



1. Introduction
Membrane filtration of fluids is ubiquitous in industrial, biological and environmental applications. The growing complexity of membrane designs and operating conditions has driven increased interest in mathematical models that can accurately capture the dynamics of flow and fouling within these systems. Many modelling approaches draw from the broader literature on porous media, where the internal geometry of a material is represented in simplified, often idealised forms, to study transport phenomena. A particularly successful class of models treats the pore space as a network, an idea that dates back to the seminal work of Fatt (Reference Fatt1956a
,Reference Fatt
b
,Reference Fatt
c
). In these models, the pore space is idealised as a collection of interconnected channels and junctions through which flow redistributes laterally according to local hydraulic resistances. Since then, network-based models have become widespread across domains including fractured rocks (Sahimi Reference Sahimi1993), oil reservoirs (Øren et al. Reference Øren, Bakke and Arntzen1998; Mehmani, Prodanović & Javadpour Reference Mehmani, Prodanović and Javadpour2013; Cui, Hassanizadeh & Sun Reference Cui, Hassanizadeh and Sun2022),
 $\mathrm{CO}_2$
sequestration (Iglauer, Pentland & Busch Reference Iglauer, Pentland and Busch2015), hydrogen storage (Hashemi, Blunt & Hajibeygi Reference Hashemi, Blunt and Hajibeygi2021; Lysyy et al. Reference Lysyy, Liu, Landa-Marbán, Ersland and Fernø2024; Zhao, Wang & Chen Reference Zhao, Wang and Chen2024), microvascular transport (Chang & Roper Reference Chang and Roper2019) and leaf networks (Katifori, Szöllősi & Magnasco Reference Katifori, Szöllősi and Magnasco2010; Katifori Reference Katifori2018). These models balance geometric fidelity with computational efficiency, making them especially attractive for simulating flow and particle transport in complex porous systems.
$\mathrm{CO}_2$
sequestration (Iglauer, Pentland & Busch Reference Iglauer, Pentland and Busch2015), hydrogen storage (Hashemi, Blunt & Hajibeygi Reference Hashemi, Blunt and Hajibeygi2021; Lysyy et al. Reference Lysyy, Liu, Landa-Marbán, Ersland and Fernø2024; Zhao, Wang & Chen Reference Zhao, Wang and Chen2024), microvascular transport (Chang & Roper Reference Chang and Roper2019) and leaf networks (Katifori, Szöllősi & Magnasco Reference Katifori, Szöllősi and Magnasco2010; Katifori Reference Katifori2018). These models balance geometric fidelity with computational efficiency, making them especially attractive for simulating flow and particle transport in complex porous systems.
In parallel, imaging and data-processing techniques for characterising the topology and connectivity of porous structures have advanced significantly. These include workflows such as micro-computed tomography image acquisition and pre-processing (Blunt et al. Reference Blunt, Bijeljic, Dong, Gharbi, Iglauer, Mostaghimi, Paluszny and Pentland2013), voxel- or pixel-based network extraction methods (such as the watershed segmentation method used by Gerke et al. Reference Gerke, Sizonenko, Karsanina, Lavrukhin, Abashkin and Korost2020 and the genetic-algorithm based approach of Ebrahimi et al. Reference Ebrahimi, Jamshidi, Iglauer and Boozarjomehry2013) and experimental measurement techniques (Ho & Zydney Reference Ho and Zydney2000). Such developments have greatly facilitated the numerical investigation of fluid flow and transport phenomena within pore-scale network models (see, e.g. Blunt Reference Blunt2001 and Blunt et al. Reference Blunt, Jackson, Piri and Valvatne2002 in the context of multiphase flows, Xiong et al. Reference Xiong, Baychev and Jivkov2016 for reactive transport, and Esser et al. Reference Esser, Löwer and Peuker2021 for a numerical model validated by X-ray tomography).
Among industrial applications, membrane filtration has emerged as a field of growing interest in terms of modelling and simulations. Research to date has focused on two primary aspects, the first being appropriate representation of the spatial structure of membrane filters. This has been successfully modelled as multilayered porous media, represented either as void spaces between material matrices (Dalwadi, Griffiths & Bruna Reference Dalwadi, Griffiths and Bruna2015; Griffiths, Kumar & Stewart Reference Griffiths, Kumar and Stewart2016; Shirataki & Wickramasinghe Reference Shirataki and Wickramasinghe2023) or as interconnected pore networks (Griffiths, Kumar & Stewart Reference Griffiths, Kumar and Stewart2014; Sanaei & Cummings Reference Sanaei and Cummings2018; Gu et al. Reference Gu, Renaud, Sanaei, Kondic and Cummings2020; Chen et al. Reference Chen, Liu, Christov and Sanaei2021; Fong et al. Reference Fong, Cummings, Chapman and Sanaei2021; Gu et al. Reference Gu, Kondic and Cummings2022a ). While many such models assume a homogeneous filter medium, some introduce porosity or pore-size gradients, designed to maximise filter usage and prolong operational lifetime (Dalwadi et al. Reference Dalwadi, Griffiths and Bruna2015; Griffiths et al. Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020; Gu, Kondic & Cummings Reference Gu, Kondic and Cummings2023). In this context, Dalwadi et al. (Reference Dalwadi, Griffiths and Bruna2015) consider fluid and particle dynamics in a two-dimensional domain with arrays of impermeable obstacles (representing filter material) decreasing in size in the direction of flow, effectively generating a porosity gradient using the void space between the obstacles. In an alternative approach, Griffiths et al. (Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020), extended the earlier network descriptions, introducing a porosity gradient by skewing the initial distribution of the pore junctions: the denser the pore junctions, the higher the porosity. Gu et al. (Reference Gu, Kondic and Cummings2023) consider a similar network model, but with a pore-size gradient instead of a porosity gradient, achieved by dividing the computational domain into several horizontal bands perpendicular to the direction of flow; specifically, porosity is fixed across all bands, and a cascade of pore radii is assigned to consecutive bands. Such design considerations influence the membrane’s internal geometry and, in turn, affect topological descriptors of the pore network such as connectivity, coordination number, and tortuosity (Tiller & Shirato Reference Tiller and Shirato1964; Yakub et al. Reference Yakub2013; Gong et al. Reference Gong, Stewart, Zelenyuk, Strzelec, Viswanathan, Rothamer, Foster and Rutland2018; Griffiths et al. Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020; Gu et al. Reference Gu, Kondic and Cummings2022a ).
Secondly, appropriate modelling of membrane fouling has also received significant attention. The properties of the porous material and the operating conditions of the filter give rise to multiple fouling mechanisms that result from foulant–material interactions: (i) adsorption (or standard blocking), a slow accretion of particles much smaller than pore sizes onto the pore walls; (ii) sieving, a more abrupt blockage of pore pathways by particles comparable in size to the pores; and (iii) caking, the buildup of a fouling layer on the membrane surface in later stages. These mechanisms directly impact filter performance and efficiency, typically quantified by measures such as filtrate throughput, foulant retention and overall filter lifetime.
Adsorption is frequently the sole fouling mechanism modelled (considered by many of the aforementioned authors), in view of its early onset in most filtration processes and the strong effect it has on filter efficiency and function. Sieving has been less considered from a modelling perspective, but can also be important. Applications of sieving, in addition to membrane filtration, include biological processes such as nutrient sieving in bone joints (Steck & Tate Reference Steck and Tate2005), renal filtration (Lawrence et al. Reference Lawrence2017), food processing techniques such as milling and differential sieving (Sultanbawa, Owens & Pandiella Reference Sultanbawa, Owens and Pandiella2001; Cheng et al. Reference Cheng, Ding, Yin, Tulbek, Chigwedere and Ai2022) and chemical treatments such as the carbon molecular sieve (Liu et al. Reference Liu, Qiu, Quan and Koros2023b ).
An accurate theoretical description of sieving requires additional assumptions about how particles arrive at the filter upstream surface and how they then navigate the pore geometry. These assumptions vary across deterministic and stochastic modelling approaches. Kelly et al. (Reference Kelly, Bizmark, Chakraborty, Datta and Fai2023) model an experimental set-up in which a suspension of colloidal particles passes under pressure through a porous medium comprising randomly distributed glass beads that form a stochastic network of channels and employ a deterministic suspension arrival process with constant rate. Their study focuses particularly on how driving pressure changes particle deposition patterns through the depth of the porous medium. For ‘track-etched’ type filters, where each pore forms an isolated path across the membrane, Griffiths et al. (Reference Griffiths, Kumar and Stewart2014) model the membrane as a discrete population of pores that admit both adsorption and sieving mechanisms. In their formulation, stochastic blocking events associated with sieving are coupled through the global permeate flux and flux-weighted particle arrival probabilities, rather than through explicit inter-pore hydraulic connectivity. Sanaei & Cummings (Reference Sanaei and Cummings2017) provide a continuum mathematical model that captures adsorption and sieving concurrently at the level of individual pores: adsorption is modelled as a sink for foulant concentration along the pore, leading to pore shrinkage via mass conservation, while sieving is represented by a partial differential equation (PDE) governing the probability of blocking events per unit area per time and incorporated into the total pore resistance. Beyond track-etched geometries, Beuscher (Reference Beuscher2010) considers sieving in parallel layers of cylindrical pores and models particle transport as a
 $k$
-nearest-neighbour random walk between pores in adjacent layers where
$k$
-nearest-neighbour random walk between pores in adjacent layers where
 $k$
is a function of lateral flow between pores. We refer interested readers to the book by Sahimi (Reference Sahimi1994) for further relevant theoretical discussions, such as the classical theory of percolation and the exclusion process (to which sieving is analogous), and to Majumdar, Krishnamurthy & Barma (Reference Majumdar, Krishnamurthy and Barma1998) for adsorption and desorption on lattice models.
$k$
is a function of lateral flow between pores. We refer interested readers to the book by Sahimi (Reference Sahimi1994) for further relevant theoretical discussions, such as the classical theory of percolation and the exclusion process (to which sieving is analogous), and to Majumdar, Krishnamurthy & Barma (Reference Majumdar, Krishnamurthy and Barma1998) for adsorption and desorption on lattice models.
Among the closest antecedents to the present work is the network model of Griffiths et al. (Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020), which also considers filtration in a (randomly generated) membrane pore network with hydraulically coupled, flux-weighted particle transport. In this formulation, particles enter and traverse the network via flux-weighted routing, undergo gradual pore constriction due to probabilistic wall adhesion with uniformly distributed deposition (adsorption) and abrupt complete pore blockage when particles encounter pores that are too small (sieving). The authors then examine how tortuosity and porosity grading influence filtration performance measures such as total throughput and filtration efficiency.
Building on the existing literature, we develop a network-based model for simulating the fouling of pore-radius-graded membrane filters under combined adsorption and sieving. Relative to Griffiths et al. (Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020), who consider a single population of particles that account for both fouling mechanisms, our formulation distinguishes between two classes of foulants: a continuously distributed adsorbing species and discrete sieving particles. Adsorption is modelled as a continuous decay in local permeability along each pore throat due to foulant deposition (see, for example, Sanaei & Cummings Reference Sanaei and Cummings2017); sieving is represented as a two-stage stochastic process on the pore network: first, particle arrival at the membrane surface is governed by a Poisson process; second, similar to Griffiths et al. (Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020), transport through the membrane follows a fluid flux-weighted random walk over network vertices, with sieving events recorded when particles reach pores too small to enter. Inclusion of the two distinct mechanisms allows the model to capture both gradual and sudden reductions in fluid flux and throughput. The model supports networks of arbitrary topology, enabling us to investigate the effects of membrane geometry and sieving-particle size on key measures of performance, such as total throughput, foulant concentration in the filtrate and filter lifetime. Moreover, we identify the onset, location and progression of fouling within the membrane pore network, including the depth of internal blocking and the dependence of filter lifetime on arrival rate and sieving-particle size. To isolate these effects, we consider pore-radius-graded networks with approximately fixed porosity, thereby removing porosity variations as a confounding factor.
This paper is organised as follows. Section 2 outlines the modelling aspects: in § 2.1, we describe the generation of the pore-radius-graded network that represents the membrane filter; in § 2.2 we present the pore-scale model for fluid flow, adsorptive transport and pore-radius evolution; and in § 2.3 we describe the sieving model. We define appropriate measures to quantify filter performance in § 3, and we non-dimensionalise and derive the governing pore network dynamics in § 4. In § 5, we outline the numerical methods and investigation strategies, then present simulation results that highlight the influence of key parameters on filter performance. We conclude in § 6 with a summary of findings and directions for future work.
2. Mathematical modelling
In this section, we introduce the mathematical model for membrane filtration in three stages. First, we outline the random pore network generation protocol following Gu et al. (Reference Gu, Kondic and Cummings2023), emphasising the geometric constraints and their relevance to practical applications. Second, we outline the first-principles model describing fluid flow, adsorptive foulant transport and pore-size kinematics, beginning with a single pore and extending to a network of interconnected pores. Third, we develop the modelling assumptions for sieving – the central focus of this work – and examine their impact on fluid dynamics within the network. Throughout this work, in describing our pore networks we use the terms pore and edge interchangeably, as well as pore junction and vertex.
2.1. Membrane pore network generation
The present work focuses on understanding the effect of sieving (pore blocking) within the interior of the pore network; hence, we will generate networks such that the pore size decreases along the depth of the filter (from upstream to downstream). We follow the approach of Gu et al. (Reference Gu, Kondic and Cummings2023), but condense and improve the presentation of that work below. We consider a metric graph
 $G= (V,E,D )$
where
$G= (V,E,D )$
where
 $V$
is the set of vertices and
$V$
is the set of vertices and
 $E$
the set of edges (which will be expanded as circular cylinders to form pores) formed by a connection metric
$E$
the set of edges (which will be expanded as circular cylinders to form pores) formed by a connection metric
 $D$
. To generate the appropriate vertex set
$D$
. To generate the appropriate vertex set
 $V$
, we first divide a rectangular prism (in
$V$
, we first divide a rectangular prism (in
 $\mathbb{R}^3$
) of square cross-section with side length
$\mathbb{R}^3$
) of square cross-section with side length
 $W$
and a height of
$W$
and a height of
 $2W$
into
$2W$
into
 $(m+2)$
horizontal bands, with uppermost and lowermost bands of thickness
$(m+2)$
horizontal bands, with uppermost and lowermost bands of thickness
 $W/2$
, and
$W/2$
, and
 $m$
additional interior bands of equal thickness
$m$
additional interior bands of equal thickness
 $W/m$
(see the schematic in figure 1, where
$W/m$
(see the schematic in figure 1, where
 $m=4$
). The outermost bands are later discarded by cutting; the computational domain used for analysis comprises only the
$m=4$
). The outermost bands are later discarded by cutting; the computational domain used for analysis comprises only the
 $m$
interior equal-thickness bands. The purpose of the outer bands is to extend the network beyond the central cubic domain of interest, creating inlets and outlets at the upstream and downstream surfaces of the membrane filter when the prism is cut. The thickness of these outer bands is arbitrary, but the vertex density must match that of the adjacent interior layers, and they must be sufficiently thick to make the process of inlet/outlet creation fair. Similar layered or banded constructions were used in prior studies of graded and multiscale porous networks (Griffiths et al. Reference Griffiths, Kumar and Stewart2016, Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020; Onur et al. Reference Onur, Ng, Batchlor and Garnier2018; Fong et al. Reference Fong, Cummings, Chapman and Sanaei2021; Shirataki & Wickramasinghe Reference Shirataki and Wickramasinghe2023).
$m$
interior equal-thickness bands. The purpose of the outer bands is to extend the network beyond the central cubic domain of interest, creating inlets and outlets at the upstream and downstream surfaces of the membrane filter when the prism is cut. The thickness of these outer bands is arbitrary, but the vertex density must match that of the adjacent interior layers, and they must be sufficiently thick to make the process of inlet/outlet creation fair. Similar layered or banded constructions were used in prior studies of graded and multiscale porous networks (Griffiths et al. Reference Griffiths, Kumar and Stewart2016, Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020; Onur et al. Reference Onur, Ng, Batchlor and Garnier2018; Fong et al. Reference Fong, Cummings, Chapman and Sanaei2021; Shirataki & Wickramasinghe Reference Shirataki and Wickramasinghe2023).
(a) A visualisation of the network generation protocol. (b) Schematic of a three-dimensional banded network represented in two dimensions. Coloured junctions and pores correspond to each band as follows: ![]() and
and ![]() are inlets. White dots are outlets. Dashed lines are pores created by the periodic boundary conditions. The path connected by lightly shaded arrows is an example of a possible flow path when the network is sieved at some point in all bands by particles of different sizes (labelled with asterisks).
are inlets. White dots are outlets. Dashed lines are pores created by the periodic boundary conditions. The path connected by lightly shaded arrows is an example of a possible flow path when the network is sieved at some point in all bands by particles of different sizes (labelled with asterisks).

We use
 $m=4$
to illustrate our procedure (easily generalisable to arbitrary
$m=4$
to illustrate our procedure (easily generalisable to arbitrary
 $m$
). First, place uniformly randomly
$m$
). First, place uniformly randomly
 $N_k$
nodes in the interior bands for
$N_k$
nodes in the interior bands for
 $k=1,2,3,4$
, increasing from the inlet side to the outlet side of the membrane (see Gu et al. Reference Gu, Kondic and Cummings2023 for details on how
$k=1,2,3,4$
, increasing from the inlet side to the outlet side of the membrane (see Gu et al. Reference Gu, Kondic and Cummings2023 for details on how
 $N_k$
is estimated for each band). We also place
$N_k$
is estimated for each band). We also place
 $N_{\textit{in}} = 2N_1$
and
$N_{\textit{in}} = 2N_1$
and
 $N_{\textit{out}} = 2N_4$
nodes in the upstream and downstream outer bands, respectively. The factor of
$N_{\textit{out}} = 2N_4$
nodes in the upstream and downstream outer bands, respectively. The factor of
 $2$
for the outermost bands ensures that the vertex density matches that of the adjacent layers (the outer bands are twice as thick), thereby creating a suitable number of inlets and outlets when the rectangular prism is cut as described below. Together, these nodes form the initial vertex set,
$2$
for the outermost bands ensures that the vertex density matches that of the adjacent layers (the outer bands are twice as thick), thereby creating a suitable number of inlets and outlets when the rectangular prism is cut as described below. Together, these nodes form the initial vertex set,
 $V_0$
.
$V_0$
.
We define our connection metric
 $D$
as follows: connect the points
$D$
as follows: connect the points
 $x_i,x_{\!j}\in V_0$
that lie in the spherical shell
$x_i,x_{\!j}\in V_0$
that lie in the spherical shell
 \begin{equation} D_{\textit{min}} \lt \left \Vert x_i - x_{\!j}\right \Vert _2 \lt D_{\textit{max}}, \end{equation}
\begin{equation} D_{\textit{min}} \lt \left \Vert x_i - x_{\!j}\right \Vert _2 \lt D_{\textit{max}}, \end{equation}
where
 $\Vert \boldsymbol{\cdot } \Vert _2$
is the Euclidean
$\Vert \boldsymbol{\cdot } \Vert _2$
is the Euclidean
 $2$
-norm. We also allow points to be connected across opposite lateral faces of the prism, which is equivalent to enforcing a periodic boundary condition. Parameters
$2$
-norm. We also allow points to be connected across opposite lateral faces of the prism, which is equivalent to enforcing a periodic boundary condition. Parameters
 $D_{\textit{max}}$
and
$D_{\textit{max}}$
and
 $D_{\textit{min}}$
control the maximum and minimum pore length (discussion on how variations influence computational results may be found in Gu et al. (Reference Gu, Kondic and Cummings2022a
) and references therein; in the present work they are held fixed). We generate membrane inlets and outlets by cutting the rectangular prism with two planes at heights of
$D_{\textit{min}}$
control the maximum and minimum pore length (discussion on how variations influence computational results may be found in Gu et al. (Reference Gu, Kondic and Cummings2022a
) and references therein; in the present work they are held fixed). We generate membrane inlets and outlets by cutting the rectangular prism with two planes at heights of
 $0.5W$
and
$0.5W$
and
 $1.5W$
, respectively, from the bottom surface, producing a cube of side length
$1.5W$
, respectively, from the bottom surface, producing a cube of side length
 $W$
with
$W$
with
 $m$
equal-thickness interior bands. The intersections of the cutting planes and the edges they cut naturally form the set of inlets
$m$
equal-thickness interior bands. The intersections of the cutting planes and the edges they cut naturally form the set of inlets
 $V_{\textit{in}}$
on the membrane top surface, and outlets
$V_{\textit{in}}$
on the membrane top surface, and outlets
 $V_{\textit{out}}$
on the bottom surface. The vertices below
$V_{\textit{out}}$
on the bottom surface. The vertices below
 $0.5W$
and above
$0.5W$
and above
 $1.5W$
are discarded from
$1.5W$
are discarded from
 $V_0$
, and the new vertices (inlets and outlets) generated by the cutting process are added, creating the final vertex set,
$V_0$
, and the new vertices (inlets and outlets) generated by the cutting process are added, creating the final vertex set,
 $V$
. The remaining vertices in the cube interior form the set of interior vertices,
$V$
. The remaining vertices in the cube interior form the set of interior vertices,
 $V_{\textit{int}} = V\backslash (V_{\textit{in}}\cup V_{\textit{out}} )$
. The edges/pores connected to the membrane’s top and bottom surfaces are called boundary edges/pores. Because of this cutting procedure, each boundary edge connects a unique pair of an inlet/outlet and an interior vertex. We note in passing that under this protocol, and with the parameter choices detailed in table 2 later, the average number of adjacent edges for an interior vertex (coordination number in the industrial literature) has a range of
$V_{\textit{int}} = V\backslash (V_{\textit{in}}\cup V_{\textit{out}} )$
. The edges/pores connected to the membrane’s top and bottom surfaces are called boundary edges/pores. Because of this cutting procedure, each boundary edge connects a unique pair of an inlet/outlet and an interior vertex. We note in passing that under this protocol, and with the parameter choices detailed in table 2 later, the average number of adjacent edges for an interior vertex (coordination number in the industrial literature) has a range of
 $10-13$
, which is representative of membrane filter materials at our considered micron-level pore scale (Hormann et al. Reference Hormann, Baranau, Hlushkou, Höltzel and Tallarek2016; Liu et al. Reference Liu, Shikhov, Cui and Arns2023a
; Zhu et al. Reference Zhu, Li, Ji, Li, Liu, Liu and Chen2024).
$10-13$
, which is representative of membrane filter materials at our considered micron-level pore scale (Hormann et al. Reference Hormann, Baranau, Hlushkou, Höltzel and Tallarek2016; Liu et al. Reference Liu, Shikhov, Cui and Arns2023a
; Zhu et al. Reference Zhu, Li, Ji, Li, Liu, Liu and Chen2024).
We assign an index
 $i$
to each vertex
$i$
to each vertex
 $v_i\in V$
. Each edge
$v_i\in V$
. Each edge
 $e_{\textit{ij}}=(v_i,v_{\!j})$
has a well-defined length
$e_{\textit{ij}}=(v_i,v_{\!j})$
has a well-defined length
 $L_{\textit{ij}}$
; we create a true pore network by expanding each edge to a circular cylinder of radius
$L_{\textit{ij}}$
; we create a true pore network by expanding each edge to a circular cylinder of radius
 $R_{\textit{ij}}$
. To construct networks with a pore-radius gradient, we initially assign the same radius to each pore in the
$R_{\textit{ij}}$
. To construct networks with a pore-radius gradient, we initially assign the same radius to each pore in the
 $k$
th band,
$k$
th band,
 \begin{equation} R_n = R_m + (m-n)sW, \quad 1\leq n \leq m, \end{equation}
\begin{equation} R_n = R_m + (m-n)sW, \quad 1\leq n \leq m, \end{equation}
where
 $s$
is the radius gradient/slope through the bands. If a pore crosses two bands its radius is assigned according to the band in which more than half its length lies; for example, in the right panel of figure 1, the red pore in the top left corner crossing from the 1st to the 2nd band is assigned to band 1. For our choice of parameters, pores cannot occupy more than two bands. This rule generates a band-specific set of edges
$s$
is the radius gradient/slope through the bands. If a pore crosses two bands its radius is assigned according to the band in which more than half its length lies; for example, in the right panel of figure 1, the red pore in the top left corner crossing from the 1st to the 2nd band is assigned to band 1. For our choice of parameters, pores cannot occupy more than two bands. This rule generates a band-specific set of edges
 $E_n$
such that
$E_n$
such that
 $E = \bigcup _{n=1}^{m} E_n$
. The parameter
$E = \bigcup _{n=1}^{m} E_n$
. The parameter
 $s$
in (2.2) should be understood as a bandwise gradient. Each pore within a given band is initially a circular cylinder of constant radius
$s$
in (2.2) should be understood as a bandwise gradient. Each pore within a given band is initially a circular cylinder of constant radius
 $R_n$
; in this sense,
$R_n$
; in this sense,
 $sW$
represents the total decrease in pore radius from inlet to outlet.
$sW$
represents the total decrease in pore radius from inlet to outlet.
To compare membrane networks on common grounds, we impose certain constraints on the band radii. First, we prescribe an average radius (taken over the bands) that provides a relationship between the radius gradient
 $s$
and the radius in the
$s$
and the radius in the
 $m$
th (bottom) band
$m$
th (bottom) band
 \begin{equation} \left (\textit {Constraint 1}\right )\qquad R_{0} :=\frac {1}{m}\sum _{n=1}^{m}R_{n}=R_{m}+\frac {sW}{2}\left (m-1\right )\!. \end{equation}
\begin{equation} \left (\textit {Constraint 1}\right )\qquad R_{0} :=\frac {1}{m}\sum _{n=1}^{m}R_{n}=R_{m}+\frac {sW}{2}\left (m-1\right )\!. \end{equation}
In previous work, porosity – defined as the total pore volume fraction – was found to strongly influence membrane performance (Gu et al. Reference Gu, Kondic and Cummings2022a
). To isolate the effect of the pore-radius gradient from that of porosity – and to ensure that differences in filtration arise from sieving rather than variations in total void volume – we therefore hold the porosity approximately constant across all bands by enforcing the following constraint. More precisely, we require that the porosity of each band is within a small relative tolerance
 $\delta$
of a prescribed porosity
$\delta$
of a prescribed porosity
 $\varPhi _0$
. The value
$\varPhi _0$
. The value
 $\delta =0.005$
is used in this work. This imposes a constraint on the number of vertices initially placed in each band, implemented via
$\delta =0.005$
is used in this work. This imposes a constraint on the number of vertices initially placed in each band, implemented via
 \begin{equation} \left (\textit {Constraint 2}\right )\qquad \frac {\left |\varPhi _{n} -\varPhi _0\right |}{\varPhi _0}\lt \delta , \end{equation}
\begin{equation} \left (\textit {Constraint 2}\right )\qquad \frac {\left |\varPhi _{n} -\varPhi _0\right |}{\varPhi _0}\lt \delta , \end{equation}
where
 \begin{align} \varPhi _n = \frac {\frac {\pi }{2} \sum _{e_{\textit{ij}}\in {E}_n} R_{\textit{ij}}^2 L_{n,ij}}{W^3/m} \end{align}
\begin{align} \varPhi _n = \frac {\frac {\pi }{2} \sum _{e_{\textit{ij}}\in {E}_n} R_{\textit{ij}}^2 L_{n,ij}}{W^3/m} \end{align}
is the porosity of the
 $n$
th band, and
$n$
th band, and
 $L_{n,ij}$
the length of the edge
$L_{n,ij}$
the length of the edge
 $e_{\textit{ij}}$
inside the
$e_{\textit{ij}}$
inside the
 $n$
th band. We choose
$n$
th band. We choose
 $\varPhi _0=0.6$
, corresponding to the porosity of typical commercial filter materials. The porosity-fixing procedure can be carried out in a predict–correct fashion, by either randomly adding nodes when porosity overshoots or deleting nodes (and their connections) when porosity undershoots.
$\varPhi _0=0.6$
, corresponding to the porosity of typical commercial filter materials. The porosity-fixing procedure can be carried out in a predict–correct fashion, by either randomly adding nodes when porosity overshoots or deleting nodes (and their connections) when porosity undershoots.
A consequence of fixing band porosities in a pore-size-graded network is that the larger the radius gradient, the larger the gradient of vertex/pore junction density. Furthermore, fulfilling constraint 2 also fixes the overall porosity of the entire membrane network via the relationship
 \begin{equation} \varPhi = \frac {1}{m}\sum _{n=1}^{m} \varPhi _n \approx \varPhi _0. \end{equation}
\begin{equation} \varPhi = \frac {1}{m}\sum _{n=1}^{m} \varPhi _n \approx \varPhi _0. \end{equation}
We refer the reader to Gu et al. (Reference Gu, Kondic and Cummings2023) for more details on generating pore-size-graded networks and on porosity-fixing techniques.
2.2. Flow, advection and adsorptive fouling on the network
The membrane filtration model couples pore-scale fluid flow, advective transport of foulant particles and time-dependent pore shrinkage due to adsorption, forming a feedback system schematised in figure 2 in which evolving pore geometry alters network hydraulics. What follows is a brief overview of the model for each pore (edge). Full mathematical details of the flow and transport equations, pore-radius evolution laws and the coupling across the pore network are provided in Appendix A.
Fluid flow through the network is modelled at the pore scale using a graph-based representation, in which each pore corresponds to an edge and each pore junction to a vertex. Under the assumption of slender pores and Newtonian flow (viscosity
 $\mu$
), volumetric flux
$\mu$
), volumetric flux
 $Q_{\textit{ij}}$
through each pore
$Q_{\textit{ij}}$
through each pore
 $e_{\textit{ij}}$
is governed by a Hagen–Poiseuille equation
$e_{\textit{ij}}$
is governed by a Hagen–Poiseuille equation
 \begin{equation} Q_{\textit{ij}}=K_{\textit{ij}}\left (P_i-P_{\!j}\right )\!, \end{equation}
\begin{equation} Q_{\textit{ij}}=K_{\textit{ij}}\left (P_i-P_{\!j}\right )\!, \end{equation}
where
 $P_i$
is the pressure at vertex
$P_i$
is the pressure at vertex
 $i$
; each pore has conductance
$i$
; each pore has conductance
 $K_{\textit{ij}}$
defined by
$K_{\textit{ij}}$
defined by
 \begin{equation} K_{\textit{ij}}=\frac {\pi }{8\mu {\displaystyle\int} _{{\kern-4pt}0}^{{\kern-1pt}L_{\textit{ij}}}\frac {1}{R_{\textit{ij}}^4(Y,T)}\,{\rm d}Y} \end{equation}
\begin{equation} K_{\textit{ij}}=\frac {\pi }{8\mu {\displaystyle\int} _{{\kern-4pt}0}^{{\kern-1pt}L_{\textit{ij}}}\frac {1}{R_{\textit{ij}}^4(Y,T)}\,{\rm d}Y} \end{equation}
determined by the instantaneous pore geometry (length
 $L_{\textit{ij}}$
and radius
$L_{\textit{ij}}$
and radius
 $R_{\textit{ij}} (Y,T)$
, where
$R_{\textit{ij}} (Y,T)$
, where
 $T$
is time and local axial coordinate
$T$
is time and local axial coordinate
 $Y$
is measured along the pore). Conservation of mass at pore junctions yields a network-scale problem for the pressure at each vertex, which then determines the distribution of fluxes throughout the pore network.
$Y$
is measured along the pore). Conservation of mass at pore junctions yields a network-scale problem for the pressure at each vertex, which then determines the distribution of fluxes throughout the pore network.
A schematic of the workflow of numerical simulations with simultaneous adsorption and sieving, according to the dimensionless governing equations in § 4. Boxes in ![]() represent initialisation steps; parallelograms in
represent initialisation steps; parallelograms in ![]() represent numerical equations solving steps; and rectangles in
represent numerical equations solving steps; and rectangles in ![]() represent binary decisions that either trigger a separate calculation or termination of the algorithm.
represent binary decisions that either trigger a separate calculation or termination of the algorithm.

The feed solution is assumed to carry suspended adsorptive foulant particles, much smaller than typical pore radii. Under the adsorptive fouling model, these are advected passively by the flow and continuously deposited on the pore wall. In this regime, adsorptive particle concentration
 $C_{\textit{ij}} (Y,T)$
along each pore is described by a one-dimensional continuum transport model, with loss to the pore walls represented through a first-order sink term. We denote by
$C_{\textit{ij}} (Y,T)$
along each pore is described by a one-dimensional continuum transport model, with loss to the pore walls represented through a first-order sink term. We denote by
 $C_i(T)$
the foulant concentration at pore junction
$C_i(T)$
the foulant concentration at pore junction
 $i$
, which serves as the upstream boundary value for transport along each connected pore
$i$
, which serves as the upstream boundary value for transport along each connected pore
 \begin{align} Q_{\textit{ij}} (T) \frac {\partial C_{\textit{ij}} (Y,T)}{\partial Y}&=-\varLambda C_{\textit{ij}} (Y,T) R_{\textit{ij}}(Y,T), \quad 0\le Y\le L_{\textit{ij}}, \\[-12pt]\nonumber \end{align}
\begin{align} Q_{\textit{ij}} (T) \frac {\partial C_{\textit{ij}} (Y,T)}{\partial Y}&=-\varLambda C_{\textit{ij}} (Y,T) R_{\textit{ij}}(Y,T), \quad 0\le Y\le L_{\textit{ij}}, \\[-12pt]\nonumber \end{align}
 \begin{align} C_{\textit{ij}}(0,T) &= C_{i}(T), \end{align}
\begin{align} C_{\textit{ij}}(0,T) &= C_{i}(T), \end{align}
where
 $\varLambda$
is a material parameter characterising the affinity between particles and the pore wall. Coupling concentration fields across the network via particle flux conservation at each pore junction yields a graph-based advection equation that determines particle concentrations at all pore junctions.
$\varLambda$
is a material parameter characterising the affinity between particles and the pore wall. Coupling concentration fields across the network via particle flux conservation at each pore junction yields a graph-based advection equation that determines particle concentrations at all pore junctions.
Adsorptive deposition causes pores to shrink over time, with the rate of pore-radius reduction proportional to the local particle concentration
 \begin{align} \frac {\partial R_{\textit{ij}}(Y,T)}{\partial T}&=-\varLambda \alpha C_{\textit{ij}}(Y,T), \\[-12pt]\nonumber \end{align}
\begin{align} \frac {\partial R_{\textit{ij}}(Y,T)}{\partial T}&=-\varLambda \alpha C_{\textit{ij}}(Y,T), \\[-12pt]\nonumber \end{align}
 \begin{align} R_{\textit{ij}}\left (Y,0\right ) &= R_m, \quad \text{for } \quad e_{\textit{ij}}\in E_n, \end{align}
\begin{align} R_{\textit{ij}}\left (Y,0\right ) &= R_m, \quad \text{for } \quad e_{\textit{ij}}\in E_n, \end{align}
where
 $\alpha$
relates to foulant particle volume, and
$\alpha$
relates to foulant particle volume, and
 $R_n$
is the initial radius of pores in the
$R_n$
is the initial radius of pores in the
 $n$
th band, determined by (2.2).
$n$
th band, determined by (2.2).
The coupling among foulant transport, pore geometry and hydraulic conductance provides a feedback mechanism whereby adsorption gradually alters the network and the flow field. For computational efficiency, pore radius is assumed to evolve as an approximately linear function of local axial distance
 $Y$
(see Appendix A for further justification), reducing the governing equations to a system of ordinary differential equations (ODEs) for time-dependent geometric parameters while preserving mass.
$Y$
(see Appendix A for further justification), reducing the governing equations to a system of ordinary differential equations (ODEs) for time-dependent geometric parameters while preserving mass.
2.3. Sieving
In this section, we highlight the paper’s main focus: the incorporation of sieving as a fouling mechanism simultaneous with adsorption. While adsorption arises from particles much smaller than the pore size and is therefore modelled using a continuum transport framework, sieving involves particles comparable to the pore dimensions and occurs through discrete, localised blocking events, motivating a stochastic description. The pore-scale particles responsible for sieving will be referred to simply as sieving particles hereafter, and the time scale on which individual sieving events alter the network geometry and flow is much shorter than that of adsorption. Sieving manifests in two primary types, according to the extent of blockage. The first type is complete blocking, when sieving particles completely cover an inlet or clog a pore throat in the interior of the membrane (see the asterisks in figure 1 representing sieving particles), prohibiting local fluid flow. The second type is incomplete blocking, in which sieving particles only partially cover the entrance to a pore throat, thereby significantly narrowing the entrance and impeding fluid flow; the feed solution leaks through the partially blocked channel but at a considerably lower volumetric flow rate. For simplicity, we consider complete blocking only in this work.
2.3.1. Assumptions
We first outline our general assumptions about the sieving process and then provide the definitions needed to set up the numerical simulations. We will continue to use the terminology introduced for the graph
 $G$
in § 2, wherever applicable.
$G$
in § 2, wherever applicable.
In this work, the arrival of sieving particles at the membrane surface is prescribed by a Poisson process. We make the simplifying assumption that the arrival rate
 $\varGamma$
is constant to decouple particle arrivals from the membrane’s evolving hydraulic state. More refined models in which arrival rates depend on the instantaneous permeate flux, as proposed by Griffiths et al. (Reference Griffiths, Kumar and Stewart2014), are not considered here, but could be employed in future work as a natural extension. Accordingly, the number of particle arrivals
$\varGamma$
is constant to decouple particle arrivals from the membrane’s evolving hydraulic state. More refined models in which arrival rates depend on the instantaneous permeate flux, as proposed by Griffiths et al. (Reference Griffiths, Kumar and Stewart2014), are not considered here, but could be employed in future work as a natural extension. Accordingly, the number of particle arrivals
 $N(T)$
over a time interval
$N(T)$
over a time interval
 $T$
is modelled as
$T$
is modelled as
 \begin{equation} {\textrm {Prob}}\left ( N(T) = k\right ) = \frac {\left (\varGamma T\right )^k}{k!}e^{-\varGamma T}, \quad k = 0,1,2\ldots , \end{equation}
\begin{equation} {\textrm {Prob}}\left ( N(T) = k\right ) = \frac {\left (\varGamma T\right )^k}{k!}e^{-\varGamma T}, \quad k = 0,1,2\ldots , \end{equation}
where
 ${\textrm {Prob}} ( N(T) = k )$
is the probability of having
${\textrm {Prob}} ( N(T) = k )$
is the probability of having
 $k$
arrivals over a time span of
$k$
arrivals over a time span of
 $T$
. We consider monodisperse sieving particles of radius
$T$
. We consider monodisperse sieving particles of radius
 $P_{\textit{size}}$
in the feed solution, with a primary goal of studying how the particle size affects the performance of filters with different pore-radius gradients.
$P_{\textit{size}}$
in the feed solution, with a primary goal of studying how the particle size affects the performance of filters with different pore-radius gradients.
When the
 $k$
th particle of radius
$k$
th particle of radius
 $P_{\textit{size}}$
arrives at the entry of a particular edge
$P_{\textit{size}}$
arrives at the entry of a particular edge
 $e_{\textit{ij}}$
at time
$e_{\textit{ij}}$
at time
 $T^{ (k )}$
, the principle of size exclusion is invoked: if
$T^{ (k )}$
, the principle of size exclusion is invoked: if
 $P_{\textit{size}}\lt R_{\textit{ij}}$
, the particle will immediately pass through and arrive at the vertex
$P_{\textit{size}}\lt R_{\textit{ij}}$
, the particle will immediately pass through and arrive at the vertex
 $j$
(pore junction). The subsequent direction of particle movement is governed by preferential flow (defined more precisely in § 2.3.2) – the larger the flux in an edge, the more likely the particle will go there; note that particles can only travel downstream. A particle will continue to travel in this fashion through the membrane until it either enters an edge with a radius smaller than or equal to its size (size exclusion) and thereby blocks the pore, or it exits the membrane. Lastly, we assume that sieving is irreversible: once an edge is blocked, it cannot be unblocked.
$j$
(pore junction). The subsequent direction of particle movement is governed by preferential flow (defined more precisely in § 2.3.2) – the larger the flux in an edge, the more likely the particle will go there; note that particles can only travel downstream. A particle will continue to travel in this fashion through the membrane until it either enters an edge with a radius smaller than or equal to its size (size exclusion) and thereby blocks the pore, or it exits the membrane. Lastly, we assume that sieving is irreversible: once an edge is blocked, it cannot be unblocked.
2.3.2. Probabilistic set-up
We simulate blocking by first generating Poisson arrival times based on the fact that inter-arrival times (of particles),
 $T^{ (k+1 )}-T^{ (k )}$
, are exponential random variables with mean
$T^{ (k+1 )}-T^{ (k )}$
, are exponential random variables with mean
 $1/\varGamma$
. At each arrival time
$1/\varGamma$
. At each arrival time
 $T^{ (k )}$
, a particle arrives at the top surface and chooses an inlet (any
$T^{ (k )}$
, a particle arrives at the top surface and chooses an inlet (any
 $v_i\in V_{\textit{in}}$
) with probability proportional to the flux through that inlet relative to the total flux from all
$v_i\in V_{\textit{in}}$
) with probability proportional to the flux through that inlet relative to the total flux from all
 $v_i \in V_{\textit{in}}$
. The size exclusion principle is then applied to the sieving particle to determine which edges it can enter next. If the particle can enter an edge, it will travel to one of the neighbouring downstream pores via the edge connecting them, with a probability determined by preferential flow, defined below. If the particle cannot enter any downstream edges, then it will block an edge, again with probability determined by preferential flow.
$v_i \in V_{\textit{in}}$
. The size exclusion principle is then applied to the sieving particle to determine which edges it can enter next. If the particle can enter an edge, it will travel to one of the neighbouring downstream pores via the edge connecting them, with a probability determined by preferential flow, defined below. If the particle cannot enter any downstream edges, then it will block an edge, again with probability determined by preferential flow.
Definition 1. (Initial arrival at membrane top surface) A sieving particle arriving at the membrane top surface has a probability of visiting vertex
 $v_i$
$v_i$
 \begin{equation} \pi _{0,i}=\begin{cases} \frac {\sum _{v_{\!j}\in \mathcal{N}\left (i\right )}{Q}_{\textit{ij}}(T)}{\sum _{v_i \in V_{\textit{in}}}\sum _{v_{\!j}\in \mathcal{N}\left (i\right )}{Q}_{\textit{ij}}(T)}, & \forall v_i \in V_{\textit{in}},\\[7pt] 0, & {{\rm otherwise}}, \end{cases} \end{equation}
\begin{equation} \pi _{0,i}=\begin{cases} \frac {\sum _{v_{\!j}\in \mathcal{N}\left (i\right )}{Q}_{\textit{ij}}(T)}{\sum _{v_i \in V_{\textit{in}}}\sum _{v_{\!j}\in \mathcal{N}\left (i\right )}{Q}_{\textit{ij}}(T)}, & \forall v_i \in V_{\textit{in}},\\[7pt] 0, & {{\rm otherwise}}, \end{cases} \end{equation}
where
 ${Q}_{\textit{ij}} (T )$
is the fluid flux that goes from vertices
${Q}_{\textit{ij}} (T )$
is the fluid flux that goes from vertices
 $v_i$
and
$v_i$
and
 $v_{\!j}$
through the edge
$v_{\!j}$
through the edge
 $e_{\textit{ij}}$
and
$e_{\textit{ij}}$
and
 $\mathcal{N} (i )$
is the set of neighbours adjacent to
$\mathcal{N} (i )$
is the set of neighbours adjacent to
 $v_i$
.
$v_i$
.
The initial distribution
 $\pi _{0}$
of the random walker (the sieving particle) is the probability of entering the membrane at each vertex on the membrane surface (it cannot enter via a vertex
$\pi _{0}$
of the random walker (the sieving particle) is the probability of entering the membrane at each vertex on the membrane surface (it cannot enter via a vertex
 $v_i \notin V_{\textit{in}}$
). It is quantified by the proportion of outgoing flux at each vertex on the membrane surface relative to the total outgoing flux from all vertices on the membrane surface. After the walker settles into position on the membrane’s top surface, as in (2.12), it traverses the rest of the network via preferential flow.
$v_i \notin V_{\textit{in}}$
). It is quantified by the proportion of outgoing flux at each vertex on the membrane surface relative to the total outgoing flux from all vertices on the membrane surface. After the walker settles into position on the membrane’s top surface, as in (2.12), it traverses the rest of the network via preferential flow.
Definition 2. (Preferential flow) The probability of moving from
 $v_i$
to
$v_i$
to
 $v_{\!j}$
(via
$v_{\!j}$
(via
 $e_{\textit{ij}}$
) is defined by the transition probability
$e_{\textit{ij}}$
) is defined by the transition probability
 \begin{equation} \mathcal{P}_{\textit{ij}}(T):= \begin{cases} \frac {Q_{\textit{ij}}(T)}{\sum _{v_{\!j}\in \mathcal{N}\left (i\right )}Q_{\textit{ij}}(T)}, & \forall v_{i}\in V\backslash V_{\textit{out}}\quad \left (\text{flux-weighted random walk}\right )\!,\\[7pt] \delta _{\textit{ij}}, & \forall v_{i}\in V_{\textit{out}}\quad \quad \left (\text{absorbing at bottom surface}\right )\!, \end{cases} \end{equation}
\begin{equation} \mathcal{P}_{\textit{ij}}(T):= \begin{cases} \frac {Q_{\textit{ij}}(T)}{\sum _{v_{\!j}\in \mathcal{N}\left (i\right )}Q_{\textit{ij}}(T)}, & \forall v_{i}\in V\backslash V_{\textit{out}}\quad \left (\text{flux-weighted random walk}\right )\!,\\[7pt] \delta _{\textit{ij}}, & \forall v_{i}\in V_{\textit{out}}\quad \quad \left (\text{absorbing at bottom surface}\right )\!, \end{cases} \end{equation}
where
 $\delta _{\textit{ij}}$
the Kronecker delta.
$\delta _{\textit{ij}}$
the Kronecker delta.
The matrix
 $\mathcal{P}$
is referred to as the normalised in-degree adjacency, representing the transition law for each sieving particle following the preferential flow (weighted by fluid flux). Note that the neighbour set
$\mathcal{P}$
is referred to as the normalised in-degree adjacency, representing the transition law for each sieving particle following the preferential flow (weighted by fluid flux). Note that the neighbour set
 $\mathcal{N} (i )$
over which we sum the
$\mathcal{N} (i )$
over which we sum the
 $i$
th row of
$i$
th row of
 $Q$
works consistently with the definition of flux-weighted adjacency matrix
$Q$
works consistently with the definition of flux-weighted adjacency matrix
 $Q$
as it contains only positive entries for flux to go from an upstream pore to a downstream one (while the reverse direction incurs zero flux). Sieving particles visiting and making it through (per the size exclusion mechanism described in § 2.3.1) the outgoing vertex set
$Q$
as it contains only positive entries for flux to go from an upstream pore to a downstream one (while the reverse direction incurs zero flux). Sieving particles visiting and making it through (per the size exclusion mechanism described in § 2.3.1) the outgoing vertex set
 $V_{\textit{out}}$
will be absorbed there, a condition given by the second line of (2.13).
$V_{\textit{out}}$
will be absorbed there, a condition given by the second line of (2.13).
Under both adsorption and blocking, building on (2.8), the conductance of the edge
 $e_{\textit{ij}}$
is given by
$e_{\textit{ij}}$
is given by
 \begin{equation} K_{\textit{ij}}(T)=\frac {\pi }{8\mu {\displaystyle\int}_{0}^{L_{\textit{ij}}}\frac {1}{R_{\textit{ij}}^{4}\left (Y,T\right )}{\rm d}Y}\mathbf{1}_{\left \{ e_{\textit{ij}}{\,open}\right \} }(T), \end{equation}
\begin{equation} K_{\textit{ij}}(T)=\frac {\pi }{8\mu {\displaystyle\int}_{0}^{L_{\textit{ij}}}\frac {1}{R_{\textit{ij}}^{4}\left (Y,T\right )}{\rm d}Y}\mathbf{1}_{\left \{ e_{\textit{ij}}{\,open}\right \} }(T), \end{equation}
where the indicator function serves as a switch between an open and a blocked pore (due to the instantaneous nature of sieving). With our assumption of a linear pore profile we are able to simplify the integral in (2.14) significantly, as detailed in Appendix A.
3. Measures of performance
Volumetric throughput of a membrane filter over its lifetime is a standard measure of performance in filtration applications (see e.g. Pieracci et al. Reference Pieracci, Armando, Westoby and Thommes2018), and is therefore one that we also employ.
Definition 3.
The volumetric throughput
 $H(T)$
through the filter is defined by
$H(T)$
through the filter is defined by
 \begin{align} H(T)=\int _{0}^{T}Q_{\textit{out}}(T^{\prime }){\rm d}T^{\prime }, \quad Q_{\textit{out}}(T)=\sum _{v_{\!j}\in V_{ {bot}}}\sum _{v_{i}\,:\, (v_{i},v_{\!j})\in E}{Q}_{\textit{ij}}(T), \end{align}
\begin{align} H(T)=\int _{0}^{T}Q_{\textit{out}}(T^{\prime }){\rm d}T^{\prime }, \quad Q_{\textit{out}}(T)=\sum _{v_{\!j}\in V_{ {bot}}}\sum _{v_{i}\,:\, (v_{i},v_{\!j})\in E}{Q}_{\textit{ij}}(T), \end{align}
where
 $Q_{\textit{out}} (T )$
is the total volumetric flux leaving the filter.
$Q_{\textit{out}} (T )$
is the total volumetric flux leaving the filter.
In particular, we are interested in
 $H_{\textit{final}}:=H (T_{\textit{final}} )$
, the total volume of filtrate processed by the filter over its lifetime
$H_{\textit{final}}:=H (T_{\textit{final}} )$
, the total volume of filtrate processed by the filter over its lifetime
 $T_{\textit{final}}$
, defined in (3.4) below.
$T_{\textit{final}}$
, defined in (3.4) below.
The second performance metric we use is the accumulated foulant concentration in the collected filtrate at the membrane outlet, which captures the aggregate efficiency of adsorptive filtration.
Definition 4. The accumulated foulant concentration is defined by
 \begin{align} C_{\textit{acm}}(T)=\frac {\int _{0}^{T}C_{\textit{out}}(T^{\prime })Q_{\textit{out}}(T^{\prime }){\rm d}T^{\prime }}{\int _{0}^{T}Q_{\textit{out}}(T^{\prime }){\rm d}T^{\prime }}, \end{align}
\begin{align} C_{\textit{acm}}(T)=\frac {\int _{0}^{T}C_{\textit{out}}(T^{\prime })Q_{\textit{out}}(T^{\prime }){\rm d}T^{\prime }}{\int _{0}^{T}Q_{\textit{out}}(T^{\prime }){\rm d}T^{\prime }}, \end{align}
where
 \begin{align} C_{\textit{out}}(T)=\frac {{\displaystyle \sum _{v_{\!j}\in V_{\textit{bot}}}\sum _{v_{i}\,:\, (v_{i},v_{\!j})\in E}}\boldsymbol{C}_{\!j}(T)\boldsymbol{Q}_{\textit{ij}}(T)}{Q_{\textit{out}}(T)}. \end{align}
\begin{align} C_{\textit{out}}(T)=\frac {{\displaystyle \sum _{v_{\!j}\in V_{\textit{bot}}}\sum _{v_{i}\,:\, (v_{i},v_{\!j})\in E}}\boldsymbol{C}_{\!j}(T)\boldsymbol{Q}_{\textit{ij}}(T)}{Q_{\textit{out}}(T)}. \end{align}
In our simulations of filtration through a pore network, we impose a
 $\mathrm{stopping\, criterion}$
that membrane filtration ends when total flux is zero. This defines our filter lifetime.
$\mathrm{stopping\, criterion}$
that membrane filtration ends when total flux is zero. This defines our filter lifetime.
Definition 5.
The
 $\mathrm{filter\, lifetime}$
is defined by
$\mathrm{filter\, lifetime}$
is defined by
 \begin{equation} T_{\textit{final}}=\left \{ T\,:\,Q_{\textit{out}}(T)=0\right \}\!. \end{equation}
\begin{equation} T_{\textit{final}}=\left \{ T\,:\,Q_{\textit{out}}(T)=0\right \}\!. \end{equation}
This condition is reached either through complete pore closure due to adsorption or through loss of global connectivity between inlets and outlets caused by sieving.
4. Non-dimensionalisation
Before carrying out simulations of filtration we non-dimensionalise the model with the following scales:
 \begin{equation} \begin{gathered} \left (D_{\textit{max}},D_{\textit{min}},L_{\textit{ij}},R_{\textit{ij}},R_n, P_{\textit{size}}, Y\right ) = W\big(d_{\textit{max}},d_{\textit{min}},l_{\textit{ij}},r_{\textit{ij}},r_n, p_{\textit{size}}, y\big ), \\ \big(T,T^{(k)},T_{\textit{final}}\big ) = \frac {W}{\varLambda \alpha C_0}\big(t,t^{(k)},t_{\textit{final}}\big),\\ P = P_0 p, \quad Q_{\textit{ij}} = \frac {\pi W^3 P_0}{8\mu } q_{\textit{ij}}, \quad K_{\textit{ij}} = \frac {\pi W^3 }{8\mu }k_{\textit{ij}}, \quad k_{\textit{ij}} = \frac {r_{\textit{ij}}^4}{l_{\textit{ij}}},\\ \big({C}, C_{\textit{out}}, C_{\textit{acm}}\big ) = C_0 \big (c,c_{\textit{out}}, c_{\textit{acm}}\big), \quad \big(H,H_{\textit{final}}\big)=\frac {W^{3}}{\alpha C_{0}}\big(h,h_{\textit{final}}\big), \\ \varLambda = \frac {\pi \textit{WP}_0}{8\mu }\lambda , \quad \varGamma = \frac {\left |E\right |\varLambda \alpha C_0}{W}\gamma , \end{gathered} \end{equation}
\begin{equation} \begin{gathered} \left (D_{\textit{max}},D_{\textit{min}},L_{\textit{ij}},R_{\textit{ij}},R_n, P_{\textit{size}}, Y\right ) = W\big(d_{\textit{max}},d_{\textit{min}},l_{\textit{ij}},r_{\textit{ij}},r_n, p_{\textit{size}}, y\big ), \\ \big(T,T^{(k)},T_{\textit{final}}\big ) = \frac {W}{\varLambda \alpha C_0}\big(t,t^{(k)},t_{\textit{final}}\big),\\ P = P_0 p, \quad Q_{\textit{ij}} = \frac {\pi W^3 P_0}{8\mu } q_{\textit{ij}}, \quad K_{\textit{ij}} = \frac {\pi W^3 }{8\mu }k_{\textit{ij}}, \quad k_{\textit{ij}} = \frac {r_{\textit{ij}}^4}{l_{\textit{ij}}},\\ \big({C}, C_{\textit{out}}, C_{\textit{acm}}\big ) = C_0 \big (c,c_{\textit{out}}, c_{\textit{acm}}\big), \quad \big(H,H_{\textit{final}}\big)=\frac {W^{3}}{\alpha C_{0}}\big(h,h_{\textit{final}}\big), \\ \varLambda = \frac {\pi \textit{WP}_0}{8\mu }\lambda , \quad \varGamma = \frac {\left |E\right |\varLambda \alpha C_0}{W}\gamma , \end{gathered} \end{equation}
where
 $|E|$
is a typical number of pores in a network, usually of the order of
$|E|$
is a typical number of pores in a network, usually of the order of
 $10^4$
via our network generation protocol. The time scale here is based on adsorptive fouling, and the dimensionless parameter
$10^4$
via our network generation protocol. The time scale here is based on adsorptive fouling, and the dimensionless parameter
 $\lambda$
is a coefficient representing the strength of the affinity between adsorptive fouling particles and the membrane material. One can view
$\lambda$
is a coefficient representing the strength of the affinity between adsorptive fouling particles and the membrane material. One can view
 $\gamma$
as the dimensionless arrival rate of large particles per pore (relative to the rate at which adsorptive fouling occurs).
$\gamma$
as the dimensionless arrival rate of large particles per pore (relative to the rate at which adsorptive fouling occurs).
Under these scalings, the governing equations summarised in § 2.2 and detailed in Appendix A retain their graph-based structure, but may be written in a compact dimensionless form, with matrix and vector notation introduced as convenient for quantities defined on edges and at vertices, respectively. For pressure
 $p$
$p$
 \begin{align} {L_k} p&= 0, \\[-12pt]\nonumber \end{align}
\begin{align} {L_k} p&= 0, \\[-12pt]\nonumber \end{align}
 \begin{align} p(v) &= 1, \quad \forall v\in V_{\textit{in}}; \quad p(v) = 0, \quad \forall v\in V_{\textit{out}}, \\[-12pt]\nonumber \end{align}
\begin{align} p(v) &= 1, \quad \forall v\in V_{\textit{in}}; \quad p(v) = 0, \quad \forall v\in V_{\textit{out}}, \\[-12pt]\nonumber \end{align}
 \begin{align} q_{\textit{ij}}&=k_{\textit{ij}} (p_i-p_{\!j}), \quad p_i = p(v_i), \quad \forall (v_i,v_{\!j}) \in E, \end{align}
\begin{align} q_{\textit{ij}}&=k_{\textit{ij}} (p_i-p_{\!j}), \quad p_i = p(v_i), \quad \forall (v_i,v_{\!j}) \in E, \end{align}
where
 $L_k$
is the dimensionless conductance-weighted graph Laplacian corresponding to the dimensional operator defined in (A5).
$L_k$
is the dimensionless conductance-weighted graph Laplacian corresponding to the dimensional operator defined in (A5).
For Poisson arrivals of sieving particles, we have
 \begin{equation} {\textrm {Prob}}\left ( N(T) = k\right ) = \frac {\left (\gamma \left |E\right |t\right )^k}{k!}e^{-\gamma \left |E\right |t}, \quad k = 0,1,2\ldots , \end{equation}
\begin{equation} {\textrm {Prob}}\left ( N(T) = k\right ) = \frac {\left (\gamma \left |E\right |t\right )^k}{k!}e^{-\gamma \left |E\right |t}, \quad k = 0,1,2\ldots , \end{equation}
for foulant concentration in each pore
 $e_{\textit{ij}}$
$e_{\textit{ij}}$
 \begin{equation} q_{\textit{ij}} \frac {\partial c_{\textit{ij}}}{\partial y} = -\lambda r_{\textit{ij}} c_{\textit{ij}}, \end{equation}
\begin{equation} q_{\textit{ij}} \frac {\partial c_{\textit{ij}}}{\partial y} = -\lambda r_{\textit{ij}} c_{\textit{ij}}, \end{equation}
and
 $\boldsymbol{c}$
at vertices
$\boldsymbol{c}$
at vertices
 $v \in V_{\textit{int}}\cup V_{\textit{out}}$
$v \in V_{\textit{int}}\cup V_{\textit{out}}$
 \begin{align} {L}_{\boldsymbol{q}}^{\textit{in}}\boldsymbol{c} &=\left (\boldsymbol{q}\circ \boldsymbol{b}\right )^{{ T}}\boldsymbol{c}_0, \quad {L}_{\boldsymbol{q}}^{\textit{in}}={D}_{q^{ {T}}}-\left (\boldsymbol{q}\circ \boldsymbol{b}\right )^{ {T}}\!, \\[-12pt]\nonumber \end{align}
\begin{align} {L}_{\boldsymbol{q}}^{\textit{in}}\boldsymbol{c} &=\left (\boldsymbol{q}\circ \boldsymbol{b}\right )^{{ T}}\boldsymbol{c}_0, \quad {L}_{\boldsymbol{q}}^{\textit{in}}={D}_{q^{ {T}}}-\left (\boldsymbol{q}\circ \boldsymbol{b}\right )^{ {T}}\!, \\[-12pt]\nonumber \end{align}
 \begin{align} \boldsymbol{c}_0 &= \left (1,\ldots ,1\right )^{{T}}, \quad {b}_{\textit{ij}} = \exp \left (\frac {-\lambda \int ^{l_{\textit{ij}}}_{0} r_{\textit{ij}}(y,t){\rm d}y}{q_{\textit{ij}}}\right )\!, \end{align}
\begin{align} \boldsymbol{c}_0 &= \left (1,\ldots ,1\right )^{{T}}, \quad {b}_{\textit{ij}} = \exp \left (\frac {-\lambda \int ^{l_{\textit{ij}}}_{0} r_{\textit{ij}}(y,t){\rm d}y}{q_{\textit{ij}}}\right )\!, \end{align}
where
 ${L}_{\boldsymbol{q}}^{\textit{in}}$
is the dimensionless in-degree flux-weighted advection operator (see (A13) in Appendix A),
${L}_{\boldsymbol{q}}^{\textit{in}}$
is the dimensionless in-degree flux-weighted advection operator (see (A13) in Appendix A),
 $\boldsymbol{q} = \{q_{\textit{ij}}\}_{ (i,j )\in E}$
is the flux matrix and
$\boldsymbol{q} = \{q_{\textit{ij}}\}_{ (i,j )\in E}$
is the flux matrix and
 $\boldsymbol{c}_0$
is the dimensionless initial inlet concentration.
$\boldsymbol{c}_0$
is the dimensionless initial inlet concentration.
For pore radius
 $r_{\textit{ij}}$
in the
$r_{\textit{ij}}$
in the
 $n$
th band (for the pore
$n$
th band (for the pore
 $e_{\textit{ij}}=(v_i,v_{\!j})\in E_n$
)
$e_{\textit{ij}}=(v_i,v_{\!j})\in E_n$
)
 \begin{equation} \frac {\partial r_{\textit{ij}} (y,t)}{\partial t}=-{c}_{\textit{ij}}(y,t), \quad r_{\textit{ij}}(y,0) = r_n, \quad \forall e_{\textit{ij}}\in E_n. \end{equation}
\begin{equation} \frac {\partial r_{\textit{ij}} (y,t)}{\partial t}=-{c}_{\textit{ij}}(y,t), \quad r_{\textit{ij}}(y,0) = r_n, \quad \forall e_{\textit{ij}}\in E_n. \end{equation}
The dimensionless throughput is given by
 \begin{equation} h(t)=\frac {1}{\lambda }\int _{0}^{\textrm {t}}q_{\textit{out}}(t^{\prime }){\rm d}t^{\prime }, \quad q_{\textit{out}}(t) = \sum _{v_{\!j}\in V_{\textit{out}}}\sum _{v_{i}\,:\, (v_{i},v_{\!j})\in E}q_{\textit{ij}}(t), \end{equation}
\begin{equation} h(t)=\frac {1}{\lambda }\int _{0}^{\textrm {t}}q_{\textit{out}}(t^{\prime }){\rm d}t^{\prime }, \quad q_{\textit{out}}(t) = \sum _{v_{\!j}\in V_{\textit{out}}}\sum _{v_{i}\,:\, (v_{i},v_{\!j})\in E}q_{\textit{ij}}(t), \end{equation}
and dimensionless accumulated foulant concentration is written as
 \begin{equation} c_{\textit{acm}}(t)=\frac {\int _{0}^{t}c_{\textit{out}}(t^{\prime })q_{\textit{out}}(t^{\prime }){\rm d}t^{\prime }}{\int _{0}^{t}q_{\textit{out}}(t^{\prime }){\rm d}t^{\prime }}, \end{equation}
\begin{equation} c_{\textit{acm}}(t)=\frac {\int _{0}^{t}c_{\textit{out}}(t^{\prime })q_{\textit{out}}(t^{\prime }){\rm d}t^{\prime }}{\int _{0}^{t}q_{\textit{out}}(t^{\prime }){\rm d}t^{\prime }}, \end{equation}
where
 \begin{align} c_{\textit{out}}(t)=\frac {{\displaystyle \sum _{v_{\!j}\in V_{\textit{out}}}\sum _{v_{i}\,:\, (v_{i},v_{\!j})\in E}}\boldsymbol{c}_{\!j}(t)q_{\textit{ij}}(t)}{q_{\textit{out}}(t)}. \end{align}
\begin{align} c_{\textit{out}}(t)=\frac {{\displaystyle \sum _{v_{\!j}\in V_{\textit{out}}}\sum _{v_{i}\,:\, (v_{i},v_{\!j})\in E}}\boldsymbol{c}_{\!j}(t)q_{\textit{ij}}(t)}{q_{\textit{out}}(t)}. \end{align}
See figure 2 for a diagram of the algorithm that simulates these governing equations, and table 1 for a list of key symbols and dimensionless quantities, including values assigned for simulations.
Key nomenclature, symbols and values for dimensionless quantities used throughout this work. Here,
 $|V_{\textit{in}}|$
,
$|V_{\textit{in}}|$
,
 $|V_{\textit{out}}|$
and
$|V_{\textit{out}}|$
and
 $|V_{\textit{int}}|$
depend on the radius gradient
$|V_{\textit{int}}|$
depend on the radius gradient
 $s$
per the porosity-fixed network generation protocol described in § 2.1. Graph-based matrix operators are formulated in Appendix A.
$s$
per the porosity-fixed network generation protocol described in § 2.1. Graph-based matrix operators are formulated in Appendix A.

Upper table: parameter values used in simulations. Lower table: radius in each band corresponding to each radius gradient.

5. Results
This section presents computational results for the physical outputs and performance metrics defined in § 4. We first outline the computational set-up and parameters employed in the simulations. Geometric parameters, such as the maximum and minimum pore length (
 $d_{\textit{max}}=0.15$
and
$d_{\textit{max}}=0.15$
and
 $d_{\textit{min}}=0.06$
), the number of bands
$d_{\textit{min}}=0.06$
), the number of bands
 $m=4$
and the adsorptive coefficient
$m=4$
and the adsorptive coefficient
 $\lambda = 5\times {10}^{-7}$
, are held fixed; see table 1. The chief uncertainty in assigning a value to
$\lambda = 5\times {10}^{-7}$
, are held fixed; see table 1. The chief uncertainty in assigning a value to
 $\lambda$
lies in determining the adsorption parameter
$\lambda$
lies in determining the adsorption parameter
 $\varLambda$
; see (4.1). In principle,
$\varLambda$
; see (4.1). In principle,
 $\varLambda$
can be estimated from mass conservation in a filtration experiment: measure the difference between injected and effluent foulant concentration over prescribed time intervals to gauge the relative purity of the filtrate. This can then be compared with the cumulative adsorption
$\varLambda$
can be estimated from mass conservation in a filtration experiment: measure the difference between injected and effluent foulant concentration over prescribed time intervals to gauge the relative purity of the filtrate. This can then be compared with the cumulative adsorption
 $c_{\textit{acm}}$
(per (4.8)) predicted by solutions to (2.9), (2.10), providing an experimental route to calibrating
$c_{\textit{acm}}$
(per (4.8)) predicted by solutions to (2.9), (2.10), providing an experimental route to calibrating
 $\varLambda$
. Since our focus here is to study the regime where sieving contributes appreciably to the fouling, we choose a
$\varLambda$
. Since our focus here is to study the regime where sieving contributes appreciably to the fouling, we choose a
 $\lambda$
-value such that adsorptive fouling does not strongly dominate, leaving an in-depth study of this parameter to future work.
$\lambda$
-value such that adsorptive fouling does not strongly dominate, leaving an in-depth study of this parameter to future work.
The goal of the present work is to understand the interplay between the new fouling mode of sieving, the pore-radius gradient
 $s$
and the monodisperse sieving-particle size
$s$
and the monodisperse sieving-particle size
 $p_{\textit{size}}$
at different arrival rates
$p_{\textit{size}}$
at different arrival rates
 $\gamma$
, forming a parameter set
$\gamma$
, forming a parameter set
 $ (s,p_{\textit{size}},\gamma )$
that we investigate; see table 2. We do not explore the effects of network variations due to the random graph generation protocol described in § 2); instead, we focus on a single realisation of the network for each radius gradient. We have verified (results not shown here for brevity) that outputs from other independent realisations are very similar, yielding results within
$ (s,p_{\textit{size}},\gamma )$
that we investigate; see table 2. We do not explore the effects of network variations due to the random graph generation protocol described in § 2); instead, we focus on a single realisation of the network for each radius gradient. We have verified (results not shown here for brevity) that outputs from other independent realisations are very similar, yielding results within
 $10\,\%$
of those shown here; see Gu et al. (Reference Gu, Kondic and Cummings2022b
) for an in-depth study of the effects of network variability in fixed-porosity pore networks. For investigations on geometric variations in set-ups similar to our work (but without sieving), see Gu et al. (Reference Gu, Kondic and Cummings2022a
, Reference Gu, Kondic and Cummings2023).
$10\,\%$
of those shown here; see Gu et al. (Reference Gu, Kondic and Cummings2022b
) for an in-depth study of the effects of network variability in fixed-porosity pore networks. For investigations on geometric variations in set-ups similar to our work (but without sieving), see Gu et al. (Reference Gu, Kondic and Cummings2022a
, Reference Gu, Kondic and Cummings2023).
To explore the effect of pore-radius gradient, we consider three cases: an ungraded ‘uniform’ network with
 $s=0$
, a moderately graded network with
$s=0$
, a moderately graded network with
 $s=0.0015$
(as our benchmark network) and a strongly graded network with
$s=0.0015$
(as our benchmark network) and a strongly graded network with
 $s=0.003$
. To place these values in context, we note that, with the constraints inherent in our model, there exists a theoretical upper limit
$s=0.003$
. To place these values in context, we note that, with the constraints inherent in our model, there exists a theoretical upper limit
 $s_{\textit{max}}$
beyond which pores would shrink to zero radius in the bottom band. For the geometry considered in this work we find that
$s_{\textit{max}}$
beyond which pores would shrink to zero radius in the bottom band. For the geometry considered in this work we find that
 $s_{\textit{max}} \approx 0.0066$
(see Appendix B for a brief calculation), so the strongly graded case
$s_{\textit{max}} \approx 0.0066$
(see Appendix B for a brief calculation), so the strongly graded case
 $s=0.003$
corresponds to approximately
$s=0.003$
corresponds to approximately
 $45\,\%$
of this limit, while the moderate case
$45\,\%$
of this limit, while the moderate case
 $s=0.0015$
corresponds to approximately
$s=0.0015$
corresponds to approximately
 $22.5\,\%$
. Since band porosity is always fixed, a gradient in node density is inevitable when
$22.5\,\%$
. Since band porosity is always fixed, a gradient in node density is inevitable when
 $s\gt 0$
– the larger the pore radius in a given band, the fewer nodes it contains. In table 2 we tabulate the pore radius in each band at each
$s\gt 0$
– the larger the pore radius in a given band, the fewer nodes it contains. In table 2 we tabulate the pore radius in each band at each
 $s$
-value. We chose four particle sizes based on their ability to initially sieve at each band in the moderately graded case. For example, a particle with
$s$
-value. We chose four particle sizes based on their ability to initially sieve at each band in the moderately graded case. For example, a particle with
 $p_{\textit{size}} = 0.0078$
(the smallest considered in this work) will initially be able to pass through the
$p_{\textit{size}} = 0.0078$
(the smallest considered in this work) will initially be able to pass through the
 $3$
rd band of the moderately graded network but not the
$3$
rd band of the moderately graded network but not the
 $4$
th.
$4$
th.
We now address the stochastic simulation using (4.3). Given the random nature of Poisson arrivals, for each parameter triple
 $ (s,p_{\textit{size}},\gamma )$
, we simulate
$ (s,p_{\textit{size}},\gamma )$
, we simulate
 $120$
realisations of the Poisson process and collect statistics (average and standard deviation) on scalar performance metrics such as total throughput
$120$
realisations of the Poisson process and collect statistics (average and standard deviation) on scalar performance metrics such as total throughput
 $v_{\textit{final}}$
, accumulated foulant concentration
$v_{\textit{final}}$
, accumulated foulant concentration
 $c_{\textit{acm}}$
and filter lifetime
$c_{\textit{acm}}$
and filter lifetime
 $t_{\textit{final}}$
(see their definitions in § 3), and on time series data such as total flux
$t_{\textit{final}}$
(see their definitions in § 3), and on time series data such as total flux
 $q_{\textit{out}}$
through the filter, pressure, and foulant concentration at each vertex. This number of realisations was found sufficient to yield stable ensemble averages. For each simulation, we first generate a sequence of arrival times, with inter-arrival times exponentially distributed with mean
$q_{\textit{out}}$
through the filter, pressure, and foulant concentration at each vertex. This number of realisations was found sufficient to yield stable ensemble averages. For each simulation, we first generate a sequence of arrival times, with inter-arrival times exponentially distributed with mean
 $1/\gamma$
. In other words, the arrival events are `predetermined’ before each simulation begins.
$1/\gamma$
. In other words, the arrival events are `predetermined’ before each simulation begins.
To solve the governing equations numerically, the ODEs in (4.6) are solved using the forward Euler method with an adaptive time-stepping scheme. This adaptivity ensures that the time step is sufficiently small to resolve short inter-arrival times, which is particularly important at high arrival rates. When no arrival event occurs, the time step is fixed at
 ${\rm d}t={10}^{-5}$
. However, when an arrival event is detected, the time step is adjusted to
${\rm d}t={10}^{-5}$
. However, when an arrival event is detected, the time step is adjusted to
 $0.9 (t^{ (k+1 )}-t^{ (k )} )$
which represents
$0.9 (t^{ (k+1 )}-t^{ (k )} )$
which represents
 $90\,\%$
of the
$90\,\%$
of the
 $k$
th inter-arrival interval, so as to prevent skipping events during time integration.
$k$
th inter-arrival interval, so as to prevent skipping events during time integration.
Given the inherent randomness of the sieving process, filters with identical input parameters may have different lifetimes. Additionally, the adaptive time-stepping scheme results in time series data from different realisations being recorded at non-uniform time points. Therefore, to ensure meaningful statistical analysis, a careful statistical averaging procedure is necessary. For each parameter set
 $ (s,p_{\textit{size}},\gamma )$
, we first determine the maximum filter lifetime,
$ (s,p_{\textit{size}},\gamma )$
, we first determine the maximum filter lifetime,
 $t_{\textit{max}}$
, among the
$t_{\textit{max}}$
, among the
 $120$
samples, via
$120$
samples, via
 \begin{align} t_{\textit{max}} = \max\limits_{1\,\leq\, i\, \leq\, 120}\left \{t_{\textit{final}}^{(i)}\right \}\!, \end{align}
\begin{align} t_{\textit{max}} = \max\limits_{1\,\leq\, i\, \leq\, 120}\left \{t_{\textit{final}}^{(i)}\right \}\!, \end{align}
where for (realised) time series
 $i$
, the stopping time
$i$
, the stopping time
 $t_{\textit{final}}^{(i)}$
follows (the dimensionless version of) (3.4). By construction, the stopping criterion implies that the total flux is identically zero for all
$t_{\textit{final}}^{(i)}$
follows (the dimensionless version of) (3.4). By construction, the stopping criterion implies that the total flux is identically zero for all
 $t \ge t_{\textit{final}}^{(i)}$
, so the throughput does not evolve beyond this time.
$t \ge t_{\textit{final}}^{(i)}$
, so the throughput does not evolve beyond this time.
Next, for each computed time series (e.g. total flux
 $q_{\textit{out}} (t )$
) corresponding to the given parameters, we define a uniform time grid over
$q_{\textit{out}} (t )$
) corresponding to the given parameters, we define a uniform time grid over
 $ [0,t_{\textit{max}} ]$
with a mesh size of
$ [0,t_{\textit{max}} ]$
with a mesh size of
 ${10}^{-8}$
, ensuring sufficient resolution to distinguish inter-arrival times at the highest arrival rate considered in this work with overwhelming probability. Each time series is then linearly interpolated onto this common grid. To handle simulations that terminate before
${10}^{-8}$
, ensuring sufficient resolution to distinguish inter-arrival times at the highest arrival rate considered in this work with overwhelming probability. Each time series is then linearly interpolated onto this common grid. To handle simulations that terminate before
 $t_{\textit{max}}$
, the flux and throughput remain constant beyond their termination point, consistent with the model dynamics, which yield zero flux and no change in throughput once the filter is fully blocked. This approach ensures that all time series associated with a given parameter set are aligned on a common time grid, enabling consistent pointwise averaging over time.
$t_{\textit{max}}$
, the flux and throughput remain constant beyond their termination point, consistent with the model dynamics, which yield zero flux and no change in throughput once the filter is fully blocked. This approach ensures that all time series associated with a given parameter set are aligned on a common time grid, enabling consistent pointwise averaging over time.
With the computational set-up described above, we are now ready to present the results and discuss their implications. All quantities of interest are the sample averages described above, unless otherwise noted.
5.1. General dynamics
Before examining performance metrics in detail, we first clarify how blocking affects each of the three pore-radius-graded networks. In the ungraded network, blocking always occurs at the top surface, regardless of
 $p_{\textit{size}}$
, because adsorptive particles have the highest upstream concentration, causing the inlet pores to shrink fastest. In contrast, graded networks can exhibit internal blocking: particles small enough to pass through larger top-surface pores may be trapped deeper in the membrane where pores are narrower. Surface blocking in these cases only arises once upstream pores have narrowed sufficiently due to adsorptive fouling. This mechanism leads to more complex dynamics and performance outcomes.
$p_{\textit{size}}$
, because adsorptive particles have the highest upstream concentration, causing the inlet pores to shrink fastest. In contrast, graded networks can exhibit internal blocking: particles small enough to pass through larger top-surface pores may be trapped deeper in the membrane where pores are narrower. Surface blocking in these cases only arises once upstream pores have narrowed sufficiently due to adsorptive fouling. This mechanism leads to more complex dynamics and performance outcomes.
5.2. Flux vs throughput
One key trend monitored in membrane filtration studies is the flux-versus-throughput plot. In figure 3, we demonstrate this relationship for all three pore-radius gradients considered, using
 $p_{\textit{size}} = 0.0078$
, the smallest sieving-particle size. With this
$p_{\textit{size}} = 0.0078$
, the smallest sieving-particle size. With this
 $p_{\textit{size}}$
value, in both moderately and strongly graded networks, the
$p_{\textit{size}}$
value, in both moderately and strongly graded networks, the
 $4$
th band will begin sieving first, since this particle size can initially pass through the
$4$
th band will begin sieving first, since this particle size can initially pass through the
 $3$
rd band in both networks. As upstream pores narrow due to adsorption, each band becomes susceptible to sieving as filtration continues (until the stopping criterion is reached). However, for the ungraded network, the sequence of events is qualitatively different. Sieving particles escape the membrane initially and, because of a higher concentration of adsorptive foulants at the membrane top surface, the pores here shrink fastest. Blocking, therefore, occurs only at the inlets in the
$3$
rd band in both networks. As upstream pores narrow due to adsorption, each band becomes susceptible to sieving as filtration continues (until the stopping criterion is reached). However, for the ungraded network, the sequence of events is qualitatively different. Sieving particles escape the membrane initially and, because of a higher concentration of adsorptive foulants at the membrane top surface, the pores here shrink fastest. Blocking, therefore, occurs only at the inlets in the
 $1$
st band, at the time when they become smaller than the particle size.
$1$
st band, at the time when they become smaller than the particle size.
Flux vs throughput for networks with pore-radius gradient (a)
 $s=0$
(ungraded), (b)
$s=0$
(ungraded), (b)
 $s=0.0015$
(moderate) and (c)
$s=0.0015$
(moderate) and (c)
 $s=0.003$
(strong). For all plots,
$s=0.003$
(strong). For all plots,
 $p_{\textit{size}} = 0.0078$
.
$p_{\textit{size}} = 0.0078$
.

Figure 3 shows results for several different values of the arrival rate
 $\gamma$
, which influences the flux and total throughput obtained. In our benchmark moderately graded network figure 3(b), we observe a consistent decline in both metrics as
$\gamma$
, which influences the flux and total throughput obtained. In our benchmark moderately graded network figure 3(b), we observe a consistent decline in both metrics as
 $\gamma$
increases: flux-throughput curves drop more rapidly, and their
$\gamma$
increases: flux-throughput curves drop more rapidly, and their
 $x$
-intercepts (total throughput over the filter lifetime) decrease. This is expected because, while adsorption contributes to fouling across all cases, the additional sieving that occurs as
$x$
-intercepts (total throughput over the filter lifetime) decrease. This is expected because, while adsorption contributes to fouling across all cases, the additional sieving that occurs as
 $\gamma$
increases accelerates filter deterioration: at higher arrival rates, the filter receives a heavier foulant load overall and thus blocks sooner. The same trend is evident in both the ungraded (figure 3
a) and strongly graded (figure 3
c) networks. We also note in passing that the initial flux decreases as a function of radius gradient
$\gamma$
increases accelerates filter deterioration: at higher arrival rates, the filter receives a heavier foulant load overall and thus blocks sooner. The same trend is evident in both the ungraded (figure 3
a) and strongly graded (figure 3
c) networks. We also note in passing that the initial flux decreases as a function of radius gradient
 $s$
(see the vertical intercepts of all parts of figure 3). This occurs since, the larger the gradient, the smaller and more numerous the pores in the bottom band, contributing significantly to the filter’s overall (initial) resistance.
$s$
(see the vertical intercepts of all parts of figure 3). This occurs since, the larger the gradient, the smaller and more numerous the pores in the bottom band, contributing significantly to the filter’s overall (initial) resistance.
For each pore-radius gradient, the total throughput does not vary dramatically with the arrival rate (though the ungraded network performs worst at all
 $\gamma$
-values). We attribute the relatively weak influence on total throughput to the small particle size, but for different reasons in each radius-gradient case. In the ungraded network, small particles initially pass through until the upstream band 1 pores become small enough to block them. Flux is unaffected by sieving for most of the filter’s lifetime, maintaining reasonably good throughput. However, when sieving begins, the flux decline is more drastic than in other cases because blocking occurs exclusively on the membrane top surface, shutting down the inlets and significantly reducing the number of possible paths from the top surface to the bottom. In essence, the relative gain in throughput due to the initial absence of sieving is mitigated by the catastrophic blocking at the inlets later. This filter pore network performs the worst of the three considered across all arrival rates. For both of the graded networks, however, blocking initially occurs in the 4th band, obstructing flow and thus filtrate production, but not drastically (pores in band 4 are much smaller and more numerous than those in upstream bands). The upstream pores do not reach the critical size that induces blocking until later than their ungraded counterparts, thereby extending filter lifetime (discussed further later) and increasing filtrate production relative to that case.
$\gamma$
-values). We attribute the relatively weak influence on total throughput to the small particle size, but for different reasons in each radius-gradient case. In the ungraded network, small particles initially pass through until the upstream band 1 pores become small enough to block them. Flux is unaffected by sieving for most of the filter’s lifetime, maintaining reasonably good throughput. However, when sieving begins, the flux decline is more drastic than in other cases because blocking occurs exclusively on the membrane top surface, shutting down the inlets and significantly reducing the number of possible paths from the top surface to the bottom. In essence, the relative gain in throughput due to the initial absence of sieving is mitigated by the catastrophic blocking at the inlets later. This filter pore network performs the worst of the three considered across all arrival rates. For both of the graded networks, however, blocking initially occurs in the 4th band, obstructing flow and thus filtrate production, but not drastically (pores in band 4 are much smaller and more numerous than those in upstream bands). The upstream pores do not reach the critical size that induces blocking until later than their ungraded counterparts, thereby extending filter lifetime (discussed further later) and increasing filtrate production relative to that case.
To further distinguish among the total throughputs of the three networks considered, we may examine the total throughput values when the sieving-particle arrival rate is high. For example, for
 $\gamma =31$
, the highest rate considered, we see that the moderately graded network (see figure 3
b) produces the most throughput, indicating that for this scenario it is the optimal radius gradient of the three considered (the kink seen in the
$\gamma =31$
, the highest rate considered, we see that the moderately graded network (see figure 3
b) produces the most throughput, indicating that for this scenario it is the optimal radius gradient of the three considered (the kink seen in the
 $\gamma =31$
curve of figure 3
c will be discussed later). This observation is particularly relevant for applications when the sieving particles are small but frequent, for which our results suggest that an intermediate value of pore-radius gradient is preferable. The same ranking holds for lower arrival rates; however, the difference in total throughput between the two graded cases becomes less pronounced. The ungraded case consistently performs the worst.
$\gamma =31$
curve of figure 3
c will be discussed later). This observation is particularly relevant for applications when the sieving particles are small but frequent, for which our results suggest that an intermediate value of pore-radius gradient is preferable. The same ranking holds for lower arrival rates; however, the difference in total throughput between the two graded cases becomes less pronounced. The ungraded case consistently performs the worst.
Flux vs throughput for networks with pore-radius gradient (a)
 $s=0$
(ungraded) (b)
$s=0$
(ungraded) (b)
 $s=0.0015$
(moderate) and (c)
$s=0.0015$
(moderate) and (c)
 $s=0.003$
(strong). For all plots,
$s=0.003$
(strong). For all plots,
 $p_{\textit{size}} = 0.0123$
.
$p_{\textit{size}} = 0.0123$
.

In figure 4, we similarly plot flux vs throughput for the same three filters and seven arrival rates as in figure 3, but now using the largest sieving-particle size considered, with
 $p_{\textit{size}}=0.0123$
. In each case, sieving begins immediately, but in band 1 for the ungraded and moderately graded networks, and in band 2 for the strongly graded network. We still see the expected trend that total throughput decreases as the arrival rate of sieving particles increases, and again, the range of total throughput is only affected by
$p_{\textit{size}}=0.0123$
. In each case, sieving begins immediately, but in band 1 for the ungraded and moderately graded networks, and in band 2 for the strongly graded network. We still see the expected trend that total throughput decreases as the arrival rate of sieving particles increases, and again, the range of total throughput is only affected by
 $s$
to a relatively small degree. However, the dependence on large-particle arrival rate is much stronger here; the gaps between the flux-throughput curves for different
$s$
to a relatively small degree. However, the dependence on large-particle arrival rate is much stronger here; the gaps between the flux-throughput curves for different
 $\gamma$
-values are far larger in figure 4 than in figure 3. For the ungraded and moderately graded cases sieving starts immediately on the top surface, and the number of clogged inlets increases faster as
$\gamma$
-values are far larger in figure 4 than in figure 3. For the ungraded and moderately graded cases sieving starts immediately on the top surface, and the number of clogged inlets increases faster as
 $\gamma$
increases, preventing downstream neighbouring pores and their subnetworks from participating in filtration (this remains true as long as the sieving-particle size is larger than the initial pore size on the top surface). For the strongly graded case, although sieving initially begins in band 2, for the larger particle size considered here, the upstream pores in band 1 need only shrink slightly to begin sieving. In other words, upstream bands sieve earlier in the filtration process for larger sieving particles, so that the sieving rate is a more important factor in determining performance.
$\gamma$
increases, preventing downstream neighbouring pores and their subnetworks from participating in filtration (this remains true as long as the sieving-particle size is larger than the initial pore size on the top surface). For the strongly graded case, although sieving initially begins in band 2, for the larger particle size considered here, the upstream pores in band 1 need only shrink slightly to begin sieving. In other words, upstream bands sieve earlier in the filtration process for larger sieving particles, so that the sieving rate is a more important factor in determining performance.
For the highest sieving-particle arrival rate,
 $\gamma =31$
, we observe in figure 4 that the moderately graded filter of figure 4(b) is the worst in terms of total throughput among the three networks considered, contrary to the results in figure 3(b) (where it is the best among the three). Taken together with the previous observation, this suggests that, in applications, filters with moderately graded pore networks may be less effective when processing large sieving particles at high arrival rates (in fact, the ungraded and strongly graded filters have nearly identical throughputs in this particular case).
$\gamma =31$
, we observe in figure 4 that the moderately graded filter of figure 4(b) is the worst in terms of total throughput among the three networks considered, contrary to the results in figure 3(b) (where it is the best among the three). Taken together with the previous observation, this suggests that, in applications, filters with moderately graded pore networks may be less effective when processing large sieving particles at high arrival rates (in fact, the ungraded and strongly graded filters have nearly identical throughputs in this particular case).
Another point to highlight in both figures 3(c) and 4(c) is the kink in the flux-throughput curve corresponding to the case of the largest arrival rate
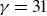 $\gamma = 31$
(faintly visible when
$\gamma = 31$
(faintly visible when
 $\gamma = 25$
as well), a phenomenon absent in the moderately graded and ungraded cases (see the relatively smoother curves in figures 3
a, 3
b, 4
a and 4
b). We discuss this point with reference to the results of figure 3, comparing both moderately and strongly graded networks for
$\gamma = 25$
as well), a phenomenon absent in the moderately graded and ungraded cases (see the relatively smoother curves in figures 3
a, 3
b, 4
a and 4
b). We discuss this point with reference to the results of figure 3, comparing both moderately and strongly graded networks for
 $p_{\textit{size}} = 0.0078$
. To relate the time of kink formation to the sieving process, we consider in figure 5 the flux
$p_{\textit{size}} = 0.0078$
. To relate the time of kink formation to the sieving process, we consider in figure 5 the flux
 $q(t)$
(red/pink curves) alongside the fraction of blocked pores in each band (blue curves), defined as
$q(t)$
(red/pink curves) alongside the fraction of blocked pores in each band (blue curves), defined as
 \begin{equation} \beta _{k}(t)=\frac {\#\text{ of blocked pores in the $k$th band at time }t}{\#\text{ of pores in the $k$th band}}. \end{equation}
\begin{equation} \beta _{k}(t)=\frac {\#\text{ of blocked pores in the $k$th band at time }t}{\#\text{ of pores in the $k$th band}}. \end{equation}
This function lies between 0 and 1 with
 $\beta _k (0)=0$
, and is monotone non-decreasing since unblocking cannot occur. When it increases, it indicates active sieving in the
$\beta _k (0)=0$
, and is monotone non-decreasing since unblocking cannot occur. When it increases, it indicates active sieving in the
 $k$
th band, whereas its flattening signifies cessation of sieving in that band.
$k$
th band, whereas its flattening signifies cessation of sieving in that band.
Strongly graded network: blocking fraction
 $\beta _k(t)$
(see (5.2), left vertical axis, shades of
$\beta _k(t)$
(see (5.2), left vertical axis, shades of ![]() ) and flux
) and flux
 $q(t)$
(right vertical axis, shades of
$q(t)$
(right vertical axis, shades of ![]() ), against time. For all plots,
), against time. For all plots,
 $p_{\textit{size}} = 0.0078$
; results correspond to those of figure 3(c). (a) Band 1, (b) band 2, (c) band 3, (d) band 4.
$p_{\textit{size}} = 0.0078$
; results correspond to those of figure 3(c). (a) Band 1, (b) band 2, (c) band 3, (d) band 4.

In figure 5(a), we focus on the fraction of blocked pores in the 1st band as a function of time for the strongly graded network and the smallest sieving particle (results of figure 3
c). We observe that for the largest arrival rate of sieving particles,
 $\gamma = 31$
, the time of kink formation in the flux curve corresponds to precisely the time at which the first band begins to sieve. Incidentally, this is also when the second band ceases to sieve, as seen in figure 5(b) by the flattening of the fraction of blocked pores,
$\gamma = 31$
, the time of kink formation in the flux curve corresponds to precisely the time at which the first band begins to sieve. Incidentally, this is also when the second band ceases to sieve, as seen in figure 5(b) by the flattening of the fraction of blocked pores,
 $\beta _2(t)$
. One particularly interesting observation lies in figures 5(b) and 5(c), where we see both
$\beta _2(t)$
. One particularly interesting observation lies in figures 5(b) and 5(c), where we see both
 $\beta _2 (t )$
and
$\beta _2 (t )$
and
 $\beta _3 (t )$
are increasing slightly beyond
$\beta _3 (t )$
are increasing slightly beyond
 $t=0.005$
before both flatten soon after. This indicates a brief interval of simultaneous sieving activity in the
$t=0.005$
before both flatten soon after. This indicates a brief interval of simultaneous sieving activity in the
 $2$
nd and
$2$
nd and
 $3$
rd bands. This phenomenon is, in fact, singular to the strongly graded network when processing small sieving particles because, during this interval, pore radii in both bands have evolved under adsorptive fouling to be similar in size due to the radius gradient between the two bands. Figure 5(d) verifies that sieving begins as soon as filtration starts, since the sieving particles are large enough to block the pores in the
$3$
rd bands. This phenomenon is, in fact, singular to the strongly graded network when processing small sieving particles because, during this interval, pore radii in both bands have evolved under adsorptive fouling to be similar in size due to the radius gradient between the two bands. Figure 5(d) verifies that sieving begins as soon as filtration starts, since the sieving particles are large enough to block the pores in the
 $4$
th band of a strongly graded network (see table 2 for initial pore radii in each band).
$4$
th band of a strongly graded network (see table 2 for initial pore radii in each band).
In figure 6, we similarly plot the flux
 $q(t)$
alongside the fraction of blocked pores
$q(t)$
alongside the fraction of blocked pores
 $\beta _k(t)$
in each band for a moderately graded network using the smallest sieving-particle size (results of figure 3
b). Here, observing the onset of sieving via the horizontal intercepts of the blue curves through figure 6(a) to 6(d), we find that each band operates sequentially without simultaneous cooperative sieving, i.e. an upstream band must ‘wait’ until its immediate downstream band finishes sieving. The sequential nature of the sieving is because the pore radii in adjacent bands are quite close to each other in this moderately graded case. Thus, when one band has a pore radius small enough to sieve, its upstream counterparts have also shrunk to a similar size due to adsorption. We verify this claim in figure 6(b), where we observe almost no sieving in the
$\beta _k(t)$
in each band for a moderately graded network using the smallest sieving-particle size (results of figure 3
b). Here, observing the onset of sieving via the horizontal intercepts of the blue curves through figure 6(a) to 6(d), we find that each band operates sequentially without simultaneous cooperative sieving, i.e. an upstream band must ‘wait’ until its immediate downstream band finishes sieving. The sequential nature of the sieving is because the pore radii in adjacent bands are quite close to each other in this moderately graded case. Thus, when one band has a pore radius small enough to sieve, its upstream counterparts have also shrunk to a similar size due to adsorption. We verify this claim in figure 6(b), where we observe almost no sieving in the
 $2$
nd band. In other words, the moderately graded network may not utilise as many pores for sieving as the strongly graded one (compare figures 5 and 6).
$2$
nd band. In other words, the moderately graded network may not utilise as many pores for sieving as the strongly graded one (compare figures 5 and 6).
The brief overlap in sieving activity observed between adjacent bands (notably
 $2$
nd and
$2$
nd and
 $3$
rd bands in the strongly graded network) occurs only under a narrow range of geometric and hydraulic conditions. In our simulations, this overlap arises when pore radii in neighbouring bands evolve to comparable magnitudes over a finite time window, allowing sieving particles to concurrently block pores in both layers. This requires sufficient initial separation in pore sizes to permit downstream sieving, together with sufficiently strong flow to maintain comparable adsorption rates across adjacent bands.
$3$
rd bands in the strongly graded network) occurs only under a narrow range of geometric and hydraulic conditions. In our simulations, this overlap arises when pore radii in neighbouring bands evolve to comparable magnitudes over a finite time window, allowing sieving particles to concurrently block pores in both layers. This requires sufficient initial separation in pore sizes to permit downstream sieving, together with sufficiently strong flow to maintain comparable adsorption rates across adjacent bands.
Although this behaviour is observed only in the strongly graded network among the cases considered in this work, we recall that this network corresponds to an intermediate fraction (45 %) of the theoretically admissible radius gradient
 $s_{\textit{max}}$
. From this perspective, we speculate that simultaneous sieving can persist only within an intermediate range of admissible gradients, provided the sieving-particle size is small enough to access downstream layers. For larger gradients (close to
$s_{\textit{max}}$
. From this perspective, we speculate that simultaneous sieving can persist only within an intermediate range of admissible gradients, provided the sieving-particle size is small enough to access downstream layers. For larger gradients (close to
 $s_{\textit{max}}$
), the fixed-porosity constraint leads to a high density of small pores in downstream bands, raising hydraulic resistance and reducing flow (see the decreasing initial fluxes across figures 3
a to 3
c). The reduced flow promotes adsorption near the inlet, accelerating upstream pore closure and eliminating the window over which interior bands can evolve toward comparable radii. On the other hand, for very small pore-size gradients, pore sizes across bands are initially similar and upstream pores shrink past the sieving threshold before downstream bands are reached. Only within this intermediate gradient regime (including the strongly graded case studied here) are pore-size separation and fluid flow sufficiently balanced to allow a brief interval of overlapping sieving activity between adjacent interior bands.
$s_{\textit{max}}$
), the fixed-porosity constraint leads to a high density of small pores in downstream bands, raising hydraulic resistance and reducing flow (see the decreasing initial fluxes across figures 3
a to 3
c). The reduced flow promotes adsorption near the inlet, accelerating upstream pore closure and eliminating the window over which interior bands can evolve toward comparable radii. On the other hand, for very small pore-size gradients, pore sizes across bands are initially similar and upstream pores shrink past the sieving threshold before downstream bands are reached. Only within this intermediate gradient regime (including the strongly graded case studied here) are pore-size separation and fluid flow sufficiently balanced to allow a brief interval of overlapping sieving activity between adjacent interior bands.
Moderately graded network (corresponding to results of figure 3
b): blocking fraction
 $\beta _k(t)$
and flux
$\beta _k(t)$
and flux
 $q(t)$
against time, otherwise the same set-up as figure 5. Note that, in (b),
$q(t)$
against time, otherwise the same set-up as figure 5. Note that, in (b),
 $\beta _2(t)$
is very close to
$\beta _2(t)$
is very close to
 $0$
for all
$0$
for all
 $\gamma$
-values, indicating that the 2nd band undergoes almost no sieving, regardless of sieving-particle arrival rate. (a) Band 1, (b) band 2, (c) band 3, (d) band 4.
$\gamma$
-values, indicating that the 2nd band undergoes almost no sieving, regardless of sieving-particle arrival rate. (a) Band 1, (b) band 2, (c) band 3, (d) band 4.

We also briefly examine how the concavity of the flux–time curves reflects the dominant fouling mechanisms at different stages of filtration, since this has been previously discussed in the literature (Bowen, Calvo & Hernández Reference Bowen, Calvo and Hernández1995; Xu & Chellam Reference Xu and Chellam2005; Cogan & Chellam Reference Cogan and Chellam2008; Krupp, Griffiths & Please Reference Krupp, Griffiths and Please2017; Griffiths et al. Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020; Drumm & Bernardi Reference Drumm and Bernardi2025). At small arrival rates
 $\gamma$
, adsorption dominates, producing flux curves that are predominantly concave up and decaying smoothly toward zero. At large arrival rates, sieving becomes more important, and the flux curves may exhibit regions where they are concave down (exemplified by, e.g. the kinked regions in figure 5), reflecting a more abrupt loss of permeability due to instantaneous removal of conducting pathways.
$\gamma$
, adsorption dominates, producing flux curves that are predominantly concave up and decaying smoothly toward zero. At large arrival rates, sieving becomes more important, and the flux curves may exhibit regions where they are concave down (exemplified by, e.g. the kinked regions in figure 5), reflecting a more abrupt loss of permeability due to instantaneous removal of conducting pathways.
The sieving-particle arrival rates considered in our work are not large enough for sieving to be the dominant fouling mechanism. Even the largest arrival rate considered,
 $\gamma =31$
, is still rather moderate, evidenced by the flux–time curves in figure 5 undergoing several concavity changes, as opposed to the solely concave down flux decline that would be expected for the sieving-dominated regime. Each concavity change marks a shift between the adsorption- and sieving-dominated dynamics. Flux is initially concave up, associated with adsorption being dominant at first. The first concavity change (from up to down) occurs near
$\gamma =31$
, is still rather moderate, evidenced by the flux–time curves in figure 5 undergoing several concavity changes, as opposed to the solely concave down flux decline that would be expected for the sieving-dominated regime. Each concavity change marks a shift between the adsorption- and sieving-dominated dynamics. Flux is initially concave up, associated with adsorption being dominant at first. The first concavity change (from up to down) occurs near
 $t=0.0035$
, a time near the height of sieving activities in the
$t=0.0035$
, a time near the height of sieving activities in the
 $3$
rd band (see figure 5
c). As sieving progresses there, and briefly overlaps with the
$3$
rd band (see figure 5
c). As sieving progresses there, and briefly overlaps with the
 $2$
nd band, adsorption in upstream bands temporarily governs the flux decay, leading to a more gradual decline. This regime ends at the pronounced kink near
$2$
nd band, adsorption in upstream bands temporarily governs the flux decay, leading to a more gradual decline. This regime ends at the pronounced kink near
 $t=0.007$
(discussed earlier), corresponding to the onset of sieving in the
$t=0.007$
(discussed earlier), corresponding to the onset of sieving in the
 $1$
st band, which has a much stronger impact on flux by blocking upstream pores and disconnecting downstream pathways.
$1$
st band, which has a much stronger impact on flux by blocking upstream pores and disconnecting downstream pathways.
Accumulated foulant concentration at membrane outlet vs throughput for networks with pore-radius gradient; (a)
 $s=0$
(ungraded), (b)
$s=0$
(ungraded), (b)
 $s=0.0015$
(moderate) and (c)
$s=0.0015$
(moderate) and (c)
 $s=0.003$
(strong). For all plots,
$s=0.003$
(strong). For all plots,
 $p_{\textit{size}} = 0.0078$
.
$p_{\textit{size}} = 0.0078$
.

The findings from this section alone suggest that the strongly graded filters perform slightly better than the moderately graded and ungraded counterparts, in terms of their superior sieving capacity while maintaining a similar level of filtrate production. The main advantage of strongly graded filters, especially when sieving small particles, is the overlap of sieving periods between the interior layers, a feature absent in other networks where only sequential sieving was observed.
In closing, we note that the depth-dependent blocking patterns observed here are consistent with trends reported in previous numerical (Dalwadi et al. Reference Dalwadi, Griffiths and Bruna2015; Griffiths et al. Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020), experimental (Wang & Tarabara Reference Wang and Tarabara2008; Onur et al. Reference Onur, Ng, Batchlor and Garnier2018; Sorrentino, Chellappah & Biscontin Reference Sorrentino, Chellappah and Biscontin2025) and theoretical (Datta & Redner Reference Datta and Redner1998) studies of graded filters, among many others. Prior work has shown that the dominant location of blockage depends on both filter geometry and feed composition, with fouling shifting between surface layers and the filter interior as particle size and operating conditions vary. The present results recover these qualitative observations within a network-based framework that explicitly resolves interior pore blocking.
5.3. Adsorptive and sieving-particle retention
Although we have shown that the strongly graded network is slightly superior in sieving capability and resilience in maintaining total throughput regardless of sieving-particle size, we must also assess efficiency in removing foulants. In this section, we focus on performance metrics that evaluate the accumulated concentration of adsorptive foulant at membrane outlet (
 $c_{\textit{acm}}$
in short, see definition in (4.8)) and the filter’s efficiency in retaining sieving particles. We say total
$c_{\textit{acm}}$
in short, see definition in (4.8)) and the filter’s efficiency in retaining sieving particles. We say total
 $c_{\textit{acm}}$
to represent
$c_{\textit{acm}}$
to represent
 $c_{\textit{acm}}(t_{\textit{final}})$
as it describes the total amount of accumulated foulant concentration at the end of filtration.
$c_{\textit{acm}}(t_{\textit{final}})$
as it describes the total amount of accumulated foulant concentration at the end of filtration.
First, we plot
 $c_{\textit{acm}}$
vs throughput in figure 7 for the three pore networks (different pore-radius gradients) considered, using the smallest sieving-particle size. In all cases,
$c_{\textit{acm}}$
vs throughput in figure 7 for the three pore networks (different pore-radius gradients) considered, using the smallest sieving-particle size. In all cases,
 $c_{\textit{acm}}$
decreases with increasing throughput, indicating improved adsorptive foulant retention independent of the sieving-particle arrival rate. Comparing the three figures, we note an obvious hierarchy in
$c_{\textit{acm}}$
decreases with increasing throughput, indicating improved adsorptive foulant retention independent of the sieving-particle arrival rate. Comparing the three figures, we note an obvious hierarchy in
 $c_{\textit{acm}}$
, with the ungraded network incurring the largest
$c_{\textit{acm}}$
, with the ungraded network incurring the largest
 $c_{\textit{acm}}$
(dirtiest filtrate) and the strongly graded network yielding the least (cleanest filtrate) for each arrival rate. Moreover, figure 7(a) (ungraded case) demonstrates that the total
$c_{\textit{acm}}$
(dirtiest filtrate) and the strongly graded network yielding the least (cleanest filtrate) for each arrival rate. Moreover, figure 7(a) (ungraded case) demonstrates that the total
 $c_{\textit{acm}}$
(the vertical coordinate where each curve ends) is a monotone increasing function of the sieving-particle arrival rate. This trend emerges because the intensifying sieving rapidly decommissions pores, effectively retiring them before they have contributed significantly to adsorption. Since adsorptive fouling efficiency depends on the available surface area of the network, this premature loss of active pores due to sieving reduces the network’s adsorptive capacity and effectiveness.
$c_{\textit{acm}}$
(the vertical coordinate where each curve ends) is a monotone increasing function of the sieving-particle arrival rate. This trend emerges because the intensifying sieving rapidly decommissions pores, effectively retiring them before they have contributed significantly to adsorption. Since adsorptive fouling efficiency depends on the available surface area of the network, this premature loss of active pores due to sieving reduces the network’s adsorptive capacity and effectiveness.
The dependence of
 $c_{\textit{acm}}$
on arrival rate is less pronounced in figure 7(b), and barely visible in figure 7(c) (as the curves collapse), indicating that a non-zero pore-size gradient mitigates the loss of adsorption foulant efficiency caused by the competing mode of sieving. This is because the larger upstream pores in these graded networks allow small sieving particles to go deeper into the filter, preserving the upstream pore space for adsorption. Even as sieving arrival rate increases, pore loss is largely confined to smaller downstream (clogged) pores, which contribute less to the loss of surface area for adsorption. In essence, the graded architecture induces a division of labour: upstream pores help with adsorption, while downstream pores sieve. The radius gradient partly decouples the two fouling modes, reducing the negative interactions observed in the ungraded case.
$c_{\textit{acm}}$
on arrival rate is less pronounced in figure 7(b), and barely visible in figure 7(c) (as the curves collapse), indicating that a non-zero pore-size gradient mitigates the loss of adsorption foulant efficiency caused by the competing mode of sieving. This is because the larger upstream pores in these graded networks allow small sieving particles to go deeper into the filter, preserving the upstream pore space for adsorption. Even as sieving arrival rate increases, pore loss is largely confined to smaller downstream (clogged) pores, which contribute less to the loss of surface area for adsorption. In essence, the graded architecture induces a division of labour: upstream pores help with adsorption, while downstream pores sieve. The radius gradient partly decouples the two fouling modes, reducing the negative interactions observed in the ungraded case.
Next, we study
 $c_{\textit{acm}}$
vs throughput using the largest sieving particle arriving at several rates in figure 8. The observation from figure 7(a), that total
$c_{\textit{acm}}$
vs throughput using the largest sieving particle arriving at several rates in figure 8. The observation from figure 7(a), that total
 $c_{\textrm { acm}}$
is an increasing function of arrival rate, is still evident in figure 8(a). Moreover, the gaps between the curves show the intensifying negative impact of increasing arrival rate on total throughput (an observation also discussed earlier in figure 4
a). Meanwhile, in figure 8(b), we see that the moderately graded network suffers a similar rapid increase in
$c_{\textrm { acm}}$
is an increasing function of arrival rate, is still evident in figure 8(a). Moreover, the gaps between the curves show the intensifying negative impact of increasing arrival rate on total throughput (an observation also discussed earlier in figure 4
a). Meanwhile, in figure 8(b), we see that the moderately graded network suffers a similar rapid increase in
 $c_{\textit{acm}}$
as a function of arrival rate, a feature absent when processing smaller sieving particles (see figure 7
b). In figure 8(c), for the strongly graded network, we see that total
$c_{\textit{acm}}$
as a function of arrival rate, a feature absent when processing smaller sieving particles (see figure 7
b). In figure 8(c), for the strongly graded network, we see that total
 $c_{\textit{acm}}$
is the lowest (the best) among all three considered networks, and here is in fact a non-monotone function of arrival rate, though it varies only a little for all arrival rates considered.
$c_{\textit{acm}}$
is the lowest (the best) among all three considered networks, and here is in fact a non-monotone function of arrival rate, though it varies only a little for all arrival rates considered.
Accumulated foulant concentration at membrane outlet vs throughput for networks with pore-radius gradient;(a)
 $s=0$
(ungraded), (b)
$s=0$
(ungraded), (b)
 $s=0.0015$
(moderate) and (c)
$s=0.0015$
(moderate) and (c)
 $s=0.003$
(strong). For all plots,
$s=0.003$
(strong). For all plots,
 $p_{\textit{size}} = 0.0123$
.
$p_{\textit{size}} = 0.0123$
.

Taken together, the results in this section show that the strongly graded pore network, in terms of adsorptive foulant control and total throughput, is superior to the moderately graded and ungraded networks. The strongly graded network is able to withstand frequent arrivals of sieving particles (large
 $\gamma$
) for the smallest and largest
$\gamma$
) for the smallest and largest
 $p_{\textit{size}}$
, respectively, by maintaining a comparable total throughput production to the other two cases, while achieving a much smaller accumulated adsorptive foulant concentration at the membrane outlet. We omit results for intermediate values of
$p_{\textit{size}}$
, respectively, by maintaining a comparable total throughput production to the other two cases, while achieving a much smaller accumulated adsorptive foulant concentration at the membrane outlet. We omit results for intermediate values of
 $p_{\textit{size}}$
for brevity, as the corresponding curves (flux-throughput and
$p_{\textit{size}}$
for brevity, as the corresponding curves (flux-throughput and
 $c_{\textit{acm}}$
-throughput) consistently fall between those obtained by
$c_{\textit{acm}}$
-throughput) consistently fall between those obtained by
 $p_{\textit{size}}=0.0078$
and
$p_{\textit{size}}=0.0078$
and
 $p_{\textit{size}}=0.0123$
, with intermediate gap sizes (between curves at different arrival rates) reflecting the monotonic trend.
$p_{\textit{size}}=0.0123$
, with intermediate gap sizes (between curves at different arrival rates) reflecting the monotonic trend.
5.4. Filter lifetime
In this section, we study how the lifetime of a pore-size-graded network depends on model parameters, with reference to the results shown in figure 9. We focus first on the ungraded case, figure 9(a), as an illustrative example to develop physical intuition for the system dynamics. Across all values of
 $p_{\textit{size}}$
and network types, filter lifetime generally decreases as
$p_{\textit{size}}$
and network types, filter lifetime generally decreases as
 $\gamma$
increases, as expected. However, for a given particle size, there appears to be a critical arrival rate above which differences in filter lifetime begin to emerge. To understand this, observe that with no sieving,
$\gamma$
increases, as expected. However, for a given particle size, there appears to be a critical arrival rate above which differences in filter lifetime begin to emerge. To understand this, observe that with no sieving,
 $\gamma =0$
, adsorption is the only fouling mechanism; and the membrane pore inlets shrink at a unit dimensionless rate, corresponding precisely to a filter lifetime of
$\gamma =0$
, adsorption is the only fouling mechanism; and the membrane pore inlets shrink at a unit dimensionless rate, corresponding precisely to a filter lifetime of
 $0.01$
(since pore inlets have an initial radius
$0.01$
(since pore inlets have an initial radius
 $0.01$
, see (4.6)). Since pore inlets on the membrane top surface will always close under absorption in the same amount of time,
$0.01$
, see (4.6)). Since pore inlets on the membrane top surface will always close under absorption in the same amount of time,
 $0.01$
represents an upper bound for the filter lifetime (in the ungraded case). For the filter lifetime to decrease from this value, there must be sufficient sieving to close all paths through the pore network before then; for the ungraded network, the critical arrival rate appears to occur at
$0.01$
represents an upper bound for the filter lifetime (in the ungraded case). For the filter lifetime to decrease from this value, there must be sufficient sieving to close all paths through the pore network before then; for the ungraded network, the critical arrival rate appears to occur at
 $\gamma \approx 10$
. As
$\gamma \approx 10$
. As
 $\gamma$
increases beyond
$\gamma$
increases beyond
 $10$
, filter lifetime exhibits distinct decay rates that depend on particle size, with larger sieving particles leading to faster decay. We attribute this distinction to the increasing difference between particle size and the membrane inlets. Filters receiving larger sieving particles begin to foul earlier as pore sizes at the membrane top surface become small enough to cause sieving. This observation explains the emerging difference in filter lifetime between
$10$
, filter lifetime exhibits distinct decay rates that depend on particle size, with larger sieving particles leading to faster decay. We attribute this distinction to the increasing difference between particle size and the membrane inlets. Filters receiving larger sieving particles begin to foul earlier as pore sizes at the membrane top surface become small enough to cause sieving. This observation explains the emerging difference in filter lifetime between ![]() and
and ![]() , the two sizes that are initially passing through the filter uncaptured (colour coding here matches the curves in figure 9). On the other hand, the curves for both
, the two sizes that are initially passing through the filter uncaptured (colour coding here matches the curves in figure 9). On the other hand, the curves for both ![]() and
and ![]() overlap each other since particles of these sizes are capable of sieving at the start of filtration.
overlap each other since particles of these sizes are capable of sieving at the start of filtration.
Filter lifetime as a function of sieving particle arrival rate for networks with pore-radius gradient; (a)
 $s=0$
(ungraded), (b)
$s=0$
(ungraded), (b)
 $s=0.0015$
(moderate) and (c)
$s=0.0015$
(moderate) and (c)
 $s=0.003$
(strong). Note that, in (a), for
$s=0.003$
(strong). Note that, in (a), for
 $\gamma \lt 10$
, sieving does not change filter lifetime for all particle sizes so the data points for each
$\gamma \lt 10$
, sieving does not change filter lifetime for all particle sizes so the data points for each
 $p_{\textit{size}}$
overlap; in (b) and (c), this overlap persists but up to different
$p_{\textit{size}}$
overlap; in (b) and (c), this overlap persists but up to different
 $\gamma$
-values. The legend shown in (a) applies to (b) and (c).
$\gamma$
-values. The legend shown in (a) applies to (b) and (c).

In figures 9(b) and 9(c), we show the corresponding results for the moderately and strongly graded pore networks. An important highlight is that, given the particle sizes we chose (see table 2), both networks are capable of interior sieving, whereas in the ungraded case, blocking occurs only at the membrane top surface. A similar phase transition still occurs at some critical arrival rate (though different for each network). When the arrival rate is below the respective critical value for each network, adsorption still dominates and the filter lifetime is determined precisely by the time when the inlet radii go to zero. The strongly graded filter lasts longer in this case, since it has larger upstream pores due to a fixed porosity (compare the
 $t_{\textit{final}}$
values for figures 9
b and 9
c). At the critical arrival rate (the value of which, in contrast to the ungraded case just discussed, now depends quite strongly on
$t_{\textit{final}}$
values for figures 9
b and 9
c). At the critical arrival rate (the value of which, in contrast to the ungraded case just discussed, now depends quite strongly on
 $p_{\textit{size}}$
) the difference in particle sizes begins to play a role. Consider
$p_{\textit{size}}$
) the difference in particle sizes begins to play a role. Consider
 $\gamma = 10$
in figure 9(b) for example. The four particle sizes contribute to four distinct filter lifetimes due to their respective capabilities of sieving initially at each layer. In all cases, beyond the critical arrival rate the filter lifetime is a monotone decreasing function of particle size. As discussed, this can be attributed to the more efficient distribution of sieving events throughout the network interior for the smaller particles.
$\gamma = 10$
in figure 9(b) for example. The four particle sizes contribute to four distinct filter lifetimes due to their respective capabilities of sieving initially at each layer. In all cases, beyond the critical arrival rate the filter lifetime is a monotone decreasing function of particle size. As discussed, this can be attributed to the more efficient distribution of sieving events throughout the network interior for the smaller particles.

To compare the relative changes in filter lifetime of graded filters with that of the ungraded one, we define
 \begin{equation} \Delta _{\textit{rel}}(\gamma ;s)=\frac {t_{\textit{final}}(\gamma ;s)-t_{\textit{final}}(\gamma ;0)}{t_{\textit{final}}(\gamma ;0)},\quad s=0.0015,0.003, \end{equation}
\begin{equation} \Delta _{\textit{rel}}(\gamma ;s)=\frac {t_{\textit{final}}(\gamma ;s)-t_{\textit{final}}(\gamma ;0)}{t_{\textit{final}}(\gamma ;0)},\quad s=0.0015,0.003, \end{equation}
where
 $t_{\textit{final}} (\gamma ;0 )$
is the lifetime of the ungraded filter, and plot this quantity as a function of
$t_{\textit{final}} (\gamma ;0 )$
is the lifetime of the ungraded filter, and plot this quantity as a function of
 $\gamma$
for the two graded filters in figure 10. We first consider the moderately graded network shown in figure 10(a). In the adsorption-dominated regime (small
$\gamma$
for the two graded filters in figure 10. We first consider the moderately graded network shown in figure 10(a). In the adsorption-dominated regime (small
 $\gamma$
), all curves lie above zero, indicating that grading extends filter lifetime relative to the ungraded case by approximately
$\gamma$
), all curves lie above zero, indicating that grading extends filter lifetime relative to the ungraded case by approximately
 $22.5\,\%$
, largely independent of particle size (consistent with the flat part of figure 9
b). As
$22.5\,\%$
, largely independent of particle size (consistent with the flat part of figure 9
b). As
 $\gamma$
increases and sieving becomes important, the relative lifetime becomes increasingly particle-size-dependent. Smaller and intermediate particle sizes continue to benefit from pore-size grading, reflecting the presence of interior blocking. In contrast, the largest particle size considered (
$\gamma$
increases and sieving becomes important, the relative lifetime becomes increasingly particle-size-dependent. Smaller and intermediate particle sizes continue to benefit from pore-size grading, reflecting the presence of interior blocking. In contrast, the largest particle size considered (![]() ) exhibits a negative relative lifetime for
) exhibits a negative relative lifetime for
 $\gamma \gt 10$
, indicating that the moderately graded network performs worse than the ungraded filter in terms of filter lifetime in this regime. We can attribute this finding to two consequences of the fixed-porosity constraint in the moderately graded network. First, the initial upstream pore radii are already smaller than the largest particle size, so sieving commences immediately at the membrane inlet and does not penetrate the interior. Second, maintaining equal porosity reduces the number of inlet pores relative to the ungraded network, increasing the effective blockage rate per inlet at high arrival rates.
$\gamma \gt 10$
, indicating that the moderately graded network performs worse than the ungraded filter in terms of filter lifetime in this regime. We can attribute this finding to two consequences of the fixed-porosity constraint in the moderately graded network. First, the initial upstream pore radii are already smaller than the largest particle size, so sieving commences immediately at the membrane inlet and does not penetrate the interior. Second, maintaining equal porosity reduces the number of inlet pores relative to the ungraded network, increasing the effective blockage rate per inlet at high arrival rates.
We now turn to the strongly graded network in figure 10(b). Here, the relative lifetime remains positive and increases with
 $\gamma$
for all particle sizes. In the adsorption-dominated regime, strong grading yields a uniform increase in lifetime of approximately
$\gamma$
for all particle sizes. In the adsorption-dominated regime, strong grading yields a uniform increase in lifetime of approximately
 $45\,\%$
relative to the ungraded filter. As sieving intensifies, this advantage grows substantially. For all particle sizes,
$45\,\%$
relative to the ungraded filter. As sieving intensifies, this advantage grows substantially. For all particle sizes,
 $\varDelta _{ {rel}}$
grows monotonically for
$\varDelta _{ {rel}}$
grows monotonically for
 $\gamma \gt 13$
, with intermediate particle sizes showing the largest gains (
$\gamma \gt 13$
, with intermediate particle sizes showing the largest gains (![]() and
and ![]() ). Notably, no particle size results in a performance penalty relative to the ungraded network, indicating that strong grading robustly enhances filter lifetime even under large arrival rates of sieving particles. This robustness arises because strong grading preserves large upstream pores while enabling sustained interior sieving, distributing blockage more effectively throughout the network.
). Notably, no particle size results in a performance penalty relative to the ungraded network, indicating that strong grading robustly enhances filter lifetime even under large arrival rates of sieving particles. This robustness arises because strong grading preserves large upstream pores while enabling sustained interior sieving, distributing blockage more effectively throughout the network.
Comparing the two cases reveals that the benefit of grading under sieving is highly sensitive to the pore-radius gradient. While both graded networks outperform the ungraded filter when adsorption dominates, their behaviours diverge once sieving becomes significant. Moderate grading can lose its advantage for large sieving particles at high arrival rates, whereas strong grading robustly extends filter lifetime across all conditions considered.
6. Discussion, conclusion and outlook
In conclusion, we have developed a model for membrane filtration in pore-size-graded networks, with a particular focus on the interplay between two simultaneous fouling mechanisms: adsorption due to small particles and sieving of large particles. By introducing a stochastic framework that combines discrete particle-level interactions with the network-scale transport dynamics, we are able to describe how sieving particles traverse the membrane and/or block pores, and how network permeability decreases due to both fouling mechanisms over time. Our simulations highlight distinct regimes of filter performance that depend on the pore-size gradient, sieving-particle size and sieving-particle arrival rate, with the potential for abrupt transitions in fouling patterns and filtration performance metrics. The approach offers a physically interpretable and computationally efficient alternative to direct numerical simulations of full-order nonlinear PDEs, providing insight into critical design trade-offs in graded porous membrane architectures.
The main findings of this study address three key design questions commonly posed in the development of membrane filters, all framed around a single structural variable – the pore-size gradient
 $s$
: Regardless of flow conditions, how should pore sizes (radii in our model) be distributed through the depth of the membrane to (i) maximise total filtrate volume, (ii) minimise foulant accumulation in the filtrate and (iii) prolong filter lifetime? We find that strongly graded pore networks outperform more uniform configurations on the latter two criteria, while offering comparable total throughput. A large pore-radius gradient – i.e. a substantial difference between the initial radii in each layer of the filter – ensures that bands further downstream remain available to adsorb foulants and contribute to flux before reaching a size small enough to initiate sieving. This buffering effect is diminished for shallow pore-size gradients and is entirely absent in filters with uniform pore size. Additionally, under the constraint of a fixed initial porosity, strongly graded networks feature larger upstream pores that are more resistant to early clogging, thereby extending the filter’s operational lifespan.
$s$
: Regardless of flow conditions, how should pore sizes (radii in our model) be distributed through the depth of the membrane to (i) maximise total filtrate volume, (ii) minimise foulant accumulation in the filtrate and (iii) prolong filter lifetime? We find that strongly graded pore networks outperform more uniform configurations on the latter two criteria, while offering comparable total throughput. A large pore-radius gradient – i.e. a substantial difference between the initial radii in each layer of the filter – ensures that bands further downstream remain available to adsorb foulants and contribute to flux before reaching a size small enough to initiate sieving. This buffering effect is diminished for shallow pore-size gradients and is entirely absent in filters with uniform pore size. Additionally, under the constraint of a fixed initial porosity, strongly graded networks feature larger upstream pores that are more resistant to early clogging, thereby extending the filter’s operational lifespan.
While our investigations focused on three representative values of the pore-size gradient
 $s$
, we anticipate an optimal
$s$
, we anticipate an optimal
 $s$
-value that maximises throughput, minimises foulant accumulation and extends filter longevity. If
$s$
-value that maximises throughput, minimises foulant accumulation and extends filter longevity. If
 $s$
becomes excessively large, the pores in the deepest band may become so constricted that, under fixed pressure conditions, negligible flux passes through them, diminishing the filter’s effectiveness. This trade-off is consistent with previous findings on graded filters. For example, Griffiths et al. (Reference Griffiths, Kumar and Stewart2016) identified a throughput-maximising pore tapering angle – an analogue to our pore-radius gradient; Onur et al. (Reference Onur, Ng, Batchlor and Garnier2018) showed that high initial flux often results in poor foulant control due to deposition deep within the filter, as seen in our ungraded networks; and Dalwadi et al. (Reference Dalwadi, Griffiths and Bruna2015) suggested that having more constricted void space downstream improves foulant retention, albeit in the context of porosity gradients rather than pore-radius gradients.
$s$
becomes excessively large, the pores in the deepest band may become so constricted that, under fixed pressure conditions, negligible flux passes through them, diminishing the filter’s effectiveness. This trade-off is consistent with previous findings on graded filters. For example, Griffiths et al. (Reference Griffiths, Kumar and Stewart2016) identified a throughput-maximising pore tapering angle – an analogue to our pore-radius gradient; Onur et al. (Reference Onur, Ng, Batchlor and Garnier2018) showed that high initial flux often results in poor foulant control due to deposition deep within the filter, as seen in our ungraded networks; and Dalwadi et al. (Reference Dalwadi, Griffiths and Bruna2015) suggested that having more constricted void space downstream improves foulant retention, albeit in the context of porosity gradients rather than pore-radius gradients.
A closely related network-based study is Griffiths et al. (Reference Griffiths, Mitevski, Vujkovac, Illingworth and Stewart2020), which also considered hydraulically coupled random pore networks with flux-weighted particle transport and concurrent adsorption and sieving, and showed that porosity grading can enhance filtration performance and admit an optimal gradient. The present results are consistent with these findings, while focusing instead on pore-radius-graded networks at approximately fixed porosity and on a formulation that distinguishes between a continuum adsorbing species and discrete sieving particles. This separation allows us to examine more directly how the two fouling mechanisms interact across the filter depth and how the radius gradient mediates their relative influence on filter performance metrics.
While the pore-radius-graded networks used in this study yield physically meaningful numerical predictions, future work will focus on improving their relevance to practical applications and alignment with experimental data. Real membrane materials, such as ceramic filters, exhibit significantly greater heterogeneity than our simple network generation algorithms capture. For instance, ceramic membranes often possess broad and irregular pore-size distributions that cannot be accurately reproduced by naïve methods. To this end, Shi & Janssen (Reference Shi and Janssen2025) have employed stratified random sampling to generate volume-weighted pore-radius distributions and Sobol sequences to model the spatial arrangement of pore junctions, offering a promising path toward more faithful computational reconstructions. Moreover, while our work highlights how structural features of pore networks can be tuned to manage concurrent sieving and adsorption – and thereby extend filter lifetime – complementary strategies have also explored modifying flow conditions to mitigate clogging. For example, Dincau et al. (Reference Dincau, Tang, Dressaire and Sauret2022) study pulsatile flow in a microfluidic device with parallel channels, showing that time-dependent driving can delay blockage and prolong filter operation. Incorporating such flow control mechanisms into network-based models like ours presents an intriguing direction for future work, especially in systems where structure and the driving dynamics may be jointly optimised.
A key numerical challenge lies in accounting for stochasticity in the sieving-particle arrival process, modelled here via Poisson experiments. Although our use of 120 simulations provides a statistically sufficient sample size for this study, a more rigorous statistical analysis is needed to assess convergence and variability in key metrics. In parallel, we have begun exploring a mean-field approximation to the blocking process, in which each pore evolves according to an average state governed by its time-dependent blocking probability. This probability can be computed using a system of Kolmogorov-type ODEs (under the Poisson measure), which bypasses the need for repeated stochastic realisations and opens the door to investigating alternative sources of randomness, such as uncertainty in pore-size distributions, within a deterministic framework. Moreover, this analytical setting naturally allows the particle arrival rate to depend on the instantaneous permeate flux, resulting in a non-homogeneous Poisson process coupled with the evolving network hydraulics. We intend to develop this method further in future work.
Other possible directions involve extending the model to account for capillary effects, particularly relevant in dry porous media prior to the start of filtration and, backwashing in later stages. In the former setting, the introduction of fluid and foulants triggers phenomena including capillary pressure build-up, air compression and spontaneous imbibition (Li, McDougall & Sorbie Reference Li, McDougall and Sorbie2017). Capillary network models, such as those studied by Markicevic & Navaz (Reference Markicevic and Navaz2009, Reference Markicevic and Navaz2010) and Markicevic, Bijeljic & Navaz (Reference Markicevic, Bijeljic and Navaz2011), provide a natural foundation for incorporating these dynamics. Capturing the early-stage saturation process may require solving the Richards equation to describe transient fluid invasion before quasi-steady operating conditions are reached (as explored in the present work). In the latter setting for backwashing, our network set-up is robust to a sign change of the applied pressure so that foulants (both adsorptive and sieving) may detach from the pores. However, the foulant transport model would have to be modified to account for erosion-type mechanisms during the backwashing (see Ye, Chen & Le-Clech Reference Ye, Chen and Le-Clech2011; Zareei, Pan & Amir Reference Zareei, Pan and Amir2022; Sims et al. Reference Sims, Kunnatha, Mazi, Joseph, Saber, Hwang and Sanaei2024).
Finally, we note that the modelling framework developed here belongs to the broader class of PDE dynamics on evolving networks, a rapidly growing field of study. Recent theoretical advances, including those by Berkolaiko & Kuchment (Reference Berkolaiko and Kuchment2016), Fijavž & Puchalska (Reference Fijavž and Puchalska2020), Chapman & Wilmott (Reference Chapman and Wilmott2021), Böttcher & Porter (Reference Böttcher and Porter2025) and Nachbin (Reference Nachbin2025), have highlighted the mathematical richness of these problems. On the computational side, numerical platforms such as the QGLAB (Goodman, Conte & Marzuola Reference Goodman, Conte and Marzuola2025) are beginning to make such models tractable at scale. The blend of analytical and data-driven approaches in this field offers exciting possibilities for further generalising our work to broader classes of (stochastically) dynamic and adaptive filtration systems.
Acknowledgements
P.S. acknowledges supports from the Department of Mathematics and Statistics at Georgia State University and Simons Foundation under Grant No.SFI-MPS-TSM-00014232. L.K. and L.J.C. acknowledge support from NSF DMS 2206127.
Declaration of interests
The authors report no conflict of interest.
Appendix A. Flow, advection and adsorptive fouling on pore networks
This appendix presents the full mathematical formulation underlying the pore-scale flow, advective transport and adsorptive fouling models summarised in § 2.2. The development follows earlier filtration models (see, e.g. Gu et al. Reference Gu, Kondic and Cummings2022a for network formulation and (Sanaei & Cummings Reference Sanaei and Cummings2017) for the governing equations for each pore) and is included here for completeness.
A.1. Fluid flow on the pore network
Each pore is represented as an edge
 $e_{\textit{ij}}=(v_i,v_{\!j})\in E$
of the graph
$e_{\textit{ij}}=(v_i,v_{\!j})\in E$
of the graph
 $G=(V,E)$
, modelled as a slender circular cylinder of length
$G=(V,E)$
, modelled as a slender circular cylinder of length
 $L_{\textit{ij}}$
and time-dependent radius
$L_{\textit{ij}}$
and time-dependent radius
 $R_{\textit{ij}}(Y,T)$
, where
$R_{\textit{ij}}(Y,T)$
, where
 $Y$
denotes a local axial coordinate along the pore. Assuming incompressible flow of a Newtonian fluid with viscosity
$Y$
denotes a local axial coordinate along the pore. Assuming incompressible flow of a Newtonian fluid with viscosity
 $\mu$
, with pore length far longer than the flow development length, the volumetric flux
$\mu$
, with pore length far longer than the flow development length, the volumetric flux
 $Q_{\textit{ij}}$
satisfies the Hagen–Poiseuille relation
$Q_{\textit{ij}}$
satisfies the Hagen–Poiseuille relation
 \begin{equation} Q_{\textit{ij}}=K_{\textit{ij}}\! \left (P(v_i)-P(v_{\!j})\right )\!, \end{equation}
\begin{equation} Q_{\textit{ij}}=K_{\textit{ij}}\! \left (P(v_i)-P(v_{\!j})\right )\!, \end{equation}
with conductance
 \begin{equation} K_{\textit{ij}}=\frac {\pi }{8\mu {\displaystyle\int} _0^{L_{\textit{ij}}}\frac {1}{R_{\textit{ij}}^4(Y,T)}\,{\rm d}Y}. \end{equation}
\begin{equation} K_{\textit{ij}}=\frac {\pi }{8\mu {\displaystyle\int} _0^{L_{\textit{ij}}}\frac {1}{R_{\textit{ij}}^4(Y,T)}\,{\rm d}Y}. \end{equation}
Flux conservation at each interior vertex
 $v\in V_{\textit{int}}$
leads to the network pressure equation
$v\in V_{\textit{int}}$
leads to the network pressure equation
 \begin{equation} L_{K}P(v)=0,\quad P(v)= \begin{cases} P_{0}, & v\in V_{\textit{in}},\\ 0, & v\in V_{\textit{out}}, \end{cases} \end{equation}
\begin{equation} L_{K}P(v)=0,\quad P(v)= \begin{cases} P_{0}, & v\in V_{\textit{in}},\\ 0, & v\in V_{\textit{out}}, \end{cases} \end{equation}
subject to prescribed pressures at inlet and outlet vertices. Here
 $L_K$
is the conductance-weighted graph Laplacian (see Grady (Reference Grady2010) for more details on discrete graph operators).
$L_K$
is the conductance-weighted graph Laplacian (see Grady (Reference Grady2010) for more details on discrete graph operators).
Definition 6 (Weighted graph Laplacian). Let
 $\mathcal{W}$
be a weighted adjacency matrix with entries
$\mathcal{W}$
be a weighted adjacency matrix with entries
 \begin{align} \mathcal{W}_{\textit{ij}}=K_{\textit{ij}} \quad \text{if } (v_i,v_{\!j})\in E, \quad \mathcal{W}_{\textit{ij}}=0 \text{ otherwise}. \end{align}
\begin{align} \mathcal{W}_{\textit{ij}}=K_{\textit{ij}} \quad \text{if } (v_i,v_{\!j})\in E, \quad \mathcal{W}_{\textit{ij}}=0 \text{ otherwise}. \end{align}
The weighted graph Laplacian is defined as
 \begin{equation} L_{\mathcal{W}}=\mathcal{D}-\mathcal{W}, \end{equation}
\begin{equation} L_{\mathcal{W}}=\mathcal{D}-\mathcal{W}, \end{equation}
where
 $\mathcal{D}$
is the diagonal weighted degree matrix with entries
$\mathcal{D}$
is the diagonal weighted degree matrix with entries
 \begin{align} \mathcal{D}_{ii}=\sum _{\!j}\mathcal{W}_{\textit{ij}}. \end{align}
\begin{align} \mathcal{D}_{ii}=\sum _{\!j}\mathcal{W}_{\textit{ij}}. \end{align}
Solving the resulting linear system yields the nodal pressures and the flux distribution
 $\{Q_{\textit{ij}}\}_{(i,j)\in E}$
throughout the network.
$\{Q_{\textit{ij}}\}_{(i,j)\in E}$
throughout the network.
A.2. Advective transport of foulant particles
The feed solution carries suspended foulant particles that are advected through the pore network, in a quasi-steady state (Fong et al. Reference Fong, Cummings, Chapman and Sanaei2021; Mazi et al. Reference Mazi, El Kahza and Sanaei2024). For each pore
 $e_{\textit{ij}}$
, the concentration
$e_{\textit{ij}}$
, the concentration
 $C_{\textit{ij}}(Y,T)$
satisfies
$C_{\textit{ij}}(Y,T)$
satisfies
 \begin{equation} U_{{avg}, ij}(Y,T)\frac {\partial C_{\textit{ij}}}{\partial Y}=-\varLambda \frac {C_{\textit{ij}}}{R_{\textit{ij}}(Y,T)}, \quad 0\le Y\le L_{\textit{ij}}, \end{equation}
\begin{equation} U_{{avg}, ij}(Y,T)\frac {\partial C_{\textit{ij}}}{\partial Y}=-\varLambda \frac {C_{\textit{ij}}}{R_{\textit{ij}}(Y,T)}, \quad 0\le Y\le L_{\textit{ij}}, \end{equation}
where
 $U_{{avg}}(Y,T)$
is the cross-sectionally averaged pore velocity (Sanaei & Cummings Reference Sanaei and Cummings2017);
$U_{{avg}}(Y,T)$
is the cross-sectionally averaged pore velocity (Sanaei & Cummings Reference Sanaei and Cummings2017);
 $\varLambda$
characterises the affinity between particles and the pore wall. We utilise the relationship between volumetric flux
$\varLambda$
characterises the affinity between particles and the pore wall. We utilise the relationship between volumetric flux
 $Q_{\textit{ij}}$
and
$Q_{\textit{ij}}$
and
 $U_{{avg}}(Y,T)$
$U_{{avg}}(Y,T)$
 \begin{align} U_{{avg}, ij}(Y,T) = Q_{\textit{ij}}(T) / \big (\pi R_{\textit{ij}}^2(Y,T)\big ), \end{align}
\begin{align} U_{{avg}, ij}(Y,T) = Q_{\textit{ij}}(T) / \big (\pi R_{\textit{ij}}^2(Y,T)\big ), \end{align}
to arrive at an equivalent flux-based advection equation
 \begin{equation} Q_{\textit{ij}}\frac {\partial C_{\textit{ij}}}{\partial Y}=-\varLambda C_{\textit{ij}}R_{\textit{ij}}(Y,T), \quad 0\le Y\le L_{\textit{ij}}, \end{equation}
\begin{equation} Q_{\textit{ij}}\frac {\partial C_{\textit{ij}}}{\partial Y}=-\varLambda C_{\textit{ij}}R_{\textit{ij}}(Y,T), \quad 0\le Y\le L_{\textit{ij}}, \end{equation}
where
 $\pi$
is absorbed into
$\pi$
is absorbed into
 $\varLambda$
.
$\varLambda$
.
Equation (A9) has the analytical solution
 \begin{equation} C_{\textit{ij}}(Y,T)=C_i(T)\exp \!\left (-\frac {\varLambda }{Q_{\textit{ij}}}\int _0^Y R_{\textit{ij}}(Z,T)\,{\rm d}Z\right )\!, \end{equation}
\begin{equation} C_{\textit{ij}}(Y,T)=C_i(T)\exp \!\left (-\frac {\varLambda }{Q_{\textit{ij}}}\int _0^Y R_{\textit{ij}}(Z,T)\,{\rm d}Z\right )\!, \end{equation}
where
 $C_i(T)$
denotes the concentration at
$C_i(T)$
denotes the concentration at
 $v_i$
. Enforcing conservation of particle flux at each interior vertex yields a network-scale advection equation for the nodal concentrations
$v_i$
. Enforcing conservation of particle flux at each interior vertex yields a network-scale advection equation for the nodal concentrations
 $\boldsymbol{C}=(C_i)_{v_i\in V}$
$\boldsymbol{C}=(C_i)_{v_i\in V}$
 \begin{equation} L_Q^{\textit{in}}\boldsymbol{C}=(Q\circ B)^{ {T}}\boldsymbol{C}_0, \end{equation}
\begin{equation} L_Q^{\textit{in}}\boldsymbol{C}=(Q\circ B)^{ {T}}\boldsymbol{C}_0, \end{equation}
where
 $\boldsymbol{C}_0$
prescribes inlet concentrations and
$\boldsymbol{C}_0$
prescribes inlet concentrations and
 $B$
is the matrix with entries
$B$
is the matrix with entries
 \begin{equation} B_{\textit{ij}}=\exp \!\left (-\frac {\pi \varLambda }{Q_{\textit{ij}}}\int _0^{L_{\textit{ij}}} R_{\textit{ij}}(Z,T)\,{\rm d}Z\right )\!. \end{equation}
\begin{equation} B_{\textit{ij}}=\exp \!\left (-\frac {\pi \varLambda }{Q_{\textit{ij}}}\int _0^{L_{\textit{ij}}} R_{\textit{ij}}(Z,T)\,{\rm d}Z\right )\!. \end{equation}
Here,
 $L_Q^{\textit{in}}$
is the in-degree weighted graph Laplacian defined by
$L_Q^{\textit{in}}$
is the in-degree weighted graph Laplacian defined by
 \begin{equation} L_Q^{\textit{in}}=D_{Q^{ {T}}}-(Q\circ B)^{{T}}, \end{equation}
\begin{equation} L_Q^{\textit{in}}=D_{Q^{ {T}}}-(Q\circ B)^{{T}}, \end{equation}
with
 $D_{Q^{{T}}}$
the diagonal matrix of incoming fluxes (see Chapman & Mesbahi (Reference Chapman and Mesbahi2011) for a similar advection operator on networks).
$D_{Q^{{T}}}$
the diagonal matrix of incoming fluxes (see Chapman & Mesbahi (Reference Chapman and Mesbahi2011) for a similar advection operator on networks).
A.3. Adsorptive pore-radius evolution
Adsorptive fouling leads to gradual pore shrinkage, modelled by
 \begin{equation} \frac {\partial R_{\textit{ij}}}{\partial T}=-\varLambda \alpha C_{\textit{ij}}(Y,T), \end{equation}
\begin{equation} \frac {\partial R_{\textit{ij}}}{\partial T}=-\varLambda \alpha C_{\textit{ij}}(Y,T), \end{equation}
where
 $\alpha$
is proportional to the volume of deposited foulant.
$\alpha$
is proportional to the volume of deposited foulant.
Prior works, such as Gu et al. (Reference Gu, Renaud, Sanaei, Kondic and Cummings2020, Reference Gu, Kondic and Cummings2022a ), used a simplifying assumption that the pores are initially cylindrical, and maintain this shape as filtration progresses. In this work, we improve upon this assumption by assuming that the pore radius is approximated as linear in the axial coordinate
 \begin{equation} R_{\textit{ij}}(Y,T)=a_{\textit{ij}}(T)+b_{\textit{ij}}(T)Y, \end{equation}
\begin{equation} R_{\textit{ij}}(Y,T)=a_{\textit{ij}}(T)+b_{\textit{ij}}(T)Y, \end{equation}
which allows analytic evaluation of the conductance integrals in (A2). This relaxation, though still inexact, is computationally inexpensive compared with a full model while improving accuracy over prior cylindrical pore models. The resulting system consists of coupled ODEs governing the evolution of the coefficients
 $a_{\textit{ij}}(T)$
and
$a_{\textit{ij}}(T)$
and
 $b_{\textit{ij}}(T)$
, coupled to the network pressure and transport equations above.
$b_{\textit{ij}}(T)$
, coupled to the network pressure and transport equations above.
A.3.1. Justification for linear pore profile
We further justify the linear approximation of the pore shape as an evolving cross-section of a circular cone, using the dimensionless form of (A15). This approximation applies to all edges considered in our networks, but we suppress the
 $ij$
notation for edges for simplicity.
$ij$
notation for edges for simplicity.
Consider a linear approximation of the pore radius in the pore axial coordinate
 $y$
$y$
 \begin{equation} r(y,t)=a(t)+b(t)y, \end{equation}
\begin{equation} r(y,t)=a(t)+b(t)y, \end{equation}
where
 $a (t )$
and
$a (t )$
and
 $b (t )$
are to be determined as follows. The concentration
$b (t )$
are to be determined as follows. The concentration
 $c (y,t )$
satisfies an analytical solution (per (4.5a
))
$c (y,t )$
satisfies an analytical solution (per (4.5a
))
 \begin{align} c(y,t)=c_{0}(t)\exp\! \left (\!-\frac {\lambda \int _{0}^{y}r(x,t){\rm d}x}{q(t)}\right )\!, \end{align}
\begin{align} c(y,t)=c_{0}(t)\exp\! \left (\!-\frac {\lambda \int _{0}^{y}r(x,t){\rm d}x}{q(t)}\right )\!, \end{align}
where the integral now becomes
 \begin{align} \int _{0}^{y}r(x,t){\rm d}x=a(t)y+b(t)\frac {y^{2}}{2}. \end{align}
\begin{align} \int _{0}^{y}r(x,t){\rm d}x=a(t)y+b(t)\frac {y^{2}}{2}. \end{align}
Knowing that the pore radius evolves according to
 $ {\partial r}/{\partial t}=-c (y,t )$
, we have
$ {\partial r}/{\partial t}=-c (y,t )$
, we have
 \begin{align} \frac {\partial r}{\partial t}=\frac {{\rm d}a}{{\rm d}t}+\frac {{\rm d}b}{{\rm d}t}y=-c_{0}(t)\exp \big(-A(t)y-B(t)y^{2}\big ), \end{align}
\begin{align} \frac {\partial r}{\partial t}=\frac {{\rm d}a}{{\rm d}t}+\frac {{\rm d}b}{{\rm d}t}y=-c_{0}(t)\exp \big(-A(t)y-B(t)y^{2}\big ), \end{align}
where
 \begin{equation} A(t)=\frac {\lambda a(t)}{q(t)},\quad B(t)=\frac {\lambda b(t)}{2q(t)}. \end{equation}
\begin{equation} A(t)=\frac {\lambda a(t)}{q(t)},\quad B(t)=\frac {\lambda b(t)}{2q(t)}. \end{equation}
The quadratised concentration profile is a reasonable assumption given pore length
 $l$
is small (in our model between
$l$
is small (in our model between
 $0.06$
and
$0.06$
and
 $0.15$
). Assuming the argument of the exponential
$0.15$
). Assuming the argument of the exponential
 $\sup _{0\,\leq\, y\, \leq\, l} |A(t)y + B(t)y^2| \ll 1$
, provided
$\sup _{0\,\leq\, y\, \leq\, l} |A(t)y + B(t)y^2| \ll 1$
, provided
 \begin{align} q(t) \gg \frac {3}{2}\lambda d_{\textit{max}} r_0, \end{align}
\begin{align} q(t) \gg \frac {3}{2}\lambda d_{\textit{max}} r_0, \end{align}
we Taylor expand the exponential up to second order in
 $y$
$y$
 \begin{align} \frac {{\rm d}a}{{\rm d}t}+\frac {{\rm d}b}{{\rm d}t}y & =-c_{0}(t)\left [1-\big(A(t)y+B(t)y^{2}\big)+\frac {\big(A(t)y+B(t)y^{2}\big)^{2}}{2}+ O\big (y^5\big )\right ] \nonumber\\ & =-c_{0}(t)\left [1-A(t)y+\left (\frac {A^{2}(t)}{2}-B(t)\right )y^{2} + O\big (y^3\big )\right ]\!. \end{align}
\begin{align} \frac {{\rm d}a}{{\rm d}t}+\frac {{\rm d}b}{{\rm d}t}y & =-c_{0}(t)\left [1-\big(A(t)y+B(t)y^{2}\big)+\frac {\big(A(t)y+B(t)y^{2}\big)^{2}}{2}+ O\big (y^5\big )\right ] \nonumber\\ & =-c_{0}(t)\left [1-A(t)y+\left (\frac {A^{2}(t)}{2}-B(t)\right )y^{2} + O\big (y^3\big )\right ]\!. \end{align}
Matching powers of
 $y$
, we find a compatibility condition for the time-dependent coefficients
$y$
, we find a compatibility condition for the time-dependent coefficients
 \begin{align} A^{2}(t)=2B(t)\implies \frac {\lambda ^{2}a^{2}(t)}{q^{2}(t)}=\frac {\lambda b(t)}{q(t)}\implies b(t)=\frac {\lambda a^{2}(t)}{q(t)}. \end{align}
\begin{align} A^{2}(t)=2B(t)\implies \frac {\lambda ^{2}a^{2}(t)}{q^{2}(t)}=\frac {\lambda b(t)}{q(t)}\implies b(t)=\frac {\lambda a^{2}(t)}{q(t)}. \end{align}
Then,
 \begin{equation} \frac {{\rm d}a}{{\rm d}t}=-c_{0}(t),\quad \frac {{\rm d}b}{{\rm d}t}=A(t)c_{0}(t)=\frac {\lambda a(t)}{q(t)}c_{0}(t), \end{equation}
\begin{equation} \frac {{\rm d}a}{{\rm d}t}=-c_{0}(t),\quad \frac {{\rm d}b}{{\rm d}t}=A(t)c_{0}(t)=\frac {\lambda a(t)}{q(t)}c_{0}(t), \end{equation}
with analytical solution for
 $a(t)$
$a(t)$
 \begin{equation} a(t)=a(0)-\int _{0}^{t}c_{0}(s){\rm d}s=r_{0}-\int _{0}^{t}c_{0}(s){\rm d}s, \end{equation}
\begin{equation} a(t)=a(0)-\int _{0}^{t}c_{0}(s){\rm d}s=r_{0}-\int _{0}^{t}c_{0}(s){\rm d}s, \end{equation}
since
 \begin{align} r(y,0)=a(0)+b(0)y\implies a(0)=r(0,0)=r_{0}. \end{align}
\begin{align} r(y,0)=a(0)+b(0)y\implies a(0)=r(0,0)=r_{0}. \end{align}
We also have
 \begin{align} \frac {{\rm d}b}{{\rm d}t}=\frac {\lambda }{q(t)}c_{0}(t)\left (r_{0}-\int _{0}^{t}c_{0}(s){\rm d}s\right )\!, \end{align}
\begin{align} \frac {{\rm d}b}{{\rm d}t}=\frac {\lambda }{q(t)}c_{0}(t)\left (r_{0}-\int _{0}^{t}c_{0}(s){\rm d}s\right )\!, \end{align}
and thus
 \begin{equation} b(t)=b(0) + \lambda \int _{0}^{t}\frac {c_{0}(s)}{q(s)}\left (r_{0}-\int _{0}^{s}c_{0}(t^{\prime }){\rm d}t^{\prime }\right ){\rm d}s. \end{equation}
\begin{equation} b(t)=b(0) + \lambda \int _{0}^{t}\frac {c_{0}(s)}{q(s)}\left (r_{0}-\int _{0}^{s}c_{0}(t^{\prime }){\rm d}t^{\prime }\right ){\rm d}s. \end{equation}
Now, since all pores are initially cylinders with radius
 $r_0$
, we must have
$r_0$
, we must have
 \begin{align} r_0 = r(y,0) = r_0 + b(0)y \implies b(0) = 0. \end{align}
\begin{align} r_0 = r(y,0) = r_0 + b(0)y \implies b(0) = 0. \end{align}
Conductance satisfies
 $k (t )= {1}/{I (t )}$
, where
$k (t )= {1}/{I (t )}$
, where
 \begin{align} I(t) & =\int _{0}^{l}(a(t)+b(t)y)^{-4}{\rm d}y \nonumber\\ & =-\frac {1}{3b(t)}(a(t)+b(t)y)^{-3} \Big|_{y=0}^{y=l} \nonumber\\ & =\frac {1}{3b(t)}\left [\frac {1}{a^{3}(t)}-\frac {1}{(a(t)+b(t)l)^{3}}\right ]\!. \end{align}
\begin{align} I(t) & =\int _{0}^{l}(a(t)+b(t)y)^{-4}{\rm d}y \nonumber\\ & =-\frac {1}{3b(t)}(a(t)+b(t)y)^{-3} \Big|_{y=0}^{y=l} \nonumber\\ & =\frac {1}{3b(t)}\left [\frac {1}{a^{3}(t)}-\frac {1}{(a(t)+b(t)l)^{3}}\right ]\!. \end{align}
Thus,
 \begin{equation} k(t)=\frac {3b(t)}{\frac {1}{a^{3}(t)}-\frac {1}{(a(t)+b(t)l)^{3}}}=\frac {3a^{3}(t)b(t)}{1-\left (\frac {a(t)}{a(t)+b(t)l}\right )^{3}}. \end{equation}
\begin{equation} k(t)=\frac {3b(t)}{\frac {1}{a^{3}(t)}-\frac {1}{(a(t)+b(t)l)^{3}}}=\frac {3a^{3}(t)b(t)}{1-\left (\frac {a(t)}{a(t)+b(t)l}\right )^{3}}. \end{equation}
We use this formula for conductance (in terms of time), to update flux and concentration per (4.2a
), (4.5a
), respectively. Both of these quantities then influence pore shape, whose evolution is then completely governed by
 $a (t )$
and
$a (t )$
and
 $b (t )$
. This procedure avoids storing
$b (t )$
. This procedure avoids storing
 $r$
numerically as a function of space, while still providing an accurate yet very efficient representation of pore evolution.
$r$
numerically as a function of space, while still providing an accurate yet very efficient representation of pore evolution.
Appendix B. Theoretical limit of radius gradient
Per constraint 1 given by (2.3), the limiting
 $s_{\textit{max}}$
is determined when
$s_{\textit{max}}$
is determined when
 $R_m=0$
, i.e. the bottom-most band has pores with zero radius. More precisely,
$R_m=0$
, i.e. the bottom-most band has pores with zero radius. More precisely,
 \begin{align} s_{\textit{max}} = \frac {2R_0}{W\left (m-1\right )} = \frac {2r_0}{m-1}, \end{align}
\begin{align} s_{\textit{max}} = \frac {2R_0}{W\left (m-1\right )} = \frac {2r_0}{m-1}, \end{align}
where the last term is in dimensionless form. Based on our assumptions,
 $r_0=0.01$
and
$r_0=0.01$
and
 $m=4$
, and therefore
$m=4$
, and therefore
 \begin{align} s_{\textit{max}} = \frac {0.02}{3} \approx 0.0066. \end{align}
\begin{align} s_{\textit{max}} = \frac {0.02}{3} \approx 0.0066. \end{align}















































 Open access
Open access