


1. Introduction
Large language models (LLMs) are reshaping natural language processing through their advanced capabilities and enhanced performance. Generic LLMs are trained on large-scale internet data and may perform poorly in tasks requiring domain-specific knowledge, such as text classification or summarisation (Brown et al. Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal, Neelakantan, Shyam, Sastry, Askell, Agarwal, Herbert-Voss, Krueger, Henighan, Child, Ramesh, Ziegler, Wu, Winter, Hesse, Chen, Sigler, Litwin, Gray, Chess, Clark, Berner, McCandlish, Radford, Sutskever and Amodei2020). As a result, there is increasing research on adapting generic LLMs to domain-specific tasks (Ziegler et al. Reference Ziegler, Stiennon, Wu, Brown, Radford, Amodei, Christiano and Irving2019; Hu et al. Reference Hu, Liu, Zhao, Hou, Nie and Li2023). This paper aims to design and evaluate LLMs for the socially relevant task of suicide prediction. Suicide accounts for more than 700,000 lives lost across the world every year. It is the second leading cause of death for adolescents and adults 15 to 29 years of age in many countries. A crucial aspect of suicide prevention is the early identification of at-risk individuals (World-Health-Organization, 2021).
A (fictitious) example of a conversation between a help-seeker and counsellor.

Our approach uses LLMs to detect and assess the severity of suicide risk in anonymous text-based interactions between help-seekers and professional counsellors (see the fictitious example of such an interaction in Figure 1). Our dataset is collected from an online counselling service operating in a low-resource language (Hebrew). Detecting suicide risk in this specific context presents several challenges. These posts differ significantly in structure, length, and context from online conversations between counsellors and help-seekers. Prior research on counselling conversations often overlooks conversation structure or restricts analysis to short exchanges (Cao et al. Reference Cao, Zhang, Feng, Wei, Wang, Li and He2019; Bialer et al. Reference Bialer, Izmaylov, Segal, Tsur, Levi-Belz and Gal2022). Moreover, assessing imminent suicide risk is challenging, even for experienced psychologists, due to its complexity. This complexity is further compounded by data scarcity, as imminent suicide risk is present in less than 2% of conversations in our dataset. Additionally, the NLP resources available for low-resource languages remain significantly limited compared to those for English.
To address this gap, this paper presents SR-BERT, a hierarchical model that includes a base layer for encoding conversation text and an additional layer for capturing aspects of conversation structure. The hierarchical structure of SR-BERT encodes each of the messages in the conversation separately and is not limited by the size of the conversation. We hypothesised that incorporating knowledge from suicide risk theory during the pre-training phase could enhance the detection model’s downstream performance. To this end, we develop a new domain knowledge-based pre-training step that embeds a suicide risk factor lexicon (SRF) into SR-BERT. The SRF lexicon was developed by a team of psychologists specialising in suicide risk theory and prevention.
We built on SR-BERT to develop a two-stage model for predicting varying levels of suicide risk severity. This approach not only identifies suicide risk in conversations but also quantifies its severity. Additionally, we applied data augmentation techniques guided by psychological theory to improve model performance.
In empirical studies, we evaluated the capability of different LLMs to predict suicide risk across various dimensions, including global and immediate risk, early detection, and different age groups. We also evaluated the sensitivity of several of these models for several conditions, including role transition and gender. The results generally show that SR-BERT significantly outperforms different classifiers from the literature for suicide risk (SR) detection. Integrating domain-expert information into SR-BERT significantly contributes to its performance.
The contributions of this work are twofold. First in providing a hierarchical model for suicide risk detection in online discussions that combines the structure of the conversation with psychological theory. We show that this approach significantly improves performance in detecting suicide risk from chat conversations compared to the state of the art (Bialer et al. (Reference Bialer, Izmaylov, Segal, Tsur, Levi-Belz and Gal2022)). Second, we expand the set of NLP tools available for resource-constrained languages and are making our code and the SRF lexicon accessible to the broader research community.
This paper expands on a previous conference version (Izmaylov et al. Reference Izmaylov, Segal, Gal, Grimland and Levi-Belz2023) in two ways. First, it introduces a new model for predicting highly urgent suicide risk, a more challenging problem due to class imbalance and data sparsity. To address this, we propose a two-stage classification model that significantly improves the predictive model’s overall performance and enables more precise risk assessment. Second, we provide a sensitivity analysis of our approach, examining its robustness to alterations in conversation structure, role transitions, the emergence of suicide ideation terms, and the help-seeker’s declared gender.
2. Related work
Our work relates to past studies in using LLMs to represent domain knowledge and conversation structure in deep language models. We expand on each of these topics in turn. For a review on using machine learning in suicide prevention, we refer the reader to Ji et al. (Reference Ji, Pan, Li, Cambria, Long and Huang2021). Most LLM-based suicide risk studies focus on social media posts (Coppersmith et al. Reference Coppersmith, Leary, Crutchley and Fine2018; Shing et al. Reference Shing, Nair, Zirikly, Friedenberg, Daumé and Resnik2018; Sawhney et al. Reference Sawhney, Manchanda, Mathur, Shah and Singh2018; Zirikly et al. Reference Zirikly, Resnik, Uzuner and Hollingshead2019; Tadesse et al. Reference Tadesse, Lin, Xu and Yang2019; Ophir et al. Reference Ophir, Tikochinski, Asterhan, Sisso and Reichart2020).
Wang et al. (Reference Wang, Yang, Ma, Wang, Yu, Zong, Huang, Ma, Hu, Hwang and Liu2021) combined a generic BERT model with predefined rules for scoring suicide risk in social media. Our work differs by focusing on online counselling conversations, which are longer, structured, and reflect psychological dynamics. We show that modelling these aspects is essential for detecting suicide risk in this context.
Few studies address suicide detection in online counselling and none model the session’s conversation structure. The most relevant prior work is by Bialer et al. (Reference Bialer, Izmaylov, Segal, Tsur, Levi-Belz and Gal2022), who combined a BERT-based model (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2018) with a manually curated lexicon of suicide-related terms. This model could only represent a portion of the conversation (512 tokens) and did not account for the counsellor’s input. The SR-BERT model extends this approach to reasoning about the entire conversation, making use of the counsellor’s input as well as aspects of the conversation structure, such as speaker roles. As we show in the paper, the SR-BERT model significantly outperforms that of Bialer et al. (Reference Bialer, Izmaylov, Segal, Tsur, Levi-Belz and Gal2022) on the same dataset, both for entire conversations and when considering early detection on parts of the conversation.
We mention two SR detection approaches in counselling that did not address early detection. Xu et al. (Reference Xu, Xu, Cheung, Cheng, Lung, Law, Chiang, Zhang and Yip2021) combined a word2vec representation of suicide concepts with a bidirectional LSTM network for SR prediction in Korean online counselling services. Each side of the conversation was represented by an independent BI-LSTM. This approach used a knowledge graph to represent a psychological lexicon, which may require more construction time from human experts. Our approach outperforms a baseline model using a similar representation (doc2vec) on our dataset. Bantilan et al. (Reference Bantilan, Malgaroli, Ray and Hull2021) used TF-IDF embedding with XGBoost to predict SR in transcribed phone calls from an English counselling service; this model did not use a lexicon.
There is strong evidence on the benefits of integrating domain knowledge in language models for downstream tasks (Childs and Washburn Reference Childs and Washburn2019; Cao et al. Reference Cao, Zhang, Feng, Wei, Wang, Li and He2019; Gaur et al. Reference Gaur, Amanuel, Joy, Ugur, Krishnaprasad, Ramakanth, Amit, Randy and Jyotishman2019; Lee et al. Reference Lee, Park, Kang, Choi and Han2020; Colon-Hernandez et al. Reference Colon-Hernandez, Havasi, Alonso, Huggins and Breazeal2021). Notable examples include Gaur et al. (Reference Gaur, Amanuel, Joy, Ugur, Krishnaprasad, Ramakanth, Amit, Randy and Jyotishman2019) and Wang et al. (Reference Wang, Yang, Ma, Wang, Yu, Zong, Huang, Ma, Hu, Hwang and Liu2021), who showed that using lexicon-based features can improve machine learning prediction of suicide risk in Chinese blogs. They use lexicons to map terms from online discussions to clinically relevant categories. We extend these approaches by presenting a new method for integrating domain knowledge in the pre-training phase of deep learning models.
In general, NLP models and solutions for low-resource languages are markedly limited. In Hebrew, two pre-trained language models were published, HeBERT (Chriqui and Yahav Reference Chriqui and Yahav2021) and AlephBERT (Seker et al. Reference Seker, Bandel, Bareket, Brusilovsky, Greenfeld and Tsarfaty2022). We used AlephBERT, which is freely available and was trained on a larger dataset than HeBERT and was able to outperform HeBERT on a variety of natural language tasks. This is the first work to use a hierarchical transformer architecture to model conversation structures in a low-resource language.
In parallel to suicide risk detection, prior research has examined approaches for identifying positive and supportive language in online interactions. For example, Desmet and Hoste (Reference Desmet and Hoste2013) explored fine-grained emotion detection in suicide notes, including emotions such as hopefulness and thankfulness. Sharma et al. (Reference Sharma, Gupta, Singh and Chakravarthi2025) developed an ensemble model to classify hope speech across English and Dravidian languages, while Singh, Sharma, and Singh (Reference Singh, Sharma and Singh2025) introduced EmoGif, a multimodal system to detect emotional support expressed through animated GIFs. These studies demonstrate that combining risk assessment with the detection of positive affect and encouragement can provide a more comprehensive understanding of mental health discourse.
3. The Sahar domain
Sahar (Hebrew acronym for Online Mental Health SupportFootnote
a
), established in 2000, is Israel’s foremost online organisation for emotional support and suicide prevention. It offers anonymous, confidential, and free crisis support through an online chat service available in Hebrew and Arabic. The organisation handles more than
 $40,000$
chat sessions per year, and this number has significantly increased during the COVID-19 pandemic (Zalsman et al. Reference Zalsman, Levy, Sommerfeld, Segal, Assa, Ben-Dayan, Valevski and Mann2021). Due to high demand for the service, counsellors may need to conduct conversations with multiple help seekers in parallel. There is ample research documenting the challenges faced by counsellors in such settings to scale up their support due to increasing traffic (Kitchingman, Caputi, and AlanWoodward Reference Kitchingman, Caputi, Woodward, Wilson, Wilson and Soundy2018; Zabelski et al. Reference Zabelski, Kaniuka, A. Robertson and Cramer2023).
$40,000$
chat sessions per year, and this number has significantly increased during the COVID-19 pandemic (Zalsman et al. Reference Zalsman, Levy, Sommerfeld, Segal, Assa, Ben-Dayan, Valevski and Mann2021). Due to high demand for the service, counsellors may need to conduct conversations with multiple help seekers in parallel. There is ample research documenting the challenges faced by counsellors in such settings to scale up their support due to increasing traffic (Kitchingman, Caputi, and AlanWoodward Reference Kitchingman, Caputi, Woodward, Wilson, Wilson and Soundy2018; Zabelski et al. Reference Zabelski, Kaniuka, A. Robertson and Cramer2023).
Sahar counsellors are volunteers who receive ongoing guidance and supervision throughout the year from mental health professionals. Counsellors work in shifts, accompanied by trained therapists who monitor conversations and provide professional support as needed. During shifts, counsellors work in a high-stress environment, typically handling multiple chat sessions simultaneously while documenting a summary of each conversation and noting whether the help-seeker shows signs of global suicide risk (GSR). Global suicide risk indicates the presence of suicidal thoughts, without implying immediate or imminent danger. When counsellors determine a help-seeker has an imminent suicide risk (IMSR) – a likelihood of suicidal behaviour in the coming hours or days – they swiftly report the conversation to the authorities. Authorities promptly dispatch a patrol to intervene and prevent harm. Despite their rarity, these cases have a profoundly significant impact. Consequently, an additional tool for early detection and validation of volunteer assessments is necessary to enhance support and intervention.
The Sahar corpus, encompassing a vast collection of over
 $40,000$
chat sessions spanning a five-year period (2017–2022), serves as a valuable resource for our research. Each conversation within the corpus includes a sequential arrangement of messages exchanged between help-seekers and counsellors, chronologically organised. These conversations serve as the primary data for our analysis and development of the two-stage suicide risk classification model. Approximately
$40,000$
chat sessions spanning a five-year period (2017–2022), serves as a valuable resource for our research. Each conversation within the corpus includes a sequential arrangement of messages exchanged between help-seekers and counsellors, chronologically organised. These conversations serve as the primary data for our analysis and development of the two-stage suicide risk classification model. Approximately
 $17,000$
of the conversations are labelled by the counsellors.
$17,000$
of the conversations are labelled by the counsellors.
Table 1 presents general statistics about the dataset. Among the labelled sessions, non-SR conversations constitute the majority, comprising
 $81.34\%$
of the dataset. These conversations involve individuals seeking help without showing signs of suicide risk. GSR conversations account for
$81.34\%$
of the dataset. These conversations involve individuals seeking help without showing signs of suicide risk. GSR conversations account for
 $17.67\%$
of the labelled sessions, indicating the presence of general suicidal thoughts. IMSR conversations, constituting only 0.98% of the labelled sessions, represent the most critical cases where immediate intervention is required due to the immediate risk to the individual’s life.
$17.67\%$
of the labelled sessions, indicating the presence of general suicidal thoughts. IMSR conversations, constituting only 0.98% of the labelled sessions, represent the most critical cases where immediate intervention is required due to the immediate risk to the individual’s life.
General statistics for Sahar corpus

Table 1 Long description
The table presents statistics for the Sahar corpus, focusing on different conversation types: Non-SR, GSR, and IMSR. It includes data on the number of labeled sessions, messages, turn exchanges, and tokens. Non-SR conversations make up the majority with 81.34 percent of the sessions, having a mean of 51 messages and 26 turn exchanges. GSR conversations account for 17.67 percent, with a mean of 57 messages and 30 turn exchanges. IMSR conversations are the least common at 0.98 percent, with a mean of 67 messages and 36 turn exchanges. The table highlights the differences in communication patterns across these conversation types.
GSR conversations are slightly longer and involve more turn exchanges compared to non-SR conversations. This pattern suggests that individuals expressing general suicidal thoughts may require more extensive dialogue to convey their concerns. IMSR conversations, which reflect imminent suicide risk, show an even greater increase in conversation length and turn exchanges, underscoring the urgency and complexity of these cases. Additionally, the mean number of tokens per conversation rises progressively from non-SR to GSR and IMSR sessions, indicating more detailed and in-depth discussions as suicide risk increases.
To validate the labels, a sample of 500 conversations (200 non SR, 200 GSR, 100 IMSR) was independently labelled by clinical psychologists specialising in suicide. The Krippendorff’s
 $\alpha$
for inter-annotator agreement between the psychologists and the SR label in the conversation is 0.766, which is on par with other works. We note that the inconsistencies found in the samples were debated by the psychologists and resolved in the data set.
$\alpha$
for inter-annotator agreement between the psychologists and the SR label in the conversation is 0.766, which is on par with other works. We note that the inconsistencies found in the samples were debated by the psychologists and resolved in the data set.
4. The SRF psychological lexicon
As part of this research, a team of psychology experts from a national centre for suicide prevention in Israel has constructed a SRF lexicon in Hebrew that is informed by psychological theory. The SRF lexicon contains terms describing personal and situational factors linked to increased suicidal thoughts, based on validated self-report questionnaires from the psychological and psychiatric literature (Nock et al. Reference Nock, Borges, Bromet, Cha, Kessler and Lee2008; Klonsky and May Reference Klonsky and May2015; Turecki and Brent Reference Turecki and Brent2016).
Each of the 3,094 sentences in the lexicon was assigned to one of 25 categories. Specifically, terms relating to depression are taken from the Patient Health Questionnaire Depression Module (PHQ-9) (Kroenke, Spitzer, and Williams Reference Kroenke, Spitzer and Williams2001). Terms relating to a sense of burdensomeness are taken from the Interpersonal Needs Questionnaire (INQ) (Van Orden et al. Reference Van Orden, Cukrowicz, Witte and Joiner2012). Terms relating to a sense of hopelessness are taken from the Beck hopelessness scale (Beck, Steer, and Brown Reference Beck, Steer and Brown1996). And terms relating to suicide behaviour were taken from the Columbia questionnaire (Posner et al. Reference Posner, Brent, Lucas, Gould, Stanley, Brown, Fisher, Zelazny, Burke, Oquendo and Mann2008), which is a standard tool to measure suicide risk. Examples of sentences for the category “perceived burdensome-ness” (translated) included sentences such as “better without me”, “I am a burden”, and “I spoil everything for my spouse”; and the lexicon category “explicit suicide mentions” contains phrases such as “to die”, “to commit suicide”, “kill myself” etc.
Similarly, the IMSR lexicon included three layers. The first comprised language representations of key theory-driven factors identified in the suicide literature, specifically the interpersonal theory of suicide (Van Orden et al. Reference Van Orden, Witte, Cukrowicz, Braithwaite, Selby and Joiner2010) and the suicide crisis syndrome (SCS) (Schuck et al. Reference Schuck, Calati, Barzilay, Bloch‐Elkouby and Galynker2019). The second layer incorporated validated questionnaires that tap into constructs from key theories (e.g., the Suicide Crisis Inventory for SCS (Galynker et al. Reference Galynker, Yaseen, Cohen, Benhamou, Hawes and Briggs2017)). The third layer was developed by reviewing 600 randomly selected chat sessions labelled as suicide risk to identify additional language expressions reflecting these theoretical factors and further enrich the IMSR section of the SRF lexicon.
5. The SR-BERT language model
Our first contribution introduces SR-BERT, a specialised language model designed to identify suicide risk in online conversations. This model predicts suicide risk by combining GSR and IMSR into a single label. SR-BERT extends DialogBERT (Gu, Yoo, and Ha Reference Gu, Yoo and Ha2021) to better capture conversational structure and integrate psychological domain knowledge. The following subsections describe the model architecture and training methodology.
Model architecture. (a) SR-BERT base architecture, encoding conversation and speaker roles. (b) Pre-training procedure on 4 self-supervised tasks including psychological knowledge learning using the SRF lexicon. (c) Fine-tuning procedure learning to predict suicide risk (SR).

Figure 2 Long description
The diagram presents the architecture of SR-BERT, a model designed for suicide risk prediction. It consists of three main parts: (a) the base architecture, which encodes conversation and speaker roles using a context encoder transformer and message encoders; (b) the pre-training procedure, involving four self-supervised tasks including psychological knowledge learning with the SRF lexicon; and (c) the fine-tuning procedure, which focuses on learning to predict suicide risk. The base architecture includes role embedding, message vectors, and message encoders that process conversations. The pre-training phase uses tasks like next utterance generation, utterance order ranking, masked utterance regression, and SSK tasks, with a weighted sum loss for backpropagation. The fine-tuning phase involves a classification head with dense layers and softmax for suicide risk prediction.
5.1 SR-BERT architecture
The SR-BERT architecture is illustrated in Figure 2(a). It consists of two main components: a transformer encoder for individual messages and a context encoder transformer for modelling the conversation as a whole. The message encoder uses AlephBERT (Seker et al. Reference Seker, Bandel, Bareket, Brusilovsky, Greenfeld and Tsarfaty2022) to convert each message into a vector representation. To capture speaker-specific patterns, this vector is combined with a representation indicating the speaker role (help-seeker or counsellor).
The context encoder transformer operates at the message level rather than the token level. It processes the sequence of encoded message vectors to produce a context-aware representation of the dialogue. This transformer includes 12 attention layers and 12 hidden layers, each with a vector size of 780 to incorporate the speaker role information (compared to 768 in AlephBERT).
This hierarchical design has two benefits. First, it enables modelling turn-taking and speaker dynamics across the conversation. Second, it avoids truncating long dialogues due to the 512-token limit in AlephBERT, since messages are encoded separately.
5.2 Pre-training with self-supervised knowledge
During pre-training (Figure 2(b)), SR-BERT is adapted to counselling data using multiple self-supervised tasks, including a new task based on the SRF lexicon.
For this new task, each conversation is represented as an
 $n$
-dimensional vector indicating the frequency of sentences belonging to each SRF category. Specifically, the value at index
$n$
-dimensional vector indicating the frequency of sentences belonging to each SRF category. Specifically, the value at index
 $k$
counts sentences containing at least one term from the
$k$
counts sentences containing at least one term from the
 $k$
th lexicon category.
$k$
th lexicon category.
We compared a 25-dimensional representation with a reduced 5-dimensional version excluding rare categories (appearing in fewer than 10% of conversations). The five retained categories were “Loss of hope,” “Self-injury,” “Lack of sense of belonging,” “Previous suicide attempt,” and “Depression.” The reduced representation achieved better performance on validation data using XGBoost.
In this pre-training task, SR-BERT learns to predict the SRF representation from partially masked conversations. Each sentence is randomly masked with an 80% probability. The model then reconstructs the SRF representation from the remaining sentences. Training minimises the mean squared error between the true and predicted vectors. This procedure is repeated with subsets of increasing length to simulate conversations of different durations.
Additionally, we include the three pre-training objectives defined in DialogBERT (Gu, Yoo, and Ha Reference Gu, Yoo and Ha2021), targeting message semantics, dialogue structure, and sequential order. The final pre-training loss is a weighted sum of the four objectives. Training uses the AdamW optimiser with linear warm-up and an initial learning rate of 5e-5. An adaptive learning-rate scheduler with 0.01 weight decay, 15,000 warm-up steps, and a batch size of 32 is applied. The model is trained for 20 epochs with a fixed random seed. All experiments were conducted on a GeForce RTX 3090 GPU using PyTorch.
5.3 Fine-tuning
In the fine-tuning stage (Figure 2(c)), SR-BERT is adapted for binary suicide risk prediction following the methodology suggested by Sun et al. (Reference Sun, Qiu, Xu and Huang2020). Specifically, a classification head is added, consisting of a dense layer with output size two and a softmax activation. During fine-tuning, both the context encoder transformer and the classification head are updated to maximise the log-likelihood of the true labels. We use the AdamW optimiser with linear warm-up, an initial learning rate of 2e-5, 0.01 weight decay, and a batch size of 16. The input to the model includes the entire conversation. The model is trained for 10 epochs with a fixed random seed to ensure reproducibility. In the fine-tuning stage (Figure 2(c)), SR-BERT is adapted for binary suicide risk prediction following standard practices reported by Sun et al. (Reference Sun, Qiu, Xu and Huang2020).
6. Empirical methodology
We randomly split the labelled Sahar dataset to train (
 $70\%$
), validation (
$70\%$
), validation (
 $15\%$
), and test (
$15\%$
), and test (
 $15\%$
) sets. The validation set was used to train the model hyperparameters. The test and validation set were excluded from pretraining.
$15\%$
) sets. The validation set was used to train the model hyperparameters. The test and validation set were excluded from pretraining.
We compare SR-BERT with SSK to the following baseline models:
-
• SR-BERT w.o. SSK . This model omits the SSK pre-training task but is otherwise identical to SR-BERT with SSK, including the hierarchical structure and pre-training on the other three tasks.
-
• Ensemble SI-BERT (Bialer et al. Reference Bialer, Izmaylov, Segal, Tsur, Levi-Belz and Gal2022). Baseline model representing state of the art for suicide detection in online discussions. It was trained on the same Sahar dataset. Ensemble SI-BERT used only the help-seeker text and truncated inputs exceeding this length. We re-implemented the model using the authors’ code and parameters and applied it to the dataset used in this study.
-
• SRF-based lexicon + XGBoost . An XGBoost (Chen and Guestrin Reference Chen and Guestrin2016) classifier based on the 5-dimension SRF conversation representation over the SRF lexicon. XGBoost outperformed Random Forest and Logistic Regression as the classifier for this baseline (and for the next two baselines).
-
• Explicit-based lexicon + XGBoost. We used an XGBoost classifier trained on conversation encodings derived from the explicit suicide-related terms proposed by Bialer et al. (Reference Bialer, Izmaylov, Segal, Tsur, Levi-Belz and Gal2022). This list contains 67 terms, including examples such as “commit suicide”, “cut wrists”, and “wish to die”.
-
• Doc2Vec + XGBoost. An XGBoost classifier trained on 300-dimensional Doc2Vec representations of each conversation (Le and Mikolov Reference Le and Mikolov2014).
7. SR prediction results
We follow prior work in evaluating model performance using ROC-AUC, which is widely employed in suicide detection research (Bernert et al. Reference Bernert, Hilberg, Melia, Kim, Shah and Abnousi2020). We also report the F2-score (Sokolova et al. Reference Sokolova, Japkowicz, Szpakowicz and Szpakowicz2006) for predicting the positive SR label. This measure assigns greater weight to false negatives, making it appropriate for SR detection, where missing positive cases can have life-threatening consequences.
7.1 SR detection from complete conversations
Table 2 compares the performance of the SR-BERT model to the baselines in predicting suicide risk from complete conversations. As seen in the table, both SR-BERT-based models (with and without SSK pre-training) outperformed the Ensemble SI-BERT model in terms of recall, F1, F2, and ROC-AUC metrics. The most notable differences in performance between the SR-BERT w. SSK and the Ensemble SI-BERT model were in the recall metric where SR-BERT w. SSK achieved a
 $19.1\%$
improvement and
$19.1\%$
improvement and
 $14.0\%$
improvement in the F2 metric.
$14.0\%$
improvement in the F2 metric.
SR Prediction results of compared models. Bold highlights the highest value

Table 2 Long description
The table presents a comparison of performance metrics for different models used to predict suicide risk from complete conversations. It includes five rows and five columns, with the models listed in the first column and the performance metrics in the subsequent columns. The metrics include recall percentage, precision percentage, ROC-AUC percentage, F2, and F1. The models compared are Doc2Vec with XGBoost, Explicit lexicon with XGBoost, SRF lexicon with XGBoost, Ensemble SI-BERT, SR-BERT without SSK, and SR-BERT with SSK. The SR-BERT with SSK model shows the highest values in recall, ROC-AUC, F2, and F1 metrics, indicating superior performance. Notable improvements are seen in the recall and F2 metrics for the SR-BERT with SSK model compared to the Ensemble SI-BERT model.
The SR-BERT w. SSK classifier outperformed the SR-BERT w.o. SSK classifier for all metrics. This supports the hypothesis that incorporating domain knowledge during pre-training can improve SR prediction. We used the McNemar paired test for labelling disagreements (Gillick and Cox Reference Gillick and Cox1989) to compare model predictions. Statistical significance with
 $p \lt 0.05$
was found for SR-BERT w. SSK versus SR-BERT w.o. SSK and for SR-BERT w. SSK versus Ensemble SI-BERT.
$p \lt 0.05$
was found for SR-BERT w. SSK versus SR-BERT w.o. SSK and for SR-BERT w. SSK versus Ensemble SI-BERT.
The SRF lexicon with XGBoost outperformed the explicit lexicon with XGBoost on all metrics except ROC-AUC. The Ensemble SI-BERT achieved the highest precision, slightly outperforming both SR-BERT models. However, it had substantially lower recall, F1, and F2 scores.
We computed precision and recall values for all possible thresholds of the predicted probabilities and plotted these values directly to obtain the precision-recall curves for the SR-BERT w. SSK and SR-BERT w.o. SSK (Figure 3). As seen in the figure, the two models have similar precision at low recall levels. However, for recall above 0.5, the range of primary interest in this study, SR-BERT with SSK shows higher precision.
Precision recall curve comparing the results of SR-BERT w. SSK and SR-BERT w.o. SSK.

Figure 3 Long description
A line graph compares the precision and recall of SR-BERT with and without SSK. The x-axis represents recall values ranging from 0.0 to 1.0, while the y-axis represents precision values ranging from 0.2 to 1.0. The graph features two lines: one green line labeled SR-BERT with SSK and one blue line labeled SR-BERT without SSK. Both lines start at a high precision near 1.0 and gradually decline as recall increases. The green line generally maintains higher precision than the blue line across most recall values. All values are approximated.
Finally, to analyse false negatives, we compare the false omission rate across models. This rate is defined as the proportion of false negatives among all instances predicted as negative (see Figure 4). As seen in the figure, the SR-BERT models without SSK reduced the false omission rate compared to Ensemble SI-BERT from 0.083 to 0.071, a
 $14.4\%$
improvement. Pre-training SR-BERT with the additional SSK task lowered the false omission rate from 0.071 to 0.052, a 26.7% reduction relative to Ensemble SI-BERT.
$14.4\%$
improvement. Pre-training SR-BERT with the additional SSK task lowered the false omission rate from 0.071 to 0.052, a 26.7% reduction relative to Ensemble SI-BERT.
False omission rate of different models.

Figure 4 Long description
The bar graph compares the false omission rate of different models, including SRF lexicon, Ensemble SI BERT, SR BERT without SSK, and SR BERT with SSK. The x axis lists the models, and the y axis measures the false omission rate, ranging from 0.00 to 0.08. The SRF lexicon model has the highest false omission rate, followed by Ensemble SI BERT, SR BERT without SSK, and SR BERT with SSK, which has the lowest rate. The bars are vertical and colored differently to represent each model. All values are approximated.
7.2 Early SR detection
Figure 5 provides important insight into the models’ ability to detect suicide risk at different stages of an unfolding conversation. This type of early detection is critical in real-world crisis intervention settings, where prompt identification of risk can inform timely support decisions. By evaluating model performance incrementally across conversation progress, we can assess not only overall accuracy but also how rapidly each model begins to outperform baseline approaches. This contextualises the relative utility of each method when limited information is available, which is often the case in live support environments.
The length of the conversations varies widely, and longer conversations don’t imply harder cases. Therefore, we compare the approaches with respect to their performance after receiving
 $\{20,40,60,80,100\}$
percent of messages in the session, rather than the number of messages. As seen in the figure, all of the models improved in performance as conversations progressed. However, the SR-BERT model with SSK was consistently the top performer, followed by SR-BERT w.o. SSK. The performance gap between the two SR-BERT models grew as the conversation progressed, particularly in the final stages of the conversation (80%–100%). This suggests that the SR-BERT model with SSK better utilises language cues throughout the conversation.
$\{20,40,60,80,100\}$
percent of messages in the session, rather than the number of messages. As seen in the figure, all of the models improved in performance as conversations progressed. However, the SR-BERT model with SSK was consistently the top performer, followed by SR-BERT w.o. SSK. The performance gap between the two SR-BERT models grew as the conversation progressed, particularly in the final stages of the conversation (80%–100%). This suggests that the SR-BERT model with SSK better utilises language cues throughout the conversation.
Furthermore, as conversations progress, the performance gap between Ensemble SI-BERT and the SR-BERT models (with and without SSK) widens. One possible explanation is that Ensemble SI-BERT truncates long conversations, potentially omitting crucial information.
Classification results for early detection of top-performing SR detection approaches.

Figure 5 Long description
The line graph displays the classification results for early detection of top-performing SR detection approaches. The x-axis represents the percentage of conversation messages, ranging from 20 to 100 percent. The y-axis represents the F2 score, ranging from 45 to 75. Three data lines are shown: SR-BERT with SSK in red, SR-BERT without SSK in blue, and Ensemble SI-BERT in green. SR-BERT with SSK consistently achieves the highest F2 scores across all percentages of conversation messages, followed by SR-BERT without SSK, and then Ensemble SI-BERT. All values are approximated.
To further assess the contribution of the SSK pretraining task, we compared the performance of the SR-BERT w. and w.o SSK on a subset of the test set that omits all conversations containing terms from an explicit-ideation-terms lexicon Bialer et al. (Reference Bialer, Izmaylov, Segal, Tsur, Levi-Belz and Gal2022). These conversations do not mention explicit suicide ideation terms and may be more difficult to classify. The performance of SR-BERT with and without SSK pre-training on this dataset is presented in Figure 6. As expected, the overall performance of both models decreased significantly compared to the original test set. However, SR-BERT w. SSK performed better than SR-BERT w.o. SSK and the difference between the two models increased as the sessions progressed. The difference in the performance between the two models was significantly larger than that reported on the original test set (Figure 5). This demonstrates the impact of incorporating domain theory during pre-training to improve SR detection in more challenging cases.
Classification results for early detection on explicit-less-conversations benchmarks.

Figure 6 Long description
A line graph compares the performance of two models, SR-BERT with SSK and SR-BERT without SSK, in terms of F2 score across varying percentages of conversation messages. The x-axis represents the percentage of conversation messages, ranging from 20 to 100 percent. The y-axis represents the F2 score, ranging from 20 to 55. The red line represents SR-BERT with SSK, which shows a steady increase in F2 score as the percentage of conversation messages increases, starting from around 27 at 20 percent and reaching approximately 53 at 100 percent. The blue line represents SR-BERT without SSK, which also shows an increase in F2 score but at a slower rate compared to the red line, starting from around 20 at 20 percent and reaching approximately 35 at 100 percent. All values are approximated.
7.3 Sensitivity analysis for the SR model
In this section, we examine the top-performing model, SR-BERT with SSK, and evaluate its sensitivity to different factors: conversation structure, the presence of suicide terms from the lexicon, and help-seeker gender. To facilitate comparison, we binned conversations into equal-width intervals for each factor (each bin contained the same number of instances).
Table 3 (top) summarises performance relative to SRF lexicon overlap. We observed a moderate Pearson correlation (
 $r = 0.333$
) between overlap and the presence of suicide risk. F2 scores increased with higher overlap, while ROC-AUC scores were slightly higher for conversations with low overlap. This suggests the model relies more on explicit lexicon cues when available.
$r = 0.333$
) between overlap and the presence of suicide risk. F2 scores increased with higher overlap, while ROC-AUC scores were slightly higher for conversations with low overlap. This suggests the model relies more on explicit lexicon cues when available.
SR-BERT performance for overlap with SRF lexicon (top) and number of tole changes (bottom)

Table 3 Long description
The table presents SR-BERT performance metrics for overlap with SRF lexicon and number of role changes. The top section shows performance relative to SRF lexicon overlap, with columns for Positive SR percentage, ROC-AUC percentage, and F2 score. The bottom section displays performance relative to the number of role changes, with the same columns. The top section includes rows for different overlap ranges: less than 1.6, 1.6 to 4.5, 4.2 to 8.1, and greater than 8.1. The bottom section includes rows for different ranges of role changes: less than 18, 18 to 24, 24 to 30, 30 to 39, and greater than 39. Notable trends include increasing F2 scores with higher overlap and slightly higher ROC-AUC scores for conversations with low overlap.
Table 3 (bottom) shows performance by the number of role changes. We observed a weak Pearson correlation (
 $r = 0.105$
) between more role changes and the presence of suicide risk. This may reflect that counsellors tend to ask more questions when suspecting SR to gather additional information.
$r = 0.105$
) between more role changes and the presence of suicide risk. This may reflect that counsellors tend to ask more questions when suspecting SR to gather additional information.
Finally, we assessed model performance across help-seeker gender (Table 4). Hebrew’s grammatical gender did not lead to systematic differences: F2 and ROC-AUC scores were comparable between male and female help-seekers. The proportion of SRF lexicon overlap was also similar across genders, suggesting no detectable gender bias.
SR-BERT performance for gender subgroups

8. Detecting imminent suicide risk
While our previous analyses focused on the binary classification of suicide risk and its early detection, real-world crisis intervention often requires a more fine-grained understanding of risk levels. In particular, distinguishing between general suicidal ideation (GSR) and IMSR is critical for prioritising intervention efforts. Counsellors must act swiftly in IMSR cases, and yet these are rare and difficult to identify.
8.1 Key challenges
Building on the strength of SR-BERT in SR detection, we now turn to the task of modelling suicide risk severity. By developing a model to assess the severity of suicide risk, we aim to provide counsellors with a more granular understanding of the situations they encounter. This nuanced approach will help them tailor their interventions more effectively.
Moreover, the integration of such a model can serve as a valuable validation instrument for counsellors’ evaluations. It can assist in verifying the consistency of severity assessments with the observations made by counsellors, thereby enhancing the overall confidence in the decision-making process.
In our pursuit of accurately predicting IMSR, we are confronted with three primary challenges. Firstly, the task of determining whether a help seeker is at an imminent suicide risk is inherently complex, posing difficulties even for experienced clinical psychologists. Secondly, we face the challenge of limited data availability. Within our dataset, there are only 172 IMSR conversations, which significantly compounds the difficulty of effectively detecting suicidal risk. Lastly, a significant hurdle we must address is the presence of a major class imbalance, as illustrated in Table 1. This class imbalance can adversely affect the performance of the model (Henning et al. Reference Henning, Beluch, Fraser and Friedrich2023).
It’s worth noting that even within the psychological literature, the accurate identification of high-risk individuals remains a challenging endeavour (Golder et al. Reference Golder, Kandane-Rathnayake, Hoi, Huq, Louthrenoo, An, Li, Luo, Sockalingam and Lau2017). It is crucial to underscore that while significant progress has been made in identifying individuals at general suicide risk, differentiating them from those who will actually transition to suicidal behaviour remains an area where substantial work is needed (Singhal, Reference Singhal2020).
To tackle these challenges, we propose a multifaceted approach. Our method for identifying IMSR entails a two-stage model designed to enhance the accuracy of risk assessment. Additionally, we leverage data augmentations by utilising domain knowledge to supplement our dataset. This comprehensive strategy aims to mitigate the inherent complexities posed by the scarcity of data and the intricacies of detecting varying levels of suicidal risk.
8.2 A two-stage model
To address the challenge posed by class imbalance and the inherent complexity of the task, we propose a hierarchy classification method approach. Our strategy involves training a model to focus exclusively on conversations related to SR, distinguishing between GSR and IMSR conversations. We believe that this approach allows the model to better discern the subtle signals that differentiate IMSR from GSR conversations, ultimately leading to improved detection accuracy. This two-stage classification model is illustrated in Figure 7.
The initial phase of our model is dedicated to the binary classification of conversations, specifically to determine whether a conversation is related to suicide (SR) or not (non-suicide-related). SR conversations encompass those labelled as either GSR or IMSR. For the first model, we employ the same model described in the preceding section of this paper.
The second stage of classification focuses on conversations that have been identified as having SR and involves using a more refined model (IMSR-BERT) to differentiate between GSR and IMSR. This model is based on the same pre-trained model as SR-BERT and is fine-tuned specifically on the training examples labelled as GSR or IMSR. The big difference from SR-BERT is that IMSR-BERT does not train on the non-suicide risk instances.
Prediction results of compared models. Bold highlights the highest value

Table 5 Long description
The table presents prediction results for three models: Non-SR, GSR, and IMSR. It compares recall percentage, precision percentage, F2 score, and F1 score for each model. The table has two rows for each model: Flat Model and Two-Stage. For Non-SR, the Flat Model shows recall of ninety-one point seventy-three percentage, precision of ninety-three point sixteen percentage, F2 of ninety-two point zero one percentage, and F1 of ninety-two point forty-four percentage. The Two-Stage model shows recall of eighty-four point seventy-eight percentage, precision of ninety-five point seventy-three percentage, F2 of eighty-six point seventy-six percentage, and F1 of eighty-nine point ninety-two percentage. For GSR, the Flat Model shows recall of sixty-eight point seventy-eight percentage, precision of sixty-two point sixty-seven percentage, F2 of sixty-seven point forty-six percentage, and F1 of sixty-five point fifty-eight percentage. The Two-Stage model shows recall of eighty point ninety-eight percentage, precision of fifty-three point forty-six percentage, F2 of seventy-three point forty-two percentage, and F1 of sixty-four point four percentage. For IMSR, the Flat Model shows recall of twenty-seven point forty-five percentage, precision of thirty-six point thirty-six percentage, F2 of nineteen point forty-two percentage, and F1 of twenty-three point fifty-three percentage. The Two-Stage model shows recall of thirty-nine point thirteen percentage, precision of forty-two point eighty-six percentage, F2 of thirty-nine point eighty-two percentage, and F1 of forty point ninety-one percentage. The highest values are highlighted in bold.
Two stage model for suicide severity classification.

Figure 7 Long description
The diagram depicts a two-stage model for suicide severity classification. It begins with a conversation that is processed by SR-BERT to determine if it is a suicide-related conversation or a non-suicide-related conversation. Suicide-related conversations are then further analyzed by IMSR-BERT to assess the level of suicide risk, categorizing it as either global suicide risk or immediate suicide risk. The diagram includes labels for each stage and the outcomes of the analysis, showing the flow from conversation to risk assessment.
By reducing the overall volume of conversations under consideration and concentrating solely on those labelled as GSR and IMSR, we effectively rebalance the class distribution. This adjustment results in an augmentation of the proportion of IMSR instances within the training dataset, elevating it from a less than 1% representation to a more substantial 5%. This approach enables the model to learn a more nuanced understanding of the different levels of suicide risk present in conversations, ultimately enhancing the performance of our suicide risk detection system.
9. Two-stage model results
In order to assess the effectiveness of our two-stage model, we conducted a comparative analysis, employing a flat model for reference, as illustrated in Figure 8. The flat model utilised an identical base model as SR-BERT but with a distinct fine-tuning methodology. In contrast to SR-BERT’s fine-tuning for binary classification (SR vs. non-SR), we fine-tuned the flat model for a three-class prediction task, distinguishing between non-SR, GSR, and IMSR conversations.
Flat model baseline for suicide severity classification.

The obtained results, presented in Table 5, showcase the performance metrics of both models across various evaluation criteria, using the same metrics as done in Section 7.
From the results, it is evident that the two-stage model outperforms the flat model in most metrics, showcasing its superiority. Specifically, for the IMSR conversations, the two-stage model achieved better results, surpassing the flat model in all evaluated metrics, particularly excelling in the F2 score. The two-stage model obtained an F2 score of 39.82%, while the flat model’s F2 was limited to 19.42%, demonstrating a substantial difference in performance. Additionally, the two-stage model maintained a favourable F1 score of 40.91%, compared to the flat model’s 25.53%.
Moving on to the classification of GSR conversations, the two-stage model also displayed notable improvements over the flat model in F2 and recall metrics. It achieved an F2 score of 73.42%, surpassing the flat model’s 62.46%. While there was a slight decrease in the F1 score for the two-stage model, reaching 64.4% compared to the flat model’s 65.6%, the considerable difference in F2 score highlights the model’s improvement in classifying GSR conversations.
Furthermore, we assessed the performance of the two-stage model in recognising non-SR conversations. Here, we observed that the flat model performed slightly better than the two-stage model. To further investigate the implications of this lower performance on non-SR conversations, we conducted an analysis of the confusion matrices for both models (Figure 9).
Comparing Models’ Confusion Matrices.

Figure 9 Long description
A heat map compares two models' confusion matrices, showing performance metrics with color intensity. The heat map features a grid layout with three rows and three columns, each cell representing a different class. The axes are labeled with 'Actual' on the vertical axis and 'Predicted' on the horizontal axis. The color scale ranges from light blue to dark blue, indicating lower to higher values respectively. The first matrix, labeled 'Flat Model', shows values such as 0.92 for NonSR, 0.69 for GSR, and 0.74 for IMSR. The second matrix, labeled 'Two-Stage Model', shows values such as 0.85 for NonSR, 0.81 for GSR, and 0.61 for IMSR. Standout regions include higher values in the diagonal cells, indicating correct predictions, and lower values in off-diagonal cells, indicating misclassifications. The overall trend shows improved performance in the Two-Stage Model compared to the Flat Model.
Upon analysing the confusion matrix of the flat model, as depicted in Figure 9a, we observed that the model demonstrated accurate classification for non-SR conversations, with relatively few mistakes. However, the model struggled to correctly classify IMSR conversations, mislabelling 9% of the conversations as non-SR. Additionally, around 30% of the GSR conversations were erroneously labelled as non-SR, indicating the need to minimise such misclassifications for both use cases.
In comparison, the confusion matrix of the two-stage model, shown in Figure 9b, revealed its improved ability to classify GSR conversations accurately, without mistakenly labelling any IMSR conversations as non-SR. Despite this advancement, there still exists room for improvement, as several IMSR conversations were not correctly classified.
Overall, the results underscore the strengths of the two-stage model in effectively distinguishing between different conversation classes, particularly exhibiting significant improvements in IMSR and GSR classification. While the flat model exhibited a slight advantage in non-SR conversation identification, the two-stage model’s superior performance across other crucial classes renders it a promising choice for our specific task. To further enhance the model’s performance, we explore data augmentation techniques.
10. Data augmentation
To improve the performance of our second-stage model, we hypothesise that the relatively low performance in IMSR prediction may stem from the limited sample size associated with this label and the overall class imbalance in the dataset. This hypothesis is consistent with prior research findings (Feng et al. Reference Feng, Gangal, JasonWei, Vosoughi, Mitamura and Hovy2021; Henning et al. Reference Henning, Beluch, Fraser and Friedrich2023) that indicate how limited sample sizes can have a detrimental impact on model performance.
10.1 Proposed methods
To address this challenge, we have undertaken a comprehensive exploration of various sampling strategies designed to increase the representation of IMSR conversations within our training dataset.
Under sampling We randomly sampled and removed a certain percentage (x%) of the GSR conversations to reduce their dominance in the training data.
Over sampling We randomly resampled the IMSR conversations to amplify their presence in the training dataset. Doing so ensures that the model receives more exposure to IMSR conversations, which are relatively rarer in the original dataset.
Lexicon-Based Augmentation To enrich the existing conversations, we utilised the IMSR lexicon. Our data augmentation approach involved substituting terms within the conversations using the lexicon. Specifically, we replaced all the terms that are present in the IMSR-SRF-factors lexicons with other terms that belong to the same SRF factors. By introducing these targeted substitutions, we introduced small variations to the text, thereby enabling the model to learn from a broader range of linguistic patterns and contexts related to suicide risk. For example, in this message, “The rope is waiting for me”, the category is “Active Suicidal Ideation with Specific Plan and Intent” and the message can be changed to “The gun is ready for me”.
In order to evaluate the model’s performance, we conducted a comparative analysis of the two-stage model trained on the same dataset with varying rates of oversampling and undersampling, ranging from 1 to 5 and 10. Oversampling was performed for the minority class (IMSR), and undersampling was performed for the majority class (non-IMSR). Additionally, we compared the performance of normal oversampling to that of using “Lexicon Based Augmentation” for each oversampling rate. Through these experiments with different sampling techniques, our goal was to understand how these adjustments impact the model’s effectiveness in classifying conversation types.
10.2 Data augmentation results
Table 6 summarises the data augmentation trails. As seen by the table, among the different approaches, the “undersample_20%” model, which employs undersampling with a ratio of 5, demonstrated competitive results. It achieved a recall of 79.51% and an F2 score of 72.35% for GSR conversations, slightly under-performing compared to the model trained on the untreated dataset. However, it significantly improved its performance in classifying IMSR conversations, achieving a recall of 52.17% and an F2 score of 49.59%.
Prediction results of compared models. Bold highlights the highest value

Table 6 Long description
The table presents a comparison of different data augmentation models, focusing on their performance metrics for GSR and IMSR conversations. It includes six models: Two-Stage, undersample_20%, oversample_500%, oversample_500%_aug, oversample_500%_undersample_20%, and oversample_500%_undersample_20%_aug. Each model's performance is evaluated using recall percentage, precision percentage, F2 score, and F1 score for both GSR and IMSR. The Two-Stage model shows a recall of 80.98% and a precision of 53.46% for GSR, with an F2 score of 73.42% and an F1 score of 64.4%. For IMSR, it has a recall of 39.13% and a precision of 42.86%, with an F2 score of 39.82% and an F1 score of 40.91%. The undersample_20% model achieves a recall of 79.51% and a precision of 53.18% for GSR, with an F2 score of 72.35% and an F1 score of 63.73%. For IMSR, it has a recall of 52.17% and a precision of 41.38%, with an F2 score of 49.59% and an F1 score of 46.15%. The oversample_500% model shows a recall of 82.68% and a precision of 53.72% for GSR, with an F2 score of 74.64% and an F1 score of 65.13%. For IMSR, it has a recall of 30.4% and a precision of 63.64%, with an F2 score of 33.98% and an F1 score of 41.18%. The oversample_500%_aug model achieves a recall of 82.44% and a precision of 53.48% for GSR, with an F2 score of 74.38% and an F1 score of 64.88%. For IMSR, it has a recall of 30.43% and a precision of 70.01%, with an F2 score of 34.31% and an F1 score of 42.42%. The oversample_500%_undersample_20% model shows a recall of 84.78% and a precision of 53.71% for GSR, with an F2 score of 72.54% and an F1 score of 64.11%. For IMSR, it has a recall of 52.17% and a precision of 47.24%, with an F2 score of 47.24% and an F1 score of 41.38%. The oversample_500%_undersample_20%_aug model achieves a recall of 79.02% and a precision of 53.38% for GSR, with an F2 score of 72.1% and an F1 score of 63.72%. For IMSR, it has a recall of 60.87% and a precision of 40.04%, with an F2 score of 55.12% and an F1 score of 48.28%. The table highlights the competitive performance of the undersample_20% model, particularly in improving recall and F2 score for IMSR conversations.
On the other hand, the “oversample_500%” model, which utilises oversampling with a ratio of 5, exhibited notable improvements in GSR classification, attaining a recall of 82.68% and a precision of 53.72%. However, its performance in IMSR classification was comparatively lower than the untreated model in terms of recall and F2. We investigated the impact of “Lexicon Based Augmentation” in conjunction with oversampling, as demonstrated by the “oversample_500%_aug” model. Although this approach improved the precision for IMSR conversations to 70.01%, the recall remained relatively low at 30.43%. Finally, the “oversample_500%_undersample_20%_aug” method, which combined oversamping and undersanpling, performed the best regarding the recall and F2 score for IMSR, achieving 60.87% and 55.12%, respectively. This indicates the effectiveness of combining oversampling, undersampling, and data augmentation in improving IMSR classification while performing only slightly worse than the model trained on the untreated training set.
Confusion matrix for the data-augmented model.

Figure 10 Long description
The confusion matrix for the data-augmented model displays predicted versus actual classifications across three categories: NonSR, GSR, and IMSR. The matrix consists of three rows and three columns, each representing one of the categories. The diagonal elements show the correct classifications: 0.85 for NonSR, 0.79 for GSR, and 0.61 for IMSR. Off-diagonal elements indicate misclassifications, such as 0.15 of NonSR predicted as GSR, 0.17 of GSR predicted as NonSR, and 0.39 of IMSR predicted as GSR. The matrix highlights the model's performance in distinguishing between these categories.
Another noteworthy aspect to consider is that due to the architecture of the two-stage model, a higher error rate in the classification of GSR conversations may result in their erroneous labelling as IMSR conversations. While this does introduce a relatively low-risk misclassification scenario, we conducted an analysis employing confusion matrix evaluation to delve deeper into this phenomenon.
Figure 10 presents the confusion matrix for the data-augmented model. As anticipated, the performance of the non-SR class remained consistent compared to the confusion matrix shown in ?? (non-augmented model). In contrast, there is a notable improvement in the recall of IMSR conversations. However, it is worth noting that approximately 2% more GSR conversations were incorrectly labelled as IMSR when compared to the non-augmented two-stage model. This particular misclassification is relatively minor in our context because we can tolerate predictions that lean towards a more severe risk prediction. Given our model’s architecture, conversations initially labelled as SR can only be classified as either GSR or IMSR in subsequent steps.
Overall, our experiments with different sampling techniques shed light on their impact on the model’s performance in classifying conversation types. The findings suggest that a careful combination of sampling methods with data augmentation can lead to significant improvements in IMSR classification without compromising the performance of GSR conversations. These insights provide valuable guidance for optimising models’ performance in real-world NLP applications.
11. Early detection of two stage models
We employed the same evaluation methodology as conducted in Subsection 7.2 to assess the performance differences in early detection. From Figure 11, we can observe the performance of the model’s for GSR conversations, where both models demonstrated similar behaviour. Notably, we observed only marginal performance reductions in the data-augmented model compared to the two-stage model. As anticipated, the performance of both models improved as the conversations progressed. This consistent pattern persisted across various percentages of the conversation duration.
Classification results on GSR class for early detection.

Figure 11 Long description
A two line graph compares the performance of two models, the Two Stage model and the Data Augmented model, in terms of F 2 score across varying percentages of conversation messages. The x axis represents the percentage of conversation messages, ranging from 20 to 100 percent. The y axis represents the F 2 score, ranging from 50 to 75. The Two Stage model, represented by a blue line with circular markers, consistently outperforms the Data Augmented model, represented by a red line with circular markers, across all percentages. Both models show an upward trend in F 2 score as the percentage of conversation messages increases. The Two Stage model starts at an F 2 score of approximately 50 at 20 percent and reaches around 75 at 100 percent. The Data Augmented model starts at an F 2 score of approximately 45 at 20 percent and reaches around 70 at 100 percent. All values are approximated.
Conversely, from Figure 12 we can notice a substantial performance enhancement emerged for the IMSR’s F2 metric. The augmented model achieved superior results compared to the two-stage model, particularly exhibiting noteworthy performance (F2 score of 39.06) even in the early stages of conversations. This starkly contrasts with the two-stage model’s performance (F2 score of 5.15) at the same early juncture. Moreover, the performance improvement in the data-augmented model exhibited only minor fluctuations as the conversations unfolded, unlike the pronounced performance boost observed in the two-stage model. This intriguingly suggests that the data-augmented model can effectively identify IMSR conversations at an early stage, potentially indicating the presence of IMSR even in the initial phases of conversations. This finding implies that certain cues or indications of IMSR might be detectable early in a conversation, contributing to the data-augmented model’s enhanced early detection performance.
11.1 Sensitivity analysis – two-stage model
From the results depicted in Table 7, it is apparent that, despite an almost twofold representation of female help-seekers, the numbers of GSR conversations from both genders are roughly equal. Additionally, a noteworthy discovery is the higher frequency of IMSR conversations initiated by male help-seekers. This observation raises the possibility that when a male help-seeker engages in a conversation, it may indicate a more severe mental state. Furthermore, it is evident that the percentage of IMSR-lexicon overlap is smaller compared to that of GSR; however, the degree of overlap between female and male help-seekers is quite similar.
Two-Stage model performance for gender subgroups

Table 7 Long description
The table presents data on the performance of a two-stage model for gender subgroups, focusing on metrics such as GSR percentage, F2-GSR, IMSR percentage, F2-IMSR, and IMSR-Lexicon overlap. The table has two rows labeled Female and Male, and six columns labeled Gender, GSR percentage, F2-GSR, IMSR percentage, F2-IMSR, and IMSR-Lexicon overlap. Female help-seekers constitute seventy point five percent of the total, with a GSR percentage of eighteen point five percent, F2-GSR of seventy one point zero two percent, IMSR percentage of zero point nine four percent, F2-IMSR of forty seven point sixty one percent, and IMSR-Lexicon overlap of one point five zero percent. Male help-seekers constitute twenty nine point five percent of the total, with a GSR percentage of seventeen point four percent, F2-GSR of seventy four point sixty six percent, IMSR percentage of one point two four percent, F2-IMSR of sixty nine point seventy six percent, and IMSR-Lexicon overlap of one point five two percent. Notably, despite a higher representation of female help-seekers, the number of GSR conversations is roughly equal for both genders. Male help-seekers initiate a higher frequency of IMSR conversations, suggesting a potential indication of a more severe mental state. The percentage of IMSR-Lexicon overlap is smaller compared to GSR, but the degree of overlap is similar between female and male help-seekers.
Classification results on IMSR class for early detection.

Figure 12 Long description
Two line graphs compare the performance of two models, the Two Stage model and the Data Augmented model, in classifying IMSR class for early detection. The x axis represents the percentage of conversation messages, ranging from 20 to 100 percent. The y axis represents the F 2 score, ranging from 0 to 50. The Two Stage model starts at a lower F 2 score of around 5 at 20 percent and increases to about 40 at 60 percent, then slightly decreases to around 35 at 100 percent. The Data Augmented model starts at a higher F 2 score of around 40 at 20 percent, increases to about 50 at 60 percent, and then slightly fluctuates around 50 at 100 percent. All values are approximated.
Comparing these findings with the outcomes in Table 4, it becomes evident that the two-stage model exhibits a susceptibility to bias, manifested in its F2 scores for both GSR and IMSR conversations. This suggests that gender-related disparities are affecting the model’s performance, potentially leading to biased predictions in conversations initiated by different genders. Such biases can significantly impact the model’s practical applicability, underscoring the importance of addressing these issues in order to enhance its effectiveness across diverse user demographics.
12. Discussion
Our results demonstrate the importance of combining domain knowledge and conversation structure with pre-trained language models for the purpose of GSR and IMSR detection. In particular, embedding domain theory into the SR-BERT pre-training step captures nuances of the conversations that go beyond explicit mentions of suicide-related terms. Furthermore, the hierarchical SR-BERT approach was able to overcome the problem of limited input size that hinders existing approaches to language modelling. It was able to identify suicide risk variables early in the discussion and to consistently improve in performance as the conversations advanced, outperforming strong baselines. These results indicate that the model may be well suited for predicting suicide risk in real time, in actual support sessions.
We demonstrate the SR model’s ability to capture nuanced textual exchanges with the two illustrative examples presented in Table 8. In the first example, SR-BERT correctly labels the session as SR positive, while the Ensemble SI-BERT classifies it as negative SR (false negative). Note that the suicide risk in this example becomes apparent after the clarification question by the counsellor and by considering the response of the help-seeker in the context of their first message. This is exactly the contribution provided by the hierarchical approach of SR-BERT.
Illustrative excerpts from conversations where SR-BERT and Ensemble SI-BERT disagree

Table 8 Long description
The textbox contains a conversation between a help seeker and a counselor. The help seeker expresses feeling overwhelmed and mentions thoughts of suicide. The counselor asks clarifying questions to understand the situation better. The help seeker reveals that they are being stopped from acting on their thoughts by a specific incident involving their sister. The counselor further inquires about the help seeker's fears regarding a police visit and the use of a gun. The help seeker indicates that they are more traumatized by the police visit than by the thought of using their gun.
In the second example, SR-BERT correctly identified a non-SR session, while Ensemble SI-BERT mistakenly classified this session as SR (false positive). We hypothesise that the flat ensemble model was misled by the “gun”, “police”, and “trauma” utterances while SR-BERT was able to weigh these terms in context.
We also looked at the samples that the models failed to predict correctly to better define future needed improvements. For this, we have enlisted a domain expert who analysed the errors performed by the model. Specifically, this expert analysed 50 GSR conversations and 20 IMSR conversations that were misclassified. The expert’s analysis revealed that misclassifications may occur in GSR calls when many topics are raised during the conversation or when the help-seeker is “beating around the bush” for a long time with only very gently referencing their mental states. In IMSR calls the expert pointed mainly to misclassifications due to short calls that were abruptly disconnected by the help-seeker. We hypothesise that improving the taxonomy used by the model, incorporating explicit time-based cues in the input data (such as utterance duration) and moving to bigger language models which capture larger contexts may help in addressing some of these failings.
13. Conclusion and future work
In conclusion, this study has introduced a novel automated approach for evaluating the severity of suicide risk within online interactions involving individuals seeking help and professional counsellors. Early identification of individuals at risk is a fundamental objective in suicide prevention efforts.
Our approach extends the state-of-the-art in deep language modelling by (1) incorporating domain knowledge relevant to suicide risk detection as part of the pre-training step, (2) reasoning about the structure of the conversation between help-seekers and counsellors, and (3) adapting to a low-resource language (Hebrew).
Furthermore, we have shown that the model can not only predict the presence of suicide risk but also assess its severity using a two-stage architecture enriched by domain-informed data augmentation techniques. This approach improves the ability to identify and address suicide risk in online conversations.
The presented approach was able to significantly outperform the state-of-the-art approaches when detecting multiple levels of suicide risk from complete conversations, as well as early detection when only part of the conversation is available.
For future work, we intend to improve our approach by capturing more aspects of conversations, such as prosody (Wilson and Wharton Reference Wilson and Wharton2006; Kliper, Yonatan, and Daphna Reference Kliper, Yonatan, Daphna and Shirley2010) as well as model the mental state dynamics of the help-seeker. We are also extending the model with explanations to be able to provide justifications for predictions made and point to key exchanges and phrases that triggered specific predictions.
Additionally, we aim to explore how our model enhances volunteers’ judgement in suicide risk assessment. This involves investigating its impact on decision-making processes within real-world counselling settings. By conducting empirical studies, we intend to evaluate the model’s practical utility and effectiveness. These insights will be critical for understanding its influence on volunteer assessments and identifying potential areas for improvement, ultimately contributing to better outcomes in suicide prevention efforts.
Finally, an important avenue for future research is to complement risk detection models with systems that can also recognise and promote supportive or hopeful content. Detecting encouragement, positive affirmations, and emotional support could help counterbalance distress signals and contribute to more holistic interventions. Prior work on hope speech detection (Sharma et al. Reference Sharma, Gupta, Singh and Chakravarthi2025) and multimodal analysis of supportive messages (Singh, Sharma, and Singh, Reference Singh, Sharma and Singh2025) highlights the feasibility and potential impact of integrating positivity-focused approaches alongside risk assessment tools.
14. Limitations
We note several limitations of this study.
First, our model was only evaluated in the Hebrew language. We have not directly compared our models to approaches for detecting suicidal risk in non-Hebrew domains, and note that the effectiveness of the model may vary across different languages and cultural contexts. Nonetheless, we note that the methodology presented in this manuscript is generalisable to other languages and cultural contexts. Adapting the approach to a new language involves two main components: (1) identifying or training a suitable pre-trained language model in the target language (e.g., AraBERT for Arabic); and (2) constructing or adapting a domain-specific lexicon reflecting suicide risk factors in that language and culture. To ensure the theoretical grounding and cultural relevance of such lexicons, we recommend involving local mental health professionals to translate, validate, or create terms based on the same underlying psychological theories (e.g., PHQ-9, INQ, and SCS).
In fact, as part of our ongoing work, we are developing an Arabic version of SR-BERT using a translated version of the SRF lexicon curated by clinical psychologists fluent in Arabic and familiar with the relevant cultural idioms of distress. We also leverage AraBERT (Antoun, Baly, and Hajj Reference Antoun, Baly and Hajj2020) as the base transformer. This demonstrates the practical feasibility of adapting our architecture across languages. Future work could explore cross-lingual pretraining or multilingual foundation models to further simplify this transfer.
Second, the annotation of the help seekers’ mental state was performed by the counsellors, rather than the help seekers themselves. Although the counsellors completed several months of training and were supervised by certified clinical psychologists, it is still possible that they misclassified the help-seekers’ mental states. This issue is prevalent in many studies that rely on observer-reported data. Specifically, while counsellor annotations provide valuable real-world labels, they may introduce systematic biases. For example, counsellors’ assessments can be influenced by personal clinical experience, training differences, or cognitive heuristics (e.g., confirmation bias). This could affect the consistency and objectivity of suicide risk labels, especially in nuanced or ambiguous cases. Additionally, since counsellors multitask and work under emotional stress, subtle signs may be overlooked or overemphasised.
As an alternative, annotation by panels of trained clinical psychologists working independently or via consensus can improve label consistency. Another approach would be to incorporate help-seeker self-assessment surveys post-conversation (though impractical in many real-world settings). In our case, we partially mitigated this concern by validating a subset of the dataset (500 conversations) with independent expert psychologists, achieving a Krippendorff’s
 $\alpha$
of 0.766, which is comparable to similar work in the literature. Future work could explore these ensemble annotation approaches to better help-seekers’ mental states.
$\alpha$
of 0.766, which is comparable to similar work in the literature. Future work could explore these ensemble annotation approaches to better help-seekers’ mental states.
Third, our experiments used a random-based train-test split (as opposed to time-based splits) and did not use cross validation. We chose random splits to ensure broad coverage of conversation variability and avoid confounds from external events. Time-based splits in our dataset would have introduced biases due to disruptions like COVID-19 and other crises, which caused abrupt shifts in conversation content and volume. Moreover, our training pipeline involves costly pretraining and augmentation steps, making repeated time-based training or cross-validation infeasible. Nonetheless, temporal robustness is important, and this is a direction for future work.
Fourth, we did not use generative models (such as ChatGPT) in this research due to privacy considerations and since such models were not yet available for the Hebrew language in an open-source configuration (which does not require data sharing).
Finally, while our current model emphasises predictive performance and the integration of domain-specific psychological knowledge, we recognise the importance of model interpretability in sensitive applications such as suicide risk detection. As a step toward addressing this critical concern, we have conducted a complementary study exploring the “black box” of suicide risk prediction models. In this work (Grimland et al. Reference Grimland, Benatov, Yeshayahu, Izmaylov, Segal, Gal and Levi‐Belz2024), we analysed the contribution of specific psychological risk factors (e.g., hopelessness, thwarted belongingness) to model decisions by leveraging a theory-driven lexicon and logistic regression analysis. This enabled a more transparent understanding of which features and linguistic cues are associated with increased suicide risk in real-time conversations. We view these efforts as part of a broader agenda toward explainable AI in crisis intervention, and our future work will integrate such insights directly into real-time, interpretable models.
Ethics statement
This study was conducted in accordance with ethical standards and approved by the institutional review boards of the participating institutions. All data used in this study, including the Sahar conversation corpus and the SRF psychological lexicon, were obtained in compliance with IRB requirements. Specifically, the Sahar dataset was anonymised and encrypted to protect participant privacy. All help-seekers provided informed consent for the anonymous use of their sessions in research. The counsellors signed consent forms allowing their text data to be used for the study.
Although the model can successfully predict GSR and IMSR during conversations, it is not intended to replace human volunteer counsellors. We believe human involvement is essential in supporting help-seekers. The automated model is intended to assist counsellors by enhancing their ability to assess conversation severity, not to replace them. We believe that in the future, once all necessary approvals and adaptations are in place, such models could be deployed as supportive tools. Rather than replacing counsellors, they would serve as an additional source of insight, like a ’friendly parrot’, to assist decision-making in the high-pressure situations counsellors face on a daily basis.
Acknowledgements
This research was funded in part by Israeli Science Foundation grant no. 1302/21.



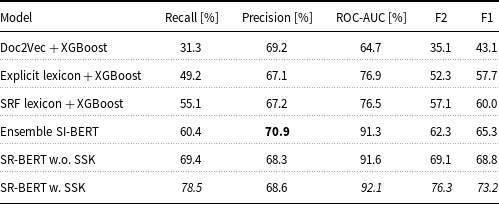




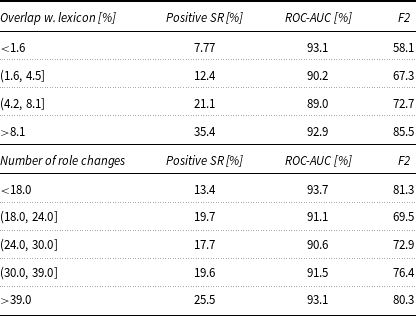



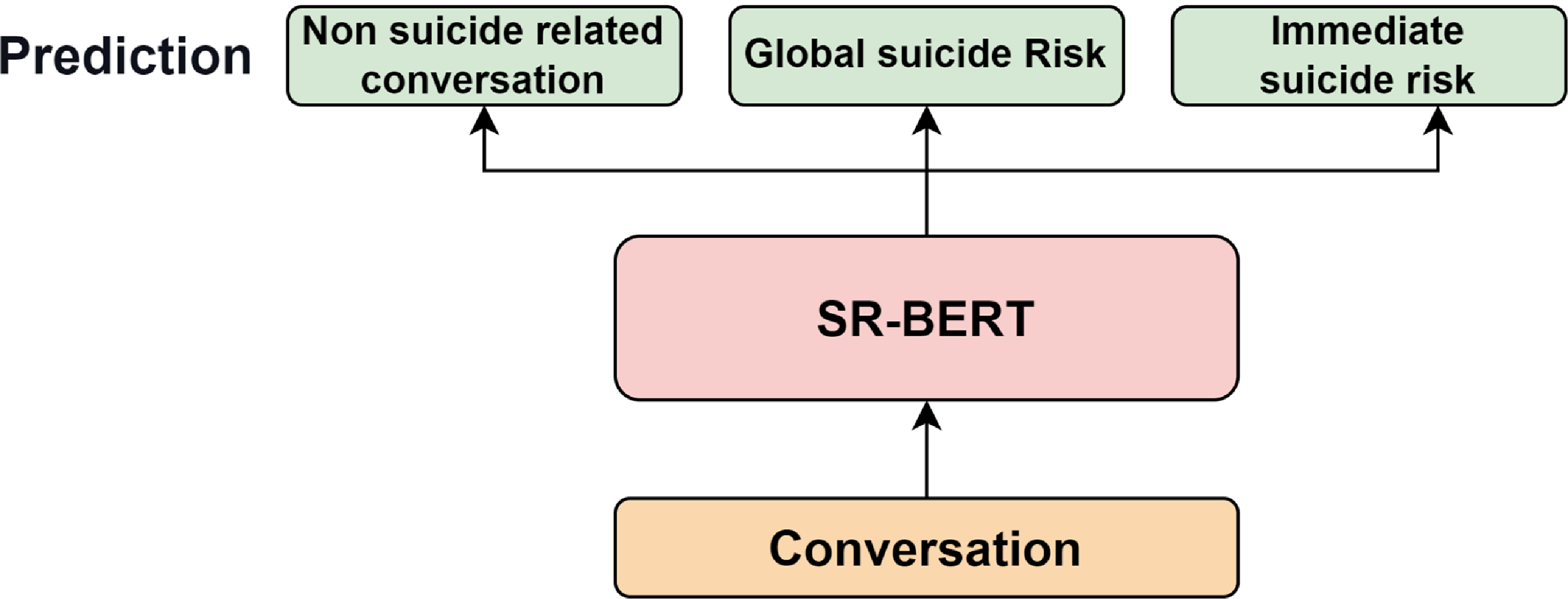

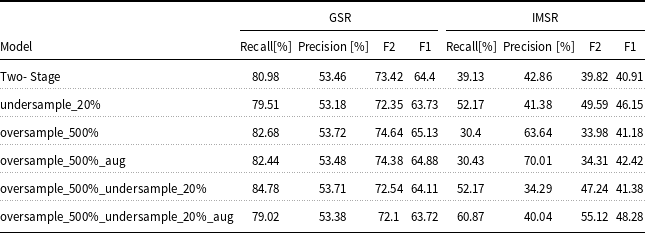






 Open access
Open access