

1 Introduction
Explanations are a central object of study in a range of fields. In particular, in the last ten years or so, explanations that display the reasons why a certain conclusion is true, or why a certain phenomenon occurs, have become a flourishing and thriving object of research in several disciplines. In philosophy, for example, there is a long and illustrious tradition—starting with Aristotle and passing by scholars such as Leibniz, Bolzano or FregeFootnote 1 —that, although often neglected for several decades, is now witnessing a renewed interest. This tradition gives pride of place to explanations that play the same role in conceptual sciences, like mathematics, as causal explanations do in the empirical sciences: as the latter explain by displaying the causes, the former explain via the reasons.Footnote 2 Recently, Poggiolesi [Reference Poggiolesi25] has formalized ideas coming from this tradition using logical tools from proof theory. She has thus introduced a sequent calculus with explanatory rules, namely, rules where not only the conclusion follows from the premisse(s), but where the premisse(s) represent the reasons why the conclusion is true.
Another notable field where explanations with reasons have been receiving an increasing amount of attention and interest is computer science, and in particular machine learning classifiers. A recent research direction has aimed to show that some common machine learning classifiers can be represented by propositional formulas and classifications of instances can be analyzed in terms of classical logical consequence. In this context, Darwiche and Hirth [Reference Darwiche and Hirth7] define the idea of sufficient reasons for a decision, which correspond to its potential explicanda,Footnote 3 and relate it to prime implicants, as well as a range of kindred concepts.
The notion of explanation with reasons thus emerges as a central topic in two distinct fields, linked to different literatures, and using different techniques to develop different approaches. Is there a connection, beyond the apparent similarity in object? The current paper provides an answer to this question, by mapping notions used in machine learning into the framework for understanding explanations developed in philosophy. More precisely, we show that the explanatory tools introduced by Poggiolesi [Reference Poggiolesi25] naturally provide all and only the sufficient reasons for a decision, in the sense of Darwiche and Hirth [Reference Darwiche and Hirth7]. This result is of double conceptual significance. On the one hand, it shows that the philosophical approach to explanation via explanatory rules has applications in practical and significant cases, where it naturally captures pre-philosophical intuitions. On the other hand, it connects the notion of sufficient reason introduced in AI to a long philosophical tradition, suggesting that there exists a sort of fil rouge going from Aristotle to the present day, confirming the deepness and interest of the concepts at issue. Our result is also of formal import, insofar as the computation of the set of sufficient reasons for a decision has long been an open problem [Reference Coudert and Madre5, Reference Shih, Choi, Darwiche and Lang29]. The result shows that the explanatory framework developed in philosophy naturally provides a novel and simple solution to this problem, which may be of use in the study of as-yet open generalisations.
The paper is structured as follows. In §2 we introduce the concepts of sufficient and complete reason as defined by Shih et al. [Reference Shih, Choi, Darwiche and Lang30], whilst in §3 we clarify the main ideas behind the explanatory sequent calculus of Poggiolesi [Reference Poggiolesi25] and a generalized version of it. §4 will be used to illustrate how we can use the explanatory calculus to compute sufficient reasons behind decisions made by boolean classifiers, whilst in §5 we will prove that explanatory calculi can compute the complete reasons behind decisions made by classifiers. We finally close with some concluding remarks in §6.
2 Sufficient and complete reasons
We use this section to introduce and clarify the key notions proper to the account developed by Darwiche and Hirth [Reference Darwiche and Hirth7], Shih et al. [Reference Shih, Choi, Darwiche and Lang30]. To do so, we proceed by means of the following example. Consider a classifier
 $\mathcal {C}$
which admits an applicant just in case she has passed the entrance exam and either she is not a first time applicant, or she has work experience, or she has a high GPA. Consider the language of classical propositional language defined as follows.
$\mathcal {C}$
which admits an applicant just in case she has passed the entrance exam and either she is not a first time applicant, or she has work experience, or she has a high GPA. Consider the language of classical propositional language defined as follows.
Definition 2.1. The language of classical propositional logic,
 $\mathcal {L}$
, is composed by: atomic formulas (
$\mathcal {L}$
, is composed by: atomic formulas (
 $p_{0}$
,
$p_{0}$
,
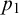 $p_{1}$
,
$p_{1}$
,
 $p_{2}$
, …), logical connectives (
$p_{2}$
, …), logical connectives (
 $\neg $
,
$\neg $
,
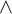 $\wedge $
,
$\wedge $
,
 $\vee $
), and parentheses: (,). Literals are either atomic formulas or their negations, whilst extended literals are formulas of the form:
$\vee $
), and parentheses: (,). Literals are either atomic formulas or their negations, whilst extended literals are formulas of the form:
 $\overbrace {\neg \dots \neg }^n p$
for
$\overbrace {\neg \dots \neg }^n p$
for
 $n\geq 0$
and atomic formula p. Extended literals will be denoted by
$n\geq 0$
and atomic formula p. Extended literals will be denoted by
 $l_{1}, l_{2}, \ldots $
. We take the symbols
$l_{1}, l_{2}, \ldots $
. We take the symbols
 $\top , \bot $
and
$\top , \bot $
and
 $\rightarrow $
to be defined as usual. The set of well-defined formulas,
$\rightarrow $
to be defined as usual. The set of well-defined formulas,
 ${\mathcal {WF}}$
, is constructed in the standard way. Finally, for the sake of brevity, the symbol
${\mathcal {WF}}$
, is constructed in the standard way. Finally, for the sake of brevity, the symbol
 $\circ $
will be used to denote either a conjunction or a disjunction.
$\circ $
will be used to denote either a conjunction or a disjunction.
As it will become clear later on, it is convenient to use the metalinguistic symbol of converse of a formula, which is defined as follows.
Definition 2.2. The converse of a formula A, written
 $A^{\bot }$
, is defined as follows:
$A^{\bot }$
, is defined as follows:
 $$ \begin{align*}A^{\bot } = \bigg \{ \begin {array}{@{}ll} \neg ^{n-1} E , & \mathit{if}\; A = \neg ^{n} B\; and\; n\; is\; odd\\ \neg ^{n+1} E, & \mathit{if}\; A = \neg ^{n} B\; and\; n\; is\; even,\\ \end {array}\end{align*} $$
$$ \begin{align*}A^{\bot } = \bigg \{ \begin {array}{@{}ll} \neg ^{n-1} E , & \mathit{if}\; A = \neg ^{n} B\; and\; n\; is\; odd\\ \neg ^{n+1} E, & \mathit{if}\; A = \neg ^{n} B\; and\; n\; is\; even,\\ \end {array}\end{align*} $$
where the main connective in B is not a negation,
 $n \geqslant $
0 and 0 is taken to be an even number.
$n \geqslant $
0 and 0 is taken to be an even number.
Suppose to use the following denotations:
-
- e denotes “applicant has passed the entrance exam;”
-
- f denotes “applicant is at her the first attempt;”
-
- w denotes “applicant has work experience;”
-
- g denotes “applicant has a high GPA.”
Following Darwiche and Hirth [Reference Darwiche and Hirth7], we can represent classifier
 $\mathcal {C}$
by the following formula A of the classical propositional language,
$\mathcal {C}$
by the following formula A of the classical propositional language,
 $A= e\wedge (\neg f\vee w\vee g)$
, where
$A= e\wedge (\neg f\vee w\vee g)$
, where
 $e, f, w, g$
are literals.
$e, f, w, g$
are literals.
Consider now the two applicants Greg and Susan. Greg and Susan have both passed the entrance exam, but whilst Greg has already applied and has work experience, Susan has work experience and a high GPA. Their features can be gathered in the following two sets (of literals)
 $\alpha _{g}$
and
$\alpha _{g}$
and
 $\alpha _{s}$
, respectively, and can be formalized as follows
$\alpha _{s}$
, respectively, and can be formalized as follows
 $\alpha _{g}=\{e, \neg f, w, \neg g\}$
and
$\alpha _{g}=\{e, \neg f, w, \neg g\}$
and
 $\alpha _{s}=\{e, f, w, g\}$
. We call both
$\alpha _{s}=\{e, f, w, g\}$
. We call both
 $\alpha _{g}$
and
$\alpha _{g}$
and
 $\alpha _{s}$
instances, where instances are defined through terms as follows.
$\alpha _{s}$
instances, where instances are defined through terms as follows.
Definition 2.3. A term is a consistent set of literals. Terms will be denoted by
 $\tau _{1}, \tau _{2}, \tau _{3}, \ldots $
. A term
$\tau _{1}, \tau _{2}, \tau _{3}, \ldots $
. A term
 $\tau _{i}$
subsumes a term
$\tau _{i}$
subsumes a term
 $\tau _{j}$
if, and only if,
$\tau _{j}$
if, and only if,
 $\tau _{i}\subseteq \tau _{j}$
.
$\tau _{i}\subseteq \tau _{j}$
.
Definition 2.4. An instance
 $\alpha $
of a formula A is a term such that, for every literal
$\alpha $
of a formula A is a term such that, for every literal
 $l$
appearing in A, either
$l$
appearing in A, either
 $l$
or
$l$
or
 $l^{\bot }$
is in
$l^{\bot }$
is in
 $\alpha $
. We sometimes refer to the literals in
$\alpha $
. We sometimes refer to the literals in
 $\alpha $
as the characteristics of the instance.
$\alpha $
as the characteristics of the instance.
Grege and Susan are both admitted by classifier
 $\mathcal {C}$
, as the admission is granted in case the formula which represents the classifier logically follows from the instance that corresponds to the applicant. It is easy to verify that we have both
$\mathcal {C}$
, as the admission is granted in case the formula which represents the classifier logically follows from the instance that corresponds to the applicant. It is easy to verify that we have both
 $\alpha _{g}\models A$
, as well as
$\alpha _{g}\models A$
, as well as
 $\alpha _{s}\models A$
.
$\alpha _{s}\models A$
.
More generally speaking, we use
 $A(\alpha )$
to denote the decision (0 or 1) of classifier A on instance
$A(\alpha )$
to denote the decision (0 or 1) of classifier A on instance
 $\alpha $
: this corresponds to
$\alpha $
: this corresponds to
 $\alpha \models A$
if, and only if,
$\alpha \models A$
if, and only if,
 $A(\alpha )$
= 1, and
$A(\alpha )$
= 1, and
 $\alpha \models \neg A$
if, and only if,
$\alpha \models \neg A$
if, and only if,
 $A(\alpha )$
= 0. We also define
$A(\alpha )$
= 0. We also define
 $A_{\alpha }$
in the following way:
$A_{\alpha }$
in the following way:
 $$ \begin{align*}A_{\alpha} = \bigg\{ \begin{array}{@{}ll} A, & \textrm{if}\; A(\alpha) = 1 \\ \neg A, & \textrm{if}\; A(\alpha) = 0. \\ \end{array} \end{align*} $$
$$ \begin{align*}A_{\alpha} = \bigg\{ \begin{array}{@{}ll} A, & \textrm{if}\; A(\alpha) = 1 \\ \neg A, & \textrm{if}\; A(\alpha) = 0. \\ \end{array} \end{align*} $$
Note that
 $\alpha \models A_{\alpha }$
and
$\alpha \models A_{\alpha }$
and
 $A(\alpha )=A(\beta )$
if, and only if,
$A(\alpha )=A(\beta )$
if, and only if,
 $A_{\alpha } = A_{\beta }$
.
$A_{\alpha } = A_{\beta }$
.
Hence, both Greg and Susan have been admitted by classifier
 $\mathcal {C}$
; however, it seems that it is so for different reasons. The main goal of Darwiche and Hirth [Reference Darwiche and Hirth7], Shih et al. [Reference Shih, Choi, Darwiche and Lang30] is to explain the decisions made by a classifier on specific instances by way of providing various insights into what motivated these decisions. In particular, they propose the captivating notion of sufficient reason.
$\mathcal {C}$
; however, it seems that it is so for different reasons. The main goal of Darwiche and Hirth [Reference Darwiche and Hirth7], Shih et al. [Reference Shih, Choi, Darwiche and Lang30] is to explain the decisions made by a classifier on specific instances by way of providing various insights into what motivated these decisions. In particular, they propose the captivating notion of sufficient reason.
Definition 2.5. A sufficient reason for decision
 $A(\alpha )$
is a term
$A(\alpha )$
is a term
 $\tau $
that satisfies A, namely,
$\tau $
that satisfies A, namely,
 $\tau \models A$
, and
$\tau \models A$
, and
 $\tau $
is not subsumed by any other term that satisfies A.Footnote
4
$\tau $
is not subsumed by any other term that satisfies A.Footnote
4
A sufficient reason identifies characteristics of an instance that justify the decision: the decision will remain the same even if other characteristics of the instance were different. Moreover, a sufficient reason is minimal as none of its strict subsets can justify the decision.
Let us go back to the classifier
 $\mathcal {C}$
which admits an applicant just in case she has passed the entrance exam and either she has already applied or she has work experience or she has a high GPA. According to what has just been said, classifier
$\mathcal {C}$
which admits an applicant just in case she has passed the entrance exam and either she has already applied or she has work experience or she has a high GPA. According to what has just been said, classifier
 $\mathcal {C}$
admits Greg for the following sufficient reasons:
$\mathcal {C}$
admits Greg for the following sufficient reasons:
-
• Passed the entrance exam and is not a first time applicant,
 $\tau _{1}=\{e, \neg f\}$
.
$\tau _{1}=\{e, \neg f\}$
. -
• Passed the entrance exam and has work experience,
$\tau _{2}=\{e, w\}$
.


Since Greg passed the entrance exam and has applied before, he will be admitted even if his other characteristics were different. Similarly, since Greg passed the entrance exam and has work experience, he will be admitted even if his other characteristics were different. Moreover, in both cases reasons are minimal: if any of their features is omitted, the decision is not longer the same.
Note that classifier
 $\mathcal {C}$
also admits Susan for the following sufficient reasons:
$\mathcal {C}$
also admits Susan for the following sufficient reasons:
-
• Passed the entrance exam and has work experience,
$\tau _{1}=\{e, w\}$
. -
• Passed the entrance exam and has a high GPA,
$\tau _{2}=\{e, g\}$
.


Since Susan passed the entrance exam and has work experience, or since Susan passed the entrance exam and she has a high GPA, she will be admitted. This is so even if her other characteristics were different and again these sets are minimal.
Definition 2.6. The complete reason for a decision is the set of all sufficient reasons.
A decision may have multiple sufficient reasons, sometimes an exponential number of them (see, e.g., [Reference Darwiche and Lang6]). As a result the enumeration of all sufficient reasons, i.e., the enumeration of the complete reasons, is a problem that has been treated in several papers (see, e.g., Coudert and Madre [Reference Coudert and Madre5] and Shih et al. [Reference Shih, Choi, Darwiche and Lang29]). The algorithms proposed over the time also had to face another difficulty which can be easily explained by means of the following example. Consider the classifier
 $\mathcal {C^{\prime }}$
represented by the formula
$\mathcal {C^{\prime }}$
represented by the formula
 $A^{\prime }=(p\wedge q)\vee (r\wedge \neg q)$
and the instance
$A^{\prime }=(p\wedge q)\vee (r\wedge \neg q)$
and the instance
 $\alpha ^{\prime }=\{p, q, r\}$
. It can be straightforwardly checked that the decision
$\alpha ^{\prime }=\{p, q, r\}$
. It can be straightforwardly checked that the decision
 $A^{\prime }(\alpha ^{\prime })$
has two sufficient reasons, namely,
$A^{\prime }(\alpha ^{\prime })$
has two sufficient reasons, namely,
 $\tau =\{p, q\}$
, but also
$\tau =\{p, q\}$
, but also
 $\tau ^{\prime }=\{p, r\}$
(because of the law of excluded middle). Algorithms proposed in the above mentioned literature may miss the sufficient reason
$\tau ^{\prime }=\{p, r\}$
(because of the law of excluded middle). Algorithms proposed in the above mentioned literature may miss the sufficient reason
 $\tau ^{\prime }=\{p, r\}$
and therefore be incomplete. Darwiche and Hirth [Reference Darwiche and Hirth7] and Shih et al. [Reference Shih, Choi, Darwiche and Lang30] have recently fixed this problem by constructing algorithms that provide in linear time the set of complete reasons; however, as the discussion shows, this is no trivial solution.
$\tau ^{\prime }=\{p, r\}$
and therefore be incomplete. Darwiche and Hirth [Reference Darwiche and Hirth7] and Shih et al. [Reference Shih, Choi, Darwiche and Lang30] have recently fixed this problem by constructing algorithms that provide in linear time the set of complete reasons; however, as the discussion shows, this is no trivial solution.
3 Explanatory sequent calculus
Extending ideas introduced in Genco [Reference Genco10] and Poggiolesi [Reference Poggiolesi22], Poggiolesi [Reference Poggiolesi25] mobilizes the resources of proof theory to formalize the notion of explanation from reasons. Two main ideas motivate this formalization. The first relates to a remark that is both ancient and central in the philosophical literature on explanations, and which consists at looking at explanations as deductive arguments that, starting from true premisses—be they the causes or the reasons—explain a certain conclusion.Footnote 5 Of course not any deductive argument constitutes an explanation, but some of them do, namely, those which have an explanatory power. The perspective that is adopted in Poggiolesi [Reference Poggiolesi25] consists in a formalization of this central idea along the following lines: explanations can be seen as proofs which, starting from true premisses, the reasons, not only prove that a certain conclusion is true, but also explain why it is such. This perspective naturally arises from the observation that proofs are deductive arguments; moreover, it is supported by the fact that notable explanations from reasons that can be found in mathematics actually are proofs of mathematical theorems, which show why those theorems are true.Footnote 6 Since proofs are standardly formalized in logic by means of derivations, explanations from reasons will be formalized as a special type of derivation, namely, a metalinguistic relation called formal explanation. As derivations are introduced via inferential rules, formal explanations will be introduced via explanatory rules, namely, rules where not only is the conclusion inferable from their premisse(s), but also such that the premisses are the reasons why the conclusion is true.
Let us now move to the second main idea linked to the formalization of explanations proposed by Poggiolesi [Reference Poggiolesi25]. The second idea relates to the observation that in many examples of explanation from reasons, reasons and conclusions, once formalized in a formal language, correspond to formulas related to each other by elements that occur inside the formulas themselves.Footnote
7
Consider the sentence “any bachelor is an unmarried man;” the intuitive reasons which explain this truth are “any bachelor is unmarried” and “any bachelor is a man.” Formalizing them we obtain
 $\forall x(Bx\rightarrow Ux\wedge Mx)$
, and
$\forall x(Bx\rightarrow Ux\wedge Mx)$
, and
 $\forall x(Bx\rightarrow Ux)$
,
$\forall x(Bx\rightarrow Ux)$
,
 $\forall x(Bx\rightarrow Mx)$
, respectively. The link between these formulas occurs deep inside the formulas themselves: in particular, the connective
$\forall x(Bx\rightarrow Mx)$
, respectively. The link between these formulas occurs deep inside the formulas themselves: in particular, the connective
 $\wedge $
inside
$\wedge $
inside
 $\forall x(Bx\rightarrow Ux\wedge Mx)$
is broken into two and thus give rise to both
$\forall x(Bx\rightarrow Ux\wedge Mx)$
is broken into two and thus give rise to both
 $\forall x(Bx\rightarrow Ux)$
and
$\forall x(Bx\rightarrow Ux)$
and
 $\forall x(Bx\rightarrow Mx)$
. However, as already said, this is no isolated case. Another example is obtained by considering the sentence“zero or the successor of any natural number is itself a natural number.” The reasons which explain this truth are “zero is a natural number” and “the successor of any natural number is a natural number.” Formalizing them we obtain
$\forall x(Bx\rightarrow Mx)$
. However, as already said, this is no isolated case. Another example is obtained by considering the sentence“zero or the successor of any natural number is itself a natural number.” The reasons which explain this truth are “zero is a natural number” and “the successor of any natural number is a natural number.” Formalizing them we obtain
 $\forall x((Zx\vee SNx)\rightarrow Nx)$
, and
$\forall x((Zx\vee SNx)\rightarrow Nx)$
, and
 $\forall x(Zx\rightarrow Nx)$
,
$\forall x(Zx\rightarrow Nx)$
,
 $\forall x(SNx\rightarrow Nx)$
. Once again, the link between these formulas occurs deep inside the formulas themselves: in particular, this time it is the connective
$\forall x(SNx\rightarrow Nx)$
. Once again, the link between these formulas occurs deep inside the formulas themselves: in particular, this time it is the connective
 $\vee $
which is broken and gives rise to the reasons of the conclusion.Footnote
8
Similar examples also arise at the propositional level. Consider the sentence “if it is a triangle, then it has three sides and the sum of its angles is 180
$\vee $
which is broken and gives rise to the reasons of the conclusion.Footnote
8
Similar examples also arise at the propositional level. Consider the sentence “if it is a triangle, then it has three sides and the sum of its angles is 180
 $^{\circ }$
;” the reasons which explain its truth are “if it is a triangle, then it has three sides” and “if it is a triangle, then the sum of its angles is 180
$^{\circ }$
;” the reasons which explain its truth are “if it is a triangle, then it has three sides” and “if it is a triangle, then the sum of its angles is 180
 $^{\circ }$
.” Formalizing them we obtain
$^{\circ }$
.” Formalizing them we obtain
 $t\rightarrow s\wedge a$
, and
$t\rightarrow s\wedge a$
, and
 $t\rightarrow s$
,
$t\rightarrow s$
,
 $t\rightarrow a$
, respectively. Once more the link between these formulas occurs deep inside the formulas themselves.
$t\rightarrow a$
, respectively. Once more the link between these formulas occurs deep inside the formulas themselves.
To deal with this kind of case, Poggiolesi introduces the notions of context and formula in a context that allow to focus on a particular part of the formula at issue.Footnote
9
For example consider again the formula
 $\forall x((Zx\vee SNx)\rightarrow Nx)$
and suppose we want to focus on a particular part of it, say
$\forall x((Zx\vee SNx)\rightarrow Nx)$
and suppose we want to focus on a particular part of it, say
 $Zx\vee SNx$
. We denote this fact by rewriting
$Zx\vee SNx$
. We denote this fact by rewriting
 $\forall x((Zx\vee SNx)\rightarrow Nx)$
as
$\forall x((Zx\vee SNx)\rightarrow Nx)$
as
 $C[Zx\vee SNx]$
, where
$C[Zx\vee SNx]$
, where
 $C[.]$
is the context and
$C[.]$
is the context and
 $Zx\vee SNx$
is the formula in the context
$Zx\vee SNx$
is the formula in the context
 $C[.]$
. Following what has been said above, the reasons why the formula
$C[.]$
. Following what has been said above, the reasons why the formula
 $C[Zx\vee SNx]$
is true will be
$C[Zx\vee SNx]$
is true will be
 $C[Zx]$
and
$C[Zx]$
and
 $C[SNx]$
.
$C[SNx]$
.
Before introducing the formal notion of context, and formula in a context, let us dwell on an important feature of explanations. When working in an explanatory framework, negation needs to be treated with special attention: indeed, as shown in Poggiolesi [Reference Poggiolesi, Boccuni and Sereni21, Reference Poggiolesi23] and Wilhelm [Reference Wilhelm32], otherwise inconsistencies might arise. In order to avoid them (even in the simple case where the context is empty), one needs to distinguish, for instance, between the reasons of formulas of the form
 $\neg (p\vee q)$
and the reasons of formulas of the form
$\neg (p\vee q)$
and the reasons of formulas of the form
 $\neg (\neg p\vee \neg q)$
. In the former case, formulas
$\neg (\neg p\vee \neg q)$
. In the former case, formulas
 $\neg p, \neg q$
explain why
$\neg p, \neg q$
explain why
 $\neg (p\vee q)$
is true, whilst in the latter case, formulas
$\neg (p\vee q)$
is true, whilst in the latter case, formulas
 $p, q$
explain why
$p, q$
explain why
 $\neg (\neg p\vee \neg q)$
is true. Thanks to the notion of converse of a formula, which we have introduced in the §2, we can treat both cases uniformly by simply saying that
$\neg (\neg p\vee \neg q)$
is true. Thanks to the notion of converse of a formula, which we have introduced in the §2, we can treat both cases uniformly by simply saying that
 $A^{\bot }, B^{^{\bot }}$
explain why
$A^{\bot }, B^{^{\bot }}$
explain why
 $\neg (A\vee B)$
is true. Indeed whilst the converse of p (or q) corresponds to
$\neg (A\vee B)$
is true. Indeed whilst the converse of p (or q) corresponds to
 $\neg p$
(
$\neg p$
(
 $\neg q$
), the converse of
$\neg q$
), the converse of
 $\neg p$
(or
$\neg p$
(or
 $\neg q$
) corresponds to p (q).
$\neg q$
) corresponds to p (q).
For contexts, similar care is needed in dealing with negations. Suppose, for instance, that one ignores the issue and, focussing on
 $p\vee q$
and
$p\vee q$
and
 $\neg p\vee \neg q$
, treated the formulas
$\neg p\vee \neg q$
, treated the formulas
 $\neg (p\vee q)$
and
$\neg (p\vee q)$
and
 $\neg (\neg p\vee \neg q)$
as
$\neg (\neg p\vee \neg q)$
as
 $C[p\vee q]$
and
$C[p\vee q]$
and
 $C[\neg p\vee \neg q]$
respectively, where
$C[\neg p\vee \neg q]$
respectively, where
 $C= \neg $
. Then, by breaking the
$C= \neg $
. Then, by breaking the
 $\vee $
, we would get
$\vee $
, we would get
 $C[p], C[q]$
in the former case, and
$C[p], C[q]$
in the former case, and
 $C[\neg p], C[\neg q]$
in the latter. But this corresponds to
$C[\neg p], C[\neg q]$
in the latter. But this corresponds to
 $\neg p$
and
$\neg p$
and
 $\neg q$
, but also to
$\neg q$
, but also to
 $\neg \neg p$
and
$\neg \neg p$
and
 $\neg \neg q$
. In this latter case, the result differs from that obtained when using the empty context, namely,
$\neg \neg q$
. In this latter case, the result differs from that obtained when using the empty context, namely,
 $p, q$
. To avoid these kinds of inconsistencies, contexts are defined so as to exclude substituting a formula into the immediate scope of an odd number of negations.
$p, q$
. To avoid these kinds of inconsistencies, contexts are defined so as to exclude substituting a formula into the immediate scope of an odd number of negations.
Definition 3.1. The set
 $Co$
of contexts is inductively defined in the following way:
$Co$
of contexts is inductively defined in the following way:
-
-
$[.]\in Co$
; -
- if
$C [.]\in Co$
, then
$\neg \neg C [.]$
,
$D\circ C [.]$
,
$C[.]\circ D \in Co$
; -
- if
$C [.]\in Co$
and
$C [.]\neq \overbrace {\neg ...\neg }^{2n} [.]$
, where
$n \geq $
0, then
$\neg C[.] \in Co$
.









Definition 3.2. For all contexts
 $C[.]$
, and formulas A, we define
$C[.]$
, and formulas A, we define
 $C[A]$
, a formula in a context, as follows:
$C[A]$
, a formula in a context, as follows:
-
- if
$C[.] = [.]$
, then
$C[A]=A$
; -
- if
$C[.] = \neg \neg D[.]$
, then
$C[A]= \neg \neg D[A]$
; -
- if
$C [.]$
=
$D^{\prime }\circ D[.]$
,
$D[.]\circ D^{\prime }$
,
$\neg D [.]$
, then
$C[A]$
=
$D^{\prime }\circ D[A]$
,
$D[A]\circ D^{\prime }$
,
$\neg D[A]$
, respectively.












Once formulas are considered in contexts, they will naturally have a polarity which is either positive or negative and that is defined as standard (see, e.g., Troelstra and Schwichtenberg [Reference Troelstra and Schwichtenberg31].
Definition 3.3. We define the set of contexts with positive
 $\mathcal {P}$
and negative polarities
$\mathcal {P}$
and negative polarities
 $\mathcal {N}$
simultaneously by an inductive definition given by the three clauses (i)–(iii) below.
$\mathcal {N}$
simultaneously by an inductive definition given by the three clauses (i)–(iii) below.
-
(i)
$[.] \in \mathcal {P}$
;

if
 $B^{+} \in \mathcal {P}$
,
$B^{+} \in \mathcal {P}$
,
 $B^{-} \in \mathcal {N}$
, and A is any formula, then:
$B^{-} \in \mathcal {N}$
, and A is any formula, then:
-
(ii)
$\neg B^{-}$
,
$A\wedge B^{+}$
,
$B^{+}\wedge A$
,
$A\vee B^{+}$
,
$B^{+}\vee A \in \mathcal {P}$
. -
(iii)
$\neg B^{+}$
,
$A\wedge B^{-}$
,
$B^{-}\wedge A$
,
$A\vee B^{-}$
,
$B^{-}\vee A \in \mathcal {N}$










whenever these objects are in
 $Co$
. We say that a formula A is positive (resp. negative) in a context
$Co$
. We say that a formula A is positive (resp. negative) in a context
 $C[A]$
if
$C[A]$
if
 $C[.] \in \mathcal {P}$
(resp.
$C[.] \in \mathcal {P}$
(resp.
 $C[.] \in \mathcal {N}$
).
$C[.] \in \mathcal {N}$
).
Summing up, we have introduced the two main ideas that characterize Poggiolesi’s formalism. The first idea amounts at looking at explanations as special types of proofs, whilst the second amounts to the requirement of working deep inside formula. Putting them together, we have that Poggiolesi [Reference Poggiolesi25] introduces explanatory rules that deal with formulas in contexts. In other words, explanatory rules will have the form of deep inferences, namely, a recently introduced variation of the sequents calculus (see, e.g., Brünnler [Reference Brünnler4, Reference Guglielmi and Bruscoli11, Reference Pimentel, Ramayanake and Lellmann19]) where rules operate deep inside formulas. Although the literature on deep inferences has been motivated by cornerstone results of structural proof theory, in this context they reveal a profound philosophical significance.
Explanatory propositional calculus (EC).

As already stated, explanatory rules are such that their premisses are the reasons why their conclusion is true. More specifically, explanatory rules provide the total reasons why the conclusion is true, where total reasons typically amount to the multiset of all, and only, those formulas, each of which contributes to explaining another (see also Schaffer [Reference Schaffer28]). Note that the notion of total reasons motivates a distinction that we illustrate with the following example. Jane has a brother, Billy, and a sister, Suzy. Jane also has a niece. Thus the reason why Jane has a niece is that her sister has a girl. Indeed a niece is the girl of someone’s brother or someone’s sister and Suzy, Jane’s sister, has a girl. Jane’s brother could have had a girl, but he does not. Hence Jane’s brother having a girl is merely a potential reason of why Jane has a niece. Potential reasons are also central for total explanations: if Jane’s brother had a girl, this would have been part of the total explanation of why Jane has a niece. We rephrase this distinction between reasons and potential reasons as the one between reasons and conditions. So, for example, we will say that under the condition that Jane’s brother does not have a girl, the total reason why Jane has a niece is that her sister has a daughter. We will indicate the distinction between conditions and reasons with a vertical bar: formulas lying on the left of the vertical bar are conditions, whilst formulas on the right of the vertical bar are reasons. Since every formula on the left side of the bar is actually the converse of a formula, to lighten the presentation, we do not write the converse symbol: we just understand that being on the left of the bar indicates this converse reading, as specified in Definition 3.5.
We now have all the elements needed to introduce sequents for the explanatory calculus EC.
Definition 3.4. For any
 $\alpha $
, A, and multiset
$\alpha $
, A, and multiset
 $X= \{B_{1}, \ldots , B_{n}\}$
, such that
$X= \{B_{1}, \ldots , B_{n}\}$
, such that
 $\alpha $
is an instance of A, but also an instance of each
$\alpha $
is an instance of A, but also an instance of each
 $B_{i}$
, 1
$B_{i}$
, 1
 $\leq i\leq n$
, we have that:
$\leq i\leq n$
, we have that:
-
-
$\alpha \Rightarrow A$
is a sequent; -
-
$X\mid \alpha \Rightarrow A$
is a sequent.


Definition 3.5. The interpretation
 $\tau $
of a sequent is the following:
$\tau $
of a sequent is the following:
-
-
$(\alpha \Rightarrow A)^{\tau }:= \bigwedge \alpha \rightarrow A$
; -
-
$(X\mid \alpha \Rightarrow A)^{\tau }:= (\bigwedge X^{\bot }\wedge \bigwedge \alpha )\rightarrow A$
.


where if
 $X=\{B_{1}, ..., B_{n}\}$
, then
$X=\{B_{1}, ..., B_{n}\}$
, then
 $\bigwedge X^{\bot }= B^{\bot }_{1}\wedge ...\wedge B^{\bot }_{n}$
.
$\bigwedge X^{\bot }= B^{\bot }_{1}\wedge ...\wedge B^{\bot }_{n}$
.
By using sequents as defined above, we introduce the explanatory calculus EC in Figure 1. Note that EC results from a modification, but also a generalization, of the ideas conveyed in Poggiolesi [Reference Poggiolesi25]. In particular, (i) whilst Poggiolesi introduces explanatory rules for first-order formulas, here we limit ourselves to propositional formulas; (ii) secondly, whilst in the sequents used by Poggiolesi, antecedents and consequents of sequents are multisets of formulas, in the present case, the antecedent is an instance, and the consequent is a single formula; (iii) thirdly, whilst Poggiolesi added explanatory rules to the standard sequent calculus for first-order classical logic, here, in a way similar to that proposed by Genco [Reference Genco10], explanatory rules plus axioms constitute a calculus on its own. (iv) Finally, in the present work conditions are generalized to multisets of formulas. Following the notation introduced in Poggiolesi [Reference Poggiolesi25], we write explanatory rules with a double line; the double line signals that not only is the conclusion inferable from the premisses, but also the premisses are the (total) reasons why the conclusion is true.Footnote 10
Definition 3.6. We assume the application of explanatory propositional rulesFootnote 11 to obey the following restrictions:
-
- rule
$\circ _2$
can be applied on a formula of the form
$C[A\circ B]$
if:
$\bigg \{ \begin {array}{@{}ll} \scriptstyle C\in \mathcal {P}\;and\; \circ =\vee , or\\ \scriptstyle C\in \mathcal {N}\;and\;\circ =\wedge .\\ \end {array} $
-
- rule
$\neg \circ _2$
can be applied on a formula of the form
$C[\neg (A\circ B)]$
if:
$\bigg \{ \begin {array}{@{}ll} \scriptstyle C\in \mathcal {P}\;and\;\circ =\wedge , or\\ \scriptstyle C\in \mathcal {N}\;and\;\circ =\vee .\\ \end {array}$






We now comment on the rules of the explanatory sequent calculus. Each of these rules is supposed to capture cases where the premisses are the total reasons for the conclusions.Footnote
12
Some examples are clear: for instance p and q are clearly the reasons for
 $p \wedge q$
; and rule
$p \wedge q$
; and rule
 $\circ _1$
reflects this. Let us then dwell on the less obvious and more novel cases. First of all, note that there is no rule for single negation. This is because explanations notoriously go from (potentially) true formulas to (potentially) true formulas; there can thus be no rule which acts, as in the case of the rule for negation in the standard sequent calculus, by shifting formulas from one side of the sequent to another. In other words, one cannot explain the truth of
$\circ _1$
reflects this. Let us then dwell on the less obvious and more novel cases. First of all, note that there is no rule for single negation. This is because explanations notoriously go from (potentially) true formulas to (potentially) true formulas; there can thus be no rule which acts, as in the case of the rule for negation in the standard sequent calculus, by shifting formulas from one side of the sequent to another. In other words, one cannot explain the truth of
 $\neg A$
, from the falsity of A. Instead negation is spread over the other connectives: either it is analyzed when it is double, or when it is in front of conjunction and disjunction. Note that, for reasons mentioned above (when introducing contexts) and which are discussed in Poggiolesi [Reference Poggiolesi20], the connective of negation must be carefully treated in an explanatory context; this is why the converse of a formula (see Definition 2.2) is used in the rules
$\neg A$
, from the falsity of A. Instead negation is spread over the other connectives: either it is analyzed when it is double, or when it is in front of conjunction and disjunction. Note that, for reasons mentioned above (when introducing contexts) and which are discussed in Poggiolesi [Reference Poggiolesi20], the connective of negation must be carefully treated in an explanatory context; this is why the converse of a formula (see Definition 2.2) is used in the rules
 $\neg \circ _{1}$
and
$\neg \circ _{1}$
and
 $\neg \circ _{2}$
.Footnote
13
$\neg \circ _{2}$
.Footnote
13
Let us now turn to those rules that do not involve conditions: i.e.,
 $\neg \neg , \circ _{1}$
and
$\neg \neg , \circ _{1}$
and
 $\neg \circ _{1}$
. Each of them stands as a straightforward generalization of standard rules concerning classical connectives, allowing them to apply deep inside formulas. This is so because these rules are not merely intended to be simple inferential rules but explanatory rules, i.e., rules that provide the (total) reason(s) why their conclusion is true. The relation between reason(s) and conclusion might hold in virtue of elements that lie inside formulas, so the rules need to reflect this possibility.
$\neg \circ _{1}$
. Each of them stands as a straightforward generalization of standard rules concerning classical connectives, allowing them to apply deep inside formulas. This is so because these rules are not merely intended to be simple inferential rules but explanatory rules, i.e., rules that provide the (total) reason(s) why their conclusion is true. The relation between reason(s) and conclusion might hold in virtue of elements that lie inside formulas, so the rules need to reflect this possibility.
Let us now move to the rules which involves conditions, namely, the rules
 $\circ _{2}$
,
$\circ _{2}$
,
 $\neg \circ _{2}$
. These rules naturally emerge for total explanations, i.e., explanations where all the reasons why a conclusion is true need to be evoked. In this setting, conditions need to be mentioned to prevent equivocation between total and partial explanations (see, e.g., Poggiolesi [Reference Poggiolesi20]). Consider the example: John got into the University, and he is rich or he passed the entrance exam. Suppose that in fact John got into the University, he is rich, but he did not pass the entrance exam. In this example, the explanation why it is true that John got into the University, and he is rich or he passed the entrance exam is that John got into University and he is rich. However, if nothing is said about the passing exam, the explanation remains ambiguous: it is indeed unclear whether the explanandum is true also because John got into University and passed the entrance exam. Conditions allow disambiguation of the explanation. Thus we say that, under the condition that it is not the case that John got into University and passed the entrance exam, it is true that John got into the University, and he is rich or he passed the entrance exam, because John got into University and he is rich. On formal terms, let us denote the sentence “John gets into the University, and he is either rich or it has passed the entrance exam,” with the formula
$\neg \circ _{2}$
. These rules naturally emerge for total explanations, i.e., explanations where all the reasons why a conclusion is true need to be evoked. In this setting, conditions need to be mentioned to prevent equivocation between total and partial explanations (see, e.g., Poggiolesi [Reference Poggiolesi20]). Consider the example: John got into the University, and he is rich or he passed the entrance exam. Suppose that in fact John got into the University, he is rich, but he did not pass the entrance exam. In this example, the explanation why it is true that John got into the University, and he is rich or he passed the entrance exam is that John got into University and he is rich. However, if nothing is said about the passing exam, the explanation remains ambiguous: it is indeed unclear whether the explanandum is true also because John got into University and passed the entrance exam. Conditions allow disambiguation of the explanation. Thus we say that, under the condition that it is not the case that John got into University and passed the entrance exam, it is true that John got into the University, and he is rich or he passed the entrance exam, because John got into University and he is rich. On formal terms, let us denote the sentence “John gets into the University, and he is either rich or it has passed the entrance exam,” with the formula
 $p\wedge (q\vee r)$
. Let us apply on this formula, focussing on the disjunction, the following instance of the rule
$p\wedge (q\vee r)$
. Let us apply on this formula, focussing on the disjunction, the following instance of the rule
 $\circ _{2}$
, we get:
$\circ _{2}$
, we get:

The rule can be applied since
 $\circ $
is a disjunction with a positive polarity (see Definition 3.6). Thanks to the rule
$\circ $
is a disjunction with a positive polarity (see Definition 3.6). Thanks to the rule
 $\circ _{2}$
, we can explain the formula
$\circ _{2}$
, we can explain the formula
 $p\wedge (q\vee r)$
by the formula
$p\wedge (q\vee r)$
by the formula
 $p\wedge r$
, which represents the total reason why it is true under the condition that the formula
$p\wedge r$
, which represents the total reason why it is true under the condition that the formula
 $p\wedge q$
does not hold. The rule matches what we have just been discussing and thus stands as an adequate instance of the rule.
$p\wedge q$
does not hold. The rule matches what we have just been discussing and thus stands as an adequate instance of the rule.
Applications of rules deep inside formulas with conditions involve some limitations: these limitations serve to preserve an adequate notion of explanation. For example, consider the formula
 $p\rightarrow (q\wedge r)$
. One cannot apply the rule
$p\rightarrow (q\wedge r)$
. One cannot apply the rule
 $\circ _{2}$
on the conjunction of this formula, since the conjunction occurs with positive polarity. On the other hand, this limitation is recommended. Indeed, the rule might have the following instance:
$\circ _{2}$
on the conjunction of this formula, since the conjunction occurs with positive polarity. On the other hand, this limitation is recommended. Indeed, the rule might have the following instance:

and it is easy to check that the formula
 $(\Rightarrow p\rightarrow (q\wedge r))^{\tau }$
is not even derivable from the formula
$(\Rightarrow p\rightarrow (q\wedge r))^{\tau }$
is not even derivable from the formula
 $(p\rightarrow q\mid \Rightarrow p\rightarrow r)^{\tau }$
(see Definition 3.5 for the interpretation of sequent).
$(p\rightarrow q\mid \Rightarrow p\rightarrow r)^{\tau }$
(see Definition 3.5 for the interpretation of sequent).
Finally note that explanatory rules do not distinguish between formulas that are equivalent by associativity and commutativity of conjunction and disjunction. This is an hyperintensional feature of the calculus, in line with the fact that explanation is an hyperintensional notion (see, e.g., Berto and Nolan [Reference Berto, Nolan, Zalta and Nodelman2] and Leitgeb [Reference Leitgeb15]).
Definition 3.7. Let
 $\vdash _{EC}X\mid \alpha \Rightarrow A$
denote that there exists a derivation of the sequent
$\vdash _{EC}X\mid \alpha \Rightarrow A$
denote that there exists a derivation of the sequent
 $X\mid \alpha \Rightarrow A$
in the explanatory calculus
$X\mid \alpha \Rightarrow A$
in the explanatory calculus
 $EC$
.
$EC$
.
Theorem 3.8. For any X,
 $\alpha $
and A, if
$\alpha $
and A, if
 $\vdash _{EC}X\mid \alpha \Rightarrow A$
, then
$\vdash _{EC}X\mid \alpha \Rightarrow A$
, then
 $\models (X\mid \alpha \Rightarrow A)^{\tau }$
.
$\models (X\mid \alpha \Rightarrow A)^{\tau }$
.
Proof. Straightforward, given Theorem 5.7 in [Reference Poggiolesi25].
Theorem 3.9. For any
 $\alpha $
and A, if
$\alpha $
and A, if
 $\alpha \models A$
, then
$\alpha \models A$
, then
 $\vdash _{EC} \alpha \Rightarrow A$
.
$\vdash _{EC} \alpha \Rightarrow A$
.
Proof. Suppose
 $\alpha \Rightarrow A$
is not a derivable sequent. This means that whatever sequence of the explanatory rules
$\alpha \Rightarrow A$
is not a derivable sequent. This means that whatever sequence of the explanatory rules
 $\neg \neg , \circ _{1}, \neg \circ _{1}$
we apply on A, we will end up with leafs of the form
$\neg \neg , \circ _{1}, \neg \circ _{1}$
we apply on A, we will end up with leafs of the form
 $\alpha , p\Rightarrow \neg p$
, or
$\alpha , p\Rightarrow \neg p$
, or
 $\alpha , \neg p\Rightarrow p$
. This means that if we assign evaluation 1 to the literals on the left side of the sequent, the literals on the right side of the sequents will have evaluation 0. Since, as it has been shown in Theorem 5.7 in [Reference Poggiolesi25], explanatory rules preserve the evaluation 0, then A will have evaluation 0 as well. Hence we have found an evaluation witnessing that A is not a logical consequence of
$\alpha , \neg p\Rightarrow p$
. This means that if we assign evaluation 1 to the literals on the left side of the sequent, the literals on the right side of the sequents will have evaluation 0. Since, as it has been shown in Theorem 5.7 in [Reference Poggiolesi25], explanatory rules preserve the evaluation 0, then A will have evaluation 0 as well. Hence we have found an evaluation witnessing that A is not a logical consequence of
 $\alpha $
.
$\alpha $
.
4 From the sequent calculus to sufficient reasons
We now describe how to use the explanatory calculus to extract sufficient (but also, as we will show, complete) reasons out of a decision. To do so, we first of all give instructions on how to define a comprehensive derivation of a sequent
 $\alpha \Rightarrow A$
, where the notion of comprehensive derivation is a crucial ingredient for extracting sufficient reasons out of decisions. Indeed, the main novelty of the calculus
$\alpha \Rightarrow A$
, where the notion of comprehensive derivation is a crucial ingredient for extracting sufficient reasons out of decisions. Indeed, the main novelty of the calculus
 $EC$
is the following. In any standard sequent calculus, given a formula A, say of the form
$EC$
is the following. In any standard sequent calculus, given a formula A, say of the form
 $s\wedge ((p\wedge q)\vee r)$
, the calculus will operate first on the main connective
$s\wedge ((p\wedge q)\vee r)$
, the calculus will operate first on the main connective
 $\wedge $
, then on the connective
$\wedge $
, then on the connective
 $\vee $
, finally on
$\vee $
, finally on
 $\wedge $
again. In the calculus
$\wedge $
again. In the calculus
 $EC$
, instead, one can start from whatever connective one prefers, i.e., either
$EC$
, instead, one can start from whatever connective one prefers, i.e., either
 $\wedge $
, or
$\wedge $
, or
 $\vee $
. In a comprehensive derivation it is demanded that the rules of
$\vee $
. In a comprehensive derivation it is demanded that the rules of
 $EC$
canonically apply to the innermost connective,Footnote
14
e.g., in the A above, the
$EC$
canonically apply to the innermost connective,Footnote
14
e.g., in the A above, the
 $\wedge $
which links p and q. This feature is crucial because working with the innermost connective uncovers potential analytic subformulas that do not contribute to the collection of the complete reasons of a decision.
$\wedge $
which links p and q. This feature is crucial because working with the innermost connective uncovers potential analytic subformulas that do not contribute to the collection of the complete reasons of a decision.
The second feature of comprehensive derivations concern rules
 $\circ _{2}$
or
$\circ _{2}$
or
 $\neg \circ _{2}$
. Typically, these rules keep one formula in the sequent, whilst they put the other in the conditions. In comprehensive derivations, any formula
$\neg \circ _{2}$
. Typically, these rules keep one formula in the sequent, whilst they put the other in the conditions. In comprehensive derivations, any formula
 $B_i$
in the conditions X is such that
$B_i$
in the conditions X is such that
 $\alpha \Rightarrow B_{i}$
is neither an axiom nor derivable via explanatory rules. In terms of the example of the classifier
$\alpha \Rightarrow B_{i}$
is neither an axiom nor derivable via explanatory rules. In terms of the example of the classifier
 $\mathcal {C}$
and applicants Greg or Susan, in comprehensive derivations, rules
$\mathcal {C}$
and applicants Greg or Susan, in comprehensive derivations, rules
 $\circ _{2}$
or
$\circ _{2}$
or
 $\neg \circ _{2}$
serve to separate those characteristics of the applicant that contribute to the success of the application—these characteristics are kept in the sequents—from those characteristics that do not contribute to the success of the application—these characteristics are put in the conditions.
$\neg \circ _{2}$
serve to separate those characteristics of the applicant that contribute to the success of the application—these characteristics are kept in the sequents—from those characteristics that do not contribute to the success of the application—these characteristics are put in the conditions.
Comprehensive derivations can easily be constructed using the algorithm provided in Appendix A, which makes clearer how comprehensive derivations work (see also the examples after Definition 4.6).
Definition 4.1. The depth of a subformula in a formula is the number of connectives it is nested into. So, for the example, the depth of
 $B\vee C$
in the formula
$B\vee C$
in the formula
 $E\wedge (B\vee C)$
is 1; whilst the depth of
$E\wedge (B\vee C)$
is 1; whilst the depth of
 $B\vee C$
in the formula
$B\vee C$
in the formula
 $(E\vee ((F\wedge (B\vee C))\wedge (G\wedge H)))\wedge (G\vee H\vee R)$
is 4.
$(E\vee ((F\wedge (B\vee C))\wedge (G\wedge H)))\wedge (G\vee H\vee R)$
is 4.
Definition 4.2. Consider the sequent
 $\alpha \Rightarrow A$
. A derivation d of
$\alpha \Rightarrow A$
. A derivation d of
 $\alpha \Rightarrow A$
is comprehensive if (reading the derivation top-down):
$\alpha \Rightarrow A$
is comprehensive if (reading the derivation top-down):
-
1. For every sequent of the form
$X \mid \alpha \Rightarrow A'$
appearing in d and every
$B_i \in X$
,
$\alpha \Rightarrow B_{i}$
is neither an axiom nor derivable via explanatory rules. -
2. If
$R \circ ' \overbrace {\neg \cdots \neg }^{m}(B_1 \circ " B_2)$
is a subformula of
$A'$
with
$\alpha \Rightarrow A'$
appearing in d, for
$\circ ', \circ " \in \{\vee , \wedge \}$
, with
$\circ ' \neq \circ "$
if
$m = 2n$
, and
$\circ ' = \circ "$
if
$m = 2n + 1$
, then:-
(a) if
$(B_1 \circ " B_2)\neq (l \vee \neg l), (l \wedge \neg l)$
for any extended literal
$l$
, then any rule applied on
$\circ '$
in this subformula is higher in d than every rule applied on
$\circ "$
; -
(b) if
$(B_1 \circ " B_2) = (l \vee \neg l), (l \wedge \neg l),$
for any extended literal
$l$
, then any rule applied on
$\circ "$
in this subformula is higher in d than every rule applied on
$\circ '$
.
-
-
3. If
$B_{1}\circ ' \ldots \circ ' B_{r}$
is a subformula of
$A'$
with
$\alpha \Rightarrow A'$
appearing in d, where each
$B_i = \overbrace {\neg \cdots \neg }^{2n}(l_{1}\circ " \ldots \circ " l_{r_i})$
or
$\overbrace {\neg \cdots \neg }^{2n + 1}(l^{\prime }_{1}\circ " \ldots \circ " l^{\prime }_{r^{\prime }_i})$
for
$\circ ', \circ " \in \{\vee , \wedge \}$
,
$\circ ' \neq \circ "$
, then any application of rules
$\circ _2$
,
$\neg \circ _2$
in d with main connective in this subformula occurs below applications of other rules with main connective in this subformula.




























Comprehensive derivations are derivations with (i) specifications on the order of application of rules, and (ii) restrictions on application of rules
 $\circ _{2}$
and
$\circ _{2}$
and
 $\neg \circ _{2}$
. A quick reflection is enough to see that (ii) is an essential feature to reach axioms, reading derivations bottom-up; so it is not restrictive. As for (i), it is straightforward to check that, in the calculus
$\neg \circ _{2}$
. A quick reflection is enough to see that (ii) is an essential feature to reach axioms, reading derivations bottom-up; so it is not restrictive. As for (i), it is straightforward to check that, in the calculus
 $EC$
, whenever rules are applied on the
$EC$
, whenever rules are applied on the
 $\vee $
and
$\vee $
and
 $\wedge $
connectives in a derivation of a sequent with no conditions, then there exists a derivation of the same sequent with the order of these rules inverted.Footnote
15
Hence it follows from Theorem 3.9 that, whenever
$\wedge $
connectives in a derivation of a sequent with no conditions, then there exists a derivation of the same sequent with the order of these rules inverted.Footnote
15
Hence it follows from Theorem 3.9 that, whenever
 $\alpha \models A$
, there exists a comprehensive derivation of
$\alpha \models A$
, there exists a comprehensive derivation of
 $\alpha \Rightarrow A$
. Moreover, comprehensive derivations can easily be constructed using a version of a standard proof search algorithm: details are provided in Appendix A. The constructed derivation is guaranteed to have proof height (maximal length of a branch from root to leaf) at most the complexity of the classifier A. Finally, it is worth noticing that in comprehensive derivations, conditions end up containing subformulas of A that do not logically follow from the instance
$\alpha \Rightarrow A$
. Moreover, comprehensive derivations can easily be constructed using a version of a standard proof search algorithm: details are provided in Appendix A. The constructed derivation is guaranteed to have proof height (maximal length of a branch from root to leaf) at most the complexity of the classifier A. Finally, it is worth noticing that in comprehensive derivations, conditions end up containing subformulas of A that do not logically follow from the instance
 $\alpha $
.
$\alpha $
.
Definition 4.3. Let
 $\tau _{1}, \ldots , \tau _{n}$
be terms. We use the notation
$\tau _{1}, \ldots , \tau _{n}$
be terms. We use the notation
 $\tau _{1}- \cdots -\tau _{n}$
, for
$\tau _{1}- \cdots -\tau _{n}$
, for
 $n\geq 1$
, to indicate a list of separated terms.
$n\geq 1$
, to indicate a list of separated terms.
Definition 4.4. We define two sets of applications of explanatory rules:
-
-
$S_{1}$
contains: rule
$\circ _{1}$
applied on formulas of the form
$C[A\wedge B]$
, where
$C[.]\in \mathcal {P}$
, or on formulas of the form
$C[A\vee B]$
, where
$C[.]\in \mathcal {N}$
, as well as rule
$\neg \circ _{1}$
applied on formulas of the form
$C[\neg (A\vee B)]$
, where
$C[.]\in \mathcal {P}$
or on formulas of the form
$C[\neg (A\wedge B)]$
, where
$C[.]\in \mathcal {N}$
. -
-
$S_{2}$
contains: rule
$\circ _1$
applied on formulas of the form
$C[A\vee B]$
, where
$C[.]\in \mathcal {P}$
or on formulas of the form
$C[A\wedge B]$
, where
$C[.]\in \mathcal {N}$
, as well as rule
$\neg \circ _{1}$
applied on formulas of the form
$C[\neg (A\wedge B)]$
, where
$C[.]\in \mathcal {N}$
or on formulas of the form
$C[\neg (A\vee B)]$
, where
$C[.]\in \mathcal {P}$
.






















To obtain sufficient reasons from comprehensive derivations, we employ the following labelling of derivations.
Definition 4.5. Let d be a comprehensive derivation of
 $\alpha \Rightarrow A$
. The labelling of (the sequents in) d by lists of separated terms is defined inductively as follows:
$\alpha \Rightarrow A$
. The labelling of (the sequents in) d by lists of separated terms is defined inductively as follows:
-
1. For each leaf of d, if it is of one of the two following forms:
-
(i)
$X, \overbrace {\neg \cdots \neg }^{2n +1}p\mid \alpha \Rightarrow p;$
-
(ii)
$X, \overbrace {\neg \cdots \neg }^{2n}p\mid \alpha \Rightarrow \neg p,$
for some integer n then associate with the leaf the empty set. Otherwise, associate with the leaf the set
$\{p\}$
or
$\{\neg p\}$
, where p or
$\neg p$
, respectively, are the literals on the right side of the sequent. -
-
2. For any sequent in d, if one of the rules
$\neg \neg $
,
$\circ _{2}, \neg \circ _{2}$
has been applied to obtain this sequent, and
$\tau _{1}-\cdots - \tau _{n}$
is the label associated with the premisse of the rule, then
$\tau _{1}-\cdots - \tau _{n}$
is label associated with the sequent. -
3. For any sequent in d, if any of the rules belonging to
$S_{1}$
have been applied to obtain this sequent, and the labels associated with the premisses of the rule are
$\tau _{n_1} -\cdots - \tau _{n_i}$
and
$\tau _{m_1}-\cdots - \tau _{m_j}$
, then the label associated with the sequent is the minimal sublist of
$\tau _{n1}\cup \tau _{m1} -\tau _{n1}\cup \tau _{m2} - \cdots - \tau _{nk}\cup \tau _{ml}$
. -
4. For any sequent in d, if any of the rules belonging to
$S_{2}$
have been applied to obtain this sequent, and the labels associated with the premisses of the node are
$\tau _{n1}-\cdots - \tau _{nk}$
and
$\tau _{m1}-\cdots - \tau _{mj}$
, then the label associated with the sequent is the minimal sublist of
$\tau _{n1}-\cdots - \tau _{nk}-\tau _{m1}-\cdots - \tau _{mj}$
. -
5. Consider the list of separated terms associated with the conclusion
$\alpha \Rightarrow A$
of the derivation d. For any two sets
$\tau _{i}$
and
$\tau _{j}$
belonging to the list, it should never be the case that
$\tau _{i}\subseteq \tau _{j}$
. If so, eliminate the bigger set. Filtering this way the list, we obtain
$SR$
the set of all sets belonging to the (possibly filtered) list,






















where the minimal sublist of a list of separated terms
 $\tau _{1}-\cdots - \tau _{n}$
contains all and only
$\tau _{1}-\cdots - \tau _{n}$
contains all and only
 $\tau _i$
such that
$\tau _i$
such that
 $\forall j \neq i,\ \tau _i \not \subset \tau _j$
.
$\forall j \neq i,\ \tau _i \not \subset \tau _j$
.
Definition 4.6. Let d be a comprehensive derivation of
 $\alpha \Rightarrow A$
, equipped with the labelling defined above, and let
$\alpha \Rightarrow A$
, equipped with the labelling defined above, and let
 $\tau _{1}-\cdots - \tau _{n}$
be the label of the conclusion.
$\tau _{1}-\cdots - \tau _{n}$
be the label of the conclusion.
 $SR = \{\tau _i: i = 1, \ldots , n\}$
.
$SR = \{\tau _i: i = 1, \ldots , n\}$
.
The labelling in Definition 4.5 specifies inductively reasons for each sequent in the derivation. Since sufficient reasons have to be minimal, the definition works in such a way that all those reasons labelling the conclusion that are not minimal, i.e., such that they are subsumed by another reason labelling the conclusion, are filtered. Below we shall show that
 $SR$
corresponds to the set of sufficient reasons for a decision
$SR$
corresponds to the set of sufficient reasons for a decision
 $A(\alpha )$
; it follows that the
$A(\alpha )$
; it follows that the
 $SR$
for
$SR$
for
 $\alpha \Rightarrow A$
only depends on the sequent and is independent of the comprehensive derivation of this sequent used.
$\alpha \Rightarrow A$
only depends on the sequent and is independent of the comprehensive derivation of this sequent used.
As an example, consider again classifier
 $\mathcal {C}$
represented by the formula
$\mathcal {C}$
represented by the formula
 $A= e\wedge (\neg f\vee w\vee g)$
, and the case of Greg (the case of Susan can be treated analogously), which can be summed up by the following instance
$A= e\wedge (\neg f\vee w\vee g)$
, and the case of Greg (the case of Susan can be treated analogously), which can be summed up by the following instance
 $\alpha = (e, \neg f, w, \neg g)$
. Greg is admitted by classifier C:
$\alpha = (e, \neg f, w, \neg g)$
. Greg is admitted by classifier C:
 $\alpha \models A$
. It is easy to check that the following is a comprehensive derivation d of
$\alpha \models A$
. It is easy to check that the following is a comprehensive derivation d of
 $\alpha \Rightarrow A$
:
$\alpha \Rightarrow A$
:

Terms associated with d. The two top-left leafs are associated with the two lists of separated terms
 $\{e\}$
and
$\{e\}$
and
 $\{\neg f\}$
, whilst the two top-right leafs are associated with the two lists of separated terms
$\{\neg f\}$
, whilst the two top-right leafs are associated with the two lists of separated terms
 $\{e\}$
and
$\{e\}$
and
 $\{w\}$
. Since for each pair of sequents associated with the lists of separated terms mentioned above a rule belonging to
$\{w\}$
. Since for each pair of sequents associated with the lists of separated terms mentioned above a rule belonging to
 $S_{1}$
has been applied, we get on the one side
$S_{1}$
has been applied, we get on the one side
 $\{e, \neg f\}$
and on the other side
$\{e, \neg f\}$
and on the other side
 $\{e, w\}$
. In each case, we then have the rule
$\{e, w\}$
. In each case, we then have the rule
 $\circ _{2}$
followed by a rule belonging to
$\circ _{2}$
followed by a rule belonging to
 $S_{2}$
, hence we get the list of separated terms
$S_{2}$
, hence we get the list of separated terms
 $\{e, \neg f\}$
-
$\{e, \neg f\}$
-
 $\{e, w\}$
. Following the procedure of Definition 4.5, we conclude that
$\{e, w\}$
. Following the procedure of Definition 4.5, we conclude that
 $SR=\{\{e, \neg f\}$
,
$SR=\{\{e, \neg f\}$
,
 $\{e, w\}\}$
is the set of two terms associated with derivation d of the sequent
$\{e, w\}\}$
is the set of two terms associated with derivation d of the sequent
 $e, \neg f, w, \neg g\Rightarrow e\wedge ((\neg f\vee w)\vee g)$
.
$e, \neg f, w, \neg g\Rightarrow e\wedge ((\neg f\vee w)\vee g)$
.
As further illustration, consider now the classifier
 $C^{\prime }$
, which is represented by the formula
$C^{\prime }$
, which is represented by the formula
 $A^{\prime }=(p\wedge q)\vee (r\wedge \neg q)$
, and which was mentioned in §2 as a more difficult example to treat. The sufficient reasons of, for instance,
$A^{\prime }=(p\wedge q)\vee (r\wedge \neg q)$
, and which was mentioned in §2 as a more difficult example to treat. The sufficient reasons of, for instance,
 $\alpha ^{\prime } = \{p, q, r\}$
are
$\alpha ^{\prime } = \{p, q, r\}$
are
 $\{p, q\}$
and
$\{p, q\}$
and
 $\{p, r\}$
; we now show how our procedure is able to generate them. First of all, it is easy to check that the following is a comprehensive derivation d of
$\{p, r\}$
; we now show how our procedure is able to generate them. First of all, it is easy to check that the following is a comprehensive derivation d of
 $\alpha ^{\prime }\Rightarrow A^{\prime }$
:
$\alpha ^{\prime }\Rightarrow A^{\prime }$
:

Terms associated with d. The four top-left leafs are associated with the four lists of separated terms
 $\{p\}$
,
$\{p\}$
,
 $\{r\}$
,
$\{r\}$
,
 $\{q\}$
and
$\{q\}$
and
 $\{r\}$
. Since for each pair of lists of separated terms,
$\{r\}$
. Since for each pair of lists of separated terms,
 $\{p\}$
and
$\{p\}$
and
 $\{r\}$
on the one side, and
$\{r\}$
on the one side, and
 $\{q\}$
and
$\{q\}$
and
 $\{r\}$
on the other side, a rule belonging to the set
$\{r\}$
on the other side, a rule belonging to the set
 $S_{2}$
has been applied, we get
$S_{2}$
has been applied, we get
 $\{p\}$
-
$\{p\}$
-
 $\{r\}$
and
$\{r\}$
and
 $\{q\}$
-
$\{q\}$
-
 $\{r\}$
, respectively. To the two sequents corresponding to these two lists of separated terms, a rule belonging to
$\{r\}$
, respectively. To the two sequents corresponding to these two lists of separated terms, a rule belonging to
 $S_{1}$
has been applied and thus we get,
$S_{1}$
has been applied and thus we get,
 $\{p, q\}$
-
$\{p, q\}$
-
 $\{p, r\}$
-
$\{p, r\}$
-
 $\{r, q\}$
-
$\{r, q\}$
-
 $\{r\}$
. By filtering it, we get the minimal list
$\{r\}$
. By filtering it, we get the minimal list
 $\{p, q\}$
-
$\{p, q\}$
-
 $\{r\}$
.
$\{r\}$
.
Let us now move to the two top-right leafs, which are associated with the two lists of separated terms
 $\{p\}$
and
$\{p\}$
and
 $\emptyset $
. To each sequent corresponding to these lists the rule
$\emptyset $
. To each sequent corresponding to these lists the rule
 $\circ _{2}$
has been applied, so the two lists remain the same. Since, afterwards a rule belonging to the set
$\circ _{2}$
has been applied, so the two lists remain the same. Since, afterwards a rule belonging to the set
 $S_{1}$
has been applied, one gets
$S_{1}$
has been applied, one gets
 $\{p\}$
.
$\{p\}$
.
Now we have two sequents associated with the lists of separated terms
 $\{p, q\}$
-
$\{p, q\}$
-
 $\{r\}$
and
$\{r\}$
and
 $\{p\}$
, respectively. Since a rule belonging to the set
$\{p\}$
, respectively. Since a rule belonging to the set
 $S_{1}$
has been applied on them, we get the terms
$S_{1}$
has been applied on them, we get the terms
 $\{p, q\}$
-
$\{p, q\}$
-
 $\{p, r\}$
. Hence, following the procedure of Definition 4.5, we conclude that
$\{p, r\}$
. Hence, following the procedure of Definition 4.5, we conclude that
 $SR=\{\{p, q\}$
and
$SR=\{\{p, q\}$
and
 $\{p, r\}\}$
is the set of terms associated with the sequent
$\{p, r\}\}$
is the set of terms associated with the sequent
 $\alpha ^{\prime }\Rightarrow (p\wedge q)\vee (r\wedge \neg q)$
.
$\alpha ^{\prime }\Rightarrow (p\wedge q)\vee (r\wedge \neg q)$
.
5 Getting the complete reasons via the sequent calculus
In this section we show that, for any decision
 $A(\alpha )$
, our procedure generates the set of all sufficient reasons for it, or equivalently, its complete reason. To do so however, we first need to show some preliminary lemmas.
$A(\alpha )$
, our procedure generates the set of all sufficient reasons for it, or equivalently, its complete reason. To do so however, we first need to show some preliminary lemmas.
Lemma 5.1. If
 $SR$
, the set of terms associated with a comprehensive derivation of the sequent
$SR$
, the set of terms associated with a comprehensive derivation of the sequent
 $X\mid \alpha \Rightarrow A$
, only contains the term
$X\mid \alpha \Rightarrow A$
, only contains the term
 $\tau =\emptyset $
, then the translation
$\tau =\emptyset $
, then the translation
 $\delta $
of
$\delta $
of
 ${X\mid \alpha \Rightarrow A}$
, namely
${X\mid \alpha \Rightarrow A}$
, namely
 $(X\mid \alpha \Rightarrow A)^{\delta }:= B^{\bot }_{1}\wedge \cdots \wedge B^{\bot }_{n}\rightarrow A$
, is a tautology, where
$(X\mid \alpha \Rightarrow A)^{\delta }:= B^{\bot }_{1}\wedge \cdots \wedge B^{\bot }_{n}\rightarrow A$
, is a tautology, where
 ${X=\{B_{1}, \ldots , B_{n}\}.}$
${X=\{B_{1}, \ldots , B_{n}\}.}$
Proof. Suppose d is a comprehensive derivation of the sequent
 $X\mid \alpha \Rightarrow A$
and
$X\mid \alpha \Rightarrow A$
and
 $SR$
, the set of terms associated with it, contains the empty set. We reason by induction on the height of d.
$SR$
, the set of terms associated with it, contains the empty set. We reason by induction on the height of d.
[-] Suppose
 $X\mid \alpha \Rightarrow A$
is an axiom, then, since the term associated with it is
$X\mid \alpha \Rightarrow A$
is an axiom, then, since the term associated with it is
 $\emptyset $
, then
$\emptyset $
, then
 $X\mid \alpha \Rightarrow A$
needs to be of either of one of the forms (i) or (ii) of Definition 4.5. It is straightforward to see that the translation
$X\mid \alpha \Rightarrow A$
needs to be of either of one of the forms (i) or (ii) of Definition 4.5. It is straightforward to see that the translation
 $\delta $
of each of them is indeed a tautology.
$\delta $
of each of them is indeed a tautology.
[-] Suppose
 $X\mid \alpha \Rightarrow A$
is such that
$X\mid \alpha \Rightarrow A$
is such that
 $A=C[B\wedge D]$
and
$A=C[B\wedge D]$
and
 $C[.]\in \mathcal {P}$
and the last rule of d is
$C[.]\in \mathcal {P}$
and the last rule of d is
 $\circ _{1}$
. Then we have the following situation:
$\circ _{1}$
. Then we have the following situation:

where the lists of separated terms associated with each of the premisses of this rule are
 $\emptyset $
. By inductive hypothesis we have that
$\emptyset $
. By inductive hypothesis we have that
 $(X\mid \alpha \Rightarrow C[B])^{\delta }$
and
$(X\mid \alpha \Rightarrow C[B])^{\delta }$
and
 $(X\mid \alpha \Rightarrow C[D])^{\delta }$
are tautologies. But then by logic, since
$(X\mid \alpha \Rightarrow C[D])^{\delta }$
are tautologies. But then by logic, since
 $C[.]\in \mathcal {P}$
,
$C[.]\in \mathcal {P}$
,
 $(X\mid \alpha \Rightarrow C[B\wedge D])^{\delta }$
is a tautology.
$(X\mid \alpha \Rightarrow C[B\wedge D])^{\delta }$
is a tautology.
[-] Suppose
 $X\mid \alpha \Rightarrow A$
is such that
$X\mid \alpha \Rightarrow A$
is such that
 $A=C[B\vee D]$
and
$A=C[B\vee D]$
and
 $C[.]\in \mathcal {P}$
and the last rule of d is
$C[.]\in \mathcal {P}$
and the last rule of d is
 $\circ _{2}$
. Then we have the following situation:
$\circ _{2}$
. Then we have the following situation:

where the list of separated terms associated with the premisse is
 $\emptyset $
. By inductive hypothesis we have that
$\emptyset $
. By inductive hypothesis we have that
 $(X, C[D]\mid \alpha \Rightarrow C[B])^{\delta }$
is a tautology. This means that
$(X, C[D]\mid \alpha \Rightarrow C[B])^{\delta }$
is a tautology. This means that
 $\bigwedge X^{\bot }\wedge C[D]^{\bot }\wedge \bigwedge \alpha \rightarrow C[B]$
is a tautology. But
$\bigwedge X^{\bot }\wedge C[D]^{\bot }\wedge \bigwedge \alpha \rightarrow C[B]$
is a tautology. But
 $\bigwedge X^{\bot }\wedge C[D]^{\bot }\wedge \bigwedge \alpha \rightarrow C[B]$
is equivalent to
$\bigwedge X^{\bot }\wedge C[D]^{\bot }\wedge \bigwedge \alpha \rightarrow C[B]$
is equivalent to
 $\bigwedge X^{\bot }\wedge \bigwedge \alpha \rightarrow (C[D]^{\bot }\rightarrow C[B])$
, which is in its turn equivalent to
$\bigwedge X^{\bot }\wedge \bigwedge \alpha \rightarrow (C[D]^{\bot }\rightarrow C[B])$
, which is in its turn equivalent to
 $\bigwedge X^{\bot }\wedge \bigwedge \alpha \rightarrow (C[D]\vee C[B])$
, which is finally equivalent to
$\bigwedge X^{\bot }\wedge \bigwedge \alpha \rightarrow (C[D]\vee C[B])$
, which is finally equivalent to
 $\bigwedge X^{\bot }\wedge \bigwedge \alpha \rightarrow C[B\vee D] = (X\mid \alpha \Rightarrow C[B \vee D])^{\delta }$
, which is thus also a tautology.
$\bigwedge X^{\bot }\wedge \bigwedge \alpha \rightarrow C[B\vee D] = (X\mid \alpha \Rightarrow C[B \vee D])^{\delta }$
, which is thus also a tautology.
[-] The cases of other rules are treated analogously.
Lemma 5.2. Consider the provable sequent
 $\alpha \Rightarrow A$
. If the set
$\alpha \Rightarrow A$
. If the set
 $SR$
associated with any comprehensive derivation of this sequent is
$SR$
associated with any comprehensive derivation of this sequent is
 $SR=\emptyset $
, then A is a tautology.
$SR=\emptyset $
, then A is a tautology.
Proof. Straightforward from Lemma 5.1.
Lemma 5.3. Consider the provable sequent
 $\alpha \Rightarrow A$
. If A is of the form
$\alpha \Rightarrow A$
. If A is of the form
 $B\vee \neg B$
or
$B\vee \neg B$
or
 $\neg (B\wedge \neg B)$
, for any B, then the set
$\neg (B\wedge \neg B)$
, for any B, then the set
 $SR$
associated with any comprehensive derivation of this sequent only contains the term
$SR$
associated with any comprehensive derivation of this sequent only contains the term
 $\tau =\emptyset $
.
$\tau =\emptyset $
.
Proof. By induction on the complexity of A. We only consider the case where A is of the form
 $B\vee \neg B$
, the other case being treated analogously. Note that having assumed that the sequent
$B\vee \neg B$
, the other case being treated analogously. Note that having assumed that the sequent
 $\alpha \Rightarrow B\vee \neg B$
is provable,
$\alpha \Rightarrow B\vee \neg B$
is provable,
 $\alpha $
either contains the literals of B or those of
$\alpha $
either contains the literals of B or those of
 $\neg B$
. In the proof, and for any analogous situation, we assume, without loss of generality, that
$\neg B$
. In the proof, and for any analogous situation, we assume, without loss of generality, that
 $\alpha $
contains the literals of B.
$\alpha $
contains the literals of B.
[-] Suppose A is of the form
 $l\vee \neg l$
. Then we have the following comprehensive derivation:
$l\vee \neg l$
. Then we have the following comprehensive derivation:

where the dots denote possible applications of the rule
 $\neg \neg $
. As the axiomatic leaf of the comprehensive derivation above is of the form
$\neg \neg $
. As the axiomatic leaf of the comprehensive derivation above is of the form
 $(i)$
of Definition 4.5,
$(i)$
of Definition 4.5,
 $SR=\emptyset $
.
$SR=\emptyset $
.
[-] Suppose A is of the form
 $C[l\wedge \neg l]\vee \neg C[l\wedge \neg l]$
, where
$C[l\wedge \neg l]\vee \neg C[l\wedge \neg l]$
, where
 $l\wedge \neg l$
is the subformula of A with the highest depth which satisfies condition 2(a) of Definition 4.2. Then we have the following comprehensive derivation:
$l\wedge \neg l$
is the subformula of A with the highest depth which satisfies condition 2(a) of Definition 4.2. Then we have the following comprehensive derivation:

Consider first the top-left branch of this derivation. By i.h. on the complexity of A, we have that the set
 $\tau $
associated with it is
$\tau $
associated with it is
 $\tau =\emptyset $
. Since the rule operating on the conclusion of this branch belongs to
$\tau =\emptyset $
. Since the rule operating on the conclusion of this branch belongs to
 $S_{2}$
(see Definitions 4.4 and 4.5), the set associated with the conclusion of the rule is
$S_{2}$
(see Definitions 4.4 and 4.5), the set associated with the conclusion of the rule is
 $\emptyset $
(as whatever list of terms is associated with the other premisse, any such term is bigger than the emptyset). By similar reasoning, the set associated with the second premisse of the final rule is
$\emptyset $
(as whatever list of terms is associated with the other premisse, any such term is bigger than the emptyset). By similar reasoning, the set associated with the second premisse of the final rule is
 $\emptyset $
. Since the last rule applied in the derivation above belongs to the set
$\emptyset $
. Since the last rule applied in the derivation above belongs to the set
 $S_{1}$
, we obtain that the set
$S_{1}$
, we obtain that the set
 $SR=\emptyset $
, as desired. The other cases can be treated analogously.
$SR=\emptyset $
, as desired. The other cases can be treated analogously.
Lemma 5.4. Consider a sequent
 $X\mid \alpha \Rightarrow A$
. Then, if a term
$X\mid \alpha \Rightarrow A$
. Then, if a term
 $\tau $
belongs to the set
$\tau $
belongs to the set
 $SR$
associated with a comprehensive derivation of it, then
$SR$
associated with a comprehensive derivation of it, then
 $\tau \subseteq \alpha $
and
$\tau \subseteq \alpha $
and
 $X^{\bot }, \tau \models A$
.
$X^{\bot }, \tau \models A$
.
Proof. By induction on the comprehensive derivation of the sequent
 $X\mid \alpha \Rightarrow A$
.
$X\mid \alpha \Rightarrow A$
.
[-] Suppose
 $X\mid \alpha \Rightarrow A$
is a leaf, then it could be of either one of the forms (i) and (ii) of Definition 4.5, or in the axiomatic form
$X\mid \alpha \Rightarrow A$
is a leaf, then it could be of either one of the forms (i) and (ii) of Definition 4.5, or in the axiomatic form
 $X \mid \alpha \Rightarrow {p}$
, where
$X \mid \alpha \Rightarrow {p}$
, where
 $ {p}$
is a literal. In the former case,
$ {p}$
is a literal. In the former case,
 $\tau =\emptyset $
, and thus clearly
$\tau =\emptyset $
, and thus clearly
 $\tau \subseteq \alpha $
. Moreover, straightforwardly,
$\tau \subseteq \alpha $
. Moreover, straightforwardly,
 $X^{\bot }, \tau \models A$
. In the latter case,
$X^{\bot }, \tau \models A$
. In the latter case,
 $ {p} \in \alpha $
, so
$ {p} \in \alpha $
, so
 $\tau =\{ {p}\} \subseteq \alpha $
. Moreover,
$\tau =\{ {p}\} \subseteq \alpha $
. Moreover,
 $X^{\bot }, {p}\models {p}$
.
$X^{\bot }, {p}\models {p}$
.
[-] Suppose
 $X\mid \alpha \Rightarrow A$
has been obtained by an explanatory rule, then we distinguish several cases. Suppose
$X\mid \alpha \Rightarrow A$
has been obtained by an explanatory rule, then we distinguish several cases. Suppose
 $A=C[B\wedge D]$
with
$A=C[B\wedge D]$
with
 $C[.]\in \mathcal {P}$
and it has been obtained by the rule
$C[.]\in \mathcal {P}$
and it has been obtained by the rule
 $\circ _{1}$
, then we have:
$\circ _{1}$
, then we have:

By inductive hypothesis we have that for any
 $\tau ^{\prime }$
associated with the sequent
$\tau ^{\prime }$
associated with the sequent
 ${X\mid \alpha \Rightarrow C[B]}$
,
${X\mid \alpha \Rightarrow C[B]}$
,
 $\tau ^{\prime }\subseteq \alpha $
and
$\tau ^{\prime }\subseteq \alpha $
and
 $X^{\bot }, \tau ^{\prime }\models C[B]$
, but also that for any
$X^{\bot }, \tau ^{\prime }\models C[B]$
, but also that for any
 $\tau ^{\prime \prime }$
associated with the sequent
$\tau ^{\prime \prime }$
associated with the sequent
 $X\mid \alpha \Rightarrow C[D]$
,
$X\mid \alpha \Rightarrow C[D]$
,
 $\tau ^{\prime \prime }\subseteq \alpha $
and
$\tau ^{\prime \prime }\subseteq \alpha $
and
 $X^{\bot }, \tau ^{\prime \prime }\models C[D]$
. By the way one construct lists of separated terms associated with sequents, we have that any
$X^{\bot }, \tau ^{\prime \prime }\models C[D]$
. By the way one construct lists of separated terms associated with sequents, we have that any
 $\tau $
associated with the sequent
$\tau $
associated with the sequent
 $X\mid \alpha \Rightarrow C[B\wedge D]$
is such that
$X\mid \alpha \Rightarrow C[B\wedge D]$
is such that
 $\tau =\tau ^{\prime }\cup \tau ^{\prime \prime }$
for some such
$\tau =\tau ^{\prime }\cup \tau ^{\prime \prime }$
for some such
 $\tau ^{\prime }$
and
$\tau ^{\prime }$
and
 $\tau ^{\prime \prime }$
. Moreover, we have from the previous conditions and logic that
$\tau ^{\prime \prime }$
. Moreover, we have from the previous conditions and logic that
 $\tau \subseteq \alpha $
and
$\tau \subseteq \alpha $
and
 $X^{\bot }, \tau \models C[B\wedge C]$
.
$X^{\bot }, \tau \models C[B\wedge C]$
.
Suppose
 $A=C[B\vee D]$
with
$A=C[B\vee D]$
with
 $C[.]\in \mathcal {P}$
and it has been obtained by the rule
$C[.]\in \mathcal {P}$
and it has been obtained by the rule
 $\circ _{2}$
, then we have:
$\circ _{2}$
, then we have:

By inductive hypothesis we have that for any
 $\tau ^{\prime }$
associated with the sequent
$\tau ^{\prime }$
associated with the sequent
 $X, C[B]\mid \alpha \Rightarrow C[D]$
,
$X, C[B]\mid \alpha \Rightarrow C[D]$
,
 $\tau ^{\prime }\subseteq \alpha $
and
$\tau ^{\prime }\subseteq \alpha $
and
 $X^{\bot }, C[B]^{\bot }\tau ^{\prime }\models C[D]$
. By the way one constructs lists of separated terms associated with sequents, we have that any
$X^{\bot }, C[B]^{\bot }\tau ^{\prime }\models C[D]$
. By the way one constructs lists of separated terms associated with sequents, we have that any
 $\tau $
associated with the sequent
$\tau $
associated with the sequent
 $X\mid \alpha \Rightarrow C[B\vee D]$
is such that
$X\mid \alpha \Rightarrow C[B\vee D]$
is such that
 $\tau =\tau ^{\prime }$
for some such
$\tau =\tau ^{\prime }$
for some such
 $\tau ^{\prime }$
. Moreover, we have from the previous conditions and logic that
$\tau ^{\prime }$
. Moreover, we have from the previous conditions and logic that
 $\tau \subseteq \alpha $
and
$\tau \subseteq \alpha $
and
 $X^{\bot }, \tau \models C[B\vee D]$
.The cases of the other forms of A and other rules are treated analogously.
$X^{\bot }, \tau \models C[B\vee D]$
.The cases of the other forms of A and other rules are treated analogously.
Theorem 5.5. Consider the provable sequent
 $\alpha \Rightarrow A_{\alpha }$
, as well as the set
$\alpha \Rightarrow A_{\alpha }$
, as well as the set
 $SR$
associated with a comprehensive derivation of this sequent. Any term
$SR$
associated with a comprehensive derivation of this sequent. Any term
 $\tau $
belonging to
$\tau $
belonging to
 $SR$
is a sufficient reason for the decision
$SR$
is a sufficient reason for the decision
 $A({\alpha })$
.
$A({\alpha })$
.
Proof. Straightforward from Lemma 5.4 and the way the set
 $SR$
is constructed.
$SR$
is constructed.
Lemma 5.6. Consider the following decisions:
 $$ \begin{align*} \mathit{for\ any}\ C[.] \in \mathcal{P} & \qquad (i)\ C[B\wedge D](\alpha) \quad\qquad\hspace{18pt} (i)^{\prime}\ C[B](\alpha), C[D](\alpha)\\&\qquad (ii)\ C[\neg(B\vee D)](\alpha) \qquad\quad (ii)^{\prime}\ C[B^{\bot}](\alpha), C[D^{\bot}](\alpha)\\\mathit{for\ any}\ C[.] \in \mathcal{N} & \qquad (iii)\ C[B\vee D](\alpha) \qquad\quad\hspace{12pt} (iii)^{\prime}\ C[B](\alpha), C[D](\alpha)\\& \qquad (iv)\ C[\neg(B\wedge D)](\alpha) \qquad\quad (iv)^{\prime}\ C[B^{\bot}](\alpha), C[D^{\bot}](\alpha), \end{align*} $$
$$ \begin{align*} \mathit{for\ any}\ C[.] \in \mathcal{P} & \qquad (i)\ C[B\wedge D](\alpha) \quad\qquad\hspace{18pt} (i)^{\prime}\ C[B](\alpha), C[D](\alpha)\\&\qquad (ii)\ C[\neg(B\vee D)](\alpha) \qquad\quad (ii)^{\prime}\ C[B^{\bot}](\alpha), C[D^{\bot}](\alpha)\\\mathit{for\ any}\ C[.] \in \mathcal{N} & \qquad (iii)\ C[B\vee D](\alpha) \qquad\quad\hspace{12pt} (iii)^{\prime}\ C[B](\alpha), C[D](\alpha)\\& \qquad (iv)\ C[\neg(B\wedge D)](\alpha) \qquad\quad (iv)^{\prime}\ C[B^{\bot}](\alpha), C[D^{\bot}](\alpha), \end{align*} $$
where B and D are extended literals or formulas of the form
 $\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
$\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
 $\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
. If
$\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
. If
 $\tau $
is a sufficient reason for any of the decisions on the left, then there exist two terms
$\tau $
is a sufficient reason for any of the decisions on the left, then there exist two terms
 $\tau ^{\prime }$
and
$\tau ^{\prime }$
and
 $\tau ^{\prime \prime }$
, such that each is a sufficient reason for one of the corresponding decisions on the right and
$\tau ^{\prime \prime }$
, such that each is a sufficient reason for one of the corresponding decisions on the right and
 $\tau ^{\prime }\cup \tau ^{\prime \prime }=\tau $
.
$\tau ^{\prime }\cup \tau ^{\prime \prime }=\tau $
.
Proof. We prove the result for (i) and (i)
 $^{\prime }$
; the other cases are treated analogously. Suppose
$^{\prime }$
; the other cases are treated analogously. Suppose
 $\tau $
is a sufficient reason for
$\tau $
is a sufficient reason for
 $C[B\wedge D]_{\alpha }$
; hence
$C[B\wedge D]_{\alpha }$
; hence
 $\tau \models C[B\wedge D]_{\alpha }$
and so, by logic and the fact that B and D are extended literals or formula of the form
$\tau \models C[B\wedge D]_{\alpha }$
and so, by logic and the fact that B and D are extended literals or formula of the form
 $\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
$\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
 $\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
,
$\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
,
 $\tau \models C[B]_{\alpha }$
and
$\tau \models C[B]_{\alpha }$
and
 $\tau \models C[D]_{\alpha }$
. It follows that there are two sets
$\tau \models C[D]_{\alpha }$
. It follows that there are two sets
 $\tau ^{\prime }$
and
$\tau ^{\prime }$
and
 $\tau ^{\prime \prime }$
such that
$\tau ^{\prime \prime }$
such that
 $\tau ^{\prime }\subseteq \tau $
and
$\tau ^{\prime }\subseteq \tau $
and
 $\tau ^{\prime \prime }\subseteq \tau $
and each is a sufficient reason for
$\tau ^{\prime \prime }\subseteq \tau $
and each is a sufficient reason for
 $C[B]_{\alpha }$
and
$C[B]_{\alpha }$
and
 $C[D]_{\alpha }$
, respectively. Suppose
$C[D]_{\alpha }$
, respectively. Suppose
 $\tau ^{\prime }\cup \tau ^{\prime \prime }=\tau ^{\prime \prime \prime }$
and
$\tau ^{\prime }\cup \tau ^{\prime \prime }=\tau ^{\prime \prime \prime }$
and
 $\tau ^{\prime \prime \prime }\subseteq \tau $
(clearly
$\tau ^{\prime \prime \prime }\subseteq \tau $
(clearly
 $\tau ^{\prime \prime \prime }$
cannot be bigger than
$\tau ^{\prime \prime \prime }$
cannot be bigger than
 $\tau $
for the way it has been constructed). Then there is a term
$\tau $
for the way it has been constructed). Then there is a term
 $\tau ^{\prime \prime \prime }$
such that
$\tau ^{\prime \prime \prime }$
such that
 $\tau ^{\prime \prime \prime }\models C[B\wedge D]_{\alpha }$
,
$\tau ^{\prime \prime \prime }\models C[B\wedge D]_{\alpha }$
,
 $\tau ^{\prime \prime \prime }\subseteq \alpha $
and
$\tau ^{\prime \prime \prime }\subseteq \alpha $
and
 $\tau ^{\prime \prime \prime }$
subsumes
$\tau ^{\prime \prime \prime }$
subsumes
 $\tau $
. However, this contradicts the fact that
$\tau $
. However, this contradicts the fact that
 $\tau $
is a sufficient reason for
$\tau $
is a sufficient reason for
 $C[B\wedge D]_{\alpha }$
. Hence
$C[B\wedge D]_{\alpha }$
. Hence
 $\tau ^{\prime }\cup \tau ^{\prime \prime }=\tau $
.
$\tau ^{\prime }\cup \tau ^{\prime \prime }=\tau $
.
Lemma 5.7. Consider the following decisions:
 $$ \begin{align*} \mathit{for\ any}\ B[.] \in \mathcal{P} &\qquad (i)\ B[C\vee D]_{\alpha} \quad\qquad\hspace{24pt} (i)^{\prime}\ B[C]_{\alpha}, B[D]_{\alpha}\\&\qquad (ii)\ B[\neg(C\wedge D)](\alpha) \quad\qquad (ii)^{\prime}\ B[C^{\bot}](\alpha), B[D^{\bot}](\alpha)\\\mathit{for\ any}\ B[.] \in \mathcal{N} &\qquad (iii)\ B[C\wedge D](\alpha) \quad\qquad\hspace{12pt} (iii)^{\prime}\ B[C](\alpha), B[D](\alpha)\\&\qquad (iv)\ B[\neg(C\vee D)](\alpha) \quad\qquad (iv)^{\prime}\ B[C^{\bot}](\alpha), B[D^{\bot}](\alpha), \end{align*} $$
$$ \begin{align*} \mathit{for\ any}\ B[.] \in \mathcal{P} &\qquad (i)\ B[C\vee D]_{\alpha} \quad\qquad\hspace{24pt} (i)^{\prime}\ B[C]_{\alpha}, B[D]_{\alpha}\\&\qquad (ii)\ B[\neg(C\wedge D)](\alpha) \quad\qquad (ii)^{\prime}\ B[C^{\bot}](\alpha), B[D^{\bot}](\alpha)\\\mathit{for\ any}\ B[.] \in \mathcal{N} &\qquad (iii)\ B[C\wedge D](\alpha) \quad\qquad\hspace{12pt} (iii)^{\prime}\ B[C](\alpha), B[D](\alpha)\\&\qquad (iv)\ B[\neg(C\vee D)](\alpha) \quad\qquad (iv)^{\prime}\ B[C^{\bot}](\alpha), B[D^{\bot}](\alpha), \end{align*} $$
where C and D are extended literals or formulas of the form
 $\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
$\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
 $\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
. If
$\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
. If
 $\tau $
is a sufficient reason for any of the decisions on the left, then it is also a sufficient reason for either both decisions on the right, or for just one of them.
$\tau $
is a sufficient reason for any of the decisions on the left, then it is also a sufficient reason for either both decisions on the right, or for just one of them.
Proof. The proof is analogous to that of the previous Lemma.
Theorem 5.8. Let
 $A(\alpha )$
be a decision and let
$A(\alpha )$
be a decision and let
 $\tau $
be a sufficient reason for it. Then
$\tau $
be a sufficient reason for it. Then
 $\tau $
belongs to the set
$\tau $
belongs to the set
 $SR$
associated with a comprehensive derivation of the sequent
$SR$
associated with a comprehensive derivation of the sequent
 $\alpha \Rightarrow A_{\alpha }$
.
$\alpha \Rightarrow A_{\alpha }$
.
Proof. Let
 $A(\alpha )$
be a decision and let
$A(\alpha )$
be a decision and let
 $\tau $
be a sufficient reason for it. We show that one can construct a comprehensive derivation of the sequent
$\tau $
be a sufficient reason for it. We show that one can construct a comprehensive derivation of the sequent
 $\alpha \Rightarrow A_{\alpha }$
such that
$\alpha \Rightarrow A_{\alpha }$
such that
 $\tau $
belongs to the set
$\tau $
belongs to the set
 $SR$
associated with it. We reason by main induction on the size of the set
$SR$
associated with it. We reason by main induction on the size of the set
 $\tau $
, and by secondary induction on the complexity of the formula A.
$\tau $
, and by secondary induction on the complexity of the formula A.
[-] Suppose
 $\tau =\emptyset $
. Then,
$\tau =\emptyset $
. Then,
 $A_{\alpha }$
is a tautology. We distinguish cases according to the form of
$A_{\alpha }$
is a tautology. We distinguish cases according to the form of
 $A_{\alpha }$
. If
$A_{\alpha }$
. If
 $A_{\alpha }$
is of the form
$A_{\alpha }$
is of the form
 $\overbrace {\neg \cdots \neg }^{m}(F \vee \neg F)$
, where m is even, or
$\overbrace {\neg \cdots \neg }^{m}(F \vee \neg F)$
, where m is even, or
 $\overbrace {\neg \cdots \neg }^{n}(F \wedge \neg F)$
, where n is odd, then, by potential applications of the
$\overbrace {\neg \cdots \neg }^{n}(F \wedge \neg F)$
, where n is odd, then, by potential applications of the
 $\neg \neg $
rule and Lemma 5.3, the set
$\neg \neg $
rule and Lemma 5.3, the set
 $SR$
associated with the sequent
$SR$
associated with the sequent
 $\alpha \Rightarrow A_{\alpha }$
only contains the empty set. Hence
$\alpha \Rightarrow A_{\alpha }$
only contains the empty set. Hence
 $\tau $
belongs to
$\tau $
belongs to
 $SR$
. If
$SR$
. If
 $A_{\alpha }$
is not of the form
$A_{\alpha }$
is not of the form
 $F \vee \neg F$
, then it must fit into one of the cases studied in the
$F \vee \neg F$
, then it must fit into one of the cases studied in the
 $\tau \neq \emptyset $
case below. For each case, the induction hypothesis can be applied to yield the conclusion that
$\tau \neq \emptyset $
case below. For each case, the induction hypothesis can be applied to yield the conclusion that
 $\tau $
belongs to
$\tau $
belongs to
 $SR$
.
$SR$
.
[-] Suppose
 $\tau \neq \emptyset $
. We distinguish cases according to the form of
$\tau \neq \emptyset $
. We distinguish cases according to the form of
 $A_{\alpha }$
. Suppose
$A_{\alpha }$
. Suppose
 $A_{\alpha }$
is an extended literal. Then the sequent
$A_{\alpha }$
is an extended literal. Then the sequent
 $\alpha \Rightarrow A_{\alpha }$
is derivable from an axiom
$\alpha \Rightarrow A_{\alpha }$
is derivable from an axiom
 $\alpha \Rightarrow \overline {A_{\alpha }}$
, where
$\alpha \Rightarrow \overline {A_{\alpha }}$
, where
 $\overline {A_{\alpha }}$
is a literal, perhaps with applications of the
$\overline {A_{\alpha }}$
is a literal, perhaps with applications of the
 $\neg \neg $
rule. Thus, according to our procedure, we directly get the set
$\neg \neg $
rule. Thus, according to our procedure, we directly get the set
 $\tau =\{A_{\alpha }\}$
, which contains all sufficient reasons for
$\tau =\{A_{\alpha }\}$
, which contains all sufficient reasons for
 $A_{\alpha }$
and belongs to
$A_{\alpha }$
and belongs to
 $SR$
.
$SR$
.
Suppose
 $A_{\alpha }= C[B\wedge D]$
,
$A_{\alpha }= C[B\wedge D]$
,
 $C[.]\in \mathcal {P}$
,
$C[.]\in \mathcal {P}$
,
 $B\wedge D$
is not of the form
$B\wedge D$
is not of the form
 $E\wedge \neg E$
, and B and D are extended literals or formulas of the form
$E\wedge \neg E$
, and B and D are extended literals or formulas of the form
 $\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
$\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
 $\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
. By Lemma 5.6, there exists two terms
$\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
. By Lemma 5.6, there exists two terms
 $\tau ^{\prime }$
and
$\tau ^{\prime }$
and
 $\tau ^{\prime \prime }$
such that each of them is a sufficient reason for
$\tau ^{\prime \prime }$
such that each of them is a sufficient reason for
 $C[B]$
and
$C[B]$
and
 $C[D]$
, respectively, and
$C[D]$
, respectively, and
 $\tau ^{\prime }\cup \tau ^{\prime \prime }=\tau $
. By the inductive hypothesis, noting that
$\tau ^{\prime }\cup \tau ^{\prime \prime }=\tau $
. By the inductive hypothesis, noting that
 $\tau ', \tau "$
are not larger than
$\tau ', \tau "$
are not larger than
 $\tau $
and
$\tau $
and
 $C[B]$
, C[D] are less complex than
$C[B]$
, C[D] are less complex than
 $C[B \wedge D]$
, there exists a comprehensive derivation
$C[B \wedge D]$
, there exists a comprehensive derivation
 $d_{1}$
of
$d_{1}$
of
 $\alpha \Rightarrow C[B]_{\alpha }$
one of whose associated terms is
$\alpha \Rightarrow C[B]_{\alpha }$
one of whose associated terms is
 $\tau ^{\prime }$
, which belongs to the SR of
$\tau ^{\prime }$
, which belongs to the SR of
 $\alpha \Rightarrow C[B]_{\alpha }$
, and there exists a comprehensive derivation
$\alpha \Rightarrow C[B]_{\alpha }$
, and there exists a comprehensive derivation
 $d_{2}$
of
$d_{2}$
of
 $\alpha \Rightarrow C[D]_{\alpha }$
one of whose associated terms is
$\alpha \Rightarrow C[D]_{\alpha }$
one of whose associated terms is
 $\tau ^{\prime \prime }$
, which belongs to the SR of
$\tau ^{\prime \prime }$
, which belongs to the SR of
 $\alpha \Rightarrow C[D]_{\alpha }$
. Applying the rule
$\alpha \Rightarrow C[D]_{\alpha }$
. Applying the rule
 $\circ _{1}$
on the end-sequents of
$\circ _{1}$
on the end-sequents of
 $d_{1}$
and
$d_{1}$
and
 $d_{2}$
, we obtain a derivation d of the sequent
$d_{2}$
, we obtain a derivation d of the sequent
 $\alpha \Rightarrow C[B\wedge D]_{\alpha }$
. d is a derivation of
$\alpha \Rightarrow C[B\wedge D]_{\alpha }$
. d is a derivation of
 $\alpha \Rightarrow C[B\wedge D]_{\alpha }$
, which is comprehensive by construction. By our procedure for associating terms to sequents,
$\alpha \Rightarrow C[B\wedge D]_{\alpha }$
, which is comprehensive by construction. By our procedure for associating terms to sequents,
 $\tau =\tau ^{\prime }\cup \tau ^{\prime \prime }$
is among the terms associated with d; hence
$\tau =\tau ^{\prime }\cup \tau ^{\prime \prime }$
is among the terms associated with d; hence
 $\tau $
belongs to the
$\tau $
belongs to the
 $SR$
associated with the sequent
$SR$
associated with the sequent
 $\alpha \Rightarrow A_{\alpha }$
.
$\alpha \Rightarrow A_{\alpha }$
.
Suppose
 $A_{\alpha }= C[B\vee D]$
,
$A_{\alpha }= C[B\vee D]$
,
 $C[.]\in \mathcal {P}$
,
$C[.]\in \mathcal {P}$
,
 $B\vee D$
is not of the form
$B\vee D$
is not of the form
 $E\vee \neg E$
, and B and D are extended literals or formulas of the form
$E\vee \neg E$
, and B and D are extended literals or formulas of the form
 $\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
$\overbrace {\neg \cdots \neg }^m (F \vee \neg F)$
or
 $\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
. By Lemma 5.7, we know that
$\overbrace {\neg \cdots \neg }^m(F \wedge \neg F)$
. By Lemma 5.7, we know that
 $\tau $
, one of the sufficient reasons for
$\tau $
, one of the sufficient reasons for
 $C[B\vee D]$
, is (i) either also a sufficient reason for
$C[B\vee D]$
, is (i) either also a sufficient reason for
 $C[B]$
and
$C[B]$
and
 $C[D]$
, or (ii) just for one of them. We show for (i) that we obtain the desired result; case (ii) is treated analogously. From (i), by inductive hypothesis, noting that
$C[D]$
, or (ii) just for one of them. We show for (i) that we obtain the desired result; case (ii) is treated analogously. From (i), by inductive hypothesis, noting that
 $C[B]$
, C[D] are less complex than
$C[B]$
, C[D] are less complex than
 $C[B \vee D]$
, one can construct a comprehensive derivation
$C[B \vee D]$
, one can construct a comprehensive derivation
 $d_{1}$
of the sequent
$d_{1}$
of the sequent
 $\alpha \Rightarrow C[B]_{\alpha }$
, one of whose associated terms is
$\alpha \Rightarrow C[B]_{\alpha }$
, one of whose associated terms is
 $\tau $
, which belongs to the SR of
$\tau $
, which belongs to the SR of
 $\alpha \Rightarrow C[B]_{\alpha }$
, and one can construct a comprehensive derivation of
$\alpha \Rightarrow C[B]_{\alpha }$
, and one can construct a comprehensive derivation of
 $d_{2}$
of
$d_{2}$
of
 $\alpha \Rightarrow C[D]_{\alpha }$
one of whose associated terms is
$\alpha \Rightarrow C[D]_{\alpha }$
one of whose associated terms is
 $\tau $
, which belongs to the SR of
$\tau $
, which belongs to the SR of
 $\alpha \Rightarrow C[D]_{\alpha }$
. Applying the rule
$\alpha \Rightarrow C[D]_{\alpha }$
. Applying the rule
 $\circ _{1}$
on the end-sequents of
$\circ _{1}$
on the end-sequents of
 $d_{1}$
and
$d_{1}$
and
 $d_{2}$
, we obtain a derivation d of the sequent
$d_{2}$
, we obtain a derivation d of the sequent
 $\alpha \Rightarrow C[B\vee D]_{\alpha }$
, which by construction is comprehensive. By our procedure for associating terms to sequents, is among the terms associated with d; hence
$\alpha \Rightarrow C[B\vee D]_{\alpha }$
, which by construction is comprehensive. By our procedure for associating terms to sequents, is among the terms associated with d; hence
 $\tau $
belongs to the
$\tau $
belongs to the
 $SR$
associated with the sequent
$SR$
associated with the sequent
 $\alpha \Rightarrow A_{\alpha }$
. The cases of the other forms of A and other rules can be treated analogously.
$\alpha \Rightarrow A_{\alpha }$
. The cases of the other forms of A and other rules can be treated analogously.
For any decision
 $A(\alpha )$
, Theorems 3.8 and 3.9 guarantee that the explanatory calculus is able to decide whether the decision is positive or negative. If it is positive, a comprehensive derivation can be constructed (using a version of standard proof search: see Appendix A), which, by Theorem 5.8, will provide the complete reason for it, i.e., the set of all sufficient reasons. In other words, the explanatory proof approach, applied to the machine learning classification problem, provides, in one stroke, a decision procedure for any decision
$A(\alpha )$
, Theorems 3.8 and 3.9 guarantee that the explanatory calculus is able to decide whether the decision is positive or negative. If it is positive, a comprehensive derivation can be constructed (using a version of standard proof search: see Appendix A), which, by Theorem 5.8, will provide the complete reason for it, i.e., the set of all sufficient reasons. In other words, the explanatory proof approach, applied to the machine learning classification problem, provides, in one stroke, a decision procedure for any decision
 $A(\alpha )$
as well as the complete reasons for it. Note that two elements of the explanatory calculus are crucial for this result. One is the possibility of working deep in formulas, the other is the presence of conditions beside reasons. The former allows decomposition of a formula along its inner parts, hence uncovering potential analytic subformulas that do not contribute to the collection of the compete reasons (such as the excluded middle in the example of classifier
$A(\alpha )$
as well as the complete reasons for it. Note that two elements of the explanatory calculus are crucial for this result. One is the possibility of working deep in formulas, the other is the presence of conditions beside reasons. The former allows decomposition of a formula along its inner parts, hence uncovering potential analytic subformulas that do not contribute to the collection of the compete reasons (such as the excluded middle in the example of classifier
 $\mathcal {C}^{\prime }$
). The latter allows one to separate those characteristics that are true for the instance under consideration from those that are not, i.e., those features that the applicant enjoys from those that she does not. It is thanks to these two elements that explanatory rules provide a natural tool to extract the sufficient reasons for a decision. Indeed it is easy to see that without these two elements the complete reasons for a decision can no longer be extracted: for instance, this is the situation if one replaces explanatory rules by standard inferential rules (or by other logics of explanations that have been recently proposed but that do not enjoy these features, e.g., see Fine [Reference Fine, Correia and Schnieder9]). Both these elements were introduced with purely philosophical motivations: their technical value provides independent confirmation of their adequateness and strength. Finally, the elegant naturalness by means of which they apply in the framework of the theory developed by Darwiche and Hirth [Reference Darwiche and Hirth7] can be seen as the indication of the deep relation between the two approaches.
$\mathcal {C}^{\prime }$
). The latter allows one to separate those characteristics that are true for the instance under consideration from those that are not, i.e., those features that the applicant enjoys from those that she does not. It is thanks to these two elements that explanatory rules provide a natural tool to extract the sufficient reasons for a decision. Indeed it is easy to see that without these two elements the complete reasons for a decision can no longer be extracted: for instance, this is the situation if one replaces explanatory rules by standard inferential rules (or by other logics of explanations that have been recently proposed but that do not enjoy these features, e.g., see Fine [Reference Fine, Correia and Schnieder9]). Both these elements were introduced with purely philosophical motivations: their technical value provides independent confirmation of their adequateness and strength. Finally, the elegant naturalness by means of which they apply in the framework of the theory developed by Darwiche and Hirth [Reference Darwiche and Hirth7] can be seen as the indication of the deep relation between the two approaches.
6 Conclusions
In this paper we have investigated the links between two theories of explanation: one developed around the notion of sufficient reason, the other, with illustrious philosophical roots, developed with the resources of proof theory. Not only is this interaction technically compelling, in that it establishes in a novel and original way a result that is neither immediate nor trivial (see, e.g., Coudert and Madre [Reference Coudert and Madre5] and Shih et al. [Reference Shih, Choi, Darwiche and Lang29]). Moreover, and perhaps most importantly too, it seems to have a strong conceptual import as well. Indeed, it establishes that two approaches from completely different backgrounds based on different principles and perspectives coincide on what counts as sufficient reasons in the case of classification decisions. This is a priori so surprising that it suggests that there is something deep connecting them. This deep interaction is not only valuable per se but it could also give rise to the most fruitful and interesting paths of research, as results of each theory can be imported in the other. Indeed, if on the one hand the notion of sufficient reason, that is directly linked to that of prime implicant, could be used to develop a semantics for the purely syntactic model developed by Poggiolesi [Reference Poggiolesi25], on the other hand, the resources of first-order logic, mobilized in Poggiolesi [Reference Poggiolesi25], may be profitably used to extend the theory of Darwiche and Hirth [Reference Darwiche and Hirth7].
A Appendix
A.1 Algorithm to construct comprehensive derivation
The following algorithm returns a comprehensive derivation for a sequence
 $\alpha \Rightarrow A$
if it is derivable.
$\alpha \Rightarrow A$
if it is derivable.
-
1. Take any subformula D of A of highest depth such that
$D = D_1 \circ " D_2$
and
$R \circ ' (D_1 \ \circ " D_2)$
is a subformula of A satisfying the conditions in point 2(a) of Definition 4.2. Apply the appropriate
$\circ _1$
or
$\neg \circ _1$
rule with main connective
$\circ "$
. -
2. Repeat while there exists D as specified in the previous step.
-
3. Take any B satisfying the conditions in point 3 of Definition 4.2, and apply the appropriate
$\circ _1$
or
$\neg \circ _1$
rule with any of these as the main connective. -
4. Repeat while there exists such B.
-
5. Take any leaf of the form
$\alpha \Rightarrow l$
for an extended literal l that is not a literal, and apply the
$\neg \neg $
rule. -
6. Repeat while there exist such leaves.
At this point, the algorithm has constructed a tree with, as each leaf, a formula of the form
$\alpha \Rightarrow l$
for some literal l. -
7. Take any leaf labelled by
$\alpha \Rightarrow l$
with
$l \notin \alpha $
.-
(a) If the first
$\circ _1$
or
$\neg \circ _1$
rule applied below this leaf does not satisfy the conditions for the application of a
$\circ _2$
or
$\neg \circ _2$
rule (Definition 3.6), then go down the tree to the first application of an
$\circ _1$
or
$\neg \circ _1$
rule satisfying the conditions in Definition 3.6 below this leaf, and replace it with the corresponding
$\circ _2$
or
$\neg \circ _2$
rule, respectively, where the formula derived from the leaf enters the condition. -
(b) If the first
$\circ _1$
or
$\neg \circ _1$
rule applied below this leaf does satisfy the conditions for the application of a
$\circ _2$
or
$\neg \circ _2$
rule (Definition 3.6), then go down the tree to the last consecutive application of this rule and replace it with the corresponding
$\circ _2$
or
$\neg \circ _2$
rule, respectively, where the extended literal from the leaf enters the condition. Re-apply the initial
$\circ _1$
or
$\neg \circ _1$
rule and step 5 to obtain a tree whose leaves are literals.
-
-
8. Repeat while there exist such leaves.
-
9. If there is a leaf labelled by
$\alpha \Rightarrow l$
with
$l \notin \alpha $
, then Return:
$\alpha \Rightarrow A$
is not valid. -
10. If not, then Return the derivation (tree).










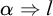




















If case 10 is satisfied, the algorithm returns a well-formed derivation (i.e., a derivation starting with axioms, where every rule is applied correctly). By construction, it satisfies the conditions in Definition 4.2, i.e., it is a comprehensive derivation.
Since this is a standard proof search algorithm adapted for the explanatory calculus EC, it not only produces a comprehensive derivation where it exists, but also identifies whether the sequent
 $\alpha \Rightarrow A$
is valid or not, i.e., whether
$\alpha \Rightarrow A$
is valid or not, i.e., whether
 $\alpha $
is an instance of A. Its complexity is comparable to standard proof search procedures (see, e.g., Troelstra and Schwichtenberg (1996)).
$\alpha $
is an instance of A. Its complexity is comparable to standard proof search procedures (see, e.g., Troelstra and Schwichtenberg (1996)).









 Open access
Open access