


1. Introduction
As a discipline that studies social relationships, the field of law inevitably evolves in both content and methods alongside social changes. With the rapid advancement of information technology, a series of new research paradigms mediated by digital information technology has emerged, extending beyond traditional legal research frameworks. As early as 1961, Loevinger et al. highlighted the significance of electronic technology in data retrieval for legal research, describing electronic data retrieval as a promising area of innovation and outlining several principles of text processing (Loevinger, Reference Loevinger1961). Subsequently, as information technology advanced further, research on legal text drafting, legal data analysis, and legal expert systems emerged in succession.
The integration of artificial intelligence technology with law can be traced back to the 1950s. Allen from Yale Law School first proposed the concept of applying artificial intelligence in the legal field in his work, “Symbolic Logic: A razor-edged tool for drafting and interpreting legal documents” (Allen and Orechkoff, Reference Allen and Orechkoff1957). In 1987, Northeastern University in Boston hosted the first International Conference on Artificial Intelligence and Law (ICAIL) (Susskind, Reference Susskind1987; Greenleaf, Mowbray, and Tyree, Reference Greenleaf, Mowbray and Tyree1987; Schlobohm and Waterman, Reference Schlobohm and Waterman1987), which eventually led to the establishment of the International Association for Artificial Intelligence and Law (IAAIL) in 1991. In China, the application of artificial intelligence in judicial adjudication began in 1986 with the national social science research project “Comprehensive Balancing of Sentencing and Research on Computer-Aided Sentencing Expert Systems,” which developed a mathematical model for sentencing in theft cases (Zhang, Reference Zhang2001). Later, in 1993, Tingguang Zhao introduced a practical criminal law expert system that provided functionalities for retrieving and consulting criminal law knowledge, as well as reasoning and qualitative sentencing for criminal cases (Weidong, Reference Weidong2018).
As artificial intelligence technology advances, it brings both significant opportunities and new challenges to the field of law (Lai et al. Reference Lai, Gan, Wu, Qi and Yu2024). Recently, large language models (LLMs), such as GPT-3.5, have garnered widespread attention for their remarkable capabilities in tasks like text generation, image creation, and speech synthesis (Wu et al. Reference Wu, He, Liu, Sun, Liu, Han and Tang2023). Representing a new generation of artificial intelligence, GPT-3.5 can naturally respond to human queries and has had a profound impact on simple legal tasks, including document drafting, translation, data organization, and proofreading (Biswas, Reference Biswas2023). Furthermore, with technological advancements and evolving demands, AI tools developed by companies like OpenAI have demonstrated impressive performance in specialized domains such as mathematical problem-solving (Daher and Gierdien, Reference Daher and Gierdien2024), programming (Zhong et al. Reference Zhong, Liu, Pan, Zhang, Zhou, Liang, Wu, Lyu, Shu and Yu2024), and psychological counseling (Liu, Zhang, and Wang, Reference Liu, Zhang and Wang2023).
The powerful capabilities of LLMs like ChatGPT prompt us to consider whether current AI technologies can effectively address the regional, specialized, logical, and rigorous requirements of legal work. To explore how existing general AI can adapt to specific legal tasks, we manually annotate 215 Chinese cases, resulting in 1,075 question-answer pairs, to analyze the advantages and limitations of artificial intelligence in legal tasks. These pairs span five judicial tasks: task-oriented information extraction, legal article citation, event extraction, judicial decision generation, and legal opinions generation, providing a comprehensive evaluation of conversational AI capabilities in handling legal cases. Notably, all annotations are completed by law graduate students from a university in China, ensuring that they are not part of any AI training data prior to the evaluation. We comprehensively evaluate the capabilities of 13 commercial AI large models in Chinese judicial case processing tasks based on these five judicial tasks and provide an in-depth analysis of the strengths and weaknesses of AI in current legal work. Additionally, we present 7,262 unannotated Chinese cases and propose a knowledge fine-tuning strategy based on weakly labeled data, aiming to effectively enhance the regional, specialized, logical, and rigorous aspects of LLMs in legal case processing tasks. All data, evaluation codes, and an example analysis using GPT-4o from this study are open source and can be accessed at https://github.com/MyOpenSpace/Law-Metrics.
The structure of the remainder of this paper is organized as follows. Section 2 offers a comprehensive overview of key issues in legal digital transformation research, with a focus on developments since the 1990s. Section 3 details the construction of our dataset, the evaluation tasks we designed, and the assessment methods used to measure performance. Section 4 presents the evaluation results along with an in-depth analysis of the findings. Finally, Section 5 provides a discussion of our work and offers concluding remarks to summarize the study.
2. Literature review
In recent years, there has been a significant surge in research focused on evaluating the performance of LLMs across a wide range of domains. Evaluation standards such as GLUE (Wang, Reference Wang2018) and MMLU (Hendrycks et al. Reference Hendrycks, Burns, Basart, Zou, Mazeika, Song and Steinhardt2020) have been introduced to measure model performance in general natural language processing tasks and multitask scenarios, respectively. GLUE serves as a comprehensive benchmark for a variety of NLP tasks, while MMLU evaluates accuracy across a broad spectrum of subject areas. More recently, Yuan Sui et al. proposed a structured evaluation framework specifically tailored for table processing tasks, emphasizing structural description detection, format comprehension, and operational interpretation (Sui et al. Reference Sui, Zhou, Zhou, Han and Zhang2024). The BIG-bench benchmark further broadens the scope of evaluation by encompassing 207 tasks, including linguistics, mathematics, social bias, and software development (Srivastava et al. Reference Srivastava, Rastogi, Rao, Shoeb, Abid, Fisch, Brown, Santoro, Gupta and Garriga-Alonso2023). In the domain of software engineering, DebugBench provides an assessment of debugging capabilities across multiple programming languages and error categories (Tian et al. Reference Tian, Ye, Qin, Cong, Lin, Liu and Sun2024). These evaluations underscore the growing emphasis on comprehensive and systematic assessments of LLMs for their diverse applications.
Building on the achievements of general-purpose models, NLP models have been widely utilized in legal tasks. Early studies primarily focused on fine-tuning models like BERT for legal-specific applications. Chalkidis et al. explored approaches to adapting pre-trained BERT models for downstream legal tasks, highlighting the challenges of effectively transferring these models to the legal domain (Chalkidis et al. Reference Chalkidis, Fergadiotis, Malakasiotis, Aletras and Androutsopoulos2020). Similarly, Shao et al. introduced BERT-PLI, a model designed for legal case retrieval, which captures semantic relationships at the paragraph level and employs a cascading framework to enhance efficiency (Shao et al. Reference Shao, Mao, Liu, Ma, Satoh, Zhang and Ma2020). The advent of LLMs has further intensified research in the legal field, including evaluations of models such as GPT-3.5 and GPT-3 for tasks like contract review and statutory interpretation. For instance, Martin et al. demonstrated that LLMs can achieve human-level precision while significantly reducing costs in contract review (Martin et al. Reference Martin, Whitehouse, Yiu, Catterson and Perera2024), whereas Stanek et al. uncovered limitations in GPT-3’s ability to understand statutory reasoning (Blair-Stanek, Holzenberger, and Van Durme, Reference Blair-Stanek, Holzenberger and Van Durme2023).
More specifically, evaluations of LLMs in legal contexts have received increasing attention. Recent studies have focused on benchmarking LLMs for tasks such as legal text comprehension, reasoning, and document drafting (Fei et al. Reference Fei, Shen, Zhu, Zhou, Han, Zhang, Chen, Shen and Ge2024; Tan, Westermann, and Benyekhlef, Reference Tan, Westermann and Benyekhlef2023; Biswas, Reference Biswas2023; Dougrez-Lewis et al. Reference Dougrez-Lewis, Akhter, He and Liakata2025). In parallel, scholars in China and elsewhere have begun systematically evaluating Chinese legal language models. For example, Zeng introduced MMCU, which covers four major domains (medicine, law, psychology, and education), with a particular focus on tasks in medicine and education (Zeng, Reference Zeng2023). CMMLU is specifically designed for Chinese contexts, encompassing 67 topics, including evaluation tasks in jurisprudence, university-level law, and international law (Li et al. Reference Li, Zhang, Koto, Yang, Zhao, Gong, Duan and Baldwin2024). Liang et al. presented the CAIL 2023 Argument Mining Track and systematically analyzed the methods and evaluation metrics used in the task of identifying and extracting interacting argument pairs from judicial documents. They also showcased how different teams improved model performance within a unified task framework and summarized key findings and future research directions (Liang et al. Reference Liang, Wang, Zhai, Zhuang, Zheng, Xu, Ran, Dong, Rong and Liu2024). Collectively, these studies demonstrate the broad applicability and transformative potential of LLMs in legal text understanding and reasoning tasks, while also underscoring the necessity of developing robust and fine-grained evaluation metrics tailored to legal applications.
Despite significant advancements, existing evaluations often fail to consider the intricate competencies required for legal tasks. Current benchmarks typically adopt a broad perspective, focusing on tasks such as legal literature review (Xia et al. Reference Xia, Chen, Qi and Wang2025) and legal question-answering (Akarajaradwong et al. Reference Akarajaradwong, Pothavorn, Chaksangchaichot, Tasawong, Nopparatbundit and Nutanong2025) without thoroughly analyzing the specialized legal skills involved. Legal tasks are inherently complex and structured, demanding systematic analysis of specific abilities such as statutory interpretation, judicial reasoning, and legal drafting. This shortcoming underscores the need for more granular evaluation methods to identify the capabilities and limitations of LLMs within legal contexts. To address this gap, our work introduces an innovative evaluation framework that rigorously assesses the performance of LLMs in legal tasks, offering valuable insights into their effectiveness and practical applicability in the legal domain.
3. Proposed method
3.1 Objectives and approach
This work explores the following research questions, aiming to investigate the performance and challenges of current LLMs in addressing legal issues, specifically:
-
• Can current AI models effectively handle legal tasks that are highly regional, specialized, logical, and rigorous?
-
• What are the strengths and limitations of current AI in legal work?
-
• How can existing general-purpose AI be adapted to address specific legal tasks?
We first obtained 215 high-quality cases from PKULaw. Subsequently, we engaged 10 trained law graduates to manually annotate the data for five legal tasks: task-oriented information extraction, legal article citation, event extraction, judicial decision generation, and legal opinion generation. The annotations are meticulously reviewed and corrected by experienced data annotators. Using this finely annotated dataset, we evaluate the legal task processing performance of 13 LLMs, including GPT-3.5 (3.5-turbo), GPT-4o (Achiam et al. Reference Achiam, Adler, Agarwal, Ahmad, Akkaya, Aleman, Almeida, Altenschmidt, Altman and Anadkat2023), Deepseek (Liu et al. Reference Liu, Feng, Xue, Wang, Wu, Lu, Zhao, Deng, Zhang and Ruan2024), ChatLaw (Cui et al. Reference Cui, Li, Yan, Chen and Yuan2023), Claude (3-sonnet),Footnote a Doubao (v3-ep-20240629095146-29dnq),Footnote b Kimi (v1),Footnote c ERNIE (3.5-8k-0613),Footnote d GLM (3-turbo) (Du et al. Reference Du, Qian, Liu, Ding, Qiu, Yang and Tang2022), Qianfan (70B), Qianwen2 (72B-instruct) (Yang et al. Reference Yang, Yang, Zhang, Hui, Zheng, Yu, Li, Liu, Huang and Wei2025), Xuanyuan (70B-chat) (Zhang, Yang, and Xu, Reference Zhang, Yang and Xu2023b), and Yi (34B-chat) (AI et al. Reference Young, Chen, Li, Huang, Zhang, Zhang, Li, Zhu, Chen, Chang, Yu, Liu, Liu, Yue, Yang, Yang, Yu, Xie, Huang, Hu, Ren, Niu, Nie, Xu, Liu, Wang, Cai, Gu, Liu and Dai2024).
Based on these fine-grained data, we adopt a few-shot learning approach, labeling 1921 weakly labeled data points and performing supervised fine-tuning on the BaichuanFootnote e model, significantly improving its performance across various tasks. This validates the importance of finely annotated data and demonstrates that LLMs still require breakthroughs in logical reasoning capabilities.
3.2 Data collection and task setup
We collect 400 case reports from four sections of the PKULawFootnote f database: typical cases, gazette cases, classic cases, and guiding cases. All case documents are originally written in Chinese, reflecting the authentic linguistic and legal style used in Chinese judicial practice. After a rigorous manual screening process, we retain 215 high-quality cases as the foundation of our dataset. The selection criteria include clear factual descriptions, complete judgment structure, well-defined legal reasoning, and moderate document length, ensuring that each case provides a sufficient basis for legal professionals to perform fundamental legal reasoning under standard circumstances. In addition, we have analyzed the distribution of Chinese case description lengths among the 215 selected samples. As shown in Figure 1, the majority of descriptions fall between 200 and 800 characters, with a gradual decline in frequency beyond this range. Cases exceeding 1,000 characters are relatively rare, and only a small number surpass 2,000 characters. The distribution results suggest that although extremely long documents were excluded due to concerns over annotation and modeling feasibility, the retained cases still exhibit substantial variation in length, encompassing both concise and medium-length descriptions. This diversity enables the dataset to serve as a realistic and flexible testbed for evaluating model performance under different input length conditions in legal tasks.
Distribution of description lengths (in number of characters) across the 215 selected Chinese legal cases.

It is also important to note that we deliberately excluded both complex and hard cases (Dworkin, Reference Dworkin1974) during data construction. Complex cases typically involve intricate factual scenarios, lengthy chains of evidence, diverse types of evidentiary materials, and the application of multiple legal provisions with substantial interpretive difficulty. Hard cases, on the other hand, are characterized not only by a high degree of factual uncertainty but also by substantial disputes over the interpretation and application of legal norms. Such cases often entail rule conflicts, legal lacunae, or ambiguous legislative intent, and sometimes require adjudication based on moral principles or political judgment. Given the considerable divergence in how legal professionals understand and evaluate these cases, their annotation tends to be highly challenging and difficult to standardize. To ensure the internal consistency and evaluability of the dataset, we excluded these hard cases during the data construction process.
The final dataset includes 215 cases, comprising 110 criminal cases, 82 civil cases, and 23 administrative cases. The case distribution reflects a balance between legal diversity and annotation feasibility. For data annotation, we engage 10 law graduates from Beijing Foreign Studies University, all of whom have passed the National Unified Legal Profession Qualification Examination in China. The annotation tasks cover five core legal subtasks: key information extraction, legal article identification, factual event labeling, judicial decision annotation, and legal opinion summarization. Each task is designed based on the original structure of the judicial document and follows a unified annotation guideline.
Specifically, judicial documents in the PKULaw database generally follow a standardized structure, typically segmented into sections such as main points of judgment, basic facts, relevant legal articles, reasoning, and final judgment. This consistent formatting provides a clear foundation for structured annotation. In task-oriented information extraction, annotators receive training in linguistic annotation protocols and follow part-of-speech definitions from the Xinhua Dictionary to accurately label verbs, nouns, and other essential linguistic elements in the case narrative, ensuring semantic alignment between legal language and factual content. For legal article citation, since the original documents already include a distinct section for “relevant legal articles,” annotators simply extract the referenced provisions without additional interpretation. Factual event extraction is based on a “who, when, where, what, and why” behavioral structure. Annotators extract and structure case facts that are directly and causally related to the judgment. Judicial decision generation is performed by directly referencing the “judgment result” section of the document, capturing decisions such as “sentenced to X years of imprisonment” or “appeal dismissed, original judgment upheld.” For legal opinion generation, annotators are required to distill the underlying legal logic that supports the ruling, based on the relevant legal provisions, judicial reasoning, and judgment result. The output is a concise yet logically complete summary that reconstructs the rationale of the decision.
To ensure the quality of annotations, we implement a systematic review mechanism. All annotations are reviewed by a team of legal data experts with extensive experience to verify consistency and correctness across annotators. This process significantly enhances the reliability and accuracy of the annotated data and provides a robust foundation for evaluating the performance of LLMs on downstream legal tasks.
3.2.1 Task-oriented information extraction
Information extraction is fundamental to understanding legal cases. Therefore, we first established a task-oriented information extraction task aimed at extracting all nouns and verbs from the input case descriptions. Specifically, we defined eight categories of information to be extracted: personal names, verbs, place names, numbers, common nouns, organizations/institutions, legal terms and phrases, and time expressions. Ten annotators were responsible for labeling all the cases, and one additional annotator subsequently consolidated the results to ensure consistency.
These eight categories were carefully selected based on the practical needs of judicial work. First, personal names, verbs, common nouns, and organizations/institutions are essential for identifying legal subjects, actions, and objects. For example, in the context of criminal law, these elements correspond to the components of a crime: the subject of the crime, the subjective element, the object of the crime, and the objective element. These components, as defined in criminal law, are the essential factual characteristics that determine the social harmfulness and severity of an act and are necessary for the act to constitute a crime. Furthermore, organizations/institutions may serve as plaintiffs or defendants in administrative litigation. For instance, a county-level public security bureau may be sued in an administrative case if it wrongfully detains an individual. Second, place names represent the spatial context of a case and are often closely related to factors such as regional ethnic autonomy and the level of economic development, which can have a substantive impact on the legal characterization and sentencing of a case. For example, in areas governed by ethnic regional autonomy, this factor is particularly significant. According to Article 90 of the Criminal Law of the People’s Republic of China, autonomous regions may formulate supplementary or alternative provisions in light of their political, economic, and cultural characteristics, subject to approval by the Standing Committee of the National People’s Congress. Similarly, local economic conditions may indirectly influence sentencing, especially in economically related crimes such as fraud or corruption. In regions with relatively prosperous economies, the same monetary amount involved in a crime might be treated more leniently due to its relatively lower social harmfulness. In addition, legal terms and phrases serve as a key indicator for assessing whether a model can recognize, understand, and appropriately use domain-specific legal language. This capability is fundamental to ensuring that the model’s outputs in processing legal texts are norm-compliant, logically rigorous, and terminologically accurate. Finally, time expressions and numbers are crucial to a range of legal determinations. These include, but are not limited to, assessing the statute of limitations, determining the applicability of old versus new laws, establishing the duration of actions, verifying the age of individuals involved (e.g., whether they are minors), calculating the amount of money involved in a case, and evaluating the scope of sentencing. Time and numerical expressions not only influence factual determinations but may also directly affect the legitimacy of applying substantive and procedural laws.
For evaluation, prompt-based inference can activate the latent capabilities of LLMs to handle specialized tasks. To enable the model to perform task-oriented information extraction, we design a specialized prompt for inference:
You are asked to act as a legal professional in China. I will provide you with a case description, and you are to list in detail the following from the case: personal names, verbs, common nouns, place names, organizations/institutions, legal terms and phrases, time expressions, and numbers (with units retained), separating them with semicolons. For example: ’personal names: San Lee; Si Zhao; Wu Wang.’
Additionally, since the output of large models can be inconsistent, we review the results to ensure no non-noun content is included using spaCy.Footnote
g
If more than
 $\beta$
% of the generated outputs are not nouns, the inference process is repeated. The threshold
$\beta$
% of the generated outputs are not nouns, the inference process is repeated. The threshold
 $\beta$
effectively improves the lower bound of model performance on this task. In our experiments, we set
$\beta$
effectively improves the lower bound of model performance on this task. In our experiments, we set
 $\beta = 10$
by default. On average, each model performs inference 1.3 times, with most models requiring only one round, while a few lower-performing models may require up to three.
$\beta = 10$
by default. On average, each model performs inference 1.3 times, with most models requiring only one round, while a few lower-performing models may require up to three.
We use precision, recall, and F1 score as metrics to evaluate the model’s annotation results:
 \begin{equation} \text{precision} = \frac {TP}{TP + FP} \end{equation}
\begin{equation} \text{precision} = \frac {TP}{TP + FP} \end{equation}
 \begin{equation} \text{recall} = \frac {TP}{TP + FN} \end{equation}
\begin{equation} \text{recall} = \frac {TP}{TP + FN} \end{equation}
 \begin{equation} \text{F1} = \frac {2 \times \text{precision} \times \text{recall}}{\text{precision} + \text{recall}} \end{equation}
\begin{equation} \text{F1} = \frac {2 \times \text{precision} \times \text{recall}}{\text{precision} + \text{recall}} \end{equation}
where
 $ TP$
represents the number of correctly predicted terms,
$ TP$
represents the number of correctly predicted terms,
 $ FP$
represents the number of incorrectly predicted terms, and
$ FP$
represents the number of incorrectly predicted terms, and
 $ FN$
represents the number of missed terms. Precision measures the proportion of correct predictions out of all predicted terms, while recall measures the proportion of correctly identified results out of all relevant terms. The F1 score combines precision and recall to provide a balanced evaluation metric.
$ FN$
represents the number of missed terms. Precision measures the proportion of correct predictions out of all predicted terms, while recall measures the proportion of correctly identified results out of all relevant terms. The F1 score combines precision and recall to provide a balanced evaluation metric.
3.2.2 Legal article citation
Accurately identifying and citing the relevant legal provisions based on case facts is a fundamental prerequisite for ensuring the legality and legitimacy of judicial decisions. In this task, the model is required to predict the legal provisions applicable to a case adjudication based on the underlying case facts. It also serves as a critical benchmark for assessing the acceptability and fairness of the ruling. This task not only evaluates a model’s accuracy in retrieving normative legal texts but also indirectly tests its capacity to correctly map facts to legal elements, which is an essential step in producing legally sound judicial reasoning. For instance, Article 1 of the Provisions of the Supreme People’s Court on Citing Laws, Regulations and Other Normative Legal Documents in Judgments clearly stipulates that people’s courts must cite relevant laws, regulations, and other normative legal documents in their judgments in accordance with the law. Such citations must accurately and completely indicate the name and article number of the normative document; where specific provisions are cited, the full article must be quoted. In other words, the correct citation of legal provisions is not only a formal requirement but also a reflection of the legal rigor and legitimacy of the judicial reasoning. It constitutes an indispensable part of the rationale in judicial decisions. Accordingly, in the Legal Article Citation task, whether the model can accurately identify and cite the applicable legal provisions reflects not only its capabilities in text matching and information retrieval, but also its understanding of the logic behind legal norm application. If a model fails to perform this task, the legitimacy and reasonableness of its judicial outputs become questionable.
In this task, we first classify the cases into three categories: civil, criminal, and administrative. Annotators then extract the applicable legal provisions based on the “Relevant Legal Provisions” section of the original judicial documents. These extracted provisions serve as the ground truth for training and evaluating the model. This annotation strategy enhances the legal relevance and specificity of the task, while providing clear benchmarks for assessing model performance in practical judicial contexts.
For this task, we design a specialized prompt to guide the LLM’s inference, as follows:
You are asked to act as a legal professional in China. I will provide you with a case description, and you are to list the titles and specific articles and clauses of the legal documents referenced in making the judicial decision. Only provide the article and clause numbers; there is no need to state the content of the provisions. For example: Product Quality Law of the People’s Republic of China, Article 5, Article 6.
The evaluation of legal article citation uses the same three metrics as task-oriented information extraction: precision, recall, and F1 score.
3.2.3 Event extraction
Correctly matching the relationships between persons, verbs, and nouns within content is a challenging task for natural language processing models and is critical for handling legal tasks (Zhou et al. Reference Zhou, Zhang, Gu, Chen and Poon2023; Zhang et al. Reference Zhang, Chen, Guo, Xu, Zhang and Chen2024). Accurate event extraction, followed by a step-by-step reconstruction of these events to uncover the underlying facts of the case, is a key process in legal reasoning. Therefore, we establish an event extraction task aimed at identifying all events from the input case descriptions. For example: “A borrowed 5,000 yuan from B”; “B hired five people to threaten A.”
For this task, we design a specialized prompt to guide the LLM’s inference, as follows:
You are asked to act as a legal professional in China. I will provide you with a case description, and you are required to extract and list all events mentioned in the case, presenting them in a factual and straightforward manner without summarizing, classifying, or integrating them. For example: ’The defendant Li Ming was criminally detained on May 10, 2013, on suspicion of intentional injury.’
Event extraction first employs a sentence tokenization model of spaCy to break each sentence into phrases or words. Then, it uses three precision metrics based on edit distance (precision, recall, and F1 score) for evaluation. The specific formula for edit distance is as follows:
 \begin{align} D_{i,j} &= \begin{cases} {\max}(i,j) & \text{if } {\min}(i,j) = 0, \\[5pt] \min \left (\begin{array}{c} D_{i-1,j} + 1, \\ D_{i,j-1} + 1, \\ D_{i-1,j-1} + \delta (s_{1_{i-1}}, s_{2_{j-1}}) \end{array}\right ) & \text{if }\ {\min}(i,j) \neq 0. \end{cases} \end{align}
\begin{align} D_{i,j} &= \begin{cases} {\max}(i,j) & \text{if } {\min}(i,j) = 0, \\[5pt] \min \left (\begin{array}{c} D_{i-1,j} + 1, \\ D_{i,j-1} + 1, \\ D_{i-1,j-1} + \delta (s_{1_{i-1}}, s_{2_{j-1}}) \end{array}\right ) & \text{if }\ {\min}(i,j) \neq 0. \end{cases} \end{align}
where
 $i$
and
$i$
and
 $j$
are the indices of two strings
$j$
are the indices of two strings
 $s_1$
and
$s_1$
and
 $s_2$
, while
$s_2$
, while
 $\max$
and
$\max$
and
 $\min$
denote the selection of the maximum and minimum values, respectively. The function
$\min$
denote the selection of the maximum and minimum values, respectively. The function
 $\delta (s_{1_{i-1}}, s_{2_{j-1}})$
is defined as follows:
$\delta (s_{1_{i-1}}, s_{2_{j-1}})$
is defined as follows:
 \begin{equation} \delta \big(s_{1_{i-1}}, s_{2_{j-1}}\big) = \begin{cases} 1 & \mathrm{if}\ \ s_{1_{i-1}} \neq s_{2_{j-1}}, \\[5pt] 0 & \mathrm{if}\ \ s_{1_{i-1}} = s_{2_{j-1}}. \end{cases} \end{equation}
\begin{equation} \delta \big(s_{1_{i-1}}, s_{2_{j-1}}\big) = \begin{cases} 1 & \mathrm{if}\ \ s_{1_{i-1}} \neq s_{2_{j-1}}, \\[5pt] 0 & \mathrm{if}\ \ s_{1_{i-1}} = s_{2_{j-1}}. \end{cases} \end{equation}
The edit distance
 $D_{i,j}$
represents the minimum number of operations required to transform the first
$D_{i,j}$
represents the minimum number of operations required to transform the first
 $i$
characters of
$i$
characters of
 $s_1$
into the first
$s_1$
into the first
 $j$
characters of
$j$
characters of
 $s_2$
. We define a prediction as incorrect if the edit distance exceeds
$s_2$
. We define a prediction as incorrect if the edit distance exceeds
 $\alpha$
% of the word count, calculated based on the longer string. The threshold
$\alpha$
% of the word count, calculated based on the longer string. The threshold
 $\alpha$
is adjustable to suit different task requirements. A smaller value enforces stricter evaluation, while a larger value allows more flexibility. In our implementation, we set the default value of
$\alpha$
is adjustable to suit different task requirements. A smaller value enforces stricter evaluation, while a larger value allows more flexibility. In our implementation, we set the default value of
 $\alpha$
to 15. In addition to edit-distance-based metrics, we also report BLEU-4 (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002) and ROUGE (Lin, Reference Lin2004) scores to capture the models’ lexical overlap and content coverage at the sequence level.
$\alpha$
to 15. In addition to edit-distance-based metrics, we also report BLEU-4 (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002) and ROUGE (Lin, Reference Lin2004) scores to capture the models’ lexical overlap and content coverage at the sequence level.
3.2.4 Judicial decision generation
As the most critical module in legal tasks, judgments and rulings allow for an extremely narrow margin of error. Therefore, we adopt the approach used in legal article annotation by categorizing cases into civil, criminal, and administrative types and assigning domain experts to annotate the judicial decisions. After the initial annotation by one annotator, the cases are reassigned to another annotator for review and verification of the annotation against the original judicial decision in the data.
For this task, we design a specialized prompt to guide the LLM’s inference, as follows:
You are asked to act as a legal professional in China. I will provide you with a case description, and based on the case details and in reference to Chinese laws and regulations, you are to briefly state the judicial decision generation. Do not summarize, categorize, or integrate the information. There is no need to explain the reasons or provide references. For example: ’Wang; intentional homicide; fine of 500 yuan; five years of imprisonment; compensation of 2,000 yuan; cancellation of administrative action,’ etc. Each individual must be listed separately.
The metric for judicial decision generation builds upon the relationship extraction measurement by adding a distance metric for numerical results, defined as follows:
 \begin{equation} D_n = \frac {|a-b|}{\max (|a|,|b|)} \end{equation}
\begin{equation} D_n = \frac {|a-b|}{\max (|a|,|b|)} \end{equation}
where
 $D_n$
indicates the relative distance between the numbers, and
$D_n$
indicates the relative distance between the numbers, and
 $|\cdot |$
denotes the absolute value. In addition to edit-distance-based metrics and numerical accuracy, we also report BLEU-4 and ROUGE scores to assess the lexical similarity and content coverage between generated and reference decisions.
$|\cdot |$
denotes the absolute value. In addition to edit-distance-based metrics and numerical accuracy, we also report BLEU-4 and ROUGE scores to assess the lexical similarity and content coverage between generated and reference decisions.
3.2.5 Legal opinion generation
After completing the annotation of entities and the generation of judicial decisions, we also require the artificial intelligence to generate legal opinions. This task aims to generate a comprehensive legal opinion based on the input case descriptions, incorporating the generation of legal terminology, extraction of legal provisions, event extraction, and judicial decision generation. For this task, we use the legal opinion section of the case materials as a reference.
For this task, we design a specialized prompt to guide the inference of the LLM, as follows:
You are asked to act as a legal professional in China. I will provide you with a case description, and you are required to analyze the case in detail using legalese while referencing Chinese laws and regulations, in one to two paragraphs. Then, issue the decision and provide a detailed explanation of its content.
The generation of legal opinions builds on the measurement method for generating rulings, while also considering the precision of the referenced legal articles. The implementation is achieved by averaging both metrics. To further assess the fluency and consistency of generated opinions, we additionally compute BLEU-4 and ROUGE scores, which capture the n-gram overlap and content similarity between the generated and reference legal texts.
3.3 Weakly supervised fine-tuning
In addition to designing a framework to evaluate the model’s performance on legal tasks, we propose a weakly supervised fine-tuning approach to enhance the performance of LLMs in legal processing tasks.
3.3.1 Weak annotation generation based on few-shot learning
Supervised data is crucial for deep learning; however, as mentioned in the previous section, the annotation process is complex and expensive. To address this, we propose weak annotation generation based on Few-shot Learning (Wang et al. Reference Wang, Yao, Kwok and Ni2020), which utilizes a small amount of annotated data to generate a large volume of weakly annotated data for model fine-tuning, thereby improving the model’s performance in legal processing tasks, as shown in Figure 2.
The process of weakly supervised data generation.

Phase 1: To construct high-quality initial data for the few-shot learning framework, we additionally collect 100 samples from the PKULaw database, which are distinct from the 215 high-quality cases introduced in Section 3.2, and manually annotate them to obtain 500 (
 $=100 \times 5$
) high-quality question–answer (Q&A) pairs. The annotation process strictly follows the method described in Section 3.2 to ensure consistency with our tasks.
$=100 \times 5$
) high-quality question–answer (Q&A) pairs. The annotation process strictly follows the method described in Section 3.2 to ensure consistency with our tasks.
Phase 2: We conduct supervised instruction fine-tuning (Zhang et al. Reference Zhang, Dong, Li, Zhang, Sun, Wang, Li, Hu, Zhang and Wu2023a) of the large model to extract case descriptions and generate questions (Model 1 as shown in Figure 2), aiming to derive judicial questions that meet the requirements from complete legal case documents, including task-oriented information extraction, legal article extraction, event extraction, judicial decision generation, and legal opinion generation. Simultaneously, based on the 500 high-quality Q&A pairs, we supervise the instruction fine-tuning of the LLM (Model 2 as shown in Figure 2) to complete the corresponding judicial tasks, with the goal of generating relevant answers based on the original case documents and questions.
Phase 3: We obtain 7,262 pieces of unlabeled case data from the PKULaw Database. Using the question-generating large model (Model 1) trained in Phase 2, we generate corresponding questions based on the case files. Then, we use GPT-3.5 to evaluate whether the generated questions are reasonable based on reference questions, discarding unreasonable samples. Subsequently, we use the fine-tuned LLM (Model 2) on the Q&A data to generate answers based on the original case-question pairs. Again, we use GPT-3.5 to assess the format and presentation of the generated answers based on reference answers, removing any unreasonable samples. This process yields 1921 weakly annotated case data, resulting in 9605 (
 $=1921\times 5$
) Q&A pairs.
$=1921\times 5$
) Q&A pairs.
3.3.2 Parameter-efficient fine-tuning
Based on weakly labeled data, we fine-tune the LLM using the instruction fine-tuning approach to enhance its capabilities in legal processing tasks. Specifically, we freeze all parameters of the LLM and incorporate low-rank adapters (LoRA) (Hu et al. Reference Hu, Shen, Wallis, Allen-Zhu, Li, Wang, Wang and Chen2021) to learn the specified instruction tasks. While the adapters are trainable, the core parameters of the large model remain unchanged.
3.3.3 Implementation details
We fine-tune the Baichuan model, setting the rank of LoRA to 8. The learning rate gradually increases from 0 to 0.000001 over the first 3% of the steps and then gradually decays to 0. We employ the Adam optimizer (Kingma, Reference Kingma2014) with a weight decay value of 0.00001, and the training lasts for a total of 5 epochs. The commercial models tested were evaluated on September 27, 2024.
4. Results
We first evaluate the capabilities of 13 LLMs in task-oriented information extraction, legal article extraction, event extraction, judicial decision generation, and legal opinion generation, based on the 215 high-quality cases collected in Section 3.2. Then, we fine-tune the Baichuan (7B) model using the method proposed in Section 3.3 and validate its performance across the five judicial assistance tasks outlined in Section 3.2.
4.1 Inter-annotator consistency analysis
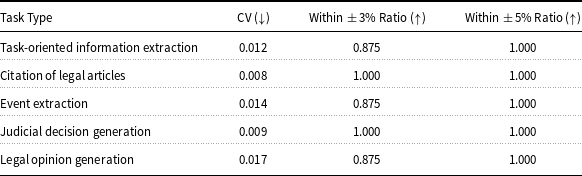
To ensure the reliability and objectivity of human annotations, we organized a consistency test involving ten annotators, each independently labeling the same set of ten legal cases. The cases covered five core tasks, and each annotator’s performance was scored using F-scores based on expert-validated gold standards. These gold standards were constructed by two legal experts through independent annotation and cross-checking to ensure accuracy. To evaluate inter-annotator consistency, we adopted two complementary approaches. First, we computed the coefficient of variation (CV) (Abdi, Reference Abdi2010) of the annotators’ scores for each task to assess the relative dispersion. Second, we measured the proportion of annotators whose scores fell within a narrow range around the task-specific average, using two predefined thresholds (within-5% and within-3%) to capture agreement under different tolerances. Table 1 presents the consistency results across the five subtasks: task-oriented information extraction, legal article citation, event extraction, judicial decision generation, and legal opinion generation. These results provide empirical support for the overall stability and trustworthiness of the human-annotated benchmark.
Inter-annotator consistency for different annotation tasks using coefficient of variation (CV), within-3% agreement ratio, and within-5% agreement ratio

The results demonstrate a high degree of consistency among annotators across all five subtasks. For instance, the CV values for citation of legal articles (0.008), judicial decision generation (0.009), and task-oriented information extraction (0.012) are all below 0.015, suggesting minimal relative variability. Event extraction and legal opinion generation also maintain low CVs of 0.014 and 0.017, respectively, indicating stable annotation quality even in more interpretive tasks. In terms of absolute agreement, all tasks achieve a within-5% ratio of 1.000, meaning that every annotator’s score falls within a narrow range of the group mean. Even under the stricter 3% threshold, four out of five tasks maintain agreement ratios of 0.875 or higher, with citation of legal articles and judicial decision generation reaching full consistency. These results indicate that annotators not only converged in overall judgments but also aligned on fine-grained score levels. Taken together, the low CVs and high agreement ratios confirm the robustness of our annotation protocol. The findings validate that annotators consistently interpreted and applied the guidelines across subtasks, ensuring the reliability of our dataset.
4.2 Results of benchmark
4.2.1 Performance on task-oriented information extraction
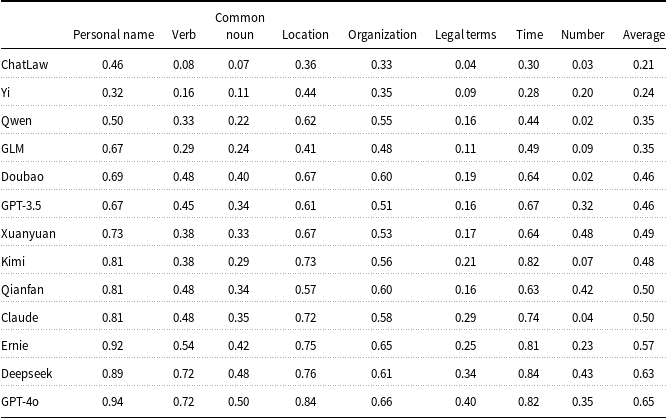
We evaluated 13 LLMs on eight task-oriented information extraction tasks, including personal names, verbs, common nouns, locations, organizations/institutions, legal terms and phrases, time expressions, and numbers. The detailed F-scores for each model and category are presented in Table 2.
Performance evaluation of 13 large language models on task-oriented information extraction (F-score only, sorted by average)

Among all models, GPT-4o achieved the highest overall performance (F-score 0.65), followed by Deepseek (0.63) and Ernie (0.57), all of which performed reliably on general entity types like personal names and locations. However, performance on legal-specific categories remains limited. In particular, the extraction of legal terms shows consistently low F-scores across all models, with most scores below 0.30. This reflects a lack of legal domain knowledge, which is essential for understanding statutes, charges, and procedural elements in legal texts. The models also struggled with numerical information, which is critical for identifying fines, sentence durations, and references to legal provisions. Even strong general-purpose models failed to handle these elements reliably, reducing their effectiveness in precise legal analysis. ChatLaw, although designed for the legal domain, performed the worst overall with an average score of 0.21. Its weak performance across both general and legal categories suggests that small-scale legal fine-tuning alone is not enough to support accurate legal information extraction. In conclusion, while some models show strong general extraction ability, none currently meet the requirements of legal tasks. To improve their applicability in the legal field, targeted training with legal corpora and attention to domain-specific expressions are necessary.
4.2.2 Performance on legal article citation
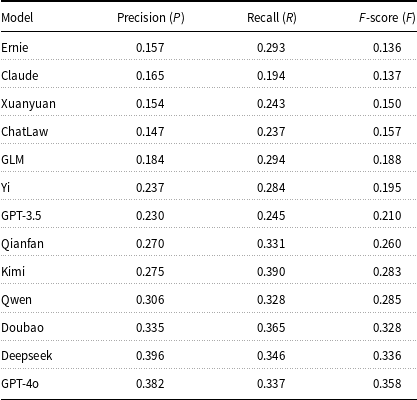
We assess the ability of 13 LLMs to accurately cite legal articles by evaluating their precision, recall, and F-score. This task is essential in legal reasoning and judgment generation, where the correct citation of relevant statutes reflects legal understanding and reliability. The results are presented in Table 3.
Performance of large language models on legal article citation

Overall, the models perform poorly on this task. Even the top model, GPT-4o, achieves an F-score of only 0.358. Doubao, Deepseek, and Qwen follow closely, showing a better balance between precision and recall. These models demonstrate some capacity to retrieve appropriate legal citations, but their scores remain far from satisfactory for real-world legal applications. Most other models fall below an F-score of 0.30, with Ernie, Claude, and ChatLaw ranking at the bottom. Despite Ernie’s strong general extraction ability, he fails to translate this strength into legal citation performance. Similarly, ChatLaw underperforms with an F-score of 0.157, revealing that domain alignment alone is not enough without robust instruction and citation data.
These findings suggest that current models lack the legal reasoning ability and citation accuracy required for reliable legal use. To support tasks such as legal opinion generation or statutory interpretation, models must undergo focused training with legal citation patterns and statute references. Without such fine-tuning, even high-performing models will remain limited in their ability to meet legal standards.
4.2.3 Performance on event extraction
We evaluate 13 LLMs on their ability to identify and interpret legal and interpersonal relationships, a core capability for understanding legal scenarios involving multiple entities and actions. Results are shown in Table 4, using precision, recall, F-score, BLEU-4, and ROUGE as evaluation metrics.
Performance of large language models in event extraction

GPT-4o ranks first with the highest F-score (0.521), BLEU-4 (28.242), and ROUGE (18.470), showing its strong capability to both correctly extract legal relationships and articulate them with high lexical consistency. This reflects its potential in tasks such as event reconstruction, causal inference, and responsibility attribution in legal texts. Following closely are Yi (F-score 0.507), GLM (0.503), and Qianfan (0.502), all achieving BLEU scores above 26 and ROUGE scores above 17. These models show balanced performance, combining reliable structure extraction with coherent expression. They are suitable for downstream applications like fact summarization and procedural role recognition. Xuanyuan (0.496) and GPT-3.5 (0.462) also perform stably, with BLEU-4 around 24–26 and consistent ROUGE scores, indicating they can handle explicit relationships but may struggle with more nuanced or indirect legal roles. Mid-performing models such as Ernie, Doubao, and Kimi (F-scores 0.458–0.459) show moderate success in both structural and linguistic accuracy. Their BLEU-4 and ROUGE scores suggest generally fluent outputs, but possible gaps in legal precision or coverage. At the lower end, Claude (F-score 0.410), Qwen (0.434), and ChatLaw (0.440) show limited performance. While ChatLaw is domain-specific, its relatively low BLEU-4 (21.765) and ROUGE (14.702) indicate challenges in handling complex or nested legal events, possibly due to its smaller model capacity or limited relational reasoning capabilities.
Overall, the results show that while most models can extract basic legal relationships, only the top-tier ones succeed in producing both structurally correct and linguistically aligned outputs. BLEU-4 and ROUGE offer complementary perspectives: BLEU-4 reflects surface-level fluency and phrasing, while ROUGE captures content completeness and overlap. Future improvements should focus on training with fine-grained legal event annotations to enhance both understanding and expression in real-world judicial scenarios.
4.2.4 Performance on judicial decision generation
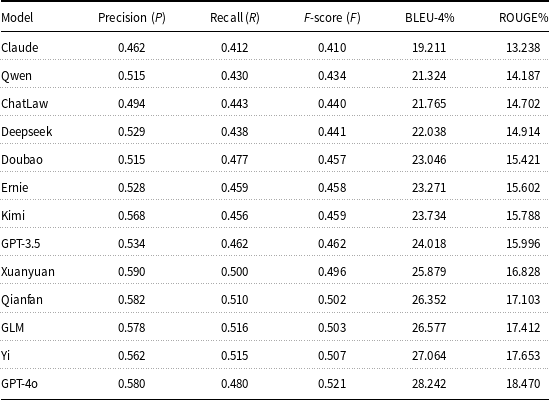
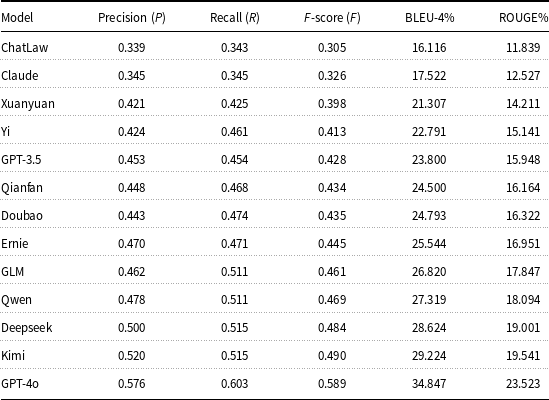
We evaluate 13 LLMs on their ability to generate judicial decisions, using precision, recall, F-score, BLEU-4, and ROUGE as evaluation metrics. This task assesses how well each model can simulate legal reasoning and produce fact-grounded, rule-based judicial outcomes. Results are shown in Table 5.
Performance of large language models in judicial decision capability

GPT-4o leads across all metrics, achieving the highest F-score (0.589), BLEU-4 (34.85), and ROUGE (23.52), demonstrating its strong capacity to produce accurate, fluent, and content-aligned judicial decisions. Kimi (F-score 0.490) and Deepseek (0.484) follow closely, both maintaining high lexical overlap and recall, which indicates they can generate decisions that are not only structurally sound but also complete in legal content. Mid-tier models such as Qwen, GLM, Ernie, and GPT-3.5 exhibit balanced performance, with F-scores in the range of 0.428–0.469 and BLEU-4 scores exceeding 23. Their outputs are generally coherent but may lack the completeness or legal precision seen in higher-ranked models. For instance, while Ernie performs well in F-score (0.445), its relatively lower ROUGE score (16.95) suggests weaker coverage of key elements in the reference decisions. ChatLaw and Claude remain at the bottom with F-scores of 0.305 and 0.326 and BLEU-4 scores below 18. These results indicate limited ability to capture judicial structures and legal reasoning patterns. Their low ROUGE scores further reflect insufficient alignment with the reference decisions.
Overall, the results show that only top-performing models like GPT-4o and Kimi are capable of generating judicial outcomes that balance factual accuracy, legal reasoning, and linguistic fluency. The inclusion of BLEU-4 and ROUGE helps reveal not only whether the decision content is correct, but also whether it is expressed in a clear and legally appropriate form. Further domain-specific tuning is essential for improving the legal reliability of mid- and lower-performing models.
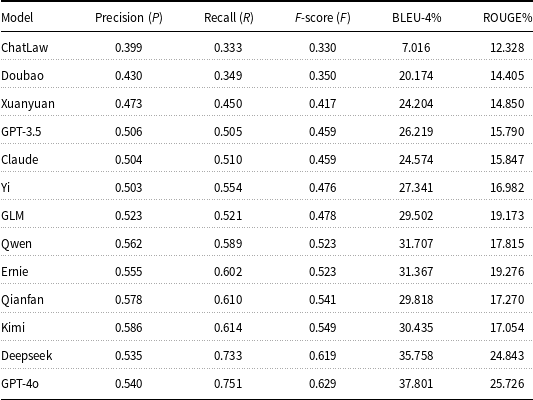
4.2.5 Performance on legal opinion generation
We evaluate 13 LLMs on their ability to generate legal opinions, focusing on precision, recall, F-score, BLEU-4 (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002), and ROUGE (Lin, Reference Lin2004). This task reflects the models’ capacity to produce accurate and well-structured legal reasoning, which is essential for professional legal drafting. The results are shown in Table 6.
Performance of large language models in legal opinion generation

GPT-4o achieves the best overall performance with an F-score of 0.629, supported by the highest BLEU-4 (37.801) and ROUGE (25.726) scores. Deepseek follows closely with an F-score of 0.619. Both models show strong recall, indicating their ability to comprehensively incorporate key legal points while maintaining acceptable precision. Kimi (0.549) and Qianfan (0.541) also perform well, offering a good balance between fluency and legal content relevance. Models such as Ernie, Qwen, and GLM demonstrate solid performance, with F-scores ranging from 0.478 to 0.523. These models are able to generate relatively coherent legal arguments but still fall short in capturing the depth and completeness needed for high-quality legal analysis. At the lower end, ChatLaw (0.330) and Doubao (0.350) struggle to produce accurate and comprehensive opinions. Their low BLEU-4 and ROUGE scores suggest difficulty in both language expression and legal reasoning, which limits their usability in professional settings.
Overall, while a few models show potential for legal opinion generation, most still lack the domain-specific understanding required for accurate legal argumentation. Enhancing performance in this task will require further fine-tuning on annotated legal corpora with structured opinion examples to improve both factual coverage and legal coherence.
4.3 Correlation analysis between annotation tasks
To explore the intrinsic relationships among different annotation tasks, we computed Pearson correlation coefficients based on the performance scores of 13 LLMs. As shown in Figure 3, legal opinion generation and judicial decision generation exhibit a strong correlation (
 $r = 0.77$
), primarily due to their substantial content overlap, as judicial decisions typically constitute the core component of legal opinions. Legal article citation also shows a high correlation with judicial decision generation (
$r = 0.77$
), primarily due to their substantial content overlap, as judicial decisions typically constitute the core component of legal opinions. Legal article citation also shows a high correlation with judicial decision generation (
 $r = 0.74$
) and a moderate correlation with legal opinion generation (
$r = 0.74$
) and a moderate correlation with legal opinion generation (
 $r = 0.50$
). These findings indicate that a model’s ability to accurately identify and cite relevant legal provisions significantly affects the legality and fairness of the judicial decisions and legal opinions it generates. Furthermore, Information Extraction correlates strongly with both Judicial Decision Generation (
$r = 0.50$
). These findings indicate that a model’s ability to accurately identify and cite relevant legal provisions significantly affects the legality and fairness of the judicial decisions and legal opinions it generates. Furthermore, Information Extraction correlates strongly with both Judicial Decision Generation (
 $r = 0.56$
) and Opinion Generation (
$r = 0.56$
) and Opinion Generation (
 $r = 0.64$
), indicating that detailed entity recognition enhances downstream legal reasoning tasks. In contrast, Event Extraction demonstrates weak correlations with the other tasks, particularly with Information Extraction (
$r = 0.64$
), indicating that detailed entity recognition enhances downstream legal reasoning tasks. In contrast, Event Extraction demonstrates weak correlations with the other tasks, particularly with Information Extraction (
 $r = 0.04$
) and Legal Citation (
$r = 0.04$
) and Legal Citation (
 $r = 0.15$
), consistent with its subjectivity and relatively distinct nature.
$r = 0.15$
), consistent with its subjectivity and relatively distinct nature.
Correlation matrix between five legal annotation tasks.

4.3.1 Human evaluation of three text-generation tasks
To complement automatic evaluation, we conducted a human evaluation on three tasks that involve free-form textual generation: event extraction, judicial decision generation, and legal opinion generation. These tasks were selected because they require the model to produce structured legal content in continuous text, making them suitable for assessing not only surface-level correctness but also the depth and quality of legal reasoning.
We randomly sampled 10 representative legal cases and asked 10 graduate students with formal legal training to evaluate the outputs of 13 LLMs. Each response was rated on a 1–5 scale (in 0.5-point increments), according to informativeness, legal appropriateness, and reasoning soundness. These dimensions were chosen specifically to reflect the ability of models to perform consistent and normatively valid legal reasoning, rather than merely producing grammatically fluent text. To ensure consistency, annotators were provided with task-specific guidelines and reference examples tailored to each legal task. These guidelines were developed to reflect the distinctive requirements of different legal activities, as detailed below: For task-oriented information extraction, annotators were instructed to consult authoritative linguistic resources such as the Xinhua Dictionary to verify whether the part-of-speech categories and semantic roles of the extracted terms aligned with the legal meanings in the case context. This ensures semantic accuracy and consistency of the extracted results within the legal domain. For event extraction, the evaluation followed a structured behavioral framework based on the “Five Ws” (who, when, where, what, and why). Annotators were required to identify factual statements that had a direct causal relationship with the judicial decision, ensuring that the extracted event chains were logically complete and clearly articulated. For legal opinion generation, we focused on whether the model could effectively reconstruct the chain of legal reasoning by integrating three key components: The judgment result, the cited legal provisions, and the reasoning section. The evaluation emphasized whether the generated opinion formed a coherent and normatively valid inferential structure between the application of legal norms and the justification of value-based conclusions. These evaluation dimensions were designed to assess the model’s ability to perform consistent and normatively sound legal reasoning, rather than merely producing grammatically correct text. To ensure consistency throughout the evaluation process, annotators were provided with task-specific operational guidelines and reference examples.
The aggregated results are shown in Figure 4, which presents the mean opinion scores (MOS) and 95% confidence intervals for each model across the three tasks. GPT-4o consistently achieved the highest scores, followed by Kimi and Deepseek. In contrast, models such as ChatLaw and Claude received the lowest ratings, often due to incomplete, inconsistent, or legally unsupported outputs. We observe a clear alignment between these subjective ratings and the models’ rankings under automatic metrics (e.g., F-score, BLEU-4, ROUGE). This consistency supports the validity of our earlier evaluation and indicates that carefully selected automatic metrics can serve as meaningful proxies for legal reasoning performance in generative tasks.
Mean Opinion Scores (MOS) of 13 LLMs across event extraction, judicial decision generation, and legal opinion generation tasks, with 95% confidence intervals.

4.4 Weakly supervised fine-tuning
4.4.1 Convergence process of fine-tuning
Following the method described in Section 3.3, we fine-tune the Baichuan model with LoRA on a dataset containing 9605 pairs of weakly labeled question-answer data. The convergence curves of the model during fine-tuning are presented in Figure 5.
From the loss curve, we observe a significant reduction in the loss value as training progresses, indicating that the model is gradually adapting to the target data domain. Initially, the loss is relatively high, reflecting the model’s unfamiliarity with the specific patterns in the dataset. However, as fine-tuning proceeds, the loss consistently decreases, demonstrating that the model is effectively learning the instructions of the target task and capturing the intricacies of the domain-specific data.
4.4.2 Performance on benchmark
As shown in Table 7, our fine-tuned model, Ours Baichuan (i.e., Baichuan fine-tuned with LoRA), achieves substantial improvements across all categories in task-oriented information extraction. In particular, the F1 scores for number and time extraction increase from 0.11 and 0.33 in the base Baichuan model to 0.51 and 0.70, respectively. The fine-tuned model also surpasses GPT-4o in several categories, including person name (0.98 vs. 0.94), verb (0.79 vs. 0.72), and common noun (0.58 vs. 0.50). Overall, Ours Baichuan achieves an average F1 score of 0.69, nearly tripling the base model’s 0.23 and outperforming GPT-4o’s 0.65. These results demonstrate the effectiveness of our fine-tuning strategy in enhancing legal domain information extraction performance.
Performance evaluation of LLMs on task-oriented legal information extraction tasks

The observed performance gains can be attributed to the fine-tuning conducted on our custom dataset of 9,605 weakly labeled question-answer pairs. This dataset tailored the model more closely to the specific requirements of the task. Overall, the fine-tuned model surpasses other models across most tasks, highlighting its potential for practical applications in task-oriented information extraction.
Convergence curves during fine-tuning of the Baichuan model.

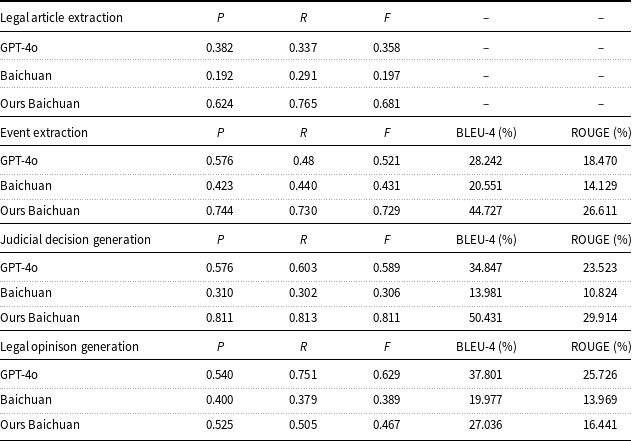
Following the fine-tuning results in task-oriented information extraction, we also evaluate the performance of Ours Baichuan across four legal tasks, as shown in Table 8.
Performance evaluation on legal article extraction, event extraction, judicial decision generation, and legal opinion generation tasks

In terms of legal article extraction, Ours Baichuan significantly outperforms both Baichuan and GPT-4o, achieving an F1 score of 0.681 compared to 0.197 and 0.358, respectively. This substantial improvement highlights its effectiveness in accurately identifying and extracting legal articles, which is a critical step in downstream legal reasoning.
For event extraction, which involves identifying relationships between legal terms and involved entities, Ours Baichuan also demonstrates strong performance. It achieves an F1 score of 0.729, which is significantly higher than Baichuan (0.431) and GPT-4o (0.521). Additionally, it obtains a BLEU-4 score of 44.727 and a ROUGE score of 26.611, showing a notable improvement in generation fidelity and content coverage over Baichuan (BLEU-4: 20.551; ROUGE: 14.129). These results indicate that the fine-tuned model is better at extracting and organizing structured legal information from text.
In judicial decision generation, Ours Baichuan achieves an F1 score of 0.811, which is substantially higher than Baichuan (0.306) and GPT-4o (0.589). It also outperforms these models in BLEU-4 (50.431) and ROUGE (29.914), reflecting improved consistency, semantic alignment, and textual coherence. These outcomes suggest that the model is capable of simulating the structure and logic required for decision-oriented outputs in judicial contexts.
Lastly, in legal opinion generation, Ours Baichuan achieves an F1 score of 0.467, which is better than Baichuan (0.389), with BLEU-4 and ROUGE scores of 27.036 and 16.441, respectively. However, it still trails GPT-4o, which achieves an F1 of 0.629 and significantly higher BLEU-4 and ROUGE scores. This indicates that generating discursive and well-structured legal documents remains a challenge for the fine-tuned model, leaving room for future improvement.
Taken together, these results validate the effectiveness of our fine-tuning approach. By training on a domain-specific dataset, we have substantially enhanced the Baichuan model’s ability to perform reliably across critical legal tasks, especially those involving structured extraction and decision-oriented generation. This demonstrates the potential of domain-adapted LLMs in legal applications where precision, reasoning, and contextual understanding are essential.
5. Discussion and conclusion
The experimental results demonstrate that current large models exhibit significant potential in foundational judicial assistance tasks, particularly in handling vast amounts of textual data, extracting key information, and generating legal documents. However, these models still display notable shortcomings in deeper legal expertise. Their generally poor performance in tasks such as legal term extraction and the citation of legal articles highlights an urgent need to enhance their understanding and application of professional legal knowledge. This issue not only affects the models’ accuracy but also risks producing misleading legal opinions in practical applications, potentially causing harm to judicial practices. Notably, even the best-performing models remain inadequate in recognizing complex legal relationships and generating accurate adjudication results, underscoring the inherent limitations of current artificial intelligence in simulating the inference and judgment capabilities of legal professionals.
This study also identifies significant performance disparities among different models on the same task, reflecting serious issues with the consistency of legal application in current AI models. Moreover, a closer inspection of the experimental results reveals that the observed performance gaps across models are not only merely quantitative but also qualitative in nature. Poorly performing models tend to exhibit recurring error patterns across multiple judicial tasks. These include failures in mapping factual elements to applicable legal norms, incomplete reconstruction of causally relevant event chains, and omissions of legally decisive factors in generated decisions and opinions. In many cases, such models produce outputs that are linguistically fluent but legally under-specified, internally inconsistent, or insufficiently grounded in statutory provisions. These weaknesses suggest the presence of common reasoning deficiencies rather than isolated task-specific errors. In particular, limitations in upstream capabilities, such as legal term recognition, numerical information extraction, and accurate legal article citation, systematically propagate to downstream failures in judicial decision and legal opinion generation. As a result, errors accumulate along the reasoning pipeline, ultimately undermining the legal validity and reliability of the generated texts. This observation is further supported by the strong correlations identified between foundational extraction tasks and higher-level reasoning tasks in our experimental analysis. Additionally, the lack of interpretability in model decision-making processes poses a major risk. Although certain models perform well on specific tasks, their decision-making paths are often difficult to trace and explain, contradicting the fundamental requirements for transparency and interpretability in judicial decisions. Another noteworthy observation is the significant impact of language and legal systems on model performance. In the context of globalization, the adaptability of models across languages and legal systems has emerged as a critical issue, particularly when addressing international legal disputes or cross-border cases.
The core issue in studying the capabilities of large models in judicial tasks lies in defining their scope of applicability within judicial assistance. In 2022, the Supreme People’s Court of China issued the Opinions on Regulating and Strengthening the Application of Artificial Intelligence in the Judiciary, explicitly stating that, regardless of the level of technological advancement, artificial intelligence must not replace judges in rendering decisions and may only serve as a tool to assist in adjudication. This directive aligns closely with the empirical findings of this study; however, the precise boundaries of such assistance still require further clarification.
Based on our empirical findings, the boundaries of large models’ participation in judicial activities are primarily reflected in two aspects. First, there are significant limitations in legal reasoning and judgment. Even the best-performing model, GPT-4o, achieves an F1 score of only 0.589 in adjudication capability tests, indicating persistent deficiencies in handling complex legal reasoning tasks such as interpreting statutory provisions, applying legal doctrines, balancing competing interests, and incorporating considerations of public order and morality. Second, their ability to analyze complex cases remains limited. In event extraction tasks involving legal and interpersonal relationships, the top-performing model reaches an F1 score of 0.521, while most others fall below 0.5. This reflects ongoing challenges in identifying multiple entities, mapping their legal roles, and understanding their relationships within structured legal contexts. These results highlight that while large models show potential for assisting in specific subtasks, their capacity for autonomous judicial reasoning remains insufficient.
Regarding the boundaries of applicability, the research highlights two key limitations. The first is the specificity of legal interpretation. Legal interpretation requires not only a literal understanding of legal texts but also a careful consideration of factors such as legislative intent, legal principles, and societal values. While current AI systems excel in information retrieval and data processing, they exhibit significant shortcomings in making complex value judgments and understanding social contexts. The second limitation is the human element in judicial discretion. Discretion is an indispensable aspect of judicial activity, built on a deep understanding of specific cases, the weighing of societal values, and the grasp of the spirit of the law (Hart and Green, Reference Hart and Green2012). It requires the professional judgment and ethical considerations of a judge, which remain beyond the capabilities of current AI systems.
In summary, analyzing the boundaries of authority and applicability for AI-assisted judicial decision-making provides a clearer understanding of both the potential and limitations of AI in the judicial field. In advancing judicial modernization, it is essential to fully leverage the auxiliary advantages of AI in areas such as fact-finding, evidence organization, and legal research, while maintaining a clear awareness of its limitations in core judicial functions such as complex legal reasoning, judicial discretion, and legal interpretation. Only by doing so can we enhance judicial efficiency while safeguarding justice and protecting human rights.
Future development should focus on improving models’ understanding of professional legal knowledge, adaptability across scenarios, and the interpretability of ruling-generation processes. Additionally, clearer guidelines for the judicial application of AI should be established, along with the refinement of human–machine collaboration mechanisms, to achieve an optimal balance between judicial fairness and efficiency.







 Open access
Open access