




Introduction
Instructed Second Language Acquisition (ISLA) research has long been interested in how linguistic input can be manipulated to optimize L2 learning. The proliferation of digital technologies facilitates a wider variety of multimodal input, in particular, in which visual (text and/or images) is coupled with auditory input in meaning-focused activities (e.g., Hui, Reference Hui2024). Studies examining the relative benefits of multimodal input on ISLA, especially in vocabulary development, have provided promising findings regarding form and form-meaning learning (e.g., Webb & Chang, Reference Webb and Chang2015; Chen, Reference Chen2021). However, few have provided a theoretical account for the source of these benefits, nor posited a potential mechanism for why these benefits have been found.
In the present study, we utilized a within-participant design in seeking to isolate one potential source of bimodal learning benefits, reading ahead of the audio, in processing and learning new L2 vocabulary during a reading while listening (RWL) task. Other recent work (e.g., Wisniewska & Mora, Reference Wisniewska, Mora and Levis2018; Conklin et al., Reference Conklin, Alotaibi, Pellicer-Sánchez and Vilkaitė-Lozdienė2020) has suggested that L2 readers often read ahead when their eye movements are not synchronized with audio, with more advanced L2 readers mirroring L1 readers by doing so more often. Reading in English obliges activation of sequential orthographic decoding and phonological encoding processes (Coltheart, Reference Coltheart, Snowling and Hulme2005; see Brysbaert, Reference Brysbaert, Snowling, Hulme and Nation2022 for a recent review), and phonological encoding of unfamiliar words in particular could be facilitated by learners encountering the audio forms asynchronously, during the orthographic decoding process, after orthographic forms are encountered, allowing learners to test phonological predictions for new word pronunciation. However, no prior studies have isolated the effects of reading ahead of the audio either on processing measures or learning outcomes, nor employed research designs allowing for within-participant comparisons. By utilizing eye-tracking measurement, this study examined the effects of reading ahead versus not reading ahead across encounters with new words on the initial stages of orthographic decoding of new words (i.e., gaze duration, or GD), in which initial form-oriented processing of vocabulary (Kida & Barcroft, Reference Kida and Barcroft2018) goes through a familiarity check (Reichle & Sheridan, Reference Reichle, Sheridan, Pollatsek and Treiman2015).
Recent eye-tracking studies examining unfamiliar LX word processing during reading have indicated that faster GD times during initial encounters with unfamiliar items indicate a form processing benefit for new words, which frees up visual processing time during subsequent encounters to facilitate the mapping of form to meaning (Elgort et al., Reference Elgort, Brysbaert, Stevens and Van Assche2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016). The present study extends this line of reasoning to test whether reading ahead of the audio would facilitate a similar form processing benefit (i.e., shorter GD when reading ahead than when reading is synchronous or behind the audio) during initial encounters with new words, facilitating form-form connections more quickly when reading ahead than not reading ahead. Additionally, we utilized the proportion of reading ahead across encounters as a predictor of three vocabulary learning posttests measuring different levels of the early stages of word learning (form/meaning recognition; meaning recall), while accounting for individual differences in proficiency and memory. In this way, we tested the extent to which reading ahead of the audio facilitated initial form-form and form-meaning learning of unfamiliar words during contextualized reading.
Background
Prominent models of continuous L1 English reading, such as EZ-Reader (e.g., Pollatsek et al., Reference Pollatsek, Reichle and Rayner2006; Rayner et al., Reference Rayner, Pollatsek, Ashby and Clifton2012), emphasize the centrality of lower-level reading processes, involving orthographic decoding and obligatory phonological encoding, particularly for unfamiliar word forms (Brysbaert, Reference Brysbaert, Snowling, Hulme and Nation2022). Given robust evidence that reading in English can be considered the translation of print to speech (see Rayner et al., Reference Rayner, Pollatsek, Ashby and Clifton2012), these models assume that processing during reading mimics auditory processing in being sequential in nature, and necessarily producing sublexical or prelexical spoken representations in memory (Pollatsek et al., Reference Pollatsek, Reichle and Rayner2006, p. 39). An initial check on word familiarity is conducted sequentially in foveal vision, with each fixated word kept in a working memory buffer. While L2 English reading involves unique challenges during accurate visual processing, it is largely assumed to operate along similar parameters, although slower, more variable, and more effortful (see Cop et al., Reference Cop, Drieghe and Duyck2015; Godfroid, Reference Godfroid2020).
Obligatory phonological encoding of the spoken form of words immediately following orthographic decoding during reading in English (Coltheart, Reference Coltheart, Snowling and Hulme2005; Brysbaert, Reference Brysbaert, Snowling, Hulme and Nation2022) potentially implies psycholinguistic benefits of RWL. Simultaneous auditory and visual information could provide an unobtrusive pathway to helping L2 readers establish form familiarity with new word forms, resulting in subsequent faster processing and more efficient word recognition, an essential aspect of developing reading fluency in L2 English (Cop et al., Reference Cop, Drieghe and Duyck2015). Additionally, providing auditory and visual information simultaneously could facilitate form-form connections by providing a direct and simultaneous comparison between visual text (orthography) and auditory information (phonology) during a continuous and fluent stream of linguistic information. Orthographic decoding would be facilitated at larger grain sizes across exposures to words through accelerating bidirectional form-form mapping, which is essential to efficient word recognition in deep orthographies such as English (Coltheart, Reference Coltheart, Snowling and Hulme2005; Grainger & Ziegler, Reference Grainger and Ziegler2011), while facilitating phonological and orthographic “bootstrapping” (Gor et al., Reference Gor, Cook, Bordag, Chrabaszcz and Opitz2021) in developing visual word identification. Faster and more efficient form-oriented processing from reading ahead than synchronous reading or reading behind the audio could facilitate free additional cognitive resources toward higher-level form-meaning processing (Kida & Barcroft, Reference Kida and Barcroft2018).
This hypothesis has often been supported through vocabulary learning studies comparing learning outcomes from RWL with reading only (RO), with superior learning from RWL typically reported in both form and meaning outcomes (e.g., Brown et al., Reference Brown, Waring and Donkaewbua2008; Webb & Chang, Reference Webb and Chang2015; Malone, Reference Malone2018; Chen, Reference Chen2021), but moderated by L1 and individual difference variables (Teng, Reference Teng2024, and The TwiLex Group, 2024 found no differences between RWL and RO in outcomes). Webb and Chang (Reference Webb and Chang2012) reported greater gains from RWL over RO among beginner-level L2 English learners, moderated by reading skill and vocabulary size. Malone (Reference Malone2018) found superior learning from RWL compared to RO for intermediate English learners on form and meaning outcomes, robust to proficiency and phonological short-term memory (PSTM), and Chen (Reference Chen2021) replicated Malone’s (Reference Malone2018) findings regarding superior effects of form and meaning recognition from RWL compared with RO. Importantly, these general findings of benefits for bimodal input on learning come from studies that included only visual items on learning tests (Uchihara et al., Reference Uchihara, Webb, Saito and Trofimovich2022). However, to this point, to our knowledge, no studies have either made or tested predictions regarding the underlying source of possible learning benefits during RWL.
An important insight into real-time L1 and L2 reading behavior was reported in Conklin et al. (Reference Conklin, Alotaibi, Pellicer-Sánchez and Vilkaitė-Lozdienė2020), who compared L1 and L2 eye movement patterns in RO and RWL groups to measure differences among university-level readers. The text consisted of two 1,500-word experimental stories, and the audio was recorded at a rate of roughly 210 words per minute. Reading was infrequently synchronized with the audio (17% for L1; 33% for L2), and for the asynchronous samples, a very high proportion (nearly 90% for the L1 group, and nearly 80% for the L2 group) read ahead of the audio (around 53% overall for L2 readers). If learners read ahead, while keeping audio in close proximity, the phonological encoding process and establishment of phonological-orthographic form-form connections could benefit substantially from immediate auditory feedback, particularly during early encounters with new words. Evidence for processing benefits would be shown through early measures of eye movements such as gaze duration, which are assumed to reflect orthographic decoding and phonological encoding processes in contextualized L2 reading and word recognition (Elgort et al., Reference Elgort, Brysbaert, Stevens and Van Assche2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016; Rayner et al., Reference Rayner, Pollatsek, Ashby and Clifton2012).
In other words, the temporal sequence of psycholinguistic processing during visual word recognition (visual orthographic decoding followed by sublexical phonological encoding) (see Jiang, Reference Jiang2000; Brysbaert, Reference Brysbaert, Snowling, Hulme and Nation2022) implies that learners see the words first, and then make hypotheses regarding their pronunciation. In this account, the audio would provide an immediate phonological exemplar during obligatory phonological encoding, thereby strengthening the fledgling representation of a newly encountered visual word. Thus, the temporal misalignment between the eyes and the audio could provide psychological alignment between phonological encoding and the exemplars provided in the audio, potentially strengthening form-form connections. Such a direct comparison would not be possible temporally during synchronous eye fixations and audio presentation, or if learners read behind the audio, since learners would not yet be at the phonological encoding stage of visual word recognition. Similarly, the theoretical benefits conferred in form-form mapping would be evidenced in behavioral, psycholinguistic-based measures of form familiarity (i.e., the familiarity check) as measured by gaze duration (GD; see Pollatsek et al., Reference Pollatsek, Reichle and Rayner2006). Faster GD when participants read ahead than when eye movements were synchronous or behind the audio during subsequent encounters with the target words would provide empirical processing evidence that reading ahead supports form-form mapping.
This account indirectly aligns with the findings from research into multimodality more broadly, as Wisniewska and Mora (Reference Wisniewska, Mora and Levis2018) examined improvement in L2 pronunciation from different types of captioned video. They reported that L2 participants read target words ahead of the audio around 70% of the time, and significantly improved pronunciation of target items when viewing a captioned video. However, since their study included video, many targets were skipped, and they did not include asynchrony as a predictor of learning. Conversely, while the findings of Conklin and colleagues (Reference Conklin, Alotaibi, Pellicer-Sánchez and Vilkaitė-Lozdienė2020) provided targeted insights into RWL behavior in L1 and L2 reading, their study made no predictions and had no research questions related to learning outcomes from these processes.
There is a growing body of research indicating vocabulary learning benefits from RWL (e.g., Webb & Chang, Reference Webb and Chang2015; Malone, Reference Malone2018; Teng, Reference Teng2018; Chen, Reference Chen2021). While many of these studies were skillfully designed and produced interesting results, few have provided a theory-based account for why simultaneous input modalities should benefit learners, or in what way(s), and even fewer have made testable predictions for potential mechanisms for benefits. Many have suggested possible sources—assisting the mapping of graphemes to phonemes (Goswami & Bryant, Reference Goswami and Bryant1990), improving L2 text and phrasal segmentation (Webb & Chang, Reference Webb and Chang2015), freeing up mental resources for semantic processing (Malone, Reference Malone2018), and enhancing affective benefits that could impact motivation (Tragant & Vallbona, Reference Tragant and Vallbona2018). However, the empirical case for psycholinguistic benefits has been sparse, and even contested, with very few testable claims beyond possible sources of benefit in discussion sections of journal articles as avenues for future research.
To our knowledge, only one recent SLA study (Galimberti et al., Reference Galimberti, Mora and Gilabert2023) examined issues surrounding the temporal relationship between visual text and auditory processing, to examine the dynamics of multimodality at a more granular level. Galimberti et al. (Reference Galimberti, Mora and Gilabert2023) examined the effects of different types of highlighting of text temporally synchronized to audio during video watching, in order to examine whether and which type of highlighting might benefit learners. They found that highlighting words from the onset of captions (300 ms condition) led to greater attention and rejection of mispronunciations of unfamiliar words, which they took to be evidence of superior phonolexical updating (i.e., more accurate mapping of new word spelling to pronunciation). However, they did not operationalize synchrony between visual and auditory information as an independent variable, but rather at the level of condition. Additionally, the inclusion of video in both Galimberti and colleagues (Reference Galimberti, Mora and Gilabert2023) and Wisniewska and Mora (Reference Wisniewska, Mora and Levis2018) rendered the eye-tracking data much more variable and difficult to interpret, and introduced the theoretical construct of visual-verbal dual coding (see Paivio & Desrochers, Reference Paivio and Desrochers1980).
In order to justify a research agenda focused on learning and instructional materials that include bimodal input and to examine their effects on the initial stages of memory encoding of form and meaning, the theoretical basis underlying assertions of the benefits of RWL on processing and learning must be matched by empirical tests regarding the source(s) of these benefits. The present study was designed to provide a unique connection between psycholinguistic theory, language processing, and vocabulary research in ISLA. In it, we first tested theoretical predictions at the individual level that reading ahead of the audio (i.e., instances where eye fixations on target items occur temporally prior to the auditory presentation) would facilitate faster familiarity checks than when participants were not reading ahead for novel pseudoword forms (measured by GD) across encounters with new words, which would be evidenced by reading ahead as a significant negative within-participant predictor of GD. If simultaneous audio facilitates the phonological encoding process during reading, we expected that it would accelerate the word recognition process itself, resulting in faster familiarity checks across encounters when participants read ahead, compared with reading synchronous to or behind the audio. Since other recent work has indicated that learners begin to process new words similarly to familiar words after 4–6 encounters within a text (Pellicer-Sánchez, Reference Pellicer-Sánchez2016), we anticipated this phonological encoding processing advantage for reading ahead to reveal itself early, during the first 4–6 instances of the words in the text, although we predicted comparable GD from reading ahead and not reading ahead during the first 1–2 encounters. Secondly, we predicted that more efficient orthographic decoding and phonological encoding of unfamiliar words across 10 instances in a contextualized reading task would result in better learning both of pseudoword form and meaning, evidenced by reading ahead as a within-participant predictor of learning in mixed-effects outcome models. To examine these issues, we asked two research questions and made two predictions:
RQ1: Does reading ahead of the audio in RWL facilitate form familiarity across encounters with new words (i.e., faster GD when reading ahead than not reading ahead)?
Prediction 1: Reading ahead of the audio will be a significant negative predictor of GD across instances (i.e., in growth curve model), resulting in faster familiarity checks across encounters when participants read ahead of the audio than when they are not reading ahead.
RQ2: Does reading ahead of the audio in RWL contribute to learning of new word form and meaning, as evidenced by posttest outcomes?
Prediction 2: Reading ahead will be a significant predictor of form and meaning learning, evidenced by the proportion of reading ahead as a significant predictor of three explicit learning outcomes (form/meaning recognition, meaning recall).
Method
For this study, we promoted open science by providing all Supplemental Material, data, and analytical code on Open Science Framework (https://osf.io/cpbqd/?view_only=dfeba92f11ee4301ae44154e33e18c83). This study was part of a larger, pre-registered project examining effects of bimodal input on L2 vocabulary processing and learning which can be found at https://osf.io/a95g6.
Participants
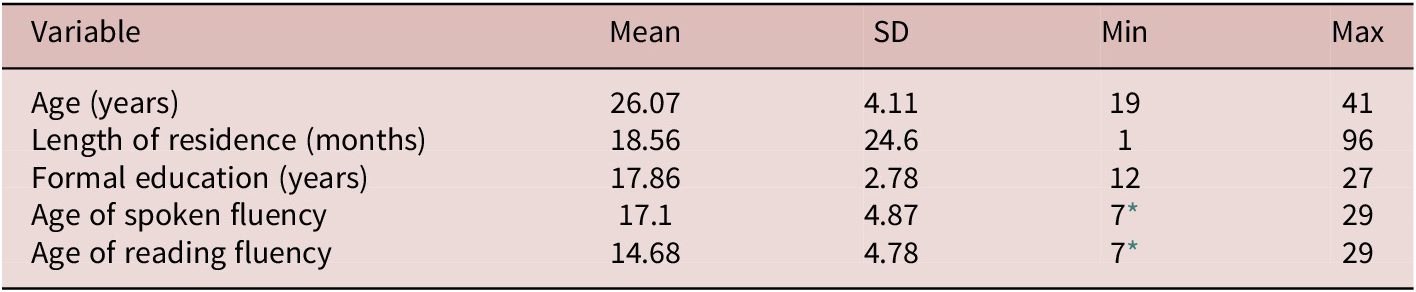
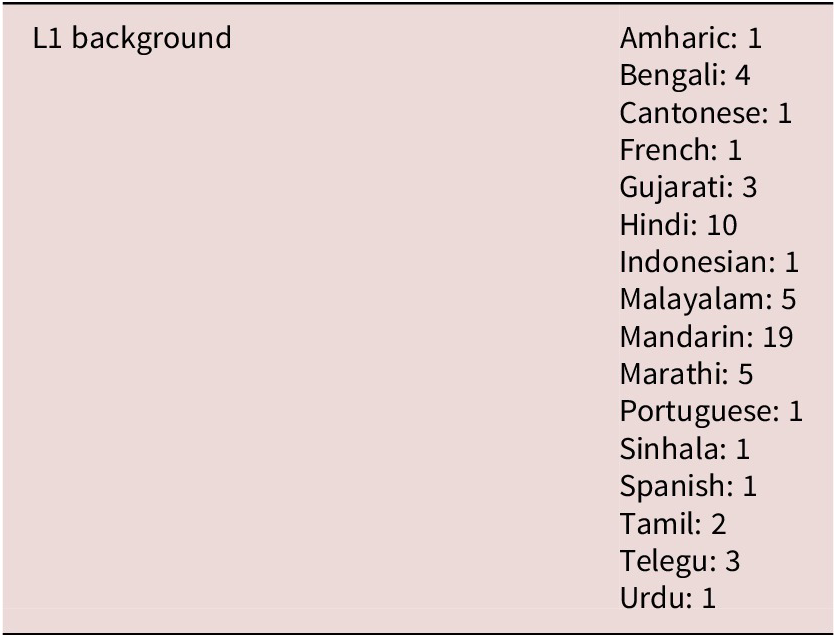
With planned generalized linear mixed-effects models, we estimated optimal sample size using Judd et al.’s (Reference Judd, Westfall and Kenny2017) recommendations and web-based application. Optimal power was set to Cohen’s (Reference Cohen1962) recommendation of .8 or above, the alpha level at .05, and the smallest effect size of interest 0.7. Given the number of targets, this resulted in an estimated sample size of 50. Since other studies utilizing similar methodology with eye-tracking data (e.g., Pellicer-Sánchez, Reference Pellicer-Sánchez2016; Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018) mentioned substantial track loss, we collected initial datasets from 60 participants. One participant’s session was interrupted, and those data were discarded, so analyses proceeded with full datasets from 59 participants. Institutional Research Board approval was granted at a U.S. university in the mid-Atlantic region, and participants were paid $15 for Part 1 of the study and an additional $35 for Part 2 (see Table 3). Participants were mostly undergraduate and graduate university students, from a variety of L1 backgrounds. Table 1 indicates demographic information for participants in terms of age, education, and age of fluency in speaking and reading in English, while Table 2 indicates L1 background. All participants reported normal or corrected-to-normal sight and hearing.
Demographic information of participants

Table 1. Long description
The table consists of five columns: Variable, Mean, S D, Min, and Max.
* Age (years): Mean 26.07, S D 4.11, Min 19, Max 41.
* Length of residence (months): Mean 18.56, S D 24.6, Min 1, Max 96.
* Formal education (years): Mean 17.86, S D 2.78, Min 12, Max 27.
* Age of spoken fluency: Mean 17.1, S D 4.87, Min 7, Max 29.
* Age of reading fluency: Mean 14.68, S D 4.78, Min 7, Max 29.
A footnote indicates that five participants became fluent in reading, listening, or both in English prior to the age of 12, corresponding to the minimum values of 7 in the fluency rows.
* Five participants had become fluent in reading, listening, or both in English prior to the age of 12.
Language background of participants

Table 2. Long description
The table consists of two columns. The left column is titled L 1 background. The right column lists the following languages and their respective participant counts. Amharic 1. Bengali 4. Cantonese 1. French 1. Gujarati 3. Hindi 10. Indonesian 1. Malayalam 5. Mandarin 19. Marathi 5. Portuguese 1. Sinhala 1. Spanish 1. Tamil 2. Telegu 3. Urdu 1.
Experimental task and pseudoword characteristics
Participants read a modified translation of How Much Land Does a Man Need? by Leo Tolstoy (original version obtained from The Literature Network, 2022; see Supplemental Material A for the complete revised version). Nouns in object positions were chosen for pseudoword replacement (see Birch & Rayner, Reference Birch and Rayner2010; Moravcsik & Healy, Reference Moravcsik and Healy1998). Nouns were chosen to maximize parsimony in analytic models, even though this choice limited the generalizability of findings. We particularly wanted to focus on how new nouns are processed and learned, while subsequent planned research can diversify part of speech. All other words in the text above the most frequent 4,000 word families in English (see Webb & Nation, Reference Webb and Nation2017) were identified utilizing the Compleat VocabProfiler (Cobb, Reference Cobb2022) and replaced with more frequent synonyms. This resulted in the replacement of 206 additional words in the text (2.8% of the total words), to ensure lexical coverage above 95% for the most frequent 4,000 word families in English, thereby increasing the likelihood that participants would understand the texts (Waring & Takaki, Reference Waring and Takaki2003). Three comprehension questions per chapter, which did not require knowledge of the target pseudowords, were piloted and implemented to ensure focus on meaning. Pilot testing indicated that participants in the same demographic and roughly the same proficiency level were sufficiently able to read the text and answer the comprehension questions accurately.
Supplemental Material B provides information regarding lexical and contextual characteristics of the original words and pseudoword replacements in the text. During initial text development, the individual words or groups of words were selected among existing concrete and imageable nouns in the text, given their centrality to communicating meaning and the likelihood that participants would try to infer meanings during reading. Given this prerogative and the topic of the text, original words were selected that ranged in meaning from family items, to clothing, to food/drink (tea, kumiss/beer, mutton/bread), to agricultural terms (i.e., hillock, meadow/pasture).Footnote 1 Words with similar or identical meanings (e.g., “child” and “son”) in the original were combined into a single pseudoword item (e.g., “lidger”). In this way, original words from the English translation of the story we used that varied in frequency (e.g., “kumiss/beer”) could be collapsed into a single pseudoword (“snall”), with the general meaning of “a drink” as the correct answer choice in the multiple-choice meaning recognition test. Since only the initial stages of form-meaning mapping were measured, this was considered adequate for maintaining both ecological validity and as much of the original structure of the story as possible.
Concreteness for original items was measured utilizing Brysbaert et al.’s (Reference Brysbaert, Warriner and Kuperman2014) method and was consistently high; frequency from SUBTLEX-US (Brysbaert & New, Reference Brysbaert and New2009) varied more than concreteness, but since original words were replaced in the text, it was considered less important than concreteness for semantic inferencing (e.g., Paivio, Reference Paivio2013). Pseudoword spelling consistency (following English orthographic and phonological conventions) was calculated by averaging rime scores per syllable, utilizing Chee et al.’s (Reference Chee, Chow, Yap and Goh2020) method, and was generally high (0.77 on a 0-1 scale), indicating that phonology and orthography for the targets were relatively connected. The average range of distribution of occurrence was between 500 and 700 words, and Elgort and Warren’s (Reference Elgort and Warren2014) procedure was followed in assessing contextual information (see Supplemental Material C for a full description).
Given the focus on developmental trajectory across instances with the text in processing, along with examples of other recent vocabulary processing studies that found developmental effects most often during the first 10 encounters (Elgort et al., Reference Elgort, Brysbaert, Stevens and Van Assche2018; Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Mohamed, Reference Mohamed2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016), we decided to standardize the repetitions in the text at 10. Instances were distributed across the story as much as possible, typically 500–700 words apart in the text, and care was taken to ensure that knowledge of the pseudowords was not necessary to answering the comprehension questions. See Supplemental Material A for the full text, and Supplemental Material B for additional information about the pseudoword replacements and their location in the reading text.
Apparatus and audio recordings
Conklin and Alotaibi’s (Reference Conklin and Alotaibi2023) methodological recommendations were followed for eye-tracking data collection, utilizing an EyeLink 1000 Plus desk-mounted camera that sampled monocular (right or left) eye movements at 1000 Hz (SR Research, 2010). Participants viewed a computer screen (size: 24 inches, 1920 × 1080 pixels, 60 Hz refresh rate) at a distance of 66 cm, with a chin and forehead rest for stability. Breaks followed each chapter, with re-calibration prior to the following chapter. Task presentation consisted of 190 trial screens, with text triple spaced, black font against white background, monospaced 18-point Courier New font (to ensure psycholinguistic consistency in letter width). Each screen consisted of 2–7 lines of text, left-aligned, and 1-inch margins to minimize spatial recording error. No more than four targets were presented on a single screen, none fewer than four words apart, or on the first or last line, as the first or last word in a line, or the first or last word in a sentence (Rayner & Pollatsek, Reference Rayner and Pollatsek2016; Godfroid, Reference Godfroid2020). One instance of one word was erroneously included as the final word in a sentence, and these data (59 total points) were discarded.
Each screen was visible for the duration of the audio recording, with a two-second delay after the audio concluded. Participants could not return to a prior screen (as explained during the initial instructions to each participant) and were provided with a nine-point calibration prior to each session and after each break, in addition to drift corrections in the top-left at the onset of each screen. Based on visual inspection of the data in real-time, additional calibrations were performed as needed. Participants were reminded to read along with the audio if they were reading noticeably ahead or behind, in order to ensure that they were attending to the reading task without ignoring either the visual text or the audio. Very few reminders were necessary for the participants, indicating that they were both reading and listening to the text. Length of audio recordings varied from 20 to 39 seconds per trial, with audio manipulated to standard rate and volume with Audacity software. Pilot testing indicated that participants at this level of English ability could comfortably read while listening at an audio rate of 160–180 words per minute, so it was manipulated to that speed (following Pawlas et al., Reference Pawlas, Ramig and Countryman1996). Audio versions of the story were recorded by a female native speaker of English and standardized to this rate. To ensure that participants were comfortable during the task and to minimize fatigue, breaks were embedded at the end of each chapter, where participants could relax and move around freely before continuing the task.
Vocabulary outcomes
Three unannounced vocabulary posttests measured initial learning—form/meaning recognition and meaning recall. These were selected to follow a theoretically based pattern of development in receptive vocabulary knowledge at the initial stages of learning from form-form to form-meaning connections, measured through receptive form recognition ➔ receptive meaning recognition ➔ receptive meaning recall (L2-L1 translation) measures (Chaudron, Reference Chaudron1985; Webb, Reference Webb2007; Webb & Nation, Reference Webb and Nation2017). These three measures were deployed utilizing the Psychopy3 Builder interface (Peirce et al., Reference Peirce, Gray, Simpson, MacAskill, Höchenberger, Sogo, Kastman and Lindeløv2019) and its online Pavlovia platform. All items were scored dichotomously and presented in randomized order and modality (visual or auditory) within each test. First, the form recognition task presented 50 items (25 targets, 25 distractors) one at a time with the question “was this word in the story”? (Supplemental Material D). Secondly, participants were instructed to write an L1 translation of each target in a meaning recall task (Supplemental Material E). Finally, a multiple-choice meaning recognition measure employed one target and two distractors (Supplemental Material F). The meaning recognition task was created with each answer (correct and two distractors) including either the correct semantic category for more general terms (i.e., the correct answer for “Berrow” (clothing terms in the original text) was “something you wear,” rather than “something you eat” or “something you look at”) or the specific meaning of targets that were more narrow in meaning (e.g., the correct answer for “Taive” was “a tool,” rather than “a vehicle” or “a person”). Each of these distractors was a viable choice from the text compared with the original and was piloted with a group of 10 participants from a similar demographic (see Supplemental Material B for the full list). For each of the three learning outcomes, auditory items could be heard up to three times.
Individual difference measures
Given previous findings regarding the facilitative roles of L2 proficiency (e.g., Tekmen & Daloğlu, Reference Tekmen and Daloǧlu2006; Chen, Reference Chen2021) and phonological short-term memory (PSTM) (e.g., Martin & Ellis, Reference Martin and Ellis2012; Malone, Reference Malone2018) in contextualized vocabulary learning under incidental conditions, it was considered important to account for both. Because the treatment included both visual and auditory information, we also sought to include proficiency and PSTM measures in both modalities, for a more complete picture of each construct. Three measures of proficiency were administered: (a) an untimed cloze measure of English ability (Brown, Reference Brown1980) (Supplemental Material G), (b) an auditory version of the LexTALE task (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012; Supplemental Material H), and (c) first-pass reading times for a two-screen story preview (with no audio) as a measure of reading speed (Supplemental Material I).
Two PSTM measures were used from the High-Level Language Aptitude Battery (Hi-LAB; Linck et al., Reference Linck, Hughes, Campbell, Silbert, Tare, Jackson, Smith, Bunting and Doughty2013; Doughty, Reference Doughty2019): (a) Auditory running memory span (RMS) (Pollack et al., Reference Pollack, Johnson and Knaff1959; Bunting et al., Reference Bunting, Cowan and Scott Saults2006) presented auditory lists of 12–20 Roman letters at a rate of three per second, with participants instructed to recall the most recent six in order; and (b) a visual nonword span task (NWS) (Gathercole et al., Reference Gathercole, Pickering, Hall and Peaker2001; Linck et al., Reference Linck, Hughes, Campbell, Silbert, Tare, Jackson, Smith, Bunting and Doughty2013) presented lists of seven nonwords visually one by one, followed by presentation of a nonword with the question of whether it was in the previous list.
Procedure
Table 3 describes the procedure for the study, including a language background questionnaire (Supplemental Material J) based on LEAP-Q (Marian et al., Reference Marian, Blumenfield and Kaushanskaya2007). Part 1 consisted of language background, proficiency, and memory measures, while Part 2 included the RWL task, comprehension questions (Supplemental Material K), vocabulary learning outcomes, and debriefing (Supplemental Material L). Table 3 also includes the time duration for each task in each of the two parts of the study.
Study Tasks and Procedure in Chronological Sequence

Table 3. Long description
The table is organized into four columns: Part, Task(s), Measure(s), and Duration.
Part 1 consists of four rows:
* Informed consent: N/A measure, less than 2 min.
* Proficiency tasks: Cloze measure and auditory LexTALE, 15 to 20 min.
* Phonological short-term memory or general processing: R M S and N W S measures, 20 to 25 min.
* Language background questionnaire and participant payment: N/A measure, 5 to 10 min.
A separator row indicates the end of Part 1 and that Part 2 is scheduled on a subsequent day.
Part 2 consists of four rows:
* Informed consent: N/A measure, less than 2 min.
* Reading task and comprehension questions: Reading speed on summary pages, eye-tracking data, and comprehension questions, 65 to 80 min.
* Vocabulary posttests: Form recognition, Meaning recognition, and Form-meaning recall for auditory and visual items, 15 to 30 min.
* Debriefing and participant payment: N/A measure, 5 to 10 min.
Data analysis
Eye-tracking data cleaning and readahead coding
The four-stage fixation cleaning procedure from the Eyelink DataViewer program was utilized (SR Research Ltd.; https://www.sr-research.com/), along with their default cognitive configuration for parsing. Vertical drifts were manually corrected, and no track loss was detected. The initial eye-tracking dataset included 14,691 data points (59 participants × 249 interest areas). Skips of target interest areas were removed to minimize skew in the dataset, which resulted in the removal of 351 data points (2.4%). The cleaned eye-tracking dataset also included extracted start (onset) and finish (offset) timings for interest areas including target words (following Conklin & Alotaibi, Reference Conklin and Alotaibi2023). The readahead variable was then coded dichotomously (1) for instances where the start and end of the first pass reading time were prior to the onset of the audio, and (0) for instances where the start and end of the first pass time were after the onset of the audio.
Model building
Following data cleaning, to answer RQ1, we conducted a growth curve analysis (Godfroid, Reference Godfroid2020; Hui, Reference Hui2020; Mirman, Reference Mirman2014) with GD as the outcome. Model fitting proceeded utilizing the lmer function in the lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) in R version 4.1.2 (R Core Team, 2024). During model fitting, restricted maximum likelihood (REML) was used as the estimation method, and GD was specified as the outcome. Distributions of GD data are positively skewed, so they were log transformed with base e. Predictor variables in the initial model were reading ahead (dummy-coded 0 (no) and 1 (yes)), and instance (i.e., the repeated occurrences of the target words), along with the interaction term. To minimize potential confounds, we included five covariate predictors in the initial model: the three individual difference measures in proficiency (cloze, LexTALE, and reading speed) and the two measures of PSTM (RMS and NWS).
For RQ2, three binomial logistic mixed-effects models (Jaeger, Reference Jaeger2008) were built utilizing the glmer function in the same lme4 package in R (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) version 4.1.2 (R Core Team, 2024). Because scores on form recognition distractor items were high (70–85% accuracy), this was considered strong evidence of accurate rejection of false positives, so distractor items for form recognition were removed from the analysis for parsimony (following Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018). Models were built for each learning outcome, with the continuous predictor of the proportion of reading ahead of the audio included as a fixed effect of interest. In the initial models, all covariate predictors of proficiency and PSTM variables were included. Additionally, given the role of total reading time (TRT) as a measure of individual attention and a predictor of vocabulary learning gains in other recent eye-tracking studies (e.g., Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018), we utilized summed total reading time across all instances for each item as a covariate predictor in the initial models for the learning outcomes.
Comparability for all continuous measures was attained through z-transformations to center and scale. Non-significant covariate fixed effects were removed in a stepwise fashion to arrive at the optimal predictor set, and random slopes for each model (for both RQ1 and RQ2) were included when they did not result in model non-convergence or singularity. Effect sizes were reported as odds ratios for best-fitting logistic models. Supplemental Material M includes all variables and syntax for both initial and best-fitting models for GD and learning outcomes, with syntax for the initial models including all predictors, fixed effects, random effects, and random slopes.
Results
Individual differences, comprehension scores, and measure reliability
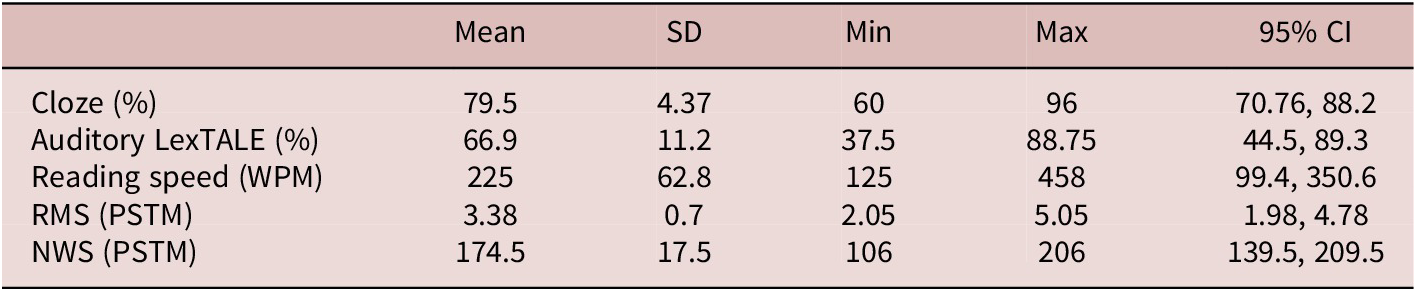
Figure 1 indicates correlations between z-transformed individual difference variables, and Table 4 indicates descriptive statistics for these variables. Correlations were mostly weak to moderate, indicating distinct aspects of each construct, so each measure was included in model building. Comprehension question scores were near ceiling (98%), indicating that participants were focused on meaning during the RWL task. Supplemental Material N provides reliability statistics for each vocabulary learning outcome and individual difference variable of interest, with reliability information (Rasch IRT person reliability and Cronbach’s α) ranging from .64 to 90. Supplemental Material O summarizes model-fit comparisons for initial and best-fitting models for growth curve analyses for GD data (RQ1) and vocabulary learning measures as outcomes (RQ2).
Pearson correlation coefficients and graphs of individual difference variables.
Note: WPM = reading speed in words per minute; RMS = running memory span; NWS = nonword span.

Figure 1. Long description
A multi-panel attribute space diagram organized in a 5 by 5 grid.
Diagonal Panels (Top-Left to Bottom-Right):
* Row 1, Column 1: Histogram for Cloze z with a bimodal distribution curve.
* Row 2, Column 2: Histogram for Lex T A L E z showing a slightly right-skewed distribution.
* Row 3, Column 3: Histogram for W P M z (reading speed) showing a sharp peak and a long right tail.
* Row 4, Column 4: Histogram for R M S z (running memory span) showing a multi-modal distribution.
* Row 5, Column 5: Histogram for N W S z (nonword span) showing a left-skewed distribution.
Upper Triangle (Correlation Coefficients):
* Cloze z correlations: 0.44 with Lex T A L E z, 0.30 with W P M z, 0.19 with R M S z, and 0.36 with N W S z.
* Lex T A L E z correlations: 0.16 with W P M z, 0.07 with R M S z, and 0.04 with N W S z.
* W P M z correlations: 0.12 with R M S z and 0.10 with N W S z.
* R M S z correlation: 0.10 with N W S z.
Lower Triangle (Scatterplots):
* The lower triangle contains scatterplots for each pair of variables. Each plot includes black data points and a red smoothed regression line.
* The plot in Row 2, Column 1 (Lex T A L E z vs Cloze z) shows the strongest positive linear trend.
* Other plots, such as those involving R M S z and N W S z, show more dispersed data points with relatively flat or slightly undulating red lines, indicating weaker correlations.
Axes:
* The x-axes and y-axes for the outer panels are labeled with z-score values ranging generally from negative 4 to positive 3.
Descriptive Statistics for Individual Difference Variables

Table 4. Long description
The table consists of six columns: Variable name, Mean, S D, Min, Max, and 95% C I.
* Cloze percentage: Mean 79.5, S D 4.37, Min 60, Max 96, 95% C I 70.76 to 88.2.
* Auditory LexTALE percentage: Mean 66.9, S D 11.2, Min 37.5, Max 88.75, 95% C I 44.5 to 89.3.
* Reading speed in W P M: Mean 225, S D 62.8, Min 125, Max 458, 95% C I 99.4 to 350.6.
* R M S (P S T M): Mean 3.38, S D 0.7, Min 2.05, Max 5.05, 95% C I 1.98 to 4.78.
* N W S (P S T M): Mean 174.5, S D 17.5, Min 106, Max 206, 95% C I 139.5 to 209.5.
Reading ahead predicting GD (RQ1)
Overall, participants read ahead of the audio nearly 50% of the time, following Conklin et al.’s (Reference Conklin, Alotaibi, Pellicer-Sánchez and Vilkaitė-Lozdienė2020) findings for RWL (roughly 53% reading ahead for advanced L2 readers). Table 5 and Figure 2 provide and visualize descriptive statistics for gaze duration, separated by instances of reading ahead versus not reading ahead across encounters in the text. The best-fitting linear growth model with GD as the outcome (summarized in Table 6 and visualized in Figure 3) indicated significant effects of reading ahead of the audio (b = −.16, SE = .01, p <.001), but not instance (b = −.04, SE = .02, p = .136), as well as a significant reading ahead by instance interaction (b = .10, SE = .03, p = .001). Both auditory LexTALE (b = −.06, SE = .02, p = .003) and reading speed (b = −.05, SE = .02, p = .023) were significant negative covariate predictors of GD.
Descriptive Statistics for Gaze Duration for Target Interest Areas by Instance When Reading Ahead of the Audio and Not Reading Ahead

Table 5. Long description
The table consists of 10 rows representing instances and two primary columns: Reading ahead and Not reading ahead. Each primary column is subdivided into n, M, S D, and 95% C I.
For Reading ahead:
- Instance 1: n 665, M 339.48, S D 202.97, C I [324, 355].
- Instance 2: n 800, M 353.87, S D 206.74, C I [340, 368].
- Instance 3: n 578, M 337.89, S D 203.89, C I [321, 355].
- Instance 4: n 715, M 341.73, S D 204.44, C I [327, 357].
- Instance 5: n 733, M 345.47, S D 196.58, C I [331, 360].
- Instance 6: n 601, M 345.43, S D 191.20, C I [330, 361].
- Instance 7: n 858, M 393.01, S D 215.96, C I [379, 407].
- Instance 8: n 946, M 352.92, S D 202.82, C I [340, 366].
- Instance 9: n 788, M 347.09, S D 186.94, C I [334, 360].
- Instance 10: n 544, M 349.76, S D 183.84, C I [334, 365].
For Not reading ahead:
- Instance 1: n 781, M 421.77, S D 228.42, C I [405, 438].
- Instance 2: n 654, M 437.26, S D 213.53, C I [421, 453].
- Instance 3: n 875, M 420.94, S D 215.41, C I [407, 435].
- Instance 4: n 727, M 420.54, S D 218.89, C I [405, 436].
- Instance 5: n 695, M 415.96, S D 211.23, C I [400, 432].
- Instance 6: n 838, M 385.08, S D 202.82, C I [371, 399].
- Instance 7: n 528, M 388.06, S D 217.13, C I [370, 407].
- Instance 8: n 487, M 388.35, S D 192.69, C I [371, 405].
- Instance 9: n 643, M 432.54, S D 218.19, C I [416, 460].
- Instance 10: n 884, M 388.31, S D 216.13, C I [374, 403].
Data visualization for gaze duration raw means across instances by reading ahead (1) versus not reading ahead (0).

Figure 2. Long description
The x-axis is labeled Instance and ranges from 1 to 10. The y-axis is labeled Gaze Duration m s and ranges from 250 to 500. A legend on the right identifies two categories for readahead. 0 represented by purple circles and 1 represented by orange triangles. Both lines include vertical error bars and are overlaid on light gray shaded confidence intervals with dashed trend lines.
* Group 0 purple line. Starts at approximately 425 m s at instance 1, peaks at 440 m s at instance 2, and gradually declines to a low of 385 m s at instance 6. It remains stable until instance 8, spikes to 435 m s at instance 9, and ends at 390 m s.
* Group 1 orange line. Starts lower at approximately 340 m s and remains relatively flat between 340 and 350 m s for instances 1 through 6. It shows a significant sharp peak at instance 7, reaching nearly 400 m s, where it briefly exceeds Group 0. It then drops back to approximately 350 m s for the remaining instances 8 through 10.
* The two groups converge most closely at instance 7, while Group 0 is consistently higher at all other points.
Best-fitting Model Summary for Gaze Duration Outcome

Table 6. Long description
The table is organized into seven columns: Fixed effects, b, S E, 95% C I, t, p, and Exp(b).
Fixed Effects section:
* Intercept: b = 5.87, S E = .02, 95% C I = 5.82 to 5.91, t = 260.260, p < .001, Exp(b) = 354.249.
* Readahead: b = -0.23, S E = .02, 95% C I = -0.26 to -0.19, t = -11.427, p < .001, Exp(b) = .79.
* Instance: b = -0.04, S E = .03, 95% C I = -0.09 to .01, t = -1.490, p = 0.136, Exp(b) = .96.
* Readahead:Instance interaction: b = .10, S E = .03, 95% C I = .04 to .15, t = 3.308, p = .001.
Covariates section:
* Lex T A L E: b = -0.06, S E = .02, 95% C I = -0.09 to -0.02, t = -3.004, p = .003, Exp(b) = .94.
* W P M (reading speed): b = -0.05, S E = .02, 95% C I = -0.09 to -0.01, t = -2.266, p = .023, Exp(b) = .95.
Random Effects section (Variance, S D):
* 1|Participant: Variance = .02, S D = .09.
* 1|Item: Variance = .01, S D = .14.
* Residual: Variance = .25, S D = .50.
Model Statistics:
* N sub participant: 59.
* N sub item: 25.
* Observations: 14340.
* Marginal R super 2 / Conditional R super 2: .048 / .146.
Notes. ***p < .001, **p <.01, *p <.05
Best-fitting model estimates of readahead by instance interaction for gaze duration.

Figure 3. Long description
The X axis is labeled Instance and ranges from 1 to 10. The Y axis is labeled Predicted Values of G D (m s) and ranges from 250 to 400. A legend to the right identifies two readahead conditions: 0 represented by purple circles and 1 represented by orange triangles.
* Readahead 0: This series starts at approximately 375 m s at Instance 1 and shows a steady linear decrease to approximately 340 m s at Instance 10.
* Readahead 1: This series starts at approximately 300 m s at Instance 1 and shows a very slight linear increase, ending just above 300 m s at Instance 10.
Both series include vertical error bars at each data point, indicating the range of variability around the predicted values.
In other words, model results indicate that in instances where participants read ahead of the audio, GD was significantly shorter across all 10 instances of pseudowords in the text than when they read synchronously or behind the audio (see Figure 3). Additionally, the reading ahead by instance interaction indicated that any reduction in GD across instances overall was due to a reduction in GD across instances in cases where participants either were synchronized or behind the audio when they initially looked at the targets, but there was no indication that GD times decreased across instances when participants were reading ahead of the audio.
Reading ahead predicting vocabulary learning (RQ2)
Table 7 indicates descriptive statistics for the three vocabulary learning outcomes. The best-fitting logistic mixed-effects model for form recognition (Table 8) indicated that the proportion of reading ahead for each target was not a significant predictor of form recognition learning (b = .13, SE = .08, p = .129). None of the covariate measures were significant predictors of form recognition in the model.
Descriptive Statistics for Learning Outcome Raw Scores

Table 7. Long description
The table consists of four columns: Learning Outcome, k, M (S D), and 95% C I.
* Form Recognition: k is 25, M (S D) is 18.71 (4.16), and 95% C I is [17.65, 19.77].
* Meaning Recognition: k is 25, M (S D) is 14.22 (3.98), and 95% C I is [13.20, 15.24].
* Meaning Recall: k is 25, M (S D) is 4.12 (4.38), and 95% C I is [3.00, 5.24].
Best-fitting Model Estimates for Learning Outcomes

Table 8. Long description
The table is divided into three main outcome sections: Form recognition, Meaning recognition, and Meaning recall. Each section includes columns for b, S E, 95% C I, z, p, and O R.
Fixed effects:
- Intercept: Significant for all three outcomes (p < .001 for Form recognition and Meaning recall; p = .047 for Meaning recognition).
- Readahead: Significant only for Meaning recall (b = .35, p = .024, O R = 1.42).
- LexTALE: Significant for Meaning recognition (b = .31, p = .003, O R = 1.35); N/A for others.
- Reading speed (W P M): Significant for Meaning recognition (b = .26, p = .017, O R = 1.30) and Meaning recall (b = .84, p < .001, O R = 2.31).
Random effects (Variance and S D):
- 1|Participant (intercept): Variance ranges from .26 (Meaning recognition) to 1.71 (Meaning recall).
- 1|Trial (intercept): Variance ranges from .18 (Meaning recall) to .44 (Meaning recognition).
- LexTALE|Item: Variance of .05 for Meaning recognition.
- Readahead|Item: Variance of 0.19 for Meaning recall.
Notes indicate significance levels: ***p < .001, **p < .01, *p < .05.
Notes. ***p < .001, **p <.01, *p <.05
The best-fitting logistic mixed-effects model for the meaning recognition outcome (Table 8) indicated that reading ahead was not a significant predictor of meaning recognition learning (b = .10, SE = .08, p = .193). Auditory LexTALE (b = .30, SE = .10, p = .003) and reading speed (b = .26, SE = .11, p = .017) were significant covariate predictors of meaning recognition in the model.
The best-fitting logistic mixed-effects model for meaning recall ( Table 8) indicated that reading ahead was a significant predictor of meaning recall learning (b = .35, SE = .16, p = .024). Reading speed (b = .84, SE = .23, p <.001) was a significant covariate predictor of meaning recall.
Table 9 summarizes RQs, predictions, findings, and alignment between predictions and findings related to audiovisual synchrony, processing, and learning outcomes. Reading ahead of the audio was not a significant predictor of form or meaning recognition learning (contra predictions), but it was a significant predictor of meaning recall (as predicted), the most difficult of the three learning tasks.
Summary of Predictions and Alignment of Results

Table 9. Long description
The table consists of four columns: R Q s, Predictions, Findings, and Alignment between R Q and prediction.
Row 1: R Q 1, Prediction 1. Findings show reading ahead resulted in faster G D than not reading ahead. There was a G D times Instance interaction with a decreasing line when not reading ahead and a stable line when reading ahead. Alignment is marked with a checkmark.
Row 2: R Q 2, Prediction 2. Findings show reading ahead was not a significant predictor of form recognition. Alignment is marked with an X.
Row 3: R Q 2, Prediction 2. Findings show reading ahead was not a significant predictor of meaning recognition. Alignment is marked with an X.
Row 4: R Q 2, Prediction 2. Findings show reading ahead was a significant predictor of meaning recall. Alignment is marked with a checkmark.
Discussion
Reading ahead facilitates efficient form processing
To our knowledge, the present study was the first to utilize reading ahead as a real-time behavioral predictor of form familiarity during early instances of contextualized vocabulary learning, while accounting for multiple individual differences in L2 proficiency and memory. We defined reading ahead as instances where eye fixations on target items occur temporally prior to the auditory presentation, and utilized reading ahead as an item-level predictor both of processing speed (RQ1) and learning gains (RQ2). In answering RQ1, we found that reading ahead was a significant, negative predictor of gaze duration (GD), indicating that when participants read ahead of the audio, they were significantly faster in form processing (Reichle & Sheridan, Reference Reichle, Sheridan, Pollatsek and Treiman2015) compared with instances in which they did not read ahead, and this finding was durable across 10 instances of the words in the text. The significant effect of instance and the reading-ahead-by-instance interaction for GD revealed that reading ahead provided a processing advantage for the initial form familiarity check, compared with reading synchronously or after the audio, across encounters with unfamiliar words. We predicted this effect, although our expectation was that during initial encounters, GD times would be roughly equivalent when reading ahead or not reading ahead of the audio. As such, the stability of GD from reading ahead as indicated in Figure 3 was surprising. However, our findings (see Figure 3) clearly indicate a processing advantage from the first instance of unfamiliar words in the text.
These findings align with both L1 (Pollatsek et al., Reference Pollatsek, Reichle and Rayner2006) and L2 (Cop et al., Reference Cop, Drieghe and Duyck2015) versions of the EZ Reader model, in which initial word recognition during reading involves a temporal sequence of lower-level processes (orthographic decoding ➔ phonological encoding), with faster word recognition indicated by faster GD times (Rayner et al., Reference Rayner, Pollatsek, Ashby and Clifton2012). Building on previous work examining the development of word recognition across instances in the text (Godfroid et al., Reference Godfroid, Ahn, Choi, Ballard, Cui, Johnston, Lee, Sarkar and Yoon2018; Pellicer-Sánchez, Reference Pellicer-Sánchez2016), these findings also provide evidence that reading ahead of the audio may facilitate form processing for unfamiliar L2 words during RWL. Even when individual reading speed, reading ability, and vocabulary knowledge were accounted for in statistical models, participants read the unfamiliar targets significantly faster when reading ahead than when eye movements and audio were synchronized, or when participants were reading behind the simultaneous audio. This misalignment between visual and auditory verbal information in the input in this case (i.e., eyes ahead of audio) may indicate psychological alignment between presentation of the audio and phonological encoding, an essential stage of orthographic decoding across prominent models of word recognition in English (see Coltheart, Reference Coltheart, Snowling and Hulme2005; Grainger & Ziegler, Reference Grainger and Ziegler2011; Rayner et al., Reference Rayner, Pollatsek, Ashby and Clifton2012). In other words, auditory presentation following the initial visual decoding process, which aligns the audio and phonological encoding, may facilitate less dependence on initial time spent looking at a word to encode it phonologically, thereby triggering faster eye movement to subsequent words (i.e., word recognition). In contrast, we interpret these findings to indicate that when participants were reading precisely with or behind the audio, the lack of synchrony between the visual decoding/phonological encoding process in the input and in the mind resulted in a slower and more effortful word recognition process, resulting in longer GD times.
Interestingly, this finding was revealed even during the first encounters with unfamiliar items and remained notably stable across instances. Our within-participant analysis showed that participants were consistently faster in the initial decoding process when reading ahead than when not. In cases where participants did not read ahead, the decreasing pattern of GD across instances followed behavioral findings of other reading-only L2 vocabulary studies utilizing eye-tracking methods in developing form familiarity for new words (e.g., Pellicer-Sánchez, Reference Pellicer-Sánchez2016), but the stable pattern of GD in cases of reading ahead provides some evidence that reading ahead of the audio may reduce the form-form decoding burden during RWL, even during initial encounters with new words. Additionally, this finding was robust to the within-participant GD analysis, even while accounting for participant differences in reading speed, multifaceted L2 reading and vocabulary proficiency, and PSTM. While other recent studies found evidence that L2 readers often read ahead of the audio (Conklin et al., Reference Conklin, Alotaibi, Pellicer-Sánchez and Vilkaitė-Lozdienė2020) and that RWL facilitates the learning of explicit form recognition compared with reading only (Chen, Reference Chen2021; Malone, Reference Malone2018; Tuzcu, Reference Tuzcu2023), this study provides unique initial evidence for an input processing advantage for initial form familiarity as reading ahead within RWL. We cautiously interpret these findings to indicate that reading ahead during RWL may facilitate form decoding for unfamiliar words, even during initial encounters. However, since other studies examining the processing of unfamiliar L2 words have not operationalized reading ahead as a predictor of processing, additional work in this area is needed.
Reading ahead facilitates form-meaning mapping for new words
RQ2 examined reading ahead as a predictor of three vocabulary learning outcomes, and results indicated that it only predicted meaning recall, the most difficult of the three learning outcome measures. Given high scores on both form and meaning recognition outcomes, we interpret this finding alongside the GD finding to indicate that reading ahead of the audio during initial encounters could facilitate form-form knowledge (evidenced by the GD data), freeing up cognitive resources for semantic processing during subsequent encounters, resulting in stronger connections between form and meaning. This account is supported by the finding that reading ahead predicted the most difficult of the two form-meaning mapping outcomes (meaning recall). Indirectly, this finding also supports the claim that reading ahead facilitates form-form mapping, given tight theoretical links between form and meaning in the establishment and development of L2 lexical items (see Bordag et al., Reference Bordag, Gor and Opitz2022).
After 10 instances in the text, differentiating effects of reading ahead on form and meaning recognition measures were not found (contra our predictions). However, given other findings regarding the central role that repetition plays in contextual vocabulary learning (see Uchihara et al., Reference Uchihara, Webb, Saito and Trofimovich2022), it is plausible that the frequency of exposure to new words mitigated effects of reading ahead on form and meaning recognition after 10 instances, and these effects were only uncovered in the most difficult outcome (meaning recall). In this study, the proficiency level of participants was high, so it was unsurprising that substantial learning of pseudoword form and meaning was revealed across 10 instances of pseudowords in the text, indicated by recognition scores (see Table 7), and even under incidental conditions. However, for the productive meaning recall task, which required more precise form-meaning mapping between L2 form and L1 concepts, the effects of reading ahead emerged, above and beyond individual differences in proficiency, reading speed, and memory.
Since no other studies have examined these relationships between reading behavior (i.e., reading ahead of the audio) during RWL and learning gains for contextualized vocabulary, comparisons to other studies are challenging. These findings follow other recent studies examining only learning outcomes from reading only and RWL groups, in reporting significant learning of both form and meaning from RWL (e.g., Webb & Chang, Reference Webb and Chang2015; Teng, Reference Teng2018). Conklin and colleagues (Reference Conklin, Alotaibi, Pellicer-Sánchez and Vilkaitė-Lozdienė2020) reported differences in reading behavior during RWL in comparing high-ability L1 readers with high-proficiency L2 readers, in that L2 readers read ahead of the audio less than L1 readers, had fewer skips, and read more slowly than L1 readers. We controlled between-participant variability by measuring and accounting for a battery of cognitive individual differences, including reading speed, to examine whether there would be effects of reading ahead on learning gains. Our findings both of reading ahead as a predictor of GD and meaning recall indicate that for L2 learners, audiovisual asynchrony (i.e., reading ahead of audio) during bimodal reading while listening may play a crucial facilitative role during reading in form familiarity and subsequent processing across exposures, resulting in more efficient word recognition and form-meaning mapping, resulting in better outcomes. In other words, even accounting for individual variability in proficiency, reading speed, and memory, participants learned more about the meaning of the words when they read ahead than when they did not. From an input processing perspective (Barcroft, Reference Barcroft2015), these findings could indicate that reading ahead of the audio during RWL could reduce structural demands on processing through aligning phonological encoding with auditory information, thereby facilitating form-meaning mapping. However, since our study is the first to uncover these effects, they should be tested rigorously in future designs, while comparing gains from reading ahead with instances where participants were reading synchronously or behind the audio.
Limitations and future directions
This study had a number of limitations. It included only immediate and receptive learning posttests of form and form-meaning mapping, which limits any claims we can make regarding durability of learning, and did not include a test of word production. Additionally, the type of mapping selected (new L2 form to existing L1 concept) was specific within the broad possibilities for form-meaning mappings in L2 vocabulary learning (see Kida & Barcroft, Reference Kida and Barcroft2018). As such, generalizable claims regarding learning are limited to L2 form-form and form-meaning mapping. One anonymous reviewer noted that we included both general and specific distractor types on the meaning recognition outcome test, tailored to the meaning associated with that pseudoword item, which could have impacted item responses; 76% of meaning recognition items (19/25) included only specific distractors, 12% (3/25) included only general distractors, and 12% (3/25) had one of each. Descriptive scores indicated notable differences in accuracy between items with specific (58% accurate), generic (67% accurate), or mixed (38% accurate) distractors, so we re-ran the main outcome analysis for the meaning recognition measure with distractor type (specific, generic, mixed) as a categorical predictor. In this analysis, distractor type was not a significant predictor of meaning recognition when other variables were included (b = −.41, SE = .27, p = .127), and did not change other results of the model, so the model without distractor type was retained as the best-fitting model. However, future studies utilizing similar outcome presentation modalities and examining learning of only specific or general items can better control for this potential source of variability in learning.
The study was highly controlled, with pseudoword targets rather than real words, while the audio rate was standardized rather than modified to follow reading speed more closely at the individual level. Reading ahead was defined dichotomously yes/no in the analytic models, so it was not possible to examine the relative effects of lagging behind the audio when reading. Since our RQs focused only on the potential benefits of reading ahead, we did not explore differential impacts of reading precisely synchronously or lagging behind the audio; future studies are warranted which do so, thereby increasing precision and allowing for more specific theoretical predictions for instances when the eye and ear are synchronous, and when the eye lags behind the ear during RWL. The L1s among participants were diverse (see Table 2), which did not allow for an examination of the effects by L1, while recent findings from L2 English reading report evidence that L1-L2 differences may result in variable reading behavior, demonstrated by eye movements (Kuperman et al., Reference Kuperman, Schroeder, Acartürk, Agrawal, Alexandre, Bolliger and Siegelman2025). This would be a fruitful area for future research.
As the present study provides initial evidence that reading ahead of the audio during RWL facilitates faster word form recognition across instances and mapping form to meaning during contextualized learning of new L2 vocabulary, compared with reading synchronously or behind the audio, it has both research and pedagogical implications. For research, future studies should measure the specific (mis)alignment between visual and auditory information, at group and individual levels, to examine the optimal temporal distance between visual and auditory processing, and further explore the theoretical psychological alignment of phonological encoding and auditory information during reading and audio presentation. At the pedagogical level, instructors should be sensitive to student proficiency levels, and the role of L2 ability and reading speed may be important to how RWL facilitates new word learning. Given the proliferation of multimodal digital materials in language learning contexts that utilize authentic materials (e.g., multimedia newspaper articles, podcasts with automatically generated transcripts), language instructors should be sensitive to differences in ability among their students, and how they could impact processing and learning. Additionally, instructors can utilize technological tools, particularly in adaptive artificial intelligence environments, to design and assign multimodal materials at the relative synchrony of individual students, and embed reminders to follow along with the auditory information.
The present study provides unique insights into a potential mechanism for vocabulary benefits of RWL, indicating that reading ahead of the audio predicted faster familiarity checks (i.e., word recognition) and superior form-meaning mapping of new words compared to reading synchronously or behind the audio, during a contextualized reading task under incidental conditions. The stable rate of predicted GD across instances indicates that RWL may change the nature of early encounters with unfamiliar L2 vocabulary in context, by facilitating form-form (phonological-orthographic) mapping, phonological encoding, and subsequent learning. As such, the findings of this study provide crucial insights into a potential underlying mechanism (audiovisual asynchrony) for previously reported benefits of RWL both on processing and outcomes during contextualized L2 vocabulary learning.
Data availability statement
The experiment in this article earned Open Data and Open Materials badges for transparent practices. The data files and R code used in this study are available on OSF: https://osf.io/a95g6.
Acknowledgments
The authors would like to thank Duolingo, The International Research Foundation for English Language Education (TIRF), and the Language Learning journal for their grant support for the larger project from which this study came. The authors would also like to thank Mona Alsalmi, Sanshiroh Ogawa, Mireia Toda Cosi, Tetiana Tytko, and Jill Woodward for their assistance with the project.










 Open access
Open access