



Policy Significance Statement
This article engages with an emerging policy question: how legitimate, large-scale data benchmarking might be sustained under shrinking resources and growing demands for evidence in AI governance. It examines the potential of a hybrid human-AI architecture as one possible pathway for balancing efficiency with transparency, inclusivity, and accountability in global assessments. The pilot study suggests that while AI can support structured tasks and broaden evidence discovery, expert interpretation continues to play an important role in handling contextual nuance and maintaining democratic legitimacy. For governments, international organizations, and donors, these findings point toward the possible value of investing in hybrid and participatory evidence infrastructures that could leverage AI capabilities while preserving independent, Global South-led perspectives in digital governance.
1. Background
The global data landscape has become increasingly central to governance, development, and policy evaluation. In parallel, a wide array of indexes and assessment tools has emerged to benchmark countries’ progress, serving as a key component of the infrastructure for evidence-based policy. Yet these tools often grapple with fundamental limitations. As highlighted in the Data for Development (D4D) Stocktaking Report (Open Data Watch, 2021) and further discussed by Zuiderwijk et al. (Reference Zuiderwijk, Pirannejad and Susha2021), traditional assessments embed normative assumptions, methodological trade-offs, and institutional perspectives. Their reliance on composite scores and expert judgment has helped establish comparative benchmarks, while also revealing opportunities to better capture contextual nuance, enhance transparency, and strengthen reproducibility.
Research across governance domains shows that indicators do not merely describe policy environments but shape them. By ordering actors and defining performance categories, benchmarks influence regulatory behavior, reform priorities, and resource allocation (Davis, Reference Davis2012; Doshi et al., Reference Doshi, Kelley and Simmons2019). Similar dynamics appear in development and aid transparency initiatives, where assessments increasingly evaluate not only the existence of policies but their operational characteristics (Ghosh and Kharas, Reference Ghosh and Kharas2011; Palagashvili and Williamson, Reference Palagashvili and Williamson2021; Reinsberg and Swedlund, Reference Reinsberg and Swedlund2023). Benchmarking, therefore, operates as an accountability mechanism whose legitimacy depends on transparent evidence, practices, and sustained expert judgment.
At the same time, the political economy supporting such benchmarking infrastructures has become increasingly fragile. Many global indicators rely heavily on aid-funded expert research, and the withdrawal of key donors (most notably USAID at the end of 2024) has exposed the vulnerability of these models (Powell et al., Reference Powell, Lagomarsino and Melamed2025). Meanwhile, policy attention has shifted toward artificial intelligence, often overlooking that reliable data governance remains a prerequisite for trustworthy AI (Verhulst and Schüür, Reference Verhulst and Schüür2023). Before AI tools can be responsibly integrated, benchmarking initiatives must therefore grapple with the political and epistemic conditions under which data are produced, validated, and used.
The emergence of large language models (LLMs) and AI research agents introduces a potential response to this tension. Automation promises scalability and lower costs, yet also introduces opacity into processes whose legitimacy depends on interpretability and contestability. The question is therefore not simply whether AI can replicate expert work, but how its integration alters the conditions under which benchmarking remains accountable and credible.
This article approaches AI-assisted benchmarking as a governance problem rather than a purely technical one. We evaluate AI integration through three observable dimensions of democratic legitimacy—transparency of the assessment process, inclusivity of the evidence base, and accountability of outcomes. Using selected indicators from the Global Data Barometer (2025), we explore how automation reshapes the production of comparative policy knowledge and what institutional arrangements are required for it to remain trustworthy.
2. Methodological lessons from the Global Data Barometer
Large-scale benchmarking initiatives in the data domain have historically relied on human experts to interpret complex and context-dependent realities. The Global Data Barometer (GDB) offers one of the most recent and ambitious examples of this model. Conceived as a successor to earlier efforts such as the Open Data Barometer, the GDB sought not only to map availability of government data but also to capture broader conditions shaping how data contributes to the public good. This ambition required methodological innovation: rather than simply measuring datasets, the GDB embedded a theory of change that linked governance frameworks, capabilities, and evidence of availability and use (Global Data Barometer, 2025). As such, the GDB is a paradigmatic case for understanding the opportunities and limits of human-driven benchmarking, and a crucial reference point for exploring the potential of hybrid AI-assisted approaches.
The GDB was designed around a multi-level indicator framework that captured not only the existence of datasets or regulations but also the enabling conditions that allow their use. Indicators also included conditional logic guiding researchers through context-specific pathways. For instance, if the existence of a dataset was confirmed, subsequent questions then assessed its quality, scope, and accessibility. This approach produced results that moved beyond binary measures and generated comparative insights across 43 countries in the second edition (and 109 in the first one). Yet the very sophistication of this layered methodology made it resource-intensive, raising persistent questions about how such depth could be sustained at scale.
To meet this challenge, the GDB relied on a distributed global research network. More than 100 national researchers in the first edition and over 40 in the second, supported by regional hubs and thematic partners, contributed to data collection and peer review. This model safeguarded the diversity of local perspectives and ensured that evidence was validated by those with contextual expertise. At the same time, it exposed a fundamental trade-off: inclusivity and contextual richness came at the cost of efficiency, as quality control required multiple review layers and often slowed the research cycle. The Barometer, therefore, illustrates a central dilemma of benchmarking: how to reconcile legitimacy with sustainability, a tension that reappears with particular intensity in debates on AI-assisted methodologies.
The AI turn sharpens these trade-offs by challenging one of the Barometer’s most deliberate design choices: transparency. Every response in the GDB was backed by documentary evidence and is available for access and reuse on its website, ensuring traceability and accountability. Machine learning systems, by contrast, often obscure their training data and internal logic, leaving end-users unable to interrogate results. If hybrid benchmarking is to leverage AI, it must replicate the evidentiary rigor of human-led research. Automated outputs need to be made auditable, so that efficiency gains do not come at the expense of transparency and trust.
Bias presents a second challenge where the GDB’s experience is instructive. Just as the Barometer mitigated regional or linguistic bias through its distributed network of local researchers, AI systems risk reproducing and amplifying biases embedded in their training data or prompt design. Here, the lesson is clear: legitimacy in benchmarking does not emerge from the elimination of bias, which is impossible, but from procedural mechanisms that surface, contextualize, and counteract it. In hybrid models, this means building in human oversight not as a safeguard of last resort, but as a structural feature of the methodology.
Taken together, these design choices illustrate the dual challenge at the heart of global benchmarking: legitimacy requires methodological transparency, inclusivity, and openness, but these same commitments increase the costs and fragility of sustaining expert-driven models at scale. It is precisely these tensions that motivate our exploration of whether—and how—AI tools might complement rather than displace the human infrastructure on which the GDB rests. To address these tensions, we turned to exploratory experimentation.
3. Toward a hybrid benchmarking framework: a pilot experiment
These methodological tensions motivated us to move beyond conceptual reflection and test, in practice, whether AI could complement rather than replace the GDB model. To that end, we conducted an exploratory pilot to pursue a dual objective: first, to assess the feasibility of integrating AI into the GDB data collection process; and second, to evaluate the quality of AI-generated outputs, particularly in comparison to GDB data (second edition) contributed by human researchers, in order to identify potential risks and barriers of the AI approach.
Unlike a hypothesis-driven experiment that proceeds with predetermined assumptions, our pilot did not set fixed research hypotheses or predefined outcomes at the outset; instead, the progression of the pilot was guided by the results observed at each stage, and we determined next steps based on these results and the actual tasks of the GDB research process. This adaptive, result-oriented approach ensured that our exploration remained closely aligned with the practical requirements of the GDB research process, rather than pursuing abstract technical goals.
To anchor our investigation in practical realities, we grounded our experimental design in the GDB framework. In the second edition of the GDB, indicators are organized under three pillars: Governance and Capability, which primarily assess governance frameworks (such as laws, policies, and strategies); and Availability, which evaluates the presence of thematic data resources (e.g., public procurement data), regardless of whether they are published directly by the government. Each of these pillars comprises a distinct group of indicators. The data collection process requires country researchers to complete indicator surveys, where each survey follows a dual structure: an “Existence Question” to determine if the object of assessment (e.g., a regulatory framework or a dataset) exists, followed by a series of “Element Questions” to evaluate its specific features.
Based on this structure, we selected a range of indicators representing varying degrees of evidence complexity—defined primarily by the nature and structure of the required evidence—to serve as the testing ground for our pilot (see Table 1). To illustrate, while both the “Data Protection” and “Data Sharing” indicators assess existing governance frameworks, they differ significantly in evidence structure. “Data Protection” indicator is typically anchored in a single, consolidated piece of legislation (e.g., a Data Protection Act). In contrast, the “Data Sharing” indicator comprises a patchwork of frameworks governing diverse practices, such as government-to-government (G2G) and business-to-business (B2B) data sharing. This fragmented composition requires researchers to navigate and synthesize evidence from multiple sources to answer the element questions.
Selection of indicators for experimental testing

Table 1. Long description
The table has four columns: Indicator, Evidence complexity, Rationale for selection, and Tested in phases. From top to bottom: Data Protection (DPL) has simple evidence, a single legal document, serves as a baseline, and is tested in phases 1, 2, and 3. Data Sharing is complex, requiring synthesis of multiple policies, tests A I’s ability to combine evidence, and is tested in phases 2 and 3. Public Procurement is moderate, based on a centralized data source, represents concentrated data implementation, and is tested in phase 3. Land Tenure is highly complex, with fragmented sources, represents decentralized data implementation, and is tested in phase 3.
Similarly, the “Public Procurement” and “Land Tenure” indicators both assess the existence of thematic data resources. Unlike governance frameworks, which are text-based, assessing data resources requires researchers to locate and evaluate actual technical implementations, such as dataset download pages, API endpoints, or interactive visualization systems. As reported in the second edition of the GDB, public procurement data are generally more widely available and often centralized within a one-stop system. Conversely, land tenure data are frequently fragmented across multiple management systems even when available. Consequently, the search and assessment process for land tenure data entails a significantly higher level of complexity.
Guided by this framework, our exploration naturally unfolded into three distinct phases, with each phase’s research question building upon the previous one:
-
• Phase 1: Feasibility test—automated analysis with predefined evidence. Our inquiry began with a foundational test: could an AI analyze a preselected piece of evidence to answer corresponding expert survey questions?
-
• Phase 2: Capability expansion—automated text-based evidence discovery. Phase 1’s focus on predefined evidence raised a critical follow-up question regarding the preceding step in the research process, leading to our next logical inquiry: could AI automate text-based evidence discovery?
-
• Phase 3: Complexity challenge—end-to-end task execution. While previous phases decoupled discovery from evaluation, Phase 3 aims to integrate them into a unified pipeline. This shift is essential for Availability indicators. Unlike text-based evidence (e.g., laws in PDF format) that can be physically stored and transferred between steps, evidence of data availability—often involving live web interactions or system functionality—cannot be easily “physicalized” for downstream processing. Thus, evaluating these indicators requires an end-to-end approach, where the AI agent assesses the evidence in situ immediately upon discovery.
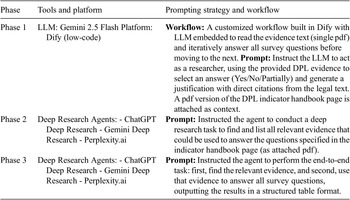
Our tool selection was guided by two core principles: prioritizing publicly available, off-the-shelf solutions to ensure relevance to the technological landscape of June–July 2025, and adapting these tools to the evolving complexity of the assessment tasks (Table 2 details the specific technical setup).
Tools and configuration by research phase

Table 2. Long description
The table has three columns labeled Phase, Tools and platform, and Prompting strategy and workflow. Row one, Phase 1: Tools and platform is L L M Gemini 2.5 Flash, Platform Dify low-code. Prompting strategy and workflow states Workflow is a customized workflow built in Dify with L L M embedded to read the evidence text single p d f and iteratively answer all survey questions before moving to the next. Prompt instructs the L L M to act as a researcher, using the provided D P L evidence to select an answer Yes, No, or Partially and generate a justification with direct citations from the legal text. A p d f version of the D P L indicator handbook page is attached as context. Row two, Phase 2: Tools and platform is Deep Research Agents, including Chat G P T Deep Research, Gemini Deep Research, and Perplexity dot a i. Prompting strategy and workflow states Prompt instructed the agent to conduct a deep research task to find and list all relevant evidence that could be used to answer the questions specified in the indicator handbook page as attached p d f. Row three, Phase 3: Tools and platform is Deep Research Agents, including Chat G P T Deep Research, Gemini Deep Research, and Perplexity dot a i. Prompting strategy and workflow states Prompt instructed the agent to perform the end-to-end task, first to find the relevant evidence, and second to use that evidence to answer all survey questions, outputting the results in a structured table format.
For Phase 1, we integrated the Gemini 2.5 Flash API via Dify to automate the assessment of the “Data Protection” indicator across 34 countries, enabling a statistical evaluation of the results. This model was selected as a cost-effective, representative state-of-the-art LLM to test general feasibility. Crucially, its knowledge cutoff (January 2025) predates the release of the GDB second edition (June 2025); this ensures the model possesses no specific memory of the new dataset, although it may retain prior context from the GDB first edition.
For Phases 2 and 3, we engaged the three dominant deep research agents (ChatGPT, Gemini, and Perplexity) to handle complex evidence discovery. Given the nascent state of autonomous research, we adopted a multi-agent cross-validation strategy to mitigate individual model hallucinations. However, the absence of public APIs limited us to conversational interfaces, precluding the large-scale automation seen in Phase 1. Consequently, we shifted to a single-country qualitative case study, focusing on detailed comparisons across agents.
We adopted a straightforward prompting strategy to assess baseline feasibility, deferring detailed optimization and comparison to future research. Table 3 lists the core prompts used in Phase 3, which served as the foundation for the simplified variations used in Phases 1 and 2.
Example prompts used during Phase 3

Table 3. Long description
The table consists of two columns. The left column is titled ‘Prompt for data protection’ and contains a prompt instructing the researcher to identify relevant frameworks in Brazil covering law, policy, and guidance, referencing two uploaded files: G D B underscore D P L underscore Questions and Governance colon Data Protection. The expected output is a detailed table with specific answers, justifications, and working links to evidence, prioritizing frameworks in PDF, plain text, or HTML format. The right column is titled ‘Prompt for land tenure’ and contains a prompt directing the researcher to assess the availability of detailed land tenure information as open data in Brazil, referencing two uploaded files: G D B underscore Land underscore Questions and Availability colon Land Tenure. The output should be a detailed table with specific answers, justifications, and working links, prioritizing official sources that allow data export or programmatic access, with literal interpretation of questions.
4. Findings from a multistage exploration
This section presents the findings from our phased exploration. We begin with a high-level summary that systematically evaluates AI’s feasibility and quality against human responses across the different experimental phases (Table 4). This overview serves as a roadmap to the detailed breakdown of findings from each phase that follows.
Summary of findings on AI feasibility, quality, and implications for democratic legitimacy

Table 4. Long description
The table consists of four columns: Assessment task (phase), AI feasibility and strengths, Observed AI risks and limitations versus human quality, and Implications for democratic legitimacy. From the top row, the first phase is Analysis with predefined evidence. AI shows high feasibility for structured questions with text-based evidence and superior evidence-weaving compared to humans. Risks include low quality on nuanced questions such as group privacy and a tendency toward over-interpretation. Democratic legitimacy is challenged by accountability and transparency issues, as AI’s opaque reasoning and subtle errors undermine verifiability and trustworthiness. The second phase, Evidence discovery, shows high feasibility for text-based evidence and partial feasibility for nontext evidence, with more comprehensive discovery than humans and supplementary context uncovered. Risks are inconsistent results across agents, link inaccuracies, and source incompleteness. Democratic legitimacy is challenged by inclusivity and transparency, as agent selection can introduce systemic bias and privilege certain evidence types. The third phase, End-to-end execution on complex indicators, shows partial feasibility, with AI able to construct novel frameworks and identify ambiguities in human questions. Risks include surface text recognition without functional validation, ineffective strategies for fragmented evidence, and decoupling of analytical quality from discovery reliability. Democratic legitimacy is challenged by accountability, as AI’s inability to synthesize fragmented evidence reliably means outputs cannot be held accountable without intensive human intervention.
4.1. Phase 1: feasibility of automated analysis
Focusing on the Data Protection Legislation (DPL) indicator, we built a workflow to assess 34 countries. The AI was tasked with analyzing the provided legal text and answering the corresponding “Elements” questions. Our analysis revealed an average match rate of 61.76 between AI-generated answers and the original GDB expert data. However, this overall figure masks a significant performance disparity based on question type, as shown in Table 5.
AI versus human answer alignment for DPL indicator by question type

Table 5. Long description
The table has two columns: Question type and Average alignment rate in percent. The first row lists Foundational provisions, Q1 to Q5, with an average alignment rate of 85.55 percent. The second row lists Advanced provisions, Q6 to Q9, with an average alignment rate of 31.62 percent. Foundational provisions show a much higher alignment rate than advanced provisions.
As observed in the results, questions concerning foundational provisions relate to the basic characteristics of a Data Protection Law (DPL), such as the inclusion of data portability. These questions typically involve direct citation of specific clauses, leading to a high degree of alignment between human and AI answers.
In contrast, questions about advanced provisions pertain to cutting-edge issues, such as clauses addressing group privacy or automated decision-making. These topics may not be covered by explicit articles and must instead be inferred from general provisions or addressed by cross-referencing other governance frameworks. Consequently, more significant discrepancies are observed between human and AI responses in these areas.
Crucially, a mismatch did not always indicate an AI error. In several cases, AI systems identified relevant legal provisions across lengthy documents that had been partially overlooked in expert assessments, illustrating the potential value of AI for consistency and quality assurance within hybrid workflows. A detailed review revealed cases where the AI’s interpretation was more accurate than the human assessment, as well as cases where it faltered. Table 6 provides two illustrative vignettes.
Case studies of AI performance in DPL analysis

Table 6. Long description
The first row, anchored at the top, covers Chile (Redress). The AI answer is Yes, justified by citing articles 12, 16, and 23 of Ley 19,628. The human answer is Yes, referencing only article 23. The outcome states AI correction, suggesting AI’s superior evidence-weaving capability in systematically connecting provisions across a lengthy legal document, acting as a quality assurance mechanism for human analysis. The second row, directly below, covers Rwanda (Group Privacy). The AI answer is Yes, justified by over-interpreting ‘corporate body’ as equivalent to ‘group of individuals.’ The human answer is No, correctly understanding that ‘corporate body’ does not cover group privacy. The outcome states human correction, highlighting AI’s weakness in contextual and normative reasoning, performing textual analysis without grasping legal intent, where human expertise remains indispensable.
4.1.1. Key insight
While AI shows high feasibility as an evidence analyzer for structured tasks, its reliability diminishes significantly with increasing conceptual nuance, highlighting the critical need for human oversight in validating complex interpretations.
4.2. Phase 2: potential of automated evidence discovery
This phase of our study tested AI’s ability to find the necessary evidence for a given indicator. We began by assessing whether the agents could successfully identify the correct framework for data protection in Brazil. The result showed that all agents successfully identified the right framework with accessible links.
Interestingly, we observed that all agents could also identify additional but relevant frameworks that complement the main data protection legislation. For instance, the ChatGPT deep research agent reported on “Projeto de Lei n 2.338/2023 – Marco Legal da Inteligência Artificial,” while the Perplexity deep research agent located the “Consumer Protection Code.” These supplementary findings were relevant to the questions of the DPL Indicator, offering valuable additional information, particularly regarding specific aspects like addressing AI decision-making.
When switching to the more complex data sharing indicator, our findings revealed that different AI agents, when faced with a complex task, employ distinct search and content strategies. For instance, Gemini adopted a depth-first strategy, concentrating on Brazil’s personal data laws and using them as the primary framework for its answers. Here, “depth-first” refers to prioritizing a single dominant framework and exploring it in detail, while “breadth-first” refers to scanning multiple frameworks more superficially. Although it also searched for things like Brazil’s open data policies and the Civil Rights Framework for the Internet, these were treated as supplementary to its personal data sharing perspective. In contrast, ChatGPT employed a breadth-first strategy, covering multiple policy frameworks such as internal government sharing policies, AI policies, and personal data laws.
This led to a key observation: no single AI product was able to perfectly cover all types of data sharing frameworks. In fact, the optimal strategy might be to synthesize the searches of multiple agents to determine the final evidence pool.
4.2.1. Key insight
Deep research agents can automate evidence discovery, but their inconsistent search patterns and the risk of incompleteness necessitate a human-in-the-loop approach for curation and validation.
4.3. Phase 3: the challenge of complexity and end-to-end execution
In Experiment 3, our focus was on whether an AI agent could automate end-to-end tasks. We tested four indicators: Data Protection, Data Sharing, Public Procurement, and Land Tenure. The results showed an average mismatch rate of 42% between the AI’s answers and those of human researchers. The lowest mismatch was for Data Protection (19%, or 2 out of 12 questions), while the highest was for Land Tenure (69%, or 17 out of 25 questions).
This outcome suggests that for complex indicators, especially those not based purely on textual evidence, the current use of AI for fully automated, end-to-end evaluation cannot yet achieve high quality.
A closer look at the Availability Indicator reveals how nontextual evidence presents a challenge to current deep research agents. For instance, the GDB requires an assessment of whether data is machine-readable and provides bulk access. We found that the AI read the text on the relevant data website and cited the “API Access” button text as evidence of bulk access. However, as the agent was not equipped to verify link functionality or interact with the interface, it could not assess whether this feature was operational in practice.
4.3.1. Key insight
For complex, multisource, or nontextual indicators, AI’s role shifts from a potential assessor to a first-draft generator. While these findings on complex indicators are primarily derived from an in-depth case study of Brazil, this exploratory example effectively reveals the general challenges current AI agents face with evidence fragmentation and functional validation, pointing the way for future large-scale research.
5. Discussion: rethinking sustainability and legitimacy
It is important to emphasize that the findings presented here are derived from an exploratory pilot rather than a comprehensive validation exercise. The purpose of the analysis is not to generalize about the performance of AI systems across all benchmarking contexts, but to generate empirically grounded hypotheses about the relationship between evidential complexity, normative judgment, and the limits of automation in global assessments. In particular, the observed variation in AI performance across indicators suggests testable propositions regarding when and where AI-assisted approaches may be appropriate, and where human oversight remains indispensable. These propositions invite further systematic investigation, rather than serving as definitive conclusions.
At the same time, the provisional nature of these findings does not diminish their significance. Even in this limited and exploratory setting, the results from our multistage exploration consistently demonstrate that AI is not a neutral tool; its integration into assessment workflows carries significant implications for democratic values (Mittelstadt et al., Reference Mittelstadt, Allo, Taddeo, Wachter and Floridi2016). Its performance is not uniform; it excels at structured, factual tasks but falters when faced with conceptual nuance. Its evidence discovery process can introduce biases, and its analytical methods can lead to factually incorrect conclusions without human validation. As such, the integration of AI into assessment workflows carries significant implications for the democratic legitimacy of the process—impacting its transparency, inclusivity, and accountability. Building on these findings, this discussion delves into the broader implications for human-AI collaboration and proposes a hybrid architecture designed to navigate these complexities.
5.1. From automation to augmentation: defining the role of AI
The appeal of full automation in research is undeniable, promising unprecedented scale and efficiency. Our initial experiments confirmed this potential for highly structured tasks. However, our results systematically reveal the boundaries of a pure automation paradigm. This model begins to fail when faced with several conditions, including conceptual ambiguity, evidence fragmentation, the need for functional validation, and systemic bias.
As seen in the assessment of advanced DPL provisions, AI struggles with nuanced legal concepts that require interpretation beyond literal text. The Land Tenure case further shows that AI lacks effective strategies for synthesizing decentralized evidence into a coherent whole. In addition, the “API button” case illustrates the current limitations of AI agents when not equipped with tools for functional validation. Finally, the inconsistent results from different deep research agents suggest that the choice of tool can itself introduce bias into the evidence base.
These limitations make a compelling case for shifting the paradigm from automation-as-replacement to Augmented Intelligence (Sadiku and Musa, Reference Sadiku and Musa2021; De Felice et al., Reference De Felice, Petrillo, De Luca and Baffo2022). This model does not seek to substitute human judgment but to enhance it with machine-processed, large-scale information. The goal is to free human experts from the toil of data collection and preliminary analysis, allowing them to focus on the higher-order cognitive tasks that AI cannot perform well: strategic planning, contextual sense-making, normative adjudication, and the final, deep synthesis of insights. At the same time, this augmented approach offers a more strategic cost model in response to the sustainability challenges outlined earlier. By automating the most resource-intensive components of measurement, particularly early-stage evidence discovery and structuring, which are often resource-intensive in the GDB workflow, such an approach reduces the financial burden of large-scale assessments and enables more continuous adaptive diagnostics, where human expertise can be allocated to the areas most needed. In this way, benchmarking becomes less a costly snapshot exercise and more a fluid, iterative process capable of capturing change as it unfolds.
5.2. The proposed solution: a hybrid human-AI architecture
Building on the findings above, we propose a Hybrid Human-AI Architecture to address these challenges. This model should be understood as a design hypothesis rather than a validated system, as it is derived from observed breakdown points in the exploratory pilot and informed by governance considerations, rather than from comparative efficiency testing. It abandons the goal of full automation in favor of a partnership that leverages the respective strengths of humans and machines, and it has three core components:
-
1. A dynamic evidence infrastructure: This component directly addresses the goal of inclusivity. It is a living repository of evidence continuously updated by AI agents but also open to participatory validation and supplementation by a community of experts and stakeholders, operating under a model similar to Wikipedia’s peer-review and open contribution mechanisms, but curated by a core team of experts to ensure methodological rigor.
-
2. A dual-track AI processing engine: This dual-track design is a direct response to our findings that AI’s performance is highly contingent on the evidence complexity of the task, thereby enhancing transparency. It employs standardized, controlled workflows for simple, single-document indicators, making the reasoning process more traceable while using adaptive, agent-based assistance to navigate the ambiguities of complex policy combinations and fragmented data sources.
-
3. Multilayered human collaboration and direction: This component establishes final accountability. It reframes the role of human experts beyond simple validation. They act as strategists, context providers, validators, and judges. Humans provide the initial strategic direction (e.g., organizing the analytical framework for complex indicators), enrich the process with contextual knowledge that AI cannot access, and perform the final validation and adjudication of complex cases, ensuring that all outputs are subject to expert human judgment.
5.3. Future research agenda
The adaptive, exploratory methodology employed in this study proved effective for mapping the capabilities of a rapidly evolving technology. The exploratory findings point to a limited set of areas for further investigation:
-
• Technical: How can we design more robust AI agent frameworks for “deep” rather than “wide” evidence gathering? How can we improve the reasoning, uncertainty calibration, and explainability of AI systems in complex analytical tasks?
-
• Applicative and ethical: This area requires a multifaceted approach:
-
– Designing human-AI collaboration: Future work must focus on designing effective mechanisms for human-AI conflict resolution and mutual learning. Our findings suggest that AI can identify potential human oversights, while humans must correct AI’s contextual errors, suggesting a need for systems that support this bidirectional feedback.
-
– Ensuring fairness and inclusivity: How can we ensure the fairness and representativeness of automated evidence discovery? This includes potential risks of language hegemony, where AI may privilege English-language sources, although this was not directly tested in our experiment, and developing governance frameworks for our proposed infrastructure that uphold the data sovereignty of participating nations.
-
– Governing participatory systems: What governance models are needed for a participatory platform? This involves designing arbitration mechanisms to resolve conflicting evidence and creating accessible pathways for experts from low-resource countries to contribute meaningfully.
-
– Defining accountability: How should accountability be defined and distributed in a process heavily reliant on AI-generated content, especially when errors in assessment could have policy implications (see, e.g., Raji et al., Reference Raji, Smart, White, Mitchell, Gebru, Hutchinson, Smith-Loud, Theron and Barnes2020)?
-
5.4. Aligning innovation with structural realities
The broader context of shrinking international funding for data initiatives underscores the urgency of adopting more sustainable and cost-effective methods. Our hybrid model reduces the reliance on manual labor while preserving the analytical depth necessary for credible assessments. However, this model is not resource-neutral; it requires upfront investments in AI infrastructure, workflow design, and capacity building.
To ensure equitable implementation, funders and global institutions must support teams and organizations in gaining access to tools, training, and computational resources. Without such support, there is a risk of reinforcing existing digital divides under the guise of methodological modernization. Critically, the ability to sustain Global South-led and independent assessments of data for the public good would be compromised, as only well-resourced international organizations would be positioned to lead and participate in these processes.
These risks are particularly acute in the absence of adequate support for Global South-led initiatives, further entrenching dependence on well-resourced international actors. Beyond methodological design, the ethical integration of AI into benchmarking requires active attention to power asymmetries in global data production. Countries with limited digital infrastructure or regulatory clarity may be disproportionately penalized by automated systems optimized for high-data environments. Moreover, without transparent mechanisms for error correction and contestation, AI-generated outputs risk reinforcing existing inequities. To mitigate this, participatory evidence infrastructures must not only allow for input but also embed rights to redress, mechanisms for community validation, and pathways to surface situated knowledge that is often excluded from conventional metrics.
To operationalize the proposed model, we recommend a set of actions that build on and reinforce existing Global South-led efforts such as the Global Data Barometer, which is designed and managed by a small, regionally embedded team:
-
• Invest in training programs to develop a new generation of AI-literate policy analysts across the Global South.
-
• Strengthen and expand existing regional hubs—such as those already engaged in the GDB—to deepen participatory benchmarking and enhance localized validation processes.
-
• Create an open repository of benchmark-aligned prompt templates and validated outputs to promote transparency, reproducibility, and collective learning.
In benchmarking contexts, acceptance of AI tools is unlikely to hinge on perfect accuracy. Rather, legitimacy depends on whether outputs are transparent, contestable, and embedded in institutional processes that allow expert judgment to intervene. These conditions are essential not only for trust in individual assessments but for preserving the independence and diversity of global benchmarking efforts as automation becomes more deeply embedded in policy environments. These measures aim not only to enhance the methodological rigor but also to safeguard the independence and diversity of global data assessments in an increasingly automated policy environment.
6. Conclusion
This commentary contributes to ongoing debates about the future of global benchmarking by situating an empirical, domain-specific assessment of the opportunities and limits of AI-assisted measurement within the literature on governance by indicators and accountability. The purpose of this analysis is not to offer definitive or generalizable claims about AI performance, but to advance empirically grounded hypotheses about the relationship between evidential complexity, normative judgment, and the limits of automation in global assessments. By indicating through preliminary findings that AI systems can augment, but not replace, expert judgment, we propose a hybrid Human-AI model to improve the reliability, transparency, and contextual fidelity of global data assessments.
Ultimately, our work responds to two converging trends: the growing pressure to scale research under constrained funding and the increasing centrality of data systems to AI governance. We argue that the measure of success for AI in this context is not simply speed or cost reduction, but whether its application makes the assessment process more transparent, inclusive, and responsive to the public interest (Bright et al., Reference Bright, Ganesh and Ching2022). The Hybrid Human-AI Architecture we propose is a blueprint for achieving this balance, offering a new model for the infrastructure of evidence-based decision-making in the age of AI. For policymakers and funders, it provides a viable pathway for innovation, ensuring that assessment initiatives can adapt and thrive. For the academic community, it contributes an empirical case study and a theoretical framework to the nascent field of AI governance and its intersection with social science research.
The ultimate goal is not to create an automated assessment machine, but to build an Augmented Democratic Intelligence, a concept that resonates with emerging proposals for augmented democracy and democratic AI (Pournaras, Reference Pournaras2020; Koster et al., Reference Koster, Evans, Weidinger, Rauh, Everitt, Pierson and Gabriel2022; Gudiño et al., Reference Gudiño, Grandi and Hidalgo2024). This envisions a future where expert work is empowered by a network of AI-assisted analysts, where human experts set high-level goals and oversee critical junctures, while intelligent agents, supported by dynamic evidence pools, handle real-time monitoring and preliminary analysis. By exploring a potential alternative to expert-only models, our proposal offers a promising direction to protect the continuity and independence of global benchmarking efforts. At the same time, it reinforces the understanding that strong participatory data infrastructures are not optional, but are foundational for equitable AI and inclusive digital governance (Verhulst and Schüür, Reference Verhulst and Schüür2023). This insight must guide both policy and investment decisions in the years to come.
Future research should move beyond theoretical discussions to pilot projects that test different configurations of human–machine collaboration. Such pilots would provide empirical evidence on what types of tasks are best delegated to AI, how human oversight can be institutionalized, and what governance arrangements are necessary to preserve legitimacy. By approaching hybrid benchmarking as both a methodological and a political endeavor, scholars and practitioners can ensure that these tools not only survive but also continue to serve the public good in an era of rapid technological change.
Data availability statement
Experiment output data and the workflow built in Dify can be found on Zenodo: https://doi.org/10.5281/zenodo.17120023 (Fumega and Gao, Reference Fumega and Gao2025).
Acknowledgments
The authors are grateful to the Global Index of Responsible AI (GIRAI) team and to Dr. Johanna Walker (King’s College London) for their valuable exchange of ideas during the experimentation phase of this study.
Author contribution
Conceptualization-Equal: S.F., F.G.; Investigation-Lead: F.G.; Methodology-Equal: S.F., F.G.; Writing – Original Draft-Equal: S.F., F.G.; Writing – Review & Editing-Lead: S.F., F.G.
Funding statement
The second edition of the Global Data Barometer, on which this study is based, was supported by a grant from Canada’s International Development Research Centre (IDRC).
Competing interests
The authors declare none.
Ethical standard
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.






 Open access
Open access
Comments
No Comments have been published for this article.