FirstView articles
Contents
Survey Paper
Lexical semantic change detection: A survey of tasks, benchmarks, models, and potential impacts in digital humanities and social sciences
-
- Published online by Cambridge University Press:
- 10 July 2026, pp. 1-39
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Book Review
Natural Language Generation by Ehud Reiter. Springer, 2025. ISBN 978-3-031-68581-1 (HB: €57.19), ISBN 978-3-031-68584-2 (PB: €57.19), and ISBN 978-3-031-68582-8 (eBook: €39.99), XIII+202 pages, 66 b/w illustrations. DOI: https://doi.org/10.1007/978-3-031-68582-8.
-
- Published online by Cambridge University Press:
- 10 July 2026, pp. 1-5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Article
Balancing accuracy and efficiency: Evaluating encoder- and decoder-based models for word sense disambiguation and regular polysemy detection
-
- Published online by Cambridge University Press:
- 08 July 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Book Review
Automating Translation, by Joss Moorkens, Andy Way and Séamus Lankford. London, Routledge, 2024. ISBN 9781032436807. 270 pages.
-
- Published online by Cambridge University Press:
- 07 July 2026, pp. 1-4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Responsible NLP
Responsible NLP: Why performance is no longer enough
-
- Published online by Cambridge University Press:
- 29 June 2026, pp. 1-7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Article
Skeleton-based approach for semantic textual similarity
-
- Published online by Cambridge University Press:
- 09 June 2026, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Hate speech on Twitter: Profiling users and interaction analysis in the Spanish language
-
- Published online by Cambridge University Press:
- 30 April 2026, pp. 1-48
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Twitter is one of the most widely used social networks globally but is also notorious for harbouring significant levels of hate speech. This paradox has garnered the attention of companies and governments concerned about how digital hate can fragment communities and incite real-world violence. While extensive research has focused on detecting hate speech, there is a lack of comprehensive analysis of the actors involved, their characteristics, and their interactions within the online environment. Common assumptions categorise users into merely two groups—haters and non-haters—overlooking the existence of other groups that may more accurately represent the dynamics of hate dissemination. Additionally, existing user classification models often rely on large volumes of tweet data, a limitation given the restricted access to the Twitter API. Social networks are also frequently visualised using graphs where edges represent only superficial relationships. This study addresses these gaps through five research questions. We propose formal user clustering methods and develop a classifier that uses exclusively profile attributes—information more readily obtainable from the network. We also introduce a more nuanced definition of interaction for graph edges, based on ideological support or opposition between users. To conduct our analysis, we have extracted two complementary datasets: (i) a keyword-based corpus of 3.3M Spanish tweets containing hate-associated terms, of which 1.6M unique tweets were retained after filtering and (ii) a user-based corpus comprising timelines of
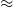 $\approx$3,000 users linked to hate speech, totalling over 3 M tweets. Our results reveal the existence of three primary user classes—haters, upstanders, and neutrals—in contrast to the conventional binary classification. We demonstrate that profile attributes are reliable indicators for automatically classifying users and find significant statistical differences between these classes. Finally, we develop a graph visualisation tool to assist authorities in analysing interactions among different user types, providing a useful exploratory tool to support the analysis of online hate and inform potential mitigation strategies.
$\approx$3,000 users linked to hate speech, totalling over 3 M tweets. Our results reveal the existence of three primary user classes—haters, upstanders, and neutrals—in contrast to the conventional binary classification. We demonstrate that profile attributes are reliable indicators for automatically classifying users and find significant statistical differences between these classes. Finally, we develop a graph visualisation tool to assist authorities in analysing interactions among different user types, providing a useful exploratory tool to support the analysis of online hate and inform potential mitigation strategies.