1. Introduction
Children typically produce their first words around 12 months of age. However, the full mastery of an adult-like sound system is not achieved before 8 (Sander Reference Sander1972) or even 10–12 years of age (Smith and McLean-Muse Reference Smith and McLean-Muse1986)Footnote 1. In English for instance, some phonemes such as /s/ or consonant clusters such as /spl/ are not acquired before 7 and 9 years of age (Smit et al. Reference Smit, Hand, Freilinger, Bernthal and Bird1991). This extended period required for the mastery of the speech sound system of the adult language is due to the fact that young children are neither endowed initially with an adult-like vocal tract configuration nor with the neuromuscular control for producing the range of sounds of their ambient language (Kent and Murray Reference Kent and Murray1982, Green et al. Reference Green, Moore and Reilly2002, Stoel-Gammon and Sosa Reference Stoel-Gammon, Sosa, Hoff and Schatz2007). These anatomical and neurophysiological constraints result in a restriction on children's early phonetic inventories (Nip et al. Reference Nip, Green and Marx2009, Green et al. Reference Green, Nip, Maassen, Lieshout, Maassen and van Leshout2010). Children's phonetic inventory is initially composed of sounds produced primarily by the jaw (MacNeilage et al. Reference MacNeilage, Davis, Kinney and Matyear2000), on which they have a better muscle control compared to the motion of lips and tongue movements (Green et al. Reference Green, Moore and Reilly2002). As a consequence of these universal biological constraints, children acquiring different languages show a similar restricted inventory of sounds (Locke Reference Locke1983, Reference Locke1995). Indeed, babbling and first-word productions demonstrate universal patterns: children show a preference for labials and coronals, stops, nasals and glides, open syllables, short utterances, few consonant clusters (and if any, they tend to be homorganic), and more reduplication than variegation (Vihman et al. Reference Vihman, Macken, Miller, Simmons and Miller1985, Oller et al. Reference Oller, Eilers., Steffens, Lynch and Urbano1994, MacNeilage et al. Reference MacNeilage, Davis, Kinney and Matyear1999). Furthermore, these preferences have been shown to influence the words that children select to produce. Thus, the inventory of children's early vocabulary is not composed of randomly selected words. Rather, it has been suggested that children select words with phonetic characteristics that are already present in their own phonological systems (Ferguson and Farwell Reference Ferguson and Farwell1975, Vihman et al. Reference Vihman, Macken, Miller, Simmons and Miller1985, Schwartz et al. Reference Schwartz, Leonard, Loeb and Swanson1987). Other studies on lexical selectivity have shown that children attempt more complex words targets according to age (Dobrich and Scarborough Reference Dobrich and Scarborough1992). An Index of Phonetic Complexity (henceforth IPC), based on the phonetic regularities observed in the babbling and the first-word period, was proposed to assess children's phonetic development (Jakielski Reference Jakielski2000, Reference Jakielski2002). The IPC has proven to be a valuable tool for different purposes such as assessing phonological skills in toddlers (Morris Reference Morris2009), comparing speech acquisition in bilingual vs. monolingual children (Gildersleeve-Neumann and Wright Reference Gildersleeve-Neumann and Wright2010), or exploring the relationships between phonetic complexity and stuttering (Howell et al. Reference Howell, Au-Yeung, Yaruss and Eldridge2006, Howell and Au-Yeung Reference Howell and Au-Yeung2007). The IPC, which considers productions composed of less preferred segments and segment associations as more complex, permits one to measure the development of phonetic complexity in words both targeted and produced by children. In addition, it was shown that IPC scores at 12 months predicted speech and language skills at 18 months (Furey Reference Furey2003). Biomechanical constraints of the production system (MacNeilage and Davis Reference MacNeilage, Davis and Jeannerod1990) and lexical selectivity are both universal tendencies.
Crosslinguistic studies hence provide support for a strong determination of early phonetic inventories by biological constraints. However, they do not rule out an influence of the ambient language. Languages differ to a large extent in terms of their phonological inventories and phonotactics, making the input more or less difficult to acquire for children. Crosslinguistic analysis of diverse languages enables us to distinguish between potentially universal and language-specific patterns (Stoel-Gammon Reference Stoel-Gammon2011). In fact, previous analyses have shown that segmental development, namely word shapes and CV co-occurrences, are influenced by input frequency in the ambient language (Saffran et al. Reference Saffran, Newport, Aslin, Tunick and Barrueco1997), as well as by the functional load of segments in the language, that is, how much use a language makes of its available contrasts (Stokes and Surendran Reference Stokes and Surendran2005). As languages vary on those parameters, previous findings suggest that some languages may be acquired at a faster rate than others. For instance, So and Dodd (Reference So and Dodd1995) showed that Cantonese children acquire phonology at a faster rate than English-speaking children as they master the contrastive use of tones and vowels by two years and that few phonological errors occur after age four. Similarly, Caselli et al. (Reference Caselli, Bates, Casadio, Fenson, Fenson, Sanderl and Weir1995) observed that Italian children were slower in vocabulary acquisition compared to English-speaking children: Italian children lag behind the English group in total vocabulary size at most ages between 8 and 16 months. Another crosslinguistic study, comparing L1 vocabulary growth at 16–30 months of age, found that Galician children produce fewer words than Basque, French and Mexican-Spanish-learning children (Pérez-Pereira et al. Reference Pérez-Pereira, Alegren, Resches, Ezeizabarrena, Díaz and García2007). In brief, phonetic development seems to be strongly influenced by universal biological constraints but also by the characteristics of the ambient language.
However, considering the ambient language, one must keep in mind that the type of language to which children are exposed (referred to as Child-Directed Speech, henceforth CDS) differs in several important ways from the adult language. When addressing children, caregivers adjust their language by simplifying and clarifying the linguistic material (Ferguson Reference Ferguson1964) in order to engage children's attention and facilitate language acquisition (Snow Reference Snow, Snow and Ferguson1977, Werker et al. Reference Werker, Pons, Dietrich, Kajikawa, Fais and Amano2007)Footnote 2. CDS is characterized by simplified syntax, shorter utterances, restricted vocabulary, repetitions, phonetic modifications (Kuhl Reference Kuhl2000), increased variations in fundamental frequency and longer pauses (Ferguson Reference Ferguson, Snow and Ferguson1977, Papoušek et al. Reference Papoušek, Papoušek and Symmes1991, Albin and Echols Reference Albin and Echols1996, Andruski and Kuhl Reference Andruski and Kuhl1996). Moreover, this specific register used by parents to promote infants’ language learning has been shown to be almost universal (Ferguson Reference Ferguson1964, Kitamura et al. Reference Kitamura, Thanavishuth, Burnham and Luksaneeyanawin2001, Kuhl et al. Reference Kuhl, Andruski, Chistovich., Chistovich, Kozhevnikova, Ryskina and Lacerda1997, Monnot Reference Monnot1999, Kitamura et al. Reference Kitamura, Thanavishuth, Burnham and Luksaneeyanawin2001).
The current study aims at examining the phonetic complexity of words produced by children acquiring four different languages: Arabic (Tunisian vernacular), Berber (Tashlhiyt variety), English (American) and French (France). These languages show different phonetic and phonological characteristics of interest for early language development, such as word length, word complexity (syllable types, consonant clusters) and phonemic inventory diversity. For example, the Arabic lexicon, which is largely derived from basic consonantal roots, includes many polysyllabic words. In terms of syllable types, French shows a strong preference for open syllables (76%), English exhibits more closed syllables (60%) (Delattre Reference Delattre1965) and Arabic displays 49,92% of closed vs. 50,08% of open syllables (Hamdi et al. Reference Hamdi, Ghazali and Barkat-Defradas2005). These languages also differ in consonant clusterFootnote 3 requirements: In Tashlhiyt Berber, clusters are found in any position within the word and in Arabic, they are rarely found in word-initial and word-final position. In French, both positions are permitted but a bias towards word initial position is attested. Phonemic inventories are also quite diverse. Indeed, when computing the consonant/vowel ratio, two groups emerge: Berber and Arabic are highly consonantal languages (Hamdi et al. Reference Hamdi, Ghazali and Barkat-Defradas2005, Ridouane and Fougeron Reference Ridouane and Fougeron2011) whereas vowels are more frequent than consonants in French and, to a lesser extent, English; Berber and Arabic display a significant proportion of fricatives as compared to English and French. Moreover, the phonological inventories of Arabic and Berber put forward a large number of back consonants (i.e., uvulars, pharyngeals and glottals) that are known to be acquired rather late (Omar Reference Omar2007). In sum, this study aims to provide informative contribution comparing the phonetic development in four languages including Berber and Arabic, languages in which studies of phonetic development are rare.
We elaborated six interrelated hypotheses for our crosslinguistic study:
H1. The different languages should display different degrees of complexity. The dictionary words in Berber and Arabic, which are highly consonantal languages, should have higher complexity scores compared to the more vocalic English and French.
The following IPC parameters are of special interest for our cross linguistic analysis:
1. Place of articulation: More complexity expected in Arabic, due to the many back (i.e., dorsal) consonants, and in French, due to the frequent /ʁ/ (Gromer and Weiss Reference Gromer and Weiss1990).
2. Clusters: More complexity expected in Berber and Arabic, in which clusters are more frequent.
3. Complex articulation Footnote 4 should contribute to complexity in Berber and Arabic.
4. Word length: More complexity on this parameter is expected in Arabic and Berber, which show many polysyllabic words due to the insertion of vocalic patterns and affixes into the root for lexical derivation.
5. Final Consonant: Less complexity is expected in French, due to its preference for open syllables.
6. Variegation (Place): More variegation is expected in Arabic, due to the non-homorganic consonantal rule, which constrains the root-skeleton.
7. Variegation (Manner): in Arabic (likewise in all Afro-Asiatic languages) it is well known that the co-occurrence of identical and homorganic consonants in the root sequence is restricted by the Homorganic Cooccurence Constraint (Greenberg Reference Greenberg1950). This restriction leads to expect Arabic will attest more variegation than the other languages under study.
8. Rhoticity Footnote 5 will contribute to complexity in American English only.
H2. In each language, we expect the words that mothers use when addressing their children (CDS) to be less complex than the words used in the “adult” language (i.e., represented here through dictionary words).
H3. According to the lexical selectivity hypothesis, children should attempt words (targets) that are less complex to produce than many other words in the adult language (Dictionary).
H4. Given the biomechanical constraint hypothesis, we expect children's actual productions to be less complex than the targets they attempt.
H5. However, we expect an effect of the ambient language: children acquiring a phonologically more complex language should target and produce more complex forms. Hence, we expect Arabic- and Berber-speaking children's IPC scores to be higher than those observed for English- and French-speaking children.
H6. In sum, if a complex parameter is frequent in the ambient language, children should use it or attempt it more often than if it is not present in the ambient language.
Table 1 recapitulates the different hypotheses.
Predictions for Dictionary, CDS, Target and Actual words in the four different languages

2. Method
In this section, we first describe the participants in the study (section 2.1), followed in section 2.2 by the procedures used to gather the data, and then turn to the analysis in section 2.3.
2.1 Participants
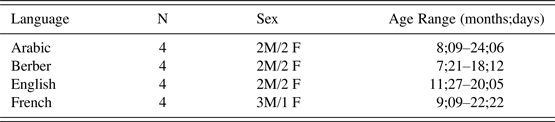
Sixteen children from four linguistic communities: Arabic (Tunisian vernacular), Berber (Tashlhiyt variety), American English and French (France) were included in the study (see Table 2). The parents did not report any concerns about the children's language development, hearing status, or general development. The Arabic and Berber data are part of The PREMs ProjectFootnote 6 (Principal Investigator: Sophie Kern). The French data are part of the French Kern corpus (Kern et al. Reference Kern, Davis, Zink, d'Errico and Hombert2009), and the English data comes from the Providence Corpus (Demuth et al. Reference Demuth, Culbertso and Alter2006).
Participants’ demographic information
2.2 Procedures
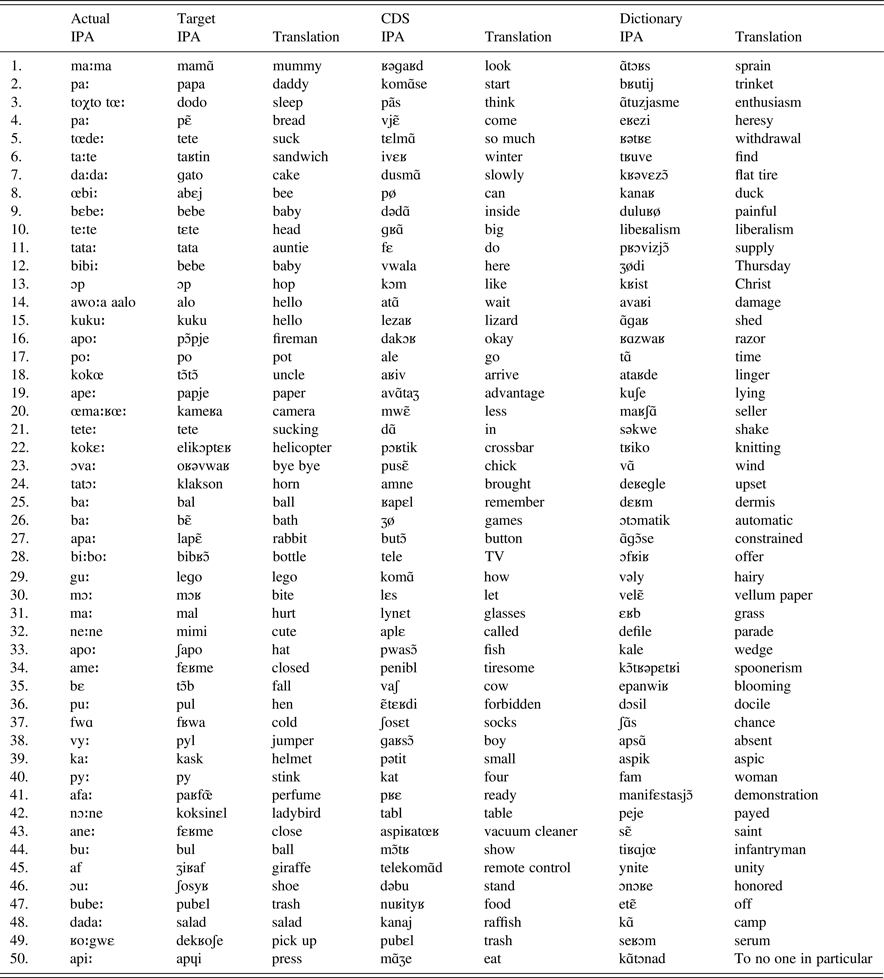
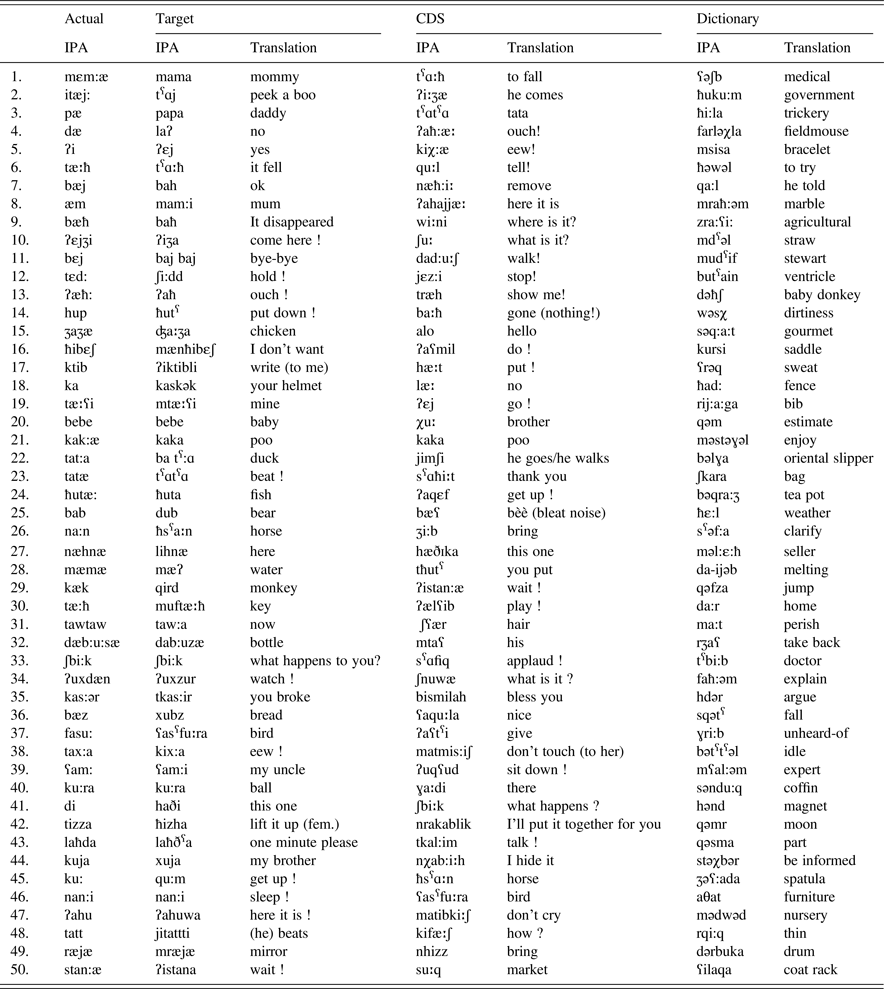
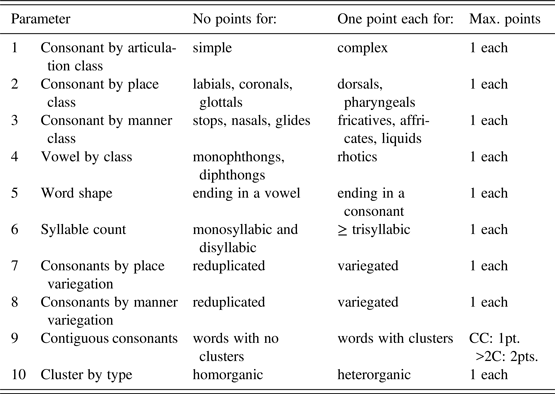
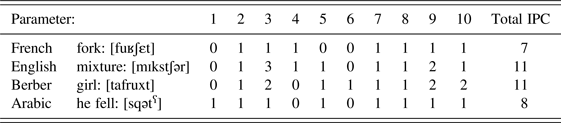
The children were recordedFootnote 7 in natural settings at home in interaction with their mother. The recording sessions took place twice a month starting slightly before the onset of first word production until a few months after the lexical spurt. As Jakielski (Reference Jakielski2000) recommends using 50 words to compute the IPC, four lists of 50 words were analyzed for each language: (i) the first 50 words actually produced by each child (hereafter referred to as Actual), (ii) the targets corresponding to these first 50 words, (iii) 50 words randomly extracted from CDS produced by each mother and (iv) 50 words from the adult language randomly selected from dictionariesFootnote 8 (See Appendix 1 to 4 for an illustration). For each list, an adaptation of the Index of Phonetic Complexity (Jakielski, Reference Jakielski2000) was computed (see Table 3). The IPC is based on the phonetic regularities observed during the babbling and the first-words periods. Vocal outputs that are composed of the less preferred segments (or segment associations) in early development are rated as more complex in the IPC. This allows measuring the development of phonetic complexity in both word targets and words actually produced by the children. The IPC consists of eight parameters: consonants by place and manner, vowels by class, word shape and word length (in syllable type and number), singleton consonants by place variegation, contiguous consonants and cluster by type (i.e., homo- vs. hetero-organic). However, as this measure was initially designed to capture the phonetic complexity of English, it must be adapted for crosslinguistic comparison in order to account for other determining features of phonetic complexity exhibited in the four languages under examination.
Adapted Index of Phonetic Complexity Scoring Scheme (based on Jakielski, Reference Jakielski2000)
2.3 Data analysis
In order to take into consideration the typological peculiarities of our linguistic sample, we first had to integrate into the original IPC model a new parameter relative to consonantal articulation. We called it consonant by articulation class in reference to Jakielski's first two parameters (i.e., Consonant by place and manner class and Consonant by place class). This new parameter was created in order to discriminate between simple vs. complex articulations (see parameter 1 in Table 3). In Arabic and Berber, two types of secondary (or complex) articulation are phonemically attested: pharyngealization (both in Arabic and Berber) and labialization (in Berber only). Basically, during the realization of a pharyngealized consonant (for example [tʕ, dʕ, ðʕ]), the pharynx is constricted and the root of the tongue is retracted. Such consonants, which require a skillful control of the back of the vocal tract (Barkat-Defradas and Embarki Reference Barkat-Defradas, Embarki, Chaker, Mettouchi and Philipson2009, Lahrouchi and Ridouane Reference Lahrouchi and Ridouane2016), are acquired very late in development (Omar 1973). We therefore added 1 point for such complex segments, that are typical of Afro-Asiatic languages (Hetzron Reference Hetzron1997). The same rationale was applied for labialization, which consists of adding lip rounding to the principal articulation. We considered radical consonants (i.e., pharyngeals) as particularly complex in terms of the consonant by place class, since they are, on the one hand, even more posterior than dorsals (that are themselves considered as complex in the original IPC model) and, on the other hand, since the mastery of production for these consonants is reported to occur rather late (Amrayeh Reference Amrayeh1994, Amrayeh and Dyson Reference Amrayeh and Dyson1998). Lastly, considering the fact that consonantal clusters are frequent in the Western varieties of colloquial Arabic, under the influence of Berber, and can thus be very long, we decided to add up to 2 points when more than two consonantal segments are contiguous. Table 3 recapitulates the different parameters included in our IPC adaptation.
Our purpose here is to compare the total phonetic complexity of children's production cross-linguistically, as well as the relative contribution of each of these ten parameters to the overall complexity. Translating each word into a phonetic sequence in which each element is described (as a vowel, a consonant, or a secondary articulation, with consonants being identified in terms of place and mode of articulation), we can identify and compute each parameter, and the IPC as their total sum. Table 4 provides an example of IPC scoring for four dictionary words, one from each language, for the numbered parameters listed in Table 3.
Index of Phonetic Complexity Scoring for one word in each language
3. Results
The dictionary sample is a window on the expected mean word phonetic complexity of the languages under study. Since we are interested in the differences/similarities between languages or samples rather than in the absolute distribution of the IPC values, we compute the 95% confidence interval error bar (5% type I error, computed through bootstrapping) rather than the standard variation interval, to allow for visual comparison of sample means. As for the actual discussion of results, differences in behavior are supported by a Kruskal-Wallis H-test to test the null hypothesis that the population medians of all of the samples (Dictionary, CDS, Actual and Target) are equal. This test is the non-parametric version of a one-way ANOVA, and is required in our case because data distributions are not normal. This test assumes a chi-square distribution but provides the advantage of allowing both fine grain comparisons between two samples, even samples of different sizes (thus allowing for repeated sampling), and a generalization over more samples.
Figure 1 shows that the four languages have indeed different mean word IPCs, with a decline from Arabic > Berber > English > French. However, confidence intervals are quite large, which was to be expected from the small sample sizes, which casts doubt on the validity of this decreasing pattern. Indeed, inter-language H-test comparisons only support the difference between Arabic and the other languages (p < 0.05), but not among Berber, English and French.
Mean word IPC showing a decreasing decline from Arabic > Berber > English > Vertical bars show the 95% confidence interval for the means for the dictionary as a whole.

This for the overall IPC. However, each of the 10 phonetic parameters used to compute the IPC could contribute differently – depending on the language – while being leveled out by the others, with the specific expectations formulated under H1. Such individual contributions for the Dictionary sample are displayed in Figure 2 as specific contributions, that is, the difference between the proportion of the overall complexity (total IPC) the parameter actually accounts for, and what would be expected from a uniform contribution of all parameters. Since there are ten of those, the uniform contribution null hypothesis would set each parameter's contribution to a tenth of the overall complexity (in other words, the baseline corresponds to a 10% contribution of the parameter). Specific parameter contributions should thus vary theoretically between −0.1 and 0.9.
Specific parameter contribution per Language (with respect to the uniform contribution null hypothesis). For each parameter, values could theoretically range between −0.1 and 0.9.

To explore the sub-hypotheses outlined for H1, we need to proceed parameter by parameter, with specific expectations for each language. To test whether the mean tendency for the language supports our expectations, we proceed to inter-language T-tests to assess whether the mean behaviors of languages taken two-by-two are statistically significantly different.
As expected in H1.a, Arabic and French display significantly greater contributions (p < 10−3) of place of articulation (parameter 2: 12–14% contribution to the overall IPC) than Berber and English (6–7%). As for Manner (parameter 3), it accounts for some 20% of the total IPC for all four languages, with no significant inter-language differences. In terms of variegation, Arabic indeed exhibits the highest contributions for both place (parameter 7: 16.2%) and manner (parameter 8: 16.3%), but they are not significantly higher than the contributions of these parameters for the other three languages, where values range from 13.8 to 16.1%, invalidating the expectations of hypotheses H1.f and H1.g. The Rhoticity parameter (parameter 4, H1.h), which is exclusive to English, only accounts in this language for 4.7% of the total IPC, but is still significantly different from zero (p < 10−4).
Moving on to complex articulations: contrary to our assumption in H1.b concerning consonantal clusters (parameter 9), Berber and Arabic (14.1% and 11.4% respectively) differ significantly only from French (7.8%, p ≤ 0.05) but not from English (11.5%), with Arabic and English only slightly above the 10% baseline of a uniform contribution of all parameters to the total IPC. However, Arabic and Berber significantly differ from English in terms of cluster composition (parameter 10: p ≤ 0.05, 6.1%, 8.6% and 3.5% respectively), but not from French (6.7%), as predicted by H1.c.
To explore the effect of word structure and shape, we first distinguished monophthongs from diphthongs in our data description, then computed word length as the number of vowels, assumed to act as syllabic nuclei (except for Berber, where, null syllabic nuclei were also identified, using Dell and Elmedlaoui's (Reference Dell and Elmedlaoui2002) syllabification algorithm). For this parameter (parameter 6, H1.d), all four languages exhibited less than the 10% contribution anticipated if all parameters had an equal contribution to the overall IPC, with values ranging from 1.7% to 6.9%, and an unexpected low value for Arabic. However, as expected in H1.e, French exhibits significantly less complexity (7.4%, p < 0.01) than all three other languages in word shape (parameter 5: 12–20%) due to a preference for open final syllables.
Complexity measures on the dictionary samples provide the baseline against which children's production and lexical selectivity, but CDS can also be analyzed. Figure 3 shows the mean IPC values for the different samples in the various languages.
Mean word IPC and 95% confidence intervals for the Dictionary/adult language, CDS, actual child production and target for Arabic, Berber, English and French

Overall, the four samples differ significantly for all four languages (p < 10−6), with a general tendency to a decreasing complexity from Dictionary to CDS to Target to Actual child productions. However, major differences exist between languages. Regarding H2, for instance, we find that the lesser complexity expected for CDS compared to the Dictionary sample is supported only for Berber (4.34 vs. 6.06) and French (3.92 vs. 5.14) with p < 0.01, but not for Arabic (5.42 vs. 6.2) or English (5.4 vs. 5.76). As for H3, while Arabic, English and French exhibit significant IPC differences between Dictionary or CDS and Target (p at least < 0.02), the Berber data only supports a difference between Dictionary and Target (4.26), but not between CDS and Target, suggesting that adults actually pre-sample their language to select for appropriate complexity in the speech they address to the child. Moving on to H4, all languages exhibit significantly lower complexity of the Actual production of the child with respect to the intended Target (p < 10−6). Arabic and Berber show similar Target complexity and Actual-to-Target complexity differential (2.96–4.31 and 2.87–4.26 respectively). Nevertheless, while English and French display lower Target complexity (3.7 and 3.06 respectively), and lower Actual complexity as predicted by H5 (1.72 and 0.81 respectively), they also display larger Actual-to-Target complexity differentials especially for French, prompting the question of accuracy.
Given that the individual parameters focus primarily on consonants, we computed the Actual-to-Target accuracy in the realization of consonants for the four languages (see Figure 4) as the proportion/percentage of conformity with target. Despite the larger overall Actual-to-Target complexity differential, French children achieve better accuracy than English children, typically, and fall within the range of accuracy of Berber kids (p < 0.02). More importantly though, and despite larger Target complexity, Arabic and Berber children show better accuracy scores (66% and 59% respectively vs. 53% for French and 44% for English). These results show that these Actual-to-Target complexity differentials do not necessary translate into Actual-to-Target accuracy, but more crucially they suggest that the typological characteristics of the language do indeed play a role in the acquisition process, calling for a detailed examination of the individual contribution of each parameter to the overall IPC score of children's actual production, as compared to the ambient language (dictionary) parameter contribution landscape.
Mean Actual-to-Target accuracy in consonant production for Arabic, Berber, English and French. Vertical bars display the 95% confidence interval

Relevant to H6, Figure 5 shows that not all parameters contribute equally to the mean IPC of the child's actual production, but also that, depending on the language, they do not depart equally from what is expected from other samples, and especially the dictionary language. For instance, Arabic Actual (16.2%) shows an enhanced tendency for children to produce closed final syllables, irrespective of what is displayed in either the Target (9.1%) or the CDS (9.6%), thus mirroring more of the dictionary tendency (12.9%) than these two latter samples do. On the other hand, clusters, which were shown previously to have a significant contribution to the overall IPC in the dictionary (14.1%), behave differently (p < 10−4) in the Targets selected by children (7.7%) and in their Actual productions (6%), while these latter do not depart significantly from the CDS (5%) sample. This suggests that both CDS and Targets selected by the children tend to misrepresent clusters during this phase of acquisition, thereby reducing the complexity of their production.
Mean parameter contribution by sample (Dictionary, CDS, Target and Actual) and by language (Arabic, Berber, English, French)

As for manner of articulation (parameter 3), Arabic and Berber tend to have comparable complexity in the Dictionary, CDS and Target samples, but this complexity is not achieved in the Actual children productions (p < 10−3). In other words, while the selected targets mirror the complexity of the ambient language for this parameter, children's productions do not. Conversely, in English and French, the CDS does mirror the complexity of the Dictionary for this parameter, but neither the children's Targets nor Actual productions do (p < 0.01) as they display similar levels of complexity for this parameter. In terms of place of articulation (parameter 2), Targets and Actual reflect the characteristics of both Dictionary and CDS for Arabic, Berber and English but not for French. In French, Target complexity for this parameter mirrors the CDS, but not the Dictionary, and Actual does not reflect either of the Dictionary, the CDS or the Target. Conversely, place variegation (parameter 7) for this language shows that the Target's complexity mirrors the Dictionary rather than the CDS. In addition, while place and manner contribute the most to Actual productions in this language, their variegation contributes the least, contrary to Arabic, Berber and English.
4. Discussion
Using an adaptation of Jakielski's (Reference Jakielski2000) Index of Phonetic Complexity (IPC), we carried out an analysis to assess phonetic complexity of children's early vocabulary in four languages: Arabic, Berber, English and French. Globally, we hypothesized that children's early productions would be shaped by universal articulatory constraints, but also by the language they are exposed to, depending on its phonological complexity.
Considering language-specific aspects, we observed that as hypothesized, some languages of our samples, namely Arabic and Berber, show higher IPC scores (complexity) than English and especially French (H1). Our results also reveal the different IPC parameters contribute differently to overall phonetic complexity depending on language specificity. Manner and place of articulation contribute significantly to complexity in all four languages, and not only in Arabic and French as predicted by H1.a. In other words, children in these languages do not systematically avoid fricatives or liquids, which are frequent in the ambient language (dos Santos Reference dos Santos2007 for French, Nahar et al. Reference Nahar, Elshafei, Al-Khatib and Al-Muhtaseb2012 for Arabic), and to which they are consequently frequently exposed to via CDS. Similarly, for place of articulation, although children prefer labials and coronals to dorsals in the early period of production, they are able to produce posterior consonants (like dorsals and/or pharyngeals) when these types of sounds are frequently encountered in the ambient language (i.e., typically in Afro-Asiatic languages where they are rather frequent as shown by Basset (Reference Basset1946) and Bonnot (Reference Bonnot1977). However, some parameters clearly differ across languages. Clusters are significant contributors to phonetic complexity in Berber, and, to a lesser extent, in Arabic and English (H1.b). In Tunisian Arabic, as in all Western Arabic vernaculars, the prevalence of complex consonantal clusters is mainly due to the loss of unstressed vowels in open syllables under the influence of linguistic substrates (i.e., namely Berber), and this contributes to the increased number of clusters. As for final consonant, French is confirmed to be easier than the other languages, as predicted by H1.e. In contrast, some other parameters that were expected to play a role in complexity scores (H1.c, d, f, g, h), in particular word length and complex articulation (H1.c and d), do not seem to contribute significantly to the global complexity score. Moreover, the expected decreasing complexity: Berber < Arabic < English < French which led us to hypothesize that these differences in phonetic complexity in the adult languages would influence phonetic development in children acquiring these languages. However, our results did not show this expected pattern: only Arabic is significantly more complex than the three other languages. An obvious assumption is that a phonetically complex language such as Arabic would take longer to acquire, and would be more challenging to reach accuracy. Nevertheless, our findings suggest that this is not the case. Although our sample is too small to draw solid conclusions, our data indicate that Arabic infants are not delayed in the timing of first words production, given that first words are produced before the age of twelve months in our sample. Similarly, children acquiring Arabic and Berber show the best accuracy scores compared to the a priori articulatory less complex languages, English and French.
Turning to universal aspects of phonetic development (H2, H3 and H4), our findings are in line with previous work underlying the universal tendency for caregivers to modify their speech when addressing children (H2) (Ferguson Reference Ferguson1964, Reference Ferguson, Greenberg, Ferguson and Moravcsik1978; Kuhl et al. Reference Kuhl, Andruski, Chistovich., Chistovich, Kozhevnikova, Ryskina and Lacerda1997; Monnot Reference Monnot1999; Kitamura et al. Reference Kitamura, Thanavishuth, Burnham and Luksaneeyanawin2001). Some studies had investigated CDS in Arabic and Berber and cultural differences have been documented in the range of modifications of CDS (Ferguson Reference Ferguson, Halle, Lunt, Mc Lean and van Schooneveld1956, Gumperz and Hymes Reference Gumperz and Hymes1964, Bynon Reference Bynon1968, Omar 1973, Haggan Reference Haggan2002, Al-Shatty Reference Al-Shatty2003, Ferguson Reference Ferguson, Lust and Foley2004), and the fact that caregivers use a special register to address young children remains indisputable cross-linguistically. The vast majority of CDS studies are focused on semantic, syntactic or prosodic characteristics. Fewer address the phonetic characteristics of CDS, but Kuhl et al. (Reference Kuhl, Andruski, Chistovich., Chistovich, Kozhevnikova, Ryskina and Lacerda1997) for instance showed that mothers in different languages (American English, Russian and Swedish) produce vowels that are acoustically more extreme when addressing their young children, thus providing information about the sound system of the infant's native language in an exaggerated form. CDS thus promotes language learning by separating sounds into contrasting categories. The present study did not focus on potential modifications of segments in CDS, but our findings show that caregivers use words that are less complex than in the adult language. This suggests the operation of lexical selectivity in CDS just as lexical selectivity is hypothesized in children's productions. Thus, one can assume that caregivers reduce the gap between children's restricted articulatory capacities and the necessary capacities to produce phonetically complex words of the adult language.
As predicted by H3, children also seem to select the words they produce or attempt to produce depending on their phonetic complexity (Ferguson and Farwell Reference Ferguson and Farwell1975, Vihman et al. Reference Vihman, Macken, Miller, Simmons and Miller1985, Schwartz et al. Reference Schwartz, Leonard, Loeb and Swanson1987). Indeed, in the four languages under study, we observed that words attempted (Target) or produced (Actual) by children have lower complexity scores than CDS or adult words (H3 and H4). Finally, the fact that in all the four languages, actual productions show reduced complexity compared to attempted words (and obviously to CDS or adult speech) illustrates the fact that during this early period of first word productions, children's early phonetic inventories are strongly limited by anatomical and neurophysiological constraints (MacNeilage et al. Reference MacNeilage, Davis, Kinney and Matyear2000, Green et al. Reference Green, Moore and Reilly2002, Stoel-Gammon and Sosa Reference Stoel-Gammon, Sosa, Hoff and Schatz2007, Geen et al. Reference Green, Nip, Maassen, Lieshout, Maassen and van Leshout2010). Looking at the detailed parameters that children either produce or avoid depending on the language, our findings show a mixed influence of language specificity and neurophysiological constraints. Globally, children's actual productions tend to reflect the tendencies displayed in adult productions (H5 and H6). The fact that in Arabic, children's use of closed syllables (cf. actual items) mirrors the adult language (dictionary words, but not targets nor CDS) can be explained by the fact that this process of simplification does not affect the word randomly but rather affects morphemes that are added to the root (for example, in the actual item #48 tatt it is the morpheme of the third person singular at the imperfective [ji-] prefixed to the verbal root which is dropped. These morphological elisions also explain why children's actual words are not as long as predicted. Another consequence of this phenomenon is illustrated in # 39 ʔam :i ‘my uncle’ which is actualized ʔam: ‘uncle’ and where the suffixed first person possessive determiner [-i] is dropped, resulting in a CVC sequence. Doing this, the child produces a form that is similar to the one recorded in dictionaries and which corresponds to the radical form of the words. Turning to clusters, which are strong contributors of complexity in Berber (and to a lesser extent in Arabic and English), they seem to be avoided by children acquiring these languages (in Arabic for example, #18 kaskək (‘your helmet’), #35 tkasir (‘you break’), #42 ħizha (‘lift it’ (fem.)) and/or #50 ʔistana (‘wait”) are actualized under the following simplified forms: ka, kasər, tiz :a and stan:æ respectively. This finding is not surprising, as consonant clusters appear to be especially challenging for children. Indeed, they are not produced before age 2 and their acquisition is one of the longest-lasting aspects of speech acquisition in normally developing children (McLeod et al. Reference McLeod, Doorn and Reed2001). In sum, the different IPC parameters are not equally difficult for children to produce: while some (such as producing fricatives or dorsals) can be overcome by children even at a very early age in spite of biological constraints, others (such as consonant clusters) need more time to master.
Examples of Arabic data
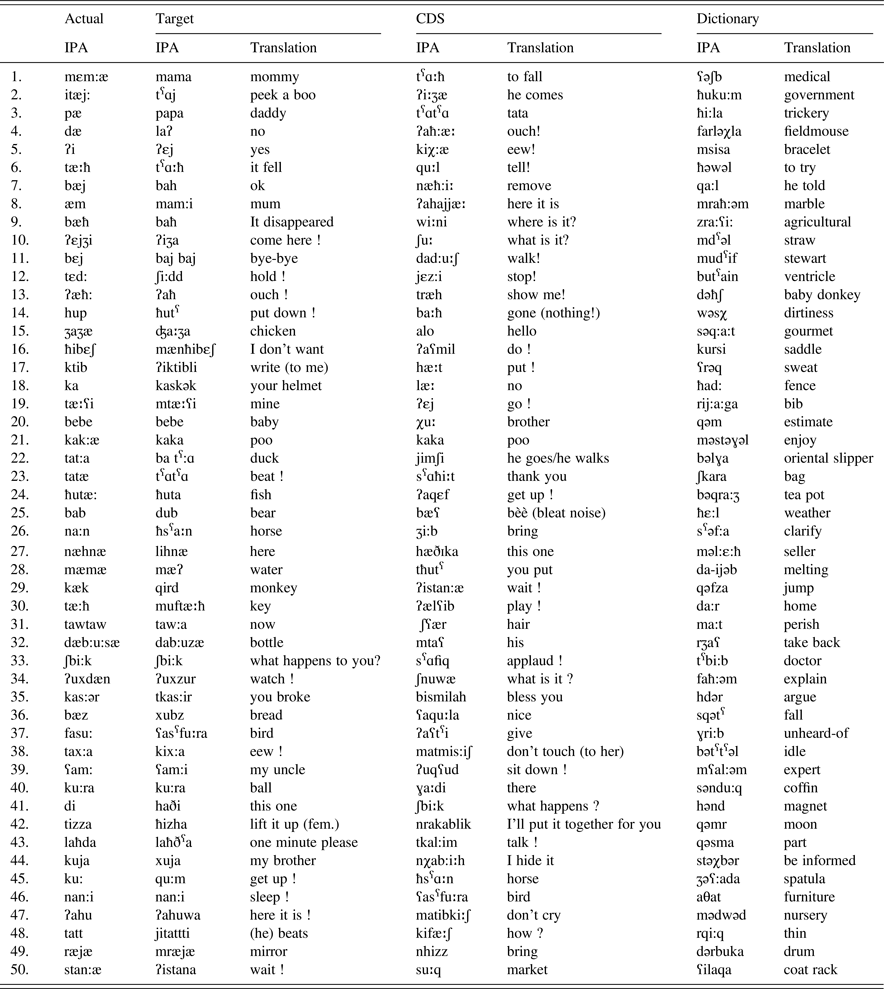
Examples of Berber data

Examples of English data
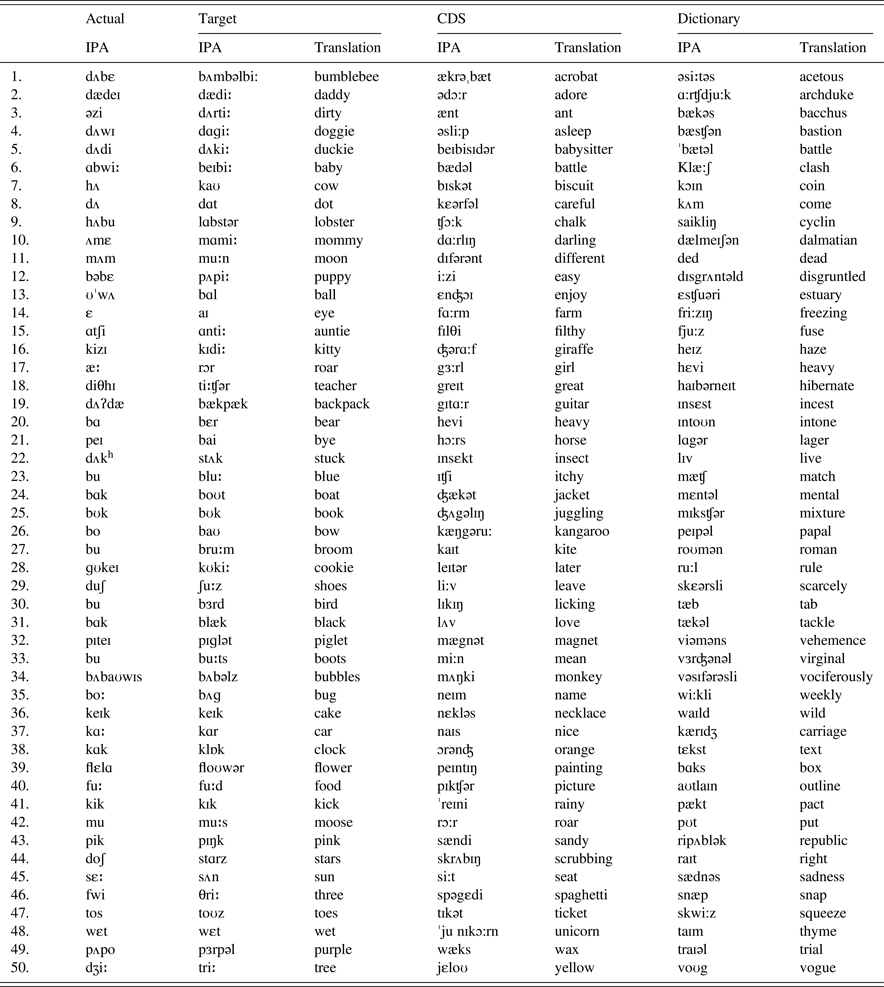
Examples of French data