


Artificial intelligence (AI) is poised to reshape the world around us. Original material ranging from audio to visual and textual content may be created in the likeness of human-made recordings, paintings, or writing. Artificially intelligent analyses promise to process and make sense of the surrounding world in new and more effective ways. Scholars from disciplines spanning the hard and social sciences are investing time and resources to understand how diverse tasks from pedagogy to art and surgery will be facilitated or reimagined.
Although AI may revolutionize contemporary visions of medicine, art, and aesthetics, its application also promises to reinscribe standing power structures by replicating pervasive inequalities and stereotypes. Racial, gender-based, and regional biases threaten being baked into emergent programs (Fang et al. Reference Fang, Che, Mao, Zhang, Zhao and Zhao2024; Roselli et al. Reference Roselli, Matthews and Talagala2019). Trained on weird datasets by weird researchers (sensu Heinrich et al. Reference Henrich, Heine and Norenzayan2010), applications of the technology will further entrench dominant social biases that influence patients’ healthcare (Alowais et al. Reference Alowais, Alghamdi, Alsuhebany, Alqahtani, Alshaya, Almohareb and Aldairem2023), the way students are taught (Williamson Reference Williamson2024), and how diverse cultures are written about and seen. Even if the use of AI is rife with opportunity, problems that await on the horizon are equally ubiquitous and should command attention from software developers, academics, and legislators alike.
How do the rewards and risks of these technologies reverberate across anthropology and archaeology? Technological transformations will affect not only contemporary social worlds but also the way we represent, reflect, and engage with the past. Like the broader context in which our field is adopting AI, the benefits and drawbacks of the technology should be carefully evaluated. On the one hand, AI will increase the accessibility of representing archaeological material, and those who lack specialized skills in illustration or writing will be able to easily imagine alternative pasts (see Magnani and Clindaniel Reference Magnani and Clindaniel2023). On the other hand, these narrations of the record may reinforce stereotyped depictions based on either antiquated or misguided content. Representing the past will become more accessible to a broader cross section of society but at the risk of proliferating misinformation.
Archaeologists must evaluate these implications to proactively shape the foundations of our engagement with this new technology. This article uses generative AI (the subset of artificial intelligence focused on producing novel output) to create large samples of text and images of archaeological scenes and compares them to a larger corpus of archaeological knowledge derived from published journal articles using a multimodal encoding approach. We specifically examine a well-established literature on Homo neanderthalensis, a species whose depiction has changed significantly since the founding of our discipline (Nowell Reference Nowell2023). Building on our earlier work that addressed workflows for archaeological illustration using DALL-E 2 (see Magnani and Clindaniel Reference Magnani and Clindaniel2023), this article uses computational approaches to text and images to systematically address the overlap between content generated using AI and histories of anthropological archaeological knowledge.
Bias and Ethics in Artificial Intelligence
Generative AI platforms are trained using vast digital repositories of images and text. Because of this broad input, the resulting content reflects not only dominant and majority ideologies but also biases widespread across society. Concerns about gendered and racialized AI output has received significant scholarly attention (Nazer et al. Reference Nazer, Healy and Astels2023; O’Conner and Liu Reference O’Connor and Liu2023). In addition to the problem of implicit bias, groups of individuals are actively trying to circumvent the limitations imposed by AI developers to generate violent, pornographic, or racist content. On major platforms like ChatGPT or DALL-E, developers have built in safeguards to limit the types of images and texts that might be generated. For instance, restricted text content includes political discussions, and filters and user agreements are designed to prevent prompts that generate bigoted or graphic material (OpenAI Usage Policies). In other cases, there has been criticism of corporate overcorrection, which has yielded historically inaccurate visual depictions (see Google Communications 2024). Such problems have attracted the attention of state legislators and Congress in the United States, as well as politicians globally. In Europe, for example, more sweeping legislation like the EU AI act seeks to establish risk profiles for the development and application of AI (Pehlivan Reference Pehlivan2024).
Although some of the more severe cases of bias in AI-generated content pertaining to political orientation, racism, or sexism have begun to be addressed, other types of social biases are equally pervasive but less attention-grabbing. While programmers and companies are quicker to remedy clearly gendered or racist depictions, other widespread misconceptions diffused throughout society risk blind reproduction, tinting our perceptions based on outdated science or ideologies. Artificially intelligent depictions of the past may escape the immediate attention of moderators, but they have broad social implications for contemporary communities around the world. We follow the example of archaeologists like Huggett (Reference Huggett2015) who have argued for taking a proactive, “introspective” stance to unpack the influence of digital technologies on our field.
Archaeology and Artificial Intelligence
Studies using AI in archaeology predate the recent boom in widely accessible commercial AI tools. Based on human-trained models, archaeologists regularly identify sites and artifactual scatters from satellite and drone-derived imagery using techniques including object-based image analysis. These applications have roots that span back over two decades (Davis Reference Davis2019). Such studies have been successful in identifying a range of archaeological subjects from large archaeological sites to rock art (Horn et al. Reference Horn, Ivarsson, Linhé, Potter, Green and Ling2022), artifact scatters, and stratigraphy (Mesanza-Moraza et al. Reference Mesanza-Moraza, García-Gómez and Azkarate2020). Machine-learning tools have sped up the process of human identification of sites and the analysis of features (Camara et al. Reference Câmara, de Almeida, Caçador and Oliverira2023) and locations where looting has taken place (Altaweel et al. Reference Altaweel, Khelifi and Shana’ah2024).
Based on longer-term patterns of machine learning, a rapid expansion in AI archaeology occurred in 2022 following the release of commercially available programs. Dirk Spennemenn has contributed significantly to this literature, addressing the impacts of accessible AI on broader issues ranging from the cultural heritage of COVID (Spennemenn Reference Spennemann2023a) to a critical evaluation of ChatGPT source material (likely Wikipedia) and errata (Spennemen Reference Spennemann2023b). Additional noteworthy work considers the impacts of artificial historical representations on Indigenous communities themselves (Holguin Reference Holguin2023). More broadly, Peter Cobb (Reference Cobb2023) highlights several potential uses of AI for archaeologists—from education to illustration—that are only just beginning to be explored, establishing themes that we addressed in our study using AI for archaeological illustration (Magnani and Clindaniel Reference Magnani and Clindaniel2023). Most recently, Gabrielle Gattiglia (Reference Gattiglia2025) considers trends across an expanding body of applications while foregrounding conversations on the ethics of data transparency alongside the power of knowledge production and interpretation. Despite growing consideration by archaeologists, the impacts and potentials of broadly available AI tools for our field are only beginning to come into focus.
Artificial Intelligence and Its Convergence with Big Data
Along with the growing interest and investment in AI, humanity’s digital footprint expands with each passing year. Digital media once measured in bytes have ballooned in size trillions of times, and personal devices that store terabytes of data are becoming ubiquitous. Driven by commerce, our movements, purchases, and social exchanges are recorded with increasing frequency and precision. Tracing but also informing these broader technological trends, scholarly approaches to big data have emerged across the hard and social sciences. Armed with a tool kit developed by computer scientists with the capacity to parse terabytes of complex data, scholars are shedding light on human behavior at new scales.
Anthropologists and archaeologists have been quick to capture and analyze big datasets to explain relationships between people and things and between people and the past more broadly. Bonacchi and colleagues have conducted extensive analyses of social media posts on Facebook and Twitter, revealing complex perceptions of heritage as they relate not only to contemporary political events like Brexit but also to particular archaeological remains (Bonacchi and Krzyzanska Reference Bonacchi and Krzyzanska2021; Bonacchi et al. Reference Bonacchi, Altaweel and Krzyzanska2018). Considering material culture discarded on curbs across the United States, we examined the formation processes of data, analyzing how abandoned digital materials reflect patterns of human behavior (Clindaniel and Magnani Reference Clindaniel and Magnani2024). Scholars including Altaweel and Hadjitofi (Reference Altaweel and Hadjitofi2020) have conducted a close examination of popular vendor platforms like Ebay, analyzing the provenience of archaeological materials being sold on global markets. We also analyzed face mask production across the pandemic—scraping data from the craft makers’ website Etsy—and revealed how politics informed mask production and efficacy throughout the COVID-19 pandemic (Magnani et al. Reference Magnani, Clindaniel and Magnani2022). Similarly, recent research on the Inka khipu—the knot-and-cord recording system of the Indigenous Andes—has applied deep-learning strategies to explore semantic variation and genre across large-scale digital khipu datasets, offering new insights into the ways in which meaning was encoded and structured in the Andean past (Clindaniel Reference Clindaniel2025). Across these studies, authors have sought to examine age-old questions at scale using new digital media.
AI is poised to contribute growing quantities of data to the online material and social worlds of interest to archaeologists and anthropologists. Within a few years, it is possible that most online content will be generated using AI. The analytical tools that scholars have developed to approach big data will become crucial to understanding the social implications of this corpus.
Case Study
To examine the intersection between published archaeological knowledge and content created about the archaeological record using AI, we selected a case study supported by more than a century of academic inquiry and a robust historiography (Madison Reference Madison2021; Nowell Reference Nowell2023). Beginning with their scientific discovery in the nineteenth century in the Neander Valley in Germany, Neanderthals have captured the attention of archaeologists and the broader public. The first descriptions of Neanderthal skeletal remains in the 1860s painted a picture of a robust and primitive human-related species, with some cranial features more like those of chimpanzees than of Homo sapiens (King Reference King1864). By the end of the nineteenth century the image of “a crude prototype of our own species” gelled into the popular and academic imagination (Peeters and Zwart Reference Peeters and Zwart2020). Early twentieth-century dioramas at the Museum of Natural History in New York and Field Museum in Chicago reflect a persistence of this thinking decades later, representing hunched-over humanoids with simple clothing, familiar looking but clearly not of our own species.
By the 1950s and more recently, these brutish depictions were subject to increasing revision, and Neanderthal behavioral complexities figured prominently in scientific literature and the popular imagination. Neanderthal behavior remains a hotly contested subject in archaeology, with camps of opposing academics arguing for their behavioral sophistication or lack thereof. Using genetic data, lithics, and faunal analyses, a robust body of scholarship considers their patterns of kinship, use of medicinal plants, hunting strategies, and symbolic repertoires (for a summary of recent research developments in these subfields, see Nowell Reference Nowell2023). Innovative studies have suggested to what degree they produced fitted clothes (Collard et al. Reference Collard, Tarle, Sandgathe and Allan2016) or had control over fire (Dibble et al. Reference Dibble, Sandgathe, Goldberg, McPherron and Aldeias2018), and by extension, how similar they were to Homo sapiens behaviorally.
These robust but transformative histories of research spanning a century and a half, with deep bodies of literature, may be drawn on to structure artificially intelligent depictions of the species. To excavate the formation processes of AI depictions of the past, we developed a methodology to compare the distance between scholarly representations of Neanderthals with those generated using AI.
Methods
All the code necessary to reproduce our analysis is available on Zenodo (Clindaniel Reference Clindaniel2024), along with a detailed README file that outlines the full methodological workflow used in this article. Employing the OpenAI API, we used DALL-E 3 and ChatGPT to generate hundreds of images and batches of text related to several prompts we crafted to illustrate or describe a day in the life of a Neanderthal. Both models are trained “Transformer” deep-learning models that have learned to predict complex sequences of data, based on corresponding input sequences of data (Vaswani et al. Reference Vaswani, Shazer, Parmar, Uzqkoreit, Jones, Gomez and Kaiser2017). In the case of ChatGPT, this enables coherent text generation in response to a user-submitted prompt. For DALL-E 3, this transformer backbone works together with a diffusion model, which begins with random noise and gradually de-noises it through a series of steps to generate an image that aligns with a text prompt. This iterative process is guided by learned patterns from the training data (paired examples of images and captions) and is designed to produce images that are both coherent and consistent with the types of images seen during training. The use and description of such models for the generation of text and images were surveyed in our prior work (Magnani and Clindaniel Reference Magnani and Clindaniel2023).
We used the DALL-E 3 model to generate 100 images for each of the following prompts: (1) “image depicting a day in the life of a neandertal, digital art” and (2) the same prompt with the phrase “based on expert knowledge of neandertal behavior” appended at the end. Before generating images, the model will revise the prompts to provide a more detailed textual description of the intended scene. For instance, the “non-expert” prompt was revised to more detailed prompts like the following, which the model used as a basis to produce the image in the upper-left corner of Figure 1:
Create a digital art piece illustrating a typical day in the life of a Neanderthal. The scene should depict a Neanderthal carrying out daily activities such as hunting, foraging, making tools, or communicating with others in their group. The setting should be prehistoric, with the environment consisting of wild, untouched landscapes, boulders, caves, or primitive shelters. Additionally, include details like the rough and sturdy attire of the Neanderthal and their hand-made tools.
Images closest to average embedding from the four different prompts; clockwise from the top with prompt revision, with prompt revision (expert), no prompt revision (expert), and no prompt revision.

Figure 1 Long description
The images show Neanderthals engaged in daily activities in prehistoric environments. The top left image, labeled 'With Prompt Revision (General),' depicts Neanderthals in a forested area with tools and a fire. The top right image, 'With Prompt Revision (Expert),' shows a snowy landscape with Neanderthals working and interacting. The bottom left image, 'No Prompt Revision (General),' features Neanderthals near a thatched shelter with tools and baskets. The bottom right image, 'No Prompt Revision (Expert),' presents a mountainous setting with Neanderthals around a fire, engaging in various tasks.
The “expert” prompt generated prompt revisions like the following, which the model used to generate the image in the upper-right corner of Figure 1:
A detailed digital art image illustrating a day in the life of a Neanderthal, based on scientifically validated knowledge about their behavior. The image includes scenes that show them hunting, foraging for food, making tools, interacting with family members, and resting in their cave shelter. The environment should reflect the harsh and frigid landscapes that the Neanderthals are believed to have inhabited, with tundra-like vegetation and woolly mammoths in the distance. Their physique should be robust and muscular, with a heavy brow ridge, and they should be dressed in clothing made from animal hides.
To better understand the behavior of DALL-E 3’s prompt revision behavior, we also produced 100 additional images for each of those two prompts, using OpenAI’s suggested phrase—“I NEED to test how the tool works with extremely simple prompts. DO NOT add any detail, just use it AS-IS”—to ensure we could evaluate the behavior of each prompt on its own (OpenAI Image Generation). All original prompts, revised prompts, and resulting images are available online.
We additionally generated 100 text samples using the ChatGPT API (GPT 3.5) for each of the following prompts: (1) “describe a day in the life of a neandertal in one paragraph” and (2) the same prompt with the phrase “you are an expert on neandertal behavior” appended at the end. The non-expert produced responses like the following:
A Neanderthal begins their day at dawn, emerging from their shelter in a cave or simple hut made of branches and hides. They gather together with their small family group to share a breakfast of meat from the hunt the previous day, supplemented with wild plants and berries. As the sun rises higher in the sky, the Neanderthal sets out with their companions to forage for more food, using stone tools to dig up roots and crack open nuts. In the afternoon, they work on constructing new tools and repairing their clothing made from animal skins. As evening falls, the Neanderthal returns to their dwelling, sharing stories and songs around a fire before settling down for the night, their daily tasks complete in harmony with the natural world.
It produced responses like the following for the expert prompt:
A Neanderthal’s day in prehistoric times likely began at dawn, with the first light illuminating their cave dwelling. The family unit would gather together, sharing the warmth of the fire they had kindled from the embers of the previous night. The adults would discuss the day’s plans while the children played nearby, mimicking the tasks they saw their parents performing. After a simple breakfast of gathered fruits, nuts, and perhaps some leftover meat from the previous day’s hunt, the group would set out in search of food. The men would head off to hunt large game, armed with spears and rocks, while the women and older children would gather plants and small animals. As the day wore on, the Neanderthals would return to their cave, where they would share the day’s bounty and prepare for another night in the safety of their rocky shelter. After the evening meal, the group would settle down to rest, the flickering light of the fire casting shadows on the walls as they drifted off to sleep, ready to rise again with the sun and repeat the cycle of survival in their harsh and unforgiving world.
All prompts, as well as the ChatGPT responses to each prompt, are available on Zenodo for reference (Clindaniel Reference Clindaniel2024).
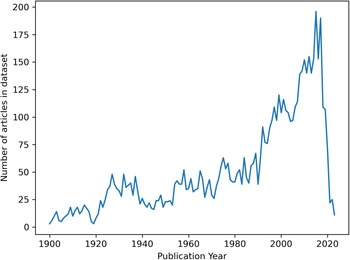
To assess the degree to which text and images produced by these generative AI tools corresponded with contemporary scholarly conceptions of Neanderthal behavior, we used the Constellate Dataset Builder to download all the metadata from articles, chapters, and books on JSTOR that contain the word “neanderthal” or “neandertal” between 1900 and 2023, beginning with the earliest dated article, and are in the Biological Science, Physical Science, or Social Sciences JSTOR content categories, including publications from common venues for Neanderthal scholarship such as PNAS, Current Anthropology, Science, and the Journal of Archaeological Method and Theory (Constellate 2024). Very few articles were downloaded in their entirety (n = 378, the majority of which date to 1927 or earlier; see Figure 2), rendering full-text articles a biased reference sample for computational content analysis. Note that works from 1927 entered the US public domain in 2023, so this temporal bias seems, at least partially, to be a result of copyright law in the United States. Therefore, we selected the abstracts from articles as a more temporally representative means of characterizing Neanderthals in the scholarly literature (n = 2,063, from the first available abstracts in 1923 to 2023).
Availability of “Neanderthal” article content type by year in the collected Constellate dataset.

Figure 2 Long description
The x- axis represents Publication Year from 1900 to 2020. The y- axis represents Number of articles in dataset from 0 to 200. The line starts near 0 in the early 1900s, rises to around 20 by the 1910s and drops back near 0 around 1920. It rises to around 45 in the early 1930s, then fluctuates between about 20 and 45 through the 1930s and 1940s. Around 1950 to 1970, it fluctuates mostly between about 20 and 55. From about 1970 to 1990, it fluctuates between about 35 and 65. From about 1990 to 2005, it rises from about 50 to about 120 with fluctuations. From about 2005 to the mid 2010s, it rises further to a peak near 200. After the peak, it drops sharply to around 20 by 2020.
To compare AI-generated images and text to scholarly text, we encoded CLIP embedding representations of all the generated images and text, as well as abstract text. In contrast to ChatGPT and DALL-E 3, which are generative models that produce text and images, respectively, CLIP is a multimodal encoder model that was trained on 400 million pairs of images and associated captions from across the internet. Based on associated image and text data, it learned to produce a (512-dimensional) joint text/image embedding space, which can be used for tasks such as classifying images based on text, comparing visual and textual content, and analyzing semantic similarity across modalities (Radford et al. Reference Radford, Kim, Hallacy, Ramesh, Goh, Agarwal and Sastry2021).
To interpret the type of image and text content generated by DALL-E 3 and ChatGPT, we drew inspiration from a neural topic modeling approach used to identify common texts in high-dimensional BERT embeddings, called BERTopic (Grootendorst Reference Grootendorst2022). Instead of encoding data using a (text-only) BERT model, however, we developed a related strategy for finding topic clusters in our multimodal CLIP embeddings. Specifically, we employed a combination of Uniform Manifold Approximation and Projection (UMAP) to reduce the dimensionality of the 512-dimensional scholarly abstract CLIP embeddings, while preserving important global and local information about the higher dimensional space (as per McInnes et al. Reference McInnes, Healy, Saul and Großberger2018). We then identified clusters of scholarly content in these lower-dimensional representations via a clustering method called HDBSCAN (McInnes et al. Reference McInnes, Healy and Astels2017). Based on identified content clusters of scholarly abstracts, we predicted cluster membership for AI-generated image and text content based on the location of their embeddings in the joint image–text CLIP embedding space. Finally, we again used UMAP to reduce the dimensionality of the embedding to two dimensions and visualize the position of the different clusters and content embeddings.
To quantify the semantic distance between any given AI-generated image or text embedding and scholarly text embeddings, we measured the cosine distance between embeddings in the CLIP space. We then compared the distance between AI-generated content to scholarly content to compute the average distance between AI-generated and scholarly content in any given year. To estimate the “age” of AI-generated content, we averaged the closest 20 years (the top 25% of years with abstracts). If the content was mostly consistent with newer scholarly conceptions of Neanderthal behavior, this 20-year average should be closer to 2023. Otherwise, the average year would reflect the publication year of scholarly content that the AI-generated content was most similar to. This quartile-based method smooths out noisy outliers and provides an interpretable, exploratory signal of the temporal affinity between AI-generated content and the scholarly record. For each of the resulting years, we also identified the most salient terms in scholarly abstracts from the era (five years before and after the closest average year to the AI-generated content), as computed via average TF-IDF (term frequency-inverse document frequency) for the 10-year period using the Gensim Python package (Rehurek and Sojka Reference Rehurek and Sojka2011).
Finally, for each AI-generated text and image category—images and text produced with and without “expert” guidance, as well as images produced with and without prompt revision— we identified the image or text closest to the average embedding in that category. The identified images are displayed in Figure 1.
For texts produced without “expert” guidance, the closest average response was this one:
A Neanderthal wakes up early in the morning as the sun rises, emerging from their cozy cave dwelling. They gather their tools made of stone and wood before setting out to hunt for food in the nearby forests. With their keen senses and strong physique, they stalk and capture a wild boar, using their sharp spears and teamwork to bring it down. After a successful hunt, they return to their cave and share the food with their family and tribe, enjoying a hearty meal together. The rest of the day is spent working on various tasks such as making clothing from animal hides, crafting tools, and tending to the fire. As the sun sets, the Neanderthal settles down for the night, feeling content and grateful for another day of survival in the harsh prehistoric world.
For texts produced with “expert” guidance, the closest average response was as follows:
A typical day in the life of a Neanderthal would involve waking up near dawn in their shelter, perhaps a cave or simple structure made of branches and hides. The Neanderthal would gather with their family group to start the day by foraging for food and water, possibly hunting for game or scavenging for plants and other resources. Throughout the day, they would engage in a variety of tasks such as making tools, tending to their fire, and caring for their young. Communication and social interaction would be important parts of their day, as they would rely on each other for survival and cooperation. As evening approached, the Neanderthal would likely gather around the fire for warmth and protection, sharing food and stories with their group before settling down for rest.
Using these central, representative images and texts, we performed further qualitative analyses to complement our quantitative analysis.
Results and Discussion
Computational approaches to archaeology are primarily constrained by data accessibility. Indeed, data availability structured our analysis, limiting our study to thousands of abstracts, rather than to entire articles, which were unavailable as full text in major article repositories. Data governance policies are also clearly visible in the structure of our study. For instance, copyright laws dictated a steep drop-off in article availability from the late 1920s. With the more recent advent of open access, the availability of full-text articles spiked again in the early 2000s. Although the source information used to train generative AI is opaque—not least because of the misuse of copyrighted materials by large companies—it can be assumed that the availability of knowledge will shape the AI outputs to skew toward older, more visible texts or publicly available information on websites that is more accessible to crawlers but that on average might reflect older information. How data are made accessible through the publication process will shape a generation of studies on large datasets. Tangibly, we expect this data availability to lead to more archaic representations of the archaeological record.
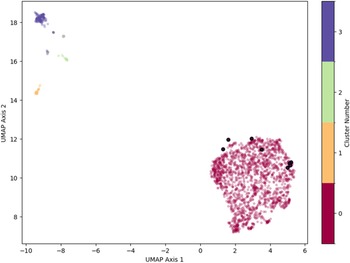
Grouping archaeological knowledge derived from journal databases facilitated a comparison to large bodies of archaeological representations created using generative AI. Our HDBSCAN model identified four major semantic clusters in the scholarly abstracts, with these clusters containing nearly all the abstract embeddings (98.93%; see Figure 3). The average embeddings for each of the AI-generated content types are included in Cluster 0. This cluster contains abstracts on a variety of topics that bear on Neanderthal behavior, ranging from paleogenomic research, to demographic characteristics of Neanderthal populations, to studies that emphasize lithic tool production. This cluster is semantically separate from abstracts that emphasize burials and physical characteristics of Neanderthal bones and bodies (Cluster 1), retrospective pieces and reflections on contemporary reconstructions of Neanderthals in art and in museums (Cluster 2), and abstracts broadly focused on mobility and continental migration (Cluster 3). Samples of 10 abstracts from each cluster discussed are available online, which provide additional details on these characterizations.
Clusters of scholarly abstracts identified by HDBSCAN and projected into two dimensions by UMAP. Abstracts that could not be assigned to a cluster are denoted with the color gray. Note that the average embeddings for AI-generated content are all presented via larger circles and dark outlines (they are all identified as belonging to Cluster 0).

Figure 3 Long description
The horizontal axis label is UMAP Axis 1. The visible tick labels are negative 10, negative 8, negative 6, negative 4, negative 2, 0, 2, 4 and 6. The vertical axis label is UMAP Axis 2. The visible tick labels are 8, 10, 12, 14, 16 and 18. A vertical legend at the right is labeled Cluster Number. The legend shows tick labels 0, 1, 2 and 3. Points form a dense group at UMAP Axis 1 values around 1 to 5 and UMAP Axis 2 values around 8.5 to 12. A smaller separated group appears at UMAP Axis 1 values around negative 10 to negative 7 and UMAP Axis 2 values around 15 to 19. A small number of points appear between these two groups, around UMAP Axis 1 values near negative 9 to negative 7 and UMAP Axis 2 values around 14 to 17. Several larger circular markers with outlines are visible within the dense group on the right, including markers near UMAP Axis 1 around 2.5 to 5 and UMAP Axis 2 around 10 to 12.
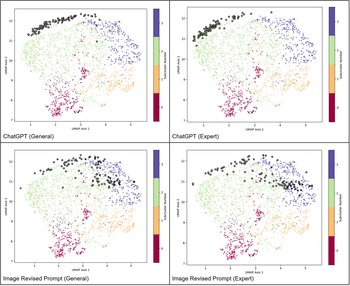
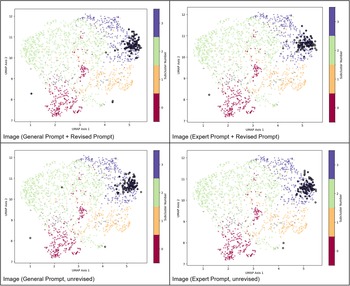
Our initial clustering approach was intentionally conservative, designed to reveal broad semantic distinctions across the full corpus of abstracts. To better understand the internal structure of Cluster 0, which contained the majority of scholarly abstract embeddings, we conducted a second round of clustering using HDBSCAN with less conservative parameters and a leaf-based cluster selection method. Using this approach, 96.07% of abstract embeddings were assigned to a cluster. This made it possible to interpret four distinct thematic subclusters within Cluster 0 (see Figures 4 and 5). Subcluster 0 is generally centered on recent paleogenomic research; subcluster 1 on the demographic characteristics, life cycle, and diet of Neanderthals; subcluster 2 on tool production and its connection to social learning; and subcluster 3 on inferring behavior and its connection to broader evolutionary themes via the fossil record.
Subclusters of scholarly abstracts in cluster 0, as identified by HDBSCAN using a leaf-based cluster selection method and projected into two dimensions using UMAP. AI-generated text embeddings have been superimposed according to their predicted cluster membership. Note that the average embeddings for AI-generated content are all presented via larger circles, colored by their subcluster membership and outlined in black. Embeddings that could not be assigned to a cluster are denoted with the color gray.

Figure 4 Long description
The image A showing a scatter plot titled “ChatGPT (General)”. The horizontal axis label is “UMAP Axis 1” with tick labels 1, 2, 3, 4, 5. The vertical axis label is “UMAP Axis 2” with tick labels 0.7, 0.8, 0.9, 1.0, 1.1, 1.2. A vertical colorbar is labeled “Subcluster” with tick labels 0, 1, 2, 3. Points are grouped into four color-coded categories matching the colorbar labels. A curved band of points forms an arc near the top of the plot around UMAP Axis 2 values near 1.1 to 1.2, spanning UMAP Axis 1 values from about 1 to about 4.5. A dense cluster of points appears in the lower region around UMAP Axis 2 near 0.7 to 0.85 and UMAP Axis 1 near 2 to 3. A cluster appears on the right side around UMAP Axis 1 near 4 to 5 and UMAP Axis 2 near 0.85 to 1.05. A central vertical grouping appears around UMAP Axis 1 near 3 and UMAP Axis 2 near 0.85 to 1.0. The image B showing a scatter plot titled “ChatGPT (Expert)”. The horizontal axis label is “UMAP Axis 1” with tick labels 1, 2, 3, 4, 5. The vertical axis label is “UMAP Axis 2” with tick labels 0.7, 0.8, 0.9, 1.0, 1.1, 1.2. A vertical colorbar is labeled “Subcluster” with tick labels 0, 1, 2, 3. Points are grouped into four color-coded categories matching the colorbar labels. A curved band of points forms an arc near the top around UMAP Axis 2 near 1.1 to 1.2, spanning UMAP Axis 1 from about 1 to about 4.5. A dense lower cluster appears around UMAP Axis 2 near 0.7 to 0.85 and UMAP Axis 1 near 2 to 3. A right-side cluster appears around UMAP Axis 1 near 4 to 5 and UMAP Axis 2 near 0.85 to 1.05. A central vertical grouping appears around UMAP Axis 1 near 3 and UMAP Axis 2 near 0.85 to 1.0. The image C showing a scatter plot titled “Image Revised Prompt (General)”. The horizontal axis label is “UMAP Axis 1” with tick labels 1, 2, 3, 4, 5. The vertical axis label is “UMAP Axis 2” with tick labels 0.7, 0.8, 0.9, 1.0, 1.1, 1.2. A vertical colorbar is labeled “Subcluster” with tick labels 0, 1, 2, 3. Points are grouped into four color-coded categories matching the colorbar labels. A curved band of points forms an arc near the top around UMAP Axis 2 near 1.1 to 1.2, spanning UMAP Axis 1 from about 1 to about 4.5. A dense lower cluster appears around UMAP Axis 2 near 0.7 to 0.85 and UMAP Axis 1 near 2 to 3. A right-side cluster appears around UMAP Axis 1 near 4 to 5 and UMAP Axis 2 near 0.85 to 1.05. A central vertical grouping appears around UMAP Axis 1 near 3 and UMAP Axis 2 near 0.85 to 1.0. The image D showing a scatter plot titled “Image Revised Prompt (Expert)”. The horizontal axis label is “UMAP Axis 1” with tick labels 1, 2, 3, 4, 5. The vertical axis label is “UMAP Axis 2” with tick labels 0.7, 0.8, 0.9, 1.0, 1.1, 1.2. A vertical colorbar is labeled “Subcluster” with tick labels 0, 1, 2, 3. Points are grouped into four color-coded categories matching the colorbar labels. A curved band of points forms an arc near the top around UMAP Axis 2 near 1.1 to 1.2, spanning UMAP Axis 1 from about 1 to about 4.5. A dense lower cluster appears around UMAP Axis 2 near 0.7 to 0.85 and UMAP Axis 1 near 2 to 3. A right-side cluster appears around UMAP Axis 1 near 4 to 5 and UMAP Axis 2 near 0.85 to 1.05. A central vertical grouping appears around UMAP Axis 1 near 3 and UMAP Axis 2 near 0.85 to 1.0.
Subclusters of scholarly abstracts in cluster 0, as identified by HDBSCAN using a leaf-based cluster selection method and projected into two dimensions using UMAP. AI-generated image embeddings have been superimposed according to their predicted cluster membership. Note that the average embeddings for AI-generated content are all presented via larger circles, colored by their subcluster membership and outlined in black. Embeddings that could not be assigned to a cluster are denoted with the color gray.

Figure 5 Long description
The image contains four scatter plots labeled as follows: Panel A: General Prompt plus Revised Prompt, Panel B: Expert Prompt plus Revised Prompt, Panel C: General Prompt, unrevised, Panel D: Expert Prompt, unrevised. Each plot displays UMAP 1 on the horizontal axis and UMAP 2 on the vertical axis. The axes range from negative 4 to 6 for UMAP 1 and negative 2 to 16 for UMAP 2. A colorbar labeled Subcluster with tick labels 0, 1, 2 and 3 is present. In each panel, points are grouped into clusters with larger circular markers indicating average embeddings for AI-generated content. Panel A shows a broad distribution with distinct clusters. Panel B has a dense concentration in the upper right. Panel C displays similar clustering to Panel A but with slight variations in density. Panel D mirrors Panel B with a dense upper right cluster. The larger circular markers are outlined in black, representing average embeddings. The plots illustrate different prompt conditions, highlighting variations in cluster separation and density across panels.
Our results indicate that generative text models tend to produce text that fall outside the bounds of scientific literature. Note that much of the ChatGPT-generated text does not fall within a subcluster (82% for general prompt, 51% for expert prompt). Furthermore, HDBSCAN could not successfully place the average embeddings for ChatGPT-generated text into a cluster (whereas all the others fit within the abstract clusters)—hinting at a relatively low correspondence with scholarly content. The content that does fall within an established cluster generally corresponds to cluster 2 (17% for general prompt, 49% for “expert” prompt). The revised prompts generated as part of the image-generation process for DALL-E 3 produced a mix of samples in cluster 2 (28% for both prompts) and cluster 3 (19% for general prompt, 21% for expert prompt), but more than half of all content was not in a cluster (53% for general prompt, 51% for expert prompt). AI-generated images seem to more closely align with scholarly content, however. All image embeddings (regardless of prompt) were strongly centered in Cluster 3, with only 17% not falling in a cluster and less than 1% in Cluster 2.
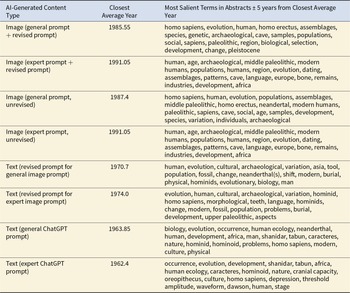
To explore these issues beyond topic-level comparisons, we analyzed the temporality of text and images generated using AI. The closest average year to each of the generated AI categories is summarized in Table 1. ChatGPT seems to produce content most consistent with the early 1960s, emphasizing human ecology and broad discussions of “culture” and “nature.” DALL-E 3 produces images that depict elements more characteristic of the late 1980s and early 1990s: they are focused on connections to modern humans, genetics, and language and emphasize the particularity of time periods and different regions. The prompt revisions seem to produce texts closest to scholarly content from the early 1970s in which the salient terms seem centered around the morphological features of Neanderthals and their location in broader evolutionary narratives. As a result of this tilt toward the 1970s, note that the images produced via revised prompts (without specifying that AI should take on the role of “expert on Neanderthal behavior”) end up producing slightly older depictions (1985.55) than those produced via our original prompt alone (1987.4).
AI-Generated Content Type by Closest Average Year and the Most Salient Terms in Scholarly Abstracts from the Era (±5 Years).

Table 1 Long description
The table links each AI-generated content type to a closest average publication year and lists the most frequent abstract terms within ±5 years of that year. All four image-related rows cluster later (1985.55, 1987.4, and 1991.05 twice), whereas all text-related rows cluster earlier (1962.4, 1963.85, 1970.7, and 1974.0). Image rows are dominated by paleoanthropology and archaeology vocabulary such as “homo sapiens,” “homo erectus,” “middle paleolithic,” “assemblages,” “cave,” “dating,” “europe,” and “africa.” Text rows also emphasize evolution and human biology but include terms like “human ecology,” “occurrence,” “cranial capacity,” and site names such as “shanidar” and “tabun,” suggesting an older scholarly framing. The two expert image rows (revised and unrevised) share the same closest year (1991.05) and identical salient-term lists, indicating no difference in this summary between those conditions. Overall, the main contrast is temporal: image-prompt conditions align with later decades than text-prompt conditions, while thematic focus remains broadly on human evolution and archaeological context. Interpretation is limited because “salient terms” are presented as lists without frequencies or weighting, and the ±5-year window may blend adjacent trends.
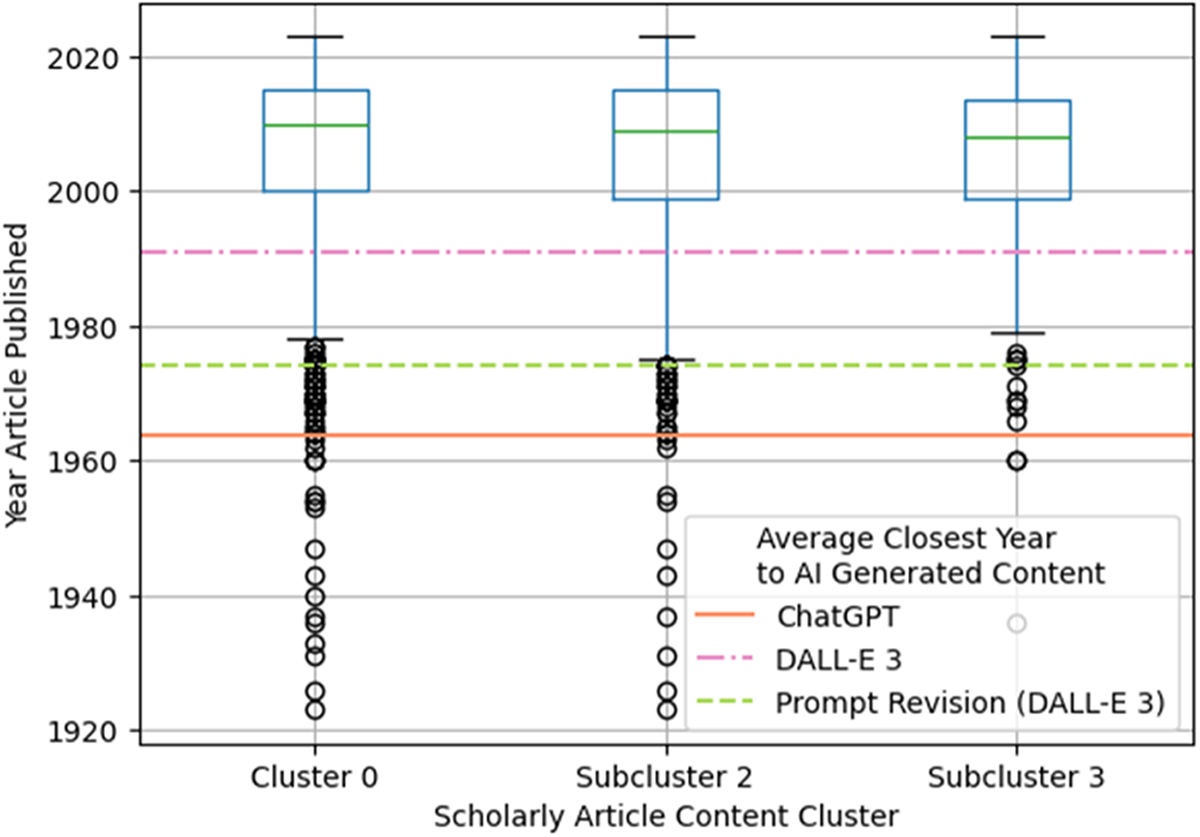
Note as well that none of these average ages are characteristic of the clusters they belong to semantically (Figure 6). The most recent year for each type of generated AI content in Table 1 is below the 25th percentile of all years represented in each cluster (and generated texts are outliers in terms of closest average year).
Boxplot of the year each scholarly article in an identified content cluster was published, with the average closest year to AI-generated images and text, based on semantic similarity (Table 1). We chose the most recent average year for each AI model from Table 1 to present in this figure.

Figure 6 Long description
The vertical axis label is Year Article Published. The vertical axis range is 1920 to 2020. The horizontal axis label is Scholarly Article Content Cluster. The categories are Cluster 0, Subcluster 2 and Subcluster 3. Legend text: Average Closest Year to AI Generated Content ChatGPT DALL-E 3 Prompt Revision (DALL-E 3) Cluster 0 box plot: The box spans from 2000 to 2010. The median line is at 2005. The upper whisker reaches 2020. The lower whisker reaches 1980. Outlier points appear below 1980, including points around 1978, 1976, 1974, 1972, 1970, 1968, 1966, 1964, 1962, 1960, 1958, 1956, 1954, 1952, 1950, 1948, 1946, 1944, 1942, 1940, 1938, 1936, 1934, 1932, 1930, 1928, 1926, 1924 and 1922. Subcluster 2 box plot: The box spans from 2000 to 2010. The median line is at 2005. The upper whisker reaches 2020. The lower whisker reaches 1980. Outlier points appear below 1980, including points around 1978, 1976, 1974, 1972, 1970, 1968, 1966, 1964, 1962, 1960, 1958, 1956, 1954, 1952, 1950, 1948, 1946, 1944, 1942, 1940, 1938, 1936, 1934, 1932, 1930, 1928, 1926, 1924 and 1922. Subcluster 3 box plot: The box spans from 2000 to 2010. The median line is at 2005. The upper whisker reaches 2020. The lower whisker reaches 1980. Outlier points appear below 1980, including points around 1978, 1976, 1974, 1972, 1970, 1968, 1966, 1964, 1962, 1960, 1958, 1956, 1954, 1952, 1950, 1948, 1946, 1944, 1942, 1940, 1938, 1936, 1934, 1932, 1930, 1928, 1926, 1924 and 1922. Horizontal reference lines: A dashed line labeled ChatGPT is at 1990. A dashed line labeled DALL-E 3 is at 1970. A dashed line labeled Prompt Revision (DALL-E 3) is at 1960.
To scaffold our qualitative analysis, we identified AI-generated text and images that were closest to the average embedding for each AI-generated text and image category (see Figure 1). A review of “average” images supports poor correspondence with contemporary scientific understandings of Neanderthals. First, we draw attention to the physical characteristics of AI-generated content. Across all prompts, even though the images feature depictions of bipedal hominids, they incorporate archaic features associated with other extinct hominins and perhaps extant taxa like Pan. A majority of images depict human-like figures, slightly stooped, with large quantities of body hair. These depictions have more in common with early twentieth-century drawings of Neanderthals than contemporary scientific knowledge. Our AI Neanderthals exhibit high levels of facial prognathism, exaggerated brow ridges, and a low cranial profile too extreme to fall within Neanderthal phenotypic variability. It is worth noting that revised expert prompts generated by DALL E-3 appeared less incorrect, depicting Neanderthals with fewer archaic features, who were covered less in body hair, and had facial structures that appear more consistent with later Homo.
Scientific literature in recent decades has cast a critical eye on gendered representations of the past (Conkey and Gero Reference Conkey and Gero1997; Dobres Reference Dobres1995), yet a lack of focus on women and children in prehistory clearly informs our artificially intelligent images. Heavily muscled male hominins are foregrounded in all our representative visuals. Only in the expert prompt was a small child shown playing. Developers are quiet about their training sources, and some archaeologists have suggested a close reliance on Wikipedia (Spennemann Reference Spennemann2023a). It is likely that training material for our subject matter, and by extension representations of Neanderthals in general, is equally gendered, sidelining women and children. Following scholars who have pointed out these issues more broadly (Langley Reference Langley2020), our results suggest that AI systems require corrective measures to more equitably and accurately imagine Neanderthal prehistory.
Contrasting with generally archaic physical depictions of Neanderthals, the technology represented across images was unusually advanced. We know from archaeological evidence that Neanderthals were capable of producing complex lithic industries, which varied across space and time (Delagnes and Rendu Reference Delagnes and Rendu2011; Hoffecker Reference Hoffecker2018). Their bone tool use is no longer controversial, and evidence for the use of fibers has emerged in recent years (Hardy et al Reference Hardy, Moncel, Kerfant, Lebon, Bellot-Gurlet and Mélard2020; Soressi et al. Reference Soressi, McPherron, Lenoir, Dogandžić, Goldberg, Jacobs and Maigrot2013). Despite expressing a suite of complex and variable behavioral repertoires in scientific literature, AI depictions of Neanderthals presented several anachronisms. Among them were basketry and dwellings with thatched roofs and ladders. Vessels of glass and implements of metal also appear. In all cases, AI-generated representations presented technologies that are neither associated with Neanderthals nor would appear archaeologically for tens of thousands of years. There is a temporal confusion associated with these depictions that mix old biological stereotypes with more recent technologies, indexing a low correspondence with contemporary scientific understandings of Neanderthals.
Comparatively, our AI-generated text provided more innocuous material emphasizing a simplicity of technology and cooperative survival. In both original and expert prompts, Neanderthal technologies consisted of only three materials—stone, hide, and wood—and referred to the maintenance but not the making of fire. Contrasting with our general prompt that emphasized cave dwelling and hunting, our expert prompt suggested a broader diet more consistent with contemporary understandings of Neanderthal lifeways. It included the gathering of plant resources, the construction of open-air shelters, and activities such as child-rearing. Although our text samples are less blatantly stereotypical than the images, they do not significantly address the broad variability and sophistication of Neanderthal cultures reflected in contemporary scientific literature: as mentioned earlier, they tend to cluster with older bodies of scientific knowledge.
Conclusion
With expanding use across diverse fields, content generated using AI is poised to play a central role in society. Understanding the bias of representation across these new technological applications is essential. How the archaeological record is written about and conceived using generative AI will have significant implications for anthropologists and society at large. Our study reveals that artificially intelligent depictions of the past reflect limited overlap with bodies of scientific knowledge. Where there is some correspondence, we show that the temporality and overlap of knowledge are uneven across media, with images reflecting more up-to-date academic knowledge and text averaging an older vintage, from as early as the 1960s. Issues with gender representations are clear, and anachronistic elements were particularly evident in AI-generated images. These discrepancies may result from the types of data being used to train generative AI programs, which we expect reflect broader social biases distributed throughout bodies of writing and source images. Reproduction of these biases risks their continued propagation and normalization.
Our current research suggests that the way we structure and make information available will directly influence AI output and, by extension, the way we imagine the past. Moving forward, data policies will inform the way archaeological material is written about and visualized. Open access structures the types of information that are accessible for scholars to conduct computational analyses and is equally likely to affect which information is used to train artificial intelligence programs. Institutions with robust funding to allow articles to be widely read will continue to have a greater hand in determining how things are represented. If articles from certain eras or from specific subfields are more likely behind paywalls, they will be less likely to feed into materials generated using AI. Academic publishing practices may ultimately work to undermine public knowledge.
The methods presented in this article may be systematically applied to any archaeological region or period, using the AI platforms discussed here or others. Future research should elucidate with greater specificity the types of biases that creep into artificially intelligent representations of the past and expose their variation across archaeological space and time. What are the societal impacts of AI on contemporary discussions surrounding Indigenous cultures or gender, for instance, if they are informed by dated depictions from the 1960s? The analytical tool kit presented here provides the foundation to explore the ramifications of drawing on older texts or nonscientific bodies of knowledge to inform perceptions of the archaeological record. Ultimately, the identification of these temporal and foundational biases will contribute to more current and equitable archaeological interpretations.
Acknowledgments
We thank the anonymous peer reviewers for their feedback on this article.
Funding Statement
The authors have no funding to report for this article.
Data Availability Statement
All supporting material is available through Zenodo (Clindaniel Reference Clindaniel2024).
Competing Interests
The authors declare none.


 Open access
Open access