


1. Introduction
When we comprehend a sentence, one of the core tasks in ensuring that we arrive at the correct interpretation is to assign a grammatical role to each noun phrase (NP) that we encounter. For example, in the English sentence Alice saw Anja, Alice gets assigned the role of subject and Anja gets assigned the role of object. This is apparent by virtue of their linear positions: English declarative sentences typically follow S(ubject)-V(erb)-O(bject) word order, and thus, an NP occurring pre-verbally in such instances is the subject, and an NP occurring post-verbally, the object. Cross-linguistically, however, word order is not the only syntactic tool that is used to indicate an NP’s grammatical role: A vast array of languages have ways of morphologically marking NPs, known as case marking systems, where nouns surface with different morphological marking for different grammatical roles. For example, in (1a) and (1b), Japanese and Icelandic use a nominative-accusative (nom-acc) case marking system. In these languages, subjects are marked with nominative case, while the objects of transitive verbs are marked with accusative case. In contrast, Shipibo (1c) is an ergative-absolutive (erg-abs) language. Here, ergative case marks the subject of a transitive verb, while absolutive case marks the object.

There are also configurations found in various unrelated languages where case marking does not allow for differentiating the subject NP from the object NP. These are called double case constructions (e.g., Gerdts & Youn Reference Gerdts and Youn1989, Jónsson Reference Jónsson, Brandner and Zinsmeister2003, Baker Reference Baker2014). As the name indicates, both the subject and the object in such clauses bear the same case morphology. In Japanese, for example, some verbs require both a nom-marked subject and a nom-marked object, yielding a double nominative alignment, as in (2a). Similarly, certain verbs in Icelandic require both an acc subject and an acc object, yielding a double accusative alignment (2b). In Shipibo (2c), a double absolutive alignment can occur, where both the subject and object are marked with absolutive.

Double case configurations are intriguing because they present a challenge to conventional theories about the role of case marking in the grammar that are based upon two NPs being as morphologically (and semantically) distinct from one another as possible (e.g., Bornkessel‐Schlesewsky & Schlesewsky Reference Bornkessel-Schlesewsky and Schlesewsky2009). This principle of distinctness has been implemented in syntactic theory in the way of a bias toward avoidance of repetition within a clause: For instance, Richards (Reference Richards2010) notes that NPs that get positioned in close proximity to each other generally avoid having the same grammatical gender and/or animacy level. Importantly, case marking generally serves in this same manner: that is, to disambiguate the grammatical role of an NP from that of its clause mate (Yip et al. Reference Yip, Maling and Jackendoff1987, Marantz Reference Marantz, Westphal, Ao and Chae1991, Yuan Reference Yuan2020). As can be seen in the examples in (2), double case constructions appear to violate this basic linguistic notion of distinctness: The subject and object are identical with respect to case.
With these issues in mind, the broad goal of the current study is to investigate what factors condition the use of double case constructions like in (2). Specifically, we seek to shed new light on questions about what the conditions are under which double case constructions are grammatically well-formed, on what role double case marking might serve in natural language, and relatedly, on the reasons why a typical distinct case array (e.g., nom-acc) is supplanted by a double case array (e.g., nom-nom) under these circumstances. The empirical focus of our investigation is on how objects get case-marked in Korean. Korean is a nominative-accusative language in the sense that subjects of intransitive verbs generally receive nominative case marking, like in (3a), as do subjects of transitive verbs in sentences in (3b).

What makes Korean special is that it also has double nominative variants of sentences like (3b), as shown in (4). Here, both the subject and object are nominative marked with the nominative marker -i/ka. Note that the choice between the allomorphs -i and -ka is phonologically conditioned: -i follows consonant-final nouns, while -ka follows vowel-final nouns. Notice also from the glosses to (3b) and (4) that this change in case marking is coupled with an alternation in the light verb forms uses (-ha- in (3b) and -ci- in (4)), a point which will become important in our study. The thematic roles of subject and object in these constructions are determined by the lexical semantics of the verb (with the subject as experiencer and the object as theme). At a narrower level, however, the thematic interpretation of the external argument is influenced by both the light verb (e.g., -ha- for activity, -ci- for achievement, or null for state). This means that both dative and nominative subjects can serve as experiencers, but the extent of their volitional involvement in the action differs: For -ha- verbs, the subject is a volitional experiencer (thus, a more ‘agent’-like one), whereas for -ci- or null verbs, the subject experiences the event passively, without initiating it themselves. As such, they are interpreted as less agentive.

In a novel acceptability judgement study, we find that double nominative constructions like in (4) are, in fact, judged as less acceptable than their nom-acc counterpart (e.g., as in (3b)). This outcome in-and-of-itself is indeed consistent with theories of case that invoke the general linguistic principle of distinctness (Bornkessel & Schlesewsky Reference Bornkessel and Schlesewsky2006, Bornkessel‐Schlesewsky & Schlesewsky Reference Bornkessel-Schlesewsky and Schlesewsky2009). The distinctness principle holds that case-marking systems tend to avoid ambiguity by ensuring that core arguments within a clause are morphologically differentiated. While much of the literature on distinctness has focused on differential object marking (DOM), the underlying motivation – namely, to distinguish grammatical functions and reduce potential ambiguity – applies more broadly to case-marking systems (Comrie Reference Comrie1989, Aissen Reference Aissen2003).
However, we will show that distinctness does not appear to be the only factor that lowers acceptability of these kinds of nom-nom constructions. This is because there Korean also has a different kind of case configuration, with a dative-marked subject and a nominative object like in (5) – a dat-nom – construction, and these constructions also receive the lower acceptability ratings than the nom-acc counterparts. We therefore reason that low acceptability of double case configurations like (4) is due not (only) to distinctness, but to a more general dis-preference for a nom-marked object, reflecting a less global, more local constraint on how morphological case is mapped onto thematic role (see Silverstein Reference Silverstein and Dixon1976, Keine Reference Keine2010, Malchukov Reference Malchukov2010, Georgi Reference Georgi, Alexiadou, Kiss and Müller2012, Clem & Deal Reference Clem and Deal2024).

To investigate the source of the dis-preference, we then carried out a corpus survey which allows for examining naturally occurring examples of configurations like (4) and (5). Strikingly, we find that constructions with nom objects are very few in number and overwhelmingly tend to have a subject that is marked with a topic marker, rather than a nom- or dat-marked subject.
Of the small number of exceptions, many involve instances where the subject experiencer is modified by a relative clause or adjectival material.
To account for our observations, we propose the Morphological-Thematic-Grammatical (MTG) Alignment Hypothesis. The MTG alignment hypothesis is intended to account for the relational (i.e., global) alignment between case, thematic, and grammatical roles, across a sentence in its entirety. This hypothesis is an extension of the thematic-grammatical alignment hypothesis (e.g., Ferreira Reference Ferreira1994, Piñango Reference Piñango, Grodzinsky, Shapiro and Swinney2000, Cupples Reference Cupples2002, Nguyen & Pearl Reference Nguyen, Pearl, Brown and Dailey2019, Do & Kaiser Reference Do and Kaiser2022, Wilson & Dillon Reference Wilson and Dillon2022) from psycholinguistic literature, which posits that sentences where the subject is a thematic experiencer (or agent), and the object a theme, are easier to process than those where the subject is a theme and the object is an experiencer. This is based upon the notion that sentences are easier to comprehend when the accessibility hierarchy of grammatical function, where subjects outrank objects (e.g., Keenan & Comrie Reference Keenan and Comrie1977), aligns with the thematic prominence hierarchy, where agents and experiencers outrank patients (Fillmore Reference Fillmore1968). We extend this by building into it the hierarchy of morphological case (Otsuka Reference Otsuka, Johns, Massam and Ndayiragije2006, Bobaljik Reference Bobaljik, Harbour, Adger and Béjar2008, Deal Reference Deal, Kaplan, Kaplan, McCarvel and Rubin2017), where unmarked cases (e.g., nom, abs) outrank marked ones (e.g., acc, dat, erg) in terms of how accessible they are for syntactic operations such as verb agreement, and A-/Ā-movement. Under this hypothesis, nom-acc constructions like (3b) are fully aligned – the higher-ranked grammatical role (subject), thematic role (experiencer), and morphological case form (nominative) extend to the same NP. We illustrate this in (6a). Conversely, nom-nom constructions like (4) are misaligned, because the lower-ranked theme is marked with higher-ranked nom, as in (6b). dat-nom constructions are also misaligned, as in (6c): The lower-ranked dat case marks the higher-ranked experiencer, and the higher-ranked nom case marks the lower-ranked theme.

As we will discuss in Section 4, configurations with a nominative object subject frequently have a subject marked with the Korean topic marker -nun instead of nominative -ka. This topic marker signals that the NP constitutes topical or backgrounded information (Kuno Reference Kuno1987, Lee & Shimojo Reference Lee and Shimojo2016). It is not a canonical case marker, however, because it does not encode grammatical or thematic role; most NPs can be topic-marked, and the choice between nom, dat, and top is governed by both syntactic and pragmatic factors. Throughout this paper, we treat top as a discourse marker and argue that it does not participate directly in the MTG alignment hierarchy, because top is not part of the morphological case hierarchy (e.g., nom > acc > dat; Otsuka Reference Otsuka, Johns, Massam and Ndayiragije2006; Bobaljik Reference Bobaljik, Harbour, Adger and Béjar2008), and so does not factor in the calculation of alignment or misalignment. For MTG calculation, if top occupies the subject position, it exempts the subject from the case alignment constraint, allowing topic marking to rescue constructions that would otherwise be misaligned (such as nom–nom). This pragmatic rescue effect of topic marking aligns with previous studies, such as Shin and Verhoeven (Reference Shin, Verhoeven, Johannes, Yoko, Yong-Min, Stavros and Elisabeth2009), who showed that information structure plays a crucial role in licensing double nominative constructions in Korean. Their analysis demonstrates that topic marking on the subject can mitigate the dis-preference for case identity, allowing for configuration with nom objects to occur more frequently in discourse than they might otherwise.
At the same time, the MTG does not account for all aspects of sentence acceptability surrounding case assignment. Rather, it operates in conjunction with principles such as abstract syntactic case-licensing conditions (e.g., the requirement that -ha- assign acc case; see Yeo Reference Yeo2004, Choi Reference Choi2019, Reference Choi2022) and other local constraints. According to models such as Extended Argument Dependency Model (eADM; Bornkessel & Schlesewsky Reference Bornkessel and Schlesewsky2006, Bornkessel‐Schlesewsky & Schlesewsky Reference Bornkessel-Schlesewsky and Schlesewsky2009), sentence comprehension proceeds incrementally: Some constraints are evaluated early, and aspects of global alignment (as captured by MTG) influence acceptability at a later, relational stage. This two-stage process is consistent with our forthcoming experimental and corpus results: Global, sentence-level misalignment compounds more local or abstract effects that are also present.
With this said, however, nom-nom and dat-nom of course are attested in Korean (as well as in other languages; see, e.g., Landau Reference Landau2010, on the syntax of experiencer predicates). Based on the data we present here, we hypothesize that in Korean, nom-nom and dat-nom serve as a means of pragmatically foregrounding a subject NP that might otherwise be interpreted as being backgrounded information – effectively, then, as a functional cue for the benefit of the addressee.
Thus, our approach is theoretically grounded in the idea that grammatical well-formedness results from the interaction of multiple constraints. These constraints may be ranked or weighted, and their violations can have additive effects on acceptability, as in Optimality Theory (Prince & Smolensky Reference Prince and Smolensky1993) and Harmonic Grammar (Smolensky & Legendre Reference Smolensky and Legendre2006). Our findings of gradient acceptability for different case patterns are compatible with these models.
The next section discusses some critical properties of nom-nom constructions in Korean and related nom-dat constructions. In Section 3, we introduce a novel acceptability judgment experiment, showing that nom-nom and dat-nom constructions are rated by speakers of Korean as less acceptable than prototypical nom-acc construction. Building on this outcome, Section 4 presents an original corpus survey which looks at naturally attested occurrences of constructions with nominative-marked objects in Korean and explores the environments in which nominative case marking on an object is attested. In Section 5, we discuss the broader implications of these findings for theories about language more generally.
2. Background
In this section, we outline the theoretical and empirical foundations for our study of nominative object constructions (NOCs) in Korean. We begin with an overview of nominative object constructions in Korean (§2.1). To establish the theoretical context for our analysis, we then introduce the background on the accessibility hierarchies (also referred to as ‘prominence scales’) of (i) grammatical function, (ii) thematic role, and (iii) morphological case (§2.2). Next, we discuss the different levels of constraint that will become relevant to our discussion, distinguishing between local (argument-level) and global (clause-level) factors (§2.3).
2.1. Nominative object constructions in Korean
Nominative object constructions (NOCs) represent a distinctive type of double nominative constructionFootnote 2 found in some languages, including Korean. In Korean, the subjects of both transitive and intransitive verbs are typically marked by the nominative case marker -i/ka, while objects of transitive verbs are marked by the accusative case marker -(l)ul, as shown in (7). While Korean sentences often have a nom-acc case frame, certain predicates – particularly those associated with experiencer psych verbs – allow two nominative-marked NPs within the same clause, creating structures with two clause-mate nominative NPs, as in (8).
This configuration features an experiencer subject and a theme object, both marked with nominative case. Notably, nominative object constructions are restricted to predicates with experiencer subjects; we do not find NOCs with other types of subject roles. Nominative objects behave as syntactic objects rather than subjects, as they do not trigger honorific agreement on the verb. The honorific verbal affix -si-, which reflects the speaker’s respect toward the subject, is only triggered by the first nominative nominal in NOCs, as shown in (8b). This indicates that this NP is formally the subject. However, in (8c), where honorific Teacher Kim is the nom-marked object, the verb cannot bear the honorific marker. In (8d), the nominative case marker appears on the subject NP to the right of the dative marker -eykey, a phenomenon called ‘case stacking’. Case stacking in Korean, where a nominal bears multiple markers, has been analyzed as combining abstract case with discourse-related markers such as topic or focus (see, e.g., Gerdts & Youn Reference Gerdts, Youn, MacLeod, Larson and Brentari1988, Yoon Reference Yoon, Bhaskararao and Subbarao2004, Lee & Nie Reference Lee and Nie2022). A detailed analysis of case stacking is beyond the scope of this paper, but we consider case stacking once again in our Conclusion section.


Constructions like these appear to violate the Distinctness Principle (Bornkessel-Schlesewsky & Schlesewsky Reference Bornkessel-Schlesewsky, Schlesewsky and Van Valin2008, Bornkessel‐Schlesewsky & Schlesewsky Reference Bornkessel-Schlesewsky and Schlesewsky2009). In terms of mental representation, this principle posits that referents in any given event should be as different as possible from each other. In terms of the linguistic form of a sentence, this means that any two clause-mate NPs should be as morphologically and functionally distinct as possible. These observations raise important questions about what factors license or constrain nominative object constructions in Korean. To address these issues, we next introduce the theoretical background on accessibility hierarchies, which will provide a framework for analyzing the well-formedness of these constructions.
2.2. Accessibility: Grammatical function, thematic role, and morphological case
In a broad sense, ‘accessibility’ refers to how salient or prominent an NP is in any given sentence. Arnold (Reference Arnold2010: 188) defines accessibility as ‘the property of information that makes it easier to access, independently of ambiguity considerations’; that is, an NP is deemed as more accessible than other NPs in the same sentence if it is the most salient NP in mental representation. Based upon typological observations about syntactic and morphological patterns across languages, three core hierarchies have been proposed (e.g., Keenan & Comrie Reference Keenan and Comrie1977, Comrie Reference Comrie1989, Aissen Reference Aissen2003), in which NPs are ranked according to how accessible they are.
The first of these is the Accessibility Hierarchy of grammatical function (Keenan & Comrie Reference Keenan and Comrie1977). Based on a survey of relative clauses in a subset of the world’s languages, these authors propose that subject is the most accessible grammatical role, followed by object, and then by indirect objects and more peripheral NPs. This hierarchy is shown in (9).
According to Keenan and Comrie (Reference Keenan and Comrie1977), the ranking in (9) is operational across languages in the sense that subject relative clauses (e.g., The reporter [who __ subject saw the senator].) are the most common kind of relative clauses cross-linguistically. If a language allows object relative clauses, then it necessarily also allows for subject relative clauses, but not vice versa. The hierarchy in (9) is also adopted in psycholinguistic literature to account for behavioral observations about how language users produce and interpret referring expressions such as pronouns (Gordon et al. Reference Gordon, Grosz and Gilliom1993, Grosz et al. Reference Grosz, Joshi and Weinstein1995).
The second type of hierarchy concerns the thematic role of an NP (e.g., as an agent, experiencer, theme, goal, etc.). The thematic role hierarchy ranks thematic roles based on their prototypical properties, with proto-agents (such as agents and experiencers) being more prominent than proto-patients (such as themes and goals) (e.g., Fillmore Reference Fillmore1968, Jackendoff Reference Jackendoff1972, Givón Reference Givón1984, Dowty Reference Dowty1991, Primus Reference Primus1999, Grimshaw Reference Grimshaw1990, Speas Reference Speas1990, Van Valin Reference Van Valin and Robert1990), as shown in (10). Across languages, a thematic role at the left edge of the hierarchy (e.g., agent) gets mapped to subject position. A role toward the right edge (e.g., patient) usually gets mapped to the object role (Dowty Reference Dowty1991).
Related to this, certain semantic features such as animacy and definiteness can make NP a better or worse fit for one specific type of thematic role compared to other roles; for example, an NP that is animate and human is more likely to get interpreted by an addressee as being a proto-agent (e.g., Rissman et al. Reference Rissman, Woodward and Goldin-Meadow2019) because such properties make it a good fit for this role (Silverstein, Reference Silverstein and Dixon1976). In this same vein, an inanimate NP is more likely to be interpreted as a proto-patient. In fact, NPs whose semantic properties are misaligned with their expected proto-role tend to be overtly case-marked in languages, a phenomenon known as differential argument marking (e.g., Moravcsik Reference Moravcsik, Greenberg, Ferguson and Moravcsik1978, Comrie Reference Comrie1979, Bossong Reference Bossong1985, Comrie Reference Comrie1989, Aissen Reference Aissen2003).
The third hierarchy we discuss is the morphological case hierarchy (Otsuka Reference Otsuka, Johns, Massam and Ndayiragije2006, Bobaljik Reference Bobaljik, Harbour, Adger and Béjar2008). This hierarchy concerns the morphological form that an NPs surfaces with, and it ranks NPs based on their case features. NPs that have so-called ‘unmarked’ case – nominative or absolutive – are more accessible for formal syntactic operations like A- and Ā-movement compared with NPs with marked case (e.g., ergative, accusative, dative), which are less accessible. For example, in some languages, only nominative or absolutive NPs can be Ā-extracted, and other NPs that have ergative, accusative, or dative case cannot be (e.g., Aldridge Reference Aldridge2004). These observations motivated Otsuka’s (Reference Otsuka, Johns, Massam and Ndayiragije2006) morphological case hierarchy, shown in (11).
Putting these three hierarchies alongside each other leads to the hypothesis that the most accessible types of NPs across languages are unmarked proto-agent subjects, whereas the least accessible are oblique-marked, proto-patient objects.
What is important is that grammatical role, thematic role, and morphological case do not necessarily align, meaning that subject NPs are not always unmarked (as in ergative-absolutive languages, for example) and/or not necessarily proto-agents (as in passive and unaccusative constructions). Likewise, object NPs are not always marked (as in Korean sentences like in (4) and (5)), and they are not always proto-patients (as object experiencer constructions; Landau Reference Landau2010). What happens in such circumstances? To date, much literature has focused on instances of misalignments between grammatical function and thematic role, as can be the case with so-called psych predicates (e.g., Belletti & Rizzi Reference Belletti and Rizzi1988, Bornkessel & Schlesewsky Reference Bornkessel and Schlesewsky2006, Landau Reference Landau2010, Wagers et al. Reference Wagers, Borja and Chung2018, Wilson & Dillon Reference Wilson and Dillon2022). Psych predicates include English verbs like delight, admire, dislike, and irritate, where one of the two NP arguments is a thematic experiencer, in the sense the referent is the bearer of a mental state. For psych verbs like admire and dislike, the experiencer is mapped to subject position (called subject experiencer verbs). But for others, like delight and irritate, it is the object that is the experiencer (called object experiencer verbs). As recently discussed by Wilson and Dillon (Reference Wilson and Dillon2022), object experiencer verbs trigger a sentence where the grammatical function hierarchy (Subject > Object) and thematic role hierarchy (Experiencer > Theme) are misaligned, because the subject is the theme, and the object is the experiencer. By contrast, subject experiencer verbs exhibit a prototypical alignment between grammatical function and thematic role (subject = experiencer; object = theme). Indeed, Wilson and Dillon (Reference Wilson and Dillon2022) examined how sentences with object experiencer verbs are processed compared with subject experiencer counterparts. In two experiments, they found that misaligned object experiencer configurations are more costly to process compared with aligned subject experiencer ones. This indicates that misalignment of these two accessibility hierarchies is associated with comprehension difficulty on the part of a language user.
With these observations in mind, we now discuss two types of constraints which are relevant for understanding the source of misalignment. The first is local constraints, which pertain to properties of individual arguments. The second is global constraints, which concern the overall configuration of arguments within the clause, and which penalize certain combinations of subject and object case marking.
2.3. Local constraints: Rarity of nominative objects
Nominative objects are relatively rare, cross-linguistically (Silverstein Reference Silverstein and Dixon1976, Keine Reference Keine2010, Malchukov Reference Malchukov2010, Georgi Reference Georgi, Alexiadou, Kiss and Müller2012, Clem & Deal Reference Clem and Deal2024): Nominative case is canonically associated with subjects or agents. Influentially, Silverstein (Reference Silverstein and Dixon1976) introduced the referential hierarchy, on which nominative (or unmarked) case is typically reserved for high-ranking arguments – most prototypically agents/subjects and/or speech-act participants (i.e., 1st or 2nd person NPs). Conversely, when low-ranking arguments (e.g., inanimate or indefinite NPs) appear in subject position, or when high-ranking arguments appear as objects, languages often employ overt or differential case marking to signal this type of “atypical” configuration. Thus, assignment of nominative case to objects, especially those low on the referential hierarchy, is typologically rare (because high-ranking arguments indeed are generally mapped to subject position).
This rarity has been linked to broader cross-linguistic constraints on case alignment and argument structure. One key issue is that nominative objects can disrupt the expected associations between case and argument thematic roles, reducing the morphosyntactic distinctiveness between subject and object. From a syntactic perspective, it has been argued that the presence of nom case on non-subjects (e.g., objects or embedded subjects) is constrained by locality conditions and structural licensing mechanisms (Keine Reference Keine2010). These mismatches, particularly when nominative is assigned to a theme or patient, frequently demand repair strategies like movement or restructuring (see Keine Reference Keine2010, Malchukov Reference Malchukov2010, Georgi Reference Georgi, Alexiadou, Kiss and Müller2012), or sometimes cannot be saved at all (e.g., Clem & Deal Reference Clem and Deal2024).
2.4. Global constraints: Alignment and distinctness
In addition to local constraints on the types of arguments that get nom case, sentence acceptability is shaped by global, clause-level constraints. According to the Distinctness Principle (Bornkessel-Schlesewsky & Schlesewsky Reference Bornkessel-Schlesewsky, Schlesewsky and Van Valin2008), two clause-mate NPs should be as morphologically and functionally distinct as possible: When two arguments within a clause are marked with the same case (such as in a nom-nom configuration), this reduces their morphosyntactic distinctness and is expected lead to increased processing difficulty or reduced acceptability.
This principle is closely related to the broader concept of alignment, which concerns the mapping between grammatical functions (subject, object), thematic roles (agent, patient, experiencer), and morphological case. In canonical nominative–accusative alignment systems, subjects of both transitive and intransitive verbs are treated alike and are distinct from objects, typically through case marking or agreement patterns. When alignment between these domains is disrupted: for example, when both subject and object receive nominative case, this creates ambiguity in argument structure and undermines the functional distinctness that case marking can provide.
In our forthcoming Morphological-Thematic-Grammatical alignment hypothesis, morphological case marking plays a central role: For example, in nom-acc constructions (as in (7b)), the subject (agent or experiencer) is marked with nominative case and the object (patient) with accusative case, preserving clear distinctions across all three domains. In contrast, double nominative constructions (nom-nom) or mixed patterns (dat-nom) disrupt this alignment, as the mapping between case, grammatical function, and thematic role is not preserved. Thus, both local constraints (e.g., the atypicality/unexpectedness of a nom-marked object) and global constraints – particularly those formalized by the MTG alignment hypothesis – weigh in to influence sentence acceptability. In our forthcoming study, we show that both levels of constraint are operative. We also propose that morphological marking of both the subject and the object, as captured by the MTG, is influential in shaping the acceptability and distribution of nominative object constructions in Korean. These local and global constraints can be further illuminated by considering broader patterns of accessibility and alignment in language.
2.5. Interim summary: Distinctness, alignment, and accessibility
To briefly summarize our opening discussion so far, we have noted that nom-nom constructions, like the Korean example in (4), appear to violate two principles of language well-formedness. First, at the local level, the assignment of nominative case to an object is unexpected (Silverstein Reference Silverstein and Dixon1976, Keine Reference Keine2010, Malchukov Reference Malchukov2010, Georgi Reference Georgi, Alexiadou, Kiss and Müller2012, Clem & Deal Reference Clem and Deal2024). Second, at the global level, NOM object constructions are predicted to disrupt expected alignments between case, grammatical function, and thematic role. Looking back at the Korean sentences in (4) and (5), we note that the nom-nom configuration violates the expectation that clause-mate NPs should be morphologically distinct (since both subject and object bear nominative case) and the expectation that case marking should consistently map onto grammatical and thematic hierarchies (since the lower-ranked object/theme receives the higher-ranked, nominative case).
Our experimental investigation tests how Korean speakers respond to these configurations. The first goal of our study is to establish how speakers of Korean respond to nom-nom and dat-nom configurations, vis-à-vis configurations that satisfy both distinctness and alignment; thus, nom-acc configurations. At the same time, however, grammaticality is of course not determined by alignment or (a)typicality alone: Certain NPs simply cannot be nominative. Specifically, the Korean light verb -ha- is obligatory for licensing accusative case in nom-acc constructions (Jung Reference Jung2002, Reference Jung2003, Yeo Reference Yeo2004, Choi Reference Choi2019, Choi Reference Choi2022). Without -ha-, even an apparently aligned NOM-ACC configuration is ungrammatical (e.g., paywu-ka (nom) kamtok-ul (acc) coha-*(ha)-yess-ta). This shows that local syntactic constraints (e.g., the Korean nom-case licensing rule) can block otherwise well-aligned case arrays. Thus, while alignment and markedness shape acceptability, they operate within the bounds of other language-specific morphosyntactic requirements. We put these matters to the test with a novel acceptability judgment study.
3. Evaluating the well-formedness of nom-nom and dat-nom compared with nom-acc: An acceptability judgment experiment
This experiment is designed to disentangle the effects of local constraints (which penalize nominative objects regardless of subject case) and global constraints (which penalize certain combinations of subject and object case within a clause). By comparing nom–nom, dat–nom, and nom–acc configurations,Footnote 3 we test whether unacceptability arises from the object’s case alone or from the overall case pattern.
To evaluate the well-formedness of different case marking constructions in Korean, we focus on nominative object constructions. According to cross-linguistic categorization for psych predicates (e.g., Belletti & Rizzi Reference Belletti and Rizzi1988, Landau Reference Landau2010), dative experiencer verbs (or Class III psych verbs) fall into this category. These verbs express the psychological state of an experiencer toward a theme. Class III psych verbs in Korean are particularly relevant to the study of double nominative (nom–nom) and dat–nom constructions, as these verbs allow for nominative or dative marking on the experiencer and the theme nominative. In contrast, Class I psych verbs, traditionally referred to as subject experiencer verbs, exhibit a nom-acc case pattern. Despite this traditional distinction between subject experiencer verbs and dative experiencer verbs, Korean nom-nom and dat-nom constructions with Class III psych verbs indicate that the nom- or dat-marked experiencer functions as the grammatical subject under subjecthood diagnostics such as subject honorific suffix (-si-) agreement, anaphor binding, and argument interpretation. Thus, we consider both Class I and Class III verbs to be subject experiencer verbs in Korean. We selected this focus for two main reasons. First, Class III psych verbs allow for both nominative and dative subjects in Korean, providing a minimal comparison between having a dative subject and a nominative subject. This comparison isolates the effect of distinctness by contrasting the distinct dat-nom case frame with the non-distinct nom-nom case frame. These constructions can be used either with the light verb ci- ‘become’, or without, as shown in (12a). Second, these verbal roots are also compatible with a canonical nom-acc case frame, provided that the light verb ha- ‘do’ is present instead of ci-. Unlike optional ci- in nom-nom and dat-nom constructions, the light verb ha- is obligatory in nom-acc configuration, as shown in (12b). The choice of light verb is also crucial in these alternations: The light verb ha- (vDO) is obligatory in nom–acc constructions and yields a more agentive, activity-like interpretation. In contrast, ci- (vBECOME) or a null verb (vBE) is used in nom–nom and dat–nom constructions, resulting in less agentive, stative, or inchoative readings.

To investigate how Korean speakers perceive these configurations, we conducted an acceptability judgment experiment. We tested three types of structures: (i) NOCs with double nominative marking (nom-nom), (ii) NOCs with a dative subject and nominative object (dat-nom), and (iii) canonical nom-acc constructions, both with and without light verbs. This design allows us to systematically examine whether deviations from canonical nom-acc configurations, which satisfy both alignment and distinctness principles, affect acceptability.
3.1. Method
3.1.1. Participants
Forty-eight native Korean speakers from university communities in Seoul, Korea, participated in an acceptability judgment experiment. Participants were aged between 18 and 40, had normal or corrected-to-normal vision, and had less than a year of international experience before the age of 16. Each participant received compensation for their participation.
3.1.2. Materials
The experiment employed a 3 × 2 within-subjects design, manipulating two factors: case (nom-acc, nom-nom, dat-nom) and light verb (light verb, no light verb). We created sentences like those in (12), both with and without light verb forms, in nom-acc, nom-nom, and dat-nom case frames. An example item set is shown in Table 1.
A sample set of target items

A total of 24 experimental trials were created, with each trial consisting of three words in SOV order: An animate subject, followed by an animate object, followed by an experiencer verb. Six lists were generated using a Latin square design, ensuring each participant saw each item only once. Participants saw a total of 4 items per condition over the course of the experiment, yielding a total of 192 tokens per condition (cf. other recent acceptability judgment experiments on Korean, e.g., Kim et al. Reference Kim, Kwon, Lee, Lee, Lee and Yoon2021).Footnote 4 Additionally, 24 fillers were included, consisting of intransitive sentences, of which half were unacceptable.
3.1.3. Procedure
Participants were asked to read sentences presented on a computer screen through the online PCIbex platform. They rated the acceptability of each sentence on a 7-point Likert scale, where 1 indicated unacceptable and 7 indicated acceptable. The experiment lasted approximately 10 minutes.
3.1.4. Predictions
If distinctness significantly impacts well-formedness, we expect dat-nom constructions, which satisfy distinctness by using different cases for the subject and object, to receive higher acceptability ratings than nom-nom constructions, which do not satisfy distinctness. We expect that nom-acc constructions will still receive the highest ratings due to satisfying both distinctness and alignment principles. If alignment plays a critical role, then we expect nom-nom and dat-nom collectively to be rated lower than nom-acc.
3.2. Results
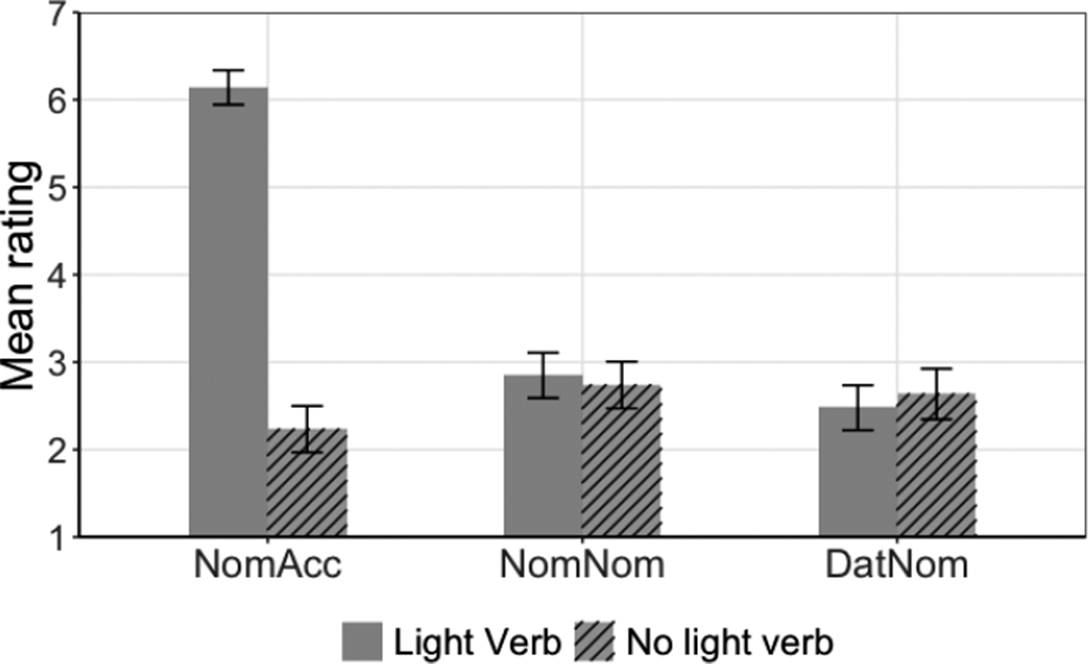
The analysis included all 1152 critical trials. The raw acceptability ratings in each condition are shown in Figure 1. Qualitatively, we found that sentences with nominative objects (nom-nom and dat-nom) were rated lower in acceptability than sentences with accusative objects (nom-acc). Additionally, sentences containing a light verb were rated more acceptable than those without one in nom-acc and nom-nom, with the largest improvement observed in the nom-acc condition. The fully acceptable fillers received a mean rating of 5.49 (SD = 2.14), while the unacceptable fillers received a mean rating of 2.73 (SD = 2.09).Footnote 5
Mean ratings for each level of case – nom-acc, nom-nom, and dat-nom – for each level of light verb (light verb in plain bars; no light verb in patterned bars). Error bars indicate 95% confidence intervals.

We analyzed ratings by fitting a 2 × 3 cumulative link mixed-effects regression model with crossed random effects for participants and items (Baayen, Davidson & Bates Reference Baayen, Davidson and Bates2008; Jaeger Reference Jaeger2008), as implemented in the Ordinal package of the statistical software R 4.3.2 (R Core Team 2015; Christensen Reference Christensen2023). The predictor light verb was sum-coded (coefficients of 1/2 for light verb and –1/2 for no light verb). We coded the 3-way case predictor using centered Helmert Contrasts, as this coding scheme best reflects our theoretical questions. Our first contrast, called nominative object, compared the nom-acc conditions (Coefficient: 2/3) with the nom-nom and dat-nom conditions, pooled (Coefficient: –1/3 for each level). This contrast asks about how ratings of the sentences are affected by the presence of a nominative-marked object. Specifically, it tests for the role of cross-hierarchical alignment: Both nom-nom and nom-dat constructions are misaligned across the three accessibility hierarchies that we introduced in Section 2, whereas nom-acc is aligned. The second contrast, called double nominative, compared the nom-nom condition (Coefficient: 1/2) with the dat-nom condition (Coefficient: –1/2). This contrasts tests for role distinctness by comparing sentences with a non-distinct case array (nom-nom) with those with a distinct one (dat-nom). The coefficient for nom-acc in this contrast is 0, because it does not participate in the comparison. We report statistical outputs for the model with the full, maximal random effect structure supported by the design (Barr et al. Reference Barr, Levy, Scheepers and Tily2013). The output of the model is shown in Table 2.
The 2 × 3 mixed-effects cumulative link regression model (top part), along with the effect of Light Verb at each level of Case (bottom part). Significant effects are bolded.

We find first, a significant main effect of light verb, with sentences with a light verb rated as higher on average than those without (means = 3.8 vs. 2.5; β = 2, SE = .23, z = 8.9, p <.0001). As indicated in the graph, this main effect was driven by the nom-acc condition, where ratings for sentences without a light verb were the lowest of all the conditions (mean rating = 2.2). We also found two other main effects: First, nom-acc sentences were rated as significantly better than the nom-nom and dat-nom conditions, pooled (means = 4.2 vs 2.7; β = 2, SE = .3, z = 5.7, p <.0001). This indicates that there is an effect of alignment, in the predicted direction: Sentences whose case array is misaligned with the grammatical and thematic accessibility hierarchies (i.e., nom-nom and dat-nom; see again §2) are rated as worse than those that are aligned (e.g., nom-acc). The second main effect showed that dat-nom sentences were also rated as lower than nom-nom sentences (means = 2.6 vs. 2.8; β = .7, SE = .3, z = 2.1, p = .03). Interestingly, sentences with a non-distinct case array (nom-nom) were, in fact, rated better than those whose NP arguments are marked with distinct cases (dat-nom), rather than worse, as might be expected under the distinctness hypothesis. We will return to this finding in our discussion section (§3.3). Lastly, there was a significant interaction of nominative object (i.e., nom-acc vs. nom-nom and dat-nom, pooled) with light verb (β = 4.9, SE = .3, z = 15.9, p <.0001). We explored this interaction by running a second model with nested planned comparisons, asking whether there was an effect of light verb at each sentence type. This model confirmed that ratings to nom-acc sentences were significantly better with a light verb than without (means = 6.1 vs. 2.2; β = 5.8, SE = .55, z = 10.5, p <.0001), but presence of a light verb did not lead to a statistically significant difference in ratings for either nom-nom or dat-nom sentences (ps >.18); Indeed, the interaction of double nominative with light verb was also not significant (p = .5).
3.3. Discussion
The results of this experiment demonstrated, first, that sentences with nominative-marked objects (nom-nom and dat-nom) were consistently rated lower in acceptability compared to sentences with accusative-marked objects (nom-acc). This pattern reflects the influence of both local and global constraints: locally, there is a general dispreference for nominative objects, while globally, certain subject–object case combinations are penalized due to misalignment and lack of case distinctness. Specifically, this finding follows from the alignment hypothesis, which penalizes violations of the alignment of morphological case, according to Otsuka’s (Reference Otsuka, Johns, Massam and Ndayiragije2006) accessibility hierarchy, with grammatical function and thematic role (as in nom-nom and dat-nom constructions). The second important finding was that nom-nom sentences were rated as higher than dat-nom ones, regardless of whether a light verb was present or not. This is especially noteworthy because it is the opposite result from that which is predicted by the distinctness hypothesis: The non-distinct nom-nom construction was the better-rated one of the two. This result suggests that the acceptability of these constructions cannot be explained by distinctness alone. Instead, the overall pattern supports a model in which both local (nom object case marking) and global constraints (case alignment of the entire clause) interact, with cumulative effects on acceptability. Does this mean that sentences with two different-cased NPs (e.g., dat-nom) are necessarily dispreferred over those with the same case (e.g., nom-nom)? We think that this would be too strong of a conclusion to draw, because there is a plausible alternative reason why dat-nom would be worse than nom-nom, owing to multiple misalignments at the global level. As illustrated in (13a), only the object is misaligned in nom-nom constructions (higher nom ➔ lower object theme). But in dat-nom (13b), both the subject (lower dat ➔ higher experiencer subject) and object (higher nom ➔ lower object theme) suffer from misalignment. It could well be that this additional misalignment in dat-nom is what leads to the lower ratings for these sentences.

This observed gradience in acceptability supports a model in which constraint violations are cumulative, as captured by Harmonic Grammar models. Rather than a categorical distinction between a sentence being ‘grammatical’ versus ‘ungrammatical’, our results suggest that the acceptability of a construction is a function of the number (and severity) of different constraints. Any type of misalignment between case, grammatical function, and thematic role incurs a penalty in acceptability, but the magnitude of the penalty depends on the nature and locus of the misalignment. Local violations, such as assigning nominative case to an object/theme, are predicted to incur larger penalties, while compounded global violations (as in dat-nom) add smaller, incremental costs, consistent with cognitive models of diminishing sensitivity (Gibson Reference Gibson, Marantz, Miyashita and O’Neil2000, Wilson & Dillon Reference Wilson and Dillon2022). The observed pattern, where the acceptability drop from nom-acc to nom-nom is larger than from nom-nom to dat-nom, indeed matches with these predictions. With this in mind, we now focus our attention on the alignment hypothesis, which we spell out below, in (14).

We reason that the MTG exists because all three of (i) case morphology, (ii) thematic role, and (iii) grammatical function are different kinds of means to the same end. They typically serve as converging cues that help the language-user infer the event role of an NP in relation to the verb. Although these cues do not always specify the role of an NP, because interpretation also depends on the lexical semantics of the verb and the presence or absence of other arguments. For this reason, the meaning of the sentence is easier to construct when each of these three pieces of information points to the same conclusion about what an NP’s event role is; in other words, this alignment reduces ambiguity and facilitates the assignment of event roles to each NP. It is important to also note that nominative object constructions are overwhelmingly restricted to predicates with experiencer subjects. Thus, the acceptability differences observed here do not reflect a difference in the core thematic roles assigned by the predicates: in all cases, the subject is an experiencer and the object is a theme. While both dative and nominative subjects can be experiencers, dative subjects are typically interpreted as less agentive or less involved in initiating the mental state, consistent with cross-linguistic findings on non-nominative subjects. Thus, the acceptability patterns observed here reflect not just morphological distinctness, but also the pragmatic inferences about agentivity that arise from the combination of case, predicate, and light verb.
While our results are consistent with the predictions of the MTG alignment hypothesis, we acknowledge that alternative explanations are possible. Processing-based theories that link acceptability to expectation or familiarity (e.g., Hale Reference Hale2001, Reference Hale2006, Levy Reference Levy2008) could also predict a preference for more frequent or more canonical argument structures. It may be that the higher acceptability of nom-acc constructions, for example, reflects their greater frequency in Korean, as confirmed by our own corpus findings (see Section 4). Interestingly, both the results of our experiment and the hypothesis in (14) raise an important question: Under what conditions are nom-nom and dat-nom configurations acceptable? We investigate this question next by looking for attested examples in a Korean language corpus.
4. Corpus survey: The distribution of misaligned case constructions
We investigated the distribution of sentences of Korean which have nominative-marked objects (e.g., nom-nom, dat-nom) compared with accusative ones (e.g., nom-acc). We examined written data extracted from the Modu Corpus Written Corpus (National Institute of Korean Language 2020). The Modu Corpus is a comprehensive collection that includes 7,061 types of written texts from various resources, such as books, magazines, reports, and other published materials.
4.1. Method
The corpus was searched for instances of the Korean psych verbs that were used in the previous experimental design shown in Section 3. This approach allows for a comparative analysis against the low acceptability ratings observed in the experiment. A total of 24 psych verbs were selected; see list in (15). Additionally, 44 distinct verb conjugations across bare-form, ha-form, and ci-form psych verbs were compiled (see Appendix A for details on conjugations). These conjugations represent the most frequently occurring forms in the corpus and were identified through a filtering process that examined verb tense, aspect, and morphological form.

The initial filtering of the Modu Corpus based on these verb conjugations resulted in a dataset of approximately 353,837 sentences. The corpus sentences were then filtered according to three criteria, which allowed for the isolation of transitive uses of psych verbs, with clearly identifiable subjects and objects that could be tagged for their properties (that is, tokens where both the subject and object are marked by a single overt marker: nominative, accusative, dative, or a topic marker. These are laid out in (16).

By applying these criteria, the initial dataset was filtered down to a subset of sentences. A total of 4,927 instances were selected for further analysis. The analysis is confined to objects in a bare noun form or those accompanied by a single determiner within matrix clauses.
4.2. Results and discussion
The distribution of case markings on subjects and objects is summarized in Table 3. Descriptively, we first note that most of the sentences had a subject that was marked by the Korean top(ic) marker -nun (4,556, or 92%). Only 354 (7.2%) had a nom-marked and fewer still had a dat-marked subject – only 17 (0.3%).
Counts of sentences with top, nom, and dat subjects, and top, nom, and acc objects, along with proportion of object marking by subject marking (in parentheses). The first of our chi-square analyses (as detailed below) was performed on the raw counts in the bolded square.

We began our analysis by testing whether the distribution of case marking on objects differs depending on whether the clause-mate subject was (i) a topic subject (i.e., a top-nom and top-acc construction), compared with (ii) a nominative subject (i.e., a nom-nom and nom-acc construction). We compared raw frequency counts of these constructions using a Pearson’s chi-square test (see the bold boxing in Table 3). The results revealed a highly significant association between subject and object case marking (χ² = 109.71, p <.0001), indicating that nominative objects are much more likely to occur with topic-marked subjects than with nominative-marked subjects. Proportionally, nominative objects are much more likely to occur with topic-marked subjects (top-nom) than with nominative subjects (nom-nom) (27% vs. 2%). In contrast, accusative objects are less frequent with topic-marked subjects (top-acc) than with nominative subjects (nom-acc) (97% vs. 72%). In short, constructions with nom objects more frequently have top subjects than nom ones. By way of reference, the same is not true for constructions with acc objects, which, in fact, occur with nom subjects more than they do with top subjects. Thus, sentences with nom subjects tend to have acc objects. Sentences with nom objects tend to have top subjects. Examples of token sentences from the corpus with top-nom, nom-nom, top-acc, and nom-acc, respectively, are given in (17).

The overall paucity of nom–nom and dat–nom constructions in the corpus is consistent with the influence of morphosyntactic constraints. Specifically, both local constraints (the general dis-preference for nominative objects) and global constraints (the avoidance of certain subject–object case combinations) likely contribute to their low frequency in this type of naturalistic data. Recall that the MTG alignment hypothesis (14) posits that sentences that have maximal alignment of morphological case marking, thematic roles, and grammatical functions are preferred by language users over sentences with one or more misalignments. In sentences with nominative-cased objects, the assigning of a higher-ranked nominative case to a lower-ranked thematic role like a theme (object) disrupts MTG alignment (as was schematized in (13a and b)). The findings from our corpus survey support this hypothesis from a different angle: there are fewer occurrences of nom objects as compared with acc objects, supporting the idea that constructions with nom objects indeed occur less frequently than those with acc objects.
However, we also observe that when sentences do occur with a nom object, they almost always have a top-marked subject. While morphosyntactic distinctness and the MTG alignment hypothesis predict a general dis-preference for nominative object constructions, they are not entirely absent from natural language use. The prevalence of top-marked subjects – especially in sentences with nom objects – suggests that topic marking plays a crucial role in enabling configurations that would have been disfavored. We consider top as a discourse marker, not a canonical case marker: it does not encode grammatical or thematic role in the same way that structural case does but rather marks information structure (Kuno Reference Kuno1987, Lee & Shimojo Reference Lee and Shimojo2016). Morphologically, it occupies the same post-nominal slot as case markers but is not part of the morphological case hierarchy (as in Otsuka Reference Otsuka, Johns, Massam and Ndayiragije2006, Bobaljik Reference Bobaljik, Harbour, Adger and Béjar2008). As such, when a subject is topic-marked, it is exempt from both the global MTG alignment constraint and the local distinctness constraint: the subject is not counted in the calculation of case alignment, nor does it trigger a distinctness violation with a nom object. In effect, top marking ‘rescues’ the alignment of an otherwise misaligned construction by removing the subject from the domain of case competition, as schematized in (18). This means that, for the purposes of distinctness and MTG alignment, a top-marked subject is effectively invisible: it does not participate in structural case competition, nor does it contribute to violations of case identity with a nominative object. It is crucially different from the situation where two NPs bear different allomorphs of the same case (e.g., -i vs. -ka for nom), which would still count as a violation of distinctness since both are functionally nominative.

This interpretation leads to a prediction: If top marking plays a role in rescuing a potential nom-nom construction from misalignment, then top marking should occur more frequently with nom objects (where it can serve this purpose) compared with acc objects (where it fulfills no such ‘rescue role’). We tested this prediction by looking at the number of sentences with nom objects which had (i) top-marked subjects and (ii) non-top-marked (i.e., nom or dat) subjects, and comparing these with the number of sentences with acc objects with top- vs. non-top-marked subjects. The counts are shown in Table 4: 99% of sentences with nom objects have a top subject, compared to 91% for sentences with ACC objects. To assess this association, we performed a Pearson’s chi-square test on the raw frequency counts (see Table 4, bolded cells). This analysis revealed a highly significant association between object case and topic marking of the subject (χ2 = 95.24, p <.0001).
Counts of sentences with top and non-top subjects with nom and acc objects, along with proportion of subject marking by object marking (in parentheses). The chi-square analysis was performed on the raw counts in the bolded square.

This distributional pattern supports the graded linking theory (see Section 2.4). As predicted, structural rescue mechanisms such as top marking with nom objects yield near-categorical frequency (99%), reflecting a grammatical necessity for licensing otherwise disfavored configurations. In contrast, optional discourse strategies like top marking with acc objects yield high but more variable frequency (91%). Though both frequencies are high, the observed 8% gap is theoretically meaningful: it signals a qualitative distinction between obligatory grammatical rescue and optional discourse marking (i.e., presence of top). This aligns with our broader claim that the magnitude and categorical nature of frequency effects are determined by the nature and locus of constraint violations, not simply by their statistical significance (e.g., Phillips et al. Reference Phillips, Gaston, Huang, Muller and Goodall2021).
Why does top marking rescue a misalignment? We hypothesize that this is connected to the discourse role of the Korean topic marker. Top indicates that the NP which it marks is pragmatically backgrounded (e.g., Lee & Shimojo Reference Lee and Shimojo2016), meaning that it is old or given information (Kuno Reference Kuno1987). Information that is topic-marked is therefore already familiar in the minds of both conversational participants (i.e., the speaker and the addressee). Therefore, we reason that top functions as a marker of discourse status rather than providing information about what role an NP plays in an event, like nom and dat do. This means that it does not participate in the MTG hierarchy, and as such, top-nom constructions are not misaligned. In short, top does not serve to indicate event role; it marks discourse role. This is consistent with Shin and Verhoeven (Reference Shin, Verhoeven, Johannes, Yoko, Yong-Min, Stavros and Elisabeth2009), whose harmonic alignment framework posits that well-formedness in Korean double case constructions depends on the alignment of multiple hierarchies, including syntactic-based, animacy-based, and pragmatic-based ones.
5. General Discussion
5.1. Concluding remarks
Overall, our experimental and corpus findings are largely consistent with the generalizations reported in previous studies based on native speaker intuition (Lim Reference Lim1997, Mok Reference Mok2003, Choi Reference Choi2009, Kim et al. Reference Kim, Park, Lee and Choi2018, among others). We extend these findings by providing new quantitative evidence from both experimental and corpus-based methods. The findings from both the acceptability judgment experiment and the corpus analysis are summarized as follows.
Low acceptability and low frequency of nominative objects. Both nom-nom and dat-nom structures demonstrate lower acceptability and frequency compared to nom-acc structures. This indicates that the presence of a nominative object, rather than merely the double nominative case, is the critical factor. We note that the gradient acceptability pattern suggests that unacceptability arises from the cumulative violation of multiple constraints, rather than one single monolithic constraint. Our results are consistent with typological work showing that nominative objects are rare and dispreferred cross-linguistically (Silverstein Reference Silverstein and Dixon1976, Malchukov Reference Malchukov, Amberber and de Hoop2005, Keine Reference Keine2010). However, harmonic alignment is a necessary but of course not sufficient condition for grammaticality in Korean. Predicate-specific licensing requirements (i.e., the presence of the light verb -ha-, here) are essential for licensing accusative case in nom-acc constructions (Jung Reference Jung2002, Reference Jung2003, Yeo Reference Yeo2004, Choi Reference Choi2019, Reference Choi2022).
Local and global constraints. Our analysis supports the view that both local and global constraints together influence the acceptability of nominative object constructions. Local constraints relate to the features of individual constituents, such as the nominative object, whose markedness renders it typologically rare and less acceptable in Korean. Global constraints, on the other hand, pertain to the overall configuration of the clause (e.g., the relation between subject marking and object marking). This necessitates that two clause-mate NPs be as morphologically distinct as possible.
The Morphological-Thematic-Grammatical (MTG) Alignment Hypothesis, which we adopt, operates as a global constraint: it assesses the degree to which morphological case, grammatical function, and thematic role are aligned within a clause. The MTG posits that sentences are more acceptable when there is a maximal alignment between morphological case marking, thematic roles, and grammatical functions. In nom-acc constructions, this alignment is achieved because the subject (a higher-ranked grammatical role) is marked with nominative case (higher-ranked case) and functions as an experiencer (a higher-ranked thematic role), while the object (a lower-ranked grammatical role) is marked with accusative case (lower-ranked case) and functions as a theme (a lower-ranked thematic role). This alignment makes nom-acc constructions more acceptable and more frequently occurring, as evidenced by their high rate of occurrence in corpus data.
In nom-nom constructions, however, alignment is disrupted because the object, which is a lower-ranked thematic role (theme), is marked with a higher-ranked unmarked case (nominative). This misalignment between the thematic role and the morphological case marking reduces the acceptability of nom-nom constructions. Similarly, in dat-nom constructions, there is a twofold misalignment: the subject, which is a higher-ranked thematic role (experiencer), is marked with a lower-ranked marked case (dative), and the object, which is a lower-ranked thematic role (theme), is marked with a higher-ranked unmarked case (nominative). This double misalignment further reduces the acceptability of dat-nom constructions compared to nom-nom constructions.Footnote 6
The graded penalty framework we adopt also predicts that the size of acceptability and frequency effects systematically reflects the type and locus of constraint violations: local violations (e.g., nominative objects) incur larger penalties, while compounded global violations (e.g., dative subjects combined with nominative objects) add smaller incremental costs. Similarly, the frequency of topic marking with nominative objects, contrasted with more variable topicalization of accusative objects, reflects a principled distinction between grammatical necessity and pragmatic preference (see, e.g., Phillips et al. Reference Phillips, Gaston, Huang, Muller and Goodall2021).
Topicality as a rescue. In our corpus survey, we found that sentences with nominative objects tend to have topic-marked subjects. We proposed that the presence of a topic marker on the subject can help rescue the MTG alignment in sentences with nominative objects. This is because top indicates that the subject is backgrounded information, meaning that it is already known or given. We think this is because top functions as a marker of information status rather than of grammatical/thematic role. In this line, we argue that the topic marker does not participate in the morphological case hierarchy of the MTG alignment system. Unlike canonical case markers (nom, acc, dat), which encode grammatical and thematic relations, top encodes discourse status. When a subject is topic-marked, it is effectively exempt from the case alignment constraints that would otherwise penalize nom-nom or dat-nom configurations.
5.2. Looking forward: Case stacking
We anticipate that further interesting patterns might emerge when case stacking occurs in nom-object constructions, as in (19), repeated from (8d). In (19), a nom marker is stacked over a dat marker.

Exploring such scenarios in future research ought to shed further new light on how morphological, thematic, and grammatical alignments interact with pragmatic factors such as topicality. Critically, our MTG alignment hypothesis provides a framework for explaining the acceptability of different case configurations, especially in NOC structures like nom-nom and dat-nom. This provides a platform for future research looking at how case stacking work, and especially what the role of information structure might be in potentially helping to rescue misalignments. In closing, we make two predictions about this. First, we predict that instances of case stacking ought to be few in number and/or contextually constrained. This is because nom case and dat case provide different kinds of information about the nature of the experiencer role of the subject (i.e., facilitating a more agentive reading vs. a non-agentive reading, respectively). Our second prediction is that top marking should not generally be stackable over dat or nom marking in constructions in nominative objects. This is because top marking would serve to background a subject that is intended to be simultaneously foregrounded, by virtue of its having nom/dat marking in this environment – a situation that would trigger a clash in discourse functions.
Acknowledgments
This work was supported by the Park Chung-Jip Scholarship Fund for the Next Generation in English Language and Literature at Seoul National University and by the University of Delaware. An earlier version of this article is based on the first author’s PhD dissertation at the University of Delaware. We are grateful to the editors and reviewers of the Journal of Linguistics for their valuable comments and suggestions.
Appendix A. A list of verb conjugations used in the corpus study






 Open access
Open access