



When investigating a crime, the police may ask eyewitnesses to create a visual likeness of the perpetrator, also known as a ‘facial composite’. To aid in the search for suspects, this composite will often be published in newspaper articles, television shows such as America's Most Wanted, and on social media, through posts on Facebook, Twitter, and Instagram, among others. When a suspect is found, the eyewitness who created the composite, as well as other eyewitnesses, may be asked to identify the suspect from a line-up. In this article, we examine how the dissemination of facial composites in the media affects police investigations.
We often search for people whose whereabouts we do not know, relying on the extensive reach of print, television, and digital media to help us find them. Sometimes the search is for people who are suspected of crimes, but we also search for those who have gone missing, or those whose bodily remains are too decomposed to identify. In the USA, for instance, more than half a million fugitives were sought by police in the year 1999 (Commonwealth of Massachusetts 1999). A variety of personal identifiers can be used in such searches, including physical and behavioural descriptions, recent or old photographs of the wanted person – which are sometimes ‘age-progressed’ – and facial composite likenesses that have been created by witnesses who saw or know the wanted person. By publishing personal identifiers, we hope that members of the public who recognise wanted persons will contact the relevant authorities with information about their whereabouts. This practice dates back several centuries, at least to 16th century Spain, where inquisitors would circulate depictions of escaped prisoners on linen cloth (Groebner Reference Groebner2007, p. 197), and to the so-called Wanted poster widely used in the western states of 19th century America.
In the 20th and early 21st centuries, the search for wanted persons has relied on mass-circulated print and television media, especially through television shows like Wanted (CBS, USA, 1955–1956), Aktenzeichen XY … ungelöst (ZDF, Germany, 1967–now), Crimewatch (BBC, UK, 1984–2017), America's Most Wanted (1988–2011; 2021–now), and many similar programmes in other countries. Viewership of these programmes is often extensive, peaking at 14 million per week in the UK for Crimewatch, 20 million per week in Germany for Aktenzeichen XY … ungelöst, and over 20 million per week for America's Most Wanted. More significantly, claims are often made for the effectiveness of these police–media collaborations: an article in Variety magazine in 2021 claimed that America's Most Wanted had led to 1187 ‘captures’ since the advent of the show in 1988 (Turchiano Reference Turchiano2021). A formal statistical analysis of the efficacy of America's Most Wanted by Miles (Reference Miles2005) drew the conclusions that broadcasting a fugitive's profile raised the apprehension hazard sevenfold and shortened fugitive time by 25 per cent.
Digital distribution of person identifiers promises an even greater reach. In recent years, law enforcement has relied heavily on social media to search for and spread information about unsolved crimes (eg, in the USA, NCJRS 2013; Canada, O'Connor Reference O'Connor2017; and Norway, Denmark, and Sweden, Rønn et al Reference Rønn, Rasmussen, Skou Roer and Meng2020). Furthermore, a phenomenon called ‘websleuthing’ has emerged (Yardley et al Reference Yardley, Lynes, Wilson and Kelly2018), which involves citizen detectives conducting elaborate amateur online investigations to help law enforcement solve crimes, for example, through ‘Facebook identifications’ (Brice Reference Brice2013). On a smaller scale, eyewitnesses to crimes may search social media to see if they can find the perpetrator (Elphick et al Reference Elphick, Philpot, Zhang, Stuart, Pike, Strathie, Havard, Walkington, Frumkin and Levine2021; Havard et al Reference Havard, Strathie, Pike, Walkington, Ness and Harrison2021). If such a social media search leads them to a person whom they recognise – rightly or wrongly – as the person who committed the crime, exposure to photos of this person is likely to alter the eyewitness's original memory for the perpetrator, as we will explain in further detail later in this chapter.
It seems clear that the well-established police–media collaboration in searching for wanted persons has largely positive effects for societies (Miles Reference Miles2005), but there are also dangers. One danger in particular concerns the use of facial composites when searching for wanted people. In some cases, this may lead to the arrest of an innocent person who happens to resemble the composite. This happened to Kirk Bloodsworth, an American military veteran, whose innocence was proven through DNA analysis after he had spent 9 years of his life in prison. Bloodsworth became a suspect because a composite that the police had released to the media depicted a person who looked like him. Bloodsworth was not able to provide an adequate alibi for his whereabouts at the time of the murder of a young girl, and furthermore, witnesses identified him in a line-up. He was sentenced to death for the murder at his first trial, which was later commuted to two life terms (Junkin Reference Junkin2005).
In this article, we first examine how eyewitnesses should be interviewed to gain the most valuable information for creating a composite, taking into account that they may have been exposed to information about the crime in the media – a common occurrence (as evidenced by the large viewership of Wanted-like programmes described earlier). We then discuss several different systems used to create composites, the benefits and constraints of each, and the associated composite quality. Furthermore, we critically evaluate how the effectiveness of facial composites has been measured in scientific studies and propose how we believe it should be measured. We also consider how face-matching difficulties may hamper the search for suspects using facial composites disseminated in the media. Next, we review how being exposed to a facial composite in various contexts, including digital and print media, affects the accuracy of later identifications of the perpetrator in line-ups and face recognition tasks. Finally, we propose important challenges for future research, for the implementation of facial composite construction in practice, and for the optimal dissemination of facial composites, bearing in mind their potential effects on eyewitness memory.
Interviewing methods
The successful creation of a facial composite depends on the completeness and accuracy of the description of the perpetrator's face provided by the witness. Therefore, it is crucial that the witness is interviewed in a way that facilitates accurate remembering. Decades of research on investigative interviewing show that the way in which witnesses are interviewed strongly affects the amount and accuracy of the information they provide. The most widely researched investigative interviewing method is the Cognitive Interview (CI; Fisher and Geiselman Reference Fisher and Geiselman1992). This method stresses the importance of transferring control over the interview to the witness, guiding the witness to mentally reinstate the context of the event, encouraging the witness to report everything about the event in a free recall without interruptions, asking open questions to follow up on the witness's account, and using multiple retrieval strategies to obtain more details from memory. Meta-analyses have shown that the CI results in much more information reported by witnesses, without substantively decreasing the accuracy of reports (Köhnken et al Reference Köhnken, Milne, Memon and Bull1999; Memon et al Reference Memon, Meissner and Fraser2010).
In the more specific context of facial composite construction, Luu and Geiselman (Reference Luu and Geiselman1993) found that facial composites made with a CI were of significantly higher quality than composites made with a standard interview, but only if the composites were constructed with a system that promoted holistic processing. Based on their findings, Koehn et al (Reference Koehn, Fisher, Cutler, Canter and Alison1999) proposed that the CI could be revised in the following two ways to optimally enhance facial composite generation: (1) emphasising visual rather than verbal processing and (2) encouraging witnesses to reflect on how they judged the target's personality while they were encoding the face. Koehn et al tested the effectiveness of the revised CI compared to a standard police interview but found no significant differences in composite quality between conditions, likely due to floor effects in their data (all composites were rated as poor quality).
Frowd et al (Reference Frowd, Bruce, Smith and Hancock2008) continued the investigation of the effects of a holistic CI (H-CI) on the quality of facial composites (see also Fodarella et al Reference Fodarella, Kuivaniemi-Smith, Gawrylowicz and Frowd2015). In the traditional CI condition, participants were instructed to freely recall the appearance of the target in as much detail as possible and then asked to elaborate on each feature. In the H-CI condition, participants received an extra instruction after the initial CI: to reflect on the personality of the target and then judge the face on seven global statements: intelligence, friendliness, kindness, selfishness, arrogance, distinctiveness, and aggressiveness. Several hours later, participants constructed a composite. Results showed that the composites constructed using the H-CI were correctly identified by independent participants more than four times as often as composites constructed using the CI. Thus, the addition of the H-CI instruction substantially improved the quality of facial composites. In subsequent studies, Skelton et al (Reference Skelton, Frowd, Hancock, Jones, Jones, Fodarella, Battersby and Logan2020) found that participants created better facial composites when they created a composite in the same way as they had recalled the target's face during the interview, that is, either holistically (full face) or featurally (internal features first, then external features). Furthermore, they found that participants interviewed with an H-CI created better composites than participants interviewed with a CI. Interestingly, the H-CI was better aligned with internals-first construction, whereas the CI was better aligned with full-face construction, suggesting that the personality judgments focused attention on internal features of the face.
Finally, Giannou et al (Reference Giannou, Frowd, Taylor and Lander2021) investigated whether another interviewing method could improve the quality of facial composites, specifically, mindfulness. First, participants studied an unfamiliar target face. After 24 h, they constructed a facial composite. Participants in the experimental condition received mindfulness instructions during the construction process, while participants in the control condition did not. The mindfulness instructions encouraged participants to visualise the target's face and focus on the process. Results showed that composites constructed in the mindfulness condition were identified accurately more often by independent participants than composites constructed in the control condition. Thus, adding mindfulness to the construction process helped to create more identifiable composites.
Another factor to take into account when interviewing witnesses for composite construction is the risk that witnesses have been exposed to potentially misleading information about the perpetrator in the media. News reports or messages circulating on social media often contain details about the perpetrator's appearance, and these can influence the witness's memory through processes of social contagion (Roediger et al Reference Roediger, Meade and Bergman2001) or memory conformity (Gabbert et al Reference Gabbert, Memon and Allan2003). For example, Loftus and Greene (Reference Loftus and Greene1980) found that witnesses exposed to an incorrect feature in someone else's description of the perpetrator's face (ie, that he had a moustache) were later significantly more likely to incorporate that feature in their descriptions of the perpetrator than a control group. A similar effect may be expected for composites created after exposure to misleading information about the perpetrator's face. An important role for the interviewer is thus to investigate what information the witness has been exposed to prior to attending the interview.
In summary, research shows that witnesses who receive the opportunity to freely recall the face and are instructed to focus on holistic judgments of the face (eg, relating to personality traits) create better facial composites than witnesses who are simply asked a series of questions about facial features. Some police interview trainings have incorporated these findings (eg, in the UK; see Frowd et al Reference Frowd, Bruce, Smith and Hancock2008), but our experiences with the police in South Africa and The Netherlands suggest that many police officers are not aware of these interview methods.
Composite construction systems
A facial composite can be created in many ways. For example, the eyewitness may instruct an artist to draw the face (composite drawing), the eyewitness may piece together the composite by selecting different facial features and placing them in a facial outline (featural systems), or the eyewitness may arrive at a facial likeness by selecting whole faces that more and more closely approximate the face in their memory (holistic systems).
Perhaps, the earliest method of constructing a face from memory used by police forces was through assistance by a police sketch artist (see Figure 1 for an example). The artist would typically have a background and training in portrait art and would interview the eyewitness, sketching the face in close interaction and discussion with the witness. Some artists developed particular techniques for doing so, sometimes even developing a ‘translation language’ to facilitate the conversion of witness memory to face composition. For instance, the witness could be asked to consider the jaw and chin as analogous in shape to a bicycle seat and could then indicate how wide or curved it was by thinking about how the seat would look. It is not common nowadays for police forces to use sketch artists, since they are costly to employ (typically being trained portrait artists), but some do, and remain convinced of the special abilities portrait artists have (cf. Boylan Reference Boylan2001).

Figure 1. Composites of the same target face created from memory through interaction with simulated witnesses. The left panel is a sketch by a police artist and the right panel is a reconstruction with featural software.
Many police forces introduced mechanical systems for constructing faces in the early- to mid-20th century (see Figure 1). One system, known as ‘Identikit’, introduced in 1959, consisted of sketches of facial features that had been copied onto acetate slides, and these could be placed as overlays to each other when interviewing a witness and constructing a face. A face could thus be created by overlaying a sketch of a face frame with additional pre-drawn sketches of eyes, noses, and other face parts, chosen from a large library of images. An artist could touch up the final image created in this way, removing lines introduced by the overlay of the acetates. A similar system was created by Penry (Reference Penry1970, Reference Penry1971) but was composed of features that had been sectioned from photographs of faces. Penry stipulated that no two features should be taken from the same face. A police technician could interview a witness in much the same way as the original sketch artists had done and assemble a face, touching it up where needed.
The limitations of early mechanical systems of face composition were widely recognised in research and practice, and studies consistently showed that facial composites were typically of poor quality: they were not a good match to the face they were intended to represent. Many authors reported that facial composites constructed under reasonably good encoding and retrieval conditions could only be matched at chance levels to the intended targets (for a review of early research on facial composites, see Davies and Valentine Reference Davies, Valentine, Lindsay, Ross, Read and Toglia2007). The advent of affordable computers and computer software in the 1970s and 1980s, however, was widely expected to improve the poor resemblance of composites to their intended targets. Specialised software was introduced for Macintosh computers (Mac-a-Mug; Shaherazam 1986), as well as IBM/DOS and Microsoft Windows-based computers (E-FIT, PRO-fit, FACES, Identikit 2000, CompuSketch, and others; cited in Frowd et al Reference Frowd, McQuiston-Surrett, Anandaciva, Ireland and Hancock2007). These systems dealt with one of the chief problems the old manual systems had, namely the difficulty in managing and navigating large libraries of features. A trained operator could work with a witness and search very large feature spaces quickly and efficiently. There was also no need to do much manual post-composition editing, as digital editing and re-sizing made the task much easier. However, empirical evaluations of computerised composite systems did not substantiate the apparent promise of these systems: attempts to create faces from memory were usually unsuccessful, although it seemed possible for the first time to create good resemblances of faces when the witness had the target in full view (Davies and Valentine Reference Davies, Valentine, Lindsay, Ross, Read and Toglia2007; Koehn and Fisher Reference Koehn and Fisher1997; Kovera et al Reference Kovera, Penrod, Pappas and Thill1997).
The continued exponential growth in computing power led to a more significant change in the technology underlying composite systems in the late 1990s in the form of the so-called eigenface statistical models of faces (Gibson et al Reference Gibson, Solomon, Pallares Bejarano, Harvey and Bangham2003; Frowd et al Reference Frowd, Hancock and Carson2004; Tredoux et al., Reference Tredoux, Rosenthal, Nunez and da Costa1999, Reference Tredoux, Nunez, Oxtoby and Prag2006). These models and software systems allow for the holistic, or configural, construction of faces, jettisoning the feature-based methods employed by earlier systems (see Figure 2). These programmes are essentially applications of the eigenface technology developed and reported by Sirovich and Kirby (Reference Sirovich and Kirby1987). A sample of high-resolution face images is collected, and coded in detail for key facial features, in order to capture two-dimensional shape. The images are then warped into a common reference shape through bi-linear mapping, and principal component analysis is conducted on the images and separately on the two-dimensional shapes. Images in the original sample can be reconstructed through linear combinations of the eigenfaces, and most usefully, so can images that are not in the sample, but with some degree of reconstruction error. This property of eigenface models underpins the new holistic facial composite systems: the face to be reconstructed by a witness has, by definition, a representation in the eigenface space as a set of coefficients (ie, the weights in the linear combination), and the witness's task is to ‘find’ these coefficients. In practice, this is achieved through a graphical user interface that the witness interacts with, either alone or with an operator. Starting with an initial array of synthetic face images (generated randomly, or from a defined starting image), the witness selects one or more of the images from the array according to their overall similarity to the target face, and algorithms generate a new set of face images based on the selection. This continues until the witness is satisfied with the reconstruction.
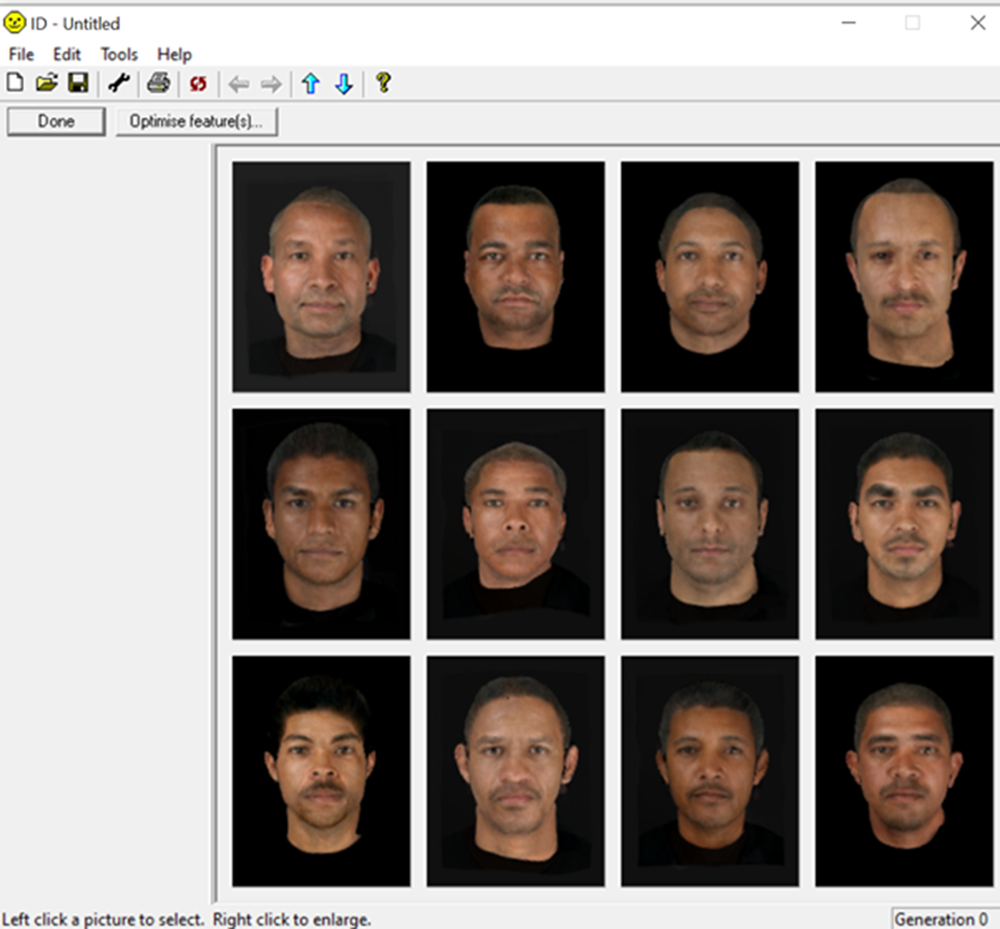
Figure 2. Typical graphical user interface of a new-generation composite system (ID, Tredoux et al Reference Tredoux, Nunez, Oxtoby and Prag2006). The user selects one or more faces of reasonable similarity to the perpetrator, and an algorithm generates new faces based on that choice.
New-generation holistic composites offer promising solutions to some of the vexing problems with facial composite systems identified in earlier research. In the first place, they do not require witnesses to work with disembodied features at any point; adjustments are always presented in a facially integrated form. Secondly, they offer the ability to synthesise faces, generating new faces and/or features, instead of relying on the features collected when developing the system. Thirdly, and perhaps most importantly, they appear to allow the witness to use recognition memory rather than recall memory, as is often required when interacting with sketch artists or police operators. Empirical evaluations of new-generation systems suggest that they can help witnesses produce composites that are recognisable likenesses of perpetrators (Tredoux et al Reference Tredoux, Nunez, Oxtoby and Prag2006; Frowd Reference Frowd, Bindemann and Megreya2017), with recognition accuracy exceeding 70 per cent in some instances (Frowd et al Reference Frowd, Portch, Killeen, Mullen, Martin and Hancock2019), although it should be said that empirical evaluations of the accuracy of the systems have almost all been conducted by the developers of the systems.
Frowd (Reference Frowd, Bindemann and Megreya2017) reports an interesting set of post-processing manipulations that improve the recognition of perpetrators from composites. Thus, he reports that ‘dynamic caricaturing’ of composites through a set of steps improves recognition, as does ‘image stretching’, ‘mild Gaussian blur’, ‘reduced facial texture’, and ‘horizontal misalignment’. Frowd speculates that these techniques may ‘conceal inaccuracies in features (as less information is revealed to the user), to allow holistic information to be more effectively processed by the cognitive system’ (p. 69). The point Frowd makes can be put in a different way. One of the problems with facial composite creation is that composite systems require witnesses to make assertions about the entire face, even if they can only remember parts accurately. It would generally be impossible for a witness to create a composite that was missing a nose, even if they could not remember any detail about the nose, but nonetheless had good information about other facial features (see also Kempen Reference Kempen2013). Thus, the composite may contain some accurate information, and some inaccurate information, and there seems no way to avoid this problem (but see Kempen Reference Kempen2013).
The effectiveness of facial composites
In the real world, a facial composite can be considered effective if it leads the police to the perpetrator of the crime. To that end, the composite is distributed in several ways, including on community noticeboards and in television, print, and digital media. It is hoped that a person who knows the perpetrator will recognise the perpetrator from the depiction and report the possible match to law enforcement. The experimental equivalent of this is not straightforward. In an experiment, there is no perpetrator on the loose that may be spotted by someone who has seen the composite created by the witness. Thus, how does one study whether a composite is effective?
The five methods used most frequently to assess composite quality are as follows: (1) likeness rating, (2) line-up evaluation, (3) composite matching, (4) mugshot elimination, and (5) naming. In likeness rating tasks, participant-judges view a composite and the target it is intended to represent (without knowing this) and rate the similarity of one to the other. In some variations, the target is paired with foils (ie, faces that the composite is not intended to represent) to control for a general likeness of the face to other faces. In line-up evaluation tasks, the composite is shown alongside a target-present or target-absent line-up, and the participant-judge is asked to select the line-up member the composite represents. In composite matching tasks, the participant-judge is given all the composites constructed by witnesses, and the set of photographs showing the targets. The composites are to be assigned to the corresponding targets, but the participant-judge is warned that targets need not be represented in any of the composites. In mugshot elimination tasks, witnesses are presented with the composite sketch and with a large collection of face images (mugshots) and are asked to indicate all those faces that they think the composite cannot feasibly represent. The measure of interest in this method is the proportion of faces that cannot be eliminated by the composite (ie, a set-reduction measure). In composite naming tasks, participant-judges are asked to indicate who (ie, which individual person) the composite represents. This task can only be used in contexts where this is feasible. In laboratory experiments, this is typically achieved by getting participant-witnesses to construct likenesses of celebrities unknown to them and subsequently asking participant-judges who do know the celebrities to name the composites. The forensic relevance of this provision is of obvious significance, and Frowd, in particular, has argued that the naming task should be the ‘gold standard’ in composite studies (eg, Frowd Reference Frowd, Bindemann and Megreya2017). However, participant-judges typically find the task extremely difficult, and naming rates are frequently at floor level. A cued naming task is often used as a remedy, which involves giving judges a list of possible names to match the composite to.
Extant studies have used a variety of techniques, making it difficult to compare results across studies, or indeed to develop a coherent understanding of factors that may affect composite quality. Composite quality is sometimes considered as having multiple dimensions (eg, Frowd et al Reference Frowd, Bruce, McIntyre, Ross, Fields, Plenderleith and Hancock2006) and other times as being one-dimensional (McNamara Reference McNamara2009). Moreover, many studies utilise more than one evaluation technique, yielding different results with different techniques (see, eg, Frowd et al Reference Frowd, Carson, Ness, McQuiston-Surrett, Richardson, Baldwin and Hancock2005). Different evaluation techniques might differ in both task difficulty and in drawing on different cognitive resources, both of which might influence the outcome. For example, likeness rating might draw on in-view feature-based comparison, whereas naming might draw on from memory recognition of a well-encoded face instead.
The assessment of composite quality is also a matter of considerable applied significance, since much of the research on facial composites has police practice in mind. Another way to think about effectiveness is to consider alternative methods of reaching the same goal (ie, leading the police to the perpetrator). A few studies have compared the effectiveness of facial composites to simply providing a verbal description of the face. Christie and Ellis (Reference Christie and Ellis1981) reported that descriptions were more accurate than Photofit composites when accuracy was assessed using identification and classification tasks. McQuiston-Surrett and Topp (Reference McQuiston-Surrett and Topp2008) replicated this finding, reporting that person descriptions were more accurate than facial composites in their study. Lech and Johnston (Reference Lech and Johnston2011) found that descriptions seem more accurate, as measured by recognition of the perpetrator, than even the new-generation E-FIT-V synthetic system. It seems reasonable to propose, as Christie and Ellis (Reference Christie and Ellis1981) did, that the task of realising a visual likeness of a face is dogged by modality-specific interference between the visual image stored in memory and the visual representation that needs to be created (as opposed to a verbal description). A finding to consider, though, is reported by Ness (Reference Ness2003): independent raters who were given both descriptions and composites performed better than those given only descriptions or composites. This was not found in the original study by Christie and Ellis who had a similar manipulation.
Face matching with composites
Publication of facial composites in the news media often results in a deluge of calls to the police, particularly if a reward is offered for finding the wanted person. For example, when a facial composite of the Yorkshire Ripper (see Figure 3) was released in the press, the suspect list exploded to over 17000 names. The press officer on the case later described the influx of tip-offs as ‘100% rubbish’ (Hardaker Reference Hardaker2019). When a facial composite is disseminated via the media and the public is asked whether they know the depicted person, they are essentially asked to match the facial composite to the target's face. People's ability to evaluate whether two different photos of a face depict the same person (or whether a photo matches the person standing in front of them) has been studied extensively in ‘face-matching’ experiments. If the target is familiar, people are generally good at face matching (Megreya and Burton Reference Megreya and Burton2006; see also Chapman et al Reference Chapman, Hawkins-Elder and Susilo2018, for a slightly different view). Of course, when the face-matching task involves matching a facial composite (rather than a photo) to a familiar person, this comes with an additional challenge: it is not clear to what extent the facial composite actually matches the target.

Figure 3. Left: a Photofit facial composite of the Yorkshire Ripper issued by the police in 1979 (Image: Keystone/Hulton Archive via Getty Images). Right: photograph of the person who was later convicted for the crimes, Peter Sutcliffe (Image: Universal History Archive/Universal Images Group via Getty Images).
Moreover, although Frowd's so-called gold standard for the use of facial composites assumes that people familiar with the face of wanted person will view the composite, composites are often also given to police officers and to border authorities who are relatively unfamiliar with the wanted person. It is then hoped that they will be able to match the composite to the face of the wanted person if the opportunity arises. There is good reason to suspect that such a task will be experienced as extraordinarily difficult and will have a low rate of success. This task is more akin to the more typical set-up for face-matching experiments, which usually involve matching depictions of a person unfamiliar to the participant. One of the seminal studies in this literature is Bruce et al's (Reference Bruce, Henderson, Greenwood, Hancock, Burton and Miller1999) demonstration that attempts to match a photo of an unfamiliar target face (in full view) to another photo of the target embedded in an array of 10 faces had error rates of up to 30 per cent (note that guessing would have resulted in 10 per cent accuracy). Since that study, many other studies have confirmed the high error rate in tasks that resemble the matching task passport clerks or cashiers often engage in (see Towler et al Reference Towler, Kemp, White, Bindemann and Megreya2017 for an overview), that is, matching a photo of an unfamiliar person to an unfamiliar person who is standing in front of them.
Thus, when a facial composite is disseminated to people who are relatively unfamiliar with the target, such as police officers and border patrol officers on the look-out for a wanted person, this constitutes an unfamiliar face-matching task with an image of unknown resemblance to the target. Given that face matching with an actual photo of an unfamiliar target is already highly error-prone (cf. Towler et al Reference Towler, Kemp, White, Bindemann and Megreya2017), and given that even people who are familiar with the target have extreme difficulty matching a facial composite to the target (see, eg, Frowd et al Reference Frowd, Carson, Ness, McQuiston-Surrett, Richardson, Baldwin and Hancock2005), the task of matching a facial composite to an unfamiliar target seems nigh impossible.
How exposure to composites in the media may affect eyewitness memory
Because the goal of creating a facial composite is to find the suspect, the composite images are often shared widely through various types of media. This distribution comes with a potential risk: When an eyewitness is exposed to a facial composite created by another eyewitness, this may affect their own memory of the perpetrator's face. Just like other forms of post-event information (for a review, see Loftus Reference Loftus2005), the facial composite may blend with or even replace the initial memory of the face. In cases of high public interest, the facial composite could even become an ‘iconic image’, similar to the iconic photographs of celebrities discussed by Carbon (Reference Carbon2008). In such cases, the iconic image may become the memory of the person and replace the original memory completely. Consider, for example, the famous composite sketches of the Yorkshire Ripper (Figure 3) and the Unabomber (Figure 4), which are seemingly much better known than any actual photograph of the people they portray (also portrayed in Figures 3 and 4). The search for a person who resembles the iconic image could then result in a wild goose chase.
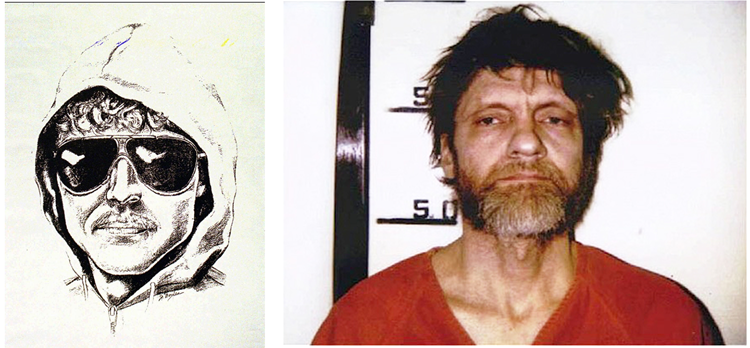
Figure 4. Left: Facial composite sketch of the Unabomber drawn by Jeanne Boylan (Image: NewsBase/NBBPS via Associated Press). Right: photograph of the person who was later convicted for the crimes, Ted Kaczynski (Image: Federal Bureau of Investigation, public domain).
In the eyewitness memory literature, when the face of the perpetrator is replaced in memory by another face (or facial composite) to which the witness was exposed, this is referred to as unconscious transference (see, eg, Read et al Reference Read, Tollestrup, Hammersley, McFadzen and Christensen1990; Ross et al Reference Ross, Ceci, Dunning, Toglia, Ross, Read and Toglia1994a, Reference Ross, Ceci, Dunning and Toglia1994b). The classic case of unconscious transference, described by Loftus (Reference Loftus1976), is that of a sailor who was mistakenly identified by a ticket agent as the person who had robbed him. When the ticket agent was later interviewed to find out why he had falsely identified the sailor, the agent said that the sailor's face had looked familiar. That was unsurprising, as the sailor had purchased tickets from the agent several times before the robbery. It thus seems that the sailor's face had unconsciously been transferred to the robber.
A particularly compelling example of unconscious transference is the story about Donald Thomson, a psychologist who himself became the subject of unconscious transference when a victim who was raped just after watching him speak on national television later accused Thomson of committing the rape (D. M. Thomson 2011, personal communication). Ironically, Thomson's television appearance was about memory for faces. He described his own face and height to illustrate a point about eyewitness identification, and the rape victim later provided that exact description to the police. The police then generated a profile of the rapist and released the description and profile to the public. A few weeks later, Thomson was visited by the police because someone had apparently told them the profile resembled him. When Thomson told the police that the Deputy Commissioner of the Police as well as the President of Civil Liberties could confirm his alibi (ie, appearing on national television around the time of the rape), the officers sneered ‘And I suppose that Jesus Christ was there too!’. Another amusing example of unconscious transference was reported about the German Crimewatch show Aktenzeichen XY … ungelöst. In April 2012, one of the re-enactment actors of the show was arrested because one of the programme's viewers had spotted him on the street and reported him as the jewel thief whom the actor had portrayed on an episode some weeks earlier (Gastaldo Reference Gastaldo2012). Fortunately, his alternative explanation for the supposed eyewitness identification was sufficiently compelling to quickly resolve the misunderstanding.
The blending or replacement of one face with another can be explained by source monitoring theory (Johnson et al Reference Johnson, Hashtroudi and Lindsay1993), which suggests that people often confuse the source of their memories, for example, whether a memorial representation of a face was created while viewing the target's face during the event, or while viewing someone else's composite after the event. When a facial composite is of high quality (and thus perhaps a better resemblance than the original memory of the face), this might be beneficial. When a composite is of poor quality, however, this is likely to be harmful. Given that composites are rarely a good resemblance to the target (eg, Frowd Reference Frowd, Bindemann and Megreya2017), chances are high that composites released in the media will be a poorer resemblance to the perpetrator's face than the eyewitness's original memory of the face. If the eyewitness then sees that composite on social media, a television show, or printed media, that exposure to the composite could potentially alter their original memory.
Sporer et al (Reference Sporer, Tredoux, Vredeveldt, Kempen and Nortje2020) conducted a critical narrative review of the limited number of studies to date investigating the effect of viewing someone else's facial composite on eyewitnesses’ subsequent recall and recognition of the target's face. They found no support for the idea that viewing a high-quality composite benefits subsequent recall of the face, with the few studies that included this experimental condition finding no effects on facial recall compared to a no-composite control condition. Based on the limited amount of evidence in this area, Sporer and colleagues do conclude that ‘viewing someone else's composite, particularly if it is misleading, may harm subsequent memory for the perpetrator, affecting the recall of specific features as well as identification accuracy’. However, they also conclude that the negative effects are limited to specific conditions, short-lived, and relatively easily reversed.
When eyewitnesses create a facial composite themselves, this may also affect their memory of the perpetrator's face. On the one hand, the construction of a facial composite could help the witness to visually rehearse the target's face and as such strengthen the memory of the face (see, eg, Meissner and Brigham Reference Meissner and Brigham2001). On the other hand, composite construction could interfere with the original memory of the face, much in the same way or even more so than viewing someone else's composite does (see, eg, Wells et al Reference Wells, Charman and Olson2005). Wells et al's finding that facial composite construction impaired subsequent facial identifications received a great deal of attention in the news media and legal reviews. For example, newspaper headlines such as ‘When crime-fighting tools go bad: Problems with the face-composite system’ (Munger Reference Munger2006) and assertions such as ‘Not only are facial composites poor indicators of the likeness of a culprit, they also have the potential to taint the memory of the eyewitness who helped to create the composite. Findings from recent studies show that the image of a composite either replaces or blends with the original image in the memory of the eyewitness.’ (McNamara Reference McNamara2009, p. 789) painted a rather catastrophic picture for the use of facial composites in police investigations.
A closer look at the scientific literature as a whole, however, reveals that studies investigating the effect of composite construction on subsequent facial identification report conflicting results, with some finding positive effects, some no effects, and some negative effects (see Tredoux et al Reference Tredoux, Sporer, Vredeveldt, Kempen and Nortje2020 for a review). Perhaps unsurprisingly, then, the recent meta-analysis by Tredoux and colleagues revealed no significant overall effect of composite construction on line-up identification performance. Furthermore, their analyses found no heterogeneity in effect sizes (once outliers were removed). Thus, although there are theoretical reasons to predict that the effects of composite construction might depend on the quality of encoding, the quality of the facial composite, and whether the perpetrator is present or absent in the line-up identification, the current literature does not provide an adequate basis to test for these potential moderating effects.
The findings of the critical review (Sporer et al Reference Sporer, Tredoux, Vredeveldt, Kempen and Nortje2020) and meta-analysis (Tredoux et al Reference Tredoux, Sporer, Vredeveldt, Kempen and Nortje2020) are surprising in light of the seemingly widespread warnings in the news media (eg, Munger Reference Munger2006; Roth Reference Roth2007) and legal and investigative guidelines (eg, McNamara Reference McNamara2009; Stoughton Police Department 2019) that viewing or creating facial composites harms memory. Critical analysis of the available scientific literature reveals that we are not yet in a position to make solid, evidence-based policy recommendations regarding the effects of facial composites on subsequent identifications.
Future challenges
As has become clear from this article, research on facial composites has provided valuable insights but has also raised many questions. In our view, the most important limitation of previous studies is the general lack of ecological validity. With a few notable exceptions (eg, Pike et al Reference Pike, Brace, Turner and Vredeveldt2019), studies have typically used unrealistic facial stimuli, short delays, inexperienced composite system operators, university students as participants, and unrepresentative measures of effectiveness. It is questionable whether the findings from these studies adequately reflect what happens in practice. Future research in this area should attempt to mimic real-life conditions more closely.
Another challenge for future research is to more systematically investigate factors that may moderate the effects reported in this article. For example, relatively few studies have investigated the consistency of composites produced by single witnesses (which is essentially a question of the reliability of composite creation) or by multiple witnesses. In our experience, police forces often have witnesses work together on a composite. Some studies have considered creating aggregate composites through image or model morphing (eg, Bruce et al Reference Bruce, Ness, Hancock, Newman and Rarity2002; Hasel and Wells Reference Hasel and Wells2007; Davis et al Reference Davis, Sulley, Solomon, Gibson, Howells, Sirlantzis, Stoica, Huntsberger and Arslan2010), but an additional question is whether witnesses working collaboratively will produce better composites than when working independently (in line with findings that witnesses can facilitate each other's memory; see, eg, Vredeveldt et al Reference Vredeveldt, Hildebrandt and Van Koppen2016, Reference Vredeveldt, Groen, Ampt and van Koppen2017, Reference Vredeveldt, Van Deuren and Van Koppen2019). In addition, even though the effects of viewing or creating a facial composite on subsequent memory are likely to depend in large part on various factors such as the quality of encoding and the quality of the composite, surprisingly few studies have experimentally manipulated these factors. Furthermore, in real life, witnesses are likely to encounter a facial composite more than once, for example, because they re-watch an episode of a television programme like America's Most Wanted multiple times or because they share the composite on social media and engage with commenters. Future research should look into the effects of such repeated exposure over an extended period of time. Other, more technical questions that need addressing are outlined in more detail in Frowd (Reference Frowd, Bindemann and Megreya2017) and Frowd et al (Reference Frowd, Portch, Killeen, Mullen, Martin and Hancock2019).
A final important challenge for the future is the incorporation of scientific insights into police practice. For some questions, such as the effects of facial composite construction on memory, we do not yet have sufficiently consistent findings to provide a solid foundation for policy recommendations, yet such recommendations have already been published in investigative interview manuals, legal regulations, and the popular media. For other questions, such as the effectiveness of a holistic Cognitive Interview to help witnesses construct better composites, the findings do seem to be consistent enough to inspire policy recommendations, yet we would dare to bet that most police officers who construct facial composites around the world have never heard of this type of interview procedure. We strongly encourage researchers in this field to seek collaborations with local police agencies to promote the implementation of evidence-based guidelines for the use of facial composites in police investigations.
Conclusion
Asking an eyewitness to create a facial composite of the perpetrator and then distributing that composite in the media has the potential to further the police investigation, provided that the composite actually resembles the perpetrator. To increase the likelihood of a high-quality composite, investigators should interview eyewitnesses holistically and ask them about potential exposure to images of the perpetrator in the media. Furthermore, they should use a composite system that results in high-quality composites, such as the new-generation holistic composite programmes. Investigators should also be aware of the risk that other eyewitnesses could be influenced by exposure to the composite, although research findings on this issue are inconclusive. Unfortunately, the insights gained from research to date are limited by the lack of ecologically valid studies and the absence of systematic investigation of potential moderating factors. We believe that these issues need to be addressed to facilitate the formulation of evidence-based recommendations regarding whether the police should use facial composites at all, and if so, how composites should be constructed and distributed to optimise their value for the investigation and minimise their potential harm to eyewitness memory.
Data availability statement
The data that support this review can be found in the cited published scientific articles.
Financial support
This work received no specific grant from any funding agency, commercial or not-for-profit sectors.
Annelies Vredeveldt is Associate Professor of legal psychology at the Department of Criminal Law and Criminology at VU University Amsterdam. Her research interests include eyewitness memory, investigative interviewing, cross-cultural differences, face recognition, facial composite construction, police reports and body-worn camera footage.
Colin Getty Tredoux is Professor of psychology at the Department of Psychology, at the University of Cape Town. His research interests include eyewitness memory, face recognition, and intergroup relations.




 Open access
Open access