






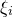

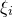
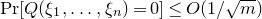

1. Introduction
Some of the most fundamental theorems in probability theory (and its applications) are concentration inequalities, which show that certain types of random variables are likely to lie in a small interval around their mean. In the other direction, anticoncentration inequalities give upper bounds on the probability that a random variable falls into a small interval or is equal to a particular value. In this area, one of the most important directions is the (polynomial) Littlewood–Offord problem. Roughly speaking, the problem is as follows.Footnote
1
Consider an n-variable polynomial
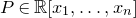 $P\in \mathbb R[x_1,\ldots,x_n]$
, and consider independent Rademacher random variables
$P\in \mathbb R[x_1,\ldots,x_n]$
, and consider independent Rademacher random variables
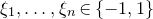 $\xi_1,\ldots,\xi_n\in\{-1,1\}$
(meaning that
$\xi_1,\ldots,\xi_n\in\{-1,1\}$
(meaning that
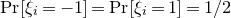 $\mathrm{Pr}[\xi_{i}=-1]=\mathrm{Pr}[\xi_{i}=1]=1/2$
for each i). What upper bounds can we prove on the point probabilities of the form
$\mathrm{Pr}[\xi_{i}=-1]=\mathrm{Pr}[\xi_{i}=1]=1/2$
for each i). What upper bounds can we prove on the point probabilities of the form
 $\mathrm{Pr}[P(\xi_1,\ldots,\xi_n)=z]$
? More specifically, how large can the maximum point probability
$\mathrm{Pr}[P(\xi_1,\ldots,\xi_n)=z]$
? More specifically, how large can the maximum point probability
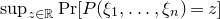 $\sup_{z\in \mathbb{R}} \mathrm{Pr}[P(\xi_1,\ldots,\xi_n)=z]$
be, without making any strong assumptions about the polynomial P?
$\sup_{z\in \mathbb{R}} \mathrm{Pr}[P(\xi_1,\ldots,\xi_n)=z]$
be, without making any strong assumptions about the polynomial P?
Historically, the starting point for this problem was the linear case, where P is a degree-one polynomial. Indeed, consider a random variable
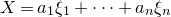 $X=a_{1}\xi_{1}+\dots+a_{n}\xi_{n}$
, where
$X=a_{1}\xi_{1}+\dots+a_{n}\xi_{n}$
, where
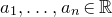 $a_{1},\ldots,a_{n}\in\mathbb{R}$
are nonzero real numbers and
$a_{1},\ldots,a_{n}\in\mathbb{R}$
are nonzero real numbers and
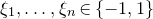 $\xi_{1},\ldots,\xi_{n}\in\{-1,1\}$
are independent Rademacher random variables. As part of their study of random polynomials, in 1943 Littlewood and Offord [Reference Littlewood and OffordLO43] proved that
$\xi_{1},\ldots,\xi_{n}\in\{-1,1\}$
are independent Rademacher random variables. As part of their study of random polynomials, in 1943 Littlewood and Offord [Reference Littlewood and OffordLO43] proved that
 $$\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]\le O \bigg(\frac{\log n}{\sqrt{n}}\bigg). $$
$$\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]\le O \bigg(\frac{\log n}{\sqrt{n}}\bigg). $$
Littlewood and Offord’s result was famously sharpened in 1945 by Erdős [Reference ErdősErd45], who found a purely combinatorial proof of what is now usually called the Erdős–Littlewood–Offord theorem: under the same assumptions,
 \begin{equation}\sup_{z\in\mathbb R}\mathrm{Pr}[X=z]\le\binom{n}{\lfloor n/2\rfloor}\cdot 2^{-n}=O\bigg(\frac{1}{\sqrt{n}}\bigg).\end{equation}
\begin{equation}\sup_{z\in\mathbb R}\mathrm{Pr}[X=z]\le\binom{n}{\lfloor n/2\rfloor}\cdot 2^{-n}=O\bigg(\frac{1}{\sqrt{n}}\bigg).\end{equation}
This result is best-possible, as can be seen by considering the case where the coefficients
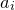 $a_{i}$
are all equal.
$a_{i}$
are all equal.
Remark 1.1. It is worth noting that the general topic of anticoncentration of sums of independent random variables was first considered in 1936 by Doeblin and Lévy [Reference Doeblin and LévyDL36], and this led to a parallel line of research with many similar results (the two lines of research seem to have not been aware of each others’ existence until quite recently). In particular, in the above setting, the bound
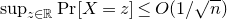 $\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]\le O(1/\sqrt{n})$
follows from a general result claimed in a 1939 paper of Doeblin [Reference DoeblinDoe39], preceding Littlewood and Offord by several years. However, this general result is also the subject of a 1958 paper of Kolmogorov [Reference KolmogorovKol58], which claims that Doeblin’s paper did not provide a full proof.
$\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]\le O(1/\sqrt{n})$
follows from a general result claimed in a 1939 paper of Doeblin [Reference DoeblinDoe39], preceding Littlewood and Offord by several years. However, this general result is also the subject of a 1958 paper of Kolmogorov [Reference KolmogorovKol58], which claims that Doeblin’s paper did not provide a full proof.
By now, the linear Littlewood–Offord problem is very well understood, and many variations and strengthenings are available. For example, there are very powerful inverse theorems that relate the maximum concentration probability to the arithmetic structure of the coefficients
 $a_1,\ldots,a_n$
, and these theorems have had a huge impact in random matrix theory (see for example the survey [Reference Nguyen and VuNV13]). Also, there are versions of the Erdős–Littlewood–Offord theorem for general distributions (i.e., allowing the variables
$a_1,\ldots,a_n$
, and these theorems have had a huge impact in random matrix theory (see for example the survey [Reference Nguyen and VuNV13]). Also, there are versions of the Erdős–Littlewood–Offord theorem for general distributions (i.e., allowing the variables
 $\xi_{1},\ldots,\xi_{n}$
to take non-Rademacher distributions), assuming that the distributions of the variables
$\xi_{1},\ldots,\xi_{n}$
to take non-Rademacher distributions), assuming that the distributions of the variables
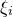 $\xi_{i}$
do not themselves concentrate too strongly. (Approximate results along these lines follow directly from the Lévy–Doeblin–Kolmogorov theorem mentioned in Remark 1.1, or can be deduced from the Erdős–Littlewood–Offord theorem; in some sense the Rademacher case is the ‘hardest case’. For exact results see [Reference JonesJon78, Reference JuškeviiusJuš22, Reference Leader and RadcliffeLR94].)
$\xi_{i}$
do not themselves concentrate too strongly. (Approximate results along these lines follow directly from the Lévy–Doeblin–Kolmogorov theorem mentioned in Remark 1.1, or can be deduced from the Erdős–Littlewood–Offord theorem; in some sense the Rademacher case is the ‘hardest case’. For exact results see [Reference JonesJon78, Reference JuškeviiusJuš22, Reference Leader and RadcliffeLR94].)
After the linear case, the next case to consider is the quadratic case: What bounds can we give on the point concentration of a quadratic polynomial
 $Q(\xi_{1},\ldots,\xi_{n})$
of independent Rademacher random variables
$Q(\xi_{1},\ldots,\xi_{n})$
of independent Rademacher random variables
 $\xi_{1},\ldots,\xi_{n}$
? This question came to the forefront in a 2005 paper by Costello, Tao and Vu [Reference Costello, Tao and VuCTV06], when they used such a bound in their proof of Weiss’ conjecture on singularity of random symmetric matrices. Specifically, they proved that if a quadratic polynomial
$\xi_{1},\ldots,\xi_{n}$
? This question came to the forefront in a 2005 paper by Costello, Tao and Vu [Reference Costello, Tao and VuCTV06], when they used such a bound in their proof of Weiss’ conjecture on singularity of random symmetric matrices. Specifically, they proved that if a quadratic polynomial
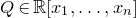 $Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
has at least
$Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
has at least
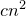 $cn^{2}$
nonzero coefficientsFootnote
2
(for some constant
$cn^{2}$
nonzero coefficientsFootnote
2
(for some constant
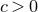 $c \gt 0$
), then
$c \gt 0$
), then
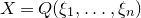 $X=Q(\xi_{1},\ldots,\xi_{n})$
(for independent Rademacher random variables
$X=Q(\xi_{1},\ldots,\xi_{n})$
(for independent Rademacher random variables
 $\xi_{1},\ldots,\xi_{n}$
) satisfies
$\xi_{1},\ldots,\xi_{n}$
) satisfies
 \begin{equation}\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]\le O\bigg(\frac{1}{n^{1/8}}\bigg).\end{equation}
\begin{equation}\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]\le O\bigg(\frac{1}{n^{1/8}}\bigg).\end{equation}
Remark 1.2. Parallelling the situation described in Remark 1.1, we remark that Costello, Tao and Vu were actually not the first to prove this inequality: in 1996, Rosiński and Samorodnitsky [Reference Rosiński and SamorodnitskyRS96] had proved essentially the same result (in fact, a generalisation of it to higher-degree polynomials), in their study of zero-one laws for Lévy chaos (chaoses are polynomials of independent random variables; they are classical and very well-studied objects in probability theory, statistics and applied mathematics). Seemingly unaware of Rosiński and Samorodnitsky’s work, in 2013 Razborov and Viola [Reference Razborov and ViolaRV13] considered a similar higher-degree generalisation (for applications in the theory of Boolean functions).
The authors of [Reference Costello, Tao and VuCTV06, Reference Rosiński and SamorodnitskyRS96] already recognised that Equation (1.2) was likely not optimal. Indeed, just as for the linear Littlewood–Offord problem, one expects a bound of the form
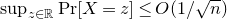 $\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]\le O(1/\sqrt{n})$
(this bound is attained in the case
$\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]\le O(1/\sqrt{n})$
(this bound is attained in the case
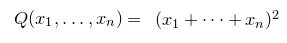 $Q(x_{1},\ldots,x_{n})=(x_{1}+\dots+x_{n})^{2}$
, for example). A conjecture to this effect has been attributed to Nguyen and Vu (see [Reference Meka, Nguyen and VuMNV16, Reference Razborov and ViolaRV13]).
$Q(x_{1},\ldots,x_{n})=(x_{1}+\dots+x_{n})^{2}$
, for example). A conjecture to this effect has been attributed to Nguyen and Vu (see [Reference Meka, Nguyen and VuMNV16, Reference Razborov and ViolaRV13]).
The first improvement on Equation (1.2) was by Costello and Vu [Reference Costello and VuCV08], who showed how to adapt the arguments in [Reference Costello, Tao and VuCTV06] to prove a bound of the form
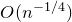 $O(n^{-1/4})$
. Introducing several new ideas, Costello [Reference CostelloCos13] then managed to obtain the nearly optimal bound
$O(n^{-1/4})$
. Introducing several new ideas, Costello [Reference CostelloCos13] then managed to obtain the nearly optimal bound
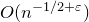 $O(n^{-1/2+\varepsilon})$
(for any constant
$O(n^{-1/2+\varepsilon})$
(for any constant
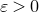 $\varepsilon \gt 0$
). Via a completely different approach, this bound was further refined to
$\varepsilon \gt 0$
). Via a completely different approach, this bound was further refined to
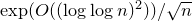 $\exp(O((\log\log n)^{2}))/\sqrt{n}$
by Meka, Nguyen and VuFootnote
3
(see arXiv version v4 of [Reference Meka, Nguyen and VuMNV16]), before it was observed that the bound
$\exp(O((\log\log n)^{2}))/\sqrt{n}$
by Meka, Nguyen and VuFootnote
3
(see arXiv version v4 of [Reference Meka, Nguyen and VuMNV16]), before it was observed that the bound
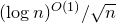 $(\log n)^{O(1)}/\sqrt{n}$
follows from a powerful general result of Kane [Reference KaneKan14] (see the journal version of [Reference Meka, Nguyen and VuMNV16] for more discussion).
$(\log n)^{O(1)}/\sqrt{n}$
follows from a powerful general result of Kane [Reference KaneKan14] (see the journal version of [Reference Meka, Nguyen and VuMNV16] for more discussion).
In this paper, we finally resolve the quadratic Littlewood–Offord problem (up to constant factors), obtaining an optimal bound of
 $O(1/\sqrt{n})$
. We are also able to make a weaker assumption on Q than in previous work.
$O(1/\sqrt{n})$
. We are also able to make a weaker assumption on Q than in previous work.
Theorem 1.1. Let
 $Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a polynomial of degree at most two, and let
$Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a polynomial of degree at most two, and let
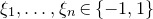 $\xi_{1},\ldots,\xi_{n}\in\{-1,1\}$
be independent Rademacher random variables. For some positive integer m, suppose that
$\xi_{1},\ldots,\xi_{n}\in\{-1,1\}$
be independent Rademacher random variables. For some positive integer m, suppose that
 $Q(\xi_{1},\ldots,\xi_{n})$
‘robustly depends on at least m of the variables
$Q(\xi_{1},\ldots,\xi_{n})$
‘robustly depends on at least m of the variables
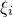 $\xi_{i}$
’ in the sense that the value of
$\xi_{i}$
’ in the sense that the value of
 $Q(\xi_{1},\ldots,\xi_{n})$
cannot be determined by specifying any outcomes of any
$Q(\xi_{1},\ldots,\xi_{n})$
cannot be determined by specifying any outcomes of any
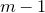 $m-1$
of the variables
$m-1$
of the variables
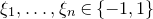 $\xi_{1},\ldots,\xi_n\in\{-1,1\}$
. Then,
$\xi_{1},\ldots,\xi_n\in\{-1,1\}$
. Then,
 $$\sup_{z\in\mathbb{R}}\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=z]\le\frac{C}{\sqrt{m}},$$
$$\sup_{z\in\mathbb{R}}\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=z]\le\frac{C}{\sqrt{m}},$$
for some absolute constant C.
Remark 1.3. Recall that the Erdős–Littlewood–Offord theorem has an assumption that each linear coefficient
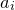 $a_i$
is nonzero. Of course, zero coefficients can be ignored, so without such an assumption one immediately obtains a bound of the form
$a_i$
is nonzero. Of course, zero coefficients can be ignored, so without such an assumption one immediately obtains a bound of the form
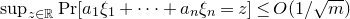 $\sup_{z\in \mathbb R}\mathrm{Pr}[a_1\xi_1+\dots+a_n\xi_n=z]\le O(1/\sqrt{m})$
, where m is the number of nonzero
$\sup_{z\in \mathbb R}\mathrm{Pr}[a_1\xi_1+\dots+a_n\xi_n=z]\le O(1/\sqrt{m})$
, where m is the number of nonzero
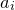 $a_{i}$
. Unfortunately, the situation is not so simple in the quadratic case. One could make the very strong assumption that every degree-two coefficient is nonzero, but this is too strong of an assumption for most applications.Footnote
4
Alternatively, one might wish to consider the very weak assumption that every variable
$a_{i}$
. Unfortunately, the situation is not so simple in the quadratic case. One could make the very strong assumption that every degree-two coefficient is nonzero, but this is too strong of an assumption for most applications.Footnote
4
Alternatively, one might wish to consider the very weak assumption that every variable
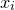 $x_{i}$
features in at least one nonzero term of
$x_{i}$
features in at least one nonzero term of
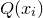 $Q(x_{i})$
, but unfortunately this is too weak to get a sensible bound: indeed, consider for example the case where
$Q(x_{i})$
, but unfortunately this is too weak to get a sensible bound: indeed, consider for example the case where
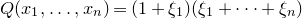 $Q(x_{1},\ldots,x_{n})=(1+\xi_{1})(\xi_{1}+\dots+\xi_{n})$
, which is zero whenever
$Q(x_{1},\ldots,x_{n})=(1+\xi_{1})(\xi_{1}+\dots+\xi_{n})$
, which is zero whenever
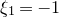 $\xi_{1}=-1$
, and therefore
$\xi_{1}=-1$
, and therefore
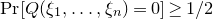 $\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=0]\ge 1/2$
. More generally, if it is possible to determine the value of
$\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=0]\ge 1/2$
. More generally, if it is possible to determine the value of
 $Q(\xi_{1},\ldots,\xi_{n})$
by fixing the outcomes of a small number of variables to certain values, then this automatically leads to a large point probability for
$Q(\xi_{1},\ldots,\xi_{n})$
by fixing the outcomes of a small number of variables to certain values, then this automatically leads to a large point probability for
 $Q(\xi_{1},\ldots,\xi_{n})$
. So it is necessary to make an assumption guaranteeing that Q ‘robustly depends on many of the
$Q(\xi_{1},\ldots,\xi_{n})$
. So it is necessary to make an assumption guaranteeing that Q ‘robustly depends on many of the
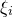 $\xi_{i}$
’.
$\xi_{i}$
’.
We believe that our assumption in Theorem 1.1 captures this ‘robust dependence on many of the
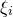 $\xi_{i}$
’ in a natural way. To compare with previous work: our assumption is slightly weaker than the assumption in [Reference Meka, Nguyen and VuMNV16] (which says that
$\xi_{i}$
’ in a natural way. To compare with previous work: our assumption is slightly weaker than the assumption in [Reference Meka, Nguyen and VuMNV16] (which says that
 $Q(x_{1},\ldots,x_{n})$
has many quadratic terms featuring disjoint variables), and is much weaker than the assumptions in [Reference CostelloCos13, Reference Costello, Tao and VuCTV06] (which say, in slightly different ways, that
$Q(x_{1},\ldots,x_{n})$
has many quadratic terms featuring disjoint variables), and is much weaker than the assumptions in [Reference CostelloCos13, Reference Costello, Tao and VuCTV06] (which say, in slightly different ways, that
 $Q(x_{1},\ldots,x_{n})$
has a huge number of nonzero coefficients).
$Q(x_{1},\ldots,x_{n})$
has a huge number of nonzero coefficients).
Remark 1.4. Of course, we could ask for the optimal constant factor C in Theorem 1.1. It is not necessarily clear what to expect: one may guess that the polynomial
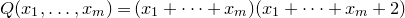 $Q(x_1,\ldots,x_m)=(x_1+\dots+x_m)(x_1+\dots+x_m+2)$
or
$Q(x_1,\ldots,x_m)=(x_1+\dots+x_m)(x_1+\dots+x_m+2)$
or
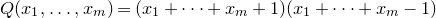 $Q(x_1,\ldots,x_m)=(x_1+\dots+x_m+1)(x_1+\dots+x_m-1)$
(depending on whether m is odd or even) is the worst case, but recent developments on the so-called Gotsman–Linial conjecture (see § 12) suggest that this might be too naïve. It is also quite possible that the optimal value for the constant factor in the bound on
$Q(x_1,\ldots,x_m)=(x_1+\dots+x_m+1)(x_1+\dots+x_m-1)$
(depending on whether m is odd or even) is the worst case, but recent developments on the so-called Gotsman–Linial conjecture (see § 12) suggest that this might be too naïve. It is also quite possible that the optimal value for the constant factor in the bound on
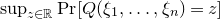 $\sup_{z\in\mathbb{R}}\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=z]$
is sensitive to the precise assumption one makes on the quadratic polynomial Q (to ensure that it ‘robustly depends on many of the variables
$\sup_{z\in\mathbb{R}}\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=z]$
is sensitive to the precise assumption one makes on the quadratic polynomial Q (to ensure that it ‘robustly depends on many of the variables
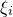 $\xi_i$
’; see Remark 1.3).
$\xi_i$
’; see Remark 1.3).
In § 2 we give a brief summary of the methods that had previously been applied to the (quadratic) LittlewoodOfford problem, their limitations and the new ideas in our proof of Theorem 1.1. In particular, our key contribution is a new inductive decoupling scheme: we take the well-known technique of decoupling, usually viewed as a tool to inefficiently ‘reduce from a quadratic problem to a linear problem’, and reinterpret it as a tool to efficiently ‘reduce the relative dimension of the quadratic part of a problem’. We also develop a new way to study the anticoncentration of random vectors, via a technique we call witness counting. We believe both these aspects of our proof may have broader applications.
We also remark that, while the details of the proof of Theorem 1.1 are rather involved, there is a certain special case of Theorem 1.1 (the case where the quadratic part of Q has ‘bounded rank’) which permits a much simpler proof. This case is already interesting, and we present its proof in § 4 to serve as an accessible illustration of our inductive decoupling scheme (and the results of § 4 will also be used later in the paper).
Finally, we remark that just, as for the linear Littlewood–Offord problem, one can deduce a version of Theorem 1.1 in which the variables
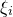 $\xi_{i}$
are allowed to take essentially any discrete distribution (not just the Rademacher distribution), as follows.
$\xi_{i}$
are allowed to take essentially any discrete distribution (not just the Rademacher distribution), as follows.
Theorem 1.2. Fix
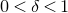 $0<\delta<1$
. Let
$0<\delta<1$
. Let
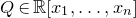 $Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a polynomial of degree at most two, and let
$Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a polynomial of degree at most two, and let
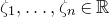 $\zeta_{1},\ldots,\zeta_{n}\in \mathbb{R}$
be independent discrete random variables.
$\zeta_{1},\ldots,\zeta_{n}\in \mathbb{R}$
be independent discrete random variables.
For nonempty subsets
 $R_1,\ldots,R_n$
of the supports of
$R_1,\ldots,R_n$
of the supports of
 $\zeta_{1},\ldots,\zeta_{n}$
, respectively, say that the product
$\zeta_{1},\ldots,\zeta_{n}$
, respectively, say that the product
 $R_1\times \dots\times R_n$
is a fixing box for Q if the polynomial Q is constant on
$R_1\times \dots\times R_n$
is a fixing box for Q if the polynomial Q is constant on
 $R_1\times \dots\times R_n$
. For some positive integer m, suppose that for any fixing box
$R_1\times \dots\times R_n$
. For some positive integer m, suppose that for any fixing box
 $R_1\times \dots\times R_n$
there are at least m indices
$R_1\times \dots\times R_n$
there are at least m indices
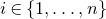 $i\in \{1,\ldots,n\}$
such that
$i\in \{1,\ldots,n\}$
such that
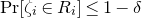 $\mathrm{Pr}[\zeta_{i}\in R_i]\le 1-\delta$
. Then, we have
$\mathrm{Pr}[\zeta_{i}\in R_i]\le 1-\delta$
. Then, we have
 $$\sup_{z\in\mathbb{R}}\mathrm{Pr}[Q(\zeta_{1},\ldots,\zeta_{n})=z]\le \frac{C_\delta}{\sqrt{m}}, $$
$$\sup_{z\in\mathbb{R}}\mathrm{Pr}[Q(\zeta_{1},\ldots,\zeta_{n})=z]\le \frac{C_\delta}{\sqrt{m}}, $$
for some constant
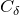 $C_\delta$
only depending on
$C_\delta$
only depending on
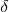 $\delta$
.
$\delta$
.
Note that, if
 $\zeta_1,\ldots,\zeta_n$
are independent uniformly random integers in
$\zeta_1,\ldots,\zeta_n$
are independent uniformly random integers in
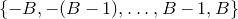 $\{-B,-(B-1),\ldots,B-1,B\}$
, then
$\{-B,-(B-1),\ldots,B-1,B\}$
, then
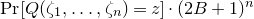 $\mathrm{Pr}[Q(\zeta_{1},\ldots,\zeta_{n})=z]\cdot (2B+1)^n$
is the number of integer solutions to
$\mathrm{Pr}[Q(\zeta_{1},\ldots,\zeta_{n})=z]\cdot (2B+1)^n$
is the number of integer solutions to
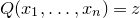 $Q(x_1,\ldots,x_n)=z$
among integers
$Q(x_1,\ldots,x_n)=z$
among integers
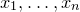 $x_1,\ldots,x_n$
with absolute value (‘height’) at most B. We remark that quantities of this form have been extensively studied in analytic number theory in the regime where n is constant and B is large (in contrast, our estimates are effective in the regime where B is constant and n is large); see for example [Reference Heath-BrownHB02, Reference PilaPil95] and [Reference Browning and GorodnikBG17, Theorem 1.11].
$x_1,\ldots,x_n$
with absolute value (‘height’) at most B. We remark that quantities of this form have been extensively studied in analytic number theory in the regime where n is constant and B is large (in contrast, our estimates are effective in the regime where B is constant and n is large); see for example [Reference Heath-BrownHB02, Reference PilaPil95] and [Reference Browning and GorodnikBG17, Theorem 1.11].
1.1 An application to edge statistics
Apart from the intrinsic value of Theorem 1.1, of course it also enables us to improve bounds in any place where quadratic Littlewood–Offord inequalities had previously been applied (see for example [Reference Addario-Berry and EslavaABE14, Reference Costello, Tao and VuCTV06, Reference Costello and VuCV10, Reference Costello and VuCV08, Reference Ferber, Kwan, Sah and SawhneyFKSS23, Reference Glasgow, Kwan, Sah and SawhneyGKSS, Reference Kwan, Sudakov and TranKST19]). Here, we highlight one particular application: we can resolve a conjecture of Alon, Hefetz, Krivelevich and Tyomkyn [Reference Alon, Hefetz, Krivelevich and TyomkynAHKT20] related to the so-called graph inducibility problem. Specifically, let
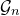 $\mathcal{G}_{n}$
be the set of n-vertex graphs, and for a graph G let
$\mathcal{G}_{n}$
be the set of n-vertex graphs, and for a graph G let
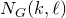 $N_{G}(k,\ell)$
be the number of sets of k vertices of G inducing exactly
$N_{G}(k,\ell)$
be the number of sets of k vertices of G inducing exactly
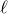 $\ell$
edges. Then, define the edge inducibility (with parameters k and
$\ell$
edges. Then, define the edge inducibility (with parameters k and
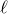 $\ell$
) by
$\ell$
) by
 $$\operatorname{ind}(k,\ell)=\lim_{n\to\infty}\max_{G\in\mathcal{G}_{n}}\frac{N_{G}(k,\ell)}{\binom{n}{k}}. $$
$$\operatorname{ind}(k,\ell)=\lim_{n\to\infty}\max_{G\in\mathcal{G}_{n}}\frac{N_{G}(k,\ell)}{\binom{n}{k}}. $$
This parameter measures, for large graphs, the maximum possible fraction of k-vertex subsets which induce
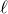 $\ell$
edges. By considering complete or empty graphs we have
$\ell$
edges. By considering complete or empty graphs we have
 $$\operatorname{ind}(k,0)=\operatorname{ind}\Big(k,\textstyle{\binom{k}{2}}\Big)=1, $$
$$\operatorname{ind}(k,0)=\operatorname{ind}\Big(k,\textstyle{\binom{k}{2}}\Big)=1, $$
but for
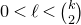 $0<\ell<\binom k 2$
we have
$0<\ell<\binom k 2$
we have
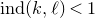 $\operatorname{ind}(k,\ell)<1$
(this follows easily from Ramsey’s theorem, which says that large graphs must have large complete or empty subgraphs). In fact, for
$\operatorname{ind}(k,\ell)<1$
(this follows easily from Ramsey’s theorem, which says that large graphs must have large complete or empty subgraphs). In fact, for
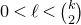 $0<\ell<\binom k 2$
, and large k, we now know that
$0<\ell<\binom k 2$
, and large k, we now know that
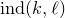 $\operatorname{ind}(k,\ell)$
cannot be much larger than
$\operatorname{ind}(k,\ell)$
cannot be much larger than
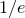 $1/e$
; this was the content of the Edge-Statistics conjecture, proved in a combination of papers by Kwan, Sudakov and Tran [Reference Kwan, Sudakov and TranKST19], Fox and Sauermann [Reference Fox and SauermannFS20] and Martinsson, Mousset, Noever and Trujić [Reference Martinsson, Mousset, Noever and TrujićMMNT19]. One can use Theorem 1.1 to prove the following much stronger bound when
$1/e$
; this was the content of the Edge-Statistics conjecture, proved in a combination of papers by Kwan, Sudakov and Tran [Reference Kwan, Sudakov and TranKST19], Fox and Sauermann [Reference Fox and SauermannFS20] and Martinsson, Mousset, Noever and Trujić [Reference Martinsson, Mousset, Noever and TrujićMMNT19]. One can use Theorem 1.1 to prove the following much stronger bound when
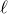 $\ell$
is far from zero and far from
$\ell$
is far from zero and far from
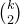 $\binom{k}{2}$
, which was conjectured by Alon, Hefetz, Krivelevich and Tyomkyn (see [Reference Alon, Hefetz, Krivelevich and TyomkynAHKT20, Conjecture 6.2]).
$\binom{k}{2}$
, which was conjectured by Alon, Hefetz, Krivelevich and Tyomkyn (see [Reference Alon, Hefetz, Krivelevich and TyomkynAHKT20, Conjecture 6.2]).
Theorem 1.3. For
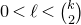 $0<\ell<\binom k 2$
we have
$0<\ell<\binom k 2$
we have
 $$ \operatorname{ind}(k,\ell)=O\left(\frac 1{\sqrt{\min\Big(\ell,\binom k2-\ell\Big)/k}}\right). $$
$$ \operatorname{ind}(k,\ell)=O\left(\frac 1{\sqrt{\min\Big(\ell,\binom k2-\ell\Big)/k}}\right). $$
The deduction of Theorem 1.3 from Theorem 1.1 is exactly as in the proof of [Reference Kwan, Sudakov and TranKST19, Theorem 1.1] (which uses the weaker quadratic Littlewood–Offord inequality from [Reference Meka, Nguyen and VuMNV16]), so we do not include it here. The idea is that, for any large graph G, the number of edges in a random set of k vertices of G can be interpreted as a quadratic polynomial of independent Rademacher random variables (via a certain coupling).
1.1.1 Notation
As usual, for a nonnegative integer n, we write
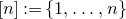 $[n]:=\{1,\ldots,n\}$
(note that for
$[n]:=\{1,\ldots,n\}$
(note that for
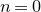 $n=0$
, this means
$n=0$
, this means
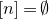 $[n]=\emptyset$
). For an
$[n]=\emptyset$
). For an
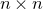 $n\times n$
matrix A and subsets
$n\times n$
matrix A and subsets
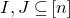 $I,J\subseteq [n]$
, we write
$I,J\subseteq [n]$
, we write
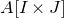 $A[I\times J]$
for the
$A[I\times J]$
for the
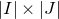 $|I|\times |J|$
submatrix of A consisting of the rows with indices in I and the columns with indices in J. Similarly, for a vector
$|I|\times |J|$
submatrix of A consisting of the rows with indices in I and the columns with indices in J. Similarly, for a vector
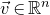 $\vec v\in \mathbb{R}^n$
and a subset
$\vec v\in \mathbb{R}^n$
and a subset
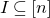 $I\subseteq [n]$
, we write
$I\subseteq [n]$
, we write
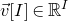 $\vec v[I]\in \mathbb{R}^{I}$
for the vector obtained from
$\vec v[I]\in \mathbb{R}^{I}$
for the vector obtained from
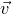 $\vec v$
by only taking the coordinates with indices in I. Finally, for a vector
$\vec v$
by only taking the coordinates with indices in I. Finally, for a vector
 $\vec v\in \mathbb{R}^n$
and
$\vec v\in \mathbb{R}^n$
and
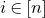 $i\in [n]$
, we write
$i\in [n]$
, we write
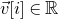 $\vec v[i]\in \mathbb{R}$
for the ith entry of
$\vec v[i]\in \mathbb{R}$
for the ith entry of
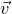 $\vec v$
.
$\vec v$
.
In this paper, we say that
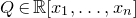 $Q\in \mathbb{R}[x_1,\ldots,x_n]$
is a quadratic polynomial if its degree is at most two. For
$Q\in \mathbb{R}[x_1,\ldots,x_n]$
is a quadratic polynomial if its degree is at most two. For
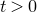 $t \gt 0$
, we write
$t \gt 0$
, we write
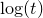 $\log(t)$
for the base-two logarithm of t.
$\log(t)$
for the base-two logarithm of t.
2. Key ideas, in comparison with previous work
By now there are several different proofs of the
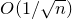 $O(1/\sqrt{n})$
bound in the (linear) Erdős–Littlewood–Offord theorem. As far as we know, they all take advantage of at least one of two very special properties of random variables of the form
$O(1/\sqrt{n})$
bound in the (linear) Erdős–Littlewood–Offord theorem. As far as we know, they all take advantage of at least one of two very special properties of random variables of the form
 $X=a_{1}\xi_{1}+\dots+a_{n}\xi_{n}$
. First, Erdős’ original proof [Reference ErdősErd45] used the monotonicity of X (for every index i, changing
$X=a_{1}\xi_{1}+\dots+a_{n}\xi_{n}$
. First, Erdős’ original proof [Reference ErdősErd45] used the monotonicity of X (for every index i, changing
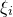 $\xi_{i}$
from
$\xi_{i}$
from
 $-1$
to 1 will always make the value of X increase, or always make the value of X decrease). Second, one can take advantage of the fact that X is a sum of independent random variables (each with a very simple distribution), so its Fourier transform is very well behaved. (The first Fourier-analytic proof seems to have been by Halász [Reference HalászHal77]; see also the very simple proof of a
$-1$
to 1 will always make the value of X increase, or always make the value of X decrease). Second, one can take advantage of the fact that X is a sum of independent random variables (each with a very simple distribution), so its Fourier transform is very well behaved. (The first Fourier-analytic proof seems to have been by Halász [Reference HalászHal77]; see also the very simple proof of a
 $O(1/\sqrt n)$
bound due to Croot [Reference CrootCro11].)
$O(1/\sqrt n)$
bound due to Croot [Reference CrootCro11].)
Unfortunately, in the quadratic setting (where
 $X=Q(\xi_{1},\ldots,\xi_{n})$
for some quadratic polynomial Q), both of the above properties of X may fail in a very strong way. There are two general approaches that have been most successful so far: Gaussian approximation, and a technique called decoupling. We briefly discuss both these approaches and their limitations, before describing our new ideas.
$X=Q(\xi_{1},\ldots,\xi_{n})$
for some quadratic polynomial Q), both of the above properties of X may fail in a very strong way. There are two general approaches that have been most successful so far: Gaussian approximation, and a technique called decoupling. We briefly discuss both these approaches and their limitations, before describing our new ideas.
2.1 Gaussian approximation and combinatorial partitioning
Whether one is interested in the linear or the quadratic cases of the Littlewood–Offord problem, perhaps the most natural starting point is to try to leverage some of the vast literature in probability theory on distributional approximation: if one can approximate the entire distribution of a random variable X, then anticoncentration should be an easy corollary.
This angle of attack is especially compelling in the linear case, since
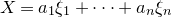 $X=a_{1}\xi_{1}+\dots+a_{n}\xi_{n}$
is a sum of independent random variables; it is tempting to try to apply a central limit theorem. One cannot be too naïve here, as the limiting distribution of X could actually be very far from Gaussian (consider for example the case where
$X=a_{1}\xi_{1}+\dots+a_{n}\xi_{n}$
is a sum of independent random variables; it is tempting to try to apply a central limit theorem. One cannot be too naïve here, as the limiting distribution of X could actually be very far from Gaussian (consider for example the case where
 $a_{i}=2^{i}$
for each i). However, in their foundational paper, Littlewood and Offord [Reference Littlewood and OffordLO43] were in fact able to prove their
$a_{i}=2^{i}$
for each i). However, in their foundational paper, Littlewood and Offord [Reference Littlewood and OffordLO43] were in fact able to prove their
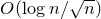 $O(\log n/\sqrt{n})$
bound via Gaussian approximation. The key idea was to partition the coefficients
$O(\log n/\sqrt{n})$
bound via Gaussian approximation. The key idea was to partition the coefficients
 $a_{i}$
into
$a_{i}$
into
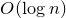 $O(\log n)$
‘buckets’ according to their orders of magnitude, in such a way that Gaussian approximation is effective within each bucket.
$O(\log n)$
‘buckets’ according to their orders of magnitude, in such a way that Gaussian approximation is effective within each bucket.
It is far from obvious how to extend this type of strategy to the higher-degree case (when
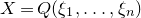 $X=Q(\xi_{1},\ldots,\xi_{n})$
for a bounded-degree polynomial Q), but this is more or less what was accomplished by Meka, Nguyen and Vu [Reference Meka, Nguyen and VuMNV16] and by Kane [Reference KaneKan14] in their bounds of the form
$X=Q(\xi_{1},\ldots,\xi_{n})$
for a bounded-degree polynomial Q), but this is more or less what was accomplished by Meka, Nguyen and Vu [Reference Meka, Nguyen and VuMNV16] and by Kane [Reference KaneKan14] in their bounds of the form
 $\exp(O((\log\log n)^{2}))/\sqrt{n}$
and
$\exp(O((\log\log n)^{2}))/\sqrt{n}$
and
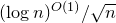 $(\log n)^{O(1)}/\sqrt{n}$
, respectively. Instead of a central limit theorem, one needs a Gaussian invariance principle (which provides sufficient conditions under which one can approximate a polynomial of independent Rademacher random variables by a polynomial of independent Gaussian random variables), and instead of a simple ‘bucketing’ argument one needs a regularity lemma to describe
$(\log n)^{O(1)}/\sqrt{n}$
, respectively. Instead of a central limit theorem, one needs a Gaussian invariance principle (which provides sufficient conditions under which one can approximate a polynomial of independent Rademacher random variables by a polynomial of independent Gaussian random variables), and instead of a simple ‘bucketing’ argument one needs a regularity lemma to describe
 $Q(\xi_{1},\ldots,\xi_{n})$
in terms of a ‘low-complexity decision tree’.
$Q(\xi_{1},\ldots,\xi_{n})$
in terms of a ‘low-complexity decision tree’.
These types of methods are very powerful and very flexible, but unfortunately it seems that one inevitably needs to ‘pay logarithmic factors’ in order to deconstruct an arbitraryFootnote
5
quadratic polynomial into ‘well-behaved pieces’ for which Gaussian approximation is effective. Even in the linear case, we are not aware of a way to prove an optimal
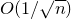 $O(1/\sqrt n)$
bound via Gaussian approximation. Perhaps this is not surprising: in some sense the entire philosophy of the Littlewood–Offord problem is that anticoncentration is an extremely robust phenomenon that holds under much weaker assumptions than central limit theorems, and we should not expect to be able to use central limit theorems to prove optimal anticoncentration.
$O(1/\sqrt n)$
bound via Gaussian approximation. Perhaps this is not surprising: in some sense the entire philosophy of the Littlewood–Offord problem is that anticoncentration is an extremely robust phenomenon that holds under much weaker assumptions than central limit theorems, and we should not expect to be able to use central limit theorems to prove optimal anticoncentration.
2.2 Decoupling
A completely different technique was employed in the papers of Costello, Tao and Vu [Reference Costello, Tao and VuCTV06] and Rosński and Samorodnitsky [Reference Rosiński and SamorodnitskyRS96], which first studied the quadratic Littlewood–Offord problem. This technique is now usually called decoupling, following [Reference Costello, Tao and VuCTV06]. Roughly speaking, decoupling is a general technique to ‘reduce a quadratic anticoncentration problem to a linear one’.Footnote 6 Below, we sketch the basic idea, incorporating an improvement due to Costello and Vu [Reference Costello and VuCV08].Footnote 7
Let
 $Q\in \mathbb{R}[x_1,\ldots,x_n]$
be a quadratic polynomial and let
$Q\in \mathbb{R}[x_1,\ldots,x_n]$
be a quadratic polynomial and let
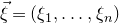 $\vec{\xi}=(\xi_{1},\ldots,\xi_{n})$
be a sequence of independent Rademacher random variables. Given a partition of the index set
$\vec{\xi}=(\xi_{1},\ldots,\xi_{n})$
be a sequence of independent Rademacher random variables. Given a partition of the index set
 $\{1,\ldots,n\}$
into two subsets I and J, we can break the random vector
$\{1,\ldots,n\}$
into two subsets I and J, we can break the random vector
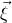 $\vec{\xi}$
into two parts
$\vec{\xi}$
into two parts
 $\vec{\xi}[I]\in\{-1,1\}^{I}$
and
$\vec{\xi}[I]\in\{-1,1\}^{I}$
and
 $\vec{\xi}[J]\in\{-1,1\}^{J}$
. Then, a simple application of the Cauchy–Schwarz inequality (see Lemma 3.6) shows that, if
$\vec{\xi}[J]\in\{-1,1\}^{J}$
. Then, a simple application of the Cauchy–Schwarz inequality (see Lemma 3.6) shows that, if
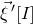 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
is an independent copy of
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
is an independent copy of
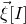 $\vec{\xi}[I]$
, we have
$\vec{\xi}[I]$
, we have
 \begin{align}\mathrm{Pr}[Q(\vec \xi)=z]=\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])=z] & \le\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])=z \text{ and } Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=z]^{1/2}\end{align}
\begin{align}\mathrm{Pr}[Q(\vec \xi)=z]=\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])=z] & \le\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])=z \text{ and } Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=z]^{1/2}\end{align}
 \begin{align}& \le \mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=0]^{1/2}.\end{align}
\begin{align}& \le \mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=0]^{1/2}.\end{align}
Now,
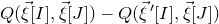 $Q(\vec{\xi}[I],\vec{\xi}[J])-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])$
can be interpreted as a linear function of
$Q(\vec{\xi}[I],\vec{\xi}[J])-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])$
can be interpreted as a linear function of
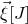 $\vec{\xi}[J]$
, with coefficients that depend on
$\vec{\xi}[J]$
, with coefficients that depend on
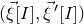 $(\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
(since the terms that are quadratic in
$(\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
(since the terms that are quadratic in
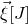 $\vec \xi[J]$
cancel out). Furthermore, this linear function typically has many nonzero coefficients (since it is unlikely that most of the ‘cross-terms’ between
$\vec \xi[J]$
cancel out). Furthermore, this linear function typically has many nonzero coefficients (since it is unlikely that most of the ‘cross-terms’ between
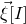 $\vec \xi[I]$
and
$\vec \xi[I]$
and
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
cancel out). So, after conditioning on a typical outcome of
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
cancel out). So, after conditioning on a typical outcome of
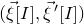 $(\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
, one can apply the Erdős–Littlewood–Offord theorem to obtain a bound of the form
$(\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
, one can apply the Erdős–Littlewood–Offord theorem to obtain a bound of the form
 $\mathrm{Pr}[Q(\vec \xi)=z]\le (O(1/\sqrt n))^{1/2}=O(n^{-1/4})$
.
$\mathrm{Pr}[Q(\vec \xi)=z]\le (O(1/\sqrt n))^{1/2}=O(n^{-1/4})$
.
The great advantage of decoupling is that the resulting linear anticoncentration problem is much easier: one has access to the much wider range of tools available to study sums of independent random variables. However, the inequality between Equations (2.1) and (2.2) is rather lossy, and one tends to end up with bounds that are at least ‘a square root away’ from best-possible.Footnote 8
Costello’s paper [Reference CostelloCos13], proving the first bound of the form
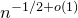 $n^{-1/2+o(1)}$
for the quadratic Littlewood–Offord problem, combined decoupling with a structural dichotomy. Namely, Costello discovered that if the quadratic polynomial Q is in a certain sense ‘robustly irreducible’, then number-theoretic arguments give the stronger bound
$n^{-1/2+o(1)}$
for the quadratic Littlewood–Offord problem, combined decoupling with a structural dichotomy. Namely, Costello discovered that if the quadratic polynomial Q is in a certain sense ‘robustly irreducible’, then number-theoretic arguments give the stronger bound
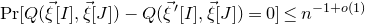 $\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=0]\le n^{-1+o(1)}$
, and so, even after the ‘square-root loss’ of decoupling, one has
$\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=0]\le n^{-1+o(1)}$
, and so, even after the ‘square-root loss’ of decoupling, one has
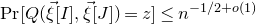 $\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])=z]\le n^{-1/2+o(1)}$
. He then gave a separate argument to handle the case where Q does not satisfy the robust irreducibility condition (i.e., when Q essentially splits into linear factors), based on the Szemerédi–Trotter theorem from discrete geometry.
$\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])=z]\le n^{-1/2+o(1)}$
. He then gave a separate argument to handle the case where Q does not satisfy the robust irreducibility condition (i.e., when Q essentially splits into linear factors), based on the Szemerédi–Trotter theorem from discrete geometry.
We cannot conclusively rule out the possibility that one could prove an optimal
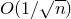 $O(1/\sqrt n)$
bound with a similar kind of case analysis, but this seems to be extremely difficult. In particular, we are not aware of any suitable candidate for a condition on Q which ensures that
$O(1/\sqrt n)$
bound with a similar kind of case analysis, but this seems to be extremely difficult. In particular, we are not aware of any suitable candidate for a condition on Q which ensures that
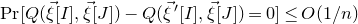 $\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=0]\le O(1/n)$
(Costello’s notion of robust irreducibility, and similar notions of ‘robust rank’ or ‘robust sum-of-squares complexity’, are only suitable for an
$\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=0]\le O(1/n)$
(Costello’s notion of robust irreducibility, and similar notions of ‘robust rank’ or ‘robust sum-of-squares complexity’, are only suitable for an
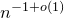 $n^{-1+o(1)}$
bound on such probabilities). Also, Costello’s Szemerédi–Trotter-based proof for the nearly reducible case does not seem to easily generalise to other simple-looking families of quadratic polynomials (for example, polynomials which can be written as the sum of four squares; see the discussion in [Reference Fox, Kwan and SpinkFKS23, Section 10]).
$n^{-1+o(1)}$
bound on such probabilities). Also, Costello’s Szemerédi–Trotter-based proof for the nearly reducible case does not seem to easily generalise to other simple-looking families of quadratic polynomials (for example, polynomials which can be written as the sum of four squares; see the discussion in [Reference Fox, Kwan and SpinkFKS23, Section 10]).
2.3 A geometric point of view, and an inductive decoupling scheme
In this paper, we consider a different perspective on decoupling: instead of using decoupling to immediately reduce from a quadratic problem to a linear one, we reinterpret decoupling as a tool to obtain a problem with a linear and a quadratic part, and to inductively ‘reduce the proportion of our problem that is quadratic’. To explain this, it is helpful to take a geometric perspective.
Specifically, for a quadratic polynomial
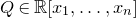 $Q\in \mathbb{R}[x_1,\ldots,x_n]$
and a random vector
$Q\in \mathbb{R}[x_1,\ldots,x_n]$
and a random vector
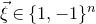 $\vec{\xi}\in \{1,-1\}^n$
, note that
$\vec{\xi}\in \{1,-1\}^n$
, note that
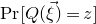 $\mathrm{Pr}[Q(\vec \xi)=z]$
can be interpreted as the probability that
$\mathrm{Pr}[Q(\vec \xi)=z]$
can be interpreted as the probability that
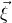 $\vec \xi$
lies in the quadric (quadratic variety)
$\vec \xi$
lies in the quadric (quadratic variety)
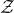 $\mathcal Z$
given by
$\mathcal Z$
given by
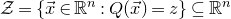 $\mathcal Z=\{\vec x \in \mathbb{R}^n: Q(\vec x)=z\}\subseteq\mathbb{R}^n$
. Similarly, the expression
$\mathcal Z=\{\vec x \in \mathbb{R}^n: Q(\vec x)=z\}\subseteq\mathbb{R}^n$
. Similarly, the expression
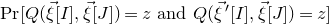 $\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])=z\text{ and }Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=z]$
appearing in Equation (2.1) can be interpreted as the probability that
$\mathrm{Pr}[Q(\vec{\xi}[I],\vec{\xi}[J])=z\text{ and }Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])=z]$
appearing in Equation (2.1) can be interpreted as the probability that
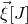 $\vec \xi[J]$
lies in the variety
$\vec \xi[J]$
lies in the variety
 $$ \mathcal Z^{(1)}=\{\vec x\in \mathbb{R}^J: Q(\vec{\xi}[I],\vec x)=z \text{ and } Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec x)=z\}=\mathcal Z_{\vec \xi[I]}\cap \mathcal Z_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\subseteq \mathbb{R}^J, $$
$$ \mathcal Z^{(1)}=\{\vec x\in \mathbb{R}^J: Q(\vec{\xi}[I],\vec x)=z \text{ and } Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec x)=z\}=\mathcal Z_{\vec \xi[I]}\cap \mathcal Z_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\subseteq \mathbb{R}^J, $$
where, for
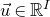 $\vec u\in \mathbb{R}^I$
, we write
$\vec u\in \mathbb{R}^I$
, we write
 $\mathcal Z_{\vec u}$
for the set of all
$\mathcal Z_{\vec u}$
for the set of all
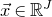 $\vec x\in \mathbb{R}^J$
with
$\vec x\in \mathbb{R}^J$
with
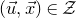 $(\vec u,\vec x)\in \mathcal Z$
(typically, this is a quadric in
$(\vec u,\vec x)\in \mathcal Z$
(typically, this is a quadric in
 $\mathbb{R}^J$
). Using this language, Equation (2.1) can be restated as
$\mathbb{R}^J$
). Using this language, Equation (2.1) can be restated as
 \begin{equation}\mathrm{Pr}[Q(\vec \xi)=z]=\mathrm{Pr}[\vec \xi\in \mathcal Z]\le \mathrm{Pr}[\vec \xi[J]\in \mathcal Z^{(1)}]^{1/2}.\end{equation}
\begin{equation}\mathrm{Pr}[Q(\vec \xi)=z]=\mathrm{Pr}[\vec \xi\in \mathcal Z]\le \mathrm{Pr}[\vec \xi[J]\in \mathcal Z^{(1)}]^{1/2}.\end{equation}
The next step leading to the traditional decoupling inequality, Equation (2.2), can geometrically be phrased as observing that
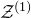 $\mathcal Z^{(1)}$
lies inside the affine-linear subspace
$\mathcal Z^{(1)}$
lies inside the affine-linear subspace
 $$ \mathcal W^{(1)}=\{\vec x \in \mathbb{R}^J :Q(\vec{\xi}[I],\vec{x})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{x})=0\}. $$
$$ \mathcal W^{(1)}=\{\vec x \in \mathbb{R}^J :Q(\vec{\xi}[I],\vec{x})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{x})=0\}. $$
Indeed, this yields the probability bound
 $$ \mathrm{Pr}[Q(\vec \xi)=z]\le \mathrm{Pr}[\vec \xi[J]\in \mathcal Z^{(1)}]^{1/2}\le \mathrm{Pr}[\vec \xi[J]\in \mathcal W^{(1)}]^{1/2} $$
$$ \mathrm{Pr}[Q(\vec \xi)=z]\le \mathrm{Pr}[\vec \xi[J]\in \mathcal Z^{(1)}]^{1/2}\le \mathrm{Pr}[\vec \xi[J]\in \mathcal W^{(1)}]^{1/2} $$
stated in Equation (2.2). One can then forget about
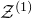 $\mathcal Z^{(1)}$
and restrict one’s attention to the affine-linear subspace
$\mathcal Z^{(1)}$
and restrict one’s attention to the affine-linear subspace
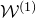 $\mathcal W^{(1)}$
, where the relevant probabilities are easier to analyse (under suitable assumptions on Q, one can show that
$\mathcal W^{(1)}$
, where the relevant probabilities are easier to analyse (under suitable assumptions on Q, one can show that
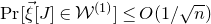 $\mathrm{Pr}[\vec \xi[J]\in \mathcal W^{(1)}]\le O(1/\sqrt{n})$
, leading to the bound
$\mathrm{Pr}[\vec \xi[J]\in \mathcal W^{(1)}]\le O(1/\sqrt{n})$
, leading to the bound
 $\mathrm{Pr}[Q(\vec \xi)=z]\le O(n^{-1/4})$
described in § 2.2).
$\mathrm{Pr}[Q(\vec \xi)=z]\le O(n^{-1/4})$
described in § 2.2).
However, it turns out that this ‘forgetting’ of
 $\mathcal{Z}^{(1)}$
is precisely the cause of the square-root loss usually associated with decoupling. Indeed,
$\mathcal{Z}^{(1)}$
is precisely the cause of the square-root loss usually associated with decoupling. Indeed,
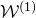 $\mathcal W^{(1)}$
is a variety with codimension 1 (being defined by a single equation), while
$\mathcal W^{(1)}$
is a variety with codimension 1 (being defined by a single equation), while
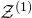 $\mathcal{Z}^{(1)}$
is typicallyFootnote
9
a variety with codimension (at least) 2 (being defined by two equations), so intuitively we should be much less likely to have
$\mathcal{Z}^{(1)}$
is typicallyFootnote
9
a variety with codimension (at least) 2 (being defined by two equations), so intuitively we should be much less likely to have
 $\vec{\xi}[J]\in\mathcal{Z}^{(1)}$
than
$\vec{\xi}[J]\in\mathcal{Z}^{(1)}$
than
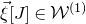 $\vec{\xi}[J]\in\mathcal{W}^{(1)}$
. More specifically, in order to have
$\vec{\xi}[J]\in\mathcal{W}^{(1)}$
. More specifically, in order to have
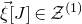 $\vec{\xi}[J]\in\mathcal{Z}^{(1)}$
, we need
$\vec{\xi}[J]\in\mathcal{Z}^{(1)}$
, we need
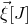 $\vec{\xi}[J]$
to satisfy two different equations simultaneously, and we might expect each of these to be satisfied with probability
$\vec{\xi}[J]$
to satisfy two different equations simultaneously, and we might expect each of these to be satisfied with probability
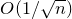 $O(1/\sqrt n)$
. So for typical outcomes of
$O(1/\sqrt n)$
. So for typical outcomes of
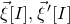 $\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
(which determine
$\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
(which determine
 $\mathcal Z^{(1)}$
) we might expect
$\mathcal Z^{(1)}$
) we might expect
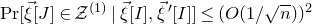 $\mathrm{Pr}[\vec{\xi}[J]\in\mathcal{Z}^{(1)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\le(O(1/\sqrt{n}))^{2}$
. If we could prove this, we would be able to deduce Theorem 1.1 (recalling Equation (2.3)).
$\mathrm{Pr}[\vec{\xi}[J]\in\mathcal{Z}^{(1)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\le(O(1/\sqrt{n}))^{2}$
. If we could prove this, we would be able to deduce Theorem 1.1 (recalling Equation (2.3)).
So, we choose not to ‘forget’
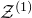 $\mathcal{Z}^{(1)}$
, and our task is to show that
$\mathcal{Z}^{(1)}$
, and our task is to show that
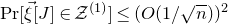 $\mathrm{Pr}[\vec{\xi}[J]\in\mathcal{Z}^{(1)}]\le(O(1/\sqrt{n}))^{2}$
. While this new task may seem harder than the previous one (as
$\mathrm{Pr}[\vec{\xi}[J]\in\mathcal{Z}^{(1)}]\le(O(1/\sqrt{n}))^{2}$
. While this new task may seem harder than the previous one (as
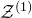 $\mathcal{Z}^{(1)}$
seems like a more complicated object than
$\mathcal{Z}^{(1)}$
seems like a more complicated object than
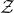 $\mathcal{Z}$
), the key observation is that we have ‘reduced the relative proportion of the quadratic part of our problem’. Indeed, at the start we were interested in a quadric
$\mathcal{Z}$
), the key observation is that we have ‘reduced the relative proportion of the quadratic part of our problem’. Indeed, at the start we were interested in a quadric
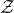 $\mathcal{Z}$
described by a single quadratic equation, but now we are interested in
$\mathcal{Z}$
described by a single quadratic equation, but now we are interested in
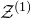 $\mathcal{Z}^{(1)}$
, which can be interpreted as a quadric inside the affine-linear subspace
$\mathcal{Z}^{(1)}$
, which can be interpreted as a quadric inside the affine-linear subspace
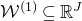 $\mathcal{W}^{(1)}\subseteq \mathbb{R}^J$
. That is to say,
$\mathcal{W}^{(1)}\subseteq \mathbb{R}^J$
. That is to say,
 $\mathcal{Z}^{(1)}$
is described by one linear and one quadratic equation, so now ‘only half of our problem is quadratic’.
$\mathcal{Z}^{(1)}$
is described by one linear and one quadratic equation, so now ‘only half of our problem is quadratic’.
Crucially, it is possible to iterate this entire procedure: we next fix a partition
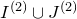 $I^{(2)}\cup J^{(2)}$
of J, and consider the variety
$I^{(2)}\cup J^{(2)}$
of J, and consider the variety
 $$ \mathcal{Z}^{(2)}=\mathcal{Z}^{(1)}_{\vec \xi[I^{(2)}]}\cap\mathcal{Z}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}\subseteq \mathbb{R}^{J^{(2)}}; $$
$$ \mathcal{Z}^{(2)}=\mathcal{Z}^{(1)}_{\vec \xi[I^{(2)}]}\cap\mathcal{Z}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}\subseteq \mathbb{R}^{J^{(2)}}; $$
(where, for
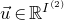 $\vec u\in \mathbb{R}^{I^{(2)}}$
, we write
$\vec u\in \mathbb{R}^{I^{(2)}}$
, we write
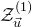 $\mathcal Z^{(1)}_{\vec u}$
for the set of all
$\mathcal Z^{(1)}_{\vec u}$
for the set of all
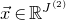 $\vec x\in \mathbb{R}^{J^{(2)}}$
with
$\vec x\in \mathbb{R}^{J^{(2)}}$
with
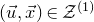 $(\vec u,\vec x)\in \mathcal Z^{(1)}$
). Now, decoupling, analogously to the inequality in Equation (2.3), yields
$(\vec u,\vec x)\in \mathcal Z^{(1)}$
). Now, decoupling, analogously to the inequality in Equation (2.3), yields
 \begin{equation}\mathrm{Pr}[\vec \xi[J]\in \mathcal Z^{(1)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\le \mathrm{Pr}[\vec \xi[J^{(2)}]\in \mathcal Z^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]^{1/2}.\end{equation}
\begin{equation}\mathrm{Pr}[\vec \xi[J]\in \mathcal Z^{(1)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\le \mathrm{Pr}[\vec \xi[J^{(2)}]\in \mathcal Z^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]^{1/2}.\end{equation}
So, it suffices to show that
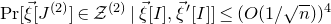 $\mathrm{Pr}[\vec \xi[J^{(2)}]\in \mathcal Z^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\le (O(1/\sqrt n))^4$
for typical outcomes of
$\mathrm{Pr}[\vec \xi[J^{(2)}]\in \mathcal Z^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\le (O(1/\sqrt n))^4$
for typical outcomes of
 $\vec \xi[I]$
and
$\vec \xi[I]$
and
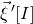 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
. Now, for
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
. Now, for
 $\mathcal{Z}^{(2)}$
to be nonempty, it must be the case that
$\mathcal{Z}^{(2)}$
to be nonempty, it must be the case that
 $\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}\cap\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
is nonempty, or equivalently that
$\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}\cap\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
is nonempty, or equivalently that
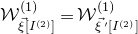 $\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}=\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
(it is not hard to see that
$\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}=\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
(it is not hard to see that
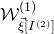 $\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}$
and
$\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}$
and
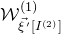 $\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
are parallel translates of each other). That is to say,
$\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
are parallel translates of each other). That is to say,
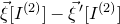 $\vec \xi[I^{(2)}]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]$
must lie in a certain affine-linear subspace which typically has codimension 1; this happens with probability
$\vec \xi[I^{(2)}]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]$
must lie in a certain affine-linear subspace which typically has codimension 1; this happens with probability
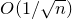 $O(1/\sqrt n)$
by the (linear) Erdős–Littlewood–Offord theorem.
$O(1/\sqrt n)$
by the (linear) Erdős–Littlewood–Offord theorem.
If we also condition on outcomes of
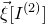 $\vec \xi[I^{(2)}]$
and
$\vec \xi[I^{(2)}]$
and
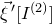 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]$
such that
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]$
such that
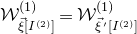 $\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}=\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
, it is not hard to see that
$\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}=\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
, it is not hard to see that
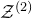 $\mathcal Z^{(2)}$
is typically a quadric inside the affine-linear subspace
$\mathcal Z^{(2)}$
is typically a quadric inside the affine-linear subspace
 $\mathcal W^{(2)}$
of
$\mathcal W^{(2)}$
of
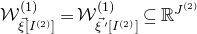 $\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}=\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}\subseteq \mathbb{R}^{J^{(2)}}$
given by the linear equation
$\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}=\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}\subseteq \mathbb{R}^{J^{(2)}}$
given by the linear equation
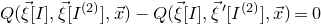 $Q(\vec \xi[I],\vec \xi[I^{(2)}],\vec x)-Q(\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}],\vec x)=0$
(in much the same way that
$Q(\vec \xi[I],\vec \xi[I^{(2)}],\vec x)-Q(\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}],\vec x)=0$
(in much the same way that
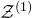 $\mathcal Z^{(1)}$
is a quadric inside the affine-linear subspace
$\mathcal Z^{(1)}$
is a quadric inside the affine-linear subspace
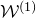 $\mathcal W^{(1)}$
). That is to say,
$\mathcal W^{(1)}$
). That is to say,
 $\mathcal Z^{(2)}$
is typically a variety of codimension (at least) 3, described by two linear equations and one quadratic equation. So we might expect that (for typical outcomes of
$\mathcal Z^{(2)}$
is typically a variety of codimension (at least) 3, described by two linear equations and one quadratic equation. So we might expect that (for typical outcomes of
 $\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec \xi[I^{(2)}],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]$
for which
$\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec \xi[I^{(2)}],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]$
for which
 $\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}=\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
)
$\mathcal{W}^{(1)}_{\vec \xi[I^{(2)}]}=\mathcal{W}^{(1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]}$
)
 \begin{equation}\mathrm{Pr}[\vec \xi[J^{(2)}]\in\mathcal{Z}^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec \xi[I^{(2)}],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]]\le(O(1/\sqrt{n}))^{3}.\end{equation}
\begin{equation}\mathrm{Pr}[\vec \xi[J^{(2)}]\in\mathcal{Z}^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec \xi[I^{(2)}],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]]\le(O(1/\sqrt{n}))^{3}.\end{equation}
If we were able to prove Equation (2.5), we would obtain a bound of the form
 $$ \mathrm{Pr}[\vec \xi[J^{(2)}]\in \mathcal Z^{(2)}]\le O(1/\sqrt{n})\cdot (O(1/\sqrt{n}))^{3}=(O(1/\sqrt{n}))^{4}, $$
$$ \mathrm{Pr}[\vec \xi[J^{(2)}]\in \mathcal Z^{(2)}]\le O(1/\sqrt{n})\cdot (O(1/\sqrt{n}))^{3}=(O(1/\sqrt{n}))^{4}, $$
which would imply Theorem 1.1, tracing back through our decoupling inequalities Equation (2.3) and Equation (2.4). We have made progress by ‘reducing the proportion of our problem that is quadratic’: if, instead of Equation (2.5), we were only able to prove that
 \begin{align*}\mathrm{Pr}[\vec \xi[J^{(2)}]\in\mathcal{Z}^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec \xi[I^{(2)}],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]] & \le \mathrm{Pr}[\vec \xi[J^{(2)}]\in\mathcal{W}^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec \xi[I^{(2)}],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]] \\& \le(O(1/\sqrt{n}))^{2} \end{align*}
\begin{align*}\mathrm{Pr}[\vec \xi[J^{(2)}]\in\mathcal{Z}^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec \xi[I^{(2)}],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]] & \le \mathrm{Pr}[\vec \xi[J^{(2)}]\in\mathcal{W}^{(2)}\,|\,\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec \xi[I^{(2)}],\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(2)}]] \\& \le(O(1/\sqrt{n}))^{2} \end{align*}
(‘forgetting’ the quadratic part of the problem and only bounding the probability that
 $\vec \xi[J^{(2)}]$
lies in the affine-linear subspace
$\vec \xi[J^{(2)}]$
lies in the affine-linear subspace
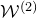 $\mathcal{W}^{(2)}$
of codimension 2), we would end up with a final bound of the form
$\mathcal{W}^{(2)}$
of codimension 2), we would end up with a final bound of the form
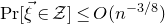 $\mathrm{Pr}[\vec \xi\in \mathcal Z]\le O(n^{-3/8})$
, which is much better than the
$\mathrm{Pr}[\vec \xi\in \mathcal Z]\le O(n^{-3/8})$
, which is much better than the
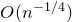 $O(n^{-1/4})$
bound we obtained with a single decoupling step.
$O(n^{-1/4})$
bound we obtained with a single decoupling step.
In general, after k steps of this scheme, we will have considered k ‘nested’ partitions of the form
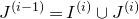 $J^{(i-1)}=I^{(i)}\cup J^{(i)}$
, and defined k varieties
$J^{(i-1)}=I^{(i)}\cup J^{(i)}$
, and defined k varieties
 $\mathcal Z^{(1)},\ldots,\mathcal Z^{(k)}$
. We will have applied the decoupling inequality k times, and considered various conditional probabilities that the vectors
$\mathcal Z^{(1)},\ldots,\mathcal Z^{(k)}$
. We will have applied the decoupling inequality k times, and considered various conditional probabilities that the vectors
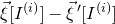 $\vec \xi[I^{(i)}]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(i)}]$
lie in certain affine-linear subspaces (to ensure that certain intersections
$\vec \xi[I^{(i)}]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(i)}]$
lie in certain affine-linear subspaces (to ensure that certain intersections
 $\mathcal{W}^{(i-1)}_{\vec \xi[I^{(i)}]}\cap\mathcal{W}^{(i-1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(i)}]}$
are nonempty). After all this, we find ourselves in a position where if we ‘forget the quadratic part of the problem’ we obtain a bound of the form
$\mathcal{W}^{(i-1)}_{\vec \xi[I^{(i)}]}\cap\mathcal{W}^{(i-1)}_{\vec{\xi}\mkern2mu\vphantom{\xi}'[I^{(i)}]}$
are nonempty). After all this, we find ourselves in a position where if we ‘forget the quadratic part of the problem’ we obtain a bound of the form
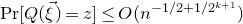 $\mathrm{Pr}[Q(\vec \xi)=z]\le O(n^{-1/2+1/2^{k+1}})$
. That is to say, if k is at least
$\mathrm{Pr}[Q(\vec \xi)=z]\le O(n^{-1/2+1/2^{k+1}})$
. That is to say, if k is at least
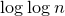 $\log \log n$
, the quadratic part of the problem is so insignificant that ‘forgetting’ it only costs us a constant factor in the final bound.
$\log \log n$
, the quadratic part of the problem is so insignificant that ‘forgetting’ it only costs us a constant factor in the final bound.
At an extremely high level, this explains our strategy to prove Theorem 1.1. However, we omitted a number of important details in this outline. In particular, our strategy heavily depends on being able to obtain suitable upper bounds on probabilities that certain random vectors fall into certain affine-linear subspaces, and there are crucial ‘robust rank’ nondegeneracy conditions that must be satisfied in order for such bounds to hold. This is not just a technicality; we require significant new ideas to maintain these robust rank properties during our iterative decoupling scheme, which we discuss in the next subsection.
Remark 2.1. In the actual proof, in order to keep everything organized, we phrase our arguments recursively: the key step is to prove a recursive bound for the maximum possible probability that a random vector
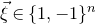 $\vec{\xi}\in \{1,-1\}^n$
falls onto some quadric on an affine-linear subspace of a given codimension, satisfying certain nondegeneracy conditions (this main recursive bound is stated in Theorem 5.5).
$\vec{\xi}\in \{1,-1\}^n$
falls onto some quadric on an affine-linear subspace of a given codimension, satisfying certain nondegeneracy conditions (this main recursive bound is stated in Theorem 5.5).
Remark 2.2. Theorem 1.1 concerns quadratic polynomials, but one may be interested in a generalisation to cubic polynomials, or to polynomials of any fixed degree. Decoupling still makes sense for general polynomials: for example, if
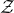 $\mathcal Z$
is a cubic (variety), then decoupling yields an inequality of the form
$\mathcal Z$
is a cubic (variety), then decoupling yields an inequality of the form
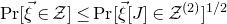 $\mathrm{Pr}[\vec \xi\in \mathcal Z]\le \mathrm{Pr}[\vec\xi[J]\in \mathcal Z^{(2)}]^{1/2}$
, where
$\mathrm{Pr}[\vec \xi\in \mathcal Z]\le \mathrm{Pr}[\vec\xi[J]\in \mathcal Z^{(2)}]^{1/2}$
, where
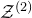 $\mathcal Z^{(2)}$
is the intersection of a quadric and a cubic. As observed by Rosiński and Samorodnitsky [Reference Rosiński and SamorodnitskyRS96] and Razborov and Viola [Reference Razborov and ViolaRV13], the basic type of decoupling argument described in § 2.2 generalises quite straightforwardly to higher degrees (but the bounds get worse as the degree increases). However, it is less clear how to generalise the inductive decoupling scheme described in this subsection. Roughly speaking, in the degree-d case, instead of affine-linear subspaces (obtained as intersections of affine-linear hyperplanes), one must work with intersections of degree-
$\mathcal Z^{(2)}$
is the intersection of a quadric and a cubic. As observed by Rosiński and Samorodnitsky [Reference Rosiński and SamorodnitskyRS96] and Razborov and Viola [Reference Razborov and ViolaRV13], the basic type of decoupling argument described in § 2.2 generalises quite straightforwardly to higher degrees (but the bounds get worse as the degree increases). However, it is less clear how to generalise the inductive decoupling scheme described in this subsection. Roughly speaking, in the degree-d case, instead of affine-linear subspaces (obtained as intersections of affine-linear hyperplanes), one must work with intersections of degree-
 $(d-1)$
varieties, which are much more complicated objects. We hope that the relevant complexities can be handled with some kind of multiple-level induction, but so far we were not able to accomplish this.
$(d-1)$
varieties, which are much more complicated objects. We hope that the relevant complexities can be handled with some kind of multiple-level induction, but so far we were not able to accomplish this.
2.4 High-dimensional anticoncentration inequalities and witness counting
Our proof, as outlined in the previous subsection, relies on bounds on probabilities that random vectors lie in certain affine-linear subspaces. More specifically, for a suitably nondegenerate affine-linear subspace
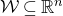 $\mathcal W\subseteq \mathbb{R}^n$
of codimension k, and a uniformly random vector
$\mathcal W\subseteq \mathbb{R}^n$
of codimension k, and a uniformly random vector
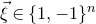 $\vec{\xi}\in \{1,-1\}^n$
, we need a probability bound of the form
$\vec{\xi}\in \{1,-1\}^n$
, we need a probability bound of the form
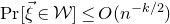 $\mathrm{Pr}[\vec \xi\in \mathcal W]\le O(n^{-k/2})$
. Intuitively, this is because
$\mathrm{Pr}[\vec \xi\in \mathcal W]\le O(n^{-k/2})$
. Intuitively, this is because
 $\vec \xi$
needs to simultaneously satisfy k different linear equations, each of which is satisfied with probability roughly
$\vec \xi$
needs to simultaneously satisfy k different linear equations, each of which is satisfied with probability roughly
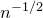 $n^{-1/2}$
. More formally, such a bound follows from a high-dimensional version of the Erdős–Littlewood–Offord theorem.
$n^{-1/2}$
. More formally, such a bound follows from a high-dimensional version of the Erdős–Littlewood–Offord theorem.
The first such high-dimensional version was due to Halász [Reference HalászHal77]. In linear-algebraic language, it can be phrased as follows: for any fixed k, if
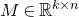 $M\in \mathbb R^{k\times n}$
is a matrix that ‘robustly has rank k’ in the sense that (for some fixed
$M\in \mathbb R^{k\times n}$
is a matrix that ‘robustly has rank k’ in the sense that (for some fixed
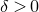 $\delta \gt 0$
) one cannot delete
$\delta \gt 0$
) one cannot delete
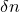 $\delta n$
columns of M to obtain a matrix with rank less than k, then for a uniformly random vector
$\delta n$
columns of M to obtain a matrix with rank less than k, then for a uniformly random vector
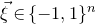 $\vec \xi\in\{-1,1\}^n$
we have
$\vec \xi\in\{-1,1\}^n$
we have
 $$ \sup_{\vec w\in \mathbb R^k}\mathrm{Pr}[M\vec \xi=\vec w]\le O(n^{-k/2}). $$
$$ \sup_{\vec w\in \mathbb R^k}\mathrm{Pr}[M\vec \xi=\vec w]\le O(n^{-k/2}). $$
Note that some kind of ‘robust rank-k’ condition is necessary here: for example, if n is even and
 $M\in \mathbb{R}^{2\times n}$
has rows
$M\in \mathbb{R}^{2\times n}$
has rows
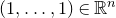 $(1,\ldots,1)\in \mathbb{R}^n$
and
$(1,\ldots,1)\in \mathbb{R}^n$
and
 $(1,\ldots,1,0,0)\in \mathbb{R}^n$
, then it is easy to check that
$(1,\ldots,1,0,0)\in \mathbb{R}^n$
, then it is easy to check that
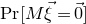 $\mathrm{Pr}[M\vec \xi=\vec 0]$
has order of magnitude
$\mathrm{Pr}[M\vec \xi=\vec 0]$
has order of magnitude
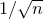 $1/\sqrt n$
.
$1/\sqrt n$
.
Several extensions and variants of Halasz’ inequality have since been proved (see for example [Reference Ferber, Jain and ZhaoFJZ22, Reference Fox, Kwan and SauermannFKS21, Reference HowardHow00, Reference Tao and VuTV06]); in particular, Ferber, Jain and Zhao [Reference Ferber, Jain and ZhaoFJZ22] proved a version of Halasz’ theorem with a much better dependence on k (allowing k to vary with n, instead of viewing it as a constant). We state (a corollary of) this theorem as Theorem 3.3.
Of course, whenever we want to apply any Halász-type theorem, we need a ‘robust rank’ condition to hold. So, in order to execute the strategy described in the last subsection, at each step of the decoupling scheme we need a ‘robust rank inheritance’ lemma, proving that a robust rank condition is likely to hold for the next step, given that it holds for the current step. The key ingredient for our robust rank inheritance lemma is a new high-dimensional anticoncentration inequality for the probability that a random vector falls in a small ball in the Hamming norm. We believe this inequality (and the techniques in its proof) to be of independent interest; an important special case is as follows.
Lemma 2.1. For any fixed positive integer r, there are constants
 $C_r \gt 0$
and
$C_r \gt 0$
and
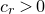 $c_r \gt 0$
only depending on r such that the following holds. Consider a matrix
$c_r \gt 0$
only depending on r such that the following holds. Consider a matrix
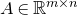 $A\in \mathbb{R} ^{m\times n}$
which has rank at least r after deletion of any t rows and t columns (for some positive integer t). Then for a sequence
$A\in \mathbb{R} ^{m\times n}$
which has rank at least r after deletion of any t rows and t columns (for some positive integer t). Then for a sequence
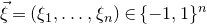 $\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^{n}$
of independent Rademacher random variables, we have
$\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^{n}$
of independent Rademacher random variables, we have
 $$\sup_{\vec v\in \mathbb R^m}\mathrm{Pr}[A\vec{\xi}\text{ differs from }\vec{v}\text{ in fewer than }c_r t\text{ coordinates}]\le C_r \cdot t^{-r/2}. $$
$$\sup_{\vec v\in \mathbb R^m}\mathrm{Pr}[A\vec{\xi}\text{ differs from }\vec{v}\text{ in fewer than }c_r t\text{ coordinates}]\le C_r \cdot t^{-r/2}. $$
The assumption in Lemma 2.1 says that A robustly has rank at least r, but in a stronger sense than typical Halász-type theorems: the rank needs to remain at least r after row deletion as well as column deletion. As a result, we are able to obtain a stronger conclusion, namely that for any vector
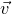 $\vec v$
, it is unlikely that
$\vec v$
, it is unlikely that
 $A\vec \xi$
agrees with
$A\vec \xi$
agrees with
 $\vec v$
in almost all its coordinates. (It is not hard to see that for this stronger conclusion, such a row-deletion assumption is indeed necessary.)
$\vec v$
in almost all its coordinates. (It is not hard to see that for this stronger conclusion, such a row-deletion assumption is indeed necessary.)
We prove Lemma 2.1 (and our more general robust rank inheritance lemma) in § 7 using a witness-counting technique, which we outline here. First, note that the most naïve strategy to prove Lemma 2.1 would be to simply take a union bound over all sets I of
 $m-c_r t$
coordinates in which
$m-c_r t$
coordinates in which
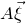 $A\vec \xi$
and
$A\vec \xi$
and
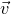 $\vec v$
could agree. For some specific I, the probability that
$\vec v$
could agree. For some specific I, the probability that
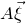 $A\vec \xi$
and
$A\vec \xi$
and
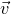 $\vec v$
agree on the coordinates indexed by I can be easily understood using existing tools (i.e., Halász’ inequality and its variants) and is at most of the order of
$\vec v$
agree on the coordinates indexed by I can be easily understood using existing tools (i.e., Halász’ inequality and its variants) and is at most of the order of
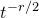 $t^{-r/2}$
. However, it is far too wasteful to simply take a union bound summing over all possibilities for I (the number of possibilities is exponential in t).
$t^{-r/2}$
. However, it is far too wasteful to simply take a union bound summing over all possibilities for I (the number of possibilities is exponential in t).
Instead, for each I we consider small ‘witness’ subsets
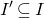 $I'\subseteq I$
, such that the submatrix of A consisting of the rows with indices in I’ still has (robustly) high rank. Note that for each
$I'\subseteq I$
, such that the submatrix of A consisting of the rows with indices in I’ still has (robustly) high rank. Note that for each
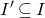 $I'\subseteq I$
, whenever
$I'\subseteq I$
, whenever
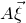 $A\vec \xi$
and
$A\vec \xi$
and
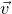 $\vec v$
agree on the coordinates indexed by I, they also in particular agree on the coordinates indexed by I’. Given the high-rank property, for each ‘witness’ subset I’ we can still easily bound the probability that
$\vec v$
agree on the coordinates indexed by I, they also in particular agree on the coordinates indexed by I’. Given the high-rank property, for each ‘witness’ subset I’ we can still easily bound the probability that
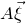 $A\vec \xi$
and
$A\vec \xi$
and
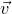 $\vec v$
agree on the coordinates indexed by I’ (using Halász’ inequality and its variants).
$\vec v$
agree on the coordinates indexed by I’ (using Halász’ inequality and its variants).
There are still too many possible ‘witness’ subsets I’ to be able to simply take a union bound over all possibilities for I’, but (roughly speaking) we can show that whenever
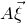 $A\vec \xi$
and
$A\vec \xi$
and
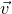 $\vec v$
agree on a large set of coordinates I, then they must agree on the coordinates of many ‘witness’ subsets
$\vec v$
agree on a large set of coordinates I, then they must agree on the coordinates of many ‘witness’ subsets
 $I'\subseteq I$
. We can show this is unlikely by computing the expected number of ‘witness’ coordinate subsets on which
$I'\subseteq I$
. We can show this is unlikely by computing the expected number of ‘witness’ coordinate subsets on which
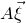 $A\vec \xi$
and
$A\vec \xi$
and
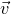 $\vec v$
agree, and applying Markov’s inequality.
$\vec v$
agree, and applying Markov’s inequality.
Remark 2.3. One might be interested in adapting Theorem 1.1 to study small-ball probabilities of the form
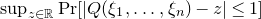 $\sup_{z\in \mathbb{R}}\mathrm{Pr}[|Q(\xi_{1},\ldots,\xi_{n})-z|\le 1]$
instead of point probabilities
$\sup_{z\in \mathbb{R}}\mathrm{Pr}[|Q(\xi_{1},\ldots,\xi_{n})-z|\le 1]$
instead of point probabilities
 $\sup_{z\in \mathbb{R}}\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=z]$
. The robust rank inheritance lemma seems to be the main point of difficulty for such an adaptation; it is not clear how to extend the witness-counting arguments to the small-ball setting (e.g., in the setting of Lemma 2.1, we would be interested in the event that there are fewer than
$\sup_{z\in \mathbb{R}}\mathrm{Pr}[Q(\xi_{1},\ldots,\xi_{n})=z]$
. The robust rank inheritance lemma seems to be the main point of difficulty for such an adaptation; it is not clear how to extend the witness-counting arguments to the small-ball setting (e.g., in the setting of Lemma 2.1, we would be interested in the event that there are fewer than
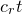 $c_r t$
coordinates i for which
$c_r t$
coordinates i for which
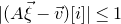 $|(A\vec \xi-\vec v)[i]|\le 1$
).
$|(A\vec \xi-\vec v)[i]|\le 1$
).
Before ending this overview section, we remark that there is a way to sidestep the robust rank inheritance issue in the special case where Q has ‘bounded rank’, meaning that the quadratic part of Q can be written as
 $\vec x^{\intercal} A\vec x$
for some symmetric matrix A of rank O(1). Indeed, in this case we can reduce our entire problem to a certain bounded-dimensional geometric anticoncentration problem (involving a quadric), where the robust rank conditions for Halasz’ inequality are always automatically satisfied when following the strategy in the previous subsection. In § 4, we give a simple self-contained proof of an essentially optimal anticoncentration bound in this setting. We believe this to be a good illustration of the basic principles of our inductive decoupling scheme, with minimal technicalities. Moreover, the result of § 4 will actually also be an ingredient for the full proof of Theorem 5.1: it allows us to restrict our attention to the case where the quadratic part of Q ‘robustly has high rank’, which allows us to avoid possible degeneracies at certain points in the proof.
$\vec x^{\intercal} A\vec x$
for some symmetric matrix A of rank O(1). Indeed, in this case we can reduce our entire problem to a certain bounded-dimensional geometric anticoncentration problem (involving a quadric), where the robust rank conditions for Halasz’ inequality are always automatically satisfied when following the strategy in the previous subsection. In § 4, we give a simple self-contained proof of an essentially optimal anticoncentration bound in this setting. We believe this to be a good illustration of the basic principles of our inductive decoupling scheme, with minimal technicalities. Moreover, the result of § 4 will actually also be an ingredient for the full proof of Theorem 5.1: it allows us to restrict our attention to the case where the quadratic part of Q ‘robustly has high rank’, which allows us to avoid possible degeneracies at certain points in the proof.
3. Preliminaries
First, as outlined in § 2, we need a ‘high-dimensional’ version of the Erdős–Littlewood–Offord theorem. This will require a robust rank condition, defined as follows.
Definition 3.1 For integers
 $0\le k\le n$
and a real number
$0\le k\le n$
and a real number
 $s\ge 0$
, let
$s\ge 0$
, let
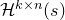 $\mathcal{H}^{k\times n}(s)$
be the set of matrices
$\mathcal{H}^{k\times n}(s)$
be the set of matrices
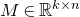 $M\in\mathbb{R}^{k\times n}$
such that
$M\in\mathbb{R}^{k\times n}$
such that
 $\operatorname{rank} M[[k]\times J]=k$
for all subsets
$\operatorname{rank} M[[k]\times J]=k$
for all subsets
 $J\subseteq [n]$
of size
$J\subseteq [n]$
of size
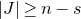 $|J|\ge n-s$
, i.e., the set of matrices having rank k after any deletion of up to s columns.
$|J|\ge n-s$
, i.e., the set of matrices having rank k after any deletion of up to s columns.
We clearly have
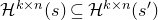 $\mathcal{H}^{k\times n}(s)\subseteq \mathcal{H}^{k\times n}(s')$
if
$\mathcal{H}^{k\times n}(s)\subseteq \mathcal{H}^{k\times n}(s')$
if
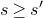 $s\ge s'$
. Furthermore, for a partition
$s\ge s'$
. Furthermore, for a partition
 $[n]=S\cup I$
with
$[n]=S\cup I$
with
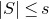 $|S|\le s$
, for every matrix
$|S|\le s$
, for every matrix
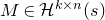 $M\in \mathcal{H}^{k\times n}(s)$
we also have
$M\in \mathcal{H}^{k\times n}(s)$
we also have
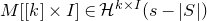 $M[[k]\times I]\in \mathcal{H}^{k\times I}(s-|S|)$
. Also note that in the case
$M[[k]\times I]\in \mathcal{H}^{k\times I}(s-|S|)$
. Also note that in the case
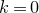 $k=0$
, the (unique) empty matrix
$k=0$
, the (unique) empty matrix
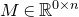 $M\in\mathbb{R}^{0\times n}$
is contained in
$M\in\mathbb{R}^{0\times n}$
is contained in
 $\mathcal{H}^{0\times n}(s)$
for all
$\mathcal{H}^{0\times n}(s)$
for all
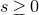 $s\ge 0$
.
$s\ge 0$
.
For integers
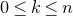 $0\le k\le n$
and
$0\le k\le n$
and
 $t\ge 0$
, we say that a matrix
$t\ge 0$
, we say that a matrix
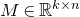 $M\in \mathbb{R}^{k\times n}$
contains t disjoint nonsingular
$M\in \mathbb{R}^{k\times n}$
contains t disjoint nonsingular
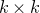 $k\times k$
submatrices if there exist disjoint subsets
$k\times k$
submatrices if there exist disjoint subsets
 $J_1,\ldots, J_t\subseteq [n]$
of size
$J_1,\ldots, J_t\subseteq [n]$
of size
 $|J_1|=\dots=|J_t|=k$
such that
$|J_1|=\dots=|J_t|=k$
such that
 $\operatorname{rank} M[[k]\times J_i]=k$
for
$\operatorname{rank} M[[k]\times J_i]=k$
for
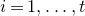 $i=1,\ldots,t$
. This is the case if and only if among the column vectors
$i=1,\ldots,t$
. This is the case if and only if among the column vectors
 $\vec{a}_1,\ldots,\vec{a}_n$
of M we can form t disjoint bases of
$\vec{a}_1,\ldots,\vec{a}_n$
of M we can form t disjoint bases of
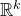 $\mathbb{R}^{k}$
(here, the vectors
$\mathbb{R}^{k}$
(here, the vectors
 $\vec{a}_1,\ldots,\vec{a}_n$
are considered with multiplicities, i.e., a vector in
$\vec{a}_1,\ldots,\vec{a}_n$
are considered with multiplicities, i.e., a vector in
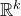 $\mathbb{R}^{k}$
can occur in two different bases if it occurs twice among
$\mathbb{R}^{k}$
can occur in two different bases if it occurs twice among
 $\vec{a}_1,\ldots,\vec{a}_n$
).
$\vec{a}_1,\ldots,\vec{a}_n$
).
Lemma 3.2. For integers
 $0\le k\le n$
and a real number
$0\le k\le n$
and a real number
 $s\ge 0$
, the following statements hold:
$s\ge 0$
, the following statements hold:
-
(i) if
 $M\in \mathbb{R}^{k\times n}$
contains t disjoint nonsingular
$k\times k$
submatrices for an integer
$t \gt s$
, then
$M\in \mathcal{H}^{k\times n}(s)$
;
$M\in \mathbb{R}^{k\times n}$
contains t disjoint nonsingular
$k\times k$
submatrices for an integer
$t \gt s$
, then
$M\in \mathcal{H}^{k\times n}(s)$
; -
(ii) if
$M\in \mathcal{H}^{k\times n}(s)$
and
$k\ge 1$
, then M contains
$\lceil s/k\rceil$
disjoint nonsingular
$k\times k$
submatrices.
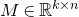
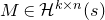

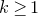
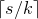
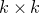
Proof. For (i), let
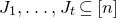 $J_1,\ldots, J_t\subseteq [n]$
be disjoint subsets of size
$J_1,\ldots, J_t\subseteq [n]$
be disjoint subsets of size
 $|J_1|=\dots=|J_t|=k$
such that
$|J_1|=\dots=|J_t|=k$
such that
 $\operatorname{rank} M[[k]\times J_i]=k$
for
$\operatorname{rank} M[[k]\times J_i]=k$
for
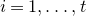 $i=1,\ldots,t$
. Then for any subsets
$i=1,\ldots,t$
. Then for any subsets
 $J\subseteq [n]$
of size
$J\subseteq [n]$
of size
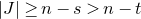 $|J|\ge n-s \gt n-t$
, we have
$|J|\ge n-s \gt n-t$
, we have
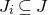 $J_i\subseteq J$
for some
$J_i\subseteq J$
for some
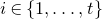 $i\in \{1,\ldots,t\}$
and hence
$i\in \{1,\ldots,t\}$
and hence
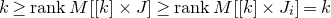 $k\ge \operatorname{rank} M[[k]\times J]\ge \operatorname{rank} M[[k]\times J_i]=k$
, meaning that
$k\ge \operatorname{rank} M[[k]\times J]\ge \operatorname{rank} M[[k]\times J_i]=k$
, meaning that
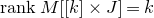 $\operatorname{rank} M[[k]\times J]=k$
.
$\operatorname{rank} M[[k]\times J]=k$
.
For (ii), we can greedily find disjoint subsets
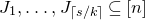 $J_1,\ldots, J_{\lceil s/k\rceil}\subseteq [n]$
of size
$J_1,\ldots, J_{\lceil s/k\rceil}\subseteq [n]$
of size
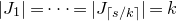 $|J_1|=\dots=|J_{\lceil s/k\rceil}|=k$
such that
$|J_1|=\dots=|J_{\lceil s/k\rceil}|=k$
such that
 $\operatorname{rank} M[[k]\times J_i]=k$
for
$\operatorname{rank} M[[k]\times J_i]=k$
for
 $i=1,\ldots,\lceil s/k\rceil$
. Indeed, after having chosen
$i=1,\ldots,\lceil s/k\rceil$
. Indeed, after having chosen
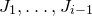 $J_1,\ldots, J_{i-1}$
for some
$J_1,\ldots, J_{i-1}$
for some
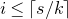 $i\le \lceil s/k\rceil$
, we have
$i\le \lceil s/k\rceil$
, we have
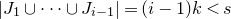 $|J_1\cup \dots\cup J_{i-1}|=(i-1)k<s$
and hence M still has rank k after deleting the columns with indices in
$|J_1\cup \dots\cup J_{i-1}|=(i-1)k<s$
and hence M still has rank k after deleting the columns with indices in
 $J_1\cup \dots\cup J_{i-1}$
. So we can find a subset
$J_1\cup \dots\cup J_{i-1}$
. So we can find a subset
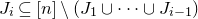 $J_i\subseteq [n]\setminus (J_1\cup \dots\cup J_{i-1})$
of size
$J_i\subseteq [n]\setminus (J_1\cup \dots\cup J_{i-1})$
of size
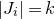 $|J_i|=k$
with
$|J_i|=k$
with
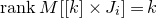 $\operatorname{rank} M[[k]\times J_i]=k$
.
$\operatorname{rank} M[[k]\times J_i]=k$
.
Halász [Reference HalászHal77] proved that for fixed constants
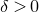 $\delta \gt 0$
and
$\delta \gt 0$
and
 $k\in \mathbb{N}$
, if
$k\in \mathbb{N}$
, if
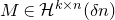 $M\in \mathcal{H}^{k\times n}(\delta n)$
then
$M\in \mathcal{H}^{k\times n}(\delta n)$
then
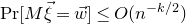 $\mathrm{Pr}[M\vec \xi=\vec w]\le O(n^{-k/2})$
. We will use the following quantitative version of Halász’ theorem, which is a special caseFootnote
10
of a result of Ferber, Jain and Zhao [Reference Ferber, Jain and ZhaoFJZ22, Theorem1.11] (see also [Reference HowardHow00] for a previous result with a weaker dependence on k).
$\mathrm{Pr}[M\vec \xi=\vec w]\le O(n^{-k/2})$
. We will use the following quantitative version of Halász’ theorem, which is a special caseFootnote
10
of a result of Ferber, Jain and Zhao [Reference Ferber, Jain and ZhaoFJZ22, Theorem1.11] (see also [Reference HowardHow00] for a previous result with a weaker dependence on k).
Theorem 3.3. Let
 $0\le k\le n$
and
$0\le k\le n$
and
 $t\ge 1$
be integers. Consider a matrix
$t\ge 1$
be integers. Consider a matrix
 $M\in \mathbb{R}^{k\times n}$
containing t disjoint nonsingular
$M\in \mathbb{R}^{k\times n}$
containing t disjoint nonsingular
 $k\times k$
submatrices, and a vector
$k\times k$
submatrices, and a vector
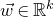 $\vec{w}\in \mathbb{R}^k$
. Letting
$\vec{w}\in \mathbb{R}^k$
. Letting
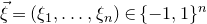 $\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^n$
be a sequence of independent Rademacher random variables, we then have
$\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^n$
be a sequence of independent Rademacher random variables, we then have
 $$ \mathbb{P}[M\vec{\xi}=\vec{w}]\le t^{-k/2}. $$
$$ \mathbb{P}[M\vec{\xi}=\vec{w}]\le t^{-k/2}. $$
Remark 3.1. The anonymous referee brought to our attention that Theorem 3.3 is essentially the only aspect of this paper which is not self-contained, and therefore it seems worthwhile to briefly sketch its short proof. (Of course, the reader may still wish to refer to [Reference Ferber, Jain and ZhaoFJZ22] for the full details of the proof.) Let
 $M_1,\ldots,M_t\in \mathbb R^{k\times k}$
be disjoint nonsingular
$M_1,\ldots,M_t\in \mathbb R^{k\times k}$
be disjoint nonsingular
 $k\times k$
submatrices of M. First, it is not hard to see that, for any
$k\times k$
submatrices of M. First, it is not hard to see that, for any
 $\ell\le t$
, we have
$\ell\le t$
, we have
 $$ \sup_{\vec w\in \mathbb R^k}\mathrm{Pr}[M\vec{\xi}=\vec{w}]\le \sup_{\vec z\in \mathbb R^k}\mathrm{Pr}[M_1\vec{\xi}^{\,(1)}+\dots +M_\ell\vec{\xi}^{\,(\ell)}=\vec z], $$
$$ \sup_{\vec w\in \mathbb R^k}\mathrm{Pr}[M\vec{\xi}=\vec{w}]\le \sup_{\vec z\in \mathbb R^k}\mathrm{Pr}[M_1\vec{\xi}^{\,(1)}+\dots +M_\ell\vec{\xi}^{\,(\ell)}=\vec z], $$
where
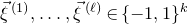 $\vec \xi^{\,(1)},\ldots,\vec\xi^{\,(\ell)}\in \{-1,1\}^k$
are independent sequences each consisting of k independent Rademacher random variables. Then, the key step is a ‘replication trick’, showing that if
$\vec \xi^{\,(1)},\ldots,\vec\xi^{\,(\ell)}\in \{-1,1\}^k$
are independent sequences each consisting of k independent Rademacher random variables. Then, the key step is a ‘replication trick’, showing that if
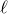 $\ell$
is even, we have
$\ell$
is even, we have
 $$ \sup_{\vec z\in \mathbb R^k}\mathrm{Pr}[M_1\vec{\xi}^{\,(1)}+\dots +M_\ell\vec{\xi}^{\,(\ell)}=\vec z]\le \prod_{i=1}^\ell \mathrm{Pr}[M_i\vec{\xi}^{\,(1)}+\dots +M_i\vec{\xi}^{\,(\ell)}=0]^{1/\ell}. $$
$$ \sup_{\vec z\in \mathbb R^k}\mathrm{Pr}[M_1\vec{\xi}^{\,(1)}+\dots +M_\ell\vec{\xi}^{\,(\ell)}=\vec z]\le \prod_{i=1}^\ell \mathrm{Pr}[M_i\vec{\xi}^{\,(1)}+\dots +M_i\vec{\xi}^{\,(\ell)}=0]^{1/\ell}. $$
In [Reference Ferber, Jain and ZhaoFJZ22], this is proved using Fourier analysis and Hölder’s inequality (the anonymous referee also pointed out that, when
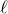 $\ell$
is a power of two, this can be proved by iterating the Cauchy–Schwarz inequality). Then, it is not hard to see that
$\ell$
is a power of two, this can be proved by iterating the Cauchy–Schwarz inequality). Then, it is not hard to see that
 $$ \mathrm{Pr}[M_i\vec{\xi}^{\,(1)}+\dots +M_i\vec{\xi}^{\,(\ell)}=0]=\mathrm{Pr}[\vec{\xi}^{\,(1)}+\dots +\vec{\xi}^{\,(\ell)}=0]=\bigg(2^{-\ell}\binom \ell{\ell/2}\bigg)^k , $$
$$ \mathrm{Pr}[M_i\vec{\xi}^{\,(1)}+\dots +M_i\vec{\xi}^{\,(\ell)}=0]=\mathrm{Pr}[\vec{\xi}^{\,(1)}+\dots +\vec{\xi}^{\,(\ell)}=0]=\bigg(2^{-\ell}\binom \ell{\ell/2}\bigg)^k , $$
for each
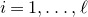 $i=1,\ldots,\ell$
. If we take
$i=1,\ldots,\ell$
. If we take
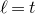 $\ell=t$
or
$\ell=t$
or
 $\ell=t-1$
(depending on whether t is even or odd), it is a straightforward matter to check that this expression is always at most
$\ell=t-1$
(depending on whether t is even or odd), it is a straightforward matter to check that this expression is always at most
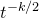 $t^{-k/2}$
.
$t^{-k/2}$
.
Corollary 3.4. Let
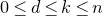 $0\le d\le k\le n$
and
$0\le d\le k\le n$
and
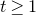 $t\ge 1$
be integers. Consider vectors
$t\ge 1$
be integers. Consider vectors
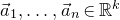 $\vec{a}_{1},\ldots,\vec{a}_{n}\in\mathbb{R}^{k}$
such that one can form t disjoint bases of
$\vec{a}_{1},\ldots,\vec{a}_{n}\in\mathbb{R}^{k}$
such that one can form t disjoint bases of
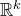 $\mathbb{R}^k$
from the vectors
$\mathbb{R}^k$
from the vectors
 $\vec{a}_{1},\ldots, \vec{a}_{n}$
, and let
$\vec{a}_{1},\ldots, \vec{a}_{n}$
, and let
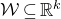 $\mathcal{W}\subseteq \mathbb{R}^k$
be a d-dimensional affine-linear subspace. Letting
$\mathcal{W}\subseteq \mathbb{R}^k$
be a d-dimensional affine-linear subspace. Letting
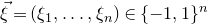 $\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^{n}$
be a sequence of independent Rademacher random variables, we then have
$\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^{n}$
be a sequence of independent Rademacher random variables, we then have
 $$\mathrm{Pr}[\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}\in\mathcal{W}]\le t^{-(k-d)/2}. $$
$$\mathrm{Pr}[\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}\in\mathcal{W}]\le t^{-(k-d)/2}. $$
Proof. Write
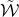 $\tilde{\mathcal{W}}$
for the d-dimensional linear subspace parallel to the affine-linear subspace
$\tilde{\mathcal{W}}$
for the d-dimensional linear subspace parallel to the affine-linear subspace
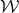 $\mathcal{W}$
(i.e.,
$\mathcal{W}$
(i.e.,
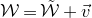 $\mathcal{W}=\tilde{\mathcal{W}}+\vec{v}$
for some
$\mathcal{W}=\tilde{\mathcal{W}}+\vec{v}$
for some
 $\vec{v}\in\mathbb{R}^{k}$
), and consider a linear map
$\vec{v}\in\mathbb{R}^{k}$
), and consider a linear map
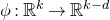 $\phi:\mathbb{R}^{k}\to\mathbb{R}^{k-d}$
with kernel
$\phi:\mathbb{R}^{k}\to\mathbb{R}^{k-d}$
with kernel
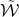 $\tilde{\mathcal W}$
(so
$\tilde{\mathcal W}$
(so
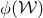 $\phi(\mathcal{W})$
consists of a single point
$\phi(\mathcal{W})$
consists of a single point
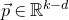 $\vec{p}\in \mathbb{R}^{k-d}$
). Writing
$\vec{p}\in \mathbb{R}^{k-d}$
). Writing
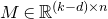 $M\in\mathbb{R}^{(k-d)\times n}$
for the matrix whose columns are the vectors
$M\in\mathbb{R}^{(k-d)\times n}$
for the matrix whose columns are the vectors
 $\phi(\vec{a}_{1}),\ldots,\phi(\vec{a}_{n})$
, we have
$\phi(\vec{a}_{1}),\ldots,\phi(\vec{a}_{n})$
, we have
 $$\mathrm{Pr}[\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}\in\mathcal{W}]=\mathrm{Pr}[\xi_{1}\phi(\vec{a}_{1})+\dots+\xi_{n}\phi(\vec{a}_{n})=\vec{p}]=\mathrm{Pr}[M\vec{\xi}=\vec{p}]\le t^{-(k-d)/2}, $$
$$\mathrm{Pr}[\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}\in\mathcal{W}]=\mathrm{Pr}[\xi_{1}\phi(\vec{a}_{1})+\dots+\xi_{n}\phi(\vec{a}_{n})=\vec{p}]=\mathrm{Pr}[M\vec{\xi}=\vec{p}]\le t^{-(k-d)/2}, $$
by Theorem 3.3 (note that, for each of the t disjoint bases formed among the vectors
 $\vec{a}_{1},\ldots, \vec{a}_{n}$
, the image under
$\vec{a}_{1},\ldots, \vec{a}_{n}$
, the image under
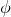 $\phi$
is a spanning set of
$\phi$
is a spanning set of
 $\mathbb{R}^{k-d}$
and hence contains a basis of
$\mathbb{R}^{k-d}$
and hence contains a basis of
 $\mathbb{R}^{k-d}$
, so we can find t disjoint bases among the columns of M and consequently M contains t disjoint nonsingular
$\mathbb{R}^{k-d}$
, so we can find t disjoint bases among the columns of M and consequently M contains t disjoint nonsingular
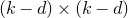 $(k-d)\times (k-d)$
submatrices).
$(k-d)\times (k-d)$
submatrices).
Corollary 3.5. Let
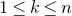 $1\le k\le n$
be integers and
$1\le k\le n$
be integers and
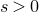 $s \gt 0$
be a real number. Consider a matrix
$s \gt 0$
be a real number. Consider a matrix
 $M\in \mathcal{H}^{k\times n}(s)$
and a vector
$M\in \mathcal{H}^{k\times n}(s)$
and a vector
 $\vec{w}\in \mathbb{R}^k$
. Letting
$\vec{w}\in \mathbb{R}^k$
. Letting
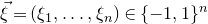 $\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^n$
be a sequence of independent Rademacher random variables, we then have
$\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^n$
be a sequence of independent Rademacher random variables, we then have
 $$ \mathbb{P}[M\vec{\xi}=\vec{w}]\le (s/k)^{-k/2}. $$
$$ \mathbb{P}[M\vec{\xi}=\vec{w}]\le (s/k)^{-k/2}. $$
Proof. By Lemma 3.2(ii) M contains
 $\lceil s/k\rceil$
disjoint nonsingular
$\lceil s/k\rceil$
disjoint nonsingular
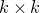 $k\times k$
submatrices, so we can apply Theorem 3.3.
$k\times k$
submatrices, so we can apply Theorem 3.3.
Next, we recall some basic facts about linear forms. A linear form
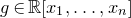 $g\in \mathbb{R}[x_1,\ldots,x_n]$
is a linear polynomial with constant term zero. That is, we can write
$g\in \mathbb{R}[x_1,\ldots,x_n]$
is a linear polynomial with constant term zero. That is, we can write
 $g(\vec{x})=\vec{v}\cdot \vec{x}=\vec{v}^{{\intercal}}\vec{x}=\vec{x}^{{\intercal}}\vec{v}$
, where
$g(\vec{x})=\vec{v}\cdot \vec{x}=\vec{v}^{{\intercal}}\vec{x}=\vec{x}^{{\intercal}}\vec{v}$
, where
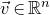 $\vec{v}\in\mathbb{R}^n$
is the coefficient vector of g. Note that, for two linear forms
$\vec{v}\in\mathbb{R}^n$
is the coefficient vector of g. Note that, for two linear forms
 $g_1,g_2\in \mathbb{R}[x_1,\ldots,x_n]$
with coefficient vectors
$g_1,g_2\in \mathbb{R}[x_1,\ldots,x_n]$
with coefficient vectors
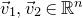 $\vec v_1,\vec v_2\in \mathbb{R}^n$
, we have
$\vec v_1,\vec v_2\in \mathbb{R}^n$
, we have
 \begin{equation}g_1(\vec{x})\cdot g_2(\vec{x})=\tfrac{1}{2}g_1(\vec{x})\cdot g_2(\vec{x})+\tfrac{1}{2}g_2(\vec{x})\cdot g_1(\vec{x})=\tfrac{1}{2}\vec{x}^{{\intercal}}\vec{v}_1\vec{v}_2^{{\intercal}}\vec{x}+\tfrac{1}{2}\vec{x}^{{\intercal}}\vec{v}_2\vec{v}_1^{{\intercal}}\vec{x}=\vec{x}^{{\intercal}}A\vec{x},\end{equation}
\begin{equation}g_1(\vec{x})\cdot g_2(\vec{x})=\tfrac{1}{2}g_1(\vec{x})\cdot g_2(\vec{x})+\tfrac{1}{2}g_2(\vec{x})\cdot g_1(\vec{x})=\tfrac{1}{2}\vec{x}^{{\intercal}}\vec{v}_1\vec{v}_2^{{\intercal}}\vec{x}+\tfrac{1}{2}\vec{x}^{{\intercal}}\vec{v}_2\vec{v}_1^{{\intercal}}\vec{x}=\vec{x}^{{\intercal}}A\vec{x},\end{equation}
where
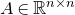 $A\in \mathbb{R}^{n\times n}$
is the symmetric matrix given by
$A\in \mathbb{R}^{n\times n}$
is the symmetric matrix given by
 $A=\frac{1}{2}(\vec{v}_1\vec{v}_2^{{\intercal}}+\vec{v}_2\vec{v}_1^{{\intercal}})$
. More generally, every quadratic form (i.e., every quadratic polynomial with no linear and no constant term), can be written in the form
$A=\frac{1}{2}(\vec{v}_1\vec{v}_2^{{\intercal}}+\vec{v}_2\vec{v}_1^{{\intercal}})$
. More generally, every quadratic form (i.e., every quadratic polynomial with no linear and no constant term), can be written in the form
 $\vec{x}^{{\intercal}}A\vec{x}$
for a unique symmetric matrix
$\vec{x}^{{\intercal}}A\vec{x}$
for a unique symmetric matrix
 $A\in \mathbb{R}^{n\times n}$
.
$A\in \mathbb{R}^{n\times n}$
.
Another important ingredient for our proof is the following decoupling lemma.
Lemma 3.6. If an event
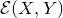 $\mathcal E(X,Y)$
depends on independent random objects X,Y, and X’ is an independent copy of X, then
$\mathcal E(X,Y)$
depends on independent random objects X,Y, and X’ is an independent copy of X, then
 $\mathrm{Pr}[\mathcal E(X,Y)]\le \mathrm{Pr}[\mathcal E(X,Y)\text{ and }\mathcal E(X',Y)]^{1/2}$
.
$\mathrm{Pr}[\mathcal E(X,Y)]\le \mathrm{Pr}[\mathcal E(X,Y)\text{ and }\mathcal E(X',Y)]^{1/2}$
.
Lemma 3.6 is a slight variant of a lemma of Costello, Tao and Vu [Reference Costello, Tao and VuCTV06, Lemma 4.7], who popularised decoupling as a tool for polynomial anticoncentration. The particular statement of Lemma 3.6 appears (for example) as [Reference CostelloCos13, Lemma 14]. For the reader’s convenience, we include the proof (which is a simple application of the Cauchy–Schwarz inequality).
Proof of Lemma 3.6. By the Cauchy–Schwarz inequality, we have
 \begin{align*} \mathrm{Pr}[\mathcal E(X,Y) \text{ and } \mathcal E(X',Y)]&=\mathbb{E}_Y[\mathrm{Pr}[\mathcal E(X,Y) \text{ and } \mathcal E(X',Y)\,|\, Y]]=\mathbb{E}_Y[\mathrm{Pr}[\mathcal E(X,Y)\,|\, Y]^2]\\ &\ge \mathbb{E}_Y[\mathrm{Pr}[\mathcal E(X,Y)\,|\, Y]]^2=\mathrm{Pr}[\mathcal E(X,Y)]^2. \end{align*}
\begin{align*} \mathrm{Pr}[\mathcal E(X,Y) \text{ and } \mathcal E(X',Y)]&=\mathbb{E}_Y[\mathrm{Pr}[\mathcal E(X,Y) \text{ and } \mathcal E(X',Y)\,|\, Y]]=\mathbb{E}_Y[\mathrm{Pr}[\mathcal E(X,Y)\,|\, Y]^2]\\ &\ge \mathbb{E}_Y[\mathrm{Pr}[\mathcal E(X,Y)\,|\, Y]]^2=\mathrm{Pr}[\mathcal E(X,Y)]^2. \end{align*}
Taking square roots on both sides gives the desired inequality.
We will also need a simple lemma usually attributed to Odlyzko [Reference OdlyzkoOdl88].
Lemma 3.7. Consider a matrix
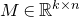 $M\in \mathbb{R}^{k\times n}$
with
$M\in \mathbb{R}^{k\times n}$
with
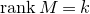 $\operatorname{rank} M=k$
and a vector
$\operatorname{rank} M=k$
and a vector
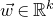 $\vec{w}\in \mathbb{R}^k$
. For a sequence of independent Rademacher random variables
$\vec{w}\in \mathbb{R}^k$
. For a sequence of independent Rademacher random variables
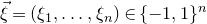 $\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^n$
, we then have
$\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^n$
, we then have
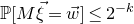 $\mathbb{P}[M\vec{\xi}=\vec{w}]\le 2^{-k}$
.
$\mathbb{P}[M\vec{\xi}=\vec{w}]\le 2^{-k}$
.
Proof. We can interpret
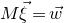 $M\vec{\xi}=\vec{w}$
as a system of linear equations (in the variables
$M\vec{\xi}=\vec{w}$
as a system of linear equations (in the variables
 $\xi_{1},\ldots,\xi_{n}$
). Bringing this system into row echelon form, it has
$\xi_{1},\ldots,\xi_{n}$
). Bringing this system into row echelon form, it has
 $n-k$
free variables (which determine the values of the k remaining variables). After exposing the
$n-k$
free variables (which determine the values of the k remaining variables). After exposing the
 $n-k$
entries of
$n-k$
entries of
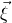 $\vec{\xi}$
corresponding to the free variables, there is at most one possibility for each of the remaining k entries of
$\vec{\xi}$
corresponding to the free variables, there is at most one possibility for each of the remaining k entries of
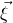 $\vec{\xi}$
satisfying this system of equations. Thus, the probability of having
$\vec{\xi}$
satisfying this system of equations. Thus, the probability of having
 $M\vec{\xi}=\vec{w}$
is at most
$M\vec{\xi}=\vec{w}$
is at most
 $2^{-k}$
.
$2^{-k}$
.
Finally, we will need a simple numerical inequality.
Lemma 3.8. For real numbers
 $a,b,c\ge0$
with
$a,b,c\ge0$
with
 $a^{2}\le ab+c$
, we have
$a^{2}\le ab+c$
, we have
 $a\le b+\sqrt{c}$
.
$a\le b+\sqrt{c}$
.
Proof. Note that for all
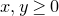 $x,y\ge 0$
we have the inequality
$x,y\ge 0$
we have the inequality
 $\sqrt{x+y}\le\sqrt{x}+\sqrt{y}$
. Now, by the quadratic formula,
$\sqrt{x+y}\le\sqrt{x}+\sqrt{y}$
. Now, by the quadratic formula,
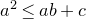 $a^{2}\le ab+c$
implies
$a^{2}\le ab+c$
implies
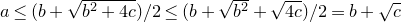 $a\le(b+\sqrt{b^{2}+4c})/2\le (b+\sqrt{b^2}+\sqrt{4c})/2=b+\sqrt{c}$
.
$a\le(b+\sqrt{b^{2}+4c})/2\le (b+\sqrt{b^2}+\sqrt{4c})/2=b+\sqrt{c}$
.
4. Inductive decoupling from a geometric point of view
Note that, for a quadratic polynomial Q and a sequence
 $\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^n$
of independent Rademacher random variables, the event
$\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^n$
of independent Rademacher random variables, the event
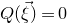 $Q(\vec \xi)=0$
is precisely the event that
$Q(\vec \xi)=0$
is precisely the event that
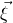 $\vec \xi$
falls in the vanishing locus of Q. Moreover, if the quadratic part of Q has rank less than r (i.e., if Q can be expressed as a linear combination of
$\vec \xi$
falls in the vanishing locus of Q. Moreover, if the quadratic part of Q has rank less than r (i.e., if Q can be expressed as a linear combination of
 $r-1$
squares of linear forms, plus an additional linear form, plus a constant term), then it is possible to interpret the event
$r-1$
squares of linear forms, plus an additional linear form, plus a constant term), then it is possible to interpret the event
 $Q(\vec \xi)=0$
as the event that
$Q(\vec \xi)=0$
as the event that
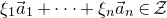 $\xi_1\vec a_1+\dots +\xi_n\vec a_n\in \mathcal Z$
, where
$\xi_1\vec a_1+\dots +\xi_n\vec a_n\in \mathcal Z$
, where
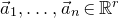 $\vec a_1,\ldots,\vec a_n\in \mathbb{R}^{r}$
are vectors in r-dimensional space, and
$\vec a_1,\ldots,\vec a_n\in \mathbb{R}^{r}$
are vectors in r-dimensional space, and
 $\mathcal Z$
is the vanishing locus of some r-variable quadratic polynomial (indeed, the entries of each
$\mathcal Z$
is the vanishing locus of some r-variable quadratic polynomial (indeed, the entries of each
 $\vec a_i$
correspond to the coefficients of
$\vec a_i$
correspond to the coefficients of
 $\xi_i$
in each of the linear forms described above).
$\xi_i$
in each of the linear forms described above).
In this section, we obtain an essentially optimal bound (in Theorem 4.2 below) on probabilities of the form
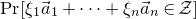 $\mathrm{Pr}[\xi_1\vec a_1+\dots +\xi_n\vec a_n\in \mathcal Z]$
, where
$\mathrm{Pr}[\xi_1\vec a_1+\dots +\xi_n\vec a_n\in \mathcal Z]$
, where
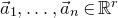 $\vec a_1,\ldots,\vec a_n\in \mathbb{R}^{r}$
are vectors satisfying some robust nondegeneracy condition and
$\vec a_1,\ldots,\vec a_n\in \mathbb{R}^{r}$
are vectors satisfying some robust nondegeneracy condition and
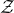 $\mathcal Z$
is a quadric in
$\mathcal Z$
is a quadric in
 $\mathbb{R}^r$
(or more generally, a quadric inside some affine-linear subspace of
$\mathbb{R}^r$
(or more generally, a quadric inside some affine-linear subspace of
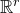 $\mathbb{R}^r$
), under the assumption that the dimension r does not grow with n. This may be viewed as a warm-up to the full proof of Theorem 1.1: it is proved via the same inductive decoupling scheme, but has fewer technicalities.
$\mathbb{R}^r$
), under the assumption that the dimension r does not grow with n. This may be viewed as a warm-up to the full proof of Theorem 1.1: it is proved via the same inductive decoupling scheme, but has fewer technicalities.
Using the connection described in the first paragraph above (with an additional ‘dropping to a subspace’ argument, of the type we will later see in § 6), one can use Theorem 4.2 to prove Theorem 1.1 in the special case where the quadratic part of Q has bounded rank. Actually, Theorem 4.2 is also an ingredient in the full proof of our main theorem (Theorem 1.1). We also remark that the result of this section fits nicely in the ‘geometric Littlewood–Offord’ framework of Fox, Kwan and Spink [Reference Fox, Kwan and SpinkFKS23]. In particular, the case of Theorem 4.2 where
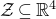 $\mathcal Z\subseteq \mathbb{R}^4$
is a sphere in four dimensions was explicitly raised as the simplest open case of the main problem in [Reference Fox, Kwan and SpinkFKS23].
$\mathcal Z\subseteq \mathbb{R}^4$
is a sphere in four dimensions was explicitly raised as the simplest open case of the main problem in [Reference Fox, Kwan and SpinkFKS23].
Before stating the main result of this section, we record some relevant terminology.
Definition 4.1. As usual, for a polynomial
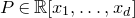 $P\in \mathbb{R}[x_1,\ldots,x_d]$
we write
$P\in \mathbb{R}[x_1,\ldots,x_d]$
we write
 $\mathrm{V}(P)=\{\vec{x}\in \mathbb{R}^d: P(\vec x)=0\}$
for the vanishing locus of P. A quadric
$\mathrm{V}(P)=\{\vec{x}\in \mathbb{R}^d: P(\vec x)=0\}$
for the vanishing locus of P. A quadric
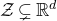 $\mathcal{Z}\subsetneq\mathbb{R}^{d}$
is the vanishing locus
$\mathcal{Z}\subsetneq\mathbb{R}^{d}$
is the vanishing locus
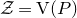 $\mathcal{Z}=\mathrm{V}(P)$
of some nonzero quadratic polynomial
$\mathcal{Z}=\mathrm{V}(P)$
of some nonzero quadratic polynomial
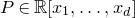 $P\in\mathbb{R}[x_{1},\ldots,x_{d}]$
. We say that a quadric
$P\in\mathbb{R}[x_{1},\ldots,x_{d}]$
. We say that a quadric
 $\mathcal{Z}\subsetneq\mathbb{R}^{d}$
is irreducible if
$\mathcal{Z}\subsetneq\mathbb{R}^{d}$
is irreducible if
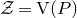 $\mathcal{Z}=\mathrm{V}(P)$
for an irreducible quadratic polynomial
$\mathcal{Z}=\mathrm{V}(P)$
for an irreducible quadratic polynomial
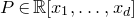 $P\in \mathbb{R}[x_1,\ldots,x_d]$
.
$P\in \mathbb{R}[x_1,\ldots,x_d]$
.
For a d-dimensional affine-linear subspace
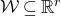 $\mathcal{W}\subseteq \mathbb{R}^{r}$
, we say that
$\mathcal{W}\subseteq \mathbb{R}^{r}$
, we say that
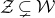 $\mathcal{Z}\subsetneq\mathcal{W}$
is a quadric on
$\mathcal{Z}\subsetneq\mathcal{W}$
is a quadric on
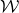 $\mathcal{W}$
if it is the image of some quadric
$\mathcal{W}$
if it is the image of some quadric
 $\mathrm{V}(P)\subsetneq\mathbb{R}^{d}$
under an affine-linear isomorphism
$\mathrm{V}(P)\subsetneq\mathbb{R}^{d}$
under an affine-linear isomorphism
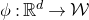 $\phi:\mathbb{R}^{d}\to\mathcal{W}$
. Equivalently,
$\phi:\mathbb{R}^{d}\to\mathcal{W}$
. Equivalently,
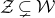 $\mathcal{Z}\subsetneq\mathcal{W}$
is a quadric on
$\mathcal{Z}\subsetneq\mathcal{W}$
is a quadric on
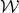 $\mathcal{W}$
if and only if
$\mathcal{W}$
if and only if
 $\mathcal{Z}=\mathcal{W}\cap \mathrm{V}(P)$
for some quadratic polynomial
$\mathcal{Z}=\mathcal{W}\cap \mathrm{V}(P)$
for some quadratic polynomial
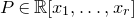 $P\in \mathbb{R}[x_1,\ldots,x_r]$
with
$P\in \mathbb{R}[x_1,\ldots,x_r]$
with
 $\mathcal{W}\not\subseteq \mathrm{V}(P)$
. We say that a quadric
$\mathcal{W}\not\subseteq \mathrm{V}(P)$
. We say that a quadric
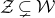 $\mathcal{Z}\subsetneq\mathcal{W}$
is irreducible if it is the image of some irreducible quadric
$\mathcal{Z}\subsetneq\mathcal{W}$
is irreducible if it is the image of some irreducible quadric
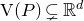 $\mathrm{V}(P)\subsetneq\mathbb{R}^{d}$
under an affine-linear isomorphism
$\mathrm{V}(P)\subsetneq\mathbb{R}^{d}$
under an affine-linear isomorphism
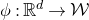 $\phi:\mathbb{R}^{d}\to\mathcal{W}$
.
$\phi:\mathbb{R}^{d}\to\mathcal{W}$
.
As an example, see Figure 1 showing a quadric on a two-dimensional affine plane in
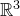 $\mathbb{R}^{3}$
. Now we are ready to state the main result of this section.
$\mathbb{R}^{3}$
. Now we are ready to state the main result of this section.
An example of a quadric on a two-dimensional affine plane in
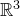 $\mathbb R^3$
.
$\mathbb R^3$
.

Theorem 4.2. Let
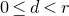 $0\le d<r$
be integers. Let
$0\le d<r$
be integers. Let
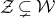 $\mathcal{Z}\subsetneq\mathcal{W}$
be a quadric on a
$\mathcal{Z}\subsetneq\mathcal{W}$
be a quadric on a
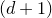 $(d+1)$
-dimensional affine-linear subspace
$(d+1)$
-dimensional affine-linear subspace
 $\mathcal{W}\subseteq\mathbb{R}^{r}$
. Consider vectors
$\mathcal{W}\subseteq\mathbb{R}^{r}$
. Consider vectors
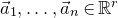 $\vec{a}_{1},\ldots,\vec{a}_{n}\in\mathbb{R}^{r}$
such that one can form t disjoint bases of
$\vec{a}_{1},\ldots,\vec{a}_{n}\in\mathbb{R}^{r}$
such that one can form t disjoint bases of
 $\mathbb{R}^{r}$
from the vectors
$\mathbb{R}^{r}$
from the vectors
 $\vec{a}_{1},\ldots, \vec{a}_n$
, where t is a positive integer divisible by
$\vec{a}_{1},\ldots, \vec{a}_n$
, where t is a positive integer divisible by
 $2^d$
. Let
$2^d$
. Let
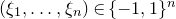 $(\xi_1,\ldots,\xi_n)\in\{-1,1\}^{n}$
be a sequence of independent Rademacher random variables. Then
$(\xi_1,\ldots,\xi_n)\in\{-1,1\}^{n}$
be a sequence of independent Rademacher random variables. Then
 $$\mathrm{Pr}[\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}\in\mathcal{Z}]\le\frac{2^{dr+1}}{t^{(r-d)/2}}. $$
$$\mathrm{Pr}[\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}\in\mathcal{Z}]\le\frac{2^{dr+1}}{t^{(r-d)/2}}. $$
If
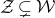 $\mathcal{Z}\subsetneq\mathcal{W}$
is a quadric on a
$\mathcal{Z}\subsetneq\mathcal{W}$
is a quadric on a
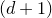 $(d+1)$
-dimensional affine-linear subspace
$(d+1)$
-dimensional affine-linear subspace
 $\mathcal{W}$
, then
$\mathcal{W}$
, then
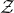 $\mathcal{Z}$
has dimension at most d (we do not formally define what ‘dimension’ means in this context, as this is not needed for our arguments, but appeal to the reader’s intuition). Note that the form of the bound in the above theorem (with
$\mathcal{Z}$
has dimension at most d (we do not formally define what ‘dimension’ means in this context, as this is not needed for our arguments, but appeal to the reader’s intuition). Note that the form of the bound in the above theorem (with
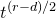 $t^{(r-d)/2}$
in the denominator) is the same as in Corollary 3.4 for d-dimensional affine-linear subspaces.
$t^{(r-d)/2}$
in the denominator) is the same as in Corollary 3.4 for d-dimensional affine-linear subspaces.
For the proof of Theorem 4.2, we will rely on the following algebraic fact.
Lemma 4.3. Let
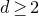 $d\ge 2$
, and let
$d\ge 2$
, and let
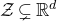 $\mathcal{Z}\subsetneq\mathbb{R}^{d}$
be an irreducible quadric. Then, at least one of the following holds:
$\mathcal{Z}\subsetneq\mathbb{R}^{d}$
be an irreducible quadric. Then, at least one of the following holds:
-
(i) there is a direction
$\vec{v}\in \mathbb{R}^d\setminus\{\vec 0\}$
such that
$\mathcal{Z}+\mathbb{R}\vec{v}=\mathcal{Z}$
(i.e.,
$\mathcal{Z}$
is invariant under translation along the direction
$\vec{v}$
); or -
(ii) for any vectors
$\vec{x},\vec{y}\in \mathbb{R}^d$
with
$\vec{x}\ne\vec{y}$
, the intersection
$(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})$
is a quadric on a
$(d-1)$
-dimensional affine-linear subspace
$\mathcal{W}_{\vec{x},\vec{y}}\subsetneq\mathbb{R}^{d}$
.
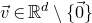
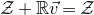

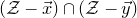
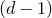
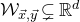
Proof. Let
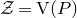 $\mathcal{Z}=\mathrm{V}(P)$
for a nonzero quadratic polynomial
$\mathcal{Z}=\mathrm{V}(P)$
for a nonzero quadratic polynomial
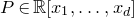 $P\in \mathbb{R}[x_1,\ldots,x_d]$
, and suppose that (i) does not hold. Note that then
$P\in \mathbb{R}[x_1,\ldots,x_d]$
, and suppose that (i) does not hold. Note that then
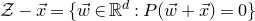 $\mathcal{Z}-\vec x=\{\vec{w}\in \mathbb{R}^d: P(\vec w+\vec x)=0\}$
for any
$\mathcal{Z}-\vec x=\{\vec{w}\in \mathbb{R}^d: P(\vec w+\vec x)=0\}$
for any
 $\vec x\in \mathbb{R}^d$
. For any
$\vec x\in \mathbb{R}^d$
. For any
 $\vec{x},\vec{y}\in \mathbb{R}^d$
with
$\vec{x},\vec{y}\in \mathbb{R}^d$
with
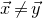 $\vec{x}\ne\vec{y}$
, consider the linear polynomial
$\vec{x}\ne\vec{y}$
, consider the linear polynomial
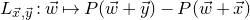 $L_{\vec{x},\vec{y}}:\vec w\mapsto P(\vec{w}+\vec{y})-P(\vec{w}+\vec{x})$
and write
$L_{\vec{x},\vec{y}}:\vec w\mapsto P(\vec{w}+\vec{y})-P(\vec{w}+\vec{x})$
and write
 $\mathcal{W}_{\vec{x},\vec{y}}=\mathrm{V}(L_{\vec{x},\vec{y}})$
, so
$\mathcal{W}_{\vec{x},\vec{y}}=\mathrm{V}(L_{\vec{x},\vec{y}})$
, so
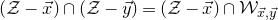 $(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})=(\mathcal{Z}-\vec{x})\cap\mathcal{W}_{\vec{x},\vec{y}}$
. This already shows that
$(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})=(\mathcal{Z}-\vec{x})\cap\mathcal{W}_{\vec{x},\vec{y}}$
. This already shows that
 $(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})$
is the vanishing locus of a quadratic polynomial on
$(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})$
is the vanishing locus of a quadratic polynomial on
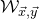 $\mathcal{W}_{\vec{x},\vec{y}}$
. To verify (ii), we will check that
$\mathcal{W}_{\vec{x},\vec{y}}$
. To verify (ii), we will check that
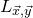 $L_{\vec{x},\vec{y}}$
is not the zero polynomial (which shows that
$L_{\vec{x},\vec{y}}$
is not the zero polynomial (which shows that
 $\dim \mathcal{W}_{\vec{x},\vec{y}}=d-1$
), and that
$\dim \mathcal{W}_{\vec{x},\vec{y}}=d-1$
), and that
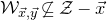 $\mathcal{W}_{\vec{x},\vec{y}}\not \subseteq \mathcal{Z}-\vec x$
(which implies
$\mathcal{W}_{\vec{x},\vec{y}}\not \subseteq \mathcal{Z}-\vec x$
(which implies
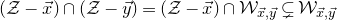 $(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})=(\mathcal{Z}-\vec{x})\cap\mathcal{W}_{\vec{x},\vec{y}}\subsetneq \mathcal{W}_{\vec{x},\vec{y}}$
).
$(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})=(\mathcal{Z}-\vec{x})\cap\mathcal{W}_{\vec{x},\vec{y}}\subsetneq \mathcal{W}_{\vec{x},\vec{y}}$
).
First, the reason
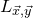 $L_{\vec{x},\vec{y}}$
cannot be the zero polynomial is that (i) does not hold. Indeed, if
$L_{\vec{x},\vec{y}}$
cannot be the zero polynomial is that (i) does not hold. Indeed, if
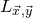 $L_{\vec{x},\vec{y}}$
were the zero polynomial, then for all
$L_{\vec{x},\vec{y}}$
were the zero polynomial, then for all
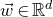 $\vec{w}\in\mathbb{R}^{d}$
and
$\vec{w}\in\mathbb{R}^{d}$
and
 $\lambda\in\mathbb{Z}$
we would have
$\lambda\in\mathbb{Z}$
we would have
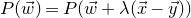 $P(\vec{w})=P(\vec{w}+\lambda(\vec{x}-\vec{y}))$
. That is to say, for all
$P(\vec{w})=P(\vec{w}+\lambda(\vec{x}-\vec{y}))$
. That is to say, for all
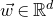 $\vec{w}\in\mathbb{R}^{d}$
the quadratic polynomial
$\vec{w}\in\mathbb{R}^{d}$
the quadratic polynomial
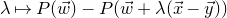 $\lambda\mapsto P(\vec{w})-P(\vec{w}+\lambda(\vec{x}-\vec{y}))$
would have infinitely many zeroes, so would be the zero polynomial, meaning that
$\lambda\mapsto P(\vec{w})-P(\vec{w}+\lambda(\vec{x}-\vec{y}))$
would have infinitely many zeroes, so would be the zero polynomial, meaning that
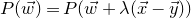 $P(\vec{w})=P(\vec{w}+\lambda(\vec{x}-\vec{y}))$
for all
$P(\vec{w})=P(\vec{w}+\lambda(\vec{x}-\vec{y}))$
for all
 $\lambda\in\mathbb{R}$
and
$\lambda\in\mathbb{R}$
and
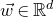 $\vec{w}\in\mathbb{R}^{d}$
. Hence we would have
$\vec{w}\in\mathbb{R}^{d}$
. Hence we would have
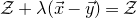 $\mathcal{Z}+\lambda(\vec{x}-\vec{y})=\mathcal{Z}$
for all
$\mathcal{Z}+\lambda(\vec{x}-\vec{y})=\mathcal{Z}$
for all
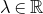 $\lambda\in\mathbb{R}$
, so (i) would hold for
$\lambda\in\mathbb{R}$
, so (i) would hold for
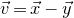 $\vec{v}=\vec{x}-\vec{y}$
.
$\vec{v}=\vec{x}-\vec{y}$
.
Finally, it remains to show
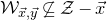 $\mathcal{W}_{\vec{x},\vec{y}}\not \subseteq \mathcal{Z}-\vec x$
. Indeed, otherwise
$\mathcal{W}_{\vec{x},\vec{y}}\not \subseteq \mathcal{Z}-\vec x$
. Indeed, otherwise
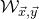 $\mathcal{W}_{\vec{x},\vec{y}}$
would be an irreducible component of
$\mathcal{W}_{\vec{x},\vec{y}}$
would be an irreducible component of
 $\mathcal{Z}-\vec x$
, but by our assumptions
$\mathcal{Z}-\vec x$
, but by our assumptions
 $\mathcal{Z}-\vec x$
is irreducible (since
$\mathcal{Z}-\vec x$
is irreducible (since
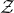 $\mathcal{Z}$
is). We also have
$\mathcal{Z}$
is). We also have
 $\mathcal{Z}-\vec x\ne \mathcal{W}_{\vec{x},\vec{y}}$
, since
$\mathcal{Z}-\vec x\ne \mathcal{W}_{\vec{x},\vec{y}}$
, since
 $\mathcal{Z}-\vec x$
not invariant under translation along the direction of any nonzero vector (since
$\mathcal{Z}-\vec x$
not invariant under translation along the direction of any nonzero vector (since
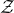 $\mathcal{Z}$
does not satisfy (i)). So we indeed have
$\mathcal{Z}$
does not satisfy (i)). So we indeed have
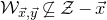 $\mathcal{W}_{\vec{x},\vec{y}}\not \subseteq \mathcal{Z}-\vec x$
.
$\mathcal{W}_{\vec{x},\vec{y}}\not \subseteq \mathcal{Z}-\vec x$
.
Now we prove Theorem 4.2.
Proof
of Theorem 4.2. We proceed by induction on d. In the base case
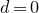 $d=0$
, our quadric
$d=0$
, our quadric
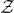 $\mathcal{Z}$
consists of at most two points, so the theorem statement holds by Corollary 3.4 (taking
$\mathcal{Z}$
consists of at most two points, so the theorem statement holds by Corollary 3.4 (taking
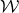 $\mathcal{W}$
in Corollary 3.4 to be zero-dimensional, i.e., a single point). Assume now that
$\mathcal{W}$
in Corollary 3.4 to be zero-dimensional, i.e., a single point). Assume now that
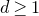 $d\ge1$
(and
$d\ge1$
(and
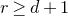 $r\ge d+1$
), and that the theorem statement holds for smaller values of d. Let
$r\ge d+1$
), and that the theorem statement holds for smaller values of d. Let
 $\vec{X}=\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}$
.
$\vec{X}=\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}$
.
Step 1: the reducible case. First, it is easy to handle the case where the quadric
 $\mathcal{Z}\subsetneq \mathcal{W}$
is reducible, i.e., where the irreducible components of
$\mathcal{Z}\subsetneq \mathcal{W}$
is reducible, i.e., where the irreducible components of
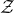 $\mathcal{Z}$
are two affine-linear subspaces of dimension d. Indeed, suppose that
$\mathcal{Z}$
are two affine-linear subspaces of dimension d. Indeed, suppose that
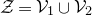 $\mathcal{Z}=\mathcal{V}_{1}\cup\mathcal{V}_{2}$
for two d-dimensional affine-linear subspaces
$\mathcal{Z}=\mathcal{V}_{1}\cup\mathcal{V}_{2}$
for two d-dimensional affine-linear subspaces
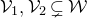 $\mathcal{V}_{1},\mathcal{V}_{2}\subsetneq\mathcal{W}$
. By Corollary 3.4 (i.e., by the version of Halász’ theorem in [Reference Ferber, Jain and ZhaoFJZ22]), we have
$\mathcal{V}_{1},\mathcal{V}_{2}\subsetneq\mathcal{W}$
. By Corollary 3.4 (i.e., by the version of Halász’ theorem in [Reference Ferber, Jain and ZhaoFJZ22]), we have
 $$\mathrm{Pr}[\vec{X}\in\mathcal{Z}]\le\mathrm{Pr}[\vec{X}\in\mathcal{V}_{1}]+\mathrm{Pr}[\vec{X}\in\mathcal{V}_{2}]\le \frac{2}{t^{(r-d)/2}}, $$
$$\mathrm{Pr}[\vec{X}\in\mathcal{Z}]\le\mathrm{Pr}[\vec{X}\in\mathcal{V}_{1}]+\mathrm{Pr}[\vec{X}\in\mathcal{V}_{2}]\le \frac{2}{t^{(r-d)/2}}, $$
which implies the desired result.
Step 2: the translation-invariant case. It is also easy to handle the case where there is a direction
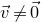 $\vec{v}\ne\vec 0$
such that
$\vec{v}\ne\vec 0$
such that
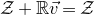 $\mathcal{Z}+\mathbb{R}\vec{v}=\mathcal{Z}$
, because then we can project our entire problem along the direction of
$\mathcal{Z}+\mathbb{R}\vec{v}=\mathcal{Z}$
, because then we can project our entire problem along the direction of
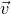 $\vec{v}$
to obtain a lower-dimensional problem (noting that then we also have
$\vec{v}$
to obtain a lower-dimensional problem (noting that then we also have
 $\mathcal{W}+\mathbb{R}\vec{v}=\mathcal{W}$
). Indeed, consider a linear map
$\mathcal{W}+\mathbb{R}\vec{v}=\mathcal{W}$
). Indeed, consider a linear map
 $\phi:\mathbb{R}^r\to \mathbb{R}^{r-1}$
with kernel
$\phi:\mathbb{R}^r\to \mathbb{R}^{r-1}$
with kernel
 $\operatorname{span}(\vec v)$
, and observe that
$\operatorname{span}(\vec v)$
, and observe that
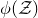 $\phi(\mathcal{Z})$
is a quadric on the
$\phi(\mathcal{Z})$
is a quadric on the
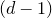 $(d-1)$
-dimensional affine-linear subspace
$(d-1)$
-dimensional affine-linear subspace
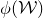 $\phi(\mathcal{W})$
. Then, we have
$\phi(\mathcal{W})$
. Then, we have
 $$\mathrm{Pr}[\vec{X}\in\mathcal{Z}]=\mathrm{Pr}[\phi(\vec{X})\in\phi(\mathcal{Z})]\le\frac{2^{(d-1)(r-1)+1}}{t^{(r-d)/2}}, $$
$$\mathrm{Pr}[\vec{X}\in\mathcal{Z}]=\mathrm{Pr}[\phi(\vec{X})\in\phi(\mathcal{Z})]\le\frac{2^{(d-1)(r-1)+1}}{t^{(r-d)/2}}, $$
by our induction hypothesis (noting that among
 $\phi(\vec{a}_1),\ldots, \phi(\vec{a}_n)$
one can still form t disjoint bases), and the desired result follows.
$\phi(\vec{a}_1),\ldots, \phi(\vec{a}_n)$
one can still form t disjoint bases), and the desired result follows.
Step 3: decoupling. Now, we can assume that
 $\mathcal{Z}\subseteq \mathcal{W}$
is an irreducible quadric and that there is no direction
$\mathcal{Z}\subseteq \mathcal{W}$
is an irreducible quadric and that there is no direction
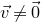 $\vec{v}\ne\vec 0$
such that
$\vec{v}\ne\vec 0$
such that
 $\mathcal{Z}+\mathbb{R}\vec{v}=\mathcal{Z}$
. Let
$\mathcal{Z}+\mathbb{R}\vec{v}=\mathcal{Z}$
. Let
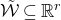 $\tilde{\mathcal{W}}\subseteq \mathbb{R}^r$
be the
$\tilde{\mathcal{W}}\subseteq \mathbb{R}^r$
be the
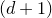 $(d+1)$
-dimensional linear subspace parallel to
$(d+1)$
-dimensional linear subspace parallel to
 $\mathcal{W}$
(i.e.,
$\mathcal{W}$
(i.e.,
 $\mathcal{W}=\tilde{\mathcal{W}}+\vec{w}$
for some
$\mathcal{W}=\tilde{\mathcal{W}}+\vec{w}$
for some
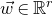 $\vec{w}\in\mathbb{R}^{r}$
). For any
$\vec{w}\in\mathbb{R}^{r}$
). For any
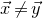 $\vec{x}\ne\vec{y}$
with
$\vec{x}\ne\vec{y}$
with
 $\vec x-\vec y\in \tilde{\mathcal W}$
, by Lemma 4.3 (with an affine-linear isomorphism
$\vec x-\vec y\in \tilde{\mathcal W}$
, by Lemma 4.3 (with an affine-linear isomorphism
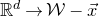 $\mathbb{R}^{d}\to \mathcal W-\vec x$
), the intersection
$\mathbb{R}^{d}\to \mathcal W-\vec x$
), the intersection
 $(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})$
is a quadric on a d-dimensional affine-linear subspace
$(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})$
is a quadric on a d-dimensional affine-linear subspace
 $\mathcal{W}_{\vec{x},\vec{y}}\subsetneq \tilde{\mathcal{W}}+\vec w_{\vec{x},\vec{y}}$
for some
$\mathcal{W}_{\vec{x},\vec{y}}\subsetneq \tilde{\mathcal{W}}+\vec w_{\vec{x},\vec{y}}$
for some
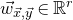 $\vec w_{\vec{x},\vec{y}}\in \mathbb{R}^r$
. The next step is to split our random variable into two parts and use the decoupling lemma (Lemma 3.6) to relate our probability
$\vec w_{\vec{x},\vec{y}}\in \mathbb{R}^r$
. The next step is to split our random variable into two parts and use the decoupling lemma (Lemma 3.6) to relate our probability
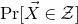 $\mathrm{Pr}[\vec{X}\in\mathcal{Z}]$
to probabilities that certain random variables lie in quadrics of the form
$\mathrm{Pr}[\vec{X}\in\mathcal{Z}]$
to probabilities that certain random variables lie in quadrics of the form
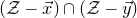 $(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})$
(these probabilities can then be bounded via the induction hypothesis).
$(\mathcal{Z}-\vec{x})\cap(\mathcal{Z}-\vec{y})$
(these probabilities can then be bounded via the induction hypothesis).
Let
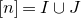 $[n]=I\cup J$
be a partition of the index set [n] into two subsets I,J such that one can form
$[n]=I\cup J$
be a partition of the index set [n] into two subsets I,J such that one can form
 $t/2$
disjoint bases from the vectors
$t/2$
disjoint bases from the vectors
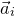 $\vec a_i$
for
$\vec a_i$
for
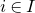 $i\in I$
, and one can also form
$i\in I$
, and one can also form
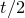 $t/2$
disjoint bases from the vectors
$t/2$
disjoint bases from the vectors
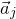 $\vec a_j$
for
$\vec a_j$
for
 $j\in J$
. Let
$j\in J$
. Let
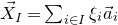 $\vec{X}_{I}=\sum_{i\in I}\xi_{i}\vec{a}_{i}$
and let
$\vec{X}_{I}=\sum_{i\in I}\xi_{i}\vec{a}_{i}$
and let
 $\vec{X}_{J}=\sum_{j\in J}\xi_{j}\vec{a}_{j}$
(so
$\vec{X}_{J}=\sum_{j\in J}\xi_{j}\vec{a}_{j}$
(so
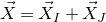 $\vec{X}=\vec{X}_I+\vec{X}_J$
) and let
$\vec{X}=\vec{X}_I+\vec{X}_J$
) and let
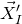 $\vec{X}_I'$
be an independent copy of the random variable
$\vec{X}_I'$
be an independent copy of the random variable
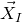 $\vec{X}_I$
. By decoupling (Lemma 3.6) we have
$\vec{X}_I$
. By decoupling (Lemma 3.6) we have
 \begin{align}\mathrm{Pr}[\vec{X}\in\mathcal{Z}]^{2} & \le\mathrm{Pr}[\vec{X}_I+\vec{X}_J\in\mathcal{Z} \text{ and } \vec{X}_I'+\vec{X}_J\in\mathcal{Z}]\nonumber \\ & =\mathrm{Pr}[\vec{X}_J\in(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I') \text{ and } \vec{X}_I\ne\vec{X}_I']+\mathrm{Pr}[\vec{X}_I+\vec{X}_J\in\mathcal{Z} \text{ and } \vec{X}_I'=\vec{X}_I].\end{align}
\begin{align}\mathrm{Pr}[\vec{X}\in\mathcal{Z}]^{2} & \le\mathrm{Pr}[\vec{X}_I+\vec{X}_J\in\mathcal{Z} \text{ and } \vec{X}_I'+\vec{X}_J\in\mathcal{Z}]\nonumber \\ & =\mathrm{Pr}[\vec{X}_J\in(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I') \text{ and } \vec{X}_I\ne\vec{X}_I']+\mathrm{Pr}[\vec{X}_I+\vec{X}_J\in\mathcal{Z} \text{ and } \vec{X}_I'=\vec{X}_I].\end{align}
Step 4: dealing with degenerate intersection. We now study the second term in Equation (4.1) (which can be thought of as a lower-order ‘error term’ corresponding to the possibility that decoupling does not actually reduce the dimension of our problem).
For any outcome of
 $\vec{X}_I$
, we have
$\vec{X}_I$
, we have
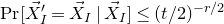 $\mathrm{Pr}[\vec{X}_I'=\vec{X}_I\,|\,\vec{X}_I]\le(t/2)^{-r/2}$
by Halász’ theorem (Corollary 3.4, taking
$\mathrm{Pr}[\vec{X}_I'=\vec{X}_I\,|\,\vec{X}_I]\le(t/2)^{-r/2}$
by Halász’ theorem (Corollary 3.4, taking
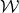 $\mathcal{W}$
to be a single point). So,
$\mathcal{W}$
to be a single point). So,
 \begin{equation}\mathrm{Pr}[\vec{X}_I+\vec{X}_J\in\mathcal{Z} \text{ and } \vec{X}_I'=\vec{X}_I]\le \mathrm{Pr}[\vec{X}_I+\vec{X}_J\in\mathcal{Z}]\cdot (t/2)^{-r/2}=\mathrm{Pr}[\vec{X}\in\mathcal{Z}]\cdot (t/2)^{-r/2}.\end{equation}
\begin{equation}\mathrm{Pr}[\vec{X}_I+\vec{X}_J\in\mathcal{Z} \text{ and } \vec{X}_I'=\vec{X}_I]\le \mathrm{Pr}[\vec{X}_I+\vec{X}_J\in\mathcal{Z}]\cdot (t/2)^{-r/2}=\mathrm{Pr}[\vec{X}\in\mathcal{Z}]\cdot (t/2)^{-r/2}.\end{equation}
Step 5: inductively bounding the main term. Now we deal with the first term in Equation (4.1). Recalling that
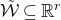 $\tilde{\mathcal{W}}\subseteq \mathbb{R}^r$
is the
$\tilde{\mathcal{W}}\subseteq \mathbb{R}^r$
is the
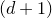 $(d+1)$
-dimensional linear subspace parallel to
$(d+1)$
-dimensional linear subspace parallel to
 $\mathcal{W}$
, note that it is impossible to have
$\mathcal{W}$
, note that it is impossible to have
 $\vec{X}_J\in(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I')$
if
$\vec{X}_J\in(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I')$
if
 $\vec{X}_I-\vec{X}_I'\not\in\tilde{\mathcal{W}}$
(since then
$\vec{X}_I-\vec{X}_I'\not\in\tilde{\mathcal{W}}$
(since then
 $(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I')\subseteq (\mathcal{W}-\vec{X}_I)\cap(\mathcal{W}-\vec{X}_I')=\emptyset$
). So, we combine our induction hypothesis with a bound on the probability that
$(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I')\subseteq (\mathcal{W}-\vec{X}_I)\cap(\mathcal{W}-\vec{X}_I')=\emptyset$
). So, we combine our induction hypothesis with a bound on the probability that
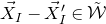 $\vec{X}_I-\vec{X}_I'\in\tilde{\mathcal{W}}$
.
$\vec{X}_I-\vec{X}_I'\in\tilde{\mathcal{W}}$
.
For all outcomes of
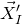 $\vec{X}_I'$
, by Halász’ theorem (Corollary 3.4) we have
$\vec{X}_I'$
, by Halász’ theorem (Corollary 3.4) we have
 $$ \mathrm{Pr}[\vec{X}_I-\vec{X}_I'\in\tilde{\mathcal{W}}\,|\,\vec{X}_I']=\mathrm{Pr}[\vec{X}_I\in\tilde{\mathcal{W}}+\vec{X}_I'\,|\,\vec{X}_I']\le(t/2)^{-(r-d-1)/2}. $$
$$ \mathrm{Pr}[\vec{X}_I-\vec{X}_I'\in\tilde{\mathcal{W}}\,|\,\vec{X}_I']=\mathrm{Pr}[\vec{X}_I\in\tilde{\mathcal{W}}+\vec{X}_I'\,|\,\vec{X}_I']\le(t/2)^{-(r-d-1)/2}. $$
Also, for any outcomes of
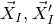 $\vec{X}_I,\vec{X}_I'$
such that
$\vec{X}_I,\vec{X}_I'$
such that
 $\vec{X}_I\ne \vec{X}_I'$
and
$\vec{X}_I\ne \vec{X}_I'$
and
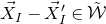 $\vec{X}_I-\vec{X}_I'\in\tilde{\mathcal{W}}$
, by the discussion in Step 3, the intersection
$\vec{X}_I-\vec{X}_I'\in\tilde{\mathcal{W}}$
, by the discussion in Step 3, the intersection
 $(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I')$
is a quadric on a d-dimensional affine-linear subspace
$(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I')$
is a quadric on a d-dimensional affine-linear subspace
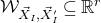 $\mathcal{W}_{\vec{X}_I,\vec{X}_I'}\subseteq \mathbb{R}^r$
. So by our induction hypothesis we have
$\mathcal{W}_{\vec{X}_I,\vec{X}_I'}\subseteq \mathbb{R}^r$
. So by our induction hypothesis we have
 $$ \mathrm{Pr}[\vec{X}_J\in(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I')\,|\,\vec{X}_I,\vec{X}_I']\le\frac{2^{(d-1)r+1}}{(t/2)^{(r-d+1)/2}}. $$
$$ \mathrm{Pr}[\vec{X}_J\in(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I')\,|\,\vec{X}_I,\vec{X}_I']\le\frac{2^{(d-1)r+1}}{(t/2)^{(r-d+1)/2}}. $$
Thus, we obtain
 \begin{align} \mathrm{Pr}[\vec{X}_J\in(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I') \text{ and } \vec{X}_I\ne\vec{X}_I'] & \le (t/2)^{-(r-d-1)/2}\cdot\frac{2^{(d-1)r+1}}{(t/2)^{(r-d+1)/2}} \nonumber\\ & =\frac{2^{(d-1)r+1}}{(t/2)^{r-d}}\le\frac{2^{dr+1}}{t^{r-d}}.\end{align}
\begin{align} \mathrm{Pr}[\vec{X}_J\in(\mathcal{Z}-\vec{X}_I)\cap(\mathcal{Z}-\vec{X}_I') \text{ and } \vec{X}_I\ne\vec{X}_I'] & \le (t/2)^{-(r-d-1)/2}\cdot\frac{2^{(d-1)r+1}}{(t/2)^{(r-d+1)/2}} \nonumber\\ & =\frac{2^{(d-1)r+1}}{(t/2)^{r-d}}\le\frac{2^{dr+1}}{t^{r-d}}.\end{align}
Step 6: concluding. We can now deduce from (4.1), (4.2) and (4.3) that
 $$ \mathrm{Pr}[X\in\mathcal{Z}]^{2} \le\mathrm{Pr}[X\in\mathcal{Z}]\cdot(t/2)^{-r/2}+\frac{2^{dr+1}}{t^{r-d}}=\mathrm{Pr}[X\in\mathcal{Z}]\cdot \frac{2^{r/2}}{t^{r/2}}+\frac{2^{dr+1}}{t^{r-d}}. $$
$$ \mathrm{Pr}[X\in\mathcal{Z}]^{2} \le\mathrm{Pr}[X\in\mathcal{Z}]\cdot(t/2)^{-r/2}+\frac{2^{dr+1}}{t^{r-d}}=\mathrm{Pr}[X\in\mathcal{Z}]\cdot \frac{2^{r/2}}{t^{r/2}}+\frac{2^{dr+1}}{t^{r-d}}. $$
So, by Lemma 3.8 we have (also using that
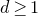 $d\ge 1$
and
$d\ge 1$
and
 $r\ge d+1\ge 2$
)
$r\ge d+1\ge 2$
)
 $$\mathrm{Pr}[X\in\mathcal{Z}]\le \frac{2^{r/2}}{t^{r/2}}+\frac{2^{(dr+1)/2}}{t^{(r-d)/2}}\le\frac{2^{dr+1}}{t^{(r-d)/2}}, $$
$$\mathrm{Pr}[X\in\mathcal{Z}]\le \frac{2^{r/2}}{t^{r/2}}+\frac{2^{(dr+1)/2}}{t^{(r-d)/2}}\le\frac{2^{dr+1}}{t^{(r-d)/2}}, $$
as desired.
5. Proof strategy for the general case
Now we turn to the general (not necessarily low-rank) case of Theorem 1.1. Actually, we consider the following variation on Theorem 1.1, with a slightly more technical assumption on Q (namely, we need to assume that the quadratic part of Q ‘robustly depends on many different variables’). This assumption is very similar to assumptions in some previous Littlewood–Offord-type theorems [Reference Meka, Nguyen and VuMNV16, Reference Razborov and ViolaRV13].
Theorem 5.1. Let
 $Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a multivariate quadratic polynomial with quadratic part
$Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a multivariate quadratic polynomial with quadratic part
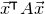 $\vec x^{\intercal} A\vec x$
for some symmetric matrix
$\vec x^{\intercal} A\vec x$
for some symmetric matrix
 $A\in \mathbb{R}^{n\times n}$
. Let
$A\in \mathbb{R}^{n\times n}$
. Let
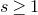 $s\ge 1$
be an integer, and assume that, for every subset
$s\ge 1$
be an integer, and assume that, for every subset
 $S\subseteq[n]$
with
$S\subseteq[n]$
with
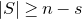 $|S|\ge n-s$
, the submatrix
$|S|\ge n-s$
, the submatrix
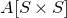 $A[S\times S]$
has at least one nonzero entry outside its diagonal. Then, for a sequence
$A[S\times S]$
has at least one nonzero entry outside its diagonal. Then, for a sequence
 $\vec{\xi}\in\{-1,1\}^{n}$
of independent Rademacher random variables, we have
$\vec{\xi}\in\{-1,1\}^{n}$
of independent Rademacher random variables, we have
 $$\mathrm{Pr}[Q(\vec{\xi})=0]\le\frac{C'}{\sqrt{s}}, $$
$$\mathrm{Pr}[Q(\vec{\xi})=0]\le\frac{C'}{\sqrt{s}}, $$
for some absolute constant C’.
The reason that the assumption in Theorem 5.1 only pays attention to the nondiagonal entries of A is that the diagonal entries correspond to square terms of the form
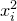 $x_i^2$
. If
$x_i^2$
. If
 $x_i\in \{-1,1\}$
then
$x_i\in \{-1,1\}$
then
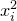 $x_i^2$
is always equal to 1, so such square terms can be treated as constants (and therefore they ‘do not really contribute’ to the quadratic part of Q).
$x_i^2$
is always equal to 1, so such square terms can be treated as constants (and therefore they ‘do not really contribute’ to the quadratic part of Q).
In § 11 we will show how to deduce Theorem 1.1 (and Theorem 1.2 for general distributions) from Theorem 5.1. For most of the rest of the paper, we will focus on proving Theorem 5.1.
At a high level, the strategy to prove Theorem 5.1 is similar to the proof of Theorem 4.2: in order to estimate the probability
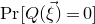 $\mathrm{Pr}[Q(\vec{\xi})=0]$
for a given quadratic polynomial
$\mathrm{Pr}[Q(\vec{\xi})=0]$
for a given quadratic polynomial
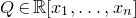 $Q\in \mathbb{R}[x_1,\ldots,x_n]$
, we inductively estimate probabilities of the form
$Q\in \mathbb{R}[x_1,\ldots,x_n]$
, we inductively estimate probabilities of the form
 $\mathrm{Pr}[Q(\vec{\xi})=0\text{ and }M\vec{\xi}=\vec{w}]$
for a given matrix
$\mathrm{Pr}[Q(\vec{\xi})=0\text{ and }M\vec{\xi}=\vec{w}]$
for a given matrix
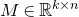 $M\in \mathbb{R}^{k\times n}$
and a given vector
$M\in \mathbb{R}^{k\times n}$
and a given vector
 $\vec{w}\in \mathbb{R}^k$
(i.e., we estimate the probability that
$\vec{w}\in \mathbb{R}^k$
(i.e., we estimate the probability that
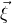 $\vec{\xi}$
lies in a given quadric on a given affine-linear subspace). However, there are additional difficulties in comparison with the proof of Theorem 4.2 in the previous section.
$\vec{\xi}$
lies in a given quadric on a given affine-linear subspace). However, there are additional difficulties in comparison with the proof of Theorem 4.2 in the previous section.
Most importantly, recall that in Theorem 4.2 we worked with a random vector
 $\xi_1\vec a_1+\cdots \xi_n\vec a_n$
which has ‘a lot of anticoncentration in each direction’ (we assumed that there are many disjoint bases among the vectors
$\xi_1\vec a_1+\cdots \xi_n\vec a_n$
which has ‘a lot of anticoncentration in each direction’ (we assumed that there are many disjoint bases among the vectors
 $\vec a_1,\ldots,\vec a_n$
). This was only possible since the dimension of our space was much less than n: to be precise, that proof approach can only obtain bounds of the form
$\vec a_1,\ldots,\vec a_n$
). This was only possible since the dimension of our space was much less than n: to be precise, that proof approach can only obtain bounds of the form
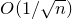 $O(1/\sqrt n)$
when we have
$O(1/\sqrt n)$
when we have
 $\Omega(n)$
disjoint bases among the vectors
$\Omega(n)$
disjoint bases among the vectors
 $\vec a_1,\ldots,\vec a_n$
, which is only possible when we are working in O(1)-dimensional space.
$\vec a_1,\ldots,\vec a_n$
, which is only possible when we are working in O(1)-dimensional space.
In the proof of Theorem 5.1 we work directly with the random vector
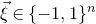 $\vec \xi\in \{-1,1\}^n$
in n-dimensional space. We cannot ensure good anticoncentration in all directions, so we need to restrict the affine-linear subspaces we can consider. Specifically, we prove bounds on
$\vec \xi\in \{-1,1\}^n$
in n-dimensional space. We cannot ensure good anticoncentration in all directions, so we need to restrict the affine-linear subspaces we can consider. Specifically, we prove bounds on
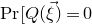 $\mathrm{Pr}[Q(\vec{\xi})=0$
and
$\mathrm{Pr}[Q(\vec{\xi})=0$
and
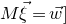 $M\vec{\xi}=\vec{w}]$
only when the matrix M satisfies a Halász-type robust rank condition (as in Definition 3.1). This means that we now need to maintain this robust rank condition as M changes over the course of the induction.
$M\vec{\xi}=\vec{w}]$
only when the matrix M satisfies a Halász-type robust rank condition (as in Definition 3.1). This means that we now need to maintain this robust rank condition as M changes over the course of the induction.
Also, we encounter much more delicate nondegeneracy issues than in the proof of Theorem 4.2. In particular, even if Q satisfies the nondegeneracy condition in Theorem 5.1 (robustly depending on many variables), it may become very degenerate when restricted to a subspace of the form
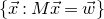 $\{\vec x :M\vec x=\vec w\}$
for a matrix
$\{\vec x :M\vec x=\vec w\}$
for a matrix
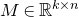 $M\in \mathbb{R}^{k\times n}$
and a vector
$M\in \mathbb{R}^{k\times n}$
and a vector
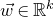 $\vec{w}\in \mathbb{R}^k$
. For example, consider the case where n is divisible by 2 and
$\vec{w}\in \mathbb{R}^k$
. For example, consider the case where n is divisible by 2 and
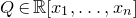 $Q\in \mathbb R[x_1,\ldots,x_n]$
,
$Q\in \mathbb R[x_1,\ldots,x_n]$
,
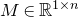 $M\in \mathbb R^{1\times n}$
and
$M\in \mathbb R^{1\times n}$
and
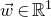 $\vec w\in\mathbb R^1$
are defined by
$\vec w\in\mathbb R^1$
are defined by
 \begin{equation}Q(\vec x)=(x_1+\dots+x_{n/2})(x_{n/2+1}+\dots+x_{n}),\quad\quad M=(1,\ldots,1,0,\ldots,0),\quad\quad \vec w=0;\end{equation}
\begin{equation}Q(\vec x)=(x_1+\dots+x_{n/2})(x_{n/2+1}+\dots+x_{n}),\quad\quad M=(1,\ldots,1,0,\ldots,0),\quad\quad \vec w=0;\end{equation}
(where the first
 $n/2$
entries of
$n/2$
entries of
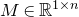 $M\in \mathbb R^{1\times n}$
are ‘1’ and the last
$M\in \mathbb R^{1\times n}$
are ‘1’ and the last
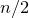 $n/2$
entries are ‘0’). In this case Q is always zero on the subspace
$n/2$
entries are ‘0’). In this case Q is always zero on the subspace
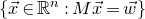 $\{\vec x\in \mathbb R^n:M\vec x=\vec w\}$
. So, in order to be able to obtain a sensible bound, we need to ensure that Q satisfies a nondegeneracy condition with respect to M.
$\{\vec x\in \mathbb R^n:M\vec x=\vec w\}$
. So, in order to be able to obtain a sensible bound, we need to ensure that Q satisfies a nondegeneracy condition with respect to M.
In the rest of this section we describe the strategy of the proof of Theorem 5.1 in a bit more detail, stating several key lemmas and definitions along the way. First, we elaborate on the ‘nondegeneracy with respect to M’ condition mentioned above. To formulate this condition (as well as other similar conditions appearing later in the proof), we define the notion of a (T,U)-perturbation, as follows.
Definition 5.2. For matrices
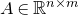 $A\in\mathbb{R}^{n\times m}$
and
$A\in\mathbb{R}^{n\times m}$
and
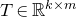 $T\in \mathbb{R}^{k\times m}$
and
$T\in \mathbb{R}^{k\times m}$
and
 $U\in\mathbb{R}^{k\times n}$
, a (T,U)-perturbation of A is a matrix
$U\in\mathbb{R}^{k\times n}$
, a (T,U)-perturbation of A is a matrix
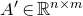 $A'\in \mathbb{R}^{n\times m}$
of the form
$A'\in \mathbb{R}^{n\times m}$
of the form
 $A'=A+LT+U^{{\intercal}}R$
for some matrices
$A'=A+LT+U^{{\intercal}}R$
for some matrices
 $L\in\mathbb{R}^{n\times k}$
and
$L\in\mathbb{R}^{n\times k}$
and
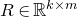 $R\in\mathbb{R}^{k\times m}$
, i.e., some matrix that can be obtained from A by adding linear combinations of rows of T to its rows, and adding linear combinations of rows of U to its columns.
$R\in\mathbb{R}^{k\times m}$
, i.e., some matrix that can be obtained from A by adding linear combinations of rows of T to its rows, and adding linear combinations of rows of U to its columns.
As the degenerate
 $k=0$
case of the above definition, note that if
$k=0$
case of the above definition, note that if
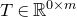 $T\in \mathbb R^{0\times m}$
and
$T\in \mathbb R^{0\times m}$
and
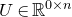 $U\in \mathbb R^{0\times n}$
are ‘empty matrices’, then
$U\in \mathbb R^{0\times n}$
are ‘empty matrices’, then
 $A'\in \mathbb{R}^{n\times m}$
is a (T,U)-perturbation of A if and only if
$A'\in \mathbb{R}^{n\times m}$
is a (T,U)-perturbation of A if and only if
 $A'=A$
.
$A'=A$
.
For
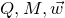 $Q,M,\vec w$
as defined in the example in Equation (5.1), we can write
$Q,M,\vec w$
as defined in the example in Equation (5.1), we can write
 $Q(\vec x)=\vec x^{\intercal} A \vec x$
for a symmetric matrix
$Q(\vec x)=\vec x^{\intercal} A \vec x$
for a symmetric matrix
 $A\in \mathbb{R}^{n\times n}$
(with a block structure where the bottom left block and the top right block, each of size
$A\in \mathbb{R}^{n\times n}$
(with a block structure where the bottom left block and the top right block, each of size
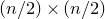 $(n/2)\times (n/2)$
, have all entries being
$(n/2)\times (n/2)$
, have all entries being
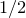 $1/2$
, and all entries outside these blocks are 0). It turns out that this matrix A is an (M,M)-perturbation of the zero matrix in
$1/2$
, and all entries outside these blocks are 0). It turns out that this matrix A is an (M,M)-perturbation of the zero matrix in
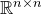 $\mathbb{R}^{n\times n}$
. Roughly speaking, this is the reason for the degenerate behaviour of Q on the subspace
$\mathbb{R}^{n\times n}$
. Roughly speaking, this is the reason for the degenerate behaviour of Q on the subspace
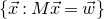 $\{\vec x :M\vec x=\vec w\}$
. In general, the notion of an (M,M)-perturbation gives a condition under which two
$\{\vec x :M\vec x=\vec w\}$
. In general, the notion of an (M,M)-perturbation gives a condition under which two
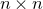 $n\times n$
matrices give rise to quadratic polynomials which are ‘essentially the same’ on an affine-linear subspace of the form
$n\times n$
matrices give rise to quadratic polynomials which are ‘essentially the same’ on an affine-linear subspace of the form
 $\{\vec x :M\vec x=\vec w\}$
, as follows.
$\{\vec x :M\vec x=\vec w\}$
, as follows.
Lemma 5.3. Fix a matrix
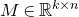 $M\in \mathbb{R}^{k\times n}$
, a vector
$M\in \mathbb{R}^{k\times n}$
, a vector
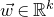 $\vec w\in \mathbb{R}^k$
, and a quadratic polynomial
$\vec w\in \mathbb{R}^k$
, and a quadratic polynomial
 $Q\in \mathbb{R}[x_1,\ldots,x_n]$
with quadratic part
$Q\in \mathbb{R}[x_1,\ldots,x_n]$
with quadratic part
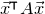 $\vec x^{\intercal} A\vec x$
(where
$\vec x^{\intercal} A\vec x$
(where
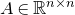 $A\in \mathbb{R}^{n\times n}$
).
$A\in \mathbb{R}^{n\times n}$
).
Consider an (M,M)-perturbation A’ of A, and let
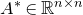 $A^*\in \mathbb{R}^{n\times n}$
be a matrix which agrees with A’ on its off-diagonal entries. Then, there is a quadratic polynomial
$A^*\in \mathbb{R}^{n\times n}$
be a matrix which agrees with A’ on its off-diagonal entries. Then, there is a quadratic polynomial
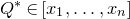 $Q^*\in [x_1,\ldots,x_n]$
with quadratic part
$Q^*\in [x_1,\ldots,x_n]$
with quadratic part
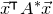 $\vec x^{\intercal} A^*\vec x$
such that
$\vec x^{\intercal} A^*\vec x$
such that
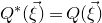 $Q^*(\vec{\xi})=Q(\vec{\xi})$
for all
$Q^*(\vec{\xi})=Q(\vec{\xi})$
for all
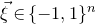 $\vec{\xi}\in \{-1,1\}^n$
with
$\vec{\xi}\in \{-1,1\}^n$
with
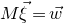 $M\vec{\xi}=\vec{w}$
. In particular, for a sequence
$M\vec{\xi}=\vec{w}$
. In particular, for a sequence
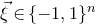 $\vec{\xi}\in\{-1,1\}^{n}$
of independent Rademacher random variables, we have
$\vec{\xi}\in\{-1,1\}^{n}$
of independent Rademacher random variables, we have
 $$ \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]=\mathrm{Pr}[Q^*(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]. $$
$$ \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]=\mathrm{Pr}[Q^*(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]. $$
Proof. Let
 $A^*=A'+D=A+LM+M^{{\intercal}}R+D$
for some matrices
$A^*=A'+D=A+LM+M^{{\intercal}}R+D$
for some matrices
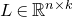 $L\in\mathbb{R}^{n\times k}$
and
$L\in\mathbb{R}^{n\times k}$
and
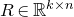 $R\in\mathbb{R}^{k\times n}$
and a diagonal matrix
$R\in\mathbb{R}^{k\times n}$
and a diagonal matrix
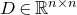 $D\in \mathbb{R}^{n\times n}$
, and let
$D\in \mathbb{R}^{n\times n}$
, and let
 $\lambda_1,\ldots,\lambda_n\in \mathbb{R}$
be the diagonal entries of D. Then
$\lambda_1,\ldots,\lambda_n\in \mathbb{R}$
be the diagonal entries of D. Then
 \begin{align*}\vec x^{\intercal} A^*\vec x & =\vec x^{\intercal} A\vec x+\vec x^{\intercal} LM\vec x+\vec x^{\intercal} M^{{\intercal}}R\vec x+\vec x^{\intercal} D\vec x \nonumber\\& =\vec x^{\intercal} A\vec x+(M\vec x)^{\intercal} L^{\intercal} \vec x+(M\vec x)^{\intercal} R \vec x +(\lambda_1x_1^2+\dots+\lambda_nx_n^2).\end{align*}
\begin{align*}\vec x^{\intercal} A^*\vec x & =\vec x^{\intercal} A\vec x+\vec x^{\intercal} LM\vec x+\vec x^{\intercal} M^{{\intercal}}R\vec x+\vec x^{\intercal} D\vec x \nonumber\\& =\vec x^{\intercal} A\vec x+(M\vec x)^{\intercal} L^{\intercal} \vec x+(M\vec x)^{\intercal} R \vec x +(\lambda_1x_1^2+\dots+\lambda_nx_n^2).\end{align*}
Thus, for every
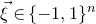 $\vec{\xi}\in \{-1,1\}^n$
with
$\vec{\xi}\in \{-1,1\}^n$
with
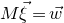 $M\vec{\xi}=\vec{w}$
, we have
$M\vec{\xi}=\vec{w}$
, we have
 $$ \vec \xi^{\intercal} A^*\vec \xi=\vec \xi^{\intercal} A\vec \xi+\vec w^{\intercal} L^{\intercal} \vec \xi+\vec w^{\intercal} R \vec x+(\lambda_1\xi_1^2+\dots+\lambda_n\xi_n^2)=\vec \xi^{\intercal} A\vec \xi+\vec w^{\intercal} (L^{\intercal}+R) \vec \xi+(\lambda_1+\dots+\lambda_n). $$
$$ \vec \xi^{\intercal} A^*\vec \xi=\vec \xi^{\intercal} A\vec \xi+\vec w^{\intercal} L^{\intercal} \vec \xi+\vec w^{\intercal} R \vec x+(\lambda_1\xi_1^2+\dots+\lambda_n\xi_n^2)=\vec \xi^{\intercal} A\vec \xi+\vec w^{\intercal} (L^{\intercal}+R) \vec \xi+(\lambda_1+\dots+\lambda_n). $$
Hence, we can define the desired quadratic polynomial
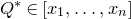 $Q^*\in [x_1,\ldots,x_n]$
with quadratic part
$Q^*\in [x_1,\ldots,x_n]$
with quadratic part
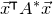 $\vec x^{\intercal} A^*\vec x$
by
$\vec x^{\intercal} A^*\vec x$
by
 $$ Q^*(\vec x)=Q(\vec x)+\vec x^{\intercal} A^*\vec x-\vec x^{\intercal} A\vec x-\vec w^{\intercal} (L^{\intercal}+R) \vec x-(\lambda_1+\dots+\lambda_n), $$
$$ Q^*(\vec x)=Q(\vec x)+\vec x^{\intercal} A^*\vec x-\vec x^{\intercal} A\vec x-\vec w^{\intercal} (L^{\intercal}+R) \vec x-(\lambda_1+\dots+\lambda_n), $$
and we indeed have
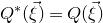 $Q^*(\vec{\xi})=Q(\vec{\xi})$
for all
$Q^*(\vec{\xi})=Q(\vec{\xi})$
for all
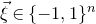 $\vec{\xi}\in \{-1,1\}^n$
with
$\vec{\xi}\in \{-1,1\}^n$
with
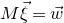 $M\vec{\xi}=\vec{w}$
.
$M\vec{\xi}=\vec{w}$
.
Now, recall that our strategy to prove Theorem 5.1 is to inductively upper-bound probabilities of the form
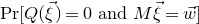 $\mathrm{Pr}[Q(\vec{\xi})=0\text{ and }M\vec{\xi}=\vec w]$
, assuming that M satisfies a robust rank condition, and assuming a nondegeneracy condition on Q with respect to M. It will be convenient to introduce some notation for the maximum possible such probability, as follows.
$\mathrm{Pr}[Q(\vec{\xi})=0\text{ and }M\vec{\xi}=\vec w]$
, assuming that M satisfies a robust rank condition, and assuming a nondegeneracy condition on Q with respect to M. It will be convenient to introduce some notation for the maximum possible such probability, as follows.
Definition 5.4. For an integer
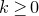 $k\ge 0$
and real number
$k\ge 0$
and real number
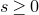 $s\ge 0$
, let us define
$s\ge 0$
, let us define
 $$ f(k,s)=\sup_{(n,Q,M,\vec w)} \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w], $$
$$ f(k,s)=\sup_{(n,Q,M,\vec w)} \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w], $$
where the supremum is taken over all quadruples
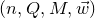 $(n,Q,M,\vec w)$
, where n is a positive integer,
$(n,Q,M,\vec w)$
, where n is a positive integer,
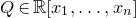 $Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
is a quadratic polynomial,
$Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
is a quadratic polynomial,
 $M\in\mathcal{H}^{k\times n}(s)$
and
$M\in\mathcal{H}^{k\times n}(s)$
and
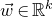 $\vec w\in \mathbb{R}^k$
, such that the following condition holds:
$\vec w\in \mathbb{R}^k$
, such that the following condition holds:
(*) If we write the quadratic part of
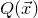 $Q(\vec{x})$
as
$Q(\vec{x})$
as
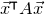 $\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix
$\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix
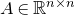 $A\in \mathbb{R}^{n\times n}$
, then for every subset
$A\in \mathbb{R}^{n\times n}$
, then for every subset
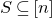 $S\subseteq[n]$
with
$S\subseteq[n]$
with
 $|S|\ge n-s$
, and every (M,M)-perturbation A’ of A, the submatrix
$|S|\ge n-s$
, and every (M,M)-perturbation A’ of A, the submatrix
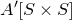 $A'[S\times S]$
has at least one nonzero entry outside the diagonal.
$A'[S\times S]$
has at least one nonzero entry outside the diagonal.
For each such quadruple
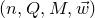 $(n,Q,M,\vec w)$
, the probability above is taken with respect to a sequence of independent Rademacher random variables
$(n,Q,M,\vec w)$
, the probability above is taken with respect to a sequence of independent Rademacher random variables
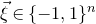 $\vec{\xi}\in\{-1,1\}^{n}$
.
$\vec{\xi}\in\{-1,1\}^{n}$
.
Note that we always have
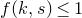 $f(k,s)\le 1$
, since f(k,s) is defined as a supremum of certain probabilities (which are all at most 1). Also note that for
$f(k,s)\le 1$
, since f(k,s) is defined as a supremum of certain probabilities (which are all at most 1). Also note that for
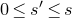 $0\le s'\le s$
, we always have
$0\le s'\le s$
, we always have
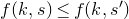 $f(k,s)\le f(k,s')$
(since the supremum in the definition of f(k,s’) is taken over a wider range of quadruples
$f(k,s)\le f(k,s')$
(since the supremum in the definition of f(k,s’) is taken over a wider range of quadruples
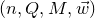 $(n,Q,M,\vec w)$
than for f(k,s)).
$(n,Q,M,\vec w)$
than for f(k,s)).
Note that for a polynomial
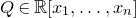 $Q\in \mathbb{R}[x_1,\ldots,x_n]$
and an integer
$Q\in \mathbb{R}[x_1,\ldots,x_n]$
and an integer
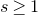 $s\ge 1$
as in Theorem 5.1, condition (
$s\ge 1$
as in Theorem 5.1, condition (
 $*$
) is satisfied for
$*$
) is satisfied for
 $k=0$
, the empty matrix
$k=0$
, the empty matrix
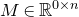 $M\in \mathbb{R}^{0\times n}$
and the empty vector
$M\in \mathbb{R}^{0\times n}$
and the empty vector
 $\vec{w}\in \mathbb{R}^0$
. Indeed, writing the quadratic part of Q as
$\vec{w}\in \mathbb{R}^0$
. Indeed, writing the quadratic part of Q as
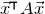 $\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix
$\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix
 $A\in \mathbb{R}^{n\times n}$
, the only (M,M) perturbation A’ of A is
$A\in \mathbb{R}^{n\times n}$
, the only (M,M) perturbation A’ of A is
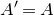 $A'=A$
, and by the assumption in Theorem 5.1 the matrix
$A'=A$
, and by the assumption in Theorem 5.1 the matrix
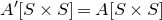 $A'[S\times S]=A[S\times S]$
has at least one nonzero entry outside the diagonal for every subset
$A'[S\times S]=A[S\times S]$
has at least one nonzero entry outside the diagonal for every subset
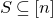 $S\subseteq[n]$
with
$S\subseteq[n]$
with
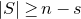 $|S|\ge n-s$
. Therefore, we have (noting that the condition
$|S|\ge n-s$
. Therefore, we have (noting that the condition
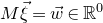 $M\vec \xi=\vec w\in \mathbb{R}^0$
is vacuous)
$M\vec \xi=\vec w\in \mathbb{R}^0$
is vacuous)
 $$ \mathrm{Pr}[Q(\vec \xi)=0]=\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w]\le f(0,s). $$
$$ \mathrm{Pr}[Q(\vec \xi)=0]=\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w]\le f(0,s). $$
Thus, proving Theorem 5.1 amounts to showing that
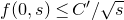 $f(0,s)\le C'/\sqrt{s}$
for some absolute constant C’.
$f(0,s)\le C'/\sqrt{s}$
for some absolute constant C’.
Now, the following recursive upper bound on f(k,s) is the main ingredient in our proof of Theorem 5.1.
Theorem 5.5. For any integer
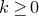 $k\ge 0$
and any real number
$k\ge 0$
and any real number
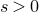 $s \gt 0$
, we have
$s \gt 0$
, we have
 $$ f(k,s)\le \max\{s_*^{-(k+1)/2}, s_*^{-(k+2)/2}+s_*^{-k/4}\cdot f(k+1,s_*)^{1/2}\}, $$
$$ f(k,s)\le \max\{s_*^{-(k+1)/2}, s_*^{-(k+2)/2}+s_*^{-k/4}\cdot f(k+1,s_*)^{1/2}\}, $$
where
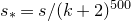 $s_*=s/(k+2)^{500}$
.
$s_*=s/(k+2)^{500}$
.
Using this recursive bound, we can obtain an upper bound for f(k,s) inductively (the formula for this upper bound is rather complicated, so we postpone this calculation to § 10). With another straightforward (although somewhat technical) calculation, one can then show that in the
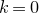 $k=0$
case this upper bound implies Theorem 5.1. This latter calculation can also be found in § 10.
$k=0$
case this upper bound implies Theorem 5.1. This latter calculation can also be found in § 10.
To prove Theorem 5.5, we need to upper-bound
 $\mathrm{Pr}[Q(\vec{\xi})=0\text{ and }M\vec{\xi}=\vec w]$
for
$\mathrm{Pr}[Q(\vec{\xi})=0\text{ and }M\vec{\xi}=\vec w]$
for
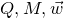 $Q,M,\vec w$
satisfying the conditions in Definition 5.4, in terms of a probability of the same form but with slightly different parameters (most importantly, with ‘
$Q,M,\vec w$
satisfying the conditions in Definition 5.4, in terms of a probability of the same form but with slightly different parameters (most importantly, with ‘
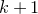 $k+1$
’ in place of ‘k’). To do so, we use our inductive decoupling scheme outlined in § 2.3: we consider a partition
$k+1$
’ in place of ‘k’). To do so, we use our inductive decoupling scheme outlined in § 2.3: we consider a partition
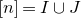 $[n]=I\cup J$
of the index set into two parts I and J, and, using the decoupling inequality in Lemma 3.6, we will obtain an upper bound on
$[n]=I\cup J$
of the index set into two parts I and J, and, using the decoupling inequality in Lemma 3.6, we will obtain an upper bound on
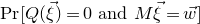 $\mathrm{Pr}[Q(\vec{\xi})=0\text{ and }M\vec{\xi}=\vec w]$
involving conditional probabilities of the form
$\mathrm{Pr}[Q(\vec{\xi})=0\text{ and }M\vec{\xi}=\vec w]$
involving conditional probabilities of the form
 \begin{equation}\mathrm{Pr}[Q_{\vec \xi[I]}(\vec{\xi}[J])=0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec{\xi}[J]=\vec w_{\xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\,|\,\xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]],\end{equation}
\begin{equation}\mathrm{Pr}[Q_{\vec \xi[I]}(\vec{\xi}[J])=0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec{\xi}[J]=\vec w_{\xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\,|\,\xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]],\end{equation}
where
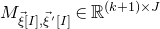 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{(k+1)\times J}$
is a
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{(k+1)\times J}$
is a
 $(k+1)\times |J|$
matrix depending on
$(k+1)\times |J|$
matrix depending on
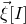 $\vec \xi[I]$
and
$\vec \xi[I]$
and
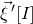 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, and
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, and
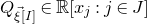 $Q_{\vec \xi[I]}\in \mathbb{R}[x_j: j\in J]$
is a quadratic polynomial whose coefficients depend on
$Q_{\vec \xi[I]}\in \mathbb{R}[x_j: j\in J]$
is a quadratic polynomial whose coefficients depend on
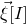 $\vec \xi[I]$
, and
$\vec \xi[I]$
, and
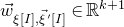 $\vec w_{\xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{k+1}$
is a vector depending on
$\vec w_{\xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{k+1}$
is a vector depending on
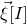 $\vec \xi[I]$
and
$\vec \xi[I]$
and
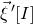 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
. In our proof of Theorem 5.5, we wish to upper-bound conditional probabilities of the form in Equation (5.2) by
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
. In our proof of Theorem 5.5, we wish to upper-bound conditional probabilities of the form in Equation (5.2) by
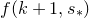 $f(k+1,s_*)$
. Recalling Definition 5.4, this requires that
$f(k+1,s_*)$
. Recalling Definition 5.4, this requires that
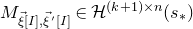 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal H^{(k+1)\times n}(s_*)$
(i.e., that
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal H^{(k+1)\times n}(s_*)$
(i.e., that
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
robustly has rank at least
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
robustly has rank at least
 $k+1$
). So, as previously outlined, an important ingredient in the proof is a ‘robust rank inheritance’ lemma, which implies that this robust rank condition for
$k+1$
). So, as previously outlined, an important ingredient in the proof is a ‘robust rank inheritance’ lemma, which implies that this robust rank condition for
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
holds with sufficiently high probability.
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
holds with sufficiently high probability.
Now, the way in which
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
is derived from M depends on Q: specifically, one can check that
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
is derived from M depends on Q: specifically, one can check that
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
is obtained from
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
is obtained from
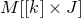 $M[[k]\times J]$
by adding the vector
$M[[k]\times J]$
by adding the vector
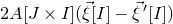 $2A[J\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
as an additional row, where
$2A[J\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
as an additional row, where
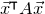 $\vec x^{\intercal} A \vec x$
is the quadratic part of
$\vec x^{\intercal} A \vec x$
is the quadratic part of
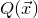 $Q(\vec x)$
. The statement of our robust rank inheritance lemma requires an assumption on Q; to specify this assumption we need another definition.
$Q(\vec x)$
. The statement of our robust rank inheritance lemma requires an assumption on Q; to specify this assumption we need another definition.
Definition 5.6. For integers
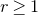 $r\ge 1$
and
$r\ge 1$
and
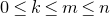 $0\le k\le m\le n$
and
$0\le k\le m\le n$
and
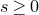 $s\ge 0$
, let
$s\ge 0$
, let
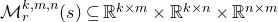 $\mathcal{M}_r^{k,m,n}(s)\subseteq\mathbb{R}^{k\times m}\times\mathbb{R}^{k\times n}\times\mathbb{R}^{n\times m}$
be the set of triples of matrices
$\mathcal{M}_r^{k,m,n}(s)\subseteq\mathbb{R}^{k\times m}\times\mathbb{R}^{k\times n}\times\mathbb{R}^{n\times m}$
be the set of triples of matrices
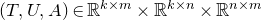 $(T,U,A)\in \mathbb{R}^{k\times m}\times\mathbb{R}^{k\times n}\times\mathbb{R}^{n\times m}$
for which there exist disjoint subsets
$(T,U,A)\in \mathbb{R}^{k\times m}\times\mathbb{R}^{k\times n}\times\mathbb{R}^{n\times m}$
for which there exist disjoint subsets
 $I_{1},\ldots,I_{s}\subseteq[m]$
and disjoint subsets
$I_{1},\ldots,I_{s}\subseteq[m]$
and disjoint subsets
 $J_{1},\ldots,J_{s}\subseteq[n]$
of size
$J_{1},\ldots,J_{s}\subseteq[n]$
of size
 $|I_1|=\dots=|I_s|=|J_1|=\dots=|J_s|=k+r$
such that the following hold.
$|I_1|=\dots=|I_s|=|J_1|=\dots=|J_s|=k+r$
such that the following hold.
-
(a) For
$t=1,\ldots,s$
, the submatrix
$T[[k]\times I_t]$
has rank k. -
(b) For
$t=1,\ldots,s$
, the submatrix
$U[[k]\times J_t]$
has rank k. -
(c) For
$t=1,\ldots,s$
, every
$(T[[k]\times I_t],U[[k]\times J_t])$
-perturbation of the matrix
$A[J_t\times I_t]$
has rank at least r.

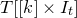

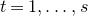

Remark 5.1. If
 $(T,U,A)\in \mathcal{M}_r^{k,m,n}(s)$
for any
$(T,U,A)\in \mathcal{M}_r^{k,m,n}(s)$
for any
 $r\ge 1$
, then we automatically have
$r\ge 1$
, then we automatically have
 $T\in \mathcal{H}^{k\times m}(s)$
and
$T\in \mathcal{H}^{k\times m}(s)$
and
 $U\in \mathcal{H}^{k\times n}(s)$
. Also note that the property
$U\in \mathcal{H}^{k\times n}(s)$
. Also note that the property
 $(T,U,A)\in \mathcal{M}_r^{k,m,n}(s)$
is invariant under rescaling any of the matrices T, U and A.
$(T,U,A)\in \mathcal{M}_r^{k,m,n}(s)$
is invariant under rescaling any of the matrices T, U and A.
In our proof of Theorem 5.5, we consider a partition
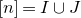 $[n]=I\cup J$
as outlined above, and take the matrix ‘A’ in Definition 5.6 to be the matrix
$[n]=I\cup J$
as outlined above, and take the matrix ‘A’ in Definition 5.6 to be the matrix
 $A[J\times I]$
together with
$A[J\times I]$
together with
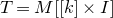 $T=M[[k]\times I]$
and
$T=M[[k]\times I]$
and
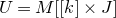 $U=M[[k]\times J]$
. In this case,
$U=M[[k]\times J]$
. In this case,
 $(M[[k]\times I],M[[k]\times J],A[J\times I])\in \mathcal{M}_r^{k,I,J}(s)$
says (roughly speaking) that
$(M[[k]\times I],M[[k]\times J],A[J\times I])\in \mathcal{M}_r^{k,I,J}(s)$
says (roughly speaking) that
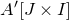 $A'[J\times I]$
robustly has rank at least r for any (M,M)-perturbation A’ of A.
$A'[J\times I]$
robustly has rank at least r for any (M,M)-perturbation A’ of A.
Now, our robust rank inheritance lemma is as follows.
Lemma 5.7. Let
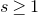 $s\ge 1$
and
$s\ge 1$
and
 $0\le k\le m\le n$
be integers. Consider
$0\le k\le m\le n$
be integers. Consider
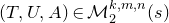 $(T,U,A)\in\mathcal{M}_2^{k,m,n}(s)$
, and vectors
$(T,U,A)\in\mathcal{M}_2^{k,m,n}(s)$
, and vectors
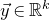 $\vec{y}\in\mathbb{R}^{k}$
and
$\vec{y}\in\mathbb{R}^{k}$
and
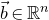 $\vec{b}\in\mathbb{R}^{n}$
. Let
$\vec{b}\in\mathbb{R}^{n}$
. Let
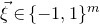 $\vec{\xi}\in\{-1,1\}^{m}$
be a sequence of independent Rademacher random variables, and write
$\vec{\xi}\in\{-1,1\}^{m}$
be a sequence of independent Rademacher random variables, and write
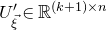 $U_{\vec \xi}'\in \mathbb{R}^{(k+1)\times n}$
for the (random) matrix obtained by appending the vector
$U_{\vec \xi}'\in \mathbb{R}^{(k+1)\times n}$
for the (random) matrix obtained by appending the vector
 $A\vec{\xi}-\vec{b}$
as an additional row to U. Then we have
$A\vec{\xi}-\vec{b}$
as an additional row to U. Then we have
 $$\mathrm{Pr}[T\vec{\xi}=\vec{y} \text{ and } U_{\vec \xi}'\notin \mathcal H^{(k+1)\times n}(s/6)]\le \bigg(\frac{s}{10^{61}(k+2)^{20}}\bigg)^{-(k+2)/2}. $$
$$\mathrm{Pr}[T\vec{\xi}=\vec{y} \text{ and } U_{\vec \xi}'\notin \mathcal H^{(k+1)\times n}(s/6)]\le \bigg(\frac{s}{10^{61}(k+2)^{20}}\bigg)^{-(k+2)/2}. $$
We will prove Lemma 5.7 in § 7. We remark that on the right-hand side of the inequality, both the ‘
 $+2$
’ in the exponent
$+2$
’ in the exponent
 $(k+2)/2$
and the ‘
$(k+2)/2$
and the ‘
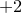 $+2$
’ in the denominator are due to the ‘2’ in the assumption
$+2$
’ in the denominator are due to the ‘2’ in the assumption
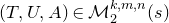 $(T,U,A)\in\mathcal{M}_2^{k,m,n}(s)$
; in general we would get a ‘
$(T,U,A)\in\mathcal{M}_2^{k,m,n}(s)$
; in general we would get a ‘
 $+r$
’ in both of these places if we assumed that
$+r$
’ in both of these places if we assumed that
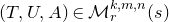 $(T,U,A)\in\mathcal{M}_r^{k,m,n}(s)$
. The exponent
$(T,U,A)\in\mathcal{M}_r^{k,m,n}(s)$
. The exponent
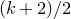 $(k+2)/2$
here leads to the exponent
$(k+2)/2$
here leads to the exponent
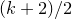 $(k+2)/2$
appearing in Theorem 5.5, and the ‘
$(k+2)/2$
appearing in Theorem 5.5, and the ‘
 $+2$
’ there is crucial in order to deduce Theorem 5.1 from Theorem 5.5 (just having ‘
$+2$
’ there is crucial in order to deduce Theorem 5.1 from Theorem 5.5 (just having ‘
 $+1$
’ there would not suffice).
$+1$
’ there would not suffice).
In order to actually apply Lemma 5.7 in the proof of Theorem 5.5, we would like to show that there is a partition
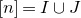 $[n]=I \cup J$
such that
$[n]=I \cup J$
such that
 $(M[[k]\times I],M[[k]\times J],A[J\times I])\in\mathcal{M}_2^{k,I,J}(s)$
for a suitable value of s. Such a partition might not in general exist, because we are making no assumption that A itself even has rank at least two. However, if every (M,M)-perturbation of A robustly has rank at least two even after changing the diagonal entries, we can find a suitable partition
$(M[[k]\times I],M[[k]\times J],A[J\times I])\in\mathcal{M}_2^{k,I,J}(s)$
for a suitable value of s. Such a partition might not in general exist, because we are making no assumption that A itself even has rank at least two. However, if every (M,M)-perturbation of A robustly has rank at least two even after changing the diagonal entries, we can find a suitable partition
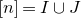 $[n]=I \cup J$
using the following lemma.
$[n]=I \cup J$
using the following lemma.
Lemma 5.8. Let
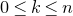 $0\le k\le n$
be integers and let
$0\le k\le n$
be integers and let
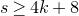 $s\ge 4k+8$
be a real number. Let
$s\ge 4k+8$
be a real number. Let
 $M\in\mathcal{H}^{k\times n}(s)$
and let
$M\in\mathcal{H}^{k\times n}(s)$
and let
 $A\in \mathbb{R}^{n\times n}$
be a symmetric matrix such that
$A\in \mathbb{R}^{n\times n}$
be a symmetric matrix such that
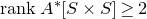 $\operatorname{rank} A^*[S\times S]\ge 2$
for any subset
$\operatorname{rank} A^*[S\times S]\ge 2$
for any subset
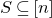 $S\subseteq [n]$
of size
$S\subseteq [n]$
of size
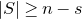 $|S|\ge n- s$
and any matrix
$|S|\ge n- s$
and any matrix
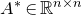 $A^*\in \mathbb{R}^{n\times n}$
that agrees with some (M,M)-perturbation of A in all off-diagonal entries. Then there is a partition
$A^*\in \mathbb{R}^{n\times n}$
that agrees with some (M,M)-perturbation of A in all off-diagonal entries. Then there is a partition
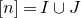 $[n]= I\cup J$
, with
$[n]= I\cup J$
, with
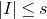 $|I|\le s$
, such that
$|I|\le s$
, such that
 $$ (M[[k]\times I],M[[k]\times J],A[J\times I])\in\mathcal{M}_2^{k,I,J}(\lfloor s/(4k+8)\rfloor). $$
$$ (M[[k]\times I],M[[k]\times J],A[J\times I])\in\mathcal{M}_2^{k,I,J}(\lfloor s/(4k+8)\rfloor). $$
We prove Lemma 5.8 in § 8. Roughly speaking, we are able to greedily find the desired subsets
 $I_1,\ldots,I_s,J_1,\ldots,J_s$
in the definition of
$I_1,\ldots,I_s,J_1,\ldots,J_s$
in the definition of
 $\mathcal{M}_2^{k,m,n}(s)$
in Definition 5.6.
$\mathcal{M}_2^{k,m,n}(s)$
in Definition 5.6.
To summarise, the proof of Theorem 5.5 combines a number of ingredients. If A does not satisfy the assumption in Lemma 5.8 (i.e., if some (M,M)-perturbation of A does not robustly have rank at least two after changing the diagonal entries), then we complete the proof using Theorem 4.2 (in the low-rank case, there are various types of degeneracies to consider, which can be gracefully handled with a geometric point of view). Otherwise, we apply Lemma 5.8 to find a suitable partition
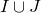 $I\cup J$
, and we apply the decoupling inequality in Lemma 3.6 to
$I\cup J$
, and we apply the decoupling inequality in Lemma 3.6 to
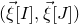 $(\vec \xi[I],\vec \xi[J])$
. We manipulate the resulting expression in roughly the same way as in the proof of Theorem 4.2, and then bound relevant quantities using Lemma 5.7 and Corollary 3.5. After proving Theorem 5.5, we can obtain Theorem 5.1 with somewhat technical calculations (presented in § 10).
$(\vec \xi[I],\vec \xi[J])$
. We manipulate the resulting expression in roughly the same way as in the proof of Theorem 4.2, and then bound relevant quantities using Lemma 5.7 and Corollary 3.5. After proving Theorem 5.5, we can obtain Theorem 5.1 with somewhat technical calculations (presented in § 10).
In the next section we state and prove a consequence of Theorem 4.2 which will be suitable to handle the low-rank case of Theorem 5.5. In § 7 we prove Lemma 5.7 and in § 8 we prove Lemma 5.8. The proof of Theorem 5.5 then appears in § 9.
6. The low-rank case
In this section, we show how to use Theorem 4.2 to deduce the following proposition, which handles the low-rank case of Theorem 5.5.
Proposition 6.1. Consider integers
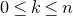 $0\le k\le n$
and
$0\le k\le n$
and
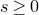 $s\ge 0$
and
$s\ge 0$
and
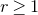 $r\ge 1$
. Let
$r\ge 1$
. Let
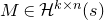 $M\in\mathcal{H}^{k\times n}(s)$
, let
$M\in\mathcal{H}^{k\times n}(s)$
, let
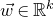 $\vec w\in \mathbb{R}^k$
and let
$\vec w\in \mathbb{R}^k$
and let
 $Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a quadratic polynomial. Writing the quadratic part of
$Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a quadratic polynomial. Writing the quadratic part of
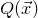 $Q(\vec{x})$
as
$Q(\vec{x})$
as
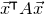 $\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix A, assume that
$\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix A, assume that
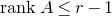 $\operatorname{rank} A\le r-1$
and that there is no subset
$\operatorname{rank} A\le r-1$
and that there is no subset
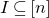 $I\subseteq [n]$
of size
$I\subseteq [n]$
of size
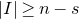 $|I|\ge n-s$
such that the matrix
$|I|\ge n-s$
such that the matrix
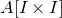 $A[I\times I]$
is an
$A[I\times I]$
is an
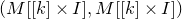 $(M[[k]\times I],M[[k]\times I])$
-perturbation of the zero matrix in
$(M[[k]\times I],M[[k]\times I])$
-perturbation of the zero matrix in
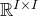 $\mathbb{R}^{I\times I}$
.
$\mathbb{R}^{I\times I}$
.
Then for a sequence
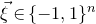 $\vec{\xi}\in\{-1,1\}^{n}$
of independent Rademacher random variables we have
$\vec{\xi}\in\{-1,1\}^{n}$
of independent Rademacher random variables we have
 \begin{equation}\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec{\xi}=\vec{w}]\le\bigg(\frac{s}{2^{3r^{2}}(k+r)^2}\bigg)^{-(k+1)/2}.\end{equation}
\begin{equation}\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec{\xi}=\vec{w}]\le\bigg(\frac{s}{2^{3r^{2}}(k+r)^2}\bigg)^{-(k+1)/2}.\end{equation}
In our proof of Theorem 5.5, we will use Proposition 6.1 only for
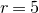 $r=5$
, but we still state it here for general r (as the proof works for any r).
$r=5$
, but we still state it here for general r (as the proof works for any r).
Deducing Proposition 6.1 from Theorem 4.2 mostly consists of translating from ‘geometric’ to ‘algebraic’ language. To give a some idea of how this works: note that under the assumptions of Proposition 6.1, we can write
 $$ Q(\vec x)=\lambda_{1}\cdot (g^{({1})}(\vec{x}))^2+\dots+\lambda_{r-1} \cdot (g^{({r-1})}(\vec{x}))^2+g^{(r)}(\vec x)+c , $$
$$ Q(\vec x)=\lambda_{1}\cdot (g^{({1})}(\vec{x}))^2+\dots+\lambda_{r-1} \cdot (g^{({r-1})}(\vec{x}))^2+g^{(r)}(\vec x)+c , $$
for some
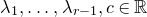 $\lambda_1,\ldots,\lambda_{r-1},c\in \mathbb{R}$
and some linear forms
$\lambda_1,\ldots,\lambda_{r-1},c\in \mathbb{R}$
and some linear forms
 $g^{({1})},\ldots,g^{({r-1})},g^{(r)} \in \mathbb{R}[x_1,\ldots,x_n]$
. That is to say, we can write
$g^{({1})},\ldots,g^{({r-1})},g^{(r)} \in \mathbb{R}[x_1,\ldots,x_n]$
. That is to say, we can write
 $$ Q(\vec x)=P(g^{(1)}(\vec{x}),\ldots,g^{(r)}(\vec{x}))=P(x_1\vec a_1+\dots+x_n\vec a_n), $$
$$ Q(\vec x)=P(g^{(1)}(\vec{x}),\ldots,g^{(r)}(\vec{x}))=P(x_1\vec a_1+\dots+x_n\vec a_n), $$
for the quadratic polynomial
 $P(\vec{y})=\lambda_1 y_1^2+\dots+\lambda_{r-1} y_{r-1}^2+y_r+c$
, where for
$P(\vec{y})=\lambda_1 y_1^2+\dots+\lambda_{r-1} y_{r-1}^2+y_r+c$
, where for
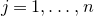 $j=1,\ldots,n$
, the vector
$j=1,\ldots,n$
, the vector
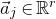 $\vec a_j\in \mathbb R^r$
records the coefficients of
$\vec a_j\in \mathbb R^r$
records the coefficients of
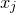 $x_j$
in the linear forms
$x_j$
in the linear forms
 $g^{({1})},\ldots,g^{(r)}$
. So, the event
$g^{({1})},\ldots,g^{(r)}$
. So, the event
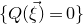 $\{Q(\vec \xi)=0\}$
can be interpreted as the event that
$\{Q(\vec \xi)=0\}$
can be interpreted as the event that
 $\xi_1\vec a_1+\dots+\xi_n\vec a_n$
falls in the vanishing locus of the polynomial P. The joint event
$\xi_1\vec a_1+\dots+\xi_n\vec a_n$
falls in the vanishing locus of the polynomial P. The joint event
 $\{Q(\vec \xi)=0\text{ and }M\vec\xi=\vec w \}$
can be given a similar geometric interpretation: roughly speaking, we consider k additional linear forms
$\{Q(\vec \xi)=0\text{ and }M\vec\xi=\vec w \}$
can be given a similar geometric interpretation: roughly speaking, we consider k additional linear forms
 $g^{({r+1})},\ldots,g^{({r+k})}\in \mathbb{R}[x_1,\ldots,x_n]$
corresponding to the k rows of M, augmenting
$g^{({r+1})},\ldots,g^{({r+k})}\in \mathbb{R}[x_1,\ldots,x_n]$
corresponding to the k rows of M, augmenting
 $\vec a_1,\ldots,\vec a_n$
accordingly with k additional entries each, and then we consider the event that the
$\vec a_1,\ldots,\vec a_n$
accordingly with k additional entries each, and then we consider the event that the
 $(r+k)$
-dimensional random vector
$(r+k)$
-dimensional random vector
 $\xi_1\vec a_1+\dots+\xi_n\vec a_n$
falls into a certain quadric
$\xi_1\vec a_1+\dots+\xi_n\vec a_n$
falls into a certain quadric
 $\mathcal Z$
(still described by the same polynomial P) on the codimension-k affine-linear subspace
$\mathcal Z$
(still described by the same polynomial P) on the codimension-k affine-linear subspace
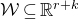 $\mathcal W\subseteq \mathbb{R}^{r+k}$
given by
$\mathcal W\subseteq \mathbb{R}^{r+k}$
given by
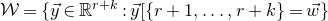 $\mathcal W=\{\vec y \in \mathbb{R}^{r+k} : \vec y [\{r+1,\ldots,r+k\}=\vec w\}$
(this subspace
$\mathcal W=\{\vec y \in \mathbb{R}^{r+k} : \vec y [\{r+1,\ldots,r+k\}=\vec w\}$
(this subspace
 $\mathcal W\subseteq \mathbb{R}^{r+k}$
corresponds to the system of equations
$\mathcal W\subseteq \mathbb{R}^{r+k}$
corresponds to the system of equations
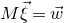 $M\vec\xi=\vec w$
).
$M\vec\xi=\vec w$
).
This more-or-less explains how to reduce Proposition 6.1 to the setting of Theorem 4.2. The only complication is that it may not be possible to find many disjoint bases of
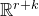 $\mathbb{R}^{r+k}$
among the vectors
$\mathbb{R}^{r+k}$
among the vectors
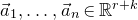 $\vec a_1,\ldots,\vec a_n\in \mathbb{R}^{r+k}$
, as is necessary to apply Theorem 4.2 (in fact, the vectors
$\vec a_1,\ldots,\vec a_n\in \mathbb{R}^{r+k}$
, as is necessary to apply Theorem 4.2 (in fact, the vectors
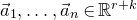 $\vec a_1,\ldots,\vec a_n\in \mathbb{R}^{r+k}$
might not span
$\vec a_1,\ldots,\vec a_n\in \mathbb{R}^{r+k}$
might not span
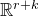 $\mathbb{R}^{r+k}$
at all). In this case, we need to ‘drop to a subspace’ that is robustly spanned by most of the
$\mathbb{R}^{r+k}$
at all). In this case, we need to ‘drop to a subspace’ that is robustly spanned by most of the
 $\vec a_1,\ldots,\vec a_n$
(i.e., we need to identify some large subset
$\vec a_1,\ldots,\vec a_n$
(i.e., we need to identify some large subset
 $I\subseteq [n]$
, such that we can find many disjoint bases of
$I\subseteq [n]$
, such that we can find many disjoint bases of
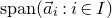 $\operatorname{span}(\vec a_i:i\in I)$
among the vectors
$\operatorname{span}(\vec a_i:i\in I)$
among the vectors
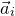 $\vec a_i$
for
$\vec a_i$
for
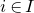 $i\in I$
). This, roughly speaking, corresponds to considering only some subset of the linear forms
$i\in I$
). This, roughly speaking, corresponds to considering only some subset of the linear forms
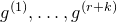 $g^{({1})},\ldots,g^{(r+k)}$
, such that the remaining linear forms are ‘close to’ being linear combinations of these linear forms (i.e., each of the remaining linear forms agrees with such a linear combination in its coefficients of the variables
$g^{({1})},\ldots,g^{(r+k)}$
, such that the remaining linear forms are ‘close to’ being linear combinations of these linear forms (i.e., each of the remaining linear forms agrees with such a linear combination in its coefficients of the variables
 $x_i$
for
$x_i$
for
 $i\in I$
). The quadratic polynomial
$i\in I$
). The quadratic polynomial
 $P(\vec{y})$
considered above then needs to be changed appropriately in order to reflect these relations between the linear forms
$P(\vec{y})$
considered above then needs to be changed appropriately in order to reflect these relations between the linear forms
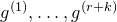 $g^{({1})},\ldots,g^{(r+k)}$
.
$g^{({1})},\ldots,g^{(r+k)}$
.
The following lemma encapsulates this translation discussed above, going from the setting of Proposition 6.1 to the setting of Theorem 4.2.
Lemma 6.2. Consider integers
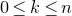 $0\le k\le n$
and
$0\le k\le n$
and
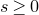 $s\ge 0$
and
$s\ge 0$
and
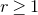 $r\ge 1$
. Let
$r\ge 1$
. Let
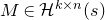 $M\in \mathcal{H}^{k\times n}(s)$
and let
$M\in \mathcal{H}^{k\times n}(s)$
and let
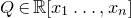 $Q\in \mathbb{R}[x_1\dots,x_n]$
be a quadratic polynomial. Writing the quadratic part of
$Q\in \mathbb{R}[x_1\dots,x_n]$
be a quadratic polynomial. Writing the quadratic part of
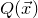 $Q(\vec{x})$
as
$Q(\vec{x})$
as
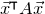 $\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix
$\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix
 $A\in \mathbb{R}^{n\times n}$
, assume that
$A\in \mathbb{R}^{n\times n}$
, assume that
 $\operatorname{rank} A\le r-1$
and that there is no subset
$\operatorname{rank} A\le r-1$
and that there is no subset
 $I\subseteq [n]$
of size
$I\subseteq [n]$
of size
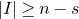 $|I|\ge n-s$
such that the matrix
$|I|\ge n-s$
such that the matrix
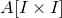 $A[I\times I]$
is an
$A[I\times I]$
is an
 $(M[[k]\times I],M[[k]\times I])$
-perturbation of the zero matrix in
$(M[[k]\times I],M[[k]\times I])$
-perturbation of the zero matrix in
 $\mathbb{R}^{I\times I}$
.
$\mathbb{R}^{I\times I}$
.
Then, we can find a positive integer
 $\ell\le r$
, a partition
$\ell\le r$
, a partition
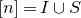 $[n]=I\cup S$
with
$[n]=I\cup S$
with
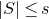 $|S|\le s$
, linear forms
$|S|\le s$
, linear forms
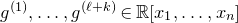 $g^{(1)},\ldots,g^{({\ell+k})} \in \mathbb{R}[x_1,\ldots,x_n]$
, and a quadratic polynomial
$g^{(1)},\ldots,g^{({\ell+k})} \in \mathbb{R}[x_1,\ldots,x_n]$
, and a quadratic polynomial
 $P\in \mathbb{R}[y_1,\ldots,y_{\ell+k}, (x_i)_{i\in S}]$
such that the following conditions hold.
$P\in \mathbb{R}[y_1,\ldots,y_{\ell+k}, (x_i)_{i\in S}]$
such that the following conditions hold.
-
(i)
$Q(x_1,\ldots,x_n)=P(g^{(1)}(\vec{x}),\ldots,g^{({\ell+k})}(\vec{x}), (x_i)_{i\in S})$
. -
(ii) For each
$j=1,\ldots,k$
, the coefficient vector of
$g^{({\ell+j})}$
is precisely the jth row of M. -
(iii) Writing
$M'\in \mathbb{R}^{(\ell+k)\times n}$
for the
$(\ell+k)\times n$
matrix whose jth row is the coefficient vector of
$g^{(j)}$
for
$j=1,\ldots,\ell+k$
, we have
$M'[[\ell+k]\times I]\in \mathcal{H}^{(\ell+k)\times I}(s/r)$
. -
(iv) There exist
$j,j'\in [\ell]$
such that the coefficient of
$y_jy_{j'}$
in P is nonzero.
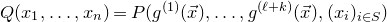
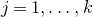
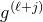


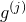
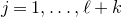
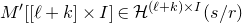
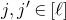

We remark that the vectors
 $\vec a_i$
for
$\vec a_i$
for
 $i\in I$
in the informal explanation above correspond to the columns of the matrix
$i\in I$
in the informal explanation above correspond to the columns of the matrix
 $M'[[\ell+k]\times I]$
in Lemma 6.2. Condition (iii) ensures that we can find many disjoint bases of
$M'[[\ell+k]\times I]$
in Lemma 6.2. Condition (iii) ensures that we can find many disjoint bases of
 $\mathbb{R}^{\ell+k}$
among these vectors
$\mathbb{R}^{\ell+k}$
among these vectors
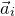 $\vec a_i$
for
$\vec a_i$
for
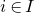 $i\in I$
(recall that this is required to apply Theorem 4.2 to these vectors). Condition (iv) ensures that the polynomial P does not vanish on our entire subspace
$i\in I$
(recall that this is required to apply Theorem 4.2 to these vectors). Condition (iv) ensures that the polynomial P does not vanish on our entire subspace
 $\mathcal{W}$
(corresponding to a system of equations of the form
$\mathcal{W}$
(corresponding to a system of equations of the form
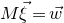 $M\vec{\xi}=\vec{w}$
).
$M\vec{\xi}=\vec{w}$
).
Proof. Let us consider the minimum number
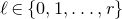 $\ell\in\{0,1,\ldots,r\}$
such that there exists a partition
$\ell\in\{0,1,\ldots,r\}$
such that there exists a partition
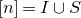 $[n]=I\cup S$
with
$[n]=I\cup S$
with
 $|S|\le s\cdot (r-\ell)/r$
, linear forms
$|S|\le s\cdot (r-\ell)/r$
, linear forms
 $g^{(1)},\ldots,g^{({\ell+k})} \in \mathbb{R}[x_1,\ldots,x_n]$
and a quadratic polynomial
$g^{(1)},\ldots,g^{({\ell+k})} \in \mathbb{R}[x_1,\ldots,x_n]$
and a quadratic polynomial
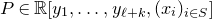 $P\in \mathbb{R}[y_1,\ldots,y_{\ell+k}, (x_i)_{i\in S}]$
, such that conditions (i) and (ii) hold (i.e., we have
$P\in \mathbb{R}[y_1,\ldots,y_{\ell+k}, (x_i)_{i\in S}]$
, such that conditions (i) and (ii) hold (i.e., we have
 $Q(x_1,\ldots,x_n)=P(g^{(1)}(\vec{x}),\ldots,g^{({\ell+k})}(\vec{x}), (x_i)_{i\in S})$
and for each
$Q(x_1,\ldots,x_n)=P(g^{(1)}(\vec{x}),\ldots,g^{({\ell+k})}(\vec{x}), (x_i)_{i\in S})$
and for each
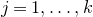 $j=1,\ldots,k$
, the coefficient vector of
$j=1,\ldots,k$
, the coefficient vector of
 $g^{({\ell+j})}$
is precisely the jth row of M).
$g^{({\ell+j})}$
is precisely the jth row of M).
First, in order to see that this minimum number
 $\ell$
is well defined, let us check that
$\ell$
is well defined, let us check that
 $\ell=r$
satisfies the conditions. Indeed, given that
$\ell=r$
satisfies the conditions. Indeed, given that
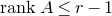 $\operatorname{rank} A\le r-1$
, we can write
$\operatorname{rank} A\le r-1$
, we can write
 $$ Q(\vec x)=\lambda_{1}\cdot (g^{({1})}(\vec{x}))^2+\dots+\lambda_{r-1} \cdot (g^{({r-1})}(\vec{x}))^2+g^{(r)}(\vec x)+c, $$
$$ Q(\vec x)=\lambda_{1}\cdot (g^{({1})}(\vec{x}))^2+\dots+\lambda_{r-1} \cdot (g^{({r-1})}(\vec{x}))^2+g^{(r)}(\vec x)+c, $$
for some
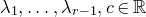 $\lambda_1,\ldots,\lambda_{r-1},c\in \mathbb{R}$
and some linear forms
$\lambda_1,\ldots,\lambda_{r-1},c\in \mathbb{R}$
and some linear forms
 $g^{({1})},\ldots,g^{({r-1})},g^{(r)} \in \mathbb{R}[x_1,\ldots,x_n]$
. That is to say, defining
$g^{({1})},\ldots,g^{({r-1})},g^{(r)} \in \mathbb{R}[x_1,\ldots,x_n]$
. That is to say, defining
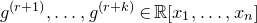 $g^{({r+1})},\ldots,g^{({r+k})} \in \mathbb{R}[x_1,\ldots,x_n]$
to be the linear forms whose coefficient vectors are given by the rows of M as in condition (ii), we can write
$g^{({r+1})},\ldots,g^{({r+k})} \in \mathbb{R}[x_1,\ldots,x_n]$
to be the linear forms whose coefficient vectors are given by the rows of M as in condition (ii), we can write
 $$ Q(\vec x)=P(g^{(1)}(\vec{x}),\ldots,g^{(r+k)}(\vec{x})), $$
$$ Q(\vec x)=P(g^{(1)}(\vec{x}),\ldots,g^{(r+k)}(\vec{x})), $$
where
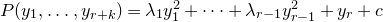 $P(y_1,\ldots,y_{r+k})=\lambda_1 y_1^2+\dots+\lambda_{r-1} y_{r-1}^2+y_r+c$
(formally this is a polynomial in
$P(y_1,\ldots,y_{r+k})=\lambda_1 y_1^2+\dots+\lambda_{r-1} y_{r-1}^2+y_r+c$
(formally this is a polynomial in
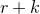 $r+k$
variables, despite the fact that
$r+k$
variables, despite the fact that
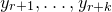 $y_{r+1},\ldots,y_{r+k}$
do not actually appear in it). Note that (ii) holds by definition, and taking
$y_{r+1},\ldots,y_{r+k}$
do not actually appear in it). Note that (ii) holds by definition, and taking
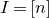 $I=[n]$
and
$I=[n]$
and
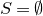 $S=\emptyset$
, condition (i) holds as well and we have
$S=\emptyset$
, condition (i) holds as well and we have
 $|S|=0\le s\cdot (r-r)/r$
. Thus,
$|S|=0\le s\cdot (r-r)/r$
. Thus,
 $\ell=r$
has the required properties, and the minimum number
$\ell=r$
has the required properties, and the minimum number
 $\ell$
above is well defined.
$\ell$
above is well defined.
Now let
 $\ell$
be this minimum number, and choose the partition
$\ell$
be this minimum number, and choose the partition
 $[n]=I\cup S$
, the linear forms
$[n]=I\cup S$
, the linear forms
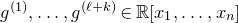 $g^{(1)},\ldots,g^{({\ell+k})} \in \mathbb{R}[x_1,\ldots,x_n]$
and the quadratic polynomial P accordingly with the properties above. Note that
$g^{(1)},\ldots,g^{({\ell+k})} \in \mathbb{R}[x_1,\ldots,x_n]$
and the quadratic polynomial P accordingly with the properties above. Note that
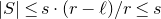 $|S|\le s\cdot (r-\ell)/r\le s$
, and consequently
$|S|\le s\cdot (r-\ell)/r\le s$
, and consequently
 $|I|\ge n-s$
. It remains to show that
$|I|\ge n-s$
. It remains to show that
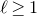 $\ell\ge 1$
and that conditions (iii) and (iv) hold.
$\ell\ge 1$
and that conditions (iii) and (iv) hold.
Let us first show (iv). Suppose for contradiction that in the quadratic polynomial P, the coefficient of
 $y_jy_{j'}$
is zero for all
$y_jy_{j'}$
is zero for all
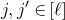 $j,j'\in [\ell]$
. Then the quadratic part of
$j,j'\in [\ell]$
. Then the quadratic part of
 $Q(x_1,\ldots,x_n)=P(g^{(1)}(\vec{x}),\ldots,g^{({\ell+k})}(\vec{x}), (x_i)_{i\in S})$
can be written as a linear combination of terms of the form
$Q(x_1,\ldots,x_n)=P(g^{(1)}(\vec{x}),\ldots,g^{({\ell+k})}(\vec{x}), (x_i)_{i\in S})$
can be written as a linear combination of terms of the form
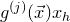 $g^{({j})}(\vec{x})x_h$
with
$g^{({j})}(\vec{x})x_h$
with
 $j\in \{\ell+1,\ldots,\ell+k\}$
and
$j\in \{\ell+1,\ldots,\ell+k\}$
and
 $h\in [n]$
, and terms of the form
$h\in [n]$
, and terms of the form
 $x_hx_{i}$
with
$x_hx_{i}$
with
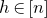 $h\in [n]$
and
$h\in [n]$
and
 $i\in S$
. By Equation (3.1), this leads to a representation of the symmetric matrix A as a linear combination of matrices of the form
$i\in S$
. By Equation (3.1), this leads to a representation of the symmetric matrix A as a linear combination of matrices of the form
 $\vec{v}_j\vec{e}_h^{\,{\intercal}}$
,
$\vec{v}_j\vec{e}_h^{\,{\intercal}}$
,
 $\vec{e}_h\vec{v}_j^{\,{\intercal}}$
,
$\vec{e}_h\vec{v}_j^{\,{\intercal}}$
,
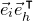 $\vec{e}_i\vec{e}_{h}^{\,{\intercal}}$
and
$\vec{e}_i\vec{e}_{h}^{\,{\intercal}}$
and
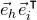 $\vec{e}_h\vec{e}_{i}^{\,{\intercal}}$
for
$\vec{e}_h\vec{e}_{i}^{\,{\intercal}}$
for
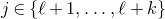 $j\in \{\ell+1,\ldots,\ell+k\}$
,
$j\in \{\ell+1,\ldots,\ell+k\}$
,
 $h\in [n]$
and
$h\in [n]$
and
 $i\in S$
, where
$i\in S$
, where
 $\vec{e}_1,\ldots,\vec{e}_n$
are the standard basis vectors in
$\vec{e}_1,\ldots,\vec{e}_n$
are the standard basis vectors in
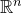 $\mathbb{R}^n$
, and
$\mathbb{R}^n$
, and
 $\vec{v}_{\ell+1},\ldots,\vec{v}_{\ell+k}\in \mathbb{R}^n$
denote the coefficient vectors of
$\vec{v}_{\ell+1},\ldots,\vec{v}_{\ell+k}\in \mathbb{R}^n$
denote the coefficient vectors of
 $g^{({\ell+1})},\ldots,g^{({\ell+k})}$
(i.e., the row vectors of M, by condition (ii)). Hence the matrix
$g^{({\ell+1})},\ldots,g^{({\ell+k})}$
(i.e., the row vectors of M, by condition (ii)). Hence the matrix
 $A[I\times I]$
is a linear combination of matrices of the form
$A[I\times I]$
is a linear combination of matrices of the form
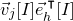 $\vec{v}_j[I]\vec{e}_h^{\,{\intercal}}[I]$
and
$\vec{v}_j[I]\vec{e}_h^{\,{\intercal}}[I]$
and
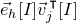 $\vec{e}_h[I]\vec{v}_j^{\,{\intercal}}[I]$
for
$\vec{e}_h[I]\vec{v}_j^{\,{\intercal}}[I]$
for
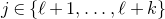 $j\in \{\ell+1,\ldots,\ell+k\}$
and
$j\in \{\ell+1,\ldots,\ell+k\}$
and
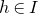 $h\in I$
. Recalling that
$h\in I$
. Recalling that
 $\vec{v}_{\ell+1},\ldots,\vec{v}_{\ell+k}$
are the row vectors of the matrix M, this means that
$\vec{v}_{\ell+1},\ldots,\vec{v}_{\ell+k}$
are the row vectors of the matrix M, this means that
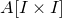 $A[I\times I]$
is a
$A[I\times I]$
is a
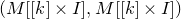 $(M[[k]\times I],M[[k]\times I])$
-perturbation of the zero matrix, contradicting our assumption. So indeed, for some monomial
$(M[[k]\times I],M[[k]\times I])$
-perturbation of the zero matrix, contradicting our assumption. So indeed, for some monomial
 $y_jy_{j'}$
with
$y_jy_{j'}$
with
 $j,j'\in [\ell]$
, the coefficient of
$j,j'\in [\ell]$
, the coefficient of
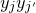 $y_jy_{j'}$
in P must be nonzero. This also automatically implies that
$y_jy_{j'}$
in P must be nonzero. This also automatically implies that
 $\ell\ge 1$
.
$\ell\ge 1$
.
It now remains to show (iii), i.e., to show that for the matrix
 $M'\in \mathbb{R}^{(\ell+k)\times n}$
whose rows are given by the coefficient vectors of
$M'\in \mathbb{R}^{(\ell+k)\times n}$
whose rows are given by the coefficient vectors of
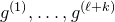 $g^{(1)},\ldots,g^{({\ell+k})}$
we have
$g^{(1)},\ldots,g^{({\ell+k})}$
we have
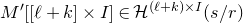 $M'[[\ell+k]\times I]\in \mathcal{H}^{(\ell+k)\times I}(s/r)$
. Assume the contrary; then there exists a nontrivial linear combination of the rows of
$M'[[\ell+k]\times I]\in \mathcal{H}^{(\ell+k)\times I}(s/r)$
. Assume the contrary; then there exists a nontrivial linear combination of the rows of
 $M'[[\ell+k]\times I]$
yielding a vector with at most
$M'[[\ell+k]\times I]$
yielding a vector with at most
 $s/r$
nonzero entries. By (ii), the rows of the matrix
$s/r$
nonzero entries. By (ii), the rows of the matrix
 $M'[\{\ell+1,\ldots,\ell+k\}\times [n]]$
agree with the rows of the matrix M, and we therefore have
$M'[\{\ell+1,\ldots,\ell+k\}\times [n]]$
agree with the rows of the matrix M, and we therefore have
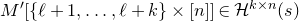 $M'[\{\ell+1,\ldots,\ell+k\}\times [n]]\in \mathcal{H}^{k\times n}(s)$
(recalling that
$M'[\{\ell+1,\ldots,\ell+k\}\times [n]]\in \mathcal{H}^{k\times n}(s)$
(recalling that
 $M\in \mathcal{H}^{k\times n}(s)$
). Using
$M\in \mathcal{H}^{k\times n}(s)$
). Using
 $|S|\le s\cdot (r-\ell)/r\le s\cdot (r-1)/r$
, we can conclude that
$|S|\le s\cdot (r-\ell)/r\le s\cdot (r-1)/r$
, we can conclude that
 $M'[\{\ell+1,\ldots,\ell+k\}\times I]\in \mathcal{H}^{k\times I}(s-|S|)\subseteq \mathcal{H}^{k\times I}(s/r)$
, so our linear combination cannot only involve rows with indices in
$M'[\{\ell+1,\ldots,\ell+k\}\times I]\in \mathcal{H}^{k\times I}(s-|S|)\subseteq \mathcal{H}^{k\times I}(s/r)$
, so our linear combination cannot only involve rows with indices in
 $\{\ell+1,\ldots,\ell+k\}$
. Thus, we may assume without loss of generality that it involves the first row of
$\{\ell+1,\ldots,\ell+k\}$
. Thus, we may assume without loss of generality that it involves the first row of
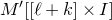 $M'[[\ell+k]\times I]$
, meaning that this first row differs in at most
$M'[[\ell+k]\times I]$
, meaning that this first row differs in at most
 $s/r$
entries from some linear combination of the other rows of
$s/r$
entries from some linear combination of the other rows of
 $M'[[\ell+k]\times I]$
. In other words, we can write
$M'[[\ell+k]\times I]$
. In other words, we can write
 $g^{({1})}$
as a linear combination of
$g^{({1})}$
as a linear combination of
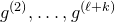 $g^{(2)},\ldots,g^{({\ell+k})}$
and
$g^{(2)},\ldots,g^{({\ell+k})}$
and
 $x_i$
for
$x_i$
for
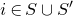 $i\in S\cup S'$
, for some subset
$i\in S\cup S'$
, for some subset
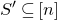 $S'\subseteq [n]$
of size
$S'\subseteq [n]$
of size
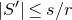 $|S'|\le s/r$
. But this means that
$|S'|\le s/r$
. But this means that
 $Q(x_1,\ldots,x_n)=P(g^{(1)}(\vec{x}),\ldots,g^{({\ell+k})}(\vec{x}), (x_i)_{i\in S})$
can be written as
$Q(x_1,\ldots,x_n)=P(g^{(1)}(\vec{x}),\ldots,g^{({\ell+k})}(\vec{x}), (x_i)_{i\in S})$
can be written as
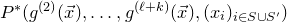 $P^*(g^{(2)}(\vec{x}),\ldots,g^{({\ell+k})}(\vec{x}), (x_i)_{i\in S\cup S'})$
for some quadratic polynomial
$P^*(g^{(2)}(\vec{x}),\ldots,g^{({\ell+k})}(\vec{x}), (x_i)_{i\in S\cup S'})$
for some quadratic polynomial
 $P^*\in \mathbb{R}[y_2,\ldots,y_{\ell+k}, (x_i)_{i\in S\cup S'}]$
. Since
$P^*\in \mathbb{R}[y_2,\ldots,y_{\ell+k}, (x_i)_{i\in S\cup S'}]$
. Since
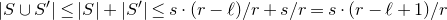 $|S\cup S'|\le |S|+|S'|\le s\cdot (r-\ell)/r+s/r=s\cdot (r-\ell+1)/r$
, this contradicts the minimality of
$|S\cup S'|\le |S|+|S'|\le s\cdot (r-\ell)/r+s/r=s\cdot (r-\ell+1)/r$
, this contradicts the minimality of
 $\ell$
(we now have a suitable representation of Q in terms of the
$\ell$
(we now have a suitable representation of Q in terms of the
 $(\ell-1)+k$
linear forms
$(\ell-1)+k$
linear forms
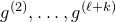 $g^{(2)},\ldots,g^{({\ell+k})}$
). So we must have
$g^{(2)},\ldots,g^{({\ell+k})}$
). So we must have
 $M'[[\ell+k]\times I]\in \mathcal{H}^{(\ell+k)\times I}(s/r)$
, as desired.
$M'[[\ell+k]\times I]\in \mathcal{H}^{(\ell+k)\times I}(s/r)$
, as desired.
Using Lemma 6.2 and Theorem 4.2, we now prove Proposition 6.1.
Proof of Proposition 6.1. First, note that we may assume that
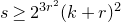 $s\ge 2^{3r^2}(k+r)^2$
, since otherwise Equation (6.1) is trivially true. Now, apply Lemma 6.2 to obtain a positive integer
$s\ge 2^{3r^2}(k+r)^2$
, since otherwise Equation (6.1) is trivially true. Now, apply Lemma 6.2 to obtain a positive integer
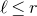 $\ell\le r$
, a partition
$\ell\le r$
, a partition
 $[n]=I\cup S$
, linear forms
$[n]=I\cup S$
, linear forms
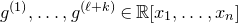 $g^{(1)},\ldots,g^{(\ell+k)}\in \mathbb{R}[x_1,\ldots,x_n]$
and a quadratic polynomial
$g^{(1)},\ldots,g^{(\ell+k)}\in \mathbb{R}[x_1,\ldots,x_n]$
and a quadratic polynomial
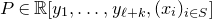 $P\in \mathbb{R}[y_1,\ldots,y_{\ell+k}, (x_i)_{i\in S}]$
satisfying conditions (i) to (iv) in the statement of the lemma.
$P\in \mathbb{R}[y_1,\ldots,y_{\ell+k}, (x_i)_{i\in S}]$
satisfying conditions (i) to (iv) in the statement of the lemma.
Our plan is to show that the bound in Equation (6.1) holds even if we condition on an arbitrary outcome of
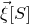 $\vec \xi[S]$
(leaving only the randomness in
$\vec \xi[S]$
(leaving only the randomness in
 $\vec \xi[I]$
). For any outcome of
$\vec \xi[I]$
). For any outcome of
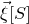 $\vec \xi[S]$
, when plugging in
$\vec \xi[S]$
, when plugging in
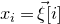 $x_i=\vec{\xi}[i]$
for
$x_i=\vec{\xi}[i]$
for
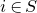 $i\in S$
into the polynomial
$i\in S$
into the polynomial
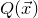 $Q(\vec x)$
and the linear forms
$Q(\vec x)$
and the linear forms
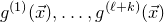 $g^{(1)}(\vec x),\ldots,g^{({\ell+k})}(\vec x)$
, we obtain a polynomial
$g^{(1)}(\vec x),\ldots,g^{({\ell+k})}(\vec x)$
, we obtain a polynomial
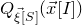 $Q_{\vec \xi[S]}(\vec x[I])$
and linear functions
$Q_{\vec \xi[S]}(\vec x[I])$
and linear functions
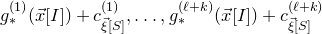 $g^{(1)}_{*}(\vec x[I])+c^{(1)}_{\vec \xi[S]},\ldots,g^{({\ell+k})}_{*}(\vec x[I])+c^{(\ell+k)}_{\vec \xi[S]}$
(where
$g^{(1)}_{*}(\vec x[I])+c^{(1)}_{\vec \xi[S]},\ldots,g^{({\ell+k})}_{*}(\vec x[I])+c^{(\ell+k)}_{\vec \xi[S]}$
(where
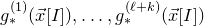 $g^{(1)}_{*}(\vec x[I]),\ldots,g^{({\ell+k})}_{*}(\vec x[I])$
are the linear forms obtained from
$g^{(1)}_{*}(\vec x[I]),\ldots,g^{({\ell+k})}_{*}(\vec x[I])$
are the linear forms obtained from
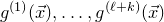 $g^{(1)}(\vec x),\ldots,g^{({\ell+k})}(\vec x)$
by omitting all terms with variables
$g^{(1)}(\vec x),\ldots,g^{({\ell+k})}(\vec x)$
by omitting all terms with variables
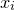 $x_i$
for
$x_i$
for
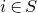 $i\in S$
, and where
$i\in S$
, and where
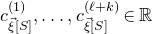 $c^{(1)}_{\vec \xi[S]},\ldots,c^{({\ell+k})}_{\vec \xi[S]}\in \mathbb{R}$
are real numbers that may depend on
$c^{(1)}_{\vec \xi[S]},\ldots,c^{({\ell+k})}_{\vec \xi[S]}\in \mathbb{R}$
are real numbers that may depend on
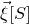 $\vec \xi[S]$
) and by (i) we obtain that
$\vec \xi[S]$
) and by (i) we obtain that
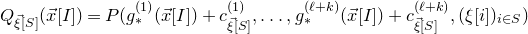 $Q_{\vec \xi[S]}(\vec{x}[I])=P(g^{(1)}_{*}(\vec x[I])+c^{(1)}_{\vec \xi[S]},\ldots,g^{({\ell+k})}_{*}(\vec x[I])+c^{(\ell+k)}_{\vec \xi[S]}, (\xi[i])_{i\in S})$
. For any outcome of
$Q_{\vec \xi[S]}(\vec{x}[I])=P(g^{(1)}_{*}(\vec x[I])+c^{(1)}_{\vec \xi[S]},\ldots,g^{({\ell+k})}_{*}(\vec x[I])+c^{(\ell+k)}_{\vec \xi[S]}, (\xi[i])_{i\in S})$
. For any outcome of
 $\vec \xi[S]$
, we can furthermore write
$\vec \xi[S]$
, we can furthermore write
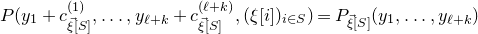 $P(y_1+c^{(1)}_{\vec \xi[S]},\ldots,y_{\ell+k}+c^{(\ell+k)}_{\vec \xi[S]},(\xi[i])_{i\in S})=P_{\vec \xi[S]}(y_1,\ldots,y_{\ell+k})$
for a polynomial
$P(y_1+c^{(1)}_{\vec \xi[S]},\ldots,y_{\ell+k}+c^{(\ell+k)}_{\vec \xi[S]},(\xi[i])_{i\in S})=P_{\vec \xi[S]}(y_1,\ldots,y_{\ell+k})$
for a polynomial
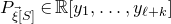 $P_{\vec \xi[S]}\in \mathbb{R}[y_1,\ldots,y_{\ell+k}]$
whose coefficients may depend on
$P_{\vec \xi[S]}\in \mathbb{R}[y_1,\ldots,y_{\ell+k}]$
whose coefficients may depend on
 $\vec \xi[S]$
. Then we always have
$\vec \xi[S]$
. Then we always have
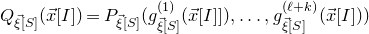 $Q_{\vec \xi[S]}(\vec{x}[I])=P_{\vec \xi[S]}(g^{(1)}_{\vec \xi[S]}(\vec{x}[I]]),\ldots,g^{({\ell+k})}_{\vec \xi[S]}(\vec{x}[I]))$
. Recall that the coefficient vectors of the linear forms
$Q_{\vec \xi[S]}(\vec{x}[I])=P_{\vec \xi[S]}(g^{(1)}_{\vec \xi[S]}(\vec{x}[I]]),\ldots,g^{({\ell+k})}_{\vec \xi[S]}(\vec{x}[I]))$
. Recall that the coefficient vectors of the linear forms
 $g^{(1)}_{*}(\vec x[I]),\ldots,g^{({\ell+k})}_{*}(\vec x[I])$
are obtained by restricting the coefficient vectors of
$g^{(1)}_{*}(\vec x[I]),\ldots,g^{({\ell+k})}_{*}(\vec x[I])$
are obtained by restricting the coefficient vectors of
 $g^{(1)}(\vec x),\ldots,g^{({\ell+k})}(\vec x)$
to the index set I. In particular, by condition (ii), for
$g^{(1)}(\vec x),\ldots,g^{({\ell+k})}(\vec x)$
to the index set I. In particular, by condition (ii), for
 $j=1,\ldots,k$
the coefficient vector of
$j=1,\ldots,k$
the coefficient vector of
 $g^{({\ell+j})}_{*}(\vec x[I])$
is the restriction
$g^{({\ell+j})}_{*}(\vec x[I])$
is the restriction
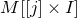 $M[[j]\times I]$
of the jth row of M to I. We then have
$M[[j]\times I]$
of the jth row of M to I. We then have
 \begin{align*}&\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec{\xi}=\vec{w}\,|\,\vec \xi[S]]\\&\qquad =\mathrm{Pr}[Q_{\vec \xi[S]}(\vec \xi[I])=0 \text{ and } M[[k]\times I]\vec{\xi}[I]=\vec{w}_{\vec \xi[S]}\,|\,\vec \xi[S]]\\&\qquad =\mathrm{Pr}[P_{\vec \xi[S]}(g^{(1)}_{*}(\vec{\xi}[I]),\ldots,g^{({\ell+k})}_{*}(\vec{\xi}[I]))=0 \text{ and } g^{({\ell+j})}_{*}(\vec{\xi}[I])=\vec{w}_{\vec \xi[S]}[j]\text{ for }j=1,\ldots,k\,|\,\vec \xi[S]],\end{align*}
\begin{align*}&\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec{\xi}=\vec{w}\,|\,\vec \xi[S]]\\&\qquad =\mathrm{Pr}[Q_{\vec \xi[S]}(\vec \xi[I])=0 \text{ and } M[[k]\times I]\vec{\xi}[I]=\vec{w}_{\vec \xi[S]}\,|\,\vec \xi[S]]\\&\qquad =\mathrm{Pr}[P_{\vec \xi[S]}(g^{(1)}_{*}(\vec{\xi}[I]),\ldots,g^{({\ell+k})}_{*}(\vec{\xi}[I]))=0 \text{ and } g^{({\ell+j})}_{*}(\vec{\xi}[I])=\vec{w}_{\vec \xi[S]}[j]\text{ for }j=1,\ldots,k\,|\,\vec \xi[S]],\end{align*}
for any outcome of
 $\vec \xi[S]$
, where
$\vec \xi[S]$
, where
 $\vec{w}_{\vec \xi[S]}=\vec{w}-M[[k]\times S]\vec{\xi}[S]\in \mathbb{R}^k$
. We wish to show that for all outcomes of
$\vec{w}_{\vec \xi[S]}=\vec{w}-M[[k]\times S]\vec{\xi}[S]\in \mathbb{R}^k$
. We wish to show that for all outcomes of
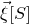 $\vec \xi[S]$
, the above conditional probability is bounded by the right-hand side of Equation (6.1).
$\vec \xi[S]$
, the above conditional probability is bounded by the right-hand side of Equation (6.1).
Recall that
 $P\in \mathbb{R}[y_1,\ldots,y_{\ell+k}, (x_i)_{i\in S}]$
is a quadratic polynomial, and by condition (iv), for some
$P\in \mathbb{R}[y_1,\ldots,y_{\ell+k}, (x_i)_{i\in S}]$
is a quadratic polynomial, and by condition (iv), for some
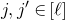 $j,j'\in [\ell]$
the coefficient of
$j,j'\in [\ell]$
the coefficient of
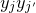 $y_j y_{j'}$
in P is nonzero. This means that the coefficient of
$y_j y_{j'}$
in P is nonzero. This means that the coefficient of
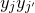 $y_jy_{j'}$
in
$y_jy_{j'}$
in
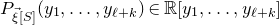 $P_{\vec \xi[S]}(y_1,\ldots,y_{\ell+k})\in \mathbb{R}[y_1,\ldots,y_{\ell+k}]$
is still nonzero, for any outcome of
$P_{\vec \xi[S]}(y_1,\ldots,y_{\ell+k})\in \mathbb{R}[y_1,\ldots,y_{\ell+k}]$
is still nonzero, for any outcome of
 $\vec \xi[S]$
.
$\vec \xi[S]$
.
Since the coefficient vectors of the linear forms
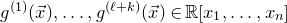 $g^{(1)}(\vec x),\ldots,g^{({\ell+k})}(\vec x)\in \mathbb{R}[x_1,\ldots,x_n]$
are the rows of the matrix M’ in condition (iii), the coefficient vectors of
$g^{(1)}(\vec x),\ldots,g^{({\ell+k})}(\vec x)\in \mathbb{R}[x_1,\ldots,x_n]$
are the rows of the matrix M’ in condition (iii), the coefficient vectors of
 $g^{(1)}_{*}(\vec x[I]),\ldots,g^{({\ell+k})}_{*}(\vec x[I])\in \mathbb{R}[x_i: i\in I]$
are the rows of the matrix
$g^{(1)}_{*}(\vec x[I]),\ldots,g^{({\ell+k})}_{*}(\vec x[I])\in \mathbb{R}[x_i: i\in I]$
are the rows of the matrix
 $M'[[\ell+k]\times I]$
. Now, define the vectors
$M'[[\ell+k]\times I]$
. Now, define the vectors
 $\vec{a}_i\in \mathbb{R}^{\ell+k}$
, for
$\vec{a}_i\in \mathbb{R}^{\ell+k}$
, for
 $i\in I$
, to be the columns of the matrix
$i\in I$
, to be the columns of the matrix
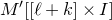 $M'[[\ell+k]\times I]$
. Then for any outcome of
$M'[[\ell+k]\times I]$
. Then for any outcome of
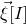 $\vec{\xi}[I]$
, the vector
$\vec{\xi}[I]$
, the vector
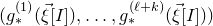 $(g^{(1)}_{*}(\vec{\xi}[I]),\ldots,g^{({\ell+k})}_{*}(\vec{\xi}[I]))$
agrees with
$(g^{(1)}_{*}(\vec{\xi}[I]),\ldots,g^{({\ell+k})}_{*}(\vec{\xi}[I]))$
agrees with
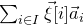 $\sum_{i\in I} \vec{\xi}[i]\vec{a}_i$
.
$\sum_{i\in I} \vec{\xi}[i]\vec{a}_i$
.
Furthermore, as
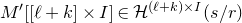 $M'[[\ell+k]\times I]\in \mathcal{H}^{(\ell+k)\times I}(s/r)$
, by Lemma 3.2(ii) the matrix
$M'[[\ell+k]\times I]\in \mathcal{H}^{(\ell+k)\times I}(s/r)$
, by Lemma 3.2(ii) the matrix
 $M'[[\ell+k]\times I]$
must contain
$M'[[\ell+k]\times I]$
must contain
 $\lceil s/(r(\ell+k))\rceil\ge \lceil s/(k+r)^2\rceil$
disjoint nonsingular
$\lceil s/(r(\ell+k))\rceil\ge \lceil s/(k+r)^2\rceil$
disjoint nonsingular
 $(\ell+k)\times (\ell+k)$
submatrices, so among the vectors
$(\ell+k)\times (\ell+k)$
submatrices, so among the vectors
 $\vec{a}_i$
for
$\vec{a}_i$
for
 $i\in I$
we can form
$i\in I$
we can form
 $\lceil s/(k+r)^2\rceil$
disjoint bases of
$\lceil s/(k+r)^2\rceil$
disjoint bases of
 $\mathbb{R}^{\ell+k}$
. Consider the largest integer
$\mathbb{R}^{\ell+k}$
. Consider the largest integer
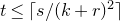 $t\le \lceil s/(k+r)^2\rceil$
which is divisible by
$t\le \lceil s/(k+r)^2\rceil$
which is divisible by
 $2^{\ell-1}$
, and note that
$2^{\ell-1}$
, and note that
 $t\ge \lceil s/(k+r)^2\rceil/2\ge s/(2(k+r)^2)$
, since
$t\ge \lceil s/(k+r)^2\rceil/2\ge s/(2(k+r)^2)$
, since
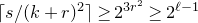 $\lceil s/(k+r)^2\rceil\ge 2^{3r^2}\ge 2^{\ell-1}$
.
$\lceil s/(k+r)^2\rceil\ge 2^{3r^2}\ge 2^{\ell-1}$
.
Now, for any outcome of
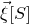 $\vec \xi[S]$
, we obtain
$\vec \xi[S]$
, we obtain
 \begin{align*}&\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec{\xi}=\vec{w}\,|\,\vec \xi[S]]\\&\qquad=\mathrm{Pr}\bigg[P_{\vec \xi[S]}\bigg(\sum_{i\in I}\vec \xi[i]\vec{a}_i\bigg)=0 \text{ and } \sum_{i\in I}\vec \xi[i]\vec{a}_i[\ell+j]=\vec{w}_{\vec \xi[S]}[j]\text{ for }j=1,\ldots,k\,|\,\vec \xi[S]\bigg]\\&\qquad=\mathrm{Pr}\bigg[P_{\vec \xi[S]}\bigg(\sum_{i\in I}\vec \xi[i]\vec{a}_i\bigg)=0 \text{ and } \sum_{i\in I}\vec \xi[i]\vec{a}_i\in \mathcal{W}_{\vec \xi[S]}\,|\,\vec \xi[S]\bigg]=\mathrm{Pr}\bigg[\sum_{i\in I}\vec \xi[i]\vec{a}_i\in \mathcal{Z}_{\vec \xi[S]}\,|\,\vec \xi[S]\bigg],\end{align*}
\begin{align*}&\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec{\xi}=\vec{w}\,|\,\vec \xi[S]]\\&\qquad=\mathrm{Pr}\bigg[P_{\vec \xi[S]}\bigg(\sum_{i\in I}\vec \xi[i]\vec{a}_i\bigg)=0 \text{ and } \sum_{i\in I}\vec \xi[i]\vec{a}_i[\ell+j]=\vec{w}_{\vec \xi[S]}[j]\text{ for }j=1,\ldots,k\,|\,\vec \xi[S]\bigg]\\&\qquad=\mathrm{Pr}\bigg[P_{\vec \xi[S]}\bigg(\sum_{i\in I}\vec \xi[i]\vec{a}_i\bigg)=0 \text{ and } \sum_{i\in I}\vec \xi[i]\vec{a}_i\in \mathcal{W}_{\vec \xi[S]}\,|\,\vec \xi[S]\bigg]=\mathrm{Pr}\bigg[\sum_{i\in I}\vec \xi[i]\vec{a}_i\in \mathcal{Z}_{\vec \xi[S]}\,|\,\vec \xi[S]\bigg],\end{align*}
where
 $\mathcal{W}_{\vec \xi[S]}\subseteq \mathbb{R}^{\ell+k}$
is the
$\mathcal{W}_{\vec \xi[S]}\subseteq \mathbb{R}^{\ell+k}$
is the
 $\ell$
-dimensional affine-linear subspace consisting of the points
$\ell$
-dimensional affine-linear subspace consisting of the points
 $\vec{y}\in \mathbb{R}^{\ell+k}$
with
$\vec{y}\in \mathbb{R}^{\ell+k}$
with
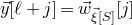 $\vec{y}[\ell+j]=\vec{w}_{\vec \xi[S]}[j]$
for
$\vec{y}[\ell+j]=\vec{w}_{\vec \xi[S]}[j]$
for
 $j=1,\ldots,k$
, and
$j=1,\ldots,k$
, and
 $\mathcal{Z}_{\vec \xi[S]}\subseteq \mathcal{W}_{\vec \xi[S]}$
is the subset of
$\mathcal{Z}_{\vec \xi[S]}\subseteq \mathcal{W}_{\vec \xi[S]}$
is the subset of
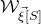 $\mathcal{W}_{\vec \xi[S]}$
given by
$\mathcal{W}_{\vec \xi[S]}$
given by
 $\mathcal{Z}_{\vec \xi[S]}=\{\vec{y}\in \mathcal{W}_{\vec \xi[S]}: P_{\vec \xi[S]}(\vec{y})=0\}$
.
$\mathcal{Z}_{\vec \xi[S]}=\{\vec{y}\in \mathcal{W}_{\vec \xi[S]}: P_{\vec \xi[S]}(\vec{y})=0\}$
.
We claim that for any outcome of
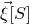 $\vec \xi[S]$
, we have
$\vec \xi[S]$
, we have
 $\mathcal{Z}_{\vec \xi[S]}\subsetneq \mathcal{W}_{\vec \xi[S]}$
, i.e.,
$\mathcal{Z}_{\vec \xi[S]}\subsetneq \mathcal{W}_{\vec \xi[S]}$
, i.e.,
 $\mathcal{Z}_{\vec \xi[S]}$
is a quadric on
$\mathcal{Z}_{\vec \xi[S]}$
is a quadric on
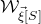 $\mathcal{W}_{\vec \xi[S]}$
. Indeed, if we had
$\mathcal{W}_{\vec \xi[S]}$
. Indeed, if we had
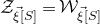 $\mathcal{Z}_{\vec \xi[S]}= \mathcal{W}_{\vec \xi[S]}$
, then the polynomial
$\mathcal{Z}_{\vec \xi[S]}= \mathcal{W}_{\vec \xi[S]}$
, then the polynomial
 $P_{\vec \xi[S]}$
would be identically zero on the entire subspace
$P_{\vec \xi[S]}$
would be identically zero on the entire subspace
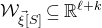 $\mathcal{W}_{\vec \xi[S]}\subseteq \mathbb{R}^{\ell+k}$
. Note that, on the space
$\mathcal{W}_{\vec \xi[S]}\subseteq \mathbb{R}^{\ell+k}$
. Note that, on the space
 $\mathcal{W}_{\vec \xi[S]}$
, we can identify
$\mathcal{W}_{\vec \xi[S]}$
, we can identify
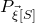 $P_{\vec \xi[S]}$
with some quadratic polynomial in the variables
$P_{\vec \xi[S]}$
with some quadratic polynomial in the variables
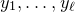 $y_{1},\ldots,y_{\ell}$
(obtained by substituting
$y_{1},\ldots,y_{\ell}$
(obtained by substituting
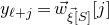 $y_{\ell+j}=\vec{w}_{\vec \xi[S]}[j]$
for
$y_{\ell+j}=\vec{w}_{\vec \xi[S]}[j]$
for
 $j=1,\ldots,k$
). This polynomial has a nonzero coefficient for some monomial of the form
$j=1,\ldots,k$
). This polynomial has a nonzero coefficient for some monomial of the form
 $y_jy_{j'}$
with
$y_jy_{j'}$
with
 $j,j'\in [\ell]$
, since
$j,j'\in [\ell]$
, since
 $P_{\vec \xi[S]}$
also has a nonzero coefficient for such a monomial. Hence the polynomial
$P_{\vec \xi[S]}$
also has a nonzero coefficient for such a monomial. Hence the polynomial
 $P_{\vec \xi[S]}$
cannot vanish on the entire subspace
$P_{\vec \xi[S]}$
cannot vanish on the entire subspace
 $\mathcal{W}_{\vec \xi[S]}$
, so indeed
$\mathcal{W}_{\vec \xi[S]}$
, so indeed
 $\mathcal{Z}_{\vec \xi[S]}\subsetneq \mathcal{W}_{\vec \xi[S]}$
.
$\mathcal{Z}_{\vec \xi[S]}\subsetneq \mathcal{W}_{\vec \xi[S]}$
.
Recalling that among the vectors
 $\vec{a}_i$
for
$\vec{a}_i$
for
 $i\in I$
we can form t disjoint bases of
$i\in I$
we can form t disjoint bases of
 $\mathbb{R}^{\ell+k}$
, we can now apply Theorem 4.2 (after conditioning on any outcome of
$\mathbb{R}^{\ell+k}$
, we can now apply Theorem 4.2 (after conditioning on any outcome of
 $\vec \xi[S]$
) and obtain the bound
$\vec \xi[S]$
) and obtain the bound
 \begin{align*}\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec{\xi}=\vec{w}\,|\, \vec \xi[S]]&=\mathrm{Pr}\Biggl[\sum_{i\in I}\vec \xi[i]\vec{a}_i\in \mathcal{Z}_{\vec \xi[S]}\,\Bigg|\, \vec \xi[S]\Biggr]\\&\le \frac{2^{(\ell-1)(\ell+k)+1}}{t^{((\ell+k)-(\ell-1))/2}}\le \frac{2^{(\ell-1)\ell(k+1)+1}}{t^{(k+1)/2}}\le \frac{2^{\ell^2(k+1)}}{(s/(2(k+r)^2))^{(k+1)/2}}\\&\le \bigg(\frac{2^{3\ell^2}(k+r)^2}{s}\bigg)^{(k+1)/2}\!\!= \bigg(\frac{s}{2^{3r^2}(k+r)^2}\bigg)^{-(k+1)/2}\!,\end{align*}
\begin{align*}\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec{\xi}=\vec{w}\,|\, \vec \xi[S]]&=\mathrm{Pr}\Biggl[\sum_{i\in I}\vec \xi[i]\vec{a}_i\in \mathcal{Z}_{\vec \xi[S]}\,\Bigg|\, \vec \xi[S]\Biggr]\\&\le \frac{2^{(\ell-1)(\ell+k)+1}}{t^{((\ell+k)-(\ell-1))/2}}\le \frac{2^{(\ell-1)\ell(k+1)+1}}{t^{(k+1)/2}}\le \frac{2^{\ell^2(k+1)}}{(s/(2(k+r)^2))^{(k+1)/2}}\\&\le \bigg(\frac{2^{3\ell^2}(k+r)^2}{s}\bigg)^{(k+1)/2}\!\!= \bigg(\frac{s}{2^{3r^2}(k+r)^2}\bigg)^{-(k+1)/2}\!,\end{align*}
as desired.
7. Robust rank inheritance
In this section, we prove Lemma 5.7 (the robust rank inheritance lemma). Actually, we will deduce Lemma 5.7 from the following somewhat simpler statement with just two matrices T,A instead of three matrices T,U,A (to deduce Lemma 5.7, we will take
 $r=2$
in the statement below).
$r=2$
in the statement below).
Lemma 7.1. Let
 $r\ge 1$
and
$r\ge 1$
and
 $s\ge 1$
and
$s\ge 1$
and
 $0\le k\le m\le n$
be integers. Consider matrices
$0\le k\le m\le n$
be integers. Consider matrices
 $T\in \mathbb{R}^{k\times m}$
and
$T\in \mathbb{R}^{k\times m}$
and
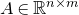 $A\in \mathbb{R}^{n\times m}$
, and vectors
$A\in \mathbb{R}^{n\times m}$
, and vectors
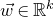 $\vec w\in\mathbb{R}^{k}$
and
$\vec w\in\mathbb{R}^{k}$
and
 $\vec v\in\mathbb{R}^{n}$
. Assume that there exist disjoint subsets
$\vec v\in\mathbb{R}^{n}$
. Assume that there exist disjoint subsets
 $I_1,\ldots, I_s\subseteq [m]$
and disjoint subsets
$I_1,\ldots, I_s\subseteq [m]$
and disjoint subsets
 $J_1,\ldots,J_s\subseteq [n]$
of size
$J_1,\ldots,J_s\subseteq [n]$
of size
 $|I_1|=\dots=|I_s|=|J_1|=\dots=|J_s|=k+r$
such that the following hold.
$|I_1|=\dots=|I_s|=|J_1|=\dots=|J_s|=k+r$
such that the following hold.
-
(i) For
$t=1,\ldots,s$
, the submatrix
$T[[k]\times I_t]$
has rank k. -
(ii) For
$t=1,\ldots,s$
, every
$(T[[k]\times I_t],0)$
-perturbation of the matrix
$A[J_t\times I_t]$
has rank at least r.

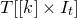



Then, for a sequence of independent Rademacher random variables
 $\vec{\xi}=(\xi_{1},\ldots,\xi_{m})\in\{-1,1\}^{m}$
, we have
$\vec{\xi}=(\xi_{1},\ldots,\xi_{m})\in\{-1,1\}^{m}$
, we have
 \begin{equation}\mathrm{Pr}[T\vec{\xi}=\vec{w} \, { and } \, A\vec{\xi}-\vec{v} \, { has \, at \, most }s/6 \, { nonzero \, coordinates}]\le\bigg(\frac{s}{10^{60}(k+r)^{20}}\bigg)^{-(k+r)/2}.\end{equation}
\begin{equation}\mathrm{Pr}[T\vec{\xi}=\vec{w} \, { and } \, A\vec{\xi}-\vec{v} \, { has \, at \, most }s/6 \, { nonzero \, coordinates}]\le\bigg(\frac{s}{10^{60}(k+r)^{20}}\bigg)^{-(k+r)/2}.\end{equation}
Note that, if
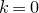 $k=0$
, then condition (i) is vacuous, and in condition (ii), there are no nontrivial
$k=0$
, then condition (i) is vacuous, and in condition (ii), there are no nontrivial
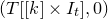 $(T[[k]\times I_t],0)$
-perturbations. This case of Lemma 7.1 implies Lemma 2.1 (the ‘Hamming norm’ anticoncentration inequality mentioned in § 2); the formal deduction can be found at the end of this section.
$(T[[k]\times I_t],0)$
-perturbations. This case of Lemma 7.1 implies Lemma 2.1 (the ‘Hamming norm’ anticoncentration inequality mentioned in § 2); the formal deduction can be found at the end of this section.
Also, note that assumptions (i) and (ii) in particular imply that for all
 $t=1,\ldots,s$
we have
$t=1,\ldots,s$
we have
 \begin{equation}\operatorname{rank}\begin{pmatrix}A[J_t\times I_t]\\ T[[k]\times I_t]\end{pmatrix}\ge k+r.\end{equation}
\begin{equation}\operatorname{rank}\begin{pmatrix}A[J_t\times I_t]\\ T[[k]\times I_t]\end{pmatrix}\ge k+r.\end{equation}
Indeed, if this rank were at most
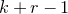 $k+r-1$
, then one would be able to form a basis of the row span of the above matrix using the k rows of
$k+r-1$
, then one would be able to form a basis of the row span of the above matrix using the k rows of
 $T[[k]\times I_t]$
and up to
$T[[k]\times I_t]$
and up to
 $r-1$
rows of
$r-1$
rows of
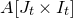 $A[J_t\times I_t]$
(recall that by assumption (i) the rows of the matrix
$A[J_t\times I_t]$
(recall that by assumption (i) the rows of the matrix
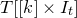 $T[[k]\times I_t]$
are linearly independent). But then it would be possible to add linear combinations of the rows of
$T[[k]\times I_t]$
are linearly independent). But then it would be possible to add linear combinations of the rows of
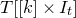 $T[[k]\times I_t]$
to the rows of
$T[[k]\times I_t]$
to the rows of
 $A[J_t\times I_t]$
to obtain a matrix of rank at most
$A[J_t\times I_t]$
to obtain a matrix of rank at most
 $r-1$
, contradicting assumption (ii).
$r-1$
, contradicting assumption (ii).
In order to prove Lemma 7.1 we will employ a witness-counting approach (as outlined in § 2.4), reminiscent of certain arguments of Ferber, Jain, Luh and Samotij [Reference Ferber, Jain, Luh and SamotijFJLS21]. We need to bound the probability that
 $T\vec{\xi}=\vec{w}$
and
$T\vec{\xi}=\vec{w}$
and
 $A\vec{\xi}-\vec{v}$
has more than
$A\vec{\xi}-\vec{v}$
has more than
 $n-s/6$
zero coordinates. Note that we can use Halász’ inequality (Theorem 3.3) to upper bound the probability that
$n-s/6$
zero coordinates. Note that we can use Halász’ inequality (Theorem 3.3) to upper bound the probability that
 $T\vec{\xi}=\vec{w}$
and a particular set of coordinates of
$T\vec{\xi}=\vec{w}$
and a particular set of coordinates of
 $A\vec{\xi}-\vec{v}$
are zero. However, it is far too wasteful to simply take a union bound over all subsets of
$A\vec{\xi}-\vec{v}$
are zero. However, it is far too wasteful to simply take a union bound over all subsets of
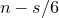 $n-s/6$
coordinates. Instead, we consider certain types of ‘witness’ sequences
$n-s/6$
coordinates. Instead, we consider certain types of ‘witness’ sequences
 $(h_1,\ldots,h_z)\in [n]^z$
of indices where the coordinates of
$(h_1,\ldots,h_z)\in [n]^z$
of indices where the coordinates of
 $A\vec{\xi}-\vec{v}$
are zero. If
$A\vec{\xi}-\vec{v}$
are zero. If
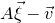 $A\vec{\xi}-\vec{v}$
has many zero coordinates, there must be many such ‘witness’ sequences, but on the other hand we can bound the expected number of such ‘witness’ sequences by considering the probability that
$A\vec{\xi}-\vec{v}$
has many zero coordinates, there must be many such ‘witness’ sequences, but on the other hand we can bound the expected number of such ‘witness’ sequences by considering the probability that
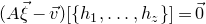 $(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
(and
$(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
(and
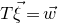 $T\vec{\xi}=\vec{w}$
) for a given such sequence
$T\vec{\xi}=\vec{w}$
) for a given such sequence
 $(h_1,\ldots,h_z)$
.
$(h_1,\ldots,h_z)$
.
The following lemma states that under the assumptions of Lemma 7.1, one can find a large submatrix of A which ‘has its rank robustly’ (the assumptions of the assumptions of Lemma 7.1 guarantee that A robustly has rank at least r, but the rank of A may actually be much larger than r, and that larger rank may be ‘fragile’). More precisely, we can find such a submatrix even within any large specified set H of rows.
Lemma 7.2. Let
 $r,k,s,m,n\in \mathbb{Z}$
, the matrices
$r,k,s,m,n\in \mathbb{Z}$
, the matrices
 $T\in \mathbb{R}^{k\times m}$
and
$T\in \mathbb{R}^{k\times m}$
and
 $A\in \mathbb{R}^{n\times m}$
and the sets
$A\in \mathbb{R}^{n\times m}$
and the sets
 $J_1,\ldots,J_s\subseteq [n]$
be as in Lemma 7.1. Then, for any subset
$J_1,\ldots,J_s\subseteq [n]$
be as in Lemma 7.1. Then, for any subset
 $H\subseteq J_1\cup\dots\cup J_s$
of size
$H\subseteq J_1\cup\dots\cup J_s$
of size
 $|H|\ge (k+r)s-(2/3)s$
, there are subsets
$|H|\ge (k+r)s-(2/3)s$
, there are subsets
 $J\subseteq H$
and
$J\subseteq H$
and
 $I\subseteq [m]$
with
$I\subseteq [m]$
with
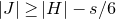 $|J|\ge |H|-s/6$
and
$|J|\ge |H|-s/6$
and
 $|I|\ge m-s/6$
and an integer
$|I|\ge m-s/6$
and an integer
 $z\ge r$
such that
$z\ge r$
such that
 \begin{equation}\operatorname{rank}\begin{pmatrix}A[J\times I]\\ T[[k]\times I]\end{pmatrix}=\operatorname{rank}\begin{pmatrix}A[J'\times I']\\ T[[k]\times I']\end{pmatrix}=k+z,\end{equation}
\begin{equation}\operatorname{rank}\begin{pmatrix}A[J\times I]\\ T[[k]\times I]\end{pmatrix}=\operatorname{rank}\begin{pmatrix}A[J'\times I']\\ T[[k]\times I']\end{pmatrix}=k+z,\end{equation}
for all subsets
 $J'\subseteq J$
and
$J'\subseteq J$
and
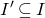 $I'\subseteq I$
of sizes
$I'\subseteq I$
of sizes
 $|J'|\ge |J|-s/(12z^2)$
and
$|J'|\ge |J|-s/(12z^2)$
and
 $|I'|\ge |I|-s/(12z^2)$
.
$|I'|\ge |I|-s/(12z^2)$
.
Proof. For every integer
 $z\ge 0$
, define
$z\ge 0$
, define
 $f(z)=\sum_{y=z+1}^{\infty} s/(12y^2)$
and note that
$f(z)=\sum_{y=z+1}^{\infty} s/(12y^2)$
and note that
 $f(z)\le \sum_{y=1}^{\infty} s/(12y^2)\lt s/6$
for all
$f(z)\le \sum_{y=1}^{\infty} s/(12y^2)\lt s/6$
for all
 $z\ge 0$
. Now consider the minimum integer
$z\ge 0$
. Now consider the minimum integer
 $z\ge 0$
such that there exist subsets
$z\ge 0$
such that there exist subsets
 $J\subseteq H$
and
$J\subseteq H$
and
 $I\subseteq[m]$
with
$I\subseteq[m]$
with
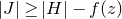 $|J|\ge |H|-f(z)$
and
$|J|\ge |H|-f(z)$
and
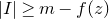 $|I|\ge m-f(z)$
and
$|I|\ge m-f(z)$
and
 $$ \operatorname{rank}\begin{pmatrix}A[J\times I]\\ T[[k]\times I]\end{pmatrix}\le k+z; $$
$$ \operatorname{rank}\begin{pmatrix}A[J\times I]\\ T[[k]\times I]\end{pmatrix}\le k+z; $$
(such an integer z exists, for example
 $z=m$
satisfies the condition when taking
$z=m$
satisfies the condition when taking
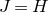 $J= H$
and
$J= H$
and
 $I=[m]$
). We claim that
$I=[m]$
). We claim that
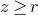 $z\ge r$
. Indeed, note that
$z\ge r$
. Indeed, note that
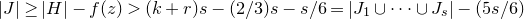 $|J|\ge |H|-f(z)\gt (k+r)s-(2/3)s-s/6=|J_1\cup\dots\cup J_s|-(5s/6)$
and
$|J|\ge |H|-f(z)\gt (k+r)s-(2/3)s-s/6=|J_1\cup\dots\cup J_s|-(5s/6)$
and
 $|I|\ge m-f(z)\gt m-s/6$
, so there are strictly fewer than s indices
$|I|\ge m-f(z)\gt m-s/6$
, so there are strictly fewer than s indices
 $t\in \{1,\ldots,s\}$
such that
$t\in \{1,\ldots,s\}$
such that
 $I_t\setminus I\ne \emptyset$
or
$I_t\setminus I\ne \emptyset$
or
 $J_t\setminus J\ne \emptyset$
. Hence, there must be some index
$J_t\setminus J\ne \emptyset$
. Hence, there must be some index
 $t\in \{1,\ldots,s\}$
with
$t\in \{1,\ldots,s\}$
with
 $I_t\subseteq I$
and
$I_t\subseteq I$
and
 $J_t\subseteq J$
, and we have
$J_t\subseteq J$
, and we have
 $$ k+z\ge \operatorname{rank}\begin{pmatrix}A[J\times I]\\ T[[k]\times I]\end{pmatrix}\ge \operatorname{rank}\begin{pmatrix}A[J_t\times I_t]\\ T[[k]\times I_t]\end{pmatrix}\ge k+r, $$
$$ k+z\ge \operatorname{rank}\begin{pmatrix}A[J\times I]\\ T[[k]\times I]\end{pmatrix}\ge \operatorname{rank}\begin{pmatrix}A[J_t\times I_t]\\ T[[k]\times I_t]\end{pmatrix}\ge k+r, $$
where the last step follows from the assumptions in Lemma 7.1, see Equation (7.2). So we indeed have
 $z\ge r\ge 1$
.
$z\ge r\ge 1$
.
Finally, for any subsets
 $I'\subseteq I$
and
$I'\subseteq I$
and
 $J'\subseteq J$
of sizes
$J'\subseteq J$
of sizes
 $|I'|\ge |I|-s/(12z^2)$
and
$|I'|\ge |I|-s/(12z^2)$
and
 $|J'|\ge |J|-s/(12z^2)$
, we have
$|J'|\ge |J|-s/(12z^2)$
, we have
 $|I'|\ge m-f(z)-s/(12z^2)=m-f(z-1)$
and
$|I'|\ge m-f(z)-s/(12z^2)=m-f(z-1)$
and
 $|J'|\ge |H|-f(z)-s/(12z^2)=|H|-f(z-1)$
, so by the choice of z we must have
$|J'|\ge |H|-f(z)-s/(12z^2)=|H|-f(z-1)$
, so by the choice of z we must have
 $$ k+z\ge \operatorname{rank}\begin{pmatrix}A[J\times I]\\ T[[k]\times I]\end{pmatrix}\ge \operatorname{rank}\begin{pmatrix}A[J'\times I']\\ T[[k]\times I']\end{pmatrix}\ge k+(z-1)+1=k+z, $$
$$ k+z\ge \operatorname{rank}\begin{pmatrix}A[J\times I]\\ T[[k]\times I]\end{pmatrix}\ge \operatorname{rank}\begin{pmatrix}A[J'\times I']\\ T[[k]\times I']\end{pmatrix}\ge k+(z-1)+1=k+z, $$
implying Equation (7.3).
We can use the robust rank submatrix guaranteed by Lemma 7.2 to find many sequences
 $(h_1,\ldots,h_z)$
to be used as ‘witnesses’, as follows.
$(h_1,\ldots,h_z)$
to be used as ‘witnesses’, as follows.
Corollary 7.3. Let
 $r,k,s,m,n\in \mathbb{Z}$
, the matrices
$r,k,s,m,n\in \mathbb{Z}$
, the matrices
 $T\in \mathbb{R}^{k\times m}$
and
$T\in \mathbb{R}^{k\times m}$
and
 $A\in \mathbb{R}^{n\times m}$
and the sets
$A\in \mathbb{R}^{n\times m}$
and the sets
 $J_1,\ldots,J_s\subseteq [n]$
be as in Lemma 7.1. Then for any subset
$J_1,\ldots,J_s\subseteq [n]$
be as in Lemma 7.1. Then for any subset
 $H\subseteq J_1\cup\dots\cup J_s$
of size
$H\subseteq J_1\cup\dots\cup J_s$
of size
 $|H|\ge (k+r)s-(2/3)s$
, there is some integer
$|H|\ge (k+r)s-(2/3)s$
, there is some integer
 $z\ge r$
such that there are at least
$z\ge r$
such that there are at least
 $s^z/(12z^2)^z$
sequences
$s^z/(12z^2)^z$
sequences
 $(h_1,\ldots,h_z)\in H^z$
with
$(h_1,\ldots,h_z)\in H^z$
with
 \begin{equation}\begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times[m]]\\T\end{pmatrix}\in \mathcal H^{(k+z)\times m}(s/(12z^2)).\end{equation}
\begin{equation}\begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times[m]]\\T\end{pmatrix}\in \mathcal H^{(k+z)\times m}(s/(12z^2)).\end{equation}
Proof. Let
 $J\subseteq H$
and
$J\subseteq H$
and
 $I\subseteq [m]$
and
$I\subseteq [m]$
and
 $z\ge r$
be as in Lemma 7.2. We first claim that there are at least
$z\ge r$
be as in Lemma 7.2. We first claim that there are at least
 $s^z/(12z^2)^z$
sequences
$s^z/(12z^2)^z$
sequences
 $(h_1,\ldots,h_z)\in J^z\subseteq H^z$
such that
$(h_1,\ldots,h_z)\in J^z\subseteq H^z$
such that
 \begin{equation} \operatorname{row-span}\begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I]\\ T[[k]\times I] \end{pmatrix} =\operatorname{row-span}\begin{pmatrix}A[J\times I]\\ T[[k]\times I] \end{pmatrix}. \end{equation}
\begin{equation} \operatorname{row-span}\begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I]\\ T[[k]\times I] \end{pmatrix} =\operatorname{row-span}\begin{pmatrix}A[J\times I]\\ T[[k]\times I] \end{pmatrix}. \end{equation}
Indeed, the matrix on the right-hand side has rank
 $k+z$
by Equation (7.3), and the rows of
$k+z$
by Equation (7.3), and the rows of
 $T[[k]\times I]$
are linearly independent by assumption (i) in Lemma 7.1 (since
$T[[k]\times I]$
are linearly independent by assumption (i) in Lemma 7.1 (since
 $|I|\ge m-s/6$
, there needs to be at least one index
$|I|\ge m-s/6$
, there needs to be at least one index
 $t\in \{1,\ldots,s\}$
with
$t\in \{1,\ldots,s\}$
with
 $I_t\subseteq I$
, meaning that
$I_t\subseteq I$
, meaning that
 $\operatorname{rank} T[[k]\times I]=T[[k]\times I_t]=k$
). So we can form a basis of the row span of the matrix on the right-hand side by taking the rows of
$\operatorname{rank} T[[k]\times I]=T[[k]\times I_t]=k$
). So we can form a basis of the row span of the matrix on the right-hand side by taking the rows of
 $T[[k]\times I]$
and adding, one by one, z different rows of
$T[[k]\times I]$
and adding, one by one, z different rows of
 $A[J\times I]$
. By Equation (7.3), at every step we have at least
$A[J\times I]$
. By Equation (7.3), at every step we have at least
 $s/(12z^2)$
choices for a new row to add to our basis (indeed, the index set
$s/(12z^2)$
choices for a new row to add to our basis (indeed, the index set
 $J'\subseteq J$
of all rows in the span of the already selected basis elements must have size
$J'\subseteq J$
of all rows in the span of the already selected basis elements must have size
 $|J'|<|J|-s/(12z^2)$
, since this span has dimension less than
$|J'|<|J|-s/(12z^2)$
, since this span has dimension less than
 $k+z$
and so otherwise we would have a contradiction to Equation (7.3) with
$k+z$
and so otherwise we would have a contradiction to Equation (7.3) with
 $I'=I$
). Thus, there are indeed at least
$I'=I$
). Thus, there are indeed at least
 $s^z/(12z^2)^z$
choices for the sequence
$s^z/(12z^2)^z$
choices for the sequence
 $(h_1,\ldots,h_z)\in J^z$
of indices of the rows of
$(h_1,\ldots,h_z)\in J^z$
of indices of the rows of
 $A[J\times I]$
selected in this process. For each such sequence Equation (7.5) holds.
$A[J\times I]$
selected in this process. For each such sequence Equation (7.5) holds.
It remains to show that every sequence
 $(h_1,\ldots,h_z)\in J^z$
satisfying Equation (7.5) also satisfies Equation (7.4). So, consider any
$(h_1,\ldots,h_z)\in J^z$
satisfying Equation (7.5) also satisfies Equation (7.4). So, consider any
 $(h_1,\ldots,h_z)\in J^z$
satisfying Equation (7.5). To show Equation (7.4), it suffices to show that
$(h_1,\ldots,h_z)\in J^z$
satisfying Equation (7.5). To show Equation (7.4), it suffices to show that
 \begin{equation} \begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I]\\ T[[k]\times I] \end{pmatrix}\in \mathcal H^{(k+z)\times I}(s/(12z^2)). \end{equation}
\begin{equation} \begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I]\\ T[[k]\times I] \end{pmatrix}\in \mathcal H^{(k+z)\times I}(s/(12z^2)). \end{equation}
Suppose the contrary; then there exists a subset
 $I'\subseteq I$
of size
$I'\subseteq I$
of size
 $|I'|\ge |I|-s/(12z^2)$
such that
$|I'|\ge |I|-s/(12z^2)$
such that
 $$ \operatorname{rank} \begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I']\\ T[[k]\times I'] \end{pmatrix}<k+z. $$
$$ \operatorname{rank} \begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I']\\ T[[k]\times I'] \end{pmatrix}<k+z. $$
But now by Equation (7.5) we have
 $$ \operatorname{row-span}\begin{pmatrix}A[J\times I']\\ T[[k]\times I'] \end{pmatrix} =\operatorname{row-span}\begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I']\\ T[[k]\times I'] \end{pmatrix} , $$
$$ \operatorname{row-span}\begin{pmatrix}A[J\times I']\\ T[[k]\times I'] \end{pmatrix} =\operatorname{row-span}\begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I']\\ T[[k]\times I'] \end{pmatrix} , $$
and hence
 $$ \operatorname{rank} \begin{pmatrix}A[J\times I']\\ T[[k]\times I'] \end{pmatrix} =\operatorname{rank} \begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I']\\ T[[k]\times I'] \end{pmatrix}<k+z, $$
$$ \operatorname{rank} \begin{pmatrix}A[J\times I']\\ T[[k]\times I'] \end{pmatrix} =\operatorname{rank} \begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times I']\\ T[[k]\times I'] \end{pmatrix}<k+z, $$
contradicting Equation (7.3). So we indeed have Equation (7.6), as desired.
Now we prove Lemma 7.1. We need two slightly different implementations of our witness-counting strategy described above, with different conditions for the ‘witness’ sequences
 $(h_1,\ldots,h_z)$
we are counting. In the case where A ‘robustly has very high rank’, we can get away with rather crude arguments using Odlyzko’s lemma. In the complementary case, we need to use Corollary 7.3 and Halász’ inequality (we cannot simply use Corollary 7.3 and Halász’ inequality in both cases, because the conclusions of Lemma 7.2 and Corollary 7.3 are very weak when z is very large).
$(h_1,\ldots,h_z)$
we are counting. In the case where A ‘robustly has very high rank’, we can get away with rather crude arguments using Odlyzko’s lemma. In the complementary case, we need to use Corollary 7.3 and Halász’ inequality (we cannot simply use Corollary 7.3 and Halász’ inequality in both cases, because the conclusions of Lemma 7.2 and Corollary 7.3 are very weak when z is very large).
Proof of Lemma 7.1. LetFootnote
11
 $L=\lceil 2(k+r)\log s\rceil$
, let
$L=\lceil 2(k+r)\log s\rceil$
, let
 $J_*=J_1\cup\dots\cup J_s\subseteq [n]$
and note that
$J_*=J_1\cup\dots\cup J_s\subseteq [n]$
and note that
 $|J_*|=(k+r)s$
. Furthermore note that (7.1) trivially holds if
$|J_*|=(k+r)s$
. Furthermore note that (7.1) trivially holds if
 $s\le 10^{60}(k+r)^{20}$
, so we may assume that
$s\le 10^{60}(k+r)^{20}$
, so we may assume that
 $s \ge 10^{60}(k+r)^{20}\ge 10^{60}$
and hence
$s \ge 10^{60}(k+r)^{20}\ge 10^{60}$
and hence
 $\log s\le s^{1/20}$
. Then we in particular have
$\log s\le s^{1/20}$
. Then we in particular have
 \begin{equation}L=\lceil 2(k+r)\log s\rceil\le 4(k+r)\cdot \log s\le \frac{s^{1/20}}{250}\cdot s^{1/20}=\frac{s^{1/10}}{250}.\end{equation}
\begin{equation}L=\lceil 2(k+r)\log s\rceil\le 4(k+r)\cdot \log s\le \frac{s^{1/20}}{250}\cdot s^{1/20}=\frac{s^{1/10}}{250}.\end{equation}
Step 1: the robust high-rank case. First, suppose that for every subset
 $J'\subseteq J_*$
with
$J'\subseteq J_*$
with
 $|J'|\ge |J_*|-s/2$
, we have
$|J'|\ge |J_*|-s/2$
, we have
 $\operatorname{rank} A[J'\times [m]]\ge L$
.
$\operatorname{rank} A[J'\times [m]]\ge L$
.
Then, for every subset
 $S\subseteq J_*$
of size
$S\subseteq J_*$
of size
 $|S|<L$
, the row span of
$|S|<L$
, the row span of
 $A[S\times [m]]$
has dimension less than L and so it can contain at most
$A[S\times [m]]$
has dimension less than L and so it can contain at most
 $|J_*|-s/2$
rows of the matrix
$|J_*|-s/2$
rows of the matrix
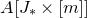 $A[J_*\times [m]]$
. This means that there are at least
$A[J_*\times [m]]$
. This means that there are at least
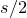 $s/2$
indices
$s/2$
indices
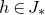 $h\in J_*$
such that
$h\in J_*$
such that
 $\operatorname{rank} A[(S\cup \{h\})\times [m]]=\operatorname{rank} A[S\times [m]]+1$
. Let
$\operatorname{rank} A[(S\cup \{h\})\times [m]]=\operatorname{rank} A[S\times [m]]+1$
. Let
 $H_S\subseteq J_*$
denote the set of the
$H_S\subseteq J_*$
denote the set of the
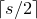 $\lceil s/2\rceil$
smallest such indices
$\lceil s/2\rceil$
smallest such indices
 $h\in J_*$
.
$h\in J_*$
.
For our double-counting argument, we will consider sequences
 $(h_{1},\ldots,h_{L})\in J_*^L$
with
$(h_{1},\ldots,h_{L})\in J_*^L$
with
 $h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
for
$h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
for
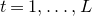 $t=1,\ldots,L$
. For every such sequence, we have
$t=1,\ldots,L$
. For every such sequence, we have
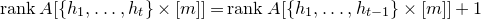 $\operatorname{rank} A[\{h_{1},\ldots,h_{t}\}\times [m]]=\operatorname{rank} A[\{h_{1},\ldots,h_{t-1}\}\times [m]]+1$
for
$\operatorname{rank} A[\{h_{1},\ldots,h_{t}\}\times [m]]=\operatorname{rank} A[\{h_{1},\ldots,h_{t-1}\}\times [m]]+1$
for
 $t=1,\ldots,L$
and hence
$t=1,\ldots,L$
and hence
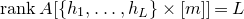 $\operatorname{rank} A[\{h_{1},\ldots,h_{L}\}\times [m]]=L$
. Furthermore, note that the total number of such sequences is exactly
$\operatorname{rank} A[\{h_{1},\ldots,h_{L}\}\times [m]]=L$
. Furthermore, note that the total number of such sequences is exactly
 $\lceil s/2\rceil^L$
(since after choosing
$\lceil s/2\rceil^L$
(since after choosing
 $h_1,\ldots,h_{t-1}$
we have exactly
$h_1,\ldots,h_{t-1}$
we have exactly
 $|H_{\{h_1,\ldots,h_{t-1}\}}|=\lceil s/2\rceil$
choices for
$|H_{\{h_1,\ldots,h_{t-1}\}}|=\lceil s/2\rceil$
choices for
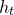 $h_t$
).
$h_t$
).
We claim that for every outcome of
 $\vec{\xi}\in \{-1,1\}^m$
such that
$\vec{\xi}\in \{-1,1\}^m$
such that
 $A\vec{\xi}-\vec{v}$
has at most
$A\vec{\xi}-\vec{v}$
has at most
 $s/6$
nonzero coordinates, there are at least
$s/6$
nonzero coordinates, there are at least
 $(s/3)^L$
sequences
$(s/3)^L$
sequences
 $(h_{1},\ldots,h_{L})\in J_*^L$
with
$(h_{1},\ldots,h_{L})\in J_*^L$
with
 $h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
for
$h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
for
 $t=1,\ldots,L$
, such that
$t=1,\ldots,L$
, such that
 $(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
. Indeed, choosing
$(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
. Indeed, choosing
 $h_{1},\ldots,h_{L}$
one at a time, at every step we need to choose
$h_{1},\ldots,h_{L}$
one at a time, at every step we need to choose
 $h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
with
$h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
with
 $(A\vec{\xi}-\vec{v})[h_{t}]=0$
. At most
$(A\vec{\xi}-\vec{v})[h_{t}]=0$
. At most
 $s/6$
of the
$s/6$
of the
 $\lceil s/2\rceil$
elements of
$\lceil s/2\rceil$
elements of
 $H_{\{h_1,\ldots,h_{t-1}\}}$
fail this condition, so we indeed have at least
$H_{\{h_1,\ldots,h_{t-1}\}}$
fail this condition, so we indeed have at least
 $\lceil s/2\rceil-s/6\ge s/3$
choices at every step and hence there are indeed at least
$\lceil s/2\rceil-s/6\ge s/3$
choices at every step and hence there are indeed at least
 $(s/3)^L$
such sequences
$(s/3)^L$
such sequences
 $(h_{1},\ldots,h_{L})\in J_*^L$
.
$(h_{1},\ldots,h_{L})\in J_*^L$
.
Thus, the expected number of sequences
 $(h_{1},\ldots,h_{L})\in J_*^L$
with
$(h_{1},\ldots,h_{L})\in J_*^L$
with
 $h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
for
$h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
for
 $t=1,\ldots,L$
such that
$t=1,\ldots,L$
such that
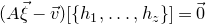 $(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
is at least
$(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
is at least
 $\mathrm{Pr}[A\vec{\xi}-\vec{v}\text{ has at most }s/6\text{ nonzero coordinates}]\cdot (s/3)^L$
. On the other hand, for every given sequence
$\mathrm{Pr}[A\vec{\xi}-\vec{v}\text{ has at most }s/6\text{ nonzero coordinates}]\cdot (s/3)^L$
. On the other hand, for every given sequence
 $(h_{1},\ldots,h_{L})\in J_*^L$
with
$(h_{1},\ldots,h_{L})\in J_*^L$
with
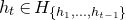 $h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
for
$h_{t}\in H_{\{h_1,\ldots,h_{t-1}\}}$
for
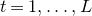 $t=1,\ldots,L$
, having
$t=1,\ldots,L$
, having
 $(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
is equivalent to
$(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
is equivalent to
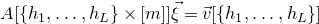 $A[\{h_{1},\ldots,h_{L}\}\times [m]]\vec{\xi}=\vec{v}[\{h_{1},\ldots,h_{L}\}]$
and by Odlyzko’s lemma (Lemma 3.7), this happens with probability at most
$A[\{h_{1},\ldots,h_{L}\}\times [m]]\vec{\xi}=\vec{v}[\{h_{1},\ldots,h_{L}\}]$
and by Odlyzko’s lemma (Lemma 3.7), this happens with probability at most
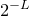 $2^{-L}$
(recalling that
$2^{-L}$
(recalling that
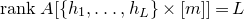 $\operatorname{rank} A[\{h_{1},\ldots,h_{L}\}\times [m]]=L$
). Hence the expected number of such sequences
$\operatorname{rank} A[\{h_{1},\ldots,h_{L}\}\times [m]]=L$
). Hence the expected number of such sequences
 $(h_{1},\ldots,h_{L})$
is at most
$(h_{1},\ldots,h_{L})$
is at most
 $\lceil s/2\rceil^L\cdot 2^{-L}$
. Thus, we obtain
$\lceil s/2\rceil^L\cdot 2^{-L}$
. Thus, we obtain
 \begin{align*} \mathrm{Pr}[A\vec{\xi}-\vec{v}\text{ has at most }s/6\text{ nonzero coordinates}]\le \frac{\lceil s/2\rceil^L\cdot 2^{-L}}{(s/3)^L} & \le \frac{(5s/9)^L\cdot 2^{-L}}{(s/3)^L}=(5/6)^L \\& \le s^{-(k+r)/2},\end{align*}
\begin{align*} \mathrm{Pr}[A\vec{\xi}-\vec{v}\text{ has at most }s/6\text{ nonzero coordinates}]\le \frac{\lceil s/2\rceil^L\cdot 2^{-L}}{(s/3)^L} & \le \frac{(5s/9)^L\cdot 2^{-L}}{(s/3)^L}=(5/6)^L \\& \le s^{-(k+r)/2},\end{align*}
recalling that
 $L=\lceil 2(k+r)\log s\rceil$
and using that
$L=\lceil 2(k+r)\log s\rceil$
and using that
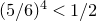 $(5/6)^4<1/2$
. This in particular implies Equation (7.1).
$(5/6)^4<1/2$
. This in particular implies Equation (7.1).
Step 2: covering events for the low-rank case. Now, we may assume that for some subset
 $J'\subseteq J_*$
with
$J'\subseteq J_*$
with
 $|J'|\ge |J_*|-s/2$
, we have
$|J'|\ge |J_*|-s/2$
, we have
 $\operatorname{rank} A[J'\times [m]]\le L$
.
$\operatorname{rank} A[J'\times [m]]\le L$
.
For every outcome of
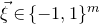 $\vec{\xi}\in \{-1,1\}^m$
, let
$\vec{\xi}\in \{-1,1\}^m$
, let
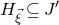 $H_{\vec{\xi}}\subseteq J'$
be the set of indices
$H_{\vec{\xi}}\subseteq J'$
be the set of indices
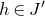 $h\in J'$
with
$h\in J'$
with
 $(A\vec{\xi}-\vec{v})[h]=0$
. Note that, whenever
$(A\vec{\xi}-\vec{v})[h]=0$
. Note that, whenever
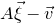 $A\vec{\xi}-\vec{v}$
has at most
$A\vec{\xi}-\vec{v}$
has at most
 $s/6$
nonzero coordinates, we have
$s/6$
nonzero coordinates, we have
 $|H_{\vec{\xi}}|\ge |J'|-s/6\ge |J_*|-s/2-s/6=(k+r)s-(2/3)s$
, and so by Corollary 7.3 there is some integer
$|H_{\vec{\xi}}|\ge |J'|-s/6\ge |J_*|-s/2-s/6=(k+r)s-(2/3)s$
, and so by Corollary 7.3 there is some integer
 $z\ge r$
such that there are at least
$z\ge r$
such that there are at least
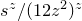 $s^z/(12z^2)^z$
sequences
$s^z/(12z^2)^z$
sequences
 $(h_1,\ldots,h_z)\in H_{\vec{\xi}}^z$
satisfying Equation (7.4). Note that for each such sequence, by Equation (7.4) we must in particular have
$(h_1,\ldots,h_z)\in H_{\vec{\xi}}^z$
satisfying Equation (7.4). Note that for each such sequence, by Equation (7.4) we must in particular have
 \begin{align*} k+z=\operatorname{rank} \begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times[m]]\\T\end{pmatrix}\le k+\operatorname{rank} A[\{h_{1},\ldots,h_{z}\}\times[m]] & \le k+\operatorname{rank} A[J'\times[m]] \\ & \le k+L, \end{align*}
\begin{align*} k+z=\operatorname{rank} \begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times[m]]\\T\end{pmatrix}\le k+\operatorname{rank} A[\{h_{1},\ldots,h_{z}\}\times[m]] & \le k+\operatorname{rank} A[J'\times[m]] \\ & \le k+L, \end{align*}
and consequently
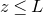 $z\le L$
.
$z\le L$
.
Thus, for every outcome of
 $\vec{\xi}\in \{-1,1\}^m$
such that
$\vec{\xi}\in \{-1,1\}^m$
such that
 $A\vec{\xi}-\vec{v}$
has at most
$A\vec{\xi}-\vec{v}$
has at most
 $s/6$
nonzero coordinates, there is some integer
$s/6$
nonzero coordinates, there is some integer
 $z\in \{r,r+1,\ldots,L\}$
such that there are at least
$z\in \{r,r+1,\ldots,L\}$
such that there are at least
 $s^z/(12z^2)^z$
sequences
$s^z/(12z^2)^z$
sequences
 $(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4) and
$(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4) and
 $(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
. For every
$(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
. For every
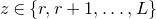 $z\in \{r,r+1,\ldots,L\}$
, let
$z\in \{r,r+1,\ldots,L\}$
, let
 $\mathcal{E}_z$
be the event that
$\mathcal{E}_z$
be the event that
 $T\vec{\xi}=\vec{w}$
and that there are at least
$T\vec{\xi}=\vec{w}$
and that there are at least
 $s^z/(12z^2)^z$
sequences
$s^z/(12z^2)^z$
sequences
 $(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4) and
$(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4) and
 $(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
. Then
$(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
. Then
 \begin{equation} \mathrm{Pr}[T\vec{\xi}=\vec{w} \text{ and } A\vec{\xi}-\vec{v}\text{ has at most }s/6\text{ nonzero coordinates}]\le \sum_{z=r}^{L} \mathrm{Pr}[\mathcal{E}_z],\end{equation}
\begin{equation} \mathrm{Pr}[T\vec{\xi}=\vec{w} \text{ and } A\vec{\xi}-\vec{v}\text{ has at most }s/6\text{ nonzero coordinates}]\le \sum_{z=r}^{L} \mathrm{Pr}[\mathcal{E}_z],\end{equation}
and it remains to bound the probability of the events
 $\mathcal{E}_z$
for
$\mathcal{E}_z$
for
 $z=r,\ldots,L$
.
$z=r,\ldots,L$
.
Step 3: double counting. Let
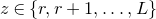 $z\in \{r,r+1,\ldots,L\}$
(and note that then in particular
$z\in \{r,r+1,\ldots,L\}$
(and note that then in particular
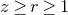 $z\ge r\ge 1$
).
$z\ge r\ge 1$
).
For every sequence
 $(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4), we have the equivalence
$(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4), we have the equivalence
 $$ T\vec{\xi}=\vec{w} \text{ and } (A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0\quad\! \iff \quad\!\begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times[m]]\\T\end{pmatrix}\vec{\xi}=\begin{pmatrix}\vec{v}[\{h_{1},\ldots,h_{z}\}]\\\vec{w}\end{pmatrix}\!. $$
$$ T\vec{\xi}=\vec{w} \text{ and } (A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0\quad\! \iff \quad\!\begin{pmatrix}A[\{h_{1},\ldots,h_{z}\}\times[m]]\\T\end{pmatrix}\vec{\xi}=\begin{pmatrix}\vec{v}[\{h_{1},\ldots,h_{z}\}]\\\vec{w}\end{pmatrix}\!. $$
So, by the version of Halász’ inequality in Corollary 3.5, we have
 $$ \mathrm{Pr}[T\vec{\xi}=\vec{w} \text{ and } (A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0]\le\bigg(\frac{s}{12z^{2}(z+k)} \bigg)^{-(k+z)/2}\le (4(k+z)^2)^{k+z}\cdot s^{-(k+z)/2}, $$
$$ \mathrm{Pr}[T\vec{\xi}=\vec{w} \text{ and } (A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0]\le\bigg(\frac{s}{12z^{2}(z+k)} \bigg)^{-(k+z)/2}\le (4(k+z)^2)^{k+z}\cdot s^{-(k+z)/2}, $$
for every sequence
 $(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4).
$(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4).
Hence, the expected number of sequences
 $(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4) such that
$(h_1,\ldots,h_z)\in J_*^z$
satisfying Equation (7.4) such that
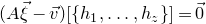 $(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
and
$(A\vec{\xi}-\vec{v})[\{h_1,\ldots,h_z\}]=\vec 0$
and
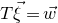 $T\vec{\xi}=\vec{w}$
hold, is at most
$T\vec{\xi}=\vec{w}$
hold, is at most
 $|J_*|^z\cdot (4(k+z)^2)^{k+z}\cdot s^{-(k+z)/2}$
. On the other hand, whenever the event
$|J_*|^z\cdot (4(k+z)^2)^{k+z}\cdot s^{-(k+z)/2}$
. On the other hand, whenever the event
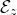 $\mathcal{E}_z$
occurs, there are at least
$\mathcal{E}_z$
occurs, there are at least
 $s^z/(12z^2)^z$
such sequences. We deduce that
$s^z/(12z^2)^z$
such sequences. We deduce that
 $$ \mathrm{Pr}[\mathcal{E}_z]\le \frac{|J_*|^z\cdot (4(k+z)^2)^{k+z}\cdot s^{-(k+z)/2}}{s^z/(12z^2)^z}\le \frac{((k+r)s)^z (48(k+z)^4)^{k+z}}{s^z\cdot s^{(k+z)/2}}\le \frac{(48(k+z)^5)^{k+z}}{s^{(k+z)/2}}, $$
$$ \mathrm{Pr}[\mathcal{E}_z]\le \frac{|J_*|^z\cdot (4(k+z)^2)^{k+z}\cdot s^{-(k+z)/2}}{s^z/(12z^2)^z}\le \frac{((k+r)s)^z (48(k+z)^4)^{k+z}}{s^z\cdot s^{(k+z)/2}}\le \frac{(48(k+z)^5)^{k+z}}{s^{(k+z)/2}}, $$
for every
 $z\in \{r,\ldots,L\}$
.
$z\in \{r,\ldots,L\}$
.
Step 4: summing up. We now obtain
 $$ \sum_{z=r}^{L} \mathrm{Pr}[\mathcal{E}_z]\le \sum_{z=r}^{L}\frac{(48(k+z)^5)^{k+z}}{s^{(k+z)/2}}= \sum_{z=r}^{L}a(z),\quad \text{where }a(z)=\frac{(48(k+z)^5)^{k+z}}{s^{(k+z)/2}}\text{ for }z=r,\ldots,L. $$
$$ \sum_{z=r}^{L} \mathrm{Pr}[\mathcal{E}_z]\le \sum_{z=r}^{L}\frac{(48(k+z)^5)^{k+z}}{s^{(k+z)/2}}= \sum_{z=r}^{L}a(z),\quad \text{where }a(z)=\frac{(48(k+z)^5)^{k+z}}{s^{(k+z)/2}}\text{ for }z=r,\ldots,L. $$
For
 $z=r,\ldots,L-1$
we compute (recalling that
$z=r,\ldots,L-1$
we compute (recalling that
 $k\le \lceil 2(k+r)\log s\rceil=L\le s^{1/10}/250$
by Equation (7.7) and hence
$k\le \lceil 2(k+r)\log s\rceil=L\le s^{1/10}/250$
by Equation (7.7) and hence
 $k+z+1\le k+L\le 2L\le s^{1/10}/100$
)
$k+z+1\le k+L\le 2L\le s^{1/10}/100$
)
 $$ \frac{a(z+1)}{a(z)}=\frac{48(k+z+1)^5}{s^{1/2}}\cdot \bigg(\frac{k+z+1}{k+z}\bigg)^{5(k+z)} \le \frac{48(s^{1/10}/100)^5}{s^{1/2}}\cdot e^5\le \frac{48\cdot 3^5}{100^5}\le \frac{1}{2}. $$
$$ \frac{a(z+1)}{a(z)}=\frac{48(k+z+1)^5}{s^{1/2}}\cdot \bigg(\frac{k+z+1}{k+z}\bigg)^{5(k+z)} \le \frac{48(s^{1/10}/100)^5}{s^{1/2}}\cdot e^5\le \frac{48\cdot 3^5}{100^5}\le \frac{1}{2}. $$
So, we have
 $a(z)\le 2^{-(z-r)}a(r)$
for
$a(z)\le 2^{-(z-r)}a(r)$
for
 $z=r,\ldots,L$
(so a(z) is bounded by a geometric series with common ratio
$z=r,\ldots,L$
(so a(z) is bounded by a geometric series with common ratio
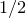 $1/2$
), and consequently
$1/2$
), and consequently
 $$ \sum_{z=r}^{L} \mathrm{Pr}[\mathcal{E}_z]\le \sum_{z=r}^{L}a(z)\le \sum_{z=r}^{L}\! 2^{-(z-r)}a(r)\le 2\cdot a(r)=\frac{2\cdot (48(k+r)^5)^{k+r}}{s^{(k+r)/2}}\le \bigg(\frac{s}{10^{60}(k+r)^{20}}\bigg)^{-(k+r)/2}. $$
$$ \sum_{z=r}^{L} \mathrm{Pr}[\mathcal{E}_z]\le \sum_{z=r}^{L}a(z)\le \sum_{z=r}^{L}\! 2^{-(z-r)}a(r)\le 2\cdot a(r)=\frac{2\cdot (48(k+r)^5)^{k+r}}{s^{(k+r)/2}}\le \bigg(\frac{s}{10^{60}(k+r)^{20}}\bigg)^{-(k+r)/2}. $$
Together with Equation (7.8), this implies Equation (7.1).
Next, we deduce Lemma 5.7 from Lemma 7.1.
Proof of Lemma 5.7. Recalling that
 $(T,U,A)\in \mathcal{M}^{k,m,n}_2(s)$
, let
$(T,U,A)\in \mathcal{M}^{k,m,n}_2(s)$
, let
 $I_1,\ldots,I_s,J_1,\ldots,J_s$
be index sets as in the definition of
$I_1,\ldots,I_s,J_1,\ldots,J_s$
be index sets as in the definition of
 $\mathcal{M}^{k,m,n}_2(s)$
in Definition 5.6 (recall in particular that
$\mathcal{M}^{k,m,n}_2(s)$
in Definition 5.6 (recall in particular that
 $I_1,\ldots,I_s\subseteq [m]$
are disjoint sets and
$I_1,\ldots,I_s\subseteq [m]$
are disjoint sets and
 $J_1,\ldots,J_s\subseteq [n]$
are disjoint sets).
$J_1,\ldots,J_s\subseteq [n]$
are disjoint sets).
Note that
 $U\in \mathcal{H}^{k\times n}(s)$
, due to condition (b) in Definition 5.6. Write
$U\in \mathcal{H}^{k\times n}(s)$
, due to condition (b) in Definition 5.6. Write
 $\mathcal{W}_{U}\subseteq\mathbb{R}^{n}$
for the row span of U, and note that we have
$\mathcal{W}_{U}\subseteq\mathbb{R}^{n}$
for the row span of U, and note that we have
 $U_{\vec \xi}'\notin \mathcal H^{(k+1)\times n}(s/6)$
if and only if
$U_{\vec \xi}'\notin \mathcal H^{(k+1)\times n}(s/6)$
if and only if
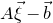 $A\vec \xi-\vec b$
agrees in at least
$A\vec \xi-\vec b$
agrees in at least
 $n-s/6$
coordinates with a vector
$n-s/6$
coordinates with a vector
 $\vec v\in \mathcal W_U$
. Hence
$\vec v\in \mathcal W_U$
. Hence
 \begin{align*} & \mathrm{Pr}[T\vec{\xi}=\vec{y} \text{ and } U_{\vec \xi}'\notin \mathcal H^{(k+1)\times n}(s/6)]\\& \quad\!\!=\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }S\subseteq[n]\text{ with }|S|\ge n-s/6 \text{ and } (A\vec{\xi}-\vec{b})[S]=\vec{v}[S]\text{ for some }\vec{v}\in\mathcal{W}_{U}]\\ &\quad\!\!\le\frac{2}{s}\sum_{t=1}^{s}\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }J_t\subseteq S\subseteq[n]\text{ with }|S|\ge n-s/6\text{ and } \\ &\qquad\qquad (A\vec{\xi}-\vec{b})[S]=\vec{v}[S]\text{ for some }\vec{v}\in\mathcal{W}_{U}],\end{align*}
\begin{align*} & \mathrm{Pr}[T\vec{\xi}=\vec{y} \text{ and } U_{\vec \xi}'\notin \mathcal H^{(k+1)\times n}(s/6)]\\& \quad\!\!=\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }S\subseteq[n]\text{ with }|S|\ge n-s/6 \text{ and } (A\vec{\xi}-\vec{b})[S]=\vec{v}[S]\text{ for some }\vec{v}\in\mathcal{W}_{U}]\\ &\quad\!\!\le\frac{2}{s}\sum_{t=1}^{s}\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }J_t\subseteq S\subseteq[n]\text{ with }|S|\ge n-s/6\text{ and } \\ &\qquad\qquad (A\vec{\xi}-\vec{b})[S]=\vec{v}[S]\text{ for some }\vec{v}\in\mathcal{W}_{U}],\end{align*}
where the inequality follows by observing that every set
 $S\subseteq[n]$
of size
$S\subseteq[n]$
of size
 $|S|\ge n-s/6$
satisfies
$|S|\ge n-s/6$
satisfies
 $J_t\subseteq S$
for at least
$J_t\subseteq S$
for at least
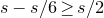 $s-s/6\ge s/2$
indices
$s-s/6\ge s/2$
indices
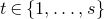 $t\in \{1,\ldots,s\}$
. So it suffices to show that for every fixed
$t\in \{1,\ldots,s\}$
. So it suffices to show that for every fixed
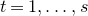 $t=1,\ldots,s$
we have
$t=1,\ldots,s$
we have
 \begin{align}&\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }J_t\subseteq S\subseteq[n]\text{ with }|S|\ge n-s/6 \text{ and } (A\vec{\xi}-\vec{b})[S]=\vec{v}[S]\text{ for some }\vec{v}\in\mathcal{W}_{U}]\notag\\&\qquad \le \bigg(\frac{s}{10^{60}(k+2)^{20}}\bigg)^{-(k+2)/2}.\end{align}
\begin{align}&\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }J_t\subseteq S\subseteq[n]\text{ with }|S|\ge n-s/6 \text{ and } (A\vec{\xi}-\vec{b})[S]=\vec{v}[S]\text{ for some }\vec{v}\in\mathcal{W}_{U}]\notag\\&\qquad \le \bigg(\frac{s}{10^{60}(k+2)^{20}}\bigg)^{-(k+2)/2}.\end{align}
By condition (b) in Definition 5.6 we can choose a subset
 $J_{t}'\subseteq J_{t}$
of size
$J_{t}'\subseteq J_{t}$
of size
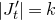 $|J_t'|=k$
such that
$|J_t'|=k$
such that
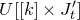 $U[[k]\times J_{t}']$
is nonsingular. Without loss of generality we may assume that
$U[[k]\times J_{t}']$
is nonsingular. Without loss of generality we may assume that
 $A[J_{t}'\times[m]]$
is the all-zero matrix, since the event on the left-hand side of Equation (7.9) does not change if we add linear combinations of the rows of U to the columns of A. But this assumption means that
$A[J_{t}'\times[m]]$
is the all-zero matrix, since the event on the left-hand side of Equation (7.9) does not change if we add linear combinations of the rows of U to the columns of A. But this assumption means that
 $(A\vec{\xi}-\vec{b})[J_{t}']=-\vec{b}[J_{t}']$
, and recalling that
$(A\vec{\xi}-\vec{b})[J_{t}']=-\vec{b}[J_{t}']$
, and recalling that
 $U[[k]\times J_{t}']$
is nonsingular, there is only exactly one vector
$U[[k]\times J_{t}']$
is nonsingular, there is only exactly one vector
 $\vec{v}_{t}\in\mathcal{W}_{U}$
with
$\vec{v}_{t}\in\mathcal{W}_{U}$
with
 $\vec{v}_{t}[J_{t}']=-\vec{b}[J_{t}']$
. Hence the event on the left-hand side of Equation (7.9) can only happen with
$\vec{v}_{t}[J_{t}']=-\vec{b}[J_{t}']$
. Hence the event on the left-hand side of Equation (7.9) can only happen with
 $\vec{v}=\vec{v}_{t}$
, and we obtain
$\vec{v}=\vec{v}_{t}$
, and we obtain
 \begin{align*}&\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }J_t\subseteq S\subseteq[n]\text{ with }|S|\ge n-s/6 \text{ and } (A\vec{\xi}-\vec{b})[S]=\vec{v}[S]\text{ for some }\vec{v}\in\mathcal{W}_{U}]\\ & \qquad=\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }J_t\subseteq S\subseteq[n]\text{ with }|S|\ge n-s/6\text{ such that }(A\vec{\xi}-\vec{b})[S]=\vec{v}_{t}[S]]\\ & \qquad\le \mathrm{Pr}[T\vec{\xi}=\vec{y} \text{ and } A\vec{\xi}-\vec{b}-\vec{v}_{t}\text{ has at least }n-s/6\text{ zero coordinates}]\\ & \qquad=\mathrm{Pr}[T\vec{\xi}=\vec{y} \text{ and } A\vec{\xi}-\vec{b}-\vec{v}_{t}\text{ has at most }s/6\text{ nonzero coordinates}].\end{align*}
\begin{align*}&\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }J_t\subseteq S\subseteq[n]\text{ with }|S|\ge n-s/6 \text{ and } (A\vec{\xi}-\vec{b})[S]=\vec{v}[S]\text{ for some }\vec{v}\in\mathcal{W}_{U}]\\ & \qquad=\mathrm{Pr}[T\vec{\xi}=\vec{y}\text{ and there is }J_t\subseteq S\subseteq[n]\text{ with }|S|\ge n-s/6\text{ such that }(A\vec{\xi}-\vec{b})[S]=\vec{v}_{t}[S]]\\ & \qquad\le \mathrm{Pr}[T\vec{\xi}=\vec{y} \text{ and } A\vec{\xi}-\vec{b}-\vec{v}_{t}\text{ has at least }n-s/6\text{ zero coordinates}]\\ & \qquad=\mathrm{Pr}[T\vec{\xi}=\vec{y} \text{ and } A\vec{\xi}-\vec{b}-\vec{v}_{t}\text{ has at most }s/6\text{ nonzero coordinates}].\end{align*}
The desired bound Equation (7.9) now follows from Lemma 7.1 with
 $r=2$
(note that conditions (i) and (ii) in Lemma 7.1 hold by conditions (a) and (c) in Definition 5.6, respectively).
$r=2$
(note that conditions (i) and (ii) in Lemma 7.1 hold by conditions (a) and (c) in Definition 5.6, respectively).
We end this section by deducing Lemma 2.1 (the ‘Hamming norm’ anticoncentration inequality stated in the outline in § 2) from Lemma 7.1.
Proof of Lemma 2.1. Let
 $C_r=(10r)^{30r}$
and
$C_r=(10r)^{30r}$
and
 $c_r=1/(6r)$
. As in the statement of the lemma, let
$c_r=1/(6r)$
. As in the statement of the lemma, let
 $A\in \mathbb{R} ^{m\times n}$
be a matrix which has rank at least r after deletion of any t rows and t columns.
$A\in \mathbb{R} ^{m\times n}$
be a matrix which has rank at least r after deletion of any t rows and t columns.
We claim that for
 $s=\lceil t/r\rceil$
we can find disjoint subsets
$s=\lceil t/r\rceil$
we can find disjoint subsets
 $I_1,\ldots,I_s\subseteq [n]$
and disjoint subsets
$I_1,\ldots,I_s\subseteq [n]$
and disjoint subsets
 $J_1,\ldots,J_s\subseteq [m]$
of size
$J_1,\ldots,J_s\subseteq [m]$
of size
 $|I_1|=\dots=|I_s|=|J_1|=\dots=|J_s|=r$
such that
$|I_1|=\dots=|I_s|=|J_1|=\dots=|J_s|=r$
such that
 $\operatorname{rank} A[J_\ell \times I_\ell]=r$
for
$\operatorname{rank} A[J_\ell \times I_\ell]=r$
for
 $\ell=1,\ldots,s$
. Indeed, we can find such subsets greedily: after having found
$\ell=1,\ldots,s$
. Indeed, we can find such subsets greedily: after having found
 $I_1,\ldots,I_\ell\subseteq [n]$
and
$I_1,\ldots,I_\ell\subseteq [n]$
and
 $J_1,\ldots,J_\ell\subseteq [m]$
for some
$J_1,\ldots,J_\ell\subseteq [m]$
for some
 $\ell<t/r$
, we can delete all columns with indices in
$\ell<t/r$
, we can delete all columns with indices in
 $I_1\cup \dots \cup I_\ell$
and all rows with indices in
$I_1\cup \dots \cup I_\ell$
and all rows with indices in
 $J_1\cup \dots \cup J_\ell$
from A and the resulting matrix must have rank at least r, so there must be subsets
$J_1\cup \dots \cup J_\ell$
from A and the resulting matrix must have rank at least r, so there must be subsets
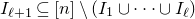 $I_{\ell+1}\subseteq [n]\setminus (I_1\cup \dots \cup I_\ell)$
and
$I_{\ell+1}\subseteq [n]\setminus (I_1\cup \dots \cup I_\ell)$
and
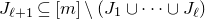 $J_{\ell+1}\subseteq [m]\setminus (J_1\cup \dots \cup J_\ell)$
with
$J_{\ell+1}\subseteq [m]\setminus (J_1\cup \dots \cup J_\ell)$
with
 $\operatorname{rank} A[J_\ell \times I_\ell]=r$
and
$\operatorname{rank} A[J_\ell \times I_\ell]=r$
and
 $|J_{\ell+1}|=|I_{\ell+1}|=r$
.
$|J_{\ell+1}|=|I_{\ell+1}|=r$
.
Having found such subsets
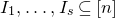 $I_1,\ldots,I_s\subseteq [n]$
and
$I_1,\ldots,I_s\subseteq [n]$
and
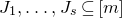 $J_1,\ldots,J_s\subseteq [m]$
, we can now apply Lemma 7.1 with
$J_1,\ldots,J_s\subseteq [m]$
, we can now apply Lemma 7.1 with
 $k=0$
and
$k=0$
and
 $T\in \mathbb{R} ^{0\times n}$
being the empty matrix and
$T\in \mathbb{R} ^{0\times n}$
being the empty matrix and
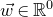 $\vec w\in \mathbb{R} ^{0}$
being the empty vector. Note that condition (i) is the vacuously true, and condition (ii) is true because for every
$\vec w\in \mathbb{R} ^{0}$
being the empty vector. Note that condition (i) is the vacuously true, and condition (ii) is true because for every
 $\ell=1,\ldots,s$
the only
$\ell=1,\ldots,s$
the only
 $(T[[k]\times I_t],0)$
-perturbation of the matrix
$(T[[k]\times I_t],0)$
-perturbation of the matrix
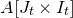 $A[J_t\times I_t]$
is the matrix
$A[J_t\times I_t]$
is the matrix
 $A[J_t\times I_t]$
itself, which has rank r. Thus, for a sequence
$A[J_t\times I_t]$
itself, which has rank r. Thus, for a sequence
 $\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^{n}$
of independent Rademacher random variables, and for any vector
$\vec{\xi}=(\xi_{1},\ldots,\xi_{n})\in\{-1,1\}^{n}$
of independent Rademacher random variables, and for any vector
 $\vec v\in \mathbb{R}^m$
, we have
$\vec v\in \mathbb{R}^m$
, we have
 \begin{align*}&\mathrm{Pr}[A\vec{\xi}\text{ differs from }\vec{v}\text{ in fewer than }t/(6r)\text{ coordinates}]\\&\qquad\le \mathrm{Pr}[A\vec{\xi}-\vec{v}\text{ has at most }s/6\text{ nonzero coordinates}]\\&\qquad\le\bigg(\frac{s}{10^{60}r^{20}}\bigg)^{-r/2}\le \bigg(\frac{t}{10^{60}r^{21}}\bigg)^{-r/2}\le (10r)^{30r}\cdot t^{-r/2};\end{align*}
\begin{align*}&\mathrm{Pr}[A\vec{\xi}\text{ differs from }\vec{v}\text{ in fewer than }t/(6r)\text{ coordinates}]\\&\qquad\le \mathrm{Pr}[A\vec{\xi}-\vec{v}\text{ has at most }s/6\text{ nonzero coordinates}]\\&\qquad\le\bigg(\frac{s}{10^{60}r^{20}}\bigg)^{-r/2}\le \bigg(\frac{t}{10^{60}r^{21}}\bigg)^{-r/2}\le (10r)^{30r}\cdot t^{-r/2};\end{align*}
(noting that
 $T\vec{\xi}=\vec{w}$
holds vacuously for all
$T\vec{\xi}=\vec{w}$
holds vacuously for all
 $\vec{\xi}\in\{-1,1\}^{n}$
).
$\vec{\xi}\in\{-1,1\}^{n}$
).
8. Splitting the index set
In this section, we prove Lemma 5.8, splitting our index set [n] into disjoint subsets I and J such that the conditions in Definition 5.6 are satisfied. This amounts to finding disjoint subsets
 $I_1,\ldots,I_s,J_1,\ldots,J_s\subseteq [n]$
satisfying certain robust rank-two conditions. Most of the work is in finding a single pair of subsets
$I_1,\ldots,I_s,J_1,\ldots,J_s\subseteq [n]$
satisfying certain robust rank-two conditions. Most of the work is in finding a single pair of subsets
 $I_1,J_1$
satisfying the desired property; we will then be able to find our subsets in a greedy fashion, in a similar way to the proof of Lemma 3.2(ii).
$I_1,J_1$
satisfying the desired property; we will then be able to find our subsets in a greedy fashion, in a similar way to the proof of Lemma 3.2(ii).
Proof of Lemma 5.8. Let
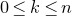 $0\le k\le n$
,
$0\le k\le n$
,
 $s\ge 4k+8$
,
$s\ge 4k+8$
,
 $M\in\mathcal{H}^{k\times n}(s)$
and
$M\in\mathcal{H}^{k\times n}(s)$
and
 $A\in \mathbb{R}^{n\times n}$
be as in the statement of the lemma. Recall that A is a symmetric matrix and that we are assuming
$A\in \mathbb{R}^{n\times n}$
be as in the statement of the lemma. Recall that A is a symmetric matrix and that we are assuming
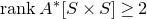 $\operatorname{rank} A^* [S\times S]\ge 2$
for any subset
$\operatorname{rank} A^* [S\times S]\ge 2$
for any subset
 $S\subseteq [n]$
of size
$S\subseteq [n]$
of size
 $|S|\ge n- s$
and any matrix
$|S|\ge n- s$
and any matrix
 $A^*\in \mathbb{R}^{n\times n}$
that agrees with some (M,M)-perturbation of A in all off-diagonal entries.
$A^*\in \mathbb{R}^{n\times n}$
that agrees with some (M,M)-perturbation of A in all off-diagonal entries.
Step 1: set-up. For
 $\ell=\lfloor s/(4k+8)\rfloor$
, we wish to find disjoint subsets
$\ell=\lfloor s/(4k+8)\rfloor$
, we wish to find disjoint subsets
 $I_1,\ldots, I_\ell, J_1,\ldots,J_\ell\subseteq [n]$
of size
$I_1,\ldots, I_\ell, J_1,\ldots,J_\ell\subseteq [n]$
of size
 $|I_1|=\dots=|I_\ell|=|J_1|=\dots=|J_\ell|=k+2$
such that the following three conditions hold for
$|I_1|=\dots=|I_\ell|=|J_1|=\dots=|J_\ell|=k+2$
such that the following three conditions hold for
 $t=1,\ldots, \ell$
.
$t=1,\ldots, \ell$
.
-
(a) The submatrix
$M[[k]\times I_t]$
has rank k. -
(b) The submatrix
$M[[k]\times J_t]$
has rank k. -
(c) Every
$(M[[k]\times I_t],M[[k]\times J_t])$
-perturbation of the matrix
$A[J_t\times I_t]$
has rank at least two.




This suffices, since we can then take
 $I=I_1\cup \dots\cup I_\ell$
and
$I=I_1\cup \dots\cup I_\ell$
and
 $J=[n]\setminus I$
to obtain a partition
$J=[n]\setminus I$
to obtain a partition
 $[n]=I\cup J$
satisfying the conclusion of the lemma (the conditions (a)–(c) in Definition 5.6 precisely correspond to conditions (a)–(c) above, and we have
$[n]=I\cup J$
satisfying the conclusion of the lemma (the conditions (a)–(c) in Definition 5.6 precisely correspond to conditions (a)–(c) above, and we have
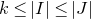 $k\le |I|\le |J|$
since
$k\le |I|\le |J|$
since
 $|I|=\ell(k+2)$
and
$|I|=\ell(k+2)$
and
 $|J|\ge |J_1\cup \dots\cup J_\ell|=\ell(k+2)$
).
$|J|\ge |J_1\cup \dots\cup J_\ell|=\ell(k+2)$
).
To find such disjoint subsets
 $I_1,\ldots, I_\ell, J_1,\ldots,J_\ell\subseteq [n]$
, it suffices to show that for any subset
$I_1,\ldots, I_\ell, J_1,\ldots,J_\ell\subseteq [n]$
, it suffices to show that for any subset
 $R\subseteq [n]$
with
$R\subseteq [n]$
with
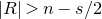 $|R| \gt n-s/2$
, we can find disjoint subsets
$|R| \gt n-s/2$
, we can find disjoint subsets
 $I_1,J_1\subseteq R$
of size
$I_1,J_1\subseteq R$
of size
 $|I_1|=|J_1|=k+2$
such that conditions (a)–(c) above hold for
$|I_1|=|J_1|=k+2$
such that conditions (a)–(c) above hold for
 $t=1$
. Indeed, then we can then construct the desired subsets
$t=1$
. Indeed, then we can then construct the desired subsets
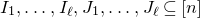 $I_1,\ldots, I_\ell, J_1,\ldots,J_\ell\subseteq [n]$
greedily (at every step choosing
$I_1,\ldots, I_\ell, J_1,\ldots,J_\ell\subseteq [n]$
greedily (at every step choosing
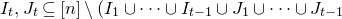 $I_t,J_t\subseteq [n]\setminus (I_1\cup\dots\cup I_{t-1}\cup J_1\cup\dots\cup J_{t-1}$
). Showing this will be our objective for the rest of the proof, so let us fix a subset
$I_t,J_t\subseteq [n]\setminus (I_1\cup\dots\cup I_{t-1}\cup J_1\cup\dots\cup J_{t-1}$
). Showing this will be our objective for the rest of the proof, so let us fix a subset
 $R\subseteq [n]$
with
$R\subseteq [n]$
with
 $|R|\gt n-s/2$
.
$|R|\gt n-s/2$
.
Since
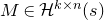 $M\in\mathcal{H}^{k\times n}(s)$
, we can find disjoint subsets
$M\in\mathcal{H}^{k\times n}(s)$
, we can find disjoint subsets
 $I_1',J_1'\subseteq R$
of size
$I_1',J_1'\subseteq R$
of size
 $|I_1'|=|J_1'|=k$
with
$|I_1'|=|J_1'|=k$
with
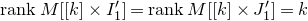 $\operatorname{rank} M[[k]\times I_1']=\operatorname{rank} M[[k]\times J_1']=k$
. We will obtain
$\operatorname{rank} M[[k]\times I_1']=\operatorname{rank} M[[k]\times J_1']=k$
. We will obtain
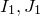 $I_1,J_1$
by augmenting
$I_1,J_1$
by augmenting
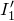 $I_1'$
and
$I_1'$
and
 $J_1'$
with two additional indices each (we will find suitable indices for this using our assumption on A).
$J_1'$
with two additional indices each (we will find suitable indices for this using our assumption on A).
Step 2: augmenting the index sets. Since the
 $k\times k$
matrices
$k\times k$
matrices
 $M[[k]\times I_1']$
and
$M[[k]\times I_1']$
and
 $M[[k]\times J_1']$
are both nonsingular, we can add linear combinations of the rows of M to the rows and columns of A to obtain an (M,M)-perturbation A’ of A such that all entries of
$M[[k]\times J_1']$
are both nonsingular, we can add linear combinations of the rows of M to the rows and columns of A to obtain an (M,M)-perturbation A’ of A such that all entries of
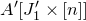 $A'[J_1'\times [n]]$
and all entries of
$A'[J_1'\times [n]]$
and all entries of
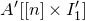 $A'[[n]\times I_1']$
are zero. Define
$A'[[n]\times I_1']$
are zero. Define
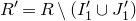 $R'=R\setminus (I_1'\cup J_1')$
and note that
$R'=R\setminus (I_1'\cup J_1')$
and note that
 $|R'|\ge n-s/2-2k\ge n-s+4$
. By our assumption on A, the submatrix
$|R'|\ge n-s/2-2k\ge n-s+4$
. By our assumption on A, the submatrix
 $A'[R'\times R']$
must have some nonzero off-diagonal entry
$A'[R'\times R']$
must have some nonzero off-diagonal entry
 $a'_{j,i}$
with distinct
$a'_{j,i}$
with distinct
 $i,j\in R'$
(if all off-diagonal entries were zero, by modifying the diagonal entries of A’ we would be able to find a matrix
$i,j\in R'$
(if all off-diagonal entries were zero, by modifying the diagonal entries of A’ we would be able to find a matrix
 $A^*\in \mathbb{R}^{n\times n}$
agreeing with the (M,M)-perturbation A’ of A in all off-diagonal entries such that
$A^*\in \mathbb{R}^{n\times n}$
agreeing with the (M,M)-perturbation A’ of A in all off-diagonal entries such that
 $\operatorname{rank} A^*[R'\times R']=0$
, contradicting our assumption on A).
$\operatorname{rank} A^*[R'\times R']=0$
, contradicting our assumption on A).
Now, let
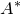 $A^*$
be the matrix obtained from A’ by adjusting the diagonal entries
$A^*$
be the matrix obtained from A’ by adjusting the diagonal entries
 $a'_{h,h}$
for
$a'_{h,h}$
for
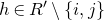 $h\in R'\setminus \{i,j\}$
in such a way that each
$h\in R'\setminus \{i,j\}$
in such a way that each
 $2\times 2$
submatrix of the form
$2\times 2$
submatrix of the form
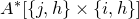 $A^*[\{j,h\}\times \{i,h\}]$
(for any
$A^*[\{j,h\}\times \{i,h\}]$
(for any
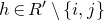 $h\in R'\setminus \{i,j\}$
) is singular. Since
$h\in R'\setminus \{i,j\}$
) is singular. Since
 $A^*$
agrees with the (M,M)-perturbation A’ of A in all off-diagonal entries, we have
$A^*$
agrees with the (M,M)-perturbation A’ of A in all off-diagonal entries, we have
 $\operatorname{rank} A^*[S\times S]\ge 2$
for every subset
$\operatorname{rank} A^*[S\times S]\ge 2$
for every subset
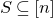 $S\subseteq [n]$
of size
$S\subseteq [n]$
of size
 $|S|\ge n-s$
, and in particular for the subset
$|S|\ge n-s$
, and in particular for the subset
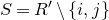 $S=R'\setminus \{i,j\}$
. Hence we obtain
$S=R'\setminus \{i,j\}$
. Hence we obtain
 $\operatorname{rank} A^*[(R'\setminus \{i\})\times (R'\setminus \{j\})]\ge 2$
, and also note that the (j,i)-entry of
$\operatorname{rank} A^*[(R'\setminus \{i\})\times (R'\setminus \{j\})]\ge 2$
, and also note that the (j,i)-entry of
 $A^*$
is
$A^*$
is
 $a^*_{j,i}=a'_{j,i}\ne 0$
.
$a^*_{j,i}=a'_{j,i}\ne 0$
.
Now, if a matrix has rank at least 2, then for any nonzero row (respectively, column), we can find a second linearly independent row (respectively, column). Applying this fact to the matrix
 $A^*[(R'\setminus \{i\})\times (R'\setminus \{j\})]$
and the row with index j, we can find an index
$A^*[(R'\setminus \{i\})\times (R'\setminus \{j\})]$
and the row with index j, we can find an index
 $j'\in R'\setminus \{i,j\}$
such that
$j'\in R'\setminus \{i,j\}$
such that
 $\operatorname{rank} A^*[\{j,j'\}\times (R'\setminus \{j\})]=2$
(i.e., such that the row with index j’ is linearly independent from the row with index j). Applying the fact again to the matrix
$\operatorname{rank} A^*[\{j,j'\}\times (R'\setminus \{j\})]=2$
(i.e., such that the row with index j’ is linearly independent from the row with index j). Applying the fact again to the matrix
 $A^*[\{j,j'\}\times (R'\setminus \{j\})]$
and the column with index i, we can find an index
$A^*[\{j,j'\}\times (R'\setminus \{j\})]$
and the column with index i, we can find an index
 $i'\in R'\setminus \{j,i\}$
such that
$i'\in R'\setminus \{j,i\}$
such that
 $\operatorname{rank} A^*[\{j,j'\}\times \{i,i'\}]=2$
. Now, we must have
$\operatorname{rank} A^*[\{j,j'\}\times \{i,i'\}]=2$
. Now, we must have
 $j'\ne i'$
(since
$j'\ne i'$
(since
 $\operatorname{rank} A^*[\{j,h\}\times \{i,h\}]\le 1$
for all
$\operatorname{rank} A^*[\{j,h\}\times \{i,h\}]\le 1$
for all
 $h\in R'\setminus \{j,i\}$
). So,
$h\in R'\setminus \{j,i\}$
). So,
 $\{j,j'\}$
and
$\{j,j'\}$
and
 $\{i,i'\}$
are disjoint subsets of
$\{i,i'\}$
are disjoint subsets of
 $R'=R\setminus (I_1'\cup J_1')$
, and we have
$R'=R\setminus (I_1'\cup J_1')$
, and we have
 $\operatorname{rank} A'[\{j,j'\}\times \{i,i'\}]=\operatorname{rank} A^*[\{j,j'\}\times \{i,i'\}]=2$
. Defining
$\operatorname{rank} A'[\{j,j'\}\times \{i,i'\}]=\operatorname{rank} A^*[\{j,j'\}\times \{i,i'\}]=2$
. Defining
 $I_1=I_1'\cup \{i,i'\}$
and
$I_1=I_1'\cup \{i,i'\}$
and
 $J_1=J_1'\cup \{i,i'\}$
, we obtain disjoint subsets of R of size
$J_1=J_1'\cup \{i,i'\}$
, we obtain disjoint subsets of R of size
 $k+2$
.
$k+2$
.
Step 3: proving the full-rank condition. We now need to show that the subsets
 $I_1,J_1\subseteq R\subseteq [n]$
satisfy conditions (a)–(c) above for
$I_1,J_1\subseteq R\subseteq [n]$
satisfy conditions (a)–(c) above for
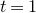 $t=1$
. This is equivalent to showing that the
$t=1$
. This is equivalent to showing that the
 $(2k+2)\times (2k+2)$
matrix
$(2k+2)\times (2k+2)$
matrix
 $$\begin{pmatrix}A[J_{1}\times I_{1}] & & & M[[k]\times J_{1}]^{{\intercal}}\\[3pt]M[[k]\times I_{1}] & & & 0\end{pmatrix}, $$
$$\begin{pmatrix}A[J_{1}\times I_{1}] & & & M[[k]\times J_{1}]^{{\intercal}}\\[3pt]M[[k]\times I_{1}] & & & 0\end{pmatrix}, $$
has full rank
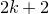 $2k+2$
. But note that the above matrix can be reduced to
$2k+2$
. But note that the above matrix can be reduced to
 $$\begin{pmatrix}0 && & 0 && & M[[k]\times J_{1}']^{{\intercal}}\\[3pt] 0 && & A'[\{j,j'\}\times \{i,i'\}] && & M[[k]\times \{j,j'\}]^{{\intercal}}\\[3pt] M[[k]\times I_{1}'] && & M[[k]\times \{i,i'\}] && & 0\end{pmatrix}, $$
$$\begin{pmatrix}0 && & 0 && & M[[k]\times J_{1}']^{{\intercal}}\\[3pt] 0 && & A'[\{j,j'\}\times \{i,i'\}] && & M[[k]\times \{j,j'\}]^{{\intercal}}\\[3pt] M[[k]\times I_{1}'] && & M[[k]\times \{i,i'\}] && & 0\end{pmatrix}, $$
by elementary row and column operations (precisely the row and column operations that were used to obtain A’ from A in the previous step of the proof). Recalling that the matrices
 $M[[k]\times J_{1}']$
,
$M[[k]\times J_{1}']$
,
 $M[[k]\times I_{1}']$
and
$M[[k]\times I_{1}']$
and
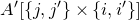 $A'[\{j,j'\}\times \{i,i'\}]$
are nonsingular, the desired result follows.
$A'[\{j,j'\}\times \{i,i'\}]$
are nonsingular, the desired result follows.
9. Proof of the recursive bound in Theorem 5.5
In this section, we finally prove Theorem 5.5, using the results established in the previous three sections.
Proof of Theorem 5.5. As in the statement of the theorem, let
 $k\ge 0$
be an integer,
$k\ge 0$
be an integer,
 $s \gt 0$
be a real number and define
$s \gt 0$
be a real number and define
 $s_*=s/(k+2)^{500}$
. To show the desired bound on f(k,s), we need to show that for any quadruple
$s_*=s/(k+2)^{500}$
. To show the desired bound on f(k,s), we need to show that for any quadruple
 $(n,Q,M,\vec w)$
as in Definition 5.4, we have
$(n,Q,M,\vec w)$
as in Definition 5.4, we have
 \begin{equation}\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w]\le \max\{s_*^{-(k+1)/2}, \quad s_*^{-(k+2)/2}+s_*^{-k/4}\cdot f(k+1,s_*)^{1/2}\},\end{equation}
\begin{equation}\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w]\le \max\{s_*^{-(k+1)/2}, \quad s_*^{-(k+2)/2}+s_*^{-k/4}\cdot f(k+1,s_*)^{1/2}\},\end{equation}
where the probability is taken with respect to a sequence of independent Rademacher random variables
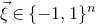 $\vec{\xi}\in\{-1,1\}^{n}$
. This is clearly true if
$\vec{\xi}\in\{-1,1\}^{n}$
. This is clearly true if
 $s_*\le 1$
, so we may assume without loss of generality that
$s_*\le 1$
, so we may assume without loss of generality that
 $s_*\gt1$
and hence
$s_*\gt1$
and hence
 $s \gt (k+2)^{500}\gt 2^{500}$
.
$s \gt (k+2)^{500}\gt 2^{500}$
.
So let n be let a positive integer,
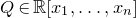 $Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a quadratic polynomial, let
$Q\in\mathbb{R}[x_{1},\ldots,x_{n}]$
be a quadratic polynomial, let
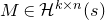 $M\in\mathcal{H}^{k\times n}(s)$
and
$M\in\mathcal{H}^{k\times n}(s)$
and
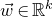 $\vec w\in \mathbb{R}^k$
. Let us write the quadratic part of
$\vec w\in \mathbb{R}^k$
. Let us write the quadratic part of
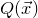 $Q(\vec{x})$
as
$Q(\vec{x})$
as
 $\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix
$\vec{x}^{{\intercal}}A\vec{x}$
for a symmetric matrix
 $A\in \mathbb{R}^{n\times n}$
, and assume that for every subset
$A\in \mathbb{R}^{n\times n}$
, and assume that for every subset
 $S\subseteq[n]$
with
$S\subseteq[n]$
with
 $|S|\ge n-s$
, and every (M,M)-perturbation A’ of A, the submatrix
$|S|\ge n-s$
, and every (M,M)-perturbation A’ of A, the submatrix
 $A'[S\times S]$
has at least one nonzero entry outside the diagonal (this is condition (
$A'[S\times S]$
has at least one nonzero entry outside the diagonal (this is condition (
 $*$
) in Definition 5.4).
$*$
) in Definition 5.4).
As the first step of the proof, we treat the case where the matrix A does not robustly have rank at least two. In the remaining steps of the proof we can then assume that the matrix A does have rank at least two robustly.
Step 1: the low-rank case. Suppose that there is a matrix
 $B \in \mathbb{R}^{n\times n}$
which can be obtained from an (M,M)-perturbation of A by changing its diagonal entries, and a set S of size
$B \in \mathbb{R}^{n\times n}$
which can be obtained from an (M,M)-perturbation of A by changing its diagonal entries, and a set S of size
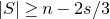 $|S|\ge n-2s/3$
, such that
$|S|\ge n-2s/3$
, such that
 $\operatorname{rank} B[S\times S]\le 2$
. Note that then
$\operatorname{rank} B[S\times S]\le 2$
. Note that then
 $B^{\intercal}$
can also be obtained from an (M,M)-perturbation of
$B^{\intercal}$
can also be obtained from an (M,M)-perturbation of
 $A^{\intercal}=A$
by changing its diagonal entries, and satisfies
$A^{\intercal}=A$
by changing its diagonal entries, and satisfies
 $\operatorname{rank} B^{\intercal}[S\times S]\le 2$
. Consider the symmetric matrix
$\operatorname{rank} B^{\intercal}[S\times S]\le 2$
. Consider the symmetric matrix
 $A^*=\frac{1}{2}(B+B^{\intercal})$
; note that
$A^*=\frac{1}{2}(B+B^{\intercal})$
; note that
 $A^*$
can be obtained from an (M,M)-perturbation of
$A^*$
can be obtained from an (M,M)-perturbation of
 $\frac{1}{2}(A+A)=A$
by changing its diagonal entries, and we have
$\frac{1}{2}(A+A)=A$
by changing its diagonal entries, and we have
 $\operatorname{rank} A^*[S\times S]\le 4$
.
$\operatorname{rank} A^*[S\times S]\le 4$
.
Let
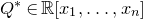 $Q^*\in \mathbb{R}[x_1,\ldots,x_n]$
be a quadratic polynomial with quadratic part
$Q^*\in \mathbb{R}[x_1,\ldots,x_n]$
be a quadratic polynomial with quadratic part
 $\vec x^{\intercal} A^*\vec x$
such that
$\vec x^{\intercal} A^*\vec x$
such that
 $Q(\vec \xi)=Q^*(\vec \xi)$
for all
$Q(\vec \xi)=Q^*(\vec \xi)$
for all
 $\vec{\xi}\in \{-1,1\}^n$
with
$\vec{\xi}\in \{-1,1\}^n$
with
 $M\vec \xi=\vec w$
(such a polynomial
$M\vec \xi=\vec w$
(such a polynomial
 $Q^*$
exists by Lemma 5.3).
$Q^*$
exists by Lemma 5.3).
Now, let
 $T=[n]\setminus S$
, and note that it suffices to prove the probability bound in Equation (9.1) conditioned on every possible outcome for
$T=[n]\setminus S$
, and note that it suffices to prove the probability bound in Equation (9.1) conditioned on every possible outcome for
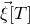 $\vec \xi[T]$
. For any given outcome of
$\vec \xi[T]$
. For any given outcome of
 $\vec \xi[T]$
, we can write
$\vec \xi[T]$
, we can write
 $Q^*(\vec \xi)$
as
$Q^*(\vec \xi)$
as
 $Q^*_{\vec \xi[T]}(\vec \xi[S])$
, for some quadratic polynomial
$Q^*_{\vec \xi[T]}(\vec \xi[S])$
, for some quadratic polynomial
 $Q^*_{\vec \xi[T]}$
in the variables
$Q^*_{\vec \xi[T]}$
in the variables
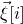 $\vec{\xi}[i]$
for
$\vec{\xi}[i]$
for
 $i\in S$
, with quadratic part
$i\in S$
, with quadratic part
 $\vec x[S]^{\intercal} A^*[S\times S]\vec x[S]$
(and whose linear and constant coefficients depend on
$\vec x[S]^{\intercal} A^*[S\times S]\vec x[S]$
(and whose linear and constant coefficients depend on
 $\vec \xi[T]$
). Simply put, this polynomial is obtained from
$\vec \xi[T]$
). Simply put, this polynomial is obtained from
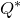 $Q^*$
by plugging in the given values of
$Q^*$
by plugging in the given values of
 $\vec{\xi}[i]$
for
$\vec{\xi}[i]$
for
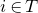 $i\in T$
. Recall that we always have
$i\in T$
. Recall that we always have
 $Q(\vec \xi)=Q^*(\vec \xi)=Q^*_{\vec \xi[T]}(\vec \xi[S])$
(for any
$Q(\vec \xi)=Q^*(\vec \xi)=Q^*_{\vec \xi[T]}(\vec \xi[S])$
(for any
 $\vec \xi\in \{-1,1\}^n$
with
$\vec \xi\in \{-1,1\}^n$
with
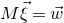 $M\vec \xi=\vec w$
).
$M\vec \xi=\vec w$
).
Now, we claim that for any subset
 $S'\subseteq S$
of size
$S'\subseteq S$
of size
 $|S'|\ge |S|-s/3\ge n-s$
, the matrix
$|S'|\ge |S|-s/3\ge n-s$
, the matrix
 $A^*[S'\times S']$
cannot be a
$A^*[S'\times S']$
cannot be a
 $(M[[k]\times S'],M[[k]\times S'])$
-perturbation of the zero matrix in
$(M[[k]\times S'],M[[k]\times S'])$
-perturbation of the zero matrix in
 $\mathbb{R}^{S'\times S'}$
. Indeed, if
$\mathbb{R}^{S'\times S'}$
. Indeed, if
 $A^*[S'\times S']$
was a
$A^*[S'\times S']$
was a
 $(M[[k]\times S'],M[[k]\times S'])$
-perturbation of the zero matrix, then from the matrix
$(M[[k]\times S'],M[[k]\times S'])$
-perturbation of the zero matrix, then from the matrix
 $A[S'\times S']$
one could obtain the zero matrix by taking an
$A[S'\times S']$
one could obtain the zero matrix by taking an
 $(M[[k]\times S'],M[[k]\times S'])$
-perturbation and changing its diagonal entries. But this means that there is some (M,M)-perturbation A’ of A such
$(M[[k]\times S'],M[[k]\times S'])$
-perturbation and changing its diagonal entries. But this means that there is some (M,M)-perturbation A’ of A such
 $A'[S'\times S']$
agrees with the zero matrix in
$A'[S'\times S']$
agrees with the zero matrix in
 $\mathbb{R}^{S'\times S'}$
in all off-diagonal entries. This means that
$\mathbb{R}^{S'\times S'}$
in all off-diagonal entries. This means that
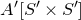 $A'[S'\times S']$
does not have any nonzero entries outside its diagonal, contradicting our assumption on A made above (coming from condition (
$A'[S'\times S']$
does not have any nonzero entries outside its diagonal, contradicting our assumption on A made above (coming from condition (
 $*$
) Definition 5.4). This means that for any subset
$*$
) Definition 5.4). This means that for any subset
 $S'\subseteq S$
of size
$S'\subseteq S$
of size
 $|S'|\ge |S|-s/3$
, the matrix
$|S'|\ge |S|-s/3$
, the matrix
 $A^*[S'\times S']$
is indeed not a
$A^*[S'\times S']$
is indeed not a
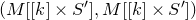 $(M[[k]\times S'],M[[k]\times S'])$
-perturbation of the zero matrix.
$(M[[k]\times S'],M[[k]\times S'])$
-perturbation of the zero matrix.
Furthermore
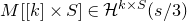 $M[[k]\times S]\in\mathcal{H}^{k\times S}(s/3)$
and
$M[[k]\times S]\in\mathcal{H}^{k\times S}(s/3)$
and
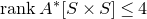 $\operatorname{rank} A^*[S\times S]\le 4$
, so we can apply Proposition 6.1 with
$\operatorname{rank} A^*[S\times S]\le 4$
, so we can apply Proposition 6.1 with
 $r=5$
to the matrix
$r=5$
to the matrix
 $M[[k]\times S]$
, the vector
$M[[k]\times S]$
, the vector
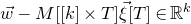 $\vec{w}-M[[k]\times T]\vec \xi[T]\in \mathbb{R}^k$
, and the quadratic polynomial
$\vec{w}-M[[k]\times T]\vec \xi[T]\in \mathbb{R}^k$
, and the quadratic polynomial
 $Q^*_{\vec \xi[T]}$
in the variables
$Q^*_{\vec \xi[T]}$
in the variables
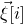 $\vec{\xi}[i]$
for
$\vec{\xi}[i]$
for
 $i\in S$
. The conclusion of the proposition then gives
$i\in S$
. The conclusion of the proposition then gives
 \begin{align*}&\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec \xi=\vec w\,|\,\vec \xi[T]]\\&\quad =\mathrm{Pr}[Q_{\vec{\xi}[T]}^*(\vec \xi[S])=0 \text{ and } M[[k]\times S]\vec \xi[S] =\vec{w}-M[[k]\times T]\vec \xi[T]\,|\,\vec \xi[T]]\\&\quad \le \bigg(\frac{\lfloor s/3\rfloor}{2^{75}(k+5)^2}\bigg)^{-(k+1)/2}\le s_*^{-(k+1)/2},\end{align*}
\begin{align*}&\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec \xi=\vec w\,|\,\vec \xi[T]]\\&\quad =\mathrm{Pr}[Q_{\vec{\xi}[T]}^*(\vec \xi[S])=0 \text{ and } M[[k]\times S]\vec \xi[S] =\vec{w}-M[[k]\times T]\vec \xi[T]\,|\,\vec \xi[T]]\\&\quad \le \bigg(\frac{\lfloor s/3\rfloor}{2^{75}(k+5)^2}\bigg)^{-(k+1)/2}\le s_*^{-(k+1)/2},\end{align*}
for every possible outcome of
 $\vec \xi[T]$
. Hence
$\vec \xi[T]$
. Hence
 $\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec \xi=\vec w]\le s_*^{-(k+1)/2}$
, which in particular proves Equation (9.1).
$\mathrm{Pr}[Q(\vec \xi)=0 \text{ and } M\vec \xi=\vec w]\le s_*^{-(k+1)/2}$
, which in particular proves Equation (9.1).
Step 2: decoupling. From now on, we may assume that
 $\operatorname{rank} B[S\times S]\ge 3$
for any matrix
$\operatorname{rank} B[S\times S]\ge 3$
for any matrix
 $B \in \mathbb{R}^{n\times n}$
which can be obtained from an (M,M)-perturbation of A by changing its diagonal entries, and any set S of size
$B \in \mathbb{R}^{n\times n}$
which can be obtained from an (M,M)-perturbation of A by changing its diagonal entries, and any set S of size
 $|S|\ge n-2s/3$
. This means in particular that the assumption in Lemma 5.8 is satisfied for
$|S|\ge n-2s/3$
. This means in particular that the assumption in Lemma 5.8 is satisfied for
 $s/2\ge 4k+8$
, and therefore Lemma 5.8 gives us a partition
$s/2\ge 4k+8$
, and therefore Lemma 5.8 gives us a partition
 $[n]=I\cup J$
with
$[n]=I\cup J$
with
 $|I|\le s/2$
, such that
$|I|\le s/2$
, such that
 $$ (M[[k]\times I],\,M[[k]\times J],\,A[J\times I])\in\mathcal{M}_2^{k,I,J}(\lfloor s/(8k+16)\rfloor ). $$
$$ (M[[k]\times I],\,M[[k]\times J],\,A[J\times I])\in\mathcal{M}_2^{k,I,J}(\lfloor s/(8k+16)\rfloor ). $$
Recalling the second part of Remark 5.1, this implies
 \begin{equation} (M[[k]\times I],\,M[[k]\times J],\,-2A[J\times I])\in \mathcal{M}_2^{k,I,J}(\lfloor s/(8k+16)\rfloor )\subseteq \mathcal{M}_2^{k,I,J}(6\cdot \lfloor s/(48k+96)\rfloor); \end{equation}
\begin{equation} (M[[k]\times I],\,M[[k]\times J],\,-2A[J\times I])\in \mathcal{M}_2^{k,I,J}(\lfloor s/(8k+16)\rfloor )\subseteq \mathcal{M}_2^{k,I,J}(6\cdot \lfloor s/(48k+96)\rfloor); \end{equation}
(which in particular means that
 $6\cdot \lfloor s/(48k+96)\rfloor\le |I|\le |J|$
).
$6\cdot \lfloor s/(48k+96)\rfloor\le |I|\le |J|$
).
Let
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
be an independent copy of
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
be an independent copy of
 $\vec{\xi}[I]$
(i.e., consider independent random variables
$\vec{\xi}[I]$
(i.e., consider independent random variables
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[i]\in \{-1,1\}$
for
$\vec{\xi}\mkern2mu\vphantom{\xi}'[i]\in \{-1,1\}$
for
 $i\in I$
, independent from all entries of
$i\in I$
, independent from all entries of
 $\vec \xi$
). Now, let us extend
$\vec \xi$
). Now, let us extend
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
to a vector
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
to a vector
 $\vec{\xi}\mkern2mu\vphantom{\xi}'\in \mathbb{R}^n$
by defining
$\vec{\xi}\mkern2mu\vphantom{\xi}'\in \mathbb{R}^n$
by defining
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[j]=\vec{\xi}[j]$
for all
$\vec{\xi}\mkern2mu\vphantom{\xi}'[j]=\vec{\xi}[j]$
for all
 $j\in J$
. Note that then
$j\in J$
. Note that then
 $\vec{\xi}\mkern2mu\vphantom{\xi}'$
consists of the data
$\vec{\xi}\mkern2mu\vphantom{\xi}'$
consists of the data
 $(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])$
, while
$(\vec{\xi}\mkern2mu\vphantom{\xi}'[I],\vec{\xi}[J])$
, while
 $\vec \xi$
consists of the data
$\vec \xi$
consists of the data
 $(\vec{\xi}[I],\vec{\xi}[J])$
. By decoupling (Lemma 3.6) we have
$(\vec{\xi}[I],\vec{\xi}[J])$
. By decoupling (Lemma 3.6) we have
 \begin{align}&\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]^{2}\notag\\&\quad\quad \le\mathrm{Pr}[Q(\vec{\xi})=Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and } M\vec{\xi}=M\vec{\xi}\mkern2mu\vphantom{\xi}'=\vec{w}]\notag\\ &\quad\quad =\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } M(\vec{\xi}-\vec{\xi}\mkern2mu\vphantom{\xi}')=\vec 0]\notag\\ &\quad\quad =\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0].\end{align}
\begin{align}&\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]^{2}\notag\\&\quad\quad \le\mathrm{Pr}[Q(\vec{\xi})=Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and } M\vec{\xi}=M\vec{\xi}\mkern2mu\vphantom{\xi}'=\vec{w}]\notag\\ &\quad\quad =\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } M(\vec{\xi}-\vec{\xi}\mkern2mu\vphantom{\xi}')=\vec 0]\notag\\ &\quad\quad =\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0].\end{align}
Note that the event
 $M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0$
depends only on the outcomes of
$M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0$
depends only on the outcomes of
 $\vec{\xi}[I]$
and
$\vec{\xi}[I]$
and
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
(and not on the outcome of
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
(and not on the outcome of
 $\vec{\xi}[J]$
). We will later bound the probability of this event using Corollary 3.5. For fixed outcomes of
$\vec{\xi}[J]$
). We will later bound the probability of this event using Corollary 3.5. For fixed outcomes of
 $\vec{\xi}[I]$
and
$\vec{\xi}[I]$
and
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, we can express the conditions
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, we can express the conditions
 $Q(\vec{\xi})=0$
and
$Q(\vec{\xi})=0$
and
 $Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0$
and
$Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0$
and
 $M\vec{\xi}=\vec{w}$
in terms of
$M\vec{\xi}=\vec{w}$
in terms of
 $\vec \xi [J]$
; namely we can write them in the form
$\vec \xi [J]$
; namely we can write them in the form
 $Q_{\vec \xi[I]}(\vec{\xi}[J])=0$
and
$Q_{\vec \xi[I]}(\vec{\xi}[J])=0$
and
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec\xi[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
for some quadratic polynomial
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec\xi[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
for some quadratic polynomial
 $Q_{\vec \xi[I]}$
and some matrix
$Q_{\vec \xi[I]}$
and some matrix
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
(which depend on the outcomes of
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
(which depend on the outcomes of
 $\vec{\xi}[I]$
and
$\vec{\xi}[I]$
and
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
).
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
).
More specifically, for a given outcome of
 $\vec{\xi}[I]$
, the event
$\vec{\xi}[I]$
, the event
 \begin{equation}\{ Q(\vec{\xi})=0\}\quad \text{can be written as}\quad \{Q_{\vec \xi[I]}(\vec{\xi}[J])=0\},\end{equation}
\begin{equation}\{ Q(\vec{\xi})=0\}\quad \text{can be written as}\quad \{Q_{\vec \xi[I]}(\vec{\xi}[J])=0\},\end{equation}
where
 $Q_{\vec \xi[I]}$
is the quadratic polynomial in the variables
$Q_{\vec \xi[I]}$
is the quadratic polynomial in the variables
 $x_j$
for
$x_j$
for
 $j\in J$
obtained from Q by replacing each variable
$j\in J$
obtained from Q by replacing each variable
 $x_i$
for
$x_i$
for
 $i\in I=[n]\setminus J$
by the given value of
$i\in I=[n]\setminus J$
by the given value of
 $\vec\xi[i]$
. Then, by definition, we have
$\vec\xi[i]$
. Then, by definition, we have
 $Q_{\vec \xi[I]}(\vec{\xi}[J])=Q(\vec\xi)$
for any outcome of
$Q_{\vec \xi[I]}(\vec{\xi}[J])=Q(\vec\xi)$
for any outcome of
 $\vec{\xi}[J]$
. Also note that the quadratic part of the polynomial
$\vec{\xi}[J]$
. Also note that the quadratic part of the polynomial
 $Q_{\vec \xi[I]}$
is given by
$Q_{\vec \xi[I]}$
is given by
 $\vec{x}[J]^{{\intercal}}A[J\times J]\vec{x}[J]$
.
$\vec{x}[J]^{{\intercal}}A[J\times J]\vec{x}[J]$
.
Furthermore, for given outcomes of
 $\vec{\xi}[I]$
and
$\vec{\xi}[I]$
and
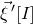 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, the event
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, the event
 \begin{equation}\{ M\vec{\xi}=\vec{w} \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0\}\quad \text{can be written as}\quad \{M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec{\xi}[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\},\end{equation}
\begin{equation}\{ M\vec{\xi}=\vec{w} \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0\}\quad \text{can be written as}\quad \{M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec{\xi}[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\},\end{equation}
where the matrix
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{(k+1)\times J}$
and the vector
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{(k+1)\times J}$
and the vector
 $\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{k+1}$
are defined as follows: when plugging in the given values for
$\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{k+1}$
are defined as follows: when plugging in the given values for
 $\vec{\xi}[i]$
for
$\vec{\xi}[i]$
for
 $i\in I$
, we can interpret
$i\in I$
, we can interpret
 $M\vec{\xi}=\vec{w}$
as a system of linear equations in the variables
$M\vec{\xi}=\vec{w}$
as a system of linear equations in the variables
 $\vec{\xi}[j]$
for
$\vec{\xi}[j]$
for
 $j\in J=[n]\setminus I$
. This system of linear equations has the form
$j\in J=[n]\setminus I$
. This system of linear equations has the form
 $M[[k]\times J]\vec{\xi}[J]=\vec w-M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
. Furthermore, when plugging the given values for
$M[[k]\times J]\vec{\xi}[J]=\vec w-M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
. Furthermore, when plugging the given values for
 $\vec{\xi}[i]$
and
$\vec{\xi}[i]$
and
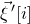 $\vec{\xi}\mkern2mu\vphantom{\xi}'[i]$
for
$\vec{\xi}\mkern2mu\vphantom{\xi}'[i]$
for
 $i\in I$
into
$i\in I$
into
 $Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0$
, we obtain another linear equation in the variables
$Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0$
, we obtain another linear equation in the variables
 $\vec{\xi}[j]$
for
$\vec{\xi}[j]$
for
 $j\in J$
(indeed, the quadratic terms in the variables
$j\in J$
(indeed, the quadratic terms in the variables
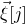 $\vec{\xi}[j]$
for
$\vec{\xi}[j]$
for
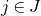 $j\in J$
cancel out in the difference
$j\in J$
cancel out in the difference
 $Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')$
). The coefficient vector of this linear equation is precisely
$Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')$
). The coefficient vector of this linear equation is precisely
 $2A[J\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
. Appending this additional linear equation to our previous system of linear equations in the variables
$2A[J\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
. Appending this additional linear equation to our previous system of linear equations in the variables
 $\vec{\xi}[j]$
for
$\vec{\xi}[j]$
for
 $j\in J$
, we obtain a system of
$j\in J$
, we obtain a system of
 $k+1$
equations that we can express in the form
$k+1$
equations that we can express in the form
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec{\xi}[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
for a matrix
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec{\xi}[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
for a matrix
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{(k+1)\times J}$
and a vector
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{(k+1)\times J}$
and a vector
 $\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{k+1}$
. Note that the first k rows of the matrix
$\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{k+1}$
. Note that the first k rows of the matrix
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{(k+1)\times J}$
are given by
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathbb{R}^{(k+1)\times J}$
are given by
 $M[[k]\times J]$
, and the last row is given by (the transpose of) the vector
$M[[k]\times J]$
, and the last row is given by (the transpose of) the vector
 $2A[J\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
.
$2A[J\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
.
For given outcomes of
 $\vec{\xi}[I]$
and
$\vec{\xi}[I]$
and
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, we would like to bound the probability of having
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, we would like to bound the probability of having
 $Q_{\vec \xi[I]}(\vec{\xi}[J])=0$
and
$Q_{\vec \xi[I]}(\vec{\xi}[J])=0$
and
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec\xi[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
(subject to the randomness of
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec\xi[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
(subject to the randomness of
 $\vec\xi[J]$
). If
$\vec\xi[J]$
). If
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal{H}^{(k+1)\times J}(s')$
for some suitable s’, then we will be able to bound this probability by
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal{H}^{(k+1)\times J}(s')$
for some suitable s’, then we will be able to bound this probability by
 $f(k+1,s')$
; see Definition 5.4. In the next step, we first handle the case where
$f(k+1,s')$
; see Definition 5.4. In the next step, we first handle the case where
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\not\in \mathcal{H}^{(k+1)\times J}(s')$
.
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\not\in \mathcal{H}^{(k+1)\times J}(s')$
.
Step 3: failure of the Halász condition. We define
 $s'=\lfloor s/(48k+96)\rfloor$
, then
$s'=\lfloor s/(48k+96)\rfloor$
, then
 $k\le 6s'\le |I|$
(recalling Equation (9.2) and
$k\le 6s'\le |I|$
(recalling Equation (9.2) and
 $s \gt (k+2)^{500}$
). Our goal in this step is to bound the probability that the outcomes of
$s \gt (k+2)^{500}$
). Our goal in this step is to bound the probability that the outcomes of
 $\vec{\xi}[I]$
and
$\vec{\xi}[I]$
and
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
are such that
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
are such that
 $M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0$
and
$M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0$
and
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\not\in \mathcal{H}^{(k+1)\times J}(s')$
. To do so, let us condition on an arbitrary outcome of
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\not\in \mathcal{H}^{(k+1)\times J}(s')$
. To do so, let us condition on an arbitrary outcome of
 $\vec\xi[I]$
. Let us apply Lemma 5.7 with
$\vec\xi[I]$
. Let us apply Lemma 5.7 with
 $0\le k\le 6s'\le |I|\le |J|$
, the random vector
$0\le k\le 6s'\le |I|\le |J|$
, the random vector
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, the matrices
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
, the matrices
 $T=M[[k]\times I]$
,
$T=M[[k]\times I]$
,
 $U=M[[k]\times J]$
and
$U=M[[k]\times J]$
and
 $-2A[J\times I]$
(noting that then
$-2A[J\times I]$
(noting that then
 $(T,U,-2A[J\times I])\in \mathcal{M}_2^{k,I,J}(6s')$
by Equation (9.2)), as well as the vectors
$(T,U,-2A[J\times I])\in \mathcal{M}_2^{k,I,J}(6s')$
by Equation (9.2)), as well as the vectors
 $\vec y=M[[k]\times I]\vec \xi[I]$
and
$\vec y=M[[k]\times I]\vec \xi[I]$
and
 $\vec b=-2A[J\times I]\vec \xi[I]$
. Note that then the random matrix
$\vec b=-2A[J\times I]\vec \xi[I]$
. Note that then the random matrix
 $U'_{\vec\xi}$
in Lemma 5.7 is precisely the matrix
$U'_{\vec\xi}$
in Lemma 5.7 is precisely the matrix
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
(namely, the matrix obtained from
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
(namely, the matrix obtained from
 $U=M[[k]\times J]$
by appending the vector
$U=M[[k]\times J]$
by appending the vector
 $-2A[J\times I]\vec{\xi}\mkern2mu\vphantom{\xi}'[I]-\vec b=2A[J\times I](\vec\xi[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
as an additional row). So, we obtain
$-2A[J\times I]\vec{\xi}\mkern2mu\vphantom{\xi}'[I]-\vec b=2A[J\times I](\vec\xi[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])$
as an additional row). So, we obtain
 \begin{align}&\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\notin \mathcal H^{(k+1)\times J}(s') \,|\,\vec{\xi}[I]] \nonumber\\& \quad \le \bigg(\frac{6s'}{10^{61}(k+2)^{20}}\bigg)^{-(k+2)/2} \le s_*^{-(k+2)/2},\end{align}
\begin{align}&\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\notin \mathcal H^{(k+1)\times J}(s') \,|\,\vec{\xi}[I]] \nonumber\\& \quad \le \bigg(\frac{6s'}{10^{61}(k+2)^{20}}\bigg)^{-(k+2)/2} \le s_*^{-(k+2)/2},\end{align}
for any outcome of
 $\vec\xi[I]$
(here, the probability is with respect to the randomness of
$\vec\xi[I]$
(here, the probability is with respect to the randomness of
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
). In the last step, we used that
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
). In the last step, we used that
 $s'=\lfloor s/(48k+96)\rfloor$
and therefore
$s'=\lfloor s/(48k+96)\rfloor$
and therefore
 $s'/(10^{61}(k+2)^{20})\ge s/(10^{63}(k+2)^{21})\ge s/(k+2)^{273} \gt s_*$
(since
$s'/(10^{61}(k+2)^{20})\ge s/(10^{63}(k+2)^{21})\ge s/(k+2)^{273} \gt s_*$
(since
 $k+2\ge 2$
).
$k+2\ge 2$
).
Step 4: bounding the main term. Recall from Step 2 that
 $\operatorname{rank} B[S\times S]\ge 3$
for any matrix
$\operatorname{rank} B[S\times S]\ge 3$
for any matrix
 $B \in \mathbb{R}^{n\times n}$
which can be obtained from an (M,M)-perturbation of A by changing its diagonal entries, and any subset
$B \in \mathbb{R}^{n\times n}$
which can be obtained from an (M,M)-perturbation of A by changing its diagonal entries, and any subset
 $S\subseteq J$
of size
$S\subseteq J$
of size
 $|S|\ge |J|-s'$
(here, we are using that
$|S|\ge |J|-s'$
(here, we are using that
 $|J|-s'\ge n-2s/3$
as
$|J|-s'\ge n-2s/3$
as
 $s'\le s/6$
and
$s'\le s/6$
and
 $|J|=n-|I|\ge n-s/2$
). Recalling that the matrix
$|J|=n-|I|\ge n-s/2$
). Recalling that the matrix
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
is obtained from
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}$
is obtained from
 $M[[k]\times J]$
by adding one row, this implies that
$M[[k]\times J]$
by adding one row, this implies that
 $\operatorname{rank} B[S\times S]\ge 1$
for any matrix
$\operatorname{rank} B[S\times S]\ge 1$
for any matrix
 $B \in \mathbb{R}^{J\times J}$
obtained from an
$B \in \mathbb{R}^{J\times J}$
obtained from an
 $(M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]},M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]})$
-perturbation of
$(M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]},M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]})$
-perturbation of
 $A[J\times J]$
by changing its diagonal entries, and any subset
$A[J\times J]$
by changing its diagonal entries, and any subset
 $S\subseteq J$
of size
$S\subseteq J$
of size
 $|S|\ge |J|-s'$
. Thus,
$|S|\ge |J|-s'$
. Thus,
 $A'[S\times S]$
must have at least one nonzero entry outside the diagonal for every subset
$A'[S\times S]$
must have at least one nonzero entry outside the diagonal for every subset
 $S\subseteq J$
of size
$S\subseteq J$
of size
 $|S|\ge |J|-s'$
and every
$|S|\ge |J|-s'$
and every
 $(M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]},M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]})$
-perturbation A’ of
$(M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]},M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]})$
-perturbation A’ of
 $A[J\times J]$
.
$A[J\times J]$
.
This means that whenever we have
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal{H}^{(k+1)\times J}(s')$
, the quadruple
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal{H}^{(k+1)\times J}(s')$
, the quadruple
 $(|J|,Q_{\vec \xi[I]},M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]},\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]})$
satisfies the conditions in Definition 5.4, with parameters
$(|J|,Q_{\vec \xi[I]},M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]},\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]})$
satisfies the conditions in Definition 5.4, with parameters
 $k+1$
and s’ (recall that
$k+1$
and s’ (recall that
 $Q_{\vec \xi[I]}$
has quadratic part
$Q_{\vec \xi[I]}$
has quadratic part
 $\vec{x}[J]^{{\intercal}}A[J\times J]\vec{x}[J]$
). Hence, for any outcomes of
$\vec{x}[J]^{{\intercal}}A[J\times J]\vec{x}[J]$
). Hence, for any outcomes of
 $\vec{\xi}[I]$
and
$\vec{\xi}[I]$
and
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
such that
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
such that
 $M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal{H}^{(k+1)\times J}(s')$
, we have the conditional probability bound
$M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal{H}^{(k+1)\times J}(s')$
, we have the conditional probability bound
 \begin{align} &\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0\,|\,\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\notag\\ &\quad\quad=\mathrm{Pr}[Q_{\vec \xi[I]}(\vec{\xi}[J])=0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec{\xi}[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\,|\,\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\le f(k+1,s')\le f(k+1,s_*);\end{align}
\begin{align} &\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0\,|\,\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\notag\\ &\quad\quad=\mathrm{Pr}[Q_{\vec \xi[I]}(\vec{\xi}[J])=0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\vec{\xi}[J]=\vec{w}_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\,|\,\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\le f(k+1,s')\le f(k+1,s_*);\end{align}
(for the first step, recall Equation (9.4) and Equation (9.5), and for the last step note that
 $s'=\lfloor s/(48k+96)\rfloor\ge s/(k+2)^{500}=s_*$
).
$s'=\lfloor s/(48k+96)\rfloor\ge s/(k+2)^{500}=s_*$
).
Step 5: concluding. For ease of notation, let us abbreviate
 $\mathcal H^{(k+1)\times J}(s')$
by
$\mathcal H^{(k+1)\times J}(s')$
by
 $\mathcal{H}$
. By Equation (9.3) we have
$\mathcal{H}$
. By Equation (9.3) we have
 \begin{align*}&\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]^{2}\\ &\quad \le \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and }M\vec{\xi}=\vec{w} \text{ and } M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0]\\ &\quad \le\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0 \text{ and }\\ &\quad\quad M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal H] +[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\notin \mathcal H]\\ &\quad \le\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0]\\&\qquad \times\sup_{\substack{\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]\\M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal H}}\!\!\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}') =0\,|\,\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\\ &\qquad +\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]\sup_{\vec{\xi}[I]}\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\notin \mathcal H \,|\,\vec{\xi}[I]].\end{align*}
\begin{align*}&\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]^{2}\\ &\quad \le \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and }M\vec{\xi}=\vec{w} \text{ and } M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0]\\ &\quad \le\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}')=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0 \text{ and }\\ &\quad\quad M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal H] +[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\notin \mathcal H]\\ &\quad \le\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0]\\&\qquad \times\sup_{\substack{\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]\\M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\in \mathcal H}}\!\!\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w} \text{ and } Q(\vec{\xi})-Q(\vec{\xi}\mkern2mu\vphantom{\xi}') =0\,|\,\vec{\xi}[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]]\\ &\qquad +\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]\sup_{\vec{\xi}[I]}\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0 \text{ and } M_{\vec \xi[I],\vec{\xi}\mkern2mu\vphantom{\xi}'[I]}\notin \mathcal H \,|\,\vec{\xi}[I]].\end{align*}
Note that
 $M[[k]\times I]\in \mathcal H^{k\times I}(6s')$
by Equation (9.2) and Remark 5.1. Therefore, by Corollary 3.5 (applied with
$M[[k]\times I]\in \mathcal H^{k\times I}(6s')$
by Equation (9.2) and Remark 5.1. Therefore, by Corollary 3.5 (applied with
 $\vec w=M[[k]\times I]\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
for any fixed outcome of
$\vec w=M[[k]\times I]\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
for any fixed outcome of
 $\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
) we have
$\vec{\xi}\mkern2mu\vphantom{\xi}'[I]$
) we have
 $\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0]\le (6s'/k)^{-k/2}\le s_*^{-k/2}$
if
$\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0]\le (6s'/k)^{-k/2}\le s_*^{-k/2}$
if
 $k\ge 1$
(recalling that
$k\ge 1$
(recalling that
 $s'=\lfloor s/(48k+96)\rfloor$
and
$s'=\lfloor s/(48k+96)\rfloor$
and
 $s_*=s/ (k+2)^{500}$
). If
$s_*=s/ (k+2)^{500}$
). If
 $k=0$
, then we trivially have
$k=0$
, then we trivially have
 $\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0]\le s_*^{-k/2}$
, so this inequality holds in either case. Plugging this observation, as well as Equation (9.7) and Equation (9.6) into the above chain of inequalities, we obtain
$\mathrm{Pr}[M[[k]\times I](\vec{\xi}[I]-\vec{\xi}\mkern2mu\vphantom{\xi}'[I])=\vec 0]\le s_*^{-k/2}$
, so this inequality holds in either case. Plugging this observation, as well as Equation (9.7) and Equation (9.6) into the above chain of inequalities, we obtain
 $$ \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]^{2}\le s_*^{-k/2}\cdot f(k+1,s_*)+\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]\cdot s_*^{-(k+2)/2} . $$
$$ \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]^{2}\le s_*^{-k/2}\cdot f(k+1,s_*)+\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]\cdot s_*^{-(k+2)/2} . $$
Applying Lemma 3.8, this yields
 $$ \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]\le s_{*}^{-(k+2)/2}+s_{*}^{-k/4}\cdot f(k+1,s_*)^{1/2}, $$
$$ \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec{w}]\le s_{*}^{-(k+2)/2}+s_{*}^{-k/4}\cdot f(k+1,s_*)^{1/2}, $$
implying the desired bound in Equation (9.1).
10. Deducing a non-recursive bound
In this section, we prove Theorem 5.1. First, from the recursive bound for f(k,s) in Theorem 5.5, one can deduce the following non-recursive bound.
Corollary 10.1. For any integers
 $0\le k\le \ell$
and any real
$0\le k\le \ell$
and any real
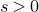 $s \gt 0$
we have
$s \gt 0$
we have
 \begin{equation}f(k,s)\le (s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}+\sum_{i=k}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}}\prod_{j=k}^{i-1}(s_{k,j})^{-j/2^{j-k+2}},\end{equation}
\begin{equation}f(k,s)\le (s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}+\sum_{i=k}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}}\prod_{j=k}^{i-1}(s_{k,j})^{-j/2^{j-k+2}},\end{equation}
where for
 $i=k,\ldots,\ell$
we define
$i=k,\ldots,\ell$
we define
 $$s_{k,i}=\frac{s}{(i+2)^{500(i-k+1)}}. $$
$$s_{k,i}=\frac{s}{(i+2)^{500(i-k+1)}}. $$
In order to analyse the bound on the left-hand side of Equation (10.1), we make the following simple observation.
Lemma 10.2. For any integers
 $0\le k\le i$
, we have
$0\le k\le i$
, we have
 $$\sum_{j=k}^{i-1}\frac{j}{2^{j-k+2}}=\frac{k+1}{2}-\frac{i+1}{2^{i-k+1}}. $$
$$\sum_{j=k}^{i-1}\frac{j}{2^{j-k+2}}=\frac{k+1}{2}-\frac{i+1}{2^{i-k+1}}. $$
Proof. The identity can easily be shownFootnote
12
by induction on
 $i-k$
. The base case
$i-k$
. The base case
 $i-k=0$
(i.e.,
$i-k=0$
(i.e.,
 $i=k$
) is trivial, as both sides are zero. For the induction step, with
$i=k$
) is trivial, as both sides are zero. For the induction step, with
 $i-k\ge 1$
, we compute
$i-k\ge 1$
, we compute
 $$ \sum_{j=k}^{i-1}\frac{j}{2^{j-k+2}}=\sum_{j=k}^{i-2}\frac{j}{2^{j-k+2}}+\frac{i-1}{2^{i-k+1}}=\frac{k+1}{2}-\frac{i}{2^{i-k}}+\frac{i-1}{2^{i-k+1}}=\frac{k+1}{2}-\frac{i+1}{2^{i-k+1}}.$$
$$ \sum_{j=k}^{i-1}\frac{j}{2^{j-k+2}}=\sum_{j=k}^{i-2}\frac{j}{2^{j-k+2}}+\frac{i-1}{2^{i-k+1}}=\frac{k+1}{2}-\frac{i}{2^{i-k}}+\frac{i-1}{2^{i-k+1}}=\frac{k+1}{2}-\frac{i+1}{2^{i-k+1}}.$$
Using the above observation, let us now deduce Corollary 10.1 from Theorem 5.5 by induction on
 $\ell-k$
and some tedious but straightforward calculations.
$\ell-k$
and some tedious but straightforward calculations.
Proof of Corollary 10.1.
We prove the desired bound by induction on
 $\ell-k$
. If
$\ell-k$
. If
 $\ell-k=0$
(i.e., if
$\ell-k=0$
(i.e., if
 $\ell=k$
), we need to show that
$\ell=k$
), we need to show that
 $f(k,s)\le (s_{k,k})^{-k/2}$
. If
$f(k,s)\le (s_{k,k})^{-k/2}$
. If
 $k=0$
, this is trivially true as
$k=0$
, this is trivially true as
 $f(k,s)\le 1=(s_{0,0})^{-0/2}$
. To check
$f(k,s)\le 1=(s_{0,0})^{-0/2}$
. To check
 $f(k,s)\le (s_{k,k})^{-k/2}$
for
$f(k,s)\le (s_{k,k})^{-k/2}$
for
 $k\ge 1$
, recall that for every quadruple
$k\ge 1$
, recall that for every quadruple
 $(n,Q,M,\vec w)$
in the supremum in the definition of f(k,s) in Definition 5.4, we have
$(n,Q,M,\vec w)$
in the supremum in the definition of f(k,s) in Definition 5.4, we have
 $M\in \mathcal{H}^{k\times n}(s)$
and therefore by Corollary 3.5
$M\in \mathcal{H}^{k\times n}(s)$
and therefore by Corollary 3.5
 $$ \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w]\le \mathrm{Pr}[M\vec{\xi}=\vec w]\le (s/k)^{-k/2}\le \bigg(\frac{s}{(k+2)^{500}}\bigg)^{-k/2}=(s_{k,k})^{-k/2}. $$
$$ \mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w]\le \mathrm{Pr}[M\vec{\xi}=\vec w]\le (s/k)^{-k/2}\le \bigg(\frac{s}{(k+2)^{500}}\bigg)^{-k/2}=(s_{k,k})^{-k/2}. $$
This shows
 $f(k,s)\le (s_{k,k})^{-k/2}$
, as desired.
$f(k,s)\le (s_{k,k})^{-k/2}$
, as desired.
Let us now assume that
 $\ell-k\ge 1$
and that we already proved the desired bound for all smaller values of
$\ell-k\ge 1$
and that we already proved the desired bound for all smaller values of
 $\ell-k$
. Note that now by Theorem 5.5 we have
$\ell-k$
. Note that now by Theorem 5.5 we have
 $$ f(k,s)\le \max\{s_*^{-(k+1)/2}, s_*^{-(k+2)/2}+s_*^{-k/4}\cdot f(k+1,s_*)^{1/2}\}, $$
$$ f(k,s)\le \max\{s_*^{-(k+1)/2}, s_*^{-(k+2)/2}+s_*^{-k/4}\cdot f(k+1,s_*)^{1/2}\}, $$
with
 $s_*=s/(k+2)^{500}$
. So it suffices to show that both terms in this maximum are bounded by the left-hand side of Equation (10.1).
$s_*=s/(k+2)^{500}$
. So it suffices to show that both terms in this maximum are bounded by the left-hand side of Equation (10.1).
First, note that
 $s_*=s/(k+2)^{500}\ge s_{k,i}$
for all
$s_*=s/(k+2)^{500}\ge s_{k,i}$
for all
 $i=k,\ldots,\ell$
. This means that in the case
$i=k,\ldots,\ell$
. This means that in the case
 $s_*\le 1$
, we also have
$s_*\le 1$
, we also have
 $s_{k,i}\le 1$
for all
$s_{k,i}\le 1$
for all
 $i=k,\ldots,\ell$
and hence Equation (10.1) follows trivially from
$i=k,\ldots,\ell$
and hence Equation (10.1) follows trivially from
 $f(k,s)\le 1$
. We may therefore assume that
$f(k,s)\le 1$
. We may therefore assume that
 $s_* \gt 1$
.
$s_* \gt 1$
.
For the first term in the maximum above, note that by Lemma 10.2 applied to
 $i=\ell$
, we have
$i=\ell$
, we have
 $$ \frac{\ell}{2^{\ell-k+1}}+\sum_{j=k}^{\ell-1}\frac{j}{2^{j-k+2}}=\frac{\ell}{2^{\ell-k+1}}+\frac{k+1}{2}-\frac{\ell+1}{2^{\ell-k+1}}=\frac{k+1}{2}-\frac{1}{2^{\ell-k+1}}<\frac{k+1}{2}. $$
$$ \frac{\ell}{2^{\ell-k+1}}+\sum_{j=k}^{\ell-1}\frac{j}{2^{j-k+2}}=\frac{\ell}{2^{\ell-k+1}}+\frac{k+1}{2}-\frac{\ell+1}{2^{\ell-k+1}}=\frac{k+1}{2}-\frac{1}{2^{\ell-k+1}}<\frac{k+1}{2}. $$
Hence
 $$ s_*^{-(k+1)/2}\le (s_*)^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_*)^{-j/2^{j-k+2}}\le (s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}, $$
$$ s_*^{-(k+1)/2}\le (s_*)^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_*)^{-j/2^{j-k+2}}\le (s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}, $$
which in particular shows that
 $s_*^{-(k+1)/2}$
is bounded by the left-hand side of Equation (10.1).
$s_*^{-(k+1)/2}$
is bounded by the left-hand side of Equation (10.1).
To bound the second term, first note that by the inductive assumption we have
 $$ f(k+1,s_*)\le(s'_{k+1,\ell})^{-\ell/2^{\ell-k}}\prod_{j=k+1}^{\ell-1}(s'_{k+1,j})^{-j/2^{j-k+1}}+\sum_{i=k+1}^{\ell-1}(s'_{k+1,i})^{-(i+2)/2^{i-k}}\prod_{j=k+1}^{i-1}(s'_{k+1,j})^{-j/2^{j-k+1}}, $$
$$ f(k+1,s_*)\le(s'_{k+1,\ell})^{-\ell/2^{\ell-k}}\prod_{j=k+1}^{\ell-1}(s'_{k+1,j})^{-j/2^{j-k+1}}+\sum_{i=k+1}^{\ell-1}(s'_{k+1,i})^{-(i+2)/2^{i-k}}\prod_{j=k+1}^{i-1}(s'_{k+1,j})^{-j/2^{j-k+1}}, $$
defining
 $$s'_{k+1,i}=\frac{s_*}{(i+2)^{500(i-k)}}=\frac{s}{(i+2)^{500(i-k)}\cdot (k+2)^{500}}, $$
$$s'_{k+1,i}=\frac{s_*}{(i+2)^{500(i-k)}}=\frac{s}{(i+2)^{500(i-k)}\cdot (k+2)^{500}}, $$
for
 $i=k+1,\ldots,\ell$
. Note that we have
$i=k+1,\ldots,\ell$
. Note that we have
 $s'_{k+1,i}\ge s_{k,i}$
for all
$s'_{k+1,i}\ge s_{k,i}$
for all
 $i=k+1,\ldots,\ell$
, implying
$i=k+1,\ldots,\ell$
, implying
 $$ f(k+1,s_*)\le (s_{k,\ell})^{-\ell/2^{\ell-k}}\prod_{j=k+1}^{\ell-1}(s_{k,j})^{-j/2^{j-k+1}}+\sum_{i=k+1}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k}}\prod_{j=k+1}^{i-1}(s_{k,j})^{-j/2^{j-k+1}}. $$
$$ f(k+1,s_*)\le (s_{k,\ell})^{-\ell/2^{\ell-k}}\prod_{j=k+1}^{\ell-1}(s_{k,j})^{-j/2^{j-k+1}}+\sum_{i=k+1}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k}}\prod_{j=k+1}^{i-1}(s_{k,j})^{-j/2^{j-k+1}}. $$
As
 $\sqrt{x+y}\le \sqrt{x}+\sqrt{y}$
for all
$\sqrt{x+y}\le \sqrt{x}+\sqrt{y}$
for all
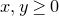 $x,y\ge 0$
, this implies
$x,y\ge 0$
, this implies
 $$ f(k+1,s_*)^{1/2}\le (s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k+1}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}+\sum_{i=k+1}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}}\prod_{j=k+1}^{i-1}(s_{k,j})^{-j/2^{j-k+2}}. $$
$$ f(k+1,s_*)^{1/2}\le (s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k+1}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}+\sum_{i=k+1}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}}\prod_{j=k+1}^{i-1}(s_{k,j})^{-j/2^{j-k+2}}. $$
Also using that
 $s_{k,k}=s_*$
, we now obtain
$s_{k,k}=s_*$
, we now obtain
 \begin{align*}&s_*^{-(k+2)/2}+s_*^{-k/4}\cdot f(k+1,s_*)^{1/2}\\&\quad\le (s_{k,k})^{-(k+2)/2}+(s_{k,\ell})^{-\ell/2^{\ell-k+1}}(s_{k,k})^{-k/4}\prod_{j=k+1}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}\\&\quad\quad+\sum_{i=k+1}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}} (s_{k,k})^{-k/4}\prod_{j=k+1}^{i-1}(s_{k,j})^{-j/2^{j-k+2}}\\&\quad=(s_{k,k})^{-(k+2)/2}+(s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}+\sum_{i=k+1}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}}\prod_{j=k}^{i-1}(s_{k,j})^{-j/2^{j-k+2}}\\&\quad=(s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}+\sum_{i=k}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}}\prod_{j=k}^{i-1}(s_{k,j})^{-j/2^{j-k+2}}.\end{align*}
\begin{align*}&s_*^{-(k+2)/2}+s_*^{-k/4}\cdot f(k+1,s_*)^{1/2}\\&\quad\le (s_{k,k})^{-(k+2)/2}+(s_{k,\ell})^{-\ell/2^{\ell-k+1}}(s_{k,k})^{-k/4}\prod_{j=k+1}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}\\&\quad\quad+\sum_{i=k+1}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}} (s_{k,k})^{-k/4}\prod_{j=k+1}^{i-1}(s_{k,j})^{-j/2^{j-k+2}}\\&\quad=(s_{k,k})^{-(k+2)/2}+(s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}+\sum_{i=k+1}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}}\prod_{j=k}^{i-1}(s_{k,j})^{-j/2^{j-k+2}}\\&\quad=(s_{k,\ell})^{-\ell/2^{\ell-k+1}}\prod_{j=k}^{\ell-1}(s_{k,j})^{-j/2^{j-k+2}}+\sum_{i=k}^{\ell-1}(s_{k,i})^{-(i+2)/2^{i-k+1}}\prod_{j=k}^{i-1}(s_{k,j})^{-j/2^{j-k+2}}.\end{align*}
Hence, the second term in the maximum above also satisfies the desired bound, completing the proof.
Finally, we show how to deduce Theorem 5.1 from the
 $k=0$
case of Corollary 10.1.
$k=0$
case of Corollary 10.1.
Proof of Theorem 5.1. Let
 $Q\in \mathbb{R}[x_1,\ldots,x_n]$
,
$Q\in \mathbb{R}[x_1,\ldots,x_n]$
,
 $A\in \mathbb{R}^{n\times n}$
and s be as in Theorem 5.1. We may assume that
$A\in \mathbb{R}^{n\times n}$
and s be as in Theorem 5.1. We may assume that
 $s\ge 4$
(otherwise the bound in Theorem 5.1 holds trivially as long as
$s\ge 4$
(otherwise the bound in Theorem 5.1 holds trivially as long as
 $C'\ge 2$
). Let
$C'\ge 2$
). Let
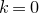 $k=0$
, let
$k=0$
, let
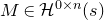 $M\in \mathcal{H}^{0\times n}(s)$
be the empty
$M\in \mathcal{H}^{0\times n}(s)$
be the empty
 $0\times n$
matrix, and let
$0\times n$
matrix, and let
 $\vec w\in \mathbb{R}^0$
be the empty vector. Note that the quadruple
$\vec w\in \mathbb{R}^0$
be the empty vector. Note that the quadruple
 $(n,Q,M,\vec{w})$
satisfies condition (
$(n,Q,M,\vec{w})$
satisfies condition (
 $*$
) in Definition 5.4, because the only (M,M)-perturbation of A is the matrix
$*$
) in Definition 5.4, because the only (M,M)-perturbation of A is the matrix
 $A'=A$
, and by the assumption in Theorem 5.1, for every subset
$A'=A$
, and by the assumption in Theorem 5.1, for every subset
 $S\subseteq [n]$
of size
$S\subseteq [n]$
of size
 $|S|\ge n-s$
, the submatrix
$|S|\ge n-s$
, the submatrix
 $A[S\times S]$
has at least one nonzero entry outside its diagonal. Thus, for a sequence
$A[S\times S]$
has at least one nonzero entry outside its diagonal. Thus, for a sequence
 $\vec \xi\in \{-1,1\}^n$
of independent Rademacher random variables, we have
$\vec \xi\in \{-1,1\}^n$
of independent Rademacher random variables, we have
 $$ \mathrm{Pr}[Q(\vec \xi)=0]=\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w]\le f(0,s), $$
$$ \mathrm{Pr}[Q(\vec \xi)=0]=\mathrm{Pr}[Q(\vec{\xi})=0 \text{ and } M\vec{\xi}=\vec w]\le f(0,s), $$
and hence by Corollary 10.1
 $$ \mathrm{Pr}[Q(\vec \xi)=0]\le (s_{0,\ell})^{-\ell/2^{\ell+1}}\prod_{j=0}^{\ell-1}(s_{0,j})^{-j/2^{j+2}}+\sum_{i=0}^{\ell-1}(s_{0,i})^{-(i+2)/2^{i+1}}\prod_{j=0}^{i-1}(s_{0,j})^{-j/2^{j+2}} , $$
$$ \mathrm{Pr}[Q(\vec \xi)=0]\le (s_{0,\ell})^{-\ell/2^{\ell+1}}\prod_{j=0}^{\ell-1}(s_{0,j})^{-j/2^{j+2}}+\sum_{i=0}^{\ell-1}(s_{0,i})^{-(i+2)/2^{i+1}}\prod_{j=0}^{i-1}(s_{0,j})^{-j/2^{j+2}} , $$
for every integer
 $\ell\ge 0$
(with
$\ell\ge 0$
(with
 $s_{0,i}=s/(i+2)^{500(i+1)}$
for
$s_{0,i}=s/(i+2)^{500(i+1)}$
for
 $i=0,\ldots,\ell$
as defined in Corollary 10.1). Then for every integer
$i=0,\ldots,\ell$
as defined in Corollary 10.1). Then for every integer
 $\ell\ge 0$
we obtain
$\ell\ge 0$
we obtain
 \begin{align*}\mathrm{Pr}[Q(\vec \xi)=0]&\le \prod_{i=0}^{\ell}(i+2)^{500(i+1)(i+2)/2^{i+1}}\cdot \bigg(s^{-\ell/2^{\ell+1}}\prod_{j=0}^{\ell-1}s^{-j/2^{j+2}}+\sum_{i=0}^{\ell-1}s^{-(i+2)/2^{i+1}}\prod_{j=0}^{i-1}s^{-j/2^{j+2}}\bigg)\\&= \exp\Big(500\sum_{i=0}^{\ell}\frac{(i+2)^2\ln (i+2)}{2^{i+1}}\Big)\cdot \bigg(s^{-1/2+1/2^{\ell+1}}+\sum_{i=0}^{\ell-1}s^{-1/2-1/2^{i+1}}\bigg),\end{align*}
\begin{align*}\mathrm{Pr}[Q(\vec \xi)=0]&\le \prod_{i=0}^{\ell}(i+2)^{500(i+1)(i+2)/2^{i+1}}\cdot \bigg(s^{-\ell/2^{\ell+1}}\prod_{j=0}^{\ell-1}s^{-j/2^{j+2}}+\sum_{i=0}^{\ell-1}s^{-(i+2)/2^{i+1}}\prod_{j=0}^{i-1}s^{-j/2^{j+2}}\bigg)\\&= \exp\Big(500\sum_{i=0}^{\ell}\frac{(i+2)^2\ln (i+2)}{2^{i+1}}\Big)\cdot \bigg(s^{-1/2+1/2^{\ell+1}}+\sum_{i=0}^{\ell-1}s^{-1/2-1/2^{i+1}}\bigg),\end{align*}
using Lemma 10.2 for
 $k=0$
. Noting that the series
$k=0$
. Noting that the series
 $\sum_{i=0}^{\infty} (i+2)^2\ln (i+2)/2^{i+1}=\sum_{i=2}^{\infty} i^2\ln i/2^{i-1}$
converges, for all integers
$\sum_{i=0}^{\infty} (i+2)^2\ln (i+2)/2^{i+1}=\sum_{i=2}^{\infty} i^2\ln i/2^{i-1}$
converges, for all integers
 $\ell\ge 0$
we obtain
$\ell\ge 0$
we obtain
 $$ \mathrm{Pr}[Q(\vec \xi)=0]\le C_1\cdot \bigg(s^{-1/2+1/2^{\ell+1}}+\sum_{i=0}^{\ell-1}s^{-1/2-1/2^{i+1}}\bigg)=C_1\cdot s^{-1/2}\cdot \bigg(s^{1/2^{\ell+1}}+\sum_{i=0}^{\ell-1}s^{-2^{\ell-i}/2^{\ell+1}}\bigg) , $$
$$ \mathrm{Pr}[Q(\vec \xi)=0]\le C_1\cdot \bigg(s^{-1/2+1/2^{\ell+1}}+\sum_{i=0}^{\ell-1}s^{-1/2-1/2^{i+1}}\bigg)=C_1\cdot s^{-1/2}\cdot \bigg(s^{1/2^{\ell+1}}+\sum_{i=0}^{\ell-1}s^{-2^{\ell-i}/2^{\ell+1}}\bigg) , $$
for some absolute constant
 $C_1\ge 1$
. Plugging in
$C_1\ge 1$
. Plugging in
 $\ell=\lfloor\log\log s\rfloor-1$
, we have
$\ell=\lfloor\log\log s\rfloor-1$
, we have
 $$ 2\le s^{1/2^{\ell+1}}\le 4 , $$
$$ 2\le s^{1/2^{\ell+1}}\le 4 , $$
and therefore
 $$ \mathrm{Pr}[Q(\vec \xi)=0]\le C_1\cdot s^{-1/2}\cdot \bigg(4+\sum_{i=0}^{\ell-1}(1/2)^{2^{\ell-i}}\bigg)\le \frac{C_1}{\sqrt{s}}\cdot \bigg(4+\sum_{i=0}^{\ell-1}(1/2)^{\ell-i}\bigg)\le \frac{5C_1}{\sqrt{s}}. $$
$$ \mathrm{Pr}[Q(\vec \xi)=0]\le C_1\cdot s^{-1/2}\cdot \bigg(4+\sum_{i=0}^{\ell-1}(1/2)^{2^{\ell-i}}\bigg)\le \frac{C_1}{\sqrt{s}}\cdot \bigg(4+\sum_{i=0}^{\ell-1}(1/2)^{\ell-i}\bigg)\le \frac{5C_1}{\sqrt{s}}. $$
Setting
 $C'=5C_1$
, this gives the desired bound.
$C'=5C_1$
, this gives the desired bound.
11. Deduction of main results
In this section, we deduce our main theorem (Theorem 1.1) and its generalisation to arbitrary distributions (Theorem 1.2) from the slightly more technical statement of Theorem 5.1. Note that Theorem 1.2 directly implies Theorem 1.1, taking
 $\xi_{1},\ldots,\xi_{n}$
to be independent Rademacher random variables, and taking
$\xi_{1},\ldots,\xi_{n}$
to be independent Rademacher random variables, and taking
 $\delta=1/2$
. So, we will just prove Theorem 1.2 (however, we remark that the proof gets easier and certain steps can be skipped if one is only interested in Theorem 1.1).
$\delta=1/2$
. So, we will just prove Theorem 1.2 (however, we remark that the proof gets easier and certain steps can be skipped if one is only interested in Theorem 1.1).
First, to apply Theorem 5.1 in the general setting of Theorem 1.2, we use that any discrete random variable can be expressed in a way such that after some further conditioning one basically obtains a Rademacher random variable. The following lemma strengthens an observation made by Meka, Nguyen and Vu [Reference Meka, Nguyen and VuMNV16] for a similar purpose.
Lemma 11.1 For every discrete random variable
 $\zeta\in \mathbb{R}$
, we can find a representation of the form
$\zeta\in \mathbb{R}$
, we can find a representation of the form
 $$ \zeta=\alpha+\xi \beta ,$$
$$ \zeta=\alpha+\xi \beta ,$$
for a Rademacher random variable
 $\xi\in\{-1,1\}$
and a discrete random vector
$\xi\in\{-1,1\}$
and a discrete random vector
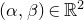 $(\alpha,\beta)\in \mathbb{R}^2$
which is independent of
$(\alpha,\beta)\in \mathbb{R}^2$
which is independent of
 $\xi$
. Moreover, this representation can be chosen such that the distribution of
$\xi$
. Moreover, this representation can be chosen such that the distribution of
 $(\alpha,\beta)$
satisfies the following two conditions.
$(\alpha,\beta)$
satisfies the following two conditions.
-
(a) There is at most one real number
$a\in \mathbb{R}$
with
$\mathrm{Pr}[(\alpha,\beta)=(a,0)] \gt 0$
. -
(b) If there is some value
$z\in \mathbb{R}$
with
$\mathrm{Pr}[\zeta=z]\gt 1/2$
, then we always have
$\alpha+\beta=z$
(for any outcome of the random vector
$(\alpha,\beta)\in \mathbb{R}^2$
).





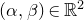
Proof. If the random variable
 $\zeta$
is constant, i.e., if
$\zeta$
is constant, i.e., if
 $\mathrm{Pr}[\zeta=z]=1$
for some
$\mathrm{Pr}[\zeta=z]=1$
for some
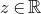 $z\in \mathbb{R}$
, we can define the random vector
$z\in \mathbb{R}$
, we can define the random vector
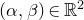 $(\alpha,\beta)\in \mathbb{R}^2$
to always take the constant value (z,0). So let us from now on assume that
$(\alpha,\beta)\in \mathbb{R}^2$
to always take the constant value (z,0). So let us from now on assume that
 $\zeta$
is not constant.
$\zeta$
is not constant.
Case 1
: there is a majority outcome. First, we consider the case where
 $\mathrm{Pr}[\zeta=z]\ge 1/2$
for some
$\mathrm{Pr}[\zeta=z]\ge 1/2$
for some
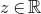 $z\in \mathbb{R}$
. Let
$z\in \mathbb{R}$
. Let
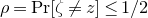 $\rho=\mathrm{Pr}[\zeta\ne z]\le 1/2$
. Then, we can take the random vector
$\rho=\mathrm{Pr}[\zeta\ne z]\le 1/2$
. Then, we can take the random vector
 $(\alpha,\beta)\in \mathbb{R}^2$
to be equal to (z,0) with probability
$(\alpha,\beta)\in \mathbb{R}^2$
to be equal to (z,0) with probability
 $1-2\rho$
and equal to
$1-2\rho$
and equal to
 $((z+Y)/2,(z-Y)/2)$
with probability
$((z+Y)/2,(z-Y)/2)$
with probability
 $2\rho$
, where Y is a sample from the distribution of
$2\rho$
, where Y is a sample from the distribution of
 $\zeta$
conditioned on the event
$\zeta$
conditioned on the event
 $\zeta\ne z$
. Note that we then always have
$\zeta\ne z$
. Note that we then always have
 $\alpha+\beta=z$
(as
$\alpha+\beta=z$
(as
 $\alpha+\beta=z+0=z$
or
$\alpha+\beta=z+0=z$
or
 $\alpha+\beta=(z+Y)/2+(z-Y)/2=z$
). Also note for all
$\alpha+\beta=(z+Y)/2+(z-Y)/2=z$
). Also note for all
 $a\in \mathbb{R}$
with
$a\in \mathbb{R}$
with
 $a\ne z$
we have
$a\ne z$
we have
 $\mathrm{Pr}[(\alpha,\beta)=(a,0)]=0$
, since Y never takes the value z and so we can only have
$\mathrm{Pr}[(\alpha,\beta)=(a,0)]=0$
, since Y never takes the value z and so we can only have
 $\beta=0$
when
$\beta=0$
when
 $\alpha=z$
. Now, taking
$\alpha=z$
. Now, taking
 $\xi\in\{-1,1\}$
to be a Rademacher random variable that is independent of the random vector
$\xi\in\{-1,1\}$
to be a Rademacher random variable that is independent of the random vector
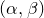 $(\alpha,\beta)$
, the expression
$(\alpha,\beta)$
, the expression
 $\alpha+\xi \beta$
evaluates to
$\alpha+\xi \beta$
evaluates to
 $z\pm 0=z$
with probability
$z\pm 0=z$
with probability
 $1-2\rho$
, to
$1-2\rho$
, to
 $(z+Y)/2+(z-Y)/2=z$
with probability
$(z+Y)/2+(z-Y)/2=z$
with probability
 $\rho$
and to
$\rho$
and to
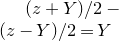 $(z+Y)/2- (z-Y)/2=Y$
with probability
$(z+Y)/2- (z-Y)/2=Y$
with probability
 $\rho$
. Hence the distribution of
$\rho$
. Hence the distribution of
 $\alpha+\xi \beta$
coincides with the distribution of
$\alpha+\xi \beta$
coincides with the distribution of
 $\zeta$
. We can therefore find a coupling of
$\zeta$
. We can therefore find a coupling of
 $\zeta$
with
$\zeta$
with
 $(\alpha,\beta)$
and
$(\alpha,\beta)$
and
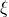 $\xi$
such that
$\xi$
such that
 $(\alpha,\beta)\in \mathbb{R}^2$
and
$(\alpha,\beta)\in \mathbb{R}^2$
and
 $\xi\in\{-1,1\}$
are independent and
$\xi\in\{-1,1\}$
are independent and
 $\zeta=\alpha+\xi \beta$
.
$\zeta=\alpha+\xi \beta$
.
Case 2
: there is no majority outcome. Now, let us consider the case where
 $\mathrm{Pr}[\zeta=z]\lt 1/2$
for all
$\mathrm{Pr}[\zeta=z]\lt 1/2$
for all
 $z\in \mathbb{R}$
. Let x be a median of
$z\in \mathbb{R}$
. Let x be a median of
 $\zeta$
(meaning that
$\zeta$
(meaning that
 $\mathrm{Pr}[\zeta\ge x]\ge 1/2$
and
$\mathrm{Pr}[\zeta\ge x]\ge 1/2$
and
 $\mathrm{Pr}[\zeta\le x]\ge 1/2$
; for example we can take
$\mathrm{Pr}[\zeta\le x]\ge 1/2$
; for example we can take
 $x=\sup \{x\in \mathbb{R}:\mathrm{Pr}[\zeta\ge x]\ge 1/2\}$
). As
$x=\sup \{x\in \mathbb{R}:\mathrm{Pr}[\zeta\ge x]\ge 1/2\}$
). As
 $\mathrm{Pr}[\zeta= x]<1/2$
, we can see that
$\mathrm{Pr}[\zeta= x]<1/2$
, we can see that
 $0<\mathrm{Pr}[\zeta\lt x]\le 1/2$
and
$0<\mathrm{Pr}[\zeta\lt x]\le 1/2$
and
 $0<\mathrm{Pr}[\zeta \gt x]\le 1/2$
.
$0<\mathrm{Pr}[\zeta \gt x]\le 1/2$
.
Now, let
 $\rho_1=\mathrm{Pr}[\zeta\lt x]$
and
$\rho_1=\mathrm{Pr}[\zeta\lt x]$
and
 $\rho_2=\mathrm{Pr}[\zeta \gt x]$
. Let us assume without loss of generality that
$\rho_2=\mathrm{Pr}[\zeta \gt x]$
. Let us assume without loss of generality that
 $\rho_1\ge \rho_2$
(the case
$\rho_1\ge \rho_2$
(the case
 $\rho_2\ge \rho_1$
is analogous). Let
$\rho_2\ge \rho_1$
is analogous). Let
 $Y_1$
(respectively,
$Y_1$
(respectively,
 $Y_2$
) be a sample from the distribution of
$Y_2$
) be a sample from the distribution of
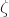 $\zeta$
conditioned on the event
$\zeta$
conditioned on the event
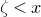 $\zeta\lt x$
(respectively, the event
$\zeta\lt x$
(respectively, the event
 $\zeta \gt x$
). We can now take the random vector
$\zeta \gt x$
). We can now take the random vector
 $(\alpha,\beta)\in \mathbb{R}^2$
to be equal to (x,0) with probability
$(\alpha,\beta)\in \mathbb{R}^2$
to be equal to (x,0) with probability
 $1-2\rho_1$
, equal to
$1-2\rho_1$
, equal to
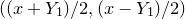 $((x+Y_1)/2,(x-Y_1)/2)$
with probability
$((x+Y_1)/2,(x-Y_1)/2)$
with probability
 $2\rho_1-2\rho_2$
, and equal to
$2\rho_1-2\rho_2$
, and equal to
 $((Y_2+Y_1)/2,(Y_2-Y_1)/2)$
with probability
$((Y_2+Y_1)/2,(Y_2-Y_1)/2)$
with probability
 $2\rho_2$
. Note that we can only have
$2\rho_2$
. Note that we can only have
 $\beta=0$
when
$\beta=0$
when
 $\alpha=x$
, since we always have
$\alpha=x$
, since we always have
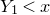 $Y_1\lt x$
and
$Y_1\lt x$
and
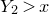 $Y_2\gt x$
. Now, taking
$Y_2\gt x$
. Now, taking
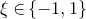 $\xi\in\{-1,1\}$
to be a Rademacher random variable that is independent of the random vector
$\xi\in\{-1,1\}$
to be a Rademacher random variable that is independent of the random vector
 $(\alpha,\beta)\in \mathbb{R}^2$
, the expression
$(\alpha,\beta)\in \mathbb{R}^2$
, the expression
 $\alpha+\xi \beta$
evaluates to
$\alpha+\xi \beta$
evaluates to
 $x\pm 0=x$
with probability
$x\pm 0=x$
with probability
 $1-2\rho_1$
, to
$1-2\rho_1$
, to
 $(x+Y_1)/2+ (x-Y_1)/2=x$
with probability
$(x+Y_1)/2+ (x-Y_1)/2=x$
with probability
 $\rho_1-\rho_2$
, to
$\rho_1-\rho_2$
, to
 $(x+Y_1)/2-(x-Y_1)/2=Y_1$
with probability
$(x+Y_1)/2-(x-Y_1)/2=Y_1$
with probability
 $\rho_1-\rho_2$
, to
$\rho_1-\rho_2$
, to
 $(Y_2+Y_1)/2-(Y_2-Y_1)/2=Y_1$
with probability
$(Y_2+Y_1)/2-(Y_2-Y_1)/2=Y_1$
with probability
 $\rho_2$
, and to
$\rho_2$
, and to
 $(Y_2+Y_1)/2+(Y_2-Y_1)/2=Y_2$
with probability
$(Y_2+Y_1)/2+(Y_2-Y_1)/2=Y_2$
with probability
 $\rho_2$
. So all in all,
$\rho_2$
. So all in all,
 $\alpha+\xi \beta$
evaluates to x with probability
$\alpha+\xi \beta$
evaluates to x with probability
 $1-\rho_1-\rho_2=\mathrm{Pr}[\zeta= x]$
, to
$1-\rho_1-\rho_2=\mathrm{Pr}[\zeta= x]$
, to
 $Y_1$
with probability
$Y_1$
with probability
 $\rho_1$
and to
$\rho_1$
and to
 $Y_2$
with probability
$Y_2$
with probability
 $\rho_2$
. Hence the distribution of
$\rho_2$
. Hence the distribution of
 $\alpha+\xi \beta$
agrees with the distribution of
$\alpha+\xi \beta$
agrees with the distribution of
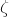 $\zeta$
, and we can again find the desired coupling such that
$\zeta$
, and we can again find the desired coupling such that
 $\zeta=\alpha+\xi \beta$
.
$\zeta=\alpha+\xi \beta$
.
In the setting of Lemma 11.1, note that if there is a real number
 $a\in \mathbb{R}$
with
$a\in \mathbb{R}$
with
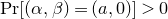 $\mathrm{Pr}[(\alpha,\beta)=(a,0)] \gt 0$
, then we have
$\mathrm{Pr}[(\alpha,\beta)=(a,0)] \gt 0$
, then we have
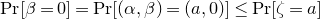 $\mathrm{Pr}[\beta=0]=\mathrm{Pr}[(\alpha,\beta)=(a,0)]\le \mathrm{Pr}[\zeta=a]$
(here we used (a)). On the other hand, if there is no such
$\mathrm{Pr}[\beta=0]=\mathrm{Pr}[(\alpha,\beta)=(a,0)]\le \mathrm{Pr}[\zeta=a]$
(here we used (a)). On the other hand, if there is no such
 $a\in \mathbb{R}$
, we clearly have
$a\in \mathbb{R}$
, we clearly have
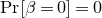 $\mathrm{Pr}[\beta=0]=0$
. Thus, in any case we can conclude that
$\mathrm{Pr}[\beta=0]=0$
. Thus, in any case we can conclude that
 \begin{equation} \mathrm{Pr}[\beta=0] \le \sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta=z].\end{equation}
\begin{equation} \mathrm{Pr}[\beta=0] \le \sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta=z].\end{equation}
We will also need a generalisation of the Erdős–Littlewood–Offord theorem to arbitrary discrete random variables (i.e., not just for Rademacher random variables). The following theorem follows directly from the result of [Reference KolmogorovKol58], and can also be deduced from the ordinary Erdős–Littlewood–Offord theorem.
Theorem 11.2. Fix
 $\delta \gt 0$
, and let
$\delta \gt 0$
, and let
 $X_1,\ldots,X_t\in \mathbb{R}$
be independent discrete random variables satisfying
$X_1,\ldots,X_t\in \mathbb{R}$
be independent discrete random variables satisfying
 $\sup_{z\in \mathbb{R}}\mathrm{Pr}[X_i=z]\le 1-\delta$
for all
$\sup_{z\in \mathbb{R}}\mathrm{Pr}[X_i=z]\le 1-\delta$
for all
 $i=1,\ldots,t$
. Then we have
$i=1,\ldots,t$
. Then we have
 $$\sup_{z\in \mathbb{R}}\mathrm{Pr}[X_1+\dots+X_t=z]\le\frac{C_\delta'}{\sqrt{t}}, $$
$$\sup_{z\in \mathbb{R}}\mathrm{Pr}[X_1+\dots+X_t=z]\le\frac{C_\delta'}{\sqrt{t}}, $$
for some constant
 $C_\delta'$
only depending on
$C_\delta'$
only depending on
 $\delta$
.
$\delta$
.
Let us first prove Theorem 1.2 under the additional assumption that all point probabilities of the variables
 $\zeta_1,\ldots,\zeta_n$
are at most
$\zeta_1,\ldots,\zeta_n$
are at most
 $1-\delta$
. This does not require the full strength of Lemma 11.1 (we will not need (b) in Lemma 11.1).
$1-\delta$
. This does not require the full strength of Lemma 11.1 (we will not need (b) in Lemma 11.1).
Proposition 11.3. The statement of Theorem 1.2 holds under the additional assumption that we have
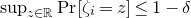 $\sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta_i=z]\le 1-\delta$
for all
$\sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta_i=z]\le 1-\delta$
for all
 $i=1,\ldots,n$
.
$i=1,\ldots,n$
.
Proof. For ease of notation, we write
 $\vec \zeta=(\zeta_1,\ldots,\zeta_n)$
. Let
$\vec \zeta=(\zeta_1,\ldots,\zeta_n)$
. Let
 $C'\ge 1$
be an absolute constant such that Theorem 5.1 holds, and let
$C'\ge 1$
be an absolute constant such that Theorem 5.1 holds, and let
 $C_\delta=\max(8C'/\delta,2C'_\delta)$
for the constant
$C_\delta=\max(8C'/\delta,2C'_\delta)$
for the constant
 $C'_\delta$
in Theorem 11.2. Note that the claimed probability bound is trivially true if
$C'_\delta$
in Theorem 11.2. Note that the claimed probability bound is trivially true if
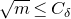 $\sqrt{m}\le C_\delta$
, so we may assume that
$\sqrt{m}\le C_\delta$
, so we may assume that
 $m\ge (C_\delta)^2\ge 64/\delta^2$
.
$m\ge (C_\delta)^2\ge 64/\delta^2$
.
Recall that
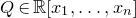 $Q\in \mathbb{R}[x_1,\ldots,x_n]$
is a quadratic polynomial, and that we are assuming that for any fixing box
$Q\in \mathbb{R}[x_1,\ldots,x_n]$
is a quadratic polynomial, and that we are assuming that for any fixing box
 $R_1\times \dots\times R_n$
of Q (where
$R_1\times \dots\times R_n$
of Q (where
 $R_1,\ldots,R_n$
are nonempty subsets of the supports of
$R_1,\ldots,R_n$
are nonempty subsets of the supports of
 $\zeta_1,\ldots,\zeta_n$
, respectively) there are at least m indices
$\zeta_1,\ldots,\zeta_n$
, respectively) there are at least m indices
 $i\in \{1,\ldots,n\}$
with
$i\in \{1,\ldots,n\}$
with
 $\mathrm{Pr}[\zeta_i\in R_i]\le 1-\delta$
. Note that this assumption is not affected by changing the constant term of Q. It therefore suffices to prove
$\mathrm{Pr}[\zeta_i\in R_i]\le 1-\delta$
. Note that this assumption is not affected by changing the constant term of Q. It therefore suffices to prove
 \begin{equation} \mathrm{Pr}[Q(\vec \zeta)=0]\le\frac{C_\delta}{\sqrt{m}}. \end{equation}
\begin{equation} \mathrm{Pr}[Q(\vec \zeta)=0]\le\frac{C_\delta}{\sqrt{m}}. \end{equation}
Indeed, for any
 $z\in \mathbb{R}$
, applying this inequality to the polynomial
$z\in \mathbb{R}$
, applying this inequality to the polynomial
 $Q-z$
gives
$Q-z$
gives
 $\mathrm{Pr}[Q(\vec \zeta)=z]\le C_\delta/\sqrt{m}$
, as claimed. To prove Equation (11.2), we distinguish two cases.
$\mathrm{Pr}[Q(\vec \zeta)=z]\le C_\delta/\sqrt{m}$
, as claimed. To prove Equation (11.2), we distinguish two cases.
Case 1:
quadratic anticoncentration. First, consider the case that for some
 $\ell\ge m/4$
there exist distinct indices
$\ell\ge m/4$
there exist distinct indices
 $i_1,\ldots,i_\ell,j_1,\ldots,j_\ell\in [n]$
such that for each
$i_1,\ldots,i_\ell,j_1,\ldots,j_\ell\in [n]$
such that for each
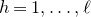 $h=1,\ldots,\ell$
the coefficient of
$h=1,\ldots,\ell$
the coefficient of
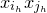 $x_{i_h}x_{j_h}$
in the quadratic polynomial Q is nonzero (and let
$x_{i_h}x_{j_h}$
in the quadratic polynomial Q is nonzero (and let
 $c_h\ne 0$
denote this coefficient). In this case, our goal is to apply Theorem 5.1.
$c_h\ne 0$
denote this coefficient). In this case, our goal is to apply Theorem 5.1.
For each
 $i=1,\ldots,n$
, let us represent the random variable
$i=1,\ldots,n$
, let us represent the random variable
 $\zeta_i$
as
$\zeta_i$
as
 $\zeta_i=\alpha_i+\xi_i \beta_i$
, for a Rademacher random variable
$\zeta_i=\alpha_i+\xi_i \beta_i$
, for a Rademacher random variable
 $\xi_i\in\{-1,1\}$
and a random vector
$\xi_i\in\{-1,1\}$
and a random vector
 $(\alpha_i,\beta_i)\in \mathbb{R}^2$
, as in Lemma 11.1, in such a way that
$(\alpha_i,\beta_i)\in \mathbb{R}^2$
, as in Lemma 11.1, in such a way that
 $\xi_1,\ldots,\xi_n$
and
$\xi_1,\ldots,\xi_n$
and
 $(\alpha_1,\beta_1),\ldots,(\alpha_n,\beta_n)$
are all mutually independent. Note that by Equation (11.1) and our assumption in the proposition, we have
$(\alpha_1,\beta_1),\ldots,(\alpha_n,\beta_n)$
are all mutually independent. Note that by Equation (11.1) and our assumption in the proposition, we have
 $$ \mathrm{Pr}[\beta_i=0] \le \sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta_i=z]\le 1-\delta, $$
$$ \mathrm{Pr}[\beta_i=0] \le \sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta_i=z]\le 1-\delta, $$
for
 $i=1,\ldots,n$
. Thus, for each
$i=1,\ldots,n$
. Thus, for each
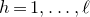 $h=1,\ldots,\ell$
, we obtain
$h=1,\ldots,\ell$
, we obtain
 $$ \mathrm{Pr}[\beta_{i_h}\beta_{j_h}\ne 0] =\mathrm{Pr}[\beta_{i_h}\ne 0]\cdot \mathrm{Pr}[\beta_{i_h}\ne 0]\ge \delta^2, $$
$$ \mathrm{Pr}[\beta_{i_h}\beta_{j_h}\ne 0] =\mathrm{Pr}[\beta_{i_h}\ne 0]\cdot \mathrm{Pr}[\beta_{i_h}\ne 0]\ge \delta^2, $$
and furthermore the events
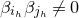 $\beta_{i_h}\beta_{j_h}\ne 0$
are independent for all
$\beta_{i_h}\beta_{j_h}\ne 0$
are independent for all
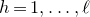 $h=1,\ldots,\ell$
. Thus, by a Chernoff bound (see for example [Reference Janson, Łuczak and RucinskiJLR00, Theorem 2.1]), we have
$h=1,\ldots,\ell$
. Thus, by a Chernoff bound (see for example [Reference Janson, Łuczak and RucinskiJLR00, Theorem 2.1]), we have
 \begin{equation} \mathrm{Pr}[\text{fewer than }\delta^2\ell/2\text{ indices }h\in \{1,\ldots,\ell\}\text{ satisfy }\beta_{i_h}\beta_{j_h}\ne 0]\le e^{-\delta^2\ell/8}\le e^{-\delta^2m/32}\le\frac{32}{\delta^2m}\le\frac{4/\delta}{\sqrt{m}}, \end{equation}
\begin{equation} \mathrm{Pr}[\text{fewer than }\delta^2\ell/2\text{ indices }h\in \{1,\ldots,\ell\}\text{ satisfy }\beta_{i_h}\beta_{j_h}\ne 0]\le e^{-\delta^2\ell/8}\le e^{-\delta^2m/32}\le\frac{32}{\delta^2m}\le\frac{4/\delta}{\sqrt{m}}, \end{equation}
recalling
 $\ell\ge m/4$
and
$\ell\ge m/4$
and
 $m\ge 64/\delta^2$
(i.e.,
$m\ge 64/\delta^2$
(i.e.,
 $ \delta \sqrt{m}\ge 8$
). Conditioning on any outcomes of
$ \delta \sqrt{m}\ge 8$
). Conditioning on any outcomes of
 $(\alpha_1,\beta_1),\ldots,(\alpha_n,\beta_n)$
, such that
$(\alpha_1,\beta_1),\ldots,(\alpha_n,\beta_n)$
, such that
 $\beta_{i_h}\beta_{j_h}\ne 0$
for at least
$\beta_{i_h}\beta_{j_h}\ne 0$
for at least
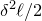 $\delta^2\ell/2$
indices
$\delta^2\ell/2$
indices
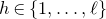 $h\in \{1,\ldots,\ell\}$
, we can interpret
$h\in \{1,\ldots,\ell\}$
, we can interpret
 $Q(\zeta_1,\ldots,\zeta_n)$
as a quadratic polynomial in the independent Rademacher random variables
$Q(\zeta_1,\ldots,\zeta_n)$
as a quadratic polynomial in the independent Rademacher random variables
 $\xi_1,\ldots,\xi_n$
by plugging in
$\xi_1,\ldots,\xi_n$
by plugging in
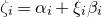 $\zeta_i=\alpha_i+\xi_i \beta_i$
for
$\zeta_i=\alpha_i+\xi_i \beta_i$
for
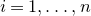 $i=1,\ldots,n$
. Note that for
$i=1,\ldots,n$
. Note that for
 $h=1,\ldots,\ell$
the coefficient of
$h=1,\ldots,\ell$
the coefficient of
 $\xi_{i_h}\xi_{j_h}$
in this quadratic polynomial is
$\xi_{i_h}\xi_{j_h}$
in this quadratic polynomial is
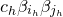 $c_h\beta_{i_h}\beta_{j_h}$
. Hence there are at least
$c_h\beta_{i_h}\beta_{j_h}$
. Hence there are at least
 $\delta^2\ell/2\ge \delta^2m/8$
indices
$\delta^2\ell/2\ge \delta^2m/8$
indices
 $h\in \{1,\ldots,\ell\}$
such that the coefficient of
$h\in \{1,\ldots,\ell\}$
such that the coefficient of
 $\xi_{i_h}\xi_{j_h}$
in this quadratic polynomial is nonzero, and so this quadratic polynomial satisfies the condition in Theorem 5.1 for any positive integer
$\xi_{i_h}\xi_{j_h}$
in this quadratic polynomial is nonzero, and so this quadratic polynomial satisfies the condition in Theorem 5.1 for any positive integer
 $s<\delta^2m/8$
(indeed, for at least
$s<\delta^2m/8$
(indeed, for at least
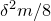 $\delta^2m/8$
indices
$\delta^2m/8$
indices
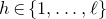 $h\in \{1,\ldots,\ell\}$
the
$h\in \{1,\ldots,\ell\}$
the
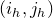 $(i_h,j_h)$
-entry of the matrix A appearing in this condition is nonzero, and for every subset
$(i_h,j_h)$
-entry of the matrix A appearing in this condition is nonzero, and for every subset
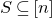 $S\subseteq [n]$
of size
$S\subseteq [n]$
of size
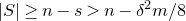 $|S|\ge n-s \gt n-\delta^2m/8$
, the submatrix
$|S|\ge n-s \gt n-\delta^2m/8$
, the submatrix
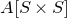 $A[S\times S]$
must contain one of these nonzero entries). Taking
$A[S\times S]$
must contain one of these nonzero entries). Taking
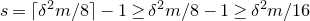 $s=\lceil\delta^2m/8\rceil-1\ge \delta^2m/8-1\ge \delta^2m/16$
(recalling that
$s=\lceil\delta^2m/8\rceil-1\ge \delta^2m/8-1\ge \delta^2m/16$
(recalling that
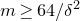 $m\ge 64/\delta^2$
), by Theorem 5.1 we obtain
$m\ge 64/\delta^2$
), by Theorem 5.1 we obtain
 $$ \mathrm{Pr}[Q(\vec \zeta)=0\,\big|\,(\alpha_1,\beta_1),\ldots,(\alpha_n,\beta_n)]\le \frac{C'}{\sqrt{\delta^2m/16}}=\frac{4C'/\delta}{\sqrt{m}}, $$
$$ \mathrm{Pr}[Q(\vec \zeta)=0\,\big|\,(\alpha_1,\beta_1),\ldots,(\alpha_n,\beta_n)]\le \frac{C'}{\sqrt{\delta^2m/16}}=\frac{4C'/\delta}{\sqrt{m}}, $$
when conditioning on any outcomes of
 $(\alpha_1,\beta_1),\ldots,(\alpha_n,\beta_n)$
such that
$(\alpha_1,\beta_1),\ldots,(\alpha_n,\beta_n)$
such that
 $\beta_{i_h}\beta_{j_h}\ne 0$
for at least
$\beta_{i_h}\beta_{j_h}\ne 0$
for at least
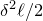 $\delta^2\ell/2$
indices
$\delta^2\ell/2$
indices
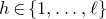 $h\in \{1,\ldots,\ell\}$
. All in all, together with Equation (11.3), this yields
$h\in \{1,\ldots,\ell\}$
. All in all, together with Equation (11.3), this yields
 $$ \mathrm{Pr}[Q(\vec \zeta)=0]\le \frac{4C'/\delta}{\sqrt{m}}+\frac{4/\delta}{\sqrt{m}}\le \frac{8C'/\delta}{\sqrt{m}}\le \frac{C_\delta}{\sqrt{m}}, $$
$$ \mathrm{Pr}[Q(\vec \zeta)=0]\le \frac{4C'/\delta}{\sqrt{m}}+\frac{4/\delta}{\sqrt{m}}\le \frac{8C'/\delta}{\sqrt{m}}\le \frac{C_\delta}{\sqrt{m}}, $$
showing the desired bound Equation (11.2).
Case 2:
linear anticoncentration. From now on we may assume that the condition in Case 1 does not hold. For the maximum possible
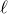 $\ell$
, consider distinct indices
$\ell$
, consider distinct indices
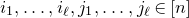 $i_1,\ldots,i_\ell,j_1,\ldots,j_\ell\in [n]$
such that for
$i_1,\ldots,i_\ell,j_1,\ldots,j_\ell\in [n]$
such that for
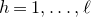 $h=1,\ldots,\ell$
the coefficient of
$h=1,\ldots,\ell$
the coefficient of
 $x_{i_h}x_{j_h}$
in Q is nonzero. By our assumption for this case, we have
$x_{i_h}x_{j_h}$
in Q is nonzero. By our assumption for this case, we have
 $\ell<m/4$
. Let
$\ell<m/4$
. Let
 $J=\{i_1,\ldots,i_\ell,j_1,\ldots,j_\ell\}$
and
$J=\{i_1,\ldots,i_\ell,j_1,\ldots,j_\ell\}$
and
 $I=[n]\setminus J$
. Note that then, by the maximality of
$I=[n]\setminus J$
. Note that then, by the maximality of
 $\ell$
, for any distinct
$\ell$
, for any distinct
 $i,i'\in I$
, the coefficient of
$i,i'\in I$
, the coefficient of
 $x_ix_{i'}$
in Q is zero.
$x_ix_{i'}$
in Q is zero.
Our plan is to condition on an arbitrary outcome of
 $\vec \zeta[J]$
, and to apply Theorem 11.2 in the resulting conditional probability space (only using the randomness of
$\vec \zeta[J]$
, and to apply Theorem 11.2 in the resulting conditional probability space (only using the randomness of
 $\zeta_i$
for
$\zeta_i$
for
 $i\in I$
).
$i\in I$
).
For any outcome of
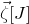 $\vec \zeta[J]$
, we can interpret
$\vec \zeta[J]$
, we can interpret
 $Q(\vec \zeta)$
as a polynomial in the remaining variables
$Q(\vec \zeta)$
as a polynomial in the remaining variables
 $\zeta_i$
for
$\zeta_i$
for
 $i\in I$
(with coefficients depending on
$i\in I$
(with coefficients depending on
 $\vec\zeta[J]$
). Writing
$\vec\zeta[J]$
). Writing
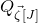 $Q_{\vec \zeta[J]}$
for this polynomial, we always have
$Q_{\vec \zeta[J]}$
for this polynomial, we always have
 $Q(\vec \zeta)=Q_{\vec \zeta[J]}(\vec \zeta[I])$
. For any distinct
$Q(\vec \zeta)=Q_{\vec \zeta[J]}(\vec \zeta[I])$
. For any distinct
 $i,i'\in I$
, the coefficient of
$i,i'\in I$
, the coefficient of
 $\zeta_i\zeta_{i'}$
in
$\zeta_i\zeta_{i'}$
in
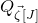 $Q_{\vec \zeta[J]}$
is zero, so
$Q_{\vec \zeta[J]}$
is zero, so
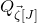 $Q_{\vec \zeta[J]}$
can be written as a sum
$Q_{\vec \zeta[J]}$
can be written as a sum
 $\sum_{i\in I} P^{(i)}_{\vec \zeta[J]}(\zeta_i)$
, where for each
$\sum_{i\in I} P^{(i)}_{\vec \zeta[J]}(\zeta_i)$
, where for each
 $i\in I$
, the summand
$i\in I$
, the summand
 $P^{(i)}_{\vec \zeta[J]}(\zeta_i)$
is a quadratic polynomial in the single variable
$P^{(i)}_{\vec \zeta[J]}(\zeta_i)$
is a quadratic polynomial in the single variable
 $\zeta_i$
(with coefficients depending on
$\zeta_i$
(with coefficients depending on
 $\vec \zeta[J]$
). We now have
$\vec \zeta[J]$
). We now have
 $$ \mathrm{Pr}[Q(\vec \zeta)=0\,|\,\vec \zeta[J]]=\mathrm{Pr}[Q_{\vec \zeta[J]}(\vec \zeta[I])=0\,|\,\vec \zeta[J]]=\mathrm{Pr}\Biggl[\,\sum_{i\in I} P^{(i)}_{\vec \zeta[J]}(\zeta_i)=0\,\Bigg|\,\vec \zeta[J]\Biggr] , $$
$$ \mathrm{Pr}[Q(\vec \zeta)=0\,|\,\vec \zeta[J]]=\mathrm{Pr}[Q_{\vec \zeta[J]}(\vec \zeta[I])=0\,|\,\vec \zeta[J]]=\mathrm{Pr}\Biggl[\,\sum_{i\in I} P^{(i)}_{\vec \zeta[J]}(\zeta_i)=0\,\Bigg|\,\vec \zeta[J]\Biggr] , $$
for every outcome of
 $\vec \zeta[J]$
.
$\vec \zeta[J]$
.
For any outcome of
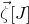 $\vec \zeta[J]$
, let
$\vec \zeta[J]$
, let
 $T_{\vec \zeta[J]}\subseteq I=[n]\setminus J$
be the set of indices
$T_{\vec \zeta[J]}\subseteq I=[n]\setminus J$
be the set of indices
 $i\in I$
with
$i\in I$
with
 $\sup_{z\in\mathbb{R}}\mathrm{Pr}[P^{(i)}_{\vec \zeta[J]}(\zeta_i)=z\,|\,\vec \zeta[J]]\le 1-\delta$
. We claim that we must always have
$\sup_{z\in\mathbb{R}}\mathrm{Pr}[P^{(i)}_{\vec \zeta[J]}(\zeta_i)=z\,|\,\vec \zeta[J]]\le 1-\delta$
. We claim that we must always have
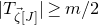 $|T_{\vec \zeta[J]}|\ge m/2$
, due to the assumption in Theorem 1.2 concerning fixing boxes. Indeed, suppose for the purpose of contradiction that there is an outcome
$|T_{\vec \zeta[J]}|\ge m/2$
, due to the assumption in Theorem 1.2 concerning fixing boxes. Indeed, suppose for the purpose of contradiction that there is an outcome
 $\vec w=(w_j)_{j\in J}\in \mathbb{R}^J$
of
$\vec w=(w_j)_{j\in J}\in \mathbb{R}^J$
of
 $\vec \zeta[J]$
such that
$\vec \zeta[J]$
such that
 $|T_{\vec w}|\lt m/2$
. Then, we have
$|T_{\vec w}|\lt m/2$
. Then, we have
 $|I\setminus T_{\vec w}| \gt n-m$
(recalling that
$|I\setminus T_{\vec w}| \gt n-m$
(recalling that
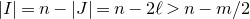 $|I|=n-|J|=n-2\ell \gt n-m/2$
). We can construct a fixing box
$|I|=n-|J|=n-2\ell \gt n-m/2$
). We can construct a fixing box
 $R_1\times \dots\times R_n$
for the polynomial Q as follows:
$R_1\times \dots\times R_n$
for the polynomial Q as follows:
-
• for
$j\in J$
, take
$R_j=\{w_j\}$
; -
• for
$t\in T_{\vec w}$
, take
$R_t=\{y_t\}$
for some arbitrary element
$y_t$
of the support of
$\zeta_t$
; -
• for
$i\in I\setminus T_{\vec w}$
, take
$z_i\in \mathbb{R}$
such that
$\mathrm{Pr}[P^{(i)}_{\vec w}(\zeta_i)=z_i]\gt 1-\delta$
(such a value
$z_i$
exists by the definition of
$T_{\vec w}$
), and let
$R_i$
be the set of all y in the support of
$\zeta_i$
such that
$P_{\vec w}^{(i)}(y)=z_i$
(i.e.,
$R_i=(P_{\vec w}^{(i)})^{-1}(z_i)\cap \operatorname{supp}(\zeta_i)$
).














Note that Q is constant on
 $R_1\times \dots\times R_n$
: indeed, for any
$R_1\times \dots\times R_n$
: indeed, for any
 $(\zeta_1,\ldots,\zeta_n)\in R_1\times\dots\times R_n$
we have
$(\zeta_1,\ldots,\zeta_n)\in R_1\times\dots\times R_n$
we have
 $$ Q(\zeta_1,\ldots,\zeta_n)=Q_{\vec w}(\vec \zeta[I])=\sum_{i\in I} P_{\vec w}^{(i)}(\zeta_i)=\sum_{t\in T_{\vec w}}P_{\vec w}^{(t)}(y_t)+\sum_{i\in I\setminus T_{\vec w}}z_i. $$
$$ Q(\zeta_1,\ldots,\zeta_n)=Q_{\vec w}(\vec \zeta[I])=\sum_{i\in I} P_{\vec w}^{(i)}(\zeta_i)=\sum_{t\in T_{\vec w}}P_{\vec w}^{(t)}(y_t)+\sum_{i\in I\setminus T_{\vec w}}z_i. $$
So,
 $R_1\times \dots\times R_n$
is indeed a fixing box of Q. On the other hand we have
$R_1\times \dots\times R_n$
is indeed a fixing box of Q. On the other hand we have
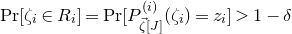 $\mathrm{Pr}[\zeta_i\in R_i]=\mathrm{Pr}[P^{(i)}_{\vec \zeta[J]}(\zeta_i)=z_i] \gt 1-\delta$
for all
$\mathrm{Pr}[\zeta_i\in R_i]=\mathrm{Pr}[P^{(i)}_{\vec \zeta[J]}(\zeta_i)=z_i] \gt 1-\delta$
for all
 $i\in I\setminus T_{\vec w}$
. As
$i\in I\setminus T_{\vec w}$
. As
 $|I\setminus T_{\vec w}|\gt n-m$
, this means that there are strictly fewer than m indices
$|I\setminus T_{\vec w}|\gt n-m$
, this means that there are strictly fewer than m indices
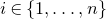 $i\in \{1,\ldots,n\}$
with
$i\in \{1,\ldots,n\}$
with
 $\mathrm{Pr}[\zeta_i\in R_i]\le 1-\delta$
, contradicting our assumption.
$\mathrm{Pr}[\zeta_i\in R_i]\le 1-\delta$
, contradicting our assumption.
We have established that
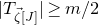 $|T_{\vec \zeta[J]}|\ge m/2$
for any outcome of
$|T_{\vec \zeta[J]}|\ge m/2$
for any outcome of
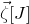 $\vec \zeta[J]$
. For any outcomes of
$\vec \zeta[J]$
. For any outcomes of
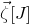 $\vec \zeta[J]$
and
$\vec \zeta[J]$
and
 $\vec\zeta[I\setminus T_{\vec \zeta[J]}]$
, we now have
$\vec\zeta[I\setminus T_{\vec \zeta[J]}]$
, we now have
 \begin{align*}\mathrm{Pr}\Biggl[\,\sum_{i\in I} P_{\vec \zeta[J]}^{(i)}(\zeta_i)=0\,\Bigg|\,\vec \zeta[J],\vec\zeta[I\setminus T_{\vec \zeta[J]}]\Biggr]&=\mathrm{Pr}\Biggl[\,\sum_{i\in T_{\vec \zeta[J]}} P_{\vec \zeta[J]}^{(i)}(\zeta_i)=-\!\!\!\sum_{i\in I\setminus T_{\vec \zeta[J]}} P_{\vec \zeta[J]}^{(i)}(\zeta_i)\,\Bigg|\,\vec \zeta[J],\vec\zeta[I\setminus T_{\vec \zeta[J]}]\Biggr]\\&\le \frac{C_\delta'}{\sqrt{|T_{\vec \zeta[J]}|}}\le \frac{C_\delta'}{\sqrt{m/2}} \le\frac{2C_\delta'}{\sqrt{m}},\end{align*}
\begin{align*}\mathrm{Pr}\Biggl[\,\sum_{i\in I} P_{\vec \zeta[J]}^{(i)}(\zeta_i)=0\,\Bigg|\,\vec \zeta[J],\vec\zeta[I\setminus T_{\vec \zeta[J]}]\Biggr]&=\mathrm{Pr}\Biggl[\,\sum_{i\in T_{\vec \zeta[J]}} P_{\vec \zeta[J]}^{(i)}(\zeta_i)=-\!\!\!\sum_{i\in I\setminus T_{\vec \zeta[J]}} P_{\vec \zeta[J]}^{(i)}(\zeta_i)\,\Bigg|\,\vec \zeta[J],\vec\zeta[I\setminus T_{\vec \zeta[J]}]\Biggr]\\&\le \frac{C_\delta'}{\sqrt{|T_{\vec \zeta[J]}|}}\le \frac{C_\delta'}{\sqrt{m/2}} \le\frac{2C_\delta'}{\sqrt{m}},\end{align*}
by Theorem 11.2. To be precise, for any possible outcomes of
 $\vec \zeta[J]$
and
$\vec \zeta[J]$
and
 $\vec\zeta[I\setminus T_{\vec \zeta[J]}]$
, we apply Theorem 11.2 in the conditional probability space given these outcomes, with the random variables
$\vec\zeta[I\setminus T_{\vec \zeta[J]}]$
, we apply Theorem 11.2 in the conditional probability space given these outcomes, with the random variables
 $X_i=P_{\vec \zeta[J]}^{(i)}(\zeta_i)$
for
$X_i=P_{\vec \zeta[J]}^{(i)}(\zeta_i)$
for
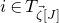 $i\in T_{\vec \zeta[J]}$
, noting that by the definition of
$i\in T_{\vec \zeta[J]}$
, noting that by the definition of
 $T_{\vec \zeta[J]}$
we then have
$T_{\vec \zeta[J]}$
we then have
 $$ \sup_{z\in \mathbb{R}}\mathrm{Pr}[X_i=z\,|\,\vec \zeta[J],\vec\zeta[I\setminus T_{\vec \zeta[J]}]]\le 1-\delta , $$
$$ \sup_{z\in \mathbb{R}}\mathrm{Pr}[X_i=z\,|\,\vec \zeta[J],\vec\zeta[I\setminus T_{\vec \zeta[J]}]]\le 1-\delta , $$
for each
 $i\in T_{\vec \zeta[J]}$
. So overall we obtain
$i\in T_{\vec \zeta[J]}$
. So overall we obtain
 $$ \mathrm{Pr}[Q(\vec \zeta)=0\,|\,\vec \zeta[J]]=\mathrm{Pr}\Biggl[\,\sum_{i\in I} P_{\vec \zeta[J]}^{(i)}(\zeta_i)=0\,\Bigg|\,\vec \zeta[J]\Biggr]\le \frac{2C_\delta'}{\sqrt{m}}\le\frac{C_\delta}{\sqrt{m}} , $$
$$ \mathrm{Pr}[Q(\vec \zeta)=0\,|\,\vec \zeta[J]]=\mathrm{Pr}\Biggl[\,\sum_{i\in I} P_{\vec \zeta[J]}^{(i)}(\zeta_i)=0\,\Bigg|\,\vec \zeta[J]\Biggr]\le \frac{2C_\delta'}{\sqrt{m}}\le\frac{C_\delta}{\sqrt{m}} , $$
for any outcome of
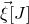 $\vec \xi[J]$
. This implies the desired bound in Equation (11.2).
$\vec \xi[J]$
. This implies the desired bound in Equation (11.2).
Finally, we deduce the full statement of Theorem 1.2 from Proposition 11.3.
Proof
of Theorem 1.2. We may assume without loss of generality that
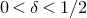 $0<\delta<1/2$
. Let
$0<\delta<1/2$
. Let
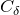 $C_\delta$
be a constant such that Proposition 11.3 holds (i.e., such that the statement in Theorem 1.2 holds under the additional assumption that
$C_\delta$
be a constant such that Proposition 11.3 holds (i.e., such that the statement in Theorem 1.2 holds under the additional assumption that
 $\sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta_i=z]\le 1-\delta$
for all
$\sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta_i=z]\le 1-\delta$
for all
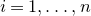 $i=1,\ldots,n$
). Let us also write
$i=1,\ldots,n$
). Let us also write
 $\vec \zeta=(\zeta_1,\ldots,\zeta_n)$
.
$\vec \zeta=(\zeta_1,\ldots,\zeta_n)$
.
Let
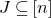 $J\subseteq [n]$
be the set of indices j for which
$J\subseteq [n]$
be the set of indices j for which
 $\mathrm{Pr}[\zeta_j=z_j]\gt 1-\delta$
holds for some
$\mathrm{Pr}[\zeta_j=z_j]\gt 1-\delta$
holds for some
 $z_j\in \mathbb{R}$
(such a
$z_j\in \mathbb{R}$
(such a
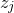 $z_j$
is unique if it exists). For each
$z_j$
is unique if it exists). For each
 $j\in J$
, let us represent the random variable
$j\in J$
, let us represent the random variable
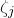 $\zeta_j$
as
$\zeta_j$
as
 $\zeta_j=\alpha_j+\xi_j \beta_j$
, for a Rademacher random variable
$\zeta_j=\alpha_j+\xi_j \beta_j$
, for a Rademacher random variable
 $\xi_j\in\{-1,1\}$
and a random vector
$\xi_j\in\{-1,1\}$
and a random vector
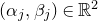 $(\alpha_j,\beta_j)\in \mathbb{R}^2$
, as in Lemma 11.1. We do this in such a way that the random variables
$(\alpha_j,\beta_j)\in \mathbb{R}^2$
, as in Lemma 11.1. We do this in such a way that the random variables
 $\xi_j$
and the random vectors
$\xi_j$
and the random vectors
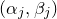 $(\alpha_j,\beta_j)$
are all mutually independent for all
$(\alpha_j,\beta_j)$
are all mutually independent for all
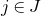 $j\in J$
. Note that we always have
$j\in J$
. Note that we always have
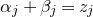 $\alpha_j+\beta_j=z_j$
for all
$\alpha_j+\beta_j=z_j$
for all
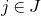 $j\in J$
(by (b) in Lemma 11.1, recalling that
$j\in J$
(by (b) in Lemma 11.1, recalling that
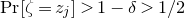 $\mathrm{Pr}[\zeta=z_j]\gt 1-\delta \gt 1/2$
).
$\mathrm{Pr}[\zeta=z_j]\gt 1-\delta \gt 1/2$
).
Now, our plan is to condition on arbitrary outcomes of
 $(\alpha_j,\beta_j)$
for
$(\alpha_j,\beta_j)$
for
 $j\in J$
, and prove the desired bound using the randomness of
$j\in J$
, and prove the desired bound using the randomness of
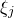 $\xi_j$
for
$\xi_j$
for
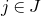 $j\in J$
, and the randomness of
$j\in J$
, and the randomness of
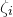 $\zeta_i$
for
$\zeta_i$
for
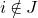 $i\notin J$
, applying Proposition 11.3.
$i\notin J$
, applying Proposition 11.3.
For each
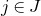 $j\in J$
and each outcome of
$j\in J$
and each outcome of
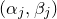 $(\alpha_j,\beta_j)$
, the conditional distribution of
$(\alpha_j,\beta_j)$
, the conditional distribution of
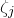 $\zeta_j$
given our outcome of
$\zeta_j$
given our outcome of
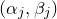 $(\alpha_j,\beta_j)$
is described by
$(\alpha_j,\beta_j)$
is described by
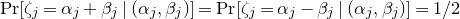 $\mathrm{Pr}[\zeta_j=\alpha_j+\beta_j\,|\,(\alpha_j,\beta_j)]=\mathrm{Pr}[\zeta_j=\alpha_j-\beta_j\,|\,(\alpha_j,\beta_j)]=1/2$
if
$\mathrm{Pr}[\zeta_j=\alpha_j+\beta_j\,|\,(\alpha_j,\beta_j)]=\mathrm{Pr}[\zeta_j=\alpha_j-\beta_j\,|\,(\alpha_j,\beta_j)]=1/2$
if
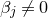 $\beta_j\ne 0$
, and
$\beta_j\ne 0$
, and
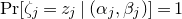 $\mathrm{Pr}[\zeta_j=z_j\,|\,(\alpha_j,\beta_j)]=1$
if
$\mathrm{Pr}[\zeta_j=z_j\,|\,(\alpha_j,\beta_j)]=1$
if
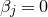 $\beta_j=0$
(then
$\beta_j=0$
(then
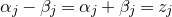 $\alpha_j-\beta_j=\alpha_j+\beta_j=z_j$
, so
$\alpha_j-\beta_j=\alpha_j+\beta_j=z_j$
, so
 $\zeta_j$
is constant). Note that conditioning on outcomes of
$\zeta_j$
is constant). Note that conditioning on outcomes of
 $(\alpha_j,\beta_j)$
for
$(\alpha_j,\beta_j)$
for
 $j\in J$
does not change the distribution of
$j\in J$
does not change the distribution of
 $\zeta_i$
for
$\zeta_i$
for
 $i\notin J$
, and does not change the fact that the random variables
$i\notin J$
, and does not change the fact that the random variables
 $\zeta_1,\ldots,\zeta_n$
are independent.
$\zeta_1,\ldots,\zeta_n$
are independent.
For any outcome of
 $\vec \beta[J]$
(i.e., for any outcomes of
$\vec \beta[J]$
(i.e., for any outcomes of
 $\beta_j$
for
$\beta_j$
for
 $j\in J$
), let
$j\in J$
), let
 $H_{\vec \beta[J]}\subseteq J$
be the set of indices
$H_{\vec \beta[J]}\subseteq J$
be the set of indices
 $j\in J$
such that
$j\in J$
such that
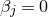 $\beta_j=0$
, and let
$\beta_j=0$
, and let
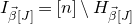 $I_{\vec \beta[J]}=[n]\setminus H_{\vec \beta[J]}$
(i.e.,
$I_{\vec \beta[J]}=[n]\setminus H_{\vec \beta[J]}$
(i.e.,
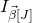 $I_{\vec \beta[J]}$
is the subset of indices for which
$I_{\vec \beta[J]}$
is the subset of indices for which
 $\zeta_i$
‘still has some randomness’ after conditioning on the outcomes of
$\zeta_i$
‘still has some randomness’ after conditioning on the outcomes of
 $(\alpha_j,\beta_j)$
for
$(\alpha_j,\beta_j)$
for
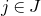 $j\in J$
). Note that we always have
$j\in J$
). Note that we always have
 $[n]\setminus J\subseteq I_{\vec \beta[J]}$
. Furthermore note that for any outcome of
$[n]\setminus J\subseteq I_{\vec \beta[J]}$
. Furthermore note that for any outcome of
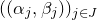 $((\alpha_j,\beta_j))_{j\in J}$
, we have
$((\alpha_j,\beta_j))_{j\in J}$
, we have
 $$ \sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta_i=z\,|\,((\alpha_j,\beta_j))_{j\in J}]\le 1-\delta , $$
$$ \sup_{z\in \mathbb{R}}\mathrm{Pr}[\zeta_i=z\,|\,((\alpha_j,\beta_j))_{j\in J}]\le 1-\delta , $$
for all
 $i\in I_{\vec \beta[J]}$
(here we are using that
$i\in I_{\vec \beta[J]}$
(here we are using that
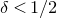 $\delta<1/2$
) and
$\delta<1/2$
) and
 $$ \mathrm{Pr}[\zeta_i=z_i\,|\,((\alpha_j,\beta_j))_{j\in J}]=1 , $$
$$ \mathrm{Pr}[\zeta_i=z_i\,|\,((\alpha_j,\beta_j))_{j\in J}]=1 , $$
for all
 $i\in H_{\vec \beta[J]}$
.
$i\in H_{\vec \beta[J]}$
.
Now, for any outcome of
 $\vec \beta[J]$
(which determines
$\vec \beta[J]$
(which determines
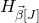 $H_{\vec \beta[J]}$
and
$H_{\vec \beta[J]}$
and
 $I_{\vec \beta[J]}$
), we have
$I_{\vec \beta[J]}$
), we have
 $Q(\vec \zeta)=Q_{\vec\beta[J]}(\vec \zeta[I_{\vec \beta[J]}])$
, where
$Q(\vec \zeta)=Q_{\vec\beta[J]}(\vec \zeta[I_{\vec \beta[J]}])$
, where
 $Q_{\vec\beta[J]}$
is the polynomial in the entries of
$Q_{\vec\beta[J]}$
is the polynomial in the entries of
 $\vec \zeta[I_{\vec \beta[J]}]$
obtained from
$\vec \zeta[I_{\vec \beta[J]}]$
obtained from
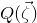 $Q(\vec \zeta)$
by substituting
$Q(\vec \zeta)$
by substituting
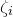 $\zeta_i$
with
$\zeta_i$
with
 $z_i$
for all
$z_i$
for all
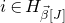 $i\in H_{\vec \beta[J]}$
(recall that we always have
$i\in H_{\vec \beta[J]}$
(recall that we always have
 $\zeta_i=z_i$
for all
$\zeta_i=z_i$
for all
 $i\in H_{\vec \beta[J]}$
).
$i\in H_{\vec \beta[J]}$
).
We claim that, if we condition on any outcomes of
 $(\alpha_j,\beta_j)$
for
$(\alpha_j,\beta_j)$
for
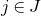 $j\in J$
, then with respect to the resulting conditional probability space,
$j\in J$
, then with respect to the resulting conditional probability space,
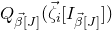 $Q_{\vec\beta[J]}(\vec \zeta_i[I_{\vec \beta[J]}])$
satisfies the fixing box assumption in Theorem 1.2 (and therefore satisfies the assumptions of Proposition 11.3). Indeed, for any outcome of
$Q_{\vec\beta[J]}(\vec \zeta_i[I_{\vec \beta[J]}])$
satisfies the fixing box assumption in Theorem 1.2 (and therefore satisfies the assumptions of Proposition 11.3). Indeed, for any outcome of
 $((\alpha_j,\beta_j))_{j\in J}$
, consider a fixing box
$((\alpha_j,\beta_j))_{j\in J}$
, consider a fixing box
 $\prod_{i\in I_{\vec \beta[J]}} R_i$
for
$\prod_{i\in I_{\vec \beta[J]}} R_i$
for
 $Q_{\vec\beta[J]}(\vec \zeta[I_{\vec \beta[J]}])$
, and suppose for the purpose of contradiction that there are fewer than m indices
$Q_{\vec\beta[J]}(\vec \zeta[I_{\vec \beta[J]}])$
, and suppose for the purpose of contradiction that there are fewer than m indices
 $i\in I_{\vec \beta[J]}$
with
$i\in I_{\vec \beta[J]}$
with
 $\mathrm{Pr}[\zeta_i\in R_i\,|\,((\alpha_j,\beta_j))_{j\in J}]\le 1-\delta$
. Then, we can extend our fixing box for
$\mathrm{Pr}[\zeta_i\in R_i\,|\,((\alpha_j,\beta_j))_{j\in J}]\le 1-\delta$
. Then, we can extend our fixing box for
 $Q_{\vec\beta[J]}$
to a fixing box
$Q_{\vec\beta[J]}$
to a fixing box
 $R_1\times \dots\times R_n$
for
$R_1\times \dots\times R_n$
for
 $Q(\zeta_1,\ldots,\zeta_n)$
by simply taking
$Q(\zeta_1,\ldots,\zeta_n)$
by simply taking
 $R_j=\{z_j\}$
for all
$R_j=\{z_j\}$
for all
 $j\in H_{\vec \beta[J]}\subseteq J$
. Note that for each
$j\in H_{\vec \beta[J]}\subseteq J$
. Note that for each
 $j\in H_{\vec \beta[J]}\subseteq J$
we have
$j\in H_{\vec \beta[J]}\subseteq J$
we have
 $\mathrm{Pr}[\zeta_j\in R_j]=\mathrm{Pr}[\zeta_j=z_j]\gt 1-\delta$
. Also, for
$\mathrm{Pr}[\zeta_j\in R_j]=\mathrm{Pr}[\zeta_j=z_j]\gt 1-\delta$
. Also, for
 $j\in J\setminus H_{\vec \beta[J]}=J\cap I_{\vec \beta[J]}$
(i.e., for
$j\in J\setminus H_{\vec \beta[J]}=J\cap I_{\vec \beta[J]}$
(i.e., for
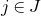 $j\in J$
with
$j\in J$
with
 $\beta_j\ne 0$
), we can only have
$\beta_j\ne 0$
), we can only have
 $\mathrm{Pr}[\zeta_j\in R_j]\le 1-\delta$
if
$\mathrm{Pr}[\zeta_j\in R_j]\le 1-\delta$
if
 $z_j\not\in R_j$
(as
$z_j\not\in R_j$
(as
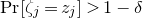 $\mathrm{Pr}[\zeta_j=z_j]\gt 1-\delta$
), and in this case we also have
$\mathrm{Pr}[\zeta_j=z_j]\gt 1-\delta$
), and in this case we also have
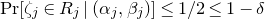 $\mathrm{Pr}[\zeta_j\in R_j\,|\,(\alpha_j,\beta_j)]\le 1/2\le 1-\delta$
(as
$\mathrm{Pr}[\zeta_j\in R_j\,|\,(\alpha_j,\beta_j)]\le 1/2\le 1-\delta$
(as
 $\mathrm{Pr}[\zeta_j=z_j\,|\,(\alpha_j,\beta_j)]=\mathrm{Pr}[\zeta_j=\alpha_j+\beta_j\,|\,(\alpha_j,\beta_j)]=1/2$
). Finally, note that conditioning on
$\mathrm{Pr}[\zeta_j=z_j\,|\,(\alpha_j,\beta_j)]=\mathrm{Pr}[\zeta_j=\alpha_j+\beta_j\,|\,(\alpha_j,\beta_j)]=1/2$
). Finally, note that conditioning on
 $((\alpha_j,\beta_j))_{j\in J}$
does not change the distributions of
$((\alpha_j,\beta_j))_{j\in J}$
does not change the distributions of
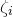 $\zeta_i$
for
$\zeta_i$
for
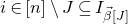 $i\in [n]\setminus J\subseteq I_{\vec \beta[J]}$
. So every index
$i\in [n]\setminus J\subseteq I_{\vec \beta[J]}$
. So every index
 $i\in [n]$
with
$i\in [n]$
with
 $\mathrm{Pr}[\zeta_i\in R_i]\le 1-\delta$
has the property that
$\mathrm{Pr}[\zeta_i\in R_i]\le 1-\delta$
has the property that
 $i\in I_{\vec \beta[J]}$
and
$i\in I_{\vec \beta[J]}$
and
 $\mathrm{Pr}[\zeta_i\in R_i\,|\,((\alpha_j,\beta_j))_{j\in J}]\le 1-\delta$
. Hence, there are fewer than m indices
$\mathrm{Pr}[\zeta_i\in R_i\,|\,((\alpha_j,\beta_j))_{j\in J}]\le 1-\delta$
. Hence, there are fewer than m indices
 $i\in [n]$
with
$i\in [n]$
with
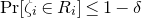 $\mathrm{Pr}[\zeta_i\in R_i]\le 1-\delta$
, contradicting our assumption on
$\mathrm{Pr}[\zeta_i\in R_i]\le 1-\delta$
, contradicting our assumption on
 $Q(\zeta_1,\ldots,\zeta_n)$
.
$Q(\zeta_1,\ldots,\zeta_n)$
.
Given the above discussion, for any outcomes of
 $(\alpha_j,\beta_j)$
for
$(\alpha_j,\beta_j)$
for
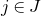 $j\in J$
, we can apply Proposition 11.3, to obtain
$j\in J$
, we can apply Proposition 11.3, to obtain
 $$ \sup_{z\in\mathbb{R}} \mathrm{Pr}[Q(\zeta_1,\ldots,\zeta_n)=z\,|\,((\alpha_j,\beta_j))_{j\in J}]\le \frac{C_\delta}{\sqrt{m}}. $$
$$ \sup_{z\in\mathbb{R}} \mathrm{Pr}[Q(\zeta_1,\ldots,\zeta_n)=z\,|\,((\alpha_j,\beta_j))_{j\in J}]\le \frac{C_\delta}{\sqrt{m}}. $$
The desired desired unconditional probability bound follows.
12. Concluding remarks
In this paper we have obtained essentially optimal bounds for the quadratic Littlewood–Offord problem. There are many interesting directions for further research.
12.1. Immediate generalisations
Theorem 1.1 is only about point concentration, and it would be interesting to prove a counterpart for small-ball concentration; i.e., under which assumptions on Q can we prove that
 $$\sup_{z\in\mathbb{R}}\mathrm{Pr}[|Q(\xi_{1},\ldots,\xi_{n})-z|\le1]\le O\bigg(\frac{1}{\sqrt{n}}\bigg)? $$
$$\sup_{z\in\mathbb{R}}\mathrm{Pr}[|Q(\xi_{1},\ldots,\xi_{n})-z|\le1]\le O\bigg(\frac{1}{\sqrt{n}}\bigg)? $$
It would also be nice to prove a generalisation of Theorem 1.1 to polynomials of degree greater than 2. Generalising the conjecture of Nguyen and Vu, we believe the statement of Theorem 1.1 should hold whenever Q is a polynomial of bounded degree (note that without a bounded-degree assumption we cannot hope for sensible anticoncentration bounds; consider for example the parity function
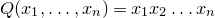 $Q(x_{1},\ldots,x_{n})=x_{1}x_{2}\dots x_{n}$
).
$Q(x_{1},\ldots,x_{n})=x_{1}x_{2}\dots x_{n}$
).
It is sometimes the case that techniques for point concentration can be straightforwardly adapted for small-ball concentration, and techniques for quadratic polynomials can be straightforwardly adapted for higher-degree polynomials (in particular, the previous bounds of Meka–Nguyen–Vu [Reference Meka, Nguyen and VuMNV16] and Kane [Reference KaneKan14], mentioned in the introduction, handle small-ball concentration for polynomials of any bounded degree). The high-level strategy of the proof of Theorem 1.1 (as sketched in § 2) makes sense in a very general context, but when trying to generalise Theorem 1.1 in the obvious ways, one runs into some subtle technical issues (see Remark 2.2, 2.3). We think it would be very interesting to investigate this further.
It would also be desirable to generalise our ‘geometric’ theorem (Theorem 4.2) to geometric objects other than quadrics inside affine-linear subspaces. For example, we make the following conjecture (closely related to higher-degree generalisations of the Littlewood–Offord problem, and closely related to the directions in [Reference Fox, Kwan and SpinkFKS23]).
Conjecture 12.1. Let
 $0\le d<r$
and q be integers. Let
$0\le d<r$
and q be integers. Let
 $\mathcal{Z}\subseteq\mathbb{R}^{r}$
be an algebraic variety of dimension d, with degree at most q. Consider vectors
$\mathcal{Z}\subseteq\mathbb{R}^{r}$
be an algebraic variety of dimension d, with degree at most q. Consider vectors
 $\vec{a}_{1},\ldots,\vec{a}_{n}\in\mathbb{R}^{r}$
such that for some positive integer t, one can form t disjoint bases from the vectors
$\vec{a}_{1},\ldots,\vec{a}_{n}\in\mathbb{R}^{r}$
such that for some positive integer t, one can form t disjoint bases from the vectors
 $\vec{a}_{1},\ldots, \vec{a}_n$
. Let
$\vec{a}_{1},\ldots, \vec{a}_n$
. Let
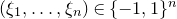 $(\xi_1,\ldots,\xi_n)\in\{-1,1\}^{n}$
be a sequence of independent Rademacher random variables. Then
$(\xi_1,\ldots,\xi_n)\in\{-1,1\}^{n}$
be a sequence of independent Rademacher random variables. Then
 $$\mathrm{Pr}\bigg[\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}\in\mathcal{Z}\bigg]\le\frac{C_{d,r,q}}{t^{(r-d)/2}}, $$
$$\mathrm{Pr}\bigg[\xi_{1}\vec{a}_{1}+\dots+\xi_{n}\vec{a}_{n}\in\mathcal{Z}\bigg]\le\frac{C_{d,r,q}}{t^{(r-d)/2}}, $$
for some
 $C_{d,r,q}$
only depending on d,r,q.
$C_{d,r,q}$
only depending on d,r,q.
12.2 The Gotsman–Linial conjecture
The Gotsman–Linial conjecture is a conjecture in Boolean analysis which generalises nearly all polynomial Littlewood–Offord-type theorems. To state this conjecture we need to introduce some notation.
The ith influence of a Boolean function
 $F:\{-1,1\}^{n}\to\{-1,1\}$
is defined as
$F:\{-1,1\}^{n}\to\{-1,1\}$
is defined as
 $$\operatorname{Inf}_{i}(F)=\mathrm{Pr}[F(\xi_{1},\ldots,\xi_{i-1},\xi_{i},\xi_{i+1},\dots\xi_{n})\ne F(\xi_{1},\ldots,\xi_{i-1},-\xi_{i},\xi_{i+1},\dots\xi_{n})]; $$
$$\operatorname{Inf}_{i}(F)=\mathrm{Pr}[F(\xi_{1},\ldots,\xi_{i-1},\xi_{i},\xi_{i+1},\dots\xi_{n})\ne F(\xi_{1},\ldots,\xi_{i-1},-\xi_{i},\xi_{i+1},\dots\xi_{n})]; $$
(i.e., the probability that changing the ith bit changes the output of the function). The total influence (also sometimes called the average sensitivity)
 $\operatorname{Inf}(F)$
of F is
$\operatorname{Inf}(F)$
of F is
 $\operatorname{Inf}_{1}(F)+\dots+\operatorname{Inf}_{n}(F)$
. For a function
$\operatorname{Inf}_{1}(F)+\dots+\operatorname{Inf}_{n}(F)$
. For a function
 $Q:\{-1,1\}^n\to \mathbb{R}$
, the threshold function
$Q:\{-1,1\}^n\to \mathbb{R}$
, the threshold function
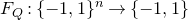 $F_{Q}:\{-1,1\}^{n}\to\{-1,1\}$
of Q is the Boolean function that detects whether
$F_{Q}:\{-1,1\}^{n}\to\{-1,1\}$
of Q is the Boolean function that detects whether
 $Q(x_{1},\ldots,x_{n})\ge0$
or not. If Q is a degree-d polynomial, we say
$Q(x_{1},\ldots,x_{n})\ge0$
or not. If Q is a degree-d polynomial, we say
 $F_{Q}$
is a degree-d threshold function.
$F_{Q}$
is a degree-d threshold function.
Gotsman and Linial [Reference Gotsman and LinialGL94] made a notorious conjecture on the highest total influence that an n-variable degree-d polynomial threshold function can have (namely, they conjectured that the total influence is maximised when
 $Q(x_{1},\ldots,x_{n})$
is a certain product of d terms of the form
$Q(x_{1},\ldots,x_{n})$
is a certain product of d terms of the form
 $(x_{1}+\dots+x_{n}+a)$
). Unfortunately, the precise form of this conjecture has been falsified [Reference ChapmanCha18, Reference Kim, Maldonado and WellensKMW17] (it holds for the linear case
$(x_{1}+\dots+x_{n}+a)$
). Unfortunately, the precise form of this conjecture has been falsified [Reference ChapmanCha18, Reference Kim, Maldonado and WellensKMW17] (it holds for the linear case
 $d=1$
but already fails in the quadratic case
$d=1$
but already fails in the quadratic case
 $d=2$
).
$d=2$
).
Nonetheless, it still seems plausible that for every n-variable degree-d polynomial the total influence of threshold function can be bounded by
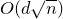 $O(d\sqrt{n})$
, or at least by
$O(d\sqrt{n})$
, or at least by
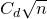 $C_{d}\sqrt{n}$
for some constant
$C_{d}\sqrt{n}$
for some constant
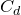 $C_{d}$
depending on d (conjectures in this direction are sometimes variously called the weak Gotsman–Linial conjecture). If such a bound were to hold, it would be an easy exercise to deduce Theorem 1.1 (and the generalisations discussed above). It would be interesting to investigate whether the techniques in this paper can be used to make progress on (at least the quadratic case of the) weak Gotsman–Linial conjecture.
$C_{d}$
depending on d (conjectures in this direction are sometimes variously called the weak Gotsman–Linial conjecture). If such a bound were to hold, it would be an easy exercise to deduce Theorem 1.1 (and the generalisations discussed above). It would be interesting to investigate whether the techniques in this paper can be used to make progress on (at least the quadratic case of the) weak Gotsman–Linial conjecture.
12.3 Inverse theory
For both the linear and quadratic Littlewood–Offord problems, one cannot hope for a general bound stronger than
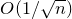 $O(1/\sqrt{n})$
. However, it is natural to investigate assumptions under which one can prove stronger bounds.
$O(1/\sqrt{n})$
. However, it is natural to investigate assumptions under which one can prove stronger bounds.
In the linear case (studying random variables of the form
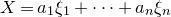 $X=a_{1}\xi_{1}+\dots+a_{n}\xi_{n}$
), this has been an enormously successful direction of research. Early highlights include Stanley’s solution of the so-called Erdős–Moser problem [Reference StanleySta80] (introducing tools from algebraic topology to prove an optimal bound under the assumption that all of the coefficients
$X=a_{1}\xi_{1}+\dots+a_{n}\xi_{n}$
), this has been an enormously successful direction of research. Early highlights include Stanley’s solution of the so-called Erdős–Moser problem [Reference StanleySta80] (introducing tools from algebraic topology to prove an optimal bound under the assumption that all of the coefficients
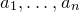 $a_{1},\ldots,a_n$
are distinct), and a paper of Halász [Reference HalászHal77] which introduced Fourier-analytic methods to prove stronger bounds when
$a_{1},\ldots,a_n$
are distinct), and a paper of Halász [Reference HalászHal77] which introduced Fourier-analytic methods to prove stronger bounds when
 $a_{1},\ldots,a_n$
are in a certain sense ‘additively unstructured’. Perhaps most famously, Tao and Vu [Reference Tao and VuTV09b] proved a so-called Inverse Littlewood–Offord theorem, which shows that
$a_{1},\ldots,a_n$
are in a certain sense ‘additively unstructured’. Perhaps most famously, Tao and Vu [Reference Tao and VuTV09b] proved a so-called Inverse Littlewood–Offord theorem, which shows that
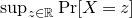 $\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]$
is extremely small (smaller than
$\sup_{z\in\mathbb{R}}\mathrm{Pr}[X=z]$
is extremely small (smaller than
 $n^{-C}$
for any constant C) unless
$n^{-C}$
for any constant C) unless
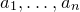 $a_{1},\ldots,a_n$
have very special additive structure (roughly speaking, most of
$a_{1},\ldots,a_n$
have very special additive structure (roughly speaking, most of
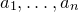 $a_{1},\ldots,a_n$
lie inside a generalised arithmetic progression). This had a number of important applications in random matrix theory [Reference Tao and VuTV07, Reference Tao and VuTV09a, Reference Tao and VuTV09b]. The inverse theory of the linear Littlewood–Offord theorem is now essentially complete, thanks to optimal inverse theorems of Nguyen and Vu [Reference Nguyen and VuNV11] and Rudelson and Vershinyn [Reference Rudelson and VershyninRV08] (see also [Reference Tao and VuTV10]) that give a precise quantification of the extent to which anticoncentration is controlled by the additive structure of
$a_{1},\ldots,a_n$
lie inside a generalised arithmetic progression). This had a number of important applications in random matrix theory [Reference Tao and VuTV07, Reference Tao and VuTV09a, Reference Tao and VuTV09b]. The inverse theory of the linear Littlewood–Offord theorem is now essentially complete, thanks to optimal inverse theorems of Nguyen and Vu [Reference Nguyen and VuNV11] and Rudelson and Vershinyn [Reference Rudelson and VershyninRV08] (see also [Reference Tao and VuTV10]) that give a precise quantification of the extent to which anticoncentration is controlled by the additive structure of
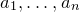 $a_{1},\ldots,a_n$
.
$a_{1},\ldots,a_n$
.
In the quadratic case (studying random variables of the form
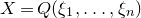 $X=Q(\xi_{1},\ldots,\xi_{n})$
for a quadratic polynomial Q), much less is known. An analogue of the original Tao–Vu inverse theorem was proved by Nguyen [Reference NguyenNgu12], but it is not clear how an optimal inverse theorem should even be formulated. Such a theorem would have to somehow incorporate the additive information that is relevant for the linear Littlewood–Offord problem, in addition to algebraic considerations (e.g., whether Q factorises into linear factors or not). See [Reference CostelloCos13, Reference KaneKan17, Reference Kwan and SauermannKS20] for some progress and conjectures related to algebraic aspects of the inverse theory of the quadratic Littlewood–Offord problem.
$X=Q(\xi_{1},\ldots,\xi_{n})$
for a quadratic polynomial Q), much less is known. An analogue of the original Tao–Vu inverse theorem was proved by Nguyen [Reference NguyenNgu12], but it is not clear how an optimal inverse theorem should even be formulated. Such a theorem would have to somehow incorporate the additive information that is relevant for the linear Littlewood–Offord problem, in addition to algebraic considerations (e.g., whether Q factorises into linear factors or not). See [Reference CostelloCos13, Reference KaneKan17, Reference Kwan and SauermannKS20] for some progress and conjectures related to algebraic aspects of the inverse theory of the quadratic Littlewood–Offord problem.
Acknowledgements
We would like to thank the anonymous referee for a number of helpful comments and suggestions.
Conflicts of interest
None.
Financial support
Matthew Kwan was supported by ERC Starting Grant “RANDSTRUCT” No. 101076777. Lisa Sauermann was supported in part by NSF Award DMS-2100157 and a Sloan Research Fellowship, and in part by the DFG Heisenberg Program.
Journal information
Compositio Mathematica is owned by the Foundation Compositio Mathematica and published by the London Mathematical Society in partnership with Cambridge University Press. All surplus income from the publication of Compositio Mathematica is returned to mathematics and higher education through the charitable activities of the Foundation, the London Mathematical Society and Cambridge University Press.


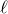
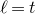
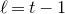
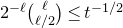

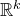
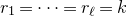




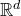
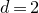

 R3
R3
 Open access
Open access