Reference Beck2007) was used as the main guideline for the assessment.
The perceptual assessment was blind; that is, the raters conducted the listening and rating procedure independently. They could listen to the voices as many times as they wished. Prior to the evaluation, they agreed to focus on the middle of each recording, as it is well known that at the beginning of the recording the speaker may not have settled to his ordinary speaking style. The analysts used the same audio software (SONY Sound Forge Pro 11.0), soundcard (Focusrite Scarlett Solo) and high quality headphones (Sennheiser HD 280 Pro).
The stages of assessment are summarized in Table 1 below. The 99 speakers were analysed in numerical order, with the exception that the first ten rated speakers were randomly selected from the corpus (speakers #006, #009, #022, #025, #028, #032, #046, #063, #072 and #105). These ten were used to pilot the procedure and to enable calibration and procedural consistency between the analysts before embarking on the rest of the corpus. After each analyst had completed the ten VPAs independently, a calibration meeting was held at which the results were compared, problematic perceptual labels were discussed, and differences in analytic strategy were identified (see Section 3.1). The ten samples were later analysed afresh, and the second pass results are included in the overall data set reported below.
Table 1 Perceptual assessment stages and number of speakers evaluated.

The remaining 89 speakers were analysed independently, and again discussed at a calibration and agreement meeting. This entailed both a process of documenting the different types of disagreements encountered, and a cross-coder calibration process in order to produce agreed profiles. While the former was necessary for measuring inter-rater agreement, the latter was essential for the calculation of correlations between settings.
2.2.3 Statistical analyses
In view of the two main aims of this study, two types of statistical analyses were conducted. Firstly, in order to assess the convergence over VPA ratings across the three analysts, we used several measures of inter-rater agreement. Secondly, in order to evaluate to what extent VPA settings are independent, we explored the degree of correlation between them.
2.2.3.1 Inter-rater agreement
Different inter-rater agreement measures exist to provide an indication of the extent to which two or more judges make the same decisions. These measures are also known as consensus estimates of reliability. For this study we tested two types of percentage agreement as well as Fleiss’ kappa:
(a) Absolute percentage agreement. Measures of overall percentage agreement are considered rough estimates of reliability, as they do not take into account the possibility that agreement may occur by chance. Around 70% is generally considered good agreement (Multon Reference Multon and Salking2010). As there were three raters, we provide pairwise percentage agreement results as well as a mean agreement per setting.
(b) Agreement within one scalar degree. This is a popular method of measuring agreement when using the VPA protocol (Beck Reference Beck1988, Reference Beck2005; Stevens & French Reference Stevens and French2012). It represents a more realistic definition of disagreement, occurring in two instances: (i) raters’ disagreement on the presence or absence of a setting (i.e. a rating of 0 versus 1/2/3), and (ii) raters’ disagreement beyond one scalar degree. In practical terms, this disagreement accounts for differences of ‘1’ vs. ‘3’ in the ratings (since there were no higher scalar degrees in this study, and the situation ‘0’ vs. ‘2’ is already covered as an ‘absent’ vs. ‘present’ disagreement). As in the case of absolute agreement, we calculated all pairwise agreements between raters and then averaged the results to provide a single (mean) percentage agreement per setting. This is of interest for the discussion, where we provide some possible explanations for the different or similar pairwise results.
(c) Fleiss’ kappa (Fleiss Reference Fleiss1971). This statistical measure is a generalization of Cohen's kappa for multiple raters. It assesses the agreement between a fixed number of raters assigning categorical ratings to a fixed number of items. It can be interpreted as expressing the extent to which the observed agreement among raters exceeds what would be expected if all raters made their ratings randomly.Footnote 1
The interpretation of the kappa statistic differs considerably from the interpretation of the percentage agreement figure. A value of zero on kappa does not indicate that the raters did not agree at all; it just indicates that they did not agree with each other any more than would be predicted by chance alone. Although the kappa is not devoid of criticism (e.g. Powers Reference Powers2012), it is recognized as a highly useful statistic when one is concerned that the percent-agreement statistic may be artificially inflated because most observations fall into a single category, for instance when a setting is rare and most ratings fall within the neutral label.
Landis & Koch (Reference Landis and Koch1977) provide some guidelines for the interpretation of kappa magnitudes: values < 0 indicate no agreement, 0–0.20 slight agreement, 0.21–0.40 fair agreement, 0.41–0.60 moderate agreement, 0.61–0.80 substantial agreement, and 0.81–1 almost perfect agreement.
We also carried out a preliminary intra-rater study with the ten voices that were rated twice. However, the subset of ten voices analysed twice in this investigation were, above all, considered part of a calibration exercise. Intra-rater consistency was not deemed a research objective for this investigation and fuller studies on this research line are under way (Klug Reference Klug2017). Therefore, we just include a brief description of results in Section 3.2.
2.2.3.2 Correlation measures
The variables (i.e. the VPA settings) analysed in this study produce nominal data. Nominal measures of correlation are: Phi, Cramer's V and Contingency Coefficients. All three measures are based on the prior calculation of the Chi-Square statistic and all three are used to determine the degree of association that exists between variables. In this case we used Contingency Coefficients (C), as there are three or more values for each nominal variable, with an equal number of possible values: 0, 1, 2 and 3.
Given the nature of nominal data, the obtained values for C always fall along a range from 0 to 1 (i.e. negative correlations are mathematically impossible). This is the reason why alongside C we also provide Spearman's rank correlation coefficient (Spearman's r). This statistic gives a value between +1 and −1 inclusive, where 1 is total positive linear correlation, 0 is no linear correlation, and −1 is total negative linear correlation. The difference between using one statistic and the other was negligible for most settings (see Section 3.3), but knowing whether a correlation is positive or negative is of interest for this study.
We considered only 13 settings for the analysis of correlations. This subset corresponds to the settings that occur with higher frequency in the examined corpus (≥ 10% of occurrence): advanced tongue tip, fronted tongue body, nasal, raised larynx, lowered larynx, tense vocal tract, lax vocal tract, tense larynx, lax larynx, creaky, whispery, breathy and harsh.
This decision was taken because including all the 32 settings would result in a high number of spurious correlations, for instance due to the fact that numerous settings were never or seldom present (e.g. tremor or falsetto), which would increase their likelihood of being correlated (i.e. these settings have just ‘0’ values for all examined speakers). Besides, it is well known that performing a large number of correlations increases the chances of finding a significant result by pure chance (Type I error). For studies with multiple correlations, focusing on the most relevant variables or the use of multivariate statistics is advocated in Curtin & Schulz (Reference Curtin and Schulz1998), together with Bonferroni correction. In this investigation we avoided spurious results by both (i) selecting a suitable subset of settings with enough variability of ratings and thus sufficiently present in this population; and (ii) applying Bonferroni correction. This type of correction implies lowering the alpha value to account for the number of comparisons being performed; in this case, 78 correlation analyses (each setting with every other setting). The resulting alpha values (αaltered) considered to determine if a correlation was significant in this study were: .0006 (for αoriginal = .05), .0001 (for αoriginal = .01) and .000012 (for αoriginal = .001).
3 Results
3.1 Results of the calibration sessions
A number of practical issues emerged from the calibration sessions. Some of them are closely related to the type of problems described by previous authors and summarized in Section 1.3 above. Nonetheless, we list these issues here with more detail and provide examples extracted from our own investigation where possible:
(a) Segments vs. settings. It was noted by the raters that sometimes a feature was perceptible, but restricted to few segments. For instance, fronted or retracted tongue tip was perceived on /s/, or fronting of tongue body on goose and goat vowels (Wells Reference Wells1982). Likewise, labiodentalization was most likely perceived just for /r/ (the variant [ʋ] is common in British English – Foulkes & Docherty Reference Foulkes and Docherty2000). Beck clarifies how the VPA is intended to be used in such cases:
[T]he task is to identify those features which are common to all, or at least some sizeable subset, of the segments in a sample of speech . . . The auditory effects of advanced or retracted tip are often most marked on /s/, but the judge should check that any deviation from alveolar placement in generalized throughout the whole set of segments. It is not uncommon for an accent, or an individual, to be characterized by non-alveolar pronunciation of only one of the set of susceptible segments. In this case it would be more appropriate to view the non-alveolar production as a segmental feature rather than a habitual setting adjustment. (Beck Reference Beck2007: 5, our emphasis)
Following this advice, we agreed to mark a perceptual effect as a setting only if most or all relevant segments were affected by the proposed setting. Labiodentalization, for example, was barely used in the final agreed versions, as it almost always affected /r/ alone and was therefore classified as a segmental effect.
(b) Scalar degrees. Some difficulty arose from trying to adapt our three-point scalar degree scale from the original six-point scale, as some of the guidelines in Beck (Reference Beck2007) seem inconsistent (e.g. degrees 4 and 6). For instance, in Beck (Reference Beck2007: 7) we find that degree 3 means ‘the strongest setting that may reasonably be expected to act as a regional or sociolinguistic marker’, degree 4 means ‘beyond the limits of any normal population’ but degree 6 is again ‘the most extreme adjustment of which the normal, non-pathological voice is capable’. For this reason, we found it helpful to define our own three labels precisely, and to map them against Beck's. As a case in point, raters could aim to avoid what Beck defines as 1 (‘just noticeable’) as it is probably useless for e.g. forensic purposes. Our degree 1 (slight) equates to Beck's 2 (‘confident that the setting is audible’), our 2 (marked) would equate to Beck's 3, and our 3 (extreme) would be anything in her 4–6 range. In any case, the DyViS corpus is quite homogenous, as mentioned above, so any marked speakers were likely to have been screened out during participant recruitment. Therefore, degree 3 was seldom used in this investigation.
(c) Correlations. As some authors have noted before, certain settings often – but not always – occur together in the perceptual realm, and logically ought to from an articulatory point of view. Beck (Reference Beck2007) notes the clustering of:
• lax larynx and lowered larynx, low pitch, and breathy/whisper
• tense larynx and raised larynx, high pitch, and harshness
In the course of our assessment, we also observed the patterns Beck lists above, and we further noted, among others, the following main correlations:
• lowered larynx – pharyngeal expansion
• advanced tongue tip – fronted tongue body
(d) Definition or perceptual issues with specific settings.
(i) Breathy and whispery. The distinction between breathy and whispery is somewhat problematic, as their perceptual effects sometimes overlap, or there is no clear consensus on how to define them. Laver (Reference Laver1980), for instance, points out that there is no clear perceptual boundary between whispery and breathy voices, which suggests that there may be a continuum between phonation types, in turn making it difficult for raters to decide between one label or the other (sometimes using both). However, Laver (Reference Laver1980: 134) provides some guidelines for distinguishing between them:
[F]rom an auditory point of view, it is practical to use the label ‘breathy voice’ for the range of qualities produced with a low degree of laryngeal effort, and where only a slight amount of friction is audible. If one thinks of the friction component and the modal voice component as being audibly co-present but able to be heard individually, then the balance between the two components in breathy voice is one where the modal voice element is markedly dominant. ‘Whispery voice’ can then be used for phonations produced with a greater degree of laryngeal effort, and where a more substantial amount of glottal friction, from a more constricted glottis, is audible. The audible balance between the friction component and the periodic component is different from that in breathy voice; the friction component is more prominent than in breathy voice, and on occasion may even equal the periodic component, (and sometimes dominate it strongly, as in ‘extremely whispery voice’).
Instrumental studies indicate a difference in epilaryngeal activity between whisper/whispery voice and breath/breathy voice, with greater constriction for whisper (Esling & Harris Reference Esling and Harris2005, Honda et al. Reference Honda, Kitamura, Takemoto, Adachi, Mokhtari, Takano, Nota, Hirata, Fujimoto, Shimada, Masaki, Fujita and Dang2010).Footnote 2
In this investigation we used a perceptually high rate of glottal friction as a key criterion for evaluating a voice as whispery, as opposed to breathy voice, since the criterion of the greater degree of adductive tension of the vocal folds seems more subjective to assess on an auditory basis. However, we still acknowledge difficulties in rating these settings. This could also be related to the existence of different types of whisper, as suggested by several authors. Catford (Reference Catford1977), for example, notes that some types of whisper may be made with the arytenoidal end of the glottis. Likewise, Laver (Reference Laver1980, Reference Laver1994) mentions that the glottis may be narrowed across most or all of its length, even though it is said that whisper is generated with a posterior triangular opening of the glottis and with the anterior portion adducted. While discussing the use of VQ diacritics in the ExtIPA (extensions to the International Phonetic Alphabet), Ball et al. (Reference Ball, Esling and Dickson1995) recognized that anterior and posterior locations should be marked for this setting, which entails the use of specific diacritics. For our purposes here, these discussions mean that the whispery voice does not represent a homogenous phonation type and can entail worse inter-rater agreement.
(ii) Murmur. Ball et al. (Reference Ball, Esling and Dickson1995) discuss whispery voice as synonymous with murmur. This is perhaps the reason why the latter does not appear in the VPA protocol described in Beck (Reference Beck2007) or older versions of the scheme. In Esling & Harris (Reference Esling and Harris2005) we find another reference to ‘vocal murmur’ as ‘Bell's category of “whisper and voice heard simultaneously”’ (Bell Reference Bell1867), which in Esling & Harris’ words ‘persists throughout the literature as “whispery voice”’ (Esling & Harris Reference Esling and Harris2005: 367). We found it useful to add this setting into the protocol as it seemed to fill a gap in the repertoire of phonatory settings.
The three-way distinction (whispery/breathy/murmur) used in casework at JP French Associates is as follows: Whispery refers to episodes of voicelessness in normally voiced portions, with audible abrasion of airflow at the larynx – which is tense – and in the supralaryngeal tract. Breathy refers to normally distributed voicing, but with audibly high airflow accompanying voiced and voiceless portions. In murmur voicing is perceived as ‘buzzy’ owing to very weak adduction and some abduction of the vocal folds, which are very lax. Beck (p.c) has described this as ‘come to bed’ voice.
(iii) Creaky and harsh. Almost all the speakers in our data had some sort of creakiness, which is likely indicative of a social group pattern, but there were also clearly different types of creak. An interesting case is #032. Two raters classified this speaker as creaky, while the third rater noted ‘hard modal akin to creak’. Very strong glottal pulses could be perceived, which were indeed clear in the acoustic signal, but no label quite captured it for this rater prior to the calibration meeting (creaky was then agreed as the best available label).Footnote 3
Likewise, some raters found it difficult to decide whether some voices fell within the creaky or harsh category. This happened when the type of perceived creak was one involving a particularly tense larynx (e.g. speaker #018). According to Laver (Reference Laver1980: 122), low fundamental frequency distinguishes creaky from harsh voice, ‘which is otherwise somewhat similar’. On the one hand, this is evidence that (some types of) creak can be confused with (some types of) harsh phonation, which would explain lower inter-rater agreement results for this dimension (see Table A1 in the appendix). On the other hand, it provides a clue for disentangling when to use one label or the other: harsh voices seem to have fundamental frequencies consistently above 100 Hz, and creaky ones consistently below 100 Hz for men (Michel Reference Michel1968, as cited in Laver Reference Laver1980). See Keating & Garellek (Reference Keating and Garellek2015) for an acoustic typology of creaky phonation modes.
Harsh phonation may also be differentiated from creak via greater intensity, which would explain the correlation between these phonation qualities and pitch.Footnote 4
We also avoided rating creakiness only on the basis of hesitation points or ends of inter-pause stretches, where it is well known that creak appears regularly. For instance, as a paralinguistic regulator of interactions, some speakers use creaky voice to signal completion of their turn and thus yield the floor to an interlocutor (Laver Reference Laver1994).
(iv) Lax and tense vocal tract. Several speakers (e.g. #006) had notably lax articulation, manifesting as marked undershoot on obstruents and extreme reduction in unstressed syllables. We first considered whether this should count as part of the VPA settings, and if so, as what? We decided to use the label lax vocal tract to mark this laxity in articulation, even though this is not exactly the meaning implied by Beck (Reference Beck2007), where laxness is basically associated with open jaw, nasal, and minimised range of lips, jaw and tongue. It is also impressionistically described by Beck as a ‘muffled quality of the voice’. Noting that Beck suggests considerable correlation with other settings, and that ‘muffled’ is a rather subjective and vague description, we found it useful to keep our ad hoc usage of lax vocal tract as a single label to refer to markedly reduced articulation.
By extension, tense vocal tract was adapted to capture very precise articulation. In other words, this setting corresponds to speakers who fully articulate vowels and consonants for which the norm (in this dialect) admits weaker allophonic articulations. The label was also used to capture fortitions, such as strong stop releases.
One problem that arose from our usage of tense/lax vocal tract is that some speakers showed combinations of both: typically they produce consonants and stressed syllables rather precisely or in citation-like form, whereas unstressed syllables were heavily reduced. This appears again to be a group pattern for young SSBE speakers. A subsidiary problem – resulting from the assessment method itself – is that the presence or absence of these settings should not be evaluated on segments where the speaker is spelling or confirming elicited words. In those cases, the speaker tends to hyperarticulate. The focus of the rater should instead be on spontaneous segments.
Finally, as all minimized and extensive range labels seemed to also represent the tense/lax vocal tract dichotomy, we did not considered it a disagreement if one rater had ticked the box of any of the extensive range settings and another had opted for one of the vocal tract tension settings.
(v) Lowered larynx and pharyngeal expansion. With some speakers (e.g. #006 and #032) raters also used impressionistic labels such as ‘booming’ or ‘resonant’ voice (in the first pass). During the calibration sessions, all raters agreed that it was partly due to low f0, and partly to lowered larynx or pharyngeal expansion, but we did not feel confident in determining whether the enlargement of the pharyngeal cavity was achieved by its distension in the vertical or the horizontal dimension.
(e) Systematic use of opposite labels. Our main concern when evaluating inter-rater agreement during our calibration meetings were those cases where opposite settings were marked by different raters. For example, when one marked constricted pharynx and one of the other analysts marked expanded pharynx, there were two possible causes:
(i) Instability of the setting within the speaker. We were listening to sound samples of several minutes’ duration, in contrast with Laver's recommendation to conduct VPA on around 40 seconds speech (Beck Reference Beck2005). It could thus be the case that both settings occurred.
(ii) Different understanding of what the setting means. In the following section we explain that many of these disagreements were actually due to labelling issues, and we propose not to treat them in the same way as proper disagreements.
(f) Types of disagreements. In order to conduct the correlation and inter-rater tests we agreed on a typology of disagreements. This would be useful for (i) creating a single and agreed version of VPA profiles, necessary for testing correlation (where maximum agreement needed to be achieved); and (ii) keeping individual ratings, after calibration sessions, as close as possible to original ratings in order to provide truthful inter-rater agreement results.
To this end, we distinguished two main types of disagreements: (i) proper disagreements, which reflect an agreed error on the part of a rater (i.e. during the calibration sessions the rater agreed that the use or non-use of a label was incorrect); and (ii) labelling issues, to account for those cases where there were good reasons to think labels were used differently by different raters while they refer to the same perceptual aspect. In other words, we had systematic agreement and within-rater consistency in perceptual judgments, but differences in labelling. For example, ES regularly used tense larynx as equivalent to harsh phonation for PF and JPF. Likewise, there was often systematic use of different labels known to correlate in a given perceptual category, such as retracted tongue body and constricted pharynx.
These labelling disagreements were corrected or adjusted in the calibration sessions so that they did not count either for correlation or inter-rater tests (i.e. after discussion, the diverging rater converged with the others in the use of labels). Type (i) differences between raters were counted as proper disagreements in order to calculate inter-rater agreement (i.e. no amendment was made in the individual ratings). However, for the creation of a cross-rater agreed version, any clear errors of this sort were amended after discussion so that a consensus-based agreed VPA profile could be created per speaker.
Essentially, the proposed methodology thus consisted of two phases:
• If any analyst registered a score > 0 for a speaker (i.e. setting presence), we listened collectively to the recording, with the rater(s) who had missed that setting focusing on it.
• If analysts agreed within one scalar degree on the presence of a certain setting, we accepted the mode score for the creation of a single VPA profile version.
3.2 Inter-rater agreement results
The first test for measuring inter-rater agreement was percentage agreement, both absolute and within one scalar degree (Table A1 in the appendix). As expected, results improve in most of the settings when it is measured within one scalar degree. However, it is considerably better in seven out of the 32 settings: advanced tongue tip, fronted tongue body, nasal, tense vocal tract, lax vocal tract, creaky and breathy. Overall, agreement is very good (> 70%), although it is strongly setting-dependent, as we will explain in more detail later. Table A1 also provides information about the frequency of occurrence (%) of the settings in the examined corpus (first column). Note that the more frequent the setting, the lower the inter-rater agreement, as it was expected.
In a second step, a chance-corrected measure was tested: Fleiss’ kappa (κ; Table A2 in the appendix). This statistic presented some issues in settings where two conditions applied simultaneously: (i) all of the raters had attained 100% agreement, and (ii) they all selected the same variable value for every speaker. For instance, falsetto was never recorded for any of the speakers (although it was noted as intermittent for a few speakers) and therefore all raters agreed on assigning ‘0’ to all of the speakers. This is called the ‘invariant value’ scenario, explained in Freelon (Reference Freelon2010).Footnote 5
If observed and expected agreement was the same (when rounded to two decimal places),Footnote 6 even if not all raters agreed on the use of the same variable value (for instance in close jaw), the resulting κ was too low (even negative) to be considered reliable. Given the effect of invariant values on the calculation of this statistic, κ appears as undefined in these cases.
When the percentage agreement between at least two raters is perfect (100%) but this is not always due to the use of the same variable value (e.g. always neutral) but to the use of other possible values, κ values are among the highest. This is the case for extensive lingual range (0.77) and murmur (0.83).
All in all, most of the settings reached very good agreement: two settings obtained values between ‘almost perfect’ (κ = 0.81–1) and ‘substantial’ (κ = 0.61–0.80) agreement: extensive lingual range and murmur; six of them fell within the ‘moderate’ agreement category (κ = 0.41–0.60): minimized mandibular range, minimized lingual range, pharyngeal constriction, pharyngeal expansion, raised larynx and lowered larynx; six further settings were classified as ‘fair’ agreement (κ = 0.21–0.40): advanced tongue tip, denasal, tense vocal tract, lax vocal tract, tense larynx and lax larynx; only three attained ‘slight’ agreement (κ = 0–0.20): lip spreading, fronted tongue body and nasal. The ten remaining settings obtained undefined κ values, which is due to their high absolute percentage agreement (giving rise to invariant values). Therefore, they also represent good agreement results, but a chance-corrected measure cannot be provided in those cases.
Despite the small number of voices available for intra-rater consistency testing, the preliminary results are promising. Agreement within a rater ranged between 93% and 96% when all settings were considered. Results considering only the settings used more frequently across the corpus as a whole (here taken as > 60%) were also very good. Percentage agreement ranged between 73% (fronted tongue body) and 87% (creaky and nasal). The only other setting that occurs very frequently in this corpus is breathy, with an average intra-rater agreement of 83% across the three raters.
3.3 Correlation results
Table 2 below shows positive and negative correlations found between pairs of settings. We only show those correlations which are higher than |.35|, that is, higher than weak–moderate correlations. Using the guide that Evans (Reference Evans1996) suggests for the interpretation of the absolute value of r, none of the correlations between settings is very strong (r = .80–1.0). However, a strong positive correlation is found between raised larynx and tense larynx (r = .62) and a strong negative correlation between lax vocal tract and tense vocal tract (r = –.65). The rest of the correlations are moderate (r = .40–.59), with a weak to moderate correlation (r = .20–.39) found between creaky and lowered larynx. Most correlations were highly significant, even after Bonferroni correction (see Section 2.2.3.2).
Table 2 Correlated VPA settings using Contingency Coefficients (C) and Spearman's r, ordered from highest to lowest following the C ranking. Italics: negative correlations (Spearman's r).

*p < .0006, ** p < .0001, *** p < .000012 (with Bonferroni correction)
4 Discussion
4.1 Reliability of ratings
The first aim of this study was to assess the reliability of VPA ratings across three different analysts. For that purpose, we tested several measures of inter-rater agreement. The results showed that overall agreement – considering absolute values – is very good for most settings, with a considerable number reaching 100% agreement. However, seven settings out of 32 improve considerably if percentage agreement is measured within one scalar degree: advanced tongue tip, fronted tongue body, nasal, tense vocal tract, lax vocal tract, creaky and breathy. Interestingly, in the discussion which followed the calibration meetings, all these settings occupied much of the raters’ discussion, suggesting that there were clearly some issues involved in their definition, labelling or perceptual salience. It seems logical, therefore, that the agreement reached for them was not as high as with other settings.
The use of percentage agreement presented some problems that were discussed in relation to the perfect agreement reached in settings that were simply not present in this population. When we calculated Fleiss’ kappa – typically considered a more reliable inter-rater measure – the issue of invariant values was revealed. It seems that this chance-corrected measure, which relies on the calculation of expected and observed agreement, is not the most appropriate for this type of variables, where raters often agree completely because they only use one value of the variable: most typically neutral. While other inter-rater measures could be investigated for those specific cases in future studies, the kappa analysis proves useful overall, yielding very good agreement results for most settings.
While most κ values lie between fair and moderate agreement, these results are considerably better than those reported by Webb et al. (Reference Webb, Carding, Deary, Mackenzie, Steen N and Wilson2004), also using the VPA protocol. Although it is not advisable to compare kappa values across different studies (Uebersax Reference Uebersax1987), the highest κ in Webb et al. (Reference Webb, Carding, Deary, Mackenzie, Steen N and Wilson2004) is 0.32, obtained for whispery, followed by 0.24 for harshness. Other settings achieve much lower agreement (e.g. lip rounding/spreading 0.03 or pharyngeal constriction 0.07). Indeed, Sellars et al. (Reference Sellars, Stanton, McConnachie, Dunnet, Chapman, Bucknall and Mackenzie2009) found that many studies focusing on the GRBAS scheme report the highest κ as no better than ‘moderate’, for overall grade. As for a previous study reporting inter-rater agreement on VPA settings, Beck (Reference Beck1988, as cited in Beck Reference Beck2005) only provides percentage agreement results for a normophonic adult population, with only two raters. For a number of settings, inter-rater agreement was no higher than 50%: tongue tip (36%), tongue body (28%), laryngeal tension (48%), or whisperiness (48%). Inter-rater results for pathological voices using the VPA scheme were also modest, in view of the results presented in Wirz & Mackenzie Beck (Reference Wirz, Beck and Wirz1995). Inter-rater reliability fluctuates widely across studies, regardless of the characteristics of the speaker (i.e. normophonic or pathological), which confirms the need for a theoretical framework to explain such variation (Kreiman et al. Reference Kreiman, Gerratt, Kempster, Erman and Berke1993).
The pairwise results for this study show that there were no striking differences between the agreements reached by any pair of analysts versus the other pairs. This is especially revealing, taking into account both native language differences and the different experience reported by each rater. In turn this provides strong evidence that calibration sessions are necessary and useful. As a case in point, murmur achieves the highest agreement of all settings. This was not included in the guidelines used in Beck (Reference Beck2007), so raters agreed on an ad hoc definition of this setting, and in view of the results they were mostly coincident in when and how to use it.
All things considered, it seems clear that there are idiosyncrasies and biases in each individual analyst, i.e. strengths and weaknesses in their assessment of specific settings. Indeed, the analysts were aware of such issues while conducting the analyses. Some biases reflect personal interests, prior assumptions, and possibly difficulty in perceptual categorization or separation of some dimensions. We think this is true for any sort of phonetic analysis, but a team approach seems to resolve most of the errors and strongest individual biases.Footnote 7 Future studies will, nevertheless, include more raters. The small sample considered in this study – although in line with previous studies – may have played a role in the results obtained.
4.2 Correlation of settings
The second aim of this investigation was to evaluate to what extent VPA settings are independent. All the correlations that were perceived during the meetings held by the raters (see Section 3.1) were confirmed using statistical tests, although with varying strength. The strongest positive correlation was found between raised larynx and tense larynx (r = .62) and the strongest negative correlation between lax vocal tract and tense vocal tract. (r = –.73). While the former points to articulatory configurations that co-occur – hence they are also correctly assessed perceptually – the latter suggest that the raters managed to define two opposite settings in a satisfactory, albeit predictable, way: they do not co-occur in perception, and while they can in principle both be used by the same speaker at different times, most did not in this corpus.
Interestingly, two of the most strongly correlated setting pairs include tense larynx, which tends to co-occur with raised larynx and harsh phonation. The combination of laryngeal tension and raising the larynx, or a harsh voice and tensing the larynx was expected.Footnote 8 As a matter of fact, the cluster analysis carried out by San Segundo et al. (Reference San Segundo, Foulkes, French, Harrison, Hughes and Kavanagh2018) revealed that speakers with tense larynx, raised larynx and harsh phonation cluster together and are clearly separated from a second cluster including speakers with lax larynx, lowered larynx and other types of phonation. Likewise, advanced tongue tip and fronted tongue body show a weak–moderate correlation. Most of these correlations seem to be physiologically motivated. However, Gold & Hughes (2015) point out that correlations in FSC may be due to sociolinguistic reasons too (e.g. belonging to the same speech community and adopting the same voice patterns).
All in all, we consider that none of these correlations means that any particular pair of settings should be collapsed. None of the correlations appear strong enough to suggest that the settings involved should be collapsed to a single dimension. On the contrary, it seems that raters may still find a speaker's larynx raised but not perceptibly tense. Therefore, it seems justified to keep both labels, at least in order to characterize this population.
4.3 VPA for forensic speaker characterization: Challenging settings and issues for future consideration
Finally, we had a general objective, which was to provide a methodological example of how the VPA can be adapted for different purposes, such as forensic speaker characterization. For that aim, we provided an account of practical issues derived from the different calibration meetings held by the raters (Section 3.1). While the discussion of these results was in part intertwined with the detailed account of methodological issues, the main points can be summarized as follows.
First, some settings appear less perceptually salient than others, at least to these raters and in respect of this particular corpus. Such settings present some difficulties in terms of agreeing on a definition. As expected, these difficulties ran parallel with a slight-fair agreement achieved by the three raters, although not in all cases. For instance, vocal tract tension or creaky phonation required extensive discussion by raters, and the inter-rater results were indeed fair-moderate. Nasal or fronted tongue body, on the other hand, did not provoke much discussion in the meetings but both settings yielded similar degrees of agreement. The reason for this is that both settings were so frequent in this population that to some extent they can be considered accent features. For that reason, agreement increased considerably when measured within one scalar degree. From a forensic perspective, however, rarity of a setting in the relevant population is very important for the strength of the evidence. Therefore, the question arises as to whether it is much more important that experts agree on the presence of very unusual settings (e.g. falsetto or tremor) than they slightly disagree on settings that are undoubtedly present in the speaker.
Finally, we briefly discuss here some settings that could be useful to include in the VPA protocol for other investigations and maybe when analysing other speaker populations. For instance, we had removed ‘audible nasal escape’ from our protocol. Sometimes there is also something close to audible oral escape, which could be marked as ‘inadequate breath control’ (a label for which is included in the supplementary page of the VPA protocol in Beck Reference Beck2007). Both were apparent for some speakers, e.g. #028 (both oral and nasal) and #063 (mainly oral). However, Beck (Reference Beck2007) defines audible nasal escape as a (presumably pathological) feature that particularly affects obstruents. In this investigation, it was originally interpreted as something being produced outside of the actual speech (extralinguistic or paralinguistic), mostly at turn ends or hesitation junctures. Probably ‘breath support’ covers this effect, but it may be preferred to separate oral and nasal breath control.
Furthermore, there is no label for overall rapidity or any rhythmic aspects in the VPA, although some features related to temporal organization or prosodic variables do appear on the supplementary page of Beck (Reference Beck2007). These features were salient in many of the assessed speakers (e.g. fast rate for #020; slow rate for #030). Articulation rate is commonly commented upon in FSC, and a number of rhythmic measures have also been proposed (Leemann, Kolly & Dellwo Reference Leemann, Kolly and Dellwo2014, Dellwo, Leemann & Kolly Reference Dellwo, Leemann and Kolly2015). However, these aspects are typically considered separately from VQ. Similarly, some of the speakers in this population were impressionistically described as ‘lively’ or ‘active’. This reflected both rapidity and also extensive pitch movement (e.g. #022, #072). The opposite is also perceived in other speakers described as ‘monotonous’.
Sibilance is a setting that appears in the version of the VPA protocol modified by JP French Associates for forensic casework. It was not included in the scheme used here because it was deemed to be covered by the setting advanced tongue tip. However, if high agreement between raters is not achieved using only that setting and its three possible scalar degrees, raters might consider adding ‘sibilance’.
In terms of phonation variation, several speakers (e.g. #009 and #046) were very distinctive, largely because most phonation settings, including intermittent falsetto, could be found in their recordings. While some raters had initially marked most phonation settings as intermittent – additionally using tremor to capture the variation/inconsistency – the ad hoc use of this label does not comply with the definition in Beck (Reference Beck2007). Therefore, the question arises as to whether the raters are satisfied with using a wide range of labels individually or whether there should be some sort of global label for these variables. For instance, the GRBAS protocol reserves the ‘G’ for overall dysphonia.
Diplophonia also appears in the VPA supplementary page (Beck Reference Beck2007). We looked at some speech fragments acoustically and found clear examples of this, e.g. speaker #032. We discussed whether it should be added as a new label but it was eventually not added for two main reasons. On the one hand, it seems that this is a feature which benefits from – and perhaps even requires – acoustic examination in order to confirm its presence. While Beck (Reference Beck2007) suggests that the acoustic signal can be consulted if something is not clear, we were not doing this with the rest of the settings. On the other hand, we felt that the perceptual effect of diplophonia in this corpus could be covered by a combination of the settings constricted pharynx, tense larynx or harsh voice. Diplophonia requires the simultaneous presence of two separate tones or pitches, typically associated with hoarseness (Dejonckere & Lebacq Reference Dejonckere and Lebacq1983). See Moisik (Reference Moisik2013) for a description of the role of the epilarynx (epilaryngeal vibration) in the diplophonic voice as well as in other voice qualities such as constricted pharynx or tense larynx.
Apart from the inter-rater and correlation results, we have discussed in detail a method for the perceptual assessment of voices. In view of the good inter-rater results, we consider the different stages of the method described in Table 1 to be a workable methodology. When a considerably large number of voices need to be assessed by two or more raters, the analysis of a small set of speakers, followed by different calibration sessions, seems a good two-stage methodology to follow in future studies.
5 Conclusions
In this study we have examined the agreement reached by three phoneticians in the perceptual assessment of VQ using an adapted version of the VPA scheme. Undertaking this investigation is of forensic relevance, as in the context of FSC experts can be required by the court to provide a reliability measure of the methods used. Despite the fact that inter-rater agreement seems to depend greatly on the specific VPA setting, we have shown that it is possible to reach a high degree of inter-rater agreement, provided several calibration and training sessions are conducted. This has been the case here, even though raters’ experience and even mother tongue differed.
The methodology described here represents a step towards formalizing VQ for wider use. Furthermore, the reliability of VPA settings has been seldom explored, especially with spontaneous speech samples in a non-pathological population, which makes this investigation relevant for a wider research community with an interest in the use of the VPA. For instance, the search for procedures which can compensate or alleviate disagreement is still a relevant issue in a range of phonetic-perceptual areas of research, as we highlighted in the introduction.
In a second step, we examined how independent the VPA settings are. This is also of forensic importance, as FSC analyses should rely on non-correlated features in order to avoid over-weighting of evidence. We suggested a methodology for agreeing on a single version of VPA scores, which served to calculate correlations between settings. These correlations were not higher than .62 (moderate correlation), which we interpreted as meaning that none of the correlated settings should be collapsed into a single one. Although it could be safer to state in forensic reports that they are not completely independent, each of them still provides specific information for the characterization of a speaker.
As for directions for future work, more investigations are needed into the acoustic correlates of certain settings. For instance, definitions for vocal tract tension seem much less precise than for the rest of the settings, or made in impressionistic terms, like ‘muffled’ voice for lax vocal tract. Although those terms can be very useful for calibration purposes, empirical tests of whether tension relates to any prosodic aspect, such as speech rate (as suggested by Beck Reference Beck2007), would be necessary. Along this line, one should consider how to align labels on perceptual profiles with acoustic measures and automatic tools.
If the ultimate goal of perceptual VPA assessment is forensic use, other corpora or speaking tasks should be used for training. DyViS Task 2 seemed a good starting point for future assessments of telephone-degraded recordings. However, this Task 2 is an information exchange with an accomplice, which might entail problems such as accommodation towards the accomplice, or acting behaviour (i.e. not naturalness) exhibited in certain speakers. Finally, different perceptual methods could be envisaged to minimize any serial effect in speaker rating, whereby the speaker that has just been rated might influence the ratings for the next. For instance, if one speaker is extremely creaky and the next one only slightly so, the contrast might lead the analyst to score the second speaker lower on this setting than might otherwise have been the case.
All in all, we conclude that the perceptual assessment of VQ through the use of the VPA is a valuable tool in fields such as forensic phonetics but, foremost, that it can be adapted and modified to a range of research areas, and not necessarily limited to the evaluation of pathological voices in clinical studies. In the same way that ‘perceptual ratings of voice quality are commonly used as one aspect of a battery of voice outcomes in the voice efficacy literature’ (Carding et al. Reference Carding, Carlson, Epstein, Mathieson and Shewell2001: 128), the VPA protocol has to be understood as one tool in the (forensic) phonetician's toolbox.
Acknowledgements
This research was conducted as part of the Arts & Humanities Research Council (AHRC) funded grant Voice and Identity – Source, Filter, Biometric (AH/M003396/1). We thank three anonymous reviewers for their useful comments as well as the DyViS team for their support which has allowed us to conduct this research. Thanks also to the audiences at IAFPA conferences for their comments on earlier versions of parts of this material.
Appendix. Modified Vocal Profile Analysis (VPA) protocol and inter-rater agreement results

Figure A1 Modified Vocal Profile Analysis (VPA) protocol.
Table A1 Inter-rater agreement.
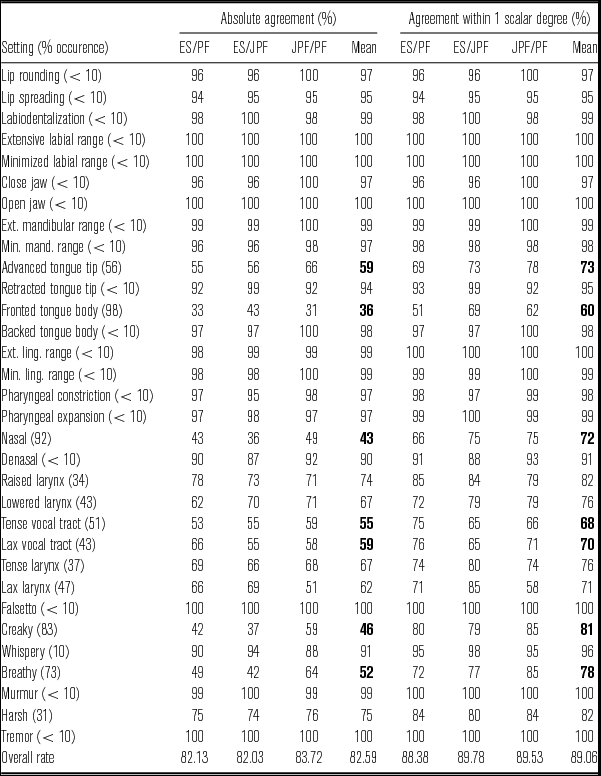
Table A2 Inter-rater agreement: Fleiss’ kappa (FK).








 Open access
Open access