


1. Introduction
Developing models capable of understanding and extracting information from textual passages to answer targeted questions is referred to as machine reading comprehension (MRC). This task poses significant challenges due to the complexity of teaching models to interpret natural language. The importance and focus on MRC have increased for various reasons. One factor is the availability of carefully assembled datasets, such as the one introduced by Biltawi et al. (Reference Biltawi, Awajan and Tedmori2020a). Additionally, there’s a rising interest among researchers in utilizing neural networks (NNs), and the accessibility of affordable and powerful graphical processing units has also played a significant role, as noted by Seo et al. (Reference Seo, Kembhavi, Farhadi and Hajishirzi2016).
According to Chen (Reference Chen2018), there exist four distinct categories of MRC datasets: span-extraction, multiple-choice, cloze-style, and free-form, each containing sets of passage-question-answer triples. Span-extraction datasets, exemplified by SQuAD (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) and NewsQA (Trischler et al. Reference Trischler, Wang, Yuan, Harris, Sordoni, Bachman and Suleman2017), involve extracting a single text span from the relevant paragraph as the answer to a given question. Multiple-choice datasets, such as SciQ (Welbl et al. Reference Welbl, Liu and Gardner2017), present questions alongside two or more potential answers, the correct one, and the corresponding paragraph. Cloze-style datasets, like CNN-Daily Mail (Hermann et al. Reference Hermann, Kočiskỳ, Grefenstette, Espeholt, Kay, Suleyman and Blunsom2015), involve questions where a term or entity is missing. Free-form datasets, exemplified by MS MARCO (Nguyen et al. Reference Nguyen, Rosenberg, Song, Gao, Tiwary, Majumder and Deng2016), present questions and paragraphs without explicit answers, requiring systems to infer the answers from the passages.
Arabic is a challenging language distinct from English (Biltawi et al. Reference Biltawi, Tedmori and Awajan2021) and is still at an early stage in terms of MRC research. With English’s global predominance, researchers have primarily focused on English MRC, developing and utilizing benchmark datasets (Alian and Al-Naymat Reference Alian and Al-Naymat2022). Experimental findings indicate that NNs and attention mechanisms can effectively improve answer extraction from passages. However, research targeting Arabic MRC remains limited, with only a few studies conducted in this area (Biltawi et al. Reference Biltawi, Tedmori and Awajan2021).
The primary focus of this paper is proposing an enhancement to the bidirectional attention flow (BIDAF) model. For evaluation, the Arabic Span-Extraction-based Reading Comprehension Benchmark (ASER), comprising 10,000 question-answer-passage triples, was utilized as the benchmark dataset. The objective of this study is to introduce an improved version of the BIDAF model specifically tailored for Arabic MRC and to compare it against four baseline models: the sequence-to-sequence model, the original BIDAF model with two input layers, the original BIDAF model with one input layer, and the AraBERT with BIDAF model. Additionally, the enhancement of the improved-BIDAF model was carried out in two stages: initially, the first layer was replaced with the parts-of-speech (POS) embedding layer, followed by the substitution of bi-LSTM with bidirectional gated recurrent unit (bi-GRU) in the contextual and model layers. This adjustment led to improved model performance on Arabic text, achieving an accuracy rate of 75.22%.
The structure of the paper is organized as follows: Section 2 discusses related work, Section 3 outlines the problem statement, Section 4 introduces ASER, Section 5 presents the improved BIDAF model, Section 6 discusses the fine-tuned AraBERT BIDAF model, Section 7 details the experimental setup, Section 8 presents the experimental findings, Section 9 provides a comparison and discussion, and finally, Section 10 concludes the paper.
2. Related work
The field of MRC has experienced notable advancements, particularly in the English language, where researchers have explored various methodologies to enhance MRC performance. Initially, the adoption of NNs and word2vec embeddings laid the groundwork for subsequent developments. The emergence of transformer models marked a significant breakthrough, achieving remarkable results on various MRC benchmarks. Recently, research focus has shifted toward tackling more intricate MRC challenges, including addressing unanswerable questions (Hu et al. Reference Hu, Wei, Peng, Huang, Yang and Li2019), integrating reasoning capabilities (Li et al. Reference Li, Cheng, Chen, Sun and Qu2022), handling queries based on multiple passages (Dong et al. Reference Dong, Wang, Dong and Zhang2023), and exploring conversational MRC (Gupta et al. Reference Gupta, Rawat and Yu2020). However, in the context of the Arabic language, MRC research remains in its early stages. Limited progress in this domain can be attributed to the inherent complexities of Arabic, characterized by its rich morphology and complex syntax, demanding specialized approaches for effective comprehension. Moreover, the scarcity of large-scale Arabic MRC datasets presents a significant hurdle to further advancements in this field.
Recently, several surveys have been conducted on the topic of MRC. For instance, Baradaran et al. (Reference Baradaran, Ghiasi and Amirkhani2022) reviewed 241 research papers spanning from 2016 to 2020, presenting three primary observations: a shift in research focus from extraction to generation, from single-document (passage) to multi-document (passage) reading comprehension, and from scratch learning to the utilization of pre-trained embeddings. Another survey by Xin et al. (Reference Xin, An, Sujian and Yizhong2019) provided a comprehensive overview of datasets, neural models, and various techniques employed in English MRC, covering popular methods such as Word2Vec, Glove, ELMO, BERT, and GPT. Liu et al. (Reference Liu, Zhang, Zhang, Wang and Zhang2019) aimed to cover MRC tasks, general NN models, their architectures used for MRC, and the emerging trends and challenges in this field. Additionally, Zeng et al. (Reference Zeng, Li, Li, Hu and Hu2020) analyzed fifty-seven MRC tasks and datasets, proposing a novel taxonomy for categorizing MRC tasks based on corpus types, questions, answers, and sources of answers. These surveys consistently emphasize the distinction between MRC and Question Answering (QA), noting that MRC involves two inputs (the question and the context) and one output (the answer), while QA typically involves one input (the question) and one output (the answer). Note that phases of MRC development can be grouped into rule-based techniques, classical ML techniques, and deep learning techniques.
For the Arabic language, the task of MRC has been explored in a few research papers. Some of these efforts include work on Quranic datasets, such as the research by Aftab and Malik (Reference Aftab and Malik2022) and the attempt by Malhas and Elsayed (Reference Malhas and Elsayed2022). These investigations conducted experiments utilizing BERT and AraBERT, respectively, on the Qur’anic Reading Comprehension Dataset. The reported highest exact match (EM) scores achieved were 8.82% and 28.01%, respectively, following the fine-tuning of the AraBERT model on classical language. Correspondingly, the highest F1-measure scores attained were 26.76% and 49.68%, respectively.
An inherent challenge in effectively implementing MRC lies in the availability of suitable datasets for training and evaluating models. The presence of high-quality and diverse datasets is important in developing MRC models capable of accurately and comprehensively answering questions. Various datasets have been created for the English language, including SQuAD (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016), NewsQA (Trischler et al. Reference Trischler, Wang, Yuan, Harris, Sordoni, Bachman and Suleman2017), MCTest (Richardson et al. Reference Richardson, Burges and Renshaw2013), and MS MARCO (Nguyen et al. Reference Nguyen, Rosenberg, Song, Gao, Tiwary, Majumder and Deng2016), among others. Additionally, numerous models have been developed based on these English datasets, such as BIDAF (Seo et al. Reference Seo, Kembhavi, Farhadi and Hajishirzi2016), FastQA (Weissenborn et al. Reference Weissenborn, Wiese and Seiffe2017), and BERT (Kenton and Toutanova Reference Kenton and Toutanova2019), to name a few. In contrast, there have been only a few endeavors to establish Arabic MRC benchmarks, as evidenced by works by Biltawi et al. (Reference Biltawi, Awajan and Tedmori2020b) and Biltawi et al. (Reference Biltawi, Awajan and Tedmori2020a). However, progress in Arabic MRC has been relatively constrained, with only a few large-scale datasets available, including Arabic SQuAD (Mozannar et al. Reference Mozannar, Maamary, Hajal and Hajj2019), AQAD (Atef et al. Reference Atef, Mattar, Sherif, Elrefai and Torki2020), and ASER (Biltawi et al. Reference Biltawi, Awajan and Tedmori2023). Recently, (Alnefaie et al. Reference Alnefaie, Atwell and Alsalka2023) presented two novel question-answer datasets, HAQA for Hadith and QUQA for the Quran, emphasizing the challenges in comparing their performance due to the absence of a standardized test dataset for Hadith and the relatively simplistic nature of questions in the Quran dataset. HAQA, the Arabic Hadith question-answer dataset, was built from various expert sources, while QUQA a series of construction phases, including integration with existing datasets and supplementation with new data from expert-authored texts, and datasets comprising 1,598 and 3,382 question-answer pairs, respectively.
The key distinction between these datasets and previous attempts primarily lies in their size, with these datasets containing 10,000 or more records of data, whereas prior attempts typically include 2,000 or fewer records of data. Moreover, these datasets are specifically tailored for the task of MRC and are structured as triples comprising a question, an answer, and a context, as opposed to only including the question and answer. Additionally, there are notable differences between Arabic SQuAD, AQAD, and ASER. First, ASER was created manually by native Arabic speakers, whereas Arabic SQuAD is essentially a translated version of the English SQuAD, and AQAD was automatically generated using Arabic articles. Second, there are variations in the length of questions and answers among these datasets. ASER poses a greater challenge as it comprises longer sentences compared to Arabic SQuAD and AQAD, which comprise shorter questions and answers.
The study by Mozannar et al. (Reference Mozannar, Maamary, Hajal and Hajj2019) evaluated the performance of QANet and BERT models on the Arabic SQuAD dataset. The experiments resulted in an EM score of 29.4% and 34.2% and an F1-measure of 44.4% and 61.3% for the QANet and BERT models, respectively. Similarly, Atef et al. (Reference Atef, Mattar, Sherif, Elrefai and Torki2020) conducted experiments on the AQAD dataset using BIDAF and BERT models. The results demonstrated an EM score of 32% for BIDAF and 33% and 37% for BERT, with corresponding F1 measures. Furthermore, Biltawi et al. (Reference Biltawi, Awajan and Tedmori2023) performed baseline experiments on the ASER dataset, employing sequence-to-sequence, BIDAF, and AraBERT BIDAF models. The findings revealed an EM score of 2.5% for the sequence-to-sequence model, 39.5% for the BIDAF model, and 0% for the AraBERT BIDAF model. Additionally, F1 measures were reported as 35.76%, 66.25%, and 19.73% for the sequence-to-sequence, BIDAF, and AraBERT BIDAF models, respectively.
Additionally, two research papers by Alkhatnai et al. (Reference Alkhatnai, Amjad, Amjad and Gelbukh2020) and Biltawi et al. (Reference Biltawi, Tedmori and Awajan2021) investigated the trends, challenges, and conducted gap analysis in MRC. Both studies highlighted the absence of standardized benchmarks and the complexities inherent in the Arabic language, which pose obstacles to progress in this domain. To advance the field of Arabic MRC, it is imperative to refrain from excluding certain techniques or models during experimentation, such as solely focusing on BERT while disregarding Word2Vec. Instead, the emphasis should be on comprehensively assessing the effectiveness of each approach, particularly in the context of Arabic. This approach seeks to evaluate the efficacy of different techniques when applied to Arabic, rather than simply following the latest trends since the available datasets for the Arabic language are still moderate in size and BERT needs more data compared to Word2Vec.
The current paper differs from related works presented in this section, by extending beyond proposing benchmark datasets and experimenting with preexisting English models for Arabic MRC. Rather, this paper introduces a novel enhancement to the BIDAF model, customized specifically for Arabic, with the objective of enhancing answer extraction. The emphasis is on introducing new features and experimenting with different neural units to tackle the unique challenges of the Arabic language. This approach aims to contribute to the development of more effective and specialized MRC models for Arabic.
3. Problem statement
It is possible to structure the MRC task as a supervised learning problem. Given training set triples of question-answer-passage
 $(q^i, a^i, p^i)_{i=1\,\ldots \, n}$
, the objective is to train a model
$(q^i, a^i, p^i)_{i=1\,\ldots \, n}$
, the objective is to train a model
 $f$
that can produce one right answer
$f$
that can produce one right answer
 $a$
, given a passage
$a$
, given a passage
 $p$
and a question
$p$
and a question
 $q$
. The model’s two inputs and output are shown in Equation (1):
$q$
. The model’s two inputs and output are shown in Equation (1):
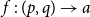 \begin{equation} f\;:\;(p,q)\rightarrow a \end{equation}
\begin{equation} f\;:\;(p,q)\rightarrow a \end{equation}
The passage, denoted as
 $p$
, consists of
$p$
, consists of
 $|p|$
tokens:
$|p|$
tokens:
 $p= (p_1,p_2,\ldots, p_{|p|} )$
. Similarly, the question, denoted as
$p= (p_1,p_2,\ldots, p_{|p|} )$
. Similarly, the question, denoted as
 $q$
, consists of
$q$
, consists of
 $|q|$
tokens:
$|q|$
tokens:
 $q=(q_1,q_2,\ldots, q_{|q|} )$
. Each passage token
$q=(q_1,q_2,\ldots, q_{|q|} )$
. Each passage token
 $p_i\in V$
for
$p_i\in V$
for
 $i=1,\ldots, |p|$
, and each question token
$i=1,\ldots, |p|$
, and each question token
 $q_i\in V$
for
$q_i\in V$
for
 $i=1,\ldots, |q|$
where
$i=1,\ldots, |q|$
where
 $V$
represents a predefined vocabulary. The answer
$V$
represents a predefined vocabulary. The answer
 $a$
is a span within the passage, represented as
$a$
is a span within the passage, represented as
 $(a_{start},a_{end})$
with the constraint that
$(a_{start},a_{end})$
with the constraint that
 $p_1\le a_{start}\le a_{end}\le p_{|p|}$
(Chen, Reference Chen2018). The trained model
$p_1\le a_{start}\le a_{end}\le p_{|p|}$
(Chen, Reference Chen2018). The trained model
 $f$
will then be evaluated using a testing set.
$f$
will then be evaluated using a testing set.
4. Arabic Span-Extraction-based Reading Comprehension Benchmark (ASER)
The experiments were conducted on ASER which is an Arabic Span-Extraction-based Reading Comprehension Benchmark created manually and proposed by Biltawi et al. (Reference Biltawi, Awajan and Tedmori2023). ASER was created over the period of two semesters, where a large number of university students helped in writing questions and their answers on articles crawled from Aljazeera website belonging to twenty-five domains. Two Arabic native speakers validated the dataset and also performed some editing, resulting in the creation of 10,000 records of question-answer-passage triples. These records were divided into a training set of 9,000 records, a testing set of 1,000 records, and another testing set consisting of 100 records sampled from the original testing set for human performance evaluation. The human performance resulted in an EM score and F1-measure of 42% and 71.62%, respectively.
The authors also conducted neural baseline experiments on ASER. Results showed an EM and F1-measure of 0% and 15.96%, respectively, on AraBERT BIDAF model, 4% and 36.9%, respectively, on the sequence-to-sequence model, and 38% and 67.54%, respectively, on the original BIDAF model, all on the 100 testing set. Figure 1 demonstrates two examples from ASER, where each record of ASER consists of semester-number, article-ID, question, answer, paragraph, first index of the answer from the paragraph, and domain of the article. ASER includes both long and short answers, with lengths varying from two to seventy-five tokens. The human performance EM score of only 42%, and the varying lengths of the answers make ASER a challenging benchmark.
Examples from ASER.
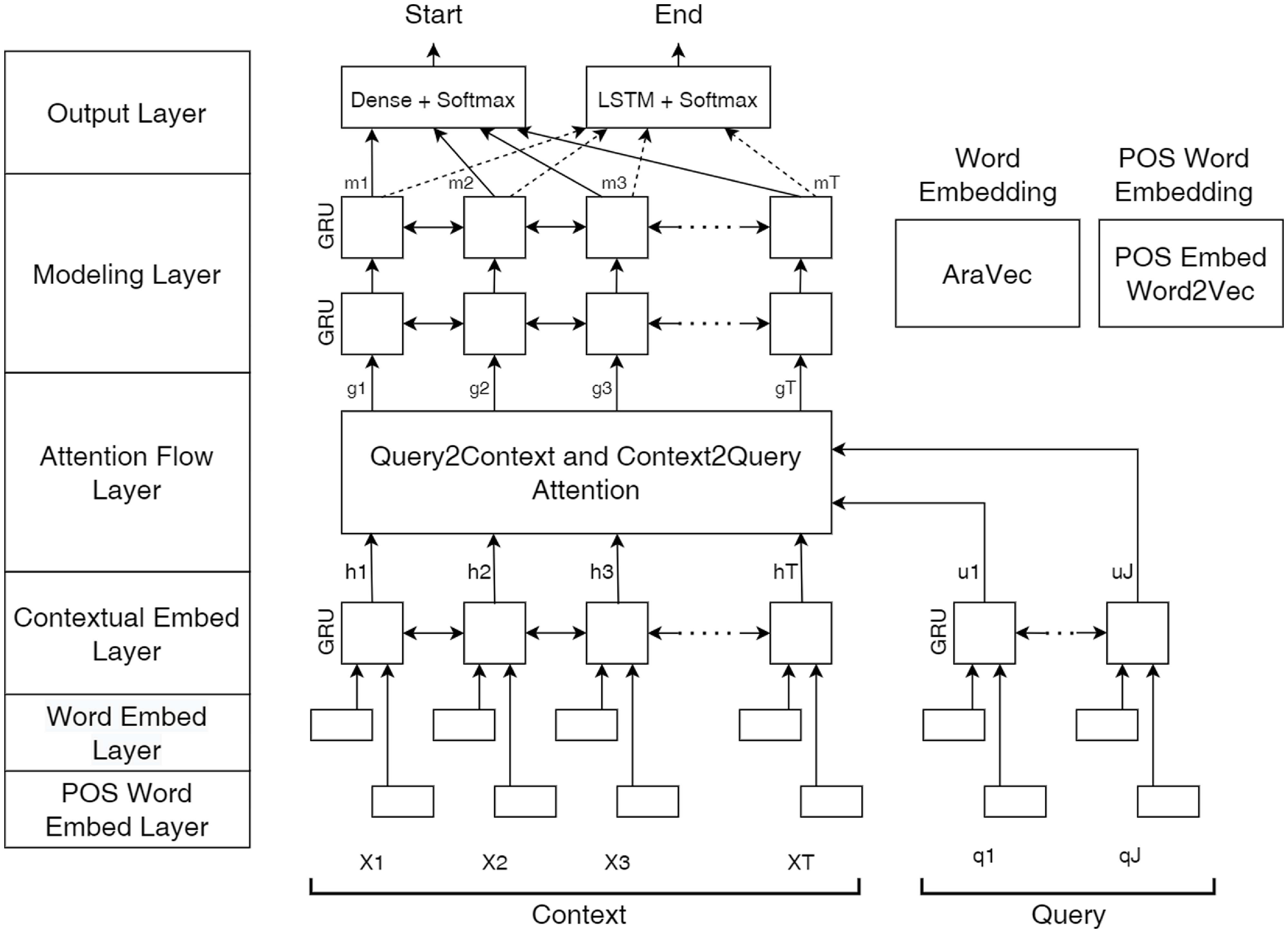
5. Improved bi-directional attention flow (BIDAF) model
Several experiments were carried out to customize BIDAF for the Arabic language. The most promising outcomes were achieved through the improved version of BIDAF (AKA improved-BIDAF), as depicted in Figure 2. This improved-BIDAF model incorporates four inputs: the POS word embeddings for both the question and the context, along with the word embeddings for both the question and the context. Prior to feeding the text into the model, tokenization of the input is necessary, where
 $x_1,x_2,\ldots, x_T$
represent the context tokens, and
$x_1,x_2,\ldots, x_T$
represent the context tokens, and
 $q_1,q_2,\ldots, q_J$
denote the question tokens.
$q_1,q_2,\ldots, q_J$
denote the question tokens.
5.1. POS word embedding layer
In this layer, pretrained POS word embeddings were utilized instead of employing character-level convolutional neural networks (CNN). These POS word embeddings were applied to both the question
 $Q_{POS}$
and the context
$Q_{POS}$
and the context
 $X_{POS}$
. The dimension of the embeddings in this layer ranges from 3 to 32, and you can find a more detailed explanation in Section 7.
$X_{POS}$
. The dimension of the embeddings in this layer ranges from 3 to 32, and you can find a more detailed explanation in Section 7.
5.2. Word embedding layer
Instead of using Glove embeddings, pre-trained Aravec embeddings (Soliman et al. Reference Soliman, Eissa and El-Beltagy2017) were employed for both the question
 $Q_{word}$
and the context
$Q_{word}$
and the context
 $X_{word}$
. The embedding dimension in this layer can either be 100 or 300.
$X_{word}$
. The embedding dimension in this layer can either be 100 or 300.
It’s important to note that the embedding dimensions of the POS and word embedding layers are different. As a result, they are not concatenated before being passed to the contextual embedding layer. Instead, the contextual embedding layer works to unify the embedding dimension for both the POS and word embeddings.
Then, the POS and word embeddings for the question are concatenated, and similarly, the POS and word embeddings for the context are concatenated as well. These concatenated embeddings are then passed to the attention flow layer for further processing. This approach ensures that the model can effectively utilize both the POS and word information during the attention flow process.
5.3. Contextual embedding layer
In this layer, a bi-GRU is utilized to capture the temporal interactions between the words in both the question
 $U_{word}\in R^{2dxJ}$
and the context
$U_{word}\in R^{2dxJ}$
and the context
 $H_{word}\in R^{2dxT}$
independently, as well as between the POS tags of both the question
$H_{word}\in R^{2dxT}$
independently, as well as between the POS tags of both the question
 $U_{POS}\in R^{2dxJ}$
and the context
$U_{POS}\in R^{2dxJ}$
and the context
 $H_{POS} \in R^{2dxT}$
. Then these are concatenated for both the question
$H_{POS} \in R^{2dxT}$
. Then these are concatenated for both the question
 $U=[U_{word};\ U_{POS}]$
and the context
$U=[U_{word};\ U_{POS}]$
and the context
 $H=[H_{word};\ H_{POS}]$
, As a result, the outputs of this layer are the column vectors
$H=[H_{word};\ H_{POS}]$
, As a result, the outputs of this layer are the column vectors
 $U\in R^{4dxJ}$
for the question and
$U\in R^{4dxJ}$
for the question and
 $H\in R^{4dxT}$
for the context, where
$H\in R^{4dxT}$
for the context, where
 $d$
represents the dimensionality of the embeddings, and
$d$
represents the dimensionality of the embeddings, and
 $J$
and
$J$
and
 $T$
represent the number of words in the question and context, respectively.
$T$
represent the number of words in the question and context, respectively.
5.4. Attention flow layer
In this layer, attention from two directions is computed: question-to-context attention (AKA Query2Context), denoted by
 $\widehat{H}$
, which signifies the context words that are more relevant to question words, and context-to-question (AKA Context2Query), denoted by
$\widehat{H}$
, which signifies the context words that are more relevant to question words, and context-to-question (AKA Context2Query), denoted by
 $\widehat{U}$
, which signifies the question words that are more relevant to context words. These attentions are derived from a shared similarity matrix
$\widehat{U}$
, which signifies the question words that are more relevant to context words. These attentions are derived from a shared similarity matrix
 $S\in R^{TxJ}$
. These attentions help identify the relevant context words for each question word and vice versa, highlighting the important connections between them. Then, these attentions are concatenated with the column vector
$S\in R^{TxJ}$
. These attentions help identify the relevant context words for each question word and vice versa, highlighting the important connections between them. Then, these attentions are concatenated with the column vector
 $H$
computed in the previous layer, generating the output of the current layer, which is the query-aware vector representation of the context words
$H$
computed in the previous layer, generating the output of the current layer, which is the query-aware vector representation of the context words
 $G$
. Essentially, this layer allows the model to refine its understanding of the context by considering the relevance of each context word to the question and vice versa, enabling a more contextually aware representation for further processing.
$G$
. Essentially, this layer allows the model to refine its understanding of the context by considering the relevance of each context word to the question and vice versa, enabling a more contextually aware representation for further processing.
5.5. Modeling layer
The goal of this layer is to record the interactions between the context words conditioned based on the questions. This layer is implemented using two bi-GRU, where
 $G$
is the layer’s input and
$G$
is the layer’s input and
 $M\in R^{4dxT}$
is the layer’s output.
$M\in R^{4dxT}$
is the layer’s output.
5.6. Output layer
In this layer, the answer span which is represented by the begin and end indices is predicted.
Improved-BIDAF Architecture.
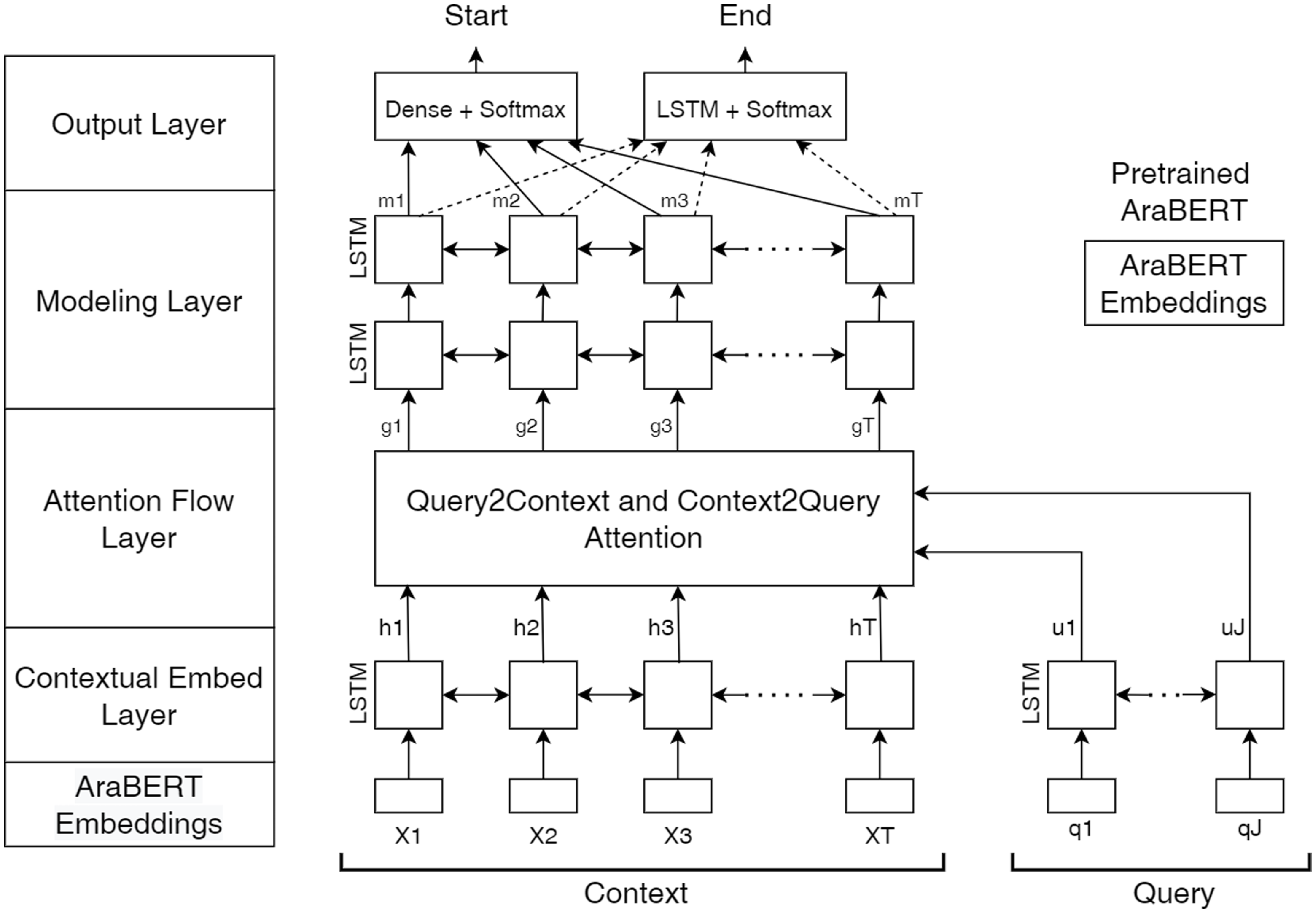
6. Fine-tuned AraBERT BIDAF
The BIDAF model and AraBERT were both used in a previous work as a baseline experiment without applying fine-tuning on ASER dataset. In this work, the authors applied fine-tuning on the AraBERT model and used the pre-trained embeddings as an input to the BIDAF model as shown in Figure 3. The experiments involved two variations. In the first experiment, bi-LSTM was utilized within both the contextual embedding layer and the modeling layer. For the second experiment, bi-LSTM was replaced with bi-GRU.
AraBERT BIDAF Architecture.
7. Experimentations
This section presents an overview of the modification steps of the BIDAF improved model and the experimental settings.
7.1. Arabic embeddings
AraVec comprises twelve pre-trained Arabic embeddings, available in two main dimensions: 100 and 300. These embeddings were trained on diverse sources, including Wikipedia, tweets, and the World Wide Web (www), using two distinct embedding methods: Continuous Bag of Words (CBOW) and Skip-gram. For this study, the pre-trained embeddings with a dimension of 300 were specifically evaluated for CBOW and Skip-gram on Wikipedia and www content. Tweet embeddings were not experimented with due to the belief that Wikipedia and the web content were more similar to Modern Standard Arabic (MSA) than tweets. Thus, the dimension of 300 was chosen for the experiments. After conducting several experiments, it was observed that the results obtained using the dimension of 300 outperformed those achieved with the dimension of 100, leading to the selection of 300 as the optimal dimension for the pre-trained embeddings used in this research.
7.2. Improvement experiments
Various experiments were conducted for the purpose of improving BIDAF for the Arabic language, including adding a new input feature and replacing bi-LSTM with bi-GRU. The new input feature is based on word embeddings for the POS tags of both the question and the passage words. The POS word embeddings were prepared as shown in the following steps:
-
1. Dataset preparation (POS tagged dataset). The training and testing sets of ASER were combined to represent a total of 10,000 records with seven columns. Then the three columns (question, answer, and paragraph) were merged into one column resulting in 30,000 records. After that, the Stanford POS tagger (Toutanova et al. Reference Toutanova, Klein, Manning and Singer2003) was used to tag the 30,000 records, and finally, these records were saved as a new dataset having only the POS tags of the original dataset.
-
2. The POS word embeddings. When creating embeddings for the POS tags, the challenge was choosing the dimension since the size of the vocabulary for the tagged dataset was only 32. Different references mentioned that the embedding dimension should range between 50 and 300 (Patel and Bhattacharyya Reference Patel and Bhattacharyya2017), and other references mentioned that the larger the embedding dimension is, the better the performance becomes (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013). However, 50 and 300 are too large for a vocabulary size of 32. Thus, after searching more on this topic, we found a general rule for choosing a dimension, which is used as a rule of thumb, this rule states that the dimension size should equal the fourth root of the number of categoriesFootnote a
 $dimensionSize = (vocabeSize)^{0.25}$
. Following this rule, with the number of categories equal to 32, the selected dimension size is 3. However, other dimensions were also experimented (32 which represents the maximum size of vocabulary, 14 which represents a number in the middle of 3 and 32, and 20 which is chosen randomly). As a result, eight POS word embeddings were obtained, four of which are CBOW and four are Skip-gram.
$dimensionSize = (vocabeSize)^{0.25}$
. Following this rule, with the number of categories equal to 32, the selected dimension size is 3. However, other dimensions were also experimented (32 which represents the maximum size of vocabulary, 14 which represents a number in the middle of 3 and 32, and 20 which is chosen randomly). As a result, eight POS word embeddings were obtained, four of which are CBOW and four are Skip-gram.

7.3. Experimental settings
This subsection presents the experimental settings for the experiments conducted in this research.
7.3.1 POS word embeddings
Eight experiments were conducted to obtain the eight different POS word embeddings. The experiments were conducted using both CBOW and Skip-gram. The implementation used Word2Vec model from Genism v4.0.1 on Python v3.7 and a standalone computer with the specifications of a 2.21 GHz Intel Core i7 CPU and 16 GB RAM. The hyperparameters used were vocabulary size of 32, context window of 2, and different sizes of embedding vectors 3, 14, 20, and 32. Both CBOW and Skip-gram models were trained on the POS tags dataset.
7.3.2 Improved-BIDAF
The improved-BIDAF experiments were conducted using the Adam optimizer with its default initial learning rate (0.001), two batch sizes were experimented 5 and 10, for five epochs. The training set was split into training and validation with a ratio of 80:20, respectively. These settings were configured manually after conducting several experiments. The hidden state dimension d of the improved-BIDAF model is 100. Improved-BIDAF has nine million parameters when POS word embeddings were used with the second word embedding layer (AraVec), while the parameters decreased to seven million when POS word embeddings used with the second word embedding layer (AraVec) along with replacing bi-LSTM with bi-GRU. The same settings were used when experimenting BIDAF with AraBERT.
7.4. Experimental measures
EM and F1-measure were the two primary metrics utilized to assess the experimental models. EM (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016) refers to the matching between the predicted values generated by the model and the actual or golden values in the dataset. EM assigns a score of 1.0 to the predicted answer that matches the golden answer for a given question and 0 otherwise. The F1-measure is a metric used to evaluate the performance of a model’s predicted answers against the true or golden answers. It is calculated as a weighted harmonic mean for the words present in both the predicted answer and the golden answer, treating both sets of words as “bags of words.”
In essence, the F1-measure represents the average level of agreement between the words found in the predicted answer and the words in the golden answer for a given question. The formula for computing the F1-measure is shown in Equation (2):
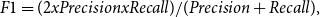 \begin{equation} F1=(2 x Precision x Recall)/(Precision+Recall), \end{equation}
\begin{equation} F1=(2 x Precision x Recall)/(Precision+Recall), \end{equation}
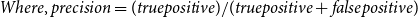 \begin{equation} Where, precision= (true positive)/(true positive+false positive) \end{equation}
\begin{equation} Where, precision= (true positive)/(true positive+false positive) \end{equation}
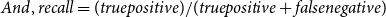 \begin{equation} And, recall= (true positive)/(true positive+false negative) \end{equation}
\begin{equation} And, recall= (true positive)/(true positive+false negative) \end{equation}
The true positive corresponds to the number of tokens that are common between the gold answer and the predicted answer. The false positive, on the other hand, represents the number of tokens present in the predicted answer but not in the gold answer. Lastly, the false negative refers to the number of tokens present in the gold answer but missing from the predicted answer.
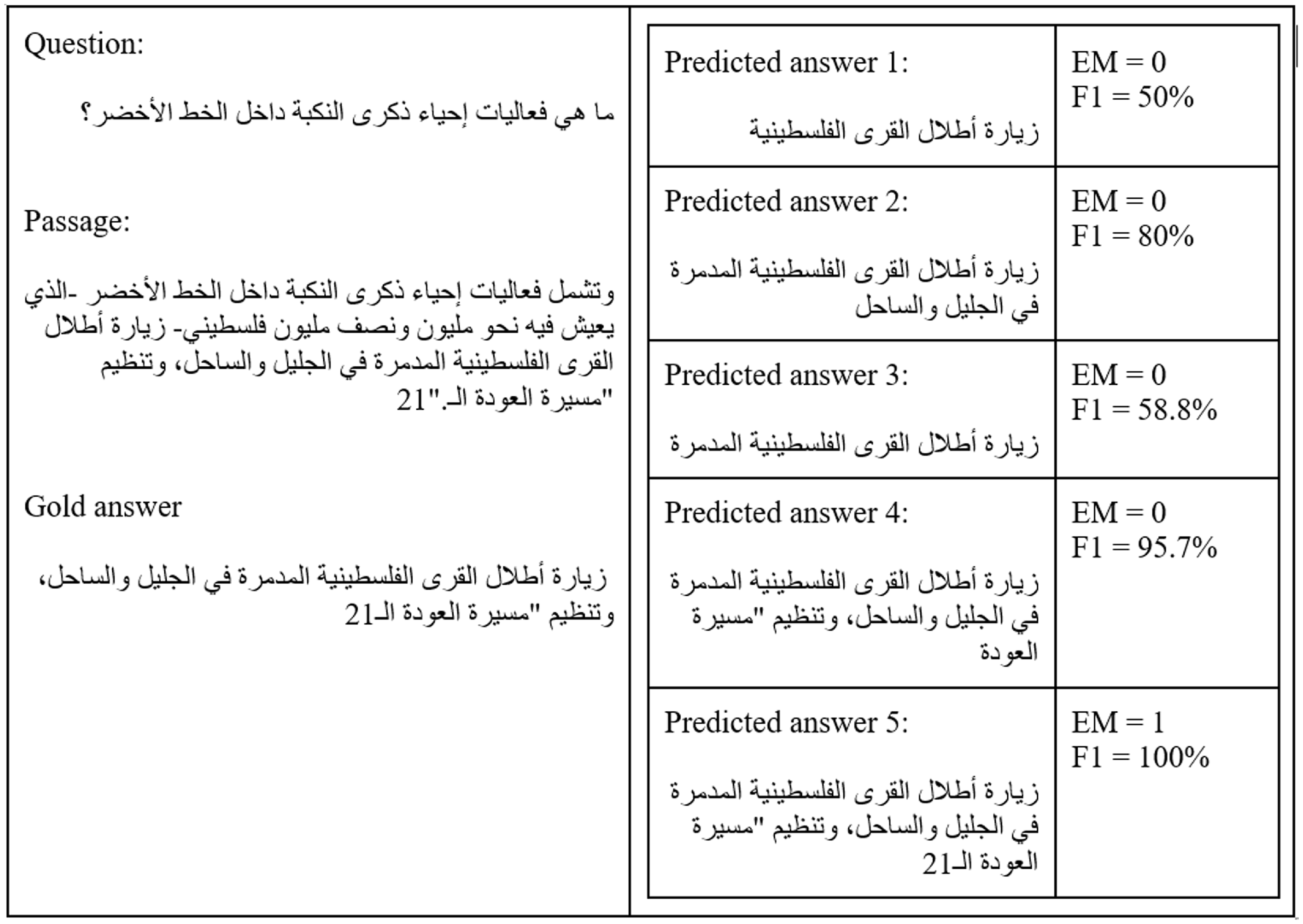
It is worth noting that although the EM measure is an indicator of accuracy; however, it is not considered an accurate measure, while the F1-measure can be more accurate. For instance, consider the example in Figure 4, all the predicted answers are correct, but the EM is 0%, while the F1-measure differs every time. The predicted answer must fully match the gold answer for the EM to equal 1. That’s why we applied the two-tailed paired samples t-test on the results of the F1-measure for all the experiments.
Example of EM and F1 measures.
8. Experimental results
In this section, the results obtained from the BIDAF improvement steps are presented. The first subsection showcases the outcomes achieved when adding a POS word embedding layer as a new feature. The second subsection presents the results after replacing bi-LSTM with bi-GRU in the model. Finally, the third subsection presents the results of the performance of the AraBERT BIDAF model. These results offer insights into the effectiveness of each improvement step and highlight the overall performance gains achieved through these modifications.
8.1. Improved-BIDAF (using POS word embeddings)
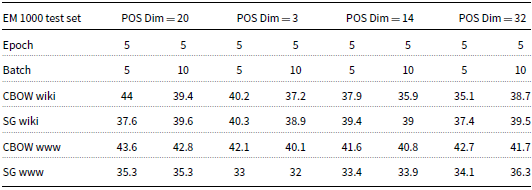
Tables 1 and 2 present the results of the EM and F1-measure of the BIDAF model on a testing set consisting of 1,000 records after adding the POS word embedding layer with various dimensions (20, 3, 14, and 32). When setting the POS word embedding dimension to 20, the best EM and F1-measure results were achieved at 44% and 74.09%, respectively. These results were obtained using CBOW wiki word embeddings with both epoch and batch equal to 5. On the other hand, the worst EM result was 35.3%, which was obtained using Skip-gram WWW word embeddings. Additionally, the worst F1-measure was 59.9%. The result was obtained using Skip-gram WWW word embeddings, with epoch and batch equal to 5 and 10, respectively.
EM after adding POS word embedding layer to the BIDAF model
F1-measure after adding POS word embedding layer to the BIDAF model
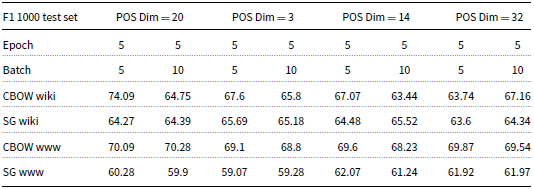
The best EM and F1-measure findings were 42.1% and 69.1%, respectively, for a POS word embedding dimension of 3. These results were produced, using CBOW WWW word embeddings with batch and epoch both set to 5. In contrast, the worst EM result was 32%, which occurred when using Skip-gram WWW word embeddings with epoch and batch both set to 5 and 10, respectively. Furthermore, the worst F1-measure was 59.07%, also obtained with Skip-gram WWW word embeddings and both epoch and batch set to 5.
When the POS word embedding dimension was set to 14, the best results achieved were 41.6% for EM and 69.6% for the F1-measure. These results were obtained using CBOW WWW word embeddings with both epoch and batch set to 5. On the other hand, the worst EM result was 33.4%, which occurred when using Skip-gram WWW word embeddings with both epoch and batch also set to 5. Similarly, the worst F1-measure was 61.24%, obtained with the same Skip-gram WWW word embeddings and with epoch and batch set to 5 and 10, respectively.
Yet, when the POS word embedding dimension was set to 32, the best results achieved were 42.7% for EM and 69.87% for the F1-measure. These results were obtained using CBOW WWW word embeddings with both epoch and batch set to 5. Conversely, the worst results were 34.1% for EM and 61.92% for the F1-measure, which were obtained using Skip-gram WWW word embeddings with both epoch and batch set to 5.
To summarize, the experimental results obtained in this study indicate that CBOW word embeddings consistently outperformed Skip-gram word embeddings. Another significant observation was that setting both epoch and batch to 5 resulted in better performance across the different configurations. The best performance was achieved when using a POS word embedding dimension of 20 along with CBOW wiki word embeddings, with both epoch and batch set to 5. This combination yielded the highest EM and F1-measure results, reaching 44% and 74.09%, respectively. Conversely, the worst results were obtained when using a POS word embedding dimension of 3 in combination with Skip-gram WWW word embeddings.
Interestingly, it is worth noting that these findings seemed to contradict the rule of thumb mentioned in Section 7, which suggested that the dimension size of embeddings should equal the fourth root of the number of categories. In this case, the experimental results demonstrated that the optimal dimension size for the POS word embeddings did not follow this rule and that other factors might have played a more significant role in determining the best-performing configuration.
8.2. Improved-BIDAF (bi-GRU replaced bi-LSTM)
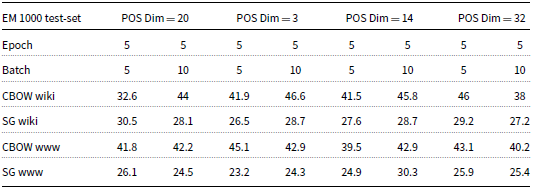
Tables 3 and 4 display the results for the EM and F1-measure of the improved-BIDAF model on a testing set comprising 1,000 records. The experiments involve adding a POS word embedding layer with various dimensions (20, 3, 14, and 32), as well as replacing the bi-LSTM with bi-GRU in the model. When the POS word embedding dimension was set to 20, the best EM and F1-measure results obtained were 44% and 74.09%, respectively. These results were achieved using CBOW wiki word embeddings with epoch and batch set to 5 and 10, respectively. Conversely, the worst EM and F1-measure results were 24.5% and 48.45%, respectively, obtained when using Skip-gram WWW word embeddings with epoch and batch both set to 5 and 10, respectively.
EM after adding POS word embedding layer and replacing bi-GRU by bi-LSTM
F1-measure after adding POS word embedding layer and replacing bi-GRU by bi-LSTM
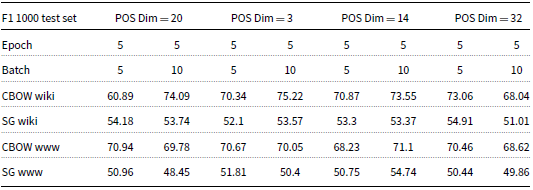
For a POS word embedding dimension of 3, the best EM and F1-measure results achieved were 46.6% and 75.22%, respectively. These results were obtained using CBOW wiki word embeddings with epoch and batch both set to 5 and 10, respectively. Conversely, the worst EM result was 23.2%, which occurred when using Skip-gram WWW word embeddings with both epoch and batch set to 5. Furthermore, the worst F1-measure result was 50.4%, which was also obtained using Skip-gram WWW word embeddings and with epoch and batch both set to 5 and 10, respectively.
When the POS word embedding dimension was set to 14, the best EM and F1-measure results obtained were 45.8% and 73.55%, respectively. These results were achieved using CBOW wiki word embeddings with epoch and batch set to 5 and 10, respectively. On the other hand, the worst EM and F1-measure results were 24.9% and 50.75%, respectively, obtained when using Skip-gram WWW word embeddings with both epoch and batch set to 5. Similarly, when the POS word embedding dimension was set to 32, the best EM and F1-measure results achieved were 46% and 73.06%, respectively. These results were obtained using CBOW wiki word embeddings with both epoch and batch set to 5. Conversely, the worst EM and F1-measure results were 25.4% and 49.86%, respectively, obtained when using Skip-gram WWW word embeddings with epoch and batch set to 5 and 10, respectively. These results provide further insights into the performance of the improved-BIDAF model with different POS word embedding dimensions and word embedding types. It appears that using CBOW wiki word embeddings generally leads to better results compared to Skip-gram WWW word embeddings across different POS word embedding dimensions.
To summarize, the experimental results consistently showed that CBOW word embeddings outperformed Skip-gram word embeddings. Particularly, CBOW wiki word embeddings yielded the best results, while Skip-gram WWW word embeddings resulted in the worst performance. The highest EM and F1-measure results (46.6% and 75.22%, respectively) were achieved using a POS word embedding dimension of 3, CBOW wiki word embeddings, and with epoch and batch both set to 5 and 10, respectively. Interestingly, this configuration adheres to the rule of thumb discussed in Section 7, indicating that a dimension size equal to the fourth root of the number of categories might lead to optimal performance. Additionally, the replacement of bi-LSTM with bi-GRU improved the results, leading to a 2% increase in EM and a 1.13% increase in the F1-measure. On the other hand, the lowest EM result was 23.2%, obtained when using a POS word embedding dimension of 3 with Skip-gram WWW word embeddings and both epoch and batch set to 5. Meanwhile, the worst F1-measure result was 48.45%, obtained when using a POS word embedding dimension of 20 with Skip-gram WWW word embeddings and with epoch and batch set to 5 and 10, respectively. These observations shed light on the impact of different configurations on the performance of the improved-BIDAF model, emphasizing the importance of word embedding types and dimensions, as well as the choice of recurrent NN architecture.
8.3. Fine-tuned AraBERT BIDAF model
Table 5 presents the F1-measure results obtained from the experiments conducted using the fine-tuned AraBERT BIDAF model. There were four different configurations tested:
-
• Pretrained AraBERT with BIDAF using bi-LSTM, with an epoch set to 5 and two different batch sizes (5 and 10).
-
• Pretrained AraBERT with BIDAF using bi-GRU, with an epoch set to 5 and two different batch sizes (5 and 10).
For all four models, the EM metric resulted in 0%, indicating that none of the models achievedEMs with the golden answers. However, the highest F1-measure obtained was 34.12%. This result was achieved when using pre-trained AraBERT embeddings and replacing bi-LSTM with bi-GRU within the BIDAF model, with an epoch set to 5 and a batch set to 10, showing an improvement of 14.39% from the baseline AraBERT BIDAF model. These results indicate that while the models did not perform well in terms of EM, the F1-measure improved slightly in the configuration with pre-trained AraBERT embeddings and bi-GRU.
F1-measure for the fine-tuned AraBERT BIDAF model

9. Comparison and discussion
In this section, a comprehensive comparison is conducted between the improved BIDAF model, human performance, several baseline models on the ASER dataset, and other models.
9.1. Improved BIDAF and baseline models
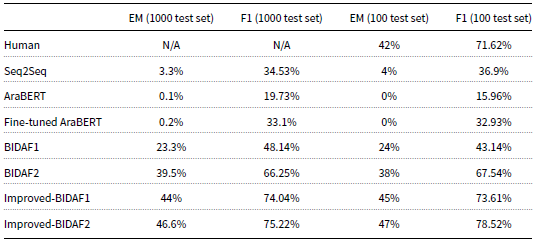
Table 6 presents the results for the EM and F1-measure for each of these models on both the 1,000 and 100 testing sets. It is important to note that the human performance evaluation was only conducted on the 100-testing set. The baseline models include:
The models selected for comparison with the highest results
-
• Sequence-to-sequence models using bi-LSTM as both the encoder and decoder.
-
• BIDAF1 model, which replaces the character embedding layer with the Arabic fastText embedding layer. This model represents the original BIDAF.
-
• BIDAF2 model, which is implemented without the character embedding layer. It also represents the original BIDAF.
-
• AraBERT BIDAF model using bi-GRU.
-
• Fine-tuned AraBERT BIDAF model using bi-LSTM.
Both the improved-BIDAF1 and improved-BIDAF2 models use a POS word embedding layer. The main difference between these two models is that the latter replaces bi-LSTM with bi-GRU. Both of these models are designed for the Arabic language. The results in Table 6 provide insights into the performance of these models on the ASER dataset. The comparison with human performance on the 100-testing set allows for assessing how well the models perform relative to human-level understanding and comprehension.
The results demonstrate that Improved-BIDAF2 achieved excellent performance on both the 1,000-record testing set and the 100-record testing set. It surpassed all other models, including human performance on the smaller testing set. For the 100-record testing set, the human performance achieved an EM and F1-measure of 42% and 71.62%, respectively. However, Improved-BIDAF2 outperformed human performance, achieving an EM and F1-measure of 47% and 78.52%, respectively. This represents a gap of 5% in EM and 6.8% in F1-measure, showing the superiority of Improved-BIDAF2 over human performance on this particular dataset. The second-best results were obtained by Improved-BIDAF1, with an EM and F1-measure of 45% and 73.61%, respectively. Interestingly, human performance ranked third on the 100-record testing set. The authors attribute the improved performance of both Improved-BIDAF1 and Improved-BIDAF2 to the addition of a POS word embedding layer. This layer contributes semantic features to the models, leading to enhanced performance and better comprehension of the data. Overall, the results highlight the effectiveness of the POS word embedding layer in boosting the performance of the models and achieving results that even surpass human-level understanding in some cases.
Indeed, the addition of POS word embeddings to the BIDAF model has proven to be beneficial in enhancing the model’s performance. In the context of the highly phonetic nature of the Arabic language, the writing reflects the pronunciation, which can lead to different meanings for homographic words based on their POS tags. This is exemplified by words like ![]() which can mean “mentioned” if tagged as a verb and “flower” if tagged as a noun. In such cases, character embeddings might not effectively differentiate between the two meanings, while POS word embeddings can capture these semantic nuances, leading to improved comprehension and disambiguation. Moreover, the utilization of POS word embeddings can aid in resolving the out-of-vocabulary problem, where the model may encounter words not present in its training vocabulary. By considering the POS tags, the model can still gain insights into the context and meaning of such OOV words, enhancing its ability to provide meaningful answers.
which can mean “mentioned” if tagged as a verb and “flower” if tagged as a noun. In such cases, character embeddings might not effectively differentiate between the two meanings, while POS word embeddings can capture these semantic nuances, leading to improved comprehension and disambiguation. Moreover, the utilization of POS word embeddings can aid in resolving the out-of-vocabulary problem, where the model may encounter words not present in its training vocabulary. By considering the POS tags, the model can still gain insights into the context and meaning of such OOV words, enhancing its ability to provide meaningful answers.
Additionally, in the improved-BIDAF2 model, the replacement of bi-LSTM with bi-GRU has resulted in performance improvements, specifically the model’s EM and F1-measure increased by 2.6% and 1.18%, respectively in the 1,000 record testing set, and by 2% and 4.91%, respectively, in the 100-testing set. Despite LSTM’s reputation for performing well with long sequences, the results demonstrated that GRU performed better in this particular scenario. The model achieved higher EM and F1-measure scores on both the 1,000-record and 100-record testing sets, showcasing the effectiveness of using GRU in this context. Overall, the combination of POS word embeddings and bi-GRU has proven to be a successful enhancement in the improved-BIDAF2 model, contributing to its superior performance on the ASER dataset. These improvements allow the model to better understand the complex semantics of the Arabic language and provide more accurate answers.
t-test statistics results
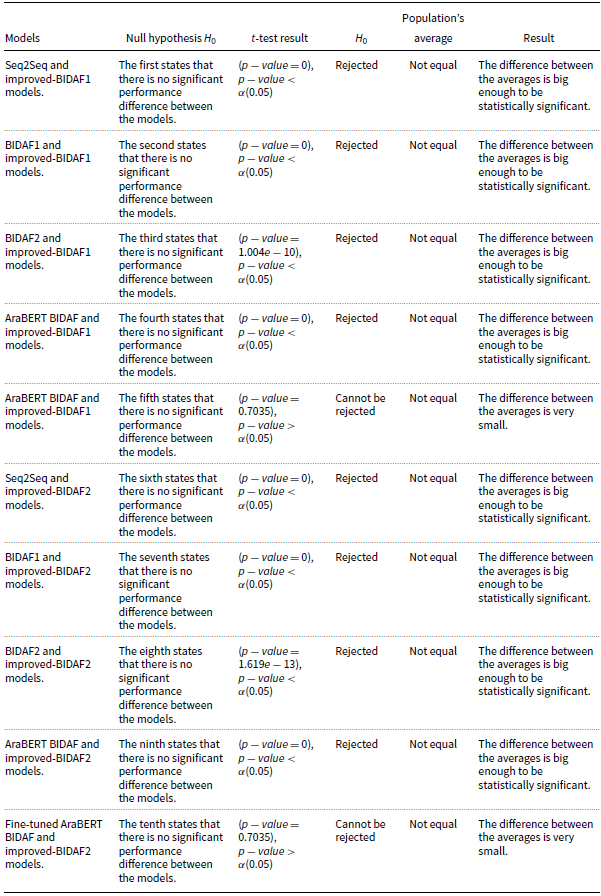
In order to show the superiority of Improved-BIDAF1 and Improved-BIDAF2 to the baseline models, we have performed statistical evidence using the t-test as depicted in Table 7. The first null hypothesis
 $H_0$
states that there is no significant performance difference between the Seq2Seq and the Improved-BIDAF1 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the Seq2Seq and the Improved-BIDAF1 model. However, the t-test resulted in
 $(p-value = 0)$
, and since the
$(p-value = 0)$
, and since the
 $p-value \lt \alpha (0.05)$
,
$p-value \lt \alpha (0.05)$
,
 $H_0$
is rejected, and the Seq2Seq population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of Seq2Seq and Improved-BIDAF1 is big enough to be statistically significant. The second null hypothesis
$H_0$
is rejected, and the Seq2Seq population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of Seq2Seq and Improved-BIDAF1 is big enough to be statistically significant. The second null hypothesis
 $H_0$
states that there is no significant performance difference between the BIDAF1 and the Improved-BIDAF1 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the BIDAF1 and the Improved-BIDAF1 model. However, the t-test resulted in
 $(p-value = 0)$
, and since the
$(p-value = 0)$
, and since the
 $p-value \lt \alpha (0.05)$
,
$p-value \lt \alpha (0.05)$
,
 $H_0$
is rejected, and the BIDAF1 population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of BIDAF1 and Improved-BIDAF1 is big enough to be statistically significant.
$H_0$
is rejected, and the BIDAF1 population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of BIDAF1 and Improved-BIDAF1 is big enough to be statistically significant.
The third null hypothesis
 $H_0$
states that there is no significant performance difference between the BIDAF2 and the Improved-BIDAF1 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the BIDAF2 and the Improved-BIDAF1 model. However, the t-test resulted in
 $(p-value = 1.004e-10)$
, and since the
$(p-value = 1.004e-10)$
, and since the
 $p-value \lt \alpha (0.05)$
,
$p-value \lt \alpha (0.05)$
,
 $H_0$
is rejected, and the BIDAF2 population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of BIDAF2 and Improved-BIDAF1 is big enough to be statistically significant. The fourth null hypothesis
$H_0$
is rejected, and the BIDAF2 population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of BIDAF2 and Improved-BIDAF1 is big enough to be statistically significant. The fourth null hypothesis
 $H_0$
states that there is no significant performance difference between the AraBERT BIDAF and the Improved-BIDAF1 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the AraBERT BIDAF and the Improved-BIDAF1 model. However, the t-test resulted in
 $(p{{-}\rm value} = 0)$
, and since the
$(p{{-}\rm value} = 0)$
, and since the
 $p-value \lt \alpha (0.05)$
,
$p-value \lt \alpha (0.05)$
,
 $H_0$
is rejected, and the AraBERT BIDAF population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of AraBERT BIDAF and Improved-BIDAF1 is big enough to be statistically significant. The fifth null hypothesis
$H_0$
is rejected, and the AraBERT BIDAF population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of AraBERT BIDAF and Improved-BIDAF1 is big enough to be statistically significant. The fifth null hypothesis
 $H_0$
states that there is no significant performance difference between the fine-tuned AraBERT BIDAF and the Improved-BIDAF1 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the fine-tuned AraBERT BIDAF and the Improved-BIDAF1 model. However, the t-test resulted in
 $(p-value = 0.7035)$
, and since the
$(p-value = 0.7035)$
, and since the
 $p-value \gt \alpha (0.05)$
,
$p-value \gt \alpha (0.05)$
,
 $H_0$
cannot be rejected, and the fine-tuned AraBERT BIDAF population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of fine-tuned AraBERT BIDAF and Improved-BIDAF1 is very small.
$H_0$
cannot be rejected, and the fine-tuned AraBERT BIDAF population’s average is not equal to the Improved-BIDAF1 population’s average. As a result, the difference between the averages of fine-tuned AraBERT BIDAF and Improved-BIDAF1 is very small.
The sixth null hypothesis
 $H_0$
states that there is no significant performance difference between the Seq2Seq and the Improved-BIDAF2 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the Seq2Seq and the Improved-BIDAF2 model. However, the t-test resulted in
 $(p-value = 0)$
, and since the
$(p-value = 0)$
, and since the
 $p-value \lt \alpha (0.05)$
,
$p-value \lt \alpha (0.05)$
,
 $H_0$
is rejected, and the Seq2Seq population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of Seq2Seq and Improved-BIDAF2 is big enough to be statistically significant. The seventh null hypothesis
$H_0$
is rejected, and the Seq2Seq population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of Seq2Seq and Improved-BIDAF2 is big enough to be statistically significant. The seventh null hypothesis
 $H_0$
states that there is no significant performance difference between the BIDAF1 and the Improved-BIDAF2 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the BIDAF1 and the Improved-BIDAF2 model. However, the t-test resulted in
 $(p-value = 0)$
, and since the
$(p-value = 0)$
, and since the
 $p-value \lt \alpha (0.05)$
,
$p-value \lt \alpha (0.05)$
,
 $H_0$
is rejected, and the BIDAF1 population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of BIDAF1 and Improved-BIDAF2 is big enough to be statistically significant.
$H_0$
is rejected, and the BIDAF1 population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of BIDAF1 and Improved-BIDAF2 is big enough to be statistically significant.
The eighth null hypothesis
 $H_0$
states that there is no significant performance difference between the BIDAF2 and the Improved-BIDAF2 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the BIDAF2 and the Improved-BIDAF2 model. However, the t-test resulted in
 $(p-value = 1.619e-13)$
, and since the
$(p-value = 1.619e-13)$
, and since the
 $p-value \lt \alpha (0.05)$
,
$p-value \lt \alpha (0.05)$
,
 $H_0$
is rejected, and the BIDAF2 population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of BIDAF2 and Improved-BIDAF2 is big enough to be statistically significant. The ninth null hypothesis
$H_0$
is rejected, and the BIDAF2 population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of BIDAF2 and Improved-BIDAF2 is big enough to be statistically significant. The ninth null hypothesis
 $H_0$
states that there is no significant performance difference between the AraBERT BIDAF and the Improved-BIDAF2 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the AraBERT BIDAF and the Improved-BIDAF2 model. However, the t-test resulted in
 $(p-value = 0)$
, and since the
$(p-value = 0)$
, and since the
 $p-value \lt \alpha (0.05)$
,
$p-value \lt \alpha (0.05)$
,
 $H_0$
is rejected, and the AraBERT BIDAF population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of AraBERT BIDAF and Improved-BIDAF2 is big enough to be statistically significant. The tenth null hypothesis
$H_0$
is rejected, and the AraBERT BIDAF population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of AraBERT BIDAF and Improved-BIDAF2 is big enough to be statistically significant. The tenth null hypothesis
 $H_0$
states that there is no significant performance difference between the fine-tuned AraBERT BIDAF and the Improved-BIDAF2 model. However, the t-test resulted in
$H_0$
states that there is no significant performance difference between the fine-tuned AraBERT BIDAF and the Improved-BIDAF2 model. However, the t-test resulted in
 $(p-value = 0.7035)$
, and since the
$(p-value = 0.7035)$
, and since the
 $p-value \gt \alpha (0.05)$
,
$p-value \gt \alpha (0.05)$
,
 $H_0$
cannot be rejected, and the fine-tuned AraBERT BIDAF population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of fine-tuned AraBERT BIDAF and Improved-BIDAF2 is very small.
$H_0$
cannot be rejected, and the fine-tuned AraBERT BIDAF population’s average is not equal to the Improved-BIDAF2 population’s average. As a result, the difference between the averages of fine-tuned AraBERT BIDAF and Improved-BIDAF2 is very small.
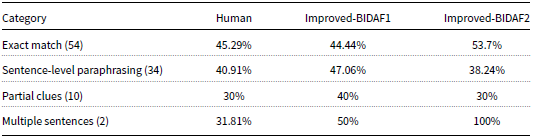
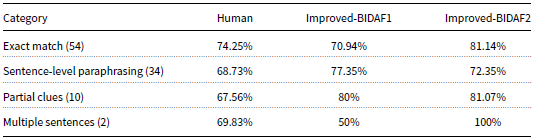
Tables 8 and 9 illustrate EM and F1-measure results, respectively, for human and improved-BIDAF models on the 100-testing set according to the evaluation label. Improved-BIDAF2 outperformed improved-BIDAF1 within the “exact-match” category, it also outperformed human performance within the same category in both EM and F1-measure with an increase of 8.41% and 6.89%, respectively. Within the “Sentence-level paraphrasing” category improved-BIDAF1 outperformed improved-BIDAF2 and human performance, while improved-BIDAF2 ranked third according to EM within this category and ranked second according to F1-measure. Within the “partial-clues” category, improved-BIDAF1 outperformed improved-BIDAF2 and human performance within the EM measure, while Improved-BIDAF2 has the highest F1-measure within this category. Improved-BIDAF2 outperformed improved-BIDAF1 and human performance with both EM and F1-measure equal to 100% within the category “multiple-sentences”. The gap difference between improved-BIDAF2 and human performance is significant in this category which reached an EM and F1-measure of 68.19% and 30.17%, respectively.
EM according to evaluation label
F1-measure according to evaluation label
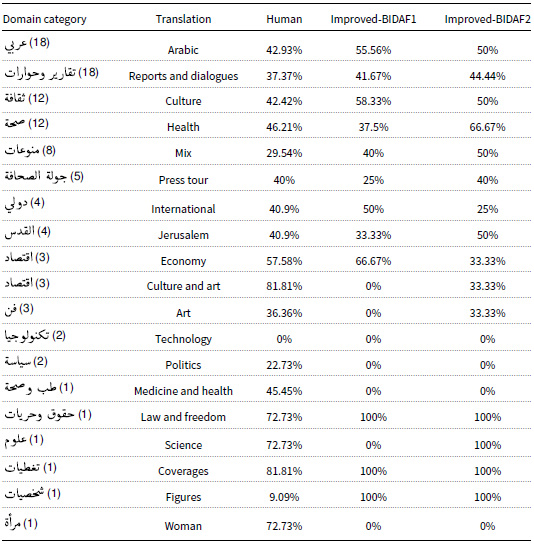
Tables 10 and 11 provide insights into the EM and F1-measure results for both human and improved-BIDAF models on the 100-testing set, categorized based on domain coverage. In the “technology” domain, both the human performance and improved-BIDAF models achieved an EM of 0%, indicating that neither were able to provide EMs with the golden answers in this domain. On the other hand, human performance reached the highest EM of 81.81% in both the “culture and art” and “coverages” domains. This suggests that humans were able to perform quite well in these domains, with a relatively high level of understanding and comprehension. In the “culture and art” domain, none of the models outperformed human performance, as they all achieved an EM of 0%. However, in the “coverages” domain, both improved models achieved an EM of 100%, indicating that they were able to provide EMs with the golden answer in this domain, outperforming human performance. These results show that while the human performance was strong in certain domains, the improved-BIDAF models were able to excel in the “coverages” domain, where they achieved a perfect match with the golden answer. This highlights the effectiveness of the enhancements made to the BIDAF model, particularly with the addition of POS word embeddings and the replacement of bi-LSTM with bi-GRU, in capturing the intricacies of the language and domain-specific information, leading to improved performance in certain domains.
EM according to domain
F1-measure according to domain
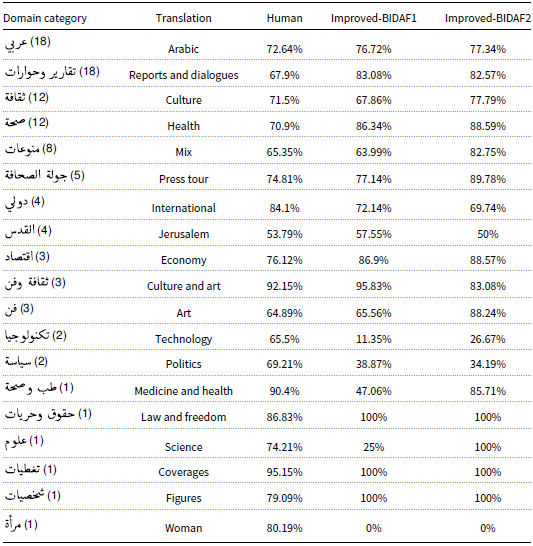
In the “medicine and health” domain, human performance achieved an EM of 45.45% and an F1-measure of 90.4%. This indicates that humans were able to provide correct answers for approximately 45.45% of the questions in this domain, and the average overlap between their answer and the golden answer was around 90.4%. In contrast, both the human and improved-BIDAF models achieved an EM of 0% in the “medicine and health” domain. This suggests that neither humans nor the models were able to provide an EM with the golden answer for the question in this domain. However, improved-BIDAF2 reached an F1-measure of 85.71% in the “medicine and health” domain, making it the second-best model in this domain based on the F1-measure. While it did not outperform human performance in terms of F1-measure, it demonstrated a relatively high level of overlap between its answers and the golden answers. Similarly, in the “woman” domain, the human performance achieved an EM of 72.73% and an F1-measure of 80.19%. Again, neither of the models, including improved-BIDAF2, outperformed human performance in this domain. All the models achieved an EM and F1-measure of 0% in this domain, indicating that they were unable to provide EMs or significant overlap with the golden answers.
These results highlight the challenges posed by specific domains, such as “medicine and health” and “woman,” where even the improved-BIDAF models struggled to achieve high performance compared to human understanding. The discrepancies between human performance and the model results in these domains suggest that there may be domain-specific complexities and nuances that are difficult for the models to capture effectively. Further research and fine-tuning of the models may be necessary to improve their performance in such challenging domains.
The comparison between improved-BIDAF1 and improved-BIDAF2 reveals interesting findings regarding their performance in different domains. While both models showed improvements over the baseline BIDAF, there are some variations in their domain-specific performance. Improved-BIDAF2 achieved an EM of 0% in only 4 domains, while improved-BIDAF1 had 7 domains with an EM of 0%. This suggests that improved-BIDAF2 performed better in a larger number of domains, as it had fewer domains with zero EM scores. Furthermore, improved-BIDAF2 achieved an EM and F1-measure of 100% in 4 domains, while improved-BIDAF1 achieved this level of performance in 3 domains. It is noteworthy that none of the domains resulted in 100% EM for human performance, indicating that the models were able to outperform humans in certain specific domains.
The results strongly suggest that replacing bi-LSTM with bi-GRU in the improved-BIDAF2 model led to significant enhancements in performance across different domains. The bi-GRU architecture appears to have better captured the linguistic patterns and context in various domains, enabling improved-BIDAF2 to achieve better results compared to improved-BIDAF1 in multiple scenarios.
These findings highlight the importance of selecting appropriate NN architectures for specific tasks and domains. The replacement of bi-LSTM with bi-GRU in the improved-BIDAF2 model demonstrated its superiority in handling the complexities and nuances of different domains, resulting in more accurate and robust performance across the dataset.
9.2. Qualitative analysis
For qualitative analysis, examples having different lengths of passages, questions, and answers were selected from the testing set. Table 12 presents the chosen lengths, the corresponding domain of each example, and the performance of the models. All the selected examples are available and shown in Appendix A, which includes Figures 5–12.
EM and F1 measures for one record having different lengths
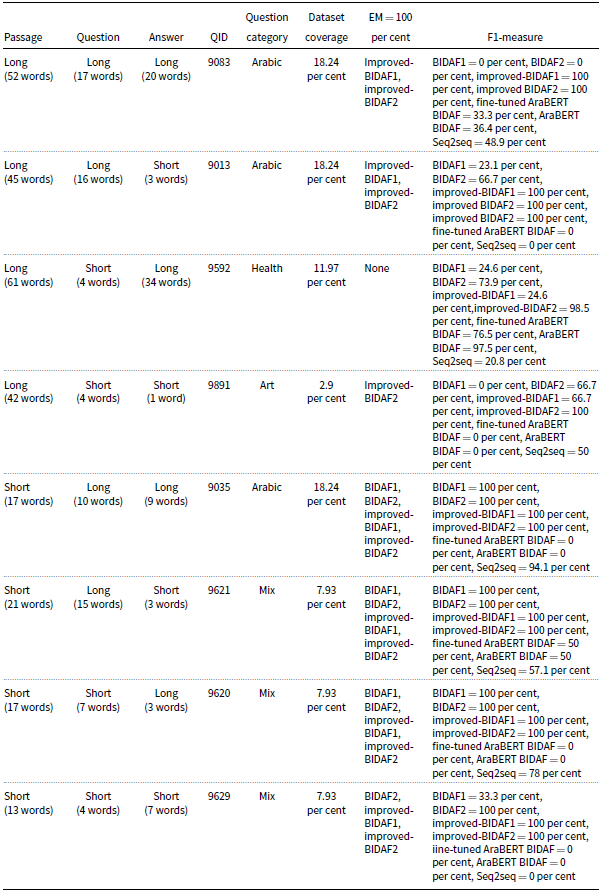
The first example belongs to the “Arabic” domain and consists of a long passage (52 words), a long question (17 words), and a long answer (20 words). Improved BIDAF1 and improved BIDAF2 are the only models that provided the EM of the answer. Noting that “Arabic” is the largest domain of the ASER dataset with a coverage of 18.24 per cent, one will suggest that all models should perform well on larger domains having more training examples. However, both BIDAF1 and BIDAF2 could not provide the correct answer scoring an EM and F1-measure of 0%. On the other hand, when an example was selected from the same domain with long passage (45 words), long question (16 words), and short answer (3 words), BIDAF2 was able to provide parts of the answer, having EM of 0% and F1-measure of 66.7%, and improved BIDAF1 and improved BIDAF2 were the only models to answer this category correctly scoring EM and F1-measure of 100
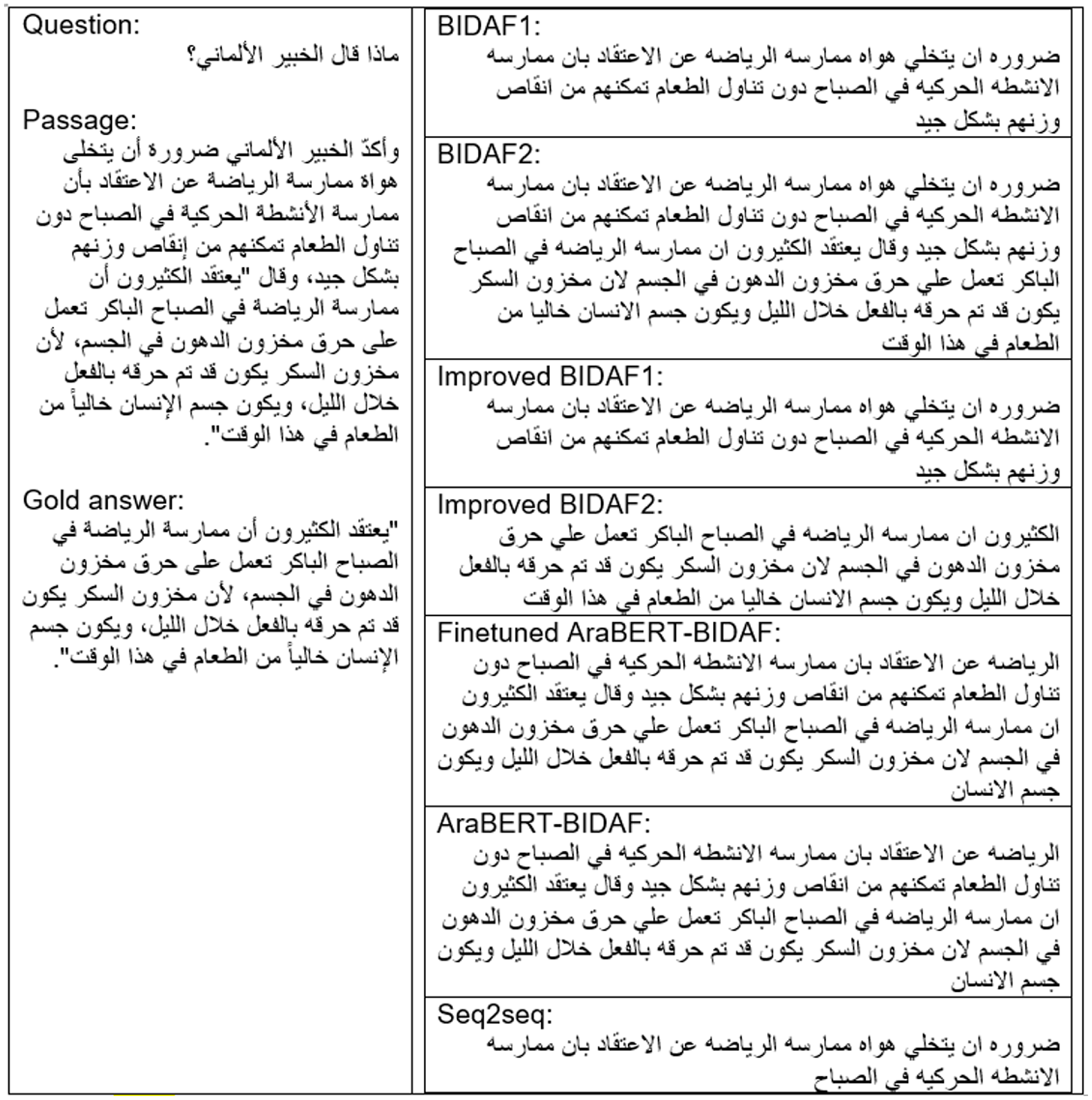
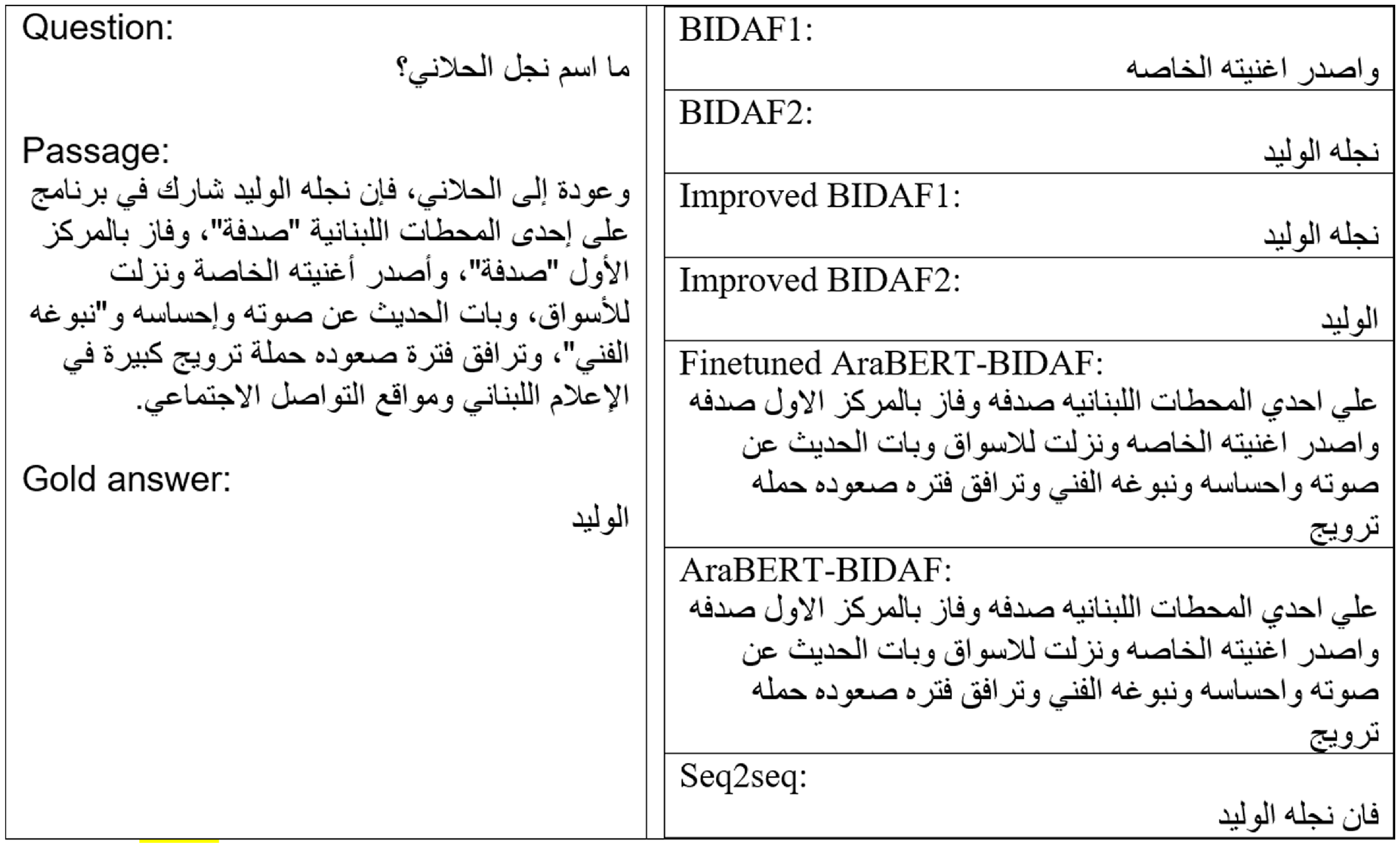
The third example consists of a long passage (61 words), a short question (4 words), and a long answer (34 words). None of the models were able to provide the correct answer, although the example is from the domain “Health” which is the fourth largest domain within ASER. The bad performance of all models is due to having few words within the question, which makes it difficult for the model to look for the correct answer. However, improved BIDAF2 provided the closest answer with an F1- measure of 98.5%. The fourth example consists of a long passage (forty-two words), a short question (four words), and a short answer (one word) from the domain “Art.” Domain “Art” covers a few training examples within the ASER dataset. Improved BIDAF2 was the only model to provide the correct answer with EM and F1 measures of 100%, while BIDAF1 scored 0% in both measures. Most of the models were able to answer questions of the remaining categories correctly with an EM and F1-measure of 100% except for AraBERT BIDAF before and after fine-tuning and seq2seq models. These categories have short passages and varying lengths of questions and answers.
These results demonstrate that improved BIDAF is capable of effectively handling long passages from diverse and complex sources, making it well-suited for the Arabic language, which is known for its lengthy sentences and intricate structure. The enhancements made to the BIDAF model have also contributed to its ability to generalize well across various questions and domains.
9.3. Improved BIDAF and other models
Table 13 provides a comprehensive comparison of improved-BIDAF with other models that were experimented on Arabic text. Despite improved-BIDAF being experimented on a smaller dataset (ASER) compared to the models in the table, it demonstrated superior performance in terms of F1-measure, outperforming QANet, BERT, and BIDAF by considerable margins of 30.82%, 13.92%, and 9.22%, respectively.
Comparison of improved-BIDAF with other models
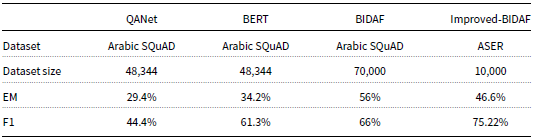
In terms of EM, improved-BIDAF also outperformed QANet and BERT, achieving higher scores with gaps of 17.2% and 12.4%, respectively. However, BIDAF managed to outperform improved-BIDAF by a gap of 9.4% in EM. The authors attribute the differences in performance to the variations in the datasets experimented. Notably, the size of the Arabic SQuAD dataset is much larger, containing 70,000 records, whereas ASER comprises only 10,000 records. Additionally, the answer lengths in SQuAD tend to be shorter, with a maximum length of forty-three tokens, while ASER has answers with a maximum length of seventy-five tokens.
The differences in dataset size and answer length likely influence the models’ performance. A larger dataset provides more diverse training examples and potentially allows the models to generalize better to unseen data. Moreover, shorter answer lengths in SQuAD may facilitate easier comprehension and extraction, whereas longer answer lengths in ASER present additional challenges for the models.
Despite these differences, improved-BIDAF demonstrated its strength in handling the ASER dataset, outperforming other models in terms of F1-measure, and achieving competitive results in EM. The performance differences underscore the significance of dataset characteristics and demonstrate the capability of improved-BIDAF in tackling the complexities of the ASER dataset with longer answer lengths.
9.4. Limitations and future directions
This study has two primary limitations. First, while the ASER dataset comprises 10,000 records, it remains relatively small compared to datasets available in other languages. This limitation may have constrained the generalizability of current findings to a larger dataset. Unfortunately, the scarcity of dependable large datasets for MRC tasks in the Arabic language means this limitation cannot be easily addressed.
Second, we encountered a lack of preexisting embeddings for POS tags in the Arabic language trained on substantial datasets, necessitating the creation of a dataset for POS tags and subsequent embeddings.
Moving forward, future research could aim to address these limitations by exploring the study’s concepts on a larger, more diverse dataset. Additionally, experimentation with an improved BIDAF model could be conducted for classification and plagiarism tasks.
10. Conclusion
In this research paper, the authors proposed an enhanced version of the BIDAF model specifically designed for the Arabic MRC task. The model was evaluated on the ASER dataset, an Arabic Span-Extraction Reading Comprehension Benchmark. The improvements to the BIDAF model involved two key modifications: replacing the character embedding layer with a POS word embedding layer and substituting the bi-LSTM with bi-GRU.
Experimental results demonstrated a significant performance gap between the baseline models experimented on ASER and the improved-BIDAF model. The improved-BIDAF model showcased superior performance, achieving higher EM and F1-measure scores compared to the baseline models. Notably, the model even surpassed human performance in this specific task, achieving an EM and F1-measure increase of 5% and 6.9%, respectively, over human performance.
The use of POS word embeddings in the BIDAF model was instrumental in enhancing its performance. POS tags provide semantic meaning to words, and incorporating this information through the POS word embeddings allowed the model to better capture the nuances and context of the Arabic language, leading to improved comprehension and more accurate answers.
The study’s findings highlight the potential of deep learning models in outperforming human performance in certain tasks, such as MRC. By effectively leveraging advanced NN architectures and linguistic features like POS word embeddings, these models can exhibit remarkable capabilities in understanding and processing complex natural language data. The results encourage further exploration and development of deep learning approaches for natural language understanding tasks, specifically for the Arabic language.
Competing interests
The author(s) declare none.
Appendix A. Examples from ASER dataset with the answers provided by the experimented models
Example from ASER: Long passage, long question with long answer.
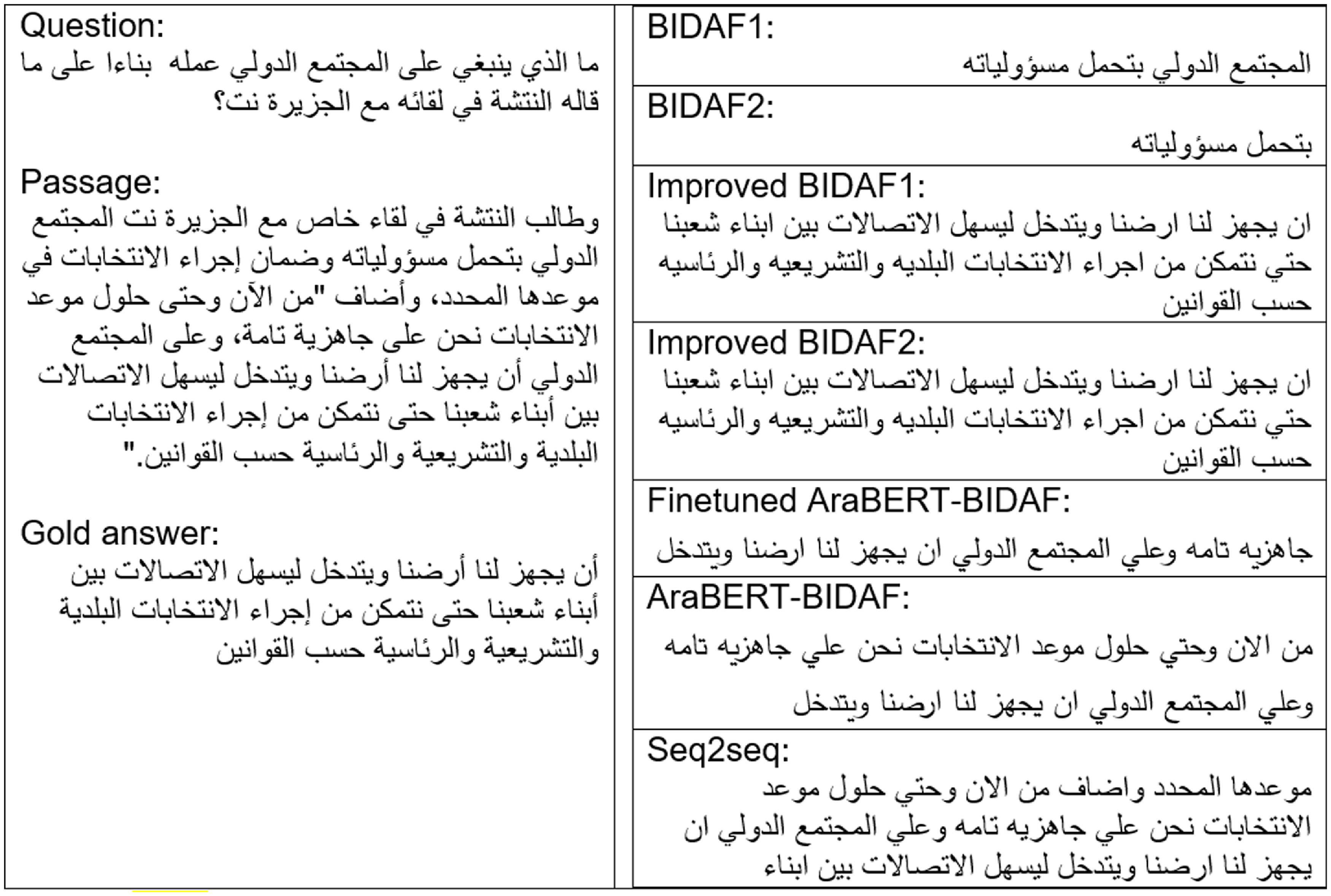
Example from ASER: Long passage, long question with short answers.

Example from ASER: Long passage, short question with long answer.
Example from ASER: Long passage, short question with short answer.
Example from ASER: Short passage, long question with long answer.

Example from ASER: Short passage, long question with short answer.

Example from ASER: Short passage, short question with short answer.

Example from ASER: Short passage, short question with long answer.



























 Open access
Open access