


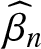
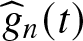
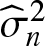
1. Introduction
Consider the following semi-parametric errors-in-variables (EV) model
 \begin{equation}
\begin{cases}
y_{i}=x_i\beta+g\left(t_{i}\right)+\varepsilon_{i},&\\
\,X_{i}=x_i+\mu_i,&
\end{cases}
\end{equation}
\begin{equation}
\begin{cases}
y_{i}=x_i\beta+g\left(t_{i}\right)+\varepsilon_{i},&\\
\,X_{i}=x_i+\mu_i,&
\end{cases}
\end{equation}where  $\left(t_{i}, X_ {i}, y_ {i} \right) $ for the sample observations,
$\left(t_{i}, X_ {i}, y_ {i} \right) $ for the sample observations,  $\beta \in \mathbb{R} $ for the unknown parameters,
$\beta \in \mathbb{R} $ for the unknown parameters,  $g(\cdot)$ is unknown functions defined on compact set
$g(\cdot)$ is unknown functions defined on compact set  $[0,1]$, random errors
$[0,1]$, random errors  $\left\{\varepsilon_{i} \right\} $ are asymptotically negatively associated (ANA) random variables with
$\left\{\varepsilon_{i} \right\} $ are asymptotically negatively associated (ANA) random variables with  $E \varepsilon_{i}=0$ and
$E \varepsilon_{i}=0$ and  $E \varepsilon_{i}^{2}=1$, and the variables
$E \varepsilon_{i}^{2}=1$, and the variables  $\{x_ {i}\} $ are measured with errors and are not directly observable. However,
$\{x_ {i}\} $ are measured with errors and are not directly observable. However,  $\{x_ {i}\} $ are observed through
$\{x_ {i}\} $ are observed through  $X_{i}=x_i+\mu_i$, where
$X_{i}=x_i+\mu_i$, where  $\{\mu_{i}\}$ are the measurement errors with
$\{\mu_{i}\}$ are the measurement errors with  $E \mu_{i}=0$,
$E \mu_{i}=0$,  $E \mu_{i}^{2}=\sigma_{\mu}^{2} \lt \infty$. Suppose
$E \mu_{i}^{2}=\sigma_{\mu}^{2} \lt \infty$. Suppose  $\{\mu_{i}\}$ are independent and identically distributed random variables, which are assumed to be independent of
$\{\mu_{i}\}$ are independent and identically distributed random variables, which are assumed to be independent of  $\left\{\varepsilon_{i} \right\}$.
$\left\{\varepsilon_{i} \right\}$.
In various applications, errors in the measurement of covariates are frequently encountered. For instance, existing literature demonstrates that covariates such as blood pressure, urinary sodium chloride levels, and exposure to pollutants are often subject to measurement errors. These errors can pose challenges and complications in the statistical analysis process. Therefore, EV models are more practical than ordinary regression models. In recent years, there has been a proliferation of research into semi-parametric EV models. In the case of independence, Cui [Reference Cui5] proved the asymptotic normality of M-estimators in the EV model; Liu and Chen [Reference Liu and Chen14] demonstrated the consistency for the least square (LS) estimators  $\widehat{\beta}_{n}$ and
$\widehat{\beta}_{n}$ and  $\widehat{g}_{n}(t)$ and concluded that strong convergence and weak convergence are equivalent; Miao et al. [Reference Miao, Wang and Zhao15] and Miao et al. [Reference Miao, Yang and Shen16] established the central limit theorem and some limit behaviors for the LS estimators in simple linear EV regression models, respectively. Nevertheless, the assumption of independence regarding the errors
$\widehat{g}_{n}(t)$ and concluded that strong convergence and weak convergence are equivalent; Miao et al. [Reference Miao, Wang and Zhao15] and Miao et al. [Reference Miao, Yang and Shen16] established the central limit theorem and some limit behaviors for the LS estimators in simple linear EV regression models, respectively. Nevertheless, the assumption of independence regarding the errors  $\{\varepsilon_{i}\}$ in model (1) is not always applicable in practice, particularly in the context of sequentially collected economic data, which frequently demonstrates evident dependencies in the errors. Scholars have expanded their horizons to research on EV models under dependent errors. For example, Zhang et al. [Reference Zhang, Liang and Amei24] established the asymptotic normality of estimators in model (1) under assumptions of stationary strong mixing and independence; Hu et al. [Reference Hu, Cui and Li9] obtained asymptotic representation of parametric estimators as well as asymptotic distributions and weak convergence rates of parametric and nonparametric estimators under long-memory errors using wavelet method; Xi et al. [Reference Xi, Wang, Yu, Shen and Wang22] obtained the asymptotic properties of LS estimators and weighted least squares (WLS) estimators under both known and unknown variances based on α-mixing errors, respectively; Wu et al. [Reference Wu, Wang and Shen21] investigated the strong consistency and convergence rates of the LS estimators and WLS estimators with widely orthant dependent samples, and so on.
$\{\varepsilon_{i}\}$ in model (1) is not always applicable in practice, particularly in the context of sequentially collected economic data, which frequently demonstrates evident dependencies in the errors. Scholars have expanded their horizons to research on EV models under dependent errors. For example, Zhang et al. [Reference Zhang, Liang and Amei24] established the asymptotic normality of estimators in model (1) under assumptions of stationary strong mixing and independence; Hu et al. [Reference Hu, Cui and Li9] obtained asymptotic representation of parametric estimators as well as asymptotic distributions and weak convergence rates of parametric and nonparametric estimators under long-memory errors using wavelet method; Xi et al. [Reference Xi, Wang, Yu, Shen and Wang22] obtained the asymptotic properties of LS estimators and weighted least squares (WLS) estimators under both known and unknown variances based on α-mixing errors, respectively; Wu et al. [Reference Wu, Wang and Shen21] investigated the strong consistency and convergence rates of the LS estimators and WLS estimators with widely orthant dependent samples, and so on.
As pointed out by Zhang and Wang [Reference Zhang and Wang26], ANA random variables include  $\rho^\ast$-mixing random variables and NA random variables as special cases. On the one hand, NA sequence is an important dependent series that has been widely used in reliability theory, probabilistic process, stochastic process, multivariate statistics, and so on. On the other hand,
$\rho^\ast$-mixing random variables and NA random variables as special cases. On the one hand, NA sequence is an important dependent series that has been widely used in reliability theory, probabilistic process, stochastic process, multivariate statistics, and so on. On the other hand,  $\rho^\ast$-mixing sequence is a more common mixed form of time series, and it has a wide range of applications in risk management, economic decision-making, and variable forecasting. They also gave an example to show that ANA sequences are not necessarily NA or
$\rho^\ast$-mixing sequence is a more common mixed form of time series, and it has a wide range of applications in risk management, economic decision-making, and variable forecasting. They also gave an example to show that ANA sequences are not necessarily NA or  $\rho^\ast$-mixing. Hence, the study of the convergence properties for ANA random variables is of more interest.
$\rho^\ast$-mixing. Hence, the study of the convergence properties for ANA random variables is of more interest.
Now, let us recall some dependence structures. The concept of ANA random variables was introduced by Zhang and Wang [Reference Zhang and Wang26].
Definition 1.1. A sequence  $\{X_n, n\geq 1\}$ of random variables is said to be ANA (or ρ −, for short) if
$\{X_n, n\geq 1\}$ of random variables is said to be ANA (or ρ −, for short) if
 \begin{eqnarray*}
\rho^-(s)=\sup\{\rho^-(S,T): S,T\subset \mathbb{N}, dist(S,T)\geq s\}\rightarrow0, ~~as~~s\rightarrow\infty,
\end{eqnarray*}
\begin{eqnarray*}
\rho^-(s)=\sup\{\rho^-(S,T): S,T\subset \mathbb{N}, dist(S,T)\geq s\}\rightarrow0, ~~as~~s\rightarrow\infty,
\end{eqnarray*}where
 \begin{eqnarray*}
\rho^-(S,T)=0\vee\left\{\frac{Cov\left(f_1(X_i, i\in S), f_2(X_j, j\in T)\right)}{\sqrt{Var(f_1(X_i, i\in S))\cdot Var(f_2(X_j, j\in T))}}: f_1,f_2\in \mathcal{C}\right\},
\end{eqnarray*}
\begin{eqnarray*}
\rho^-(S,T)=0\vee\left\{\frac{Cov\left(f_1(X_i, i\in S), f_2(X_j, j\in T)\right)}{\sqrt{Var(f_1(X_i, i\in S))\cdot Var(f_2(X_j, j\in T))}}: f_1,f_2\in \mathcal{C}\right\},
\end{eqnarray*}and  $\mathcal{C}$ is the set of nondecreasing functions.
$\mathcal{C}$ is the set of nondecreasing functions.
Since Zhang and Wang [Reference Zhang and Wang26] proposed the concept of ANA random variables, many results on ANA random variables have been established. For the probabilistic limit theory of ANA random variables, one can refer to [Reference Zhang and Wang26], [Reference Wang and Lu18], and [Reference Yuan and Wu23] for some moment inequalities and some limiting behavior; [Reference Zhang25] for some central limit theorems; [Reference Ko12] for the Hájek–Rényi inequality and the strong law of large numbers; [Reference Wu and Jiang20] for almost sure convergence of ANA random variables; and [Reference Chen, Lu, Shen, Wang and Wang4] for complete and complete moment convergence. Based on the probability inequality of ANA random variables, researchers have further extended its application to various statistical models. For example, Tang et al. [Reference Tang, Xi, Wu and Wang17] derived asymptotic normality of wavelet estimator for nonparametric fixed design regression model with ANA errors, Zhang and Liu [Reference Zhang and Liu27] studied the consistency of estimators in heteroscedasticity partially linear model with ANA errors. So far, there is no literature studying the asymptotic properties of model (1) under ANA random error. This research contributes to the existing body of knowledge by extending the scope of ANA random variable studies.
As is well known, following the introduction of the wavelet method by [Reference Antoniadis, Gregoire and Mckeague1], numerous researchers have begun to explore its applications in the field of statistics. For example, Antoniadis et al. [Reference Antoniadis, Gregoire and Mckeague1] and Donoho et al. [Reference Donoho, Johnstone, Kerkyacharian and Picard7] estimated regression function and density function with wavelet technique, respectively; Chai and Liu [Reference Chai and Liu3] discussed the weak convergence, strong convergence, and convergence rate of wavelet estimators in nonparametric regression models with ρ-mixing sequence; Liu et al. [Reference Li, Yang and Zhou13] obtained consistency and uniform asymptotic normality of wavelet estimators in regression models with associated samples; Zhou and Lin [Reference Zhou and Lin28] studied the asymptotic properties of wavelet estimator in a semi-parametric regression model with the mixing dependent errors; Ding and Chen [Reference Ding and Chen6] studied the asymptotic normality of wavelet estimators of slope parameters and nonparametric components in semi-parametric regression models with known error variance and so on.
It can be seen from the above literature that the wavelet method has a great adaptability to the local features of unknown curves. In the event that the errors in the semi-parametric EV model are ANA sequences, we are prepared to employ wavelet smoothing and LS methods to estimate the parameters, non-parameters, and variance functions in the model, respectively. In addition, under certain standard assumptions, it has been demonstrated that they exhibit strong consistency.
The work is organized as follows. In Section 2, we introduce the estimators of β, g(t), and σ 2 in the semi-parametric EV model. It also describes some assumptions and remarks and presents the main results. Some numerical simulations are provided in Section 3. Proofs of the main results and the preliminary lemmas are provided in Sections 4 and A, respectively.
Throughout this article, the symbol C represents some positive constant which may vary in different places. The symbol  $\xrightarrow{a.s.}$ represent almost sure convergence. Let I(B) be the indicator function of the set B and
$\xrightarrow{a.s.}$ represent almost sure convergence. Let I(B) be the indicator function of the set B and  $\lfloor x \rfloor$ denote the integer part of x. Denote
$\lfloor x \rfloor$ denote the integer part of x. Denote  $x^+=xI(x \geq 0)$ and
$x^+=xI(x \geq 0)$ and  $x^- = -x I(x \lt 0)$.
$x^- = -x I(x \lt 0)$.  $a_n=O(b_n)$ means
$a_n=O(b_n)$ means  $|a_n|\leq C|b_n|$, while
$|a_n|\leq C|b_n|$, while  $a_n=o(b_n)$ means
$a_n=o(b_n)$ means  $a_n/b_n\rightarrow 0$. All limits are taken as the sample size n tends to
$a_n/b_n\rightarrow 0$. All limits are taken as the sample size n tends to  $\infty$, unless it is specially mentioned.
$\infty$, unless it is specially mentioned.
2. Assumptions and main results
2.1. Construction of estimators
In order to avoid symbol abuse, we adopt the symbols and definitions set forth by [Reference Antoniadis, Gregoire and Mckeague1] for the introduction of the wavelet estimator.
Definition 2.1. A function space  $S_q~(q\in \mathbb{R})$ is said to be Sobolev space with order q, if Sq is continuous differentiable for Sq-times function space, and the function in Sq rapidly decreasing at infinity, that is for
$S_q~(q\in \mathbb{R})$ is said to be Sobolev space with order q, if Sq is continuous differentiable for Sq-times function space, and the function in Sq rapidly decreasing at infinity, that is for  $h\in S_q$, there exists a constant
$h\in S_q$, there exists a constant  $C_{pq} \gt 0$ such that
$C_{pq} \gt 0$ such that
 \begin{equation*}\left|h^{(k)}(t)\right|\leq C_{pk}(1+|t|)^{-p},~~~k=0,1,\ldots,q,~~~p\in \mathbb{N},~~~t\in \mathbb{R}.\end{equation*}
\begin{equation*}\left|h^{(k)}(t)\right|\leq C_{pk}(1+|t|)^{-p},~~~k=0,1,\ldots,q,~~~p\in \mathbb{N},~~~t\in \mathbb{R}.\end{equation*}Definition 2.2. A function space  $H^\nu~(\nu\in \mathbb{R})$ is said to be Sobolev space with order ν, that is, if
$H^\nu~(\nu\in \mathbb{R})$ is said to be Sobolev space with order ν, that is, if  $h\in H^\nu$ then
$h\in H^\nu$ then
 \begin{equation*}\int |\hat{h}(\omega)|^2(1+\omega^2)^\nu d\omega \lt \infty,\end{equation*}
\begin{equation*}\int |\hat{h}(\omega)|^2(1+\omega^2)^\nu d\omega \lt \infty,\end{equation*}where  $\hat{h}$ is the Fourier transform of h.
$\hat{h}$ is the Fourier transform of h.
Let  $\varphi(x)$ be a given scaling function in the Schwarz space with order l. A multiresolution analysis of
$\varphi(x)$ be a given scaling function in the Schwarz space with order l. A multiresolution analysis of  $L^{2}(\mathbb{R})$ consists of an increasing sequence of the closed subspace
$L^{2}(\mathbb{R})$ consists of an increasing sequence of the closed subspace  $\left\{V_{m},~m\in \mathbb{Z}\right\}$, where
$\left\{V_{m},~m\in \mathbb{Z}\right\}$, where  $\mathbb{Z}$ is the integer set and
$\mathbb{Z}$ is the integer set and  $L^{2}(\mathbb{R})$ is a set of square integral functions over the real line. Since
$L^{2}(\mathbb{R})$ is a set of square integral functions over the real line. Since  $\left\{\varphi(x-k),~k\in \mathbb{Z}\right\}$ is an orthogonal family of
$\left\{\varphi(x-k),~k\in \mathbb{Z}\right\}$ is an orthogonal family of  $L^{2}(\mathbb{R})$ and V 0 is the subspace spanned, if we define
$L^{2}(\mathbb{R})$ and V 0 is the subspace spanned, if we define
 \begin{equation*}\varphi_{mk}(x)=2^{m/2}\varphi(2^mx-k),~~k\in \mathbb{Z},\end{equation*}
\begin{equation*}\varphi_{mk}(x)=2^{m/2}\varphi(2^mx-k),~~k\in \mathbb{Z},\end{equation*}then  $\left\{\varphi_{0k},~k\in \mathbb{Z}\right\}$ is an orthogonal basis of V 0 , and
$\left\{\varphi_{0k},~k\in \mathbb{Z}\right\}$ is an orthogonal basis of V 0 , and  $\left\{\varphi_{mk},~k\in \mathbb{Z}\right\}$ is an orthogonal basis of Vm. The associated integral kernel of Vm is given by
$\left\{\varphi_{mk},~k\in \mathbb{Z}\right\}$ is an orthogonal basis of Vm. The associated integral kernel of Vm is given by
 \begin{equation*}
E_{m}(t, s)=2^{m} E_{0}\left(2^{m} t, 2^{m} s\right)=2^{m} \sum_{k \in \mathbb{Z}} \varphi\left(2^{m} t-k\right) \varphi\left(2^{m} s-k\right).
\end{equation*}
\begin{equation*}
E_{m}(t, s)=2^{m} E_{0}\left(2^{m} t, 2^{m} s\right)=2^{m} \sum_{k \in \mathbb{Z}} \varphi\left(2^{m} t-k\right) \varphi\left(2^{m} s-k\right).
\end{equation*} The following wavelet method similar to [Reference Hu, Cui and Li9] is used to estimate  $\beta,~g(t)$, and σ 2. From model (1), it can be obtained
$\beta,~g(t)$, and σ 2. From model (1), it can be obtained
 \begin{equation}
y_{i}=X_{i} \beta+g\left(t_{i}\right)+\varepsilon_{i}-\mu_{i} \beta.
\end{equation}
\begin{equation}
y_{i}=X_{i} \beta+g\left(t_{i}\right)+\varepsilon_{i}-\mu_{i} \beta.
\end{equation} Let  $\xi_{i}:=\varepsilon_{i}-\mu_{i} \beta$. Then the model (2) becomes
$\xi_{i}:=\varepsilon_{i}-\mu_{i} \beta$. Then the model (2) becomes
 \begin{equation}
y_{i}=X_{i} \beta+g\left(t_{i}\right)+\xi_{i} .
\end{equation}
\begin{equation}
y_{i}=X_{i} \beta+g\left(t_{i}\right)+\xi_{i} .
\end{equation}Denote
 \begin{equation}
x_{i}=f\left(t_{i}\right)+\eta_{i},~~~~i=1,2,\ldots,n,
\end{equation}
\begin{equation}
x_{i}=f\left(t_{i}\right)+\eta_{i},~~~~i=1,2,\ldots,n,
\end{equation}where  $f(\cdot) $ is a function defined on interval
$f(\cdot) $ is a function defined on interval  $ [0, 1] $,
$ [0, 1] $,  $\left\{\eta_{i}\right\}$ is independent and identically distributed with
$\left\{\eta_{i}\right\}$ is independent and identically distributed with  $E \eta_ {i} = 0$ and
$E \eta_ {i} = 0$ and  $\operatorname{Var}\left(\eta_{i}\right)=\sigma_{\eta}^{2} \lt \infty$. Moreover,
$\operatorname{Var}\left(\eta_{i}\right)=\sigma_{\eta}^{2} \lt \infty$. Moreover,  $\left\{\eta_{i}\right\}$ are independent of
$\left\{\eta_{i}\right\}$ are independent of  $\left\{(\varepsilon_{i}, \mu_{i})\right\}$.
$\left\{(\varepsilon_{i}, \mu_{i})\right\}$.
Let  $A_{i}=\left[s_{i-1}, s_{i}\right)$ denote intervals that partition
$A_{i}=\left[s_{i-1}, s_{i}\right)$ denote intervals that partition  $[0,1]$ with
$[0,1]$ with  $t_{i} \in A_{i}$ for
$t_{i} \in A_{i}$ for  $ 1 \leq i \leq n$. First, we assume that β is known and that
$ 1 \leq i \leq n$. First, we assume that β is known and that  $g\left(t_{i}\right)=E\left(y_{i}-X_{i} \beta\right)$ can be obtained from
$g\left(t_{i}\right)=E\left(y_{i}-X_{i} \beta\right)$ can be obtained from  $E\xi_{i}=0$. Therefore, the estimate of
$E\xi_{i}=0$. Therefore, the estimate of  $g(\cdot)$ is defined as
$g(\cdot)$ is defined as
 \begin{equation}
\widehat{g}_{0}(t, \beta)=\sum_{i=1}^{n}\left(y_{i}-X_{i} \beta\right) \int_{A_{i}} E_{m}(t, s) \mathrm{d} s .
\end{equation}
\begin{equation}
\widehat{g}_{0}(t, \beta)=\sum_{i=1}^{n}\left(y_{i}-X_{i} \beta\right) \int_{A_{i}} E_{m}(t, s) \mathrm{d} s .
\end{equation}On this basis, the estimator of β can be defined as
 \begin{equation}
\widehat{\beta}_{n}=\arg \min _{\beta} \sum_{i=1}^{n}\left[\left(y_{i}-X_{i} \beta-\widehat{g}_{0}(t, \beta)\right)^{2}-\sigma_{\mu}^{2} \beta^{2}\right]=\left(\widetilde{X}^{T} \widetilde{X}-n \sigma_{\mu}^{2}\right)^{-1} \widetilde{X}^{T} \widetilde{Y},
\end{equation}
\begin{equation}
\widehat{\beta}_{n}=\arg \min _{\beta} \sum_{i=1}^{n}\left[\left(y_{i}-X_{i} \beta-\widehat{g}_{0}(t, \beta)\right)^{2}-\sigma_{\mu}^{2} \beta^{2}\right]=\left(\widetilde{X}^{T} \widetilde{X}-n \sigma_{\mu}^{2}\right)^{-1} \widetilde{X}^{T} \widetilde{Y},
\end{equation}where  $
X=\left(X_{1}, \ldots, X_{n}\right)^{T},~ Y=\left(y_{1}, \ldots, y_{n}\right)^{T},~
S=\left(S_{i j}\right)_{n \times n},~S_{i j}=\int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s,~
\widetilde{X}=(I-S) X,~\widetilde{Y}=(I-S) Y.
$ Therefore, the estimator of
$
X=\left(X_{1}, \ldots, X_{n}\right)^{T},~ Y=\left(y_{1}, \ldots, y_{n}\right)^{T},~
S=\left(S_{i j}\right)_{n \times n},~S_{i j}=\int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s,~
\widetilde{X}=(I-S) X,~\widetilde{Y}=(I-S) Y.
$ Therefore, the estimator of 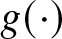 $g(\cdot)$ is defined as
$g(\cdot)$ is defined as
 \begin{equation}
\widehat{g}_{n}(t)=\widehat{g}_{0}\left(t, \widehat{\beta}_{n}\right)=\sum_{i=1}^{n}\left(y_{i}-X_{i} \widehat{\beta}_{n}\right) \int_{A_{i}} E_{m}(t, s) \mathrm{d} s.
\end{equation}
\begin{equation}
\widehat{g}_{n}(t)=\widehat{g}_{0}\left(t, \widehat{\beta}_{n}\right)=\sum_{i=1}^{n}\left(y_{i}-X_{i} \widehat{\beta}_{n}\right) \int_{A_{i}} E_{m}(t, s) \mathrm{d} s.
\end{equation} Since  $\sigma^{2}=\mathrm{E}\left(y_{i}-x_{i} \beta-g\left(t_{i}\right)\right)^{2}$, using the method in [Reference Baek and Liang2], the estimator of σ 2 can be defined as
$\sigma^{2}=\mathrm{E}\left(y_{i}-x_{i} \beta-g\left(t_{i}\right)\right)^{2}$, using the method in [Reference Baek and Liang2], the estimator of σ 2 can be defined as
 \begin{equation}
\widehat{\sigma}_{n}^{2}=\frac{1}{n} \sum_{i=1}^{n}\left(\widetilde{y}_{i}-\widetilde{X}_{i} \widehat{\beta}_{n}\right)^{2}-\sigma_{\mu}^{2} \widehat{\beta}_{n}^{2}.
\end{equation}
\begin{equation}
\widehat{\sigma}_{n}^{2}=\frac{1}{n} \sum_{i=1}^{n}\left(\widetilde{y}_{i}-\widetilde{X}_{i} \widehat{\beta}_{n}\right)^{2}-\sigma_{\mu}^{2} \widehat{\beta}_{n}^{2}.
\end{equation}Remark 2.3. If  $\sigma_{\mu}^{2} $ is unknown, we can estimate
$\sigma_{\mu}^{2} $ is unknown, we can estimate  $\sigma_{\mu}^{2} $ by repeatedly measuring X. The specific method can be found in [Reference Baek and Liang2].
$\sigma_{\mu}^{2} $ by repeatedly measuring X. The specific method can be found in [Reference Baek and Liang2].
2.2. Assumptions
Now we list the following assumptions.
 $\mathbf{(H1)}$ (i) Functions
$\mathbf{(H1)}$ (i) Functions  $g(\cdot)$ and
$g(\cdot)$ and  $f(\cdot)$ satisfy the Lipschitz condition of order γ > 0;
$f(\cdot)$ satisfy the Lipschitz condition of order γ > 0;
(ii)  $g(\cdot)\in H^\alpha~\mathrm{and}~f(\cdot) \in H^\alpha$,
$g(\cdot)\in H^\alpha~\mathrm{and}~f(\cdot) \in H^\alpha$,  $\alpha \gt \frac{1}{2}$.
$\alpha \gt \frac{1}{2}$.
 $\mathbf{(H2)}$
$\mathbf{(H2)}$  $\varphi(x)$ belongs to Sl, which is a Schwartz space for
$\varphi(x)$ belongs to Sl, which is a Schwartz space for  $l\geq \alpha $.
$l\geq \alpha $.  $\varphi(x)$ is a Lipschitz function of order 1 and have compact support, in addition to
$\varphi(x)$ is a Lipschitz function of order 1 and have compact support, in addition to  $|\hat{\varphi}(\varrho)-1|=O(\varrho)$ as
$|\hat{\varphi}(\varrho)-1|=O(\varrho)$ as  $\varrho\rightarrow0$, where
$\varrho\rightarrow0$, where  $\hat{\varphi}$ is the Fourier transform of φ.
$\hat{\varphi}$ is the Fourier transform of φ.
 $\mathbf{(H3)}$ (i)
$\mathbf{(H3)}$ (i)  $\max\limits_{1 \leq i \leq n}\left|s_i-s_{i-1}\right|=O\left(n^{-1}\right)$;
$\max\limits_{1 \leq i \leq n}\left|s_i-s_{i-1}\right|=O\left(n^{-1}\right)$;
(ii)  $\frac{2^m}{n} \rightarrow 0$ and
$\frac{2^m}{n} \rightarrow 0$ and  $\frac{2^{3m}}{n} \rightarrow \infty$ as
$\frac{2^{3m}}{n} \rightarrow \infty$ as  $n \rightarrow \infty$.
$n \rightarrow \infty$.
Remark 2.4. Assumptions  $\mathbf{(H1)}$–
$\mathbf{(H1)}$– $\mathbf{(H3)}$ represent standard conditions for the asymptotic normality of wavelet estimation. Additional insights can be found in [Reference Antoniadis, Gregoire and Mckeague1], [Reference Li, Yang and Zhou13], [Reference Zhou and Lin28], [Reference Tang, Xi, Wu and Wang17], [Reference Ding and Chen6] among others. Thus, the conditions outlined in this paper are deemed appropriate and rational.
$\mathbf{(H3)}$ represent standard conditions for the asymptotic normality of wavelet estimation. Additional insights can be found in [Reference Antoniadis, Gregoire and Mckeague1], [Reference Li, Yang and Zhou13], [Reference Zhou and Lin28], [Reference Tang, Xi, Wu and Wang17], [Reference Ding and Chen6] among others. Thus, the conditions outlined in this paper are deemed appropriate and rational.
2.3. Main results
Our main results can be given below.
Theorem 2.5. Suppose that assumptions  $(\mathbf{H1})$–
$(\mathbf{H1})$– $(\mathbf{H3})$ hold. Let
$(\mathbf{H3})$ hold. Let  $\{\varepsilon_i,~i\geq1\}$ be a sequence of identically distributed ANA random variables with
$\{\varepsilon_i,~i\geq1\}$ be a sequence of identically distributed ANA random variables with  $E\varepsilon_i = 0$ and
$E\varepsilon_i = 0$ and  $E|\varepsilon_i|^p \lt \infty$ for some p > 2. Assume that
$E|\varepsilon_i|^p \lt \infty$ for some p > 2. Assume that  $\rho^{-}(N)\leq r $ for
$\rho^{-}(N)\leq r $ for  $N\geq1$ and
$N\geq1$ and  $0 \leq r \lt (\frac{1}{6p})^{p/2}$. Then
$0 \leq r \lt (\frac{1}{6p})^{p/2}$. Then
(i) as  $n\rightarrow \infty$,
$n\rightarrow \infty$,
 \begin{equation*}\widehat{\beta}_{n} \xrightarrow{a.s.} \beta;\end{equation*}
\begin{equation*}\widehat{\beta}_{n} \xrightarrow{a.s.} \beta;\end{equation*} (ii) for any  $t\in[0,1]$,
$t\in[0,1]$,
 \begin{equation*}\widehat{g}_{n}(t) \xrightarrow{a.s.} g(t).\end{equation*}
\begin{equation*}\widehat{g}_{n}(t) \xrightarrow{a.s.} g(t).\end{equation*}Theorem 2.6. Suppose that assumptions  $(\mathbf{H1})$–
$(\mathbf{H1})$– $(\mathbf{H3})$ hold. Let
$(\mathbf{H3})$ hold. Let  $\{\varepsilon_i,~i\geq1\}$ be a sequence of identically distributed ANA random variables with
$\{\varepsilon_i,~i\geq1\}$ be a sequence of identically distributed ANA random variables with  $E\varepsilon_i = 0$ and
$E\varepsilon_i = 0$ and  $E|\varepsilon_i|^{2p} \lt \infty$ for some p > 2. Assume that
$E|\varepsilon_i|^{2p} \lt \infty$ for some p > 2. Assume that  $\rho^{-}(N)\leq r $ for
$\rho^{-}(N)\leq r $ for  $N\geq1$ and
$N\geq1$ and  $0 \leq r \lt (\frac{1}{6p})^{p/2}$. Then
$0 \leq r \lt (\frac{1}{6p})^{p/2}$. Then
 \begin{equation*}
\widehat{\sigma}_{n}^{2} \xrightarrow{a.s.} \sigma^{2}.
\end{equation*}
\begin{equation*}
\widehat{\sigma}_{n}^{2} \xrightarrow{a.s.} \sigma^{2}.
\end{equation*}Remark 2.7. The above theorems show that the estimators  $\widehat {\beta}_{n}$,
$\widehat {\beta}_{n}$,  $\widehat{g}_{n}(t)$, and
$\widehat{g}_{n}(t)$, and  $\widehat{\sigma}_{n}^{2}$ have strong consistency. Compared with the corresponding ones in [Reference Wu and Hu19], we extend the model errors from NA sequences to ANA sequences. It is worth noting that, to the best of our knowledge, there is no literature on the strong consistency for the estimators of the parametric, nonparametric, and error variances in model (1) based on ANA random errors.
$\widehat{\sigma}_{n}^{2}$ have strong consistency. Compared with the corresponding ones in [Reference Wu and Hu19], we extend the model errors from NA sequences to ANA sequences. It is worth noting that, to the best of our knowledge, there is no literature on the strong consistency for the estimators of the parametric, nonparametric, and error variances in model (1) based on ANA random errors.
3. Simulation
In this section, we carry out a simulation to study the finite sample performance of the proposed estimators. We will carry out a numerical simulation to study the consistency and asymptotic normality of wavelet estimation for  $\widehat{\beta}_{n},~\widehat{g}_{n}(t),~ \widehat{\sigma}_{n}^{2}$, respectively.
$\widehat{\beta}_{n},~\widehat{g}_{n}(t),~ \widehat{\sigma}_{n}^{2}$, respectively.
Observations are generated from
 \begin{equation}
\begin{cases}
Y_{i}=x_i\beta+g\left(t_{i}\right)+\varepsilon_{i},&\\
\,X_{i}=x_i+\mu_i,&
\end{cases}
\end{equation}
\begin{equation}
\begin{cases}
Y_{i}=x_i\beta+g\left(t_{i}\right)+\varepsilon_{i},&\\
\,X_{i}=x_i+\mu_i,&
\end{cases}
\end{equation}where  $\beta=3, ~g(t)=\sin \left(2 \pi t\right),~t_i=i /n $,
$\beta=3, ~g(t)=\sin \left(2 \pi t\right),~t_i=i /n $,  $\mu_{i} \stackrel{i.i.d.}{\sim} N(0,0.1^2) $, and
$\mu_{i} \stackrel{i.i.d.}{\sim} N(0,0.1^2) $, and  $x_i=2 t_i^2+\eta_i$ with
$x_i=2 t_i^2+\eta_i$ with  $\eta_{i} \stackrel{i.i.d.}{\sim} U(-1,1)$ for
$\eta_{i} \stackrel{i.i.d.}{\sim} U(-1,1)$ for  $1 \leq i \leq n$. For any
$1 \leq i \leq n$. For any  $n\geq3$, assume
$n\geq3$, assume  $(\varepsilon_{1},\varepsilon_{2},\ldots,\varepsilon_{n})\sim N_{n}(\mathbf{0},\boldsymbol{\Sigma})$, where 0 is a zero vector and
$(\varepsilon_{1},\varepsilon_{2},\ldots,\varepsilon_{n})\sim N_{n}(\mathbf{0},\boldsymbol{\Sigma})$, where 0 is a zero vector and
 \begin{eqnarray*}
\boldsymbol{\Sigma}
=\left(
\begin{array}{ccccccc}
1+\theta^{2} &-\theta &0 &\cdots& 0 & 0 & 0 \\
-\theta &1+\theta^{2} &-\theta &\cdots& 0 & 0 & 0 \\
0 &-\theta &1+\theta^{2} &\cdots& 0 & 0 & 0 \\
\vdots &\vdots & \vdots & & \vdots & \vdots& \vdots \\
0 &0 &0 &\cdots& 1+\theta^{2} & -\theta &0 \\
0 &0 &0 &\cdots& -\theta & 1+\theta^{2} & -\theta \\
0 &0 &0 &\cdots& 0&-\theta & 1+\theta^{2}
\end{array}
\right)_{n\times n},
~~0 \lt \theta \lt 1.
\end{eqnarray*}
\begin{eqnarray*}
\boldsymbol{\Sigma}
=\left(
\begin{array}{ccccccc}
1+\theta^{2} &-\theta &0 &\cdots& 0 & 0 & 0 \\
-\theta &1+\theta^{2} &-\theta &\cdots& 0 & 0 & 0 \\
0 &-\theta &1+\theta^{2} &\cdots& 0 & 0 & 0 \\
\vdots &\vdots & \vdots & & \vdots & \vdots& \vdots \\
0 &0 &0 &\cdots& 1+\theta^{2} & -\theta &0 \\
0 &0 &0 &\cdots& -\theta & 1+\theta^{2} & -\theta \\
0 &0 &0 &\cdots& 0&-\theta & 1+\theta^{2}
\end{array}
\right)_{n\times n},
~~0 \lt \theta \lt 1.
\end{eqnarray*} According to [Reference Joag-Dev and Proschan11], it is obvious that  $(\varepsilon_{1},\varepsilon_{2},\ldots,\varepsilon_{n})$ is an NA vector for each
$(\varepsilon_{1},\varepsilon_{2},\ldots,\varepsilon_{n})$ is an NA vector for each  $n\geq5$ with finite moment of any order, and thus is an ANA vector with
$n\geq5$ with finite moment of any order, and thus is an ANA vector with  $\rho^{-}(1)=0$. In order to verify the consistency of the estimators, we choose the scale function
$\rho^{-}(1)=0$. In order to verify the consistency of the estimators, we choose the scale function  $\varphi\left(x\right)=I(0\leq x\leq 1)$. Set the sample sizes n as
$\varphi\left(x\right)=I(0\leq x\leq 1)$. Set the sample sizes n as  $n=50,~100,~150$, and 200. For a given sample size n, taking
$n=50,~100,~150$, and 200. For a given sample size n, taking  $2^m=(n\log n)^{1/3}$. We compute the values of
$2^m=(n\log n)^{1/3}$. We compute the values of  $\widehat{\beta}_{n} -\beta$,
$\widehat{\beta}_{n} -\beta$,  $\widehat{g}_{n}(t)-g(t)$, and
$\widehat{g}_{n}(t)-g(t)$, and  $\widehat{\sigma}_{n}^{2}- \sigma^{2}$ for 1,000 times under t = 0.2 and 0.5. The boxplots of the estimators under different sample sizes are shown in Figures 1–6. The corresponding values of bias, SD, and RMSE for
$\widehat{\sigma}_{n}^{2}- \sigma^{2}$ for 1,000 times under t = 0.2 and 0.5. The boxplots of the estimators under different sample sizes are shown in Figures 1–6. The corresponding values of bias, SD, and RMSE for  $\widehat{\beta}_{n}$,
$\widehat{\beta}_{n}$,  $\widehat{g}_{n}(t)$, and
$\widehat{g}_{n}(t)$, and  $\widehat{\sigma}_{n}^{2}$ are listed in Table 1.
$\widehat{\sigma}_{n}^{2}$ are listed in Table 1.
Boxplots of  $\widehat{\beta}_{n} -\beta$ with β = 3,
$\widehat{\beta}_{n} -\beta$ with β = 3,  $g(t)=\sin(2 \pi t)$, and t = 0.2.
$g(t)=\sin(2 \pi t)$, and t = 0.2.

Boxplots of  $\widehat{g}_{n}(t)-g(t)$ with β = 3,
$\widehat{g}_{n}(t)-g(t)$ with β = 3,  $g(t)=\sin(2 \pi t)$, and t = 0.2.
$g(t)=\sin(2 \pi t)$, and t = 0.2.

Boxplots of  $\widehat{\sigma}_{n}^{2}- \sigma^{2}$ with β = 3,
$\widehat{\sigma}_{n}^{2}- \sigma^{2}$ with β = 3,  $g(t)=\sin(2 \pi t)$, and t = 0.2.
$g(t)=\sin(2 \pi t)$, and t = 0.2.

Boxplots of  $\widehat{\beta}_{n} -\beta$ with β = 3,
$\widehat{\beta}_{n} -\beta$ with β = 3,  $g(t)=\sin(2 \pi t)$, and t = 0.5.
$g(t)=\sin(2 \pi t)$, and t = 0.5.

Boxplots of  $\widehat{g}_{n}(t)-g(t)$ with β = 3,
$\widehat{g}_{n}(t)-g(t)$ with β = 3,  $g(t)=\sin(2 \pi t)$, and t = 0.5.
$g(t)=\sin(2 \pi t)$, and t = 0.5.

Boxplots of  $\widehat{\sigma}_{n}^{2}- \sigma^{2}$ with β = 3,
$\widehat{\sigma}_{n}^{2}- \sigma^{2}$ with β = 3,  $g(t)=\sin(2 \pi t)$, and t = 0.5.
$g(t)=\sin(2 \pi t)$, and t = 0.5.

The bias, SD, and RMSE of  $\widehat{\beta}_{n}$,
$\widehat{\beta}_{n}$,  $\widehat{g}_{n}(t)$, and
$\widehat{g}_{n}(t)$, and  $\widehat{\sigma}_{n}^{2}$.
$\widehat{\sigma}_{n}^{2}$.

Figures 1–6 show that  $\widehat{\beta}_{n} -\beta$,
$\widehat{\beta}_{n} -\beta$,  $\widehat{g}_{n}(t)-g(t)$, and
$\widehat{g}_{n}(t)-g(t)$, and  $\widehat{\sigma}_{n}^{2}- \sigma^{2}$, regardless of t = 0.2 or 0.5, fluctuate around zero and the variation ranges decrease substantially as the increasing of sample size n. From Table 1, we can see that the estimators of β, g(t), and σ 2 have small SD and RMSE, and they decrease as the increasing of sample size n. It demonstrates that
$\widehat{\sigma}_{n}^{2}- \sigma^{2}$, regardless of t = 0.2 or 0.5, fluctuate around zero and the variation ranges decrease substantially as the increasing of sample size n. From Table 1, we can see that the estimators of β, g(t), and σ 2 have small SD and RMSE, and they decrease as the increasing of sample size n. It demonstrates that  $\widehat{\beta}_{n}$,
$\widehat{\beta}_{n}$,  $\widehat{g}_{n}(t)$, and
$\widehat{g}_{n}(t)$, and  $\widehat{\sigma}_{n}^{2}$ are close to the true values as the increasing of sample size n. Hence, numerical results here are sufficient to verify the consistency of
$\widehat{\sigma}_{n}^{2}$ are close to the true values as the increasing of sample size n. Hence, numerical results here are sufficient to verify the consistency of  $\widehat{\beta}_{n}$,
$\widehat{\beta}_{n}$,  $\widehat{g}_{n}(t)$, and
$\widehat{g}_{n}(t)$, and  $\widehat{\sigma}_{n}^{2}$ based on finite samples.
$\widehat{\sigma}_{n}^{2}$ based on finite samples.
4. Proofs of main results
Proof of Theorem 2.5
To facilitate the notations, write
 \begin{equation*}\tilde{\xi}=(I-S)(\xi_1,\ldots,\xi_n)^T:=(I-S){\xi} ,~ ~ ~ ~ ~ ~ ~ \widetilde{g}=(I-S)(g(t_1),\ldots,g(t_n))^T:=(I-S)g.\end{equation*}
\begin{equation*}\tilde{\xi}=(I-S)(\xi_1,\ldots,\xi_n)^T:=(I-S){\xi} ,~ ~ ~ ~ ~ ~ ~ \widetilde{g}=(I-S)(g(t_1),\ldots,g(t_n))^T:=(I-S)g.\end{equation*}By (6), we obtain that
 \begin{equation}
\widehat{\beta}_{n}-\beta=\left(n^{-1} \widetilde{X}^{T} \widetilde{X}-\sigma_{\mu}^{2}\right)^{-1}\left(n^{-1} \widetilde{X}^{T} \widetilde{g}+n^{-1} \widetilde{X}^{T} \widetilde{\xi}+\sigma_{\mu}^{2} \beta\right).
\end{equation}
\begin{equation}
\widehat{\beta}_{n}-\beta=\left(n^{-1} \widetilde{X}^{T} \widetilde{X}-\sigma_{\mu}^{2}\right)^{-1}\left(n^{-1} \widetilde{X}^{T} \widetilde{g}+n^{-1} \widetilde{X}^{T} \widetilde{\xi}+\sigma_{\mu}^{2} \beta\right).
\end{equation} We just need to prove  $n^{-1} \widetilde{X}^{T} \widetilde{X}-\sigma_{\mu}^{2} \xrightarrow{a.s.} \sigma_{\eta}^{2}$,
$n^{-1} \widetilde{X}^{T} \widetilde{X}-\sigma_{\mu}^{2} \xrightarrow{a.s.} \sigma_{\eta}^{2}$,  $n^{-1} \widetilde{X}^{T} \widetilde{g} \xrightarrow{a.s.} 0$, and
$n^{-1} \widetilde{X}^{T} \widetilde{g} \xrightarrow{a.s.} 0$, and  $n^{-1} \widetilde{X}^{T} \widetilde{\xi} \xrightarrow{a.s.} - \sigma_{\mu}^{2} \beta$ as
$n^{-1} \widetilde{X}^{T} \widetilde{\xi} \xrightarrow{a.s.} - \sigma_{\mu}^{2} \beta$ as  $n \rightarrow \infty$.
$n \rightarrow \infty$.
First, let’s prove
 \begin{equation}
n^{-1} \widetilde{X}^{T} \widetilde{X}-\sigma_{\mu}^{2} \xrightarrow{a.s.} \sigma_{\eta}^{2}.
\end{equation}
\begin{equation}
n^{-1} \widetilde{X}^{T} \widetilde{X}-\sigma_{\mu}^{2} \xrightarrow{a.s.} \sigma_{\eta}^{2}.
\end{equation}It is easily seen that
 \begin{align}
n^{-1} \widetilde{X}^{T} \widetilde{X}= & \frac{1}{n} \sum_{i=1}^{n}\left\{f\left(t_{i}\right)+\eta_{i}+\mu_{i}-\sum_{j=1}^{n} S_{i j}\left[f\left(t_{j}\right)+\eta_{j}+\mu_{j}\right]\right\}^{2}\nonumber\\
= & \frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right]^{2}\nonumber\\
& +2 \cdot \frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right]\left[\eta_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right] \nonumber\\
& +2 \cdot \frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right]\left[\mu_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{j}\right] \nonumber\\
& +2 \cdot \frac{1}{n} \sum_{i=1}^{n}\left[\eta_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left[\mu_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{j}\right] \nonumber\\
& +\frac{1}{n} \sum_{i=1}^{n}\left[\eta_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]^{2}+\frac{1}{n} \sum_{i=1}^{n}\left[\mu_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{j}\right]^{2} \nonumber\\
:= & F_{1}+2 F_{2}+2F_{3}+2 F_{4}+F_{5}+F_{6} .
\end{align}
\begin{align}
n^{-1} \widetilde{X}^{T} \widetilde{X}= & \frac{1}{n} \sum_{i=1}^{n}\left\{f\left(t_{i}\right)+\eta_{i}+\mu_{i}-\sum_{j=1}^{n} S_{i j}\left[f\left(t_{j}\right)+\eta_{j}+\mu_{j}\right]\right\}^{2}\nonumber\\
= & \frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right]^{2}\nonumber\\
& +2 \cdot \frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right]\left[\eta_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right] \nonumber\\
& +2 \cdot \frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right]\left[\mu_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{j}\right] \nonumber\\
& +2 \cdot \frac{1}{n} \sum_{i=1}^{n}\left[\eta_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left[\mu_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{j}\right] \nonumber\\
& +\frac{1}{n} \sum_{i=1}^{n}\left[\eta_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]^{2}+\frac{1}{n} \sum_{i=1}^{n}\left[\mu_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{j}\right]^{2} \nonumber\\
:= & F_{1}+2 F_{2}+2F_{3}+2 F_{4}+F_{5}+F_{6} .
\end{align}According to Lemma A.2, it can be concluded that
 \begin{equation}
\left|F_{1}\right| \leq \max _{1 \leq i \leq n}\left|f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right|^{2}\xrightarrow{a.s.} 0.
\end{equation}
\begin{equation}
\left|F_{1}\right| \leq \max _{1 \leq i \leq n}\left|f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right|^{2}\xrightarrow{a.s.} 0.
\end{equation}It is known from Lemma A.6 that
 \begin{align}
& \max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \eta_{j}\right|\xrightarrow{a.s.}0
\end{align}
\begin{align}
& \max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \eta_{j}\right|\xrightarrow{a.s.}0
\end{align}and
 \begin{align}
& \max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s\mu_{j}\right|\xrightarrow{a.s.}0
\end{align}
\begin{align}
& \max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s\mu_{j}\right|\xrightarrow{a.s.}0
\end{align}By the Kolmogorov’s strong law of numbers, (14), and Lemma A.2, we have
 \begin{align}
\left|F_{2}\right| \leq & \left[\max _{1 \leq i \leq n}\left|f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right|\right]\cdot\left[\frac{1}{n} \sum_{i=1}^{n}\left|\eta_{i}\right|+\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right|\right] \nonumber\\
= & o(1)\left[E\left|\eta_{i}\right|+o(1)\right] \xrightarrow{a.s.} 0.
\end{align}
\begin{align}
\left|F_{2}\right| \leq & \left[\max _{1 \leq i \leq n}\left|f\left(t_{i}\right)-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s f\left(t_{j}\right)\right|\right]\cdot\left[\frac{1}{n} \sum_{i=1}^{n}\left|\eta_{i}\right|+\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right|\right] \nonumber\\
= & o(1)\left[E\left|\eta_{i}\right|+o(1)\right] \xrightarrow{a.s.} 0.
\end{align}Similar to the proof process in (16), it is easy to obtain
 \begin{equation}
|F_{3}|=o(1)\left[E\left|\mu_{i}\right|+o(1)\right] \xrightarrow{a.s.} 0.
\end{equation}
\begin{equation}
|F_{3}|=o(1)\left[E\left|\mu_{i}\right|+o(1)\right] \xrightarrow{a.s.} 0.
\end{equation}Based on the Kolmogorov’s strong law of large numbers, (14), and (15), it can be inferred that
 \begin{align}
\left|F_{4}\right|=&\left|\frac{1}{n} \sum_{i=1}^{n}\left[\eta_{i}-o(1)\right]\left[\mu_{i}-o(1)\right]\right|\nonumber\\
\leq&\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \mu_{i}\right|+o(1)\left|\frac{1}{n}\sum_{i=1}^{n}\left(\mu_{i}+\eta_{i}\right)\right|+o^2(1)\nonumber\\
=&[o(1)+o(1)E|\mu_i|+o(1)E|\eta_i|+o^2(1)]\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
\left|F_{4}\right|=&\left|\frac{1}{n} \sum_{i=1}^{n}\left[\eta_{i}-o(1)\right]\left[\mu_{i}-o(1)\right]\right|\nonumber\\
\leq&\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \mu_{i}\right|+o(1)\left|\frac{1}{n}\sum_{i=1}^{n}\left(\mu_{i}+\eta_{i}\right)\right|+o^2(1)\nonumber\\
=&[o(1)+o(1)E|\mu_i|+o(1)E|\eta_i|+o^2(1)]\xrightarrow{a.s.} 0.
\end{align} By the Kolmogorov’s strong law of large numbers, (14),  $E \eta_{i}=0$, and
$E \eta_{i}=0$, and  $\operatorname{Var}\left(\eta_{i}\right)=\sigma_{\eta}^{2}$, we find
$\operatorname{Var}\left(\eta_{i}\right)=\sigma_{\eta}^{2}$, we find
 \begin{align}
&|F_{5} -\sigma_{\eta}^{2}| \nonumber\\
=& \left|\frac{1}{n} \sum_{i=1}^{n}\left[\eta_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]^{2} -\sigma_{\eta}^{2}\right|\nonumber\\
\leq&\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i}^{2}-\sigma_{\eta}^{2}\right|+2\frac{1}{n}\left| \sum_{i=1}^{n} \eta_{i} \sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right|+\frac{1}{n} \left| \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]^{2} \right|\nonumber\\
\leq&\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i}^{2}-\sigma_{\eta}^{2}\right|+2\frac{1}{n} \sum_{i=1}^{n} \left|\eta_{i}\right|\max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \eta_{i}\right|+\max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \eta_{j}\right|^2\nonumber\\
= & [o(1)+2o(1) E|\eta_{i}|+o^2(1)]\xrightarrow{a.s.}0.
\end{align}
\begin{align}
&|F_{5} -\sigma_{\eta}^{2}| \nonumber\\
=& \left|\frac{1}{n} \sum_{i=1}^{n}\left[\eta_{i}-\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]^{2} -\sigma_{\eta}^{2}\right|\nonumber\\
\leq&\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i}^{2}-\sigma_{\eta}^{2}\right|+2\frac{1}{n}\left| \sum_{i=1}^{n} \eta_{i} \sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right|+\frac{1}{n} \left| \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]^{2} \right|\nonumber\\
\leq&\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i}^{2}-\sigma_{\eta}^{2}\right|+2\frac{1}{n} \sum_{i=1}^{n} \left|\eta_{i}\right|\max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \eta_{i}\right|+\max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \eta_{j}\right|^2\nonumber\\
= & [o(1)+2o(1) E|\eta_{i}|+o^2(1)]\xrightarrow{a.s.}0.
\end{align}Likewise, it can be inferred that
 \begin{equation}
F_{6} \xrightarrow{a.s.} \sigma_{\mu}^{2}.
\end{equation}
\begin{equation}
F_{6} \xrightarrow{a.s.} \sigma_{\mu}^{2}.
\end{equation}By using (12), (13), (16), (17), (18), (19), and (20), we can determine that
 \begin{equation}
n^{-1} \widetilde{X}^{T} \tilde{X} \xrightarrow{a.s.} \sigma_{\eta}^{2}+\sigma_{\mu}^{2}.
\end{equation}
\begin{equation}
n^{-1} \widetilde{X}^{T} \tilde{X} \xrightarrow{a.s.} \sigma_{\eta}^{2}+\sigma_{\mu}^{2}.
\end{equation}The (11) is derived from (21).
Second, we will prove
 \begin{equation}
n^{-1} \widetilde{X}^{T} \widetilde{g} \xrightarrow{a.s.} 0.
\end{equation}
\begin{equation}
n^{-1} \widetilde{X}^{T} \widetilde{g} \xrightarrow{a.s.} 0.
\end{equation}It is evident that
 \begin{align}
n^{-1} \widetilde{X}^{T} \widetilde{g}= & \frac{1}{n} \sum_{i=1}^{n}\left(X_{i}-\sum_{j=1}^{n} S_{i j} X_{j}\right)\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right] \nonumber\\
= & \frac{1}{n} \sum_{i=1}^{n}\left(\eta_{i}-\sum_{j=1}^{n} S_{i j} \eta_{j}\right)\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right] \nonumber\\
& +\frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right] \nonumber\\
& +\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right] \nonumber\\
:= & G_{1}+G_{2}+G_{3}.
\end{align}
\begin{align}
n^{-1} \widetilde{X}^{T} \widetilde{g}= & \frac{1}{n} \sum_{i=1}^{n}\left(X_{i}-\sum_{j=1}^{n} S_{i j} X_{j}\right)\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right] \nonumber\\
= & \frac{1}{n} \sum_{i=1}^{n}\left(\eta_{i}-\sum_{j=1}^{n} S_{i j} \eta_{j}\right)\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right] \nonumber\\
& +\frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right] \nonumber\\
& +\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right] \nonumber\\
:= & G_{1}+G_{2}+G_{3}.
\end{align}Similar to the proof of (16), one can easily show that
 \begin{equation}
G_{1}\xrightarrow{a.s.} 0 ~~~~\mathrm{and} ~~~~G_{3}\xrightarrow{a.s.}0.
\end{equation}
\begin{equation}
G_{1}\xrightarrow{a.s.} 0 ~~~~\mathrm{and} ~~~~G_{3}\xrightarrow{a.s.}0.
\end{equation}By Lemma A.2, it can be inferred that
 \begin{align}
\left|G_{2}\right| & \leq \max _{1 \leq i \leq n}\left|\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right]\right| =O\left(n^{-2 \gamma}\right)+O\left(\tau_{m}^{2}\right) \xrightarrow{a.s.} 0.
\end{align}
\begin{align}
\left|G_{2}\right| & \leq \max _{1 \leq i \leq n}\left|\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left[g\left(t_{i}\right)-\sum_{k=1}^{n} S_{i k} g\left(t_{k}\right)\right]\right| =O\left(n^{-2 \gamma}\right)+O\left(\tau_{m}^{2}\right) \xrightarrow{a.s.} 0.
\end{align}Hence, (22) is derived from (23) to (25).
Finally, we will prove
 \begin{equation}
n^{-1} \tilde{X}^{T} \tilde{\xi}+\sigma_{\mu}^{2} \beta \xrightarrow{a.s.}0.
\end{equation}
\begin{equation}
n^{-1} \tilde{X}^{T} \tilde{\xi}+\sigma_{\mu}^{2} \beta \xrightarrow{a.s.}0.
\end{equation}It is easily seen that
 \begin{align}
n^{-1} \widetilde{X}^{T} \widetilde{\xi}+\sigma_{\mu}^{2} \beta = & \frac{1}{n} \sum_{i=1}^{n}\left(X_{i}-\sum_{j=1}^{n} S_{i j} X_{j}\right)\left(\xi_{i}-\sum_{k=1}^{n} S_{i k} \xi_{k}\right)+\sigma_{\mu}^{2} \beta \nonumber\\
= & \frac{1}{n} \sum_{i=1}^{n}\left(\eta_{i}-\sum_{j=1}^{n} S_{i j} \eta_{j}\right)\left(\xi_{i}-\sum_{k=1}^{n} S_{i k} \xi_{k}\right) \nonumber\\
& +\frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left(\xi_{i}-\sum_{k=1}^{n} S_{i k} \xi_{k}\right) \nonumber\\
& +\left[\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left(\xi_{i}-\sum_{k=1}^{n} S_{i k} \xi_{k}\right)+\sigma_{\mu}^{2} \beta\right]\nonumber\\
: =& J_{1}+J_{2}+J_{3} .
\end{align}
\begin{align}
n^{-1} \widetilde{X}^{T} \widetilde{\xi}+\sigma_{\mu}^{2} \beta = & \frac{1}{n} \sum_{i=1}^{n}\left(X_{i}-\sum_{j=1}^{n} S_{i j} X_{j}\right)\left(\xi_{i}-\sum_{k=1}^{n} S_{i k} \xi_{k}\right)+\sigma_{\mu}^{2} \beta \nonumber\\
= & \frac{1}{n} \sum_{i=1}^{n}\left(\eta_{i}-\sum_{j=1}^{n} S_{i j} \eta_{j}\right)\left(\xi_{i}-\sum_{k=1}^{n} S_{i k} \xi_{k}\right) \nonumber\\
& +\frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left(\xi_{i}-\sum_{k=1}^{n} S_{i k} \xi_{k}\right) \nonumber\\
& +\left[\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left(\xi_{i}-\sum_{k=1}^{n} S_{i k} \xi_{k}\right)+\sigma_{\mu}^{2} \beta\right]\nonumber\\
: =& J_{1}+J_{2}+J_{3} .
\end{align}Clearly, we obtain
 \begin{align}
J_{1} & =\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \xi_{i}-\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \eta_{j}\right) \xi_{i}-\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{k=1}^{n} S_{i k} \xi_{k}\right) \eta_{i}+\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \eta_{j}\right)\left(\sum_{k=1}^{n} S_{i k} \xi_{k}\right) \nonumber\\
&: =J_{11}-J_{12}-J_{13}+J_{14}.
\end{align}
\begin{align}
J_{1} & =\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \xi_{i}-\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \eta_{j}\right) \xi_{i}-\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{k=1}^{n} S_{i k} \xi_{k}\right) \eta_{i}+\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \eta_{j}\right)\left(\sum_{k=1}^{n} S_{i k} \xi_{k}\right) \nonumber\\
&: =J_{11}-J_{12}-J_{13}+J_{14}.
\end{align} According to Lemma A.3, it can be seen that  $\left\{\varepsilon_{i}^{+},~1\leq i\leq n\right\}$ and
$\left\{\varepsilon_{i}^{+},~1\leq i\leq n\right\}$ and  $\left\{\varepsilon_{i}^{-},~1\leq i\leq n\right\}$ are both ANA sequences and their mixing coefficients are not greater than
$\left\{\varepsilon_{i}^{-},~1\leq i\leq n\right\}$ are both ANA sequences and their mixing coefficients are not greater than 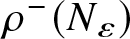 $\rho^-(N_\varepsilon)$. Since
$\rho^-(N_\varepsilon)$. Since  $\left\{\eta_{i}\right\}$ and
$\left\{\eta_{i}\right\}$ and  $\left\{\varepsilon_{i}\right\}$ are independent, it can be inferred from Lemma A.4 that
$\left\{\varepsilon_{i}\right\}$ are independent, it can be inferred from Lemma A.4 that  $\left\{\eta_{i}^+\varepsilon_{i}^+, 1\leq i\leq n\right\}$,
$\left\{\eta_{i}^+\varepsilon_{i}^+, 1\leq i\leq n\right\}$,  $\left\{\eta_{i}^+\varepsilon_{i}^-, 1\leq i\leq n\right\}$,
$\left\{\eta_{i}^+\varepsilon_{i}^-, 1\leq i\leq n\right\}$,  $\left\{\eta_{i}^-\varepsilon_{i}^+, 1\leq i\leq n\right\}$, and
$\left\{\eta_{i}^-\varepsilon_{i}^+, 1\leq i\leq n\right\}$, and  $\left\{\eta_{i}^-\varepsilon_{i}^-, 1\leq i\leq n\right\}$ are all ANA random variables with mixing coefficients
$\left\{\eta_{i}^-\varepsilon_{i}^-, 1\leq i\leq n\right\}$ are all ANA random variables with mixing coefficients  $\rho^-(N_{\eta\varepsilon}) \lt r$ for
$\rho^-(N_{\eta\varepsilon}) \lt r$ for  $0\leq r \lt (\frac{1}{6p})^{p/2}$. Because
$0\leq r \lt (\frac{1}{6p})^{p/2}$. Because  $E|\eta_{i} \varepsilon_{i}|^2 \lt \infty$, it can be inferred from Lemma A.6 and the Kolmogorov’s strong law of numbers that
$E|\eta_{i} \varepsilon_{i}|^2 \lt \infty$, it can be inferred from Lemma A.6 and the Kolmogorov’s strong law of numbers that
 \begin{align}
&|J_{11}|\nonumber\\
\leq& \left|\frac{1}{n} \sum_{i=1}^{n}\left(\eta_{i} \varepsilon_{i}-E\eta_{i} \varepsilon_{i}\right)\right|+\left|\beta\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \mu_{i} \right| \nonumber\\
= & \left|\frac{1}{n} \sum_{i=1}^{n}\left\{\left[\eta_{i}^+\varepsilon_{i}^+-E(\eta_{i}^+ \varepsilon_{i}^+)\right]+\left[\eta_{i}^-\varepsilon_{i}^--E(\eta_{i}^- \varepsilon_{i}^-)\right]-\left[\eta_{i}^+\varepsilon_{i}^--E(\eta_{i}^+ \varepsilon_{i}^-)\right]-\left[\eta_{i}^-\varepsilon_{i}^+-E(\eta_{i}^- \varepsilon_{i}^+)\right]\right\}\right|\nonumber\\
& +\left|\beta\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \mu_{i} \right| \nonumber\\
\leq & \frac{1}{n} \left|\sum_{i=1}^{n}\left[\eta_{i}^+ \varepsilon_{i}^+-E(\eta_{i}^+ \varepsilon_{i}^+)\right]\right|+\frac{1}{n} \left|\sum_{i=1}^{n}\left[\eta_{i}^- \varepsilon_{i}^--E(\eta_{i}^- \varepsilon_{i}^-)\right]\right|+\frac{1}{n}\left| \sum_{i=1}^{n}\left[\eta_{i}^+ \varepsilon_{i}^--E(\eta_{i}^+ \varepsilon_{i}^-)\right]\right|\nonumber\\
&+\frac{1}{n} \left|\sum_{i=1}^{n}\left[\eta_{i}^- \varepsilon_{i}^+-E(\eta_{i}^- \varepsilon_{i}^+)\right]\right|+\beta\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \mu_{i} \right| \nonumber\\
=&[4 o(1)+\beta o(1)]\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
&|J_{11}|\nonumber\\
\leq& \left|\frac{1}{n} \sum_{i=1}^{n}\left(\eta_{i} \varepsilon_{i}-E\eta_{i} \varepsilon_{i}\right)\right|+\left|\beta\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \mu_{i} \right| \nonumber\\
= & \left|\frac{1}{n} \sum_{i=1}^{n}\left\{\left[\eta_{i}^+\varepsilon_{i}^+-E(\eta_{i}^+ \varepsilon_{i}^+)\right]+\left[\eta_{i}^-\varepsilon_{i}^--E(\eta_{i}^- \varepsilon_{i}^-)\right]-\left[\eta_{i}^+\varepsilon_{i}^--E(\eta_{i}^+ \varepsilon_{i}^-)\right]-\left[\eta_{i}^-\varepsilon_{i}^+-E(\eta_{i}^- \varepsilon_{i}^+)\right]\right\}\right|\nonumber\\
& +\left|\beta\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \mu_{i} \right| \nonumber\\
\leq & \frac{1}{n} \left|\sum_{i=1}^{n}\left[\eta_{i}^+ \varepsilon_{i}^+-E(\eta_{i}^+ \varepsilon_{i}^+)\right]\right|+\frac{1}{n} \left|\sum_{i=1}^{n}\left[\eta_{i}^- \varepsilon_{i}^--E(\eta_{i}^- \varepsilon_{i}^-)\right]\right|+\frac{1}{n}\left| \sum_{i=1}^{n}\left[\eta_{i}^+ \varepsilon_{i}^--E(\eta_{i}^+ \varepsilon_{i}^-)\right]\right|\nonumber\\
&+\frac{1}{n} \left|\sum_{i=1}^{n}\left[\eta_{i}^- \varepsilon_{i}^+-E(\eta_{i}^- \varepsilon_{i}^+)\right]\right|+\beta\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i} \mu_{i} \right| \nonumber\\
=&[4 o(1)+\beta o(1)]\xrightarrow{a.s.} 0.
\end{align}Furthermore, it can be concluded from Lemma A.6 that
 \begin{equation}
\frac{1}{n}\left| \sum_{i=1}^{n}\varepsilon_{i}\right|\xrightarrow{a.s.}0.
\end{equation}
\begin{equation}
\frac{1}{n}\left| \sum_{i=1}^{n}\varepsilon_{i}\right|\xrightarrow{a.s.}0.
\end{equation}Based on the (14), (30), and Kolmogorov’s strong law of large numbers, it can be inferred that
 \begin{align}
|J_{12} |& =\left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left(\varepsilon_{i}-\mu_{i} \beta\right)\right| \nonumber\\
& \leq\left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\varepsilon_{i}\right|+\left|\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right] \mu_{i} \right|\nonumber\\
& \leq\max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \eta_{j}\right| \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\varepsilon_{i}\right|+\beta \cdot\max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \eta_{j}\right| \cdot\left(\frac{1}{n} \sum_{i=1}^{n}\left|\mu_{i}\right|\right)\nonumber\\
&=o(1)\left[o(1)+\beta\cdot\mathrm{E}\left|\mu_{i}\right|\right] \xrightarrow{a.s.}0.
\end{align}
\begin{align}
|J_{12} |& =\left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left(\varepsilon_{i}-\mu_{i} \beta\right)\right| \nonumber\\
& \leq\left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\varepsilon_{i}\right|+\left|\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right] \mu_{i} \right|\nonumber\\
& \leq\max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \eta_{j}\right| \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\varepsilon_{i}\right|+\beta \cdot\max _{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \eta_{j}\right| \cdot\left(\frac{1}{n} \sum_{i=1}^{n}\left|\mu_{i}\right|\right)\nonumber\\
&=o(1)\left[o(1)+\beta\cdot\mathrm{E}\left|\mu_{i}\right|\right] \xrightarrow{a.s.}0.
\end{align}Based on the Kolmogorov’s strong law of large numbers, Lemma A.1, Lemma A.7, and (15), it can be inferred that
 \begin{align}
|J_{13}|= & \left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \xi_{k}\right] \eta_{i}\right| \nonumber\\
\leq& \left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right] \eta_{i}\right|+\left|\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{k}\right] \eta_{i}\right| \nonumber\\
\leq&\max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right| \cdot\left(\frac{1}{n} \sum_{i=1}^{n}\left|\eta_{i}\right|\right)\nonumber\\
&+\beta \cdot\max _{1\leq i\leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{k}\right| \cdot\left(\frac{1}{n} \sum_{i=1}^{n}\left|\eta_{i}\right|\right) \nonumber\\
= & o(1)\left[ \mathrm{E}\left|\eta_{i}\right|+\beta\cdot\mathrm{E}\left|\eta_{i}\right|\right] \xrightarrow{a.s.}0.
\end{align}
\begin{align}
|J_{13}|= & \left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \xi_{k}\right] \eta_{i}\right| \nonumber\\
\leq& \left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right] \eta_{i}\right|+\left|\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{k}\right] \eta_{i}\right| \nonumber\\
\leq&\max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right| \cdot\left(\frac{1}{n} \sum_{i=1}^{n}\left|\eta_{i}\right|\right)\nonumber\\
&+\beta \cdot\max _{1\leq i\leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{k}\right| \cdot\left(\frac{1}{n} \sum_{i=1}^{n}\left|\eta_{i}\right|\right) \nonumber\\
= & o(1)\left[ \mathrm{E}\left|\eta_{i}\right|+\beta\cdot\mathrm{E}\left|\eta_{i}\right|\right] \xrightarrow{a.s.}0.
\end{align}Based on the Kolmogorov’s strong law of large numbers, Lemma A.1, Lemma A.7, (14), and (15), it can be inferred that
 \begin{align}
|J_{14}|= & \left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \xi_{k}\right]\right| \nonumber\\
\leq & \left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right]\right| \nonumber\\
& +\left|\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{k}\right]\right| \nonumber\\
\leq & \max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right| \cdot\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \eta_{j}\right|\nonumber\\
&+\beta \cdot \max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{k}\right| \cdot\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \eta_{j}\right| \nonumber\\
=& o(1)\left[ o(1)+\beta \cdot o(1)\right] \xrightarrow{a.s.}0.
\end{align}
\begin{align}
|J_{14}|= & \left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \xi_{k}\right]\right| \nonumber\\
\leq & \left|\frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right]\right| \nonumber\\
& +\left|\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left[\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \eta_{j}\right]\left[\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{k}\right]\right| \nonumber\\
\leq & \max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right| \cdot\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \eta_{j}\right|\nonumber\\
&+\beta \cdot \max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{k}\right| \cdot\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \eta_{j}\right| \nonumber\\
=& o(1)\left[ o(1)+\beta \cdot o(1)\right] \xrightarrow{a.s.}0.
\end{align}Therefore, from (28), (29), (31), (32), and (33), it can be concluded that
 \begin{equation}
J_{1} \xrightarrow{a.s.} 0.
\end{equation}
\begin{equation}
J_{1} \xrightarrow{a.s.} 0.
\end{equation}For J 2, it can be inferred from (30), Lemmas A.1, A.2, and A.7 that
 \begin{align}
|J_{2}|= & \left|\frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left(\varepsilon_{i}-\sum_{k=1}^{n} S_{i k} \varepsilon_{k}\right)\right| \nonumber\\
& +\left|\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left(\mu_{i}-\sum_{k=1}^{n} S_{i k} \mu_{k}\right)\right| \nonumber\\
\leq & \max _{1 \leq i \leq n}\left|f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right| \cdot\left(\frac{1}{n} \left|\sum_{i=1}^{n}\varepsilon_{i}\right|+\max _{1 \leq i\leq n}\left|\sum_{k=1}^{n} S_{i k} \varepsilon_{k}\right|\right) \nonumber\\
& +\beta \cdot \max _{1 \leq i \leq n}\left|f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right|\left(\frac{1}{n}\sum_{i=1}^{n}|\mu_{i}|+\max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} S_{i k} \mu_{k}\right|\right) \nonumber\\
= & [O(n^{-\gamma})+O(\tau_m)]\cdot\{2 o(1)+\beta [E|\mu_i|+o(1)]\} \xrightarrow{a.s.} 0.
\end{align}
\begin{align}
|J_{2}|= & \left|\frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left(\varepsilon_{i}-\sum_{k=1}^{n} S_{i k} \varepsilon_{k}\right)\right| \nonumber\\
& +\left|\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right]\left(\mu_{i}-\sum_{k=1}^{n} S_{i k} \mu_{k}\right)\right| \nonumber\\
\leq & \max _{1 \leq i \leq n}\left|f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right| \cdot\left(\frac{1}{n} \left|\sum_{i=1}^{n}\varepsilon_{i}\right|+\max _{1 \leq i\leq n}\left|\sum_{k=1}^{n} S_{i k} \varepsilon_{k}\right|\right) \nonumber\\
& +\beta \cdot \max _{1 \leq i \leq n}\left|f\left(t_{i}\right)-\sum_{j=1}^{n} S_{i j} f\left(t_{j}\right)\right|\left(\frac{1}{n}\sum_{i=1}^{n}|\mu_{i}|+\max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} S_{i k} \mu_{k}\right|\right) \nonumber\\
= & [O(n^{-\gamma})+O(\tau_m)]\cdot\{2 o(1)+\beta [E|\mu_i|+o(1)]\} \xrightarrow{a.s.} 0.
\end{align}From the Kolmogorov’s strong law of large numbers, Lemma A.1, Lemma A.7, (15), and (30), it follows that
 \begin{align}
|J_{3}| = & \left|\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left[\left(\varepsilon_{i}-\mu_{i} \beta\right)-\sum_{k=1}^{n} S_{i k}\left(\varepsilon_{k}-\mu_{k} \beta\right)\right] +\sigma_{\mu}^{2}\beta\right|\nonumber\\
= &\left| \frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left(\varepsilon_{i}-\sum_{k=1}^{n} S_{i k} \varepsilon_{k}\right) -\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left(\mu_{i}-\sum_{k=1}^{n} S_{i k} \mu_{k}\right) +\sigma_{\mu}^{2}\beta\right|\nonumber\\
\leq& \left[\frac{1}{n} \sum_{i=1}^{n}\left|\mu_{i}\right|+\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{j}\right|\right]\cdot\left[\frac{1}{n} \left|\sum_{i=1}^{n}\varepsilon_{i}\right|+\max _{1 \leq i\leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right|\right] \nonumber\\
&+\beta \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left(\mu_{i}-\sum_{k=1}^{n} S_{i k} \mu_{k}\right)-\sigma_{\mu}^{2}\right|\nonumber\\
\leq & \left[\mathrm{E}\left|\mu_{i}\right|+o(1)\right] o(1)+\beta \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}^{2}-\sum_{j=1}^{n} S_{i j} \mu_{j} \mu_{i}-\sum_{k=1}^{n} S_{i k} \mu_{k} \mu_{i}+\sum_{j=1}^{n} S_{i j} \mu_{j} \sum_{k=1}^{n} S_{i k} \mu_{k}\right)-\sigma_{\mu}^{2}\right|\nonumber\\
\leq &o(1)+\beta\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}^{2}-\sigma_{\mu}^{2}\right|+\beta\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} S_{i j} \mu_{j} \right| \frac{1}{n} \sum_{i=1}^{n}|\mu_{i}| +\beta\max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} S_{i k} \mu_{k} \right|\frac{1}{n} \sum_{i=1}^{n}|\mu_{i}|\nonumber\\
&+\beta\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} S_{i j} \mu_{j}\right|\cdot\max _{1 \leq i \leq n}\left| \sum_{k=1}^{n} S_{i k} \mu_{k}\right|\nonumber\\
=&\{o(1)+\beta [o(1)+o(1)E\left|\mu_{i}\right|+o(1)E\left|\mu_{i}\right|+o(1)]\}\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
|J_{3}| = & \left|\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left[\left(\varepsilon_{i}-\mu_{i} \beta\right)-\sum_{k=1}^{n} S_{i k}\left(\varepsilon_{k}-\mu_{k} \beta\right)\right] +\sigma_{\mu}^{2}\beta\right|\nonumber\\
= &\left| \frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left(\varepsilon_{i}-\sum_{k=1}^{n} S_{i k} \varepsilon_{k}\right) -\beta \cdot \frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left(\mu_{i}-\sum_{k=1}^{n} S_{i k} \mu_{k}\right) +\sigma_{\mu}^{2}\beta\right|\nonumber\\
\leq& \left[\frac{1}{n} \sum_{i=1}^{n}\left|\mu_{i}\right|+\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \mu_{j}\right|\right]\cdot\left[\frac{1}{n} \left|\sum_{i=1}^{n}\varepsilon_{i}\right|+\max _{1 \leq i\leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right|\right] \nonumber\\
&+\beta \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\left(\mu_{i}-\sum_{k=1}^{n} S_{i k} \mu_{k}\right)-\sigma_{\mu}^{2}\right|\nonumber\\
\leq & \left[\mathrm{E}\left|\mu_{i}\right|+o(1)\right] o(1)+\beta \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}^{2}-\sum_{j=1}^{n} S_{i j} \mu_{j} \mu_{i}-\sum_{k=1}^{n} S_{i k} \mu_{k} \mu_{i}+\sum_{j=1}^{n} S_{i j} \mu_{j} \sum_{k=1}^{n} S_{i k} \mu_{k}\right)-\sigma_{\mu}^{2}\right|\nonumber\\
\leq &o(1)+\beta\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}^{2}-\sigma_{\mu}^{2}\right|+\beta\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} S_{i j} \mu_{j} \right| \frac{1}{n} \sum_{i=1}^{n}|\mu_{i}| +\beta\max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} S_{i k} \mu_{k} \right|\frac{1}{n} \sum_{i=1}^{n}|\mu_{i}|\nonumber\\
&+\beta\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} S_{i j} \mu_{j}\right|\cdot\max _{1 \leq i \leq n}\left| \sum_{k=1}^{n} S_{i k} \mu_{k}\right|\nonumber\\
=&\{o(1)+\beta [o(1)+o(1)E\left|\mu_{i}\right|+o(1)E\left|\mu_{i}\right|+o(1)]\}\xrightarrow{a.s.} 0.
\end{align}From (27) and (34)–(36), we get (26).
Theorem 2.5(i) is proved by (10), (11), (22), and (26).
For the proof of Theorem 2.5(ii), it is easily seen that
 \begin{align}
\sup _{t\in [0,1]}\left|\widehat{g}_{n}(t)-g(t)\right|= & \sup _{t\in [0,1]}\left|\widehat{g}_{0}(t, \beta)-g(t)+\sum_{j=1}^{n} X_{j}\left(\beta-\widehat{\beta}_{n}\right) \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\right| \nonumber\\
\leq & \sup _{t\in [0,1]}\left|\sum_{j=1}^{n} g\left(t_{j}\right) \int_{A_{j}} E_{m}(t, s) \mathrm{d} s-g(t)\right|+\sup_{t\in [0,1]}\left|\sum_{j=1}^{n} \xi_{j} \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\right| \nonumber\\
&+\left|\widehat{\beta}_{n}-\beta\right| \sup _{t\in [0,1]}\left|\sum_{j=1}^{n}\int_{A_{j}} E_{m}(t, s) \mathrm{d} s \eta_{j} \right|+\left|\widehat{\beta}_{n}-\beta\right| \sup _{t\in [0,1]}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\mu_{j} \right| \nonumber\\
& +\left|\widehat{\beta}_{n}-\beta\right| \sup _{t\in [0,1]}\left|\sum_{j=1}^{n} f\left(t_{j}\right) \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\right| \nonumber\\
:= & K_1+K_2+K_3+K_4+K_5.
\end{align}
\begin{align}
\sup _{t\in [0,1]}\left|\widehat{g}_{n}(t)-g(t)\right|= & \sup _{t\in [0,1]}\left|\widehat{g}_{0}(t, \beta)-g(t)+\sum_{j=1}^{n} X_{j}\left(\beta-\widehat{\beta}_{n}\right) \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\right| \nonumber\\
\leq & \sup _{t\in [0,1]}\left|\sum_{j=1}^{n} g\left(t_{j}\right) \int_{A_{j}} E_{m}(t, s) \mathrm{d} s-g(t)\right|+\sup_{t\in [0,1]}\left|\sum_{j=1}^{n} \xi_{j} \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\right| \nonumber\\
&+\left|\widehat{\beta}_{n}-\beta\right| \sup _{t\in [0,1]}\left|\sum_{j=1}^{n}\int_{A_{j}} E_{m}(t, s) \mathrm{d} s \eta_{j} \right|+\left|\widehat{\beta}_{n}-\beta\right| \sup _{t\in [0,1]}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\mu_{j} \right| \nonumber\\
& +\left|\widehat{\beta}_{n}-\beta\right| \sup _{t\in [0,1]}\left|\sum_{j=1}^{n} f\left(t_{j}\right) \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\right| \nonumber\\
:= & K_1+K_2+K_3+K_4+K_5.
\end{align}By Lemma A.2, it follows that
 \begin{align}
K_1=O\left(n^{-\gamma}\right)+O\left(\tau_{m}\right)\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
K_1=O\left(n^{-\gamma}\right)+O\left(\tau_{m}\right)\xrightarrow{a.s.} 0.
\end{align}From Lemma A.1, Lemma A.7, and (15), it follows that
 \begin{align}
|K_2|\leq &\beta \max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s\mu_{j} \right|+\max_{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\varepsilon_{j} \right|\nonumber\\
=& \left[o(1)+\beta o(1)\right]\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
|K_2|\leq &\beta \max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s\mu_{j} \right|+\max_{1\leq i\leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t, s) \mathrm{d} s\varepsilon_{j} \right|\nonumber\\
=& \left[o(1)+\beta o(1)\right]\xrightarrow{a.s.} 0.
\end{align}By Theorem 2.5(i), (14), and (15), we have that
 \begin{align}
K_3\xrightarrow{a.s.}0~~ \mathrm{and} ~~K_4\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
K_3\xrightarrow{a.s.}0~~ \mathrm{and} ~~K_4\xrightarrow{a.s.} 0.
\end{align}From Theorem 2.5(i) and Lemma A.1, we know that
 \begin{align}
|K_5|\leq \left|\hat{\beta}_{n}-\beta\right| \cdot \sup _{t\in [0,1]}\left|f\left(t\right)\right| \cdot \sup_{t\in [0,1]} \int_{0}^{1}\left|E_{m}(t, s)\right| \mathrm{d} s\leq C\left|\hat{\beta}_{n}-\beta\right|\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
|K_5|\leq \left|\hat{\beta}_{n}-\beta\right| \cdot \sup _{t\in [0,1]}\left|f\left(t\right)\right| \cdot \sup_{t\in [0,1]} \int_{0}^{1}\left|E_{m}(t, s)\right| \mathrm{d} s\leq C\left|\hat{\beta}_{n}-\beta\right|\xrightarrow{a.s.} 0.
\end{align}Therefore, the result of the Theorem 2.5(ii) can be obtained by (37)–(41).
Proof of Theorem 2.6
According to (8) and  $\widetilde{y}_{i}=\widetilde{X}_{i} \beta+\widetilde{g}\left(t_{i}\right)+\widetilde{\xi}_{i}$, we have that
$\widetilde{y}_{i}=\widetilde{X}_{i} \beta+\widetilde{g}\left(t_{i}\right)+\widetilde{\xi}_{i}$, we have that
 \begin{align}
\widehat{\sigma}_{n}^{2}-\sigma^{2} = & \frac{1}{n} \sum_{i=1}^{n}\left[\widetilde{X}_{i}\left(\beta-\widehat{\beta}_{n}\right)\right]^{2}+\frac{1}{n} \sum_{i=1}^{n} \widetilde{g}^{2}\left(t_{i}\right)+\frac{1}{n} \sum_{i=1}^{n} \widetilde{\xi}_{i}^{2} +2 \frac{1}{n} \sum_{i=1}^{n} \widetilde{X}_{i}\left(\beta-\widehat{\beta}_{n}\right) \widetilde{g}\left(t_{i}\right)\nonumber\\
& +2 \frac{1}{n} \sum_{i=1}^{n} \widetilde{X}_{i}\left(\beta-\widehat{\beta}_{n}\right) \widetilde{\xi}_{i} +2 \frac{1}{n} \sum_{i=1}^{n} \widetilde{g}\left(t_{i}\right) \widetilde{\xi}_{i}-\sigma^{2} -\sigma_{\mu}^{2} \widehat{\beta}_{n}^{2} \nonumber\\
: =& L_{1}+L_{2}+L_{3}+2 L_{4}+2 L_{5}+2 L_{6}-\sigma^{2} -\sigma_{\mu}^{2} \widehat{\beta}_{n}^{2}.
\end{align}
\begin{align}
\widehat{\sigma}_{n}^{2}-\sigma^{2} = & \frac{1}{n} \sum_{i=1}^{n}\left[\widetilde{X}_{i}\left(\beta-\widehat{\beta}_{n}\right)\right]^{2}+\frac{1}{n} \sum_{i=1}^{n} \widetilde{g}^{2}\left(t_{i}\right)+\frac{1}{n} \sum_{i=1}^{n} \widetilde{\xi}_{i}^{2} +2 \frac{1}{n} \sum_{i=1}^{n} \widetilde{X}_{i}\left(\beta-\widehat{\beta}_{n}\right) \widetilde{g}\left(t_{i}\right)\nonumber\\
& +2 \frac{1}{n} \sum_{i=1}^{n} \widetilde{X}_{i}\left(\beta-\widehat{\beta}_{n}\right) \widetilde{\xi}_{i} +2 \frac{1}{n} \sum_{i=1}^{n} \widetilde{g}\left(t_{i}\right) \widetilde{\xi}_{i}-\sigma^{2} -\sigma_{\mu}^{2} \widehat{\beta}_{n}^{2} \nonumber\\
: =& L_{1}+L_{2}+L_{3}+2 L_{4}+2 L_{5}+2 L_{6}-\sigma^{2} -\sigma_{\mu}^{2} \widehat{\beta}_{n}^{2}.
\end{align} Let  $ \widetilde{\vartheta}_{i}= \vartheta_i -\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \vartheta_j,$ where
$ \widetilde{\vartheta}_{i}= \vartheta_i -\sum_{j=1}^{n} \int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \vartheta_j,$ where  $\widetilde{\vartheta}_{i}=\widetilde{\varepsilon}_{i}, ~\widetilde{\mu}_{i}$, or
$\widetilde{\vartheta}_{i}=\widetilde{\varepsilon}_{i}, ~\widetilde{\mu}_{i}$, or  $\widetilde{\eta}_{i}$. By the Kolmogorov’s strong law of large numbers and (14), we have
$\widetilde{\eta}_{i}$. By the Kolmogorov’s strong law of large numbers and (14), we have
 \begin{align*}
&\left|\frac{1}{n} \sum_{i=1}^{n}\widetilde{\eta}_{i}^{2}-\sigma_\eta\right|\nonumber\\
\leq & \left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i}^{2}-\sigma_\eta\right|+2\max _{1 \leq i \leq n}\left|\sum_{i=1}^{n} \int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s \eta_{i}\right|\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i}\right| +\max _{1 \leq i \leq n}\left|\sum_{i=1}^{n} \int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s \eta_{i}\right|^2\nonumber\\
\leq &[o(1)+2o(1)E|\eta_i| +o^2(1)] \xrightarrow{a.s.} 0.
\end{align*}
\begin{align*}
&\left|\frac{1}{n} \sum_{i=1}^{n}\widetilde{\eta}_{i}^{2}-\sigma_\eta\right|\nonumber\\
\leq & \left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i}^{2}-\sigma_\eta\right|+2\max _{1 \leq i \leq n}\left|\sum_{i=1}^{n} \int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s \eta_{i}\right|\left|\frac{1}{n} \sum_{i=1}^{n}\eta_{i}\right| +\max _{1 \leq i \leq n}\left|\sum_{i=1}^{n} \int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s \eta_{i}\right|^2\nonumber\\
\leq &[o(1)+2o(1)E|\eta_i| +o^2(1)] \xrightarrow{a.s.} 0.
\end{align*}Likewise, it can be inferred that
 \begin{equation*} \frac{1}{n} \sum_{i=1}^{n}\widetilde{\mu}_{i}^{2}\xrightarrow{a.s.}\sigma_\mu,~~~~ \frac{1}{n} \sum_{i=1}^{n}\widetilde{\eta}_{i}\widetilde{\mu}_{i}\xrightarrow{a.s.}0.\end{equation*}
\begin{equation*} \frac{1}{n} \sum_{i=1}^{n}\widetilde{\mu}_{i}^{2}\xrightarrow{a.s.}\sigma_\mu,~~~~ \frac{1}{n} \sum_{i=1}^{n}\widetilde{\eta}_{i}\widetilde{\mu}_{i}\xrightarrow{a.s.}0.\end{equation*}Through the Kolmogorov’s strong law of large numbers, (14), (15), and Theorem 2.5(i), we can prove
 \begin{align}
\left|L_{1}\right| \leq & \left|\beta-\widehat{\beta}_{n}\right|^{2} \cdot\left\{\frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n}\left(\int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \right)f(t_j)\right]^2+\frac{1}{n}\left|\sum_{i=1}^{n}(\widetilde{\eta}_{i}^{2}+\widetilde{\mu}_{i}^{2})\right|\right\} \nonumber\\
& +2\left|\beta-\widehat{\beta}_{n}\right|^{2} \cdot\left\{\left|\frac{1}{n} \sum_{i=1}^{n}\left(\widetilde{\eta}_{i}+\widetilde{\mu}_{i}\right)\cdot\left[f\left(t_{i}\right)-\sum_{j=1}^{n}\left(\int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \right)f(t_j)\right]\right|+\left|\frac{1}{n} \sum_{i=1}^{n} \widetilde{\eta}_{i} \widetilde{\mu}_{i}\right| \right\}\nonumber\\
\leq & o^{2}(1) \cdot\sup _{t\in [0,1]}\left|f(t)-\sum_{i=1}^{n}\left(\int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s\right) f\left(t_{i}\right)\right|^2+o^{2}(1)\left|\frac{1}{n} \sum_{i=1}^{n}\left\{\widetilde{\eta}_{i}^{2}+\widetilde{\mu}_{i}^{2}\right\}\right| \nonumber\\
& +2o^{2}(1) \cdot\sup _{t\in [0,1]}\left|f(t)-\sum_{i=1}^{n}\left(\int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s\right) f\left(t_{i}\right)\right| \left| \frac{1}{n} \sum_{i=1}^{n}\left(\widetilde{\eta}_{i}+\widetilde{\mu}_{i}\right)\right|+2o^{2}(1) \cdot\left|\frac{1}{n} \sum_{i=1}^{n} \widetilde{\eta}_{i} \widetilde{\mu}_{i}\right| \nonumber\\
\leq & o^{4}(1)+o^{2}(1)\cdot\left(\sigma_\eta+\sigma_\mu\right)+2o^{3}(1) \cdot \left| \frac{1}{n} \sum_{i=1}^{n}\left(\eta_{i}+\mu_{i}\right)\right|+2o^{3}(1) \cdot \max _{1 \leq i \leq n}\left|\sum_{i=1}^{n} \int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s \eta_{i}\right|\nonumber\\
& +2o^{3}(1) \cdot \max _{1 \leq i \leq n}\left|\sum_{i=1}^{n} \int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s \mu_{i}\right|+2o^{3}(1) \nonumber\\
\leq & o^{2}(1) \cdot\left[5o^{2}(1)+\sigma_{\eta}^{2}+\sigma_{\mu}^{2}+2o(1)E|\eta_i|+2o(1)E|\mu_i|+2o(1) \right] \xrightarrow{a.s.} 0.
\end{align}
\begin{align}
\left|L_{1}\right| \leq & \left|\beta-\widehat{\beta}_{n}\right|^{2} \cdot\left\{\frac{1}{n} \sum_{i=1}^{n}\left[f\left(t_{i}\right)-\sum_{j=1}^{n}\left(\int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \right)f(t_j)\right]^2+\frac{1}{n}\left|\sum_{i=1}^{n}(\widetilde{\eta}_{i}^{2}+\widetilde{\mu}_{i}^{2})\right|\right\} \nonumber\\
& +2\left|\beta-\widehat{\beta}_{n}\right|^{2} \cdot\left\{\left|\frac{1}{n} \sum_{i=1}^{n}\left(\widetilde{\eta}_{i}+\widetilde{\mu}_{i}\right)\cdot\left[f\left(t_{i}\right)-\sum_{j=1}^{n}\left(\int_{A_{j}} E_{m}(t_i, s) \mathrm{d} s \right)f(t_j)\right]\right|+\left|\frac{1}{n} \sum_{i=1}^{n} \widetilde{\eta}_{i} \widetilde{\mu}_{i}\right| \right\}\nonumber\\
\leq & o^{2}(1) \cdot\sup _{t\in [0,1]}\left|f(t)-\sum_{i=1}^{n}\left(\int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s\right) f\left(t_{i}\right)\right|^2+o^{2}(1)\left|\frac{1}{n} \sum_{i=1}^{n}\left\{\widetilde{\eta}_{i}^{2}+\widetilde{\mu}_{i}^{2}\right\}\right| \nonumber\\
& +2o^{2}(1) \cdot\sup _{t\in [0,1]}\left|f(t)-\sum_{i=1}^{n}\left(\int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s\right) f\left(t_{i}\right)\right| \left| \frac{1}{n} \sum_{i=1}^{n}\left(\widetilde{\eta}_{i}+\widetilde{\mu}_{i}\right)\right|+2o^{2}(1) \cdot\left|\frac{1}{n} \sum_{i=1}^{n} \widetilde{\eta}_{i} \widetilde{\mu}_{i}\right| \nonumber\\
\leq & o^{4}(1)+o^{2}(1)\cdot\left(\sigma_\eta+\sigma_\mu\right)+2o^{3}(1) \cdot \left| \frac{1}{n} \sum_{i=1}^{n}\left(\eta_{i}+\mu_{i}\right)\right|+2o^{3}(1) \cdot \max _{1 \leq i \leq n}\left|\sum_{i=1}^{n} \int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s \eta_{i}\right|\nonumber\\
& +2o^{3}(1) \cdot \max _{1 \leq i \leq n}\left|\sum_{i=1}^{n} \int_{A_{i}} E_{m}(t_i, s) \mathrm{d} s \mu_{i}\right|+2o^{3}(1) \nonumber\\
\leq & o^{2}(1) \cdot\left[5o^{2}(1)+\sigma_{\eta}^{2}+\sigma_{\mu}^{2}+2o(1)E|\eta_i|+2o(1)E|\mu_i|+2o(1) \right] \xrightarrow{a.s.} 0.
\end{align}From Lemma A.1 and Lemma A.2, we get directly that
 \begin{equation}
\left|L_{2}\right|\leq\left[O\left(n^{-2 \gamma}\right)+O\left(\tau_{m}^{2}\right)\right] \cdot o(1) \xrightarrow{a.s.} 0.
\end{equation}
\begin{equation}
\left|L_{2}\right|\leq\left[O\left(n^{-2 \gamma}\right)+O\left(\tau_{m}^{2}\right)\right] \cdot o(1) \xrightarrow{a.s.} 0.
\end{equation}Next, we will prove that
 \begin{equation}
L_{3}\xrightarrow{a.s.} \sigma^{2}+\sigma_{\mu}^{2} \beta^{2}.
\end{equation}
\begin{equation}
L_{3}\xrightarrow{a.s.} \sigma^{2}+\sigma_{\mu}^{2} \beta^{2}.
\end{equation}It is easy to check that
 \begin{align}
&\left|L_{3}-\sigma^{2}-\sigma_{\mu}^{2} \beta^{2}\right|\nonumber\\
= & \left|\frac{1}{n} \sum_{i=1}^{n} \hat{\xi}_{i}^{2}-\sigma^{2}-\sigma_{\mu}^{2} \beta^{2}\right| \nonumber\\
\leq & \left|\frac{1}{n} \sum_{i=1}^{n}\left[\left(\varepsilon_{i}-\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)^{2}-\sigma^{2}\right]\right| +2\left|\frac{1}{n} \sum_{i=1}^{n}\left(\varepsilon_{i}-\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right) \beta\right| \nonumber\\
& +\left|\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)^{2} \beta^{2}-\sigma_{\mu}^{2} \beta^{2}\right| \nonumber\\
:= & L_{31}+2 L_{32}+L_{33}.
\end{align}
\begin{align}
&\left|L_{3}-\sigma^{2}-\sigma_{\mu}^{2} \beta^{2}\right|\nonumber\\
= & \left|\frac{1}{n} \sum_{i=1}^{n} \hat{\xi}_{i}^{2}-\sigma^{2}-\sigma_{\mu}^{2} \beta^{2}\right| \nonumber\\
\leq & \left|\frac{1}{n} \sum_{i=1}^{n}\left[\left(\varepsilon_{i}-\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)^{2}-\sigma^{2}\right]\right| +2\left|\frac{1}{n} \sum_{i=1}^{n}\left(\varepsilon_{i}-\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right) \beta\right| \nonumber\\
& +\left|\frac{1}{n} \sum_{i=1}^{n}\left(\mu_{i}-\sum_{j=1}^{n} S_{i j} \mu_{j}\right)^{2} \beta^{2}-\sigma_{\mu}^{2} \beta^{2}\right| \nonumber\\
:= & L_{31}+2 L_{32}+L_{33}.
\end{align}Let
 \begin{equation*}\varsigma_{i}:=\varepsilon_{i}^{2}-\sigma^{2}=\varepsilon_{i}^{2}-\mathrm{E} \varepsilon_{i}^{2}=\left(\varepsilon_{i}^{+}\right)^{2}-\left(\mathrm{E} \varepsilon_{i}^{+}\right)^{2}-\left(\left(\varepsilon_{i}^{-}\right)^{2}-\left(\mathrm{E} \varepsilon_{i}^{-}\right)^{2}\right):=\varsigma_{i}^{+}-\varsigma_{i}^{-}.\end{equation*}
\begin{equation*}\varsigma_{i}:=\varepsilon_{i}^{2}-\sigma^{2}=\varepsilon_{i}^{2}-\mathrm{E} \varepsilon_{i}^{2}=\left(\varepsilon_{i}^{+}\right)^{2}-\left(\mathrm{E} \varepsilon_{i}^{+}\right)^{2}-\left(\left(\varepsilon_{i}^{-}\right)^{2}-\left(\mathrm{E} \varepsilon_{i}^{-}\right)^{2}\right):=\varsigma_{i}^{+}-\varsigma_{i}^{-}.\end{equation*} We can see from Lemma A.3 that  $\left\{\varsigma_{i}^{+}, i \geq 1\right\}$ and
$\left\{\varsigma_{i}^{+}, i \geq 1\right\}$ and  $\left\{\varsigma_{i}^{-}, i \geq 1\right\}$ are both ANA sequences and their mixing coefficients are not greater than
$\left\{\varsigma_{i}^{-}, i \geq 1\right\}$ are both ANA sequences and their mixing coefficients are not greater than  $\rho^-(N_\varepsilon)$. It is easy to verify that
$\rho^-(N_\varepsilon)$. It is easy to verify that  $E \varsigma_{i}^{\pm}=0$,
$E \varsigma_{i}^{\pm}=0$,  $\operatorname{Var}\left(\varsigma_{i}^{\pm}\right) \lt \infty$. Furthermore, it follows from the Kolmogorov’s strong law of large numbers, Lemma A.6, Lemma A.7, and (30) that
$\operatorname{Var}\left(\varsigma_{i}^{\pm}\right) \lt \infty$. Furthermore, it follows from the Kolmogorov’s strong law of large numbers, Lemma A.6, Lemma A.7, and (30) that
 \begin{align}
|L_{31}| & \leq\left|\frac{1}{n} \sum_{i=1}^{n}\left(\varepsilon_{i}^{2}-\sigma^{2}\right)\right|+2\left|\frac{1}{n} \sum_{i=1}^{n} \varepsilon_{i}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\right|+\left|\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)^{2}\right| \nonumber\\
& \leq o(1)+2 \max _{1 \leq i \leq n}\left|\frac{1}{n} \sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right| \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\varepsilon_{i}\right|+\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right|^{2}\nonumber\\
& = o(1) +o(1) \cdot o(1)+o^{2}(1)\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
|L_{31}| & \leq\left|\frac{1}{n} \sum_{i=1}^{n}\left(\varepsilon_{i}^{2}-\sigma^{2}\right)\right|+2\left|\frac{1}{n} \sum_{i=1}^{n} \varepsilon_{i}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\right|+\left|\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)^{2}\right| \nonumber\\
& \leq o(1)+2 \max _{1 \leq i \leq n}\left|\frac{1}{n} \sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right| \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\varepsilon_{i}\right|+\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right|^{2}\nonumber\\
& = o(1) +o(1) \cdot o(1)+o^{2}(1)\xrightarrow{a.s.} 0.
\end{align} Similar to the proof of (29), we can get  $\frac{1}{n}\sum_{i=1}^{n}\varepsilon_{i} \mu_{i}=o(1)$. Furthermore, from the Kolmogorov’s strong law of large numbers, Lemma A.1, Lemma A.7, (14), (29), and (30), we know that
$\frac{1}{n}\sum_{i=1}^{n}\varepsilon_{i} \mu_{i}=o(1)$. Furthermore, from the Kolmogorov’s strong law of large numbers, Lemma A.1, Lemma A.7, (14), (29), and (30), we know that
 \begin{align}
|L_{32}|\leq & \beta \left|\frac{1}{n} \sum_{i=1}^{n}\left[\varepsilon_{i} \mu_{i}-\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right) \mu_{i}-\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right) \varepsilon_{i} \right]\right| +\beta\left|\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\right| \nonumber\\
\leq & \beta\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\right|+\beta\left|\frac{1}{n} \sum_{i=1}^{n} \varepsilon_{i}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\right|+\beta\left|\frac{1}{n} \sum_{i=1}^{n} \varepsilon_{i} \mu_{i}\right|\nonumber\\
& +\beta\left|\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\right| \nonumber\\
\leq & \beta\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{j}\right| \cdot\left(\frac{1}{n} \sum_{i=1}^{n}\left|\mu_{i}\right|\right)+\beta\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{j}\right| \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\varepsilon_{i}\right|\nonumber\\
&+\beta\cdot \left|\frac{1}{n}\sum_{i=1}^{n}\varepsilon_{i} \mu_{i}\right|+\max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right| \cdot\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{j}\right| \nonumber\\
= & \beta \left[ o(1) \cdot E\left|u_{i}\right|+ 2o^2(1)+ o(1) \right]\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
|L_{32}|\leq & \beta \left|\frac{1}{n} \sum_{i=1}^{n}\left[\varepsilon_{i} \mu_{i}-\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right) \mu_{i}-\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right) \varepsilon_{i} \right]\right| +\beta\left|\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\right| \nonumber\\
\leq & \beta\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\right|+\beta\left|\frac{1}{n} \sum_{i=1}^{n} \varepsilon_{i}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\right|+\beta\left|\frac{1}{n} \sum_{i=1}^{n} \varepsilon_{i} \mu_{i}\right|\nonumber\\
& +\beta\left|\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \varepsilon_{j}\right)\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)\right| \nonumber\\
\leq & \beta\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{j}\right| \cdot\left(\frac{1}{n} \sum_{i=1}^{n}\left|\mu_{i}\right|\right)+\beta\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{j}\right| \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\varepsilon_{i}\right|\nonumber\\
&+\beta\cdot \left|\frac{1}{n}\sum_{i=1}^{n}\varepsilon_{i} \mu_{i}\right|+\max _{1 \leq i \leq n}\left|\sum_{k=1}^{n} \int_{A_{k}} E_{m}\left(t_{i}, s\right) \mathrm{d} s \varepsilon_{k}\right| \cdot\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{j}\right| \nonumber\\
= & \beta \left[ o(1) \cdot E\left|u_{i}\right|+ 2o^2(1)+ o(1) \right]\xrightarrow{a.s.} 0.
\end{align}According to the Kolmogorov’s strong law of large numbers and (15), we have that
 \begin{align}
|L_{33}| & = \beta^{2}\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}^{2}-\sigma_{\mu}^{2} -2 \frac{1}{n} \sum_{i=1}^{n} \mu_{i}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)+\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)^{2}\right|\nonumber\\
& \leq \beta^{2}\left[\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}^{2}-\sigma_{\mu}^{2}\right|+2\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right) \right|+\left|\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)^{2} \right|\right] \nonumber\\
& \leq \beta^{2}\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}^{2}-\sigma_{\mu}^{2}\right|+2\beta^{2}\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{j}\right| \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\mu_{i}\right|\nonumber\\
&+\beta^{2}\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{j}\right|^2\nonumber\\
& =\beta^{2}\left[o(1)+2 \cdot o(1) \cdot E\left|\mu_{i}\right|+o^{2}(1) \right]\xrightarrow{a.s.} 0.
\end{align}
\begin{align}
|L_{33}| & = \beta^{2}\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}^{2}-\sigma_{\mu}^{2} -2 \frac{1}{n} \sum_{i=1}^{n} \mu_{i}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)+\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)^{2}\right|\nonumber\\
& \leq \beta^{2}\left[\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}^{2}-\sigma_{\mu}^{2}\right|+2\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right) \right|+\left|\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{n} S_{i j} \mu_{j}\right)^{2} \right|\right] \nonumber\\
& \leq \beta^{2}\left|\frac{1}{n} \sum_{i=1}^{n} \mu_{i}^{2}-\sigma_{\mu}^{2}\right|+2\beta^{2}\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{j}\right| \cdot\left|\frac{1}{n} \sum_{i=1}^{n}\mu_{i}\right|\nonumber\\
&+\beta^{2}\max _{1 \leq i \leq n}\left|\sum_{j=1}^{n} \int_{A_{j}} E_{m}\left(t_i, s\right) \mathrm{d} s \mu_{j}\right|^2\nonumber\\
& =\beta^{2}\left[o(1)+2 \cdot o(1) \cdot E\left|\mu_{i}\right|+o^{2}(1) \right]\xrightarrow{a.s.} 0.
\end{align}Formula (45) is established by (46)–(49).
By Cauchy’s inequality, (43) and (44), we can prove
 \begin{equation}
L_{4}^{2} \leq \left[\frac{1}{n}\sum_{i=1}^{n}\tilde{X}_{i}^2\left(\beta-\widehat{\beta}_{n}\right)^2\right]\cdot \left[\frac{1}{n} \sum_{i=1}^{n} \widetilde{g}^{2}\left(t_{i}\right)\right]=L_{1} \cdot L_{2} \xrightarrow{a.s.} 0.
\end{equation}
\begin{equation}
L_{4}^{2} \leq \left[\frac{1}{n}\sum_{i=1}^{n}\tilde{X}_{i}^2\left(\beta-\widehat{\beta}_{n}\right)^2\right]\cdot \left[\frac{1}{n} \sum_{i=1}^{n} \widetilde{g}^{2}\left(t_{i}\right)\right]=L_{1} \cdot L_{2} \xrightarrow{a.s.} 0.
\end{equation}By Cauchy’s inequality, (43) and (45), we have that
 \begin{equation}
L_{5}^{2} \leq \left[\frac{1}{n}\sum_{i=1}^{n}\tilde{X}_{i}^2\left(\beta-\widehat{\beta}_{n}\right)^2\right] \cdot \left[\frac{1}{n} \sum_{i=1}^{n} \tilde{\xi}_{i}^{2}\right]=L_{1} \cdot L_{3} \xrightarrow{a.s.} 0.
\end{equation}
\begin{equation}
L_{5}^{2} \leq \left[\frac{1}{n}\sum_{i=1}^{n}\tilde{X}_{i}^2\left(\beta-\widehat{\beta}_{n}\right)^2\right] \cdot \left[\frac{1}{n} \sum_{i=1}^{n} \tilde{\xi}_{i}^{2}\right]=L_{1} \cdot L_{3} \xrightarrow{a.s.} 0.
\end{equation}By Cauchy’s inequality, (44) and (45), we get directly that
 \begin{equation}
L_{6}^{2} \leq \frac{1}{n} \sum_{i=1}^{n} \tilde{g}^{2}\left(t_{i}\right) \cdot \frac{1}{n} \sum_{i=1}^{n} \tilde{\xi}_{i}^{2}=L_{2} \cdot L_{3} \xrightarrow{a.s.} 0.
\end{equation}
\begin{equation}
L_{6}^{2} \leq \frac{1}{n} \sum_{i=1}^{n} \tilde{g}^{2}\left(t_{i}\right) \cdot \frac{1}{n} \sum_{i=1}^{n} \tilde{\xi}_{i}^{2}=L_{2} \cdot L_{3} \xrightarrow{a.s.} 0.
\end{equation}Therefore, by combining (42)–(45) and (50)–(4.43), the theorem is proved.
Acknowledgments
The authors are most grateful to the editor and anonymous referee for carefully reading the manuscript and valuable suggestions which helped in improving an earlier version of this paper. This paper is supported by the National Natural Science Foundation of China (12201600, 12201004, 12301181, 11901149, 12471248), the Natural Science Foundation of Anhui Province (2308085MA07), and the Key Projects of Natural Science Research in Universities in Anhui Province (KJ2020A0679, 2022AH051723).
Conflict of interest
No potential conflict of interest was reported by the authors.
Appendix A.
To prove the main results of the paper, we need the following useful lemmas. The first one is the basic property of wavelet estimation, which comes from [Reference Antoniadis, Gregoire and Mckeague1].
Lemma A.1. Suppose that Assumptions  $(\mathbf{H}1)$–
$(\mathbf{H}1)$– $(\mathbf{H}3)$ hold. For each
$(\mathbf{H}3)$ hold. For each  $t \in [0,1]$, we can conclude that:
$t \in [0,1]$, we can conclude that:
(i)  $\left|E_{0}(t, s)\right| \leq \frac{C_{k}}{(1+|t-s|)^{k}}$,
$\left|E_{0}(t, s)\right| \leq \frac{C_{k}}{(1+|t-s|)^{k}}$,  $\left|E_{m}(t, s)\right| \leq \frac{2^{m} C_{k} }{\left(1+2^{m}|t-s|\right)^{k}}$, where
$\left|E_{m}(t, s)\right| \leq \frac{2^{m} C_{k} }{\left(1+2^{m}|t-s|\right)^{k}}$, where  $k \in \mathbb{N}$, Ck is a constant depending on k only;
$k \in \mathbb{N}$, Ck is a constant depending on k only;
(ii)  $\sup _{0 \leq s \leq 1}\left|E_{m}(t, s)\right|=O\left(2^{m}\right)$;
$\sup _{0 \leq s \leq 1}\left|E_{m}(t, s)\right|=O\left(2^{m}\right)$;
(iii)  $\sup_{t\in [0,1]} \int_{0}^{1}\left|E_{m}(t, s)\right| \mathrm{d} s \leq C$;
$\sup_{t\in [0,1]} \int_{0}^{1}\left|E_{m}(t, s)\right| \mathrm{d} s \leq C$;
(iv)  $\int_{A_{i}}\left|E_{m}(t, s)\right| \mathrm{d} s=O\left(2^{m} / n\right)$, where
$\int_{A_{i}}\left|E_{m}(t, s)\right| \mathrm{d} s=O\left(2^{m} / n\right)$, where  $A_{i}=\left[s_{i-1}, s_{i}\right)$ represents the arbitrarily divided interval of
$A_{i}=\left[s_{i-1}, s_{i}\right)$ represents the arbitrarily divided interval of  $[0,1]$.
$[0,1]$.
The second lemma is about the important properties of wavelet estimators, which is given by [Reference Hu and Hu10].
Lemma A.2. Suppose that Assumptions  $(\mathbf{H}1)$–
$(\mathbf{H}1)$– $(\mathbf{H}3)$ hold. Then
$(\mathbf{H}3)$ hold. Then
 \begin{equation*}
\sup _{t\in [0,1]}\left|f(t)-\sum_{i=1}^{n}\left(\int_{A_{i}} E_{m}(t, s) \mathrm{d} s\right) f\left(t_{i}\right)\right|=O\left(n^{-\gamma}\right)+O\left(\tau_{m}\right) \end{equation*}
\begin{equation*}
\sup _{t\in [0,1]}\left|f(t)-\sum_{i=1}^{n}\left(\int_{A_{i}} E_{m}(t, s) \mathrm{d} s\right) f\left(t_{i}\right)\right|=O\left(n^{-\gamma}\right)+O\left(\tau_{m}\right) \end{equation*}and
 \begin{equation*}\sup _{t\in [0,1]}\left|g(t)-\sum_{i=1}^{n}\left(\int_{A_{i}} E_{m}(t, s) \mathrm{d} s\right) g\left(t_{i}\right)\right|=O\left(n^{-\gamma}\right)+O\left(\tau_{m}\right),
\end{equation*}
\begin{equation*}\sup _{t\in [0,1]}\left|g(t)-\sum_{i=1}^{n}\left(\int_{A_{i}} E_{m}(t, s) \mathrm{d} s\right) g\left(t_{i}\right)\right|=O\left(n^{-\gamma}\right)+O\left(\tau_{m}\right),
\end{equation*}where
 \begin{equation*}
\tau_m=\begin{cases}
2 ^ {-m(\alpha-1/2)},~~&1/2 \lt \alpha \lt 3/2;\\
\sqrt {m} \cdot 2 ^ {- m},~~ &\alpha =3/2;\\
\,2 ^ {- m},~~&\alpha \gt 3/2.
\end{cases}
\end{equation*}
\begin{equation*}
\tau_m=\begin{cases}
2 ^ {-m(\alpha-1/2)},~~&1/2 \lt \alpha \lt 3/2;\\
\sqrt {m} \cdot 2 ^ {- m},~~ &\alpha =3/2;\\
\,2 ^ {- m},~~&\alpha \gt 3/2.
\end{cases}
\end{equation*}The next one is the basic property of ANA random variables, which comes from [Reference Zhang and Wang26].
Lemma A.3. Let  $\{X_n,~n\geq1\}$ be a sequence of ANA random variables with mixing coefficients
$\{X_n,~n\geq1\}$ be a sequence of ANA random variables with mixing coefficients  $\rho^{-}(s)$. If
$\rho^{-}(s)$. If  $\{g_n(\cdot),~n\geq1\}$ are nondecreasing or nonincreasing functions, then
$\{g_n(\cdot),~n\geq1\}$ are nondecreasing or nonincreasing functions, then  $\{g_n(X_n),~n\geq1\}$ is still a sequence of ANA random variables with mixing coefficients not greater than
$\{g_n(X_n),~n\geq1\}$ is still a sequence of ANA random variables with mixing coefficients not greater than  $\rho^{-}(s)$.
$\rho^{-}(s)$.
The fourth lemma is an extension of the fundamental property of ANA random variables, which has been proved by [Reference Dung and Son8].
Lemma A.4. Let  $\{X_i, 1\leq i \leq n\}$ and
$\{X_i, 1\leq i \leq n\}$ and  $\{Y_i, 1 \leq i \leq n\}$ be sequences of ANA nonnegative random variables with mixing coefficients
$\{Y_i, 1 \leq i \leq n\}$ be sequences of ANA nonnegative random variables with mixing coefficients  $\rho^{-}(s_1)$ and
$\rho^{-}(s_1)$ and  $\rho^{-}(s_2)$, respectively. Assume that
$\rho^{-}(s_2)$, respectively. Assume that  $\{X_i, 1 \leq i \leq n\}$ and
$\{X_i, 1 \leq i \leq n\}$ and  $\{Y_i, 1\leq i\leq n\}$ are independent. Then
$\{Y_i, 1\leq i\leq n\}$ are independent. Then  $\{X_iY_i, 1 \leq i \leq n\}$ is a sequence of ANA random variables with mixing coefficients not greater than
$\{X_iY_i, 1 \leq i \leq n\}$ is a sequence of ANA random variables with mixing coefficients not greater than  $\rho^{-}(s_1)+\rho^{-}(s_2)$.
$\rho^{-}(s_1)+\rho^{-}(s_2)$.
The fifth lemma is the Rosenthal-type inequality for ANA random variables, which has been established by [Reference Wang and Lu18].
Lemma A.5. Let  $\{X_i,~i\geq1\}$ be an ANA sequence of random variables with
$\{X_i,~i\geq1\}$ be an ANA sequence of random variables with  $EX_i = 0$ and
$EX_i = 0$ and  $E|X_i|^p \lt \infty$ for some
$E|X_i|^p \lt \infty$ for some  $p\geq4$. Assume that
$p\geq4$. Assume that  $\rho^{-}(N)\leq r $ for
$\rho^{-}(N)\leq r $ for  $N\geq1$ and
$N\geq1$ and  $0 \leq r \lt (\frac{1}{6p})^{p/2}$. Then there exists a positive constant
$0 \leq r \lt (\frac{1}{6p})^{p/2}$. Then there exists a positive constant  $D=D(p,N,r)$ such that
$D=D(p,N,r)$ such that
 \begin{eqnarray*}
E\max_{1\leq i \leq n}\left|\sum_{j=1}^i X_j\right|^p\leq D\left\{\sum_{i =1}^nE|X_i|^p+\left(\sum_{i= 1}^nE|X_i|^2\right)^{p/2}\right\}.
\end{eqnarray*}
\begin{eqnarray*}
E\max_{1\leq i \leq n}\left|\sum_{j=1}^i X_j\right|^p\leq D\left\{\sum_{i =1}^nE|X_i|^p+\left(\sum_{i= 1}^nE|X_i|^2\right)^{p/2}\right\}.
\end{eqnarray*}Note that the complete convergence implies the almost sure convergence in view of the Borel–Cantelli lemma. So the sixth one can be derived from Theorem 4.2 in [Reference Yuan and Wu23].
Lemma A.6. Let  $p\geq4$ and let integer
$p\geq4$ and let integer  $N\geq1$. Suppose that
$N\geq1$. Suppose that  $\{X_i,~i\geq1\}$ be an ANA sequence of random variables with mixing coefficients
$\{X_i,~i\geq1\}$ be an ANA sequence of random variables with mixing coefficients  $\rho^{-}(N)\leq r $ for
$\rho^{-}(N)\leq r $ for  $0 \leq r \lt (\frac{1}{6p})^{p/2}$. If
$0 \leq r \lt (\frac{1}{6p})^{p/2}$. If
 \begin{eqnarray*}
\sup_{n\geq1}\frac{1}{n}\sum_{i=1}^n E |X_i|^p \lt \infty,
\end{eqnarray*}
\begin{eqnarray*}
\sup_{n\geq1}\frac{1}{n}\sum_{i=1}^n E |X_i|^p \lt \infty,
\end{eqnarray*}then for any  $\delta \gt 1/2$,
$\delta \gt 1/2$,
 \begin{eqnarray*}
n^{-\delta}\max_{1\leq i\leq n}\left|\sum_{i=1}^n X_i-E\left(\sum_{i=1}^n X_i\right)\right| \xrightarrow{a.s.} 0.
\end{eqnarray*}
\begin{eqnarray*}
n^{-\delta}\max_{1\leq i\leq n}\left|\sum_{i=1}^n X_i-E\left(\sum_{i=1}^n X_i\right)\right| \xrightarrow{a.s.} 0.
\end{eqnarray*}The last lemma plays an important role in the proof of the theorem.
Lemma A.7. Let  $\{X_i,~i\geq1\}$ be an ANA sequence of random variables with
$\{X_i,~i\geq1\}$ be an ANA sequence of random variables with  $EX_i = 0$ and
$EX_i = 0$ and  $\sup_{j\geq1}E|X_j|^p \lt \infty$ for some p > 2. Assume that
$\sup_{j\geq1}E|X_j|^p \lt \infty$ for some p > 2. Assume that  $\rho^{-}(N)\leq r $ for
$\rho^{-}(N)\leq r $ for  $N\geq1$ and
$N\geq1$ and  $0 \leq r \lt (\frac{1}{6p})^{p/2}$. If
$0 \leq r \lt (\frac{1}{6p})^{p/2}$. If  $\{w_{nj}(t_i),~1 \leq i, j\leq n, n \geq 1\}$ is an array of real numbers satisfying
$\{w_{nj}(t_i),~1 \leq i, j\leq n, n \geq 1\}$ is an array of real numbers satisfying  $\max_{1\leq i,j \leq n} |w_{nj}(t_i)| = O(n^{-1/2}) $ and
$\max_{1\leq i,j \leq n} |w_{nj}(t_i)| = O(n^{-1/2}) $ and  $\max_{1\leq i \leq n} \sum_{j=1}^n |w_{nj}(t_i)|^2 = O(n^{-s} \log^{-1} n)$ for some
$\max_{1\leq i \leq n} \sum_{j=1}^n |w_{nj}(t_i)|^2 = O(n^{-s} \log^{-1} n)$ for some  $\frac{1}{2}\leq s \leq \frac{1}{p}+1$. Then
$\frac{1}{2}\leq s \leq \frac{1}{p}+1$. Then
 \begin{equation*}\max_{1\leq i \leq n} \left |\sum_{j=1}^nw_{nj}(t_i) X_j\right|\xrightarrow{a.s.} 0,~~~~\mathrm{as}~~~~n\rightarrow\infty.\end{equation*}
\begin{equation*}\max_{1\leq i \leq n} \left |\sum_{j=1}^nw_{nj}(t_i) X_j\right|\xrightarrow{a.s.} 0,~~~~\mathrm{as}~~~~n\rightarrow\infty.\end{equation*}Proof of Lemma A.7
Without loss of generality, we assume that  $w_{nj}(t_i)\geq 0,~1 \leq i, j\leq n, n \geq 1$ (otherwise, we can note that
$w_{nj}(t_i)\geq 0,~1 \leq i, j\leq n, n \geq 1$ (otherwise, we can note that  $w_{nj}(t_i)=(w_{nj}(t_i))^+-(w_{nj}(t_i))^-$. For any
$w_{nj}(t_i)=(w_{nj}(t_i))^+-(w_{nj}(t_i))^-$. For any  $0 \lt q \lt \frac{1}{2}-\frac{1}{2(p-1)}$ and
$0 \lt q \lt \frac{1}{2}-\frac{1}{2(p-1)}$ and  $1\leq i,j \leq n$, denote
$1\leq i,j \leq n$, denote
 \begin{equation*}Y_{n,i,j} =-n^{-q}I(w_{nj}(t_i)X_j \lt -n^{-q})+w_{nj}(t_i)X_jI(|w_{nj}(t_i)X_j| \lt n^{-q})+n^{-q}I(w_{nj}(t_i)X_j \gt n^{-q}),\end{equation*}
\begin{equation*}Y_{n,i,j} =-n^{-q}I(w_{nj}(t_i)X_j \lt -n^{-q})+w_{nj}(t_i)X_jI(|w_{nj}(t_i)X_j| \lt n^{-q})+n^{-q}I(w_{nj}(t_i)X_j \gt n^{-q}),\end{equation*} \begin{equation*}Z_{n,i,j}= [w_{nj}(t_i)X_j+n^{-q}]I(w_{nj}(t_i)X_j \lt -n^{-q})+[w_{nj}(t_i)X_j-n^{-q}]I(w_{nj}(t_i)X_j \gt n^{-q}).\end{equation*}
\begin{equation*}Z_{n,i,j}= [w_{nj}(t_i)X_j+n^{-q}]I(w_{nj}(t_i)X_j \lt -n^{-q})+[w_{nj}(t_i)X_j-n^{-q}]I(w_{nj}(t_i)X_j \gt n^{-q}).\end{equation*} Since  $EX_j=0$, for
$EX_j=0$, for  $1\leq j \leq n$ and
$1\leq j \leq n$ and  $n \geq1$, it can be argued that
$n \geq1$, it can be argued that
 \begin{eqnarray}
\max_{1\leq i \leq n} \left |\sum_{j=1}^nEY_{n,i,j}\right|
&\leq&\max_{1\leq i\leq n} \sum_{j=1}^nE\left |w_{nj}(t_i) X_j\right|I(|w_{nj}(t_i)X_j | \gt n^{-q})\nonumber\\
&\leq&Cn^{(p-1)q} \left[\max_{1\leq i \leq n}\sum_{j=1}^n w_{nj}^2(t_i) \right] \left[\max_{1\leq i,j \leq n} w_{nj}(t_i) \right]^{p-2} \sup_{j\geq1}E\left|X_j\right|^p\nonumber\\
&\leq&C n^{(p-1)q-s-(p-2)/2}\log^{-1}n\leq C n^{(p-1)q-q-(p-2)/2}\log^{-1}n\nonumber\\
&\leq&C n^{(p-2)(q-1/2)}\rightarrow 0,~~~\mathrm{as}~~~~n\rightarrow\infty.
\end{eqnarray}
\begin{eqnarray}
\max_{1\leq i \leq n} \left |\sum_{j=1}^nEY_{n,i,j}\right|
&\leq&\max_{1\leq i\leq n} \sum_{j=1}^nE\left |w_{nj}(t_i) X_j\right|I(|w_{nj}(t_i)X_j | \gt n^{-q})\nonumber\\
&\leq&Cn^{(p-1)q} \left[\max_{1\leq i \leq n}\sum_{j=1}^n w_{nj}^2(t_i) \right] \left[\max_{1\leq i,j \leq n} w_{nj}(t_i) \right]^{p-2} \sup_{j\geq1}E\left|X_j\right|^p\nonumber\\
&\leq&C n^{(p-1)q-s-(p-2)/2}\log^{-1}n\leq C n^{(p-1)q-q-(p-2)/2}\log^{-1}n\nonumber\\
&\leq&C n^{(p-2)(q-1/2)}\rightarrow 0,~~~\mathrm{as}~~~~n\rightarrow\infty.
\end{eqnarray} Hence, we know by Lemma A.3 that  $\{Y_{n,i,j}-EY_{n,i,j}, 1 \leq i, j\leq n \}$ are also ANA random variables with zero mean and mixing coefficients
$\{Y_{n,i,j}-EY_{n,i,j}, 1 \leq i, j\leq n \}$ are also ANA random variables with zero mean and mixing coefficients  $\rho^-(N) \lt r$ for
$\rho^-(N) \lt r$ for  $0\leq r \lt (\frac{1}{6p})^{p/2}$. Take
$0\leq r \lt (\frac{1}{6p})^{p/2}$. Take  $\tau \gt \max\{p, 1+2/q\}$. From (51), Markov’s inequality and Lemma A.5, we have that for all ε > 0,
$\tau \gt \max\{p, 1+2/q\}$. From (51), Markov’s inequality and Lemma A.5, we have that for all ε > 0,
 \begin{eqnarray}
&&\sum_{n=1}^\infty P\left(\max_{1\leq i \leq n} \left |\sum_{j=1}^nY_{n,i,j}\right| \gt \varepsilon\right)\nonumber\\
&\leq&C\sum_{n=1}^\infty \sum_{i=1}^n P\left(\left |\sum_{j=1}^nY_{n,i,j}-E Y_{n,i,j}\right| \gt \varepsilon/2\right)\nonumber\\
&\leq& C\sum_{n=1}^\infty \sum_{i=1}^n E\left(\left|\sum_{j=1}^n(Y_{n,i,j}-EY_{n,i,j})\right|^\tau\right)\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \sum_{j=1}^nE\left|Y_{n,i,j}-EY_{n,i,j}\right|^\tau+C\sum_{n=1}^\infty\sum_{i=1}^n \left(\sum_{j=1}^nE | Y_{n,i,j}-EY_{n,i,j}|^2\right)^{\tau/2}\nonumber\\
&:=&M_{n1}+M_{n2}.
\end{eqnarray}
\begin{eqnarray}
&&\sum_{n=1}^\infty P\left(\max_{1\leq i \leq n} \left |\sum_{j=1}^nY_{n,i,j}\right| \gt \varepsilon\right)\nonumber\\
&\leq&C\sum_{n=1}^\infty \sum_{i=1}^n P\left(\left |\sum_{j=1}^nY_{n,i,j}-E Y_{n,i,j}\right| \gt \varepsilon/2\right)\nonumber\\
&\leq& C\sum_{n=1}^\infty \sum_{i=1}^n E\left(\left|\sum_{j=1}^n(Y_{n,i,j}-EY_{n,i,j})\right|^\tau\right)\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \sum_{j=1}^nE\left|Y_{n,i,j}-EY_{n,i,j}\right|^\tau+C\sum_{n=1}^\infty\sum_{i=1}^n \left(\sum_{j=1}^nE | Y_{n,i,j}-EY_{n,i,j}|^2\right)^{\tau/2}\nonumber\\
&:=&M_{n1}+M_{n2}.
\end{eqnarray} For  $M_{n1}$, we can obtain by Cr-inequality, Jensen’s inequality and Markov’s inequality that
$M_{n1}$, we can obtain by Cr-inequality, Jensen’s inequality and Markov’s inequality that
 \begin{eqnarray}
M_{n1}&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \sum_{j=1}^nE\left|Y_{n,i,j}\right|^\tau\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n\sum_{j=1}^n\left[E|w_{nj}(t_i)X_{j}|^\tau I(|w_{nj}(t_i)X_{j}|\leq n^{-q})+n^{-\tau q}P(|w_{nj}(t_i)X_{j}| \gt n^{-q}) \right]\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n\sum_{j=1}^nE|w_{nj}(t_i)X_{j}|^p \left[n^{-(\tau-p)q} I(|w_{nj}(t_i)X_{j}|\leq n^{-q})+n^{-(\tau-p)q}\right]\nonumber\\
&\leq&C\sum_{n=1}^\infty n^{-(\tau-p)q} \sum_{i=1}^n \left[\max_{1\leq i \leq n}\sum_{j=1}^n w_{nj}^2(t_i) \right] \left[\max_{1\leq i,j \leq n} w_{nj}(t_i) \right]^{p-2} \sup_{j\geq1}E\left|X_j\right|^p\nonumber\\
&\leq&C\sum_{n=1}^\infty n^{-(\tau-p)q+1-s-(p-2)/2}\log^{-1}n \leq C\sum_{n=1}^\infty n^{-(\tau-1)q+1}\log^{-1}n \lt \infty.
\end{eqnarray}
\begin{eqnarray}
M_{n1}&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \sum_{j=1}^nE\left|Y_{n,i,j}\right|^\tau\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n\sum_{j=1}^n\left[E|w_{nj}(t_i)X_{j}|^\tau I(|w_{nj}(t_i)X_{j}|\leq n^{-q})+n^{-\tau q}P(|w_{nj}(t_i)X_{j}| \gt n^{-q}) \right]\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n\sum_{j=1}^nE|w_{nj}(t_i)X_{j}|^p \left[n^{-(\tau-p)q} I(|w_{nj}(t_i)X_{j}|\leq n^{-q})+n^{-(\tau-p)q}\right]\nonumber\\
&\leq&C\sum_{n=1}^\infty n^{-(\tau-p)q} \sum_{i=1}^n \left[\max_{1\leq i \leq n}\sum_{j=1}^n w_{nj}^2(t_i) \right] \left[\max_{1\leq i,j \leq n} w_{nj}(t_i) \right]^{p-2} \sup_{j\geq1}E\left|X_j\right|^p\nonumber\\
&\leq&C\sum_{n=1}^\infty n^{-(\tau-p)q+1-s-(p-2)/2}\log^{-1}n \leq C\sum_{n=1}^\infty n^{-(\tau-1)q+1}\log^{-1}n \lt \infty.
\end{eqnarray}By Cr-inequality and Jensen’s inequality, we can get that
 \begin{eqnarray}
M_{n2}&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \left(\sum_{j=1}^nE |Y_{n,i,j}-EY_{n,i,j}|^2\right)^{\tau/2}\leq C\sum_{n=1}^\infty\sum_{i=1}^n \left(\sum_{j=1}^nE|Y_{n,i,j})|^2\right)^{\tau/2}\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \left[\sum_{j=1}^n w_{nj}^2(t_i)E|X_{j}|^2I(|w_{nj}(t_i)X_{j}|\leq n^{-q})+n^{2q}P(|w_{nj}(t_i)X_{j}| \gt n^{-q})\right]^{\tau/2}\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \left[\max_{1\leq i \leq n}\sum_{j=1}^n w_{nj}^2(t_i)\sup_{j\geq1}E\left|X_j\right|^p\right]^{\tau/2}\nonumber\\
&\leq&C\sum_{n=1}^\infty n^{-\tau s/2+1}\log^{-1}n \lt C\sum_{n=1}^\infty n^{- \tau q/2+1}\log^{-1}n \lt \infty.
\end{eqnarray}
\begin{eqnarray}
M_{n2}&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \left(\sum_{j=1}^nE |Y_{n,i,j}-EY_{n,i,j}|^2\right)^{\tau/2}\leq C\sum_{n=1}^\infty\sum_{i=1}^n \left(\sum_{j=1}^nE|Y_{n,i,j})|^2\right)^{\tau/2}\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \left[\sum_{j=1}^n w_{nj}^2(t_i)E|X_{j}|^2I(|w_{nj}(t_i)X_{j}|\leq n^{-q})+n^{2q}P(|w_{nj}(t_i)X_{j}| \gt n^{-q})\right]^{\tau/2}\nonumber\\
&\leq&C\sum_{n=1}^\infty\sum_{i=1}^n \left[\max_{1\leq i \leq n}\sum_{j=1}^n w_{nj}^2(t_i)\sup_{j\geq1}E\left|X_j\right|^p\right]^{\tau/2}\nonumber\\
&\leq&C\sum_{n=1}^\infty n^{-\tau s/2+1}\log^{-1}n \lt C\sum_{n=1}^\infty n^{- \tau q/2+1}\log^{-1}n \lt \infty.
\end{eqnarray}According to (52)–(54), combined with Borel–Cantelli lemma, it can be inferred that
 \begin{eqnarray*}
\max_{1\leq i \leq n} \left |\sum_{j=1}^nY_{n,i,j}\right|\xrightarrow{a.s.}0.
\end{eqnarray*}
\begin{eqnarray*}
\max_{1\leq i \leq n} \left |\sum_{j=1}^nY_{n,i,j}\right|\xrightarrow{a.s.}0.
\end{eqnarray*} Next, we will prove that  $\max_{1\leq i \leq n} \left |\sum_{j=1}^nZ_{n,i,j}\right|\xrightarrow{a.s.}0$. Since
$\max_{1\leq i \leq n} \left |\sum_{j=1}^nZ_{n,i,j}\right|\xrightarrow{a.s.}0$. Since  $0 \lt q \lt \frac{1}{2}-\frac{1}{2(p-1)}$, we can get
$0 \lt q \lt \frac{1}{2}-\frac{1}{2(p-1)}$, we can get
 \begin{eqnarray*}
\sum_{j=1}^\infty j^{-1/2} E|X_j| I(|X_j| \gt C j^{1/2-q})\leq\sum_{j=1}^\infty j^{-1/2}j^{(1/2-q)(1-p)} \sup_{j\geq1}E\left|X_j\right|^p\leq\sum_{i=1}^\infty j^{(p-1)q-p/2} \lt \infty,
\end{eqnarray*}
\begin{eqnarray*}
\sum_{j=1}^\infty j^{-1/2} E|X_j| I(|X_j| \gt C j^{1/2-q})\leq\sum_{j=1}^\infty j^{-1/2}j^{(1/2-q)(1-p)} \sup_{j\geq1}E\left|X_j\right|^p\leq\sum_{i=1}^\infty j^{(p-1)q-p/2} \lt \infty,
\end{eqnarray*}which implies
 \begin{eqnarray*}
\sum_{j=1}^\infty j^{-1/2} |X_j| I(|X_j| \gt C j^{1/2-q}) \lt \infty~~a.s.
\end{eqnarray*}
\begin{eqnarray*}
\sum_{j=1}^\infty j^{-1/2} |X_j| I(|X_j| \gt C j^{1/2-q}) \lt \infty~~a.s.
\end{eqnarray*} Therefore, we can derive by  $|Z_{n,i,j}| \leq |w_{nj}(t_i)X_{j}|I(|w_{nj}(t_i)X_{j}| \gt n^{-q})$ and the Kronecker’s lemma that
$|Z_{n,i,j}| \leq |w_{nj}(t_i)X_{j}|I(|w_{nj}(t_i)X_{j}| \gt n^{-q})$ and the Kronecker’s lemma that
 \begin{eqnarray*}
\max_{1\leq i \leq n} \left |\sum_{j=1}^nZ_{n,i,j}\right|&\leq &\max_{1\leq i \leq n}\sum_{j=1}^n \left |w_{nj}(t_i)X_j\right|I(|w_{nj}(t_i)X_j| \gt n^{-q})\nonumber\\
&\leq &C n^{-1/2}\sum_{j=1}^n \left |X_j\right|I(|X_j| \gt n^{1/2-q})\nonumber\\
&\leq &C n^{-1/2}\sum_{j=1}^n \left |X_j\right|I(|X_j| \gt j^{1/2-q})\nonumber\\
&\xrightarrow{a.s.}& 0.
\end{eqnarray*}
\begin{eqnarray*}
\max_{1\leq i \leq n} \left |\sum_{j=1}^nZ_{n,i,j}\right|&\leq &\max_{1\leq i \leq n}\sum_{j=1}^n \left |w_{nj}(t_i)X_j\right|I(|w_{nj}(t_i)X_j| \gt n^{-q})\nonumber\\
&\leq &C n^{-1/2}\sum_{j=1}^n \left |X_j\right|I(|X_j| \gt n^{1/2-q})\nonumber\\
&\leq &C n^{-1/2}\sum_{j=1}^n \left |X_j\right|I(|X_j| \gt j^{1/2-q})\nonumber\\
&\xrightarrow{a.s.}& 0.
\end{eqnarray*}This completes the proof of the lemma.
























 Open access
Open access