


1. Introduction
Language is one of the most dynamic skills humans have acquired, constantly evolving to adapt communication to new purposes and needs (Pinker, Reference Pinker2003, p 13–23). While no single unified theory explains its origins (Allan, Reference Allan2013, p 13–52), language has clearly undergone significant modifications throughout human history. One of the prevailing theories of language evolution is based on the assumption of ‘continuity of change’ (Rilling et al. Reference Rilling, Glasser, Jbabdi, Andersson and Preuss2012).
This theory posits that language, being too complex to have appeared suddenly, must have evolved gradually from earlier pre-linguistic systems used by our ancestors (Pinker and Bloom Reference Pinker and Bloom1990, p 725–726). In this context, comprehending language change contributes to the fields of history, sociology, linguistics, philosophy, and Natural Language Processing (NLP) (Campbell, Reference Campbell2013, p 1–8), as it is essential to understand the origins of language, cultural development, grammatical theories, and the relationship between language and thought (Sherwood, Subiaul, and Zawidzki Reference Sherwood, Subiaul and Zawidzki2008, p 426–454).
Language change is driven by many unplanned factors, such as linguistic evolution, sociocultural and historical influences, and technological advancements. A variety of grammatical factors also promote changes, including:
-
• Phonological changes: Changes in the pronunciation and sound systems of a language. For instance, the pronunciation of vowel sounds changed significantly due to the Great Vowel Shift in Medieval English (Nevalainen and Traugott Reference Nevalainen and Traugott2016, p 367).
-
• Orthographic changes: Alterations in spelling conventions, often reflecting phonological changes, for example, Latin panem to French pain (‘bread’).
-
• Syntactic changes: Changes in grammar and word order. For example, Modern English emphasizes word order and auxiliary verbs more than the intricate inflectional system of Old English (Nevalainen and Traugott Reference Nevalainen and Traugott2016, p 616).
-
• Semantic changes: Words or phrases acquiring new meanings over time, for example, notebook from ‘a book for notes’ to ‘a portable computer’.
While phonological and morphological changes are crucial, semantics plays a pivotal role in language evolution. Semantic change reflects how words adapt to evolving cultural, technological, and societal contexts, creating new meanings and preserving language’s fundamental purpose of effective communication. Despite being a recurring topic in scientific research, semantic change remains less understood than other forms of linguistic evolution due to its often subtle nature compared to more observable shifts, like those resulting from grammar reforms (Allan and Robinson Reference Allan and Robinson2012, p 2–3).
Historically, the study of semantic change relied on manual analysis. Linguists carefully examined historical texts, dictionaries, and corpora to track how word meanings evolved. While these studies provided valuable insights, they were slow, labor-intensive, and difficult to replicate.
The advent of computational linguistics and advanced models marked a major shift in the field. With vast digital corpora and efficient algorithms, researchers began to apply statistical methods from NLP to analyze text automatically. This marked a transition from purely observational methods to data-driven statistical analysis (Allan and Robinson Reference Allan and Robinson2012, p 161–164).
With access to large text corpora and powerful algorithms, linguists can now detect subtle patterns in language with greater accuracy and efficiency. This allows for the study of languages with limited prior linguistic knowledge (Conneau et al. Reference Conneau, Lample, Ranzato, Denoyer and J’egou2018; Wu and Dredze Reference Wu and Dredze2019), given sufficient data, and enables comparison of multiple languages to test for universal properties in latent space (Vulic, Ruder, and Søgaard Reference Vulic, Ruder and Søgaard2020; Wang, Wu, and Neubig Reference Wang, Wu and Neubig2022).
By adopting a model-based approach, linguists can now explore complex language phenomena across different cultures and backgrounds (Nivre et al. Reference Nivre, de Marneffe, Ginter, Hajivc, Manning, Pyysalo, Schuster, Tyers and Zeman2020). These computational tools provide a structured way to test hypotheses, refine mathematical models, and validate findings against real-world linguistic data (Hammarström et al. Reference Hammarström, Rönchen, Elgh and Wiklund2019).
While initially a topic of theoretical interest, the computational study of semantic change has intrinsic value for understanding language evolution and supporting linguistic research. Beyond its linguistic importance, it also informs certain computer science tasks that involve historical language or evolving terminology. For example, historical knowledge graphs such as Wikidata need to account for changes in entity and relation meanings over time to maintain consistency (Polleres et al. Reference Polleres, Pernisch, Bonifati, Dell’Aglio, Dobriy, Dumbrava, Etcheverry, Ferranti, Hose, Jiménez-Ruiz, Lissandrini, Scherp, Tommasini and Wachs2023). In digital humanities, tracking the semantic shift of key concepts (e.g., liberal, gay, computer) over centuries enables a more accurate interpretation of historical texts. Similarly, domain-specific information retrieval can benefit from awareness of semantic drift – for example, the term cloud in technical literature has shifted significantly over the past decades.
Developing cost-effective tools that can handle linguistic variation and precisely characterize semantic changes is crucial for many applications. While the phenomena causing semantic change have been studied extensively in Linguistics (Traugott, Reference Traugott2017), providing deep analyses and typologies, and considerable effort has been devoted to detecting such changes by the computational linguistics community (Tahmasebi, Borin, and Jatowt Reference Tahmasebi, Borin and Jatowt2018), to the best of our knowledge, few efforts have focused on formalizing the problem to characterize the type of change a word has undergone (Hengchen et al. Reference Hengchen, Tahmasebi, Schlechtweg and Dubossarsky2021).
A formal, mathematical language can serve as a valuable tool in the computational study of semantic change. While we acknowledge that language evolution is deeply intertwined with cultural, societal, and historical dynamics – factors that often resist formalization – developing a structured framework allows us to isolate and investigate specific computational aspects of this complex phenomenon. Our aim is not to reduce semantic change to purely formal terms, but to provide a simplified, tractable representation that supports the development of methods and evaluation tools within computational linguistics. We recognize that such formalizations are necessarily reductive and do not capture the full richness of linguistic and cultural processes; rather, they offer a complementary perspective that can contribute to broader, interdisciplinary understandings of meaning change.
This survey addresses the need to understand and formalize the characterization of semantic change. Characterizing such changes will open new perspectives, particularly since we often lack the resources to study them in detail.Footnote a This is especially problematic in contexts where multiple word meanings are relevant, potentially leading to political or social misinterpretations. This survey’s objectives include:
-
(1) Identifying the limitations of current representations and methodologies in categorizing semantic changes.
-
(2) Evaluating the strengths of approaches used to classify Lexical Semantic Change (LSC).
-
(3) Finding and analyzing formal definitions based on first-order logic to reduce ambiguity and facilitate the comparison of findings.
-
(4) Demonstrate the task of the LSC conceptually.
In this survey, we select categories that are both addressable by computational methods in a comparative setting (Tang, Qu, and Chen Reference Tang, Qu and Chen2013) and well-established in the linguistic literature (Campbell, Reference Campbell2013, p 221–246), that is, changes that can be systematically measured and are backed by theoretical analysis (Hammarström et al. Reference Hammarström, Rönchen, Elgh and Wiklund2019). For instance, euphemistic shifts often depend on social norms. When the word ‘weed’ acquired the sense of ‘cannabis’, this shift was motivated by the intention to obscure the literal meaning, given that cannabis carried negative or prohibited connotations within that particular cultural and historical context. Capturing this type of change requires not only knowledge of the lexical relation between ‘grass’ and ‘cannabis’, but also an understanding of external social and cultural factors.
Another example concerns cases in which a word’s sense becomes more general or more specific. Such changes cannot always be detected through direct comparison of the two senses, as the more general sense may still appear appropriate in both contexts, thus obscuring the shift. We focus on three factors of semantic change: orientation (i.e., whether a word’s meaning becomes more pejorative or positive, e.g.,, the word awful acquired a negative meaning), relation (i.e., whether a word’s meaning changes through figurative usage, ‘head’ used to address the director of a company), and dimension (i.e., whether a word’s meaning becomes broader or more specific, ‘cell’ used to mean only a room in prison).
These poles of change also encode fundamental aspects of meaning: denotative (dimension), connotative (orientation), and cognitive (relation). Some of these properties, as we detail later, are crucial for understanding the intent of a sentence, for writing tools, to assist with translation, or to interact with users (e.g., in a social robot). Finally, this will open new opportunities to improve the reasoning capabilities of NLP tools (Danilevsky et al. Reference Danilevsky, Qian, Aharonov, Katsis, Kawas and Sen2020).
To our knowledge, this is the first survey to comprehensively cover semantic change characterization by consolidating and categorizing existing approaches and identifying research gaps. It introduces formal descriptions and proposes enhancements for a more robust understanding of semantic change. By synthesizing prior research and addressing its limitations, this survey aims to streamline existing work and advance our understanding of this complex phenomenon.
The remainder of the paper is structured as follows: Section 2 reviews existing surveys, highlights their differences from this work and presents our survey method. In Section 3, we investigate available corpora for semantic change analysis. In Section 4, we explore methods for representing and characterizing meaning change. In Section 5, we present a formal model derived from the reviewed methodologies. Section 6 presents our analysis and open questions. Finally, Section 7 concludes the survey and outlines future work.
2. Lexical semantic change
For the characterization of change, we adopt the mainstream linguistic typology for semantic change (Traugott, Reference Traugott2017): (i) broadening and narrowing, (ii) amelioration and pejoration, and (iii) metonymization and metaphorization. Before studying change characterization, we first review work on change identification. This is a well-developed topic that focuses on evaluating whether a word’s meaning has changed. Papers addressing change identification often state the need for further characterization of the type of change, but the state of computational change characterization remains unclear. This conclusion motivated the work presented in this paper and differentiates our survey from existing ones on LSC.
In the following subsections, we present existing surveys on the semantic change problem and identify gaps in the current literature. Inspired by their definitions, we propose our own typology of changes. The last subsection introduces the objectives of this survey and our plan to address the gap in semantic change characterization.
2.1 Related works on identification of lexical semantic changes
Existing surveys on semantic change regularly cover detection but seldom focus on characterization, which is the topic of this paper. In the context of identification, Tang (Reference Tang2018) proposes splitting LSC analysis into four steps: obtaining and preparing a diachronic corpus, identifying word senses, modeling semantic change, and presenting and validating hypotheses. This empirical, rather than historical, paradigm enables the study of semantic change through scientific and statistical methods, allowing findings to be reproduced and tested – a key element for computational research.
Tang’s framework structures the survey by describing studies related to each step. Change identification is mainly discussed in the ‘modeling semantic change’ section, which explains the difference between historiographical and empirical analysis. However, it does not cover approaches that classify changes into categories like broadening, narrowing, pejoration, amelioration, or figurative shifts.
A second survey on computational approaches to LSC (Tahmasebi et al. Reference Tahmasebi, Borin and Jatowt2018) focuses on word-level differentiation, sense differentiation, and lexical replacement. While it includes some types of change categories (e.g., metaphor, metonymy), the main change categories discussed are broadening, narrowing, and correlated types (split, join, birth).
However, one recommendation from the authors is to conduct deeper studies on methods for automatically detecting other types of change and using them to build word histories. The authors provide an in-depth analysis of the linguistic literature, grounding each domain, followed by evaluation strategies and applications. The difficulty of comparing approaches is highlighted and attributed to the absence of standard metrics and reference datasets, but also to the inherent challenges of the task itself.
Kutuzov et al. (Reference Kutuzov, Øvrelid, Szymanski and Velldal2018) survey word representation models and data for semantic change identification and describe a framework for comparing these methodologies. The authors focus on defining consistent terminology and coherent evaluation practices. In this work, they claim there’s still a gap in studying sub-classifications of change:
‘However, more detailed analysis of the nature of the shift is needed. […] This problem was to some degree addressed by Mitra et al. (Reference Mitra, Mitra, Maity, Riedl, Biemann, Goyal and Mukherjee2015), but much more work is certainly required to empirically test classification schemes proposed in much of the theoretical work […]’
For the study of LSC and NLP in general, there are four main ways to represent word meaning: (i) frequency of co-occurrence, (ii) graphs of associated words or meanings, (iii) topic modeling for a list of meaningful terms, and (iv) word embeddings. Initial studies in the field employed graph- or frequency-based methods. Later approaches benefited from advances in the state of the art, replacing discrete methods with those based on static and contextual embeddings. Although contextual embeddings represented a massive improvement for a series of NLP tasks (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), the improvement for LSC did not follow this trend (Schlechtweg et al. Reference Schlechtweg, McGillivray, Hengchen, Dubossarsky and Tahmasebi2020), showing that there is still room for improvement in this domain (Zhou, Ethayarajh, and Jurafsky Reference Zhou, Ethayarajh and Jurafsky2021; Kutuzov, Velldal, and Øvrelid Reference Kutuzov, Velldal and Øvrelid2022).
Other surveys in LSC investigate the phenomenon of change at the ontological level, trying to discover which laws govern the semantic evolution of words. For example, which kinds of words are more prone to broadening, given their current properties? In this context, Dubossarsky et al. (Reference Dubossarsky, Weinshall and Grossman2017) investigate existing evidence for claims such as (i) word frequency affects meaning change, (ii) a negative correlation exists between meaning change and prototypicality, and (iii) a positive correlation exists between meaning change and polysemy. The authors observed that laws proposed in previous studies are affected by model or data bias. When other investigators reduced the bias, the ‘laws’ either did not hold or were less precise than initially reported.
Research in this field also delves into methodological issues, including the challenges of characterizing semantic shifts. As pointed out by Hengchen et al. (Reference Hengchen, Tahmasebi, Schlechtweg and Dubossarsky2021), few studies detail the nature of these changes, mainly because it is difficult to model meaning from textual data. The paper further concludes that no particular measures for quantifying category change exist and that a consensus on a taxonomy for classifying types of change is required.
In the work of Montanelli and Periti (Reference Montanelli and Periti2023), the authors review methodologies based on contextualized word embeddings. They categorize methodologies for training contextualized embeddings based on how they represent meaning, how time information is presented to the model, and what kind of learning procedure is performed. In this paper, the authors also discuss the importance of characterization:
‘Most of the literature papers do not investigate the nature of the detected shifts, meaning that they do not classify the semantic shifts according to the existing linguistic theory (e.g., amelioration, pejoration, broadening, narrowing, metaphorisation, and metonymisation) […]. These studies could be crucial to detect “laws” of semantic shift that describe the condition under which the meanings of words are prone to change. […]’
For this survey, we argue that semantic change characterization needs appropriate methods and tools to analyze each fine-grained category. We also defend that observing variations in a single property cannot describe all forms of LSC well. For instance, changes in the angle between word vectors (Dubossarsky et al. Reference Dubossarsky, Weinshall and Grossman2017) are not the best solution to identify the narrowing or broadening of a sense (Tahmasebi et al. Reference Tahmasebi, Borin and Jatowt2018). Specific methods for identifying different types of change could lead to a better understanding of LSC than straightforward dissimilarity measures.
This survey addresses the need to depict the characterization problem in semantic change and present recent works dealing with this problem. In the next section, we define the survey objectives and the criteria for selecting papers on change characterization.
2.2 Objectives
Different terms refer to LSC, such as semantic drift or semantic shift. In this paper, we distinguish between the identification of a change and the characterization of that change. The former refers to detecting that a word’s meaning has changed, while the latter refers to describing how it has changed. We formally differentiate these problems in Subsection 5.1. The analysis of work on the identification problem has been well covered by Tahmasebi et al. (Reference Tahmasebi, Borin and Jatowt2018), Kutuzov et al. (Reference Kutuzov, Øvrelid, Szymanski and Velldal2018), and Tang (Reference Tang2018).
Semantic change occurs from the need to convey more complex concepts and ideas with a restricted set of known words (Hock and Joseph Reference Hock and Joseph2019). While some authors categorize changes by their cause (e.g., social, cultural), others use linguistic mechanisms (e.g., metaphor, metonymy) as the basis for classification. The focus of our literature review is on the characterization of change, where we look for common properties that allow for grouping identified semantic changes into categories. From a computational perspective, determining the cause of a semantic change is very complex to implement, and, to the best of our knowledge, no computational approach has been implemented yet.
Frameworks have been proposed on how to track LSC, such as the Cambridge and McTaggart views (Tang et al. Reference Tang, Qu and Chen2013), which did not initially consider computational methods. These approaches differ in how they use temporal information to identify changes: while the Cambridge view involves comparing two static corpora from different time periods, the McTaggart view involves tracking the evolution of a word’s usage over time. The Cambridge approach best suits the computational perspective, as the McTaggart approach would require historiographical work to acquire socio-cultural knowledge that goes beyond contextual analysis of word occurrences (Tang et al. Reference Tang, Qu and Chen2013, p 4–7).
This core distinction causes considerable disagreement, as empirical and historiographical methods are based on different ideas and focus on distinct aspects of research. Empirical methods rely on direct observation and measurable data, whereas historiographical methods involve interpreting past events and written records. Since these two approaches operate in different ways and aim to answer distinct kinds of questions, they often yield contrasting views.
For this review, we assume the Cambridge setting for change analysis, using linguistic figures as a basis for change categories, which aligns with current state-of-the-art methods for computational LSC (Pivovarova and Kutuzov Reference Pivovarova and Kutuzov2021). Given these considerations, we adopt the typology from Traugott (Reference Traugott2017), which is also predominant in the literature, as seen in Koch (Reference Koch2016, p 21–66), Hock and Joseph (Reference Hock and Joseph2019, p 189–222), and Campbell (Reference Campbell2013, p 221–246):
-
• Broadening: A word gains new meanings, making it applicable to more concepts, for example, ‘cloud’ as a computing infrastructure.
-
• Narrowing: A word’s meaning becomes more restricted, applying to fewer concepts. For example, ‘gay’ once meant ‘jolly’ or ‘festive’ but now primarily refers to homosexuality.
-
• Amelioration: A word gains a more positive sense. For example, nice changed from ‘foolish, innocent’ to ‘pleasant.’
-
• Pejoration: A word is used with a worse connotation. For example, Old English stincan (‘to smell sweet or bad’) changed to stink.
-
• Metonymization: A change based on contiguity or association between concepts, for example, board from ‘table’ to ‘a governing body of people who sit at a table’.
-
• Metaphorization: Conceptualizing one thing in terms of another, for example, using the heart to represent ‘feelings.’
Since the types in this typology form natural pairs that often involve similar computational challenges (e.g., broadening/narrowing requires sense counting; amelioration/pejoration requires sentiment analysis; metaphorization/metonymization requires a relatedness measure (Blank, Reference Blank2003; Koch, Reference Koch2016; Hock and Joseph Reference Hock and Joseph2019)), we group them into three overarching poles to better compare and categorize research. We only include approaches that compare corpora, as this typology is designed for diachronic studies rather than synchronic variation (e.g., across domains). Figure 1 illustrates the hierarchical taxonomy for LSC.
Taxonomy for the poles of Lexical Semantic Change, based on the work of Blank et al. (Reference Blank2003); Koch (Reference Koch2016); Hock and Joseph (Reference Hock and Joseph2019).

Change in meaning and orientation for the word awful. On the left side, we reproduce the figure from Hamilton et al. (Reference Hamilton, Leskovec and Jurafsky2016b) that shows the evolution of the word ‘awful’ in the embedding space. On the right side, we present the hypothetical function (
 $\mathfrak{f}$
) for this word over time.
$\mathfrak{f}$
) for this word over time.

Figure 2 Long description
A line graph illustrates the semantic evolution of the word awful from the 1850s to the 1990s. The x-axis represents years, ranging from 1800 to 2000, while the y-axis indicates semantic change, with amelioration (positive change) upwards and pejoration (negative change) downwards. The graph shows three key points: in the 1850s, awful had a positive connotation associated with respect and solemnity; by the 1950s, it had shifted to a negative connotation linked to dread and horror; and by the 1990s, it had further evolved to mean something very bad or unpleasant. The graph also includes examples of usage, such as 'God is awful' and 'My holidays were awesome,' to illustrate the changes in meaning. The left side of the image shows a diagram with words like awe, majestic, terrible, and horrible, indicating the semantic shifts. The right side shows a hypothetical function for the word awful over time, with dotted lines representing the trajectory of its meaning. All values are approximated.
We assign studies that track sense broadening or narrowing to the dimension (
 $\mathscr{D}$
) pole, where words gaining or losing senses see a change in their dimension value (see Subsection 5.2). This pole is self-complementary, as the change in the dimension’s value addresses both broadening and narrowing. A change in dimension could signal, for example, that a word requires more careful translation (Mohammed, Reference Mohammed2009).
$\mathscr{D}$
) pole, where words gaining or losing senses see a change in their dimension value (see Subsection 5.2). This pole is self-complementary, as the change in the dimension’s value addresses both broadening and narrowing. A change in dimension could signal, for example, that a word requires more careful translation (Mohammed, Reference Mohammed2009).
We group changes related to metaphorization or metonymization into the relation (
 $\mathscr{R}$
) pole. These changes occur when a new sense develops from an existing one through a figurative link (see Subsection 5.3). Relations like hypernymy, hyponymy, and synonymy are also factors for semantic change (Koch, Reference Koch2016; Hock and Joseph Reference Hock and Joseph2019) as they involve a conceptual relation and can potentially be encompassed in this pole.
$\mathscr{R}$
) pole. These changes occur when a new sense develops from an existing one through a figurative link (see Subsection 5.3). Relations like hypernymy, hyponymy, and synonymy are also factors for semantic change (Koch, Reference Koch2016; Hock and Joseph Reference Hock and Joseph2019) as they involve a conceptual relation and can potentially be encompassed in this pole.
For the orientation (
 $\mathscr{O}$
) pole, we group studies that identify amelioration, pejoration, or any perceptual change in the sentiment associated with a word (e.g., criticism, compliment). This pole also encompasses many forms of change in perception, as some studies suggest that concepts like ‘taboo’ also affect changes in word usage (Koch, Reference Koch2016).
$\mathscr{O}$
) pole, we group studies that identify amelioration, pejoration, or any perceptual change in the sentiment associated with a word (e.g., criticism, compliment). This pole also encompasses many forms of change in perception, as some studies suggest that concepts like ‘taboo’ also affect changes in word usage (Koch, Reference Koch2016).
To illustrate a word that changed in orientation, consider ‘awful’. In the 1850s, it meant ‘full of awe’, but today it means ‘extremely disagreeable’. As the first sense is semantically positive and the second is negative, this word underwent pejoration, as illustrated in Figure 2. Notice that the word’s orientation may have first undergone amelioration before pejoration. In the same figure, the word ‘awesome,’ which has a close relation to ‘awe’, gained a more positive sense, undergoing amelioration over time.
In the next section, we describe our method for reviewing the literature based on the poles presented above.
2.3 Review criteria
In this survey, we select papers that represent and analyze words from one of the poles mentioned above in an automatic manner. We exclude works that involve manual analysis, as we focus on computational methods. For the relation and orientation poles, these searches returned many unrelated results, such as studies on synchronic metaphor detection, which do not infer diachronic change and were therefore excluded.
Querying scientific databases required an iterative process to include all relevant terms. In our initial efforts, we searched for ‘[type of change, e.g., broadening] semantic change’ in Scopus, which returned 33 articles; however, none of them were relevant. Due to the lack of consensus in terminology and the rapid pace of the field, we adopted a semantic search approach, starting with key papers and iteratively expanding our search query. Table 1 presents the final set of search terms used to collect articles.
Search terms used to discover articles related to change characterization

Table 1 Long description
The table categorizes search terms into three main groups: Dimension, Relation, and Orientation. Under Dimension, terms include semantic change broadening, semantic change narrowing, novel sense change, innovative meaning, new sense identification, and neologism identification. The Relation category lists metonymy semantic change, metonymization semantic change, metaphor semantic change, and metaphorization semantic change. The Orientation category includes semantic change polarity, semantic change feeling, semantic change emotions, and semantic change sentiment. These terms are used to iteratively search scientific databases for relevant articles on semantic change.
From these initial queries, we could find 11 seed papers that satisfy our criteria. We then employed a network semantic citation graph to recover more papers, Research Rabbit.Footnote b From the 11 initial papers, the graph suggested 83 new papers; from this, we were able to recover 7 that matched our criteria. We again included these additional 7 papers as seed, obtaining 129 papers. From 129 papers, we obtained 5 more relevant papers. In the last interaction, we obtained 151 paper suggested, but no new relevant papers were found. In Figure 3, we present the graph of documents, where green nodes represent the input papers, and blue nodes represent papers suggested by the tool.
Graph of selected works (green) and related articles (blue).

Figure 3 Long description
A scatter plot featuring green and blue nodes interconnected by lines. The green nodes represent selected works, while the blue nodes indicate related articles. The plot shows a network of connections between these nodes, illustrating relationships and clusters. The green nodes are generally larger and more central, suggesting they are more influential or frequently cited. The blue nodes are smaller and more peripheral, indicating they are less central but still part of the network. The connections between nodes vary in thickness, possibly representing the strength or frequency of the relationships. The plot does not include axes or a legend, focusing solely on the network of connections. All values are approximated.
In the next sections, we investigate three elements of semantic change characterization in depth: (i) the corpora (
 $T$
) analyzed, (ii) the representation method (
$T$
) analyzed, (ii) the representation method (
 $\mathfrak{R}$
) for capturing characteristics of change, and (iii) the kind of characterization (
$\mathfrak{R}$
) for capturing characteristics of change, and (iii) the kind of characterization (
 $\{\mathscr{D},\mathscr{R},\mathscr{O}\}$
) addressed.
$\{\mathscr{D},\mathscr{R},\mathscr{O}\}$
) addressed.
3. Corpora for semantic change analysis
Corpora for semantic change can be selected based on differences in time (diachronic studies), domain (academic fields (Schlechtweg et al. Reference Schlechtweg, Hätty, Tredici and im Walde2019)), culture (social media (Carpuat et al. Reference Carpuat, Daumé, Henry, Irvine, Jagarlamudi and Rudinger2013; Shoemark et al. Reference Shoemark, Liza, Nguyen, Hale and McGillivray2019), countries), or dialect (Takamura, Nagata, and Kawasaki Reference Takamura, Nagata and Kawasaki2017; Uban, Ciobanu, and Dinu Reference Uban, Ciobanu and Dinu2021), provided the corpora share a sufficient vocabulary for comparison.
In diachronic studies, some methods divide a corpus into discrete time windows, striking a balance between the size of the window and the quantity of data it contains. In contrast, others use a continuous representation of time, providing the timestamp of each text directly to the model (Rosenfeld and Erk Reference Rosenfeld and Erk2018; Hu, Li, and Liang Reference Hu, Li and Liang2019; Wang, Buccio, and Melucci Reference Wang, Buccio and Melucci2021). These corpora were designed for specific purposes. For example, corpora with discrete time bins enable a comparative perspective on meaning, while continuous time representations allow for an evolutionary view of the changes.
With respect to characterization, the collected papers show an increasing interest in diachronic corpora, with many proposing handcrafted rules for automatically annotating change categories (Tang et al. Reference Tang, Qu and Chen2013). Few works rely on human annotation (Schlechtweg et al. Reference Schlechtweg, Eckmann, Santus, im Walde and Hole2017). While these approaches have advantages and drawbacks, the data required to train large representation models is often insufficient from a computational perspective.
Most of the works reviewed here follow a specific formula for diachronic studies, one historical corpus (
 $C_1$
) and a more modern corpus (
$C_1$
) and a more modern corpus (
 $C_2$
). Splitting the Corpus of Historical American English (COHA) Davies (Reference Davies2012), a diversified corpus with a span from the 1810s to the 2000s, into two corpora is the standard choice. Recent state-of-the-art NLP models require training on billions or even trillions of tokens (He, Gao, and Chen Reference He, Gao and Chen2021), but diachronic corpora are often on the scale of millions of tokens (Schlechtweg et al. Reference Schlechtweg, McGillivray, Hengchen, Dubossarsky and Tahmasebi2020). Given that increasing the amount of historical training data is often infeasible, a viable approach is to develop better algorithms for learning from limited data. In Table 2 we present the table of diachronic corpus in the reviewed works.
$C_2$
). Splitting the Corpus of Historical American English (COHA) Davies (Reference Davies2012), a diversified corpus with a span from the 1810s to the 2000s, into two corpora is the standard choice. Recent state-of-the-art NLP models require training on billions or even trillions of tokens (He, Gao, and Chen Reference He, Gao and Chen2021), but diachronic corpora are often on the scale of millions of tokens (Schlechtweg et al. Reference Schlechtweg, McGillivray, Hengchen, Dubossarsky and Tahmasebi2020). Given that increasing the amount of historical training data is often infeasible, a viable approach is to develop better algorithms for learning from limited data. In Table 2 we present the table of diachronic corpus in the reviewed works.
Overview of Various Corpora for Diachronic Studies

Table 2 Long description
A table comparing various diachronic corpora, their descriptions, and statistics, including date and size ranges. The table has three columns: Corpus Name, Description, and Statistics. It lists 12 different corpora, each with a unique name, a brief description of the corpus, and statistics that include the date range and size of the corpus. For example, the CLMET corpus covers diachronic English corpora from 1710 to 1920, divided into three 70-year sub-periods, and contains 34 million words. The COHA corpus spans from the 1810s to the 2000s and includes over 400 million words from about 107,000 documents. The Google N-Gram Book corpus is the largest historical corpus, containing over 1 terabyte of text data with about 0.3 trillion words spanning from 1600 to 2009. Each row provides detailed information about the specific diachronic corpus, highlighting the diversity and scope of the historical data available for linguistic studies.
Even with progress in low-resource learning fields like rapid adaptation (Neubig and Hu Reference Neubig and Hu2018), few-shot learning (Liu et al. Reference Liu, Tam, Muqeeth, Mohta, Huang, Bansal and Raffel2022), or in-context learning (Min et al. Reference Min, Lyu, Holtzman, Artetxe, Lewis, Hajishirzi and Zettlemoyer2022), there is still a significant lack of freely available corpora for semantic change studies (Kutuzov et al. Reference Kutuzov, Øvrelid, Szymanski and Velldal2018).
4. Methods for semantic change characterization
While interest in detecting semantic change is growing, less effort is being applied to characterizing these changes. Computational linguistics has not yet fully explored the utility of having detailed information about the type of change. For example, a change in relation might have a low impact on a sentiment analysis algorithm, whereas a change in orientation is more likely to affect it.
In this context, meaning representation (
 $\mathfrak{R}$
) methods are highly relevant to understanding what kind of change can be described and characterized. This section investigates representation methods from the literature based on word frequency, topics, graphs, and embeddings. We analyze how each method was used to characterize LSC within our three proposed poles.
$\mathfrak{R}$
) methods are highly relevant to understanding what kind of change can be described and characterized. This section investigates representation methods from the literature based on word frequency, topics, graphs, and embeddings. We analyze how each method was used to characterize LSC within our three proposed poles.
4.1 Word frequency
Methods based on word frequency were among the first computational attempts to tackle semantic change and remain central to many linguistic approaches. Analyzing word frequency offers a direct interpretation of change, which, for characterization, usually involves counting co-occurrences with other words.
4.1.1 Dimension
To detect changes along the dimension axis (
 $\mathscr{D}$
), Sagi et al. (Reference Sagi, Kaufmann and Clark2009) proposed counting co-occurrences of words and phonemes and measuring the cluster density of the cosine distance on a decomposition of the term-frequency matrix. They assumed that Latent Semantic Analysis is appropriate for examining vectors representing the context of each term’s occurrence and estimated cohesiveness by measuring the density of these context vectors. While they explored the methodology for taxonomic change analysis, they state that the method in fact measures word polysemy.
$\mathscr{D}$
), Sagi et al. (Reference Sagi, Kaufmann and Clark2009) proposed counting co-occurrences of words and phonemes and measuring the cluster density of the cosine distance on a decomposition of the term-frequency matrix. They assumed that Latent Semantic Analysis is appropriate for examining vectors representing the context of each term’s occurrence and estimated cohesiveness by measuring the density of these context vectors. While they explored the methodology for taxonomic change analysis, they state that the method in fact measures word polysemy.
Tang et al. (Reference Tang, Qu and Chen2013) proposed a framework for semantic change computation based on the assumption that it is an inherently successive and diachronic process. They distinguished between the word level (overall meaning) and the sense level (individual senses), building their approach around these two notions. A key step involves first identifying a word’s senses in a corpus and then analyzing their diachronic distribution.
Emms and Jayapal (Reference Emms and Jayapal2016) proposed a generative conditional model to detect if a word has acquired a new sense (a semantic neologism). They modeled the word’s sense distribution using Gibbs sampling, applying the model to time-stamped text to infer how the probabilities of a word’s senses change over time. The authors obtain all usages for a word in a specific year (
 $C_1$
) from Google N-gram Corpus and compare with the usage frequency for the following year(
$C_1$
) from Google N-gram Corpus and compare with the usage frequency for the following year(
 $C_2$
), obtaining n-grams that change above a threshold.
$C_2$
), obtaining n-grams that change above a threshold.
Bochkarev et al. (Reference Bochkarev, Khristoforov, Shevlyakova and Solovyev2022) used a neural network to predict whether a word is used as a named entity. With this approach, they constructed a temporal view of word usage by tracking occurrences as nouns versus non-nouns over time, aiming to detect if the word acquired a new meaning.
4.1.2 Relation
The work of Tang et al. (Reference Tang, Qu and Chen2013) transforms the problem of relation identification into detecting change patterns in time series data. They analyze semantic change at the word and individual-sense levels, using rules to infer whether a word is used metonymically or metaphorically. A different approach computes the entropy of target words to identify if a word was used in a non-standard context (Schlechtweg et al. Reference Schlechtweg, Eckmann, Santus, im Walde and Hole2017). The authors split the usage of words from the Deutsches Textarchiv (DTA) in two time periods (varying by word) and measure the increase in entropy as a proxy for metaphorization. According to the authors, a word’s higher entropy makes it more likely to be used in a newly created metaphorical sense. However, the authors do not differentiate this from the emergence of a new, unrelated sense. They use a corpus of German documents to validate their approach.
4.1.3 Orientation
Frequency metrics that detect co-occurrences with sets of ‘good’ or ‘bad’ sentiment words have been widely used to infer the amelioration and pejoration of a word over time, especially for neologisms (Cook and Stevenson Reference Cook and Stevenson2010; Jatowt and Duh Reference Jatowt and Duh2014). Similarly, Buechel et al. (Reference Buechel, Hellrich and Hahn2016) used seed words in German and English to track emotions captured in corpora. They represent these emotions in the Valence-Arousal-Dominance framework rather than simple positive/negative connotation. A limitation of the latter study is that it doesn’t track the evolution of orientation in words.
4.2 Topics
Topic modeling is a statistical method used to identify the main themes in a collection of documents by grouping words that frequently appear together. For example, a topic model might identify the topic of ‘banking’ in a news corpus by grouping words like ‘government’, ‘money’, and ‘insurance’.
Topic modeling can be used to understand the meaning of words and phrases by tracking the different topics a word is associated with in various contexts (e.g., time, domain, culture). For example, a topic model could be used to understand the different meanings of ‘bank’ in a financial context versus a geographical one. The different topics associated with a word are tracked and compared to identify and characterize changes in its senses.
4.2.1 Dimension
These approaches assume that changes in the number of topics assigned to a word can indicate changes in dimension. Lau et al. (Reference Lau, Cook, McCarthy, Newman and Baldwin2012) introduced the idea of novelty as the proportion of a word’s usages corresponding to senses in a focus corpus versus a reference corpus. The goal is to use word sense induction based on topic modeling to detect if a word is used with a new meaning.
Cook et al. (Reference Cook, Lau, Rundell, McCarthy and Baldwin2013) extended this work by quantifying a topic’s usage, estimating that a previously ‘culturally silent’ topic that becomes frequent in a focus corpus is highly likely to contain neologisms. They introduced the concept of topic relevance to compute a ranked list of potential neologisms.
Figure adapted from Inoue et al. (Reference Inoue, Komachi, Ogiso, Takamura and Mochihashi2022). The stacked bar plots represent the topics obtained over time for the words ‘coach’, ‘record’, and ‘power’ respectively. We can observe new senses emerging and becoming dominant.

Figure 4 Long description
The stacked bar graph compares the emergence and dominance of topics over time for the words coach, record, and power. The x-axis represents time periods from 1810 to 1990, while the y-axis represents the proportion of topics. The graph is divided into three sections, each representing a different word. For the word coach, the topics include come, go, horse, drive, stage, door, stop, take, football, team, year, head, say, and season. For the word record, the topics include phonograph, music, tape, play, get, sound, make, history, life, fact, leave, great, and find. For the word power, the topics include high, year, new, set, world, break, mile, last, man, know, god, love, life, mind, men, give, political, party, military, balance, great, congress, state, government, court, law, plant, water, steam, electric, engine, and supply. The bars are color-coded, with blue, orange, and green representing different topics. The graph shows how new senses emerge and become dominant over time. All values are approximated.
Lau et al. (Reference Lau, Cook, McCarthy, Gella and Baldwin2014) improved the definition of novelty by adding the word’s frequency in the corpus, then proposed combining novelty and relevance to rank neologisms. Frermann and Lapata (Reference Frermann and Lapata2016) introduced SCAN, a Bayesian topic model where topics are preserved across adjacent time periods. Inoue et al. (Reference Inoue, Komachi, Ogiso, Takamura and Mochihashi2022) introduced InfiniteSCAN, an improvement over SCAN. While most topic models rely on a predefined number of topics, InfiniteSCAN uses a logistic stick-breaking process to adapt the number of topics dynamically. This modification allows it to track a varying number of senses, enabling it to count each meaning to measure broadening and narrowing, as shown in Figure 4. The authors split Clean COHA into intervals of 20 years to represent the senses.
4.2.2 Relation
To the best of our knowledge, no methodology for tackling conceptual change with topic-based representation has been published, although a work uses it in a synchronic detection setting (Heintz et al. Reference Heintz, Gabbard, Srivastava, Barner, Black, Friedman and Weischedel2013).
4.2.3 Orientation
To the best of our knowledge, no methodology approaching orientation change with topic-based representation has been published. Wankhade et al. (Reference Wankhade, Rao and Kulkarni2022) use topic models in their workflow to refine data for a sentiment classifier, but topics are not directly used to detect a change in feelings.
4.3 Graphs
Graph structures are a natural way to represent relationships between words. They are often constructed manually from dictionaries or automatically based on word co-occurrence.
Co-occurrence graphs can capture richer contextual information than count-based methods because their edges represent more complex relationships. For example, the words ‘feline,’ ‘cat,’ and ‘pet’ would likely form a clique in a co-occurrence graph, indicating they are often used together and share close meanings.
4.3.1 Dimension
Comparing the size and structure of a graph over time can provide rich information about a word’s semantic change. Biemann (Reference Biemann2006) was among the first to use this approach to detect sense broadening. He created a graph of associated nouns from a corpus and then applied the Chinese whispers algorithm to find clusters. By comparing these clusters over time, he could infer whether a word had acquired a new meaning.
Mitra et al. (Reference Mitra, Mitra, Maity, Riedl, Biemann, Goyal and Mukherjee2015) analyzed tweets, counting word co-occurrences in bi-grams to build a graph. They ran a graph-clustering algorithm (Chinese Whispers) to determine a set of senses, where each cluster represents a different sense. By comparing these sets of senses over time, they could infer if a word’s senses split or became broader.
Adaptation from Ehmüller et al. (Reference Ehmüller, Kohlmeyer, McKee, Paeschke, Repke, Krestel and Naumann2020). Ego-network, built from the word co-occurrence graph, for ‘mouse’. We observe that in 1830 it was used with the sense of ‘weak’ and ‘rat,’ where in 1960 the sense of ‘computer device’ emerged.

Figure 5 Long description
A line graph illustrates the semantic changes of the word mouse over time, from 1830 to 2000. The x-axis represents the years 1830, 1980, and 2000, while the y-axis lists various words associated with mouse. In 1830, the word mouse is associated with tail, shyness, quiet, mammal, bread, cheese, and carrot. By 1980, the associations shift to include computer and trap. In 2000, the word mouse is linked with duck, computer, rat, and food. The graph uses dashed lines to represent co-occurrences and word identity. The co-occurrences show how the meaning of mouse evolves, starting with associations related to its biological characteristics and food items, then shifting to include technological references like computer, and finally incorporating additional associations like duck and rat. The word identity lines indicate the consistent identity of the word mouse throughout the timeline. All values are approximated.
Mathew et al. (Reference Mathew, Maity, Sarkar, Mukherjee and Goyal2017) improved the filtering and sense selection methods of previous works (McCarthy et al. Reference McCarthy, Koeling, Weeds and Carroll2004; Lau et al. Reference Lau, Cook, McCarthy, Gella and Baldwin2014; Mitra et al. Reference Mitra, Mitra, Maity, Riedl, Biemann, Goyal and Mukherjee2015) to better capture sense evolution in Google Books and newspaper datasets. Tahmasebi and Risse (Reference Tahmasebi and Risse2017) considered a graph of two-word noun phrases as a cluster of meaning, then merged sub-graphs based on Lin similarity (Lin, Reference Lin1998). They tracked the change in dimension by analyzing how these sub-graphs change over time.
Ehmüller et al. (Reference Ehmüller, Kohlmeyer, McKee, Paeschke, Repke, Krestel and Naumann2020) built a co-occurrence graph, filtering it with point-wise mutual information to remove non-relevant edges, and then created ego-networks to run graph-clustering algorithms. This approach allowed them to build a sense tree – a tree of word usage evolution where new senses are new branches, as shown in Figure 5. Similar to previous work, the authors restricted their analysis to nouns only.
4.3.2 Relation
Graphs are a good way to represent word relations, and some approaches have used them to detect metonymy usage, for example, Teraoka (Reference Teraoka2016); Pedinotti and Lenci (Reference Pedinotti and Lenci2020). Their models use WordNet or a graph-based distributional model to determine a contextualized representation of word semantics. However, to the best of our knowledge, no work has proposed using graphs at a representation level to compare which words have changed their relations between corpora.
4.3.3 Orientation
The orientation of words is generally inferred from similarity or proximity to seed words. Many word graphs are constructed for this purpose, and some works (Reagan et al. Reference Reagan, Danforth, Tivnan, Williams and Dodds2017; Barnes et al. Reference Barnes, Kurtz, Oepen, Ovrelid and Velldal2021) use these graphs to infer orientation. Hamilton et al. (Reference Hamilton, Clark, Leskovec and Jurafsky2016a) used the SentiProp algorithm to propagate a word’s polarity to its synonyms and connected words, analyzing changes in polarity for words across different times and domains. In Figure 6, we reproduce the illustration of this algorithm.
Adapted from Hamilton et al. (Reference Hamilton, Clark, Leskovec and Jurafsky2016a). The SentiProp algorithm propagates the polarity from seed words based on the distance of the connected nodes. Words are connected based on co-occurrence statistics.

Figure 6 Long description
The diagram consists of two panels labeled a and b. Panel a shows a network of words connected by arrows, indicating the flow of polarity from seed words. The seed words 'love' and 'hate' are highlighted with positive and negative polarity scores, respectively. Words like 'adore', 'relish', and 'appreciate' are connected to 'love', while words like 'abhor', 'dislike', and 'despise' are connected to 'hate'. Panel b shows the same network with polarity scores assigned to each word based on the frequency of random walk visits. The words 'love', 'adore', 'relish', and 'appreciate' have positive polarity scores, while 'hate', 'abhor', 'dislike', and 'despise' have negative polarity scores. The arrows indicate the direction of polarity propagation.
4.4 Embeddings
Word embeddings are representations of words as numeric vectors. The vectors are constructed such that words with close values in the vector space are expected to have similar meanings. The distance between these vectors can help in interpreting their sense.
Word embeddings have been used for various tasks, including LSC identification and characterization. This is done by comparing word vectors between two moments in time; the distance between them, and relative to neighboring vectors, can indicate if the word’s sense has changed (Hu et al. Reference Hu, Li and Liang2019).
4.4.1 Dimension
Ryskina et al. (Reference Ryskina, Rabinovich, Berg-Kirkpatrick, Mortensen and Tsvetkov2020) proposed a statistical approach to identify neologisms based on frequency count and semantic sparsity (measured with embeddings). They claim that words and concepts are subject to supply and demand, so emerging concepts (i.e., neologisms or sense broadening) appear to populate sparse semantic regions until the space becomes uniformly covered.
In Giulianelli et al. (Reference Giulianelli, Tredici and Fern’andez2020), the authors use BERT to create contextualized embeddings of words and then cluster them to obtain usage types. They apply entropy difference, Jensen-Shannon divergence (JSD), and average pairwise distance (APD) as proxies to measure word broadening and narrowing, finding that higher APD and JSD were the best metrics for broadening.
Plot obtained from Moss (Reference Moss2020). The author represents words as Gaussian embeddings, and analyzes it’s variance and proximity over time. The word gay increased in variance and got closer to ‘homosexual’.

Figure 7 Long description
The scatter plot consists of two panels, one for the year 1980 and one for the year 2010. Each panel displays the positions of the words cheerful, gay, and homosexual as Gaussian embeddings. In 1980, the words cheerful, gay, and homosexual are distinctly separated, with cheerful in the top left, gay in the center, and homosexual in the bottom right. By 2010, the words gay and homosexual have moved closer together, indicating an increased proximity and variance over time. The word cheerful remains relatively stable in its position. The x-axis and y-axis represent the dimensions of the Gaussian embeddings, with values ranging from negative to positive. The plot highlights the shift in the semantic relationship between these words over the 30-year period.
By analyzing the deviation of a Gaussian word embedding, Yüksel et al. (Reference Yüksel, Ugurlu and Koç2021) identified a way to measure narrowing and broadening in word senses. In Moss (Reference Moss2020), the authors also performed per-sense training of these embeddings. In Figure 7, we observe the distribution of the word ‘gay’ becoming wider and closer to ‘homosexual’.
Lautenschlager et al. (Reference Lautenschlager, Sköldberg, Hengchen and Schlechtweg2024) use XL-LEXEME (Cassotti et al. Reference Cassotti, Siciliani, Degemmis, Semeraro and Basile2023) clustered embeddings to progressively discover new senses in the historical COHA corpus. They frame the task as Unknown Sense Detection: given an initial dictionary, the goal is to identify unrecorded senses. The system compares a word’s usage to all its dictionary senses, and if the highest similarity score falls below a threshold, the usage is flagged as a potential new sense.
4.4.2 Relation
Fonteyn and Manjavacas (Reference Fonteyn and Manjavacas2021) investigate the metaphorization of the concept ‘to death’. They combined cluster analysis and sentiment analysis to contextualize occurrences of this phrasal verb and detect if metaphorization had taken place. Another approach is to create a training corpus and use it to train a BERT model to predict if a word is metaphorical or literal. The work of Maudslay and Teufel (Reference Maudslay and Teufel2022) follows this approach and proposes a framework to detect words that started being used metaphorically.
4.4.3 Orientation
Methods based on word embeddings have been widely used for many sentiment analysis tasks (Raffel et al. Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2019) and to investigate sentiment at the lexicon level (Ito et al. Reference Ito, Tsubouchi, Sakaji, Yamashita and Izumi2020). In the context of LSC characterization, Fonteyn and Manjavacas (Reference Fonteyn and Manjavacas2021) used the distance between the word vectors of ‘good’ and ‘bad’ to measure the polarity of the expression ‘to death,’ as illustrated in Figure 8.
Similarly, Hellrich et al. (Reference Hellrich, Buechel and Hahn2018) and Xie et al. (Reference Xie, Junior, Hirst and Xu2019) employed diachronic static embeddings to analyze the sentiment of words over time. Hellrich et al. train word embeddings in COHA from 1810-1830 as
 $C_1$
and a VAD lexicon Warriner et al. (Reference Warriner, Kuperman and Brysbaert2013) as
$C_1$
and a VAD lexicon Warriner et al. (Reference Warriner, Kuperman and Brysbaert2013) as
 $\mathfrak{R} (C_2)$
, tracking for orientation of words the valence-arousal-dominance framework. They access the polarity of the word based on the k-nearest-neighbors from a VAD sentiment lexicon. Xie et al. use ‘moral’ seed words to compare, like ‘cheating’ and ‘fairness,’ also for COHA, as shown in Figure 9.
$\mathfrak{R} (C_2)$
, tracking for orientation of words the valence-arousal-dominance framework. They access the polarity of the word based on the k-nearest-neighbors from a VAD sentiment lexicon. Xie et al. use ‘moral’ seed words to compare, like ‘cheating’ and ‘fairness,’ also for COHA, as shown in Figure 9.
Adaptation from Fonteyn and Manjavacas (Reference Fonteyn and Manjavacas2021). The line plot shows the evolution of the polarity of the multi-word ‘to death.’ It went from a negative concept to a more positive one, ameliorating the dominant sense.

Figure 8 Long description
The image contains two graphs side by side. The left graph is a line plot showing the evolution of sentiment polarity for the multi-word expression 'to death' from the period 1600 to 1900. The x-axis represents the period, and the y-axis represents sentiment. The line plot shows a trend from negative sentiment to more positive sentiment over time. The plot includes three credible intervals: 0.99, 0.89, and 0.5, represented by different shades of blue. The right graph is a scatter plot showing individual sentiment data points over the same period. The x-axis represents the period, and the y-axis represents sentiment. The scatter plot shows a distribution of sentiment values around a central trend line. The trend line indicates a slight increase in sentiment over time. All values are approximated.
Illustration adapted from Xie et al. (Reference Xie, Junior, Hirst and Xu2019). The figure shows how moral sentiment toward slavery, democracy, and gay rights evolved over two centuries, mapped in a 2D embedding space.

Figure 9 Long description
A scatter plot illustrates the evolution of moral sentiment toward slavery, democracy, and gay rights over the 1800s, 1900s, and 1990s. The plot is divided into three sections, each representing a century. The x-axis represents moral relevance, ranging from moral irrelevance to moral vice, while the y-axis represents moral virtue. Each section contains data points labeled with terms such as democracy, gay, and slavery, along with associated moral sentiments like subversion, cheating, authority, fairness, and loyalty. The data points are color-coded and shaped differently to indicate various moral sentiments. In the 1800s, democracy is associated with subversion, gay is considered irrelevant, and slavery is linked to cheating. In the 1900s, slavery is associated with cheating, gay remains irrelevant, and democracy is linked to authority. In the 1990s, slavery is associated with subversion, gay is linked to loyalty, and democracy is associated with fairness. The scatter plot shows how these moral sentiments have shifted over time, with some terms moving from moral irrelevance to moral virtue or vice. All values are approximated.
4.5 Synthesis and summary
In this section, we synthesize the pros and cons of representation methods for characterizing semantic change and present a table that provides an overview of the current poles of change addressed in the literature.
Word frequency-based methods are simple to implement, offer an easily interpretable analysis, and require a relatively small corpus of data. However, these methods struggle with capturing word similarity (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013) and compositionality (Mitchell and Lapata Reference Mitchell and Lapata2010), limiting their semantic analysis capabilities. While N-grams slightly improve compositionality, they are constrained by Zipf’s law (Zipf, Reference Zipf1949), requiring an exponential increase in data to increase the size of N. Additionally, frequency alone cannot distinguish between sense broadening and narrowing, requiring extra steps to handle polysemy. Co-occurrence tables also fail to correlate well with polysemy or semantic shifts. In parallel studies, these methods perform poorly in detecting word orientation (Socher et al. Reference Socher, Perelygin, Wu, Chuang, Manning, Ng and Potts2013) and struggle with contexts involving sarcasm, irony, or negation due to their limited contextual awareness. Topic modeling is a powerful text analysis tool with many good libraries implementing state-of-the-art algorithms, and it doesn’t require supervision or data annotation. The downside is that these methods require manual interpretation, as statistically derived word clusters can be ambiguous. Automated topic selection using dictionary-based filtering aids in neologism detection but remains insufficient for change characterization. Metrics like coherence and diversity, along with visualization techniques, help reduce manual effort.
Graph-based approaches rely heavily on annotated and structured data, which is often costly or, in some domains, unfeasible. However, Large Language Models (LLMs) enable automatic annotation and structuring of information. We have yet to fully leverage modern structures like knowledge graphs for LSC detection. Resources like Wikidata could help model semantic shifts (Giulianelli et al. Reference Giulianelli, Luden, Fernández and Kutuzov2023; Tang et al. Reference Tang, Zhou, Aida, Sen and Bollegala2023), such as metonymization. Existing lexical databases (WordNet, BabelNet, ConceptNet) assist in change detection but lack temporal information, limiting their effectiveness.
Word embeddings often exhibit instability, where minor corpus variations alter vector representations, especially for low-frequency or polysemous words (Hellrich and Hahn Reference Hellrich and Hahn2016; Gladkova and Drozd Reference Gladkova and Drozd2016; Günther et al. Reference Günther, Rinaldi and Marelli2019). Solutions such as larger embeddings, quantization, and alignment help mitigate this instability (Hamilton, Leskovec, and Jurafsky Reference Hamilton, Leskovec and Jurafsky2016b); however, the meaning conflation deficiency (Camacho-Collados and Pilehvar Reference Camacho-Collados and Pilehvar2018) remains an issue, as a single vector – even when contextualized – does not provide enough information to differentiate fine-grained senses (Ballout et al. Reference Ballout, Dedert, Abdelmoneim, Krumnack, Heidemann and Kühnberger2024; Periti et al. Reference Periti, Cassotti, Dubossarsky and Tahmasebi2024). Subsequent work has explored various modifications to transformer architectures to enable better representation of meaning (Zhang, van de Meent, and Wallace Reference Zhang, van de Meent and Wallace2021; Tay et al. Reference Tay, Dehghani, Tran, García, Wei, Wang, Chung, Bahri, Schuster, Zheng, Zhou, Houlsby and Metzler2022), but these approaches remain underexplored in the semantic change literature.
Contextualized embeddings (e.g., from ELMo, BERT) enhance sense detection but can produce overly contextualized vectors, resulting in unreliable diachronic analysis and false positives (Kutuzov et al. Reference Kutuzov, Velldal and Øvrelid2022). Recent methods using contrastive learning and similarity-based training enhance isotropy and sense differentiation (Reimers and Gurevych Reference Reimers and Gurevych2019; Gao, Yao, and Chen Reference Gao, Yao and Chen2021). Other approaches, like density-based embeddings (e.g., word2gauss), aim to model polysemy directly. The current state of the art in LSC identification fine-tunes cross-lingual models trained on Word Sense Disambiguation (WSD) tasks, benefiting from transfer learning across languages.
While generative Artificial Intelligence (AI), particularly LLMs, is rapidly transforming NLP, its application to the systematic characterization of semantic change in diachronic data remains largely unexplored. However, some initial studies have successfully leveraged these models for related tasks, such as generating synthetic data for LSC detection (Cassotti, De Pascale, and Tahmasebi Reference Cassotti, De Pascale and Tahmasebi2024) and automatically comparing word senses in context (de Sá et al. Reference de Sá, Silveira and Pruski2024).
Table 3 summarizes the literature surveyed in the previous sections. The rows list relevant papers, and the columns represent the key properties of LSC evaluated in this survey. An ‘X’ indicates that the paper applied the sense computation technology (listed in the fifth column) to analyze the corresponding pole.
Comparison table between studies highlighting the type of methods utilized and category of change. We mark which kind of characterization the work conducts
 $\mathscr{D}$
for dimension,
$\mathscr{D}$
for dimension,
 $\mathscr{R}$
for relation, and
$\mathscr{R}$
for relation, and
 $\mathscr{O}$
for orientation. Also, we highlight the main representation method (
$\mathscr{O}$
for orientation. Also, we highlight the main representation method (
 $\mathfrak{R}$
) for the word meaning
$\mathfrak{R}$
) for the word meaning

Table 3 Long description
The table compares various studies on methods and change categories in Lexical Semantic Change (LSC). It lists relevant papers in rows and key properties in columns. The columns indicate whether the study focuses on dimension, relation, or orientation, and the main representation method used. Each cell is marked with an X to show the application of sense computation technology to the corresponding property.
We can observe that no single methodology characterizes all three poles, highlighting the complexity of the problem and researchers’ tendency to focus on a specific type of change. The majority of studies were developed to characterize changes in the dimension pole, which seems to be where computational approaches achieve the best results. Another observation is the underexplored use of graph- and topic-based methods to represent sense, compared to embedding- and frequency-based methods. It is also important to note that the most recent works use embeddings, showing a current trend toward this type of approach. In Table 4 we summarize these findings.
Pros and Cons of Representation Methods for Semantic Change Characterization

Table 4 Long description
A table that compares the advantages and disadvantages of different representation methods used for characterizing semantic change. The methods include Frequency, Topics, Graphs, and Embeddings, each evaluated across three poles of change: Dimension, Relation, and Orientation. The table highlights the strengths and weaknesses of each method in detecting and modeling semantic shifts.
Although computational linguistics has been used to characterize LSC for over a decade, there is still no standardized formalization of these changes. Each author proposes their own solution, and many interpretations of change are presented in a textual or semi-formal format. To contribute to this discussion, we propose a set of formal descriptions of change characterization in the next section.
5. Formalization
Formalizing a problem is a foundational step in computer science, enabling computational reasoning and the design of algorithms. A shared formalization ensures that researchers operate with consistent assumptions and terminology, facilitating meaningful comparison across methodologies. In our review, we observed that although many studies conceptually addressed the same problem, the absence of a unified formal framework hindered direct comparison. To bridge this gap, we propose a formalization grounded in the surveyed literature and informed by linguistic theory, focusing specifically on semasiological comparative analysis; that is, comparing word meanings across time without invoking external socio-cultural knowledge.
To the core of this formalization, a central challenge arises in defining what ‘meaning’ is. While linguistic literature often invokes terms like ‘concepts’ and ‘sentiments’ to describe meaning (Blank et al. Reference Blank2003; Koch, Reference Koch2016; Traugott, Reference Traugott2017), these notions are rarely operationalized in a way suitable for formal modeling. This lack of clarity makes the computational implementation of semantic analysis particularly complex.
To address this, we adopt a minimal form of sense objectivism; the idea that word senses can be treated as identifiable units at specific points in time. Where the senses were conveyed by a community of speakers during the production of the corpus under study. While absolute objectivity is philosophically untenable (Geeraerts, Reference Geeraerts1997; Wittgenstein, Reference Wittgenstein2009, pg. 182, pg. 32), this abstraction is both methodologically necessary and practically effective (as we target static corpora). It mirrors other linguistic constructs like phonemes: not directly observable or in practical terms precise, yet essential for systematic analysis. Indeed, the very concept of semantic change presupposes a stable referent; without identifiable senses, we cannot speak coherently of change; change compared to what?
This pragmatic stance aligns with both historical linguistic practice (e.g., stating that ‘gay’ once meant “happy” and now means ‘homosexual’) and computational models, which require discrete sense representations (e.g., embeddings, clusters) across time slices. Our position is not ontological but operational: sense objectivism enables formal articulation, empirical comparison, and computational modeling of LSC. Without this assumption, both theory and method lose coherence.
We build our formalization by posing the meaning of a word as a set of senses, that is, glosses, inspired by Hock and Joseph (Reference Hock and Joseph2019, p 194), and define all constructions in set theory. First, we assume that for a set of text corpora
 $T$
, there is a universe of senses
$T$
, there is a universe of senses
 $S_T$
that holds all senses for these corpora. Given an alphabet
$S_T$
that holds all senses for these corpora. Given an alphabet
 $\alpha$
, we define
$\alpha$
, we define
 $\mathscr{S}$
as a function that takes a string from the Kleene closure of
$\mathscr{S}$
as a function that takes a string from the Kleene closure of
 $\alpha$
, where
$\alpha$
, where
 $\alpha ^*=V$
(the possible vocabulary), and returns a subset of
$\alpha ^*=V$
(the possible vocabulary), and returns a subset of
 $S_T$
. For instance, given a word
$S_T$
. For instance, given a word
 $w \in V$
and a corpus
$w \in V$
and a corpus
 $t \in T$
, the subset of senses
$t \in T$
, the subset of senses
 $\mathscr{S}\,(w,t)$
for the universe of senses (
$\mathscr{S}\,(w,t)$
for the universe of senses (
 $S_t$
) of the word
$S_t$
) of the word
 $w$
in this corpus is:
$w$
in this corpus is:
 \begin{equation} \begin{split} \mathscr{S}\,:\,V \times T \rightarrow \wp (S_t), \\ \mathscr{S}\,(w,t) = \{s_1,s_2,\ldots ,s_k\}. \end{split} \end{equation}
\begin{equation} \begin{split} \mathscr{S}\,:\,V \times T \rightarrow \wp (S_t), \\ \mathscr{S}\,(w,t) = \{s_1,s_2,\ldots ,s_k\}. \end{split} \end{equation}
We define that two sets of senses are different if, and only if, the symmetrical difference between a set of senses for the word
 $a$
in a corpus
$a$
in a corpus
 $x$
and the word
$x$
and the word
 $b$
in a corpus
$b$
in a corpus
 $y$
is non-empty, where
$y$
is non-empty, where
 $a,b \in V$
and
$a,b \in V$
and
 $x,y \in T$
$x,y \in T$
 \begin{equation} \begin{split} \mathscr{S}\,(a,x) &\neq \mathscr{S}\,(b,y) \iff \\ (\mathscr{S}\,(a,x) - \mathscr{S}\,(b,y) \neq \emptyset ) &\lor (\mathscr{S}\,(b,y) - \mathscr{S}\,(a,x) \neq \emptyset ), \end{split} \end{equation}
\begin{equation} \begin{split} \mathscr{S}\,(a,x) &\neq \mathscr{S}\,(b,y) \iff \\ (\mathscr{S}\,(a,x) - \mathscr{S}\,(b,y) \neq \emptyset ) &\lor (\mathscr{S}\,(b,y) - \mathscr{S}\,(a,x) \neq \emptyset ), \end{split} \end{equation}
in simple terms, there are objective senses of the word ‘a’ in corpus ‘x’ that do not appear in corpus ‘y’ for the word ‘b,’ or vice versa. This underlying assumption is made implicitly in most previous works, even though it is rarely stated explicitly, e.g., when Hamilton et al. (Reference Hamilton, Leskovec and Jurafsky2016b) and Inoue et al. (Reference Inoue, Komachi, Ogiso, Takamura and Mochihashi2022) state that the word ‘record’ has a different meaning because it gained the sense of ‘tape/music’ when comparing the word in corpora before and after 1920.
5.1 Semantic change
Koch (Reference Koch2016, p 23) presents a definition of meaning change that combines semasiological and onomasiological perspectives. In Figure 10, ‘belly’ was initially associated with the source concept ‘bag’ (M1). Later, it acquired the meaning of the target concept ‘body part between the breast and the thighs’ (M2). In computational linguistics, we primarily focus on the semasiological view: our interest lies in the word itself and the evolution of its meanings, rather than the origins of the concepts it represents.
Definition of semantic change adapted from Koch (Reference Koch2016, p 23, 25).

Figure 10 Long description
A line graph illustrating the evolution of semantic change over time. The graph features multiple lines representing different stages of meaning change with respect to lexical items, source concepts, and target concepts. The x-axis represents time, labeled as T1 through T7, while the y-axis represents the form and meaning of the lexical items. The graph shows how the meaning of a lexical item evolves from its original state (M1) through various stages (M1 to M2, M1 equals M2, M1 less than M2, M2, and M2 with a return to M1) over time. The source concept (SC) and target concept (TC) are also depicted, illustrating the change of designation with respect to the target concept. The graph provides a visual representation of how language evolves gradually from earlier pre-linguistic systems.
The process of meaning change is depicted on the right side of the figure. At time T1, the word ‘belly’ possessed only the meaning M1. Subsequently, at T2, it began to be used with the new meaning M2 as well. This usage of M2 increased over time (T3-T5) until it eventually became the dominant meaning (T6). Finally, at T7, the original meaning M1 was completely lost.
To formalize this definition, we say that a word
 $w$
had a semantic change (
$w$
had a semantic change (
 $\mathscr{C}$
), if the set of senses, given by the function
$\mathscr{C}$
), if the set of senses, given by the function
 $\mathscr{S}$
, evaluated in the corpus
$\mathscr{S}$
, evaluated in the corpus
 $t_1$
is different from the set of senses in
$t_1$
is different from the set of senses in
 $t_2$
, given that
$t_2$
, given that
 $t_1\neq t_2$
,
$t_1\neq t_2$
,
 \begin{equation} \mathscr{C}\,(w, t_1, t_2) = \begin{cases} \text{True} & \mathscr{S}\,(w,t_1) \neq \mathscr{S}\,(w,t_2) \\ \text{False} & \text{otherwise.} \end{cases} \end{equation}
\begin{equation} \mathscr{C}\,(w, t_1, t_2) = \begin{cases} \text{True} & \mathscr{S}\,(w,t_1) \neq \mathscr{S}\,(w,t_2) \\ \text{False} & \text{otherwise.} \end{cases} \end{equation}
The subset of words in vocabulary
 $\bar {W} \subset V$
that suffered a semantic change between corpus
$\bar {W} \subset V$
that suffered a semantic change between corpus
 $t_1$
and
$t_1$
and
 $t_2$
is given by,
$t_2$
is given by,
 \begin{equation} \bar {W}_{t_1,t_2} = \{w \mid \mathscr{C}(w, t_1, t_2), \hspace {1em} \forall w \in V\}. \end{equation}
\begin{equation} \bar {W}_{t_1,t_2} = \{w \mid \mathscr{C}(w, t_1, t_2), \hspace {1em} \forall w \in V\}. \end{equation}
These changes in lexical meaning across corpora are caused by many different phenomena, like time period (1930 and 2020, gay), culture (Brazil and Portugal, rapariga), and domain (engineering and biology, cell).
5.2 Change in dimension
We define that a word
 $w$
had a changed in dimension if the set of meanings increased or decreased, with respect to the cardinality of the set, when comparing two corpus
$w$
had a changed in dimension if the set of meanings increased or decreased, with respect to the cardinality of the set, when comparing two corpus
 $t_1,t_2$
. It means that the word suffered a broadening or a narrowing change between these corpora, that is
$t_1,t_2$
. It means that the word suffered a broadening or a narrowing change between these corpora, that is
 \begin{equation} |\mathscr{S}\,(w,t_1)| \neq |\mathscr{S}\,(w,t_2)|, \hspace {1em} w \in V. \end{equation}
\begin{equation} |\mathscr{S}\,(w,t_1)| \neq |\mathscr{S}\,(w,t_2)|, \hspace {1em} w \in V. \end{equation}
Consequentially, if
 $|\mathscr{S}\,(w,t_1)| \lt |\mathscr{S}\,(w,t_2)|$
it suffered a broadening, and if
$|\mathscr{S}\,(w,t_1)| \lt |\mathscr{S}\,(w,t_2)|$
it suffered a broadening, and if
 $|\mathscr{S}\,(w,t_1)| \gt |\mathscr{S}\,(w,t_2)|$
, it suffered a narrowing.
$|\mathscr{S}\,(w,t_1)| \gt |\mathscr{S}\,(w,t_2)|$
, it suffered a narrowing.
This definition is compatible with the concept of innovative/reductive meaning change from Koch (Reference Koch2016, p 24–26), in which words acquire new senses (sememes) by being used with different meanings. It differs, however, from the more general notion of broadening, where words may also lose intension (the precision of their meaning), making them vaguer.
Under this definition, phenomena like sense splitting, birth, and joining are special cases of change in dimension for a single lexical item. For instance, birth or death of a sense is considered a change from or to an empty set. Split and join are instances of broadening or narrowing with respect to a word. For example, the word ‘plane’ gained the sense of ‘aeroplane’ after the 19th century, while previously it was only used to describe the act of planning or a flat surface. This new sense greatly increased the dimension of the word ‘plane’, as many correlated senses, like ‘traveling in an aeroplane’, were also added.
In this survey, we define broadening as the degree of polysemy in a word. This is aligned with the NLP literature, given its application in data analysis and its measurable nature, compared to the notion of intension. We differ from the definition in Tang et al. (Reference Tang, Qu and Chen2013), where broadening is a superclass of metaphorization and metonymization, as the literature reviewed here does not perform this aggregation.
5.3 Change in relation
Metaphorization or metonymization occurs when a word takes on a new meaning that inherits qualities from its original meaning through a figurative relationship the speaker aims to convey (Lakoff and Johnson, Reference Lakoff and Johnson2008, p 3–6). The original meaning is invoked by establishing a material or abstract relation with the initial sense, where the listener is able to resolve the non-literal target concept (Fass, Reference Fass1988). Material relations are built on physical-world contiguity (e.g., replacing an institution with its location, as in ‘Washington decided…’). In contrast, abstract relations are formed through conceptual similarity (e.g., applying human body parts to objects, as in ‘the arm of the chair’).
The theory defining metaphor and metonymy is often informal, relying on subjective perception or overlapping definitions. For example, Choi et al. (Reference Choi, Lee, Choi, Park, Lee, Lee and Lee2021) define metaphor as a case where the ‘literal meaning of a word is different from its contextual meaning’, which also applies to metonymy. As discussed by Koch (Reference Koch2016, p 42–51), there is no precise rule to define a metonymy. Some computational work, such as Schlechtweg et al. (Reference Schlechtweg, Eckmann, Santus, im Walde and Hole2017), measures a word’s entropy to capture metaphorization, but it is not clear that this measure can differentiate a metaphor from a metonymy or a completely new, unrelated sense (e.g., ‘Apple’ in a technology context).
Given these considerations, we define that a word
 $w$
has changed in relation if the aggregated sum of the relational similarity (
$w$
has changed in relation if the aggregated sum of the relational similarity (
 $\mathit{l}: S \times S \rightarrow \mathbf{R}$
) between its senses changes between corpora. The function
$\mathit{l}: S \times S \rightarrow \mathbf{R}$
) between its senses changes between corpora. The function
 $\mathit{l}$
takes two senses,
$\mathit{l}$
takes two senses,
 $s_i$
and
$s_i$
and
 $s_j$
, and returns a real value corresponding to their material or abstract relation (a greater value means a stronger relation). The total relation for a word is:
$s_j$
, and returns a real value corresponding to their material or abstract relation (a greater value means a stronger relation). The total relation for a word is:
 \begin{equation} \mathscr{R}(w, t)= \left \{ \begin{aligned} \sum ^{N-1}_{i=1}\sum ^{N}_{j=i+1}{\mathit{l}(s_i, s_j)} \hspace {3em} s_i,s_j \in \mathscr{S}\,(w, t)\\ 0 \hspace {6em} N \leq 1, \end{aligned} \right . \end{equation}
\begin{equation} \mathscr{R}(w, t)= \left \{ \begin{aligned} \sum ^{N-1}_{i=1}\sum ^{N}_{j=i+1}{\mathit{l}(s_i, s_j)} \hspace {3em} s_i,s_j \in \mathscr{S}\,(w, t)\\ 0 \hspace {6em} N \leq 1, \end{aligned} \right . \end{equation}
where
 $N=|\mathscr{S}\,(w, t)|$
.
$N=|\mathscr{S}\,(w, t)|$
.
A word
 $w$
increases in relation between corpora
$w$
increases in relation between corpora
 $t_1$
and
$t_1$
and
 $t_2$
if
$t_2$
if
 $\mathscr{R}(w,t_1) \lt \mathscr{R}(w,t_2)$
, and decreases if the opposite occurs. Since we lack methods to perfectly differentiate material and abstract relations, and since a word can undergo both metaphorization and metonymization, we simplify the interpretation: if a word’s figurative usage increases, it ‘increases in relation’ ; if its figurative usage decreases, it ‘decreases in relation’.
$\mathscr{R}(w,t_1) \lt \mathscr{R}(w,t_2)$
, and decreases if the opposite occurs. Since we lack methods to perfectly differentiate material and abstract relations, and since a word can undergo both metaphorization and metonymization, we simplify the interpretation: if a word’s figurative usage increases, it ‘increases in relation’ ; if its figurative usage decreases, it ‘decreases in relation’.
5.4 Change in orientation
A word’s change in orientation (positive or negative connotation) reflects amelioration or pejoration in its usage from one corpus to another. This is measured by analyzing how the collective perception of a word’s meaning evolves (Campbell, Reference Campbell2013, p 227–229). A classic example is ‘terrific,’ which originally meant ‘terrible’ but shifted to mean ‘formidable’ or ‘impressive.’
While some frameworks like Buechel et al. (Reference Buechel, Hellrich and Hahn2016) use a multi-dimensional Valence-Arousal-Dominance setting, most sentiment analysis research focuses on a simpler polarity setting (Cui et al. Reference Cui, Wang, Ho and Cambria2023). Therefore, we restrict our formalism to this more general positive/negative view to align with current research and applications (Susanto et al. Reference Susanto, Livingstone, Ng and Cambria2020).
We define that a word
 $w$
had changed in orientation, if for some notion of orientation
$w$
had changed in orientation, if for some notion of orientation
 $\mathfrak{f}$
(feeling), there is a mapping from a word
$\mathfrak{f}$
(feeling), there is a mapping from a word
 $w$
in a corpora
$w$
in a corpora
 $t$
to an orientation value, for example, in case of positive, neutral, or negative feeling,
$t$
to an orientation value, for example, in case of positive, neutral, or negative feeling,
 \begin{equation} \mathfrak{f}\,:\,V \times T \rightarrow \{-1, 0, +1\}, \end{equation}
\begin{equation} \mathfrak{f}\,:\,V \times T \rightarrow \{-1, 0, +1\}, \end{equation}
the orientation changes between corpora
 $t_1,t_2$
,
$t_1,t_2$
,
 \begin{equation} \mathfrak{f}(w, t_1) \neq \mathfrak{f}(w, t_2). \end{equation}
\begin{equation} \mathfrak{f}(w, t_1) \neq \mathfrak{f}(w, t_2). \end{equation}
Analogous to the previous definition, if
 $\mathfrak{f}(w, t_1) \lt \mathfrak{f}(w, t_2)$
it suffered an amelioration, and a pejoration if
$\mathfrak{f}(w, t_1) \lt \mathfrak{f}(w, t_2)$
it suffered an amelioration, and a pejoration if
 $\mathfrak{f}(w, t_1) \gt \mathfrak{f}(w, t_2)$
.
$\mathfrak{f}(w, t_1) \gt \mathfrak{f}(w, t_2)$
.
This task relies on a subjective notion of orientation captured by the function
 $\mathfrak{f}$
. Generally, studies define ‘orientation’ as the proximity to positive or negative seed words. However, the problem is broader than just polarity, as words can be classified along other emotional dimensions.
$\mathfrak{f}$
. Generally, studies define ‘orientation’ as the proximity to positive or negative seed words. However, the problem is broader than just polarity, as words can be classified along other emotional dimensions.
5.5 Semantic change identification
Core to computational approaches, words in a corpus are not compared directly to one another; instead, they are first represented using one of the many methods reviewed in this survey. A common step taken by all authors is to represent the word ‘a’ in corpus ‘x’, denoted as
 $\mathfrak{R}(a,x)$
, and then compare this representation to
$\mathfrak{R}(a,x)$
, and then compare this representation to
 $\mathfrak{R}(b,y)$
. For example, Moss (Reference Moss2020) represents the word ‘a’ as a Gaussian embedding obtained after training a language model on corpus ‘x’. Similarly, Ehmüller et al. (Reference Ehmüller, Kohlmeyer, McKee, Paeschke, Repke, Krestel and Naumann2020) represent ‘a’ using a co-occurrence graph derived from corpus ‘x’. Meanwhile, Inoue et al. (Reference Inoue, Komachi, Ogiso, Takamura and Mochihashi2022) partition the original corpus into 20-year intervals and, for each resulting corpus ‘x’, obtain a distribution of topics for the word ‘a’.
$\mathfrak{R}(b,y)$
. For example, Moss (Reference Moss2020) represents the word ‘a’ as a Gaussian embedding obtained after training a language model on corpus ‘x’. Similarly, Ehmüller et al. (Reference Ehmüller, Kohlmeyer, McKee, Paeschke, Repke, Krestel and Naumann2020) represent ‘a’ using a co-occurrence graph derived from corpus ‘x’. Meanwhile, Inoue et al. (Reference Inoue, Komachi, Ogiso, Takamura and Mochihashi2022) partition the original corpus into 20-year intervals and, for each resulting corpus ‘x’, obtain a distribution of topics for the word ‘a’.
In this context, we now define in computational terms the task of semantic change characterization. Consider a function
 $f_{\mathscr{C}}$
that takes two representations
$f_{\mathscr{C}}$
that takes two representations
 $\mathfrak{R}$
(e.g., embeddings, graphs, etc.) of the word
$\mathfrak{R}$
(e.g., embeddings, graphs, etc.) of the word
 $w$
in corpora
$w$
in corpora
 $t_1,t_2$
. We define the problem of semantic change identification as assigning a value (
$t_1,t_2$
. We define the problem of semantic change identification as assigning a value (
 $y$
) to this word,
$y$
) to this word,
 \begin{equation} f_{\mathscr{C}}(\mathfrak{R}(w,t_1), \mathfrak{R}(w,t_2)) \rightarrow y. \end{equation}
\begin{equation} f_{\mathscr{C}}(\mathfrak{R}(w,t_1), \mathfrak{R}(w,t_2)) \rightarrow y. \end{equation}
Schlechtweg and im Walde (Reference Schlechtweg and im Walde2020) proposed two notions of semantic change: binary classification, where
 $y \in \{0,1\}$
, and graded (continuous) semantic change, where
$y \in \{0,1\}$
, and graded (continuous) semantic change, where
 $y \in \mathbf{R}$
is a distance between word representations.Footnote
c
$y \in \mathbf{R}$
is a distance between word representations.Footnote
c
The binary classification task aligns with classic LSC literature (Blank, Reference Blank2012, p 113) and human perception, which is often influenced by sensory thresholds (Smith, Reference Smith2008, p 34). This view is interested in the gain or loss of senses. There is no general threshold criterion for the binary setting; it’s not enough for representations to be different, the magnitude of this difference should align with human judgment.
The graded task originates from computational linguistics, where a natural way to compare objects is by measuring the distance between their representations. This approach allows for a more in-depth analysis of change, as the degree of change can be compared across a wide range of contexts.
5.6 Semantic change characterization
Deriving from the reviewed literature, we define semantic change characterization as a classification problem where we need to assign identified semantic changes to categories, such as
 $f_{\mathscr{D}},f_{\mathscr{R}},f_{\mathscr{O}}$
,
$f_{\mathscr{D}},f_{\mathscr{R}},f_{\mathscr{O}}$
,
 \begin{equation} f_x(\mathfrak{R}(w,t_1), \mathfrak{R}(w,t_2)) \rightarrow y,\hspace {2em} x \in \{\mathscr{D},\mathscr{R},\mathscr{O}\}. \end{equation}
\begin{equation} f_x(\mathfrak{R}(w,t_1), \mathfrak{R}(w,t_2)) \rightarrow y,\hspace {2em} x \in \{\mathscr{D},\mathscr{R},\mathscr{O}\}. \end{equation}
While the first equation only measured some notion of distance between the representations, for characterization, we first apply the type function on the representation, to then compare. For example, in Buechel et al. (Reference Buechel, Hellrich and Hahn2016), we have an orientation characterization, for example,
 \begin{equation} f(\mathscr{O}(\mathfrak{R}(w,t_1)), \mathscr{O}(\mathfrak{R}(w,t_2))) \rightarrow y, \end{equation}
\begin{equation} f(\mathscr{O}(\mathfrak{R}(w,t_1)), \mathscr{O}(\mathfrak{R}(w,t_2))) \rightarrow y, \end{equation}
where the
 $\mathscr{O}$
function is the Valence-Arousal-Dominance framework and they measure the distance
$\mathscr{O}$
function is the Valence-Arousal-Dominance framework and they measure the distance
 $f$
through the
$f$
through the
 $\beta$
-coefficient of a linear regression.
$\beta$
-coefficient of a linear regression.
Again, we set two possibilities of change, binary and graded. In this setting, the binary form allows us to answer interesting questions in an automatic manner, for example, at what point in time the word ‘head’ started being used in a figurative manner? Another possibility is to track the precise corpus where words were pejorated, and then manually understand the socio-linguistic process of this phenomenon, saving many hours of historiography work.
5.7 Framework evaluation
The proposed framework enables a spatial understanding of a word’s change and direct statistical comparison of corpora. In Figure 11, we illustrate this analysis with a possible evolution of the word ‘heart’ between two corpora from different times (1993 and 2013). A gradual analysis of this evolution can provide a detailed picture across the three poles of change.
Illustrative example of the word ‘heart’ changing over time. Metaphorization, amelioration and broadening can occur for the same word, depending on the senses it gained/lost.

Figure 11 Long description
A 3D scatter plot illustrates the evolution of the word heart in 3D space. The plot features two labeled data points, heart (1993) and heart (2013), indicating the word's semantic change over time. The x-axis represents dimension, the y-axis represents relation, and the z-axis represents orientation. The data points are connected by dashed lines, showing the trajectory of change. The plot suggests a shift in the word's meaning over the 20-year period. All values are approximated.
To illustrate the framework’s practical aspects, we investigate two corpora: SEMCOR (Miller et al. Reference Miller, Leacock, Tengi and Bunker1993) and MASC.Footnote d SEMCOR is a sense-tagged corpus of 200,000 words created in 1993. MASC is a manually annotated sub-corpus of 500,000 words of modern American English released around 2013.
While the corpora were produced at different times (1993 and 2013), we do not claim this analysis is sufficient to discover all examples of historical LSC. The corpora have narrow coverage and are inadequate for robust diachronic analysis. Additionally, WordNet doesn’t cover all existing senses for a given word. We use these datasets for illustrative purposes only. For the purpose of this demonstration, we define corpus
 $t_1$
as SEMCOR and
$t_1$
as SEMCOR and
 $t_2$
as MASC, with a time difference of 20 years between the corpora.
$t_2$
as MASC, with a time difference of 20 years between the corpora.
SEMCOR and MASC are corpora manually annotated using WordNet senses. We obtain annotations for the poles of change from two lexical resources: ChainNet, a WordNet extension linking senses by metaphor and metonymy, and SentiWordNet, which provides a positive/negative score for every sense in WordNet. This step allows us to skip sense inference and focus on demonstrating the framework. For automatic WordNet annotation, we suggest Navigli et al. (Reference Navigli, Camacho-Collados and Raganato2017). For work on annotating data for the poles of change independently of a lexical resource, we suggest de Sá et al. (Reference de Sá, Silveira and Pruski2024). From SEMCOR and MASC, we computed occurrences of ‘heart’ and ‘plane,’ two well-known words that have changed semantically.
According to SentiWordNet, ‘heart’ has two positive senses: courage (heart.n.03) and the vital part of an idea (kernel.n.03). From ChainNet, the absolute literal meanings are the organ (heart.n.02) and courage (heart.n.03). We can observe that in MASC, the literal meaning ‘organ’ (heart.n.02) has no occurrences, while figurative usage becomes dominant. The word also gained a new sense (heart.n.10, the playing card suit).
From Table 5, we can compute the equations to verify the semantic change across the corpus. We first start with the dimension test. From Equation (5) we have:
Distribution of WordNet senses for the word ‘heart’ in SEMCOR and MASC. The score column indicates a positive score for that sense from SentiWordNet, figurative column indicates if the meaning is figurative or literal

Table 5 Long description
The table presents the distribution of WordNet senses for the word heart across the SEMCOR and MASC corpora. It includes columns for sense, score, figurative indicator, SEMCOR, and MASC. The sense column lists different senses of the word heart, such as heart dot n dot 03 and kernel dot n dot 03. The score column indicates a positive score for that sense from SentiWordNet, with values ranging from 0 to 0.25. The figurative column specifies whether the meaning is figurative or literal. The SEMCOR and MASC columns provide specific values for each sense in those corpora. Notable entries include heart dot n dot 03 with a score of 0.25 and a SEMCOR value of 0.121212, and kernel dot n dot 03 with a score of 0.25 and a SEMCOR value of 0.030303. The table helps verify semantic change across the corpus by comparing these values.
 \begin{equation} |\mathscr{S}\,(w,t_1)| \stackrel {?}{=} |\mathscr{S}\,(w,t_2)| \end{equation}
\begin{equation} |\mathscr{S}\,(w,t_1)| \stackrel {?}{=} |\mathscr{S}\,(w,t_2)| \end{equation}
 \begin{equation} |\mathscr{S}\,(\text{heart},\text{SEMCOR})| \stackrel {?}{=} |\mathscr{S}\,(\text{heart},\text{MASC})| \end{equation}
\begin{equation} |\mathscr{S}\,(\text{heart},\text{SEMCOR})| \stackrel {?}{=} |\mathscr{S}\,(\text{heart},\text{MASC})| \end{equation}
 \begin{equation} \begin{gathered} |\{\texttt {heart.n.03}, \texttt {kernel.n.03}, \texttt {center.n.01}, \texttt {heart.n.01}, \texttt {heart.n.02}\}| \\ \stackrel {?}{=} \\ |\{\texttt {heart.n.03}, \texttt {kernel.n.03}, \texttt {heart.n.10}\}| \end{gathered} \end{equation}
\begin{equation} \begin{gathered} |\{\texttt {heart.n.03}, \texttt {kernel.n.03}, \texttt {center.n.01}, \texttt {heart.n.01}, \texttt {heart.n.02}\}| \\ \stackrel {?}{=} \\ |\{\texttt {heart.n.03}, \texttt {kernel.n.03}, \texttt {heart.n.10}\}| \end{gathered} \end{equation}
 \begin{equation*} 5 \gt 3, \text{we conclude that it narrowed.} \end{equation*}
\begin{equation*} 5 \gt 3, \text{we conclude that it narrowed.} \end{equation*}
To evaluate changes in Orientation, we define the feeling function
 $\mathfrak{f}$
as the weighted sum of the positive scores of a word’s senses. Specifically, we compute
$\mathfrak{f}$
as the weighted sum of the positive scores of a word’s senses. Specifically, we compute
 $\mathfrak{f}$
as the sum of
$\mathfrak{f}$
as the sum of
 $\text{positive}(s_i) \cdot p(s_i)$
, where
$\text{positive}(s_i) \cdot p(s_i)$
, where
 $\text{positive}(s_i)$
is the score of sense
$\text{positive}(s_i)$
is the score of sense
 $s_i$
, and
$s_i$
, and
 $p(s_i)$
is its associated probability. A sense is considered positive if its score is greater than 0.
$p(s_i)$
is its associated probability. A sense is considered positive if its score is greater than 0.
We use the weighted sum as a proxy for the prototypical sense, assuming that more frequently used senses have a greater influence on the perceived feeling of the word.
 \begin{equation} \mathfrak{f}(w, t) = \frac {1}{N}\sum _{i=1}^N p(s_i) \text{positive}(s_i), \hspace {1em}s_i \in \mathscr{S}\,(w, t) \end{equation}
\begin{equation} \mathfrak{f}(w, t) = \frac {1}{N}\sum _{i=1}^N p(s_i) \text{positive}(s_i), \hspace {1em}s_i \in \mathscr{S}\,(w, t) \end{equation}
Plugging the values into our equations, we have:
 \begin{equation} \mathfrak{f}(\text{heart}, \text{SEMCOR}) \stackrel {?}{=} \mathfrak{f}(\text{heart}, \text{MASC}) \end{equation}
\begin{equation} \mathfrak{f}(\text{heart}, \text{SEMCOR}) \stackrel {?}{=} \mathfrak{f}(\text{heart}, \text{MASC}) \end{equation}
 \begin{equation} \begin{gathered} 1 \times 0.12 + 1 \times 0.03 + 0 \times 0.06 + 0 \times 0.0 + 0 \times .44 + 0 \times 0.35\\ \stackrel {?}{=} \\ 1 \times 0.9 + 1 \times .07 + 0 \times 0.0 + 0 \times 0.02 + 0 \times 0.0 + 0 \times 0.0 \end{gathered} \end{equation}
\begin{equation} \begin{gathered} 1 \times 0.12 + 1 \times 0.03 + 0 \times 0.06 + 0 \times 0.0 + 0 \times .44 + 0 \times 0.35\\ \stackrel {?}{=} \\ 1 \times 0.9 + 1 \times .07 + 0 \times 0.0 + 0 \times 0.02 + 0 \times 0.0 + 0 \times 0.0 \end{gathered} \end{equation}
 \begin{equation*} 0.15 \lt 0.97, \text{we observe an amelioration.} \end{equation*}
\begin{equation*} 0.15 \lt 0.97, \text{we observe an amelioration.} \end{equation*}
Distribution of WordNet senses for the word ‘plane’ in SEMCOR and MASC. The score column indicates a positive score for that sense from SentiWordNet, and figurative column indicates if the meaning is figurative or literal

Table 6 Long description
A table displays the distribution of WordNet senses for the word plane across SEMCOR and MASC datasets. The table includes columns for sense, score, figurative indicator, SEMCOR, and MASC. Each row lists a specific sense of the word plane, its corresponding score from SentiWordNet, whether the sense is figurative or literal, and its occurrence in SEMCOR and MASC. The senses listed are plane.n.03, airplane.n.01, flat.s.01, plane.v.01, and plane.n.02.
Change in meaning distribution for the word ‘heart’ in SEMCOR and MASC.

Figure 12 Long description
The bar graph titled 'Distribution of Sense Keys for heart' compares the proportion of different sense keys for the word 'heart' in two datasets, SEMCOR and MASC. The x-axis represents the sense keys, including heart.n.03, heart.n.02, heart.n.01, kernel.n.03, center.n.01, and heart.n.10. The y-axis represents the proportion, ranging from 0.0 to 0.8. The graph is divided into two sections: SEMCOR on the left and MASC on the right. In the SEMCOR dataset, heart.n.01 has the highest proportion, followed by heart.n.02 and heart.n.03. The proportions for kernel.n.03 and center.n.01 are relatively low, with heart.n.10 having the lowest proportion. In the MASC dataset, heart.n.03 dominates with a proportion close to 0.9, while the other sense keys have significantly lower proportions, with heart.n.02 and heart.n.10 being the lowest. The color scheme varies, with each sense key represented by a different color. All values are approximated.
Figure 12 illustrates the change in meaning distribution for ‘heart.’ Under our framework, the word becomes more metaphorical (increasing in Relation,
 $\mathscr{R}$
), narrowed for these corpora (decreasing its Dimension,
$\mathscr{R}$
), narrowed for these corpora (decreasing its Dimension,
 $\mathscr{D}$
), and more positive (increasing in Orientation,
$\mathscr{D}$
), and more positive (increasing in Orientation,
 $\mathscr{O}$
).
$\mathscr{O}$
).
For the word ‘plane’ (Table 6), we note that while SEMCOR reports five distinct senses, MASC presents only two. In MASC, ‘plane’ has lost its usage as a surface (flat.s.01), a level of existence (plane.n.03), and a type of cut (plane.v.01), while the prototypical usage of ‘airplane’ has become more prevalent.
For the Relation dimension, we compute
 $l$
by counting the number of linked senses as described in Equation (6).
$l$
by counting the number of linked senses as described in Equation (6).
 \begin{equation} \mathscr{R}(\text{plane}, \text{SEMCOR}) \stackrel {?}{=} \mathscr{R}(\text{plane}, \text{MASC}) \end{equation}
\begin{equation} \mathscr{R}(\text{plane}, \text{SEMCOR}) \stackrel {?}{=} \mathscr{R}(\text{plane}, \text{MASC}) \end{equation}
 \begin{equation} \begin{gathered} \mathscr{R}(\text{plane}, \text{SEMCOR}) = \mathit{l}(\text{plane.n.03}, \text{plane.n.02}) = 1\\ \stackrel {?}{=} \\ \mathscr{R}(\text{plane}, \text{MASC}) = 0 \end{gathered} \end{equation}
\begin{equation} \begin{gathered} \mathscr{R}(\text{plane}, \text{SEMCOR}) = \mathit{l}(\text{plane.n.03}, \text{plane.n.02}) = 1\\ \stackrel {?}{=} \\ \mathscr{R}(\text{plane}, \text{MASC}) = 0 \end{gathered} \end{equation}
 \begin{equation*} 1 \gt 0, \text{so the sense is less metaphorical and decreased in relation.} \end{equation*}
\begin{equation*} 1 \gt 0, \text{so the sense is less metaphorical and decreased in relation.} \end{equation*}
Change in meaning distribution for the word ‘plane’ in SEMCOR and MASC.

Figure 13 Long description
The bar graph compares the distribution of sense keys for the word plane in two datasets, SEMCOR and MASC. The x-axis lists the sense keys: plane dot n 03, airplane dot n 01, plane dot n 02, plane dot v 01, and flat dot s 01. The y-axis represents the proportion, ranging from 0 to 0.8. In the SEMCOR dataset, airplane dot n 01 has the highest proportion, followed by plane dot n 02, plane dot n 03, plane dot v 01, and flat dot s 01. In the MASC dataset, airplane dot n 01 dominates with a proportion close to 0.9, while plane dot n 02 has a smaller proportion, and the other sense keys have negligible proportions. The color scheme uses different colors for each sense key, with airplane dot n 01 in blue, plane dot n 02 in green, plane dot n 03 in teal, plane dot v 01 in orange, and flat dot s 01 in gray. The graph highlights the significant difference in the distribution of sense keys between the two datasets. All values are approximated.
In Figure 13, we can see the narrowing effect this word suffered in this corpus. The decreased usage as a positive meaning (flat.s.01) causes a decrease in its Orientation (
 $\mathscr{O}$
).
$\mathscr{O}$
).
6. Discussion
In this section, we synthesize the reviewed approaches for change characterization and discuss their limitations according to the dimension, relation, and orientation aspects we have introduced and formalized.
6.1 Dimension
The majority of studies found in this survey propose methods to characterize how words change in dimension, while the other poles are less studied. Change in dimension seems easier to detect because it does not rely on subjective interpretation, such as relation or feeling, but mainly on a countable quantity (see Section 5). Work along this axis often relies on word sense induction, a research area with well-developed tooling and many data sources, such as dictionaries and synsets, used for supervised learning.
The key factor differentiating the approaches is the word representation method. We identified four main types – frequency, topics, graphs, and embeddings – each with different trade-offs in implementation cost, representation power, and interpretability. It is difficult to compare the effectiveness of each method for the current state of the art, given the qualitative nature of reported results, the use of different corpora, and the need for external knowledge. However, our analysis reveals that frequency- and embedding-based methods appear to produce better results for identifying neologisms (new words), while topic- and graph-based approaches are more effective at detecting sememes (new senses) over time.
A limitation for approaches based on dictionaries is the temporal delay between a neologism’s first appearance and its inclusion in dictionaries. Another limitation is the presence of metaphorical senses at the same level as literal ones, increasing the complexity of distinguishing between ‘dimension’ and ‘relation.’ Some authors prefer to group these two poles into one (Tang et al. Reference Tang, Qu and Chen2013). For topic- and graph-based approaches, the limitation is that interpreting the meaning of a topic or a graph branch is not always clear and can require expert intervention.
6.2 Relation
Outside of this LSC survey, a vast body of work proposes methods to predict if a word in a sentence has a metaphorical sense (Heintz et al. Reference Heintz, Gabbard, Srivastava, Barner, Black, Friedman and Weischedel2013; Shutova and Sun Reference Shutova and Sun2013; Hovy et al. Reference Hovy, Shrivastava, Jauhar, Sachan, Goyal, Li, Sanders and Hovy2013). These approaches analyze texts but do not consider temporal information, so they cannot determine if a word has undergone metaphorization over time. Some works claim to detect the metaphorization of words (e.g., Tredici, Nissim, and Zaninello Reference Tredici, Nissim and Zaninello2016), but they rely on the general hypothesis that any sense change implies a metaphorical change, which still needs to be demonstrated.
For metonymization, we could not find studies that performed metonymy identification in a comparative setting. However, related recent studies investigate metonymy usage with various methods for material relation identification (Nastase et al. Reference Nastase, Judea, Markert and Strube2012; Soares et al. Reference Soares, FitzGerald, Ling and Kwiatkowski2019; Mathews and Strube Reference Mathews and Strube2021). We expect that future investigations can extend these approaches to detect word metonymization.
Among the four meaning representation methods, frequency-based approaches were the first investigated for relation characterization. However, their underlying hypothesis doesn’t differentiate between new metaphorical/metonymical usage and new homonymous usage, making interpretation difficult. More recent works employed embeddings, but interpreting vectors in high-dimensional space remains a challenge. Finally, graphs, well-known for representing relations, remain under-investigated for identifying changes in relations.
Tang et al. (Reference Tang, Qu and Chen2013) mainly rely on dictionaries of heuristics to infer metaphoricity, which served for qualitative analysis, but still require more extensive validation. A single work used ground-truth annotations for metaphors (Schlechtweg et al. Reference Schlechtweg, Eckmann, Santus, im Walde and Hole2017), but did not report a final precision of the proposed methodology.
As noted, studies on the ‘relation pole’ are few and inconclusive. The research community’s limited interest in this topic could be justified by three reasons: (I) the difficulty of formally defining metaphor and metonymy from a computational perspective, (II) the rarity and insufficiency of annotated corpora for relation detection, and (III) the nonexistence of standard metrics to measure and compare approaches.
6.3 Orientation
Interest in orientation analysis is increasing with the wide adoption of social networks. Orientation is usually determined using a feeling function (
 $\mathfrak{f}$
) that relies on seed words and the assumption that these seed words don’t vary over time. As we illustrated, word meanings evolve and can differ between communities. Most works found in this survey addressed the change in orientation for particular words Miller-Lewis et al. (Reference Miller-Lewis, Lewis, Tieman, Rawlings, Parker and Sanderson2021); Xiao et al. (Reference Xiao, Baes, Vylomova and Haslam2023).
$\mathfrak{f}$
) that relies on seed words and the assumption that these seed words don’t vary over time. As we illustrated, word meanings evolve and can differ between communities. Most works found in this survey addressed the change in orientation for particular words Miller-Lewis et al. (Reference Miller-Lewis, Lewis, Tieman, Rawlings, Parker and Sanderson2021); Xiao et al. (Reference Xiao, Baes, Vylomova and Haslam2023).
The example of ‘sick’ shows that a word can have two opposite orientations depending on the context. Creating corpora that include all these variations with statistical significance is a complex task. The annotation process can suffer from many biases, both from annotators and data. Selected seed words may not generalize across all contexts or long time spans, and a series of misleading results can occur, as presented in Antoniak and Mimno (Reference Antoniak and Mimno2021).
Of the four meaning representation methods, embedding- and frequency-based approaches are the most common. Few works use graphs, and we could not find any approach that uses topic analysis for detecting word orientation. The preference for embeddings and frequency is likely because current approaches compute distances or co-occurrences with seed words, which is easier with these methods.
While there is a huge body of work on sentence-level sentiment analysis, fewer studies infer sentiment at the word level (Guo, Yu, and Wang Reference Guo, Yu and Wang2021), and only a small fraction of those do so in a comparative manner, as we have assessed in this survey. While works in topics provide lexical entries that could be used similarly to what was done in embeddings, this was not investigated so far.
An important outcome of this survey is that there is some harmonization in how a change in feeling is defined and applied. However, we did not observe a harmonized approach to error analysis for the feeling function. Some works adopt a binary orientation function (positive, negative), while others use multidimensional orientations (valence, arousal, dominance) (Buechel et al. Reference Buechel, Hellrich and Hahn2016). Further study is needed to analyze which function (
 $\mathfrak{f}$
) is most suitable for characterizing change.
$\mathfrak{f}$
) is most suitable for characterizing change.
A converging point from the many approaches analyzed is the difficulty of evaluating and comparing results because, for most tasks, no gold standard exists. Many papers have raised this problem (Schlechtweg et al. Reference Schlechtweg, Eckmann, Santus, im Walde and Hole2017), but some initiatives to create reference datasets are underway. Another point is multilingualism; the vast majority of experiments use only English documents, making it difficult to generalize methods to other languages. The recent emergence of new-generation language models has opened up new possibilities for identifying and characterizing semantic changes, but this area of research is still underexplored.
We begin this survey with five objectives, which we believe have been achieved:
-
1. We discussed the limitations of current representations and methodologies in this section.
-
2. We evaluated the strengths of various approaches and the complexity of their computational interpretation in Table 4.
-
3. We proposed formal definitions in Section 5 to reduce ambiguity.
-
4. We demonstrate our proposed formalization with real data in Subsection 5.7.
7. Conclusion
In this survey, we reviewed current work on semantic change characterization with respect to the mainstream typology (broadening/narrowing, amelioration/pejoration, and metaphorization/metonymization). We observed four major approaches to representing meaning – frequency, topics, embeddings, and graphs – and their respective strengths and drawbacks.
After analyzing the literature, we observed that many tasks are underexplored or addressed without systematic evaluation. Therefore, we introduced a formal definition for the task of semantic change characterization, a more complex instance of the semantic change identification problem. This new task is extremely relevant for the field of LSC, as this study and other surveys have argued.
The suggested tasks are crucial for both linguistic change research and NLP. Numerous applications, such as sentiment analysis (orientation), semantic similarity (relation), and word sense inference (dimension), call for a deeper understanding of these representational characteristics. Additionally, awareness of how these changes affect word representations leads to better knowledge and interpretability of these systems. For word embeddings specifically, a better understanding of how these changes affect vector space geometries could improve our understanding of the semantics of vectors.
As future work, we expect to investigate the relation pole to better differentiate categories of change and further explore how the four representational methods relate to the three poles. Another important goal is the consolidation of datasets and metrics by which semantic change characterization can be compared across methodologies. In this survey, we performed an initial investigation of existing sense-annotated corpora; in future studies, we expect to analyze words in more comprehensive corpora.
Finally, this survey has limitations in its coverage of LSC and computational linguistics. Since the study of word meaning involves multiple, rapidly evolving fields, we focused on key works related to computational characterization and traditional meaning representations. The rise of new-generation language models and new theories of language development offers further opportunities for studying semantic change, but this area is still not fully explored.
Acknowledgements
The research reported in this publication was supported by the Luxembourg National Research Fund (FNR), project D4H grant number PRIDE21/16758026.
Use of AI tools
The production of this manuscript used AI tools solely to improve grammar and readability, as English is not the authors’ native language.


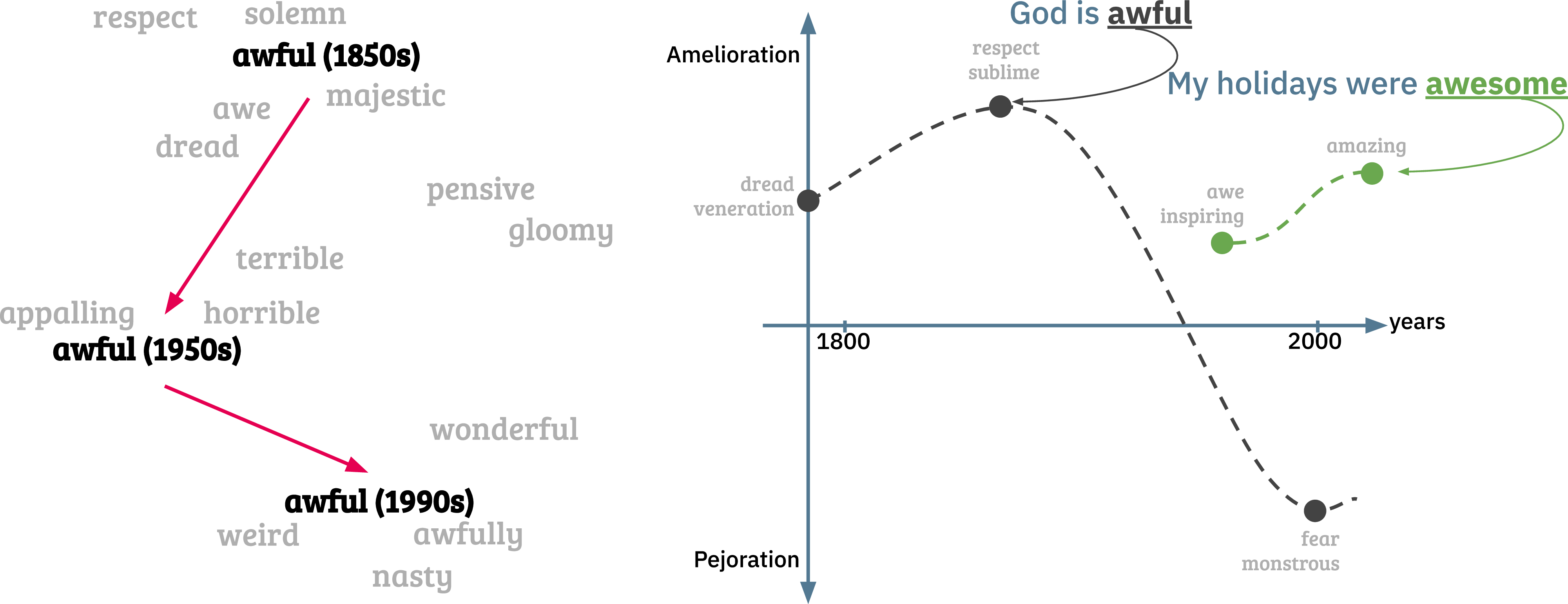
 f
f

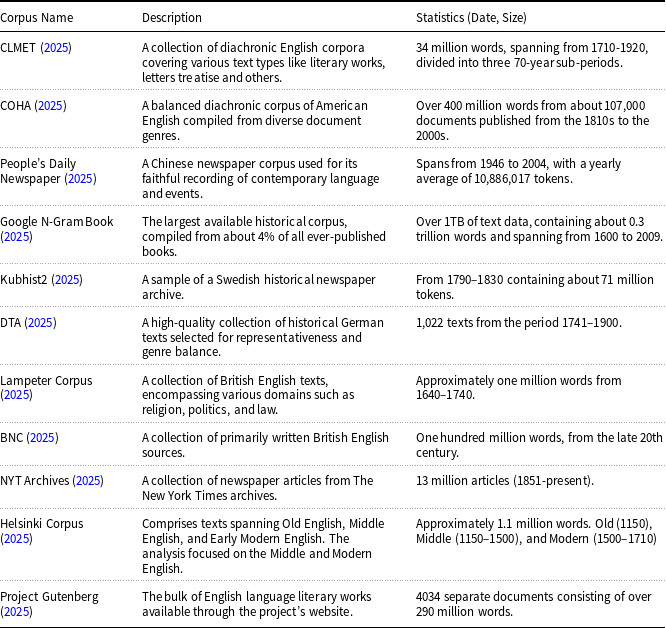






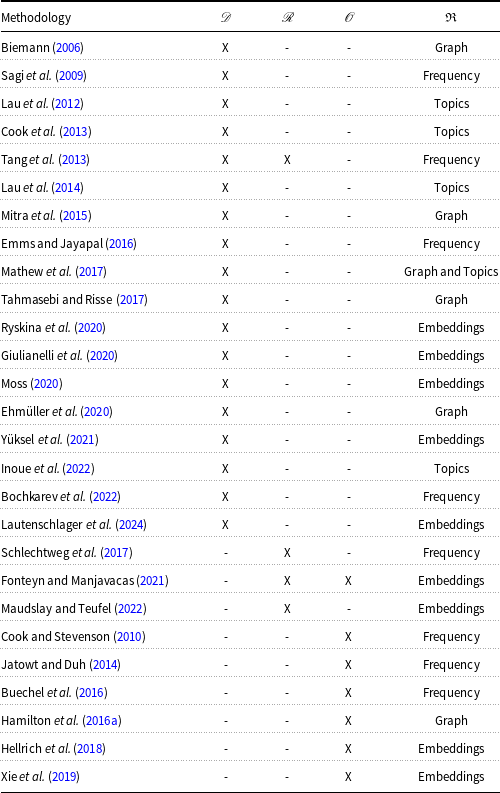
 D
D R
R O
O R
R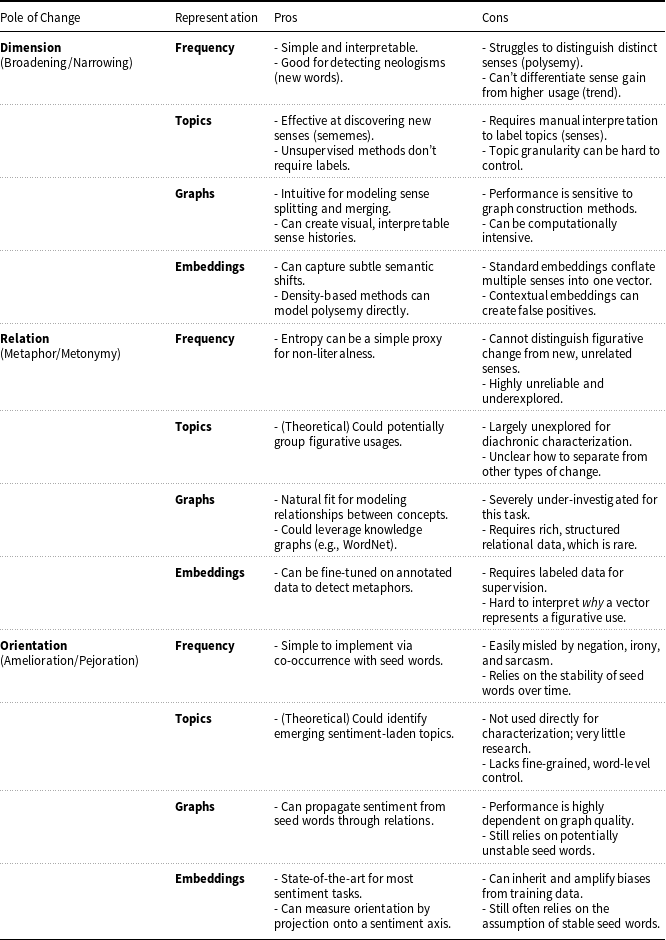


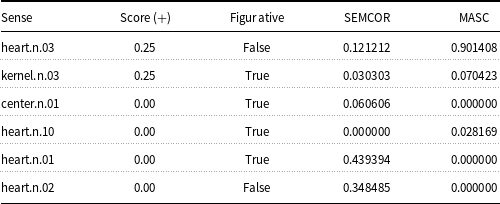




 Open access
Open access