


1. Introduction
Mapping the structure of word representations in memory, or the mental lexicon, is a long-standing investigation in the cognitive sciences. Early work on mental lexicon representation used associative networks to capture semantic relationships between words and concepts (Collins & Loftus, Reference Collins and Loftus1975; Quillian, Reference Quillian1967), with a history of the free association task dating back to at least Galton (Reference Galton1879). As Nelson et al. (Reference Nelson, McEvoy and Dennis2000) define, the free association task ‘requires participants to produce the first word to come to mind that is related in a specified way to a presented cue’ (p. 887). For example, when presented with the cue word dog, many people respond with associates like cat, bark, or wag. The free association task has largely been used to capture semantic relationships between words (Borge-Holthoefer & Arenas, Reference Borge-Holthoefer and Arenas2010; De Deyne et al., Reference De Deyne, Navarro, Perfors, Brysbaert and Storms2019; De Deyne & Storms, Reference De Deyne and Storms2008; Nelson et al., Reference Nelson, McEvoy and Dennis2000, Reference Nelson, McEvoy and Schreiber2004; Vivas et al., Reference Vivas, Manoiloff, Garcia, Lizarralde and Vivas2019) but has also been used to capture phonological (Castro & Vitevitch, Reference Castro and Vitevitch2023; Libkuman, Reference Libkuman1994; Luce & Large, Reference Luce and Large2001; Neergaard et al., Reference Neergaard, Luo and Huang2019; Vitevitch et al., Reference Vitevitch, Goldstein, Johnson, Mehler, Lucking, Banisch, Blanchard and Job2016) and orthographic relationships between words (Graf & Williams, Reference Graf and Williams1987; Mueller & Thanasuan, Reference Mueller and Thanasuan2014). For example, in a phonological association task, participants would be asked to produce a word that sounds similar to the cue (e.g., cue: cat; response: bat, mat, or cap).
Perhaps unsurprisingly, given the complexity of the mental lexicon, including the fact that word representations can be linguistically related to each other in multiple ways (Castro et al., Reference Castro, Stella and Siew2020; Stella et al., Reference Stella, Citraro, Rossetti, Marinazzo, Kenett and Vitevitch2024), free association responses can reflect more than just one linguistic relationship to cues despite an intended, specified association of focus. For example, phonological similarity between cues and responses emerges in semantic association data (Bolinger, Reference Bolinger1953; Haslett & Cai, Reference Haslett and Cai2024; Levy et al., Reference Levy, Kenett, Oxenberg, Castro, De Deyne, Vitevitch and Havlin2021; Meara, Reference Meara1983). Cue and response words on a semantic association task have been found to be not just semantically closer, but also phonologically closer, than random expectation (Allassonniere-Tang et al., Reference Allassonniere-Tang, Wan, Lee, Dong, Hong, Lin and Lin2023). Other examples of linguistic influence on free association tasks include semantic similarity between cues and responses emerging in phonological association data (Castro & Vitevitch, Reference Castro and Vitevitch2023), as well as orthographic similarity between cues and responses in phonological association data (Muneaux & Ziegler, Reference Muneaux and Ziegler2004). One suggestion for these findings is that individuals may rely on other linguistic information when a cue word is weakly represented in the mental lexicon. For example, Haslett and Cai (Reference Haslett and Cai2024) examined the phonological similarity of responses to cue words on a semantic association task. They found that cues with sparse semantic neighborhoods or cues that had abstract meanings tended to produce more associates that were phonologically related than cues with denser semantic neighborhoods or cues that had more concrete meanings. However, these phonologically related associates tended to be less semantically similar to cue words than expected of the semantic neighbors of the cue words. These results were interpreted to reflect that similar-sounding associates may come to mind when there is a weak semantic representation of the cue word in the mental lexicon. When cue words have a rich semantic representation, there is no need to rely on phonology to support completion of the semantic free association task (Haslett & Cai, Reference Haslett and Cai2024). Such data can be interpreted within the context of interactive activation models (Dell, Reference Dell1986; Rapp & Goldrick, Reference Rapp and Goldrick2000), where semantic and phonological domains interact during lexical selection and production.
One aspect of linguistic similarity that has been underexplored in association tasks is the role of morphology, despite the potential for morphology to capture both semantic and phonological similarity between words (Marslen-Wilson et al., Reference Marslen-Wilson, Tyler, Waksler and Obler1994). Inflectional morphemes add grammatical functions to words. For example, in English, the suffixes ‘-s’ and ‘-es’ indicate plural (e.g., fruits, buses), ‘-ed’ indicates past tense (e.g., painted, talked) and ‘-er’ and ‘-est’ have a comparative function (e.g., smart, smarter, smartest). Derivational morphemes create new words by altering meaning; for example, the prefix ‘un-’ indicates negation (e.g., happy – unhappy) and ‘re-’ indicates repetition (e.g., write – rewrite). Also, the suffix ‘-ness’ can turn an adjective into a noun (e.g., happy – happiness), ‘-ful’ a noun into an adjective (e.g., hope – hopeful) and ‘-ize’ turns a noun into a verb (e.g., symbol – symbolize). Critically, lexical production models tend to represent root words (Waksler, Reference Waksler and Wheeldon2000). Thus, it is unknown how morphological similarity might play a role in the free association task based on the lexical production models currently employed to understand word retrieval and production.
On a free association task, one could hypothesize that an ‘easy’ strategy for task completion is to harness morphology, particularly morphological families. Morphological families are sets of words represented in the mental lexicon that are typically related in form and meaning (Nagy et al., Reference Nagy, Anderson, Schommer, Scott and Stallman1989) and known to influence performance on a variety of word recognition (Beyersmann & Grainger, Reference Beyersmann and Grainger2018; De Jong IV et al., Reference De Jong, Schreuder and Baayen2000; Dijkstra et al., Reference Dijkstra, Moscoso del Prado Martin, Schulpen, Schreuder and Baayen2005; Nikolaev et al., Reference Nikolaev, Ashaie, Hallikainen, Hanninen, Higby, Hyun, Lehtonen and Soininen2019), among other linguistic tasks. By exploiting morphological families on free association tasks, fewer mental resources might be needed to search for associates related to a cue (e.g., by simply manipulating the morphology of the cue word). This strategy could be applied in both semantic and phonological free association tasks. Explicit use of this strategy would help participants generate more response words and/or generate response words more quickly. For example, given the cue word smart, participants may harness morphological families to add prefixes (e.g., unsmart, outsmart) and/or suffixes (e.g., smarter, smartness). Another possible strategy is to generate compound words, which, to a certain extent, fall into derivational morphology (e.g., smartphone, smartwatch, smartcard).
In contrast, it might be the case that morphology does not play a substantial role in the completion of free association tasks. For example, given a two-stage model of language processing (Levelt, Reference Levelt1999; Roelofs et al., Reference Roelofs, Meyer and Levelt1998), participants first access the lexeme corresponding to the cue word, which contains the form and appropriate morphological properties of the cue (e.g., through a written or auditory cue word prompting). Then, to produce a semantic or phonologically related response word, participants access a new lemma and then the corresponding lexeme of the new lemma. Given these two-stage models and the fact that the cues typically provided in these tasks are morphologically simple (e.g., dog, cat versus dogs, doglike, dogwalker, underdog, cats, catlike, catfish, copycat), accessing lemmas may be a central tenet of free association tasks, limiting the role of morphology and morphological families on completion of the task. Phonology and semantics may still interact across free association tasks (e.g., using phonology to retrieve responses on a semantic free association task) during lemma selection, leading to participants giving precedence to conceptual and phonological information over morphological form to complete free association tasks.
To our knowledge, there has been limited consideration of the role of morphology in free association tasks. One inspiration for this paper was a reference to morphology impacting performance on a phonological association task in Castro and Vitevitch (Reference Castro and Vitevitch2023). In a coarse review of their phonological association dataset, they found that about 7% of phonological associates had a morphological relationship to cue words. In their study, a morphological relation was assumed to occur when pairs of words shared both semantic and phonological information (e.g., ‘abdomen – abdominal’). However, they noted that their coarse method of identifying morphological similarity resulted in some cue–response pairs, like out – about, which had semantic and phonological similarity but no morphological relation. Further, there were several indications that participants completed the phonological association task as intended (e.g., 60% of cue–response pairs were only one or two phonemes different; Castro & Vitevitch, Reference Castro and Vitevitch2023), and this task has been used in several other studies assessing phonological similarity (e.g., Neergaard & Huang, Reference Neergaard and Huang2019; Vitevitch et al., Reference Vitevitch, Chan and Goldstein2014, Reference Vitevitch, Goldstein, Johnson, Mehler, Lucking, Banisch, Blanchard and Job2016). Thus, a more systematic approach to examining morphological influence on association tasks (semantic and phonological) is warranted.
1.1. Aims and predictions
This paper aims to determine the role of morphological similarity between cues and responses produced during free association tasks and, by doing so, understand whether free association tasks drive exploration of lemma and/or lexeme representations. To do so, we analyzed existing, large datasets of the free association task: one dataset of semantic associations (De Deyne et al., Reference De Deyne, Navarro, Perfors, Brysbaert and Storms2019) and one dataset of phonological associations (Castro & Vitevitch, Reference Castro and Vitevitch2023). The idea was to test the extent to which semantic and phonological word associations are predicted by morphological relationships between cues and responses in tasks where morphology is not explicitly implied. We did not expect a difference in the number of morphologically related associations between semantic and phonological association tasks. We also examined whether there are key psycholinguistic properties of cues and responses that predict the occurrence of morphological similarity to emerge in the association tasks. Some words may be structured in memory to afford more opportunity for linguistically similar words to come to mind (e.g., Haslett & Cai, Reference Haslett and Cai2024). In this case, we would expect that cue words with richer lexical representations (e.g., greater semantic diversity, larger phonological neighborhoods, or larger morphological families) would have more opportunities for morphologically similar response words to emerge.
When morphological similarity was present between a cue and response, we also examined whether there was a systematic difference in the types of morphological relationships present. First, we considered the proportion of inflectional versus derivational morphological relationships. On the one hand, English has a small number of inflectional affixes (Stump & Finkel, Reference Stump and Finkel2015), with a much larger number of derivational affixes, as exemplified by the MorphoLex database (Sánchez-Gutiérrez et al., Reference Sánchez-Gutiérrez, Mailhot, Deacon and Wilson2018). On the other hand, English inflectional affixes tend to be more frequently used than derivational affixes. Inflected forms and their base words (e.g., trees versus tree) are also more semantically and phonologically similar to one another than derived forms and their base words (e.g., useless versus use). Thus, hypotheses could be made to support either derivational or inflectional relationships occurring more often in the free association task. Second, we explored the proportion of compound words and tested the extent to which morphological associations can be explained by differences in prefixation versus suffixation and composition versus decomposition.
Finally, an exploratory methodological aspect of this study was to understand the accuracy of a Python-based program to analyze morphological relations in these two large datasets. Identifying and coding morphological relationships can be time and resource-intensive if done manually. It is not our intention to discuss the role of human ratings as the gold standard. Rather, we aim to use the Python-based program as a ‘first-pass’ to decide which pairs of words are morphologically related, given the large number of word pairs analyzed in this study, and manually assess the accuracy of morphologically related cue–response pairs identified by the Python program.
2. Method
2.1. Datasets
The data used in this study were retrospectively analyzed from existing datasets. All data are de-identified and available for research use; IRB approval was not required for the current analyses. Readers are referred to the original datasets (described below) for additional information on ethics and consent.
2.1.1. Semantic association dataset
We used the semantic association data from the Small World of Words (SWOW) (https://smallworldofwords.org/), which is an ongoing semantic association data collection project (De Deyne et al., Reference De Deyne, Navarro, Perfors, Brysbaert and Storms2019; De Deyne & Storms, Reference De Deyne and Storms2008). The specific data used in this study were pulled from the SWOW-English project on July 24, 2017, for use in the analyses of Castro and Vitevitch (Reference Castro and Vitevitch2023). We did not re-pull SWOW data for the present study to keep the historical time point consistent between both semantic and phonological association datasets used in this study. For the Castro and Vitevitch (Reference Castro and Vitevitch2023) study, there were 9,337 cue words extracted from the SWOW dataset after narrowing the set list to exclude multi-word cues (e.g., apple juice), proper nouns (e.g., America), different spellings of the same word (e.g., labour and labor, where the American English version was retained), or in appropriate words (e.g., taboo words).
Full details of the SWOW methods are provided in De Deyne et al. (Reference De Deyne, Navarro, Perfors, Brysbaert and Storms2019), with a brief overview provided here. Native English-speaking participants completed the semantic association task remotely using the SWOW website (N = 88,722 reported in De Deyne et al. (Reference De Deyne, Navarro, Perfors, Brysbaert and Storms2019)). Participants were shown a typed cue word and were asked to provide up to three words that immediately came to mind. Participants typed their responses into text boxes and could indicate when no responses came to mind. Each participant was presented with a random set of 14–18 cue words, one at a time. Several pre-processing steps were applied to the dataset, including addressing misspellings and removing multiword and nonword responses.
2.1.2. Phonological association dataset
We used the phonological association data reported in Castro and Vitevitch (Reference Castro and Vitevitch2023). These data were collected in 2016–2017. The phonological association study started with 9,337 cue words pulled from the SWOW dataset. Upon completion of the study, the phonological association dataset included 56,747 unique cue–response pairs, with 9,298 cue words and a total of 20,575 unique words across cues and responses. The lower cue word total reflects that 39 cue words used in the study did not elicit any phonological association responses (i.e., all participants who received one of those cue words responded with ‘don’t know’).
Full details of the phonological association method are provided in the Supplementary Material of Castro and Vitevitch (Reference Castro and Vitevitch2023), with a brief overview provided here. Native English-speaking participants completed the phonological association task remotely using (N = 1,051). Participants were shown a typed cue word and were asked to provide up to three words that ‘sound similar’ to the cue word. Participants typed their responses into text boxes and could indicate when no responses came to mind. Each participant was presented with a random set of 60 cue words, one at a time. Several pre-processing steps were applied to the dataset, including addressing misspellings and removing multiword and nonword responses.
2.2. Identifying morphological relations between cues and responses
We identified morphological relations between cue–response word pairs in both association datasets using two methods. First, we used a Python-based program called spaCy (Honnibal et al., Reference Honnibal, Montani, Van Landeghem and Boyd2020). SpaCy is an open-source Python library that can be used to process large volumes of text by applying tasks such as tokenization, part-of-speech tagging, named entity recognition and dependency parsing. This step was deemed necessary given the very large number of word pairs in our datasets. Afterward, morphological relations were identified manually by authors AR and EB.
2.2.1. Python-based program (spaCy)
Regarding the Python-based program, the code assesses whether there is a morphological relation and, if so, whether the relation is inflectional or derivational (see Supplementary materials). The code reads pairs of words from a CSV file, either from the semantic association dataset or the phonological association dataset. All derivational affixes were retrieved from the MorphoLex database (Sánchez-Gutiérrez et al., Reference Sánchez-Gutiérrez, Mailhot, Deacon and Wilson2018). In particular, we extracted all derivational affixes with a Hyperspace Analogue to Language (HAL) frequency above 100.
To determine an inflectional relation, the code assesses whether the two given words share the same root and the same lemma using spaCy’s English model and, additionally, if one of the words contains one of five pre-specified inflectional affixes (i.e., ‘-s’, ‘-es’, ‘-ed’, ‘-ing’ and ‘-est’). For example, the pair ‘run’ – ‘running’ corresponds to an inflectional relation because the two words share the same root (i.e., run), share the same meaning or lemma (i.e., the action or movement of a runner), and because one of the words in the pair contains the inflectional morpheme ‘-ing’.
To determine a derivational relation, the code assesses whether the two derived words share the same root and if one of the words contains one of 124 pre-specified derivational prefixes or one of 189 pre-specified derivational suffixes. For example, the pair ‘happy’ – ‘unhappy’ would correspond to a derivational relation because the words share the same root (i.e., happy) and because one of the words contains the derivational prefix ‘un-’. Note that the lemma of ‘happy’ and ‘unhappy’ is not the same, provided that ‘happy’ corresponds to someone showing pleasure or contentment, while ‘unhappy’ reflects the opposite meaning.
When using the Python-script, some irregular inflections (e.g., teach – taught) were not considered because we were primarily interested in word associations where the root or morphemic stem was preserved (e.g., walk – walked), as arguably this is the information that we expect participants to use to produce morphologically related words given a specific cue.
2.2.2. Manual (human) analysis
The datasets were also manually marked to confirm the Python-based decisions and to include more detailed information regarding different types of morphological complexity. For all cue–response word pairs identified as having a morphological relation using the Python-based program, the human coders assessed whether there was a true morphological relation and indicated the morphological type as derivational (e.g., happiness), inflectional (e.g., walking), compounding (e.g., starship) or simplex (e.g., happy). For those responses deemed to have a morphological relation by the coders, the word pairs were next assessed for whether a composition or decomposition took place from the cue word to the response word. Composition included affix additions (e.g., happy-happiness), while decomposition referred to affix deletions (e.g., happiness-happy), always going from cue to response. The same criterion was applied to compound words. For example, star-starship was marked as a composition, while starship-star as a decomposition. Note that it was possible for affix substitutions (e.g., acting-actress), rather than addition or deletion of affixes, or irregularly inflected forms (e.g., begin-begun) to occur, and these were marked as ‘other’, instead of composition or decomposition. Finally, for word pairs noted as composition or decomposition, response words were finally classified based on whether the affix was a prefix or a suffix. For example, happy-happiness was marked as suffixation, while happy-unhappy was marked as prefixation.
2.3. Statistical analyses
First, we identified the rate of morphologically related words generated in response to cue words in both semantic and phonological association tasks. We checked the accuracy of the Python-based program with a simple percent agreement between the number of TRUE morphological relationships identified by the Python-based program and a revision of these relationships by the human raters. For all remaining analyses, we defaulted to the human raters’ determination of morphological similarity between cue and response words, which required first an affirmative indication by the Python script. We note that there are limitations to this approach (e.g., missing TRUE morphological relations not identified by the Python script first), a point we return to in the Limitations section. After that, we checked for differences in the types of morphologically related response words for each task using chi-square tests. Specifically, we compared the number of inflections versus derivations, compounding versus no compounding, composition versus decomposition and prefixation versus suffixation. Note that prefixes in English are derivations and suffixes in English can be derivations or inflections.
Next, we analyzed the semantic and phonological similarity of cue and response words in both semantic and phonological association tasks by whether they were or were not morphologically related. In Python, we used ‘Levenshtein’ to calculate the phonological similarity of cue and response words and used ‘fasttext’ to calculate the semantic similarity of cue and response words (see Supplementary materials). Wilcoxon rank sum tests were used to determine if there were differences in the phonological and semantic similarity between the cue and response words of pairs that did or did not have a morphological relationship. We used an R script to conduct Wilcoxon rank sum tests (see Supplementary materials). We used the same script for the semantic and phonological association datasets.
We also obtained psycholinguistic properties of cue words to assess whether there were differences between cue words that do and do not elicit morphologically related responses. The following psycholinguistic properties of cue words were obtained: age of acquisition (Kuperman et al., Reference Kuperman, Stadthagen-Gonzalez and Brysbaert2012), concreteness (Brysbaert et al., Reference Brysbaert, Warriner and Kuperman2014), log SUBTLEX-US word frequency (Brysbaert & New, Reference Brysbaert and New2009), number of letters, number of phonological neighbors (Marian et al., Reference Marian, Bartolotti, Chabal and Shook2012), semantic diversity (i.e., a measure of the range of contexts a word is found in using Latent Semantic Analysis; Hoffman et al., Reference Hoffman, Lambon Ralph and Rogers2013) and morphological family size of the root (i.e., the number of words sharing the same root; Sánchez-Gutiérrez et al., Reference Sánchez-Gutiérrez, Mailhot, Deacon and Wilson2018). The values of these variables were derived from the datasets associated with the citations noted and also used in the English Lexicon Project, a large dataset for psycholinguistic analyses (Balota et al., Reference Balota, Yap, Cortese, Hutchison, Kessler, Loftis, Neely, Nelson, Simpson and Treiman2007). A correlation matrix of the psycholinguistic variables of cue words is provided in the Supplementary Material.
3. Results
3.1. Semantic association dataset
Of the 239,483 semantic association pairs, 4,083 pairs were identified as morphologically related by the Python-based program (1.7% of the data). After manual assessment of morphological similarity, there were 2,675 pairs that were retained as truly morphologically related (2675/4083 = 0.65). Therefore, 65% of the morphological relations identified by the Python-based program were deemed correct. If we consider all the semantic association pairs, 1.1% of the data included morphologically related cue–response pairs, as determined by an affirmative identification by the Python script and the human raters.
Of the 2,675 word-pairs that were morphologically similar, 518 were classified as inflectional (19.3%), 792 were classified as derivational (29.6%), 198 were classified as compounding (7.4%) and 1,167 were classified as simplex (43.6%). Table 1 provides counts, chi-square tests and p-values for comparisons of different types of morphological relationships. When morphologically related responses were identified, we found more derived than inflected words, more words that were non-compounds than compounds, more decomposition than composition and more suffixation than prefixation (all ps < 0.0001).
Counts and Chi-square tests comparing morphological relationships of cue–response pairs produced in the semantic association task

a We only include cases where a single affixation without compounding was needed to produce the response word relative to the cue word. There were an additional 40 cue–response pairs where more than one morphological change was needed: compounding + suffixation (n = 14; e.g., CUE: blueberries – RESPONSE: blue), compounding + other (n = 1; i.e., CUE: grandchildren – RESPONSE: child), prefixation + suffixation (n = 24; e.g., CUE: disagreement – RESPONSE: agree) and prefixation + other (n = 1; i.e., CUE: undone; RESPONSE: do).
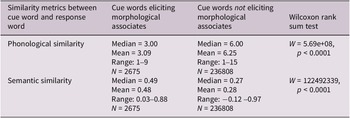
Table 2 provides descriptive statistics, Wilcoxon rank sum tests and p-values for the assessment of semantic and phonological similarity between cue–response word pairs by whether they did or did not have a morphological relationship. Wilcoxon rank sum tests showed that cue–response pairs with a morphological relationship had closer phonological similarity and higher semantic similarity than pairs that did not have a morphological relationship (all ps < 0.0001).
Descriptive statistics and Wilcoxon Rank Sum Test of similarity metrics between cue and response words for cues eliciting and not eliciting morphologically related responses in the semantic association dataset

Table 3 provides descriptive statistics, Wilcoxon rank sum tests and p-values for the psycholinguistic variables of cue words that did or did not elicit at least one response word that was morphologically related. Wilcoxon rank sum tests showed that cues eliciting morphologically related responses were shorter, more frequent, earlier learned, lower concreteness, greater semantic diversity and larger morphological family size than cues that did not elicit morphologically related responses (all ps < 0.0001). However, there was no difference in phonological neighborhood size between cue words that elicited a morphologically related response and those that did not (p = 0.132).
Descriptive statistics and Wilcoxon Rank Sum Test of psycholinguistic properties for all unique cue words eliciting and not eliciting morphologically related response words in the semantic association dataset

3.2. Phonological association dataset
Of the 56,747 phonological associate pairs, 3,628 pairs were identified as morphologically related by the Python-based program (6.3% of the data). After manual assessment of morphological similarity, there were 1,068 pairs that were retained as truly morphologically related (1068/3628 = 0.29). Therefore, 29% of the morphological relations identified by the Python-based program were deemed correct. If we consider all the phonological association pairs, 1.8% of the data included morphologically related cue–response pairs, as determined by an affirmative identification by the Python script and the human raters.
Of the 1,068 word-pairs that were morphologically similar, 273 were classified as inflectional (25.5%), 288 were classified as derivational (26.9%), 19 were classified as compounding (1.7%) and 488 were classified as simplex (45.6%). Table 4 provides counts, chi-square tests and p-values for comparisons of different types of morphological relationships. When morphologically related responses were identified, we found more words that were non-compounds than compounds, more decomposition than composition and more suffixation than prefixation (all ps < 0.0001). The difference between derived and inflected words was not significant (p = 0.527).
Counts and Chi-square tests comparing morphological relationships of cue–response pairs produced in the phonological association task

Note: We only include cases where a single affixation and without compounding was needed to produce the response word relative to the cue word. There were an additional six cue–response pairs where more than one morphological change was needed: compounding + suffixation (n = 4; e.g., CUE: eyebrows – RESPONSE: eye) and prefixation + suffixation (n = 2; e.g., CUE: unconditional – RESPONSE: condition).
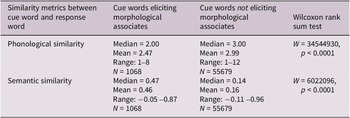
Table 5 provides descriptive statistics, Wilcoxon rank sum tests and p-values for the assessment of semantic and phonological similarity between cue–response word pairs by whether they did or did not have a morphological relationship. Wilcoxon rank sum tests showed that cue–response pairs with a morphological relationship had closer phonological similarity and higher semantic similarity than pairs that did not have a morphological relationship (all ps < 0.0001).
Descriptive statistics and Wilcoxon Rank Sum Test of similarity metrics between cue and response words for cues eliciting and not eliciting morphologically related responses in the phonological association dataset

Table 6 provides descriptive statistics, Wilcoxon rank sum tests and p-values for the psycholinguistic variables for cue words that did or did not elicit at least one response word that was morphologically related. Wilcoxon rank sum tests showed that cues eliciting morphologically related responses were shorter, had fewer phonological neighbors, lower concreteness, greater semantic diversity and larger morphological family size than cues that did not elicit morphologically related responses (all ps < 0.0001). However, there was no difference in age of acquisition (p = 0.193) or word frequency (p = 0.527) between cue words that elicited a morphologically related response and those that did not.
Descriptive statistics and Wilcoxon Rank Sum Test of psycholinguistic properties for all unique cue words eliciting and not eliciting morphologically related response words in the phonological association dataset

4. Discussion
This study sought to determine the extent to which morphological similarity emerges in the cue–response pairs generated in semantic and phonological free association tasks. When morphological similarity appeared, we also sought to understand characteristics of that similarity. As a natural consequence of data coding, we were also able to explore different methods to identify morphological similarity in cue–response pairs, with implications for future research needs.
Our results demonstrated that response words are infrequently morphologically related to cue words on both types of free association tasks (< 2% of unique cue–response pairs), as determined by a Python-based script and human raters. As expected of morphological similarity, cue–response pairs with a morphological relationship in both association tasks were more closely related phonologically and semantically than cue–response pairs without a morphological relationship. Decomposition was frequent across both association tasks. That is, it was more often the case that cue words had the morphology already present and participants were removing the morphology to produce a response word, rather than adding. Morphological relationships were more prominent in the suffix position, which may be related to the fact that suffixes in English can be either derivations or inflections, whereas prefixes in English can only be derivations. However, we only found greater derivations in the semantic association task, which indicates that the higher rate of suffixation than prefixation is not simply due to whether the morphological relationship was derived or inflected. Finally, there was also limited compounding emerging in cue–response word pairs.
With regard to the relationship between psycholinguistic factors of cue words and morphological relationships with response words, we found similarities and differences across association tasks. First, in both association tasks, cue words eliciting morphologically similar response words tended to have longer length, lower concreteness, higher semantic diversity and larger morphological family size. The longer length of cue words likely reflects the inclusion of morphology, aligning with the finding that response words tended to reflect decomposition more frequently than composition. Words with lower concreteness tend to be not just more abstract in meaning but also longer and more derivationally complex (Reilly & Kean, Reference Reilly and Kean2007), which may allow for greater opportunity for morphological relations to be accessed. Words with high semantic diversity have an increased number of contexts that a word can be used in (e.g., current is both a noun and an adjective), allowing for more lexemes to be accessible and subsequently more opportunities for morphological relations to emerge. Likewise, cue words with larger morphological families (e.g., head, headed, heading, headings, heads, …) have a greater number of morphologically related words in their phonological and semantic space than words with small morphological families (e.g., alpaca, alpacas), which may increase the likelihood of morphological associates being produced in the free association tasks.
Differences were noted between the two association tasks, though. Cue words acquired earlier in life and with higher word frequency were more likely to elicit morphologically related response words in the semantic association task, with no effect of these psycholinguistic properties in the phonological association task. Additionally, cue words with smaller phonological neighborhoods were more likely to elicit morphologically related response words in the phonological association task, with no effect of this psycholinguistic property in the semantic association task.
4.1. Theoretical interpretation of morphology in free association tasks
The small proportion of morphological relationships in our data suggests that the free association task may drive exploration of conceptual representations or lemmas, as opposed to or more so than lexemes or words related in [morphological] form, in the mental lexicon, generally (Vivas et al., Reference Vivas, Manoiloff, Garcia, Lizarralde and Vivas2019). Such a finding aligns with a two-stage model of lexical processing, whereby the participant accesses a lemma containing meaning and syntactic properties of the word, followed by the lexeme containing the form and morphophonological properties (Levelt, Reference Levelt1999; Roelofs et al., Reference Roelofs, Meyer and Levelt1998). This is supported by the finding that morphological relations tended to occur more in the semantic association task when cue words had strong conceptual representations (i.e., early age of acquisition, high lexical frequency). The lemma of the cue word was quickly accessed and lexemes of the cue word, including different morphological forms (especially if the word had a large morphological family), were then easily retrievable, allowing for morphologically related response words to be produced. Further, the finding that derived forms were more frequently used in the semantic association task, but not the phonological association task, points to the reliance on conceptual knowledge.
A curious difference emerges, though, in the phonological association task. We found that morphological relations tended to occur more often when cue words had small phonological neighborhoods. A cue word with many phonological neighbors may allow for completion of the task by changing a single phoneme, without the need to access more complex morphophonological changes. However, when a cue word has few phonological neighbors, the task may only be possible to complete by accessing the morphology of the lexeme. This finding suggests that there may be greater weight on lexeme processing in the phonological association task than the semantic association task, which also aligns with the finding of no difference between inflected and derived forms. Because the phonological association task focuses on form changes, an inflected relationship (e.g., apple – apples) is just as valid in the phonological association task as a derived relationship (e.g., happy – unhappy). Indeed, based on the two-stage model of lexical processing (Levelt, Reference Levelt1999; Roelofs et al., Reference Roelofs, Meyer and Levelt1998), the phonological association task could be completed through lexeme processing only. That is, a participant would not necessarily need to access conceptual knowledge to complete the phonological association task (e.g., by changing the morphology of a cue word). It is not clear based on these data if lemma processing is actively inhibited during the phonological association task, or if it is the case that there is just a greater opportunity for lexeme-only processing to emerge.
Future work could examine cases that constrain the exploration of conceptual/lemma space to provide the right conditions for morphological similarity to emerge more robustly on free association tasks. This might include examining whether morphologically related responses are more likely to emerge when in a cognitive demanding situation as compared to a less cognitively demanding situation (e.g., Baror & Bar, Reference Baror and Bar2016), examining whether there are differences in the rate of morphologically related responses between high and low creative individuals (e.g., Beaty & Kenett, Reference Beaty and Kenett2023; Kenett et al., Reference Kenett, Anaki and Faust2014), or even examining whether individuals who have language impairment (e.g., acquired or progressive aphasia; acquired dyslexia) produce morphologically related responses at a different rate than healthy individuals (Beyersmann et al., Reference Beyersmann, Turney, Arrow and Fischer-Baum2022; Beyersmann et al., Reference Beyersmann, Arrow, Behzadnia and Fischer-Baum2025). Further, if free association tasks explore lemma representations over lexeme representations, the results we showed for semantic and phonological association datasets should be similar if we were to add an orthographic free association task. Also, free association may correlate with tasks that tap into the semantic system, such as word-to-picture matching or non-verbal association (e.g., Pyramids and Palm Trees; Howard & Patterson, Reference Howard and Patterson1992) but not with tasks that put more emphasis on lexemes, such as lexical decision (e.g., Is ‘apple’ a real word? How about ‘fapple’?). Comparison of languages with different morphological complexity (e.g., Spanish, Chinese) may also be relevant to replicate the results.
4.2. Limitations
We analyzed two datasets with different participants and cue words. The main aim of the paper was to describe patterns of morphologically related words in free association rather than directly comparing the semantic and phonological free association tasks. The primary and more descriptive aim of this paper is therefore achieved, given that the number of word pairs examined in both datasets is rather large (i.e., > 239,000 in the semantic association data and > 57,000 in the phonological association dataset). However, in future work, participants with similar demographic characteristics, if not the same participants, could be included. Also, the cue words of each task could be the same and include specific morphological manipulations (e.g., cues that systematically vary in morphological family size, polymorphemic vs. monomorphemic cues), allowing for a more controlled environment to study task differences regarding morphological characteristics of cue–response word pairs (e.g., inflection vs. derivation, composition vs. decomposition). Further, weighting data should be retained (i.e., how many people gave the same response word to a cue word) to identify potential relationships between weighting and morphological similarity.
We also must note the methodology to identify morphological similarity. We used a Python-based program to run a first pass on the cue–response word pairs generated in both free association tasks. Importantly, the Python script did not pick up on all instances of morphologically related cue–response pairs in the data of the semantic and phonological associations tasks. Therefore, the reported numbers of morphologically related cue–response word pairs are likely an underestimate of the actual proportion of morphologically related cue–response pairs in the data. Additionally, there was a high false positive rate for the phonological association dataset compared to the semantic association dataset. One potential explanation is that the Python script incorrectly marked works for morphological relation based on orthographic similarity, which would impact the phonological association dataset more than the semantic association dataset; for example, the words cable, fable and stable were marked as morphologically related to the cue word able by the Python program. Whether or not our results hold up on the basis of a fully manually coded dataset remains a question for future research. However, the Python program seemed necessary, at least for a first pass at identifying morphological relations, given the large number of responses that both datasets contained.
Additionally, the difference between inflectional and derivational affixes can sometimes be a bit blurry. The affixes ‘-en’, ‘-ing’, ‘est’ and ‘-er’ can be both inflectional and derivational depending on context. For example, if -er is used as a comparative adjective (‘his dessert is larger…’), it is inflectional; if it is used as a noun (‘farmer’), it is derivational. With the current free association method, we could not distinguish between different syntactic word classes because we were looking at single-word responses. Therefore, we limited ourselves to the inflectional affixes that were unambiguously inflectional but also included ‘-ing’ because the majority of words ending in ‘-ing’ can be interpreted as verbs, and ‘est’ because it is used to form the superlative of adjectives and adverbs (e.g., ‘darkest’, ‘smallest’, ‘greenest’, etc.).
Finally, it is not always clear how responses are chosen by participants when only considering cue–response relations. For example, compounding relations could occur because of co-occurrence rather than a morphological relationship (e.g., star – starship). Future research could conduct studies that are focused on depth, rather than breadth, by explicitly capturing from participants the strategies or rationale behind chosen responses to presented cue words.
5. Conclusion
Morphological similarity does not have a strong role in semantic or phonological free association tasks. Nevertheless, the small proportion of morphological relationships between cue words and response words demonstrated patterns consistent with constrained access to morphology in the lexicon. These results strengthen the idea that free association tasks explore lemma representations, as opposed to (or more so than) lexeme representations, and contribute to a better understanding of how individuals complete free association tasks. Further understanding of when and how morphological similarity is used in free association is needed.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/langcog.2026.10065.
Data availability statement
Data and supplementary material are available at https://osf.io/vjke4.
Competing interests
There are no competing interests to declare.







 Open access
Open access