


1. Introduction
Fractional calculus is a generalization of differential calculus invented by Isaac Newton and Gottfried Leibniz, which includes non-integer order differential and integral. The origin of fractional calculus dates back to the late 17th century, since in 1695 L’Hospital wrote a letter to Leibniz, in which the following famous question arose – “What if n be 1/2?” (this question referred to a differential of
 $1/2\textrm{th}$
order) [Reference Ross1]. Over the years, many famous mathematicians contributed to the development of fractional calculus including Euler, Lagrange, Laplace, Fourier, etc. [Reference Ross1, Reference Ross2], also various definitions were developed for fractional order operators, which can be used in different research areas [Reference de Oliveira and Machado3, Reference Machado and Kiryakova4]. The most commonly used definitions are the Riemann-Liouville, the Grünwald-Letnikov and the Caputo versions [Reference Shah and Agashe5]. In the past few decades, fractional order calculus gained a great deal of attention both from scientific and industrial community. Extensive research was carried out in different application areas, showing that it has ample applications in biology [Reference Copot, Keyser, Juchem and Ionescu6], modeling distributed systems [Reference Dulf, Timis and Muresan7], viscoelastic phenomena [Reference Sasso, Palmieri and Amodio8], systems with delay [Reference Machado and Moghaddam9], industrial applications [Reference Monje, Vinagre, Feliu and Chen10], etc. It is considered at the deepest level of formulating physical principles [Reference Baleanu11]. Discrete-time realization of the concept was considered for example in ref. [Reference Folea, De Keyser, Birs, Muresan and Ionescu12]. Regarding control applications, the superiority of fractional order control solutions was emphasized in refs. [Reference Gutierrez, Rosário and Machado13, Reference Tepljakov, Alagoz, Yeroglu, Gonzalez, Hosseinnia, Petlenkov, Ates and Cech14], foreshadowing the widespread of Fractional Order Proportional-Integral-Derivative (FOPID) controllers in industrial applications. Perhaps one of the most known features of FOPID controllers is the excellent startup response. In ref. [Reference Lino, Maione, Stasi, Padula and Visioli15], a Fractional Order Proportional Integral (FOPI) and a conventional PI ( Proportional Integral) control solution were tested on an electromechanical drive system in which the FOPI controller outperformed the PI controller, by almost fully eliminating the initial overshoot and the oscillation of the system, both in position and speed control. Various other studies showed similar results using fractional order feedback terms in their design, in robotics and in other process control applications (e.g.: refs. [Reference Kizir and Elşavi16–Reference Dumlu and Erenturk18]). Besides excellent startup response of fractional order controllers (FOCs), some studies also showed that they can work more energy efficiently [Reference Khubalkar, Chopade, Junghare, Aware and Das19], which makes this control approach more suitable for “off grid” applications (i.e., mobile robots, drones, etc.).
$1/2\textrm{th}$
order) [Reference Ross1]. Over the years, many famous mathematicians contributed to the development of fractional calculus including Euler, Lagrange, Laplace, Fourier, etc. [Reference Ross1, Reference Ross2], also various definitions were developed for fractional order operators, which can be used in different research areas [Reference de Oliveira and Machado3, Reference Machado and Kiryakova4]. The most commonly used definitions are the Riemann-Liouville, the Grünwald-Letnikov and the Caputo versions [Reference Shah and Agashe5]. In the past few decades, fractional order calculus gained a great deal of attention both from scientific and industrial community. Extensive research was carried out in different application areas, showing that it has ample applications in biology [Reference Copot, Keyser, Juchem and Ionescu6], modeling distributed systems [Reference Dulf, Timis and Muresan7], viscoelastic phenomena [Reference Sasso, Palmieri and Amodio8], systems with delay [Reference Machado and Moghaddam9], industrial applications [Reference Monje, Vinagre, Feliu and Chen10], etc. It is considered at the deepest level of formulating physical principles [Reference Baleanu11]. Discrete-time realization of the concept was considered for example in ref. [Reference Folea, De Keyser, Birs, Muresan and Ionescu12]. Regarding control applications, the superiority of fractional order control solutions was emphasized in refs. [Reference Gutierrez, Rosário and Machado13, Reference Tepljakov, Alagoz, Yeroglu, Gonzalez, Hosseinnia, Petlenkov, Ates and Cech14], foreshadowing the widespread of Fractional Order Proportional-Integral-Derivative (FOPID) controllers in industrial applications. Perhaps one of the most known features of FOPID controllers is the excellent startup response. In ref. [Reference Lino, Maione, Stasi, Padula and Visioli15], a Fractional Order Proportional Integral (FOPI) and a conventional PI ( Proportional Integral) control solution were tested on an electromechanical drive system in which the FOPI controller outperformed the PI controller, by almost fully eliminating the initial overshoot and the oscillation of the system, both in position and speed control. Various other studies showed similar results using fractional order feedback terms in their design, in robotics and in other process control applications (e.g.: refs. [Reference Kizir and Elşavi16–Reference Dumlu and Erenturk18]). Besides excellent startup response of fractional order controllers (FOCs), some studies also showed that they can work more energy efficiently [Reference Khubalkar, Chopade, Junghare, Aware and Das19], which makes this control approach more suitable for “off grid” applications (i.e., mobile robots, drones, etc.).
Fractional order feedback can be formulated in various manners. Perhaps the most intuitive solution is the generalization of a PID controller, introduced by Podlubny in ref. [Reference Podlubny20] as
 \begin{equation} u(t)=K_p e(t)+K_i\mathscr{I}_t^{\lambda }e(t)+K_d\mathscr{D}_t^{\mu }e(t) \,, \end{equation}
\begin{equation} u(t)=K_p e(t)+K_i\mathscr{I}_t^{\lambda }e(t)+K_d\mathscr{D}_t^{\mu }e(t) \,, \end{equation}
where
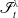 $\mathscr{I}_t^{\lambda }$
is a general non-integer order integral operator of order
$\mathscr{I}_t^{\lambda }$
is a general non-integer order integral operator of order
 $\lambda \in \mathbb{R}$
, and in similar manner,
$\lambda \in \mathbb{R}$
, and in similar manner,
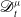 $ \mathscr{D}_t^{\mu }$
is a general non-integer order differential operator of order
$ \mathscr{D}_t^{\mu }$
is a general non-integer order differential operator of order
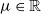 $\mu \in \mathbb{R}$
and
$\mu \in \mathbb{R}$
and
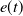 $e(t)$
is the error. Equation (1) is often called the output equation of a
$e(t)$
is the error. Equation (1) is often called the output equation of a
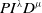 $PI^{\lambda }D^{\mu }$
controller, which yields a simple PID controller with
$PI^{\lambda }D^{\mu }$
controller, which yields a simple PID controller with
 $K_p$
proportional,
$K_p$
proportional,
 $K_i$
integral and
$K_i$
integral and
 $K_d$
derivative gain, for
$K_d$
derivative gain, for
 $\lambda, \mu =1$
parameter settings. For FOPID controllers, theoretically
$\lambda, \mu =1$
parameter settings. For FOPID controllers, theoretically
 $\lambda, \mu$
might have any values, however, due to the physical interpretations, it is usually chosen from
$\lambda, \mu$
might have any values, however, due to the physical interpretations, it is usually chosen from
 $[0,2]$
interval [Reference Shah and Agashe5], providing additional tuning options to the user to more efficiently shape the system response, that way stabilizing the controlled system and improve its robustness. Using the Laplace transform of fractional derivative and integral with zero initial conditions [Reference Podlubny21], the parallel form of transfer function can be obtained,
$[0,2]$
interval [Reference Shah and Agashe5], providing additional tuning options to the user to more efficiently shape the system response, that way stabilizing the controlled system and improve its robustness. Using the Laplace transform of fractional derivative and integral with zero initial conditions [Reference Podlubny21], the parallel form of transfer function can be obtained,
 \begin{equation} C(s)= K_p+\frac{K_i}{s^{\lambda }}+K_d s^{\mu } \,. \end{equation}
\begin{equation} C(s)= K_p+\frac{K_i}{s^{\lambda }}+K_d s^{\mu } \,. \end{equation}
It is well known that fractional order systems are infinite dimensional so, in a control application, infinite number of elements should be considered from error signal’s past (infinite memory). That way, digital implementation of FOCs usually involves some kind of approximation of fractional operators, for example, Oustaloup’s recursive filter method [Reference Oustaloup, Levron, Mathieu and Nanot22] (or its improved version [Reference Xue, Zhao and Chen23]) is often used [Reference Petráš24–Reference Timis, Muresan and Dulf27]. The essence of this solution is the approximation of
 $s^q$
,
$s^q$
,
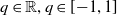 $q\in \mathbb{R}, q\in [\!-\!1,1]$
fractional terms in a given frequency range
$q\in \mathbb{R}, q\in [\!-\!1,1]$
fractional terms in a given frequency range
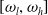 $[\omega _l, \omega _h]$
as,
$[\omega _l, \omega _h]$
as,
 \begin{equation} H(s)=s^q=K\prod _{k=-N}^{N}\frac{s+\tilde \omega _{k}}{s+\omega _k} \,, \end{equation}
\begin{equation} H(s)=s^q=K\prod _{k=-N}^{N}\frac{s+\tilde \omega _{k}}{s+\omega _k} \,, \end{equation}
where the
 $\tilde \omega _k$
and
$\tilde \omega _k$
and
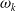 $\omega _k$
are consecutive zero and pole frequencies, which can be recursively calculated
$\omega _k$
are consecutive zero and pole frequencies, which can be recursively calculated
 $\tilde \omega _{k}=\omega _l \frac{\omega _h}{\omega _l}^{\frac{k+N+0.5(1-q)}{2N+1}}$
,
$\tilde \omega _{k}=\omega _l \frac{\omega _h}{\omega _l}^{\frac{k+N+0.5(1-q)}{2N+1}}$
,
 $\omega _{k}=\omega _l \frac{\omega _h}{\omega _l}^{\frac{k+N+0.5(1-q)}{2N-1}}$
,
$\omega _{k}=\omega _l \frac{\omega _h}{\omega _l}^{\frac{k+N+0.5(1-q)}{2N-1}}$
,
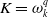 $K=\omega _k^q$
is the filter gain and the order of the recursive filter is
$K=\omega _k^q$
is the filter gain and the order of the recursive filter is
 $n=2N+1$
.
$n=2N+1$
.
Oustaloup’s recursive filter provides very good approximations of the fractional order elements, however, it is limited to the
 $[\omega _l, \omega _h]$
frequency range. To overcome this issue, a time domain approximation was introduced in ref. [Reference Machado28] by Machado et al. for motion control applications. This solution is a simple
$[\omega _l, \omega _h]$
frequency range. To overcome this issue, a time domain approximation was introduced in ref. [Reference Machado28] by Machado et al. for motion control applications. This solution is a simple
 $n$
-term truncated series approximation of the Grünwald-Letnikov definition of fractional derivatives, which provides a simple digital implementation and robust behavior, however, it requires very low sampling times and high number of terms for good approximation.
$n$
-term truncated series approximation of the Grünwald-Letnikov definition of fractional derivatives, which provides a simple digital implementation and robust behavior, however, it requires very low sampling times and high number of terms for good approximation.
These two examples nicely exhibit the implementation complexity of FOCs compared to that of the traditional PID controllers, since Eq. (1) can be implemented in a single line of code for
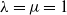 $\lambda =\mu =1$
integer order case. This induced our research in a simple weighted sum feedback design (some preliminary results can be found in ref. [Reference Varga, Horváth, Tar, Müller and Brandstötter29]), which has properties similar to that of a FOC, such as short-term finite memory, robust behavior and excellent transient response with no overshoots, but completely independent from the mathematical framework of fractional order control that way providing a simple alternative to FOCs in motion control applications. The proposed weighted sum feedback design can be implemented in a fixed-point iteration-based (FPI-based) control scenario, that way a robust adaptive control solution can be achieved with good error convergence. The control method can be used in various applications, for example, controlling industrial robots (Section 5) or in life sciences. The application of FPI-based control in robotics has been widely investigated and it was shown that it can be combined with various classical methods, for example, it can improve the stability of a Slotine-Li Adaptive Robot Controller [Reference Tar, Rudas, Dineva and Várkonyi-Kóczy30] or improve the parameter identification process in case of Adaptive Inverse Dynamics Controller [Reference Dineva, Várkonyi-Kóczy and Tar31]. The adaptive deformation, which is the essence of FPI-based control, can guarantee a strictly prescribed behavior for the components of
$\lambda =\mu =1$
integer order case. This induced our research in a simple weighted sum feedback design (some preliminary results can be found in ref. [Reference Varga, Horváth, Tar, Müller and Brandstötter29]), which has properties similar to that of a FOC, such as short-term finite memory, robust behavior and excellent transient response with no overshoots, but completely independent from the mathematical framework of fractional order control that way providing a simple alternative to FOCs in motion control applications. The proposed weighted sum feedback design can be implemented in a fixed-point iteration-based (FPI-based) control scenario, that way a robust adaptive control solution can be achieved with good error convergence. The control method can be used in various applications, for example, controlling industrial robots (Section 5) or in life sciences. The application of FPI-based control in robotics has been widely investigated and it was shown that it can be combined with various classical methods, for example, it can improve the stability of a Slotine-Li Adaptive Robot Controller [Reference Tar, Rudas, Dineva and Várkonyi-Kóczy30] or improve the parameter identification process in case of Adaptive Inverse Dynamics Controller [Reference Dineva, Várkonyi-Kóczy and Tar31]. The adaptive deformation, which is the essence of FPI-based control, can guarantee a strictly prescribed behavior for the components of
 $e(t)$
, which is highly desirable for robot control applications, where no overshoot in the joint coordinates is also necessary for safe operation. The main contributions of this paper are:
$e(t)$
, which is highly desirable for robot control applications, where no overshoot in the joint coordinates is also necessary for safe operation. The main contributions of this paper are:
-
In this paper, further improvement of a simple weighted sum feedback design is introduced, which eliminates the design issues of the originally proposed solution [Reference Varga, Horváth, Tar, Müller and Brandstötter29]. This improved version generates a nice continuous output signal without output chattering, and it is easy to implement in a simple microcontroller.
-
The proposed control solution is tested and compared to a PID control solution on experimental basis on a simple electromechanical system using FPI-based adaptive control scenario. It can be an important milestone in the research of FPI control since although this control solution was introduced in 2009 [Reference Tar, Bitó, Nádai and Machado32], no systematic experimental results have been presented on this topic so far.
The paper is structured in the following manner. In Section 2, some implementation details of a fractional order computed torque controller are introduced, which served as an inspiration for our feedback design. Section 3 was divided into two parts. In the first part, some details were introduced about the originally proposed weighted sum design, and in the second part, the newly proposed and improved weighted sum design is introduced. In Section 4, a detailed description of FPI-based control is presented. Section 5 contains some simulation results for a robotic system since this paper serves as continuation of ref. [Reference Varga, Horváth, Tar, Müller and Brandstötter29]. The proposed control solution was also verified on experimental basis in Section 6. Finally, in Section 7, the conclusions are summarized.
2. Fractional order computed torque control
In control applications, to achieve asymptotic error convergence, most commonly PID-type error feedback is used, which was developed at the beginning of the 20th century [Reference Bennett33, Reference Bennett34]. For complex non-linear systems such as industrial robots, the mathematically simplest control solution is the Computed Torque Control (CTC) [Reference Armstrong, Khatib and Burdick35], which directly utilizes the available dynamic model of the system. However, later it was revealed that CTC controllers – as well as other model-based control solutions – were burdened by modeling imprecisions [Reference Corke and Armstrong-Helouvry36] which makes precise trajectory tracking rather difficult. CTC is a special implementation of PID control for trajectory-tracking application. If
 $q^N(t) \in \mathbb{R}^n$
denotes the nominal trajectory (in joint space), which should be precisely tracked by the robot and
$q^N(t) \in \mathbb{R}^n$
denotes the nominal trajectory (in joint space), which should be precisely tracked by the robot and
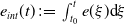 $e_{int}(t)\;:\!=\;\int _{t_0}^te(\xi )\textrm{d}\xi$
is the integral of the trajectory tracking error (
$e_{int}(t)\;:\!=\;\int _{t_0}^te(\xi )\textrm{d}\xi$
is the integral of the trajectory tracking error (
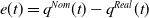 $e(t)=q^{Nom}(t)-q^{Real}(t)$
), then a kinematic prescription can be formulated as
$e(t)=q^{Nom}(t)-q^{Real}(t)$
), then a kinematic prescription can be formulated as
 \begin{equation} \left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^3 e_{int}(t)\equiv 0 \,. \end{equation}
\begin{equation} \left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^3 e_{int}(t)\equiv 0 \,. \end{equation}
Evidently, the general solution of (4) can be given as the linear combination of certain basis functions that span the linear space of the solutions as
 $ e_{int}(t)=\sum _{\ell =0}^2 a_\ell (t-t_0)^\ell \exp \left (-\Lambda (t-t_0)\right )$
. In that solution the initial conditions are determined by the parameters
$ e_{int}(t)=\sum _{\ell =0}^2 a_\ell (t-t_0)^\ell \exp \left (-\Lambda (t-t_0)\right )$
. In that solution the initial conditions are determined by the parameters
 $\{a_0,a_1,a_2\}$
, and the exponential terms of
$\{a_0,a_1,a_2\}$
, and the exponential terms of
 $a_0$
,
$a_0$
,
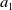 $a_1$
and
$a_1$
and
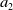 $a_2$
coeffcients are mapped to zero by the corresponding operators
$a_2$
coeffcients are mapped to zero by the corresponding operators
 $\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )$
,
$\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )$
,
 $\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^2$
and finally
$\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^2$
and finally
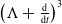 $\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^3$
. That yields that the “desired value” of second derivative of the joint coordinates (
$\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^3$
. That yields that the “desired value” of second derivative of the joint coordinates (
 $\ddot q^{Des}(t) \in \mathbb{R}^n$
) can be obtained as
$\ddot q^{Des}(t) \in \mathbb{R}^n$
) can be obtained as
 \begin{equation} \ddot q^{Des}(t)=\ddot q^N(t)+\Lambda ^3 e_{int}(t)+3\Lambda ^2 e(t)+3\Lambda \dot e(t) \,. \end{equation}
\begin{equation} \ddot q^{Des}(t)=\ddot q^N(t)+\Lambda ^3 e_{int}(t)+3\Lambda ^2 e(t)+3\Lambda \dot e(t) \,. \end{equation}
In Eq. (5),
 $\mathbb{R} \ni \Lambda \gt 0$
is the “error decay time constant” and
$\mathbb{R} \ni \Lambda \gt 0$
is the “error decay time constant” and
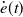 $\dot e(t)$
is the derivative error. Similar considerations can be done for the
$\dot e(t)$
is the derivative error. Similar considerations can be done for the
 $\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^2e(t)\equiv 0$
(PD controller) and for the
$\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^2e(t)\equiv 0$
(PD controller) and for the
 $\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right ) e(t)\equiv 0$
(the P controller for first-order systems), too. The obtained values of
$\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right ) e(t)\equiv 0$
(the P controller for first-order systems), too. The obtained values of
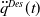 $\ddot q^{Des}(t)$
can be directly applied in the available dynamic model of our system in order to calculate the necessary control force (
$\ddot q^{Des}(t)$
can be directly applied in the available dynamic model of our system in order to calculate the necessary control force (
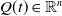 $Q(t) \in \mathbb{R}^n$
), which is then applied to the system. However, such solutions can generate significant overshoots or undershoots due to the integer order calculus used in their design. They are very sensitive to modeling errors, too. The PID feedback gains can be identified in (5) as
$Q(t) \in \mathbb{R}^n$
), which is then applied to the system. However, such solutions can generate significant overshoots or undershoots due to the integer order calculus used in their design. They are very sensitive to modeling errors, too. The PID feedback gains can be identified in (5) as
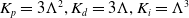 $K_p=3\Lambda ^2, K_d=3\Lambda, K_i=\Lambda ^3$
. These gains can be calculated independently in more sophisticated manner, too, using the Lyapunov-equation [Reference Lyapunov37, Reference Lyapunov38], however, usually this requires continuous tuning of the parameters.
$K_p=3\Lambda ^2, K_d=3\Lambda, K_i=\Lambda ^3$
. These gains can be calculated independently in more sophisticated manner, too, using the Lyapunov-equation [Reference Lyapunov37, Reference Lyapunov38], however, usually this requires continuous tuning of the parameters.
The control performance can be increased by introducing the second integral of the tracking error [Reference Díaz, Rodríguez-Angeles and Yurkevich39], but this may result in more significant overshoots and undershoots of the system,
 \begin{equation} e_{int2}(t)\;:\!=\;\int _{t_0}^t e_{int}(\xi ) \textrm{d}\xi \mbox{ with }\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^4 e_{int2}(t) \equiv 0 \,. \end{equation}
\begin{equation} e_{int2}(t)\;:\!=\;\int _{t_0}^t e_{int}(\xi ) \textrm{d}\xi \mbox{ with }\left (\Lambda +\frac{\textrm{d}}{\textrm{d}t}\right )^4 e_{int2}(t) \equiv 0 \,. \end{equation}
In similar manner, multiple integral terms can be incorporated into the kinematic prescription, which leads to one of the simplest definitions of fractional order feedback [Reference Munkhammar40]. The multiple integral terms can be expressed using “Riemann-Liouville
 $n$
-fold Integral” formula,
$n$
-fold Integral” formula,
 \begin{equation} F_{n+1} (t) = \int _{t_0}^t F_n(\xi ) \textrm{d}\xi \,,\, F_n(t)=\frac{1}{(n-1)!}\int _{t_0}^t f(\xi ) (t-\xi )^{n-1} \textrm{d} \xi \,. \end{equation}
\begin{equation} F_{n+1} (t) = \int _{t_0}^t F_n(\xi ) \textrm{d}\xi \,,\, F_n(t)=\frac{1}{(n-1)!}\int _{t_0}^t f(\xi ) (t-\xi )^{n-1} \textrm{d} \xi \,. \end{equation}
In Eq. (7), the solution can be extended to real and complex numbers if the
 $\frac{1}{(n-1)!}$
term is replaced with Euler’s Gamma function (
$\frac{1}{(n-1)!}$
term is replaced with Euler’s Gamma function (
 $\Gamma (s)=(s-1)!$
,
$\Gamma (s)=(s-1)!$
,
 $s \in \mathbb{C}$
), which can be calculated for complex numbers as well. The Riemann-Liouville Fractional Integral and Derivative of order
$s \in \mathbb{C}$
), which can be calculated for complex numbers as well. The Riemann-Liouville Fractional Integral and Derivative of order
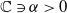 $\mathbb{C} \ni \alpha \gt 0$
are defined as the generalization of the Riemann-Liouville
$\mathbb{C} \ni \alpha \gt 0$
are defined as the generalization of the Riemann-Liouville
 $n$
-fold integral as,
$n$
-fold integral as,
 \begin{equation} \begin{aligned} &\mathscr{I}^{\;\;\alpha}_{\;a\;}f(t) \stackrel{def}{=}\frac{1}{\Gamma (\alpha )} \int _a^t f(\xi ) (t-\xi )^{\alpha -1} \textrm{d} \xi \,, \, (s-1)! \equiv \Gamma (s)\,,\\[5pt] & \mathscr{D}^{\;\alpha}_{a}f(t)\stackrel{def}{=} \frac{1}{\Gamma (1-\alpha )}\frac{\textrm{d}}{\textrm{d}t}\int _a^t f(\xi )(t-\xi )^{-\alpha } \textrm{d}\xi \,, \Gamma (s) \stackrel{def}{=}\int _0^\infty \xi ^{s-1}e^{-\xi } \textrm{d} \xi \,. \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\mathscr{I}^{\;\;\alpha}_{\;a\;}f(t) \stackrel{def}{=}\frac{1}{\Gamma (\alpha )} \int _a^t f(\xi ) (t-\xi )^{\alpha -1} \textrm{d} \xi \,, \, (s-1)! \equiv \Gamma (s)\,,\\[5pt] & \mathscr{D}^{\;\alpha}_{a}f(t)\stackrel{def}{=} \frac{1}{\Gamma (1-\alpha )}\frac{\textrm{d}}{\textrm{d}t}\int _a^t f(\xi )(t-\xi )^{-\alpha } \textrm{d}\xi \,, \Gamma (s) \stackrel{def}{=}\int _0^\infty \xi ^{s-1}e^{-\xi } \textrm{d} \xi \,. \end{aligned} \end{equation}
Upon careful revision of Eq. (8), some numerical issues can be revealed, since in the definition of Riemann-Liouville Fractional Derivative, the integrand is singular at its upper boundary (
 $\xi =t$
). To tackle this problem, a simple solution was introduced in refs. [Reference Redjimi and Tar41, Reference Tar, Bitó, Kovács and Faitli42], in which the numerical issues were avoided by applying an integer order integral of the fractionally derivated term. The idea is that consider the derivative term in (5) as the integral of the second derivative (
$\xi =t$
). To tackle this problem, a simple solution was introduced in refs. [Reference Redjimi and Tar41, Reference Tar, Bitó, Kovács and Faitli42], in which the numerical issues were avoided by applying an integer order integral of the fractionally derivated term. The idea is that consider the derivative term in (5) as the integral of the second derivative (
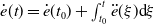 $\dot e(t)=\dot e(t_0)+\int _{t_0}^t \ddot e(\xi ) \textrm{d}\xi$
), in which the derivative can be replaced with a fractional order
$\dot e(t)=\dot e(t_0)+\int _{t_0}^t \ddot e(\xi ) \textrm{d}\xi$
), in which the derivative can be replaced with a fractional order
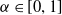 $\alpha \in [0,1]$
derivative as
$\alpha \in [0,1]$
derivative as
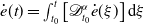 $ \dot e(t)=\int _{t_0}^t \left [\mathscr{D}_{t_0}^\alpha \dot e(\xi )\right ] \textrm{d} \xi$
. That way a simple fractional order PID-type kinematic design can be achieved as,
$ \dot e(t)=\int _{t_0}^t \left [\mathscr{D}_{t_0}^\alpha \dot e(\xi )\right ] \textrm{d} \xi$
. That way a simple fractional order PID-type kinematic design can be achieved as,
 \begin{equation} \ddot q^{Des}=\ddot q^N(t)+ \Lambda _1^3 e_{int}(t) + 3 \Lambda _1^2 e(t) + 3 \Lambda _2 \int _{t_0}^t \left [\mathscr{D}_{t_0}^\alpha \dot e(\xi )\right ] \textrm{d} \xi \,. \end{equation}
\begin{equation} \ddot q^{Des}=\ddot q^N(t)+ \Lambda _1^3 e_{int}(t) + 3 \Lambda _1^2 e(t) + 3 \Lambda _2 \int _{t_0}^t \left [\mathscr{D}_{t_0}^\alpha \dot e(\xi )\right ] \textrm{d} \xi \,. \end{equation}
Due to the integer order integral applied on the fractional derivative of
 $\dot e(t)$
, the numerically problematic integral in (8) can be eliminated. The integral in the last term of (9) can be numerically approximated, due to the “forgetting nature” of the integral term in the definition equation of fractional derivative, which allows the application of finite memory length (“old” data on the trajectory tracking error makes only negligible contribution – “short memory principle” [Reference Podlubny and Differential Equations43]). The interval
$\dot e(t)$
, the numerically problematic integral in (8) can be eliminated. The integral in the last term of (9) can be numerically approximated, due to the “forgetting nature” of the integral term in the definition equation of fractional derivative, which allows the application of finite memory length (“old” data on the trajectory tracking error makes only negligible contribution – “short memory principle” [Reference Podlubny and Differential Equations43]). The interval
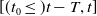 $[(t_0 \leq ) t-T,t]$
was considered as a grid of points
$[(t_0 \leq ) t-T,t]$
was considered as a grid of points
 $\{t-K\delta t=t-T, \ldots,t-2\delta t,t-\delta t,t\}$
, and it was assumed that
$\{t-K\delta t=t-T, \ldots,t-2\delta t,t-\delta t,t\}$
, and it was assumed that
 $\dot e(t)$
did not vary considerably within the intervals. So
$\dot e(t)$
did not vary considerably within the intervals. So
 $\int _{t_i}^{t_i+\delta t} \dot e(\xi )(t-\xi )^{-\alpha } \textrm{d}\xi \approx \dot e(t_i+\delta t) \int _{t_i}^{t_i+\delta t} (t-\xi )^{-\alpha } \textrm{d}\xi$
was applied in which for the integral simple closed-form formula was available. The closed-form integral term can be easily calculated for each
$\int _{t_i}^{t_i+\delta t} \dot e(\xi )(t-\xi )^{-\alpha } \textrm{d}\xi \approx \dot e(t_i+\delta t) \int _{t_i}^{t_i+\delta t} (t-\xi )^{-\alpha } \textrm{d}\xi$
was applied in which for the integral simple closed-form formula was available. The closed-form integral term can be easily calculated for each
 $[t_i, t_i +\delta t]$
interval, which yields
$[t_i, t_i +\delta t]$
interval, which yields
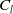 $C_l$
coefficients in (10), that way a “weighted sum type” feedback can be achieved as,
$C_l$
coefficients in (10), that way a “weighted sum type” feedback can be achieved as,
 \begin{equation} \sum _{\ell =0}^{\ell _{\max}} \dot e(t_i-\ell \delta t) C_\ell \,,\, C_0\gt C_1\gt \ldots \gt C_{\ell _{\max}}\gt 0 \,. \end{equation}
\begin{equation} \sum _{\ell =0}^{\ell _{\max}} \dot e(t_i-\ell \delta t) C_\ell \,,\, C_0\gt C_1\gt \ldots \gt C_{\ell _{\max}}\gt 0 \,. \end{equation}
In the above equation, the “forgetting nature” of the solution can be revealed by
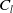 $C_l$
coefficients, also it becomes apparent that this solution is free from the singularity issue mentioned previously (when
$C_l$
coefficients, also it becomes apparent that this solution is free from the singularity issue mentioned previously (when
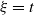 $\xi =t$
) by the fact that
$\xi =t$
) by the fact that
 $C_0 \gg C_1 \gt 0$
. The parameters
$C_0 \gg C_1 \gt 0$
. The parameters
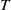 $T$
and
$T$
and
 $\alpha$
can be arbitrarily set by the user. The latter describes the “speed of forgetting the past,” and on the other hand,
$\alpha$
can be arbitrarily set by the user. The latter describes the “speed of forgetting the past,” and on the other hand,
 $T$
characterizes the “memory length” of this solution. If a small value is selected for
$T$
characterizes the “memory length” of this solution. If a small value is selected for
 $T$
, a similar solution can be achieved as in (5).
$T$
, a similar solution can be achieved as in (5).
In both refs. [Reference Redjimi and Tar41] and [Reference Tar, Bitó, Kovács and Faitli42], it was shown that this type of fractional feedback can yield better transient response than conventional PID control solution. If
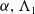 $\alpha, \Lambda _1$
and
$\alpha, \Lambda _1$
and
 $ \Lambda _2$
parameters are set correctly, the initial overshoot of the system can be reduced or sometimes completely evaded.
$ \Lambda _2$
parameters are set correctly, the initial overshoot of the system can be reduced or sometimes completely evaded.
3. Fractional order inspired weighted sum-type feedback
One of the key features of the solution proposed in (9) is the finite memory length incorporated in its design due to fractional feedback term, which makes the trajectory tracking of a particular control system in the initial phase much better. That invokes the question “What if a similar principle is applied without the mathematical restrictions of fractional order calculus?”. An answer to this question was proposed in ref. [Reference Varga, Horváth, Tar, Müller and Brandstötter29], which is a simple forgetting weighted sum-type solution characterized in the following subsection, including some of its advantages and disadvantages as well.
3.1. Preliminary research
Consider an order 2 system in which, on the basis of the dynamic model,
 $\ddot q(t)$
can be set by the controller. Suppose that the trajectory tracking error is exponentially driven to
$\ddot q(t)$
can be set by the controller. Suppose that the trajectory tracking error is exponentially driven to
 $0$
in monotonic manner, which makes it possible to apply the following time approximation,
$0$
in monotonic manner, which makes it possible to apply the following time approximation,
 \begin{align} & \dot e(t)=-\Lambda e(t) \,, \mbox{that numerically is} \end{align}
\begin{align} & \dot e(t)=-\Lambda e(t) \,, \mbox{that numerically is} \end{align}
 \begin{align} & e(t_{i+1})=e(t_i)(1-\delta t\Lambda )\,. \end{align}
\begin{align} & e(t_{i+1})=e(t_i)(1-\delta t\Lambda )\,. \end{align}
This approximation has obviously no memory effect, so the following modification was applied (the following feedback design will be denoted as Weighted Sum or WS feedback in the rest of the paper):
 \begin{equation} e(t_{i+1})=e(t_i)\left (1-\delta t \Lambda C_0\right )-\sum _{\ell =1}^{H-1} \delta t \Lambda C_\ell e(t_{i-\ell })=a_0e(t_i)-\sum _{\ell =1}^{H-1}a_\ell e(t_{i-\ell }) \,, \end{equation}
\begin{equation} e(t_{i+1})=e(t_i)\left (1-\delta t \Lambda C_0\right )-\sum _{\ell =1}^{H-1} \delta t \Lambda C_\ell e(t_{i-\ell })=a_0e(t_i)-\sum _{\ell =1}^{H-1}a_\ell e(t_{i-\ell }) \,, \end{equation}
in which the discrete memory length is
 $H-1$
. In the above equation, the
$H-1$
. In the above equation, the
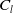 $C_l$
coefficients serve a similar purpose as in Eq. (10), describing the “speed of forgetting the past”. Equation (12) can be applied over a grid of points
$C_l$
coefficients serve a similar purpose as in Eq. (10), describing the “speed of forgetting the past”. Equation (12) can be applied over a grid of points
 $\{t-l\delta t=t-T, \ldots,t-2\delta t,t-\delta t,t\}$
, where the coefficient can be calculated using an arbitrarily chosen function,
$\{t-l\delta t=t-T, \ldots,t-2\delta t,t-\delta t,t\}$
, where the coefficient can be calculated using an arbitrarily chosen function,
 $C_\ell \propto f(t)$
, so that
$C_\ell \propto f(t)$
, so that
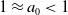 $1 \approx a_0\lt 1$
, and for
$1 \approx a_0\lt 1$
, and for
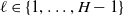 $\ell \in \{1,\ldots,H-1\}$
$\ell \in \{1,\ldots,H-1\}$
 $0 \approx a_\ell \gt 0$
for small
$0 \approx a_\ell \gt 0$
for small
 $\delta t$
and reasonable
$\delta t$
and reasonable
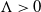 $\Lambda \gt 0$
. As long as in a
$\Lambda \gt 0$
. As long as in a
 $t_i$
time instant, the calculated value of the desired trajectory tracking error is
$t_i$
time instant, the calculated value of the desired trajectory tracking error is
 $e^{Des}(t_{i+1})$
, the desired value of joint coordinates (sticking to a robotic control application) can be calculated as
$e^{Des}(t_{i+1})$
, the desired value of joint coordinates (sticking to a robotic control application) can be calculated as
 $q^{Des}(t_{i+1})=q^N(t_{i+1})-e^{Des}(t_{i+1})$
, which leads to:
$q^{Des}(t_{i+1})=q^N(t_{i+1})-e^{Des}(t_{i+1})$
, which leads to:
 \begin{equation} \ddot q(t_{i-1})^{Des} \approx (q^{Des}(t_{i+1})-2q(t_i)+q(t_{i-1}))/\delta t^2\,, \end{equation}
\begin{equation} \ddot q(t_{i-1})^{Des} \approx (q^{Des}(t_{i+1})-2q(t_i)+q(t_{i-1}))/\delta t^2\,, \end{equation}
using forward differences for differentiation. The convergence of sequence (Eq. (9)) can be described in matrix form, for example, for a particular memory length (
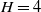 $H=4$
)
$H=4$
)
 \begin{equation} \left [\begin{array}{c} e(t_{i+1})\\[5pt] e(t_i) \\[5pt] e(t_{i-1}) \\[5pt] e(t_{i-2}) \end{array}\right ]=\left [\begin{array}{c@{\quad}c@{\quad}c@{\quad}|@{\quad}c} a_{11} & a_{12} & a_{13} & a_{14}\\[5pt] 1 & 0 & 0 & 0 \\[5pt] 0 & 1 & 0 & 0 \\[5pt] 0 & 0 & 1 & 0 \\[5pt] \end{array}\right ] \left [\begin{array}{c} e(t_{i})\\[5pt] e(t_{i-1}) \\[5pt] e(t_{i-2}) \\[5pt] e(t_{i-3}) \end{array}\right ]\,, \end{equation}
\begin{equation} \left [\begin{array}{c} e(t_{i+1})\\[5pt] e(t_i) \\[5pt] e(t_{i-1}) \\[5pt] e(t_{i-2}) \end{array}\right ]=\left [\begin{array}{c@{\quad}c@{\quad}c@{\quad}|@{\quad}c} a_{11} & a_{12} & a_{13} & a_{14}\\[5pt] 1 & 0 & 0 & 0 \\[5pt] 0 & 1 & 0 & 0 \\[5pt] 0 & 0 & 1 & 0 \\[5pt] \end{array}\right ] \left [\begin{array}{c} e(t_{i})\\[5pt] e(t_{i-1}) \\[5pt] e(t_{i-2}) \\[5pt] e(t_{i-3}) \end{array}\right ]\,, \end{equation}
where matrix
 $A$
contains all coefficients of each error term as
$A$
contains all coefficients of each error term as
 $a_{11}=a_0=1-\delta t \Lambda C_0$
,
$a_{11}=a_0=1-\delta t \Lambda C_0$
,
 $a_{12}=-a_1=-\delta t \Lambda C_1$
, etc., and it can be easily transformed into the Jordan canonical form through similarity transformation. From the structure of each Jordan Blocks (
$a_{12}=-a_1=-\delta t \Lambda C_1$
, etc., and it can be easily transformed into the Jordan canonical form through similarity transformation. From the structure of each Jordan Blocks (
 $\lambda I+\Delta$
) in the main diagonal, it immediately follows that
$\lambda I+\Delta$
) in the main diagonal, it immediately follows that
 \begin{equation} (\lambda I+\Delta )^n=\sum _{\ell =0}^{m-1}\frac{n!}{\ell !(n-\ell )!}\lambda ^{n-\ell } \Delta ^\ell \rightarrow 0 \mbox{ as } n \rightarrow \infty \mbox{ if }|\lambda |\lt 1\,. \end{equation}
\begin{equation} (\lambda I+\Delta )^n=\sum _{\ell =0}^{m-1}\frac{n!}{\ell !(n-\ell )!}\lambda ^{n-\ell } \Delta ^\ell \rightarrow 0 \mbox{ as } n \rightarrow \infty \mbox{ if }|\lambda |\lt 1\,. \end{equation}
where
 $\lambda \in \mathbb{C}$
is an eigenvalue of the matrix in (14), and
$\lambda \in \mathbb{C}$
is an eigenvalue of the matrix in (14), and
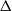 $\Delta$
is a nilpotent upper triangular matrix of size
$\Delta$
is a nilpotent upper triangular matrix of size
 $m\times m$
with the property of
$m\times m$
with the property of
 $\Delta ^m=0$
. The eigenvalues are the roots of the characteristic polynomial (
$\Delta ^m=0$
. The eigenvalues are the roots of the characteristic polynomial (
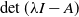 $\det{(\lambda I-A)}$
), which can be simply formulated as
$\det{(\lambda I-A)}$
), which can be simply formulated as
 $p_{(H)} (\lambda )=\lambda p_{(H-1)} -a_{1H}$
, for example, for memory length
$p_{(H)} (\lambda )=\lambda p_{(H-1)} -a_{1H}$
, for example, for memory length
 $H=4$
$H=4$
 \begin{equation} p_{(4)}(\lambda )=\left |\begin{array}{c@{\quad}c@{\quad}c@{\quad}|@{\quad}c} \lambda -a_{11} & -a_{12} & -a_{13} & -a_{14}\\[5pt] -1 & \lambda & 0 & 0 \\[5pt] 0 & -1 & \lambda & 0 \\[5pt] 0 & 0 & -1 & \lambda \\[5pt] \end{array}\right |=(\lambda -a_{11})\lambda ^3-a_{12}\lambda ^2-a_{13}\lambda -a_{14}\,, \end{equation}
\begin{equation} p_{(4)}(\lambda )=\left |\begin{array}{c@{\quad}c@{\quad}c@{\quad}|@{\quad}c} \lambda -a_{11} & -a_{12} & -a_{13} & -a_{14}\\[5pt] -1 & \lambda & 0 & 0 \\[5pt] 0 & -1 & \lambda & 0 \\[5pt] 0 & 0 & -1 & \lambda \\[5pt] \end{array}\right |=(\lambda -a_{11})\lambda ^3-a_{12}\lambda ^2-a_{13}\lambda -a_{14}\,, \end{equation}
 $p_{(4)}(\lambda )=\lambda p_{(3)}(\lambda )-a_{14}$
, or in similar manner
$p_{(4)}(\lambda )=\lambda p_{(3)}(\lambda )-a_{14}$
, or in similar manner
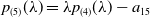 $p_{(5)}(\lambda )=\lambda p_{(4)}(\lambda )-a_{15}$
, etc., that is easy to see when the determinant of (16) obtained through expansion according the last column, since most of the minors of matrix
$p_{(5)}(\lambda )=\lambda p_{(4)}(\lambda )-a_{15}$
, etc., that is easy to see when the determinant of (16) obtained through expansion according the last column, since most of the minors of matrix
 $A$
are canceled due to the
$A$
are canceled due to the
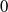 $0$
elements. For
$0$
elements. For
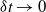 $\delta t \rightarrow 0$
limit, the roots of the polynomial can be easily obtained since
$\delta t \rightarrow 0$
limit, the roots of the polynomial can be easily obtained since
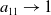 $a_{11} \rightarrow 1$
, and for
$a_{11} \rightarrow 1$
, and for
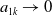 $a_{1k} \rightarrow 0$
for all
$a_{1k} \rightarrow 0$
for all
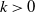 $k\gt 0$
, for example,
$k\gt 0$
, for example,
 $p_{(5)}(\lambda )=(\lambda -1)\lambda ^4$
has the roots
$p_{(5)}(\lambda )=(\lambda -1)\lambda ^4$
has the roots
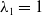 $\lambda _1=1$
, and with greater multiplicity
$\lambda _1=1$
, and with greater multiplicity
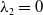 $\lambda _2=0$
. For a small but non-zero
$\lambda _2=0$
. For a small but non-zero
 $\delta t$
, this polynomial varies continuously and its roots remain in the vicinity of
$\delta t$
, this polynomial varies continuously and its roots remain in the vicinity of
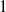 $1$
and
$1$
and
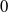 $0$
, so based on the convergence requirement given in Eq. (15), the only concern is the root near
$0$
, so based on the convergence requirement given in Eq. (15), the only concern is the root near
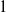 $1$
, when
$1$
, when
 $\delta t\gt 0$
. For the estimation of its modification the form,
$\delta t\gt 0$
. For the estimation of its modification the form,
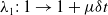 $\lambda _1:\,1 \rightarrow 1+\mu \delta t$
can be considered in the first order of
$\lambda _1:\,1 \rightarrow 1+\mu \delta t$
can be considered in the first order of
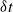 $\delta t$
while the other terms are modified as
$\delta t$
while the other terms are modified as
 $a_{11}:\, 1 \rightarrow 1-\Lambda C_0 \delta t$
, and
$a_{11}:\, 1 \rightarrow 1-\Lambda C_0 \delta t$
, and
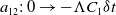 $a_{12}:\, 0 \rightarrow -\Lambda C_1 \delta t$
, etc. Consequently
$a_{12}:\, 0 \rightarrow -\Lambda C_1 \delta t$
, etc. Consequently
 $(1-a_{11})$
varies as
$(1-a_{11})$
varies as
 $0:\, \rightarrow 1+\mu \delta t-(1-\Lambda C_0 \delta t)=(\mu +\Lambda C_0) \delta t$
that has first order in
$0:\, \rightarrow 1+\mu \delta t-(1-\Lambda C_0 \delta t)=(\mu +\Lambda C_0) \delta t$
that has first order in
 $\delta t$
. Therefore, only the order
$\delta t$
. Therefore, only the order
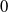 $0$
terms must be taken into account in
$0$
terms must be taken into account in
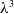 $\lambda ^3$
, in
$\lambda ^3$
, in
 $\lambda ^2$
and in
$\lambda ^2$
and in
 $\lambda ^1$
as
$\lambda ^1$
as
 $1$
. For instance, for the equation
$1$
. For instance, for the equation
 $p_{(4)}(1+\mu \delta t)=0$
, the approximation
$p_{(4)}(1+\mu \delta t)=0$
, the approximation
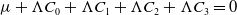 $\mu +\Lambda C_0+\Lambda C_1+\Lambda C_2+\Lambda C_3=0$
is obtained leading to
$\mu +\Lambda C_0+\Lambda C_1+\Lambda C_2+\Lambda C_3=0$
is obtained leading to
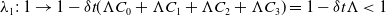 $\lambda _1:\, 1 \rightarrow 1-\delta t(\Lambda C_0+\Lambda C_1+\Lambda C_2+\Lambda C_3)=1-\delta t \Lambda \lt 1$
that guarantees convergence for small
$\lambda _1:\, 1 \rightarrow 1-\delta t(\Lambda C_0+\Lambda C_1+\Lambda C_2+\Lambda C_3)=1-\delta t \Lambda \lt 1$
that guarantees convergence for small
 $\delta t$
and reasonable
$\delta t$
and reasonable
 $\Lambda \gt 0$
values [Reference Varga, Horváth, Tar, Müller and Brandstötter29].
$\Lambda \gt 0$
values [Reference Varga, Horváth, Tar, Müller and Brandstötter29].
The proposed solution method was successfully applied in an FPI-based adaptive control scene for controlling a 3-Dof PUMA-type robot arm (some simulation results are presented in Section 5 for comparison purposes). The simulations showed very nice behavior of the controlled system in the early stages of the control. The monotonic decrease of the trajectory tracking error was observed with no overshoots, on the other hand, the computational demand increased (which is a general problem for fractional order control). Later upon further investigation of the control solution, the following issues were revealed:
-
When the proposed solution was applied without adaptive control, a significant chattering was observed in the control force (which was nicely smoothed when FPI-based adaptive control was used).
-
Although chattering was sufficiently reduced in our preliminary simulations with the use of adaptive deformation, significant speed fluctuation was observed when applying the proposed control method in a motor control application. This can be caused by the time delays of the system and the higher cycle time of controller, which made the adaptive controller slightly less efficient than in the simulations, that way the chattering could not be smoothed anymore.
-
The solution became divergent when noise filtering was applied.
To resolve these issues a revised control solution will be proposed in the next section.
3.2. Higher order implementation of lower order control task
By considering the discrete-time approximation of the problem with time-resolution
 $\delta t$
, the following statement can be done for (11a):
$\delta t$
, the following statement can be done for (11a):
 \begin{equation}{e^{Des}(t+\delta t)}\approx (1-\Lambda \delta t){e(t)}\,. \end{equation}
\begin{equation}{e^{Des}(t+\delta t)}\approx (1-\Lambda \delta t){e(t)}\,. \end{equation}
Assuming that in a given
 $t-\delta t$
control cycle, the initial conditions are
$t-\delta t$
control cycle, the initial conditions are
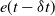 $e(t-\delta t)$
(trajectory tracking error in the current control cycle)
$e(t-\delta t)$
(trajectory tracking error in the current control cycle)
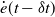 $\dot e(t-\delta t)$
(derivative of trajectory tracking error) that determines
$\dot e(t-\delta t)$
(derivative of trajectory tracking error) that determines
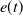 $e(t)$
, too. Using forward differences according to (13), the acceleration, which should be applied to the system assuming that
$e(t)$
, too. Using forward differences according to (13), the acceleration, which should be applied to the system assuming that
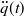 $\ddot q(t)$
can be set instantly, can be calculated as (a similar solution was applied in ref. [Reference Attinga, Bitó and Tar44]):
$\ddot q(t)$
can be set instantly, can be calculated as (a similar solution was applied in ref. [Reference Attinga, Bitó and Tar44]):
 \begin{equation} \ddot e^{Des}(t-\delta t) \approx \frac{e^{Des}(t+\delta t)-2e(t)+e(t-\delta t)}{\delta t^2}\,, \end{equation}
\begin{equation} \ddot e^{Des}(t-\delta t) \approx \frac{e^{Des}(t+\delta t)-2e(t)+e(t-\delta t)}{\delta t^2}\,, \end{equation}
 \begin{equation}{\ddot e^{Des}(t-\delta t)} \approx \frac{(1-\Lambda \delta t){e(t)}-2 e(t)+{e(t-\delta t)}}{\delta t^2}\,, \end{equation}
\begin{equation}{\ddot e^{Des}(t-\delta t)} \approx \frac{(1-\Lambda \delta t){e(t)}-2 e(t)+{e(t-\delta t)}}{\delta t^2}\,, \end{equation}
 \begin{equation}{\ddot e^{Des}(t-\delta t)} \approx \frac{-\Lambda \delta t e(t)-e(t)+e(t-\delta t)}{\delta t^2}\,, \end{equation}
\begin{equation}{\ddot e^{Des}(t-\delta t)} \approx \frac{-\Lambda \delta t e(t)-e(t)+e(t-\delta t)}{\delta t^2}\,, \end{equation}
 \begin{equation}{\ddot e^{Des}(t-\delta t)} \approx \frac{-\Lambda e(t)}{\delta t} -\frac{\dot e(t-\delta t)}{\delta t}\,, \end{equation}
\begin{equation}{\ddot e^{Des}(t-\delta t)} \approx \frac{-\Lambda e(t)}{\delta t} -\frac{\dot e(t-\delta t)}{\delta t}\,, \end{equation}
 \begin{equation}{\ddot e^{Des}(t-\delta t)} \approx -\Lambda \frac{e(t)-e(t-\delta t)}{\delta t}-\Lambda \frac{e(t-\delta t)}{\delta t} - \frac{\dot e(t-\delta t)}{\delta t}\,, \end{equation}
\begin{equation}{\ddot e^{Des}(t-\delta t)} \approx -\Lambda \frac{e(t)-e(t-\delta t)}{\delta t}-\Lambda \frac{e(t-\delta t)}{\delta t} - \frac{\dot e(t-\delta t)}{\delta t}\,, \end{equation}
 \begin{equation}{\ddot e^{Des}(t-\delta t)} \approx -\Lambda \dot e(t-\delta t)-\frac{\Lambda }{\delta t}e(t-\delta t)-\frac{\dot e(t-\delta t)}{\delta t}\,, \end{equation}
\begin{equation}{\ddot e^{Des}(t-\delta t)} \approx -\Lambda \dot e(t-\delta t)-\frac{\Lambda }{\delta t}e(t-\delta t)-\frac{\dot e(t-\delta t)}{\delta t}\,, \end{equation}
 \begin{equation}{\ddot e^{Des}(t-\delta t) \approx -\Lambda \dot e(t-\delta t) -\frac{1}{\delta t} \left (\dot e(t-\delta t)+\Lambda e(t-\delta t)\right )}\,, \mbox{ where} \end{equation}
\begin{equation}{\ddot e^{Des}(t-\delta t) \approx -\Lambda \dot e(t-\delta t) -\frac{1}{\delta t} \left (\dot e(t-\delta t)+\Lambda e(t-\delta t)\right )}\,, \mbox{ where} \end{equation}
 \begin{equation}{\dot e(t-\delta t)\approx \frac{e(t)-e(t-\delta t)}{\delta t}}\,. \end{equation}
\begin{equation}{\dot e(t-\delta t)\approx \frac{e(t)-e(t-\delta t)}{\delta t}}\,. \end{equation}
The freshly set value of
 $\ddot q^{Des}(t-\delta t)$
can be calculated as:
$\ddot q^{Des}(t-\delta t)$
can be calculated as:
 \begin{equation}{\ddot q^{Des}(t-\delta t) \approx q^{N}(t-\delta t) +\Lambda \dot e(t-\delta t) +\frac{1}{\delta t} \left (\dot e(t-\delta t)+\Lambda e(t-\delta t)\right )}\,. \end{equation}
\begin{equation}{\ddot q^{Des}(t-\delta t) \approx q^{N}(t-\delta t) +\Lambda \dot e(t-\delta t) +\frac{1}{\delta t} \left (\dot e(t-\delta t)+\Lambda e(t-\delta t)\right )}\,. \end{equation}
If the dynamic model of the controlled system is available, the necessary force can be computed as
 \begin{equation} Q(t-\delta t)=F(q(t-\delta t),\dot q(t-\delta t), \ddot q^{Des}(t-\delta t))\,, \end{equation}
\begin{equation} Q(t-\delta t)=F(q(t-\delta t),\dot q(t-\delta t), \ddot q^{Des}(t-\delta t))\,, \end{equation}
this control strategy can be realized for a second-order system consistently.
In a more sophisticated manner, the solution can be formulated using differential equations since the second derivative of the tracking error can be introduced as
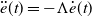 $\ddot e(t)=-\Lambda \dot e(t)$
, however, this would result in information loss since the value of
$\ddot e(t)=-\Lambda \dot e(t)$
, however, this would result in information loss since the value of
 $e$
remains undetermined to the tune of a constant value. Instead, the following idea can be chosen: consider the difference of
$e$
remains undetermined to the tune of a constant value. Instead, the following idea can be chosen: consider the difference of
 $\dot e(t)$
and
$\dot e(t)$
and
 $-\Lambda e(t)$
and drive it asymptotically to zero by the strategy
$-\Lambda e(t)$
and drive it asymptotically to zero by the strategy
 \begin{equation} \left (\lambda +\frac{\textrm{d}}{\textrm{d}t}\right )\left (\dot e(t)+\Lambda e(t)\right )\equiv 0 \mbox{ resulting } \ddot e(t)=-\Lambda \dot e(t) -\lambda (\dot e(t)+\Lambda e(t))\,. \end{equation}
\begin{equation} \left (\lambda +\frac{\textrm{d}}{\textrm{d}t}\right )\left (\dot e(t)+\Lambda e(t)\right )\equiv 0 \mbox{ resulting } \ddot e(t)=-\Lambda \dot e(t) -\lambda (\dot e(t)+\Lambda e(t))\,. \end{equation}
Evidently, if
 $\lambda \gg \Lambda$
,
$\lambda \gg \Lambda$
,
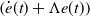 $\left (\dot e(t)+\Lambda e(t)\right )$
very quickly has to converge to zero, that is, the original first-order strategy is soon realized. Furthermore, it can be observed that (28) essentially corresponds to (24) if
$\left (\dot e(t)+\Lambda e(t)\right )$
very quickly has to converge to zero, that is, the original first-order strategy is soon realized. Furthermore, it can be observed that (28) essentially corresponds to (24) if
 $\lambda =\frac{1}{\delta t}$
. In a digital controller, the
$\lambda =\frac{1}{\delta t}$
. In a digital controller, the
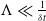 $\Lambda \ll \frac{1}{\delta t}$
condition used to be generally valid.
$\Lambda \ll \frac{1}{\delta t}$
condition used to be generally valid.
Introducing an
 $x\stackrel{\text{def}}{=}\left [e \, \, \dot e\right ]^T$
state variable and its time derivative
$x\stackrel{\text{def}}{=}\left [e \, \, \dot e\right ]^T$
state variable and its time derivative
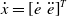 $\dot x=\left [\dot e \, \, \ddot e\right ]^T$
, the Eq. (28) can be rewritten in matrix form
$\dot x=\left [\dot e \, \, \ddot e\right ]^T$
, the Eq. (28) can be rewritten in matrix form
 \begin{equation} \dot x= \left [\begin{array}{c} \dot e\\[5pt] \ddot e \\[5pt] \end{array}\right ]=\left [\begin{array}{c@{\quad}c} 0 & 1\\[5pt] -\Lambda \lambda & -(\Lambda +\lambda ) \end{array}\right ] \left [\begin{array}{c} e\\[5pt] \dot e \\[5pt] \end{array}\right ]= Ax\,. \end{equation}
\begin{equation} \dot x= \left [\begin{array}{c} \dot e\\[5pt] \ddot e \\[5pt] \end{array}\right ]=\left [\begin{array}{c@{\quad}c} 0 & 1\\[5pt] -\Lambda \lambda & -(\Lambda +\lambda ) \end{array}\right ] \left [\begin{array}{c} e\\[5pt] \dot e \\[5pt] \end{array}\right ]= Ax\,. \end{equation}
The characteristic polynomial of matrix
 $A$
that is
$A$
that is
 $\det (\xi I-A)=\xi ^2 +\xi (\Lambda +\lambda )+\Lambda \lambda$
and its roots are
$\det (\xi I-A)=\xi ^2 +\xi (\Lambda +\lambda )+\Lambda \lambda$
and its roots are
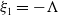 $\xi _1=-\Lambda$
and
$\xi _1=-\Lambda$
and
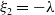 $\xi _2=-\lambda$
. Ensuring that the real part of the eigenvalues are negative (
$\xi _2=-\lambda$
. Ensuring that the real part of the eigenvalues are negative (
 $\mathfrak{Re}(\xi _1)\lt 0$
and (
$\mathfrak{Re}(\xi _1)\lt 0$
and (
 $\mathfrak{Re}(\xi _2)\lt 0$
), so
$\mathfrak{Re}(\xi _2)\lt 0$
), so
 $\Lambda, \lambda \gt 0$
a stable solution can be obtained.
$\Lambda, \lambda \gt 0$
a stable solution can be obtained.
Obviously neither Eq. (28) nor (27) (which is a discrete-time approximation) have memory effect. However, utilizing (12) and its derivative, the following solution can be obtained,
 \begin{equation} \ddot q^{Des}(t)=\ddot q^{N}(t)+(\lambda +\Lambda ) \dot e(t)+\Lambda \lambda e(t)\,, so \end{equation}
\begin{equation} \ddot q^{Des}(t)=\ddot q^{N}(t)+(\lambda +\Lambda ) \dot e(t)+\Lambda \lambda e(t)\,, so \end{equation}
 \begin{equation} \ddot q^{Des}(t)=\ddot q^{N}(t)+(\lambda +\Lambda ) \dot e(t_i) +\Lambda \lambda e(t_i)-(\lambda +\Lambda ) \sum _{\ell =0}^{H-1}C_\ell \Lambda \delta t \dot e(t_{i-\ell })-\Lambda \lambda \sum _{\ell =0}^{H-1}C_\ell \Lambda \delta t e(t_{i-\ell })\,, \end{equation}
\begin{equation} \ddot q^{Des}(t)=\ddot q^{N}(t)+(\lambda +\Lambda ) \dot e(t_i) +\Lambda \lambda e(t_i)-(\lambda +\Lambda ) \sum _{\ell =0}^{H-1}C_\ell \Lambda \delta t \dot e(t_{i-\ell })-\Lambda \lambda \sum _{\ell =0}^{H-1}C_\ell \Lambda \delta t e(t_{i-\ell })\,, \end{equation}
which can be implemented in a simple embedded system. This feedback solution will be denoted as WSPD or Weighted Sum PD feedback in the rest of the paper since it is the augmentation of Eq. (12) with a derivative term.
4. Fixed point iteration-based adaptive control
The first efforts to develop adaptive control solutions were made in the 1950s when the design of autopilot solutions for high-performance aircraft was started [Reference Johan and Björn45]. These machines work in various operating conditions (various speeds and altitudes, different weather circumstances, other external disturbances, etc.), which means that the system dynamics are almost constantly changing from controller’s point of view. This could not be handled by an ordinary constant-gain feedback controller. Despite the enthusiasm in the early stages of the research, due to lack of knowledge in stability analysis (although the foundations were already given by Lyapunov at that time [Reference Lyapunov38]) and catastrophic failure in a flight test [Reference Dydek, Annaswamy and Lavretsky46], the research in adaptive control came almost to a halt by the end of the decade [Reference Johan47]. However, the research in adaptive control came to a new life in the next decade when various mathematical concepts were established [Reference Ioannou and Fidan48] and the Lyapunov theory was successfully applied in the design [Reference Parks49]. Since then the Lyapunov function-based design has become superior in adaptive control (few application examples, e.g., refs. [Reference Nicol, Macnab and Ramirez-Serrano50, Reference Fang, Ma, Wang and Zhang51]).
In the last few decades, adaptive backstepping control got a great deal of attention from the scientific community [Reference Zouari, Saad and Benrejeb52–Reference Zou and Schueller54]. This control method is built on a recursive solution, based on Lyapunov’s approach, and it can ensure the stability of the system. It was shown in a recent article that backstepping control can be combined with fixed point iteration-based adaptive deformation [Reference Mohammad and Tar55] as well, that way a robust adaptive controller can be obtained. The essence of this solution is that the design starts from a known stable state which is separated by the largest number of integration from control input and backs out step by step, stabilizing each subsystem until final external control input is achieved. Although backstepping control is an effective non-linear control solution, it requires some tedious design work from the control engineer and the problem complexity drastically increases for higher-order systems.
In the recent years, artificial intelligence techniques came into prominence in adaptive control, such as neural network (NN) [Reference Na, Wang, Liu, Huang and Ren56] and fuzzy logic system [Reference Na, Huang, Wu, Su and Li57]. These techniques are mainly used to address unknown system dynamics (e.g., friction, dead-zone, etc.) through parameter estimation where some kind of friction model is utilized, although in ref. [Reference Na, Wang, Liu, Huang and Ren56], a new learning algorithm was introduced for simultaneous motion control and parameter estimation. In NN-based control, a general problem is that small residual approximation errors can affect the control performance and also usually these techniques involve slow learning resulting in long transient stage. The transient response of the controlled system can be improved in various manner. In ref. [Reference Wang, Na and Ren58], prescribed performance controller (PPC) was introduced and experimentally verified, where asymptotic error convergence was achieved through RISE-based (robust integral of sign of error) control design. In this paper, a smooth friction model [Reference Na, Chen, Ren and Guo59] was also used in combination with an echo state neural network to learn the system dynamics and compensate for unknown non-linear model components. However, PPCs could be burdened by singularity due to the inverse error transform function in their design. On the other hand, the asymptotic tracking and prescribed transient behavior can be also guaranteed using funnel control [Reference Wang, Ren, Na and Zeng60, Reference Wang, Yu, Yu, Na and Ren61], which is simple to implement and does not require precise parameter identification.
Fixed point iteration-based adaptive control was introduced in 2009 [Reference Tar, Bitó, Nádai and Machado32] as an alternative option for motion control applications. It can be regarded as primitive case of machine learning and it can ensure fast convergence without precise dynamic model of the controlled system. Its introduction was motivated by certain important features of the Lyapunov function-based design as follows:
-
The Lyapunov function can be regarded as the square of a special norm in which the metric tensor’s components depend on the feedback gains. In this technique, only the monotonic decrease of this norm can be guaranteed while the individual components of which this norm is built up can increase and decrease, too. In certain application fields as for example, life sciences, the monotonic decrease of the individual components may have significance.
-
In many application fields, it is impossible to directly measure the components of which the Lyapunov function is built up. Since they are organic part of the metric in use, often complicated state estimation techniques have to be implemented to make the Lyapunov function-based design applicable.
The suggested new approach was exempt from such difficulties: it directly aimed at the decrease of a given component without needing the measurement or estimation of each component of the state variable. It was extended to multivariable systems, too, and operated on the basis of Banach’s fixed point theorem. It needed the observation only of the variable of interest on the following basis. In the case of a control task of relative order
 $n \in \mathbb{N}$
, the
$n \in \mathbb{N}$
, the
 $q^{(n)}$
derivative of the generalized coordinate can be immediately set by the control force, while the lower order derivatives evolve relatively slowly. Normally, by the use of the Lie derivatives it is possible to calculate the functional relationship between the control force and the appropriate derivative, however, this computation is often very complicated, time consuming, and in the possession of only an approximate system model, often is useless. Instead, a simple affine model in the form
$q^{(n)}$
derivative of the generalized coordinate can be immediately set by the control force, while the lower order derivatives evolve relatively slowly. Normally, by the use of the Lie derivatives it is possible to calculate the functional relationship between the control force and the appropriate derivative, however, this computation is often very complicated, time consuming, and in the possession of only an approximate system model, often is useless. Instead, a simple affine model in the form
 $Q(t)=Aq^{(n)}(t)+B$
can be used as initial approximation, since the other slowly varying components approximately can be considered as constants. In many single variable systems, the sign of
$Q(t)=Aq^{(n)}(t)+B$
can be used as initial approximation, since the other slowly varying components approximately can be considered as constants. In many single variable systems, the sign of
 $A$
can be assumed to be constant positive or negative. The output of the kinematic design can generate a
$A$
can be assumed to be constant positive or negative. The output of the kinematic design can generate a
 $q^{(n)Des}$
derivative so that if it would be realized the tracking error should asymptotically converge to zero. If the available mathematical model of the system would be precise this scenario could be realized. However, in the case of an approximate model, the model itself together with the controlled system bring about a response function that maps the desired input to the observable output as
$q^{(n)Des}$
derivative so that if it would be realized the tracking error should asymptotically converge to zero. If the available mathematical model of the system would be precise this scenario could be realized. However, in the case of an approximate model, the model itself together with the controlled system bring about a response function that maps the desired input to the observable output as
 $q^{(n)Real}(t)=f\left (q^{(n)Des}(t)\right ) \neq q^{(n)Des}(t)$
. To realize the desired input, according to Fig. 1, the input of the approximate model should be deformed so that
$q^{(n)Real}(t)=f\left (q^{(n)Des}(t)\right ) \neq q^{(n)Des}(t)$
. To realize the desired input, according to Fig. 1, the input of the approximate model should be deformed so that
 $q^{(n)Des}(t)=f\left (q^{(n)Def}(t)\right )$
, in which
$q^{(n)Des}(t)=f\left (q^{(n)Def}(t)\right )$
, in which
 $q^{(n)Def}(t)$
is an adaptively deformed input. The necessary deformation can be iteratively found if it is known that the response function is approximately direction keeping, that is, if for an infinitesimally small
$q^{(n)Def}(t)$
is an adaptively deformed input. The necessary deformation can be iteratively found if it is known that the response function is approximately direction keeping, that is, if for an infinitesimally small
 $\Delta x$
,
$\Delta x$
,
 $\Delta f\;:\!=\;f(x+\Delta x)-f(x)$
the scalar product
$\Delta f\;:\!=\;f(x+\Delta x)-f(x)$
the scalar product
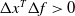 $\Delta x^T\Delta f\gt 0$
. (This concept can be regarded as the generalization of the single variable monotonic increasing function.) Consider a small
$\Delta x^T\Delta f\gt 0$
. (This concept can be regarded as the generalization of the single variable monotonic increasing function.) Consider a small
 $\alpha \in \mathbb{R}$
number and the sequence
$\alpha \in \mathbb{R}$
number and the sequence
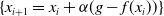 $\{x_{i+1}=x_i+\alpha (g-f(x_i))\}$
where
$\{x_{i+1}=x_i+\alpha (g-f(x_i))\}$
where
 $g$
is some goal value. For a differentiable response function it can be estimated that
$g$
is some goal value. For a differentiable response function it can be estimated that
 \begin{equation} \begin{aligned} & f(x_{i+1})-g \approx f(x_i)+\alpha \left .\frac{\partial f}{\partial x}\right |_{x_i}(g-f(x_i)) -g \\[5pt] & f(x_{i+1})-g \approx \left [I-\alpha \left .\frac{\partial f}{\partial x}\right |_{x_i}\right ] \left (f(x_i)-g\right ) \,, \end{aligned} \end{equation}
\begin{equation} \begin{aligned} & f(x_{i+1})-g \approx f(x_i)+\alpha \left .\frac{\partial f}{\partial x}\right |_{x_i}(g-f(x_i)) -g \\[5pt] & f(x_{i+1})-g \approx \left [I-\alpha \left .\frac{\partial f}{\partial x}\right |_{x_i}\right ] \left (f(x_i)-g\right ) \,, \end{aligned} \end{equation}
that, if the matrix
 $I-\alpha \left .\frac{\partial f}{\partial x}\right |_{x_i}$
decreases the norm of the vectors iteratively will result in
$I-\alpha \left .\frac{\partial f}{\partial x}\right |_{x_i}$
decreases the norm of the vectors iteratively will result in
 $x_i \rightarrow x_\star$
,
$x_i \rightarrow x_\star$
,
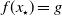 $f(x_\star )=g$
. For an arbitrary array
$f(x_\star )=g$
. For an arbitrary array
 $w$
, it can be written that
$w$
, it can be written that
 \begin{eqnarray} \left \| \left [I-\alpha \left .\frac{\partial f}{\partial x}\right |_{x_i}\right ] w\right \|^2= w^Tw-\alpha w^T\left [\left (\left .\frac{\partial f}{\partial x}\right |_{x_i}\right )^T+\left .\frac{\partial f}{\partial x}\right |_{x_i}\right ] w+ \alpha ^2 w^T\left (\left .\frac{\partial f}{\partial x}\right |_{x_i}\right )^T \left .\frac{\partial f}{\partial x}\right |_{x_i}w \,, \end{eqnarray}
\begin{eqnarray} \left \| \left [I-\alpha \left .\frac{\partial f}{\partial x}\right |_{x_i}\right ] w\right \|^2= w^Tw-\alpha w^T\left [\left (\left .\frac{\partial f}{\partial x}\right |_{x_i}\right )^T+\left .\frac{\partial f}{\partial x}\right |_{x_i}\right ] w+ \alpha ^2 w^T\left (\left .\frac{\partial f}{\partial x}\right |_{x_i}\right )^T \left .\frac{\partial f}{\partial x}\right |_{x_i}w \,, \end{eqnarray}
in which for a finite partial derivative and a very small
 $\alpha \gt 0$
the third term can be neglected, and for an approximate direction-keeping function, the second term is negative, that is the distance between the actual response and the goal can be step by step decreased. In the case of robots, for instance, the existence of the positive definite inertia matrix can guarantee the approximate direction-keeping nature of the response function. Figure 1 describes how this method is inserted into the control scheme of the Computed Torque Control for robots (i.e., for second-order systems) so that during one digital control step only one step of the above adaptive iteration can be done, while the goal value
$\alpha \gt 0$
the third term can be neglected, and for an approximate direction-keeping function, the second term is negative, that is the distance between the actual response and the goal can be step by step decreased. In the case of robots, for instance, the existence of the positive definite inertia matrix can guarantee the approximate direction-keeping nature of the response function. Figure 1 describes how this method is inserted into the control scheme of the Computed Torque Control for robots (i.e., for second-order systems) so that during one digital control step only one step of the above adaptive iteration can be done, while the goal value
 $g(t)\;:\!=\;\ddot q^{Des}(t)$
slowly drifts in time. According to (32), the speed of convergence of this iteration depends on the value of
$g(t)\;:\!=\;\ddot q^{Des}(t)$
slowly drifts in time. According to (32), the speed of convergence of this iteration depends on the value of
 $\alpha$
, and in the lack of information on the exact model parameters, the method experimentally can be installed and investigated.
$\alpha$
, and in the lack of information on the exact model parameters, the method experimentally can be installed and investigated.

Figure 1. Fixed point iteration-based adaptive control schematics using a particular adaptive deformation method (the Euler integration in the bottom of the figure refers to the fact that the exact integration is done by the “physical operation” of the controlled system); the iterative sequence can be initiated with
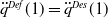 $\ddot q^{Def}(1)=\ddot q^{Des}(1)$
.
$\ddot q^{Def}(1)=\ddot q^{Des}(1)$
.
Equation (32) indicates that the iteration can turn into a divergent one if the parameter
 $\alpha$
is too big, while the convergence becomes too slow if it is too small. In both cases, the quality of the adaptive control is corrupted. Over the years, various transformation functions were proposed for use in the block “Adaptive Deformation” (e.g., refs. [Reference Dineva, Tar and Várkonyi-Kóczy62–Reference Issa and Tar64]) and the solution was applied in a Model Reference Adaptive Control scenario as well [Reference Tar, Bitó and Rudas65]. For making it more easy to find an appropriate
$\alpha$
is too big, while the convergence becomes too slow if it is too small. In both cases, the quality of the adaptive control is corrupted. Over the years, various transformation functions were proposed for use in the block “Adaptive Deformation” (e.g., refs. [Reference Dineva, Tar and Várkonyi-Kóczy62–Reference Issa and Tar64]) and the solution was applied in a Model Reference Adaptive Control scenario as well [Reference Tar, Bitó and Rudas65]. For making it more easy to find an appropriate
 $\alpha$
, the linear iteration outlined in (31) was replaced by a non-linear one in ref. [Reference Csanádi, Galambos, Tar, Györök and Serester66] in the following simple manner: by choosing a big value
$\alpha$
, the linear iteration outlined in (31) was replaced by a non-linear one in ref. [Reference Csanádi, Galambos, Tar, Györök and Serester66] in the following simple manner: by choosing a big value
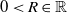 $0\lt R \in \mathbb{R}$
so that
$0\lt R \in \mathbb{R}$
so that
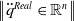 $\left \|\ddot q^{Real} \in \mathbb{R}^n \right \|$
,
$\left \|\ddot q^{Real} \in \mathbb{R}^n \right \|$
,
 $\left \|\ddot q^{Des} \in \mathbb{R}^n\right \|$
,
$\left \|\ddot q^{Des} \in \mathbb{R}^n\right \|$
,
 $\left \|\ddot q^{Def} \in \mathbb{R}^n\right \|$
$\left \|\ddot q^{Def} \in \mathbb{R}^n\right \|$
 $\ll R$
, these vectors were so augmented by the use of a “complementary, physically not interpreted dimension” that they obtained the common “augmented norm”
$\ll R$
, these vectors were so augmented by the use of a “complementary, physically not interpreted dimension” that they obtained the common “augmented norm”
 $R$
. Consequently, the
$R$
. Consequently, the
 $\mathcal A\;:\!=\;[\ddot q^{Des};\; D^{Des}]$
,
$\mathcal A\;:\!=\;[\ddot q^{Des};\; D^{Des}]$
,
 $\mathcal B\;:\!=\;[\ddot q^{Real};\; D^{Real}]$
and
$\mathcal B\;:\!=\;[\ddot q^{Real};\; D^{Real}]$
and
 $\mathcal C\;:\!=\;[\ddot q^{Def};\; D^{Def}] \in \mathbb{R}^{n+1}$
vectors can be rotated into each other in
$\mathcal C\;:\!=\;[\ddot q^{Def};\; D^{Def}] \in \mathbb{R}^{n+1}$
vectors can be rotated into each other in
 $\mathbb{R}^{n+1}$
, and it is easy to construct the orthogonal matrix that rotates
$\mathbb{R}^{n+1}$
, and it is easy to construct the orthogonal matrix that rotates
 $\mathcal B(i)$
to
$\mathcal B(i)$
to
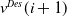 $v^{Des}(i+1)$
so that the orthogonal subspace of these vectors remains invariant. By interpolating the angle of rotation by a factor
$v^{Des}(i+1)$
so that the orthogonal subspace of these vectors remains invariant. By interpolating the angle of rotation by a factor
 $\lambda _a \in (0,1)$
, the physically interpreted projections of the vectors will not be completely identical: they will only approach each other. The next deformed value
$\lambda _a \in (0,1)$
, the physically interpreted projections of the vectors will not be completely identical: they will only approach each other. The next deformed value
 $\mathcal C(i+1)$
will be created from
$\mathcal C(i+1)$
will be created from
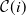 $\mathcal C(i)$
with this rotation of limited angle. To sum up, the parameter of the adaptive rotation will be
$\mathcal C(i)$
with this rotation of limited angle. To sum up, the parameter of the adaptive rotation will be
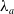 $\lambda _a$
instead of
$\lambda _a$
instead of
 $\alpha$
in (31). In the practice, it was found that it is more easy to set
$\alpha$
in (31). In the practice, it was found that it is more easy to set
 $\lambda _a$
than
$\lambda _a$
than
 $\alpha$
.
$\alpha$
.
Algorithm 1. Adaptive Deformation using Abstract Rotations [Reference Issa and Tar67].

The solution can be regarded as a primitive case of machine learning, as in each control cycle, the control force is calculated based on the observation of the behavior of the system in the previous control cycle, although this information is not used for amending the imperfect dynamic model parameters (in ref. [Reference Issa and Tar67] some efforts were made to improve the dynamic model as well, by combining the FPI controller with Particle Swarm Optimization). Also, it can be noted that this approach can be regarded as a special version of the “Data Driven Modeling Technology” (e.g., refs. [Reference Roman, Precup, Petriu and Dragan68, Reference Fényes, Németh and Gáspár69]) in which the usual regression-based approach is replaced with the adaptive deformation.
This approach has the following interesting properties:
-
Since it applies Euler integration, the precision of the computations with the PID-type feedback terms is improved by the refinement of the discrete-time-resolution in the usual manner.
-
However, if a time interval of given duration is tackled with a finer time resolution, with the increase of the number of the digital control cycles, the adaptive iteration obtains a possibility for the realization of more adaptive iterative steps during unit time, so it is expected that the method’s precision increases with this refinement.
-
By feeding back higher-order derivative, its noise sensitivity may be stronger than that of the non-adaptive case: the application of stronger noise filtering may decrease the quality of precision due to its delaying effects. This property is a common feature of the Acceleration Feedback Controllers (e.g., ref. [Reference Ding, Luo, Cai and Chang70]).
5. Simulation-based analysis
As a continuation of our previous research in replacing a fractional order controller with a simple weighted sum feedback design (first efforts were introduced in ref. [Reference Varga, Horváth, Tar, Müller and Brandstötter29]), further simulation-based results are shown in this section, on a simple model of a 3 Degree of Freedom (DoF) PUMA-type robot arm. The simplified schematic of the robotic arm is shown in Fig. 2. In this section, a PID (Eq. (5)) and the originally proposed weighted sum (WS) feedback (Eq. (12)) are compared to the improved version of the weighted sum feedback (WSPD) (Eq. (30)) proposed in this paper, through a trajectory tracking application in a FPI-based adaptive control scenario.

Figure 2. Simplified model of a 3-DoF Puma-type robot arm.
5.1. Control design for simulations
For the trajectory tracking applications, the nominal trajectory (
 $q^N$
) was generated in joint space as a sinusoidal function with increasing amplitude. Our simulations were made according to the following considerations:
$q^N$
) was generated in joint space as a sinusoidal function with increasing amplitude. Our simulations were made according to the following considerations:
-
Mathematical Model: In order to imitate modeling deficiencies, an “approximate” and an “exact” model parameter set is introduced (see in Table I). The necessary control force (
 $Q$
) was calculated using the approximate parameter set and the system response, which would be measured in a real application, was calculated using the exact model parameters. The dynamic equations of the investigated system (
$C_x=\cos{q_x}$
,
$S_x=\sin{q_x}$
,
$C_{xy}=\cos ({q_x+q_y})$
,
$S_{xy}=\sin ({q_x+q_y})$
):(33a)
\begin{align} & Q_1=\left (\Theta _1+ \frac{1}{4}m_2 L_2^2 C_2^2+ \frac{1}{4}m_3 L_3^2 C_{23}^2 + m_3 L_2^2 C_2^2+\frac{1}{2}m_3 L_2 L_3 C_{23} C_2\right )\ddot q_1 + \nonumber \\[5pt] & +\left (-\frac{1}{2}m_2 L_2^2 C_2 S_2 \dot q_2 -\frac{1}{2}m_3 L_3^2 C_{23} S_{23} (\dot q_2+\dot q_3) -2 m_3 L_2^2 C_2 S_2 \dot q_2 \right )\dot q_1+ \nonumber \\[5pt] &+ \left (-\frac{1}{2}m_3 L_2 L_3 S_{23} C_2(\dot q_2+\dot q_3) -\frac{1}{2}m_3 L_2 L_3 C_{23} S_2 \dot q_2\right )\dot q_1 \,, \end{align}
(33b)
\begin{align} & Q_2 = \left (\frac{1}{4}m_2 L_2^2 + \frac{1}{4}m_3 L_3^2 + m_3 L_2^2 + \frac{1}{2} m_3 L_3 L_2 C_3 \right )\ddot q_2 -\frac{1}{2} m_3 L_3 L_2 S_3 \dot q_3\dot q_2 + \nonumber \\[5pt] & +\left (\frac{1}{4}m_3 L_3^2 + \frac{1}{4}m_3 L_3 L_2 C_3\right ) \ddot q_3 -\frac{1}{4}m_3 L_3 L_2 S_3 \dot q_3^2 + \frac{1}{4}m_2 L_2^2 C_2 S_2\dot q_1^2 +\nonumber \\[5pt] & + \left (\frac{1}{4}m_3 L_3^2 C_{23} S_{23} +m_3 L_2^2 C_2 S_2 +\frac{1}{4}m_3 L_2 L_3 S_{23}C_2 +\frac{1}{4}m_3 L_2 L_3 C_{23}S_2\right )\dot q_1^2+ \nonumber \\[5pt] & +\frac{1}{2} m_2 L_2 g C_2 +m_3 g L_2 C_2 +\frac{1}{2} m_3 L_3 g C_{23} \,, \end{align}
(33c)
\begin{align} & Q_3= \left [\frac{1}{4}m_3 L_3^2 + \frac{1}{4}m_3 L_3 L_2 C_3\right ]\ddot q_2 + \frac{1}{4}m_3 L_3^2 \ddot q_3 +\frac{1}{4}m_3 L_3^2 C_{23} S_{23} \dot q_1^2+ \nonumber \\[5pt] &+ \frac{1}{4}m_3 L_3 L_2 S_{23} C_2 \dot q_1^2 +\frac{1}{4}m_3 L_3 L_2 S_3 \dot q_2^2 + \frac{1}{2} m_3 g L_3 C_{23} \,. \end{align}
$Q$
) was calculated using the approximate parameter set and the system response, which would be measured in a real application, was calculated using the exact model parameters. The dynamic equations of the investigated system (
$C_x=\cos{q_x}$
,
$S_x=\sin{q_x}$
,
$C_{xy}=\cos ({q_x+q_y})$
,
$S_{xy}=\sin ({q_x+q_y})$
):(33a)
\begin{align} & Q_1=\left (\Theta _1+ \frac{1}{4}m_2 L_2^2 C_2^2+ \frac{1}{4}m_3 L_3^2 C_{23}^2 + m_3 L_2^2 C_2^2+\frac{1}{2}m_3 L_2 L_3 C_{23} C_2\right )\ddot q_1 + \nonumber \\[5pt] & +\left (-\frac{1}{2}m_2 L_2^2 C_2 S_2 \dot q_2 -\frac{1}{2}m_3 L_3^2 C_{23} S_{23} (\dot q_2+\dot q_3) -2 m_3 L_2^2 C_2 S_2 \dot q_2 \right )\dot q_1+ \nonumber \\[5pt] &+ \left (-\frac{1}{2}m_3 L_2 L_3 S_{23} C_2(\dot q_2+\dot q_3) -\frac{1}{2}m_3 L_2 L_3 C_{23} S_2 \dot q_2\right )\dot q_1 \,, \end{align}
(33b)
\begin{align} & Q_2 = \left (\frac{1}{4}m_2 L_2^2 + \frac{1}{4}m_3 L_3^2 + m_3 L_2^2 + \frac{1}{2} m_3 L_3 L_2 C_3 \right )\ddot q_2 -\frac{1}{2} m_3 L_3 L_2 S_3 \dot q_3\dot q_2 + \nonumber \\[5pt] & +\left (\frac{1}{4}m_3 L_3^2 + \frac{1}{4}m_3 L_3 L_2 C_3\right ) \ddot q_3 -\frac{1}{4}m_3 L_3 L_2 S_3 \dot q_3^2 + \frac{1}{4}m_2 L_2^2 C_2 S_2\dot q_1^2 +\nonumber \\[5pt] & + \left (\frac{1}{4}m_3 L_3^2 C_{23} S_{23} +m_3 L_2^2 C_2 S_2 +\frac{1}{4}m_3 L_2 L_3 S_{23}C_2 +\frac{1}{4}m_3 L_2 L_3 C_{23}S_2\right )\dot q_1^2+ \nonumber \\[5pt] & +\frac{1}{2} m_2 L_2 g C_2 +m_3 g L_2 C_2 +\frac{1}{2} m_3 L_3 g C_{23} \,, \end{align}
(33c)
\begin{align} & Q_3= \left [\frac{1}{4}m_3 L_3^2 + \frac{1}{4}m_3 L_3 L_2 C_3\right ]\ddot q_2 + \frac{1}{4}m_3 L_3^2 \ddot q_3 +\frac{1}{4}m_3 L_3^2 C_{23} S_{23} \dot q_1^2+ \nonumber \\[5pt] &+ \frac{1}{4}m_3 L_3 L_2 S_{23} C_2 \dot q_1^2 +\frac{1}{4}m_3 L_3 L_2 S_3 \dot q_2^2 + \frac{1}{2} m_3 g L_3 C_{23} \,. \end{align}
-
Adaptive Deformation: All three compared feedback solutions are implemented in a Fixed Point Iteration-based control scenario, in which convergent iteration is calculated using Abstract Rotations [Reference Csanádi, Galambos, Tar, Györök and Serester66]. The essence of this solution is given in Section 4. The adaptive parameter
$\lambda _a=0.06$
and the initial condition is
$\ddot q^{Des} (1)=\ddot q^{Def} (1)$
. -
Kinematic Block: The parameter settings for all three kinematic feedback designs are summarized in Table II. The parameter settings were kept the same throughout our simulations. For the weighted sum-type feedback solutions, the forgetting nature of the solution was characterized as
(34)where
\begin{equation} C_{\ell }=((\epsilon +\ell )\delta t)^{-p}\,, \end{equation}
$\epsilon =0.1$
and
$\delta t=0.001\,\textrm{s}$
, which is the control cycle time, finally
$p$
is the forgetting sharpness which can arbitrarly set.
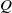
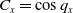

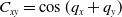
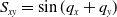



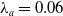





Simulations were made in Julia programing language on an HP 250 G6 computer under Windows10 operating system.
Table I. Modelling parameters.

Table II. Kinematic parameter setting for simulations.

5.2. Simulation results
In the first set of simulations (Figs. 3–5), the three kinematic feedback designs were compared in an FPI-based adaptive control scenario. Figure 3 gives us a good basis for comparison, as in this case, the kinematic block was implemented using PID-type feedback. This solution generated a considerable overshoot at the beginning of the control, however later the modeling errors were nicely compensated through the adaptive deformation which yields a very low (less than
 $0.5\,\textrm{mrad}$
) trajectory tracking error in the steady state (after the initial error is compensated). Figure 4 shows the simulation results for a weighted sum-type feedback in kinematic design. In this simulation, the initial overshoot of the system was completely eliminated and even lower trajectory tracking error was achieved in the steady state. However, a very drastic control action can be observed in the initial stage of the control. On the other hand, in Fig. 5, the excessively high control forces in the initial stage of the control were avoided and still very nice asymptotic error convergence was achieved.
$0.5\,\textrm{mrad}$
) trajectory tracking error in the steady state (after the initial error is compensated). Figure 4 shows the simulation results for a weighted sum-type feedback in kinematic design. In this simulation, the initial overshoot of the system was completely eliminated and even lower trajectory tracking error was achieved in the steady state. However, a very drastic control action can be observed in the initial stage of the control. On the other hand, in Fig. 5, the excessively high control forces in the initial stage of the control were avoided and still very nice asymptotic error convergence was achieved.

Figure 3. Simulation results for fixed point iteration-based adaptive control with PID feedback (
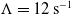 $\Lambda =12\,\textrm{s}^{-1}$
,
$\Lambda =12\,\textrm{s}^{-1}$
,
 $\lambda _a=0.06$
).
$\lambda _a=0.06$
).
In the second set of experiments, no adaptive deformation was applied but all kinematic parameters were kept the same as before. This simulation exhibits the advantage of the newly proposed weighted sum PD-type feedback, as in Fig. 6, using a simple weighted sum solution, a serious chattering can be observed in the control forces which could not be implemented on a real system. This effect was nicely smoothed by the adaptive deformation so the chattering effect did not appear in the previous results. On the other hand, the proposed solution produced suitable control forces without the adaptive deformation and nice tracking was achieved obviously with higher tracking errors due to modeling imprecisions (Fig. 7).

Figure 4. Simulation results for fixed point iteration-based adaptive control with weighted sum feedback (
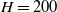 $H=200$
,
$H=200$
,
 $p=2$
,
$p=2$
,
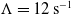 $\Lambda =12\,\textrm{s}^{-1}$
,
$\Lambda =12\,\textrm{s}^{-1}$
,
 $\lambda _a=0.06$
).
$\lambda _a=0.06$
).

Figure 5. Simulation results for fixed point iteration-based adaptive control with the proposed weighted sum PD-type feedback (
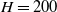 $H=200$
,
$H=200$
,
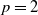 $p=2$
,
$p=2$
,
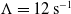 $\Lambda =12\,\textrm{s}^{-1}$
,
$\Lambda =12\,\textrm{s}^{-1}$
,
 $\lambda =25\,\textrm{s}^{-1}$
,
$\lambda =25\,\textrm{s}^{-1}$
,
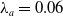 $\lambda _a=0.06$
).
$\lambda _a=0.06$
).

Figure 6. Simulation results for weighted sum feedback without adaptive deformation (
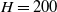 $H=200$
,
$H=200$
,
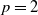 $p=2$
,
$p=2$
,
 $\Lambda =12\,\textrm{s}^{-1}$
,
$\Lambda =12\,\textrm{s}^{-1}$
,
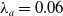 $\lambda _a=0.06$
).
$\lambda _a=0.06$
).

Figure 7. Simulation results for the proposed weighted sum PD-type feedback with no adaptive deformation (
 $H=200$
,
$H=200$
,
 $p=2$
,
$p=2$
,
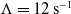 $\Lambda =12\,\textrm{s}^{-1}$
,
$\Lambda =12\,\textrm{s}^{-1}$
,
 $\lambda =25\,\textrm{s}^{-1}$
,
$\lambda =25\,\textrm{s}^{-1}$
,
 $\lambda _a=0.06$
).
$\lambda _a=0.06$
).

Figure 8. Simulation results for 3-DoF PUMA-type robot arm using fixed point iteration-based adaptive control with the proposed weighted sum PD-type feedback with Gaussian noise (
 $\sigma =10^{-6}\,\textrm{rad}$
) on the feedback (
$\sigma =10^{-6}\,\textrm{rad}$
) on the feedback (
 $H=200$
,
$H=200$
,
 $p=2$
,
$p=2$
,
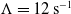 $\Lambda =12\,\textrm{s}^{-1}$
,
$\Lambda =12\,\textrm{s}^{-1}$
,
 $\lambda =25\,\textrm{s}^{-1}$
,
$\lambda =25\,\textrm{s}^{-1}$
,
 $\lambda _a=0.06$
).
$\lambda _a=0.06$
).
In the last simulation, which is presented in Fig. 8, the proposed weighted sum PD-type feedback solution was tested with “noisy signal measurements”. In the simulation, the feedback terms/signals were loaded with Gaussian noise (
 $\sigma =10^{-6}\,\textrm{rad}$
) and a 3rd-order low-pass filter was applied as,
$\sigma =10^{-6}\,\textrm{rad}$
) and a 3rd-order low-pass filter was applied as,
 \begin{equation} \left (\Lambda _f+\frac{\textrm{d}}{\textrm{d}t}\right )^3 q^{S}(t)=\Lambda _f^3 q^O(t) \,, \end{equation}
\begin{equation} \left (\Lambda _f+\frac{\textrm{d}}{\textrm{d}t}\right )^3 q^{S}(t)=\Lambda _f^3 q^O(t) \,, \end{equation}
 \begin{equation} \dddot q^{S}(t)=\Lambda _f^3(q^O(t) -q^S(t))-3\Lambda _f^2 \dot q^S(t)-3\Lambda _f \ddot q^S(t)\,, \end{equation}
\begin{equation} \dddot q^{S}(t)=\Lambda _f^3(q^O(t) -q^S(t))-3\Lambda _f^2 \dot q^S(t)-3\Lambda _f \ddot q^S(t)\,, \end{equation}
where
 $q^S(t)$
is the filtered signal and
$q^S(t)$
is the filtered signal and
 $q^O(t)$
is the observed noisy signal, from
$q^O(t)$
is the observed noisy signal, from
 $\dddot q^{S}(t)$
the
$\dddot q^{S}(t)$
the
 $\ddot q^{S}(t), \dot q^{S}(t), q^{S}(t)$
values were calculated using Euler integration. In Fig. 8, the effect of the applied noise filtering technique can be well seen as there is a significant difference between observed
$\ddot q^{S}(t), \dot q^{S}(t), q^{S}(t)$
values were calculated using Euler integration. In Fig. 8, the effect of the applied noise filtering technique can be well seen as there is a significant difference between observed
 $\ddot q^O(t)\approx (q^{O}(t_{i+1})-2q^O(t_i)+q^O(t_{i-1}))/\delta t^2$
and filtered
$\ddot q^O(t)\approx (q^{O}(t_{i+1})-2q^O(t_i)+q^O(t_{i-1}))/\delta t^2$
and filtered
 $\ddot q^S(t)$
values. In the last simulation to reduce the initial force applied by the controller, the feedback gains in the kinematic block are gradually incremented by function,
$\ddot q^S(t)$
values. In the last simulation to reduce the initial force applied by the controller, the feedback gains in the kinematic block are gradually incremented by function,
 \begin{equation} g=g^{N}\tanh{\frac{S}{S^{\max}}}\,, \end{equation}
\begin{equation} g=g^{N}\tanh{\frac{S}{S^{\max}}}\,, \end{equation}
where
 $g$
is a particular control gain (
$g$
is a particular control gain (
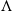 $\Lambda$
or
$\Lambda$
or
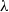 $\lambda$
),
$\lambda$
),
 $g^{N}$
is the nominal value of the control gain,
$g^{N}$
is the nominal value of the control gain,
 $S$
is the current control step and
$S$
is the current control step and
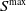 $S^{\max}$
is the number of steps to reach the nominal gain (simulation setting
$S^{\max}$
is the number of steps to reach the nominal gain (simulation setting
 $S^{\max}=120$
). This technique could reduce the joint torques in the beginning of the control (most significant reduction was achieved in case of joint 2), the effect is also visible on the
$S^{\max}=120$
). This technique could reduce the joint torques in the beginning of the control (most significant reduction was achieved in case of joint 2), the effect is also visible on the
 $\ddot q$
values. Figure 8 shows that with noisy feedback signal still high precision trajectory tracking could be achieved. The results also nicely exhibits properties of an FPI-based adaptive control solution, as in the figures the deformed values of the second derivatives of the joint coordinates (
$\ddot q$
values. Figure 8 shows that with noisy feedback signal still high precision trajectory tracking could be achieved. The results also nicely exhibits properties of an FPI-based adaptive control solution, as in the figures the deformed values of the second derivatives of the joint coordinates (
 $\ddot q^{Def}$
) are significantly different from the desired values (
$\ddot q^{Def}$
) are significantly different from the desired values (
 $\ddot q^{Des}$
) which are calculated purely on kinematic basis. This is also indicated by the angle of abstract rotation which is a good measure of the adaptive deformation.
$\ddot q^{Des}$
) which are calculated purely on kinematic basis. This is also indicated by the angle of abstract rotation which is a good measure of the adaptive deformation.
The proposed solution may be applicable in various practical fields, especially in life sciences [Reference Tašić, Takács and Kovács71, Reference Dineva, Tar, Vákonyi-Kóczi and Piuri72], fluid tank control [Reference Khan, Issa and Tar73] or in robotics where control robustness and fast asymptotic error convergence is essential.
6. Experimental analysis
To further validate the effectiveness of the proposed control method, a simple experimental setup is presented in this section. The control method was evaluated through a DC motor control application with time varying load.
The experimental setup consisted of a 12 V DC motor (type FIT0185 [74]) with an inbuilt encoder and planetary gearbox with 131:1 reduction ratio. The electric motor was driven with a BTS7960-M [75] dual half bridge motor drive.
The output shaft was connected to a spring through a special coupling which provided a time varying load in our system. The loading torque (
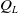 $Q_L$
) applied by the spring on the output shaft can be calculated using Lagrangian-equation and Euler-Lagrange Equation of motion as
$Q_L$
) applied by the spring on the output shaft can be calculated using Lagrangian-equation and Euler-Lagrange Equation of motion as
 \begin{equation} Q_L=\theta _{w}\ddot{q}+D_{s} l_el_t\sin{q}\left ( 1-\frac{ l_{r0}}{\sqrt{l_e ^2+ l_t^2- 2 l_el_t\cos{q}}}\right ) \,, \end{equation}
\begin{equation} Q_L=\theta _{w}\ddot{q}+D_{s} l_el_t\sin{q}\left ( 1-\frac{ l_{r0}}{\sqrt{l_e ^2+ l_t^2- 2 l_el_t\cos{q}}}\right ) \,, \end{equation}
where
 $\theta _w$
is the inertia of the coupling,
$\theta _w$
is the inertia of the coupling,
 $D_s$
is the spring constant,
$D_s$
is the spring constant,
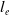 $l_e$
denotes the lever on which the loading torque of the spring is applied,
$l_e$
denotes the lever on which the loading torque of the spring is applied,
 $l_t$
is the distance between the fixed mounting point of the spring and the motor shaft and finally
$l_t$
is the distance between the fixed mounting point of the spring and the motor shaft and finally
 $l_{r0}$
is the length of the spring in the initial position of the motor (shown in Fig. 9).
$l_{r0}$
is the length of the spring in the initial position of the motor (shown in Fig. 9).

Figure 9. Mechanical design of the experimental setup (left) and simplified dynamic model (right).
The position of the output shaft was measured through the inbuilt incremental encoder, which has a relatively low resolution (16 CPR – Counts per Rotations – for the motor shaft). However, the position of the output shaft could be precisely measured, as the encoder resolution for the output shaft is 2096 CPR, due to the high reduction ratio of the planetary gearbox.
In our experimental setup, the control algorithm was written in C++ and running on an Arduino DUE Board with Atmel SAM3X8E ARM Cortex-M3 32-bit processor. The adaptive deformation was applied for the PWM (Pulse Width Modulation) output of the controller (see Fig. 10). All measurement data were sent to a PC with a custom-made monitoring software, which allowed us to display multiple data in real-time. The measurement results were saved in .csv (comma separated values) file and then processed in a separate script. The schematic of the full experimental setup is given in Fig. 11.

Figure 10. Program flow chart for the two different control solutions. In case of WSPD controller, the FIFO buffer with appropriate memory length
 $(H)$
is used (short-term memory of the proposed control solution), for PID control
$(H)$
is used (short-term memory of the proposed control solution), for PID control
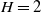 $H=2$
, only the current and the data from the previous control cycle is used to do the backward difference estimation for the
$H=2$
, only the current and the data from the previous control cycle is used to do the backward difference estimation for the
 $\dot q^R(t)$
and
$\dot q^R(t)$
and
 $\ddot q^R(t)$
signals.
$\ddot q^R(t)$
signals.

Figure 11. Schematic of the experimental setup.
6.1. Control design for the experimental setup
The position feedback of the output shaft was obtained through the inbuilt magnetic quadrature encoder of the motor. The speed measurement (
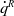 $\dot q^R$
) was characterized by considerable noise component due to quantization error (which is typical for low-resolution encoders). In order to reduce effects of the measurement noise, a simple Infinite Impulse Response low pass filter was implemented in our control algorithm. The cutoff frequency of the low pass filter was selected as
$\dot q^R$
) was characterized by considerable noise component due to quantization error (which is typical for low-resolution encoders). In order to reduce effects of the measurement noise, a simple Infinite Impulse Response low pass filter was implemented in our control algorithm. The cutoff frequency of the low pass filter was selected as
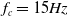 $f_c=15Hz$
, which resulted in good noise attenuation without significant delay. The transfer function of the digital low-pass filter was obtained through bilinear transformation [Reference Ifeachor and Jervis76].
$f_c=15Hz$
, which resulted in good noise attenuation without significant delay. The transfer function of the digital low-pass filter was obtained through bilinear transformation [Reference Ifeachor and Jervis76].
The control design procedure was divided into three parts according to Fig. 1.
-
Mathematical Model: In Fixed Point Iteration-based adaptive control methods, the necessary control forces (
$Q$
) are generated from the adaptively deformed
$\ddot q^{Def}$
value using an “available” dynamic model of the controlled system which is typically imprecise. However, in ref. [Reference Varga, Horváth and Tar77], “quasi” model-free approach was introduced which utilized a very simple affine model as
$Q=A \ddot q^{Def}+B$
to control an under-actuated system where not all state variables could be measured. The affine model parameters
$A,B$
could be arbitrarily set by the user and it was shown through simulations that the parameters could be set in wide range without significantly compromising the control performance. To further simplify the control approach and reduce the amount of “tunable” parameters, in our experiments, the adaptive deformation was directly applied on the PWM output (
$Q_{PWM}$
) of the controller, essentially
$\ddot q^{Def}\equiv Q_{PWM}$
. -
Adaptive Deformation: Throughout the trajectory tracking applications, in our experiments the same adaptive deformation block was applied, which was implemented using abstract rotations [Reference Csanádi, Galambos, Tar, Györök and Serester66]. The essence of this solution is given in Section 4. The adaptive parameter was
$\lambda _a=1$
and the initial condition was
$\ddot q^{Des} (1)=\ddot q^{Def} (1)$
. -
Kinematic Prescription: The kinematic prescription can be formulated in various manners. The most commonly used solution is a PID-type feedback, which will be our baseline for comparison. For the PID-type feedback, the desired value of the
$2\textrm{nd}$
derivative of the angular position (
$\ddot q^{Des}$
) was calculated according Eq. (4). For the proposed WSPD feedback in Eq. (30), each weight coefficient was set as
$C_{\ell }=((\epsilon +\ell )\delta t)^{-p}$
, where
$\epsilon =0.1$
,
$\delta t$
is the cycle time of the controller (or sampling time) and
$p$
was appropriately set to achieve sufficient control performance. The memory length for all of our experiments is
$H=350$
.
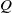
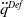
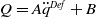



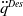





6.2. Set-point tracking
In the first set of experiments, the motor was driven through multiple set points with no adaptive deformation, which provides a good basis for comparison of the transient behavior of different control solutions. The quality of the control was characterized by the steady-state error (
 $e_{ss}[\textrm{rad}]$
), the percentage overshoot (
$e_{ss}[\textrm{rad}]$
), the percentage overshoot (
 $\sigma _{\%} [\%]$
) and the settling time (
$\sigma _{\%} [\%]$
) and the settling time (
 $t_s [\textrm{s}]$
), shown in Table III. The settling time was measured for
$t_s [\textrm{s}]$
), shown in Table III. The settling time was measured for
 $0.05\,\textrm{rad}$
error band. The measurement results are given in Fig. 12 for PID controller on the left and for the proposed WSPD on the right. The experiments were carried out for multiple gain settings for both control solutions.
$0.05\,\textrm{rad}$
error band. The measurement results are given in Fig. 12 for PID controller on the left and for the proposed WSPD on the right. The experiments were carried out for multiple gain settings for both control solutions.
Table III. Transient response analysis (steady-state error (
 $e_{ss} [\textrm{rad}]$
), percentage overshoot (
$e_{ss} [\textrm{rad}]$
), percentage overshoot (
 $\sigma _{\%} [\%]$
) and settling time (
$\sigma _{\%} [\%]$
) and settling time (
 $t_s [\textrm{s}]$
)), kinematic block parameters (
$t_s [\textrm{s}]$
)), kinematic block parameters (
 $\Lambda [\textrm{s}^{-1}],\lambda [\textrm{s}^{-1}]$
).
$\Lambda [\textrm{s}^{-1}],\lambda [\textrm{s}^{-1}]$
).


Figure 12. Measurement results for set-point tracking with multiple gain settings (
 $ \Lambda [s^{-1}],\lambda [s^{-1}]$
) with no adaptive deformation and no load on the motor.
$ \Lambda [s^{-1}],\lambda [s^{-1}]$
) with no adaptive deformation and no load on the motor.

Figure 13. Measurement results with adaptive deformation and no load on the motor.
The measurement result meets our preliminary expectations. In case of PID controller, higher
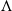 $\Lambda$
values yield lower steady-state error and faster control response, however, induce more oscillations and more significant overshoots, especially for higher jumps in the set point (e.g., set-point 3). Furthermore, more oscillations can compromise settling time as well. On the other hand, low
$\Lambda$
values yield lower steady-state error and faster control response, however, induce more oscillations and more significant overshoots, especially for higher jumps in the set point (e.g., set-point 3). Furthermore, more oscillations can compromise settling time as well. On the other hand, low
 $\Lambda$
values produce slow control responses, which yield high settling times as well and also higher steady-state errors. In our experiments, we found
$\Lambda$
values produce slow control responses, which yield high settling times as well and also higher steady-state errors. In our experiments, we found
 $\Lambda =15$
as the optimal gain value for set-point tracking as it provided acceptable oscillations and overshoot with a relatively low settling time.
$\Lambda =15$
as the optimal gain value for set-point tracking as it provided acceptable oscillations and overshoot with a relatively low settling time.
Table IV. Trajectory tracking comparison (maximum absolute error –
 $e_{\max}\,[\textrm{rad}]$
, average absolute tracking error –
$e_{\max}\,[\textrm{rad}]$
, average absolute tracking error –
 $\mu _e [\textrm{rad}]$
, standard deviation of the trajectory tracking error –
$\mu _e [\textrm{rad}]$
, standard deviation of the trajectory tracking error –
 $\sigma _e$
).
$\sigma _e$
).

In our experiments, we found that relatively low forgetting speed (
 $p=1$
) yielded good results for set-point tracking for the proposed WSPD. With appropriate
$p=1$
) yielded good results for set-point tracking for the proposed WSPD. With appropriate
 $\Lambda$
and
$\Lambda$
and
 $\lambda$
settings, very nice asymptotic error convergence was achieved with no overshoot and without compromising the settling time (fast control response). However, high
$\lambda$
settings, very nice asymptotic error convergence was achieved with no overshoot and without compromising the settling time (fast control response). However, high
 $\Lambda$
gain combined with a relatively low
$\Lambda$
gain combined with a relatively low
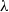 $\lambda$
value could still produce some oscillations with small overshoot (e.g.,
$\lambda$
value could still produce some oscillations with small overshoot (e.g.,
 $\Lambda =60$
with
$\Lambda =60$
with
 $\lambda =85$
) but still much less significant than that in case of PID feedback. We found that approximately
$\lambda =85$
) but still much less significant than that in case of PID feedback. We found that approximately
 $1\;:\;4$
,
$1\;:\;4$
,
 $\Lambda$
to
$\Lambda$
to
 $\lambda$
ratio (e.g.,
$\lambda$
ratio (e.g.,
 $\Lambda =25, \lambda =95$
) yielded very nice control response and no oscillations for set-point tracking. All in all, the proposed weighted sum feedback outperformed the simple PID controller for set-point tracking, since it eliminated overshoots which yielded much lower settling times with similar steady-state error.
$\Lambda =25, \lambda =95$
) yielded very nice control response and no oscillations for set-point tracking. All in all, the proposed weighted sum feedback outperformed the simple PID controller for set-point tracking, since it eliminated overshoots which yielded much lower settling times with similar steady-state error.
6.3. Trajectory tracking
In the second set of experiments, the proposed feedback term was tested in a trajectory tracking application, with
 $q^N=4\pi \cos (0.2\pi t)$
reference trajectory. Our experiments included multiple scenarios for PID control and the proposed WSPD feedback as well, including experiments with- and without FPI-based adaptive deformation and different loading conditions to test the robustness of the controllers. The control performance indexes for these experiments were:
$q^N=4\pi \cos (0.2\pi t)$
reference trajectory. Our experiments included multiple scenarios for PID control and the proposed WSPD feedback as well, including experiments with- and without FPI-based adaptive deformation and different loading conditions to test the robustness of the controllers. The control performance indexes for these experiments were:
-
Maximum absolute error:
$e_{\max}=\max \limits _{i=1,2,\ldots,N}(|e(i)|)$
; -
Average absolute tracking error:
$\mu _e=\frac{1}{N}\sum _{i=1}^{N}{|e(i)|}$
; -
Standard deviation of the trajectory tracking error:
$\sigma _e=\sqrt{\frac{1}{N}\sum _{i=1}^{N}{(|e(i)|-\mu _e)^2}}$
.
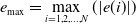
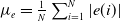

The performance indexes were calculated only for the
 $10-45\,\textrm{s}$
interval, that way eliminating the effects of the transient phase, since it was already observed that the proposed control method can eliminate the oscillations and overshoots at the initial phase of the control.
$10-45\,\textrm{s}$
interval, that way eliminating the effects of the transient phase, since it was already observed that the proposed control method can eliminate the oscillations and overshoots at the initial phase of the control.
In Fig. 13, some results are given for FPI-based adaptive controller with PID and WSPD kinematic block. In these experiments, the spring was not mounted on the DC motor, that way no external load was applied to the output shaft. These figures nicely exhibit the effect of the quantization error of the encoder signal, causing considerable noise in the first derivative (
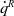 $\dot q^R$
) and more so in the second derivative (
$\dot q^R$
) and more so in the second derivative (
 $\ddot q^R$
) of the state variable
$\ddot q^R$
) of the state variable
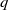 $q$
. The noise was attenuated by the applied low pass filter (
$q$
. The noise was attenuated by the applied low pass filter (
 $f_c=15\,\textrm{Hz}$
) and the filtered signals (
$f_c=15\,\textrm{Hz}$
) and the filtered signals (
 $\dot q^S$
,
$\dot q^S$
,
 $ \ddot q^S$
) were used to calculate the control response. The control cycle time for the FPI-based adaptive PID controller was
$ \ddot q^S$
) were used to calculate the control response. The control cycle time for the FPI-based adaptive PID controller was
 $\delta t_{PID}=0.0015\,\textrm{s}$
and for the FPI-based adaptive WSPD controller, it was
$\delta t_{PID}=0.0015\,\textrm{s}$
and for the FPI-based adaptive WSPD controller, it was
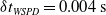 $\delta t_{WSPD}=0.004\,\textrm{s}$
due to higher computational requirements. Both controllers yielded precise trajectory tracking, and the average and the standard deviation were near to the resolution of the encoder (2096 CPR yields approximately
$\delta t_{WSPD}=0.004\,\textrm{s}$
due to higher computational requirements. Both controllers yielded precise trajectory tracking, and the average and the standard deviation were near to the resolution of the encoder (2096 CPR yields approximately
 $0.003\,\textrm{rad}$
resolution). The proposed WSPD method in combination with the adaptive deformation could completely eliminate the initial oscillations, however, it is more noise sensitive and produced slightly higher error. In Table IV, PID controller with FPI-based adaptive deformation slightly outperformed the adaptive WSPD controller almost in all aspects when no load was applied.
$0.003\,\textrm{rad}$
resolution). The proposed WSPD method in combination with the adaptive deformation could completely eliminate the initial oscillations, however, it is more noise sensitive and produced slightly higher error. In Table IV, PID controller with FPI-based adaptive deformation slightly outperformed the adaptive WSPD controller almost in all aspects when no load was applied.
In the next step, we repeated the same experiments with the spring applied to the shaft. To test the controllers‘ robustness, the measurements were made with two different springs (Fig. 14):

Figure 14. Tracking error for DC motor control with different loads (Load 1 –
 $D_s=1.611\,\frac{\textrm{N}}{\textrm{mm}}$
Load 2 –
$D_s=1.611\,\frac{\textrm{N}}{\textrm{mm}}$
Load 2 –
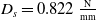 $D_s=0.822\,\frac{\textrm{N}}{\textrm{mm}}$
) using FPI control, implemented with different kinematic blocks (PID and WSPD).
$D_s=0.822\,\frac{\textrm{N}}{\textrm{mm}}$
) using FPI control, implemented with different kinematic blocks (PID and WSPD).
-
Load 1 –
$D_s=1.611\,\frac{\textrm{N}}{\textrm{mm}}$
; -
Load 2 –
$D_s=0.822\,\frac{\textrm{N}}{\textrm{mm}}$
.
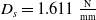

These results are given in Table IV as well, which revealed that, despite that the adaptive PID controller yielded better average tracking error and standard deviation when no load was applied, the proposed adaptive WSPD controller had better results for both performance indices when the load was applied. The difference in robustness is more significant when no adaptive deformation was applied (Fig. 15).

Figure 15. Measurement results for DC motor control without adaptive deformation (
 $\Lambda [\textrm{s}^{-1}],\lambda [\textrm{s}^{-1}]$
) under multiple loading conditions (Load 1 –
$\Lambda [\textrm{s}^{-1}],\lambda [\textrm{s}^{-1}]$
) under multiple loading conditions (Load 1 –
 $D_s=1.611\,\frac{\textrm{N}}{\textrm{mm}}$
Load 2 –
$D_s=1.611\,\frac{\textrm{N}}{\textrm{mm}}$
Load 2 –
 $D_s=0.822\,\frac{\textrm{N}}{\textrm{mm}}$
).
$D_s=0.822\,\frac{\textrm{N}}{\textrm{mm}}$
).
7. Conclusion
In this paper, a fractional order calculus-inspired weighted sum-type feedback was investigated, which can be used in a fixed point iteration-based control scenario for motion control applications. It is similar to FOC solutions since the proposed feedback term exhibits memory effect, which correlates to better transient response and robust behavior but is exempt from the complex formal restrictions of fractional calculus and has a very simple mathematical structure. This control method does not require the continuous tuning of control gain parameters compared to other adaptive FOC solutions [Reference Timis, Muresan and Dulf27], which can be computationally expensive. It also directly aims the decrease the error of certain state variables in an iterative manner, that way the unexpected behavior of the state variables can be avoided in the transient state. The proposed controller can work with a very simple affine mathematical model in a “quasi” model-free approach. The basic idea was introduced in ref. [Reference Varga, Horváth, Tar, Müller and Brandstötter29], with a simple weighted sum feedback. However, it was shown through simulations that original solution can generate very high control force which can lead to significant chattering in the control output. To avoid this effect the control method was further developed in this paper by incorporating the solution in a PD-type feedback. The proposed control structure is applicable for strongly non-linear systems, where traditional frequency domain-based (e.g., ref. [Reference Dulf26]) controller tuning methods are hard to implement.
It was shown on simulation basis that the proposed Weighted Sum PD-type (WSPD) feedback yields very good transient response, similar to its predecessor without generating excessive control force and output chattering. However, it was also revealed that it requires relatively large number of terms (longer memory) and low control cycle time in the weighted sum design. However, it was also shown through the experiments that modern micro-controllers are more than capable to deal with the extra computational demand since relatively low control cycle time was achieved for the weighted sum design (
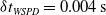 $\delta t_{WSPD}=0.004\,\textrm{s}$
), although for the PID-type kinematic block, it was
$\delta t_{WSPD}=0.004\,\textrm{s}$
), although for the PID-type kinematic block, it was
 $\delta t_{PID}=0.0015\,\textrm{s}$
. The robustness of the WSPD method was also exhibited in this paper since load variations had less effect on the trajectory tracking error, but it had significantly affected the PID controller for adaptive and non-adaptive cases as well. At the same time in certain control scenarios, the PID controller could provide better control performance (e.g., when no load was applied) than the WSPD method, which originates from two issues. (1) In WSPD method, much higher derivative gain is applied, so the solution is slightly more noise-sensitive. (2) With PID-based kinematic block, lower control cycle time was achieved and that way, more adaptive iteration could be made in the same interval compared to the WSPD method. It is also confirmed by the non-adaptive control scenarios presented in Fig. 15 where the WSPD feedback resulted in better control performance for the unloaded case as well.
$\delta t_{PID}=0.0015\,\textrm{s}$
. The robustness of the WSPD method was also exhibited in this paper since load variations had less effect on the trajectory tracking error, but it had significantly affected the PID controller for adaptive and non-adaptive cases as well. At the same time in certain control scenarios, the PID controller could provide better control performance (e.g., when no load was applied) than the WSPD method, which originates from two issues. (1) In WSPD method, much higher derivative gain is applied, so the solution is slightly more noise-sensitive. (2) With PID-based kinematic block, lower control cycle time was achieved and that way, more adaptive iteration could be made in the same interval compared to the WSPD method. It is also confirmed by the non-adaptive control scenarios presented in Fig. 15 where the WSPD feedback resulted in better control performance for the unloaded case as well.
The proposed experimental setup served as a “good proof of concept” which has revealed that a fixed point iteration-based control algorithm can be implemented even on relatively low-power equipment. The noise sensitivity of WSPD method can be investigated in the future by applying a more sophisticated filter design. Also, further investigation can be done about the optimal tuning of the proposed Weighted Sum PD-type feedback using some kind of genetic algorithm.
Author contributions
All authors contributed equally to this work.
Financial support
The publication of this paper was supported by the ÚNKP-22-3 New National Excellence Program of the Ministry for Culture and Innovation from the source of the National Research, Development and Innovation Fund. The research reported in this paper is the part of project no. 2019-1.1.1-PIACI-KFI-2019-00303 supported by the Hungarian State.
Competing interests
The authors declare no competing interests exist.



































































 Open access
Open access