

8.1 Introduction: Background and Aims of a Multi-user Database in EU Law
Empirical legal studies (ELS) in Europe have successfully overcome the inertia of publication outlets, competition for institutional support, and absence from law school curricula and university chairs. It is beginning to build durable research structures, calling for huge investments in projects with uncertain gains. Against this backdrop, ELS in EU law will prosper as a grassroots movement, building and sharing reliable and relevant data resources, collectively adapting to the climate of the day. We initiated the IUROPA CJEU Database Project (IUROPA) in that spirit. The collaborators set out to compile and publish an open source, accessible multi-user database that would increase the visibility of the decision-makers and the decision-making of the Court of Justice of the European Union (CJEU).Footnote 1
The United States Supreme Court (USSC) Database offered a gold standard and an inspiration.Footnote 2 As the most successful social science database facilitating quantitative research on judicial politics in the United States and beyond, it built an entire interdisciplinary field of judicial behaviour, while also supporting other endeavours such as the ELS movement.Footnote 3 The challenges of replicating it were both practical and legal. The USSC Database is focused on a court with substantively different institutional features and strongly exercised docket control, operating in a stable national legal system with solidified institutional structures. Moreover, political scientists are its primary creators, users, and audiences. Scholars approaching the database have typically received post-graduate (PhD) training in social sciences; they are adapted to working with data and are typically versed in empirical qualitative or quantitative methodology, dwelling less on questions of legal complexity and detail.
As a supranational, multicultural, and multilingual (23 languages) Court that insists on complete secrecy regarding its deliberations, and neither publishes the votes of its members in concrete cases nor allows dissents, the CJEU has dealt a more frustrating hand to ELS researchers. The CJEU issues hundreds of judgments and thousands of decisions yearly, rotates chambers, presidents, and members irregularly and adheres to an abstract, repetitive, and formulaic reasoning style.Footnote 4 With few exceptions, the CJEU judges keep a distinctly low profile, often engaging with narrower national academic, judicial, or political circles and professional associations.Footnote 5 They employ ‘faceless’ legal clerks,Footnote 6 who expertly analyse cases and draft the initial reports summarising the facts, the arguments of the parties, and the relevant case law in the cabinet of the individual judge before the deliberations in the chambers.Footnote 7 The public and many academics have not been paying attention to the detailed procedural arrangements and their effect on the working culture and the outcomes, the work of the Registry and other departments that support the CJEU’s judicial activity.Footnote 8 The power of the President to influence the procedure and substance of a ruling is only slowly being demystified.Footnote 9
IUROPA’s resolve to design a database should be understood in this environment. So should its adoption of the criteria for databases, proposed by Weinshall and Epstein: that a database addresses real-world problems, that it is open and accessible, reliable and reproducible, and finally, sustainable and foundational.Footnote 10 This chapter explains these criteria and the related trade-offs in the context of the CJEU and the EU legal order.
The chapter proceeds in two parts. The first part briefly describes the process of developing the CJEU Database within the IUROPA project (Section 8.2). The second part is organised in sections addressing the four criteria above and the challenges they presented to IUROPA. In brief, any database on national and supranational courts that features information about judgments, judges, and the institution intuitively meets the first criterion. However, a database for multidisciplinary use might need to consider that legal realities are realities, too,Footnote 11 meaning that legal scholars have a keen interest in legal concepts for their own sake.Footnote 12 The requirement of openness and accessibility may appear equally obvious in the digitalisation age and in view of growing demands on open source and open access from research funders and publishers alike. As the inclusion of personal data, including sensitive data, is all but unavoidable, these laudable ambitions are, however, challenged by both ethical and legal concerns. The latter are particularly prominent in the European setting, with EU data protection laws being among the strictest in the world. Striking an adequate balance between these interests is a delicate task, whose stakes are risen by the possibility of legal liability for the creators of the database and the institutions that maintain them.
Meeting the criterion of reliable and reproducible data includes producing and publishing code books and reliability reports that help prospective users understand the data and evaluate its quality. It may also trigger hard choices to discard unreliable, incomplete, or low-quality data. In a multidisciplinary setting, the notion of validity becomes germane, as disciplines seek different information and levels of detail in the judgments – such as judicial reasoning and case outcomes.
The sustainable and foundational database criterion requires that the data is easily calibrated, updated, and age/time-resistant. Foundational means that researchers can use the database for their own creative research purposes, reliably transforming and adding to it when answering their research questions. The variables in the database must be clearly defined and substantiated, allowing researchers unfamiliar with the data collection to make informed decisions about the data’s relevance and validity. Among the trade-offs here are the balance between automatic data collection using web scraping, and resource-heavy data collection through hand-coding; sustainability and human intervention are inversely proportionate.
All of these criteria and trade-offs are illustrated with examples from the IUROPA database. The chapter closes with a discussion of how ELS in EU law can leverage and support the available data infrastructure to enrich the knowledge of EU law and courts.
8.2 IUROPA as the Infrastructure for ELS in EU Law
The IUROPA database establishes the necessary infrastructure for empirical legal studies in European Union law. It has collected, pre-processed, and systematised the information including past and present members of the CJEU, Member State governments submitting observations or acting as parties to the case, European institutions, national courts submitting preliminary questions, litigants (including firms and NGOs), legal counsel, and legal agents acting on behalf of the European institutions in the proceedings.
IUROPA is a long-term project that has grown and developed over a decade. Initially, it consolidated existing datasets on EU law and politics.Footnote 13 Then, it worked around the expansive interpretation of data protection rules which restricted data access to completed cases, to collect new data from court and Member State files, such as the submissions of the parties and the reports for the hearings. With the rise of optical character recognition (OCR) and large language models, it developed new ambitions to understand legal developments from the text of the judgments.Footnote 14 Given the CJEU’s institutional traits described above, the database had to be interdisciplinary, the ‘legal content’ of the decisions complementing the analysis of judicial choices and other observable information about the judges.
IUROPA harvests the growing scholarly interest in how law, politics, and society interact. Its backbone is the synergy between legal scholars and political scientists to answer the questions of how to explain legal change, what motivates the decisions of European judges, and whether the legislator can constrain and control judicial power – and thus the process of European integration – through law. This combined legal information with circumstantial information about the judges and the judgments, finding ways of articulating and measuring the CJEU’s legal choices and potentially also assessing their societal implications.
The database caters to legal scholars and political scientists, potentially extending further, supporting empirical studies generally – history, sociology, linguistics, and anthropology come to mind. This is reflected in its structure, or separation of data into the so-called (sub-)components. These include information about (1) cases; (2) proceedings, which are individual or joined cases that can result in decisions; (3) decisions issued by the CJEU, including judgments, orders, and Advocate General (AG) opinions; (4) data on the parties in each proceeding; (5) the composition of the chamber/sitting judges; (6) positions, meaning observations and interventions submitted in the proceedings; (7) national courts submitting preliminary references; (8) citations to case law, Treaties, and legislation; (9) current and former Members of the CJEU (judges and Advocates General); and (10) legal issues and doctrine.Footnote 15 The datasets are available separately but can be easily combined for diverse research needs through common identifiers. IUROPA offers a download tool through which variables can be selected from different components and be merged into a single spreadsheet/database. It also functions as a filter and can convert data (i.e., years into days).
From the outset, IUROPA could capitalise on the increased convenience of publicly available data on the CJEU on EUR-Lex and Curia. In the future, IUROPA and similar projects will be able to benefit from the CJEU’s increasing openness. Over the past couple of years, the CJEU’s public face has become more transparent, obliging, and cooperative, and its PR more forthcoming and wide-ranging, with short YouTube clips and animated presentations on its website, frequent press releases about its rulings, an agreement to deposit older dossiers into the Archives of the European Union, publication of orders for reference from referring national courts on its website, progressive publication of the submissions of the parties and the participants in closed cases, and, most recently, selected final judgments in the main proceedings of national referring courts in preliminary reference decisions.Footnote 16
The development of the IUROPA database has been guided throughout by the four criteria for databases identified by Weinshall and Epstein, as set out in the introduction to this chapter. The work has demonstrated that, while these criteria apply globally, they need to be adjusted locally to match the specific characteristic of the court in question and the jurisdiction in which it operates (and in which the database is being created). The following sections address the individual criteria and the specific challenges they pose for ELS, demonstrating and explaining why databases should be societally relevant, open and accessible, sustainable and foundational, reliable and reproducible.
8.3 Societally Relevant: A Real-World Problem and EU Law
A societally relevant database must capture societally relevant processes, actors, and decisions. A database on courts, including supranational courts, intuitively flies high above the threshold of this criterion. Political scientists studying the CJEU have long collected data to answer questions about its relationship with political actors, the choices its judges make, and the effect of their choices on society.Footnote 17 That said, a database for interdisciplinary use must consider and accept that different disciplines construct their object of inquiry differently. To a legal scholar, a hypothetical normative gap amounts to a viable and worthy object of normative inquiry, regardless of its practical or political implications. Legal linguists are concerned with variations of phrases or divergent descriptions of the same concept, regardless of case outcomes. Political scientists are mostly interested in the political nature of courts debated in many jurisdictions worldwide and often focused on individual justices. In EU law, without a smoking gun, the debate of judicial politics has primarily concerned the CJEU’s methodology and modes of reasoning, forcing the debate into a more legally oriented direction.Footnote 18
The IUROPA database includes information about all the judges of the European Court of Justice and the General Court (GC), established in 1989, such as nationality or professional background, information on the judgments that individual judges have participated in, and the outcomes of the judgments for direct actions and internal market cases. However, the positions of actors appearing before the CJEU can often only be guessed based on their overall function, or at best summarily read from the judgment of the CJEU (which is not always a reliable source as it may not reflect their actual positions well).Footnote 19 Addressing this issue, the Issues and Positions component contains data on the position taken by intervening Member States and EU institutions as well as by the CJEU and the Advocate General (AG) on each legal issue raised in a preliminary reference proceeding.Footnote 20 The information about Member States’ positions were gathered from the Reports for the Hearings, since the actual briefs have not been made public. Unfortunately, the CJEU stopped producing these reports in 2012, which makes it difficult to systematically analyse positions in more recent years.
A legal scholar might be mostly interested in legal concepts or general principles, particularly their (strategic) use or conceptual evolution over time. The Legal Issues and Doctrine component supports such systematic investigation. For instance, Figure 8.1 presents the CJEU’s use of proportionality in all judgments, showing an increase in two policy areas, free movement of persons and freedom of establishment, and a decrease in one, free movement of goods. The findings can contribute to the study of Member State autonomy to introduce, maintain, and enforce national regulatory choices. Additionally, the finding can potentially corroborate the claims raised in recent literature that proportionality is a form of judicial deference to the political actors,Footnote 21 or a form of abdication of judicial constitutional authority and responsibility.Footnote 22
The share of judgments with proportionality review of national measures over time. The solid line shows free movement of goods, the dashed line the free movement of persons, and the short dashed line the freedom to provide services and freedom of establishment. The shaded area indicates the accuracy of the measure (standard errors).
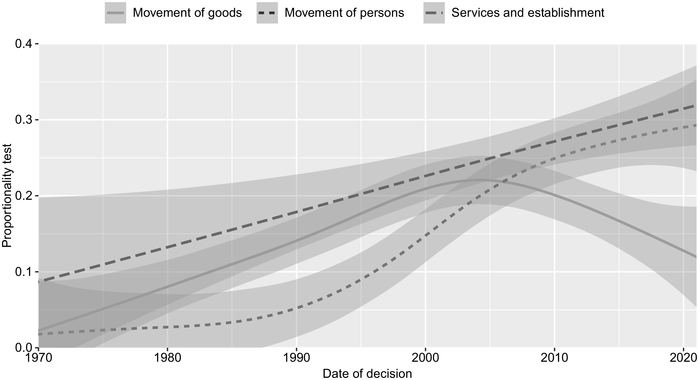
Figure 8.1 Long description
The y-axis represents the proportionality test, ranging from 0.0 to 0.4. The X-axis represents years from 1970 to 2020. The graph plots three distinct lines, each representing a different category, namely, movement of goods, movement of persons, and services and establishment. Each line is accompanied by a shaded area, indicating the uncertainty around the trend. The line for the movement of goods starts at 0.1 in 1970, gradually increases to 0.22 in 2004, and decreases to 0.13 in 2020. The line for the movement of persons begins at approximately 0.1 in 1970, steadily increases over time, and reaches around 0.3 in 2020. The line for services and establishments begins at 0.01 in 1970, forms a concave up increasing curve, followed by 0.03 in 1980, 0.05 in 1990, and 0.15 in 2000, and then a concave down increasing curve following 0.25 in 2010 and 0.29 in 2020. Note, all data are approximated.
A note for the future: while the CJEU’s decision-making has been subject to data collection and countless studies in law, political science, sociology, and history, its homogeneity and diversity in terms of race, ethnicity, political beliefs, and genderFootnote 23 remains underexplored and the implications for the law unexplained. This goes for the judges, Advocates General, the CJEU’s secretariat, staff of the cabinets, and the support services.Footnote 24 Collecting information about these characteristics would considerably enrich our understanding of the CJEU’s law-making, completing the groundbreaking contributions by SolankeFootnote 25 and Guth and ElfvingFootnote 26 in the socio-legal domain, VauchezFootnote 27 in the sociology of law, and FritzFootnote 28 in legal history.
8.4 Open and Accessible: FAIR
The second criterion for a high-quality data infrastructure is openness and accessibility. Access to knowledge, in other words, must literally be free and unrestricted. This means, first, full transparency regarding what data exists,Footnote 29 how it is structured, how it can be interpreted,Footnote 30 how it has been collected, how reliable it is, and so on. Second, data infrastructure must support data-sharing in a narrow sense, while also enabling, supporting, and ideally encouraging the broadest possible participation and collaboration. Removing barriers to data access will empower stakeholders from different disciplines to contribute their unique perspectives and expertise, enriching the data ecosystem and enhancing its value for everyone.
There are strong and compelling reasons to encourage and even demand that researchers who have collected data as part of their research share their data. Making data publicly available is necessary to verify the integrity and reproducibility of conducted studies. Collected data is also a significant research output in and of itself,Footnote 31 useful for answering a variety of research questions beyond those that originally motivated data collection.Footnote 32
The authors of a multi-user database do not know who will be using or contributing to the database over the course of its lifetime, nor how or why they will do so. Multi-user databases in the legal realm are in this sense like other data infrastructures, meaning that they must comply with four foundational principles of data management: Findable, Accessible, Interoperable, and Reusable (FAIR).Footnote 33
Accordingly, there are growing expectations, emphasis, and frequent demands from scientific journals, research funders, and legislators that research data should be treated as a collective resource and shared publicly.Footnote 34 This preference for open research data can be seen as a specific element of the broader Open Data movement,Footnote 35 as well as the academic Open Science movementFootnote 36 ‘with its emphasis on ensuring that research outputs, components and methods are widely disseminated, scrutinised and reused for the good of science and society …’.Footnote 37
Openness competes with other societal interests and values, especially in the EU. It often demands considerable attention from database designers and data collectors. Concretely, the value of openness must be weighed against (1) the protection of privacy of individuals included in the dataset, and (2) the intellectual property rights of any commercial and non-commercial actors that have generated any underlying data. Striking a workable balance between these interests is an ethical and professional responsibility for researchers that increasingly includes legal considerations. In recent years, scholars have faced complex and even contradictory demands. The stakes could be perceived to be high for the scholars and the higher-education institutions in which they work, with potentially severe professional, legal, and economic consequences from poor decisions. These factors explain the slow and uneven adoption of Open Data in academic practice across disciplines.Footnote 38
The exact requirements depend on the type of data and its location. Judicial data has some key features, such as the focus on legal rules, legal issues, or personal information about the judges. It may seem counterintuitive that the data’s geographic locality should matter in such a globalised and digitalised era, but this is nevertheless the case.
Building a multi-user database focused on EU judicial data in the European Union involves, in addition, specific challenges and trade-offs. The EU has been highly active in data regulation; most readers will be familiar with EU legal measures seeking to protect personal information and individual privacy. Fewer may know, however, that the EU has also taken action to enhance the collection and sharing of data, that is, to strengthen the free movement of data.Footnote 39 Free movement of data is part of the EU’s Digital Single Market StrategyFootnote 40 and the European strategy for data.Footnote 41 The plan is to set up a comprehensive regulatory framework that can support the use of data to drive development and progress while simultaneously protecting personal data and fundamental rights. The establishment of the European data space is the central point of this vision: ‘a genuine single market for data, open to data from across the world’.Footnote 42 While much of this plan focuses on commercial use and economic development, it does also seek to promote collecting, using, and sharing data for purpose of conducting research.Footnote 43 In this spirit, the EU and European bodies that fund research generally condition the financing on open data sharing.Footnote 44 Research into courts and judicial behaviour is generally included in such requirements.
This might seem like fertile conditions for the development of multi-user databases. However, at the same time, the EU has some of the world’s strictest privacy laws. Squeezed between the principles and ideals of Open Science on the one hand, and privacy and data protection on the other, European scholars are facing harder choices than many of their peers in other jurisdictions. The EU General Data Protection Regulation (GDPR)Footnote 45 has recently imposed new and stricter legal limits on researchers. The practical obstacles these pose for constructing judicial databases which unavoidably contain personal information, such as the names of judges, parties, and lawyers, as well as sensitive personal information, such as information on racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, or even criminal convictions, is beyond significant.Footnote 46 Entirely excluding sensitive personal information in a judicial database is near impossible, and entirely impossible if that database is to include a corpus of entire texts of judgments.
The European system for handling research data is based on the principle of proportionality: ‘as open as possible, as closed as necessary’.Footnote 47 To justify collecting, organising, structuring, storing, and disseminating judicial data that contains personal data, European database designers must, in lieu of individual approval (which is generally not a feasible option), (1) have a pre-defined aim that is legitimate, and (2) show that the processing of such information is proportionate to that aim. This involves a careful consideration of two questions. First, what legitimate aims will such a database fulfil? This is reinforced by the requirement that a database should address real-world problems, as discussed above. The processing of personal information – and potentially sensitive personal information about actors with significant political power and legal authority, including judges – is thus easily justifiable. Second, what is the potential and likely harm to privacy that the collection and dissemination of data may cause? The answer to this question hinges on the nature of the underlying data and on database design choices. However, the greater the care database designers put into effectively protecting personal information where it is not strictly needed, the greater the chance of achieving proportionality. The important interests of transparency and accountability of judicial and political institutions, which judicial databases serve, would make the design and the establishment of judicial databases in Europe possible.
Multi-user judicial databases pose a dilemma: one of the ‘basic rules’ of collecting judicial data and building judicial databases is ‘the more data the better’.Footnote 48 While it remains relatively unproblematic to maintain a Gotta-Catch-’Em-All approach to non-personal data, its application to personal data directly conflicts with two of the GDPR’s basic principles: the principle of purpose limitationFootnote 49 and the principle of data minimisation.Footnote 50 Compliance with these principles requires a demonstration of a specific purpose. Defining such a specific aim is obviously difficult when it comes to a database intended to be used by unknown users for unknown reasons to study unknown problems.
Within this context, the IUROPA CJEU Database was developed with security and privacy issues front of mind. The Database only includes personal information that is publicly available through public sources. Moreover, the names of natural person parties have been anonymised where feasible in order to minimise privacy harm. We have sought and received approval for the compilation and dissemination of the IUROPA CJEU Database from the Swedish Ethical Review Authority (nr 2020-04273), which, under Swedish law, constitutes compliance with EU data privacy law.
In sum, while full openness and accessibility to extensive data is laudable, the ethical benchmark of privacy should be considered and applied in a way that does not render the creators, maintainers, or users of the database open to legal liability – understanding, too, that these two criteria are not always in sync.
8.5 Sustainable and Foundational: Standing the Test of Time
A sustainable database is easy to maintain and stands the test of time. Here, however, the aim of providing relevant data and valid measurements capable of addressing real-world problems comes up against the limitation of resources. While automated data collection in the form of, for example, web scraping is more sustainable, resource-heavy data collection like manual hand-coding potentially increases the quality – accuracy and validity – of the data.
The foundational criterion can be addressed through the following reminder from Tim Berners-Lee, one of the founders of the worldwide web: ‘[d]ata is a precious thing and will last longer than the systems themselves’.Footnote 51 Data infrastructure must be technically, structurally, and conceptually flexible and inclusive. New users can easily calibrate foundational databases to their own creative purpose, with the data lending itself to accurate transformation and development, when three requirements are met: (1) that the database includes clear definitions of variables and outcomes, coding protocols and coding instructions; (2) that the process of collection, the criteria of data selection (inclusion), and the content of the database are clearly described in supporting documents or a user manual; and (3) that the database includes information about the reliability of data such as inter-coder reliability tests (see also Section 8.6 on reliability and reproducibility).
IUROPA’s National Courts component, which contains data on the national courts that have referred questions to the CJEU for preliminary rulings under Article 267 of the Treaty on the Functioning of the EU (TFEU), illustrates the trade-off between maintenance and relevance, and between the criteria of sustainability and tackling real-world problems.Footnote 52 While the data were hand-coded, most variables were designed so that coders with a legal background could easily acquire the necessary expertise, for instance through searching for information on whether the court operates as part of a national hierarchy and, if so, at what level and whether it has general or specialised jurisdiction. These variables are comparatively straightforward and stable, standing the test of time (bar a complete overhaul of the judicial system). To add new courts to the dataset at their first referral is a simple process because coders can draw on the existing units: for example, if the dataset already includes the Bezirksgerichte (‘district courts’) of Bregenz, Dombim, and Linz, the addition of the Bezirksgericht of Villach will present no difficulties and could easily be automated, subject only to random expert quality checks.
Ensuring that the data will be useful for deeper enquiry, the National Courts component also features more challenging variables which require legal expertise. One example is the variable concerning whether the court in question typically sits as a single judge or a collegiate court, where the coding requires some knowledge of procedural law of the Member State. Another is court prestige, which supports the categorisation of specialised courts operating outside of the judicial hierarchy. These include constitutional courts, but also specialised courts that act simultaneously as first and last instance. The coding of such variables was accomplished with the assistance of national legal experts, who provided the initial classification for the prestige variable, checked the coding of the collegiality variable and responded to the queries of non-expert coders. The upkeep of these variables could prove more challenging and would need to be weighed against their added value of more nuanced explanations of the functioning of the EU legal system. Coding protocols, codebooks, and user manuals will, however, give users the necessary tools to update the database, which is always more efficient than developing new protocols, codebooks, and manuals. Often, these ‘start-up’ tasks take a disproportionately long time in such projects.
Another example requiring manual coding and expertise on the part of the coder is the component on Legal Issues and Doctrine,Footnote 53 which currently includes all judgments issued in three central policy areas of the internal market where the CJEU played a key role:Footnote 54 the free movement of persons and European citizens, the free movement of goods, and the freedom of establishment and services.Footnote 55 Hand-coded variables capture information about the parties to the case such as gender or legal status, the legal questions or issues raised in the dispute, the strictness of judicial review expressed in proportionality tests, and the allocation of decision-making authority between the European and the national levels. The latter is typically conceptualised in legal terms as deference, or in social science terms as national regulatory autonomy. The information offers a concise but detailed overview of legal outcomes – of what the CJEU decided, such as the decisions about the compatibility of national measures and policies with European Union law. Crucially, this information cannot be easily compiled from the official data repositories like CuriaFootnote 56 or EUR-Lex.Footnote 57 Of twenty-two observed legal characteristics (variables) included in the Legal Issues and Doctrine component of the IUROPA CJEU Database, eight are common to all policy areas and potentially to all judgments, and fourteen are policy-specific, meaning that they are narrower, addressing legal issues of the disputes typically attached to one of a handful of policy areas.
Such information is relevant for empirical legal studies in law and political science. For example, Figure 8.2 illustrates the patterns in the litigation of free movement and European Union citizenship rights.Footnote 58 The initial Treaties supported the free movement of workers as essential to the establishment and the functioning of the European internal market. The Treaty of Maastricht (1992) introduced the concept of EU citizenship in an attempt to bring the EU closer to its citizens.Footnote 59 Figure 8.2 shows that the share of judgments including workers or economically active persons moving across state borders (dotted line) decreased from more than 70 per cent in the early 1960s to less than 50 per cent during the 2010s. Second, the share of judgments where the CJEU upheld the applicant’s claims based on free movement and European citizenship rights (dashed line), decreased from over 80 per cent in the 1960s to less than 60 per cent after 2015. These findings imply that the type of free movement of persons cases, the type of the applicants litigating their free movement rights, and the CJEU’s willingness to recognise the rights of the applicants have changed.
The share of free movement of persons judgments (y-axis) over time where the CJEU rules in favour of private individuals (dashed line) and the share of judgments where the applicant is economically active (dotted line). The x-axis represents the date of the judgment. The shaded area indicates the Standard Error intervals.
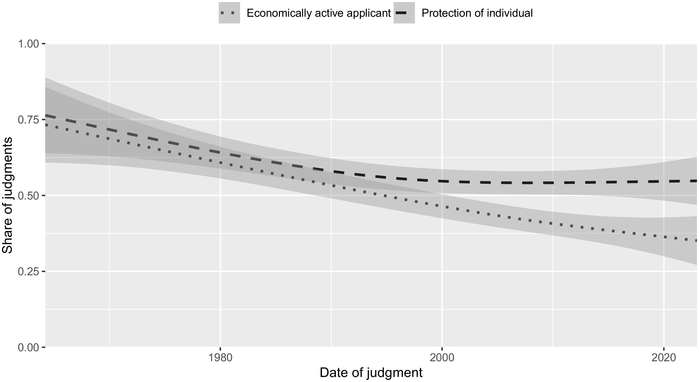
Figure 8.2 Long description
The X-axis represents the date of judgment, ranging from 1960 to 2020. The Y-axis represents the share of judgments, ranging from 0 to 1. It plots lines for economically active applicants and the protection of individuals. The lines have a shaded area around them to indicate the confidence interval. The line for the protection of individual begins at 0.76 in 1964, follows a concave up declining curve with 0.63 in 1980, 0.60 in 1990, 0.57 in 2000, 0.57 in 2010, and 0.58 in 2020. The line for economically active applicant begins at 0.74 in 1964, decreases to 0.60 in 1970, 0.58 in 1980, 0.54 in 1990, 0.47 in 2000, 0.40 in 2010, and 0.35 in 2020. Note, all data are approximated.
Further analysis can unpack these patterns and changes, contributing to various strands of literature. Most relevantly, it could help clarify the effect of political pressure from Member State governments on the CJEU, or the effect of the financial crisis on the rights of economically inactive migrants. Those have typically – even if often inaccurately – been portrayed in public debate as taking resources away from citizens.Footnote 60
Scholars aspiring to update the Issues and Positions and Legal Issues and Doctrine components will observe two things: first, manual coding requires resources. Future data collection efforts might address some of the challenges and limitations, especially with the help of machine learning, natural language processing (NLP), and large language models in annotating the judgments in lieu of human coders. This would not only considerably lower the cost of repeated calibration, rounds of recoding, inter-coder reliability tests, updating codebooks, and extensive training of research assistants,Footnote 61 but also increase sustainability by enabling computerised database expansion and updates. Second, the doctrinally most interesting questions are rare in the case law. In the context of free movement of persons, this includes issues such as the occurrence of a purely internal situation (a dispute entirely confined to the legal system or the territory of the state, lacking a connection to EU law, and thus excluding the competence of the EU and potentially the CJEU’s jurisdiction), recognition of derived rights of third-country nationals caring for young European citizens, and even questions related to the protection of public finances. Coding these variables might not merit the coding effort. Legal analysis of the few relevant judgments identified by transparent search criteria in the official case law repositories will be far more productive and rewarding.
Epstein and Weinshall wisely caution against data exuberance. A reasonable balance must be struck between the ambition of including analytical legal information on the one hand and burdening the database with data unsuitable for ELS methods on the other. With doctrinally interesting matters not only being rare but also complex, this is also a question of reliability.
8.6 Reliable and Reproducible
Reliability and validity are concepts that communicate the trustworthiness of data and thus, of the research based on it. A multi-user database should enable wider use of data while preventing the creation of sub-par surrogates and bad research.Footnote 62 Because creators of multi-user databases must assume that the database will outlive them, enhancing reliability and reproducibility is a top priority. Epstein and Weinshall suggest that the criterion of reliability and reproducibility obliges the database developers and users to treat all observations and variables as part of a chain of evidence; we must be able to explain and recall how they were generated. Further, anyone with sufficient skill should be able to understand, evaluate, and reproduce the content without the collaboration of the creators.Footnote 63 This task becomes easier if the database includes an explanation of how the variables were selected and constructed. Striving for reliability and facilitating reproduction, a database for multidisciplinary use should also minimise the use of monodisciplinary jargon or find efficient ways to convey specificities.
The process starts by carefully considering the extraction of necessary and useful information from the judgments.Footnote 64 Legal researchers must think beyond doctrine and concepts of political and social reality; political scientists must think beyond outcomes and ways to extract individual votes from collegiate decisions – beyond power politics. Both must consider which types of information will lend themselves to systematic coding by human coders, which information could be recorded automatically or semi-automatically from text of the judgment, and which information could be harvested and organised from official data sources and repositories (metadata). When deciding on the list of variables to use for conducting research based on the data, researchers must make sure that the measurements reflect the phenomena they aim to study. The validity of measurements should be obvious to researchers adding to the dataset or creating similar measurements.
For instance, legal scholars and political scientists often speak of judicial deference to political actors. In the EU context this deference can be expressed through deference from the CJEU to the national court deciding the dispute in the main proceedings under the preliminary reference procedure (Article 267 TFEU). Some observers would not consider deference from one court to another court in a case that concerns a correct interpretation of EU rules as a primarily ‘political’ or ‘strategic’ move of the CJEU. This point would become clearer when explaining that deference to national courts is typically synonymous with deference to Member States, as most referrals concern the compatibility between national legal acts and EU law and national courts. The matter can be further unpacked. A legal scholar would reluctantly accept the CJEU’s deference as primarily strategic in the context of Article 267 TFEU, because national courts often ask fuzzy questions, supply patchy information to the CJEU, and draft their questions from the perspective of the national legal systems for shortsighted and narrow purposes.Footnote 65 The CJEU cannot always offer clear and precise answers to such questions. But this does not mean that it defers important legal decisions to the national courts. Also, Article 267 TFEU includes a division of labour – the national courts decide the case at hand based on the interpretation of the rule by the CJEU. The CJEU has no competence to rule in the case, thus inevitably leaving the decision of whether and how to apply the interpretation of the rule to the national court. In this sense, the CJEU must always defer, at least minimally. This debate touches on a familiar question of validity, highlighting the importance of clear, legally correct, and transparent definitions.
The Legal Issues and Doctrine component captures the established concepts and doctrine. It is designed to closely correspond to legal reality – meaning that the variables are valid proxies for the CJEU’s decision-making – including the methods of interpretation, judicial tests, and normative implications. The problem of validity and replicability can be solved by explaining that the deference variable captures the CJEU’s passing of decision-making (in this case also interpretive) power and important legal choices to the national courts and by extension to the Member States, which exceeds the necessary division of labour inherent in Article 267 TFEU. Further, the researchers must select a reasonable number of values that a variable can assume. While coding deference as a binary variable, with outcomes deference_yes and deference_no, would render higher inter-coder reliability scores and possibly also lend itself to automated coding,Footnote 66 it might not be informative enough for legal scholars trying to systematise the case law on the scale of deference or devise specific types of deference.
Multi-user databases will not satisfy all research requirements and aims. This must, however, be made clear from the outset. The publication of codebooks and inter-coder reliability scores offer a simple and effective solution but raise a dilemma: When is data ‘good enough’?
We would all agree that unreliable data should not be published and that the question of reliability should be answered based on accurate and full information supplied by the creator of the data. What is trickier is agreeing on when data is reliable enough. Existing metrics are often developed in the context of natural science and medical research requiring high inter-coder reliability before data can be published and reused. Legal scholars engaging with ELS must live up to high standards. Even when they code their data individually, they must ensure to code the data consistently (internal consistency/internal validity). When they solicit the opinion of close colleagues, incorporating their input, they must report this even if omitting a full inter-coder reliability report in the form of written notes of disagreement. While the Issues and Positions component includes strict reliability tests, the National Courts component combined hand-coding of most variables about national referring courts with consistent expert checks. This involved two steps: first, the project team hand-coded the data based on the code book and then national legal experts performed quality checks. In this sense, it did not lower the standards but adapted them to the nature of the data and the task.
Moreover, legal scholars disagree about the importance of a ruling, its contribution to doctrine, its landmark character, and symbolic importance.Footnote 67 The disagreement translates into low inter-coder reliability scores for variables such as case importance. Fine-tuning of codebooks, extensive training of research assistants, hand-coding, and often several rounds of recoding might prove prohibitive for short-term projects or smaller teams under pressure to publish research findings and data. Even for larger, generously financed teams, the gains of such enterprise would not compensate the cost. Many variables must simply be scrapped, and the data discarded as unreliable.Footnote 68 That said, legal scholars might find value in such data. For instance, they might find it useful to select and carefully examine judgments marked as important or use codebooks and the results of inter-coder reliability checks in developing their own measurements and learning from existing errors. Again, this does not lower the standards of ELS but tailors them to the research needs – a legal scholar using the ‘data’ will not claim that they are engaging in empirical research.
By analogy to the recording of language patterns and the meaning of text in content analysis, the coding of legal texts and legal meaning is typically more objective and reliable if content is manifest rather than latent.Footnote 69 Legal concepts are expressed using different terms and coders must bring in subjective interpretation. While all trained coders can be confident in the accuracy of their own interpretations, new coders and the users of data will suggest alternative interpretations. Providing concrete examples in the codebook can help ensure that coders understand and code variables with more than two outcomes in the same way and that future contributors can code future cases in the same way.
High inter-coder reliability may be reasonably expected for the coding of textual information (such as gender of the applicants), but it is harder for the coding of legal meaning and concepts (such as the proportionality test). The more coders are asked to make difficult judgments, the more they bring subjective understanding and pre-conceptions into play, and codebooks will not always offer the necessary guidance to approximate the coding to a simple task of recording instances.
Moreover, reliability issues at times arise because of class imbalance, meaning that one of the variable’s values occurs much more often than the others.Footnote 70 For example, for the deference variable in the Legal Issues and Doctrine component it is very common to observe the CJEU’s decision not to defer, while it is much less common that the CJEU defers. Consequently, an inattentive coder who always codes no_deference is statistically likely to have a high level of agreement with the careful coder who identifies the few cases of deference. A reliability coefficient such as Krippendorff’s Alpha considers this situation of by-chance agreement. When comparing reliability scores across different studies it should be noted that disagreements among coders tend to result in a lower Krippendorff’s Alpha score in cases with class imbalance compared to coding a variable whose values are more evenly distributed.Footnote 71
8.7 Conclusion: Why Invest in a Common Future?
This chapter has reflected on the trade-offs and considerations involved in the building and maintenance of multi-user databases which live up to four criteria proposed by Epstein and Weinshall: they address real-world problems; they are open and accessible; they deliver reliable and reproducible data; and they are ageless and easily calibrated to research purposes unknown at the time of data collection and cleaning. The most obvious and hardest choices when trying to live up to these criteria include decisions about the sufficient reliability of data, whether to discard or improve upon imperfect data, and whether to publish or postpone the publication of incomplete data. Furthermore, the sustainability criterium can more easily be satisfied when the need for human intervention in the updating and maintaining the data is minimal. This could push scholars to strive for the most accurate (valid) or most reasonable measurements for pragmatic reasons. By consequence, it will not support the ambition of obtaining the most nuanced and legally relevant information. The quest for openness and maximum data moreover clashes with the protection of privacy regulation, imposing the principles of purpose limitation and data minimisation.
Looking back, IUROPA was an enormous investment, requiring significant financial resources, organisation, and management with an uncertain outcome and potentially limited payoff for individual researchers. Yet, regardless of these challenges and trade-offs, we should invest in multi-user databases in EU law. High-quality data enriches inquiry, generates new questions, increases the quality of research findings, and in turn improves our understanding of the EU legal system. Thereby, it underwrites the relevance, contribution, and legitimacy of ELS, a field that has expanded from isolated studies and events into a lively community of scholars pursuing similar goals and sharing an interest in data-based or data-driven work.Footnote 72
We should also invest in multi-user databases to avoid unproductive conversations about the merits of ELS in EU law. Until ELS has a firm data foundation, it will continue to struggle for recognition, university chairs, and inclusion in the law curriculum. We should invest in multi-user databases to grow a scientific community rather than an echo chamber. A scientific community is a group of scholars working on shared problems in parallel or together, who mostly agree about methods, standards, valid research questions, and approaches.Footnote 73 However, a dynamic scientific community with a common future must share information, and progress towards consensus over standards and knowledge claims.Footnote 74 Data sharing is progress.

 Open access
Open access