



Highlights
-
• Belgian Dutch and European Spanish listeners were exposed to casual English speech.
-
• Offline intelligibility and online word recognition data were collected.
-
• Unreduced words were recognized more accurately and quickly than reduced words.
-
• Similar L1 reduction processes did not facilitate processing of reduced L2 words.
-
• No interaction effect between speaker accents and phonetic reduction was observed.
1. Introduction
Everyday spoken language varies widely both between and within talkers. Between-talker variation stems from differences in age, biological sex, vocal tract size and shape and vocal cord length. Additionally, speakers may have a noticeable (regional) native (L1) or non-native (L2) accent. These talker characteristics partially explain why the concrete realization of sounds and words differs between speakers. In relation to within-talker variation, words also commonly have a different pronunciation in casual speech and careful speech across languages. In casual speech, words are typically produced with weakened segments, resulting from durational shortening and articulatory undershoot (e.g., consonant lenition: Warner & Tucker, Reference Warner and Tucker2011; vowel centralization: Gahl et al., Reference Gahl, Yao and Johnson2012), or with fewer segments (Clopper & Turnbull, Reference Clopper, Turnbull, Clopper, Turnbull, Cangemi, Clayards, Niebuhr, Schuppler and Zellers2018). In English, for instance, speakers frequently elide schwas in high-frequency words like memory (mem’ry [ˈmem.ri]) or support (s’port [sphɔːt]) (Davidson, Reference Davidson2006). Examples of single segment reductions have been found in other languages as well, including French (Bürki et al., Reference Bürki, Ernestus, Gendrot, Fougeron and Frauenfelder2011), Dutch (Mitterer & Ernestus, Reference Mitterer and Ernestus2006) and German (Kohler, Reference Kohler2001). In some cases, words might even have multiple missing segments in production. For example, the word hilarious is often reduced to [hlɛrɛs] (Johnson, Reference Johnson, Yoneyama and Maekawa2004), and the phrase do you have time (/du ju hæv taɪm/) to [tjutəm] (Ernestus & Warner, Reference Ernestus and Warner2011). A substantial body of research has already examined how listeners perceptually deal with phonetic variation originating from speaker accents and phonetic reduction, but little is known about how these factors together influence spoken word recognition and speech comprehension. This study addresses this gap by investigating how phonetic vowel reduction in different accents of English impacts intelligibility for L1 and L2 listeners.
A common observation in earlier research is that words tend to be phonetically reduced in ‘easy’ contexts compared to ‘hard’ contexts. The ease or difficulty of a particular context is determined by the weight of the articulatory burden placed on the talker and/or the processing burden placed on the listener. The following contexts are generally considered easy for production and perception: words with high lexical frequencies (Pluymaekers et al., Reference Pluymaekers, Ernestus and Baayen2005), words with few phonological neighbors (Munson & Solomon, Reference Munson and Solomon2004; Wright, Reference Wright, Local, Ogden and Temple2004; but see Gahl et al., Reference Gahl, Yao and Johnson2012), words with high semantic predictability within a given context (Clopper & Pierrehumbert, Reference Clopper and Pierrehumbert2008), words already mentioned earlier in the discourse (Baker & Bradlow, Reference Baker and Bradlow2009) and words in prosodically weak positions (i.e., words not directly preceded or followed by a strong prosodic boundary and without sentence stress; Byrd & Choi, Reference Byrd, Choi, Fougeron, Kuhnert, d’Imperio and Vallee2010; see, however, Ernestus & Smith, Reference Ernestus, Smith, Clopper, Turnbull, Cangemi, Clayards, Niebuhr, Schuppler and Zellers2018). Essentially, talkers typically produce reduced variants in highly predictable contexts, thereby conserving articulatory effort (cf. production-based accounts of phonetic reduction), while at the same time ensuring that there is sufficient acoustic-phonetic substance in the speech signal for listeners to successfully understand the message (cf. intelligibility-based accounts; see Clopper & Turnbull, Reference Clopper, Turnbull, Clopper, Turnbull, Cangemi, Clayards, Niebuhr, Schuppler and Zellers2018, for a review).
Two distinct mechanisms have been proposed to account for how listeners deal with reduced word forms in perception. On the one hand, listeners may apply a set of general rules and constraints to reconstruct the unreduced pronunciation variant. For instance, French listeners might recognize [ʀnaʀ] as a reduced variant of renard /ʀənaʀ/ (“fox”) by inserting a schwa sound between two consonants that would make a phonotactically illegal onset sequence in French (*/rn/). This reconstructed form is then matched with the unreduced word representation stored in the mental lexicon (see TRACE: McClelland & Elman, Reference McClelland and Elman1986; Shortlist B: Norris & McQueen, Reference Norris and McQueen2008). On the other hand, French listeners might recognize [ʀnaʀ] because both the reduced and unreduced forms of this word are stored in their lexicon. That is, they recognize the reduced form in the speech signal by mapping it onto the corresponding representation of that pronunciation variant. Such a lexical-storage account suggests that either detailed episodic traces (Goldinger, Reference Goldinger1998) or more abstract representations of pronunciation variants are stored in the mental lexicon (Ranbom & Connine, Reference Ranbom and Connine2007). Whether computation or lexical storage plays a more prominent role in spoken word recognition is still a topic of debate (see Ernestus, Reference Ernestus2014; Warner, Reference Warner2023) and may depend on the type of reduction (Mitterer, Reference Mitterer2011). Instead of being mutually exclusive, both mechanisms might operate concurrently during speech processing. Reconstruction accounts can explain how listeners recognize reduced forms they have not previously encountered. Lexical storage accounts, by contrast, can explain how listeners recover from severe reductions (e.g., [ˈɔnri] for ordinary), as it seems unlikely that they reconstruct all missing segments based on the highly reduced input alone.
Several studies have observed an advantage for unreduced words during lexical activation (e.g., Ernestus & Baayen, Reference Ernestus and Baayen2007; Racine et al., Reference Racine, Bürki and Spinelli2014; Tucker & Warner, Reference Tucker and Warner2007). As there is more acoustic-phonetic input in the auditory signal, it might be easier for listeners to map unreduced forms onto entries in the mental lexicon, especially when these forms are presented in isolation or simple carrier sentences. However, the observed privileged status of unreduced variants could, in fact, be an artifact of the recording procedure. Speakers are often instructed to produce reduced forms in contexts that do not legitimize the use of particular phonetically reduced forms (e.g., carefully read speech). If reduced forms are presented in supportive sentence contexts, no robust processing advantage for unreduced forms is found (Ernestus et al., Reference Ernestus, Baayen and Schreuder2002; Kemps et al., Reference Kemps, Ernestus, Schreuder and Baayen2004; Sumner, Reference Sumner2013). Bürki et al. (Reference Bürki, Viebahn, Racine, Mabut and Spinelli2018) demonstrated, for instance, that reduced variants can be equally intelligible as their unreduced counterparts, depending on the type and strength of phonetic reduction and on how often listeners are exposed to each pronunciation variant (see Brand & Ernestus, Reference Brand and Ernestus2018; Ranbom & Connine, Reference Ranbom and Connine2007).
Native listeners typically experience few problems recognizing and understanding pronunciation variants in context. When hearing reduced forms, they can resort to different kinds of knowledge to reconstruct or successfully map these forms, including prior linguistic knowledge, phonotactic rules and contextual information (Spinelli & Gros-Balthazard, Reference Spinelli and Gros-Balthazard2007; Tuinman et al., Reference Tuinman, Mitterer and Cutler2014; Van de Ven et al., Reference Van de Ven, Tucker and Ernestus2011). Moreover, reduced or deleted segments sometimes leave acoustic traces (i.e., acoustic information between the preceding and following segment, indicating the deletion of a speech sound), allowing listeners to identify which word the speaker intended to produce (Mitterer & Ernestus, Reference Mitterer and Ernestus2006; Cole & Shattuck-Hufnagel, Reference Cole, Shattuck-Hufnagel, Clopper, Turnbull, Cangemi, Clayards, Niebuhr, Schuppler and Zellers2018). For example, lexical competition between s’port and sport is resolved once there is audible aspiration of /p/ during the production of reduced support [sphɔːt], but not during the production of unreduced sport [spɔːt].
Non-native listeners might encounter more difficulties when (unfamiliar) pronunciation variants occur in their non-native language. Their linguistic skills in the target language are generally more limited across the board than those of L1 listeners, making it harder to reliably exploit lexical and contextual cues, at least in the initial stages of L2 acquisition (Tuinman et al., Reference Tuinman, Mitterer and Cutler2012; Wong et al., Reference Wong, Mok, Chung, Leung, Bishop and Chow2017). These listeners may also be less frequently exposed to reduced forms when they are learning the target language in a foreign language classroom. In this context, pronunciation variation and casual speech processes tend to receive little attention, and as a consequence, learners predominantly hear unreduced word forms (Morano et al., Reference Morano, ten Bosch and Ernestus2023). But even when learners are acquiring the target language in a naturalistic, immersive environment, processing reduced forms remains challenging, despite potentially encountering these forms more frequently than in classroom environments (except in the case of foreigner-directed speech: Piazza et al., Reference Piazza, Martin and Kalashnikova2022). Ernestus et al. (Reference Ernestus, Dikmans and Giezenaar2017a) showed that even advanced second language learners, similar to beginning second or foreign language learners, are affected by reduced variants in spontaneous speech.
The extent to which speech reductions affect intelligibility may vary among non-native listeners with diverse language backgrounds. There is mounting evidence that shared or similar phonetic processes in listeners’ L1 and L2 facilitate the recognition of pronunciation variants (e.g., Ernestus et al., Reference Ernestus, Kouwenhoven and Van Mulken2017b; Mitterer & Tuinman, Reference Mitterer and Tuinman2012). In some Germanic languages like English, Dutch and German, there is an alternating pattern between prosodically stressed and unstressed syllables (stress-rhythm languages). Vowels in unstressed syllables commonly undergo changes in quality and duration, becoming more spectrally centralized and shorter compared to vowels in stressed syllables. This may result in the complete deletion of unstressed vowels in casual speech (e.g., seconde “second” /səˈkɔn.də/ > [skɔndə] in Dutch). When Dutch listeners hear r’vanche for revanche “revenge” in French, for example, they can apply their L1 reconstruction process (i.e., schwa-insertion to avoid illegal consonant clusters) to reduced word forms in the target language, thereby alleviating processing difficulties (Mitterer & Tuinman, Reference Mitterer and Tuinman2012; Spinelli & Gros-Balthazard, Reference Spinelli and Gros-Balthazard2007). In Spanish, Italian and French, conversely, all syllables have approximately equal prominence and length, regardless of stressing (syllable-rhythm languages).Footnote 1 Words are usually realized with full vowel sounds in both stressed and unstressed syllables (e.g., segundo [seˈɣun.do] in Spanish; Cobb & Simonet, Reference Cobb and Simonet2015), although French allows schwa-deletion (Bürki et al., Reference Bürki, Ernestus, Gendrot, Fougeron and Frauenfelder2011).Footnote 2 Since Spanish lacks phonological vowel reduction in unstressed syllables, L1 Spanish listeners are less familiar from their first language with the acoustic-phonetic cues to strong reductions, and thus the mechanisms to deal with this casual speech phenomenon are potentially delayed or even inhibited in word recognition.
It is noteworthy that research on how phonetic reduction, or casual speech processes more generally, affects speech perception has almost invariably focused on the speech of native speakers with an acrolectal accent (i.e., an accent lacking noticeable deviations from the standard language pronunciation norm). To our knowledge, no earlier studies have explored how listeners deal with phonetic reduction in regionally and non-native-accented speech. Production research has nonetheless demonstrated that instances of phonetic reduction also occur in non-native speech, albeit less frequently than in native speech, and that L2 speakers may approach the level of reduction found in the spontaneous speech of L1 speakers as proficiency in the target language increases (Bradlow, Reference Bradlow2022). Perception studies then showed that native listeners can quickly accommodate to phonetic variation in speech, originating from both speaker accents and phonetic reduction (Norris et al., Reference Norris, McQueen and Cutler2003; Van de Ven et al., Reference Van de Ven, Tucker and Ernestus2011). Non-native listeners, by contrast, may be doubly burdened when phonetically reduced words occur in accented L2 speech. This leads us to formulate the following research questions (RQs):
RQ1: To what extent do instances of phonetic reduction in casual speech affect listening for native and non-native listeners?
RQ2: To what extent does the presence or absence of similar phonetic reduction processes in non-native listeners’ first language affect L2 word recognition and intelligibility?
RQ3: To what extent does the processing of reduced and unreduced words differ when speakers have an acrolectal, regional or non-native accent?
To address these questions, we conducted a study with monolingual listeners of English, Dutch and Spanish. These listeners were exposed to spontaneous speech produced by English speakers with a General British English (acrolectal), Newcastle (regional) or French accent (non-native), which contained instances of phonetically reduced words. We hypothesize that non-native listeners of English encounter more difficulties recognizing reduced words than unreduced words compared to native listeners (cf. RQ1). An intelligibility benefit for L1 English listeners could be expected on the grounds of frequency of exposure and language proficiency. That is, L1 listeners are repeatedly confronted with both pronunciation variants in everyday conversations and generally have a better command of the target language, enabling them to mobilize bottom-up and top-down processing resources more effectively than L2 listeners (Ernestus, Reference Ernestus2014; Janse & Ernestus, Reference Janse and Ernestus2011).
We also hypothesize that listeners’ ability to recognize reduced word forms might vary depending on their language background (cf. RQ2). Spectral and temporal reduction (politie “police” /poː'li.si/ > [pɔlisi]) and (schwa) deletion (gewoonte “habit/custom” /ɣəˈwoːn.tə/ > [ɣwo:ntə]) are common reduction processes in Belgian Dutch (Coussé et al., Reference Coussé, Gillis and Kloots2007). Spanish, conversely, does not have strong vowel reduction or deletion (Cobb & Simonet, Reference Cobb and Simonet2015; but see Hernandez et al., Reference Hernandez, Perry, Tucker, Skarnitzl and Volín2023, on spectral and temporal differences between stressed and unstressed vowels in Spanish). As previous research has shown that non-native listeners can compensate for phonetically reduced segments in L2 speech when similar phonetic processes occur in their L1, we expect that Spanish-speaking listeners experience more word recognition problems than Dutch-speaking listeners when hearing reduced forms in casual speech.
Finally, we hypothesize that listeners recognize reduced word forms more accurately when speakers have an acrolectal accent than when speakers have a regional or non-native accent (cf. RQ3). Previous research has suggested that native speech (acrolectal and regional accents) is easier to understand than non-native speech for both L1 and L2 listeners (e.g., McLaughlin & Van Engen, Reference McLaughlin and Van Engen2020). Acrolectal and regional accents are therefore expected to have a rather limited effect on native listeners’ processing of reduced words, while the recognition of reduced words might be more demanding when these forms occur in non-native speech. However, an intelligibility benefit for native accents has not invariably been observed when it comes to L2 listeners (see Hansen Edwards et al., Reference Hansen Edwards, Zampini and Cunningham2018; Verbeke & Simon, Reference Verbeke and Simon2023). While it is true that many English as a Foreign Language learners predominantly have in-class and out-of-class exposure to General British and American English, some non-native speakers might be equally intelligible to L2 listeners, particularly when they share a language with the speaker or when listeners are highly familiar with a speaker’s accent (Bent & Bradlow, Reference Bent and Bradlow2003; Kang & Moran, Reference Kang, Moran, Gary and Wagner2018; Xie & Fowler, Reference Xie and Fowler2013). To what extent phonetic reduction in native and non-native English speech affects intelligibility, and how accent familiarity may modulate this effect, is the topic of investigation in this study.
2. Experiment 1
Experiment 1 examines to what extent phonetic reduction in acrolectal, regional and non-native English accents challenges intelligibility for native and non-native listeners of English. In an orthographic transcription task, we test how well L1 English, L1 Dutch and L1 Spanish listeners recognize and understand phonetically reduced and unreduced words in casual speech, with transcription accuracy as a proxy for intelligibility.
2.1. Methodology
2.1.1. Speakers
We selected 12 speakers with either a General British, Newcastle or French accent in English (4 speakers per accent, balanced for gender; Mage = 39.0 years, SD = 7.8, range = 24–55), representing speakers with an acrolectal, regional and non-native English accent. All speakers were guests invited for an interview or featured in a talk show, and they were actively involved in politics, the cultural sector or sports. Speakers in this study (i) had mature voice quality, (ii) sounded conversational and (iii) had an authentic and recognizable accent. The first two criteria were satisfied given the age of the speakers at the time of recording and the nature of the interview and talk show format from which excerpts were extracted. To verify the third criterion, 20 L1 English listeners (Mage = 23.0 years, SD = 2.3, range = 19–25) performed an accent verification task. Participants were presented with short excerpts from the same interviews and talk shows that were used to create the stimuli for the main experiment, and they were asked to identify the English accents they heard in a six-alternative forced-choice task. Each speaker’s accent was correctly identified by at least 18 participants, with the accent of four speakers correctly recognized by all participants. These near-ceiling accuracy levels suggest that the excerpts contain sufficient acoustic-phonetic cues for the listeners to recognize the different accents.
2.1.2. Listeners
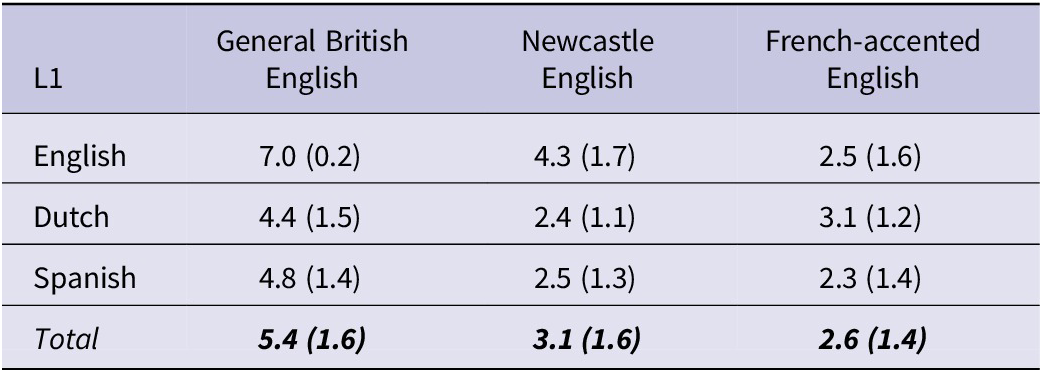
120 monolingual British English, Belgian Dutch and European Spanish listeners (40 per group; Mage = 22.6 years, SD = 1.6, range = 19–25) with self-reported normal or corrected-to-normal hearing were recruited through Prolific. Female participants (n = 63, 52.5%) outnumbered male participants (n = 52, 43.3%) and those who did not identify with either gender (n = 5, 4.2%). At the time of testing, 70 participants (58.3%) were students at a higher education institution. The L1 English listeners were born and raised in Southern England, the L1 Dutch listeners in Flanders (the Dutch-speaking part of Belgium) and the L1 Spanish listeners in Spain. The Dutch and Spanish participants started learning English in a classroom context at the ages of 12.8 (SD = 1.4) and 5.7 (SD = 2.3), respectively, and none of them had spent more than three months in an English-speaking country. All participants had at least an upper-intermediate level of English (B2) in the Common European Framework of Reference for Languages (CEFR) scale, as measured by the Lexical Test for Advanced Learners of English (LexTALE) test of vocabulary knowledge for advanced learners of English (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012). Specifically, L1 Dutch participants had a mean LexTALE score of 84.6 (SD = 9.5, range = 63.8–97.5) and L1 Spanish participants had a mean score of 84.0 (SD = 7.2, range = 67.5–96.3). L1 English participants, by contrast, scored on average 89.8 (SD = 6.6, range = 70–100) on the LexTALE test. In a language background questionnaire, participants were also asked to indicate how often they hear speakers with a General British, Newcastle and French accent in English on a 7-point scale (1 = very rarely, 7 = very often). The English and Spanish participants indicated that they were most familiar with a General British accent and least familiar with a French accent (see Table 1). Similarly, the Dutch-speaking participants reported hearing speakers with a General British accent most often, but they indicated being exposed more frequently to a French accent than to a Newcastle accent.
Listeners’ self-reported frequency of exposure to the three accents of English (1 = very rarely, 7 = very often)

2.1.3. Materials
For the transcription task, 120 short sentences (10 per speaker) were extracted from talk shows and interviews, covering a range of topics. Care was taken not to select sentences that included explicit references to the speaker’s name, first language or country of origin. Each sentence contained one critical multisyllabic target word of moderate to high lexical frequency, based on the frequency measures in the SUBTLEX-UK database (van Heuven et al., Reference van Heuven, Mandera, Keuleers and Brysbaert2014; MZipf = 4.0, SD = 0.8). Target words either had a schwa in the pre-stressed syllable (e.g., police /pəˈliːs/) or in the syllable immediately following the word-initial stressed syllable (e.g., bakery /ˈbeɪ.kə.ri/, which contains schwa, not [ɚ], in British English). To assess the effect of phonetic reduction on intelligibility, half of the selected target words were phonetically reduced due to schwa-deletion ([phliːs] for police); the other half was phonetically unreduced ([səˈphɔːt] for support). The presence or absence of reduction was determined by two trained phoneticians using visual spectrographic (i.e., evidence of periodicity in the oscillogram and voicing in the spectrogram, even for short or low-amplitude segments) and auditory cues in Praat (Boersma & Weenink, Reference Boersma and Weenink2023; Version 6.3.14; see Figure 1).
Oscillograms and spectrograms for the reduced form of police and the unreduced form of support.

To increase inter-stimulus similarity, the root-mean-square intensity of the audio excerpts was scaled to 70 dB, and instances of backchannelling, false starts and other salient background noises were removed in Praat. Moreover, the stimulus sentences were controlled along multiple speech dimensions (see Table 2). The mean duration of the excerpts was 2.8 seconds (SD = 0.6), with sentences containing on average 14.2 (SD = 1.6) syllables. The average speaking rate was 5.3 syllables per second (SD = 0.8), and signal-to-noise ratios in the audio recordings were on average 35.6 dB (SD = 5.0).Footnote 3 To account for contextual predictability effects, the same 20 English listeners who completed the accent verification test performed a cloze task for the target words in the stimulus sentences and a predictability judgment task in which they rated how predictable each target word is given the sentence context on an 11-point scale (−5 = very unpredictable; +5 = very predictable). The proportion of words matching the target word in the cloze task was 0.04 (SD = 0.19), and the average predictability score was 1.89 (SD = 1.46), demonstrating that the target words could not be readily identified despite being contextually predictable. Multiple one-way ANOVAs and post-hoc comparisons using t-tests with Bonferroni correction confirmed that the speech dimensions of the transcription sentences did not differ significantly across accents (General British, Newcastle and French) and reduction conditions (unreduced and reduced).
Properties of the speech excerpts used for the orthographic transcription task by reduction condition and speaker accent (BrEng = General British English; NewEng = Newcastle English; FrEng = French-accented English)

2.1.4. Procedure
The web-based experiment was designed in PsychoJS (Peirce & MacAskill, Reference Peirce and MacAskill2018; Version 2023.1.2). Informed consent was obtained from the participants at the beginning of the experiment. Listeners were invited to test their audio using headphones and adjust the volume to a more comfortable listening level. Participants completed the experiment in a single session in a quiet room of their choice. Upon completion of the experiment, participants were compensated for their time.
In the first part of the experiment, participants completed a demographic and language background questionnaire. The second part was a transcription task, where participants were asked to write down 120 sentences produced by several speakers of English. Each audio excerpt was played only once, and participants were encouraged to write down as many words as possible. Multi-talker babble, containing the speech of four male and four female speakers of English, was added to the speech signal with a signal-to-noise ratio of +13 dB. A low level of masking noise was selected to avoid ceiling effects in the transcription task while keeping the participants engaged. Listeners first completed two practice trials to become familiarized with the procedure. These trials were produced by a male speaker with a General American English accent to avoid learning effects in the main task. Stimulus sentences were evenly divided into five experimental blocks and were randomized within and across blocks, with the restriction that no more than two consecutive sentences were produced by the same speaker. After each block, participants could take a self-paced break. In the final part of the experiment, participants completed the LexTALE test, which provided a measure of vocabulary knowledge and general language proficiency in English.
2.1.5. Analysis
Transcription accuracy was measured as the number of correctly transcribed target words, which we interpreted as a proxy for intelligibility. All target words were manually coded as either correct or incorrect. Transcription errors that could clearly be identified as spelling mistakes (*priviledge for privilege) were considered correct. The morphological addition or omission of plural (gardener for gardeners) or past tense affixes (pressurized for pressurize) was also coded as correct. Derivational forms (social for socialize), semantically related words (run or led for governed) or transcriptions lacking a graphemic representation of the deleted schwa-sound (*boundry for boundary) were coded as incorrect.
To assess to what extent phonetic reduction in spoken English affects intelligibility, we built a generalized linear mixed-effects model in R (R Core Team, 2023; Version 4.3.1) using lme4 (Bates et al., Reference Bates, Maechler, Bolker and Walker2015), with transcription accuracy (correct versus incorrect transcription) as the outcome variable (see Verbeke et al., Reference Verbeke, Mitterer and Simon2025). Fixed factors were listener group (English, Dutch and Spanish), speaker accent (General British, Newcastle and French) and reduction condition (reduced and unreduced target word). The three levels of Listener group were contrast coded with two independent contrasts, the first of which compared between L1 and L2 listeners (contrast weights: 0.66, −0.33 and −0.33, for English, Dutch and Spanish listeners). The second contrast compared Dutch and Spanish listeners (contrast weights: 0, 0.5 and −0.5, for English, Dutch and Spanish listeners). Here and for the other contrasts, we set the contrast weights so that the expected main effect should be positive (e.g., English listeners are expected to transcribe more items correctly than L2 listeners). The three-level factor Accent was also contrast coded with two independent contrasts to compare the difference in transcription accuracy between L1 (acrolectal, regional) and L2 (non-native) speaker accents (contrast weights: 0.33, 0.33 and −0.66, for General British, Newcastle and French-accented English) and a General British versus Newcastle accent (0.5, −0.5 and 0, with French-accented English set to zero). Reduction condition was contrast coded such that positive beta values were associated with unreduced target words (0.5) and negative values with reduced target words (−0.5). The potential effect of language proficiency (LexTALE scores), which was residualized to account for its correlation with listeners’ L1, and participants’ self-reported familiarity with the accents (score 1–7) was also tested. The model was fit with the maximal random effect structure, which included random intercepts and slopes for participants by speaker accent and for items by listener group.
2.2 Results
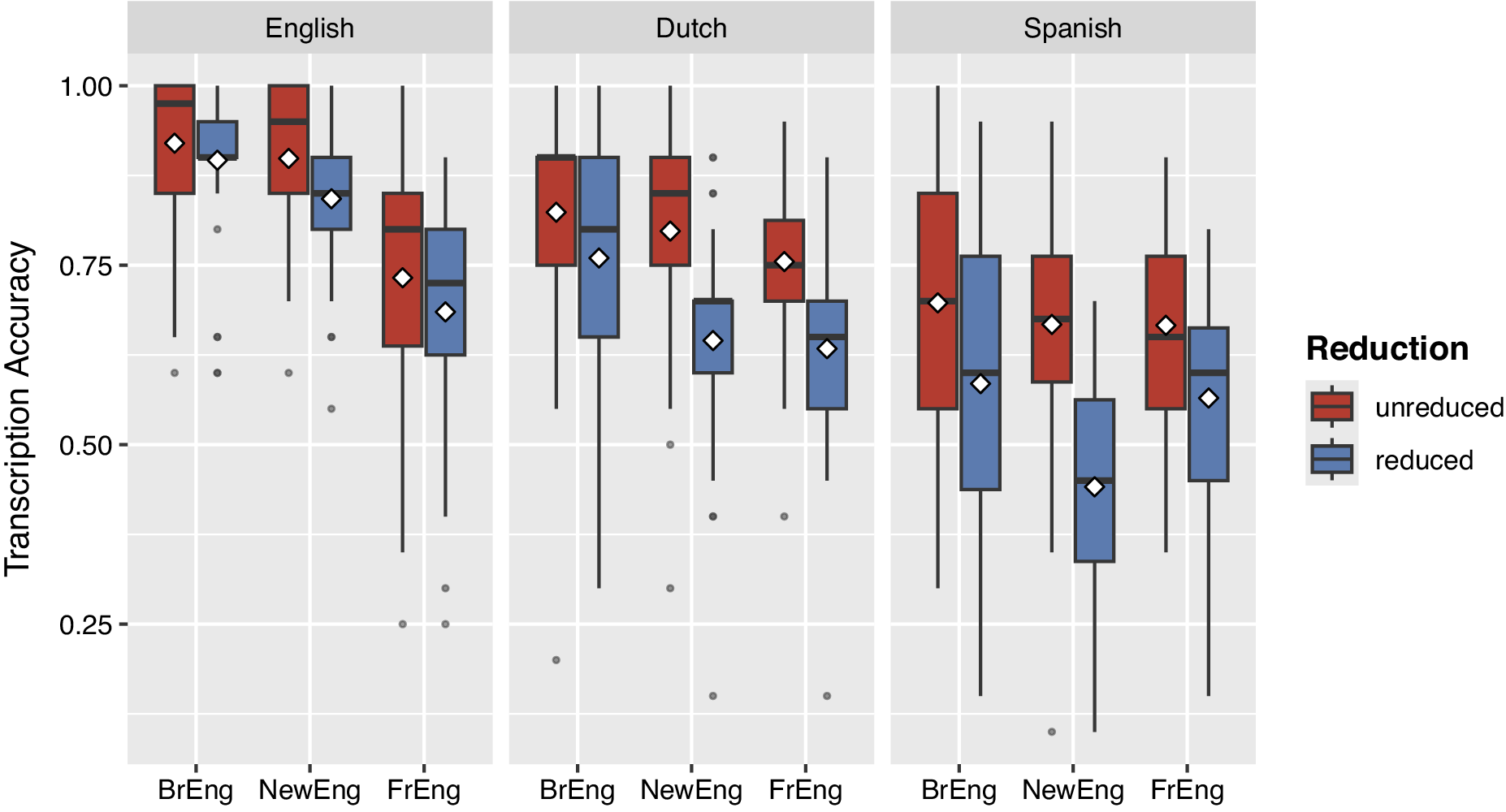
Figure 2 summarizes the proportion of correctly transcribed target words across the three listener groups. Overall, L1 English listeners outperformed both groups of L2 listeners (M = 0.83, SD = 0.38), with the L1 Dutch participants (M = 0.74, SD = 0.44), achieving higher transcription accuracy than the L1 Spanish participants (M = 0.60, SD = 0.49). In other words, the number of correctly transcribed target words varies as a function of listeners’ language background. Figure 2 also visualizes participants’ transcription accuracy across the reduction conditions and speaker accents. An inspection of the group means clearly shows that unreduced target words were transcribed more accurately than reduced target words. The overall mean difference in accuracy is, however, negligible for the L1 English listeners (0.85–0.81 = 0.04). The difference between unreduced and reduced target words is noticeably more pronounced for the L1 Spanish listeners (0.68–0.53 = 0.15), while the scores of the L1 Dutch group (0.79–0.68 = 0.11) fall in between those of the British and Spanish participants. The observed intelligibility advantage for unreduced forms generally holds across speaker groups, but listener groups, as well as the individual listeners within each group, differ in how many target words they transcribed correctly when listening to English speakers with a General British, Newcastle or French accent. Interestingly, between-group differences in transcription accuracy become smaller when listeners are exposed to the stimulus sentences produced by the French speakers: the mean transcription accuracy for French-accented English was 70.9% for the English-speaking listeners, 69.4% for the Dutch-speaking and 61.6% for the Spanish-speaking listeners.
Transcription accuracy, visualized as the proportion of correctly transcribed target words, across the three listener groups, further split up by speaker accents and reduction conditions. The diamonds in the boxplots represent group means and the error bars represent the standard error of by-participant mean values.

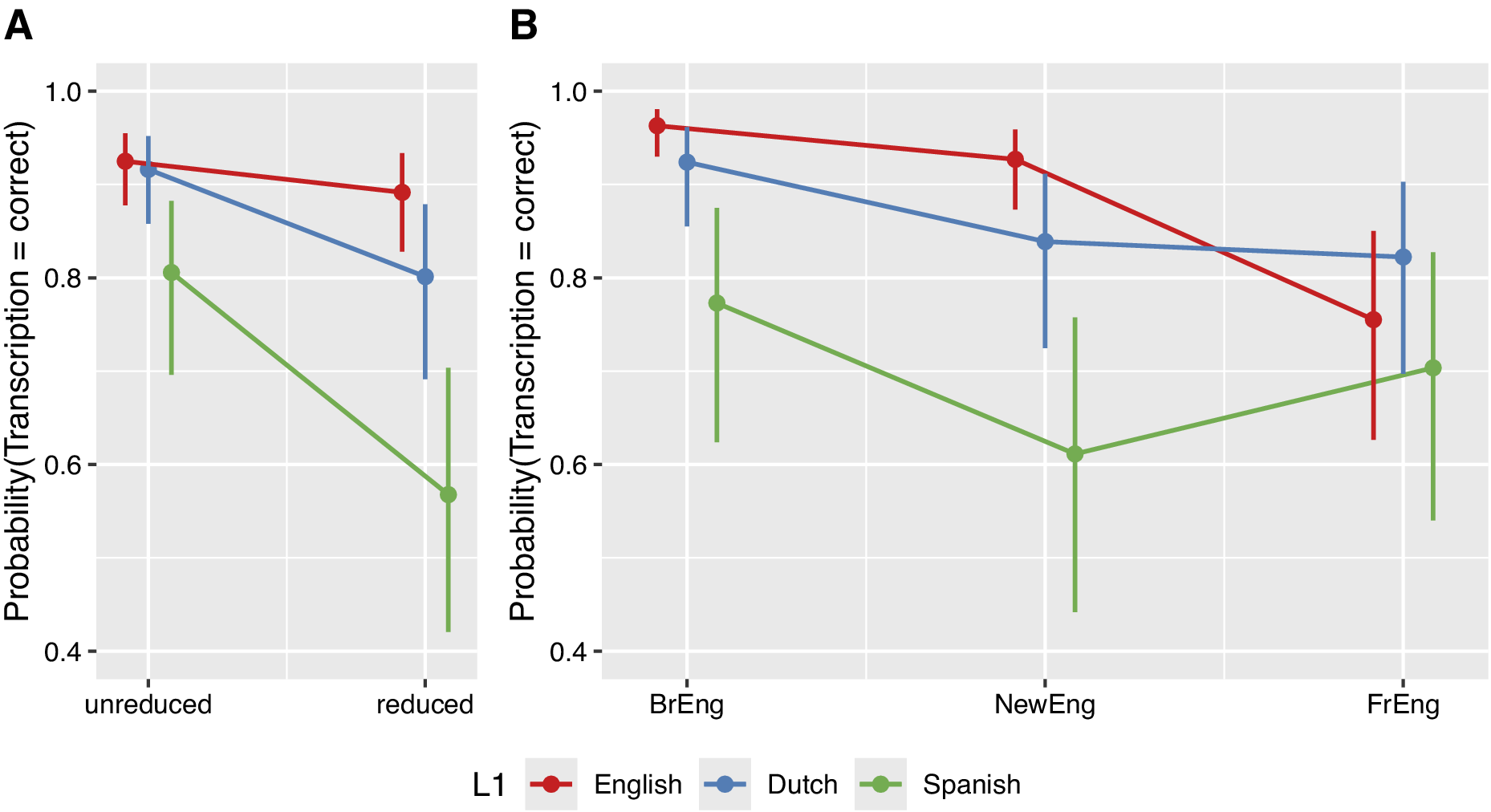
These observations were tested with a generalized linear mixed-effects model, with participants’ transcription accuracy of the target words as the dependent variable. Systematic model comparisons (i.e., non-significant three-way interactions were simplified to multiple two-way interactions and pruned when non-significant), based on likelihood-ratio tests and Akaike’s information criterion, showed that a model with two-way interactions between listener groups and reduction conditions and between listener groups and speaker accents was best-fitting. Self-reported Familiarity with the accents was not a significant predictor of accuracy and was removed from the model (χ2(3) = 5.41, p = 0.14). The results of the regression analysis are summarized in Table 3. Transcription accuracy was significantly different between listener groups, as L1 English listeners overall transcribed the target words better than the non-native listeners. Regarding the L2 listeners, the L1 Dutch group obtained significantly higher transcription scores than the L1 Spanish group. The main effect of language proficiency on transcription accuracy was also significant but independent of listeners’ L1 (i.e., no interaction effect between listener groups and proficiency). That is, irrespective of their L1 background, listeners with a higher level of proficiency in English, as indexed by their LexTALE scores, transcribed the target words more accurately. There was also a main effect of reduction condition, and the interaction effect between listener groups and phonetic reduction conditions shows that both groups of L2 listeners were more strongly affected by instances of phonetic reduction than the L1 listeners (Panel A in Figure 3), but no significant difference in the reduction effect could be established between the Dutch and Spanish listeners.
Generalized linear mixed-effects model output for transcription accuracy

Effect displays of the two-way interactions between listener group and reduction condition (Panel A) and listener group and speaker accent (Panel B).

Finally, we assessed the interaction effect of listener groups (L1 versus L2 and Dutch versus Spanish) and speaker accents (L1 versus L2 and General British versus Newcastle) on transcription task performance. The results show that speakers with a General British English or Newcastle accent were equally intelligible – equally after taking into account the main effect of listener group – to the L1 and L2 listeners. We then contrasted the transcription scores for the General British and Newcastle English speakers with those for the French speakers, further split up by participants’ L1 background. This comparison revealed that the L1 English listeners have a larger intelligibility benefit for speakers with General British and Newcastle accents relative to the Dutch-speaking and Spanish-speaking listeners, but they are much more troubled by the French accent compared to the two groups of L2 listeners. The L1 Dutch participants’ transcriptions are also generally more accurate than those of the Spanish participants, but Dutch-speaking listeners seem to be more strongly affected by a French accent than Spanish listeners. Phrased differently, French-accented English seems to ‘level the playing field,’ as the overall advantage of English and Dutch listeners is attenuated when they are transcribing the French-accented English stimuli (Panel B in Figure 3).
2.3. Discussion
The results of Experiment 1 showed, as expected, that transcription accuracy differed by listener groups and reduction conditions. Overall, L1 English listeners performed better in the transcription task than L1 Dutch and L1 Spanish listeners, and they transcribed the reduced target words more accurately than the two groups of L2 listeners. These findings support earlier research, suggesting that native listeners are better able to recognize reduced word forms in casual speech than non-native listeners (Brand & Ernestus, Reference Brand and Ernestus2018; Ernestus et al., Reference Ernestus, Dikmans and Giezenaar2017a). Interestingly, only the interaction of reduction by L1 versus L2 listeners reached significance. The effect of phonetic reduction on intelligibility was similar for the Dutch-speaking and Spanish-speaking listeners, despite the presence of (strong) phonetic vowel reduction processes in Dutch.
Speaker accents also influenced listeners’ transcription accuracy of the target words, but again no interaction effect with phonetic reduction was observed. In other words, there was no evidence for an over-additive effect of phonetic reduction and accent variation on intelligibility, at least based on the current transcription data. Listeners’ transcription scores did, however, vary as a function of speakers’ language backgrounds in that L1 English speakers (speakers with a General British English or Newcastle accent) were overall more intelligible than L1 French speakers. This finding corroborates previous research, which demonstrated that intelligibility is usually higher, and processing demands are lower, when listeners are exposed to speakers with a familiar native accent – be it non-regionally or regionally colored – relative to speakers with an unfamiliar non-native accent (Kang & Moran, Reference Kang, Moran, Gary and Wagner2018; but see Hansen Edwards et al., Reference Hansen Edwards, Zampini and Cunningham2018; Verbeke & Simon, Reference Verbeke and Simon2023). Despite the observed intelligibility benefit of native English speakers for L1 English and L1 Dutch listeners relative to L1 Spanish listeners, the between-group differences in transcription accuracy became more level for French-accented English. This, by itself, is a remarkable finding because additional difficulties, such as noise masking or unfamiliar speaker accents, usually tend to increase between-group differences rather than attenuate them (Adank et al., Reference Adank, Evans, Stuart-Smith and Scott2009; Garcia Lecumberri & Cooke, Reference Garcia Lecumberri and Cooke2006).
The fact that Spanish listeners were noticeably less hindered by French accents in English seems to suggest that the shared Romance language background between French speakers and Spanish listeners, and particularly the shared rhythm timing, may have led to a cross-linguistic facilitation effect for speech processing. While English and Dutch listeners use stress-rhythm segmentation strategies to deal with casual speech in their native language (e.g., lexical stress tends to fall on a word’s first syllable; Cutler & Norris, Reference Cutler and Norris1988), syllable stress might be a less informative acoustic cue for Spanish listeners to successfully parse the speech signal, given that these listeners typically rely on syllable-based segmentation procedures (Cutler et al., Reference Cutler, Mehler, Norris and Segui1986). Moreover, the French speakers in the excerpts may have adopted the language rhythm of their L1 when speaking English. Post-hoc auditory-acoustic analyses revealed that some words in the stimulus sentences were produced without reduced segments (e.g., comfortable /ˈkʌmf.tə.bəl/ as [ˌkʌm.fɔːrˈteɪ.bəl]), and some prepositions were produced in their unreduced form (e.g., part of the blame /pɑː(r)t ə ðə bləɪm/ realized as [pɑːrt ɒv ðə bleɪm]). Under this view, the syllable-rhythm accent of the French speakers may have had a relatively smaller impact on the Spanish listeners than the stress-rhythm accent of the English speakers.
This last point brings us to the role of the surrounding linguistic context in speech segmentation and word recognition. Recall that target words were embedded in sentences taken from authentic interviews and talk shows. Inevitably, listeners can rely on the semantic information in the sentences to retrieve the identity of reduced pronunciation variants (Bradlow & Alexander, Reference Bradlow and Alexander2007; Ernestus et al., Reference Ernestus, Baayen and Schreuder2002). Furthermore, word segmentation, a task influenced by speech rate and rhythm, is likely to impact on the likelihood of transcribing the target word correctly. The transcription task results thus inform us about whether listeners understood the speaker’s intended message and recognized the target words. They do, however, not provide insights into the time course of spoken word recognition, which could reveal differences in lexical activation between Dutch-speaking and Spanish-speaking listeners. Given the discrepancy in the overall transcription accuracy of the two groups, we will explore the time course of recognizing pronunciation variants in Experiment 2.
3. Experiment 2
Experiment 2 examines how readily Dutch-speaking and Spanish-speaking listeners accept and how quickly they recognize phonetically unreduced and reduced words when these are presented in isolation during an auditory lexical decision task.
3.1. Methodology
3.1.1. Speakers
Speakers were the same as in Experiment 1.
3.1.2. Listeners
40 monolingual Belgian Dutch and 40 European Spanish L2 learners of English who did not participate in Experiment 1 were recruited from the same population. 40 participants identified as female (50%), 38 as male (47.5%) and 2 did not identify with either gender (2.5%). Participants were on average 22.9 years old (SD = 1.7; range = 18–25), and 53 of them (66.3%) were students in tertiary education at the time of testing. The L1 Dutch participants started learning English when they were 12.6 years old (SD = 1.8), and the L1 Spanish participants when they were 6.4 years old (SD = 2.1). Dutch-speaking participants scored on average 84.8 (SD = 8.3, range = 65–100) on the LexTALE test; Spanish-speaking participants obtained a mean LexTALE score of 83.6 (SD = 7.4; range = 68.8–95).
3.1.3. Materials
Stimuli were 120 English words and 84 English nonwords. The real words were the phonetically unreduced and reduced target words, excised from the stimulus sentences used in Experiment 1. The phonotactically legal nonwords (7 per speaker) were digitally generated by concatenating the first part of a real English word and the second part of another real word. For example, the nonword submantic (*/səbˈmæn.tɪk/) was created from submerge /səbˈmɜːdʒ/ and romantic /rəˈmæn.tɪk/). Syllables were spliced at positive-going zero crossings at the release phase of the plosive or in the mid-portion of the overlapping sound. The pitch of the two parts to be spliced together was closely matched to avoid auditory creaks or unnatural pitch contours. As the words used to create nonwords were produced in authentic casual speech and thus not in isolation, phrase-final lengthening effects were simulated in Praat to render the recordings more natural, given that speech sounds at the ends of linguistic units tend to be lengthened (Byrd & Choi, Reference Byrd, Choi, Fougeron, Kuhnert, d’Imperio and Vallee2010). This was done by applying a final lengthening factor to the last syllable and fade-in and fade-out transitions to avoid abrupt changes. Based on earlier studies that manipulated phrase-final lengthening (Mitterer et al., Reference Mitterer, Kim and Cho2021), we lengthened the final syllable by 75%.
3.1.4. Procedure
The procedure was similar to that of Experiment 1, except that the transcription task was replaced by a lexical decision task. Written on-screen instructions explained that listeners would hear words produced by several speakers of English. Their task was to decide whether that word was a real word (e.g., support) or a nonword in English (e.g., *littoir) by pressing the J- or F-key on their keyboard, respectively. Participants could only press a key after the audio had finished playing. They were continuously reminded of the response options and the corresponding keys, and they were encouraged to respond as quickly as possible, without neglecting the accuracy of their response. Participants first completed three practice trials with feedback to become familiarized with the testing procedure. Shortly after, the main experiment started, in which participants no longer received feedback. A total of 204 test items (60 unreduced target words + 60 reduced target words + 84 nonwords) were divided into five experimental blocks and randomized across participants and blocks, with the restriction that no more than two trials of the same speaker and item type could follow each other. After every block, participants could take a self-paced break. Participants completed the experiment in one session in a quiet room of their choice while wearing headphones. Upon completion of the experiment, they were compensated for their time.
3.1.5. Analysis
Participants’ lexical decision performance, as measured by word endorsement (accepting a trial as a real word), was analyzed with a generalized mixed-effects regression. A second mixed-effects regression model was built with participants’ log-transformed response times as the outcome variable. Both models included three fixed factors: Listener group (Dutch and Spanish), speaker accent (General British, Newcastle and French) and reduction condition (unreduced and reduced target word). The variable Listener group was contrast coded such that positive beta values were associated with Dutch listeners’ (0.5) and negative values with Spanish listeners’ task performance (−0.5). The three levels of the variable Accent were contrast coded with two independent contrasts: the first contrast compared the difference in word endorsement and response latency for L1 (acrolectal and regional) and L2 (non-native) accents (contrast weights: 0.33, 0.33 and −0.66, for General British, Newcastle and French-accented English), and the second contrast was for a General British versus Newcastle accent (0.5, −0.5 and 0 with French-accented English set to zero). Reduction condition was contrast coded to compare phonetically unreduced (0.5) and reduced target words (−0.5). The potential effect of language proficiency (LexTALE scores), accent familiarity (scores 1–7), lexical frequency (Zipf values) and the log-transformed duration of the target words was also tested. The maximal random effects structure that would converge was implemented, with random intercepts and slopes specified for items by listener groups and participants by speaker accents.
3.2. Results
3.2.1. Word endorsement
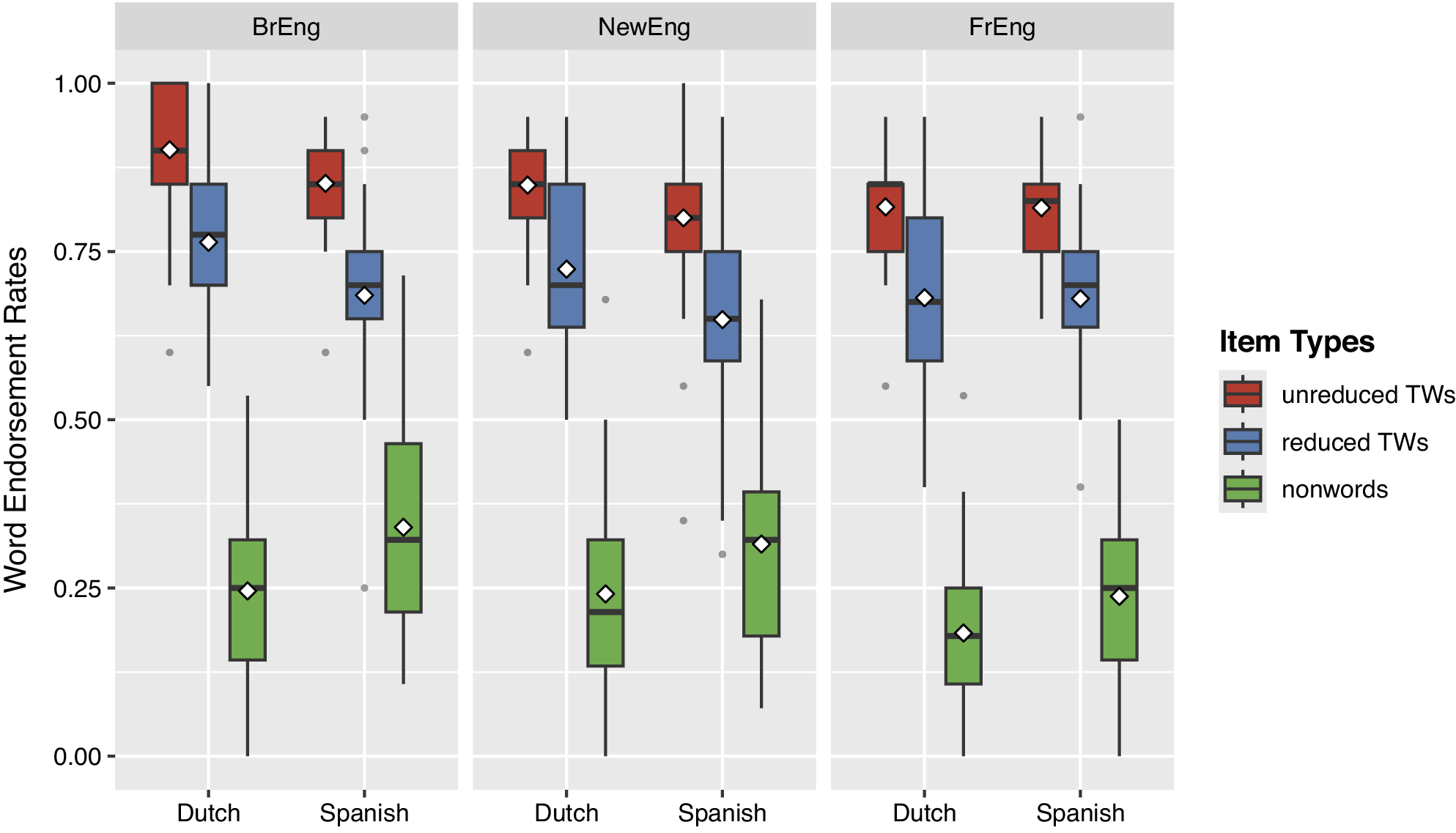
In Figure 4, word endorsement rates for each item type (unreduced target words, reduced target words and nonwords) are plotted against listener groups (Dutch and Spanish) and speaker accents (General British, Newcastle and French). For the real-word targets, higher endorsement rates indicate that participants recognized these items as real English words, while higher scores for the nonwords indicate that participants erroneously accepted the items as real words, despite them being nonwords in English. Generalizing over speaker accents, we can see that most unreduced target words were accurately identified as real English words. Reduction led to slightly lower word endorsements, and Spanish listeners were also less likely to endorse the existing words as such; these effects seem roughly additive in Figure 4. Nonwords were rejected in approximately 75% of cases, which means that in about 25% of the cases, nonwords were mistakenly perceived as real English words. The absence of ceiling effects highlights that the nonwords closely resembled real English words and could not straightforwardly be identified as nonwords, indicating that participants were making genuine lexical decisions based on their vocabulary knowledge.
Word endorsement rates, visualized as the proportion of ‘word’-responses, across the three speaker accents, further split up by listeners groups and item types. The diamonds in the boxplots represent group means and the error bars represent the standard error of by-participant mean values.

Two separate generalized mixed-effects regression models were used to assess the word endorsement rates of nonwords and target words. Again, participants’ self-reported familiarity with the accents did not significantly improve model fit and was removed from all subsequent models. For the nonwords, there was a significant main effect of listener group, proficiency and speaker accent (see Table 4). Spanish listeners accepted significantly more nonwords as real English words than Dutch listeners. Correctly rejecting nonwords was also found to depend on participants’ level of proficiency, since participants with lower LexTALE scores accepted more nonwords as real words. Further, nonwords produced by speakers with a General British English or Newcastle accent received significantly more ‘word’-responses than nonwords produced by speakers with a French accent. The interaction between listener group and speaker accent did not reach significance. That is, Dutch and Spanish participants’ endorsement rates for the nonwords were similar across accents. For the target words, there was no significant between-group difference in word endorsement, but the analysis revealed a main effect of phonetic reduction (see Table 4). Unreduced target words were accepted significantly more often as words than reduced target words. The only interaction that reached significance was between listener groups and L1-L2 speaker accents: Dutch-speaking participants categorized target words produced by L1 English speakers more often as ‘words’ than those produced by L1 French speakers compared to the Spanish-speaking participants. In other words, while Spanish listeners’ lexical decision behavior for the target words was fairly similar across the different groups of speakers, Dutch listeners endorsed more target words as real words when they were produced by speakers with a General British English or Newcastle accent.
Generalized linear mixed-effects model output for endorsement rates of the nonwords and the target words

3.2.2. Reaction times
We also analyzed the effect of phonetic reduction on participants’ reaction times. Lexical decision responses for two reduced target words (choruses and police) were removed from the dataset, as the reduced forms closely resemble real English words (courses and please). Although deleted segments often leave acoustic traces in the speech signal that listeners can detect, endorsing these target words does not allow us to determine whether participants perceived the reduced form or the competitor as a real English word. Additionally, trials where reduced or unreduced target words were incorrectly identified as nonwords were removed from the dataset (2209 trials). Single lexical decision responses were also removed if participants’ response latency was shorter than 150 ms or longer than 3000 ms (140 trials) or when responses had large residuals (10 trials). The number of observations left for reaction time analysis was 7081 (75% of the data).
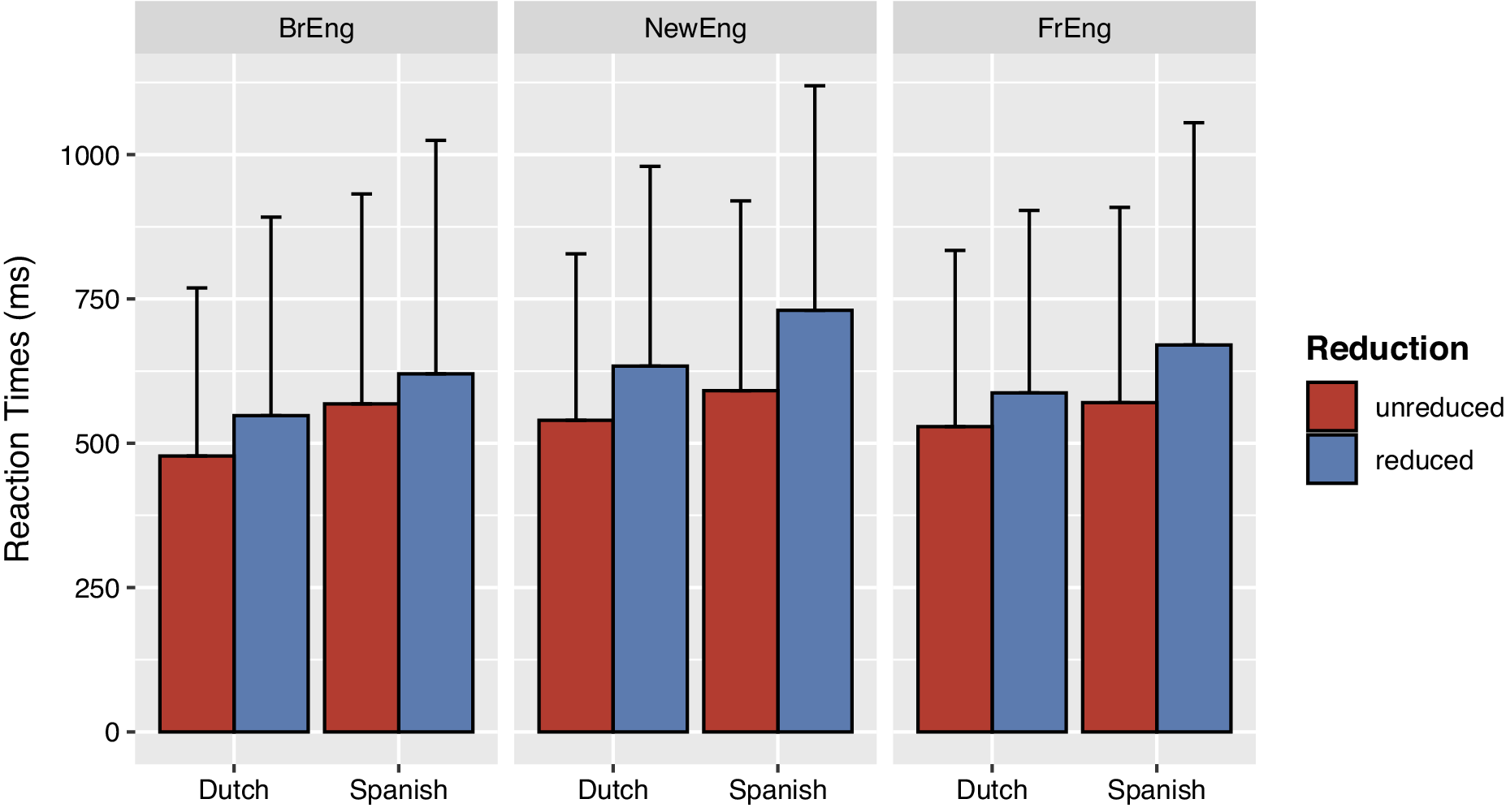
As visualized in Figure 5, response times were longer when participants heard reduced words (M = 628.1 ms, SD = 367.9) compared to unreduced words (M = 545.2 ms, SD = 321.9). Reaction times also differed between listener groups: Dutch-speaking participants responded on average 109.4 ms faster than Spanish-speaking participants (MDutch = 548.8 ms, SD = 317.5; MSpanish = 618.3 ms, SD = 370.1). This between-group difference in response times holds across reduction conditions and speaker accents. We also see that target words produced by speakers with a General British English accent (M = 549.6 ms, SD = 353.4) were recognized faster than those produced by speakers with a French accent (M = 585.8 ms, SD = 339.9). Reaction times for the words produced by the Newcastle speakers were longer than those for the other two speaker groups (M = 614.4 ms, SD = 340.7).
Mean response times (ms) for the reduced and unreduced target words by listener group and speaker accent. Error bars represent the standard error of the mean.

Participants’ log-transformed response times were further analyzed using a linear mixed-effects model (see Table 5). The main effect of listener group on response latency was significant. Spanish-speaking participants took significantly more time to identify the target words as existing English words than Dutch-speaking participants. There was also a significant main effect of phonetic reduction: participants responded more slowly to reduced target words than to unreduced target words. Despite the trend in Figure 5, which hints at a between-group difference in reaction times, there was no significant interaction between listener group and reduction condition. This indicates that the effect of phonetic reduction on the time course of spoken word recognition for the L1 Dutch listeners was comparable to that of the L1 Spanish listeners. Speaker accents did not impact participants’ response times, and no interactions with the other fixed effects could be established. The absence of an interaction effect indicates that phonetic reduction slows down listeners similarly, regardless of whether reduced forms occur in native or non-native English speech. Rather than the presence of phonetic reduction, the word frequency and the log-transformed duration of the target words appeared to play a more crucial role in lexical decision-making. As shown in Table 5, target words with higher lexical frequencies or longer pronunciation durations were identified more quickly as real English words relative to lower frequency target words or words with shorter durations. The effect of target word characteristics on word recognition is further discussed below.
Linear mixed-effects model output for participants’ log-transformed reaction times

3.3. Discussion
Experiment 2 explored the influence of phonetic reduction on the temporal dynamics of spoken word recognition. Results of the lexical decision task showed that reaction times were consistently longer for phonetically reduced words relative to unreduced words. Participants needed more time to recognize, for instance, the reduced form of library [ˈlaɪ.bri] compared to the unreduced form of misery [ˈmɪ.zə.ri]. This delay was observed regardless of whether speakers had an acrolectal, regional or non-native accent in English. These findings suggest that mapping reduced pronunciation variants onto entries in the mental lexicon requires more time than mapping unreduced variants, irrespective of the type of speaker accent. Contrary to our hypothesis, there was no differential effect of phonetic reduction on word recognition across listener groups; Dutch and Spanish participants were slowed down similarly during trials with reduced words. Thus, the presence of similar reduction processes in listeners’ L1 does not necessarily speed up the recognition of phonetically reduced variants in their L2, which corroborates the findings of Experiment 1.
Target word characteristics, particularly pronunciation duration and lemma frequency, were found to robustly predict the speed of lexical activation, more so than listeners’ language background or the reduction condition of the item. Participants recognized target words with shorter durations less effectively than target words with longer durations. Words with higher frequency of occurrence were also processed more quickly than lower frequency words. However, lexical frequency alone cannot account for the differences in reaction times, as both suppose (Zipf: 5.02) and national (Zipf: 5.02) have higher frequencies than arrogant (Zipf: 3.64) or bravery (Zipf: 3.84) in the SUBTLEX-UK database (van Heuven et al., Reference van Heuven, Mandera, Keuleers and Brysbaert2014), but were processed more slowly. It is in this context relevant to point out that some reaction time data point toward a cognate facilitation effect. For instance, arrogant has cognates (i.e., etymologically related words sharing form and meaning across languages) in both Dutch and Spanish. Such words are typically recognized faster than non-cognate words in lexical decision tasks, as cognates are stored in the lexicons of both languages (see Muylle et al., Reference Muylle, Van Assche and Hartsuiker2022). Nevertheless, a cognate facilitation effect cannot always be observed. In fact, the longest reaction times were observed for particular target words with cognates in Dutch (e.g., English: capable, Dutch: capabel) and Spanish (e.g., English: suppose, Spanish: suponer), or in both languages (e.g., English: national, Dutch: nationaal, Spanish: nacional). These observations underscore the complex interplay between listeners’ language backgrounds and individual word characteristics during speech processing.
4. General discussion
This study set out to investigate how phonetic reduction affects intelligibility for listeners with different language backgrounds. Specifically, we wanted to examine to what extent the presence of vowel reduction processes in listeners’ first language facilitates the recognition of phonetically reduced pronunciation variants in spontaneous L2 speech. The results of the transcription task in Experiment 1 support previous research, in that L1 listeners’ overall transcription performance was better than that of L2 listeners, and unreduced word forms were recognized more accurately than reduced word forms (cf. RQ1; Brand & Ernestus, Reference Brand and Ernestus2018; Bürki et al., Reference Bürki, Viebahn, Racine, Mabut and Spinelli2018; Ernestus et al., Reference Ernestus, Dikmans and Giezenaar2017a). As target words occurred in casual speech, rather than in laboratory-elicited read speech, the observed intelligibility benefit for unreduced target words suggests an advantage for phonetically unreduced pronunciation variants. This advantage is, however, negligible for L1 listeners of English, but proportionally larger for L2 listeners, since they are more burdened by reductions. The fact that non-native listeners are generally less often exposed to pronunciation variation in the target language and typically mobilize bottom-up and top-down information less easily and less accurately during L2 speech processing may explain why the effect of phonetic reduction on transcription accuracy is larger for L2 listeners.
Contrary to our prediction, this effect was independent of L2 listeners’ language background (cf. RQ2). As shown in Experiment 1, recognizing phonetically reduced or unreduced words in spontaneous speech was equally challenging for Dutch-speaking and Spanish-speaking listeners. This finding is at odds with earlier work, which demonstrated that casual speech processes that are similar in listeners’ L1 and L2 tend to benefit comprehension (Mitterer et al., Reference Mitterer, Yoneyama and Ernestus2008; Mitterer & Tuinman, Reference Mitterer and Tuinman2012). Since strong vowel reduction processes are operative in English and Dutch but lacking in Spanish, we hypothesized that Spanish participants would encounter more difficulties in transcribing phonetically reduced target words. Considering that participants could use the surrounding sentence context to disambiguate between lexical candidates, we ran a follow-up experiment to obtain deeper insights into the time course of recognizing reduced and unreduced variants in isolation. In Experiment 2, L1 Dutch and L1 Spanish listeners completed a lexical decision task. The results corroborated the findings of the transcription task: word endorsement rates were significantly lower and response latency was significantly longer for reduced target words, but once again, no differential effect of phonetic reduction between the listener groups could be detected. Cumulatively, offline intelligibility measures and online word recognition measures provide strong evidence against a facilitation effect in lexical access when phonetic reduction processes occur in both listeners’ first and second language.
One plausible explanation for this may be that in stress-rhythm languages like English, the stressed syllable’s perceptual weight is the main driver for word recognition, making the presence or absence of unstressed syllables of minor importance. As such, the consonants and vowels of prosodically stressed syllables are the phonetic essence that enables listeners to retrieve the identity of spoken words (Cole & Shattuck-Hufnagel, Reference Cole, Shattuck-Hufnagel, Clopper, Turnbull, Cangemi, Clayards, Niebuhr, Schuppler and Zellers2018; Niebuhr & Kohler, Reference Niebuhr and Kohler2011). Van de Ven and Ernestus (Reference Van de Ven and Ernestus2018) indeed demonstrated that for native listeners of Dutch, the absence of unstressed vowels in word-initial syllables hardly affects word recognition, and that the presence of such vowels might even lead to delays in processing. While no such delays were observed (i.e., there were no inhibitory effects associated with unreduced forms), our study does provide evidence for the prominent role of stressed syllables in lexical activation.
Finding no difference between the two groups of L2 listeners is also relevant for the question of whether reduced forms are recognized through lexical storage of pronunciation variants or pre-lexical restoration. A pre-lexical restoration account would predict that Dutch listeners should have an easier time acquiring such a pre-lexical strategy based on transfer from their L1 and consequently find it easier to recognize reduced forms. Hence, the absence of an interaction effect between listener groups and reduction conditions suggests that reduced forms are recognized by storing them as variants in the mental lexicon. It bears mentioning, however, that this argument does not necessarily extend to L1 listening. After all, the fact that the L1 listeners have a much smaller reduction cost in Experiment 1 may indicate that L1 listeners are able to use pre-lexical restoration.
Finally, pronunciation variants are not processed differently in the speech of speakers with an acrolectal accent than in the speech of speakers with a regional or non-native accent (cf. RQ3). Native English speakers, regardless of their accent, were generally easier to understand than non-native speakers of English. The observed intelligibility benefit for L1 English speakers was primarily evident among L1 English listeners and, to some extent, also L1 Dutch listeners, but it was less pronounced among L1 Spanish listeners. Spanish-speaking participants, by contrast, were noticeably less troubled by French-accented English speech than English-speaking and Dutch-speaking participants, which can potentially be explained by their shared (syllable-rhythm) Romance language background (Bent & Bradlow, Reference Bent and Bradlow2003; Xie & Fowler, Reference Xie and Fowler2013). These findings are independent of listeners’ familiarity with the accents, since self-reported frequency of exposure to General British, Newcastle and French-accented English was not a significant predictor of participants’ performance in both experiments. Similarly, the interaction between reduction conditions and speaker accents was not significant, suggesting that these variables do not compound over-additively.
While no between-group differences were observed for phonetic reduction effects, L1 Dutch listeners achieved overall higher transcription scores and recognized target words faster than L1 Spanish listeners. They also endorsed more target words and fewer nonwords as real English words than the Spanish participants in the lexical decision task. This disparity in performance is surprising, given that language proficiency was controlled for using the LexTALE vocabulary test. Although we have no direct indication of participants’ listening skills, neither through self-report nor test performance, L2 learners’ vocabulary knowledge has been found to correlate with listening comprehension (Noreillie et al., Reference Noreillie, Kestemont, Heylen, Desmet and Peters2018). Moreover, Spanish participants reported that they started learning English in a classroom context considerably earlier in life than the Dutch-speaking participants. Although proficiency and age of onset of acquisition are predictive of L2 speech perception, the frequency of exposure to casual English speech differs in Spain and Flanders, the Dutch-speaking part of Belgium. In Spain, dubbing films, series and interviews with English speakers into Spanish has traditionally been the dominant practice, while subtitling is the most common practice in Flanders. L1 Dutch listeners are expected to be more familiar with pronunciation variants from both their first and second language, and as a consequence have an intelligibility benefit over L1 Spanish listeners, although no such benefit was observed. Note that participants had at least a B2 level of proficiency in English. Being an upper-intermediate or advanced learner of English may potentially overrule the processing advantage associated with shared or similar speech phenomena in one’s L1 and L2 (see Mukai, Reference Mukai2020). Follow-up studies could further explore if phonetic reduction effects on word recognition, which were not found in this study, are more likely to emerge between groups of L2 learners with different levels of proficiency.
5. Conclusion
In two experiments, we examined to what extent phonetically reduced words in native and non-native English accents affect intelligibility and spoken word recognition for L1 and L2 listeners. The results of a transcription task and a lexical decision task revealed that unreduced words are recognized more accurately and more quickly than reduced words, and that the effect of phonetic reduction on word recognition is larger for L2 listeners compared to L1 listeners. The results also showed that processing reduced pronunciation variants in casual speech is not facilitated when phonetic reduction processes in the target language are similar to those in listeners’ first language. Furthermore, recognition of reduced and unreduced words is similar in native and non-native accents of English, suggesting that there is no over-additive effect of phonetic reduction and speaker accents on comprehension. To conclude, this study provides valuable insights into how phonetic reduction impacts spoken word recognition and highlights the complex interaction between casual speech processes, word characteristics, and speaker accents in L2 listening. With this study, we hope to pave the way for future studies to delve deeper into these issues, which can enhance our understanding of why native and non-native listeners perceive and comprehend casual speech differently.
Data availability statement
Data and data analysis are shared in The Tromsø Repository of Language and Linguistics (TROLLing) and are available at https://doi.org/10.18710/OHP3O3 (Verbeke et al., Reference Verbeke, Mitterer and Simon2025).
Acknowledgements
The authors would like to thank the editors and the three anonymous reviewers for their valuable comments on previous versions of this paper. This work was supported by the Research Foundation Flanders (FWO) (grant number: 1178623N) awarded to the first author.
Ethics statement
The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008.






 Open access
Open access