




1. Introduction
Multilinguals – individuals who use more than one language in daily life – often show enhanced cognitive functioning, potentially shaped through the experience of using multiple languages (Bialystok, Reference Bialystok2017, Reference Bialystok2021). However, quantifying this experience remains challenging (Voits et al., Reference Voits, DeLuca and Abutalebi2022). Most studies rely on self-reported language proficiency, which may not fully capture the nuances of actual language use. Therefore, it is essential to explore a range of complementary and objective measures. Crucially, the sensitivity of these tools may vary depending on whether they assess native or non-native language use. This study examines multiple approaches to measuring multilingual language experience and compares their effectiveness in distinguishing between native and non-native language skills.
Multilinguals often activate all of their known languages during language processing even when they are required to use only one language, a phenomenon supported by behavioral and neuroimaging evidence (Thierry & Wu, Reference Thierry and Wu2007; Wu & Thierry, Reference Wu and Thierry2012). According to the Adaptive Control Hypothesis (Green & Abutalebi, Reference Green and Abutalebi2013), this co-activation requires managing cross-linguistic interference, involving specialized cognitive control mechanisms, depending on the interactional context. Understanding multilingual experience is therefore crucial for accurately characterizing their linguistic and cognitive profiles (Bialystok, Reference Bialystok2017; Gallo et al., Reference Gallo, Novitskiy, Myachykov and Shtyrov2021; Gullifer & Titone, Reference Gullifer and Titone2019).
Multilingual experience can be quantified through both ability-based variables (e.g., language proficiency) and usage-based variables (e.g., language exposure, language switching frequency and contexts). Traditionally, these measures have relied on self-reported data, with participants completing language history questionnaires and reporting their proficiency and usage patterns for each language. While standardized questionnaires have been developed to reduce variability between studies (Anderson et al., Reference Anderson, Mak, Keyvani Chahi and Bialystok2018; Li et al., Reference Li, Zhang, Yu and Zhao2020; Luk & Esposito, Reference Luk and Esposito2020; Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007), these self-reports remain vulnerable to subjective bias and individual variability (Tomoschuk et al., Reference Tomoschuk, Ferreira and Gollan2019). For example, a review of 22 meta-analyses by Zell and Krizan (Reference Zell and Krizan2014) found only a moderate correlation between individuals’ self-evaluations of their abilities and their actual performance. Therefore, the development of standardized, objective measures is crucial for accurately quantifying multilingual language experience.
Regarding ability-based variables, several objective measures of language proficiency have been developed and validated. For example, Marian et al. (Reference Marian, Blumenfeld and Kaushanskaya2007) developed a battery of objective proficiency measures (including picture naming, passage comprehension, reading fluency, sound awareness and grammaticality judgment). Additionally, the multilingual naming test (MINT) was developed and further validated in multiple languages (Gollan et al., Reference Gollan, Weissberger, Runnqvist, Montoya and Cera2012; Gollan et al., Reference Gollan, Starr and Ferreira2015). These objective measures have been widely used and considered sufficient for quantifying language proficiency.
However, objective measures of usage-based multilingual experience remain lacking. Standardized language history questionnaires, such as the Language History Questionnaire (LHQ3, Li et al., Reference Li, Zhang, Yu and Zhao2020) and Language Experience and Proficiency Questionnaire (LEAP-Q, Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007), do include detailed sections on daily language use. These sections typically ask about the frequency or duration of language use in various contexts – including interactions with friends and family and media use. However, estimations of time or proportion are susceptible to memory biases, social desirability effects and subjective perceptions of language dominance (Castro et al., Reference Castro, Kałamała, Bukowski and Wodniecka2025; Schacter et al., Reference Schacter, Guerin and Jacques2011). For instance, an individual might overestimate their use of a heritage language due to strong cultural identification, while another might underestimate it due to perceived lack of proficiency. These discrepancies underscore the need for more objective and nuanced measures of multilingual language experience to complement self-reports and better capture the complexity of multilingual language use. Furthermore, even with consistent methods and questions, the accuracy of these self-reported measures may differ between native and non-native languages (Gullifer et al., Reference Gullifer, Kousaie, Gilbert, Grant, Giroud, Coulter, Klein, Baum, Phillips and Titone2021; Tomoschuk et al., Reference Tomoschuk, Ferreira and Gollan2019). To objectively assess multilingual language use, this study combines and adapts existing tools to capture usage from multiple perspectives. We introduce each method below to highlight their unique contributions.
A limitation of estimating language use with traditional language history questionnaires is their reliance on retrospective recall over extended periods, which compromises ecological validity (Bradburn et al., Reference Bradburn, Rips and Shevell1987; Verbeke et al., Reference Verbeke, Buysschaert and Lefèvre2024; Wu et al., Reference Wu, Stangl, Chipara, Gudjonsdottir, Oleson and Bentler2020). To address this, the ecological momentary assessment (EMA, Shiffman et al., Reference Shiffman, Stone and Hufford2008) approach can be used, where participants reported language switching frequency at short intervals – for example, every 2 hours for 2 weeks – using a phone application (Jylkkä et al., Reference Jylkkä, Soveri, Laine and Lehtonen2020). This approach has been shown to be more reliable than general retrospective self-reports of language switches. Building on the EMA approach, the current study developed a Daily Report Form method. We expanded the scope of self-reported metrics beyond language switching frequency to encompass a broader range of everyday language use scenarios. Specifically, participants documented their language use – including the specific language used, duration, contexts and interlocutors – in an Excel document every 3 hours over a week.
In addition to self-reported measures, other studies have explored objective ways to quantify language use. One approach utilizes an electronically activated recorder (EAR, Macbeth et al., Reference Macbeth, Bruni, De La Cruz, Erens, Atagi, Robbins, Chiarello and Montag2022), a research tool that collects naturalistic audio samples of individuals’ daily lives. Participants wear a small, portable recording device that periodically captures brief snippets of ambient sound. With sufficient recording, researchers can gather a stable proportion of language use and bilingual exposure, verified by previous studies (Cychosz et al., Reference Cychosz, Villanueva and Weisleder2021). While this method allows researchers to analyze real-world speech and language use contexts, it raises concerns regarding privacy, participant consent and potential behavior changes due to being recorded. Inspired by the EAR but designed to address these privacy concerns, the current study developed the Online Messages assessment. This method captures language usage by collecting participants’ online text and voice messages sent to different interlocutors via social media platforms over a week. Crucially, participants were not informed about the study’s objectives and were encouraged to screen their messages themselves, sharing only those they felt comfortable with. Participants also needed to document the context and interlocular for each message they submitted.
Additionally, standardized in-lab tasks are key methods for capturing language profiles, as validated in objective language proficiency measures. However, few tasks focus on eliciting language use in diverse contexts. To assess codeswitching behaviors in multilingual speakers, researchers have utilized a MAP (Multilingual Naming and Production) task, where director/matcher pairs verbally communicate to reproduce a set of images on the matcher’s map from the director’s map within a time limit (Beatty-Martínez et al., Reference Beatty-Martínez, Valdés Kroff and Dussias2018; Beatty-Martínez & Dussias, Reference Beatty-Martínez and Dussias2017). However, this task typically involves two participants forming groups and is limited to the contexts elicited by the task images. Adapted from free speech tasks, the current study introduced In-Lab Language Tasks eliciting a variety of conversational and monologous situations, encouraging natural language production in any language.
Accurate measurement of language use is increasingly important, yet the equivalence validity of different assessments across languages remains largely unverified. In the present study, we developed three ways of language assessments – Daily Report Form (DR), Online Messages (OM) and In-Lab Language Tasks (EXP) – to examine consistency and differences in data collected across languages and contexts, along with the self-reported LHQ as a reference comparison. We hypothesized that consistency would differ between assessments of native and non-native language use, reflecting distinct patterns in how each is measured rather than suggesting a hierarchy in validity. We also predicted that combined contexts would yield higher consistency levels than isolated ones, underscoring the importance of capturing language use across diverse situations to more accurately reflect multilingual experience.
2. Methods
2.1. Participants
A total of 24 participants in this study were recruited from the University of Macau (19 females, mean age = 23.4 years, SD = 2.3, range = 18 to 26 years). All participants were multilingual and reported regular use of two or more languages in daily life. All participants also used mobile social platforms for voice-based communication (e.g., WeChat, QQ, Instagram, etc.). Chinese dialects that differ substantially from Mandarin in phonology were treated as separate languages. However, dialects with minimal linguistic divergence from Mandarin – such as those spoken in northeast China and Beijing – were grouped as Mandarin. All participants were right-handed and reported no neurological or cognitive impairment. All participants provided written consent to participate, and all materials were approved by the Research Ethics Committee of the University of Macau.
2.2. Procedure and tasks
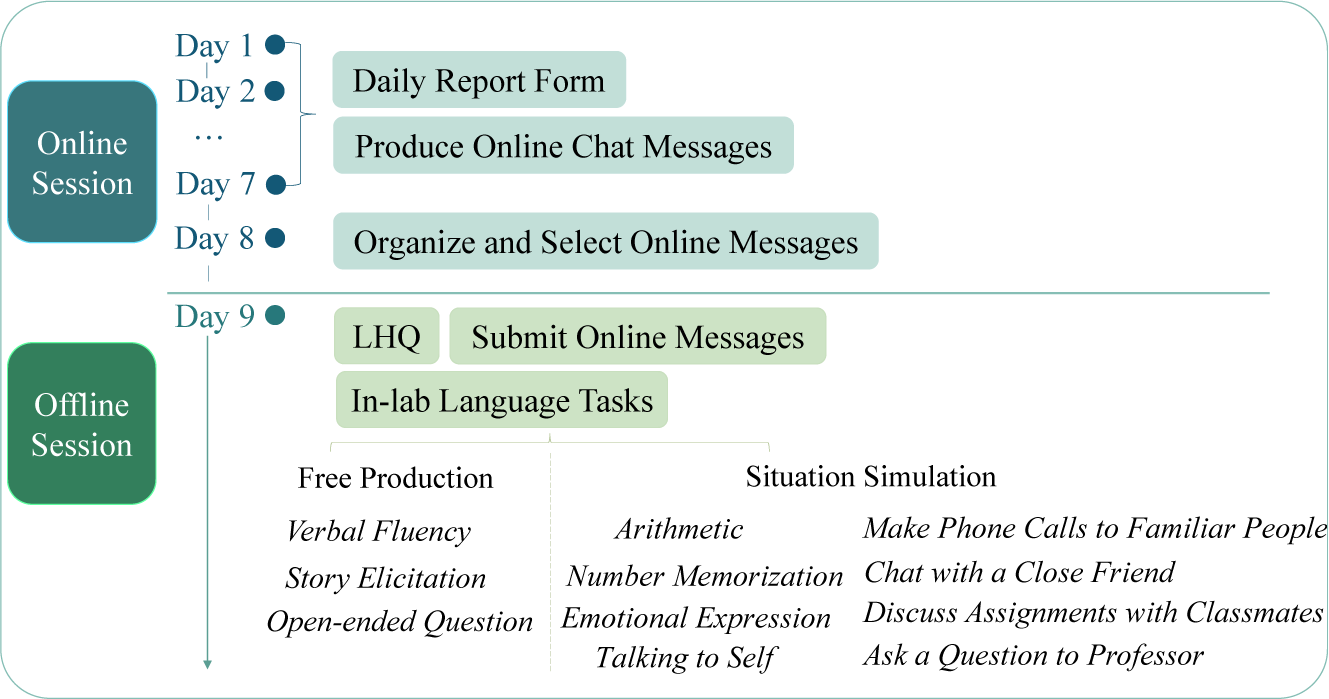
Participants’ language use was measured using four methods over 9 days (Figure 1). Two measures were collected remotely over seven consecutive days (i.e., daily report form and online messages). Two measures were completed in the laboratory after the remote period (i.e., customized language history questionnaire and in-lab language tasks).
Experiment procedure spanning over 9 days, starting from the remote weekly report form, remote online messages from social platforms, to in-lab customized language history questionnaire and in-lab language tasks.

2.2.1. Daily report form (DR)
Participants first completed a daily language use report for 7 days (See Supplementary Material 1 for an example). They recorded language use in approximately 3-hour intervals. For each language event, they reported the time, duration, context, language/dialect, mode of use (listening, speaking, reading, writing or combinations) and interlocutor identity. Participants were encouraged to complete the form at each interval rather than retrospectively to reduce omissions. All participants submitted complete DR forms for the 7-day period (i.e., no missing intervals). As with diary-based measures, we cannot verify whether entries were completed exactly every 3 hours. To encourage timely reporting, the research team sent daily reminders and collected the completed forms at the end of each day. When clarifications were needed, participants were contacted promptly to reduce memory delay. Interlocutors were classified into five categories, including 1 – family (N = 18), 2 – friends (N = 19), 3 – classmates (N = 11), 4 – colleagues (N = 17) and 5 – other (N = 20), with N representing the number of participants who reported each category. Additionally, participants were encouraged to report their language use in different self-engaged activities and describe the activities in the “situation” column. The research team classified these activities into different categories including “video,” “audio,” “reading for fun,” “reading for school/work,” “internet,” “writing for fun” and “writing for school/work.”
2.2.2. Online messages (OM)
Online chat messages were collected from participants’ social media platforms over the same 7-day period as the daily report. The research team sent daily reminders encouraging participants to use voice messages when communicating online. To protect privacy, participants screened their own messages before sharing them. Messages were sampled across all social communication applications used during the week. From each participant, up to 10 text messages (minimum length: 10 characters) and 10 voice messages (minimum duration: 10 seconds) with each interlocutor were requested. When fewer messages were available, participants were instructed to submit as many as possible. Group chats were treated as with a single interlocutor.
After the remote week, participants attended a lab session. Text messages were submitted directly to the research team, while voice messages were recorded using a voice recorder. Interlocutor relationship categories were documented and coded using the same criteria as DR. The number of participants who provided OM data in each category was including 1 – family (N = 18), 2 – friends (N = 20), 3 – classmates (N = 8), 4 – colleagues (N = 9) and 5 – other (N = 9).
2.2.3. Customized language history questionnaire (LHQ)
Participants completed a language history questionnaire in the lab. The questionnaire was adapted from the original version (LHQ3; Li et al., Reference Li, Zhang, Yu and Zhao2020) to better match daily contexts and to capture a broader range of language-use scenarios. To streamline the questionnaire, we retained only essential items about educational background and residence history. The adapted version focused on participants’ language repertoire, including languages used, age of acquisition, self-rated proficiency, contexts and interlocutors and frequency of use (Supplementary Material 2).
Several context categories were revised to reflect the daily lives of university students living on campus. For instance, “Watching TV” and “Listening to the radio” were updated to “Watching videos” (e.g., movies and long-form streaming content) and “Listening to audio” (e.g., music, radio dramas, podcasts); Reading e-books was added under “Reading for fun,” while short-form videos (e.g., TikTok) were incorporated under “Using social media and the Internet.” We also added “Writing for fun” (e.g. writing novels, diaries or blogs). Interlocutor categories were refined by separating “colleagues/co-workers” from “others.” “Colleagues” included academic or lab-related contacts (e.g., teachers, tutors, student collaborators), whereas “others” included roommates and unfamiliar individuals. To maintain consistency across tools, the categories family, friends, classmates, colleagues and others were aligned with DR and OM. Overall, all contexts in LHQ included in the current study are “family,” “friends,” “classmates,” “colleagues” and “others” context in the conversation category “watching videos,” “listening to audio,” “reading for fun,” “reading for school/work,” “using social media and the internet,” “writing for school/work,” and “writhing for fun” context in the self-engaged activity domain. To capture diverse language exposure, the questionnaire allowed participants to report languages they encountered and used in daily life, even if they had not formally learned them. For example, listening to music in a language was recorded even when formal proficiency was limited.
2.2.4. In-lab language tasks (EXP)
In the lab, participants completed language tasks presented via a Microsoft PowerPoint program. To reduce potential bias in language choice, interaction with the research team was minimized and instructions were presented on-screen in English, Mandarin and Cantonese – the three most commonly spoken languages in the testing region. Participants were encouraged to use any language or dialect they preferred and to switch languages freely. The tasks included two parts: free production section and situation simulation section. Free production section included a one-minute verbal fluency task (name as many items as possible in a semantic category), a no-time limit story elicitation task (narrate a story based on a wordless comic book) and a 1-minute free-speech task (produce speech about “What do you think happiness is?”). Participants could complete the story elicitation at their own pace.
Participants then completed simulated one-sided conversations adapted from the LHQ. To ensure ecological validity, these scenarios were adapted to reflect common interactions within a university context. Four interlocutor scenarios were included: (a) calling parents/family to provide updates, (b) chatting with a close friend, (c) discussing a group assignment with classmates and (d) asking a professor a question after class. The “others” category was not simulated because it was difficult to define a representative interlocutor. Self-engaged activities were also simulated, including (a) mental arithmetic – subtracting 7 sequentially from 100 while verbalizing the calculation process; (b) number memorization and recall; (c) self-directed speech – self talk for 1 minute and (d) emotion expression – producing exclamations/mantras, including swear words if applicable. All verbal responses were recorded using a digit voice recorder for transcription and analysis.
2.3. Data coding and analysis
2.3.1. Data coding
Language use was coded separately for each interlocutor context. Although some participants reported additional languages, the primary analyses focused on participants’ native language and English, because these were reported by all participants and allowed consistent comparisons across the sample.
Data obtained from each assessment method were standardized by calculating the proportion of use for each language per participant. Specifically, for DR, language-use proportion was computed within each context as the total duration for a given language divided by the total reported duration across languages in that context. For LHQ, the proportion was computed as the reported frequency of use of the target language divided by total reported language use within that context.
Regarding online messages, although participants were encouraged to submit voice messages whenever possible, fewer than expected did so. Consequently, most online message data consisted primarily of text messages, with relatively fewer voice recordings. In total, 1779 text messages and 465 voice messages were collected. For text messages, language use was quantified by word counts across languages. For voice messages, language use was quantified based on speech duration, because recording lengths varied across participants. OM proportion was computed by averaging the text-based proportion and the voice-based proportion when both were available. When only one modality was available, the available modality was used. EXP recordings were first transcribed, and language use proportions were subsequently calculated using the same procedures as other assessment tools.
All data were coded by one trained member of the research team who was proficient in Mandarin, Cantonese and English. When a participant’s dominant language was a dialect not spoken by the primary coder, a native speaker of that dialect conducted the initial coding, and the primary coder then checked the coded output for consistency. To avoid overestimating English use in OM and EXP, we used explicit rules for ambiguous Latin-letter tokens. In typed messages, language was assigned by intended lexical identity and surrounding context (not keyboard settings); pinyin-based abbreviations or Chinese shorthand (e.g., “wx” for “微信”) were coded as Chinese. In voice messages, phonetically/semantically equivalent forms (e.g., “Hi/嗨”) were coded using immediate context (e.g., “Hi Tom …” as English; “Hi 汤姆 …” as Chinese). We distinguished between contexts with no observation and observed contexts with zero use of the target language. If a participant provided no data for a specific context within a tool (e.g., no OM messages for that context), that context was treated as missing and excluded from analyses that require a defined proportion. If the context was observed but the participant did not use the target language, the proportion was coded as 0.
Four interlocutor categories were shared across tools: family, friends, classmates and colleagues. These contexts were first analyzed separately to compare the reported language use for each language across different assessment tools. Additionally, these four contexts were combined to calculate the overall reported language use in different assessments (i.e., combination_four). Specifically, the proportion of language use across all four contexts was calculated through the summation of target language usage divided by the summation of all language use time. To compare overall language use across tools, combination_all was computed as the average target-language proportion across all available contexts within each tool.
2.3.2. Correlation and ANOVA analysis
With the coded data for each language from each assessment tool, we conducted a series of analyses to compare the similarities and differences among different assessments and languages. All analyses were conducted under R environment (R Core Team, 2013). Several analyses were conducted based on reported language use with each interlocutor and across all contexts. We used correlational analyses to examine the consistency of language use reported by different assessment tools (DR, OM, LHQ and EXP). Specifically, we calculated Pearson’s pairwise correlations across all measurements for each interlocutor context, both individually and combined, and applied family-wise error (FWE) correction with Bonferroni methods for multiple comparisons. To ensure sufficient representativeness and statistical reliability, any measurement reported by fewer than 10 participants was excluded from the correlational analyses. Additionally, we used analysis of variance (ANOVA) to examine differences in reported language use across assessment tools, for each interlocutor context separately and combined. Tukey’s post hoc tests were conducted to correct for multiple comparisons.
2.3.3. Network analysis
In addition to traditional analyses, we applied a network approach to examine the relationships among different contexts for each language. Each measurement method (DR, OM, LHQ and EXP) was represented as a node in the network. Edges between nodes were drawn when a statistical association was identified. The network was estimated using the estimateNetwork() function from the bootnet package (Epskamp et al., Reference Epskamp, Borsboom and Fried2018), employing the Least Absolute Shrinkage and Selection Operator in conjunction with the Extended Bayesian Information Criterion for model selection. Given that most variables did not meet normality assumptions, nonparametric correlations were estimated using nonparanormal transformations. The resulting network was visualized using the qgraph and bootnet packages.
To evaluate the influence of each node within the network, strength centrality indices of each network were calculated. Node strength was defined as the sum of the absolute weights of all edges connected to that node, reflecting its total connectivity. Given the modest sample size, no additional bootstrapping procedures were applied.
2.3.4. Validation with a counterbalanced sample
To evaluate whether reversing the order of the online (DR and OM) and offline (LHQ and EXP) sessions introduced systematic differences, we additionally tested a counterbalanced validation group (N = 9; mean age = 23.1 years, range = 20–28 years), with similar profiles with the original sample. These participants completed the offline tasks on Day 1 and the online tasks from Days 2–9. Analyses targeted all combination variables, as these served as the aggregated outcome measures across interaction contexts. For each variable, we computed the difference in means (Validate − Original) and conducted two-sided label-permutation tests with 1,000 permutations. In each iteration, group labels were randomly reassigned while preserving the number of participants in each group and the number of non-missing observations for that variable. The resulting permutation distribution of mean differences was then used to compute a p-value based on the proportion of permuted differences whose absolute value was equal to or greater than the observed difference. To adjust for multiple comparisons across all variables and both datasets combined, we applied the Benjamini–Hochberg false discovery rate (FDR) procedure at q = .05.
Additionally, to provide an objective external criterion, these new set of participants completed an English picture-naming task consisting of 298 images (300 originally; two items were removed due to quality issues). We computed picture-naming accuracy as the proportion of correctly named items, then plotted the correlation between the accuracy and the English use proportion across different measurement tools.
3. Results
3.1. Descriptive results
Among the 24 participants, 5 reported Cantonese as their native language, 14 reported Mandarin, 3 reported the Sichuan dialect, 1 reported the Xiaogan dialect and 1 reported the Shanghai dialect. These dialects are all Mandarin variants but phonologically independent from Mandarin. All participants reported English as one of their commonly used non-native languages. Table 1 presents the proportion of native language and English use across various contexts, as assessed by different measurement methods. Overall, participants consistently reported higher usage of their native language compared to English. However, the proportion of use varied across methods, reflecting context-dependent differences in language use behavior captured by each assessment approach.
Reported proportions of each language used across different contexts

Note: Values reflect mean proportions across all participants, with standard deviations in parentheses. N indicates the number of participants who reported using that language in the corresponding context.
Abbreviations: DR, daily report form; EXP, in-lab language tasks; LHQ, customized language history questionnaire; OM, online messages.
3.2. Correlational analyses across measurement tools in each language
Correlations were examined between reported language use across different social contexts (family, friends, classmates, colleagues and combined contexts) for native language and English (see Table 2). All p-values were corrected for multiple comparisons using the FWE with Bonferroni methods.
Correlation results among different measurements in native language vs English under different contexts

Family context: In native language, significant correlations were found between DR and LHQ (r = .79, p < .001) and LHQ and EXP (r = .58, p = .02). For English, no correlational analysis was conducted because none of the measurement tools had sufficient representation.
Friend context: For native language, all the correlations were observed significant including the relationships between DR and OM (r = .85, p < .001), DR and LHQ (r = .61, p = .02), DR and EXP (r = .71, p = .003), OM and LHQ (r = .80, p < .001), OM and EXP (r = .68, p = .002) and LHQ and EXP (r = .68, p = .002). For English, only the association between EXP and OM was significant (r = .56, p = .04), while other correlations were not examined due to insufficient sample sizes.
Classmate context: All reported correlations in native language were found significant including the relationships between DR and LHQ (r = .90, p < .001), DR and EXP (r = .80, p = .002) and LHQ and EXP (r = .74, p < .001). In English, no correlational analysis was significant or conducted because no tool had sufficient representation.
Colleague context: In native language, only the correlation between DR and LHQ (r = .81, p < .001) was found significant. In English, a similar correlation was found between DR and LHQ (r = .84, p < .001).
Combination across four contexts: For native language, all the correlations were found significant. DR showed significant correlations with OM (r = .78, p < .001), LHQ (r = .76, p < .001) and EXP (r = .62, p < .001). Additional correlations included OM and LHQ (r = .84, p < .001), OM and EXP (r = .81, p < .001) and LHQ and EXP (r = .74, p < .001). No significant correlations were found in English.
Combination across all contexts: In native language, all pairwise correlations were significant: DR and OM (r = .75, p < .001), DR and LHQ (r = .80, p < .001), DR and EXP (r = .69, p = .001), OM and LHQ (r = .83, p < .001), OM and EXP (r = .86, p < .001) and LHQ and EXP (r = .78, p < .001). For English, only the association between DR and LHQ was found significant (r = .68, p = .002).
3.3. ANOVA analyses across measurement tools in each language
A set of ANOVAs were conducted to examine differences across four measurement methods (DR, OM, LHQ and EXP) in participants’ reported use of native language and English across various social contexts (Figure 2).
ANOVA and post hoc tests results. * p < .05, ** p < .01, *** p < .001. DR = Daily Report Form, OM = Online Messages, LHQ = Customized Language History Questionnaire, EXP = In-lab Language Tasks.

No significant differences among measurement methods were found in the family (native language: F (2.09, 33.47) = .49, p = .62; English: F (3, 48) = 1.92, p = .14), friend (native language: F (2.49, 44.75) = 1.96, p = .14; English: F (1.60, 28.92) = 1.84, p = .18), classmate (native language: F (1.71, 15.35) = .28, p = .73; English: F(1.10, 9.86) = 1.03, p = .34), or colleague (native language: F (1.98, 25.79) = 1.46, p = .25; English: F (1.81, 23.58) = 2.08, p = .15).
When combining the four critical contexts, no significant measurement difference emerged for native language (F (2.35, 54.05) = 2.70, p = .07), although post hoc tests indicated LHQ was lower than OM (difference = −.13, p = .01). For English, however, there was a significant main effect of measurement tool (F (2.53, 58.12) = 4.91, p = .006). Post hoc comparisons showed significant difference only between OM and LHQ (difference = −.07, p = .009).
Across all available contexts, significant measurement method differences were found for both languages (native language: F (2.26, 51.90) = 14.84, p < .001; English: F (1.64, 37.77) = 30.30, p < .001). Post hoc comparisons with Bonferroni correction showed significant differences between DR and OM (difference = −.19, p = .002), DR and EXP (difference = −.21, p = .006), OM and LHQ (difference = .21, p < .001) and LHQ and EXP (difference = −.23, p < .001) for native language; DR and OM (difference = .17, p < .001), DR and EXP (difference = .15, p < .001), OM and LHQ (difference = −.17, p < .001) and LHQ and EXP (difference = .15, p < .001) for English.
3.4. Network analysis
Networks were developed separately depending on the context and language (Figure 3). Detailed results are described below.
Networks and the strength centrality indices of different contexts and different languages. (A) Native language networks across contexts. (B) Network centrality strength of native language across contexts. (C) Non-native language networks across contexts. (D) Network centrality strength of non-native language across contexts. Blue lines in the networks indicate a positive connection and pink lines indicate a negative connection, thicker lines indicate a stronger connection between the two measurements and vice versa. Regarding strength centrality (calculated as the summation of absolute weights of all edges connected to that node), the y-axis represents the z-scored values of centrality index; the x-axis represents the measurements. DR = Daily report form, OM = Online messages, LHQ = Customized language history questionnaire, EXP = In-lab language tasks.

Family context: For native language, within the network, positive relationships were found between DR and LHQ, OM and EXP and LHQ and EXP. Strength centrality indices of DR and LHQ were higher than average (z > 0) while OM and EXP were lower. For English, the network cannot be constructed because the lack of sufficient non-zero data.
Friends context: For native language, positive relationships were found between DR and OM, DR and EXP, OM and LHQ, OM and EXP and LHQ and EXP. The strength centrality indices of EXP was above the average and the centrality of other measurements were below the average. For English, an empty network was constructed because of the lack of sufficient non-zero data.
Classmates context: For native language, the relationships between DR and OM, DR and LHQ, LHQ and OM, LHQ and EXP and EXP and DR were positively significant. Strength centrality indices of DR and LHQ were higher than average, and the centrality indices of EXP and OM were lower. For English, the network cannot be constructed.
Colleagues context: For native language, the relationships between DR and LHQ, LHQ and EXP, EXP and OM and OM and DR were found positively significant, while EXP and DR was negatively connected. Strength centrality indices of DR and LHQ were higher than average, whereas the centrality of OM was lower. For English, only the connection between LHQ and EXP was positively significant, and the strength centrality indices of LHQ and EXP were higher than DR and OM.
Combination across four contexts: For native language, positive associations between DR and OM, DR and LHQ, OM and LHQ, OM and EXP and LHQ and EXP were found significant. Only the strength centrality of DR was lower than average, whereas the centrality indices of OM, LHQ and EXP were higher than average. For English, LHQ was found positively associated with DR and EXP. Strength centrality indices of LHQ and EXP were higher than average, whereas the centrality indices of other measurements were lower than average.
Combination across all contexts: For native language, positive relationships were found between DR and OM, DR and LHQ, OM and LHQ, OM and EXP, LHQ and EXP. Negative correlation was found between DR and EXP. Only the strength centrality of LHQ was lower than average. For English, positive relationships were found between DR and LHQ, DR and EXP. Strength centrality indices of DR and LHQ were higher than average whereas the centrality indices of other measurements were lower.
3.5. Further validation with new sample
3.5.1. Testing order effect
To evaluate whether reversing the order of the online (DR and OM) and offline (LHQ and EXP) sessions introduced systematic differences in performance, we compared the counterbalanced sample (N = 9) with the original sample (N = 24) on all combined contexts in both languages using two-sided label-permutation tests (B = 1,000). Only one variable, LHQ_combination_four in the English dataset, remained significant after global FDR correction, p perm = .003, p FDR-global = .048, with higher scores in the counterbalanced group (M = 0.24) than in the original sample (M = 0.08). All remaining variables produced non-significant permutation p-values after global FDR correction (pFDR-global > .05). Taken together, these results suggest that task order did not lead to systematic performance differences across the DR, OM, LHQ or EXP combination measures, indicating that carry-over effects between online and offline sessions are unlikely to have influenced our main findings.
3.5.2. Prediction to task performance
To explore whether these measurements can predict task performance, we further examined the relationship between English picture-naming accuracy and English use proportion derived from each measurement tool. Because the external-validation sample size was limited, we report these findings descriptively using correlation plots rather than inferential statistics (Figure 4). Across most conditions, higher reported English use was associated with higher picture-naming accuracy. This positive trend was absent only in the EXP condition, in which participants reported minimal English use. Overall, the pattern suggests that the self-report tools capture variance that is meaningfully related to objective performance, with OM and DR showing slightly stronger alignment than LHQ in this dataset.
Relationship between English picture-naming accuracy and English use proportion estimated by each measurement tool in the validation sample. Except for EXP, higher estimated English use was associated with higher naming accuracy, with slightly stronger alignment for DR and OM than for LHQ. DR = Daily report form, OM = Online messages, LHQ = Customized language history questionnaire, EXP = In-lab language tasks.

4. Discussion
Compared to traditional approaches that solely rely on a single tool – typically a self-reported language history questionnaire – to quantify multilingual language use, the current study innovatively designed and compared multiple complementary methods. We investigated the consistency of language use reports across several measurement tools and social contexts, focusing on both native language and one non-native language (i.e., English). Correlational, ANOVA and network-based analyses demonstrated similarities and differences among measurement tools, as well as between native and the non-native English. While different tools show overall consistency, they vary in sensitivity to language use contexts. This variability introduces potential bias, especially in the assessment of non-native English, which is more susceptible to contextual influences. This is particularly relevant in Macau, where Cantonese, Mandarin and English are often functionally specialized across domains, which can shape both language choice and what each tool captures. The following sections provide a detailed discussion of these results.
The LHQ is one of the most commonly used tools for assessing multilingual language use, offering a broad retrospective overview of language exposure across various contexts and life stages (Li et al., Reference Li, Zhang, Yu and Zhao2020). However, despite its utility, the number of participants who reported using English via LHQ was notably lower than the counts obtained from objective measures such as online messages or in-lab experiments (e.g., Table 1, where the number of LHQ responses was generally lower than other tools in contexts like family, friends and classmates). This discrepancy suggests that LHQ estimates may be shaped by subjective judgments about what “counts” as language use, which may reduce sensitivity to low-frequency non-native use. In Macau, English is often associated with formal or academic domains, which may raise the threshold for reporting English in a retrospective questionnaire; participants may omit brief, passive, or mixed-language instances. In response to these limitations, the present study introduced and evaluated alternative tools designed to more accurately capture multilingual language experience.
The Daily Report Form (DR) provides detailed, context-rich data by prompting participants to self-report their language use across various settings, activities and interlocutors at regular intervals. Unlike the LHQ, which relies on retrospective estimates spanning long periods, the DR captures recent language use within short, structured time frames (e.g., every 3 hours over a week), thereby reducing susceptibility to memory distortion (Bradburn et al., Reference Bradburn, Rips and Shevell1987; Shiffman et al., Reference Shiffman, Stone and Hufford2008). Although this diary-like method offers high ecological validity, it requires sustained participant engagement and accurate logging (Shiffman et al., Reference Shiffman, Stone and Hufford2008). Strong correlations between DR and LHQ were anticipated, as both instruments assess self-reported language use. Indeed, the number of participants reporting the use of both their native and non-native languages was highly consistent between two measurement tools across all contexts (Table 1). Furthermore, across all contexts assessing native language use, and in most contexts assessing English use with sufficient data, significant correlations were observed between the DR and LHQ. No significant differences were found between these two tools in any context. These findings suggest that self-report instruments for assessing language use demonstrate a high degree of consistency. Acknowledging this high consistency, the network-based analysis revealed that DR exhibited slightly higher centrality than LHQ when assessing both languages across all available contexts. This pattern suggests that DR demonstrates stronger overall connectivity with other measures compared to the LHQ. In addition to self-report measures, this study incorporated more objective methods for assessing language use.
The Online Messages (OM) tool offers naturalistic data derived from participants’ actual digital communications, reducing reliance on introspective recall and minimizing participant burden (Macbeth et al., Reference Macbeth, Bruni, De La Cruz, Erens, Atagi, Robbins, Chiarello and Montag2022). However, OM mainly samples informal, text-based communication with close contacts (e.g., “family” and “friends”), and it may therefore underrepresent English use in academic or professional interactions (Table 1; Figure 2, English). This limitation is especially relevant in Macau, where English is often used in educational and work settings that occur outside personal social-media chats (e.g., meetings or face-to-face conversations). As a result, OM may underestimate English use in the “classmates” and “colleagues” contexts. In addition, OM records were participant-screened for privacy, and participants could withhold sensitive messages before submission. Because we did not quantify the amount of withheld or redacted content, OM should be interpreted as a naturalistic but partial sample of digital communication. Furthermore, the duration of available voice messages fell considerably short of the 49-minute benchmark recommended by previous studies (Cychosz et al., Reference Cychosz, Villanueva and Weisleder2021), thereby constraining our ability to analyze spoken language. A likely explanation for this limitation is the sociocultural communication norm in which sending voice messages is not a primary mode of interaction. In fact, sending numerous or lengthy voice messages may even be perceived as inconvenient or intrusive. To address this issue in future research, it may be beneficial to encourage participants to utilize the voice-to-text function available in communication applications (e.g., WeChat). This approach would allow participants to select their preferred messaging method while simultaneously increasing their willingness to produce voice-based content.
The In-lab Language Tasks (EXP) provide standardized spoken language samples, both spontaneous and context-driven, enabling controlled comparisons across participants (Beatty-Martínez et al., Reference Beatty-Martínez, Valdés Kroff and Dussias2018; Munarriz & Parafita Couto, Reference Munarriz and Parafita Couto2014). However, our results suggest that the ecological validity of EXP is limited. Participants often defaulted to a single language across trials, regardless of the assigned interlocutor, likely to minimize cognitive effort. This anchoring behavior compromised the measure’s representativeness, reducing its sensitivity to naturalistic code-switching or context-driven language adaptation. This may also reflect perceived norms about what language is “appropriate” in a lab task, which can discourage spontaneous switching. As shown in the results, EXP showed relatively weak correlations with other tools, particularly in the non-native English. Additionally, the method’s exclusive focus on verbal communication neglects other essential language modalities such as reading and writing, thereby narrowing its applicability. Furthermore, EXP often lacks genuine communicative intent and interactive engagement, resembling stereotypical lab-based speech samples that are artificially constructed and socially detached (Xu, Reference Xu2010). Taken together, these limitations suggest that the current method requires ongoing refinement to better support natural, multimodal language use.
It is important to note that, significantly higher consistency was found when language use was aggregated across multiple contexts – particularly for the native language. This pattern suggests that context-specific discrepancies may reflect the distinct strengths and limitations of each measurement tool, whereas broader estimates spanning multiple settings tend to converge more reliably. Moreover, combining four daily communication contexts resulted in smaller differences between methods compared to aggregating all available contexts. These findings indicate that assessing language use solely within everyday communication contexts may obscure intensity differences between different measurement tools. These results underscore the importance of incorporating multiple communicative contexts in language use assessments – not only to enhance measurement validity and tool comparability, but also to better reflect real-life language experiences, which are naturally distributed across dynamic and overlapping social and situational domains.
Although our analyses focused on group-level patterns, cross-tool consistency may vary across individuals. Future work could quantify person-level agreement across tools and test whether participants show distinct consistency profiles. As an initial step toward linking usage estimates to individual performance, we added an external validation group (N = 9) with an objective English picture-naming task. In this sample, higher English-use estimates generally aligned with higher naming accuracy across tools, with the weakest trend in EXP and slightly stronger alignment for OM and DR than LHQ. Finally, we emphasize that the present work is a feasibility evaluation of intensive, multi-method measurement, rather than a definitive large-scale validation study. Accordingly, the sample size (N = 24) may limit some context-specific analyses, particularly when English use is low. To assess robustness, the external validation group completed the offline and online measures in reverse order. Combination-level results showed minimal order-related differences, supporting the stability of our main conclusions. Future studies should recruit larger and more linguistically diverse samples, including participants with a wider range of English use, to further evaluate cross-tool consistency and tool-specific sensitivities.
To interpret differences across tools, it is helpful to distinguish expected divergence from patterns that may reflect measurement error. Divergence is expected when tools differ in sampling frame (channel/context), time window, or task demands. For example, OM primarily captures informal digital messaging and may not reflect academic or workplace language use; EXP elicits speech under standardized laboratory conditions and may attenuate natural code-switching; and DR reflects one specific week, which may differ from LHQ’s longer-term retrospective averages if that week is atypical. By contrast, when tools are designed to index the same construct under comparable conditions, strong convergence is expected. Consistent with this, the two self-report measures (DR and LHQ) showed high correspondence and no significant differences in comparable contexts, suggesting limited measurement error–driven divergence. These considerations motivate the practical guidance in our decision tree (Figure 5): tool choice should follow the research question (broad retrospective profile, recent context-resolved use, naturalistic messaging or standardized speech), and combining tools can broaden coverage (e.g., DR + OM for contextual detail plus naturalistic output; LHQ + DR for standardized background plus short-term context; the full protocol when feasible).
Decision tree and comparison table for multilingual language use assessment tool selection and combination. DR = Daily report form, OM = Online messages, LHQ = Customized language history questionnaire, EXP = In-lab language tasks.

In summary, this study advances the assessment of multilingual language use by systematically comparing multiple complementary tools across diverse social contexts. While traditional approaches typically rely on a single retrospective questionnaire, the present study explored alternative methods – including structured interval-based self-reports, naturalistic digital communications and controlled experimental tasks – to capture a more comprehensive picture of language use. Each tool demonstrated distinct strengths and limitations: self-report measures showed high internal consistency, objective tools offered strong ecological validity and experimental methods enabled standardized comparisons. However, differences in sensitivity to context and modality highlight the need for integrated, context-rich approaches and continued refinement, particularly in assessing non-native language use. Crucially, our findings underscore the importance of incorporating dynamic, multimodal assessments that reflect the complexity of real-life language behavior. This multidimensional framework not only improves measurement validity and tool comparability but also provides valuable insights and alternative approaches for future research aiming to capture the dynamic nature of multilingual language use across real-world contexts.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S1366728926101424.
Data availability statement
The behavioral data and analysis scripts are openly available on OSF Platform at https://osf.io/2wsyu/?view_only=61ce48b0d4164b6b9b518fd4d4fb11bc.
Acknowledgments
This project was funded by the Science and Technology Development Fund, Macao S.A.R [FDCT, 0153/2022/A], the National Natural Science Foundation of China [32200845] and the Multi-Year Research Grant [MYRG-GRG2025-00227-ICI] from the University of Macau to Haoyun Zhang. Authors declare no competing interests.
Competing interests
The authors declare none.









 Open access
Open access