Introduction
The perception of societal and personal risk is at the heart of public policy, influencing the allocation of resources by governments and organisations (Sunstein, Reference Sunstein2005a). While efficient policies likely depend on accurate risk estimates, people's estimates regarding risk can be misaligned with the available evidence (Weinstein, Reference Weinstein1980; Taylor & Brown, Reference Taylor and Brown1988; Carver et al., Reference Carver, Scheier and Segerstrom2010; Shepperd et al., Reference Shepperd, Waters, Weinstein and Klein2015; Sharot & Garrett, Reference Sharot and Garrett2016). For example, providing people with statistics about the risk of smoking, unhealthy eating or drunk driving does not lead to adequate belief adjustments (Weinstein & Klein, Reference Weinstein and Klein1995; Carver et al., Reference Carver, Scheier and Segerstrom2010). Most explanations for why people fail to update beliefs in the face of evidence point to motivated reasoning: cognitive processes that attempt to confirm a preferred outcome, belief or judgement (Kunda, Reference Kunda1990; Ditto & Lopez, Reference Ditto and Lopez1992; Nickerson, Reference Nickerson1998; Ditto et al., Reference Ditto, Pizarro, Tannenbaum and Ross2009). Surprisingly, however, while reasoning is a central aspect of such models, we are unaware of a direct test on whether it is required for motivated beliefs to emerge.
An alternative mechanism may involve automatic rejection of unwanted information without reasoning (Taber & Lodge, Reference Taber and Lodge2006; Mercier & Sperber, Reference Mercier and Sperber2011). People then will engage only in post-hoc rationalisation if prompted (Haidt, Reference Haidt2001; Mercier & Sperber, Reference Mercier and Sperber2011; Taber & Lodge, Reference Taber and Lodge2016). In moral decision-making, for instance, people might have a strong emotional reaction to a certain type of behaviour (e.g., having sex with a dead chicken) that leads them to condemn it even when unable to explain why (Haidt et al., Reference Haidt, Bjorklund and Murphy2000; but see Royzman et al., Reference Royzman, Kim and Leeman2015). Similarly, when confronted with data suggesting one is more likely to become a victim of crime than previously suspected, a negative reaction may be triggered, leading to automatic rejection of the information without reasoning. Here, we test if reasoning is needed to maintain skewed beliefs, focusing on belief updating about personal risks.
Ample research has shown that people are more likely to incorporate good news (i.e., learning the risk of alcohol is lower than they thought) than bad news (i.e., learning it is higher) into prior beliefs (Eil & Rao, Reference Eil and Rao2011; Sharot et al., Reference Sharot, Korn and Dolan2011). Such motivated belief updating has been demonstrated for a range of beliefs relating to personal and societal risks (see Sharot & Garrett, Reference Sharot and Garrett2016, for an overview), including beliefs about medical risks, safety risks, personal traits, climate change and more (Eil & Rao, Reference Eil and Rao2011; Sharot et al., Reference Sharot, Korn and Dolan2011; Sharot et al., Reference Sharot, Guitart-Masip, Korn, Chowdhury and Dolan2012a; Sharot et al., Reference Sharot, Kanai, Marston, Korn, Rees and Dolan2012b; Moutsiana et al., Reference Moutsiana, Garrett, Clarke, Lotto, Blakemore and Sharot2013; Garrett et al., Reference Garrett, Sharot, Faulkner, Korn, Roiser and Dolan2014; Garrett & Sharot, Reference Garrett and Sharot2014; Korn et al., Reference Korn, Sharot, Walter, Heekeren and Dolan2014; Kuzmanovic et al., Reference Kuzmanovic, Jefferson and Vogeley2015; Lefebvre et al., Reference Lefebvre, Lebreton, Meyniel, Bourgeois-Gironde and Palminteri2017). For instance, a study conducted a few months before the 2016 US presidential campaign showed that voters were more inclined to revise their predictions of who was likely to win the elections after receiving good news – that their candidate is leading the polls – than bad news – that the opposing candidate was leading the polls (Tappin et al., Reference Tappin, van der Leer and McKay2017). Because different people have different motivations, as in the example above, a relative failure to update beliefs in response to bad news as compared to good news can lead to an increase in belief polarisation within a population (Sunstein et al., Reference Sunstein, Bobadilla-Suarez, Lazzaro and Sharot2016).
A reasoning-centric account of motivated belief updating would suggest that people construct reasons for discounting bad news (e.g., a smoker who reads an article that ties smoking to lung cancer may tell himself: “My grandfather smoked all his life and lived to 100. Thus, I have genes that protect me from the ill effects of smoking”) (Lovallo & Kahneman, Reference Lovallo and Kahneman2003). Here, reasoning is needed to reject incoming information (Gilbert et al., Reference Gilbert, Tafarodi and Malone1993) and if deliberation is restricted people will update their beliefs equally for good and bad news. However, if bad news can be discounted automatically without deliberation, we should observe motivated belief updating even when cognitive resources are restricted. To test whether deliberation is required for motivated belief updating, we utilised two common manipulations to limit the cognitive resources needed for deliberation: cognitive load and time restriction (Moors & De Houwer, Reference Moors and De Houwer2006).
Experiment 1
Method
Participants and design
Power calculation
Previous research found large effect sizes for motivated belief updating (Sharot et al., Reference Sharot, Korn and Dolan2011; Sharot et al., Reference Sharot, Guitart-Masip, Korn, Chowdhury and Dolan2012a; Sharot et al., Reference Sharot, Kanai, Marston, Korn, Rees and Dolan2012b; Moutsiana et al., Reference Moutsiana, Garrett, Clarke, Lotto, Blakemore and Sharot2013; Garrett et al., Reference Garrett, Sharot, Faulkner, Korn, Roiser and Dolan2014; Garrett & Sharot, Reference Garrett and Sharot2014; Korn et al., Reference Korn, Sharot, Walter, Heekeren and Dolan2014; Kuzmanovic et al., Reference Kuzmanovic, Jefferson and Vogeley2015). We assumed a potentially small to medium difference between the load and no-load manipulation (η2partial ~0.2). Using G*Power (Faul et al., Reference Faul, Erdfelder, Buchner and Lang2009), we estimated that for an acceptable power of 0.8, we would need about 50 participants, and we recruited 49 participants (22 male, 27 female, Mage = 23.56, SD = 4.08).
The study was approved by the University College London Research Ethics Committee. Participants received £10 for participation. We intended to exclude participants with a depression score on the Beck Depression Inventory-II (BDI-II; Beck et al., Reference Beck, Steer, Ball and Ranieri1996) of 12 or higher as done previously (Moutsiana et al., Reference Moutsiana, Garrett, Clarke, Lotto, Blakemore and Sharot2013). Depression has been shown to eliminate the update bias (Garrett et al., Reference Garrett, Sharot, Faulkner, Korn, Roiser and Dolan2014; Korn et al., Reference Korn, Sharot, Walter, Heekeren and Dolan2014). However, none of the participants had a BDI-II score that high. The study had a within-subject design with valence of news (good versus bad) and cognitive load (no load versus load) as within-subject factors. Order of condition was randomly assigned. Order did not affect the results, and hence we will not discuss it further.
Belief updating task
Stimuli
Eighty short descriptions of negative life events (e.g., passenger in a car accident, home burglary) were presented in random order. The stimuli were ones used in previous research (Sharot et al., Reference Sharot, Korn and Dolan2011; Moutsiana et al., Reference Moutsiana, Garrett, Clarke, Lotto, Blakemore and Sharot2013; Garrett & Sharot, Reference Garrett and Sharot2014). All events were shown to all participants. For each event, the average probability (base rate) of that event occurring at least once to a person living in the same sociocultural environment as the participant was determined from online resources (e.g., Office for National Statistics, Eurostat and PubMed). Our participants were all living in a similar sociocultural environment, so probabilities were the same for all. Very rare or very common events were not included; all event probabilities were between 10% and 70%. To ensure that the range of possible overestimation was equal to the range of possible underestimation, participants were told that the range of probabilities was between 3% and 77%.
Procedure
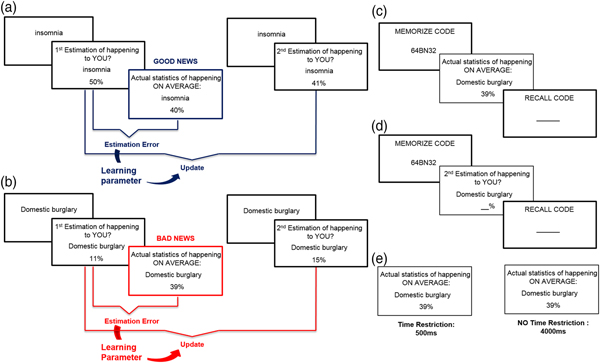
We used the frequently used ‘belief update’ procedure (Sharot et al., Reference Sharot, Korn and Dolan2011; Sharot et al., Reference Sharot, Guitart-Masip, Korn, Chowdhury and Dolan2012a; Sharot et al., Reference Sharot, Kanai, Marston, Korn, Rees and Dolan2012b; Chowdhury et al., Reference Chowdhury, Sharot, Wolfe, Düzel and Dolan2014; Korn et al., Reference Korn, Sharot, Walter, Heekeren and Dolan2014; Kuzmanovic et al., Reference Kuzmanovic, Jefferson and Vogeley2015). On each trial, one of the 80 adverse life events was presented in random order for 4 s, and participants were asked to estimate how likely the event was to happen to them in the future. Participants had up to 8 s to respond. They were then presented with the base rate of the event in a demographically similar population for 4 s (see Figure 1). Between each trial, a fixation cross appeared (1 s).
Belief updating task. (a) Example of a good news trial – the first estimate is higher than the average likelihood displayed. The estimation error is then calculated by subtracting the first estimate from the average likelihood and the update is calculated by subtracting the first estimate from the second estimate. The learning parameter indicates how well the estimation error predicted subsequent update. (b) Example of a bad news trial – the first estimate is lower than the average likelihood. The estimation error is then calculated by subtracting the average likelihood from the first estimate and the update is calculated by subtracting the second estimate from the first estimate. (c) Cognitive load in Experiment 1 was induced by asking participants to memorise a code before observing the average information and recalling it immediately thereafter. (d) Cognitive load in Experiment 2 was induced by asking participants to memorise a code before entering their second estimate and recalling it immediately thereafter. (e) In Experiment 3, information was presented for either 500 ms (time restriction) or for 4000 ms (no time restriction).
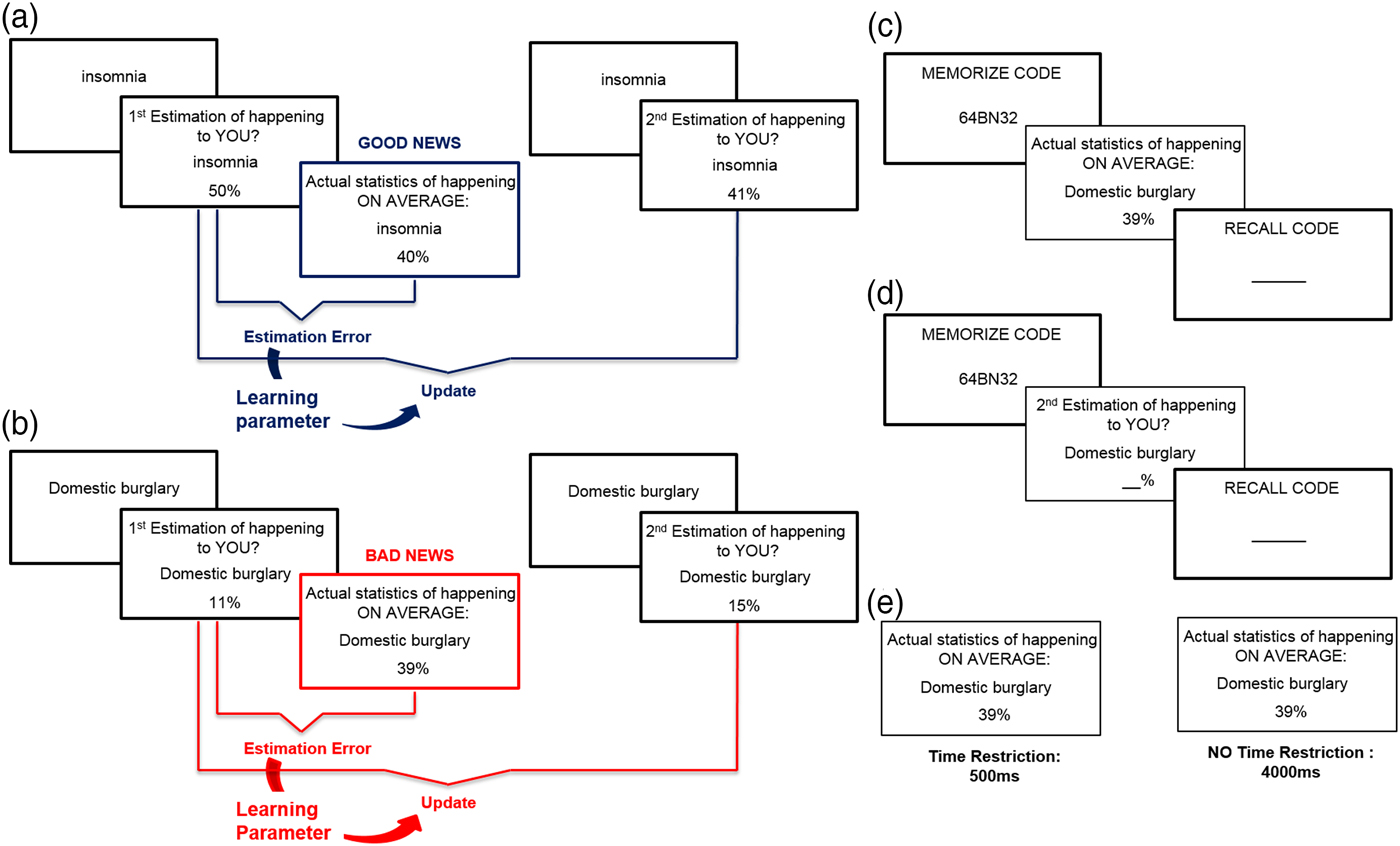
Cognitive load manipulation
To manipulate cognitive resources, participants performed a second task while processing the base rate. Participants were informed that they would complete the task with two different kinds of distraction, since we were interested in studying how people learn under distraction. In the cognitive load condition, participants memorised a password-like digit string (e.g., fA72B6) before the presentation of each base rate and recalled it immediately thereafter (e.g., see DeShon et al., Reference DeShon, Brown and Greenis1996; Conway & Gawronski, Reference Conway and Gawronski2013, for similar procedures). In order to ensure that participants were motivated to do so, we paid them an additional £2 if they correctly recalled at least 60% of passwords. All but one participant did so. On average, participants correctly remembered 88% (SD = 8%) of passwords. In the no load condition, participants saw the same digit strings as in the load condition, but were asked to ignore them.
In a second session immediately after the first, participants were asked again to provide estimates of their likelihood of encountering the same events, so that we could assess how they updated their estimates in response to the information presented. After participants finished the task, participants rated all stimuli on prior experience (for the question “Has this event happened to you before?” the responses ranged from 1 [never] to 6 [very often]), familiarity (for the question “Regardless if this event has happened to you before, how familiar do you feel it is to you from TV, friends, movies and so on?” the responses ranged from 1 [not at all familiar] to 6 [very familiar]) and negativity (for the question “How negative would this event be for you?” the responses ranged from 1 [not negative at all] to 6 [very negative]). To test memory for the information presented, subjects were asked at the end to provide the actual probability previously presented of each event. Data of the control variables from one participant were lost due to a computer crash.
Data analysis
Data analysis was equivalent to previous research (Sharot et al., Reference Sharot, Korn and Dolan2011, Reference Sharot, Guitart-Masip, Korn, Chowdhury and Dolan2012a, Reference Sharot, Kanai, Marston, Korn, Rees and Dolan2012b; Moutsiana et al., Reference Moutsiana, Garrett, Clarke, Lotto, Blakemore and Sharot2013; Chowdhury et al., Reference Chowdhury, Sharot, Wolfe, Düzel and Dolan2014; Garrett et al., Reference Garrett, Sharot, Faulkner, Korn, Roiser and Dolan2014). For each event, an estimation error term was calculated as the difference between participants’ first estimate and the corresponding base rate: estimation error = first estimation – base rate presented. Estimation errors were positive for overestimations and negative for underestimations. When participants initially overestimated the probability of the adverse event relative to the average probability, they received good news (i.e., the negative event is less likely to happen than estimated; Figure 1(a)). By contrast, when participants underestimated the probability of the event relative to the average probability, they received bad news (i.e., the negative event is more likely to happen than estimated; Figure 1(b)). Therefore, for each participant, trials were classified according to whether the participant initially overestimated or underestimated the probability of the event (i.e., according to whether estimation errors were positive or negative).
For each trial and each participant, we then estimated update as follows: good news update = first estimation – second estimation; bad news update = second estimation – first estimation. Thus, positive updates indicate a change towards the base rate and negative updates indicate a change away from the base rate. For each participant, we then averaged updates scores across trials for which good news was presented and separately for which bad news was presented. To test the strength of association between estimation errors and updates (i.e., learning parameter), Pearson correlation coefficients were calculated separately for good and bad news trials within each participant.
Results and discussion
Dual-task paradigms test the automaticity (efficiency or independence of deliberation) of the main task (here, the belief updating task) by letting participants simultaneously perform a second task (here, remembering passwords) (Moors & De Houwer, Reference Moors and De Houwer2006). If motivated belief updating is automatically achieved, then we should see no difference in the update bias between the cognitive load condition and the no load condition. However, if deliberation is needed in order to bias the updating, then we should see an update bias only in the no load condition, but not in the cognitive load condition.
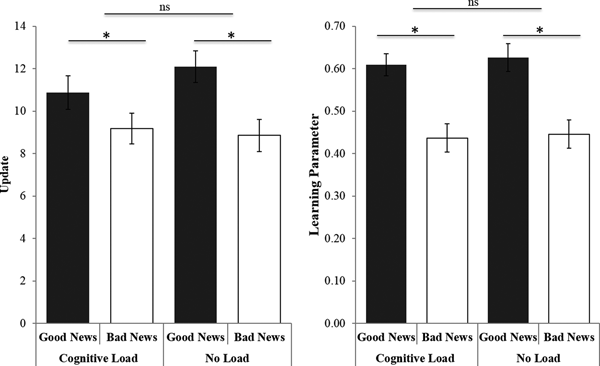
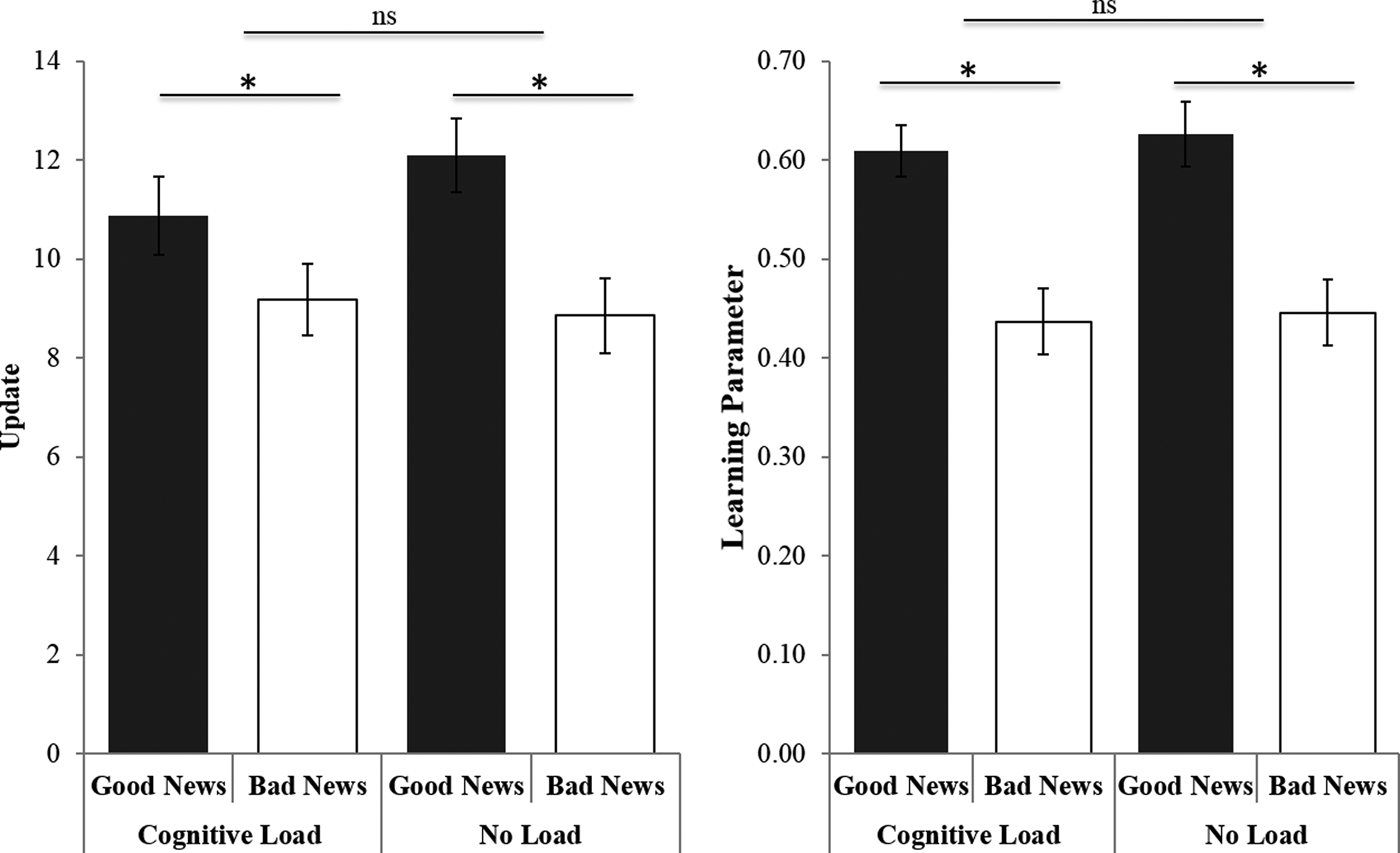
In order to test if motivated belief updating is automatic or deliberate, we entered update as the dependent variable into a repeated measure of analysis, and as independent variables the valence of the information (good versus bad news) and load manipulation (cognitive load versus no load) (Figure 2). We controlled for differences in estimation errors for good versus bad news in each condition to ensure that differences in learning for good versus bad news do not reflect differences in the initial estimates (i.e., prior beliefs) between conditions or mean estimation errors (Garrett & Sharot, Reference Garrett and Sharot2017). Note that we find the same results when not controlling for differences in estimation errors. First, we found a main effect for the load manipulation, F(1,46) = 6.59, p = 0.01, η2partial = 0.09. Participants updated less in the cognitive load condition (M = 8.35, SE = 0.62) compared to the no load condition (M = 10.23, SE = 0.58). The main effect indicates that our cognitive load manipulation was successful, reducing belief updating when a strain was put on the available cognitive resources.
Cognitive load did not affect valence-dependent asymmetric updating (left) nor asymmetric learning parameters (right). Participants updated their belief to a greater extent after receiving good news compared to bad news and had higher learning parameters. Error bars represent standard errors of the mean.
*p < 0.05. ns = non-significant.
As predicted, we found a main effect for valence, F(1,46) = 9.61, p = 0.003, η2partial = 0.17. Participants updated their beliefs more in response to good news (M = 10.71, SE = 0.76) than bad news (M = 7.87, SE = 0.66). Importantly, we did not find an interaction effect between condition and valence, F(1,46) = 0.17, p = 0.68, η2partial = 0.004. The effect size of η2partial = 0.004 for the interaction effect is well below a small effect (~η2partial = 0.02).
We repeated the same analysis using the learning parameter as the dependent variable. Again, we found a main effect for load, F(1,46) = 8.88, p = 0.005, η2partial = 0.16, showing that the learning parameter under load was significantly smaller (M = 0.39, SE = 0.037) than under no load (M = 0.50, SE = 0.033). Our manipulation effectively interfered with the relationship between the estimation error and the subsequent update. We additionally found the predicted effect of valence (good versus bad news), F(1,46) = 20.24, p < 0.0001, η2partial = 0.31; participants’ learning parameters were significantly stronger in response to good news (M = 0.54, SE = 0.35) than bad news (M = 0.36, SE = 0.03). Finally, as for update, we did not find a significant interaction effect of condition and valence on the learning parameter, F(1,46) = 0.08, p = 0.77, η2partial = 0.002. Again, the effect size was well below a small effect size, suggesting that such bias does not require deliberation.
Next, we tested whether the control variables (memory, vividness, experience, negativity and arousal) could explain either the main effect of valence and/or the main effect of load we observed. Only for participants’ memory did we find a main effect of valence, F(1,47) = 7.62, p = 0.008, η2partial = 0.13 and load F(1,47) = 6.37, p = 0.015, η2partial = 0.14. We then repeated the main analyses reported above, this time controlling for the differences in memory between good and bad news, as well as load versus no load. For belief update, we found that when controlling for difference in memory, the main effect of valence remained significant, F(1,45) = 5.81, p = 0.02, η2partial = 0.11, while the main effect of load disappeared, F(1,45) = 0.82, p = 0.37, η2partial = 0.01. For learning parameters, we again found that when controlling for difference in memory, the main effect of valence remained significant, F(1,45) = 8.81, p = 0.005, η2partial = 0.16, while the main effect of load disappeared, F(1,45) = 0.95, p = 0.335, η2partial = 0.021. These findings suggests that the cognitive load manipulation interfered with participants’ ability to successful encode the average information, but not with their bias.
One limitation of the presented analysis is that classic frequentist analyses (testing the significance of differences, for instance) does not provide evidence for a null effect, as we reported here. So, we complemented our results with Bayesian analyses, which can provide evidence in favour of the null hypothesis. In particular, we performed Bayesian t-tests for accepting or rejecting the null hypothesis, comparing the bias in updating and learning parameter under load versus no load to generate Bayes factors (BF10) (Rouder et al., Reference Rouder, Speckman, Sun, Morey and Iverson2009). We used JASP (Love et al., Reference Love, Selker, Marsman, Jamil, Verhagen and Ly2015). A BF10 greater than 1 provides evidence for rejecting the null hypothesis, a BF10 smaller than 1 provides evidence for the null hypothesis. When comparing the difference between update from good versus bad news when participants learned under cognitive load versus no cognitive load, we find BF10 = 0.192, suggesting substantial evidence for the null hypothesis (Rouder et al., Reference Rouder, Speckman, Sun, Morey and Iverson2009). Repeating the same analysis for the learning parameter produced a BF10 = 0.179, again providing substantial evidence for the null hypothesis.
In summary, we found evidence suggesting that the difference in updating from good and bad news does not require deliberation. In particular, while our load manipulation successfully affected learning – participants learned less under load than under no load as indicated by lower updates and learning parameters – it did not affect the bias towards good news. Participants in both conditions showed the same difference between learning from good versus bad news.
Experiment 2
Experiment 1 suggests that restricting cognitive resources at the time evidence is presented does not eliminate motivated belief updating. In Experiment 2, we ask whether cognitive load at the time participants entered their updated beliefs will affect their bias (see Figure 1(d)). We assumed belief updating occurs when evidence is presented, not when new estimates are elicited, and thus predicted no effect of the manipulation on belief updating. However, it is plausible that a process of rationalisation, which contributes to the update bias, occurs when people are asked to provide their new estimates. If this is the case, we should observe no bias and a reduced bias in belief updating under cognitive load.
Method
Participants and design
Power calculation
We assumed a potentially small difference between load and no-load manipulation (η2partial ~0.1). Using G*Power (Faul et al., Reference Faul, Erdfelder, Buchner and Lang2009), we estimated that for a power of 0.9, we would need about 60 participants, and we recruited 68 participants (23 male, 45, female, Mage = 23.02, SD = 4.51). The study was approved by the University College London Research Ethics Committee. Participants received £10 as a participation fee. We exclude 12 participants with a depression score on the BDI-II (Beck et al., Reference Beck, Steer, Ball and Ranieri1996) of 12 or higher, indicating moderate depression, as done previously (Moutsiana et al., Reference Moutsiana, Garrett, Clarke, Lotto, Blakemore and Sharot2013). The study had a within-subject design with valence of news (good versus bad) and cognitive load (no load versus load) as within-subject factors. Order of condition was random and did not affect the results.
Cognitive load manipulation
The belief updating task was the same one used in Experiment 1. However, this time we manipulated the availability of cognitive resources when participants were prompted to enter their updated beliefs (see Figure 1(d)). In the cognitive load condition, participants memorised a password-like digit string (e.g., fA72B6) before they re-entered their belief about the likelihood of the negative life event happening to them and recalled it immediately after.
Results and discussion
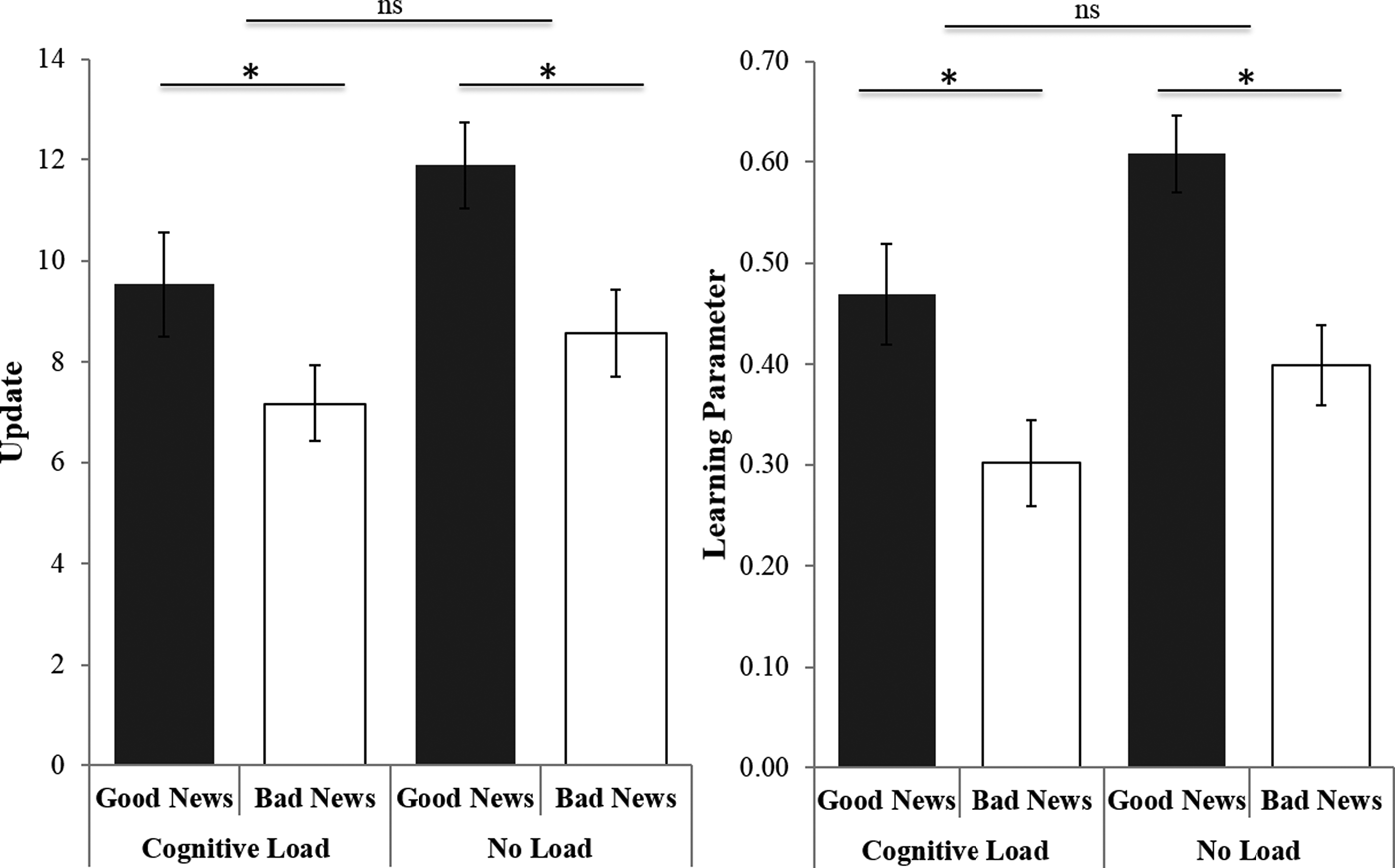
We entered update as the dependent variable into a repeated-measures analysis of variance (ANOVA), and as independent variables the valence of the information (good versus bad news) and manipulation (cognitive load versus no cognitive load) (Figure 3). Again, we controlled for differences in estimation errors for good versus bad news in each condition to ensure that differences in learning for good versus bad news did not reflect differences in the initial estimates (i.e., prior beliefs) between conditions or mean estimation errors (Garrett & Sharot, Reference Garrett and Sharot2017). We found a main effect for valence, F(1,52) = 8.24, p = 0.006, η2partial = 0.14. As expected, participants updated their beliefs more in response to good news (M = 11.49, SE = 0.64) than bad news (M = 9.02, SE = 0.62). As predicted, we did not find a main effect for the load manipulation, F(1,52) = 1.19, p = 0.28. Participants on average updated as much under cognitive load (M = 10.03, SE = 0.49) as under no load (M = 10.47, SE = 0.55). Given that the same cognitive load manipulation influenced learning when applied during the presentation of the new information, the lack of main effect here suggests that learning already took place before participants entered their second estimate. Finally, we did not find an interaction effect between condition and valence, F(1,52) = 0.70, p = 0.40, η2partial = 0.01. When repeating our analysis with learning parameter as the dependent variable, we found the same results. In particular, we found the expected main effect for valence, F(1,52) = 32.46, p < 0.001, η2partial = 0.38, no main effect for load manipulation, F(1,52) = 0.56, p = 0.46, and no interaction effect, F(1,52) = 0.003, p = 0.96.
Cognitive load manipulation did not affect updating (left) nor learning parameters (right) after receiving either good or bad news. Participants updated their belief to a greater extent following good news compared to bad news and had higher learning parameters. Error bars represent standard errors of the mean.
*p < 0.05. ns = non-significant.
Taken together, the findings of Experiments 1 and 2 suggest that learning took place when participants received new information. Furthermore, Experiment 1 suggests that the update bias does not require deliberation. In order to conceptually replicate our finding, we next used a time manipulation to restrain cognitive resources. Specifically, participants had either 0.5 s to process the information (i.e., time restriction) or 4 s (no time restriction).
Experiment 3: Asymmetric belief updating under time restriction
Method
Participants and design
Power calculation
We assumed a potentially small to medium difference between time restriction and no time restriction manipulation (η2partial ~0.2). Using G*Power (Faul et al., Reference Faul, Erdfelder, Buchner and Lang2009), we estimated that for an acceptable power of 0.8, we would need about 50 participants, and we recruited 55 participants (26 male, 29 female, Mage = 22.12, SD = 3.91). Participants received £10 as a participation fee. The study was approved by the University College London Research Ethics Committee. Three participants with a depression score of 12 or higher on the BDI-II (Beck et al., Reference Beck, Steer, Ball and Ranieri1996) indicating moderate depression were excluded. The study had a 2 × 2 within-subjects design with factors valence of news (good versus bad news) and time restriction (no time restriction versus time restriction). Condition order was random and did not affect the results.
Time restriction manipulation
The belief updating task had the same structure as in Experiment 1. However, this time, we manipulated the time participants had to process the evidence (e.g., see Suter & Hertwig, Reference Suter and Hertwig2011; Rand et al., Reference Rand, Greene and Nowak2012, for similar manipulations). In particular, in the time restriction condition, participants were presented with the information for only 0.5 s. Such a limited amount of time is not sufficient for conscious deliberation (Suter & Hertwig, Reference Suter and Hertwig2011). In contrast, in the no time restriction condition, participants were presented with the information for 4 s. This is an equal duration to that in Experiment 1 and allows conscious deliberation.
Results and discussion
Time restriction manipulations are based on a similar assumption as dual-task manipulations. Under time restriction, participants do not have enough cognitive resources available to deliberate and hence, if asymmetric belief updating is dependent on such deliberation, it should disappear. However, if asymmetric belief updating is automatic, we should find no difference between the time restriction and the no time restriction conditions.
We entered update as the dependent variable into a repeated-measures ANOVA, and as independent variables the valence of the information (good versus bad news) and time manipulation (time restriction versus no time restriction) (Figure 4). Again, we controlled for differences in estimation errors for good versus bad news in each condition to ensure that differences in learning for good versus bad news did not reflect differences in the initial estimates (i.e., prior beliefs) between conditions or mean estimation errors (Garrett & Sharot, Reference Garrett and Sharot2017). First, we found a main effect for time manipulation, F(1,49) = 4.76, p = 0.034, η2partial = 0.09. Participants on average updated less in the time restriction condition (M = 9.7, SE = 0.62) compared to the no time restriction condition (M = 10.98, SE = 0.53). The main effect indicates that our time restriction manipulation was successful, reducing learning when time reduced available cognitive resources. We also found a main effect for valence, F(1,49) = 4.36, p = 0.042, η2partial = 0.14. As expected, participants updated their beliefs more in response to good news (M = 12.01, SE = 0.79) than bad news (M = 8.67, SE = 1.06). Importantly, we again did not find an interaction effect between condition and valence, F(1,49) = 0.04, p = 0.83, η2partial = 0.001. The effect size is well below a small effect, indicating a lack of effect.
The time restriction manipulation did not affect the difference between updating (left) in response to good news versus bad news nor the difference in learning parameters (right). Participants updated their beliefs to a greater extent in response to good news versus bad news and had higher learning parameters. Error bars represent standard errors of the mean.
*p < 0.05. ns = non-significant.
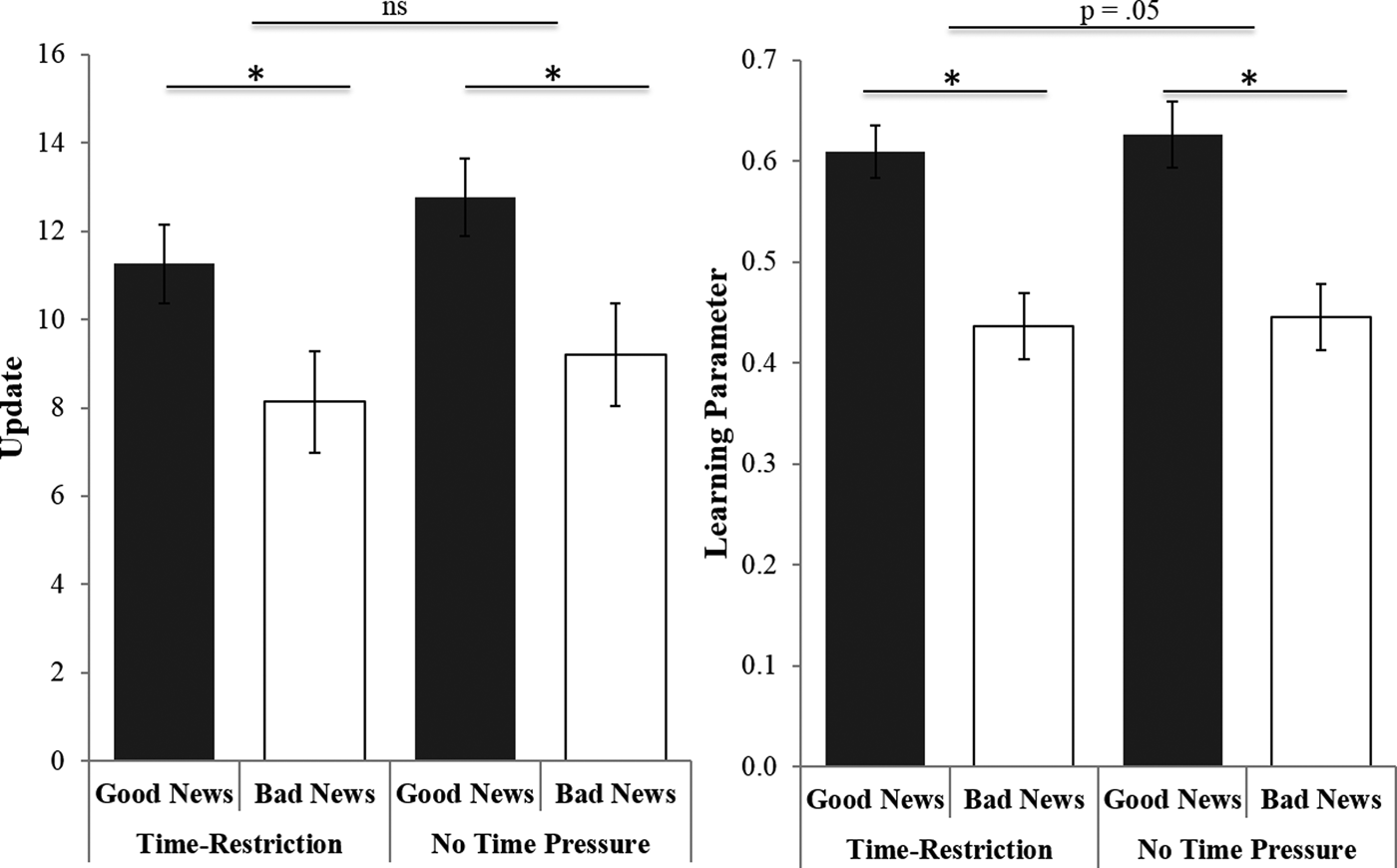
We repeated the same analysis, this time using the learning parameter as the dependent variable. Again, we found the main effect of valence, F(1,49) = 25.52, p < 0.0001, η2partial = 0.32, showing that the learning parameter related to positive news was significantly larger (M = 0.56, SE = 0.029) than the one related to negative news (M = 0.39, SE = 0.029). However, we did not find a main effect for the time manipulation, F(1,49) = 0.55, p = 0.46, η2partial = 0.01. Here, there was an interaction effect between valence and time manipulation, F(1,49) = 4.24, η2partial = 0.08. However, in contradiction to a deliberative account of the update bias, the difference between the learning parameters from good and bad news was more pronounced under time restriction (Mdiff = 0.22) than under no time restriction (Mdiff = 0.11). However, given that we did not find the same interaction effect between valence and condition for update, and nor did we find such an interaction effect in Experiment 1, this result must be interpreted cautiously.
We then used Bayesian statistics to find support in favour of the hypothesis of an automatic learning bias. When comparing the difference between updating from good versus bad news under time restriction with the difference under no time restriction, we found a BF10 = 0.16, suggesting substantial evidence for the null hypothesis.
General discussion
We set out to test whether motivated belief updating is dependent on deliberation. Using two methods for limiting controlled processing – cognitive load and time manipulation – we found evidence that deliberation is not required for a bias to emerge by which people update their belief more in response to good news than bad news. In particular, while our manipulations reduced the amount by which beliefs were updated, suggesting that cognitive resources were successfully restricted, they did not influence the bias. This suggests that discounting bad news can occur automatically when cognitive resources are limited and ability to reason is restricted. Our findings also suggest that belief updating takes place when evidence is presented rather than at a later stage. In particular, belief updating was impaired when cognitive resources were restricted at the time evidence was presented, but not at the time the new belief was elicited.
Our results support the suggestion that motivated cognition might be driven by automatic rather than deliberate processes (e.g., Sunstein, Reference Sunstein2005b; Weber, Reference Weber2006; Taber & Lodge, Reference Taber and Lodge2016). However, it is important to note that we examined only one paradigm, looking specifically at beliefs regarding negative life events. It is possible that deliberation does play a role in other situations (Hamilton et al., Reference Hamilton, Cutler and Schaefer2012; Kahan et al., Reference Kahan, Peters, Dawson and Slovic2017). Our study highlights that in order to claim as much, cognitive resources need to be manipulated.
An automatic failure to integrate bad news relative to good news into one's beliefs could be an innate tendency, potentially reflecting an evolutionary advantage (Haselton & Nettle, Reference Haselton and Nettle2006; McKay & Dennett, Reference McKay and Dennett2009; Johnson & Fowler, Reference Johnson and Fowler2011). Maintaining positively skewed beliefs about oneself and one's future has utility for the individual, reducing stress and contributing positively to physical and mental health (Taylor & Brown, Reference Taylor and Brown1988; Taylor et al., Reference Taylor, Kemeny, Reed, Bower and Gruenewald2000; Hernandez et al., Reference Hernandez, Kershaw, Siddique, Boehm, Kubzansky, Diez-Roux and Lloyd-Jones2015). In addition, having an overly positive self-view may help convince others of one's value (Smith et al., Reference Smith, Trivers and von Hippel2017). Similarly, evolutionary computational models suggest that being overly optimistic about one's own capabilities helps to outdo the competition in environments where the rewards of winning resources (e.g., food or mating partners) outweigh the potential costs of competing (Johnson & Fowler, Reference Johnson and Fowler2011).
Yet, even if motivated updating of beliefs provides an advantage to the individual, automatic processes do not have to be innate, but rather the result of a learning process (Dolan & Dayan, Reference Dolan and Dayan2013). With respect to neglecting bad news, children might have been rewarded for thinking positively about themselves and their future from an early age and discouraged from a pessimistic, self-critical worldview (Carver & Scheier, Reference Carver and Scheier2014). Parental instruction and praise might have established an automatic habit of rejecting bad news. A learned rejection of bad news would help explain why people in cultures that reward a self-critical focus lack positively skewed self-beliefs (Heine et al., Reference Heine, Lehman, Markus and Kitayama1999). More research is needed to test whether the automatic tendency to dismiss bad news is innate, overlearned or a combination of both.