

1 Introduction
Some phonological processes apply variably. The rate of application of such variable processes is often influenced by phonological factors similar to those which condition the occurrence of corresponding categorical processes (Kiparsky Reference Kiparsky1993, Anttila Reference Anttila, Hinskens, van Hout and Leo Wetzels1997, Zuraw Reference Zuraw2000, Reference Zuraw2002, Reference Zuraw2010, Hayes & Londe Reference Hayes and Londe2006, Hayes et al. Reference Hayes, Zuraw, Siptár and Londe2009). For instance, optional t/d-deletion in English is more likely to apply before a consonant (e.g. west side) than before a vowel (e.g. west end) (e.g. Guy Reference Guy and Labov1980, Kiparsky Reference Kiparsky1993, Coetzee Reference Coetzee2004). In variable nasal substitution in Tagalog, a prefix-final nasal is more likely to fuse with a voiceless obstruent than a voiced one (Zuraw Reference Zuraw2010). It is typically the case in phonological research that such tendencies are initially observed in existing words, and then tested on loanwords or nonce words. If similar tendencies are mirrored in such novel words, it can be confirmed that they are part of speakers’ internalised grammars. As discussed by Coetzee & Pater (Reference Coetzee, Pater, Goldsmith, Riggle and Yu2011), various probabilistic constraint-based theories and their related learning models have been proposed to explain variable phonological patterns and their acquisition (see e.g. Boersma Reference Boersma1997, Boersma & Hayes Reference Boersma and Hayes2001, Goldwater & Johnson Reference Goldwater, Johnson, Spenador, Eriksson and Dahl2003, Boersma & Pater Reference Boersma, Pater, McCarthy and Paterforthcoming).
In order to establish whether speakers learn all the tendencies which can be observed in existing words of their native language, the present study investigates variable n-insertion in Seoul Korean: /n/ is optionally inserted after a syllable-final consonant and before a high front vocoid /i j/ of the following syllable (e.g. /com-jak/ [comjak] ~ [comnjak] ‘mothball’). Based on data from three different sources, a dictionary, previous surveys and experiments, and my own survey, I will show that the rate of n-insertion in existing Seoul Korean words is influenced by a number of phonological factors. The main tendencies found are that n-insertion is more likely before the glide /j/ than before the vowel /i/, and less likely after an obstruent or velar nasal than after other sonorant consonants. In addition, n-insertion is more likely when /j/ is followed by a high vowel, and when the morpheme preceding the insertion site is longer. Results of a wug test show that most of the tendencies observed from the existing words are mirrored in Seoul Korean speakers’ production of and intuitions about novel words, suggesting that they are aware of these tendencies. However, the high rate of insertion for longer morphemes preceding the insertion site is not mirrored in novel words. This data vs. learning mismatch suggests that speakers do not internalise all the statistically prominent patterns of a language (Hayes et al. Reference Hayes, Zuraw, Siptár and Londe2009, Becker et al. Reference Becker, Ketrez and Nevins2011, Hayes & White Reference Hayes and White2013).
An additional goal of the present study is to develop a plausible formal account of Korean n-insertion, relying crucially on P-map theory (Steriade Reference Steriade, Hume and Johnson2001, Reference Steriade, Hanson and Inkelas2009). I will adopt optimality-theoretic (OT) constraints (Prince & Smolensky Reference Prince and Smolensky1993, McCarthy & Prince Reference McCarthy, Prince, Beckman, Dickey and Urbanczyk1995) to account for the occurrence of n-insertion and the tendencies observed. Characterising probabilistic patterns of n-insertion, the constraints are assigned numerical weights within the framework of maximum entropy (maxent) grammar (Goldwater & Johnson Reference Goldwater, Johnson, Spenador, Eriksson and Dahl2003, Hayes & Wilson Reference Hayes and Wilson2008, Hayes & White Reference Hayes and White2013). I conducted a learning simulation to demonstrate that the grammar posited for the analysis of n-insertion can be learned from the Korean data, and that the grammar learned can in fact explain the observed probabilistic patterns. Analysing the n-insertion data will show that the main aspects of Korean n-insertion are motivated by the requirement of perceptually minimal modification, and can be accounted for within Steriade's P-map theory. Specifically, /n/ is perceptually weak in the insertion site, and thus confusable with zero, and even more so in the context where n-insertion is likely to take place. This context-dependent perceptibility is reflected in a fixed ranking (or relative weights) of relevant faithfulness constraints. The observed data vs. learning mismatch will also be attributed to the lack of a perceptual basis for the tendency related to the length of the morpheme preceding the insertion site.
This paper is organised as follows. In the rest of this section, I first describe the basic characteristics of Seoul Korean n-insertion and then introduce three phonological tendencies involved in the application of n-insertion, discussing Hwang's (Reference Hwang2008) experiments involving novel words. §2 shows that these tendencies, along with others, are observed in existing Seoul Korean words, based on the distribution of n-insertion found in the data from my own survey, a dictionary and a number of previous studies. §3 presents a basic analysis of n-insertion employing OT constraints, while illustrating how characteristic patterns of n-insertion can be understood within P-map theory. §4 provides a learning simulation using a maxent learner. In §5, I show that the results of an experiment involving novel words are relatively well matched with existing word patterns in crucial respects, supporting the view that Seoul Korea speakers have stochastic phonological knowledge that originates from the patterns of existing words. §6 discusses how the aims of the present study are achieved, and what problems remain. §7 concludes and summarises this paper.
1.1 The basic pattern
In a dialect of Korean spoken in the Seoul-Gyeonggi area (henceforth Seoul Korean), /n/ is inserted at the juncture of two morphemes, M1 and M2, when M1 ends in a consonant and M2 begins in a high front vocoid /i j/, as summarised in (1), where C1 is a M1-final consonant.
-
(1)

This phenomenon has been much discussed in the literature on Korean phonology and morphology (Kim Reference Kim1970, Choi Reference Choi1971, Kim-Renaud Reference Kim-Renaud1974, Im Reference Im1981, Huh Reference Huh1984 and many others).
M1 and M2 may form an affixed word, compound or syntactic phrase, as shown in (2).Footnote 1
-
(2)

As illustrated in (3), the epenthetic consonant /n/ is phonetically realised as a palatalised coronal sonorant, [ɲ] or, after a lateral, [ʎ], due to allophonic palatalisation (accompanied by lateralisation when C1 is a liquid).Footnote 2
-
(3)

With n-insertion, a non-liquid C1 is typically realised as a nasal, due to the nasalisation of an obstruent before a nasal.
-
(4)
When C1 is a liquid underlyingly, it is realised as a lateral, as can be seen in (3b).
1.2 Variation
In addition to the conditions mentioned above on the application of n-insertion, it has been argued in the literature (Huh Reference Huh1984: 267, Ki Reference Ki1990: 130–131, Ko Reference Ko1992: 32, Han Reference Han and Clancy1993: 124–125, Kim et al. Reference Kim, Park, Ahn and Lee2002: 41, 44, Hong Reference Hong2006: 400) that n-insertion occurs only when M2 is a stem or root which can be an independent word. There are lexical exceptions (see e.g. Ko Reference Ko1992: 32, Kim et al. Reference Kim, Park, Ahn and Lee2002: 46–53, Bae Reference Bae2003: 241–242). Not all /i j/-initial M2 stems trigger n-insertion, as shown in (5), where se=sentence ender (from Ko Reference Ko1992: 32).
-
(5)
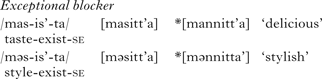
On the other hand, certain /j/-initial M2 suffixes may trigger n-insertion (Ko Reference Ko1992: 37, Kim et al. Reference Kim, Park, Ahn and Lee2002).
-
(6)

More importantly, it is usually the case that the application of n-insertion is not obligatory (Kim-Renaud Reference Kim-Renaud1974: 150, Ko Reference Ko1992: 32, Kwack Reference Kwack1992: 84, Han Reference Han and Clancy1993: 124–125, Lee Reference Lee1996: 167–171, Hong Reference Hong1997: 175, Kim et al. Reference Kim, Park, Ahn and Lee2002: 46, Bae Reference Bae2003: 240–243, Oh Reference Oh2006: 119, Ahn Reference Ahn2009: 279), as shown in (7) (from Kwack Reference Kwack1992, Ko Reference Ko1992, Han Reference Han and Clancy1993).
-
(7)

The probability of n-insertion varies across speakers and words, as will become clear below.
The present study examines the factors influencing the rate of this optional n-insertion. The next section discusses Hwang's (Reference Hwang2008) productivity test, the results of which reveal that the frequency of n-insertion differs crucially depending on the type of C1 consonant and following vocoids.
1.3 Tendencies in novel words
Hwang (Reference Hwang2008) carried out a production experiment on n-insertion in Seoul Korean. Experimental stimuli were composed of two morphemes, M1 and M2 (e.g. /hiphap + juniphom/ ‘hiphop uniform’), as shown in (8). M1 was a loanword ending in one of the consonants /m n ŋ l p s k/. M2 was a loanword or nonce word beginning with /i/ or /j/.
-
(8)

Twenty Seoul Korean speakers were asked to read aloud the written stimuli in a sentence. The occurrence of n-insertion was judged based on the author's acoustic analysis and three listeners’ perception of the recordings of the subjects’ productions. The results are summarised in Table I. Insertion rates differed, depending on the M2-initial vocoid. Almost no insertion was found before /i/: only 0·7% insertion (2 out of 280 production outputs). In contrast, n-insertion applied frequently before /j/: 49·2% (124 out of 252). In addition, insertion rates before /j/ differed according to the M1-final C1: /n m/ > /l/ > /k/ > /p s/ > /ŋ/. Notice that the probability of n-insertion is much lower after the obstruents and the velar nasal than after the other sonorants. These C1-dependent differences can be better seen in Table II.
Results of Hwang's (2008) experiment with novel words, giving rate of insertion as a percentage of the number of inserted outputs divided by the total number of outputs. The total number in each cell varies because outputs were excluded from the analysis when the listeners’ perceptual judgements failed to reach a certain level of consensus on the occurrence of n-insertion (see Hwang 2008 on the details of the judgement process.)

Insertion rate (%) in Hwang's (2008) experiment, by C1 type (son=sonorant except /ŋ/, obs=obstruent).

A Pearson's χ2 test with Yates’ continuity correction was performed to see whether these differences were statistically significant. Results showed that the relevant differences, i.e. son–obs (χ2=93·275, p<2·2e-16) and son–N (χ2=61·123, p=5·361e-15), were significant.Footnote 3
Thus the three phonological tendencies in (9) can be established from the results of Hwang's experiments on Seoul Korean n-insertion in novel words.
-
(9)

Where do these asymmetries come from? Why do Seoul Korean speakers apply n-insertion to novel words less frequently before /i/ and after obstruents and /ŋ/? One hypothesis based on recent research on phonological variation (Ernestus & Baayen Reference Ernestus and Baayen2003, Hayes & Londe Reference Hayes and Londe2006, Hayes et al. Reference Hayes, Zuraw, Siptár and Londe2009, Zuraw Reference Zuraw2010) is that Seoul Korean speakers use their knowledge about existing Korean words in the production of novel words. The same tendencies are expected to be found in Seoul Korean speakers’ production of and intuitions about existing Korean words. The following section discusses the n-insertion patterns in existing Seoul Korean words.
2 Tendencies in existing words
In this section I investigate patterns of n-insertion in existing Seoul Korean words, based on data from the three sources mentioned above.
2.1 n-insertion in the dictionary
Seoul Korean is considered to be the standard dialect of Korean. Thus Korean dictionaries are primarily composed of Seoul Korean words. It is usually the case that the dictionary of a language contains many words that are unknown even to most native speakers of that language. Thus when we use dictionary data in linguistic research, we should exclude such words that are never or very rarely used in real speech situations. For this reason, I constructed a dictionary database containing only words attested in the Sejong text corpus of 5·5 million words.Footnote 4
I started with Kang & Kim's (Reference Kang and Hung-gyu2004) list of words attested in the Sejong text corpus (116,417 nouns, 5,253 verbs, 1,105 adjectives and 4,925 adverbs). From this list, I selected words meeting the minimal requirement for the application of n-insertion, i.e. those with orthographic sequences of a syllable-final consonant followed by /i/ or /j/ (4,997 in total).Footnote 5 Finally, words were excluded if they were (i) not listed in the Standard Korean dictionary (Kwuklip kwuke yenkwuwen 1999), or (ii) listed, but classified as non-standard dialectal or archaic forms in the same dictionary (henceforth SKD). The resulting database (3,239 words) contains Seoul Korean words which occurred at least once in the Sejong corpus and were also listed as standard Korean words in the SKD.
Each word in the database was encoded for the occurrence or absence of n-insertion, based on the pronunciation given in the SKD. Morphological complexity was additionally encoded on the basis of the criteria in (10).
-
(10)

Table III shows the distribution of n-insertion in the resulting data according to morphological complexity.
Distribution of n-insertion (%) in the SKD, by morphological complexity. The number of words in each category is also shown. Variable forms are those which are listed in the dictionary both with and without insertion.
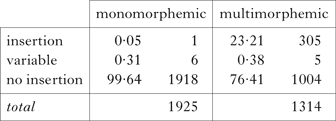
This suggests that n-insertion applies only to multimorphemic words, with a very small number of exceptions; this is consistent with the conventional characterisation of Seoul Korean n-insertion discussed above. The reason that monomorphemic words have so little n-insertion is probably that if the word were typically pronounced with /n/, it would be spelled with the corresponding symbol.Footnote 6 In what follows, only multimorphemic words are considered.
The distribution of n-insertion according to the type of M2-initial vocoid in multimorphemic words is given in Table IV.
Distribution of n-insertion (%) in the SKD in multimorphemic words, by M2-initial vocoid type.

Fewer than 10% of words with /i/-initial M2 undergo n-insertion, as opposed to 67·5% of words with /j/-initial M2. The difference between /i/ and /j/ is statistically significant (Pearson's χ2 with Yates’ continuity correction: χ2=456·957, p<2·2e-16). Thus the syllabicity effect is confirmed.
The distribution of n-insertion according to C1 and M2-initial vocoid types is presented in Table V. Words with a compound marker (traditionally called sai-sios) were excluded from this calculation, since it is not clear which category the compound marker belongs to. The compound marker should probably not be classified as either obstruent or sonorant, although the symbol for /s/ is used in standard Korean orthography.
Insertion rate (%) in the SKD in multimorphemic words, by C1 and M2-initial vocoid type.

For words with /i/-initial M2, the ratio of n-inserted forms is higher when C1 is a sonorant other than /ŋ/ than when C1 is an obstruent or /ŋ/. Only the difference between /ŋ/ and the other sonorants is statistically significant (Pearson's χ2 test with Yates’ continuity correction: χ2=4·804, p=0·028), confirming the velar nasal effect. However, for words with /j/-initial M2 when C1 is a sonorant other than /ŋ/, the ratio of n-inserted forms is lowest, and the relevant differences, i.e. son–obs and son–ŋ, are not statistically significant. Consequently, the obstruency and velar nasal effects are not confirmed in words with /j/-initial M2, where n-insertion is relatively frequent.
To summarise this section, only the syllabicity effect is clearly confirmed by the distribution of Seoul Korean words in the dictionary database, whereas the remaining two effects were not found, at least among words with /j/-initial M2, the majority of which are subject to n-insertion. Only words with /i/-initial M2, where n-insertion applies infrequently, show a statistically significant velar nasal effect. We should notice that most words in the SKD are given as forms with either insertion or non-insertion; only a very small number of words have both forms. Not surprisingly, variation is underrepresented in the SKD, as will become clear in the next section.
2.2 n-insertion in previous studies
Previous studies on n-insertion in Seoul Korean have employed a sizeable pool of native speakers, as shown in Table VI.
Numbers of subjects and test words employed in previous surveys and experimental studies. The total number of words is 268, rather than 298, because some words were used in more than one study. All the overlapping words appear in Kook et al. (2005).

Choi (Reference Choi2002) and Kim (Reference Kim2003) base their results on phonetic transcriptions of the speech of subjects who read experimental sentences. In order to construct a database, I took the number of their reported responses, which was roughly equal to the number of the subjects who produced inserted or non-inserted forms for each test word. The responses for some of the test words are shown in Table VII.
Response frequencies for some of the test words employed by Choi (2002) and Kim (2003).

This simple data collection was not possible for the results reported by Kook et al. (Reference Kook, Kim and Lee2005), who consulted Seoul Korean speakers about their preferred pronunciations. They provide only percentages, not raw frequencies, for male and female subjects separately.
I first obtained the mean percentage insertion by averaging the percentages of male and female subjects, and then multiplied it by the total number of subjects, 209. This number was taken as the frequency of forms with insertion, and the result of subtracting it from the total number of subjects was taken as that of forms without insertion. The number of total responses for each test item is not always 209, since it is possible that subjects might have preferred multiple forms for some test items and failed to respond to others. But, with no better option available, I adopted this data-conversion method.
As indicated in Table VII, substantial variation can be observed in the data derived from the previous studies. In many cases, speakers did not agree on the occurrence (or absence) of n-insertion for a particular test word. More importantly, insertion rate (i.e. the relative usage frequency of the inserted form indicated by the number of inserted responses divided by the number of both inserted and non-inserted responses) varies greatly across words.
Let us now consider whether the variable n-insertion data from the previous studies reveal the three phonological tendencies under consideration, i.e. the syllabicity, obstruency and velar nasal effects. I calculated the insertion rates in Table VIII for different M2-initial vocoid types from the results of the previous studies.
Insertion rate (%) in previous studies, by M2-initial vocoid type. The number of words in each category is also shown.

Notice that all test words with /i/-initial M2 are multimorphemic. Among the multimorphemic words, insertion rate is higher when the M2-initial vocoid is a glide than when it is a vowel. This difference is statistically significant (Pearson's χ2 test with Yates’ continuity correction: χ2=3597·215, p<2·2e-16). Thus the syllabicity effect is confirmed.
In order to examine the obstruency and velar nasal effects, I now focus on multimorphemic words, since there are no monomorphemic words in the studies under consideration with C1 obstruents, and thus they are not balanced with respect to C1 type. In addition, for the reasons mentioned in §2.1, words containing a compound marker are excluded. Table IX shows insertion rates for different C1 and M2-initial vocoid types.
Insertion rate (%) in previous studies, by C1 and M2-initial vocoid types.

In Table IX the insertion rates for words with /j/-initial M2 are consistent with the obstruency and velar nasal effects, since the rates are lower when C1 is an obstruent or /ŋ/ than when it is a sonorant other than /ŋ/. But the insertion rates for words with /i/-initial M2 are not at all consistent with the two effects, since the rate is lowest when C1 is a sonorant consonant other than /ŋ/.
For a systematic investigation of the factors influencing the rate of n-insertion, I fitted a logistic regression model on the frequency data of multimorphemic words with /j/-initial M2 with the glm function from the MASS package (Venables & Ripley Reference Venables and Ripley2002) in R (R Development Core Team 2014). The dependent variable is binary: n-inserted or not (reference level). The independent variables are the following factors: C1 type (son (reference), obs, ŋ), M1 syllable count (σ1), M2 syllable count (σ2), M1 origin (origin1: native (reference), sino, loan) and M2 origin (origin2: native (reference), sino).Footnote 7 The results are shown in Table X.
Logistic regression results for data from previous studies: coefficients. Significance is indicated by * (p<0·05), ** (p<0·01) and *** (p<0·001).
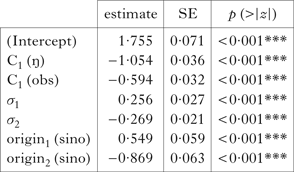
Positive and negative estimates indicate that the relevant factors encourage and discourage n-insertion respectively. All the factors adopted in the model affect insertion rate significantly. When C1 is an obstruent or /ŋ/ (as opposed to other sonorants), n-insertion is discouraged, confirming the obstruency and velar nasal effects. n-insertion is encouraged if what precedes the insertion site is longer, and discouraged if what follows it is longer. If what precedes the insertion site is Sino-Korean, n-insertion is encouraged, and if what follows it is Sino-Korean, it is discouraged.Footnote 8
To summarise this section, the syllabicity effect is confirmed by the data from previous studies. The velar nasal and obstruency effects are also confirmed by the results for multimorphemic words with /j/-initial M2, although they were not found for words with /i/-initial M2. Since n-insertion frequently takes place before /j/, and its application before /i/ is only a minor part of n-insertion, I will only consider words with /j/-initial M2 in exploring the velar nasal and obstruency effects. (Note that the results of both Hwang's Reference Hwang2008 experiments on novel words, discussed in §1.3, and my own, which will be presented in §5, show that n-insertion is unproductive before /i/ in Seoul Korean.) The syllabicity effect is confirmed by both sets of data, but the obstruency and velar nasal effects are confirmed only by the data from previous studies, not by the dictionary database. Notice that the results of the previous studies show that Seoul Korean speakers may apply n-insertion even to the words that have no inserted forms in the SKD, such as those in Table VII above, e.g. /pul-jənsok/ and /kusok-jəŋcaŋ/. We can conclude that the occurrence of n-insertion is underreported in the SKD. Since the results of previous research do not display this problem, they should be considered more reliable than the SKD. However, the number of test words and phrases considered in these studies, ranging from 55 to 182, is not large enough to explore all the effects under consideration. Given that the words and phrases are complex and heterogeneous, involving the substantial number of factors listed in Table X, the inventory used in the previous studies is too small. In order to ensure the presence and robustness of the velar nasal and obstruency effects, I therefore carried out a survey of Seoul Korean speakers’ intuitions on n-insertion, employing a larger but more uniform set of words. Since it has become obvious that multimorphemic words with /j/-initial M2 frequently undergo n-insertion, I focused on them in the survey reported on in the next section.
2.3 A study of existing Korean words
I carried out a survey on n-insertion amongst 22 Seoul Korean speakers, employing 304 multimorphemic words with /j/-initial M2.Footnote 9 Both inserted and non-inserted forms of the words were presented in standard Korean orthography as a questionnaire. For each test word, the participants were instructed to indicate their preferred pronunciation from options such as those in (11) for /com-jak/ and /thaŋ-jak/ ‘herbal decoction’.
-
(11)
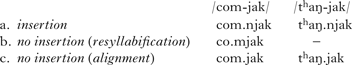
If C1 was /ŋ/, only two options, (a) and (c), were given, since there is no way to represent the second option in the standard Korean orthography, and it is generally assumed that /ŋ/ in onset position is prohibited in the phonology (see §3.2 for related discussion). Participants were allowed to give more than one possibility, and, if their preferred pronunciation was not given, they were asked to write it in a blank space on questionnaire.Footnote 10
One reason for conducting a self-evaluation survey using written forms is that both data collection and analysis are much easier and faster than in a production experiment. Hwang (Reference Hwang2008: 14–16) states that it was often very difficult in the production experiment described in §1.3 to determine the presence or absence of n-insertion in the output purely on the basis of auditory and/or visual spectrogram inspection. This difficulty is mainly due to the acoustic and perceptual similarity of /j/ and /nj/. (In §3.3, I will consider some important aspects of Korean n-insertion, including the fact that, because of this similarity, /n/, rather than any other consonant, is inserted before a high front vocoid, but not other vocoids.) In addition, in Kang's (Reference Kang1997: 143–146) experimental study there was no crucial difference in the reported rates of a variable phonological process between the self-evaluation and production tests. The results of the survey reported here may be as reliable as those of a production experiment.
In the analysis of the results, I excluded the responses to test words with a compound marker in C1 position, for the reasons mentioned in §2.1. The total number of test words considered in the analysis is 303.
Like the studies discussed in §2.2, the results of the current survey show substantial variation across speakers and words. To establish whether obstruency and velar nasal effects were present, insertion rates were calculated for different C1 types, as shown in Table XI.
Insertion rate (%) in the current survey of existing Korean words, by C1 type.

Insertion rate was lower after an obstruent or /ŋ/ than after other sonorants. This difference is statistically significant, as established by a mixed effects logistic regression model analysis. The results of the present survey were fitted with the lmer function from the lme4 package (Bates et al. Reference Bates, Maechler and Bolker2011) in R (R Development Core Team 2014). The dependent variable was binary, i.e. n-inserted or not. Each subject and each test word was included as a random intercept. Fixed factors are as above, with the addition of M2-initial vocoid (ja (reference), jə, je, jo, ju), and log-transformed token frequency in the Sejong corpus. The resulting fixed effects are shown in Table XII.
Mixed effects logistic regression results in the current survey of existing Korean words (fixed effects).

These results suggest that n-insertion is significantly discouraged when C1 is an obstruent or /ŋ/, as opposed to the other sonorants. Thus both the velar nasal and obstruency effects are confirmed.
Some additional significant effects were found. First, n-insertion was significantly more frequent before /ju/ (i.e. when /j/ is followed by a high vowel) than before other vocoid sequences.Footnote 11 This asymmetry, which I will refer to as the height effect, can also be seen in Table XIII, where insertion rates are given for different vocoid sequences at the beginning of M2.
Insertion rate (%) in the current survey of existing Korean words, by M2 initial vocoid sequence.

Second, n-insertion is significantly encouraged with a longer M1, consistent with the results of previous work, as reported in Table X. More specifically, n-insertion is less likely with words with monosyllabic M1 than those with disyllabic M1; I will refer to this as the length effect. The relevant insertion rates are shown in Table XIV.
Insertion rate (%) in the current survey of existing Korean words, by M1 length.

In addition, n-insertion is discouraged when M1 is Sino-Korean, rather than native Korean. Although this lexical origin effect is statistically significant at the 0·05 level, the difference in insertion rate involved is very small (native Korean 45·96% vs. Sino-Korean 43·13%). Moreover, the corresponding results from previous studies given in Table X show the opposite tendency, i.e. a higher insertion rate with Sino-Korean M1. On the assumption that the effect in question is at best minor, I will not consider the origin of M1 to be a significant factor in the application of n-insertion.
All other factors, i.e. the length and origin of M2 and token frequency, do not affect the rate of n-insertion significantly.
2.4 Summary
The significant tendencies in the distribution of n-insertion in existing Korean words are summarised in (12).
-
(12)

The results of my own survey provide support for all these tendencies, with the exception of the syllabicity effect, which was not tested. The syllabicity effect was significant in my dictionary database as well as in previous studies, in which the height and length effects were also confirmed.Footnote 12 The remaining two effects, i.e. the obstruency and velar nasal effects, were supported by the previous studies, but not by the dictionary database. I conclude that all five effects hold true for existing Seoul Korean words, on the assumption that the results of the present survey and previous studies are more reliable in detecting the obstruency and velar nasal effects than the dictionary database, for the reasons mentioned at the end of §2.2.
3 Analysis
As discussed by Coetzee & Pater (Reference Coetzee, Pater, Goldsmith, Riggle and Yu2011), variation data have been analysed in a number of constraint-based theories, e.g. Partially Ordered Constraints Theory (Kiparsky Reference Kiparsky1993, Anttila Reference Anttila, Hinskens, van Hout and Leo Wetzels1997), Stochastic OT (Boersma Reference Boersma1997, Reference Boersma1998, Boersma & Hayes Reference Boersma and Hayes2001), Noisy Harmonic Grammar (Boersma & Reference Boersma, Pater, McCarthy and PaterPater forthcoming) and maxent grammar (Goldwater & Johnson Reference Goldwater, Johnson, Spenador, Eriksson and Dahl2003, Wilson Reference Wilson2006, Hayes & Wilson Reference Hayes and Wilson2008). With the excepion of Partially Ordered Constraints Theory, which has no learning model, all these OT and OT-like theories adopt constraints with a numerical value to encode probability distributions over variants. I analyse the observed patterns of Seoul Korean n-insertion using constraints which are assigned numerical weights. This section discusses the constraints which are responsible for the occurrence of Seoul Korean n-insertion and the observed asymmetric phonological tendencies. The specific weights of the constraints will be determined in the next section, which reports the results of a learning simulation using a maxent learner.
3.1 What drives insertion?
When /n/ is not inserted, M1-final C1 consonants can be either resyllabified into the onset of the M2-initial syllable or aligned with the end of the M1-final syllable, as shown in (13).
-
(13)
The resyllabified forms in (13a) have misaligned morpheme–syllable edges. More specifically, M1-final consonants are not right-aligned with a syllable edge, violating the constraint in (14).
-
(14)
Alignment constraints of this type have been employed for the analysis of n-insertion by Shin (Reference Shin1997), Park (Reference Park2005), Lee (Reference Lee2006), Lee & Lee (Reference Lee and Lee2006), Hwang (Reference Hwang2008) and Ahn (Reference Ahn2009). The idea that n-insertion occurs to prevent resyllabification is suggested by Kim-Renaud (Reference Kim-Renaud1974: 148–149), Im (Reference Im1981: 7) and Ki (Reference Ki1990: 85, §3.5).
Notice that Align-R is active in Korean, independently of n-insertion. In Korean, an intervocalic consonant (with the possible exception of /ŋ/) is always syllabified as an onset, e.g. /aka/ [a.ka] ‘baby’. But when a morpheme boundary intervenes, especially in the case of compounding, a morpheme-final intervocalic consonant is variably syllabified between an onset and a coda, as shown in (15) (Park Reference Park2001: 730, citing Lee Reference Lee1992: 42).Footnote 13
-
(15)

Although resyllabification is in general preferred to alignment, as will be discussed in §4, aligned forms such as [si.kol.a.i] and [mul.o.ri] are possible. The occurrence of the aligned forms, i.e. blocking of resyllabification, can be attributed to Align-R, regardless of whether there is an intervocalic consonant in an n-insertion context.
The aligned forms in (13b) satisfy Align-R, but violate other constraints, including *Coda (‘syllables do not have codas’). In addition, when the M2-initial vocoid is /i/, as in [som.i.pul], Onset (‘syllables must have onsets’) is obviously violated. When the M2-initial vocoid is /j/, as in [com.jak], the violation of Onset is less clear. If /j/ is syllabified in the onset, Onset is satisfied, but if it is syllabified in the nucleus, Onset is violated. Both syllabifications have been proposed in the literature on Korean phonology. Many previous studies (Kim-Renaud Reference Kim-Renaud1974, Kim Reference Kim1986, Sohn Reference Sohn1987, Kang Reference Kang1991, Kim & Kim Reference Kim and Kim1991, Park Reference Park2001, K.-Reference Boersma, Pater, McCarthy and PaterS. Kang Reference Kang2003, Yun Reference Yun2004) argue that glides in Korean are basically syllabified in the nucleus. However, at least some of them (Park Reference Park2001, K.-S. Kang Reference Kang2003, Yun Reference Yun2004) further argue, or assume, that, although glides in Korean are initially syllabified in the nucleus, they may move into the onset position, especially when it is empty.Footnote 14 /j/ in the aligned forms would then end up in onset position, violating the constraint in (16) (adapted from Rubach Reference Rubach2000: 274) banning onset vocoids.
-
(16)
Based on the previous studies on Korean glides discussed above, I assume that both syllabifications of /j/ are possible.
Finally, forms with n-insertion such as [som.ni.pul] and [com.njak] would violate Dep(n) (‘no insertion of /n/’) and *Coda. Table XV summarises which constraints would be violated by each of the possible output forms.
Possible variant forms and constraints violated.

Variable application of n-insertion can be explained by adopting variable ranking or similar weights of the above constraints. Notice that all these constraints (except for Dep(n), which will be discussed in detail below) are relatively well established independently of Korean n-insertion. Moreover, the above set of constraints is sufficient to explain how the main variants may occur. Thus, for the analysis of the basic pattern of Korean n-insertion, it is not necessary to adopt any additional constraints, such as a syllable-contact constraint prohibiting rising sonority over a syllable boundary. (For analyses of Korean n-insertion based on syllable contact, see Shin Reference Shin1997, Chung Reference Chung2001, Lee Reference Lee2004 and Lee & Lee Reference Lee and Lee2006.)
3.2 The obstruency and velar nasal effects
This section discusses the constraints responsible for the obstruency and velar nasal effects. The obstruency effect is due to automatic obstruent nasalisation in Korean, by which an obstruent becomes a nasal before a nasal. If n-insertion applied to words with obstruent C1, C1 would become a nasal (e.g. /hεk-jəlljo/ [hεŋnjəlljo] ‘nuclear fuel’), violating Ident[son] (‘do not change the value of [sonorant]’). Since inserted forms of words with M1-final sonorants (e.g. /com-jak/ [com.njak]) would not violate Ident[son], other things being equal, n-insertion would be less likely after an obstruent than after a sonorant. Hwang (Reference Hwang2008) adopts Ident[son] for the same purpose.
Let us now consider how to explain the velar nasal effect. It has been assumed in the literature on Korean phonology (e.g. Kim Reference Kim1986, Chung Reference Chung2001, Hwang Reference Hwang2002, Park Reference Park2008, Kim Reference Kim2011) that, unlike other consonants, /ŋ/ cannot initiate a syllable. This assumption, which can be captured by the constraint *[ŋ (‘no velar nasal in the onset’), is based on the fact that /ŋ/ can neither initiate a word nor follow a consonant word-medially. The absence of /#ŋV/ and /VCŋV/ sequences, along with the presence of /Vŋ#/ and /VŋCV/ sequences, suggests that /ŋ/ in Korean needs to be licensed in the coda. Thus it is generally accepted that a velar nasal occurring between vowels cannot be syllabified in the onset (17a). However, syllabifying it in the coda, as in (17b), which is widely accepted in the literature, is not the only option for satisfying coda licensing. An intervocalic velar nasal can be ambisyllabic, as in (17c).Footnote 15
-
(17)
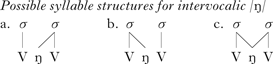
The ambisyllabicity of Korean /ŋ/ gains support from an impressionistic description of the intervocalic velar nasal (Huh Reference Huh1984: 208), which claims that when /ŋ/ occurs between vowels, it is difficult to determine whether it is the coda of a preceding syllable or the onset of a following syllable. Some phonetic and phonological facts in Korean show that /ŋ/ does not pattern with other unambiguous coda consonants, which is inconsistent with the prediction based on the structure in (17b).
The duration of Korean nasals varies greatly, depending on their position in the syllable. In general, they are much longer in the coda than in the onset. As shown in Table XVI, from Hwang (Reference Hwang2002), labial and alveolar nasals occurring before a consonant, i.e. in coda position, have much longer durations than those occurring between vowels, i.e. in onset position.
Mean durations (in ms) and standard deviations (in parentheses) of nasals in Korean (from Hwang 2002). C=lenis stop.

The duration of a velar nasal occurring in the V_CV coda position is not significantly different from that of other nasal codas. Notice that intervocalic /ŋ/ is much shorter than both its preconsonantal counterpart and other nasals which are unambiguously in the coda. Thus intervocalic /ŋ/ can hardly be grouped with other coda nasals with respect to duration, casting doubt on its syllabification exclusively in the coda in (17b).
Hiatus-avoidance phenomena in suffixal allomorph selection in Korean provide additional evidence against the syllabification of intervocalic /ŋ/ in the coda. Some suffixes have different allomorphs depending on whether the stems preceding them end in a consonant or a vowel, as illustrated in (18).
-
(18)
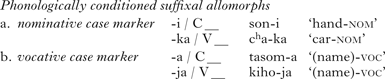
For stems ending in a vowel, the choice of the consonant-initial allomorphs /-ka/ and /-ja/ can be attributed to Onset. If intervocalic /ŋ/ is syllabified in the coda, /ŋ/-final stems would be followed by consonant-initial allomorphs. As shown in (19), this is not the case.
-
(19)
The choice of vowel-initial allomorphs for /ŋ/-final stems strongly suggests that Onset is satisfied by a stem-final velar nasal, which is thus not syllabified exclusively in the coda.
Given the above phonetic and phonological facts, I consider intervocalic /ŋ/ in Korean to be ambisyllabic. This suggests that the constraint prohibiting an ambisyllabic velar nasal (*Ambi-ŋ) has only a minor effect, compared to the corresponding constraint for other consonants (*Ambi-C). M1-final /ŋ/ would then be ambisyllabic before M2-initial high front vocoids, unless n-insertion applies. Given that the ambisyllabic /ŋ/ may satisfy both Onset and Align-R (see Itô & Mester Reference Itô, Mester, Merchant, Padgett and Walker1994, Reference Itô, Mester, Kager, van der Hulst and Zonneveld1999 on non-crisp alignment), words with /ŋ/ in C1 would be likely to surface as such, resisting n-insertion. Accordingly, the velar nasal effect may arise.
As mentioned above, my analysis of Korean n-insertion is couched within a probabilistic OT theory. Specifically, I adopt a maxent grammar, where weighted constraints interact to assign probabilities to possible outputs. The specific weights and probabilities will be determined through the learning simulation presented in §4; the OT tableaux in (20) illustrate crucial points of the analysis of obstruency and velar nasal effects presented above. In each tableau, five crucial candidate forms are given, involving (i) insertion, (ii) resyllabification, (iii) alignment, with /j/ in the onset, (iv) alignment, with /j/ in the nucleus, and (v) ambisyllabicity (represented by {C}). Dominant, i.e. high-weighted, constraints are separated from the rest of the constraints by a solid line. Constraints with relatively similar weights are indicated by dashed vertical lines, and those which play no role in the comparison between forms with different C1 consonants are shaded. The obstruency effect can be seen by comparing (20a.i) and (20b.i). The form with n-insertion with an underlying obstruent C1 in (20b.i) violates Ident[son], due to obstruent nasalisation, whereas that with a sonorant C1 in (20a.i) does not. Thus, other things being equal, the rate of occurrence of the former is lower than that of the latter.Footnote 16
-
(20)
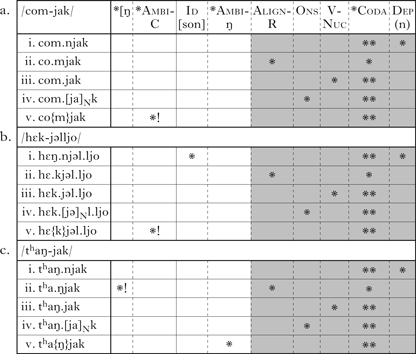
The analysis of the velar nasal effect is a little more complicated. There are two differences between the analysis of a velar nasal C1 and that of any other sonorant C1, as can be seen by comparing (20a) and (20c). Since *Ambi-ŋ, the constraint which bans ambisyllabic velar nasals, is low-weighted, but the corresponding constraint for other consonants is dominant, the candidate with ambisyllabic C1 can compete with the n-insertion candidate only when C1 is /ŋ/. Thus, consistent with the velar nasal effect, n-insertion is relatively less favoured when C1 is /ŋ/ than when it is any other sonorant consonant. However, if C1 is /ŋ/, the candidate with resyllabification (20c.ii) would never occur as an attested variant, due to dominant *[ŋ. The absence of this candidate would raise the relative frequency of the competing candidates, including the one with n-insertion. This is in conflict with the velar nasal effect. Consequently, the velar nasal effect can be obtained by keeping the weight of *Ambi-ŋ low enough to cancel out the frequency/preference change caused by the absence of the form with resyllabification.
3.3 P-map effects
Why do Seoul Korean speakers insert a coronal nasal, rather than any other consonant? And, why is it inserted only before high front vocoids, not before other vocoids? I first give a brief introduction to Steriade's (Reference Steriade, Hume and Johnson2001, 2009) P-map theory, which proposes that it is segments with low perceptibility that are typically inserted or deleted, due to the fixed ranking of faithfulness constraints reflecting the relevant perceptibility scale. I then provide arguments for the perceptual weakness of the coronal nasal before high front vocoids in Korean. The syllabicity and height effects will also be explained in a similar way.
P-map theory is motivated by the claim that only perceptually tolerated modifications to input forms are accepted (Kohler Reference Kohler, Hardcastle and Marchal1990). A segment can be inserted or deleted only when its insertion or deletion is not perceptually noticeable. Specifically, the choice of an epenthetic segment is determined on the basis of a context-dependent hierarchy of perceptual similarity between input and output. The segment most confusable with zero in the relevant context is predicted to be the epenthetic segment. The reason for [Ɂ h] and the glides [j w] (adjacent to their homorganic vowels) being frequent epenthetic segments across languages is that they do not induce coarticulatory changes on neighbouring segments, and thus input–output pairs like V–ɁV, V–hV and V–GV (where G is homorganic with V) are the most similar. The choice of epenthetic [Ɂ] can be illustrated by the P-map and ranking of Dep constraints in (21), where Δ(a–b)=the perceptual difference between a and b.
-
(21)
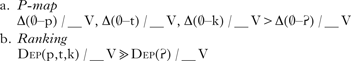
If /n/ occurs before high front vocoids, it undergoes allophonic palatalisation, failing to induce coarticulatory changes on the following vocoids. Thus, the input–output pairs i–ni (or, more precisely, i–ɲi) and j–nj (or j–ɲj) are perceptually similar pairs, just like V–GV, where G is homorganic with V. Since formant transitions from [ɲ] to [i j] are flat (as if there is no preceding consonant), the perceptual difference of the relevant pairs i–ni and j–nj (Δ(Ø–n)/_{i, j}) must be smaller than that of non-homorganic pairs involving different inserted segments like i–mi and j–mj (Δ(Ø–m)/_{i, j}) and of those involving different vocoids like a–na, e–na and w–nw (Δ(Ø–n)/_{a, e, w}). This suggests not only that insertion of /n/ before high front vocoids is perceptually less salient than insertion of segments like /p m/ in the same environment, but also that insertion of /n/ is less salient before high front vocoids /i j/ than before other vocoids, such as /a e/ and /w/. In addition, /i j/ are high vocoids with a low-frequency resonance, and are acoustically like nasals.Footnote 17 Given that the insertion of a segment which is similar to its neighbouring segment is less noticeable than the insertion of a dissimilar segment, addition of /n/ before nasal-like high vocoids /i j/ would be perceptually less prominent than addition of a true oral segment such as /p t k/ before /i j/, and of /n/ before a non-high truly oral vocoid such as /a e o/.Footnote 18 In P-map theory, these perceptibility differences can be reflected in the fixed ranking (or relative weights) of the Dep constraints in (22), explaining why it is the coronal nasal that is inserted before high front vocoids.
-
(22)
Dep(n)/_{i, j} needs to be further parameterised for the explanation of the syllabicity and height effects. In Korean, unlike /ni/, the sequence /nj/ is phonetically realised almost as a single segment [ɲ] (O. Kang Reference Kang2003, Lee & Lee Reference Lee and Lee2006).Footnote 19 Thus the input–output pair j–nj is perceptually almost identical to j–ɲ, which must be more similar than i–ɲi, since the input–output difference is less than a single segment in the former, but the entire segment [ɲ] in the latter. This perceptibility difference (Δ(Ø–n)/_i > Δ(Ø–n)/_j) can be incorporated into the ranking (or relative weights) of the relevant Dep constraints in (23), accounting for the syllabicity effect.
-
(23)
Finally, the degree of perceptual modification involved in pre-/j/ n-insertion also differs depending on the height of the vowel following /j/. /j/ normally coarticulates with a following vowel. When /j/ is followed by a high vowel, its low-frequency resonance, which it shares with nasals, can be fully maintained, making it perceptually more similar in nasality to its corresponding output with n-insertion, i.e. [ɲ]. But when it is followed by a non-high vowel, which lacks resonance in the low-frequency range, /j/'s low-frequency resonance is not maintained for as long, making it less nasal-like, so that the relevant input–output pair is less similar. The height effect can be attributed to this perceptual similarity of the high vowel input–output pair, which determines the relative weights of the relevant Dep constraints in (24).
-
(24)
In summary, the choice of the epenthetic and contextual segments in n-insertion and the syllabicity and height effects can be analysed in terms of a context-dependent perceptibility hierarchy: /n/ is confusable with zero in the n-insertion context, and even more so in the context where n-insertion is highly frequent.
4 Learning simulation
In this section, I show not only that the OT grammar presented in the previous section can be learned from the Korean data, but also that the learned grammar can in fact explain the observed asymmetric patterns of Korean n-insertion. Specifically, using a maxent learner implemented in the maxent grammar tool (Hayes Reference Hayes2009), I conducted a learning simulation. A maxent grammar (see Goldwater & Johnson Reference Goldwater, Johnson, Spenador, Eriksson and Dahl2003 for a detailed description) adopts constraint weights, like Harmonic Grammar (Smolensky Reference Smolensky, Rumelhart and MacClelland1986, Legendre et al. Reference Legendre, Miyata and Smolensky1990), but, unlike standard OT, defines a probability distribution over the possible outputs. Constraint weights are determined to maximise the probability of the observed output forms. In the present learning simulation, weights of the constraints presented in the previous section were set on the basis of the training data, which were essentially composed of the results of my own survey on n-insertion. To test the insertion rates predicted, the grammar learned was applied to a test set of words which was the same as the training set.Footnote 20 The survey data had responses to words with /j/-initial M2, but not /i/-initial M2, and thus constraints responsible for the syllabicity effect (such as Dep(n)/_i) were excluded from the simulation. For simplicity, the constraint prohibiting ambisyllabicity for consonants other than /ŋ/ (*Ambi-C), which is obviously high-weighted in Korean, was also excluded.
The frequencies of inserted and non-inserted forms (resyllabified or aligned) were taken from the relevant distribution in the results of the current survey, shown in Table XVII.Footnote 21
Training data for Korean n-insertion.

Notice that the grammar learned must reflect not just n-insertion patterns, but also the general phonology of Korean. It should not contradict what is known about Korean morphophonology. In order to incorporate the general resyllabification rate in Korean into the learning simulation, the training data had to include the resyllabified and aligned forms of words with /VC1+V2/, where V2 is not a high front vocoid (e.g. /sikol-ai/).
One indication of the resyllabification rate in Korean can be found in Jun's (Reference Jun, Connell and Arvaniti1995: 242, 251) experiment on Korean speakers’ production of word-final /l/ before a vowel-initial word. She reports that the flap, which can be interpreted as a resyllabified /l/, occurs in 65%–98% of cases across an Accentual Phrase boundary and 70%–100% within an Accentual Phrase. Assuming that most, if not all, of the words in the training data are within an Accentual Phrase, I took the relevant average value, i.e. 85%, as the rate of resyllabification for the words with /VC1 + V2/ (V2 ≠ i/j) in the training data. In the learning and training data, words of this type (e.g. /sikol-ai/), where M2-initial vocoids can be any vowels and glides other than /i j/, should be much more frequent than those shown in Table XVII, where the M2-initial vocoid is always /j/. Thus I simply multiplied the total number of survey responses, i.e. 6,796, by 10, and added the resulting number of words (67,960) with /VC1 + V2/ to the training data: of these, 85% (57,766) were resyllabified (e.g. [si.ko.ra.i]), whereas 15% (10,194) were aligned (e.g. [si.kol.a.i]).
The complete training data given to the learner can be seen in the Appendix. The learner was run on the training set for 1,000,000 cycles, with the default setting for the preferred weight value of the constraint, and with no fixed rankings (or, more precisely, relative weights), including those discussed in the previous section. The resulting constraint weights are presented in Table XVIII.
Constraint weights returned by the learner.

Let us consider how these learned weights can explain the patterns under consideration. Recall that /VC+V/ sequences in Korean are syllabified as [V.CV], violating Align-R, or [VC.V], violating Onset and *Coda. The general preference for the former can be captured by the weights of the relevant constraints: the sum of the weights of Onset and *Coda exceeds the weight of Align-R. The height effect (i.e. n-insertion is less likely with a non-high vowel following /j/) can be explained by the greater weight of Dep(n) /_j [V, —high] in comparison with Dep(n) /_j [V, +high]. The velar nasal effect can be captured by the very low weight of *Ambi-ŋ, since the velar nasal in C1, without n-insertion, would be likely to be ambisyllabic, satisfying both Onset and Align-R. Finally, the obstruency effect can be explained by the non-zero weight of Ident[son], which is violated only when n-insertion takes place in words with an obstruent C1.
Table XIX shows the encoded probability distributions (which can be considered as the prediction of the grammar learned) for each combination of C1 type and vowel height, along with the corresponding observed proportion of inserted forms (i.e. the input to the simulation).
Insertion rates (%) in the learning simulation: comparison of the survey data (observed) with the maxent model (learned).

The maxent model successfully reproduces the relative frequencies reflecting the crucial effects, i.e. obstruency, velar nasal and height, confirming the validity of the proposed analysis.
Finally, note that the P-map-based fixed rankings, or relative weights, of the constraints discussed in the previous section were not employed in the present simulation. Nonetheless, the constraint weights in Table XVIII are consistent with them. This is probably because the distribution of n-insertion in existing Korean words already reflects the requirement of minimal perceptual modification.
5 Speakers’ knowledge of n-insertion tendencies
In this section, I address the question of whether and how much the learned grammar presented in the previous section does in fact reflect Korean speakers’ mental grammar. Specifically, I conducted an experiment on n-insertion in Seoul Korean, using novel words, to find out whether speakers are aware of the tendencies observed in existing words and, if so, which. This wug test is basically a replication of Hwang's (Reference Hwang2008) productivity test, with the addition of two factors which turned out to influence the insertion rate of existing Seoul Korean words in my own survey: (i) length of M1, and (ii) height of the vowel following M2-initial /j/.
All test words consisted of two morphemes, a loanword M1 and a wug stem M2.Footnote 22 M1, which was either monosyllabic or disyllabic, ended in one of seven consonants, /m n ŋ l p s k/, as shown in (25). M2 began with one of /i ju ja/. The total number of test items was 84 (2 (syllable count) ú 7 (coda) ú 3 (vocoid type) ú 2 (repeating blocks)). The same number of control items (with vowel-final M1 or /a e/-initial M2) was employed. In the test form, no two words which were similar in some crucial aspect were adjacent. For instance, no two test items were shown successively, but were always separated by a control item.
-
(25)

Two orders were prepared: one set was the reversed version of the other. 37 speakers participated in the test, none of whom had participated in the survey of existing Seoul Korean words discussed in §2.3. 24 subjects were tested on one set and 13 on the other. In the test form, both inserted and non-inserted forms for each word were presented, in standard Korean orthography. The experimenter told the participants that the words were made-up compound nouns for new chemical products. The participants were instructed to choose a pronunciation of each of the given compounds, from options such as those in (26).
-
(26)

As in the survey of existing words, when C1 was /ŋ/, only options (a) and (c) were given. Participants were allowed to give more than one possibility, and, if their preferred pronunciation was not given, they were asked to write it in.
In the analysis of the test results, I excluded the responses of two subjects in which n-insertion was observed even more frequently among control items than test items, along with those of three subjects in which no insertion was indicated at all. I analysed the responses of the remaining 32 subjects.
The insertion rates according to C1 type were calculated over the responses to the test words, i.e. those with /i ju ja/-initial M2, as shown in Table XX.
Insertion rate (%) in the wug test, by C1 type.

Insertion rate was lower after obstruents and /ŋ/ than after other sonorant consonants. This difference is statistically significant, as can be seen in a mixed effects logistic regression model analysis.
As before, the results of the present test were fitted with the lmer function from the lme4 package in R. The dependent variable is binary, inserted or not (reference). The independent variables are: C1 type (son (reference), obs, ŋ), M2-initial vocoid type (V: ja (reference), ju, i) and M1 syllable count (σ1). Random intercepts were set for item and subject.Footnote 23
The results are shown in Table XXI.
Mixed effects logistic regression results for the wug test.

These results suggest that n-insertion is significantly discouraged when C1 is an obstruent or /ŋ/ (as opposed to the other sonorants), and the M2-initial vocoid is /i/ (as opposed to /ja/). In addition, n-insertion is significantly encouraged when /j/ is followed by a high vowel. Thus all three main effects, syllabicity, obstruency and velar nasal, are confirmed, as well as the height effect. The lower insertion rate before /i/ can also be seen in Table XXII, where the insertion rates for /i/ and the control vowels /a e/ at the beginning of M2 are almost identical, suggesting that pre-/i/ n-insertion is unproductive.
Insertion rate (%) in the wug test, by M2 initial vocoid sequence (n/a indicates that an item was not available).

Insertion rate is higher with monosyllabic M1 (25·20; cf. disyllabic M1=20·95).Footnote 24 This is the opposite of the tendency in existing words, as can be seen from the results of the current existing word survey and the data from previous studies. Recall that in the results of the current survey on existing Korean words, the insertion rates of monosyllabic and disyllabic M1 were 29·10 and 55·96 respectively. This suggests that the speakers failed to learn the tendency involving the M1 length of existing words.
Let us consider how well these wug-test results match the predictions of the maxent model learning simulations presented in §4. Table XXIII shows the insertion rates from the wug-test results, along with the predictions of the maxent model.
Insertion rate (%) in the wug test, by C1 and M2-initial vocoid types.

These rates are consistently lower after obstruents and /ŋ/, and higher before /j [+high]/, and show a relatively good match between the wug-test results and the predictions of the learned grammar, suggesting that the learned grammar can explain not only existing word patterns, as shown in §4, but also novel word patterns.
To summarise the results of the current experiment with novel words, all three main effects, syllabicity, obstruency and velar nasal, are confirmed, replicating Hwang's (Reference Hwang2008) experimental results.Footnote 25 In addition, insertion rate is higher before /ju/ than before /ja/, confirming the height effect. However, the insertion rate is higher for shorter M1, which is the opposite of the tendency for existing words. Thus the length effect is not confirmed. These results suggest that Seoul Korean speakers learn many prominent patterns among existing words through phonological generalisations, but not all prominent patterns of existing words can be learned.
6 Discussion
The present study has two aims: (i) to find out whether speakers learn all the tendencies which can be observed in existing words in their native language, and (ii) to develop a plausible formal account of Korean n-insertion, relying crucially on P-map theory. In this section, I discuss how the two aims have been achieved, and what problems remain, along with the question of how this study differs from previous studies on Korean n-insertion.
6.1 Previous studies
As mentioned in the introduction, there has been a great deal of research on n-insertion in Korean. Most of it has discussed both gradient and categorical patterns, but none of it has provided an analysis of gradient patterns. As far as I know, no previous study has provided a detailed description and analysis of variation involved in n-insertion in both existing and novel words and phrases. Zuraw (Reference Zuraw2011), which inspired the present study, provides a systematic investigation of the distribution of variant output forms of n-insertion. But the focus of her study is sai-sios, not n-insertion. The data from sai-sios and n-insertion are considered together, which I think might be inappropriate, since sai-sios is basically a compound marker, whereas n-insertion can occur freely in other constructions, such as affixed words and phrases (Im Reference Im1981: 6).Footnote 26 As discussed in §1.3, Hwang (Reference Hwang2008) investigates Korean speakers’ production of novel words, while providing an analysis of the experiment results within the framework of Partially Ordered Constraints Theory (Anttila Reference Anttila, Hinskens, van Hout and Leo Wetzels1997). He does not provide a detailed description of variation in existing words, and thus a true comparison between existing and novel word patterns is not possible.
6.2 P-map effects
In §3.3, I provided a P-map account of n-insertion. Based on Steriade's (Reference Steriade, Hume and Johnson2001, 2009) P-map theory, I explained (i) the choice of the epenthetic consonant and basic application conditions of n-insertion (i.e. why /n/, as opposed to other consonants, is inserted before /i j/, as opposed to other vocoids), (ii) the syllabicity effect (i.e. why insertion is more likely before a glide /j/ than a vowel /i/) and (iii) the height effect (i.e. why insertion is more likely when /j/ is followed by a high vowel than by a non-high vowel). Based on the discussion of acoustic and perceptual factors involved in the context of n-insertion, I argued that /n/ in Korean is perceptually confusable with zero in the n-insertion context, and even more so in the context where n-insertion is highly productive.
In order to complete my P-map analysis of n-insertion, several potential problems need to be addressed, as pointed out by anonymous reviewers. First, the P-map account presented in §3.3 focuses on typical cases of n-insertion, in which the epenthetic consonant appears as a palatalised nasal [ɲ]. When C1 is /l/, the epenthetic consonant /n/ undergoes lateralisation, becoming [l], which differs in a number of acoustic aspects from [n].Footnote 27 Thus, unlike [n]-insertion, [l]-insertion might be perceptually obtrusive, so that it might not be possible to maintain the proposed P-map account in cases in which C1 is /l/. However, at least in the n-insertion context, the acoustic and perceptual properties of epenthetic [l] and [n] seem very similar. Both [l] and [n] are sonorant consonants with anti-formants (Johnson Reference Johnson1997: 153). More importantly, in Korean, [l] is palatalised before /i j/, just like [n]. Thus [l] is no different from [n] in its lack of coarticulatory influence on following high front vocoids. Moreover, just like glides, [l] has rapidly moving formants, and thus its insertion adjacent to a glide /j/ would not be very obtrusive perceptually. Thus, as far as I can see, lateralisation of the epenthetic /n/ does not require any substantial revision of the P-map account of n-insertion.
Second, when C1 is an obstruent, n-insertion is accompanied by the nasalisation of C1, as in /hεk-jəlljo/ [hεŋnjəlljo]. One might think that this nasalisation would create a rather large perceptual departure from the input. However, it seems that the nasalisation of C1 has only a minor role in the P-map's effect. This is understandable, given that final position in a word or morpheme is acoustically less salient and less important in speech processing than the corresponding initial position, and thus changes there would be perceptually less salient (Casali Reference Casali1997). Accordingly, the nasalisation of C1 at the end of M1 does not have a large perceptual effect on the input.Footnote 28 Consequently, the proposed P-map account can be maintained, regardless of C1 type.
Third, word-initial [nj ni] (and [lj li]) sequences are severely restricted in Korean. There are few native Korean words where /n/ (or /l/) occur before /i j/ at the beginning of the word. Sino-Korean words beginning with /n/ (or /l/) followed by /i j/ undergo n-deletion, as shown in (27).
-
(27)
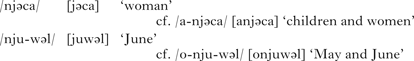
Although it might be controversial whether n-deletion is currently synchronic or not, as recent loanwords are not subject to it (e.g. [njusî] ‘news’), it is at least true that n-deletion has taken place synchronically in the past. Notice that n-deletion and n-insertion occur in exactly the same environment, i.e. before a high front vocoid, although the former occurs at the beginning of the word, and the latter word-medially. The fact that the epenthetic segment, i.e. /n/, is the same as the deletion target is accounted for within P-map theory, where, as we have seen, a segment can be inserted or deleted when it is confusable with zero. Since the criterion for the choice of the epenthetic segment is the same as the one for the choice of the deletion target, it is predicted that ‘the segments most likely to be inserted are also most likely to be deleted’ (Steriade Reference Steriade, Hanson and Inkelas2009: 175). In Korean, as discussed in §3.3, /n/ is inserted before a high front vocoid, because it is the most confusable with zero in that environment. For the same reason, /n/ is the target of deletion before a high front vocoid at the beginning of the word.
Is there a causation relationship between n-deletion and n-insertion? Ko (Reference Ko1992) proposes a rule-inversion account of n-insertion in which word-initial n-deletion is reanalysed as a word-medial n-insertion rule. Note too the similarity between the insertion/deletion of /n/ before /i j/ in Korean and the insertion/deletion of postvocalic /r/ in English dialects, which has also been analysed as a case of rule inversion (Vennemann Reference Vennemann1972). Ko's proposal is criticised by Kim et al. (2002: 58), who point out that the contexts of the n-insertion and n-deletion rules are not perfectly complementary, since n-insertion is confined to postconsonantal position. I agree with Kim et al. that word-initial n-deletion was not the direct cause of n-insertion. However, it is quite possible that alternations involved in n-deletion might enhance the confusability between /n/ and zero before high front vocoids, leading to n-insertion. This possibility is based on the assumption that the P-map can be constructed from language learners’ experience not only of (universal and language-specific) phonetics, as discussed in §3.3, but also of alternations.Footnote 29
Finally, the analysis presented in §3 does not differentiate between word-initial and medial morphemes beginning with high front vocoids. Specifically, the ranking (or relative weights) Onset, V-NucêDep(n) would lead to n-insertion not only after a consonant (/com-jak/ → [com.njak]), but also, incorrectly, at the beginning of a word (/jaku/ → [jaku], *[njaku]) ‘baseball’). Two possible solutions can be suggested. First, word-initial n-insertion might be blocked by the constraint banning a coronal nasal before high front vocoids at the beginning of the prosodic word. This constraint is independently needed to explain word-initial n-deletion, as discussed above. One problem is that, as mentioned above, recent loanwords are not subject to this constraint, and thus its synchronic status is questionable. The second solution, which is more in line with the rest of the proposed analysis of n-insertion, is P-map-based. The inserted /n/ after a consonant would at least partially be hidden by the preceding consonant, and thus n-insertion would be perceptually less noticeable after a consonant than at the beginning of a word, where word-initial /n/ would be realised with almost no loss of its perception cues. In P-map theory, this perceptibility difference suggests that the Dep constraint prohibiting word-initial n-insertion (Dep(n) / ω[_V) must be ranked above that for postconsonantal n-insertion (Dep(n) / C_V). The absence of word-initial n-insertion can be attributed to high-weighted Dep(n) / ω[_V. In contrast, word-medial n-insertion might be due to low-weighted Dep-(n) / C_V. Therefore, the Dep(n) constraints presented above for the analysis of Korean n-insertion belong to the Dep(n) / C_V constraint family. For instance, the correct form of the constraint Dep(n) /_j adopted in the proposed analysis would be Dep(n) / C_j. Either of these solutions can explain why n-insertion does not occur word-initially.
6.3 Do speakers learn all statistically prominent patterns?
The results of the present study suggest that Seoul Korean speakers are aware of most of the tendencies in the distribution of existing words, and use this knowledge when they apply n-insertion to novel words. As shown in §3 and §4, the internalised grammar and how it is learned can be formalised and implemented in a probabilistic constraint-based grammar, such as a maxent grammar, and its related learning model.
However, the results of the present study also suggest that speakers do not know all statistically prominent patterns in existing words. When M1 is disyllabic, rather than monosyllabic, insertion rate is higher in existing words, but lower in novel words. This means that speakers are not aware of the length effect, i.e. the higher rate of insertion with longer M1, in existing Korean words.
Why do Korean speakers fail to learn the tendency about the length of M1? Given that only phonologically natural patterns can be learned easily (Becker et al. Reference Becker, Ketrez and Nevins2011, Hayes et al. Reference Hayes, Zuraw, Siptár and Londe2009, Hayes & White Reference Hayes and White2013), the failure to learn the length effect would indicate that the length of M1 is not a phonologically natural factor which can condition the application of n-insertion or affect the probability that n-insertion applies. This seems to be true, especially under the proposed P-map account, in which the P-map determines many important aspects of n-insertion, including the basic application conditions and factors affecting its probability.
As discussed in the previous section, this P-map effect is mostly concerned with the elements of M2. There does not seem to be a plausible reason for a longer M1 enhancing the confusability between /n/ and zero at the beginning of M2. More generally, I cannot find any phonetic or phonological grounding for the length effect. Accordingly, I attribute Korean speakers’ failure to learn the length effect to the lack of phonological naturalness involved.
It should also be noticed that the results of the previous studies report non-negligible amounts of n-insertion (44·7% on average) when the M2-initial vocoid is a vowel /i/. But the results of the wug test suggest that the productivity of n-insertion before /i/ is no different from that of vowels such as /a e/, which are known not to trigger n-insertion in Korean. Hwang's (Reference Hwang2008) results are no different in this respect from mine. Is this then another case in which speakers failed to learn a statistically prominent pattern? The answer is not clear. The test words employed in the previous studies constitute a very small subset of the relevant Seoul Korean words, especially when the M2 initial vocoid is /i/. Notice that the dictionary database discussed in §2.1, which reports n-insertion in fewer than 10% of the words with /i/-initial M2, includes many more words than previous studies, which focused on words likely to undergo n-insertion. It is thus probable that most of the words not employed in those studies are unlikely (or less likely) to undergo n-insertion. The actual rate of n-insertion in existing Seoul Korean words with /i/-initial M2 must be much lower than the average insertion rate calculated from the results of previous studies. Further research is needed to determine whether the n-insertion rate for existing Korean words with /i/-initial M2 is low enough to be ignored by Korean speakers.
7 Conclusion
In this paper, I have explored variation in Seoul Korean n-insertion, with the following two aims: (i) to find out whether speakers learn the tendencies which can be observed in existing words in their native language, and (ii) to develop a formal account of Korean n-insertion. I first discussed a number of tendencies in the distribution of n-insertion in existing Seoul Korean words, on the basis of data from my own survey, the SKD and previous studies. These tendencies can be summarised as follows: (i) n-insertion is more likely before a glide than before a vowel; (ii) n-insertion is less likely after obstruents than after sonorants, except /ŋ/; (iii) n-insertion is less likely after /ŋ/ than after other sonorants; (iv) n-insertion is more likely when /j/ precedes a high vowel; (v) n-insertion is more likely when the morpheme preceding the insertion site is longer.
I then provided a constraint-based analysis of n-insertion, crucially relying on P-map theory. Based on this analysis, I conducted a maxent-model learning simulation of Seoul Korean n-insertion, taking the distribution of the responses in my own survey as the training data. The results of the learning simulation demonstrate that the proposed grammar can be learned from the Korean data, and that it can explain the observed quantitative patterns of n-insertion.
Finally, I conducted an experiment using novel words, specifically loanwords and nonce words. The results confirmed most of the effects found in existing Korean words, but the length effect was not confirmed. From this data vs. learning mismatch, it seems that language learners are not aware of all the prominent tendencies in existing words. To explain the mismatch, I argued that the length of M1 is not a phonologically natural factor which can condition the application of n-insertion, or influence the probability that it applies. Specifically, I attributed the data vs. learning mismatch to the lack of perceptual basis for the length effect.
Appendix: Training input file

























 Open access
Open access