



Impact Statement
Controlling complex physical systems described by partial differential equations is central to many applications in engineering and applied sciences. In recent years, data-driven control strategies, particularly reinforcement learning, have gained attention due to their effectiveness and real-time applicability. However, these techniques often struggle with sample inefficiency and lack of interpretability, especially when dealing with high-dimensional systems. The proposed data-driven approach combines autoencoders with sparse model discovery, enabling scalable, robust, and interpretable control of high-dimensional systems. Our method significantly reduces the need for expensive simulations or experiments while uncovering low-dimensional and interpretable dynamics models. These advances open new possibilities for the design and deployment of reliable, data-efficient control strategies across industries, such as energy, aerospace, and manufacturing, and provide a foundation for more transparent and trustworthy AI-based control in safety-critical systems.
1. Introduction
Feedback control for complex physical systems is essential in many fields of engineering and applied sciences, which are typically governed by partial differential equations (PDEs). In these cases, the state of the systems is often challenging or even impossible to observe completely; the systems exhibit nonlinear dynamics and require low-latency feedback control (Brunton et al., Reference Brunton, Noack and Koumoutsakos2020; Peitz and Klus, Reference Peitz and Klus2020; Kim and Jeong, Reference Kim and Jeong2021). Consequently, effectively controlling these systems is a computationally intensive task. For instance, significant efforts have been devoted in the last decade to the investigation of optimal control problems governed by PDEs (Hinze et al., Reference Hinze, Pinnau, Ulbrich and Ulbrich2008; Manzoni et al., Reference Manzoni, Quarteroni and Salsa2022); however, classical feedback control strategies face limitations with such highly complex dynamical systems. For instance, (nonlinear) model predictive control (MPC) (Grün and Pannek, Reference Grüne and Pannek2017) has emerged as an effective and important control paradigm. MPC utilizes an internal model of the dynamics to create a feedback loop and provide optimal controls, resulting in a difficult trade-off between model accuracy and computational performance. Despite its impressive success in disciplines such as robotics (Williams et al., Reference Williams, Aldrich, Roderick, Blackmore, Kuwata, Burnell, Vleugels, Weiss, Hauser and Alonso-Mora2018) and controlling PDEs (Altmüller, Reference Altmüller2014), MPC struggles with real-time applicability in providing low-latency actuation, due to the need for solving complex optimization problems.
In recent years, reinforcement learning (RL), particularly deep RL (DRL) (Sutton and Barto, Reference Sutton and Barto2018), an extension of RL relying on deep neural networks, has gained popularity as a powerful and real-time applicable control paradigm. Especially in the context of solving FPDEs, DRL has demonstrated outstanding capabilities in controlling complex and high-dimensional dynamical systems at low latency (Yousif et al., Reference Yousif, Kolesova, Yang, Zhang, Yu, Rabault, Vinuesa and Limn.d.; Botteghi and Fasel, Reference Botteghi and Fasel2024; Peitz et al., Reference Peitz, Stenner, Chidananda, Wallscheid, Brunton and Taira2024; Vinuesa, Reference Vinuesa2024). Additionally, recent community contributions of benchmark environments such as ControlGym (https://github.com/xiangyuan-zhang/controlgym) (Zhang et al., Reference Zhang, Mo, Mowlavi, Benosman and Başarn.d.), PDEControlGym (https://github.com/lukebhan/PDEControlGym) (Bhan et al., Reference Bhan, Bian, Krstic and Shi2024), and HydroGym (https://github.com/dynamicslab/hydrogym), all wrapped under the uniform Gym (Brockman et al., Reference Brockman, Cheung, Pettersson, Schneider, Schulman, Tang and Zaremba2016) interface, highlight the importance of DRL in the context of controlling PDEs. Despite its impressive success, DRL faces three major challenges:
-
1. Data usage: DRL algorithms are known to be sample inefficient, requiring a large number of environment interactions, resulting in long training times and high computational requirements (Zoph and Le, Reference Zoph and Le2016). This is particularly problematic in the context of controlling PDEs, as generating training data often requires either long simulations (Zolman et al., Reference Zolman, Fasel, Kutz and Bruntonn.d., section B.3) or would necessitate very expensive real-world experiments (OpenAI, 2020).
-
2. Robustness of the control performance: In high-dimensional state-action spaces, as in the context of (discretized) PDEs, it is challenging to generate sufficient training data for the agent to adequately cover the state-action space. This is crucial for ensuring a reliable and trustworthy controller, impeding the application to safety-critical use-cases like nuclear fusion (Zhi et al., Reference Zhi, Fan, Zhou, Li and Noack2018) or wind energy (Aubru et al., Reference Aubrun, Leroy and Devinant2017).
-
3. Black-box model: DRL methods often result in policies and learned dynamics that are difficult to interpret. While interpretability may not be critical when the sole objective is control performance, it becomes important in scenarios where understanding the underlying PDE dynamics or ensuring transparent and verifiable decision-making is necessary. This includes applications in scientific discovery, safety-critical systems, or when diagnosing and improving controllers. In the context of PDE control, interpretability aids both in gaining insights into complex dynamics and in building trust in the learned controllers (Alla et al., Reference Alla, Pacifico, Palladino and Pesare2023; Botteghi and Fasel, Reference Botteghi and Fasel2024).
A popular approach to address the aforementioned problem of sample inefficiency is the use of model-based algorithms, specifically model-based RL (MBRL) (Sutton, Reference Sutton, Porter and Mooney1990; Deisenroth and Rasmussen, Reference Deisenroth and Rasmussen2011; Chua et al., Reference Chua, Calandra, McAllister, Levine, Bengio, Wallach, Larochelle, Grauman, Cesa-Bianchi and Garnett2018; Clavera et al., Reference Clavera, Rothfuss, Schulman, Fujita, Asfour and Abbeel2018; Wang et al., Reference Wang, Bao, Clavera, Hoang, Wen, Langlois, Zhang, Zhang, Abbeel and Ba2019; Hafner et al., Reference Hafner, Lillicrap, Norouzi and Ba2020). One of its various forms is the Dyna-style MBRL algorithm (Sutton, Reference Sutton1991), which iteratively collects samples from the full-order environment to learn a surrogate dynamics model. The agent then alternates between interacting with the surrogate model and the actual environment, significantly reducing the amount of required training data, allowing faster rollouts. Recent contributions in MBRL for PDEs include the use of convolutional long-short term memory with actuation networks (Werner and Peitz, Reference Werner and Peitz2023) and Bayesian linear regression for model identification in the context of the State-Dependent Riccati Equation control approach (Alla et al., Reference Alla, Pacifico, Palladino and Pesare2023).
Sparse dictionary learning is a class of data-driven methods that seek to approximate a nonlinear function using a sparse linear combination of candidate dictionary functions, for example, polynomials of degree
 $ d $
or trigonometric functions. In the context of identification of dynamical systems, sparse dictionary learning is used by the Sparse Identification of Nonlinear Systems (SINDy) method (cf. Section 2.3). SINDy is a very powerful method to identify a parsimonious, that is, with a limited number of terms, dynamics model and resolve the issue of lacking interpretability, for example, of deep neural networks. The PySINDy (https://github.com/dynamicslab/pysindy) package (Kaptanoglu et al., Reference Kaptanoglu, de Silva, Fasel, Kaheman, Goldschmidt, Callaham, Delahunt, Nicolaou, Champion, Loiseau, Kutz and Brunton2021) makes implementations easy and fast. With its active community, SINDy has been extended to various forms, such as ensemble versions (Fasel et al., Reference Fasel, Kutz, Brunton and Brunton2022), uncertainty quantification for SINDy (Hirsh et al., Reference Hirsh, Barajas-Solano and Kutz2022), Bayesian autoencoder (AE)-based SINDy (Gao and Kutz, Reference Gao and Kutz2024) and applied to a variety of different applications, including turbulence closures (Zanna and Bolton, Reference Zanna and Bolton2020), PDEs (Rudy et al., Reference Rudy, Brunton, Proctor and Kutz2016), continuation methods (Conti et al., Reference Conti, Gobat, Fresca, Manzoni and Frangi2023), and variational architectures (Conti et al., Reference Conti, Kneifl, Manzoni, Frangi, Fehr, Brunton and Kutz2024). In practice, problems governed by PDEs usually require a fine enough discretization in order to be solved effectively, leading to high-dimensional dynamical systems (order of magnitude 50 ×
$ d $
or trigonometric functions. In the context of identification of dynamical systems, sparse dictionary learning is used by the Sparse Identification of Nonlinear Systems (SINDy) method (cf. Section 2.3). SINDy is a very powerful method to identify a parsimonious, that is, with a limited number of terms, dynamics model and resolve the issue of lacking interpretability, for example, of deep neural networks. The PySINDy (https://github.com/dynamicslab/pysindy) package (Kaptanoglu et al., Reference Kaptanoglu, de Silva, Fasel, Kaheman, Goldschmidt, Callaham, Delahunt, Nicolaou, Champion, Loiseau, Kutz and Brunton2021) makes implementations easy and fast. With its active community, SINDy has been extended to various forms, such as ensemble versions (Fasel et al., Reference Fasel, Kutz, Brunton and Brunton2022), uncertainty quantification for SINDy (Hirsh et al., Reference Hirsh, Barajas-Solano and Kutz2022), Bayesian autoencoder (AE)-based SINDy (Gao and Kutz, Reference Gao and Kutz2024) and applied to a variety of different applications, including turbulence closures (Zanna and Bolton, Reference Zanna and Bolton2020), PDEs (Rudy et al., Reference Rudy, Brunton, Proctor and Kutz2016), continuation methods (Conti et al., Reference Conti, Gobat, Fresca, Manzoni and Frangi2023), and variational architectures (Conti et al., Reference Conti, Kneifl, Manzoni, Frangi, Fehr, Brunton and Kutz2024). In practice, problems governed by PDEs usually require a fine enough discretization in order to be solved effectively, leading to high-dimensional dynamical systems (order of magnitude 50 ×
 $ {10}^3 $
, or even larger). However, SINDy does not scale to high-dimensional systems, which is why we learn the latent representation of the high-dimensional states and actions of the PDE with two AEs. This dimensionality-reduction step allows for using SINDy and improves the robustness (we learn a low-dimensional representation of the PDE states) of the control policies (Lesort et al., Reference Lesort, Díaz-Rodríguez, Goudou and Filliat2018; Botteghi et al., Reference Botteghi, Poel and Brune2025).
$ {10}^3 $
, or even larger). However, SINDy does not scale to high-dimensional systems, which is why we learn the latent representation of the high-dimensional states and actions of the PDE with two AEs. This dimensionality-reduction step allows for using SINDy and improves the robustness (we learn a low-dimensional representation of the PDE states) of the control policies (Lesort et al., Reference Lesort, Díaz-Rodríguez, Goudou and Filliat2018; Botteghi et al., Reference Botteghi, Poel and Brune2025).
Our contribution can be summarized as follows:
-
• With AE+SINDy-C, we present a novel combination of the AE framework and the SINDy-C algorithm, incorporating controls into the AE framework as a Dyna-style MBRL method for controlling PDEs.
-
• AE+SINDy-C enables fast rollouts, significantly reducing the required number of full-order environment interactions and provides an interpretable, low-dimensional latent representation of the dynamical system.
-
• We demonstrate the feasibility of our approach by solving two different fluid-flow PDEs, comparing it to a state-of-the-art model-free baseline algorithm.
-
• We provide an extensive analysis of the learned dynamics and numerical ablation studies.
In particular, our work relies on two SINDy (Brunton et al., Reference Brunton, Proctor and Kutz2016) extensions:
-
1. For control applications, SINDy has been extended to work with controls, namely SINDy-C, MPCs (Kaiser et al., Reference Kaiser, Kutz and Brunton2018; Fasel et al., Reference Fasel, Kaiser, Kutz, Brunton and Brunton2021), and importantly, in the context of RL in the work of Arora et al. (Arora et al., Reference Arora, da Silva and Moss2022), and more recently by Zolman et al. (Zolman et al., Reference Zolman, Fasel, Kutz and Bruntonn.d.) (see Section 2.3.1 for more details).
-
2. The work of Champion et al. (Champion et al., Reference Champion, Lusch, Kutz and Brunton2019) enables data-driven discovery using SINDy and an AE framework for high-dimensional dynamical systems (see Section 2.3.2 for more details), which has been extended to the continuation of parameter-dependent PDE solutions by Conti et al. (Conti et al., Reference Conti, Gobat, Fresca, Manzoni and Frangi2023).
The remainder of this paper is structured as follows: Section 2 provides a brief overview of the general problem setting, related with control strategies relying on DRL, and the two aforementioned SINDy extensions upon which AE+SINDy-C is based. Section 3 explains the proposed method in detail and highlights the usage of AE+SINDy-C in the context of DRL for controlling PDEs. In Section 4, we explain the two PDE benchmark cases and analyze the numerical results in detail. Section 5 provides an overview of possible interesting directions for follow-up work and variations of AE+SINDy-C. All details about the used environments, DRL, and the training of AE+SINDy-C can be found in Appendix A.
2. Background and related work
2.1. Problem setting
In this work, we address the problem of controlling a nonlinear, distributed, dynamical system described by the equation:
 $$ \frac{\mathrm{d}}{\mathrm{d}t}\mathbf{x}(t)=f\left(\mathbf{x}(t),\mathbf{u}(t)\right), $$
$$ \frac{\mathrm{d}}{\mathrm{d}t}\mathbf{x}(t)=f\left(\mathbf{x}(t),\mathbf{u}(t)\right), $$
where the state
 $ \mathbf{x}(t)\in {\mathrm{\mathbb{R}}}^{N_x} $
and control input
$ \mathbf{x}(t)\in {\mathrm{\mathbb{R}}}^{N_x} $
and control input
 $ \mathbf{u}(t)\in {\mathrm{\mathbb{R}}}^{N_u} $
are continuous variables, with potentially very large dimensions
$ \mathbf{u}(t)\in {\mathrm{\mathbb{R}}}^{N_u} $
are continuous variables, with potentially very large dimensions
 $ {N}_x $
and
$ {N}_x $
and
 $ {N}_u $
, respectively. The function
$ {N}_u $
, respectively. The function
 $ f:{\mathrm{\mathbb{R}}}^{N_x}\times {\mathrm{\mathbb{R}}}^{N_u}\to {\mathrm{\mathbb{R}}}^{N_x} $
is assumed to be unknown, but we can observe a time-discrete evolution of the system, resulting in a sequence of (partially or fully) observable measurements
$ f:{\mathrm{\mathbb{R}}}^{N_x}\times {\mathrm{\mathbb{R}}}^{N_u}\to {\mathrm{\mathbb{R}}}^{N_x} $
is assumed to be unknown, but we can observe a time-discrete evolution of the system, resulting in a sequence of (partially or fully) observable measurements
 $ {\mathbf{m}}_t,{\mathbf{m}}_{t+1},\dots, {\mathbf{m}}_{t+H} $
of the state over a horizon
$ {\mathbf{m}}_t,{\mathbf{m}}_{t+1},\dots, {\mathbf{m}}_{t+H} $
of the state over a horizon
 $ H\in {\mathrm{\mathbb{N}}}_{+} $
. A system is fully observable (FO) if the observations
$ H\in {\mathrm{\mathbb{N}}}_{+} $
. A system is fully observable (FO) if the observations
 $ {\mathbf{m}}_i\in {\mathrm{\mathbb{R}}}^{N_x} $
allow to observe each (full) state of the system directly, that is,
$ {\mathbf{m}}_i\in {\mathrm{\mathbb{R}}}^{N_x} $
allow to observe each (full) state of the system directly, that is,
 $ {N}_x^{\mathrm{Obs}}={N}_x $
and
$ {N}_x^{\mathrm{Obs}}={N}_x $
and
 $ {\mathbf{m}}_i={\mathbf{x}}_i $
. On the other hand, a system is partially observable (PO) if only a limited number of sensors is available, resulting in a lower-dimensional observation space
$ {\mathbf{m}}_i={\mathbf{x}}_i $
. On the other hand, a system is partially observable (PO) if only a limited number of sensors is available, resulting in a lower-dimensional observation space
 $ {\mathbf{m}}_i\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
, where
$ {\mathbf{m}}_i\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
, where
 $ {N}_x^{\mathrm{Obs}}\ll {N}_x $
that does not capture the full state of the PDE. In this work, we consider both FO and PO systems. Similarly, we assume a limited number of actuators are available to control the system. The combination of nonlinear system dynamics with a limited number of state sensors and control actuators entails a complex and challenging problem in PDE control.
$ {N}_x^{\mathrm{Obs}}\ll {N}_x $
that does not capture the full state of the PDE. In this work, we consider both FO and PO systems. Similarly, we assume a limited number of actuators are available to control the system. The combination of nonlinear system dynamics with a limited number of state sensors and control actuators entails a complex and challenging problem in PDE control.
2.2. Reinforcement learning
RL is a general framework for solving sequential decision-making processes. RL has been applied to a variety of different tasks, including natural language processing for dialogue generation (OpenAI Team, 2024) and text summarization (Li et al., Reference Li, Monroe, Shi, Jean, Ritter and Jurafsky2016), computer vision for object detection and image classification (Mnih et al., Reference Mnih, Kavukcuoglu, Silver, Graves, Antonoglou, Wierstra and Riedmiller2013), robotics for autonomous control and manipulation (Levine et al., Reference Levine, Finn, Darrell and Abbeel2016), finance for portfolio management and trading strategies (Jiang et al., Reference Jiang, Xu and Liang2017), and game playing for mastering complex strategic games (Silver et al., Reference Silver, Huang, Maddison, Guez, Sifre, Driessche, Schrittwieser, Antonoglou, Panneershelvam and Lanctot2016). These applications highlight the broad versatility and significant impact of RL across multiple fields.
RL is the subset of machine learning that focuses on training agents to make decisions by interacting with an environment. The RL framework is typically modeled as a Markov decision process (MDP), defined by the tuple
 $ \mathcal{M}:= \left(\mathcal{X},\mathcal{U},\mathcal{P},\mathcal{R},\gamma \right) $
, where
$ \mathcal{M}:= \left(\mathcal{X},\mathcal{U},\mathcal{P},\mathcal{R},\gamma \right) $
, where
 $ \mathcal{X}\subseteq {\mathrm{\mathbb{R}}}^{N_x} $
is the set of observable states,
$ \mathcal{X}\subseteq {\mathrm{\mathbb{R}}}^{N_x} $
is the set of observable states,
 $ \mathcal{U}\subseteq {\mathrm{\mathbb{R}}}^{N_u} $
is the set of actions,
$ \mathcal{U}\subseteq {\mathrm{\mathbb{R}}}^{N_u} $
is the set of actions,
 $ \mathcal{P}:\mathcal{X}\times \mathcal{X}\times \mathcal{U}\to \left[0,1\right] $
is the transition probability kernel with
$ \mathcal{P}:\mathcal{X}\times \mathcal{X}\times \mathcal{U}\to \left[0,1\right] $
is the transition probability kernel with
 $ \mathcal{P}\left({\mathbf{x}}^{\prime },\mathbf{x},\mathbf{u}\right) $
representing the probability of reaching the state
$ \mathcal{P}\left({\mathbf{x}}^{\prime },\mathbf{x},\mathbf{u}\right) $
representing the probability of reaching the state
 $ {\mathbf{x}}^{\prime}\in \mathcal{X} $
while being in the state
$ {\mathbf{x}}^{\prime}\in \mathcal{X} $
while being in the state
 $ \mathbf{x}\in \mathcal{X} $
and applying action
$ \mathbf{x}\in \mathcal{X} $
and applying action
 $ \mathbf{u}\in \mathcal{U} $
,
$ \mathbf{u}\in \mathcal{U} $
,
 $ \mathcal{R}:\mathcal{X}\times \mathcal{U}\to \mathrm{\mathbb{R}} $
is the reward function, and
$ \mathcal{R}:\mathcal{X}\times \mathcal{U}\to \mathrm{\mathbb{R}} $
is the reward function, and
 $ \gamma \in \left(0,1\right] $
is the discount factor.
$ \gamma \in \left(0,1\right] $
is the discount factor.
The goal of an RL agent is to learn an optimal policy
 $ \pi $
that maps states
$ \pi $
that maps states
 $ \mathbf{x} $
of the environment to actions
$ \mathbf{x} $
of the environment to actions
 $ \mathbf{u} $
in a way that maximizes the expected cumulative reward over time a control horizon
$ \mathbf{u} $
in a way that maximizes the expected cumulative reward over time a control horizon
 $ H $
:
$ H $
:
 $$ {R}_H=\unicode{x1D53C}\left[\sum \limits_{t=0}^H{\gamma}^t{r}_t\right], $$
$$ {R}_H=\unicode{x1D53C}\left[\sum \limits_{t=0}^H{\gamma}^t{r}_t\right], $$
with rewards
 $ {r}_t $
collected at timesteps
$ {r}_t $
collected at timesteps
 $ t $
and a control horizon
$ t $
and a control horizon
 $ H $
being finite or infinite—in this work we focus on finite control horizons. RL agents often optimize the policy by approximating either the value function
$ H $
being finite or infinite—in this work we focus on finite control horizons. RL agents often optimize the policy by approximating either the value function
 $ V:\mathcal{X}\to \mathrm{\mathbb{R}} $
or the action-value function
$ V:\mathcal{X}\to \mathrm{\mathbb{R}} $
or the action-value function
 $ Q:\mathcal{X}\times \mathcal{U}\to \mathrm{\mathbb{R}} $
to quantify, and optimize the cumulative reward (eq. [2.1]) for a state
$ Q:\mathcal{X}\times \mathcal{U}\to \mathrm{\mathbb{R}} $
to quantify, and optimize the cumulative reward (eq. [2.1]) for a state
 $ \mathbf{x}\in \mathcal{X} $
or a state-action pair
$ \mathbf{x}\in \mathcal{X} $
or a state-action pair
 $ \left(\mathbf{x},\mathbf{u}\right)\in \mathcal{X}\times \mathcal{U} $
, respectively. When dealing with high-dimensional state spaces, continuous actions, and nonlinear dynamics, the estimation of the value function becomes a very challenging and data-inefficient optimization problem.
$ \left(\mathbf{x},\mathbf{u}\right)\in \mathcal{X}\times \mathcal{U} $
, respectively. When dealing with high-dimensional state spaces, continuous actions, and nonlinear dynamics, the estimation of the value function becomes a very challenging and data-inefficient optimization problem.
In general, we distinguish between model-free and model-based RL algorithms. Model-free algorithms do not assume any explicit model of the system dynamics, and aim at optimizing the policy directly by interacting with the environment. This approach offers more flexibility and is more robust to model inaccuracies but usually requires a large number of interactions to achieve good performance, making it difficult to apply in cases of data sparsity or expensive interactions. On the other hand, model-based RL algorithms internally create a model of the environment’s dynamics, that is, the transition probability kernel
 $ \mathcal{P} $
and the reward function
$ \mathcal{P} $
and the reward function
 $ \mathcal{R} $
(note that in this work we only consider the case of a known full-order reward functions). The agent leverages this model to simulate the environment and plan its actions accordingly, typically resulting in more sample-efficient training. We focus on Dyna-style (Sutton, Reference Sutton1991) RL algorithms, which learn a surrogate model of the system dynamics, allowing the agent to train on an approximation of the environment and thus requiring fewer data.
$ \mathcal{R} $
(note that in this work we only consider the case of a known full-order reward functions). The agent leverages this model to simulate the environment and plan its actions accordingly, typically resulting in more sample-efficient training. We focus on Dyna-style (Sutton, Reference Sutton1991) RL algorithms, which learn a surrogate model of the system dynamics, allowing the agent to train on an approximation of the environment and thus requiring fewer data.
A general scheme of the RL cycle we used for training, including a Dyna-style surrogate dynamics model of the environment is shown in Figure 1. Since this work focuses on Dyna-style RL algorithms with the surrogate model being the center of this work, we use the proximal policy optimization (PPO) algorithm (Schulman et al., Reference Schulman, Wolski, Dhariwal, Radford and Klimov2017) as a state-of-the-art actor-critic algorithm. Actor-critic methods learn both the value-function, that is, the critic, and the policy, that is, the actor, at the same time and have shown very promising results in the last years.
Overview of the RL training loop. In Dyna-style algorithms, we choose if the agent interacts with the full-order model, requiring (expensive) environment rollouts or the learned surrogate, that is reduced order, model, providing fast approximated rollouts. In this work, we focus on the setting where the full-order reward is (analytically) known and only the dynamics are approximated. In general, the observed state is computed by
 $ {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}}\ni {\mathbf{x}}_{t+1}^{\mathrm{Obs}}=C\cdot {\mathbf{x}}_{t+1} $
. In the partially observable (PO) case, the projection matrix
$ {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}}\ni {\mathbf{x}}_{t+1}^{\mathrm{Obs}}=C\cdot {\mathbf{x}}_{t+1} $
. In the partially observable (PO) case, the projection matrix
 $ C\in {\left\{0,1\right\}}^{N_x\times {N}_x^{\mathrm{Obs}}} $
is structured with a single 1 per row and zero elsewhere, that is,
$ C\in {\left\{0,1\right\}}^{N_x\times {N}_x^{\mathrm{Obs}}} $
is structured with a single 1 per row and zero elsewhere, that is,
 $ {N}_x^{\mathrm{Obs}}\ll {N}_x $
. In the fully observable case
$ {N}_x^{\mathrm{Obs}}\ll {N}_x $
. In the fully observable case
 $ C\equiv {\mathrm{Id}}_{{\mathrm{\mathbb{R}}}^{N_x}} $
, that is,
$ C\equiv {\mathrm{Id}}_{{\mathrm{\mathbb{R}}}^{N_x}} $
, that is,
 $ {N}_x^{\mathrm{Obs}}={N}_x $
.
$ {N}_x^{\mathrm{Obs}}={N}_x $
.

2.3. SINDy: Sparse Identification of Nonlinear Dynamics
We briefly review two versions of Sparse Identification of Nonlinear Dynamics (SINDy) used in the SINDy-RL (Zolman et al., Reference Zolman, Fasel, Kutz and Bruntonn.d.) and AE+SINDy (Champion et al., Reference Champion, Lusch, Kutz and Brunton2019) frameworks. SINDy (Brunton et al., Reference Brunton, Proctor and Kutz2016) is an extremely versatile and popular dictionary learning method, that is, a data-driven algorithm aiming at approximating a nonlinear function through a dictionary of user-defined functions. In particular, SINDy assumes that this approximation takes the form of a sparse linear combination of (potentially nonlinear) candidate functions, such as polynomials or trigonometric functions.
In its general formulation, given a set of
 $ N $
data points
$ N $
data points
 $ \left({\mathbf{x}}_1,{\mathbf{y}}_1\right),\dots, \left({\mathbf{x}}_N,{\mathbf{y}}_N\right) $
with
$ \left({\mathbf{x}}_1,{\mathbf{y}}_1\right),\dots, \left({\mathbf{x}}_N,{\mathbf{y}}_N\right) $
with
 $ {\mathbf{x}}_k\in {\mathrm{\mathbb{R}}}^m $
and
$ {\mathbf{x}}_k\in {\mathrm{\mathbb{R}}}^m $
and
 $ {\mathbf{y}}_k=f\left({\mathbf{x}}_k\right)\in {\mathrm{\mathbb{R}}}^n $
,
$ {\mathbf{y}}_k=f\left({\mathbf{x}}_k\right)\in {\mathrm{\mathbb{R}}}^n $
,
 $ k=1,\dots, N $
, and collected as
$ k=1,\dots, N $
, and collected as
 $$ \mathbf{X}={\left[{\mathbf{x}}_1,\dots, {\mathbf{x}}_N\right]}^{\top}\in {\mathrm{\mathbb{R}}}^{N\times m},\hskip2em \mathbf{Y}={\left[{\mathbf{y}}_1,\dots, {\mathbf{y}}_N\right]}^{\top}\in {\mathrm{\mathbb{R}}}^{N\times n}, $$
$$ \mathbf{X}={\left[{\mathbf{x}}_1,\dots, {\mathbf{x}}_N\right]}^{\top}\in {\mathrm{\mathbb{R}}}^{N\times m},\hskip2em \mathbf{Y}={\left[{\mathbf{y}}_1,\dots, {\mathbf{y}}_N\right]}^{\top}\in {\mathrm{\mathbb{R}}}^{N\times n}, $$
and a set of
 $ d $
candidate functions
$ d $
candidate functions
 $ \boldsymbol{\Theta} \left(\mathbf{X}\right)=\left[{\theta}_1\left(\mathbf{x}\right),\dots, {\theta}_d\left(\mathbf{x}\right)\right]\in {\mathrm{\mathbb{R}}}^{N\times d} $
, we aim to find a representation of the form
$ \boldsymbol{\Theta} \left(\mathbf{X}\right)=\left[{\theta}_1\left(\mathbf{x}\right),\dots, {\theta}_d\left(\mathbf{x}\right)\right]\in {\mathrm{\mathbb{R}}}^{N\times d} $
, we aim to find a representation of the form
 $$ \mathbf{Y}=\boldsymbol{\Theta} \left(\mathbf{X}\right)\cdot \boldsymbol{\Xi}, $$
$$ \mathbf{Y}=\boldsymbol{\Theta} \left(\mathbf{X}\right)\cdot \boldsymbol{\Xi}, $$
where
 $ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times n} $
is the coefficients to be fit. These are usually trained in a Lasso-style optimization (Tibshirani, Reference Tibshirani2018) since we assume sparsity, that is, the system dynamics can be sufficiently represented by a small subset of terms in the library. Overall, we optimize (a variation of) the following loss:
$ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times n} $
is the coefficients to be fit. These are usually trained in a Lasso-style optimization (Tibshirani, Reference Tibshirani2018) since we assume sparsity, that is, the system dynamics can be sufficiently represented by a small subset of terms in the library. Overall, we optimize (a variation of) the following loss:
 $$ \boldsymbol{\Xi} =\underset{\hat{\boldsymbol{\Xi}}}{\arg \min }{\left\Vert \mathbf{Y}-\boldsymbol{\Theta} \left(\mathbf{X}\right)\hat{\boldsymbol{\Xi}}\right\Vert}_F+\mathrm{\mathcal{L}}\left(\hat{\boldsymbol{\Xi}}\right), $$
$$ \boldsymbol{\Xi} =\underset{\hat{\boldsymbol{\Xi}}}{\arg \min }{\left\Vert \mathbf{Y}-\boldsymbol{\Theta} \left(\mathbf{X}\right)\hat{\boldsymbol{\Xi}}\right\Vert}_F+\mathrm{\mathcal{L}}\left(\hat{\boldsymbol{\Xi}}\right), $$
with a regularization term
 $ \mathrm{\mathcal{L}} $
promoting sparsity, that is, usually
$ \mathrm{\mathcal{L}} $
promoting sparsity, that is, usually
 $ \mathrm{\mathcal{L}}\left(\boldsymbol{\Xi} \right)={\left\Vert \boldsymbol{\Xi} \right\Vert}_1 $
, and
$ \mathrm{\mathcal{L}}\left(\boldsymbol{\Xi} \right)={\left\Vert \boldsymbol{\Xi} \right\Vert}_1 $
, and
 $ {\left\Vert \cdot \right\Vert}_F $
is the Frobenius norm defined as
$ {\left\Vert \cdot \right\Vert}_F $
is the Frobenius norm defined as
 $ {\left\Vert A\right\Vert}_F=\sqrt{\sum_{i=1}^m{\sum}_{j=1}^n{a}_{ij}^2} $
for a matrix
$ {\left\Vert A\right\Vert}_F=\sqrt{\sum_{i=1}^m{\sum}_{j=1}^n{a}_{ij}^2} $
for a matrix
 $ A\in {\mathrm{\mathbb{R}}}^{m\times n} $
. While in Champion et al. (Reference Champion, Lusch, Kutz and Brunton2019)) and Zolman et al. (Reference Zolman, Fasel, Kutz and Bruntonn.d.)), the loss eq. (2.3) is an
$ A\in {\mathrm{\mathbb{R}}}^{m\times n} $
. While in Champion et al. (Reference Champion, Lusch, Kutz and Brunton2019)) and Zolman et al. (Reference Zolman, Fasel, Kutz and Bruntonn.d.)), the loss eq. (2.3) is an
 $ {\left\Vert \cdot \right\Vert}_2 $
-penalty with sequential thresholding least squares (STLS), we use PyTorch’s automatic differentiation framework (Paszke et al., Reference Paszke, Gross, Chintala, Chanan, Yang, DeVito, Lin, Desmaison, Antiga and Lerer2017) and optimize the
$ {\left\Vert \cdot \right\Vert}_2 $
-penalty with sequential thresholding least squares (STLS), we use PyTorch’s automatic differentiation framework (Paszke et al., Reference Paszke, Gross, Chintala, Chanan, Yang, DeVito, Lin, Desmaison, Antiga and Lerer2017) and optimize the
 $ {\left\Vert \cdot \right\Vert}_1 $
-loss as in (Brunton et al., Reference Brunton, Proctor and Kutz2016).
$ {\left\Vert \cdot \right\Vert}_1 $
-loss as in (Brunton et al., Reference Brunton, Proctor and Kutz2016).
2.3.1. SINDy-RL
SINDy-RL is a very recent extension of SINDy that combines SINDy with an RL algorithm for Dyna-style RL (Zolman et al., Reference Zolman, Fasel, Kutz and Bruntonn.d.; Arora et al., Reference Arora, da Silva and Moss2022). This approach involves using SINDy to learn a surrogate model of the environment and then train the RL agent using this approximation of the full-order model. This method results in a drastically-reduced number of necessary full-order interactions and very fast convergence. Specifically, Zolman et al. (Zolman et al., Reference Zolman, Fasel, Kutz and Bruntonn.d.) work with the discrete SINDy-C formulation, that is, including controls, for the discovery task
 $ {\mathbf{x}}_{k+1}=f\left({\mathbf{x}}_k,{\mathbf{u}}_k\right) $
, where
$ {\mathbf{x}}_{k+1}=f\left({\mathbf{x}}_k,{\mathbf{u}}_k\right) $
, where
 $ \mathbf{X}={\left(\mathbf{x}\left({t}_k\right),\mathbf{u}\left({t}_k\right)\right)}_{k=1,\dots, N} $
and
$ \mathbf{X}={\left(\mathbf{x}\left({t}_k\right),\mathbf{u}\left({t}_k\right)\right)}_{k=1,\dots, N} $
and
 $ \mathbf{Y}={\left(\mathbf{x}\left({t}_{k+1}\right)\right)}_{k=1,\dots, N} $
in the notation of eq. (2.2). Note that since in our work we focus on enabling efficient surrogate representations for controlling distributed systems, we do not further review the reward approximation nor the policy approximation aspects addressed in Zolman et al. (Reference Zolman, Fasel, Kutz and Bruntonn.d.)).
$ \mathbf{Y}={\left(\mathbf{x}\left({t}_{k+1}\right)\right)}_{k=1,\dots, N} $
in the notation of eq. (2.2). Note that since in our work we focus on enabling efficient surrogate representations for controlling distributed systems, we do not further review the reward approximation nor the policy approximation aspects addressed in Zolman et al. (Reference Zolman, Fasel, Kutz and Bruntonn.d.)).
Despite significantly reducing the number of full-order interactions, not requiring derivatives of (potentially noisy) measurements, and incorporating controls in the surrogate model, so far SINDy-RL lacks the scalability to high-dimensional systems (see Zolman et al., Reference Zolman, Fasel, Kutz and Bruntonn.d., section 6). While it shows convincing results for state spaces with up to eight dimensions and action spaces with up to two dimensions, controlling distributed systems require much larger state and action spaces to be solved and controlled accurately.
2.3.2. AE+SINDy: Autoencoder framework for data-driven discovery in high-dimensional spaces
In their work, Champion et al. (Reference Champion, Lusch, Kutz and Brunton2019)) rely on the classical SINDy formulation for the discovery task in the latent space. Indeed, they generalize the concept of data-driven dynamics discovery to high-dimensional dynamical systems by combining the classical SINDy formulation with an AE framework (Hinton and Salakhutdinov, Reference Hinton and Salakhutdinov2006; Bengio et al., Reference Bengio, Courville and Vincent2012; Goodfellow et al., Reference Goodfellow, Bengio and Courville2016) to allow for nonlinear dimensionality reduction. Hence, instead of directly working with high-dimensional systems, the SINDy algorithm is applied to the compressed, lower-dimensional representation of the system with
 $ {N}_x^{\mathrm{Lat}}\ll {N}_x $
.
$ {N}_x^{\mathrm{Lat}}\ll {N}_x $
.
Given the encoder
 $ \varphi \left(\cdot, {\mathbf{W}}_{\varphi}\right):{\mathrm{\mathbb{R}}}^{N_x}\to {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}} $
and the decoder network
$ \varphi \left(\cdot, {\mathbf{W}}_{\varphi}\right):{\mathrm{\mathbb{R}}}^{N_x}\to {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}} $
and the decoder network
 $ \psi \left(\cdot, {\mathbf{W}}_{\psi}\right):{\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}}\to {\mathrm{\mathbb{R}}}^{N_x} $
, as well as the latent representation
$ \psi \left(\cdot, {\mathbf{W}}_{\psi}\right):{\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}}\to {\mathrm{\mathbb{R}}}^{N_x} $
, as well as the latent representation
 $ \mathbf{z}(t)=\varphi \left(\mathbf{x}(t)\right)\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}} $
, the following loss is minimized:
$ \mathbf{z}(t)=\varphi \left(\mathbf{x}(t)\right)\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}} $
, the following loss is minimized:
 $$ {\displaystyle \begin{array}{l}\underset{{\mathbf{W}}_{\varphi },{\mathbf{W}}_{\psi },\boldsymbol{\Xi}}{\min}\hskip0.24em \underset{\mathrm{reconstruction}\ \mathrm{loss}}{\underbrace{{\left\Vert \mathbf{x}-\psi \left(\mathbf{z}\right)\right\Vert}_2^2}}+\underset{\mathrm{SINDy}\ \mathrm{loss}\ \mathrm{in}\;\dot{\mathbf{x}}}{\underbrace{\lambda_1{\left\Vert \dot{\mathbf{x}}-\left({\nabla}_{\mathbf{z}}\psi \left(\mathbf{z}\right)\right)\left(\boldsymbol{\Theta} \left({\mathbf{z}}^{\top}\right)\boldsymbol{\Xi} \right)\right\Vert}_2^2}}\\ {}\hskip5.5em +\underset{\mathrm{SINDy}\ \mathrm{loss}\ \mathrm{in}\ \mathrm{the}\ \mathrm{latent}\ \mathrm{space}}{\underbrace{\lambda_2{\left\Vert \dot{\mathbf{z}}-\boldsymbol{\Theta} \left({\mathbf{z}}^{\top}\right)\boldsymbol{\Xi} \right\Vert}_2^2}}+\underset{\mathrm{sparse}\ \mathrm{regularization}}{\underbrace{\lambda_3{\left\Vert \boldsymbol{\Xi} \right\Vert}_1}},\end{array}} $$
$$ {\displaystyle \begin{array}{l}\underset{{\mathbf{W}}_{\varphi },{\mathbf{W}}_{\psi },\boldsymbol{\Xi}}{\min}\hskip0.24em \underset{\mathrm{reconstruction}\ \mathrm{loss}}{\underbrace{{\left\Vert \mathbf{x}-\psi \left(\mathbf{z}\right)\right\Vert}_2^2}}+\underset{\mathrm{SINDy}\ \mathrm{loss}\ \mathrm{in}\;\dot{\mathbf{x}}}{\underbrace{\lambda_1{\left\Vert \dot{\mathbf{x}}-\left({\nabla}_{\mathbf{z}}\psi \left(\mathbf{z}\right)\right)\left(\boldsymbol{\Theta} \left({\mathbf{z}}^{\top}\right)\boldsymbol{\Xi} \right)\right\Vert}_2^2}}\\ {}\hskip5.5em +\underset{\mathrm{SINDy}\ \mathrm{loss}\ \mathrm{in}\ \mathrm{the}\ \mathrm{latent}\ \mathrm{space}}{\underbrace{\lambda_2{\left\Vert \dot{\mathbf{z}}-\boldsymbol{\Theta} \left({\mathbf{z}}^{\top}\right)\boldsymbol{\Xi} \right\Vert}_2^2}}+\underset{\mathrm{sparse}\ \mathrm{regularization}}{\underbrace{\lambda_3{\left\Vert \boldsymbol{\Xi} \right\Vert}_1}},\end{array}} $$
with
 $ \dot{\mathbf{z}}=\left({\nabla}_{\mathbf{x}}\mathbf{z}\right)\dot{\mathbf{x}} $
. The SINDy loss in
$ \dot{\mathbf{z}}=\left({\nabla}_{\mathbf{x}}\mathbf{z}\right)\dot{\mathbf{x}} $
. The SINDy loss in
 $ \dot{\mathbf{x}} $
, that is, the consistency loss, ensures that the time derivatives of the prediction matches the input time derivative
$ \dot{\mathbf{x}} $
, that is, the consistency loss, ensures that the time derivatives of the prediction matches the input time derivative
 $ \dot{\mathbf{x}} $
; we refer to figure 1 in Champion et al. (Reference Champion, Lusch, Kutz and Brunton2019)) for more details (the AE+SINDy algorithm could be seen as the upper half of Figure 2 with a different loss). As described in the supplementary material of Champion et al. (Reference Champion, Lusch, Kutz and Brunton2019)), due to its nonconvexity and to obtain a parsimonious dynamical model, the loss in eq. (2.4) is optimized via STLS.
$ \dot{\mathbf{x}} $
; we refer to figure 1 in Champion et al. (Reference Champion, Lusch, Kutz and Brunton2019)) for more details (the AE+SINDy algorithm could be seen as the upper half of Figure 2 with a different loss). As described in the supplementary material of Champion et al. (Reference Champion, Lusch, Kutz and Brunton2019)), due to its nonconvexity and to obtain a parsimonious dynamical model, the loss in eq. (2.4) is optimized via STLS.
AE+SINDy provides very promising results for (re-)discovering the underlying true low-dimensional dynamics representation of high-dimensional dynamical systems. Further extensions of the AE+SINDy framework have been recently proposed in Conti et al. (Reference Conti, Gobat, Fresca, Manzoni and Frangi2023)) and Bakarji et al. (Reference Bakarji, Kathleen Champion and Brunton2023)). However, to be applicable in a control setting with (potentially noisy) data, AE+SINDy suffers from the necessity of requiring derivatives of the observed data and the inability to include controls in the SINDy framework. In the next section, we will combine and generalize the approaches of SINDy-RL and AE+SINDy to develop AE+SINDy-C within an RL setting.
3. AE+SINDy-C: Low-dimensional sparse dictionary learning for simultaneous discovery and control of distributed systems
3.1. Latent model discovery
To efficiently scale SINDy to high-dimensional state spaces, incorporate controls, and eliminate reliance on derivatives, we introduce AE+SINDy-C. This approach aims to accelerate DRL for control tasks involving distributed—potentially large-scale—systems, by combining the derivative-free Dyna-style DRL training in the SINDy-C case, as demonstrated by (Zolman et al., Reference Zolman, Fasel, Kutz and Bruntonn.d.; Arora et al., Reference Arora, da Silva and Moss2022), with the scalable approach to high-dimensional state- and action-spaces from (Champion et al., Reference Champion, Lusch, Kutz and Brunton2019).
Our method approximates the environment dynamics to speed up computationally-expensive simulations, significantly reducing the need for interactions with the full-order model. Additionally, it yields an interpretable and parsimonious dynamics model within a low-dimensional surrogate space. When setting the dimensions of the latent spaces,
 $ {N}_x^{\mathrm{Lat}} $
and
$ {N}_x^{\mathrm{Lat}} $
and
 $ {N}_u^{\mathrm{Lat}} $
, representing the reduced-order state and control, respectively, we distinguish between two scenarios:
$ {N}_u^{\mathrm{Lat}} $
, representing the reduced-order state and control, respectively, we distinguish between two scenarios:
-
• Intrinsic dimension known a priori. In some applications, domain knowledge or prior analysis provides insight into the intrinsic dimension of the system’s solution manifold. For example, in Section 4.1, Burgers’ equation evolves over a one-dimensional spatial domain and time, suggesting a low-dimensional solution manifold of intrinsic dimension two. Accordingly, we choose
 $ {N}_x^{\mathrm{Lat}}=2 $
and set
$ {N}_u^{\mathrm{Lat}}=2 $
for reasons of symmetry. This choice is validated by the model’s ability to accurately reconstruct the dynamics.
$ {N}_x^{\mathrm{Lat}}=2 $
and set
$ {N}_u^{\mathrm{Lat}}=2 $
for reasons of symmetry. This choice is validated by the model’s ability to accurately reconstruct the dynamics. -
• Intrinsic dimension unknown. In the absence of prior information,
$ {N}_x^{\mathrm{Lat}} $
and
$ {N}_u^{\mathrm{Lat}} $
are treated as hyperparameters to be inferred from data. In this setting, we adopt a data-driven strategy to explore and tune these dimensions, aiming to approximate the minimal latent space that captures the essential dynamics and control dependencies. For example, in Section 4.2, we experiment with multiple choices of latent dimensions to estimate a lower bound on the dimensionality of the surrogate representation. This tuning process enables the discovery of a compact latent model solely from observational data.




In support of this approach, our results in Section 4 show that AE+SINDy-C is capable of identifying latent dimensions that are consistent with the underlying structure of the control space, even when no prior information is used.
We operate in the (discrete-time) SINDy-C setting (see Section 2.3.1) with
 $ {\mathbf{x}}_k=\left(\mathbf{x}\left({t}_k\right),\mathbf{u}\left({t}_k\right)\right) $
and
$ {\mathbf{x}}_k=\left(\mathbf{x}\left({t}_k\right),\mathbf{u}\left({t}_k\right)\right) $
and
 $ {\mathbf{y}}_k=\mathbf{x}\left({t}_{k+1}\right) $
. Here,
$ {\mathbf{y}}_k=\mathbf{x}\left({t}_{k+1}\right) $
. Here,
 $ \mathbf{x}\left({t}_k\right)\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
, where
$ \mathbf{x}\left({t}_k\right)\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
, where
 $ {N}_x^{\mathrm{Obs}}={N}_x $
in the fully observable case, and
$ {N}_x^{\mathrm{Obs}}={N}_x $
in the fully observable case, and
 $ {N}_x^{\mathrm{Obs}}\ll {N}_x $
in the partially observable case (compared to Figure 1, we simplify the
$ {N}_x^{\mathrm{Obs}}\ll {N}_x $
in the partially observable case (compared to Figure 1, we simplify the
 $ {\mathbf{x}}_t^{\mathrm{Obs}} $
notation by omitting the superscript), respectively, and
$ {\mathbf{x}}_t^{\mathrm{Obs}} $
notation by omitting the superscript), respectively, and
 $ \mathbf{u}\left({t}_k\right)\in {\mathrm{\mathbb{R}}}^{N_u} $
. Overall, we are interested in the discovery task
$ \mathbf{u}\left({t}_k\right)\in {\mathrm{\mathbb{R}}}^{N_u} $
. Overall, we are interested in the discovery task
 $ {\mathbf{x}}_{k+1}=f\left({\mathbf{x}}_k,{\mathbf{u}}_k\right) $
. Instead of applying SINDy-C directly on our measurements, we follow the idea of Champion et al. (Champion et al., Reference Champion, Lusch, Kutz and Brunton2019) to first compress the states and actions using the encoder, then apply SINDy-C in the low-dimensional latent space, predict the next state, and subsequently decompress the obtained prediction back to the observation space using the decoder.
$ {\mathbf{x}}_{k+1}=f\left({\mathbf{x}}_k,{\mathbf{u}}_k\right) $
. Instead of applying SINDy-C directly on our measurements, we follow the idea of Champion et al. (Champion et al., Reference Champion, Lusch, Kutz and Brunton2019) to first compress the states and actions using the encoder, then apply SINDy-C in the low-dimensional latent space, predict the next state, and subsequently decompress the obtained prediction back to the observation space using the decoder.
3.1.1. Offline training
As already described in the previous section, the overall framework is shown in Figure 2 and can be divided into three steps:
-
(i) Encoding: The observed state
$ {\mathbf{x}}_t\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
and the current control
$ {\mathbf{u}}_t\in {\mathrm{\mathbb{R}}}^{N_u} $
are individually compressed by two separated encoder networks
$ {\varphi}_x\left(\cdot; {\mathbf{W}}_{\varphi_x}\right):{\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}}\to {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}} $
and
$ {\varphi}_u\left(\cdot; {\mathbf{W}}_{\varphi_u}\right):{\mathrm{\mathbb{R}}}^{N_u}\to {\mathrm{\mathbb{R}}}^{N_u^{\mathrm{Lat}}} $
, yielding their low-dimensional latent-space equivalent
$ {\mathbf{z}}_x(t)\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}} $
and
$ {\mathbf{z}}_u(t)\in {\mathrm{\mathbb{R}}}^{N_u^{\mathrm{Lat}}} $
, respectively. -
(ii) Discrete SINDy-C in the latent space: Given a set of
$ d $
dictionary functions (e.g., polynomials, trigonometric functions) the dictionary
$ \boldsymbol{\Theta} \left({\mathbf{z}}_x(t),{\mathbf{z}}_u(t)\right)=\boldsymbol{\Theta} \left({\varphi}_x\left({\mathbf{x}}_t;{\mathbf{W}}_{\varphi_x}\right),{\varphi}_u\left({\mathbf{u}}_t;{\mathbf{W}}_{\varphi_u}\right)\right)\in {\mathrm{\mathbb{R}}}^d $
is evaluated and multiplied by
$ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times {N}_x^{\mathrm{Lat}}} $
, that is, the coefficients to be fit. -
(iii) Decoding: The result
$ {\mathbf{z}}_x\left(t+1\right)=\boldsymbol{\Theta} \left({\mathbf{z}}_x(t),{\mathbf{z}}_u(t)\right)\boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}} $
is then decoded to obtain a prediction for the next state of the high-dimensional system by using the state-decoder
$ {\psi}_x\left(\cdot; {\mathbf{W}}_{\psi_x}\right):{\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Lat}}}\to {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
. To train the AE, the compressed state and action are also decoded and fed into the loss function by using the state-decoder and the control-decoder
$ {\psi}_u\left(\cdot; {\mathbf{W}}_{\psi_u}\right):{\mathrm{\mathbb{R}}}^{N_u^{\mathrm{Lat}}}\to {\mathrm{\mathbb{R}}}^{N_u} $
.Figure 2.AE architecture and loss function used during the training stage. Trainable parameters are highlighted in red. The different stages of the training scheme can be listed as follows. (1) the current state
$ {\mathbf{x}}_t $
, applied control
$ {\mathbf{u}}_t $
, and the next state
$ {\mathbf{x}}_{t+1} $
are provided as input data. (2) After compressing both the current state and the control vector, the SINDy-C algorithm is applied in the latent space, yielding a low-dimensional representation of the prediction for the next state. (3) The latent space representations of the current state, the control, and the next state prediction are decoded. (4) The classical AE loss is computed. (5) The SINDy-C loss and a regularization term to promote sparsity are computed. Figure inspired by Conti et al. (Reference Conti, Gobat, Fresca, Manzoni and Frangi2023, figure 1).
















Overall, we obtain the following loss function:
 $$ {\displaystyle \begin{array}{ll}\underset{{\mathbf{W}}_{\varphi_x},{\mathbf{W}}_{\varphi_u},{\mathbf{W}}_{\psi_x},{\mathbf{W}}_{\psi_u},\boldsymbol{\Xi}}{\min}\hskip1em & \underset{\mathrm{forward}\ \ \mathrm{SINDy}\hbox{-} \mathrm{C}\hskip0.22em \mathrm{prediction}\ \mathrm{loss}}{\underbrace{{\left\Vert {\mathbf{x}}_{t+1}-{\psi}_x\left(\boldsymbol{\Theta} \Big({\varphi}_x\left({\mathbf{x}}_t;{\mathbf{W}}_{\varphi_x}\right),{\varphi}_u\Big({\mathbf{u}}_t;{\mathbf{W}}_{\varphi_u}\left)\right)\cdot \boldsymbol{\Xi}; {\mathbf{W}}_{\psi_x}\right)\right\Vert}_2^2}}\\ {}& +{\lambda}_1\underset{\mathrm{autoencoder}\ \mathrm{loss}\ \mathrm{state}}{\underbrace{{\left\Vert {\mathbf{x}}_t-{\psi}_x\Big({\varphi}_x\left({\mathbf{x}}_t;{\mathbf{W}}_{\varphi_x}\right);{\mathbf{W}}_{\psi_x}\Big)\right\Vert}_2^2}}\\ {}& +{\lambda}_2\underset{\mathrm{autoencoder}\ \mathrm{loss}\ \mathrm{control}}{\underbrace{{\left\Vert {\mathbf{u}}_t-{\psi}_u\Big({\varphi}_u\left({\mathbf{u}}_t;{\mathbf{W}}_{\varphi_u}\right);{\mathbf{W}}_{\psi_u}\Big)\right\Vert}_2^2}}\\ {}& +{\lambda}_3\underset{\mathrm{sparsity}\ \mathrm{regularization}}{\underbrace{{\left\Vert \boldsymbol{\Xi} \right\Vert}_1}},\end{array}} $$
$$ {\displaystyle \begin{array}{ll}\underset{{\mathbf{W}}_{\varphi_x},{\mathbf{W}}_{\varphi_u},{\mathbf{W}}_{\psi_x},{\mathbf{W}}_{\psi_u},\boldsymbol{\Xi}}{\min}\hskip1em & \underset{\mathrm{forward}\ \ \mathrm{SINDy}\hbox{-} \mathrm{C}\hskip0.22em \mathrm{prediction}\ \mathrm{loss}}{\underbrace{{\left\Vert {\mathbf{x}}_{t+1}-{\psi}_x\left(\boldsymbol{\Theta} \Big({\varphi}_x\left({\mathbf{x}}_t;{\mathbf{W}}_{\varphi_x}\right),{\varphi}_u\Big({\mathbf{u}}_t;{\mathbf{W}}_{\varphi_u}\left)\right)\cdot \boldsymbol{\Xi}; {\mathbf{W}}_{\psi_x}\right)\right\Vert}_2^2}}\\ {}& +{\lambda}_1\underset{\mathrm{autoencoder}\ \mathrm{loss}\ \mathrm{state}}{\underbrace{{\left\Vert {\mathbf{x}}_t-{\psi}_x\Big({\varphi}_x\left({\mathbf{x}}_t;{\mathbf{W}}_{\varphi_x}\right);{\mathbf{W}}_{\psi_x}\Big)\right\Vert}_2^2}}\\ {}& +{\lambda}_2\underset{\mathrm{autoencoder}\ \mathrm{loss}\ \mathrm{control}}{\underbrace{{\left\Vert {\mathbf{u}}_t-{\psi}_u\Big({\varphi}_u\left({\mathbf{u}}_t;{\mathbf{W}}_{\varphi_u}\right);{\mathbf{W}}_{\psi_u}\Big)\right\Vert}_2^2}}\\ {}& +{\lambda}_3\underset{\mathrm{sparsity}\ \mathrm{regularization}}{\underbrace{{\left\Vert \boldsymbol{\Xi} \right\Vert}_1}},\end{array}} $$
representing the loss of the decoded forward prediction in the SINDy-C latent space formulation, that is, parts (ii) and (iii), the classical AE loss and also the regularization loss to promote sparsity in the SINDy-coefficients. Since our entire pipeline is implemented in the PyTorch library (Paszke et al., Reference Paszke, Gross, Chintala, Chanan, Yang, DeVito, Lin, Desmaison, Antiga and Lerer2017), we train eq. (3.1) by using the automatic differentiation framework and thus do not rely on STLS. We use Kaptanoglu et al. (Reference Kaptanoglu, de Silva, Fasel, Kaheman, Goldschmidt, Callaham, Delahunt, Nicolaou, Champion, Loiseau, Kutz and Brunton2021)) to create the set of
 $ d $
dictionary functions once in the beginning of the pipeline. The parameters
$ d $
dictionary functions once in the beginning of the pipeline. The parameters
 $ {\lambda}_1,{\lambda}_2\in {\mathrm{\mathbb{R}}}_{>0} $
are hyperparameters to individually weight the contribution of each term.
$ {\lambda}_1,{\lambda}_2\in {\mathrm{\mathbb{R}}}_{>0} $
are hyperparameters to individually weight the contribution of each term.
3.1.2. Online deployment
Following the training stage, where the parameters
 $ {\mathbf{W}}_{\varphi_x} $
,
$ {\mathbf{W}}_{\varphi_x} $
,
 $ {\mathbf{W}}_{\varphi_u} $
,
$ {\mathbf{W}}_{\varphi_u} $
,
 $ {\mathbf{W}}_{\psi_x} $
,
$ {\mathbf{W}}_{\psi_x} $
,
 $ {\mathbf{W}}_{\psi_u} $
, and
$ {\mathbf{W}}_{\psi_u} $
, and
 $ \boldsymbol{\Xi} $
are learned, the trained network can be deployed as a Dyna-style environment approximation to train the DRL agent. The surrogate environment enables extremely fast inferences and, if well-trained, provides accurate predictions of the system dynamics. Given a current state
$ \boldsymbol{\Xi} $
are learned, the trained network can be deployed as a Dyna-style environment approximation to train the DRL agent. The surrogate environment enables extremely fast inferences and, if well-trained, provides accurate predictions of the system dynamics. Given a current state
 $ {\mathbf{x}}_t\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
(either observed or simulated) and a control
$ {\mathbf{x}}_t\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
(either observed or simulated) and a control
 $ {\mathbf{u}}_t\sim \pi \left(\cdot |{\mathbf{x}}_t\right) $
, the prediction of the next state is computed as follows:
$ {\mathbf{u}}_t\sim \pi \left(\cdot |{\mathbf{x}}_t\right) $
, the prediction of the next state is computed as follows:
 $$ {\hat{\mathbf{x}}}_{t+1}={\psi}_x\left(\boldsymbol{\Theta} \Big({\varphi}_x\left({\mathbf{x}}_t;{\mathbf{W}}_{\varphi_x}\right),{\varphi}_u\Big({\mathbf{u}}_t;{\mathbf{W}}_{\varphi_u}\left)\right)\cdot \boldsymbol{\Xi}; {\mathbf{W}}_{\psi_x}\right)\approx f\left({\mathbf{x}}_t,{\mathbf{u}}_t\right), $$
$$ {\hat{\mathbf{x}}}_{t+1}={\psi}_x\left(\boldsymbol{\Theta} \Big({\varphi}_x\left({\mathbf{x}}_t;{\mathbf{W}}_{\varphi_x}\right),{\varphi}_u\Big({\mathbf{u}}_t;{\mathbf{W}}_{\varphi_u}\left)\right)\cdot \boldsymbol{\Xi}; {\mathbf{W}}_{\psi_x}\right)\approx f\left({\mathbf{x}}_t,{\mathbf{u}}_t\right), $$
which involves only one matrix multiplication, the evaluation of
![]() dictionary functions, and three neural network forward passes, resulting in exceptionally low inference times.
dictionary functions, and three neural network forward passes, resulting in exceptionally low inference times.
3.2. DRL training procedure
We describe the usage of AE+SINDy-C in a Dyna-style MBRL in Algorithm 1. A key hyperparameter in this approach is
 $ {k}_{\mathrm{dyn}} $
(line 7), which controls how many times the agent is trained on the surrogate model before collecting new data from the full-order environment. Specifically, the agent is trained
$ {k}_{\mathrm{dyn}} $
(line 7), which controls how many times the agent is trained on the surrogate model before collecting new data from the full-order environment. Specifically, the agent is trained
 $ {k}_{\mathrm{dyn}}-1 $
times per iteration on the surrogate. Choosing
$ {k}_{\mathrm{dyn}}-1 $
times per iteration on the surrogate. Choosing
 $ {k}_{\mathrm{dyn}} $
involves a trade-off: a larger
$ {k}_{\mathrm{dyn}} $
involves a trade-off: a larger
 $ {k}_{\mathrm{dyn}} $
increases sample efficiency by maximizing learning from the surrogate but may lead to instability or degraded performance if the surrogate model is imperfect. Conversely, a smaller
$ {k}_{\mathrm{dyn}} $
increases sample efficiency by maximizing learning from the surrogate but may lead to instability or degraded performance if the surrogate model is imperfect. Conversely, a smaller
 $ {k}_{\mathrm{dyn}} $
reduces this risk at the price of more frequent interactions with the environment, increasing computational cost and data requirements. In our experiments,
$ {k}_{\mathrm{dyn}} $
reduces this risk at the price of more frequent interactions with the environment, increasing computational cost and data requirements. In our experiments,
 $ {k}_{\mathrm{dyn}} $
was selected via preliminary tuning to achieve a balance between stable convergence, learning speed, and efficient data usage. Future work could explore adaptive strategies that adjust
$ {k}_{\mathrm{dyn}} $
was selected via preliminary tuning to achieve a balance between stable convergence, learning speed, and efficient data usage. Future work could explore adaptive strategies that adjust
 $ {k}_{\mathrm{dyn}} $
dynamically based on surrogate model accuracy or policy performance metrics to optimize training. We use the PPO algorithm (Schulman et al., Reference Schulman, Wolski, Dhariwal, Radford and Klimov2017) as a state-of-the-art actor-critic policy. As in Zolman et al. (Reference Zolman, Fasel, Kutz and Bruntonn.d.)), we also use the PPO gradients to update the parameters of the autoencoder surrogate model.
$ {k}_{\mathrm{dyn}} $
dynamically based on surrogate model accuracy or policy performance metrics to optimize training. We use the PPO algorithm (Schulman et al., Reference Schulman, Wolski, Dhariwal, Radford and Klimov2017) as a state-of-the-art actor-critic policy. As in Zolman et al. (Reference Zolman, Fasel, Kutz and Bruntonn.d.)), we also use the PPO gradients to update the parameters of the autoencoder surrogate model.
To also correctly emulate the partial observability, that is,
 $ {N}_x^{\mathrm{Obs}}<{N}_x $
, in the reward function, we project the target state into the lower-dimensional observation space and compute the projected reward. Namely, for Burgers’ equation, we compute
$ {N}_x^{\mathrm{Obs}}<{N}_x $
, in the reward function, we project the target state into the lower-dimensional observation space and compute the projected reward. Namely, for Burgers’ equation, we compute
 $ {\left({\mathbf{x}}_t^{\mathrm{Obs}}-C\cdot {\mathbf{x}}_{\mathrm{ref}}\right)}^{\top }{Q}^{\mathrm{Proj}}\left({\mathbf{x}}_t^{\mathrm{Obs}}-C\cdot {\mathbf{x}}_{\mathrm{ref}}\right) $
, where
$ {\left({\mathbf{x}}_t^{\mathrm{Obs}}-C\cdot {\mathbf{x}}_{\mathrm{ref}}\right)}^{\top }{Q}^{\mathrm{Proj}}\left({\mathbf{x}}_t^{\mathrm{Obs}}-C\cdot {\mathbf{x}}_{\mathrm{ref}}\right) $
, where
 $ {Q}^{\mathrm{Proj}} $
is a scaled identity matrix in the lower-dimensional observation space. This procedure makes the training more challenging since we only obtain partial information via the reward function. In the case of
$ {Q}^{\mathrm{Proj}} $
is a scaled identity matrix in the lower-dimensional observation space. This procedure makes the training more challenging since we only obtain partial information via the reward function. In the case of
 $ {N}_x^{\mathrm{Obs}}={N}_x $
and for the evaluation of all final models, we use the closed form of the full-order reward function.
$ {N}_x^{\mathrm{Obs}}={N}_x $
and for the evaluation of all final models, we use the closed form of the full-order reward function.
1: Algorithm 1 Dyna-style MBRL using AE+SINDy-C.
Require:
 $ \mathrm{\mathcal{E}}\hskip0.42em \mathrm{full}\hbox{-} \mathrm{order}\hskip0.42em \mathrm{env}.\left(\mathrm{FOE}\right),{\pi}_0\hskip0.42em \mathrm{init}.\mathrm{policy},\Theta, {N}_{\mathrm{off}},{N}_{\mathrm{collect}},{n}_{\mathrm{batch}},{k}_{\mathrm{dyn}} $
.
$ \mathrm{\mathcal{E}}\hskip0.42em \mathrm{full}\hbox{-} \mathrm{order}\hskip0.42em \mathrm{env}.\left(\mathrm{FOE}\right),{\pi}_0\hskip0.42em \mathrm{init}.\mathrm{policy},\Theta, {N}_{\mathrm{off}},{N}_{\mathrm{collect}},{n}_{\mathrm{batch}},{k}_{\mathrm{dyn}} $
.
2:
 $ {D}_{\mathrm{off}}=\mathrm{CollectData}\;\left(\mathrm{\mathcal{E}},{\pi}_0,{N}_{\mathrm{off}}\right) $
// Off-policy data using FOE
$ {D}_{\mathrm{off}}=\mathrm{CollectData}\;\left(\mathrm{\mathcal{E}},{\pi}_0,{N}_{\mathrm{off}}\right) $
// Off-policy data using FOE
3:
 $ D=\mathrm{InitializeDatastore}\left({D}_{\mathrm{off}}\right) $
$ D=\mathrm{InitializeDatastore}\left({D}_{\mathrm{off}}\right) $
4:
 $ \hat{\mathrm{\mathcal{E}}}=\mathrm{AE}+\mathrm{SINDy}\hbox{-} \mathrm{C}\left(D,\Theta \right) $
// Fit surrogate env.
$ \hat{\mathrm{\mathcal{E}}}=\mathrm{AE}+\mathrm{SINDy}\hbox{-} \mathrm{C}\left(D,\Theta \right) $
// Fit surrogate env.
5:
 $ \pi =\mathrm{InitializePolicy}\left(\right) $
$ \pi =\mathrm{InitializePolicy}\left(\right) $
6: while not done do
7: for
 $ {k}_{\mathrm{dyn}}-1 $
steps do
$ {k}_{\mathrm{dyn}}-1 $
steps do
8:
 $ \pi =\mathrm{PPO}.\mathrm{update}\left(\hat{\mathrm{\mathcal{E}}},\pi, {n}_{\mathrm{batch}}\right) $
// Train agent with surrogate env.
$ \pi =\mathrm{PPO}.\mathrm{update}\left(\hat{\mathrm{\mathcal{E}}},\pi, {n}_{\mathrm{batch}}\right) $
// Train agent with surrogate env.
9: end for
10:
 $ {D}_{\mathrm{on}}=\mathrm{CollectData}\left(\mathrm{\mathcal{E}},\pi, {N}_{\mathrm{collect}}\right) $
// Collect on-policy data
$ {D}_{\mathrm{on}}=\mathrm{CollectData}\left(\mathrm{\mathcal{E}},\pi, {N}_{\mathrm{collect}}\right) $
// Collect on-policy data
11:
 $ D=\mathrm{UpdateStore}\left(D,{D}_{\mathrm{on}}\right) $
$ D=\mathrm{UpdateStore}\left(D,{D}_{\mathrm{on}}\right) $
12:
 $ \hat{\mathrm{\mathcal{E}}}=\mathrm{AE}+\mathrm{SINDy}\hbox{-} \mathrm{C}\left(D,\Theta \right) $
// Update surrogate env.
$ \hat{\mathrm{\mathcal{E}}}=\mathrm{AE}+\mathrm{SINDy}\hbox{-} \mathrm{C}\left(D,\Theta \right) $
// Update surrogate env.
13: end while
14: return
 $ \pi $
$ \pi $
4. Numerical experiments
To validate our approach, we study Burgers’ equation and the Navier–Stokes equations on two test benchmark implementations provided by the well-established ControlGym library (Zhang et al., Reference Zhang, Mo, Mowlavi, Benosman and Başarn.d.) and the PDEControlGym library (Bhan et al., Reference Bhan, Bian, Krstic and Shi2024), respectively. In both cases, we compare our Dyna-style MBRL Algorithm 1 with the model-free PPO baseline which only interacts with the full-order environment. Burgers’ equation serves as an initial example to highlight the data efficiency of the algorithm, explore both partially and fully observable cases, examine robustness to noisy observations, and experiment with discovering control dimensions in the latent space. While the model-free PPO baseline achieves slightly better final performance (cf. Table 1), AE+SINDy-C reaches competitive results using significantly fewer full-order interactions, demonstrating its advantage in terms of sample efficiency. Additionally, we emphasize the method’s strengths in out-of-distribution generalization for the initial condition, interpretability of the learned surrogate dynamics, and details about the AE’s training, which are covered in Section 4.1. In contrast, the Navier–Stokes equations offer a more challenging example, with only boundary controls and a much higher-dimensional state space, underscoring AE+SINDy-C’s scalability. This case will showcase how the method can be applied to complex, high-dimensional systems, discussed in Section 4.2.
Performance comparison of the Dyna-style AE+SINDy-C method for Burgers’ equation

Note: We test
 $ {k}_{\mathrm{dyn}}=5,10 $
against the full-order baseline for the partially observable (PO) and FO case. The models correspond to the dashed vertical lines in Figure 3 and represent all models after 100 epochs. We compare the number of full-order model (FOM) interactions, the performance for a random initialization (cf. Appendix A.1), the bell-shape initialization and
$ {k}_{\mathrm{dyn}}=5,10 $
against the full-order baseline for the partially observable (PO) and FO case. The models correspond to the dashed vertical lines in Figure 3 and represent all models after 100 epochs. We compare the number of full-order model (FOM) interactions, the performance for a random initialization (cf. Appendix A.1), the bell-shape initialization and
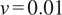 $ \nu =0.01 $
(cf. Section 4.1.2), and the total number of parameters. Best performances (bold) are highlighted row-wise. For the evaluation the performance over five fixed random seeds is used.
$ \nu =0.01 $
(cf. Section 4.1.2), and the total number of parameters. Best performances (bold) are highlighted row-wise. For the evaluation the performance over five fixed random seeds is used.
Sample efficiency of the Dyna-style AE+SINDy-C method for Burgers’ equation. We test
 $ {k}_{\mathrm{dyn}}=5,10 $
against the full-order baseline for the fully observable (solid line) and partially observable (dashed line). The dashed vertical lines indicate the point of early stopping for each of the model classes (FO + PO) after 100 epochs and represent the models which are evaluated in detail in Appendix A.1. For the evaluation, the performance over five fixed random seeds is used.
$ {k}_{\mathrm{dyn}}=5,10 $
against the full-order baseline for the fully observable (solid line) and partially observable (dashed line). The dashed vertical lines indicate the point of early stopping for each of the model classes (FO + PO) after 100 epochs and represent the models which are evaluated in detail in Appendix A.1. For the evaluation, the performance over five fixed random seeds is used.

Since AE+SINDy-C serves as a Dyna-style MBRL algorithm, we analyze the efficiency of the proposed framework with respect to the number of full-order model interactions. For all our experiments, we use the Ray RLLib package (Liang et al., Reference Liang, Liaw, Nishihara, Moritz, Fox, Gonzalez, Goldberg and Stoica2017); AE+SINDy-C is implemented in PyTorch (Paszke et al., Reference Paszke, Gross, Chintala, Chanan, Yang, DeVito, Lin, Desmaison, Antiga and Lerer2017). All details about the PDE environments parameters are available in Appendix B. For further details on the DRL training, we refer to Appendix C; specific details about the AE training can be found in Appendix D.
4.1. Burgers’ equation (ControlGym)
The viscous Burgers’ equation can be interpreted as a one-dimensional, simplified version of the Navier–Stokes equations, describing fluid dynamics and capturing key phenomena such as shock formations in water waves and gas dynamics. Solving Burgers’ equation is particularly challenging for RL and other numerical methods due to its nonlinearity and the presence of sharp gradients and discontinuities. Given a spatial domain
 $ \Omega =\left[0,L\right]\subset \mathrm{\mathbb{R}} $
and a time horizon
$ \Omega =\left[0,L\right]\subset \mathrm{\mathbb{R}} $
and a time horizon
 $ T $
, we consider the evolution of continuous fields
$ T $
, we consider the evolution of continuous fields
 $ \mathbf{x}\left(x,t\right):\Omega \times \left[0,T\right]\to \mathrm{\mathbb{R}} $
under a the temporal dynamics:
$ \mathbf{x}\left(x,t\right):\Omega \times \left[0,T\right]\to \mathrm{\mathbb{R}} $
under a the temporal dynamics:
 $$ \hskip0.5em {\displaystyle \begin{array}{c}{\partial}_t\mathbf{x}\left(x,t\right)+\mathbf{x}\left(x,t\right){\partial}_x\mathbf{x}\left(x,t\right)-\nu {\partial}_{xx}^2\mathbf{x}\left(x,t\right)=\mathbf{u}\left(x,t\right)\\ {}\mathbf{x}\left(x,0\right)={\mathbf{x}}_{\mathrm{init}}(x)\end{array}}, $$
$$ \hskip0.5em {\displaystyle \begin{array}{c}{\partial}_t\mathbf{x}\left(x,t\right)+\mathbf{x}\left(x,t\right){\partial}_x\mathbf{x}\left(x,t\right)-\nu {\partial}_{xx}^2\mathbf{x}\left(x,t\right)=\mathbf{u}\left(x,t\right)\\ {}\mathbf{x}\left(x,0\right)={\mathbf{x}}_{\mathrm{init}}(x)\end{array}}, $$
given an initial state
 $ {\mathbf{x}}_{\mathrm{init}}:\Omega \to \mathrm{\mathbb{R}} $
, a constant diffusivity
$ {\mathbf{x}}_{\mathrm{init}}:\Omega \to \mathrm{\mathbb{R}} $
, a constant diffusivity
 $ \nu >0 $
, a source term (also called forcing function)
$ \nu >0 $
, a source term (also called forcing function)
 $ \mathbf{u}\left(x,t\right):\Omega \times \left[0,T\right]\to \mathrm{\mathbb{R}} $
, and periodic boundary conditions. Internally, ControlGym discretizes the PDE in space and time, assuming uniformly spatially distributed control inputs
$ \mathbf{u}\left(x,t\right):\Omega \times \left[0,T\right]\to \mathrm{\mathbb{R}} $
, and periodic boundary conditions. Internally, ControlGym discretizes the PDE in space and time, assuming uniformly spatially distributed control inputs
 $ {\mathbf{u}}_t $
, which are piecewise constant over time. This results in a discrete-time finite-dimensional nonlinear system of the form:
$ {\mathbf{u}}_t $
, which are piecewise constant over time. This results in a discrete-time finite-dimensional nonlinear system of the form:
 $$ {\mathbf{x}}_{t+1}=f\left({\mathbf{x}}_t,{\mathbf{u}}_t;{\mathbf{w}}_k\right), $$
$$ {\mathbf{x}}_{t+1}=f\left({\mathbf{x}}_t,{\mathbf{u}}_t;{\mathbf{w}}_k\right), $$
including (optional) Gaussian noise
 $ {\mathbf{w}}_k $
(to be precise, the discrete dynamics
$ {\mathbf{w}}_k $
(to be precise, the discrete dynamics
 $ f $
also depend on the mesh size of the discretization). In this work, the internally used solution parameters are set to their default and for more details we refer to Zhang et al. (Reference Zhang, Mo, Mowlavi, Benosman and Başarn.d.), p. 6) and Appendix B. As previously mentioned, since our new encoding-decoding scheme does not rely on derivatives, we explicitly want to test the robustness of AE+SINDy-C with respect to observation noise. Thus, we follow the observation process by ControlGym given by
$ f $
also depend on the mesh size of the discretization). In this work, the internally used solution parameters are set to their default and for more details we refer to Zhang et al. (Reference Zhang, Mo, Mowlavi, Benosman and Başarn.d.), p. 6) and Appendix B. As previously mentioned, since our new encoding-decoding scheme does not rely on derivatives, we explicitly want to test the robustness of AE+SINDy-C with respect to observation noise. Thus, we follow the observation process by ControlGym given by
 $$ {\mathbf{x}}_t^{\mathrm{Obs}}=C\cdot {\mathbf{x}}_t+{\mathbf{v}}_t, $$
$$ {\mathbf{x}}_t^{\mathrm{Obs}}=C\cdot {\mathbf{x}}_t+{\mathbf{v}}_t, $$
where the matrix
 $ C\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}\times {N}_x} $
is as described in Figure 1 and
$ C\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}\times {N}_x} $
is as described in Figure 1 and
 $ {\mathbf{v}}_t\sim \mathcal{N}\left(0,{\Sigma}_v\right) $
is zero-mean Gaussian noise with symmetric positive definite covariance matrix
$ {\mathbf{v}}_t\sim \mathcal{N}\left(0,{\Sigma}_v\right) $
is zero-mean Gaussian noise with symmetric positive definite covariance matrix
 $ {\Sigma}_v={\sigma}^2\cdot {\mathrm{Id}}_{N_x^{\mathrm{Obs}}}\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}\times {N}_x^{\mathrm{Obs}}},{\sigma}^2>0 $
. For both problems, we define a target state
$ {\Sigma}_v={\sigma}^2\cdot {\mathrm{Id}}_{N_x^{\mathrm{Obs}}}\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}\times {N}_x^{\mathrm{Obs}}},{\sigma}^2>0 $
. For both problems, we define a target state
 $ {\mathbf{x}}_{\mathrm{ref}} $
and use the following objective function to be maximized:
$ {\mathbf{x}}_{\mathrm{ref}} $
and use the following objective function to be maximized:
 $$ \mathcal{J}\left({\mathbf{x}}_t,{\mathbf{u}}_t\right)=-\unicode{x1D53C}\left\{\sum \limits_{t=0}^{K-1}\left[{\left({\mathbf{x}}_t^{\mathrm{Obs}}-{\mathbf{x}}_{\mathrm{ref}}\right)}^{\top }Q\left({\mathbf{x}}_t^{\mathrm{Obs}}-{\mathbf{x}}_{\mathrm{ref}}\right)+{\mathbf{u}}_t^{\top }R{\mathbf{u}}_t\right]\right\}, $$
$$ \mathcal{J}\left({\mathbf{x}}_t,{\mathbf{u}}_t\right)=-\unicode{x1D53C}\left\{\sum \limits_{t=0}^{K-1}\left[{\left({\mathbf{x}}_t^{\mathrm{Obs}}-{\mathbf{x}}_{\mathrm{ref}}\right)}^{\top }Q\left({\mathbf{x}}_t^{\mathrm{Obs}}-{\mathbf{x}}_{\mathrm{ref}}\right)+{\mathbf{u}}_t^{\top }R{\mathbf{u}}_t\right]\right\}, $$
with positive definite matrices
 $ Q\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}\times {N}_x^{\mathrm{Obs}}} $
and
$ Q\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}\times {N}_x^{\mathrm{Obs}}} $
and
 $ R\in {\mathrm{\mathbb{R}}}^{N_u\times {N}_u} $
balancing the control effort and the tracking performance, and
$ R\in {\mathrm{\mathbb{R}}}^{N_u\times {N}_u} $
balancing the control effort and the tracking performance, and
 $ K\in \mathrm{\mathbb{N}} $
denotes the number of discrete time steps. As reference state and controls, we both use the zero-vector. The inherent solution manifold of eq. (4.1) is two-dimensional, representing both space and time.
$ K\in \mathrm{\mathbb{N}} $
denotes the number of discrete time steps. As reference state and controls, we both use the zero-vector. The inherent solution manifold of eq. (4.1) is two-dimensional, representing both space and time.
In this work, the diffusivity constant
 $ \nu =1.0 $
is fixed and we choose
$ \nu =1.0 $
is fixed and we choose
 $ \Omega =\left(0,1\right) $
as spatial domain, that is, we select
$ \Omega =\left(0,1\right) $
as spatial domain, that is, we select
 $ L=1 $
. In this example, we set the reduced dimension to
$ L=1 $
. In this example, we set the reduced dimension to
 $ {N}_x^{\mathrm{Lat}}=2 $
, as Burgers’ equation depends on both space and time and is known to exhibit a solution manifold of (approximately) intrinsic dimension two. For symmetry, we choose
$ {N}_x^{\mathrm{Lat}}=2 $
, as Burgers’ equation depends on both space and time and is known to exhibit a solution manifold of (approximately) intrinsic dimension two. For symmetry, we choose
 $ {N}_u^{\mathrm{Lat}}=2 $
. In cases where such prior information is not available, these dimensions can be treated as tunable parameters and inferred from data, as discussed in Section 3.1.
$ {N}_u^{\mathrm{Lat}}=2 $
. In cases where such prior information is not available, these dimensions can be treated as tunable parameters and inferred from data, as discussed in Section 3.1.
The target state of
 $ {\mathbf{x}}_{\mathrm{ref}}\equiv \mathbf{0}\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
is used. In Section 4.1.3, we will see how AE+SINDy-C is independently able to compress the controls even further.
$ {\mathbf{x}}_{\mathrm{ref}}\equiv \mathbf{0}\in {\mathrm{\mathbb{R}}}^{N_x^{\mathrm{Obs}}} $
is used. In Section 4.1.3, we will see how AE+SINDy-C is independently able to compress the controls even further.
For Burgers’ equation, we trained AE+SINDy-C with different full-order model update frequencies
 $ {k}_{\mathrm{dyn}}=\mathrm{5,10,15} $
to analyze the sample efficiency and the sensitivity of the surrogate model. In the case
$ {k}_{\mathrm{dyn}}=\mathrm{5,10,15} $
to analyze the sample efficiency and the sensitivity of the surrogate model. In the case
 $ {k}_{\mathrm{dyn}}=15 $
, the internal modeling bias was too big for a successful DRL training, which is the reason why this case is excluded from the analysis. This appears to be a natural limitation since the number of full-order interactions was too low and thus not sufficient to adequately model the system dynamics under investigation.
$ {k}_{\mathrm{dyn}}=15 $
, the internal modeling bias was too big for a successful DRL training, which is the reason why this case is excluded from the analysis. This appears to be a natural limitation since the number of full-order interactions was too low and thus not sufficient to adequately model the system dynamics under investigation.
4.1.1. Sample efficiency and speed-ups
As in the training, the initial condition is given by a uniform
 $ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
distribution; for more details, we refer to Appendix A.1. We use an evaluation time horizon of
$ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
distribution; for more details, we refer to Appendix A.1. We use an evaluation time horizon of
 $ {T}_{\mathrm{eval}}=1\mathrm{s} $
and let the agent extrapolate over time for four more seconds, that is,
$ {T}_{\mathrm{eval}}=1\mathrm{s} $
and let the agent extrapolate over time for four more seconds, that is,
 $ {T}_{\mathrm{extrap}}=4\mathrm{s} $
, resulting in
$ {T}_{\mathrm{extrap}}=4\mathrm{s} $
, resulting in
 $ T=5\mathrm{s} $
, four times more than the training horizon. Figure 3 shows the average reward (
$ T=5\mathrm{s} $
, four times more than the training horizon. Figure 3 shows the average reward (
 $ \pm $
one standard deviation) given the number of full-order interactions each model has observed. For a quantitative overview, we refer to Table 1, where we display the results with further detail. We separately illustrate the performance on the evaluation horizon
$ \pm $
one standard deviation) given the number of full-order interactions each model has observed. For a quantitative overview, we refer to Table 1, where we display the results with further detail. We separately illustrate the performance on the evaluation horizon
 $ \left[0s,1s\right] $
, that is, the time horizon the agent interacts for during the training, and the extrapolation horizon
$ \left[0s,1s\right] $
, that is, the time horizon the agent interacts for during the training, and the extrapolation horizon
 $ \left(1s,5s\right] $
. The vertical dashed lines in Figure 3 represent the models after 100 epochs and are deployed to evaluate the agent’s performance, that is, Table 1. We save all intermediate models and stop the training for all models after exactly 100 epochs, which is approximately the point where the extrapolation performance drops, that is, performing early stopping. In the case of the AE+SINDy-C algorithm, this performance drop is also evident in the evaluation data, caused by the high sensitivity of the online training of the AE.
$ \left(1s,5s\right] $
. The vertical dashed lines in Figure 3 represent the models after 100 epochs and are deployed to evaluate the agent’s performance, that is, Table 1. We save all intermediate models and stop the training for all models after exactly 100 epochs, which is approximately the point where the extrapolation performance drops, that is, performing early stopping. In the case of the AE+SINDy-C algorithm, this performance drop is also evident in the evaluation data, caused by the high sensitivity of the online training of the AE.
In general, we can see that all of the models overfit the dynamics. While the performance on the evaluation time interval still improves, the model becomes very unstable when extrapolating in time and at the end of the training interval almost all model solutions diverge. As expected, generally the model fully observing the PDE outperforms the model that only observes partial measurements. Additionally, the partially observable cases exhibit a higher standard deviation and thus higher variability in their performance.
Partially observable. Generally, the models only partially observing the system exhibit worse performances and suffer under higher variability. At the end of the training horizon, in both cases, the AE+SINDy-C method overfits the dynamics model, resulting in divergent solutions when extrapolating in time. The highest performance for each of the PO cases is almost similar, although AE+SINDy-C with
 $ {k}_{\mathrm{dyn}}=10 $
requires nearly 10 times less data compared to the full-order model, and with
$ {k}_{\mathrm{dyn}}=10 $
requires nearly 10 times less data compared to the full-order model, and with
 $ {k}_{\mathrm{dyn}}=5 $
close to five times less data, respectively (cf. Table 1)—matching the intuition of sample efficiency of Algorithm 1 based on
$ {k}_{\mathrm{dyn}}=5 $
close to five times less data, respectively (cf. Table 1)—matching the intuition of sample efficiency of Algorithm 1 based on
 $ {k}_{\mathrm{dyn}} $
.
$ {k}_{\mathrm{dyn}} $
.
Fully observable. As already mentioned, a direct comparison all of the trained models in the FO case outperforms their PO counterparts, quantitatively and qualitatively. As visualized in Table 1, and similarly to the PO case, we achieve nearly the same level of performance with 10 times, respectively, five times, less data.
4.1.2. Generalization: Variation of initial condition and diffusivity constant
Compared to the
 $ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
distribution, we used during the training phase and the detailed analysis in Appendix A.1, we are also interested in the generalization capabilities of the agents trained with AE+SINDy-C on out-of-distribution initial conditions with more regularity. Given
$ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
distribution, we used during the training phase and the detailed analysis in Appendix A.1, we are also interested in the generalization capabilities of the agents trained with AE+SINDy-C on out-of-distribution initial conditions with more regularity. Given
 $ {N}_{\mathrm{spatial}} $
discretization points in space, we modify the default initial condition of the ControlGym library and define the initial state
$ {N}_{\mathrm{spatial}} $
discretization points in space, we modify the default initial condition of the ControlGym library and define the initial state
 $$ {\left({\mathbf{x}}_{\mathrm{init}}\right)}_i=5\cdot \frac{1}{\cosh \left(10\left({\Delta}_i-\alpha \right)\right)}\in \left[0,5\right],\hskip1em {\Delta}_i=\frac{i}{N_{\mathrm{spatial}}},i=0,\dots, {N}_{\mathrm{spatial}}, $$
$$ {\left({\mathbf{x}}_{\mathrm{init}}\right)}_i=5\cdot \frac{1}{\cosh \left(10\left({\Delta}_i-\alpha \right)\right)}\in \left[0,5\right],\hskip1em {\Delta}_i=\frac{i}{N_{\mathrm{spatial}}},i=0,\dots, {N}_{\mathrm{spatial}}, $$
for our second test case, exhibiting a higher degree of regularity. The term
 $ \alpha \sim \mathcal{U}\left[\mathrm{0.25,0.75}\right] $
randomly moves the peak of the curve, enabling the ablation studies presented in Table 1. For the plots reported in Figures 4 and 5, we centered the function in the domain by taking
$ \alpha \sim \mathcal{U}\left[\mathrm{0.25,0.75}\right] $
randomly moves the peak of the curve, enabling the ablation studies presented in Table 1. For the plots reported in Figures 4 and 5, we centered the function in the domain by taking
 $ \alpha =0.5 $
. With a nonnegative domain of
$ \alpha =0.5 $
. With a nonnegative domain of
 $ \left[0,5\right] $
, this initial state clearly exceed the training domain of
$ \left[0,5\right] $
, this initial state clearly exceed the training domain of
 $ \left[-1,1\right] $
. To make the test case more interesting and more realistic, we also change the diffusivity constant to
$ \left[-1,1\right] $
. To make the test case more interesting and more realistic, we also change the diffusivity constant to
 $ \nu =0.01 $
, that is, two orders of magnitude smaller than on the training data, and we let the PDE evolve uncontrolled for 1 s before the controller starts actuating for five more seconds, that is, a delayed start and a total observation horizon of
$ \nu =0.01 $
, that is, two orders of magnitude smaller than on the training data, and we let the PDE evolve uncontrolled for 1 s before the controller starts actuating for five more seconds, that is, a delayed start and a total observation horizon of
 $ T=6\mathrm{s} $
of which the controller is activated in
$ T=6\mathrm{s} $
of which the controller is activated in
 $ \left[1\mathrm{s},6\mathrm{s}\right] $
.
$ \left[1\mathrm{s},6\mathrm{s}\right] $
.
State and control trajectories for Burgers’ equation in the PO case. The initial condition is a bell-shaped hyperbolic cosine (eq. [4.3] with
 $ \alpha =0.5 $
fixed), we use
$ \alpha =0.5 $
fixed), we use
 $ \nu =0.01 $
(two orders of magnitude smaller compared to the training phase), and the black solid line indicates the timestep
$ \nu =0.01 $
(two orders of magnitude smaller compared to the training phase), and the black solid line indicates the timestep
 $ t $
when the controller is activated. (a) FOM states. (b) AE + SINDy-C states,
$ t $
when the controller is activated. (a) FOM states. (b) AE + SINDy-C states,
 $ {k}_{\mathrm{dyn}}=5 $
. (c) AE + SINDy-C states,
$ {k}_{\mathrm{dyn}}=5 $
. (c) AE + SINDy-C states,
 $ {k}_{\mathrm{dyn}}=10 $
. (d) FOM controls. (e) AE + SINDy-C controls,
$ {k}_{\mathrm{dyn}}=10 $
. (d) FOM controls. (e) AE + SINDy-C controls,
 $ {k}_{\mathrm{dyn}}=5 $
. (f) AE + SINDy-C controls,
$ {k}_{\mathrm{dyn}}=5 $
. (f) AE + SINDy-C controls,
 $ {k}_{\mathrm{dyn}}=10 $
.
$ {k}_{\mathrm{dyn}}=10 $
.

State and control trajectories for Burgers’ equation in the FO case. The initial condition is a bell-shaped hyperbolic cosine (eq. [4.3] with
 $ \alpha =0.5 $
fixed), we use
$ \alpha =0.5 $
fixed), we use
 $ \nu =0.01 $
(two orders of magnitude smaller compared to the training phase), and the black solid line indicates the timestep
$ \nu =0.01 $
(two orders of magnitude smaller compared to the training phase), and the black solid line indicates the timestep
 $ t $
when the controller is activated. (a) FOM states. (b) AE + SINDy-C states,
$ t $
when the controller is activated. (a) FOM states. (b) AE + SINDy-C states,
 $ {k}_{\mathrm{dyn}}=5 $
. (c) AE + SINDy-C states,
$ {k}_{\mathrm{dyn}}=5 $
. (c) AE + SINDy-C states,
 $ {k}_{\mathrm{dyn}}=10 $
. (d) FOM controls. (e) AE + SINDy-C controls,
$ {k}_{\mathrm{dyn}}=10 $
. (d) FOM controls. (e) AE + SINDy-C controls,
 $ {k}_{\mathrm{dyn}}=5 $
. (f) AE + SINDy-C controls,
$ {k}_{\mathrm{dyn}}=5 $
. (f) AE + SINDy-C controls,
 $ {k}_{\mathrm{dyn}}=10 $
.
$ {k}_{\mathrm{dyn}}=10 $
.

Clearly, this task is much more challenging than the one previously considered, As in the first test setting, the fully observable case seems to be overall easier for all of the models, although the differences between the fully and partially observable case are more significant. Most importantly, as discussed in Appendix A.1, working with a regular initial state, the agent also generates regular control trajectories. Although we did not apply actuation bounds, the order of magnitude of the controls is almost the same as in the previous test case, indicating a very robust generalization of the policy.
Partially observable. In the PO case (cf. Figure 4), the baseline model clearly outperforms the AE+SINDy-C method. While, for both values of
 $ {k}_{\mathrm{dyn}}=5,10 $
, the agent is able to stabilize the PDE toward a steady state and slowly decreases it is constant, only the baseline agent fully converges toward to the desired zero-state. Interestingly, the AE+SINDy-C controllers seem to focus on channel-wise high and low control values, while the full-order baseline agents exhibit a switching behavior after circa 3 s for seven out of eight actuators. Similar to the case of the uniform initial condition, the AE+SINDy-C with
$ {k}_{\mathrm{dyn}}=5,10 $
, the agent is able to stabilize the PDE toward a steady state and slowly decreases it is constant, only the baseline agent fully converges toward to the desired zero-state. Interestingly, the AE+SINDy-C controllers seem to focus on channel-wise high and low control values, while the full-order baseline agents exhibit a switching behavior after circa 3 s for seven out of eight actuators. Similar to the case of the uniform initial condition, the AE+SINDy-C with
 $ {k}_{\mathrm{dyn}}=10 $
does not seem to rely on actuator two.
$ {k}_{\mathrm{dyn}}=10 $
does not seem to rely on actuator two.
Fully observable. As in the PO case, the FO test case (cf. Figure 5) shows a similar pattern. The baseline model outperforms both the AE+SINDy-C agents. In contrast to the PO case, now also the two agents trained with the surrogate model are close to the zero-state target, with
 $ {k}_{\mathrm{dyn}}=5 $
slightly outperforming the
$ {k}_{\mathrm{dyn}}=5 $
slightly outperforming the
 $ {k}_{\mathrm{dyn}}=10 $
agent. Notably, parts of the controls in all models exhibit zero-like actuators, the baseline model again showing a switching behavior after circa three and a half seconds. It seems like having access to more state measurements requires the usage of less actuators, resulting in a higher reward, as displayed in Table 1. For real-world applications, this can be really useful when designing position and size of controllers for an actual system.
$ {k}_{\mathrm{dyn}}=10 $
agent. Notably, parts of the controls in all models exhibit zero-like actuators, the baseline model again showing a switching behavior after circa three and a half seconds. It seems like having access to more state measurements requires the usage of less actuators, resulting in a higher reward, as displayed in Table 1. For real-world applications, this can be really useful when designing position and size of controllers for an actual system.
4.1.3. Dynamics in the latent space
A relevant aspect of AE+SINDy-C is the compression of high-dimensional PDE discretization into a low-dimensional surrogate space, resulting in a closed-form and interpretable representation and the potential to discover unknown system dynamics. The coefficient matrices
 $ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times {N}_x^{\mathrm{Obs}}} $
are visualized in Figure 6 for Burgers’ case, highlighting the coefficients as a heatmap as well as some key points of interests (e.g., sparsity).
$ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times {N}_x^{\mathrm{Obs}}} $
are visualized in Figure 6 for Burgers’ case, highlighting the coefficients as a heatmap as well as some key points of interests (e.g., sparsity).
Analysis of the coefficient matrix
 $ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times {N}_x^{\mathrm{Obs}}} $
for Burgers’ equation. (a) Partially observable case,
$ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times {N}_x^{\mathrm{Obs}}} $
for Burgers’ equation. (a) Partially observable case,
 $ {k}_{\mathrm{dyn}}=5 $
. (b) Fully observable case,
$ {k}_{\mathrm{dyn}}=5 $
. (b) Fully observable case,
 $ {k}_{\mathrm{dyn}}=5 $
. (c) Partially observable case,
$ {k}_{\mathrm{dyn}}=5 $
. (c) Partially observable case,
 $ {k}_{\mathrm{dyn}}=10 $
. (d) Fully observable case,
$ {k}_{\mathrm{dyn}}=10 $
. (d) Fully observable case,
 $ {k}_{\mathrm{dyn}}=10 $
.
$ {k}_{\mathrm{dyn}}=10 $
.

Based on the coefficients
 $ \boldsymbol{\Xi} $
, one can compute the closed-form representation of the SINDy-C dynamics model in the surrogate space. Since our algorithm is not trained with sequential thresholding, we chose a threshold of
$ \boldsymbol{\Xi} $
, one can compute the closed-form representation of the SINDy-C dynamics model in the surrogate space. Since our algorithm is not trained with sequential thresholding, we chose a threshold of
 $ 0.15 $
to cutoff nonsignificant contributions and improve readability. Exemplarily, we obtain the following surrogate space dynamics for
$ 0.15 $
to cutoff nonsignificant contributions and improve readability. Exemplarily, we obtain the following surrogate space dynamics for
 $ {k}_{\mathrm{dyn}}=5 $
:
$ {k}_{\mathrm{dyn}}=5 $
:
• PO,
 $ {k}_{\mathrm{dyn}}=5 $
:
$ {k}_{\mathrm{dyn}}=5 $
:
 $$ {\displaystyle \begin{array}{c}{\mathbf{z}}_{x,1}\left(t+1\right)=-0.688\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,2}(t)+0.497\cdot {\mathbf{z}}_{x,1}{(t)}^3\\ {}-0.195\cdot {\mathbf{z}}_{x,1}{(t)}^2{\mathbf{z}}_{x,2}(t)+0.288\cdot {\mathbf{z}}_{u,1}(t)\\ {}{\mathbf{z}}_{x,2}\left(t+1\right)=+0.297\cdot {\mathbf{z}}_{x,2}(t)-0.180\cdot {\mathbf{z}}_{x,1}{(t)}^2-0.245\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,2}(t)\\ {}-0.381\cdot {\mathbf{z}}_{x,2}{(t)}^2+0.304\cdot {\mathbf{z}}_{x,1}{(t)}^2{\mathbf{z}}_{x,2}(t)+0.487\cdot {\mathbf{z}}_{u,1}(t).\end{array}} $$
$$ {\displaystyle \begin{array}{c}{\mathbf{z}}_{x,1}\left(t+1\right)=-0.688\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,2}(t)+0.497\cdot {\mathbf{z}}_{x,1}{(t)}^3\\ {}-0.195\cdot {\mathbf{z}}_{x,1}{(t)}^2{\mathbf{z}}_{x,2}(t)+0.288\cdot {\mathbf{z}}_{u,1}(t)\\ {}{\mathbf{z}}_{x,2}\left(t+1\right)=+0.297\cdot {\mathbf{z}}_{x,2}(t)-0.180\cdot {\mathbf{z}}_{x,1}{(t)}^2-0.245\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,2}(t)\\ {}-0.381\cdot {\mathbf{z}}_{x,2}{(t)}^2+0.304\cdot {\mathbf{z}}_{x,1}{(t)}^2{\mathbf{z}}_{x,2}(t)+0.487\cdot {\mathbf{z}}_{u,1}(t).\end{array}} $$
• FO,
 $ {k}_{\mathrm{dyn}}=5 $
:
$ {k}_{\mathrm{dyn}}=5 $
:
 $$ {\displaystyle \begin{array}{c}{\mathbf{z}}_{x,1}\left(t+1\right)=+0.795\cdot {\mathbf{z}}_{x,1}{(t)}^2+0.420\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,2}(t)-0.676\cdot {\mathbf{z}}_{x,1}{(t)}^3\\ {}+0.224\cdot {\mathbf{z}}_{x,1}{(t)}^2{\mathbf{z}}_{x,2}(t)+0.159\cdot {\mathbf{z}}_{u,2}(t)\\ {}{\mathbf{z}}_{x,2}\left(t+1\right)=+0.310\cdot {\mathbf{z}}_{x,1}{(t)}^3-0.454\cdot {\mathbf{z}}_{x,1}{(t)}^2{\mathbf{z}}_{x,2}(t)\\ {}+0.655\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,2}{(t)}^2+0.426\cdot {\mathbf{z}}_{x,2}{(t)}^3.\end{array}} $$
$$ {\displaystyle \begin{array}{c}{\mathbf{z}}_{x,1}\left(t+1\right)=+0.795\cdot {\mathbf{z}}_{x,1}{(t)}^2+0.420\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,2}(t)-0.676\cdot {\mathbf{z}}_{x,1}{(t)}^3\\ {}+0.224\cdot {\mathbf{z}}_{x,1}{(t)}^2{\mathbf{z}}_{x,2}(t)+0.159\cdot {\mathbf{z}}_{u,2}(t)\\ {}{\mathbf{z}}_{x,2}\left(t+1\right)=+0.310\cdot {\mathbf{z}}_{x,1}{(t)}^3-0.454\cdot {\mathbf{z}}_{x,1}{(t)}^2{\mathbf{z}}_{x,2}(t)\\ {}+0.655\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,2}{(t)}^2+0.426\cdot {\mathbf{z}}_{x,2}{(t)}^3.\end{array}} $$
Denoting by
 $ {\mathbf{z}}_{x,i} $
and
$ {\mathbf{z}}_{x,i} $
and
 $ {\mathbf{z}}_{u,i} $
the
$ {\mathbf{z}}_{u,i} $
the
 $ i $
th component of the state and the control in the latent space, respectively, SINDy individually compressed both state and action into a two-dimensional latent space representation. While for the state the corresponding AE requires both dimensions, the control AE correctly compressed the control into a one-dimensional representation. Overall, each of the representations is different, which can be explained by (a) a different training procedure, (b) different full-order interactions observed by the models, and (c) the nonuniqueness of the representation.
$ i $
th component of the state and the control in the latent space, respectively, SINDy individually compressed both state and action into a two-dimensional latent space representation. While for the state the corresponding AE requires both dimensions, the control AE correctly compressed the control into a one-dimensional representation. Overall, each of the representations is different, which can be explained by (a) a different training procedure, (b) different full-order interactions observed by the models, and (c) the nonuniqueness of the representation.
4.1.4. Training of AE+SINDy-C
To analyze the goodness of fit of the internal surrogate model, we provide in Table 2 the average training and validation error, that is, eq. (3.1), of the last iteration of each surrogate model update, that is, step 12. We clearly see that keeping the training epochs of AE+SINDy-C low helps to reduce overfitting, and for each of the four methods the order of magnitude of the training and validation loss is the same (internally, we use an 80/20 splitting for training and validation and train for 100 epochs. Debugging plots show that in all cases an upper bound of 30 epochs would be enough to train the AE+SINDy-C representation). Additionally, Table 2 also displays the average duration of a surrogate model update, that is, step 12, which is due to the small number of parameters.
Training time and overview of the loss distribution of eq. (3.1) during the training phase of the Dyna-style AE+SINDy-C method for Burgers’ equation

Note: Mean and variance are computed over all training epochs. The training was performed on a MacBook M1 (2021, 16GB RAM).
4.2. Incompressible Navier–Stokes Equations (PDEControlGym)
This second example focuses on a much more challenging equation and control setting. The temporal dynamics of the 2D velocity field
 $ \mathbf{x}\left({y}_1,{y}_2,t\right):\Omega \times \left[0,T\right]\to {\mathrm{\mathbb{R}}}^2 $
, and the pressure field
$ \mathbf{x}\left({y}_1,{y}_2,t\right):\Omega \times \left[0,T\right]\to {\mathrm{\mathbb{R}}}^2 $
, and the pressure field
 $ p\left({y}_1,{y}_2,t\right):\Omega \times \left[0,T\right]\to \mathrm{\mathbb{R}} $
is given by
$ p\left({y}_1,{y}_2,t\right):\Omega \times \left[0,T\right]\to \mathrm{\mathbb{R}} $
is given by
 $$ {\displaystyle \begin{array}{ll}& \nabla \cdot \mathbf{x}=0,\\ {}& {\partial}_t\mathbf{x}+\mathbf{x}\cdot \nabla \mathbf{x}=-\frac{1}{\rho}\nabla p+\nu {\nabla}^2\mathbf{x},\end{array}} $$
$$ {\displaystyle \begin{array}{ll}& \nabla \cdot \mathbf{x}=0,\\ {}& {\partial}_t\mathbf{x}+\mathbf{x}\cdot \nabla \mathbf{x}=-\frac{1}{\rho}\nabla p+\nu {\nabla}^2\mathbf{x},\end{array}} $$
in
 $ \Omega \times \left[0,T\right] $
, denoting the kinematic viscosity of the fluid by
$ \Omega \times \left[0,T\right] $
, denoting the kinematic viscosity of the fluid by
 $ \nu $
, and its density by
$ \nu $
, and its density by
 $ \rho $
. For the experiments, the equation is fully observable, we consider Dirichlet boundary conditions with velocities set to 0, and we control along the top boundary
$ \rho $
. For the experiments, the equation is fully observable, we consider Dirichlet boundary conditions with velocities set to 0, and we control along the top boundary
 $ {u}_t={u}_t\left({y}_1\right)=\mathbf{x}\left({y}_1,1,t\right) $
, for
$ {u}_t={u}_t\left({y}_1\right)=\mathbf{x}\left({y}_1,1,t\right) $
, for
 $ {y}_1\in \Omega $
, that is,
$ {y}_1\in \Omega $
, that is,
 $ {y}_2=1 $
is fixed. Following the benchmark of Bhan et al. (Reference Bhan, Bian, Krstic and Shi2024, section 5.3), the domain
$ {y}_2=1 $
is fixed. Following the benchmark of Bhan et al. (Reference Bhan, Bian, Krstic and Shi2024, section 5.3), the domain
 $ \Omega ={\left(0,1\right)}^2 $
and the time interval
$ \Omega ={\left(0,1\right)}^2 $
and the time interval
 $ T=0.2\mathrm{s} $
are used, parameters for the solution procedure are kept. The equation is noise-free fully observed. The DRL agents are trained with a discretized version of the following objective function:
$ T=0.2\mathrm{s} $
are used, parameters for the solution procedure are kept. The equation is noise-free fully observed. The DRL agents are trained with a discretized version of the following objective function:
 $$ {\displaystyle \begin{array}{c}\mathcal{J}\left({u}_t,\mathbf{x}\right)=-\frac{1}{2}{\int}_0^T{\int}_{\Omega}{\left\Vert \mathbf{x}\left({y}_1,{y}_2,t\right)-{\mathbf{x}}_{\mathrm{ref}}\Big({y}_1,{y}_2,t\Big)\right\Vert}^2\mathrm{d}\left({y}_1,{y}_2\right)\mathrm{d}t\\ {}+\frac{\gamma }{2}{\int}_0^T{\left\Vert {u}_t-{u}_t^{\mathrm{ref}}\right\Vert}^2\mathrm{d}t,\end{array}} $$
$$ {\displaystyle \begin{array}{c}\mathcal{J}\left({u}_t,\mathbf{x}\right)=-\frac{1}{2}{\int}_0^T{\int}_{\Omega}{\left\Vert \mathbf{x}\left({y}_1,{y}_2,t\right)-{\mathbf{x}}_{\mathrm{ref}}\Big({y}_1,{y}_2,t\Big)\right\Vert}^2\mathrm{d}\left({y}_1,{y}_2\right)\mathrm{d}t\\ {}+\frac{\gamma }{2}{\int}_0^T{\left\Vert {u}_t-{u}_t^{\mathrm{ref}}\right\Vert}^2\mathrm{d}t,\end{array}} $$
where the reference solution
 $ {\mathbf{x}}_{\mathrm{ref}} $
is given by the resulting velocity field when applying the controls
$ {\mathbf{x}}_{\mathrm{ref}} $
is given by the resulting velocity field when applying the controls
 $ u:\left[0,T\right]\to \mathrm{\mathbb{R}},t\mapsto 3-5t $
. For the reference controls in the objective function,
$ u:\left[0,T\right]\to \mathrm{\mathbb{R}},t\mapsto 3-5t $
. For the reference controls in the objective function,
 $ {u}_t^{\mathrm{ref}}\equiv 2.0 $
is used.
$ {u}_t^{\mathrm{ref}}\equiv 2.0 $
is used.
Based on the superior results from Burgers’ equation example, we initially explored larger values of
 $ {k}_{\mathrm{dyn}} $
for the Navier–Stokes case. However, for
$ {k}_{\mathrm{dyn}} $
for the Navier–Stokes case. However, for
 $ {k}_{\mathrm{dyn}}=10 $
, training stability deteriorated and policy performance declined, likely due to the increased complexity of the dynamics and accumulation of surrogate model errors. Consequently, we focus on
$ {k}_{\mathrm{dyn}}=10 $
, training stability deteriorated and policy performance declined, likely due to the increased complexity of the dynamics and accumulation of surrogate model errors. Consequently, we focus on
 $ {k}_{\mathrm{dyn}}=5 $
for the Navier–Stokes experiments, which achieves a favorable balance between sample efficiency and training stability. We then compare the Dyna-style MBRL scheme at this setting with the model-free benchmark. To investigate the sensitivity of AE+SINDy-C to the choice of latent dimensions and to estimate a lower bound on the intrinsic dimensionality of the solution manifold, we conduct experiments with varying latent space sizes. Specifically, we train models with three different latent architectures:
$ {k}_{\mathrm{dyn}}=5 $
for the Navier–Stokes experiments, which achieves a favorable balance between sample efficiency and training stability. We then compare the Dyna-style MBRL scheme at this setting with the model-free benchmark. To investigate the sensitivity of AE+SINDy-C to the choice of latent dimensions and to estimate a lower bound on the intrinsic dimensionality of the solution manifold, we conduct experiments with varying latent space sizes. Specifically, we train models with three different latent architectures:
-
•
$ \left(\mathrm{882,84,6}\right)\times \left(\mathrm{1,4,2}\right) $
, corresponding to a six-dimensional state and two-dimensional control representation, that is, an eight-dimensional latent space; -
•
$ \left(\mathrm{882,52,3}\right)\times \left(\mathrm{1,4,1}\right) $
, corresponding to a three-dimensional state and one-dimensional control representation, that is, a four-dimensional latent space; and -
•
$ \left(\mathrm{882,30,1}\right)\times \left(\mathrm{1,4,1}\right) $
, corresponding to a one-dimensional state and one-dimensional control representation, that is, a two-dimensional latent space.



As expected, reducing the number of degrees of freedom in the latent space negatively impacts the surrogate model’s expressiveness and fidelity. In particular, with only two latent state dimensions, the learned representation failed to capture sufficient dynamics for the agent to effectively learn a control policy. As a result, this configuration is excluded from the analysis. These experiments demonstrate how latent space dimensionality can be treated as a tunable parameter, enabling a data-driven estimation of the minimal dimensionality required for successful policy learning.
4.2.1. Sample efficiency and scalability
Figure 7 and Table 3 clearly highlights the sample efficiency of AE+SINDy-C compared to the model-free baseline in the case of an eight-dimensional surrogate space. Not only does AE+SINDy-C need approximately five times less data but simultaneously outperforms the baseline—a clear indication that the internal dynamics model in the latent space helps the agent to understand the underlying system dynamics. The bumps in performances of AE+SINDy-C at approximately 12 k and 20 k FOM interactions represent the point where the dynamics model correctly represents the directions of the flow. Before that, AE+SINDy-C was able to correctly control the magnitude of the flow field and adjust the controls, but the orientation of the vector field was reversed. The four-dimensional version is not outperforming the baseline and the final model exhibits high uncertainty, also suffering under very fuzzy controls (cf. Figure 8f). Since the corresponding velocity-field cannot be considered a valid solution (cf. Figure 8e), it is thus excluded from the following analysis. The plateau at around 15 k interactions corresponds to very fuzzy controls and only with a big delay the baseline model can stabilize the controls, missing at the end the correct magnitude of the flow field (cf. Figure 8a). Interestingly, the fuzzy overfitting at the end of the training procedure for Burgers’ equation does not appear, which is most probably due to simpler initial conditions and thus more regular systems dynamics, although the dynamics in general are harder to capture, that is, more full-order interactions are needed.
Sample efficiency of the Dyna-style AE+SINDy-C method for the Navier–Stokes equations. We test
 $ {k}_{\mathrm{dyn}}=5 $
against the full-order model-free baseline. The dashed vertical lines indicate the point of early stopping for each of the model after 750 epochs and represent the models which are evaluated in detail in Section 4.2.2. For the evaluation, the performance over five fixed random seeds is used.
$ {k}_{\mathrm{dyn}}=5 $
against the full-order model-free baseline. The dashed vertical lines indicate the point of early stopping for each of the model after 750 epochs and represent the models which are evaluated in detail in Section 4.2.2. For the evaluation, the performance over five fixed random seeds is used.

Velocity field and control trajectories for the model-free baseline and AE+SINDy-C for the Navier–Stokes equations. Black arrows represent the velocity fields and the background color the magnitude of the velocity vector. (a) Full-order baseline model, Velocity field at t = 0.2. (b) Full-order baseline model, control trajectory. (c) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}} $
= 5 and an eight-dimensional latent space, velocity field at 𝑡 = 0.2. (d) AE + SINDy-C with
$ {k}_{\mathrm{dyn}} $
= 5 and an eight-dimensional latent space, velocity field at 𝑡 = 0.2. (d) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}} $
= 5 and an eight-dimensional latent space, control trajectory. (e) AE + SINDy-C with
$ {k}_{\mathrm{dyn}} $
= 5 and an eight-dimensional latent space, control trajectory. (e) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}} $
= 5 and a four-dimensional latent space, velocity field at t = 0.2. (f) AE + SINDy-C with
$ {k}_{\mathrm{dyn}} $
= 5 and a four-dimensional latent space, velocity field at t = 0.2. (f) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}} $
= 5 and a four-dimensional latent space, control trajectory.
$ {k}_{\mathrm{dyn}} $
= 5 and a four-dimensional latent space, control trajectory.

Performance comparison of the Dyna-style AE+SINDy-C method for the Navier–Stokes equations

Note: We test
 $ {k}_{\mathrm{dyn}}=5 $
against the full-order baseline (both
$ {k}_{\mathrm{dyn}}=5 $
against the full-order baseline (both
 $ {N}_x^{\mathrm{Obs}}\times {N}_u=882\times 1 $
). The models correspond to the dashed vertical lines in Figure 7 and represent all models after 750 epochs. We compare the number of FOM interactions, the reward using five fixed random seeds and the total number of parameters. Best performances (bold) are highlighted row-wise.
$ {N}_x^{\mathrm{Obs}}\times {N}_u=882\times 1 $
). The models correspond to the dashed vertical lines in Figure 7 and represent all models after 750 epochs. We compare the number of FOM interactions, the reward using five fixed random seeds and the total number of parameters. Best performances (bold) are highlighted row-wise.
4.2.2. Velocity field and control analysis
In Figure 8 the resulting velocity fields at the end of the observation horizon are visualized (Bhan et al., Reference Bhan, Bian, Krstic and Shi2024, cf. figure 4]. It is evident that AE+SINDy-C nearly perfectly matches the desired flow and clearly outperforms the model-free baseline which has difficulties finding the correct magnitude of the velocity field, although the general directions are correct (since we use with Ray RLLib (Liang et al., Reference Liang, Liaw, Nishihara, Moritz, Fox, Gonzalez, Goldberg and Stoica2017) instead of Stable-Baselines3 (Raffin et al., Reference Raffin, Hill, Gleave, Kanervisto, Ernestus and Dormann2021) a different RL-engine and we run PPO with different settings, we are not slightly able to achieve the performance presented in (Bhan et al., Reference Bhan, Bian, Krstic and Shi2024, table 3) with our baseline model. But, our AE+SINDy-C outperforms the presented baseline algorithms). Thus, imposing a Dyna-style dynamics model does not only significantly decrease reducing the number of full-order model interactions, however it helps the agent to grasp the general dynamics faster. While the controls of the agent AE+SINDy-C stay close to the reference value, the baseline algorithm has difficulties in smoothly increasing the controls (previous epochs exhibit strongly oscillating behavior, similar to bang-bang controls) (Table 3).
4.2.3. Dynamics in the latent space
As in Burgers’ equation example, we visualize the coefficient matrix
 $ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times {N}_x^{\mathrm{Lat}}} $
for the eight-dimensional latent space version. Figure 9 shows the sparse nature of the dynamics model. Interestingly, with 29, and respectively 27, coefficients with absolute values above the threshold of 0.15, both representations need almost the same amount of basis functions, indicating the amount of information carried by the state and action of the PDE.
$ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times {N}_x^{\mathrm{Lat}}} $
for the eight-dimensional latent space version. Figure 9 shows the sparse nature of the dynamics model. Interestingly, with 29, and respectively 27, coefficients with absolute values above the threshold of 0.15, both representations need almost the same amount of basis functions, indicating the amount of information carried by the state and action of the PDE.
Analysis of the coefficient matrix
 $ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times {N}_x^{\mathrm{Obs}}} $
for the Navier–Stokes equations. (a) Eight-dimensional latent space. (b) Four-dimensional latent space.
$ \boldsymbol{\Xi} \in {\mathrm{\mathbb{R}}}^{d\times {N}_x^{\mathrm{Obs}}} $
for the Navier–Stokes equations. (a) Eight-dimensional latent space. (b) Four-dimensional latent space.

We obtain the following dynamics equations for the eight-dimensional latent space:
 $$ {\displaystyle \begin{array}{c}{\mathbf{z}}_{x,1}\left(t+1\right)=+0.960\cdot {\mathbf{z}}_{x,2}(t)+0.165\cdot {\mathbf{z}}_{x,4}(t)+0.251\cdot {\mathbf{z}}_{x,6}(t)\\ {}+0.228\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,4}(t)+0.981\cdot {\mathbf{z}}_{u,1}(t)\\ {}{\mathbf{z}}_{x,2}\left(t+1\right)=+0.631\cdot {\mathbf{z}}_{x,2}(t)-0.308\cdot {\mathbf{z}}_{x,4}(t)-0.245\cdot {\mathbf{z}}_{x,6}(t)-0.652\cdot {\mathbf{z}}_{u,1}(t)\\ {}{\mathbf{z}}_{x,3}\left(t+1\right)=+0.941\cdot {\mathbf{z}}_{x,3}(t)+0.166\cdot {\mathbf{z}}_{x,3}{(t)}^2+0.265\cdot {\mathbf{z}}_{x,3}(t){\mathbf{z}}_{x,6}(t)\\ {}+0.190\cdot {\mathbf{z}}_{x,3}(t){\mathbf{z}}_{x,4}{(t)}^2+0.286\cdot {\mathbf{z}}_{x,3}(t){\mathbf{z}}_{x,4}(t){\mathbf{z}}_{x,6}(t)\\ {}{\mathbf{z}}_{x,4}\left(t+1\right)=+0.208\cdot {\mathbf{z}}_{x,1}(t)-0.828\cdot {\mathbf{z}}_{x,2}(t)-0.158\cdot {\mathbf{z}}_{x,4}(t)\\ {}+0.216\cdot {\mathbf{z}}_{x,1}{(t)}^2-0.235\cdot {\mathbf{z}}_{x,2}(t){\mathbf{z}}_{x,4}(t)\\ {}+0.175\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,6}{(t)}^2-0.464\cdot {\mathbf{z}}_{u,2}(t)\\ {}{\mathbf{z}}_{x,5}\left(t+1\right)=+0.949\cdot {\mathbf{z}}_{x,5}(t)-0.290\cdot {\mathbf{z}}_{x,6}(t)-0.177\cdot {\mathbf{z}}_{u,1}(t)+0.310\cdot {\mathbf{z}}_{u,2}(t)\\ {}{\mathbf{z}}_{x,6}\left(t+1\right)=-0.396\cdot {\mathbf{z}}_{x,5}(t)+0.314\cdot {\mathbf{z}}_{x,6}(t)-0.695\cdot {\mathbf{z}}_{u,1}(t)+1.451\cdot {\mathbf{z}}_{u,2}(t)\end{array}} $$
$$ {\displaystyle \begin{array}{c}{\mathbf{z}}_{x,1}\left(t+1\right)=+0.960\cdot {\mathbf{z}}_{x,2}(t)+0.165\cdot {\mathbf{z}}_{x,4}(t)+0.251\cdot {\mathbf{z}}_{x,6}(t)\\ {}+0.228\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,4}(t)+0.981\cdot {\mathbf{z}}_{u,1}(t)\\ {}{\mathbf{z}}_{x,2}\left(t+1\right)=+0.631\cdot {\mathbf{z}}_{x,2}(t)-0.308\cdot {\mathbf{z}}_{x,4}(t)-0.245\cdot {\mathbf{z}}_{x,6}(t)-0.652\cdot {\mathbf{z}}_{u,1}(t)\\ {}{\mathbf{z}}_{x,3}\left(t+1\right)=+0.941\cdot {\mathbf{z}}_{x,3}(t)+0.166\cdot {\mathbf{z}}_{x,3}{(t)}^2+0.265\cdot {\mathbf{z}}_{x,3}(t){\mathbf{z}}_{x,6}(t)\\ {}+0.190\cdot {\mathbf{z}}_{x,3}(t){\mathbf{z}}_{x,4}{(t)}^2+0.286\cdot {\mathbf{z}}_{x,3}(t){\mathbf{z}}_{x,4}(t){\mathbf{z}}_{x,6}(t)\\ {}{\mathbf{z}}_{x,4}\left(t+1\right)=+0.208\cdot {\mathbf{z}}_{x,1}(t)-0.828\cdot {\mathbf{z}}_{x,2}(t)-0.158\cdot {\mathbf{z}}_{x,4}(t)\\ {}+0.216\cdot {\mathbf{z}}_{x,1}{(t)}^2-0.235\cdot {\mathbf{z}}_{x,2}(t){\mathbf{z}}_{x,4}(t)\\ {}+0.175\cdot {\mathbf{z}}_{x,1}(t){\mathbf{z}}_{x,6}{(t)}^2-0.464\cdot {\mathbf{z}}_{u,2}(t)\\ {}{\mathbf{z}}_{x,5}\left(t+1\right)=+0.949\cdot {\mathbf{z}}_{x,5}(t)-0.290\cdot {\mathbf{z}}_{x,6}(t)-0.177\cdot {\mathbf{z}}_{u,1}(t)+0.310\cdot {\mathbf{z}}_{u,2}(t)\\ {}{\mathbf{z}}_{x,6}\left(t+1\right)=-0.396\cdot {\mathbf{z}}_{x,5}(t)+0.314\cdot {\mathbf{z}}_{x,6}(t)-0.695\cdot {\mathbf{z}}_{u,1}(t)+1.451\cdot {\mathbf{z}}_{u,2}(t)\end{array}} $$
4.2.4. Training of AE+SINDy-C
For the sake of completeness, the goodness of fit in terms of the average training and validation error are provided in Table 4 for the Navier–Stokes case. Compared to Burgers’ equation, the training and validation loss are of the same order of magnitude. Since the AE+SINDy-C model is much larger in this case, the training takes longer. Interestingly, while in Burgers’ equation case our internal logging metrics show that usually even 20–30 epochs would be enough, in the more complex Navier–Stokes equations case on average at least 70–80 epochs are needed before the loss converges.
Analysis of the internal loss distribution for the training and validation data during the AE training as well as the training time for the Navier–Stokes equations, trained on a MacBook M1 (2021, 16GB RAM)

5. Discussion and conclusion
We propose a data-efficient and interpretable Dyna-style MBRL framework for controlling distributed systems, such as those governed by PDEs. Combining SINDy-C with an AE framework not only scales to high-dimensional systems but also provides a low-dimensional learned representation as a dynamical system in the latent space. The proposed controllers have proven to be effective and robust in both PO and FO cases. Additionally, we showed how the proposed framework can be used to estimate an approximate lower bound for a low-dimensional surrogate representation of the dynamics.
A limitation of our method is the training of an AE online. Problems such as overfitting (Goodfellow et al., Reference Goodfellow, Bengio and Courville2016; Zhang et al., Reference Zhang, Bengio, Hardt, Recht and Vinyals2021) and catastrophic forgetting (McCloskey and Cohen, Reference McCloskey and Cohen1989; Kirkpatrick et al., Reference Kirkpatrick, Pascanu, Rabinowitz, Veness, Desjardins, Rusu, John Quan, Ramalho, Grabska-Barwinska, Hassabis, Clopath, Kumaran and Hadsell2017) lead to decreasing performance if the AE is trained for too long and on too little data. Potential options to overcome this issue could include the usage of shorter roll-outs (Janner et al., Reference Janner, Fu, Zhang and Levine2019), ensemble methods (Zolman et al., Reference Zolman, Fasel, Kutz and Bruntonn.d.), or training the AE using sequential thresholding to enforce zero-valued coefficients. Burgers’ PDE example demonstrated that, provided the initial condition is sufficiently regular, the complexity of learning a reduced representation can be significantly mitigated. In contrast, the Navier–Stokes equation example highlights the critical importance of selecting an appropriate latent space dimensionality. These experiments underscore the need to actively explore different surrogate space configurations in order to avoid inadequate model expressiveness and reduced policy learning performance.
Further research should address these limitations to enhance the robustness and generalizability of our framework across diverse PDE scenarios. Beyond the current improvements, integrating SINDy-C with AEs opens new avenues in multiple fields. In future work, we plan to extend the latent space representation to include parameter dependencies, as seen in (Conti et al., Reference Conti, Gobat, Fresca, Manzoni and Frangi2023), enabling more effective learning of parametric systems, such as parameterized PDEs.
Data availability statement
The code for AE+SINDy-C is publicly available under https://doi.org/10.5281/zenodo.17098125 (Wolf, Reference Wolf2025).
Acknowledgements
AM acknowledges the Project “Reduced Order Modeling and Deep Learning for the real- time approximation of PDEs (DREAM)” (starting grant no. FIS00003154), funded by the Italian Science Fund (FIS) – Ministero dell’Università e della Ricerca and the project FAIR (Future Artificial Intelligence Research), funded by the NextGenerationEU program within the PNRR-PE-AI scheme (M4C2, Investment 1.3, Line on Artificial Intelligence).
Author contribution
Conceptualization: F.W., A.M.; Methodology: F.W.; Software: F.W.; Validation: F.W.; Formal analysis: F.W.; Investigation: F.W.; Writing – original draft: F.W.; Writing – review and editing: F.W., A.M., N.B., and U.F.; Visualization: F.W.; Supervision: A.M., N.B., and U.F. All authors approved the final submitted draft.
Funding statement
FW was supported by a scholarship from the Italian Ministry of Foreign Affairs and International Cooperation.
Competing interests
AM is member of the Gruppo Nazionale Calcolo Scientifico-Istituto Nazionale di Alta Matematica (GNCS- INdAM). The other authors declare none.
Ethical standard
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.
A. Burgers’ equation: Additional evaluation
A.1. Random initial condition: State and control trajectories
We analyze the models indicated by the dashed line in Figure 3 with the same fixed random seed for one specific initial condition. As in the training, the initial condition is drawn from a uniform
 $ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
distribution. The idea of training the agent in this way might seem counterintuitive at first due to the non-regularity of the initial state, but turns out to be a very effective strategy, as we will see in Section 4.1.2. We impose low penalties on the controls (cf. Appendix B), resulting in very aggressive control strategies. Figures A1 and A2 visualize the results for the partially respectively fully observable case. Both of them confirm the results we have already seen from Figure 3. Overall, the controls show a very chaotic behavior and are not regular. This can clearly be explained by the nonregularity of the initial state distribution and the resulting state trajectories, as well as the low penalty on the control itself. The issue of regularity has been discussed in detail in Section 4.1.2, when we consider regular, but out-of-distribution, initial conditions. With a regular initial condition, the problem of chaotic controls does not appear. In a model-by-model comparison, the FO case is overall solved more effectively and with less variation between different random seeds—confirming the intuition that, in general, more measurement points increase the performance of the agent.
$ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
distribution. The idea of training the agent in this way might seem counterintuitive at first due to the non-regularity of the initial state, but turns out to be a very effective strategy, as we will see in Section 4.1.2. We impose low penalties on the controls (cf. Appendix B), resulting in very aggressive control strategies. Figures A1 and A2 visualize the results for the partially respectively fully observable case. Both of them confirm the results we have already seen from Figure 3. Overall, the controls show a very chaotic behavior and are not regular. This can clearly be explained by the nonregularity of the initial state distribution and the resulting state trajectories, as well as the low penalty on the control itself. The issue of regularity has been discussed in detail in Section 4.1.2, when we consider regular, but out-of-distribution, initial conditions. With a regular initial condition, the problem of chaotic controls does not appear. In a model-by-model comparison, the FO case is overall solved more effectively and with less variation between different random seeds—confirming the intuition that, in general, more measurement points increase the performance of the agent.
Partially observable. Compared to the FO case, the PO case (cf. Figure A1) is as expected more challenging for all of the methods. All three controllers struggle to correctly capture the system dynamics and effectively regulate the system—represented by lower rewards in general and higher standard deviations (cf. Table 1). In the PO case, the baseline model is outperformed by the AE+SINDy-C method, although taking into account the standard deviation, the difference is not significant. Interestingly, while the baseline model seems to rely on all of the controls, both, the
 $ {k}_{\mathrm{dyn}}=5 $
and
$ {k}_{\mathrm{dyn}}=5 $
and
 $ {k}_{\mathrm{dyn}}=10 $
exhibit one
$ {k}_{\mathrm{dyn}}=10 $
exhibit one
 $ {u}_i $
with close to zero controls over the entire time horizon (cf. Figure A1e index one and Figure A2f index two). Overall, the PDE is aggressively controlled and successfully regulated toward the zero-state.
$ {u}_i $
with close to zero controls over the entire time horizon (cf. Figure A1e index one and Figure A2f index two). Overall, the PDE is aggressively controlled and successfully regulated toward the zero-state.
Fully observable. In the FO case (cf. Figure A2), the baseline model outperforms the AE+SINDy-C method. Nevertheless, Table 1 highlights that the differences between the models are marginal although the baseline model specifically stands out by a much lower standard deviation and thus can be trusted more. The performance of AE+SINDy-C for
 $ {k}_{\mathrm{dyn}}=5 $
and
$ {k}_{\mathrm{dyn}}=5 $
and
 $ {k}_{\mathrm{dyn}}=10 $
are similar, also regarding their standard deviations, even though at the end of the extrapolation horizon in the case of
$ {k}_{\mathrm{dyn}}=10 $
are similar, also regarding their standard deviations, even though at the end of the extrapolation horizon in the case of
 $ {k}_{\mathrm{dyn}}=5 $
the DRL agent seems to slightly overshoot the target while in the case of
$ {k}_{\mathrm{dyn}}=5 $
the DRL agent seems to slightly overshoot the target while in the case of
 $ {k}_{\mathrm{dyn}}=10 $
the agent undershoots the target (see Figure A2b and c, respectively).
$ {k}_{\mathrm{dyn}}=10 $
the agent undershoots the target (see Figure A2b and c, respectively).
State and control trajectories for Burgers’ equation in the partially observable (PO) case with
 $ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
as initial distribution. The black dashed line indicates the timestep
$ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
as initial distribution. The black dashed line indicates the timestep
 $ t $
of extrapolation in time. (a) FOM: states. (b) AE + SINDy-C with
$ t $
of extrapolation in time. (a) FOM: states. (b) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}}=5 $
. (c) AE + SINDy-C with
$ {k}_{\mathrm{dyn}}=5 $
. (c) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}}=10 $
. (d) FOM: controls. (e) AE + SINDy-C with
$ {k}_{\mathrm{dyn}}=10 $
. (d) FOM: controls. (e) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}}=5 $
. (f) AE + SINDy-C with
$ {k}_{\mathrm{dyn}}=5 $
. (f) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}}=5 $
.
$ {k}_{\mathrm{dyn}}=5 $
.

State and control trajectories for Burgers’ equation in the fully observable (FO) case with
 $ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
as initial distribution. The black dashed line indicates the timestep
$ \mathcal{U}\left({\left[-1,1\right]}^{N_x}\right) $
as initial distribution. The black dashed line indicates the timestep
 $ t $
of extrapolation in time. a) FOM: states. (b) AE + SINDy-C with
$ t $
of extrapolation in time. a) FOM: states. (b) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}}=5 $
. (c) AE + SINDy-C with
$ {k}_{\mathrm{dyn}}=5 $
. (c) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}}=10 $
. (d) FOM: controls. (e) AE + SINDy-C with
$ {k}_{\mathrm{dyn}}=10 $
. (d) FOM: controls. (e) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}}=5 $
. (f) AE + SINDy-C with
$ {k}_{\mathrm{dyn}}=5 $
. (f) AE + SINDy-C with
 $ {k}_{\mathrm{dyn}}=10 $
.
$ {k}_{\mathrm{dyn}}=10 $
.

B. Environments: Hyperparameters
Environment details for ControlGym’s implemention of Burgers’ equation, the diffusivity constant
 $ \nu =1.0 $
is fixed
$ \nu =1.0 $
is fixed

Environment details for PDEControlGym’s implemention of the Navier–Stokes equations

C. Deep RL: Hyperparameters
DRL algorithm configuration details for Burgers’ equation experiment

Note: We use Ray RLLib (Liang et al., Reference Liang, Liaw, Nishihara, Moritz, Fox, Gonzalez, Goldberg and Stoica2017) to train our models. The PPO (Schulman et al., Reference Schulman, Wolski, Dhariwal, Radford and Klimov2017) policy is trained by using the Adam algorithm (Kingma and Ba, Reference Kingma and Ba2015).
DRL algorithm configuration details for the Navier–Stokes equations experiment

Note: We use Ray RLLib (Liang et al., Reference Liang, Liaw, Nishihara, Moritz, Fox, Gonzalez, Goldberg and Stoica2017) to train our models. The PPO (Schulman et al., Reference Schulman, Wolski, Dhariwal, Radford and Klimov2017) policy is trained by using the Adam algorithm (Kingma and Ba, Reference Kingma and Ba2015).
D. Autoencoder: Hyperparameters and training details
Internally, an
 $ 80/20 $
splitting is used for training and validation, and once new data are available, the surrogate model is trained for 100 epochs. In all of the cases, we computed the number of neurons of the hidden layer such that the ratio between the size of the input and the hidden layer is the same as the ratio between the size of the hidden and the output layer. Only for the controls of the Navier–Stokes equations we went for an increase in neurons to find an effective latent space representation (cf. Table D2).
$ 80/20 $
splitting is used for training and validation, and once new data are available, the surrogate model is trained for 100 epochs. In all of the cases, we computed the number of neurons of the hidden layer such that the ratio between the size of the input and the hidden layer is the same as the ratio between the size of the hidden and the output layer. Only for the controls of the Navier–Stokes equations we went for an increase in neurons to find an effective latent space representation (cf. Table D2).
Details of the AE+SINDy-C surrogate model for Burgers’ equation

Note: We use PySINDy (Kaptanoglu et al., Reference Kaptanoglu, de Silva, Fasel, Kaheman, Goldschmidt, Callaham, Delahunt, Nicolaou, Champion, Loiseau, Kutz and Brunton2021) to generate the set of dictionary functions.
Details of the AE+SINDy-C surrogate model for the Navier–Stokes equations

Note: We use PySINDy (Kaptanoglu et al., Reference Kaptanoglu, de Silva, Fasel, Kaheman, Goldschmidt, Callaham, Delahunt, Nicolaou, Champion, Loiseau, Kutz and Brunton2021) to generate the set of dictionary functions.





































































 Open access
Open access
Comments
No Comments have been published for this article.