


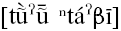 or Tu’un Savi
or Tu’un Savi 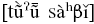 ) is an Otomanguean language spoken by roughly 11,500 people in the municipality of San Martín Peras, in Oaxaca, Mexico (Instituto Nacional de Estadística y Geografía, 2020), as shown in Figure 1. The municipality is in the district of Juxtlahuaca, bordering the state of Guerrero. As of 2020, approximately 97% of the population of the municipality over three years old is a speaker of an Indigenous language. Of those that speak an Indigenous language, approximately 60% also speak Spanish, meaning that around 37% of the total population is monolingual in Mixtec (Instituto Nacional de Estadística y Geografía, 2020). Despite these figures, it is difficult to estimate the total number of native speakers of the language, as many community members have migrated to other parts of Mexico and the United States, especially to several towns in California (Mendoza, 2020).
) is an Otomanguean language spoken by roughly 11,500 people in the municipality of San Martín Peras, in Oaxaca, Mexico (Instituto Nacional de Estadística y Geografía, 2020), as shown in Figure 1. The municipality is in the district of Juxtlahuaca, bordering the state of Guerrero. As of 2020, approximately 97% of the population of the municipality over three years old is a speaker of an Indigenous language. Of those that speak an Indigenous language, approximately 60% also speak Spanish, meaning that around 37% of the total population is monolingual in Mixtec (Instituto Nacional de Estadística y Geografía, 2020). Despite these figures, it is difficult to estimate the total number of native speakers of the language, as many community members have migrated to other parts of Mexico and the United States, especially to several towns in California (Mendoza, 2020).San Martín Peras Mixtec
San Martín Peras Mixtec (autonym: Tu’un Nta’vi ![]() or Tu’un Savi
or Tu’un Savi ![]() ) is an Otomanguean language spoken by roughly 11,500 people in the municipality of San Martín Peras, in Oaxaca, Mexico (Instituto Nacional de Estadística y Geografía, 2020), as shown in Figure 1. The municipality is in the district of Juxtlahuaca, bordering the state of Guerrero. As of 2020, approximately 97% of the population of the municipality over three years old is a speaker of an Indigenous language. Of those that speak an Indigenous language, approximately 60% also speak Spanish, meaning that around 37% of the total population is monolingual in Mixtec (Instituto Nacional de Estadística y Geografía, 2020). Despite these figures, it is difficult to estimate the total number of native speakers of the language, as many community members have migrated to other parts of Mexico and the United States, especially to several towns in California (Mendoza, Reference Mendoza2020).
) is an Otomanguean language spoken by roughly 11,500 people in the municipality of San Martín Peras, in Oaxaca, Mexico (Instituto Nacional de Estadística y Geografía, 2020), as shown in Figure 1. The municipality is in the district of Juxtlahuaca, bordering the state of Guerrero. As of 2020, approximately 97% of the population of the municipality over three years old is a speaker of an Indigenous language. Of those that speak an Indigenous language, approximately 60% also speak Spanish, meaning that around 37% of the total population is monolingual in Mixtec (Instituto Nacional de Estadística y Geografía, 2020). Despite these figures, it is difficult to estimate the total number of native speakers of the language, as many community members have migrated to other parts of Mexico and the United States, especially to several towns in California (Mendoza, Reference Mendoza2020).
San Martín Peras Mixtec is part of the Otomanguean language family. It forms part of the Eastern Otomanguean branch, the Amuzgo-Mixtecan subgroup and the Mixtecan major subgroup (Campbell, Reference Campbell2017). There is no consensus on the number of distinct varieties of Mixtec languages. San Martín Peras Mixtec is classified by Josserand (Reference Josserand1983) as part of the Southern Baja dialect region, one of the 12 major dialect groups that she defines. Ethnologue considers San Martín Peras Mixtec to be part of the Western Juxtlahuaca variety (ISO 639-3: JMX), one of 52 distinct varieties that has been assigned an ISO code (Eberhard, Simons & Fenning, Reference Eberhard, Simons and Fennig2022). A recent Bayesian phylogenetic analysis of Mixtecan languages identified 23 distinct subgroups and classified San Martín Peras Mixtec as being a part of group 7.3 (Auderset et al., Reference Auderset, Greenhill, DiCanio and Campbell2023). Finally, the Mexican government recognizes 80 varieties of Mixtec and considers residents of San Martín Peras and some neighboring municipalities to speak To’on Savi del Oeste (Instituto Nacional de Lenguas Indígenas, 2008). According to INALI, given that: (i) more than 25% of the speakers of To’on Savi del Oeste are between the ages of 5 and 14; (ii) there are more than 1000 total speakers of To’on Savi del Oeste; (iii) To’on Savi del Oeste is spoken in more than 50 communities; the language is not considered to be at immediate risk of language loss (Embriz Osorio & Zamora Alarcón, Reference Embriz Osorio and Zamora Alarcón2012). However, there is clear phonological variation across the 83 different communities that speak To’on Savi del Oeste. For instance, the Mixtec spoken in San Martín Peras has contrastive breathy phonation (see section 3), while the Mixtec spoken in neighboring Coicoyán de las Flores does not (Beatham & Beatham, Reference Beatham and Beatham2019). Moreover, as migration and increased connectedness with other communities have expanded the number of young people who primarily speak Spanish in San Martín Peras, there is reason to be concerned about the long-term longevity of the specific variety of the language spoken in the municipality.
The State of Oaxaca (left) and the municipality of San Martín Peras (right).

Suffice to say that the term “San Martín Peras Mixtec” should be interpreted as an umbrella term that primarily provides a geographic description of where most speakers reside. Throughout this Illustration, we abbreviate the language name as “SMPM.”
This work adds to a substantial list of phonological and phonetic studies of the sound systems of Mixtec languages, going back to the mid-twentieth century (Pankratz & Pike, Reference Pankratz and Pike1967; Pike & Small, Reference Pike and Small1974; North & Shields, Reference North and Shields1977; Josserand, Reference Josserand1983; Marlett, Reference Marlett1992; Macaulay & Salmons, Reference Macaulay and Salmons1995; Iverson & Salmons, Reference Iverson and Salmons1996; Gerfen & Baker, Reference Gerfen and Baker2005; Daly & Hyman, Reference Daly and Hyman2007; Gerfen, Reference Gerfen2013; McKendry, Reference McKendry2013; Herrera Zendejas, Reference Herrera Zendejas2014; DiCanio et al., Reference DiCanio, Amith and Castillo García2014; Becerra Roldán, Reference Becerra Roldán2015; Mendoza, Reference Mendoza Ruiz2016; León-Vázquez, Reference León Vázquez2017; DiCanio et al., Reference DiCanio, Benn and Castillo García2018; Peters, Reference Peters2018; Becerra Roldán, Reference Becerra Roldán2019; Penner, Reference Penner2019; Rueda Chaves, Reference Rueda Chaves2019; DiCanio et al., Reference DiCanio, Zhang, Whalen and Castillo García2020; Peters & Mendoza, Reference Peters and Mendoza2020; DiCanio et al., Reference DiCanio, Benn and Castillo García2021; Cortés et al., Reference Cortés, Mantenuto and Steffman2023; Eischens, Reference Eischens2022; Stremel, Reference Stremel2022; Uchihara & Mendoza, Reference Uchihara and Mendoza Ruiz2021; Eischens, Reference Eischens2023; Caballero et al., Reference Caballero, Juárez Chávez and Yuan2024; among others).
The data in this article were collected from three speakers of the language. All audio recordings illustrating the phones of the language come from one 71-year-old male speaker (JGO) born in the community of Ahuejutla, where he has lived his whole life. Ahuejutla, a town of roughly 1,200 inhabitants, is approximately 10 miles from the municipal center of San Martín Peras. The recording of the retelling of the North Wind and the Sun story is from a 52-year-old woman (NGC) who is originally from Ahuejutla and who has lived in California for approximately 20 years. The data used for fast Fourier transforms and center of gravity measurements for fricatives, voice onset time (VOT) in plain and prenasalized consonants, vowel formants, strength of excitation (SoE) for non-modal vowels, and tone plots come from a task in which NGC and one additional female speaker in her fifties (RDC) produced target words in a carrier sentence at normal and slow rates of speech. This data is also accompanied by representative audio recordings. RDC is originally from the town of San Martín Peras and has lived in California for approximately 20 years. To our knowledge, the varieties of Mixtec spoken in Ahuejutla and San Martín Peras are almost identical, though some small lexical differences may exist. We know of no tonal distinctions between the two towns, though NGC and RDC occasionally have minor differences in their pronunciations of affricates (e.g., ![]() vs.
vs. ![]() for ‘worm’).
for ‘worm’).
Recordings were made using a Zoom H5 Handy Recorder (16-bit quantization rate and 44.1 kHz sampling frequency) and a Nady HM-45U headset microphone. Recordings were spliced using Audacity. Wherever possible, individual examples of words were spliced out of carrier phrases in which the target word was immediately preceded and followed by a mid-tone to avoid known effects of tone sandhi. The nature of the elicitation task with JGO required the use of a number of distinct carrier phrases, and the carrier phrase corresponding to each example in the manuscript is listed in the appendix. In addition to the audio files for each individual word produced, audio files are also available for each target word in its carrier phrase, with the filenames for these recordings ending in ‘_CP’. Carrier phrases for audio recordings from NGC and RDC are not provided in the appendix because the same carrier phrase was used in all cases.
1. Consonants
The following table illustrates the basic phonemic contrasts in the language (Peters, Reference Peters2018; Mendoza, Reference Mendoza2020; Eischens, Reference Eischens2022).Footnote 1


1.1 Obstruents
San Martín Peras Mixtec has three phonemic plosive consonants: /p/, /t/, and /k/. However, /p/ is restricted to the loan vocabulary of the language and is not found in non-loans. In some environments, /k/ is pronounced allophonically as [ɡ]. The environment that most commonly seems to license this type of allophonic variation is non-root-medial position between two vowels. For example, in the word /t͡ʃáá=ka/ (‘more, most’), the /k/ is usually pronounced as a [ɡ] or a [Ɣ]. This voicing process seems to be subject to both interspeaker and inter-utterance variation. We note, however, that this allophonic voicing never seems to happen root-internally and only seems to occur in multi-morphemic words.
Within plosives, SMPM also has contrastive secondary articulations. For instance, both /t/ and /k/ can be contrastively palatalized, e.g., tiàtá [tjàhtá] ‘type of oak tree’ and kiá’mĭ [kjáʔmĩ̌] ‘(a type of) squash’. In addition, /k/ can be contrastively labialized, e.g., kuá’à [kwáʔà] ‘red’. There are two principal reasons to consider palatalization and labialization secondary articulations, rather than consonants in and of themselves. The first is that [w] is not an independent consonant in SMPM and only appears in conjunction with [k]. The second is that there are distributional differences between palatalized consonants and the palatal glide [j]. Specifically, [j] may precede the high front vowel [i], as in ñà yivĭ [ɲã̀ jīβǐ] ‘person’ (20d), but palatalized consonants never precede the vowel [i]. That is, a hypothetical word like [kʲīβǐ] does not exist. Because palatalized consonants are more distributionally restricted than consonant [j], it is unlikely that palatalization is actually an instance of the consonant [j].
Mean and standard deviation CoG (Hz) measurements by speaker and fricative.

San Martín Peras Mixtec has two voiceless fricatives: /s/ and /ʃ/. In a small number of words, /s/ is contrastively palatalized, e.g., siâ’ă [sjâʔǎ] ‘Tecomaxtlahuaca (a town)’. Fast Fourier transforms (FFTs) of individual tokens of [s] and [ʃ] from NGC are shown in Figure 2, along with average center of gravity (CoG) measurements for both fricatives for NGC and RDC in Table 1. In all cases, measurements were taken from a 50ms window centered on the peak of noise intensity for the fricative. The data were measured and visualized in Praat (Boersma & Weenink, Reference Boersma and Weenink2023).
FFTs for [s] (left) and [ʃ] (right) produced by NGC. Examples taken from the words ![]() (‘crazy’) and
(‘crazy’) and ![]() (‘cigarette’).
(‘cigarette’).

In addition to fricatives, SMPM has two voiceless affricate consonants, /t͡s/ and /t͡ʃ/, which each contrast with a prenasalized counterpart. The contrast between /t͡s/ and /ⁿt͡s/ can be seen in the consonant word-list, and the contrast between /t͡ʃ/ and /ᶮt͡ʃ/ can be seen in (1) below.

Unlike the plosive series, these affricates are not contrastively palatalized. /t͡ʃ/ and /ᶮt͡ʃ/ never occur with palatalization, and [t͡s] and [ⁿt͡s] are predictably palatalized before all vowels except /i/ (Stremel, Reference Stremel2022), as shown in example (2) below. Given this predictability, we assume that /t͡sʲ/ and /ⁿt͡sʲ/ are underlyingly palatalized and are allophonically depalatalized before a high front vowel. Impressionistically, /t͡s/ sounds like palatalized [t͡ɕ] on some productions before [i]. We leave for future research whether this is a phonological alternation or a coarticulatory effect.

There is no plain voicing distinction in San Martín Peras Mixtec. However, all stops and affricates except /kʲ/ and /kʷ/ contrast with prenasalized versions. Throughout the article, we will refer to this as a contrast between plain and prenasalized consonants. The phonological status of prenasalized consonants in the language is a point of debate. Peters (Reference Peters2018:13) analyzes them as sequences of a nasal consonant and a stop, noting that they syllabify as a coda in words like lantyi ![]() ‘lamb’. On the other hand, Eischens (Reference Eischens2022) analyzes them as complex segments, since onset consonant clusters are banned in the language, but pre-nasalized stops and affricates may occur word-initially (see consonant examples above). We adopt Eischens’ (Reference Eischens2022) analysis, given the general ban on consonant clusters and the fact that a word-initial nasal + obstruent cluster would violate the sonority sequencing principle (e.g., Kiparsky, Reference Kiparsky1979; also noted in Iverson & Salmons, Reference Iverson and Salmons1996:166), making it an unlikely onset. We also consider phonotactic restrictions on the distribution of prenasalized consonants as evidence that they are single segments. That is, they may only be followed by oral vowels, never nasal vowels (see section 2 below). This is unexpected if they are, in fact, a sequence of a nasal and a plain consonant, since plain consonants may be followed by both oral and nasal vowels.
‘lamb’. On the other hand, Eischens (Reference Eischens2022) analyzes them as complex segments, since onset consonant clusters are banned in the language, but pre-nasalized stops and affricates may occur word-initially (see consonant examples above). We adopt Eischens’ (Reference Eischens2022) analysis, given the general ban on consonant clusters and the fact that a word-initial nasal + obstruent cluster would violate the sonority sequencing principle (e.g., Kiparsky, Reference Kiparsky1979; also noted in Iverson & Salmons, Reference Iverson and Salmons1996:166), making it an unlikely onset. We also consider phonotactic restrictions on the distribution of prenasalized consonants as evidence that they are single segments. That is, they may only be followed by oral vowels, never nasal vowels (see section 2 below). This is unexpected if they are, in fact, a sequence of a nasal and a plain consonant, since plain consonants may be followed by both oral and nasal vowels.
The unary analysis of prenasalized consonants is somewhat complicated, though, by the distribution of the prenasalized consonant [ŋk] in the language, which only occurs root-medially. We know of only two monomorphemic words with [ŋk],Footnote 4 both shown in (3) below.

There are three possible ways to account for this restricted distribution. First, one could adopt Peters’ (Reference Peters2018ː13) analysis of pre-nasalized consonants as a bi-consonantal series of a nasal + plosive. Under this analysis, the [ŋ] in the preceding examples would be a nasal coda of the first syllable. However, given that there are no other codas in the language, and that we analyze pre-nasalized stops in other cases as complex segments, we do not adopt this analysis. The second possible analysis is to suppose that [ŋk] may only occur in loan words, as is the case for [p] and [mp]. Indeed, linko is plausibly related to the Mexican Spanish word gualumbos (also spelled golumbos or hualumbos), which also refers to the edible flowers of the maguey cactus (Piedra-Malagón et al., Reference Piedra-Malagón, Sosa, Angulo and Díaz-Toribio2022).Footnote 5 Notably, these terms all involve a lateral followed by a nasal + stop sequence, like the word in SMPM. Given the rarity of pre-nasalized labial obstruents in San Martín Peras Mixtec, it is possible that the labial place of articulation was borrowed as a dorsal. However, we currently have no evidence that tyi’nkì is a loan word. The third possible analysis—and the one that we tentatively adopt here—is that [ŋk] is restricted phonotactically to root-medial position. This possibility is bolstered by the fact that [ŋk] only occurs in root-medial position in other Mixtec varieties as well, such as Chalcatongo (Iverson & Salmons, Reference Iverson and Salmons1996), Alcozauca, (Mendoza Ruiz, Reference Mendoza Ruiz2016) and Yucuquimi de Ocampo Mixtec (Leon Vázquez, Reference León Vázquez2017).
In what remains of this section, we qualitatively and quantitatively illustrate the phonetic characteristics of plain and prenasalized stops and affricates, focusing on VOT and the internal structure of prenasalized stops and affricates. For plain stops, VOT was measured from the release burst until the beginning of periodic voicing associated with the following vowel. For plain affricates, VOT was measured from the offset of frication associated with the affricate, marked by cessation of high-frequency aperiodic noise in the spectrogram, to the onset of periodic voicing (Abramson & Whalen, Reference Abramson and Whalen2017). Measurements were taken from stops and affricates with no palatalization or labialization. Examples of VOT measures are shown in Figure 3, which are taken from the words [táʰtě] (‘sir/father’), [kînĩ̀] (‘pig’), [t͡siʰkà] (‘grasshopper’), and [t͡ʃíᶮt͡ʃi] (‘cricket’), respectively.
Representative examples of plain stops and affricates. Shaded portion shows VOT.

While VOT is an informative measure of voicing for the plain stops and affricates, it does not capture the internally complex structure of prenasalized stops and affricates. These consonants are characterized by a sequence of periodically voiced prenasalization, followed by a period of voicelessness during the oral closure and/or frication, and there is also almost always a positive VOT measured from the stop burst or cessation of frication. In many cases, weak voicing persisted from prenasalization into a portion of the stop closure, though this voicing was never strong and almost always ceased prior to the stop burst (cf. Cortés et al., Reference Cortés, Mantenuto and Steffman2023). Figure 4 below illustrates this sequencing of prenasalization (PN), weak voicing (WV), no voicing (NV), and a positive VOT. The examples are taken from the words [ⁿtiβi] (‘beautiful’), [líᵑko] (‘bud of the flower of the maguey cactus’), [ⁿt͡sîʰkà] (‘wide’), and [ᶮt͡ʃiʰʃǐ] (‘corn cob’), respectively. The example illustrating [ᵑk] is root-medial, since this segment never occurs root-initially.
Representative examples of prenasalized stops and affricates. NV = no voicing; PN = prenasalized; VOT = VOT from stop burst or cessation of oral frication; WV = weak voicing.

VOT by consonant type and speaker in the series of plain stops and affricates (left) and prenasalized stops and affricates (right). Error bars represent one standard deviation.
NGC [t͡ʃ] = 35, [k] = 51, [t] = 18, [t͡s] = 6, [ⁿt] = 18, [ᵑk] = 12, [ⁿt͡s] = 11.
RDC [t͡ʃ] = 18, [k] = 51, [t] = 15, [t͡s] = 6, [ⁿt] = 18, [ᵑk] = 15, [207F;t͡s] = 17.

One point of interest is that both plain and prenasalized stops and affricates have a positive VOT, measured either from the stop burst or from the cessation of oral frication. As shown in Figure 5, VOT values roughly line up between the plain and prenasalized versions of a consonant. Note, though, that the VOT values for [ᵑk] are taken from root-medial tokens, since there are no root-initial tokens of [ᵑk], and that [ᶮt͡ʃ] was excluded because of a low number of tokens for analysis (three per consultant). The data were measured in Praat and illustrated using the ggplot package (Wickham, Reference Wickham2016) in R (R Core Team, 2013).
The VOT of [t], [t͡ʃ], and [t͡s] are all short lag, with averages around 20ms. As is usually the case with backer places of articulation (Lisker & Abramson, Reference Lisker and Abramson1967), [k] has higher VOT than [t]. However, the difference between [t] and [k] here appears larger than the difference in VOT between [t] and [k] in English (Lisker & Abramson, Reference Lisker and Abramson1967:6), as well as in other Mixtec languages (DiCanio et al., Reference DiCanio, Zhang, Whalen and Castillo García2020; Cortés et al., Reference Cortés, Mantenuto and Steffman2023). Notably, [k] also displays more variance than [t]. The higher VOT variance for [k], and potentially the higher average value, may stem from the distinction between speech rates in the production task.
As discussed previously, prenasalized stops and affricates are made up of a sequence of PN, WV, and NV. The voiceless portion also includes a positive VOT measured from the offset of oral constriction to the beginning of periodic voicing. Figure 6 shows the duration of each of these subparts of a prenasalized consonant as a proportion of the entire duration of the consonant. Given that the period of voicelessness and positive VOT are two subparts of the voiceless period of the consonant, they are combined under the category “voiceless” here.
Proportional duration of prenasalization, weak voicing, and voicelessness in prenasalized consonants for NGC (left) and RDC (right). Error bars show one standard deviation.

Before moving on, it is worth noting that prenasalized stops in a number of Mixtec languages alternate between fully voiced forms and forms with a voiceless interval (see, e.g., Rueda Chaves, Reference Rueda Chaves2019:139 and sources therein). In these varieties, the devoiced versions of prenasalized consonants appear in particular phonological environments, such as root-initially, motivating an analysis in which their voicelessness is derived by either a phonological or phonetic process of strengthening. In San Martín Peras Mixtec, however, prenasalized stops and affricates almost always have a voiceless interval regardless of position in the root. Because of this, we do not analyze the voicelessness in prenasalized consonants as derived by a phonological process. It is possible that across-the-board voicelessness in prenasalized consonants is an innovation in the phonological system of SMP Mixtec, though we leave this question to future research.
Waveforms and spectrograms showing four distinct realizations of /j/. Vertical black bar represents the offset of the sound.

Waveforms and spectrograms showing two distinct realizations of /j/. Vertical black bars represent the onset and end of the sound.

1.2 Sonorants
In addition to its obstruent consonants, San Martín Peras Mixtec has a set of seven sonorant consonants. There are three contrastive nasal consonants with bilabial, alveolar, and palatal places of articulation, e.g., málì [mãlì] ‘godmother of one’s child, or mother of one’s godchild’, nánà [nãnã] ‘mother’ or ‘madam’, and ñani [ɲãnĩ] ‘brother (of a male)’. In addition, there are three non-nasal approximants in the language: /l/, /β/, and /j/. Finally, there is one voiced alveolar tap /ɾ/. Of these consonants, /ɾ/ is the most clearly restricted. To our knowledge, it only occurs almost exclusively in the clitic pronoun series and function words. [ɾà] is used for human males, [ɾí] is used for animals and round objects, [ɾá] is used for liquids, and [ɾa] is the conjunction and. There are very few other native lexical items with /ɾ/ in the language. Of the approximants, /j/ appears to vary most widely in its phonetic realizations, even between productions of the same word in the same context by the same speaker. The examples below, which were all produced by the same consultant in the same carrier phrase, show /j/ realized as an approximant (Figure 7, left), a transition from an approximant into a nearly voiceless fricative (Figure 7, middle), and a voiceless palatal fricative (Figure 7, right). Voiced fricative realizations of /j/ can also be seen in (4a–c).
This variation is not limited to couplet-initial position, unlike cases of fortition in other Mixtec languages (see, e.g., Rueda Chaves, Reference Rueda Chaves2019). In couplet-medial position, /j/ can be realized as a glide (Figure 8, left), or as partially voiced and fricated (Figure 8, right). In these examples, the black vertical lines mark the left and right boundary of /j/.
Despite the fricative realizations of /j/, we classify it as an approximant and not a voiced fricative, unlike in other Mixtec varieties (e.g., Cortés et al., Reference Cortés, Mantenuto and Steffman2023). This is because, if it were a fricative, it would be the only phonemically voiced consonant in SMPM’s obstruent series. Additionally, like the other approximants (/l/ and /β/), it is only ever followed by oral vowels in non-morphologically complex contexts.
2. Vowels
San Martín Peras Mixtec has five oral vowels and three contrastively nasal vowels.Footnote 6

While there are only three contrastive nasal vowels, we note that many speakers pronounce nasal [ũ] lower in the vowel space than oral [u], leading it to sound like [õ]. However, we know of no examples of [ũ] contrasting with [õ]. Nasal vowels only contrast after plain stops and affricates. Vowels are predictably nasal when following nasal consonants, and oral when following prenasalized consonants and approximants.
Figure 9 displays two plots showing the average formant values for SMPM’s five oral vowels and three nasal vowels for NGC and RDC. The graphs represent root-final vowels, where there is no phonation type contrast.
Plots of average formant values (Hz) for NGC and RDC. Ellipses show one standard deviation around the mean. Solid lines represent oral vowels; dotted lines represent nasal vowels.
Number of tokens for NGC: 69 [a], 36 [ã], 21 [e], 88 [i], 77 [ĩ], 84 [o], 30 [u], 32 [ũ].
Number of tokens for RDC: 75 [a], 39 [ã], 18 [e], 84 [i], 78 [ĩ], 87 [o], 36 [u], 33 [ũ].

3. Prosodic features
3.1 Syllable structure and the couplet
In arguably all Mixtec languages, words are organized around a bimoraic unit known in the Mixtecanist literature as the ‘couplet’ (Pike, Reference Pike1948; see Penner, Reference Penner2019 for a comprehensive overview). This is the case in SMPM, where lexical roots are minimally, and usually maximally, bimoraic (Peters, Reference Peters2018; Eischens, Reference Eischens2022). They are made up of two monomoraic short vowels, or one bimoraic long vowel, and there is a ban on coda consonants, which gives rise to the canonical root shapes of (C)VCV and (C)VV. The couplet in SMPM is the locus of phonation contrasts and tonal melodies, which are the subjects of the following sections. Given that the bimoraic lexical root and the couplet are usually interchangeable, we use the more generic term ‘root’ throughout.
3.2 Phonation type
Across Mixtec languages, the glottal stop [ʔ] patterns differently from other consonants, as outlined in Macaulay and Salmons (Reference Macaulay and Salmons1995). For example, it is usually the only licit coda consonant (e.g., kiá’mĭ [kjáʔmǐ] ‘squash’), and it never occurs phonemically in root-initial or root-final position in most Mixtec languages (though see Pankratz & Pike, Reference Pankratz and Pike1967 and Herrera Zendejas, Reference Herrera Zendejas2014 for Ayutla Mixtec; and Towne, Reference Towne2011 for Zacatepec Mixtec). Additionally, there may only be one glottal stop per root, and when it occurs between two vowels in a mono-morphemic context, the vowels always match in quality and nasalization. In addition, in some Mixtec languages, CVʔV and CVV roots act as a natural class regarding tone sandhi processes, to the exclusion of roots with a medial oral consonant (Macaulay & Salmons, Reference Macaulay and Salmons1995:58). Because of these characteristics, many researchers have adopted the hypothesis that the glottal stop in Mixtec languages is not a consonant proper, but rather a supra-segmental feature of the vowel, root, or word (Macaulay & Salmons, Reference Macaulay and Salmons1995; Gerfen, Reference Gerfen2013; McKendry, Reference McKendry2013; Becerra Roldán, Reference Becerra Roldán2015; León Vázquez, Reference León Vázquez2017; Penner, Reference Penner2019; Rueda Chaves, Reference Rueda Chaves2019, Cortés et al., Reference Cortés, Mantenuto and Steffman2023, a.o., but see Herrera Zendejas, Reference Herrera Zendejas2014 for treatment of glottal stop as a consonant). Because most of these characteristics also hold of the glottal stop in SMPM, we follow the trend in the Mixtec literature and represent glottal stop as a contrastive phonation type, referred to throughout as glottalization. It may surface root-medially between two homorganic vowels or before root-medial sonorants and prenasalized consonants. In addition, SMPM makes use of a contrastive [h] with the same phonotactic distribution as [ʔ], occurring root-medially between two homorganic vowels or before root-medial sonorants and prenasalized consonants.Footnote 7 [h] is uncommon in other Mixtec languages, and thus is likely a relatively recent innovation in SMPM (Peters, Reference Peters2018). Because of its phonotactic similarity to [ʔ], we also analyze [h] as a contrastive phonation type, referred to herein as breathy phonation. Following Ve’e Tu’un Savi, we represent glottalization orthographically as an apostrophe. Due to the rarity of breathy phonation in Mixtec languages, there is no orthographic convention to represent it proposed by Ve’e Tu’un Savi. In what follows, we choose to represent breathiness orthographically as j.Footnote 8 All five phonemic oral vowels can be contrastively breathy (b examples) and glottalized (c examples) (4–8).

In addition, all three nasalized vowels can be contrastively breathy and glottalized (9–11). For clarity, we transcribe the underlying level tones as opposed to the surface falling tones in examples (17) and (18).

[h] is allophonically nasalized between nasal vowels, and it surfaces as the palatal fricative [ç] after the high front vowel [i] (Eischens, Reference Eischens2022). In addition to contrastive breathiness, vowels are predictably aspirated when they precede a plain, root-medial consonant.Footnote 9 Examples of this allophonic variation can be found throughout this Illustration, including, for example, tátà [táhtà] ‘father/sir’ and tyìkí [t͡ʃìhkí] ‘prickly pear fruit’. However, plain consonants that are non-root-medial (that is, word-medial consonants that surface after a prefix) are not pre-aspirated. For example, kò-ká’àn [kò-kã́ˀã̀] ‘does not talk’ and kúká’nù ini [kúkáʔnù īnī] ‘to forgive (lit. to be big inside)’. At present, it is unclear whether allophonic [h] is best understood as preaspiration of plain consonants, as is found in Alcozauca (Mendoza Ruiz, Reference Mendoza Ruiz2016) and Ayutla Mixtec (Pankratz & Pike, Reference Pankratz and Pike1967), or as allophonic breathy phonation similar to the allophonic glottalization found in Coatzospan Mixtec (Gerfen, Reference Gerfen2013). On the one hand, both allophonic [h] and contrastive [h] are restricted to root-medial position, lending support to the view that they both constitute breathy phonation. On the other hand, vowels preceding allophonic [h] may host any tone, while vowels preceding contrastive [h] may only host a subset of the possible tones, as discussed in the section on lexical tone. This latter point lends support to a view of allophonic and contrastive [h] as phonologically distinct. Given the contradictory evidence, we leave a definitive answer to this question for future research.
In what follows of this section, we briefly discuss the phonetic realization of glottalization, breathiness, and preaspiration in SMPM. As is the case in many Mixtec languages (Pike & Small, Reference Pike and Small1974:122–124; Macaulay, Reference Macaulay1996:42; Gerfen & Baker, Reference Gerfen and Baker2005; Herrera Zendejas, Reference Herrera Zendejas2014:72–74; Becerra Roldán, Reference Becerra Roldán2019:112–116; Penner, Reference Penner2019:254; Cortés et al., Reference Cortés, Mantenuto and Steffman2023:11–14), the articulation of glottalization varies greatly both within and between speakers. Though the most common realization of glottalization in the examples in Figure 10 involves full glottal closure, glottalization is often produced with creaky voice or periodic voicing accompanied by amplitude and/or pitch modulations (see Eischens, Reference Eischens2022 for more details on the variable realization of glottalization). Breathiness is most commonly realized as a short period of breathy voicing followed by voiceless aspiration, as shown in Figure 11. The difference between breathiness and glottalization can be seen by comparing the examples in Figure 11 to their corresponding (near-)minimal pairs in Figure 10.
Individual tokens of glottalized vowels from the words /kúɁù/ (‘sick’), /kòɁŏ/ (‘plate’), and /jāɁǎ/ (‘chile pepper’) from NGC (top) and RDC (bottom).

Individual tokens of breathy vowels from the words /kòʰǒ/ (‘snake’) and /jáʰǎ/ (‘tongue’) from NGC (top) and RDC (bottom).

Preaspiration is also most commonly realized as an interval of breathy voicing followed by voiceless frication, though the frication has a much shorter duration than in breathy vowels. This can be seen in Figure 12, which shows a vowel followed by a preaspirated [t].
Individual tokens of vowels followed by preaspiration from the word /āʰtū/ (‘bitter’) from NGC (left) and RDC (right).

To quantitatively examine the phonetic realization of glottalization, breathiness, and preaspiration, we calculated Strength of Excitation (SoE) across phonation types, using the same data set used to calculate VOT, formant frequencies, and fricative spectra. SoE is a measure of the relative amplitude of voicing in the speech signal (see, e.g., Murty & Yegnanarayana, Reference Murty and Yegnanarayana2008; Garellek et al., Reference Garellek, Chai, Huang and Van Doren2023), and as such is a useful tool for examining the strength of periodic voicing throughout the implementation of non-modal phonation types (see Cortés et al., Reference Cortés, Mantenuto and Steffman2023 for a recent example on another Mixtec language). Following similar methods in Cortés et al. (Reference Cortés, Mantenuto and Steffman2023) and Garellek et al. (Reference Garellek, Chai, Huang and Van Doren2023), SoE was calculated using VoiceSauce (Shue et al., Reference Shue, Keating, Vicenik and Yu2011) at 1 ms intervals over a 10 ms window, then averaged over 20 equally spaced intervals for each token. SoE measurements were log-transformed and then normalized by subtracting a speaker’s minimum SoE value from every measurement, and dividing the result by the difference between the speaker’s maximum and minimum SoE. The results ranged between 0 and 1, with 1 representing the speaker’s highest SoE, and 0 representing the speaker’s lowest SoE.
The plots in Figure 13 show aggregated SoE contours over the course of the vocalic portion of laryngealized and breathy vowels (e.g., [VʔV] and [VhV]). The steep dip in SoE during the middle of the timecourse is consistent with creaky voice and glottal closure during the realization of laryngealization, and aperiodic frication during the realization of breathiness. In general, RDC’s productions show a steeper dip in SoE than NGC’s productions, suggesting that the realization of laryngealization and breathiness is likely subject to interspeaker variation. The plots in Figure 14 show the SoE contours for vowels and following preaspiration (e.g., the underlined portion of [t͡ʃı̀ʰ–kí] (‘prickly pear fruit’)) alongside that of vowels and following prenasalization (e.g., the underlined portion of [lı́ᵑ–ko] (‘bud of the flower of the maguey cactus’)). Since preaspiration involves aperiodic noise and prenasalization involves periodic voicing, SoE stays relatively high for a sequence of a vowel and following prenasalization, but dips for a sequence of a vowel and following preaspiration. This is consistent with the presence of breathy voicing and eventual aspiration, which lowers the relative strength of voicing in the acoustic signal.
SoE for [VʰV] (solid) and [VʔV] (dashed) sequences. Lines are smoothed LOESS regression lines, and gray bars represent a 95% confidence interval around the regression line. NGC [VʰV] = 57, [VˀV] = 58. RDC [VʰV] = 66, [VˀV] = 63.

SoE for vowels followed by preaspiration (solid) and prenasalization (dashed). Lines are smoothed LOESS regression lines, and gray bars represent a 95% confidence interval around the regression line. NGC [VʰC] = 84, [VⁿC] = 63. RDC [VʰC] = 66, [VⁿC] = 66.

3.3 Lexical Tone
There are at least five phonemic tones in SMPM, with three level tones and at least two contour tones. The three level tones are High tone (marked with an acute accent á), Mid tone (no diacritic), and Low tone (marked with a grave accent à). There is one phonemic rising tone, which rises from Low to High (marked with a hacek ă), and at least one falling tone (marked with a circumflex accent â). Phonological tone sandhi evidence suggests that HM, ML, or HL falls may all occur. HL and H certainly contrast, as evidenced by the difference between the H-L root [táʰtà] (‘señor’) and the HL-L root [ntsı𠋆ʰkà] (‘wide’). However, it is not at present clear whether HM and H contrast, or whether ML and M contrast. The mora is the tone-bearing unit, and any one of SMPM’s five tones may appear on a mono-moraic vowel (Peters, Reference Peters2018). Additionally, SMPM is a laryngeally complex language (Silverman, Reference Silverman1997), meaning that contrastive tone and contrastive phonation type are cross-classified: any one of SMPM’s five tones may appear on modal and non-modal vowels alike, with the exception of contrastively breathy vowels, which almost exclusively host falling or low tones. The initial vowel in roots with only modal vowels (both CVCV (12) and CVV (13) roots), in roots with glottalized vowels (14), and in roots with initial vowels followed by non-contrastive [h] (15) may all host any one of SMPM’s five contrastive tones.

Unlike other phonation types, contrastively breathy vowels almost always host Low or Falling tones on their first mora. These falling tones contrast, and they differ in their starting pitch. For example, the word for ‘skinny’ in (16a) begins with a fall whose pitch begins roughly at the level of a high tone, while the word for ‘ear of corn’ in (16b) begins with a fall whose pitch starts roughly at the level of a mid tone. We analyze these distinct falling tones as derived from underlying level tones, as represented in the difference between the phonemic transcription in slashes and the allophonic transcription in square brackets.

The motivation to analyze the falling tone in (16a) and the falling tone in (16b) as derived from underlying high and mid tones, respectively, is due to their asymmetric behavior with respect to the phonological tone sandhi process of Rise Flattening. In Rise Flattening, discussed in the Tone Sandhi section (section 3.4), word-final rising tones flatten to level low tones when followed by high tones across a word boundary. Example (17) shows that the underlying final rise of [kòʰǒ] (‘snake’) surfaces faithfully before ![]() (‘ear of corn’), suggesting that the fall in ‘ear of corn’ does not begin with an underlying high tone. However, the final rise of [kòʰǒ] (‘snake’) surfaces as a low tone before
(‘ear of corn’), suggesting that the fall in ‘ear of corn’ does not begin with an underlying high tone. However, the final rise of [kòʰǒ] (‘snake’) surfaces as a low tone before ![]() (‘skinny’) in (18), suggesting that the fall in ‘skinny’ does begin with an underlying high tone.Footnote 10 Given the sandhi patterns and that HL and ML falls on breathy vowels are in complementary distribution with level tones, we analyze the falling tones on breathy vowels as derived from underlying level tones.
(‘skinny’) in (18), suggesting that the fall in ‘skinny’ does begin with an underlying high tone.Footnote 10 Given the sandhi patterns and that HL and ML falls on breathy vowels are in complementary distribution with level tones, we analyze the falling tones on breathy vowels as derived from underlying level tones.

We know of only one instance of a non-falling high tone on the first mora of a contrastively breathy vowel, shown in (22). This word is likely derived from the root ![]() (‘for there to be an earthquake’). Importantly, the following tone is mid, not rising. There appear to be no surface level high or mid tones on contrastively breathy vowels followed by a rising tone.
(‘for there to be an earthquake’). Importantly, the following tone is mid, not rising. There appear to be no surface level high or mid tones on contrastively breathy vowels followed by a rising tone.
On the second vowel of a bi-moraic root, only four tones are found in non-derived contexts; we have found no evidence of contrastive falling tones in this context (though see Peters (Reference Peters2018) and Peters & Mendoza (Reference Peters and Mendoza2020) for examples). With this restriction in mind, any one of the four remaining phonemic tones—high, mid, low, or rising—may occur on the second mora of the bi-moraic root. This is the case whether the preceding vowel is modal (whether in a CVCV (20) or CVV (21) root), is a glottalized vowel (22), or is followed by non-contrastive [h] (23).


Vowels following contrastively breathy vowels always host mid tones (24a) or rising tones (24b). We know of no examples where a high, low, or falling tone occurs on the second mora of a contrastively breathy root.

Figure 15 shows pitch contours for tonal categories, with values aggregated across many productions for two speakers. The plots on the left show pitch for high, mid, low, and falling tones on the first short vowel of bi-syllabic words, since this is the environment in which most falling tones occur. Falling tones are divided between those that start at the level of high tones (coded as HL) and those that start at the level of mid tones (coded as ML). The vast majority of these falls occur on contrastively breathy vowels, which almost always host falling or low tones. Rising tones are excluded from the V1 plots because they are very rare in this position, and roots with medial [ʔ] were excluded from the V1 plots because pitch readings for the vowel preceding a [ʔ] are often unreliable and sometimes even absent in this language. The plots on the right show pitch for high, mid, low, and rising tones on the second short vowel of a root. Rises were included because most rising tones in the language occur on the second vowel of the root. Falling tones were excluded because we know of no underlying Falling tones in this environment. Roots with medial [ʔ] were included in the V2 plots because pitch on the second mora is not significantly perturbed by the preceding [ʔ].
Pitch (Hz) by tone type on V1 (left) and V2 (right) for consultants NGC (top) and RDC (bottom). Colored lines are LOESS regression curves, and gray bars around the lines represent 95% confidence intervals for the curve.
Number of tokens for NGC V1: H = 51, HL = 33, M = 93, ML = 24, L = 113.
Number of tokens for RDC V1: H = 36, HL = 33, M = 93, ML = 24, L = 129.
Number of tokens for NGC V2: H = 42, M = 107, L = 80, R = 157.
Number of tokens for RDC V2: H = 51, M = 119, L = 102, R = 180.

3.4 Tone Sandhi
San Martín Peras Mixtec has relatively few tone sandhi processes when compared to some other varieties of Mixtec, like the Yucuquimi de Ocampo and Nochixtlan varieties (León Vázquez, Reference León Vázquez2017; Mckendry, Reference McKendry2013). In this regard, it is similar to Alcozauca Mixtec (Mendoza Ruiz, Reference Mendoza Ruiz2016; Uchihara & Mendoza Ruiz, Reference Uchihara and Mendoza Ruiz2021), though Alcozauca Mixtec has more tone levels than SMPM—four as opposed to three. We know of two tone sandhi processes in the language, which were first described in Hedding (Reference Hedding2019). The first, which we call Rise Flattening, changes an underlying rising tone to a low tone when it is immediately followed by a high tone. This process can be seen in that the underlying word-final rise on [nũ̀ʰnĩ̌] ‘corn’, seen in (25a), surfaces as a low tone when the following word begins with a high tone (25b). Additionally, rising tones often surface with level low pitch at the end of an utterance, suggesting that an identical or similar process applies at utterance edges.

The second tone sandhi process, which we refer to as Low Tone Spread, changes an underlying high tone to a rising tone when it is immediately preceded by a low tone. Additionally, as demonstrated by Eischens (Reference Eischens2022), this process is only triggered when the high tone is docked on a glottalized low vowel [aˀ], and the only words known to undergo it are adjectives. This process can be seen below, where the word [káˀnũ̀] ‘big’ surfaces with its underlying initial high tone in (26a), but with an initial rise when it follows a low tone in (26b).

As noted in Hedding (Reference Hedding2019), these two sandhi processes interact opaquely with each other. While Rise Flattening may create the conditioning environment for Low Tone Spread to apply, the second process does not apply; that is, low tones derived by Rise Flattening do not trigger Low Tone Spread. For example, the word /jûʰkǔ/ (‘mountain/wilderness’) has an underlying, final rising tone (23d). This rising tone becomes a low tone when followed by the initial high tone of [káˀnũ̀] (‘big’). However, the initial high tone of ‘big’ does not undergo Low Tone Spread (27), even though it is immediately preceded by a derived low tone.

4. Illustrative Passage
The story of the North Wind and the Sun is not a native Mixtec story, so consultant NGC read the story in Spanish and translated it into San Martín Peras Mixtec. To familiarize the consultant with the story, she first translated it sentence-by-sentence into Mixtec. Once she was familiar enough with the story, she told it several times from beginning to end without referencing her sentence-by-sentence translation, and she chose the telling that seemed most natural and accurate to her. This telling differed substantially from the sentence-by-sentence translation and is the one written below. We have included a transcription of the story in the working orthography described earlier in the article, as well as a narrow transcription including a three-line gloss.
4.1 Orthographic version
Tàtyǐ nórtè xí’ìn tsìkàntsìjǐ kìxaà nà kâ’àn nà yòó nà ntakù tyáákà, tá nìyà’ǎ iin rà xíka ìníì 𠃱uù yivǐ xí’ìn tsiàà kǎ’nù ítiví rà. Nìka’àn nà yòó nà kevà’a kasa ntúxa nà xí’ìn rà tàvǎ nà míí tsiàà ítiví rà, rà kúu nà nà ntakù nùjǔ ntsìkúu ñà’a ñuù yivǐ. Míí tàtyǐ ñà nórtè ntakù và’a tsìvià xí’ìn ntsìkúu ntsiêjâ, só nú kuà’á và’ǎ tsívià, kuà’á tyáákà ná tìjviâ tsiàà kǎ’nù míí rà xǐka ìníì ñuù yivǐ. Nǔ ntsí’i kùntaà ini míí tàtyǐ nórtè kòníkùù tyiñà. Sáá nàye’è tsìkàntsìjǐ xí’ìn ntsìkúu ñà i’níà. Kamà và’a tàvǎ míí rà xíka ìníì ñuù yivǐ tsiàà kǎ’nù ítiví rà. Nǔ kùndaà ini tàtyǐ tsìkàntsìjǐ yá ntakù tyáákà nùjǔ ntsìkúu ñà’a.
4.2 Transcription


Acknowledgments
We are extremely grateful to the community of San Martín Peras, both in Oaxaca and in California, for their continued generosity and support in sharing their language with us. For their invaluable assistance in providing the data used in this article, we thank Juan Gracida Ortiz, Natalia Gracida Cruz, and Roselia Durán Cruz. We would also like to thank JIPA Editor Maria Tabain, Associate Editor Marc Garellek, and two anonymous reviewers for their insightful feedback. Partial financial support for this project comes from a Jacobs Research Fund Grant awarded to the second author.
Abbreviations
We use the following abbreviations (adopting, where possible, the Leipzig Glossing Rules): 1 = first person, 3 = third person, ADD = Additive, COMPL = Completive aspect, CONT = Continuative aspect, DEM = Demonstrative, EXCL = Exclusive, F = Feminine, FAM = Familiar referent, FOC = Focus, LIQ = Liquid pronoun, M = Masculine, MOOD = Mood marker, N = Neuter, NEG = Negative, PL = Plural, POT = Potential aspect, SG = Singular.
Appendix
The vocabulary items produced by JGO in this manuscript were elicited in carrier phrases in order to control for the effect of tone sandhi and utterance-level intonation on the realization of tones. However, the carrier phrase that was used was not the same in every case. The carrier phrases were adjusted as needed to create naturalistic and plausible utterances according to the preferences of our language consultant. Consequently, we used multiple carrier phrases, with the constraint that, whenever possible, the tones immediately preceding and following the target word be mid tones. Because the carrier phrases are helpful in hearing tonal contrasts, and because the carrier phrases were not always identical, the following list contains the gloss of each carrier phrase for each target word given throughout this Illustration. The glosses are organized by folder section name and numbered in the order that they occur in their respective folders. For ease of cross-referencing, any example or figure number is also included following an underscore, if applicable. Any examples for which carrier phrases were not available are excluded from the list, and their number in each folder is skipped.
1. Consonants

1.1 Obstruents

1.2 Sonorants

2. Vowels

3.2 Phonation type

3.3 Lexical tone


















 Open access
Open access