


1. Introduction
Feedback in second language (L2) writing instruction is at the core of effective teaching and learning, offering students valuable opportunities to refine their language skills (Ferris & Kurzer, Reference Ferris, Kurzer, Hyland and Hyland2019; Kerr, Reference Kerr2020). As a pedagogical tool, feedback takes many forms, and it can guide learners toward improvement while promoting autonomy in their writing practices (Hyland, Reference Hyland2000). However, the practical realities of large class sizes and limited teacher time often hinder the provision of personalized, actionable, and timely feedback (Steiss et al., Reference Steiss, Tate, Graham, Cruz, Hebert, Wang, Moon, Tseng, Warschauer and Olson2024; Zhang, Reference Zhang2024). These challenges have prompted the exploration of supplementary solutions, including the use of AI-powered tools like automated writing evaluation (AWE) and automated written corrective feedback (AWCF) systems, to address these limitations. Now with AI chatbots, such as ChatGPT, it is easier for instructors and students to access different technologies immediately; however, their effectiveness for beginning-level learners in specific contexts, such as Spanish L2 writing, remains underexplored. Moreover, the potential for customized AI models tailored to task-specific needs (such as custom-trained GPT models) presents new opportunities for enhancing feedback quality.
This study investigates the efficacy and accuracy of a task-customized GPT model, “Belinda,” developed to provide constructive and actionable feedback on beginner Spanish learners’ writing. Belinda (she/her/hers) was trained to assess a single task – describing a mural in 10 sentences. She was also provided with a scoring rubric that she was instructed to apply when evaluating each learner’s response. In doing so, this research contributes to ongoing discussions about the integration of AI into beginner-level instruction for languages other than English.
2. Literature review
There are various forms of feedback in L2 classrooms, with corrective feedback – which focuses on addressing (grammatical) errors – emerging as the most common type (Ferris & Kurzer, Reference Ferris, Kurzer, Hyland and Hyland2019; Kerr, Reference Kerr2020). Corrective feedback helps learners identify and address their mistakes, guiding them toward greater linguistic accuracy and fluency. Within L2 writing, written corrective feedback (WCF) is widely recognized as a critical tool for fostering learning and linguistic development. As Hyland and Hyland (Reference Hyland, Hyland, Hyland and Hyland2019) assert, WCF plays a vital role in “encouraging and consolidating learning” (p. 1), supporting students’ gradual mastery of the target language. WCF has been linked to meaningful gains in second language acquisition (Bitchener, Reference Bitchener, Hyland and Hyland2019), as it provides learners with explicit opportunities to engage with their errors and make progress over time.
WCF can take several forms, including direct feedback, where instructors correct errors explicitly, and indirect feedback, where codes (e.g., sp for spelling, wc for word choice) or cues indicate the presence of an error for the learner to address. Research on the relative efficacy of these approaches has produced mixed findings, suggesting that the “best” type of feedback may depend on individual learner preferences and instructional contexts (Ferris & Kurzer, Reference Ferris, Kurzer, Hyland and Hyland2019; Kerr, Reference Kerr2020). In addition to addressing errors, it is essential to include feedback that also celebrates and encourages learners’ successes. This type of feedback promotes confidence and engagement, particularly for novice language learners, who may feel overwhelmed by the challenges of learning a new language (Dörnyei, Reference Dörnyei2001; Hattie, Reference Hattie, Meyer, Davidson, Anderson, Fletcher, Johnston and Rees2009; Hyland & Hyland, Reference Hyland, Hyland, Hyland and Hyland2019).
2.1 Automated writing evaluation and automated writing feedback
AWE and AWCF systems have emerged as transformative tools in language learning as they offer opportunities to streamline assessment and provide consistent, immediate feedback to learners (Steiss et al., Reference Steiss, Tate, Graham, Cruz, Hebert, Wang, Moon, Tseng, Warschauer and Olson2024; Zhang, Reference Zhang2024). These technologies utilize natural language processing (NLP) and machine learning algorithms to assess written language and generate feedback on grammar, vocabulary, syntax, coherence, etc. In the context of language education, AWE and automated writing feedback (AWF) tools hold particular promise for addressing challenges such as large class sizes and limited teacher time, enabling more personalized learning and promoting student independence (Fu et al., Reference Fu, Zou, Xie and Cheng2024).
AWE tools such as Criterion, Turnitin Revision Assistant, or Pigai typically provide summative feedback in the form of holistic evaluations or identification of errors after a draft is completed, while AWCF systems like Grammarly deliver formative feedback continuously during the writing process (Godwin-Jones, Reference Godwin-Jones2022; Shi & Aryadoust, Reference Shi and Aryadoust2024). These tools are being increasingly used to supplement instructor feedback due to their potential to “alleviate” the aforementioned challenges through consistent, immediate, and scalable feedback on surface-level elements like grammar, vocabulary, and punctuation mechanics (Gayed et al., Reference Gayed, Carlon, Oriola and Cross2022; Wolf & Oh, Reference Wolf and Oh2024, p. 19). AWE systems have been reported to be more effective in identifying surface-level errors than addressing higher-order writing concerns like content, organization, and rhetorical structure (Link et al., Reference Link, Mehrzad and Rahimi2022; Stevenson & Phakiti, Reference Stevenson, Phakiti, Hyland and Hyland2019), a limitation that stresses the importance of complementing AWE tools with teacher and peer feedback to achieve a balanced focus on both form and meaning (Kerr, Reference Kerr2020).
In contrast to AWE systems, which supply feedback after a text is written, AWCF tools “supply corrections and suggestions continuously and concurrently as a text is in the process of being written” (Godwin-Jones, Reference Godwin-Jones2022, p. 8). Still, these tools typically focus on lower-level writing problems like grammar and vocabulary errors and do not address content or organization (Godwin-Jones, Reference Godwin-Jones2022). However, Shadiev and Feng (Reference Shadiev and Feng2024) conducted a systematic review on AWCF tools present in publications from 2016 to 2022 and identified a total of 43, 20 of which offered feedback on higher-level writing features, including content, organization, idea development, mechanics, and style. Similarly, a review by Shi and Aryadoust (Reference Shi and Aryadoust2024) of 83 studies on AWF published between 1993 and 2022 found that (1) most research focused on English language learning contexts, and (2) the most common type of feedback focused on form rather than meaning. Nonetheless, AWCF tools have shown promise in reducing errors in learners’ L2 writing. For example, Barrot (Reference Barrot2023) and Guo et al. (Reference Guo, Feng and Hua2022) found that first-year undergraduate and graduate students, respectively, improved their English writing when critically using AWCF tools such as Grammarly.
Tools like Grammarly and newer applications, such as ChatGPT, illustrate the dual functionality of many AI systems in operating as both AWCF and AWE tools depending on how they are implemented (Barrot, Reference Barrot2023). For example, when Grammarly is integrated into a word processor, it provides real-time feedback and suggestions during the writing process (AWCF). Conversely, when used via its online platform, and a draft is uploaded, it acts more like an AWE tool, generating feedback and an overall summative score. Similarly, ChatGPT can serve as an AWCF tool when prompted for detailed feedback, rewriting sentences, or suggesting improvements in clarity, tone, and organization during the writing process, and it can also function as an AWE tool when asked to evaluate a piece of writing based on specific criteria, such as coherence, grammar, or vocabulary.
Still, while these tools have been reported to be effective at identifying and addressing surface-level errors such as grammar and mechanics, they have also been reported to have limitations in providing feedback on higher-order writing skills like content development, organization, and rhetorical coherence – a challenge shared by other AWE systems. As noted by Wolf and Oh (Reference Wolf and Oh2024), AWE tools can play a complementary role by alleviating teachers’ workload on lower-order concerns and enabling educators to focus more on higher-order aspects of student writing, such as content and structure.
2.2 Using ChatGPT to generate feedback
Research examining the quality and effectiveness of ChatGPT feedback has yielded mixed findings that reveal the potential and limitations of this chatbot as both an AWE and an AWCF tool. Steiss et al. (Reference Steiss, Tate, Graham, Cruz, Hebert, Wang, Moon, Tseng, Warschauer and Olson2024), for example, conducted a comprehensive comparison between the formative feedback provided by experienced educators and that generated by ChatGPT-3.5 on 200 source-based argumentative essays written by secondary students. Using only a single prompt and no additional training, ChatGPT-3.5 delivered feedback that was judged to be of “relatively high quality” (p. 7), though human feedback generally outperformed the bot in four of five quality dimensions (clarity, accuracy, prioritization of essential features, and tone). The study, however, identified key limitations that contributed to its weaker performance, particularly in providing clear directions for improvement on low-quality essays as well as accurate feedback on high-quality ones.
Similar concerns about the quality of ChatGPT feedback emerge when examining specific aspects of writing competence. Yoon et al. (Reference Yoon, Miszoglad and Pierce2023) investigated ChatGPT-generated feedback on coherence and cohesion in essays written by English language learners, and they found a strong association between AI and human rater scores that suggested general agreement in evaluation. However, a closer analysis revealed “a few major issues” (p. 21), particularly in the feedback for lower-scoring essays, which led them to conclude that ChatGPT’s feedback quality is insufficient for students “to make adjustments and meaningful revisions” (p. 21). Interestingly, their study also found that including sample essays as part of the prompt did not lead to improvements in feedback quality, which raises questions about optimization strategies for AI-generated feedback.
In contrast to the predominantly English-focused research, Huete-García and Tarp (Reference Huete-García and Tarp2024) offer a rare examination of ChatGPT’s capabilities and limitations as a Spanish writing assistant. They determined that although ChatGPT can generate grammatically correct and well-structured output, its reliability as a writing assistant is still questionable. For example, it may correctly describe a grammatical problem in the abstract but then follow it with incorrect or nonsensical examples, which reveals a disconnect between theoretical explanation and practical application. This inconsistency stems from the model’s reliance on probabilistic pattern-matching rather than genuine linguistic understanding, consistent with the conclusions provided by Yoon et al. (Reference Yoon, Miszoglad and Pierce2023) and Steiss et al. (Reference Steiss, Tate, Graham, Cruz, Hebert, Wang, Moon, Tseng, Warschauer and Olson2024).
Despite mixed findings regarding the effectiveness of AI-generated feedback relative to teacher feedback, there is broad agreement on the value of combining AI tools with teacher-mediated support (Kerr, Reference Kerr2020; Steiss et al., Reference Steiss, Tate, Graham, Cruz, Hebert, Wang, Moon, Tseng, Warschauer and Olson2024). However, much of the existing research on ChatGPT-generated feedback focuses on intermediate-to-advanced learners writing in English, often in ESL or EFL settings, and typically emphasizes essay composition and higher-order concerns such as argument structure, organization, and coherence. By contrast, novice language learners – particularly those engaged in more controlled writing tasks – often struggle with lower-order concerns (LOC) like spelling, syntax, and basic sentence formation. Relatedly, ChatGPT has been shown to perform less reliably when responding to “low-quality” and “low-scoring” essays (Steiss et al., Reference Steiss, Tate, Graham, Cruz, Hebert, Wang, Moon, Tseng, Warschauer and Olson2024; Yoon et al., Reference Yoon, Miszoglad and Pierce2023) as well as to produce inconsistent or inaccurate metalinguistic explanations, particularly in the context of Spanish (Huete-García & Tarp, Reference Huete-García and Tarp2024). This study aims to address this gap through the exploration of the effectiveness and usability of ChatGPT-generated feedback for novice learners of Spanish as an L2.
2.3 Perceptions of AI in education
Student trust in these systems can significantly influence their engagement with the generated feedback. As Ranalli (Reference Ranalli2021) emphasizes, learners with higher confidence in these tools’ accuracy are more likely to use feedback effectively, which reinforces the importance of transparency and intuitive design in such systems. However, perceptions about the classroom utility of tools like ChatGPT vary considerably: Educators generally view AI tools positively and demonstrate a willingness to integrate them into classrooms (Intelligent.com, 2023; Marzuki et al., 2023). Students, on the other hand, exhibit mixed preferences, often comparing AI-generated feedback to teacher-provided insights. Given the limitations identified in AI feedback quality, Steiss et al. (Reference Steiss, Tate, Graham, Cruz, Hebert, Wang, Moon, Tseng, Warschauer and Olson2024) and Guo et al. (Reference Guo, Feng and Hua2022) urge users to critically evaluate AI-generated feedback, deciding what to take up or ignore, a practice that could be especially challenging for novice learners – like the ones in our study – whose language production is still developing and often at the phrase level.
The learning outcomes associated with different feedback modalities also vary depending on how students engage with the feedback. Yan (Reference Yan2024) found that students who processed AI feedback independently showed greater immediate gains in writing skills, whereas those who engaged collaboratively with teachers during feedback sessions experienced enhanced long-term learning outcomes. This suggests that the effectiveness of AI feedback may depend not only on its quality but also on how it is integrated into the learning process.
Beyond quality considerations, the psychological and motivational effects of AI feedback appear promising. The feedback from applications like Google’s Dialogflow, when perceived as authentic and pedagogically valuable, has been found to increase learner comfort and reduce anxiety, creating a low-stakes environment for language practice (Jeon, Reference Jeon2024). Furthermore, Kwon et al. (Reference Kwon, Shin and Lee2023) reported that students using AI tools felt more comfortable practicing their target language compared to those who relied solely on traditional methods.
3. Feedback from ChatGPT 3.5
The original goal of the research team was to compare students’ perceptions of ChatGPT- and instructor-generated feedback and examine how effectively participants would use each to revise their writing. Students signed an institutional review board consent form to have their writings used in the study. The first writing (see supplementary material) was an in-class 10-sentence description of a mural. We removed students’ names and replaced them with an identifier. We transcribed the written responses (exactly as handwritten) and then used the assignment instructions, rubric (see supplementary material), sample feedback (see supplementary material), and information about the Spanish level of the students to engineer the prompt for ChatGPT 3.5. After looking at the type of feedback generated, as well as its usability, we divided it into three categories: Appropriate Feedback, Unhelpful Feedback, and False Negatives. As Table 1 shows, Appropriate Feedback refers to comments that accurately identify an actual error and offer helpful guidance for revision (e.g., noting an issue with subject–verb agreement or a problem with the vocabulary) or that correctly affirm a sentence as accurate. Unhelpful Feedback describes responses that focus on aspects of the sentence that are not problematic and whose suggestions would not contribute to improving the text. This category also includes instances where the feedback provided is limited to “it is mostly correct” without further guidance. False Negatives occur when ChatGPT incorrectly flags a correct sentence as erroneous – for instance, when it suggests an unnecessary change in tense or vocabulary where no error exists.
Examples of the types of feedback generated

Additionally, there was a tendency to fix the errors even though the model had been trained to provide constructive feedback and not fix errors. For example, one student wrote “La pictura es una ilistztión traditional,” in which “ilistztión” and “traditional” are misspelled in Spanish. The feedback generated was, “You’ve described the nature of the picture. Consider the spelling and meaning of ‘ilustración’ and ‘tradicional.’” In this case, the model saw an issue, but instead of providing helpful feedback, it just fixed the spelling errors and asked a confusing question about the “meaning” of said words.
We determined that it was not ethically appropriate to provide students with ChatGPT-generated feedback in its original form due to the frequent occurrence of unhelpful responses, false negatives, and the tendency of the model to offer corrections without sufficient explanation or pedagogical value. While we did not formally quantify these issues, the consistency and nature of the problematic feedback raised concerns about potential harm to learners – particularly novice writers – and led us to reconsider asking learners to use this feedback. Although we do not explore the possible negative effects of that type of feedback – for ethical reasons – we firmly believe that such feedback without additional scaffolding could be counterproductive at this level of proficiency. As a result, we continued collecting student writing but pivoted to a new set of research questions. Around this time (November 2023), OpenAI introduced the option to create customized GPTs, which could be built and deployed by instructors or students using basic inputs (such as rubrics and sample responses) without requiring advanced prompt engineering or formal training. This shift opened new possibilities for tailoring feedback to specific tasks and learner needs. Consequently, our research questions (RQs) became the following:
-
1. Can a customized GPT score A1 Spanish students’ writing accurately based on a provided rubric?
-
2. Can a customized GPT provide constructive, qualitative feedback for A1 Spanish students?
4. Data training materials
A total of 32 students from first- and second-semester Spanish courses at a large public university in the Western US agreed to have their in-class writings form part of the dataset for this project. These involved describing a picture of a mural (see supplementary material) in 10 sentences in Spanish using ser/estar/haber and tener as appropriate. Students were allowed to use their textbook to review vocabulary and/or grammar and were given 25 minutes to complete the task in class.
5. Methods and data analysis
5.1 GPT customization and training
First, we trained a customized GPT for this study. Customized GPTs involve fine-tuning the base GPT model (3.5 in our case) with domain-specific data, such as the rubric or writing examples. Task-specific instructions define how the model should behave, such as scoring essays or generating corrective feedback for grammar/vocabulary mistakes. On the other hand, knowledge, which refers to the ability to upload files as part of the GPT’s training, ensures the model understands relevant linguistic rules and beginner-level Spanish writing conventions.
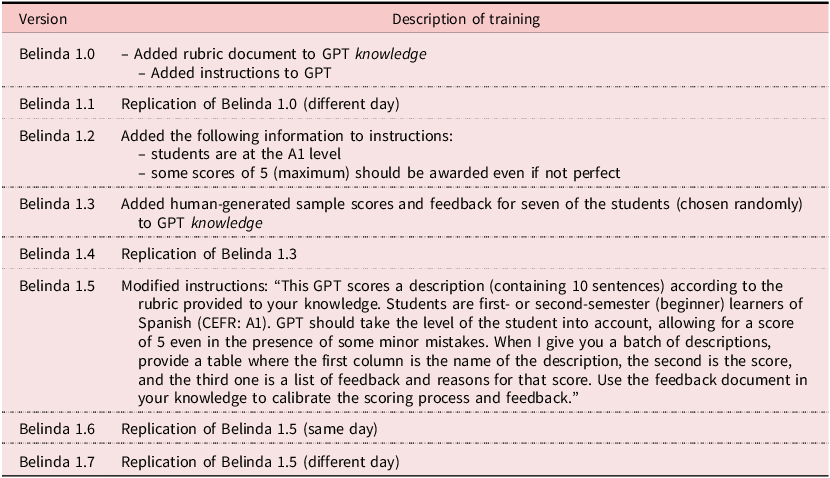
We named our GPT “Belinda,” and, throughout training and tweaking, we ended up developing seven versions (some with slight modifications), as shown in Table 2. We started with Belinda 1.0, where we added training materials (i.e., rubric) to Belinda’s instructions and knowledge (supplementary material). For Belinda 1.3, we randomly selected seven in-class writings to add to the knowledge. These writings were not included in subsequent data analysis. The Belinda 1.5 version included modified instructions, as seen in Table 2, and we ended with Belinda 1.7, which had the same instructions and knowledge as Belinda 1.5 and 1.6 but was run on a different day. Despite Belinda 1.5, 1.6, and 1.7 being identical in terms of instructions and knowledge, the model produced inconsistent feedback. This variability led us to conclude that the issue was less about the quality of the prompt or training data and more about how ChatGPT was processing the task; therefore, we stopped training Belinda at Version 1.7.
GPT version history

5.2 Rating
Once the GPT was trained, both members of the research team independently rated the in-class writings (n = 25) using the same rubric used to train Belinda. After completing their initial ratings, the two human raters met to compare their scores and conducted a calibration session, after which they rescored problematic samples. While the uncalibrated interrater reliability was already strong, r(23) = .739, p < .001, the calibration process considerably strengthened this reliability score, r(23) = .96, p < .001. Then, each version of Belinda (Belinda 1.0–Belinda 1.7) scored the same 25 writing samples. Finally, we conducted inter- and intrarater reliability analyses using Spearman’s rho to compare the scores generated by the human raters and the seven versions of Belinda. We expected Belinda’s scores to show a strong reliability of at least .79 when compared to the average scores of the human raters (matching the uncalibrated reliability between the human raters). Additionally, we hypothesized the intrarater reliability for Belinda’s scores to approach a perfect agreement of 1.0, particularly for Versions 1.5, 1.6, and 1.7, which were identical in design and should, in principle, produce the same results. This process was completed to answer RQ1.
To answer RQ2, we analyzed the qualitative feedback provided by Belinda 1.7 and categorized it to evaluate its appropriateness for future classroom implementation.
6. Results
6.1 Descriptives, inter- and intrarater reliability
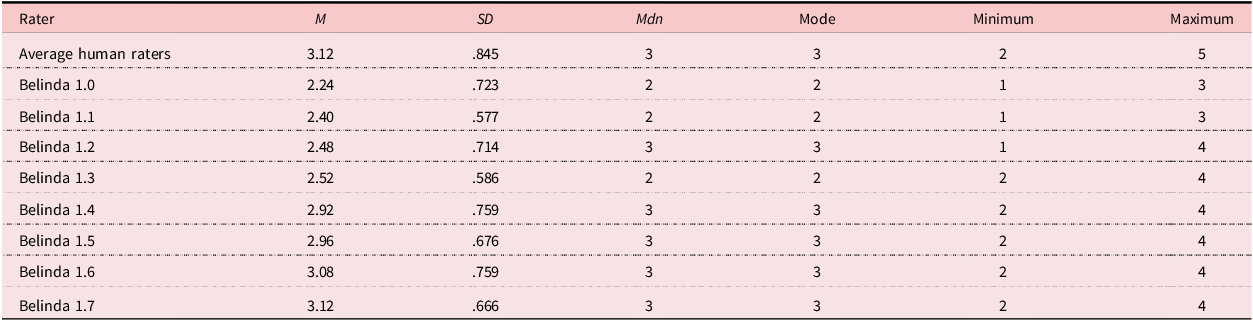
Table 3 shows a comparison of descriptive statistics between the two human raters and the different versions of Belinda.
Summary of descriptive statistics

Table 4 shows the interrater reliability between the human rater average and all seven versions of Belinda. All versions of Belinda, except for Belinda 1.5, showed significant interrater reliability coefficients with varying degrees of strength, with the human rater average ranging from r = .457 (p = .022) to r = .615 (p = .001). The strongest correlation was identified between Belinda 1.4 and the human rater average (.615).
Interrater reliability between human raters and Belinda

*p < .05. **p < .01.
Table 5 presents the intrarater reliability among Belinda 1.5, Belinda 1.6, and Belinda 1.7. All three versions, which were identical to each other but were run at different times/days with the same data, exhibited strong to very strong correlations (r > .7). Despite this, the correlation coefficients fell short of the expected near-perfect alignment (r ≈ 1) that should theoretically occur between identical models. As we will see, this raises a significant concern regarding the reliability of this GPT.
Intrarater reliability between three versions of Belinda

***p < .001.
6.2 Feedback generated by Belinda 1.7
Qualitative analysis of the feedback provided by Belinda 1.7 indicated that corrective feedback was limited to the first sentence with issues. For the remaining sentences, feedback was generalized, often taking the form of broad recommendations such as “review verb forms and agreement” or “review verb conjugations and gender agreement.” The feedback was categorized into four main types: Appropriate Feedback, False Negatives, Incomplete Feedback, or False Negatives and Incomplete Feedback.
The following is an example of Appropriate Feedback from Student #66614-1. Errors are identified in italics.
-
1. Los dos personas en este dibujo estan divertiendo.
-
2. Los dos personas estan andando en motocicleta.
-
3. La pareja está juntos.
-
4. La mujer está sonrise.
-
5. El hombre tiene mucho pelo en su cara.
-
6. El hombre tiene pelo blanco en su cara.
-
7. Los dos personas son viejos.
-
8. Tienen vestidos para otoño.
-
9. Pero tienen que se visten para tiempo calor.
-
10. Esta motocicleta es negro.
Belinda 1.7 generated the following feedback for the student: “Understandable but contains errors. ‘Los dos personas en este dibujo estan divertiendo’ should be ‘Las dos personas en este dibujo se están divertiendo.’ Review verb forms and agreement.” As shown, Belinda 1.7 fixed the error in the first sentence before providing generalized feedback about verb forms and agreement.
An example of a False Negative is from Student #97108-1, who wrote:
-
1. Hay un hombre y una mujer andan en motocicleta.
-
2. Ellos son viejos.
-
3. El hombre es pelón.
-
4. Él lleva guantes negros.
-
5. Ellos llevan gafas de sol.
-
6. La mujer tiene pelo gris.
-
7. Ella se sonríe.
-
8. La motocicleta es negra.
-
9. La mujer lleva una camisa azul.
-
10. Él tiene barba.
Belinda 1.7–generated feedback stated:
Good use of vocabulary and structure with minor errors. ‘Hay un hombre y una mujer andan en motocicleta’ could be improved to ‘Hay un hombre y una mujer que andan en una motocicleta.’ Watch for noun-adjective agreement, as in ‘La motocicleta es negra.’ Overall, well done.
In this instance, Belinda 1.7 advises the student to check their noun–adjective agreement and provides the example of “La motocicleta es negra,” which does not have an error. In fact, none of the sentences have errors relating to noun–adjective agreement. Additionally, while Belinda 1.7 successfully identifies an issue with the first sentence, it merely suggests that it “could be improved” when in fact it requires revision.
This next example from Student #84504-1 shows Incomplete Feedback:
-
1. Ellos estan montando una moto.
-
2. La moto es negro.
-
3. Ellos quieren ir rapido en moto.
-
4. Ellos tienen pantalones.
-
5. Ellos tienen los lentes.
-
6. Hay dos personas en la moto.
-
7. Ellos han montando una moto.
-
8. Su pello es gris.
-
9. Sus lentes son blanco y naranjas.
-
10. Su camisa es marrón.
Belinda 1.7’s feedback stated, “Adequate with some errors. ‘Ellos estan montando una moto’ should be ‘Ellos están montando una moto.’ Review verb conjugations and gender agreement.” While Belinda effectively identifies the need to fix verb conjugations (#7) and gender agreement (#2), it overlooks other issues such as spelling errors (#3 and #8) and problems with number agreement (#9).
The last category is a combination of False Negatives and Incomplete Feedback, and it is exemplified by the feedback provided to Student #00503-1:
-
1. El hombre maneja bicicleta.
-
2. A ellaes sonriente.
-
3. A ella le gusta andar la motocicleta.
-
4. Los hombres llevan gafas.
-
5. Los hombres son viejo.
-
6. A ella es la esposa del hombre.
-
7. A hombre parecerse el Santa Claus porque tiene beard.
-
8. A hombre lleva los guantes.
-
9. A hombre no tiene pelo.
-
10. El pelo de lla es loco porque hace viento cuando a ella maneja el motocicleta.
The feedback generated stated, “Several grammatical and lexical errors affecting comprehension. ‘El hombre maneja bicicleta’ should be ‘El hombre maneja una bicicleta.’ Review the use of ‘ser’ and ‘estar,’ and ensure proper gender agreement.” In this example, false negatives are evident in the suggestion to review ser and estar, as there are no issues with these verbs. Additionally, the feedback is incomplete, as it fails to address errors in lexical choice (e.g., using los hombres to describe a man and a woman), number agreement (#5), spelling issues (#10), and the ungrammatical use of “a” before subjects (#2, #6, #7, #8, #9, and #10).
7. Discussion
The iterative process of training Belinda revealed significant challenges and limitations in adapting an AI model for providing constructive feedback on A1-level Spanish writing. Despite modifications through different versions, Belinda 1.7 still demonstrated considerable shortcomings in delivering actionable, supportive, and reliable feedback. One major limitation was its tendency to deliver corrective feedback only for the first sentence, despite being trained to provide other types of feedback instead of corrective. Beyond the first sentence, feedback became heavily error-focused, often failing to recognize students’ strengths. This contradicted the training materials, which explicitly included instructions to balance critique with positive feedback. Encouraging feedback that highlights successes is essential to promote confidence and engagement, especially among novice language learners (Dörnyei, Reference Dörnyei2001; Hattie & Timperley, Reference Hattie and Timperley2007; Hyland & Hyland, Reference Hyland, Hyland, Hyland and Hyland2019). From a pedagogical perspective, Belinda’s focus on negativity and its inability to celebrate incremental learner progress may have negative implications for student motivation and confidence.
Furthermore, all versions of Belinda exhibited a harsh grading style, frequently assigning lower scores than the human raters (see descriptive statistics in Table 3) and failing to provide much leniency. Unlike human raters, who often accommodate the limitations of beginning learners, Belinda operated with rigid precision, penalizing errors without offering forgiveness for lack of perfection, even though the rubric explicitly stated that errors that did not impede basic comprehension were expected due to the early stages of language learning. Unfortunately, none of the Belinda versions gave a rating of 5 out of 5, whereas the human raters did. Belinda 1.0 gave the harshest ratings, which were almost a full point lower than the human raters. Interestingly, each version of Belinda scored the writings higher and higher. This makes sense for Versions 1.1–1.5 as more information and directives were included in the training process of the GPT. However, Versions 1.5–1.7 were replications of each other, meaning that they had the exact same training information and should have produced equal ratings, yet the mean score averages were 2.96, 3.08, and 3.12, respectively. These inconsistencies not only demonstrate Belinda’s inability to accurately align with human evaluative standards but also raise critical questions about the reliability of AI feedback tools like these in beginning-level language learning.
RQ1 investigated whether a customized GPT could accurately score A1 Spanish students’ writing using a provided rubric. The findings indicate that while most versions of Belinda demonstrated a somewhat moderate interrater reliability with the human raters, none achieved or exceeded the level of agreement achieved by the human raters, either before or after calibration. Despite iterative training, the GPT consistently failed to replicate the nuanced judgment applied by human evaluators, particularly in balancing error identification with acknowledgment of strengths. These results suggest that while Belinda shows potential in aligning with human scoring patterns to some extent, it lacks the adaptability and contextual sensitivity required for accurate and equitable grading at this stage.
RQ2 explored whether a customized GPT like Belinda could provide constructive feedback for A1-level Spanish students. Unfortunately, the Belinda-generated feedback was often corrective, false, incomplete, or overly generalized, rendering it ineffective in guiding students to improve their writing. While Belinda occasionally identified errors accurately, it primarily focused on correcting them rather than offering actionable suggestions for improvement. In some cases, the feedback contained inaccuracies, such as identifying nonexistent issues or misclassifying errors, which could create confusion for learners. Furthermore, much of the feedback was overly generalized – for example, vague suggestions like “review verb conjugations and gender agreement” – and lacked the specificity that students require to make meaningful revisions.
Overall, these findings reveal that the Belinda GPT is not yet a viable tool for accurately scoring or providing constructive feedback to A1-level Spanish learners. The limitations identified – including inconsistent scoring, overly harsh grading, a focus on errors rather than strengths, and vague or inaccurate feedback – pose significant barriers to its practical application in a classroom setting and undermine the pedagogical goals of promoting confidence and engagement among beginner learners.
7.1 Pedagogical and ethical implications
This study offers important pedagogical and ethical insights into the use of AI-generated feedback in beginning-level L2 writing classrooms. While tools like Belinda show potential as instructional aids, our findings underscore that AI-generated feedback presents serious challenges when used without human interplay. This study implemented ChatGPT 3.5 from November 2023, and more current versions may perform differently; however, the following implications should still be considered when using AI in the classroom.
From a pedagogical standpoint, instructors should not rely on AI tools like Belinda as a standalone mechanism for assessment or feedback. While Belinda occasionally produced accurate corrections, the overwhelming tendency toward vague, incomplete, or erroneous feedback makes it an unreliable tool for independent use. Similarly, students should not rely on AI tools as their linguistic awareness and confidence are still developing, especially for A1 learners. Without the metalinguistic tools necessary to recognize or question poor feedback, students may inadvertently learn or reinforce incorrect language forms, which in turn could impede progress and foster confusion.
Furthermore, the structure and quality of the feedback that Belinda gave raise clear concerns related to potential learners’ experiences. Feedback that overemphasizes errors, lacks praise, or includes contradictory or incorrect information has the potential to demoralize and/or frustrate students. In L2 writing, feedback plays a critical role not only in correction but also in affective support, as it helps students feel capable, motivated, and encouraged to take risks with the language. Belinda’s consistent failure to offer positive reinforcement or acknowledge learner progress runs counter to well-established best practices in L2 pedagogy (Dörnyei, Reference Dörnyei2001; Hyland & Hyland, Reference Hyland, Hyland, Hyland and Hyland2019).
In addition to pedagogical implications, there are ethical considerations at play as well. One consideration concerns the implied promise of instruction at institutions of education. Especially in higher education settings, students are paying for access to expert guidance, instruction, and pedagogical support from qualified educators. They are not paying for unsupervised or automated interactions with AI tools alone. Furthermore, instructors have a responsibility to ensure the integrity and usefulness of feedback given to learners. As this study showed, not only was the feedback generated by Belinda inappropriate to give to students but Belinda also did not provide consistent and reliable results even when the training data and instructions were consistent. Instead, instructors who choose to use AI in conjunction with their own feedback should use the AI output as a starting point not as a replacement for thoughtful, accurate feedback. While the integration of technology and AI into instruction is not inherently problematic, it becomes ethically questionable when AI-generated feedback is used as a replacement for teacher input. When used as a supplement to instructor-generated feedback, AI tools have the potential to streamline the feedback process; however, it is important to understand the current limitations. Nevertheless, replacing humans with AI tools erodes the value of educational experiences and undermines student trust. If AI tools are used in the classroom, there should be transparency, from both educators and students, and there must be careful oversight of the tools.
7.2 Limitations and future research
One possible explanation for ChatGPT’s limitations lies in its stronger performance on higher-order concerns (HOC) of writing, such as structure, argumentation, and content, compared to LOC, such as grammar, word choice, or mechanics. As Steiss et al. (Reference Steiss, Tate, Graham, Cruz, Hebert, Wang, Moon, Tseng, Warschauer and Olson2024) and Huete-Gracía and Tarp (Reference Huete-García and Tarp2024) found, ChatGPT struggled particularly with providing feedback on low-quality essays and metalinguistic analysis, likely because its predictive algorithm is less effective at interpreting the non-standard, error-prone language typical of beginning writers. These linguistic variations may be mistakenly processed as random or incoherent, leading to the generic (not helpful) or inaccurate feedback we have discussed. This suggests that prompting ChatGPT with more explicit instructions tailored to the specific task, as suggested by Yoon et al. (Reference Yoon, Miszoglad and Pierce2023), may help it better address unexpected or nonstandard learner output. In our own analysis, even when providing rubrics and model examples of what we would like to receive as output, ChatGPT did not reach acceptable levels of feedback accuracy or clarity for beginner-level Spanish learners. However, its performance may improve with longer, more coherent texts that allow it to focus on HOC feedback, where its strengths in text-level prediction are more applicable.
This study faced several limitations, particularly regarding the training and use of the GPT, Belinda. A significant challenge was the limited size of the training dataset. Research suggests that training models for automated scoring require datasets in the thousands, alongside ongoing updates, monitoring, and validation to ensure reliability and accuracy (Habermehl et al., Reference Habermehl, Nagarajan, Dooley, Yan, Rupp and Foltz2020). However, due to logistical and resource constraints, the training data for this study was relatively small, which may have affected Belinda’s ability to generalize across diverse language learner outputs. This limitation suggests the need for future research to incorporate larger datasets, adaptive learning algorithms, and user-centered evaluations to refine the utility of AI-driven feedback tools in language learning. This, however, might prove to be out of reach for many instructors who wish to design their own GPTs due to the substantial resources required. Developing a reliable AI tool requires not only access to large and diverse datasets but also expertise in machine learning, computational infrastructure, and ongoing technical support – all of which can pose significant barriers for educators with limited budgets or technical training. As a result, there is a critical need for collaborative efforts between educators, researchers, and technology developers to create scalable, cost-effective solutions that address these challenges. Without such support, using a model like Belinda could be detrimental to students. Inappropriate feedback or overly harsh scoring could undermine learner confidence, mislead their understanding of the language, and ultimately hinder their progress.
Additionally, the impact of formative feedback – whether generated by humans or AI – on learners’ written production cannot be meaningfully assessed without a pre- and post-test design. Although the original aim of our study was to evaluate the effect of Belinda’s formative feedback on student performance, the quality of the feedback produced, along with the unexpected absence of intrarater reliability, raises serious ethical concerns. Providing such inconsistent or unclear feedback to students – particularly without disclosing its AI origin – would be ethically problematic. It also remains an open research question whether exposure to this type of feedback might negatively affect students’ writing performance or motivation, which further adds to the concern about using it uncritically in the classroom.
Moreover, Belinda provided different results across versions even when the training data and instructions were identical, with the only difference being the time and day when the GPT was accessed. This finding further illuminates the need for caution when scholars, researchers, educators, and others use custom GPTs in their work or for those interested in developing a similar tool, as outputs seem to vary substantially.
Future research could explore incorporating this type of AI-generated feedback in controlled classroom settings to gauge student attitudes and its impact on learning. However, based on the findings from this study, ChatGPT 3.5 and Belinda cannot currently be recommended as a substitute for human scoring and feedback for this type of activity. Continued advancements in NLP and AI customization may eventually address these challenges, but these tools require significant improvement before they can offer equitable and pedagogically sound support in L2 writing contexts. In the meantime, future studies could investigate hybrid feedback models, where AI assists human instructors by pre-identifying common error patterns, thus streamlining the feedback process rather than replacing it entirely.
8. Conclusion
This study contributes to the ongoing discussion on the role of AI in language pedagogy and aims to inform applied linguistics and L2 writing research on the use of GPT tools like Belinda in beginning-level language courses. The findings reinforce the growing body of literature advocating for collaboration between humans and AI, emphasizing that while AI can streamline certain processes and provide some corrective feedback, human expertise still remains essential to effective feedback and assessment.
The results also stress the challenges of implementing AI-driven tools, like Belinda, in novice-level Spanish courses. While AI holds potential, its current limitations, including the need for extensive datasets and training to achieve reliability, make it impractical for individual instructors to develop or deploy such systems independently on their own. More importantly, until these limitations are addressed, tools like Belinda risk doing more harm than good. Their inability to provide actionable, supportive guidance and their tendency to focus excessively on errors could undermine student motivation, confuse learners, and hinder their progress.
For most instructors, creating a customized GPT to give the type of L2 writing feedback that is wanted or needed is not feasible using freely available AI tools and without a technical background. Successfully building such a tool requires significant expertise, resources, and the ability to implement retrieval-augmented generation (RAG) systems or properly train a model using extensive, domain-specific datasets. Meeting these requirements can be challenging for the average educator, who may not have access to the specialized resources, technical support, time, or financial investment needed to develop such systems independently. While this study demonstrates the potential of AI tools in language education, it also concludes that achieving practical and reliable implementations remains a significant challenge for most practitioners.
While our results indicate that training alone did not resolve issues such as interrater inconsistency or overly harsh feedback, several strategies may help mitigate these challenges. For classroom use, teachers might frame AI feedback as diagnostic rather than prescriptive and guide students to critically evaluate suggestions rather than accept them wholesale. One practical approach is to treat AI-generated feedback similarly to peer feedback provided by classmates, where mistake identification, false positives, and inconsistent comments are common and must be sorted out or filtered by the writer. This reframing positions AI feedback as a resource for developing metalinguistic awareness and critical thinking rather than as an authoritative source.
Ultimately, freely available AI-driven tools have a role to play in the future of language education, but they are not yet ready to function as standalone solutions. Substantial refinements are needed to enhance their reliability, contextual sensitivity, and capacity to deliver feedback that truly supports learners.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0958344026100469
Data availability statement
Data available within the supplementary material. The data that support the findings of this study are available from the corresponding author, upon reasonable request.
Authorship contribution statement
Alyssia Miller De Rutté: Conceptualization, Investigation, Methodology, Project administration, Resources, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing; Maite Correa: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Resources, Software, Validation, Visualization, Writing – review & editing.
Funding disclosure statement
This research did not receive any specific funding.
Competing interests statement
The authors declare no competing interests.
Ethical statement
This research received institutional review board approval from Colorado State University prior to the start of the study.
GenAI use disclosure statement
ChatGPT 3.5 and a customized GPT were used as part of this research study’s methodology to determine if GenAI could give adequate feedback. ChatGPT 4o was used during the manuscript editing process.
About the authors
Alyssia Miller De Rutté is an assistant professor of Spanish for Specific Purposes and director of the Center for Languages for Specific Purposes Education and Research (CLEaR) at Colorado State University. She is the director of medical Spanish at the University of Colorado School of Medicine and serves as treasurer of the National Association of Medical Spanish. Her research centers on medical Spanish and language learning technology.
Maite Correa is an associate professor of applied linguistics and Spanish linguistics and a steering committee member of CLEaR at Colorado State University. She teaches language teaching methodology, introduction to Hispanic linguistics, phonetics and phonology, among other subjects. She has published on educational linguistics, academic integrity, critical pedagogies, and heritage language learning.






 Open access
Open access