


1. Introduction
The present study sets out to investigate which variables affect L1 and L2 speakers’ use of degree modifiers (DMs) in a cross-linguistic setting, namely in Finnish and English. In this study, we define DMs as words or phrases that change the intensity or extent of their main word. DMs allow the language user to express their stance toward a proposition or event and social affiliations within a speech community. In sociolinguistic research, it has been found that DM use can be affected by several social factors such as age, gender, and identity of the speaker (e.g. Stratton & Beaman Reference Stratton, Beaman, Stratton and Beaman2025). A language learner’s ability to use DMs can be seen as one indication of language proficiency (Hasselgård Reference Hasselgård2022:383–384) and it is one of the criteria for language test evaluation (Jantunen Reference Jantunen2015:112). Mastering the use of DMs can, however, be challenging even for advanced L2 learners for many reasons, especially given that DMs are prone to change (Bolinger Reference Bolinger1972:18–19, Ito & Tagliamonte Reference Ito and Tagliamonte2003, Stratton Reference Stratton2020b).
Since absolute synonymy is questionable (e.g. Lyons Reference Lyons1968, Cruse Reference Cruse1986), in this study we use the concept of near-synonymy to refer to words that are functionally equivalent enough so that language users understand that they, in the Labovian sense, refer to the same thing (Labov Reference Labov1972:188). Near-synonymy may be vital for effective and precise language use (Edmonds & Hirst Reference Edmonds and Hirst2002), especially in academic writing (Danglli & Abazaj Reference Danglli and Abazaj2014). However, as the expressions in a set of near-synonyms can differ with subtle distinctions in meaning both within and across languages, synonymy mis-selection has quite naturally been recognized as one of the most common reasons for L2 learners’ lexical problems even on the advanced level (Hasselgren Reference Hasselgren1994:245).
While the use of DMs in English is most widely represented in the literature, from both L1 (e.g. Paradis Reference Paradis1997, Ito & Tagliamonte Reference Ito and Tagliamonte2003, Xiao & Tao Reference Xiao and Tao2007, Stratton Reference Stratton2020b) and L2 perspectives (e.g. Granger Reference Granger and Cowie1998, Hendrikx et al. Reference Hendrikx, van Goethem and Wulff2019, Hasselgård Reference Hasselgård2022), research on their use in other Indo-European languages is growing (e.g. in L1 German, Stratton Reference Stratton2020a, and L2 German, Wirtz Reference Wirtz2025; in L1 Norwegian, Stratton & Sundquist Reference Stratton and Sundquist John2022). However, the use of DMs in other language families, especially those that differ typologically from Indo-European, remains scarce (for exceptions, see Huumo Reference Huumo2021 for L1 Finnish, and Jantunen Reference Jantunen2015 for L2 Finnish).
In the present study, we focus on the use of one set of near-synonymous DMs known as downtoners, in two languages: Finnish aika, melko, and ihan ‘quite’ and English quite, rather, and fairly in written L1 and L2 academic texts (e.g. tämä on aika/melko/ihan helppoa ‘this is quite/rather/fairly easy’). To our knowledge, downtoning DMs have received less attention compared to the amplifying ones in L2 research, perhaps because they are generally less frequent in language use (e.g. Stratton Reference Stratton2020a). Nevertheless, they play an equally important role in offering insight into the personal view of the speaker, and the choice between them often influences how a proposition is interpreted. Because social variables have been explored widely in previous literature, the emphasis in this study is on the language-internal constraints. We focus on the constructional features of the DMs by employing the Multifactorial Prediction and Deviation Analysis using Random Forests (MuPDARF) approach (Deshors & Gries Reference Deshors and Gries2016). As MuPDARF-based multifactorial modelling has been shown to be suitable for comparing closely related languages (Ivaska & Tamm Reference Ivaska and Tamm2024), our aim is to broaden the contrastive design to non-related (learner) languages. While the focus in contrastive studies is often on closely related languages, a more distant cross-linguistic perspective can help distinguish L1-related patterns from ones commonly shared by all learners (Deshors Reference Deshors2016). By contrasting two non-related languages and applying a fine-grained quantitative method, we aim to provide a new perspective on a central question on L2 vocabulary use. We seek to answer the following research questions.
-
1. Which speaker-, text-, and grammatical context -specific variables contribute to the choice between the investigated degree modifiers in academic L1 and L2 Finnish/English?
-
2. How do the results of the MuPDARF modelling differ between the two languages?
The paper is structured as follows. Section 2 discusses previous work on DMs in English and Finnish, especially corpus studies that focus on DM use in learner language. Section 3 presents the methodology and materials of the present study. In Section 4 we introduce the results and discuss them in relation to previous research. Finally, in Section 5, we discuss the limitations of the study and present the conclusions.
2. Previous research on DMs and their use in learner language
2.1 Degree modifiers: classifications in Finnish and English
Paradis (Reference Paradis1997:87) describes most DMs as typologically unstable since they do not consistently align with the functional categories linguists have designated for them. The core function of DMs is to modify other words by presenting the degree of a feature as higher or lower than expected (Paradis Reference Paradis1997, Hakulinen et al. Reference Hakulinen, Vilkuna, Korhonen, Koivisto, Heinonen and Alho2004:§615, Biber et al. Reference Biber, Johansson, Leech, Conrad and Finegan2021:551). They can be categorized and labelled in multiple ways, for example as amplifiers (increasing intensity; e.g. very) versus downtoners (decreasing intensity; e.g. rather) (e.g. Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985:589–590). These umbrella labels can be further divided into subcategories: downtoners, for example, can be divided into diminishers and moderators.Footnote 1 In this paper the focus is on DMs whose most frequently used function is to moderate the degree of the word they are connected to. They ‘seek to express only part of the potential force of the item concerned’ (Quirk et al. Reference Quirk, Greenbaum, Leech and Svartvik1985:598). However, especially in the cases of quite and ihan, they can also amplify the feature and therefore both of these functions are included as distinct levels in the analysis (see Desagulier Reference Desagulier, Glynn and Robinson2014:149 on the ambiguity of quite and Lauranto Reference Lauranto2025 of ihan; similar multifunctionality has been observed also with German ganz in Stratton Reference Stratton2020a and Norwegian ganske in Stratton & Sundquist Reference Stratton and Sundquist John2022).
Finnish and English belong to different language families, and they also diverge typologically in many respects. Finnish is primarily a synthetic language, relying heavily on grammatical agglutination. In contrast, English is predominantly an analytic language, relying more on word order and auxiliary items to convey grammatical relationships. While both Uralic and Indo-European languages share some similar synthetic ways to express degree (e.g. suffixes -hkO [halpa ‘cheap’, halvahko ‘cheapish’] and -ish for Finnish and English respectively), both language families are known to have a rich system of DMs as well (Jantunen Reference Jantunen2004:69). Previous research states that the classification of English DMs also applies well to Finnish DMs, although on a lexical level DMs are language-specific (Huumo Reference Huumo2021:89). This means that translating a specific DM from one language to another hardly works with a one-to-one correspondence. For example, the DMs under scope in this study can be used as translation pairs in some but not in other contexts: it was quite good/se oli ihan hyvä, she is quite tall/hän on ?ihan pitkä. In this case, the difference in use lies in that, unlike quite, the Finnish ihan ‘quite’ is typically not combined with open-ended scalar words such as pitkä ‘tall’ (Huumo Reference Huumo2021:89–90). From a language learner’s point of view, the use of such ambiguous expressions can be challenging.
According to Sinclair (Reference Sinclair1991:109−110), language use is a combination of open-choice and idiom principles. When following the open-choice principle, speakers can freely and flexibly construct expressions, the only constraint being grammatical correctness. Coexisting with this, the idiom principle suggests that speakers rely on semi-preconstructed, fixed expressions which are not analysable into segments and which, essentially, help streamline communication. Hasselgård (Reference Hasselgård2022:384) has noted that the combinations of DMs and the words they attribute range from relatively fixed, idiomatic combinations to free combinations that leave room for linguistic creativity.
2.2 Previous usage-based studies to learning near-synonymous DMs
This study approaches language and its learning from a usage-based perspective, according to which a language structure emerges from language use (e.g. Tomasello Reference Tomasello2003). For the language learner to be able to reach the goal of understanding and conveying messages in the target language, they must learn constructions of that language (i.e. the ways in which forms, meanings, and functions of these messages are combined). According to Goldberg (Reference Goldberg2019:2), constructions allow speakers to express messages effectively and apply their linguistic knowledge to new situations while respecting the conventions of the speech community. NSs are known to be able to use constructions in a productive and creative manner while intuitively avoiding expressions that would be considered ‘not quite right’ (ibid.). From the point of view of near-synonymous words, this intuition guides the speaker to prefer one expression over the other to convey the wanted meaning-in-context (Goldberg Reference Goldberg2019:25). How to model this kind of hidden knowledge to language learners to give them access to nuanced use and understanding of the target language remains an intriguing question.
Comparing L1 use to L2 use is not unusual in corpus-based research, and DMs have also received attention in previous corpus-based L2 studies. Some studies have identified a tendency for learners to over-use DMs (e.g. Lorenz Reference Lorenz and Granger1998, Hinkel Reference Hinkel2003, de Haan & van der Haagen Reference de Haan, van der Haagen, Granger, Gilquin and Meunier2013), while other studies have found the opposite (e.g. Granger Reference Granger and Cowie1998, Schweinberger Reference Schweinberger2020). For example, Wirtz (Reference Wirtz2025) concludes based on an overview of earlier research that these opposing results could be explained by L2 learners’ different exposure times to the target language, and that increasing language proficiency can lead to mirroring or even exceeding typical intensification rates observed among L1 speakers. Additionally, Pyykönen (Reference Pyykönen2023a, Reference Pyykönen2023b) studied epistemic expressions which are functionally related to DMs in that both can be used to express the speaker’s confidence in a proposition, and found that the frequency and types of epistemic expressions used by Finnish learners of English is influenced by proficiency level and task type.
In L2 Finnish (F2), the use of DMs has been examined by Jantunen (Reference Jantunen2015), who used keyword analysis to compare the prominence of different kinds of DMs in different varieties of F2. The comparison was between two adult learner groups, one of whom had learned Finnish mostly outside Finland and another who had learned Finnish mostly in Finland. The results of Jantunen’s (Reference Jantunen2015) study indicate that while DMs were frequent across the board, it seemed that informal or more colloquial DMs were more common especially in the context of Finnish learned in Finland, suggesting that learners who are likely exposed to a higher amount of (informal) spoken language are more likely to transfer informal expressions into their written output as well. A similar tendency of NNSs over-using DMs typical for conversational style in more formal, written contexts has also been observed in English (e.g. Hinkel Reference Hinkel2003, Schweinberger Reference Schweinberger2020).
The use of DMs is linked to both lexicon- and grammar-related variables, and these interactions have been studied in previous L2 studies as well, most exploring L2 English (E2). For example, Schweinberger’s (Reference Schweinberger2020) findings highlight the importance of considering a multitude of features in the surrounding context of the DM. Applying the same multivariate MuPDARF method as this study, Schweinberger (Reference Schweinberger2020) found that the semantic category of the adjectives amplified with the amplifier very was connected to the likelihood of E2 speakers making non-target-like choices. Additionally, the syntactic function of the modified adjectives proved important to the target-like use. Thus, to gain a comprehensive view of DM use, it is important to examine a multitude of constructional features related to them, which we do in the present study by employing the MuPDARF approach.
3. Dataset and methodology
3.1 Corpus data: native and non-native written academic Finnish and English
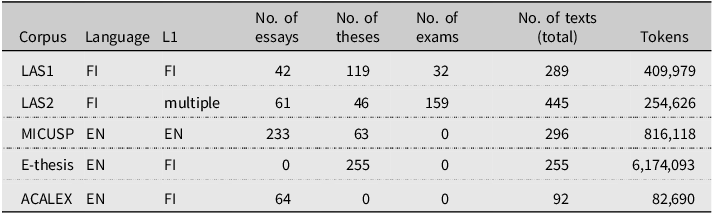
For Finnish, we make use of two corpora (Ivaska Reference Ivaska2014) compiled at the University of Turku: The Corpus of Advanced Learner Finnish (LAS2) and The Corpus of Academic Finnish (LAS1). Both corpora have been lemmatized and annotated grammatically. Additionally, a professional evaluator assessed at least two texts of each writer in the LAS2 for proficiency level according to the CEFR scale, and most texts in the current dataset were found to be at the B2 and C1 levels.
For E2, we make use of the University of Helsinki’s E-thesis and the University of Turku’s Academic Lexis in L2 Speech and Writing (ACALEX) corpora. For L1 English (E1), we draw data from the Michigan Corpus of Upper-Level Student Papers (MICUSP), which contains samples of academic writing collected in the United States; our results thus only pertain to US English. Of the English corpora, E-thesis is tagged for part-of-speech and syntactic function following a slightly different terminology to the Finnish data; MICUSP and ACALEX are unannotated. The necessary syntactic annotations were coded and unified manually using the same scheme as the Finnish data by one of the authors. Additionally, E-thesis contains no record of the L1 of the writer. To determine if the authors’ L1 was Finnish, we used the method adopted in for example Gao (Reference Gao2016) and Wu & Pan (Reference Wu and Pan2024): after retrieving all the instances of quite/rather/fairly from the data, a list of names was retrieved for all the writers. This list was then independently annotated by both authors with respect to whether the name was a traditionally Finnish one, which, based on the Finnish linguistic landscape, is a fairly good indicator of the writer’s L1. The precision of the method is likely rather good, as although some F1 writers might have been left out, the remaining writers are very likely to be F1 speakers. After the annotation, the authors agreed on 93.5% of the cases, and after only including the cases where both authors agreed, we were left with altogether 255 MA theses. The reported token count (Table 1) for the E-thesis is relatively high compared to others as it also includes the lists of references, which have been left out of the other corpora.
Overview of the corpora

To ensure the comparability across the different datasets (i.e. FI/EN and L1/L2), we limited our scope to academic undergraduate texts from two major fields of study: the humanities and social sciences. In addition to this, we matched the datasets according to academic genre, one of the variables in our statistical model. In our data, we use the labels ‘essay’ (a shorter text investigating an idea or an experience) or ‘thesis’ (a text that involves original research or the plans to conduct one) for the different types of texts. The Finnish data also include texts labelled ‘exams’ (a short text showcasing the writer’s knowledge about a certain topic, often shorter and more free-form than essays). The exams were written in a supervised setting. Our hypothesis is, that while the chosen operationalization of genre will not give a full picture of general genre differences, the stylistic conventions between essays and theses, for example, could show signs of similar, albeit more subtle, patterns that have been found between academic texts and spoken conversation (Biber et al. Reference Biber, Johansson, Leech, Conrad and Finegan2021:560–564). An overview of the datasets is shown in Table 1. As seen in Table 1, the proportions of genre between the corpora vary, which is accounted for in the MuPDARF model.
3.2 Data extraction and annotation
The DM groups examined in this study are aika/melko/ihan ‘quite’ and quite/rather/fairly. The selection of the target expressions began by retrieving all adverbs in the F2 corpus (LAS2). From this list, we narrowed our scope to the most frequent downtoning DM (aika) that had sufficiently frequent near-synonyms (melko and ihan) to include in a quantitative analysis. As an external support for the near-synonymity, we used Kielitoimiston sanakirja (KS 2020), an easily accessible, general online Finnish dictionary. KS (2020) uses aika to define the meaning of melko and vice versa. Neither variant is mentioned in the definition of ihan, which is described mainly as an amplifying adverb but having downtoning use in everyday spoken Finnish. After this, we selected a comparable DM group in English. A widely used Finnish–English learner dictionary, MOT sanakirja (n.d.), gives quite as a translation for all the chosen Finnish DMs. To determine the synonyms of quite to be used in the analysis for English, we retrieved all adverbs in the grammatically annotated E-thesis corpus. Of the synonyms given for quite (‘as in “pretty”, to some degree or extent’) in the Merriam-Webster dictionaries (2025), we found that fairly and rather were the most frequent, and thus we decided to use them in our analysis.
After this, we retrieved all the instances of the target expressions in the L1 corpora as well. The retrieval was conducted using AntConc 4.0.11 (Anthony Reference Anthony2022) for LAS1, LAS2, ACALEX, and MICUSP. A web-based interface was used for E-thesis. All instances of the target DMs, along with their immediate surrounding context (i.e. the sentences they were used in) were then saved into a spreadsheet file. As the E-thesis dataset was substantially larger than the other datasets, a random sample of 300 uses was drawn to match the number of results from the E1 data. The frequencies of the target DMs are shown in Table 2 along with their distributions within the datasets.
The frequencies of the target DMs in the data

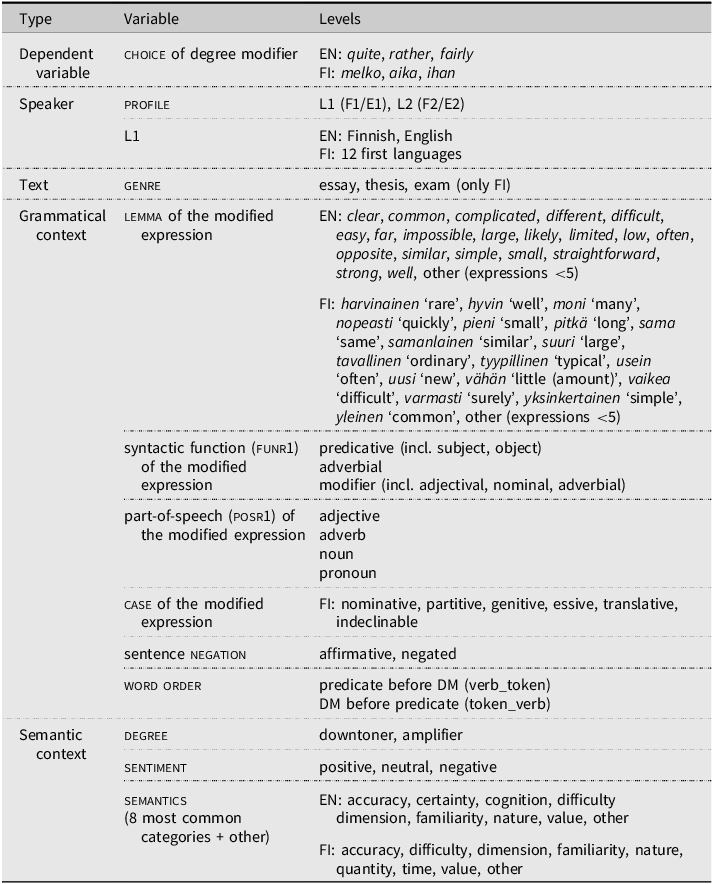
To investigate which speaker-, text- and grammatical context-specific factors influence the choice of DMs in both L1 and L2 Finnish and English, each instance of the target expressions was coded for 12 variables based on earlier research. All variables included in the analysis are shown in Table 3 and will be more closely discussed in what follows.
An overview of the variables used in the analysis

As the choice of DM is closely related to the expression it modifies (e.g. Ito & Tagliamonte Reference Ito and Tagliamonte2003, Jantunen Reference Jantunen2015, Schweinberger Reference Schweinberger2020, Stratton Reference Stratton2020a), many of the variables used in the analysis characterize the modified expression in the R1 position (first word after the DM excluding possible articles). These include its lemma (e.g. quite well , melko hyvin ), syntactic function (funr1), part of speech (posr1), and case. Given that some of the lemmas were used very infrequently, we decided to include only the more frequent ones in the FI and EN datasets and classify the lemmas with fewer than five instances as ‘other’ (see Table 3). funr1 covers the syntactic function of the modified expression in the R1 position: predicative (e.g. I’m fairly sure ), adverbial (e.g. This corresponds fairly well with the information), or a modifier (e.g. There has been quite a consensus ). Adjectival, adverbial, and nominal modifiers were conflated into one category as the number of R1 expressions acting as adjectival and adverbial modifiers was extremely low.
The variable case is only included in the Finnish data as, in Finnish, unlike in English, the modified expressions often appear in an inflected form. In our dataset, there are five possible cases for the modified expressions: nominative (e.g. vaatimustaso on aika kova ‘the requirement level is quite tough’), partitive (e.g. opiskelijat olivat aika eritasoisia ‘the students were of quite different levels’), genitive (e.g. sain melko hyvän kokonaiskuvan ‘I got a pretty good overall picture’), essive (e.g. olen pitänyt osaamistani melko vahvana ‘I have considered my skill set quite strong’), and translative (e.g. tehtävä osoittautui aika haastavaksi ‘the task turned out to be quite challenging’).
The variables negation and word order are related to the broader syntactic structure where the DM appears in. Both variables have been found to be important either for DM use (e.g. Jantunen Reference Jantunen2004, Bylinina et al. Reference Bylinina, Tikhonov, Garmash, Bouamor, Pino and Bali2023) or for distinguishing between L1 and L2 language use (e.g. Ivaska Reference Ivaska2015, Kekki & Ivaska Reference Kekki and Ivaska2022). Of these, negation is related to whether the sentence the DM is used in is negated or not (e.g. not quite the same vs. to be rather sceptical). word order, in turn, refers to the placement of the DM and the expression it modifies in the sentence: before the predicate verb (token_verb; e.g. Also fairly clear is the relationship between gender and power) or after it (verb_token; e.g. There is rather little evidence).
Finally, three variables related to the semantic qualities of the DMs and their context of use were included in the analysis, as semantic variables have been reported to impact the likelihood of NNSs making non-targetlike DM choices (e.g. Ito & Tagliamonte Reference Ito and Tagliamonte2003, Jantunen Reference Jantunen2015, Schweinberger Reference Schweinberger2020). First, degree is related to whether the DM was used as a downtoner or an amplifier. Although the target expressions are mainly used as downtoners, some of them (ihan, quite, rather) can also be used as amplifiers (e.g. KS 2020, Merriam-Webster 2025). sentiment, on the other hand, pertains to the emotional tone and message of the DM’s context of use (i.e. the sentence in which the DM is used). More specifically, sentiment is divided into the categories positive (e.g. seems quite sensible, ymmärsin […] melko hyvin ‘I understood quite well’), negative (e.g. the rather peculiar description, suunnistus oli melko summittaista ‘orienteering was quite random’), and neutral (e.g. it is quite likely, ei tarkoita ihan samaa ‘does not mean quite the same’). Finally, semantics was used to categorize the modified expressions into semantically related groups using the categorization proposed by Jantunen (Reference Jantunen2004:137–138). For example, expressions such as confident were placed under ‘certainty’ and easy under ‘difficulty’. As many of the original sixteen categories in Jantunen (Reference Jantunen2004) occurred extremely infrequently in our datasets, we decided to include only the eight most frequent classes in the FI and EN datasets and conflate the other categories under the group ‘other’. The remaining groups in each of the datasets are listed in Table 3.
To ensure that the coding scheme for the three semantic variables (degree, sentiment, and semantics) was consistent, a random sample of 200 DMs (100 in Finnish and 100 in English) was coded by both authors independently; the initial agreement rates from the two annotations are shown in Table 4. All instances where disagreements arose were examined more closely and resolved by devising a general code of conduct for similar cases.
Agreement in the coding of the semantic variables

3.3 MuPDARF method
Methodologically, we make use of the MuPDARF approach (Gries & Deshors Reference Gries and Deshors2014, Deshors & Gries Reference Deshors and Gries2016, Gries & Deshors Reference Gries and Deshors2020). The method has been developed to compare NNS production with NS production, but it has also been applied to other types of research designs, such as comparing different varieties of world Englishes (Deshors & Gries Reference Deshors and Gries2016) and closely related Finnic languages (Ivaska & Tamm Reference Ivaska and Tamm2024).
This approach allows us to explore the linguistic choices an NS makes under the exact same circumstances as an NNS: in other words, if they make similar choices, and if they do not, the constructional factors that explain it are examined by considering the multiple factors affecting the speakers’ language use (Gries & Deshors Reference Gries and Deshors2014, Reference Gries and Deshors2015). As language use, especially the use of near-synonymous expressions, is rarely an either/or situation but rather a continuum between choices, the more recent applications of the method also model the so-called middle ground where the NS would likely be satisfied with either (or, in our case, any) option (Gries & Deshors Reference Gries and Deshors2020). We conduct the MuPDARF analysis to both languages separately and then compare the results to shed light on (i) possible features shared by language learners of both languages and (ii) possible language-specific differences of near-synonymous DM use. The general steps of the method are shown in Figure 1 (adapted from Ivaska & Tamm Reference Ivaska and Tamm2024:21).
Flowchart of the implemented MuPDARF approach.

To begin our statistical analysis, we used the ranger (Wright & Ziegler Reference Wright and Ziegler2017) package in R to train two language-specific multi-class random forest models to predict which one of the near-synonymous DMs (aika/melko/ihan; quite/rather/fairly) the NSs were likely to use in academic written texts.Footnote 2 The model uses the variables described in Section 3.2 to make predictions as to how likely it is that a certain DM is used in each case (e.g. if the genre is X and the lemma is Y, the DM choice is most likely to be Z). The resulting model for Finnish is as follows:
 $$\eqalign{ & {\rm{FI\!:}}\;{\rm\small{{CHOICE}}} \sim {\rm\small{GENRE}} + {\rm\small{LEMMA}} + {\rm\small{FUNR}}1 + {\rm\small{POSR}}1 + {\rm\small{CASE}} + {\rm\small{NEGATION}} + {\rm\small{WORD ORDER}} \cr & + {\rm\small{SENTIMENT}} + {\rm\small{SEMANTICS}} + {\rm\small{DEGREE}} \cr} $$
$$\eqalign{ & {\rm{FI\!:}}\;{\rm\small{{CHOICE}}} \sim {\rm\small{GENRE}} + {\rm\small{LEMMA}} + {\rm\small{FUNR}}1 + {\rm\small{POSR}}1 + {\rm\small{CASE}} + {\rm\small{NEGATION}} + {\rm\small{WORD ORDER}} \cr & + {\rm\small{SENTIMENT}} + {\rm\small{SEMANTICS}} + {\rm\small{DEGREE}} \cr} $$
The English model is the same, except for the variable case, which was left out as irrelevant.
According to the approach, if the model can predict DM use in the NS data sufficiently accurately, it can be used on the NNS data to predict which of the near-synonymous DMs NSs would choose in each context of occurrence, as well as to determine whether the NNS choice is canonical, or ‘nativelike’.Footnote 3 To evaluate both models, we compared their performance to a baseline determined by how well the model would perform in a situation where it always predicted the most common DM in the data. For Finnish, this level of chance was 86.0%, and with an out-of-bag (OOB) error of 0.075 and a (micro-averaged) F-score of 0.959 the model performed extremely well. For English, the level of chance was 62.4%, which was also outperformed by the model with an OOB error of 0.24 and a (micro-averaged) F-score of 0.762. Thus the fit of both models was good enough to proceed to the next step of the analysis.
Next, we trained two language-specific random forest models that focused on the NS-likeness of the choices observed in the NNS data. More specifically, the model made it possible to analyse whether and how the canonical NNS choices diverge from the non-canonical NNS choices. With the addition of the chosen DM and the NNSs’ L1s for the F2 data, the predictor variables are the same as in the first models for both languages (again, the English model is the same, except for the variable case):
 $$\eqalign{ & {\rm{FI: F}}1{\rm{ - likeness}}\sim{\rm\small{{CHOICE}}} + {\rm\small{{L}}}1 + {\rm\small{{GENRE}}} + {\rm\small{{LEMMA}}} + {\rm\small{{FUNR}}}1 + {\rm\small{{POSR}}}1 + {\rm\small{{CASE}}} \cr & + {\rm\small{{NEGATION}}} + {\rm\small{{WORDORDER}}} + {\rm\small{{SENTIMENT}}} + {\rm\small{{SEMANTICS}}} + {\rm\small{{DEGREE}}} \cr} $$
$$\eqalign{ & {\rm{FI: F}}1{\rm{ - likeness}}\sim{\rm\small{{CHOICE}}} + {\rm\small{{L}}}1 + {\rm\small{{GENRE}}} + {\rm\small{{LEMMA}}} + {\rm\small{{FUNR}}}1 + {\rm\small{{POSR}}}1 + {\rm\small{{CASE}}} \cr & + {\rm\small{{NEGATION}}} + {\rm\small{{WORDORDER}}} + {\rm\small{{SENTIMENT}}} + {\rm\small{{SEMANTICS}}} + {\rm\small{{DEGREE}}} \cr} $$
This step accounts for the cases where the NS would actually be comfortable using two or all of the near-synonymous DM variants under scope by quantifying the middle ground, which makes use of the degree of certainty that the model predicts as the non-canonical L2 choice. Following Gries & Deshors (Reference Gries and Deshors2020:80), we defined the middle ground as ‘the predicted probability that corresponds to one unit of log loss, i.e. to classifications/predictions that, if wrong, lead to log loss values of 1 [or more]’. In most previous studies, the focus has been on cases where there are two choices, and therefore the middle ground has been calculated using the cut-off point of 0.5 +/− log loss. As our study examines the choice between three different DMs, the cut-off point was set to 0.333 +/− logloss. This meant that our middle ground probability estimates varied between 0.226 and 0.440 for Finnish, and 0.033 and 0.633 for English. Thus the predictions with probabilities that landed within the middle ground are likely to be cases where more than one near-synonymous option is possible. Finally, when looking into the variable-specific results, we explored the NS-likeness of the NNS choices by omitting the middle ground and only examining DM choices that the model confidently predicted as either nativelike or non-nativelike.
4. Results
4.1 Using F2/E2 data to predict F1/E1-likeness in the L2 data
For both Finnish and English, the frequency distributions of the target expressions (see Table 2) already show different patterns across the L1 and L2 populations. For Finnish, melko is clearly the most common option in the F1 data, whereas the F2 speakers favour aika. In the English dataset, the E1 speakers rather heavily prefer quite, while for the E2 speakers quite and rather are almost equally common. In both Finnish and English, the L1 and L2 populations thus seem to have different standard variants or ‘lexical teddy bears’ (Hasselgren Reference Hasselgren1994:250) that they opt for, the difference being particularly prominent in the Finnish data. These differences are also reflected in the results yielded from the MuPDARF analyses, which we will present in the following.
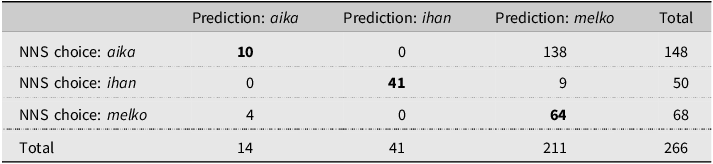
For F1 and F2, the trend of different standard variants between the two populations is clearly reflected in the first prediction model (Table 5). The model labels over 93% of the F2 uses of aika as non-nativelike compared to the 85.8% of non-nativelike uses when the middle ground is also considered (Table 6). Interestingly, the ten nativelike uses of aika predicted in the first prediction fall also in the middle ground.
Confusion matrix for the number of predictions between aika, ihan, and melko (boldface = native-Finnish-like)

Confusion matrix for the number of predictions between aika, ihan, and melko that also considers the middle ground (boldface = native-Finnish-like)

When considering the twenty-nine cases assigned to the middle ground, such as the one in example (1), our native speaker intuition supports the prediction and recognizes that either aika or melko (the variant the model deemed accurate in the first prediction) would be plausible in its context of occurrence in an essay describing a personal experience.Footnote 4

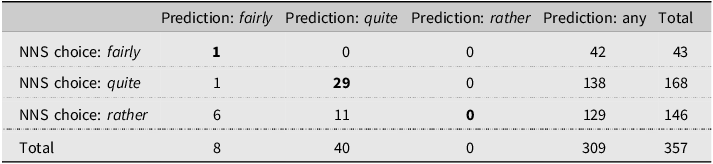
For English, the first prediction results are shown in Table 7. It seems that the use of rather is particularly often predicted as non-nativelike, since in the majority of its uses, the model predicts that an NS would opt for either fairly or quite. A different picture emerges when the middle ground is included, however (Table 8): for rather, only seventeen of its uses remain as clearly non-nativelike, and for quite, only one. Thus, compared to Finnish, a noticeably larger proportion of the English non-nativelike DM uses from the first prediction model fall in the middle ground. This means that, in these cases, the DMs occur in contexts where one or more variants would be acceptable based on the NS data. This might hint towards a different level of near-synonymity for the three variants between Finnish and English. Example (2) is one of the middle ground predictions given by the model; in this case, all three variants would seem intuitively acceptable.
Confusion matrix for the number of predictions between fairly, rather, and quite (boldface = native-English-like)

Confusion matrix for the number of predictions between fairly, rather, and quite that also considers the middle ground (boldface = native-English-like)

4.2 Variables distinguishing L1 and L2 DM use
Our next step was to focus on the DM uses where the model clearly predicted NSs to favour one DM variant over the others. For Finnish, the 101 clearly accurate predictions could be confidently distinguished from the 136 clearly inaccurate predictions with an OOB prediction error of 0.024. For English, the twenty-eight clearly accurate predictions were distinguished from the seventeen clearly inaccurate ones with an OOB error of 0.042. For both languages, the non-nativelike uses occurred in multiple texts written by multiple IDs, meaning that any trends could not be traced to one individual writer. For both languages, this shows that the non-nativelike choices in the NNS data diverge systematically from the nativelike ones.
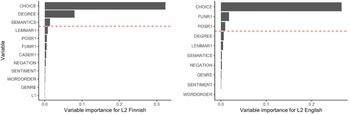
To reveal where the systematic differences for both languages appear, we explored the models by means of permutation-based variable importance. As shown in Figure 2, the DM choice itself is by far the most distinctive variable for distinguishing between the nativelike and non-nativelike uses in both the F2 and E2 data. For F2, the degree of the DM stands out, followed by a variable describing the semantic meaning of the word the DM modifies (semantics). For E2, the second and third most important variables are tied to the grammatical features: syntactic function (funr1) and part-of-speech (posr1) of the modified expression. As the relative importance of the remaining variables is comparatively small, we decided to limit our analysis to the three most important variables for each language.
Variable importance distinguishing nativelike and non-nativelike choices of the advanced Finnish learners (left) and advanced English learners (right). The dashed line marks the cut-off point for the variables taken under further investigation.

In the following section, each of the three most important variables per language are examined by visualizing their marginal effects in the form of a bar chart (Figures 3–8). In the figures, the height of the bars indicates how likely it is that an instance of NNS DM use is predicted as nativelike or non-nativelike depending on the level of the variable in question (e.g. when choice is either aika, melko, or ihan, as in Figure 3). The closer the bar is to zero, the more likely it is that the use is predicted as non-nativelike, and the closer it is to one, the more likely it is that the use is predicted as nativelike. The dashed lines show the overall default for the reference level, meaning the nativelike predictions divided by the sum of the clearly predicted nativelike and non-nativelike cases (i.e. predictions without the middle ground).
Marginal effects of choice for DM use in F2.

Marginal effects of degree for DM use in F2.

Marginal effects of semantics for DM use in F2.

Marginal effects of choice for DM use in E2.

Marginal effects for the syntactic function of the modified expression for DM use in E2.

Marginal effects for the part-of-speech of the modified expression for DM use in E2.

4.2.1 Variables distinguishing F1 and F2
Figures 3−5 visualize the marginal effects of the three variables (choice, degree, semantics) that differentiate the most between F1 and F2 DM use.
The choice of the DM itself was the best predictor of accuracy for both languages. As Table 6 already indicates, for Finnish especially the typical use of a different ‘standard’ DM variant differentiates between the population groups, as the NNSs favour aika and NSs melko. Based on the marginal effects, this is also shown in Figure 3, which indicates that instances of aika have been predicted as much more likely to be non-nativelike than the other variants (e.g. (3)). In all of these uses of aika predicted as non-nativelike, the model predicted NSs to use melko. This corroborates the findings of Kekki & Ivaska (Reference Kekki and Ivaska2022:84), who suggest based on a MuPDARF analysis of near-synonymous adjectives that it is predominantly the typical use of the less common option that distinguishes NS and NNS data from one another.

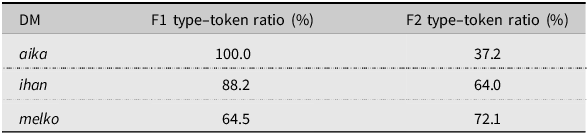
To operationalize how preconstructed – or idiomatic in the sense of Sinclair (Reference Sinclair1991:109–110) – the choice between the DM variants is, we calculated the type–token percentages of each DM (Table 9). The higher the type–token percentage, the more unique lemmas appear with each DM, and therefore the expression can be seen as more open-ended. Table 9 shows that the F1 speakers use melko more strictly with specific main words, whereas ihan and especially aika have more free variation with R1 position lemmas. A different tendency is seen with the F2 speakers: aika is more prone to appear with specific main words compared to the other two DM variants. Thus the differences in the type–token ratios seem to reveal that for both the F1 and F2 speakers the choice of the most common DM is guided by treating the DM expression as semi-fixed.Footnote 5
Type–token ratio of the DMs in the Finnish data

The variable degree (if the DM is used as a downtoner or an amplifier) was the second-best predictor of accuracy for Finnish NNS DM use. Based on the marginal effects (Figure 4), the predictions deviate from the NNS use the most when the DM is used as a downtoner (e.g. (4)). However, when looking at the data, the variable seems to differentiate only between the nativelike and non-nativelike uses of ihan, since aika and melko never appear as an amplifier in either the F1 or F2 dataset.

In our data, both NSs and NNSs use ihan more often as an amplifier than a downtoner. However, it is a known problem for F2 learners to recognize when ihan should be used to downtone or amplify the main word (Lauranto Reference Lauranto2025). When used inconsistently, it becomes unclear which role the language user means to assign to the phrase, as is also the case in (6). The DM in question was labelled in our annotation as a downtoner based on the overall interpreted meaning of the phrase. The model predicted an NS to use the unambiguously downtoning melko in the same environment.
Based on the variable degree, the use of aika and melko is much closer to each other (i.e. more synonymous) than the third variant ihan. The variable thus seems to differentiate one variant from the other two, but not between the NS and NNS groups. This result is also in line with the KS (2020) dictionary, which defines aika and melko as each other’s synonyms and ihan sharing a similar downtoning meaning.
As Figure 5 visualizes, aika/ihan/melko DM choice between Finnish NSs and NNSs diverges to some extent between the semantic categories. DMs attached to main words expressing value (e.g. (5)), time, and quantity are predicted more often as non-nativelike. DMs that occur with main words categorized into the semantic categories of dimension, familiarity, nature and the group ‘other’ are slightly more likely to be predicted as nativelike.

The category ‘other’ includes semantic labels, and consequently lemmas, that appear in the data infrequently, yet F2 speakers have made similar DM choices with F1 speakers relatively often within the category. This finding is in line with for example Schweinberger’s (Reference Schweinberger2020:184) results comparing the use of very for adjective amplification among E1 and E2 speakers: NNSs were more likely to make target-like choices when amplifying low-frequency adjectives. Interestingly, our data also reveal a contradicting pattern when it comes to high-frequency modified expressions. On the one hand, in the semantic categories that are predicted relatively more often as nativelike, there are some frequent lemmas that the NNSs have commonly used with the same DM as the NSs, e.g. melko samanlainen ‘similar’ in the familiarity category and melko suuri ‘big’ in the dimension category. However, the more non-nativelike predicted categories also include frequent lemmas which the NNSs pair with aika and NSs with melko, e.g. paljon ‘a lot’ in the quantity category, usein ‘often’ in the time category, and hyvin ‘well’ in the value category. This inconsistent result could be explained by register differences. Aika and ihan are more common in spoken Finnish than melko (Jantunen Reference Jantunen2015). It seems that the F2 speakers are unaware of the register difference between melko and the other two variants especially when it comes to collocations which are frequent in everyday language. Then again, collocations which are possibly more common in academic contexts than everyday language (e.g. dimension-related) the NNSs use target-like.
4.2.2 Variables distinguishing E1 and E2
Figures 6–8 visualize the marginal effects of the three most important variables (choice, funr1, posr1) differentiating between E1 and E2 DM use.
For English, too, the choice of DM was the most important predictor distinguishing between NS and NNS uses. Figure 6 shows that fairly and quite are more likely to be predicted as nativelike than rather. The distribution of the three expressions (Table 2) shows the E1 and E2 groups have different preferences related to DM use: while the most used variant by the E1 speakers is, by a wide margin, quite, the learners use quite and rather in an almost equal frequency. As was the case with the Finnish data, a further look into the type–token ratios of the R1 position lemmas (Table 10) might explain the significance of the choice variable for English, too.
Type–token ratio of the DMs in the English data

Table 10 shows that the distribution of different lemmas for English is noticeably more uniform than in the Finnish datasets, especially when it comes to the E2 data. More specifically, it seems that mostly E1 uses of quite show signs of appearing with certain lemmas, as the type–token ratio is lower than for the other expressions. This suggests that the use of quite could be more fixed (as in Sinclair Reference Sinclair1991:109–110) in English (L1), which might also explain its high frequency in the E1 data. On the other hand, the E2 type–token ratios suggest a similar level of idiomatic fixedness for both quite and rather, which could be related to their similar frequencies in the E2 data.
In the English model, the middle ground predictions cover the majority of all uses (Table 8), meaning there seems to be quite a bit of flexibility in the use of the three expressions, especially when compared to their Finnish counterparts. Example (6) shows an instance of rather, where the model assigned fairly as the most likely NS choice.
The second most important predictor in the English model was the syntactic function (funr1) of the modified expression. This variable was also involved in all the significant interactions in Schweinberger’s (Reference Schweinberger2020) study investigating the use of the amplifier very. Based on the marginal effects shown in Figure 7, it seems that particularly cases where the DM’s main word is used as a modifier are more likely to receive a non-nativelike label, as in (7).
In both the E1 and E2 data, quite is used to modify a modifier less frequently than either rather or fairly. More specifically, quite is most predominantly used with subject/object predicatives (e.g. it seems quite possible ). Rather and fairly, in turn, are used rather evenly with subject/object predicatives and modifiers in both the E1 and E2 data. Out of the two, rather is also used more frequently in the E2 dataset, which could explain why most of the non-nativelike predictions are instances of rather. Thus it seems that much as was the case with degree in Finnish, in English, funr1 is more likely to differentiate between the three target expressions rather than NS and NNS populations.
The third most important predictor in the English model was the part-of-speech of the modified expression (posr1). The marginal effects in Figure 8 show that especially cases where the main words are adjectives are likely to differentiate between NS and NNS choices. Accordingly, in almost all clearly non-nativelike predictions the main words are adjectives, as in (8).
In both E1 and E2 data, adjectives were the most common part-of-speech for the modified expressions. It is also closely connected to the syntactic function of the modified expression (funr1), as the clear majority of the modified expressions used as modifiers in the data were adjectives. As funr1 was the second most important predictor in the English model, it seems natural that posr1 would stand out as an important predictor as well.
5. Discussion and conclusions
Returning to the first research question, the MuPDARF modeling was able to reliably predict which variables influence the use of DMs in academic L1 and L2 Finnish and English. The most important variable was choice in both languages, but, interestingly, for Finnish, the second and third most important ones were meaning-related (degree of the DM and semantics of the modified expression), whereas for English they were grammatical ones (posr1, funr1). The variable genre was not significant. However, most of the F2 uses of aika predicted as melko appeared in contexts where aika could be intuitively seen as too informal. The different type–token ratios of the modified expressions for each DM might further account for the register difference, as F2 speakers seem to opt for collocations they are familiar with in other situations. Yet, as the variable genre covered only the different types of academic texts (essays, exams and theses) found in the corpora under investigation, it was insufficient to explain this phenomenon. Even though previous studies have also found that E2 speakers tend to use amplifiers suited to more conversational than written discourse in their academic texts (e.g. Schweinberger Reference Schweinberger2020), our data did not show such a pattern. The result might be explained by the different scope of the current study: a majority of previous English DM studies has focused on amplifiers rather than downtoners, in addition to which the restricted range of search terms in the current study might have induced more conformity.
The modelling also showed reliably that, in both academic Finnish and English, L1 and L2 speakers made partially different choices when using the degree modifiers aika/ihan/melko and quite/rather/fairly. Language background was, thus, a significant variable with respect to these DMs. Interestingly, when similar epistemic adverbs were used in a different function as stance adverbials in academic E1/E2 texts in a study by Larsson et al. (Reference Larsson, Callies, Hasselgård, Laso, van Vuuren, Verdaguer and Paquot2020), writer-related variables such as NS status had little discriminatory power when compared to linguistic (e.g. position, clause type) variables. In further examination, some of the significant variables in our study (degree for Finnish and funr1 for English) also seemed to differentiate more between the DM variants than between populations.
To answer the second research question, the model predicted the DM use of both languages well. However, it explained the variation of the Finnish DMs better. The model also labelled a greater proportion of F2 DM use as either nativelike or non-nativelike, whereas for E2 the clear majority of the uses fell in the middle ground. This means that there were a lot more instances where, according to the E1 data, an NS would be comfortable using two or more of the DM variants. In general, the E2 use of the DMs was closer to E1 use than was the case in Finnish, where the NSs and NNSs had a clearly different favourite among the three DM variants. Thus, while quite/rather/fairly and aika/melko/ihan can in some contexts be used as translation pairs to each other, their level of synonymity is different between the languages, and therefore the language learner cannot transfer knowledge of a DM group in one language to the other. Namely, in English there is a bigger middle ground for these expressions, whereas in Finnish, many collocations that are typical for everyday spoken language should be avoided in the academic setting. This could also suggest that in the sinclairian sense (Sinclair Reference Sinclair1991), the examined DM group is more fixed in academic Finnish, whereas in English the choice between these near-synonymous DMs is more open. As an easy pedagogical implication, F2 speakers should be guided to use melko in academic contexts if they are otherwise unsure about the choice between the variants. On the other hand, E2 speakers can be guided to alternate between the DMs to compose stylistically rich academic texts.
Our study is subject to some limitations. The size of our data sample was somewhat limited. For English, a much bigger data sample would have been attainable. However, since for Finnish we used the largest corpus available for academic F2, we decided to limit the English dataset to match the Finnish one for better compatibility. Even with the limited data sample, the MuPDARF method was able to confidently model some similarities and differences between the L1 and L2 DM use in both languages.
Only a few language-external factors were chosen to be included in the analysis, as the main focus was in finding out how the language-internal constructional factors guide the L1 and L2 writers in their use of near-synonymous DMs. As it was not possible to retrieve information on, for example, gender or other social factors (see e.g. Stratton & Beaman Reference Stratton, Beaman, Stratton and Beaman2025) in all of the corpora employed in this study, the influence of different social factors on the use of the examined near-synonymous DMs remains a topic for future research. In addition to this, the E1 data used in the present study only contained US English, meaning the influence of geography could not be examined. As there is known to be many differences in different varieties of English (e.g. Deshors & Gries Reference Deshors and Gries2016, Biber et al. Reference Biber, Johansson, Leech, Conrad and Finegan2021), it is a topic that would merit further research.
Our L2 data consist of Finnish-speaking E2 learners and F2 learners of versatile first-language backgrounds. While this means that the groups are not fully comparable, they provide a good representation of the E2 and F2 adult learners in Finland, which is also reflected in that they are the learner groups sampled in the Finnish academic text corpora. In Finnish higher education institutions, English is often used as an auxiliary language of instruction in Finnish courses. Thus, contrastive knowledge between English and Finnish can help both L2 learner groups under scope better understand the DM use in the academic target language. While the results of this study reveal an interesting pattern between one DM group that shares a similar function between Finnish and English, more research is needed to see how this phenomenon extends to other DMs.
Even though the model was able to uncover differences in use between the different DM expressions and the NS and NNS groups, it is of course not able to spot non-targetlike use that is not in the scope of the examined context (i.e. something that is not coded in the variables). This means that when an NNS uses the DM in a context where there is something non-targetlike additional to the implemented variables, the model does not necessarily recognize it. For instance, mansilla on melko ?sama historia kuin hantilla (‘Mansi has a quite ?same history as Hanti’) is labelled nativelike even though the main word does not fit the context (better suited: samanlainen ‘similar’).
According to the usage-based view, in all language production, language users aim to produce an optimal combination of constructions to express their intended messages in context. Goldberg & Ferreira (Reference Goldberg and Ferreira2022:307) argue that for language learners this often leads to good-enough productions, ‘non-optimal constructions from the intended semantic ball-park’. The idea of what is a good-enough production is interesting from the point of view of near-synonymous lexical expressions. Even though the semantic meaning between the DMs investigated in this study can be often seen as one to one, there are subtle differences in their functions. While choosing any of the three variants is certainly within the good-enough ball-park, in the context of academic texts, a non-targetlike option might result in less credibility for the author. Therefore, it is important to be aware of the differences. This argument can be made for NSs and NNs alike, as also NSs often need guidance in academic writing.
Acknowledgements
We would like to thank the three anonymous reviewers and the editors for their thoughtful and helpful comments. Our deepest gratitude to Ilmari Ivaska for his invaluable guidance with conducting the statistical analyses of this study in R. Any shortcomings are our own.
The authors made an equal contribution to this work.
Competing interests
The authors declare none.













 Open access
Open access