


1. Introduction
Since Labov’s (Reference Labov1966) seminal work on quantifying rates of rhotic and non-rhotic productions of words by New York City department store clerks, the study of how speakers vary in their use of phonological variables as a function of their role in society has exploded as a way to understand the mechanisms for language change and the cognitive representations underlying linguistic variation. However, sociolinguistics has a long-standing bias towards speech communities in Western – and especially Anglophone – societies (Stanford Reference Stanford2016; Mansfield & Stanford Reference Mansfield and Stanford2017). Yet, in order to find the most generalizable frameworks for understanding the relationships between language variation and stratifications in society, a much broader set of languages and speech communities needs to be examined (Adli & Guy Reference Adli and Guy2022). A compelling example of a phonological variation in an understudied non-Indo-European language is postvocalic r-elision in Tarifit. This paper examines variation in postvocalic r-elision in Tarifit across speakers (social conditioning), in response to dynamic variation produced by an interlocutor (imitation), and social evaluation by listeners (perception). We examine this phenomenon in the current study with respect to its relevance for models of language use and illustration of a phonological change in progress in an under-examined speech community.
1.1. Tarifit
Tarifit (ISO: rif) is an Amazigh (Berber) language spoken by about 1.5 million people in northern Morocco (Lafkioui Reference Lafkioui2018; Mourigh & Kossmann Reference Mourigh and Kossmann2019). Tarifit contains a large consonantal inventory (about 40 consonant phonemes), and only four vowels: /ə/, /i/, /u/ and /a/ (the status of schwa as phonemic is controversial – some argue it is phonemic: Guerssel Reference Guerssel1976; Saib Reference Saib1976; Tangi Reference Tangi1992, while others argue it is epenthetic: Basset Reference Basset1952; Chami Reference Chami1979). Generally speaking, Tarifit can be categorized into two main dialectal sub-groups: Western varieties (spoken around the region of Al-Hoceima) and Eastern varieties (spoken in the region around the city of Nador) (Lafkioui Reference Lafkioui2007). The dialect that is the focus of the current work is spoken in and around the city of Nador. This dialect is referred to as θaqərʔaft, or Guelaya.
In Guelaya Tarifit, the realization of coda /r/ is optional when preceded by /a/ (and when not preceded by another vowel) i.e., /r/ → Ø/a _ # or C (Tangi Reference Tangi1992; Amrous & Bensoukas Reference Amrous, Bensoukas, Boumalk and Ameur2004, Reference Amrous and Bensoukas2006; Lafkioui Reference Lafkioui2011; Mourigh & Kossmann Reference Mourigh and Kossmann2019). For example, /aðrar/ ‘mountain’ can be pronounced either as ‘r-ful’ [aðrar] or ‘r-less’ [aðra]. There has been some work describing the phonetic realization of vowels in r-ful and r-less forms. In particular, several researchers have demonstrated that postvocalic /r/ deletion results in phonetic vowel changes in the preceding vowel, resulting in compensatory lengthening, diphthongization, lowering, and/or backing, depending on the specific dialect (Amrous & Bensoukas Reference Amrous, Bensoukas, Boumalk and Ameur2004; Lafkioui Reference Lafkioui2007). Thus, r-elision is not merely segmental but also can have phonetic consequences for the preceding vowel. As described in Lafkioui (Reference Lafkioui2007), the deletion of postvocalic /r/ can result in longer or phonetically distinct vowels, depending on the dialect. Post-vocalic r-elision is assumed to be a case of a change in progress in Tarifit, and subject to ongoing phonetic and cross-dialectal variation (Lafkioui Reference Lafkioui2007). Yet, to our knowledge, there have been no quantitative reports of the distribution of rates and patterns of r-elision across speakers of Tarifit and its role in indexing social meaning.
Some phonological and historical facts about Tarifit interact in interesting ways with rhoticity. For one, in this dialect of Tarifit, there has also been a historical merger in which earlier instances of the lateral approximant /l/ are now realized as /r/ (i.e., *l → /r/). In cases where this has happened, derhoticization does not apply. Also, in some more recent loanwords from Arabic, postvocalic r-elision does not occur (e.g., Arabic /el-fal/ ‘the omen’ → Tarifit /erfar/ [erfar], but *erfa). Arabic loanwords that historically contain /r/, however, are subject to postvocalic /r/ deletion: e.g., Arabic /s-sərwal/ ‘pants’ → Tarifit [ssarwər] ∼ [ssawər]. These examples illustrate that r-elision is lexically-specific in Tarifit, and one of several sound changes that affect liquid consonants in the language.
In the present study, though, we focus on variation in Tarifit words where r-elision can take place. One question investigated in the current study is what the rates of postvocalic r-dropping in Guelaya Tarifit are. Following the variationist approach to quantifying differences in rates of production of a phonological variable across individuals in a speech community (Labov Reference Labov1966), we ask more specifically whether r-elision is socially stratified in Tarifit. We predict that speakers from different social groups produce different rates of rhoticity, focusing on speaker gender and age, two highly robust variables that have been shown to condition phonological variation for ongoing sound changes across languages of the world (e.g., Eckert Reference Eckert1989; Medina-Rivera Reference Medina-Rivera and Díaz-Campos2011; Guy Reference Guy, Brian and Richard2017).
We focus on postvocalic /r/ in Tarifit because it represents a salient and socially variable phonological feature in the language. Rhoticity has been extensively studied in sociolinguistics due to its sensitivity to social factors such as gender, class, and age (Labov Reference Labov1966; Romaine Reference Romaine1981). In Tarifit, /r/ is particularly interesting because it interacts with historical sound changes (e.g., *l > r merger), shows dialectal variation, and is subject to optional deletion in specific phonological environments. These features make it an ideal candidate for investigating socially conditioned phonological variation in an understudied language. It is also important to note that Tarifit, like other Amazigh varieties, lacks a widely used formal or standardized written register. While efforts have been made to standardize Amazigh languages (e.g., IRCAM initiatives), most speakers use Tarifit primarily in oral contexts. This sociolinguistic reality may influence the salience and social indexing of phonological variants like /r/, as speakers rely more heavily on spoken cues for identity and social positioning. The absence of a standardized register also underscores the importance of studying variation in naturalistic speech settings.
Describing the social stratification of rhoticity in Tarifit can provide a test to some of the foundational principles of variationist sociolinguistics. Social dynamics can vary in small and endangered speech communities. Understanding how phonological variation and change diffuse in languages such as Tarifit can contribute to sociolinguistic and phonological theory, by challenging ideas about how socially conditioned variation works that are based only on western and large language communities. This paper is also part of growing work emphasizing the importance of documenting and examining variation in understudied languages, which can bolster the generalizability of variationist frameworks (e.g., Stanford Reference Stanford2016).
1.2. Variation in postvocalic /r/ across languages and speakers
Understanding how and why pronunciations of words vary within a speech community is the main focus of the field of variationist sociolinguistics (Labov Reference Labov1966, Reference Labov2001). Outlining the factors that condition phonological variation across speakers, and over the course of an interaction, is an area of interest for psycholinguistics and cognitive science, more broadly (Pickering & Garrod Reference Pickering and Garrod2004). Postvocalic /r/ dropping is one of the most highly studied sociolinguistic phonological variables for English dialects. In fact, classic variationist studies, from which the foundational principles of the field of sociolinguistics have been established, are based on quantitative analyses of rhoticity. In his seminal study, Labov (Reference Labov1966) investigated the social stratification of postvocalic /r/ in New York City English. He found that store clerks in department stores with more upper- and middle- class clientele were more likely to produce r-ful forms of words than those interacting with working-class shoppers. For instance, the decades of research since Labov (Reference Labov1966) on variation in postvocalic /r/ across dialects of English have shown that its patterning can be incredibly socially complex across speech communities. For instance, in Scotland, middle-class speakers are producing more r-ful variants while working class speakers become more derhoticized over time (Romaine Reference Romaine1981; Stuart-Smith Reference Stuart-Smith, Kortmann and Upton2008).
Quantitative analysis of rhoticity actually has advanced sociolinguistic theory in understanding the relationship between speech variation and social stratification of individuals. Coda liquid deletion is a commonly observed process cross-linguistically, often with robust social conditioning: e.g., [ɾ] coda deletion is more commonly produced by male speakers in Cartagena, Colombian Spanish (Vergara & Fernanda, Reference Vergara and Fernanda2024), and Puerto Rican Spanish (Beaton Reference Beaton2015), and by younger, working-class male speakers in Buenos Aires (Gilbert & Rohena-Madrazo Reference Gilbert, Rohena-Madrazo and Ruth2017); rhotic coda deletion is more common in child- than adult-directed speech in French (Peperkamp et al. Reference Peperkamp, Hegde and Julia Carbajal2019); derhoticization of coda /r/ is also a feature of Modern Dutch (Vieregge & Broeders Reference Vieregge and Broeders1993; Van den Heuvel & Cucchiarini Reference Van den Heuvel, Cucchiarini, van de Velde and van Hout2001), and there is robust cross-regional and cross-speaker variation (Plug & Ogden Reference Plug and Ogden2003; Scobbie et al. Reference Scobbie, Wyke and Dixon2009).
The phonetic explanations for coda liquid deletion can explain why it is such a common cross-linguistic historical process. Coda derhoticization is part of a general trend of liquid coda deletion found cross-linguistically and one common form of gestural weakening of codas, with articulatory motivations that sonorants in weak syllable positions are susceptible to lenition (Browman & Goldstein Reference Browman and Goldstein1992). The phonetic motivations for coda rhotic deletion are also found in child speech: liquid codas are often late-acquired by children, cross linguistically, due to their articulatory complexity (Song & Demuth Reference Song and Demuth2008; Lin & Demuth Reference Lin and Demuth2015).
As outlined in section (1.A), Tarifit has postvocalic r-dropping. While there is some prior work outlining its variation in phonetic realization across dialects of Tarifit (Amrous & Bensoukas Reference Amrous, Bensoukas, Boumalk and Ameur2004; Lafkioui Reference Lafkioui2007), there is no study to our knowledge quantifying differences in derhoticization across speakers. In the current study we examine variation in postvocalic r-dropping across speakers varying in age (younger adults – below 40 years old – and older adults – above 40 years old) and gender (female and male).
1.3. Imitation of rhoticity in Tarifit
In addition to how speakers vary in rates of postvocalic /r/ in Tarifit at ‘baseline’, we also ask whether interaction with another speaker who varies derhoticization influences production. There is much prior work demonstrating that when talkers interact, they converge in their speech and language patterns (known as alignment, convergence, or imitation). Many researchers propose that alignment functions to facilitate linguistic processing and enhance communicative effectiveness (Garrod & Doherty Reference Garrod and Doherty1994; Pickering & Garrod Reference Pickering and Garrod2004; Pardo Reference Pardo2006). Yet, alignment can be also conditioned by social characteristics between interlocutors, including gender (Natale Reference Natale1975; Babel Reference Babel2012), regional affiliation (Bourhis & Giles Reference Bourhis, Giles and Giles1977; Giles et al. Reference Giles, Taylor and Bourhis1973) and attractiveness (Babel Reference Babel2012). This has led researchers to propose that alignment can be used during conversational interaction to achieve social goals, such as signal interpersonal distance (e.g., Communication Accommodation Theory (CAT): Shepard et al. Reference Shepard, Giles, Le Poire, Robinson and Giles Chichester2001; Giles & Powesland Reference Giles and Powesland1975; Giles et al. Reference Giles, Coupland, Coupland, Howard Giles and Coupland1991).
Whether socially-conditioned allophonic variation is imitated in Tarifit can speak to the underlying mechanisms for linguistic alignment. For example, Mitterer and Ernestus (Reference Mitterer and Ernestus2008) explored this by observing whether Dutch participants, who produced the rhotic as either the alveolar or the uvular trill, aligned toward an interlocutor who produced nonwords containing variants of the two allophones of /r/. They found speakers do imitate their non-habitual phonological variant. They did not look at whether social conditioning of rhotic variation conditions phonetic imitation in Dutch. We explore this in the current study. Do Tarifit speakers also imitate rhotic or non-rhotic productions of words?
Laboratory phonetic imitation tasks are also one approach to investigate how sound change spreads and diffuses across speakers (Garrett & Johnson Reference Garrett and Johnson2011; Babel Reference Babel2012; Harrington & Stevens Reference Harrington and Stevens2014; Nguyen & Delvaux Reference Nguyen and Delvaux2015). For instance, Pinget (Reference Pinget2022) looked at phonetic imitation of labiodental fricative devoicing in Dutch, a highly advanced sound change. They found that Dutch speakers who exhibit the highest rates of the innovative phonological variant use are the most likely to spontaneously imitate when a speaker produces conservative forms of words. Does imitation of rhoticity follow similar patterns of social conditioning. For example, does the group that produces the highest rate of non-rhotic variants most or least likely to imitate rhoticity?
1.4. Social evaluation of postvocalic r-elision
Since phonological variables like r-elision can be highly socially stratified, researchers have also examined listeners’ subjective reactions to speakers who produce different speech patterns. Labov (Reference Labov1972) played recordings of speech to American English listeners and asked them to make evaluations about the talker, such as guess the professions of the speakers they heard. He found that listeners are more likely to say that rhotic talkers had higher-status occupations and also sounded ‘better’ than non-rhotic talkers. Robust social evaluations of rhotic talkers have also been reported in other English regions where it varies across speakers, such as Massachusetts (Babcock Reference Babcock2014), New Hampshire (Stanford Reference Stanford2019), and Scotland (Wiemann Reference Wiemann2024).
Thus, in order to comprehensively investigate the status of postvocalic r-dropping in Tarifit, we designed a study testing the perceptual evaluation of rhotic and non-rhotic productions of words by listeners. Most Tarifit speakers have metalinguistic awareness of postvocalic rhoticity as a variable form of words in the language. For instance, in our related work (Afkir & Zellou, to appear), we report (in section 4.4.3) the results of Tarifit speakers’ responses to an open-ended question about r-dropping and most reported awareness of the variable. Does non-rhoticity index distinct social characteristics of talkers? In the current study, we investigate this question. Our aim is a comprehensive description of both the production and perception of rhoticity in Tarifit. Many researchers point out that understanding how sound patterns emerge and evolve in a speech community depends on complex social factors, and the relationship between language use and language attitudes for a particular linguistic variation (Grenoble & Whaley Reference Grenoble and Whaley2005). Thus, by examining the perception of derhoticization in Tarifit, we contribute a rich understanding of the interplay between the production and perception of this ongoing sound change in an understudied language.
1.5. Current study
The present study was designed to investigate the specific research questions raised above about the social conditioning of postvocalic /r/ in a Tarifit speech community. Past work has identified postvocalic r-elision as an innovative phonological process in Tarifit (Amrous & Bensoukas Reference Amrous, Bensoukas, Boumalk and Ameur2004), yet that there is cross-speaker variation (Lafkioui Reference Lafkioui2007). However, no prior work to our knowledge has explored the social factors conditioning its variation. We ask three specific questions, across three different experiments. First, in Experiment 1, we investigate whether postvocalic r-elision is socially conditioned in Tarifit, specifically comparing rates of rhotic and non-rhotic productions based on speaker gender and age. Second, Experiment 2 tests whether speakers imitate an interlocutor’s variable use of postvocalic /r/. Finally, Experiment 3 explores the social evaluation of a speaker when they produce rhotic and non-rhotic variants of words. The paper contributes to documenting variation and change in an understudied, endangered, small speech community. Moreover, looking at cross-linguistic socially-conditioned phonological patterns can speak to fundamental theoretical issues of how sound patterns change and diffuse over time in a speech community and add to the generalizability of variationist frameworks across languages and cultures.
2. Experiment 1. Social factors conditioning postvocalic /r/
2.1. Methods
2.1.1. Participants
30 native speakers of Tarifit participated in Experiment 1. They were recruited in Nador and reported growing up and living in Nador at the time of the study. Subjects completed informed consent before participating. The study was approved by the UC Davis Institutional Review Board.
Participants varied in reported age (range = 50 years old; mean = 35 years old) and gender (11 female, 19 male; note that while we aimed for balance across demographic groups, we found it difficult to recruit an equal number of women and men participants, and an equal number of older and younger speakers, due to the makeup of our social networks in Morocco). The demographic characteristics of the speakers are provided in Table 1. Following the apparent-time construct (Bailey et al. Reference Bailey, Wikle, Tillery and Sand1991), we grouped participants into age categories of ‘younger’ (< 40) and ‘older’ (≥ 40), following a main significant generational split in Moroccan society. In addition to Tarifit being their first language, all speakers reported speaking Arabic, and most reported speaking at least one other language (French: n = 22; English: n = 13; Spanish: n = 4).
Demographics of the Tarifit participants.

2.1.2. Procedure and materials
The task for Experiment 1 consisted of an oral translation task. Recordings were done in a quiet room in Nador, Morocco, using a head-mounted microphone (Shure WH20XLR) and digitized at a 44.1 kHz sampling rate.
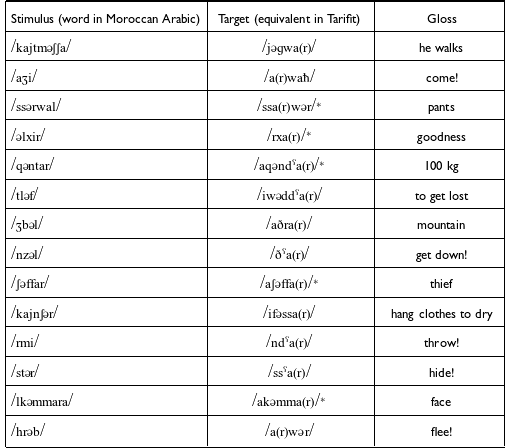
Speakers produced 14 Tarifit words that contain the condition for postvocalic r-elision (i.e., a coda /r/ following the low vowel /a/). The target words could not be presented in written form – since providing an orthographic representation of the words would mean explicitly writing the ‘r’, we were concerned that this might bias speakers to produce r-ful productions. Therefore, a task was designed where participants heard a recording of a word in Moroccan Arabic and then were instructed to provide a translation of the word in Tarifit (thus, producing one of the words with an r-elision context).
First, participants heard an audio clip containing the interlocutor’s introduction and experiment instructions. In the introduction, the interlocutor explained that they are a robot who is learning the Tarifit language. Then, another audio clip was presented to the participants providing instructions for the study. The robot said that they know some words in ‘Darija’ (Moroccan Arabic), but they want to learn what the words are in Tarifit. So, participants will hear the robot say a word in Darija and then they should respond with the equivalent word in Tarifit. The scripts for the introduction and instructions used in this experiment are provided in the Supplementary Materials, along with an English gloss.
Following the introduction and instructions, participants completed Experiment 1. In each trial, speakers were first presented auditorily with the interlocutor’s recording of a word in Moroccan Arabic, a language which Tarifit speakers speak fluently as a second language, and were asked to say its equivalent in Tarifit. The target Tarifit words were designed to contain an optional /r/ following a full vowel /a/. (List of Moroccan Arabic stimuli and Tarifit target word equivalent is provided in Table 2). For instance, participants would hear a recording of a speaker producing the Moroccan Arabic word /aʒi/ ‘come!’ and then they were instructed to provide the corresponding Tarifit word, so here they would say /arwaħ/ ‘come! (variably as [arwaħ]∼[awaħ]). We did not provide any instructions or guidance on speaking style in this task and participants produced each of the 14 rhotic words in isolation (no frame sentence) only once in this task.
Stimuli for the oral translation task. Forms in Tarifit showing the /r/ in parentheses indicate it is optionally present as a result of postvocalic r-elision. An asterisk indicates borrowing from Moroccan Arabic.

For the interlocutor, we recorded a male native Tarifit speaker in a sound attenuated booth producing all the instructions in Tarifit and the stimulus words in Moroccan Arabic. These sound files were digitized at a 44.1 kHz sampling rate, amplitude normalized to 65 dB, and presented to participants in the experiment via a Qualtrics survey.
2.1.3. Rhoticity coding
Each token was coded by two human raters as either r-ful or r-less, following prior work on English categorical rhoticity coding (e.g., Nagy & Irwin Reference Nagy and Irwin2010; Becker Reference Becker2009). The raters were native English speakers, phonetically trained coders. Since postvocalic /r/ variation is present in American English dialect variation, the coders had no trouble applying their coding of tokens as r-ful or r-less from English to a non-native language. While native Tarifit speakers may have intuitive familiarity with rhoticity in their language, our goal was to ensure consistency and replicability in coding across tokens using established phonetic criteria. Additionally, recruiting phonetically trained Tarifit coders was not feasible. Coding consistency was ensured through iterative training and discussion, resulting in strong agreement across raters. Coders demonstrated high concordance in identifying linguistic variants, with only minor discrepancies resolved through consensus.
Since /r/ is realized as a tap, flap, or trill in Tarifit, it was also sometimes visually clear through examination of the waveform and spectrogram of a target word production whether /r/ was present (or not). Figure 1 provides examples of a word produced with and without r-elision. In the top image, /arwər/ is produced as r-ful, [arwər]; in the bottom image, /arwər/ is produced with non-rhoticity as [awər].
Top: /arwər/ produced with post-/a/ /r/ as [arwər]; Bottom: /arwər/ produced with non-rhoticity as [awər].

Following standard practice, we omitted tokens where the two coders disagreed (indicating those were ambiguous tokens). Sometimes, speakers repeated words twice in a given trial. Both of these productions were recorded and coded. In total, we collected 434 target Tarifit word productions from the 30 speakers in Experiment 1. After omissions of ambiguous productions, our data set consisted of codings from 409 tokens from 30 speakers.
All the supplementary materials, data, models, and code are available for the current study in the Open Science Framework (OSF) repository for the project.
2.2. Results
Figure 2 plots the results for mean proportion of r-fulness in productions of target words in Tarifit by speaker age group and gender. We ran a mixed effect logistic regression in R using the glmer() function in the lme4 package (Bates et al. Reference Bates, Mächler, Bolker and Walker2015). The model was run on binary rhoticity coding (1 = produced /r/, 0 = dropped /r/) and included fixed effects of speaker gender (female vs. male), speaker age group (older vs. younger), and their interaction. The model also included a fixed effect for whether the word was a native Tarifit word or a Moroccan Arabic cognate (sum-coded). By-participant and by-word random intercepts were also included in the model. The full model output is provided in the Supplemental Materials (in the OSF page, along with the data and code).
Rates of postvocalic /r/ presence in productions of Tarifit target words across speaker age and gender groups. Points represent individual speaker means. Error bars represent 95% confidence intervals.

Rates of postvocalic /r/ presence in productions of across Tarifit words with a Moroccan Arabic cognate containing /r/ and not. Points represent individual item means. Error bars represent 95% confidence intervals.

The model computed an effect of speaker gender (Estimate = –1.4, SE = 0.5, z = –2.7, p < 0.01). As seen in Figure 2, women produce lower rates of postvocalic /r/ than men. There was not an effect of age group (p = 0.9) and there was not an interaction between gender and age (p = 0.5).
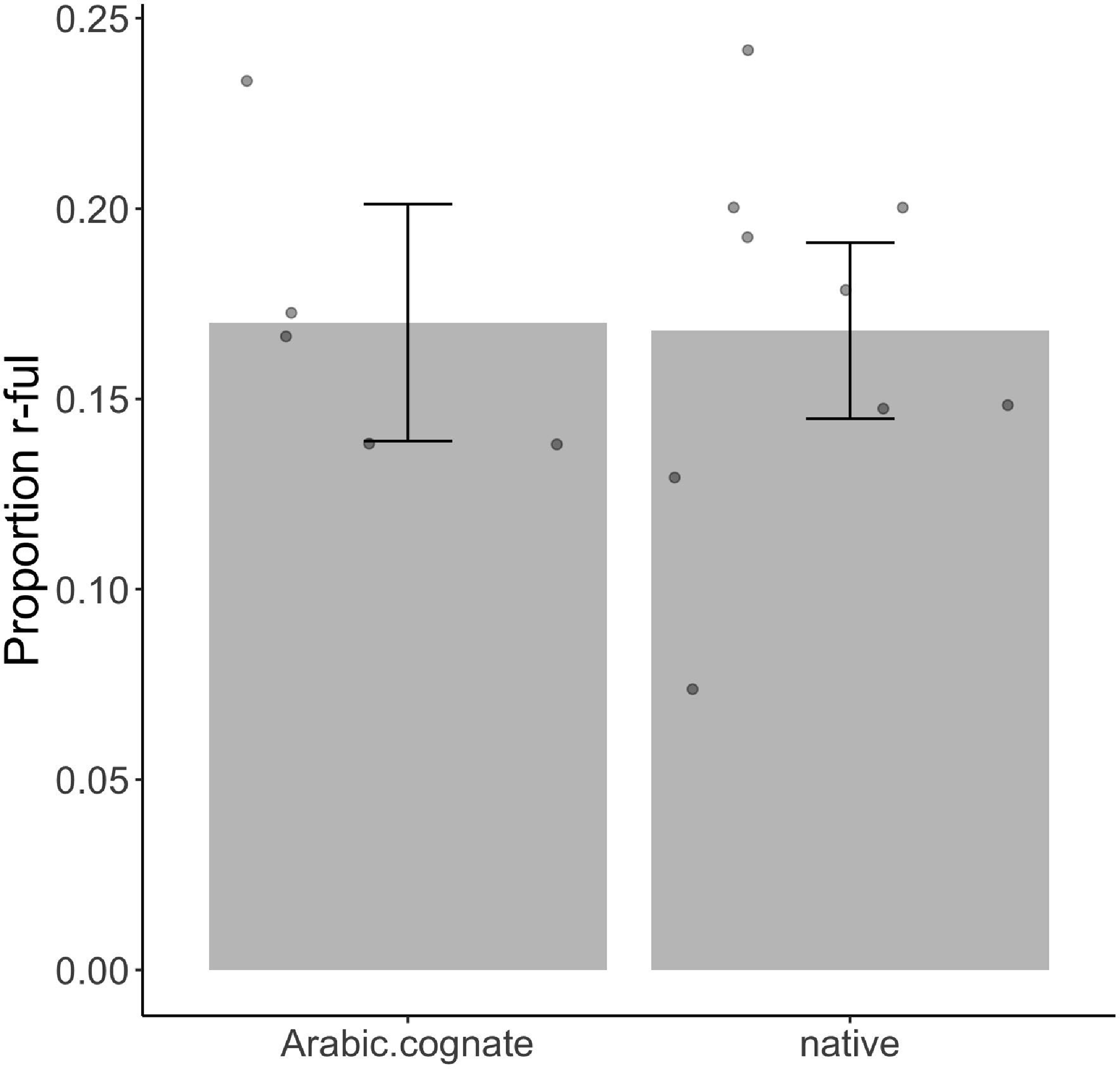
No other effects or interactions were significant. There was not an effect of word type on rates of rhoticity. This is illustrated in Figure 3. In other words, even when participants heard the interlocutor produce an Arabic cognate of the word that contained a pronounced /r/, they were not more likely to drop /r/ compared to when they were producing a native Tarifit lexical item.
3. Experiment 2. Accommodation toward postvocalic /r/
3.1. Methods
3.1.1. Participants and procedure
The same 30 participants who completed Experiment 1 participated in Experiment 2. They completed Experiment 2 directly after finishing Experiment 1.
At the beginning of Experiment 2, participants were instructed that they would now hear the robot say the words from Experiment 1 in Tarifit. In the Supplementary Materials, the scripts and responses presented to the participants are provided in Tarifit with English translations. In each trial, participants heard the robot say a word in Moroccan Arabic, followed by what they learned is the equivalent word in Tarifit. Participants were instructed to repeat the word if the robot was correct, but provide the accurate response if the robot was incorrect.
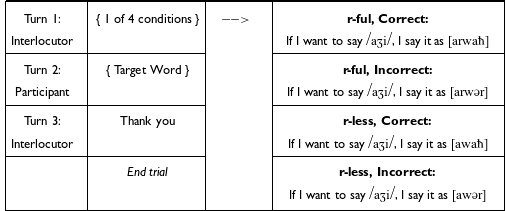
Across the trials, the robot’s Tarifit word productions varied to be either r-ful or r-less (balanced equally across trials) and either the correct or incorrect Tarifit translation (balanced equally across trials). Each trial proceeded as a multi-turn interaction with the robot across one of these 4 conditions. Table 3 provides an English-translated schematic of the trial structure and examples illustrating the different response conditions.
Sample dialogue of Experiment 2 trials.

The interlocutor’s productions were recorded as individual sound files, digitized at a 44.1 kHz sampling rate, amplitude normalized to 65 dB, and presented to participants in the experiment via a Qualtrics survey. Participants’ recordings were done in a quiet room in Nador, Morocco, using a head-mounted microphone (Shure WH20XLR) and digitized at a 44.1 kHz sampling rate.
Participants completed 16 trials in Experiment 2 (half correct, half incorrect; half r-ful, half r-less; fully crossed).
3.1.2. Rhoticity coding
We coded all participants’ productions in Experiment 2 as r-ful or r-less following the same procedure as in Experiment 1. After omissions, there were 433 tokens from the 30 participants who completed Experiment 2.
Rates of postvocalic /r/ presence in productions of Tarifit target words across speaker gender for different production conditions: baseline (Experiment 1), following the interlocutor’s r-less production, and following the interlocutor’s r-ful production. Points represent individual speaker means for each condition. Error bars represent 95% confidence intervals.

3.2. Results
3.2.1. Comparing r production rates across Experiments 1 and 2
First, we investigated whether rates of r-fulness varied across Experiment 1, before the speakers are exposed to productions of Tarifit words by the interlocutor, and Experiment 2, following interactions with an interlocutor when they produce r-ful vs. r-less target words. To that end, we ran a mixed effect logistic regression model on the combined data from both Experiments 1 and 2. Experiment 1 productions can be considered a ‘baseline’ production condition, reflecting speakers’ /r/ dropping behavior without hearing an interlocutor’s production patterns of /r/ in Tarifit. Thus, for this analysis, we re-labeled Experiment 1 productions as a Baseline Condition, and productions in Experiment 2 following the interlocutor’s production of target words as r-less and r-ful as two additional comparison levels. Our model included this predictor, Condition, which consisted of three levels and was treatment-coded with Baseline set as the reference level. The model also included speaker age (female vs. male, sum-coded) and speaker age group (older vs. younger, sum-coded), as well as two-way interactions between gender and condition and age group and condition (three-way interactions lead to convergence errors). A fixed effect of word nativeness (native vs. Moroccan Arabic borrowing) was also included in the model (sum-coded), as well as the interaction between word nativeness and Condition. By-speaker and by-word random intercepts were also included in the model. We additionally included by-speaker random slopes for word nativeness, but that led to a convergence error, so it was removed. The full model output is provided in the Supplementary Materials.
Figure 4 plots the mean rates of r-ful productions of target words across conditions for female and male Tarifit speakers. The model computed a main effect of speaker gender. As in Experiment 1, females produce overall fewer r-ful productions than men (Estimate = –1.4, SE = 0.4, z = –3.1, p < 0.01). The model also revealed that, relative to Baseline productions, target words are more likely to be produced as r-ful after the interlocutor produced r-ful items (Estimate = 0.99, SE = 0.4, z = 2.9, p < .05). This can be seen in Figure 4: Tarifit speakers’ r-fulness increases after the interlocutor produces r-ful words.
There was not an effect of word nativeness on rates of r-fulness. No other effects or interactions were significant.
3.2.2. Comparing r production rates across conditions within Experiment 2
Next, we analyzed just the post-interlocutor productions to examine whether participants produced more or less r-elision following correct or incorrect word translations. Note that the interlocutor’s and participants’ target words were not matching in the incorrect response type trials (e.g., the interlocutor makes a ‘mistake’ for the Tarifit equivalent of a Moroccan Arabic word and the participant responds with a correction). So, any alignment in /r/ production for these trials would reflect a generalization of the production pattern, not a veridical imitation of the word form.
We analyzed participants’ r-ful responses using a mixed effects logistic regression. The model included fixed effects of participant gender, participant age category, interlocutor r-ful type (r-ful vs. r-less), and interlocutor response type (correct vs. incorrect). All effects were sum-coded. The model also included all possible two-way interactions between gender, age, interlocutor r-fulness, and interlocutor response type. Random effects consisted of by-participant and by-word random intercepts, in addition to by-participant random slopes for interlocutor r-fulness and interlocutor response type. The full model output is provided in the Supplementary Materials.
The model revealed an effect of gender; as in all the previous models, females produce lower rates of r-ful Tarifit words than males (Estimate = –0.8, SE = 0.4, z = –1.9, p < 0.05). There was also an effect of interlocutor r-ful type: participants are more likely to produce r in target words when the interlocutor’s production contains an /r/ (Estimate = –0.7, SE = 0.3, z = –2.4, p < 0.05). No other effects or interactions were significant.
Figure 5 plots the rates of r-fulness in participants’ productions of target words following the different interlocutor response conditions, which illustrates the effect of interlocutor r-fulness. As seen in Figure 5, speakers produce more r-ful productions after the interlocutor produces r-ful target words. This effect is equivalent across correct and incorrect response types. In other words, even when the interlocutor produces a different target word, but the word contains r, speakers respond with a r-ful production. Thus, speakers align toward r-fulness in Tarifit in generalized, rather than word-specific, ways.
Rates of postvocalic /r/ presence in productions of Tarifit target words across speaker gender for different interlocutor conditions: Interlocutor’s r-presence (following the interlocutor’s r-less production vs. following the interlocutor’s r-ful production) and Interlocutor’s Response Type (correct vs. incorrect response). Points represent individual speaker means for each condition. Error bars represent 95% confidence intervals.

3.3. Interim Discussion of Production Experiments and Post-hoc survey
Our production studies revealed three key findings. First, overall, speakers’ rates of rhoticity in the Nador (Guelaya, or θaqərʔaft) dialect of Tarifit are high: in our full dataset of productions, r-ful variants occur in about 18% of productions. Second, there is variation across speaker groups: women produce, on average, only 9% r-ful target words while men produce about 24% r-ful productions. Third, speakers are more likely to produce the more conservative r-ful form of words after just hearing an interlocutor produce r-fulness (whether in the same or different word). Thus, r realization is highly social in Tarifit – affected by speaker and interlocutor factors.
The final research question we raised in the introduction about rhoticity in Tarifit is whether Tarifit speakers had any explicit attitudes or intuitions about what types of speakers produce /r/. Before designing a carefully controlled perception study, we first conducted an exploratory qualitative survey. After completing our production studies, we asked the participants from Experiments 1 and 2 to tell us if they had any comments or discussion about /r/ production in Tarifit. Most of our Tarifit speakers did provide responses which suggest that /r/ variation is socially conditioned. In particular, their responses pointed to r-fulness being associated with geographic or generational differences across speakers. None of the participants mentioned gender as a factor that correlates with r-elision. Given the responses from participants in the post-hoc survey to the production studies, we designed a perception study to systematically assess social evaluations of r-elision and r-fulness.
4. Experiment 3. Social attitudes toward postvocalic r-dropping
4.1. Methods
4.1.1. Participants
The experiment was presented to participants via a Qualtrics survey and distributed online to Tarifit listeners. Thirty-one native Tarifit listeners completed the study (17 female, 0 non-binary/other, 14 male; mean age = 39.2 years old, age range = 18–62). This was an independent group of participants than those who completed Experiments 1 and 2. All the participants reported that Tarifit was their first language. Participants also reported that they spoke other languages, including Classical Arabic (all instructions were provided in written Arabic) and Moroccan Arabic.
The listeners were recruited through email flyers. All participants completed informed consent before participating. None of the listeners reported having a hearing or language impairment. Participants were instructed to complete the experiment in a quiet room without distractions or noise, to silence their phones, and to wear headphones. The study was approved by the UC Davis Institutional Review Board.
4.1.2. Stimulus Materials
We had a native speaker of Tarifit (male) produce 6 of the target words (we selected only the bisyllabic target words which contain greater phonological content for listeners to find the words most intelligible when presented in isolation). The speaker produced both r-ful and r-less forms of each target word. The speaker (the first author of this paper) is a phonetically trained linguist and is able to naturally produce both r-ful and r-less forms of words. The recordings were made in a sound attenuated booth and digitized at a 44.1 kHz sampling rate, amplitude normalized to 65 dB.
Since we recruited participants via email flyers through our social networks, we were concerned listeners might recognize the identity of the speaker and that would bias their responses in the social attitudes survey. Therefore, we modified the voice, using the change gender function in R, to contain the formant frequency and pitch characteristics of a smaller talker. This resulted in a voice that was not identifiable as the original speaker by acquaintances.
In addition to the 6 target words, we also recorded and included 5 filler items that did not contain underlying rhoticity (e.g., /bkəm/ ‘shut up’).
4.1.3. Procedure
On each trial, listeners heard one of the stimulus items. They were then presented with three rating scales showing the three attitudinal dimensions. They were asked to provide a rating of the speaker for each of the three scales, ranging from 0–100.
The first response asked listeners to provide a ‘solidarity’ rating of the speaker. In this case, we asked listeners ‘how nice does the speaker seem?’ (the actual instructions were provided in Arabic: ![]() ) and the scale ranged from 0 (= not nice) to 100 (= nice). The second rating response asked listeners to assess how educated the speaker sounds (
) and the scale ranged from 0 (= not nice) to 100 (= nice). The second rating response asked listeners to assess how educated the speaker sounds (![]() ), from 0 (= uneducated) to 100 (= educated). The third response scale asked participants to rate the speaker on their rural or urban affiliation (specifically, ‘how urban does this speaker sound?’;
), from 0 (= uneducated) to 100 (= educated). The third response scale asked participants to rate the speaker on their rural or urban affiliation (specifically, ‘how urban does this speaker sound?’; ![]() ), with ratings from 0 (= rural) to 100 (= urban).
), with ratings from 0 (= rural) to 100 (= urban).
4.2. Results
We modeled the 31 listeners’ responses to the social evaluations using a linear mixed effects regression model. The model included fixed effects of /r/ variant type (r-less, r-ful), Attitudinal dimension (Geography, Education, Solidarity), and the interaction between them. By-listener and by-item random intercepts were included, as well as by-listener random slopes for variant type and attitudinal dimension.
Figure 6 plots the mean social evaluations across Attitudinal dimensions for r-ful and r-dropped variants of words. The model revealed a significant effect of Variant type on listeners’ social ratings: r-dropped productions are given overall higher social evaluations on all dimensions (est. = 6.1, t = 2.1, p < 0.05). There were no effects of attitudinal dimension and no interactions between variant and dimension.
Mean ratings scores for the three attitudinal dimensions of r-less and r-ful forms of the target words. Points represent individual listener means for each condition. Error bars represent 95% confidence intervals.

5. General Discussion
The current study examined quantitative patterns of postvocalic r-elision in Tarifit, a Moroccan Amazigh language, based on social factors of speakers and interlocutors. Documenting and investigating sociolinguistic variation in lesser-studied indigenous languages is not well represented in the literature (Stanford Reference Stanford2016; Mansfield & Stanford Reference Mansfield and Stanford2017). Thus, this research contributes to broadening our descriptive knowledge of how socially-conditioned phonological variation is patterned in production, perception, and dynamic speech interactions across languages of the world, with different linguistic, social, and community-size characteristics.
5.1. The social distribution of rhoticity in Tarifit
A seminal framework for understanding how linguistic variation is patterned across socio-economic, gender, and age was laid out in Labov (Reference Labov1966) with a study of rhoticity in New York City English. In Experiment 1, we applied this framework to examining variation in rhoticity by Tarifit speakers varying in age and gender. Notably, we do not find an effect of age on r-elision. Thus, there is no change in rates of r-less productions over apparent time in this dialect of Tarifit. Overall, rates of r-lessness are quite high in our data – over 80% of the target words – indicating that this is a highly advanced sound change. It is possible that examination of a group of even older aged individuals would reveal lower rates of r-elision (the mean age of our ‘older’ adult sample was mid-40s).
We do find, however, that women produce much higher rates of r-elision than men. This observation is consistent with the social stratification hypothesis and the often-observed tendency for females in a society to be the more frequent users of innovative linguistic forms (e.g., Eckert Reference Eckert1989).
We note, also, that our sample included more male than female participants (19 male vs. 11 female), an imbalance that reflects the demographic composition of our recruitment networks in Nador. We acknowledge that this skew might influence the robustness of the gender effect observed in rhoticity patterns in the present study. Future work should aim for more balanced sampling across gender to validate and refine these observations.
5.2. Accommodation toward rhoticity
We asked whether Tarifit speakers accommodate towards an interlocutor’s variation in the realization of /r/, and if such accommodation is socially-mediated. In Experiment 2, we do indeed find that speakers increase their production of r after responding to an interlocutor who has just produced an r-ful word. Thus, r-fulness is flexible and adaptive within Tarifit speakers. Communicative interactions with an interlocutor who produces higher rates of r-ful word forms leads talkers to produce more r-ful words as well. In this case, we see accommodation toward the more conservative form, rather than toward the more innovative form (i.e., speakers are not more likely to drop /r/ following r-less forms). Perhaps, as mentioned earlier, this is due to the more advanced nature of this sound change – speakers already produce r-elision so frequently that there is little room for reduction in rates of r-lessness.
Alignment toward r-fulness occurs at equal rates across different words, when a speaker is responding with a different word than what the interlocutor has immediately produced, as for an identical word. Thus, accommodation toward an interlocutor’s r-fulness can be described as an abstract phonological alignment, rather than veridical replication of an experienced word form. Such cross-word phonological alignment supports proposals that the target of linguistic accommodation is abstract and generalizable (Nielsen Reference Nielsen2011; Zellou, Dahan, & Embick Reference Zellou, Dahan and Embick2017).
We did not find differences in accommodation toward r-fulness across any of the social groups. Thus, even though women produce lower rates of rhoticity, they do not show less (or more) alignment in r-fulness toward the interlocutor than men. Prior work has shown that speech alignment can vary based on the social characteristics of the speaker (Babel Reference Babel2012; Pardo Reference Pardo2006; Zellou, Cohn, & Ferenc Segedin Reference Zellou, Cohn and Ferenc Segedin2021). Yet, we do not observe this in the present study.
It is worth noting that the use of a robot tutor as the interlocutor in our accommodation experiment may have influenced participants’ speech style. Prior work suggests that speakers may hyperarticulate or shift toward more conservative forms when interacting with artificial agents, particularly when the agent is perceived as having lower communicative competence (Cohn, Ferenc Segedin, & Zellou Reference Cohn, Segedin and Zellou2022). This could partially explain the increased production of r-ful forms following robot prompts. Future studies using human interlocutors could help disentangle whether this alignment reflects genuine phonological accommodation or a style-shifting artifact of the experimental setup.
5.3. No difference in rhoticity for native and Arabic loan words
We do not find that speakers vary their rates of rhoticity – nor do they show differential patterns of accommodation – for Arabic loanwords in Tarifit. Tarifit contains a large number of Arabic borrowings (Kossmann Reference Kossmann2013). An open question for a speech community such as Tarifit, where the majority of speakers are multilingual and Arabic is the socially and politically dominant language in Morocco, is how language contact might affect patterns of language variation and change. Several of the target words in our study are Arabic loanwords, with transparent cognates in Moroccan Arabic. In fact, in Experiment 1, the target words were elicited via a translation task where they first heard the Moroccan Arabic word and provided the Tarifit equivalent. For the loanwords, this means that they would hear a cognate form that obligatorily contained a postvocalic r before producing the Tarifit word (Moroccan Arabic does not have r-elision). Yet, the status of the word as native or borrowed in Tarifit did not affect patterns of rhoticity, in both Experiment 1 and Experiment 2. Thus, even though speakers are bilingual and produce cognate word forms for Tarifit and Moroccan Arabic, they do not show an influence of the lack of r-elision in borrowed forms when applying the phonological process in Tarifit.
5.4. Social evaluations of rhoticity
Our perceptual experiment found that r-elision in Tarifit leads to more positive social evaluations of the speaker, particularly that the speaker sounds more educated and nicer when producing r-less forms than when producing r-ful forms. The higher ratings for ‘educated’ are somewhat surprising given that r-ful productions are the more conservative forms of words (Lafkioui Reference Lafkioui2011). Yet, as many researchers have pointed out, the social meanings of linguistic variants are flexible, fluid, and relative to a particular context and community (Eckert Reference Eckert2008). Here, for this group of listeners at this point in time, the more innovative non-rhotic form is associated with more positive social evaluations of the speaker.
One factor that may contribute to the observed social evaluations of rhoticity in Tarifit is regional variation within the broader Tarifit speech community. As noted by Lafkioui (Reference Lafkioui2007), nearby rural areas such as Ikebdanen, Beni Buyehyi, and Metalsa exhibit lower rates of r-elision, and speakers from these regions often retain postvocalic /r/ in their speech. It is possible that listeners’ positive evaluations of r-less forms reflect a sociolinguistic distinction between urban Nador speech and more conservative rural varieties. This interpretation aligns with our finding that r-elision is associated with perceptions of higher education and urban affiliation. Future work should investigate regional origin as a variable in rhoticity production and perception, to better understand how intra-community variation shapes linguistic attitudes and sound change.
Our observation that speakers evaluate r-lessness more positively aligns with our observation that the non-rhotic variant is the most commonly produced form for Nador speakers. In other words, non-rhoticity is the most frequent in production and also the most prestigious. It raises questions, however, about what is driving speakers to imitate the interlocutor’s less socially prestigious r-ful patterns in Experiment 2. There is some prior work indicating that phonetic imitation can be socially selective in that speakers prefer to align toward the more prestigious phonological forms during shadowing (Babel et al. Reference Babel, McGuire, Walters and Nicholls2014). On the other hand, the apparent paradox between the social preference for r-less forms and the observed imitation of r-ful variants may also be resolved by considering principles from Communication Accommodation Theory (CAT; Giles et al. Reference Giles, Coupland, Coupland, Howard Giles and Coupland1991). CAT posits that speakers adjust their speech to align with their interlocutor in order to manage social distance and foster affiliation. In our study, participants may have accommodated toward the robot’s r-ful productions not because those forms are socially prestigious, but because alignment itself serves a pro-social function: signaling attentiveness, cooperation, or solidarity. This interpretation is consistent with prior findings that linguistic convergence can occur even toward less socially valued forms when the goal is to maintain positive interaction (Adank et al. Reference Adank, Stewart, Connell and Wood2013; Babel Reference Babel2012). Thus, imitation of r-fulness may reflect a general tendency toward interpersonal alignment rather than a direct endorsement of the variant’s social meaning.
5.5. Limitations and future directions
There are several limitations of the present study which serve as directions for future work. For one, our production experiments were designed under the guise of a robot learning application. This scenario could have influenced the production patterns observed in the present study (e.g., alignment toward the conservation of more r-ful forms). Future work can compare productions from this study to one in a different type of elicitation condition. Comparing, for instance, differences in production responses toward a human vs. robot interlocutor could speak to the role of rhoticity in Tarifit as something speakers use to make speech more intelligible to an interlocutor they deem to have lower communicative competence (cf. more hyperarticulation in Robot-DS in English, Cohn, Ferenc Segedin, & Zellou Reference Cohn, Segedin and Zellou2022). Also, only one talker’s voice was used in each study. Future work can look at more diverse types of voices, which have variable apparent speaker characteristics, to test how the social properties of the talker influence listener evaluations of postvocalic /r/.
We also acknowledge that the relatively small number of lexical items used in the production (14) and perception (6) tasks may limit the generalizability of our findings. Additionally, the use of a voice-shifted stimulus in the attitude experiment (implemented to anonymize the speaker) could have introduced subtle perceptual artifacts that affect listener evaluations. While these design choices were necessary for practical and ethical reasons, future work should aim to expand the item set and incorporate natural, unmodified voices to enhance ecological validity and ensure more robust attitudinal assessments.
Another gap in the current work is that we did not examine variation in rhoticity as a function of socio-economic status (SES) in Morocco. While we did not collect direct measures of socio-economic status (SES) due to logistical constraints, we acknowledge that SES may play a role in shaping both production and perception of rhoticity in Tarifit. SES is a variable that conditions rhoticity in many of the dialects of English and Spanish in which it varies. We predict it could be playing a role in variable /r/ patterns within Nador, as well. In future work, even coarse proxies, such as speaker education level or neighborhood of residence, could be used to contextualize patterns of linguistic prestige. These proxies may help clarify whether r-elision is associated with upward mobility, urban affiliation, or other socio-economic factors, especially given the perception results linking non-rhoticity to higher education and urbanity.
Also, as mentioned in the introduction, prior work on derhoticization in Tarifit found variable patterns of compensatory vowel lengthening or quality changes. We did not examine phonetic patterns in the present study, though our recent related work has explored this for this specific dialect. In Afkir and Zellou (in press), we investigated phonetic vowel changes for speakers who do vary in their realization of rhoticity (only a subset of speakers can be examined because many speakers, as in the current study, are almost fully r-less). In that work, we find no differences in vowel length or formant patterns for r-less and r-ful forms. Thus, it is possible this speech community does not have the phonetic variation associated with r-dropping. Though, one direction for future work is to continue to perform acoustic analyses to investigate any relation between phonetic patterns and social groups, as well.
Acknowledgements
We thank Editor Jesus and two anonymous reviewers for their thoughtful comments and suggestions, which have made this paper stronger. We thank Jack Hawkins for comments and feedback on an earlier version of this paper. We are grateful to Ahmed Afkir, Najat Marrouaa, Ibrahim Marrouaa, Mohamed Elhachmi, Asma Afkir, and others for assistance with data collection.
Author declarations
No other conflicts of interest or competing interests are reported.
Data availability statement
Supplementary materials, data, models, and code are available in the Open Science Framework (OSF) repository for the project: https://osf.io/wpg8x/?view_only=413a3390f169456d8967417c3b58232c.
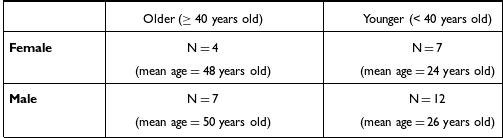






 Open access
Open access