Refine listing
Actions for selected content:
315 results in 60Cxx
Perfect partitions of a random set of integers
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 06 April 2026, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
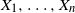 $X_1,\ldots, X_n$ be independent integers distributed uniformly on [M],
$X_1,\ldots, X_n$ be independent integers distributed uniformly on [M], 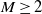 $M\ge 2$. A partition S of [n] into
$M\ge 2$. A partition S of [n] into  $\nu$ non-empty subsets
$\nu$ non-empty subsets 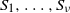 $S_1,\ldots, S_{\nu}$ is called perfect if all
$S_1,\ldots, S_{\nu}$ is called perfect if all  $\nu$ values
$\nu$ values  $\sum_{j\in S_{\alpha}}X_j$ are equal. For a perfect partition to exist,
$\sum_{j\in S_{\alpha}}X_j$ are equal. For a perfect partition to exist, 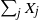 $\sum_j X_j$ has to be divisible by
$\sum_j X_j$ has to be divisible by  $\nu$. In 2001, for
$\nu$. In 2001, for 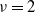 $\nu=2$, Christian Borgs, Jennifer Chayes, and the author proved that, conditioned on
$\nu=2$, Christian Borgs, Jennifer Chayes, and the author proved that, conditioned on 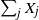 $\sum_j X_j$ being even, with high probability a perfect partition exists if
$\sum_j X_j$ being even, with high probability a perfect partition exists if 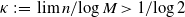 $\kappa\;:\!=\; \lim {{n}/{\log M}}>{{1}/{\log 2}}$, and that with high probability no perfect partition exists if
$\kappa\;:\!=\; \lim {{n}/{\log M}}>{{1}/{\log 2}}$, and that with high probability no perfect partition exists if 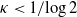 $\kappa<{{1}/{\log 2}}$. Responding to a question by George Varghese, we prove that for
$\kappa<{{1}/{\log 2}}$. Responding to a question by George Varghese, we prove that for  $\nu\ge 3$ with high probability no perfect partition exists if
$\nu\ge 3$ with high probability no perfect partition exists if  $\kappa<{{2}/{\log \nu}}$, which is twice as large as the naive threshold
$\kappa<{{2}/{\log \nu}}$, which is twice as large as the naive threshold  $1/\log 3$ for
$1/\log 3$ for 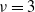 $\nu=3$. We identify the range of
$\nu=3$. We identify the range of  $\kappa$ where the expected number of perfect partitions is exponentially high. We show that for
$\kappa$ where the expected number of perfect partitions is exponentially high. We show that for 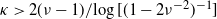 $\kappa> {{2(\nu-1)}/{\log[(1-2\nu^{-2})^{-1}]}}$ the total number of perfect partitions is exponentially high with probability
$\kappa> {{2(\nu-1)}/{\log[(1-2\nu^{-2})^{-1}]}}$ the total number of perfect partitions is exponentially high with probability 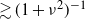 $\gtrsim (1+\nu^2)^{-1}$, i.e. below
$\gtrsim (1+\nu^2)^{-1}$, i.e. below  $1/\nu$, the limiting probability that
$1/\nu$, the limiting probability that 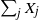 $\sum_j X_j$ is divisible by
$\sum_j X_j$ is divisible by  $\nu$.
$\nu$.
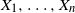
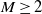

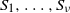


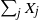

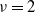
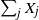
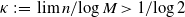
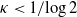



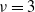

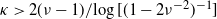
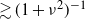

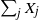

Record-biased permutations and their permuton limit
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-39
-
- Article
- Export citation
The random
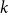 $\textit{k}$-SAT Gibbs uniqueness threshold revisited
$\textit{k}$-SAT Gibbs uniqueness threshold revisited
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 27 March 2026, pp. 1-53
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove that for any
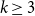 $k\geq 3$ for clause/variable ratios up to the Gibbs uniqueness threshold of the corresponding Galton-Watson tree, the number of satisfying assignments of random
$k\geq 3$ for clause/variable ratios up to the Gibbs uniqueness threshold of the corresponding Galton-Watson tree, the number of satisfying assignments of random 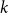 $k$-SAT formulas is given by the ‘replica symmetric solution’ predicted by physics methods [Monasson, Zecchina: Phys. Rev. Lett. 76 (1996)]. Furthermore, while the Gibbs uniqueness threshold is still not known precisely for any
$k$-SAT formulas is given by the ‘replica symmetric solution’ predicted by physics methods [Monasson, Zecchina: Phys. Rev. Lett. 76 (1996)]. Furthermore, while the Gibbs uniqueness threshold is still not known precisely for any 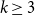 $k\geq 3$, we derive new lower bounds on this threshold that improve over prior work [Montanari and Shah: SODA (2007)]. The improvement is significant particularly for small
$k\geq 3$, we derive new lower bounds on this threshold that improve over prior work [Montanari and Shah: SODA (2007)]. The improvement is significant particularly for small 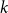 $k$.
$k$.
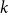
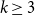
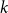
Trace reconstruction of matrices and hypermatrices
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 10 March 2026, pp. 1-19
-
- Article
- Export citation
-
A trace of a sequence is generated by deleting each bit of the sequence independently with a fixed probability. The well-studied trace reconstruction problem asks how many traces are required to reconstruct an unknown binary sequence with high probability. In this paper, we study the multidimensional version of this problem for matrices and hypermatrices, where a trace is generated by deleting each row/column of the matrix or each slice of the hypermatrix independently with a constant probability. Previously, Krishnamurthy, Mazumdar, McGregor and Pal showed that
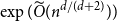 $\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{d/(d+2)}))$ traces suffice to reconstruct any unknown 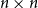 $n\times n$ matrix (for
$n\times n$ matrix (for 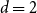 $d=2$) and any unknown
$d=2$) and any unknown 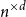 $n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around
$n^{\times d}$ hypermatrix. By developing a dimension reduction procedure and establishing a multivariate version of the Littlewood-type result that lower bounds sparse complex polynomials around 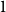 $1$, we improve this upper bound by showing that
$1$, we improve this upper bound by showing that 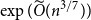 $\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/7}))$ traces suffice to reconstruct any unknown 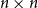 $n\times n$ matrix, and
$n\times n$ matrix, and 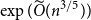 $\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown
$\exp (\widetilde {O}(n^{3/5}))$ traces suffice to reconstruct any unknown 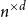 $n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from
$n^{\times d}$ hypermatrix. In contrast to the earlier bound, our new exponent is bounded away from 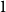 $1$ even as
$1$ even as 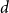 $d$ becomes very large.
$d$ becomes very large.
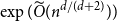
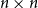
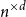
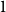
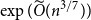
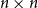
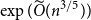
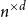
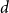
Analysis of clustering and degree index in random graphs and complex networks
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Monochromatic subgraphs in randomly colored dense multiplex networks
- Part of
-
- Journal:
- Advances in Applied Probability , First View
- Published online by Cambridge University Press:
- 05 March 2026, pp. 1-36
-
- Article
- Export citation
-
Given a sequence of graphs
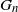 $G_n$ and a fixed graph H, denote by
$G_n$ and a fixed graph H, denote by 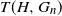 $T(H, G_n)$ the number of monochromatic copies of the graph H in a uniformly random c-coloring of the vertices of
$T(H, G_n)$ the number of monochromatic copies of the graph H in a uniformly random c-coloring of the vertices of 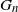 $G_n$. In this paper we study the joint distribution of a finite collection of monochromatic graph counts in networks with multiple layers (multiplex networks). Specifically, given a finite collection of graphs
$G_n$. In this paper we study the joint distribution of a finite collection of monochromatic graph counts in networks with multiple layers (multiplex networks). Specifically, given a finite collection of graphs 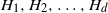 $H_1, H_2, \ldots, H_d$ we derive the joint distribution of
$H_1, H_2, \ldots, H_d$ we derive the joint distribution of 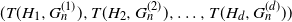 $(T(H_1, G_n^{(1)}), T(H_2, G_n^{(2)}), \ldots, T(H_d, G_n^{(d)}))$, where
$(T(H_1, G_n^{(1)}), T(H_2, G_n^{(2)}), \ldots, T(H_d, G_n^{(d)}))$, where 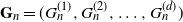 $\mathbf{G}_n = (G_n^{(1)}, G_n^{(2)}, \ldots, G_n^{(d)})$ is a collection of dense graphs on the same vertex set converging in the multiplex cut-metric. The limiting distribution is the sum of two independent components: a multivariate Gaussian and a sum of independent bivariate stochastic integrals. This extends previous results on the marginal convergence of monochromatic subgraphs in a sequence of graphs to the joint convergence of a finite collection of monochromatic subgraphs in a sequence of multiplex networks. Several applications and examples are discussed.
$\mathbf{G}_n = (G_n^{(1)}, G_n^{(2)}, \ldots, G_n^{(d)})$ is a collection of dense graphs on the same vertex set converging in the multiplex cut-metric. The limiting distribution is the sum of two independent components: a multivariate Gaussian and a sum of independent bivariate stochastic integrals. This extends previous results on the marginal convergence of monochromatic subgraphs in a sequence of graphs to the joint convergence of a finite collection of monochromatic subgraphs in a sequence of multiplex networks. Several applications and examples are discussed.
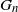
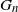
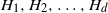
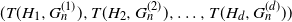
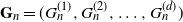
The largest subcritical component in inhomogeneous random graphs of preferential attachment type
- Part of
-
- Journal:
- Combinatorics, Probability and Computing , First View
- Published online by Cambridge University Press:
- 04 March 2026, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Differential transcendence and walks on self-similar graphs
- Part of
-
- Journal:
- Canadian Mathematical Bulletin , First View
- Published online by Cambridge University Press:
- 30 January 2026, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Symmetrically self-similar graphs are an important type of fractal graph. Their Green’s functions satisfy order one iterative functional equations. We show that when the branching number of a generating cell is two, either the graph is a star consisting of finitely many one-sided lines meeting at an origin vertex, in which case the Green’s function is algebraic, or the Green’s function is differentially transcendental over
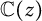 $\mathbb {C}(z)$. The proof strategy relies on a result in a recent preprint of Di Vizio, Fernandes, and Mishna. The result adds evidence to a conjecture of Krön and Teufl about the spectra of the difference Laplacian of this family of graphs.
$\mathbb {C}(z)$. The proof strategy relies on a result in a recent preprint of Di Vizio, Fernandes, and Mishna. The result adds evidence to a conjecture of Krön and Teufl about the spectra of the difference Laplacian of this family of graphs.
Random Fibonacci Words via Clone Schur Functions
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 14 / 2026
- Published online by Cambridge University Press:
- 23 January 2026, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We investigate positivity and probabilistic properties arising from the Young–Fibonacci lattice
 $\mathbb {YF}$, a 1-differential poset on words composed of 1’s and 2’s (Fibonacci words) and graded by the sum of the digits. Building on Okada’s theory of clone Schur functions, we introduce clone coherent measures on
$\mathbb {YF}$, a 1-differential poset on words composed of 1’s and 2’s (Fibonacci words) and graded by the sum of the digits. Building on Okada’s theory of clone Schur functions, we introduce clone coherent measures on  $\mathbb {YF}$ which give rise to random Fibonacci words of increasing length. Unlike coherent systems associated to classical Schur functions on the Young lattice of integer partitions, clone coherent measures are generally not extremal on
$\mathbb {YF}$ which give rise to random Fibonacci words of increasing length. Unlike coherent systems associated to classical Schur functions on the Young lattice of integer partitions, clone coherent measures are generally not extremal on  $\mathbb {YF}$. Our first main result is a complete characterization of Fibonacci positive specializations – parameter sequences which yield positive clone Schur functions on
$\mathbb {YF}$. Our first main result is a complete characterization of Fibonacci positive specializations – parameter sequences which yield positive clone Schur functions on  $\mathbb {YF}$. Second, we establish a broad array of correspondences that connect Fibonacci positivity with: (i) the total positivity of tridiagonal matrices; (ii) Stieltjes moment sequences; (iii) the combinatorics of set partitions; and (iv) families of univariate orthogonal polynomials from the (q-)Askey scheme. We further link the moment sequences of broad classes of orthogonal polynomials to combinatorial structures on Fibonacci words, a connection that may be of independent interest. Our third family of results concerns the asymptotic behavior of random Fibonacci words derived from various Fibonacci positive specializations. We analyze several limiting regimes for specific examples, revealing stick-breaking-like processes (connected to GEM distributions), dependent stick-breaking processes of a new type, or limits supported on the discrete component of the Martin boundary of the Young–Fibonacci lattice. Our stick-breaking-like scaling limits significantly extend the result of Gnedin–Kerov on asymptotics of the Plancherel measure on
$\mathbb {YF}$. Second, we establish a broad array of correspondences that connect Fibonacci positivity with: (i) the total positivity of tridiagonal matrices; (ii) Stieltjes moment sequences; (iii) the combinatorics of set partitions; and (iv) families of univariate orthogonal polynomials from the (q-)Askey scheme. We further link the moment sequences of broad classes of orthogonal polynomials to combinatorial structures on Fibonacci words, a connection that may be of independent interest. Our third family of results concerns the asymptotic behavior of random Fibonacci words derived from various Fibonacci positive specializations. We analyze several limiting regimes for specific examples, revealing stick-breaking-like processes (connected to GEM distributions), dependent stick-breaking processes of a new type, or limits supported on the discrete component of the Martin boundary of the Young–Fibonacci lattice. Our stick-breaking-like scaling limits significantly extend the result of Gnedin–Kerov on asymptotics of the Plancherel measure on 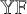 $\mathbb {YF}$. We also establish Cauchy-like identities for clone Schur functions whose right-hand side is presented as a quadridiagonal determinant rather than a product, as in the case of classical Schur functions. We construct and analyze models of random permutations and involutions based on Fibonacci positive specializations along with a version of the Robinson–Schensted correspondence for
$\mathbb {YF}$. We also establish Cauchy-like identities for clone Schur functions whose right-hand side is presented as a quadridiagonal determinant rather than a product, as in the case of classical Schur functions. We construct and analyze models of random permutations and involutions based on Fibonacci positive specializations along with a version of the Robinson–Schensted correspondence for 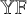 $\mathbb {YF}$.
$\mathbb {YF}$.




A stochastic process defined via the random permutation divisors
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 02 January 2026, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Resolution of the quadratic Littlewood–Offord problem
- Part of
-
- Journal:
- Compositio Mathematica / Volume 161 / Issue 12 / December 2025
- Published online by Cambridge University Press:
- 30 March 2026, pp. 3089-3139
- Print publication:
- December 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Consider a quadratic polynomial
 $Q(\xi_{1},\ldots,\xi_{n})$ of independent Rademacher random variables
$Q(\xi_{1},\ldots,\xi_{n})$ of independent Rademacher random variables  $\xi_{1},\ldots,\xi_{n}$. To what extent can
$\xi_{1},\ldots,\xi_{n}$. To what extent can  $Q(\xi_{1},\ldots,\xi_{n})$ concentrate on a single value? This quadratic version of the classical Littlewood–Offord problem was popularised by Costello, Tao and Vu in their study of symmetric random matrices. In this paper, we obtain an essentially optimal bound for this problem, as conjectured by Nguyen and Vu. Specifically, if
$Q(\xi_{1},\ldots,\xi_{n})$ concentrate on a single value? This quadratic version of the classical Littlewood–Offord problem was popularised by Costello, Tao and Vu in their study of symmetric random matrices. In this paper, we obtain an essentially optimal bound for this problem, as conjectured by Nguyen and Vu. Specifically, if  $Q(\xi_{1},\ldots,\xi_{n})$ ‘robustly depends on at least m of the
$Q(\xi_{1},\ldots,\xi_{n})$ ‘robustly depends on at least m of the 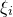 $\xi_{i}$’ in the sense that there is no way to pin down the value of
$\xi_{i}$’ in the sense that there is no way to pin down the value of  $Q(\xi_{1},\ldots,\xi_{n})$ by fixing values for fewer than m of the variables
$Q(\xi_{1},\ldots,\xi_{n})$ by fixing values for fewer than m of the variables 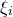 $\xi_{i}$, then we have
$\xi_{i}$, then we have 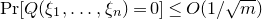 $\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=0]\le O(1/\sqrt{m})$. This also implies a similar result in the case where
$\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=0]\le O(1/\sqrt{m})$. This also implies a similar result in the case where  $\xi_{1},\ldots,\xi_{n}$ have arbitrary distributions. Our proof combines a number of ideas that may be of independent interest, including an inductive decoupling scheme that reduces quadratic anticoncentration problems to high-dimensional linear anticoncentration problems. Also, one application of our main result is the resolution of a conjecture of Alon, Hefetz, Krivelevich and Tyomkyn related to graph inducibility.
$\xi_{1},\ldots,\xi_{n}$ have arbitrary distributions. Our proof combines a number of ideas that may be of independent interest, including an inductive decoupling scheme that reduces quadratic anticoncentration problems to high-dimensional linear anticoncentration problems. Also, one application of our main result is the resolution of a conjecture of Alon, Hefetz, Krivelevich and Tyomkyn related to graph inducibility.






A large deviation principle for block models
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 5 / September 2025
- Published online by Cambridge University Press:
- 30 June 2025, pp. 680-753
-
- Article
- Export citation
On the size of temporal cliques in subcritical random temporal graphs
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 5 / September 2025
- Published online by Cambridge University Press:
- 26 June 2025, pp. 671-679
-
- Article
- Export citation
-
A random temporal graph is an Erdős-Rényi random graph
 $G(n,p)$, together with a random ordering of its edges. A path in the graph is called increasing if the edges on the path appear in increasing order. A set
$G(n,p)$, together with a random ordering of its edges. A path in the graph is called increasing if the edges on the path appear in increasing order. A set  $S$ of vertices forms a temporal clique if for all
$S$ of vertices forms a temporal clique if for all  $u,v \in S$, there is an increasing path from
$u,v \in S$, there is an increasing path from  $u$ to
$u$ to  $v$. Becker, Casteigts, Crescenzi, Kodric, Renken, Raskin and Zamaraev [(2023) Giant components in random temporal graphs. arXiv,2205.14888] proved that if
$v$. Becker, Casteigts, Crescenzi, Kodric, Renken, Raskin and Zamaraev [(2023) Giant components in random temporal graphs. arXiv,2205.14888] proved that if  $p=c\log n/n$ for
$p=c\log n/n$ for  $c\gt 1$, then, with high probability, there is a temporal clique of size
$c\gt 1$, then, with high probability, there is a temporal clique of size  $n-o(n)$. On the other hand, for
$n-o(n)$. On the other hand, for  $c\lt 1$, with high probability, the largest temporal clique is of size
$c\lt 1$, with high probability, the largest temporal clique is of size  $o(n)$. In this note, we improve the latter bound by showing that, for
$o(n)$. In this note, we improve the latter bound by showing that, for  $c\lt 1$, the largest temporal clique is of constant size with high probability.
$c\lt 1$, the largest temporal clique is of constant size with high probability.











Limit laws for the generalized Zagreb indices of random graphs
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 26 May 2025, pp. 1539-1558
- Print publication:
- December 2025
-
- Article
- Export citation
-
In this paper, we study the asymptotic behavior of the generalized Zagreb indices of the classical Erdős–Rényi (ER) random graph G(n, p), as
 $n\to\infty$. For any integer
$n\to\infty$. For any integer  $k\ge1$, we first give an expression for the kth-order generalized Zagreb index in terms of the number of star graphs of various sizes in any simple graph. The explicit formulas for the first two moments of the generalized Zagreb indices of an ER random graph are then obtained from this expression. Based on the asymptotic normality of the numbers of star graphs of various sizes, several joint limit laws are established for a finite number of generalized Zagreb indices with a phase transition for p in different regimes. Finally, we provide a necessary and sufficient condition for any single generalized Zagreb index of G(n, p) to be asymptotic normal.
$k\ge1$, we first give an expression for the kth-order generalized Zagreb index in terms of the number of star graphs of various sizes in any simple graph. The explicit formulas for the first two moments of the generalized Zagreb indices of an ER random graph are then obtained from this expression. Based on the asymptotic normality of the numbers of star graphs of various sizes, several joint limit laws are established for a finite number of generalized Zagreb indices with a phase transition for p in different regimes. Finally, we provide a necessary and sufficient condition for any single generalized Zagreb index of G(n, p) to be asymptotic normal.


A VERY SHORT PROOF OF SIDORENKO’S INEQUALITY FOR COUNTS OF HOMOMORPHISMS BETWEEN GRAPHS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 113 / Issue 1 / February 2026
- Published online by Cambridge University Press:
- 14 April 2025, pp. 10-14
- Print publication:
- February 2026
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estranged facets and k-facets of Gaussian random point sets
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 02 April 2025, pp. 859-875
- Print publication:
- September 2025
-
- Article
- Export citation
-
Gaussian random polytopes have received a lot of attention, especially in the case where the dimension is fixed and the number of points goes to infinity. Our focus is on the less-studied case where the dimension goes to infinity and the number of points is proportional to the dimension d. We study several natural quantities associated with Gaussian random polytopes in this setting. First, we show that the expected number of facets is equal to
 $C(\alpha)^{d+o(d)}$, where
$C(\alpha)^{d+o(d)}$, where  $C(\alpha)$ is some constant which depends on the constant of proportionality
$C(\alpha)$ is some constant which depends on the constant of proportionality  $\alpha$. We also extend this result to the expected number of k-facets. We then consider the more difficult problem of the asymptotics of the expected number of pairs of estranged facets of a Gaussian random polytope. When the number of points is 2d, we determine the constant C such that the expected number of pairs of estranged facets is equal to
$\alpha$. We also extend this result to the expected number of k-facets. We then consider the more difficult problem of the asymptotics of the expected number of pairs of estranged facets of a Gaussian random polytope. When the number of points is 2d, we determine the constant C such that the expected number of pairs of estranged facets is equal to  $C^{d+o(d)}$.
$C^{d+o(d)}$.




The asymptotics of the expected Betti numbers of preferential attachment clique complexes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 57 / Issue 3 / September 2025
- Published online by Cambridge University Press:
- 10 March 2025, pp. 940-968
- Print publication:
- September 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Minimal H-factors and covers
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 62 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 14 February 2025, pp. 136-152
- Print publication:
- March 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a fixed small graph H and a larger graph G, an H-factor is a collection of vertex-disjoint subgraphs
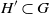 $H'\subset G$, each isomorphic to H, that cover the vertices of G. If G is the complete graph
$H'\subset G$, each isomorphic to H, that cover the vertices of G. If G is the complete graph 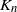 $K_n$ equipped with independent U(0,1) edge weights, what is the lowest total weight of an H-factor? This problem has previously been considered for
$K_n$ equipped with independent U(0,1) edge weights, what is the lowest total weight of an H-factor? This problem has previously been considered for 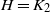 $H=K_2$, for example. We show that if H contains a cycle, then the minimum weight is sharply concentrated around some
$H=K_2$, for example. We show that if H contains a cycle, then the minimum weight is sharply concentrated around some 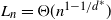 $L_n = \Theta(n^{1-1/d^*})$ (where
$L_n = \Theta(n^{1-1/d^*})$ (where 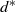 $d^*$ is the maximum 1-density of any subgraph of H). Some of our results also hold for H-covers, where the copies of H are not required to be vertex-disjoint.
$d^*$ is the maximum 1-density of any subgraph of H). Some of our results also hold for H-covers, where the copies of H are not required to be vertex-disjoint.
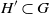
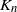
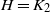
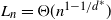
Measurable Vizing’s theorem
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 13 / 2025
- Published online by Cambridge University Press:
- 07 February 2025, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We prove a full measurable version of Vizing’s theorem for bounded degree Borel graphs, that is, we show that every Borel graph
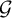 $\mathcal {G}$ of degree uniformly bounded by
$\mathcal {G}$ of degree uniformly bounded by 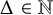 $\Delta \in \mathbb {N}$ defined on a standard probability space
$\Delta \in \mathbb {N}$ defined on a standard probability space 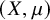 $(X,\mu )$ admits a
$(X,\mu )$ admits a 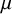 $\mu $-measurable proper edge coloring with
$\mu $-measurable proper edge coloring with 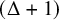 $(\Delta +1)$-many colors. This answers a question of Marks [Question 4.9, J. Amer. Math. Soc. 29 (2016)] also stated in Kechris and Marks as a part of [Problem 6.13, survey (2020)], and extends the result of the author and Pikhurko [Adv. Math. 374, (2020)], who derived the same conclusion under the additional assumption that the measure
$(\Delta +1)$-many colors. This answers a question of Marks [Question 4.9, J. Amer. Math. Soc. 29 (2016)] also stated in Kechris and Marks as a part of [Problem 6.13, survey (2020)], and extends the result of the author and Pikhurko [Adv. Math. 374, (2020)], who derived the same conclusion under the additional assumption that the measure 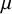 $\mu $ is
$\mu $ is 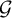 $\mathcal {G}$-invariant.
$\mathcal {G}$-invariant.
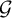
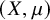
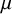
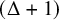
Extending Wormald’s differential equation method to one-sided bounds
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 34 / Issue 4 / July 2025
- Published online by Cambridge University Press:
- 06 February 2025, pp. 545-558
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
