


No CrossRef data available.
Enhancing linguistic research through critical use of race and ethnicity information
Published online by Cambridge University Press: 27 April 2026
Abstract
All linguistic research has the potential to reproduce or challenge racial notions.
—Linguistic Society of America Statement on Race (2019)
The LSA Statement on Race stems from a larger conversation around undertheorized treatment of race and ethnicity in linguistics research and practice. In this commentary, we define racial identity and ethnicity and explain their relevance for linguistic research. We discuss considerations that linguistic researchers should take prior to research, during study design, and following research, and we offer specific recommendations when soliciting or using race and ethnicity data. These recommendations aim to help researchers avoid social harm, ensure ethical compliance and research integrity, and improve descriptive accuracy, especially for undersampled groups, by balancing research transparency with generalizability. We consider issues germane to collecting self-disclosures of ethnicity and racial identity in a range of study types spanning several subfields of linguistics. We give concrete examples of questions that may arise in planning studies in computational and corpus-based linguistics, formal linguistics, experimental linguistics, and qualitative linguistics. We speak to ethical considerations, including the importance of using locally constructed labels, analyst positionality, and respect for communities. Our goals are to provide linguistic researchers with a firmer basis for conceptualizing racial identity and ethnicity particularly as pertains to linguistics, and to supply a guide that aids linguists in reflecting on their own study design, positionality, and responsibility to participants and communities.
Information
- Type
- Commentary
- Information
- Creative Commons


 This is an Open Access article, distributed under the terms of the Creative Commons Attribution-ShareAlike licence (http://creativecommons.org/licenses/by-sa/4.0), which permits re-use, distribution, and reproduction in any medium, provided the same Creative Commons licence is used to distribute the re-used or adapted article and the original article is properly cited.
This is an Open Access article, distributed under the terms of the Creative Commons Attribution-ShareAlike licence (http://creativecommons.org/licenses/by-sa/4.0), which permits re-use, distribution, and reproduction in any medium, provided the same Creative Commons licence is used to distribute the re-used or adapted article and the original article is properly cited.- Copyright
- © The Author(s), 2026. Published by Cambridge University Press on behalf of the Linguistic Society of America
Footnotes
1 The fact that several of our examples in this paper are related to an anglophone context should not be taken to suggest that racism, race essentialism, and ethnocentrism are phenomena restricted to, or primarily occurring in, English-speaking countries.
2 A further question is what constitutes a negligible linguistic difference.
3 For a comprehensive overview of this variation as pertains to sociolinguistic research, see Noels Reference Noels2014.
4 For an overview of this and its relevance to linguistics, see Charity Hudley et al. Reference Charity Hudley, Mallinson and Bucholtz2020.
5 In this paper, we capitalize ‘White’ when referring to race. Whiteness is entrenched as normative in US society (among others), and keeping ‘White’ lowercase would both reinforce this harmful social norm and disregard the way Whiteness functions in communities and in academic practice.
6 This figure is necessarily a simplified and general schematic; we note that including more enriched demographic data might in fact change the discipline of a paper. For example, a sufficiently advanced description of the racial positionality of consultants might change a paper from a formal syntax paper to an interdisciplinary syntax and linguistic anthropology paper, given current disciplinary norms.
7 In the interest of collegiality, we are not naming or criticizing specific articles or giving identifying details. Our criticism is not toward particular scholars, but toward the norms of the subfield(s) more generally.
8 We contend that a syntax paper on a marginalized variety (such as ‘African American English’) would face harsher scrutiny in a journal’s review process if the author(s) did not explicitly name the variety as nonstandard. This asymmetry can reflect linguistic hegemonization, centering a default (see Charity Hudley et al. Reference Charity Hudley, Mallinson and Bucholtz2020 for discussion).
9 We recognize the apparent discrepancy in suggesting that linguists are typically concerned with ethnicity while simultaneously citing studies of racial classification schemes as evidence of the harms of fixed, monolithic categorization. We believe it follows logically that stigmatization and identity denial can also stem from monolithic ethnic categorization and that it is common for multiethnic individuals to change their identification throughout their lives. We also note that these studies investigate social construction of power inequalities, consistent with our use of ‘race’ in Section 2.1.
10 Information about a speaker’s native language is not information about a speaker’s ethnicity or race; see Rosa Reference Rosa2019 for a thorough discussion.
11 See Austin Reference Austin2010, Nduna et al. Reference Nduna, Mayisela, Balton, Gobodo-Madikizela, Kheswa, Khumalo, Makusha and Naidu2022, and Svalastog & Eriksson Reference Svalastog and Eriksson2010 for further discussion.
12 A paper that takes this tack—assuming ‘white supremacy etc. are bad’ unapologetically—is Bender et al. Reference Bender, Gebru, McMillan-Major and Shmitchell2021.
13 See, for example, the guidelines from NAACL 2021 (https://2021.naacl.org/ethics/faq/), ACL 2021 (https://2021.aclweb.org/ethics/Ethics-FAQ/), and NeurIPS 2021 (https://neuripsconf.medium.com/introducing-the-neurips-2021-paper-checklist-3220d6df500b).
References
Abreu, Manuel Arturo. 2015. Online imagined Black English. Arachne. https://arachne.cc/issues/01/online-imagined_manuel-arturo-abreu.html.Google Scholar
Albuja, Analia F.; Sanchez, Diana T.; and Gaither, Sarah E.. 2019. Identity questioning: Antecedents and consequences of prejudice attributions. Journal of Social Issues 75(2).515–37. https://doi.org/10.1111/josi.12322.CrossRefGoogle Scholar
Albuja, Analia F.; Sanchez, Diana T.; and Gaither, Sarah E.. 2020. Intra-race intersectionality: Identity denial among dual-minority biracial people. Translational Issues in Psychological Science 6(4).392–403. https://doi.org/10.1037/tps0000264.CrossRefGoogle Scholar
Alim, H. Samy. 2016. Introducing raciolinguistics: Racing language and languaging race in hyperracial times. Raciolinguistics: How language shapes our ideas about race, ed. by Alim, H. Samy, Rickford, John R., and Ball, Arnetha F., 1–30. New York: Oxford University Press. https://doi.org/10.1093/acprof:oso/9780190625696.003.0001.CrossRefGoogle Scholar
Austin, Peter K. 2010. Communities, ethics and rights in language documentation. Language Documentation and Description 7.34–54. https://doi.org/10.25894/ldd226.Google Scholar
Baker-Bell, April. 2020. Linguistic justice: Black language, literacy, identity, and pedagogy. New York: Routledge. https://doi.org/10.4324/9781315147383.CrossRefGoogle Scholar
Baugh, John. 2017. Linguistic profiling and discrimination. The Oxford handbook of language and society, ed. by García, Ofelia, Flores, Nelson, and Spotti, Massimiliano, 349–68. Oxford: Oxford University Press. https://doi.org/10.1093/oxfordhb/9780190212896.013.13.Google Scholar
Bender, Emily M.; Gebru, Timnit; McMillan-Major, Angelina; and Shmitchell, Shmargaret. 2021. On the dangers of stochastic parrots: Can language models be too big?  . FAccT ’21: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–23. https://doi.org/10.1145/3442188.3445922.CrossRefGoogle Scholar
. FAccT ’21: Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–23. https://doi.org/10.1145/3442188.3445922.CrossRefGoogle Scholar
Bender, Emily M., and Langendoen, D. Terence. 2010. Computational linguistics in support of linguistic theory. Linguistic Issues in Language Technology 3. https://doi.org/10.33011/lilt.v3i.1213.CrossRefGoogle Scholar
Berg, Bruce. L. 2007. Qualitative research methods for the social sciences. 6th edn. London: Pearson.Google Scholar
Black, Steven P. 2023. Ethics and language. A new companion to linguistic anthropology, ed. by Duranti, Alessandro, George, Rachel, and Riner, Robin Conley, 299–314. Oxford: Wiley-Blackwell. https://doi.org/10.1002/9781119780830.ch16.CrossRefGoogle Scholar
Bobo, Lawrence D. 2001. Racial attitudes and relations at the close of the twentieth century. America becoming: Racial trends and their consequences , vol. 1, ed. by Smelser, Neil J., Wilson, William Julius, and Mitchell, Faith, 264–301. Washington, DC: National Academy Press. https://www.nationalacademies.org/read/9599/chapter/10.Google Scholar
Bonam, Courtney M., and Margaret, Shih. 2009. Exploring multiracial individuals’ comfort with intimate interracial relationships. Journal of Social Issues 65(1).87–103. https://doi.org/10.1111/j.1540-4560.2008.01589.x.CrossRefGoogle Scholar
Briggs, Charles L. 2012. Learning how to ask: A sociolinguistic appraisal of the role of the interview in social science research. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9781139165990.Google Scholar
Bucholtz, Mary. 2020. Race, research, and linguistic activism. The Routledge companion to the work of John R. Rickford, ed. by Blake, Renée and Buchstaller, Isabelle, 242–50. New York: Routledge. https://doi.org/10.4324/9780429427886.Google Scholar
Čermák, František. 2002. Research methods in linguistics: Essential principles, based on a general theory of science. Prague: Universita Karlova v Praze, Nakladatelství Karolinum.Google Scholar
Charity Hudley, Anne H. 2017. Language and racialization. The Oxford handbook of language and society, ed. by García, Ofelia, Flores, Nelson, and Spotti, Massimiliano, 381–402. Oxford: Oxford University Press. https://doi.org/10.1093/oxfordhb/9780190212896.013.29.Google Scholar
Charity Hudley, Anne H.; Mallinson, Christine; and Bucholtz, Mary. 2020. Toward racial justice in linguistics: Interdisciplinary insights into theorizing race in the discipline and diversifying the profession. Language 96(4).200–235. https://doi.org/10.1353/lan.2020.0074.CrossRefGoogle Scholar
Chen, Jacqueline M., and Hamilton, David L.. 2012. Natural ambiguities: Racial categorization of multiracial individuals. Journal of Experimental Social Psychology 48.152–64. http://doi.org/10.1016/j.jesp.2011.10.005.CrossRefGoogle Scholar
Chen, Jacqueline M.; Moons, Wesley G.; Gaither, Sarah E.; Hamilton, David L.; and Sherman, Jeffery W.. 2014. Motivation to control prejudice predicts categorization of multiracials. Personality and Social Psychology Bulletin 40(5).590–603. https://doi.org/10.1177/0146167213520457.CrossRefGoogle ScholarPubMed
Cheng, Andrew; Faytak, Matthew; and Cychosz, Meg. 2016. Language, race, and vowel space: Contemporary Californian English. Berkeley: University of California, Berkeley, ms. http://langsci.uci.edu/~acheng14/files/Cheng-Faytak-Cychosz_2016_CVS.pdf.Google Scholar
Cheng, Chi-Ying, and Lee, Fiona. 2009. Multiracial identity integration: Perceptions of conflict and distance among multiracial individuals. Journal of Social Issues 65.51–68. https://doi.org/10.1111/j.1540-4560.2008.01587.x.CrossRefGoogle Scholar
Cheng, John. 2003. What is the difference between race and ethnicity? Race: The power of an illusion. Online: https://www.racepowerofanillusion.org/qa/what-difference-between-race-and-ethnicity.Google Scholar
Cheryan, Sapna, and Monin, Benoît. 2005. ‘Where are you really from?’: Asian Americans and identity denial. Journal of Personality and Social Psychology 89.717–30. https://doi.org/10.1037/0022-3514.89.5.717.CrossRefGoogle ScholarPubMed
Choo, Hae Yeon, and Ferree, Myra Marx. 2010. Practicing intersectionality in sociological research: A critical analysis of inclusions, interactions, and institutions in the study of inequalities. Sociological Theory 28(2).129–49. https://doi.org/10.1111/j.1467-9558.2010.01370.x.CrossRefGoogle Scholar
Clément, Richard, and Noels, Kimberly A.. 1992. Towards a situated approach to ethnolinguistic identity: The effects of status on individuals and groups. Journal of Language and Social Psychology 11(4).203–32. https://doi.org/10.1177/0261927X92114002.CrossRefGoogle Scholar
Cohen, Abner. 1996 [1974]. The lesson of ethnicity (1974). Theories of ethnicity: A classical reader, ed. by Werner, Sollors, 370–84. New York: NYU Press.CrossRefGoogle Scholar
Comaroff, John L., and Comaroff, Jean. 2009. Ethnicity, Inc. Chicago: University of Chicago Press.CrossRefGoogle Scholar
Crenshaw, Kimberlé. 1989. Demarginalizing the intersection of race and sex: A Black feminist critique of antidiscrimination doctrine, feminist theory and antiracist politics. University of Chicago Legal Forum 1989(1):8. http://chicagounbound.uchicago.edu/uclf/vol1989/iss1/8.Google Scholar
Crenshaw, Kimberlé. 2017. On intersectionality: Essential writings. New York: The New Press.Google Scholar
Davenport, Lauren D. 2016. The role of gender, class, and religion in biracial Americans’ racial labeling decisions. American Sociological Review 81.57–84. https://doi.org/10.1177/0003122415623286.CrossRefGoogle Scholar
Davis, Kathy. 2008. Intersectionality as buzzword: A sociology of science perspective on what makes a feminist theory successful. Feminist Theory 9(1).67–85. https://doi.org/10.1177/1464700108086364.CrossRefGoogle Scholar
DeGraff, Michel. 2020. Toward racial justice in linguistics: The case of Creole studies (Response to Charity Hudley et al.). Language 96(4).e292–e306. https://doi.org/10.1353/lan.2020.0080.CrossRefGoogle Scholar
Dillman, Don A.; Smyth, Jolene D.; and Christian, Leah Melani. 2014. Reducing people’s reluctance to respond to surveys. Internet, phone, mail, and mixed-mode surveys: The tailored design method, 19–55. Hoboken, NJ: John Wiley and Sons. https://doi.org/10.1002/9781394260645.ch2.CrossRefGoogle Scholar
D’Onofrio, Annette. 2019. Complicating categories: Personae mediate racialized expectations of non-native speech. Journal of Sociolinguistics 23(4).346–66. https://doi.org/10.1111/josl.12368.CrossRefGoogle Scholar
Dovchin, Sender. 2019a. Language crossing and linguistic racism: Mongolian immigrant women in Australia. Journal of Multicultural Discourses 14(4).334–51. https://doi.org/10.1080/17447143.2019.1566345.CrossRefGoogle Scholar
Dovchin, Sender. 2019b. The politics of inequality in translingualism and linguistic discrimination. Critical inquiries in the studies of sociolinguistics of globalization, ed. by Barrett, Tyler Andrew and Dovchin, Sender, 84–102. Bristol: Multilingual Matters.Google Scholar
Doyle, Jamie Mihoko, and Kao, Grace. 2007. Are racial identities of multiracials stable? Changing self-identification among single and multiple race individuals. Social Psychology Quarterly 70(4).405–23. https://doi.org/10.1177/019027250707000409.CrossRefGoogle ScholarPubMed
Eckert, Penelope. 2005. Variation, convention, and social meaning. Paper presented at the annual meeting of the Linguistic Society of America, Oakland, CA.Google Scholar
Eckert, Penelope. 2012. Three waves of variation study: The emergence of meaning in the study of sociolinguistic variation. Annual Review of Anthropology 41.87–100. https://doi.org/10.1146/annurev-anthro-092611-145828.CrossRefGoogle Scholar
Edgar, Heather J. H., and Hunley, Keith L.. 2009. Race reconciled?: How biological anthropologists view human variation. American Journal of Physical Anthropology 139(1).1–4. https://doi.org/10.1002/ajpa.20995.CrossRefGoogle ScholarPubMed
Espinosa, Adriana; Tikhonov, Alexsandr; Ellman, Lauren M.; Kern, David M.; Lui, Florence; and Anglin, Deidre. 2018. Ethnic identity and perceived stress among ethnically diverse immigrants. Journal of Immigrant and Minority Health. 20(1).155–63. https://doi.org/10.1007/s10903-016-0494-z.CrossRefGoogle ScholarPubMed
Etienne, Arnelle; Laroia, Tarana; Weigle, Harper; Afelin, Amber; Kelly, Shawn K.; Krishnan, Ashwati; and Grover, Pulkit. 2020. Novel electrodes for reliable EEG recordings on coarse and curly hair. 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), 6151–54. https://doi.org/10.1109/EMBC44109.2020.9176067.CrossRefGoogle Scholar
Feliciano, Cynthia, and Rumbaut, Rubén G.. 2018. Varieties of ethnic self-identities: Children of immigrants in middle adulthood. RSF: The Russell Sage Foundation Journal of the Social Sciences 4(5).26–46. https://doi.org/10.7758/rsf.2018.4.5.02.CrossRefGoogle Scholar
Feliciano, Cynthia, and Rumbaut, Rubén G.. 2019. The evolution of ethnic identity from adolescence to middle adulthood: The case of the immigrant second generation. Emerging Adulthood 7(2).85–96. https://doi.org/10.1177/2167696818805342.CrossRefGoogle Scholar
Fishman, Joshua A. 1977. Language and ethnicity. Language, ethnicity and intergroup relations, ed. by Giles, Howard, 15–58. New York: Academic Press.Google Scholar
Freeman, Jonathan B.; Penner, Andrew M.; Saperstein, Aliya; Scheutz, Matthias; and Ambady, Nalini. 2011. Looking the part: Social status cues shape race perception. PLoS ONE 6. https://doi.org/10.1371/journal.pone.0025107.CrossRefGoogle ScholarPubMed
Furbee, N. Louanna. 2010. Language documentation: Theory and practice. Language documentation: Practice and values, ed. by Grenoble, Lenore A. and Furbee, N. Louanna, 3–24. Amsterdam: John Benjamins. https://doi.org/10.1075/z.158.04fur.CrossRefGoogle Scholar
Gaby, Alice, and Woods, Lesley. 2020. Toward linguistic justice for Indigenous people: A response to Charity Hudley, Mallinson, and Bucholtz. Language 96(4).e268–e280. https://doi.org/10.1353/lan.2020.0078.CrossRefGoogle Scholar
Gaither, Sarah E. 2015. ‘Mixed’ results: Multiracial research and identity explorations. Current Directions in Psychological Science 24(2).114–19. https://doi.org/10.1177/0963721414558115.CrossRefGoogle Scholar
García, Justin D. 2020. Race and ethnicity. Perspectives: An open invitation to cultural anthropology, 2nd edn., ed. by Brown, Nina, McIlwraith, Thomas, and de González, Laura Tubelle, 444–55. Arlington, VA: American Anthropological Association. https://pressbooks.pub/perspectives/chapter/race-and-ethnicity/.Google Scholar
Geller, Jason; Holmes, Ann; Schwalje, Adam; Berger, Joel I.; Gander, Phillip E.; Choi, Inyong; and McMurray, Bob. 2021. Validation of the Iowa Test of Consonant Perception. The Journal of the Acoustical Society of America 150(3).2131–53. https://doi.org/10.1121/10.0006246CrossRefGoogle ScholarPubMed
Giddens, Anthony. 1979. Positivism and its critics. A history of sociological analysis, ed. by Bottomore, Tom and Nisbet, Robert, 239–86. London: Heinemann.Google Scholar
Giles, Howard, and Johnson, Patricia. 1987. Ethnolinguistic identity theory: A social psychological approach to language maintenance. International Journal of the Sociology of Language 68.66–99. https://doi.org/10.1515/ijsl.1987.68.69.Google Scholar
Gurin, Patricia; Peng, Timonthy; Lopez, Gretchen; and Nagda, Biren A.. 1999. Context, identity, and intergroup relations. Cultural divides: Understanding and overcoming group conflict, ed. by Prentice, Deborah A. and Miller, Dale T., 133–70. New York: Russell Sage Foundation. https://muse.jhu.edu/book/38572.Google Scholar
Hammersley, Martyn, and Atkinson, Paul. 2007. Ethnography: Principles in practice. 3rd edn. London: Routledge.Google Scholar
Harris, David R., and Sim, Jeremiah Joseph. 2002. Who is multiracial? Assessing the complexity of lived race. American Sociological Review 67(4).614–27. https://doi.org/10.1177/000312240206700407.CrossRefGoogle Scholar
Haslam, Nick; Rothschild, Louis; and Ernst, Donald. 2000. Essentialist beliefs about social categories. British Journal of Social Psychology 39(1).113–27. https://doi.org/10.1348/014466600164363.CrossRefGoogle ScholarPubMed
Heller, Monica; Pietikäinen, Sari; and Pujolar, Joan. 2018. Critical sociolinguistic research methods: Studying language issues that matter. London: Routledge. https://doi.org/10.4324/9781315739656.Google Scholar
Hilton, Katherine. 2018. What does an interruption sound like? Stanford, CA: Stanford University dissertation. https://purl.stanford.edu/vf660gm5432.Google Scholar
Hitlin, Steven; Brown, J. Scott; and Elder, Glen H. Jr. 2006. Racial self-categorization in adolescence: Multiracial development and social pathways. Child Development 77.1298–1308. https://doi.org/10.1111/j.1467-8624.2006.00935.x.CrossRefGoogle ScholarPubMed
Holt, Yolanda. 2023. Kids talk too: Linguistic justice and child African American English. The Journal of the Acoustical Society of America 153:A211. https://doi.org/10.1121/10.0018686.CrossRefGoogle Scholar
Houle, Nichole; Lerario, Mackenzie P.; and Levi, Susannah V.. 2023. Spectral analysis of strident fricatives in cisgender and transfeminine speakers. The Journal of the Acoustical Society of America 154(5).3089–3100. https://doi.org/10.1121/10.0022387.CrossRefGoogle Scholar
Hurtado, Aida; Gurin, Patricia; and Peng, Timothy. 1994. Social identities—A framework for studying the adaptations of immigrants and ethnics: The adaptations of Mexicans in the United States. Social Problems 41(1).129–51. https://doi.org/10.2307/3096846.CrossRefGoogle Scholar
Johnson, Alexander; Shankar, Natarajan Balaji; Ostendorf, Mari; and Alwan, Abeer. 2024. An exploratory study on dialect density estimation for children and adult’s African American English. The Journal of the Acoustical Society of America 155(4).2836–48. https://doi.org/10.1121/10.0025771.CrossRefGoogle Scholar
Jones, Nicholas A., and Bullock, Jungmiwha. 2012. The two or more races population: 2010. 2010 Census Briefs. Washington, DC: US Census Bureau. https://www.census.gov/library/publications/2012/dec/c2010br-13.html.Google Scholar
Jørgensen, Anna; Hovy, Dirk; and Søgaard, Anders. 2015. Challenges of studying and processing dialects in social media. Proceedings of the Workshop on Noisy User-generated Text, 9–18. https://doi.org/10.18653/v1/W15-4302.CrossRefGoogle Scholar
Kang, Okim, and Rubin, Donald L.. 2009. Reverse linguistic stereotyping: Measuring the effect of listener expectations on speech evaluation. Journal of Language and Social Psychology 28(4).441–56. DOI: https://doi.org/10.1177/0261927X09341950.CrossRefGoogle Scholar
Kang, Okim; Rubin, Donald L.; and Lindemann, Stephanie. 2015. Mitigating U.S. undergraduates’ attitudes toward international teaching assistants. TESOL Quarterly 49(4).681–706. https://doi.org/10.1002/tesq.192.CrossRefGoogle Scholar
Keita, Shomarka Omar Yahya; Kittles, R. A.; Royal, C. D. M.; Bonney, G. E.; Furbert-Harris, P.; Dunston, G. M.; and Rotimi, C. N.. 2004. Conceptualizing human variation. Nature Genetics 36.S17–S20. https://doi.org/10.1038/ng1455.CrossRefGoogle ScholarPubMed
Koenecke, Allison; Nam, Andrew; Lake, Emily; Nudell, Joe; Quartey, Minnie; Mengesha, Zion; Toups, Connor; Rickford, John R.; Jurafsky, Dan; and Goel, Sharad. 2020. Racial disparities in automated speech recognition. Proceedings of the National Academy of Sciences 117(14).7684–89. https://doi.org/10.1073/pnas.1915768117.CrossRefGoogle ScholarPubMed
Kurien, Prema. 2018. Shifting U.S. racial and ethnic identities and Sikh American activism. RSF: The Russell Sage Foundation Journal of the Social Sciences 4.81–98. https://doi.org/10.7758/RSF.2018.4.5.04.CrossRefGoogle Scholar
Labov, William. 1963. The social motivation of a sound change. WORD 19(3).273–309. https://doi.org/10.1080/00437956.1963.11659799.CrossRefGoogle Scholar
Labov, William. 1984. Field methods of the project on linguistic change and variation. Language in use: Readings in sociolinguistics, ed. by Baugh, John and Sherzer, Joel, 28–53. Englewood Cliffs, NJ: Prentice-Hall.Google Scholar
Lanehart, Sonja. 2023. Language in African American communities. (Routledge guides to linguistics.) London: Routledge.Google Scholar
Lanehart, Sonja, and Malik, Ayesha. 2015. What should we call it and what does it mean? The Oxford handbook of African American Language, ed. by Bloomquist, Jennifer, Green, Lisa J., and Lanehart, Sonja L., 3–5. New York: Oxford University Press. https://doi.org/10.1093/oxfordhb/9780199795390.013.62.Google Scholar
Legate, Julie Anne; Akkuş, Faruk; Šereikaitė, Milena; and Ringe, Don. 2020. On passives of passives. Language 96(4).771–818. https://doi.org/10.1353/lan.2020.0062.CrossRefGoogle Scholar
Levon, Erez. 2015. Integrating intersectionality in language, gender, and sexuality research. Language and Linguistics Compass 9(7).295–308. https://doi.org/10.1111/lnc3.12147.CrossRefGoogle Scholar
Levy, Sheri R., and Dweck, Carol S.. 1999. The impact of children’s static versus dynamic conceptions of people on stereotype formation. Child Development 70(5).1163–80. https://doi.org/10.1111/1467-8624.00085.CrossRefGoogle Scholar
Levy, Sheri R.; Stroessner, Steven J.; and Dweck, Carol S.. 1998. Stereotype formation and endorsement: The role of implicit theories. Journal of Personality and Social Psychology 74.1421–36. https://doi.org/10.1037/0022-3514.74.6.1421.CrossRefGoogle Scholar
Liebkind, Karmela; Mähönen, Tuuli Anna Elisa; Varjonen, Sirkku Anneli; and Jasinskaja-Lahti, Inga. 2016. Acculturation and identity. The Cambridge handbook of acculturation psychology, 2nd edn., ed. by Sam, David L. and Berry, John W., 30–49. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9781316219218.004.CrossRefGoogle Scholar
Linguistic Society of America. 2018. The state of linguistics in higher education: Annual report 2018. http://files.eric.ed.gov/fulltext/ED607313.pdf.Google Scholar
Linguistic Society of America. 2019. Statement on race. https://www.lsadc.org/statement_on_race.Google Scholar
López, Nancy; Vargas, Edward D.; Juarez, Melina; Cacari-Stone, Lisa; and Bettez, Sonia. 2017. What’s your ‘street race’? Leveraging multidimensional measures of race and intersectionality for examining physical and mental health status among Latinxs. Sociology of Race and Ethnicity 4(1).49–66. https://doi.org/10.1177/2332649217708798.CrossRefGoogle ScholarPubMed
Mahowald, Kyle; Graff, Peter; Hartman, Jeremy; and Gibson, Edward. 2016. SNAP judgments: A small N acceptability paradigm (SNAP) for linguistic acceptability judgments. Language 92(3).619–35. https://doi.org/10.1353/lan.2016.0052.CrossRefGoogle Scholar
Markus, Hazel Rose. 2010. Who am I?: Race, ethnicity and identity. Doing race: 21 essays for the 21st century, ed. by Markus, Hazel Rose and Paula, L. M. Moya, 359–89. New York: W. W. Norton and Co.Google Scholar
Matteson, Samuel E.; Olness, Gloria Streit; and Caplow, Nancy J.. 2013. Toward a quantitative account of pitch distribution in spontaneous narrative: Method and validation. The Journal of the Acoustical Society of America 133(5).2953–71. https://doi.org/10.1121/1.4796111.CrossRefGoogle Scholar
miles-hercules, deandre. 2020. Scoping the scope: Revisiting the aims and paradigms of Linguistics. Part of online webinar, ‘This IS Linguistics: Scope, positionality, and graduate apprenticeship when diversifying the linguistics curriculum’, Linguistic Society of America, 11 September 2020.Google Scholar
Milroy, James, and Milroy, Lesley. 1978. Belfast: Change and variation in an urban vernacular. Sociolinguistic patterns in British English, ed. by Trudgill, Peter, 19–36. Cambridge: Cambridge University Press.Google Scholar
Milroy, Lesley, and Gordon, Matthew. 2003. Sociolinguistics: Method and interpretation. Oxford: Blackwell. https://doi.org/10.1002/9780470758359.CrossRefGoogle Scholar
Morning, Ann. 2007. ‘Everyone knows it’s a social construct’: Contemporary science and the nature of race. Sociological Focus 40(4).436–54. https://doi.org/10.1080/00380237.2007.10571319.CrossRefGoogle Scholar
Morning, Ann. 2011. The nature of race: How scientists think and teach about human difference. Berkeley: Univerisity of California Press.CrossRefGoogle Scholar
Mullings, Leith. 1978. Ethnicity and stratification in the urban United States. Annals of the New York Academy of Sciences 318.10–22. https://doi.org/10.1111/j.1749-6632.1978.tb16351.xCrossRefGoogle Scholar
Nduna, Mzikazi; Mayisela, Simangele; Balton, Sadna; Gobodo-Madikizela, Pumla; Kheswa, Jabulani G.; Khumalo, Itumeleng P.; Makusha, Tawanda; Naidu, Maheshvari; et al. 2022. Research site anonymity in context. Journal of Empirical Research on Human Research Ethics 17(5).554–64. https://doi.org/10.1177/15562646221084838.CrossRefGoogle ScholarPubMed
Nguyen, Angela-MinhTu D., and Benet-Martinez, Verónica. 2010. Multicultural identity: What it is and why it matters. The psychology of social and cultural diversity, ed. by Crisp, Richard, 87–114. Hoboken, NJ: Wiley-Blackwell. https://doi.org/10.1002/9781444325447.ch5.Google Scholar
Noels, Kimberly A. 2014. Language variation and ethnic identity: A social psychological perspective. Language and Communication 35(1).88–96. https://doi.org/10.1016/j.langcom.2013.12.001.CrossRefGoogle Scholar
Noels, Kimberly A.; Leavitt, Peter; and Clément, Richard. 2010. ‘To see ourselves as others see us’: On the implications of reflected appraisals for ethnic identity and discrimination. Journal of Social Issues 66(4).740–58. https://doi.org/10.1111/j.1540-4560.2010.01673.x.CrossRefGoogle Scholar
Omi, Michael, and Winant, Howard. 2014. Racial formation in the United States. 3rd edn. New York: Routledge.CrossRefGoogle Scholar
Panicacci, Alex. 2021. Exploring identity across language and culture: The psychological, emotional, linguistic, and cultural changes following migration. New York: Routledge. https://doi.org/10.4324/9781003017417.CrossRefGoogle Scholar
Park, Jerry Z. 2008. Second-generation Asian American pan-ethnic identity: Pluralized meanings of a racial label. Sociological Perspectives 51(3).541–61. https://doi.org/10.1525/sop.2008.51.3.541.CrossRefGoogle Scholar
Pauker, Kristin; Apfelbaum, Evan P.; and Spitzer, Brian. 2015. When societal norms and social identity collide: The race talk dilemma for racial minority children. Social Psychological and Personality Science 6(8).887–95. https://doi.org/10.1177/1948550615598379.CrossRefGoogle ScholarPubMed
Peery, Destiny, and Bodenhausen, Galen V.. 2008. Black + White = Black: Hypodescent in reflexive categorization of racially ambiguous faces. Psychological Science 19(10).973–77. https://doi.org/10.1111/j.1467-9280.2008.02185.x.CrossRefGoogle ScholarPubMed
Phinney, Jean S., and Ong, Anthony D.. 2007. Conceptualization and measurement of ethnic identity: Current status and future directions. Journal of Counseling Psychology 54(3).271–81. https://doi.org/10.1037/0022-0167.54.3.271.CrossRefGoogle Scholar
Prentice, Deborah A., and Miller, Dale T.. 2007. Psychological essentialism of human categories. Current Directions in Psychological Science 16(4).202–6. https://doi.org/10.1111/j.1467-8721.2007.00504.x.CrossRefGoogle Scholar
Purdie-Vaughns, Valerie, and Eibach, Richard P.. 2008. Intersectional invisibility: The distinctive advantages and disadvantages of multiple subordinate-group identities. Sex Roles 59(5–6).377–91. https://doi.org/10.1007/s11199-008-9424-4.CrossRefGoogle Scholar
Purnell, Thomas; Idsardi, William; and Baugh, John. 1999. Perceptual and phonetic experiments on American English. Journal of Language and Social Psychology 18(1).10–30. https://doi.org/10.1177/0261927X99018001002.CrossRefGoogle Scholar
Relethford, John H. 2009. Race and global patterns of phenotypic variation. American Journal of Physical Anthropology 139(1).16–22. https://doi.org/10.1002/ajpa.20900.CrossRefGoogle ScholarPubMed
Rice, Keren. 2010. The linguist’s responsibilities to the community of speakers: Community-based research. Language documentation: Practice and values, ed. by Grenoble, Lenore A. and Furbee, N. Louanna, 25–36. Amsterdam: John Benjamins. https://doi.org/10.1075/z.158.05ric.CrossRefGoogle Scholar
Rickford, John R. 1986. The need for new approaches to social class analysis in sociolinguistics. Language & Communication 6(3).215–21. https://doi.org/10.1016/0271-5309(86)90024-8.CrossRefGoogle Scholar
Rickford, John R. 1997. Unequal partnership: Sociolinguistics and the African American speech community. Language in Society 26(2).161–97. https://doi.org/10.1017/S0047404500020893.CrossRefGoogle Scholar
Rockquemore, Kerry Ann; Brunsma, David L.; Delgado, Daniel J.. 2009. Racing to theory or retheorizing race? Understanding the struggle to build a multiracial identity theory. Journal of Social Issues 65(1).13–34. https://doi.org/10.1111/j.1540-4560.2008.01585.x.CrossRefGoogle Scholar
Rosa, Jonathan. 2019. Looking like a language, sounding like a race: Raciolinguistic ideologies and the learning of Latinidad. Oxford: Oxford University Press. https://doi.org/10.1093/oso/9780190634728.001.0001.CrossRefGoogle Scholar
Rosa, Jonathan, and Flores, Nelson. 2017. Unsettling race and language: Toward a raciolinguistic perspective. Language in Society 46(5).621–47. https://doi.org/10.1017/S0047404517000562.CrossRefGoogle Scholar
Rzepnikowska, Alina. 2018. Racism and xenophobia experienced by Polish migrants in the UK before and after Brexit vote. Journal of Ethnic and Migration Studies 45(1).61–77. https://doi.org/10.1080/1369183X.2018.1451308.CrossRefGoogle Scholar
Sanchez, Diana; Shih, Margaret J.; and Wilton, Leigh S.. 2014. Exploring the identity autonomy perspective: An integrative theoretical approach to multicultural and multiracial identity. The handbook of multicultural identity: Basic and applied psychological perspectives, ed. by Benet-Martínez, Verónica and Hong, Ying-Yi, 139–59. New York: Oxford University Press. https://doi.org/10.1093/oxfordhb/9780199796694.013.016.Google Scholar
Sap, Maarten; Card, Dallas; Gabriel, Saadia; Choi, Yejin; and Smith, Noah A.. 2019. The risk of racial bias in hate speech detection. Proceedings of the 57th annual meeting of the Association for Computational Linguistics, 1668–78. https://doi.org/10.18653/v1/P19-1163.CrossRefGoogle Scholar
Sen, Maya, and Wasow, Omar. 2016. Race as a bundle of sticks: Designs that estimate effects of seemingly immutable characteristics. Annual Review of Political Science 19.499–522. https://doi.org/10.1146/annurev-polisci-032015-010015.CrossRefGoogle Scholar
Shih, Margaret; Bonam, Courtney; Sanchez, Diana; and Peck, Courtney. 2007. The social construction of race: Biracial identity and vulnerability to stereotypes. Cultural Diversity and Ethnic Minority Psychology 13.125–33. https://doi.org/10.1037/1099-9809.13.2.125.CrossRefGoogle ScholarPubMed
Smith, Maya A. 2019. Senegal abroad: Linguistic borders, racial formations, and diasporic imaginaries. Madison: University of Wisconsin Press. https://doi.org/10.2307/j.ctvfjcz3b.CrossRefGoogle Scholar
Smith, Patriann. 2023. A call for raciolinguistic epistemologies: Transnational languaging of immigrant literacy teacher educators.
Critical Inquiry in Language Studies
21(1).1–22. https://doi.org/10.1080/15427587.2023.2218618.CrossRefGoogle Scholar
Smitherman, Geneva. 2000. Talkin that talk: Language, culture and education in African America. London: Routledge.CrossRefGoogle Scholar
Smitherman, Geneva. 2020. Foreword. In Baker-Bell, vii–xvii. https://doi.org/10.4324/9781315147383.CrossRefGoogle Scholar
Spears, Arthur K. 2020. Racism, colorism, and language within their macro contexts. The Oxford handbook of language and race, ed. by Alim, H. Samy, Reyes, Angela, and Kroskrity, Paul V., 47–67. New York: Oxford University Press. https://doi.org/10.1093/oxfordhb/9780190845995.013.5.CrossRefGoogle Scholar
Squizzero, Robert. 2025. The effects of perceived ethnicity and prosodic accuracy on intelligibility, comprehensibility, and accentedness in L2 Mandarin Chinese. Language and Speech. https://doi.org/10.1177/00238309251361010.CrossRefGoogle ScholarPubMed
Squizzero, Robert; Horst, Martin; Wassink, Alicia Beckford; Panicacci, Alex; Jensen, Monica; Moroz, Anna Kristina; Conrod, Kirby; and Bender, Emily M.. 2021. Collecting and using race and ethnicity information in linguistic studies. Seattle: University of Washington, ms. http://hdl.handle.net/1773/48570.Google Scholar
Svalastog, Anna-Lydia, and Eriksson, Stefan. 2010. You can use my name; you don’t have to steal my story—A critique of anonymity in indigenous studies. Developing World Bioethics 10(2).104–10. https://doi.org/10.1111/j.1471-8847.2010.00276.x.CrossRefGoogle ScholarPubMed
Tatman, Rachael. 2017. Gender and dialect bias in YouTube’s automatic captions. Proceedings of the First ACL Workshop on Ethics in Natural Language Processing, 53–59. https://doi.org/10.18653/v1/W17-1606.CrossRefGoogle Scholar
Wassink, Alicia Beckford, and Curzan, Anne. 2004. Addressing ideologies around African American English. Journal of English Linguistics 32(3).171–85. https://doi.org/10.1177/0075424204268229.CrossRefGoogle Scholar
Wassink, Alicia Beckford; Gansen, Cady; and Bartholomew, Isabel. 2022. Uneven success: Automatic speech recognition and ethnicity-related dialects. Speech Communication 140.50–70. https://doi.org/10.1016/j.specom.2022.03.009.CrossRefGoogle Scholar
Williams, Brackette F. 1989. A class act: Anthropology and the race to nation across ethnic terrain. Annual Review of Anthropology 18.401–44. https://doi.org/10.1146/annurev.an.18.100189.002153.CrossRefGoogle Scholar
Williams, Melissa J., and Eberhardt, Jennifer L.. 2008. Biological conceptions of race and the motivation to cross racial boundaries. Journal of Personality and Social Psychology 94.1033–47. https://doi.org/10.1037/0022-3514.94.6.1033.CrossRefGoogle ScholarPubMed
Wolfram, Walt, and Dannenberg, Clare. 1999. Dialect identity in a tri-ethnic context: The case of Lumbee American Indian English. English World-Wide 20(2).179–216. https://doi.org/10.1075/eww.20.2.01wol.CrossRefGoogle Scholar
Yip, Tiffany. 2005. Sources of situational variation in ethnic identity and psychological wellbeing: A Palm Pilot study of Chinese American students. Personality and Social Psychology Bulletin 31(12).1603–16. https://doi.org/10.1177/0146167205277094.CrossRefGoogle ScholarPubMed
Zuberi, Tukufu. 2001. Thicker than blood: How racial statistics lie. Minneapolis: University of Minnesota Press. https://www.jstor.org/stable/10.5749/j.cttttcnc.Google Scholar
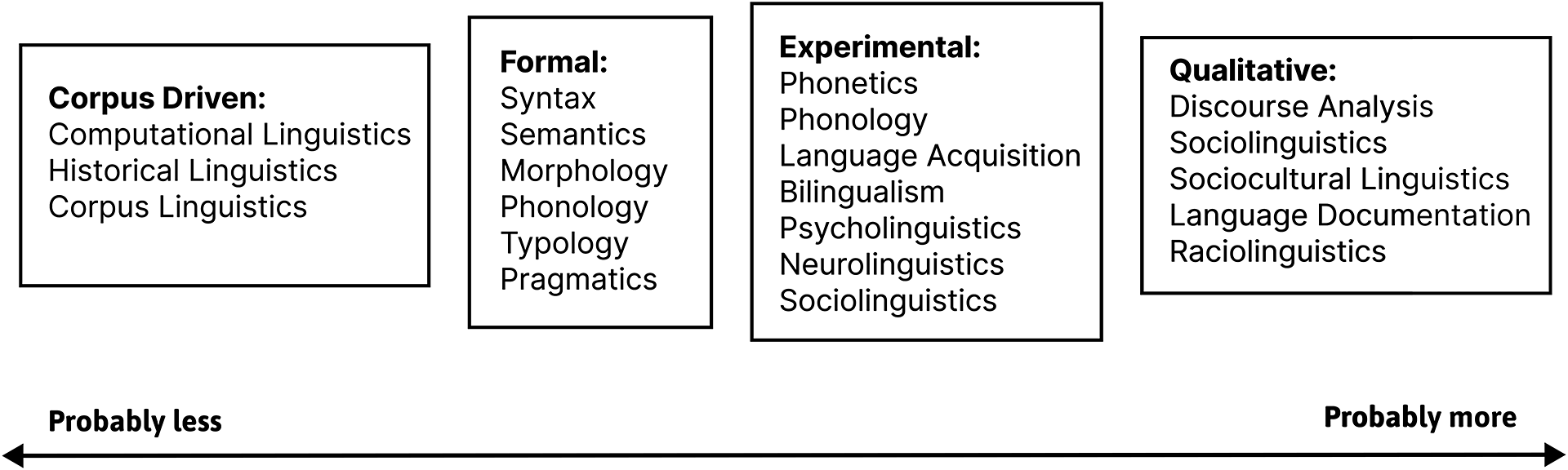
Figure 1. A schematization of subfields of linguistics according to how much demographic information is typically expected or available.Figure 1. long description.

Squizzero et al. supplementary material 1
Squizzero et al. supplementary material

File
94.3 KB
Squizzero et al. supplementary material 2
Squizzero et al. supplementary material
File
134.5 KB
 You have
Access
You have
Access
 Open access
Open access
1. Introduction
Linguists have been engaging in racist practice by underattending to the place of racialization in linguistic analysis, leading to inaccurate, misleading, and harmful classification of language users (Charity Hudley et al. Reference Charity Hudley, Mallinson and Bucholtz2020). Even when using racial categories, linguists rarely discuss how researchers select participants as suitable consultants and include, exclude, and classify participants in study samples, often falling back on undertheorized and/or essentialized racial categories rather than ones grounded in an understanding of how racialization functions in the community they are studying. When we classify speakers into a presumed speech community on the basis of appearance, place of birth or residence, or convenience, for example, we may be excluding people from consideration who, in fact, form part of the community we intend to study and thus may be biasing or otherwise damaging our empirical results. Existing publications have discussed, at length, the enduring racist practices employed in linguistic research (e.g. Charity Hudley Reference Charity Hudley, García, Flores and Spotti2017, Charity Hudley et al. Reference Charity Hudley, Mallinson and Bucholtz2020, Linguistic Society of America 2019, Rosa & Flores Reference Rosa and Flores2017); we therefore do not dwell on that here. However, a review of linguistics textbooks shows that the field lacks clear praxis for avoiding race essentialism in respondent selection (see below). The chief goal of this piece is to provide recommendations to linguists at all career stages for implementing antiracist practices in working with racial categories in research. By employing these practices, linguists can better fulfill our mission to describe human language and can also reduce our likelihood of furthering social harm and racial injustice.
Uncritical connections between language and the race of language users contribute to and sustain socially imposed divisions between arbitrarily defined racial groups. These connections have often been created without the involvement of members of racially minoritized groups, subscribing to and perpetuating the deeply flawed ideology that the viewpoint of an outsider is the most ‘objective’ one. We argue that, in spite of widespread perceptions that race and ethnicity are the exclusive province of sociolinguists and linguistic anthropologists, linguists in all subfields must carefully consider what race and ethnicity signify in the context of their research and whether their recruitment practices involve essentialization. We also argue that all linguists must reflect on the possibility that their sampling or recruiting processes—however well intentioned—may be exclusionary.
Our previous work (Squizzero et al. Reference Squizzero, Horst, Wassink, Panicacci, Jensen, Moroz, Conrod and Bender2021) finds from a detailed survey of sixty-two linguistics textbooks from nine subfields, published between 1951 and 2020, that the majority of these focus on obtaining an adequate understanding of linguistic data (cf. Čermák Reference Čermák2002:62), explicating the methods for and ‘propos[ing] testable inventories of universal categories, properties, relations, and interactions that may constitute a language’ (Furbee Reference Furbee, Grenoble and Furbee2010:3). Early methods texts in structural description gave way to deductive classification of forms and features. Methods for quantification and mathematical and statistical modeling emerged in the 1980s, together with guidance on use of qualitative techniques. It is not until the 1990s that we see guidance for detailed demographic elicitation within speaker communities or respectful treatment of and accountability to communities (e.g. Hale Reference Hale2007, Heller et al. Reference Heller, Pietikäinen and Pujolar2018, Milroy & Gordon Reference Milroy and Gordon2003, Rice Reference Rice, Grenoble and Furbee2010).
Open discussion of the treatment of race and ethnicity in linguistics is an important part of student mentorship and training in the responsible conduct of research, as well as in professional development for researchers at all levels of their careers. The focus on feature classification in the field has meant that students will tend to learn about informant selection, community sampling, and representing racial and ethnic categories when such discussions arise with informed and interested advisors, their committees, other students, or from consulting the internet. At present, advising practices appear to vary widely because there has not been a fieldwide emphasis on human classification. Resources may have been published in subfields or sister disciplines that students do not typically read or that do not directly apply to their topic. Resourceful as they are, students would benefit from readings like the present one, which gathers, synthesizes, and discusses a range of literature. Models of reflexivity (Section 2.4) need to be accessible to students seeking to learn and practice human classification. Because we desire to see continued growth in our field’s inclusion of all types of human languages and in our responsible conduct of research, this type of training is critical. While this paper provides guidance on conceptualization, collection, and use of race and ethnicity information for researchers at any stage of their careers, it is written with particular attention to the perspective of students and newer researchers.
This commentary is a direct response to requests we have received from colleagues across the field who desire guidance regarding use of demographic categories, particularly potentially sensitive race- and ethnicity-related ones, in their own research. In considering how to address this need, we found that the topic resolved itself into three problems, which are addressed in these pages:
(i) Linguists lack training in conceptualizations and articulations around race, relying on outdated or flawed models and definitions. This leads, sometimes, to attributing linguistic practices to the wrong groups of speakers and signers.
(ii) Feeling this lack of training, linguists often avoid gathering demographic information altogether or use representations that lack nuance, imposing such representations on their consultants and participants.
(iii) Students are unlikely to find explicit guidance regarding point (i) in linguistics texts covering study design.
1.1. Structure of this document
In Sections 2.1–2.2, we build foundations for a conceptual understanding of the notions of race and ethnicity, drawing on their complex evolution in the humanities and social sciences. Being equipped with this understanding precedes undertaking research. The remainder of Section 2 provides specific recommendations for how to address those design issues, and Section 3 highlights issues likely to be encountered when collecting and using race and ethnicity information in various linguistic methodologies. Recommendations are provided throughout for addressing issues that arise. Following these, we consider specific ways that linguistic research may be enhanced by following the suggestions provided. Section 4 raises post-research considerations. Readers should note that certain recommendations, though appearing in only one section for brevity’s sake, may be applicable at all stages of the research process. The paper concludes with final thoughts about the project and our hopes for the future of linguistic research. Additionally, two supplementary documents accompany this paper: the first is a case study that describes problems tackled in the design of one long-term linguistic project, and the second consists of the authors’ positionality statements.
2. Foundations: before research starts
2.1. Racial identity and ethnicity
The terms race and ethnicity are often used interchangeably, both in everyday conversation and in academic venues. This section explores theorization and use of these terms in linguistics’ sibling fields, especially anthropology, psychology, and sociology. We acknowledge that there is not a universally accepted formal definition for either term—even in these disciplines. Therefore, linguists cannot simplistically employ definitions used in other disciplines, but we argue that differentiating race from ethnicity is important for linguistic research and that linguists should reject static, essentializing views of each concept, which are nevertheless still embedded in scientific practice.
We begin with the conceptual distinction between biological inheritance that is given social meaning in a hierarchical system and cultural inheritance. Race and ethnicity are both complex, fluid, and manufactured terms that largely overlap and vary contextually and cross-culturally. However, we start from the recognition that historically, race has most typically referred to a taxonomic grouping of people sharing physical features, especially skin color, facial features, eye shape, and hair texture (Bobo Reference Bobo, Smelser, Wilson and Mitchell2001, Spears Reference Spears, Alim, Reyes and Kroskrity2020). As described later in this section, this is a flawed definition of race, even though it is a commonly understood one. Zuberi (Reference Zuberi2001) argues that the concept of race likely arose from fifteenth-century European efforts to rationalize slavery and colonialism. From this came the idea that members of races share ‘essences’ that are inherent, innate, or otherwise fixed (Morning Reference Morning2011). Racial groupings, in this conception, are arbitrary and are traditionally mutually exclusive. Race theories are often classified as either essentialist or constructivist. Race essentialism is the tendency to view intergroup differences as phenotypically indexed, biologically based, immutable, and informative (e.g. Haslam et al. Reference Haslam, Rothschild and Ernst2000, Prentice & Miller Reference Prentice and Miller2007). It has been linked to racial stereotyping and prejudice (Levy & Dweck Reference Levy and Dweck1999, Williams & Eberhardt Reference Williams and Eberhardt2008) and relies upon constructed categories as objectively meaningful (Levy et al. Reference Levy, Stroessner and Dweck1998, Prentice & Miller Reference Prentice and Miller2007). Race essentialism enacts the process of racialization, including ‘differentiating and assigning group membership based on racial attributes including but not limited to cultural and social history, physical features, and skin color’ (Charity Hudley Reference Charity Hudley, García, Flores and Spotti2017:1). Anthropological studies have shown essentialist racial classification schemes based on biology or genetics to be unreliable (García Reference García, Brown, McIlwraith and de González2020, Relethford Reference Relethford2009), entirely arbitrary (Omi & Winant Reference Omi and Winant2014), and severely flawed (Keita et al. Reference Keita, Kittles, Royal, Bonney, Furbert-Harris, Dunston and Rotimi2004). The latter echo Edgar and Hunley’s (Reference Edgar and Hunley2009:2) finding that ‘“race” is not an accurate or productive way to describe human biological variation’. As Keita et al. observe, ‘race’ designates ‘socially constructed units’ in contexts where the powerful reified their political aims over the less powerful based on an undesirable trait (Reference Keita, Kittles, Royal, Bonney, Furbert-Harris, Dunston and Rotimi2004:S18).
One example of race essentialism is classification into a presumed speech community on the basis of appearance, place of birth or residence, or convenience. Another example is use of terms for ethnolects in such a way as to suggest that they are monolithic, such as ‘African American English’ or ‘Chicanx English’, in the US context, or ‘Black British English’ in the UK context; these terms may be exclusionary and inaccurate (see Charity Hudley et al. Reference Charity Hudley, Mallinson and Bucholtz2020).Footnote 1 While many linguists are aware that none of the three ethnolects mentioned above is monolithic and treat these labels as convenient stand-ins for varieties they know to show internal variation, it is still common for studies to select ‘African American English’ speakers without specifying which regional or socioeconomic stratum of the ethnolect is used, or without ensuring that all of their African American speakers are from the same background. It may be assumed that any internal variation will introduce only ‘negligible’ differences in the linguistic forms, acquisition processes, and so forth under investigation.Footnote 2 It would be best to (i) name the variety under study or, better, (ii) demonstrate that differences are in fact negligible, rather than make untested assumptions. Furthermore, labels matter, and they are not benign cover terms for language varieties. Labels emerge from historical, cultural, ideological, and academic contexts that may be contested (Heller et al. Reference Heller, Pietikäinen and Pujolar2018, Lanehart & Malik Reference Lanehart, Malik, Bloomquist, Green and Lanehart2015:3–5, Smitherman Reference Smitherman2000, Wassink & Curzan Reference Wassink and Curzan2004:176–78). Linguists should be prepared to recognize the cultural meanings entailed in the linguistic labels they use and to contextualize their use in their own writings.
Constructivist theories emphasize that sociohistorical forces create popular perceptions of differences between groups that share specific phenotypic features (Sen & Wasow Reference Sen and Wasow2016). These models also base racial classification on expectations, activated stereotypes, social perception (Freeman et al. Reference Freeman, Penner, Saperstein, Scheutz and Ambady2011), and cultural and social history (Charity Hudley Reference Charity Hudley, García, Flores and Spotti2017) and often conflate race with culture, nationality, and language (Rosa & Flores Reference Rosa and Flores2017). These interacting aspects may also be used as ‘shorthand’ to categorize linguistic consultants. But racial formation is not this simple. Omi and Winant (Reference Omi and Winant2014) call ‘the sociohistorical process by which racial identities are created, lived out, and destroyed’ racial formation (Reference Omi and Winant2014:109), drawing attention to the way this social process may change over time.
Racial identity, category, and identification should not be conflated. Racial identities are typically self-appointed, based on contingent factors and immediate social context as well as broader cultural practices that can shift over time (Markus Reference Markus, Markus and Paula2010). Factors such as culture, birthplace, language, socioeconomic status, and transnational movements (Davenport Reference Davenport2016, Kurien Reference Kurien2018, Park Reference Park2008, Smith Reference Smith2023) influence racial self-identification. Likewise, the terms people use to describe their identities also vary, reflecting cultural influences (Panicacci Reference Panicacci2021) and assimilation processes (Feliciano & Rumbaut Reference Feliciano and Rumbaut2018, Reference Feliciano and Rumbaut2019). By contrast, racial categories refer to the racial taxonomies institutionally available, created to serve sociohistorical goals (Rockquemore et al. Reference Rockquemore, Brunsma and Delgado2009, Sen & Wasow Reference Sen and Wasow2016) and reflect power dynamics (Charity Hudley Reference Charity Hudley, García, Flores and Spotti2017), while a racial identification is an outsider’s categorization or assignment (Rockquemore et al. Reference Rockquemore, Brunsma and Delgado2009).
Lanehart (Reference Lanehart2023) argues that defining race is pointless without acknowledgment of the existence of racism. Race implies and requires hierarchy, and it positions the categories it creates hegemonically. Categories lower in this ranking are particularly contested and used ascriptionally; terms carry positive or negative valence. This is the essence of racism. Spears (Reference Spears, Alim, Reyes and Kroskrity2020:50) refers to race as a taxonomy that arranges people into a referential and preferential hierarchy. We see this, for example, in the difficulty in naming African American Language with a neutral term that is either comprehensive or enduring (Smitherman Reference Smitherman2020, Wassink & Curzan Reference Wassink and Curzan2004). Alim notes that American society is ‘hyperracial’, meaning that it is ‘constantly orienting to race while at the same time denying the overwhelming evidence that shows the myriad ways that American society is fundamentally structured by it’ (Reference Alim, Alim, Rickford and Ball2016:3). Linguists, certainly those working in the American context, must attend to the fact that rather than being fixed and predetermined, racial and ethnic categories are reinforced through language use (Alim Reference Alim, Alim, Rickford and Ball2016:5). Linguists, as individuals embedded in a social milieu, are among the people who use and interpret these categories. In this paper, when we refer to race, we refer to the socially constructed, racialized groupings of people within the hegemonic power structure of racism, and do not presume that any prediscursive or ontological ‘race’ can be categorized outside of such a system.
Ethnicity generally refers to a group identified on the basis of shared signs (in the semiotic sense), aspects of a common culture, or practices, taking the form of, for example, shared knowledge, value systems, or language (García Reference García, Brown, McIlwraith and de González2020). Our definition leans on work from anthropology, whose scholars express varied perspectives. Nonetheless, we follow Comaroff and Comaroff, who write that ethnicity is
best understood as a loose, labile repertoire of signs by means of which relations are constructed and communicated; through which a collective consciousness of cultural likeness is rendered sensible; with reference to which shared sentiment is made substantial. (Comaroff & Comaroff Reference Comaroff and Comaroff2009:38)
Aspects of a common culture also include shared, locally relevant knowledge and value systems and a sense of belonging and community. According to the American Anthropological Association and the Society for Anthropology in Community Colleges, material manifestations of shared aspects of culture include, but are not limited to: patterns of dress, eating and food practices, holidays, religion, and languages or language varieties (García Reference García, Brown, McIlwraith and de González2020). But while anthropologists have centered shared patterns of normative behavior in their definitions of ethnicity, they have also invoked other constructions that bring ethnicity closer to (essentialized) race as a concept. Williams (Reference Williams1989) notes that some anthropologists of the 1970s linked descent and nationalism with collective behavior. Others, in contrast, especially Cohen (Reference Cohen and Werner1996 [1974]), have asserted the import of symbolic interpersonal or within-group formations, such as kinship, marriage, friendship, ritual, and ceremonial activities constituted through language. These are collective, rather than subjective, because they may be objectively observed through patterns of collective adherence and interpersonal interaction (Cohen 1974).
While heredity is included in some definitions of ethnicity, creating an overlap with definitions of race, we use the term ethnicity to refer to shared aspects that are practice-based, rather than genetic or phenotypic as in the racial essentialist construct. This recognizes that individuals can be raised with or choose to participate in practices that associate them with an ethnic group that is not a heredity-based one (Cheng Reference Cheng2003). For example, individuals may be members of speech communities that might be unexpected, if attributions are based solely on appearance or heredity. The concept of ethnicity, however, is problematized by Mullings (Reference Mullings1978), who argues that ethnicity consists of two distinct dimensions: the symbolic-ideological dimension, consisting of cultural content (‘shared … norms, values, symbols’; Reference Mullings1978:10), and the social-structural dimension, consisting of cultural context (‘how differences are used; between the perception of differences, the explanations advanced to explain the divisions in society, and the analysis of what these divisions mean for the structure and functioning of society’; Reference Mullings1978:12). Mullings argues that, at least in the American context, individuals are only equally ethnic at the symbolic-ideological level; while European Americans can distinguish themselves in terms of cultural content, they are not subject to the kinds of structural constraints that relegate other Americans to a subordinate social position. Participation in ethnic practices, however, can be an important component of one’s social and personal identity, and the language variety used can be reflective of attachment toward one’s ethnic group, according to ethnolinguistic identity theory (Giles & Johnson Reference Giles and Johnson1987, Phinney & Ong Reference Phinney and Ong2007).
In contrast to racial categories, which are generally arbitrary, socially imposed, and perceptual in nature, ethnicity is both self-recognized by a collectivity and recognized by outsiders (Fishman Reference Fishman and Giles1977), though whether a person’s ethnic affiliation is recognized depends both on social context and individual-level variation (Clément & Noels Reference Clément and Noels1992, Gurin et al. Reference Gurin, Peng, Lopez, Nagda, Prentice and Miller1999, Hurtado et al. Reference Hurtado, Gurin and Peng1994, Noels et al. Reference Noels, Leavitt and Clément2010). The ethnic affiliation of members of socially subordinate ethnic groups may also go unnoticed, such as in cases of intersectional invisibility (Purdie-Vaughns & Eibach Reference Purdie-Vaughns and Eibach2008), where such individuals are also members of other socially subordinate groups, for example, based on sexual orientation or hearing status. Lastly, analogous to the way that race identification is shaped by sociohistorical forces, one’s ethnic identification can change over time via acculturation processes (Panicacci Reference Panicacci2021, Liebkind et al. Reference Liebkind, Mähönen, Varjonen, Jasinskaja-Lahti, Sam and Berry2016, Phinney & Ong Reference Phinney and Ong2007) or in response to contextual factors, which may have crucial consequences for psychological well-being (Yip Reference Yip2005).
What race and ethnicity have in common is that they reflect the intersection between cultural practice and social dynamics, where ethnicity is more practice-oriented than race (Fishman Reference Fishman and Giles1977). For this reason, it is more broadly accepted that individuals can choose their ethnicity, but not their race (Cheng Reference Cheng2003). This belief, and the lack of coherent theoretical models of social identities, may explain the continued prevalence of essentialized views of race. Namely, race is still seen as less dependent on perspective, and not open to individuals’ choice (Morning Reference Morning2007).
Practice-based approaches, we argue, are beneficial for all types of linguistic research. First, linguists using community-defined practices, emerging from attention to a community’s own sense of its shared signs, are less likely to essentialize speech communities. Additionally, learning about community-based practices, where learning stems from time spent within the community (in a posture of receptiveness), ideally indicates greater accountability to and respect for the community (see Section 2.4). Finally, practice-based approaches may be less exclusionary, where community membership is not linked to, for example, a closed set of phenotypic types. Linguistics further stands to benefit from a view of ethnicity that takes into account its variable nature based on reference group, social context, and situational context.Footnote 3
Finally, linguistics also stands to benefit from the greater problematization of race that is taking place in neighboring fields.Footnote 4 In linguistics research, multiracial individuals are frequently excluded or assigned to one category, and a study participant’s race is commonly treated as a static feature. In some disciplines, race is treated as fluid, rather than static; for example, sociological studies such as that by López et al. (Reference López, Vargas, Juarez, Cacari-Stone and Bettez2017) propose a multidimensional measurement of race. In their study of Latin[e] Americans, respondents provided their race in three contexts: street race, how a respondent believes a stranger who saw them walking down the street would classify their race; ascribed race, how a respondent believes others usually classify their race in the United States; and self-perceived race, how a respondent usually self-classifies their race on questionnaires. A more nuanced view of race explicitly acknowledges that racial categorization is context-dependent and that recognizing the nuances and complexity inherent in racialization can ultimately lead to greater descriptive accuracy of the relationship between language and race. Thus, racial categories and identities are fluid and can be ‘ambiguous’ (see Section 3.4). In some cases, contextual or locally constructed notions of race help the analyst understand practices by, or oriented toward, speakers (see Dovchin Reference Dovchin2019a,Reference Dovchin, Barrett and Dovchinb, Espinosa et al. Reference Espinosa, Tikhonov, Ellman, Kern, Lui and Anglin2018, Rzepnikowska Reference Rzepnikowska2018). But it is imperative for researchers to understand the basis of their groupings (and describe or clarify such states of affairs carefully in any published work). Outgroup perceptions of speakers can, for example, help to inform these speakers’ linguistic choices. Again, this is not behavior based upon their biological heritage, but reflects the intersection between practice, social dynamics, and racial consciousness.
In most cases, linguistic research questions (regardless of subfield) tend to probe issues of language structure, use, and perception, which emerge by virtue of a language user’s setting of language acquisition and linguistic practice, supported by membership in one or more language communities. Of course, these are practices, and they are not deterministically inherited. In such cases, then, the linguist may be said to primarily be concerned with ethnicity, if we agree to follow the distinction made above. However, we note that research participants may themselves conflate race with ethnicity. Further, we acknowledge that factors such as race—intended as socially constructed categorizations that serve power dynamics—can influence the way research participants shape and negotiate their linguistic identities. The researcher must be sensitive to community members’ usages, so it may be necessary to use the term ‘race’ in communicating the goals of the research project, where study of groupings of people is part of the study design. Yet addressing racial identities vs. racial groups is preferable. This is because it is paramount for the linguist to recognize where practice-based language acquisition and use are actually of interest. In instances where the most salient social groupings are constructed with respect to racialized hierarchies (e.g. when reporting that all your study participants from a US college are WhiteFootnote 5), it may be appropriate to label these racialized groupings, so long as they are directly addressed and explained. Particularly, it is the researcher’s responsibility to ensure that the racialized labels used are the best representation—among the options available—of participants’ racial identities and that these groupings are not interpreted as participants’ acts of self-identification.
When race is mentioned in the pages below, it is always with regard to social dynamics, social construction of power inequalities, and locally constructed notions of group salience, never biology (or any of its close cousins, such as phenotype). Linguists should never talk about biological predispositions toward language use.
2.2. Historical models of race used in linguistics
As the preceding definitions underscore the nuance required for using features of race or ethnicity as variables in a linguistic study, we note that correctly modeling race and ethnicity more broadly within linguistics is similarly important. An example of how the modeling of race and ethnicity has evolved can be found in sociolinguistics. Eckert (Reference Eckert2005, Reference Eckert2012) describes three major, historical trends (‘waves’) in how sociolinguists attribute social meaning to linguistic variables. While the earliest analyses could only group participants into monolithic, macrosociological categories such as those belonging to a gender or a race, waves two and three incorporated ethnographic techniques enabling study of how language users shape their linguistic self-presentation, rather than simply reflecting a static group identity.
Extending this work, Charity Hudley (Reference Charity Hudley, García, Flores and Spotti2017) describes a fourth wave, with models that transcend a taxonomic view of race altogether, focusing on the interaction between the participant and their role within their community:
The fourth wave emphasizes the differences between what you learn about a language and/or racial group by studying it and what you learn by living the experience. In this model, both linguistic and racial ideology are co-constructed and co-negotiated between researcher, individual, and community. As such, the emphasis is on what the individual, group, race, and/or culture value and see as crucial to the investigation of language, as well as linguistic social justice. (Charity Hudley Reference Charity Hudley, García, Flores and Spotti2017:388)
More recent scholarship therefore centers the linguistic community during research and allows race and ethnicity to play an auxiliary, rather than deterministic, role in the linguistic model of interest. To be sure, Rickford (Reference Rickford1997) reminds us that while many linguists have built their careers on the generous sharing of linguistic expertise by those in marginalized communities, ‘[linguists] have by and large failed to demonstrate an equal commitment to the well-being of the communities where we conduct our research’ (Bucholtz Reference Bucholtz, Blake and Buchstaller2020:242). This is evidenced in part by the enduring absence of linguists of color in peer-reviewed research (Linguistic Society of America (LSA) 2018:28) as well as in the leadership of the LSA itself (LSA 2019). To that end, several scholars have sought to improve racial justice through increased representation within the discipline. Our focus here is on research practices rather than representation and other issues of racial justice in scholarly communities. However, we see these issues as intimately linked: essentializing race in our research practices will only produce further hurdles to becoming an inclusive research community, as race essentialism in research signals to racially minoritized potential participants and scholars that they should expect stereotyping and prejudice from our discipline. For further reading on racial justice in linguistics, see Baker-Bell Reference Baker-Bell2020, Charity Hudley et al. Reference Charity Hudley, Mallinson and Bucholtz2020, DeGraff Reference DeGraff2020, and Gaby & Woods Reference Gaby and Woods2020.
2.3. Intersectionality should inform use of social categories
The notion of intersectionality (Crenshaw Reference Crenshaw1989) is important for improving descriptive accuracy, avoiding support for or endorsement of racist viewpoints, and ensuring that linguistic research does not harm consultants and participants. Crenshaw (Reference Crenshaw1989) first coined the term to discuss how, for example, Black women may experience discrimination both in similar ways as other women or as other Black people (which would mean that existing antidiscrimination laws would apply) but also as Black women, beyond a simple additive effect. Since its inception in legal scholarship, theorizing intersectionality has expanded beyond describing the lived experience of intersectional identities; the dynamism and mutually constitutive nature of intersectional identities and the intersections themselves are current topics of discussion (Choo & Ferree Reference Choo and Ferree2010, Crenshaw Reference Crenshaw2017, Davis Reference Davis2008; see Levon Reference Levon2015 for a linguistics-specific review). For the purposes of this paper, we acknowledge that linguistic features associated with other social systems (gender, sexuality, class, caste, place) may also be recruited in the construction of ethnic identities and linguistic performances.
Furthermore, failure to properly consider a respondent’s or consultant’s intersectionality when investigating social phenomena closely tied to identity can negatively impact participants (and readers of the research). Albuja et al. (Reference Albuja, Sanchez and Gaither2020) show the stressors placed on individuals who occupy multiply marginalized identities, and Cheryan and Monin (Reference Cheryan and Monin2005) illustrate how these can lead to identity questioning or even denial. These stressors are associated with poorer mental health outcomes, lower feelings of autonomy and belonging (Panicacci Reference Panicacci2021), and greater self-conflict. Linguists should recognize that insufficiently intersectional research question design and materials can exacerbate the stressors of identity threat in participants, and we should endeavor to address this proactively as part of our core ethical responsibility to our consultants and communities.
Recommendations:
1. When reporting quantitative data, especially in aggregate, include a summary table or graphic that shows the distribution of participants in multiple identity categories; for example, rather than ‘fifty participants, forty women, ten nonbinary; twenty-five White, twenty-five Black’, one should show ‘seventeen White women, twenty-three Black women; eight White nonbinary, two Black nonbinary’. The report should also specify the regional or geographic location(s) from which the participants come. For some studies, further divisions might be called for (e.g. since White and Black are not monolithic categories).
2. When formulating research questions concerning identity, ask yourself what other intersecting identities might impact possible findings.
3. Give equal attention to collecting and analyzing data for all demographic information you collect.
4. In qualitative research, investigate intracommunity variation and attend to participants’ reports of their experiences at intersections of multiple identities.
2.4. Analyst positionality
All social research is founded on the human capacity for participant observation. We act in the social world and yet are able to reflect upon ourselves and our actions as objects in that world.
—Hammersley & Atkinson Reference Hammersley and Atkinson2007:18
Our consultants are part of a broader social world. Social researchers, including linguists, are also part of the social world we study. This runs counter to the belief that it is possible to isolate a body of data uncontaminated by the researcher. Reflexivity means two things in the field of ethnography (Hammersley and Atkinson’s audience): (i) the researcher’s critical awareness of their positioning within their field of study, and (ii) ways that the analyst can introduce consciousness and commentary on their practices and activities in a cultural context. Reflexivity implies that our work, including the knowledge we produce and how we produce it, is influenced by our sociohistorical location and academic heritage, including the earlier foci, findings, and limitations of our field. Social research has been criticized for supporting the political status quo in Western societies (Hammersley & Atkinson Reference Hammersley and Atkinson2007:15), and linguistics has been criticized for a lack of interest in critical reflexivity on systems of power and oppression (miles-hercules Reference miles-hercules2020).
Giddens (Reference Giddens, Bottomore and Nisbet1979) and Hammersley and Atkinson (Reference Hammersley and Atkinson2007:15) consider all social research as bearing hallmarks of participant observation: ‘it involves participating in the social world, in whatever role, and reflecting on the products of that participation’. Thus, the linguist’s social-situatedness inevitably influences the knowledge produced. To mitigate harm, we can acknowledge our limited understanding, involve communities in study design, and ask locals about how respect is shown in their community. Smith (Reference Smith2019) invites questions from respondents about her background, identity, and work, to diffuse the power differential in interviews. She remains accessible to participants during fieldwork (see also supplemental materials, S1.3).
In a similar vein, when it comes to conceptualizing fieldwork, Milroy and Gordon (Reference Milroy and Gordon2003) highlight the importance of recognizing that interviews are speech events with socially defined roles and expectations. Assume that respondents will automatically attempt to comply with the ‘cooperative principle’ and assume power relations to be asymmetrical, resulting, for example, in respondents’ reducing their talk volume. Respondents may view invitations to talk freely with suspicion if a nonfamiliar researcher asks personal questions when these seem to be at odds with a demonstrated interest in particular linguistic structures (the data, not the person). To overcome this, the interviewer should make clear the relevance of their questions and acknowledge their position as a learner (Milroy & Gordon Reference Milroy and Gordon2003). Briggs (Reference Briggs2012) and Labov (Reference Labov, Baugh and Sherzer1984) suggest that researchers honestly acknowledge their position of lower authority and respect the respondent as an expert on their community. We note that power differentials are often racialized, as well. Assumptions about the researcher’s authority (or lack thereof), intelligence, and status are made based on the analyst’s appearance, desired or not.
Our research planning often builds on past research. It may reflect outdated practices in our field rather than the contemporary community or phenomenon of interest. This can result in reduced descriptive accuracy via biased respondent samples and exclusion of certain individuals based on past research, limiting which individuals represent the speech of the community. To address this, we must consult with the community to understand how it defines itself and educate ourselves on the diversity within the community in order to accurately represent it rather than essentialize away from it.
Recommendations:
1. Before conducting fieldwork, consider your social role explicitly (see Briggs Reference Briggs2012). If you are planning to work as an outsider in a community whose social norms you do not know or understand, position yourself as a learner by learning about role relations in the community, and consider where a respondent might position you.
2. Consider the impact your own racial and ethnic identity(ies) will have on data collection.
3. Consider the racial power dynamic your interview sets up. Are there actions you can take to diffuse the power differential and to avoid oppression, threat, or the appearance of coercion?
4. Strengthen your reflexivity chops. Read critiques of our field and consider how to mitigate them in your personal research practices.
5. Acknowledge or discuss the racial and ethnic identities of the researchers participating in the study (for an example, see supplemental materials: positionality statements).
3. Considerations for designing and conducting research studies
3.1. How much demographic data do I need?
The goal of this section is to help the analyst determine how much ethnicity or race information might be appropriate for their needs. Studies in different linguistic subfields, however, will not be expected to provide or leverage the same demographic details. While the specific research questions of a study should always guide analysts’ choices, there are common within-subdiscipline objectives that may permit us to offer a helpful schematization. Figure 1 presents this idea, arranging selected subfields from those typically expecting or requiring less to more race or ethnicity information.Footnote 6 Sections 3.2–3.5 follow this order, offering recommendations based upon typical research objectives, and types of questions to elicit the necessary information. The interested reader may skip to the section that they feel best fits their research. We also clarify why, in no case, is the answer to the heading question ‘none’
A schematization of subfields of linguistics according to how much demographic information is typically expected or available.
Figure 1. Long description
From left to right, four labeled boxes are arranged above a horizontal arrow. The leftmost box is titled Corpus Driven in bold and lists Computational Linguistics, Historical Linguistics, Corpus Linguistics. The next box is titled Formal in bold and lists Syntax, Semantics, Morphology, Phonology, Typology, Pragmatics. The third box is titled Experimental in bold and lists Phonetics, Phonology, Language Acquisition, Bilingualism, Psycholinguistics, Neurolinguistics, Sociolinguistics. The rightmost box is titled Qualitative in bold and lists Discourse Analysis, Sociolinguistics, Sociocultural Linguistics, Language Documentation, Raciolinguistics. Below the boxes, a horizontal arrow runs from left to right, labeled Probably less at the left end and Probably more at the right end, indicating an increasing expectation or availability of demographic information from left to right.
.
3.2. Corpus-driven studies
This section provides recommendations for improving corpus-driven studies, which will include many computational linguistic projects; our recommendations focus on transparency and clarity about what demographic information is and is not available. Computational and corpus studies involve hypothesis testing using very large data sets (Bender & Langendoen Reference Bender and Langendoen2010). Unlike data used by other subfields, these databases are largely anonymous and often internet-sourced. However, racial information may be needed when working with social media data (e.g. Twitter, Reddit, etc.), or when explicitly exploring hypotheses linking language and social identity in terms of the operation of racial bias (e.g. hate speech detection). In addition, in order to build broadly useful language technology, work in natural language processing should ensure that the technology works equally well for language varieties other than mainstream, standardized, prestige dialects. As such, it is important to construct data sets to train and test automated systems that represent a broad range of racialized varieties (Jørgensen et al. Reference Jørgensen, Hovy and Søgaard2015, Tatman Reference Tatman2017, Sap et al. Reference Sap, Card, Gabriel, Choi and Smith2019, Koenecke et al. Reference Koenecke, Nam, Lake, Nudell, Quartey, Mengesha, Toups, Rickford, Jurafsky and Goel2020, Wassink et al. Reference Wassink, Gansen and Bartholomew2022). Avoiding racial grouping and working in terms of ethnic background is important during data set construction because varieties spoken by oft-racialized speakers are not monolithic, as has been mentioned. Building data sets—for example, one covering ‘Asian English’—constitutes post-hoc racial essentialization.
One typical computational approach when working with a large, unlabeled data set is to train a classifier on a smaller, labeled data set (here the labels would be the attributed racialized identities of speakers) and then to ‘predict’ the labels in the larger data set. The classifier’s features might include linguistic features (e.g. lexical items, spelling variations, morphosyntactic inflections), metadata (e.g. user profiles), or social network information (i.e. a user’s connections, patterns of ‘liking’, or similar). However, creating a classifier can be harmful to the people it is used to classify and to the goals of the research project for several reasons:
• Racializing others, rather than allowing for self-identification, is problematic a priori.
• Classifier creation might permit harmful misuse of the classifier beyond the purpose of labeling the current data set.
• Inaccuracy of the classifier will give misleading results during data analysis or conclusions drawn from the study.
Recommendations:
1. Be transparent about any lack of race and ethnicity information in the data set.
2. Compare large data sets to relevant studies drawn from the user population (e.g. surveys of Wikipedia editors where participants self-reported demographic information).
3. Intentionally construct data sets that include self-reported demographic information (in which participants opt in and give informed consent).
4. Base error analyses on linguistic features rather than language varieties and link to well-grounded sociolinguistic research linking these features to varieties (though avoid essentializing) (Charity Hudley Reference Charity Hudley, García, Flores and Spotti2017).
5. Be wary of linguistic appropriation/digital blackface (e.g. Abreu Reference Abreu2015) within your data set.
Our discussion suggests that the overall benefits of incorporating more-nuanced ethnicity information for corpus studies lie in improved descriptive adequacy, right-sized generalizations, and respect for persons.
3.3. Formal studies
This section discusses the role of demographic data in formal linguistics, such as syntax, semantics, and phonology; our recommendations will be to enrich demographic data where possible for these types of studies. In formal linguistic research, it is common to report the grammatical intuitions of the researcher or of unnamed consultants. There has been some empirical validation of the reliability of these reports (e.g. Mahowald et al. Reference Mahowald, Graff, Hartman and Gibson2016), but it is not normative for papers in formal subdisciplines to directly discuss social aspects of language. This methodology relies on an often-undiscussed assumption that the intuitions of a speaker reflect a stable state of the grammar of a larger community (i.e. presuming that a mental grammar reflects community language norms).
We recommend that all linguists, including those in formal subfields (including but not limited to syntax, semantics, and phonology) should take social factors into consideration, both to ensure empirical validity (and descriptive adequacy; cf. Chomsky Reference Chomsky1965, inter alia) and for the ethical reasons that we have discussed above. If, for example, syntacticians do not collect and describe social information in concert with reported judgments, then they are at risk of overgeneralizing patterns of grammaticality and potentially misrepresenting the actual facts of language as it is used.
For an example of these formal methods, we selected recent publications in Language that were deemed to be typical of the methods employed in theoretical syntax.Footnote 7 In these articles, examples were not cited to any sources and were presumed (but not explicitly stated) to reflect the judgments of the authors or unnamed consultants. The authors did not include positionality or biographical statements about either themselves or their consultants. We presume, based on experiences in submitting and reviewing this type of paper, that editors and reviewers did not generally ask whether judgments of well-formedness were typical or whether they might vary by social identity.
This methodology is important to discuss in the context of examining race and ethnicity in linguistics research precisely because this methodology obscures social identity, leaving open the possibility of overlooking or misconstruing the generality of linguistic statements. While the data reported in our sample of recent formal syntax papers were not known to vary sociolinguistically, they also were not shown empirically not to vary. Without any report of the positionality of informants (including authors), we cannot know whether the judgments are reflective of all speakers, or whether they represent a particular subset of speakers (such as social or regional dialects or associations with any given ethnic group).
Sampled also from a recent volume of Language, we also find a counterexample where the social position of consultants is made explicit. Legate et al. (Reference Legate, Akkuş, Šereikaitė and Ringe2020) include details about their Turkish and Lithuanian consultants in a note about the paper:
We had ten primary Turkish consultants, ranging in age from mid-twenties to early forties, four from Bitlis, and one each from Adıyaman, Bursa, Denizli, Hatay, Isparta, and Mersin. We had two additional Turkish consultants, in their thirties, from Bitlis and İzmir, whose grammar is systematically different; we discuss their grammar when relevant. We had eight Lithuanian consultants, five in their late twenties, three in their late thirties to forties, six from Vilnius and Kaunas, two from Šiauliai. (Legate et al. Reference Legate, Akkuş, Šereikaitė and Ringe2020:771)
This level of social detail goes above and beyond acknowledging consultants’ contributions (also an important practice); providing sociolinguistic details allows readers to determine whether reported utterances and judgments may reflect previously undescribed linguistic variation. In our perusal of recent Language issues we found syntax papers that included no sociolinguistic information, ones that thanked consultants but gave no biographical information, and ones that (as above) provided a good amount of detail. This variety demonstrates that no standard expectation for acknowledgment or positionality practices exists in the discipline, even for a single journal.
We urge researchers in formal subfields to denormalize the presumed ‘default’ assumption that data represent a homogenous, normative variety unless otherwise stated. A good practice toward this goal would challenge the assumption that any syntax paper about English (for example) is reporting by default on White, mainstream American English unless otherwise stated.Footnote 8 A better approach for researchers would be to include the judges’ social locations (e.g. age, gender identification, ethnicity, region of birth or residence). Such a practice would challenge the assumption that any syntax paper on English is reporting by default on White, mainstream American English, for example.
Recommendations:
1. Describe the sources of all judgments and examples, including social information about anyone whose judgments are reported (e.g. age, gender, ethnicity, location) for both consultants and authors where appropriate.
2. Mark the unmarked by including equal amounts of information about hegemonically powerful and marginalized language varieties.
3. Directly address and discuss whether any variation in judgments was identified.
If researchers follow the recommendations above, the benefits include appropriately sized generalizations, empirical validity, and increased representation of nonmainstream language varieties.
3.4. Experimental and quantitative studies
This section gives recommendations for experimental and quantitative linguistics research, which may include psycholinguistic, neurolinguistic, language acquisition, phonetic, and some variationist sociolinguistic projects; our recommendations focus on how to best include questions that balance between rich information and ease of quantitative analysis. The data sets used in these subdisciplines are often large, collected using judgment or random-sampling techniques, time-series, or repeated interventions, and analyzed using inferential statistical procedures. Research objectives might include exploring language production, perception, or processing, the relationship between setting of acquisition and emergence of features, social category and use of features, or likelihood of features given a particular syntactic or phonetic context, to mention only a few possible designs. These share the need to code data for aggregation, modeling, or hypothesis testing.
As described in Section 2.1, linguists working on experimental and quantitative production studies are typically concerned with ethnicity, not race; therefore, we refer only to ethnicity in the remainder of this section, unless otherwise specified. Because the focus is on adequacy of description, cooccurrence constraints, or emergence in acquisition, attention to the community or linguistic environment of acquisition and use is key. We focus on obtaining information about these aspects of social group membership, with reference to ethnicity.
Large quantitative data sets differ greatly in structure and content, but share a reliance on data sets of tokens coded in rows and columns; token labels provide summary, macrosocial information about the subject (age, year of birth, bilingual status, social class, gender assigned at birth, race or ethnicity, exposure to target language, and many more), as well as codes detailing the linguistic form, its features, and its context. Because exploring the linguistic phenomenon, rather than the social background of the participant, is the typical focus of the study, minimal coding schemes are sometimes adopted for representing subject information, with the intent that these are sufficiently meaningful and accurate. Several authors of this paper have been asked by colleagues, ‘So how much social information do I need, and what do you use?’. Not all codes will be used for inferential testing, so undue complexity in data sets is to be avoided.
Race essentialization might rear its head in the study design phase, when the analyst must decide upon categories to use for subject coding. It might also arise when formulating hypotheses regarding groups of people (speakers or signers) to include or exclude from a study. Categories would ideally be locally relevant, reflect local language experience, and be supported by prior ethnographic fieldwork in the community to establish salient groupings (Heller et al. Reference Heller, Pietikäinen and Pujolar2018).
It is a particular feature of quantitative studies that in the analysis phase, participant responses are grouped into discrete categories (multiracial subjects, for example, are often categorized only with respect to one of their identities). It is important to note where using this practice and to make comments about intersectionality and nuanced self-identities in the report. Linguists should be aware that both racial and ethnic identity can be multiplex and fluid over a person’s lifetime. If researchers provide fixed, monolithic category labels, multiethnic individuals may feel forced to choose just one part of their identity. Sanchez et al. (Reference Sanchez, Shih, Wilton, Benet-Martínez and Hong2014) discuss the ways that researcher-imposed category labels strip subjects of their complex identities and autonomy for self-categorization; this imposition of labels can take place either when researchers label participants or when researchers delimit the possible categories by which participants can label themselves. In fact, overreliance on fixed racial categories has been shown to lead to inaccurate representations of social phenomena and to foster stigmatization and identity denial (Albuja et al. Reference Albuja, Sanchez and Gaither2019, Cheryan & Monin Reference Cheryan and Monin2005). Additionally, flexibility in adequate inclusion and description of research participants’ full-lived experiences and identities, which may change across perceivers, context, and time (Bonam & Shih Reference Bonam and Margaret2009, Chen & Hamilton Reference Chen and Hamilton2012, Cheng & Lee Reference Cheng and Lee2009, Gaither Reference Gaither2015, Nguyen & Benet-Martinez Reference Nguyen, Benet-Martinez and Crisp2010, Shih et al. Reference Shih, Bonam, Sanchez and Peck2007), is strongly related to individuals’ psychological well-being (Yip Reference Yip2005). Furthermore, identity may vary in differing social contexts or be influenced by long-term experiences like migration or heritage connections (Davenport Reference Davenport2016). Identity shifting over time is attested (Doyle & Kao Reference Doyle and Kao2007, Harris & Sim Reference Harris and Sim2002, Hitlin et al. Reference Hitlin, Brown and Elder2006) and is especially common in multiracial individuals, with approximately 30% reporting having changed their identification throughout their lives (Jones & Bullock Reference Jones and Bullock2012).Footnote 9 Categories should be able to grasp, at least to a minimal extent, this fluidity and multiplexity.
While templates exist for categorizing groups of people (in the US and in China, the National Census, for example), offering ease of use in both large- and small-scale studies, familiarity to subjects, and simplicity in aggregation and analysis through use of fixed-response choices, templates have major shortcomings. They may conflate ethnic groups whose linguistic background is actually different. They may lead to a study design that is exclusionary (e.g. leaves out racially different people who were adopted as infants into a family in the community and thereby should be eligible for study enrollment because they are fully native users of the language of study), or use labels that are confusing, inadequate, irrelevant, or unfamiliar. This may result in unreliable findings, high rates of nonresponse, or other issues. Additionally, the way that participants interpret category choices may not be straightforward. If social identity information were gathered using a multiple-choice response prompt and the categories do not ‘fit’, the ‘Other’ option might be overused, leaving a researcher to decide how (or whether) to categorize these individuals post hoc. If using multiple-choice questions, prior knowledge of the community’s own practices is essential for choosing category labels.
Using free-response questions in conjunction with fixed-response methods may ameliorate some of these issues (see supplemental materials S1.2). Free-response questions use an open-ended format such as, ‘How would you describe your ethnicity or family background?’ (see e.g. D’Onofrio Reference D’Onofrio2019, Hilton Reference Hilton2018). Other advantages include respect for persons: participants feel better represented; efficiency: use of free-response questions adds minimal time to study design; and an increase in participant response rates (Dillman et al. Reference Dillman, Smyth and Christian2014). The disadvantages associated with free-response questions primarily lie in complicating the aggregation and interpretation of data. In surveys with large numbers of participants, or very diverse responses to an open question, it may be challenging for researchers to group responses into categories that are analytically valid and replicable. If some respondents give very broad categories and some give very narrow ones (e.g. participants answering ‘Polish American’ vs. ‘White’), then the researcher needs to decide post hoc whether it is appropriate for those responses to be grouped together. Cheng et al. (Reference Cheng, Faytak and Cychosz2016) offer one possible solution. Ethnicity information was elicited for 786 speakers using an open-ended prompt, called the Self-Determined Ethnicity (SDE) question. Following locale-based data collection, researchers categorized participants into twelve groups (Black, Chinese, Filipino, Hapa, Japanese, Korean, Latino, Middle Eastern, Native American, South Asian, Vietnamese, and White) based on volunteered responses and the experimenters’ reasoning. Categorization decisions were spelled out in the report of research with statements such as ‘“Chinese” and “Chinese American” were both considered “Chinese”—keeping in mind that all participants were Californian’ (Cheng et al. Reference Cheng, Faytak and Cychosz2016:65). This study demonstrates useful self-reflection about methodological choices.
Experimental and quantitative studies in linguistics occasionally include demographic information about participants, but we observe that many such works either do not collect or do not report data on race and ethnicity. As an example, we sampled recent psycholinguistics articles in Language and found that these papers frequently report information about binary gender or sex (‘males’ and ‘females’), age, and some information about linguistic background (when related to the recruitment criteria, such as whether participants were L1 speakers of the target language). Neurolinguistics studies also occasionally reported hand-dominance, vision, and participants’ (lack of) diagnosed disorders of speech or communication. No further information about the participants is typically given; the participants’ social identity, including ethnic and racial identity, is not discussed.Footnote 10 It is often not clear from the article whether the authors collected this information and then neglected to report it due to a lack of significant effects, or whether it was not collected at all.
Demographic detail allows the generalizability of results to be qualified. In excluding demographic information, experimental linguists may gloss over important biases in the data; for example, Etienne et al. (Reference Etienne, Laroia, Weigle, Afelin, Kelly, Krishnan and Grover2020) reported on recent innovations in electroencephalogram (EEG) technology necessary for equipment to accurately record readings from participants with certain natural hair textures. If linguists working with EEG and other technology reported race and ethnicity, it would allow the field to identify biases like a relative lack of Black participants across studies. Without this data, biases are difficult to report and correct. As with formal subfields (Section 3.3), it is also important in experimental linguistics to report on social information in order to avoid erroneously making overgeneralizations or failing to identify variation.
A range of approaches to handling ‘race’ (authors’ usage) is evident in three papers investigating dialect density in use of African American English published in the Journal of the Acoustical Society of America (a journal in which linguistic phoneticians regularly publish) between 2023 and 2024. Johnson et al. (Reference Johnson, Shankar, Ostendorf and Alwan2024) use a preexisting corpus (CORAAL) to sample different AAE speakers’ dialect density, combining rural with urban dialects of AAE; Geller et al. (Reference Geller, Holmes, Schwalje, Berger, Gander, Choi and McMurray2021) distinguish four macroethnic groupings (‘Asian, Black or African American, White and unknown’). Holt Reference Holt2023, Houle et al. Reference Houle, Lerario and Levi2023, and Matteson et al. Reference Matteson, Olness and Caplow2013 are examples of articles published in the same journal that provide richer information regarding speaker self-identification (e.g. mixed ethnicity), which affords greater descriptive adequacy. For example, Matteson et al. provide a useful description of the social class and geographic origin of respondents (not just labels). This enhances their investigation of intonation. By identifying ‘discourse-relevant demographic data’ they arrive at an account of differences in distribution of pitch features in spontaneous narratives that would not have been possible without differentiating speaker communities.
Recommendations:
1. Make an effort to understand which labels might be relevant in the community of interest.
2. Allow participants to decline to answer questions.
3. Allow participants to choose multiple options, rather than including only a separate nondescript ‘multiracial’ category, as this option alone can result in misleading results (see Chen & Hamilton Reference Chen and Hamilton2012, Chen et al. Reference Chen, Moons, Gaither, Hamilton and Sherman2014, Peery & Bodenhausen Reference Peery and Bodenhausen2008).
4. Avoid imposing new labels on participants, unless they were specifically indicated by participants themselves, for example, describing participants that selected multiple race categories as ‘Multiracial’. Particularly, we suggest describing the sample vs. the participants’ selections, for instance: ‘When asked about their race, 50% of participants indicated Black alone or in combination with other race categories’.
5. Always include options for participants to self-identify.
6. When using multiple-choice questions, always acknowledge the limitations of racial categories in representing racial identities and inquiry about the accuracy of participants’ response in representing their identity(ies).
7. Do not assume participants’ identities a priori.
8. Remain flexible in case participants’ identities change throughout the research process.
9. If participants show reticence, and demographic data is truly requisite to the experiment, consider using proxies for ethnic identity, such as family history or neighborhood segregation (Charity Hudley Reference Charity Hudley, García, Flores and Spotti2017).
10. Report what demographic information was collected, how it was collected, and a summary of all collected information, even if in a footnote or supplementary materials appended to the article itself. Additionally, avoid essentialized language (i.e. participants were White) or language that implies participants would use those labels to self-describe, unless they had the opportunity to do so (i.e. participants identified as White).
Based on our survey of research above, the overall benefits of incorporating nuanced ethnicity and racial identity information for experimental and quantitative studies include: better precision in description of linguistic phenomena and in ascription of linguistic phenomena to participants and communities, as well as improved research integrity and transparency.
3.5. Qualitative studies
This section discusses considerations for qualitative studies, which include sociolinguistics, linguistic anthropology, discourse and conversation analysis, and other fields that use ethnographic or similar methods. Our recommendations primarily focus on how to ensure richness and accuracy of racial and ethnic information in the study’s cultural context. Studies at the rightmost edge of the continuum in Figure 1 span a range of qualitative linguistic subfields, from discourse analysis to language documentation to sociocultural linguistics and raciolinguistics. Although the research objectives vary widely, these studies often share an ethnographic approach to observing the ‘lived routines’ in which language is used, contextualized, and imbued with social meaning. Ethnicity may therefore be the best focus, as has been said. The time a researcher spends in the community may span months or years, and it may involve the recording of large amounts of data. Language documentation researchers may make observations and notes regarding clan or family membership, social role relations, village of origin, intergroup contact, and participation in community life. Data can be collected by the analyst, but quite frequently, it is collected by community partners or insiders.
All of the recommendations at the heart of this paper are effectively based in the practices of ethnography, which investigates the customs of particular peoples and cultures. In fact, ethnographic work must be customized to the community in which a study takes place. Theories of the routines of daily life (and language) are formulated and refined as the analyst documents linguistic forms in context over time. It must be recognized that identity co-construction and the discussion of racial and ethnic self-identities are sometimes taboo topics (Pauker et al. Reference Pauker, Apfelbaum and Spitzer2015). Uncovering local constructs of race and ethnicity may be tricky. However, shortcuts are problematic, as we have seen. Rickford (Reference Rickford1986) warns against using a one-size-fits-all approach in designing studies; social categories used in one speech community should not be borrowed for use in another without careful reflection. Berg (Reference Berg2007:96) argues for gathering racial and ethnic self-identification using a conversational interview. Such interviews allow participants to ‘speak in their own voice and express their own thoughts and feelings’. As race is a social construction (and ethnicity is often conflated with race), an interview also allows participants to ask for clarification if their own internal models of racial and ethnic identities are incongruent with the questions asked. In this, it is imperative to give participants full control over what they consider relevant to disclose regarding their own identities.
There is a high value placed on developing a deep knowledge of the community that an analyst plans to enter, on avoiding unintentional harm, and on conducting research that emphasizes authentic partnership (see Squizzero et al. Reference Squizzero, Horst, Wassink, Panicacci, Jensen, Moroz, Conrod and Bender2021, section 1.3.3). In this way, the key practices recommended in all previous sections are especially relevant here.
Recommendations:
1. Understand what social identity labels for race and ethnicity are most relevant for the community of study.
2. Report the analyst’s positionality (see Section 2.4).
3. In publishing, identify racial identity and ethnicity data sources to the fullest extent possible.
4. Consider partnerships with participants, which may include coauthorship with community partners and sharing of racial/ethnicity data. This is particularly crucial when working with vulnerable or minoritized populations to ensure that publishing racial identity data does not harm participants.
As alluded to in preceding sections, we encourage researchers to examine the case study in the supplemental materials (especially S1.2) for a tangible example of how race and ethnicity data might be collected. The case study exemplifies the recommendations of allowing for flexibility and partnership with the linguistic communities of study and entrenches consideration of racial and ethnic identities from its conception to its completion (see S1.3). Allowing for an iterative, collaborative process will build trust within the community of study and thus provide the researcher with a nuanced understanding of participants’ subjectivity and experience in a real-world settings—something inaccessible otherwise—and will offer them the chance to leave their own unique imprint on the data.
3.6. Potential influence on study participants
Whether the research is qualitative or follows a different methodology, linguists risk promoting racist and ethnocentric ideas to consultants and research participants through experimental manipulations and even through presentation of linguistic variation. For an example of how presentation of linguistic variation in an interview can be harmful, for example, see supplementary materials, S1.3.
Experimental perception research in linguistics may investigate the role of a speaker’s perceived race and the subsequent perception or production of the language produced by that speaker. Such research, when critically considering race, can often positively contribute to greater understanding of the mechanisms and motivations underlying bias against racialized language varieties and their users (Baugh Reference Baugh, García, Flores and Spotti2017, Purnell et al. Reference Purnell, Idsardi and Baugh1999). Nevertheless, this line of inquiry must delicately balance these potential gains with the harm that may arise through study designs reinforcing race essentialism to their participants.
Some scholars attempt to answer their research questions by artificially manipulating the race or ethnicity of a hypothetical person or group (e.g. Squizzero Reference Squizzero2025). In doing so, these experiments’ study designs could risk validating or promoting essentialist beliefs to participants. For example, in their study offering empirical support for the idea of reverse linguistic stereotyping, that is, the process by which a speaker’s perceived group membership influences perception of their language proficiency or style, Kang and Rubin (Reference Kang and Rubin2009) had respondents listen to portions of a recorded lecture while projecting a photograph of ‘an Asian face’ or ‘a Caucasian face’, ostensibly that of the speaker, and had respondents evaluate the degree of speaker accentedness. By manipulating a hypothetical speaker’s race—a method evoking stereotypes associated with certain phenotypes or phenotypical cues (Sen & Wasow Reference Sen and Wasow2016)—and then asking about accentedness, participants might inaccurately infer that a speaker’s race can validly, reliably predict accentedness. The harms caused by studies that manipulate the race or ethnicity of a hypothetical person or group, as well as through interview content and the presentation of linguistic variation, can be mitigated as follows.
Recommendations:
1. Carefully consider how participants might interpret their experimental or interview methods and materials when using racial identity or ethnicity as a research variable.
2. Consult beforehand with members of the communities of study to understand potential racial beliefs or biases that could impact the reliability of results.
3. Debrief participants at the conclusion of an experiment or interview, addressing any race-essentialist beliefs that the experiment or interaction might have promoted.
4. Consider follow-up interventional studies that can challenge participant’s racial biases (e.g. Kang et al. Reference Kang, Rubin and Lindemann2015) to balance risks and benefits.
The main benefits of following this section’s recommendations include promoting, to participants, a more just and accurate view of racial identity and ethnicity, and respecting and validating the experiences of participants who may have encountered adversity due to their use of a racialized language variety.
3.7. Potential harm to study participants
As we strive to adopt new antiracist practices in our research and move away from uncritical use of racial, ethnic, and linguistic categories, we must also be mindful that collecting certain types of data (including race and ethnicity data) can potentially endanger participants. Ethnic categories are locally defined and can be loaded due to their linkage to national identity and sociopolitical concerns, such as immigration status.
In one relevant study, Smith (Reference Smith2019) investigated multilingualism among Senegalese expatriates in Rome, Paris, and New York, with particular attention to the powerful way that speakers achieved layered social meanings by code-switching between Italian, French, English, and Wolof. Some of Smith’s respondents in Rome in the early 2000s faced difficulties in obtaining permanent residency due to changes in Italy’s immigration laws and due to rhetoric from the highest levels of government that dehumanized immigrants. Smith (Reference Smith2019) did not focus on difficulties obtaining permanent residency in Italy, but instead invited narratives of travel and mobility as a method of gathering speech, which included the possibility of discovering undocumented status (2019:103). She deliberately avoided gathering citizenship or immigration-status information, as such data may have put expatriates in danger of deportation or detention. If these topics came up in an interview, she de-identified the recordings and transcripts of respondents who might be in danger. But it is also common in sociolinguistic surveys to directly request neighborhood (Milroy & Milroy Reference Milroy, Milroy and Trudgill1978), town (Labov Reference Labov1963) or region of residence (Wolfram & Dannenberg Reference Wolfram and Dannenberg1999), or nationality information as part of the sampling protocol or screening process that determines eligibility for participation in a study or in a demographic survey. It is important to understand that such data might have negative repercussions for our respondents and to consider when it may be best not to gather sensitive data that we never plan to use (e.g. in summary reports of usage of linguistic forms) or to present. This falls within the scope of the linguist’s responsibility to the ‘larger human community that might be affected’ by the analyst’s research (Hale Reference Hale2007).
In another study, Black (Reference Black, Duranti, George and Riner2023) conducted ethnographic research in Durban, South Africa, with members of a Zulu gospel choir, focusing particularly on HIV status and disclosure. Black notes (Reference Black, Duranti, George and Riner2023:306, fn. 7) that all participants wished to remain pseudonymous. Given the topic of the research, as well as the racialized context (the community had been previously segregated by law; Reference Black, Duranti, George and Riner2023:306), a great deal of sensitive information could be linked to participants’ identities.
In addition to concerns of citizenship status and HIV status, other reasons why participants might particularly prioritize preserving anonymity include social status within a community (e.g. if discussing cultural knowledge with outsiders is stigmatized), allowing participants to discuss sensitive or controversial topics (e.g. discussing experiences of racism or racist violence), or protecting against ‘outing’ participants who occupy multiply marginalized identities (e.g. avoiding outing trans or queer participants within their communities). These concerns should be carefully balanced with the many other arguments in favor of deanonymization and attribution.Footnote 11
Recommendations:
1. Consider the intersection of participant racial and ethnic identities with other social or political attributes including citizenship, vaccination status, in-group social standing, homelessness, or queer identity.
2. Devote time to learn about potentially sensitive topics that may come up before you start recruiting participants from a particular community.
3. For field data collection settings, give subjects the freedom to ask why we are gathering the information we are and how we plan to use it, and answer truthfully.
4. If asking participants to divulge personal information, give them control over their own demographic details. Work toward building trust by discussing the reasons for eliciting the information and self-disclosing some of your own personal information, as appropriate.
5. If the fieldwork involves migrants, carefully consider whether there are potential harms in reporting citizenship status. The same goes for collecting potentially harmful self-identity information from other vulnerable groups (e.g. trans/queer participants, etc.).
6. For portions of interviews that may record sensitive topics, consider turning off the recorder and instead writing notes free of compromising details (as Smith (Reference Smith2019) did). Alternatively, allow participants to listen to the interview after a recording session is done and to exercise their right to wipe any part.
7. Consider de-identifying portions of recordings not required for linguistic or demographic analysis.
8. For online settings, provide a webpage explaining how respondent data will be used and describing more about the aims of the study.
9. Incorporate prose into the consent form allowing respondents to determine how their data may be used and with whom it may be shared.
10. Give participants the option to remain pseudonymous in research reports, and use discretion when providing participant demographic information.
4. Post-research considerations
If we (as linguists) prefer that our science not be used to harm others, we should continue to investigate, adopt, and expand existing approaches toward citational ethics more generally. This section addresses post-research considerations, such as anticipating potential issues after publication. One of this section’s main goals is to discuss how to embed intentional antiracist framing into the writing of a publication, to (ideally) prevent bad-faith actors from citing the publication in racist writings. The other main goal is to present potential ways to mitigate harm if one’s publication does get cited in support of racist causes. This section is only a preliminary approach toward what must be a larger discussion in linguistics and our sibling sciences. Until there is a general change in citational ethics, adopting an intentional antiracist perspective in our writing and science communication can hinder the misrepresentation or harm caused by citing our work.
4.1. Identifying and discussing potentially harmful implications of one’s work
Typically, the focus of writing a report of primary research is conveying the details of the research: goals, theoretical framing, results, and contributions. However, it can be important, while writing the report, to read for the audience(s) and proactively identify and discuss potentially harmful implications of certain interpretations of the work. While we cannot anticipate all (mis)readings, there are some things that might be done to mitigate misreadings related to race-related content.
Recommendations:
1. Look through your writing for specific references to race. How would each such sentence sound if taken out of context?
2. When you refer to your participants, avoid using overgeneralizing phrases: if your study includes Black people and your writing refers to that subgroup of your study participants, the phrases Black participants or Black study participants are less likely to make it easy for others to use direct quotes out of context or overgeneralize than Black people, while likely being more accurate in terms of what you can claim based on your study.
3. Check your writing for ‘White gaze’ and ‘othering’: Do you only mention race when describing racialized participants? Are the practices of a living Indigenous people primarily described in the past tense?
4. Check your writing for being overly accommodating of hegemonic viewpoints. That is, there are times when it is worth directly engaging with and refuting ideologies of race and language. But outside of such discussions, it is preferable to just assume as common ground such notions as ‘White supremacy is bad’ and not defensively motivate that position.Footnote 12
5. Consider including an ‘ethical considerations’ or ‘broader impacts’ section in your paper. Use this space to specifically warn against misappropriation and explain why certain uses of your results would be invalid and/or inappropriate. This practice is gaining ground in computational linguistics conferences and related fields.Footnote 13
4.2. Handling bad-faith citation
Beyond proactively identifying and discussing potentially harmful implications of one’s work, it may be appropriate to respond when a bad-faith actor uses your work in ways that reinforce or support racist systems. Below are some general tips for handling such cases.
Recommendations:
1. Decide whether a reply is warranted or would just give something fairly obscure more visibility. If a reply is not warranted, then nothing needs to be done immediately. However, it is nonetheless worth keeping an eye on whether the bad-faith piece is gaining traction. Consider drafting a reply to have ready.
2. Analyze how your work was misappropriated. What jumps in reasoning are being made to connect your research to the point the bad-faith actor is trying to make?
3. Draft your response and share it with a trusted colleague, to check for tone and accessibility.
4. Claim the academic high ground and avoid taking a defensive stance. This should be written for a general audience, since it is likely that the bad-faith piece you are responding to was as well.
5. Create a platform (if you don’t have one already). This can be a website, blogging platform, or social media presence associated with your research. Sites like medium.com are useful for putting up content.
6. Publicize the response, keeping in mind that you are trying to reach both the linguistics audience and others who may have seen the bad-faith piece and not your own research. Consider posting to social media and pitching op-eds to news outlets.
7. If there is media attention and reporters are contacting you, set aside time to talk with them. Before agreeing to an interview, look at previous work by the reporter making the query and consider the angle they approach you with. Before giving an interview, write down your main talking points, so you can be sure to include them in your answers.
5. Conclusions
The main purpose of this work is to offer specific guidance in addressing pressing issues related to the collection, analysis, use, and interpretation of race and ethnicity data, grounded in a critique of traditional practices in linguistic research that incorporated unanalyzed or flawed conceptualizations of race and ethnicity. Drawing on recent work in linguistics and our sibling fields in the social sciences and humanities, we have aimed to develop a more critical, ethical, and widely applicable representation of racial identity and ethnicity in linguistic studies. While a distinction between racial identity and ethnicity can be stipulated, it is often hard to operationalize. This operationalization is even more challenging if we consider the multiple psychological implications that ascribing racial identity (or ethnicity) can have for individuals and how these concepts often intertwine in subjective self-identifications. These potentially harmful implications exist for research study participants, for policy-makers, and for researchers themselves.
This guide illustrates why it is important to collect such data, why analysts need to be able to understand and justify their research practices, and why it is important to discuss how ethnicity and race are conceptualized within linguistics. This guide has also made recommendations for more ethical research practices and highlighted how to avoid potential harm and incongruencies. We recognize the sensitivity and relevance of the topic. Finally, we strongly counter the use of phenotypically or biologically determined definitions of race in any linguistic investigation. In the bigger picture, we hope that this work not only sets a path for improved research practices and stronger scientific validity, but also helps foster linguistic and social justice, empower different ethnic communities, and dismantle patterns of inequality.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0097850726000093.
Data availability statement
There is no data to make available.
Acknowledgments
The authors would like to thank Anne Charity Hudley, Sonja Lanehart, and Arthur Spears, in addition to the anonymous referees and the editors, for their constructive feedback on this piece. [Full editorial history: Received 04 July 2023; revision invited 04 June 2024; revision received 17 September 2024; accepted pending revisions 26 June 2025; revision received 23 August 2025; accepted 12 January 2026.]
Competing interests
The authors declare none.
Ethics statement
Ethical approval was not required.