


1. Introduction
Quantitative bounds on the distance between distributions generated by Markov models have many applications in statistics, computer science, and the natural and social sciences (see, e.g., [Reference Montenegro and Tetali20, Reference Rosenthal25]). One approach to producing such bounds uses total variation distance and exploits minorization conditions (see, e.g., [Reference Bardet, Christen, Guillin, Malrieu and Zitt2, Reference Connor and Fort8, Reference Jiang, Liu, Lou, Rosenthal, Shangguan, Wang and Wu13, Reference Rosenthal24). Another branch of the literature bounds deviations using Wasserstein distance (see, e.g., [Reference Butkovsky4, Reference Butkovsky and Scheutzow5, Reference ChafaÏ, Malrieu and Paroux7, Reference Qin and Hobert21, Reference Qu, Blanchet and Glynn22]). In general, total variation bounds require relatively strong mixing conditions on the law of motion in some ‘attracting’ region of the state space, while Wasserstein bounds rely on some degree of continuity of the laws of motion with respect to a specified metric. Total variation bounds can also be studied within the setting of Wasserstein distance by choosing the ground metric on the state space to be the discrete metric (see, e.g., [Reference Butkovsky4]).
Although this research covers many important applications, there are also significant cases where Markov chains lack both the minorization and the continuity properties discussed above, making total variation and Wasserstein-type bounds difficult or impossible to apply. Fortunately, some of these models also possess valuable structure in the form of stochastic monotonicity. Such monotonicity can be exploited to obtain stability and ergodicity via order-theoretic versions of mixing conditions [Reference Bhattacharya and Lee3, Reference Foss and Scheutzow9, Reference Foss, Shneer, Thomas and Worrall10, Reference Kamihigashi and Stachurski15, Reference Kamihigashi and Stachurski16]. In this article, we complement these stability and ergodicity results by providing quantitative bounds for stochastically monotone Markov chains.
While there are some existing results that use stochastic monotonicity to bound the distributions generated by Markov chains [Reference Gaudio, Amin and Jaillet11, Reference Lund, Meyn and Tweedie19], these bounds are stated in terms of total variation distance, which again requires traditional minorization conditions (as opposed to the order-theoretic mixing conditions discussed in the previous paragraph). In this article, we aim to fully exploit monotonicity by instead bounding total ordered variation distance [Reference Kamihigashi and Stachurski16] between distributions. This works well because (a) our mixing conditions are stated in terms of order and (b) total ordered variation distance respects order structure on the state space.
Our main theorem is closely related to the total variation bound in Theorem 1 in [Reference Rosenthal24], which is representative of existing work on total variation bounds and provides a simple and elegant proof. The main differences between that theorem and the one presented below is that we use total ordered variation distance instead of total variation distance and an order-theoretic mixing condition instead of a standard minorization condition. At the same time, as we show in Section 5.1, it is possible to recover Theorem 1 in [Reference Rosenthal24] from our main theorem by adopting a particular choice of partial order.
Our work is also related to Wasserstein bounds on the deviation between distributions for Markov models, as found, for example, in [Reference Butkovsky4, Reference Qu, Blanchet and Glynn22]. However, rather than bounding Wasserstein distance, our main theorem bounds deviations measured in terms of two directed Wasserstein semimetrics, each of which is connected to the same partial order on the state space. Further details are given in Section 5.2.
2. Setup
We first recall key definitions and state some preliminary results.
2.1. Environment
Throughout this article,
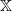 $\mathbb X$
is a Polish space,
$\mathbb X$
is a Polish space,
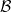 $\mathcal B$
is its Borel sets, and
$\mathcal B$
is its Borel sets, and
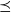 $\preceq$
is a closed partial order on
$\preceq$
is a closed partial order on
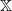 $\mathbb X$
. The last statement means that the graph of
$\mathbb X$
. The last statement means that the graph of
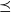 $\preceq$
, denoted by
$\preceq$
, denoted by
 \begin{equation} \mathbb G = \{ (x, x^{\prime}) \in \mathbb X \times \mathbb X \,:\, x \preceq x^{\prime} \} ,\end{equation}
\begin{equation} \mathbb G = \{ (x, x^{\prime}) \in \mathbb X \times \mathbb X \,:\, x \preceq x^{\prime} \} ,\end{equation}
is closed under the product topology on
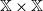 $\mathbb X \times \mathbb X$
. A map
$\mathbb X \times \mathbb X$
. A map
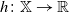 $h \colon \mathbb X\to \mathbb R$
is called increasing if
$h \colon \mathbb X\to \mathbb R$
is called increasing if
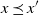 $x \preceq x^{\prime}$
implies
$x \preceq x^{\prime}$
implies
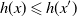 $h(x) \leqslant h(x^{\prime})$
. We take
$h(x) \leqslant h(x^{\prime})$
. We take
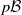 $p\mathcal B$
to be the set of all probability measures on
$p\mathcal B$
to be the set of all probability measures on
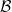 $\mathcal B$
and let
$\mathcal B$
and let
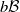 $b\mathcal B$
be the bounded Borel measurable functions sending
$b\mathcal B$
be the bounded Borel measurable functions sending
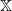 $\mathbb X$
into
$\mathbb X$
into
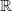 $\mathbb R$
. Given
$\mathbb R$
. Given
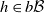 $h \in b\mathcal B$
and
$h \in b\mathcal B$
and
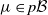 $\mu \in p\mathcal B$
we set
$\mu \in p\mathcal B$
we set
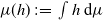 $\mu(h) \,:\!=\, \int h \mathop{}\!\mathrm{d} \mu$
. The symbol
$\mu(h) \,:\!=\, \int h \mathop{}\!\mathrm{d} \mu$
. The symbol
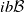 $ib\mathcal B$
represents all increasing
$ib\mathcal B$
represents all increasing
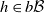 $h \in b\mathcal B$
.
$h \in b\mathcal B$
.
For
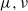 $\mu, \nu$
in
$\mu, \nu$
in
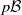 $p\mathcal B$
, we say that
$p\mathcal B$
, we say that
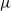 $\mu$
is stochastically dominated by
$\mu$
is stochastically dominated by
 $\nu$
and write
$\nu$
and write
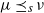 $\mu \preceq_{s} \nu$
if
$\mu \preceq_{s} \nu$
if
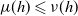 $\mu(h) \leqslant \nu(h)$
for all
$\mu(h) \leqslant \nu(h)$
for all
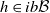 $h \in ib\mathcal B$
. In addition, we set
$h \in ib\mathcal B$
. In addition, we set
 \begin{equation} \rho(\mu, \nu) \,:\!=\, \sup\nolimits_{I \in i\mathcal B} (\mu(I) - \nu(I)) + \sup\nolimits_{I \in i\mathcal B} (\nu(I) - \mu(I)).\end{equation}
\begin{equation} \rho(\mu, \nu) \,:\!=\, \sup\nolimits_{I \in i\mathcal B} (\mu(I) - \nu(I)) + \sup\nolimits_{I \in i\mathcal B} (\nu(I) - \mu(I)).\end{equation}
This is the total ordered variation metric on
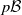 $p\mathcal B$
. A proof that
$p\mathcal B$
. A proof that
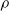 $\rho$
is indeed a metric can be found in Lemma 4.1 in [Reference Kamihigashi and Stachurski16]. Positive definiteness follows from the fact that
$\rho$
is indeed a metric can be found in Lemma 4.1 in [Reference Kamihigashi and Stachurski16]. Positive definiteness follows from the fact that
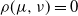 $\rho(\mu, \nu)=0$
implies
$\rho(\mu, \nu)=0$
implies
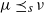 $\mu \preceq_{s} \nu$
and
$\mu \preceq_{s} \nu$
and
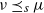 $\nu \preceq_{s} \mu$
. Since
$\nu \preceq_{s} \mu$
. Since
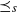 $\preceq_{s} $
is antisymmetric on
$\preceq_{s} $
is antisymmetric on
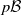 $p\mathcal B$
[Reference Kamae and Krengel14, Lemma 1], we then have
$p\mathcal B$
[Reference Kamae and Krengel14, Lemma 1], we then have
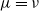 $\mu=\nu$
. Connections between
$\mu=\nu$
. Connections between
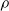 $\rho$
and the total variation and Wasserstein metrics are discussed in Section 5.
$\rho$
and the total variation and Wasserstein metrics are discussed in Section 5.
A function
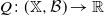 $Q \colon (\mathbb X, \mathcal B) \to \mathbb R$
is called a transition kernel on
$Q \colon (\mathbb X, \mathcal B) \to \mathbb R$
is called a transition kernel on
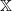 $\mathbb X$
if Q is a map from
$\mathbb X$
if Q is a map from
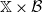 $\mathbb X \times \mathcal B$
to [0,1] such that
$\mathbb X \times \mathcal B$
to [0,1] such that
 $x\mapsto Q(x, A)$
is measurable for each
$x\mapsto Q(x, A)$
is measurable for each
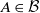 $A \in \mathcal B$
and
$A \in \mathcal B$
and
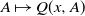 $A \mapsto Q(x, A)$
is a probability measure on
$A \mapsto Q(x, A)$
is a probability measure on
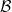 $\mathcal B$
for each
$\mathcal B$
for each
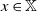 $x \in \mathbb X$
. At times we use the symbol
$x \in \mathbb X$
. At times we use the symbol
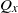 $Q_x$
to represent the distribution
$Q_x$
to represent the distribution
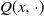 $Q(x, \cdot)$
at given x. A transition kernel Q on
$Q(x, \cdot)$
at given x. A transition kernel Q on
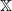 $\mathbb X$
is called increasing if
$\mathbb X$
is called increasing if
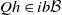 $Qh \in ib\mathcal B$
whenever
$Qh \in ib\mathcal B$
whenever
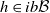 $h \in ib\mathcal B$
. Equivalently,
$h \in ib\mathcal B$
. Equivalently,
 \begin{equation*} Q_x \preceq_{s} Q_{x^{\prime}} \quad \text{whenever} \quad x \preceq x^{\prime}.\end{equation*}
\begin{equation*} Q_x \preceq_{s} Q_{x^{\prime}} \quad \text{whenever} \quad x \preceq x^{\prime}.\end{equation*}
For a transition kernel Q on
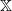 $\mathbb X$
, we define the left and right Markov operators generated by Q via
$\mathbb X$
, we define the left and right Markov operators generated by Q via
 \begin{equation*} \mu Q(A) = \int Q(x, A) \mu (\mathop{}\!\mathrm{d} x) \quad \text{and} \quad Qf(x) = \int f(y) Q(x, \mathop{}\!\mathrm{d} y).\end{equation*}
\begin{equation*} \mu Q(A) = \int Q(x, A) \mu (\mathop{}\!\mathrm{d} x) \quad \text{and} \quad Qf(x) = \int f(y) Q(x, \mathop{}\!\mathrm{d} y).\end{equation*}
(The left Markov operator
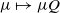 $\mu \mapsto \mu Q$
maps
$\mu \mapsto \mu Q$
maps
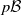 $p\mathcal B$
to itself, while the right Markov operator
$p\mathcal B$
to itself, while the right Markov operator
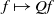 $f \mapsto Qf$
acts on
$f \mapsto Qf$
acts on
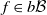 $f \in b\mathcal B$
.) A discrete-time
$f \in b\mathcal B$
.) A discrete-time
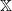 $\mathbb X$
-valued stochastic process
$\mathbb X$
-valued stochastic process
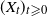 $(X_t)_{t \geqslant 0}$
on a filtered probability space
$(X_t)_{t \geqslant 0}$
on a filtered probability space
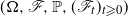 $(\Omega, \mathscr F, \mathbb P, (\mathscr F_t)_{t \geqslant 0})$
is called Markov-
$(\Omega, \mathscr F, \mathbb P, (\mathscr F_t)_{t \geqslant 0})$
is called Markov-
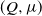 $(Q,\mu)$
if
$(Q,\mu)$
if
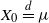 $X_0 \stackrel {\scriptsize{d}} {=} \mu$
and
$X_0 \stackrel {\scriptsize{d}} {=} \mu$
and
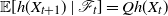 $\mathbb E [ h(X_{t+1}) \,|\, \mathscr F_t ] = Qh(X_t)$
with probability 1 for all
$\mathbb E [ h(X_{t+1}) \,|\, \mathscr F_t ] = Qh(X_t)$
with probability 1 for all
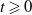 $t \geqslant 0$
and
$t \geqslant 0$
and
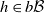 $h \in b \mathcal B$
.
$h \in b \mathcal B$
.
2.2. Couplings
A coupling of
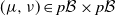 $(\mu, \nu) \in p\mathcal B \times p\mathcal B$
is a probability measure
$(\mu, \nu) \in p\mathcal B \times p\mathcal B$
is a probability measure
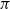 $\pi$
on
$\pi$
on
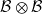 $\mathcal B \otimes \mathcal B$
satisfying
$\mathcal B \otimes \mathcal B$
satisfying
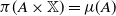 $\pi(A \times \mathbb X) = \mu(A) $
and
$\pi(A \times \mathbb X) = \mu(A) $
and
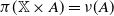 $\pi(\mathbb X \times A) = \nu(A)$
for all
$\pi(\mathbb X \times A) = \nu(A)$
for all
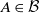 $A \in \mathcal B$
. Let
$A \in \mathcal B$
. Let
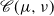 $\mathscr {C} \, (\mu, \nu)$
denote the set of all couplings of
$\mathscr {C} \, (\mu, \nu)$
denote the set of all couplings of
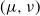 $(\mu, \nu)$
and let
$(\mu, \nu)$
and let
 \begin{equation} \alpha(\mu, \nu) = \sup\nolimits_{\pi \in \mathscr {C} \, (\mu, \nu)} \pi(\mathbb G).\end{equation}
\begin{equation} \alpha(\mu, \nu) = \sup\nolimits_{\pi \in \mathscr {C} \, (\mu, \nu)} \pi(\mathbb G).\end{equation}
The value
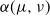 $\alpha(\mu, \nu)$
can be understood as a measure of ‘partial stochastic dominance’ of
$\alpha(\mu, \nu)$
can be understood as a measure of ‘partial stochastic dominance’ of
 $\nu$
over
$\nu$
over
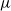 $\mu$
[Reference Kamihigashi and Stachurski17]. In line with this interpretation, and applying Strassen’s theorem [Reference Lindvall18, Reference Strassen26], we have
$\mu$
[Reference Kamihigashi and Stachurski17]. In line with this interpretation, and applying Strassen’s theorem [Reference Lindvall18, Reference Strassen26], we have
 \begin{equation} \alpha(\mu, \nu) = 1 \quad \text{whenever} \quad \mu \preceq_{s} \nu.\end{equation}
\begin{equation} \alpha(\mu, \nu) = 1 \quad \text{whenever} \quad \mu \preceq_{s} \nu.\end{equation}
Let Q be a transition kernel on
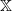 $\mathbb X$
. A Markov coupling of Q is a real-valued function
$\mathbb X$
. A Markov coupling of Q is a real-valued function
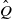 $\hat Q$
on
$\hat Q$
on
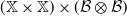 $(\mathbb X \times \mathbb X) \times (\mathcal B \otimes \mathcal B)$
such that
$(\mathbb X \times \mathbb X) \times (\mathcal B \otimes \mathcal B)$
such that
-
(i)
 $(x,x^{\prime}) \mapsto \hat Q((x, x^{\prime}), E)$
is measurable for each
$E \in \mathcal B \otimes \mathcal B$
and
$(x,x^{\prime}) \mapsto \hat Q((x, x^{\prime}), E)$
is measurable for each
$E \in \mathcal B \otimes \mathcal B$
and -
(ii)
$\hat Q_{(x, x^{\prime})}$
is a coupling of
$Q_x$
and
$Q_{x^{\prime}}$
for all
$x, x^{\prime} \in \mathbb X$
.
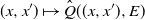
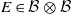
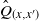
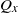
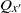
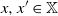
In other words,
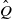 $\hat Q$
is a transition kernel on
$\hat Q$
is a transition kernel on
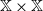 $\mathbb X \times \mathbb X$
that couples the distributions
$\mathbb X \times \mathbb X$
that couples the distributions
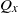 $Q_x$
and
$Q_x$
and
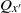 $Q_{x^{\prime}}$
at every pair of points in the state space.
$Q_{x^{\prime}}$
at every pair of points in the state space.
We call
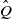 $\hat Q$
a
$\hat Q$
a
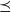 $\preceq$
-maximal Markov coupling of Q if
$\preceq$
-maximal Markov coupling of Q if
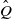 $\hat Q$
is a Markov coupling of Q and, in addition,
$\hat Q$
is a Markov coupling of Q and, in addition,
 \begin{equation} \hat Q((x, x^{\prime}), \mathbb G) = \alpha(Q_x, Q_{x^{\prime}}) \quad \text{for all } (x,x^{\prime}) \in \mathbb X \times \mathbb X.\end{equation}
\begin{equation} \hat Q((x, x^{\prime}), \mathbb G) = \alpha(Q_x, Q_{x^{\prime}}) \quad \text{for all } (x,x^{\prime}) \in \mathbb X \times \mathbb X.\end{equation}
Informally,
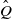 $\hat Q$
serves as a transition kernel of a ‘joint’ chain
$\hat Q$
serves as a transition kernel of a ‘joint’ chain
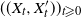 $((X_t,X_t'))_{t \geqslant 0}$
that maximizes the probability of attaining
$((X_t,X_t'))_{t \geqslant 0}$
that maximizes the probability of attaining
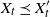 $X_t \preceq X_t'$
at each step. Below we use the following existence result.
$X_t \preceq X_t'$
at each step. Below we use the following existence result.
Lemma 1. If Q is a transition kernel on
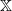 $\mathbb X$
then Q has at least one
$\mathbb X$
then Q has at least one
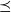 $\preceq$
-maximal Markov coupling.
$\preceq$
-maximal Markov coupling.
Proof. Let Q be a transition kernel on
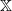 $\mathbb X$
. By Theorem 1.1 in [Reference Zhang27], given lower semicontinuous
$\mathbb X$
. By Theorem 1.1 in [Reference Zhang27], given lower semicontinuous
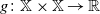 $g \colon \mathbb X \times \mathbb X \to \mathbb R$
, there exists a transition kernel
$g \colon \mathbb X \times \mathbb X \to \mathbb R$
, there exists a transition kernel
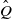 $\hat Q$
on
$\hat Q$
on
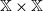 $\mathbb X \times \mathbb X$
such that
$\mathbb X \times \mathbb X$
such that
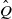 $\hat Q$
is a Markov coupling of Q and, in addition
$\hat Q$
is a Markov coupling of Q and, in addition
 \begin{equation*} (\hat Q g)(x, x^{\prime}) = \inf \left\{ \int g \mathop{}\!\mathrm{d} \pi \, : \, \pi \in \mathscr {C} \, (Q_x, Q_{x^{\prime}}) \right\} \! . \end{equation*}
\begin{equation*} (\hat Q g)(x, x^{\prime}) = \inf \left\{ \int g \mathop{}\!\mathrm{d} \pi \, : \, \pi \in \mathscr {C} \, (Q_x, Q_{x^{\prime}}) \right\} \! . \end{equation*}
As
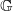 $\mathbb G$
is closed, this equality is attained when
$\mathbb G$
is closed, this equality is attained when
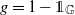 $g = 1 - \unicode{x1D7D9}_{\mathbb G}$
. Since
$g = 1 - \unicode{x1D7D9}_{\mathbb G}$
. Since
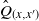 $\hat Q_{(x, x^{\prime})}$
and
$\hat Q_{(x, x^{\prime})}$
and
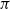 $\pi$
are probability measures, we then have
$\pi$
are probability measures, we then have
 \begin{equation*} \hat Q((x, x^{\prime}), \mathbb G) = \sup \left\{ \pi(\mathbb G) \, : \, \pi \in \mathscr {C} \, (Q_x, Q_{x^{\prime}}) \right\} \! . \end{equation*}
\begin{equation*} \hat Q((x, x^{\prime}), \mathbb G) = \sup \left\{ \pi(\mathbb G) \, : \, \pi \in \mathscr {C} \, (Q_x, Q_{x^{\prime}}) \right\} \! . \end{equation*}
This shows that
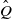 $\hat Q$
is a
$\hat Q$
is a
 $\preceq$
-maximal Markov coupling of Q.
$\preceq$
-maximal Markov coupling of Q.
The following simple lemma will be important for our bounds.
Lemma 2. If Q is increasing and
 $\hat Q$
is a
$\hat Q$
is a
 $\preceq$
-maximal Markov coupling of Q, then
$\preceq$
-maximal Markov coupling of Q, then
 $\mathbb G$
is absorbing for
$\mathbb G$
is absorbing for
 $\hat Q$
.
$\hat Q$
.
Proof. Let Q and
 $\hat Q$
be as stated. If
$\hat Q$
be as stated. If
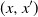 $(x,x^{\prime})$
is in
$(x,x^{\prime})$
is in
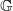 $\mathbb G$
then, since Q is increasing, we have
$\mathbb G$
then, since Q is increasing, we have
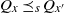 $Q_x \preceq_{s} Q_{x^{\prime}}$
. Combining this inequality with (4), we obtain
$Q_x \preceq_{s} Q_{x^{\prime}}$
. Combining this inequality with (4), we obtain
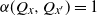 $\alpha(Q_x, Q_{x^{\prime}}) = 1$
. Application of the property (5) produces
$\alpha(Q_x, Q_{x^{\prime}}) = 1$
. Application of the property (5) produces
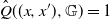 $\hat Q((x,x^{\prime}), \mathbb G) = 1$
; hence,
$\hat Q((x,x^{\prime}), \mathbb G) = 1$
; hence,
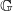 $\mathbb G$
is absorbing for
$\mathbb G$
is absorbing for
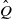 $\hat Q$
.
$\hat Q$
.
3. Main Result
In this section we state our main result concerning rates of convergence.
3.1. A quantitative bound
Let Q be an increasing transition kernel on
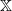 $\mathbb X$
and let
$\mathbb X$
and let
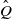 $\hat Q$
be a
$\hat Q$
be a
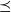 $\preceq$
-maximal Markov coupling of Q. Let W be a measurable function from
$\preceq$
-maximal Markov coupling of Q. Let W be a measurable function from
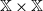 $\mathbb X \times \mathbb X$
to
$\mathbb X \times \mathbb X$
to
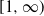 $[1,\infty)$
. Suppose that, for some measurable set C in
$[1,\infty)$
. Suppose that, for some measurable set C in
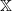 $\mathbb X$
and some strictly increasing convex function
$\mathbb X$
and some strictly increasing convex function
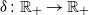 $\delta \colon \mathbb R_+ \to\mathbb R_+$
with
$\delta \colon \mathbb R_+ \to\mathbb R_+$
with
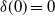 $\delta(0)=0$
, the kernel
$\delta(0)=0$
, the kernel
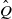 $\hat Q$
obeys the drift condition
$\hat Q$
obeys the drift condition
 \begin{equation} \hat Q W(x, x^{\prime}) \leqslant \delta( W(x, x^{\prime}) ) \quad \text{for all } (x,x^{\prime}) \notin C \times C.\end{equation}
\begin{equation} \hat Q W(x, x^{\prime}) \leqslant \delta( W(x, x^{\prime}) ) \quad \text{for all } (x,x^{\prime}) \notin C \times C.\end{equation}
We set
 \begin{equation} B = \max \big\{1, \;\delta^{-1} \left(B_0\right)\big\} \! , \quad \text{where} \quad B_0 \,:\!=\, \sup\nolimits_{(x, x^{\prime}) \in C \times C} \hat R W(x,x^{\prime}),\end{equation}
\begin{equation} B = \max \big\{1, \;\delta^{-1} \left(B_0\right)\big\} \! , \quad \text{where} \quad B_0 \,:\!=\, \sup\nolimits_{(x, x^{\prime}) \in C \times C} \hat R W(x,x^{\prime}),\end{equation}
and
 \begin{equation} \hat R W (x,x^{\prime}) \,:\!=\, \int \int W(y,y') \unicode{x1D7D9}\{y \npreceq y'\} \hat Q((x,x^{\prime}), \mathop{}\!\mathrm{d} (y,y')).\end{equation}
\begin{equation} \hat R W (x,x^{\prime}) \,:\!=\, \int \int W(y,y') \unicode{x1D7D9}\{y \npreceq y'\} \hat Q((x,x^{\prime}), \mathop{}\!\mathrm{d} (y,y')).\end{equation}
In addition, let
 \begin{equation} \varepsilon = \inf \left\{ \alpha(Q_x, Q_{x^{\prime}}) \, : \, (x, x^{\prime}) \in C \times C \right\} \! . \end{equation}
\begin{equation} \varepsilon = \inf \left\{ \alpha(Q_x, Q_{x^{\prime}}) \, : \, (x, x^{\prime}) \in C \times C \right\} \! . \end{equation}
Given
 $\mu, \mu'$
in
$\mu, \mu'$
in
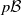 $p\mathcal B$
, we set
$p\mathcal B$
, we set
 \begin{equation*} (\mu \times \mu')(W) = \int \int W(x, x^{\prime}) \mu(\! \mathop{\mathrm{d}}x) \mu'(\! \mathop{\mathrm{d}} x^{\prime}).\end{equation*}
\begin{equation*} (\mu \times \mu')(W) = \int \int W(x, x^{\prime}) \mu(\! \mathop{\mathrm{d}}x) \mu'(\! \mathop{\mathrm{d}} x^{\prime}).\end{equation*}
In (7),
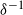 $\delta^{-1}$
is the inverse of
$\delta^{-1}$
is the inverse of
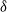 $\delta$
. Below,
$\delta$
. Below,
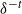 $\delta^{-t}$
indicates t compositions of
$\delta^{-t}$
indicates t compositions of
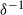 $\delta^{-1}$
with itself. We are now ready to state the main result on quantitative bounds.
$\delta^{-1}$
with itself. We are now ready to state the main result on quantitative bounds.
Theorem 1. For all
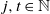 $j, t \in \mathbb N$
with
$j, t \in \mathbb N$
with
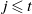 $j \leqslant t$
, we have
$j \leqslant t$
, we have
 \begin{equation*} \rho( \mu Q^t, \mu' Q^t) \leqslant 2(1-\varepsilon)^j + \frac{B^{\, j-1}}{\delta^{-t}(1)} [(\mu \times \mu')(W) + (\mu' \times \mu)(W)]. \end{equation*}
\begin{equation*} \rho( \mu Q^t, \mu' Q^t) \leqslant 2(1-\varepsilon)^j + \frac{B^{\, j-1}}{\delta^{-t}(1)} [(\mu \times \mu')(W) + (\mu' \times \mu)(W)]. \end{equation*}
Theorem 1 provides a total ordered variation bound on the deviation between the time-t distributions
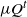 $\mu Q^t$
and
$\mu Q^t$
and
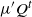 $\mu' Q^t$
generated by iteration with the Markov operator Q, taking as given an arbitrary pair of initial distributions
$\mu' Q^t$
generated by iteration with the Markov operator Q, taking as given an arbitrary pair of initial distributions
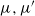 $\mu, \mu'$
in
$\mu, \mu'$
in
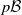 $p\mathcal B$
. Convergence of the bound in Theorem 1 to zero as
$p\mathcal B$
. Convergence of the bound in Theorem 1 to zero as
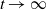 $t \to \infty$
requires that
$t \to \infty$
requires that
 $\varepsilon > 0$
and
$\varepsilon > 0$
and
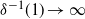 $\delta^{-1}(1) \to \infty$
.
$\delta^{-1}(1) \to \infty$
.
When
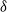 $\delta$
is linear we obtain the geometric case. Since this case is important we state it as a corollary.
$\delta$
is linear we obtain the geometric case. Since this case is important we state it as a corollary.
Corollary 1. If the conditions above hold with (6) replaced by
 \begin{equation} \hat Q W(x, x^{\prime}) \leqslant \gamma W(x, x^{\prime}) \quad \text{for all } (x,x^{\prime}) \notin C \times C \end{equation}
\begin{equation} \hat Q W(x, x^{\prime}) \leqslant \gamma W(x, x^{\prime}) \quad \text{for all } (x,x^{\prime}) \notin C \times C \end{equation}
for some positive constant
 $\gamma$
, then, for all
$\gamma$
, then, for all
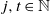 $j, t \in \mathbb N$
with
$j, t \in \mathbb N$
with
 $j \leqslant t$
,
$j \leqslant t$
,
 \begin{equation*} \rho( \mu Q^t, \mu' Q^t) \leqslant 2(1-\varepsilon)^j + \gamma^t B^{j-1} [(\mu \times \mu')(W) + (\mu' \times \mu)(W)]. \end{equation*}
\begin{equation*} \rho( \mu Q^t, \mu' Q^t) \leqslant 2(1-\varepsilon)^j + \gamma^t B^{j-1} [(\mu \times \mu')(W) + (\mu' \times \mu)(W)]. \end{equation*}
Convergence of the bound in Corollary 1 to zero as
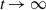 $t \to \infty$
requires that the constants
$t \to \infty$
requires that the constants
 $\varepsilon$
and
$\varepsilon$
and
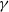 $\gamma$
obey
$\gamma$
obey
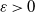 $\varepsilon > 0$
and
$\varepsilon > 0$
and
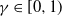 $\gamma \in [0, 1)$
. The bound can be viewed as an order-theoretic version of the geometric total variation bound in Theorem 1 in [Reference Rosenthal24]. Further comparisons are given in Section 5.1.
$\gamma \in [0, 1)$
. The bound can be viewed as an order-theoretic version of the geometric total variation bound in Theorem 1 in [Reference Rosenthal24]. Further comparisons are given in Section 5.1.
3.2. Sketch of the proof
The bound in Theorem 1 is obtained by tracking a joint chain
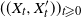 $((X_t, X_t'))_{t \geqslant 0}$
generated by a
$((X_t, X_t'))_{t \geqslant 0}$
generated by a
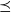 $\preceq$
-maximal Markov coupling
$\preceq$
-maximal Markov coupling
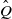 $\hat Q$
and started from initial condition
$\hat Q$
and started from initial condition
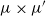 $\mu \times \mu'$
. Because
$\mu \times \mu'$
. Because
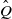 $\hat Q$
is a Markov coupling of Q, the individual chains
$\hat Q$
is a Markov coupling of Q, the individual chains
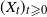 $(X_t)_{t \geqslant 0}$
and
$(X_t)_{t \geqslant 0}$
and
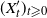 $(X'_t)_{t \geqslant 0}$
are Markov-
$(X'_t)_{t \geqslant 0}$
are Markov-
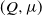 $(Q, \mu)$
and Markov-
$(Q, \mu)$
and Markov-
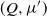 $(Q, \mu')$
, respectively. Taking
$(Q, \mu')$
, respectively. Taking
 $\tau$
to be the first time that
$\tau$
to be the first time that
 $X_t \preceq X_t'$
occurs, we can use the fact that
$X_t \preceq X_t'$
occurs, we can use the fact that
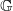 $\mathbb G$
is absorbing for
$\mathbb G$
is absorbing for
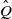 $\hat Q$
(Lemma 2) to obtain
$\hat Q$
(Lemma 2) to obtain
 \begin{equation} \tau \leqslant t \quad \text{if and only if} \quad X_t \preceq X_t'.\end{equation}
\begin{equation} \tau \leqslant t \quad \text{if and only if} \quad X_t \preceq X_t'.\end{equation}
Next, an order-theoretic version of a standard total variation coupling argument is used to generate the bound
 $(\mu Q^t)(I) - (\mu' Q^t)(I) \leqslant \mathbb P \{X_t \npreceq X'_t\}$
for all
$(\mu Q^t)(I) - (\mu' Q^t)(I) \leqslant \mathbb P \{X_t \npreceq X'_t\}$
for all
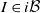 $I \in i\mathcal B$
. In view of (11), the left-hand side is also bounded above by
$I \in i\mathcal B$
. In view of (11), the left-hand side is also bounded above by
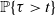 $\mathbb P \{\tau > t\}$
. This in turn is bounded with the use of the drift to
$\mathbb P \{\tau > t\}$
. This in turn is bounded with the use of the drift to
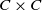 $C \times C$
implied by (6), and the
$C \times C$
implied by (6), and the
 $\varepsilon$
-probability of the joint chain
$\varepsilon$
-probability of the joint chain
 $((X_t, X_t'))_{t \geqslant 0}$
entering
$((X_t, X_t'))_{t \geqslant 0}$
entering
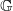 $\mathbb G$
after
$\mathbb G$
after
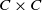 $C \times C$
implied by (9). Reversing the roles of
$C \times C$
implied by (9). Reversing the roles of
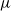 $\mu$
and
$\mu$
and
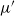 $\mu'$
and then adding the two inequalities leads to the bound in Theorem 1. Details are given in Section 4.
$\mu'$
and then adding the two inequalities leads to the bound in Theorem 1. Details are given in Section 4.
3.3. Univariate drift
In applications, drift conditions on the underlying kernel Q are usually easier to test and interpret than drift conditions on a joint kernel such as (6). Fortunately, there are relatively straightforward ways to map the former (let us call them ‘univariate’ drift conditions) to the latter (‘joint’ drift conditions). For example, suppose that Q is a transition kernel on
 $\mathbb X$
and V is a measurable function from
$\mathbb X$
and V is a measurable function from
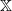 $\mathbb X$
to
$\mathbb X$
to
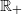 $\mathbb R_+$
. Suppose there exist
$\mathbb R_+$
. Suppose there exist
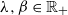 $\lambda, \beta \in \mathbb R_+$
such that
$\lambda, \beta \in \mathbb R_+$
such that
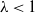 $\lambda < 1$
and
$\lambda < 1$
and
 \begin{equation} QV(x) \leqslant \lambda V(x) + \beta \qquad \text{for all } x \in \mathbb X.\end{equation}
\begin{equation} QV(x) \leqslant \lambda V(x) + \beta \qquad \text{for all } x \in \mathbb X.\end{equation}
In this setting, we can attain (10) by setting
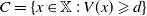 $C = \{ x \in\mathbb X \, : \, V(x) \geqslant d \} $
for some fixed
$C = \{ x \in\mathbb X \, : \, V(x) \geqslant d \} $
for some fixed
 $d \geqslant 1$
, and then
$d \geqslant 1$
, and then
 \begin{equation*} W(x,x^{\prime}) = 1 + V(x) + V(x^{\prime}) \quad \text{ and } \quad \gamma = \frac{1 + \lambda d + 2\beta}{1 + d}.\end{equation*}
\begin{equation*} W(x,x^{\prime}) = 1 + V(x) + V(x^{\prime}) \quad \text{ and } \quad \gamma = \frac{1 + \lambda d + 2\beta}{1 + d}.\end{equation*}
A proof that (10) holds with these definitions can be found in Theorem 12 in [Reference Rosenthal23].
Alternatively, if
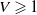 $V \geqslant 1$
then we can choose C in the same way and then set
$V \geqslant 1$
then we can choose C in the same way and then set
 \begin{equation*} W(x,x^{\prime}) = \frac{V(x) + V(x^{\prime})}{2} \quad \text{ and } \quad \gamma = \lambda + \frac{2\beta}{d}.\end{equation*}
\begin{equation*} W(x,x^{\prime}) = \frac{V(x) + V(x^{\prime})}{2} \quad \text{ and } \quad \gamma = \lambda + \frac{2\beta}{d}.\end{equation*}
Indeed, since
 $\hat Q$
is a Markov coupling of Q, an application of (12) yields
$\hat Q$
is a Markov coupling of Q, an application of (12) yields
 \begin{equation*} \hat Q W(x, x^{\prime}) = \frac{Q V(x) + QV(x^{\prime})}{2} \leqslant \lambda W(x, x^{\prime}) + \beta = \left( \lambda + \frac{\beta}{W(x, x^{\prime})}\right) W(x, x^{\prime}).\end{equation*}
\begin{equation*} \hat Q W(x, x^{\prime}) = \frac{Q V(x) + QV(x^{\prime})}{2} \leqslant \lambda W(x, x^{\prime}) + \beta = \left( \lambda + \frac{\beta}{W(x, x^{\prime})}\right) W(x, x^{\prime}).\end{equation*}
The drift condition (10) now follows from
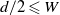 $d/2 \leqslant W$
on the complement of
$d/2 \leqslant W$
on the complement of
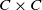 $C \times C$
.
$C \times C$
.
4. Proof of Theorem 1
In this section we prove Theorem 1. Throughout, Q is an increasing transition kernel on
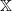 $\mathbb X$
,
$\mathbb X$
,
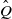 $\hat Q$
is a
$\hat Q$
is a
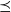 $\preceq$
-maximal Markov coupling of Q, and the conditions in Section 3.1 are in force. We fix
$\preceq$
-maximal Markov coupling of Q, and the conditions in Section 3.1 are in force. We fix
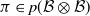 $\pi \in p(\mathcal B \otimes \mathcal B)$
and take
$\pi \in p(\mathcal B \otimes \mathcal B)$
and take
 $((X_t, X'_t))_{t \geqslant 0}$
to be Markov-
$((X_t, X'_t))_{t \geqslant 0}$
to be Markov-
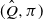 $(\hat Q, \pi)$
on a filtered probability space
$(\hat Q, \pi)$
on a filtered probability space
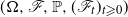 $(\Omega, \mathscr F, \mathbb P, (\mathscr F_t)_{t \geqslant 0})$
. Let
$(\Omega, \mathscr F, \mathbb P, (\mathscr F_t)_{t \geqslant 0})$
. Let
 $\tau$
be the stopping time
$\tau$
be the stopping time
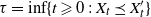 $\tau = \inf \{ t \geqslant 0 \, : \, X_t\preceq X_t' \} $
with
$\tau = \inf \{ t \geqslant 0 \, : \, X_t\preceq X_t' \} $
with
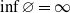 $\inf \varnothing = \infty$
. Let
$\inf \varnothing = \infty$
. Let
 \begin{equation*} N_t = \sum_{j=0}^t \unicode{x1D7D9} \{ (X_j, X'_j) \in C \times C \}\end{equation*}
\begin{equation*} N_t = \sum_{j=0}^t \unicode{x1D7D9} \{ (X_j, X'_j) \in C \times C \}\end{equation*}
count the number of visits of this joint chain to
 $C \times C$
. In addition, we set
$C \times C$
. In addition, we set
 $N_{-1} \,:\!=\, 0$
.
$N_{-1} \,:\!=\, 0$
.
Lemma 3. The process
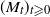 $(M_t)_{t \geqslant 0}$
defined by
$(M_t)_{t \geqslant 0}$
defined by
 \begin{equation*} M_t = B^{-N_{t-1}} \delta^{-t} [ W(X_t, X_t') ] \unicode{x1D7D9}\{ \tau > t\} \end{equation*}
\begin{equation*} M_t = B^{-N_{t-1}} \delta^{-t} [ W(X_t, X_t') ] \unicode{x1D7D9}\{ \tau > t\} \end{equation*}
is a supermartingale.
Proof. In the argument below, we use the implication
 \begin{equation} (x, x^{\prime}) \in C \times C \quad \implies \quad B^{-1} \delta^{-(t+1)} [\hat R W(x, x^{\prime})] \leqslant \delta^{-t} (W(x, x^{\prime})), \end{equation}
\begin{equation} (x, x^{\prime}) \in C \times C \quad \implies \quad B^{-1} \delta^{-(t+1)} [\hat R W(x, x^{\prime})] \leqslant \delta^{-t} (W(x, x^{\prime})), \end{equation}
which holds for all
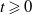 $t \geqslant 0$
. To establish (13), we fix t and use
$t \geqslant 0$
. To establish (13), we fix t and use
 $(x,x^{\prime}) \in C \times C$
and the definition of B to obtain
$(x,x^{\prime}) \in C \times C$
and the definition of B to obtain
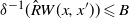 $\delta^{-1}( \hat R W(x, x^{\prime}) ) \leqslant B$
. Use of
$\delta^{-1}( \hat R W(x, x^{\prime}) ) \leqslant B$
. Use of
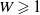 $W \geqslant 1$
now produces
$W \geqslant 1$
now produces
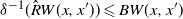 $\delta^{-1}( \hat R W(x, x^{\prime}) ) \leqslant B W(x, x^{\prime})$
. Since
$\delta^{-1}( \hat R W(x, x^{\prime}) ) \leqslant B W(x, x^{\prime})$
. Since
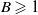 $B \geqslant 1$
and
$B \geqslant 1$
and
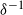 $\delta^{-1}$
is increasing and concave with
$\delta^{-1}$
is increasing and concave with
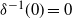 $\delta^{-1}(0)=0$
, application of
$\delta^{-1}(0)=0$
, application of
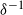 $\delta^{-1}$
to both sides of the previous bound and use of the scaling inequality gives
$\delta^{-1}$
to both sides of the previous bound and use of the scaling inequality gives
 \begin{equation*} \delta^{-2}( \hat R W(x, x^{\prime}) ) \leqslant \delta^{-1}(B W(x, x^{\prime})) \leqslant B \delta^{-1}(W(x, x^{\prime})). \end{equation*}
\begin{equation*} \delta^{-2}( \hat R W(x, x^{\prime}) ) \leqslant \delta^{-1}(B W(x, x^{\prime})) \leqslant B \delta^{-1}(W(x, x^{\prime})). \end{equation*}
Continued iteration in the same way yields (13).
Now we show that
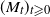 $(M_t)_{t \geqslant 0}$
is an
$(M_t)_{t \geqslant 0}$
is an
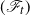 $(\mathscr F_t)$
-supermartingale. Clearly
$(\mathscr F_t)$
-supermartingale. Clearly
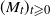 $(M_t)_{t \geqslant 0}$
is adapted. In proving
$(M_t)_{t \geqslant 0}$
is adapted. In proving
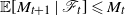 $\mathbb E[ M_{t+1} \, | \, \mathscr F_t] \leqslant M_t$
, we can and do assume that
$\mathbb E[ M_{t+1} \, | \, \mathscr F_t] \leqslant M_t$
, we can and do assume that
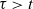 $\tau > t$
, since
$\tau > t$
, since
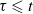 $\tau \leqslant t$
implies
$\tau \leqslant t$
implies
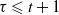 $\tau \leqslant t+1$
, in which case the inequality is trivial. Let us first consider the case
$\tau \leqslant t+1$
, in which case the inequality is trivial. Let us first consider the case
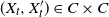 $(X_t, X_t') \in C \times C$
. When this holds, we have
$(X_t, X_t') \in C \times C$
. When this holds, we have
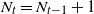 $N_t = N_{t-1} + 1$
, so
$N_t = N_{t-1} + 1$
, so
 \begin{align*} \mathbb E \big[M_{t+1} \, | \, \mathscr F_t \big] & = B^{-N_{t-1} - 1} \mathbb E \big[ \delta^{-(t+1)} \big(W\big(X_{t+1}, X_{t+1}'\big)\big) \unicode{x1D7D9}\{\tau \gt t+1\} \, | \, \mathscr F_t \big] \\ & = B^{-N_{t-1} - 1} \mathbb E \big[ \delta^{-(t+1)} \big(W\big(X_{t+1}, X_{t+1}'\big)\big) \unicode{x1D7D9}\big\{X_{t+1} \npreceq X_{t+1}'\big\} \, | \, \mathscr F_t \big] \\ & = B^{-N_{t-1} - 1} \mathbb E \big[ \delta^{-(t+1)} \big(W\big(X_{t+1}, X_{t+1}'\big) \unicode{x1D7D9}\big\{X_{t+1} \npreceq X_{t+1}'\big\}\big) \, | \, \mathscr F_t \big]. \end{align*}
\begin{align*} \mathbb E \big[M_{t+1} \, | \, \mathscr F_t \big] & = B^{-N_{t-1} - 1} \mathbb E \big[ \delta^{-(t+1)} \big(W\big(X_{t+1}, X_{t+1}'\big)\big) \unicode{x1D7D9}\{\tau \gt t+1\} \, | \, \mathscr F_t \big] \\ & = B^{-N_{t-1} - 1} \mathbb E \big[ \delta^{-(t+1)} \big(W\big(X_{t+1}, X_{t+1}'\big)\big) \unicode{x1D7D9}\big\{X_{t+1} \npreceq X_{t+1}'\big\} \, | \, \mathscr F_t \big] \\ & = B^{-N_{t-1} - 1} \mathbb E \big[ \delta^{-(t+1)} \big(W\big(X_{t+1}, X_{t+1}'\big) \unicode{x1D7D9}\big\{X_{t+1} \npreceq X_{t+1}'\big\}\big) \, | \, \mathscr F_t \big]. \end{align*}
The second equality follows from the identity in (11), while the third follows from
 $\delta(0)=\delta^{-1}(0)=0$
. Since
$\delta(0)=\delta^{-1}(0)=0$
. Since
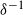 $\delta^{-1}$
is concave, using the previous chain of equalities and Jensen’s inequality for conditional expectations, along with the definition of
$\delta^{-1}$
is concave, using the previous chain of equalities and Jensen’s inequality for conditional expectations, along with the definition of
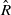 $\hat R$
in (8), we have
$\hat R$
in (8), we have
 \begin{align*} \mathbb E \left[ M_{t+1} \, | \, \mathscr F_t \right] & \leqslant B^{-N_{t-1}} B^{-1} \delta^{-(t+1)} \big[ \mathbb E \big[ W\big(X_{t+1}, X_{t+1}'\big) \unicode{x1D7D9}\big\{X_{t+1} \npreceq X_{t+1}'\big\} \, | \, \mathscr F_t \big] \big] \\ & = B^{-N_{t-1}} B^{-1} \delta^{-(t+1)} \big[ \hat R W\big(X_t, X_t'\big) \big] \\ & \leqslant B^{-N_{t-1}} \delta^{-t} \big[W\big(X_t, X_t'\big)\big] \\ & = M_t, \end{align*}
\begin{align*} \mathbb E \left[ M_{t+1} \, | \, \mathscr F_t \right] & \leqslant B^{-N_{t-1}} B^{-1} \delta^{-(t+1)} \big[ \mathbb E \big[ W\big(X_{t+1}, X_{t+1}'\big) \unicode{x1D7D9}\big\{X_{t+1} \npreceq X_{t+1}'\big\} \, | \, \mathscr F_t \big] \big] \\ & = B^{-N_{t-1}} B^{-1} \delta^{-(t+1)} \big[ \hat R W\big(X_t, X_t'\big) \big] \\ & \leqslant B^{-N_{t-1}} \delta^{-t} \big[W\big(X_t, X_t'\big)\big] \\ & = M_t, \end{align*}
where the second inequality is by (13), as well as the restriction
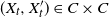 $(X_t, X_t') \in C \times C$
. The last equality holds because we are specializing to
$(X_t, X_t') \in C \times C$
. The last equality holds because we are specializing to
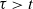 $\tau > t$
.
$\tau > t$
.
Now we turn to the case
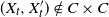 $(X_t, X_t') \notin C \times C$
. In this case we have
$(X_t, X_t') \notin C \times C$
. In this case we have
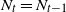 $N_t = N_{t-1}$
, so
$N_t = N_{t-1}$
, so
 \begin{align*} \mathbb E[ M_{t+1} \, | \, \mathscr F_t] & = B^{-N_{t-1}} \mathbb E \big[ \delta^{-(t+1)} \big[W\big(X_{t+1}, X_{t+1}'\big)\big] \unicode{x1D7D9}\{\tau \gt t+1\} \, | \, \mathscr F_t \big] \\ & \leqslant B^{-N_{t-1}} \mathbb E \big[ \delta^{-(t+1)} \big[W\big(X_{t+1}, X_{t+1}'\big)\big] \, | \, \mathscr F_t \big] \\ & \leqslant B^{-N_{t-1}} \delta^{-(t+1)} \big[ \mathbb E \big[ W\big(X_{t+1}, X_{t+1}'\big) \, | \, \mathscr F_t \big] \big] \\ & \leqslant B^{-N_{t-1}} \delta^{-(t+1)} \big[ \delta \big[W\big(X_t, X_t'\big)\big] \big] \\ & = B^{-N_{t-1}} \delta^{-t} \big[W\big(X_t, X_t'\big)\big] \\ & = M_t, \end{align*}
\begin{align*} \mathbb E[ M_{t+1} \, | \, \mathscr F_t] & = B^{-N_{t-1}} \mathbb E \big[ \delta^{-(t+1)} \big[W\big(X_{t+1}, X_{t+1}'\big)\big] \unicode{x1D7D9}\{\tau \gt t+1\} \, | \, \mathscr F_t \big] \\ & \leqslant B^{-N_{t-1}} \mathbb E \big[ \delta^{-(t+1)} \big[W\big(X_{t+1}, X_{t+1}'\big)\big] \, | \, \mathscr F_t \big] \\ & \leqslant B^{-N_{t-1}} \delta^{-(t+1)} \big[ \mathbb E \big[ W\big(X_{t+1}, X_{t+1}'\big) \, | \, \mathscr F_t \big] \big] \\ & \leqslant B^{-N_{t-1}} \delta^{-(t+1)} \big[ \delta \big[W\big(X_t, X_t'\big)\big] \big] \\ & = B^{-N_{t-1}} \delta^{-t} \big[W\big(X_t, X_t'\big)\big] \\ & = M_t, \end{align*}
where the second inequality uses Jensen’s inequality again and the third inequality uses the drift condition (6). As before, the last equality holds because we are specializing to
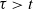 $\tau > t$
. We have now shown that
$\tau > t$
. We have now shown that
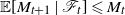 $\mathbb E [ M_{t+1} \, | \, \mathscr F_t] \leqslant M_t$
holds almost surely, so
$\mathbb E [ M_{t+1} \, | \, \mathscr F_t] \leqslant M_t$
holds almost surely, so
 $(M_t)$
is a supermartingale, as claimed.
$(M_t)$
is a supermartingale, as claimed.
Lemma 4. If
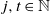 $j, t \in \mathbb N$
with
$j, t \in \mathbb N$
with
 $j \leqslant t$
then
$j \leqslant t$
then
 \begin{equation*} \mathbb P\{\tau \gt t, N_{t-1} \lt j \} \leqslant \frac{B^{j-1}}{\delta^{-t}(1)} \int W \mathop{}\!\mathrm{d} \pi. \end{equation*}
\begin{equation*} \mathbb P\{\tau \gt t, N_{t-1} \lt j \} \leqslant \frac{B^{j-1}}{\delta^{-t}(1)} \int W \mathop{}\!\mathrm{d} \pi. \end{equation*}
Proof. Fix
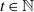 $t \in \mathbb N$
and
$t \in \mathbb N$
and
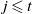 $j \leqslant t$
. Since
$j \leqslant t$
. Since
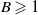 $B \geqslant 1$
, we have
$B \geqslant 1$
, we have
 \begin{equation*} \mathbb P\{\tau \gt t, \; N_{t-1} \lt j \} = \mathbb P\{\tau \gt t, \; N_{t-1} \leqslant j-1 \} = \mathbb P \big\{\tau \gt t, \; B^{-N_{t-1}} \geqslant B^{-(j-1)} \big\} \! . \end{equation*}
\begin{equation*} \mathbb P\{\tau \gt t, \; N_{t-1} \lt j \} = \mathbb P\{\tau \gt t, \; N_{t-1} \leqslant j-1 \} = \mathbb P \big\{\tau \gt t, \; B^{-N_{t-1}} \geqslant B^{-(j-1)} \big\} \! . \end{equation*}
On
 $\tau > t$
we have
$\tau > t$
we have
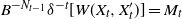 $B^{-N_{t-1}} \delta^{-t}[W(X_t, X_t')] = M_t$
, so the final term in the previous expression is dominated by
$B^{-N_{t-1}} \delta^{-t}[W(X_t, X_t')] = M_t$
, so the final term in the previous expression is dominated by
 \begin{align*} \mathbb P \big\{ \tau \gt t, \; M_t \geqslant B^{-(j-1)} \delta^{-t}\big[W\big(X_t, X_t'\big)\big] \big\} & \leqslant \mathbb P \big\{ \tau \gt t, \; M_t \geqslant B^{-(j-1)} \delta^{-t}(1) \big\} \\ & \leqslant \mathbb P \big\{ M_t \geqslant B^{-(j-1)} \delta^{-t}(1) \big\} \\ & \leqslant \frac{B^{j-1}}{\delta^{-t}(1)} \mathbb E [ M_t ] \end{align*}
\begin{align*} \mathbb P \big\{ \tau \gt t, \; M_t \geqslant B^{-(j-1)} \delta^{-t}\big[W\big(X_t, X_t'\big)\big] \big\} & \leqslant \mathbb P \big\{ \tau \gt t, \; M_t \geqslant B^{-(j-1)} \delta^{-t}(1) \big\} \\ & \leqslant \mathbb P \big\{ M_t \geqslant B^{-(j-1)} \delta^{-t}(1) \big\} \\ & \leqslant \frac{B^{j-1}}{\delta^{-t}(1)} \mathbb E [ M_t ] \end{align*}
Here the first inequality is by
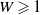 $W \geqslant 1$
and the last is by Markov’s inequality. Collecting terms and using the supermartingale property, we obtain
$W \geqslant 1$
and the last is by Markov’s inequality. Collecting terms and using the supermartingale property, we obtain
 \begin{equation*} \mathbb P\{\tau \lt t, \; N_{t-1} \lt j \} \leqslant \frac{B^{j-1}}{\delta^{-t}(1)} \mathbb E [ M_0 ] . \end{equation*}
\begin{equation*} \mathbb P\{\tau \lt t, \; N_{t-1} \lt j \} \leqslant \frac{B^{j-1}}{\delta^{-t}(1)} \mathbb E [ M_0 ] . \end{equation*}
Since
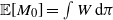 $\mathbb E [M_0] = \int W \mathop{}\!\mathrm{d} \pi$
, the claim in Lemma 4 is proved.
$\mathbb E [M_0] = \int W \mathop{}\!\mathrm{d} \pi$
, the claim in Lemma 4 is proved.
Lemma 5. If
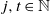 $j, t \in \mathbb N$
with
$j, t \in \mathbb N$
with
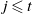 $j \leqslant t$
then
$j \leqslant t$
then
 \begin{equation} \mathbb P\{ \tau > t,\, N_{t-1} \geqslant j \} \leqslant (1 - \varepsilon)^j. \end{equation}
\begin{equation} \mathbb P\{ \tau > t,\, N_{t-1} \geqslant j \} \leqslant (1 - \varepsilon)^j. \end{equation}
Proof. Fix
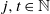 $j, t \in \mathbb N$
with
$j, t \in \mathbb N$
with
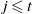 $j \leqslant t$
. Let
$j \leqslant t$
. Let
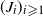 $(J_i)_{i \geqslant 1}$
be the times of the successive visits of
$(J_i)_{i \geqslant 1}$
be the times of the successive visits of
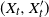 $(X_t,X_t')$
to
$(X_t,X_t')$
to
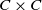 $C \times C$
. That is,
$C \times C$
. That is,
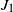 $J_1$
is the time of the first visit and
$J_1$
is the time of the first visit and
 \begin{equation*} J_{i+1} = \inf \big\{ m \geqslant J_i + 1 \, : \, \big(X_m,X_m'\big) \in C \times C \big\} . \end{equation*}
\begin{equation*} J_{i+1} = \inf \big\{ m \geqslant J_i + 1 \, : \, \big(X_m,X_m'\big) \in C \times C \big\} . \end{equation*}
Note that
 $N_{t-1} > j$
implies
$N_{t-1} > j$
implies
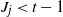 $J_j < t - 1$
. As a result,
$J_j < t - 1$
. As a result,
 \begin{equation} \mathbb P \{ \tau \gt t, \, N_{t-1} \gt j \} \leqslant \mathbb P \{ \tau \gt t, \, J_j + 1 \lt t\}. \end{equation}
\begin{equation} \mathbb P \{ \tau \gt t, \, N_{t-1} \gt j \} \leqslant \mathbb P \{ \tau \gt t, \, J_j + 1 \lt t\}. \end{equation}
Fix
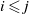 $i \leqslant j$
and consider all paths in the set
$i \leqslant j$
and consider all paths in the set
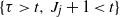 $\{ \tau > t, \, J_j + 1 < t\}$
. Since
$\{ \tau > t, \, J_j + 1 < t\}$
. Since
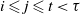 $i \leqslant j \leqslant t < \tau$
, we have
$i \leqslant j \leqslant t < \tau$
, we have
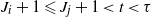 $J_i + 1 \leqslant J_j + 1 < t < \tau$
and hence
$J_i + 1 \leqslant J_j + 1 < t < \tau$
and hence
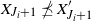 $X_{J_i + 1} \npreceq X_{J_i + 1}'$
. Therefore,
$X_{J_i + 1} \npreceq X_{J_i + 1}'$
. Therefore,
 \begin{equation} \mathbb P \{ \tau \gt t, \, J_j + 1 \lt t\} \leqslant \mathbb P \cap_{i=1}^j \big\{X_{J_i + 1} \npreceq X_{J_i + 1}' \big\}. \end{equation}
\begin{equation} \mathbb P \{ \tau \gt t, \, J_j + 1 \lt t\} \leqslant \mathbb P \cap_{i=1}^j \big\{X_{J_i + 1} \npreceq X_{J_i + 1}' \big\}. \end{equation}
Observe that, with
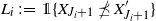 $L_i \,:\!=\, \unicode{x1D7D9}\{X_{J_i + 1} \npreceq X_{J_i + 1}' \}$
, we have
$L_i \,:\!=\, \unicode{x1D7D9}\{X_{J_i + 1} \npreceq X_{J_i + 1}' \}$
, we have
 \begin{equation*} \mathbb P \cap_{i=1}^j \big\{X_{J_i + 1} \npreceq X_{J_i + 1}' \big\} = \mathbb E \prod_{i=1}^{j} L_i = \mathbb E \left[ \, \prod_{i=1}^{j-1} L_i \cdot \mathbb E \left[ L_j \, | \, \mathscr F_{J_j} \right] \right] \! . \end{equation*}
\begin{equation*} \mathbb P \cap_{i=1}^j \big\{X_{J_i + 1} \npreceq X_{J_i + 1}' \big\} = \mathbb E \prod_{i=1}^{j} L_i = \mathbb E \left[ \, \prod_{i=1}^{j-1} L_i \cdot \mathbb E \left[ L_j \, | \, \mathscr F_{J_j} \right] \right] \! . \end{equation*}
By the definition of
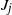 $J_j$
we have
$J_j$
we have
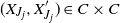 $(X_{J_j}, X'_{J_j}) \in C \times C$
. Using this fact, the strong Markov property, and the definition of
$(X_{J_j}, X'_{J_j}) \in C \times C$
. Using this fact, the strong Markov property, and the definition of
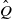 $\hat Q$
(see (5)), we find that
$\hat Q$
(see (5)), we find that
 \begin{equation*} \mathbb P \big[ X_{J_j + 1} \preceq X_{J_j + 1}' \, | \, \mathscr F_{J_j} \big] = \hat Q\big(\big(X_{J_j}, X_{J_j}'\big), \mathbb G\big) = \alpha\big(Q\big(X_{J_j}, \cdot\big), Q\big(X_{J_j}', \cdot\big)\big). \end{equation*}
\begin{equation*} \mathbb P \big[ X_{J_j + 1} \preceq X_{J_j + 1}' \, | \, \mathscr F_{J_j} \big] = \hat Q\big(\big(X_{J_j}, X_{J_j}'\big), \mathbb G\big) = \alpha\big(Q\big(X_{J_j}, \cdot\big), Q\big(X_{J_j}', \cdot\big)\big). \end{equation*}
Applying the definition of
 $\varepsilon$
in (9), we obtain
$\varepsilon$
in (9), we obtain
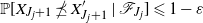 $\mathbb P [ X_{J_j + 1} \npreceq X_{J_j + 1}' \, | \, \mathscr F_{J_j} ] \leqslant 1 - \varepsilon$
, so
$\mathbb P [ X_{J_j + 1} \npreceq X_{J_j + 1}' \, | \, \mathscr F_{J_j} ] \leqslant 1 - \varepsilon$
, so
 \begin{equation*} \mathbb P \cap_{i=1}^j \big\{X_{J_i + 1} \npreceq X_{J_i + 1}' \big\} \leqslant (1 - \varepsilon) \, \mathbb P \cap_{i=1}^{j-1} \big\{X_{J_i + 1} \npreceq X_{J_i + 1}' \big\}. \end{equation*}
\begin{equation*} \mathbb P \cap_{i=1}^j \big\{X_{J_i + 1} \npreceq X_{J_i + 1}' \big\} \leqslant (1 - \varepsilon) \, \mathbb P \cap_{i=1}^{j-1} \big\{X_{J_i + 1} \npreceq X_{J_i + 1}' \big\}. \end{equation*}
Iteration backwards in this way yields
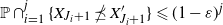 $\mathbb P \cap_{i=1}^j \{X_{J_i + 1} \npreceq X_{J_i + 1}' \} \leqslant (1 - \varepsilon)^j$
. Combining this inequality with (15) and (16), we verify (14).
$\mathbb P \cap_{i=1}^j \{X_{J_i + 1} \npreceq X_{J_i + 1}' \} \leqslant (1 - \varepsilon)^j$
. Combining this inequality with (15) and (16), we verify (14).
We now complete the proof of Theorem 1. The proof uses an order-theoretic version of a standard total variation coupling argument [Reference Lindvall18, Reference Rosenthal24].
Proof of Theorem 1.We continue to take
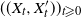 $((X_t, X_t'))_{t \geqslant 0}$
, the stopping time
$((X_t, X_t'))_{t \geqslant 0}$
, the stopping time
 $\tau$
, and the process
$\tau$
, and the process
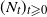 $(N_t)_{t \geqslant 0}$
as defined at the start of Section 4. In addition, we specialize to the case where the initial distribution
$(N_t)_{t \geqslant 0}$
as defined at the start of Section 4. In addition, we specialize to the case where the initial distribution
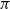 $\pi$
has the form
$\pi$
has the form
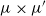 $\mu \times \mu'$
for fixed
$\mu \times \mu'$
for fixed
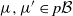 $\mu, \mu' \in p\mathcal B$
. Fix h in
$\mu, \mu' \in p\mathcal B$
. Fix h in
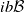 $ib\mathcal B$
with
$ib\mathcal B$
with
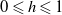 $0 \leqslant h \leqslant 1$
. Since
$0 \leqslant h \leqslant 1$
. Since
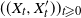 $((X_t, X'_t))_{t \geqslant 0}$
is Markov-
$((X_t, X'_t))_{t \geqslant 0}$
is Markov-
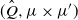 $(\hat Q, \mu \times \mu')$
and
$(\hat Q, \mu \times \mu')$
and
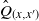 $\hat Q_{(x,x^{\prime})}$
is a coupling of
$\hat Q_{(x,x^{\prime})}$
is a coupling of
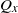 $Q_x$
and
$Q_x$
and
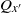 $Q_{x^{\prime}}$
, the random element
$Q_{x^{\prime}}$
, the random element
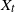 $X_t$
has distribution
$X_t$
has distribution
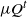 $\mu Q^t$
and
$\mu Q^t$
and
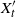 $X_t'$
has distribution
$X_t'$
has distribution
 $\mu' Q^t$
. As a result,
$\mu' Q^t$
. As a result,
 \begin{multline*} (\mu Q^t)(h) - (\mu' Q^t)(h) = \mathbb E h(X_t) - \mathbb E h(X'_t) \\ = \mathbb E \big[ \big(h(X_t) - h(X'_t)\big) \unicode{x1D7D9}\big\{X_t \preceq X'_t\big\} \big] + \mathbb E \big[ \big(h(X_t) - h\big(X'_t\big)\big) \unicode{x1D7D9}\big\{X_t \npreceq X'_t\big\} \big]. \end{multline*}
\begin{multline*} (\mu Q^t)(h) - (\mu' Q^t)(h) = \mathbb E h(X_t) - \mathbb E h(X'_t) \\ = \mathbb E \big[ \big(h(X_t) - h(X'_t)\big) \unicode{x1D7D9}\big\{X_t \preceq X'_t\big\} \big] + \mathbb E \big[ \big(h(X_t) - h\big(X'_t\big)\big) \unicode{x1D7D9}\big\{X_t \npreceq X'_t\big\} \big]. \end{multline*}
Since h is increasing and
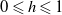 $0 \leqslant h \leqslant 1$
, the previous expression leads to
$0 \leqslant h \leqslant 1$
, the previous expression leads to
 \begin{equation*} (\mu Q^t)(h) - (\mu' Q^t)(h) \leqslant \mathbb E \big[ \big(h(X_t) - h\big(X'_t\big)\big) \unicode{x1D7D9}\big\{X_t \npreceq X'_t\big\} \big] \leqslant \mathbb P \big\{X'_t \npreceq X_t\big\}. \end{equation*}
\begin{equation*} (\mu Q^t)(h) - (\mu' Q^t)(h) \leqslant \mathbb E \big[ \big(h(X_t) - h\big(X'_t\big)\big) \unicode{x1D7D9}\big\{X_t \npreceq X'_t\big\} \big] \leqslant \mathbb P \big\{X'_t \npreceq X_t\big\}. \end{equation*}
Application of (11) produces
 \begin{equation} (\mu Q^t)(h) - (\mu' Q^t)(h) \leqslant \mathbb P \{\tau > t\} \quad \text{for all } t \geqslant 0. \end{equation}
\begin{equation} (\mu Q^t)(h) - (\mu' Q^t)(h) \leqslant \mathbb P \{\tau > t\} \quad \text{for all } t \geqslant 0. \end{equation}
Fixing
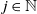 $j \in \mathbb N$
with
$j \in \mathbb N$
with
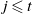 $j \leqslant t$
, we decompose the right-hand side of (17) to get
$j \leqslant t$
, we decompose the right-hand side of (17) to get
 \begin{equation*} \mathbb P\{ \tau \gt t \} = \mathbb P\{ \tau \gt t, N_{t-1} \lt j \} + \mathbb P\{ \tau \gt t, N_{t-1} \geqslant j \}. \end{equation*}
\begin{equation*} \mathbb P\{ \tau \gt t \} = \mathbb P\{ \tau \gt t, N_{t-1} \lt j \} + \mathbb P\{ \tau \gt t, N_{t-1} \geqslant j \}. \end{equation*}
Use of Lemmas 4 and 5 allows us to obtain
 \begin{equation} \mathbb P\{ \tau > t \} \leqslant (1-\varepsilon)^j + \frac{B^{j-1}}{\delta^{-t}(1)} (\mu \times \mu')(W). \end{equation}
\begin{equation} \mathbb P\{ \tau > t \} \leqslant (1-\varepsilon)^j + \frac{B^{j-1}}{\delta^{-t}(1)} (\mu \times \mu')(W). \end{equation}
Combining (17) and (18), we obtain
 \begin{equation} \sup\nolimits_{I \in i\mathcal B} \left\{ (\mu Q^t)(I) - (\mu' Q^t)(I) \right\} \leqslant (1 - \varepsilon)^j + \frac{B^{j-1}}{\delta^{-t}(1)} (\mu \times \mu')(W). \end{equation}
\begin{equation} \sup\nolimits_{I \in i\mathcal B} \left\{ (\mu Q^t)(I) - (\mu' Q^t)(I) \right\} \leqslant (1 - \varepsilon)^j + \frac{B^{j-1}}{\delta^{-t}(1)} (\mu \times \mu')(W). \end{equation}
Reversing the roles of
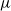 $\mu$
and
$\mu$
and
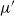 $\mu'$
, we obtain
$\mu'$
, we obtain
 \begin{equation} \sup\nolimits_{I \in i\mathcal B} \left\{ (\mu' Q^t)(I) - (\mu Q^t)(I) \right\} \leqslant (1 - \varepsilon)^j + \frac{B^{j-1}}{\delta^{-t}(1)} (\mu' \times \mu)(W). \end{equation}
\begin{equation} \sup\nolimits_{I \in i\mathcal B} \left\{ (\mu' Q^t)(I) - (\mu Q^t)(I) \right\} \leqslant (1 - \varepsilon)^j + \frac{B^{j-1}}{\delta^{-t}(1)} (\mu' \times \mu)(W). \end{equation}
Adding the last two inequalities and using the definition of
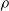 $\rho$
in (2), we generate the bound in Theorem 1.
$\rho$
in (2), we generate the bound in Theorem 1.
5. Related Convergence Results
In this section we discuss connections between Theorem 1 and convergence results in other metrics.
5.1. Connection to total variation results
One interesting special case of Theorem 1 is obtained by setting
 $\preceq$
to the identity order, so that
$\preceq$
to the identity order, so that
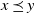 $x \preceq y$
if and only if
$x \preceq y$
if and only if
 $x = y$
. For this order we have
$x = y$
. For this order we have
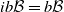 $ib\mathcal B = b\mathcal B$
, so every transition kernel is increasing, and, moreover, the total ordered variation distance becomes the total variation distance. In this setting, Theorem 1 becomes a version of well-known geometric bounds for total variation distance, such as Theorem 1 in [Reference Rosenthal24].
$ib\mathcal B = b\mathcal B$
, so every transition kernel is increasing, and, moreover, the total ordered variation distance becomes the total variation distance. In this setting, Theorem 1 becomes a version of well-known geometric bounds for total variation distance, such as Theorem 1 in [Reference Rosenthal24].
In the total variation setting,
 $\varepsilon$
in (9) is at least as large as the analogous term
$\varepsilon$
in (9) is at least as large as the analogous term
 $\varepsilon$
in Theorem 1 in [Reference Rosenthal24]. Indeed, in [Reference Rosenthal24], the value
$\varepsilon$
in Theorem 1 in [Reference Rosenthal24]. Indeed, in [Reference Rosenthal24], the value
 $\varepsilon$
, which we now write as
$\varepsilon$
, which we now write as
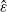 $\hat \varepsilon$
to avoid confusion, comes from an assumed minorization condition: there exists a
$\hat \varepsilon$
to avoid confusion, comes from an assumed minorization condition: there exists a
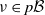 $\nu \in p\mathcal B$
such that
$\nu \in p\mathcal B$
such that
 \begin{equation} \hat \varepsilon \nu(B) \leqslant Q(x, B) \quad \text{for all } B \in \mathcal B \text{ and } x \in C.\end{equation}
\begin{equation} \hat \varepsilon \nu(B) \leqslant Q(x, B) \quad \text{for all } B \in \mathcal B \text{ and } x \in C.\end{equation}
To compare
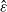 $\hat \varepsilon$
with
$\hat \varepsilon$
with
 $\varepsilon$
defined in (9), suppose that this minorization condition holds and set
$\varepsilon$
defined in (9), suppose that this minorization condition holds and set
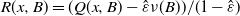 $R(x, B) = (Q(x, B) - \hat \varepsilon \nu(B))/(1-\hat \varepsilon)$
. Fixing
$R(x, B) = (Q(x, B) - \hat \varepsilon \nu(B))/(1-\hat \varepsilon)$
. Fixing
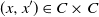 $(x, x^{\prime}) \in C \times C$
, we draw
$(x, x^{\prime}) \in C \times C$
, we draw
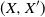 $(X, X^{\prime})$
as follows: With probability
$(X, X^{\prime})$
as follows: With probability
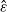 $\hat \varepsilon$
, we draw
$\hat \varepsilon$
, we draw
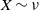 $X \sim \nu$
and set
$X \sim \nu$
and set
 $X' = X$
. With probability
$X' = X$
. With probability
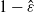 $1-\hat \varepsilon$
, we independently draw
$1-\hat \varepsilon$
, we independently draw
 $X \sim R(x, \cdot)$
and
$X \sim R(x, \cdot)$
and
 $X' \sim R(x^{\prime}, \cdot)$
. Simple arguments confirm that X is a draw from
$X' \sim R(x^{\prime}, \cdot)$
. Simple arguments confirm that X is a draw from
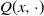 $Q(x, \cdot)$
and
$Q(x, \cdot)$
and
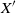 $ X^{\prime}$
is a draw from
$ X^{\prime}$
is a draw from
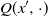 $Q(x^{\prime}, \cdot)$
. Recalling that
$Q(x^{\prime}, \cdot)$
. Recalling that
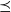 $\preceq$
is the identity order, we obtain
$\preceq$
is the identity order, we obtain
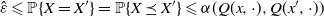 $\hat \varepsilon \leqslant \mathbb P\{X = X'\} = \mathbb P\{X \preceq X'\} \leqslant \alpha(Q(x, \cdot), Q(x^{\prime}, \cdot))$
. Since, in this discussion, the point (x,x’) was arbitrarily chosen from
$\hat \varepsilon \leqslant \mathbb P\{X = X'\} = \mathbb P\{X \preceq X'\} \leqslant \alpha(Q(x, \cdot), Q(x^{\prime}, \cdot))$
. Since, in this discussion, the point (x,x’) was arbitrarily chosen from
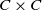 $C\times C$
, we conclude that
$C\times C$
, we conclude that
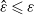 $\hat \varepsilon \leqslant \varepsilon$
, where
$\hat \varepsilon \leqslant \varepsilon$
, where
 $\varepsilon$
is as defined in (9).
$\varepsilon$
is as defined in (9).
5.2. Connection to Wasserstein bounds
Theorem 1 is also connected to research on convergence rates for distributions in Wasserstein distance. To see this, recall that if d is a metric on
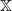 $\mathbb X$
then the induced Wasserstein distance between probability measures
$\mathbb X$
then the induced Wasserstein distance between probability measures
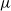 $\mu$
and
$\mu$
and
 $\nu$
is expressed as
$\nu$
is expressed as
 \begin{equation} W_d(\mu, \nu) \,:\!=\, \inf_{\pi \in \mathscr {C} \, (\mu, \nu)} \int d(x, x^{\prime}) \pi(\mathop{}\!\mathrm{d} x, \mathop{}\!\mathrm{d} x^{\prime}).\end{equation}
\begin{equation} W_d(\mu, \nu) \,:\!=\, \inf_{\pi \in \mathscr {C} \, (\mu, \nu)} \int d(x, x^{\prime}) \pi(\mathop{}\!\mathrm{d} x, \mathop{}\!\mathrm{d} x^{\prime}).\end{equation}
To connect this distance to the total ordered variation metric, we use Theorem 3.1 in [Reference Kamihigashi and Stachurski16] to write
 \begin{equation*} \sup\nolimits_{I \in i\mathcal B} (\mu(I) - \nu(I)) = \inf_{\pi \in {\mathscr{C}} \, (\mu, \nu)} \int \unicode{x1D7D9}\{ x \npreceq x^{\prime} \} \pi(\mathop{}\!\mathrm{d} x, \mathop{}\!\mathrm{d} x^{\prime}).\end{equation*}
\begin{equation*} \sup\nolimits_{I \in i\mathcal B} (\mu(I) - \nu(I)) = \inf_{\pi \in {\mathscr{C}} \, (\mu, \nu)} \int \unicode{x1D7D9}\{ x \npreceq x^{\prime} \} \pi(\mathop{}\!\mathrm{d} x, \mathop{}\!\mathrm{d} x^{\prime}).\end{equation*}
Thus, if
 \begin{equation} s(x, x^{\prime}) = \unicode{x1D7D9}\big\{x \npreceq x^{\prime}\big\} \quad \text{and} \quad W_s(\lambda, \kappa) = \inf_{\pi \in {\mathscr {C}} \, (\lambda, \kappa)} \int s(x, x^{\prime}) \pi(\mathop{}\!\mathrm{d} x, \mathop{}\!\mathrm{d} x^{\prime}),\end{equation}
\begin{equation} s(x, x^{\prime}) = \unicode{x1D7D9}\big\{x \npreceq x^{\prime}\big\} \quad \text{and} \quad W_s(\lambda, \kappa) = \inf_{\pi \in {\mathscr {C}} \, (\lambda, \kappa)} \int s(x, x^{\prime}) \pi(\mathop{}\!\mathrm{d} x, \mathop{}\!\mathrm{d} x^{\prime}),\end{equation}
then, by the definition of
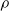 $\rho$
in (2), we have
$\rho$
in (2), we have
 \begin{equation} \rho(\mu, \nu) = W_s(\mu, \nu) + W_s(\nu, \mu).\end{equation}
\begin{equation} \rho(\mu, \nu) = W_s(\mu, \nu) + W_s(\nu, \mu).\end{equation}
We can understand s as a ‘directed semimetric’ that fails symmetry and positive definiteness but obeys
 $s(x,x)=0$
and the triangle inequality. The ‘directed Wasserstein semimetric’
$s(x,x)=0$
and the triangle inequality. The ‘directed Wasserstein semimetric’
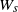 $W_s$
inherits these properties. The sum of this directed Wasserstein semimetric and its reversed deviation creates a metric, as in (24). The inequalities (19) and (20), which we combined to prove Theorem 1, are just bounds on
$W_s$
inherits these properties. The sum of this directed Wasserstein semimetric and its reversed deviation creates a metric, as in (24). The inequalities (19) and (20), which we combined to prove Theorem 1, are just bounds on
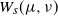 $W_s(\mu, \nu)$
and
$W_s(\mu, \nu)$
and
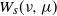 $W_s(\nu, \mu)$
. For example, (19) tells us that
$W_s(\nu, \mu)$
. For example, (19) tells us that
 \begin{equation*} W_s(\mu Q^t, \mu' Q^t) \leqslant (1 - \varepsilon)^j + \frac{B^{j-1}}{\delta^{-t}(1)} (\mu \times \mu')(W).\end{equation*}
\begin{equation*} W_s(\mu Q^t, \mu' Q^t) \leqslant (1 - \varepsilon)^j + \frac{B^{j-1}}{\delta^{-t}(1)} (\mu \times \mu')(W).\end{equation*}
The discussion above helps us understand the relationship between the order-theoretic mixing condition used in this article and the Wasserstein distance mixing condition in [Reference Butkovsky4]. In the latter, the notion of d-small sets is introduced in order to study Wasserstein distance convergence rates for distributions: for transition kernel Q, a Borel set C is called d-small if there exists an
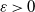 $\varepsilon > 0$
such that
$\varepsilon > 0$
such that
 $W_d(Q_x, Q_{x^{\prime}}) \leqslant (1-\varepsilon) d(x, x^{\prime})$
for all
$W_d(Q_x, Q_{x^{\prime}}) \leqslant (1-\varepsilon) d(x, x^{\prime})$
for all
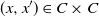 $(x, x^{\prime}) \in C \times C$
. Here d is an arbitrary ground metric on
$(x, x^{\prime}) \in C \times C$
. Here d is an arbitrary ground metric on
 $\mathbb X$
and
$\mathbb X$
and
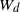 $W_d$
is defined as in (22). By analogy, we replace d with s from (23) and call C s-small if there exists an
$W_d$
is defined as in (22). By analogy, we replace d with s from (23) and call C s-small if there exists an
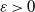 $\varepsilon > 0$
such that
$\varepsilon > 0$
such that
 \begin{equation*} W_s(Q_x, Q_{x^{\prime}}) \leqslant (1-\varepsilon) s(x, x^{\prime}) \quad \text{for all } (x, x^{\prime}) \in C \times C.\end{equation*}
\begin{equation*} W_s(Q_x, Q_{x^{\prime}}) \leqslant (1-\varepsilon) s(x, x^{\prime}) \quad \text{for all } (x, x^{\prime}) \in C \times C.\end{equation*}
Fixing
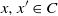 $x, x^{\prime} \in C$
and using the definition of s, we can equivalently write this as
$x, x^{\prime} \in C$
and using the definition of s, we can equivalently write this as
 \begin{equation} \inf_{\pi} \pi(\mathbb G^c) \leqslant (1-\varepsilon) \unicode{x1D7D9}\{x \npreceq x^{\prime}\},\end{equation}
\begin{equation} \inf_{\pi} \pi(\mathbb G^c) \leqslant (1-\varepsilon) \unicode{x1D7D9}\{x \npreceq x^{\prime}\},\end{equation}
where
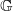 $\mathbb G$
is as defined in (1) and the infimum is over all
$\mathbb G$
is as defined in (1) and the infimum is over all
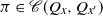 $\pi \in \mathscr {C} \, (Q_x, Q_{x^{\prime}})$
. Rearranging and using the definition of
$\pi \in \mathscr {C} \, (Q_x, Q_{x^{\prime}})$
. Rearranging and using the definition of
 $\alpha$
in (3), we can also write (25) as
$\alpha$
in (3), we can also write (25) as
 \begin{equation} \alpha(Q_x, Q_{x^{\prime}}) \geqslant \unicode{x1D7D9}\{x \preceq x^{\prime}\} + \varepsilon \unicode{x1D7D9}\big\{x \npreceq x^{\prime}\big\} \quad \text{for all } (x, x^{\prime}) \in C \times C.\end{equation}
\begin{equation} \alpha(Q_x, Q_{x^{\prime}}) \geqslant \unicode{x1D7D9}\{x \preceq x^{\prime}\} + \varepsilon \unicode{x1D7D9}\big\{x \npreceq x^{\prime}\big\} \quad \text{for all } (x, x^{\prime}) \in C \times C.\end{equation}
When Q is increasing, as required in Theorem 1, we can use (4) to obtain
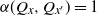 $\alpha(Q_x, Q_{x^{\prime}}) = 1$
whenever
$\alpha(Q_x, Q_{x^{\prime}}) = 1$
whenever
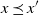 $x \preceq x^{\prime}$
. In this case, (26) is equivalent to
$x \preceq x^{\prime}$
. In this case, (26) is equivalent to
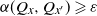 $\alpha(Q_x, Q_{x^{\prime}})\geqslant \varepsilon$
whenever
$\alpha(Q_x, Q_{x^{\prime}})\geqslant \varepsilon$
whenever
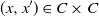 $(x, x^{\prime}) \in C \times C$
. Thus, the requirement that C is s-small is equivalent to the condition that we can extract a positive
$(x, x^{\prime}) \in C \times C$
. Thus, the requirement that C is s-small is equivalent to the condition that we can extract a positive
 $\varepsilon$
in (9).
$\varepsilon$
in (9).
6. Examples and Applications
In this section we discuss several examples, focusing in particular on how to obtain an estimate of the value
 $\varepsilon$
in (9).
$\varepsilon$
in (9).
6.1. Stochastic recursive sequences
The preceding section showed that Theorem 1 reduces to existing results for bounds on total variation distance when the partial order
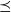 $\preceq$
is the identity order. Next we illustrate how Theorem 1 can lead to new results in other settings. To this end, consider the process
$\preceq$
is the identity order. Next we illustrate how Theorem 1 can lead to new results in other settings. To this end, consider the process
 \begin{equation} X_{t+1} = F(X_t, \xi_{t+1})\end{equation}
\begin{equation} X_{t+1} = F(X_t, \xi_{t+1})\end{equation}
where
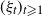 $(\xi_t)_{t \geqslant 1}$
is an independent and identically distributed (i.i.d.) shock process taking values in some space
$(\xi_t)_{t \geqslant 1}$
is an independent and identically distributed (i.i.d.) shock process taking values in some space
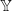 $\mathbb Y$
, and F is a measurable function from
$\mathbb Y$
, and F is a measurable function from
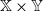 $\mathbb X \times \mathbb Y$
to
$\mathbb X \times \mathbb Y$
to
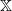 $\mathbb X$
. The common distribution of each
$\mathbb X$
. The common distribution of each
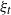 $\xi_t$
is denoted by
$\xi_t$
is denoted by
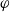 $\varphi$
. We suppose that F is increasing, in the sense that
$\varphi$
. We suppose that F is increasing, in the sense that
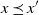 $x \preceq x^{\prime}$
implies
$x \preceq x^{\prime}$
implies
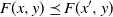 $F(x,y) \preceq F(x^{\prime},y)$
for any fixed
$F(x,y) \preceq F(x^{\prime},y)$
for any fixed
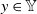 $y \in \mathbb Y$
. We let Q represent the transition kernel corresponding to (27), so that
$y \in \mathbb Y$
. We let Q represent the transition kernel corresponding to (27), so that
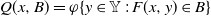 $Q(x,B) = \varphi \{ y \in \mathbb Y \, : \, F(x,y) \in B \} $
for all
$Q(x,B) = \varphi \{ y \in \mathbb Y \, : \, F(x,y) \in B \} $
for all
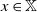 $x \in \mathbb X$
and
$x \in \mathbb X$
and
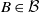 $B \in \mathcal B$
. Since F is increasing, the kernel Q is increasing. Hence, Theorem 1 applies. We can obtain a lower bound on
$B \in \mathcal B$
. Since F is increasing, the kernel Q is increasing. Hence, Theorem 1 applies. We can obtain a lower bound on
 $\varepsilon$
in (9) by calculating
$\varepsilon$
in (9) by calculating
 \begin{equation} e \,:\!=\, \inf \left\{ \int \int \unicode{x1D7D9}\{ F(x^{\prime}, y') \preceq F(x, y) \} \varphi(\mathop{}\!\mathrm{d} y) \varphi(\mathop{}\!\mathrm{d} y') \, : \, (x, x^{\prime}) \in C \times C \right\} \! . \end{equation}
\begin{equation} e \,:\!=\, \inf \left\{ \int \int \unicode{x1D7D9}\{ F(x^{\prime}, y') \preceq F(x, y) \} \varphi(\mathop{}\!\mathrm{d} y) \varphi(\mathop{}\!\mathrm{d} y') \, : \, (x, x^{\prime}) \in C \times C \right\} \! . \end{equation}
To see this, fix
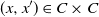 $(x,x^{\prime}) \in C \times C$
and let
$(x,x^{\prime}) \in C \times C$
and let
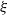 $\xi$
and
$\xi$
and
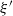 $\xi'$
be drawn independently from
$\xi'$
be drawn independently from
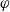 $\varphi$
. Since
$\varphi$
. Since
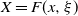 $X = F(x, \xi)$
is a draw from
$X = F(x, \xi)$
is a draw from
 $Q(x, \cdot)$
and
$Q(x, \cdot)$
and
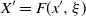 $X' = F(x^{\prime}, \xi)$
is a draw from
$X' = F(x^{\prime}, \xi)$
is a draw from
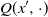 $Q(x^{\prime}, \cdot)$
, we have
$Q(x^{\prime}, \cdot)$
, we have
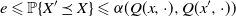 $e \leqslant \mathbb P\{X' \preceq X\} \leqslant \alpha(Q(x, \cdot), Q(x^{\prime}, \cdot))$
. As this inequality holds for all
$e \leqslant \mathbb P\{X' \preceq X\} \leqslant \alpha(Q(x, \cdot), Q(x^{\prime}, \cdot))$
. As this inequality holds for all
 $(x,x^{\prime}) \in C \times C$
, we obtain
$(x,x^{\prime}) \in C \times C$
, we obtain
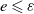 $e \leqslant \varepsilon$
.
$e \leqslant \varepsilon$
.
To illustrate how these calculations can be used, consider the TCP window size process (see, e.g., [Reference Bardet, Christen, Guillin, Malrieu and Zitt2]) with embedded jump chain
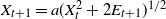 $X_{t+1} = a (X_t^2 + 2E_{t+1})^{1/2}$
. Here
$X_{t+1} = a (X_t^2 + 2E_{t+1})^{1/2}$
. Here
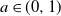 $a \in (0,1)$
and
$a \in (0,1)$
and
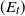 $(E_t)$
is i.i.d. exponential with unit rate. If
$(E_t)$
is i.i.d. exponential with unit rate. If
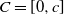 $C = [0, c]$
, then drawing E and E’ as independent standard exponentials and using (28), we obtain
$C = [0, c]$
, then drawing E and E’ as independent standard exponentials and using (28), we obtain
 \begin{equation*} e = \inf_{0 \leqslant x, y \leqslant c} \mathbb P \big\{ a (y^2 + 2E')^{1/2} \leqslant a (x^2 + 2E)^{1/2} \big\} = \mathbb P\{ c^2 + 2E' \leqslant 2E \} .\end{equation*}
\begin{equation*} e = \inf_{0 \leqslant x, y \leqslant c} \mathbb P \big\{ a (y^2 + 2E')^{1/2} \leqslant a (x^2 + 2E)^{1/2} \big\} = \mathbb P\{ c^2 + 2E' \leqslant 2E \} .\end{equation*}
Since
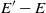 $E' - E$
has the Laplace-(0,1) distribution, we can use
$E' - E$
has the Laplace-(0,1) distribution, we can use
 $e \leqslant\varepsilon$
to get
$e \leqslant\varepsilon$
to get
 \begin{equation*} 1 - \varepsilon \leqslant 1 - e = \mathbb P\{ c^2 + 2E' > 2E \} = \mathbb P\{ E' - E > c^2/2 \} = \tfrac{1}{2} \exp(\! - c^2/2 ).\end{equation*}
\begin{equation*} 1 - \varepsilon \leqslant 1 - e = \mathbb P\{ c^2 + 2E' > 2E \} = \mathbb P\{ E' - E > c^2/2 \} = \tfrac{1}{2} \exp(\! - c^2/2 ).\end{equation*}
6.2. Example: when minorization fails
We provide an elementary scenario where Theorem 1 provides a usable bound, while the minorization based methods described in Section 5.1 do not. Let
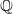 $\mathbb Q$
be the rational numbers, let
$\mathbb Q$
be the rational numbers, let
 $\mathbb X = \mathbb R$
, and assume that
$\mathbb X = \mathbb R$
, and assume that
 \begin{equation*} X_{t+1} = \frac{X_t}{2} + \xi_{t+1}, \quad \text{where $\xi_t$ is i.i.d. on $\{0,1\}$ and $\mathbb P\{\xi_t = 0\} = 1/2$}.\end{equation*}
\begin{equation*} X_{t+1} = \frac{X_t}{2} + \xi_{t+1}, \quad \text{where $\xi_t$ is i.i.d. on $\{0,1\}$ and $\mathbb P\{\xi_t = 0\} = 1/2$}.\end{equation*}
Let C contain at least one rational number and one irrational number. Let
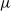 $\mu$
be a measure on the Borel sets of
$\mu$
be a measure on the Borel sets of
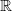 $\mathbb R$
obeying
$\mathbb R$
obeying
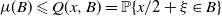 $\mu(B) \leqslant Q(x, B) = \mathbb P\{x/2 + \xi \in B\}$
for all
$\mu(B) \leqslant Q(x, B) = \mathbb P\{x/2 + \xi \in B\}$
for all
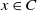 $x \in C$
and Borel sets B. If x is rational then
$x \in C$
and Borel sets B. If x is rational then
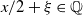 $x/2 + \xi \in \mathbb Q$
with probability 1, so
$x/2 + \xi \in \mathbb Q$
with probability 1, so
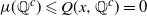 $\mu(\mathbb Q^c)\leqslant Q(x, \mathbb Q^c) = 0$
. Similarly, if x is irrational then
$\mu(\mathbb Q^c)\leqslant Q(x, \mathbb Q^c) = 0$
. Similarly, if x is irrational then
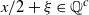 $x/2 + \xi \in \mathbb Q^c$
with probability 1, so
$x/2 + \xi \in \mathbb Q^c$
with probability 1, so
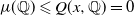 $\mu(\mathbb Q) \leqslant Q(x, \mathbb Q) = 0$
. Hence,
$\mu(\mathbb Q) \leqslant Q(x, \mathbb Q) = 0$
. Hence,
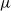 $\mu$
is the zero measure on
$\mu$
is the zero measure on
 $\mathbb R$
. Thus, we cannot take a
$\mathbb R$
. Thus, we cannot take a
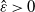 $\hat \varepsilon > 0$
and probability measure
$\hat \varepsilon > 0$
and probability measure
 $\nu$
obeying the minorization condition (21). On the other hand, if we let
$\nu$
obeying the minorization condition (21). On the other hand, if we let
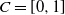 $C = [0, 1]$
, the value e from (28) obeys
$C = [0, 1]$
, the value e from (28) obeys
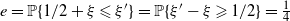 $e = \mathbb P\{1/2 + \xi \leqslant \xi'\} = \mathbb P\{\xi' - \xi \geqslant1/2 \} = \frac{1}{4}$
. Since
$e = \mathbb P\{1/2 + \xi \leqslant \xi'\} = \mathbb P\{\xi' - \xi \geqslant1/2 \} = \frac{1}{4}$
. Since
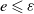 $e \leqslant \varepsilon$
(see the discussion after (28)), the constant
$e \leqslant \varepsilon$
(see the discussion after (28)), the constant
 $\varepsilon$
in (9) is positive.
$\varepsilon$
in (9) is positive.
6.3. Example: wealth dynamics
Many economic models examine wealth dynamics in the presence of credit market imperfections (see, e.g., [Reference Antunes and Cavalcanti1]). These often result in dynamics of the form
 \begin{equation} X_{t+1} = \eta_{t+1} \, G(X_t) + \xi_{t+1}, \quad (\eta_t) \stackrel {\textrm{i.i.d.}} {\sim} \varphi, \quad (\xi_t) \stackrel {\textrm{i.i.d.}} {\sim} \psi.\end{equation}
\begin{equation} X_{t+1} = \eta_{t+1} \, G(X_t) + \xi_{t+1}, \quad (\eta_t) \stackrel {\textrm{i.i.d.}} {\sim} \varphi, \quad (\xi_t) \stackrel {\textrm{i.i.d.}} {\sim} \psi.\end{equation}
Here
 $(X_t)$
is some measure of household wealth, G is a function from
$(X_t)$
is some measure of household wealth, G is a function from
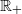 $\mathbb R_+$
to itself, and
$\mathbb R_+$
to itself, and
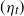 $(\eta_t)$
and
$(\eta_t)$
and
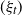 $(\xi_t)$
are independent
$(\xi_t)$
are independent
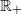 $\mathbb R_+$
-valued sequences. The function G is increasing, since greater current wealth relaxes borrowing constraints and increases financial income. We assume that there exists a
$\mathbb R_+$
-valued sequences. The function G is increasing, since greater current wealth relaxes borrowing constraints and increases financial income. We assume that there exists a
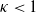 $\kappa < 1$
such that
$\kappa < 1$
such that
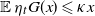 $\mathbb E \,\eta_t G(x) \leqslant \kappa x$
for all
$\mathbb E \,\eta_t G(x) \leqslant \kappa x$
for all
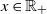 $x \in \mathbb R_+$
, and, in addition, that
$x \in \mathbb R_+$
, and, in addition, that
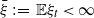 $\bar \xi \,:\!=\, \mathbb E \xi_t < \infty$
.
$\bar \xi \,:\!=\, \mathbb E \xi_t < \infty$
.
Let Q be the transition kernel corresponding to (29). With
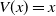 $V(x) = x$
, we have
$V(x) = x$
, we have
 \begin{equation*} QV(x) = \mathbb E [ \eta_{t+1} \, G(x) + \xi_{t+1} ] \leqslant \kappa x + \bar \xi = \kappa V(x) + \bar \xi .\end{equation*}
\begin{equation*} QV(x) = \mathbb E [ \eta_{t+1} \, G(x) + \xi_{t+1} ] \leqslant \kappa x + \bar \xi = \kappa V(x) + \bar \xi .\end{equation*}
Fixing
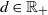 $d \in \mathbb R_+$
and setting
$d \in \mathbb R_+$
and setting
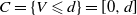 $C = \{V \leqslant d\} = [0, d]$
, we can obtain e in (28) via
$C = \{V \leqslant d\} = [0, d]$
, we can obtain e in (28) via
 \begin{equation*} e = \mathbb P \{\eta' G(d) + \xi' \leqslant \eta G(0) + \xi\} \quad \text{when } \quad (\eta', \xi', \eta, \xi) \sim \varphi \times \psi \times \varphi \times \psi.\end{equation*}
\begin{equation*} e = \mathbb P \{\eta' G(d) + \xi' \leqslant \eta G(0) + \xi\} \quad \text{when } \quad (\eta', \xi', \eta, \xi) \sim \varphi \times \psi \times \varphi \times \psi.\end{equation*}
This term, which provides a lower bound for
 $\varepsilon$
, will be strictly positive under suitable conditions, such as when
$\varepsilon$
, will be strictly positive under suitable conditions, such as when
 $\psi$
has a sufficiently large support. By the discussion in Section 3.3, the drift condition (10) holds with
$\psi$
has a sufficiently large support. By the discussion in Section 3.3, the drift condition (10) holds with
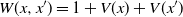 $W(x,x^{\prime}) = 1 + V(x) + V(x^{\prime})$
and
$W(x,x^{\prime}) = 1 + V(x) + V(x^{\prime})$
and
 $\gamma$
set to
$\gamma$
set to
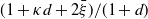 $(1 + \kappa d + 2\bar \xi)/(1 + d)$
. The function W is bounded above by
$(1 + \kappa d + 2\bar \xi)/(1 + d)$
. The function W is bounded above by
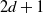 $2d+1$
on
$2d+1$
on
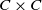 $C \times C$
, so we can set
$C \times C$
, so we can set
 $B = 2d+1$
. With
$B = 2d+1$
. With
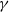 $\gamma$
and B so defined, the bound in Corollary 1 is valid.
$\gamma$
and B so defined, the bound in Corollary 1 is valid.
Notice that for this model, we cannot compute useful total variation or Wasserstein bounds without adding more assumptions.
7. Conclusion
We exploited monotonicity properties of certain discrete-time Markov models to provide quantitative bounds on total ordered variation distance between distributions over time. There are several avenues for future research on these topics. One would be to extend the results to continuous-time Markov processes. Another would be to investigate the connection between the conditions listed here and sample path results, such as the central limit theorem. A third would be to attempt to reframe, prove, and generalize our results using a variation on the analytical arguments in, say, [Reference Butkovsky4, Reference Cañizo and Mischler6, Reference Hairer and Mattingly12]. This third avenue seems promising because, at least in the Polish space setting, the total ordered variation metric used in this article is complete [Reference Kamihigashi and Stachurski16].
Acknowledgements
We are very grateful to the two referees for many detailed and insightful comments and suggestions.
Funding information
There are no funding bodies to thank relating to the creation of this article.
Competing interests
There are no competing interests to declare that arose during the preparation of or the publication process for this article.

 Open access
Open access