


1. Introduction
Theories of syntax and production make distinct, testable predictions about the ease of producing the two orders in English verb–particle constructions (VPCs), as in (1). If one order is derived from the other, additional structure-building or displacement should raise planning demands for the derived order. If usage-based accounts are right, frequency and idiomaticity should grant one order faster access. If information-theoretic pressures matter, greater choice uncertainty should slow utterance onset. We test these claims in SWITCHBOARD (Godfrey et al., Reference Godfrey, Holliman and McDaniel1992), a well-used and large corpus of American English telephone conversations, by asking whether pre-verbal silence differs between the orders and whether idiomaticity, frequency, and contextual uncertainty modulate any difference.

These competing accounts yield clear empirical predictions. Derivational proposals – whether treating the joined order as basic with the split derived (e.g., Johnson, Reference Johnson1991) or vice versa (e.g., Kayne, Reference Kayne, Guéron, Obenauer and Pollock1985) – predict that the derived form should incur greater planning cost. If usage-based accounts are right, frequency and idiomaticity should grant one order faster access, as high-frequency and semantically non-compositional chunks are retrieved holistically (e.g., Bybee, Reference Bybee2010; Gries, Reference Gries1999). If information-theoretic pressures matter, greater choice uncertainty (i.e., more balanced variant probabilities) should slow utterance onset, as predicted by theories of uniform information density (e.g., Jaeger, Reference Jaeger2010). If any of these mechanisms are at work, we should observe differences in production ease between variants.
Throughout, we use terms like choice and selection as convenient shorthand for a variable outcome in usage and for the modelling of token-wise variant probabilities. In a variationist (Labovian) tradition, patterned distributions in production are an empirical object of study in their own right, and we do not assume that corpus conditioning profiles transparently identify an internal competence mechanism. Accordingly, our ‘choice’ models should not be read as a psychological decision tree in which speakers first decide on object type and only then decide on particle placement; rather, they summarise associations between annotated contexts and observed variant rates. The contribution of the present article is to link those distributional regularities to an independent behavioural measure that we operationalise below – pre-verbal silence – and to ask a deliberately modest question: do sites of variable realisation, or contexts in which variant probabilities are more balanced, show any reliable increase in pre-verbal planning time?
We therefore measure planning difficulty where it peaks: immediately before VPC onset (the verb head). Pauses robustly index cognitive load, and pre-verbal silences, in particular, reflect the assembly of upcoming structure (Goldman-Eisler, Reference Goldman-Eisler1968; Schneider, Reference Schneider2016; Shriberg, Reference Shriberg1996). We thus adopt pre-verbal silence as our metric of production ease (see Section 3.2) and test whether it differs significantly between VPC orders and whether idiomaticity, frequency or choice symmetry are modulating factors. If one order is harder, pauses should be longer before it. If both are equally accessible, the difference should be null. Our results support the latter.
1.1. Hypotheses
Research on syntactic variation raises two distinct questions about production cost. First, does the mere availability of choice itself impose a cost – does optionality complicate planning? Recent corpus work suggests not, finding that syntactic choice sites do not consistently attract hesitations (Gardner et al., Reference Gardner, Uffing, Van Vaeck and Szmrecsanyi2021; Szmrecsanyi et al., Reference Szmrecsanyi, Gardner, Ma, Van Hoey, Cukor-Avila, Tagliamonte and Bailey2026a, Reference Szmrecsanyi, Gardner and Van Hoey2026b). Second, even if variation itself is cost-free, might individual variants differ in production ease due to their structural properties? Experimental evidence shows that structurally complex constructions like passives take longer to produce than their active counterparts (Ferreira, Reference Ferreira1994; Tannenbaum & Williams, Reference Tannenbaum and Williams1968). VPCs provide a critical test case for the latter question: theories strongly predict structural asymmetries between orders, but whether this translates to measurable planning difficulty in spontaneous speech remains unknown.
H1 (Generative: joined underlying). Accounts that treat the joined order (pick up the book) as underlying analyse the split order as derived by movement of the direct object (DO). If derivation entails extra operations, the split variant should incur greater planning cost. Prediction: split orders should be preceded by longer pre-verbal pauses than joined orders.
H2 (Generative: split underlying). Other accounts posit the split order (pick the book up) as underlying and the joined order as derived by particle movement. Prediction: joined orders should be preceded by longer pre-verbal pauses than split orders.
H3 (Mixed base generation). Some proposals allow both orders to be underlying, often tied to idiomaticity: idiomatic VPCs pattern with joined order, compositional ones with split order. Mismatches should raise planning effort. Prediction: idiomatic VPCs in split order and compositional VPCs in joined order should be preceded by longer pauses.
H4 (Usage-based / choice symmetry).
From a usage-based and information-theoretic view, cost reflects contextual predictability. Symmetrical choice contexts (
 $ \approx $
50/50 split versus joined) require greater selection effort than asymmetrical contexts. Prediction: pauses should be longer when both variants are equally probable than when one variant is strongly favoured.
$ \approx $
50/50 split versus joined) require greater selection effort than asymmetrical contexts. Prediction: pauses should be longer when both variants are equally probable than when one variant is strongly favoured.
These hypotheses do not presuppose a particular syntactic theory. Our goal is to test whether their distinct assumptions – derivational direction, dual availability, predictability – entail measurable differences in production. If one order is derived from the other, we expect planning asymmetries. If both are equally available, we expect none. If predictability dominates, we expect planning effort to track choice symmetry (balanced versus skewed contexts) rather than derivational complexity.
1.1.1. Auxiliary predictions (chunkiness)
As a complement to the theory-driven hypotheses above, we probe a second dimension: how tightly the verb and particle cohere in memory. We refer to this cohesion as ‘chunkiness’ and define it in Section 2.3. We do not assume that either order is intrinsically harder to plan. Rather, we ask (i) whether idiomaticity shifts choice towards the joined order without lengthening pre-verbal pauses (semantic chunkiness), and (ii) whether higher head-verb frequency shortens pre-verbal pauses, especially at higher speech rates, by easing access to a familiar verb–particle template (frequency-based chunkiness). The first prediction concerns selection; the second concerns launch timing.
C1 (Semantic chunkiness / idiomaticity). Idiomatic VPCs should favour the joined order. No prediction that idiomaticity lengthens pre-verbal pauses.
C2 (Frequency-based chunkiness / entrenchment). Higher head-verb frequency should shorten pre-verbal pauses, especially at faster speech rates, by easing access to the upcoming verb–particle template.
We therefore distinguish tests of order-cost contrast (H1–H4) from chunkiness effects (C1–C2). The former target whether one order is harder to plan; the latter target which order is selected and how quickly articulation begins.
1.2. Outline of the article
Section 2 reviews prior work on VPCs and situates our study with respect to generative, usage-based and information-theoretic perspectives. It also outlines our definition of ‘chunkiness’. Section 3 describes the data, coding and our dependent measure of speech-planning time. Section 4 presents distributional patterns and tree-based regression models. Section 5 discusses implications for theories of variation and complexity. Section 6 concludes.
2. Background
2.1. Verb–particle constructions in English
VPCs are a hallmark of the Germanic languages: a verb and a particle form a unit with verbal properties (Rodríguez-Puente, Reference Rodríguez-Puente2019). In English, the particle originated as an adverbial element and has developed into a grammatical marker with varying degrees of semantic transparency. There are an estimated 3,000 productive VPCs in present-day English (McArthur & Aikins, Reference McArthur and Aikins1974), though not all take part in the alternation studied here.
Transitive VPCs alternate in the linear order of verb, particle and DO, as in (2a). The particle can appear after the verb (pick up something, joined order) or after the DO (pick something up, split order). Intransitives (calm down, come back), as in (2b), do not alternate and are excluded in the present analysis.

A standard descriptive claim is that pronominal DOs require the split order (pick it up, not *pick up it). While pronouns overwhelmingly favour the split order, they can occur in the joined order in specific contexts – for instance under indefiniteness (2a), focus/emphasis or deictic force (3) (Bolinger, Reference Bolinger1971; Johnson, Reference Johnson1991). We retain pronominal tokens because they vary in principle and because they provide a near-categorical baseline for split order in spoken discourse.

VPC alternation is robust across the history of English and varies across registers and varieties. Written English often favours the joined order, while spoken English shows higher split rates (Cappelle, Reference Cappelle, Bergs and Diewald2009; Gries, Reference Gries2003). Cross-dialectal studies report differences as well: British and Irish English show more split order than North American English, and apparent-time studies suggest possible change (Haddican & Johnson, Reference Haddican and Johnson2012; Röthlisberger & Tagliamonte, Reference Röthlisberger and Tagliamonte2020). These patterns indicate that VPC order is conditioned by grammatical, pragmatic and social factors that any predictive model must include.
2.2. Competing accounts of VPC order
Analyses differ on whether one order is derived from the other or both are independently generated. We remain agnostic about grammatical architecture; we ask what each family of accounts implies for production under the linking assumption that extra structure-building or displacement can raise planning time (see Table 1).
Theoretical accounts of VPC variation and their predictions for production planning

2.2.1. Generative accounts
One line of generative theorizing treats the split order as basic (particle projects a small clause or resultative phrase), with the joined order arising by particle raising or incorporation (e.g., den Dikken, Reference den Dikken1995; Kayne, Reference Kayne, Guéron, Obenauer and Pollock1985). Another treats the joined order as basic (verb–particle complex head), with the split order derived by object movement or linearisation constraints (e.g., Dehé, Reference Dehé2002; Johnson, Reference Johnson1991). Other proposals allow both orders in the grammar, distinguished lexically or semantically – for instance, idiomatic VPCs as complex heads and transparent combinations as small clauses (e.g., Punske, Reference Punske2013; Ross, Reference Ross1967; Wurmbrand, Reference Wurmbrand2000). Recent work highlights prosody and information structure, with surface realisation set at the phonological form (PF)–discourse interface (Büring, Reference Büring and den Dikken2013; Köhn et al., Reference Köhn, Baumann and Dörfler2018; Samek-Lodovici, Reference Samek-Lodovici2017). If one order is consistently derived, a planning contrast should follow; if both are equally represented, no contrast is expected.
2.2.2. Usage-based and constructional accounts
Usage-based approaches treat both orders as entrenched patterns shaped by frequency, idiomaticity and discourse (Bybee, Reference Bybee2010; Cappelle, Reference Cappelle2006; Gries, Reference Gries2003). Idiomatic VPCs are more likely to be stored as holistic chunks, which favours adjacency, while compositional combinations more readily allow separation. Production ease depends on the accessibility of stored exemplars more than on derivational complexity. For Luo (Reference Luo2019), in a construal account, the preferred order reflects whether the event is packaged as a tight gestalt (joined order) or as a sequence that foregrounds the object (split order). Because construal attaches to particular VPC senses, the expectation is for item-specific baselines: some VPCs will favour adjacency across contexts, others separation. Production ease then, still, follows from entrenchment: frequent, idiomatic combinations are retrieved quickly and tend to keep verb and particle adjacent, while transparent, semantically compositional combinations more readily allow separation.
2.2.3. Information-theoretic perspectives
A complementary view links selection cost to entropy: when the distribution of variants is symmetrical, uncertainty is higher and selection may be harder; when one variant is strongly favoured, selection is easier (Jaeger, Reference Jaeger2010). For a binary alternation, entropy is maximised at
 $ \hat{p}=0.5 $
and decreases monotonically as
$ \hat{p}=0.5 $
and decreases monotonically as
 $ \mid \eta \mid $
increases; we therefore use
$ \mid \eta \mid $
increases; we therefore use
 $ \mid \eta \mid $
as a simple proxy for choice uncertainty in the present study. This prediction is theory-neutral about representation but interacts with representational choices insofar as they shape contextual probabilities.
$ \mid \eta \mid $
as a simple proxy for choice uncertainty in the present study. This prediction is theory-neutral about representation but interacts with representational choices insofar as they shape contextual probabilities.
2.3. Chunkiness and cohesion
Across traditions, accounts of VPCs appeal to cohesion between the verb and the particle. We use chunkiness as a neutral cover term for this cohesion and distinguish two sources for it that matter for production.
2.3.1. Semantic chunkiness
We use ‘semantic chunkiness’ for cases in which a verb–particle pairing is stored and retrieved as a single lexicalised unit rather than assembled compositionally. Idiomaticity is graded: combinations range from transparent to fully idiomatic, with many intermediate cases arising through semantic extension (Luo, Reference Luo2019). In constructional accounts, such units are multi-word constructions, that is, conventional form–meaning pairings larger than a word; the grammar licenses their internal syntax and their preferred linearisation (Culicover et al., Reference Culicover, Jackendoff and Audring2017; Goldberg, Reference Goldberg, Nash and Samvelian2016). Accordingly, idiomatic VPCs count as ‘chunks’, which explains their tendency towards verb–particle adjacency without any claim that they impose extra planning cost.
While idiomaticity is graded in principle, our analyses require an operational contrast; we therefore adopt a binary coding that collapses fully idiomatic and conventionalised non-literal/resultative uses into a single ‘idiomatic’ (semantically chunked) category (details in Appendix A).
2.3.2. Frequency-based chunkiness
Independent of semantic opacity, repeated experience with a verb–particle combination can make it behave as a planning unit. We use frequency-based chunkiness for this accessibility effect of token frequency and entrenchment in usage. Usage-based accounts predict that frequent VPCs are retrieved more readily and initiated sooner (e.g., Bybee, Reference Bybee2010; Gries, Reference Gries2003). Frequency strengthens access to a multi-word template, which should reduce pre-verbal delay, particularly when overall speech is fast and planning time is tight.
2.3.3. Production evidence
Production studies of spontaneous speech support treating chunks as planning units. In conversational data, established expressions tend to be realised without internal hesitations, whereas frame-like, discontinuous constructions are more likely to span pause boundaries – a classic signal of increased planning work (Schneider, Reference Schneider2016; Xie et al., Reference Xie, Chen and Li2023). Broader reviews of chunking in spoken interaction likewise tie chunk status to prosodic phrasing and planning scope (Barth-Weingarten & Ogden, Reference Barth-Weingarten and Ogden2021). These results legitimise our use of pre-verbal silence as a window on chunk-mediated planning because pauses concentrate at constituent onsets where speakers complete selection and retrieval of the upcoming verb–object–particle material, and they shorten when that material is accessed as a single stored unit.
Taken together, the production-oriented view of chunkiness yields concrete predictions for our data. Semantic chunkiness (idiomaticity) should push speakers towards joined order but need not lengthen pre-verbal pauses. Frequency-based chunkiness should shorten pauses, especially during rapid speech, by easing access to the upcoming verb–particle template. Crucially, neither prediction entails that one order is intrinsically costlier to plan; the claim is that lexical cohesion affects which order is chosen and that frequency affects how quickly articulation can begin.
3. Methods
3.1. Data
Our analysis is based on a new collection of VPC tokens extracted from the SWITCHBOARD corpus of spoken American English (Godfrey et al., Reference Godfrey, Holliman and McDaniel1992; Linguistic Data Consortium, 1997). The corpus contains approximately 240 hours of semi-spontaneous telephone conversations between strangers who are native speakers of American English.Footnote 1 The 520 speakers are stratified by gender, age, education and dialect region. Conversations were recorded between 1989 and 1990.
We identified 3,154 tokens of transitive VPCs. Tokens were included only if they exhibited the potential for order variation; intransitives (calm down, come back), passives (was given out) and cases with intervening adverbs (pay the bill right up) were excluded. Potential preposition–verb confounds (put the dress on the table) were distinguished from true VPCs (put the dress on). Full exclusion criteria and examples are given in the Appendix.
Pronominal tokens were retained despite their near-categorical preference for split order. They occasionally occur in the joined order, which makes them variable in principle, and they form a large share of VPC tokens. Excluding them would misrepresent the distribution and remove a crucial control.
Table 2 summarises the demographic distribution of speakers. Speaker ID was retained as a random effect in statistical modelling to account for individual baselines.
Summary of speaker demographics in SWITCHBOARD (Godfrey et al., Reference Godfrey, Holliman and McDaniel1992)

3.2. Speech-planning time as a metric of cognitive effort
We operationalise cognitive effort as pre-verbal silence: the duration of unfilled pauses immediately preceding the verb head of the VPC. Silence duration is a well-established indicator of planning load in spontaneous speech (e.g., Clark & Wasow, Reference Clark and Wasow1998; Goldman-Eisler, Reference Goldman-Eisler1968; Lickley, Reference Lickley and Redford2015). Longer silences suggest greater planning difficulty; shorter silences indicate easier retrieval or production.
We focus on the silence immediately preceding the verb because pauses at clause and constituent boundaries correlate with the complexity of upcoming material. Early work showed clustering of pauses before major constituents with lengthening as structural complexity increases (Cooper & Paccia-Cooper, Reference Cooper and Paccia-Cooper1980; Goldman-Eisler, Reference Goldman-Eisler1968; Maclay & Osgood, Reference Maclay and Osgood1959). Analysis of SWITCHBOARD – our dataset – shows hesitation peaks at constituent onsets (Schneider, Reference Schneider2016). Experimental results further indicate that verbs and complements are planned in advance of articulation, so pre-verbal pauses reflect the load of assembling the upcoming clause (Momma & Yoshida, Reference Momma and Yoshida2023).
Silence duration was extracted automatically from the audio using Praat’s silence detection (Sound: To TextGrid (silences); Boersma & Weenink, Reference Boersma and Weenink2020). Silence was defined as intervals below
 $ -50 $
dB and longer than 10 ms (Gardner et al., Reference Gardner, Uffing, Van Vaeck and Szmrecsanyi2021; Hieke et al., Reference Hieke, Kowal and O’Connell1983). For each token, we measured the pause immediately before the verb. Tokens with extreme outliers (silences
$ -50 $
dB and longer than 10 ms (Gardner et al., Reference Gardner, Uffing, Van Vaeck and Szmrecsanyi2021; Hieke et al., Reference Hieke, Kowal and O’Connell1983). For each token, we measured the pause immediately before the verb. Tokens with extreme outliers (silences
 $ >3 $
s) were excluded. In the final dataset, pauses ranged from 11 ms to 1,792 ms (mean 164 ms, SD 220 ms; median 96 ms).
$ >3 $
s) were excluded. In the final dataset, pauses ranged from 11 ms to 1,792 ms (mean 164 ms, SD 220 ms; median 96 ms).
Because pause duration is right-skewed and bounded by zero, analyses used log-transformed values. This reduces the influence of outliers and better meets linear-model assumptions.
3.3. Coding of constraints
Each token was coded for order and for factors known to condition VPC variation. We group these as grammatical, constructional and social.
3.3.1. Grammatical conditioning
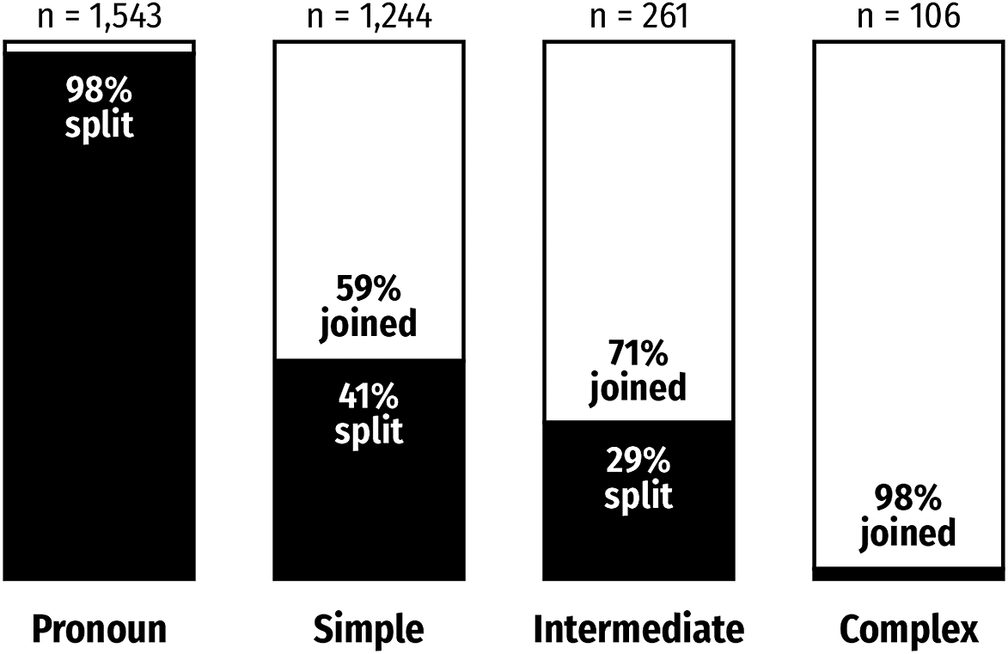
We coded the DO for type and complexity. Simple noun phrases (NPs) comprise either a pronoun or a head noun with optional determiners; intermediate NPs contain non-finite post-nominal modification or coordination; complex NPs contain finite modification. This captures the tendency for heavier objects to favour the joined order (Gries, Reference Gries2003; Lohse et al., Reference Lohse, Hawkins and Wasow2004) (see Figure 1). Pronominal objects were coded separately as a near-categorical baseline for split order.
Distribution of joined and split vpc order by complexity of the direct object.

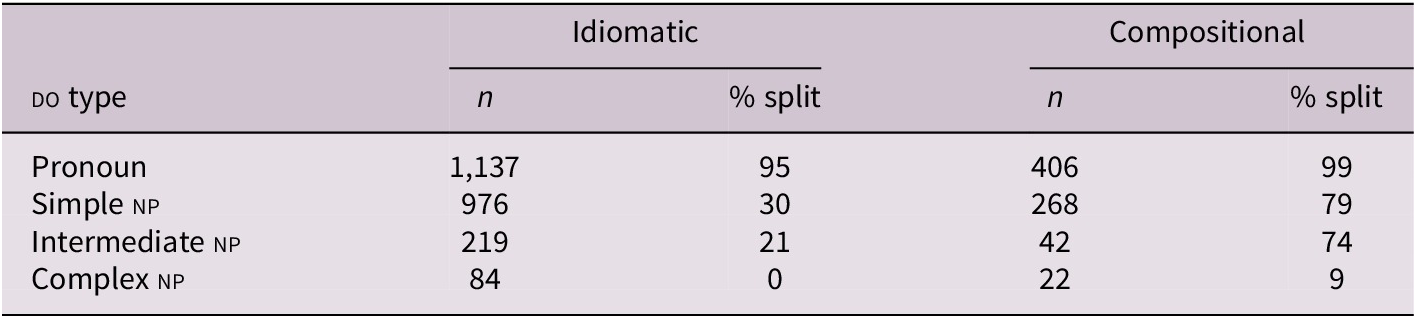
Each do was further coded for animacy (animate versus inanimate), definiteness and concreteness, given their links to particle placement (Gries, Reference Gries1999, Reference Gries2003). Because order choice is also sensitive to the lexical–semantic cohesion of the verb–particle pairing itself (independently of do properties), we additionally coded each token for idiomaticity, treating it as a construction-level property that can interact with do type and complexity in conditioning particle placement.
For transparency, (4) gives a single attested sentence that contains two vpc tokens; we list each token and its coding for do properties and idiomaticity.

Token-level coding in (4):
-
• Broke things off (split order): do = things (NP; simple NP; inanimate; indefinite; abstract); idiomaticity = idiomatic (conventionalised non-literal sense ‘end a relationship’).
-
• Picked up a needle (joined order): do = a needle (NP; simple NP; inanimate; indefinite; concrete); idiomaticity = compositional (literal/spatial up ‘lift’).
Throughout, we use idiomaticity as a practical cover term for semantic chunkiness: whether the verb–particle pairing in its attested sense and context is plausibly accessed as a cohesive form–meaning unit in usage.Footnote 2 This operationalisation is intentionally broader than ‘idiom’ narrowly construed. In particular, it includes (i) fully idiomatic/holistic senses (e.g., pick up guys ‘meet/attract’) and (ii) conventionalised resultative/aspectual particle uses such as up in cheer someone up or brighten something up, which are productive but non-spatial and often pattern with cohesive vpc behaviour. Crucially, this does not claim that productive resultative/aspectual particles are strictly non-compositional; rather, because they involve a conventionalised non-spatial particle contribution and often behave as cohesive verb–particle units in usage, we group them with the ‘idiomatic’ (semantically chunked) category for the purposes of a binary operational contrast.
Coding followed an entailment-based diagnostic used in prior corpus work on vpcs (Lohse et al., Reference Lohse, Hawkins and Wasow2004, 244–246; Grafmiller & Szmrecsanyi, Reference Grafmiller and Szmrecsanyi2018, 392) and subsequent applications (Röthlisberger & Tagliamonte, Reference Röthlisberger and Tagliamonte2020). Tokens were coded as compositional only when the utterance-level meaning transparently entailed both (a) the corresponding simplex-verb event and (b) a literal/spatial paraphrase contributed by the particle; otherwise, the token was coded as idiomatic in the present operational sense. Idiomaticity was coded independently by both authors; disagreements were resolved through discussion to a single consensus coding (Table 3). The diagnostic and fully annotated examples are provided in Appendix A.
Distribution of split vpc order by type of DO and idiomaticity of the vpc

3.3.2. Constructional conditioning
We coded frequency and lexical identity. Head-verb frequency was measured as relative frequency within SWITCHBOARD. Verbs occurring more than 1% of the time (
 $ \ge 32 $
tokens) were coded as ‘frequent’ (Erker & Guy, Reference Erker and Guy2012). Each VPC type (e.g., pick up, get back) was included as a random effect to account for item-specific baselines, because some combinations are near-categorical in one order.
$ \ge 32 $
tokens) were coded as ‘frequent’ (Erker & Guy, Reference Erker and Guy2012). Each VPC type (e.g., pick up, get back) was included as a random effect to account for item-specific baselines, because some combinations are near-categorical in one order.
3.3.3. Social conditioning
Tokens were linked to speaker metadata in the corpus: age, gender, education level and dialect region. These factors allow tests of social conditioning, as reported in other varieties (Röthlisberger & Tagliamonte, Reference Röthlisberger and Tagliamonte2020). Speaker identity was included as a random effect to control for individual baselines.
Analysis plan. We distinguish two analytic goals: (i) testing whether particle placement is associated with increased speech-planning cost (H1–H4) and (ii) characterising how grammatical and lexical–semantic factors condition order choice, including auxiliary chunkiness predictions (C1–C2). All primary modelling uses tree-based mixed-effects models; where a theoretically central predictor is unsupported, we quantify evidence for a negligible effect with targeted Bayesian follow-up.
Step 1: Model order choice with a GLMM tree (C1; inputs for H4). We first fit a binomial generalised linear mixed-effects model (GLMM) tree predicting split versus joined vpc order. Candidate predictors include object properties (type/complexity, animacy, definiteness, concreteness, length in words), construction-level status (idiomaticity), lexical accessibility (head-verb frequency) and speaker controls; random intercepts are included for speaker and lexical item. The GLMM tree uses model-based recursive partitioning to discover subpopulations in which effects differ, while retaining subject and item variability. Idiomaticity is treated as a carried fixed effect estimated within each terminal-node model rather than being enforced by hard partitioning, allowing us to evaluate whether semantic chunkiness systematically shifts order choice across grammatical contexts (C1).
Step 2: Derive a choice-symmetry index from fitted logits (H4). From the fitted GLMM tree we obtain, for each token, the terminal-node linear predictor (log-odds) of the split order,
 $ {\eta}_i $
.Footnote 3 We operationalise choice symmetry as the absolute fitted logit:
$ {\eta}_i $
.Footnote 3 We operationalise choice symmetry as the absolute fitted logit:
 $$ {s}_i=\mid {\eta}_i\mid . $$
$$ {s}_i=\mid {\eta}_i\mid . $$
Small
 $ {s}_i $
values indicate balanced contexts with
$ {s}_i $
values indicate balanced contexts with
 $ {\hat{p}}_i\approx 0.5 $
(high choice uncertainty); large
$ {\hat{p}}_i\approx 0.5 $
(high choice uncertainty); large
 $ {s}_i $
values indicate skewed contexts with
$ {s}_i $
values indicate skewed contexts with
 $ {\hat{p}}_i $
near 0 or 1 (low choice uncertainty). This provides a model-based operationalisation of the usage-based/uncertainty prediction in H4.
$ {\hat{p}}_i $
near 0 or 1 (low choice uncertainty). This provides a model-based operationalisation of the usage-based/uncertainty prediction in H4.
Step 3: Model planning time with an LMM tree (H1–H4; C2). We then model log pre-verbal silence with a linear mixed-effects model (LMM) tree. Candidate predictors include vpc order (H1–H2), its interaction with idiomaticity to capture mismatch predictions (H3), the symmetry index
 $ {s}_i=\mid {\eta}_i\mid $
(H4), speech rate (words per minute), head-verb frequency (C2), object properties (type/complexity, length in words, animacy, definiteness, concreteness) and speaker controls; random intercepts are speaker and lexical item. The LMM tree tests for parameter instability and partitions the data where relationships differ, yielding a flexible, interaction-sensitive model of planning time under established performance controls for SWITCHBOARD.
$ {s}_i=\mid {\eta}_i\mid $
(H4), speech rate (words per minute), head-verb frequency (C2), object properties (type/complexity, length in words, animacy, definiteness, concreteness) and speaker controls; random intercepts are speaker and lexical item. The LMM tree tests for parameter instability and partitions the data where relationships differ, yielding a flexible, interaction-sensitive model of planning time under established performance controls for SWITCHBOARD.
Step 4: Quantifying evidence for negligible effects (H4 and order effects if needed). When the tree-based analyses suggest no support for a theoretically central predictor (in particular the symmetry index
 $ {s}_i $
in H4), we follow up with a Bayesian linear mixed model to quantify evidence that any remaining effect is negligible. We predefine a region of practical equivalence (ROPE) on the log-seconds scale corresponding to changes in pause duration too small to be meaningful (here,
$ {s}_i $
in H4), we follow up with a Bayesian linear mixed model to quantify evidence that any remaining effect is negligible. We predefine a region of practical equivalence (ROPE) on the log-seconds scale corresponding to changes in pause duration too small to be meaningful (here,
 $ \pm 0.05 $
). We then evaluate whether the posterior for the symmetry effect lies within the ROPE and compare models with versus without the symmetry term using Bayes factors and out-of-sample predictive checks.
$ \pm 0.05 $
). We then evaluate whether the posterior for the symmetry effect lies within the ROPE and compare models with versus without the symmetry term using Bayes factors and out-of-sample predictive checks.
3.3.3.1. Interpretive scope
Idiomaticity and frequency are treated as sources of lexical–semantic cohesion (‘chunkiness’) that may influence (i) which order is realised (C1) and (ii) how quickly articulation begins (C2). They are not taken to imply that either order is intrinsically harder to plan. H1–H3 concern order-linked planning asymmetries; H4 concerns whether balanced choice contexts (small
 $ \mid \eta \mid $
) impose additional planning cost beyond established performance factors.
$ \mid \eta \mid $
) impose additional planning cost beyond established performance factors.
4. Results
4.1. VPC order and speech planning time
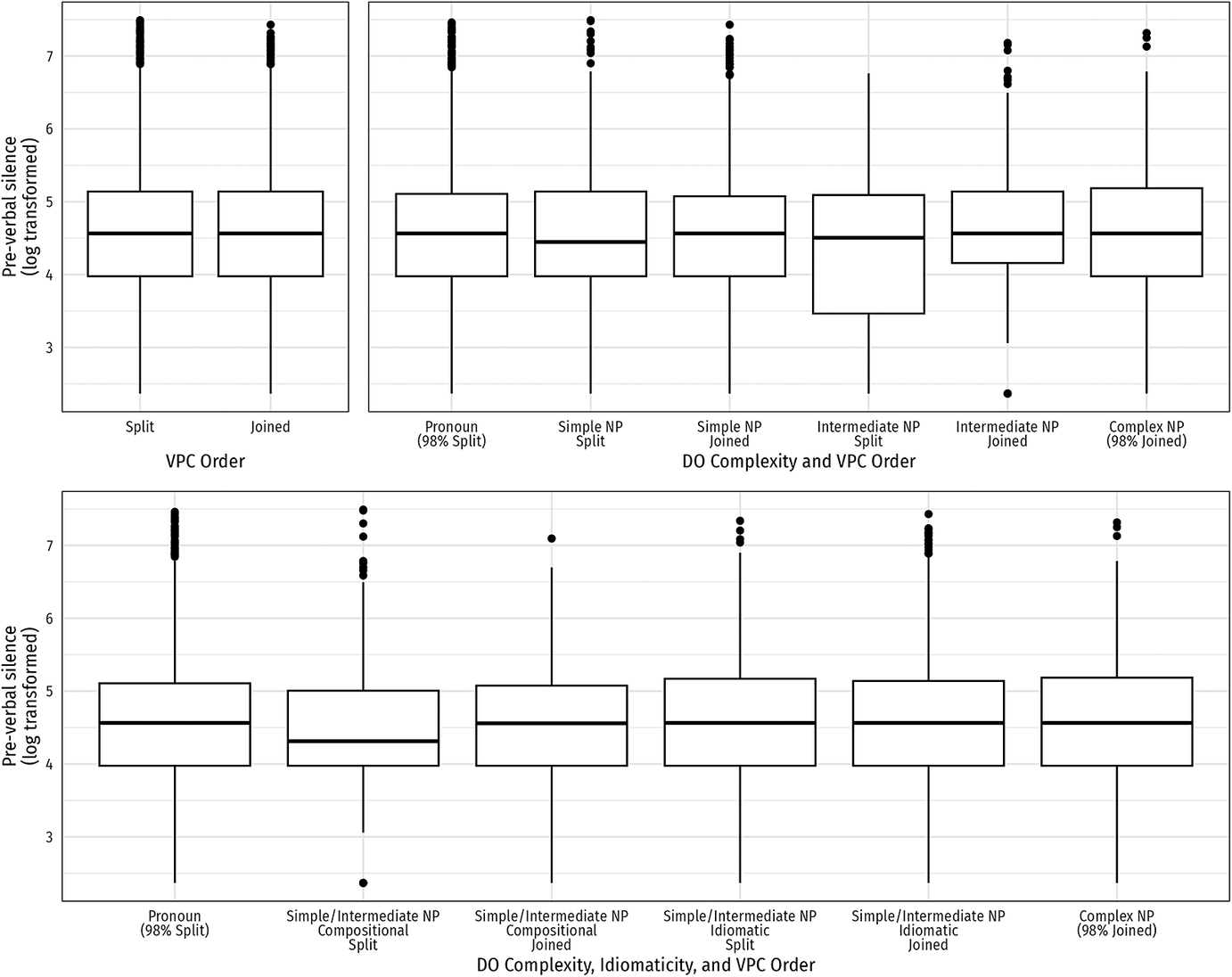
We first asked whether split and joined orders differ in pre-verbal silence. Figure 2 plots log-transformed pause duration by order, and by order crossed with DO complexity and idiomaticity. Across all comparisons, mean silence durations for split and joined tokens overlap substantially.
Distribution of pre-verbal silence (log-transformed) by VPC order (top left), by order and direct-object complexity (top right), and by order, complexity and idiomaticity (bottom). Horizontal bars mark means. Error bars show 95% CIs computed on the log scale.

These results run directly against the theoretical expectation that one order should be costlier to plan – whether because it is derivationally more complex, less entrenched or less predictable. In the top-left panel of Figure 2, split and joined tokens are indistinguishable: a one-way analysis of variance (ANOVA) shows no difference in pre-verbal silence between orders,
 $ F\left(\mathrm{1,3149.8}\right)=0.41 $
,
$ F\left(\mathrm{1,3149.8}\right)=0.41 $
,
 $ p=.522 $
,
$ p=.522 $
,
 $ {\eta}_p^2\approx 0 $
. The top-right panel, which separates Simple and Intermediate NPs (the genuinely variable cases), again shows no difference between the orders. Moreover, the near-categorical contexts (Pronouns
$ {\eta}_p^2\approx 0 $
. The top-right panel, which separates Simple and Intermediate NPs (the genuinely variable cases), again shows no difference between the orders. Moreover, the near-categorical contexts (Pronouns
 $ \approx 98\% $
split; Complex NPs
$ \approx 98\% $
split; Complex NPs
 $ \approx 98\% $
joined) are indistinguishable from the variable Simple/Intermediate NP contexts in their pre-verbal silence; an omnibus comparison across six groups yields no differences,
$ \approx 98\% $
joined) are indistinguishable from the variable Simple/Intermediate NP contexts in their pre-verbal silence; an omnibus comparison across six groups yields no differences,
 $ F\left(5,3144\right)=1.33 $
,
$ F\left(5,3144\right)=1.33 $
,
 $ p=.25 $
. H1 and H2, predicting longer pauses for whichever order is derived, find no support. H3, predicting a mismatch cost when idiomaticity and order ‘disagree’, is likewise not borne out: the bottom panel shows overlapping distributions with no interaction pattern. In short, where several theories would predict asymmetries, we find sameness across the board.
$ p=.25 $
. H1 and H2, predicting longer pauses for whichever order is derived, find no support. H3, predicting a mismatch cost when idiomaticity and order ‘disagree’, is likewise not borne out: the bottom panel shows overlapping distributions with no interaction pattern. In short, where several theories would predict asymmetries, we find sameness across the board.
These results indicate that neither order carries an inherent processing cost. The top-left panel of Figure 2 compares joined versus split tokens in aggregate and shows overlapping distributions with no shift in central tendency, which directly contradicts H1 and H2 (no order-specific planning penalty). The top-right panel conditions on DO complexity and restricts attention to the most variable object types (Simple and Intermediate NPs). Within each of these classes, split and joined tokens again exhibit indistinguishable pre-verbal silences, so the null for H1/H2 persists even when we partition out near-categorical contexts.
Having found no order-level difference in pre-verbal silence, we now model what predicts the two orders in order to quantify the choice landscape. We fit a GLMM tree to obtain token-wise fitted probabilities of the split order. These probabilities yield a choice-symmetry index
 $ s $
for each token, which lets us test H4: that more balanced contexts should slow utterance initiation if selection is costly. The model also operationalises our two chunkiness claims: C1 that semantic chunkiness (idiomaticity) favours adjacency without adding cost, and C2 that frequency-based chunkiness (head-verb entrenchment) eases retrieval and could shorten pauses. We first report the distributional model of order choice and then link its fitted probabilities to pause duration, separating predictors of linearisation from predictors of planning cost.
$ s $
for each token, which lets us test H4: that more balanced contexts should slow utterance initiation if selection is costly. The model also operationalises our two chunkiness claims: C1 that semantic chunkiness (idiomaticity) favours adjacency without adding cost, and C2 that frequency-based chunkiness (head-verb entrenchment) eases retrieval and could shorten pauses. We first report the distributional model of order choice and then link its fitted probabilities to pause duration, separating predictors of linearisation from predictors of planning cost.
4.2. Predictors of order choice
We model order choice as a binary outcome between the joined and split orders. Guided by Table 1 and prior sociolinguistic/corpus research, we code predictors that theory and previous evidence associate with this alternation: object properties (type, structural complexity, animacy, definiteness, concreteness), constructional status (idiomaticity), lexical pressure (head-verb frequency) and the presence of a following directional adverbial. Coding follows, e.g., Gries, Reference Gries2003; Wasow, Reference Wasow2002; Lohse et al., Reference Lohse, Hawkins and Wasow2004; Diessel, Reference Diessel2005; Szmrecsanyi et al., Reference Szmrecsanyi, Grafmiller, Heller and Röthlisberger2016; Grafmiller & Szmrecsanyi, Reference Grafmiller and Szmrecsanyi2018; Röthlisberger & Tagliamonte, Reference Röthlisberger and Tagliamonte2020. We also include speaker gender, age, education and dialect region as sociolinguistic controls. These linguistic and social variables constitute the predictor set; all enter as candidate predictors.
To model these effects we fit a binomial GLMM tree (Bernaisch, Reference Bernaisch, Schützler and Schlüter2022; Fokkema et al., Reference Fokkema, Edbrooke-Childs and Wolpert2020; Gardner, Reference Gardner2025) with random intercepts for speaker and lexical item. The tree uses model-based recursive partitioning: it tests for parameter instability, splits the predictor space where effects differ and refits a local mixed model in each node. This retains subject and item variability, surfaces interactions and effect heterogeneity without pre-enumerating them and accommodates non-monotone, piecewise effects with minimal functional-form assumptions. We treat idiomaticity as a carried, node-wise fixed effect: it is included in the GLMM component and estimated in every node, while the partitioning set comprises the remaining candidate predictors. This lets the tree discover subpopulations via splits on pronominality, complexity, animacy, definiteness and related properties and within each subpopulation, estimate the idiomaticity effect, rather than collapsing it through a hard split.
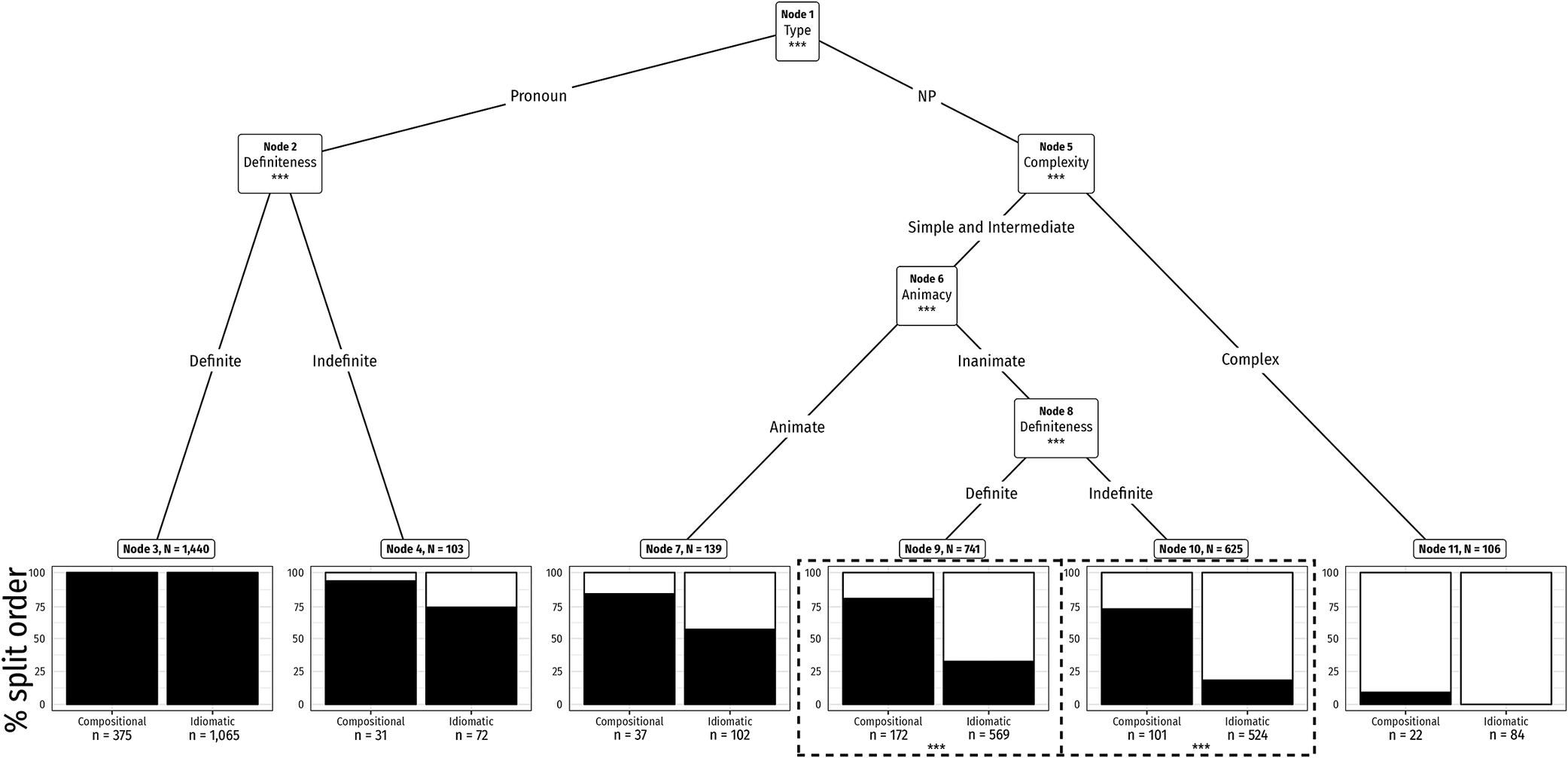
The fitted tree echoes Figure 1; the first and strongest split is pronominality (Node 1). Definite pronouns are essentially categorically split order (Node 3); indefinite pronouns admit some joined tokens (Node 4), with a stronger joined bias when the VPC is idiomatic (node-wise idiomaticity effect). For NP objects, complexity separates a branch of complex NPs that are overwhelmingly joined (Node 11), with the residual split tokens largely compositional. Among non-complex NPs, animacy (Node 6) yields a more split-friendly branch for animate NPs (Node 7) and a more joined-friendly branch for inanimate NPs, where definiteness further divides strong joined order (definite; Node 9) from less strong joined order (indefinite; Node 10). Idiomaticity consistently biases towards the joined order; its coefficient reaches node-wise significance where data are dense (Nodes 9–10) and shows the same direction but is underpowered in (Nodes 4, 7 and 11). Other candidate predictors – speaker demographics, verb frequency, and directional adverbials – are not selected once grammatical and idiomatic cues are in the model; this is model-based non-selection rather than evidence of no effect (Figure 3).
GLMM tree for split versus joined order in SWITCHBOARD. Predictors: object properties, idiomaticity, frequency and social factors. Random intercepts: speaker, lexical item. Subgroup partition: idiomatic versus compositional. Error ribbons indicate 95% CIs.

4.2.1. How to read the tree
Internal nodes show the variable used to partition the data (with the split criterion on the connecting edges); terminal nodes correspond to subgroups in which a local mixed model is fit. Within each terminal node, points indicate fitted probabilities of the split order (with 95% confidence intervals), and the idiomaticity effect is estimated as a fixed effect in every node rather than being enforced via a hard split.
Having fitted the model, we code each token by the node-specific log-odds of the split order
 $ \eta $
: the Node 3 intercept plus that token’s terminal-node coefficient. Node 3 is the reference at
$ \eta $
: the Node 3 intercept plus that token’s terminal-node coefficient. Node 3 is the reference at
 $ \eta =5.267 $
log-odds (
$ \eta =5.267 $
log-odds (
 $ p\approx 0.995 $
split). The coefficient at Node 11 is
$ p\approx 0.995 $
split). The coefficient at Node 11 is
 $ -8.316 $
, so
$ -8.316 $
, so
 $ {\eta}_{11}=5.267-8.316=-3.0486 $
(
$ {\eta}_{11}=5.267-8.316=-3.0486 $
(
 $ p\approx 0.045 $
split). Tokens from Nodes 3 or 11 are therefore highly skewed (one order overwhelmingly preferred). Tokens from Node 7 lie much closer to
$ p\approx 0.045 $
split). Tokens from Nodes 3 or 11 are therefore highly skewed (one order overwhelmingly preferred). Tokens from Node 7 lie much closer to
 $ \eta =0 $
and hence nearer 50/50; within nodes where data allow estimation (e.g., Nodes 9–10), idiomaticity shifts
$ \eta =0 $
and hence nearer 50/50; within nodes where data allow estimation (e.g., Nodes 9–10), idiomaticity shifts
 $ \eta $
toward the joined order.
$ \eta $
toward the joined order.
Our next step asks whether highly predictive contexts are easier to plan than balanced ones: that is, whether tokens from skewed contexts (one variant strongly favoured) show shorter pre-verbal silences than tokens from balanced contexts (variants near 50/50, predicted to be harder). We operationalise skew with the absolute value of the node-specific logit (
 $ \mid \eta \mid $
) and visualise it as the x-axis in Figure 4. Small
$ \mid \eta \mid $
) and visualise it as the x-axis in Figure 4. Small
 $ \mid \eta \mid $
values (on the left) mark a balanced, high-choice context; large
$ \mid \eta \mid $
values (on the left) mark a balanced, high-choice context; large
 $ \mid \eta \mid $
values (on the right) mark a low-choice, skewed context. In Figure 4, black circles represent joined order tokens and grey squares are split order tokens. The y-axis represents the log-transformed amount of pre-verbal silence per token (higher values indicate longer pausing) A regression line fitted to the data is effectively flat (
$ \mid \eta \mid $
values (on the right) mark a low-choice, skewed context. In Figure 4, black circles represent joined order tokens and grey squares are split order tokens. The y-axis represents the log-transformed amount of pre-verbal silence per token (higher values indicate longer pausing) A regression line fitted to the data is effectively flat (
 $ {R}^2=0.00035,p=0.98 $
), indicating no detectable association between choice symmetry and pre-verbal pausing.
$ {R}^2=0.00035,p=0.98 $
), indicating no detectable association between choice symmetry and pre-verbal pausing.
Log-transformed pre-verbal silence by the absolute fitted log-odds of the split order (
 $ \mid \eta \mid $
) for vpc tokens in SWITCHBOARD. Fitted values are from the GLMM tree in Section 4.2.
$ \mid \eta \mid $
) for vpc tokens in SWITCHBOARD. Fitted values are from the GLMM tree in Section 4.2.

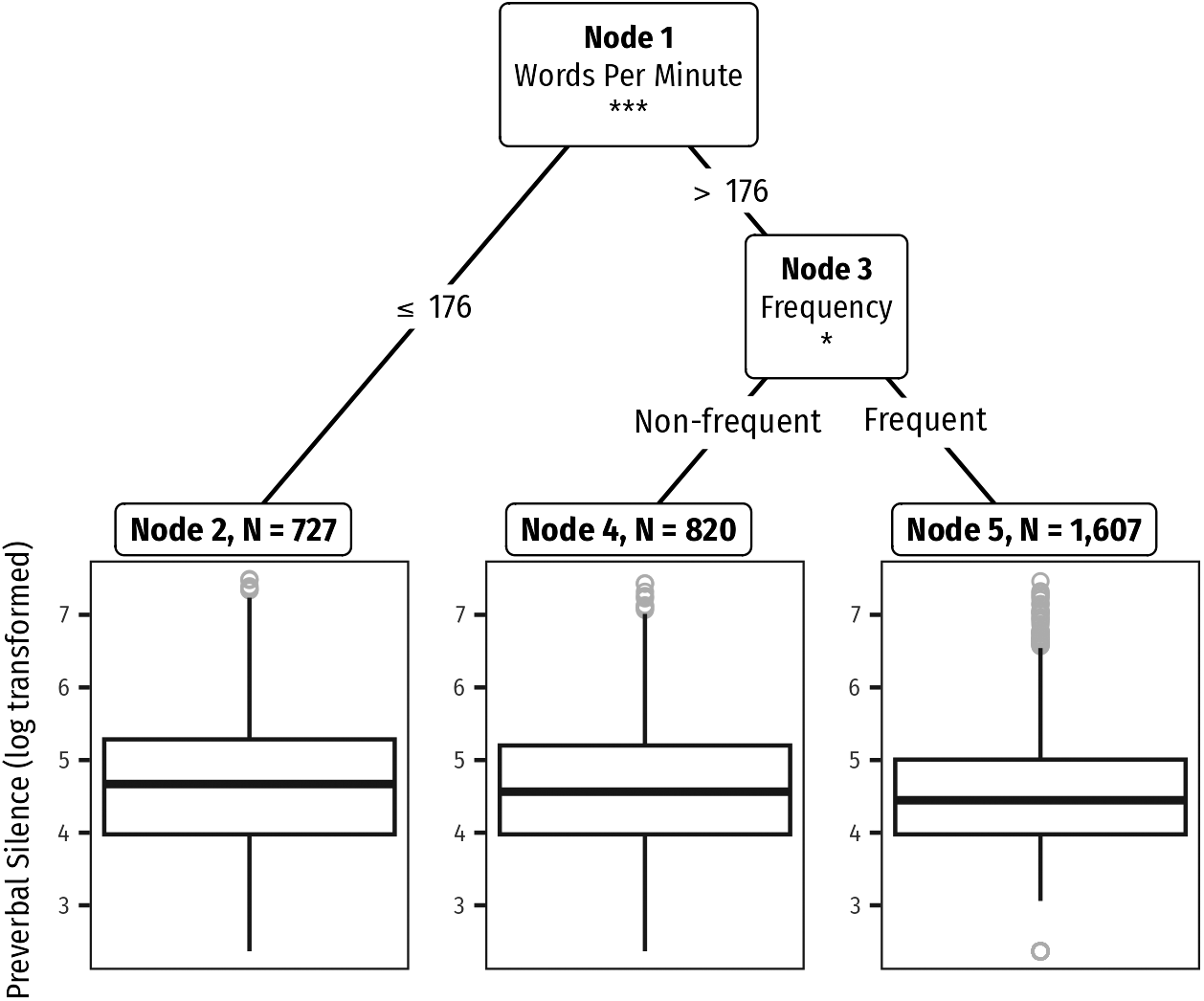
We analyse pre-verbal silence directly with a LMM tree (Figure 5) under controls that are well established for SWITCHBOARD, most notably overall speech rate.Footnote 4 Our predictor of interest is the symmetry index
 $ s=\mid \eta \mid $
from the order-choice model, which operationalises how predictable the upcoming syntactic configuration is (small
$ s=\mid \eta \mid $
from the order-choice model, which operationalises how predictable the upcoming syntactic configuration is (small
 $ s $
= balanced; large
$ s $
= balanced; large
 $ s $
= skewed). To cover lexical accessibility without conflating it with order predictability, we include head-verb frequency. Accordingly, candidate predictors are
$ s $
= skewed). To cover lexical accessibility without conflating it with order predictability, we include head-verb frequency. Accordingly, candidate predictors are
 $ s $
, speech rate (words per minute), idiomaticity, head-verb frequency, object properties (type, complexity, length in words, animacy, definiteness, concreteness) and speaker gender, age, education and dialect region; random intercepts are speaker and lexical item.
$ s $
, speech rate (words per minute), idiomaticity, head-verb frequency, object properties (type, complexity, length in words, animacy, definiteness, concreteness) and speaker gender, age, education and dialect region; random intercepts are speaker and lexical item.
LMM tree of pre-verbal silence. Predictors: symmetry index
 $ s=\mid \eta \mid $
, speech rate, idiomaticity, head-verb frequency, object properties and speaker factors. Random intercepts: speaker, lexical item.
$ s=\mid \eta \mid $
, speech rate, idiomaticity, head-verb frequency, object properties and speaker factors. Random intercepts: speaker, lexical item.

The fitted tree corroborates the null for the symmetry predictor. It first splits on speech rate at
 $ \approx 176 $
wpm: slower turns show longer pre-verbal silences. In the faster branch, head-verb frequency is selected: frequent verbs are associated with shorter pauses than infrequent verbs. The symmetry index
$ \approx 176 $
wpm: slower turns show longer pre-verbal silences. In the faster branch, head-verb frequency is selected: frequent verbs are associated with shorter pauses than infrequent verbs. The symmetry index
 $ s $
is not selected at any split, and idiomaticity and the social predictors likewise drop out once rate and frequency are in the model.
$ s $
is not selected at any split, and idiomaticity and the social predictors likewise drop out once rate and frequency are in the model.
With respect to H4, the LMM tree does not select the symmetry index
 $ s=\mid \eta \mid $
at any split, so there is no detectable penalty for balanced contexts (small
$ s=\mid \eta \mid $
at any split, so there is no detectable penalty for balanced contexts (small
 $ \mid \eta \mid $
). By contrast, C2 is supported: after an initial split on speech rate (
$ \mid \eta \mid $
). By contrast, C2 is supported: after an initial split on speech rate (
 $ \approx 176 $
wpm), the fast-rate branch selects head-verb frequency, with higher-frequency verbs showing shorter pre-verbal silences – consistent with frequency-based chunking easing access to the verb–particle template. We therefore treat H4 as a null and test it with a Bayesian linear mixed model using bridge-sampled Bayes factors and a ROPE equivalence test, followed by robustness checks.
$ \approx 176 $
wpm), the fast-rate branch selects head-verb frequency, with higher-frequency verbs showing shorter pre-verbal silences – consistent with frequency-based chunking easing access to the verb–particle template. We therefore treat H4 as a null and test it with a Bayesian linear mixed model using bridge-sampled Bayes factors and a ROPE equivalence test, followed by robustness checks.
To further test H4, we use Bayesian methods to ask two simple questions: first, is any relationship between symmetry
 $ s $
and pause length large enough to matter; and second, does adding
$ s $
and pause length large enough to matter; and second, does adding
 $ s $
to the model actually make predictions better? For the first question, we define what ‘large enough to matter’ means in advance: changes smaller than about 5% in pause duration (
$ s $
to the model actually make predictions better? For the first question, we define what ‘large enough to matter’ means in advance: changes smaller than about 5% in pause duration (
 $ \pm 0.05 $
on the log-seconds scale) count as negligible. This range is called a ROPE. In the fitted model, the estimated effect of
$ \pm 0.05 $
on the log-seconds scale) count as negligible. This range is called a ROPE. In the fitted model, the estimated effect of
 $ s $
falls entirely inside this negligible band – the 95% credible interval runs from
$ s $
falls entirely inside this negligible band – the 95% credible interval runs from
 $ -0.03 $
to
$ -0.03 $
to
 $ 0.04 $
, meaning the data support at most a
$ 0.04 $
, meaning the data support at most a
 $ \pm 4\% $
change in pause length (Table 4 and Figure 6). In other words, varying the symmetry index
$ \pm 4\% $
change in pause length (Table 4 and Figure 6). In other words, varying the symmetry index
 $ s $
, which quantifies the balance in choice between split and joined orders, has no measurable impact on pre-verbal pause duration at the scale observable in our data.
$ s $
, which quantifies the balance in choice between split and joined orders, has no measurable impact on pre-verbal pause duration at the scale observable in our data.
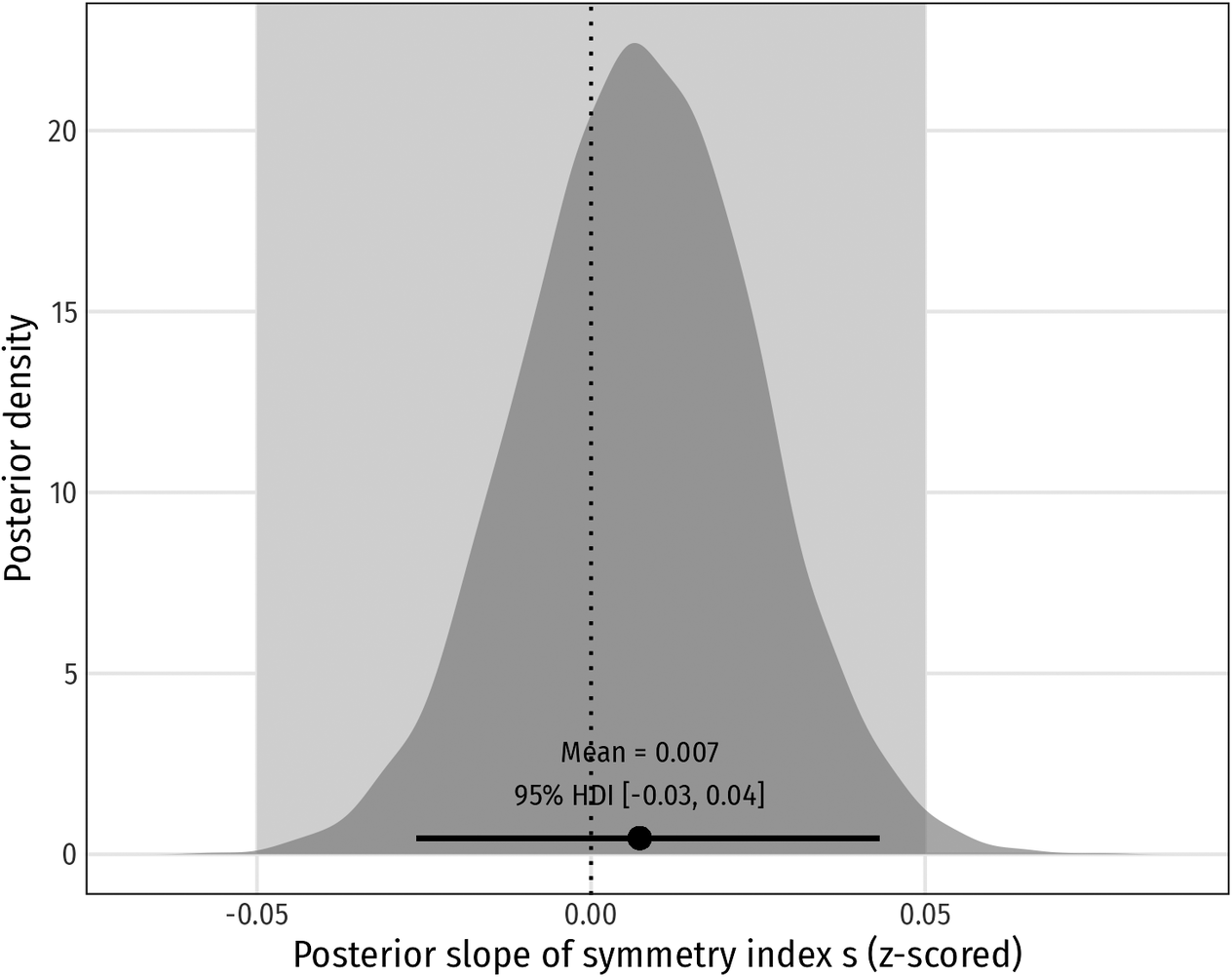
Bayesian evaluation of the symmetry effect s (log-seconds scale). HDI = highest-density interval; ROPE = [−0.05,0.05]

Posterior distribution of the slope for the symmetry index
 $ s $
(z-scored). The dark grey curve shows the posterior density; the light grey band marks the ROPE
$ s $
(z-scored). The dark grey curve shows the posterior density; the light grey band marks the ROPE
 $ \left[-\mathrm{0.05,0.05}\right] $
where effects on log pause duration are considered negligible. The black dot and horizontal bar indicate the posterior mean and 95% HDI, respectively. The
$ \left[-\mathrm{0.05,0.05}\right] $
where effects on log pause duration are considered negligible. The black dot and horizontal bar indicate the posterior mean and 95% HDI, respectively. The
 $ x $
-axis gives possible effects of
$ x $
-axis gives possible effects of
 $ s $
on pre-verbal silence, the
$ s $
on pre-verbal silence, the
 $ y $
-axis their relative plausibility. The entire distribution lies within the ROPE (HDI
$ y $
-axis their relative plausibility. The entire distribution lies within the ROPE (HDI
 $ \left[-\mathrm{0.03,0.04}\right] $
), indicating no meaningful effect of symmetry.
$ \left[-\mathrm{0.03,0.04}\right] $
), indicating no meaningful effect of symmetry.

To check whether including
 $ s $
improves prediction, we compare two otherwise identical models – one with
$ s $
improves prediction, we compare two otherwise identical models – one with
 $ s $
, one without it – using a Bayes factor, which expresses how much more likely the data are under one model than the other. The ratio overwhelmingly favours the model without
$ s $
, one without it – using a Bayes factor, which expresses how much more likely the data are under one model than the other. The ratio overwhelmingly favours the model without
 $ s $
(
$ s $
(
 $ \log {\mathrm{BF}}_{01}=29.27 $
, roughly
$ \log {\mathrm{BF}}_{01}=29.27 $
, roughly
 $ 5\times {10}^{12}:1 $
against an effect). When we deliberately relax our prior assumptions about the size of the effect, the conclusion is the same (
$ 5\times {10}^{12}:1 $
against an effect). When we deliberately relax our prior assumptions about the size of the effect, the conclusion is the same (
 $ \log {\mathrm{BF}}_{01}=2.19 $
, about
$ \log {\mathrm{BF}}_{01}=2.19 $
, about
 $ 9:1 $
for no effect). Out-of-sample checks tell the same story: when predicting unseen data, the model with
$ 9:1 $
for no effect). Out-of-sample checks tell the same story: when predicting unseen data, the model with
 $ s $
does not perform better than the simpler model (
$ s $
does not perform better than the simpler model (
 $ \Delta \mathrm{ELPD}=-1.0 $
), and information-weighting methods put essentially all weight on the model without
$ \Delta \mathrm{ELPD}=-1.0 $
), and information-weighting methods put essentially all weight on the model without
 $ s $
. A speaker-wise permutation test shows that the observed slope for
$ s $
. A speaker-wise permutation test shows that the observed slope for
 $ s $
is entirely consistent with chance (
$ s $
is entirely consistent with chance (
 $ p=0.63 $
), and allowing a non-linear effect of
$ p=0.63 $
), and allowing a non-linear effect of
 $ s $
or using projection-based variable selection likewise offers no support for including it. Taken together, these converging results indicate that choice symmetry (the
$ s $
or using projection-based variable selection likewise offers no support for including it. Taken together, these converging results indicate that choice symmetry (the
 $ \mid \eta \mid $
index) does not measurably affect pre-verbal silence, with any possible influence smaller than our 5% threshold. We therefore regard H4 as unsupported (effectively rejected) and turn to the broader implications of this finding in the discussion.
$ \mid \eta \mid $
index) does not measurably affect pre-verbal silence, with any possible influence smaller than our 5% threshold. We therefore regard H4 as unsupported (effectively rejected) and turn to the broader implications of this finding in the discussion.
5. Discussion
Our findings provide a focused test of whether syntactic variation incurs measurable production cost. Across more than 3,000 VPCs in SWITCHBOARD, we find no evidence that one order (split versus joined) is harder to produce than the other. Pre-verbal silences do not differ systematically between orders, even when controlling for object type, complexity, animacy and idiomaticity. This result directly bears on H1 and H2: the split and joined orders are produced with comparable ease, and there is no indication that either ordering imposes extra planning load. This is consistent with the fact that analyses trade off different notions of complexity (e.g., syntactic configuration versus morphological cohesion), and it provides no production-based support for accounts that predict a general timing penalty from additional operations in one ordering. This undermines the assumption, common to many derivational accounts, that formally ‘marked’ variants require greater production effort. Pauses reliably lengthen before syntactically complex clauses, infrequent words and unexpected constituents (e.g., Clark & Wasow, Reference Clark and Wasow1998; Ferreira, Reference Ferreira1991; Goldman-Eisler, Reference Goldman-Eisler1968; Momma & Yoshida, Reference Momma and Yoshida2023; Shriberg, Reference Shriberg1994); the absence of any such pattern here suggests that both orders are equally available to speakers in real time despite their formal differences.
H3 and H4 addressed whether optionality itself, as reflected in more balanced choice contexts (small
 $ \mid \eta \mid $
), adds to planning difficulty. If symmetrical contexts (where two variants are equally likely) impose additional cognitive load, tokens with fitted probabilities near 0.5 should show longer pre-verbal silences. No such pattern emerged. Pauses are no longer in balanced contexts than in skewed contexts. In information-theoretic terms, choice-set uncertainty, operationalised here as
$ \mid \eta \mid $
), adds to planning difficulty. If symmetrical contexts (where two variants are equally likely) impose additional cognitive load, tokens with fitted probabilities near 0.5 should show longer pre-verbal silences. No such pattern emerged. Pauses are no longer in balanced contexts than in skewed contexts. In information-theoretic terms, choice-set uncertainty, operationalised here as
 $ \mid \eta \mid $
, does not predict production cost in our production measure. Bayesian model comparison, equivalence testing and permutation analysis all converge on the same conclusion: any effect of symmetry, if present at all, is smaller than a few percentage points on the log–seconds scale.
$ \mid \eta \mid $
, does not predict production cost in our production measure. Bayesian model comparison, equivalence testing and permutation analysis all converge on the same conclusion: any effect of symmetry, if present at all, is smaller than a few percentage points on the log–seconds scale.
The chunkiness hypotheses (C1–C2) were partially borne out. Speech rate and head-verb frequency together predict planning time: slower turns show longer pre-verbal pauses, and within fast speech, frequent verbs shorten them. This confirms that frequency-based chunking eases retrieval, not that any specific order is inherently costlier. Idiomaticity, as a form of semantic chunkiness, strongly predicts order choice but not planning duration. Thus both frequency-based and semantic chunkiness shape which variant is chosen, but neither increases the time needed to produce it.
These findings align with prior corpus work on production fluency. Gardner et al. (Reference Gardner, Uffing, Van Vaeck and Szmrecsanyi2021) found that optionality in itself does not attract disfluency across more than 20 alternations in SWITCHBOARD, and subsequent studies report no correlation between uncertainty/balance in syntactic choice and filled pauses, repairs or hesitations (Szmrecsanyi et al., Reference Szmrecsanyi, Gardner, Ma, Van Hoey, Cukor-Avila, Tagliamonte and Bailey2026a, Reference Szmrecsanyi, Gardner and Van Hoey2026b). By isolating a single alternation and modelling choice symmetry directly (via
 $ \mid \eta \mid $
), our results confirm this pattern with greater precision: across alternations and measures, syntactic variation is not harder to produce. Absolute complexity in the grammar does not entail relative complexity in use.
$ \mid \eta \mid $
), our results confirm this pattern with greater precision: across alternations and measures, syntactic variation is not harder to produce. Absolute complexity in the grammar does not entail relative complexity in use.
5.1. Easy, chunky, all the time
Evidence from related systems that particles can be syntactically and prosodically phrasal rather than clitic-like (e.g., Swedish; Toivonen, Reference Toivonen2003; Svenonius, Reference Svenonius1996) weakens any expectation that a single head-movement derivation should govern English verb–particle order. If surface order is resolved at the PF–discourse interface – via information structure, prosody and weight – then neither order is inherently ‘derived’ in a way that should increase planning cost. Our null difference in pre-verbal silence is consistent with this view: idiomaticity influences adjacency preferences, but there is no general production penalty for either order.
The distinction between semantic and frequency-based chunkiness clarifies why both matter yet remain independent of processing cost. Semantic chunkiness (idiomaticity) guides adjacency and lexical cohesion; frequency-based chunkiness (entrenchment) facilitates retrieval, particularly under temporal pressure. Neither drives measurable changes in pausing. This dissociation helps explain why production is sensitive to lexical accessibility but buffered against the structural ‘difficulty’ often assumed in derivational models.
Theoretical implications follow on both sides. For generative accounts that posit one order as derived, there is no processing evidence of a derivational direction: if additional operations imposed cost, silences would lengthen before the derived form, but they do not. For usage-based approaches, idiomaticity effects are real but bounded: idiomaticity chiefly shapes selection (order choice), while frequency shows a limited fluency benefit under time pressure (shorter pre-verbal silences in faster speech). Processing ease depends more on lexical entrenchment than on structural markedness, while semantic cohesion mainly constrains linearisation.
Finally, these results help clarify how production and comprehension can diverge in what counts as ‘difficulty’ in the presence of variation. In comprehension, processing cost is often linked to the unexpectedness of upcoming material, typically operationalised as surprisal (negative log probability of a specific ‘next thing’, e.g., word/structure/sound, etc.), whereas entropy quantifies uncertainty over a set of alternatives prior to observing a particular outcome (approximated in our production analyses by
 $ \mid \eta \mid $
for this binary alternation) (Frank, Reference Frank2013; Hale, Reference Hale2001; Levy, Reference Levy2008). These are related but distinct notions: a context can have high uncertainty (several plausible ‘next things’) without any single one being especially surprising, and a context can have low entropy (i.e., few possible ‘next things’) while still yielding a highly surprising outcome. Our production measure tests a different question: whether the availability of two surface realisations, or balanced variant probabilities, is associated with longer pre-verbal planning time. We find no evidence that it is: pre-verbal silences are insensitive to choice symmetry in this alternation. This does not imply that vpc variation would be cost-free in comprehension. A comprehension-focused test would instead ask whether listeners incur greater cost when the realised order is less expected in its context (high surprisal), and whether any such effects track item-specific entrenchment (idiomaticity, frequency) and discourse cues. The broader implication is that distributional predictability can matter for comprehension and production in different ways, and that the absence of an entropy effect on production timing here sets a concrete boundary condition for theories that would equate variant uncertainty with planning difficulty.
$ \mid \eta \mid $
for this binary alternation) (Frank, Reference Frank2013; Hale, Reference Hale2001; Levy, Reference Levy2008). These are related but distinct notions: a context can have high uncertainty (several plausible ‘next things’) without any single one being especially surprising, and a context can have low entropy (i.e., few possible ‘next things’) while still yielding a highly surprising outcome. Our production measure tests a different question: whether the availability of two surface realisations, or balanced variant probabilities, is associated with longer pre-verbal planning time. We find no evidence that it is: pre-verbal silences are insensitive to choice symmetry in this alternation. This does not imply that vpc variation would be cost-free in comprehension. A comprehension-focused test would instead ask whether listeners incur greater cost when the realised order is less expected in its context (high surprisal), and whether any such effects track item-specific entrenchment (idiomaticity, frequency) and discourse cues. The broader implication is that distributional predictability can matter for comprehension and production in different ways, and that the absence of an entropy effect on production timing here sets a concrete boundary condition for theories that would equate variant uncertainty with planning difficulty.
5.2. Limitations and robustness checks
The evidence derives from semi-spontaneous American English telephone speech and may not generalise to other registers or languages. Because the conversations are semi-spontaneous and topic-prompted, some planning behaviour may differ from fully unelicited interaction; however, the design still captures natural turn-taking, lexical retrieval and incremental utterance launch under real-time constraints. Pre-verbal silence is an indirect index of planning effort and can misclassify short low-amplitude segments. We mitigated this with conservative thresholds (
 $ -50 $
dB,
$ -50 $
dB,
 $ \ge $
10 ms), log-transformation and exclusion of outliers (
$ \ge $
10 ms), log-transformation and exclusion of outliers (
 $ >3 $
s). The key results are robust to alternative preprocessing choices (e.g., different thresholds or winsorising) and to modelling on the raw millisecond scale. Beyond the GLMM and LMM trees reported, the null effect of symmetry was verified through a Bayesian mixed model with ROPE and Bayes factor tests, sensitivity analyses with wider priors, out-of-sample model comparison and a speaker-wise permutation test. All converge on the same outcome: symmetry does not measurably influence pre-verbal silence, and any residual effect is smaller than the predefined 5% equivalence margin.
$ >3 $
s). The key results are robust to alternative preprocessing choices (e.g., different thresholds or winsorising) and to modelling on the raw millisecond scale. Beyond the GLMM and LMM trees reported, the null effect of symmetry was verified through a Bayesian mixed model with ROPE and Bayes factor tests, sensitivity analyses with wider priors, out-of-sample model comparison and a speaker-wise permutation test. All converge on the same outcome: symmetry does not measurably influence pre-verbal silence, and any residual effect is smaller than the predefined 5% equivalence margin.
6. Conclusion
The study asked whether syntactic variation in VPCs adds to production complexity. It does not. Across multiple models and validation methods, pre-verbal silence is unaffected by order, idiomaticity or choice symmetry. Planning effort reflects only general performance factors – speech rate and under time pressure, head-verb frequency. Within this alternation, syntactic variation carries no measurable cost.
This result does not imply that derivational complexity never affects timing: clause-initial pauses and repair sites remain sensitive to structural load. But at the verb–object juncture, where lexical access and incremental planning occur, no cost appears. At the point immediately before vpc onset (the verb), we find no timing penalty associated with the eventual ordering: pre-verbal silences are indistinguishable across split and joined tokens. Variation in VPCs is structured by grammatical and semantic constraints, stable across speakers and efficient in production.
In short, syntactic alternations can be both probabilistic and fluent. Variation is not a symptom of inefficiency but a property of a production system that is flexible, resilient and low-cost. Variation is sometimes treated as a challenge for strongly economy-driven or efficiency-shaped views of grammar and processing (e.g., Chomsky, Reference Chomsky1995; Fukui, Reference Fukui1993; Gibson et al., Reference Gibson, Futrell, Piantadosi, Dautriche, Mahowald, Bergen and Levy2019; Hawkins, Reference Hawkins2004; Henry, Reference Henry1998), but our results suggest that (at least for VPC placement) probabilistic alternation can be fully fluent in production. Future work should test whether this pattern generalises to other alternations and languages, but within this domain the evidence is clear: VPC variation does not slow speakers down.
Data availability statement
An Open Science Framework (OSF) repository hosting R scripts, derived (non-identifying) data and session info (exact package versions) can be found here: osf.io/pr2bw. Raw transcripts and audio files are not available as they are licensed from the Linguistic Data Consortium; however, interested readers may seek out the data there.
Acknowledgements
The authors thank Benedikt Szmrecsanyi, Thomas Van Hoey, and the broader Complexity and Change research project at KU Leuven, Belgium. The authors also thank early reviewers for their valuable feedback. This manuscript was prepared in LaTeX using the CUP-JNL-LCO class. We used an AI-assisted editor to copy-edit wording and refactor LaTeX (preamble, citation commands, and cross-references). The model did not generate results, annotations, analyses or claims; all analyses and interpretations are by the authors.
Funding statement
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Competing interest
The authors declare none.
Ethics statement
This study involves the secondary use of data exclusively. No identifying information about speakers is presented.
Appendices
A. Inclusion and exclusion criteria: annotated examples
The following examples (all from SWITCHBOARD; Godfrey et al., Reference Godfrey, Holliman and McDaniel1992) illustrate the data conditions under which tokens were included in, or excluded from, analysis. Speaker metadata are given in parentheses.
A.1. Included: transitive VPCs with variable particle placement


Pronominal objects and complex NPs were retained (as controls and because they exhibit limited variability):


A.2. Excluded contexts
A.2.1. Intransitives (no DO)
A.2.2. Passives (no active particle-placement alternation)
A.2.3. Intervening adverbs (e.g., right) between DO and particle
A.2.4. Extracted DO (object outside the VP domain of the VPC)
A.2.5. Preposition–verb constructions (non-alternating) versus particle verbs

B. Idiomaticity coding: diagnostic and examples
Idiomaticity was coded following an entailment-based diagnostic (Lohse et al., Reference Lohse, Hawkins and Wasow2004, 244–246) and subsequent applications (Grafmiller & Szmrecsanyi, Reference Grafmiller and Szmrecsanyi2018; Röthlisberger & Tagliamonte, Reference Röthlisberger and Tagliamonte2020, 392). Throughout, we use idiomaticity as an operational cover term for semantic chunkiness. A token was coded as compositional only if the utterance-level meaning transparently entailed both (i) the corresponding simplex-verb event and (ii) a literal/spatial paraphrase contributed by the particle. Otherwise, it was coded as idiomatic in the present operational sense, which includes both fully idiomatic/holistic senses and conventionalised non-spatial resultative/aspectual particle uses (e.g., up in cheer someone up, brighten something up). The following tokens illustrate the distinction; coded values for other variables are provided for transparency.

The following examples illustrate the broader operationalisation used here, where conventionalised non-spatial resultative/aspectual particle uses are also coded as idiomatic (i.e., semantically chunked) for the purposes of a binary contrast. As noted above, this grouping is an operational decision for a binary contrast and should not be read as a claim that all resultative/aspectual uses are categorically non-compositional:

C. Colophon
Software and reproducibility
We used R v. 4.5.2 (R Core Team, 2025) and the following R packages: ggparty v. 1.0.0.1 (Borkovec & Madin, Reference Borkovec and Madin2025), ggpubr v. 0.6.2 (Kassambara, Reference Kassambara2025), glmertree v. 0.2.6 (Fokkema et al., Reference Fokkema, Smits, Zeileis, Hothorn and Kelderman2018; Fokkema & Zeileis, Reference Fokkema and Zeileis2024), here v. 1.0.2 (Müller, Reference Müller2025), knitr v. 1.50 (Xie, Reference Xie, Stodden, Leisch and Peng2014, Reference Xie2015, Reference Xie2025a), lme4 v. 1.1.37 (Bates et al., Reference Bates, Mächler, Bolker and Walker2015), lmerTest v. 3.1.3 (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017), partykit v. 1.2.24 (Hothorn et al., Reference Hothorn, Hornik and Zeileis2006; Hothorn & Zeileis, Reference Hothorn and Zeileis2015; Zeileis et al., Reference Zeileis, Hothorn and Hornik2008), patchwork v. 1.3.2 (Pedersen, Reference Pedersen2025), rmarkdown v. 2.30 (Allaire et al., Reference Allaire, Xie, Dervieux, McPherson, Luraschi, Ushey, Atkins, Wickham, Cheng, Chang and Iannone2025; Xie et al., Reference Xie, Allaire and Grolemund2018, Reference Xie, Dervieux and Riederer2020), scales v. 1.4.0 (Wickham et al., Reference Wickham, Pedersen and Seidel2025b), sessioninfo v. 1.2.3 (Wickham et al., Reference Wickham, Chang, Flight, Müller and Hester2025a), sjPlot v. 2.9.0 (Lüdecke, Reference Lüdecke2025), tidyverse v. 2.0.0 (Wickham et al., Reference Wickham, Averick, Bryan, Chang, McGowan, François, Grolemund, Hayes, Henry, Hester, Kuhn, Pedersen, Miller, Bache, Müller, Ooms, Robinson, Seidel, Spinu and Yutani2019), xfun v. 0.54 (Xie, Reference Xie2025b), brms v. 2.23 (Bürkner, Reference Bürkner2025), bayestestR v. 0.17 (Makowski et al., Reference Makowski, Lüdecke, Ben-Shachar, Patil, Wilson and Wiernik2025), bridgesampling v. 1.x1–2 (Gronau & Singmann, Reference Gronau and Singmann2021), and loo v. 2.8 (Vehtari et al., Reference Vehtari, Gabry, Magnusson, Yao, Bürkner, Paananen and Gelman2024). Audio segmentation for silence durations used Praat v. 6.1.19 (Boersma & Weenink, Reference Boersma and Weenink2020).

















 Open access
Open access