




Introduction
Most current accounts of bilingual lexical organization assume that the bi-/multilingual lexicon is integrated (words from both languages are stored together; e.g., Meade et al., Reference Meade, Midgley, Dijkstra and Holcomb2017; van Heuven et al., Reference Van Heuven, Dijkstra and Grainger1998). Moreover, it has been shown that first (L1) and second language (L2) words are activated in parallel during lexical access, even when the context calls for a fully unilingual mode (e.g., Thierry & Wu, Reference Thierry and Wu2007). Nonselective access has been observed in numerous studies examining comprehension and/or production of isolated words (e.g., Kroll et al., Reference Kroll, Bobb and Wodniecka2006). The most compelling evidence of nonselectivity comes from coactivation in sentence comprehension studies, where the sentential context could be expected to constrain the search space to only one of the languages (e.g., Duyck et al., Reference Duyck, Van Assche, Drieghe and Hartsuiker2007; van Assche et al., Reference Van Assche, Duyck and Hartsuiker2012).
An important question following from these findings is how exactly words from different languages are connected at each level of representation (sublexical, lexical, semantic), and whether the nature and strength of these connections change dynamically as a function of relative experience with each language (e.g., Kroll & Stewart, Reference Kroll and Stewart1994). One of the most direct ways to explore cross-language connections in the bilingual lexicon is to use priming techniques, with prime and target words belonging to different languages. By manipulating the factors postulated to constrain and regulate these connections and measuring how this affects priming, we can test theories about the architecture of the lexicon. In word recognition research, this logic has most often been embodied in lexical decision tasks with translation priming (e.g., Wen & van Heuven, Reference Wen and van Heuven2017, for review).
In a primed lexical decision task, the subject is presented with a prime word followed by a string of letters upon which they make a lexical decision (i.e., a yes/no answer to the implicit question “is this a real word?”). In the critical condition, prime and target are related at some level of interest—for example, semantics, morphology, orthography—while in the control condition they are unrelated. In a translation priming paradigm, related primes and targets are translation equivalents (e.g., flecha-ARROW, in a Spanish–English experiment), and cross-language unrelated pairs constitute the control condition (e.g., camisa, Spanish for “shirt”-ARROW). Priming effects manifest as significantly different mean response times (RTs) and/or error rates between the two conditions, typically with shorter latencies and/or greater accuracy in the related condition. Under interactive theories of lexical-semantic processing (e.g., Collins & Loftus, Reference Collins and Loftus1975), priming effects are interpreted as a given amount of (pre)activation spreading from a related prime to a target within the lexical network, facilitating its processing and speeding up retrieval.
The priming literature on bilingual lexical access has used both cognate and noncognate words (e.g., Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2010; see Sánchez-Casas & García-Albea, Reference Sánchez-Casas, García-Albea, Kroll and de Groot2005, for an early review). Cognate words are etymologically related pairs in different languages that retain some similarity in both form and meaning. Noncognate translation equivalents refer to semantically related pairs with no overlap at the form level (e.g., English dog and Spanish perro). Because orthography and phonology are not shared in these pairs, priming effects between noncognate translation equivalents have been used to gauge the availability of links between such words at the lexeme and conceptual levels. A recurrent finding in these experiments is a priming asymmetry (Wen & van Heuven, Reference Wen and van Heuven2017). While priming effects in the L1 (prime) to L2 (target) translation direction tend to be robust and have been replicated in numerous studies, L2-L1 effects are rare and almost invariably smaller. Although the effect has been mostly studied with masked priming paradigms (e.g., Schoonbaert et al., Reference Schoonbaert, Duyck, Brysbaert and Hartsuiker2009; Wen & van Heuven, Reference Wen and van Heuven2017), larger L1-L2 priming has been consistently found with unmasked primes as well (e.g., Chen & Ng, Reference Chen and Ng1989; Jin, Reference Jin1990; Keatley & Gelder, Reference Keatley and Gelder1992; Keatly et al., Reference Keatley, Spinks and De Gelder1994; Kiran & Lebel, Reference Kiran and Lebel2007; Smith et al., Reference Smith, Walters and Prior2019). This asymmetry is consistently observed with late bilinguals who are more proficient or dominant in one of their languages (generally the L1). High L2 proficiency (e.g., Nakayama et al., Reference Nakayama, Ida and Lupker2016; cf. Dimitropoulou et al., Reference Dimitropoulou, Duñabeitia and Carreiras2011) and early onset of bilingualism (e.g., Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2010; Wang, Reference Wang2013) have been reported to attenuate or eliminate the asymmetry. While these effects have been interpreted from various models of the bilingual lexicon (see the following text), all must account for why exactly factors relating to bilingual experience (e.g., language use, L2 proficiency) should strongly moderate the effect. A further complication is that relative language exposure/use and L2 proficiency seem to be correlated, making it difficult to tease apart their effects. The goal of the present study is to contribute useful data in this respect, by examining late bilinguals matched for L2 proficiency but differing in their amount of active L2 use.
To the previously mentioned end, we tested 200 highly proficient Spanish–English sequential bilinguals split into two groups equally, differing only in their societal language (L2 immersed vs. nonimmersed). Crucially, immersion proxied not only exposure to the L2 but also active use of that language, as confirmed by the significantly different mean scores of both groups in a linguistic background questionnaire (see the following text). We created a set of 314 noncognate translation pairs. In comparison to previous studies of this type, this generated a large number of observations, to which we applied a conservative analysis. In doing so, we answer recent calls for sufficiently powered studies in bilingualism (see Brysbaert, Reference Brysbaert2019, Reference Brysbaert2021; Brysbaert & Stevens, Reference Brysbaert and Stevens2018). Following from current theories as described previously, we predicted that immersion—proxying the amount of active L2 exposure/use—would modulate priming effects, especially in the L2-L1 direction. As a result, participants with L2 English as their societal language were expected to show a larger advantage in related trials (i.e., those with L2 translation primes) over control trials as compared to the nonimmersed group.
Models of bilingual lexical-semantic representation
Although several comprehensive theories have been advanced (see Kroll & Ma, Reference Kroll, Ma, Fernández and Cairns2017, for review), the two most prominent models of bilingual lexical-semantic processing are arguably the Revised Hierarchical Model (RHM; Kroll & Stewart, Reference Kroll and Stewart1994; Kroll et al., Reference Kroll, Van Hell, Tokowicz and Green2010) and Multilink (Dijkstra et al., Reference Dijkstra, Wahl, Buytenhuijs, Van Halem, Al-Jibouri, De Korte and Rekké2019), which aims to integrate the tenets of the RHM and the Bilingual Interactive Activation model(s) (BIA/BIA+; Dijkstra & van Heuven, Reference Dijkstra and Van Heuven2002).
The RHM is a developmental model proposing qualitative differences in the way L1 and L2 words are represented and connected. L1 words have direct and robust links to the conceptual features that make up their meanings. For L2 words, however, lexical-semantic connections are weaker, at least at low proficiency. The RHM proposes that, over development, the bilingual lexicon bridges L2 lexeme-concept connections through L1 lexemes, which have more robust access to the conceptual level. As proficiency increases, L2 lexeme-concept links become stronger, granting direct, independent access from L2 words to concepts, and vice versa, without L1 mediation. Although the RHM was originally proposed to account for asymmetries in word production (see Brysbaert & Duyck, Reference Brysbaert and Duyck2010, and Kroll et al., Reference Kroll, Van Hell, Tokowicz and Green2010, for discussion), it has been widely discussed in the word recognition literature, including translation priming. The RHM can predict the priming asymmetry only if we assume that translation priming is largely a semantic effect (e.g., Schoonbaert et al., Reference Schoonbaert, Duyck, Brysbaert and Hartsuiker2009; Xia & Andrews, Reference Xia and Andrews2015) and if there are asymmetric connections between the L2 lexical forms and the semantic store, with the route from meaning to form being stronger. Then, recognition of the L1 word would activate the shared conceptual node, which in turn would preactivate the L2 word. Bilinguals with lower L2 proficiency have L2 weaker lexical-semantic connections. In translation priming experiments, this means that L2 primes cannot (sufficiently) stimulate conceptual features shared with the L1 target, which results in a weak or no observable preactivation advantage with respect to an unrelated control word. The contrary is expected in the L1-L2 direction. L1 primes activate shared conceptual nodes, and these in turn preactivate their L2 target counterparts. Priming effects in both directions should gradually become more symmetrical with increased L2 proficiency or L2 use, which are expected to reinforce L2 lexical-semantic connections.
Multilink, developed within a localist-connectionist framework, is a comprehensive computational model of word recognition and production. For Multilink, most of the differences between L1 and L2 word processing can be accounted for by an intrinsic property of lexical representations, independent of their language membership: their resting level activation (RLA). RLA is conceptualized as a word’s baseline activation, from which task-related activation can push the lexical item over a given selection threshold. The model assumes that RLA is not static over time, and largely depends on subjective word frequency, defined as the speaker-specific frequency of each word (i.e., how many times a particular individual has encountered a particular word). Subjective frequency is, of course, not directly observable, but it may be proxied by different measurable factors, such as active language exposure/use or corpus word frequency. Like the RHM, Multilink predicts larger L2-L1 priming with more L2 experience. In this case, experience is assumed to increase the RLA for L2 words, speeding up prime recognition and increasing opportunities to preactivate the L1 target.
In sum, current models of bilingual lexical processing assume that L2 development brings about better connectivity and faster access for L2 words. This should result in less asymmetrical translation priming patterns between forward (L1-L2) and backward (L2-L1) translation directions. Whether patterns of L2 task performance can be faithfully captured, in this domain, through variables such as L2 proficiency or L2 active exposure/use is an open question.
L2 proficiency and L2 use in translation priming studies
Attempts have been made to assess the influence of L2 proficiency on translation priming effects. Dimitropoulou et al. (Reference Dimitropoulou, Duñabeitia and Carreiras2011) tested Greek–English bilinguals in three groups with varying L2 proficiency (i.e., low, intermediate, high). Priming patterns in the three groups did not significantly differ, leading to the conclusion that L2 proficiency was not a deterministic factor explaining the asymmetry. In contrast, in a series of experiments, Nakayama and colleagues reported a major modulation of L2-L1 priming by L2 proficiency. In Nakayama et al. (Reference Nakayama, Ida and Lupker2016), significant L2-L1 priming effects were obtained in two experiments with highly proficient Japanese–English bilinguals (TOEIC mean score [out of 990]: 872 and 917). It is worth noting that in one of the experiments in Nakayama et al. (Reference Nakayama, Ida and Lupker2016), the same stimuli as in Experiment 2B of Nakayama et al. (Reference Nakayama, Sears, Hino and Lupker2013) were used. Notably, these stimuli had previously failed to show significant L2-L1 priming at lower proficiency (TOEIC mean score: 740). A third experiment in Nakayama et al. (Reference Nakayama, Ida and Lupker2016) with lower-proficiency subjects (mean TOEIC: 710) replicated the results in Nakayama et al. (Reference Nakayama, Sears, Hino and Lupker2013, Experiment 2B). Taken together, this suggests that differences in L2 proficiency are a good candidate for explaining the misalignment of results in backward translation priming. That is, the 2016 findings overall seem to indicate that there is a lower bound of relatively high L2 proficiency required for L2-L1 priming.
Few studies have directly examined the role of language experience in noncognate translation priming with late bilinguals. In Experiment 1, Wang (Reference Wang2013) tested English–Chinese bilinguals who were more dominant in their L1, living in a bilingual society like Singapore. In Experiment 2, participants were more balanced bilinguals. Wang reports a priming asymmetry only in Experiment 1, suggesting an effect of dominance on priming effects. However, the cohort of participants in Experiment 2 was highly heterogeneous. For instance, 10 out of 20 subjects were early bilinguals, previously shown to yield symmetric priming patterns (e.g., Duñabeitia et al., Reference Duñabeitia, Perea and Carreiras2010), which might partly explain their results. Perhaps the most compelling evidence for the role of L2 use comes from Zhao et al. (Reference Zhao, Li, Liu, Fang, Shu, Carlson, Hölscher and Shipley2011). They tested four groups of Chinese–English bilinguals. In two of them, participants were highly proficient in their L2 but differed in whether their societal language was also English (L2-immersed vs. nonimmersed). The results showed that the size of the L2-L1 priming effect increased as a function of the amount of L2 experience. In particular, significant L2-L1 priming was only observed in the immersed, high-proficiency group (but not in a nonimmersed group with similar proficiency). However, the small number of observations potentially compromises their results—they tested 16 participants in the immersed group and employed 32 translation equivalents.
Taken together, these studies paint a mixed picture of the role of experiential factors in bilingual lexical processing and representation. Whereas some studies have suggested a fundamental role of L2 proficiency in the presence or absence of L2-L1 priming, others have failed to replicate these effects. This is true across the full range of L2 proficiency, even and most importantly for our purposes, at high levels of L2 proficiency where one would expect (cumulative) experience to be the most observable, if not testable. As per active L2 use, some findings seem to point toward a relevant involvement of this factor in modulating translation priming, but more research is needed to understand the magnitude of this role and disentangle it from those of L2 proficiency and language dominance.
It should come as no surprise that investigating such intertwined constructs results in a muddled picture. Indeed, the close relationship between proficiency and use is problematic for the study of the bilingual lexicon. Yet, it is hard to conceive why formal knowledge of a language—as L2 proficiency purportedly reflects—would be deterministic in lexical processing if this predictor were not intimately related to other aspects of bilingual experience. L2 proficiency, as an experimental construct, may be masking the contribution of other relevant factors, obscuring our understanding of the processes taking place within the lexical-semantic network. For instance, a bilingual with higher L2 proficiency will almost invariably have more frequent or intensive use of the L2 than someone with lower proficiency. L2 proficiency is a compound construct, necessarily including not only knowledge of a language but also experience with that language. Thus, proficiency perhaps introduces a confound in the equation, complicating the ability to accurately estimate the impact of language experience on bilingual lexical processing. In this sense, and despite the attention L2 proficiency has traditionally received, this construct may not be the best approximation to the contribution of language experience in the development of the bilingual lexicon. In contrast, the amount of active, meaningful experiences with the L2 may be more deterministic for dynamic changes in how (L1 and) L2 words are represented and processed.
In another relevant study, Chaouch-Orozco et al. (Reference Chaouch-Orozco, Alonso and Rothman2021) attempted to disentangle these effects by studying the interaction between L2 proficiency and use in a translation priming experiment. They tested Spanish–English bilinguals with English as their societal language (i.e., L2-immersed) and varying degrees of L2 proficiency and L2 use, both of which were operationalized as continuous variables. Participants’ L2 proficiency ranged from upper-intermediate to advanced. The L2 use scores—obtained from a linguistic background questionnaire—ranged from those reflecting equal use of both languages to greater L1 use. Chaouch-Orozco et al. (Reference Chaouch-Orozco, Alonso and Rothman2021) reported L2-L1 priming effects that were modulated by L2 use only, while L2 proficiency did not affect the priming effects significantly. Thus, the authors concluded that L2 use was a better predictor of L2 lexical processing than standard measures of L2 grammar knowledge. At 60 participants and 50 word pairs, however, the dataset in Chaouch-Orozco et al. (Reference Chaouch-Orozco, Alonso and Rothman2021) may have been underpowered to explore complex interactions of the type that the study focused on. Furthermore, the range of relative L1-L2 use was biased toward the L1 side of the scale, despite these being immersed L2 speakers.
The present study improves upon Zhao et al. (Reference Zhao, Li, Liu, Fang, Shu, Carlson, Hölscher and Shipley2011) and Chaouch-Orozco et al. (Reference Chaouch-Orozco, Alonso and Rothman2021) with a much larger sample and a more extensive set of word pairs, which guarantee sufficient statistical power to investigate the interactions of interest. In addition, here we introduce a more systematic exploration of L1/L2 use—operationalized through immersion—while factoring out potential effects of L2 proficiency by controlling this factor across participants. The goal is to offer a robust dataset that sheds light on the role of language use in bilingual lexical-semantic processing as reflected by translation priming effects.
Method
Participants
Two hundred Spanish–English sequential bilinguals (see Table 1 for participant characteristics) took part in two translation priming lexical decision tasks (LDT) under overt priming conditions, one experiment per priming direction. Participants were recruited from two different populations. Half of them were L1-immersed, living in Spain; the other half were L2-immersed, living in the United Kingdom. L2 proficiency was controlled across participants to isolate the effect of L2 use and was assessed with the LexTALE test (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012), a validated measure of L2 vocabulary and knowledge. A minimum score of 80/100 was required to participate in the study. This threshold was based on Lemhöfer & Broersma’s report of LexTALE correlating with the Oxford Quick Placement Test (OQPT; Oxford University Press, University of Cambridge, and Association of Language Testers in Europe, 2001). In particular, 80% correct responses in the OQPT, which corresponds to a CEFR (Common European Framework of Reference for Languages; Council of Europe, 2001) C1 level, corresponded to a LexTALE score of 80.5% in the authors’ analyses (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012, p. 335). A two-sample t-test showed that the groups differed significantly in their LexTALE score (t = –44.79, p < .001; see Table 1 for averages), despite small numerical differences in mean and standard deviation. However, further exploration with a parsimonious mixed-effects model showed that the factor, treated continuously across the whole population, did not significantly modulate overall RTs nor priming effects. Moreover, we further inspected a potential effect of proficiency by subsetting the groups to have nonsignificant differences in LexTALE scores between them. We achieved this by removing eight participants in each group (t = 0.47, p = 0.64). We then ran a new model with this subset, which yielded remarkably similar outcomes to our final model reported in the text that follows. Therefore, the analysis continued as planned.
Table 1. Participant characteristics

Note: Mean values (standard deviation; range). “LSBQ” column shows composite L2 use score across contexts (home, social, etc.).
Language use information was collected through the Language and Social Background Questionnaire (LSBQ; Anderson et al., Reference Anderson, Mak, Chahi and Bialystok2018), which provides a fine-grained, context-dependent, and dynamic measure of relative L1/L2 use. Mean values differed significantly between these groups (p < .05), with the immersed group reporting more L2 use. Therefore, the intuition about immersion proxying not only exposure but also active use of the L2 was supported and deemed the critical manipulation of immersion adequate for our empirical purposes. The LexTALE and LSBQ scores were not correlated (r = –0.11, p < .001). All participants reported having started to learn English in primary school and never before age six. Only four participants in the Spain-based group reported previous immersion experience, but not within the 12 months before the experiment.
Task order was as follows: first direction of the translation priming LDT – LSBQ – second direction of the LDT. Order of LDT priming direction (L1-L2 or L2-L1) was counterbalanced across participants. Participants were recruited online and compensated with £20 (or the equivalent in euros) for their participation.
Materials
A total of 314 noncognate translation equivalent pairs were used in each translation direction (see Appendix A for the stimuli list and Table 2 for stimuli characteristics). Targets were extracted from a continuum of frequencies and concreteness. Given that the stimuli consisted of translation pairs, we opted for using only the English words’ values to avoid employing different norms. Thus, each English word within each pair was given a concreteness value extracted from Brysbaert et al.’s (Reference Brysbaert, Warriner and Kuperman2014) norms. English word frequencies were obtained from the SUBTLEXUK corpus (van Heuven et al., Reference Van Heuven, Mandera, Keuleers and Brysbaert2014), whereas Spanish frequencies were extracted from SUBTLEXESP (Cuetos et al., Reference Cuetos, Glez-Nosti, Barbon and Brysbaert2011). Mean values between languages did not differ significantly. Words in both languages were also matched for length and orthographic neighborhood.
Table 2. Stimuli characteristics

Note: Mean values (standard deviation and ranges). Concreteness values for Spanish words are assumed to approximate that of their English translations.
To generate “no” trials necessary for lexical decision, 314 pseudowords were created for both translation directions with the Wuggy software (Keuleers & Brysbaert, Reference Keuleers and Brysbaert2010). These pseudowords matched their word counterparts on length of subsyllabic segments, letter length, transition frequencies, and two out of three segments. The pseudowords were paired with 314 different words that served as their primes. Four lists were created (two for each target language). For each language, one list had half the target words preceded by their translation equivalents and the other half by control primes, whereas the other list inverted these conditions for the same targets. Control primes were created by scrambling the related primes in the other list. We ensured that control pairs remained orthographically and semantically unrelated. The words in each list were matched for frequency, word length, and orthographic neighborhood. Each list began with 16 practice items.
To ensure that participants knew the English stimuli, they completed a picture-word matching task with the concrete stimuli, where they were presented with pictures depicting objects accompanied by two words in English: the correct picture name and a distractor. The lowest individual accuracy score was 89%. Only five words received responses with an accuracy lower than 80% overall. These were removed from the dataset. Knowledge of the abstract word pairs, which have much lower imageability, was evaluated through a translation recognition task. Five participants showed an accuracy below 85% and were removed from the dataset. Thirty-nine (abstract) words showed an accuracy below 80% and were removed from the dataset. In all cases, these tasks were conducted after the LDTs.
Procedure
All experiments were created and presented online using Gorilla Experiment Builder (Anwyl-Irvine et al., Reference Anwyl-Irvine, Massonnié, Flitton, Kirkham and Evershed2020). Given the limits that online presentation poses to the experimenter’s role on controlling participants’ performance, data quality control, and exclusion criteria were implemented to ensure participants’ constant attention during the experimental tasks. First, there was a time limit (95 minutes—on average, a session took 60–70 minutes to complete) to finish each session. Attention checks were implemented, and their presentation was pseudorandomized (i.e., within blocks of 20 trials) so participants could not know when they would appear. Participants had to press “B” on the keyboard within 2 seconds from the instructions’ onset. Participants failing to pass less than 95% of these checks were excluded from the study. We also examined their responses to ensure they were not blatantly random. Failing to meet these criteria resulted in exclusion from the study. Twenty-five participants out of 225 failed to meet these criteria, resulting in the final 200 participants whose data were analyzed.
Each trial began with a fixation cross on the centre of the screen (500 ms), followed by the prime in lowercase letters (200 ms) and the target in upper case letters, which remained on the screen until the subject provided a response. Right-handed participants had to press “0” on the keyboard to indicate YES, and “1” for NO. This order was inverted for left-handed participants. They were asked to respond as fast and as accurately as possible. Each task (priming direction) was further divided into 15 blocks of approximately 40 trials. Participants were given the chance to rest between these 40-trial blocks. They were asked to avoid any distractions during the session and to ensure their vision was corrected if needed. No participant completed the sessions at night, and they were encouraged not to participate when they felt tired. In sum, we paid special attention to simulating, to the extent possible, lab testing conditions.
Data analysis
Data and analysis code can be found in the first author’s OSF repository (https://osf.io/yx6hw/). Besides the five participants excluded due to low accuracy on the translation recognition task, two more participants were removed for the same reason after inspecting the LDT data. The analysis continued with the remaining 193 participants (96 in the Spain group, 97 in the UK group) and 270 word pairs. Incorrect responses and pseudoword trials, as well as RTs below 200 ms (4 in total) and above 5,000 ms (80 in total), were removed (see Baayen and Milin, Reference Baayen and Milin2010). We transformed the latencies to obtain inverse Gaussian, log-normal, and BoxCox distributions. After visual inspection (Q-Q plots) and Shapiro–Wilk tests, the inverse Gaussian distribution was selected to perform the analysis, as it provided a better correction of the skewness (inverse Gaussian: p = .42; BoxCox: p = .33; log-normal: p = .08). Sum contrasts were employed for categorical variables, and all continuous independent variables were scaled, centred, and converted to z units.
Error rates and response times were analyzed employing (generalized) linear mixed-effects models (Baayen et al., Reference Baayen, Davidson and Bates2008) in R (version 3.6.1; R Core Team, 2021) with the lme4 package (Bates et al., Reference Bates, Maechler, Bolker and Walker2015). We followed Scandola and Tidoni (Reference Scandola and Tidoni2021) for an optimal trade-off between maximal random structure specification, convergence, and computational power in random-effects specification and model selection. Scandola and Tidoni show that computational times are linked with convergence and overfitting issues. Consequently, in cases of high model complexity—as with our models—and relatively low computational power (standard lab equipment), they recommend employing Complex Random Intercepts (CRI). In a full-CRI model, (complex) random slopes (with many interactions) are replaced by different random intercepts for each grouping factor. The method minimizes Type-I error risk. For each analysis, we fitted a maximal model. If the model did not converge, we removed the CRI that explained the least variance and tried again until a maximal model converged. Further criticism was applied to this convergent model, including checking assumptions (e.g., normality of residuals’ distribution, homoscedasticity) and removing observations with absolute standardized residuals above 2.5 SD (Baayen & Milin, Reference Baayen and Milin2010). Thus, we employed a maximal model approach, as suggested by Barr et al. (Reference Barr, Levy, Scheepers and Tily2013; but see also Brauer & Curtin, Reference Brauer and Curtin2018; Scandola & Tidoni, Reference Scandola and Tidoni2021), because (i) it offered an optimal trade-off between Type-I and II errors (Scandola & Tidoni, Reference Scandola and Tidoni2021:13), and (ii) given our large number of observations, a more parsimonious method (Matuschek et al., Reference Matuschek, Kliegl, Vasishth, Baayen and Bates2017) did not seem as necessary.
We included main effects and interactions of interest as fixed effects in the analyses for both accuracy and RTs (Brauer & Curtin, Reference Brauer and Curtin2018). The grouping factors were language (i.e., translation direction), prime type (related vs. control), group (immersed vs. nonimmersed), and their interactions; that is, the factors that varied within subjects, primes, and targets (Brauer & Curtin, Reference Brauer and Curtin2018).Footnote 1 Thus, a full-CRI structure was specified with random intercepts for subjects, primes, and targets for each grouping factor.
Results
Response times
Table 3 summarizes RTs and error rates in all conditions. Appendix B provides the summary of the final model. Full specification and outcomes of other models can be found in the first author’s OSF repository. In the main analysis of response latencies, the final model revealed a significant effect of language (β = –0.05, t = –3.43, p < .001), indicating that responses to Spanish targets were faster. The main effect of prime type was also significant (β = –0.15, t = –26.93, p < .001), revealing overall faster RTs to related trials. However, a significant interaction between language and prime type (β = 0.03, t = 4.19, p < .001) showed that priming effects were larger in the L1-L2 direction. The interaction between group and prime type was significant (β = 0.02, t = 2.48, p = .014), indicating that priming effects were larger for the nonimmersed participants in both translation directions. Finally, the three-way interaction between language, prime type, and group was nonsignificant (β = 0.002, t = 0.28, p = .78), suggesting no differential role of immersion between translation directions.
Table 3. Mean response times (RTs, in milliseconds; standard errors), error rates (%), and priming effects (in milliseconds)
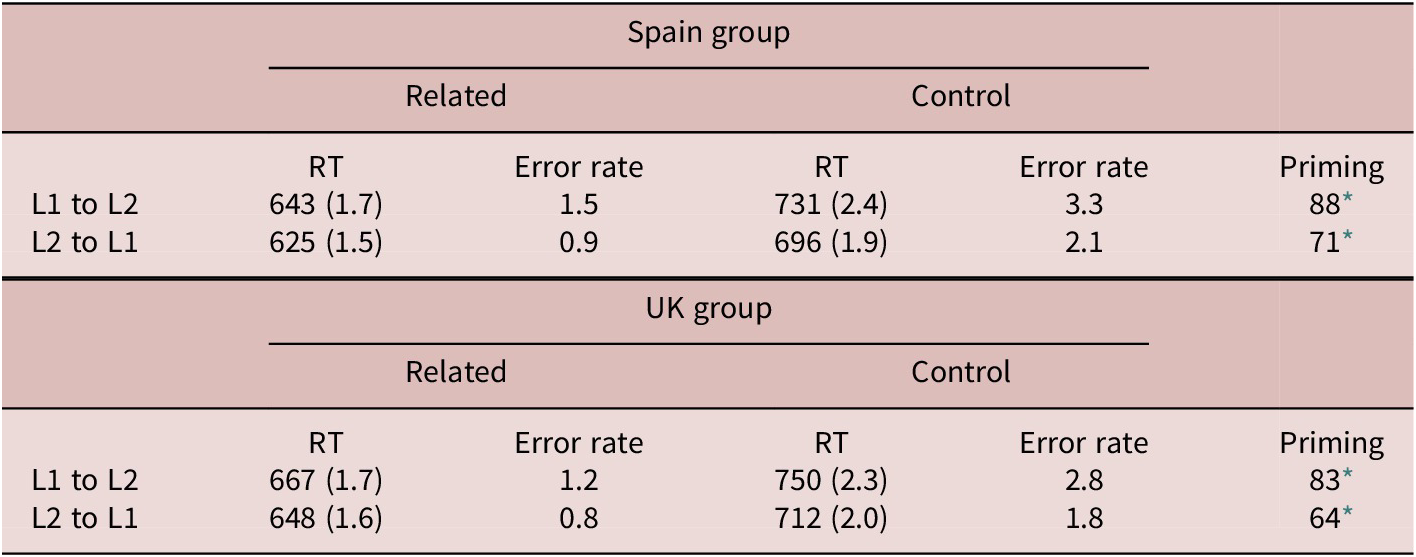
* p < .05.
To follow up on this null effect of immersion as a modulator of the priming asymmetry, we conducted further analyses. First, given that our stimuli consisted of words from all frequencies and from the whole concreteness spectrum, we controlled for the effect of both factors by running two separate analyses with interactions with the factors of interest as well as frequency and concreteness specified in the models. The potential effects of prime and target frequency were analysed in separate models to avoid multicollinearity issues (because the frequencies of translation equivalents tend to be correlated). Results in all these models revealed the same effects as in the main model. That is, there were significant effects of language and prime type, as well as significant interactions between these two factors. Further, in all the models, the two-way interaction between group and prime type was significant (all ps < .02), and the three-way interaction between group, prime type, and language was nonsignificant. Finally, complex four- and five-way interactions involving group and frequency or concreteness were observed, although none of them substantially changed the findings of the main analysis with respect to immersion.
However, to further inspect these interactions, we conducted separate analyses with subsets of the data. First, we looked at concreteness. The new models with subsets containing only concrete or abstract words, revealed the same pattern of results (i.e., a significant interaction between prime type and group; ps < .001). Then, we ran four new models with subsets splitting the data by prime and target frequency. The results showed that, with low-frequency stimuli, the small interaction between prime type and group disappeared. With high-frequency stimuli, however, the interactions between prime type and group were significant in the two models (ps < .001). Therefore, this result suggests that the significant interaction between prime type and condition is mainly driven by the high-frequency stimuli.
Moreover, although our main analysis focused on the effect of immersion, individual variation in language experience could also impact the priming effects. To investigate this possibility, we conducted independent analyses on the participants of each group, replacing the categorical variable group with the continuous LSBQ score. The results of these analyses showed that the LSBQ score did not modulate the priming patterns. Finally, we wondered whether our main finding would be replicated if the LSBQ score was employed instead of the group variable in a model with all the participants’ data. Notably, the results emerging from this new model mimicked those of the main model. We observed a significant interaction between prime type and LSBQ score (β = 0.01, t = 2.26, p = .025), indicating that priming was larger for the participants who reported using more the L1 (i.e., the nonimmersed ones).
Accuracy analysis
Accuracy was dummy-coded as 1 (correct) or 0 (incorrect). Generalized linear mixed-effects models with a binomial family were fit to the error data. Significant effects of language (β = 0.36, z = 2.68, p < .001), prime type (β = 0.80, z = 9.61, p < .001), and group (β = 0.26, z = 2.01, p < .05) were observed. This indicated that participants were more accurate when responding to Spanish targets, as well as in related trials. In addition, participants in the UK group were overall more accurate. The interaction between language and prime type was not significant, suggesting no priming asymmetry across tasks for accuracy. Note that accuracy analyses tend to be less sensitive to these experimental manipulations and, as usual in the relevant literature, were not central to the current study.
Discussion
We have presented data from a study investigating the effect of active L2 use on bilingual lexical representation and processing, employing two lexical decision tasks with noncognate translation priming. We tested highly proficient L1 Spanish-L2 English late bilinguals in two groups that differed in their societal language: L2-immersed versus nonimmersed. We ensured that the immersion factor accurately proxied for differences in L2 use between the groups by measuring this more precisely through a detailed questionnaire (LSBQ). A significant difference in LSBQ score between the groups suggests that the categorical split is justifiable in our sample. Furthermore, we controlled L2 proficiency across groups, which allowed us to isolate the potential effects of immersion/L2 use.
In line with much of the literature (see Wen & van Heuven, Reference Wen and van Heuven2017) and despite our participants’ high proficiency, we observed an asymmetry in priming effects between translation directions, with L2-L1 priming being significantly less pronounced. This finding aligns with the significant L2-L1 priming effects with high-proficiency Japanese–English bilinguals reported by Nakayama and colleagues (Reference Nakayama, Ida and Lupker2016).
More important for our study is the impact of immersion. According to the models of bilingual lexical representation and processing we presented in the preceding text, bilingual experience-related factors such as immersion (and what it proxies, i.e., active exposure to and use of the L2) should play a prominent role in the representation and functioning of the lexicon. In the context of translation priming, increased exposure to and active use of the L2 should lead to larger priming effects in the L2-L1 direction.
The Revised Hierarchical Model states that the links between L2 lexical representations and their meanings are relatively weak at low proficiency, in contrast with the fully developed L1 lexical-semantic connections. These architectural dissimilarities can explain the priming asymmetry, as long as translation priming is assumed to take place through coactivation of shared conceptual features between translation equivalents (and not through lexeme-to-lexeme links). At higher proficiencies, or with increased L2 use, stronger L2 lexical-semantic connections would ensure more direct access to the conceptual store for L2 translation primes. This would result in enhanced semantic activation between translation pairs and larger L2-L1 priming effects. In Multilink, resting level activation (RLA) is assumed to be sensitive to changes in the amount of use of the language(s), ultimately a proxy for how often a given lexical item may be retrieved. Hence, the more often a second language is used, the higher RLA should be for L2 words, which would translate into faster processing. With higher RLA, L2 related primes should be recognized faster and prove more effective in preactivating the L1 target, leading to larger L2-L1 priming effects.
Our results clearly challenge these hypotheses. First, although immersion (or more L2 use) did have a significant effect on translation priming effects, this did not result in the expected priming patterns. L2-L1 priming was in fact larger for those participants with less L2 use, contradicting our main hypothesis. Therefore, we cannot conclude that more active use of the L2 led our participants to benefit further from the presence of L2 primes. Analyses controlling for word frequency and concreteness further confirmed these results. Moreover, this modulation of priming effects by immersion was true of both translation directions, which prevents a straightforward interpretation by the RHM or Multilink. For both models, relative L1/L2 use should have a bearing on how fast prime and target words are retrieved, and this should in turn influence priming effects. In this sense, while larger L1-L2 priming for the Spain group could be explained by their comparatively higher L1 use, the same account fails to predict larger L2-L1 priming for the same group.
Crucially, other aspects of our data can offer some insights on the nature of this effect. A relevant difference between the groups is that the UK-based participants were overall more accurate. While there are several ways to interpret this, one may argue that the Spain group was thus slightly less confident in their responses (especially because they were not faster overall, which may have suggested a speed-accuracy trade-off). This makes longer trials more susceptible of showing a difference between the groups, as priming effects in standard (unmasked) priming paradigms are known to occur early or late in the RT distribution, potentially underlain by different mechanisms (e.g., Balota et al., Reference Balota, Yap, Cortese and Watson2008). A look at priming effects for each group across quantiles of the RT distribution suggests that this account might be on the right track. In Figure 1, we can see how participants in the Spain group obtained comparatively larger priming effects toward the highest quantiles, that is, in longer trials. Further left in the distribution, the two groups show priming effects that are similar in magnitude.Footnote 2 Furthermore, motivated by our result in the main analysis, we inspected the relation between word frequency and the immersion effect. Visual examination suggested that immersion seemed not to impact priming effects at lower quantiles irrespective of frequency. When differences appeared at higher quantiles, they seemed to be driven by high-frequency words. To further inspect this effect, we run omnibus ANOVAs on the mean RTs for each participant in each quantile with prime type, group, frequency, and quantile and with each subset. The analysis showed that the larger priming effect in higher quantiles for the Spain group was not significant in any subset. That is, these analyses did not show that frequency significantly modulated the interaction between prime type, group, and quantile. However, more direct research would be needed to determine these patterns, as these priming effects were relatively small and distributional analyses typically need larger numbers of observations to detect significant effects (Balota et al., Reference Balota, Yap, Cortese and Watson2008).

Figure 1. Plot of overall priming effects across quantiles for the two groups. Each point represents a quantile. Note that nine quantiles, 0.1 to 0.9, were employed for smoother curves.
In the literature on semantic priming with monolingual speakers, priming effects at higher quantiles have been associated to processes where the prime-target relationship is checked in memory before providing a lexical decision (e.g., McKoon & Ratcliff, Reference McKoon and Ratcliff1998; Thomas et al., Reference Thomas, Neely and O’Connor2012). That is, the more evidence on the prime-target translation relationship participants accumulate over time, the greater the (priming) benefit. In this light, both groups seem to have comparable priming effects of the early, more automatic type (a headstart effect through preactivation; Forster et al., Reference Forster, Mohan, Hector, Kinoshita and Lupker2003), but differ in the amount of priming caused by a prime-target compound cue. Note that independently from which model’s tenets are on the right track, both the RHM’s and Multilink’s mechanisms are based on spreading activation, which, crucially, would take place early in the trial. Therefore, we can safely conclude, that, at least with regard to the implications for the models discussed, our two groups elicited similar priming effects in the two translation directions and behave similarly. While this is a more fine-grained description of our results, the ultimate reasons behind these different patterns of priming effects across groups remain unclear.
Overall, our results do not support an effect of immersion in the size of L2-L1 priming effects. This finding contrasts with the more deterministic role of this factor reported by Chaouch-Orozco et al. (Reference Chaouch-Orozco, Alonso and Rothman2021) and Zhao et al. (Reference Zhao, Li, Liu, Fang, Shu, Carlson, Hölscher and Shipley2011). In both cases, L2 use clearly modulated L2-L1 priming effects. Discrepancies between the present study and Zhao et al.’s results are particularly intriguing. They observed that L2-L1 priming was significant in a group of highly proficient L2-immersed bilinguals, but not in a similarly proficient nonimmersed group, which is essentially at odds with our current results. Differences in power (100 subjects judging 314 items vs. 16 subjects judging 32 items) might explain at least some of these divergencies.
One possible explanation for the minimal impact of L2 use on L2-L1 priming here is that very high-proficiency marks some upper boundary for the effects of L2 use, so that its effect becomes negligible past some threshold of proficiency. A weaker version of this hypothesis would be that experience-driven changes in the lexicon do not occur at the same pace throughout development but slow down (i.e., require more experience to maintain the same rate) toward the higher end of the proficiency spectrum. This account reconciles two aspects of our data: the absence of a strong immersion/L2 use effect in our high-proficiency sample and the fact that we observe a difference in the magnitude of priming effects between translation directions (i.e., a priming asymmetry), which suggests that RLA/semantic connectivity for L2 words has not reached its maximum. Further research is needed to specifically test this hypothesis.
Moving forward, future efforts could target highly proficient immersed bilinguals with a broader range of immersion time, heritage speakers with different code-switching profiles, professional interpreters, or passive bilinguals, among others. Each bilingual profile offers unique opportunities to disentangle the roles of different experiential factors and, with it, obtain an ever-so-slightly clearer picture of the bilingual lexicon’s architecture.
Data Availability Statement
The experiment in this article earned Open Materials and Open Data badges for transparent practices. The materials and data are available at https://osf.io/yx6hw/.
Appendix
Appendix A. Complete list of stimuli
Table A1. Prime and target words and pseudowords

Appendix B. Maximal and final main model for the RTs analysis
Maximal model
invRT ~ Language + Prime type + Group + Language : Prime type + Language : Group + Prime type : Group + Language : Prime type : Group + (1 | Participant) + (1 | Participant : Language) + (1 | Participant : Prime type) + (1 | Participant : Language : Prime type) + (1 | Target) + (1 | Target : Prime type) + (1 | Prime) + (1 | Prime : Prime type)
Final model after reduction of random structure and further criticism
invRT ~ Language + Prime type + Group + Language : Prime type + Language : Group + Prime type : Group + Language : Prime type : Group + (1 | Participant) + (1 | Participant : Language) + (1 | Participant : Prime type) + (1 | Participant : Language : Prime type) + (1 | Target) + (1 | Prime) + (1 | Prime : Prime type)
Appendix C
Table C1. Summary of final model for the analysis of RTs, including intercept and factors and their coefficients, standard errors, t-values, and p-values








 Open access
Open access