




Policy Significance Statement
Good policy starts with good information. In the case of policy relating to democratic resilience, whilst there is a very large set of choices available to the policymaker who desires to strengthen democracy, there is a remarkably slender set of rich information on citizen narratives of democracy on which to draw. Whilst surveys will always be important, we are now in an age where voluminous alternative data forms are arising in social media, digital media, and political discourse in real time. These new sources present a huge opportunity for policymakers to identify, track, and analyse rich belief structures—how individuals frame issues and events—in near real time. In this paper, we examine the potential for new AI technologies to do just this. By first situating these technologies in a framework linking democratic resilience to natural language processing, we then step through the core ideas of transformer AI—what makes it different, how it can be applied, before presenting two practical demonstrations of these tools on two discourse areas related to democratic resilience: populism and immigration. We conclude with the centrality of harmonised data sources to any future endeavour, and make recommendations for policymakers to foster these methods and tools.
1. Introduction
Story-telling has always been a powerful form of human expression: we venerate our literary giants, and we encode our culture, history, and identity in the stories that we tell our children and each other in so many private moments. Yet for democracies, storytelling, or more formally, “narratives,” seem to take on a particularly potent guise. Each election cycle, those of us fortunate enough to live in an open, democratic society, will encounter political leaders who’s chief form of political speech will be in narrative form: a vision for a better future; a depiction of an opponent’s “world”; a personal life “story,” connecting the leader to the lounge-room.
Policy experts, economists, sociologists, and political scientists have long theorised over the role of public narratives in our national political and policymaking journey. For some, narratives have the power to both initiate and catalyse major economic events, from the Great Depression to financial crises (Shiller, Reference Shiller2019), whilst others articulate the common finding that public narratives are at their most powerful when they resonate with personal convictions already held (Polletta and Callahan, Reference Polletta and Callahan2017). Indeed, reflecting on the potency of Trump’s campaign tactics, Polletta and Callahan note that it was the “small stories” heard through a complex web of radio, TV, social media, and personal networks which (p.13), “meshed with the experiences of others in a way that made them all seem personal.” More forceful of all, narratives have been rediscovered by some as providing a kind of ontology of self—public narrative as “identity compass” to the inner self. According to Somers (Reference Somers1994) (p.606) (emphasis added),
It matters not whether we are social scientists or subjects of historical research, but that all of us come to be who we are (however ephemeral, multiple, and changing) by being located or locating ourselves (usually unconsciously) in social narratives rarely of our own making.
In other words, we now recognise that public narratives matter, not only for how public debate proceeds but also for the composition and sense-making of individuals themselves.
Yet if the power of public narratives to shape individuals and society was already recognised in the 90s, how much more should we pay attention to them today, given the unprecedented acceleration in the availability, volume, and velocity (Mauro et al., Reference Mauro, Greco and Grimaldi2016) of public discourse surging through our democracies? Parallel mega-trends, including the ubiquity of the internet, social media platforms, the 24/7 news cycle, the spectre of mis-information, “echo-chambers” and geo-political interference, each contribute to a sense that for those who carry the fire for our democracies, characterising, mapping, and tracking the maelstrom of competing narratives has become an essential task.
But are our methodological tools up to the task? Traditional political narrative discovery and analysis methods (e.g. focus-groups, surveys, human labelling of texts) will continue to be part of the democratic resilience analysis toolbox, yet they are ill-equipped to handle the scale or immediacy of the modern narrative tracking challenge. By contrast, modern machine-learning, natural language processing (NLP), and artificial intelligence (AI) technologies present compelling opportunities to bridge this gap.
In this paper, we ask,
How can advances in NLP and AI technologies, particularly large language models, enhance our ability to track and analyse narratives related to democratic resilience at scale?
To tackle this question, we first present a framework (Section 2) that connects the democratic resilience analysis challenge with traditional narrative discovery and analysis techniques, and then introduce automated methods as automated companions to these techniques. In so doing, the framework introduces the contention of this paper that modern, transformer-based (AI) technologies have arrived at a level of capability such that human-level narrative discrimination is now available at scale, ready for application to tracking policy-relevant narratives of democratic resilience.
We use this framework to structure the rest of the paper. Section 2.1 positions narrative tracking within the broader question of democratic resilience, drawing on theories of communication to introduce the “framing” task as the common object of analysis, and in Section 2.2 we provide examples of pernicious narratives that can be pursued by this analysis. Section 3 then situates automated methods as an extension of human-expert textual analysis, and positions the transformer revolution as the third “wave” in natural language processing, with Section 4 introducing key components of transformer technology and the key advances they bring to related textual analysis tasks. We then provide, in Section 5 two distinct applied demonstrations of these technologies to fix ideas and ground our analysis of these tools. In so doing, we shall encounter the enormous potential inherent in the latest wave of language modelling technology, opening up new research frontiers to harness this potential in ways that explicitly seek to strengthen democracy. Given that we see few, if any, examples of this research to date, we conclude by proposing (Section 6) a new computational research agenda that takes advantage of these tools for strengthening democracy.
Together, this study makes a number of contributions to the data—policy nexus in relation to democratic resilience: a conceptual framework to orientate and rationalise frontier transformer-based computational methods as revolutionary technologies in the democratic resilience toolset; a multi-disciplinary synthesis of theories of resilience, framing, and implementation to situate these technologies in a non-trivial intellectual context; a set of demonstration exercises to exemplify, in an accessible way, the power of these new technologies relative to former approaches; and a computational research agenda with recommendations for data controllers and research funding bodies alike (Note: a suite of tools associated with methods discussed in this paper is also available at the Github repository: https://github.com/sodalabsio/textwaves).
2. A framework for analysing narrative aspects of democratic resilience with machines
Conceptually, we propose a three-tier framework, as illustrated in Figure 1 and expanded in the following sections, to situate the tracking of narrative aspects of democratic resilience via computational approaches:
A framework to connect the democratic resilience challenge to narrative analysis with transformers. Left panel: Democratic resilience analysis requires a dynamic approach, one aspect being that of narrative tracking, especially pernicious narratives such as populism (see Section 2.1). Centre panel: Narrative analysis seeks to discover and decompose narratives arising in texts, including public discourse, typically through focus groups, surveys, or human labelling using framing analysis. Right panel: Computational methods can scale up narrative analysis through a variety of means, including traditional NLP approaches, and lately, transformer-based techniques such as direct prompting.

Tier 1: The narrative aspect of democratic resilience
Conceptualising democratic resilience as a dynamic concept (Holloway and Manwaring, Reference Holloway and Manwaring2023) the related analysis objective is to explore how a democratic system withstands dynamic shocks and threats. Among a constellation of threats, pernicious narratives feed into most of these (Biddle et al., Reference Biddle, Fischer, Angus, Ercan, Grömping and Gray2025). For instance, the Australian Government’s own identification of eight threats to democracy lists six which have a narrative element: “foreign interference,” “social media and platforms,” “misinformation and disinformation,” “polarisation and division,” “discrimination and intolerance” and “dissatisfaction with government and governing” (Strengthening Democracy Taskforce, 2024). By example, populism (covered in more detail in Section 2.2) is a commonly studied narrative which most directly undermines democratic resilience as it seeks to delegitimise state institutions, including the executive, legislature, and judiciary.
Tier 2: Narrative analysis to identify and quantify threats to democratic resilience
Within narrative analysis, the objective of the study is typically to discover and decompose narratives arising in political discourse. Whilst surveys and focus-groups continue to be the core methodological approaches for many organisations and government efforts, expert-labelling of texts from a variety of sources (e.g. social media, op-eds, news, speeches etc.) has the power of converting unstructured, “messy” text data into structured, tabular data forms which lend themselves to the kind of quantitative analysis we are concerned with. In this realm, narrative labelling is often operationalised via framing analysis, either via specific frames (e.g. “immigrants are victims”) (Mendelsohn et al., Reference Mendelsohn, Budak and Jurgens2021) or more generic approaches (e.g. “fairness and equality” vs. “economic” vs. “political”) (Boydstun et al., Reference Boydstun, Gross, Resnik and Smith2013) (covered in 2.1 below).
Tier 3: Computational methods to scale narrative analysis
Third, computational methods can be employed to automate and scale a variety of useful “text-as-data” tasks, supporting quantitative insights on narratives related to democratic resilience. There has been a marked evolution of these technologies over the last three decades (Section 3), with traditional NLP methods treating text simply as a collection (a “bag”) of disconnected words without context, compared to subsequent waves of NLP technology, which are able to handle semantic components of words, and even sentences in their machinery. However, with the advent of the transformer revolution, powering amongst other technologies the wave of generative AI chatbots, we are entering an analytical world where models can be asked direct, nuanced questions about narratives related to democratic resilience and in response provide human-level intelligence at a fraction of the cost. It is this revolution that is the focus of our technological study (Section 4), drives our demonstration exercises (Section 5), and motivates our research agenda and data recommendations (Section 6).
2.1. Connecting democratic resilience to framing analysis
What are the narrative aspects of democratic resilience? Here, we integrate widely used definitions of both democratic resilience and “framing” to narrow in on the focus of our study. First, according to Holloway and Manwaring’s definition of democratic resilience, a population riven by discordant narratives is a threat to democracy itself. For them, democratic resilience is that quality of a democratic system that can stand despite the narrowest intersection of agreement on the issues that matter. Namely, “democratic resilience” is (p.76),
A system’s capacity to withstand a major shock such as the onset of extreme polarization and to continue to perform the basic functions of democratic governance—electoral accountability, representation, effective restraints on excessive or concentrated power, and collective decision-making.
As such, and integrating Snow and Benford’s decomposition of framing in social movements, a resilient democracy is one which can hold on to its foundational apparatus, even when the society at large is captured by highly opposing diagnoses, prognoses, or motivations regarding the issues of the day. Holloway and Manwaring (Reference Holloway and Manwaring2023)’s wide-lens review of literature on democratic resilience finds that (Table 2, p.72) “diversity (of groups, individuals),” “learning,” and “community participation and inclusion” are amongst the common characteristics of resilient systems. So democratic resilience is about finding ways for diverse narratives to co-exist—that is to challenge the status-quo, and/or seek inclusion—whilst at the same time, being wary of narratives which foment excessive polarisation, distrust of electoral institutions and representation, and undermine social cohesion. The most resilient democracy may be able to withstand the worst of these narratives, but recent international experience suggests that democratic systems can be surprisingly susceptible to hitherto marginal narratives.
Second, a common approach to classifying narratives for quantitative social science, is to draw on theories of issue-framing (or just “framing”). Here, one or more positions on any given topic or issue can be identified by examining how a communicator crafts their message on the topic, that is how they “frame” the topic. Entman (Reference Entman1993) defines framing thus (p.52) (emphasis added),
To frame is to select some aspects of a perceived reality and make them more salient in a communicating text, in such a way as to promote a particular problem definition, causal interpretation, moral evaluation, and/or treatment recommendation for the item described.
Key in Entman’s definition is selection and saliency, to serve the objective of promotion of the speaker’s particular messaging on the topic. As such, issue framing can be seen as a specific aspect of narrative. Where narrative involves characters, events, and often a temporal component, framing is concerned with the specific treatment of an issue, event, or topic by the speaker who wishes to convince the receiver of the same. Chong and Druckman (Reference Chong and Druckman2007) makes this connection in their more recent theorising (p.104) (emphasis added),
The major premise of framing theory is that an issue can be viewed from a variety of perspectives and be construed as having implications for multiple values or considerations. Framing refers to the process by which people develop a particular conceptualisation of an issue or reorient their thinking about an issue.
Critically then, issue-framing applies equally to the speaker and receiver. The speaker seeks to promote a particular framing of an issue (ala Entman), with the objective of bringing the receiver to the same perspective (ala Chong & Druckman).
But framing is not merely an individual consideration, in democracies, individuals freely join with others to form groups, groups join again to form movements. And here, at these higher orders of organisation, social theorists see that framing applies equally well. Indeed, there is an important interplay between the framing of the group or movement and the individuals who compose it. Snow and Benford (Reference Snow and Benford1988) write (p.198),
Movements function as carriers and transmitters of mobilizing beliefs and ideas, to be sure; but they are also actively engaged in the production of meaning for participants, antagonists, and observers…. They frame, or assign meaning to and interpret, relevant events and conditions in ways that are intended to mobilize potential adherents and constituents, to garner bystander support, and to demobilize antagonists.
So together, we find that narratives matter to democratic resilience (at least) because of the power of framing in the hands of political leaders to coerce reality to their messages, because of the way that framing can form and locate political identities, and because framing can mobilise the masses. For these reasons, we should not have been surprised by our earlier observation that the majority of threats to democracy identified by the Australian Strengthening Democracy Taskforce have a narrative component.
2.2. So which frames matter to democratic resilience?
The literature offers up a number of recognisable narratives that any democratic society may wish to be wary of. We briefly consider three.
First, the “Us vs. Them’” narrative is the most transparently polarising, reducing complex, multi-dimensional issues down to a single dimension, and at its worst, encouraging a kind of “purity test” of belief for those who adhere to one “side” of the political landscape or the other (Hetherington and Rudolph, Reference Hetherington and Rudolph2015; McCoy et al., Reference McCoy, Rahman and Somer2018; Iyengar et al., Reference Iyengar, Lelkes, Levendusky, Malhotra and Westwood2019; McCoy and Somer, Reference McCoy and Somer2019). Despite wide variation in how a specific country becomes extremely polarised, authors contend that the subsequent undermining of democracy follows a very common path: political opponents dis-engage from meaningful communication and compromise; government reform agendas are gridlocked; each side dismantles the other’s legislative agenda immediately on gaining power; and in the end-state, democratic transfer of power falls under restrictions of civil liberties and sees the military’s entry to replace government.
Relatedly, narratives of nationalism can also work to undermine a plural, inclusive democratic society. As argued by Mylonas and Tudor (Reference Mylonas and Tudor2021), we should distinguish between nationalism which draws on ideals of freedom and justice (e.g. the American and French Revolutions), and (p.111), “exclusionary nationalism (also called ethnic or essentialist nationalism).” Exclusionary nationalism shares rhetorical approaches with the “us versus them” narrative in its reductionism, that is driving a hierarchical narrative along racial, ethnic or religious grounds, “othering” some group or groups in society to achieve some idealised, patriotic objective.
Third, as Algan et al. (Reference Algan, Guriev, Papaioannou and Passari2017) ominously begin, “a spectre is haunting Europe and the West—the spectre of populism.” Populism is perhaps the narrative which is most directly opposed to the democratic project, for its proponents set themselves against the very institutions of democracy itself—established political parties, established institutions of state, even the judiciary, are all said to be held captive by “elites,” set against the best interests of the common people. Here, former president Donald Trump’s dark framing of modern America, promising to “drain the swamp” (that is of elites), and “make America great again,” spoke to the felt experiences of the American people and dove-tailed with right-wing programming across print, radio, TV and online (Polletta and Callahan, Reference Polletta and Callahan2017; Norris and Inglehart, Reference Norris and Inglehart2019). The message was particularly appealing to those who felt like “outsiders” in their own country due to social and economic marginalisation (Gidron and Hall, Reference Gidron and Hall2020).
But how prevalent are these narratives in a modern democracy? Are narratives of populism or exclusionary nationalism already making themselves heard in the United Kingdom, Australia, or the United States? Has there been a change over time? Where? Is this only for the online “echo-chambers” or do we see growing evidence of these narratives in our public discourses arising in Parliament, print or on the air-waves?
The answer to all these questions requires empirical tools.
2.3. Aside: social listening and surveillance
Before moving to empirical methods, it is worth spending a moment to distinguish present considerations from “surveillance” orientated methods, or what is sometimes referred to as “surreptitious social listening.” Listening—the active or passive act of receiving/collecting information from people in a given context—can take a variety of forms, best considered as sitting on a spectrum (Martino, Reference Martino2020). According to such typologies, tracking of public narratives related to social cohesion and democratic resilience, sits in the “active listening” category, and, according to Martino seeks to enhance democratic and foreign policy objectives by promoting trust and understanding. In a word, the government or actor who actively listens to citizens and counterparts, including those who hold opposing views, demonstrates a long-term commitment to dialogue, relation-building, and engagement. Importantly, such active listening, or “public discourse tracking”as we consider here, is far away from surreptitious listening, or what is otherwise known as surveillance or spying. Here, there are spaces for legitimate uses of such methods in democracies, but such uses must carefully balance personal rights and freedoms with policing and counter-terrorism objectives (Moore, Reference Moore2011; Hagen and Lysne, Reference Hagen and Lysne2016). Importantly, it should be acknowledged that all surveillance carries harm (Richards, Reference Richards2013) either because of a chilling effect on civil liberties (Penney, Reference Penney2016), or by introducing unhealthy power dynamics due to information asymmetries. Nevertheless, tracking public narratives related to democracy, where it seeks to understand, characterise, build trust, and engage, aims to support democratic values, not undermine them, and should be kept distinct from states or actors who seek to infiltrate the private sphere to advance coercive, controlling, or chilling purposes.
3. From experts to transformers: the evolution and revolution in narrative analysis methods
With the advent of more advanced natural-language-processing (NLP) tools over the past two decades, and in particular, with the rise of powerful large-language-model (LLM) generative artificial intelligence (AI) systems, there has been a rapid growth in methodologies that seek to automate labelling tasks at scale with near-human levels of accuracy.
The ultimate aim of such efforts is to generate a structured dataset where each record represents a given text, metadata, or attributes related to that text (e.g. the date, speaker, party affiliation, location, medium, etc.), and a series of labels which indicate whether a given framing relating to some issue exists or does not exist in that text. From there, the wide array of standard empirical tools can be applied to generate analytical objects (e.g. time-series, histograms), statistical tests, and causal inferences.
We focus here on non-survey methods, charting the pathway from labor-intensive labelling to automated approaches (For a review of survey based methods, see surveys such as Levi and Stoker (Reference Levi and Stoker2000); Citrin and Stoker (Reference Citrin and Stoker2018), or projects such as the Australian Social Cohesian index (https://scanloninstitute.org.au/research/australian-cohesion-index), or the Social Cohesion Radar (Dragolov et al., Reference Dragolov, Ignácz, Lorenz, Delhey, Boehnke and Unzicker2016).
Traditionally, labelling texts for the presence of a frame has followed a standard procedure by human experts, which we cover briefly to set the scene to ground our discussion of automated approaches. In their review of framing theory, Chong and Druckman (Reference Chong and Druckman2007) note that the identification of frames in communication by domain experts has become a, “virtual cottage industry” (p.106). And, whilst they note that no uniform definition of how to proceed exists, the “most compelling studies” follow six standard steps: 1) identify the issue (e.g. “immigration”); 2) isolate an attitude (dimension) (e.g. “posture towards refugees”); 3) define frames (e.g. “humanitarian approach” versus “border security approach”); 4) select sources; 5) develop a validated coding scheme; and 6) undertake the coding.
Examples of the standard approach in practice include Terkildsen and Schnell (Reference Terkildsen and Schnell1997) who analyse weekly news coverage of the women’s movement over four decades for the presence of frames related to sex roles, feminism/anti-feminism, political rights, and economic rights, and Jennings and John (Reference Jennings and John2009) who code discourse frames, including social inclusion/exclusion in successive releases of the poverty reduction strategy in Ontario, Canada. The approach is also used at the level above frames, that is to identify the presence or absence of a given set of issues in texts such as in Smith-Carrier and Lawlor (Reference Smith-Carrier and Lawlor2016) who code the Queen’s speech to Parliament for policy areas and join this to Gallup surveys on “the most urgent problem” to examine whether the government agenda responds to public opinion.
The development of computational approaches has seen the automation of this standard procedure, and more, producing a voluminous applied literature in the social sciences (e.g. Grimmer and Stewart, Reference Grimmer and Stewart2013; Gentzkow et al., Reference Gentzkow, Kelly and Taddy2019). Indeed, we can chart the trajectory of NLP research which, starting with proximate abstractions of narrative framing analysis (e.g. word occurrences, topic modelling, semantic analysis), has been narrowing closer towards the object itself—trying to identify accurately elements of speech which encode one framing or another (rich, nuanced and contextual) in text, at scale. Along the way, several ingenious approaches to quantifying discourse dynamics aside from simply “coding” have arisen, yielding insights derived from much larger volumes of text than could ever have been feasibly handled by human means alone. See Supplementary Information S1 for an extended treatment of this literature; for now, we mention briefly the key turning points in this technological journey.
At least two prior waves of innovation can be identified in these approaches:
-
• Token frequencies (“Bag of Words”)—The simplest approach is, after some preparatory steps, to replace remaining unique words by corresponding index values, and then calculate a vector of occurrence frequencies to represent a given text. Typically, within-document word frequencies are modified by inverse cross-document frequencies to create a weighed numerical vector (“tf-idf”) (e.g. Hager and Hilbig, Reference Hager and Hilbig2020).
-
• Semantic embeddings—Using neural architecture (i.e. large matrix calculations), a model is pre-trained to identify similar semantic words due to their similar usage context in a very large training corpus (e.g. Word2Vec (Mikolov et al., Reference Mikolov, Chen, Corrado and Dean2013). So trained, the model can then produce a vector which locates a given word (or, via aggregation, a document) in semantic space for further analysis (e.g. Kozlowski et al., Reference Kozlowski, Taddy and Evans2019).
Common to both of these methodological “waves” is the aim of mapping a word or text to a common vector space for further quantitative manipulation. The challenge for “bag of words,” as the name suggests, is that vector positions so yielded have nothing to do with the context of word use, that is there is no reason why “cat” should reside near “dog” in some “pet” sub-space. Whilst for semantic embeddings, though they provide a step-change in accuracy of word/text location due to pre-training, they have no ability to recognise rich rhetorical strategies such as sarcasm, irony, or humour. And it goes without saying that, from the perspective of a world now saturated by generative AI methods, these earlier NLP methods focus purely on representation, and do not provide a generative capability. Be that as it may, as we will highlight below, representation is still very much a key tool for the computational social scientist, the question is just how accurate (or not) is the derived representation of human language.
4. Harnessing the AI–transformer revolution
Sometime during 2016 or 2017, work began in the Google Research and Google Brain research groups on a revolutionary neural approach to the fundamental machine—human language problem. Known as the “transformer” architecture, and introduced by the now famous paper entitled, “Attention is all you need,” Vaswani et al. (Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, Polosukhin, Guyon, Luxburg, Bengio, Wallach, Fergus, Vishwanathan and Garnett2017) demonstrated how, with vast quantities of human language training data, the new architecture could be taught, via the simplest of tasks—guess the next word in the sequence—to apparently infer complex linguistic and semantic properties of human speech. Subsequent work followed at Google and other labs, extending, refining, and enlarging the scale of the approach, resulting in breathtaking performance by transformer models on standard NLP benchmarks (Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019; Brown et al., Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal, Neelakantan, Shyam, Sastry, Askell, Agarwal, Herbert-Voss, Krueger, Henighan, Child, Ramesh, Ziegler, Wu, Winter, Hesse, Chen, Sigler, Litwin, Gray, Chess, Clark, Berner, McCandlish, Radford, Sutskever, Amodei, Larochelle, Ranzato, Hadsell, Balcan and Lin2020; Raffel et al., Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2020).
In Figure 2 a generalised schematic of the transformer model architecture is shown. As neural models (i.e. large matrix multiplication models), transformer models take input “at the left” and pass the transformed matrices of information from “left to right” to arrive at a statistical prediction for the most likely word (token) that might come next. The model is trained by passing it billions of tokens from real sequences of human-authored text obtained from online repositories of news, books, and social media, but hiding (or “masking”) the next word from the model. The model’s guess for that next word (token) is then compared to the real (ground-truth) word (token) and the internal model weights are adjusted accordingly to nudge it towards more accurate next word prediction.
Schematic of the large-language-model (LLM), encoder-decoder architecture. For the first time in NLP technology, text is fed into the model as a sequence (A), with positional encoding ensuring that subsequent steps retain knowledge of this ordering; transformer blocks are then applied in encoder, and/or decoder layers which enable the model to simultaneously attend to many aspects of the text (e.g. pronouns, verbs, nouns, punctuation) (B); the final layer is a statistical prediction for the next word (token) (C); and, each new token can be added to the input sequence, such that the model is able to keep generating new words (tokens) based on the generative steps already undertaken (D).

Importantly, these models can be auto-regressive in nature, that is, they can read their own produced tokens as input. This means that rather than a single next-word prediction, they can be set to repeatedly generate next words, feeding the expanding sequence back into their input at each turn. This makes them truly “generative” models, and has led to a large number of applications to traditionally complex NLP tasks. What once required a complex, multi-step pipeline to achieve can now be achieved by simply describing the task to the model in plain English and subsequently passing the textual record (phrase, sentence, paragraph, or even whole document) to analyse to the model, and having the model “generate” the information, label, or decision as desired.
Perhaps most remarkably, recent LLMs have been shown to exhibit a kind of emergent intelligence, performing tasks that cannot possibly have been part of their training data, even on complex logical problems hitherto thought of as well beyond the reach of “thinking machines.” For example, Trinh et al. (Reference Trinh, Wu, Le, He and Luong2024) demonstrate “AlphaGeometry”—a LLM trained on millions of examples of Euclidean plane geometry—which is able to perform close to gold medal (human) performance outcomes on the latest International Maths Olympiad problem set. Similarly, Bubeck et al. (Reference Bubeck, Chandrasekaran, Eldan, Gehrke, Horvitz, Kamar, Lee, Lee, Li, Lundberg, Nori, Palangi, Ribeiro and Zhang2023) demonstrate OpenAI’s GPT-4 (General Pre-trained Transformer, 4) ability to stack physical objects, draw unicorns (via coding), compose music, and write complex code. Whilst still a topic of debate in the field of computer science, there are indications that recent LLMs have some kind of “world model,” that is, despite “simply” next token predicting, the model’s training has somehow conferred some degree of knowledge of how physical objects and abstract concepts relate in real worlds, perhaps even encoding so-called “common knowledge” (Mitchell and Krakauer, Reference Mitchell and Krakauer2022; Mitchell, Reference Mitchell2023).
Can these new technologies be turned to the challenges of tracking narratives in public discourse at scale? We consider several promising applications.
Transformers as (better) encoders
From the perspective of today’s remarkable generative models, one can easily forget that the non-generative, encoder-only function of transformers was their first astounding achievement; a capability still used actively by researchers and engineers alike. With reference to Figure 2, “encoder-only” models are comprised of the left-hand encoder transformer block only, and do not pass their output to the generative decoder block to form next word/token outputs. Instead, the output from the encoder-only system is a real-valued vector, its length being dependent on the LLM in use, representing the rich, high-dimensional, latent semantic content of the input sequence. Part of the reason for the early, rapid adoption of encoder-only models has been that the vector representation produced is a “drop-in” replacement for either a tf-idf or word-embedding vector as introduced earlier. Hence, any ensemble pipeline NLP method using these earlier representational vectors would likely be improved by the richer, contextual, and sequential representation of the input text encoded in the LLM encoder-vector. Popular transformer-based embedding models for NLP applications include BERT (Bidirectional Encoder Representations from Transformers) (Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019), RoBERTa (Liu et al., Reference Liu, Ott, Goyal, Du, Joshi, Chen, Levy, Lewis, Zettlemoyer and Stoyanov2019) (an optimised version of BERT), Sentence-BERT (Reimers and Gurevych, Reference Reimers, Gurevych, Inui, Jiang, Ng and Wan2019) (a sentence-to-sentence similarity optimised version), and BERTopic (Grootendorst, Reference Grootendorst2022) (a system for clustering texts using BERT embeddings). Examples of these technologies applied to related topics include Mendelsohn et al. (Reference Mendelsohn, Budak and Jurgens2021), who fine-tune the RoBERTa model to predict human-labelled tweets related to immigration. They find a significant uplift in performance from fine-tuning to their dataset, with an average F1 score above 0.65 on a variety of framing tasks relative to 0.61 for RoBERTa without fine-tuning, or just 0.3 for a simple logistic regression on tf-idf vectors. Bonikowski et al. (Reference Bonikowski, Luo and Stuhler2022) similarly employ a fine-tuned RoBERTa model with active labelling to train a neural layer to identify paragraphs of text as populist. Again, they find a RoBERTa-backed classifier superior to ensemble (random forest) models backed by word-embeddings or tf-idf vectors.
Transformers as labellers
– Perhaps the most obvious first application of the power of LLMs to understand and encode language is to apply them to the labelling task (“step 5” in the Standard Approach, above), at scale. Here, it has become very apparent that LLMs are extremely good at this task, outperforming both expert and crowd-sourced human labelling. Törnberg (Reference Törnberg2023)’s 2023 study shows that OpenAI’s ChatGPT-4 achieved not only higher accuracy (
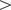 $ > $
0.90 vs. 0.82), but also much higher inter-rater reliability (
$ > $
0.90 vs. 0.82), but also much higher inter-rater reliability (
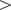 $ > $
0.95 vs. 0.65) than expert human coders, yet with statistically similar levels of bias. Rathje et al. (Reference Rathje, Mirea, Sucholutsky, Marjieh, Robertson and Bavel2024) find similar success in a related task in the psychological sciences, demonstrating convincingly the power of generative transformer (decoder) models to undertake such tasks, using prompting directly with, or without definitions of concepts (e.g. “moral foundations”) to label over 16,000 posts on Reddit with high accuracy. And most recently, applied to labelling party positions on a Left–Right spectrum, Mens and Gallego (Reference Mens and Gallego2025) label positions of thousands of tweets by US congress members, British party manifestos (sentence at a time), and EU policy speeches in 10 languages (Prompt used in the study: “You will be provided with the text of a tweet published by a member of the US Congress. Where does this text stand on the “left‘ to “right’ wing scale? Provide your response as a score between 0 and 100 where 0 means “Extremely left’ and 100 means “Extremely right’. If the text does not have political content, set the score to “NA.” You will only respond with a JSON object with the key Score. Do not provide explanations. “Text of the tweet.’). Through ground-truth comparison, they find the strongest language models perform at or above 0.90 correlation with human annotation, and outperform examples of all prior NLP approaches (tf-idf vectors, word-embeddings, and BERT fine-tuned). Indeed, small amounts of human-labelled data can now be used to directly train LLMs towards higher accuracy in labelling large datasets very cheaply (Wang et al., Reference Wang, Liu, Xu, Zhu and Zeng2021), or to “teach” simple models to do the same, lifting their performance in a process likened to slingshotting a space probe around a larger planet to go further, faster (O’Neill et al., Reference O’Neill, Anantharama, Borgohain, Angus, Vlachos and Augenstein2023).
$ > $
0.95 vs. 0.65) than expert human coders, yet with statistically similar levels of bias. Rathje et al. (Reference Rathje, Mirea, Sucholutsky, Marjieh, Robertson and Bavel2024) find similar success in a related task in the psychological sciences, demonstrating convincingly the power of generative transformer (decoder) models to undertake such tasks, using prompting directly with, or without definitions of concepts (e.g. “moral foundations”) to label over 16,000 posts on Reddit with high accuracy. And most recently, applied to labelling party positions on a Left–Right spectrum, Mens and Gallego (Reference Mens and Gallego2025) label positions of thousands of tweets by US congress members, British party manifestos (sentence at a time), and EU policy speeches in 10 languages (Prompt used in the study: “You will be provided with the text of a tweet published by a member of the US Congress. Where does this text stand on the “left‘ to “right’ wing scale? Provide your response as a score between 0 and 100 where 0 means “Extremely left’ and 100 means “Extremely right’. If the text does not have political content, set the score to “NA.” You will only respond with a JSON object with the key Score. Do not provide explanations. “Text of the tweet.’). Through ground-truth comparison, they find the strongest language models perform at or above 0.90 correlation with human annotation, and outperform examples of all prior NLP approaches (tf-idf vectors, word-embeddings, and BERT fine-tuned). Indeed, small amounts of human-labelled data can now be used to directly train LLMs towards higher accuracy in labelling large datasets very cheaply (Wang et al., Reference Wang, Liu, Xu, Zhu and Zeng2021), or to “teach” simple models to do the same, lifting their performance in a process likened to slingshotting a space probe around a larger planet to go further, faster (O’Neill et al., Reference O’Neill, Anantharama, Borgohain, Angus, Vlachos and Augenstein2023).
Transformers as synthetic data generators
Alternatively, instead of dramatically reducing the cost of labelling real data, LLMs can be used to create large, synthetic textual datasets, with a highly controllable form. The benefit here is that LLM systems can be evaluated for accuracy, bias, and reliability on large amounts of labelled synthetic data, where either real data are unavailable or are very costly to curate, meaning that a system can be deployed on real data after significant refinement has already occurred on synthetic data. Techniques here focus on enforcing structured outputs (Willard and Louf, Reference Willard and Louf2023), or reducing hallucinations (Ayala and Béchard, Reference Ayala and Béchard2024). However, recent advances by LLM platforms have meant that model control is now even more precise, with the ability for models to provide exact structured outputs fitting a researcher’s schema (Pokrass, Reference Pokrass2024).
Transformers as direct framing analysers
Finally, recent research has shown that LLMs can be used directly as highly capable “language models.” That is, that LLMs can be used to identify issue-framing in text directly, with low cost, and low bias. Angus and O’Neill (Reference Angus and O’Neill2024) introduce “paired completion,” a technique whereby LLMs are primed with examples of statements from one framing or another on a particular issue, and then the text to be analysed is fed as a “completion” to the model. The method collects the likelihood that the model would have generated the completion text, conditional on already having “said” the priming text. By comparing the completion likelihoods, a quantitative metric is obtained for the text’s textual alignment with one frame or another. The study reports balanced accuracy scores as high as 0.93 across three synthetic narrative datasets covering climate change, domestic violence, and misogyny.
Alternatively, LLMs can encode an entire “world” of a given source, such as a particular newspaper or online media outlet (Guo et al., Reference Guo, Ma and Vosoughi2022). The approach here is to fine-tune an LLM, a method that trains an LLM to learn the particular patterns of speech of a given source corpus, by feeding it (say) news from one outlet only. In this way, a series of fine-tuned LLMs can be trained, one per news source, and then each LLM can be analysed for how it might complete a sentence, or use a keyword in a sentence (e.g. complete the sentence, “Immigrants travelling by boat to Australia are a
 $ \_\_\_ $
to our society.”)
$ \_\_\_ $
to our society.”)
And, we note that whereas our emphasis in this study is the tracking of specific narratives related to democratic resilience at scale (i.e. “supervised” analysis), one can also employ transformers to assist with narrative discovery (i.e. “unsupervised” analysis). Here, the “Concept Induction” tool, LLooM, of Lam et al. (Reference Lam, Teoh, Landay, Heer and Bernstein2024) represents a good example of the possibilities. With LLooM, a user can input a large body of text and have the sysem iteratively uncover latent concepts, at a variety of levels of analysis (e.g. “subconcepts” such as “Women’s responsibilities,” “Traditional gender roles,” and “Power dynamics and women” lead to an emergent meta-concept, “Criticism of traditional gender roles”). It is likely that many other applications will emerge in the near future along these lines (For a flavour of what is possible in the broader areas of political science, Li et al. (Reference Li, Li, Chen, Gui, Yang, Yu, Wang, Cai, Zhou, Shen, Qian, Chen, Xue, Sun, He, Chen, Ding, Du, Mu, Pei, Zhao, Swayamdipta, Neiswanger, Wei, Hu, Zhu, Chen, Lu, Shi, Qin, Fu, Tu, Yang, Yoo, Zhang, Rossi, Zhan, Zhao, Ferrara, Liu, Huang, Zhang, Rothenberg, Ji, Yu, Zhao and Dong2024) provides a recent white-paper review of for the application of LLMs to political science.).
4.1. Risks associated with using transformers
Using LLMs for framing analysis at scale is not without concerns. Generative LLMs present outstanding opportunities for quantified approaches to tracking narratives at scale, but their effective use requires a robust understanding of a suite of risks (Bommasani et al., Reference Bommasani, Hudson, Adeli, Altman, Arora, von Arx, Bernstein, Bohg, Bosselut, Brunskill, Brynjolfsson, Buch, Card, Castellon, Chatterji, Chen, Creel, Davis, Demszky, Donahue, Doumbouya, Durmus, Ermon, Etchemendy, Ethayarajh, Fei-Fei, Finn, Gale, Gillespie, Goel, Goodman, Grossman, Guha, Hashimoto, Henderson, Hewitt, Ho, Hong, Hsu, Huang, Icard, Jain, Jurafsky, Kalluri, Karamcheti, Keeling, Khani, Khattab, Kohd, Krass, Krishna, Kuditipudi, Kumar, Ladhak, Lee, Lee, Leskovec, Levent, Li, Li, Ma, Malik, Manning, Mirchandani, Mitchell, Munyikwa, Nair, Narayan, Narayanan, Newman, Nie, Niebles, Nilforoshan, Nyarko, Ogut, Orr, Papadimitriou, Park, Piech, Portelance, Potts, Raghunathan, Reich, Ren, Rong, Roohani, Ruiz, Ryan, Ré, Sadigh, Sagawa, Santhanam, Shih, Srinivasan, Tamkin, Taori, Thomas, Tramèr, Wang and Wang2021). Attention must be paid to the provenance of training data, bias in generated text, processing cost, and open or closed access, given that many of the most performant models are closed-source, run by large platforms. As mentioned, the training of LLMs (next word prediction) does not guarantee correctness or completeness in responses obtained, and even the most frontier LLMs can still be tripped up by seemingly trivial completion tasks (For example, if one asks the most performant language model to date, Anthropic’s Claude 3.5 Sonnet, “How many i’s in Kit-Kat?’, it answers, “The correct answer is that there are zero i’s in Kit Kat.’ This behaviour is common for all the major models alike.). In the computational social sciences recent reviews of LLM opportunities and risks catalogue these issues in more detail (Thapa et al., Reference Thapa, Shiwakoti, Shah, Adhikari, Veeramani, Nasim and Naseem2025), with some authors arguing that the impact of LLMs will go beyond efficiency and opportunity to start re-shaping the scientific method itself (Fecher et al., Reference Fecher, Hebing, Laufer, Pohle and Sofsky2023), and exacerbate existing resource and access inequalities in the political economy of ideas (Luitse and Denkena, Reference Luitse and Denkena2021). On the former, work has already been done to create entire ecosystems of LLMs (Agentic-AI systems) which operate as virtual, automated scientific laboratories reading each other’s (AI) lab’s work, and improving upon it (Schmidgall and Moor, Reference Schmidgall and Moor2025). For now, these studies are largely confined to computer science domains, where algorithmic optimisation is well handled by such systems; nonetheless, the question of how far science is willing to bring LLMs into the scientific method is open and dynamic.
Direct assessments of political bias, perhaps most relevant to the present study, in LLMs are important and require constant updating due to the rapid developments in model releases and capabilities. For instance, Choudhary (Reference Choudhary2024) put four recent, major commercial “models” (“ChatGPT-4, Perplexity, Google Gemini, and Claude”—unfortunately, we do not learn which exact model variant in the paper) through major political orientation questionnaires such as the Pew Research Centre’s Political Typology Quiz, PoliticalCompass.org, and ISideWith political party quiz, and find that all models lean left of centre, with “ChatGPT-4” and “Google Gemini” aligning with “establishment liberals” (three categories to the left, of four), whilst “Claude” and “Perplexity” aligned just left of centre, as “outsider left” (one category to the left, of four). Political Compass results were similar. These results appear robust to model choice and language (Pit et al., Reference Pit, Ma, Conway, Chen, Bailey, Pit, Keo, Diep and Jiang2024; Rettenberger et al., Reference Rettenberger, Reischl and Schutera2025). It is important to note that such outcomes are more likely when models are used in a “zero-shot” manner, that is, when they are asked, without examples or further definitions, to answer a direct question (see a demonstration of prompt variation below Section 5). Further, we note that human annotation in politically relevant domains is itself subject to annotator bias (Plisiecki et al., Reference Plisiecki, Lenartowicz, Flakus and Pokropek2025), as such, it is unlikely that LLMs (which rely on human guidance) will obtain entirely “bias-free” behaviours. For now, these considerations, like any research involving judgements (human or machine), require thoughtful design and interpretation decisions with replication across models/labs/contexts, as ever, the most likely protection against false-hood. In this light, AI documentation literacy is key for success in this direction (Smith et al., Reference Smith, Bello, Bialic-Murphy, Clark, Delavaux, de Lauriere, van den Hoogen, Lauber, Ma, Maynard, Mirman, Lidong, Rebindaine, Reek, Werden, Wu, Yang, Zhao, Zohner and Crowther2024).
5. Demonstrating tracking public narratives with transformers
We conclude this section by conducting demonstration exercises related to tracking narrative aspects of democratic resilience with transformer methods. Our aim is not to conduct a thorough empirical study with these demonstrations, but rather, to provide tangible examples of the new possibilities of these technologies: the kinds of implementation setup involved; how model choices impact insights; what a fully fledged “tracking” project would demand.
In the first example, we exemplify the most direct use of LLMs, namely, leveraging their ability to make human-level judgements regarding semantic content in natural language through “just asking the model” in the spirit of Törnberg (Reference Törnberg2023), Rathje et al. (Reference Rathje, Mirea, Sucholutsky, Marjieh, Robertson and Bavel2024) and Mens and Gallego (Reference Mens and Gallego2025) introduced above. By applying nine different models from three major providers, across five text excerpts across the populism—democrat spectrum, under two prompt treatments (90 model calls in all), we demonstrate both the efficiency with which AI judgements can be achieved, and some of the considerations practitioners and readers alike need to keep in mind when undertaking these exercises or consuming their findings.
In the second example, we move to a more scaled “tracking” demonstration, by applying the quantitative LLM paired-completion approach (Angus and O’Neill, Reference Angus and O’Neill2024) to the democratic resilience-relevant issue of immigration. By using the method to analyse over 2800 speeches from 11 prominent speakers appearing in the Australian (Federal) Parliamentary Hansard over 15 years we are able to generate time-series position statements on the “border security”—”humanitarian” spectrum, revealing quantitatively the dynamics of this issue, including patterns related to the election cycle.
5.1. Identifying populism with transformers
Populism is a common object of study for the political analysis of text, and as noted earlier, is one of the key pernicious narratives related to democratic resilience. That said, defining the populism narrative is the first methodological challenge. Early studies typically looked to Mudde (Reference Mudde2004)’s succinct rendering,
“An ideology that considers society to be ultimately separated into two homogeneous and antagonistic groups, “the pure people’ versus “the corrupt elite’, and which argues that politics should be an expression of the volonté générale (general will) of the people.”
This definition focuses on the core idea of a binary struggle between (a monolithic) “the people” and “the elite.” However, more recent authors contend that populism is a latent construct that can only be truly identified via a multi-dimensional tool. Meijers and Zaslove (Reference Meijers and Zaslove2021) make this argument and develop a five-dimensional survey tool for validation with an expert judgement panel comprising 294 respondents “with expertise in party politics” (p.382) across 28 countries (Included countries: Austria, Belgium, Bulgaria, Croatia, Cyprus, Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Ireland, Italy, Lithuania, Malta, The Netherlands, Norway, Poland, Portugal, Romania, Slovakia, Slovenia, Spain, Sweden, Switzerland, United Kingdom.). Using exploratory factor analysis (EFA) and item response theory (IRT), they conclude that their five-dimensions of populism are a valid operationalisation of the latent concept. The five dimensions are given as (p. 384),
-
1. Manichean worldview: “Politics is a moral struggle between good and bad”
-
2. Indivisible people: “The ordinary people to be indivisible (i.e., the people are seen as homogenous)”
-
3. General will: “The ordinary people’s interests to be singular (i.e., a “general will’)”
-
4. People-centrism: “Sovereignty should lie exclusively with the ordinary people (i.e., the ordinary people, not the elites, should have the final say in politics)”
-
5. Anti-elitism: “Anti-elite dispositions”
Given the more robust validation approach of Meijers and Zaslove (Reference Meijers and Zaslove2021), in what follows, we shall adopt this definition in our second, expanded, prompt strategy.
Approach
To provide a concise demonstration of how generative transformers perform, we shall conduct a small text (
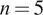 $ n=5 $
) corpus evaluation, leveraging variation across commercial platforms (Anthropic, OpenAI, Google), model flavours (chat models vs. so-called “reasoning” models) from these providers, and prompt design. On the latter, we will demonstrate two prompting strategies, starting with a “zero-shot” style prompt, which leans on the particular model’s “world-knowledge understanding” (from training and alignment) of “populist narrative” compared to an extended prompt, in which we explicitly define the concept, and require the model to only label a text as exhibiting a populist narrative if it fulfils all five dimensions. Both prompts variants are shown in Figure 3 (Note: prior to the prompt, a general system prompt was provided the model and was constant across all calls, “You are a helpful, knowledgeable, expert assistant. You are proficient in many tasks, such as coding, math, science, humanities, and more.’). The extended definition flows from the “ideational approach” to defining populism as a latent concept taken from Meijers and Zaslove (Reference Meijers and Zaslove2021) introduced above. For the purposes of the demonstration, the extended prompt treatment represents a more controlled setting (since we explicitly define the labelling policy) whilst simultaneously raising the bar for the positive labelling of the text as populist since the prompt requires the text to “fulfil all five dimensions.”
$ n=5 $
) corpus evaluation, leveraging variation across commercial platforms (Anthropic, OpenAI, Google), model flavours (chat models vs. so-called “reasoning” models) from these providers, and prompt design. On the latter, we will demonstrate two prompting strategies, starting with a “zero-shot” style prompt, which leans on the particular model’s “world-knowledge understanding” (from training and alignment) of “populist narrative” compared to an extended prompt, in which we explicitly define the concept, and require the model to only label a text as exhibiting a populist narrative if it fulfils all five dimensions. Both prompts variants are shown in Figure 3 (Note: prior to the prompt, a general system prompt was provided the model and was constant across all calls, “You are a helpful, knowledgeable, expert assistant. You are proficient in many tasks, such as coding, math, science, humanities, and more.’). The extended definition flows from the “ideational approach” to defining populism as a latent concept taken from Meijers and Zaslove (Reference Meijers and Zaslove2021) introduced above. For the purposes of the demonstration, the extended prompt treatment represents a more controlled setting (since we explicitly define the labelling policy) whilst simultaneously raising the bar for the positive labelling of the text as populist since the prompt requires the text to “fulfil all five dimensions.”
Two prompt variants were employed in the populism labelling demonstration. Both prompts contain the same task: to respond with a label from a five-item ordinal set (and brief justification), as to whether the TEXT exhibits a populist narrative (blue text in both prompts). The extended prompt (bottom) adds a five-dimensional definition (Meijers and Zaslove, Reference Meijers and Zaslove2021) to fix ideas and effectively raise the threshold for positive identification.

Corpus
The small text corpus was constructed to contain a core of three texts representing populist politicians or populist political parties (Trump, Vlaams Belang, Left Front), plus two strongly pro-democracy politicians (Albanese, Obama). Of the two pro-democracy politicians, one text (Obama) gives a full throated affirmation of democratic institutions, whilst the other text (Albanese) represents a tricky case, since the (then) Australian Opposition Labor Leader leader accuses the incumbent government with quasi-elitist language (“[they have] treated. public money as a political slush fund”), calling for a vote to oust them, yet steering well clear of explicit populist rhetoric. We include the text as a mid-point between the explicitly populist texts of Trump, Vlaams Belang and the Left Front on the one hand, and the explicitly anti-populist text of Obama on the other. The texts have the following notes:
-
• TRUMP—Excerpt from US Presidential inauguration speech, 20 Jan 2017. In one sentence, perhaps the “textbook” populist position, juxtaposing the “small group” in the “nation’s Capital” (i.e. the elites) profiting whilst “the people” (homogenous, united) “bear the cost.” (See: https://trumpwhitehouse.archives.gov/briefings-statements/the-inaugural-address/, April 2025).
-
– Hypothesis: We expect direct (zero-shot) calls to identify the text as populist, but it is an open question whether models will find this single sentence ticks all five dimensions of the extended prompt requirement.
-
-
• VLAAMS BELANG (VB)—Founded in 2004, Vlaams Belang is a Flemish nationalist party in Belgium. We select here an excerpt from the VB Membership Magazine, Oct 2008. Of interest for the demonstration, this text arises from Pauwels (Reference Pauwels2011)’s study of Belgian parties, wherein they find that not only is VB “often labelled as populist by both commentators and scholars” (p.98) but according to the study results, VB is “by far the most populist of all the examined parties” (p.101).
-
– Hypothesis: Strong anti-elite messaging should satisfy zero-shot prompt, satisfy three of five dimensions of the extended prompt, but is not explicit about the indivisible people and their will.
-
-
• LEFT FRONT (“Front de Gauche”)—“Front de gauche” (FG) was founded in 2009 as an alliance between the French Communist Party and the Left Party, with the excerpt taken from the party manifesto, Jun 2012. The manifesto was extracted from the Manifesto Project (See (requires login): https://manifesto-project.wzb.eu//down/originals/31021_2012.pdf, April 2025) and has been translated from the original French to English using Anthropic’s Claude 3.7 Sonnet model (Specifically: claude-3-7-sonnet-20,250,219, prompt: “Translate to English: {text}’. It is worth noting that each model tested in this demonstration could have handled undertaking the task in the original language (French), however, to reduce contamination due to their respective strengths at translation, pre-translation to each model’s main training language (EN) was undertaken.). The Left Front represents one of the most prominent left-leaning populist movements today, scoring−47.925 on the rile score (extreme left) per the Manifest Project’s own data. As such, this text provides a useful test of populist language from the left, as counter point to the VB text, from the right.
-
– Hypothesis: This extended text encapsulates well the multi-dimensional populism concept, including strong phrasing around the “the people,” their will, their return to power through a “citizen revolution” of the incumbent “greed of a few.” Likely to pass both the zero-shot and extended prompt version.
-
-
• ALBANESE—Excerpt from campaign speech delivered 1st May, 2022 in Perth, Australia (See: https://electionspeeches.moadoph.gov.au/speeches/2022-anthony-albanese, April 2025). Anthony Albanese was at that time the leader of the federal opposition Labor Party of Australia. The text was selected as a potentially challenging case for automated methods since in isolation, it has some flavour of anti-elite sentiment—accusing the incumbent leadership as shirking responsibility, and mis-using public money for their own interests—but a human expert would be unlikely to strongly identify this text as populist since there is little contrast of “the people” with the “elites” and his call for an anti-corruption commission supports the rule of law and democratic institutions in general.
-
– Hypothesis: Mixed outcomes. Zero-shot outputs could fall either side of populist or not, but unlikely strongly so. However, it should fail the extended, multi-dimensional prompt, with models unable to find convincing evidence across all aspects of populism required.
-
-
• OBAMA—Excerpt from US Presidential inauguration speech, 21 Jan 2013 (See: https://obamawhitehouse.archives.gov/the-press-office/2013/01/21/inaugural-address-president-barack-obama, April 2025). This text was delivered by Obama near the top of his speech. It affirms the founding democratic principles of the United States Constitution strongly, it uses inclusive language for the peoples of the country and notes the protections provided each of them under the Constitution and the rule of law.
-
– Hypothesis: Neither the zero-shot nor the extended prompts should return any positive identification of populism. The text is anti-populist from start to finish.
-
Models
Models were included to present a spectrum of capabilities and varieties. From each provider, a strong “reasoning” model was included, that is one which undertakes chain-of-thought reasoning by design (Wei et al., Reference Wei, Wang, Schuurmans, Bosma, Ichter, Xia, Quoc, Le and Zhou2022) with reasoning effort or length set to “high,” a small/fast model, that is one which is intended for simpler tasks emphasising low latency and low cost, and an intermediate model, typically the strong model without reasoning, or an equivalent recommended model from the provider (Exact model details (reading left to right of Fig. 4): Anthropic – “claude-3-7-sonnet-20,250,219-high’ (thinking enabled, budget tokens 32,768, cut-off Oct 2024), “claude-3-7-sonnet-20250219’ (LLM mode, no thinking enabled, cut-off Oct 2024), “claude-3-5-sonnet-20241022’ (cut-off Apr 2024); OpenAI – “o3-high’ (“o3–2025-04-16’, reasoning effort: “high’, cut-off 1 Jun 2024), “gpt-4.1’ (“gpt-4.1-2025-04-14’, cut-off 1 Jun 2024), “gpt-4o’ (“gpt-4o-2024-08-06’, cut-off 1 Oct 2023); Google/Gemini—“gemini-2.5-flash-preview-04-17’ (thinking enabled, budget tokens 24 k, cutoff Jan 2025), “gemini-2.5-flash-preview-04-17’ (LLM mode, no thinking, cutoff Jan 2025), “gemini-2.0-flash’ (cutoff June 2024).). All calls were made via API with default API parameter settings. It is important to note that models are trained only up to a certain cut-off date. These dates ranged from the earliest in Oct 2023 (OpenAI’s gpt-4o) to the most recent in Jan 2025 (Google’s Gemini 2.5). As such, all texts were within the training context window of each model, bringing in the potential (or advantage), that the model may bring prior training world knowledge to bear on the task at hand (e.g. the model may recognise an excerpt is from a broadly known populist party or figure and so, be biased by the “reputation” of the source in its adjudication of the given text). Whilst the researcher could attempt to redact identifying characteristics from the text, the reality is that today’s models will likely recognise the surrounding text anyway (see below), hence, this consideration is more of a source of potential bias to be assessed through validation against ground-truth rather than something that can be completely avoided.
Results for the labelling of populism in the small political texts corpus. Each column indicates the model response, colour-coded according to the Key (bottom): more red colours indicate a finding of populism, more green colours indicate a finding against populism. Results are grouped according to model family (Anthropic, OpenAI, Google) with stronger to weaker variants of each family presented left to right within a family, and prompt in use (Zero-shot prompt: first 9 cols; Extended prompt: last 9 cols). The final two cols give a majority rating under each prompt.

Findings
Figure 4 presents results across the 90 model calls, noting that these are strictly for demonstration purposes only; a full study would incorporate a human validation and sensitivity strategy. Results are presented to facilitate ease of comparison: across prompt strategies (zero-shot, then extended prompt: main panels), across model families (groupings within panels), and across model strengths within each family (stronger to weaker models are presented left to right within each family). We also provide a majority outcome for the zero-shot and extended prompt variants, weighting models equally.
From this exercise, we draw the following insights:
-
1. Labelling with transformers is very flexible. It is hard not to overstress this point, though many practitioners may take for granted the new “chat-based” world of AI, the ability to take the full text, of varying lengths, and even languages (all models considered in this demonstration are multi-lingual), and obtain valid labels in fractions of a second demonstrates much of the remarkable opportunity these methods bring to the table.
-
2. Labelling with transformers is very cost-effective. Model calls were of the order of USD 0.01–0.02 for the most expensive (strongest) models (e.g. Claude 3.7 Sonnet, OpenAI’s o3(high)) and fractions of a cent for the weaker models. Together, doing an ensemble call over the nine models cost on the range USD 0.05 to USD 0.10. Human labelling would take around 30s of reading time (e.g. Left Front, Obama), and perhaps 30s of judgement time, in all around 60s, at a typical data labelling rate of USD 25/hour, or USD 0.40/minute, we have an approx. 4 to 8x cost saving. However, this is a lower bound, given that one would rarely call three “reasoning” models in practice, so the real cost saving is likely on the order of 12 to 24x (Noting that this simple analysis equally does not price development time for the model pipelines, nor equivalent time spent setting up human labellers.).
-
3. Zero-shot prompting comes with model risks. The most striking pattern across the two panels is the uniformity of findings under the zero-shot scenario. Here, the three populist texts (Trump, VB, Left Front) were universally found to be populist by each of the nine models, Albanese’s tricky case leaned populist, whilst Obama’s anti-populist case leaned strongly anti-populist. Whilst on face value this seems reasonable, the Albanese results are troubling given our prior hypothesis that Albanese’s text should not be confused as populist despite the inherent government critique. Without defining terms, the models must leverage their own (hidden, “black-box”) understanding of the term “populist,” which poses a control risk to any study design.
-
4. Extended prompting is more robust, but results need careful interpretation. Extended prompting has confirmed Obama’s anti-populism, and moved the dial towards the same for Albanese, especially so in five of the six stronger model calls. However, we also see that positive populism labels are harder to obtain in general, with only the Left Front universally receiving the populist tag. Aligning with our hypotheses, Trump’s short, sharp text, and VB’s less explicitly five-dimensional excerpt both receive mixed reviews. We return to this point below.
-
5. Ensembling models can recover signal from noise. The pattern of the final columns in the figure, where we take the majority view from across the nine models, delivers an almost exact imprint of our grounded pre-trial expectations for each text. Ensembling is well known in machine learning to be a helpful technique for distinguishing signal from noise, and the same appears true from our demonstration in the world of transformer-based labelling.
We close this exercise with one final observation around transformer behaviour. Recall that our two prompts (Figure 3) both asked the model to provide a label and a brief justification for the model response. These justifications are instructive but need to be taken with a grain of salt (Recent work by Anthropic under the heading of model “biology’ has been able to show strong evidence that model explanations, and even internal chains of thought, do not always align with model outputs. See: “On the Biology of a Large Language Model’, published at https://transformer-circuits.pub/2025/attribution-graphs/biology.html#dives-cot). We focus on the anomalous cases, specifically the differential ways that models handled the VB text under the extended prompt (where most variation in outcome was observed). The three strongest models, across each provider, gave the following:
-
• Anthropic:: Claude 3.7 Sonnet (High): “weak yes” (“Only demonstrates anti-elitism, missing other required populist dimensions.”)
-
• OpenAI:: o3 (High): “strong no” (“Only anti-elite language; no unified people or general will.”)
-
• Google:: Gemini 2.5 Flash (High): “strong no” (“Lacks explicit indivisible people, general will, and people-centrism.”)
As expected, we can see that with the extended definition, each model struggled to endorse populism due to the requirement that all five dimensions should be present. It would be wrong, therefore, to conclude that the stronger models have made a “mistake” here; instead, it is crucial to understand that as models have grown in capability, they have also grown in their ability to more closely follow the task given to them. We can contrast these explanations with those of the weaker models. Google’s Gemini 2.0 Flash commented, “Anti-establishment, anti-elite sentiment is very strong” on the way to a “strong yes” to populism. Whilst OpenAI’s GPT-4o labelled “weak yes,” saying, “Anti-elitism and people-centrism are evident,” focussing on what was evident, not what was missing. A deeper exploration of model variability and human validation along these lines would be a fruitful line of further inquiry for this method.
5.2. Tracking narratives of immigration with transformers
In our second demonstration, we use the novel paired-completion approach detailed in Angus and O’Neill, Reference Angus and O’Neill2024 to analyse texts related to immigration. Our aim here is to provide a demonstration of what can be done with paired-completion by carrying out a small (non-causal) longitudinal study on Australian Parliamentary Hansard during a particularly tumultuous time for the issue of asylum seeker policy in Australia. While robustness, model-choice, and validation are important considerations, these have been addressed in prior work (Angus and O’Neill (Reference Angus and O’Neill2024)). The present study’s purpose is to demonstrate the feasibility and policy relevance of transformer-based narrative tracking, rather than to conduct a full empirical evaluation. To this end, we provide and critically discuss below several examples of extant speeches and their scores via the method. Any full, stand-alone, empirical study would be expected to conduct a grounded validation study with human-expert evaluation.
Approach
We follow the method of paired-completion as provided in the reference. Paired-completion requires two key inputs: 1) a set of opposing “seed” statements which define the opposing framings on the topic under study; and 2) a corpus of texts to apply the method to. On the first, OpenAI’s GPT-4 (gpt-4-turbo) model was used to generate five statements to represent two perspectives on asylum seekers in the Australian context (Prompt 1: “Provide two perspectives on asylum seekers in the Australian context. Name each perspective. For each perspective, provide five sentences that together represent that perspective.’, followed by Prompt 2: “For each perspective, turn the sentences into example statements that represent these views.’). This produced the following seed statements for use as priming texts in the paired-completion method:
Perspective 1: Humanitarian Approach:
-
1. Human Rights Focus: “We must remember that asylum seekers are escaping dire situations where their basic human rights are often violated; it’s our duty to offer them sanctuary.”
-
2. International Obligations: “As a signatory to the UN Refugee Convention, Australia has a legal and ethical obligation to protect those who arrive on our shores seeking refuge from persecution.”
-
3. Moral Duty: “It is our moral obligation as a prosperous and stable nation to extend a helping hand to those in need, showing compassion beyond our borders.”
-
4. Community Benefits: “Asylum seekers bring a wealth of diverse cultural perspectives and skills that can greatly benefit our society and economy, particularly in sectors with labor shortages.”
-
5. Legal and Fair Processing: “We must ensure our asylum processing system is fair and transparent, adhering to international laws and respecting the dignity of each individual.”
Perspective 2: Border Security Approach:
-
1. National Security: “It is crucial to maintain stringent border controls to prevent the entry of potential threats to our national security, ensuring the safety of all Australians.”
-
2. Economic Concerns: “The economic burden of supporting a large number of asylum seekers could strain our public services and welfare systems, impacting the financial stability of our country.”
-
3. Legal Immigration Channels: “We need to uphold the integrity of our legal immigration system; allowing people to bypass it by arriving irregularly sets a precedent that could undermine the entire framework.”
-
4. Sovereignty and Control: “Australia must have the sovereign right to control its borders and decide who can enter and stay in our country, to preserve the order and effectiveness of our immigration policies.”
-
5. Deterring Smuggling Operations: “Implementing strict asylum policies can act as a deterrent to human trafficking and smuggling operations, which often exploit vulnerable individuals seeking refuge.”
To proceed, the method requires interaction with a chat-completion (generative) LLM from which completion log-probabilities are available (That is Typically via the “echo’ switch.). Since many commercial models do not support this feature, the open-source model “llama-2” from Meta was employed (Touvron et al., Reference Touvron, Martin, Stone, Albert, Almahairi, Babaei, Bashlykov, Batra, Bhargava, Bhosale, Bikel, Blecher, Ferrer, Chen, Cucurull, Esiobu, Fernandes, Fu, Fu, Fuller, Gao, Goswami, Goyal, Hartshorn, Hosseini, Hou, Inan, Kardas, Kerkez, Khabsa, Kloumann, Korenev, Koura, Lachaux, Lavril, Lee, Liskovich, Lu, Mao, Martinet, Mihaylov, Mishra, Molybog, Nie, Poulton, Reizenstein, Rungta, Saladi, Schelten, Silva, Smith, Subramanian, Tan, Tang, Taylor, Williams, Kuan, Xu, Yan, Zarov, Zhang, Fan, Kambadur, Narang, Rodriguez, Stojnic, Edunov and Scialom2023), using the
 $ k=2 $
variant of the paired-completion approach (Specifically, the 70B parameter variant, having a context length of 4096 chars. Meta does not give a precise endpoint for the training window, but notes training on “publicly available data”.). This means providing the model with two randomly selected seed sentences on a given perspective, concatenated together, as a primer, and then appending the text under study “as if” the model had generated the whole sequence itself (primer(s) plus completion). One can read off the log-probabilities (i.e. the likelihoods) of the completion text, given the priming text(s) as explained earlier. The “diff” metric is then computed for each text, that is the difference in likelihoods between the text being a completion of perspective 1 versus a completion of perspective 2. Each text thus receives a textual alignment score on the humanitarian—border-security dimension, with higher (positive) scores associating most strongly with the humanitarian framing, and lower (negative) scores associating with the border-security framing.
$ k=2 $
variant of the paired-completion approach (Specifically, the 70B parameter variant, having a context length of 4096 chars. Meta does not give a precise endpoint for the training window, but notes training on “publicly available data”.). This means providing the model with two randomly selected seed sentences on a given perspective, concatenated together, as a primer, and then appending the text under study “as if” the model had generated the whole sequence itself (primer(s) plus completion). One can read off the log-probabilities (i.e. the likelihoods) of the completion text, given the priming text(s) as explained earlier. The “diff” metric is then computed for each text, that is the difference in likelihoods between the text being a completion of perspective 1 versus a completion of perspective 2. Each text thus receives a textual alignment score on the humanitarian—border-security dimension, with higher (positive) scores associating most strongly with the humanitarian framing, and lower (negative) scores associating with the border-security framing.
Corpus
To illustrate the method, we emphasise the longitudinal dimension whilst reducing complexity by focussing only on 7 Prime Ministers along with four minor party or independent prominent speakers on the topic over this period. In alphabetical order the selected speakers were:
-
• Andrew Wilkie, Independent (Prominent speaker);
-
• Anthony Norman Albanese, Australian Labor Party (PM 2022-);
-
• John Winston Howard, Liberal Party of Australia (PM 1996–2007);
-
• Julia Eileen Gillard, Australian Labor Party (PM 2010–2013);
-
• Kevin Michael Rudd, Australian Labor Party (PM 2007–2010, 2013);
-
• Malcolm Bligh Turnbull, Liberal Party of Australia (PM 2015–2018);
-
• Nick McKim, Australian Greens (Prominent speaker);
-
• Richard Di Natale, Australian Greens (Prominent speaker);
-
• Sarah Hanson-Young, Australian Greens (Prominent speaker);
-
• Scott John Morrison, Liberal Party of Australia (PM 2018–2022); and
-
• Tony John Abbott, Liberal Party of Australia (PM 2013–2015)
In terms of hypotheses, the debate in Australia during the boat arrival period was highly polarised between the coalition (liberal/national) “stop the boats” policy framing and the greens and independents who articulated a strongly humanitarian critique of the coalition’s approach. Labor notoriously tried to pursue a more humanitarian approach under Rudd/Gillard, seeking to accommodate and/or process asylum seekers in a mix of onshore and (eventually wholly) offshore detention centres, which in the eyes of the Greens and independents created more humanitarian disasters. Ultimately, with the “success” of the strengthened (military run) turn-back policy of the coalition, Labor in recent years has been accused of effectively adopting the identical policy formulation they previously rejected in opposition. Taken together, we might expect to see:
-
• Hypothesis 1: Polarisation between the Greens/Independents and the Liberal party on this topic;
-
• Hypothesis 2: Labor’s policy position shifting from somewhat humanitarian to strongly border security based in recent years;
Hansard speeches for the Australian House of Representatives (Australia’s lower, legislative, house in its bicameral system) were obtained from the Open Australia project API (See: http://data.openaustralia.org.au/) covering Jan 2006 to Mar 2023 (At the time of ingestion, these were the extent of data available through the project, as the engineering team were having trouble fixing their methods. See comments below on data availability), a period of particular interest in Australian politics due to the outsized increase in asylum seeker boat arrivals (typically from waters North of Australia) over this period. By illustration, just one boat arrived in 2003, carrying 53 asylum seekers, by 2008 these numbers rose to 161 people on seven boats, increasing rapidly to 6555 arrivals on 134 boats in 2011 and an astonishing 20,587 people on 300 boats by 2013 (Figures from the Refugee Council of Australia, https://www.refugeecouncil.org.au/asylum-boats-statistics/, April 2025), Asylum seeker policy of the major parties was a key concern during this period with the tragic loss of life at sea from failed crossings, coupled with images and stories of immigration detention (including children), intermingling with the wars and political hardships being fled by the occupants of these boats, weighing heavily on the Australian psyche.
Following the paired-completion method, speeches (texts) were first selected into the study through classical, strict (literal) keyword matching (Terms used for literal matches: [asylum seeker, seeking asylum, border protection, sovereign border, people smuggling, mandatory detention, refugee status, migration policy, stop the boat, turn-back, detention centre, maritime arrival, unauthorised boat, boat arrival, Australian border force, offshore processing, offshore detention, regional processing.)). In addition, speeches were restricted to those having lengths of between 150 and 1200 characters to ensure speeches were long enough for accurate analysis (i.e. not interjections), and not too long that the speech may cover multiple topics. Together, these steps resulted in a corpus comprising 2856 speeches related to the asylum seeker issue from the 11 party leaders.
Findings
Figure 5 presents longitudinal results of the diff scores arising for the 11 speakers in the corpus. Time was dynamically binned based on the pooled count of speeches in the corpus to adaptively focus on the rhythm of the intensity of debate. Markers are included for a speaker if, for that time period, they had at least three speeches from which to draw an inference. Speaker diff average scores are plotted, with 90% confidence intervals (bootstrapped) provided for reference.
Framing analysis with LLMs: “paired-completion” (Angus and O’Neill, Reference Angus and O’Neill2024) applied to asylum seeker debate framing in Australian Federal Parliament (2006–2023). Each line represents paired completion scores on a scale from negative (pro Border Security Approach) to positive (pro Humanitarian Approach) for the speaker shown. Rings around markers indicate that the speaker was the Prime Minister at the time. Federal election dates are indicated with vertical grey lines for context.

We draw the following insights with respect to the paired completion (P-C) analysis:
-
1. P-C is well suited to identifying debate polarisation—as a method which, by construction, exploits the differential textual alignment between one framing and another, by placing speakers on a Humanitarian—Border Security axis, the method is well suited to debate polarisation analysis. In this case, P-C strongly finds two “camps” emerge in the debate, with all PMs drawn from the lower score, “border-security” camp, with clear day-light to the higher score, “humanitarian” camp of the independents and greens. Thus, confirming Hypothesis 1.
-
2. P-C can pick up significant shifts in framing—since P-C assigns a real-valued score to every text, it is possible to bring statistical machinery to the results. Here, bootstrapped confidence intervals reveal that the gap between camps, or even speakers are significant from a statistical standpoint, thus P-C lends itself to stronger forms of hypothesis testing. Here, we can see that Albanese’s trajectory charts a course which begins within the distribution of Independent/Greens speakers, but ends statistically different from them, and thus indistinguishable from the Liberal position of the Abbott/Turnbull years, thus supporting Hypothesis 2;
-
3. P-C reveals interesting cyclical dynamics—an unexpected result that the method reveals is the way that the independent/greens show cyclical framing dynamics around elections. We can see that in the case of Hanson-Young, Wilkie, and Natale, speeches just after an election are found to be most aligned with the humanitarian framing, but as the next election approaches, their speeches shift towards the centre. The same dynamics (but from the opposite direction) for leaders such as Rudd, Abbott, Turnbull, and Morrison is evident; further analysis would need to be done to explore these dynamics causally, but centre-shifts in political framing prior to elections are unsurprising.
As a complement to the time-series analysis, we can also inspect the most “extreme” speeches in the corpus, as scored by paired-completion on this topic. The highest three scored speeches (i.e. most aligned with the Humanitarian Approach) unsurprisingly come from the Green/Independent speakers (Note: some speeches end with a hyphen, indicating an interjection.):
Speaker: Sarah Hanson-Young (19 June 2014) (diff: 14.49).
As one asylum seeker put it to me recently, “I either decide to die on Manus Island or to die at home,” and that is the choice that this government is putting to these men, women and, indeed, children. So how many Iraqi asylum seekers have we deported in the last month back to a conflict zone? On what basis has it been determined that it is safe to do so? And, for the man in question, what is the government doing to ensure his safety is protected, now that he has been dumped back in the middle of a brutal, violent war, as the Prime Minister himself has identified? It is unconscionable that we are sending Iraqi asylum seekers back to these war zones. This coming Monday in this place we will vote to suspend the deportation of those people—.
Speaker: Andrew Wilkie (21 Oct 2019) (diff: 14.42).
The physical and mental suffering of these people cannot be understated. Indeed, under the medivac legislation, where people can only be transferred for urgent medical treatment to save their lives, over 130 applications have already been approved, with many more applications pending. That’s a lot of gravely ill people, and many of them sick because of the way they have been treated in Australia’s offshore detention. Twelve people have died. In this context, it simply beggars belief that the government is ignoring the advice of Australian medical professionals and wants to repeal Medevac.
Speaker: Sarah Hanson-Young (14 July 2014) (diff: 14.36).
Rather than putting forward these ridiculous, fearmongering, insulting vilification-driven code of behaviour protocols, this government should be focussing on what is wrong with a policy that pushes an individual to the point of setting themselves on fire to take their own life so they do not have to be subjected to the awful tortures and persecution that they believe waits for them at home. It is beyond me why this government thinks it is important to continue to peddle the myths and fears around asylum seekers and refugees.
These speeches are clearly in the Humanitarian camp, with each text arguing strongly against the “unconscionable,” “ridiculous,” “fearmongering” stance of the government of the day. As with prompt-based methods in our earlier demonstration, paired-completion can flexibly handle text of any length.
Turning to the other framing, the lowest three (i.e. most negative, most aligned with the Border Security Approach) scored speeches all come from the main party leaders:
Speaker: Scott John Morrison (2 Nov 2011) (diff: −23.42).
Our amendment seeks to maintain those protections through one simple measure, which the government stubbornly refuse to adopt. Rather than have that matter accepted and the bill passed in this parliament, rather than return to the proven measures that they abolished, they have not only decided to continue their current policy of onshore processing; they have processed nobody offshore. We have had onshore processing ever since they abolished offshore processing. They would seek to further soften the policies by adopting those of the Greens, refusing, out of stubborn pride, to accept the coalition’s amendment and return to policies that are proven and work, and, indeed, even pick up some of their own policies. Our amendment would enable the government to establish offshore processing again at Manus Island, which is their policy, yet they stubbornly refuse our amendment, as they have done consistently. Therefore, refusing to look at a simple, straightforward, modest amendment, the government deny themselves the opportunity to restore policies that are proven and work.
Speaker: Kevin Michael Rudd (26 Oct 2009) (diff: −19.99).
In the period that the government has been in, we have had some 85 disruptions of planned smuggling adventures since September 2008, involving nearly 2000 persons. That has been with the assistance of the Indonesian national police. The government has already returned almost 100 people because their asylum claims have been refused. Since September 2008, 15 people have been convicted in Australian courts, and eight separate people are facing people-smuggling prosecutions. Further, currently before the Australian courts are 38 defendants in 14 separate matters, with three defendants in three separate matters involving organisers and facilitators. This is the practical action which goes to a practical and balanced policy on dealing with the scourge of people smugglers and the humanitarian plight of asylum seekers. It is a balanced approach, a mainstream approach; one which unapologetically also engages our friends and partners in the region, as previous Australian governments—were they to honestly reflect—have done as well.
Malcolm Bligh Turnbull (9 Nov 2016) (diff: −18.50).
The reaction from the opposition benches is entirely consistent with the complacency their party showed when they were in government in 2008, 2009, 2010, 2011 and 2012 when, ignoring all of the evidence and all of the experience, they unpicked John Howard’s tough and effective border protection policies. As a result—as a direct consequence—we saw 50,000 unauthorised arrivals, the opening of 17 new detention centres in Australia, an immigration blowout in cost of $11 billion, 8000 children put into detention, the reopening of regional processing centres on Nauru and Manus and, most tragically of all, 1200 deaths at sea of which we know.
Of interest, and showing the strength of recent transformer based models, whilst the first text (Morrison) argues strongly for a hardened, offshore, processing amendment to the incumbent’s policy, the second and third texts (Rudd, Turnbull) both include language pointing to the humanitarian consequences (Rudd: “the scourge of people smugglers and the humanitarian plight of asylum seekers”; Turnbull: “most tragically of all, 1200 deaths at sea of which we know”) yet rightly the model understands that these notes sit within a wider semantic posture supporting tougher border policies in respect of asylum seekers. This kind of nuanced understanding of human language is both critical for political narrative analysis and unachievable in the pre-transformer technology era.
6. Recommendations: the future of tracking public narratives of democracy
The demonstrations above show that transformer-based methods can now identify and track nuanced political narratives at scale. These capabilities directly inform the following data and policy recommendations, which aim to enable such analysis in practice.
6.1. Recommendations for data: removing blockers to policy-relevant discourse analysis at scale
Policymakers who wish to analyse the strength or fragility of our democracy by tracking narratives of democratic resilience may rightly consider starting with the narratives spun by our own elected ministers and the election platforms that would-be ministers are touting. Together, these would provide a key input to narrative analysis for policy-relevant questions such as: is populist language on the rise? What fraction of election platforms in the recent election touted exclusionary nationalism? Which jurisdictions are on the receiving end of political platforms that portray an “Us vs. Them” narrative?
Unfortunately, through an analysis of the situation in several apparently healthy democracies, e.g. the United Kingdom (scoring 91 on Freedom House’s “Global Freedom Scores” [Freedom House, https://freedomhouse.org/countries/freedom-world/scores]), Australia (95), and Finland (100), we find that, despite the promise of NLP/AI technology, answering these questions is still frustrated by failures in rather more basic requirements.
6.1.1. Data recommendation 1: an official API for parliamentary Hansard
Contrary to what are likely reasonable public expectations, the public discourse that one would most expect to be freely available under well documented and supported means, and which was core to the demonstration of Section 5.2 above, namely Parliamentary Hansard, is not, in fact, easy to come by for the kind of analysis proposed in the current paper. The lack of a single, comprehensive access point for Parliamentary discourse data appears to bedevil efforts across jurisdictions. Key to such access is support for an application programming interface (API). As opposed to browsing, where an individual clicks on links and reads the content of a webpage visited, an API enables scripted (i.e. computational) access to a database, which any downstream, large-scale, and real-time analysis of public discourse requires.
Efforts vary by country, but the pattern is the same. In the United Kingdom, after a historical period of access (See the historical Hansard Millbank home for such data at https://api.parliament.uk/historic-hansard/api), the “data.parliament.uk“ initiative hosts a series of APIs to access various aspects of UK Parliamentary activity (See https://explore.data.parliament.uk/index.html). However, the API is still in “beta” mode, and does not support access to Parliamentary Debate Hansard. The situation in Australia is worse. Whilst each jurisdiction has a user-facing web portal for Hansard access (e.g. Federal Parliament provides a search front-end: https://www.aph.gov.au/Parliamentary_Business/Hansard/ and Victorian Parliament the same: https://www.parliament.vic.gov.au/parliamentary-activity/hansard/hansard-debate/, neither offer programmatic (API), or bulk down-load access directly.) these require laborious human operation to download a large number of speeches. To the best of our knowledge, only the NSW Parliament has created an API access point to their Hansard, hosted via data.gov.au (See: https://parliament-api-docs.readthedocs.io/en/latest/new-south-wales/) which demonstrates that the task is surmountable. Likewise, Finland provides no official API to its Hansard, publishing instead links to sessions of Parliamentary plenaries, including webcasts (See https://verkkolahetys.eduskunta.fi/fi/ (Finnish/Swedish).).
Into the breach, community funded, not-for-profit, projects have arisen to make parliamentary Hansard available. Typically, these efforts effectively reverse-engineer the task by visiting the user-facing (non-API) Hansard pages, downloading the page, and then transforming the information from the page back into a database to be finally made available on a community funded API portal. Naturally, these efforts, although well-intentioned and often achieving a high level of reliability, are not assured, and are not an “official” source of political speech. For instance, the “TheyWorkForYou” (See: https://www.theyworkforyou.com/api/) initiative in the UK provides such a service, whilst in Australia, the “Open Australia” initiative (See: https://www.openaustralia.org.au/api/) tries to provide this access, but is typically not up to date, struggling to get the man-power to provide reliable service. Likewise in Finland, community scraped APIs are available with methods which unlock them, but these projects do not appear to be up-to-date (See for example, https://github.com/rOpenGov/finpar).
Clearly, for any major policy-relevant democratic resilience analysis of Parliamentary discourse, or for the building of tools on top of Hansard to drive transparency, accountability, and public understanding, enabling civil society and academia to process the very speeches of our democracy is a critical starting point.
6.1.2. Data recommendation 2: an official repository of political platforms
Relatedly, there are rarely official comprehensive sources for election literature, speeches, or materials, yet, as shown in Section 5.1, cross-party or cross-national narrative tracking requires harmonised access to political texts. In Australia, whilst the National Library offers a portal (See: https://www.nla.gov.au/collections/what-we-collect/ephemera/federal-election-campaigns), following links is again a laborious task and not designed for programmatic access. Digital election materials are available through the “Trove” web archive site, however, links back to state Hansard are often dead due to stale or broken connections. In the UK, the Electoral Commission is tentatively exploring API development, with an “alpha” version providing some information on candidates (name, party affiliation), though this API is itself delivered by a not-for-profit, “Democracy Club,” which hosts a more thorough API which can provide, among other things, candidate information including “statements to voters” (“where collected”) (See https://democracyclub.org.uk/data_apis/voting_information_api/ and links therein.).
To be sure, there are promising international initiatives in this direction, however, their coverage is typically restricted to major political platforms, at the National level, befitting an international research initiative. For example, The Political Party Database Project (See https://www.politicalpartydb.org/countries/) provides a smattering of official party documents for Australia, the United Kingdom, and Finland’s major parties (e.g. in Australia: Labor, Liberal, National, Greens) over the last two decades. Similarly, the highly regarded Manifesto-Project (See https://manifesto-project.wzb.eu/) provides a small sub-set of national party platforms for each country, albeit with a much greater longitudinal coverage. Yet, the choice of which party platform to include, and even which document is stored, is down to academic discretion and resourcing. Without official support, these databases miss the small, tail-end party platforms, which arguably have the most potent information for policymakers wishing to track emergent narratives of democracy.
To facilitate open and active engagement by the research community with the platform and positional materials of the full range of democratic actors, programmatic (API) end-points of political platforms should be created in the ideal case, or at least a location enabling download with filtering should be made, so that large-scale textual research can be realised.
6.2. Recommendations for future research: towards real-time tracking of policy-relevant democratic discourse
We finish by sketching a potential agenda for further democratic narrative research that would support policymakers, academic researchers, and the wider community alike. Granted, significant data challenges exist, but laying these to one side, we consider a world where data were more available, enabling enriched analysis with AI-Transformer backed technologies already in use in other disciplines and fields as described in Section 4.
6.2.1. Research recommendation 1: hearing from the fringe—augmenting surveys with alternative data
LLM-backed methods offer a chance to overcome two key challenges with traditional, survey-based methods of tracking anti-democratic narratives at nation-scale. First, surveys are typically expensive to run, and therefore are undertaken at most annually, though often less frequently. Second, a common concern of those who run surveys of trust in government and institutions, is that, despite rigorous attempts, survey respondents are typically self-selecting. That is, if there is a growing group of people in a country who support anti-democratic narratives, they are also highly likely to be wary of institutional mechanisms in general, and so, unlikely to be willing to participate in surveys run by “official” organisations. The UK Government, for example, acknowledge this source of bias explicitly in their “Trust in Government Survey QMI” report (2024) (Office for National Statistics (ONS), released 1 March 2024, ONS website, methodology, Trust in Government Survey QMI. See https://www.ons.gov.uk/peoplepopulationandcommunity/wellbeing/methodologies/trustingovernmentsurveyqmi).
There may be a sampling bias, because the sampling frame comes from those who have already responded to a government survey; these people may differ to the general population in how much they trust the government and other public institutions.
However, alternative data sources abound in these countries, from online discussion-boards, to YouTube and Instagram content, to broad-based social media and alt- group websites. By converting these sources to text (admittedly, not an insignificant task in some cases), LLM-enabled framing analysis on dimensions of populism, “Us vs. Them’” and other anti-democratic narratives can be tracked. By building up a time-series of these markers, movements up and down in the concentration and strength of these narratives can be compared statistically to baseline levels. Significant movements could trigger more intensive survey or focus-group work, or deeper dive analysis of specific narratives and the basis of their claims. In this way, the “fringe” of society who may be actively engaging in digital media and platforms, but who are already disengaged from government surveys and institutions, can be better understood in policy-relevant analysis of the state or health of democratic values in society at large.
6.2.2. Research recommendation 2: estimating rates of anti-democratic support with revealed preferences, the case of Australia
Australia’s democracy is one of only a handful of free countries world-wide to enforce compulsory voting. With the measure’s introduction in 1924, Australia will see 100 years of the practice through the election cycle of 2025. However, for similar selection issues discussed above, a significant challenge in Australia is estimating the true fraction of the population that holds more extreme anti-democratic views. Given that voter turnout is very high across the country, and that voting is considered a private act, one can consider voter support for radical party positions as a more revealed preference indicator of support than perhaps stated preference measures as considered above. Here, the challenge is to collect and analyse the thousands of political tracts from major and minor parties across all election cycles, at the state and national level, and analyse these for narratives of democratic resilience and opposition. By applying vote-share to those party platforms that score strongly on textual alignment with particular narratives of democratic opposition, one can calculate, for the first time, a true level of revealed support for these positions. These data would go significantly towards answering the question of whether Australia really does have a “hidden” underbelly of support for radical positions on democratic issues, or if instead, public posturing does not speak to privately held beliefs.
Whilst this research direction focuses on the case of Australia, there are over a dozen countries which share the compulsory voting approach, providing further contexts for the application of AI-transformer methodologies to track relevant narratives of democracy by jurisdiction.
6.3. Research recommendation 3: supporting accountability in our Parliamentary discourses: a public monitor of democratic discourse
One of the major challenges facing the public, journalists, and academics alike is the challenge of identifying objectively that a speaker or outlet is saying something unusual (for them) or fitting a particular narrative of democracy. Without accurate, quantitative tools, we are left relying on “opinion” pieces and expert talking heads to opine on whether a particular speaker’s comments really were anti-democratic, populist, or divisive. Whilst expert commentary will always be important, what we lack is a way for the public to see insightful visualisations, driven by accurate discourse measurement, of how a particular discourse fits in to a spectrum of discourse at a point in time, or across time. Such a “Narrative Observatory” like tool would be a major benefit to the democratic project. Speakers would be held immediately accountable for their words, policymakers, journalists, and analysts would more easily be able to draw comparisons and make data-driven insights about the positions being taken on the floors of our Parliaments nationally. Fact-checking initiatives exemplify this kind of public good provision; a narrative observatory would complement and empower our society to better understand and hold to account those who represent us.
7. Conclusion
Our starting point was that story-telling matters deeply to the way that we communicate and encode our culture and beliefs in society, and so, for policymakers concerned with democratic resilience, narrative analysis at scale is now an immensely valuable capability alongside traditional methodologies. We have seen that in social science, narratives can be analysed and tracked in a variety of ways, with issue-framing being one of the most common approaches. However, coding texts for the presence or absence of one or other framing has traditionally been a laborious process for experts and research assistants alike. And, human approaches are not without their own bias and reliability concerns. For this reason, we have considered how automated techniques arising from the computational sciences have been developed to analyse discourse in a variety of ways, including automation of the labelling task. Significantly, we have seen that the most recent wave of technological advance, the wave that is sweeping every major discipline of the academy, the generative AI/LLM wave, holds enormous promise for application to tracking narratives with relatively low costs, low bias, and high reliability. Together, this study, whilst conceptual and demonstrative in nature, aims to open new pathways for data-driven policy development and analysis related to the increasingly pressing needs of democratic resilience research.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/dap.2026.10063.
Data availability statement
Data and code to replicate the results of the experiments of this paper are contained in the public GitHub repository https://github.com/specialistgeneralist/narratives-of-democratic-resilience, release https://doi.org/10.5281/zenodo.15493085. In addition, we note that the related tiny repository “Text Waves” developed by the author may be a useful additional resource to those wishing to pursue text-as-data applications in the social sciences: https://github.com/sodalabsio/textwaves.
Acknowledgements
I am grateful to fellow members of the Resilient Democracy Research and Data Network (Australia) for discussions that informed the development of this paper. In particular, from the network, Prof Nicholas Biddle (Australian National University) provided useful comments on earlier drafts of this work. All errors and omissions are my own. I am also indebted to SoDa Labs AI Research Lead, Lachlan O’Neill, for their technical assistance in obtaining the data from the Open Australia API end-point for the Hansard demonstration and running the paired-completion estimates with the Llama 2 LLM. Their expertise in handling these steps was invaluable for this portion of the research. All errors and omissions are my own. The listed author is the sole author of the study, developing, writing, and editing all text and figures therein. AI-backed tooling developed at SoDa Laboratories, Monash University, was used by the author to assist in a limited manner, including: identifying relevant literature; triaging and summarising reviewer commentary on earlier drafts; and by providing counterpoint discussion with the author to clarify and sharpen the author’s thinking. All decisions regarding the manuscript, experimental design, writing and editing remain the sole responsibility of the author.
Author contribution
S.D.A. is the sole author of this manuscript and is responsible for the conceptualization, methodology, formal analysis, investigation, data curation, writing (original draft preparation and review/editing), visualization, and project administration.
Funding statement
Early work on this project was supported by a small grant from the Social Cohesion Unit, Department of Home Affairs, Australian Government.
Competing interest
The author declare none.
Ethical standard
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.

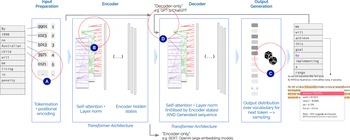






 Open access
Open access
Comments
No Comments have been published for this article.