

This paper presents a new study of variable complementizer omission in Montréal French (also known as que drop). In most varieties of Canadian French, que may be optionally omitted when it introduces a complement, circumstantial, or relative clause, as shown in (1)-(3).
(1) Bien je pense que c'est: c'est important … (complement clause, speaker 128, Corpus Montréal 84, Thibault & Vincent [Reference Thibault and Vincent1990])
‘Okay I think that it's: it's important…’
(2) … parce qu’ ici c'est bizarre. (circumstantial clause, speaker 2, Corpus Montréal 84)
‘… because that here it is weird.’
(3) C'est là que ma mère à moi vivait. (relative clause, Roberge & Rosen [Reference Roberge and Rosen1999])
‘It was there that my mom had lived.’
Que drop was first studied in the early days of variationist sociolinguistics by Sankoff, Sarrasin, and Cedergren (Reference Sankoff, Sarrasin and Cedergren1971), and the social and grammatical conditions under which que is likely to be pronounced/omitted have since been widely investigated and given rise to debate in the variationist literature. Since the early 2000s, there have been advances both in our understanding of the social and cognitive factors that condition language variation and change (see for example Ferreira & Dell [Reference Ferreira and Dell2000] for that omission, Bresnan, Cueni, Nikitina, & Baayen [Reference Bresnan, Cueni, Nikitina, Baayen, Bouma, Kraemer and Zwarts2007] for the dative alternation, and more recently Kleinschmidt, Weatherholtz, & Jaeger [Reference Kleinschmidt, Weatherholtz and Jaeger2018] for phonological variants), and in available computational and statistical tools. Likewise, in the past ten years, a rich line of research on variable complementizer drop in other languages has emerged, and we now have reason to believe that cognitive factors, particularly those related to the distribution of information across utterances (Jaeger, Reference Jaeger2010; Levy & Jaeger, Reference Levy, Jaeger, Schlökopf, Platt and Hoffman2007), play a role. Our new investigation allows us to tease apart the syntactic and phonological factors conditioning complementizer que drop in a way that was not possible for previous studies and brings to light the additional role that information-based reasoning plays in the variable production of complementizer in the French spoken in Montréal.
In the next two sections of the paper, we review the previous variationist literature on complementizer drop in French and compare it to more recent work on complementizer drop in English and other languages. We argue that the literature on English complementizer omission has identified a number of new factors that are predicted to be relevant for the Canadian French variable. Then, we present the methodology of our study: the annotation, extraction, coding, and statistical analysis of que drop in the Montréal 84 corpus. We then present our results and discuss how they relate both to the previous work on this variable in French and cross-linguistically. The final section concludes with future perspectives on variation in Montréal corpora.
COMPLEMENTIZER DROP IN FRENCH
The study of que drop in Canadian French has a rich history in sociolinguistics, but there has been very little agreement on what motivates the deletion of que in complement clauses (henceforth CC). Based on a first study of the Sankoff-Cedergren corpus of spoken Montréal French (Sankoff & Cedergren, Reference Sankoff and Cedergren1972), Sankoff et al. (Reference Sankoff, Sarrasin and Cedergren1971) and Sankoff (Reference Sankoff1980) suggested that the phonological contexts preceding and following que condition the omission. In particular, Sankoff and colleagues showed that sibilants favor que omission, compared to other sounds. Based on this result, they proposed that que omission may be conditioned by the sonority hierarchy (Clements, Reference Clements, Kingston and Beckman1990) and hypothesized that omission could be motivated by consonant cluster simplification.
Sankoff et al.'s proposal is supported in Warren's (Reference Warren1994) study of Montréal 84. Working on que-omission in complement, circumstantial, and relative clauses, she reported the stability of que omission from the 1971 to the 1984 Montreal corpus. A simple syntactic structure preceding or following the complementizer favors que drop. Like Martineau's (Reference Martineau1985) study of the Ottawa-Hull corpus (Poplack, Reference Poplack, Fasold and Schiffrin1989), Warren observed a correlation between the omission and some specific verbs and contexts, like je pense ‘I think’ and disons ‘let's say,’ which should result from the grammaticalization of these contexts into “epistemic phrases” (Thompson & Mulac, Reference Thompson and Mulac1991a, Reference Thompson and Mulac1991b). The omission of que has also been argued to be conditioned by the type of the CC subject rather than the phonological environment following que: Connors (Reference Connors1975) showed, also using the Sankoff-Cedergren corpus, that speakers tend to drop que when the subject of the CC is a pronoun rather than a NP. She contested Sankoff et al.'s (Reference Sankoff, Sarrasin and Cedergren1971) analysis, arguing that frequent pronouns in French often begin with a sibilant (like [ʒ] in je ‘I’ and [s] in ce and ça ‘it’), which makes sibilants more likely to favor omission. Drawing on the Français parlé à Ottawa-Hull (OH) (Poplack, Reference Poplack, Fasold and Schiffrin1989) and Récits du français Québécois d'Autrefois (RFQ) (Poplack & St-Amand, Reference Poplack and St-Amand2007), Dion (Reference Dion2003) replicated the effect of the sonority hierarchy described by Sankoff and colleagues, reporting that omission occurs most before obstruents, less so before sonorants and least before vowels. Moreover, she argued that the syntactic effect observed by Connors (Reference Connors1975) should actually be analyzed as part of the phonological effect, since the pronouns starting with a vowel clearly disfavor omission. She also noticed a lexical effect, whereby certain verbs, like rappeler ‘remind,’ sembler ‘seem,’ and penser ‘think’ favor que-deletion. These studies have some limitations. First, Connors (Reference Connors1975), Sankoff (Reference Sankoff1980), and Sankoff et al. (Reference Sankoff, Sarrasin and Cedergren1971) could only analyze small subsets of their corpora (sixteen speakers). Similarly, Warren (Reference Warren1994) worked on twenty-four of seventy-two speakers from the Montréal 84 corpus, and Dion (Reference Dion2003) and Martineau (Reference Martineau1985) studied only thirty and fourteen speakers, which only represent a quarter and one-tenth of the total data found in the OH corpus respectively. Second, mixed-effects models that take into account random effects, such as interspeaker variation (see Johnson, Reference Johnson2009), were not available. Finally, these previous studies have not investigated the cognitive aspects of this phenomenon.
THAT OMISSION IN ENGLISH
Although que omission is observed in spoken French, according to French prescriptive grammar, the use of the complementizer is obligatory in subordinate structures. In English, the omission of that is fully acceptable and widely observed. Linguistic and cognitive factors on choices between omitting and preserving that in a CC include: matrix subject (Thompson & Mulac, Reference Thompson and Mulac1991a, Reference Thompson and Mulac1991b; Torres Cacoullos & Walker, Reference Torres Cacoullos and Walker2009), subject of the embedded clause (Elsness, Reference Elsness1984; Ferreira & Dell, Reference Ferreira and Dell2000), the distance of the subordinate clause from matrix verb (Elsness, Reference Elsness1984; Hawkins, Reference Hawkins2001), and the presence of production difficulties at the beginning of CCs (Ferreira & Firato, Reference Ferreira and Firato2002; Jaeger, Reference Jaeger2005), among others. Building on this work, Jaeger (Reference Jaeger2010) shows that information density also plays a role in determining whether or not the complementizer that will be omitted.
Previous accounts of complementizer that dropping
We first present some of the most influential accounts for that dropping: availability-based accounts, dependency processing accounts, ambiguity avoidance accounts, and grammaticalization accounts.
Availability-based accounts hold that the relative accessibility of referents affects speakers’ syntactic choices in production. Here accessibility refers to the ease with which a word can be retrieved from the mental lexicon. According to Principle of Immediate Mention (Ferreira & Dell, Reference Ferreira and Dell2000), given the time pressure of spontaneous speech, speakers tend to structure their message such that accessible words are pronounced first since they are available earlier for production. Therefore, speakers are assumed to pronounce the optional complementizer more often when the words at the CC onset (e.g., the CC subject) are more difficult to be retrieved from memory. Evidence for this hypothesis comes from both experiments and corpus studies: speakers prefer to insert that when the CC subject is a third-person pronoun or a lexical NP rather than the local pronoun I (Elsness, Reference Elsness1984; Ferreira & Dell, Reference Ferreira and Dell2000; Jaeger, Reference Jaeger2010); speakers use that more frequently when having production difficulties, such as repetition and disfluency, at the beginning of CC (Ferreira & Firato, Reference Ferreira and Firato2002; Jaeger, Reference Jaeger2005).
An alternative account predicts the ease of dependency processing to be the primary driving force behind speakers’ preferences. Hawkins (Reference Hawkins2001, Reference Hawkins2004) proposes the Principle of Minimize Domains, suggesting that speakers prefer syntactic options that lead to shorter dependencies. Dependency processing accounts have received support from studies reporting a correlation between an increased distance from the matrix verb to the CC and a higher rate of that-use (Hawkins, Reference Hawkins2001; Rohdenburg, Reference Rohdenburg, Neumann and Schülting1998). In (4), where intervening material (much too late in [4]) appears, the use of complementizer shortens the length from the matrix verb realize to its VP domain, thus facilitating dependency processing.
(4) We realized much too late (that) Jill was not coming back. (Rohdenburg, Reference Rohdenburg, Neumann and Schülting1998)
Ambiguity avoidance accounts, however, have attributed the use of the optional complementizer to temporary ambiguity avoidance (Hawkins, Reference Hawkins2004). For example, speakers are assumed to insert that more frequently in (5a) as a way to reduce the chance that you would be temporarily interpreted as the direct object of knew. Nevertheless, this prediction has not been verified by any other studies (Ferreira & Dell, Reference Ferreira and Dell2000; Jaeger, Reference Jaeger2010; Roland et al., Reference Roland, Elman and Ferreira2006; see also Jaeger [2011] for reducible subject relatives). One plausible explanation is that speakers only avoid ambiguity leading to severe garden path effects (as shown in [5b]).
(5)
a. I knew (that) you missed the train.
b. The horse raced past the barn fell. (Bever, Reference Bever and Hayes1970:40)
Finally, the three processing accounts mentioned above have been contrasted with grammaticalization accounts (Thompson & Mulac, Reference Thompson and Mulac1991a, Reference Thompson and Mulac1991b), which hold that when the complementizer is absent, the matrix clause loses its primordial syntactic function in the sentence and behaves like a parenthetical that can float to different positions, as shown in (6). Epistemic main subjects (first- and second-person pronouns) and verbs (like think and guess), which are often used to express speakers’ epistemic claims or degree of speaker's commitment, are more likely to be grammaticalized into epistemic phrases or discourse formulas, and hence should correlate with a lower rate of that-use (Thompson & Mulac, Reference Thompson and Mulac1991b). However, this hypothesis seems to be contradictory to recent diachronic findings, where many frequent mental verbs, such as think, suppose, know, believe, and understand undergo an overall increase in use of that from the sixteenth to twenty-first centuries (Shank & Plevoets, Reference Shank and Plevoets2018).
(6)
a. I think exercise is really beneficial, to anybody.
b. It's just your point of view you know what you like to do in your spare time I think. (Thompson & Mulac, Reference Thompson and Mulac1991b:313)
Uniform Information Density Hypothesis
Previous work has shown that more predictable words tend to be pronounced more quickly and with less phonetic and phonological details (e.g., Bell, Brenier, Gregory, Girand, & Jurafsky, Reference Bell, Brenier, Gregory, Girand and Jurafsky2009). Speakers’ syntactic preferences are also driven by predictability of a syntactic structure. According to the Uniform Information Density (UID) hypothesis (Jaeger, Reference Jaeger2006, Reference Jaeger2010; Levy & Jaeger, Reference Levy, Jaeger, Schlökopf, Platt and Hoffman2007), human communication is viewed as information transmission over a capacity-limited noisy channel. The optimal strategy to transfer a message with high efficiency and with low risks of comprehension error is for speakers to try to distribute information uniformly across a message.
In traditional linguistic definitions, the information content of a sentence or a discourse is based on the compositional meaning of its words and constituents. However, in psycholinguistics and computational linguistics, information is used in its information-theoretic sense (i.e., Shannon information, Shannon, Reference Shannon1948), and information density means the amount of information conveyed per linguistic unit (e.g., phoneme, word, constituent, etc.). Associating information with surprisal, the more surprising a linguistic unit is in its context, the more information it conveys. For example, the more surprising the occurrence of a CC is in a given context, the more informative the CC onset is. Therefore, the UID hypothesis predicts that, where grammar permits, speakers will seek to structure their utterances so as to avoid peaks and troughs in information density. Peaks risk exceeding the channel's capacity, thus leading to comprehension difficulties whereas troughs would bring about redundancy and reduce transmission efficiency. In the case of complementizer drop, Jaeger (Reference Jaeger2010) estimated the predictability of CC by the matrix verb's subcategorization frequency. If a CC is not predictable given the matrix verb, its appearance would be quite intense in information (because information and predictability are negatively correlated), and that information would have been added to the first words of the CC if the complementizer had been omitted. In order to avoid such a peak, speakers are predicted to pronounce the complementizer to make the distribution of information more uniform. Inversely, if the appearance of a CC is highly expected, the complementizer will be redundant, and therefore its omission would be preferable. For example, since a CC is more predictable with think than with confirm, that-drop is more likely in (8) than in (7):Footnote 1
(7) My boss confirmed (that) we were absolutely crazy.
(8) My boss thinks (that) I am absolutely crazy. (Jaeger, Reference Jaeger2010)
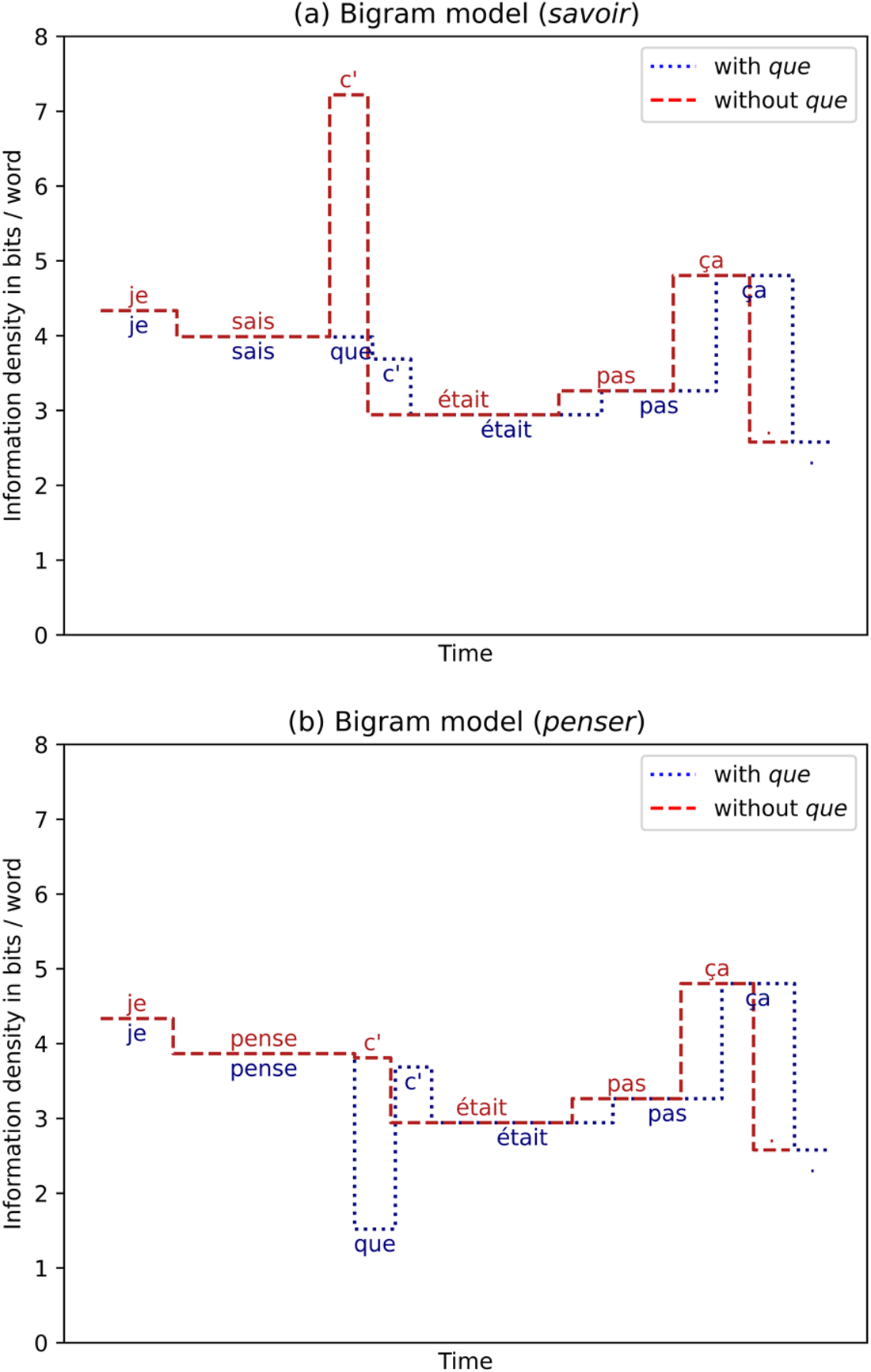
Figure 1 illustrates the idea of the UID hypothesis applied to complementizer omission in French: for each word of sentences (9) and (10), we have estimated a conditional probability using a bigram language model trained on the whole corpus Montréal 84 (see Jurafsky & Martin [Reference Jurafsky and Martin2020], Chapter 3 for a brief introduction to n-gram models), so that we can plot each word's Shannon information.Footnote 2 In Figure 1, we see that the CC onset (c’ ‘it’) would be highly surprising if it immediately followed the verb savoir ‘know,’ as shown by the dashed line in Figure 1(a), so that speakers will tend to use the complementizer, which is not only less surprising but also makes the CC onset less surprising, so that the information density is more uniform with the complementizer. On the contrary, if the information density at CC onset is low (shown by the dotted line in Figure 1[b]), speakers are predicted to omit que, which would avoid a trough in information at CC onset and make the production more efficient (see example [10] and dashed line in Figure 1[b]).
(9) Je sais (que) c’était pas ça.
(10) Je pense (que) c’était pas ça.
‘I know/think (that) it wasn't that.’
Illustration of the information density in bits per word in time for two French CCs with (dotted lines) and without (dashed lines) the complementizer que. Figures (a) and (b) respectively show the information density of a nonpredictable CC embedded by the matrix verb savoir ‘know’ and a predictable CC embedded by penser ‘think.’
UID plays a significant role in conditioning complementizer drop in the Switchboard corpus (Godfrey, Holliman, & McDaniel, Reference Godfrey, Holliman and McDaniel1992), on top of all the other factors (syntactic effects, disfluency effects, etc.) that have been argued to play a role in previous work (Jaeger, Reference Jaeger2010) and successfully predicts other morphological and syntactic reduction phenomena in English, such as auxiliary contraction as, for example, I have versus I've (Frank & Jaeger, Reference Frank and Jaeger2008) and that-relativizer omission (Levy & Jaeger, Reference Levy, Jaeger, Schlökopf, Platt and Hoffman2007). We therefore investigate the effect of information density on optional French complementizer que-omission by calculating the predictability of the CC given the matrix verb (i.e., subcategorization frequency of the matrix verb or CC-bias), to test the crosslinguistic validity of the UID hypothesis.
DATA AND METHOD
Corpus and semiautomatic annotation
The present study is based on Montréal 84 (Thibault & Vincent, Reference Thibault and Vincent1990), a French spoken corpus consisting of approximately 1.6 million words across sociolinguistic interviews with seventy-two Montréal natives of different genders, ages, education levels, and neighborhoods. All the interviews were transcribed and the main social characteristics of speakers such as genders and occupation are documented. A large corpus like this allows for the quantitative analysis of an infrequent syntactic phenomenon like que-omission in spontaneous speech.
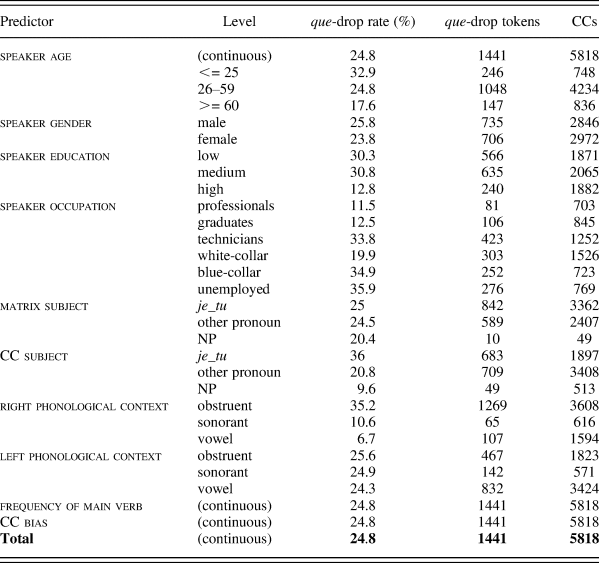
We adopted a semiautomatic approach to annotate the corpus. The corpus was first POS-tagged with MElt (Denis & Sagot, Reference Denis and Sagot2012), and then, using a Python script, we extracted all the utterances containing a verb that can possibly embed a CC. We limited our attention in this study to verbs that occur more than one hundred times in the corpus. As a matter of fact, due to less data, the estimation of the CC-bias (which is an approximation to information density of the CC onset in our study) of infrequent matrix verbs would be less reliable and the inclusion of these data might make the uneven distribution problem even worse. The extraction yielded a dataset with 24,635 sentences across seventeen verbs (see Table 1). The script also identified the contexts preceding and following the verb. A second script subsequently coded complement clauses and que-omission cases along with all the factors (described in the next section) with the help of regular expressions. In case of difficulty, we manually checked and annotated the token. At the end of this procedure, we coded 6,113 observations as CCs, and more than three quarters of this data was coded by the script. However, 295 occurrences had to be removed because of missing values for some factors.
Verbs chosen for the study, ordered by CC-bias. Frequency = Frequency of the verb lemma in the corpus, CC = number of occurrences of CCs, CC-biasFootnote 3 = verb's subcategorization bias for a CC, O = number of que omissions
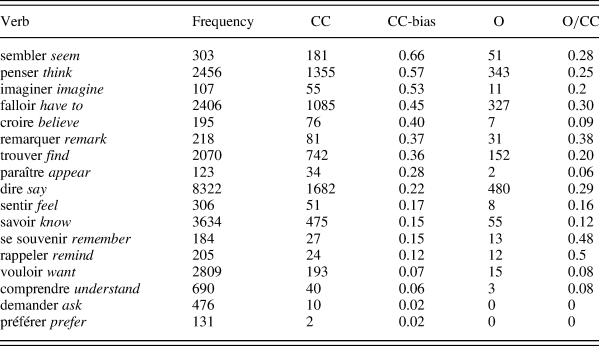
The omission rate for the remaining 5,818 complement clauses produced by seventy-two speakers is 24.7%Footnote 4 (1,510 cases), which is similar to Sankoff's (Reference Sankoff1980) findings (23%) in Montreal French and does not differ much from Martineau (Reference Martineau1985) (32%) and Dion (Reference Dion2003) (37% for young speakers and 32% for older speakers) among complement clauses in Ottawa-Hull French. However, our omission rate differs from the 14% observed by Warren (Reference Warren1994) in the Montréal 84 corpus. This difference may result from different methodology: Warren looked at the first four hundred lines of each interview, whereas we used the entire interview but only for selected (high-frequency) verbs. Complementizer omission may vary over the course of the interview, because the first part of speech is generally one of the most formal parts, as observed by Martineau (Reference Martineau1985). We are not in the position to say whether this variable is stable from 1971 to 1984 because previous work on the 1971 Montreal corpus only concentrates on the beginning of recordings.
FACTORS CODED
Social factors
As shown by previous work, the omission of que is socially stratified (e.g., Dion, Reference Dion2003; Martineau, Reference Martineau1985, Reference Martineau, Montreuil and Birdsong1988; Sankoff, Reference Sankoff1980; Sankoff & Cedergren, Reference Sankoff and Cedergren1971; Warren, Reference Warren1994). The coding of social factors was mainly based on the classification made by the authors of the corpus:
1. Speaker age. Given the observation of Labov (Reference Labov1966) on linguistic variation in English, young speakers are more likely to use nonstandard variants. This is consistent with Warren's (Reference Warren1994) observations on que omission. However, such an effect is less clear in Martineau (Reference Martineau1985) and in Dion (Reference Dion2003). We coded speaker age in two ways: (1) a continuous variable ranging from fifteen to seventy-five in the main statistical model, and (2) alternatively, a three-level categorical variable: “under 25,” “26–60,” and “over 60.” These groups correspond roughly to speakers’ relation to the workplace (cf., Wagner & Sankoff, Reference Wagner and Sankoff2011): those below twenty-five years old have not, or have just, entered into the working careers while those beyond sixty years old should have retired and have no longer closed relation to the workplace.Footnote 5
2. Speaker gender. Regarding que-omission, Warren (Reference Warren1994) shows that men are more likely to omit que than women, but this holds only for young speakers. Other studies (Dion, Reference Dion2003; Martineau, Reference Martineau1985; Martineau, Reference Martineau, Montreuil and Birdsong1988) have failed to detect a gender effect. Speaker gender was included as a binary variable in our model.
3. Speaker education. Based on groups made in the corpus documentation, speaker education was coded as a three-level ordinal variable: low (some high school education), medium (high school graduates with no university degree), high (university graduates).
4. Speaker occupation. Optional que omission is also affected by speaker's occupation. Dion (Reference Dion2003) and Sankoff et al. (Reference Sankoff, Sarrasin and Cedergren1971) found that workers without diplomas tend to make more omissions than other speakers. Following the classification and the ordering made by the authors of Montréal 84, speaker occupation was coded as a six-level ordinal variable: professionals (liberal professionals and business leaders), graduates (other university graduates), technicians (technicians and foremen), white-collar, blue-collar, unemployed.
Since Canadian French is in close contact with English, some researchers raise questions about the influence of bilingualism on que omission. However, Blondeau and Nagy's (Reference Blondeau, Nagy, Meyerhoff and Nagy2008) study of Anglo-Montrealers in both French and English reported that the rate of complementizer omission in French is 23%, which is the same as Sankoff (Reference Sankoff1980)'s observation. Since the information about speakers’ bilingual status is not available in our data, we did not investigate this factor.
Linguistic factors
Four linguistic factors were included in the analysis, ranging from phonological to syntactic:
1. Right phonological context. The omission of que is strongly driven by the right phonological environment of the complementizer (Dion, Reference Dion2003; Martineau, Reference Martineau1985; Sankoff, Reference Sankoff1980; Sankoff et al., Reference Sankoff, Sarrasin and Cedergren1971; Warren, Reference Warren1994). Speakers show a higher preference for que-omission if the right phonological context is less sonorant, and this effect has been attributed to consonant cluster simplification in Quebec French. We used the Python module epitran (Mortensen, Dalmia, & Littell, Reference Mortensen, Dalmia and Littell2018) to transcribe automatically the first word following the complementizer into the International Phonetic Alphabet (IPA). We checked manually the automatic transcription then coded the first phoneme adjacent to the complementizer, that is, right phonological context, as a three-level ordinal variable based on the sonority hierarchy: obstruent (n = 3608), sonorant (n = 616), and vowel (n = 1594). We do not distinguish sibilants from other types of obstruents, since in Canadian French fricatives (including sibilants) and plosives are on the same sonority level (Côté, Reference Côté2004).
We are aware of the potential nonorthogonality of the factors, especially between the following phonological context and the CC subject, which has triggered a long debate (cf., Connors, Reference Connors1975; Dion, Reference Dion2003). Note that the right phonological context is not necessarily the first phoneme of the CC subject, because of intervening material like prepositional phrases at the beginning of the CC, as illustrated by the following examples. For example, the right phonological context is coded as “vowel” in (11a) and “sonorant” in (11b). These represent 14.7% of cases (more than eight hundred observations). The use of the adjacent phonological context rather than the first segment of CC subject helps to dissociate these two factors to some extent. In addition, several statistical tests have been employed to ensure that there is no severe nonorthogonality between the phonological context and the CC subject.
(11)
a. Je pense pas qu’en soixante-et-onze je travaillais là. (speaker 2) ‘I think during the seventies I worked there.’
b. Puis on a toujours pensé que les cinq et demie on pouvait pas s'en acheter. (speaker 4) ‘Then we were always thinking that we could not afford to buy five and a half.’
2. Left phonological context. Sankoff (Reference Sankoff1980) and Sankoff et al. (Reference Sankoff, Sarrasin and Cedergren1971) found that the phonological environment preceding the complementizer also affects the omission of que; whereas Dion (Reference Dion2003), Martineau (Reference Martineau1985), and Warren (Reference Warren1994) found no evidence for this effect. The last sound preceding the CC, that is, the left phonological context, is therefore included in the model as a three-level ordinal variable based on the sonority hierarchy: obstruent (n = 1823), sonorant (n = 571), and vowel (n = 3424). Likewise, we use the left adjacent phonological context instead of the last segment of the embedding verb so as to separate these two factors in variable coding.Footnote 6 As a matter of fact, the left phonological context is coded as “vowel” in both (11a) and (11b). We found that in 13.8% of cases, the matrix subject is not adjacent to the CC.
3. Matrix subject. According to grammaticalization accounts, first- and second-person matrix subjects can express epistemicity (Thompson & Mulac, Reference Thompson and Mulac1991b). It is observed that first- and second-person matrix subjects correlate with lower rates of complementizer use than other types (Thompson & Mulac, Reference Thompson and Mulac1991b), while Torres Cacoullos and Walker (Reference Torres Cacoullos and Walker2009) argued that when frequent main clause subject-verb collocations are excluded, pronominal matrix subjects favor zero-complementation more than full NPs. Matrix subject was therefore coded as three ordered levels: je_tu (first- and second-person pronouns, n = 3362), other type of pronoun (n = 2407), and lexical NP (n = 49).
4. CC subject. Availability accounts (Ferreira & Dell, Reference Ferreira and Dell2000) predict that more accessible CC subjects are associated with a higher rate of complementizer drop. This prediction is supported by previous work on English, which has reported that pronouns, especially those with local denotation like first-person pronoun, are correlated with a higher rate of that-omission (Elsness, Reference Elsness1984; Ferreira & Dell, Reference Ferreira and Dell2000; Jaeger, Reference Jaeger2010). This pattern is, nevertheless, less clear for French, since Connors (Reference Connors1975) showed that pronouns differ from lexical NPs in favoring omission of que; whereas, Dion (Reference Dion2003) attributed it to phonological effects. CC subject was coded as a three-level ordinal variable based on the accessibility of its referential expression: je_tu (first- and second-person pronouns, n = 1897), other pronouns (n = 3408), and NP (n = 513). For example, CC subject is je_tu and “other pronoun” in (11a) and in (11b), respectively. Moreover, in case of left dislocation (e.g., the lexical NP mon père ‘my father’ repeated by the third-person pronoun il in [12]), the CC subject was coded as “lexical NP” (for example in [12]). This notation is consistent with the proposition of Auger (Reference Auger1998), who argued that in Quebec French the anaphoric pronoun can be analyzed as a clitic that agrees with the NP like inflections.Footnote 7
(12) […] parce que je pense que mon père il buvait beaucoup […] (speaker 4) ‘…because I think that my father he used to drink a lot…’
Cognitive factors
We investigated two factors that are associated with general cognition:
1. Frequency of main verb. A continuous variable ranging from 107 to 8,322. It was calculated based on the frequencies of matrix verb observed in the Montréal 84 corpus. Increasing production pressure could be attributed to less frequent words (Jescheniak & Levelt, Reference Jescheniak and Levelt1994). According to availability accounts, if a CC is adjacent to the matrix verb, production pressure may spill over from the matrix verb to the CC onset, thus favoring the use of a complementizer. Several corpus studies have found a correlation between a less frequent matrix verb and a higher rate of that-use (Elsness, Reference Elsness1984; Jaeger, Reference Jaeger2010; Roland, Elman, & Ferreira, Reference Roland, Elman and Ferreira2006). 2. CC bias. The UID hypothesis (Jaeger, Reference Jaeger2010) assumes an increasing preference for que-drop as the information density at the CC onset (i.e., the first word in the CC without the complementizer) lowers. We estimate the information density at the CC onset by the CC bias of the matrix verb (i.e., the number of CCs divided by the sum of CCs and non-CCs after removal of ambiguous cases). Therefore, the prediction is that speakers omit que more often if the CC is predictable, given the matrix verb. For example, since the CC is more predictable with penser ‘think’ than with savoir ‘know,’ we predict that speakers omit the complementizer more often with penser ‘think.’ The CC bias, ranging from 0.02 to 0.66 (see Table 1), was therefore included in the model.
Statistical modeling procedure
We employed a generalized linear mixed model (GLMM) to perform a multivariate regression analysis on our data, which is highly unbalanced and clustered (mean number of observations per speaker = 80.8, median = 68.5, mode = 59, range = 8 - 280, SD = 54.8). We used the glmer() function of the lme4 package (Bates, Mächler, Bolker, & Walker, Reference Bates, Mächler, Bolker and Walker2015) in the statistical software R (R Core Team, 2020). Apart from all the fixed effects, the model also includes a random effect of speaker to control interspeaker variation.Footnote 8 The specification of the final model is shown as follows.Footnote 9 Omission or preservation of the complementizer que is respectively denoted by one and zero. Results will be visualized by effect graphsFootnote 10 in the following section.
The Model: que-omission modeled as depending on:
• Fixed effects: speaker age + speaker gender + speaker education + speaker occupation + matrix subject + CC subject + right phonological context + left phonological context + CC bias + frequency of main verb
• Random effect: speaker
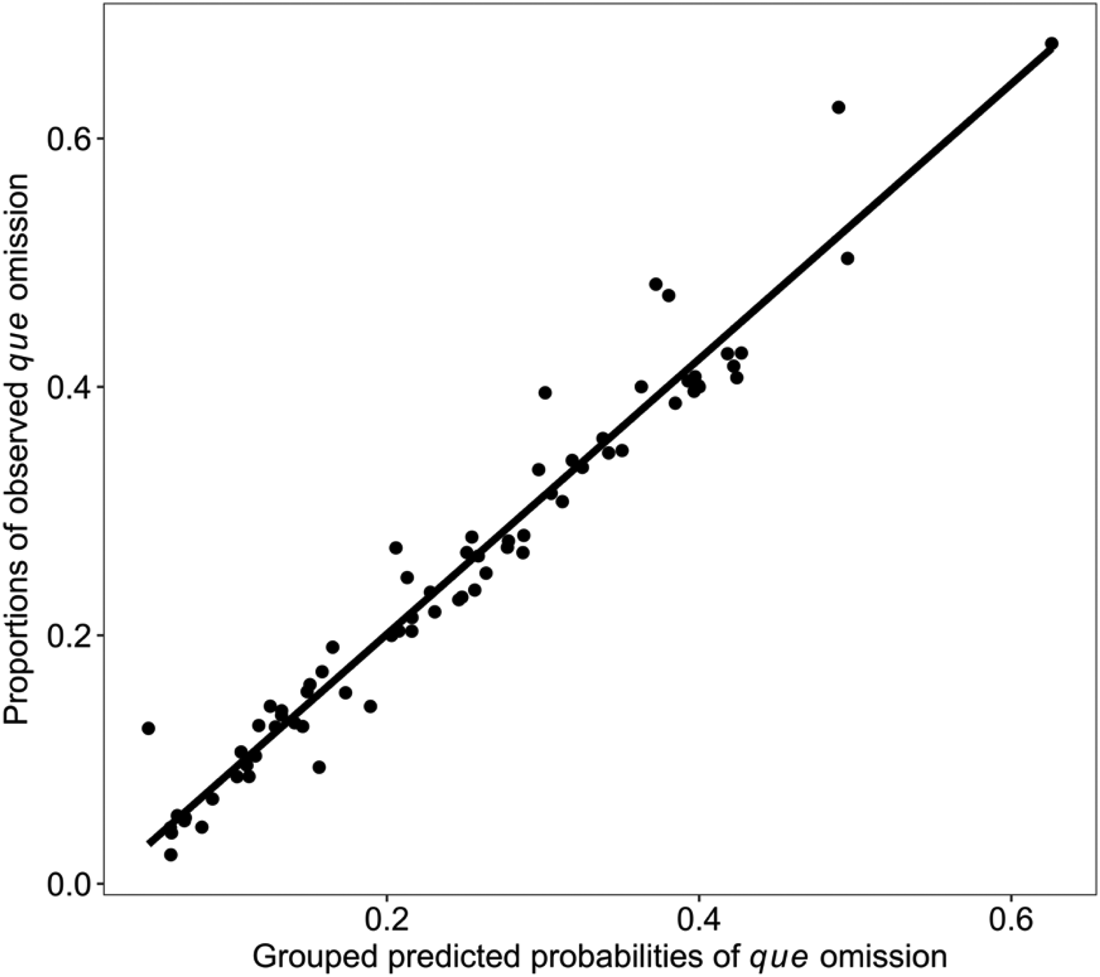
After fitting the statistical model to the data, we evaluated the fitted model. The model correctly classifies 79% of the data overall. The estimated probabilities of the model shown in Figure 2 also show an acceptable fit.
Mean predicted probabilities versus observed proportions of omitted que. The data are grouped by speakers and the diagonal line represents a perfect match between predicted and actual proportions.
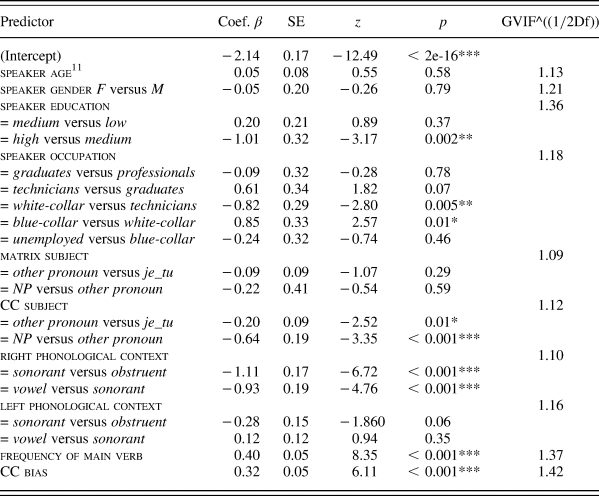
We also evaluated the eventual collinearity problem by calculating the variance inflation factor (VIF) of each variable. Collinearity is a severe modeling problem that appears when two independent variables are highly correlated with each other in the model (Allen, Reference Allen1997). Since some variables in the model are polynomial, we applied the GVIF (General variance inflation factors) measure (Fox & Monette, Reference Fox and Monette1992). The GVIF is proportional to the inflation due to collinearity in the confidence interval for the coefficient. We checked that GVIF^([1/2Df]) < 2 for each variable (Df is a variable's degree of freedom), which is usually interpreted as a low degree of collinearity (more or less corresponding to VIF < 4 for one-coefficient variables). The value for each variable is presented in Table 2, and we concluded that our model has no major concern of collinearity.
Result summary: coefficient estimates β, standard errors SE, z value, p value and significance level indicated by stars * for all the variables in the model. A positive coefficient means that the first level correlates with a higher rate of que-omission than the second (number of CCs = 5818, number of que-omission cases = 1441)
RESULTS AND DISCUSSION
Table 2 summarizes the results of all the fixed effects that were tested in the present study. In our regression model, for categorical predictors, we have compared each of the lower level with the higher one in the order clarified in Section Data and method. For example, for polynomial variables like CC subject, we have contrasted “other pronoun” against “je_tu,” and “NP” against “other pronoun.” The results show that que omission is conditioned by cognitive, linguistic, and social factors.
Table 3 provides the que-omission rate and number of tokens of each predictor level.
Que-omission rate, number of omission cases and number of CCs for each predictor level
Cognitive factors
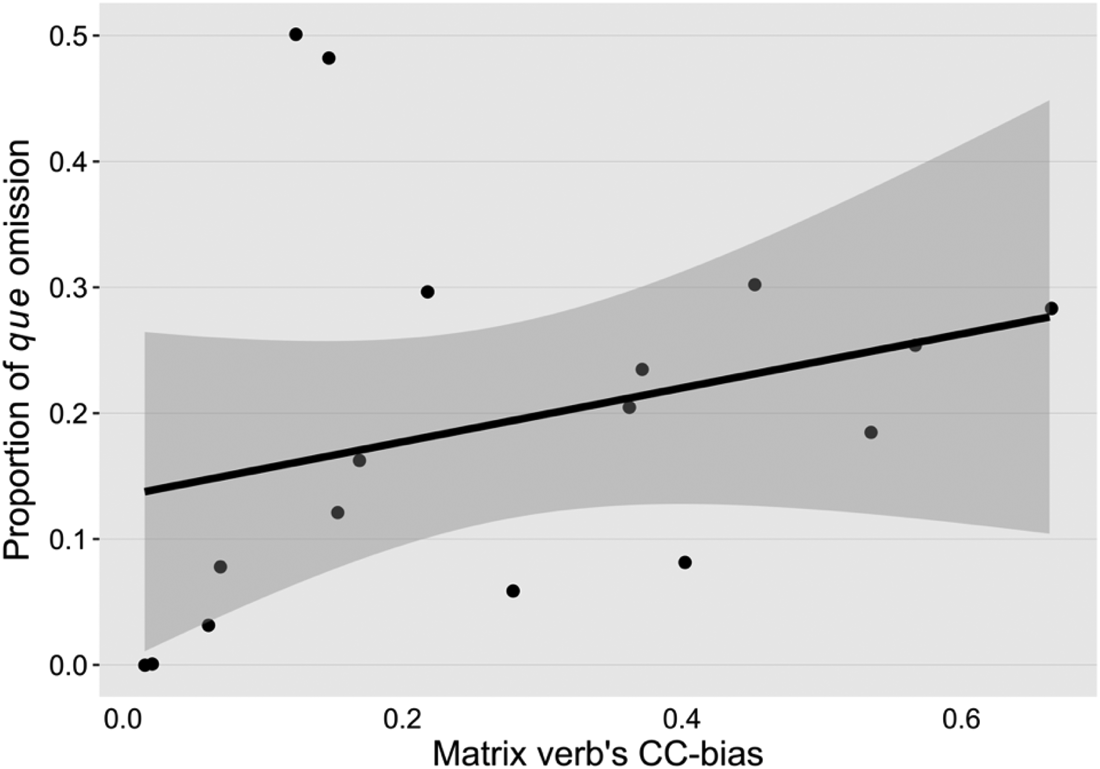
As predicted by UID hypothesis, there was a clearly significant effect of information density on que omission: the more likely a verb is to appear with a CC, the more it favors the omission (p < 0.001) (see Figure 3). For example, it is more likely to observe que drop with sembler ‘seem’ in (13a) than with comprendre ‘understand’ in (13b), given that sembler is more often followed by CCs than comprendre. Since CC-bias is an indicator of the information density at the CC onset, the result implies that speakers show a higher preference for que-drop if the CC onset is less informative so as to avoid redundancy and thus increase communication efficiency.
(13)
a. […] (il) me semble que la musique est belle […] (speaker 6) ‘…(it) seems to me that the music is beautiful…’
b. Je comprends que c'est pas gros. (speaker 27) ‘I understand that it is not much.’
Effect of the matrix verb's CC bias on the omission of the complementizer que, along with 95% confidence interval (shaded area). The dots represent matrix verbs, and the line indicates the linear model.Footnote 12
Furthermore, χ 2-tests were performed to compare the model described in Section Data and method against the same one without one predictor. It turns out that the CC-bias has emerged as the third most important predictor in terms of its contribution to the improvement in model quality ($\chi _{\Delta ( \Lambda ) }^2 ( 1 ) = 38.671$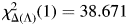 , p = 5.017e − 10 < 0.001, after the right phonological context and the frequency of main verb), which contrasts with Jaeger's (Reference Jaeger2010) work where it is the strongest predictor. The effect of predictability on syntactic variation across languages is expected given that the UID makes predictions about general cognitive and communication principles that should not differ much among speakers. However, the importance of information density with regard to syntactic reduction may vary across languages, since speakers’ preferences may be the result of competition among different linguistic rules (in particular phonological rules) and communication strategies in different ways. For example, phonological constraints do not play an important role in governing complementizer drop in English, while information density has a dominant role; whereas in French, the sonority hierarchy is more influential, so information density has a weaker role.
, p = 5.017e − 10 < 0.001, after the right phonological context and the frequency of main verb), which contrasts with Jaeger's (Reference Jaeger2010) work where it is the strongest predictor. The effect of predictability on syntactic variation across languages is expected given that the UID makes predictions about general cognitive and communication principles that should not differ much among speakers. However, the importance of information density with regard to syntactic reduction may vary across languages, since speakers’ preferences may be the result of competition among different linguistic rules (in particular phonological rules) and communication strategies in different ways. For example, phonological constraints do not play an important role in governing complementizer drop in English, while information density has a dominant role; whereas in French, the sonority hierarchy is more influential, so information density has a weaker role.
In line with previous findings on that-use (Jaeger, Reference Jaeger2010; Roland et al., Reference Roland, Elman and Ferreira2006), our results also show that matrix verb frequency is a highly significant predictor: the more frequent a verb is in the corpus, the more likely que is to be omitted when it introduces a CC (p < 0.001). Jaeger (Reference Jaeger2010) has attributed this effect to the availability accounts, since less frequent matrix verbs are less accessible and may lead to production pressure that can spill over into the upcoming adjacent complement clause, thus encouraging the use of a complementizer. However, since a word's probability can be simply estimated by its frequency when ignoring context (Jaeger, Reference Jaeger, Bender and Arnold2011), it is possible that the frequency effect could be related to the information density.Footnote 13 Hence, further work is needed to flesh out how exactly verb frequency and CC onset informativity are related and whether this effect is related to availability accounts or to the UID hypothesis.
Linguistic factors
As Table 2 shows, the segment following the site of que has a significant effect on whether or not it will be omitted (p < 0.001). Confirming Dion (Reference Dion2003), Sankoff (Reference Sankoff1980), and Warren's (Reference Warren1994) findings, the highest rate of que omission is when it would be followed by an obstruent (35.2%),Footnote 14 then a sonorant (10.6%), and finally a vowel (6.7%) (see Figure 4 and examples in [14]). Chi-squared tests for partial effects show that the effect of right phonological context is larger than any other variable in the model ($\chi _{\Delta ( \Lambda ) }^2 ( 2 ) = 436.3$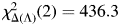 , p = 2.2e − 16 < 0.001). However, the effect of the left phonological context has not been observed in our study.
, p = 2.2e − 16 < 0.001). However, the effect of the left phonological context has not been observed in our study.
(14)
a. Bon bien je pense que j'ai tout. (obstruent, speaker 27) ‘Well I think that I have all.’
b. Disons que moi j'ai été refusée comme di distributeur […] (sonorant, speaker 7) ‘Let's say that me I was refused as a distributor […]’
c. Ici on dit qu’ on va étirer ça. (vowel, speaker 1) ‘Here we say that we will avoid this.’
Right phonological context versus que omission (with 95% confidence interval).
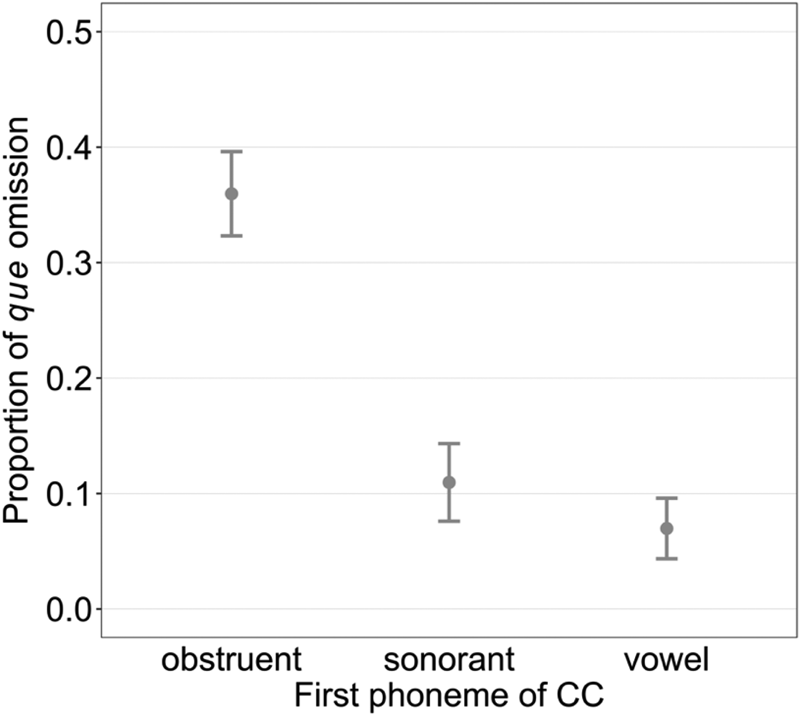
This pattern can be understood if we view que omission as the optimal strategy in Quebec French for repairing disfavored consonant clusters at the beginning of CC. Since, in modern French, the complementizer que (pronounced [k])Footnote 15 is the head of the CP domain (complementizer phrase) and should first merge with its complement clause (Kayne, Reference Kayne, Hensey and Luján1976), it must be syllabified with the phonological material to its right. When the material following the obstruent [k] starts also with an obstruent, like [t] in the sequence je pense que tu dors ‘I think that you sleep,’ it creates a cluster [kt], which violates the Sonority Sequencing Principle (SSP, particularly that onsets must increase in sonority, see Clements, Reference Clements, Kingston and Beckman1990; Dell, Reference Dell1995). European dialects of French often insert a schwa to repair such clusters. However, Quebec French prefers consonant cluster simplification: for example, evidence shows that speakers tend to simplify complex clusters in coda (Côté, Reference Côté, Gess, Lyche and Meisenburg2012). Therefore, the best option here is to simply delete que, particularly if its information is low. In the case the SSP is not violated, we observed that speakers still omit que, and that happens more often when que is followed by a sonorant (e.g., [m] in [14b]) than a vowel (e.g., [ɔ̃] in [14c]), which suggests that Quebec French prefers larger intervals on the sonority scale. Hence, the less sonorous the right phoneme, the more likely the que is to be omitted.
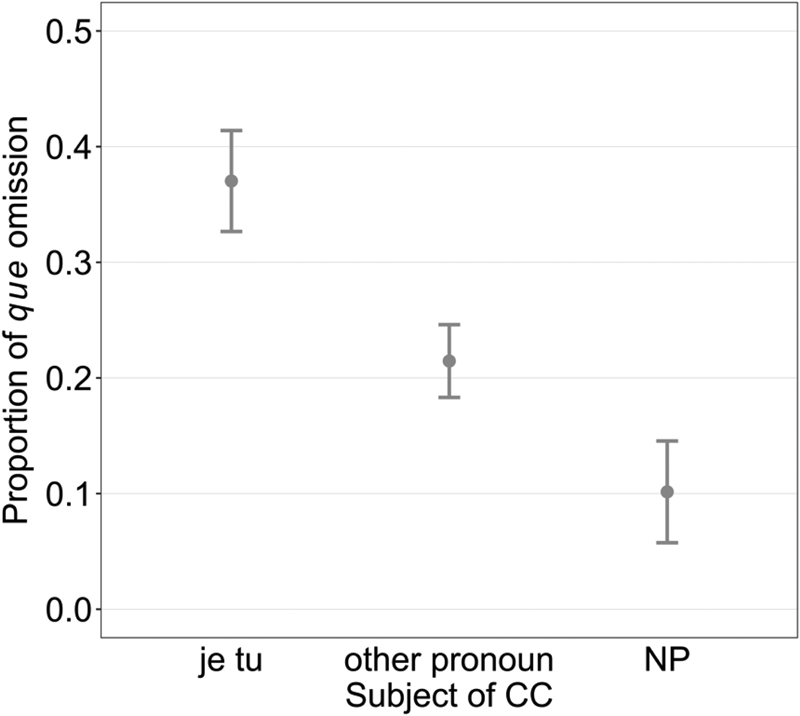
As for CC subject, our study shows that the most accessible CC subjects differ significantly from other pronouns (p = 0.01), and the contrast between other pronouns versus lexical CC subjects also reaches significance (p < 0.001): je_tu (36%) > other pronoun (20.8%) > NPs (9.6%) (cf., Figure 5 and examples in [15]). These results are partially comparable with Connors (Reference Connors1975) and Dion (Reference Dion2003) in Canadian French and Jaeger (Reference Jaeger2010) in English, who found that pronouns and NPs behave differently with regard to complementizer drop. Moreover, we found an additional contrast between first- and second-person pronouns versus other pronouns, which provides further support for availability-based accounts. In line with findings on English, que-omission is also driven by the accessibility of the CC subjects.
(15)
a. Faut que tu regardes le positif dans ça. (je_tu, speaker 1) ‘You have to look at the positive side of it.’
b. Quand je sais que quelqu-un parle très bien le français […] (other pronoun, speaker 77) ‘When I know that someone speaks French very well […]’
c. Je sais que mon père a fait la Polytechnique. (NP, speaker 123) ‘I know that my father went to the Polytechnique.’
CC subject versus que omission (with 95% confidence interval).
Although the GVIF measure has shown no collinearity concern in the model, given the debate on whether cc subject and right phonological context have independent effects on que omission, we performed stepwise regression to further study this issue. More concretely, we use ANOVA to compare the model with all fixed factors (m1) and the identical model without CC subject (m3) or right phonological context (m2). Results shown in Tables 4 and 5 show that the model m1, the one including both CC subject and right phonological context, significantly fits the data better, with a lower AIC than the identical model without one of these variables like m2 or m3, meaning a preference to include both variables. Besides, the cross-tabulation of right phonological context and CC subject (cf., Table 6) also shows that these two factors are quite different, given the nonnegligible number of tokens in each cell.
Results of comparison between the full model (m1) and the model without right phonological context (m2)

Results of comparison between the full model (m1) and the model without CC subject (m3)

Cross-tabulation of right phonological context and CC subject

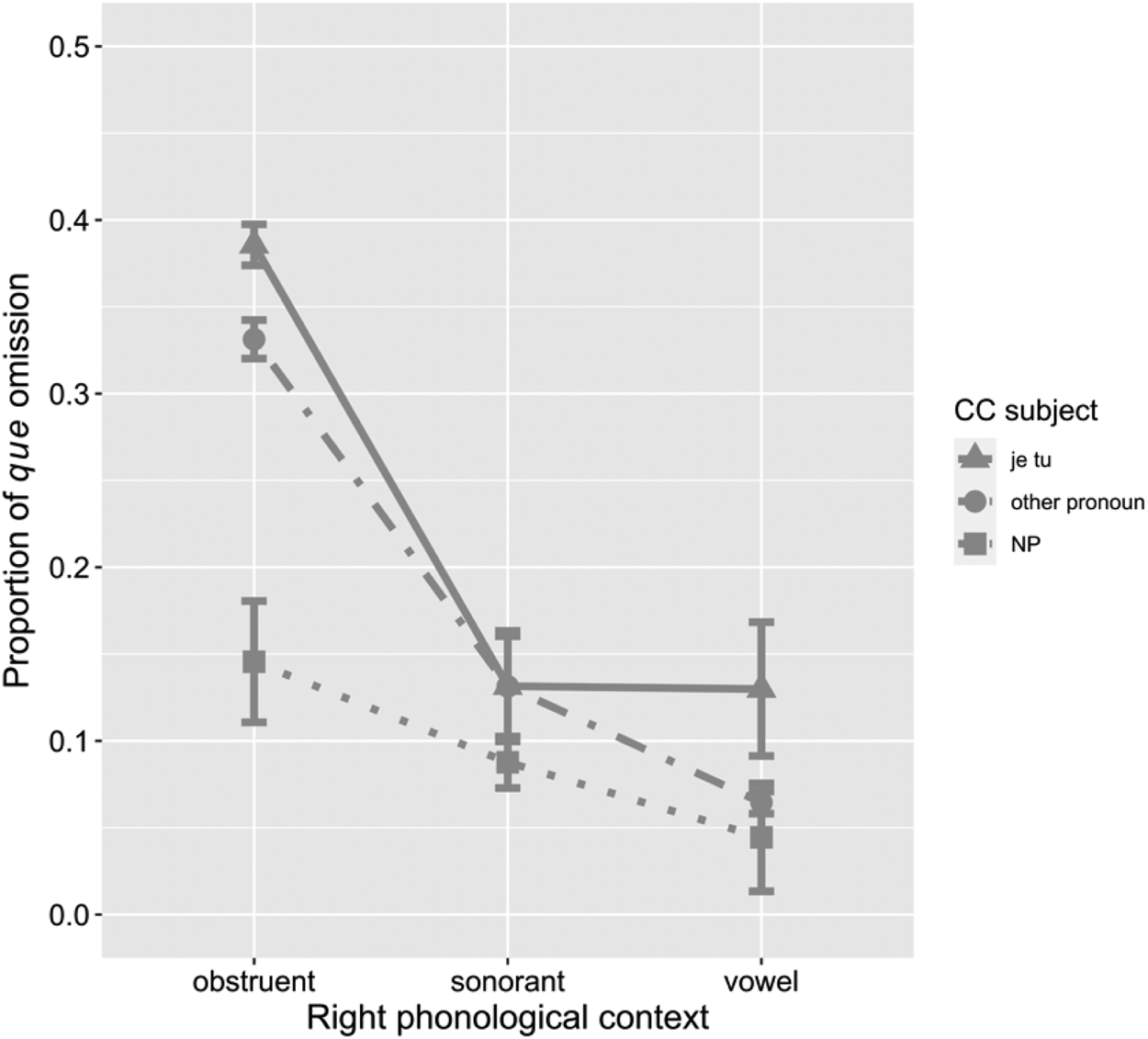
Figure 6 further shows that pronouns behave quite differently from NPs within the same phonological group, especially when the CC begins with an obstruent; we have tried to encode the interaction between these two variables and refitted the model, but the interaction effect is not significant. Hence, unlike previous work that reduces phonotactic constraints and syntactic effect one to another (e.g., Connors, Reference Connors1975; Dion, Reference Dion2003), we conclude that both effects are independently important for que omission.
que-drop rate across CC subject and right phonological context groupings.Footnote 16
Social factors
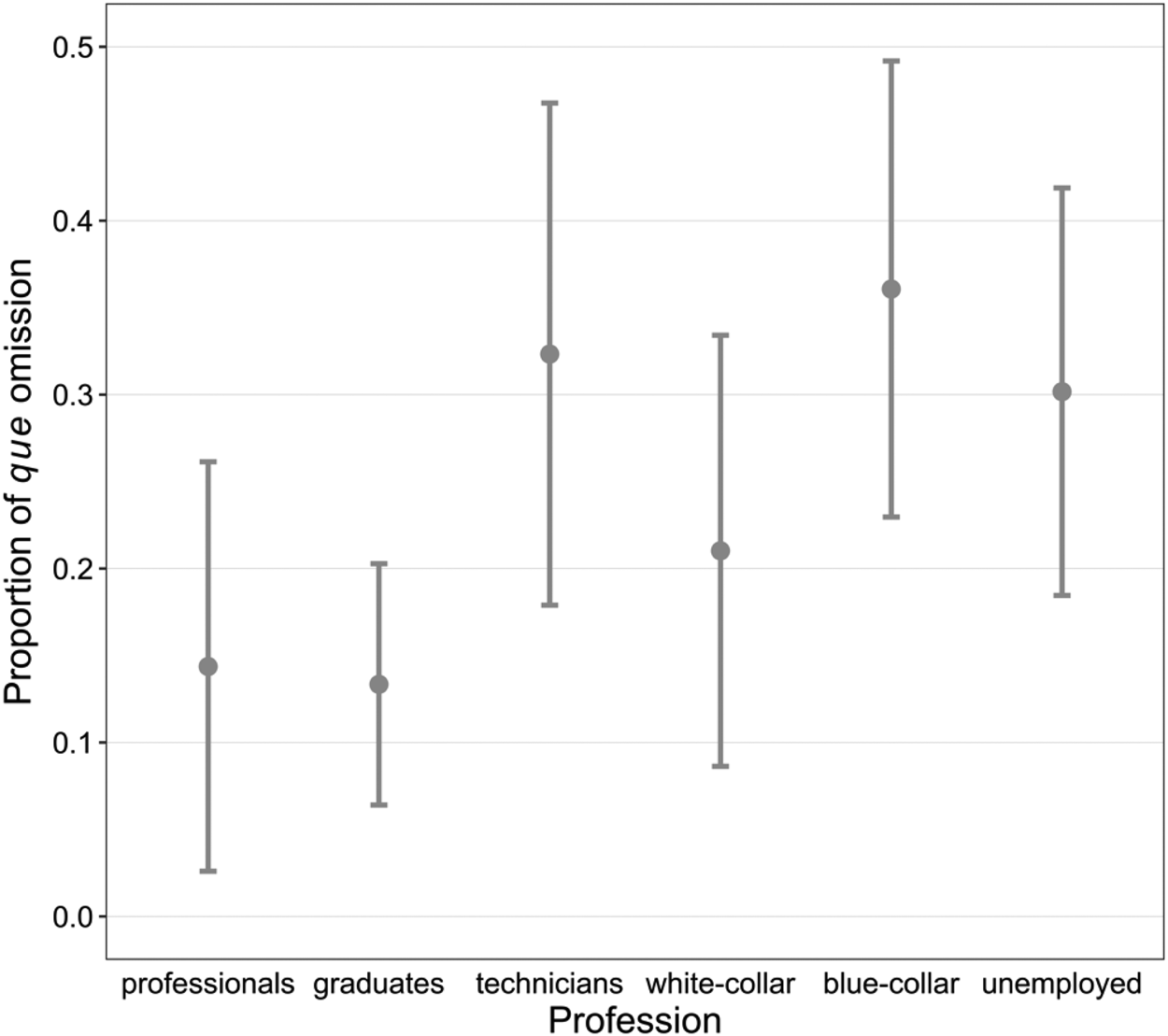
Both profession and education have significant effects on que omission (cf., Figures 7 and 8). In particular, we find that “speakers whose economic activity […] requires or is necessarily associated with competence in the legitimized language (or standard, elite, educated, etc., language)” (D. Sankoff & Laberge, Reference Sankoff, Laberge and Sankoff1978:239), that is, liberal professionals, white-collar workers, and other university graduates omit que less often than do the other members of the community, whose economic success does not depend so much on language (technicians and foremen, blue-collar workers, and the unemployed). These results partially contradict Warren (Reference Warren1994) on the same data, who groups each of the two adjacent groups into one group and shows that the new “blue-collar and unemployed” and “technicians and white-collar” groups prefer omission whereas the new “professionals and graduates” group tends to retain que. We doubt whether it is pertinent to combine technicians and white-collar, since their working environments are quite different. The statistical results in Table 2 also reveal a higher omission rate associated with technicians and forepeople than with white-collar workers (p < 0.01). As for education, speakers having received a university degree (i.e., high) are more likely to use the complementizer than those who have a medium or low education level.
Profession versus que omission.
Education level versus que omission.
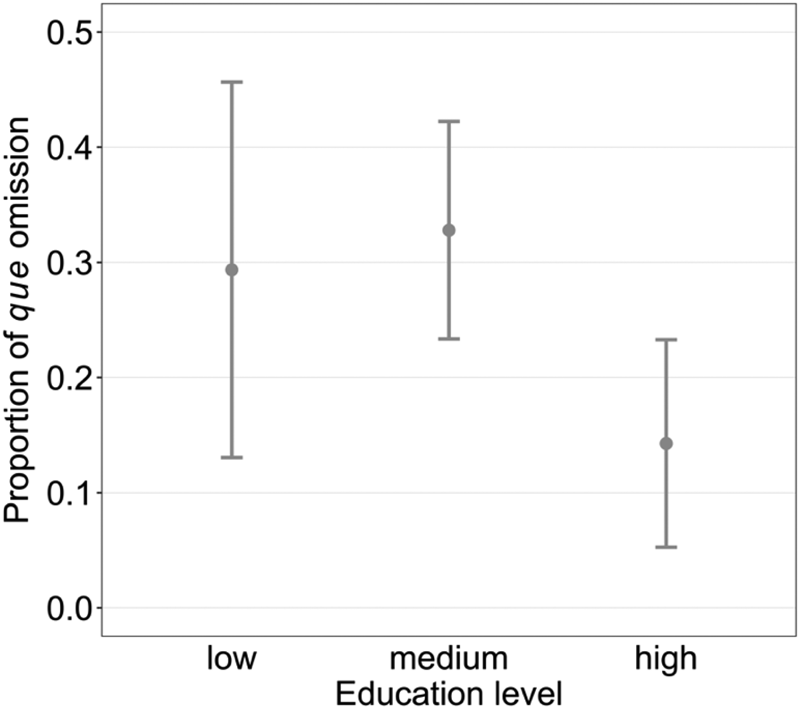
These results can be explained by the linguistic market or linguistic marketplace Footnote 17 (in French le marché linguistique, Bourdieu & Boltanski, Reference Bourdieu and Boltanski1975), which refers to the symbolic market where linguistic exchange takes place. In order to achieve the highest profit from linguistic exchange, speakers should “produce the adequate speech in a given situation” (Bourdieu, Reference Bourdieu1977:647), that is, choose the linguistic variety with the best value in the linguistic market, which varies, for example, by the social relation between speaker and listener. Since the linguistic market related to higher education context (universities) and occupations such as those performed by white collar workers, liberal professionals and business leaders favor the use of the standard language, speakers occupying these social roles are under more pressure to pronounce the que (the standard variant) for the linguistic success in school or working life.
CONCLUSION
In this paper, we have provided an empirical study of que drop in the Montréal 84 corpus of spoken Montréal French. Our study is a contribution to the existing literature on this well-known variable, one which takes advantage of recent advances in computational linguistics, statistics, and cognitive science and reveals that the que omission variable is conditioned by linguistic, cognitive, and social factors. We show that many of the earlier results obtained by previous researchers on smaller subsets of corpora, including the Montréal 84 corpus, still hold at the level of the whole variationist corpus. Most importantly, the least sonorant right phonological context is shown to be the most important factor favoring que omission, but the accessibility of the syntactic subject of CC also has an independent role. In particular, we find that not all pronominal CC subjects behave in the same way: more accessible pronouns like je_tu favor the omission more than less accessible ones. In addition, two of the three most important factors conditioning the variable had not been tested before: frequency and information density. These two factors have been extensively studied in psycholinguistics, and our study shows that they are also useful for understanding how linguistic, social, and general cognitive factors interact in variation. However, the importance of either of these factors is weaker than the phonological constraint in French, which suggests that the importance of different types of constraints on speakers’ preferences may vary in different languages.
More generally, we believe that our study illustrates an important way in which variationist corpora can continue to be valuable resources for studying fine-grained patterns of variation, particularly in their cognitive aspects. Currently, such corpora have been shown to be useful for diachronic comparative work (see Blondeau, Mougeon, & Tremblay [Reference Blondeau, Mougeon and Tremblay2019] for a recent example); however, given the greater rapprochement between variationist sociolinguistics and psycholinguistics in the past fifteen years (see Tamminga, MacKenzie, & Embick, Reference Tamminga, MacKenzie and Embick2016), these corpora continue to be valuable resources for studying language in its social and cognitive aspects.
COMPETING INTERESTS
The authors declare none.
ACKNOWLEDGMENTS
We would like to thank Yair Haendler for his help in the statistical analysis. We are also grateful to anonymous reviewers for their feedback on earlier versions of this paper. This research has received funding from the ERC under the European Union's Horizon 2020 research and innovation program (grant agreement N°850539).
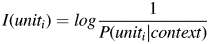















 Open access
Open access