




Introduction
This study investigated the effect of two types of vocabulary instruction for visually impaired (VI) and sighted (SI) upper high school learners of English as a foreign language (EFL) in Saudi Arabia, using an “identity-first” approach to terminology “to recognize and honor disability as an inseparable part of one’s identity” (Randez & Cornell, Reference Randez and Cornell2023, p. 998). This kind of investigation is important for several reasons. First, around 2.2 billion people (around 15%) of the global population have some degree of VI (World Health Organization, 2019). Such impairment has been defined as “sight loss that cannot be fully corrected using glasses or contact lenses” (Stewart, Reference Stewart2014, p. 3), covering a broad spectrum of visual acuity “from low vision through total blindness”, with definitions and classifications used variably in different contexts and countries (American Foundation for the Blind, n.d.). Second, rigorous empirical research into how to improve the attainment of VI learners is limited across all curricular areas (Cooney et al., Reference Cooney, Young, Luckner and Ferrell2015), even though they tend to have poorer educational outcomes than SI learners (World Health Organization, 2019). Those outcomes arise potentially because there is some, albeit contested, evidence that VI and limited or absent visual cues may impact cognitive and language development in childhood (Jedynak, Reference Jedynak2016). The dearth of research seems to apply even more so to foreign language learning, where a review article (Schultz & Savaiano, Reference Schultz and Savaiano2023) revealed publications outlining methodologies that can be used for teaching languages to VI learners (all 10 years old or more and/or considering individual learners only) rather than investigating the effects of these methodologies on learners at a class level.
This lack of research may stem in part from an assumption that VI learners acquire a foreign or second language (L2) in the same ways as SI learners do and that, in fact, their better auditory skills place them in an advantageous position (Araluce, Reference Araluce2002). While it is likely that listening is the primary channel through which VI learners obtain information, as we detail in the Literature Review section, their more limited visual experience and, hence, potential difficulty in concept formation may pose a challenge to a fundamental aspect of language learning, namely vocabulary knowledge (Jedynak, Reference Jedynak2016; Staehr, Reference Staehr2008). Therefore, understanding more about how to facilitate L2 vocabulary learning for this group is vital.
Such enhanced understanding is also timely, given moves in many contexts to integrate VI learners into mainstream education over recent years. That is equally true of the context of the present study, Saudi Arabia, where educational integration has been a policy since the early 2000s and is set to expand as part of the country’s 2030 vision goals (Alharbi, Reference Alharbi2022). Yet in inclusive classrooms, where a majority of learners are SI, VI learners of English face particular challenges. Language lessons tend to include a large amount of visually presented input, and teachers reportedly lack insights into how to adapt their teaching to the needs of VI learners (Araluce, Reference Araluce2002; Susanto & Nanda, Reference Susanto and Nanda2018). Hence, an improved understanding of the impact of different teaching methods on VI learners’ L2 outcomes is urgently needed.
Literature review
Visual impairment and language development
Since the 1980s, an important but unresolved area of debate in research concerns how well VI children form general concepts in the L1. It has been suggested that VI children experience a delay in forming concepts and categorization schemata because of lack of vision and hence being less able to draw on external context (Andersen, Dunlea & Kekelis, Reference Andersen, Dunlea and Kekelis1984). Other researchers, following the seminal work of Warren (Reference Warren1994), have proposed that while lack of vision may restrict VI children’s ability to generalize language use across different contexts, they are nevertheless still able to understand the meaning of words, perhaps because they use touch and other senses to form mental images (Pérez-Pereira & Conti-Ramsden, Reference Pérez-Pereira and Conti-Ramsden2013). As such, they seem to have capabilities in understanding word meanings that are very similar to those of SI children.
More recent research has not resolved these debates (Jedynak, Reference Jedynak2016; Smeds, Reference Smeds2015), meaning that it is perhaps safest to conclude that VI individuals may experience some difficulties with L1 concept formation, yet the exact nature and extent of such difficulties are contested and variable (Campbell et al., Reference Campbell, Casillas and Bergelson2024). Turning to L2, those difficulties suggest that they may struggle within an L2 classroom to comprehend the meaning of both non-abstract and abstract concepts. The possibility of concept formation difficulty may make it all the more important to provide support for VI learners in the L1–L2 mapping phase, perhaps by drawing on the L1 (Jedynak, Reference Jedynak2016). Likewise, L2 instruction is likely most effective if it is tailored to VI learners’ strengths, such as enhanced auditory skills, believed to occur because sensory impairment leads to the enhancement of other sensory modalities through a compensatory mechanism (Sabourin et al., Reference Sabourin, Merrikhi and Lomber2022). VI individuals have also been found to have superior verbal memory performance, heightened phonological awareness for speech sound, and greater pitch discrimination compared to SI participants, although there may be variability depending on the age of onset of blindness (Gougoux et al., Reference Gougoux, Lepore, Lassonde, Voss, Zatorre and Belin2004; Sepúlveda et al., Reference Sepúlveda-Palomo, del Río, Villalobos and Fernández González2024; Smeds, Reference Smeds2015). These last two areas of strength suggest that L2 input can be most helpfully provided in auditory format. To understand what this might mean for vocabulary learning, we turn next to theories of L2 vocabulary learning.
Theories of vocabulary learning and their relevance to VI learners
Noticing
A critical aspect of vocabulary learning is noticing. According to Schmidt (Reference Schmidt, Chan, Chin, Bhatt and Walker2012), input that is consciously noticed becomes intake for language learning, and while vocabulary can be learned incidentally, deliberate attention is crucial. Furthermore, learners must focus on the words’ form and input cues to recognize meaning. Learners may not, however, necessarily do that spontaneously, especially if they are of low proficiency and/or have limited attentional resources. As VanPatten (Reference VanPatten and VanPatten1996) has argued (primarily in relation to grammar but with implications for vocabulary learning as well), L2 learners process input for meaning before form, and their cognitive resources are exploited to attend to only aspects of form that are essential for understanding the meaning.
Input enhancement
A pedagogical response to these noticing issues is input enhancement (Sharwood Smith, Reference Sharwood Smith1993), whereby the input is manipulated in different ways to increase the likelihood of drawing learners’ attention to target lexical items. Studies investigating the impact of such enhancement have mainly done so with respect to written input through, for example, boldening or underlining (LaBrozzi, Reference LaBrozzi2016). Given that for VI learners, the input channel is most likely to be aural, other input enhancement methods are needed.
Enhancement methods that have been investigated for aural input for SI learners include explanations of the target items in either the L2 or L1 (Hennebry et al., Reference Hennebry, Rogers, Macaro and Murphy2017; Lee & Levine, Reference Lee and Levine2020; Tian & Macaro, Reference Tian and Macaro2012; Zhang & Graham, Reference Zhang and Graham2020a) or manipulation of aspects of the aural input itself (aural input manipulation [AIM]), such as volume, pitch, speed, and pausing (Cho & Reinders, Reference Cho, Reinders, Bergsleithner, Frota and Yoshioka2013; Ito, Reference Ito2021; Jones & Waller, Reference Jones and Waller2017; Mall-Amiri et al., Reference Mall-Amiri, Oghyanous and Zohrehvand2017). These two groups of studies have largely followed the pedagogical approach of lexical focus-on-form (lexical FonF). FonF has been defined as teaching that “overtly draws students’ attention to linguistic elements as they arise incidentally in lessons whose overriding focus is on meaning or communication” (Long, Reference Long1991, pp. 45–46). Lexical FonF arguably combines the merits of incidental vocabulary learning (i.e., as a by-product of reading or listening to language for communicative purposes) and intentional or explicit vocabulary learning/teaching. Given VI learners’ challenges from lack of visual cues and potential difficulties with mapping L1 concepts to L2 words, lexical FonF may offer particular benefits for them.
L1 use as input enhancement. In the studies cited above exploring oral explanations, all examined the impact of codeswitched (CS) explanations, in which the L1 featured alongside the L2. Such use of L1, as well as being potentially useful for VI learners’ L1–L2 mapping challenges, is supported theoretically by influential models of L2 vocabulary acquisition. Jiang’s (Reference Jiang2000) psycholinguistic model supports L1 mediation in L2 vocabulary processing, proposing that the creation of a lexical entry in the L1 entails various aspects of information about a word (semantics, syntactic, etc.), which are highly connected inside each entry so that when the entry is accessed, the information is instantly available. The model proposes three stages of vocabulary acquisition in the L2: first, at the formal stage, an L2 lexical entry contains just formal entities, and L2 word processing relies on L1 translation; at the second, L1 lemma mediation stage, L1 lemma information connects the L2 word to a conceptual representation, creating a weak connection because the information is not highly integrated but is copied from L1 rather than created during the process of learning the L2 word; finally, at the L2 integration stage, all details about L2 words are merged and instituted in the lexical entry. Jiang (Reference Jiang2000), while highlighting the importance of the L1 in the acquisition of L2 vocabulary, also emphasizes the importance of contextualized language input, without which learners may become over-reliant on the L1 and less likely to develop the full range of knowledge about a word, which would then prevent them from moving beyond the first stage of his model of vocabulary learning.
A combination of teacher L1 use alongside L2 contextualized input would, therefore, seem to be supported theoretically. It also finds empirical support through studies that compared teacher CS explanations (in which L1 translations of target words are given within an otherwise L2 explanation of words encountered in aural L2 input) for university learners of English (Lee & Levine, Reference Lee and Levine2020; Tian & Macaro, Reference Tian and Macaro2012), adolescent school learners of French (Hennebry et al., Reference Hennebry, Rogers, Macaro and Murphy2017), and adolescent learners of English (Zhang & Graham, Reference Zhang and Graham2020a). All compared vocabulary learning from CS explanations with gains from L2 explanations or just listening to the input with no explanations. Overall, these studies indicated that CS explanations led to greater vocabulary gains than L2 explanations and no explanations at all, particularly for short-term learning. Less marked effects on longer-term learning (measured by delayed post-tests that were between 2 and 7 weeks after the interventions, with variability across studies) may perhaps indicate that teacher explanations on their own after listening, even using CS, did not promote the deeper processing such learning requires (Craik & Lockhart, Reference Craik and Lockhart1972).
Results also differed across the studies regarding whether the effects of the interventions applied equally to learners of different proficiency levels. While there was no effect of proficiency in either Tian and Macaro (Reference Tian and Macaro2012) or Hennebry et al. (Reference Hennebry, Rogers, Macaro and Murphy2017), Lee and Levine (Reference Lee and Levine2020) found that the benefits of CS were limited to lower proficiency learners.
All three studies divided learners into proficiency groups based on a combination of different measures: general English proficiency and listening proficiency in Tian and Macaro (Reference Tian and Macaro2012), listening proficiency and scores on a C-test in Hennebry et al. (Reference Hennebry, Rogers, Macaro and Murphy2017), and English conversation grade in Lee and Levine (Reference Lee and Levine2020). As argued by Zhang and Graham (Reference Zhang and Graham2020b), however, using proficiency as a categorical rather than as a continuous variable leads to a less sensitive analysis because subtle differences in learners’ proficiency levels are lost. Such an approach may, therefore, have limited the insights these studies could give into the role of proficiency in moderating the effects of the different interventions experienced. In Zhang and Graham’s (Reference Zhang and Graham2020b) study, learners’ preexisting vocabulary knowledge and listening proficiency scores were used as continuous predictors in analyses of vocabulary gains, showing that listening proficiency was a more important predictor than preexisting vocabulary knowledge. Comparing gains in the CS and L2 conditions, the former was more helpful for learners with lower vocabulary knowledge and learners with higher listening proficiency than the latter. By contrast, CS explanations were less helpful than L2 explanations for learners with greater vocabulary knowledge and those with lower listening proficiency.
Aural input manipulation as input enhancement. A literature search indicates that AIM as an input enhancement method has received scant empirical attention. AIM entails manipulating spoken input itself to direct learners’ attention to target features. Such manipulation might be especially relevant for teaching L2 vocabulary to VI learners because of their presumed superior auditory skills, as outlined earlier. These skills may make them particularly likely to pay increased attention to AIM-enhanced input and hence achieve greater noticing of target words and subsequent vocabulary gains. Yet whether VI learners’ enhanced auditory skills then extend to enhanced listening comprehension proficiency in the L2 is another matter, and there may well be variability across VI learners as for SI learners. We know of no existing empirical evidence to support that claim, however.
Research that has investigated the efficacy of AIM in drawing SI learners’ attention to L2 target items is limited (Cho & Reinders, Reference Cho, Reinders, Bergsleithner, Frota and Yoshioka2013; Ito, Reference Ito2021). Studies that have explored the effectiveness of using AIM to teach L2 vocabulary rather than grammar are particularly scarce (Jones & Waller, Reference Jones and Waller2017; Mall-Amiri et al., Reference Mall-Amiri, Oghyanous and Zohrehvand2017). They also vary in the type of AIM used, making it difficult to compare across studies. Examining grammar, both Cho and Reinders (Reference Cho, Reinders, Bergsleithner, Frota and Yoshioka2013) and Ito (Reference Ito2021) inserted pauses before and after target structures in aural input, with additional slowed delivery of the target structures and volume increase, respectively. In neither study did AIM have a significant impact on learning gains compared with those of a control group.
More positive findings for AIM have been established in the only studies that have considered AIM for vocabulary learning, by Mall-Amiri et al. (Reference Mall-Amiri, Oghyanous and Zohrehvand2017) and Jones and Waller (Reference Jones and Waller2017). The former investigated the impact of both visual and aural input enhancement on learning non-congruent phrasal verbs by 90 intermediate level Iranian L2 students. For the aural input enhancement treatment group, the teacher repeated the target items loudly with raised intonation and higher pitch; for the visual enhancement group, methods such as underlining, boldening, and italicization were used. Post-test findings indicated that enhancement was effective in both modalities, with no significant differences between them. Both treatment groups outperformed the control group on the post-test, but longer-term retention was not examined.
Jones and Waller (Reference Jones and Waller2017) investigated the efficacy of using textual and aural enhancements to teach Turkish L2 vocabulary to adult beginner Turkish learners. Both treatment and control groups (20 learners each) received 60 min of instruction using a direct communicative approach for restaurant vocabulary, namely delivered through the L2 and using methods such as showing visuals of target items and drilling. Following this presentation, the control group practiced the items with an unenhanced menu and heard the teacher repeat each item orally once, while the treatment group used a menu with target items in bold and heard them repeated orally three times by the teacher. Pre- to post-tests and delayed post-tests indicated that both groups showed significant gains in receptive and productive knowledge of the target items, particularly for the pre- to post-test period. However, the treatment group showed greater gains across all tests, suggesting a short-term advantage for textual and aural enhancement, which was partly maintained in the longer term. It is not clear, however, which form of enhancement contributed the most to that advantage nor what the role was of using target items productively in the communicative practice activities featured in the lesson.
Taken together, these studies suggest a mixed picture regarding the benefits of AIM, with studies of vocabulary learning finding some positive effects and studies of grammar learning having no effect when compared to a control condition. Furthermore, key elements that are missing from the reviewed AIM studies include their relevance for VI learners and an examination of whether the effects differed across varying proficiency levels. Given that listening proficiency emerged as an important moderating factor for SI learners in learning vocabulary through an aural modality in Zhang and Graham (Reference Zhang and Graham2020b), while vocabulary knowledge had a negative moderation effect, this appears to be a significant oversight. One might assume both SI and VI learners with better listening proficiency to be more sensitive to manipulations in the aural input, while those with lower vocabulary levels have the most room for progress. Finally, to our knowledge, no previous study has considered AIM in relation to VI learners, even though, like CS, it might hold particular benefits for that group.
Summary and relevance of L1 and AIM input enhancement for VI learners
The limited research that has employed CS and AIM to teach vocabulary through listening suggests both are viable approaches to L2 vocabulary learning for SI learners. However, there is no empirical evidence supporting their pedagogical benefits for VI learners nor any that indicates whether such benefits are greater or less than for SI learners. Theoretically, using the L1 during vocabulary explanations would be supported for VI learners in that it may aid the development of the second stage of concept formation, the L1 lemma mediation stage (Jiang, Reference Jiang2000), with which VI learners may face difficulties because of their vision deficit. CS explanations might help ensure that VI learners understand terms in their L1 before they are introduced in the L2 (Jedynak, Reference Jedynak2016). Likewise, AIM may benefit VI learners because of their presumed superior auditory abilities. Combining the two approaches might lead to the strongest benefits; the artificially increased volume may aid noticing by directing the learners’ attention to the target words, with follow-up CS explanations clarifying their meaning. There is, however, a complete absence of research into using either CS or AIM in the teaching of L2 vocabulary to VI learners, a gap that this study seeks to fill. Furthermore, given that in some contexts, SI and VI learners study together in the same class, it is vital to know whether both groups benefit equally from different teaching approaches and across different proficiency levels.
The following research questions (RQs) were therefore posed, investigating the relative benefits of CS alone or CS combined with AIM in the teacher’s explanations, a design chosen to help tease out the added value of AIM over and above that of CS:
RQ1: What is the effect of two types of vocabulary instruction (CS and AIMCS—artificially increasing the volume followed by CS) during aural activities on (a) VI and (b) SI learners?
RQ2: How is the instruction effect on vocabulary learning moderated by learners’ listening proficiency and their existing vocabulary size?
For RQ1, we expected that CS would lead to gains in vocabulary learning because of the existing evidence regarding the positive impact of teacher CS explanations for SI learners (Hennebry et al., Reference Hennebry, Rogers, Macaro and Murphy2017; Lee & Levine, Reference Lee and Levine2020; Tian & Macaro, Reference Tian and Macaro2012) that would extend to VI learners (Jedynak, Reference Jedynak2016). Both groups might be expected to benefit from links created between the L1 and L2, which may also entail deeper processing. We hypothesized, however, that the addition of AIM to CS would lead to the greatest benefits, especially for VI learners, for whom the added salience and attention to form achieved through AIM would give further important support for L1-L2 concept mapping (Jedynak, Reference Jedynak2016). While it might seem intuitive that AIMCS, a method combining two modes of instruction and bringing additional salience to items, would enhance learning more than CS alone, empirical evidence to support that hypothesis is needed. For RQ2, we expected gains from both forms of instruction to be greater for learners with higher levels of listening proficiency but for there to be less effect of existing vocabulary size, in line with Zhang and Graham (Reference Zhang and Graham2020b). While we expected these moderation effects for both VI and SI learners, we anticipated they would be the largest for the VI learners because of their reliance on listening as the main sensory channel. In other words, VI learners with higher L2 listening proficiency would benefit more from AIMCS than VI learners with lower listening proficiency.
Methodology
Participants
This quasi-experimental study included 16 VI and 16 SI Saudi female high school EFL learners (16–20 years, L1 Arabic, 6 years of English schooling). Recognized challenges in recruiting participants with disabilities (Banas et al., Reference Banas, Magasi, The and Victorson2019) led us to use convenience sampling to draw the VI group from an institute for blind people and a high school that had a dedicated class for VI learners. The SI group came from that same high school. Participants all had low–intermediate English proficiency (4.5–5 International English Language Testing System [IELTS]). Full informed consent was gained from school gatekeepers, parents and participants. See Figure 1.
Recruitment and ethical procedures.

Study design
The study followed a counterbalanced, mixed within- and between-subjects design, chosen to maximize power (achieving 5,400 observations over 60 taught target items). After baseline tests assessing listening comprehension and vocabulary knowledge (including knowledge of target items), the two teaching methods, CS alone and AIMCS, were used in each of six intervention sessions over two academic terms (three intervention sessions in each term, all taught by the first author); see Figure 2. For counterbalancing, AIMCS was used in the first session for the first five items, followed by CS for the next five items, then vice versa in the next session, and so on for the remaining sessions. A vocabulary post-test was employed at the end of each session to measure the participants’ knowledge of target lexical items. Two weeks after each session, a delayed post-test was administered to measure longer-term retention (see Materials section for all tests), a time period comparable to that in Jones and Waller (Reference Jones and Waller2017), Zhang and Graham (Reference Zhang and Graham2020a), and Tian and Macaro (Reference Tian and Macaro2012), and which was selected because of the number of weeks for which participants were available. The wider study from which the data in the present study were drawn (Badri, Reference Badri2025) also included interviews and questionnaires to explore learners’ views of the intervention and the learning strategies they applied during sessions (not discussed here because of space).
Study design.

Teaching procedure
Each of the six intervention sessions lasted 50 min. Participants received a multiple-choice listening comprehension question sheet before they heard a listening passage, to help them concentrate on meaning instead of unfamiliar lexical items (Tian & Macaro, Reference Tian and Macaro2012). Microsoft Forms, permitting the use of the Immersive Reader function, made the question sheet accessible to VI learners. After hearing the listening passage once, students answered the comprehension questions and engaged in a discussion with the instructor about the passage’s meaning. All discussions this far were carried out in the L2.
Next, the passage was replayed in segments. During the replay, the teacher interjected at the end of each sentence to explain the meaning of the target vocabulary, counterbalanced as outlined under Study Design section. In the CS phase, CS was used to explain the meaning of the target lexical item in Arabic (L1), while in the AIMCS phase, the target lexical item was artificially manipulated through volume increase, followed by CS. Figure 3 gives an example of both types of instruction, in which the researcher also provided the students with an additional example of the target item. Care was taken to ensure that explanations in both conditions were identical in length and time taken to deliver them. Both groups could also access the written form of target items—in PowerPoint slides for SI learners and as an Immersive Reader–enabled Word document for VI learners.
Examples of CS and AIMCS instruction.

Following these explanations, the instructor went over the passage’s general meaning again in L2 only, and the respective explanations for the target items were repeated. The passage recording was then played for a third time to ensure participants understood its meaning, and answers to the comprehension questions were provided.
Materials
Listening comprehension test
The first two sections of an IELTS listening comprehension practice test were used as pre-tests, chosen to suit all participants’ proficiency levels based on the topic, lexical diversity, complexity, and the Common European Framework of Reference for Languages level of the passages it included (see supplementary material, Appendix A.1). Each section included dialogues and monologues, accompanied by 10 questions, with an optional Immersive Reader format, and also was read aloud (with options) for VI learners. Question types included short-answer with word limits to minimize the impact on writing ability, concise multiple-choice options to avoid excessive reading, and sequencing rather than the labelling task normally used in the IELTS test. The test (out of 20) indicated a high level of internal consistency, Cronbach’s alpha = .90.
General vocabulary knowledge test
As a pre-test (supplementary material, Appendix A.2.1), the McLean et al. (Reference McLean, Kramer and Beglar2015) Listening Vocabulary Levels Test (LVLT) was administered (adapted for Arabic L1 speakers) to gain more insights about the participants’ level of proficiency and assess their preexisting knowledge of the intervention items. The 60 target lexical items were intermingled into the LVLT to avoid a pre-treatment assessment effect in which participants in an experiment are alerted to what they will be assessed on later (Gyllstad et al., Reference Gyllstad, Vilkaitė and Schmitt2015). Cronbach’s alpha for the test was high, .94. Only the first three 1,000-word frequency levels and the Academic Word List, i.e., 102 words altogether, were tested, given participants’ proficiency level. The researcher read aloud the target item, an example sentence, and the answer options, adding 40 min to the test completion time for all learners to maximize accessibility. Then, participants had to choose the Arabic equivalent of the English word in an adaptation of the original monolingual version, as in this example:
Examinees hear: Time: They have a lot of time.
-
a. money (مال)
-
b. food (طعام)
-
c. hours (وقت)
-
d. friends (أصدقاء)
Post-tests and delayed post-tests
To measure short- and longer-term vocabulary gains, six post-tests (overall Cronbach’s alpha = .89) and six delayed post-tests (Cronbach’s alpha = .93) were administered using the same format (supplementary material, Appendix A.2.2) and procedure as the pre-test (all scored out of 60). To mitigate any practice effects, the target items (supplementary material, Appendix A.3) were embedded in a different set of sentences from the pre-test. The delayed tests included a combination of pre- and post-test sentences.
Listening passages and target vocabulary items
The listening passages for vocabulary instruction were selected from two textbooks (British Council, n.d.; Tilbury et al., Reference Tilbury, Clementson, Hendra and Rea2015). Passages were modified to account for factors that would affect difficulty for all participants: similarity of the contents to those found in the learners’ English textbooks, linguistic complexity, speech rate, and text length (Zhang & Graham, Reference Zhang and Graham2020a). Sixty target vocabulary items (31 nouns, 18 adjectives, and 11 verbs) were selected from the modified passages after consulting the glossary and exercises presented before the listening, lexical text analysis tools (Cobb, Reference Cobb2002), and teachers, regarding words learners would be unlikely to know. These were selected from the K2, K3, and K4 frequency bands. Academic Word Lists and off-list words were also included. See supplementary material, Appendix A.3 for details of items and passages.
Data analysis
The data were analyzed using generalized linear mixed effects models in R (R Core Team, 2024) with the lmerTest (test in linear mixed effects models) package (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017). For each of the three vocabulary meaning recognition tests (pre-, post-, and delayed post-tests), items were coded as either right (1) or wrong (0); hence, all items were given equal weighting. The fixed effects structure was primarily theory-driven, including five fixed factors: Time (1. pre-test versus; 2. post-test versus; 3. delayed post-test), Group (VI versus SI), Condition (CS versus AIMCS), LVLT (preexisting vocabulary levels), and Listening (pre-listening proficiency). Both continuous fixed factors (i.e., LVLT and Listening) were standardized as z scores before being entered into the model. To address the RQ1, three-way Time × Group × Condition interactions were added to the fixed effects structure. We also allowed LVLT and Listening to respectively interact with the Time × Group × Condition interactions to explore the moderation effects of learners’ preexisting vocabulary levels and listening proficiency and hence address RQ2. The random effects structure included by-participant and by-item random intercepts and by-participant and by-item random slopes for Time. The model with the full random effects structure, however, did not converge. The random slopes were, therefore, taken out one by one until a final converged model was obtained. The final model included by-participant and by-item random intercepts, which allowed us to control for variability in item difficulty and individual learner performance. As our full model had a rather complex structure, albeit with 5,400 valid observations, there was still a risk that it might be underpowered. To overcome that problem, subsequent backward model simplification was performed by removing one by one the random and fixed effects, which accounted for the least variance. Model comparisons were undertaken to compare the original model and the simplified model through a likelihood ratio test using the analysis of variance function within the car (companion to applied regression) package (Fox & Weisberg, Reference Fox and Weisberg2019). In cases where a simplified model was not significantly different from the original model, the simplified model was retained. Such model selection procedures were believed to be able to maintain the Type I error rate as close as possible to that of the full model yet substantially increase the overall power (Matuschek et al., Reference Matuschek, Kliegl, Vasishth, Baayen and Bates2017). The results of the model comparisons are given in supplementary material, Appendix B. The raw data are openly available from the University of Reading Research Data Archive at https://doi.org/10.17864/1947.001430.
Results
Descriptive statistics were first calculated (Table 1) for the outcome variable (i.e., meaning recognition) by each test time point (pre-test, post-test, delayed post-test), group (SI, VI), and instruction condition (AIMCS, CS) and for the two moderation variables (LVLT and Listening) by group. Table 1 indicates that at pre-test, SI learners had higher scores than VI learners in all tests.
Descriptive statistics for all variables

Note: Target items: aout of 60, bout of 102, and cout of 20. M, mean; Max, maximum; Min, minimum; SD, standard deviation.
In the model simplification process, both by-item and by-participant random intercepts were retained, as removing any one of them significantly reduced the model fit. The four-way Time × Group × Condition × LVLT and Time × Group × Condition × Listening interactions, however, were removed from the fixed effects structure. Three-way Time × Group × LVLT, Time × Condition × LVLT, LVLT × Group × Condition, Listening × Group × Condition, and Time × Group × Condition interactions were also removed. Furthermore, model selection showed that two two-way interactions, Group × LVLT and Condition × LVLT, could be taken out. As a result, two findings emerged. First, answering RQ1, the between-group vocabulary learning differences did not interact with the instruction conditions. In other words, the effects of AIMCS and CS on learning were similar across the two groups. Second, and partly answering RQ2, learners’ preexisting levels of vocabulary knowledge did not seem to moderate learning gains across groups or instructional conditions.
The results of the final model appear in supplementary material, Appendix C. The model fit was judged to be good, that is, with R 2 above .50 (Plonsky & Ghanbar, Reference Plonsky and Ghanbar2018). Fixed effects explained 50.9% of the variance (marginal R2), and both the fixed and random effects explained 62.7% of the variance (conditional R2) in the data. All five fixed factors were retained in the final model.
Beginning with the higher level interactions, there were significant three-way Time × Group × Listening and Time × Condition × Listening interactions, meaning that the learning differences between groups and between the two teaching conditions were significantly moderated by learners’ listening proficiency. In addition, there were also significant Time × LVLT interactions, suggesting that regardless of group or teaching condition, vocabulary learning was moderated by learners’ preexisting vocabulary knowledge. For simplicity, these interactions were further explored through pairwise comparisons, adjusting for multiple comparisons, and are presented below, as interpreting the model results directly was complex because categorical fixed factors were involved, and each contrast was made against the baseline level of the categorical fixed factors. Lastly, significant Time × Group and Time × Condition interactions indicated that when learners’ listening proficiency was centered at the mean, learning gains significantly differed between the two groups as well as between the two teaching conditions. As these two-way interactions were nested in the above three-way interactions, insights into the nature of these differences were also sought through pairwise comparisons.
The emmeans (estimated marginal means) package (Lenth, Reference Lenth2024) was used to perform the pairwise comparisons. We focused on two contrasts within the effect of Time, that is, Time 2 / Time 1 and Time 3 / Time 1. The former indicated short-term learning gains, whereas the latter showed longer-term retention of the target vocabulary. The p values were adjusted using Bonferroni corrections for three contrasts, including the Time 2 / Time 3 contrast. Three reference points were chosen for Listening to represent lower proficiency listeners (z score = –1), mean level listeners (z score = 0), and higher proficiency listeners (z score = 1), allowing us to keep listening as a continuous fixed factor but also interpret interactions (Michel et al., Reference Michel, Kormos, Brunfaut and Ratajczak2019). Each interaction effect was subsequently plotted using the sjPlot (data visualization in statistics in social science) package (Lüdecke, Reference Lüdecke2024).
Regarding the three-way Time × Condition × Listening interactions (Figure 4), pairwise comparisons (Table 2) first showed that for short-term vocabulary gains, learners’ listening proficiency significantly moderated how well they learned in the two instructional conditions. With every increase in z score of listening proficiency, gains became significantly larger under the AIMCS condition (12.71 → 79.05 → 491.67) than under the CS condition (10.08 → 31.03 → 95.50). This indicated that higher proficiency learners benefited significantly more from AIMCS than from CS, whereas for lower proficiency listeners, both conditions seemed to have similar effects. Such moderation effects diminished, however, at the delayed post-test. Although more proficient listeners still benefited more from AIMCS than from CS (15.20 versus 7.10), the difference was smaller than it was for short-term learning.
Effect plot for Time × Condition × Listening interactions.

Pairwise comparisons for Time × Condition × Listening interactions

Note: SE, standard error; Time 1, pre-test; Time 2, post-test; Time 3, delayed post-test.
Additionally, AIMCS was overall more helpful than CS for short-term vocabulary learning: For learners who shared similar listening proficiency levels, larger odds ratios were consistently observed for AIMCS than for CS in Time 2 / Time 1 contrasts. There was, however, no such clear advantage of AIMCS over CS for longer-term retention. Learners with average listening proficiency had gains that were very similar across the two conditions (6.84 versus 4.65).
The three-way Time × Group × Listening interactions appear in Figure 5 (effect plot). The Time 2 / Time 1 contrasts (Table 3) indicating short-term learning showed that learners’ listening proficiency had a significantly larger moderation effect on vocabulary gains for the VI learners than for the SI learners. With every increase in z score of listening proficiency, gains became significantly larger in the VI group (13.34 → 130.86 → 1283.44) than in the SI group (9.61 → 18.75 → 36.58). Furthermore, across different listening proficiency levels, the odds ratios were always larger for VI learners than for SI learners, meaning that VI learners overall benefited more than SI learners from the intervention.
Effect plot for Time × Group × Listening interactions.

Pairwise comparisons for Time × Group × Listening interactions

Note: Time 1, pre-test; Time 2, post-test; Time 3, delayed post-test.
We then examined the Time 3 / Time 1 contrasts representing longer-term retention, finding similar moderation effects of listening proficiency on the between-group learning differences. Although odds ratios (Table 3) showed that less proficient VI listeners retained a smaller amount of vocabulary than SI learners did, more proficient VI listeners made larger longer-term gains compared to SI learners. Finally, the two groups seemed to have benefited equally from the intervention for longer-term vocabulary gains overall, with similar odds ratios for average listeners.
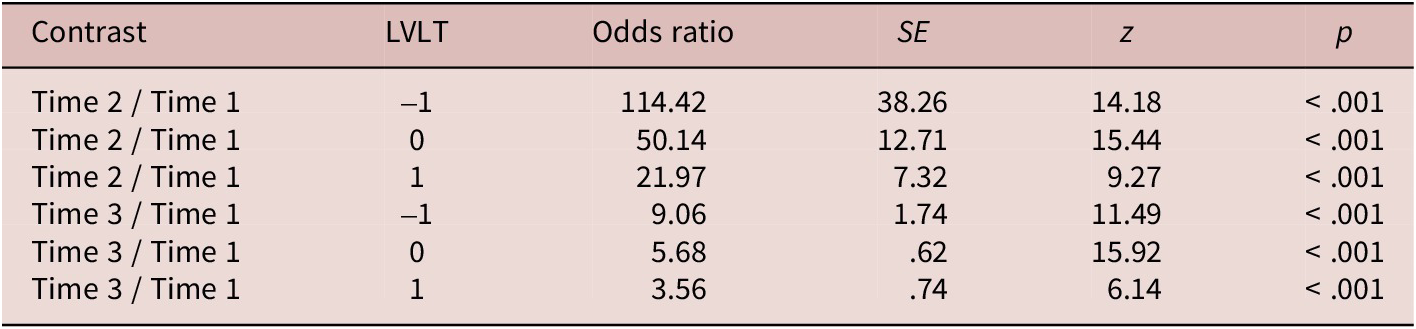
Regarding the two-way Time × LVLT interactions (Figure 6), pairwise comparisons (Table 4) showed that learners’ preexisting vocabulary levels negatively moderated how well they benefited from the intervention. In other words, learners with the lowest levels benefited the most. These predictive effects were independent of the effect of Group or Condition, meaning that they were observed across the two instructional conditions and across the two intervention groups. When learners’ preexisting vocabulary levels increased by 1 z score, the gains became significantly smaller, and this was true for both short-term learning and longer-term retention.
Effect plot for Time × LVLT interactions.

Pairwise comparisons for Time × LVLT interactions

Note: Time 1, pre-test; Time 2, post-test; Time 3, delayed post-test.
Discussion
This study sought to discover, for the first time, the short-and longer-term effects on both VI and SI learners of two different approaches to vocabulary instruction using listening input, the first using CS explanations and the second combining CS explanations and auditory input manipulation involving enhanced volume (RQ1). The possible moderating effect of learners’ preexisting vocabulary knowledge (measured through the LVLT) and listening proficiency on learning gains was also investigated (RQ2).
All our hypotheses for the study were largely confirmed. For RQ1, we found significant short-term effects of instructional condition; that is, AIMCS was more beneficial than CS for both groups of learners. However, on a longer-term basis, both conditions seemed to show similar effects on learning. There were also significant short-term effects of Group, i.e., VI learners benefited more from the intervention overall than SI learners. This advantage in favor of VI learners disappeared at the delayed post-test, however. Turning to RQ2, we found negative moderation effects of the LVLT, meaning learners with a smaller amount of preexisting vocabulary knowledge made larger gains regardless of Group or Condition. The moderation effects of listening proficiency differed across short- and longer-term learning. For the former, larger and positive moderation effects of listening proficiency were observed for AIMCS than for CS, meaning that with every increase in the z score of listening proficiency, learners benefited significantly more from AIMCS than from CS. For longer-term learning, learners with different listening proficiency levels seemed to have benefited similarly from both AIMCS and CS. Finally, the moderation effects of listening proficiency also differed according to whether learners were VI or SI. For both short- and longer-term learning, there were larger and positive moderation effects of listening proficiency for VI learners than for SI learners. The effects of the intervention were significantly greater for more proficient VI listeners than for their more proficient SI peers.
The pedagogical benefit of AIMCS over CS for both groups of learners indicated by the results of this study may be explained with reference to theories that emphasize the importance of directing learners’ attention to linguistic features in the input, as in input processing theory (VanPatten, Reference VanPatten and VanPatten1996). The increased volume used with target items in AIMCS may have made them more salient and hence led both VI and SI learners to attend to their form before their meaning (VanPatten, Reference VanPatten and VanPatten1996). Furthermore, Schmidt’s noticing hypothesis contends that attention is crucial for all L2 learning aspects, and learners must attend to the target items to achieve noticing, a fundamental starting point of acquisition (Schmidt, Reference Schmidt, Chan, Chin, Bhatt and Walker2012). Increasing the volume seems to have directed learners’ attention to the target lexical items, allowing input to “become intake” (Schmidt, Reference Schmidt, Chan, Chin, Bhatt and Walker2012, p. 27). Furthermore, subsequent CS in the teacher’s explanation may have taken these affordances still further. Indeed, a comparison with the two previous studies employing some kind of AIM in vocabulary teaching underscores the value of combining AIM with some other form of input enhancement. Thus, AIM alone in Mall-Amiri et al. (Reference Mall-Amiri, Oghyanous and Zohrehvand2017) was no more effective than visual enhancement alone, but combining AIM and visual enhancements led to improved learning in Jones and Waller (Reference Jones and Waller2017).
Explanations for the benefits of the CS element within AIMCS as well as on its own can be drawn from Jiang’s (Reference Jiang2000) psycholinguistic model of vocabulary acquisition, which postulates that the L1 is strongly linked to its existing semantic system and that the L2 word is mapped onto the same system. Zhang and Graham (Reference Zhang and Graham2020a) argued that CS facilitates the advancement toward the second stage of Jiang’s model (L1 lemma mediation stage) by linking the L2 word and its corresponding concept. Based on this argument, this study’s results suggest that employing CS, either alone or with AIM, seems to have aided learners’ progress toward the second stage. Given VI learners’ possible difficulties in the second stage of concept formation because of their vision deficit, such assistance may have been especially important for VI learners, who needed to have and seemingly gained a correct mental representation in the L1 before the L2 version was learned, an essential milestone when teaching these learners (Jedynak, Reference Jedynak2016).
The study also found that AIMCS’ superiority over CS disappeared during the 2-week delayed post-test, as it did for CS (compared with L2 instruction) in Tian and Macaro (Reference Tian and Macaro2012) and Zhang and Graham (Reference Zhang and Graham2020a). Although it is difficult to compare our findings to those former studies because of different modes of instruction, both sets of findings might be explained by the depth of processing hypothesis, which suggests that “manipulations that influence processing at a structural level should have transitory, but no long-term, effects” (Craik & Lockhart, Reference Craik and Lockhart1972, p. 680). Increasing the volume seems to have drawn VI and SI learners’ attention to the target lexical items momentarily. Pairing the increased volume with CS may have aided these learners’ movement toward Jiang’s (Reference Jiang2000) second stage of vocabulary acquisition (L1 mediation stage), which would involve a somewhat deeper level of processing than just focusing attention on the target lexical item. Yet the disappearance of longer-term effect indicates that the AMICS explanation did not “induce deeper or more elaborative processing,” which is needed for long-term retention (Craik & Lockhart, Reference Craik and Lockhart1972, p. 680). Further encounters with target items within contextualized L2 input (Jiang, Reference Jiang2000) alongside the kind of interactive, productive language use that seems to have contributed to more durable learning in Jones and Weller (Reference Jones and Waller2017) might have induced that deeper processing and hence longer-term retention.
Effects of Group were also short term only, but VI learners benefited more from the intervention overall than SI learners did. These findings can be explained by taking into account the notion of sensory compensation from the field of neuropsychology, whereby neural plasticity of the brain means that the loss or impairment of one sense results in the enhancement of other senses (Sabourin et al., Reference Sabourin, Merrikhi and Lomber2022). Such sensory compensation may lead VI individuals to develop superior auditory abilities and superior verbal memory performance, heightened phonological awareness for speech sound, and greater pitch discrimination (Gougoux et al., Reference Gougoux, Lepore, Lassonde, Voss, Zatorre and Belin2004; Sepúlveda-Palomo et al., Reference Sepúlveda-Palomo, del Río, Villalobos and Fernández González2024). In the present study, such compensation might have led VI learners to be more adept at processing the auditory input than SI learners; consequently, they were more responsive to the vocabulary instruction that exploited aural input, L1, and auditory cues. Thus, both the CS and the AIMCS interventions were well aligned with VI learners’ strengths.
The disappearance of Group effects at the delayed post-test can be explained with reference to episodic or long-term memory, for which VI learners have been found to have no particular advantage (Smeds, Reference Smeds2015). In other words, in the present study, it could be assumed that vision deficit and its concomitant enhancement of other cognitive and sensory attributes seemed to be an advantage for VI learners compared to SI learners in relation to short-term but not long-term learning.
With respect to RQ2, learners’ preexisting vocabulary knowledge and listening proficiency scores were used as continuous predictors to answer the second question, following Zhang and Graham (Reference Zhang and Graham2020b). Their findings indicated that, for SI learners, listening proficiency was a more important predictor of vocabulary gains than preexisting vocabulary knowledge when learning vocabulary through listening. Similarly, in the present study, learners’ preexisting vocabulary knowledge did not interact with listening proficiency or other predictors, taking SI and VI learners together. There were also negative moderation effects of the LVLT, implying that learners with a smaller amount of preexisting vocabulary knowledge achieved larger learning gains independent of Group or Condition. In contrast, those with higher vocabulary knowledge benefited less from both interventions (i.e., CS and AIMCS). This may be because the intervention was designed for lower intermediate level learners; as indicated by the relatively high pre-test means, many of the target items may have been already known by learners with higher preexisting vocabulary knowledge, leaving little room for improvement. The opposite would then have been true of learners with lower preexisting knowledge.
Turning to listening proficiency, the present study findings are again in line with Zhang and Graham (Reference Zhang and Graham2020b), who found that listening proficiency played an essential role in vocabulary learning when the instruction was delivered aurally, with greater benefits for those with higher levels of listening proficiency. In the present study, for short-term learning, larger moderation effects of listening proficiency were observed for AIMCS than for CS across VI and SI learners. While in relation to RQ1 it was argued that all VI learners were better able to notice the increased volume modification and hence the target items when initially presented in context in the listening passages, this was even more true for higher proficiency VI learners and also higher proficiency SI learners. Therefore, instead of listening with “global” attention, their attention was “specifically focused” (Schmidt, Reference Schmidt, Chan, Chin, Bhatt and Walker2012, p. 31). These initial encounters would then have been followed up by the teacher’s CS explanations, providing learners with further encounters with target items, with more encounters likely to lead to better learning, as found by Zhang (Reference Zhang2022). For longer-term learning, however, both AIMCS and CS approaches seemed to help learners with different listening proficiency equally. A potential reason for this may relate to the association between auditory perceptual acuity but not longer-term memory referred to in relation to RQ1 for VI learners, but which might also apply to a certain extent to high proficiency SI learners.
Furthermore, there were larger, positive moderation effects of listening proficiency for VI learners than for SI learners for both short- and longer-term learning. That effect again aligns with literature that emphasizes that listening serves as a primary conduit by which VI learners acquire knowledge rather than through visual input because of their more developed brain regions for auditory information processing compared to SI individuals (Gougoux et al., Reference Gougoux, Lepore, Lassonde, Voss, Zatorre and Belin2004). That, in turn, might make them more adept at processing and retaining input presented through listening. SI learners, by contrast, are usually able to draw on a combination of visual and auditory input rather than a single sensory input. In the present study, the main input channel was auditory, although the teacher explanations were also given in written form, which SI learners may have drawn on more than VI learners. Because SI learners may have thus processed information using different sensory modalities, levels of listening proficiency were likely less crucial than they were for VI learners, for whom the moderation effects of listening were thus greater.
Lastly, the effects of the intervention overall (i.e., both CS and AIMCS) were significantly greater for more proficient VI listeners than for their more proficient SI peers. As indicated in relation to RQ1, where the greater benefits of both interventions to VI learners overall were highlighted, both CS and AIMCS interventions aligned with VI learners’ strengths by delivering instruction largely through the auditory channel. These benefits would then have been magnified, especially for VI learners with greater listening proficiency.
Limitations and future research
We compared outcomes from CS with AIMCS but not with AIM alone, as we sought to tease out the added value of AIM over and above that of CS. Future studies might seek to compare learning from AIMCS with AIM to establish more firmly whether the CS or the AIM element is most helpful for VI learners. They should also compare AIMCS with learning from the more traditional L2 teaching VI learners frequently experience, especially in inclusive classrooms, where there is greater reliance on visual input without enhancements to aural input. We also did not assess how well both groups of learners comprehended the listening passages through which instruction took place, which might have provided useful additional support for our findings.
Conclusions
This study is the first attempt to rigorously evaluate the effect of different teaching approaches for L2 vocabulary instruction for both VI and SI learners, using a research design that maximized power for the analysis of data from a hard-to-recruit group of participants. Establishing that AIMCS had particular benefits for VI learners but was also helpful for SI learners, the study has empirical and pedagogical importance in that it suggests a viable way forward for inclusive teaching and for enhancing learning for a group whose educational needs tend to be neglected. The finding also extends theoretical models of L2 vocabulary development to a previously uninvestigated group, indicating that the L1, as outlined in Jiang’s (Reference Jiang2000) model, carries out similar functions for VI learners as it does for SI learners. It may also have even greater relevance because of VI learners’ possible difficulties in the second stage of concept formation, which CS can alleviate.
The particular benefits of AIMCS for VI learners also support the notion of sensory compensation (Sabourin et al., Reference Sabourin, Merrikhi and Lomber2022), at least for short-term learning, whereby auditory strengths make up for loss of vision. More significantly, however, the fact that larger moderation effects of listening proficiency were observed for AIMCS than for CS across VI and SI learners underlines the importance of developing strong L2 listening proficiency for both groups of learners. It cannot be assumed that VI learners’ strong auditory skills will necessarily transfer automatically into strong L2 listening proficiency. Future studies are needed that both explore L2 listening proficiency development in a larger sample of VI learners and also investigate the value of listening proficiency interventions for that group. In interviews conducted in the wider study, VI participants commented that AIMCS made understanding the aural L2 input easier because the increased volume drew attention to key items. Yet VI learners differed in the strategies they reported applying to make sense of those items. Such information might form a useful basis for future interventions.
In the meantime, AIMCS offers an important pedagogical tool for equalizing learning opportunities for VI learners, including when they are taught alongside SI learners.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0272263125101101.
Data availability statement
The experiment in this article earned Open Data badge for transparent practices. The data are available at https://doi.org/10.17864/1947.001430.












 Open access
Open access