


1 Introduction
A central question in phonological typology (and in phonology more generally) is whether there are principles that govern the size, structure and constituent parts of phonological inventories, and if so, what they are. Research in recent decades has proposed numerous factors, often extralinguistic, that predict the composition of phonological inventories. Such proposed factors include demography (Pericliev Reference Pericliev2004, Hay & Bauer Reference Hay and Bauer2007, Donohue & Nichols Reference Donohue and Nichols2011, Moran et al. Reference Moran, McCloy and Wright2012, Greenhill Reference Greenhill, Bowern and Evans2014), environment and climate (Everett Reference Everett2013, Everett et al. Reference Everett, Blasi and Roberts2015, Reference Everett, Blasi and Roberts2016), genetics (Dediu & Ladd Reference Dediu and Ladd2007, Creanza et al. Reference Creanza, Ruhlen, Pemberton, Rosenberg, Feldman and Ramachandran2015), geography and population movements (Atkinson Reference Atkinson2011), culture (Labov et al. Reference Labov, Rosenfelder and Fruehwald2013) and anatomy (Dediu et al. Reference Dediu, Janssen and Moisik2017).
Structural, i.e. language-internal or systemic, factors, include the ‘size predicts’ generalisation: the number of segments in an inventory largely determines its content, such that small systems recruit few (and basic) dimensions, while larger systems entail additional (and secondary) dimensions (Lindblom & Maddieson Reference Lindblom, Maddieson, Hyman and Li1988). In this paper, we focus on another structural factor, namely feature economy. The feature-economy principle is one of the mainstays of contemporary discussions of phonological segment inventories in the languages of the world. Two different, albeit largely congruent, formulations of this principle were proposed by Lindblom & Maddieson (‘small paradigms tend to exhibit ‘unmarked’ phonetics whereas large systems have ‘marked’ phonetics’; Reference Lindblom, Maddieson, Hyman and Li1988: 70) and Clements (‘languages tend to maximise the ratio of sounds over features’; Reference Clements2003: 287). This idea goes back at least to early work in structuralist phonology, including Trubetzkoy (Reference Trubetzkoy1939), Martinet (Reference Martinet1952) and Hockett (Reference Hockett1955), who were interested in the extent to which phonological inventories are symmetrical with respect to features, or, in other words, how much ‘mileage’ phonological inventories get out of individual features; see an overview of early developments of this concept in Clements (Reference Clements2003). Similar conclusions were later reached using different formulations and/or different datasets (Marsico et al. Reference Marsico, Maddieson, Coupé and Pellegrino2004, Coupé et al. Reference Coupé, Marsico, Pellegrino, Pellegrino, Marsico, Chitoran and Coupé2009, Mackie & Mielke Reference Mackie, Mielke, Clements and Ridouane2011, Moran Reference Moran2012, Dunbar & Dupoux Reference Dunbar and Dupoux2016), and theoretical and experimental investigations of feature economy have become a major line of phonological research: see Pater (Reference Pater2012), Verhoef et al. (Reference Verhoef, Kirby and de Boer2016) and Seinhorst (Reference Seinhorst2017).
The aim of the current paper is not to propose another explanation or interpretation of the feature-economy principle, but to take a step back in order to reassess how well it actually fits the structure of phonological segment inventories of the world's languages, focusing on consonants.
Clements (Reference Clements2003: 288–289) hypothesises that the feature-economy principle can only be constrained by functional factors: ‘avoided feature combinations can be shown to be inefficient from the point of view of speech communication. That is, their articulation is relatively complex, or their auditory attributes are not distinct enough from those of some other sound in the system’.Footnote 1 Marsico et al. (Reference Marsico, Maddieson, Coupé and Pellegrino2004) and Coupé et al. (Reference Coupé, Marsico, Pellegrino, Pellegrino, Marsico, Chitoran and Coupé2009) attempted to quantify the amount of residual variance left unexplained by the feature-economy principle by computing the redundancy factors and the cohesion of phonological inventories in UPSID (Maddieson & Precoda Reference Maddieson and Precoda1992). Our aim is to provide an exploratory assessment of the structure of this residual variance. Our premise is that if Clements’ assessment of the explanatory power of the feature-economy principle were correct, we would be able to explain the majority of exceptions to the feature-economy principle by invoking perception and/or production factors, and that the variance left unexplained after that would consist of random noise due to the probabilistic nature of sound change. Clements’ hypothesis therefore would be falsified (in a non-statistical, observationist way) if we were to discover that there are principles governing inventory structures that do not stem from the abovementioned types of functional factors.
The core of our approach to testing this hypothesis is the notion of a co-occurrence class. Co-occurrence classes are groups of sounds that tend to be found together in inventories. We provide a fully algorithmic definition of this notion in §2, but at this stage we would like to explore its implications. We regard co-occurrence classes as a particularly powerful method of phonological analysis, since nearly all principles governing the structure of phonological inventories are plausibly reflected in the structure of these classes. We give two examples in (1).
-
(1)
Footnote 2

Our primary interest is how the feature-economy principle is reflected in the structure of co-occurrence classes. In order to investigate this, we propose to first reformulate the principle in a more structural fashion. Building on the notion of sound-inventory symmetry explored by Dunbar & Dupoux (Reference Dunbar and Dupoux2016), we operationalise the feature-economy principle by interpreting it as largely synonymous with the layering principle: new classes of sounds arise by virtue of adding new features to already existing combinations. An empirical confirmation of this is found in Moran (Reference Moran2012: 248) with respect to vowels, such that ‘once languages expand their inventories beyond cardinal vowels, they tend to do so by either nasalization or lengthening, and to a lesser extent by adding diphthongs to the inventory’.
This formulation has the advantage of providing a simple way to articulate a structural prediction: if we investigate empirical co-occurrence classes, we should see that they are progressively defined by a succession of additional features. Thus we should see both large classes dominated by basic distinctions (place, manner and VOT) and smaller classes in which these distinctions are augmented by different additional articulations. We call classes that respect the feature-economy/layering principle conformant classes. Most importantly, the feature-economy/layering principle predicts that certain constellations should not exist. In particular, it prohibits cross-layer connections (the close patterning of segments with different numbers of features turned on) and cross-feature connections (the close patterning of segments with different privative features turned on). That is, if there exists a class of palatalised segments, we do not expect some of the members of this class to pattern with either labialised segments (which would be a cross-feature connection) or plain segments (which would be a cross-layer connection), as this would imply that languages do not exhaust the usefulness of the [+palatalised] feature. We call classes that do not respect the feature-economy/layering principle non-conformant classes. A good example of a conformant class is long voiced stops: /bː dː gː/. They are distinguished by a single distinctive feature value [+long], and exhaust the possible combinations of VOT and manner values for all places of articulation. Short voiced stops /b d g/, however, do not form a conformant class in our data. Instead they are embedded inside a large complex class, the ‘first extension set’. We discuss conformant and non-conformant classes in §4.
It is important to stress that this type of analysis is based on bidirectional dependences (the presence of segment A is probabilistically dependent on the presence of segment B, and vice versa), not on unidirectional implicational universals (languages with segment A tend to also have segment B, but segment B is also frequently found without segment A). For example, languages with /pʲ/ have a very strong tendency to have /p/ as well. Nevertheless, the bidirectional co-occurrence dependence between these segments is very low: the absence of /pʲ/ is a very weak indicator of the absence of /p/. On the other hand, the absence of /pʲ/ is a strong indicator of the absence of /bʲ/, and vice versa.
This paper aims to make the following contributions. First, we propose a statistical method for identifying co-occurrence classes of sounds in the world's languages. Second, using this method, we empirically identify several co-occurrence classes worthy of attention in themselves, one of them being the basic consonant inventory. Third, using the structure of the co-occurrence classes identified by this new method, we show the limits of the applicability of the feature-economy principle in its various formulations.
The paper is organised as follows. In §2, the method used to derive co-occurrence classes is described, together with the dataset it is applied to. In §3, the resulting classification of the major types of segments in the languages of the world is presented, and a brief overview of the classes is given. §4 is devoted to the consequences of the structure of the co-occurrence classes for the feature-economy principle, and §5 presents conclusions.
2 Deriving co-occurrence classes
2.1 Dataset
Our data comes from the PHOIBLE database, the most comprehensive openly accessible cross-linguistic repository of phonological inventories and associated data and metadata. Version 2.0 (Moran & McCloy Reference Moran and McCloy2019) includes 3020 phonological inventories, with 3183 segment types found in 2186 distinct languages. One doculect was randomly selected for each language;Footnote 3 the resulting dataset contains information about the phonological inventories of 2761 languages. Only segments occurring 30 or more times in the dataset were included in the analysis (N = 193), giving a binary 2761 × 193 matrix with rows corresponding to inventories (with 1's for segments present in the inventory and 0's for segments absent from the inventory) and columns corresponding to segment distributions. The picture presented by the rows of this matrix is incomplete (rare segments are not represented), but this is not an issue, as the analysis is restricted to the columns. In addition to providing more robust inference (frequencies of rare segments are vulnerable to sampling noise), restricting the analysis to relatively frequent segments has empirical support, as the frequency distribution of segments in worldwide samples such as PHOIBLE shows a strong positive skew: it declines exponentially, such that the tenth most frequent segment, /ŋ/, is found in 63% of the languages in the sample, the twentieth most frequent, /ʃ/, is found in 35% and the fortieth most frequent, /d̪/, in only 21%. Most of PHOIBLE is in fact a very long tail of segments, each of which is documented only in a single language.
There are pitfalls inherent in any cross-linguistic study of phonological segments and segment inventories. The first is the nature of the objects of study. As has been pointed out in earlier critiques of UPSID and PHOIBLE (Lass Reference Lass1984, Simpson Reference Simpson, Ohala, Hasegawa, Ohala, Granville and Bailey1999, Vaux Reference Vaux2009, Kiparsky Reference Kiparsky, Hyman and Plank2018), phonemes are not ideally suitable objects for cross-linguistic study. The primary reason is that phonemic solutions are not unique, as shown long ago by Chao (Reference Chao1934), and suggested even earlier by Sapir (Reference Sapir1925). Moreover, in many approaches, phonemes are defined structurally or negatively, i.e. in terms of their oppositions within a system. This relates to the problem of normalisation, especially in descriptions. For example, it is common for grammar writers to note a phoneme /p/, which turns out to be realised as [pʰ] in most environments. However, grammar writers typically do provide usably detailed information about the distribution of allophones. The decision that has informed the collection of data up to now has been to record the allophone with the least limited distribution, rather than the normalised variant. So for example, the /p/ phoneme of Sanandaj Neo-Aramaic (Khan Reference Khan2009) is recorded in the database as /pʰ/, since it has the least limited distribution of the various allophones. See Moran (Reference Moran2012, Reference Moran and Aronoff2019) for additional responses to the criticism of segment-based typology.
We would like to address another potential problem with our data, one which is shared with any large cross-linguistic sample and does not have to do with the quality of the data per se. The issue, which has been called ‘Galton's Problem’, is that individual languages may not be independent data points. This is due to two main facts. The first is that languages in the sample may have developed from a common ancestor, which means that for a particular feature of interest, two languages, say French and Italian, may have retained this property from Proto-Romance. The second fact is that languages almost universally undergo change as a result of language contact. In particular, languages that are in geographical proximity tend to show the influence of their neighbours. This is often visible in case studies of specific contact situations, but it may also scale up to continent-sized macro-areas, at least with respect to some features. Finally, common descent and geographical proximity can interact: overall, languages are often geographically close to languages of the same family, so it becomes difficult to tease apart the respective contributions of inheritance on the one hand and language contact on the other.
Various methods have been proposed to deal with this problem. One is balanced or stratified sampling, which aims to create samples of languages that are as geographically and genealogically independent as possible. However, since some features may characterise entire macro-areas (Dryer Reference Dryer1989), the a priori possibility of constructing a sample of truly independent languages is small. Moreover, carefully balanced samples – if the unit being sampled is individual languages – cannot reach large sizes, so the quantity of data in such samples is by necessity restricted (Piantadosi & Gibson Reference Piantadosi and Gibson2014).
Another approach that has been gaining currency is the use of a family of methods that directly test the contribution of genealogy and area by modelling them as predictors. Such approaches, known as ‘Distributional Typology’ (Bickel & Nichols Reference Bickel and Nichols2006, Bickel Reference Bickel, Bickel, Grenoble, Peterson and Timberlake2013, Reference Bickel, Heine and Narrog2015, Reference Bickel and Hickey2017), handle large and dense samples well, and in fact require more and denser data than the classical balanced sampling approach. An example illustrating these approaches involves two competing theories regarding the presence of case marking on core arguments in verbal clauses (Bickel Reference Bickel, Heine and Narrog2015). One theory claims that case marking is more prevalent in languages with verb-final basic order, ultimately due to processing constraints (Hawkins Reference Hawkins2004); the other theory claims that case marking is especially prevalent in Eurasian languages due to language contact (Jakobson Reference Jakobson1931). Bickel (Reference Bickel, Heine and Narrog2015) used the ‘family bias’ method, which investigates diachronic biases within families, to test the extent to which both verb-finality and areality predict case marking, and found that the two effects were independent: verb-finality did indeed predict case marking to some extent, but the effect size was much larger in Eurasia than in other parts of the world, suggesting historical contact events as the source of the areal patterning. Similar studies have been conducted in other domains, such as differential object marking (Sinnemäki Reference Sinnemäki2014).
In the present study, we do not attempt to estimate the relative contributions of genealogy, areality and other functional and structural factors. Instead, we point out that areality and common descent are themselves proxies for a potentially large set of factors that shape diachronic pathways of change. Ultimately, if feature economy – or any other proposed principle – exerts an effect on phonological inventories, it can only do so by influencing the probability of a language to (i) innovate a property A, (ii) lose a property A or (iii) retain a property A. In other words, feature economy is a good candidate for what Bickel (Reference Bickel and Hickey2017: 42) calls ‘functional triggers’ (or factors), i.e. factors that ‘systematically bias the way linguistic structures evolve’, the defining property of which ‘is that they affect transition probabilities universally, independent of concrete historical events’.
As such, the essentially static picture that we present in this exploratory study is in all likelihood the result of the highly complex interaction of a diverse set of factors that play out in diachrony. Since phonetic variation and sound change are so rampant in human language, we can conceptualise the feature-economy principle as a factor – whether ultimately rooted in the human language faculty or in domain-general cognitive or articulatory and perceptual biases – that works to keep certain sounds grouped together. We would expect this principle to promote the retention of individual sounds in some cases and their loss in others, and perhaps even their borrowing when contact situations permit it.Footnote 4 While we do not attempt to directly test the contributions of these factors to the results of our analysis, we do throughout the paper point out cases in which areal factors are suggested by the data.
2.2 The feature set
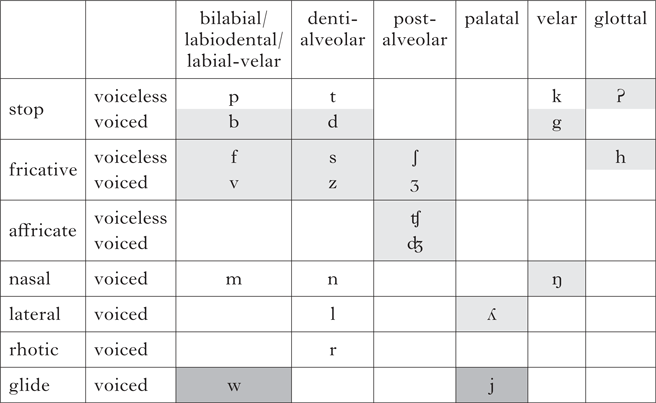
Clements’ original formulation of the feature-economy principle was based on the principle of the economy of representation, ‘according to which features are specified in a given language only to the extent that they are needed in order to express generalizations about the phonological system’ (Reference Clements and Hall2001: 72). This makes it impossible to give a featural description of a segment from an inventory without analysing this inventory as a whole, which would be very time-consuming. Moreover, it aggravates the issue of unstable phonemicisation discussed in the previous section: misleading phonemicisation of a single segment can potentially lead to an incorrect feature specification for the whole inventory. In order to safeguard against this possibility, we adopted a shallow but robust approach to feature specification: all segments from all inventories were analysed in terms of IPA features (IPA handbook 1999). The IPA feature set for consonants is articulatory in nature, and is oriented towards describing inventories as assemblages of individual segments. This is different from the feature sets prevalent in the theoretical literature, where the focus is on succinct description of phonological rules or constraints (Hayes Reference Hayes2009). However, many languages in the sample have not been analysed from the point of view of their rule/constraint systems, and the focus on individual segments seems warranted.
2.3 Methods
2.3.1 Distance measure
The focus on bidirectional connections between segment distributions, which we represent as binary vectors with 1's for languages that have a particular segment and 0's for languages that do not have it, makes Pearson's correlation coefficient a natural measure of the strength of the association. The value of the coefficient ranges from ―1 (the presence of one segment predicts the absence of another with absolute certainty, and vice versa, i.e. they are never found together) to +1 (the presence of one segment predicts the presence of another with absolute certainty, and vice versa, i.e. they are always found together). The middle value of 0 indicates the absence of any association (i.e. for any segment of the two, we are as likely to find an inventory that contains only this segment as to find an inventory containing both). Cases of an implicational universal – segment A strongly predicts segment B, but not vice versa – give rise to small positive values of the coefficient (which, unfortunately, makes them indistinguishable from chance relationships between segment distributions).
The next step is to divide segments into co-occurrence classes based on their pairwise distributional similarities. Given the high number of segments, it is hardly feasible to do this by manually investigating several thousand correlation coefficients. Methods for dimensionality reduction and clustering offer a convenient shortcut, but in order to use them we need to convert correlational similarity values to a non-negative dissimilarity (more precisely, distance) measure.
The simple step of adding 1 to all the coefficients and subtracting the result from 2 will produce a distance measure satisfying non-negativity, symmetry and zero distance from the object to itself. However, this measure does not obey triangle inequality (a rule that the distance between points A and C cannot be larger than the sum of distances from A to B and from B to C for any point B), which may lead to nonsensical results. Fortunately, there are several methods for converting Pearson's correlation coefficient to a proper distance measure (van Dongen & Enright Reference Dongen and Enright2012). One of them is the simple arccosine transformation D = arccos(Cor(x, y)), and we therefore use it in our analysis.Footnote 5
2.3.2 Dimensionality reduction and clustering
Every segment in our dataset is represented as a binary vector of length 2761. The data are very high-dimensional, which makes it impossible to directly visualise them or even to use Principle Components Analysis, which prohibits the number of variables from being larger than the number of data points (2761 vs. 193, in our case).
For the analysis of our dataset, we used ‘Uniform Manifold Approximation and Projection’ (UMAP; McInnes et al. Reference McInnes, Healy, Saul and Großberger2018), a novel method for dimensionality reduction which has been adopted in the machine-learning and bioinformatics communities, thanks to its ability to uncover hidden structure in high-dimensional data, both at the level of immediate neighbourhoods of individual points and at the level of larger clusters, if these can be detected.Footnote 6
UMAP takes as input a table with the original data points or a matrix of pairwise distances between them (in our case, arccosine-transformed Pearson's correlation coefficients) and chooses a lower-dimensional representation of the point assemblage in such a way that neighbourhoods of individual points and relative positions of larger clusters are preserved, as far as possible. UMAP has fairly involved mathematical foundations, but in practice its operation boils down to several transparent steps:
(i) A number of neighbouring points, k, is selected, guided by the researcher's guess as to how many points constitute a valid neighbourhood. In this case, this corresponds to the intuition as to how many points constitute a minimal cluster. In the extreme case, k can be taken to be equal to 1, giving rise to two-point clusters. Larger values essentially prohibit small clusters, and make the macro-structure more homogeneous and ‘lumpy’ (we can also force the algorithm to never lump individual points together by setting a non-negative value for the min_dist parameter, which dictates how far individual points should be from each other in the resulting embedding; this parameter, however, has a weaker influence on the overall structure). k = 3 and min_dist = 1 were used for the analysis.
(ii) A multidimensional ball is drawn around each data point, such that it includes its k neighbours. A neighbour graph is then created, where each point is connected to its k neighbours.
(iii) The edges in this graph have varying weights, depending on how far from the target point its neighbours are. Mathematically, the neighbourhood of the points are regarded as fuzzy sets (i.e. sets with probabilistic membership), and the UMAP algorithm defines a way to combine them where the edge lengths are regarded as probabilities of the fact that an edge really exists (if two nodes are not immediate neighbours, the probability that an edge between them exists is set to 0).
(iv) An arrangement of points in a lower-dimensional space is selected in such a way that, when we construct the same union of fuzzy sets based on Euclidean distances, the cross entropy between the probability distributions of the existence of edges in this lower-dimensional neighbour graph and the original high-dimensional neighbour-graph is minimised.
For further details of the mathematical foundations of the method and the implementation details, readers are referred to McInnes et al. (Reference McInnes, Healy, Saul and Großberger2018).
UMAP does not propose a ready-made clustering of the points. The latter can be created either (i) on an ad hoc basis, inspecting the scatter plot of the points if the representation is two-dimensional (the most commonly used trade-off between interpretability and the possibility of preserving complex configurations) or (ii) by using a clustering algorithm.
To separate points into clusters, we used the density-based clustering algorithm DBSCAN (Ester et al. Reference Ester, Kriegel, Sander, Xu, Simoudis, Han and Fayyad1996). It divides the space (in our case, the space of segment distributions interpreted as points on the two-dimensional plane) into regions of high density (those around core points of clusters) surrounded by peripheral points (those reachable from core points) and noise points (those not reachable from core points and not belonging to any cluster).
To summarise, in order to derive co-occurrence classes of consonants in the world's languages, we constructed an analytical pipeline from four well-defined mathematical procedures (Pearson's correlation coefficient → arccosine transform → UMAP dimensionality reduction → DBSCAN clustering). The pipeline separates data points into groups without any prior knowledge about their nature or properties. It should be noted that we have a margin of freedom in our choice of the parameters for these procedures. For UMAP, this is the number of nearest neighbours and minimal distance between resulting points; for DBSCAN, it is the minimal number of neighbouring points (again set at 3) and the reachability distance (set at 1.8). The choice of the distance measure for the initial data points is even more important. This freedom, however, is not nearly enough to create an easily interpretable structure from chaos in the initial data: in any case, the pipeline will cluster the points that are closest to each other, and separate them from points lying further afield.Footnote 7
3 Co-occurrence classes in the languages of the world
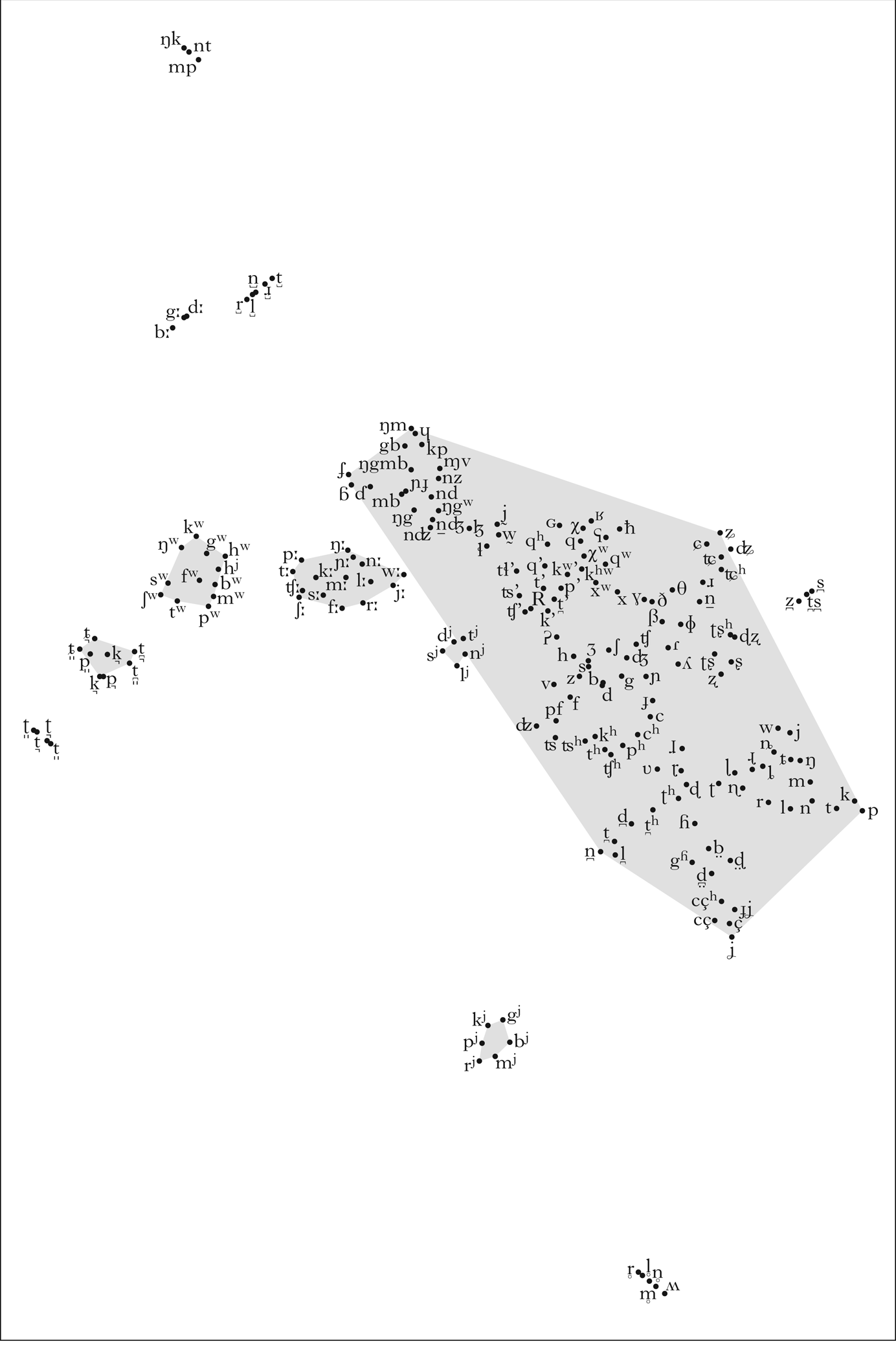
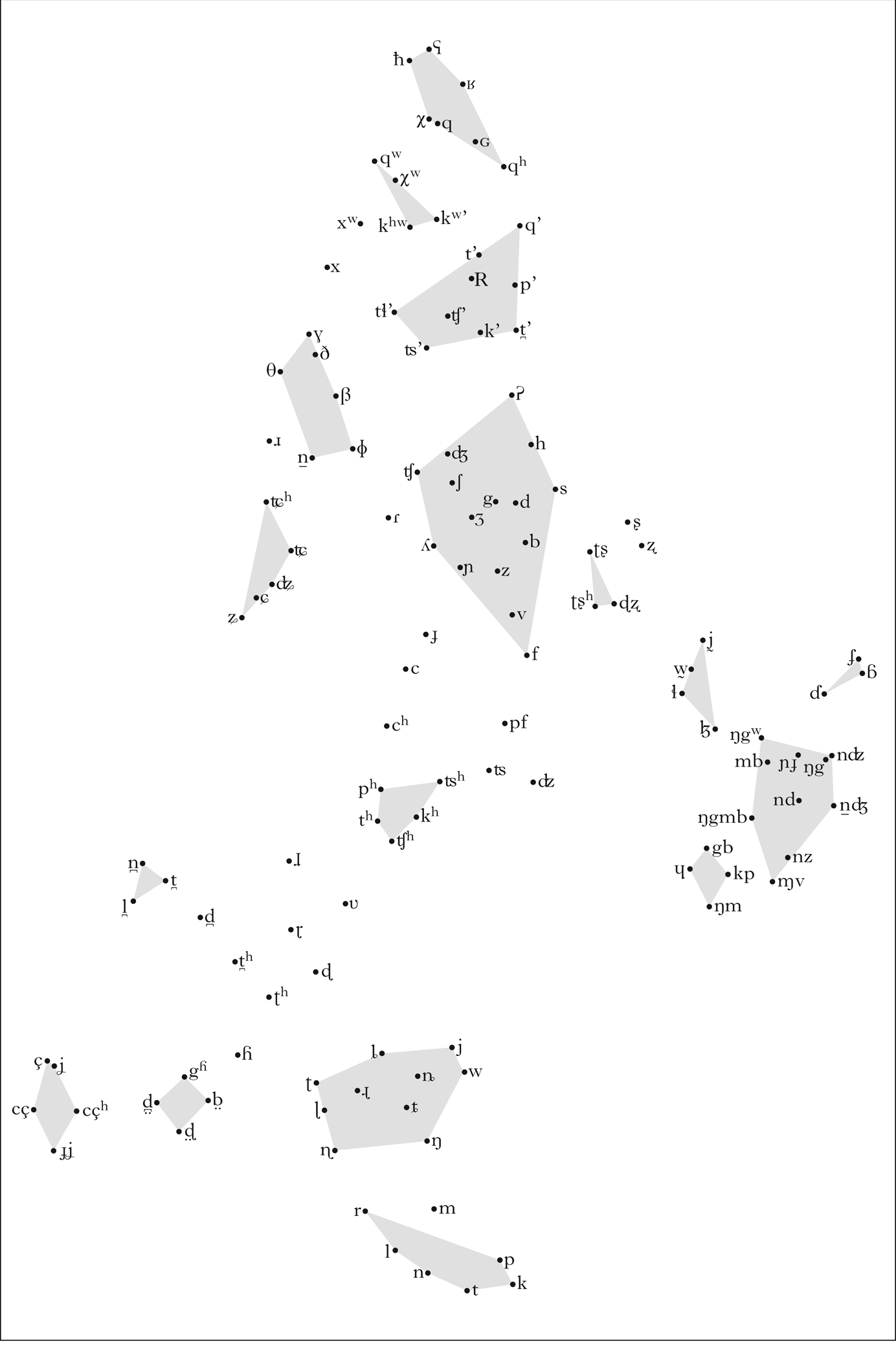
The distribution of the 193 common segments into co-occurrence classes is shown in Fig. 1, with polygons highlighting the boundaries of clusters identified by DBSCAN. This picture is not particularly informative, since most of the segments are lumped together into a large cluster of relatively frequent segments. We re-ran the analysis on a subset of data consisting only of these segments. The results are presented in Fig. 2, and are discussed in §3.2. First, however, we survey the divergent classes of segments, i.e. those that fall outside the large cluster.
Major consonant co-occurrence classes in the world's languages.
Groups inside the large cluster in Fig. 1.
3.1 Divergent classes
In this section, we survey divergent classes of segments not included in the major cluster in Fig. 1. These classes can be divided into various groups.
3.1.1 Palatalised segments
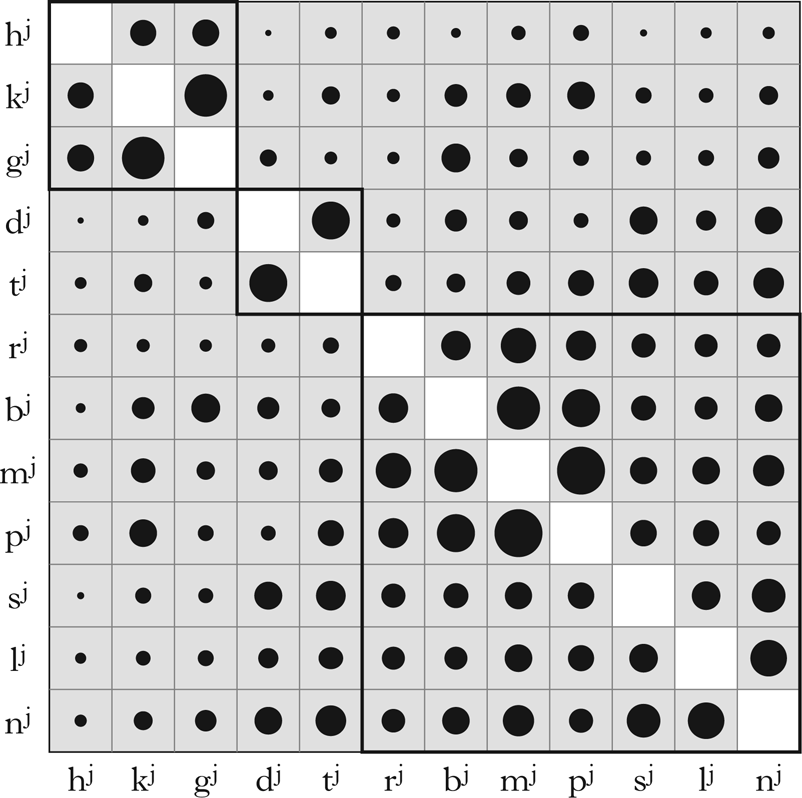
Two classes of palatalised segments were picked out by the pipeline: coronal /tʲ dʲ lʲ nʲ sʲ/ and non-coronal /pʲ bʲ mʲ gʲ kʲ/, together with /rʲ/.
The marginal position of the rhotic with respect to other coronals is relatively easy to account for: it has been observed that palatalised liquids do not form a recurrent pair: /lʲ/ is more typologically frequent and more diachronically stable than /rʲ/ (Kochetov Reference Kochetov2005). Similarly, Hall (Reference Hall2000: 1) claims that /rʲ/ is ‘far more marked’ than other palatalised coronals. Indeed, /rʲ/ (N = 31) is more than twice as rare as /lʲ/ (N = 66) in our data, as shown in (2).
-
(2)
The general coronal vs. the rest split, however, is less expected. Palatalised labial segments are considered to be rarer than both palatalised coronals and dorsals, and both coronals and dorsals are evidently more likely than labials to undergo ‘full palatalisation’, which in most cases means affrication (Bateman Reference Bateman2011).
Inspection of the plot of the correlations of distributions of palatalised segments in Fig. 3, however, shows that there is indeed a noticeable affinity between palatalised dorsals and bilabials on the one hand and between palatalised bilabials and /rʲ/ on the other, suggesting a centre vs. periphery articulatory split, with coronals serving as a default locus for palatalisation; this should be explored further.
The plot of the correlations between distributions of palatalised segments. The sizes of the circles are proportional to the values of correlation coefficients. Thick frames denote groups of segments with high pairwise mutual correlations established using Ward's clustering algorithm.
3.1.2 Phonologically long consonants
These are split into the voiced stops, /bː dː gː/, and everything else. As shown in (3), they are largely in the same frequency range as the palatalised segments.
-
(3)
It is tempting to assume that this split can be explained by the well-known observation that it is hard to maintain voicing in long stops, which makes long voiced plosives susceptible to shortening, loss of voicing or implosion (Ohala Reference Ohala and MacNeilage1983), but the fact that /bː/ is more frequent than /pː/ makes this explanation rather weak.
Bilabial long voiced stops are indeed easier to produce, due to the larger oral cavity available for maintaining higher subglottal pressure. Nevertheless, this does not explain why /bː/ does not pattern with /pː tː/. Moreover, /gː/ is arguably the most disfavoured voiced long plosive, characterised by the smallest oral cavity, and yet it is more prevalent than /dː/.
A simpler, albeit clearly incomplete, explanation in terms of the layering principle presents itself: when adding voiced long plosives, languages tend to exhaust this segment class despite differences in the articulatory difficulty of different segments. In other words, languages are more likely to acquire /bː dː gː/ as a group, rather than the individual pairs /bː pː/, /dː tː/ and /gː kː/.
The strength of connections between segments on the same level of the layering hierarchy can be illustrated by the fact that there are more languages with /bː/ but no /pː/ (N = 29) than there are with /bː/ but no /dː/ (N = 19), even though /pː/ is nearly 1.5 times as frequent as /dː/.
3.1.3 Labialised segments
A further divergent cluster is formed by a subset of labialised segments, together with the palatalised glottal fricative, as shown in (4).
-
(4)
It is notable that this cluster is coherent, despite substantial frequency disparities between its elements (/kʷ/ is more than ten times as frequent as /ʃʷ/, and nine times as frequent as /tʷ/, for example). The visual structure of this cluster in Fig. 1, further supported by the correlation coefficients, suggests four subgroups, mostly corresponding to frequency bands and exactly corresponding to place of articulation: /hʲ hʷ/, /ŋʷ gʷ kʷ/, /ʃʷ tʷ sʷ/ and /pʷ fʷ bʷ mʷ/.
Three tendencies are discernible. First, different regions of articulation are more productive for labialised stops and fricatives respectively. Second, the use of particular values of the place feature for labialised segments (especially the postvelar articulations, cf. §3.2) is dependent on whether there are other segments with the same value of this feature, rather on whether there are other labialised segments in general. Third, the glottal fricative /h/ either (i) lacks any additional articulation or (ii) tends to have both palatalised and labialised versions.
3.1.4 Voiceless approximants, liquids and nasals. The small group in (5) consists of low-frequency and, on average, rather tightly correlated sounds, except for /r ʍ/, which rarely appear together (r = 0.13). /m n/, on the contrary, are nearly inseparable (r = 0.847).
-
(5)
3.1.5 Other clusters
The remaining groups consist of truly marginal sounds:
(i) Tense and weakly articulated stops, /p ˜ Ç ˙ á ¯ É ˘/, are very rarely described outside Australia and are almost exclusively found together.Footnote 8
(ii) Phonologically apical stops and liquids, /ˆ û ¢ ı ´/, are also predominantly found in Australia, whose languages are famous for their extended range of place oppositions (Butcher Reference Butcher, Harrington and Tabain2006).
(iii) The voiceless prenasalised stops /mp nt ŋk/ are found in Africa, Eurasia and South America, but are rare (N = 36, 42, 41 respectively), and are twice as likely as not to be found in inventories that also have corresponding voiced prenasalised stops; see the contingency tables in Table I.
Contingency tables for the co-occurrence of voiced and voiceless prenasalised stops. Cells contain counts of inventories with (+) or without (−) a particular segment.

3.2 The large cluster
Boundaries between groups inside the large cluster in Fig. 2 identified by DBSCAN are more uncertain, as is evident from the large number of noise points scattered around the figure. In many cases, however, the visual structure of the plot makes it clear to which cluster the unattached points ‘really’ belong, and we will group them accordingly.
3.2.1 The basic consonant inventory
The cluster consisting of /p t k n l r/ and, although it is just outside the core group, /m/ (the most common segment in the dataset) can be considered a serious contender for the title ‘basic consonant inventory’ (a group of consonantal sounds that we expect to find in a randomly picked language).
The question of which set of segments can be considered basic one has been raised by many scholars, recent notable contributions including Hyman (Reference Hyman2008) and Gordon (Reference Gordon2016). The main stumbling blocks are the facts that (i) there are no really universal segments (even the most frequent segment, /m/, is found in only 96% of the languages), and (ii) raw frequency counts make it impossible to draw the boundary between quasi-universal segments and merely very frequent ones. Should the boundary be drawn between, say /s/ (frequency 72%, as shown in Fig. 4) and /ŋ/ (63%), or between /g/ (56%) and /d/ (49%)?
The 40 most frequent segments in the sample.
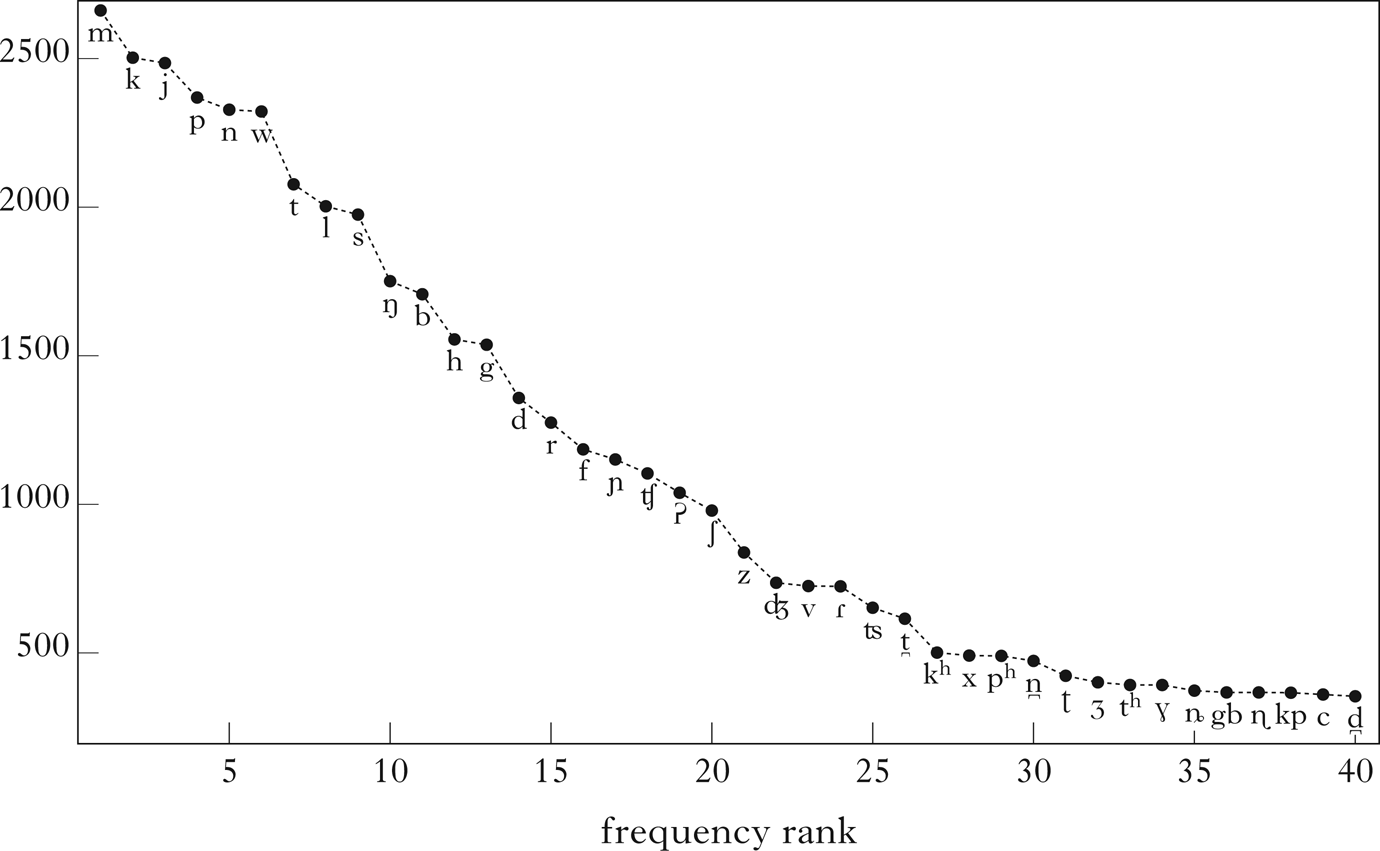
The approach based on the identification of co-occurrence classes seems to provide a way of overcoming this impasse. If there is a single co-occurrence cluster consisting of some of the most frequent segments, this means that inventories lacking any of these sounds are somehow statistically anomalous. Such a cluster, therefore, is a good contender for the title of the basic consonant inventory.
A somewhat unexpected feature of the basic inventory cluster in Fig. 2 is the fact that /j/ and /w/, which are also exceedingly common (N = 2485, 2322 respectively), do not form part of this cluster, and are grouped together with alveolo-palatal stops, which are found predominantly in Australian languages. What we see here is probably the case of macro-areal influence being strong enough to skew the worldwide distribution of basic segments.Footnote 9 In order to test this hypothesis, we first re-ran the analyses on the same dataset, but with Australian languages (N = 384) excluded. In the resulting clustering, /j w/ are grouped together with /p t k m n l r/. To further ascertain their status vis-à-vis the ‘basic set’, we then conducted a cluster analysis on the segments from it together with /j w/, based on two versions of the dataset: one with and one without the Australian languages.Footnote 10
The results are shown in Fig. 5. They indicate that in both cases /j w/, /p k/ and /t n/ form basic pairings, and that /p k/ are then merged together with /t n/; this cluster is then augmented by /l r m/ and finally merged with /j w/. The only difference is in the order in which the segments are added: /l/ > /r/ > /m/ in the full dataset, and /m/ > /l/ > /r/ when Australian languages are left out.
Single-linkage clustering of the most common segments based on arccosine-transformed correlations.
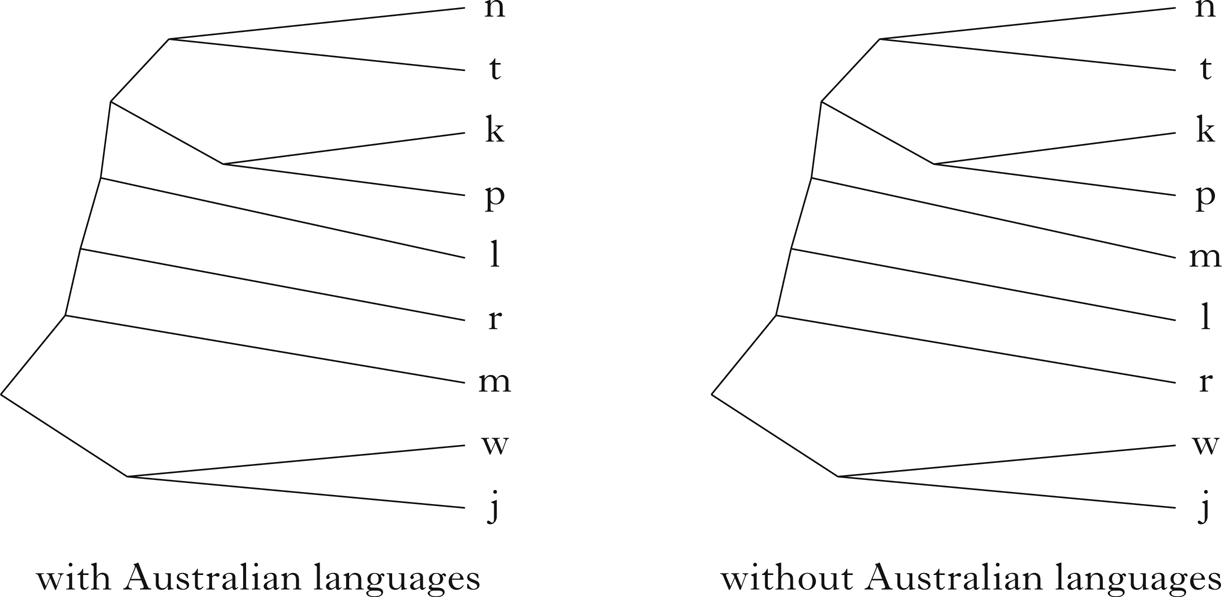
Thus it seems that even though /j w/ are very frequent, languages care mostly about having both these segments. Losing a segment from the /p t k m n l r/ set, on the other hand, even though clearly possible, leads to a statistically marginal configuration.
3.2.2 The Australian extension set
The cluster in Fig. 2 that includes /j w/ otherwise consists of three types of segments: retroflexes, /ɭ ɳ ɽ ʈ/, forming a counterpart to the subset of the basic inventory, alveolo-palatal /ȴ ȵ ȶ/, and /ŋ/. In a worldwide perspective, these sounds fall into three different frequency bands:
(i) /ŋ/ is a very frequent segment (N = 1751), but its overall relative frequency (63%) pales in comparison to its relative frequency in Australia (it is present in all Australian languages in the sample). The same applies to /j w/, found in all Australian languages in the sample.
(ii) Retroflex segments are traditionally associated with South Asia and the Himalayas, where a greater variety is indeed found than elsewhere. The relative frequencies of /ɭ ɳ ɽ ʈ/ in Australia, however, are all very high (≈ 0.6), while in other regions retroflex inventories display more variation (Nikolaev & Grossman Reference Nikolaev and Grossman2018).
(iii) Alveolo-palatal /ȴ ȵ ȶ/ are not reported outside Australia.
Other retroflex segments, /ɖ ʈʰ ɽ/, are found with similar frequencies in Australian and South Asian languages. As a consequence, they are classified as noise points.
3.2.3 The non-Australian extension set
Whereas Australian languages expand the basic inventory by means of an extended set of places of articulation, avoiding both voiced plosives and voiced fricatives, languages from outside Australia almost universally add to the basic set using some or most of the segments in (6). We refer to the resulting set as the first extension set.
-
(6)

The hierarchical clustering plot for these segments shown in Fig. 6 demonstrates that there is more structure to this extension than mere frequencies: the voiced plosives /b d g/ cluster together, as do /f v z/ and the postalveolar pairs /ʃ ʒ/ and /ʧ ʤ/. /s/ is placed separately, presumably because its very high frequency dilutes correlations with other segments, while other less frequent ‘semi-basic’ segments do not form pairs. The most notable observation is a relatively weak correlation between the glottal segments /h/ and /Ɂ/ (r = 0.257). /Ɂ/ is more than twice as likely to appear with /h/ than on its own (283 vs. 756 cases), but /h/ appears with and without /Ɂ/ with nearly equal frequencies, with a slight preference for inventories without /Ɂ/ (756 vs. 799 cases). It must be noted, however, that a great number of languages are postulated to have a non-phonemic glottal stop. The influence of this factor on the distribution is unclear.
Single-linkage hierarchical clustering of the first major extension to the basic inventory based on arccosine-transformed correlations.
Close to the extension set but not inside it are the tap /ɾ/ and two groups of what the algorithm deems to be noise points, although they seem to form subclusters of their own:
(i) The affricates /ʦ ʣ pf/ have widely different frequencies (N = 652, 297, 39 respectively), but /ʦ ʣ/ are strongly correlated (r = 0.52), and out of 39 occurrences of /pf/, 35 are in languages with /ʦ/; all the exceptions are found in Africa.
(ii) The palatal plosives /c ɟ/ have comparable frequencies (N = 360, 320). Similarly to fricatives and in contrast to basic plosives, they are grouped on the basis of their place of articulation, rather than voice. The position of the much rarer /cʰ/ (N = 83) is ambiguous: it is situated between the palatal plosives and the prominent cluster of voiceless aspirates.
Voiceless aspirated plosives and affricates cluster together. The addition of a non-basic VOT feature seems in this case to be more important than place and manner differences. This is not true, however, for the retroflex affricates /Ú Úʰ ó/, which are separated by their place–manner combination, disregarding VOT. Retroflex affricates form a tight co-occurrence class mostly associated with the affricate-rich languages of Eurasia (see Nikolaev & Grossman Reference Nikolaev and Grossman2018).
The retroflex fricatives /ʂ ʐ/, treated as noise points by the clustering algorithm, enjoy a much wider and geographically unstructured distribution (languages with retroflex affricates tend to also have corresponding fricatives, but this connection is one-directional).
The alveolo-palatal fricatives and affricates /ɕ ʑ ʨ ʨʰ ʥ/ are medium-frequency segments forming the cluster characterised exclusively by place of articulation in (7).
-
(7)
They are found in all major areas, and seem to be especially prevalent in the Circum-Tibetan area. The frequencies, however, may be unreliable, as the frequency of reports of alveolo-palatal segments in descriptions has increased in recent years, replacing earlier reports of postalveolar /ʃ ʒ ʧ ʤ/.
Languages rarely have both alveolo-palatals and postalveolars, and it has even been suggested that this is impossible, due to their acoustic and articulatory similarity (Hall Reference Hall1997). However, there are 16 languages – nearly all of them Eurasian, and mostly Circum-Tibetan – that have both /ʃ/ and /ɕ/, and 13, mostly from the same set, with both /ʧ/ and /ʨ/.
The breathy voiced/murmured stops /b d  G/ are found predominantly in South Asia and the surrounding regions. They were evidently inherited in the Indo-Aryan languages of the area, and later spread, due to phonological borrowing and convergent processes of sound change. A similar scenario has been proposed to account for the distribution of retroflex segments, which presumably spread from their homeland in the Dravidian southern periphery of South Asia (Bomhard Reference Bomhard1986, Bohnert et al. Reference Bohnert, Myers, Smith and Berkson2018).
Another group of segments augmenting the extension set are the bilabial and interdental fricatives together with the voiced velar fricative and, surprisingly, the retracted dental nasal stop /ṉ/, as in (8).
-
(8)
The appearance of /ṉ/ here is probably a statistical artefact: it is very weakly correlated with other segments (no r ≥ 0.06), which, it must be said, are generally rather weakly interconnected, except for /θ ð/ (r = 0.44).
Interestingly, voiced bilabial and interdental fricatives seem to be more common than their voiceless counterparts. /x/ (N = 491) does trump /ɣ/, but it also tends to co-occur with the ‘guttural segments’ (cf. below), which separates it from this cluster. Another possible peripheral member of this cluster is the alveolar approximant /ɹ/, a surprisingly rare segment (N = 54). It is known, however, that the description of rhotic segments often suffers from overnormalisation, with taps and approximants being inaccurately described as trills (Catford Reference Catford2001), so this datum is unreliable.
Postvelar (uvular and pharyngeal segments) have low to mid frequencies, as in (9).
-
(9)
Uvulars are generally more common than pharyngeals, with the notable exception of the voiced uvular stop /ɢ/, which suffers from the same kind of articulatory disadvantage as described above for /g/ (an extremely small cavity for maintaining high subglottal pressure for voicing). The interleaving of frequencies, however, does not influence the internal structure of the cluster, where the two pharyngeals are opposed to all the uvulars (cf. Fig. 7); uvular fricatives form a tight unit, but uvular stops, due to a wide discrepancy in frequencies, do not.
Single-linkage clustering of guttural segments based on arccosine-transformed correlations.

Ejective segments, whose geographic distribution has been debated since the publication of Everett (Reference Everett2013) (see Hammarström Reference Hammarström2013 and Roberts Reference Roberts2013, for example), undoubtedly form a clearly delineated group subsuming different places and manners of articulation, as in (10) (‘R’ is a symbol for an underspecified rhotic used in UPSID, one of the sources for PHOIBLE).
-
(10)
Interestingly, /R/ tends to co-occur with ejective segments. It is also notable that the non-ejective voiceless lateral affricate occurs more rarely than its ejective counterpart, and does not pass the 30-language threshold.
The labialised velar and uvular segments in (11) form a cluster of their own, midway between ejectives and plain (i.e. non-labialised) postvelars. /xʷ/, a nearby noise point, can also probably be considered a part of this cluster.
-
(11)
These segments tend to appear in large inventories, which, in addition to sporting a wide range of places of articulation in the postvelar region, also employ labialisation, in accordance with the layering principle.
The appearance of the ejective /kʷ’/ in this cluster can be explained by the fact that labialised velar and uvular segments tend to appear in large inventories, especially those with ejectives, i.e. in the Caucasus and parts of North America. It should be pointed out that some languages with extremely large inventories (Saamic languages and some Tibetan dialects) lack both labialised plosives and ejectives.
Lateral fricatives and creaky voiced approximants form a surprising grouping. /J/ and /W/ are both quite rare (appearing in 30 languages each), and are very highly correlated (r = 0.9). /ɬ/ appears in half of the languages in which they appear in (14 for /J/ and 15 for /W/); these languages are all from North America, making this connection a localised one.
3.2.4 Other clusters
The remaining subgroups of the large cluster are:
(i) The implosives /ɓ ɖ ʄ/ (N = 293, 254, 44), which form a natural group. /ʄ/ is mostly found in Africa, but /ɓ ɖ/ have an intriguing distribution: they are found in Africa, Eurasia, both Americas and in Oceania, but never above the 41st northern parallel.
(ii) The labial-velar segments /kp gb ŋm/, together with /ɥ/, the former almost exclusive to Africa.
(iii) The prenasalised segments /mb nd ŋg nʤ ŋmgb ŋgʷ nʣ nz ɱv ɲɟ/ (N = 284, 278, 264, 127, 93, 57, 53, 46, 46, 36), which are also confined to the southern hemisphere, with /mb nd ŋg/ enjoying a rather wide distribution, and others found predominantly in Africa.
(iv) The palatal affricates /cç cçʰ ɟʝ/ (N = 112, 43, 97), which occur primarily in languages of the Indian subcontinent, together with the palatal fricatives /ç ʝ/ (N = 116, 54), which have a much wider unstructured distribution.
(v) The dental segments /t̪ n̪ l̪/, together with nearby /d̪/ (N = 615, 473, 191, 354). Common descriptive practices may suppress the real frequency of these segments, which are often described as alveolar or ‘denti-alveolar’, but there is little doubt about the status of this cluster.
4 Co-occurrence classes and the feature-economy principle
In this section, we review the co-occurrence clusters identified by the method described in §2 in light of their conformity with the layering principle, which we consider a reformulation of the feature-economy principle.
In order to compare clusters in a principled manner, we first explain and illustrate the notion of conformant class of segments. A conformant class (i) uses all of the feature-value combinations available after pooling feature values from all its members, and (ii) if it includes stops and fricatives, also includes bilabials/labiodentals, denti-alveolars and velars.
For example, /p t k/ would be a conformant class, along with both /b d g/ and /p t k b d g/, because (i) it is impossible to define a new phoneme which would include a combination of the feature values found in the segments of these classes, and (ii) no requisite places of articulation are missing.Footnote 11 We regard place, manner and VOT as categorical features, and all other features as privative, i.e. features that can be either present or absent in a given segment's specification (e.g. a voiced implosive segment is taken as having a feature [+implosive] and non-modal voicing is modelled as [+breathy voice] or [+creaky voice]). A typical example of a non-conformant class will be /t k b d/, because available feature combinations {voiceless bilabial plosive} and {voiced velar plosive} are not represented. A class consisting of /t k d g/ is also non-conformant, because it does not include bilabials.
In the basic inventory, the cluster /p t k m n l r/ does not display any additional articulation or non-modal voicing, and utilises a comprehensive set of place features, but it is still hardly minimal. Even if we contend that voiceless stops cannot be in opposition with voiced continuants on the basis of a difference in their VOT values, this array of segments uses two privative features ([+lateral], [+rhotic]), which would not be required if, for example, /l r/ were replaced with /m n/. It is therefore evident that, for currently unknown reasons, languages are remarkably reluctant to skip items in a minimal set of combinations of place and manner of articulation values with some ‘default’ voicing settings for these combinations.
In Table II, the basic consonant inventory augmented with /j w/ is compared to the minimal inventories discussed by Hyman (Reference Hyman2008). We see that the basic consonant inventory can be considered a good predictor for what a minimal consonantal inventory will look like. The two noticeable discrepancies are that minimal inventories tend not to have both a rhotic and a liquid, and that the basic consonant inventory does not include /h/.Footnote 12
The basic consonant inventory compared with the minimal inventories discussed by Hyman (2008) and the basic consonant inventory proposed by Clements (2009: 46).

Perhaps more interesting is the comparison of our basic consonant inventory with that proposed by Clements (Reference Clements2009: 46), which is based on the 15 most common segment types in UPSID. Clements’ proposed basic consonant inventory is phrased in terms of feature combinations, given as capital letters, with representative sounds given in IPA. The first five sounds, /t k n m p/, converge, as do /l r/, which are less frequent in UPSID. However, other sound types in Clements’ basic consonant inventory, in particular all fricatives, affricates and glottals, as well as voiced stops, are not part of our basic consonant inventory proper, but rather belong to extension sets. Furthermore, as we have shown, the glides /j w/ are part of the basic consonant inventory only if Australian languages are excluded. In other words, our approach shows that even within the set of basic sounds proposed in prior work on the basis of frequency, there is additional structure to be uncovered.
In the first extension set, the cluster /ʎ ʒ v ʤ ʒ z ʃ Ɂ ʧ ɲ f d g h b s/ enlarges the minimal inventory by adding a series of voiced stops, but instead of exhausting the usefulness of the VOT opposition (by introducing voiceless sonorants and liquids), it adds two new major classes of sounds: fricatives and affricates, both voiced and voiceless, at two places of articulation (denti-alveolar and postalveolar; affricates are only postalveolar), together with the glottal stop (the status of /ʎ/ in this cluster is clearly peripheral, due to its lower frequency). This can be regarded as the ‘second best’ set of sounds that languages tend to have when the inventory is large enough to go beyond the basic set. It has been shown that some members of this inventory may be rather recent historically (Blasi et al. Reference Blasi, Moran, Moisik, Widmer, Dediu and Bickel2019), demonstrating that even the structure of comparatively basic parts of phonological inventories can be shaped by the forces of language contact and historical contingency. Furthermore, some of these sounds, in particular the fricatives and affricates, are among the most frequently ‘borrowed’ sounds, i.e. sounds that become contrastive as the result of lexical borrowing (Grossman et al. Reference Grossman, Eisen, Nikolaev and Moran2020). Table III shows the basic consonant inventory and the first extension set together.
The basic consonant inventory (white cells) and the non-Australian extension set (light grey cells). Dark grey cells fall into the basic consonant inventory if Australian languages are excluded from the clusterisation.
4.1 Conformant classes
Voiceless aspirated segments are a conformant class: voiceless stops and affricates from different places of articulation have an additional distinctive feature. The problem with this class, however, is that it can be argued that it is incomplete: as will be shown below, voiceless affricates at several places of articulation form non-conformant classes.
The algorithm divided palatalised segments into coronals and non-coronals, but both classes are strictly conformant with the layering principle: they consist of voiced and voiceless consonants at different places of articulation with no other additional articulations.
Phonologically long segments form another conformant class: this cluster consists of voiced and voiceless consonants of different places of articulation characterised by no other features, such as additional articulations or non-modal phonation.
The treatment of the class of voiceless approximants and liquids depends on the problematic setting of the feature VOT for this class of segments. If voicing of approximants and liquids is regarded as a basic opposition, this class is not conformant, because it should also include voiced approximants and liquids. However, voicing may be treated as an integral feature of these segments, enforced by a fill-in rule of sorts (Keating Reference Keating1988), in which case their voiceless counterparts are united by the presence of an additional feature value [―voice].
Breathy voiced stops form a conformant class defined by the addition of non-modal voicing to basic voiced stops. This class has a tight areal distribution, being a characteristic feature of South Asia.
Ejective segments as selected by the algorithm also form a well-behaved cluster, defined by an additional articulation superimposed on voiceless stops and affricates. Ejective fricatives are not frequent, and were not included in the data analysed.
The phonological analysis and feature specification of implosives are a matter of debate (Clements & Osu Reference Clements, Osu, Gussenhoven and Warner2002). However, their articulation, acoustic properties and historical origins (they usually derive from geminated voiced stops; Xi Reference Xi2009) point to their being an augmented version of voiced plosives, which is appropriately reflected by their place in the layered system.
4.2 Non-conformant classes
4.2.1 Classes defined by a particular value for place
Several classes violate the layering principle by being defined not by an additional feature or a combination of features, but by a particular value for place. Most place values do not determine their own co-occurrence classes, and are subsumed under broader conformant classes.
The alveolo-palatal segments /ʑ ɕ ʥ ʨ ʨʰ/, in addition to being defined by a particular place value, contain only a single element with an additional articulation (aspiration).
The uvular segments /qʰ ɢ q χ/ are similar to alveolo-palatals in consisting of voiced and voiceless segments with different manners of articulation and including one aspirated segment.
4.2.2 Classes defined by a particular value of the manner feature
The group /θ ɸ ð ꞵ ɣ/, together with /ṉ/, whose presence may be a statistical artefact due to its relatively low frequency, constitutes an intriguing extension to the basic inventory. Most notably, three groups of fricatives defined by different places of articulation – interdental, bilabial and voiced velar – form a group, even though they are all comparatively rare, and do not have obvious features in common which distinguish them from other modally voiced fricatives. A further violation of the layering principle is the fact that even though bilabial fricatives are in nearly complementary distribution with labiodental fricatives, it seems that precisely those languages which have bilabial fricatives tend to also have interdental fricatives and the voiced velar fricative.
The voiceless prenasalised stops /mp nt ŋk/ form a separate class by virtue of occurring in a small subset of languages with voiced prenasalised stops. This may be regarded as a prominent violation of the layering principle, since most languages with prenasalised stops do not have voiced ones, and therefore underutilise the available feature combinations.
A prenasalised stop, however, may be also regarded as voiced by default in the same way as a sonorant, as one of its constituent elements is sonorant. In this scenario, voiceless prenasalised stops are characterised by an additional feature [―voice], making them a conformant class.
4.2.3 Classes defined by a combination of place and manner features
The two small classes of palatal and retroflex affricates are defined by their combination of place and manner features and their ability to incorporate voiceless aspirated segments (under the layering principle, voiceless aspirated fricatives are expected to cluster with voiceless aspirated stops, as we see at other places of articulation). These segments tend to appear as a group in large inventories (cf. the analysis of retroflex affricates by Nikolaev & Grossman Reference Nikolaev and Grossman2018), and are largely geographically concentrated in and around South Asia. In the dimensionality-reduction plot in Fig. 2, both classes are also connected with respective fricative segments, which enjoy much wider and less structured distributions.
4.2.4 Mixed classes
Labialised segments are a complex case. The clearly separated class of non-guttural labialised segments in Fig. 1 is largely conformant. At the same time, the analysis shows that /hʲ/ forms a part of this cluster, due to its tight distributional connection with /hʷ/. This can be considered a minor violation of the layering principle. The predictive power of the principle is severely damaged, however, by the existence of a separate cluster of labialised segments consisting of /kʰʷ kʷ’ χʷ qʷ/. These segments do not have a common distinguishing feature (one of them is aspirated, one is ejective and the other two are plain voiceless labialised). It is evident that this particular region of feature space tends to be adopted in its entirety by languages with rich inventories, including ejective sounds.
The lateral fricatives and creaky voiced approximants, /ɬ ɮ J W/, form a rather surprising grouping, as they have nothing in common. Languages underlying this connection are North American, and it may have arisen due to geographically and phylogenetically restricted sound-change processes.
The featural analysis of the labial-velar segments, /kp gb ŋm/, presents difficulties, due to their dual nature. However, Cahill (Reference Cahill1999) presents evidence in favour treating them as underlyingly labial segments with an additional velar coarticulation. In our data they strongly pattern with /ɥ/, which can also be analysed as a labial sound with an additional coarticulation. However, as this coarticulation is palatal, the class is non-conformant.
5 Conclusion
The contributions of this study are largely empirical, although they have a bearing on theoretical concerns. The primary contribution is the articulation of an empirical method for identifying co-occurrence clusters of segments in inventories. These are essentially groups of sounds between which bilateral dependences obtain. This in itself can contribute to future studies of the structure of sound inventories, but also to the analysis of the geographical distribution of rule sets, grammatical categories or indeed any phenomenon that is governed by a point process (i.e. a process where each observation is a subset of some base set; see the analysis of vowel inventories from this perspective in Cotterell & Eisner Reference Cotterell and Eisner2017).
From a theoretical perspective, we have investigated the extent to which the feature-economy principle accounts for sound systems. The interpretation of our findings depends somewhat on the reader's outlook. On the one hand, we found that a large number of clusters conform to the feature-economy principle. To this extent, the feature-economy principle is validated by these classes. However, we also identified a number of non-conformant classes. Rather than reflecting mere noise, these classes tend to reflect fairly clear organisational principles, such as particular values for place or manner features, or a combination thereof.
Nonetheless, the feature-economy principle cannot really explain the structure of the most basic parts of inventories, in particular the classes we termed the basic consonant inventory and the first extension set, which always span a ‘non-minimal’ set of place and manner feature combinations with preferred values for VOT for some of these combinations. An intriguing finding of our study is that some earlier proposals for a basic consonant inventory, which were based purely on frequency in cross-linguistic databases, conceal additional structure. For example, Clements’ proposal includes the basic consonant inventory proper, as well as parts of the first extension set and classes whose inclusion or exclusion depends on areal factors.
Secondly, several well-defined classes identified by the algorithm are carved out of the wider space of feature combinations with no regard for the feature-economy principle. Among the important exceptions to the principle are alveolo-palatal and postvelar segments, and retroflex and palatal affricates. These segments tend to be found mostly in complex inventories that utilise several additional articulations, and are usually found together. Consequently, these co-occurrence classes include members with and without additional articulations, going against the expected sequence of co-occurrence classes defined by adding extra features: plain segments appearing before palatalised, aspirated and labialised segments. It therefore seems that particular combinations of values of the basic place and manner features, very frequently found individually, are underrepresented in small and medium-sized inventories, to the detriment of feature economy.
Moreover, some combinations of feature values are highly correlated, especially labialisation of velar and postvelar segments.Footnote 13 This is unexpected on the basis of the feature-economy principle, which predicts that labialisation, when introduced to an inventory, should not be preferentially associated with any particular place of articulation.
Additionally, it is apparent that there are strong macro-areal effects in the number and structure of co-occurrence classes. Australian inventories are a clear outlier, demonstrating deviating tendencies even in the structure of the most basic parts of the system, but Africa, North America and some large sections of Eurasia also have their own co-occurrence classes. We also have to account for the highly localised worldwide distribution of ejectives and for the skewed worldwide distribution of prenasalised segments and implosives, which are primarily found in the southern hemisphere.
These findings suggest that, in order to more fully account for the structure of actual phonological inventories of the world's languages, the feature-economy principle, which is structural in nature, should probably be augmented with other principles. The most important of these seems to be the tendency of consonant inventories to be modular. Instead of progressive multiplicative expansion by means of adding new features to some base set of segments, predicted by the feature-economy principle and related hypotheses, we see that inventories grow by exploring particular regions in the segment space. Some of these regions and co-occurrence clusters can be construed as following the feature-economy principle, but many cannot, and this leads to the conclusion that there is perhaps no universal principle of inventory growth. And if there is one, it may be something along the lines of Stevens’ quantal theory of speech (Reference Stevens1989), with particular regions of feature-combination space having outsized prominence. The economy of inventories then can be construed as consisting of a minimisation not of the number of features used, but of the number of explored co-occurrence classes. Interestingly, apart from the fact that languages do not skip the basic consonant inventory and, for the most part, the first extension set, all other attractor regions are essentially unordered.
After presenting our conclusions, we would like to end the paper by repeating that this study is first and foremost an exploratory one. The analytical pipeline we used consists of a set of well-proven components, but as a whole it is very much a novel method that has not been extensively tested on other datasets in order to evaluate proposed phonological principles like feature economy. We therefore acknowledge that our results, despite being in line with reasonable expectations, may turn out to be somewhat brittle, and that other pipelines may identify other patterns of co-occurrence classes, although we would expect the structure as a whole to be relatively robust. We hope that our effort will spur a search for new, data-driven approaches in the field of consonant-inventory typology and that, as a result, the field will be able to break new ground, and at some point converge on a set of commonly accepted procedures for testing hypotheses.











 Open access
Open access