


1. Introduction
1.1. Diffusion limited aggregation
In the classical model of diffusion limited aggregation (DLA), introduced by Witten and Sander [Reference Witten and Sander13, Reference Witten and Sander14], the process begins with a single-particle cluster placed at the origin of a space, and then, one at a time, particles make a random walk ‘from infinity’ until they collide with and stick to the existing cluster. The process is particularly natural in Euclidean space with particles making Brownian motion, or on the d-dimensional lattice
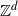 $\mathbb{Z}^d$
. Simulations of DLA in two dimensions show tree-like figures with long branches. For
$\mathbb{Z}^d$
. Simulations of DLA in two dimensions show tree-like figures with long branches. For
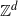 $\mathbb{Z}^d$
, Kesten [Reference Kesten8] proved that when the cluster size is N, the length of these arms is almost surely upper bounded by
$\mathbb{Z}^d$
, Kesten [Reference Kesten8] proved that when the cluster size is N, the length of these arms is almost surely upper bounded by
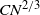 $CN^{2/3}$
when
$CN^{2/3}$
when
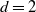 $d = 2$
, and by
$d = 2$
, and by
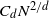 $C_d N^{2/d}$
when
$C_d N^{2/d}$
when
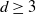 $d\ge 3$
.
$d\ge 3$
.
A distinct but related process, internal diffusion limited aggregation (IDLA), was introduced by Diaconis and Fulton [Reference Diaconis and Fulton3], as a protocol for recursively building a random aggregate of particles. In IDLA particles are added to the source vertex of an infinite graph, and make a random walk (over occupied vertices) until they visit an unoccupied vertex at which point they halt. Thus, the first particle occupies the source, and subsequent particles stick to the outside of the component rooted at the source. Although the DLA and IDLA processes differ, the point in common is that they both describe the evolution of a unique cluster by adhesion to the cluster boundary. As with DLA, the focus in IDLA has been on the limiting shape of the component formed by the occupied vertices. The formative work by Lawler et al. [Reference Lawler, Bramson and Griffeath9], proved that, on d-dimensional lattices the limiting shape approaches a Euclidean ball; a result subsequently refined in [Reference Asselah and Gaudilliere1, Reference Jerison, Levine and Sheffield7, Reference Lawler10], amongst others.
DLA has been proposed as a model of physical processes in systems as diverse as coagulated aerosols [Reference Witten and Sander13] and urban growth [Reference Batty, Longley and Fotheringham2], a common factor being the dendritic shape of the cluster so obtained (see [Reference Halsey5] for illustrative examples). However, the main and an original motivation for the DLA process was as a model of dendritic growth in dielectric breakdown and lightning formation. Niemeyer et al. [Reference Niemeyer, Pietronero and Wiesmann12], introduced a dielectric breakdown model which considers DLA in the presence of an electric field which biasses the particles to move in a given direction (e.g. downwards). In established models of lightning formation, paths of negatively charged particles (leaders) descend downwards from the base of the cloud layer, and paths of positively charged particles percolate upwards from the ground towards them, inducing a lightning strike on meeting. The DLA process was seen as a first approximation of this process, which is itself finite in extent with a source at the top (cloud layer) and a sink (the ground) at the bottom.
We consider a version of the DLA process on large but finite graphs with a designated source and sink vertex. DLA on finite graphs was studied previously for complete binary trees by Hastings and Halsey [Reference Hastings and Halsey6], and for the Boolean lattice (hypercube) by Frieze and Pegden [Reference Frieze and Pegden4]. The current paper continues this analysis of DLA on finite layered graphs, of which the binary tree and hypercube are typical examples.
1.2. The layers model
Let G be a finite graph
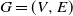 $G=(V,E)$
, whose vertices can be partitioned into sets
$G=(V,E)$
, whose vertices can be partitioned into sets
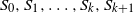 $S_0,S_1,\ldots,S_k,S_{k+1}$
to form a layered structure in which all edges are between layer
$S_0,S_1,\ldots,S_k,S_{k+1}$
to form a layered structure in which all edges are between layer
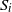 $S_i$
and
$S_i$
and
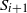 $S_{i+1}$
(
$S_{i+1}$
(
 $i=0,1,\ldots,k$
). The sets
$i=0,1,\ldots,k$
). The sets
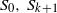 $S_0,\,S_{k+1}$
are of size one with
$S_0,\,S_{k+1}$
are of size one with
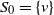 $S_0=\{\nu\}$
and
$S_0=\{\nu\}$
and
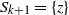 $S_{k+1}=\{z\}$
. The vertex v is the source vertex and the vertex z is the sink vertex. In certain cases the source and sink may be attached as extra (artificial) vertices to an existing graph G to complete the layered structure. This induces a natural orientation of the edges downwards from source to sink.
$S_{k+1}=\{z\}$
. The vertex v is the source vertex and the vertex z is the sink vertex. In certain cases the source and sink may be attached as extra (artificial) vertices to an existing graph G to complete the layered structure. This induces a natural orientation of the edges downwards from source to sink.
Examples of layered graphs with a symmetric structure include the following: the Boolean lattice (hypercube)
 ${\mathcal B}=\{0,1\}^n$
, with
${\mathcal B}=\{0,1\}^n$
, with
 $\nu=\mathbf{1}$
,
$\nu=\mathbf{1}$
,
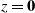 $z=\textbf{0}$
, see [Reference Frieze and Pegden4]; two-dimensional square grids with source the top left=hand corner and sink the bottom right-hand corner, thus inducing a diagonal orientation; finite Cayley trees with source the root and an artificial sink; and layered multipartite graphs with attached source and sink. A layers model on
$z=\textbf{0}$
, see [Reference Frieze and Pegden4]; two-dimensional square grids with source the top left=hand corner and sink the bottom right-hand corner, thus inducing a diagonal orientation; finite Cayley trees with source the root and an artificial sink; and layered multipartite graphs with attached source and sink. A layers model on
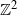 $\mathbb{Z}^2$
with diagonal downwards orientation was studied by Martineau [Reference Martineau.11]. The paper gives bounds on the height and width at a given step of the cluster rooted at the origin and within the positive quadrant.
$\mathbb{Z}^2$
with diagonal downwards orientation was studied by Martineau [Reference Martineau.11]. The paper gives bounds on the height and width at a given step of the cluster rooted at the origin and within the positive quadrant.
Graphs in the layers model have a top (the source) and a bottom (the sink). Particles are constrained to move downwards. As such they can be seen as simple models of particles percolating downwards through some porous medium.
1.3. DLA in the layers model
Informally, at a given step s, a particle labelled s starts from the source and percolates downwards through the graph, halting when it attempts to move to a vertex which is already occupied by a previous particle.
We next give a formal description of the DLA process, and the occupied component. Initially at step
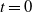 $t=0$
, only the sink vertex z is occupied, and the occupied component is
$t=0$
, only the sink vertex z is occupied, and the occupied component is
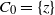 $C_0=\{z\}$
. At a given step t, let
$C_0=\{z\}$
. At a given step t, let
 $\rho_t$
be a random walk on the underlying graph starting at the source v and moving forwards level by level to the sink z. A particle placed on the source vertex (assumed unoccupied) follows the walk
$\rho_t$
be a random walk on the underlying graph starting at the source v and moving forwards level by level to the sink z. A particle placed on the source vertex (assumed unoccupied) follows the walk
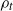 $\rho_t$
until it encounters an occupied vertex. Let the trajectory of the random walk from v to z be
$\rho_t$
until it encounters an occupied vertex. Let the trajectory of the random walk from v to z be
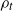 $\rho_t$
be
$\rho_t$
be
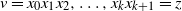 $\nu=x_0x_1x_2,\ldots,x_kx_{k+1}=z$
, where v and z are the start and end vertices of the walk,
$\nu=x_0x_1x_2,\ldots,x_kx_{k+1}=z$
, where v and z are the start and end vertices of the walk,
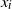 $x_i$
is the ith vertex on the walk, and
$x_i$
is the ith vertex on the walk, and
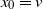 $x_0=\nu$
.
$x_0=\nu$
.
Let
 $x_{i}$
(
$x_{i}$
(
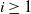 $i \ge 1$
) be the first occupied vertex encountered by particle t on the walk
$i \ge 1$
) be the first occupied vertex encountered by particle t on the walk
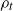 $\rho_t$
. The particle halts at position
$\rho_t$
. The particle halts at position
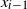 $x_{i-1}$
and permanently occupies that vertex. The component
$x_{i-1}$
and permanently occupies that vertex. The component
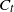 $C_{t}$
is formed by adding the vertex
$C_{t}$
is formed by adding the vertex
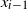 $x_{i-1}$
and directed edge
$x_{i-1}$
and directed edge
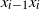 $x_{i-1}x_i$
to the component
$x_{i-1}x_i$
to the component
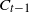 $C_{t-1}$
thus extending the directed tree formed by the occupied vertices and rooted at the sink z. As the sink is occupied from the start, any particle which reaches level k automatically halts there. The process ends at a step
$C_{t-1}$
thus extending the directed tree formed by the occupied vertices and rooted at the sink z. As the sink is occupied from the start, any particle which reaches level k automatically halts there. The process ends at a step
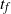 $t_f$
, the finish time, when the source vertex v first becomes occupied by a halted particle. Thus,
$t_f$
, the finish time, when the source vertex v first becomes occupied by a halted particle. Thus,
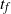 $t_f$
is the final number of particles occupying the graph (not including the sink). Thus, the term step s refers to the introduction of the particle s to the network and encompasses all actions performed by the particle s from the source until it halts, the next step being the addition of particle
$t_f$
is the final number of particles occupying the graph (not including the sink). Thus, the term step s refers to the introduction of the particle s to the network and encompasses all actions performed by the particle s from the source until it halts, the next step being the addition of particle
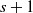 $s+1$
. We do not count the individual transitions of the random walk undertaken by particle s.
$s+1$
. We do not count the individual transitions of the random walk undertaken by particle s.
1.4. The models of this paper
Let
 $N_i=|S_i|$
be the size of the set
$N_i=|S_i|$
be the size of the set
 $S_i$
, the ith layer (or level) of the graph G. We regard all edges as directed from the source towards the sink. We consider two models.
$S_i$
, the ith layer (or level) of the graph G. We regard all edges as directed from the source towards the sink. We consider two models.
-
• The Cayley tree G(d, k) with branching factor d and height k. For convenience we take the size of the last level to be
 $d^k=n$
. Here
$d\ge 2$
is fixed or tends to infinity with n sufficiently slowly, so that
$k=\log n/\log d$
also tends to infinity with n. The source v is the root vertex at level zero of the tree and the sink z is an artificial vertex connected to all vertices in the final layer
$S_k$
of the tree. Excluding the sink, G(d, k) is a
$(d^{k+1}-1)/(d-1)$
-vertex graph.
$d^k=n$
. Here
$d\ge 2$
is fixed or tends to infinity with n sufficiently slowly, so that
$k=\log n/\log d$
also tends to infinity with n. The source v is the root vertex at level zero of the tree and the sink z is an artificial vertex connected to all vertices in the final layer
$S_k$
of the tree. Excluding the sink, G(d, k) is a
$(d^{k+1}-1)/(d-1)$
-vertex graph. -
• The multipartite layers model. The sets
$S_0, S_{k+1}$
have size one, the layers
$S_i$
have size
$N_i$
. For
$i=0,\ldots,k$
there is a complete bipartite graph between
$S_i$
and
$S_{i+1}$
. Here
$k \ge 1$
is fixed or tends to infinity with n.The equal (multipartite) layers model is a graph
$M_E(n,k)$
in which the sets of
$S_i$
(
$i =1,\ldots,k$
) are the same size
$N_i= n/k$
, where
$N_i \rightarrow \infty$
. Excluding the source and sink, the equal layers model G is an n-vertex graph. The parameter k can either be a fixed integer
$k \ge 1$
, or a function of n. In the extremes the graph has one layer,
$S_1$
, of n vertices (
$k=1$
), or is a path (
$k=n$
).The growing layers model is a graph
$M_G(d,k)$
in which the sets
$S_i$
grow geometrically in size with parameter d. As
$|S_0|=1$
, then
$|S_i|=N_i=d^i$
, and we take
$d^k=n$
. Here
$d,k \rightarrow \infty$
with n. Excluding the sink, the growing layers model G is a
$(d^{k+1}-1)/(d-1)$
-vertex graph.
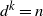
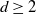
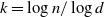
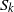
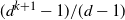
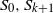
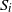
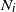
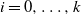
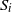
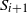

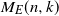

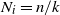
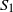
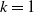
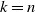
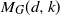
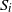
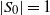
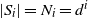
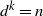
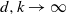
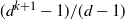
Analysis of the DLA process is in terms of n, which is, up to a constant multiple, the number of vertices in the graph. The model is probabilistic and corrections arising from the exceptional events are estimated as a function of n, even if this is not always made explicit. The parameter k determines the number of levels in the graph, and d the growth rate (if any) of the levels. The value of k or d can be constant in some models or it can tend to infinity as a function of n within some bounds. As
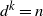 $d^k=n$
in the growing layers model, they are related by
$d^k=n$
in the growing layers model, they are related by
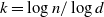 $k=\log n/\log d$
.
$k=\log n/\log d$
.
1.5. Notation
We say a sequence of events
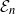 ${\mathcal E}_n$
,
${\mathcal E}_n$
,
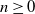 $n\geq 0$
occurs with high probability (w.h.p.) if
$n\geq 0$
occurs with high probability (w.h.p.) if
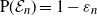 $\mathrm{P}({\mathcal E}_n)=1-\varepsilon_n$
where
$\mathrm{P}({\mathcal E}_n)=1-\varepsilon_n$
where
 $\varepsilon_n=o_n(1)$
for some function
$\varepsilon_n=o_n(1)$
for some function
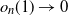 $o_n(1) \rightarrow 0$
with n, and thus
$o_n(1) \rightarrow 0$
with n, and thus
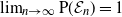 $\lim_{n\to\infty}\mathrm{P}({\mathcal E}_n)=1$
. Typically we write
$\lim_{n\to\infty}\mathrm{P}({\mathcal E}_n)=1$
. Typically we write
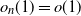 $o_n(1)=o(1)$
and similarly for other asymptotic notation such as
$o_n(1)=o(1)$
and similarly for other asymptotic notation such as
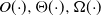 $O({\cdot}), \Theta({\cdot}), \Omega({\cdot})$
. We use
$O({\cdot}), \Theta({\cdot}), \Omega({\cdot})$
. We use
 $A_n \sim B_n$
to denote
$A_n \sim B_n$
to denote
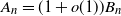 $A_n=(1+o(1)) B_n$
and, thus,
$A_n=(1+o(1)) B_n$
and, thus,
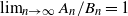 $\lim_{n \rightarrow \infty} A_n/B_n=1$
. We use
$\lim_{n \rightarrow \infty} A_n/B_n=1$
. We use
 $\omega=\omega_n$
in two ways; either to denote any quantity
$\omega=\omega_n$
in two ways; either to denote any quantity
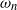 $\omega_n$
which tends to infinity with n but suitably slowly as required in the given proof context, or as a fixed divergent quantity whose value is stated explicitly. The expression
$\omega_n$
which tends to infinity with n but suitably slowly as required in the given proof context, or as a fixed divergent quantity whose value is stated explicitly. The expression
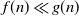 $ f(n) \ll g(n)$
indicates
$ f(n) \ll g(n)$
indicates
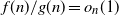 $f(n)/g(n)=o_n(1)$
. The notation
$f(n)/g(n)=o_n(1)$
. The notation
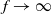 $f \rightarrow \infty$
indicates that
$f \rightarrow \infty$
indicates that
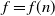 $f=f(n)$
grows unboundedly with increasing n. All results claimed are for sufficiently large n. The notation
$f=f(n)$
grows unboundedly with increasing n. All results claimed are for sufficiently large n. The notation
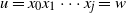 $u=x_0x_1\cdots x_j=w$
indicates a path from u to w whose vertices have been labelled
$u=x_0x_1\cdots x_j=w$
indicates a path from u to w whose vertices have been labelled
 $x_i$
,
$x_i$
,
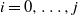 $i=0,\ldots,j$
, in the path order.
$i=0,\ldots,j$
, in the path order.
1.6. Results for the multipartite layers model
An arborescence is a rooted tree in which all edges are directed towards the root vertex. At any step t, the occupied component
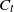 $C_{t}$
is an arborescence, with edges directed downwards towards the sink z. At the finish time
$C_{t}$
is an arborescence, with edges directed downwards towards the sink z. At the finish time
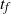 $t_f$
the source becomes occupied, and the component
$t_f$
the source becomes occupied, and the component
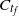 $C_{t_f}$
contains a directed connecting path from the source v to the sink z, all of whose vertices contain halted particles. In either layers model there is a value
$C_{t_f}$
contains a directed connecting path from the source v to the sink z, all of whose vertices contain halted particles. In either layers model there is a value
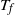 $T_f$
, depending on the model under consideration, which serves to approximate the finish time
$T_f$
, depending on the model under consideration, which serves to approximate the finish time
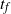 $t_f$
.
$t_f$
.
Theorem 1. The following results hold w.h.p. in the multipartite layers model.
-
(1) Equal layers model,
$M_E(n,k)$
. Let
$2\le k \le \sqrt{\log n}/\log \log n$
, and for
$i=1,\ldots,k$
let
$N_i=n/k$
. Let where
\[T_f= \big[ (k+1)! (n/k)^k \big]^{1/(k+1)} = \gamma_k \,n^{k/(k+1)},\]
$\gamma_k>0$
constant, and where
$\gamma_k \rightarrow 1/e$
as
$k \rightarrow \infty$
.
If k is constant then the finish time
$t_f$
satisfies
$T_f/\omega' \le t_f \le \omega' T_f$
with probability
$1-O(1/\omega')$
; where
$\omega'$
tends to infinity arbitrarily slowly with n. Whereas if
$k\rightarrow \infty$
then w.h.p.
$t_f=\Theta(T_f)$
. -
(2) Growing layers model,
$M_G(d,k)$
. For
$i=0,\ldots,k$
, let
$N_i=d^i$
, where
$d^k=n$
and, thus,
$k = \log n/\log d$
. Let
\[T_f= \sqrt{k}\; d^{k+3/2-\sqrt{2k+2}}.\]
-
(a) Provided
$d \rightarrow \infty$
and
$k \rightarrow \infty$
, but
$k \le ((\log d)/(\log \log d))^2$
, the finish time
$t_f$
satisfies
$d^{-O(1/\sqrt k)}\, T_f \le t_f \le d^{\,O(1/\sqrt k)}\, T_f$
. -
(b) At
$t_f$
, the levels
$i=1,\ldots, k- \lceil \sqrt{2k+2}-1 \rceil$
contain a single occupied vertex, the vertex
$u_i$
of the connecting path.
-
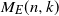
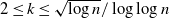
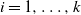










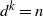
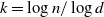







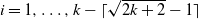

The
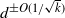 $d^{\pm O(1/\sqrt{k})}$
terms in the bounds on the finish time of the growing layers model come from possible rounding errors arising in the proof. Given the bounds on k, this error diverges, albeit slowly.
$d^{\pm O(1/\sqrt{k})}$
terms in the bounds on the finish time of the growing layers model come from possible rounding errors arising in the proof. Given the bounds on k, this error diverges, albeit slowly.
On deletion of the sink vertex, the digraph
 $D_t=C_t \! \setminus \! \{z\}$
consists of a forest of smaller arborescences whose components are rooted at the occupied vertices of level k. At the end of the process, let
$D_t=C_t \! \setminus \! \{z\}$
consists of a forest of smaller arborescences whose components are rooted at the occupied vertices of level k. At the end of the process, let
 $\nu=u_0 u_1\cdots u_k u_{k+1}=z$
be the connecting path from source
$\nu=u_0 u_1\cdots u_k u_{k+1}=z$
be the connecting path from source
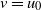 $\nu=u_0$
to sink
$\nu=u_0$
to sink
 $z=u_{k+1}$
. We prove that w.h.p. the arborescence rooted at vertex
$z=u_{k+1}$
. We prove that w.h.p. the arborescence rooted at vertex
 $u_k$
of the connecting path is precisely the path
$u_k$
of the connecting path is precisely the path
 $\nu=u_0 u_1\cdots u_k$
. Thus, this path grew back to the source without gaining any off-path branches due to other particles colliding with it.
$\nu=u_0 u_1\cdots u_k$
. Thus, this path grew back to the source without gaining any off-path branches due to other particles colliding with it.
Theorem 2. Let
 $\nu=u_0u_1\cdots u_k z$
be the path connecting source v and sink z at
$\nu=u_0u_1\cdots u_k z$
be the path connecting source v and sink z at
 $t_f$
, and let
$t_f$
, and let
 $D_{t_f}=C_{t_f}\! \setminus \!\{z\}$
be the occupied component with the sink deleted.
$D_{t_f}=C_{t_f}\! \setminus \!\{z\}$
be the occupied component with the sink deleted.
In either multipartite model, w.h.p., the vertices
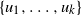 $\{u_1,\ldots ,u_k\}$
have in-degree one in
$\{u_1,\ldots ,u_k\}$
have in-degree one in
 $C_{t_f}$
. Thus the directed tree rooted at
$C_{t_f}$
. Thus the directed tree rooted at
 $u_k$
in
$u_k$
in
 $D_{t_f}$
is exactly this path.
$D_{t_f}$
is exactly this path.
1.7. Results for Cayley trees
For the Cayley tree
 $G=G(d,k)$
, the connecting path is by definition the unique path from source to sink. We give values for the finish time both for d finite and for
$G=G(d,k)$
, the connecting path is by definition the unique path from source to sink. We give values for the finish time both for d finite and for
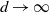 $d \rightarrow \infty$
. By an indicative argument Hastings and Halsey [Reference Hastings and Halsey6] derived an estimate of
$d \rightarrow \infty$
. By an indicative argument Hastings and Halsey [Reference Hastings and Halsey6] derived an estimate of
 $\sqrt{2k}\,2^{k-\sqrt{2k}}$
for the expected finish time of DLA on the binary tree G(2, k) of height k. We confirm their estimate is of the correct order of magnitude, and give results for G(d, k) for any constant d.
$\sqrt{2k}\,2^{k-\sqrt{2k}}$
for the expected finish time of DLA on the binary tree G(2, k) of height k. We confirm their estimate is of the correct order of magnitude, and give results for G(d, k) for any constant d.
Theorem 3. With high probability the finish time
 $t_f$
of DLA on a Cayley tree of branching factor d and height k is as follows.
$t_f$
of DLA on a Cayley tree of branching factor d and height k is as follows.
-
(1) Let
$T_f= \sqrt{k}\; d^{k+3/2-\sqrt{2k+2}}$
. Provided
$d \rightarrow \infty$
and
$k \rightarrow \infty$
, but
$k =o(d)$
, the finish time
$t_f$
satisfies
$d^{-O(1/\sqrt k)}\, T_f \le t_f \le d^{\,O(1/\sqrt k)}\, T_f$
. -
(2) Let
$T_f= \sqrt{k}\, d^{k-\sqrt{2k}}$
. If
$d \ge 2$
is constant, then
$ t_f =\Theta(T_f)$
.







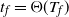
1.8. Comparison of occupancy
How to compare the results of DLA on different models with each other? One possibility is to define the packing ratio
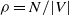 $\rho=N/|V|$
of a process as the number of particles N at the finish divided by the number of vertices in the graph. Ignoring constants and lower order terms,
$\rho=N/|V|$
of a process as the number of particles N at the finish divided by the number of vertices in the graph. Ignoring constants and lower order terms,
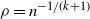 $\rho=n^{-1/(k+1)}$
for the equal layers model and
$\rho=n^{-1/(k+1)}$
for the equal layers model and
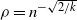 $\rho=n^{-\sqrt{2/k}}$
for the growing layers model.
$\rho=n^{-\sqrt{2/k}}$
for the growing layers model.
How can the packing ratio be used to compare results for DLA on infinite graphs such as
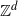 $\mathbb{Z}^d$
? The sink in
$\mathbb{Z}^d$
? The sink in
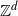 $\mathbb{Z}^d$
is the origin
$\mathbb{Z}^d$
is the origin
 $\boldsymbol{0}$
, as this is where the initial particle is located. At any fixed moment the longest arm of the figure formed by the occupied vertices defines a path back to the edge of the current bounding figure; which we take as the source (of particles entering from outside).
$\boldsymbol{0}$
, as this is where the initial particle is located. At any fixed moment the longest arm of the figure formed by the occupied vertices defines a path back to the edge of the current bounding figure; which we take as the source (of particles entering from outside).
For the two-dimensional grid it is a result of Kesten [Reference Kesten8], that, when N particles are added, the longest arm of the DLA figure is upper bounded by
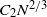 $C_2N^{2/3}$
, for some constant
$C_2N^{2/3}$
, for some constant
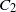 $C_2$
. A circle of radius
$C_2$
. A circle of radius
 $N^{2/3}$
contains order
$N^{2/3}$
contains order
 $n=N^{4/3}$
vertices in
$n=N^{4/3}$
vertices in
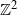 $\mathbb{Z}^2$
, so
$\mathbb{Z}^2$
, so
 $N =\Theta( n^{3/4})$
. Ignoring constants, this gives
$N =\Theta( n^{3/4})$
. Ignoring constants, this gives
 $\rho \le n^{-1/4}$
for
$\rho \le n^{-1/4}$
for
 $\mathbb{Z}^2$
, at any point in the (infinite) process. For
$\mathbb{Z}^2$
, at any point in the (infinite) process. For
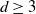 $d \ge 3$
, the longest arm length in
$d \ge 3$
, the longest arm length in
 $\mathbb{Z}^d$
is
$\mathbb{Z}^d$
is
 $C_d N^{2/d}$
. A figure of radius
$C_d N^{2/d}$
. A figure of radius
 $R=N^{2/d}$
has order
$R=N^{2/d}$
has order
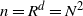 $n=R^d=N^2$
vertices, so
$n=R^d=N^2$
vertices, so
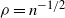 $\rho=n^{-1/2}$
.
$\rho=n^{-1/2}$
.
1.9. Road map of proofs
The following is an outline description and we often suppress minor details and qualifiers such as w.h.p.
The first step is to derive a solution to the recurrence (1)–(2) for the expected occupancy of the levels in the multipartite layers model. Under certain assumptions, the solution is asymptotic to (3), and the actual occupancy is concentrated around this value. This is particularly true in the equal layers model where the levels fill up in a more or less regular manner as given by (3), allowing us to estimate the finish time.
Things differ somewhat for the growing layers model. Although the higher levels fill in a regular manner, as given by (3), eventually we reach a level (with a well defined index
 $k-j^*$
) where, in expectation, only a single occupancy occurs. The expected waiting time for further occupancy of this level is much longer than the expected waiting time for a unique path of halted particles to grow backwards to the origin, thus terminating the process. This is the content of Theorem 1.(2).(b). On the other hand Theorem 2 (which requires a separate proof) says something stronger. Namely that the connecting path grows back from level k to the source as a unique path, and without gaining any off-path neighbours due to other particles colliding with it.
$k-j^*$
) where, in expectation, only a single occupancy occurs. The expected waiting time for further occupancy of this level is much longer than the expected waiting time for a unique path of halted particles to grow backwards to the origin, thus terminating the process. This is the content of Theorem 1.(2).(b). On the other hand Theorem 2 (which requires a separate proof) says something stronger. Namely that the connecting path grows back from level k to the source as a unique path, and without gaining any off-path neighbours due to other particles colliding with it.
Because of the similarity in which the layers grow, the results for the growing layers model tell us enough about the likely behaviour of the Cayley tree model to allow us to construct proofs for the finish time. The results for Cayley trees of branching factor d at least 2, are given in Theorem 3.
2. Bounds on occupancy in the layers model
The term step t (or time t) refers to the entire DLA process undertaken by particle t from introduction at the source until it halts and permanently occupies a vertex. The main task is to estimate the number of particles halted in each level (or layer) at the end of step t; that is, after the DLA process of tth particle has been completed.
Recall that
 $N_i$
is the size of layer i for
$N_i$
is the size of layer i for
 $i=0,1,\ldots,k$
, where the value of
$i=0,1,\ldots,k$
, where the value of
 $N_i$
depends on the model in question. For
$N_i$
depends on the model in question. For
 $t \ge 0$
, let
$t \ge 0$
, let
 $L_i(t)$
be the number of particles halted in level i at the end of step t. Thus
$L_i(t)$
be the number of particles halted in level i at the end of step t. Thus
 $L_i(0)=0$
for all
$L_i(0)=0$
for all
 $i\le k$
, and
$i\le k$
, and
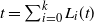 $t=\sum_{i=0}^k L_i(t)$
. We refer to
$t=\sum_{i=0}^k L_i(t)$
. We refer to
 $L_i$
as the occupancy of level i. Note that
$L_i$
as the occupancy of level i. Note that
 $L_0(t)=0$
for
$L_0(t)=0$
for
 $t < t_f$
,
$t < t_f$
,
 $L_k(t) \le t$
, and generally
$L_k(t) \le t$
, and generally
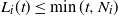 $L_i(t) \le \min(t, N_i)$
.
$L_i(t) \le \min(t, N_i)$
.
2.1. General formulation of layers occupancy
Let
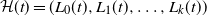 $\mathcal{H}(t)=(L_0(t),L_1(t),\ldots,L_k(t))$
be the occupancy vector of the DLA process at step t. Then,
$\mathcal{H}(t)=(L_0(t),L_1(t),\ldots,L_k(t))$
be the occupancy vector of the DLA process at step t. Then,
 \begin{align}\mathrm{E} (L_i(t+1) \mid {\mathcal H}(t)) &= L_i(t) + \frac{L_{i+1}(t)}{N_{i+1}} \prod_{j=0}^i \left( 1-\frac{L_{j}(t)}{N_{j}} \right)\!,\quad i < k, \\[-12pt] \nonumber \end{align}
\begin{align}\mathrm{E} (L_i(t+1) \mid {\mathcal H}(t)) &= L_i(t) + \frac{L_{i+1}(t)}{N_{i+1}} \prod_{j=0}^i \left( 1-\frac{L_{j}(t)}{N_{j}} \right)\!,\quad i < k, \\[-12pt] \nonumber \end{align}
 \begin{align}\mathrm{E} (L_k(t+1) \mid {\mathcal H}(t)) &= L_k(t) + \prod_{j=0}^k \left( 1-\frac{L_{j}(t)}{N_{j}} \right)\!. \\[9pt] \nonumber \end{align}
\begin{align}\mathrm{E} (L_k(t+1) \mid {\mathcal H}(t)) &= L_k(t) + \prod_{j=0}^k \left( 1-\frac{L_{j}(t)}{N_{j}} \right)\!. \\[9pt] \nonumber \end{align}
Note that (2) follows from (1) on defining
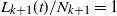 $L_{k+1}(t)/N_{k+1}=1$
for all t, and that if
$L_{k+1}(t)/N_{k+1}=1$
for all t, and that if
 $L_0(t)=1$
, the above recurrences give
$L_0(t)=1$
, the above recurrences give
 $L_i(t+1)=L_i(t)$
.
$L_i(t+1)=L_i(t)$
.
The next proposition gives the solution to these recurrences under suitable conditions.
Proposition 1. For
 $t \ge 0$
let
$t \ge 0$
let
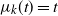 $\mu_k(t)=t$
, and for
$\mu_k(t)=t$
, and for
 $1 \le j \le k-1$
, let
$1 \le j \le k-1$
, let
 \begin{align}\mu_{k-j}(t)= \frac 1{N_k N_{k-1}\cdots N_{k-j+1}} \frac {t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}.\end{align}
\begin{align}\mu_{k-j}(t)= \frac 1{N_k N_{k-1}\cdots N_{k-j+1}} \frac {t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}.\end{align}
For
 $j<k$
in the equal layers model, and for
$j<k$
in the equal layers model, and for
 $j \le \sqrt{2k+2}-2$
in the growing layers model there are deterministic values
$j \le \sqrt{2k+2}-2$
in the growing layers model there are deterministic values
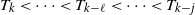 $T_k < \cdots < T_{k-\ell} < \cdots < T_{k-j}$
, such that w.h.p. for all
$T_k < \cdots < T_{k-\ell} < \cdots < T_{k-j}$
, such that w.h.p. for all
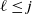 $\ell \le j$
and
$\ell \le j$
and
 $T_{k-\ell}\le t \le t_f$
we have
$T_{k-\ell}\le t \le t_f$
we have
 $L_{k-\ell}(t) \sim \mu_{k-\ell}(t)$
, whereas for
$L_{k-\ell}(t) \sim \mu_{k-\ell}(t)$
, whereas for
 $\ell > j$
, and
$\ell > j$
, and
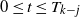 $0 \le t \le T_{k-j}$
,
$0 \le t \le T_{k-j}$
,
 $L_{k-\ell}(t)=0$
.
$L_{k-\ell}(t)=0$
.
This proposition summarizes a gap property that when level
 $k-j$
starts to fill enough for the occupancy to become concentrated, the levels with lower index
$k-j$
starts to fill enough for the occupancy to become concentrated, the levels with lower index
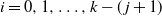 $i=0,1,\ldots,k-(\kern1.5pt j+1)$
still remain empty. Most of the work is to prove that
$i=0,1,\ldots,k-(\kern1.5pt j+1)$
still remain empty. Most of the work is to prove that
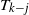 $T_{k-j}$
can be chosen to be
$T_{k-j}$
can be chosen to be
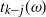 $t_{k-j}(\omega)$
as given by (6) and (7). The proof of Proposition 1 is inductive backwards from level k. The precise growth of the levels, and values of j which make it work are to be determined. The first steps are common to the equal and growing layers models, and we include them together in this section. For the equal layers model we complete the proof of Proposition 1 in Sections 3.1 and 3.2. The analogous proof for the growing layers model is given in Section 4.
$t_{k-j}(\omega)$
as given by (6) and (7). The proof of Proposition 1 is inductive backwards from level k. The precise growth of the levels, and values of j which make it work are to be determined. The first steps are common to the equal and growing layers models, and we include them together in this section. For the equal layers model we complete the proof of Proposition 1 in Sections 3.1 and 3.2. The analogous proof for the growing layers model is given in Section 4.
2.2. Upper bound on occupancy at step t
The underlying random walk
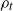 $\rho_t$
from source v to sink z at step t defines a path given by
$\rho_t$
from source v to sink z at step t defines a path given by
 $\nu=u_0u_1\cdots u_ku_{k+1}=z$
, where
$\nu=u_0u_1\cdots u_ku_{k+1}=z$
, where
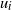 $u_i$
is a random vertex in level i. Particle t follows this walk until halting at a vertex
$u_i$
is a random vertex in level i. Particle t follows this walk until halting at a vertex
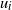 $u_i$
, where
$u_i$
, where
 $u_{i+1}$
is the first occupied vertex encountered by
$u_{i+1}$
is the first occupied vertex encountered by
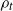 $\rho_t$
.
$\rho_t$
.
Let
 $B_i(t)$
denote the occupied (blocked) vertices in level i in the DLA process at the end of step t. We define an upper-blocked process which we use to upper bound
$B_i(t)$
denote the occupied (blocked) vertices in level i in the DLA process at the end of step t. We define an upper-blocked process which we use to upper bound
 $L_i(t)=|B_i(t)|$
. This new process gives rise to sets
$L_i(t)=|B_i(t)|$
. This new process gives rise to sets
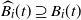 $\widehat {B_i}(t)\supseteq B_i(t)$
and random variables
$\widehat {B_i}(t)\supseteq B_i(t)$
and random variables
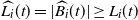 $\widehat{L_i}(t)=|\widehat{B_i}(t)|\geq L_i(t)$
. For every vertex
$\widehat{L_i}(t)=|\widehat{B_i}(t)|\geq L_i(t)$
. For every vertex
 $u_j$
,
$u_j$
,
 $0 \le j \le k$
, on the walk
$0 \le j \le k$
, on the walk
 $\rho_{t+1}$
, if
$\rho_{t+1}$
, if
 $u_{j+1}$
is occupied (
$u_{j+1}$
is occupied (
 $u_{j+1} \in \widehat B_{j+1}(t)$
) add a vertex to
$u_{j+1} \in \widehat B_{j+1}(t)$
) add a vertex to
 $\widehat{B_j}(t)$
as follows. If
$\widehat{B_j}(t)$
as follows. If
 $u_j \not \in \widehat{B_j}(t)$
add
$u_j \not \in \widehat{B_j}(t)$
add
 $u_j$
to
$u_j$
to
 $\widehat{B_j}(t+1)$
. If
$\widehat{B_j}(t+1)$
. If
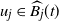 $u_j \in \widehat{B_j}(t)$
add some other
$u_j \in \widehat{B_j}(t)$
add some other
 $u'_j \in S_j \! \setminus \! \widehat{B_j}(t)$
to
$u'_j \in S_j \! \setminus \! \widehat{B_j}(t)$
to
 $\widehat{B_j}(t+1)$
. If the layer
$\widehat{B_j}(t+1)$
. If the layer
 $S_j$
becomes full we continue with the layer
$S_j$
becomes full we continue with the layer
 $S_{j-1}$
. As we prove, this contingency is unlikely to occur, as w.h.p. the first layer to become full is the source.
$S_{j-1}$
. As we prove, this contingency is unlikely to occur, as w.h.p. the first layer to become full is the source.
If particle
 $t+1$
halts at vertex
$t+1$
halts at vertex
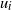 $u_i$
in the DLA process, then either
$u_i$
in the DLA process, then either
 $u_i$
is added to both
$u_i$
is added to both
 $B_i(t+1)$
and
$B_i(t+1)$
and
 $\widehat{B_i}(t+1)$
, or
$\widehat{B_i}(t+1)$
, or
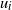 $u_i$
is already a member of
$u_i$
is already a member of
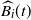 $\widehat{B_i}(t)$
. In either case
$\widehat{B_i}(t)$
. In either case
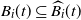 $B_i(t) \subseteq \widehat{B_i}(t)$
for all i and
$B_i(t) \subseteq \widehat{B_i}(t)$
for all i and
 $t \ge 0$
. It follows that
$t \ge 0$
. It follows that
 $L_i(t) \le \widehat{L_i}(t) \le t$
, as
$L_i(t) \le \widehat{L_i}(t) \le t$
, as
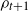 $\rho_{t+1}$
can add at most one vertex to
$\rho_{t+1}$
can add at most one vertex to
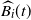 $\widehat{B_i}(t)$
. Moreover,
$\widehat{B_i}(t)$
. Moreover,
 $\widehat{L_k}(t)=t$
deterministically (provided
$\widehat{L_k}(t)=t$
deterministically (provided
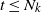 $t \le N_k$
). As a consequence the finish time
$t \le N_k$
). As a consequence the finish time
 $t_f(UB)$
of the upper-blocked process satisfies
$t_f(UB)$
of the upper-blocked process satisfies
 $t_f(UB) \le t_f(DLA)$
.
$t_f(UB) \le t_f(DLA)$
.
Let
 $\widehat{\mathcal{H}}(t)=(\widehat{L_0}(t),\widehat{L_1}(t),\ldots,\widehat{L_k}(t))$
be the occupancy vector of the upper-blocked process at step t. For
$\widehat{\mathcal{H}}(t)=(\widehat{L_0}(t),\widehat{L_1}(t),\ldots,\widehat{L_k}(t))$
be the occupancy vector of the upper-blocked process at step t. For
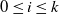 $0 \le i \le k$
, the expectation
$0 \le i \le k$
, the expectation
 $\mathrm{E}\,\widehat{L_i}(t)$
satisfies the recurrence
$\mathrm{E}\,\widehat{L_i}(t)$
satisfies the recurrence
 \begin{align}\mathrm{E}\big(\widehat{L_i}(t+1) \mid \widehat{H}(t)\big)= \widehat{L_i}(t) + \frac{\widehat L_{i+1}(t)}{N_{i+1}}\, {\unicode{x1D7D9}}_{\{{{\mathcal E}(t)}\}}, \end{align}
\begin{align}\mathrm{E}\big(\widehat{L_i}(t+1) \mid \widehat{H}(t)\big)= \widehat{L_i}(t) + \frac{\widehat L_{i+1}(t)}{N_{i+1}}\, {\unicode{x1D7D9}}_{\{{{\mathcal E}(t)}\}}, \end{align}
where
 ${\mathcal E}(t)$
is the event that
${\mathcal E}(t)$
is the event that
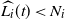 $\widehat{L_i}(t) < N_i$
and that
$\widehat{L_i}(t) < N_i$
and that
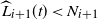 $\widehat L_{i+1}(t) < N_{i+1}$
for
$\widehat L_{i+1}(t) < N_{i+1}$
for
 $i<k$
. Setting
$i<k$
. Setting
 ${\unicode{x1D7D9}}_{\{{{\mathcal E}(t)}\}}=1$
always gives an upper bound on
${\unicode{x1D7D9}}_{\{{{\mathcal E}(t)}\}}=1$
always gives an upper bound on
 $\mathrm{E}\, \widehat{L_i}(t)$
, and as we only propose to analyse the process as long as no level i (
$\mathrm{E}\, \widehat{L_i}(t)$
, and as we only propose to analyse the process as long as no level i (
 $1 \le i \le k$
) is full, we assume
$1 \le i \le k$
) is full, we assume
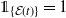 ${\unicode{x1D7D9}}_{\{{{\mathcal E}(t)}\}}=1$
forthwith. Equation (4) follows because the upper-blocked process increases the size of
${\unicode{x1D7D9}}_{\{{{\mathcal E}(t)}\}}=1$
forthwith. Equation (4) follows because the upper-blocked process increases the size of
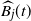 $\widehat{B_j}(t)$
(if possible) whenever the walk
$\widehat{B_j}(t)$
(if possible) whenever the walk
 $\rho_t$
contains a vertex of
$\rho_t$
contains a vertex of
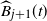 $\widehat B_{j+1}(t)$
, this being true at all levels
$\widehat B_{j+1}(t)$
, this being true at all levels
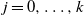 $j=0,\ldots,k$
.
$j=0,\ldots,k$
.
The evolution of
 ${\widehat{\mathcal{H}}}(t)=(\widehat{L_0}(t),\widehat{L_1}(t),\ldots,\widehat{L_k}(t))$
is Markovian, and for
${\widehat{\mathcal{H}}}(t)=(\widehat{L_0}(t),\widehat{L_1}(t),\ldots,\widehat{L_k}(t))$
is Markovian, and for
 $t \le t_f$
we henceforth assume for
$t \le t_f$
we henceforth assume for
 $i \ge 1$
that
$i \ge 1$
that
 $\widehat{L_i}(t) < N_i$
in our calculations. If so, referring to (1) and (2), we have
$\widehat{L_i}(t) < N_i$
in our calculations. If so, referring to (1) and (2), we have
 \[\mathrm{E} (L_i(t+1)\mid {\mathcal H}(t)) \le L_i(t) +\frac{L_{i+1}(t)}{N_{i+1}}\le \widehat{L_i}(t) +\frac{\widehat L_{i+1}(t)}{N_{i+1}}=\mathrm{E} \big( \widehat L_{i+1}(t+1) \mid \widehat{\mathcal H}(t)\big).\]
\[\mathrm{E} (L_i(t+1)\mid {\mathcal H}(t)) \le L_i(t) +\frac{L_{i+1}(t)}{N_{i+1}}\le \widehat{L_i}(t) +\frac{\widehat L_{i+1}(t)}{N_{i+1}}=\mathrm{E} \big( \widehat L_{i+1}(t+1) \mid \widehat{\mathcal H}(t)\big).\]
When
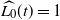 $\widehat{L_0}(t)=1$
at
$\widehat{L_0}(t)=1$
at
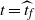 $t=\widehat{t}_f$
the upper-blocked process stops, and
$t=\widehat{t}_f$
the upper-blocked process stops, and
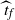 $\widehat{t}_f$
gives a lower bound on the finish time
$\widehat{t}_f$
gives a lower bound on the finish time
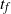 $t_f$
of the corresponding DLA process.
$t_f$
of the corresponding DLA process.
We next give w.h.p. bounds for
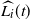 $\widehat{L_i}(t)$
assuming none of the layers
$\widehat{L_i}(t)$
assuming none of the layers
 $i=1,\ldots,k$
are full for
$i=1,\ldots,k$
are full for
 $t \le \widehat{t}_f$
. The proofs of level occupancy are inductive backwards from level k. For a given level
$t \le \widehat{t}_f$
. The proofs of level occupancy are inductive backwards from level k. For a given level
 $k-j$
we identify two (not necessarily integer) times,
$k-j$
we identify two (not necessarily integer) times,
 $t_1(k-j)$
and
$t_1(k-j)$
and
 $t_{k-j}(\omega)$
, defined as follows. For level k, as
$t_{k-j}(\omega)$
, defined as follows. For level k, as
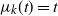 $\mu_k(t)=t$
,
$\mu_k(t)=t$
,
 $t_1(k)=1$
and for
$t_1(k)=1$
and for
 $j\ge 1$
, let
$j\ge 1$
, let
 $t_1(k-j)$
is the solution to
$t_1(k-j)$
is the solution to
 $\mu_{k-j}(t)=1$
in (3). Thus,
$\mu_{k-j}(t)=1$
in (3). Thus,
 \begin{align}t_{1}(k-j)= \big[(\kern1.5pt j+1)! N_k N_{k-1}\cdots N_{k-j+1}\big]^{1/(\kern1.5pt j+1)}.\end{align}
\begin{align}t_{1}(k-j)= \big[(\kern1.5pt j+1)! N_k N_{k-1}\cdots N_{k-j+1}\big]^{1/(\kern1.5pt j+1)}.\end{align}
The variable
 $t_1(k-j)$
is used as a reference point in many of our calculations.
$t_1(k-j)$
is used as a reference point in many of our calculations.
Let
 $t_k(\omega)=1$
, and for
$t_k(\omega)=1$
, and for
 $1\le j \le k-1$
, let
$1\le j \le k-1$
, let
 $t_{k-j}(\omega)=(4\omega^{3})^{1/(\kern1.5pt j+1)} t_1(k-j)$
. Thus,
$t_{k-j}(\omega)=(4\omega^{3})^{1/(\kern1.5pt j+1)} t_1(k-j)$
. Thus,
 \begin{align}t_{k-j}(\omega)= \big( (4\omega^{3})\big[(\kern1.5pt j+1)! N_k N_{k-1}\cdots N_{k-j+1}\big] \big)^{1/(\kern1.5pt j+1)}.\end{align}
\begin{align}t_{k-j}(\omega)= \big( (4\omega^{3})\big[(\kern1.5pt j+1)! N_k N_{k-1}\cdots N_{k-j+1}\big] \big)^{1/(\kern1.5pt j+1)}.\end{align}
Henceforth, we choose
 \begin{align} \omega=6 \log n.\end{align}
\begin{align} \omega=6 \log n.\end{align}
In Section 2.3 we show that with the value of
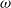 $\omega$
given in (7), for
$\omega$
given in (7), for
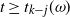 $t \ge t_{k-j}(\omega)$
, the value of
$t \ge t_{k-j}(\omega)$
, the value of
 $\widehat L_{k-j}(t)$
is concentrated around
$\widehat L_{k-j}(t)$
is concentrated around
 $\mu_{k-j}(t)$
w.h.p., thus establishing the first part of the claim in Proposition 1.
$\mu_{k-j}(t)$
w.h.p., thus establishing the first part of the claim in Proposition 1.
Note. For
 $j \ge 1$
, the values of
$j \ge 1$
, the values of
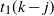 $t_1(k-j)$
and
$t_1(k-j)$
and
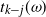 $t_{k-j}(\omega)$
are not necessarily integer. In this case the nearest step t to
$t_{k-j}(\omega)$
are not necessarily integer. In this case the nearest step t to
 $t_1$
would be obtained by rounding to
$t_1$
would be obtained by rounding to
 $t=t_1+\varepsilon$
for some
$t=t_1+\varepsilon$
for some
 $-1/2<\varepsilon<1/2$
, so that
$-1/2<\varepsilon<1/2$
, so that
 $\mu_{k-j}(t)= (1+\varepsilon/t_1)^{\kern1.5pt j+1}$
. For
$\mu_{k-j}(t)= (1+\varepsilon/t_1)^{\kern1.5pt j+1}$
. For
 $j \ge 1$
, the values of k we consider satisfy
$j \ge 1$
, the values of k we consider satisfy
 $j/t_1(k-j) =o(1)$
. Thus,
$j/t_1(k-j) =o(1)$
. Thus,
 $\mu_{k-j}(t) \sim 1$
and the effect of rounding is negligible. This is shown for the equal layers model in Lemma 4(3) and for the growing layers model in (45).
$\mu_{k-j}(t) \sim 1$
and the effect of rounding is negligible. This is shown for the equal layers model in Lemma 4(3) and for the growing layers model in (45).
The next lemma gives the expected value of
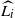 $\widehat{L_i}$
and conditions for its concentration at any step
$\widehat{L_i}$
and conditions for its concentration at any step
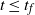 $t \le t_f$
. Recall that
$t \le t_f$
. Recall that
 $t_1(k-j)$
is given by (5), and
$t_1(k-j)$
is given by (5), and
 $ t_{k-j}(\omega)$
is given by (6).
$ t_{k-j}(\omega)$
is given by (6).
Lemma 1. Let
 $\mu_{i}(t)$
be given by (3), then for
$\mu_{i}(t)$
be given by (3), then for
 $i=0,1,\ldots,k$
and any
$i=0,1,\ldots,k$
and any
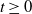 $t\ge 0$
, it holds that
$t\ge 0$
, it holds that
 $\mathrm{E}\, \widehat{L_i}(t) \le \mu_i(t)$
. Moreover, provided
$\mathrm{E}\, \widehat{L_i}(t) \le \mu_i(t)$
. Moreover, provided
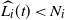 $\widehat{L_i}(t) < N_i$
for
$\widehat{L_i}(t) < N_i$
for
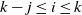 $k-j \le i \le k$
then the following hold.
$k-j \le i \le k$
then the following hold.
-
(1) For
$j\ge 1$
,
$\mathrm{E}\,\widehat L_{k-j}(t) = \mu_{k-j}(t)(1-O(\kern1.5pt j^2/t))$
. Thus, if
$j^2/t=o(1)$
then
$\mathrm{E}\,\widehat L_{k-j}(t) \sim \mu_{k-j}(t)$
. -
(2) Suppose that
$t_1(k-j+1) \ll t_1(k-j)$
, and that
$j^2/t_1(k-j)=o(1)$
. Let
$\omega=6 \log n$
. If
$t \ge t_{k-j}(\omega)$
then w.h.p.
$\widehat L_{k-j}(t) =\mu_{k-j}(t)(1+ O(1/\omega))$
.








Proof. As the sink is occupied at
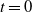 $t=0$
,
$t=0$
,
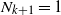 $N_{k+1}=1$
, and we define
$N_{k+1}=1$
, and we define
 $\widehat L_{k+1}(t)=1$
. This implies that, provided
$\widehat L_{k+1}(t)=1$
. This implies that, provided
 $t \le N_k$
,
$t \le N_k$
,
 $\widehat{L_k}(s)=s=\mu_k(s)$
for
$\widehat{L_k}(s)=s=\mu_k(s)$
for
 $0\leq s\leq t$
. Moreover, as at most one vertex can be added to
$0\leq s\leq t$
. Moreover, as at most one vertex can be added to
 $\widehat{L_i}(t-1)$
at step t, this implies
$\widehat{L_i}(t-1)$
at step t, this implies
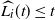 $\widehat{L_i}(t) \le t$
.
$\widehat{L_i}(t) \le t$
.
Iterating (4) backwards for
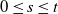 $0\leq s\leq t$
, and using
$0\leq s\leq t$
, and using
 $\widehat{L_i}(0)=0$
, gives
$\widehat{L_i}(0)=0$
, gives
 \begin{align}\mathrm{E}\,\widehat{L_i}(t)= \frac{1}{N_{i+1}} \sum_{s=0}^{t-1} \mathrm{E}\, \widehat{L}_{i+1}(s).\end{align}
\begin{align}\mathrm{E}\,\widehat{L_i}(t)= \frac{1}{N_{i+1}} \sum_{s=0}^{t-1} \mathrm{E}\, \widehat{L}_{i+1}(s).\end{align}
We claim for
 $j \ge 0$
that
$j \ge 0$
that
 \begin{align} {\unicode{x1D7D9}}_{\{{t \ge j}\}} \frac{(t-j)^{\kern1.5pt j+1}}{(\kern1.5pt j+1)!} \le \big(N_k N_{k-1}\cdots N_{k-j+1}\big) \mathrm{E}\, \widehat L_{k-j}(t) \le \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}.\end{align}
\begin{align} {\unicode{x1D7D9}}_{\{{t \ge j}\}} \frac{(t-j)^{\kern1.5pt j+1}}{(\kern1.5pt j+1)!} \le \big(N_k N_{k-1}\cdots N_{k-j+1}\big) \mathrm{E}\, \widehat L_{k-j}(t) \le \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}.\end{align}
For given t, the induction is backwards on
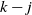 $k-j$
from
$k-j$
from
 $j=0$
. When
$j=0$
. When
 $j=0$
, (9) becomes
$j=0$
, (9) becomes
 $\mathrm{E}\, \widehat{L_k}(t)=t$
which is true, so the first non-trivial case is
$\mathrm{E}\, \widehat{L_k}(t)=t$
which is true, so the first non-trivial case is
 $j=1$
. From (8) we see that
$j=1$
. From (8) we see that
 \begin{align}\mathrm{E}\, \widehat L_{k-1}(t)= \frac{1}{N_k} \sum_{s=0}^{t-1} s,\end{align}
\begin{align}\mathrm{E}\, \widehat L_{k-1}(t)= \frac{1}{N_k} \sum_{s=0}^{t-1} s,\end{align}
which illustrates how (9) arises from bounding this sum.
For the induction at step
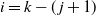 $i=k-(\kern1.5pt j+1)$
, let
$i=k-(\kern1.5pt j+1)$
, let
 \begin{align}M_{j-1}=N_k N_{k-1}\cdots N_{k-j+1}.\end{align}
\begin{align}M_{j-1}=N_k N_{k-1}\cdots N_{k-j+1}.\end{align}
Multiply (8) by
 $M_{j-1}$
, and insert the bounds on
$M_{j-1}$
, and insert the bounds on
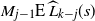 $M_{j-1} \mathrm{E}\, \widehat L_{k-j}(s)$
from (9) (with
$M_{j-1} \mathrm{E}\, \widehat L_{k-j}(s)$
from (9) (with
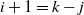 $i+1=k-j$
) into this, to give
$i+1=k-j$
) into this, to give
 \begin{align}\frac 1{N_{k-j}} \sum_{s=j}^{t-1} \frac{(s-j)^{\kern1.5pt j+1}}{(\kern1.5pt j+1)!}\le M_{j-1} \mathrm{E}\, \widehat L_{k-(\kern1.5pt j+1)}(t) \le \frac 1{N_{k-j}} \sum_{{s=1}}^{t-1} \frac{s^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}\end{align}
\begin{align}\frac 1{N_{k-j}} \sum_{s=j}^{t-1} \frac{(s-j)^{\kern1.5pt j+1}}{(\kern1.5pt j+1)!}\le M_{j-1} \mathrm{E}\, \widehat L_{k-(\kern1.5pt j+1)}(t) \le \frac 1{N_{k-j}} \sum_{{s=1}}^{t-1} \frac{s^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}\end{align}
By comparison of the sum with the related integral we have that
 \begin{align}\frac{(t-1)^{m+1}}{m+1} \le 1^m+2^m+\cdots+(t-1)^m \le \frac{t^{m+1}}{m+1}.\end{align}
\begin{align}\frac{(t-1)^{m+1}}{m+1} \le 1^m+2^m+\cdots+(t-1)^m \le \frac{t^{m+1}}{m+1}.\end{align}
Use (13) in (12) with
 $m=j+1$
to give
$m=j+1$
to give
 \[\frac{{\unicode{x1D7D9}}_{\{{t \ge j+1}\}}}{N_{k-j}} \frac{(t-(\kern1.5pt j+1))^{ \kern1.5pt j+2}}{(\kern1.5pt j+2)!}\le M_{j} \mathrm{E}\, \widehat L_{k-(\kern1.5pt j+1)}(t) \le \frac 1{N_{k-j}} \frac{t^{ \kern1.5pt j+2}}{(\kern1.5pt j+2)!},\]
\[\frac{{\unicode{x1D7D9}}_{\{{t \ge j+1}\}}}{N_{k-j}} \frac{(t-(\kern1.5pt j+1))^{ \kern1.5pt j+2}}{(\kern1.5pt j+2)!}\le M_{j} \mathrm{E}\, \widehat L_{k-(\kern1.5pt j+1)}(t) \le \frac 1{N_{k-j}} \frac{t^{ \kern1.5pt j+2}}{(\kern1.5pt j+2)!},\]
which completes the induction for (9).
Setting the indicator
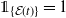 ${\unicode{x1D7D9}}_{\{{{\mathcal E}(t)}\}}=1$
in (4), provides an upper bound on
${\unicode{x1D7D9}}_{\{{{\mathcal E}(t)}\}}=1$
in (4), provides an upper bound on
 $\mathrm{E}\, \widehat{L_i}(t)$
, and as the upper bound in this induction is
$\mathrm{E}\, \widehat{L_i}(t)$
, and as the upper bound in this induction is
 $\mu_i(t)$
, this gives
$\mu_i(t)$
, this gives
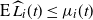 $\mathrm{E}\, \widehat L_{i}(t)\le\mu_{i}(t)$
as required.
$\mathrm{E}\, \widehat L_{i}(t)\le\mu_{i}(t)$
as required.
Furthermore, provided
 $\widehat L_{k-j}(t) < N_{k-j}$
,
$\widehat L_{k-j}(t) < N_{k-j}$
,
 $j^2/t=o(1)$
,
$j^2/t=o(1)$
,
 \begin{align}\mathrm{E}\, \widehat L_{k-j}(t) = \frac {1}{N_k N_{k-1}\cdots N_{k-j+1}} \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}\big( 1 -O\big(\kern1.5pt j^2/t \big) \big)=\mu_{k-j}(t) \big( 1 -O\big(\kern1.5pt j^2/t \big) \big).\end{align}
\begin{align}\mathrm{E}\, \widehat L_{k-j}(t) = \frac {1}{N_k N_{k-1}\cdots N_{k-j+1}} \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}\big( 1 -O\big(\kern1.5pt j^2/t \big) \big)=\mu_{k-j}(t) \big( 1 -O\big(\kern1.5pt j^2/t \big) \big).\end{align}
This completes the proof of Lemma 1(1).
The next thing to check is that, for the values of k given in Theorem 1, for
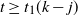 $t \ge t_1(k-j)$
,
$t \ge t_1(k-j)$
,
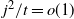 $j^2/t=o(1)$
, allowing us to use Lemma 1(1) in the proof of Lemma 1(2).
$j^2/t=o(1)$
, allowing us to use Lemma 1(1) in the proof of Lemma 1(2).
Lemma 2. Let
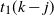 $t_1(k-j)$
be the value of t such that
$t_1(k-j)$
be the value of t such that
 $\mu_{k-j}(t)=1$
as given by (5). The condition
$\mu_{k-j}(t)=1$
as given by (5). The condition
 $j^2/t_1(k-j)=o(1)$
is satisfied in the equal layers model provided
$j^2/t_1(k-j)=o(1)$
is satisfied in the equal layers model provided
 $k=o(n^{1/5})$
and in the growing layers model provided
$k=o(n^{1/5})$
and in the growing layers model provided
 $d \rightarrow \infty$
. This allows us to assume that for
$d \rightarrow \infty$
. This allows us to assume that for
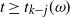 $t \ge t_{k-j}(\omega)$
,
$t \ge t_{k-j}(\omega)$
,
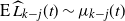 $\mathrm{E}\, \widehat L_{k-j}(t)\sim \mu_{k-j}(t)$
in subsequent calculations.
$\mathrm{E}\, \widehat L_{k-j}(t)\sim \mu_{k-j}(t)$
in subsequent calculations.
Proof. For
 $j \ge 1$
, the value of
$j \ge 1$
, the value of
 $t_{k-j}(\omega)$
given in (6) satisfies
$t_{k-j}(\omega)$
given in (6) satisfies
 \begin{align*}t_{k-j}(\omega) & = (4 \omega^3)^{1/(\kern1.5pt j+1)} t_1(k-j)\ge t_1(k-j)= ((\kern1.5pt j+1)!N_k\cdots N_{k-j+1})^{1/(\kern1.5pt j+1)} \nonumber \\ & = \left( (\kern1.5pt j+1)! M_{j-1} \right)^{1/(\kern1.5pt j+1)},\end{align*}
\begin{align*}t_{k-j}(\omega) & = (4 \omega^3)^{1/(\kern1.5pt j+1)} t_1(k-j)\ge t_1(k-j)= ((\kern1.5pt j+1)!N_k\cdots N_{k-j+1})^{1/(\kern1.5pt j+1)} \nonumber \\ & = \left( (\kern1.5pt j+1)! M_{j-1} \right)^{1/(\kern1.5pt j+1)},\end{align*}
where
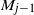 $M_{j-1}$
is given in (11). The product
$M_{j-1}$
is given in (11). The product
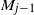 $M_{j-1}$
is model specific. For the equal layers model it has value
$M_{j-1}$
is model specific. For the equal layers model it has value
 $M_{j-1}(E)=(n/k)^j$
, as
$M_{j-1}(E)=(n/k)^j$
, as
 $N_i=n/k$
. For the growing layers model the value is
$N_i=n/k$
. For the growing layers model the value is
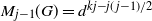 $M_{j-1}(G)=d^{kj-j(\kern1.5pt j-1)/2}$
, see (42).
$M_{j-1}(G)=d^{kj-j(\kern1.5pt j-1)/2}$
, see (42).
In the first case
 $M_{j-1}(E)^{1/(\kern1.5pt j+1)} \ge (n/k)^{1/2}$
, and in the second
$M_{j-1}(E)^{1/(\kern1.5pt j+1)} \ge (n/k)^{1/2}$
, and in the second
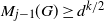 $M_{j-1}(G)\ge d^{k/2}$
, this minimum being achieved at
$M_{j-1}(G)\ge d^{k/2}$
, this minimum being achieved at
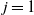 $j=1$
or
$j=1$
or
 $j= k$
. Checking
$j= k$
. Checking
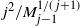 $j^2/M_{j-1}^{1/(\kern1.5pt j+1)}$
we see that the condition
$j^2/M_{j-1}^{1/(\kern1.5pt j+1)}$
we see that the condition
 $j^2/t_1 (k-j)=o(1)$
is satisfied in the equal layers model provided
$j^2/t_1 (k-j)=o(1)$
is satisfied in the equal layers model provided
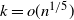 $k=o(n^{1/5})$
and in the growing layers model provided
$k=o(n^{1/5})$
and in the growing layers model provided
 $d \rightarrow \infty$
.
$d \rightarrow \infty$
.
The other assumptions of Lemma 1(1) and (2) are dealt with as follows. Theorem 1 gives a w.h.p. finish time
 $t_f \approx T_f$
. As
$t_f \approx T_f$
. As
 $\mathrm{E}\, \widehat{L_i}(t) \le \mu_i(t)$
follows from Lemma 1, checking that
$\mathrm{E}\, \widehat{L_i}(t) \le \mu_i(t)$
follows from Lemma 1, checking that
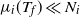 $\mu_i(T_f) \ll N_i$
and using the Markov inequality will imply that w.h.p.
$\mu_i(T_f) \ll N_i$
and using the Markov inequality will imply that w.h.p.
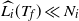 $\widehat{L_i}(T_f) \ll N_i$
holds as asserted. For the equal layers model,
$\widehat{L_i}(T_f) \ll N_i$
holds as asserted. For the equal layers model,
 $\mu_i(T_f) \ll N_i$
is proved in Lemma 4(1), and for the growing layers model in (54) and (55). The condition that
$\mu_i(T_f) \ll N_i$
is proved in Lemma 4(1), and for the growing layers model in (54) and (55). The condition that
 $t_1(k-(\kern1.5pt j-1)) \ll t_1(k-j)$
is checked in Lemma 4(2) for the equal layers model and in (53) of for the growing layers model.
$t_1(k-(\kern1.5pt j-1)) \ll t_1(k-j)$
is checked in Lemma 4(2) for the equal layers model and in (53) of for the growing layers model.
With this in hand, we can now continue with the proof of Lemma 1(2).
2.3. Concentration of
$\widehat{\boldsymbol{L}_\boldsymbol{i}}(t)$
for sufficiently large t

Lemma 3. Let
 $\mu_{k-j}(t)$
as be given by (3), let k be as given in Theorem 1 and let
$\mu_{k-j}(t)$
as be given by (3), let k be as given in Theorem 1 and let
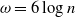 $\omega = 6\log n$
. Let
$\omega = 6\log n$
. Let
 $t_k(\omega)=1$
, and for
$t_k(\omega)=1$
, and for
 $1\le j \le k-1$
, let
$1\le j \le k-1$
, let
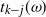 $t_{k-j}(\omega)$
be as given in (6). Then with probability
$t_{k-j}(\omega)$
be as given in (6). Then with probability
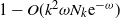 $1-O(k^2\omega N_k \mathrm{e}^{-\omega})$
it holds that for all
$1-O(k^2\omega N_k \mathrm{e}^{-\omega})$
it holds that for all
 $j \le k-1$
and all
$j \le k-1$
and all
 $t \ge t_{k-j}(\omega)$
that
$t \ge t_{k-j}(\omega)$
that
 $\widehat L_{k-j}(t) \in [\mu_{k-j}(t) (1-1/\omega),\mu_{k-j}(t)(1+1/\omega) ]$
.
$\widehat L_{k-j}(t) \in [\mu_{k-j}(t) (1-1/\omega),\mu_{k-j}(t)(1+1/\omega) ]$
.
Proof. The proof is inductive and for level
 $k-j$
it depends on establishing the result for levels
$k-j$
it depends on establishing the result for levels
 $k,k-1,\ldots,k-j+1$
. By definition,
$k,k-1,\ldots,k-j+1$
. By definition,
 $\widehat{L_k}(t)=t=\mu_k(t)$
. Let
$\widehat{L_k}(t)=t=\mu_k(t)$
. Let
 $t_k(\omega)=1$
, establishing Lemma 1(2) for
$t_k(\omega)=1$
, establishing Lemma 1(2) for
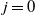 $j=0$
. For
$j=0$
. For
 $j\ge 0$
, let
$j\ge 0$
, let
 $t_1(k-j)$
as given by (5) and note that
$t_1(k-j)$
as given by (5) and note that
 $\mu_{k-j}(t_1(k-j))=1$
. For
$\mu_{k-j}(t_1(k-j))=1$
. For
 $j \ge 1$
, as
$j \ge 1$
, as
 $t_{k-j}(\omega)=(4\omega^3)^{1/(\kern1.5pt j+1)}t_1(k-j)$
then
$t_{k-j}(\omega)=(4\omega^3)^{1/(\kern1.5pt j+1)}t_1(k-j)$
then
 $\mu_{k-j}(t_{k-j}(\omega))=4\omega^3$
.
$\mu_{k-j}(t_{k-j}(\omega))=4\omega^3$
.
The random variable
 $\widehat L_{k-j}(t)$
is obtained from
$\widehat L_{k-j}(t)$
is obtained from
 $\widehat L_{k-j}(t-1)$
by choosing a random vertex
$\widehat L_{k-j}(t-1)$
by choosing a random vertex
 $u \in S_{k-j}$
irrespective of the current occupancy of u, and a random neighbour
$u \in S_{k-j}$
irrespective of the current occupancy of u, and a random neighbour
 $w \in S_{k-j+1}$
. If w is occupied then
$w \in S_{k-j+1}$
. If w is occupied then
 $\widehat L_{k-j}(t+1)=\widehat L_{k-j}(t)+1$
. Thus,
$\widehat L_{k-j}(t+1)=\widehat L_{k-j}(t)+1$
. Thus,
 $\widehat L_{k-j}(t+1)=\widehat L_{k-j}(t)+ Q_{k-j}(t)$
, where
$\widehat L_{k-j}(t+1)=\widehat L_{k-j}(t)+ Q_{k-j}(t)$
, where
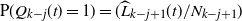 $\mathrm{P}( Q_{k-j}(t)=1)=(\widehat L_{k-j+1}(t)/N_{k-j+1})$
independently of any previous outcomes. As
$\mathrm{P}( Q_{k-j}(t)=1)=(\widehat L_{k-j+1}(t)/N_{k-j+1})$
independently of any previous outcomes. As
 $t_1(k-j) \gg j^2$
, Lemma 1(1) implies that
$t_1(k-j) \gg j^2$
, Lemma 1(1) implies that
 $\mathrm{E}\, \widehat L_{k-j}(t)= \mu_{k-j}(t) (1+o(1))$
$\mathrm{E}\, \widehat L_{k-j}(t)= \mu_{k-j}(t) (1+o(1))$
For
 $j \ge 1$
, and
$j \ge 1$
, and
 $ t \ge t_{k-j}(\omega)$
let
$ t \ge t_{k-j}(\omega)$
let
 ${\mathcal A}_j(t)$
denote the event that
${\mathcal A}_j(t)$
denote the event that
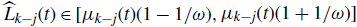 $\widehat L_{k-j}(t)\in [\mu_{k-j}(t)(1- 1/\omega), \mu_{k-j}(t)(1+ 1/\omega)]$
. As
$\widehat L_{k-j}(t)\in [\mu_{k-j}(t)(1- 1/\omega), \mu_{k-j}(t)(1+ 1/\omega)]$
. As
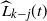 $\widehat L_{k-j}(t)$
is the sum of independent Bernoulli random variables, by Hoeffding’s inequality,
$\widehat L_{k-j}(t)$
is the sum of independent Bernoulli random variables, by Hoeffding’s inequality,
 \begin{align} \mathrm{P}( \neg {\mathcal A}_j(t))\leq 2\exp\left\{-\frac{\mu_{k-j}(t)}{3\omega^2}\left( 1-\delta \right)\right\}\le2\exp\left\{-\frac{\mu(t_{k-j}(\omega))}{4\omega^2}\right\} \le 2\mathrm{e}^{-\omega},\end{align}
\begin{align} \mathrm{P}( \neg {\mathcal A}_j(t))\leq 2\exp\left\{-\frac{\mu_{k-j}(t)}{3\omega^2}\left( 1-\delta \right)\right\}\le2\exp\left\{-\frac{\mu(t_{k-j}(\omega))}{4\omega^2}\right\} \le 2\mathrm{e}^{-\omega},\end{align}
where
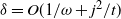 $\delta=O(1/{\omega}+j^2/t)$
, includes the correction from (14).
$\delta=O(1/{\omega}+j^2/t)$
, includes the correction from (14).
Let
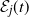 ${\mathcal E}_j(t)$
be the event that
${\mathcal E}_j(t)$
be the event that
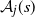 ${\mathcal A}_j(s)$
holds for all
${\mathcal A}_j(s)$
holds for all
 $s \in [t_{k-j}(\omega), t]$
. For
$s \in [t_{k-j}(\omega), t]$
. For
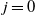 $j=0$
,
$j=0$
,
 $\mathrm{P}({\mathcal E}_{0}(t))=1$
, and for
$\mathrm{P}({\mathcal E}_{0}(t))=1$
, and for
 $j\ge 1$
, given
$j\ge 1$
, given
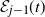 ${\mathcal E}_{j-1}(t)$
, as an inductive assumption, we have that
${\mathcal E}_{j-1}(t)$
, as an inductive assumption, we have that
 \begin{align} \mathrm{P} \big(\neg {\mathcal E}_{j}(t)\mid {\mathcal E}_{j-1}(t) \big) \le \sum_{s=t_{k-j}(\omega)}^t \mathrm{P}\big(\neg {\mathcal A}_j(s)\big).\end{align}
\begin{align} \mathrm{P} \big(\neg {\mathcal E}_{j}(t)\mid {\mathcal E}_{j-1}(t) \big) \le \sum_{s=t_{k-j}(\omega)}^t \mathrm{P}\big(\neg {\mathcal A}_j(s)\big).\end{align}
Summing over
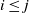 $i \le j$
we will be able to complete the induction, via
$i \le j$
we will be able to complete the induction, via
 \begin{align}\mathrm{P}\big(\neg{\mathcal E}_j \big)\leq \mathrm{P}\big(\neg{\mathcal E}_j\mid {\mathcal E}_{j-1}\big)+\mathrm{P}\big(\neg{\mathcal E}_{j-1}\big)\le\sum_{i\le j} \sum_{t \ge t_{k-i}(\omega)} \mathrm{P}\big(\neg{\mathcal A}_i(t)\big)\le c j \omega N_k \mathrm{e}^{-\omega},\end{align}
\begin{align}\mathrm{P}\big(\neg{\mathcal E}_j \big)\leq \mathrm{P}\big(\neg{\mathcal E}_j\mid {\mathcal E}_{j-1}\big)+\mathrm{P}\big(\neg{\mathcal E}_{j-1}\big)\le\sum_{i\le j} \sum_{t \ge t_{k-i}(\omega)} \mathrm{P}\big(\neg{\mathcal A}_i(t)\big)\le c j \omega N_k \mathrm{e}^{-\omega},\end{align}
provided we can establish the bound on the right-hand side of (17), which we now do. Here c is some absolute constant.
As
 $\mu_{k-j}(t)$
in (3) is monotone increasing in t and by (15) is bounded above by
$\mu_{k-j}(t)$
in (3) is monotone increasing in t and by (15) is bounded above by
 $2\mathrm{e}^{-\omega}=o(1)$
, we use the Euler–MacLaurin theorem to replace the summation over t in (16) by an integral. Thus,
$2\mathrm{e}^{-\omega}=o(1)$
, we use the Euler–MacLaurin theorem to replace the summation over t in (16) by an integral. Thus,
 \[\sum_{t \ge t_{k-j}(\omega)} \mathrm{P}\big(\neg{\mathcal A}_j(t)\big) \le 2\sum_{t \ge t_{k-j}(\omega)}\exp\left\{-\frac{\mu(t_{k-j}(\omega))}{4\omega^2}\right\} \le 3 \int_{t \ge t_0}\exp\left\{-\frac{t^{ \kern1.5pt j+1}}{C}\right\}\, \mathrm{d}t,\]
\[\sum_{t \ge t_{k-j}(\omega)} \mathrm{P}\big(\neg{\mathcal A}_j(t)\big) \le 2\sum_{t \ge t_{k-j}(\omega)}\exp\left\{-\frac{\mu(t_{k-j}(\omega))}{4\omega^2}\right\} \le 3 \int_{t \ge t_0}\exp\left\{-\frac{t^{ \kern1.5pt j+1}}{C}\right\}\, \mathrm{d}t,\]
where,
 $t_0=t_{k-j}(\omega)$
,
$t_0=t_{k-j}(\omega)$
,
 $C=[4\omega^2 (\kern1.5pt j+1)! N_k \cdots N_{k-j+1}]$
, and from (5) and (6),
$C=[4\omega^2 (\kern1.5pt j+1)! N_k \cdots N_{k-j+1}]$
, and from (5) and (6),
 $t_{k-j}(\omega)=(4\omega^3 C)^{1/(\kern1.5pt j+1)}$
.
$t_{k-j}(\omega)=(4\omega^3 C)^{1/(\kern1.5pt j+1)}$
.
Put
 $t^{ \kern1.5pt j+1}/C=z^2/2$
, so that
$t^{ \kern1.5pt j+1}/C=z^2/2$
, so that
 $t=(Cz^2/2)^{1/(\kern1.5pt j+1)}$
, and
$t=(Cz^2/2)^{1/(\kern1.5pt j+1)}$
, and
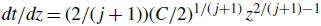 $dt/dz= (2/(\kern1.5pt j+1)) (C/2)^{1/(\kern1.5pt j+1)} z^{2/(\kern1.5pt j+1)-1}$
. Let
$dt/dz= (2/(\kern1.5pt j+1)) (C/2)^{1/(\kern1.5pt j+1)} z^{2/(\kern1.5pt j+1)-1}$
. Let
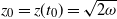 $z_0=z(t_0)=\sqrt{2 \omega}$
, and note that as
$z_0=z(t_0)=\sqrt{2 \omega}$
, and note that as
 $j\ge 1$
,
$j\ge 1$
,
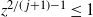 $z^{2/(\kern1.5pt j+1)-1}\le 1$
. Finally
$z^{2/(\kern1.5pt j+1)-1}\le 1$
. Finally
 $(C/2)^{1/(\kern1.5pt j+1)} = O(\omega k N_k)$
, as
$(C/2)^{1/(\kern1.5pt j+1)} = O(\omega k N_k)$
, as
 $N_k$
is a largest level in both models. Thus,
$N_k$
is a largest level in both models. Thus,
 \begin{align}\int_{t \ge t_0}\exp\left\{-\frac{t^{ \kern1.5pt j+1}}{C}\right\}\, \mathrm{d}t \le \frac{2}{j+1}\left(\frac{C}{2}\right)^{1/(\kern1.5pt j+1)} \int_{z \ge z_0} \mathrm{e}^{-z^2/2}\,\mathrm{d}z\le O(\omega k N_k) \frac{1}{\sqrt \omega} \mathrm{e}^{-\omega} ,\end{align}
\begin{align}\int_{t \ge t_0}\exp\left\{-\frac{t^{ \kern1.5pt j+1}}{C}\right\}\, \mathrm{d}t \le \frac{2}{j+1}\left(\frac{C}{2}\right)^{1/(\kern1.5pt j+1)} \int_{z \ge z_0} \mathrm{e}^{-z^2/2}\,\mathrm{d}z\le O(\omega k N_k) \frac{1}{\sqrt \omega} \mathrm{e}^{-\omega} ,\end{align}
by using a standard bound on the tail of the normal distribution,
 $\mathrm{P}(Z \ge z) \le 1/(\sqrt{2\pi}z) \mathrm{e}^{-z^2/2}$
.
$\mathrm{P}(Z \ge z) \le 1/(\sqrt{2\pi}z) \mathrm{e}^{-z^2/2}$
.
Lemma 3 follows for all
 $1\le j \le k$
by adding the upper bound on the right-hand side of (17) given in (18) over
$1\le j \le k$
by adding the upper bound on the right-hand side of (17) given in (18) over
 $j \le k$
, and choosing
$j \le k$
, and choosing
 $\omega=6 \log n$
.
$\omega=6 \log n$
.
2.4. Lower bound on occupancy at step t
So far we only have an upper bound on
 $\mathrm{E}\, L_j(t)$
given by
$\mathrm{E}\, L_j(t)$
given by
 $\mathrm{E}\, L_j(t) \le \mathrm{E}\, \widehat L_j(t)$
. We construct a lower bound
$\mathrm{E}\, L_j(t) \le \mathrm{E}\, \widehat L_j(t)$
. We construct a lower bound
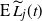 $\mathrm{E}\, \widetilde L_j(t)$
and prove that for large enough t these bounds converge, thus giving the asymptotic value of
$\mathrm{E}\, \widetilde L_j(t)$
and prove that for large enough t these bounds converge, thus giving the asymptotic value of
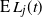 $\mathrm{E}\, L_j(t)$
.
$\mathrm{E}\, L_j(t)$
.
For a given level j, a lower bound on
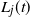 $L_j(t)$
can be found as follows. Define a subprocess of DLA which requires that the particle avoids upper-blocked vertices. Thus, to reach level j, a particle must avoid choosing neighbours in
$L_j(t)$
can be found as follows. Define a subprocess of DLA which requires that the particle avoids upper-blocked vertices. Thus, to reach level j, a particle must avoid choosing neighbours in
 $\widehat B_1,\ldots,\widehat{B_j}$
at steps
$\widehat B_1,\ldots,\widehat{B_j}$
at steps
 $0,\ldots,j-1$
of its random walk.
$0,\ldots,j-1$
of its random walk.
Let
 $L^*_j(t)$
be an upper bound on
$L^*_j(t)$
be an upper bound on
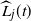 $\widehat L_j(t)$
that holds w.h.p. This will, for example, be obtained from Lemma 3 if
$\widehat L_j(t)$
that holds w.h.p. This will, for example, be obtained from Lemma 3 if
 $t \ge t_j(\omega)$
. Referring to (1) and (2), let
$t \ge t_j(\omega)$
. Referring to (1) and (2), let
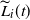 $\widetilde L_i(t)$
be obtained by replacing L by
$\widetilde L_i(t)$
be obtained by replacing L by
 $L^*$
in the bracketed terms on the right-hand side. This defines a lower bound
$L^*$
in the bracketed terms on the right-hand side. This defines a lower bound
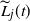 $\widetilde L_j(t)$
, such that w.h.p.
$\widetilde L_j(t)$
, such that w.h.p.
 $\widetilde L_j(t)\le L_j(t) \le \widehat L_j(t)$
. Let
$\widetilde L_j(t)\le L_j(t) \le \widehat L_j(t)$
. Let
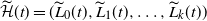 $\widetilde{\mathcal{H}}(t)=(\widetilde L_0(t),\widetilde L_1(t),\ldots,\widetilde L_k(t))$
be the occupancy vector obtained from this lower bound, then we have the following recurrences:
$\widetilde{\mathcal{H}}(t)=(\widetilde L_0(t),\widetilde L_1(t),\ldots,\widetilde L_k(t))$
be the occupancy vector obtained from this lower bound, then we have the following recurrences:
 \begin{align}\mathrm{E} \big(\widetilde L_i(t+1)\mid \widetilde {\mathcal{H}}(t)\big) &= \widetilde L_i(t) + \frac{ \widetilde L_{i+1}(t)}{N_{i+1}} \prod_{j=0}^i \left( 1-\frac{L^*_{j}(t)}{N_{j}} \right) \!, \\[-12pt] \nonumber \end{align}
\begin{align}\mathrm{E} \big(\widetilde L_i(t+1)\mid \widetilde {\mathcal{H}}(t)\big) &= \widetilde L_i(t) + \frac{ \widetilde L_{i+1}(t)}{N_{i+1}} \prod_{j=0}^i \left( 1-\frac{L^*_{j}(t)}{N_{j}} \right) \!, \\[-12pt] \nonumber \end{align}
 \begin{align}\mathrm{E} \big(\widetilde L_k(t+1)\mid \widetilde{\mathcal{H}}(t)\big) &= \widetilde L_k(t) + \prod_{j=0}^k \left( 1-\frac{L^*_{j}(t)}{N_{j}} \right)\!. \\[9pt] \nonumber \end{align}
\begin{align}\mathrm{E} \big(\widetilde L_k(t+1)\mid \widetilde{\mathcal{H}}(t)\big) &= \widetilde L_k(t) + \prod_{j=0}^k \left( 1-\frac{L^*_{j}(t)}{N_{j}} \right)\!. \\[9pt] \nonumber \end{align}
These recurrences are solved in Section 3.2 for the equal layers model and in Section 4 for the growing layers model.
2.5. The gap property
It is clear that
 $0 \le \widetilde L_{k-j}(t) \le L_{k-j}(t) \le \widehat L_{k-j}(t) \le t$
, and that these values are monotone non-decreasing. We choose times
$0 \le \widetilde L_{k-j}(t) \le L_{k-j}(t) \le \widehat L_{k-j}(t) \le t$
, and that these values are monotone non-decreasing. We choose times
 \[t^-(k-j) < t_1(k-j) <t^+(k-j)=t_{k-j}(\omega),\]
\[t^-(k-j) < t_1(k-j) <t^+(k-j)=t_{k-j}(\omega),\]
(where
 $\omega=6 \log n$
) such that
$\omega=6 \log n$
) such that
 \[\mu_{k-j}(t^-) =1/\omega^3, \quad \mu_{k-j}(t_1)=1, \quad \mu_{k-j}(t^+)=4\omega^3.\]
\[\mu_{k-j}(t^-) =1/\omega^3, \quad \mu_{k-j}(t_1)=1, \quad \mu_{k-j}(t^+)=4\omega^3.\]
Below
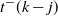 $t^-(k-j)$
,
$t^-(k-j)$
,
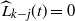 $\widehat L_{k-j}(t)=0$
w.h.p. for all
$\widehat L_{k-j}(t)=0$
w.h.p. for all
 $j=1,\ldots,k$
. This follows from Lemma 1, and the Markov inequality, as
$j=1,\ldots,k$
. This follows from Lemma 1, and the Markov inequality, as
 $k=o(\omega)$
in either model. Above
$k=o(\omega)$
in either model. Above
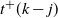 $t^+(k-j)$
we will see that
$t^+(k-j)$
we will see that
 $\mathrm{E}\, \widetilde L_{k-j}(t) \sim \mathrm{E}\,\widehat L_{k-j}(t)$
and thus
$\mathrm{E}\, \widetilde L_{k-j}(t) \sim \mathrm{E}\,\widehat L_{k-j}(t)$
and thus
 $\mathrm{E}\, L_{k-j}(t) \sim \mu_{k-j}(t)$
. The main content of Sections 3 and 4 is a proof of this via a gap property which implies that
$\mathrm{E}\, L_{k-j}(t) \sim \mu_{k-j}(t)$
. The main content of Sections 3 and 4 is a proof of this via a gap property which implies that
 \[t^+(k-j)= t_{k-j}(\omega) \ll t^-(k-(\kern1.5pt j+1)) \ll t_1(k-(\kern1.5pt j+1)),\]
\[t^+(k-j)= t_{k-j}(\omega) \ll t^-(k-(\kern1.5pt j+1)) \ll t_1(k-(\kern1.5pt j+1)),\]
so that w.h.p. concentration for
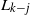 $L_{k-j}$
occurs while
$L_{k-j}$
occurs while
 $L_{k-(\kern1.5pt j+1)}$
is still zero.
$L_{k-(\kern1.5pt j+1)}$
is still zero.
3. Analysis of DLA in the equal layers model
It is convenient at this point to obtain an asymptotic estimate for the finish time of DLA in the equal layers model. From (3), as
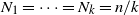 $N_1=\cdots=N_k=n/k$
,
$N_1=\cdots=N_k=n/k$
,
 \[\mu_{k-j}(t)=\left(\frac{k}{n}\right)^j \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}.\]
\[\mu_{k-j}(t)=\left(\frac{k}{n}\right)^j \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!}.\]
Let
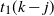 $t_1(k-j)$
be given by (5) and let
$t_1(k-j)$
be given by (5) and let
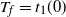 $T_f=t_1(0)$
be the value of t for which
$T_f=t_1(0)$
be the value of t for which
 $\mu_0(t)=1$
. Then
$\mu_0(t)=1$
. Then
 \begin{align}T_f= \left( \frac{(k+1)!}{k^k} n^k \right)^{1/(k+1)}.\end{align}
\begin{align}T_f= \left( \frac{(k+1)!}{k^k} n^k \right)^{1/(k+1)}.\end{align}
At this time the source has expected occupancy asymptotic to one in the upper-blocked process. That
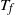 $T_f$
indeed approximates the finish time is shown in Section 3.3.
$T_f$
indeed approximates the finish time is shown in Section 3.3.
Lemma 4. Let G be a graph in the equal layers model with level sizes
 $N_i= n/k$
,
$N_i= n/k$
,
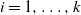 $i=1,\ldots,k$
, where
$i=1,\ldots,k$
, where
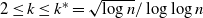 $2 \le k \le k^*= \sqrt{\log n}/\log \log n$
.
$2 \le k \le k^*= \sqrt{\log n}/\log \log n$
.
-
(1) Let
$\gamma_k=\mathrm{e}^{-1} (1+O(\log k/k))$
, then (22)and, thus,
\begin{align}T_f=n^{k/(k+1)}\gamma_k,\end{align}
$T_f \ll n/k=N_k$
.
-
(2) For
$1\le j \le k$
, let
$t_1(k-j)$
be as given in (5), then and
\[t_1(k-j)=\left( (\kern1.5pt j+1)! \right)^{1/(\kern1.5pt j+1)}(n/k)^{ \kern1.5pt j/(\kern1.5pt j+1)}= \Theta(\kern1.5pt j)(n/k)^{ \kern1.5pt j/(\kern1.5pt j+1)},\]
If
\[t_1(k-j)=t_1(k-(\kern1.5pt j-1)) \cdot \Theta(1) (n/k)^{1/(\kern1.5pt j(\kern1.5pt j+1))}. \]
$k \le k^*$
then
$t_1(k-j) \gg t_1(k-(\kern1.5pt j-1))$
in the equal layers model, as claimed in the note below Lemma 1.
-
(3) Let t be
$t_1(k-j)$
rounded to an integer. For
$j \ge 1$
,
$j/t_1(k-j)=o(1)$
and, thus,
$\mu_{k-j}(t) \sim 1$
, as asserted in the note under (6).













Proof. Note that
 \[\frac{(k+1)!}{k^k}=\mathrm{e}^{O(1/k)}\frac{1}{k^k}\sqrt{2\pi}\mathrm{e}^{-(k+1)}k^{k+3/2}(1+1/k)^{k+3/2}=\mathrm{e}^{-(k+1)} \Theta_k,\]
\[\frac{(k+1)!}{k^k}=\mathrm{e}^{O(1/k)}\frac{1}{k^k}\sqrt{2\pi}\mathrm{e}^{-(k+1)}k^{k+3/2}(1+1/k)^{k+3/2}=\mathrm{e}^{-(k+1)} \Theta_k,\]
where
 $\Theta_k\sim(\mathrm{e}^{1+O(1/k)}\sqrt{2\pi} k^{3/2})$
. Thus,
$\Theta_k\sim(\mathrm{e}^{1+O(1/k)}\sqrt{2\pi} k^{3/2})$
. Thus,
 \[(\Theta_k)^{1/k+1}=\mathrm{e}^{O( \log k/k)}=1+O(\log k/k)\]
\[(\Theta_k)^{1/k+1}=\mathrm{e}^{O( \log k/k)}=1+O(\log k/k)\]
is bounded for
 $k \ge 2$
and tends to one as
$k \ge 2$
and tends to one as
 $k \rightarrow \infty$
. From (21)
$k \rightarrow \infty$
. From (21)
 \begin{align}T_f=\left( \frac{(k+1)!}{k^k}{n}^{k} \right)^{1/(k+1)}=n^{\frac k{k+1}}\mathrm{e}^{-1} (1+O(\log k/k)).\end{align}
\begin{align}T_f=\left( \frac{(k+1)!}{k^k}{n}^{k} \right)^{1/(k+1)}=n^{\frac k{k+1}}\mathrm{e}^{-1} (1+O(\log k/k)).\end{align}
Thus,
 $kT_f/n=O(kn^{1/(k+1)})=o(1)$
for
$kT_f/n=O(kn^{1/(k+1)})=o(1)$
for
 $k \le k^*$
.
$k \le k^*$
.
The second part follows by direct calculation using
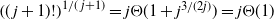 $\left( (\kern1.5pt j+1)! \right)^{1/(\kern1.5pt j+1)}=j\Theta(1+j^{3/(2j)})=j\Theta(1)$
. The third part follows from
$\left( (\kern1.5pt j+1)! \right)^{1/(\kern1.5pt j+1)}=j\Theta(1+j^{3/(2j)})=j\Theta(1)$
. The third part follows from
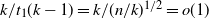 $k/t_1(k-1)=k/(n/k)^{1/2}=o(1)$
, and
$k/t_1(k-1)=k/(n/k)^{1/2}=o(1)$
, and
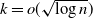 $k=o(\sqrt{\log n})$
.
$k=o(\sqrt{\log n})$
.
3.1. Evolution of the state vector
$\widehat {\boldsymbol{L}}$
in the equal layers model

We prove there is a large gap in the number of steps between the time when
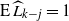 $\mathrm{E}\, \widehat L_{k-j}=1$
with all lower values zero, and the time when
$\mathrm{E}\, \widehat L_{k-j}=1$
with all lower values zero, and the time when
 $\mathrm{E}\, \widehat L_{k-(\kern1.5pt j+1)}=1$
. The gap allows
$\mathrm{E}\, \widehat L_{k-(\kern1.5pt j+1)}=1$
. The gap allows
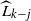 $\widehat L_{k-j}$
to increase and become concentrated around
$\widehat L_{k-j}$
to increase and become concentrated around
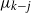 $\mu_{k-j}$
, whilst all values with a lower index
$\mu_{k-j}$
, whilst all values with a lower index
 $i<k-j$
remain zero. This confirms the inductive assumption stated below (5) in Lemma 3.
$i<k-j$
remain zero. This confirms the inductive assumption stated below (5) in Lemma 3.
Let
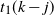 $t_1(k-j)$
and
$t_1(k-j)$
and
 $t_{k-j}(\omega)$
be as given by (5) and (6). We list various assumptions used in this and the next section:
$t_{k-j}(\omega)$
be as given by (5) and (6). We list various assumptions used in this and the next section:
 \begin{align} 1 \le k \le k^*=\frac{\sqrt{\log n}}{\log \log n},\quad \omega =6\log n, \quad \beta= \frac{N_k}{\omega T_f}.\end{align}
\begin{align} 1 \le k \le k^*=\frac{\sqrt{\log n}}{\log \log n},\quad \omega =6\log n, \quad \beta= \frac{N_k}{\omega T_f}.\end{align}
Let
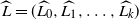 $\widehat L=(\widehat{L_0}, \widehat{L_1},\ldots, \widehat{L_k})$
be the state vector of the upper-blocked process. The entries in
$\widehat L=(\widehat{L_0}, \widehat{L_1},\ldots, \widehat{L_k})$
be the state vector of the upper-blocked process. The entries in
 $\widehat L$
are non-negative integers, and if
$\widehat L$
are non-negative integers, and if
 $\widehat{L_i}=0$
then
$\widehat{L_i}=0$
then
 $\widehat L_{i-1}=0$
.
$\widehat L_{i-1}=0$
.
The following argument for
 $t \le \omega T_f$
proves there is a large enough gap
$t \le \omega T_f$
proves there is a large enough gap
 $t''-t$
between
$t''-t$
between
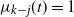 $\mu_{k-j}(t)=1$
and
$\mu_{k-j}(t)=1$
and
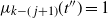 $\mu_{k-(\kern1.5pt j+1)}(t'')=1$
for
$\mu_{k-(\kern1.5pt j+1)}(t'')=1$
for
 $\widehat L_{k-j}(t'')$
to be concentrated, as assumed in Lemma 3. In particular w.h.p. at
$\widehat L_{k-j}(t'')$
to be concentrated, as assumed in Lemma 3. In particular w.h.p. at
 $t_{k-j}(\omega)$
, where
$t_{k-j}(\omega)$
, where
 $t''\gg t_{k-j}(\omega) > t'$
we will have (32), as is to be shown.
$t''\gg t_{k-j}(\omega) > t'$
we will have (32), as is to be shown.
From (22),
 \begin{align}\beta=\frac{N_k}{\omega T_f}=\frac{n}{ \omega k}\frac 1{\gamma_k n^{k/(k+1)}}=\frac{1}{\gamma_k} \frac 1{\omega k}n^{1/(k+1)} \ge (6\log n)^{4+k/2}.\end{align}
\begin{align}\beta=\frac{N_k}{\omega T_f}=\frac{n}{ \omega k}\frac 1{\gamma_k n^{k/(k+1)}}=\frac{1}{\gamma_k} \frac 1{\omega k}n^{1/(k+1)} \ge (6\log n)^{4+k/2}.\end{align}
This is true as
 $\omega= 6 \log n$
and we assumed that
$\omega= 6 \log n$
and we assumed that
 $k \leq \sqrt{\log n}/\log \log n$
.
$k \leq \sqrt{\log n}/\log \log n$
.
As
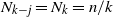 $N_{k-j}=N_k=n/k$
in the equal layers model, for any
$N_{k-j}=N_k=n/k$
in the equal layers model, for any
 $t \le \omega T_f$
,
$t \le \omega T_f$
,
 \begin{align}\mu_{k-(\kern1.5pt j+1)}(t) = \frac{t}{(\kern1.5pt j+2){ N_{k-j}}}\cdot \mu_{k-j}(t) \le \frac 1{(\kern1.5pt j+1)\beta}\mu_{k-j}(t).\end{align}
\begin{align}\mu_{k-(\kern1.5pt j+1)}(t) = \frac{t}{(\kern1.5pt j+2){ N_{k-j}}}\cdot \mu_{k-j}(t) \le \frac 1{(\kern1.5pt j+1)\beta}\mu_{k-j}(t).\end{align}
For
 $j+\ell \le k$
, we can iterate this to give
$j+\ell \le k$
, we can iterate this to give
 \begin{align} \mu_{k-(\kern1.5pt j+\ell)}(t) \le \mu_{k-j}(t)\frac 1{\beta^\ell} \frac{1}{(\kern1.5pt j+\ell+1)(\kern1.5pt j+\ell)\cdots (\kern1.5pt j+2)}\le \mu_{k-j}(t)\frac 1{((\kern1.5pt j+1)\beta )^\ell}.\end{align}
\begin{align} \mu_{k-(\kern1.5pt j+\ell)}(t) \le \mu_{k-j}(t)\frac 1{\beta^\ell} \frac{1}{(\kern1.5pt j+\ell+1)(\kern1.5pt j+\ell)\cdots (\kern1.5pt j+2)}\le \mu_{k-j}(t)\frac 1{((\kern1.5pt j+1)\beta )^\ell}.\end{align}
Consider
 $\mathrm{E}\,\widehat L_{k-j}(t)$
. At
$\mathrm{E}\,\widehat L_{k-j}(t)$
. At
 $t = t_1(k-j)$
when
$t = t_1(k-j)$
when
 $\mu_{k-j}(t)= 1$
, then by Lemmas 1 and 2,
$\mu_{k-j}(t)= 1$
, then by Lemmas 1 and 2,
 $\mathrm{E}\, \widehat L_{k-j}(t) \sim 1$
. The Markov inequality implies that w.h.p.
$\mathrm{E}\, \widehat L_{k-j}(t) \sim 1$
. The Markov inequality implies that w.h.p.
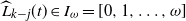 $\widehat L_{k-j}(t) \in I_\omega=[0,1,\ldots,\omega]$
. From (26) and (27),
$\widehat L_{k-j}(t) \in I_\omega=[0,1,\ldots,\omega]$
. From (26) and (27),
 \begin{align} \mu_{k-(\kern1.5pt j+\ell)}(t) \le \frac {1+o(1)}{((\kern1.5pt j+1)\beta)^\ell}, \quad\text{for } 1\le \ell\leq k-j,\end{align}
\begin{align} \mu_{k-(\kern1.5pt j+\ell)}(t) \le \frac {1+o(1)}{((\kern1.5pt j+1)\beta)^\ell}, \quad\text{for } 1\le \ell\leq k-j,\end{align}
and, thus, w.h.p.
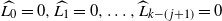 $\widehat{L_0}=0,\widehat{L_1}=0,\ldots,\widehat L_{k-(\kern1.5pt j+1)}=0$
. Using (26) and (27), we see that
$\widehat{L_0}=0,\widehat{L_1}=0,\ldots,\widehat L_{k-(\kern1.5pt j+1)}=0$
. Using (26) and (27), we see that
 \begin{align} \mu_{k-j+\ell}(t) \ge \mu_{k-j}(t) j(\kern1.5pt j-1)\cdots(\kern1.5pt j-\ell+1) \beta^{\ell}, \quad \text{for } \ell\leq j.\end{align}
\begin{align} \mu_{k-j+\ell}(t) \ge \mu_{k-j}(t) j(\kern1.5pt j-1)\cdots(\kern1.5pt j-\ell+1) \beta^{\ell}, \quad \text{for } \ell\leq j.\end{align}
Thus, if
 $\mu_{k-j}(t)= 1$
then for
$\mu_{k-j}(t)= 1$
then for
 $1\le \ell \leq j$
,
$1\le \ell \leq j$
,
 $t\ge t_{k-j+\ell}(\omega)$
, and
$t\ge t_{k-j+\ell}(\omega)$
, and
 \begin{align}\mu_{k-j+\ell}(t) \ge \beta^\ell \ge (6\log n)^{4+k/2}.\end{align}
\begin{align}\mu_{k-j+\ell}(t) \ge \beta^\ell \ge (6\log n)^{4+k/2}.\end{align}
It now follows that Lemma 1(2) holds, and w.h.p.
 $\widehat L_{k-j+\ell}$
is equal to
$\widehat L_{k-j+\ell}$
is equal to
 $(1+o(1))\mathrm{E}\, \widehat L_{k-j+\ell}\sim\mu_{k-j+\ell}(t)$
.
$(1+o(1))\mathrm{E}\, \widehat L_{k-j+\ell}\sim\mu_{k-j+\ell}(t)$
.
In summary, at time t such that
 $\mu_{k-j}(t) \sim 1$
(implying that
$\mu_{k-j}(t) \sim 1$
(implying that
 $t\leq T_f$
, see Lemma 4(2)), w.h.p., the state vector
$t\leq T_f$
, see Lemma 4(2)), w.h.p., the state vector
 $\widehat L$
is such that
$\widehat L$
is such that
 $\mu_{k-\ell}\rightarrow \infty$
for
$\mu_{k-\ell}\rightarrow \infty$
for
 $\ell \le j-1$
, and
$\ell \le j-1$
, and
 \begin{align} \widehat L(t)=(0,\ldots,0, \widehat L_{k-j}\in I_\omega, (1+o(1))\mu_{k-j+1}, (1+o(1))\mu_{k-j+2},\ldots, \mu_k).\end{align}
\begin{align} \widehat L(t)=(0,\ldots,0, \widehat L_{k-j}\in I_\omega, (1+o(1))\mu_{k-j+1}, (1+o(1))\mu_{k-j+2},\ldots, \mu_k).\end{align}
Let
 $t=t_1(k-j)$
, let
$t=t_1(k-j)$
, let
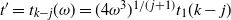 $t' =t_{k-j}(\omega)=(4\omega^3)^{1/(\kern1.5pt j+1)} t_1(k-j)$
, so
$t' =t_{k-j}(\omega)=(4\omega^3)^{1/(\kern1.5pt j+1)} t_1(k-j)$
, so
 $\mu_{k-j}(t') \sim 4\omega^3$
. By Lemma 3 it holds w.h.p. that
$\mu_{k-j}(t') \sim 4\omega^3$
. By Lemma 3 it holds w.h.p. that
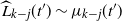 $\widehat L_{k-j}(t')\sim \mu_{k-j}(t')$
.
$\widehat L_{k-j}(t')\sim \mu_{k-j}(t')$
.
Let
 $t''=t_1(k-(\kern1.5pt j+1))$
. By Proposition 4(2),
$t''=t_1(k-(\kern1.5pt j+1))$
. By Proposition 4(2),
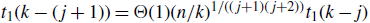 $t_1(k-(\kern1.5pt j+1))=\Theta(1) (n/k)^{1/((\kern1.5pt j+1)(\kern1.5pt j+2))} t_1(k-j)$
. As
$t_1(k-(\kern1.5pt j+1))=\Theta(1) (n/k)^{1/((\kern1.5pt j+1)(\kern1.5pt j+2))} t_1(k-j)$
. As
 $t'=(4\omega^3)^{1/((\kern1.5pt j+1)}t_1(k-j)$
, it can be checked that
$t'=(4\omega^3)^{1/((\kern1.5pt j+1)}t_1(k-j)$
, it can be checked that
 $t'' \gg t'$
. In addition, by (27)
$t'' \gg t'$
. In addition, by (27)
 \[\sum_{\ell \ge 1} \mu_{k-(\kern1.5pt j+\ell)}(t')=O\left(\frac{\mu_{k-j}(t')}{\beta}\right)=O\left(\frac{\omega^3}{\beta}\right)=O\left(\frac{1}{\log^{1+k/2}n}\right).\]
\[\sum_{\ell \ge 1} \mu_{k-(\kern1.5pt j+\ell)}(t')=O\left(\frac{\mu_{k-j}(t')}{\beta}\right)=O\left(\frac{\omega^3}{\beta}\right)=O\left(\frac{1}{\log^{1+k/2}n}\right).\]
Thus, applying the Markov inequality to the above, at
 $t'=t_{k-j}(\omega)$
, w.h.p.
$t'=t_{k-j}(\omega)$
, w.h.p.
 \begin{align} \widehat L(t_{k-j}(\omega))=(0,\ldots,0, (1+o(1))\mu_{k-j}, (1+o(1))\mu_{k-j+1},\ldots, \mu_k),\end{align}
\begin{align} \widehat L(t_{k-j}(\omega))=(0,\ldots,0, (1+o(1))\mu_{k-j}, (1+o(1))\mu_{k-j+1},\ldots, \mu_k),\end{align}
so that
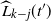 $\widehat L_{k-j}(t')$
is concentrated around its mean, and all lower levels are unoccupied, and thus the claimed gap exists. This condition persists w.h.p. until around
$\widehat L_{k-j}(t')$
is concentrated around its mean, and all lower levels are unoccupied, and thus the claimed gap exists. This condition persists w.h.p. until around
 $t_1(k-(\kern1.5pt j+1))=t''\gg t'=t_{k-j}(\omega)$
, when
$t_1(k-(\kern1.5pt j+1))=t''\gg t'=t_{k-j}(\omega)$
, when
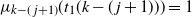 $\mu_{k-(\kern1.5pt j+1)}(t_1(k-(\kern1.5pt j+1)))=1$
at which point
$\mu_{k-(\kern1.5pt j+1)}(t_1(k-(\kern1.5pt j+1)))=1$
at which point
 $\widehat L(t'')$
resembles (31) and the induction continues.
$\widehat L(t'')$
resembles (31) and the induction continues.
3.2. Lower bound on occupancy in the equal layers model
We prove that, for
 $t \ge t_i(\omega)$
, we have
$t \ge t_i(\omega)$
, we have
 $\mathrm{E}\, \widetilde L_i(t) \sim \mathrm{E}\, \widehat{L_i}(t) \sim \mu_i(t)$
. As with the upper bounds, we have that
$\mathrm{E}\, \widetilde L_i(t) \sim \mathrm{E}\, \widehat{L_i}(t) \sim \mu_i(t)$
. As with the upper bounds, we have that
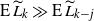 $\mathrm{E}\, \widetilde L_k \gg \mathrm{E}\, \widetilde L_{k-j}$
for
$\mathrm{E}\, \widetilde L_k \gg \mathrm{E}\, \widetilde L_{k-j}$
for
 $j \ge 1$
. The first step is to draw a line between these quantities.
$j \ge 1$
. The first step is to draw a line between these quantities.
Let
 $t^-=t_1(k-1)/\omega$
, so that
$t^-=t_1(k-1)/\omega$
, so that
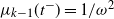 $\mu_{k-1}(t^-)=1/\omega^2$
. Then (14) and the Markov inequality imply that w.h.p.
$\mu_{k-1}(t^-)=1/\omega^2$
. Then (14) and the Markov inequality imply that w.h.p.
 $\widehat L_{k-1}(t^-)=0$
and as
$\widehat L_{k-1}(t^-)=0$
and as
 $\widehat L_{j}(t)$
is monotone non-decreasing in j, w.h.p.
$\widehat L_{j}(t)$
is monotone non-decreasing in j, w.h.p.
 $\widehat L_j(t)=0$
for all
$\widehat L_j(t)=0$
for all
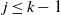 $j \le k-1$
and
$j \le k-1$
and
 $t \le t^-$
. As
$t \le t^-$
. As
 $\widehat{L_k}(t)=L^*_k(t)=t$
deterministically, this simplifies (20) for
$\widehat{L_k}(t)=L^*_k(t)=t$
deterministically, this simplifies (20) for
 $t \le t^-$
.
$t \le t^-$
.
As before let
 $\beta=N_k/\omega T_f$
where
$\beta=N_k/\omega T_f$
where
 $\omega, k$
satisfy (24). Provided
$\omega, k$
satisfy (24). Provided
 $k \ge 2$
, if
$k \ge 2$
, if
 $t \ge t^-$
then
$t \ge t^-$
then
 $t/\beta \gg \omega^3$
. Indeed using (25),
$t/\beta \gg \omega^3$
. Indeed using (25),
 \[t^-=\frac{t_1(k-1)}{\omega} = \frac{1}{\omega} \sqrt{\frac{2n}{k}} \quad \implies \quad \frac{t^-}{\beta} = \frac{\gamma_k \omega k}{n^{1/(k+1)}} \cdot \frac{1}{\omega} \sqrt{\frac{2n}{k}} \ge 2\gamma_k n^{1/6} \gg \omega^3.\]
\[t^-=\frac{t_1(k-1)}{\omega} = \frac{1}{\omega} \sqrt{\frac{2n}{k}} \quad \implies \quad \frac{t^-}{\beta} = \frac{\gamma_k \omega k}{n^{1/(k+1)}} \cdot \frac{1}{\omega} \sqrt{\frac{2n}{k}} \ge 2\gamma_k n^{1/6} \gg \omega^3.\]
For
 $t \ge t^-$
and
$t \ge t^-$
and
 $1\le i \le k-1$
, we first consider the product term in (19). Recalling that
$1\le i \le k-1$
, we first consider the product term in (19). Recalling that
 $N_i=N_k=n/k$
, we next prove that
$N_i=N_k=n/k$
, we next prove that
 \begin{align}\prod_{j=0}^i \left( 1-\frac{L^*_{j}(t)}{N_{j}} \right) \ge 1- \sum_{j=0}^i \frac{L^*_{j}(t)}{N_{j}}=1-O\left(\frac{t}{\beta N_k}\right)=1-o(1).\end{align}
\begin{align}\prod_{j=0}^i \left( 1-\frac{L^*_{j}(t)}{N_{j}} \right) \ge 1- \sum_{j=0}^i \frac{L^*_{j}(t)}{N_{j}}=1-O\left(\frac{t}{\beta N_k}\right)=1-o(1).\end{align}
By (27),
 $\mu_{k-j} \le \mu_k/\beta^j$
. Assume
$\mu_{k-j} \le \mu_k/\beta^j$
. Assume
 $t \ge t^-$
and that for some
$t \ge t^-$
and that for some
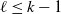 $\ell \le k-1$
,
$\ell \le k-1$
,
 $t_{\ell+1}(\omega) \le t < t_{\ell}(\omega)$
. Lemma 3 gives concentration of
$t_{\ell+1}(\omega) \le t < t_{\ell}(\omega)$
. Lemma 3 gives concentration of
 $\widehat L_j(t)$
for
$\widehat L_j(t)$
for
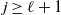 $j\ge \ell+1$
, which we use along with (31) and (32).
$j\ge \ell+1$
, which we use along with (31) and (32).
If
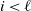 $i< \ell$
then
$i< \ell$
then
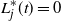 $L^*_{j}(t)=0$
, for
$L^*_{j}(t)=0$
, for
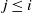 $j \le i$
. Next, if
$j \le i$
. Next, if
 $i=\ell$
,
$i=\ell$
,
 $L^*_j(t)=0$
for
$L^*_j(t)=0$
for
 $j<i$
and
$j<i$
and
 $L^*_i(t)\le 2 \mu_i(t_i(\omega))\le 8\omega^3$
, since
$L^*_i(t)\le 2 \mu_i(t_i(\omega))\le 8\omega^3$
, since
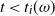 $t < t_i(\omega)$
, and again Lemma 3 gives this upper bound at
$t < t_i(\omega)$
, and again Lemma 3 gives this upper bound at
 $t_i(\omega)$
. Finally assume
$t_i(\omega)$
. Finally assume
 $i \ge \ell+1$
. Then (as
$i \ge \ell+1$
. Then (as
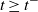 $t \ge t^-$
) using (27),
$t \ge t^-$
) using (27),
 \begin{align}\sum_{j=0}^i \frac{L^*_{j}(t)}{N_{j}}\le \frac{8\omega^3}{N_k}+2\sum_{j=\ell+1}^{i} \frac{t}{\beta^{k-j} N_k} \le \frac{O(1)}{N_k}\left( \omega^3+\frac{t}{\beta} \right)=O\left(\frac{t}{\beta N_k}\right)\!.\end{align}
\begin{align}\sum_{j=0}^i \frac{L^*_{j}(t)}{N_{j}}\le \frac{8\omega^3}{N_k}+2\sum_{j=\ell+1}^{i} \frac{t}{\beta^{k-j} N_k} \le \frac{O(1)}{N_k}\left( \omega^3+\frac{t}{\beta} \right)=O\left(\frac{t}{\beta N_k}\right)\!.\end{align}
This confirms (33).
We turn now to the solution of (19) and (20). Consider first
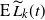 $\mathrm{E}\, \widetilde L_k(t)$
. For all
$\mathrm{E}\, \widetilde L_k(t)$
. For all
 $t \ge 0$
,
$t \ge 0$
,
 $\widehat{L_k}(t)=t$
, and
$\widehat{L_k}(t)=t$
, and
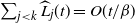 $\sum_{j < k} \widehat L_j(t)=O(t/\beta)$
follows from (34). Thus, from (20)
$\sum_{j < k} \widehat L_j(t)=O(t/\beta)$
follows from (34). Thus, from (20)
 \[\mathrm{E}\, \widetilde L_k(t)=t -\sum_{ s=0}^t O\left(\frac{s}{\beta N_k}\right)=t-O\left(\frac{t^2}{\beta N_k}\right)=t\left( 1-O\left(\frac{t}{\beta N_k}\right) \right)\!.\]
\[\mathrm{E}\, \widetilde L_k(t)=t -\sum_{ s=0}^t O\left(\frac{s}{\beta N_k}\right)=t-O\left(\frac{t^2}{\beta N_k}\right)=t\left( 1-O\left(\frac{t}{\beta N_k}\right) \right)\!.\]
For
 $t\ge t_0$
where
$t\ge t_0$
where
 $t_0 \rightarrow \infty$
arbitrarily slowly we have
$t_0 \rightarrow \infty$
arbitrarily slowly we have
 $\widetilde L_k(t) \sim t$
w.h.p., initializing an induction for
$\widetilde L_k(t) \sim t$
w.h.p., initializing an induction for
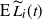 $\mathrm{E}\, \widetilde L_i(t)$
using arguments equivalent to those in Lemma 1 for
$\mathrm{E}\, \widetilde L_i(t)$
using arguments equivalent to those in Lemma 1 for
 $\mathrm{E}\,\widehat{L_i}(t)$
.
$\mathrm{E}\,\widehat{L_i}(t)$
.
At step
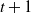 $t+1$
, (33) implies that, for the lower bounds on the process, with probability
$t+1$
, (33) implies that, for the lower bounds on the process, with probability
 $(1-o(1))$
particle
$(1-o(1))$
particle
 $t+1$
will arrive at level i. If
$t+1$
will arrive at level i. If
 $i<k$
, it halts at this level with probability
$i<k$
, it halts at this level with probability
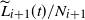 $\widetilde L_{i+1}(t)/N_{i+1}$
. Thus,
$\widetilde L_{i+1}(t)/N_{i+1}$
. Thus,
 \begin{align}\mathrm{E}\,\widetilde L_i(t+1) = \mathrm{E}\,\widetilde L_i(t) + \left( 1-O\left(\frac{t}{\beta N_k}\right) \right)\cdot\frac{\mathrm{E}\, \widetilde L_{i+1}(t)}{N_{i+1}}. \end{align}
\begin{align}\mathrm{E}\,\widetilde L_i(t+1) = \mathrm{E}\,\widetilde L_i(t) + \left( 1-O\left(\frac{t}{\beta N_k}\right) \right)\cdot\frac{\mathrm{E}\, \widetilde L_{i+1}(t)}{N_{i+1}}. \end{align}
Arguing as in (8) on the inductive assumption that
 \[\mathrm{E}\, \widetilde L_{i+1}(t)=\mu_{i+1}(t) \left( 1-O\left(\frac{t (k-(i+1) +1)}{\beta N_k}\right) \right)\!,\]
\[\mathrm{E}\, \widetilde L_{i+1}(t)=\mu_{i+1}(t) \left( 1-O\left(\frac{t (k-(i+1) +1)}{\beta N_k}\right) \right)\!,\]
which is true when
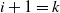 $i+1=k$
, using (35) we find
$i+1=k$
, using (35) we find
 \begin{align*} \mathrm{E}\, \widetilde L_i(t)& = \frac{1}{N_{i+1}} \sum_{s=0}^{t-1} \mathrm{E}\, \widetilde L_{i+1}(s) \left( 1-O\left(\frac{s}{\beta N_k}\right) \right)\\ & = \frac{1}{N_{i+1}} \sum_{s=0}^{t-1} \mu_{i+1}(s)\left( 1-O\left(\frac{s(k-(i+1)+1)}{\beta N_k}\right) \right) \left( 1-O\left(\frac{s}{\beta N_k}\right) \right)\\ & = \frac{1}{N_{i+1}} \sum_{s=0}^{t-1} \frac{s^{k-i}}{(k-i)! N_k \cdots N_{i+2}} \left( 1-O\left(\frac{s (k-i+1)}{\beta N_k}\right) \right)\\ & = \mu_i(t)-\frac{t \mu_{i}(t)}{N_k} O\left(\frac{k-i+1}{\beta}\right)=\mu_i(t)\left( 1- O\left(\frac{(k-i+1) t}{\beta N_k}\right) \right).\end{align*}
\begin{align*} \mathrm{E}\, \widetilde L_i(t)& = \frac{1}{N_{i+1}} \sum_{s=0}^{t-1} \mathrm{E}\, \widetilde L_{i+1}(s) \left( 1-O\left(\frac{s}{\beta N_k}\right) \right)\\ & = \frac{1}{N_{i+1}} \sum_{s=0}^{t-1} \mu_{i+1}(s)\left( 1-O\left(\frac{s(k-(i+1)+1)}{\beta N_k}\right) \right) \left( 1-O\left(\frac{s}{\beta N_k}\right) \right)\\ & = \frac{1}{N_{i+1}} \sum_{s=0}^{t-1} \frac{s^{k-i}}{(k-i)! N_k \cdots N_{i+2}} \left( 1-O\left(\frac{s (k-i+1)}{\beta N_k}\right) \right)\\ & = \mu_i(t)-\frac{t \mu_{i}(t)}{N_k} O\left(\frac{k-i+1}{\beta}\right)=\mu_i(t)\left( 1- O\left(\frac{(k-i+1) t}{\beta N_k}\right) \right).\end{align*}
Provided
 $t \le \omega T_f$
, which is true w.h.p. by Lemma 5, then
$t \le \omega T_f$
, which is true w.h.p. by Lemma 5, then
 $kt/\beta N_k \le k(\omega T_f/N_k)^2 =o(1)$
, see (24) and Lemma 4; in this case
$kt/\beta N_k \le k(\omega T_f/N_k)^2 =o(1)$
, see (24) and Lemma 4; in this case
 \begin{align}\mathrm{E}\, \widetilde L_i(t) \sim \mathrm{E}\, L_i(t) \sim \mathrm{E}\, \widehat{L_i}(t)\sim \mu_i(t)= \frac{t^{i+1}}{(i+1)! N_k \cdots N_{i+1}}\end{align}
\begin{align}\mathrm{E}\, \widetilde L_i(t) \sim \mathrm{E}\, L_i(t) \sim \mathrm{E}\, \widehat{L_i}(t)\sim \mu_i(t)= \frac{t^{i+1}}{(i+1)! N_k \cdots N_{i+1}}\end{align}
as required.
Let
 $t_i(\omega)$
be given by (6). For those
$t_i(\omega)$
be given by (6). For those
 $i \le k$
, such that
$i \le k$
, such that
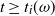 $t \ge t_i(\omega)$
, then
$t \ge t_i(\omega)$
, then
 $\mu_i(t) \rightarrow \infty$
suitably fast and the concentration results of Lemma 3 hold. The gaps inherited from the upper-bound argument of Section 3.1 are essentially unaltered.
$\mu_i(t) \rightarrow \infty$
suitably fast and the concentration results of Lemma 3 hold. The gaps inherited from the upper-bound argument of Section 3.1 are essentially unaltered.
This completes the proof of Proposition 1 for the equal layers model.
3.3. Finish time of DLA in the equal layers model
A lower bound on the finish time follows from the upper-blocked process, and an upper bound from the lower bound estimates for DLA. The range of k requires us to split the finish time analysis into two cases; k constant, and
 $k \rightarrow \infty$
with n.
$k \rightarrow \infty$
with n.
Lemma 5. For
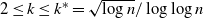 $ 2 \le k \le k^*=\sqrt{\log n}/\log\log n$
, let G be an equal layers graph with level sizes
$ 2 \le k \le k^*=\sqrt{\log n}/\log\log n$
, let G be an equal layers graph with level sizes
 $N_i= n/k$
,
$N_i= n/k$
,
 $i=1,\ldots,k$
. Let
$i=1,\ldots,k$
. Let
 $T_f$
be given by (21). If k is constant then the finish time
$T_f$
be given by (21). If k is constant then the finish time
 $t_f$
of the DLA process in G satisfies
$t_f$
of the DLA process in G satisfies
 $T_f/\omega' \le t_f \le \omega' T_f$
, with probability
$T_f/\omega' \le t_f \le \omega' T_f$
, with probability
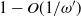 $1-O(1/\omega')$
, where
$1-O(1/\omega')$
, where
 $\omega' \rightarrow \infty$
arbitrarily slowly. However, if
$\omega' \rightarrow \infty$
arbitrarily slowly. However, if
 $k \rightarrow \infty$
then
$k \rightarrow \infty$
then
 $t_f=\Theta(T_f)$
.
$t_f=\Theta(T_f)$
.
Proof. By Lemma 1,
 $\mathrm{E}\, \widehat{L_0}(t) \le \mu_0(t)$
. As usual let
$\mathrm{E}\, \widehat{L_0}(t) \le \mu_0(t)$
. As usual let
 $t_1(0)$
denote the step t when
$t_1(0)$
denote the step t when
 $\mu_1(t)\sim 1$
. From Lemma 4(2), with
$\mu_1(t)\sim 1$
. From Lemma 4(2), with
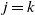 $j=k$
we have
$j=k$
we have
 $t_1(0)= \Theta(k) n^{k/(k+1)}$
, which follows because
$t_1(0)= \Theta(k) n^{k/(k+1)}$
, which follows because
 $k^{1/(k(k+1))}=\Theta(1)$
. On the other hand, from Lemma 4(1), we have that
$k^{1/(k(k+1))}=\Theta(1)$
. On the other hand, from Lemma 4(1), we have that
 $T_f=\gamma_k n^{k/(k+1)}$
, so
$T_f=\gamma_k n^{k/(k+1)}$
, so
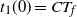 $t_1(0)= C T_f$
for some constant
$t_1(0)= C T_f$
for some constant
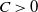 $C>0$
.
$C>0$
.
Case k constant. Let
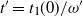 $t'=t_1(0)/\omega'$
, where
$t'=t_1(0)/\omega'$
, where
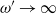 $\omega' \rightarrow \infty$
arbitrarily slowly. Then w.h.p.,
$\omega' \rightarrow \infty$
arbitrarily slowly. Then w.h.p.,
 $\mathrm{E}\, \widehat{L_0}(t')\le \mu_0(t')=O(1/(\omega')^{k+1})$
and, thus,
$\mathrm{E}\, \widehat{L_0}(t')\le \mu_0(t')=O(1/(\omega')^{k+1})$
and, thus,
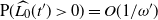 $\mathrm{P}(\widehat{L_0}(t')>0)=O(1/\omega')$
.
$\mathrm{P}(\widehat{L_0}(t')>0)=O(1/\omega')$
.
We next investigate the concentration of
 $L_1(T_f)$
. By Lemma 4(1), as
$L_1(T_f)$
. By Lemma 4(1), as
 $T_f=t_1(0)$
,
$T_f=t_1(0)$
,
 $\mu_0(T_f)=1$
and, thus,
$\mu_0(T_f)=1$
and, thus,
 \begin{align} \mu_1(T_f)=\mu_0(T_f) \frac{N_1 (k+2)}{T_f}\ge \frac{n}{\gamma_k n^{k/(k+1)}}=\Theta(1) n^{1/(k+1)} \gg 4 \omega^3,\end{align}
\begin{align} \mu_1(T_f)=\mu_0(T_f) \frac{N_1 (k+2)}{T_f}\ge \frac{n}{\gamma_k n^{k/(k+1)}}=\Theta(1) n^{1/(k+1)} \gg 4 \omega^3,\end{align}
where
 $\omega=6 \log n$
as usual. Thus,
$\omega=6 \log n$
as usual. Thus,
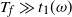 $T_f \gg t_1(\omega)$
and, hence, Lemma 3 holds for
$T_f \gg t_1(\omega)$
and, hence, Lemma 3 holds for
 $\widetilde L_1(T_f)$
. Suppose that
$\widetilde L_1(T_f)$
. Suppose that
 $L_0(T_f)=0$
at step
$L_0(T_f)=0$
at step
 $T_f$
. By (37) the expected waiting time
$T_f$
. By (37) the expected waiting time
 $\tau$
for a particle to hit
$\tau$
for a particle to hit
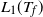 $L_1(T_f)$
is
$L_1(T_f)$
is
 \begin{align}\tau\le (1+o(1)) \frac{N_1}{\mu_1(T_f)}=\Theta(1) \frac n{k n^{1/(k+1)}}=\Theta(1) \frac{n^{k/(k+1)}}{k}=\Theta(T_f/k)=O(T_f).\end{align}
\begin{align}\tau\le (1+o(1)) \frac{N_1}{\mu_1(T_f)}=\Theta(1) \frac n{k n^{1/(k+1)}}=\Theta(1) \frac{n^{k/(k+1)}}{k}=\Theta(T_f/k)=O(T_f).\end{align}
Thus, by step
 $\omega' T_f$
, w.h.p.
$\omega' T_f$
, w.h.p.
 $L_0(\omega'T_f)=1$
.
$L_0(\omega'T_f)=1$
.
Case
 $k \rightarrow \infty$
with n. Let
$k \rightarrow \infty$
with n. Let
 $t'=(1-\varepsilon) t_1(0)$
, where
$t'=(1-\varepsilon) t_1(0)$
, where
 $0<\varepsilon<1$
constant, then
$0<\varepsilon<1$
constant, then
 $t'=C(1-\varepsilon)T_f$
and
$t'=C(1-\varepsilon)T_f$
and
 $\mu_0(t') \sim (1-\varepsilon)^{k+1}$
. Thus,
$\mu_0(t') \sim (1-\varepsilon)^{k+1}$
. Thus,
 $\mathrm{P}(\widehat{L_0}(t')>0)\le \mathrm{e}^{-\varepsilon k}$
and so w.h.p.
$\mathrm{P}(\widehat{L_0}(t')>0)\le \mathrm{e}^{-\varepsilon k}$
and so w.h.p.
 $t_f>t'$
, lower bounding the finish time. On the other hand, for the upper bound, the inequality (37) still holds. By (38), the expected waiting time for the source to be occupied satisfies
$t_f>t'$
, lower bounding the finish time. On the other hand, for the upper bound, the inequality (37) still holds. By (38), the expected waiting time for the source to be occupied satisfies
 $\tau =\Theta(T_f/k)=o(T_f)$
. Taking
$\tau =\Theta(T_f/k)=o(T_f)$
. Taking
 $\varepsilon=o(1)$
we see that
$\varepsilon=o(1)$
we see that
 $t_f \sim CT_f$
for some constant C.
$t_f \sim CT_f$
for some constant C.
This completes the proof of Lemma 5 and, hence, Theorem 1(1).
3.4. Existence of a unique connecting path component
We now prove Theorem 2 for the equal layers model. We must show w.h.p. that at step
 $t_f$
, the finish time, the path of occupied vertices connecting the source to level k (and, hence, to the sink), has no off-path neighbours in
$t_f$
, the finish time, the path of occupied vertices connecting the source to level k (and, hence, to the sink), has no off-path neighbours in
 $C_{t_f}$
.
$C_{t_f}$
.
At a given step t, the edge-induced component
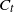 $C_t$
is obtained from
$C_t$
is obtained from
 $C_{t-1}$
by adding a newly occupied vertex which points to the neighbour in
$C_{t-1}$
by adding a newly occupied vertex which points to the neighbour in
 $C_{t-1}$
which halted the particle: Thus, a particle halts at vertex u in level i if it chooses an edge uw to an occupied neighbour w in level
$C_{t-1}$
which halted the particle: Thus, a particle halts at vertex u in level i if it chooses an edge uw to an occupied neighbour w in level
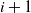 $i+1$
. We consider this edge uw as being directed from u to w in the component
$i+1$
. We consider this edge uw as being directed from u to w in the component
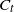 $C_t$
rooted at the sink. An arborescence is a rooted tree with all edges directed towards the root vertex. Thus
$C_t$
rooted at the sink. An arborescence is a rooted tree with all edges directed towards the root vertex. Thus
 $C_t$
is an arborescence with root z. On deletion of the z,
$C_t$
is an arborescence with root z. On deletion of the z,
 $D_t=C_t\! \setminus \!\{z\}$
becomes a directed forest of arborescences each rooted at a vertex in level k.
$D_t=C_t\! \setminus \!\{z\}$
becomes a directed forest of arborescences each rooted at a vertex in level k.
Let
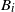 $B_i$
be the set of occupied vertices in level i, where
$B_i$
be the set of occupied vertices in level i, where
 $L_i=|B_i|$
. Given that a particle at u chooses a vertex in
$L_i=|B_i|$
. Given that a particle at u chooses a vertex in
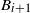 $B_{i+1}$
as a neighbour, then this neighbour is chosen uniformly at random (u.a.r.) from the set
$B_{i+1}$
as a neighbour, then this neighbour is chosen uniformly at random (u.a.r.) from the set
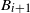 $B_{i+1}$
.
$B_{i+1}$
.
We regard vertices occupied by halted particles as coloured either red or blue, with all occupied vertices in level k coloured blue. If u is the first in-neighbour of w then u is coloured blue. If however w already has an in-neighbour
 $u'$
then u,
$u'$
then u,
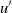 $u'$
and all other in-neighbours are (re)coloured red. At any step, the red vertices in a level are those with siblings and the blue vertices are the unique in-neighbour of some vertex in the next level. The choice of w by the particle at u is independent of the colour of w at this step.
$u'$
and all other in-neighbours are (re)coloured red. At any step, the red vertices in a level are those with siblings and the blue vertices are the unique in-neighbour of some vertex in the next level. The choice of w by the particle at u is independent of the colour of w at this step.
The process halts when there is a directed path of occupied vertices
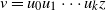 $\nu=u_0 u_1\cdots u_kz$
from the source to sink. The source vertex v is blue at
$\nu=u_0 u_1\cdots u_kz$
from the source to sink. The source vertex v is blue at
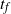 $t_f$
as it is the first in-neighbour of
$t_f$
as it is the first in-neighbour of
 $u_1$
.
$u_1$
.
Lemma 6. With high probability, the path
 $\nu=u_0 u_1\cdots u_k =w$
from the source to level k is blue, and thus the arborescence of halted particles rooted at
$\nu=u_0 u_1\cdots u_k =w$
from the source to level k is blue, and thus the arborescence of halted particles rooted at
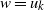 $w=u_k$
is exactly this path.
$w=u_k$
is exactly this path.
Proof. As before, let
 $B_i$
be the set of occupied vertices in level i, and
$B_i$
be the set of occupied vertices in level i, and
 $L_i=|B_i|$
. The subset Out
$L_i=|B_i|$
. The subset Out
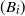 $(B_i)$
of
$(B_i)$
of
 $B_{i+1}$
with at least one in-neighbour in
$B_{i+1}$
with at least one in-neighbour in
 $B_i$
has size at most
$B_i$
has size at most
 $L_i$
. This is because
$L_i$
. This is because
 $u \in B_i$
has a unique occupied out-neighbour in
$u \in B_i$
has a unique occupied out-neighbour in
 $C_t$
.
$C_t$
.
Let
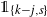 ${\unicode{x1D7D9}}_{\{{k-j,s}\}}$
be the indicator that particle s halts in level
${\unicode{x1D7D9}}_{\{{k-j,s}\}}$
be the indicator that particle s halts in level
 $k-j$
and is coloured red due to a pre-existing sibling. In this case particle s has chosen an out-neighbour in the existing set Out
$k-j$
and is coloured red due to a pre-existing sibling. In this case particle s has chosen an out-neighbour in the existing set Out
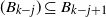 $(B_{k-j}) \subseteq B_{k-j+1}$
and, thus, as
$(B_{k-j}) \subseteq B_{k-j+1}$
and, thus, as
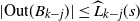 $|\mathrm{Out}(B_{k-j})| \le \widehat L_{k-j}(s)$
,
$|\mathrm{Out}(B_{k-j})| \le \widehat L_{k-j}(s)$
,
 \[\mathrm{E}\,{\unicode{x1D7D9}}_{\{{k-j,s}\}} \le \frac{\mathrm{E}\, \widehat L_{k-j}(s)}{(n/k)} \sim \frac{\mu_{k-j}(s)}{(n/k)}.\]
\[\mathrm{E}\,{\unicode{x1D7D9}}_{\{{k-j,s}\}} \le \frac{\mathrm{E}\, \widehat L_{k-j}(s)}{(n/k)} \sim \frac{\mu_{k-j}(s)}{(n/k)}.\]
Let
 $Z_{k-j}(t)$
be the number of red vertices in level
$Z_{k-j}(t)$
be the number of red vertices in level
 $k-j$
. We associate the number of possibly red vertices at each step with a super-process
$k-j$
. We associate the number of possibly red vertices at each step with a super-process
 $\widehat Z_{k-j}(t)=Z_{k-j}(t)+Q_{k-j}(t)$
, where
$\widehat Z_{k-j}(t)=Z_{k-j}(t)+Q_{k-j}(t)$
, where
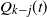 $Q_{k-j}(t)$
is Bernoulli with parameter
$Q_{k-j}(t)$
is Bernoulli with parameter
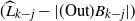 $(\widehat L_{k-j}-|(\mathrm{Out})B_{k-j}|)$
. Thus,
$(\widehat L_{k-j}-|(\mathrm{Out})B_{k-j}|)$
. Thus,
 $Z_{k-j}(t) \le \widehat Z_{k-j}(t)$
and
$Z_{k-j}(t) \le \widehat Z_{k-j}(t)$
and
 \[\mathrm{E}\, \big(\widehat Z_{k-j}(t+1) \mid \widehat{\mathcal{H}}(t)\big)=\widehat Z_{k-j}(t)+\frac{\widehat L_{k-j}(t)}{N_{k-j}}.\]
\[\mathrm{E}\, \big(\widehat Z_{k-j}(t+1) \mid \widehat{\mathcal{H}}(t)\big)=\widehat Z_{k-j}(t)+\frac{\widehat L_{k-j}(t)}{N_{k-j}}.\]
The recurrence for
 $\mathrm{E}\, \widehat Z$
mirrors the recurrence (4) for
$\mathrm{E}\, \widehat Z$
mirrors the recurrence (4) for
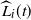 $\widehat L_{i}(t)$
with
$\widehat L_{i}(t)$
with
 $k-j$
replacing
$k-j$
replacing
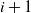 $i+1$
. The variable
$i+1$
. The variable
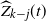 $\widehat Z_{k-j}(t)$
occurs in place of
$\widehat Z_{k-j}(t)$
occurs in place of
 $\widehat{L_i}(t)$
, and will grow as
$\widehat{L_i}(t)$
, and will grow as
 $\widehat L_{k-(\kern1.5pt j+1)}(t)$
. Specifically,
$\widehat L_{k-(\kern1.5pt j+1)}(t)$
. Specifically,
 \begin{align}\mathrm{E}\, \widehat Z_{k-j}(t) & \sim \frac 1{(n/k)}\sum_{s=1}^t{\mu_{k-j}(s)}= \frac{1}{(n/k)} \sum_{s=1}^t \frac{s^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)! (n/k)^j} \nonumber\\& \sim \frac{t^{ \kern1.5pt j+2}}{(\kern1.5pt j+2)! (n/k)^{\kern1.5pt j+1}}= \mu_{k-(\kern1.5pt j+1)}(t). \end{align}
\begin{align}\mathrm{E}\, \widehat Z_{k-j}(t) & \sim \frac 1{(n/k)}\sum_{s=1}^t{\mu_{k-j}(s)}= \frac{1}{(n/k)} \sum_{s=1}^t \frac{s^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)! (n/k)^j} \nonumber\\& \sim \frac{t^{ \kern1.5pt j+2}}{(\kern1.5pt j+2)! (n/k)^{\kern1.5pt j+1}}= \mu_{k-(\kern1.5pt j+1)}(t). \end{align}
We note that
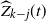 $\widehat Z_{k-j}(t)$
is the sum of independent indicator variables, and will be concentrated for
$\widehat Z_{k-j}(t)$
is the sum of independent indicator variables, and will be concentrated for
 $t \ge t_{k-(\kern1.5pt j+1)}(\omega)$
, where
$t \ge t_{k-(\kern1.5pt j+1)}(\omega)$
, where
 $\omega=6 \log n$
as before. The total number of red vertices is at most
$\omega=6 \log n$
as before. The total number of red vertices is at most
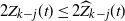 $2Z_{k-j}(t) \le 2 \widehat Z_{k-j}(t)$
, where the factor 2 covers the case where the pre-existing sibling was blue but is recoloured red.
$2Z_{k-j}(t) \le 2 \widehat Z_{k-j}(t)$
, where the factor 2 covers the case where the pre-existing sibling was blue but is recoloured red.
Assume
 $T_f/\omega' \le t_f \le \omega' T_f$
, where
$T_f/\omega' \le t_f \le \omega' T_f$
, where
 $\omega'$
from Lemma 5 tends to infinity arbitrarily slowly with n. Denote the path connecting
$\omega'$
from Lemma 5 tends to infinity arbitrarily slowly with n. Denote the path connecting
 $\nu=u_0$
to level k by
$\nu=u_0$
to level k by
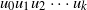 $u_0 u_1 u_2\cdots u_k$
, where by definition the source
$u_0 u_1 u_2\cdots u_k$
, where by definition the source
 $\nu=u_0$
is blue at
$\nu=u_0$
is blue at
 $t_f$
. For
$t_f$
. For
 $i \ge 1$
, let
$i \ge 1$
, let
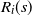 $R_i(s)$
be the red vertices in level i at step s. Let
$R_i(s)$
be the red vertices in level i at step s. Let
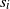 $s_i$
denote the step at which
$s_i$
denote the step at which
 $u_i$
became occupied. Consider the colour of
$u_i$
became occupied. Consider the colour of
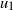 $u_1$
at
$u_1$
at
 $t_f$
. As
$t_f$
. As
 $T_f= t_1(0)$
, and
$T_f= t_1(0)$
, and
 $t_f \ge T_f/\omega' \gg t_1(\omega)$
by the gap property, so we have that
$t_f \ge T_f/\omega' \gg t_1(\omega)$
by the gap property, so we have that
 $L_1(t_f) \sim \mu_1(t_f)$
. Let
$L_1(t_f) \sim \mu_1(t_f)$
. Let
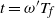 $t=\omega' T_f$
, be a w.h.p. upper bound on
$t=\omega' T_f$
, be a w.h.p. upper bound on
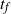 $t_f$
, then by (3)
$t_f$
, then by (3)
 $\mu_0(t)=(\omega')^{k+1}$
. On the other hand,
$\mu_0(t)=(\omega')^{k+1}$
. On the other hand,
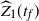 $\widehat Z_1(t_f)$
may not be concentrated, but we can assume
$\widehat Z_1(t_f)$
may not be concentrated, but we can assume
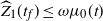 $\widehat Z_1(t_f) \le \omega \mu_0(t)$
where
$\widehat Z_1(t_f) \le \omega \mu_0(t)$
where
 $\omega=6 \log n$
will be large enough to use in the Markov inequality for
$\omega=6 \log n$
will be large enough to use in the Markov inequality for
 $k=o(\sqrt{\log n})$
levels.
$k=o(\sqrt{\log n})$
levels.
Vertex
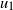 $u_1$
was chosen u.a.r. from the occupied vertices in level one by the particle halting at
$u_1$
was chosen u.a.r. from the occupied vertices in level one by the particle halting at
 $u_0$
, thus,
$u_0$
, thus,
 \begin{align}\mathrm{P}( u_1 \in R_1(t)) \le \frac{2\widehat Z_1(t)}{L_1(t)} \le \frac{2 \omega \mu_0(t)}{\mu_1(t)} \le \frac{2 \omega t}{(k+1)(n/k)}\le \frac{2 \omega t}{n}.\end{align}
\begin{align}\mathrm{P}( u_1 \in R_1(t)) \le \frac{2\widehat Z_1(t)}{L_1(t)} \le \frac{2 \omega \mu_0(t)}{\mu_1(t)} \le \frac{2 \omega t}{(k+1)(n/k)}\le \frac{2 \omega t}{n}.\end{align}
Next consider the colour of
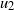 $u_2$
. If
$u_2$
. If
 $u_2$
is red at step t then either (i) it became red before step
$u_2$
is red at step t then either (i) it became red before step
 $s_1$
when it was chosen u.a.r. by
$s_1$
when it was chosen u.a.r. by
 $u_1$
or (ii) it became red at some later step.
$u_1$
or (ii) it became red at some later step.
In the first case,
 \[\mathrm{P}(u_2 \in R_2(s_1))\le\frac{2\widehat Z_2(s_1)}{L_2(s_1)} \le 2\omega\frac{\mu_1(s_1)}{\mu_2(s_1)}=\frac{2\omega s_1}{k(n/k)}=\frac{2 \omega s_1}{n}.\]
\[\mathrm{P}(u_2 \in R_2(s_1))\le\frac{2\widehat Z_2(s_1)}{L_2(s_1)} \le 2\omega\frac{\mu_1(s_1)}{\mu_2(s_1)}=\frac{2\omega s_1}{k(n/k)}=\frac{2 \omega s_1}{n}.\]
By the gap property,
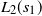 $L_2(s_1)$
is already concentrated, for otherwise
$L_2(s_1)$
is already concentrated, for otherwise
 $L_1(s_1)$
would be empty, a contradiction. The
$L_1(s_1)$
would be empty, a contradiction. The
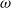 $\omega$
covers possible lack of concentration of
$\omega$
covers possible lack of concentration of
 $\widehat Z_2(s_1)$
as explained previously.
$\widehat Z_2(s_1)$
as explained previously.
In the second case, as
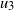 $u_3$
is the chosen out-neighbour of
$u_3$
is the chosen out-neighbour of
 $u_2$
, then
$u_2$
, then
 $u_2$
will turn red if some particle chooses
$u_2$
will turn red if some particle chooses
 $u_3$
after time
$u_3$
after time
 $s_1$
, and thus
$s_1$
, and thus
 \[\mathrm{P}(u_2 \in R_2(t) \! \setminus \! R_2(s_1)) \le \frac{1}{(n/k)} \sum_{\tau=s_1+1}^t \mathrm{E}\, \,{\unicode{x1D7D9}}_{\{{u_3 \text{ chosen at }\tau}\}}=\frac{t-s_1}{(n/k)}.\]
\[\mathrm{P}(u_2 \in R_2(t) \! \setminus \! R_2(s_1)) \le \frac{1}{(n/k)} \sum_{\tau=s_1+1}^t \mathrm{E}\, \,{\unicode{x1D7D9}}_{\{{u_3 \text{ chosen at }\tau}\}}=\frac{t-s_1}{(n/k)}.\]
Thus
 \[\mathrm{P}(u_2 \in R_2(t)) \le \frac{2\omega kt}{n},\]
\[\mathrm{P}(u_2 \in R_2(t)) \le \frac{2\omega kt}{n},\]
and similarly for vertices
 $u_3,\ldots,u_{k-1}$
. Thus
$u_3,\ldots,u_{k-1}$
. Thus
 \[\mathrm{P}(\text{path } vu_1\cdots u_k \text{ is blue}) \ge 1-\sum_{i=1}^{k-1} \frac{2\omega kt}{n}=1-O\left(\frac{\omega k^2t}{n}\right).\]
\[\mathrm{P}(\text{path } vu_1\cdots u_k \text{ is blue}) \ge 1-\sum_{i=1}^{k-1} \frac{2\omega kt}{n}=1-O\left(\frac{\omega k^2t}{n}\right).\]
By Lemma 5,
 $t= \omega' T_f \le \omega' n^{k/(k+1)}$
, where
$t= \omega' T_f \le \omega' n^{k/(k+1)}$
, where
 $\omega' \rightarrow \infty$
arbitrarily slowly. As
$\omega' \rightarrow \infty$
arbitrarily slowly. As
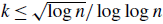 $k \le \sqrt{\log n}/ \log \log n$
, then
$k \le \sqrt{\log n}/ \log \log n$
, then
 $\omega k^2 \omega' T_f/n \le \omega^3/n^{1/(k+1)}=o(1)$
, by upper bounding
$\omega k^2 \omega' T_f/n \le \omega^3/n^{1/(k+1)}=o(1)$
, by upper bounding
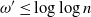 $\omega' \le \log \log n$
. Thus the path from the source to vertex
$\omega' \le \log \log n$
. Thus the path from the source to vertex
 $w=u_k$
level k is blue w.h.p., and thus the arborescence rooted at w is exactly this path.
$w=u_k$
level k is blue w.h.p., and thus the arborescence rooted at w is exactly this path.
4. Analysis of DLA in the growing layers model
In the growing layers model, each layer is larger than the previous one by a factor of d. Thus,
 $N_j=d^j$
for
$N_j=d^j$
for
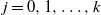 $j=0,1,\ldots,k$
and we take
$j=0,1,\ldots,k$
and we take
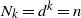 $N_k=d^k=n$
. Many of the properties of this model such as a gap property and unique connecting path are similar to the equal layers model.
$N_k=d^k=n$
. Many of the properties of this model such as a gap property and unique connecting path are similar to the equal layers model.
The main, and most striking difference, is that there is a well-defined level
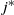 $j^*$
at a distance
$j^*$
at a distance
 $\sqrt{2k+2}-1$
from the end (ignoring rounding) at which agglomerative growth stops and from which a single path grows back towards the source. Moreover at the end, except for the last
$\sqrt{2k+2}-1$
from the end (ignoring rounding) at which agglomerative growth stops and from which a single path grows back towards the source. Moreover at the end, except for the last
 $j^*-1$
levels, the connecting path is the only occupied vertex in the layer. This is in contrast to the equal layers model where all levels have significant occupancy, and even that of the first level at the end is
$j^*-1$
levels, the connecting path is the only occupied vertex in the layer. This is in contrast to the equal layers model where all levels have significant occupancy, and even that of the first level at the end is
 $\Theta(n^{1/(k+1)})$
.
$\Theta(n^{1/(k+1)})$
.
Proposition 2. Let G be a growing layers graph with level sizes
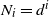 $N_i=d^i$
, for
$N_i=d^i$
, for
 $i=0,\ldots,k$
, where
$i=0,\ldots,k$
, where
 $d \rightarrow \infty$
,
$d \rightarrow \infty$
,
 $k \rightarrow \infty$
, and
$k \rightarrow \infty$
, and
 $k\le (\log d /(\log\log d)^2$
. Let
$k\le (\log d /(\log\log d)^2$
. Let
 \begin{align}T_f= \sqrt{k} d^{k+3/2-\sqrt{2k+2}}.\end{align}
\begin{align}T_f= \sqrt{k} d^{k+3/2-\sqrt{2k+2}}.\end{align}
-
(1) The finish time
$t_f$
of DLA on G satisfies
$ d^{-O(1/\sqrt k)} T_f \le t_f \le d^{O(1/\sqrt k)} T_f$
. -
(2) At
$t_f$
, levels
$i=1,\ldots, k- \lceil \sqrt{2k+2}-1 \rceil$
contain a single occupied vertex, the vertex
$u_i$
of the connecting path.
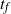


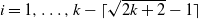

Proof. The size
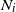 $N_{i}$
of layer i is
$N_{i}$
of layer i is
 $N_i=d^{i}$
. It follows that the product of the set sizes in the denominator of
$N_i=d^{i}$
. It follows that the product of the set sizes in the denominator of
 $\mu_{k-j}(t)$
in (3) is given by
$\mu_{k-j}(t)$
in (3) is given by
 \begin{align}M_{j-1}=N_kN_{k-1}\cdots N_{k-j+1}= d^k d^{k-1}\cdots d^{k-j+1}= d^{kj-j(\kern1.5pt j-1)/2},\end{align}
\begin{align}M_{j-1}=N_kN_{k-1}\cdots N_{k-j+1}= d^k d^{k-1}\cdots d^{k-j+1}= d^{kj-j(\kern1.5pt j-1)/2},\end{align}
and, thus, (3) becomes
 \begin{align}\mu_{k-j}(t)=\frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)! d^k d^{k-1}\cdots d^{k-j+1}}= \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)! d^{kj-j(\kern1.5pt j-1)/2}}.\end{align}
\begin{align}\mu_{k-j}(t)=\frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)! d^k d^{k-1}\cdots d^{k-j+1}}= \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)! d^{kj-j(\kern1.5pt j-1)/2}}.\end{align}
Assume d is sufficiently large. The upper bound
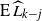 $\mathrm{E}\, \widehat L_{k-j}$
is obtained in Section 2. However, a problem can arise in the growing layers model in the upper bound calculations. The value of
$\mathrm{E}\, \widehat L_{k-j}$
is obtained in Section 2. However, a problem can arise in the growing layers model in the upper bound calculations. The value of
 $\mu_{k-j}$
can decrease with increasing j and then (anomalously) increase again. This is because the recurrence used to establish it assumes
$\mu_{k-j}$
can decrease with increasing j and then (anomalously) increase again. This is because the recurrence used to establish it assumes
 $\mu_{k-\ell} \rightarrow \infty$
for all
$\mu_{k-\ell} \rightarrow \infty$
for all
 $\ell < j$
, which is not the case. We next locate where this happens; this is where the unique path back to the source begins.
$\ell < j$
, which is not the case. We next locate where this happens; this is where the unique path back to the source begins.
4.1. An important level
We next show the existence of a level
 $i\sim k+1-\sqrt{2k+2}$
, such that the first occupancy of this level effectively determines the finish time of the process.
$i\sim k+1-\sqrt{2k+2}$
, such that the first occupancy of this level effectively determines the finish time of the process.
From (43),
 \begin{align}\mu_{k-j}(t_1)=\frac{t_1^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)! d^{kj-j(\kern1.5pt j-1)/2}}= 1 \quad \implies \quad t_1(k-j)=[(\kern1.5pt j+1)!]^{1/(\kern1.5pt j+1)} d^{\frac{ 2kj-j(\kern1.5pt j-1)}{2(\kern1.5pt j+1)}}.\end{align}
\begin{align}\mu_{k-j}(t_1)=\frac{t_1^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)! d^{kj-j(\kern1.5pt j-1)/2}}= 1 \quad \implies \quad t_1(k-j)=[(\kern1.5pt j+1)!]^{1/(\kern1.5pt j+1)} d^{\frac{ 2kj-j(\kern1.5pt j-1)}{2(\kern1.5pt j+1)}}.\end{align}
Before proceeding we note that rounding
 $t_1(k-j)$
up or down to the nearest step has negligible effect on
$t_1(k-j)$
up or down to the nearest step has negligible effect on
 $\mu_{k-j}(t_1)$
, as asserted in the note under (6). Indeed
$\mu_{k-j}(t_1)$
, as asserted in the note under (6). Indeed
 \begin{align} \max_{j \ge 1} \frac{j}{t_1(k-j)} \le \frac{k}{t_1(k-1)}=\frac{k}{d^{k/2}}=o(1).\end{align}
\begin{align} \max_{j \ge 1} \frac{j}{t_1(k-j)} \le \frac{k}{t_1(k-1)}=\frac{k}{d^{k/2}}=o(1).\end{align}
We next determine the maximum value of
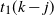 $t_1(k-j)$
. From (3), for any t,
$t_1(k-j)$
. From (3), for any t,
 \begin{align}\frac{\mu_{k-j+1}(t)}{\mu_{k-j}(t)}=\frac{(\kern1.5pt j+1)d^{k-j+1}}{t},\end{align}
\begin{align}\frac{\mu_{k-j+1}(t)}{\mu_{k-j}(t)}=\frac{(\kern1.5pt j+1)d^{k-j+1}}{t},\end{align}
so setting
 $\mu_{k-j}(t_1(k-j))= 1$
gives
$\mu_{k-j}(t_1(k-j))= 1$
gives
 \begin{align}\mu_{k-j+1}(t_1) & = \frac{j+1}{[(\kern1.5pt j+1)!]^{1/j+1}} d^{k-j+1-\frac{ 2kj-j(\kern1.5pt j-1)}{2(\kern1.5pt j+1)}}\nonumber\\& = \frac{\Theta(1)}{(2\pi/e (\kern1.5pt j+1))^{1/2(\kern1.5pt j+1)}} d^{\frac{2k+2-j(\kern1.5pt j+1)}{2(\kern1.5pt j+1)}}.\end{align}
\begin{align}\mu_{k-j+1}(t_1) & = \frac{j+1}{[(\kern1.5pt j+1)!]^{1/j+1}} d^{k-j+1-\frac{ 2kj-j(\kern1.5pt j-1)}{2(\kern1.5pt j+1)}}\nonumber\\& = \frac{\Theta(1)}{(2\pi/e (\kern1.5pt j+1))^{1/2(\kern1.5pt j+1)}} d^{\frac{2k+2-j(\kern1.5pt j+1)}{2(\kern1.5pt j+1)}}.\end{align}
The leading term on the right-hand side of (47) is bounded, and the exponent of d on the right-hand side is positive provided
 $2k+2 > j(\kern1.5pt j+1)$
, which ensures that
$2k+2 > j(\kern1.5pt j+1)$
, which ensures that
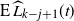 $\mathrm{E}\, \widehat L_{k-j+1}(t)$
is sufficiently large close to
$\mathrm{E}\, \widehat L_{k-j+1}(t)$
is sufficiently large close to
 $t_1(k-j)$
.
$t_1(k-j)$
.
What value of
 $k-j$
maximizes the value of
$k-j$
maximizes the value of
 $t_1=t_1(k-j)$
at which
$t_1=t_1(k-j)$
at which
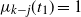 $\mu_{k-j}(t_1)= 1$
? Write the exponent of d on the right-hand side of (44) as
$\mu_{k-j}(t_1)= 1$
? Write the exponent of d on the right-hand side of (44) as
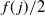 $f(\kern1.5pt j)/2$
where
$f(\kern1.5pt j)/2$
where
 \begin{align}f(\kern1.5pt j)=\frac{2kj-j(\kern1.5pt j-1)}{(\kern1.5pt j+1)}=(2k+2) -j -\frac{2k+2}{j+1}.\end{align}
\begin{align}f(\kern1.5pt j)=\frac{2kj-j(\kern1.5pt j-1)}{(\kern1.5pt j+1)}=(2k+2) -j -\frac{2k+2}{j+1}.\end{align}
The maximum of f(j) occurs at
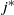 $j^*$
with solution
$j^*$
with solution
 \begin{align} (\kern1.5pt j^*+1)^2=(2k+2), \quad \text{giving } f(\kern1.5pt j^*)=(\kern1.5pt j^*)^2.\end{align}
\begin{align} (\kern1.5pt j^*+1)^2=(2k+2), \quad \text{giving } f(\kern1.5pt j^*)=(\kern1.5pt j^*)^2.\end{align}
The (not necessarily integer) values of
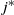 $j^*$
,
$j^*$
,
 $k-j^*$
and
$k-j^*$
and
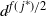 $d^{f(\kern1.5pt j^*)/2}$
are
$d^{f(\kern1.5pt j^*)/2}$
are
 \begin{align}j^*=\sqrt{2k+2}-1, \quad k-j^*=k+1-\sqrt{2k+2}, \quad d^{f(\kern1.5pt j^*)/2}=d^{k+3/2-\sqrt{2k+2}}.\end{align}
\begin{align}j^*=\sqrt{2k+2}-1, \quad k-j^*=k+1-\sqrt{2k+2}, \quad d^{f(\kern1.5pt j^*)/2}=d^{k+3/2-\sqrt{2k+2}}.\end{align}
In the case where
 $j^*$
is not an integer, the effect of the rounding error is addressed in Section 4.4.
$j^*$
is not an integer, the effect of the rounding error is addressed in Section 4.4.
Ignoring rounding effects, we evaluate
 $t_1=t_1(k-j)$
at
$t_1=t_1(k-j)$
at
 $j=j^*$
, in which case
$j=j^*$
, in which case
 $f(\kern1.5pt j)=j^2$
, to find
$f(\kern1.5pt j)=j^2$
, to find
 \begin{align}t_1 & = [(\kern1.5pt j+1)!]^{1/(\kern1.5pt j+1)} d^{\,f(\kern1.5pt j)/2}\nonumber\\& \sim \mathrm{e}^{-1}(\sqrt{2\pi})^{1/(\kern1.5pt j+1)} (\kern1.5pt j+1)^{1+1/2(\kern1.5pt j+1)} d^{ \kern1.5pt j^2/2}\nonumber\\& = C_{k-j} \sqrt{2k+2} d^{k+3/2-\sqrt{2k+2}},\end{align}
\begin{align}t_1 & = [(\kern1.5pt j+1)!]^{1/(\kern1.5pt j+1)} d^{\,f(\kern1.5pt j)/2}\nonumber\\& \sim \mathrm{e}^{-1}(\sqrt{2\pi})^{1/(\kern1.5pt j+1)} (\kern1.5pt j+1)^{1+1/2(\kern1.5pt j+1)} d^{ \kern1.5pt j^2/2}\nonumber\\& = C_{k-j} \sqrt{2k+2} d^{k+3/2-\sqrt{2k+2}},\end{align}
on inserting the values from (50), and where
 $ C_{k-j}=\mathrm{e}^{-1}(1+O(1/j))$
. Note that
$ C_{k-j}=\mathrm{e}^{-1}(1+O(1/j))$
. Note that
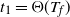 $t_1=\Theta( T_f)$
. From (46),
$t_1=\Theta( T_f)$
. From (46),
 \[\frac{\mu_{k-(\kern1.5pt j+1)}(t)}{\mu_{k-j}(t)}=\frac{t}{(\kern1.5pt j+2)d^{k-j}}\]
\[\frac{\mu_{k-(\kern1.5pt j+1)}(t)}{\mu_{k-j}(t)}=\frac{t}{(\kern1.5pt j+2)d^{k-j}}\]
so that at
 $t_1$
, for some
$t_1$
, for some
 $C,C'=\Theta(1)$
,
$C,C'=\Theta(1)$
,
 \begin{align}\mu_{k-j^*}(t_1)= 1, \quad \mu_{k-(\kern1.5pt j^*-1)}(t_1)=Cd^{1/2}, \quad \mu_{k-(\kern1.5pt j^*+1)}(t_1)=C'd^{1/2}.\end{align}
\begin{align}\mu_{k-j^*}(t_1)= 1, \quad \mu_{k-(\kern1.5pt j^*-1)}(t_1)=Cd^{1/2}, \quad \mu_{k-(\kern1.5pt j^*+1)}(t_1)=C'd^{1/2}.\end{align}
At first this seems confusing, as one might expect to have
 $ \mu_{k-(\kern1.5pt j^*+1)}(t_1)=o(1)$
by analogy with the equal layers model. Assuming
$ \mu_{k-(\kern1.5pt j^*+1)}(t_1)=o(1)$
by analogy with the equal layers model. Assuming
 $d^{1/2} \rightarrow \infty$
, level
$d^{1/2} \rightarrow \infty$
, level
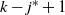 $k-j^*+1$
is the last level at which the condition
$k-j^*+1$
is the last level at which the condition
 $\mu_{k-j+1} \rightarrow \infty$
is valid in the recurrence from
$\mu_{k-j+1} \rightarrow \infty$
is valid in the recurrence from
 $k-j+1$
to
$k-j+1$
to
 $k-j$
given in (4). Indeed
$k-j$
given in (4). Indeed
 $j^*-1=\sqrt{2k+2}-2$
is the last value of j for which we claim Proposition 1 holds.
$j^*-1=\sqrt{2k+2}-2$
is the last value of j for which we claim Proposition 1 holds.
Finally, we need to check
 $t_1(k-j+1) \ll t_1(k-j)$
for all
$t_1(k-j+1) \ll t_1(k-j)$
for all
 $j\le j^*-1$
as required in Lemma 1(2). Using (44)
$j\le j^*-1$
as required in Lemma 1(2). Using (44)
 \begin{align}\frac{t_1(k-j)}{t_1(k-j+1)} & = \frac{[(\kern1.5pt j+1)!]^{1/(\kern1.5pt j+1)}}{[j!]^{1/j}}d^{\left( \frac{2kj-j(\kern1.5pt j-1)}{2(\kern1.5pt j+1)}-\frac{2k(\kern1.5pt j-1)-(\kern1.5pt j-1)(\kern1.5pt j-2)}{2j} \right)}\nonumber\\& = \Theta(1)d^{\frac{2k-(\kern1.5pt j-1)(\kern1.5pt j+2)}{2j(\kern1.5pt j+1)}}\nonumber\\& \ge \Theta(1) d^{\frac{3\sqrt{2k+2}-2}{2(2k-3\sqrt{2k+2}+4)}}=\Theta(d^{ 3/\sqrt{8 k}}).\end{align}
\begin{align}\frac{t_1(k-j)}{t_1(k-j+1)} & = \frac{[(\kern1.5pt j+1)!]^{1/(\kern1.5pt j+1)}}{[j!]^{1/j}}d^{\left( \frac{2kj-j(\kern1.5pt j-1)}{2(\kern1.5pt j+1)}-\frac{2k(\kern1.5pt j-1)-(\kern1.5pt j-1)(\kern1.5pt j-2)}{2j} \right)}\nonumber\\& = \Theta(1)d^{\frac{2k-(\kern1.5pt j-1)(\kern1.5pt j+2)}{2j(\kern1.5pt j+1)}}\nonumber\\& \ge \Theta(1) d^{\frac{3\sqrt{2k+2}-2}{2(2k-3\sqrt{2k+2}+4)}}=\Theta(d^{ 3/\sqrt{8 k}}).\end{align}
The last line is evaluated at
 $j = j^*-1=\sqrt{2k+2}-2$
, and this is the largest value of j for which Proposition 1 is claimed to hold. By Theorem 1(2),
$j = j^*-1=\sqrt{2k+2}-2$
, and this is the largest value of j for which Proposition 1 is claimed to hold. By Theorem 1(2),
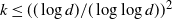 $k\le ((\log d)/( \log \log d))^2$
so the right-hand side of (53) is
$k\le ((\log d)/( \log \log d))^2$
so the right-hand side of (53) is
 $\Theta((\log d)^{3/\sqrt{8}})$
which tends to infinity with d, thus validating the of concentration condition of Lemma 1(2) for
$\Theta((\log d)^{3/\sqrt{8}})$
which tends to infinity with d, thus validating the of concentration condition of Lemma 1(2) for
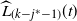 $\widehat L_{(k-j^*-1)}(t)$
.
$\widehat L_{(k-j^*-1)}(t)$
.
4.2. Gap property of
$\widehat {\boldsymbol{L}}$
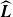
Let
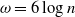 $\omega= 6 \log n$
as before. From the definition of
$\omega= 6 \log n$
as before. From the definition of
 $t_1=t_1(k-j^*)$
, at
$t_1=t_1(k-j^*)$
, at
 $t_1/\omega$
, we have
$t_1/\omega$
, we have
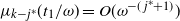 $\mu_{k-j^*}(t_1/\omega)=O(\omega^{-(\kern1.5pt j^*+1)})$
, where
$\mu_{k-j^*}(t_1/\omega)=O(\omega^{-(\kern1.5pt j^*+1)})$
, where
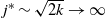 $j^* \sim \sqrt{2k} \rightarrow \infty$
. Thus, w.h.p.
$j^* \sim \sqrt{2k} \rightarrow \infty$
. Thus, w.h.p.
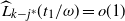 $\widehat L_{k-j^*}(t_1/\omega)=o(1)$
in the upper process. Consequently all levels
$\widehat L_{k-j^*}(t_1/\omega)=o(1)$
in the upper process. Consequently all levels
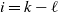 $i=k-\ell$
,
$i=k-\ell$
,
 $\ell \ge j^*$
, have
$\ell \ge j^*$
, have
 $\widehat{L_i}(t)=0$
, w.h.p., for
$\widehat{L_i}(t)=0$
, w.h.p., for
 $t \le t_1/\omega$
.
$t \le t_1/\omega$
.
In what follows we only consider gaps between indices
 $k-\ell$
where
$k-\ell$
where
 $0 \le \ell \le k-j^*+1$
.
$0 \le \ell \le k-j^*+1$
.
By (50) we have
 $k-j^*+1=k+2-\sqrt{2k+2}$
. We see from (52) that
$k-j^*+1=k+2-\sqrt{2k+2}$
. We see from (52) that
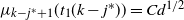 $\mu_{k-j^*+1}(t_1(k-j^*))=Cd^{1/2}$
. As
$\mu_{k-j^*+1}(t_1(k-j^*))=Cd^{1/2}$
. As
 $d \rightarrow \infty$
, then
$d \rightarrow \infty$
, then
 $\widehat L_{k-j^*+1}$
will be concentrated around
$\widehat L_{k-j^*+1}$
will be concentrated around
 $\mu_{k-j^*+1}(t_1)$
, although we cannot expect it to be as strong as in Lemma 3. Fortunately this will not matter as
$\mu_{k-j^*+1}(t_1)$
, although we cannot expect it to be as strong as in Lemma 3. Fortunately this will not matter as
 $k-j^*$
is the last level to which we apply a gap argument. For
$k-j^*$
is the last level to which we apply a gap argument. For
 $\ell \le j^*-1$
at
$\ell \le j^*-1$
at
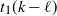 $t_1(k-\ell)$
, the value of
$t_1(k-\ell)$
, the value of
 $\widehat L_{k-\ell+1}$
obeys Lemma 3. In particular, it can be checked that
$\widehat L_{k-\ell+1}$
obeys Lemma 3. In particular, it can be checked that
 $t_1(k-j^*+1)=\Theta(1) \sqrt k d^{k+5/2-(3/2)\sqrt{2k+2}}$
. Using (46), we obtain
$t_1(k-j^*+1)=\Theta(1) \sqrt k d^{k+5/2-(3/2)\sqrt{2k+2}}$
. Using (46), we obtain
 $\mu_{k-j^*+2}(t_1(k-j^*+1)) =\Theta(d^{(\sqrt{2k+2}+1)/2})$
, establishing a gap property between
$\mu_{k-j^*+2}(t_1(k-j^*+1)) =\Theta(d^{(\sqrt{2k+2}+1)/2})$
, establishing a gap property between
 $\widehat L_{k-j^*+1}$
and
$\widehat L_{k-j^*+1}$
and
 $\widehat L_{k-j^*+2}$
; the situation being better for smaller
$\widehat L_{k-j^*+2}$
; the situation being better for smaller
 $\ell$
.
$\ell$
.
4.3. Lower bound on L
Turning to the lower bound
 $\widetilde L$
as given in (19) and (20), we need to prove that (33) holds. This requires that
$\widetilde L$
as given in (19) and (20), we need to prove that (33) holds. This requires that
 $\sum_{j=0}^iL^*_j(t)/N_j=o(1)$
for
$\sum_{j=0}^iL^*_j(t)/N_j=o(1)$
for
 $1 \le i \le k-1$
and
$1 \le i \le k-1$
and
 $t \le t_f$
. We only consider this sum up to the time (in order of magnitude) when level
$t \le t_f$
. We only consider this sum up to the time (in order of magnitude) when level
 $k-j^*$
first becomes occupied, and thus levels
$k-j^*$
first becomes occupied, and thus levels
 $0 \le i \le k-j^*-1$
are empty.
$0 \le i \le k-j^*-1$
are empty.
The main task is to choose a value of
 $\beta$
for the growing layers model analogous to (25) which we can use with the arguments given in Section 3.2 for the equal layers model. There is not so much room for manoeuvre here if we do not want to restrict the value of d. Let
$\beta$
for the growing layers model analogous to (25) which we can use with the arguments given in Section 3.2 for the equal layers model. There is not so much room for manoeuvre here if we do not want to restrict the value of d. Let
 $\varpi$
to be a function tending to infinity more slowly than
$\varpi$
to be a function tending to infinity more slowly than
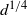 $d^{1/4}$
, and assume
$d^{1/4}$
, and assume
 $t_f \le \varpi T_f$
; a value which satisfies Proposition 2. We choose
$t_f \le \varpi T_f$
; a value which satisfies Proposition 2. We choose
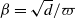 $\beta=\sqrt d/\varpi$
. As we assume
$\beta=\sqrt d/\varpi$
. As we assume
 $d \rightarrow \infty$
, then also
$d \rightarrow \infty$
, then also
 $\beta \rightarrow \infty$
.
$\beta \rightarrow \infty$
.
For
 $1 \le \ell \le j^*-1$
, we use (41), (43), and
$1 \le \ell \le j^*-1$
, we use (41), (43), and
 $N_{k-\ell}=d^{k-\ell}$
. As
$N_{k-\ell}=d^{k-\ell}$
. As
 $d^\ell/(\ell+1)$
is monotone increasing, the worst case is
$d^\ell/(\ell+1)$
is monotone increasing, the worst case is
 $\ell=j^*-1$
, so, assuming
$\ell=j^*-1$
, so, assuming
 $t_f\le \varpi T_f$
$t_f\le \varpi T_f$
 \begin{align}\frac{\mu_{k-\ell}}{N_{k-\ell}} & = \frac{t}{(\ell+1)d^{k-\ell}}\frac{\mu_{k-\ell+1}}{N_{k-\ell+1}} \\[-12pt] \nonumber \end{align}
\begin{align}\frac{\mu_{k-\ell}}{N_{k-\ell}} & = \frac{t}{(\ell+1)d^{k-\ell}}\frac{\mu_{k-\ell+1}}{N_{k-\ell+1}} \\[-12pt] \nonumber \end{align}
 \begin{align}& \le \frac{\mu_{k-\ell+1}}{N_{k-\ell+1}} \frac{\varpi \sqrt{k}}{ \sqrt{2k+2}-1} \frac{d^{k+3/2-\sqrt{2k+2}}}{d^{k+2-\sqrt{2k+2}}} \nonumber\\& \le \frac{\varpi }{\sqrt{d}} \frac{\mu_{k-\ell+1}}{N_{k-\ell+1}} = \frac 1{\beta}\frac{\mu_{k-\ell+1}}{N_{k-\ell+1}}\le \left(\frac{1}{\beta}\right)^\ell \frac{t}{N_k}=o(1), \\[9pt] \nonumber \end{align}
\begin{align}& \le \frac{\mu_{k-\ell+1}}{N_{k-\ell+1}} \frac{\varpi \sqrt{k}}{ \sqrt{2k+2}-1} \frac{d^{k+3/2-\sqrt{2k+2}}}{d^{k+2-\sqrt{2k+2}}} \nonumber\\& \le \frac{\varpi }{\sqrt{d}} \frac{\mu_{k-\ell+1}}{N_{k-\ell+1}} = \frac 1{\beta}\frac{\mu_{k-\ell+1}}{N_{k-\ell+1}}\le \left(\frac{1}{\beta}\right)^\ell \frac{t}{N_k}=o(1), \\[9pt] \nonumber \end{align}
as
 $\varpi T_f/d^k=o(1)$
and
$\varpi T_f/d^k=o(1)$
and
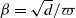 $\beta= \sqrt{d}/\varpi$
. Equation (34) becomes
$\beta= \sqrt{d}/\varpi$
. Equation (34) becomes
 \begin{align*}\sum_{\ell=j^*+1}^i \frac{L^*_{k-\ell}}{N_{k-\ell}} & \le \frac{O(\omega^3)}{N_{k-j^*}}+2 \sum_{\ell=j^*+1}^i\left(\frac{1}{\beta}\right)^\ell \frac{t}{N_k}= \frac{O(\omega^3)}{N_{k-j^*}}+O \left(\frac{t}{\beta^i N_k}\right)\\& \le \left(\frac{\log^3 n}{n^{1-o(1)}}\right) + \left(\frac{ \varpi T_f}{ d^k}\right)\\& \le O\left(\frac{ \varpi \sqrt k}{d^{\sqrt{2k +2}-3/2}}\right)=O\left(\frac{\sqrt k}{d^{\sqrt{2k +2}-2}}\right)=o(1).\end{align*}
\begin{align*}\sum_{\ell=j^*+1}^i \frac{L^*_{k-\ell}}{N_{k-\ell}} & \le \frac{O(\omega^3)}{N_{k-j^*}}+2 \sum_{\ell=j^*+1}^i\left(\frac{1}{\beta}\right)^\ell \frac{t}{N_k}= \frac{O(\omega^3)}{N_{k-j^*}}+O \left(\frac{t}{\beta^i N_k}\right)\\& \le \left(\frac{\log^3 n}{n^{1-o(1)}}\right) + \left(\frac{ \varpi T_f}{ d^k}\right)\\& \le O\left(\frac{ \varpi \sqrt k}{d^{\sqrt{2k +2}-3/2}}\right)=O\left(\frac{\sqrt k}{d^{\sqrt{2k +2}-2}}\right)=o(1).\end{align*}
The
 $\omega^3$
term comes from using Lemma 3 to bound the size of
$\omega^3$
term comes from using Lemma 3 to bound the size of
 $L^*_{k-\ell}(t)$
for
$L^*_{k-\ell}(t)$
for
 $t\le t_{k-\ell}(\omega)$
. The last line follows on assuming
$t\le t_{k-\ell}(\omega)$
. The last line follows on assuming
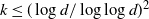 $k\le (\log d/\log \log d)^2$
.
$k\le (\log d/\log \log d)^2$
.
It now follows from the proof in Section 3.2 that if
 $k-j^*+1 \le i \le k$
and
$k-j^*+1 \le i \le k$
and
 $t \ge t_i(\omega)$
then
$t \ge t_i(\omega)$
then
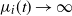 $\mu_i(t) \rightarrow \infty$
suitably fast. We hence obtain that
$\mu_i(t) \rightarrow \infty$
suitably fast. We hence obtain that
 $\mathrm{E}\, \widetilde L_i(t) \sim \mu_i(t) \sim \mathrm{E}\, \widehat{L_i}(t)$
, and so we have
$\mathrm{E}\, \widetilde L_i(t) \sim \mu_i(t) \sim \mathrm{E}\, \widehat{L_i}(t)$
, and so we have
 $L_{k-\ell}(t) \sim \widehat L_{k-\ell}(t)\sim \mu_{k-\ell}(t)$
.
$L_{k-\ell}(t) \sim \widehat L_{k-\ell}(t)\sim \mu_{k-\ell}(t)$
.
4.4. The finish time in the growing layers model
We now turn to the proof of (41). We first give a bound ignoring rounding errors on the value of
 $j^*$
, and subsequently give a correction. We show that, w.h.p., a path (of occupied vertices) grows back to the source from the first vertex to be occupied in level
$j^*$
, and subsequently give a correction. We show that, w.h.p., a path (of occupied vertices) grows back to the source from the first vertex to be occupied in level
 $k-j^*$
, thus halting the process; and, moreover, this occurs before a second vertex becomes occupied in level
$k-j^*$
, thus halting the process; and, moreover, this occurs before a second vertex becomes occupied in level
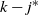 $k-j^*$
.
$k-j^*$
.
4.4.1. Proof ignoring rounding
Using (51) we know that
 $t_1(k-j^*)= C T_f$
for some constant C. Let
$t_1(k-j^*)= C T_f$
for some constant C. Let
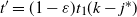 $t'=(1-\varepsilon)t_1(k-j^*)$
, then arguing as in Proposition 5, we have that at
$t'=(1-\varepsilon)t_1(k-j^*)$
, then arguing as in Proposition 5, we have that at
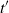 $t'$
, as by assumption
$t'$
, as by assumption
 $k \rightarrow \infty$
,
$k \rightarrow \infty$
,
 \[\mathrm{E}\, \widehat L_{k-j^*}(t') \le \mu_{k-j^*}(t') \sim (1-\varepsilon)^{k+1} \le \mathrm{e}^{-\varepsilon k}=o(1).\]
\[\mathrm{E}\, \widehat L_{k-j^*}(t') \le \mu_{k-j^*}(t') \sim (1-\varepsilon)^{k+1} \le \mathrm{e}^{-\varepsilon k}=o(1).\]
Thus, at
 $t'=C'T_f$
, w.h.p. level
$t'=C'T_f$
, w.h.p. level
 $k-j^*$
is unoccupied.
$k-j^*$
is unoccupied.
Let
 $t_0$
be the first step t for which
$t_0$
be the first step t for which
 $L_{k-j^*}(t) =1$
, where w.h.p.
$L_{k-j^*}(t) =1$
, where w.h.p.
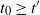 $t_0 \ge t'$
. Then either
$t_0 \ge t'$
. Then either
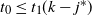 $t_0 \le t_1(k-j^*)$
, or if not we upper bound
$t_0 \le t_1(k-j^*)$
, or if not we upper bound
 $t_0$
as follows. Consider the probability
$t_0$
as follows. Consider the probability
 $\phi$
that a particle halts at level
$\phi$
that a particle halts at level
 $k-j^*$
. This is given by
$k-j^*$
. This is given by
 \[\phi=\frac{L_{k-(\kern1.5pt j^*-1)}(t_1)}{N_{k-(\kern1.5pt j^*-1)}} \sim\frac{C d^{1/2}}{d^{k-j^*+1}}=\frac{C}{d^{k+3/2-\sqrt{2k+2}}}.\]
\[\phi=\frac{L_{k-(\kern1.5pt j^*-1)}(t_1)}{N_{k-(\kern1.5pt j^*-1)}} \sim\frac{C d^{1/2}}{d^{k-j^*+1}}=\frac{C}{d^{k+3/2-\sqrt{2k+2}}}.\]
Then the probability no particle halts there in a further
 $t_1(k-j^*)=O(T_f)$
steps is (see (51))
$t_1(k-j^*)=O(T_f)$
steps is (see (51))
 \[(1-\phi)^{t_1} \le \mathrm{e}^{-t_1\phi}= \mathrm{e}^{-C'\sqrt{2k+2}}=o(1),\]
\[(1-\phi)^{t_1} \le \mathrm{e}^{-t_1\phi}= \mathrm{e}^{-C'\sqrt{2k+2}}=o(1),\]
where
 $C'\sim C/e$
and we assume
$C'\sim C/e$
and we assume
 $k \rightarrow \infty$
.
$k \rightarrow \infty$
.
Let u be the vertex in level
 $k-j^*$
containing the unique particle halted at
$k-j^*$
containing the unique particle halted at
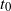 $t_0$
. Construct a path back from u to the source as follows. Wait until a particle halts at
$t_0$
. Construct a path back from u to the source as follows. Wait until a particle halts at
 $w_{k-j^*-1}$
in level
$w_{k-j^*-1}$
in level
 $k-j^*-1$
by choosing edge
$k-j^*-1$
by choosing edge
 $w_{k-j^*-1}u$
. The expected time for this is
$w_{k-j^*-1}u$
. The expected time for this is
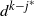 $d^{k-j^*}$
. In a further expected time
$d^{k-j^*}$
. In a further expected time
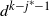 $d^{k-j^*-1}$
, the path will extend backwards, as a particle will halt in level
$d^{k-j^*-1}$
, the path will extend backwards, as a particle will halt in level
 $k-j^*-2$
by choosing an edge to
$k-j^*-2$
by choosing an edge to
 $w_{k-j^*-1}$
, etc. Thus, in a further
$w_{k-j^*-1}$
, etc. Thus, in a further
 \[T=d^{k-j^*}+ d^{k-j^*-1}+ \cdots +d= d^{k-j^*} \left(\frac{1-1/d^{k-j^*}}{1-1/d}\right)= \Theta(d^{k-j^*})=\Theta \big(d^{k+1-\sqrt{2k+2}}\big)\]
\[T=d^{k-j^*}+ d^{k-j^*-1}+ \cdots +d= d^{k-j^*} \left(\frac{1-1/d^{k-j^*}}{1-1/d}\right)= \Theta(d^{k-j^*})=\Theta \big(d^{k+1-\sqrt{2k+2}}\big)\]
expected steps there will be a path
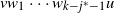 $vw_1\cdots w_{k-j^*-1}u$
of halted particles extending from the source v to vertex u, thus stopping the DLA process (if it has not already halted).
$vw_1\cdots w_{k-j^*-1}u$
of halted particles extending from the source v to vertex u, thus stopping the DLA process (if it has not already halted).
The value of T given above is
 $O(T_f/\sqrt{kd})$
, and we conclude from the Markov inequality that the source will be occupied in at most
$O(T_f/\sqrt{kd})$
, and we conclude from the Markov inequality that the source will be occupied in at most
 $t_0+(kd)^{1/4}T= C'' T_f$
steps, with probability
$t_0+(kd)^{1/4}T= C'' T_f$
steps, with probability
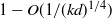 $1-O(1/(kd)^{1/4})$
. This completes the proof that
$1-O(1/(kd)^{1/4})$
. This completes the proof that
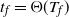 $t_f=\Theta(T_f)$
w.h.p.
$t_f=\Theta(T_f)$
w.h.p.
We next give the proof of Proposition 2(2). The expected number of steps (after
 $t_0$
) needed to create another halted particle in level
$t_0$
) needed to create another halted particle in level
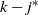 $k-j^*$
is
$k-j^*$
is
 \[\frac 1\phi= \Theta \big(d^{k+3/2-\sqrt{2k+2}}\big)= \Theta \big(T d^{1/2} \big),\]
\[\frac 1\phi= \Theta \big(d^{k+3/2-\sqrt{2k+2}}\big)= \Theta \big(T d^{1/2} \big),\]
whereas, w.h.p., on the assumption that
 $d \rightarrow \infty$
, it is in at most
$d \rightarrow \infty$
, it is in at most
 $(kd)^{1/4}T$
further steps after
$(kd)^{1/4}T$
further steps after
 $t_0$
the process has halted as claimed. This occurs before a second vertex can become occupied in level
$t_0$
the process has halted as claimed. This occurs before a second vertex can become occupied in level
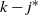 $k-j^*$
.
$k-j^*$
.
4.4.2. The effect of rounding error on
$T_f$
in the growing layers model
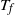
Recall that
 $j^*$
is the solution to
$j^*$
is the solution to
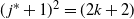 $(\kern1.5pt j^*+1)^2=(2k+2)$
as given in (49). Integer solutions exist for some values of k. To see this, let a be a positive integer, and put
$(\kern1.5pt j^*+1)^2=(2k+2)$
as given in (49). Integer solutions exist for some values of k. To see this, let a be a positive integer, and put
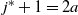 $j^*+1=2a$
so that
$j^*+1=2a$
so that
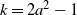 $k=2a^2-1$
; this holds for example for
$k=2a^2-1$
; this holds for example for
 $k=1,5,17,31$
.
$k=1,5,17,31$
.
In the case that
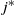 $j^*$
is not an integer, we require the value of j given by
$j^*$
is not an integer, we require the value of j given by
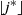 $\lfloor j^* \rfloor$
or
$\lfloor j^* \rfloor$
or
 $ \lceil j^* \rceil$
which maximizes
$ \lceil j^* \rceil$
which maximizes
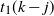 $t_1(k-j)$
. Expand f(j) in (48) about
$t_1(k-j)$
. Expand f(j) in (48) about
 $j^*$
, giving
$j^*$
, giving
 \begin{align*}f(\kern1.5pt j^*+h) &= f(\kern1.5pt j^*)+h f'(\kern1.5pt j^*)+\frac{h^2}{2} f''(\kern1.5pt j^*+\theta h)\\& = (\kern1.5pt j^*)^2 +0 -h^2 \frac{2k+2}{(\kern1.5pt j^*+1+ \theta h)^3}\\& = (\kern1.5pt j^*)^2 -\frac{h^2}{\sqrt{2k+2}}\left( 1+O\left(\frac{h}{(\kern1.5pt j^*)^3}\right) \right).\end{align*}
\begin{align*}f(\kern1.5pt j^*+h) &= f(\kern1.5pt j^*)+h f'(\kern1.5pt j^*)+\frac{h^2}{2} f''(\kern1.5pt j^*+\theta h)\\& = (\kern1.5pt j^*)^2 +0 -h^2 \frac{2k+2}{(\kern1.5pt j^*+1+ \theta h)^3}\\& = (\kern1.5pt j^*)^2 -\frac{h^2}{\sqrt{2k+2}}\left( 1+O\left(\frac{h}{(\kern1.5pt j^*)^3}\right) \right).\end{align*}
Let
 $\varepsilon=\min \left( j^*-\lfloor j^* \rfloor, \lceil j^* \rceil-j^* \right)$
, then by the above
$\varepsilon=\min \left( j^*-\lfloor j^* \rfloor, \lceil j^* \rceil-j^* \right)$
, then by the above
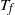 $T_f$
is altered to
$T_f$
is altered to
 $T_f(\varepsilon)=T_fd^{-\varepsilon^2/\sqrt{2k+2}(1+o(1))}$
, other arguments about
$T_f(\varepsilon)=T_fd^{-\varepsilon^2/\sqrt{2k+2}(1+o(1))}$
, other arguments about
 $t_f$
being unchanged.
$t_f$
being unchanged.
4.5. Theorem 2: existence of a unique connecting path at
$t_f$

Finally, we prove that the directed tree rooted at level k containing the connecting path from source to sink, consists uniquely of that path. The proof is similar to Lemma 6 for the equal layers model. At
 $t=t_f$
, w.h.p. there is a unique path from level
$t=t_f$
, w.h.p. there is a unique path from level
 $k-j^*$
to level zero, so that level
$k-j^*$
to level zero, so that level
 $k-j^*+1$
plays the role of level one. By analogy with Section 3.4 and (40), etc., and with
$k-j^*+1$
plays the role of level one. By analogy with Section 3.4 and (40), etc., and with
 $\omega=6 \log n$
,
$\omega=6 \log n$
,
 \[\mathrm{P}( u_{k-j^*+1} \in R_{k-j^*+1}(t)) = \frac{Z_{k-j^*+1}(t)}{L_{k-j^*+1}(t)} \le \frac{\omega}{\mu_{k-j^*+1}(t)} \le O\left(\frac{\omega^2}{d^{1/2}}\right),\]
\[\mathrm{P}( u_{k-j^*+1} \in R_{k-j^*+1}(t)) = \frac{Z_{k-j^*+1}(t)}{L_{k-j^*+1}(t)} \le \frac{\omega}{\mu_{k-j^*+1}(t)} \le O\left(\frac{\omega^2}{d^{1/2}}\right),\]
where we used an earlier result from (52) that
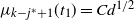 $\mu_{k-j^*+1}(t_1)=Cd^{1/2}$
.
$\mu_{k-j^*+1}(t_1)=Cd^{1/2}$
.
Thus, as
 $t_f \le \varpi t_1(\kern1.5pt j^*)$
, where
$t_f \le \varpi t_1(\kern1.5pt j^*)$
, where
 $\varpi=o(d^{1/4})$
,
$\varpi=o(d^{1/4})$
,
 $j^*=\sqrt{2k+2}-1$
, and
$j^*=\sqrt{2k+2}-1$
, and
 $t_1(k-j^*)$
is given by (51), then
$t_1(k-j^*)$
is given by (51), then
 \begin{align*}\mathrm{P}( (v,u_k)\text{-path is blue}) & \ge 1-O\bigg( \frac{\omega \varpi}{d^{1/2}}+\sum_{j=1}^{ \kern1.5pt j^*-2} \frac{\varpi t_f}{d^{k-j}} \bigg)\\& = 1-O\left(\frac{\omega \varpi }{d^{1/2}}\right)-O\left(\frac{\varpi \sqrt k}{d^{3/2}}\right) = 1-o(1),\end{align*}
\begin{align*}\mathrm{P}( (v,u_k)\text{-path is blue}) & \ge 1-O\bigg( \frac{\omega \varpi}{d^{1/2}}+\sum_{j=1}^{ \kern1.5pt j^*-2} \frac{\varpi t_f}{d^{k-j}} \bigg)\\& = 1-O\left(\frac{\omega \varpi }{d^{1/2}}\right)-O\left(\frac{\varpi \sqrt k}{d^{3/2}}\right) = 1-o(1),\end{align*}
as
 $k \le (\log d/ \log \log d)^2$
.
$k \le (\log d/ \log \log d)^2$
.
5. Analysis of DLA on Cayley trees
Things are easier from now on for several reasons. The values of the parameters needed in the analysis of DLA on trees have been derived in the previous section. Furthermore, the DLA process corresponds in some sense to a percolation on the corresponding infinite tree which is halted at a fixed level. Finally, for brevity, we omit any structural results about the connecting path.
5.1. Trees with large branching factor: proof of Theorem 3(1)
Let
 $G=G(k,d)$
be a labelled tree with branching factor d and final level k, where
$G=G(k,d)$
be a labelled tree with branching factor d and final level k, where
 $d^k=n$
. The source of the particles is the unique vertex v at level zero. An artificial sink vertex z placed at level
$d^k=n$
. The source of the particles is the unique vertex v at level zero. An artificial sink vertex z placed at level
 $k+1$
is attached to the vertices at the final level k.
$k+1$
is attached to the vertices at the final level k.
We borrow several ideas from the growing layers model. Let
 $j^*=\sqrt{2k+2}-1$
as in (50), and as in (41), let
$j^*=\sqrt{2k+2}-1$
as in (50), and as in (41), let
 $T_f$
be given by
$T_f$
be given by
 \begin{align}T_f= \sqrt{k} d^{k+3/2-\sqrt{2k+2}}.\end{align}
\begin{align}T_f= \sqrt{k} d^{k+3/2-\sqrt{2k+2}}.\end{align}
We first ignore rounding on
 $j^*$
and prove w.h.p. that
$j^*$
and prove w.h.p. that
 $t_f=\Theta(T_f)$
. Correcting for rounding then gives Theorem 3(1).
$t_f=\Theta(T_f)$
. Correcting for rounding then gives Theorem 3(1).
By symmetry, the expected number of particle walks arriving at a given vertex in level
 $k-j^*$
by step
$k-j^*$
by step
 $T_f$
, is
$T_f$
, is
 $T_f/d^{(k-j^*)}=\sqrt{kd}$
. However, the expected number arriving at a vertex w at level
$T_f/d^{(k-j^*)}=\sqrt{kd}$
. However, the expected number arriving at a vertex w at level
 $k-j^*+1$
is
$k-j^*+1$
is
 \begin{align}\frac{T_f}{d^{k-j^*+1}}= \sqrt{\frac{k}{d}}=o(1),\end{align}
\begin{align}\frac{T_f}{d^{k-j^*+1}}= \sqrt{\frac{k}{d}}=o(1),\end{align}
provided
 $k \ll d$
, which we assume to be true. In order for w to be occupied, the subtree rooted at w must contain a path from w to level k on which all
$k \ll d$
, which we assume to be true. In order for w to be occupied, the subtree rooted at w must contain a path from w to level k on which all
 $j^*$
vertices are occupied. By the Markov inequality, the event that
$j^*$
vertices are occupied. By the Markov inequality, the event that
 $j^*=\Theta(\sqrt k)$
particles arrive at w by step
$j^*=\Theta(\sqrt k)$
particles arrive at w by step
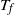 $T_ f$
, has probability
$T_ f$
, has probability
 $O(1/\sqrt d)$
. Thus, there should be few vertices in level
$O(1/\sqrt d)$
. Thus, there should be few vertices in level
 $k-j^*+1$
with such a path to level k containing
$k-j^*+1$
with such a path to level k containing
 $j^*$
halted particles.
$j^*$
halted particles.
Consider t particles percolating downwards from the root of the infinite d-ary tree
 $G(d,\infty)$
. Particle s starts at step s and each particle transitions one edge at each step, so that they never collide.
$G(d,\infty)$
. Particle s starts at step s and each particle transitions one edge at each step, so that they never collide.
We approximate the distribution of the number of particles arriving at a vertex w of layer
 $k-j$
in t steps, where eventually we assume
$k-j$
in t steps, where eventually we assume
 $j \le j^*-1$
. Let
$j \le j^*-1$
. Let
 $X_w=X_w(k-j,\ell,t)$
be the indicator for the event that exactly
$X_w=X_w(k-j,\ell,t)$
be the indicator for the event that exactly
 $\ell$
particles arrive at vertex w of layer
$\ell$
particles arrive at vertex w of layer
 $k-j$
at or before step t, then
$k-j$
at or before step t, then
 \begin{align}\mathrm{E}\, X_w(k-j,\ell,t)= \left(\begin{array}{l}t \\ \ell\end{array}\right) \left(\frac{1}{d^{k-j}}\right)^\ell \left( 1-\frac{1}{d^{k-j}} \right)^{t-\ell}.\end{align}
\begin{align}\mathrm{E}\, X_w(k-j,\ell,t)= \left(\begin{array}{l}t \\ \ell\end{array}\right) \left(\frac{1}{d^{k-j}}\right)^\ell \left( 1-\frac{1}{d^{k-j}} \right)^{t-\ell}.\end{align}
Let
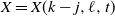 $X=X(k-j,\ell,t)$
where
$X=X(k-j,\ell,t)$
where
 $X=\sum_{w \in S_{k-j}}X_w$
is the number of vertices at level
$X=\sum_{w \in S_{k-j}}X_w$
is the number of vertices at level
 ${k-j}$
which have exactly
${k-j}$
which have exactly
 $\ell$
particles reaching them. Thus
$\ell$
particles reaching them. Thus
 $\mathrm{E}\, X= d^{k-j} \mathrm{E}\, X_w$
, and
$\mathrm{E}\, X= d^{k-j} \mathrm{E}\, X_w$
, and
 \begin{align*}\mathrm{E}\, X(X-1) & = \big(d^{k-j}\big) \big(d^{k-j}-1 \big) \left(\begin{array}{l}t \\ 2\ell\end{array}\right) { \left(\begin{array}{l}2\ell \\ \ell\end{array}\right)} \left(\frac{1}{d^{k-j}}\right)^\ell\left(\frac{1}{d^{k-j}-1}\right)^\ell \left( 1-\frac{2}{d^{k-j}} \right)^{t-2\ell}\\& = \left( 1+O\left(\frac{\ell}{d^{k-j}}\right)- O\left(\frac{t}{d^{2(k-j)}}\right) -O\left(\frac{\ell^2}{t}\right) \right) (\mathrm{E}\, X)^2,\end{align*}
\begin{align*}\mathrm{E}\, X(X-1) & = \big(d^{k-j}\big) \big(d^{k-j}-1 \big) \left(\begin{array}{l}t \\ 2\ell\end{array}\right) { \left(\begin{array}{l}2\ell \\ \ell\end{array}\right)} \left(\frac{1}{d^{k-j}}\right)^\ell\left(\frac{1}{d^{k-j}-1}\right)^\ell \left( 1-\frac{2}{d^{k-j}} \right)^{t-2\ell}\\& = \left( 1+O\left(\frac{\ell}{d^{k-j}}\right)- O\left(\frac{t}{d^{2(k-j)}}\right) -O\left(\frac{\ell^2}{t}\right) \right) (\mathrm{E}\, X)^2,\end{align*}
and so
 \[\mathrm{Var}\, X=\mathrm{E}\, X+ O\left(\frac{\ell}{d^{k-j}}\right) (\mathrm{E}\, X)^2.\]
\[\mathrm{Var}\, X=\mathrm{E}\, X+ O\left(\frac{\ell}{d^{k-j}}\right) (\mathrm{E}\, X)^2.\]
Next let
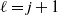 $\ell=j+1$
so that
$\ell=j+1$
so that
 $X(k-j,\ell,t)=X(k-j,j+1,t)$
. As
$X(k-j,\ell,t)=X(k-j,j+1,t)$
. As
 $\mathrm{E}\, X= d^{k-j} \mathrm{E}\, X_w$
, using (58),
$\mathrm{E}\, X= d^{k-j} \mathrm{E}\, X_w$
, using (58),
 \[\mathrm{E}\, X = \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!} \left(\frac{1}{d^{k-j}}\right)^{ \kern1.5pt j}\left( 1-O\left(\frac{j^2}{t}\right) \right)\left( 1-O\left(\frac{t-j}{d^{k-j}}\right) \right).\]
\[\mathrm{E}\, X = \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!} \left(\frac{1}{d^{k-j}}\right)^{ \kern1.5pt j}\left( 1-O\left(\frac{j^2}{t}\right) \right)\left( 1-O\left(\frac{t-j}{d^{k-j}}\right) \right).\]
In what follows we choose
 $j=j^*-1$
and
$j=j^*-1$
and
 $k^2 \le t \le CT_f$
where
$k^2 \le t \le CT_f$
where
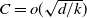 $C=o(\sqrt{d/k})$
so that, by (57),
$C=o(\sqrt{d/k})$
so that, by (57),
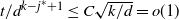 $t/d^{k-j^*+1}\le C\sqrt{k/d}=o(1)$
. In addition,
$t/d^{k-j^*+1}\le C\sqrt{k/d}=o(1)$
. In addition,
 $(\kern1.5pt j^*)^2/t=O(1/k)=o(1)$
.
$(\kern1.5pt j^*)^2/t=O(1/k)=o(1)$
.
With these choices, it will be the case that
 \begin{align}\mathrm{E}\, X \sim \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!} \left(\frac{1}{d^{k-j}}\right)^{ \kern1.5pt j}.\end{align}
\begin{align}\mathrm{E}\, X \sim \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!} \left(\frac{1}{d^{k-j}}\right)^{ \kern1.5pt j}.\end{align}
Furthermore, again by (57)
 \[\frac j{d^{k-j}}\mathrm{E}\, X \sim \frac 1{j!} \left(\frac{t}{d^{k-j}}\right)^{\kern1.5pt j+1}=o(1),\]
\[\frac j{d^{k-j}}\mathrm{E}\, X \sim \frac 1{j!} \left(\frac{t}{d^{k-j}}\right)^{\kern1.5pt j+1}=o(1),\]
so that
 \begin{align}\mathrm{Var}\, X=\mathrm{E}\, X+ O\left(\frac{j}{d^{k-j}}\right) (\mathrm{E}\, X)^2=(1+o(1))\mathrm{E}\, X.\end{align}
\begin{align}\mathrm{Var}\, X=\mathrm{E}\, X+ O\left(\frac{j}{d^{k-j}}\right) (\mathrm{E}\, X)^2=(1+o(1))\mathrm{E}\, X.\end{align}
This being the case, by the Chebychev inequality we have that w.h.p.
 $X\sim \mathrm{E}\, X$
.
$X\sim \mathrm{E}\, X$
.
Continuing our discussion in the infinite d-ary tree
 $G(d,\infty)$
, let w be a vertex in level
$G(d,\infty)$
, let w be a vertex in level
 $k-j$
of
$k-j$
of
 $G(d,\infty)$
. Let u be a vertex at level k contained in the subtree
$G(d,\infty)$
. Let u be a vertex at level k contained in the subtree
 $R_w$
rooted at w, and let H(w, u) be the unique path
$R_w$
rooted at w, and let H(w, u) be the unique path
 $w=w_0w_1\cdots w_j=u$
from w in level
$w=w_0w_1\cdots w_j=u$
from w in level
 $k-j$
to u in level k. Let
$k-j$
to u in level k. Let
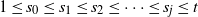 $1 \le s_0\le s_1 \le s_2 \le \cdots \le s_j \le t$
be the labels of particles which have arrived at w at these steps. Assume that on entering the subtree
$1 \le s_0\le s_1 \le s_2 \le \cdots \le s_j \le t$
be the labels of particles which have arrived at w at these steps. Assume that on entering the subtree
 $R_w$
, the particles behave as follows. Particles
$R_w$
, the particles behave as follows. Particles
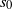 $s_0$
and
$s_0$
and
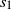 $s_1$
transition all edges of H, particle
$s_1$
transition all edges of H, particle
 $s_2$
transitions (at least) edges
$s_2$
transitions (at least) edges
 $w_0w_1\cdots w_{j-1}$
; in general,
$w_0w_1\cdots w_{j-1}$
; in general,
 $s_{i}$
transitions (at least)
$s_{i}$
transitions (at least)
 $w_0w_1\cdots w_{j-i+1}$
, and
$w_0w_1\cdots w_{j-i+1}$
, and
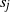 $s_{j}$
transitions
$s_{j}$
transitions
 $w_0w_1$
. The probability of this is
$w_0w_1$
. The probability of this is
 \begin{align}P(s_0,s_1,\ldots,s_j)= \frac 1{d^j} \frac 1{dd^2\cdots d^j}.\end{align}
\begin{align}P(s_0,s_1,\ldots,s_j)= \frac 1{d^j} \frac 1{dd^2\cdots d^j}.\end{align}
As there are
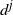 $d^j$
vertices at level k which belong to the subtree
$d^j$
vertices at level k which belong to the subtree
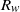 $R_w$
rooted at w, then provided exactly
$R_w$
rooted at w, then provided exactly
 $j+1$
particles have arrived at w, the probability
$j+1$
particles have arrived at w, the probability
 $P_w(\kern1.5pt j+1)$
that such a transition ordering exists is
$P_w(\kern1.5pt j+1)$
that such a transition ordering exists is
 \[P_w(\kern1.5pt j+1)= \frac 1{dd^2\cdots d^j}=\frac{1}{d^{ \kern1.5pt j(\kern1.5pt j+1)/2}}.\]
\[P_w(\kern1.5pt j+1)= \frac 1{dd^2\cdots d^j}=\frac{1}{d^{ \kern1.5pt j(\kern1.5pt j+1)/2}}.\]
For distinct vertices w,
 $w'$
in level
$w'$
in level
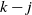 $k-j$
which contribute to X (i.e. exactly
$k-j$
which contribute to X (i.e. exactly
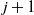 $j+1$
particles enter the given vertex in the given time period), the subsequent ordered transition events which occur in the subtrees
$j+1$
particles enter the given vertex in the given time period), the subsequent ordered transition events which occur in the subtrees
 $R_w$
and
$R_w$
and
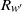 $R_{w'}$
are independent. Let
$R_{w'}$
are independent. Let
 $Z(k-j,j+1,t)$
be the number of vertices in level
$Z(k-j,j+1,t)$
be the number of vertices in level
 $k-j$
of
$k-j$
of
 $G(d,\infty)$
for which exactly
$G(d,\infty)$
for which exactly
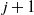 $j+1$
particles enter the vertex and which satisfy the ordering. Then
$j+1$
particles enter the vertex and which satisfy the ordering. Then
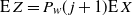 $\mathrm{E}\, Z= P_w(\kern1.5pt j+1) \mathrm{E}\, X$
and
$\mathrm{E}\, Z= P_w(\kern1.5pt j+1) \mathrm{E}\, X$
and
 \begin{align}\mathrm{E}\, Z(k-j,j+1,t)\sim \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!} \left(\frac{1}{d^{k-j}}\right)^{ \kern1.5pt j}\frac{1}{d^{ \kern1.5pt j(\kern1.5pt j+1)/2}}=\frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!} \frac{1}{d^{kj-j(\kern1.5pt j-1)/2}}= \mu_{k-j}(t),\end{align}
\begin{align}\mathrm{E}\, Z(k-j,j+1,t)\sim \frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!} \left(\frac{1}{d^{k-j}}\right)^{ \kern1.5pt j}\frac{1}{d^{ \kern1.5pt j(\kern1.5pt j+1)/2}}=\frac{t^{ \kern1.5pt j+1}}{(\kern1.5pt j+1)!} \frac{1}{d^{kj-j(\kern1.5pt j-1)/2}}= \mu_{k-j}(t),\end{align}
where
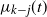 $ \mu_{k-j}(t)$
is given by (43). We choose
$ \mu_{k-j}(t)$
is given by (43). We choose
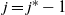 $j=j^*-1$
in
$j=j^*-1$
in
 $P_w(\kern1.5pt j+1)$
, and use the values of
$P_w(\kern1.5pt j+1)$
, and use the values of
 $\mathrm{E}\, X$
and
$\mathrm{E}\, X$
and
 $\textbf{Var} X$
derived via (59) and (60). As remarked previously, with these values, w.h.p.
$\textbf{Var} X$
derived via (59) and (60). As remarked previously, with these values, w.h.p.
 $X \sim \mathrm{E}\, X$
. Thus, as long as
$X \sim \mathrm{E}\, X$
. Thus, as long as
 $ \mu_{k-j}(t)$
is sufficiently large, w.h.p.
$ \mu_{k-j}(t)$
is sufficiently large, w.h.p.
 $Z \sim \mu_{k-j}(t)$
.
$Z \sim \mu_{k-j}(t)$
.
Return now to the finite Cayley tree G(k, d). For some vertex in level
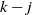 $k-j$
to be occupied at step t there must be some sequence
$k-j$
to be occupied at step t there must be some sequence
 $(s_0,s_1,\ldots,s_j)$
, which satisfies the ordered transition construction given above for
$(s_0,s_1,\ldots,s_j)$
, which satisfies the ordered transition construction given above for
 $G(d,\infty)$
. Indeed, on contact with the sink z, particle
$G(d,\infty)$
. Indeed, on contact with the sink z, particle
 $s_0$
will halt in level k, causing
$s_0$
will halt in level k, causing
 $s_1$
to halt in level
$s_1$
to halt in level
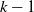 $k-1$
and so on, until
$k-1$
and so on, until
 $s_j$
halts in level
$s_j$
halts in level
 $k-j$
.
$k-j$
.
Say a path of occupied vertices from vertex w to level k is an exact path, if it is the unique occupied path in the subtree
 $R_w$
rooted at w. Thus, the paths from level
$R_w$
rooted at w. Thus, the paths from level
 $k-j$
to level k counted by Z are exact in G(d, k). Informally, as t tends to
$k-j$
to level k counted by Z are exact in G(d, k). Informally, as t tends to
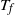 $ T_f$
, w.h.p. there will be many exact paths at level
$ T_f$
, w.h.p. there will be many exact paths at level
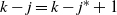 $k-j=k-j^*+1$
waiting to extend backwards towards the source.
$k-j=k-j^*+1$
waiting to extend backwards towards the source.
5.1.1. Lower bound on
$t_f$

The above calculations are used to establish an upper bound on the finish time. For a lower bound, a similar but cruder approach can be used. The total number of
 $j+1$
tuples which percolate a given vertex in level
$j+1$
tuples which percolate a given vertex in level
 $k-j$
and form an ordered transition event in
$k-j$
and form an ordered transition event in
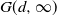 $G(d,\infty)$
is
$G(d,\infty)$
is
 \begin{align}d^{k-j} \left(\begin{array}{l}t \\ j+1\end{array}\right) \left(\frac{1}{d^{k-j}}\right)^{\kern1.5pt j+1} \frac 1{d^{ \kern1.5pt j(\kern1.5pt j+1)/2}} \sim \mu_{k-j}(t).\end{align}
\begin{align}d^{k-j} \left(\begin{array}{l}t \\ j+1\end{array}\right) \left(\frac{1}{d^{k-j}}\right)^{\kern1.5pt j+1} \frac 1{d^{ \kern1.5pt j(\kern1.5pt j+1)/2}} \sim \mu_{k-j}(t).\end{align}
Here
 $\mu_{k-j}(t)$
is as defined in (43); this latter calculation being made without any regard for exactness.
$\mu_{k-j}(t)$
is as defined in (43); this latter calculation being made without any regard for exactness.
Let
 $j=j^*$
and
$j=j^*$
and
 $t'=(1-\varepsilon)t_1(k-j^*)$
where
$t'=(1-\varepsilon)t_1(k-j^*)$
where
 $\varepsilon$
is a small positive constant. Using (63), and as by definition
$\varepsilon$
is a small positive constant. Using (63), and as by definition
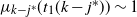 $\mu_{k-j^*}(t_1(k-j^*))\sim 1$
, at
$\mu_{k-j^*}(t_1(k-j^*))\sim 1$
, at
 $t'$
the expected number of paths between level
$t'$
the expected number of paths between level
 $k-j^*$
and level k consisting of halted particles is upper bounded by
$k-j^*$
and level k consisting of halted particles is upper bounded by
 \begin{align} \mu_{k-j^*}(t')={(1-\varepsilon)^{ \kern1.5pt j^*+1}}\mu_{k-j^*}(t_1(k-j^*))\le \mathrm{e}^{-\varepsilon j^*}=o(1).\end{align}
\begin{align} \mu_{k-j^*}(t')={(1-\varepsilon)^{ \kern1.5pt j^*+1}}\mu_{k-j^*}(t_1(k-j^*))\le \mathrm{e}^{-\varepsilon j^*}=o(1).\end{align}
We conclude that at
 $t'$
no such path exists w.h.p. and levels
$t'$
no such path exists w.h.p. and levels
 $0,1,\ldots,k-j^*$
are empty. By (51),
$0,1,\ldots,k-j^*$
are empty. By (51),
 $t_1(k-j^*) =C T_f$
, for some constant
$t_1(k-j^*) =C T_f$
, for some constant
 $C>0$
, so w.h.p. the finish time
$C>0$
, so w.h.p. the finish time
 $t_f \ge t' \ge C' T_f$
, for some constant C’.
$t_f \ge t' \ge C' T_f$
, for some constant C’.
Note. This calculation is valid for any
 $d \ge 2$
, and will be reused in the next section for the case where d is finite.
$d \ge 2$
, and will be reused in the next section for the case where d is finite.
5.1.2. Upper bound on
$t_f$

Let
 $t_1=t_1(k-j^*)$
. Using (52),
$t_1=t_1(k-j^*)$
. Using (52),
 $\mu_{k-j^*+1}(t_1)=C_1 \sqrt d$
, for some positive constant
$\mu_{k-j^*+1}(t_1)=C_1 \sqrt d$
, for some positive constant
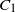 $C_1$
. Thus, w.h.p.,
$C_1$
. Thus, w.h.p.,
 $Z(k-j^*+1, j^*,t')=\Theta(\sqrt d)$
which is large, provided
$Z(k-j^*+1, j^*,t')=\Theta(\sqrt d)$
which is large, provided
 $d\rightarrow \infty$
.
$d\rightarrow \infty$
.
A path of occupied vertices back from the sink to level i, is a leading path at level i if all vertices at level
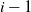 $i-1$
are unoccupied. If we increase t above
$i-1$
are unoccupied. If we increase t above
 $t_1$
, then either some leading path is already at level
$t_1$
, then either some leading path is already at level
 $i\le k-j^*$
, or level
$i\le k-j^*$
, or level
 $k-j^*$
is still unoccupied. If the latter, how long does it take in
$k-j^*$
is still unoccupied. If the latter, how long does it take in
 $G(d,\infty)$
for a particle to hit a vertex with an exact path in level
$G(d,\infty)$
for a particle to hit a vertex with an exact path in level
 $k-j^*+1$
as counted by
$k-j^*+1$
as counted by
 $Z(k-j^*+1, j^*,t_1)$
? The hitting probability of such vertices at a given step is
$Z(k-j^*+1, j^*,t_1)$
? The hitting probability of such vertices at a given step is
 $p_h=Z(t_1)/d^{k-j^*+1}$
, so
$p_h=Z(t_1)/d^{k-j^*+1}$
, so
 \begin{align}\mathrm{E}\, T(\text{wait})=\frac 1p_h \sim \frac{d^{k-j^*+1}}{\mathrm{E}\, Z(t_1)} =\Theta\left(\frac{T_f}{\sqrt k}\right)= o(T_f),\end{align}
\begin{align}\mathrm{E}\, T(\text{wait})=\frac 1p_h \sim \frac{d^{k-j^*+1}}{\mathrm{E}\, Z(t_1)} =\Theta\left(\frac{T_f}{\sqrt k}\right)= o(T_f),\end{align}
assuming
 $k \rightarrow \infty$
. Thus, the probability we wait a further
$k \rightarrow \infty$
. Thus, the probability we wait a further
 $T_f$
steps is o(1). Once a leading path is at
$T_f$
steps is o(1). Once a leading path is at
 $i \le k-j^*$
the same waiting time argument as used in Section 4.4 applies, the expected waiting times reducing at each step. In conclusion, w.h.p. the source vertex is now occupied in
$i \le k-j^*$
the same waiting time argument as used in Section 4.4 applies, the expected waiting times reducing at each step. In conclusion, w.h.p. the source vertex is now occupied in
 $\Theta(T_f)$
steps after
$\Theta(T_f)$
steps after
 $t_1$
, completing the proof of Theorem 3(1).
$t_1$
, completing the proof of Theorem 3(1).
Note. We found
 $t_f$
on the assumption that
$t_f$
on the assumption that
 $j^*$
is an integer. In the case that it is not an integer, we use the rounding correction of (at most)
$j^*$
is an integer. In the case that it is not an integer, we use the rounding correction of (at most)
 $d^{O(1/\sqrt k)}$
derived previously for the growing layers model. The value of
$d^{O(1/\sqrt k)}$
derived previously for the growing layers model. The value of
 $t_f \le CT_f$
used above with
$t_f \le CT_f$
used above with
 $C=o(\sqrt{d/k})$
is large enough to absorb any rounding errors.
$C=o(\sqrt{d/k})$
is large enough to absorb any rounding errors.
5.2. Trees with constant or slowly growing branching factor: proof of Theorem 3(2)
In the previous section we assumed that
 $k \ll d$
. In this section the assumption
$k \ll d$
. In this section the assumption
 $k \ll d$
may no longer hold. For example, when
$k \ll d$
may no longer hold. For example, when
 $d=2$
,
$d=2$
,
 $k=\log n/\log 2$
.
$k=\log n/\log 2$
.
We always assume
 $k \rightarrow \infty$
with n, even if arbitrarily slowly, which places an upper limit on d. However, if
$k \rightarrow \infty$
with n, even if arbitrarily slowly, which places an upper limit on d. However, if
 $k \ge \log^2 d$
, for example, then the rounding error is
$k \ge \log^2 d$
, for example, then the rounding error is
 $d^{1/\sqrt k}= \Theta (1)$
, so for d constant or growing suitably slowly (say
$d^{1/\sqrt k}= \Theta (1)$
, so for d constant or growing suitably slowly (say
 $d \le k^2$
) we can ignore rounding.
$d \le k^2$
) we can ignore rounding.
Proposition 3. For
 $d \ge 2$
, let
$d \ge 2$
, let
 $G=G(k,d)$
be the Cayley tree with branching factor d and height k, where
$G=G(k,d)$
be the Cayley tree with branching factor d and height k, where
 $d^k=n$
. Let
$d^k=n$
. Let
 $T_f$
be given by
$T_f$
be given by
 \[T_f= \sqrt{k} d^{k+3/2-\sqrt{2k+2}}.\]
\[T_f= \sqrt{k} d^{k+3/2-\sqrt{2k+2}}.\]
Let
 $t_f$
be the finish time of DLA on G. Then w.h.p.
$t_f$
be the finish time of DLA on G. Then w.h.p.
 $T_f/C \le t_f \le C T_f$
for some constant
$T_f/C \le t_f \le C T_f$
for some constant
 $C\ge 1$
.
$C\ge 1$
.
Proof. The lower bound on the finish time
 $t_f$
follows directly from the lower bound proof in the previous section, Section 5.1. The upper bound in the previous section used a result from (52) that when
$t_f$
follows directly from the lower bound proof in the previous section, Section 5.1. The upper bound in the previous section used a result from (52) that when
 $\mu_{k-j^*}(t_1)\sim 1$
, then
$\mu_{k-j^*}(t_1)\sim 1$
, then
 $ \mu_{k-j^*+1}(t_1)=Cd^{1/2}$
; this latter value being large when d is. However, then d is constant
$ \mu_{k-j^*+1}(t_1)=Cd^{1/2}$
; this latter value being large when d is. However, then d is constant
 $\mu_{k-j^*}(t) $
and
$\mu_{k-j^*}(t) $
and
 $\mu_{k-j^*+1}(t)$
are of the same order, so we need to compare two levels whose distance apart, h, is larger than one. Thus, for the upper bound, let
$\mu_{k-j^*+1}(t)$
are of the same order, so we need to compare two levels whose distance apart, h, is larger than one. Thus, for the upper bound, let
 $j=j^*-h$
where
$j=j^*-h$
where
 $h= \lceil 1/2+\log_d k \rceil$
. When
$h= \lceil 1/2+\log_d k \rceil$
. When
 $k\ll d$
as in Section 5.1, then
$k\ll d$
as in Section 5.1, then
 $h=1$
, which led to the argument based on the occupancy of levels
$h=1$
, which led to the argument based on the occupancy of levels
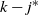 $k-j^*$
and
$k-j^*$
and
 $k-j^*+1$
. The largest value of k satisfying
$k-j^*+1$
. The largest value of k satisfying
 $h=1$
is when
$h=1$
is when
 $k=d^{1/2}$
; in which case as
$k=d^{1/2}$
; in which case as
 $d^k=n$
we have
$d^k=n$
we have
 $d \rightarrow \infty$
and, thus,
$d \rightarrow \infty$
and, thus,
 $k \ll d$
, the case of the previous section. We assume henceforth that
$k \ll d$
, the case of the previous section. We assume henceforth that
 $h\ge 2$
.
$h\ge 2$
.
The value of
 $\mu_{k-j*}$
given by (46), satisfies
$\mu_{k-j*}$
given by (46), satisfies
 $\mu_{k-j+1}(t)=[(\kern1.5pt j+1)d^{k-j+1}/t] \cdot \mu_{k-j}(t)$
. Iterate this, and evaluate at
$\mu_{k-j+1}(t)=[(\kern1.5pt j+1)d^{k-j+1}/t] \cdot \mu_{k-j}(t)$
. Iterate this, and evaluate at
 $t=t_1(k-j^*)=(1+O(1/j))\mathrm{e}^{-1}\sqrt{2k+2}\,d^{k-j^*+1/2}$
from (51). As
$t=t_1(k-j^*)=(1+O(1/j))\mathrm{e}^{-1}\sqrt{2k+2}\,d^{k-j^*+1/2}$
from (51). As
 $j^*+1=\sqrt{2k+2}$
, then on the assumption that
$j^*+1=\sqrt{2k+2}$
, then on the assumption that
 $h^2 \ll j^*$
,
$h^2 \ll j^*$
,
 \begin{align}\frac{\mu_{k-j^*+h}(t)}{\mu_{k-j^*}(t)}= \frac{(\kern1.5pt j^*+1)\cdots(\kern1.5pt j^*+h)}{t^h}d^{k-j^*+1}\cdots d^{k-j^*+h}=\Theta(1) \mathrm{e}^{h}d^{h^2/2}.\end{align}
\begin{align}\frac{\mu_{k-j^*+h}(t)}{\mu_{k-j^*}(t)}= \frac{(\kern1.5pt j^*+1)\cdots(\kern1.5pt j^*+h)}{t^h}d^{k-j^*+1}\cdots d^{k-j^*+h}=\Theta(1) \mathrm{e}^{h}d^{h^2/2}.\end{align}
This ratio is
 $\omega(1)$
, as either (i)
$\omega(1)$
, as either (i)
 $d \rightarrow \infty$
or (ii) d is constant and as
$d \rightarrow \infty$
or (ii) d is constant and as
 $h= \lceil 1/2+\log_d k \rceil$
and
$h= \lceil 1/2+\log_d k \rceil$
and
 $d^k=n$
then
$d^k=n$
then
 $k=\log_d n$
, this implies that
$k=\log_d n$
, this implies that
 $h=\omega(1)$
.
$h=\omega(1)$
.
In either case, the calculations for X, Z leading to (62) in the previous section hold for the cases given here, with
 $j^*-h$
now replacing
$j^*-h$
now replacing
 $j^*-1$
. At
$j^*-1$
. At
 $t_1=t_1(k-j^*)$
, where
$t_1=t_1(k-j^*)$
, where
 $t_1=\Theta(T_f)$
then
$t_1=\Theta(T_f)$
then
 $\mu_{k-j^*+h}(t_1)=\Theta(\mathrm{e}^hd^{h^2/2})\rightarrow \infty$
, by the comments below (66). Thus, w.h.p.
$\mu_{k-j^*+h}(t_1)=\Theta(\mathrm{e}^hd^{h^2/2})\rightarrow \infty$
, by the comments below (66). Thus, w.h.p.
 $Z(k-j^*+h,j^*, t_1)=(1-o(1))\mu_{k-j^*+h}(t_1)$
, and there are
$Z(k-j^*+h,j^*, t_1)=(1-o(1))\mu_{k-j^*+h}(t_1)$
, and there are
 $Z(t_1)=\Theta(\mathrm{e}^hd^{h^2/2})$
exact paths from level
$Z(t_1)=\Theta(\mathrm{e}^hd^{h^2/2})$
exact paths from level
 $k-j^*+h$
to level k.
$k-j^*+h$
to level k.
Choose a step
 $t' \ge T_f >t_1$
. Then either some leading path of halted particles already extends to a level i where
$t' \ge T_f >t_1$
. Then either some leading path of halted particles already extends to a level i where
 $i<k-j^*+h$
, or all vertices in these levels are still unoccupied. In the latter case, as in (65), in expectation, it takes at most
$i<k-j^*+h$
, or all vertices in these levels are still unoccupied. In the latter case, as in (65), in expectation, it takes at most
 \[\mathrm{E}\, T(\text{wait})=\tau=\frac{d^{k-j^*+h}}{Z(t_1)}=\Theta(1) \frac{d^{k-j^*+h}}{\mathrm{e}^hd^{h^2/2}}\]
\[\mathrm{E}\, T(\text{wait})=\tau=\frac{d^{k-j^*+h}}{Z(t_1)}=\Theta(1) \frac{d^{k-j^*+h}}{\mathrm{e}^hd^{h^2/2}}\]
further steps for one of these paths to extend back to the source.
The proof in the previous section depended on the ratio
 $T_f/d^{k-j^*+1}=o(1)$
(see (57)). Recall that
$T_f/d^{k-j^*+1}=o(1)$
(see (57)). Recall that
 $j^*=\sqrt{2k+2}-1$
, and the generic level
$j^*=\sqrt{2k+2}-1$
, and the generic level
 $k-j$
in the proof between (58) and (62) is now
$k-j$
in the proof between (58) and (62) is now
 $k-j^*+h$
, so that
$k-j^*+h$
, so that
 \begin{align}\rho_h= \frac{T_f}{d^{k-j^*+h}}=\frac{\sqrt k d^{k+3/2-\sqrt{2k+2}}}{d^{k-j^*+h}}= \frac{\sqrt{kd}}{d^{h}}. \end{align}
\begin{align}\rho_h= \frac{T_f}{d^{k-j^*+h}}=\frac{\sqrt k d^{k+3/2-\sqrt{2k+2}}}{d^{k-j^*+h}}= \frac{\sqrt{kd}}{d^{h}}. \end{align}
The final step is now to prove that
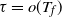 $\tau=o(T_f)$
. From the expression for
$\tau=o(T_f)$
. From the expression for
 $\rho_h$
in (67), we have that
$\rho_h$
in (67), we have that
 \[d^{k-j^*+h}= \frac{d^h}{\sqrt{kd}} T_f,\]
\[d^{k-j^*+h}= \frac{d^h}{\sqrt{kd}} T_f,\]
and as we assumed
 $h \ge 2$
,
$h \ge 2$
,
 \[\tau= \Theta(1) \frac{d^{k-j^*+h}}{\mathrm{e}^hd^{h^2/2}}= \Theta(1)\left(\frac{d}{e d^{h/2}}\right)^h \frac {1}{\sqrt {kd}} T_f \le \Theta(1) \frac 1{\sqrt {kd}} T_f=o(T_f),\]
\[\tau= \Theta(1) \frac{d^{k-j^*+h}}{\mathrm{e}^hd^{h^2/2}}= \Theta(1)\left(\frac{d}{e d^{h/2}}\right)^h \frac {1}{\sqrt {kd}} T_f \le \Theta(1) \frac 1{\sqrt {kd}} T_f=o(T_f),\]
as required.
Acknowledgements
We thank the editors and anonymous reviewers for their substantial help, useful suggestions and feedback which significantly improved this paper from its original submission.
Funding information
Research by C. Cooper was supported at the University of Hamburg by a Mercator fellowship from DFG Project 491453517. Research by A. Frieze was supported in part by NSF Grant DMS1952285
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.

 Open access
Open access