


1. Introduction
The traditional methods of data analysis of dialectology and dialectometry (Wieling & Nerbonne, Reference Wieling and Nerbonne2015; Goebl, Reference Goebl, Boberg, Nerbonne and Watt2018) have in recent years been supplemented by new quantitative approaches of spatial statistics.Footnote 1 These methods are particularly useful for determining the existence of spatial patterns in the geographical distribution of linguistic features and have been successfully applied to acoustic (Grieve, Reference Grieve2013; Grieve, Speelman, & Geeraerts, Reference Grieve, Speelman and Geeraerts2013), phonosyntactic (Grieve, Reference Grieve2011), and lexical (Grieve, Speelman, & Geeraerts, Reference Grieve, Speelman and Geeraerts2011) features. In particular, measures of local spatial autocorrelation have been able to identify clusters of locations exhibiting similar values for a given linguistic feature. However, the measures used hitherto, such as Getis-Ord G i and G * i (Ord & Getis, Reference Ord and Getis1995) or local Moran’s I (Anselin, Reference Anselin1995), only apply to continuous variables, such as the relative frequency of variants measured at different locations, and not to categorical variables, where each observation is associated with one of several values at a location, like the presence versus absence of a feature. Until recently, only global indicators, such as the global join count (see Section 2.2), were available for such discrete variables, but Anselin and Li (Reference Anselin and Li2019) recently proposed a local version of that indicator. In this article, we show how this local indicator can be applied to linguistic data in order to detect local spatial clusters with the example of Japanese rendaku.
Rendaku, or sequential voicing, designates the initial consonant alternation between different realizations of a lexeme in Japanese, that is, cases where a lexeme is usually realized with an initial voiceless obstruent but with an initial voiced obstruent when it appears in noninitial position within a compound (1).Footnote 2

Rendaku is a complex phenomenon, largely irregular, that is well-studied from the historical, theoretical, and psycholinguistic points of view.Footnote 3 However, little research has been done on the extent of regional variation in the frequency of rendaku. Most of the few existing studies conclude that there is no clear difference across dialects (Asai, Reference Asai2014; Irwin & Vance, Reference Irwin and Vance2015; Takemura et al. Reference Takemura, Pellard, Kyung Hwang and Vance2019; Tamaoka & Ikeda, Reference Tamaoka and Ikeda2010), but these suffer from limitations in data coverage and/or methodology.
In the present study, we examine the occurrence of rendaku for four lexemes in 4,921 place names from all Japan and apply a statistical analysis of local spatial association followed by a cluster analysis in order to detect the presence of local spatial clusters of high rendaku frequency, that is, areas where either place names exhibiting rendaku tend to co-occur together more frequently that would be expected if they were randomly distributed. Our results show the existence of two cluster areas of high rendaku frequency in different regions of Japan, which suggests that rendaku is more frequent in those dialects.
2. Materials and methods
2.1 Data
In the absence of any large coverage survey on rendaku in Japanese dialects, we chose to investigate the spatial variation of rendaku frequency in place names across Japan. We used the database assembled by Takemura et al. (Reference Takemura, Pellard, Kyung Hwang and Vance2019), which derives from the comprehensive database of postal codes and the corresponding addresses provided by the Japan Post (Reference Post2014). It contains all place names including any of the six lexemes listed in Table 1 in noninitial position, to the exclusion of place names from Okinawa prefecture and the Amami Islands of Kagoshima, since these areas are traditionally Ryukyuan-speaking areas with peculiar place names (Shimoji & Pellard, Reference Shimoji and Pellard2010). Each entry consists of the postal code of a location, the corresponding place name in Japanese script, its pronunciation in kana, the prefecture of the location, and an added annotation by Takemura et al. (Reference Takemura, Pellard, Kyung Hwang and Vance2019) as to whether the place name exhibits rendaku or not. The database contains a total of 7,725 different place names (Table 1).
Rendaku rate by lexeme (original data of Takemura et al., Reference Takemura, Pellard, Kyung Hwang and Vance2019)

Since the original database does not provide the geographical coordinates of the locations, the CSV address matching service of the Center for Spatial Information Science of the University of TokyoFootnote 4 was used to retrieve them. The geocoding process was successful for 7,470 entries, that is, 96.7% of the 7,725 entries, and the 255 (3.3%) remaining ones were discarded.
The lexemes chosen by Takemura et al. (Reference Takemura, Pellard, Kyung Hwang and Vance2019) are commonly used in place names across Japan, and all of them undergo rendaku in at least some compounds. However, inspecting Table 1 reveals disparities in the rendaku frequency of the different lexemes (χ 2(5, N = 7725) = 191.73, p < .001, V = .16). Place names containing “plain” (hara ∼ bara) tend not to exhibit rendaku, while for other lexemes, the opposite tendency is observed. On the other hand, “valley” (tani ∼ dani) exhibits a much higher rendaku frequency than other lexemes. This is problematic, since the dependency between lexeme identity and rendaku frequency makes the data heterogeneous and the probability of rendaku not uniform. There is thus a risk that lexeme identity acts as a confounding variable, since it could result in spurious clusters of either high or low rendaku frequency that would simply be spatial clusters of a certain lexeme. The two outliers, “plain” and “valley,” were thus removed from the geocoded data, resulting in an overall homogeneous data set (Table 2, χ²(3, N = 4921) = 0.17, p = .982, V = .01). Map 1 indicates the location of the place names in the final version of our database.
Map of the 4,921 locations investigated.

Rendaku rate by lexeme (filtered and geocoded data)

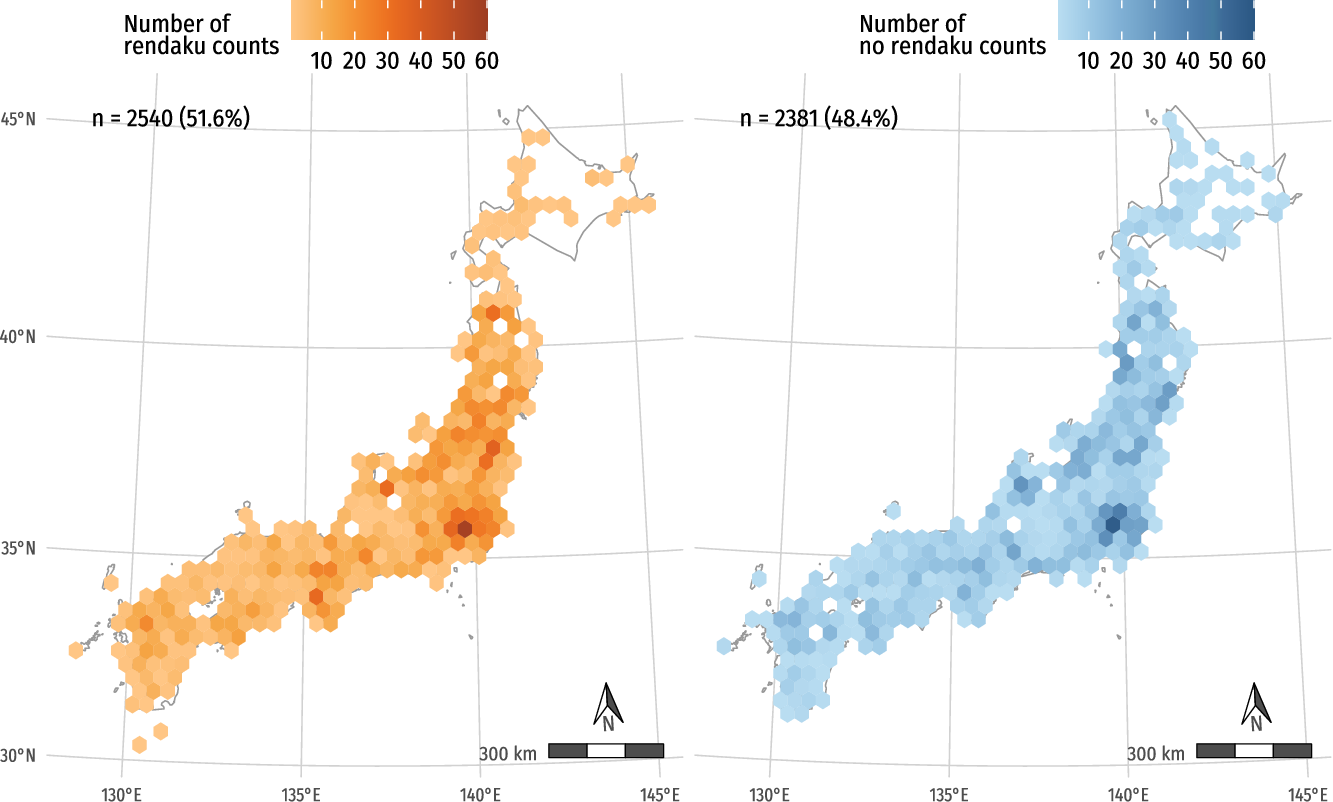
The spatial distribution of presence versus absence of rendaku is difficult to interpret by simply mapping the data, partly due to the large number of data points, even if we examine separately place names with and without rendaku and use hexagonal bins (Map 2) and even if we further map separately the different lexemes (Map 3).Footnote 5 A statistical analysis is thus needed in order to assess the existence of clusters.
Presence versus absence of rendaku in all place names.
Presence versus absence of rendaku by lexeme.

2.2 Statistical analysis
In order to investigate whether the spatial distribution of rendaku is random or follows a pattern, we need to measure the spatial autocorrelation for the variable of interest, that is, the degree to which observations of presence versus absence of rendaku agree between neighboring place names. First, we defined a location’s neighbors as the set of all locations within a radius of 50 km of that location (Figure 1), which results in a circle with an area roughly equal to the mean area of Japanese prefectures without the Ryukyu Islands (7,982 km²).
Density distribution of the number per location of neighbors within a 50 km distance; vertical white lines indicate the quartiles (Q
1 = 79, Q
2 = 116, Q
3 = 155,
 $$\bar x$$
= 128.8).
$$\bar x$$
= 128.8).

For exploratory purposes, a global join count (Moran, Reference Moran1948) was computed, with three different measures: J BB , the number of neighboring locations that exhibit rendaku (“black-black”); J WW , the number of neighboring locations that do not exhibit rendaku (“white-white”); and J BW , the number of neighboring locations that exhibit opposite values (“black-white”).Footnote 6 The results (Table 3) indicate the existence of a statistically significant (z = 2.02, p = 0.02, one-sided test) positive spatial autocorrelation for J BB , that is, place names exhibiting rendaku tend to co-occur more often than would be expected by chance alone.
Global join count statistics

However, though the global join count indicates the existence of rendaku clusters, it does not specify where these clusters are located. In order to locate these clusters, the local indicator of spatial association for binary marked points proposed by Anselin and Li (Reference Anselin and Li2019) was calculated for each location with a place name exhibiting rendaku as the number of its neighbors that also exhibit rendaku.Footnote 7 Then, a conditional permutation test with 999 repetitions was performed in order to obtain for each location the pseudo p-value of getting, by chance, an indicator at least as high as observed. Since many tests were performed, the false discovery rate of multiple hypothesis testing was controlled by applying the procedure of Benjamini and Hochberg (Reference Benjamini and Hochberg1995) in accordance with Castro and Singer (Reference Castro and Singer2006). Locations with an adjusted p-value below the .05 α-level were considered to constitute cores of rendaku clusters, and the neighbors of those cores that exhibit rendaku were also considered to be part of the clusters, since, even though their indicator is not significant by itself, it contributes to make those of the cores significant.
Such cores and their neighbors exhibiting rendaku were then submitted to an unsupervised density-based cluster analysis with the DBSCAN algorithm (Ester et al., Reference Ester, Kriegel, Sander, Xu, Simoudis, Han and Fayyad1996) with parameters ϵ = 50 km and MinPts = 30.
All analyses were performed using the R Statistical Software (v4.2.1, R Core Team, 2022) and the spdep (v1.2.5, Bivand, Pebesma, & Gómez-Rubio, Reference Bivand, Pebesma and Gómez-Rubio2013) and dbscan (v1.1.10, Hahsler, Piekenbrock, & Doran, Reference Hahsler, Piekenbrock and Doran2019) packages. Geospatial data was processed using the R package sf (v1.0.8, Pebesma, Reference Pebesma2018).
3. Results
The statistical analysis of local spatial association indicates the existence of 167 cores of clusters, which represent 3.4% of all locations and 6.6% of locations exhibiting rendaku. These are surrounded by a total of 376 neighbors, which themselves represent 7.6% of all locations and 14.8% of locations exhibiting rendaku. Conversely, 78.6% of place names exhibiting rendaku do not belong to a cluster. Map 4 shows the location of the cores of clusters.
Cores of rendaku clusters.

These cores and neighbors form two different geographical cluster areas, as revealed by both the visual inspection of the data (Map 5) and the application of the clustering algorithm. Table 4 and Table 5 summarize the number of cores and neighbors by cluster area and, respectively, prefecture and lexeme.
Cores (full colors) of rendaku clusters and their neighbors (dimmed colors).

Cores (full colors) of individual rendaku cluster areas and their neighbors (dimmed colors).

Number of cores and neighbors by area and prefecture

Number of cores and neighbors by area and lexeme

4. Discussion
We observed that place names exhibiting rendaku are not distributed completely at random across Japan but tend to co-occur in some areas, and we detected two different geographical rendaku cluster areas. This contrasts with the findings of Takemura et al. (Reference Takemura, Pellard, Kyung Hwang and Vance2019): that there is no clear geographical pattern. The major problem with that preliminary study is that it ignored the problems of spatial autocorrelation and calculated the mean rendaku rate by prefecture, though there is little justification for believing that dialectal zones and their differences in rendaku rate strictly follow the boundaries of modern administrative units. This probably had the unfortunate consequence of masking the existence of rendaku clusters distributed over several prefectures, as revealed in our more fine-grained study. It also suffers from a lack of homogeneity in the rendaku rate of the different lexemes studied.
Tamaoka and Ikeda (Reference Tamaoka and Ikeda2010) conclude that dialect has no influence on rendaku frequency. Their study is based on an experiment with 405 speakers from six different localities (Kagoshima, Ōita, Fukuoka, Yamaguchi, Hiroshima, and Shizuoka). However, their conclusion is expected from our perspective, since none of these prefectures belongs to a rendaku cluster area.
Similarly, Irwin and Vance (Reference Irwin and Vance2015) record the absence of presence of rendaku in 32 examples of 31 lexemes in the speech of 67 speakers of dialects from four different regions (Yamagata, Ehime, Miyazaki, and Hyōgo) but do not find a significant difference in average rendaku rate across locations. From our perspective, no such difference is indeed expected between Ehime, Miyazaki, and Hyōgo: Ehime and Miyazaki do not belong to a rendaku cluster area, and Hyōgo only contains a few neighbors. On the other hand, Yamagata contains several cores of rendaku clusters, and our results are thus at variance with theirs.
Asai (Reference Asai2014) found rendaku to be slightly more frequent in Northeastern Japanese dialect recordings (58%) than in Standard Japanese (50%).Footnote 8 His sample of Northeastern Japanese consists of dialects from Aomori, Akita, Iwate, Miyagi, Yamagata, and Fukushima, which substantially overlaps with our rendaku cluster area A. Such results are thus compatible with ours and are at variance with those of Irwin and Vance (Reference Irwin and Vance2015).
The existence of a large rendaku cluster area in Northeast Japan is interesting, since it is known that in dialects of that region, the voiceless versus voiced distinction is realized differently than in Standard Japanese; that is, in intervocalic position, voiceless stops are realized as voiced and voiced ones as prenasalized (Miyashita et al., Reference Miyashita, Irwin, Wilson, Vance, Vance and Irwin2016). It is, however, unlikely that this cluster area is the result of place names without rendaku but intervocalic voicing erroneously recorded as exhibiting rendaku. Though the consonant s does not undergo intervocalic voicing, half of the lexemes examined have an initial s-, and as much as 13.3% of the place names in cluster area A involve a lexeme with an initial s-.
5. Conclusions
This article shows the benefits of fine-grained analyses of spatial statistics for the study of linguistic variation and how a new measure of local spatial autocorrelation can be applied to linguistic categorical variables for detecting and localizing clusters. We were able to show that the frequency of rendaku varies across Japanese regions, and we detected the existence of two cluster areas of rendaku that could not be detected by simply looking at the data or by averaging frequency by prefecture and that had not been identified by previous studies.
Our study used place names to investigate the spatial variation of rendaku frequency. This raises the problem of the reliability of our data as a representative sample of dialects. Place names are often ancient and can predate the formation of the modern dialects, and the origin of their current pronunciation is unknown. Moreover, there is no assurance that the recorded place names readings that we used are always the same as the pronunciations in actual use locally.
Nevertheless, our statistical procedure detected a spatial pattern that cannot be reasonably attributed to chance only and that needs to be explained, in any case. Moreover, we think of place names as a proxy for a pandialectal study covering all Mainland Japan, which is unfeasible by the means of traditional dialectology. We recommend that the spatial cluster areas of rendaku that we detected be subjected to conventional dialectological surveys in order to try to replicate our results with experimental data. In other words, we suggest that further dialectal studies of rendaku start by looking at the areas of Fukushima-Yamagata and Wakayama.
Data availability statement
The data and code used for this study are openly available in an Open Science Framework repository at http://doi.org/10.17605/OSF.IO/MA8Q7.


















 Open access
Open access