


1 Introduction
Velar laterals are a rare class of sounds that involve posterior closure and lateral release (Ladefoged, Cochran & Disner Reference Ladefoged, Cochran and Disner1977, Blevins Reference Blevins1994, François Reference François2010). Relatively little is known about the exact realization of velar laterals, and the existing phonetically detailed descriptions mostly pertain to the sounds that pattern as sonorants phonologically (Ladefoged et al. Reference Ladefoged, Cochran and Disner1977, Steed & Hardie Reference Steed, Peter and Catherine2004, François Reference François2010). Similarly, the comprehensive overviews of the language sounds in Maddieson (Reference Maddieson1984) and Ladefoged & Maddieson (Reference Ladefoged and Ian1996) discuss velar laterals alongside other liquids, not among stops or affricates. Very few studies address the acoustic effects of velar laterals on neighboring vowels, and the contextual variation in velar lateral phonetic realization.
The aim of this paper is to document the realization of a velar laterally released stop in Mee (iso: ekg; a.k.a. Ekari, Ekagi, Kapauku) – a Paniai Lakes Nuclear Trans New Guinea language spoken in the Indonesian part of Papua New Guinea (Doble Reference Doble1962, Reference Doble1987; Steltenpool Reference Steltenpool1969; Hyman & Kobepa Reference Hyman and Niko2013).
Unlike the cases cited above, the Mee velar lateral patterns with stops phonologically (Doble Reference Doble1962, Reference Doble1987; François Reference François2010; Hyman & Kobepa Reference Hyman and Niko2013). The Mee sound also exhibits a pattern of regular and predictable positional allophony, which is documented here for the first time for velar laterals. The Mee velar lateral appears as [ɡᶫ] before front vowels and diphthongs starting in a front vowel, but is realized with uvular closure and fricative release, i.e. [ɢʁ], before back vowels and corresponding diphthongs. The sound [ɢʁ], which regularly occurs in Mee, has so far only been reported as marginal in Xumi (Chirkova & Chen Reference Chirkova and Yiya2013).
Although our main goal is descriptive, we hope that our data will ultimately contribute to a broader cross-linguistic understanding of the phonetics, phonology and history of velar laterals. To that end, we compare our results with the existing studies of laterals (including velar laterals), affricates and stops. This comparison allows us to understand how the Mee velar lateral fits into phonetic typology and to draw some tentative implications for its history and its featural representation.
After presenting some background information on Mee (Section 2), we present and motivate our hypotheses in Section 3. Section 4 presents our elicitation study and Section 5 presents the controlled acoustic study. We explore the implications of our results for the typology of velar laterals in Section 6.
2 Background on Mee
Mee is spoken in the Paniai region of the central highlands of the Indonesian province of Papua, in the valleys surrounding and to the north of Paniai and Tigi lakes (Steltenpool Reference Steltenpool1969, Doble Reference Doble1987) (see Figure 1). Mee is closely related to Wodani and Moni (Larson & Larson Reference Larson and Larson1972) and possibly to Auye (Moxness Reference Moxness2011, Tebay Reference Tebay2018b).

Figure 1 Approximate location of the native Mee-speaking community.
© OpenStreetMap contributors.
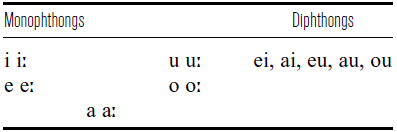
The Mee consonant inventory is presented in Table 1. We use the transcription symbols [ɡᶫ] and [ɢʁ] throughout the paper, anticipating our findings. Doble (Reference Doble1987) transcribes the voiced velar as /ɡ/ and acknowledges that it is laterally released and that ‘Allophones of the voiced velar stop range over various degrees of the lateral’ (Doble Reference Doble1987: 58). Although no detailed measurements are provided, Doble also reports two kinds of allophonic processes applying to both dorsals: labialization after back vowels and intervocalic lenition. Our elicitation results on these processes are reported in Section 4.3. Importantly, Mee has no pure lateral or rhotic phonemes. The vowels and diphthongs are listed in Table 2.
Table 1 Mee consonant inventory.
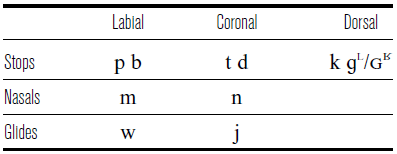
Table 2 Mee vowel inventory.
Mee exhibits some interesting tonal alternations, as analyzed by Hyman & Kobepa (Reference Hyman and Niko2013) and Worbs (Reference Worbs2016). Since the Mee tonal system has been described extensively elsewhere, we will not focus on tone in this paper, and our transcription omits tones. Mee allows (C)V(V) syllables. Onsetless syllables appear word-initially, but word-medially a variety of strategies is employed to resolve potential hiatus, e.g. vowel coalescence (Tebay Reference Tebay2018a). The following section formulates our main hypotheses about the Mee velar lateral and gives the necessary theoretical and cross-linguistic background.
3 Background and hypothesis
Our initial investigation of the Mee sound inventory revealed the existence of both [ɡᶫ] and [ɢʁ] sounds. However, our Mee consultants expressed the intuition that [ɡᶫ] and [ɢʁ] cannot occur before the same vowels, so that no words in Mee contain sequences like *[ɡᶫa] or *[ɢʁe]. We therefore initially formulated the positional allophony hypothesis as follows: [ɡᶫ] and [ɢʁ] are positional allophones of the same phoneme, and they are distributed according to the backness of the following vowel. /a/ patterns with back /u o/ in conditioning velar lateral allophony. Diphthongs pattern according to the backness of their first member. This hypothesis is addressed in our elicitation study, presented in Section 4 below.
Our elicitations also helped us to formulate the posterior allophone realization hypothesis: the allophone occurring before front vowels has velar closure and lateral release whereas the allophone occurring before back vowels has uvular closure and fricated release. In order to address this hypothesis, we conducted a separate acoustic study, as described in Section 5. Our exact predictions for the acoustic study are detailed below, based on the existing studies of velar vs. uvular distinction and of lateral acoustics in general.
3.1 Posterior articulations: Velars and uvulars
The acoustic distinctions between uvular and velar consonants are rarely addressed in the literature, although it is acknowledged that this contrast is particularly interesting since it might be hard to perceive (Shosted Reference Shosted and Heriberto2011). Across languages, uvular and pharyngeal consonants are often associated with vowel lowering and backing (Bessell Reference Bessell1998, Wilson Reference Wilson2007, Shosted Reference Shosted and Heriberto2011, Denzer-King Reference Denzer-King2013, Sylak-Glassman Reference Sylak-Glassman2014).Footnote 1
Shosted (Reference Shosted and Heriberto2011) compared the effects of velars and uvulars on a preceding vowel in the Mayan language Q’anjob’al, observing that uvulars tend to lower F2 and raise F1. Denzer-King (Reference Denzer-King2013) finds that uvulars lower the F2 of the following /a/ in Tlingit (Na-Dene), compared to velars. The lowering and retraction effects of uvulars are also found for Nuu-chah-nulth (Wakashan) by Wilson (Reference Wilson2007) and for Interior Salish languages by Bessell (Reference Bessell1998), although these two studies compare uvulars and pharyngeals to both velars and coronals. Sylak-Glassman (Reference Sylak-Glassman2014: 69) – in a large typological sample – finds that vowel backing is much more common next to uvular consonants than next to pharyngeals. His sample also shows that backing is mostly non-neutralizing, i.e. allophonic, and that lowering is common for most post-velar consonants.
The velar–uvular distinction often manifests itself differently for preceding vs. following vowels, and for different vowel qualities. In Q’anjob’al, the F2 effects of uvulars are more pronounced for front vowels [i e] (Shosted Reference Shosted and Heriberto2011). Similarly, the results in Alwan (Reference Alwan1986) suggest that in Arabic the uvular consonants lower F2 of a following front vowel /iː/ much more drastically than for /aː uː/ (see especially pp. 70–77 and Figure 3.10). Wilson (Reference Wilson2007) reports varying degrees of lowering and backing for different vowels in Nuu-chah-nulth.
Based on these findings, we expect that Mee allophone [ɢʁ] may have a backing and/or lowering effect on the preceding vowels. We also anticipate that these effects may be realized differently for different preceding vowel qualities.
3.2 Lateral acoustics
In this section, we review the existing literature on the acoustics of velar laterals, and laterals in general, in order to infer possible hypotheses about the acoustics of the velar lateral in Mee. We expect only one of the relevant allophones in Mee to have a lateral release, and therefore it is important to also summarize the acoustic characteristics of laterals that set them aside of fricatives.
One such characteristic is periodicity. As Maddieson (Reference Maddieson1984) uncovers in his typological study, lateral consonants tend to be sonorants in the languages of the world. This also means that they are part of the class of sounds exhibiting spontaneous voicing (Rice & Avery Reference Rice, Peter, Carole and Jean-François1991, among others).Footnote 2 Similarly, Maddieson & Emmorey (Reference Maddieson and Karen1984) report that even voiceless lateral approximants tend to anticipate the voicing of the following vowels more than the corresponding fricatives. Therefore we expect that lateral release in Mee velars will exhibit periodicity, and it will be less likely to undergo devoicing than [ɢʁ], even in contexts where obstruents may be fully or partially devoiced. On the other hand, the fricated release of [ɢʁ] may be more susceptible to devoicing than [ɡᶫ].
Laterals are also characterized by the presence of formant structure, and since in their articulation the passage of air has a side branch, the acoustic models of laterals include an anti-formant (Fant Reference Fant1970, Bladon Reference Bladon, Harry and Patricia1979, Stevens Reference Stevens1998, Johnson Reference Johnson2012). However, laterals exhibit a high degree of variability in their acoustics (Stevens Reference Stevens1998, Proctor Reference Proctor2009, Tabain et al. Reference Tabain, Butcher, Breen and Beare2016), and Ladefoged (Reference Ladefoged2003: 148) notes that the place of articulation of lateral consonants is not easily inferred from the acoustic signal. The existing classical acoustic models of coronal laterals are also different in a number of respects. As we will see, these models are underdeveloped for velar laterals, primarily due to lack of articulatory data. Stevens (Reference Stevens1998: 543–554) estimates the first three resonances for English onset (i.e. light) /l/ at 360 Hz, 1100 Hz and 2800 Hz with a clustering of at least three additional formants in the region between 3500 Hz and 4500 Hz. However, according to Stevens, the F4 at 3500 Hz is effectively canceled by the anti-resonance which is estimated at around 3400 Hz. Fant (Reference Fant1970: 162–168) presents an acoustic model of the Russian non-palatalized /l/ which also predicts a separation of F2 and higher resonances. However, Fant estimates the anti-formant for Russian /l/ at about 2 KHz, much lower than the estimate for English by Stevens. Fant also estimates a clustering of several resonating frequencies in the higher-frequency region above 2250 Hz.
In contrast, Johnson (Reference Johnson2012) models the English lateral with a schwa-like tube with a side track and predicts 531 Hz, 1594 Hz and 2656 Hz resonances for a uniform tube. Johnson notes that F1 is likely to be lowered by the fact that the cavity in front of the constriction is smaller in diameter than the cavity behind it. F2 is possibly also lowered for velarized (i.e. dark) /l/, which in English occurs syllable-finally. The small pocket of air trapped on top of the tongue just behind the alveolar constriction is expected to yield an anti-formant at around 2125 Hz, although Johnson’s acoustic data from Thai suggest a higher frequency for the anti-formant.
Acoustic studies of laterals also uncover a lot of cross-linguistic variation, even in supposedly similar sounds. In a cross-linguistic study on laterals by Bladon (Reference Bladon, Harry and Patricia1979), F1 is found to be uniformly low (200–500 Hz), and F2 varies considerably depending on the language surveyed. Additionally, Bladon suggests two anti-formants at 1 KHz and 2 KHz–3 KHz for most lateral consonants. He also reports some variation for F3 based on place of articulation and thus finds that a low F1 and the two anti-formants identify laterals as a class.
Comparing laterals in three different Australian languages at different places of articulation (alveolar, dental, retroflex and palatal), Tabain et al. (Reference Tabain, Butcher, Breen and Beare2016) find that for the F2 and F3 of alveolar laterals the estimates by Johnson (Reference Johnson2012) are more or less accurate (1620 Hz and 2840 Hz, respectively), whereas F1 (370 Hz) is closer to Fant’s (Reference Fant1970) and Stevens’ (Reference Stevens1998) suggestions. Based on their acoustic measurements, Tabain et al. (Reference Tabain, Butcher, Breen and Beare2016) also suggest that the largest gap in lateral resonances is between F1 and F2 rather than between F2 and F3, as suggested by Fant (Reference Fant1970) and Stevens (Reference Stevens1998). This is interpreted as potential evidence of an anti-formant with much lower frequency than previously estimated.
Out of the laterals investigated by Tabain et al. (Reference Tabain, Butcher, Breen and Beare2016), the palatal lateral is closest to the type of articulation observed in the release of the Mee velar lateral, since its place of articulation is closest to the velum. Tabain et al. (Reference Tabain, Butcher, Breen and Beare2016) find that the palatal lateral has a significantly higher F2 and a slightly lower F1 than the alveolar lateral. They conclude that Centre of Gravity (CoG) is enough to distinguish places of articulation in lateral consonants.Footnote 3 The palatal lateral has a higher CoG (around 2800 Hz) than the alveolar and retroflex places of articulation.Footnote 4 The CoG is considered to be more robust in distinguishing places of articulation in laterals, since the individual formants show a greater inter-speaker variation. Similarly, Bladon’s (Reference Bladon, Harry and Patricia1979) study on laterals in several European languages yields the highest F2 for palatal laterals, compared to other coronal laterals. Recently, both Wong (Reference Wong2017) and Charles & Lulich (Reference Charles and Lulich2018, Reference Charles and Lulich2019) found that the palatal lateral in Brazilian Portuguese can be distinguished from the alveolar lateral by a considerably higher F2 and a slightly lower F1.
In contrast to palatal laterals, velarized alveolar laterals are reported to have a lower F2 than their non-velarized counterparts, and hence a smaller gap between F2 and F1, see Sproat & Fujimura (1993), among others, on English ‘dark l’, and Ladefoged & Maddieson (Reference Ladefoged and Ian1996: 196) for a survey of existing results on Russian, Bulgarian and Albanian. As we shall see, these comparatively low F2 values make the velarized alveolar laterals rather distinct from velar laterals acoustically. For this reason, we do not include velarized laterals in our summary in Table 3.
Table 3 Summary of model predictions and acoustic findings in existing literature. Antiformants abbreviated as ‘AF’.
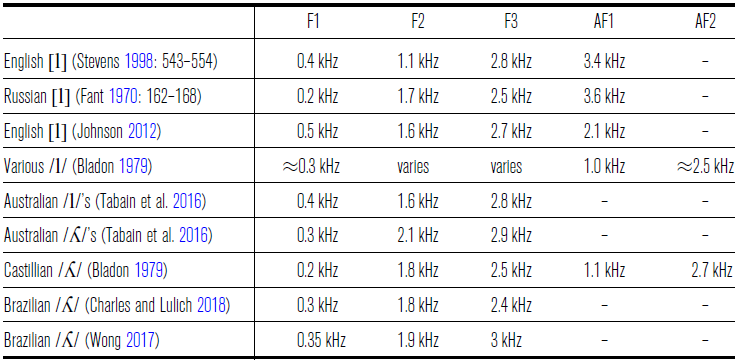
To summarize, the existing studies of coronal, including palatal, laterals seem to converge on relatively low F1 values. Multiple studies report comparatively high F2 for palatal laterals. The values of anti-formants are to some extent debated, and even the resonating frequencies are often variable within a particular language. There are at least three different acoustic models of laterals, and at present it seems premature to claim that one of these models matches the data better.
The available data on velar lateral acoustics is much more scarce than for coronals. Steed & Hardie (Reference Steed, Peter and Catherine2004) propose a preliminary model for velar laterals that is similar to the one proposed by Johnson (Reference Johnson2012) except the constriction is further back and the side branch of the tube is shorter. No estimates of the actual length of the tube or of the side cavity can be made since articulatory measurements of velar laterals (such as x-ray or ultrasound) are not available. Ladefoged & Maddieson (Reference Ladefoged and Ian1996) found that velar laterals in Melpa and Mid-Wahgi have a higher F1 than laterals at other places of articulation in these languages. On the other hand, F2 of the velar laterals is expected to be higher than that of alveolars since it is expected to be inversely related to the volume of oral-pharyngeal cavity behind the constriction (Bladon Reference Bladon, Harry and Patricia1979, Ladefoged & Maddieson Reference Ladefoged and Ian1996, Steed & Hardie Reference Steed, Peter and Catherine2004). Indeed, this relatively high F2 is reported by Ladefoged et al. (Reference Ladefoged, Cochran and Disner1977) and Ladefoged & Maddieson (Reference Ladefoged and Ian1996) for Mid-Wahgi, although F2 is lower in this latter language for the velar laterals than it is for the laminal dental lateral.
Based on the existing descriptions of laterals, we expect that the two /ɡᶫ/ allophones will have different release spectra, although we also anticipate that this prediction is hard to test in practice since [ɡᶫ] and [ɢʁ] occur in front of different vowels. If the closure and parts of the release undergo partial devoicing, we would expect that [ɢʁ] is more likely to be aperiodic than [ɡᶫ]. The existing data on formant values of velar laterals, and the acoustic models (which mostly pertain to coronal laterals) unfortunately do not yield enough consistent predictions for us to formulate an informed hypothesis about the formant values in the release of the [ɡᶫ] allophone.
3.3 Summary
Our study addresses several specific hypotheses about the realization of the Mee velar lateral. First, we hypothesize that the velar lateral has two allophones realized as [ɡᶫ] vs. [ɢʁ] and distributed complementarily, according to the following vowel quality. These distributional facts will be tested in our elicitation study (Section 4) which attempted to elicit a representative sample of Mee words with a dorsal.
Second, we expect that the two allophones of the velar lateral will have a different effect on the preceding vowel: the uvular allophone is expected to exhibit comparatively more lowering and backing, and this can be addressed by measuring the preceding vowel’s formant values. Finally, we expect that the two allophones will also differ in the acoustics of their release. The release of [ɢʁ] may be more likely to exhibit aperiodicity than that of [ɡᶫ]. The exact formant values of lateral release are hard to extrapolate from the existing literature, most of which deals with coronal laterals. We may also expect the CoG of [ɡᶫ] to be higher compared to [ɢʁ], based on the measurements for the similar palatal laterals by Tabain et al. (Reference Tabain, Butcher, Breen and Beare2016). The predicted acoustic differences will be assessed in a more detailed acoustic study described in Section 5.
4 Elicitation study
4.1 Method
The main goal of our elicitation study was to address our initial intuition about the positional allophony of the Mee velar lateral. An additional goal is to confirm that the allophony pattern is robust across speakers and across items. These goals predetermined many aspects of the methods we used.
4.1.1 Participants
Our elicitation data come from fieldwork with two male speakers of Mee, to be referred to as S01 and S02. Both our speakers are male, aged between 25 and 35. Both are bilingual in Mee and Indonesian (which is common for Mee speakers), showing very good L2 command of German and some knowledge of English. Both speakers lived in Germany at the time of elicitation. S01 speaks the Paniai dialect of Mee, which also shows some influence of the central Tigi dialect. S02 is a speaker of the Tigi dialect.
Of course, it should be acknowledged that the data obtained from speakers of Mee who live in a non-native environment (in our case in Germany) could potentially differ from the way Mee is spoken in the native community. We offer some additional preliminary indications of why our data may be representative in Section 4.3.
4.1.2 Procedure
Our elicitations were carried out in a quiet room with continuous sound recording using a Zoom H5 portable recorder. An AKG C-1000s microphone was used to record S01’s elicitations and a Shure SM10A microphone was used to record S02’s elicitations.
The elicitation procedure involved a continuous conversation between the Mee speaker and the researchers, in order to elucidate the exact meanings of Mee words and grammatical markers. For that reason we felt it was not practical to record all our elicitation sessions in a sound-attenuated room, which only allows limited contact between the researchers and the speaker. Although the recording set-up may have yielded additional background noise in our recordings, we felt it was appropriate for a preliminary elicitation study.
Each elicitation session involved just one speaker, so dialogues between the two speakers were never recorded. During the elicitation sessions, the researchers identified Mee words and phrases of interest in co-operation with the speaker. Afterwards the speaker was asked to pronounce the relevant word or phrase, repeating it several times, speaking at a constant rate, and keeping a constant distance from the microphone. Each relevant word was recorded both in isolation and in a phrase, although the exact context could be different for different words. The recorded elicitation sessions were later examined, both auditorily and through basic acoustic analysis in Praat (Boersma & Weenink 2019).
4.1.3 Elicitation materials
The elicitation materials consisted of words and phrases focusing on the basic sound contrasts of Mee, and on the elements of Mee morphology. In order to assess the distribution of velar lateral allophones, the available Mee dictionaries (Steltenpool Reference Steltenpool1969, and later Takimai Reference Takimai2015) were searched for words containing the orthographic <g> – the grapheme for the velar lateral. We then attempted to elicit at least five distinct words with the velar lateral in each possible vocalic context. In some cases, this was not possible since some vowels occur less frequently than others in Mee. Specifically, the simple vowels /i e a o/ turned out to occur frequently in Mee, whereas diphthongs and /u/ were particularly rare.
4.2 Elicitation results
The recordings from our elicitations are compatible with the categorical velar lateral allophony pattern.Footnote 5 The velar lateral is realized phonetically with dorsal closure and lateral release, transcribed [ɡᶫ], before front vowels and corresponding diphthongs /ei eu/, see (1a). Before back vowels /a o u/ and corresponding diphthongs /ai au ou/, it is realized with uvular closure and fricative release, transcribed [ɢʁ], as in (1b). We will tentatively write the corresponding Mee phoneme, i.e. the mental unit comprising both allophones as /ɡᶫ/ – this is discussed further in Section 4.3
(1) Examples of Mee posterior lateral

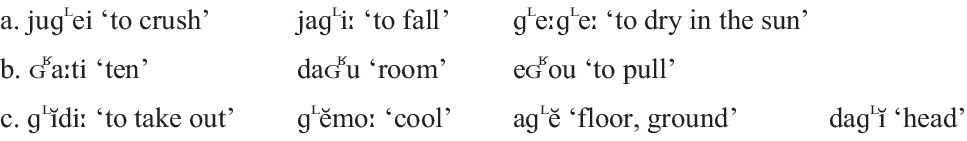
Short /i e/ are reduced and highly lateralized after [ɡᶫ], transcribed with a breve sign in (1c) and in what follows. The reduction process is more pronounced in connected speech and in non-initial syllables. The contrast between /ɡᶫi/ and /ɡᶫe/ in non-initial syllables, as in the last two words in (1c) appears to present a perceptual challenge to us, as non-native listeners. Our consultants do distinguish such words. Moreover, short word-final /i/ vs. /e/ serve as distinct subject agreement markers in some tenses, including after /ɡᶫ/, where /-i/ corresponds to ‘masculine 3sg’, and /-e/ to ‘1pl’ and ‘2sg’ (Doble Reference Doble1987). The cues for differentiating [ɡᶫĭ] vs. [ɡᶫĕ] sequences in Mee remain to be further investigated.
We illustrate the variation in Mee velar lateral realization with some representative spectrograms (Figures 2–5). As mentioned in Section 4.1.2, our elicitation sessions were not conducted in an attenuated booth, and show some level of background noise. In an attempt to present the clearest possible illustrations, we present the spectrograms from S01 obtained from later booth recordings (see Section 5.1.1). Therefore, the level of noise in spectrograms from speaker S01 is lower than that for S02. The speech rate also differed for our two speakers. The vowel–consonant boundaries are presented only as rough pointers.

Figure 2 Spectrograms and waveforms: [aɡᶫe] ‘floor/ground’.

Figure 3 Spectrograms and waveforms: [boɢʁomai] ‘to collapse’.
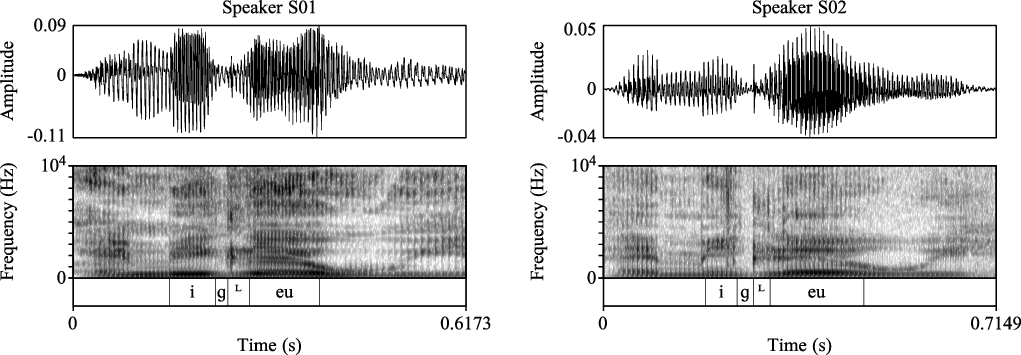
Figure 4 Spectrograms and waveforms: [emiɡᶫeuwi] ‘go and throw it in!’

Figure 5 Spectrograms and waveforms: [aɢʁapi] ‘midday, noon’.
As can be seen in these Figures, the Mee velar lateral is characterized by the presence of a clearly identifiable closure or constriction phase. Even when the constriction was apparently not complete, i.e. in cases of lenition, the constriction phase is distinct from surrounding vowels and from the release. The constriction is also relatively long, similar in duration to that of stops.
The variability in closure and release duration observed in the figures is probably accounted for by the speech rate differences across different speakers and elicitation sessions. Our elicitations did not suggest a difference in closure or release duration for the two allophones.
Finally, the spectral properties of the release reveal several typical /ɡᶫ/ realizations. Before front vowels, the [ɡᶫ] allophone has a lateral release. One common realization of this release involves formant continuity with the following vowel (V2), as can be observed in Figure 2 (especially left panel). V2 sounds lateralized to us in these cases.
The release of the allophone [ɢʁ] is often, but not always, characterized by diffuse high-frequency noise (over 4 KHz), as apparent in Speaker S01’s pronunciation in Figure 3 (left panel). This noise may coincide in time with the formant transitions from the following vowel (see Figure 3). This high-frequency noise is characteristic of fricatives, and the release is heard as fricated.
Figures 4 and 5 illustrate the realization of velar lateral release that does not have as much temporal overlap with the following vowel. For the allophone [ɡᶫ], the release in these cases shows formant discontinuity relative to the following vowel, and the release often starts with a transient. This realization of [ɡᶫ] is shown in Figure 4.
Before back vowels, the allophone [ɢʁ] is often realized with a fricated release occurring before the onset of formant structure for V2 (see Figure 5). Unlike for [ɡᶫ], both release and closure were often at least partially devoiced in these cases.
To summarize, both allophones show considerable variability in the temporal overlap between the release and the following vowel. The release of the uvular allophone [ɢʁ] is often associated with high-frequency frication noise and with partial devoicing.
4.3 Discussion of elicitation results
Overall, our elicitations confirmed that for both speakers the velar lateral has two allophones which are distributed according to the backness of the following vowel. This allophony pattern has not been previously reported either for Mee or for velar laterals in other languages. The obligatory closure in Mee velar lateral is unlike the optional closure in Mid-Wahgi (Ladefoged et al. Reference Ladefoged, Cochran and Disner1977, Ladefoged & Maddieson Reference Ladefoged and Ian1996) or the optional and possibly incomplete or very short closure in Kuman (Steed & Hardie Reference Steed, Peter and Catherine2004). In Hiw, the velar lateral is obligatorily pre-stopped (François Reference François2010), but the closure duration is short, judging from the spectrograms presented by François. On the other hand, the closure of the Mee velar lateral is usually relatively long in our elicitation data – an impression to be verified in our controlled acoustic study in Section 5.
Since we could record only two speakers, both living outside of their native community at the time of recording, it remains to be seen how robustly these results would generalize to a broader community of native speakers. Although practical circumstances prevented us from undertaking a full fieldwork trip to the native Mee communities, our preliminary travel allowed for some observations of Mee speech in Nabire, in Dogiyai, and in Enarotali (Indonesia). Based on these observations, velar lateral allophony was also present in these Mee-speaking communities. Another indirect indication that the patterns found with our speakers are representative of a broader community comes from the speakers’ dialects. Based on familiarity with different parts of the Mee lexicon, and on background information from our two speakers, it was clear that they speak slightly different dialects of Mee (see Section 4.1.1). However, our results in Section 4.2 show that the patterns of velar lateral allophony appear to be very similar for the two speakers. Thus although our findings may be further refined by future data from native Mee communities, we do not anticipate that new data would be completely incompatible with what we find here.
In line with Reference DobleDoble (Reference Doble1987), our elicitations revealed that the Mee velar lateral has an obligatory closure or constriction phrase, and that both /k/ and /ɡᶫ/ may undergo some lenition between vowels. Thus the velar stop /k/ is often lenited to [x/χ] inter-vocalically, and occasionally lenition also applies to /ɡᶫ/, thus yielding a variant closer to [ɣᶫ]. In our impression, lenition is less pronounced for the voiced sound.
Some other phonetic details noted by Reference DobleDoble (Reference Doble1987) do not match our elicitation results. We attribute these differences (all noted below) to a possible dialectal difference in the studied speakers. Doble (Reference Doble1987: 58) reports that /k, ɡᶫ/ undergo labialization following back vowels, but we did not observe labialization in our data (it is possible that a more controlled acoustic analysis would reveal some labialization). The reduction of short /i e/ after [ɡᶫ] is also not mentioned by Doble (Reference Doble1962, Reference Doble1987), yet it is prominent in the speech of our consultants.
Although our elicitations are mainly phonetic, our results have implications for the phonological status and underlying representation of the Mee velar lateral. Our results are consistent with the existing phonological descriptions which interpret /ɡᶫ/ as a laterally released stop (Doble Reference Doble1962, Reference Doble1987; Hyman Reference Hyman2008; François Reference François2010; Hyman & Kobepa Reference Hyman and Niko2013). Our data do not allow us to distinguish between laterally released stops and affricates with a lateral release, and our transcription should be interpreted as indeterminate between the two interpretations. The Mee sound patterns with other non-continuants in several respects. First, it is consistently realized phonetically with a closure phase. Second, both /k/ and /ɡᶫ/ undergo lenition between vowels to some extent. Third, the Mee velar lateral also derives historically from a stop. Evidence for this comes from Moni, where the corresponding sound is described as a stop [kʰ/g] in most contexts (Larson & Larson Reference Larson and Larson1958). See Larson & Larson (Reference Larson and Larson1972) on the relation between Mee, Wodani and Moni, and Tebay (Reference Tebay2018b) for a list of cognate words. Fourth, our consultants seem to associate [ɡᶫ~ɢʁ] with other stops, as evidenced by their orthographic intuitions. While the consultants were not aware of a standardized orthography for Mee, they agreed that the velar lateral sound should be written with the <g> symbol, rather than <l> or <r>. Finally, Mee /ɡᶫ/ occupies the place of /ɡ/ in the consonant inventory.
At the same time, it would be hard to derive the Mee velar from an underlying plain stop for the simple reason that /ɡᶫ/ is never realized as a stop proper. Our consultants are aware of the special release properties of /ɡᶫ/ and the phonetic salience of the release manifests itself in loanword adaptations such as [tekoɢʁa] ‘school’ from Indonesian sekolah [səkolah]. Based on all this evidence, we will analyze the Mee velar lateral as an underlying laterally released stop/affricate, transcribed /ɡᶫ/. We hasten to add that our data are mostly phonetic, and a more thorough investigation of Mee phonology may uncover additional synchronic phonological evidence for this interpretation.
While the elicitation study confirmed that the Mee velar lateral has two allophones, our results were imperfect in a number of ways. First, the recordings were made in a quiet room with portable recording equipment which necessarily also captured some environment noise – this is apparent in spectrograms from Speaker S02 in Figures 2–5. The elicitation data are thus not sufficient to perform detailed acoustic analysis. The speech rate, context and aspects of the recording situation are also not controlled for in this study, and therefore our judgment of the difference between [ɡᶫ] and [ɢʁ] allophones remains impressionistic and preliminary at this point.
In order to study the difference between velar lateral allophones in more detail, we conducted a controlled acoustic study where all relevant words were recorded in the same context. The recordings for the acoustic study were made in a sound-attenuated booth, thus reducing the levels of background noise captured. The acoustic study is described in what follows.
5 Acoustic study of velar lateral allophony
Our main hypotheses for the acoustic study of the Mee velar lateral are connected to the difference between [ɡᶫ] and [ɢʁ], as detailed below.
5.1 Acoustic study: Method
5.1.1 Acoustic study: Speaker and procedures
Speaker S01 participated in the acoustic study, speaker S02 was unfortunately not available. The experiment took place in a sound-attenuated booth at Leipzig University, with continuous sound recording using Neumann TLM103 cardioid microphone and M-Audio Mobile Pre preamplifier. Stimuli sentences were presented in a random order on a computer screen. The experiment started with an instruction screen in German, asking the speaker to read the sentences as naturally as possible, and to repeat a sentence if a slip of the tongue occurred. The speaker was also informed that some sentences may occur more than once. Three trial sentences preceded the main task, and a short break occurred in the middle of the experiment. The whole recording session lasted about forty minutes.
5.1.2 Acoustic study: Materials
Stimuli for the acoustic study consisted of words with /ɡᶫ/ in a diverse set of vocalic contexts. Our words were minimally disyllabic, and were not controlled for tone, syllable structure or morphological complexity – controlling these factors appeared impractical given the lack of tonal annotation and the overall relatively small size of our main dictionary source (Steltenpool Reference Steltenpool1969). Three tokens were later excluded from acoustic measurements since extraneous noise was present or the realization of /ɡᶫ/ was clearly deviant (see Section 5.1.3). The stimuli words and fillers used in the acoustic study are listed in Appendix A.
Our final token set contained about the same number of /ɡᶫ/ before front vowels (158 tokens of 52 words) and /ɡᶫ/ before back vowels (154 tokens of 45 words). In designing the word sets we attempted to include at least three distinct words with /ɡᶫ/ in each V_V context. From now on, we will refer to the vowel preceding the velar lateral as V1 and to the vowel following it as V2. In principle, all vocalic contexts were recorded, except V1 was never a diphthong – this facilitated later formant transition analysis.
In some of the vocalic environments we could not identify enough words that would be familiar to our consultant. This problem was particularly pronounced for /u/, which is the least frequent vowel of Mee. To balance our stimulus set, we included more repetitions of the available words in those cases. Table 4 presents the number of distinct words (types) with /ɡᶫ/ in each environment in our stimuli set. Table 5 presents the number of individual tokens/repetitions.
Table 4 Stimuli words by environment. V1 and V2 stand for vowels before and after /ɡᶫ/.
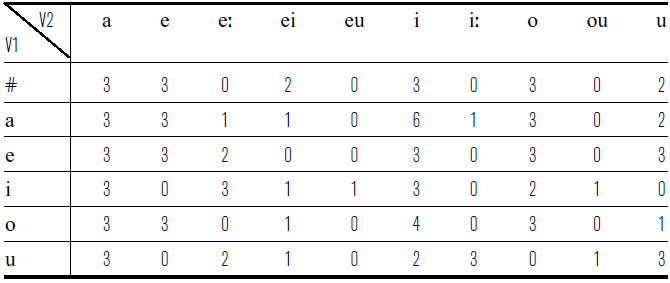
Table 5 Stimuli tokens by environment. V1 and V2 stand for vowels before and after /ɡᶫ/.
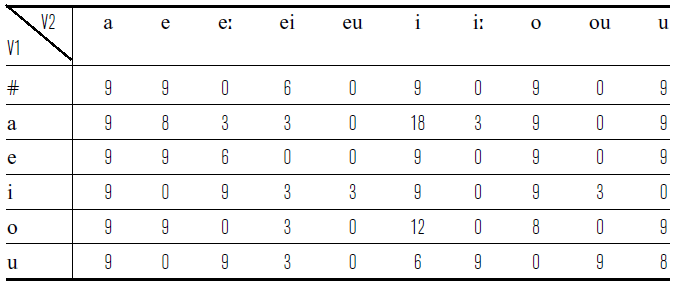
In the /i_u/ environment, only a few words could be found in the dictionary (Steltenpool Reference Steltenpool1969), and none of these words were familiar to our consultant. For all other environments, we recorded at least nine tokens in each case. The total number of target tokens we analyzed was 312.
The 312 stimuli tokens were randomly interspersed with 300 filler tokens. Our fillers were 100 disyllabic or longer frequent Mee words identified in our elicitations. Each filler word was repeated three times to yield 300 tokens. As with the target words, some of our fillers were morphologically complex. None of the fillers contained the phoneme /ɡᶫ/. All items were recorded in a carrier phrase given in (2).Footnote 6
-
(2)
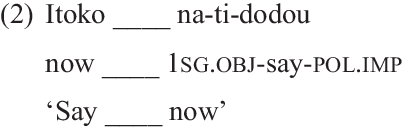
5.1.3 Annotation
Target tokens containing /ɡᶫ/ were extracted from the main recordings and annotated for acoustic analysis in Praat (Boersma and Weenink 2019). The annotations relevant to our current hypotheses included the V1 interval (if present) and the closure or constriction interval for /ɡᶫ/.Footnote 7
Acoustic annotations were performed by the second author. A random subset of tokens was annotated first, and these pilot annotations were used to jointly establish clear criteria for V1 and closure boundaries, as described below. The potentially ambiguous annotations (identified by the second author) were also checked by the first author and by another colleague who is a trained phonetician, until an agreement was reached.Footnote 8 In addition to that, after the annotations had been completed, a random subset of about thirty tokens was selected from the second author’s annotations and checked by the first author and by the colleague. No annotation issues were identified during this check.
The /ɡᶫ/ closure interval was annotated from the abrupt lowering of energy in higher frequencies after V1 up until an abrupt rise for /ɡᶫ/ release and V2. These boundary points were usually clearly identifiable in our data (see also Figures 2–5). In a minority of cases the closure was either very short or contained low-intensity aperiodic noise in higher frequencies, consistent with /ɡᶫ/ being lenited.
The V1 interval was also annotated. The onset of V1 was assumed to be the onset of periodic signal (after voiceless sounds or a pause) or the abrupt rise of energy in higher frequencies (after sonorants). The offset of V1 coincided with the beginning of /ɡᶫ/ closure.
Performing the annotations allowed us to inspect all relevant tokens in some detail, and helped us to identify three items that had to be excluded from acoustic measurements. Two tokens exhibited an apparent non-speech noise during /ɡᶫ/ production, presumably from the speaker’s lips getting too close to the microphone. These excluded tokens were: the sixth repetition of [wiɢʁoːta] ‘torn’ and the second repetition of [akawaɡᶫe] ‘they fight each other’. One token of /ɡᶫ/ (third repetition of [buɢʁuwa] ‘forest’) was excluded due to an extremely high degree of lenition where the closure was hard to separate from the surrounding vowel intervals.
It should be acknowledged that annotations are inherently subjective and thus they could in principle introduce a bias in our data. Such a bias would apply particularly to the duration measurements based on the relevant intervals. However, only closure duration is potentially relevant to our hypotheses (see Section 5.1.4), and the closure interval was relatively uncontroversial in our case.
5.1.4 Analysis
Acoustic measurements were taken automatically in Praat (Boersma and Weenink 2019). Duration was measured for the closure interval in order to address our preliminary impressions of a relatively long closure duration from elicitations (Section 4). However, recall that the distinction between the two velar lateral allophones is not expected to manifest itself in duration, hence we expect similar duration measures for [ɡᶫ] and [ɢʁ].
Preliminary observations in our elicitation study showed that /ɡᶫ/ closure and release were sometimes subject to partial devoicing (see Section 4). Based on the distinction between laterals and fricatives (see Section 3.2), we expected that the uvular allophone [ɢʁ] would be more likely to undergo this devoicing than the velar [ɡᶫ], since uvular release is fricated while velar release is sonorant. To address this hypothesis, we measured harmonics to noise ratio (HNR) within 20 ms of the closure offset – this interval was estimated to include the release of /ɡᶫ/. HNR was measured using the accurate autocorrelation method (Boersma Reference Boersma1993) with the time step of 10 ms, the minimum pitch of 75 Hz, the relative silence threshold of 0.1, and assuming 4.5 periods per window.
According to our hypothesis, the two allophones of the velar lateral differ in place of articulation for the main constriction, and this difference in constriction location is likely to have an effect on the preceding vowel, as discussed for formant transitions into velars vs. uvulars in Section 3.1. Specifically, the uvular allophone is expected to trigger a local backing (hence lower F2) and potentially lowering (higher F1) effect on the preceding vowel formants, not to be confused with formant structure in the lateral release interval itself. To address the formant trajectory of V1, formant measurements were taken at 30 equally spaced intervals within the V1 interval. All formant measurements were taken automatically in Praat, using linear interpolation Burg LPC with a time step of 10 ms and window length of 25 ms.
We also attempted to measure formants of the lateral release of the [ɡᶫ] allophone in order to compare our results to other existing studies of velar lateral acoustics (see Section 3.2). Formant measurements were taken 3 ms after the closure offset in order to capture a point closer to the lateral rather than to the vowel. However, we anticipated several potential problems with these measurements. First, the formant structure of the release of the [ɡᶫ] allophone is highly affected by the following vowels since the release is directly followed by a vowel. Therefore, it may be hard to detect acoustic properties of the velar lateral release itself. Second, lateral release realization may be very highly variable, preventing us from getting meaningful formant data. Resonating frequencies of laterals have been found to be highly variable across languages (see Section 3.2), and in our case this variability is expected to be even higher since, as our elicitations reveal (Section 4), the degree of temporal overlap between the lateral release and the following vowel is variable too.
A more meaningful study of velar lateral release in Mee could probably be done by comparing the formants of front vowels /i e/ after the velar lateral and after other consonants. However, our stimuli set was not designed to address this question as our main goal was to compare the two velar lateral allophones rather than to study the [ɡᶫ] allophone in more detail.
In an attempt to compare the spectrum of [ɡᶫ] vs. [ɢʁ] allophones, we also measured Centre of Gravity with weighting by the power spectrum in the 20 ms interval after the closure offset. This interval is expected to include the release of /ɡᶫ/ that we are interested in. Centre of Gravity was measured in the range from 500 Hz to 7 KHz. This range on the one hand avoids capturing the very low frequencies dominated by voicing and on the other hand excludes the very high frequencies that are likely to be linguistically irrelevant.
Statistical analysis of the results was performed in R (R Development Core Team 2018). In order to inspect the formant trajectories of V1, we used Smoothing Splines ANOVA (Davidson Reference Davidson2006, Gu Reference Gu2015) implemented in the gss package (Gu Reference Gu2019). Linear mixed effects regression modeling was done using the lme4 package (Bates, Maechler & Bolker Reference Bates, Maechler and Bolker2011). Vowel space plots were rendered using the package phonR (McCloy Reference McCloy2016).
5.2 Results
Mean duration of the closure interval in our dataset was found to be 34.2 ms (s.d. 17 ms), and closure duration did not present a substantial difference between [ɡᶫ] and [ɢʁ] allophones: mean 33.4 ms (s.d. 16.4 ms) for [ɡᶫ] vs. mean 35 ms (s.d. 17.6 ms) for [ɢʁ].
5.2.1 Release quality
The observations from our elicitations led us to expect that the [ɢʁ] allophone is more likely to have aperiodic, i.e. partially devoiced release (see the discussion of Figure 5) – this was assessed based on the mean Harmonics-to-Noise Ratio within 20 ms of closure offset. HNR was undefined for 8 tokens, listed in (3). An inspection of the spectrograms of these tokens revealed that in most of these words /ɡᶫ/ had an exceptionally long and completely aperiodic release, thus the HNR measuring algorithm was inapplicable (Boersma Reference Boersma1993). Two tokens (the second repetition of [nakaɡᶫĭ] ‘smoke’ and the third repetition of [nomeneːɡᶫĭ] ‘he gave someone a drink’) showed a partial devoicing of the whole final vowel.
(3) Tokens excluded from HNR measurements

For the remaining tokens, HNR could be reliably measured in the 20 ms after closure offset. [ɡᶫ] showed more periodic release with a mean HNR of 7.08 dB (s.d. 2.74) vs. 5.47 dB (s.d. 3.3) for [ɢʁ]. Since HNR is a logarithmic measure, the small difference in the mean corresponds to a relatively large perceptual distinction. The difference in HNR between two /ɡᶫ/ allophones was significant (Intercept = 5.31; β = 2; SE = 0.5; df = 90.8; t-value = 3.89; p < .001), based on a linear mixed effects model with consonant place (velar vs. uvular) as a fixed effect, item and repetition number as random effects.
Our elicitations revealed a high degree of variability in release spectra for both allophones (see Section 4.3). Since we assume the [ɡᶫ] allophone to have a sonorous release, we attempted formant measurements 3 ms after the closure offset. However, the measured formants turned out to have very high standard deviations (372 Hz for F1; 399 Hz for F2; 277 Hz for F3), so it does not seem sensible to quote representative formant values.
Given the very high variability of release spectra, it seems hard to find an objective acoustic spectral measure that would meaningfully apply to all cases. We measured Centre of Gravity in the 20 ms after closure offset, for the range 500 Hz–7 KHz. [ɢʁ] release has a mean CoG of 1337 Hz (s.d. 687 Hz), which is lower than the mean CoG for [ɡᶫ]: 2066 Hz (s.d. 724 Hz). The high standard deviations are consistent with release spectra being highly variable for both allophones. Despite this high variability, the difference in CoG is significant (Intercept = 1357; β = 724, SE = 123, df = 94.8; t-value = 5.89; p < .001), as revealed by a linear mixed effects regression model with consonant place as a fixed effect and item and repetition number as random effects.
To summarize, we found a difference in periodicity and overall spectral shape between the releases of the two /ɡᶫ/ allophones. Acoustically, [ɢʁ] release is less periodic, and it has a lower Centre of Gravity. These results should also be interpreted with caution since the acoustics of velar lateral release is affected by the following vowel which is different for different allophones – this point is further elaborated in Section 5.3.
5.2.2 V1 formants and transitions
For the vowel preceding /ɡᶫ/ (V1), formants were measured at thirty time points from the beginning until the end of the vowel interval. Vowel formant measurements were not normalized since they all come from one speaker. To assess the variability of formant trajectories, each formant track was then modeled with SSANOVA with /ɡᶫ/ allophone place (velar vs. uvular) and interval number (1:30) as main effects.
Figure 6 shows formant trajectories as estimated by the model with Bayesian 95% confidence intervals. For comparison, a graph of raw formant means is presented in Appendix B. In Figure 6, the most relevant part of each curve is the stretch roughly from the midpoint until the end. Since the left context of each vowel is not controlled in our dataset, formant values closer to the vowel beginning are expected to show relatively high variability.
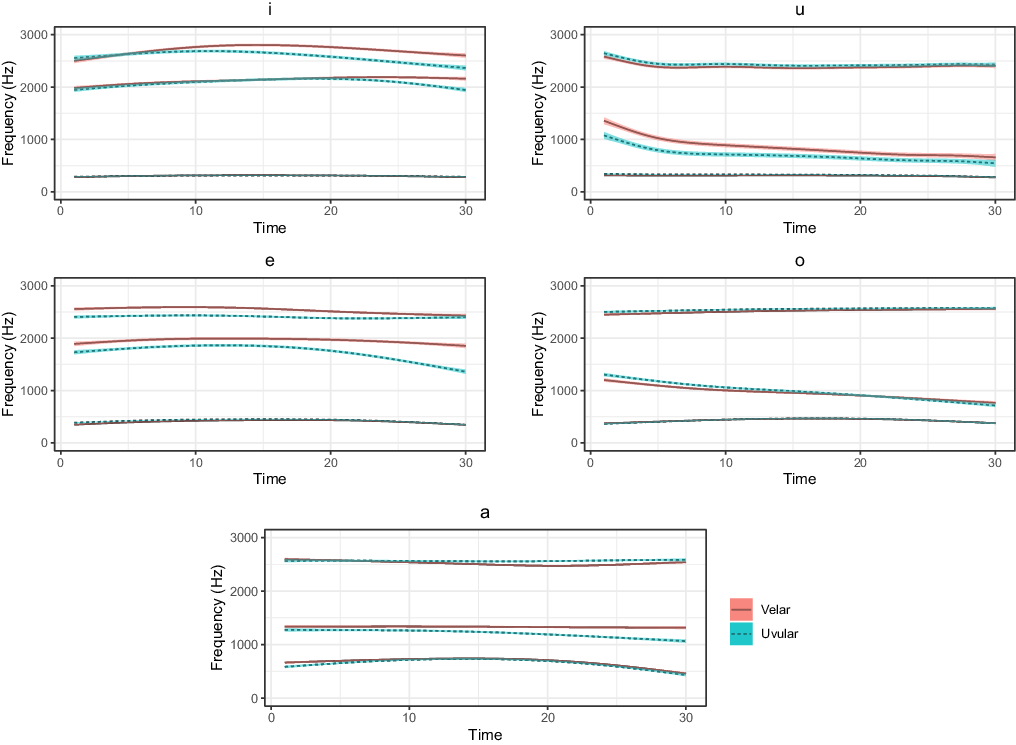
Figure 6 Smoothing Spline ANOVA model curves for F1, F2 and F3 of the vowel before /ɡᶫ/. Lines show model estimates with Bayesian 95% confidence intervals. Vowels before [ɡᶫ] shown as solid lines in coral, vowels before [ɢʁ] shown as dashed lines in teal.
Most vowels preceding a uvular [ɢʁ] show a clear lowering of F2 towards the endpoint, and lowering usually becomes more pronounced towards the vowel offset. An exception to this pattern is seen for [o], where no clear difference in F2 can be observed. The F2 of [u] seems to pattern in the same general direction but also seems more variable than the formants for other vowels. The formants of [u] may be hard to track automatically since F1 is close to F2, leading to more mistracking. Interestingly, the F1 tracks do not seem to show a robust difference in velar vs. uvular context. Thus Figure 6 shows no obvious lowering effect before [ɢʁ].
The effects of velar lateral allophones on the preceding vowel are expected to be observed most robustly towards the end of the vowel. The transitional formant values for each vowel, taken at 90% duration, are plotted in Figure 7. Note that our stimuli set limits the set of V1 qualities to simple vowels – hence diphthongs do not appear.

Figure 7 Formant transitions from the preceding vowel into [ɡᶫ] (dotted line) and [ɢʁ] (solid line), taken at 90% of the vowel interval.
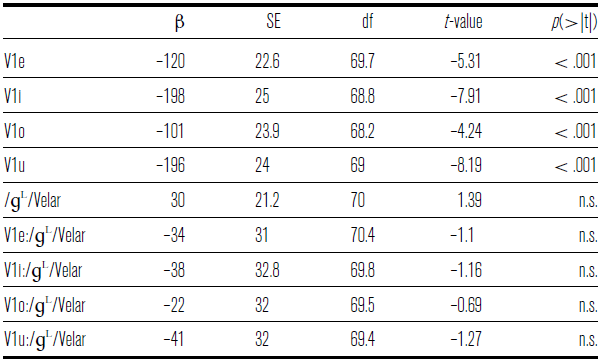
As seen in Figure 7, at the 90% time point all vowels with the exception of /o/ show a clear separation between the formant transitions into [ɡᶫ] and the formant transitions into [ɢʁ]. This distinction is based primarily on F2 rather than F1, consistent with the trend already observed in Figure 6.
We analyzed F2 transitions into /ɡᶫ/ at 90% of V1 duration with a linear mixed effects regression model taking V1 quality and consonant place (velar vs. uvular) as fixed effects and including item and repetition number as random effects (see Table 6). The model compared each vowel to the V1 vowel /a/ and the velar place to the uvular. Vowels before [ɢʁ] were found to have a significantly lower F2, consistent with backing. An expected significant effect of V1 quality was also found for all vowels.
Table 6 Linear mixed effects model results for the second formant of the vowel before /ɡᶫ/, taken at 90% of the vowel duration.

The difference in F2 values is particularly pronounced for /e/, as witnessed by a significant interaction between V1 being /e/ and consonant place. On the other hand, as observed above, the effect of /ɡᶫ/ allophones on V1 F2 transitions is particularly small for the vowel /o/ – the interaction between V1 being /o/ and consonant place was marginal. These interactions are also seen in Figure 7, where the F2 values for /e/ are very clearly distinct between the two contexts while the F2 values for /o/ are hardly separable.
Based on Figures 6–7, /ɡᶫ/ allophony does not seem to have a consistent effect on the first formant of the preceding vowel. F1 transitions into /ɡᶫ/ at 90% of V1 duration were analyzed with a linear regression model similar to the model for F2 transitions. The model showed an expected significant effect of V1 quality, but the effect of consonant place was not significant (see Table 7). Thus we do not find numeric evidence of vowel lowering before [ɢʁ].
Table 7 Linear mixed effects model results for the first formant of the vowel before /ɡᶫ/, taken at 90% of the vowel duration.
5.3 Discussion of acoustic study results
Our results on closure duration confirm that the Mee velar lateral has a relatively long closure or constriction phase. In this way it contrasts with velar laterals in other languages such as Mid-Wahgi (Ladefoged et al. Reference Ladefoged, Cochran and Disner1977, Ladefoged & Maddieson Reference Ladefoged and Ian1996), Kuman (Steed & Hardie Reference Steed, Peter and Catherine2004), and Hiw (François Reference François2010), discussed in Section 4.3.
Our acoustic results also align with our main hypothesis that Mee /ɡᶫ/ is realized as a velar [ɡᶫ] before front vowels but uvular [ɢʁ] before back vowels. We find a distinction in release periodicity: on average [ɡᶫ] release was more periodic than for [ɢʁ]. This is consistent with the release target being a fricative rather than a sonorant for [ɢʁ] and with a higher likelihood of partial devoicing for [ɢʁ] release. The release for [ɡᶫ] was also found to have a higher CoG than that of [ɢʁ], consistent with the high CoG for palatal laterals in Tabain et al. (Reference Tabain, Butcher, Breen and Beare2016).
The results on release CoG, and possibly even on Harmonics-to-Noise ratio, should be interpreted with caution since these measures could be affected by V2, which is different after each allophone. For example, measured CoG could be influenced by the highest-amplitude resonant of the following vowel – in the relevant frequency range (0.5–7KHz) this would be F2. The front vowels after [ɡᶫ] will have a higher F2 than the back vowels after [ɢʁ], and this could be contributing to the CoG difference we found, which is in the same direction.
The acoustic cues to the release quality likely reside not only in the release interval, but also in the quality of the following vowel. We found that the lateral release of [ɡᶫ] is very highly variable in its formant structure. This variability probably stems from several factors: the inherent variability in lateral formants and their relative weakness (Stevens Reference Stevens1998, Steed & Hardie Reference Steed, Peter and Catherine2004, Proctor Reference Proctor2009, Tabain et al. Reference Tabain, Butcher, Breen and Beare2016), as well as the variation in temporal overlap between the release and the following vowel (see Figures 2–5). A detailed investigation of the Mee velar lateral release would thus compare the vowels after /ɡᶫ/ to vowels in other contexts. Our materials do not allow for such a controlled comparison, but this is a likely future direction.
Our analysis of V1 formants and transitions into /ɡᶫ/ revealed that the uvular allophone had a backing effect on the preceding vowel, as evidenced by lower F2 values before [ɢʁ]. The relative timing of F2 lowering may be slightly different for different vowels, but overall lowering occurs towards the end of the vowel, and it usually starts after the vowel’s temporal midpoint (Figure 6). This is consistent with F2 lowering being a local coarticulation effect and with a difference in constriction location for [ɡᶫ] vs. [ɢʁ] consonant closure. Our results also match the reports of vowel retraction next to uvulars in other languages (Bessell Reference Bessell1998, Wilson Reference Wilson2007, Shosted Reference Shosted and Heriberto2011, Sylak-Glassman Reference Sylak-Glassman2014). A typological survey by Sylak-Glassman (Reference Sylak-Glassman2014) found that vowel backing occurs particularly commonly next to uvulars, out of all post-velar consonants. In Mee, the difference in F2 effects between [ɢʁ] and [ɡᶫ] appears to be the most pronounced for /i e a/, and the least pronounced for /o/. Interestingly, Shosted (Reference Shosted and Heriberto2011: Figure IV–4) also finds that /i e a/ are the most distinct in his study of velar vs. uvular distinction in Q’anjob’al.
We did not find a significant lowering effect on the vowel before [ɢʁ], or at least uvular [ɢʁ] showed no more lowering than velar [ɡᶫ]. A number of existing studies of vowels next to uvulars show either just lowering or just backing for some vowels or for some contexts (Alwan Reference Alwan1986, Wilson Reference Wilson2007, Sylak-Glassman Reference Sylak-Glassman2014). It is interesting to observe that in Mee vowel backness is affected by uvulars more robustly than vowel height. This finding contributes to our understanding of how uvulars and velars are distinguished perceptually across languages.
Coarticulation between the vowels before and after /ɡᶫ/ likely also contributes to the F2 effects we observed. However, the salient difference in release quality between the two allophones also suggests that V–V coarticulation cannot be the whole story: the quality of the intervening consonant is also affected by coarticulation. In other words, although none of our acoustic measurements pertain to the closure interval itself, together the differences in release and V1 formant transitions suggest that the constriction location for the closure is likely also distinct.
A reviewer asks if glottalization could have affected our acoustic results or boundary annotation. Our elicitation study did not yield any auditory impressions of high glottalization word-medially. The only context where we did observe some glottalization was phrase-initial, and indeed initial glottalization is common across languages (see e.g. Garellek Reference Garellek2013). For /ɡᶫ/-initial words, glottalization usually did not appear to extend over an interval longer than the consonant closure. The presence of glottalization did not obscure the boundaries of the closure interval. Although it is possible that glottalization would affect our measurements of /ɡᶫ/ release periodicity (measured as HNR) in phrase-initial context, this factor would apply to both velar lateral allophones about equally since we recorded a roughly equal number of tokens of initial [ɡᶫ] (24 tokens) and [ɢʁ] (27 tokens; see Table 5). For that reason glottalization would not explain the difference in release periodicity between the allophones that we found.
6 General discussion and conclusions
Our study has provided new phonetic data on the realization of velar lateral in Mee, based on elicitations with two speakers and on a controlled acoustic study with one of the speakers. Our elicitation data support our initial hypothesis that the Mee velar lateral has two allophones distributed according to the following vowel frontness. Diphthongs condition velar lateral allophony based on their first element: /ai au ou/ condition the back vowel allophone and /ei eu/ condition the front vowel allophone.
The nature of velar lateral allophones was the subject of the posterior allophone realization hypothesis, examined in our acoustic study. We presented evidence from release acoustics and V1 formant transitions suggesting that the allophone before a front vowel has a lateral release and a velar closure, hence [ɡᶫ], whereas the allophone before back vowels has a fricative release and a uvular closure, hence [ɢʁ].
To our knowledge, this pattern of velar lateral allophony has not been described before, and is observed so far only in Mee. In what follows, we will situate the velar lateral allophony within a broader typological discussion. We will also formulate some directions for future research and tentative hypotheses about phonetic factors involved in velar lateral allophony. Our discussion will first address the typology of velar laterals and laterals in general, followed by affricates and stops.
As mentioned above, none of the other existing descriptions of velar laterals report contextual allophony of the sort observed in Mee. Another potential example of a contextually variable velar lateral comes from Auye (closely related to Mee), where Moxness (Reference Moxness2011: 42) reports: ‘/g/ is laterally released and implosive preceding front vowels /i,e/’ (see also Donohue Reference Donohue2007: 530). Although the pronunciation of Auye /ɡ/ before back vowels is not explicitly discussed, Moxness’s description may suggest that it exhibits a similar pattern of variation, especially given the fact that Mee and Auye are potentially related.
Most existing phonetically detailed descriptions of velar laterals deal with sonorant-like sounds (Ladefoged et al. Reference Ladefoged, Cochran and Disner1977, Steed & Hardie Reference Steed, Peter and Catherine2004, François Reference François2010). The Mee velar lateral patterns with stops phonologically, and it has an obligatory (see Section 4.3) and relatively long closure phase (Section 5.3). Thus, to our knowledge, our study is also among the first phonetically detailed descriptions of stop-like velar laterals.
There are other allophonic alternations in the languages of the world that involve changes in laterality and are conditioned by vowel quality. These usually involve a change from a lateral approximant to a rhotic sound or vice versa. Interestingly, these seem to be tied to vowel backness in several cases. Languages where a lateral allophone occurs before front vowels and a non-lateral allophone shows up before back vowels include Nimboran (Anceaux Reference Anceaux1965: 24) and Tukang Besi (Donohue Reference Donohue2011).Footnote 9 These allophonic patterns present a parallel to Mee in part also because the uvular fricative, which is the release of the [ɢʁ] allophone, often phonologically patterns with rhotics.
The Mee velar lateral can also be meaningfully compared to the attested affricates and stops. Both [ɡᶫ] and [ɢʁ] are phonetically voiced affricates, and this is very rare since comparable sounds in other languages are usually voiceless or voiceless ejective. The existence of these sounds in Mee thus confirms that ‘Most of the distinctions that can distinguish unaffricated stops also occur with affricates’ (Ladefoged & Maddieson Reference Ladefoged and Ian1996: 91). The place and manner of Mee allophone [ɡᶫ] is similar to the voiceless ejective [k͡Ⅼ̝̊ʼ] in Zulu (Ladefoged & Maddieson Reference Ladefoged and Ian1996: 204–206) and to the affricates [k͡Ⅼ̝̊, k͡Ⅼ̝̊ʼ] in the Nakh-Dagestanian language Archi (Kodzasov Reference Kodzasov, Kibrik, Kodzasov, Olovyannikova and Samedov1977, Ladefoged & Maddieson 1996).Footnote 10 Mee [ɡᶫ] differs from these affricates in being voiced, and in having a release that varies phonetically between fricative and approximant: in both Zulu and Archi the release is reported to be fricative.
On the other hand, the Mee allophone [ɢʁ] is a sound that does not occur contrastively to our knowledge. Chirkova & Chen (Reference Chirkova and Yiya2013) list [ɢʁ] as an allophone of the marginal phoneme /ɢ/ in Xumi. A voiceless counterpart [q͡χ] is reported in Archi (Kodzasov Reference Kodzasov, Kibrik, Kodzasov, Olovyannikova and Samedov1977), among other languages.
Allophonic variation that relates vowel frontness to the velar–uvular distinction in consonants is fairly common across languages (Sylak-Glassman Reference Sylak-Glassman2014). In Archi, vowel frontness varies allophonically depending on the velar/uvular quality of stops and affricates. Thus vowels undergo allophonic fronting after palatal-velar or prevelar laterally released stops and lateral fricatives (Kodzasov Reference Kodzasov, Kibrik, Kodzasov, Olovyannikova and Samedov1977: 217). On the other hand, Archi front vowels undergo backing after the uvular voiceless affricate [q͡χ] and its ejective and emphatic counterparts.
Vowel frontness or tenseness also covaries allophonically with the velar/uvular distinction in stops and fricatives in a number of vowel harmony systems in Altaic languages (see e.g. Svantesson et al. (Reference Svantesson, Tsendina, Karlsson and Franzén2005) on Mongolian, Becker (Reference Becker2017) on Uyghur). In these vowel harmony languages, the allophonic covariation can be triggered non-locally, that is the harmonizing vowels do not have to be adjacent to the varying velar/uvular consonants. Similarly, a number of Interior Salish languages show both local and non-local allophonic variation in vowels (Bessell Reference Bessell1998), based on velar vs. post-velar quality of consonants.
The typological commonality of the relationship between vowel frontness and velar vs. post-velar distinction in consonants suggests that this relation may have a phonetic basis or a natural history. Working within the framework of Articulatory Phonology, Gick and Wilson (2006) and Wilson (Reference Wilson2007) hypothesize that frontness distinctions in vowels may correlate with tongue root advancement/retraction gestures, which are also involved in the production of velar vs. uvular distinction. This hypothesized articulatory closeness between uvular stops and back vowels has recently also been encoded in phonological feature models of velar and post-velar consonants. Sylak-Glassman (Reference Sylak-Glassman2014) extends the articulatory model for vowels proposed by Esling (Reference Esling2005) to post-velar consonants and concludes that back vowels are phonologically specified as either [+raised] or [+open]. Uvular consonants are specified with both of these features. Articulatorily, these features correlate with ‘movement of the tongue by the styloglossus upward and backward’ and ‘relatively open jaw position’ respectively (Sylak-Glassman Reference Sylak-Glassman2014: 137). Our study thus contributes to the cross-linguistic body of evidence suggesting that the articulatory closeness of back vowels and uvulars, and the phonological models encoding this closeness, may require more attention in future research. On the other hand, the typologically common covariation of vowel frontness and velar/uvular distinction is harder to explain in other phonological models where both velars and uvulars share a [+back] or [dorsal] specification with back vowels (e.g. Chomsky & Halle 1968).
One somewhat surprising finding of our study is that we only found backing (lower F2) and no lowering (higher F1) in the vowels preceding the uvular allophone when compared to the velar allophone. One possible explanation lies in the lateral release of the velar allophone.Footnote 11 Since laterals in general require an actively lowered jaw position (Geumann Reference Geumann2001; Mooshammer, Hoole & Geumann Reference Mooshammer, Hoole and Geumann2007), one could argue that the vowels before the velar allophone are already pronounced with a lowered jaw position, anticipating the lowered lateral release. This would explain the similar F1 values before the velar and the uvular allophone, although we might expect a more pronounced formant transition to a higher F1 before both [ɡᶫ] and [ɢʁ] on this view (cf. Figure 6). Future research could evaluate this explanation by comparing our findings to the formant values of vowels preceding the velar stop /k/, which has no lateral release in Mee.
Finally, we hope that our data can be used for a deeper cross-linguistic understanding of the diachronic phonetic sources of velar laterals. Since velar laterals sometimes pattern with sonorants and sometimes with obstruents, it is to be expected that they may not emerge according to a single diachronic trajectory. In the Paniai Lakes languages discussed here, they apparently emerge from stops (Tebay Reference Tebay2018b). On the other hand, the source of velar laterals in the Oceanic language Hiw is most likely a rhotic sound (François Reference François2011). It makes sense to hypothesize that the acoustic predecessors of lateral release lay in the C–V coarticulation zone, but aside from Mee no language so far has shown a relationship between velar lateral realization and the following vowel quality. Although a pattern where the velar lateral varies with the following vowel is suggestive, more data would be needed to address the potential role of C–V coarticulation in the emergence of velar lateral release quality across languages.
Acknowledgments
We thank our Mee consultants for sharing their language with us. For their comments, support and discussion during our fieldwork and data annotation we are indebted to Martina Martinović, Barbara Stiebels, Elena Pyatigorskaya and the participants in the 2016 Field Methods class at Leipzig University. For helpful comments on earlier versions of this work we thank the editors and three anonymous reviewers, as well as Sandra Ferrari Disner, Edward Flemming, Marc Garellek, Martha Ratliff, Sharon Rose and the participants at Annual Meeting on Phonology 2018 and Phonetics and Phonology in Europe 2019. Financial support came from DFG (GRK 2011); Leipzig University; Wayne State University. All errors are our own.
Appendix A. List of items and fillers
Tables A1 and A2 list the words recorded in our acoustic study. Words are given in the practical Mee orthography that was developed for the purpose of this study in consultation with speaker S01 in the ‘Word’ column.
Table A1 List of items used in the acoustic study.

Table A2 List of fillers used in the acoustic study.

Appendix B. Mean vowel formant values
Figure B1 presents the data on mean formant values for the vowel before /ɡᶫ/, depending on the allophone of the consonant. These data are presented for comparison with the main text where SSANOVA model data are presented.

Figure B1 Average F1, F2 and F3 tracks for vowels preceding /ɡᶫ/.


















 Open access
Open access