


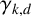
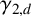
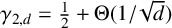
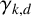
1 Introduction
The longest common subsequence (LCS) is a fundamental measure of the similarity of two or more strings that is important in theory and practice. A subsequence of a string is obtained by removing zero or more characters, and the LCS of d strings
$X^1,\ldots ,X^d$
 is the longest subsequence that occurs in all of
$X^1,\ldots ,X^d$
is the longest subsequence that occurs in all of
$X^1,\ldots ,X^d$
 . For d strings
$X^1,\ldots ,X^d$
. For d strings
$X^1,\ldots ,X^d$
 , we let
$\operatorname *{\mathrm {LCS}}(X^1,\ldots ,X^d)$
, we let
$\operatorname *{\mathrm {LCS}}(X^1,\ldots ,X^d)$
 denote the length of their LCS. For example,
$\operatorname *{\mathrm {LCS}}(0011,0101) = 3$
denote the length of their LCS. For example,
$\operatorname *{\mathrm {LCS}}(0011,0101) = 3$
 . Computing the LCS is a textbook application of dynamic programming in computer science [Reference Wagner and Fischer24], and the algorithm has many applications from text processing, to linguistics and computational biology. As one example, the Linux diff tool uses a variation of the LCS algorithm.
. Computing the LCS is a textbook application of dynamic programming in computer science [Reference Wagner and Fischer24], and the algorithm has many applications from text processing, to linguistics and computational biology. As one example, the Linux diff tool uses a variation of the LCS algorithm.
Chvátal and Sankoff [Reference Chvátal and Sankoff5] showed that as n approaches infinity, the normalised expected length of the LCS of two independent uniformly random binary strings converges to a constant. This limit is known as the Chvátal–Sankoff constant,

where the expectation is over independent uniformly random binary strings
$X^1, X^2$
 . Determining
$\gamma $
. Determining
$\gamma $
 is an open question with a rich history [Reference Baeza-Yates, Gavaldá, Navarro and Scheihing1–Reference Chvátal and Sankoff5, Reference Deken9, Reference Lueker18–Reference Paterson, Dančík, Prívara, Rovan and Ruzička20, Reference Soiffer, Salls, Miller, Reichman, Sárközy and Heineman22, Reference Steele23]. Currently the best bounds are roughly
$ 0.792\,665\le \gamma \le 0.826\,280$
is an open question with a rich history [Reference Baeza-Yates, Gavaldá, Navarro and Scheihing1–Reference Chvátal and Sankoff5, Reference Deken9, Reference Lueker18–Reference Paterson, Dančík, Prívara, Rovan and Ruzička20, Reference Soiffer, Salls, Miller, Reichman, Sárközy and Heineman22, Reference Steele23]. Currently the best bounds are roughly
$ 0.792\,665\le \gamma \le 0.826\,280$
 [Reference Lueker19, Reference Soiffer, Salls, Miller, Reichman, Sárközy and Heineman22].
[Reference Lueker19, Reference Soiffer, Salls, Miller, Reichman, Sárközy and Heineman22].
Table 1 presents a summary of key works that have contributed to establishing bounds on the Chvátal–Sankoff constant. Only some studies offer rigorously proven bounds, while others present estimates.
History of bounds and estimates for the Chvátal–Sankoff constant,
$ \gamma $
 .
.

Table 1 Long description
The table contains four columns: Authors, Year, Proven bounds, and Estimates.
* Chvátal and Sankoff, 1975: Proven bounds 0.697 844 less than or equal to gamma less than or equal to 0.866 595. Estimate gamma is approximately 0.8082.
* Deken, 1979: Proven bounds 0.7615 less than or equal to gamma less than or equal to 0.8575.
* Steele, 1986: Estimate gamma is approximately 0.8284.
* Dančík and Paterson, 1995: Proven bounds 0.773 91 less than or equal to gamma less than or equal to 0.837 63.
* Boutet de Monvel, 1999: Estimate gamma is approximately 0.812 282.
* Baeza-Yates et al., 1999: Estimate gamma is approximately 0.8118.
* Bundschuh, 2001: Estimate gamma is approximately 0.812 653.
* Lueker, 2009: Proven bounds 0.788 071 less than or equal to gamma less than or equal to 0.826 28.
* Bukh and Cox, 2022: Estimate gamma is approximately 0.8122.
* Soiffer et al., 2024: Proven bounds 0.792 665 less than or equal to gamma.
There are two natural ways to generalise the Chvátal–Sankoff problem: (1) increase the alphabet size; and (2) increase the number of strings. In this way, we may generalise the Chvátal–Sankoff constant by asking for
$\gamma _{k,d}$
 , the (normalised) expected longest common subsequence of d independent uniformly random strings over a size-k alphabet. Formally, let
, the (normalised) expected longest common subsequence of d independent uniformly random strings over a size-k alphabet. Formally, let

where the expectation is over independent uniformly random strings
$X^1,\ldots X^d\sim [k]^n$
 and
$[k]=\{1,\ldots ,k\}$
and
$[k]=\{1,\ldots ,k\}$
 . By definition,
$\gamma = \gamma _{2,2}$
. By definition,
$\gamma = \gamma _{2,2}$
 .
.
The generalisation to larger alphabet size k is well studied and well understood. This line of work in [Reference Baeza-Yates, Gavaldá, Navarro and Scheihing1, Reference Dančík6, Reference Deken9, Reference Paterson, Dančík, Prívara, Rovan and Ruzička20] culminated in a beautiful result that
$\gamma _{k,2} \to {2}/{\sqrt {k}}$
 as
$k\to \infty $
as
$k\to \infty $
 [Reference Kiwi, Loebl and Matouěk16], answering a conjecture of Sankoff and Mainville [Reference Sankoff, Mainville, Sankoff and Mainville21].
[Reference Kiwi, Loebl and Matouěk16], answering a conjecture of Sankoff and Mainville [Reference Sankoff, Mainville, Sankoff and Mainville21].
We study the generalisation to more strings d, which is also an important question. Mathematically it is a fundamental generalisation of the Chvátal–Sankoff constant. In computer science, it is intimately connected to error-correcting codes list-decodable against deletions [Reference Kash, Mitzenmacher, Thaler and Ullman15] (see also [Reference Guruswami, Haeupler, Shahrasbi, Makarychev, Makarychev, Tulsiani, Kamath and Chuzhoy10, Reference Guruswami, He and Li11, Reference Guruswami and Wang13]). Specifically,
$1-\gamma _{k,d}$
 is the maximum fraction of deletions that a positive-rate random code can list-decode against with list size
$d-1$
is the maximum fraction of deletions that a positive-rate random code can list-decode against with list size
$d-1$
 . This connection follows from a generalisation of a martingale concentration argument shown in [Reference Kash, Mitzenmacher, Thaler and Ullman15]. For completeness, we show the connection in Appendix B.
. This connection follows from a generalisation of a martingale concentration argument shown in [Reference Kash, Mitzenmacher, Thaler and Ullman15]. For completeness, we show the connection in Appendix B.
Several works have previously considered generalising the number of strings d, but less is known than for the larger-alphabet generalisation. Jiang and Li [Reference Jiang and Li14] showed that when
$d=n$
 , the expected LCS of d strings is roughly
${n}/{k}$
, the expected LCS of d strings is roughly
${n}/{k}$
 . Dančík [Reference Dančík7] showed that, for fixed d,
$\gamma _{k,d} = {c}/{k^{1-1/d}}$
. Dančík [Reference Dančík7] showed that, for fixed d,
$\gamma _{k,d} = {c}/{k^{1-1/d}}$
 for some constant
$c\in [1,e]$
for some constant
$c\in [1,e]$
 , disproving a conjecture of Steele [Reference Steele23] that
$\gamma _{k,d}=\gamma _{k,2}^{d-1}$
, disproving a conjecture of Steele [Reference Steele23] that
$\gamma _{k,d}=\gamma _{k,2}^{d-1}$
 . Kiwi and Soto [Reference Kiwi and Soto17] established numerical bounds on
$\gamma _{k,d}$
. Kiwi and Soto [Reference Kiwi and Soto17] established numerical bounds on
$\gamma _{k,d}$
 for small values of k and d. For example, they obtain bounds on
$\gamma _{k,d}$
for small values of k and d. For example, they obtain bounds on
$\gamma _{k,d}$
 up to
$d=14$
up to
$d=14$
 for a binary alphabet, and up to alphabet size
$k=10$
for a binary alphabet, and up to alphabet size
$k=10$
 for
$d=3$
for
$d=3$
 strings. Recent work of Soiffer et al. [Reference Soiffer, Salls, Miller, Reichman, Sárközy and Heineman22] improves upon [Reference Kiwi and Soto17] and establishes stronger numerical bounds.
strings. Recent work of Soiffer et al. [Reference Soiffer, Salls, Miller, Reichman, Sárközy and Heineman22] improves upon [Reference Kiwi and Soto17] and establishes stronger numerical bounds.
1.1 Our contributions
We give tight asymptotic bounds on the binary Chvátal–Sankoff constant as the number of strings increases, showing
$\gamma _{2,d} = \tfrac 12+\Theta ({1}/{\sqrt {d}})$
 .
.
Theorem 1.1. There exists constants
$0<c_1<c_2$
 such that, for all integers
$d\ge 2$
such that, for all integers
$d\ge 2$
 ,
,

Our main contribution is the lower bound, which combines a technique of Lueker [Reference Lueker19] and Kiwi and Soto [Reference Kiwi and Soto17] with a greedy matching strategy. Our upper bound follows from a counting argument of Guruswami and Wang [Reference Guruswami and Wang13], who studied codes for list-decoding deletions.
We also give bounds that are asymptotically near-optimal for larger alphabets.
Theorem 1.2. There exist constants
$c_0,c_1,c_2> 0$
 such that, for all integers d and k with
$d\ge c_0\log k$
such that, for all integers d and k with
$d\ge c_0\log k$
 ,
,

The lower bound of Theorem 1.2 follows from Theorem 1.1 by noting that
$\gamma _{k,d} \ge 2\gamma _{2,d}/k$
 : random k-ary strings of length n typically have binary subsequences of length roughly
$2n/k$
: random k-ary strings of length n typically have binary subsequences of length roughly
$2n/k$
 (see Appendix A). The upper bound again follows from a counting argument of Gurusuwami and Wang [Reference Guruswami and Wang13].
(see Appendix A). The upper bound again follows from a counting argument of Gurusuwami and Wang [Reference Guruswami and Wang13].

2 Proof overview
We now sketch the proof of Theorem 1.1 in the binary case,
$k=2$
 . We start with the lower bound.
. We start with the lower bound.
2.1 The Kiwi–Soto reduction to diagonal LCS
Our first step is to reduce the generalised Chvátal–Sankoff
$\gamma _{k,d}$
 problem to estimating the expected diagonal LCS. This approach was considered by Lueker [Reference Lueker18], who focused on the two-string case (
$d=2$
problem to estimating the expected diagonal LCS. This approach was considered by Lueker [Reference Lueker18], who focused on the two-string case (
$d=2$
 ) and obtained numerical lower bounds. It was then generalised by Kiwi and Soto [Reference Kiwi and Soto17] (see also [Reference Soiffer, Salls, Miller, Reichman, Sárközy and Heineman22]) to obtain numerical lower bounds for more strings
$d\ge 3$
) and obtained numerical lower bounds. It was then generalised by Kiwi and Soto [Reference Kiwi and Soto17] (see also [Reference Soiffer, Salls, Miller, Reichman, Sárközy and Heineman22]) to obtain numerical lower bounds for more strings
$d\ge 3$
 . We use the same technique to find lower bounds for any number of strings d.
. We use the same technique to find lower bounds for any number of strings d.
Let
$A_1,\ldots , A_d$
 be a collection of d finite binary strings. Let
$X_1, \ldots , X_d$
be a collection of d finite binary strings. Let
$X_1, \ldots , X_d$
 be a collection of d independent uniformly random binary strings of length n. For a string X, let
$X[1\cdots i]$
be a collection of d independent uniformly random binary strings of length n. For a string X, let
$X[1\cdots i]$
 denote the substring formed by the first i characters of string X and
$A_jX_j[1\cdots i]$
denote the substring formed by the first i characters of string X and
$A_jX_j[1\cdots i]$
 denote the concatenation of strings
$A_j$
denote the concatenation of strings
$A_j$
 and
$X_j[1\cdots i]$
and
$X_j[1\cdots i]$
 . Lueker (for
$d=2$
. Lueker (for
$d=2$
 ) and Kiwi and Soto (for all d) define
) and Kiwi and Soto (for all d) define

and show

for all fixed strings
$A_1,\ldots ,A_d$
 . Leuker and Kiwi and Soto combine this result with a dynamic programming approach to find numerical lower bounds on
$\lim _{n\to \infty } {W_{nd}}/{n}$
. Leuker and Kiwi and Soto combine this result with a dynamic programming approach to find numerical lower bounds on
$\lim _{n\to \infty } {W_{nd}}/{n}$
 , and thus
$\gamma _{2,d}$
, and thus
$\gamma _{2,d}$
 (and, more generally,
$\gamma _{k,d}$
(and, more generally,
$\gamma _{k,d}$
 ).
).
We take
$A_1,\ldots ,A_d$
 to be the empty string. Define the expected diagonal LCS as
to be the empty string. Define the expected diagonal LCS as

where
$\lambda $
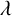 denotes the empty string. By (2.1), we have
denotes the empty string. By (2.1), we have

Intuitively, (2.3) is true because the maximum in (2.2) is obtained when
$i_1,i_2,\ldots ,i_d$
 are all roughly
$n/d$
are all roughly
$n/d$
 , so
$W_n$
, so
$W_n$
 approaches the expected LCS of d strings of length
$n/d$
approaches the expected LCS of d strings of length
$n/d$
 .
.
2.2 Our greedy matching scheme and binary lower bound
We now find a lower bound for the relative diagonal LCS
$\lim _{n\to \infty }{W_{nd}}/{n}$
 , and thus
$\gamma _{2,d}$
, and thus
$\gamma _{2,d}$
 . To do this, we define a greedy matching strategy that finds a common subsequence of d random strings, one bit at a time. We track the number of bits we ‘consume’ across the d strings, per matched LCS bit. We show that our greedy matching consumes on average
$2d-\Theta (\sqrt {d})$
. To do this, we define a greedy matching strategy that finds a common subsequence of d random strings, one bit at a time. We track the number of bits we ‘consume’ across the d strings, per matched LCS bit. We show that our greedy matching consumes on average
$2d-\Theta (\sqrt {d})$
 bits per matched LCS bit, which on average gives us
bits per matched LCS bit, which on average gives us

LCS bits for
$nd$
 symbols consumed. These estimates suggest
$W_{nd} \ge n(\tfrac 12 + \Theta ({1}/{\sqrt {d}}))$
symbols consumed. These estimates suggest
$W_{nd} \ge n(\tfrac 12 + \Theta ({1}/{\sqrt {d}}))$
 , and thus
$\gamma _{2,d} \ge \tfrac 12 + \Theta ({1}/{\sqrt {d}})$
, and thus
$\gamma _{2,d} \ge \tfrac 12 + \Theta ({1}/{\sqrt {d}})$
 , and we then prove this estimate.
, and we then prove this estimate.
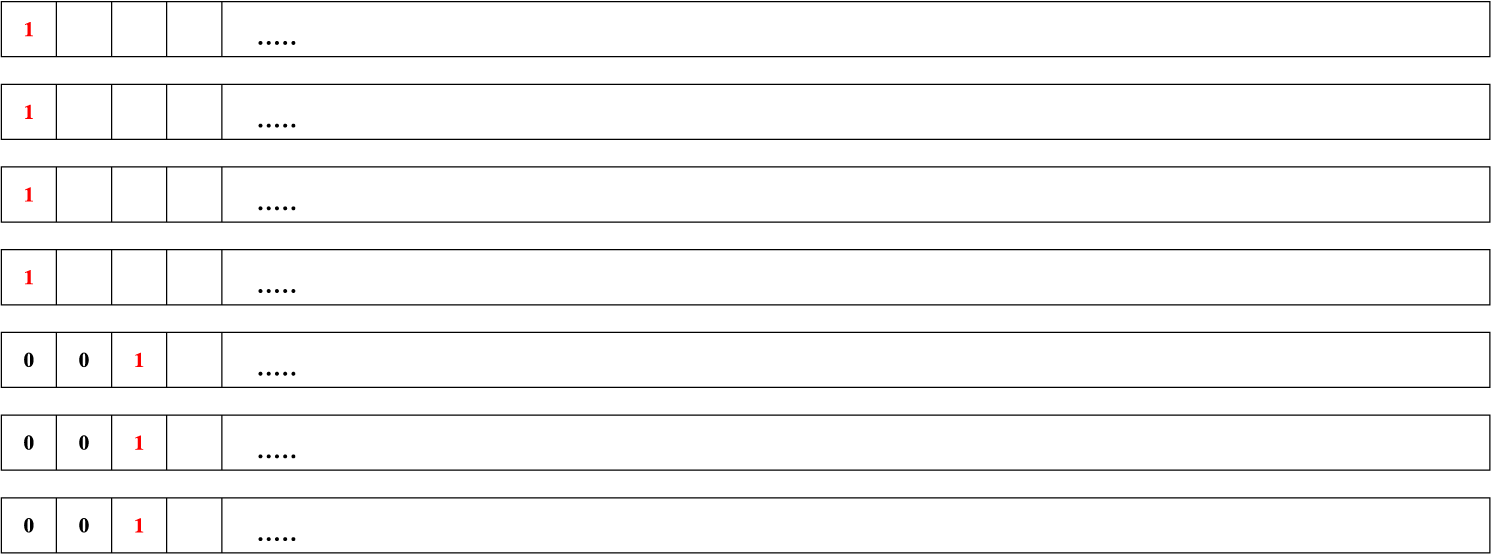
We now describe the matching strategy (illustrated in Figure 1). We match the LCS bit by bit, revealing the random bits as we need them; importantly, because the bits are independently random, we can reveal them in any desired order. For each LCS bit, we reveal the next bit in each of the d strings. We then take the next LCS bit to be the majority bit, say 0, and find the next 0 in each of the d strings. The number of bits consumed can be described by a process of repeatedly flipping d fair coins until all coins show the same face. We first flip all d coins. We keep reflipping all the coins in the minority until they show the majority face. For example, suppose we have flipped the d coins and heads appears
$ \lceil {d}/{2} \rceil $
 times. Then we repeatedly reflip the
$\lfloor {d}/{2} \rfloor $
times. Then we repeatedly reflip the
$\lfloor {d}/{2} \rfloor $
 coins that landed tails, until each shows heads. We let Z be the random variable denoting the total number of coin flips, or, equivalently, the total number of bits consumed per LCS bit.
coins that landed tails, until each shows heads. We let Z be the random variable denoting the total number of coin flips, or, equivalently, the total number of bits consumed per LCS bit.
Our matching strategy for
$d=7$
 random binary strings. Because all bits are independent, we can reveal the randomness in any order. We generate seven random bits. Suppose, as illustrated, four bits are a
$1$
random binary strings. Because all bits are independent, we can reveal the randomness in any order. We generate seven random bits. Suppose, as illustrated, four bits are a
$1$
 , and
$Y=3$
, and
$Y=3$
 are a
$0$
are a
$0$
 . We reveal more bits in the strings with
$0$
. We reveal more bits in the strings with
$0$
 s until we see
$1$
s until we see
$1$
 s. Here, in total, to get the one LCS bit, we revealed the randomness from
$Z=13$
s. Here, in total, to get the one LCS bit, we revealed the randomness from
$Z=13$
 bits across the seven strings.
bits across the seven strings.

To analyse the expected number of flips, we first consider the random variable Y, the number of coins in the minority after the first d flips. In the binary case, it is not hard to compute the expectation of Y explicitly. For example, when d is even,

and a similar computation holds when d is odd. Intuitively, the estimate
$\mathbf{E }[Y]=\tfrac 12d-\Theta (\sqrt {d})$
 makes sense because
$Y=\tfrac 12d - |\tfrac 12d-h|$
makes sense because
$Y=\tfrac 12d - |\tfrac 12d-h|$
 , where h is the number of heads. The standard deviation of h is
$\Theta (\sqrt {d})$
, where h is the number of heads. The standard deviation of h is
$\Theta (\sqrt {d})$
 , so we ‘expect’
$|\tfrac 12d-h|$
, so we ‘expect’
$|\tfrac 12d-h|$
 to be
$\Theta (\sqrt {d})$
to be
$\Theta (\sqrt {d})$
 , and thus Y to be
$\tfrac 12d-\Theta (\sqrt {d})$
, and thus Y to be
$\tfrac 12d-\Theta (\sqrt {d})$
 .
.
Now that we have a handle on Y, we can study Z, the total number of bits consumed for one LCS bit. The number of reflips of each minority coin is a geometric random variable with
$p=1/2$
 . Thus, the expected number of reflips of each minority coin is 2. Taking into account the conditional expectations, we can show that the expected total number of reflips of minority coins is thus
$2\cdot \mathbf{E }[Y] =d - \Theta (\sqrt {d})$
. Thus, the expected number of reflips of each minority coin is 2. Taking into account the conditional expectations, we can show that the expected total number of reflips of minority coins is thus
$2\cdot \mathbf{E }[Y] =d - \Theta (\sqrt {d})$
 . Adding on the d initial flips, we have
. Adding on the d initial flips, we have

This shows (modulo some details) that our greedy matching strategy consumes
$2d-\Theta (\sqrt {d})$
 bits per matched bit. Our back-of-the-envelope calculation suggests that, because we have
$nd$
bits per matched bit. Our back-of-the-envelope calculation suggests that, because we have
$nd$
 bits to consume across the d strings, and we consume an average of
$2d-\Theta (\sqrt {d})$
bits to consume across the d strings, and we consume an average of
$2d-\Theta (\sqrt {d})$
 bits per matched bit, we expect to find a common subsequence of length at least
${nd}/{(2d-\Theta (\sqrt {d}))} = n(\tfrac 12 + \Theta ({1}/{\sqrt {d}}))$
bits per matched bit, we expect to find a common subsequence of length at least
${nd}/{(2d-\Theta (\sqrt {d}))} = n(\tfrac 12 + \Theta ({1}/{\sqrt {d}}))$
 , as desired.
, as desired.
However, we have to work harder to formally justify this. Let
$Z_1,Z_2,\ldots $
 be the random variables where
$Z_i$
be the random variables where
$Z_i$
 denotes the number of bits we need to consume to match the ith bit with our matching strategy. By carefully choosing the order in which we reveal our bits, we can arrange for
$Z_1,Z_2,\ldots $
denotes the number of bits we need to consume to match the ith bit with our matching strategy. By carefully choosing the order in which we reveal our bits, we can arrange for
$Z_1,Z_2,\ldots $
 to be mutually independent. Further, the
$Z_i$
to be mutually independent. Further, the
$Z_i$
 are identically distributed as Z, and thus have expectation
$2d-\Theta (\sqrt {d})$
are identically distributed as Z, and thus have expectation
$2d-\Theta (\sqrt {d})$
 . The number of bits we matched by our strategy is the largest L such that
$Z_1+\cdots +Z_L\le nd$
. The number of bits we matched by our strategy is the largest L such that
$Z_1+\cdots +Z_L\le nd$
 . Importantly, because we work with diagonal LCS, we do not need to worry that we use a different number of bits in different strings. To show the expected number of bits matched is close to our estimate, we show that
. Importantly, because we work with diagonal LCS, we do not need to worry that we use a different number of bits in different strings. To show the expected number of bits matched is close to our estimate, we show that

We cannot use a standard concentration inequality because the
$Z_i$
 are unbounded. However, each
$Z_i$
are unbounded. However, each
$Z_i$
 is the sum of at most d geometric random variables. Thus, setting
$Z_i' \stackrel {\mathrm {def}}{=} \min (Z_i, O_d(\log n))$
is the sum of at most d geometric random variables. Thus, setting
$Z_i' \stackrel {\mathrm {def}}{=} \min (Z_i, O_d(\log n))$
 , with high probability,
$Z_i'=Z_i$
, with high probability,
$Z_i'=Z_i$
 for all i. We then use concentration inequalities to show
$Z_1'+\cdots +Z_{L_0}'\le nd$
for all i. We then use concentration inequalities to show
$Z_1'+\cdots +Z_{L_0}'\le nd$
 with high probability, and then (2.4) holds. Thus, the expected number of bits matched is at least
with high probability, and then (2.4) holds. Thus, the expected number of bits matched is at least ![]() . Hence, we arrive at our bound,
. Hence, we arrive at our bound,

2.3 The binary upper bound
The upper bound follows from a counting argument. Guruswami and Wang [Reference Guruswami and Wang13, Lemma 2.3] (Lemma 4.1 below) bound the number of supersequences of any string of length
$\ell>{n}/{k}$
 . By applying this bound and carefully tracking the lower-order terms, we show that
$\Pr [\operatorname *{\mathrm {LCS}}(X_1,\ldots ,X_d)\ge \ell ]$
. By applying this bound and carefully tracking the lower-order terms, we show that
$\Pr [\operatorname *{\mathrm {LCS}}(X_1,\ldots ,X_d)\ge \ell ]$
 is exponentially small for
is exponentially small for

Our bound on the expectation follows.
3 Preliminaries
Throughout
$\log $
 is log base 2 unless otherwise specified, and
$\ln $
is log base 2 unless otherwise specified, and
$\ln $
 is log base e. We use Wald’s lemma and Hoeffding’s inequality.
is log base e. We use Wald’s lemma and Hoeffding’s inequality.
Lemma 3.1 (Wald)
Let
$Y,W_1,W_2,\ldots $
 be independent random variables supported on the nonnegative integers with finite expectations and such that
$W_1,W_2,\ldots $
be independent random variables supported on the nonnegative integers with finite expectations and such that
$W_1,W_2,\ldots $
 are identically distributed. Define
$ W = W_1 + W_2 + \cdots + W_Y $
are identically distributed. Define
$ W = W_1 + W_2 + \cdots + W_Y $
 . Then
. Then

Lemma 3.2 (Hoeffding)
Let
$ X_1, X_2,\ldots , X_n $
 be independent random variables such that
$ X_i \in [a_i, b_i] $
be independent random variables such that
$ X_i \in [a_i, b_i] $
 almost surely. Then, for any
$ t> 0 $
almost surely. Then, for any
$ t> 0 $
 ,
,

For
$p \in (0,1)$
 , we define the q-ary entropy by
, we define the q-ary entropy by

where
$ h(p) $
 is the binary entropy function. We use a well-known estimate on binomial terms and the following estimate for k-ary entropy.
is the binary entropy function. We use a well-known estimate on binomial terms and the following estimate for k-ary entropy.
Lemma 3.3 (see, for example, [Reference Guruswami, Rudra and Sudan12, Proposition 3.3.1])
We have

Lemma 3.4 (see, for example, [Reference Guruswami, Rudra and Sudan12, Proposition 3.3.5])
For small enough
$\varepsilon \in (0, {1}/{k})$
 ,
,

As described in Section 2, define the expected diagonal LCS

where the randomness is over uniformly random infinite binary strings
$X^1,\ldots ,X^d$
 . The following lemma shows that the diagonal LCS equals the expected LCS up to lower-order terms.
. The following lemma shows that the diagonal LCS equals the expected LCS up to lower-order terms.
Lemma 3.5 [Reference Kiwi and Soto17]
We have
$\gamma _{k,d}=\lim _{n \to \infty } {W_{nd}}/{n}$
 .
.
4 Full proof of the k-ary LCS
4.1 Theorem 1.1, lower bound
Proof of Theorem 1.1, lower bound
By Lemma 3.5, it suffices to show that there is an absolute constant
$c_1>0$
 such that, for sufficiently large n,
such that, for sufficiently large n,

We now present our greedy matching strategy for finding a long ‘diagonal’ common subsequence, that is, a common subsequence of
$X^1[1\cdots i_1], \ldots , X^d[1\cdots i_d]$
 for
${i_1+\cdots +i_d=nd}$
for
${i_1+\cdots +i_d=nd}$
 . Given d random infinite strings
$X^1,\ldots ,X^d$
. Given d random infinite strings
$X^1,\ldots ,X^d$
 , we find the LCS bit by bit, revealing the random bits of
$X^1,\ldots ,X^d$
, we find the LCS bit by bit, revealing the random bits of
$X^1,\ldots ,X^d$
 as we need them. Importantly, because the bits are independently random, we can reveal them in any desired order. Use the following process.
as we need them. Importantly, because the bits are independently random, we can reveal them in any desired order. Use the following process.
-
(1) Initialize a string s to the empty string, representing our common subsequence of $X^1,\ldots ,X^d$
 .
. -
(2) Repeat the following.
-
(a) Reveal the next unrevealed bit $b_1,\ldots ,b_d$
in each of
$X^1,\ldots ,X^d$
. -
(b) Let b be the majority bit among these d bits.
-
(c) For each string $X^j$
that did not reveal the majority bit (
$b_i\neq b$
), reveal bits of
$X^j$
until we reveal a bit equal to b. -
(d) If the number of revealed bits is at most $nd$
, append b to s, else exit.
-







See Figure 1 for an illustration of this process. The length of the subsequence we find is the number of times we successfully complete the loop.
Let Y denote the random variable that denotes the number of minority bits among d uniformly random bits. Let Z denote the random variable that first samples Y and is set to
$d + W_1+\cdots +W_Y$
 , where
$W_1,\ldots ,W_Y$
, where
$W_1,\ldots ,W_Y$
 are independent geometric random variables with probability 1/2. Because the bits are independent, the number of bits revealed in each iteration of the loop is distributed as Z. Thus, letting
$Z_1,Z_2,\ldots $
are independent geometric random variables with probability 1/2. Because the bits are independent, the number of bits revealed in each iteration of the loop is distributed as Z. Thus, letting
$Z_1,Z_2,\ldots $
 be independent random variables identically distributed as Z, the length of our LCS is distributed as
be independent random variables identically distributed as Z, the length of our LCS is distributed as

We wish to find a lower bound for
$\mathbf{E }[L_{\mathrm {greedy}}]$
 .
.
We start by analysing the expectations of Y and Z. Explicit calculations yield, for all d,

for some absolute constant
$c>0$
 . To see this, note that for d even,
. To see this, note that for d even,

and for d odd,

where
$c>0$
 is some absolute constant. Thus, (4.1) holds. By Lemma 3.1 we have
$\mathbf{E }[Z]\le d + 2\,\mathbf{E }[Y] = d-2c\sqrt {d}$
is some absolute constant. Thus, (4.1) holds. By Lemma 3.1 we have
$\mathbf{E }[Z]\le d + 2\,\mathbf{E }[Y] = d-2c\sqrt {d}$
 .
.
Let
$ L_0 = {nd}(1 - \gamma )/{\mathbb {E}[Z]} $
 for
$\gamma ={1}/{100\log n}$
for
$\gamma ={1}/{100\log n}$
 . We show that the sum
$ \sum _{i=1}^{L_0} Z_i $
. We show that the sum
$ \sum _{i=1}^{L_0} Z_i $
 is less than
$ nd $
is less than
$ nd $
 with very high probability, so that
$L_{\mathrm {greedy}}\ge L_0$
with very high probability, so that
$L_{\mathrm {greedy}}\ge L_0$
 with very high probability. This follows from concentration inequalities, but we cannot apply the inequalities directly because our random variables
$Z_i$
with very high probability. This follows from concentration inequalities, but we cannot apply the inequalities directly because our random variables
$Z_i$
 are unbounded. Define truncated variables
$ Z_i' = \min (Z_i, T) $
are unbounded. Define truncated variables
$ Z_i' = \min (Z_i, T) $
 for
$T=100 d \log n$
for
$T=100 d \log n$
 , so that each
$Z_i'$
, so that each
$Z_i'$
 is in
$[0,T]$
is in
$[0,T]$
 .
.
We show that all
$Z_i=Z_i'$
 with high probability. In step 2(c), for each
$X^j$
with high probability. In step 2(c), for each
$X^j$
 , we see the correct bit b within
$99\log n$
, we see the correct bit b within
$99\log n$
 steps with probability at least
$1-{1}/{n^{99}}$
steps with probability at least
$1-{1}/{n^{99}}$
 . By the union bound, this happens for all
$j=1,\ldots ,d$
. By the union bound, this happens for all
$j=1,\ldots ,d$
 with probability at least
$1-{d}/{n^{99}}$
with probability at least
$1-{d}/{n^{99}}$
 , in which case
$Z_i\le d+99d\log n < T$
, in which case
$Z_i\le d+99d\log n < T$
 and
$Z_i=Z_i'$
and
$Z_i=Z_i'$
 . Thus, union-bounding over
$i=1,\ldots ,L_0$
. Thus, union-bounding over
$i=1,\ldots ,L_0$
 ,
,

Since
$Z_1',\ldots , Z_{L_0}'$
 are independent, Hoeffding’s inequality (Lemma 3.2) implies
are independent, Hoeffding’s inequality (Lemma 3.2) implies

where
$t = nd - \mathbb {E}[\sum _{i=1}^{L_0} Z_i'] = nd-L_0\cdot \mathbf{E }[Z'] \ge \gamma nd$
 . Substituting t gives
. Substituting t gives

Combining (4.2) and (4.3), for sufficiently large n,

Finally, the expected LCS length after
$ nd $
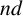 bits is
bits is

for some absolute constant
$c_1>0$
 . Hence,
. Hence,

4.2 Theorem 1.1, upper bound
We use the following lemma from [Reference Guruswami and Wang13] that counts superstrings of a string of a given length.
Lemma 4.1 [Reference Guruswami and Wang13, Lemma 2.3]
For any string w of length
$\ell>{n}/{k}$
 , the number of strings of length n with w as a subsequence is at most
, the number of strings of length n with w as a subsequence is at most

We remark that the result in [Reference Guruswami and Wang13] is stated for
$\ell>(1-1/k)n$
 , and states that there are at most
$\sum _{t=\ell }^n\binom {t-1}{\ell -1}k^{n-t}(k-1)^{t-\ell }$
, and states that there are at most
$\sum _{t=\ell }^n\binom {t-1}{\ell -1}k^{n-t}(k-1)^{t-\ell }$
 subsequences. However, this bound comes from a counting argument and actually holds for all
$\ell $
subsequences. However, this bound comes from a counting argument and actually holds for all
$\ell $
 . For
$\ell> n/k$
. For
$\ell> n/k$
 , the summands increase with t, so bounding each summand by the
$t=n$
, the summands increase with t, so bounding each summand by the
$t=n$
 summand gives the bound stated here.
summand gives the bound stated here.
Proof of Theorem 1.1, upper bound
With hindsight, let
$c_0=16$
 , and let
${\ell = {n}(1 + \varepsilon )/k}$
, and let
${\ell = {n}(1 + \varepsilon )/k}$
 where
$\varepsilon = 4\cdot \sqrt {{\ln k}/{d}}$
where
$\varepsilon = 4\cdot \sqrt {{\ln k}/{d}}$
 . Assume
$c_0\log k < d$
. Assume
$c_0\log k < d$
 , so that
$\varepsilon <1$
, so that
$\varepsilon <1$
 . By Lemma 4.1, for all strings w of length
$\ell $
. By Lemma 4.1, for all strings w of length
$\ell $
 ,
,

By a union bound over all strings of length
$\ell $
 , taking
$c_k={k}/{(4\ln k)}$
, taking
$c_k={k}/{(4\ln k)}$
 in Lemma 3.4,
in Lemma 3.4,

The second inequality uses Lemma 3.3 and the definition of
$\ell $
 . The third inequality uses Lemma 3.4. The fourth inequality follows from
$\varepsilon <1$
. The third inequality uses Lemma 3.4. The fourth inequality follows from
$\varepsilon <1$
 . The equality follows from substituting
$c_k$
. The equality follows from substituting
$c_k$
 . Our bound on the expectation follows.
. Our bound on the expectation follows.

Taking the limit
$n\to \infty $
 , we conclude
$\gamma _{k,d}\le {(1+\varepsilon )}/{k}$
, we conclude
$\gamma _{k,d}\le {(1+\varepsilon )}/{k}$
 , as desired.
, as desired.
Appendix A. Binary lower bounds implies k-ary lower bounds
The k-ary lower bound in Theorem 1.2 follows from the binary lower bound in Theorem 1.1 because of the following lemma.
Lemma A.1.
$\gamma _{k,d}\ge {2}\gamma _{2,d}/k$
 .
.
Proof. Consider d random strings
$X^1,\ldots ,X^d$
 over the alphabet
$[k]$
over the alphabet
$[k]$
 . Let
$Y^1,\ldots ,Y^d$
. Let
$Y^1,\ldots ,Y^d$
 be the subsequences of
$X^1,\ldots ,X^d$
be the subsequences of
$X^1,\ldots ,X^d$
 consisting of the symbols
$\{1,2\}$
consisting of the symbols
$\{1,2\}$
 . By standard concentration arguments, the lengths
$|Y^1|,\ldots ,|Y^d|$
. By standard concentration arguments, the lengths
$|Y^1|,\ldots ,|Y^d|$
 are all at least
$n_0={2}n/k-O_k(n^{2/3})$
are all at least
$n_0={2}n/k-O_k(n^{2/3})$
 with high probability
$1-2^{\Omega _k(n^{1/3})}$
with high probability
$1-2^{\Omega _k(n^{1/3})}$
 . Conditioned on the lengths
$|Y^1|,\ldots ,|Y^d|$
. Conditioned on the lengths
$|Y^1|,\ldots ,|Y^d|$
 all being at least
$n_0$
all being at least
$n_0$
 , the expected LCS of
$Y^1,\ldots ,Y^d$
, the expected LCS of
$Y^1,\ldots ,Y^d$
 is at least
$\gamma _{2,d}\cdot n_0$
is at least
$\gamma _{2,d}\cdot n_0$
 . Thus,
. Thus,

and it follows that
$\gamma _{k,d}\ge ({2}/{k})\gamma _{2,d}$

Appendix B. List-decoding against deletions
We connect the generalised Chvátal–Sankoff constant to list-decoding against deletions. The connection uses Azuma’s inequality.
Lemma B.1. (Azuma’s inequality)
Let
$Z_1, Z_2, \ldots , Z_n$
 be a martingale with bounded differences, that is,
$|Z_{i+1}-Z_i| \leq c$
be a martingale with bounded differences, that is,
$|Z_{i+1}-Z_i| \leq c$
 for some constant c. Then, for any
$\varepsilon \geq 0$
for some constant c. Then, for any
$\varepsilon \geq 0$
 ,
,

A code is a subset of
$[k]^n$
 . A random code C is obtained by sampling independent uniformly random strings from
$[k]^n$
. A random code C is obtained by sampling independent uniformly random strings from
$[k]^n$
 . For
$p\in (0,1)$
. For
$p\in (0,1)$
 and an integer
$d\ge 2$
and an integer
$d\ge 2$
 , a code C is
$(p,d-1)$
, a code C is
$(p,d-1)$
 list-decodable against deletions if any d strings
$X^1,\ldots ,X^d\in C$
list-decodable against deletions if any d strings
$X^1,\ldots ,X^d\in C$
 satisfy
$\operatorname *{\mathrm {LCS}}(X^1,\ldots ,X^d)< (1-p)n$
satisfy
$\operatorname *{\mathrm {LCS}}(X^1,\ldots ,X^d)< (1-p)n$
 .
.
The first result in Proposition B.2 says that random codes of positive rate (with
${|C|\ge 2^{\Omega (n)}}$
 ) are list-decodable against deletions with radius
$p=1-\gamma _{k,d}-\varepsilon $
) are list-decodable against deletions with radius
$p=1-\gamma _{k,d}-\varepsilon $
 . The second result says that random codes even of constant size are not list-decodable against deletions with radius
$1-\gamma _{k,d}+\varepsilon $
. The second result says that random codes even of constant size are not list-decodable against deletions with radius
$1-\gamma _{k,d}+\varepsilon $
 . Thus,
$1-\gamma _{k,d}$
. Thus,
$1-\gamma _{k,d}$
 is the maximum fraction of deletions that a positive-rate random code list-decodes against with list-size d.
is the maximum fraction of deletions that a positive-rate random code list-decodes against with list-size d.
Proposition B.2. For all
$\varepsilon> 0$
 , there exists a constant
$c>0$
, there exists a constant
$c>0$
 such that a random code
$C\subset [k]^n$
such that a random code
$C\subset [k]^n$
 of size
$|C|\ge 2^{cn}$
of size
$|C|\ge 2^{cn}$
 is
$(1-\gamma _{k,d}-\varepsilon ,d-1)$
is
$(1-\gamma _{k,d}-\varepsilon ,d-1)$
 list-decodable against deletions. Furthermore, a random code of size d, with high probability, is not
$(1-\gamma _{k,d}+\varepsilon ,d-1)$
list-decodable against deletions. Furthermore, a random code of size d, with high probability, is not
$(1-\gamma _{k,d}+\varepsilon ,d-1)$
 list-decodable against deletions.
list-decodable against deletions.
Proof. With hindsight, choose
$c=\varepsilon ^2/10d$
 . We construct the code C as a set of
$ 2^{cn} $
. We construct the code C as a set of
$ 2^{cn} $
 independent random strings, each of length
$ n $
independent random strings, each of length
$ n $
 , drawn from the alphabet
$ [k] $
, drawn from the alphabet
$ [k] $
 . We consider the longest common subsequence (LCS) of
$ d $
. We consider the longest common subsequence (LCS) of
$ d $
 codewords
$ X^1, X^2,\ldots , X^d $
codewords
$ X^1, X^2,\ldots , X^d $
 from
$ C $
from
$ C $
 .
.
The length LCS
$(X^1, X^2,\ldots , X^d) $
 can be treated as a martingale sequence by revealing the symbols one at a time. Define
$ Z_i $
can be treated as a martingale sequence by revealing the symbols one at a time. Define
$ Z_i $
 as the expected value of the LCS length given the first
$ i $
as the expected value of the LCS length given the first
$ i $
 symbols of each sequence
$ X^1,\ldots , X^d $
symbols of each sequence
$ X^1,\ldots , X^d $
 :
:

Here,
$ Z_0, Z_1,\ldots , Z_n $
 form a martingale, where
form a martingale, where

Further, this martingale has bounded difference
$|Z_{i+1}-Z_i|\le 1$
 . By Azuma’s inequality, for any
$ \varepsilon> 0 $
. By Azuma’s inequality, for any
$ \varepsilon> 0 $
 ,
,

This result implies that, with high probability, the LCS length is close to its expected value
$\gamma _{k,d} n$
 . With large enough n, the probability that LCS exceeds
$\gamma _{k,d} n$
. With large enough n, the probability that LCS exceeds
$\gamma _{k,d} n$
 is exponentially small. Thus, for each individual set of
$ d $
is exponentially small. Thus, for each individual set of
$ d $
 codewords,
codewords,

By the union bound, the probability that any d-tuple of codewords in C violates this bound is at most

Thus, with high probability,
$LCS(X^1, X^2,\ldots , X^d) \leq ( \gamma _{k,d} + \varepsilon ) n$
 for all codewords
$ X^1, X^2,\ldots , X^d \in C $
for all codewords
$ X^1, X^2,\ldots , X^d \in C $
 , and our code is
$(1-\gamma _{k,d}-\varepsilon ,d-1)$
, and our code is
$(1-\gamma _{k,d}-\varepsilon ,d-1)$
 list-decodable against deletions.
list-decodable against deletions.
To show the second result, note that, by (B.2), for d independent random strings
$X^1,\ldots ,X^d$
 ,
,

so a random code of size d is not
$(1-\gamma _{k,d}+\varepsilon ,d-1)$
 list-decodable with high probability.
list-decodable with high probability.
Acknowledgement
We thank Shamil Asgarli for helpful discussions.









 Open access
Open access