


Policy Significance Statement
This research demonstrates that there is a preference for public over private sector provisioning of AI in high-stakes social impact applications among key stakeholders in the Indian AI ecosystem. Technologists in particular are likely to show greater support for the public sector across contexts. Of the different contexts, there is the greatest overall support for AI tools for health care and the least support for judicial applications. Our study has important implications for the social acceptability of public sector expansion of such AI systems in India.
1. Introduction
Both public and private entities in India have been expeditiously adopting Artificial Intelligence (AI) deployments in a variety of contexts, including high-stakes decisions like personal finance, policing, and healthcare, spurred by a nation-wide push toward “AI Sovereignty” (Panday and Samdub, Reference Panday and Samdub2024). In particular, large-scale public sector projects employing algorithmic systems are being run in partnership with private sector entities like IT companies. While heavy investments in these ambitious projects carry on, there is a need for investigating if attitudes toward algorithmic systems are affected by whether a public or private entity develops and/or deploys these systems.
There is by now a burgeoning literature on the intersection between AI and Society in India, investigating the incorporation of AI tools in different social contexts, such as the use of LLMs in legal tasks (Tripathi et al., Reference Tripathi, Donakanti, Girhepuje, Kavathekar, Vedula, Krishnan, Goyal, Goel, Ravindran and Kumaraguru2024), healthcare in rural communities (Okolo et al., Reference Okolo, Agarwal, Dell and Vashistha2024), and predictive policing systems (Marda and Narayan, Reference Marda and Narayan2020). The accuracy of non-traditional data collection techniques has also been investigated, for example, bandit algorithms for healthcare work (Verma et al., Reference Verma, Mate, Wang, Madhiwalla, Hegde, Taneja and Tambe2023), crowdsourcing for safety mapping (Sengupta et al., Reference Sengupta, Vaidya and Evans2023a), and deep learning for economic status estimation (Dar et al., Reference Dar, Sengupta and Arora2024; Daoud et al., Reference Daoud, Jordán, Sharma, Johansson, Dubhashi, Paul and Banerjee2023).
There is relatively less literature from India on attitudes toward such systems (Sengupta et al., Reference Sengupta, Subramanian, Mukhopadhyay and Scaria2023b) with such studies mostly based in countries in Europe, UK and the US (Kozyreva et al. Reference Kozyreva, Lorenz-Spreen, Hertwig, Lewandowsky and Herzog2021; Grassini and Ree, Reference Grassini and Ree2023). The acceptance of AI systems may be affected by the context within which they are embedded (Wenzelburger et al., Reference Wenzelburger, König, Felfeli and Achtziger2022; Brown et al., Reference Brown, Davidovic and Hasan2021) and by the nature of the task (Ingrams et al., Reference Ingrams, Kaufmann and Jacobs2022). Studies conducted in the Global North also highlight the discomfort with AI adoption in applications like criminal risk assessment and credit scoring (Garcia et al., Reference Garcia, Garcia and Rigobon2024; Bruckner, Reference Bruckner2019; Smith, Reference Smith2018) and differing trust levels within sub-groups, especially marginalized groups (Lee and Rich, Reference Lee and Rich2021). Nascent literature from India indicates that such findings of context-specific mistrust do not generalize to India (Kapania et al., Reference Kapania, Siy, Clapper, Azhagu Meena and Sambasivan2022; Sambasivan et al., Reference Sambasivan, Arnesen, Hutchinson, Doshi and Prabhakaran2021). There is also evidence of widespread acceptability of AI by the general public in India, which authors conceptualize as aspirational and techno-optimistic (Pal, Reference Pal2012; Sambasivan et al., Reference Sambasivan, Arnesen, Hutchinson, Doshi and Prabhakaran2021).
Via this article, we contribute to the burgeoning literature on AI attitudes in India by investigating whether attitudes are affected by the source of the AI system development and/or deployed, namely the public or private sector. To do so, we conduct a series of vignette experiments to estimate differences in attitudes across a variety of hypothetical contexts in contemporary India. In each vignette the source of the AI technology, that is, the public or the private sector is randomly varied and average support is estimated to provide a causal estimate of the source of provisioning.
Participants in the experiment consist of 192 students recruited from two leading technology and law institutions in India. Both institutes consistently rank in the top three positions in the country’s National Institutional Ranking Framework and produce a steady stream of leading professionals in India’s technology and legal sectors. Both institutions have also produced illustrious alumni who have often had outsize influence in setting the business and policy landscape of the nation. These domain specialists are distinct from the general public and are likely to have a more nuanced understanding of the processes and stakes involved in the AI application, as has been demonstrated in previous literature (O’Shaughnessy et al., Reference O’Shaughnessy, Schiff, Varshney, Rozell and Davenport2023). Our choice is motivated by Tomsett et al. (Reference Tomsett, Braines, Harborne, Preece and Chakraborty2018) who theorize six different roles within an AI ecosystem with creators (corresponding to our sample of technology students) and examiners (corresponding to our sample of law students) at two ends of the ecosystem.
The experiment is designed to address the following three research questions:
-
1. How do attitudes differ based on the source of algorithm development/deployment?
-
2. How do these attitudes differ based on the context and objectives of employing algorithmic tools?
-
3. How do these attitudes differ based on the disciplinary background of the respondents?
Our results demonstrate the following: (1) there is an overall preference for AI tools to be developed and/or deployed by the public sector over the private sector in high-stakes social contexts; (2) support for AI tools in general is significantly lower amongst law students; (3) in some contexts such as judicial applications and content moderation there is apprehension against AI tools and (4) significant associations exist between AI attitudes and respondents’ religious and caste characteristics.
We consider the introduction of the novel set of stakeholders—namely, lawyers—as a particularly important contribution of our article, because the use of AI challenges the traditional application of law by complicating the definition of a legal subject and the function of rule-making under the rule of law requirements (De Lucia Dahlbeck, Reference De Lucia Dahlbeck2022). Within the Indian context, the growing interest in the use of AI tools within the legal community may be attributed to the mounting pendency of cases in the judiciary leading to judicial delays in the adjudication of cases (Aithala et al., Reference Aithala, Sachan, Sen, Payal and Bhattacharya2024; Aithala et al., Reference Aithala, Sudheer and Sengupta2021). This has contributed in popularizing the perception that the adoption of AI can plug in gaps related to inefficiency, enhance productivity and support in tasks related to case management, thereby expediting the judicial process (Joshi et al., Reference Joshi, Mathur, Koranga and Singh2023). Legal and constitutional acceptability, especially in the context of the uptick in public–private partnerships for the deployment of algorithmic systems, also demands that AI-assisted decisions adhere to long-evolved administrative law norms such as non-arbitrariness, reasonableness, and proportionality, which are rooted in the Indian constitution itself (Garrett, Reference Garrett2025; Prasanna, Reference Prasanna2023). However, the lack of codified legislation in the field of AI is a serious limitation when it comes to erecting proper guardrails for regulating the proper development and deployment of AI systems in the Indian context [Sayyed Reference Sayyed2024]. Even the Digital Personal Data Protection Act, India’s first comprehensive data protection law, which was codified after multiple iterations, lacks provisions to address the risks stemming from the wholesale use of AI in diverse applications and across different sectors.
To our knowledge, ours is the first study in the Indian context exploring the effect of public vs private sector deployment on attitudes toward AI. Previous literature on this topic has been set in economically advanced nations like the United States (Smith, Reference Smith2019) and Singapore (Ballantyne et al., Reference Ballantyne, Lysaght, Toh, Ong, Lau, Owen Schaefer, Xafis, Tai, Newson, Carter, Degeling and Braunack-Mayer2022). The results of our inceptive study become critically important when coupled with past findings of the Indian public exhibiting heightened propensities toward AI aspiration and giving into AI authority (Kapania et al., Reference Kapania, Siy, Clapper, Azhagu Meena and Sambasivan2022) as well as the pervasive application of AI systems in the Indian public administration ecosystem. Our main result on overall preference for public sector provisioning of AI tools implies potentially higher social acceptability of public sector expansion of such AI systems. We stress however that our work is an initial contribution to this topic and that there is an urgent need for more scholarship empirically exploring public vs private provisioning of AI systems for large-scale social applications in India across a richer set of stakeholders and contexts.
The rest of the article is organized as follows. Section 2 reviews the related literature. Section 3 and 4 present our research methodology and results respectively. Section 5 provides an overview discussion and Section 6 concludes.
2. Related literature
2.1. AI stakeholders: domain-specialists and general public
A key component of emerging literature on AI explainability and AI accountability addresses the importance of identifying distinct communities that are part of the AI ecosystem. These distinct sets of stakeholders are expected to have distinct attitudes toward AI deployment and therefore need to be considered separately. We follow Tomsett et al. (Reference Tomsett, Braines, Harborne, Preece and Chakraborty2018) who define six different types of agents in an AI ecosystem: creators, operators, executors, decision-subjects, data-subjects and examiners.
Preece et al. (Reference Preece, Harborne, Braines, Tomsett and Chakraborty2018) further identify four broad sets of stakeholders that the six roles are distributed across: developers, theorists, ethicists and users. Technologists are likely to predominantly be part of the developer communities (although they will also be represented in the theorist and ethicist communities) whereas lawyers are likely to play an outsize role within the ethicist community. We refer to members of these communities as “domain-specialists,” in contrast with the community of users who are part of the “general public” that is directly impacted by the systems. Research from the US indicates that experts in technical domains tend to be more tolerant of risk from new technologies arising in their domains and this has been validated for experts of algorithmic technologies (O’Shaughnessy et al., Reference O’Shaughnessy, Schiff, Varshney, Rozell and Davenport2023). Trained specialists or experts hold nuanced opinions depending on the policy-domain in question in comparison with the public whose attitudes were found to be uniform across domains (Belfield, Reference Belfield2020).
While previous scholarship (O’Shaughnessy et al., Reference O’Shaughnessy, Schiff, Varshney, Rozell and Davenport2023) has equated undergraduate students in technology with experts, we prefer to refer to them as “domain-specialists” instead. Our work extends the literature on AI attitudes and specialized domain knowledge by a) bringing it to the Indian context and b) extending it to a set of stakeholders, that is, lawyers, whose attitudes have not been hitherto examined in this context.
By focusing on technology and law students from elite institutes we narrow down on the two extremes of creators vs examiners. India’s higher education ecosystem is highly unequal and dominated by a few institutes. Both institutes in our study have consistently ranked in the top 3 positions in the country’s National Institutional Ranking Framework and produce a steady stream of leading professionals in India’s technology and legal sectors. Both institutions have also produced illustrious alumni who have often had outsize influence in setting the business and policy landscape of the nation. Thus these sets of students will form a considerable part of the pool from which the next generation of developers and regulators in the Indian AI ecosystem will emerge.
2.2. Public vs private sector deployment of algorithmic systems
While there is widespread adoption in public sector functions (Busuioc, Reference Busuioc2021, the stages of problem definition, data collation and deployment may not occur entirely in-house leading to potential blurring of the boundaries between public and private sector functions (Nissenbaum, Reference Nissenbaum2021, Levy et al., Reference Levy, Chasalow and Riley2021). However both the priorities and accountability structures of public and private sector entities differ substantially. Public sector is often associated with normative values like benevolence and service along with low efficiency and red tape, whereas the private-sector is perceived as performing positively on productivity related aspects such as efficiency (Hvidman and Andersen, Reference Hvidman and Andersen2016). The use of algorithmic systems in applications like healthcare and criminal law (Scaria et al., Reference Scaria, Subramanian, George and Sengupta2024) have been met with more skepticism in the hands of private entities as opposed to its adoption by the government in geographies like the US (Smith, Reference Smith2019) and Singapore (Ballantyne et al., Reference Ballantyne, Lysaght, Toh, Ong, Lau, Owen Schaefer, Xafis, Tai, Newson, Carter, Degeling and Braunack-Mayer2022). Concerns around data sharing in particular may be elevated when private companies get access to public sector data (Xafis, Reference Xafis2015; Hartman et al., Reference Hartman, Kennedy, Steedman and Jones2020).
There is an extended body of literature unraveling questions on private vs public ownership of algorithmic systems and the corresponding shift in public attitudes (Hill et al., Reference Hill, Turner, Martin and Donovan2013; Xafis, Reference Xafis2015). Scholars have also examined the effect on opinions of governmental performance with the intervention of private organizations (Walker et al., Reference Walker, Brewer, Barry Bozeman and Wu2013). Here too, the scholarly engagement is predominantly from the Global North, despite the topic being particularly relevant for like India where the government sees it as a strategic imperative to deploy and adopt algorithmic systems for public administration, a gap this study addresses.
2.3. AI authority
Preliminary empirical evidence on AI attitudes from India highlights a marked deviation from western economies. In cross-country public perception surveys, participants from the Global North tend to have mixed expectations on the social impact of AI and support the need for responsible AI frameworks, amidst concerns of privacy, fairness and usefulness (Kozyreva et al., Reference Kozyreva, Lorenz-Spreen, Hertwig, Lewandowsky and Herzog2021; Kelley et al., Reference Kelley, Yang, Heldreth, Moessner, Sedley, Kramm, Newman and Woodruff2021). Participants from countries including India, Brazil and China were found to repose higher degrees of trust in the AI systems compared to their western counterparts (Gillespie et al., Reference Gillespie, Lockey, Curtis, Pool and Ali2023a). Respondents based in India exhibit greater confidence in their government in the development, usage and governance of AI (Gillespie et al., Reference Gillespie, Lockey, Curtis and Pool2023b). While earlier research conceptualized these divergent attitudes to technology as aspirational (Pal, Reference Pal2012), Kapania et al. (Reference Kapania, Siy, Clapper, Azhagu Meena and Sambasivan2022) find indications of a potential case of “AI authority” in India indicating a propensity for accepting algorithmic decision-making even when there is inadequate proof regarding the capabilities of the systems. Indian participants, demonstrate high levels of acceptance for AI outputs even for high-stakes decision making, often viewing AI as inherently reliable and infallible (Kapania et al., Reference Kapania, Siy, Clapper, Azhagu Meena and Sambasivan2022).
Our study differs from Kapania et al. (Reference Kapania, Siy, Clapper, Azhagu Meena and Sambasivan2022) in three important ways. First, we consider the specific (and critical) nuance of public vs private provisioning of AI systems. Second, in doing so we choose a causal experimentation design via vignettes as opposed to a standard survey that can provide distributional insights only. Third, we move beyond general public attitudes and focus on two specific subgroups of technology and law students, that are expected to have large variation in their attitudes and are also likely to contribute to the pool of stakeholders in India’s future AI policy ecosystem.
3. Methodology
Our vignette experiment consisted of a survey where respondent attitudes were elicited through a set of 6 vignettes covering a range of high-stakes application scenarios. A single factor was randomly varied across participants: whether the algorithm is developed and/or deployed by the public or private sector. We refer to participants receiving the two types of surveys as the “private” and “public” groups respectively. Comparing the two groups leads to an internally valid estimate of the causal effect of the factor (i.e. source of algorithm) since it is randomly varied and all else is kept constant. Survey-based experiments, such as the vignette experiment, have received a lot of interest in recent years (Steiner et al., Reference Steiner, Atzmüller and Su2016; Liebe et al., Reference Liebe, Moumouni, Bigler, Ingabire and Bieri2017) due to their ability to isolate effects of a single attribute of interest. Much of the application of vignette experiments too has concentrated on the Global North with a handful of exceptions in India, conducted primarily in rural settings (Banerjee et al., Reference Banerjee, Green, McManus and Pande2014; Masset, Reference Masset2015). Vignette experiments have also been successfully utilized for studying AI attitudes (Nussberger et al., Reference Nussberger, Lan Luo and Crockett2022; Ingrams et al., Reference Ingrams, Kaufmann and Jacobs2022) and have been relied upon to provide insights on the question of private provisioning of public goods (Walker et al., Reference Walker, Brewer, Barry Bozeman and Wu2013; Hattke and Kalucza, Reference Hattke and Kalucza2019; van den Bekerom et al., Reference Van den Bekerom, Van der Voet and Christensen2021). Our article applies vignette experiments to a novel population of law and technology students in India as well as adds to the limited literature on the use of vignette experiments to estimate public vs private provisioning of AI based solutions.
3.1. Sample size and respondents
Respondents in our study were recruited from each of the two institutions via institute-wide emails soliciting interest in participation. Based on previous experiences in conducting institute-wide studies, with low student participation rates, we were conservative when calculating a feasible sample size. Setting confidence at 90%, margin of error at 8%, and considering expected response rates and total population sizes at the technology and law institutes, our target sample sizes were 103 and 96 respectively. Our final dataset consists of 192 students across the technology (108) and law (84) institutes respectively, corresponding to a slightly lower than target margin of error (~7.8%) for the technology students and a slightly higher than margin of error (~8.5%) for the law students.
The survey was administered in a large lecture hall at each institute. Only a single session was held at each institute to avoid any spillover effects. Each respondent was asked to complete a single paper survey where the private vs public group assignment was randomly distributed. Group assignment was masked. Project staff and volunteers walked around the lecture hall to ensure that no participant communicated with others while filling the survey. The choice to run the survey on paper was taken to avoid any spillover or crossover effects of the treatment that may arise from students communicating with each other via chat or email. This also allowed us to control for any additional web-browsing that may inform participant responses. Participants filled in their responses after signing informed consent sheets prior to the survey. The average completion time of the survey was approximately 20 minutes with the maximum completion time being 30 minutes. Participants received an honorarium of INR 300 per head (approximately USD 4) as a token of appreciation via electronic bank transfers from the project team. Participation in the survey was voluntary and participants could choose to not respond and/or quit the survey at any point without any repercussions.
All participants in our sample were 18 years of age or older. Of the 108 technology students, 54 were randomly assigned to the “private” group and the remaining 54 to the “public” group. Of the 84 law students 40 were randomly assigned to the “private” group and the remaining 44 to the “public” group. Project staff entered the survey data onto a google drive which could only be accessed by them. Each survey’s data entry was fully anonymized and carried out by two members of the project team independently and finalized only if both entries matched exactly.
3.2. Vignette experiment design
The first section of the survey collected socio-demographic characteristics including age, gender, religion, caste group and hometown. Information was also elicited regarding whether the participant had previously taken a course in data science or related subject to control for familiarity of the subject matter. The second section consisted of a set of vignettes.
Each vignette was between 130 to 180 words long and introduced a social issue, followed by an AI solution along with its potential benefits and risks. The vignettes covered six hypothetical high-stakes contexts of large-scale AI tools rollout in India: (i) Facial Recognition Technology (FRT) for preventing ATM thefts, (ii) machine learning for skin cancer detection, (iii) Large Language Models or LLMs for assisting in judicial decision making, (iv) FRT for metro rail ticket evasion, (v) content moderation algorithms for filtering hate speech by Internet Service Providers or ISPs (vi) Risk Assessment Tools or RATs to assist with bail decisions. Each page consisted of a single vignette. Respondents read the vignettes and then reported their attitudes to the use of AI in that context on a 5-point Likert scale coded as follows: Strongly Oppose (Reference Aithala, Sachan, Sen, Payal and Bhattacharya1), Oppose (2), Neutral (3), Support (4) and Strongly Support (5). Participants were also given space on each page to provide a justification for their rating.
A single factor was varied between the surveys for respondents belonging to the “public” vs “private” groups—whether the algorithm was deployed and/or developed by the public or the private sector. In 3 contexts (FRT in ATMs, Cancer-screening and FRT in Metro) both deployment and development were described as done by either the public or the private sector. In 2 contexts (LLM and RAT use in high courts), only the development of the AI tool was done by the public vs private sector since realistic deployment had to be restricted to a public sector context, that is, high court. In 1 context (content moderation of ISPs) only the development of the AI tool was done by the public vs private sector since the vast majority of internet users in India (~ 97%) subscribe to private ISPs so public sector deployment would not be perceived as realistic. The final data consisted of 4 subgroups—technology students assigned to the “public” group, technology students assigned to the “private” group, law students assigned to the “public” group and law students assigned to the “private” group.
The order in which the vignettes were presented to all respondents was kept fixed. This was done consciously to maintain the integrity of the data and avoid potential data entry errors—given that each survey was manually entered onto worksheets. We gave priority to the design element of doing the surveys offline and in-person, as well as ensuring data quality. While this decision may introduce order effects into any direct comparisons on mean ratings across contexts, our key interest, that is, effect of public vs private provisioning within each context is still valid since each context is still an internally valid experiment given that all respondents see the exact same set of contexts before responding to that specific context. Between every pair of experimental vignettes, we also provided one distraction vignette which presented a non-AI technological tool within a socially-relevant context. Unscored and (slightly) differing distractors scattered between vignettes of experimental interest have been proven to be effective at deterring participants from capturing the experimental intent (Burstin et al., Reference Burstin, Doughtie and Raphaeli1980). Our distractor vignettes were worded and placed optimally such that they served as deterrents while preserving internal validity. During our pilot surveys we confirmed the efficiency of these distractors by analyzing volunteers’ self-reported understanding of the aims of the experiment after participation. Our study design was approved by ethics committees in both participating institutions. Extensive pilot studies were conducted to arrive at the apt vignettes. All vignettes are available in the supplementary material of the article.
3.3. Analysis
Covariate balance checks, available in the supplementary material, indicate that the randomization across treatment was. Thus, any difference in the means of the ratings across the groups can be attributed to whether respondents were assigned to the public or the private group. We present summary statistics of mean attitude ratings along with t-tests and Mann Whitney tests to verify if the differences between the “public” and “private” groups is statistically significant.
Standard multivariate linear regressions are then carried out on the pooled sample of respondents to isolate the main treatment effect of getting assigned the “private” group compared with being assigned the “public” group. By controlling for other variables, these regressions allow us to comment on associations between attitudes and other demographic factors like religion, caste, and gender. For each context the basic regression specification is as follows:
 $$ Ratin{g}_i={\beta}_0+\tau\;Privat{e}_i+\gamma Institute. La{w}_i+{\sum}_j{\beta}_j\;{X}_{ij}+{\varepsilon}_i $$
$$ Ratin{g}_i={\beta}_0+\tau\;Privat{e}_i+\gamma Institute. La{w}_i+{\sum}_j{\beta}_j\;{X}_{ij}+{\varepsilon}_i $$
where
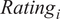 $ Ratin{g}_i $
is individual i’s level of support for the use of the algorithm,
$ Ratin{g}_i $
is individual i’s level of support for the use of the algorithm,
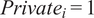 $ Privat{e}_i=1 $
if individual i is assigned to the “private” group,
$ Privat{e}_i=1 $
if individual i is assigned to the “private” group,
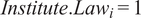 $ Institute. La{w}_i=1 $
if the respondent is enrolled at the law institute and
$ Institute. La{w}_i=1 $
if the respondent is enrolled at the law institute and
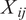 $ {X}_{ij} $
is the value of the control
$ {X}_{ij} $
is the value of the control
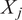 $ {X}_j $
for individual i. Our main parameter of interest is
$ {X}_j $
for individual i. Our main parameter of interest is
 $ \tau \hskip0.24em $
which estimates the causal effect of private sector provisioning of the algorithm. Since group assignment is random, we can isolate the causal effect of private sector provisioning across the different.
$ \tau \hskip0.24em $
which estimates the causal effect of private sector provisioning of the algorithm. Since group assignment is random, we can isolate the causal effect of private sector provisioning across the different.
A unique feature of our dataset is that alongside the ratings, we also collected a set of justifications in the form of comments from participants. We elicited 259 total comments from law students and 127 total comments from technology students. All vignettes and comments were in English, and analysis was also conducted in the same language via a systematic approach. Following Kapania et al. (Reference Kapania, Siy, Clapper, Azhagu Meena and Sambasivan2022), we began by open coding instantiations of perceptions and assumptions of AI. An inductive coding approach was adopted to allow themes to emerge directly from the data. A subset of these themes overlapping with our quantitative analysis is presented alongside the main regression results where they provide insights into the quantitative estimates.
4. Results
Table 1 presents mean attitude ratings for AI tools across each of the 6 contexts and 4 sub-groups, along with associated differences between the “public” and “private” groups in both institutes. Statistically significant differences are highlighted. Figure 1 is a visual representation of the same information with technology students assigned to the “public” group (panel A), technology students assigned to the “private” group (panel B), law students assigned to the “public” group (panel C) and law students assigned to the “private” group (panel D). The horizontal axis represents the ratings on the Likert scale (with 5 corresponding to “Strongly support”) and the vertical axis represents the different contexts. The dashed vertical lines in the plots correspond to a level of “3” on the Likert scale indicating a neutral mean response.
Summary of mean ratings and proportions supporting by sub-groups and contexts
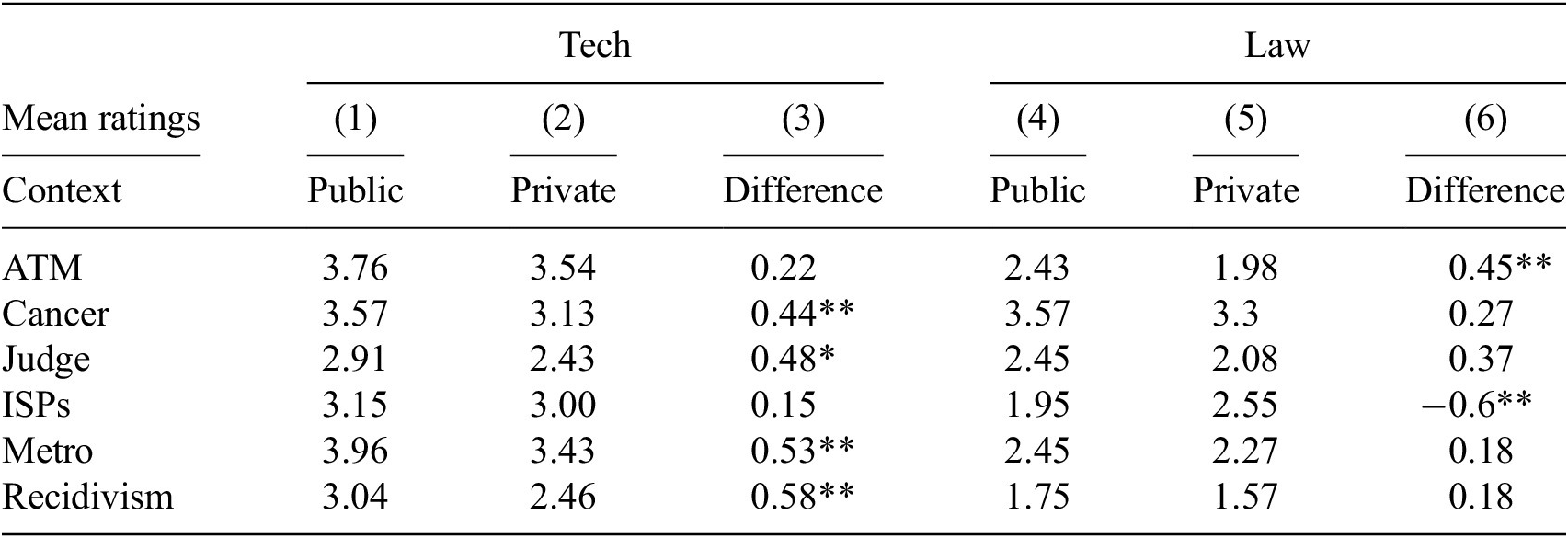
Table 1. Long description
The table has six context rows: ATM, Cancer, Judge, ISPs, Metro, and Recidivism. For each, Tech and Law columns are grouped into Public, Private, and Difference. ATM: Tech Public 3.76, Private 3.54, Difference 0.22; Law Public 2.43, Private 1.98, Difference 0.45 double asterisk. Cancer: Tech Public 3.57, Private 3.13, Difference 0.44 double asterisk; Law Public 3.57, Private 3.3, Difference 0.27. Judge: Tech Public 2.91, Private 2.43, Difference 0.48 single asterisk; Law Public 2.45, Private 2.08, Difference 0.37. ISPs: Tech Public 3.15, Private 3.00, Difference 0.15; Law Public 1.95, Private 2.55, Difference negative 0.6 double asterisk. Metro: Tech Public 3.96, Private 3.43, Difference 0.53 double asterisk; Law Public 2.45, Private 2.27, Difference 0.18. Recidivism: Tech Public 3.04, Private 2.46, Difference 0.58 double asterisk; Law Public 1.75, Private 1.57, Difference 0.18. Asterisks indicate significance: single asterisk p less than 0.1, double asterisk p less than 0.05, triple asterisk p less than 0.01.
Note: *p < 0.1; **p < 0.05; ***p < 0.01
Mean ratings (with 95% confidence intervals) from the 4 study sub-groups: technology students in public and private (Panels A and B) and law students in public and private groups (Panels C and D). Respondent ratings for six contexts are shown on a five-point scale, with 3 corresponding to a neutral attitude. We note that technology students’ mean ratings tend to cluster higher than 3 with muted values for the private condition. On the other hand, law students’ mean ratings tend to cluster below 3 and are in visually similar ranges for both public and private conditions.
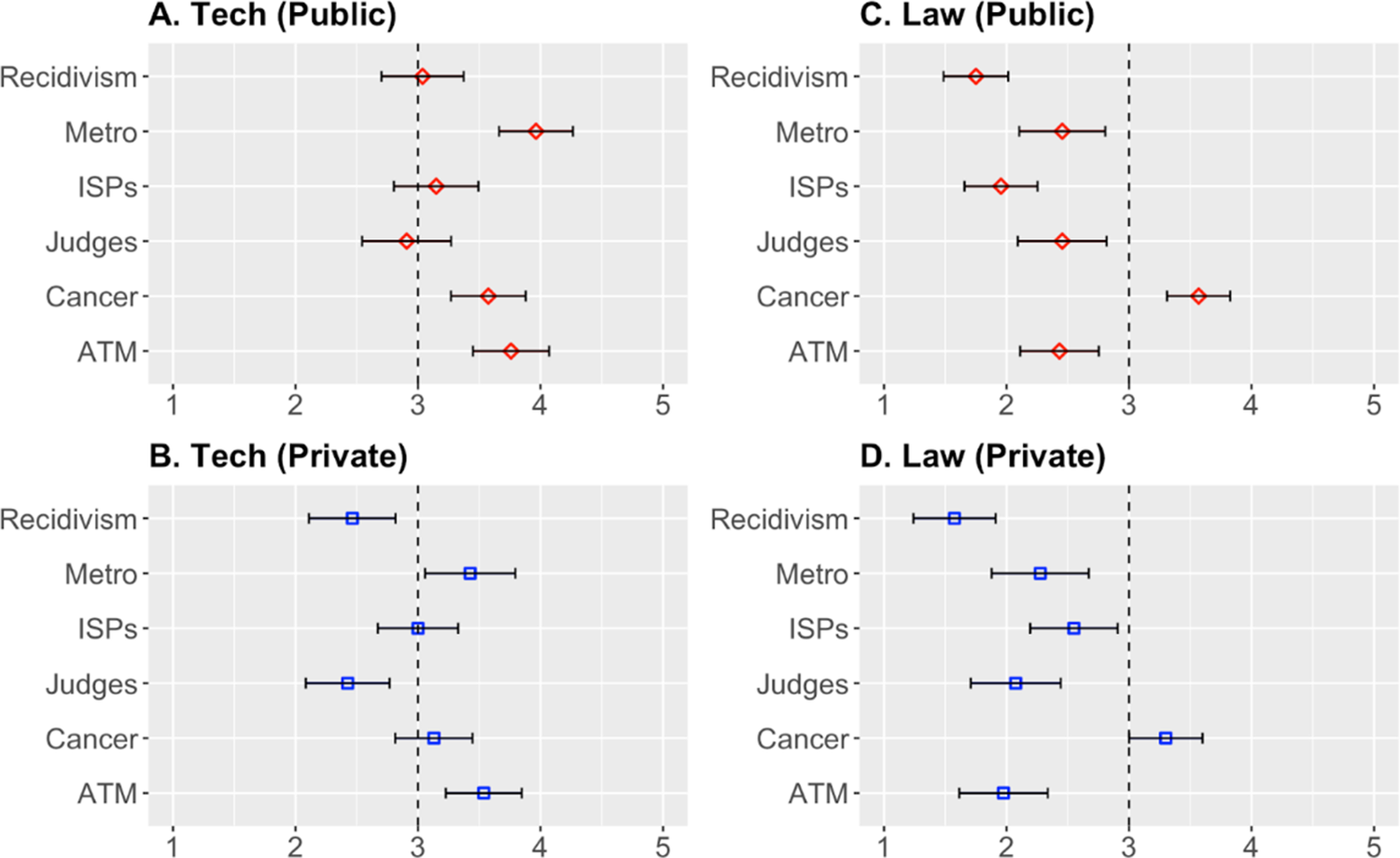
Figure 1. Long description
There are four panels. Top left is labeled A. Tech (Public), top right is C. Law (Public), bottom left is B. Tech (Private), and bottom right is D. Law (Private). Each panel displays horizontal error bars for six contexts: Recidivism, Metro, I S P s, Judges, Cancer, and A T M, listed from top to bottom on the y-axis. The x-axis ranges from 1 to 5, with a dashed vertical line at 3. In panel A, all mean ratings are above 3 except Recidivism, which is at 3. In panel B, all means are near or just above 3, with lower values than panel A. In panel C, all means are below 3 except Cancer, which is at 3.5. In panel D, all means are below 3. Error bars represent 95 percent confidence intervals. Red diamonds indicate public groups, blue squares indicate private groups. Technology students show higher ratings than law students, and private group ratings are generally lower than public within each discipline.
The main finding from these summaries is that across almost all contexts both technology and law students in our sample have more supportive attitudes toward public sector provisioning of AI systems. This is demonstrated by the positive values of the difference in mean attitudes columns (1 and 6) in Table 1. For technology students in particular we note that several of these differences are statistically significant whereas for law students we note that while 5 of the 6 contexts the direction is in favour of public sector, only one of these is statistically significant. Given our low sample size, the lack of significance may be attributed to the sample of law students being under-powered. The 2 contexts that received the least support overall across both samples of students were (1) the use of LLMs for assistance in judicial decision making and (2) the use of RATs for bail decisions. Only 1 context-sample pair is more supportive of private sector AI deployment, namely law students’ mean attitudes toward content moderation of ISPs.
The other broad pattern that emerges from the data is along expected lines, that is, technology students on average are more supportive of AI use in high-stakes contexts as demonstrated by average ratings of 3 or more in all contexts except in the context of judicial applications. In sharp contrast, law students on average have unfavorable attitudes toward AI, as demonstrated by mean ratings below 3, in all contexts except in the case of cancer detection. Regressions from the separate samples of technology and law students largely mirror these findings and are available as supplementary material for this article.
Estimates from the multivariate regressions on the pooled sample are presented in Table 2 and are described next.
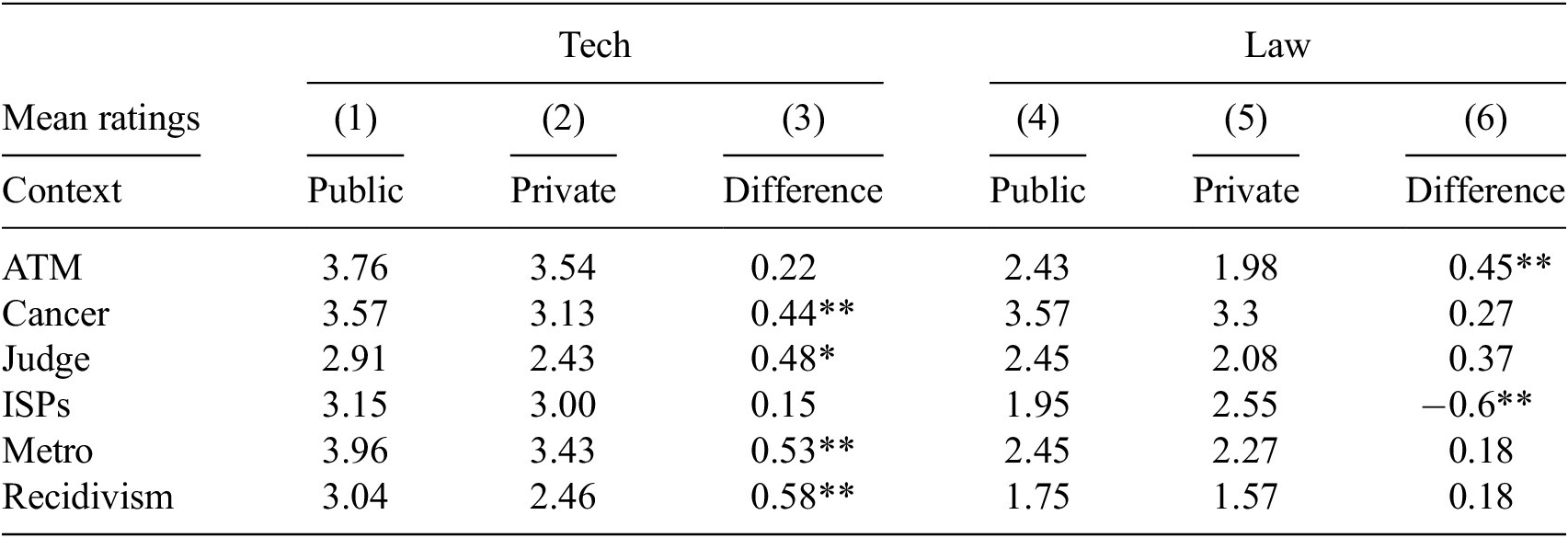
Multivariate regression results for the pooled sample of technology and law students
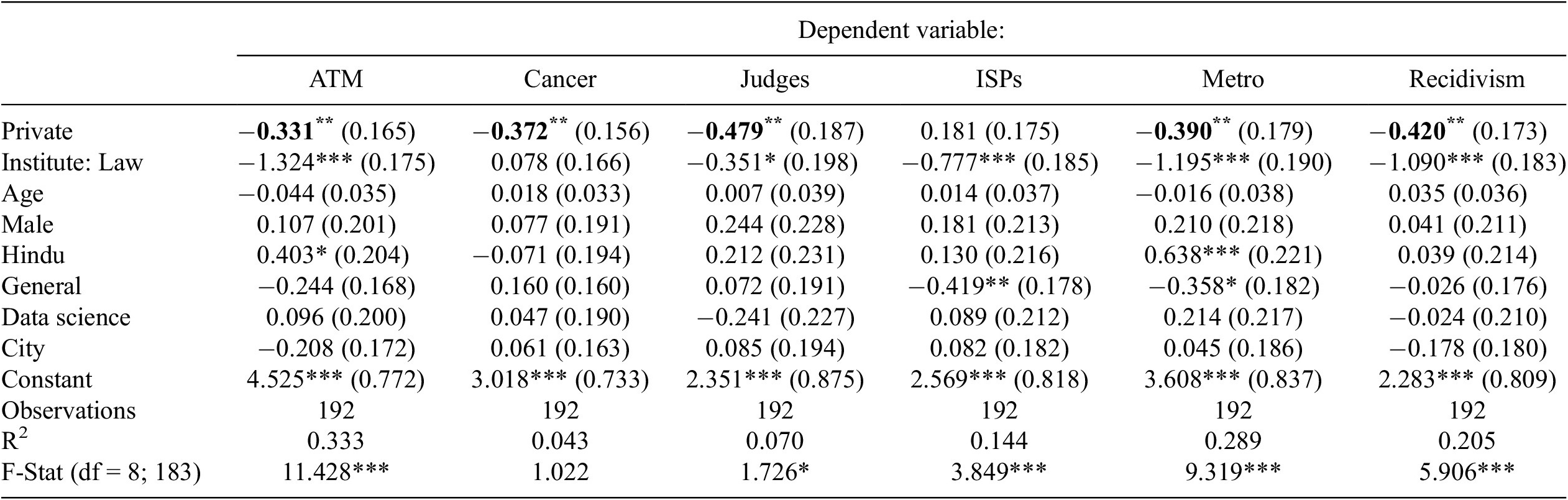
Table 2. Long description
The table presents multivariate regression coefficients with standard errors in parentheses for six dependent variables: A T M, Cancer, Judges, I S Ps, Metro, and Recidivism. Rows list predictors: Private, Institute Law, Age, Male, Hindu, General, Data science, City, Constant, Observations, R-squared, and F-Stat. For Private, significant negative coefficients are observed for A T M (−0.331, p less than 0.05), Cancer (−0.372, p less than 0.05), Judges (−0.479, p less than 0.05), Metro (−0.390, p less than 0.05), and Recidivism (−0.420, p less than 0.05), with I S Ps not significant. Institute Law shows strong negative associations for A T M (−1.324, p less than 0.01), I S Ps (−0.777, p less than 0.01), Metro (−1.195, p less than 0.01), Recidivism (−1.090, p less than 0.01), and a weaker negative effect for Judges (−0.351, p less than 0.1). Age, Male, Data science, and City are not significant across outcomes. Hindu is positively significant for Metro (0.638, p less than 0.01) and marginally for A T M (0.403, p less than 0.1). General is negatively significant for I S Ps (−0.419, p less than 0.05) and Metro (−0.358, p less than 0.1). Constants are all positive and highly significant. Observations are 192 for all models. R-squared values range from 0.043 (Cancer) to 0.333 (A T M). F-Statistics are significant for A T M (11.428, p less than 0.01), Judges (1.726, p less than 0.1), I S Ps (3.849, p less than 0.01), Metro (9.319, p less than 0.01), and Recidivism (5.906, p less than 0.01). Statistical significance is denoted by asterisks: one for p less than 0.1, two for p less than 0.05, three for p less than 0.01.
Note. *p < 0.1; **p < 0.05; ***p < 0.01.
4.1. Preference for public sector provisioning
Our article’s primary result is that across all but one context (that of content moderation) respondents show a strong causal preference for public sector provisioning of AI tools in high stakes societal applications, as demonstrated by statistically significant (at
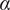 $ \alpha $
= 0.05) negative coefficient estimates corresponding to the main treatment variable
$ \alpha $
= 0.05) negative coefficient estimates corresponding to the main treatment variable
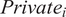 $ Privat{e}_i $
. This result persists even after controlling for multiple covariates to address individual level heterogeneity. An analysis of the qualitative responses indicates that preference for public sector is mainly driven by discomfort with the private sector entering into high stakes social applications. The private sector evoked concerns about equity and privacy. This aligns with extant literature on diminishing public confidence in scenarios where private entities are in control of public sector data, opening up possibilities for commercial gains (Xafis, Reference Xafis2015; Hartman et al., Reference Hartman, Kennedy, Steedman and Jones2020).
$ Privat{e}_i $
. This result persists even after controlling for multiple covariates to address individual level heterogeneity. An analysis of the qualitative responses indicates that preference for public sector is mainly driven by discomfort with the private sector entering into high stakes social applications. The private sector evoked concerns about equity and privacy. This aligns with extant literature on diminishing public confidence in scenarios where private entities are in control of public sector data, opening up possibilities for commercial gains (Xafis, Reference Xafis2015; Hartman et al., Reference Hartman, Kennedy, Steedman and Jones2020).
Both sets of students expressed concern over the commodification of data, potential price discrimination and private profiteering. For instance, on the use of FRT use in metro rail services,
-
- “Public transport’s main goal should not be the generation of revenue and profits. This is what happens when you entrust this service with private corporations…”
And on the use of machine learning algorithms in medical care,
-
- “The use of such algorithms would strongly create a bigger division between rich and poor. As such private hospitals would charge enormous amount of for such facility.”
4.2. AI apprehension amongst law students
Of further interest are the coefficient estimates corresponding to
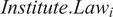 $ Institute. La{w}_i $
which are negative and highly signification (
$ Institute. La{w}_i $
which are negative and highly signification (
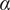 $ \alpha $
= 0.01) in 4 of the 6 contexts indicating an overall lower level of support for AI tools among law students in general as compared to technology students. These results are robust across multiple specification include logistic regression specifications and models with different subsets of controls. In the qualitative responses we found law students demonstrated an inclination toward upholding judicial precedents and legal standards set by the courts of law as they relate to algorithmic decision-making. In particular there were repeated mentions of the “Puttaswamy standard” (from a judgment which was instrumental in laying down a test to determine infringement of the right to privacy of individuals) especially in the context of FRT systems. Some representative comments:
$ \alpha $
= 0.01) in 4 of the 6 contexts indicating an overall lower level of support for AI tools among law students in general as compared to technology students. These results are robust across multiple specification include logistic regression specifications and models with different subsets of controls. In the qualitative responses we found law students demonstrated an inclination toward upholding judicial precedents and legal standards set by the courts of law as they relate to algorithmic decision-making. In particular there were repeated mentions of the “Puttaswamy standard” (from a judgment which was instrumental in laying down a test to determine infringement of the right to privacy of individuals) especially in the context of FRT systems. Some representative comments:
Right to privacy is fundamental right and can be curtailed only if there are no less restrictive measures that can achieve the same objective
Law students also repeatedly brought up concerns around curbing of free speech, violation of fundamental rights and state surveillance aided by AI technology. For instance, on content moderation using AI:
Any such technology has huge free speech implications. There is mistrust in the Govt. especially when it comes to blocking out voices selectively.
4.3. Attitudes of vulnerable groups
Interestingly we find that Hindu respondents are more inclined to support FRT in metro stations (significant at
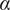 $ \alpha $
= 0.01).
$ \alpha $
= 0.01).
While only a limited number of respondents belonging to minority religions offered comments justifying their ratings in the case of FRT, all comments elicited opposed the use of this tool particularly in ATMs. Overall their responses indicated concerns about a database of facial data that one cannot opt out of, the possibility of surveillance and the disproportionate criminalization of minorities. A representative comment:
Leads to violation of privacy and stigmatization of people convicted of crimes… Particularly problematic since minorities are disproportionately criminalized …
The other consistent association we note is that respondents belonging to historically disadvantaged social groups being more supportive on average of both content moderation via AI tools (significant at
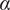 $ \alpha $
= 0.05). Several respondents belonging to historically disadvantaged caste communities offered their comments in the context of content moderation where we find that a larger proportion of comment providers in these communities (compared to the “general” caste category) were neutral about or supported content moderation. Interestingly, many of these comments mentioned the necessity of curbing hate speech. This is indicative of historically backward caste respondents being greater targets of abuse online, which in turn may have an impact on their attitudes toward AI tools in these contexts. Consider the comment:
$ \alpha $
= 0.05). Several respondents belonging to historically disadvantaged caste communities offered their comments in the context of content moderation where we find that a larger proportion of comment providers in these communities (compared to the “general” caste category) were neutral about or supported content moderation. Interestingly, many of these comments mentioned the necessity of curbing hate speech. This is indicative of historically backward caste respondents being greater targets of abuse online, which in turn may have an impact on their attitudes toward AI tools in these contexts. Consider the comment:
AI content moderation can be used … to root out extreme content on hate speech, violence and so forth but the subtle/sarcastic hinting of the content is subjective and wouldn’t be identified by an AI.
Taken together our results demonstrate that: 1) there is a preference for AI tools to be developed and/or deployed by the public sector over the private sector in high-stakes social contexts across two sets of critical AI stakeholders; 2) support for AI tools in general is, as expected, significantly lower amongst law students; 3) in judicial application contexts there is apprehension against AI tools across respondents and 4) associations between religious and caste characteristics show up in the case of FRT use and content moderation, respectively. We note here that while the main result on public vs private provisioning is a causal one, the remainders are simply associations. We thus caution against attaching explanation without a more thorough investigation. No other respondent characteristic, including age, gender, and location, demonstrates a systematic association with attitudes toward AI.
5. Discussion
In this article, we extend the literature on AI attitudes in India by studying the effect of whether the algorithmic system is provisioned by the public or the private sector, an important emerging issue given the recently launched “India AI Mission” promoting AI applications across both public and private sectors of the economy (Panday and Samdub, Reference Panday and Samdub2024).
We also introduce into the literature attitudes from a pool of future domain-specialists from students belonging to two premier technology and law institutes in the country, a deviation from the norm of general public attitude surveys. Engaging in domain-specific studies can unearth potential differences and commonalities, leading to a more nuanced understanding of attitudes toward AI (Klingbeil et al., Reference Klingbeil, Grützner and Schreck2024).
Our results demonstrate that students in our sample tend to have significantly more supportive attitudes toward the public sector over private sector involvement in AI within high-stakes social applications. We also find that law students on average are less supportive of AI tools overall and exhibit signs of AI apprehension. Of the different contexts we study, we find the greatest overall support for AI tools in health care and the least support in judicial applications and content moderation. Finally, our results also demonstrate that membership in a minority or disadvantaged community leads to nuanced attitudes in these contexts, cautioning against broad strokes generalization of AI attitudes in a diverse country like India.
A number of policy and future research implications emerge from our study.
First, and most crucially, our results demonstrate an overall preference for public over private sector provisioning of algorithmic tools in high-stakes contexts. Probing these attitudes via the qualitative data reveals that the primary concerns around private provisioning center on data privacy and theft, as well as potential concerns around long-run inequality, especially in the medical context. This indicates that despite critics’ highlighting the government’s overreach in FRT scale-up and the overarching exemptions granted to the government for data processing under the Digital Personal Data Protection Act, 2023, these are unlikely to result in a popular backlash against the government. While we acknowledge that our work is an initial contribution to the study of public vs private sector rollout of AI technologies, this result is an important one that, considered in conjunction with evidence of AI authority, has implications on the potential expansion of state surveillance in India. We believe that there is an urgent need for more scholarship empirically exploring public vs private sector provisioning of AI across a richer set of stakeholders and contexts.
Second, certain contexts emerge where both technology and law students are skeptical of algorithmic application, irrespective of the sector developing/deploying the AI system. The most apparent is the context of content-moderation of ISPs, where both sets of students have low to muted support of algorithmic intervention. Law students in fact exhibit significantly greater support for private sector provisioning of algorithmic. Curbing of dissent and free speech show up as important justifications for these attitudes. The other broad area where algorithmic intervention is opposed on average is in legal contexts, both the use of LLMs by judges and the use of RATs for bail decisions, where respondents exhibit clear concerns around potential algorithmic bias. These results should caution any government plans of rapid expansion of algorithmic tooling in these domains. In contrast to the above, in the context of medical applications such as cancer screening, there is broad support for AI tools across respondents, indicating support for the expansion of AI tools in medicine.
Third, respondent background matters. We find that technology students in general are supportive of AI applications across a variety of contexts, whereas law students are generally more skeptical. Assuming at least part of the explanation lies with the pedagogical training and predominant disciplinary focus at such institutes [Becher Reference Becher1994], our study highlights the need for greater social science exposure for technology students in India, particularly on the subject of AI ethics (Brundage et al., Reference Brundage, Shahar, Clark, Toner and Eckersley2018). We also find differences associated with demographic characteristics such as religion and caste; minority religions demonstrate lower support for FRT tools (signaling potential concerns around profiling) and disadvantaged caste communities demonstrate greater support for content moderation (signaling greater experience of online abuse). Thus, the lived experiences of individuals belonging to such vulnerable groups can lead to more nuanced and involved negotiations with AI tools, which any socially responsible algorithmic system must necessarily engage with.
We acknowledge the limitations of our research. First, while our survey included a diverse sample involving technology and law students, we cannot claim external validity as the recruitment of participants hinged on voluntary self-selection. By virtue of their social location, these participants are disproportionately urban, upper-class, and elite-educated, who are future stakeholders but are not representative of public opinion or frontline implementers. Having said that, we can claim internal validity of our causal question around the effect of the source of AI provisioning on attitudes. We also acknowledge that the study may be underpowered to capture lower magnitude effects, particularly in the case of law students. While we would have liked to include a larger number of students from more institutes, we were limited by budget and feasibility constraints. Given that the pooled sample does produce several estimates significant at 95% confidence, it somewhat allays statistical power concerns. Of the six types of roles within an AI ecosystem (Tomsett et al., Reference Tomsett, Braines, Harborne, Preece and Chakraborty2018), our samples align most closely with only the roles at the extremes: AI creators and examiners. Similarly, of the four categories of stakeholder communities in AI (Preece et al., Reference Preece, Harborne, Braines, Tomsett and Chakraborty2018), our samples include members of the future developer and ethicist communities. In our future work, we hope to expand our study on differing perceptions of public vs private sector AI provisioning to other roles and stakeholder communities within the AI pipeline, including regulators, bureaucrats, civil society experts, and journalists.
Second, while this study provides an empirical assessment toward AI attitudes amongst current law students, it is by no means meant to underplay the importance of the role of legal theory in shaping AI acceptance. AI technology is being utilized in multiple government settings in India, including in applications which may end up adversely impacting the constitutional and due process rights of the individuals. The risk is heightened in the absence of adequate procedural safeguards accounting for due process concerns arising out of the large-scale adoption of AI (Garrett, Reference Garrett2025). For these systems to achieve true acceptability in governance, especially when adopted by the state for decision-making that impacts the rights and privileges of individuals, it is crucial to factor in their compatibility and alignment with established legal and constitutional norms, beyond their mere technological capability. Techniques of control over administrative discretion become less necessary as technology assistance increases and human intervention decreases, and there is a need to reinforce foundational constitutional promises (Prasanna, Reference Prasanna2023) within high-stakes contexts where AI tools are applied.
Finally, our study concentrated on a simple indicator of AI acceptance, that is, an ordinal scale of support toward an AI tool in a given context. Future studies could be strengthened by measuring attitudes using multidimensional trust indicators (Kohring and Matthes, Reference Kohring and Matthes2007; Grimmelikhuijsen and Knies, Reference Grimmelikhuijsen and Knies2017; Malle and Ullman, Reference Malle, Ullman, Nam and Lyons2021;).
In conclusion, this article contributes to the nascent literature on empirical measurement of attitudes toward AI in the Global South and demonstrates an overall preference for AI tools to be developed and/or deployed by the public sector over the private sector in high-stakes social contexts, particularly among technologists, with more muted support among lawyers. We stress that our work is an initial contribution to the study of public sector vs private sector rollout of AI technologies and that there is an urgent need for more scholarship empirically exploring this topic across a richer set of stakeholders and contexts.
Data availability statement
Replication data and code can be found at: https://doi.org/10.5281/zenodo.19640916
Author contribution
N.S., A.S.: Conceptualization. N.S., A.S.: Funding acquisition. N.S., A.S.: Methodology. N.S., A.S., N.G, V.S.: Data curation. N.S., A.S., N.G., V.S.: Project administration. N.S., A.S., N.G., V.S.: Writing original draft. All authors approved the final submitted draft.
Funding statement
This research was supported by a Multi-Institutional Faculty Interdisciplinary Research Project Grant jointly funded by IIT Delhi and NLU Delhi (Grant No. MI02457G). The funder had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Competing interests
None.


 Open access
Open access
Comments
No Comments have been published for this article.