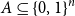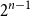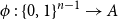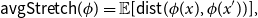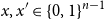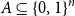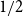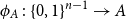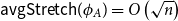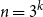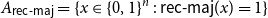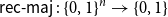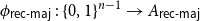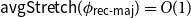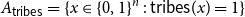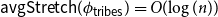Refine listing
Actions for selected content:
89 results in 68Rxx
Record-biased permutations and their permuton limit
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-39
-
- Article
- Export citation
The random
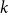 $\textit{k}$-SAT Gibbs uniqueness threshold revisited
$\textit{k}$-SAT Gibbs uniqueness threshold revisited
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove that for any
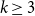 $k\geq 3$ for clause/variable ratios up to the Gibbs uniqueness threshold of the corresponding Galton-Watson tree, the number of satisfying assignments of random
$k\geq 3$ for clause/variable ratios up to the Gibbs uniqueness threshold of the corresponding Galton-Watson tree, the number of satisfying assignments of random 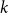 $k$-SAT formulas is given by the ‘replica symmetric solution’ predicted by physics methods [Monasson, Zecchina: Phys. Rev. Lett. 76 (1996)]. Furthermore, while the Gibbs uniqueness threshold is still not known precisely for any
$k$-SAT formulas is given by the ‘replica symmetric solution’ predicted by physics methods [Monasson, Zecchina: Phys. Rev. Lett. 76 (1996)]. Furthermore, while the Gibbs uniqueness threshold is still not known precisely for any 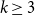 $k\geq 3$, we derive new lower bounds on this threshold that improve over prior work [Montanari and Shah: SODA (2007)]. The improvement is significant particularly for small
$k\geq 3$, we derive new lower bounds on this threshold that improve over prior work [Montanari and Shah: SODA (2007)]. The improvement is significant particularly for small 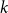 $k$.
$k$.
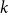
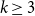
Hamiltonian Sets of Polygonal Paths in Assembly Graphs
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society , First View
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We provide four equivalent combinatorial conditions for a simple assembly graph (rigid vertex graph where all vertices are of degree 1 or 4) to have the largest number of Hamiltonian sets of polygonal paths relative to its size. These conditions serve to prove the conjecture that such a maximum, which is equal to
 $F_{2n+1}-1$, where
$F_{2n+1}-1$, where  $F_k$ denotes the
$F_k$ denotes the  $k$th Fibonacci number, is achieved only for special assembly graphs, called tangled cords.
$k$th Fibonacci number, is achieved only for special assembly graphs, called tangled cords.



EXPECTED LENGTH OF THE LONGEST COMMON SUBSEQUENCE OF MULTIPLE STRINGS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society , First View
- Published online by Cambridge University Press:
- 02 March 2026, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the generalised Chvátal–Sankoff constant
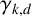 $\gamma _{k,d}$, which represents the normalised expected length of the longest common subsequence of d independent uniformly random strings over an alphabet of size k. We derive asymptotically tight bounds for
$\gamma _{k,d}$, which represents the normalised expected length of the longest common subsequence of d independent uniformly random strings over an alphabet of size k. We derive asymptotically tight bounds for 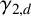 $\gamma _{2,d}$, establishing that
$\gamma _{2,d}$, establishing that 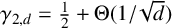 $\gamma _{2,d} = \tfrac 12 + \Theta ({1}/{\sqrt {d}})$. We also derive asymptotically near-optimal bounds on
$\gamma _{2,d} = \tfrac 12 + \Theta ({1}/{\sqrt {d}})$. We also derive asymptotically near-optimal bounds on 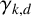 $\gamma _{k,d}$ for
$\gamma _{k,d}$ for 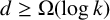 $d\ge \Omega (\log k)$.
$d\ge \Omega (\log k)$.
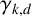
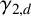
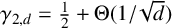
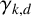
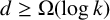
k-11-representations of graphs, revisited
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society , First View
- Published online by Cambridge University Press:
- 15 December 2025, pp. 1-15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we study the existence of
 $k$-
$k$- $11$-representations of graphs. Inspired by work on permutation patterns, these representations are ways of representing graphs by words where adjacencies between vertices are captured by patterns in the corresponding letters. Our main result is that all graphs are
$11$-representations of graphs. Inspired by work on permutation patterns, these representations are ways of representing graphs by words where adjacencies between vertices are captured by patterns in the corresponding letters. Our main result is that all graphs are  $1$-
$1$- $11$-representable, answering a question originally raised by Cheon et al. in 2018 and repeated in several follow-up papers – including a very recent paper, where it was shown that all graphs on at most
$11$-representable, answering a question originally raised by Cheon et al. in 2018 and repeated in several follow-up papers – including a very recent paper, where it was shown that all graphs on at most  $8$ vertices are
$8$ vertices are  $1$-
$1$- $11$-representable. Moreover, we prove that all graphs are permutationally
$11$-representable. Moreover, we prove that all graphs are permutationally  $1$-
$1$- $11$-representable – that is representable as the concatenation of permutations of the vertices – answering the existence question in extremely strong fashion. Our construction leads to nearly optimal bounds on the length of the words, as well. It can, moreover, be adapted to represent all acyclic orientations of graphs; this generalizes the fact that word-representations capture semi-transitive orientations of graphs. Our construction also adapts easily to other
$11$-representable – that is representable as the concatenation of permutations of the vertices – answering the existence question in extremely strong fashion. Our construction leads to nearly optimal bounds on the length of the words, as well. It can, moreover, be adapted to represent all acyclic orientations of graphs; this generalizes the fact that word-representations capture semi-transitive orientations of graphs. Our construction also adapts easily to other  $k \geq 2$ as well, giving representations using a linear number of permutations when the best known previous bounds used a quadratic number. Finally, we also consider the (non-)existence of ‘even–odd’-representations of graphs. This answers a question raised by Wanless after a conference talk in 2018.
$k \geq 2$ as well, giving representations using a linear number of permutations when the best known previous bounds used a quadratic number. Finally, we also consider the (non-)existence of ‘even–odd’-representations of graphs. This answers a question raised by Wanless after a conference talk in 2018.










The
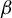 $\beta $-transformation with a hole at
$\beta $-transformation with a hole at 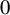 $0$: the general case
$0$: the general case
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 46 / Issue 3 / March 2026
- Published online by Cambridge University Press:
- 04 December 2025, pp. 633-659
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given
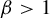 $\beta>1$, let
$\beta>1$, let 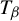 $T_\beta $ be the
$T_\beta $ be the 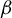 $\beta $-transformation on the unit circle
$\beta $-transformation on the unit circle 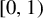 $[0,1)$, defined by
$[0,1)$, defined by 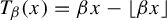 $T_\beta (x)=\beta x-\lfloor \beta x\rfloor $. For each
$T_\beta (x)=\beta x-\lfloor \beta x\rfloor $. For each 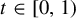 $t\in [0,1)$, let
$t\in [0,1)$, let 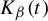 $K_\beta (t)$ be the survivor set consisting of all
$K_\beta (t)$ be the survivor set consisting of all 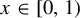 $x\in [0,1)$ whose orbit
$x\in [0,1)$ whose orbit 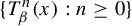 $\{T^n_\beta (x): n\ge 0\}$ never enters the interval
$\{T^n_\beta (x): n\ge 0\}$ never enters the interval 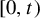 $[0,t)$. Kalle et al [Ergod. Th. & Dynam. Sys. 40(9) (2020), 2482–2514] considered the case
$[0,t)$. Kalle et al [Ergod. Th. & Dynam. Sys. 40(9) (2020), 2482–2514] considered the case 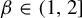 $\beta \in (1,2]$. They studied the set-valued bifurcation set
$\beta \in (1,2]$. They studied the set-valued bifurcation set 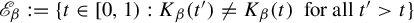 $\mathscr {E}_\beta :=\{t\in [0,1): K_\beta (t')\ne K_\beta (t)~\text { for all } t'>t\}$ and proved that the Hausdorff dimension function
$\mathscr {E}_\beta :=\{t\in [0,1): K_\beta (t')\ne K_\beta (t)~\text { for all } t'>t\}$ and proved that the Hausdorff dimension function 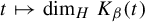 $t\mapsto \dim _H K_\beta (t)$ is a non-increasing Devil’s staircase. In a previous paper [Ergod. Th. & Dynam. Sys. 43(6) (2023), 1785–1828], we determined, for all
$t\mapsto \dim _H K_\beta (t)$ is a non-increasing Devil’s staircase. In a previous paper [Ergod. Th. & Dynam. Sys. 43(6) (2023), 1785–1828], we determined, for all 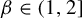 $\beta \in (1,2]$, the critical value
$\beta \in (1,2]$, the critical value 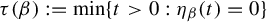 $\tau (\beta ):=\min \{t>0: \eta _\beta (t)=0\}$. The purpose of the present article is to extend these results to all
$\tau (\beta ):=\min \{t>0: \eta _\beta (t)=0\}$. The purpose of the present article is to extend these results to all 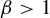 $\beta>1$. In addition to calculating
$\beta>1$. In addition to calculating 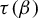 $\tau (\beta )$, we show that: (i) the function
$\tau (\beta )$, we show that: (i) the function 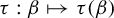 $\tau : \beta \mapsto \tau (\beta )$ is left-continuous on
$\tau : \beta \mapsto \tau (\beta )$ is left-continuous on 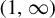 $(1,\infty )$ with right-hand limits everywhere, but has countably infinitely many discontinuities; (ii)
$(1,\infty )$ with right-hand limits everywhere, but has countably infinitely many discontinuities; (ii) 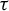 $\tau $ has no downward jumps; and (iii) there exists an open set
$\tau $ has no downward jumps; and (iii) there exists an open set 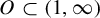 $O\subset (1,\infty )$, whose complement
$O\subset (1,\infty )$, whose complement 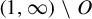 $(1,\infty )\setminus O$ has zero Hausdorff dimension, such that
$(1,\infty )\setminus O$ has zero Hausdorff dimension, such that 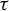 $\tau $ is real-analytic, strictly convex, and strictly decreasing on each connected component of O. We also prove several topological properties of the bifurcation set
$\tau $ is real-analytic, strictly convex, and strictly decreasing on each connected component of O. We also prove several topological properties of the bifurcation set 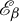 $\mathscr {E}_\beta $. The key to extending the results from
$\mathscr {E}_\beta $. The key to extending the results from 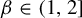 $\beta \in (1,2]$ to all
$\beta \in (1,2]$ to all 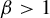 $\beta>1$ is an appropriate generalization of the Farey words that are used to parameterize the connected components of the set O. Some of the original proofs from the above-mentioned papers are simplified.
$\beta>1$ is an appropriate generalization of the Farey words that are used to parameterize the connected components of the set O. Some of the original proofs from the above-mentioned papers are simplified.
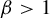
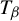
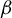
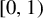
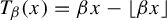
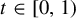
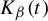
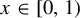
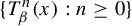
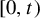
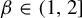
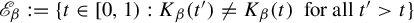
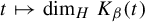
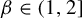
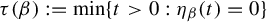
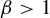
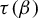
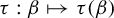
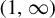
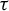
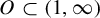
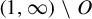
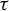
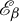
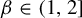
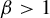
Limit theorems for the number of crossings and stress in projections of a random geometric graph
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 63 / Issue 1 / March 2026
- Published online by Cambridge University Press:
- 01 October 2025, pp. 258-281
- Print publication:
- March 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We consider the number of edge crossings in a random graph drawing generated by projecting a random geometric graph on some compact convex set
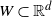 $W\subset \mathbb{R}^d$,
$W\subset \mathbb{R}^d$, 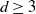 $d\geq 3$, onto a plane. The positions of these crossings form the support of a point process. We show that if the expected number of crossings converges to a positive but finite value, this point process converges to a Poisson point process in the Kantorovich–Rubinstein distance. We further show a multivariate central limit theorem between the number of crossings and a second variable called the stress that holds when the expected vertex degree in the random geometric graph converges to a positive finite value.
$d\geq 3$, onto a plane. The positions of these crossings form the support of a point process. We show that if the expected number of crossings converges to a positive but finite value, this point process converges to a Poisson point process in the Kantorovich–Rubinstein distance. We further show a multivariate central limit theorem between the number of crossings and a second variable called the stress that holds when the expected vertex degree in the random geometric graph converges to a positive finite value.
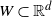
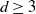
Graphes dans les surfaces et ergodicité topologique
- Part of
-
- Journal:
- Canadian Journal of Mathematics , First View
- Published online by Cambridge University Press:
- 15 August 2025, pp. 1-42
-
- Article
- Export citation
-
La façon la plus simple de faire d’un graphe fini connexe G un système dynamique est de lui donner une polarisation, c’est-à-dire un ordre cyclique des arêtes incidentes à chaque sommet. L’espace de phase
 $\mathcal {P}(G)$ d’un graphe consiste en toutes les paires
$\mathcal {P}(G)$ d’un graphe consiste en toutes les paires  $(v,e)$ où v est un sommet et e une arête incidente à v. Elle donne donc la position et le vecteur initiaux. Une telle condition est équivalente à une arête que l’on munit d’une orientation
$(v,e)$ où v est un sommet et e une arête incidente à v. Elle donne donc la position et le vecteur initiaux. Une telle condition est équivalente à une arête que l’on munit d’une orientation  $e_{\mathcal O}$. Avec la polarisation, chaque donnée initiale mène à une marche à gauche en tournant à gauche à chaque sommet rencontré, ou en rebondissant s’il n’y a en ce sommet aucune autre arête. Une marche à gauche est appelée complète si elle couvre toutes les arêtes de G (pas nécessairement dans les deux sens). Nous définissons la valence d’un sommet comme le nombre d’arêtes adjacentes à ce sommet, et la valence d’un graphe comme étant la moyenne des valences de ses sommets. Dans cet article, nous démontrons que si un graphe plongé dans une surface orientée fermée de genre g possède une marche à gauche complète, alors sa valence est d’au plus
$e_{\mathcal O}$. Avec la polarisation, chaque donnée initiale mène à une marche à gauche en tournant à gauche à chaque sommet rencontré, ou en rebondissant s’il n’y a en ce sommet aucune autre arête. Une marche à gauche est appelée complète si elle couvre toutes les arêtes de G (pas nécessairement dans les deux sens). Nous définissons la valence d’un sommet comme le nombre d’arêtes adjacentes à ce sommet, et la valence d’un graphe comme étant la moyenne des valences de ses sommets. Dans cet article, nous démontrons que si un graphe plongé dans une surface orientée fermée de genre g possède une marche à gauche complète, alors sa valence est d’au plus  $1 + \sqrt {6g+1}$. Nous prouvons de plus que ce résultat est optimal pour une infinité de genres g et qu’il est asymptotiquement optimal lorsque
$1 + \sqrt {6g+1}$. Nous prouvons de plus que ce résultat est optimal pour une infinité de genres g et qu’il est asymptotiquement optimal lorsque  $g \to + \infty $. Cela mène à des obstructions pour les plongements de graphes sur une surface. Puisque vérifier si un graphe polarisé possède ou non une marche à gauche complète s’opère en temps au plus
$g \to + \infty $. Cela mène à des obstructions pour les plongements de graphes sur une surface. Puisque vérifier si un graphe polarisé possède ou non une marche à gauche complète s’opère en temps au plus  $4N$, où N est le nombre d’arêtes (il suffit de le vérifier sur les deux orientations d’une seule arête donnée), cette obstruction est particulièrement efficace. Ce problème trouve sa motivation dans ses conséquences intéressantes sur ce que nous appellerons ici l’ergodicité topologique d’un système conservatif, par exemple un système hamiltonien H en dimension deux où l’existence d’une marche complète à gauche correspond à une orbite du système topologiquement ergodique, donc une orbite qui visite toute la topologie de la surface. Nous nous limitons ici à la dimension
$4N$, où N est le nombre d’arêtes (il suffit de le vérifier sur les deux orientations d’une seule arête donnée), cette obstruction est particulièrement efficace. Ce problème trouve sa motivation dans ses conséquences intéressantes sur ce que nous appellerons ici l’ergodicité topologique d’un système conservatif, par exemple un système hamiltonien H en dimension deux où l’existence d’une marche complète à gauche correspond à une orbite du système topologiquement ergodique, donc une orbite qui visite toute la topologie de la surface. Nous nous limitons ici à la dimension  $2$, mais une généralisation de cette théorie devrait tenir pour des systèmes hamiltoniens autonomes sur une variété symplectique de dimension arbitraire.
$2$, mais une généralisation de cette théorie devrait tenir pour des systèmes hamiltoniens autonomes sur une variété symplectique de dimension arbitraire.







Models for information propagation on graphs
- Part of
-
- Journal:
- European Journal of Applied Mathematics / Volume 36 / Issue 5 / October 2025
- Published online by Cambridge University Press:
- 24 January 2025, pp. 1040-1061
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Noisy group testing via spatial coupling
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 2 / March 2025
- Published online by Cambridge University Press:
- 19 November 2024, pp. 210-258
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study the problem of identifying a small number
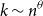 $k\sim n^\theta$,
$k\sim n^\theta$, 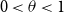 $0\lt \theta \lt 1$, of infected individuals within a large population of size
$0\lt \theta \lt 1$, of infected individuals within a large population of size  $n$ by testing groups of individuals simultaneously. All tests are conducted concurrently. The goal is to minimise the total number of tests required. In this paper, we make the (realistic) assumption that tests are noisy, that is, that a group that contains an infected individual may return a negative test result or one that does not contain an infected individual may return a positive test result with a certain probability. The noise need not be symmetric. We develop an algorithm called SPARC that correctly identifies the set of infected individuals up to
$n$ by testing groups of individuals simultaneously. All tests are conducted concurrently. The goal is to minimise the total number of tests required. In this paper, we make the (realistic) assumption that tests are noisy, that is, that a group that contains an infected individual may return a negative test result or one that does not contain an infected individual may return a positive test result with a certain probability. The noise need not be symmetric. We develop an algorithm called SPARC that correctly identifies the set of infected individuals up to 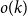 $o(k)$ errors with high probability with the asymptotically minimum number of tests. Additionally, we develop an algorithm called SPEX that exactly identifies the set of infected individuals w.h.p. with a number of tests that match the information-theoretic lower bound for the constant column design, a powerful and well-studied test design.
$o(k)$ errors with high probability with the asymptotically minimum number of tests. Additionally, we develop an algorithm called SPEX that exactly identifies the set of infected individuals w.h.p. with a number of tests that match the information-theoretic lower bound for the constant column design, a powerful and well-studied test design.
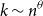
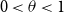

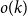
Decidability of the isomorphism problem between multidimensional substitutive subshifts
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 45 / Issue 7 / July 2025
- Published online by Cambridge University Press:
- 19 November 2024, pp. 2054-2094
- Print publication:
- July 2025
-
- Article
- Export citation
Equality cases of the Alexandrov–Fenchel inequality are not in the polynomial hierarchy
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 12 / 2024
- Published online by Cambridge University Press:
- 11 November 2024, e21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Indistinguishable asymptotic pairs and multidimensional Sturmian configurations
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 45 / Issue 2 / February 2025
- Published online by Cambridge University Press:
- 31 May 2024, pp. 337-395
- Print publication:
- February 2025
-
- Article
- Export citation
-
Two asymptotic configurations on a full
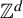 $\mathbb {Z}^d$-shift are indistinguishable if, for every finite pattern, the associated sets of occurrences in each configuration coincide up to a finitely supported permutation of
$\mathbb {Z}^d$-shift are indistinguishable if, for every finite pattern, the associated sets of occurrences in each configuration coincide up to a finitely supported permutation of 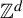 $\mathbb {Z}^d$. We prove that indistinguishable asymptotic pairs satisfying a ‘flip condition’ are characterized by their pattern complexity on finite connected supports. Furthermore, we prove that uniformly recurrent indistinguishable asymptotic pairs satisfying the flip condition are described by codimension-one (dimension of the internal space) cut and project schemes, which symbolically correspond to multidimensional Sturmian configurations. Together, the two results provide a generalization to
$\mathbb {Z}^d$. We prove that indistinguishable asymptotic pairs satisfying a ‘flip condition’ are characterized by their pattern complexity on finite connected supports. Furthermore, we prove that uniformly recurrent indistinguishable asymptotic pairs satisfying the flip condition are described by codimension-one (dimension of the internal space) cut and project schemes, which symbolically correspond to multidimensional Sturmian configurations. Together, the two results provide a generalization to 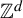 $\mathbb {Z}^d$ of the characterization of Sturmian sequences by their factor complexity
$\mathbb {Z}^d$ of the characterization of Sturmian sequences by their factor complexity 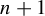 $n+1$. Many open questions are raised by the current work and are listed in the introduction.
$n+1$. Many open questions are raised by the current work and are listed in the introduction.
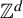
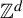
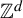
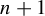
Bracket words along Hardy field sequences
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 44 / Issue 9 / September 2024
- Published online by Cambridge University Press:
- 14 December 2023, pp. 2621-2648
- Print publication:
- September 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study bracket words, which are a far-reaching generalization of Sturmian words, along Hardy field sequences, which are a far-reaching generalization of Piatetski-Shapiro sequences
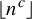 $\lfloor n^c \rfloor $. We show that sequences thus obtained are deterministic (that is, they have subexponential subword complexity) and satisfy Sarnak’s conjecture.
$\lfloor n^c \rfloor $. We show that sequences thus obtained are deterministic (that is, they have subexponential subword complexity) and satisfy Sarnak’s conjecture.
A word of low complexity without uniform frequencies
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 44 / Issue 4 / April 2024
- Published online by Cambridge University Press:
- 29 May 2023, pp. 1013-1025
- Print publication:
- April 2024
-
- Article
- Export citation
The first-order theory of binary overlap-free words is decidable
- Part of
-
- Journal:
- Canadian Journal of Mathematics / Volume 76 / Issue 4 / August 2024
- Published online by Cambridge University Press:
- 26 May 2023, pp. 1144-1162
- Print publication:
- August 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that the first-order logical theory of the binary overlap-free words (and, more generally, the
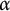 $\alpha $-free words for rational
$\alpha $-free words for rational 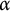 $\alpha $,
$\alpha $, 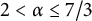 $2 < \alpha \leq 7/3$), is decidable. As a consequence, many results previously obtained about this class through tedious case-based proofs can now be proved “automatically,” using a decision procedure, and new claims can be proved or disproved simply by restating them as logical formulas.
$2 < \alpha \leq 7/3$), is decidable. As a consequence, many results previously obtained about this class through tedious case-based proofs can now be proved “automatically,” using a decision procedure, and new claims can be proved or disproved simply by restating them as logical formulas.
Universal geometric graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 15 May 2023, pp. 742-761
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We extend the notion of universal graphs to a geometric setting. A geometric graph is universal for a class
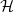 $\mathcal H$ of planar graphs if it contains an embedding, that is, a crossing-free drawing, of every graph in
$\mathcal H$ of planar graphs if it contains an embedding, that is, a crossing-free drawing, of every graph in 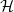 $\mathcal H$. Our main result is that there exists a geometric graph with
$\mathcal H$. Our main result is that there exists a geometric graph with  $n$ vertices and
$n$ vertices and 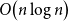 $O\!\left(n \log n\right)$ edges that is universal for
$O\!\left(n \log n\right)$ edges that is universal for  $n$-vertex forests; this generalises a well-known result by Chung and Graham, which states that there exists an (abstract) graph with
$n$-vertex forests; this generalises a well-known result by Chung and Graham, which states that there exists an (abstract) graph with  $n$ vertices and
$n$ vertices and 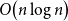 $O\!\left(n \log n\right)$ edges that contains every
$O\!\left(n \log n\right)$ edges that contains every  $n$-vertex forest as a subgraph. The upper bound of
$n$-vertex forest as a subgraph. The upper bound of 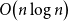 $O\!\left(n \log n\right)$ edges cannot be improved, even if more than
$O\!\left(n \log n\right)$ edges cannot be improved, even if more than  $n$ vertices are allowed. We also prove that every
$n$ vertices are allowed. We also prove that every  $n$-vertex convex geometric graph that is universal for
$n$-vertex convex geometric graph that is universal for  $n$-vertex outerplanar graphs has a near-quadratic number of edges, namely
$n$-vertex outerplanar graphs has a near-quadratic number of edges, namely 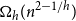 $\Omega _h(n^{2-1/h})$, for every positive integer
$\Omega _h(n^{2-1/h})$, for every positive integer 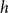 $h$; this almost matches the trivial
$h$; this almost matches the trivial 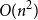 $O(n^2)$ upper bound given by the
$O(n^2)$ upper bound given by the  $n$-vertex complete convex geometric graph. Finally, we prove that there exists an
$n$-vertex complete convex geometric graph. Finally, we prove that there exists an  $n$-vertex convex geometric graph with
$n$-vertex convex geometric graph with  $n$ vertices and
$n$ vertices and 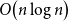 $O\!\left(n \log n\right)$ edges that is universal for
$O\!\left(n \log n\right)$ edges that is universal for  $n$-vertex caterpillars.
$n$-vertex caterpillars.



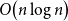

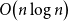



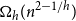
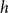
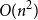



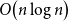

Mixing properties of erasing interval maps
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 44 / Issue 2 / February 2024
- Published online by Cambridge University Press:
- 06 March 2023, pp. 408-431
- Print publication:
- February 2024
-
- Article
- Export citation
-
We study the measurable dynamical properties of the interval map generated by the model-case erasing substitution
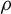 $\rho $, defined by We prove that, although the map is singular, its square preserves the Lebesgue measure and is strongly mixing, thus ergodic, with respect to it. We discuss the extension of the results to more general erasing maps.
$\rho $, defined by We prove that, although the map is singular, its square preserves the Lebesgue measure and is strongly mixing, thus ergodic, with respect to it. We discuss the extension of the results to more general erasing maps.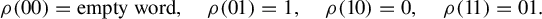 $$ \begin{align*} \rho(00)=\text{empty word},\quad \rho(01)=1,\quad \rho(10)=0,\quad \rho(11)=01. \end{align*} $$
$$ \begin{align*} \rho(00)=\text{empty word},\quad \rho(01)=1,\quad \rho(10)=0,\quad \rho(11)=01. \end{align*} $$
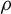
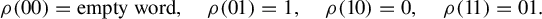
Multiple random walks on graphs: mixing few to cover many
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 4 / July 2023
- Published online by Cambridge University Press:
- 15 February 2023, pp. 594-637
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Random walks on graphs are an essential primitive for many randomised algorithms and stochastic processes. It is natural to ask how much can be gained by running
 $k$ multiple random walks independently and in parallel. Although the cover time of multiple walks has been investigated for many natural networks, the problem of finding a general characterisation of multiple cover times for worst-case start vertices (posed by Alon, Avin, Koucký, Kozma, Lotker and Tuttle in 2008) remains an open problem. First, we improve and tighten various bounds on the stationary cover time when
$k$ multiple random walks independently and in parallel. Although the cover time of multiple walks has been investigated for many natural networks, the problem of finding a general characterisation of multiple cover times for worst-case start vertices (posed by Alon, Avin, Koucký, Kozma, Lotker and Tuttle in 2008) remains an open problem. First, we improve and tighten various bounds on the stationary cover time when  $k$ random walks start from vertices sampled from the stationary distribution. For example, we prove an unconditional lower bound of
$k$ random walks start from vertices sampled from the stationary distribution. For example, we prove an unconditional lower bound of 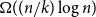 $\Omega ((n/k) \log n)$ on the stationary cover time, holding for any
$\Omega ((n/k) \log n)$ on the stationary cover time, holding for any  $n$-vertex graph
$n$-vertex graph 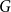 $G$ and any
$G$ and any 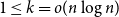 $1 \leq k =o(n\log n )$. Secondly, we establish the stationary cover times of multiple walks on several fundamental networks up to constant factors. Thirdly, we present a framework characterising worst-case cover times in terms of stationary cover times and a novel, relaxed notion of mixing time for multiple walks called the partial mixing time. Roughly speaking, the partial mixing time only requires a specific portion of all random walks to be mixed. Using these new concepts, we can establish (or recover) the worst-case cover times for many networks including expanders, preferential attachment graphs, grids, binary trees and hypercubes.
$1 \leq k =o(n\log n )$. Secondly, we establish the stationary cover times of multiple walks on several fundamental networks up to constant factors. Thirdly, we present a framework characterising worst-case cover times in terms of stationary cover times and a novel, relaxed notion of mixing time for multiple walks called the partial mixing time. Roughly speaking, the partial mixing time only requires a specific portion of all random walks to be mixed. Using these new concepts, we can establish (or recover) the worst-case cover times for many networks including expanders, preferential attachment graphs, grids, binary trees and hypercubes.
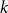
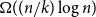

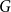
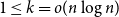
On mappings on the hypercube with small average stretch
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 18 October 2022, pp. 334-348
-
- Article
- Export citation
-
Let
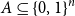 $A \subseteq \{0,1\}^n$ be a set of size
$A \subseteq \{0,1\}^n$ be a set of size 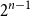 $2^{n-1}$, and let
$2^{n-1}$, and let 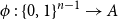 $\phi \,:\, \{0,1\}^{n-1} \to A$ be a bijection. We define the average stretch of
$\phi \,:\, \{0,1\}^{n-1} \to A$ be a bijection. We define the average stretch of 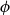 $\phi$ aswhere the expectation is taken over uniformly random
$\phi$ aswhere the expectation is taken over uniformly random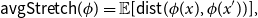 \begin{equation*} {\sf avgStretch}(\phi ) = {\mathbb E}[{{\sf dist}}(\phi (x),\phi (x'))], \end{equation*}
\begin{equation*} {\sf avgStretch}(\phi ) = {\mathbb E}[{{\sf dist}}(\phi (x),\phi (x'))], \end{equation*}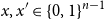 $x,x' \in \{0,1\}^{n-1}$ that differ in exactly one coordinate.
$x,x' \in \{0,1\}^{n-1}$ that differ in exactly one coordinate.In this paper, we continue the line of research studying mappings on the discrete hypercube with small average stretch. We prove the following results.
For any set
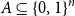 $A \subseteq \{0,1\}^n$ of density
$A \subseteq \{0,1\}^n$ of density 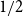 $1/2$ there exists a bijection
$1/2$ there exists a bijection 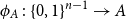 $\phi _A \,:\, \{0,1\}^{n-1} \to A$ such that
$\phi _A \,:\, \{0,1\}^{n-1} \to A$ such that 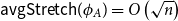 ${\sf avgStretch}(\phi _A) = O\left(\sqrt{n}\right)$.
${\sf avgStretch}(\phi _A) = O\left(\sqrt{n}\right)$.For
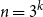 $n = 3^k$ let
$n = 3^k$ let 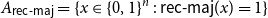 ${A_{\textsf{rec-maj}}} = \{x \in \{0,1\}^n \,:\,{\textsf{rec-maj}}(x) = 1\}$, where
${A_{\textsf{rec-maj}}} = \{x \in \{0,1\}^n \,:\,{\textsf{rec-maj}}(x) = 1\}$, where 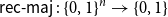 ${\textsf{rec-maj}} \,:\, \{0,1\}^n \to \{0,1\}$ is the function recursive majority of 3’s. There exists a bijection
${\textsf{rec-maj}} \,:\, \{0,1\}^n \to \{0,1\}$ is the function recursive majority of 3’s. There exists a bijection 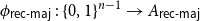 $\phi _{{\textsf{rec-maj}}} \,:\, \{0,1\}^{n-1} \to{A_{\textsf{rec-maj}}}$ such that
$\phi _{{\textsf{rec-maj}}} \,:\, \{0,1\}^{n-1} \to{A_{\textsf{rec-maj}}}$ such that 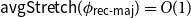 ${\sf avgStretch}(\phi _{{\textsf{rec-maj}}}) = O(1)$.
${\sf avgStretch}(\phi _{{\textsf{rec-maj}}}) = O(1)$.Let
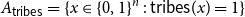 ${A_{{\sf tribes}}} = \{x \in \{0,1\}^n \,:\,{\sf tribes}(x) = 1\}$. There exists a bijection
${A_{{\sf tribes}}} = \{x \in \{0,1\}^n \,:\,{\sf tribes}(x) = 1\}$. There exists a bijection 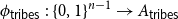 $\phi _{{\sf tribes}} \,:\, \{0,1\}^{n-1} \to{A_{{\sf tribes}}}$ such that
$\phi _{{\sf tribes}} \,:\, \{0,1\}^{n-1} \to{A_{{\sf tribes}}}$ such that 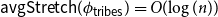 ${\sf avgStretch}(\phi _{{\sf tribes}}) = O(\!\log (n))$.
${\sf avgStretch}(\phi _{{\sf tribes}}) = O(\!\log (n))$.
These results answer the questions raised by Benjamini, Cohen, and Shinkar (Isr. J. Math 2016).